Cassandra - Guía rápida
Apache Cassandra es una base de datos distribuida altamente escalable y de alto rendimiento diseñada para manejar grandes cantidades de datos en muchos servidores básicos, proporcionando alta disponibilidad sin un solo punto de falla. Es un tipo de base de datos NoSQL. Primero entendamos qué hace una base de datos NoSQL.
NoSQLDatabase
Una base de datos NoSQL (a veces denominada No solo SQL) es una base de datos que proporciona un mecanismo para almacenar y recuperar datos distintos de las relaciones tabulares utilizadas en las bases de datos relacionales. Estas bases de datos no tienen esquemas, admiten una replicación sencilla, tienen una API simple, eventualmente son consistentes y pueden manejar grandes cantidades de datos.
El objetivo principal de una base de datos NoSQL es tener
- simplicidad de diseño,
- escala horizontal, y
- control más preciso sobre la disponibilidad.
Las bases de datos NoSql utilizan diferentes estructuras de datos en comparación con las bases de datos relacionales. Acelera algunas operaciones en NoSQL. La idoneidad de una base de datos NoSQL determinada depende del problema que debe resolver.
NoSQL frente a base de datos relacional
La siguiente tabla enumera los puntos que diferencian una base de datos relacional de una base de datos NoSQL.
| Base de datos relacional | Base de datos NoSql |
|---|---|
| Admite un potente lenguaje de consulta. | Admite un lenguaje de consulta muy simple. |
| Tiene un esquema fijo. | Sin esquema fijo. |
| Sigue ACID (atomicidad, consistencia, aislamiento y durabilidad). | Es sólo "eventualmente consistente". |
| Soporta transacciones. | No admite transacciones. |
Además de Cassandra, tenemos las siguientes bases de datos NoSQL que son bastante populares:
Apache HBase- HBase es una base de datos distribuida de código abierto, no relacional, modelada a partir de BigTable de Google y está escrita en Java. Se desarrolla como parte del proyecto Apache Hadoop y se ejecuta sobre HDFS, proporcionando capacidades similares a BigTable para Hadoop.
MongoDB - MongoDB es un sistema de base de datos orientado a documentos multiplataforma que evita el uso de la estructura de base de datos relacional tradicional basada en tablas en favor de documentos similares a JSON con esquemas dinámicos que hacen que la integración de datos en ciertos tipos de aplicaciones sea más fácil y rápida.
¿Qué es Apache Cassandra?
Apache Cassandra es un sistema de almacenamiento (base de datos) de código abierto, distribuido y descentralizado / distribuido, para gestionar grandes cantidades de datos estructurados repartidos por todo el mundo. Proporciona un servicio de alta disponibilidad sin un solo punto de falla.
A continuación se enumeran algunos de los puntos notables de Apache Cassandra:
Es escalable, tolerante a fallas y consistente.
Es una base de datos orientada a columnas.
Su diseño de distribución se basa en Dynamo de Amazon y su modelo de datos en Bigtable de Google.
Creado en Facebook, se diferencia mucho de los sistemas de gestión de bases de datos relacionales.
Cassandra implementa un modelo de replicación estilo Dynamo sin un solo punto de falla, pero agrega un modelo de datos de "familia de columnas" más poderoso.
Cassandra está siendo utilizada por algunas de las empresas más grandes como Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix y más.
Características de Cassandra
Cassandra se ha vuelto tan popular debido a sus excelentes características técnicas. A continuación se presentan algunas de las características de Cassandra:
Elastic scalability- Cassandra es altamente escalable; permite agregar más hardware para dar cabida a más clientes y más datos según los requisitos.
Always on architecture - Cassandra no tiene un solo punto de falla y está continuamente disponible para aplicaciones críticas para el negocio que no pueden permitirse una falla.
Fast linear-scale performance- Cassandra es linealmente escalable, es decir, aumenta su rendimiento a medida que aumenta la cantidad de nodos en el clúster. Por tanto, mantiene un tiempo de respuesta rápido.
Flexible data storage- Cassandra admite todos los formatos de datos posibles, incluidos: estructurados, semiestructurados y no estructurados. Puede adaptarse dinámicamente a los cambios en sus estructuras de datos de acuerdo con sus necesidades.
Easy data distribution - Cassandra ofrece la flexibilidad de distribuir datos donde los necesite mediante la replicación de datos en varios centros de datos.
Transaction support - Cassandra admite propiedades como atomicidad, consistencia, aislamiento y durabilidad (ACID).
Fast writes- Cassandra fue diseñado para ejecutarse en hardware básico barato. Realiza escrituras increíblemente rápidas y puede almacenar cientos de terabytes de datos, sin sacrificar la eficiencia de lectura.
Historia de Cassandra
- Cassandra se desarrolló en Facebook para la búsqueda en la bandeja de entrada.
- Fue de código abierto por Facebook en julio de 2008.
- Cassandra fue aceptada en Apache Incubator en marzo de 2009.
- Se convirtió en un proyecto de alto nivel de Apache desde febrero de 2010.
El objetivo de diseño de Cassandra es manejar cargas de trabajo de big data en múltiples nodos sin ningún punto único de falla. Cassandra tiene un sistema distribuido de igual a igual en todos sus nodos y los datos se distribuyen entre todos los nodos de un clúster.
Todos los nodos de un clúster desempeñan el mismo papel. Cada nodo es independiente y al mismo tiempo está interconectado con otros nodos.
Cada nodo de un clúster puede aceptar solicitudes de lectura y escritura, independientemente de dónde se encuentren realmente los datos en el clúster.
Cuando un nodo deja de funcionar, las solicitudes de lectura / escritura se pueden atender desde otros nodos de la red.
Replicación de datos en Cassandra
En Cassandra, uno o más de los nodos de un clúster actúan como réplicas de un dato determinado. Si se detecta que algunos de los nodos respondieron con un valor desactualizado, Cassandra devolverá el valor más reciente al cliente. Después de devolver el valor más reciente, Cassandra realiza unread repair en segundo plano para actualizar los valores obsoletos.
La siguiente figura muestra una vista esquemática de cómo Cassandra usa la replicación de datos entre los nodos de un clúster para garantizar que no haya un solo punto de falla.
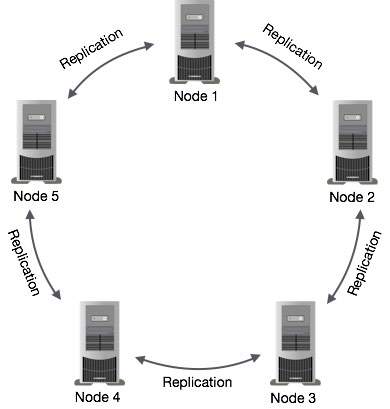
Note - Cassandra usa el Gossip Protocol en segundo plano para permitir que los nodos se comuniquen entre sí y detecten cualquier nodo defectuoso en el clúster.
Componentes de Cassandra
Los componentes clave de Cassandra son los siguientes:
Node - Es el lugar donde se almacenan los datos.
Data center - Es una colección de nodos relacionados.
Cluster - Un clúster es un componente que contiene uno o más centros de datos.
Commit log- El registro de confirmación es un mecanismo de recuperación de fallos en Cassandra. Cada operación de escritura se escribe en el registro de confirmación.
Mem-table- Una tabla de memoria es una estructura de datos residente en memoria. Después del registro de confirmación, los datos se escribirán en la tabla de memoria. A veces, para una familia de una sola columna, habrá varias mem-tables.
SSTable - Es un archivo de disco al que se vacían los datos de la tabla de memoria cuando su contenido alcanza un valor umbral.
Bloom filter- Estos no son más que algoritmos rápidos, no deterministas, para probar si un elemento es miembro de un conjunto. Es un tipo especial de caché. Se accede a los filtros Bloom después de cada consulta.
Lenguaje de consulta de Cassandra
Los usuarios pueden acceder a Cassandra a través de sus nodos utilizando Cassandra Query Language (CQL). CQL trata la base de datos(Keyspace)como contenedor de mesas. Los programadores utilizancqlsh: un mensaje para trabajar con CQL o controladores de idioma de aplicaciones independientes.
Los clientes se acercan a cualquiera de los nodos para sus operaciones de lectura y escritura. Ese nodo (coordinador) juega un proxy entre el cliente y los nodos que contienen los datos.
Operaciones de escritura
Cada actividad de escritura de los nodos es capturada por el commit logsescrito en los nodos. Posteriormente los datos serán capturados y almacenados en elmem-table. Siempre que la tabla de memoria esté llena, los datos se escribirán en el SStablearchivo de datos. Todas las escrituras se particionan y replican automáticamente en todo el clúster. Cassandra consolida periódicamente las SSTables, descartando los datos innecesarios.
Leer operaciones
Durante las operaciones de lectura, Cassandra obtiene valores de la tabla de memoria y comprueba el filtro de floración para encontrar la SSTable adecuada que contenga los datos necesarios.
El modelo de datos de Cassandra es significativamente diferente de lo que normalmente vemos en un RDBMS. Este capítulo proporciona una descripción general de cómo Cassandra almacena sus datos.
Racimo
La base de datos de Cassandra se distribuye en varias máquinas que operan juntas. El contenedor más externo se conoce como Cluster. Para el manejo de fallas, cada nodo contiene una réplica y, en caso de falla, la réplica se hace cargo. Cassandra organiza los nodos en un clúster, en un formato de anillo, y les asigna datos.
Espacio de claves
Keyspace es el contenedor más externo de datos en Cassandra. Los atributos básicos de un espacio de claves en Cassandra son:
Replication factor - Es la cantidad de máquinas en el clúster que recibirán copias de los mismos datos.
Replica placement strategy- No es más que la estrategia de colocar réplicas en el ring. Contamos con estrategias comosimple strategy (estrategia basada en rack), old network topology strategy (estrategia de reconocimiento de rack), y network topology strategy (estrategia de centro de datos compartido).
Column families- Keyspace es un contenedor para una lista de una o más familias de columnas. Una familia de columnas, a su vez, es un contenedor de una colección de filas. Cada fila contiene columnas ordenadas. Las familias de columnas representan la estructura de sus datos. Cada espacio de teclas tiene al menos una y, a menudo, muchas familias de columnas.
La sintaxis para crear un espacio de claves es la siguiente:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};La siguiente ilustración muestra una vista esquemática de un espacio de claves.
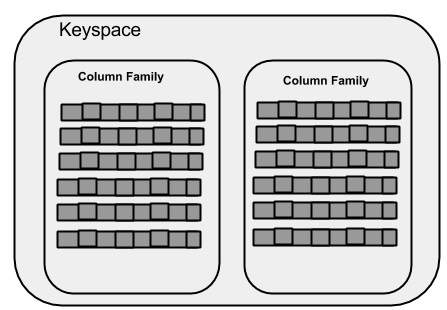
Familia de columnas
Una familia de columnas es un contenedor para una colección ordenada de filas. Cada fila, a su vez, es una colección ordenada de columnas. La siguiente tabla enumera los puntos que diferencian una familia de columnas de una tabla de bases de datos relacionales.
| Tabla relacional | Familia de columnas Cassandra |
|---|---|
| Un esquema en un modelo relacional es fijo. Una vez que definimos ciertas columnas para una tabla, al insertar datos, en cada fila todas las columnas deben llenarse al menos con un valor nulo. | En Cassandra, aunque las familias de columnas están definidas, las columnas no. Puede agregar libremente cualquier columna a cualquier familia de columnas en cualquier momento. |
| Las tablas relacionales definen solo columnas y el usuario completa la tabla con valores. | En Cassandra, una tabla contiene columnas o se puede definir como una superfamilia de columnas. |
Una familia de columnas Cassandra tiene los siguientes atributos:
keys_cached - Representa el número de ubicaciones para mantener en caché por SSTable.
rows_cached - Representa la cantidad de filas cuyo contenido completo se almacenará en la memoria caché.
preload_row_cache - Especifica si desea rellenar previamente la caché de filas.
Note − A diferencia de las tablas relacionales en las que el esquema de una familia de columnas no es fijo, Cassandra no obliga a las filas individuales a tener todas las columnas.
La siguiente figura muestra un ejemplo de una familia de columnas Cassandra.
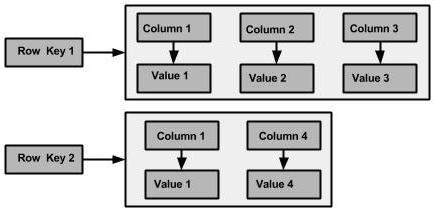
Columna
Una columna es la estructura de datos básica de Cassandra con tres valores, a saber, el nombre de la clave o columna, el valor y una marca de tiempo. A continuación se muestra la estructura de una columna.

Supercolumna
Una supercolumna es una columna especial, por lo tanto, también es un par clave-valor. Pero una supercolumna almacena un mapa de subcolumnas.
Generalmente, las familias de columnas se almacenan en el disco en archivos individuales. Por lo tanto, para optimizar el rendimiento, es importante mantener las columnas que probablemente consultará juntas en la misma familia de columnas, y una súper columna puede ser útil aquí. A continuación se muestra la estructura de una súper columna.

Modelos de datos de Cassandra y RDBMS
La siguiente tabla enumera los puntos que diferencian el modelo de datos de Cassandra del de un RDBMS.
| RDBMS | Casandra |
|---|---|
| RDBMS se ocupa de datos estructurados. | Cassandra se ocupa de datos no estructurados. |
| Tiene un esquema fijo. | Cassandra tiene un esquema flexible. |
| En RDBMS, una tabla es una matriz de matrices. (FILA x COLUMNA) | En Cassandra, una tabla es una lista de "pares clave-valor anidados". (ROW x COLUMN key x COLUMN value) |
| La base de datos es el contenedor más externo que contiene los datos correspondientes a una aplicación. | Keyspace es el contenedor más externo que contiene datos correspondientes a una aplicación. |
| Las tablas son las entidades de una base de datos. | Las tablas o familias de columnas son la entidad de un espacio de claves. |
| Row es un registro individual en RDBMS. | Row es una unidad de replicación en Cassandra. |
| La columna representa los atributos de una relación. | La columna es una unidad de almacenamiento en Cassandra. |
| RDBMS admite los conceptos de claves foráneas, uniones. | Las relaciones se representan mediante colecciones. |
Se puede acceder a Cassandra utilizando cqlsh, así como controladores de diferentes idiomas. Este capítulo explica cómo configurar los entornos cqlsh y java para trabajar con Cassandra.
Configuración previa a la instalación
Antes de instalar Cassandra en un entorno Linux, necesitamos configurar Linux usando ssh(Cubierta segura). Siga los pasos que se indican a continuación para configurar el entorno Linux.
Crear un usuario
Al principio, se recomienda crear un usuario separado para Hadoop para aislar el sistema de archivos Hadoop del sistema de archivos Unix. Siga los pasos que se indican a continuación para crear un usuario.
Abra la raíz usando el comando “su”.
Cree un usuario desde la cuenta raíz usando el comando “useradd username”.
Ahora puede abrir una cuenta de usuario existente usando el comando “su username”.
Abra la terminal de Linux y escriba los siguientes comandos para crear un usuario.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfiguración de SSH y generación de claves
La configuración de SSH es necesaria para realizar diferentes operaciones en un clúster, como iniciar, detener y distribuir operaciones de shell de demonio. Para autenticar diferentes usuarios de Hadoop, es necesario proporcionar un par de claves pública / privada para un usuario de Hadoop y compartirlo con diferentes usuarios.
Los siguientes comandos se utilizan para generar un par clave-valor mediante SSH:
- copie el formulario de claves públicas id_rsa.pub a allowed_keys,
- y proporcionar propietario,
- permisos de lectura y escritura en el archivo Authorized_keys respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys- Verificar ssh:
ssh localhostInstalación de Java
Java es el principal requisito previo para Cassandra. En primer lugar, debe verificar la existencia de Java en su sistema usando el siguiente comando:
$ java -versionSi todo funciona bien, le dará el siguiente resultado.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Si no tiene Java en su sistema, siga los pasos que se indican a continuación para instalar Java.
Paso 1
Descargue java (JDK <última versión> - X64.tar.gz) desde el siguiente enlace:
Then jdk-7u71-linux-x64.tar.gz will be downloaded onto your system.
Paso 2
Generalmente, encontrará el archivo java descargado en la carpeta Descargas. Verifíquelo y extraiga eljdk-7u71-linux-x64.gz archivo usando los siguientes comandos.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzPaso 3
Para que Java esté disponible para todos los usuarios, debe moverlo a la ubicación “/ usr / local /”. Abra root y escriba los siguientes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitEtapa 4
Para configurar PATH y JAVA_HOME variables, agregue los siguientes comandos a ~/.bashrc archivo.
export JAVA_HOME = /usr/local/jdk1.7.0_71
export PATH = $PATH:$JAVA_HOME/binAhora aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcPaso 5
Utilice los siguientes comandos para configurar alternativas de Java.
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarAhora usa el java -version comando desde el terminal como se explicó anteriormente.
Marcando el camino
Establezca la ruta de la ruta de Cassandra en “/.bashrc” como se muestra a continuación.
[hadoop@linux ~]$ gedit ~/.bashrc
export CASSANDRA_HOME = ~/cassandra
export PATH = $PATH:$CASSANDRA_HOME/binDescarga Cassandra
Apache Cassandra está disponible en Download Link Cassandra usando el siguiente comando.
$ wget http://supergsego.com/apache/cassandra/2.1.2/apache-cassandra-2.1.2-bin.tar.gzDescomprima Cassandra usando el comando zxvf Como se muestra abajo.
$ tar zxvf apache-cassandra-2.1.2-bin.tar.gz.Cree un nuevo directorio llamado cassandra y mueva el contenido del archivo descargado a él como se muestra a continuación.
$ mkdir Cassandra $ mv apache-cassandra-2.1.2/* cassandra.Configurar Cassandra
Abre el cassandra.yaml: archivo, que estará disponible en el bin directorio de Cassandra.
$ gedit cassandra.yamlNote - Si ha instalado Cassandra desde un paquete deb o rpm, los archivos de configuración se ubicarán en /etc/cassandra directorio de Cassandra.
El comando anterior abre el cassandra.yamlarchivo. Verifique las siguientes configuraciones. De forma predeterminada, estos valores se establecerán en los directorios especificados.
data_file_directories “/var/lib/cassandra/data”
commitlog_directory “/var/lib/cassandra/commitlog”
directorio_cachés_guardado “/var/lib/cassandra/saved_caches”
Asegúrese de que estos directorios existan y se puedan escribir en ellos, como se muestra a continuación.
Crear directorios
Como superusuario, crea los dos directorios /var/lib/cassandra y /var./log/cassandra en el que Cassandra escribe sus datos.
[root@linux cassandra]# mkdir /var/lib/cassandra
[root@linux cassandra]# mkdir /var/log/cassandraDar permisos a carpetas
Otorgue permisos de lectura y escritura a las carpetas recién creadas como se muestra a continuación.
[root@linux /]# chmod 777 /var/lib/cassandra
[root@linux /]# chmod 777 /var/log/cassandraInicio Cassandra
Para iniciar Cassandra, abra la ventana de terminal, navegue hasta el directorio de inicio de Cassandra / inicio, donde desempaquetó Cassandra, y ejecute el siguiente comando para iniciar su servidor Cassandra.
$ cd $CASSANDRA_HOME $./bin/cassandra -fEl uso de la opción –f le dice a Cassandra que permanezca en primer plano en lugar de ejecutarse como un proceso en segundo plano. Si todo va bien, puede ver que se inicia el servidor Cassandra.
Entorno de programación
Para configurar Cassandra mediante programación, descargue los siguientes archivos jar:
- slf4j-api-1.7.5.jar
- cassandra-driver-core-2.0.2.jar
- guava-16.0.1.jar
- metrics-core-3.0.2.jar
- netty-3.9.0.Final.jar
Colócalos en una carpeta separada. Por ejemplo, estamos descargando estos frascos en una carpeta llamada“Cassandra_jars”.
Establezca la ruta de clase para esta carpeta en “.bashrc”archivo como se muestra a continuación.
[hadoop@linux ~]$ gedit ~/.bashrc //Set the following class path in the .bashrc file. export CLASSPATH = $CLASSPATH:/home/hadoop/Cassandra_jars/*Entorno Eclipse
Abra Eclipse y cree un nuevo proyecto llamado Cassandra _Examples.
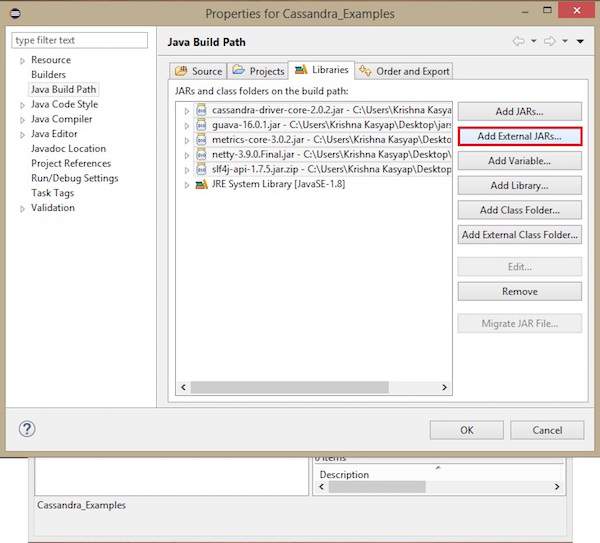
Haga clic derecho en el proyecto, seleccione Build Path→Configure Build Path Como se muestra abajo.
Abrirá la ventana de propiedades. En la pestaña Bibliotecas, seleccioneAdd External JARs. Navegue hasta el directorio donde guardó sus archivos jar. Seleccione los cinco archivos jar y haga clic en Aceptar como se muestra a continuación.
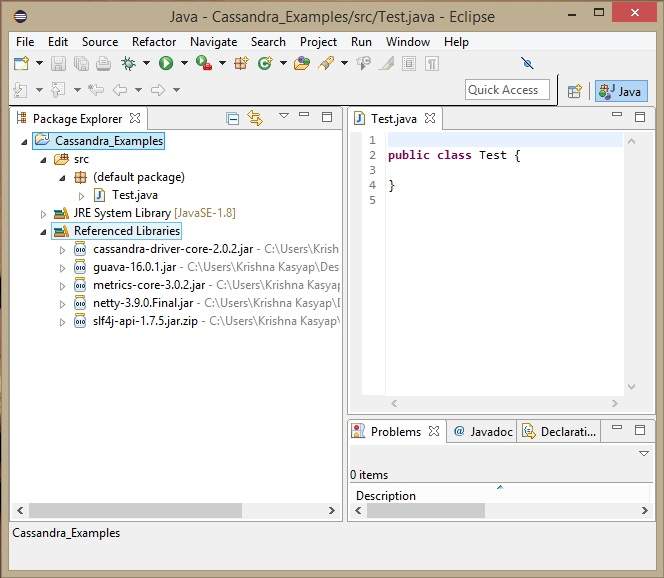
En Bibliotecas de referencia, puede ver todos los frascos necesarios agregados como se muestra a continuación:
Dependencias de Maven
A continuación se muestra el pom.xml para construir un proyecto de Cassandra usando maven.
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.9.0.Final</version>
</dependency>
</dependencies>
</project>Este capítulo cubre todas las clases importantes de Cassandra.
Racimo
Esta clase es el principal punto de entrada del conductor. Pertenece acom.datastax.driver.core paquete.
Métodos
| S. No. | Métodos y descripción |
|---|---|
| 1 | Session connect() Crea una nueva sesión en el clúster actual y la inicializa. |
| 2 | void close() Se utiliza para cerrar la instancia del clúster. |
| 3 | static Cluster.Builder builder() Se utiliza para crear una nueva instancia de Cluster.Builder. |
Cluster.Builder
Esta clase se usa para instanciar el Cluster.Builder clase.
Métodos
| S. No | Métodos y descripción |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) Este método agrega un punto de contacto al clúster. |
| 2 | Cluster build() Este método construye el clúster con los puntos de contacto dados. |
Sesión
Esta interfaz contiene las conexiones al clúster de Cassandra. Con esta interfaz, puede ejecutarCQLconsultas. Pertenece acom.datastax.driver.core paquete.
Métodos
| S. No. | Métodos y descripción |
|---|---|
| 1 | void close() Este método se utiliza para cerrar la instancia de sesión actual. |
| 2 | ResultSet execute(Statement statement) Este método se utiliza para ejecutar una consulta. Requiere un objeto de declaración. |
| 3 | ResultSet execute(String query) Este método se utiliza para ejecutar una consulta. Requiere una consulta en forma de objeto String. |
| 4 | PreparedStatement prepare(RegularStatement statement) Este método prepara la consulta proporcionada. La consulta se proporcionará en forma de declaración. |
| 5 | PreparedStatement prepare(String query) Este método prepara la consulta proporcionada. La consulta debe proporcionarse en forma de cadena. |
Este capítulo presenta el shell del lenguaje de consulta de Cassandra y explica cómo usar sus comandos.
De forma predeterminada, Cassandra proporciona un shell de lenguaje de consulta de Cassandra rápido (cqlsh)que permite a los usuarios comunicarse con él. Usando este shell, puede ejecutarCassandra Query Language (CQL).
Usando cqlsh, puede
- definir un esquema,
- insertar datos y
- ejecutar una consulta.
Iniciando cqlsh
Inicie cqlsh usando el comando cqlshComo se muestra abajo. Da el indicador de Cassandra cqlsh como salida.
[hadoop@linux bin]$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>Cqlsh- Como se mencionó anteriormente, este comando se usa para iniciar el indicador cqlsh. Además, también admite algunas opciones más. La siguiente tabla explica todas las opciones decqlsh y su uso.
| Opciones | Uso |
|---|---|
| cqlsh --ayuda | Muestra temas de ayuda sobre las opciones de cqlsh comandos. |
| cqlsh --versión | Proporciona la versión de cqlsh que está utilizando. |
| cqlsh --color | Dirige al shell para que utilice la salida en color. |
| cqlsh --debug | Muestra información adicional de depuración. |
| cqlsh --execute cql_statement |
Indica al shell que acepte y ejecute un comando CQL. |
| cqlsh --file = “file name” | Si usa esta opción, Cassandra ejecuta el comando en el archivo dado y sale. |
| cqlsh --no-color | Indica a Cassandra que no utilice la salida en color. |
| cqlsh -u “user name” | Con esta opción, puede autenticar a un usuario. El nombre de usuario predeterminado es: cassandra. |
| cqlsh-p “pass word” | Con esta opción, puede autenticar a un usuario con una contraseña. La contraseña predeterminada es: cassandra. |
Comandos Cqlsh
Cqlsh tiene algunos comandos que permiten a los usuarios interactuar con él. Los comandos se enumeran a continuación.
Comandos de shell documentados
A continuación se muestran los comandos de shell documentados de Cqlsh. Estos son los comandos que se utilizan para realizar tareas como mostrar temas de ayuda, salir de cqlsh, describir, etc.
HELP - Muestra temas de ayuda para todos los comandos cqlsh.
CAPTURE - Captura el resultado de un comando y lo agrega a un archivo.
CONSISTENCY - Muestra el nivel de coherencia actual o establece un nuevo nivel de coherencia.
COPY - Copia datos hacia y desde Cassandra.
DESCRIBE - Describe el grupo actual de Cassandra y sus objetos.
EXPAND - Expande la salida de una consulta verticalmente.
EXIT - Con este comando, puede terminar cqlsh.
PAGING - Habilita o deshabilita la paginación de consultas.
SHOW - Muestra los detalles de la sesión cqlsh actual, como la versión de Cassandra, el host o los supuestos de tipo de datos.
SOURCE - Ejecuta un archivo que contiene declaraciones CQL.
TRACING - Habilita o deshabilita el seguimiento de solicitudes.
Comandos de definición de datos CQL
CREATE KEYSPACE - Crea un KeySpace en Cassandra.
USE - Se conecta a un KeySpace creado.
ALTER KEYSPACE - Cambia las propiedades de un KeySpace.
DROP KEYSPACE - Elimina un KeySpace
CREATE TABLE - Crea una tabla en un KeySpace.
ALTER TABLE - Modifica las propiedades de columna de una tabla.
DROP TABLE - Quita una mesa.
TRUNCATE - Elimina todos los datos de una tabla.
CREATE INDEX - Define un nuevo índice en una sola columna de una tabla.
DROP INDEX - Elimina un índice con nombre.
Comandos de manipulación de datos CQL
INSERT - Agrega columnas para una fila en una tabla.
UPDATE - Actualiza una columna de una fila.
DELETE - Elimina datos de una tabla.
BATCH - Ejecuta varias declaraciones DML a la vez.
Cláusulas CQL
SELECT - Esta cláusula lee datos de una tabla
WHERE - La cláusula where se usa junto con select para leer datos específicos.
ORDERBY - La cláusula orderby se usa junto con select para leer datos específicos en un orden específico.
Cassandra proporciona comandos de shell documentados además de los comandos CQL. A continuación se muestran los comandos de shell documentados de Cassandra.
Ayuda
El comando HELP muestra una sinopsis y una breve descripción de todos los comandos cqlsh. A continuación se muestra el uso del comando de ayuda.
cqlsh> help
Documented shell commands:
===========================
CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
CONSISTENCY DESC EXIT HELP SHOW TRACING.
CQL help topics:
================
ALTER CREATE_TABLE_OPTIONS SELECT
ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
ALTER_ALTER CREATE_USER SELECT_EXPR
ALTER_DROP DELETE SELECT_LIMIT
ALTER_RENAME DELETE_COLUMNS SELECT_TABLECapturar
Este comando captura el resultado de un comando y lo agrega a un archivo. Por ejemplo, eche un vistazo al siguiente código que captura la salida en un archivo llamadoOutputfile.
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'Cuando escribimos cualquier comando en la terminal, la salida será capturada por el archivo dado. A continuación se muestra el comando utilizado y la instantánea del archivo de salida.
cqlsh:tutorialspoint> select * from emp;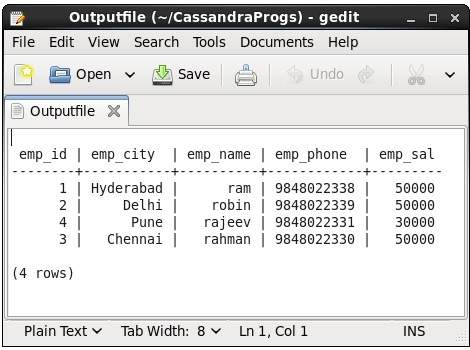
Puede desactivar la captura con el siguiente comando.
cqlsh:tutorialspoint> capture off;Consistencia
Este comando muestra el nivel de coherencia actual o establece un nuevo nivel de coherencia.
cqlsh:tutorialspoint> CONSISTENCY
Current consistency level is 1.Copiar
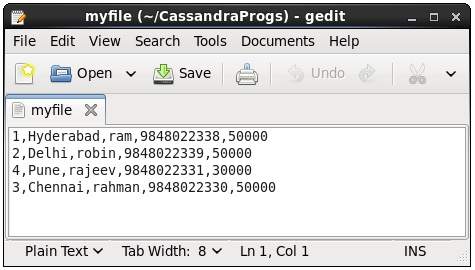
Este comando copia datos ay desde Cassandra a un archivo. A continuación se muestra un ejemplo para copiar la tabla denominadaemp al archivo myfile.
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.Si abre y verifica el archivo proporcionado, puede encontrar los datos copiados como se muestra a continuación.
Describir
Este comando describe el grupo actual de Cassandra y sus objetos. Las variantes de este comando se explican a continuación.
Describe cluster - Este comando proporciona información sobre el clúster.
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]Describe Keyspaces- Este comando enumera todos los espacios de claves en un clúster. A continuación se muestra el uso de este comando.
cqlsh:tutorialspoint> describe keyspaces;
system_traces system tp tutorialspointDescribe tables- Este comando enumera todas las tablas en un espacio de teclas. A continuación se muestra el uso de este comando.
cqlsh:tutorialspoint> describe tables;
empDescribe table- Este comando proporciona la descripción de una tabla. A continuación se muestra el uso de este comando.
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);Describe el tipo
Este comando se utiliza para describir un tipo de datos definido por el usuario. A continuación se muestra el uso de este comando.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Describir tipos
Este comando enumera todos los tipos de datos definidos por el usuario. A continuación se muestra el uso de este comando. Suponga que hay dos tipos de datos definidos por el usuario:card y card_details.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardExpandir
Este comando se usa para expandir la salida. Antes de usar este comando, debe activar el comando expandir. A continuación se muestra el uso de este comando.
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)Note - Puede desactivar la opción de expansión con el siguiente comando.
cqlsh:tutorialspoint> expand off;
Disabled Expanded output.Salida
Este comando se usa para terminar el shell cql.
mostrar
Este comando muestra los detalles de la sesión cqlsh actual, como la versión de Cassandra, el host o los supuestos de tipo de datos. A continuación se muestra el uso de este comando.
cqlsh:tutorialspoint> show host;
Connected to Test Cluster at 127.0.0.1:9042.
cqlsh:tutorialspoint> show version;
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]Fuente
Con este comando, puede ejecutar los comandos en un archivo. Supongamos que nuestro archivo de entrada es el siguiente:
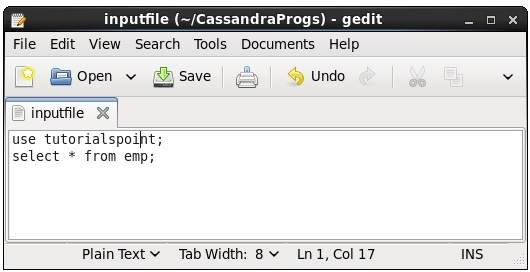
Luego puede ejecutar el archivo que contiene los comandos como se muestra a continuación.
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)Creando un espacio de claves usando Cqlsh
Un espacio de claves en Cassandra es un espacio de nombres que define la replicación de datos en los nodos. Un clúster contiene un espacio de claves por nodo. A continuación se muestra la sintaxis para crear un espacio de claves utilizando la declaraciónCREATE KEYSPACE.
Sintaxis
CREATE KEYSPACE <identifier> WITH <properties>es decir
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}
AND durable_writes = ‘Boolean value’;La instrucción CREATE KEYSPACE tiene dos propiedades: replication y durable_writes.
Replicación
La opción de replicación es especificar el Replica Placement strategyy el número de réplicas deseadas. La siguiente tabla enumera todas las estrategias de ubicación de réplicas.
| Nombre de la estrategia | Descripción |
|---|---|
| Simple Strategy' | Especifica un factor de replicación simple para el clúster. |
| Network Topology Strategy | Con esta opción, puede establecer el factor de replicación para cada centro de datos de forma independiente. |
| Old Network Topology Strategy | Esta es una estrategia de replicación heredada. |
Con esta opción, puede indicarle a Cassandra si debe usar commitlogpara obtener actualizaciones sobre el KeySpace actual. Esta opción no es obligatoria y, de forma predeterminada, está establecida en true.
Ejemplo
A continuación se muestra un ejemplo de creación de un KeySpace.
Aquí estamos creando un KeySpace llamado TutorialsPoint.
Estamos utilizando la primera estrategia de colocación de réplicas, es decir, Simple Strategy.
Y estamos eligiendo el factor de replicación para 1 replica.
cqlsh.> CREATE KEYSPACE tutorialspoint
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};Verificación
Puede verificar si la tabla se crea o no usando el comando Describe. Si usa este comando sobre espacios de teclas, mostrará todos los espacios de teclas creados como se muestra a continuación.
cqlsh> DESCRIBE keyspaces;
tutorialspoint system system_tracesAquí puede observar el KeySpace recién creado tutorialspoint.
Durable_writes
De forma predeterminada, las propiedades durable_writes de una tabla se establecen en true,sin embargo, se puede establecer en falso. No puede establecer esta propiedad ensimplex strategy.
Ejemplo
A continuación se muestra el ejemplo que demuestra el uso de la propiedad de escritura duradera.
cqlsh> CREATE KEYSPACE test
... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
... AND DURABLE_WRITES = false;Verificación
Puede verificar si la propiedad durable_writes del KeySpace de prueba se estableció en falso consultando el System Keyspace. Esta consulta le proporciona todos los KeySpaces junto con sus propiedades.
cqlsh> SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}
(4 rows)Aquí puede observar que la propiedad durable_writes de la prueba KeySpace se estableció en falso.
Usando un espacio de claves
Puede usar un KeySpace creado usando la palabra clave USE. Su sintaxis es la siguiente:
Syntax:USE <identifier>Ejemplo
En el siguiente ejemplo, estamos usando KeySpace tutorialspoint.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>Creación de un espacio de claves mediante la API de Java
Puede crear un espacio de claves utilizando el execute() método de Sessionclase. Siga los pasos que se indican a continuación para crear un espacio de claves utilizando la API de Java.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster en una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Crea una instancia de Session objeto usando el connect() método de Cluster clase como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );Paso 3: ejecutar la consulta
Puedes ejecutar CQL consultas utilizando el execute() método de Sessionclase. Pase la consulta en formato de cadena o comoStatement objeto de clase al execute()método. Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En este ejemplo, estamos creando un KeySpace llamado tp. Estamos utilizando la primera estrategia de colocación de réplicas, es decir, estrategia simple, y estamos eligiendo el factor de réplica para 1 réplica.
Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";
session.execute(query);Paso 4: Utilice el KeySpace
Puede usar un KeySpace creado usando el método execute () como se muestra a continuación.
execute(“ USE tp ” );A continuación se muestra el programa completo para crear y usar un espacio de claves en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_KeySpace {
public static void main(String args[]){
//Query
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1};";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
//using the KeySpace
session.execute("USE tp");
System.out.println("Keyspace created");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Create_KeySpace.java
$java Create_KeySpaceEn condiciones normales, producirá la siguiente salida:
Keyspace createdModificar un espacio clave
ALTER KEYSPACE se puede utilizar para alterar propiedades como el número de réplicas y durable_writes de un KeySpace. A continuación se muestra la sintaxis de este comando.
Sintaxis
ALTER KEYSPACE <identifier> WITH <properties>es decir
ALTER KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};Las propiedades de ALTER KEYSPACEson los mismos que CREATE KEYSPACE. Tiene dos propiedades:replication y durable_writes.
Replicación
La opción de replicación especifica la estrategia de ubicación de la réplica y el número de réplicas deseadas.
Durable_writes
Con esta opción, puede indicarle a Cassandra si debe usar el registro de confirmación para las actualizaciones del KeySpace actual. Esta opción no es obligatoria y, de forma predeterminada, está establecida en true.
Ejemplo
A continuación se muestra un ejemplo de alteración de un KeySpace.
Aquí estamos alterando un KeySpace llamado TutorialsPoint.
Estamos cambiando el factor de replicación de 1 a 3.
cqlsh.> ALTER KEYSPACE tutorialspoint
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};Modificación de Durable_writes
También puede modificar la propiedad durable_writes de un KeySpace. A continuación se muestra la propiedad durable_writes deltest KeySpace.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)ALTER KEYSPACE test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = true;Una vez más, si verifica las propiedades de KeySpaces, producirá el siguiente resultado.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)Modificación de un espacio de claves mediante la API de Java
Puede modificar un espacio de teclas utilizando el execute() método de Sessionclase. Siga los pasos que se indican a continuación para modificar un espacio de claves utilizando la API de Java
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Crea una instancia de Session objeto usando el connect() método de Clusterclase como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o comoStatementobjeto de clase al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En este ejemplo,
Estamos alterando un espacio de teclas llamado tp. Estamos modificando la opción de replicación de estrategia simple a estrategia de topología de red.
Estamos alterando el durable_writes a falso
Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";
session.execute(query);A continuación se muestra el programa completo para crear y usar un espacio de claves en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Alter_KeySpace {
public static void main(String args[]){
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"
+ "AND DURABLE_WRITES = false;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace altered");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Alter_KeySpace.java
$java Alter_KeySpaceEn condiciones normales, produce la siguiente salida:
Keyspace AlteredDejar caer un espacio de claves
Puede soltar un KeySpace usando el comando DROP KEYSPACE. A continuación se muestra la sintaxis para soltar un KeySpace.
Sintaxis
DROP KEYSPACE <identifier>es decir
DROP KEYSPACE “KeySpace name”Ejemplo
El siguiente código elimina el espacio de claves tutorialspoint.
cqlsh> DROP KEYSPACE tutorialspoint;Verificación
Verifique los espacios de teclas con el comando Describe y compruebe si la tabla se ha eliminado como se muestra a continuación.
cqlsh> DESCRIBE keyspaces;
system system_tracesDado que hemos eliminado el punto de tutoría del espacio de claves, no lo encontrará en la lista de espacios de claves.
Descartar un espacio de claves usando la API de Java
Puede crear un espacio de claves utilizando el método execute () de la clase Session. Siga los pasos que se indican a continuación para soltar un espacio de claves utilizando la API de Java.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en cqlsh.
En el siguiente ejemplo, estamos eliminando un espacio de teclas llamado tp. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
String query = "DROP KEYSPACE tp; ";
session.execute(query);A continuación se muestra el programa completo para crear y usar un espacio de claves en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_KeySpace {
public static void main(String args[]){
//Query
String query = "Drop KEYSPACE tp";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace deleted");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Delete_KeySpace.java
$java Delete_KeySpaceEn condiciones normales, debería producir el siguiente resultado:
Keyspace deletedCrear una tabla
Puedes crear una tabla usando el comando CREATE TABLE. A continuación se muestra la sintaxis para crear una tabla.
Sintaxis
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)Definición de una columna
Puede definir una columna como se muestra a continuación.
column name1 data type,
column name2 data type,
example:
age int,
name textClave primaria
La clave principal es una columna que se utiliza para identificar de forma exclusiva una fila. Por lo tanto, definir una clave principal es obligatorio al crear una tabla. Una clave primaria está formada por una o más columnas de una tabla. Puede definir una clave principal de una tabla como se muestra a continuación.
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type.
)or
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type,
PRIMARY KEY (column1)
)Ejemplo
A continuación se muestra un ejemplo para crear una tabla en Cassandra usando cqlsh. Aquí estamos
Uso del punto de tutoriales del espacio de claves
Creando una tabla llamada emp
Tendrá detalles como el nombre del empleado, identificación, ciudad, salario y número de teléfono. La identificación del empleado es la clave principal.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>; CREATE TABLE emp(
emp_id int PRIMARY KEY,
emp_name text,
emp_city text,
emp_sal varint,
emp_phone varint
);Verificación
La declaración de selección le dará el esquema. Verifique la tabla usando la declaración de selección como se muestra a continuación.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Aquí puede observar la tabla creada con las columnas dadas. Dado que hemos eliminado el punto de tutoría del espacio de claves, no lo encontrará en la lista de espacios de claves.
Crear una tabla usando la API de Java
Puede crear una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para crear una tabla utilizando la API de Java.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia del Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session usando el connect() método de Cluster clase como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );Aquí estamos usando el espacio de teclas llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“ tp” );Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en cqlsh.
En el siguiente ejemplo, estamos creando una tabla llamada emp. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
session.execute(query);A continuación se muestra el programa completo para crear y usar un espacio de claves en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Table {
public static void main(String args[]){
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table created");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Create_Table.java
$java Create_TableEn condiciones normales, debería producir el siguiente resultado:
Table createdModificar una tabla
Puedes alterar una tabla usando el comando ALTER TABLE. A continuación se muestra la sintaxis para crear una tabla.
Sintaxis
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>Usando el comando ALTER, puede realizar las siguientes operaciones:
Agregar una columna
Suelta una columna
Agregar una columna
Usando el comando ALTER, puede agregar una columna a una tabla. Al agregar columnas, debe tener cuidado de que el nombre de la columna no entre en conflicto con los nombres de columna existentes y de que la tabla no esté definida con la opción de almacenamiento compacto. A continuación se muestra la sintaxis para agregar una columna a una tabla.
ALTER TABLE table name
ADD new column datatype;Example
A continuación se muestra un ejemplo para agregar una columna a una tabla existente. Aquí estamos agregando una columna llamadaemp_email del tipo de datos de texto a la tabla denominada emp.
cqlsh:tutorialspoint> ALTER TABLE emp
... ADD emp_email text;Verification
Utilice la instrucción SELECT para verificar si la columna se agrega o no. Aquí puede observar la columna emp_email recién agregada.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal
--------+----------+-----------+----------+-----------+---------Dejar caer una columna
Usando el comando ALTER, puede eliminar una columna de una tabla. Antes de eliminar una columna de una tabla, verifique que la tabla no esté definida con la opción de almacenamiento compacto. A continuación se muestra la sintaxis para eliminar una columna de una tabla usando el comando ALTER.
ALTER table name
DROP column name;Example
A continuación se muestra un ejemplo para eliminar una columna de una tabla. Aquí estamos eliminando la columna llamadaemp_email.
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;Verification
Verifique si la columna se elimina usando el select declaración, como se muestra a continuación.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Ya que emp_email La columna ha sido eliminada, ya no puede encontrarla.
Modificar una tabla usando la API de Java
Puede crear una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para modificar una tabla con la API de Java.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos agregando una columna a una tabla llamada emp. Para hacerlo, debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
//Query
String query1 = "ALTER TABLE emp ADD emp_email text";
session.execute(query);A continuación se muestra el programa completo para agregar una columna a una tabla existente.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Add_column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp ADD emp_email text";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Column added");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Add_Column.java
$java Add_ColumnEn condiciones normales, debería producir el siguiente resultado:
Column addedEliminar una columna
A continuación se muestra el programa completo para eliminar una columna de una tabla existente.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp DROP emp_email;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//executing the query
session.execute(query);
System.out.println("Column deleted");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Delete_Column.java
$java Delete_ColumnEn condiciones normales, debería producir el siguiente resultado:
Column deletedDejar caer una mesa
Puedes soltar una tabla usando el comando Drop Table. Su sintaxis es la siguiente:
Sintaxis
DROP TABLE <tablename>Ejemplo
El siguiente código elimina una tabla existente de un KeySpace.
cqlsh:tutorialspoint> DROP TABLE emp;Verificación
Utilice el comando Describir para verificar si la tabla se elimina o no. Dado que la tabla emp ha sido eliminada, no la encontrará en la lista de familias de columnas.
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES;
employeeEliminar una tabla usando la API de Java
Puede eliminar una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para eliminar una tabla mediante la API de Java.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación -
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“Your keyspace name”);Aquí estamos usando el espacio de teclas llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“tp”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos eliminando una tabla llamada emp. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
// Query
String query = "DROP TABLE emp1;”;
session.execute(query);A continuación se muestra el programa completo para colocar una tabla en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Table {
public static void main(String args[]){
//Query
String query = "DROP TABLE emp1;";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table dropped");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Drop_Table.java
$java Drop_TableEn condiciones normales, debería producir el siguiente resultado:
Table droppedTruncar una tabla
Puede truncar una tabla usando el comando TRUNCATE. Cuando trunca una tabla, todas las filas de la tabla se eliminan de forma permanente. A continuación se muestra la sintaxis de este comando.
Sintaxis
TRUNCATE <tablename>Ejemplo
Supongamos que hay una tabla llamada student con los siguientes datos.
| s_id | nombre de | s_branch | s_aggregate |
|---|---|---|---|
| 1 | RAM | ESO | 70 |
| 2 | Rahman | EEE | 75 |
| 3 | robbin | Mech | 72 |
Cuando ejecuta la instrucción select para obtener la tabla student, le dará la siguiente salida.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
1 | 70 | IT | ram
2 | 75 | EEE | rahman
3 | 72 | MECH | robbin
(3 rows)Ahora trunca la tabla usando el comando TRUNCATE.
cqlsh:tp> TRUNCATE student;Verificación
Verifique si la tabla está truncada ejecutando el selectdeclaración. A continuación se muestra la salida de la declaración de selección en la tabla de estudiantes después de truncar.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
(0 rows)Truncar una tabla usando la API de Java
Puede truncar una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para truncar una tabla.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Aquí estamos usando el espacio de teclas llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos truncando una tabla llamada emp. Tienes que almacenar la consulta en una variable de cadena y pasarla alexecute() método como se muestra a continuación.
//Query
String query = "TRUNCATE emp;;”;
session.execute(query);A continuación se muestra el programa completo para truncar una tabla en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Truncate_Table {
public static void main(String args[]){
//Query
String query = "Truncate student;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table truncated");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Truncate_Table.java
$java Truncate_TableEn condiciones normales, debería producir el siguiente resultado:
Table truncatedCreando un índice usando Cqlsh
Puede crear un índice en Cassandra usando el comando CREATE INDEX. Su sintaxis es la siguiente:
CREATE INDEX <identifier> ON <tablename>A continuación se muestra un ejemplo para crear un índice para una columna. Aquí estamos creando un índice para una columna 'emp_name' en una tabla llamada emp.
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);Crear un índice usando la API de Java
Puede crear un índice para una columna de una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para crear un índice en una columna de una tabla.
Paso 1: crear un objeto de clúster
En primer lugar, cree una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session usando el método connect () de Cluster clase como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“ tp” );Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos creando un índice para una columna llamada emp_name, en una tabla llamada emp. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
session.execute(query);A continuación se muestra el programa completo para crear un índice de una columna en una tabla en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Index {
public static void main(String args[]){
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index created");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Create_Index.java
$java Create_IndexEn condiciones normales, debería producir el siguiente resultado:
Index createdDejar caer un índice
Puedes soltar un índice usando el comando DROP INDEX. Su sintaxis es la siguiente:
DROP INDEX <identifier>A continuación se muestra un ejemplo para colocar un índice de una columna en una tabla. Aquí estamos soltando el índice del nombre de la columna en la tabla emp.
cqlsh:tp> drop index name;Eliminar un índice usando la API de Java
Puede soltar un índice de una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para eliminar un índice de una tabla.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builder object. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“ tp” );Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o comoStatementobjeto de clase al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, descartamos un "nombre" de índice de empmesa. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
//Query
String query = "DROP INDEX user_name;";
session.execute(query);A continuación se muestra el programa completo para colocar un índice en Cassandra utilizando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Index {
public static void main(String args[]){
//Query
String query = "DROP INDEX user_name;";
//Creating cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index dropped");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Drop_index.java
$java Drop_indexEn condiciones normales, debería producir el siguiente resultado:
Index droppedUsar declaraciones por lotes
Utilizando BATCH,puede ejecutar múltiples declaraciones de modificación (insertar, actualizar, eliminar) simultáneamente. Su sintaxis es la siguiente:
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCHEjemplo
Suponga que hay una tabla en Cassandra llamada emp que tiene los siguientes datos:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | Robin | Delhi | 9848022339 | 50000 |
| 3 | Rahman | Chennai | 9848022330 | 45000 |
En este ejemplo, realizaremos las siguientes operaciones:
- Inserte una nueva fila con los siguientes detalles (4, rajeev, pune, 9848022331, 30000).
- Actualice el salario del empleado con la identificación de fila 3 a 50000.
- Elimina la ciudad del empleado con la identificación de fila 2.
Para realizar las operaciones anteriores de una sola vez, use el siguiente comando BATCH:
cqlsh:tutorialspoint> BEGIN BATCH
... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
... DELETE emp_city FROM emp WHERE emp_id = 2;
... APPLY BATCH;Verificación
Después de hacer cambios, verifique la tabla usando la instrucción SELECT. Debería producir el siguiente resultado:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Aquí puede observar la tabla con datos modificados.
Declaraciones por lotes utilizando la API de Java
Las sentencias por lotes se pueden escribir mediante programación en una tabla utilizando el método execute () de la clase Session. Siga los pasos que se indican a continuación para ejecutar varias declaraciones utilizando la declaración por lotes con la ayuda de la API de Java.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. Utilice el siguiente código para crear el objeto de clúster:
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ”);Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“tp”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En este ejemplo, realizaremos las siguientes operaciones:
- Inserte una nueva fila con los siguientes detalles (4, rajeev, pune, 9848022331, 30000).
- Actualice el salario del empleado con la identificación de fila 3 a 50000.
- Elimine la ciudad del empleado con la identificación de fila 2.
Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
DELETE emp_city FROM emp WHERE emp_id = 2;
APPLY BATCH;”;A continuación se muestra el programa completo para ejecutar múltiples declaraciones simultáneamente en una tabla en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Batch {
public static void main(String args[]){
//query
String query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,
emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"
+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"
+ "DELETE emp_city FROM emp WHERE emp_id = 2;"
+ "APPLY BATCH;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Changes done");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Batch.java
$java BatchEn condiciones normales, debería producir el siguiente resultado:
Changes doneCrear datos en una tabla
Puede insertar datos en las columnas de una fila en una tabla usando el comando INSERT. A continuación se muestra la sintaxis para crear datos en una tabla.
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>Ejemplo
Supongamos que hay una tabla llamada emp con columnas (emp_id, emp_name, emp_city, emp_phone, emp_sal) y debe insertar los siguientes datos en el emp mesa.
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | Robin | Hyderabad | 9848022339 | 40000 |
| 3 | Rahman | Chennai | 9848022330 | 45000 |
Utilice los comandos que se indican a continuación para completar la tabla con los datos necesarios.
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);Verificación
Después de insertar datos, use la instrucción SELECT para verificar si los datos se han insertado o no. Si verifica la tabla emp usando la instrucción SELECT, le dará la siguiente salida.
cqlsh:tutorialspoint> SELECT * FROM emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Hyderabad | robin | 9848022339 | 40000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Aquí puede observar que la tabla se ha llenado con los datos que insertamos.
Crear datos usando la API de Java
Puede crear datos en una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para crear datos en una tabla usando la API de Java.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. El siguiente código muestra cómo crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear un objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ” );Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“ tp” );Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o comoStatementobjeto de clase al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos insertando datos en una tabla llamada emp. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación.
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ;
String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ;
String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ;
session.execute(query1);
session.execute(query2);
session.execute(query3);A continuación se muestra el programa completo para insertar datos en una tabla en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Data {
public static void main(String args[]){
//queries
String query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;
String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal)"
+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;
String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query1);
session.execute(query2);
session.execute(query3);
System.out.println("Data created");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Create_Data.java
$java Create_DataEn condiciones normales, debería producir el siguiente resultado:
Data createdActualizar datos en una tabla
UPDATEes el comando utilizado para actualizar datos en una tabla. Las siguientes palabras clave se utilizan al actualizar datos en una tabla:
Where - Esta cláusula se utiliza para seleccionar la fila a actualizar.
Set - Establezca el valor con esta palabra clave.
Must - Incluye todas las columnas que componen la clave primaria.
Al actualizar filas, si una fila determinada no está disponible, ACTUALIZAR crea una nueva fila. A continuación se muestra la sintaxis del comando UPDATE:
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>Ejemplo
Suponga que hay una tabla llamada emp. Esta tabla almacena los detalles de los empleados de una determinada empresa y tiene los siguientes detalles:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | Robin | Hyderabad | 9848022339 | 40000 |
| 3 | Rahman | Chennai | 9848022330 | 45000 |
Actualicemos ahora emp_city de robin a Delhi, y su salario a 50000. A continuación se muestra la consulta para realizar las actualizaciones necesarias.
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id=2;Verificación
Utilice la instrucción SELECT para verificar si los datos se han actualizado o no. Si verifica la tabla emp usando la instrucción SELECT, producirá la siguiente salida.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Aquí puede observar que los datos de la tabla se han actualizado.
Actualización de datos mediante la API de Java
Puede actualizar datos en una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para actualizar los datos en una tabla usando la API de Java.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. Utilice el siguiente código para crear el objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name”);Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“tp”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos actualizando la tabla emp. Debe almacenar la consulta en una variable de cadena y pasarla al método execute () como se muestra a continuación:
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id = 2;” ;A continuación se muestra el programa completo para actualizar datos en una tabla usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Update_Data {
public static void main(String args[]){
//query
String query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data updated");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Update_Data.java
$java Update_DataEn condiciones normales, debería producir el siguiente resultado:
Data updatedLeer datos usando la cláusula de selección
La cláusula SELECT se usa para leer datos de una tabla en Cassandra. Con esta cláusula, puede leer una tabla completa, una sola columna o una celda en particular. A continuación se muestra la sintaxis de la cláusula SELECT.
SELECT FROM <tablename>Ejemplo
Suponga que hay una tabla en el espacio de teclas llamado emp con los siguientes detalles -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | Robin | nulo | 9848022339 | 50000 |
| 3 | Rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
El siguiente ejemplo muestra cómo leer una tabla completa usando la cláusula SELECT. Aquí estamos leyendo una tabla llamadaemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Lectura de columnas obligatorias
El siguiente ejemplo muestra cómo leer una columna en particular en una tabla.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Dónde cláusula
Usando la cláusula WHERE, puede poner una restricción en las columnas requeridas. Su sintaxis es la siguiente:
SELECT FROM <table name> WHERE <condition>;Note - Una cláusula WHERE se puede utilizar solo en las columnas que forman parte de la clave principal o que tienen un índice secundario.
En el siguiente ejemplo, estamos leyendo los detalles de un empleado cuyo salario es 50000. En primer lugar, establezca el índice secundario en la columna emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Leer datos usando la API de Java
Puede leer datos de una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para ejecutar varias declaraciones utilizando la declaración por lotes con la ayuda de la API de Java.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. Utilice el siguiente código para crear el objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“Your keyspace name”);Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“tp”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En este ejemplo, estamos recuperando los datos de empmesa. Almacene la consulta en una cadena y páselo al método execute () de la clase de sesión como se muestra a continuación.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Ejecute la consulta usando el método execute () de la clase Session.
Paso 4: Obtenga el objeto ResultSet
Las consultas seleccionadas devolverán el resultado en forma de ResultSet objeto, por lo tanto, almacene el resultado en el objeto de RESULTSET clase como se muestra a continuación.
ResultSet result = session.execute( );A continuación se muestra el programa completo para leer datos de una tabla.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Read_Data.java
$java Read_DataEn condiciones normales, debería producir el siguiente resultado:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Leer datos usando la cláusula de selección
La cláusula SELECT se usa para leer datos de una tabla en Cassandra. Con esta cláusula, puede leer una tabla completa, una sola columna o una celda en particular. A continuación se muestra la sintaxis de la cláusula SELECT.
SELECT FROM <tablename>Ejemplo
Suponga que hay una tabla en el espacio de teclas llamado emp con los siguientes detalles -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | Robin | nulo | 9848022339 | 50000 |
| 3 | Rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
El siguiente ejemplo muestra cómo leer una tabla completa usando la cláusula SELECT. Aquí estamos leyendo una tabla llamadaemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Lectura de columnas obligatorias
El siguiente ejemplo muestra cómo leer una columna en particular en una tabla.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Dónde cláusula
Usando la cláusula WHERE, puede poner una restricción en las columnas requeridas. Su sintaxis es la siguiente:
SELECT FROM <table name> WHERE <condition>;Note - Una cláusula WHERE se puede utilizar solo en las columnas que forman parte de la clave principal o que tienen un índice secundario.
En el siguiente ejemplo, estamos leyendo los detalles de un empleado cuyo salario es 50000. En primer lugar, establezca el índice secundario en la columna emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Leer datos usando la API de Java
Puede leer datos de una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para ejecutar varias declaraciones utilizando la declaración por lotes con la ayuda de la API de Java.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. Utilice el siguiente código para crear el objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect( );Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“Your keyspace name”);Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“tp”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En este ejemplo, estamos recuperando los datos de empmesa. Almacene la consulta en una cadena y páselo al método execute () de la clase de sesión como se muestra a continuación.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Ejecute la consulta usando el método execute () de la clase Session.
Paso 4: Obtenga el objeto ResultSet
Las consultas seleccionadas devolverán el resultado en forma de ResultSet objeto, por lo tanto, almacene el resultado en el objeto de RESULTSET clase como se muestra a continuación.
ResultSet result = session.execute( );A continuación se muestra el programa completo para leer datos de una tabla.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Read_Data.java
$java Read_DataEn condiciones normales, debería producir el siguiente resultado:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Eliminar datos de una tabla
Puede eliminar datos de una tabla usando el comando DELETE. Su sintaxis es la siguiente:
DELETE FROM <identifier> WHERE <condition>;Ejemplo
Supongamos que hay una mesa en Cassandra llamada emp teniendo los siguientes datos -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | RAM | Hyderabad | 9848022338 | 50000 |
| 2 | Robin | Hyderabad | 9848022339 | 40000 |
| 3 | Rahman | Chennai | 9848022330 | 45000 |
La siguiente declaración elimina la columna emp_sal de la última fila:
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;Verificación
Utilice la instrucción SELECT para verificar si los datos se han eliminado o no. Si verifica la tabla emp usando SELECT, producirá la siguiente salida:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | null
(3 rows)Dado que hemos eliminado el salario de Rahman, observará un valor nulo en lugar del salario.
Eliminar una fila completa
El siguiente comando elimina una fila completa de una tabla.
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;Verificación
Utilice la instrucción SELECT para verificar si los datos se han eliminado o no. Si verifica la tabla emp usando SELECT, producirá la siguiente salida:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
(2 rows)Como hemos eliminado la última fila, solo quedan dos filas en la tabla.
Eliminar datos mediante la API de Java
Puede eliminar datos en una tabla usando el método execute () de la clase Session. Siga los pasos que se indican a continuación para eliminar datos de una tabla usando la API de Java.
Paso 1: crear un objeto de clúster
Crea una instancia de Cluster.builder clase de com.datastax.driver.core paquete como se muestra a continuación.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Agregue un punto de contacto (dirección IP del nodo) usando el addContactPoint() método de Cluster.Builderobjeto. Este método devuelveCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Con el nuevo objeto generador, cree un objeto de clúster. Para hacerlo, tienes un método llamadobuild() en el Cluster.Builderclase. Utilice el siguiente código para crear un objeto de clúster.
//Building a cluster
Cluster cluster = builder.build();Puede crear el objeto de clúster con una sola línea de código como se muestra a continuación.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Paso 2: crear un objeto de sesión
Cree una instancia del objeto Session utilizando el método connect () de la clase Cluster como se muestra a continuación.
Session session = cluster.connect();Este método crea una nueva sesión y la inicializa. Si ya tiene un espacio de claves, puede establecerlo en el existente pasando el nombre del espacio de claves en formato de cadena a este método como se muestra a continuación.
Session session = cluster.connect(“ Your keyspace name ”);Aquí estamos usando el KeySpace llamado tp. Por lo tanto, cree el objeto de sesión como se muestra a continuación.
Session session = cluster.connect(“tp”);Paso 3: ejecutar la consulta
Puede ejecutar consultas CQL utilizando el método execute () de la clase Session. Pase la consulta en formato de cadena o como un objeto de clase Statement al método execute (). Todo lo que pase a este método en formato de cadena se ejecutará en elcqlsh.
En el siguiente ejemplo, estamos eliminando datos de una tabla llamada emp. Tienes que almacenar la consulta en una variable de cadena y pasarla al execute() método como se muestra a continuación.
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”;
session.execute(query);A continuación se muestra el programa completo para eliminar datos de una tabla en Cassandra usando la API de Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Data {
public static void main(String args[]){
//query
String query = "DELETE FROM emp WHERE emp_id=3;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data deleted");
}
}Guarde el programa anterior con el nombre de la clase seguido de .java, busque la ubicación donde está guardado. Compile y ejecute el programa como se muestra a continuación.
$javac Delete_Data.java
$java Delete_DataEn condiciones normales, debería producir el siguiente resultado:
Data deletedCQL proporciona un amplio conjunto de tipos de datos integrados, incluidos los tipos de recopilación. Junto con estos tipos de datos, los usuarios también pueden crear sus propios tipos de datos personalizados. La siguiente tabla proporciona una lista de tipos de datos integrados disponibles en CQL.
| Tipo de datos | Constantes | Descripción |
|---|---|---|
| ascii | instrumentos de cuerda | Representa una cadena de caracteres ASCII |
| Empezando | Empezando | Representa 64 bits con firma larga |
| blob | manchas | Representa bytes arbitrarios |
| Booleano | booleanos | Representa verdadero o falso |
| counter | enteros | Representa la columna del contador |
| decimal | enteros, flotantes | Representa decimal de precisión variable |
| doble | enteros | Representa punto flotante IEEE-754 de 64 bits |
| flotador | enteros, flotantes | Representa punto flotante IEEE-754 de 32 bits |
| inet | instrumentos de cuerda | Representa una dirección IP, IPv4 o IPv6 |
| En t | enteros | Representa un int firmado de 32 bits |
| texto | instrumentos de cuerda | Representa una cadena codificada en UTF8 |
| timestamp | enteros, cadenas | Representa una marca de tiempo |
| timeuuid | uuids | Representa el UUID de tipo 1 |
| uuid | uuids | Representa el tipo 1 o el tipo 4 |
| UUID | ||
| varchar | instrumentos de cuerda | Representa una cadena codificada en uTF8 |
| varint | enteros | Representa un entero de precisión arbitraria |
Tipos de colección
Cassandra Query Language también proporciona una colección de tipos de datos. La siguiente tabla proporciona una lista de colecciones disponibles en CQL.
| Colección | Descripción |
|---|---|
| lista | Una lista es una colección de uno o más elementos ordenados. |
| mapa | Un mapa es una colección de pares clave-valor. |
| conjunto | Un conjunto es una colección de uno o más elementos. |
Tipos de datos definidos por el usuario
Cqlsh ofrece a los usuarios la posibilidad de crear sus propios tipos de datos. A continuación se muestran los comandos que se utilizan al tratar con tipos de datos definidos por el usuario.
CREATE TYPE - Crea un tipo de datos definido por el usuario.
ALTER TYPE - Modifica un tipo de datos definido por el usuario.
DROP TYPE - Elimina un tipo de datos definido por el usuario.
DESCRIBE TYPE : Describe un tipo de datos definido por el usuario.
DESCRIBE TYPES - Describe tipos de datos definidos por el usuario.
CQL ofrece la posibilidad de utilizar tipos de datos de colección. Con estos tipos de colección, puede almacenar varios valores en una sola variable. Este capítulo explica cómo usar Colecciones en Cassandra.
Lista
La lista se utiliza en los casos en que
- el orden de los elementos debe mantenerse, y
- un valor debe almacenarse varias veces.
Puede obtener los valores de un tipo de datos de lista utilizando el índice de los elementos de la lista.
Crear una tabla con una lista
A continuación se muestra un ejemplo para crear una tabla de muestra con dos columnas, nombre y correo electrónico. Para almacenar varios correos electrónicos, estamos usando list.
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);Insertar datos en una lista
Al insertar datos en los elementos de una lista, ingrese todos los valores separados por comas entre llaves [] como se muestra a continuación.
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',
['[email protected]','[email protected]'])Actualizar una lista
A continuación se muestra un ejemplo para actualizar el tipo de datos de la lista en una tabla llamada data. Aquí estamos agregando otro correo electrónico a la lista.
cqlsh:tutorialspoint> UPDATE data
... SET email = email +['[email protected]']
... where name = 'ramu';Verificación
Si verifica la tabla usando la instrucción SELECT, obtendrá el siguiente resultado:
cqlsh:tutorialspoint> SELECT * FROM data;
name | email
------+--------------------------------------------------------------
ramu | ['[email protected]', '[email protected]', '[email protected]']
(1 rows)CONJUNTO
Set es un tipo de datos que se utiliza para almacenar un grupo de elementos. Los elementos de un conjunto se devolverán en orden.
Crear una mesa con set
El siguiente ejemplo crea una tabla de muestra con dos columnas, nombre y teléfono. Para almacenar varios números de teléfono, usamos set.
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);Insertar datos en un conjunto
Al insertar datos en los elementos de un conjunto, ingrese todos los valores separados por comas entre llaves {} como se muestra a continuación.
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});Actualizar un conjunto
El siguiente código muestra cómo actualizar un conjunto en una tabla denominada data2. Aquí estamos agregando otro número de teléfono al conjunto.
cqlsh:tutorialspoint> UPDATE data2
... SET phone = phone + {9848022330}
... where name = 'rahman';Verificación
Si verifica la tabla usando la instrucción SELECT, obtendrá el siguiente resultado:
cqlsh:tutorialspoint> SELECT * FROM data2;
name | phone
--------+--------------------------------------
rahman | {9848022330, 9848022338, 9848022339}
(1 rows)MAPA
Map es un tipo de datos que se utiliza para almacenar un par de elementos clave-valor.
Crear una tabla con mapa
El siguiente ejemplo muestra cómo crear una tabla de muestra con dos columnas, nombre y dirección. Para almacenar múltiples valores de dirección, usamos map.
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, address
map<timestamp, text>);Insertar datos en un mapa
Al insertar datos en los elementos de un mapa, ingrese todos los key : value pares separados por comas entre llaves {} como se muestra a continuación.
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)
VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );Actualizar un conjunto
El siguiente código muestra cómo actualizar el tipo de datos del mapa en una tabla denominada data3. Aquí estamos cambiando el valor de la oficina clave, es decir, estamos cambiando la dirección de la oficina de una persona llamada robin.
cqlsh:tutorialspoint> UPDATE data3
... SET address = address+{'office':'mumbai'}
... WHERE name = 'robin';Verificación
Si verifica la tabla usando la instrucción SELECT, obtendrá el siguiente resultado:
cqlsh:tutorialspoint> select * from data3;
name | address
-------+-------------------------------------------
robin | {'home': 'hyderabad', 'office': 'mumbai'}
(1 rows)CQL ofrece la posibilidad de crear y utilizar tipos de datos definidos por el usuario. Puede crear un tipo de datos para manejar varios campos. Este capítulo explica cómo crear, modificar y eliminar un tipo de datos definido por el usuario.
Creación de un tipo de datos definido por el usuario
El comando CREATE TYPEse utiliza para crear un tipo de datos definido por el usuario. Su sintaxis es la siguiente:
CREATE TYPE <keyspace name>. <data typename>
( variable1, variable2).Ejemplo
A continuación se muestra un ejemplo para crear un tipo de datos definido por el usuario. En este ejemplo, estamos creando uncard_details tipo de datos que contiene los siguientes detalles.
| Campo | Nombre del campo | Tipo de datos |
|---|---|---|
| numero de tarjeta de credito | num | En t |
| pin de tarjeta de crédito | alfiler | En t |
| nombre en la tarjeta de crédito | nombre | texto |
| cvv | cvv | En t |
| Datos de contacto del titular de la tarjeta | teléfono | conjunto |
cqlsh:tutorialspoint> CREATE TYPE card_details (
... num int,
... pin int,
... name text,
... cvv int,
... phone set<int>
... );Note - El nombre utilizado para el tipo de datos definido por el usuario no debe coincidir con los nombres de los tipos reservados.
Verificación
Utilizar el DESCRIBE comando para verificar si el tipo creado ha sido creado o no.
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>
);Modificación de un tipo de datos definido por el usuario
ALTER TYPE- El comando se usa para alterar un tipo de datos existente. Con ALTER, puede agregar un nuevo campo o cambiar el nombre de un campo existente.
Agregar un campo a un tipo
Utilice la siguiente sintaxis para agregar un nuevo campo a un tipo de datos existente definido por el usuario.
ALTER TYPE typename
ADD field_name field_type;El siguiente código agrega un nuevo campo al Card_detailstipo de datos. Aquí estamos agregando un nuevo campo llamado correo electrónico.
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;Verificación
Utilizar el DESCRIBE comando para verificar si el nuevo campo se agrega o no.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
);Cambiar el nombre de un campo en un tipo
Utilice la siguiente sintaxis para cambiar el nombre de un tipo de datos definido por el usuario existente.
ALTER TYPE typename
RENAME existing_name TO new_name;El siguiente código cambia el nombre del campo en un tipo. Aquí estamos cambiando el nombre del campo de correo electrónico a correo.
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;Verificación
Utilizar el DESCRIBE comando para verificar si el nombre del tipo cambió o no.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Eliminar un tipo de datos definido por el usuario
DROP TYPEes el comando utilizado para eliminar un tipo de datos definido por el usuario. A continuación se muestra un ejemplo para eliminar un tipo de datos definido por el usuario.
Ejemplo
Antes de eliminar, verifique la lista de todos los tipos de datos definidos por el usuario usando DESCRIBE_TYPES comando como se muestra a continuación.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardDe los dos tipos, elimine el tipo denominado card Como se muestra abajo.
cqlsh:tutorialspoint> drop type card;Utilizar el DESCRIBE comando para verificar si el tipo de datos se eliminó o no.
cqlsh:tutorialspoint> describe types;
card_details