CherryPy - Guía rápida
CherryPy es un marco web de Python que proporciona una interfaz amigable para el protocolo HTTP para desarrolladores de Python. También se denomina biblioteca de aplicaciones web.
CherryPy utiliza las fortalezas de Python como lenguaje dinámico para modelar y vincular el protocolo HTTP en una API. Es uno de los marcos web más antiguos para Python, que proporciona una interfaz limpia y una plataforma confiable.
Historia de CherryPy
Remi Delon lanzó la primera versión de CherryPy a finales de junio de 2002. Este fue el punto de partida de una biblioteca web de Python exitosa. Remi es un hacker francés que ha confiado en Python por ser una de las mejores alternativas para el desarrollo de aplicaciones web.
El proyecto desarrollado por Remi atrajo a varios desarrolladores interesados en el enfoque. El enfoque incluyó las siguientes características:
CherryPy estaba cerca del patrón modelo-vista-controlador.
Una clase CherryPy debe ser procesada y compilada por el motor CherryPy para producir un módulo Python autónomo que incrusta la aplicación completa y también su propio servidor web integrado.
CherryPy puede mapear una URL y su cadena de consulta en una llamada al método Python, por ejemplo:
http://somehost.net/echo?message=hello would map to echo(message='hello')Durante los dos años de desarrollo del proyecto CherryPy, fue apoyado por la comunidad y Remi lanzó varias versiones mejoradas.
En junio de 2004, se inició una discusión sobre el futuro del proyecto y si debería continuar con la misma arquitectura. La lluvia de ideas y el debate de varios usuarios habituales del proyecto llevaron al concepto de motor de publicación de objetos y filtros, que pronto se convirtió en una parte central de CherryPy2. Más tarde, en octubre de 2004, se lanzó la primera versión de CherryPy 2 alpha como prueba del concepto de estas ideas centrales. CherryPy 2.0 fue un verdadero éxito; sin embargo, se reconoció que su diseño aún podía mejorarse y necesitaba refactorización.
Después de discusiones basadas en comentarios, la API de CherryPy se modificó aún más para mejorar su elegancia, lo que llevó al lanzamiento de CherryPy 2.1.0 en octubre de 2005. Después de varios cambios, el equipo lanzó CherryPy 2.2.0 en abril de 2006.
Puntos fuertes de CherryPy
Las siguientes características de CherryPy se consideran sus fortalezas:
Sencillez
Desarrollar un proyecto en CherryPy es una tarea simple con pocas líneas de código desarrolladas según las convenciones y sangrías de Python.
CherryPy también es muy modular. Los componentes principales están bien administrados con un concepto lógico correcto y las clases principales se pueden expandir a clases secundarias.
Poder
CherryPy aprovecha todo el poder de Python. También proporciona herramientas y complementos, que son puntos de extensión poderosos necesarios para desarrollar aplicaciones de clase mundial.
Fuente abierta
CherryPy es un marco web Python de código abierto (con licencia BSD de código abierto), lo que significa que este marco se puede utilizar comercialmente a un costo CERO.
Ayuda de la comunidad
Tiene una comunidad dedicada que brinda apoyo completo con varios tipos de preguntas y respuestas. La comunidad intenta brindar asistencia completa a los desarrolladores desde el nivel principiante hasta el nivel avanzado.
Despliegue
Hay formas rentables de implementar la aplicación. CherryPy incluye su propio servidor HTTP listo para producción para alojar su aplicación. CherryPy también se puede implementar en cualquier puerta de enlace compatible con WSGI.
CherryPy viene en paquetes como la mayoría de los proyectos de código abierto, que se pueden descargar e instalar de varias formas que se mencionan a continuación:
- Usando un Tarball
- Usando easy_install
- Usando Subversion
Requisitos
Los requisitos básicos para la instalación de CherryPy framework incluyen:
- Python con la versión 2.4 o superior
- CherryPy 3.0
La instalación de un módulo de Python se considera un proceso sencillo. La instalación incluye el uso de los siguientes comandos.
python setup.py build
python setup.py installLos paquetes de Python se almacenan en los siguientes directorios predeterminados:
- En UNIX o Linux,
/usr/local/lib/python2.4/site-packages
or
/usr/lib/python2.4/site-packages- En Microsoft Windows,
C:\Python or C:\Python2x- En Mac OS,
Python:Lib:site-packageInstalación usando Tarball
Un Tarball es un archivo comprimido de archivos o un directorio. El marco CherryPy proporciona un Tarball para cada una de sus versiones (alfa, beta y estable).
Contiene el código fuente completo de la biblioteca. El nombre proviene de la utilidad utilizada en UNIX y otros sistemas operativos.
Estos son los pasos a seguir para la instalación de CherryPy utilizando tar ball:
Step 1 - Descargue la versión según los requisitos del usuario de http://download.cherrypy.org/
Step 2- Busque el directorio donde se descargó Tarball y descomprímalo. Para el sistema operativo Linux, escriba el siguiente comando:
tar zxvf cherrypy-x.y.z.tgzPara Microsoft Windows, el usuario puede utilizar una utilidad como 7-Zip o Winzip para descomprimir el archivo a través de una interfaz gráfica.
Step 3 - Vaya al directorio recién creado y use el siguiente comando para construir CherryPy -
python setup.py buildPara la instalación global, se debe utilizar el siguiente comando:
python setup.py installInstalación usando easy_install
Python Enterprise Application Kit (PEAK) proporciona un módulo de Python llamado Instalación sencilla. Esto facilita la implementación de los paquetes de Python. Este módulo simplifica el procedimiento de descarga, construcción e implementación de aplicaciones y productos Python.
Easy Install debe instalarse en el sistema antes de instalar CherryPy.
Step 1 - Descargue el módulo ez_setup.py de http://peak.telecommunity.com y ejecútelo usando los derechos administrativos en la computadora: python ez_setup.py.
Step 2 - El siguiente comando se utiliza para instalar Easy Install.
easy_install product_nameStep 3- easy_install buscará en el índice de paquetes de Python (PyPI) para encontrar el producto dado. PyPI es un repositorio centralizado de información para todos los productos Python.
Use el siguiente comando para implementar la última versión disponible de CherryPy:
easy_install cherrypyStep 4 - easy_install luego descargará CherryPy, lo compilará e instalará globalmente en su entorno Python.
Instalación usando Subversion
Se recomienda la instalación de CherryPy con Subversion en las siguientes situaciones:
Existe una característica o se ha corregido un error y solo está disponible en el código en desarrollo.
Cuando el desarrollador trabaja en CherryPy.
Cuando el usuario necesita una rama de la rama principal en el repositorio de control de versiones.
Para corregir errores de la versión anterior.
El principio básico de la subversión es registrar un repositorio y realizar un seguimiento de cada una de las versiones, que incluyen una serie de cambios en ellas.
Siga estos pasos para comprender la instalación de CherryPy usando Subversion
Step 1 - Para usar la versión más reciente del proyecto, es necesario verificar la carpeta troncal que se encuentra en el repositorio de Subversion.
Step 2 - Ingrese el siguiente comando desde un shell
svn co http://svn.cherrypy.org/trunk cherrypyStep 3 - Ahora, cree un directorio CherryPy y descargue el código fuente completo en él.
Prueba de la instalación
Es necesario verificar si la aplicación se ha instalado correctamente en el sistema o no de la misma manera que lo hacemos para aplicaciones como Java.
Puede elegir cualquiera de los tres métodos mencionados en el capítulo anterior para instalar e implementar CherryPy en su entorno. CherryPy debe poder importar desde el shell de Python de la siguiente manera:
import cherrypy
cherrypy.__version__
'3.0.0'Si CherryPy no está instalado globalmente en el entorno Python del sistema local, entonces debe configurar la variable de entorno PYTHONPATH, de lo contrario, mostrará un error de la siguiente manera:
import cherrypy
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ImportError: No module named cherrypyHay algunas palabras clave importantes que deben definirse para comprender el funcionamiento de CherryPy. Las palabras clave y las definiciones son las siguientes:
| S. No | Palabra clave y definición |
|---|---|
| 1. | Web Server Es una interfaz que se ocupa del protocolo HTTP. Su objetivo es transformar las solicitudes HTTP al servidor de aplicaciones para que obtengan las respuestas. |
| 2. | Application Es un software que recopila información. |
| 3. | Application server Es el componente que contiene una o más aplicaciones. |
| 4. | Web application server Es la combinación de servidor web y servidor de aplicaciones. |
Ejemplo
El siguiente ejemplo muestra un código de muestra de CherryPy:
import cherrypy
class demoExample:
def index(self):
return "Hello World!!!"
index.exposed = True
cherrypy.quickstart(demoExample())Entendamos ahora cómo funciona el código:
El paquete llamado CherryPy siempre se importa en la clase especificada para garantizar su correcto funcionamiento.
En el ejemplo anterior, la función denominada index devuelve el parámetro "¡¡¡Hola mundo !!!".
La última línea inicia el servidor web y llama a la clase especificada (aquí, demoExample) y devuelve el valor mencionado en el índice de función predeterminado.
El código de ejemplo devuelve la siguiente salida:

CherryPy viene con su propio servidor web (HTTP). Es por eso que CherryPy es autónomo y permite a los usuarios ejecutar una aplicación CherryPy a los pocos minutos de obtener la biblioteca.
los web server actúa como puerta de entrada a la aplicación con la ayuda de la cual todas las solicitudes y respuestas se mantienen al día.
Para iniciar el servidor web, un usuario debe realizar la siguiente llamada:
cherryPy.server.quickstart()los internal engine of CherryPy es responsable de las siguientes actividades:
- Creación y gestión de objetos de solicitud y respuesta.
- Controlar y gestionar el proceso CherryPy.
CherryPy - Configuración
El marco viene con su propio sistema de configuración que le permite parametrizar el servidor HTTP. Los ajustes para la configuración se pueden almacenar en un archivo de texto con una sintaxis cercana al formato INI o como un diccionario Python completo.
Para configurar la instancia del servidor CherryPy, el desarrollador debe usar la sección global de la configuración.
global_conf = {
'global': {
'server.socket_host': 'localhost',
'server.socket_port': 8080,
},
}
application_conf = {
'/style.css': {
'tools.staticfile.on': True,
'tools.staticfile.filename': os.path.join(_curdir, 'style.css'),
}
}
This could be represented in a file like this:
[global]
server.socket_host = "localhost"
server.socket_port = 8080
[/style.css]
tools.staticfile.on = True
tools.staticfile.filename = "/full/path/to.style.css"Cumplimiento de HTTP
CherryPy ha ido evolucionando lentamente pero incluye la compilación de especificaciones HTTP con el soporte de HTTP / 1.0 y luego se transfiere con el soporte de HTTP / 1.1.
Se dice que CherryPy cumple condicionalmente con HTTP / 1.1, ya que implementa todos los niveles obligatorios y obligatorios, pero no todos los niveles obligatorios de la especificación. Por lo tanto, CherryPy admite las siguientes características de HTTP / 1.1:
Si un cliente afirma admitir HTTP / 1.1, debe enviar un campo de encabezado en cualquier solicitud realizada con la versión de protocolo especificada. Si no se hace, CherryPy detendrá inmediatamente el procesamiento de la solicitud.
CherryPy genera un campo de encabezado de fecha que se utiliza en todas las configuraciones.
CherryPy puede manejar el código de estado de respuesta (100) con el apoyo de los clientes.
El servidor HTTP integrado de CherryPy admite conexiones persistentes que son las predeterminadas en HTTP / 1.1, mediante el uso del encabezado Connection: Keep-Alive.
CherryPy maneja solicitudes y respuestas correctamente fragmentadas.
CherryPy admite solicitudes de dos maneras distintas: los encabezados If-Modified-Since y If-Unmodified-Since y envía respuestas según las solicitudes en consecuencia.
CherryPy permite cualquier método HTTP.
CherryPy maneja las combinaciones de versiones HTTP entre el cliente y la configuración establecida para el servidor.
Servidor de aplicaciones multiproceso
CherryPy está diseñado en base al concepto de subprocesos múltiples. Cada vez que un desarrollador obtiene o establece un valor en el espacio de nombres CherryPy, se hace en el entorno de subprocesos múltiples.
Tanto cherrypy.request como cherrypy.response son contenedores de datos de subprocesos, lo que implica que su aplicación los llama de forma independiente al saber qué solicitud se envía a través de ellos en tiempo de ejecución.
Los servidores de aplicaciones que utilizan el patrón de subprocesos no son muy apreciados porque se considera que el uso de subprocesos aumenta la probabilidad de problemas debido a los requisitos de sincronización.
Las otras alternativas incluyen:
Patrón multiproceso
Cada solicitud es manejada por su propio proceso de Python. Aquí, el rendimiento y la estabilidad del servidor pueden considerarse mejores.
Patrón asincrónico
Aquí, aceptar nuevas conexiones y enviar los datos al cliente se realiza de forma asincrónica desde el proceso de solicitud. Esta técnica es conocida por su eficacia.
Envío de URL
La comunidad de CherryPy quiere ser más flexible y que se agradecerían otras soluciones para los despachadores. CherryPy 3 proporciona otros despachadores integrados y ofrece una forma sencilla de escribir y usar sus propios despachadores.
- Aplicaciones utilizadas para desarrollar métodos HTTP. (OBTENER, PUBLICAR, PONER, etc.)
- El que define las rutas en la URL - Routes Dispatcher
Despachador del método HTTP
En algunas aplicaciones, los URI son independientes de la acción, que debe realizar el servidor en el recurso.
Por ejemplo,http://xyz.com/album/delete/10
La URI contiene la operación que el cliente desea realizar.
De forma predeterminada, el despachador de CherryPy se asignaría de la siguiente manera:
album.delete(12)El despachador mencionado anteriormente se menciona correctamente, pero se puede hacer independiente de la siguiente manera:
http://xyz.com/album/10El usuario puede preguntarse cómo el servidor distribuye la página exacta. Esta información es transportada por la propia solicitud HTTP. Cuando hay una solicitud de cliente a servidor, CherryPy parece el mejor controlador adecuado, el controlador es la representación del recurso al que apunta el URI.
DELETE /album/12 HTTP/1.1Despachador de rutas
Aquí hay una lista de los parámetros para el método requerido en el envío:
El parámetro de nombre es el nombre exclusivo de la ruta para conectarse.
La ruta es el patrón para hacer coincidir los URI.
El controlador es la instancia que contiene los controladores de página.
El despachador de rutas conecta un patrón que coincide con los URI y asocia un controlador de página específico.
Ejemplo
Tomemos un ejemplo para entender cómo funciona:
import random
import string
import cherrypy
class StringMaker(object):
@cherrypy.expose
def index(self):
return "Hello! How are you?"
@cherrypy.expose
def generate(self, length=9):
return ''.join(random.sample(string.hexdigits, int(length)))
if __name__ == '__main__':
cherrypy.quickstart(StringMaker ())Siga los pasos que se indican a continuación para obtener el resultado del código anterior:
Step 1 - Guarde el archivo mencionado anteriormente como tutRoutes.py.
Step 2 - Visite la siguiente URL -
http://localhost:8080/generate?length=10Step 3 - Recibirá el siguiente resultado -

Dentro de CherryPy, las herramientas integradas ofrecen una única interfaz para llamar a la biblioteca CherryPy. Las herramientas definidas en CherryPy se pueden implementar de las siguientes formas:
- Desde los ajustes de configuración
- Como decorador de Python o mediante el atributo especial _cp_config de un controlador de página
- Como un Python invocable que se puede aplicar desde cualquier función
Herramienta de autenticación básica
El propósito de esta herramienta es proporcionar autenticación básica a la aplicación diseñada en la aplicación.
Argumentos
Esta herramienta utiliza los siguientes argumentos:
| Nombre | Defecto | Descripción |
|---|---|---|
| reino | N / A | Cadena que define el valor del reino. |
| usuarios | N / A | Diccionario de la forma - nombre de usuario: contraseña o una función invocable de Python que devuelve dicho diccionario. |
| cifrar | Ninguna | Python invocable utilizado para cifrar la contraseña devuelta por el cliente y compararla con la contraseña cifrada proporcionada en el diccionario de los usuarios. |
Ejemplo
Tomemos un ejemplo para entender cómo funciona:
import sha
import cherrypy
class Root:
@cherrypy.expose
def index(self):
return """
<html>
<head></head>
<body>
<a href = "admin">Admin </a>
</body>
</html>
"""
class Admin:
@cherrypy.expose
def index(self):
return "This is a private area"
if __name__ == '__main__':
def get_users():
# 'test': 'test'
return {'test': 'b110ba61c4c0873d3101e10871082fbbfd3'}
def encrypt_pwd(token):
return sha.new(token).hexdigest()
conf = {'/admin': {'tools.basic_auth.on': True,
tools.basic_auth.realm': 'Website name',
'tools.basic_auth.users': get_users,
'tools.basic_auth.encrypt': encrypt_pwd}}
root = Root()
root.admin = Admin()
cherrypy.quickstart(root, '/', config=conf)los get_usersLa función devuelve un diccionario codificado pero también obtiene los valores de una base de datos o de cualquier otro lugar. El administrador de la clase incluye esta función que hace uso de una herramienta de autenticación integrada de CherryPy. La autenticación cifra la contraseña y el ID de usuario.
La herramienta de autenticación básica no es realmente segura, ya que un intruso puede codificar y decodificar la contraseña.
Herramienta de almacenamiento en caché
El propósito de esta herramienta es proporcionar almacenamiento en caché de contenido generado por CherryPy.
Argumentos
Esta herramienta utiliza los siguientes argumentos:
| Nombre | Defecto | Descripción |
|---|---|---|
| métodos_ inválidos | ("POST", "PUT", "BORRAR") | Las tuplas de cadenas de métodos HTTP no se deben almacenar en caché. Estos métodos también invalidarán (eliminarán) cualquier copia en caché del recurso. |
| cache_Class | Memoria caché | Objeto de clase que se utilizará para el almacenamiento en caché |
Herramienta de decodificación
El propósito de esta herramienta es decodificar los parámetros de la solicitud entrante.
Argumentos
Esta herramienta utiliza los siguientes argumentos:
| Nombre | Defecto | Descripción |
|---|---|---|
| codificacion | Ninguna | Busca el encabezado de tipo de contenido |
| Codificación_predeterminada | "UTF-8" | Codificación predeterminada que se utilizará cuando no se proporcione ni se encuentre ninguna. |
Ejemplo
Tomemos un ejemplo para entender cómo funciona:
import cherrypy
from cherrypy import tools
class Root:
@cherrypy.expose
def index(self):
return """
<html>
<head></head>
<body>
<form action = "hello.html" method = "post">
<input type = "text" name = "name" value = "" />
<input type = ”submit” name = "submit"/>
</form>
</body>
</html>
"""
@cherrypy.expose
@tools.decode(encoding='ISO-88510-1')
def hello(self, name):
return "Hello %s" % (name, )
if __name__ == '__main__':
cherrypy.quickstart(Root(), '/')El código anterior toma una cadena del usuario y lo redirigirá a la página "hello.html" donde se mostrará como "Hola" con el nombre dado.
La salida del código anterior es la siguiente:
hello.html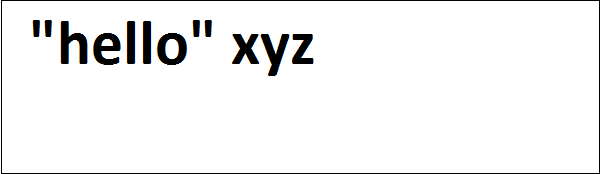
Las aplicaciones de pila completa brindan la posibilidad de crear una nueva aplicación mediante algún comando o ejecución del archivo.
Considere las aplicaciones de Python como el framework web2py; todo el proyecto / aplicación se crea en términos del marco MVC. Asimismo, CherryPy permite al usuario configurar y configurar el diseño del código según sus requisitos.
En este capítulo, aprenderemos en detalle cómo crear una aplicación CherryPy y ejecutarla.
Sistema de archivos
El sistema de archivos de la aplicación se muestra en la siguiente captura de pantalla:
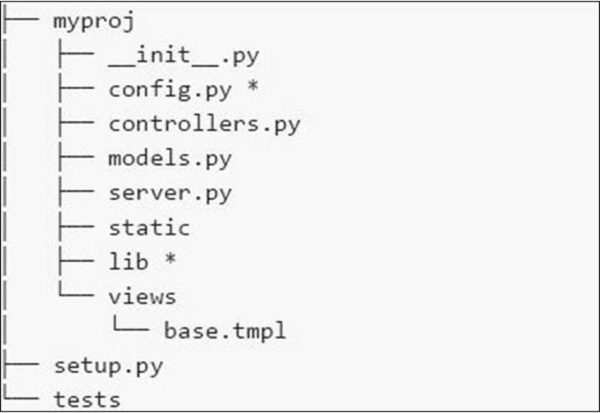
Aquí hay una breve descripción de los diversos archivos que tenemos en el sistema de archivos:
config.py- Cada aplicación necesita un archivo de configuración y una forma de cargarlo. Esta funcionalidad se puede definir en config.py.
controllers.py- MVC es un patrón de diseño popular seguido por los usuarios. El controllers.py es donde se implementan todos los objetos que se montarán en el cherrypy.tree .
models.py - Este archivo interactúa con la base de datos directamente para algunos servicios o para almacenar datos persistentes.
server.py - Este archivo interactúa con el servidor web listo para producción que funciona correctamente con el proxy de equilibrio de carga.
Static - Incluye todos los archivos CSS y de imagen.
Views - Incluye todos los archivos de plantilla para una aplicación determinada.
Ejemplo
Aprendamos en detalle los pasos para crear una aplicación CherryPy.
Step 1 - Cree una aplicación que debe contener la aplicación.
Step 2- Dentro del directorio, cree un paquete de Python correspondiente al proyecto. Cree el directorio gedit e incluya el archivo _init_.py dentro del mismo.
Step 3 - Dentro del paquete, incluya el archivo controllers.py con el siguiente contenido -
#!/usr/bin/env python
import cherrypy
class Root(object):
def __init__(self, data):
self.data = data
@cherrypy.expose
def index(self):
return 'Hi! Welcome to your application'
def main(filename):
data = {} # will be replaced with proper functionality later
# configuration file
cherrypy.config.update({
'tools.encode.on': True, 'tools.encode.encoding': 'utf-8',
'tools.decode.on': True,
'tools.trailing_slash.on': True,
'tools.staticdir.root': os.path.abspath(os.path.dirname(__file__)),
})
cherrypy.quickstart(Root(data), '/', {
'/media': {
'tools.staticdir.on': True,
'tools.staticdir.dir': 'static'
}
})
if __name__ == '__main__':
main(sys.argv[1])Step 4- Considere una aplicación donde el usuario ingresa el valor a través de un formulario. Incluyamos dos formularios: index.html y submit.html en la aplicación.
Step 5 - En el código anterior para controladores, tenemos index(), que es una función predeterminada y se carga primero si se llama a un controlador en particular.
Step 6 - La implementación de la index() El método se puede cambiar de la siguiente manera:
@cherrypy.expose
def index(self):
tmpl = loader.load('index.html')
return tmpl.generate(title='Sample').render('html', doctype='html')Step 7- Esto cargará index.html al iniciar la aplicación dada y la dirigirá al flujo de salida dado. El archivo index.html es el siguiente:
index.html
<!DOCTYPE html >
<html>
<head>
<title>Sample</title>
</head>
<body class = "index">
<div id = "header">
<h1>Sample Application</h1>
</div>
<p>Welcome!</p>
<div id = "footer">
<hr>
</div>
</body>
</html>Step 8 - Es importante agregar un método a la clase Root en controller.py si desea crear un formulario que acepte valores como nombres y títulos.
@cherrypy.expose
def submit(self, cancel = False, **value):
if cherrypy.request.method == 'POST':
if cancel:
raise cherrypy.HTTPRedirect('/') # to cancel the action
link = Link(**value)
self.data[link.id] = link
raise cherrypy.HTTPRedirect('/')
tmp = loader.load('submit.html')
streamValue = tmp.generate()
return streamValue.render('html', doctype='html')Step 9 - El código que se incluirá en submit.html es el siguiente:
<!DOCTYPE html>
<head>
<title>Input the new link</title>
</head>
<body class = "submit">
<div id = " header">
<h1>Submit new link</h1>
</div>
<form action = "" method = "post">
<table summary = "">
<tr>
<th><label for = " username">Your name:</label></th>
<td><input type = " text" id = " username" name = " username" /></td>
</tr>
<tr>
<th><label for = " url">Link URL:</label></th>
<td><input type = " text" id=" url" name= " url" /></td>
</tr>
<tr>
<th><label for = " title">Title:</label></th>
<td><input type = " text" name = " title" /></td>
</tr>
<tr>
<td></td>
<td>
<input type = " submit" value = " Submit" />
<input type = " submit" name = " cancel" value = "Cancel" />
</td>
</tr>
</table>
</form>
<div id = "footer">
</div>
</body>
</html>Step 10 - Recibirá el siguiente resultado -
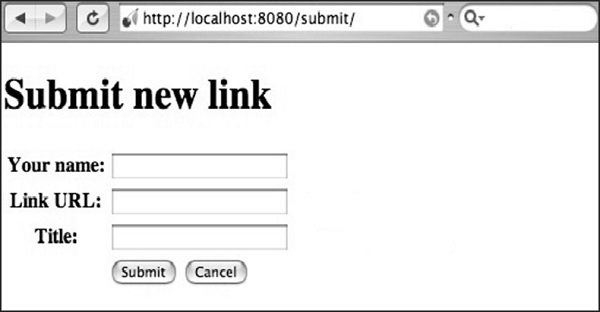
Aquí, el nombre del método se define como "POST". Siempre es importante realizar una verificación cruzada del método especificado en el archivo. Si el método incluye el método "POST", los valores deben volver a comprobarse en la base de datos en los campos correspondientes.
Si el método incluye el método "GET", los valores a guardar serán visibles en la URL.
Un servicio web es un conjunto de componentes basados en web que ayuda en el intercambio de datos entre la aplicación o los sistemas que también incluye protocolos y estándares abiertos. Se puede publicar, utilizar y encontrar en la web.
Los servicios web son de varios tipos, como RWS (Servicio web RESTfUL), WSDL, SOAP y muchos más.
REST - Transferencia de estado representacional
Un tipo de protocolo de acceso remoto, que transfiere el estado del cliente al servidor que se puede utilizar para manipular el estado en lugar de llamar a procedimientos remotos.
No define ninguna codificación o estructura específica ni formas de devolver mensajes de error útiles.
Utiliza "verbos" HTTP para realizar operaciones de transferencia de estado.
Los recursos se identifican de forma única mediante URL.
No es una API, sino una capa de transporte de API.
REST mantiene la nomenclatura de los recursos en una red y proporciona un mecanismo unificado para realizar operaciones en estos recursos. Cada recurso está identificado por al menos un identificador. Si la infraestructura REST se implementa con la base de HTTP, estos identificadores se denominan comoUniform Resource Identifiers (URIs).
Los siguientes son los dos subconjuntos comunes del conjunto de URI:
| Subconjunto | Forma completa | Ejemplo |
|---|---|---|
| URL | Localizador Uniforme de Recursos | http://www.gmail.com/ |
| URNA | Nombre de recurso uniforme | urna: isbn: 0-201-71088-9 urna: uuid: 13e8cf26-2a25-11db-8693-000ae4ea7d46 |
Antes de comprender la implementación de la arquitectura CherryPy, centrémonos en la arquitectura de CherryPy.
CherryPy incluye los siguientes tres componentes:
cherrypy.engine - Controla el inicio / desmontaje del proceso y el manejo de eventos.
cherrypy.server - Configura y controla el servidor WSGI o HTTP.
cherrypy.tools - Una caja de herramientas de utilidades que son ortogonales para procesar una solicitud HTTP.
Interfaz REST a través de CherryPy
El servicio web RESTful implementa cada sección de la arquitectura CherryPy con la ayuda de lo siguiente:
- Authentication
- Authorization
- Structure
- Encapsulation
- Manejo de errores
Autenticación
La autenticación ayuda a validar a los usuarios con los que estamos interactuando. CherryPy incluye herramientas para manejar cada método de autenticación.
def authenticate():
if not hasattr(cherrypy.request, 'user') or cherrypy.request.user is None:
# < Do stuff to look up your users >
cherrypy.request.authorized = False # This only authenticates.
Authz must be handled separately.
cherrypy.request.unauthorized_reasons = []
cherrypy.request.authorization_queries = []
cherrypy.tools.authenticate = \
cherrypy.Tool('before_handler', authenticate, priority=10)La función de autenticación () anterior ayudará a validar la existencia de los clientes o usuarios. Las herramientas integradas ayudan a completar el proceso de forma sistemática.
Autorización
La autorización ayuda a mantener la cordura del proceso a través de URI. El proceso también ayuda en la transformación de objetos mediante clientes potenciales de token de usuario.
def authorize_all():
cherrypy.request.authorized = 'authorize_all'
cherrypy.tools.authorize_all = cherrypy.Tool('before_handler', authorize_all, priority=11)
def is_authorized():
if not cherrypy.request.authorized:
raise cherrypy.HTTPError("403 Forbidden",
','.join(cherrypy.request.unauthorized_reasons))
cherrypy.tools.is_authorized = cherrypy.Tool('before_handler', is_authorized,
priority = 49)
cherrypy.config.update({
'tools.is_authorized.on': True,
'tools.authorize_all.on': True
})Las herramientas de autorización integradas ayudan a manejar las rutinas de manera sistemática, como se mencionó en el ejemplo anterior.
Estructura
Mantener una estructura de API ayuda a reducir la carga de trabajo de mapear el URI de la aplicación. Siempre es necesario mantener la API visible y limpia. La estructura básica de API para el marco CherryPy debe tener lo siguiente:
- Cuentas y usuario
- Autoresponder
- Contact
- File
- Folder
- Lista y campo
- Mensaje y lote
Encapsulamiento
La encapsulación ayuda a crear una API que sea liviana, legible por humanos y accesible para varios clientes. La lista de elementos junto con Creación, Recuperación, Actualización y Eliminación requiere encapsulación de API.
Manejo de errores
Este proceso gestiona los errores, si los hay, si la API no se ejecuta según el instinto particular. Por ejemplo, 400 es para solicitud incorrecta y 403 es para solicitud no autorizada.
Ejemplo
Considere lo siguiente como un ejemplo de errores de base de datos, validación o aplicación.
import cherrypy
import json
def error_page_default(status, message, traceback, version):
ret = {
'status': status,
'version': version,
'message': [message],
'traceback': traceback
}
return json.dumps(ret)
class Root:
_cp_config = {'error_page.default': error_page_default}
@cherrypy.expose
def index(self):
raise cherrypy.HTTPError(500, "Internal Sever Error")
cherrypy.quickstart(Root())El código anterior producirá el siguiente resultado:

La administración de API (Interfaz de programación de aplicaciones) es fácil a través de CherryPy debido a las herramientas de acceso integradas.
Métodos HTTP
La lista de métodos HTTP que operan en los recursos es la siguiente:
| S. No | Método y operación HTTP |
|---|---|
| 1. | HEAD Recupera los metadatos del recurso. |
| 2. | GET Recupera el contenido y los metadatos del recurso. |
| 3. | POST Solicita al servidor que cree un nuevo recurso utilizando los datos incluidos en el cuerpo de la solicitud. |
| 4. | PUT Solicita al servidor que reemplace un recurso existente por el incluido en el cuerpo de la solicitud. |
| 5. | DELETE Solicita al servidor que elimine el recurso identificado por ese URI. |
| 6. | OPTIONS Solicita al servidor que devuelva detalles sobre las capacidades de forma global o específica hacia un recurso. |
Protocolo de publicación de Atom (APP)
APP ha surgido de la comunidad Atom como un protocolo de nivel de aplicación sobre HTTP para permitir la publicación y edición de recursos web. La unidad de mensajes entre un servidor de aplicaciones y un cliente se basa en el formato de documento XML de Atom.
El protocolo de publicación Atom define un conjunto de operaciones entre un servicio de aplicación y un agente de usuario que utiliza HTTP y sus mecanismos y el formato de documento XML de Atom como unidad de mensajes.
APP primero define un documento de servicio, que proporciona al agente de usuario el URI de las diferentes colecciones atendidas por el servicio APP.
Ejemplo
Tomemos un ejemplo para demostrar cómo funciona la aplicación:
<?xml version = "1.0" encoding = "UTF-8"?>
<service xmlns = "http://purl.org/atom/app#" xmlns:atom = "http://www.w3.org/2005/Atom">
<workspace>
<collection href = "http://host/service/atompub/album/">
<atom:title> Albums</atom:title>
<categories fixed = "yes">
<atom:category term = "friends" />
</categories>
</collection>
<collection href = "http://host/service/atompub/film/">
<atom:title>Films</atom:title>
<accept>image/png,image/jpeg</accept>
</collection>
</workspace>
</service>APP especifica cómo realizar las operaciones CRUD básicas contra un miembro de una colección o la colección misma mediante el uso de métodos HTTP como se describe en la siguiente tabla:
| Operación | Método HTTP | Código de estado | Contenido |
|---|---|---|---|
| Recuperar | OBTENER | 200 | Una entrada de Atom que representa el recurso |
| Crear | ENVIAR | 201 | El URI del recurso recién creado a través de los encabezados Location y Content-Location |
| Actualizar | PONER | 200 | Una entrada de Atom que representa el recurso |
| Eliminar | ELIMINAR | 200 | Ninguna |
La capa de presentación asegura que la comunicación que pasa a través de ella se dirige a los destinatarios previstos. CherryPy mantiene el funcionamiento de la capa de presentación mediante varios motores de plantilla.
Un motor de plantillas toma la entrada de la página con la ayuda de la lógica empresarial y luego la procesa a la página final que se dirige solo al público objetivo.
Kid - El motor de plantillas
Kid es un motor de plantilla simple que incluye el nombre de la plantilla a procesar (que es obligatorio) y la entrada de los datos que se pasarán cuando se procese la plantilla.
Al crear la plantilla por primera vez, Kid crea un módulo de Python que se puede servir como una versión en caché de la plantilla.
los kid.Template La función devuelve una instancia de la clase de plantilla que se puede utilizar para representar el contenido de salida.
La clase de plantilla proporciona el siguiente conjunto de comandos:
| S. No | Comando y descripción |
|---|---|
| 1. | serialize Devuelve el contenido de salida como una cadena. |
| 2. | generate Devuelve el contenido de salida como un iterador. |
| 3. | write Vuelca el contenido de salida en un objeto de archivo. |
Los parámetros utilizados por estos comandos son los siguientes:
| S. No | Comando y descripción |
|---|---|
| 1. | encoding Informa cómo codificar el contenido de salida. |
| 2. | fragment Es un valor booleano que le dice a XML prolog o Doctype |
| 3. | output Este tipo de serialización se utiliza para representar el contenido. |
Ejemplo
Tomemos un ejemplo para entender cómo kid trabaja -
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html xmlns:py = "http://purl.org/kid/ns#">
<head>
<title>${title}</title> <link rel = "stylesheet" href = "style.css" /> </head> <body> <p>${message}</p>
</body>
</html>
The next step after saving the file is to process the template via the Kid engine.
import kid
params = {'title': 'Hello world!!', 'message': 'CherryPy.'}
t = kid.Template('helloworld.kid', **params)
print t.serialize(output='html')Atributos del niño
Los siguientes son los atributos de Kid:
Lenguaje de plantillas basado en XML
Es un lenguaje basado en XML. Una plantilla Kid debe ser un documento XML bien formado con convenciones de nomenclatura adecuadas.
Kid implementa atributos dentro de los elementos XML para actualizar el motor subyacente sobre la acción a seguir para llegar al elemento. Para evitar la superposición con otros atributos existentes dentro del documento XML, Kid ha introducido su propio espacio de nombres.
<p py:if = "...">...</p>Sustitución de variables
Kid viene con un esquema de sustitución de variables y un enfoque simple: $ {nombre-variable}.
Las variables se pueden utilizar en atributos de elementos o como contenido de texto de un elemento. Kid evaluará la variable cada vez que se lleve a cabo la ejecución.
Si el usuario necesita la salida de una cadena literal como $ {algo}, se puede escapar usando la sustitución de variables duplicando el signo de dólar.
Sentencia condicional
Para alternar diferentes casos en la plantilla, se utiliza la siguiente sintaxis:
<tag py:if = "expression">...</tag>Aquí, etiqueta es el nombre del elemento, por ejemplo, DIV o SPAN.
La expresión es una expresión de Python. Si como booleano se evalúa como Verdadero, el elemento se incluirá en el contenido de salida o, de lo contrario, no será parte del contenido de salida.
Mecanismo de bucle
Para hacer un bucle de un elemento en Kid, se utiliza la siguiente sintaxis:
<tag py:for = "expression">...</tag>Aquí, etiqueta es el nombre del elemento. La expresión es una expresión de Python, por ejemplo, para el valor en [...].
Ejemplo
El siguiente código muestra cómo funciona el mecanismo de bucle:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
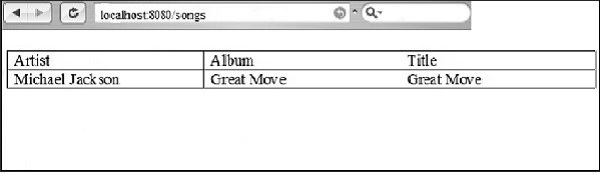
<title>${title}</title> <link rel = "stylesheet" href = "style.css" /> </head> <body> <table> <caption>A few songs</caption> <tr> <th>Artist</th> <th>Album</th> <th>Title</th> </tr> <tr py:for = "info in infos"> <td>${info['artist']}</td>
<td>${info['album']}</td> <td>${info['song']}</td>
</tr>
</table>
</body>
</html>
import kid
params = discography.retrieve_songs()
t = kid.Template('songs.kid', **params)
print t.serialize(output='html')los output para el código anterior con el mecanismo de bucle es el siguiente:
Hasta el año 2005, el patrón seguido en todas las aplicaciones web fue administrar una solicitud HTTP por página. La navegación de una página a otra requería cargar la página completa. Esto reduciría el rendimiento a un nivel mayor.
Por lo tanto, hubo un aumento en rich client applications que solía incrustar AJAX, XML y JSON con ellos.
AJAX
JavaScript y XML asíncronos (AJAX) es una técnica para crear páginas web rápidas y dinámicas. AJAX permite que las páginas web se actualicen de forma asincrónica mediante el intercambio de pequeñas cantidades de datos entre bastidores con el servidor. Esto significa que es posible actualizar partes de una página web, sin recargar toda la página.
Google Maps, Gmail, YouTube y Facebook son algunos ejemplos de aplicaciones AJAX.
Ajax se basa en la idea de enviar solicitudes HTTP usando JavaScript; más específicamente, AJAX se basa en el objeto XMLHttpRequest y su API para realizar esas operaciones.
JSON
JSON es una forma de transportar objetos JavaScript serializados de tal manera que la aplicación JavaScript puede evaluarlos y transformarlos en objetos JavaScript que se pueden manipular más tarde.
Por ejemplo, cuando el usuario solicita al servidor un objeto de álbum formateado con el formato JSON, el servidor devolverá el resultado de la siguiente manera:
{'description': 'This is a simple demo album for you to test', 'author': ‘xyz’}Ahora los datos son una matriz asociativa de JavaScript y se puede acceder al campo de descripción a través de -
data ['description'];Aplicar AJAX a la aplicación
Considere la aplicación que incluye una carpeta llamada "media" con index.html y el complemento Jquery, y un archivo con implementación AJAX. Consideremos el nombre del archivo como "ajax_app.py"
ajax_app.py
import cherrypy
import webbrowser
import os
import simplejson
import sys
MEDIA_DIR = os.path.join(os.path.abspath("."), u"media")
class AjaxApp(object):
@cherrypy.expose
def index(self):
return open(os.path.join(MEDIA_DIR, u'index.html'))
@cherrypy.expose
def submit(self, name):
cherrypy.response.headers['Content-Type'] = 'application/json'
return simplejson.dumps(dict(title="Hello, %s" % name))
config = {'/media':
{'tools.staticdir.on': True,
'tools.staticdir.dir': MEDIA_DIR,}
}
def open_page():
webbrowser.open("http://127.0.0.1:8080/")
cherrypy.engine.subscribe('start', open_page)
cherrypy.tree.mount(AjaxApp(), '/', config=config)
cherrypy.engine.start()La clase “AjaxApp” redirige a la página web de “index.html”, que se incluye en la carpeta multimedia.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
" http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns = "http://www.w3.org/1999/xhtml" lang = "en" xml:lang = "en">
<head>
<title>AJAX with jQuery and cherrypy</title>
<meta http-equiv = " Content-Type" content = " text/html; charset=utf-8" />
<script type = " text/javascript" src = " /media/jquery-1.4.2.min.js"></script>
<script type = " text/javascript">
$(function() { // When the testform is submitted... $("#formtest").submit(function() {
// post the form values via AJAX...
$.post('/submit', {name: $("#name").val()}, function(data) {
// and set the title with the result
$("#title").html(data['title']) ;
});
return false ;
});
});
</script>
</head>
<body>
<h1 id = "title">What's your name?</h1>
<form id = " formtest" action = " #" method = " post">
<p>
<label for = " name">Name:</label>
<input type = " text" id = "name" /> <br />
<input type = " submit" value = " Set" />
</p>
</form>
</body>
</html>La función para AJAX se incluye dentro de las etiquetas <script>.
Salida
El código anterior producirá el siguiente resultado:

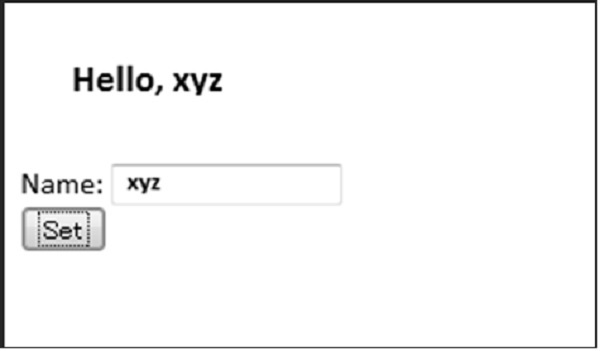
Una vez que el usuario envía el valor, se implementa la funcionalidad AJAX y la pantalla se redirige al formulario como se muestra a continuación:
En este capítulo, nos centraremos en cómo se crea una aplicación en el marco CherryPy.
Considerar Photoblogaplicación para la aplicación de demostración de CherryPy. Una aplicación de Photoblog es un blog normal, pero el texto principal serán fotos en lugar de texto. El principal problema de la aplicación Photoblog es que el desarrollador puede centrarse más en el diseño y la implementación.
Estructura básica - Diseño de entidades
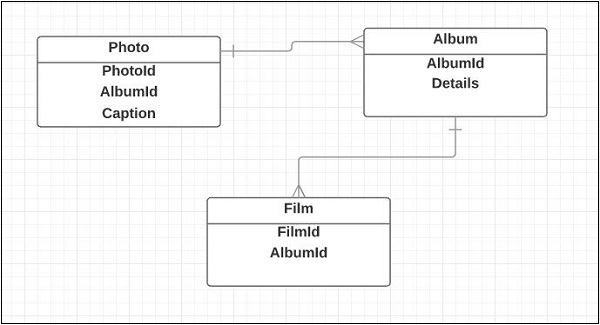
Las entidades diseñan la estructura básica de una aplicación. Las siguientes son las entidades para la aplicación Photoblog:
- Film
- Photo
- Album
El siguiente es un diagrama de clases básico para la relación de entidades:
Estructura de diseño
Como se discutió en el capítulo anterior, la estructura de diseño del proyecto sería como se muestra en la siguiente captura de pantalla:

Considere la aplicación dada, que tiene subdirectorios para la aplicación Photoblog. Los subdirectorios son Photo, Album y Film, que incluirían controllers.py, models.py y server.py.
Funcionalmente, la aplicación Photoblog proporcionará API para manipular esas entidades a través de la interfaz CRUD tradicional: crear, recuperar, actualizar y eliminar.
Conexión a la base de datos
Un módulo de almacenamiento incluye un conjunto de operaciones; La conexión con la base de datos es una de las operaciones.
Como es una aplicación completa, la conexión con la base de datos es obligatoria para API y para mantener la funcionalidad de Crear, Recuperar, Actualizar y Eliminar.
import dejavu
arena = dejavu.Arena()
from model import Album, Film, Photo
def connect():
conf = {'Connect': "host=localhost dbname=Photoblog user=test password=test"}
arena.add_store("main", "postgres", conf)
arena.register_all(globals())La arena en el código anterior será nuestra interfaz entre el administrador de almacenamiento subyacente y la capa de lógica empresarial.
La función de conexión agrega un administrador de almacenamiento al objeto arena para un RDBMS de PostgreSQL.
Una vez que se obtiene la conexión, podemos crear formularios según los requisitos comerciales y completar el trabajo de la aplicación.
Lo más importante antes de la creación de cualquier aplicación es entity mapping y diseñar la estructura de la aplicación.
La prueba es un proceso durante el cual la aplicación se lleva a cabo desde diferentes perspectivas para:
- Encuentra la lista de problemas
- Encuentre diferencias entre el resultado, la producción, los estados, etc. esperados y reales
- Comprende la fase de implementación.
- Encuentre la aplicación útil para propósitos realistas.
El objetivo de las pruebas no es culpar al desarrollador, sino proporcionar herramientas y mejorar la calidad para estimar el estado de la aplicación en un momento dado.
Las pruebas deben planificarse con anticipación. Esto requiere definir el propósito de las pruebas, comprender el alcance de los casos de prueba, hacer la lista de requisitos comerciales y ser consciente de los riesgos involucrados en las diferentes fases del proyecto.
Las pruebas se definen como una serie de aspectos a validar en un sistema o aplicación. A continuación se muestra una lista decommon test approaches -
Unit testing- Esto suele ser realizado por los propios desarrolladores. Esto tiene como objetivo comprobar si una unidad de código funciona como se esperaba o no.
Usability testing- Los desarrolladores generalmente pueden olvidar que están escribiendo una aplicación para los usuarios finales que no tienen conocimiento del sistema. Las pruebas de usabilidad verifican los pros y los contras del producto.
Functional/Acceptance testing - Mientras que las pruebas de usabilidad verifican si una aplicación o sistema es utilizable, las pruebas funcionales garantizan que se implementen todas las funciones especificadas.
Load and performance testing- Esto se lleva a cabo para comprender si el sistema se puede ajustar a las pruebas de carga y rendimiento que se van a realizar. Esto puede provocar cambios en el hardware, optimización de consultas SQL, etc.
Regression testing - Verifica que lanzamientos sucesivos de un producto no rompan ninguna de las funcionalidades anteriores.
Reliability and resilience testing - Las pruebas de confiabilidad ayudan a validar la aplicación del sistema con el desglose de uno o varios componentes.
Examen de la unidad
Las aplicaciones de Photoblog utilizan constantemente pruebas unitarias para comprobar lo siguiente:
- Las nuevas funcionalidades funcionan correctamente y como se esperaba.
- Las funcionalidades existentes no se rompen con la publicación de un nuevo código.
- Los defectos se arreglan y permanecen fijos.
Python viene con un módulo de prueba unitaria estándar que ofrece un enfoque diferente para las pruebas unitarias.
Prueba de unidad
unittest tiene sus raíces en JUnit, un paquete de pruebas unitarias de Java desarrollado por Kent Beck y Erich Gamma. Las pruebas unitarias simplemente devuelven datos definidos. Se pueden definir objetos simulados. Estos objetos permiten realizar pruebas con una interfaz de nuestro diseño sin tener que depender de la aplicación general. También proporcionan una forma de ejecutar pruebas en modo de aislamiento con otras pruebas incluidas.
Definamos una clase ficticia de la siguiente manera:
import unittest
class DummyTest(unittest.TestCase):
def test_01_forward(self):
dummy = Dummy(right_boundary=3)
self.assertEqual(dummy.forward(), 1)
self.assertEqual(dummy.forward(), 2)
self.assertEqual(dummy.forward(), 3)
self.assertRaises(ValueError, dummy.forward)
def test_02_backward(self):
dummy = Dummy(left_boundary=-3, allow_negative=True)
self.assertEqual(dummy.backward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.backward(), -3)
self.assertRaises(ValueError, dummy.backward)
def test_03_boundaries(self):
dummy = Dummy(right_boundary=3, left_boundary=-3,allow_negative=True)
self.assertEqual(dummy.backward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.forward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.backward(), -3)La explicación del código es la siguiente:
El módulo unittest debe importarse para proporcionar capacidades de prueba unitaria para la clase dada.
Se debe crear una clase subclasificando unittest.
Todos los métodos del código anterior comienzan con una prueba de palabras. Todos estos métodos son llamados por unittest handler.
Los métodos de aserción / falla son llamados por el caso de prueba para administrar las excepciones.
Considere esto como un ejemplo para ejecutar un caso de prueba:
if __name__ == '__main__':
unittest.main()El resultado (salida) para ejecutar el caso de prueba será el siguiente:
----------------------------------------------------------------------
Ran 3 tests in 0.000s
OKPruebas funcionales
Una vez que las funcionalidades de la aplicación comienzan a tomar forma según los requisitos, un conjunto de pruebas funcionales puede validar la exactitud de la aplicación con respecto a la especificación. Sin embargo, la prueba debe automatizarse para obtener un mejor rendimiento, lo que requeriría el uso de productos de terceros como Selenium.
CherryPy proporciona funciones integradas como clases auxiliares para facilitar la escritura de pruebas funcionales.
Prueba de carga
Dependiendo de la aplicación que esté escribiendo y de sus expectativas en términos de volumen, es posible que deba ejecutar pruebas de carga y rendimiento para detectar posibles cuellos de botella en la aplicación que impiden que alcance un cierto nivel de rendimiento.
Esta sección no detallará cómo realizar una prueba de rendimiento o carga, ya que está fuera del paquete FunkLoad.
El ejemplo muy básico de FunkLoad es el siguiente:
from funkload.FunkLoadTestCase
import FunkLoadTestCase
class LoadHomePage(FunkLoadTestCase):
def test_homepage(self):
server_url = self.conf_get('main', 'url')
nb_time = self.conf_getInt('test_homepage', 'nb_time')
home_page = "%s/" % server_url
for i in range(nb_time):
self.logd('Try %i' % i)
self.get(home_page, description='Get gome page')
if __name__ in ('main', '__main__'):
import unittest
unittest.main()Aquí hay una explicación detallada del código anterior:
El caso de prueba debe heredar de la clase FunkLoadTestCase para que FunkLoad pueda hacer su trabajo interno de rastrear lo que sucede durante la prueba.
El nombre de la clase es importante ya que FunkLoad buscará un archivo basado en el nombre de la clase.
Los casos de prueba diseñados tienen acceso directo a los archivos de configuración. Los métodos get () y post () simplemente se invocan contra el servidor para obtener la respuesta.
Este capítulo se centrará más en SSL de aplicaciones basadas en CherryPy habilitado a través del servidor HTTP CherryPy integrado.
Configuración
Hay diferentes niveles de ajustes de configuración necesarios en una aplicación web:
Web server - Configuraciones vinculadas al servidor HTTP
Engine - Configuraciones asociadas con el alojamiento del motor
Application - Aplicación que utiliza el usuario
Despliegue
La implementación de la aplicación CherryPy se considera un método bastante sencillo en el que todos los paquetes necesarios están disponibles en la ruta del sistema Python. En un entorno alojado en web compartido, el servidor web residirá en el front-end, lo que permite al proveedor de host realizar las acciones de filtrado. El servidor front-end puede ser Apache olighttpd.
Esta sección presentará algunas soluciones para ejecutar una aplicación CherryPy detrás de los servidores web Apache y lighttpd.
cherrypy
def setup_app():
class Root:
@cherrypy.expose
def index(self):
# Return the hostname used by CherryPy and the remote
# caller IP address
return "Hello there %s from IP: %s " %
(cherrypy.request.base, cherrypy.request.remote.ip)
cherrypy.config.update({'server.socket_port': 9091,
'environment': 'production',
'log.screen': False,
'show_tracebacks': False})
cherrypy.tree.mount(Root())
if __name__ == '__main__':
setup_app()
cherrypy.server.quickstart()
cherrypy.engine.start()SSL
SSL (Secure Sockets Layer)puede ser compatible con aplicaciones basadas en CherryPy. Para habilitar la compatibilidad con SSL, se deben cumplir los siguientes requisitos:
- Tener el paquete PyOpenSSL instalado en el entorno del usuario
- Tener un certificado SSL y una clave privada en el servidor.
Creación de un certificado y una clave privada
Tratemos con los requisitos del certificado y la clave privada -
- Primero, el usuario necesita una clave privada:
openssl genrsa -out server.key 2048- Esta clave no está protegida por contraseña y, por lo tanto, tiene una protección débil.
- Se emitirá el siguiente comando:
openssl genrsa -des3 -out server.key 2048El programa requerirá una frase de contraseña. Si su versión de OpenSSL le permite proporcionar una cadena vacía, hágalo. De lo contrario, ingrese una frase de contraseña predeterminada y luego elimínela de la clave generada de la siguiente manera:
openssl rsa -in server.key -out server.key- La creación del certificado es la siguiente:
openssl req -new -key server.key -out server.csrEste proceso le pedirá que ingrese algunos detalles. Para hacerlo, se debe emitir el siguiente comando:
openssl x509 -req -days 60 -in server.csr -signkey
server.key -out server.crtEl certificado recién firmado tendrá una validez de 60 días.
El siguiente código muestra su implementación:
import cherrypy
import os, os.path
localDir = os.path.abspath(os.path.dirname(__file__))
CA = os.path.join(localDir, 'server.crt')
KEY = os.path.join(localDir, 'server.key')
def setup_server():
class Root:
@cherrypy.expose
def index(self):
return "Hello there!"
cherrypy.tree.mount(Root())
if __name__ == '__main__':
setup_server()
cherrypy.config.update({'server.socket_port': 8443,
'environment': 'production',
'log.screen': True,
'server.ssl_certificate': CA,
'server.ssl_private_key': KEY})
cherrypy.server.quickstart()
cherrypy.engine.start()El siguiente paso es iniciar el servidor; Si tiene éxito, verá el siguiente mensaje en su pantalla:
HTTP Serving HTTPS on https://localhost:8443/