Programación D - Guía rápida
El lenguaje de programación D es un lenguaje de programación de sistema de múltiples paradigmas orientado a objetos desarrollado por Walter Bright de Digital Mars. Su desarrollo comenzó en 1999 y se lanzó por primera vez en 2001. La versión principal de D (1.0) se lanzó en 2007. Actualmente, tenemos la versión D2 de D.
D es un lenguaje con sintaxis de estilo C y usa escritura estática. Hay muchas características de C y C ++ en D, pero también hay algunas características de este lenguaje que no se incluyen como parte de D. Algunas de las adiciones notables a D incluyen,
- Examen de la unidad
- Verdaderos módulos
- Recolección de basura
- Matrices de primera clase
- Libre y abierto
- Matrices asociativas
- Matrices dinámicas
- Clases internas
- Closures
- Funciones anónimas
- Evaluación perezosa
- Closures
Múltiples paradigmas
D es un lenguaje de programación de paradigmas múltiples. Los múltiples paradigmas incluyen,
- Imperative
- Orientado a objetos
- Meta programación
- Functional
- Concurrent
Ejemplo
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Aprendiendo D
Lo más importante que debe hacer al aprender D es centrarse en los conceptos y no perderse en los detalles técnicos del idioma.
El propósito de aprender un lenguaje de programación es convertirse en un mejor programador; es decir, volverse más eficaces en el diseño e implementación de nuevos sistemas y en el mantenimiento de los antiguos.
Alcance de D
La programación D tiene algunas características interesantes y el sitio oficial de programación D afirma que D es conveniente, potente y eficiente. La programación D agrega muchas características en el lenguaje central que el lenguaje C ha proporcionado en forma de bibliotecas estándar, como matriz redimensionable y función de cadena. D es un excelente segundo idioma para programadores de nivel intermedio a avanzado. D es mejor para manejar la memoria y administrar los punteros que a menudo causan problemas en C ++.
La programación D está destinada principalmente a programas nuevos que convierten programas existentes. Proporciona pruebas y verificación integradas, ideales para grandes proyectos nuevos que se escribirán con millones de líneas de código por equipos grandes.
Configuración del entorno local para D
Si aún está dispuesto a configurar su entorno para el lenguaje de programación D, necesita los siguientes dos softwares disponibles en su computadora, (a) Editor de texto, (b) Compilador D.
Editor de texto para programación D
Esto se utilizará para escribir su programa. Algunos ejemplos de algunos editores incluyen el Bloc de notas de Windows, el comando de edición del sistema operativo, Brief, Epsilon, EMACS y vim o vi.
El nombre y la versión del editor de texto pueden variar en diferentes sistemas operativos. Por ejemplo, el Bloc de notas se usará en Windows, y vim o vi se pueden usar en Windows, así como en Linux o UNIX.
Los archivos que crea con su editor se denominan archivos fuente y contienen el código fuente del programa. Los archivos de origen de los programas D se nombran con la extensión ".d".
Antes de comenzar su programación, asegúrese de tener un editor de texto en su lugar y de tener suficiente experiencia para escribir un programa de computadora, guardarlo en un archivo, compilarlo y finalmente ejecutarlo.
El compilador D
La mayoría de las implementaciones actuales de D se compilan directamente en código de máquina para una ejecución eficiente.
Tenemos varios compiladores D disponibles e incluye lo siguiente.
DMD - El compilador Digital Mars D es el compilador D oficial de Walter Bright.
GDC - Un front-end para el back-end de GCC, construido usando el código fuente del compilador DMD abierto.
LDC - Un compilador basado en el front-end DMD que usa LLVM como su back-end del compilador.
Los diferentes compiladores anteriores se pueden descargar de D Downloads
Usaremos D versión 2 y recomendamos no descargar D1.
Tengamos un programa helloWorld.d de la siguiente manera. Usaremos esto como el primer programa que ejecutamos en la plataforma que elija.
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Podemos ver el siguiente resultado.
$ hello worldInstalación de D en Windows
Descarga el instalador de Windows .
Ejecute el ejecutable descargado para instalar la D, lo que se puede hacer siguiendo las instrucciones en pantalla.
Ahora podemos compilar y ejecutar un archivo de anuncios, digamos holaWorld.d, cambiando a la carpeta que contiene el archivo usando cd y luego siguiendo los siguientes pasos:
C:\DProgramming> DMD helloWorld.d
C:\DProgramming> helloWorldPodemos ver el siguiente resultado.
hello worldC: \ DProgramming es la carpeta que estoy usando para guardar mis muestras. Puede cambiarlo a la carpeta en la que ha guardado los programas D.
Instalación de D en Ubuntu / Debian
Descargue el instalador de Debian .
Ejecute el ejecutable descargado para instalar la D, lo que se puede hacer siguiendo las instrucciones en pantalla.
Ahora podemos compilar y ejecutar un archivo de anuncios, digamos holaWorld.d, cambiando a la carpeta que contiene el archivo usando cd y luego siguiendo los siguientes pasos:
$ dmd helloWorld.d
$ ./helloWorldPodemos ver el siguiente resultado.
$ hello worldInstalación de D en Mac OS X
Descarga el instalador de Mac .
Ejecute el ejecutable descargado para instalar la D, lo que se puede hacer siguiendo las instrucciones en pantalla.
Ahora podemos compilar y ejecutar un archivo de anuncios, digamos holaWorld.d, cambiando a la carpeta que contiene el archivo usando cd y luego siguiendo los siguientes pasos:
$ dmd helloWorld.d $ ./helloWorldPodemos ver el siguiente resultado.
$ hello worldInstalación de D en Fedora
Descarga el instalador de Fedora .
Ejecute el ejecutable descargado para instalar la D, lo que se puede hacer siguiendo las instrucciones en pantalla.
Ahora podemos compilar y ejecutar un archivo de anuncios, digamos holaWorld.d, cambiando a la carpeta que contiene el archivo usando cd y luego siguiendo los siguientes pasos:
$ dmd helloWorld.d
$ ./helloWorldPodemos ver el siguiente resultado.
$ hello worldInstalación de D en OpenSUSE
Descargue el instalador de OpenSUSE .
Ejecute el ejecutable descargado para instalar la D, lo que se puede hacer siguiendo las instrucciones en pantalla.
Ahora podemos compilar y ejecutar un archivo de anuncios, digamos holaWorld.d, cambiando a la carpeta que contiene el archivo usando cd y luego siguiendo los siguientes pasos:
$ dmd helloWorld.d $ ./helloWorldPodemos ver el siguiente resultado.
$ hello worldD IDE
Tenemos soporte IDE para D en forma de complementos en la mayoría de los casos. Esto incluye,
El complemento Visual D es un complemento para Visual Studio 2005-13
DDT es un complemento de eclipse que proporciona finalización de código y depuración con GDB.
Finalización de código mono-D , refactorización con soporte dmd / ldc / gdc. Ha sido parte de GSoC 2012.
Code Blocks es un IDE multiplataforma que admite la creación, el resaltado y la depuración de proyectos D.
D es bastante simple de aprender y ¡comencemos a crear nuestro primer programa D!
Primer programa D
Escribamos un programa D simple. Todos los archivos D tendrán la extensión .d. Así que ponga el siguiente código fuente en un archivo test.d.
import std.stdio;
/* My first program in D */
void main(string[] args) {
writeln("test!");
}Suponiendo que el entorno D está configurado correctamente, ejecutemos la programación usando -
$ dmd test.d
$ ./testPodemos ver el siguiente resultado.
testVeamos ahora la estructura básica del programa D, para que le resulte fácil comprender los bloques de construcción básicos del lenguaje de programación D.
Importar en D
Las bibliotecas que son colecciones de partes de programas reutilizables pueden estar disponibles para nuestro proyecto con la ayuda de la importación. Aquí importamos la biblioteca io estándar que proporciona las operaciones básicas de E / S. Writeln, que se usa en el programa anterior, es una función en la biblioteca estándar de D. Se utiliza para imprimir una línea de texto. Los contenidos de la biblioteca en D se agrupan en módulos que se basan en los tipos de tareas que pretenden realizar. El único módulo que usa este programa es std.stdio, que maneja la entrada y salida de datos.
Función principal
La función principal es el inicio del programa y determina el orden de ejecución y cómo se deben ejecutar otras secciones del programa.
Fichas en D
El programa AD consta de varios tokens y un token es una palabra clave, un identificador, una constante, una cadena literal o un símbolo. Por ejemplo, la siguiente declaración D consta de cuatro tokens:
writeln("test!");Los tokens individuales son:
writeln (
"test!"
)
;Comentarios
Los comentarios son como texto de apoyo en su programa D y el compilador los ignora. El comentario de varias líneas comienza con / * y termina con los caracteres * / como se muestra a continuación -
/* My first program in D */El comentario único se escribe usando // al principio del comentario.
// my first program in DIdentificadores
El identificador de AD es un nombre que se utiliza para identificar una variable, función o cualquier otro elemento definido por el usuario. Un identificador comienza con una letra de la A a la Z o de la aa la z o un guión bajo _ seguido de cero o más letras, guiones bajos y dígitos (0 a 9).
D no permite caracteres de puntuación como @, $ y% dentro de los identificadores. D es uncase sensitivelenguaje de programación. Por lo tanto, la mano de obra y la mano de obra son dos identificadores diferentes en D. Aquí hay algunos ejemplos de identificadores aceptables:
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValPalabras clave
La siguiente lista muestra algunas de las palabras reservadas en D. Estas palabras reservadas no se pueden usar como constantes o variables o cualquier otro nombre de identificador.
| resumen | alias | alinear | asm |
| afirmar | auto | cuerpo | bool |
| byte | caso | emitir | captura |
| carbonizarse | clase | constante | Seguir |
| dchar | depurar | defecto | delegar |
| obsoleto | hacer | doble | más |
| enumeración | exportar | externo | falso |
| final | finalmente | flotador | para |
| para cada | función | ir | Si |
| importar | en | En fuera | En t |
| interfaz | invariante | es | largo |
| macro | mezclando | módulo | nuevo |
| nulo | afuera | anular | paquete |
| pragma | privado | protegido | público |
| real | árbitro | regreso | alcance |
| corto | estático | estructura | súper |
| cambiar | sincronizado | modelo | esta |
| lanzar | cierto | tratar | typeid |
| tipo de | ubyte | uint | ulong |
| Unión | prueba de unidad | corto | versión |
| vacío | wchar | mientras | con |
Espacio en blanco en D
Una línea que contiene solo espacios en blanco, posiblemente con un comentario, se conoce como línea en blanco y un compilador D la ignora por completo.
Espacio en blanco es el término utilizado en D para describir espacios en blanco, tabulaciones, caracteres de nueva línea y comentarios. El espacio en blanco separa una parte de una declaración de otra y permite al intérprete identificar dónde termina un elemento de una declaración, como int, y comienza el siguiente. Por lo tanto, en la siguiente declaración:
local ageDebe haber al menos un carácter de espacio en blanco (generalmente un espacio) entre el local y la edad para que el intérprete pueda distinguirlos. Por otro lado, en el siguiente comunicado
int fruit = apples + oranges //get the total fruitsNo se necesitan espacios en blanco entre fruta y =, o entre = y manzanas, aunque puede incluir algunos si lo desea por motivos de legibilidad.
Una variable no es más que un nombre que se le da a un área de almacenamiento que nuestros programas pueden manipular. Cada variable en D tiene un tipo específico, que determina el tamaño y el diseño de la memoria de la variable; el rango de valores que se pueden almacenar dentro de esa memoria; y el conjunto de operaciones que se pueden aplicar a la variable.
El nombre de una variable puede estar compuesto por letras, dígitos y el carácter de subrayado. Debe comenzar con una letra o un guión bajo. Las letras mayúsculas y minúsculas son distintas porque D distingue entre mayúsculas y minúsculas. Según los tipos básicos explicados en el capítulo anterior, habrá los siguientes tipos de variables básicas:
| No Señor. | Tipo y descripción |
|---|---|
| 1 | char Normalmente, un solo octeto (un byte). Este es un tipo entero. |
| 2 | int El tamaño más natural de número entero para la máquina. |
| 3 | float Un valor de coma flotante de precisión simple. |
| 4 | double Un valor de coma flotante de doble precisión. |
| 5 | void Representa la ausencia de tipo. |
El lenguaje de programación D también permite definir otros tipos de variables como Enumeración, Puntero, Matriz, Estructura, Unión, etc., que trataremos en capítulos posteriores. Para este capítulo, estudiemos solo los tipos de variables básicas.
Definición de variable en D
Una definición de variable le dice al compilador dónde y cuánto espacio crear para la variable. Una definición de variable especifica un tipo de datos y contiene una lista de una o más variables de ese tipo de la siguiente manera:
type variable_list;Aquí, type debe ser un tipo de datos D válido que incluya char, wchar, int, float, double, bool o cualquier objeto definido por el usuario, etc., y variable_listpuede constar de uno o más nombres de identificadores separados por comas. Aquí se muestran algunas declaraciones válidas:
int i, j, k;
char c, ch;
float f, salary;
double d;La línea int i, j, k;declara y define las variables i, j y k; que indica al compilador que cree variables denominadas i, j y k de tipo int.
Las variables se pueden inicializar (asignar un valor inicial) en su declaración. El inicializador consta de un signo igual seguido de una expresión constante de la siguiente manera:
type variable_name = value;Ejemplos
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Cuando una variable se declara en D, siempre se establece en su 'inicializador predeterminado', al que se puede acceder manualmente como T.init dónde T es el tipo (ej. int.init). El inicializador predeterminado para los tipos enteros es 0, para los booleanos es falso y para los números de coma flotante NaN.
Declaración de variable en D
Una declaración de variable proporciona seguridad al compilador de que existe una variable con el tipo y nombre dados, de modo que el compilador proceda a una compilación adicional sin necesidad de detalles completos sobre la variable. Una declaración de variable tiene su significado solo en el momento de la compilación, el compilador necesita una declaración de variable real en el momento de vincular el programa.
Ejemplo
Pruebe el siguiente ejemplo, donde las variables se han declarado al inicio del programa, pero se definen e inicializan dentro de la función principal:
import std.stdio;
int a = 10, b = 10;
int c;
float f;
int main () {
writeln("Value of a is : ", a);
/* variable re definition: */
int a, b;
int c;
float f;
/* Initialization */
a = 30;
b = 40;
writeln("Value of a is : ", a);
c = a + b;
writeln("Value of c is : ", c);
f = 70.0/3.0;
writeln("Value of f is : ", f);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Value of a is : 10
Value of a is : 30
Value of c is : 70
Value of f is : 23.3333Valores L y valores R en D
Hay dos tipos de expresiones en D:
lvalue - Una expresión que es un valor l puede aparecer como el lado izquierdo o derecho de una asignación.
rvalue - Una expresión que es un rvalue puede aparecer en el lado derecho pero no en el lado izquierdo de una asignación.
Las variables son valores l y, por lo tanto, pueden aparecer en el lado izquierdo de una tarea. Los literales numéricos son valores r y, por lo tanto, no se pueden asignar y no pueden aparecer en el lado izquierdo. La siguiente declaración es válida:
int g = 20;Pero lo siguiente no es una declaración válida y generaría un error en tiempo de compilación:
10 = 20;En el lenguaje de programación D, los tipos de datos se refieren a un sistema extenso que se utiliza para declarar variables o funciones de diferentes tipos. El tipo de variable determina cuánto espacio ocupa en el almacenamiento y cómo se interpreta el patrón de bits almacenado.
Los tipos en D se pueden clasificar de la siguiente manera:
| No Señor. | Tipos y descripción |
|---|---|
| 1 | Basic Types Son tipos aritméticos y constan de tres tipos: (a) entero, (b) punto flotante y (c) carácter. |
| 2 | Enumerated types De nuevo son tipos aritméticos. Se utilizan para definir variables a las que solo se les pueden asignar ciertos valores enteros discretos en todo el programa. |
| 3 | The type void El especificador de tipo void indica que no hay ningún valor disponible. |
| 4 | Derived types Incluyen (a) tipos de puntero, (b) tipos de matriz, (c) tipos de estructura, (d) tipos de unión y (e) tipos de función. |
Los tipos de matriz y los tipos de estructura se denominan colectivamente tipos agregados. El tipo de una función especifica el tipo de valor de retorno de la función. Veremos los tipos básicos en la siguiente sección, mientras que otros tipos se tratarán en los próximos capítulos.
Tipos de enteros
La siguiente tabla proporciona listas de tipos de enteros estándar con sus tamaños de almacenamiento y rangos de valores:
| Tipo | Tamaño de almacenamiento | Rango de valores |
|---|---|---|
| bool | 1 byte | falso o verdadero |
| byte | 1 byte | -128 hasta 127 |
| ubyte | 1 byte | 0 hasta 255 |
| En t | 4 bytes | -2,147,483,648 a 2,147,483,647 |
| uint | 4 bytes | 0 a 4.294.967.295 |
| corto | 2 bytes | -32.768 hasta 32.767 |
| corto | 2 bytes | 0 hasta 65.535 |
| largo | 8 bytes | -9223372036854775808 al 9223372036854775807 |
| ulong | 8 bytes | 0 a 18446744073709551615 |
Para obtener el tamaño exacto de un tipo o una variable, puede utilizar el sizeofoperador. El tipo de expresión . (Sizeof) produce el tamaño de almacenamiento del objeto o tipo en bytes. El siguiente ejemplo obtiene el tamaño del tipo int en cualquier máquina:
import std.stdio;
int main() {
writeln("Length in bytes: ", ulong.sizeof);
return 0;
}Cuando compila y ejecuta el programa anterior, produce el siguiente resultado:
Length in bytes: 8Tipos de punto flotante
La siguiente tabla menciona los tipos de punto flotante estándar con tamaños de almacenamiento, rangos de valores y su propósito:
| Tipo | Tamaño de almacenamiento | Rango de valores | Propósito |
|---|---|---|---|
| flotador | 4 bytes | 1.17549e-38 a 3.40282e + 38 | 6 lugares decimales |
| doble | 8 bytes | 2.22507e-308 a 1.79769e + 308 | 15 decimales |
| real | 10 bytes | 3.3621e-4932 a 1.18973e + 4932 | el tipo de punto flotante más grande que admite el hardware, o el doble; lo que sea más grande |
| ifloat | 4 bytes | 1.17549e-38i a 3.40282e + 38i | tipo de valor imaginario de flotador |
| doble | 8 bytes | 2.22507e-308i a 1.79769e + 308i | tipo de valor imaginario de doble |
| Es real | 10 bytes | 3.3621e-4932 a 1.18973e + 4932 | tipo de valor imaginario de real |
| cfloat | 8 bytes | 1.17549e-38 + 1.17549e-38i a 3.40282e + 38 + 3.40282e + 38i | tipo de número complejo formado por dos flotadores |
| cdouble | 16 bytes | 2.22507e-308 + 2.22507e-308i a 1.79769e + 308 + 1.79769e + 308i | tipo de número complejo formado por dos dobles |
| creal | 20 bytes | 3.3621e-4932 + 3.3621e-4932i a 1.18973e + 4932 + 1.18973e + 4932i | tipo de número complejo formado por dos reales |
El siguiente ejemplo imprime el espacio de almacenamiento tomado por un tipo flotante y sus valores de rango:
import std.stdio;
int main() {
writeln("Length in bytes: ", float.sizeof);
return 0;
}Cuando compila y ejecuta el programa anterior, produce el siguiente resultado en Linux:
Length in bytes: 4Tipos de caracteres
La siguiente tabla enumera los tipos de caracteres estándar con tamaños de almacenamiento y su propósito.
| Tipo | Tamaño de almacenamiento | Propósito |
|---|---|---|
| carbonizarse | 1 byte | Unidad de código UTF-8 |
| wchar | 2 bytes | Unidad de código UTF-16 |
| dchar | 4 bytes | Unidad de código UTF-32 y punto de código Unicode |
El siguiente ejemplo imprime el espacio de almacenamiento ocupado por un tipo de char.
import std.stdio;
int main() {
writeln("Length in bytes: ", char.sizeof);
return 0;
}Cuando compila y ejecuta el programa anterior, produce el siguiente resultado:
Length in bytes: 1El tipo vacío
El tipo vacío especifica que no hay ningún valor disponible. Se utiliza en dos tipos de situaciones:
| No Señor. | Tipos y descripción |
|---|---|
| 1 | Function returns as void Hay varias funciones en D que no devuelven valor o se puede decir que devuelven vacío. Una función sin valor de retorno tiene el tipo de retorno como vacío. Por ejemplo,void exit (int status); |
| 2 | Function arguments as void Hay varias funciones en D que no aceptan ningún parámetro. Una función sin parámetro puede aceptarse como nula. Por ejemplo,int rand(void); |
Es posible que en este momento no entienda el tipo vacío, así que continuemos y cubriremos estos conceptos en los próximos capítulos.
Se utiliza una enumeración para definir valores constantes con nombre. Un tipo enumerado se declara utilizando elenum palabra clave.
La sintaxis de enum
La forma más simple de una definición de enumeración es la siguiente:
enum enum_name {
enumeration list
}Dónde,
El enum_name especifica el nombre del tipo de enumeración.
La lista de enumeración es una lista de identificadores separados por comas.
Cada uno de los símbolos de la lista de enumeración representa un valor entero, uno mayor que el símbolo que lo precede. De forma predeterminada, el valor del primer símbolo de enumeración es 0. Por ejemplo:
enum Days { sun, mon, tue, wed, thu, fri, sat };Ejemplo
El siguiente ejemplo demuestra el uso de la variable enum:
import std.stdio;
enum Days { sun, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
Days day;
day = Days.mon;
writefln("Current Day: %d", day);
writefln("Friday : %d", Days.fri);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Current Day: 1
Friday : 5En el programa anterior, podemos ver cómo se puede usar una enumeración. Inicialmente, creamos una variable denominada día de nuestros días de enumeración definidos por el usuario. Luego lo configuramos en mon usando el operador de punto. Necesitamos usar el método writefln para imprimir el valor de mon que se ha almacenado. También necesita especificar el tipo. Es del tipo entero, por lo que usamos% d para imprimir.
Propiedades de enumeraciones con nombre
El ejemplo anterior usa un nombre Días para la enumeración y se denomina enumeraciones con nombre. Estas enumeraciones con nombre tienen las siguientes propiedades:
Init - Inicializa el primer valor de la enumeración.
min - Devuelve el menor valor de enumeración.
max - Devuelve el mayor valor de enumeración.
sizeof - Devuelve el tamaño de almacenamiento para enumeración.
Modifiquemos el ejemplo anterior para hacer uso de las propiedades.
import std.stdio;
// Initialized sun with value 1
enum Days { sun = 1, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Min : %d", Days.min);
writefln("Max : %d", Days.max);
writefln("Size of: %d", Days.sizeof);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Min : 1
Max : 7
Size of: 4Enum anónimo
La enumeración sin nombre se llama enumeración anónima. Un ejemplo paraanonymous enum se da a continuación.
import std.stdio;
// Initialized sun with value 1
enum { sun , mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Sunday : %d", sun);
writefln("Monday : %d", mon);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Sunday : 0
Monday : 1Las enumeraciones anónimas funcionan casi de la misma manera que las enumeraciones con nombre, pero no tienen las propiedades max, min y sizeof.
Enum con sintaxis de tipo base
La sintaxis para la enumeración con tipo base se muestra a continuación.
enum :baseType {
enumeration list
}Algunos de los tipos básicos incluyen long, int y string. A continuación se muestra un ejemplo de uso de long.
import std.stdio;
enum : string {
A = "hello",
B = "world",
}
int main(string[] args) {
writefln("A : %s", A);
writefln("B : %s", B);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
A : hello
B : worldMás características
La enumeración en D proporciona características como la inicialización de múltiples valores en una enumeración con múltiples tipos. A continuación se muestra un ejemplo.
import std.stdio;
enum {
A = 1.2f, // A is 1.2f of type float
B, // B is 2.2f of type float
int C = 3, // C is 3 of type int
D // D is 4 of type int
}
int main(string[] args) {
writefln("A : %f", A);
writefln("B : %f", B);
writefln("C : %d", C);
writefln("D : %d", D);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
A : 1.200000
B : 2.200000
C : 3
D : 4Los valores constantes que se escriben en el programa como parte del código fuente se denominan literals.
Los literales pueden ser de cualquiera de los tipos de datos básicos y se pueden dividir en números enteros, números de coma flotante, caracteres, cadenas y valores booleanos.
Nuevamente, los literales se tratan como variables regulares, excepto que sus valores no se pueden modificar después de su definición.
Literales enteros
Un literal entero puede ser uno de los siguientes tipos:
Decimal usa la representación numérica normal con el primer dígito no puede ser 0 ya que ese dígito está reservado para indicar el sistema octal. Esto no incluye 0 por sí solo: 0 es cero.
Octal utiliza 0 como prefijo del número.
Binary utiliza 0b o 0B como prefijo.
Hexadecimal usa 0x o 0X como prefijo.
Un literal entero también puede tener un sufijo que sea una combinación de U y L, para unsigned y long, respectivamente. El sufijo puede estar en mayúsculas o minúsculas y puede estar en cualquier orden.
Cuando no usa un sufijo, el compilador elige entre int, uint, long y ulong en función de la magnitud del valor.
Aquí hay algunos ejemplos de literales enteros:
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixA continuación se muestran otros ejemplos de varios tipos de literales enteros:
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned long
0b001 // binaryLiterales de coma flotante
Los literales de coma flotante se pueden especificar en el sistema decimal como en 1.568 o en el sistema hexadecimal como en 0x91.bc.
En el sistema decimal, un exponente se puede representar agregando el carácter e o E y un número después de eso. Por ejemplo, 2,3e4 significa "2,3 por 10 elevado a 4". Se puede especificar un carácter "+" antes del valor del exponente, pero no tiene ningún efecto. Por ejemplo, 2.3e4 y 2.3e + 4 son iguales.
El carácter “-” agregado antes del valor del exponente cambia el significado a "dividido por 10 a la potencia de". Por ejemplo, 2.3e-2 significa "2.3 dividido por 10 elevado a 2".
En el sistema hexadecimal, el valor comienza con 0x o 0X. El exponente se especifica mediante p o P en lugar de e o E. El exponente no significa "10 elevado a", sino "2 elevado a". Por ejemplo, el P4 en 0xabc.defP4 significa "abc.de multiplicado por 2 elevado a 4".
Aquí hay algunos ejemplos de literales de punto flotante:
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fraction
0xabc.defP4 // Legal Hexa decimal with exponent
0xabc.defe4 // Legal Hexa decimal without exponent.De forma predeterminada, el tipo de literal de coma flotante es doble. F y F significan flotante, y el especificador L significa real.
Literales booleanos
Hay dos literales booleanos y forman parte de las palabras clave D estándar:
Un valor de true representando verdadero.
Un valor de false representando falso.
No debe considerar el valor de verdadero igual a 1 y el valor de falso igual a 0.
Literales de caracteres
Los literales de caracteres se incluyen entre comillas simples.
Un literal de carácter puede ser un carácter simple (por ejemplo, 'x'), una secuencia de escape (por ejemplo, '\ t'), un carácter ASCII (por ejemplo, '\ x21'), un carácter Unicode (por ejemplo, '\ u011e') o como carácter con nombre (por ejemplo, '\ ©', '\ ♥', '\ €').
Hay ciertos caracteres en D cuando están precedidos por una barra invertida tendrán un significado especial y se usan para representar como nueva línea (\ n) o tabulación (\ t). Aquí tienes una lista de algunos de esos códigos de secuencia de escape:
| Secuencia de escape | Sentido |
|---|---|
| \\ | \ personaje |
| \ ' | ' personaje |
| \ " | " personaje |
| \? | ? personaje |
| \un | Alerta o campana |
| \segundo | Retroceso |
| \F | Alimentación de formulario |
| \norte | Nueva línea |
| \ r | Retorno de carro |
| \ t | Pestaña horizontal |
| \ v | Pestaña vertical |
El siguiente ejemplo muestra algunos caracteres de secuencia de escape:
import std.stdio;
int main(string[] args) {
writefln("Hello\tWorld%c\n",'\x21');
writefln("Have a good day%c",'\x21');
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello World!
Have a good day!Literales de cadena
Los literales de cadena se encierran entre comillas dobles. Una cadena contiene caracteres que son similares a los literales de caracteres: caracteres simples, secuencias de escape y caracteres universales.
Puede dividir una línea larga en varias líneas usando cadenas literales y separarlas usando espacios en blanco.
Aquí hay algunos ejemplos de cadenas literales:
import std.stdio;
int main(string[] args) {
writeln(q"MY_DELIMITER
Hello World
Have a good day
MY_DELIMITER");
writefln("Have a good day%c",'\x21');
auto str = q{int value = 20; ++value;};
writeln(str);
}En el ejemplo anterior, puede encontrar el uso de q "MY_DELIMITER MY_DELIMITER" para representar caracteres de varias líneas. Además, puede ver q {} para representar una declaración en lenguaje D en sí misma.
Un operador es un símbolo que le dice al compilador que realice manipulaciones matemáticas o lógicas específicas. El lenguaje D es rico en operadores integrados y proporciona los siguientes tipos de operadores:
- Operadores aritméticos
- Operadores relacionales
- Operadores logicos
- Operadores bit a bit
- Operadores de Asignación
- Operadores varios
Este capítulo explica los operadores aritméticos, relacionales, lógicos, bit a bit, de asignación y otros, uno por uno.
Operadores aritméticos
La siguiente tabla muestra todos los operadores aritméticos compatibles con el lenguaje D. Asumir variableA tiene 10 y variable B sostiene 20 entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| + | Agrega dos operandos. | A + B da 30 |
| - | Resta el segundo operando del primero. | A - B da -10 |
| * | Multiplica ambos operandos. | A * B da 200 |
| / | Divide numerador por denumerador. | B / A da 2 |
| % | Devuelve el resto de una división entera. | B% A da 0 |
| ++ | El operador de incremento aumenta el valor entero en uno. | A ++ da 11 |
| - | El operador de decrementos reduce el valor entero en uno. | A-- da 9 |
Operadores relacionales
La siguiente tabla muestra todos los operadores relacionales compatibles con el lenguaje D. Asumir variableA tiene 10 y variable B tiene 20, entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| == | Comprueba si los valores de dos operandos son iguales o no, si es así, la condición se convierte en verdadera. | (A == B) no es cierto. |
| ! = | Comprueba si los valores de dos operandos son iguales o no, si los valores no son iguales, la condición se convierte en verdadera. | (A! = B) es cierto. |
| > | Comprueba si el valor del operando izquierdo es mayor que el valor del operando derecho, si es así, la condición se convierte en verdadera. | (A> B) no es cierto. |
| < | Comprueba si el valor del operando izquierdo es menor que el valor del operando derecho, si es así, la condición se convierte en verdadera. | (A <B) es cierto. |
| > = | Comprueba si el valor del operando izquierdo es mayor o igual que el valor del operando derecho, si es así, la condición se convierte en verdadera. | (A> = B) no es cierto. |
| <= | Comprueba si el valor del operando izquierdo es menor o igual que el valor del operando derecho, si es así, la condición se convierte en verdadera. | (A <= B) es cierto. |
Operadores logicos
La siguiente tabla muestra todos los operadores lógicos compatibles con el lenguaje D. Asumir variableA contiene 1 y variable B tiene 0, entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| && | Se llama operador AND lógico. Si ambos operandos son distintos de cero, la condición se vuelve verdadera. | (A && B) es falso. |
| || | Se llama Operador OR lógico. Si alguno de los dos operandos es distinto de cero, la condición se vuelve verdadera. | (A || B) es cierto. |
| ! | Se llama Operador NOT lógico. Úselo para revertir el estado lógico de su operando. Si una condición es verdadera, el operador NOT lógico la convertirá en falsa. | ! (A && B) es cierto. |
Operadores bit a bit
Los operadores bit a bit funcionan en bits y realizan operaciones bit a bit. Las tablas de verdad para &, | y ^ son las siguientes:
| pags | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Suponga si A = 60; y B = 13. En el formato binario serán los siguientes:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
Los operadores bit a bit compatibles con el lenguaje D se enumeran en la siguiente tabla. Suponga que la variable A tiene 60 y la variable B tiene 13, entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| Y | El operador AND binario copia un bit al resultado si existe en ambos operandos. | (A y B) dará 12, significa 0000 1100. |
| | | El operador OR binario copia un bit si existe en cualquiera de los operandos. | (A | B) da 61. Significa 0011 1101. |
| ^ | El operador binario XOR copia el bit si está configurado en un operando pero no en ambos. | (A ^ B) da 49. Significa 0011 0001 |
| ~ | El operador de complemento binario es unario y tiene el efecto de "voltear" bits. | (~ A) da -61. Significa 1100 0011 en forma de complemento a 2. |
| << | Operador binario de cambio a la izquierda. El valor de los operandos de la izquierda se mueve a la izquierda el número de bits especificado por el operando de la derecha. | A << 2 da 240. Significa 1111 0000 |
| >> | Operador de cambio a la derecha binario. El valor de los operandos de la izquierda se mueve hacia la derecha el número de bits especificado por el operando de la derecha. | A >> 2 da 15. Significa 0000 1111. |
Operadores de Asignación
Los siguientes operadores de asignación son compatibles con el lenguaje D:
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| = | Es un simple operador de asignación. Asigna valores de los operandos del lado derecho al operando del lado izquierdo | C = A + B asigna el valor de A + B a C |
| + = | Es un operador de asignación de AND. Agrega operando derecho al operando izquierdo y asigna el resultado al operando izquierdo | C + = A es equivalente a C = C + A |
| - = | Es un operador de asignación Y resta. Resta el operando derecho del operando izquierdo y asigna el resultado al operando izquierdo. | C - = A es equivalente a C = C - A |
| * = | Es operador de multiplicación Y asignación. Multiplica el operando derecho con el operando izquierdo y asigna el resultado al operando izquierdo. | C * = A es equivalente a C = C * A |
| / = | Es el operador de división Y asignación. Divide el operando izquierdo con el operando derecho y asigna el resultado al operando izquierdo. | C / = A es equivalente a C = C / A |
| % = | Es operador de módulo Y asignación. Toma el módulo usando dos operandos y asigna el resultado al operando izquierdo. | C% = A es equivalente a C = C% A |
| << = | Es operador de desplazamiento Y asignación a la izquierda. | C << = 2 es lo mismo que C = C << 2 |
| >> = | Es el operador de desplazamiento Y asignación a la derecha. | C >> = 2 es lo mismo que C = C >> 2 |
| & = | Es un operador de asignación AND bit a bit. | C & = 2 es lo mismo que C = C & 2 |
| ^ = | Es operador de asignación y OR exclusivo bit a bit. | C ^ = 2 es lo mismo que C = C ^ 2 |
| | = | Es operador de asignación y OR inclusivo bit a bit | C | = 2 es lo mismo que C = C | 2 |
Operadores miscilares: tamaño y ternario
Hay algunos otros operadores importantes, incluidos sizeof y ? : compatible con D Language.
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| tamaño de() | Devuelve el tamaño de una variable. | sizeof (a), donde a es un número entero, devuelve 4. |
| Y | Devuelve la dirección de una variable. | &un; da la dirección real de la variable. |
| * | Puntero a una variable. | *un; da puntero a una variable. |
| ? : | Expresión condicional | Si la condición es verdadera, entonces valor X: De lo contrario, valor Y. |
Precedencia de operadores en D
La precedencia del operador determina la agrupación de términos en una expresión. Esto afecta cómo se evalúa una expresión. Ciertos operadores tienen prioridad sobre otros.
Por ejemplo, el operador de multiplicación tiene mayor precedencia que el operador de suma.
Consideremos una expresión
x = 7 + 3 * 2.
Aquí, a x se le asigna 13, no 20. La simple razón es que el operador * tiene mayor precedencia que +, por lo tanto, 3 * 2 se calcula primero y luego el resultado se suma a 7.
Aquí, los operadores con mayor precedencia aparecen en la parte superior de la tabla, los que tienen la menor prioridad aparecen en la parte inferior. Dentro de una expresión, los operadores de mayor precedencia se evalúan primero.
Mostrar ejemplos
| Categoría | Operador | Asociatividad |
|---|---|---|
| Sufijo | () [] ->. ++ - - | De izquierda a derecha |
| Unario | + -! ~ ++ - - (tipo) * & sizeof | De derecha a izquierda |
| Multiplicativo | * /% | De izquierda a derecha |
| Aditivo | + - | De izquierda a derecha |
| Cambio | << >> | De izquierda a derecha |
| Relacional | <<=>> = | De izquierda a derecha |
| Igualdad | ==! = | De izquierda a derecha |
| Y bit a bit | Y | De izquierda a derecha |
| XOR bit a bit | ^ | De izquierda a derecha |
| O bit a bit | | | De izquierda a derecha |
| Y lógico | && | De izquierda a derecha |
| OR lógico | || | De izquierda a derecha |
| Condicional | ?: | De derecha a izquierda |
| Asignación | = + = - = * = / =% = >> = << = & = ^ = | = | De derecha a izquierda |
| Coma | , | De izquierda a derecha |
Puede haber una situación en la que necesite ejecutar un bloque de código varias veces. En general, las sentencias se ejecutan secuencialmente: la primera sentencia de una función se ejecuta primero, seguida de la segunda, y así sucesivamente.
Los lenguajes de programación proporcionan varias estructuras de control que permiten rutas de ejecución más complicadas.
Una declaración de bucle ejecuta una declaración o un grupo de declaraciones varias veces. La siguiente forma general de una declaración de bucle se utiliza principalmente en los lenguajes de programación:

El lenguaje de programación D proporciona los siguientes tipos de bucle para manejar los requisitos de bucle. Haga clic en los siguientes enlaces para verificar su detalle.
| No Señor. | Tipo de bucle y descripción |
|---|---|
| 1 | while loop Repite una declaración o un grupo de declaraciones mientras una condición determinada es verdadera. Prueba la condición antes de ejecutar el cuerpo del bucle. |
| 2 | en bucle Ejecuta una secuencia de declaraciones varias veces y abrevia el código que administra la variable de ciclo. |
| 3 | hacer ... mientras bucle Como una instrucción while, excepto que prueba la condición al final del cuerpo del bucle. |
| 4 | bucles anidados Puede usar uno o más bucles dentro de cualquier otro bucle while, for o do.. while. |
Declaraciones de control de bucle
Las sentencias de control de bucle cambian la ejecución de su secuencia normal. Cuando la ejecución abandona un ámbito, todos los objetos automáticos que se crearon en ese ámbito se destruyen.
D admite las siguientes declaraciones de control:
| No Señor. | Declaración de control y descripción |
|---|---|
| 1 | declaración de ruptura Termina la instrucción de bucle o cambio y transfiere la ejecución a la instrucción que sigue inmediatamente al bucle o cambio. |
| 2 | Continuar declaración Hace que el bucle omita el resto de su cuerpo e inmediatamente vuelva a probar su condición antes de reiterar. |
El bucle infinito
Un bucle se convierte en bucle infinito si una condición nunca se vuelve falsa. losforloop se utiliza tradicionalmente para este propósito. Dado que no se requiere ninguna de las tres expresiones que forman el bucle for, puede crear un bucle sin fin dejando la expresión condicional vacía.
import std.stdio;
int main () {
for( ; ; ) {
writefln("This loop will run forever.");
}
return 0;
}Cuando la expresión condicional está ausente, se asume que es verdadera. Puede tener una expresión de inicialización e incremento, pero los programadores de D usan más comúnmente la construcción for (;;) para significar un bucle infinito.
NOTE - Puede terminar un bucle infinito presionando las teclas Ctrl + C.
Las estructuras de toma de decisiones contienen la condición a evaluar junto con los dos conjuntos de declaraciones a ejecutar. Un conjunto de declaraciones se ejecuta si la condición es verdadera y otro conjunto de declaraciones se ejecuta si la condición es falsa.
La siguiente es la forma general de una estructura de toma de decisiones típica que se encuentra en la mayoría de los lenguajes de programación:
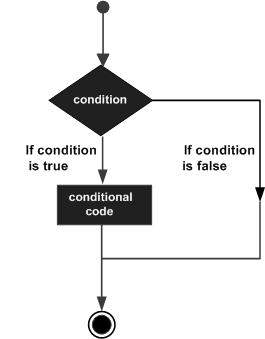
El lenguaje de programación D asume cualquier non-zero y non-null valores como true, y si es zero o null, entonces se asume como false valor.
El lenguaje de programación D proporciona los siguientes tipos de declaraciones para la toma de decisiones.
| No Señor. | Declaración y descripción |
|---|---|
| 1 | si declaración Un if statement consta de una expresión booleana seguida de una o más declaraciones. |
| 2 | declaración if ... else Un if statement puede ir seguido de un opcional else statement, que se ejecuta cuando la expresión booleana es falsa. |
| 3 | declaraciones if anidadas Puedes usar uno if o else if declaración dentro de otra if o else if declaración (s). |
| 4 | declaración de cambio UN switch La declaración permite probar la igualdad de una variable con una lista de valores. |
| 5 | declaraciones de cambio anidadas Puedes usar uno switch declaración dentro de otra switch declaración (s). |
Los ? : Operador en D
Nosotros hemos cubierto conditional operator ? : en el capítulo anterior que se puede utilizar para reemplazar if...elsedeclaraciones. Tiene la siguiente forma general
Exp1 ? Exp2 : Exp3;Donde Exp1, Exp2 y Exp3 son expresiones. Observe el uso y la ubicación del colon.
¿El valor de un? La expresión se determina de la siguiente manera:
Se evalúa Exp1. Si es cierto, entonces Exp2 se evalúa y se convierte en el valor de la totalidad? expresión.
Si Exp1 es falso, entonces se evalúa Exp3 y su valor se convierte en el valor de la expresión.
Este capítulo describe las funciones utilizadas en la programación D.
Definición de función en D
Una definición de función básica consta de un encabezado de función y un cuerpo de función.
Sintaxis
return_type function_name( parameter list ) {
body of the function
}Aquí están todas las partes de una función:
Return Type- Una función puede devolver un valor. losreturn_typees el tipo de datos del valor que devuelve la función. Algunas funciones realizan las operaciones deseadas sin devolver un valor. En este caso, return_type es la palabra clavevoid.
Function Name- Este es el nombre real de la función. El nombre de la función y la lista de parámetros juntos constituyen la firma de la función.
Parameters- Un parámetro es como un marcador de posición. Cuando se invoca una función, se pasa un valor al parámetro. Este valor se conoce como parámetro o argumento real. La lista de parámetros se refiere al tipo, orden y número de parámetros de una función. Los parámetros son opcionales; es decir, una función puede no contener parámetros.
Function Body - El cuerpo de la función contiene una colección de declaraciones que definen lo que hace la función.
Llamar a una función
Puede llamar a una función de la siguiente manera:
function_name(parameter_values)Tipos de funciones en D
La programación D admite una amplia gama de funciones y se enumeran a continuación.
- Funciones puras
- Funciones de Nothrow
- Funciones de referencia
- Funciones automáticas
- Funciones variadas
- Funciones Inout
- Funciones de propiedad
Las diversas funciones se explican a continuación.
Funciones puras
Las funciones puras son funciones que no pueden acceder al estado mutable global o estático salvo a través de sus argumentos. Esto puede habilitar optimizaciones basadas en el hecho de que se garantiza que una función pura no mutará nada que no se le pase, y en los casos en que el compilador puede garantizar que una función pura no puede alterar sus argumentos, puede habilitar la pureza funcional completa, que es decir, la garantía de que la función siempre devolverá el mismo resultado para los mismos argumentos).
import std.stdio;
int x = 10;
immutable int y = 30;
const int* p;
pure int purefunc(int i,const char* q,immutable int* s) {
//writeln("Simple print"); //cannot call impure function 'writeln'
debug writeln("in foo()"); // ok, impure code allowed in debug statement
// x = i; // error, modifying global state
// i = x; // error, reading mutable global state
// i = *p; // error, reading const global state
i = y; // ok, reading immutable global state
auto myvar = new int; // Can use the new expression:
return i;
}
void main() {
writeln("Value returned from pure function : ",purefunc(x,null,null));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Value returned from pure function : 30Funciones de Nothrow
Las funciones de Nothrow no arrojan ninguna excepción derivada de la clase Exception. Las funciones de Nothrow son covariantes con las de lanzar.
Nothrow garantiza que una función no emite ninguna excepción.
import std.stdio;
int add(int a, int b) nothrow {
//writeln("adding"); This will fail because writeln may throw
int result;
try {
writeln("adding"); // compiles
result = a + b;
} catch (Exception error) { // catches all exceptions
}
return result;
}
void main() {
writeln("Added value is ", add(10,20));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
adding
Added value is 30Funciones de referencia
Las funciones de referencia permiten que las funciones regresen por referencia. Esto es análogo a los parámetros de la función de referencia.
import std.stdio;
ref int greater(ref int first, ref int second) {
return (first > second) ? first : second;
}
void main() {
int a = 1;
int b = 2;
greater(a, b) += 10;
writefln("a: %s, b: %s", a, b);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
a: 1, b: 12Funciones automáticas
Las funciones automáticas pueden devolver valor de cualquier tipo. No hay restricciones sobre qué tipo se devolverá. A continuación se ofrece un ejemplo sencillo de la función de tipo automático.
import std.stdio;
auto add(int first, double second) {
double result = first + second;
return result;
}
void main() {
int a = 1;
double b = 2.5;
writeln("add(a,b) = ", add(a, b));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
add(a,b) = 3.5Funciones variadas
Las funciones de Variadiac son aquellas funciones en las que el número de parámetros para una función se determina en tiempo de ejecución. En C, existe la limitación de tener al menos un parámetro. Pero en la programación D, no existe tal limitación. A continuación se muestra un ejemplo sencillo.
import std.stdio;
import core.vararg;
void printargs(int x, ...) {
for (int i = 0; i < _arguments.length; i++) {
write(_arguments[i]);
if (_arguments[i] == typeid(int)) {
int j = va_arg!(int)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(long)) {
long j = va_arg!(long)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(double)) {
double d = va_arg!(double)(_argptr);
writefln("\t%g", d);
}
}
}
void main() {
printargs(1, 2, 3L, 4.5);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
int 2
long 3
double 4.5Funciones Inout
El inout se puede utilizar tanto para parámetros como para tipos de funciones de retorno. Es como una plantilla para mutable, constante e inmutable. El atributo de mutabilidad se deduce del parámetro. Significa que inout transfiere el atributo de mutabilidad deducido al tipo de retorno. A continuación se muestra un ejemplo sencillo que muestra cómo se modifica la mutabilidad.
import std.stdio;
inout(char)[] qoutedWord(inout(char)[] phrase) {
return '"' ~ phrase ~ '"';
}
void main() {
char[] a = "test a".dup;
a = qoutedWord(a);
writeln(typeof(qoutedWord(a)).stringof," ", a);
const(char)[] b = "test b";
b = qoutedWord(b);
writeln(typeof(qoutedWord(b)).stringof," ", b);
immutable(char)[] c = "test c";
c = qoutedWord(c);
writeln(typeof(qoutedWord(c)).stringof," ", c);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
char[] "test a"
const(char)[] "test b"
string "test c"Funciones de propiedad
Las propiedades permiten usar funciones miembro como variables miembro. Utiliza la palabra clave @property. Las propiedades están vinculadas con funciones relacionadas que devuelven valores según los requisitos. A continuación se muestra un ejemplo sencillo de propiedad.
import std.stdio;
struct Rectangle {
double width;
double height;
double area() const @property {
return width*height;
}
void area(double newArea) @property {
auto multiplier = newArea / area;
width *= multiplier;
writeln("Value set!");
}
}
void main() {
auto rectangle = Rectangle(20,10);
writeln("The area is ", rectangle.area);
rectangle.area(300);
writeln("Modified width is ", rectangle.width);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The area is 200
Value set!
Modified width is 30Los personajes son los componentes básicos de las cadenas. Cualquier símbolo de un sistema de escritura se llama carácter: letras de alfabetos, números, signos de puntuación, el carácter de espacio, etc. De manera confusa, los componentes básicos de los caracteres también se denominan caracteres.
El valor entero de la minúscula a es 97 y el valor entero del número 1 es 49. Estos valores se asignaron simplemente por convenciones cuando se diseñó la tabla ASCII.
La siguiente tabla menciona los tipos de caracteres estándar con sus tamaños de almacenamiento y propósitos.
Los caracteres están representados por el tipo char, que solo puede contener 256 valores distintos. Si está familiarizado con el tipo de caracteres de otros idiomas, es posible que ya sepa que no es lo suficientemente grande para admitir los símbolos de muchos sistemas de escritura.
| Tipo | Tamaño de almacenamiento | Propósito |
|---|---|---|
| carbonizarse | 1 byte | Unidad de código UTF-8 |
| wchar | 2 bytes | Unidad de código UTF-16 |
| dchar | 4 bytes | Unidad de código UTF-32 y punto de código Unicode |
Algunas funciones de carácter útiles se enumeran a continuación:
isLower - ¿Determina si es un carácter en minúsculas?
isUpper - ¿Determina si es un carácter en mayúsculas?
isAlpha - ¿Determina si es un carácter alfanumérico Unicode (generalmente, una letra o un número)?
isWhite - ¿Determina si es un carácter de espacio en blanco?
toLower - Produce la minúscula del carácter dado.
toUpper - Produce las mayúsculas del carácter dado.
import std.stdio;
import std.uni;
void main() {
writeln("Is ğ lowercase? ", isLower('ğ'));
writeln("Is Ş lowercase? ", isLower('Ş'));
writeln("Is İ uppercase? ", isUpper('İ'));
writeln("Is ç uppercase? ", isUpper('ç'));
writeln("Is z alphanumeric? ", isAlpha('z'));
writeln("Is new-line whitespace? ", isWhite('\n'));
writeln("Is underline whitespace? ", isWhite('_'));
writeln("The lowercase of Ğ: ", toLower('Ğ'));
writeln("The lowercase of İ: ", toLower('İ'));
writeln("The uppercase of ş: ", toUpper('ş'));
writeln("The uppercase of ı: ", toUpper('ı'));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Is ğ lowercase? true
Is Ş lowercase? false
Is İ uppercase? true
Is ç uppercase? false
Is z alphanumeric? true
Is new-line whitespace? true
Is underline whitespace? false
The lowercase of Ğ: ğ
The lowercase of İ: i
The uppercase of ş: Ş
The uppercase of ı: ILeer personajes en D
Podemos leer caracteres usando readf como se muestra a continuación.
readf(" %s", &letter);Dado que la programación D admite unicode, para leer caracteres Unicode, necesitamos leer dos veces y escribir dos veces para obtener el resultado esperado. Esto no funciona en el compilador en línea. El ejemplo se muestra a continuación.
import std.stdio;
void main() {
char firstCode;
char secondCode;
write("Please enter a letter: ");
readf(" %s", &firstCode);
readf(" %s", &secondCode);
writeln("The letter that has been read: ", firstCode, secondCode);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Please enter a letter: ğ
The letter that has been read: ğD proporciona los siguientes dos tipos de representaciones de cadenas:
- Matriz de caracteres
- Cadena de idioma principal
Matriz de caracteres
Podemos representar la matriz de caracteres en una de las dos formas que se muestran a continuación. El primer formulario proporciona el tamaño directamente y el segundo formulario utiliza el método dup que crea una copia escribible de la cadena "Buenos días".
char[9] greeting1 = "Hello all";
char[] greeting2 = "Good morning".dup;Ejemplo
Aquí hay un ejemplo simple usando las formas simples de matriz de caracteres anteriores.
import std.stdio;
void main(string[] args) {
char[9] greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello all
Good morningCadena de idioma principal
Las cadenas están integradas en el lenguaje principal de D. Estas cadenas son interoperables con la matriz de caracteres que se muestra arriba. El siguiente ejemplo muestra una representación de cadena simple.
string greeting1 = "Hello all";Ejemplo
import std.stdio;
void main(string[] args) {
string greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
string greeting3 = greeting1;
writefln("%s",greeting3);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello all
Good morning
Hello allConcatenación de cadenas
La concatenación de cadenas en la programación D usa el símbolo de tilde (~).
Ejemplo
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
char[] greeting2 = "morning".dup;
char[] greeting3 = greeting1~" "~greeting2;
writefln("%s",greeting3);
string greeting4 = "morning";
string greeting5 = greeting1~" "~greeting4;
writefln("%s",greeting5);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Good morning
Good morningLongitud de la cadena
La longitud de la cadena en bytes se puede recuperar con la ayuda de la función de longitud.
Ejemplo
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
writefln("Length of string greeting1 is %d",greeting1.length);
char[] greeting2 = "morning".dup;
writefln("Length of string greeting2 is %d",greeting2.length);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Length of string greeting1 is 4
Length of string greeting2 is 7Comparación de cadenas
La comparación de cadenas es bastante fácil en la programación D. Puede utilizar los operadores ==, <y> para comparaciones de cadenas.
Ejemplo
import std.stdio;
void main() {
string s1 = "Hello";
string s2 = "World";
string s3 = "World";
if (s2 == s3) {
writeln("s2: ",s2," and S3: ",s3, " are the same!");
}
if (s1 < s2) {
writeln("'", s1, "' comes before '", s2, "'.");
} else {
writeln("'", s2, "' comes before '", s1, "'.");
}
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
s2: World and S3: World are the same!
'Hello' comes before 'World'.Reemplazo de cuerdas
Podemos reemplazar cadenas usando la cadena [].
Ejemplo
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello world ".dup;
char[] s2 = "sample".dup;
s1[6..12] = s2[0..6];
writeln(s1);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
hello sampleMétodos de índice
Los métodos de índice para la ubicación de una subcadena en una cadena, incluidos indexOf y lastIndexOf, se explican en el siguiente ejemplo.
Ejemplo
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo"));
writeln(s1);
writeln("lastIndexOf of O in hello is " ,std.string.lastIndexOf(s1,"O",CaseSensitive.no));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
indexOf.of llo in hello is 2
hello World
lastIndexOf of O in hello is 7Manejo de casos
Los métodos utilizados para cambiar los casos se muestran en el siguiente ejemplo.
Ejemplo
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("Capitalized string of s1 is ",capitalize(s1));
writeln("Uppercase string of s1 is ",toUpper(s1));
writeln("Lowercase string of s1 is ",toLower(s1));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Capitalized string of s1 is Hello world
Uppercase string of s1 is HELLO WORLD
Lowercase string of s1 is hello worldRestricción de caracteres
La restricción de caracteres en cadenas se muestra en el siguiente ejemplo.
Ejemplo
import std.stdio;
import std.string;
void main() {
string s = "H123Hello1";
string result = munch(s, "0123456789H");
writeln("Restrict trailing characters:",result);
result = squeeze(s, "0123456789H");
writeln("Restrict leading characters:",result);
s = " Hello World ";
writeln("Stripping leading and trailing whitespace:",strip(s));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Restrict trailing characters:H123H
Restrict leading characters:ello1
Stripping leading and trailing whitespace:Hello WorldEl lenguaje de programación D proporciona una estructura de datos, denominada arrays, que almacena una colección secuencial de tamaño fijo de elementos del mismo tipo. Una matriz se utiliza para almacenar una colección de datos. A menudo es más útil pensar en una matriz como una colección de variables del mismo tipo.
En lugar de declarar variables individuales, como número0, número1, ... y número99, declara una variable de matriz como números y utiliza números [0], números [1] y ..., números [99] para representar variables individuales. Se accede a un elemento específico de una matriz mediante un índice.
Todas las matrices constan de ubicaciones de memoria contiguas. La dirección más baja corresponde al primer elemento y la dirección más alta al último elemento.
Declaración de matrices
Para declarar una matriz en lenguaje de programación D, el programador especifica el tipo de elementos y el número de elementos requeridos por una matriz de la siguiente manera:
type arrayName [ arraySize ];Esto se llama matriz unidimensional. El arraysize debe ser un número entero mayor que cero constante y el tipo puede ser cualquier tipo de datos lenguaje de programación D válida. Por ejemplo, para declarar una matriz de 10 elementos llamada balance de tipo double, use esta declaración:
double balance[10];Inicialización de matrices
Puede inicializar los elementos de la matriz del lenguaje de programación D uno por uno o usando una sola declaración de la siguiente manera
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];El número de valores entre corchetes [] en el lado derecho no puede ser mayor que el número de elementos que declara para la matriz entre corchetes []. El siguiente ejemplo asigna un solo elemento de la matriz:
Si omite el tamaño de la matriz, se crea una matriz lo suficientemente grande como para contener la inicialización. Por tanto, si escribes
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];luego creará exactamente la misma matriz que hizo en el ejemplo anterior.
balance[4] = 50.0;La declaración anterior asigna al elemento número 5 en la matriz un valor de 50,0. La matriz con el cuarto índice será el quinto, es decir, el último elemento porque todas las matrices tienen 0 como índice de su primer elemento, que también se llama índice base. La siguiente representación pictórica muestra la misma matriz que discutimos anteriormente:

Acceso a elementos de matriz
Se accede a un elemento indexando el nombre de la matriz. Esto se hace colocando el índice del elemento entre corchetes después del nombre de la matriz. Por ejemplo
double salary = balance[9];La declaración anterior toma el décimo elemento de la matriz y asigna el valor al salario variable . El siguiente ejemplo implementa la declaración, la asignación y el acceso a matrices:
import std.stdio;
void main() {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Element \t Value");
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
writeln(j," \t ",n[j]);
}
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Matrices estáticas versus matrices dinámicas
Si se especifica la longitud de una matriz mientras se escribe el programa, esa matriz es una matriz estática. Cuando la longitud puede cambiar durante la ejecución del programa, esa matriz es una matriz dinámica.
Definir matrices dinámicas es más simple que definir matrices de longitud fija porque omitir la longitud crea una matriz dinámica:
int[] dynamicArray;Propiedades de la matriz
Aquí están las propiedades de las matrices:
| No Señor. | Descripción de propiedad |
|---|---|
| 1 | .init La matriz estática devuelve un literal de matriz con cada elemento del literal siendo la propiedad .init del tipo de elemento de matriz. |
| 2 | .sizeof La matriz estática devuelve la longitud de la matriz multiplicada por el número de bytes por elemento de la matriz, mientras que las matrices dinámicas devuelven el tamaño de la referencia de matriz dinámica, que es 8 en compilaciones de 32 bits y 16 en compilaciones de 64 bits. |
| 3 | .length La matriz estática devuelve el número de elementos en la matriz, mientras que las matrices dinámicas se utilizan para obtener / establecer el número de elementos en la matriz. La longitud es del tipo size_t. |
| 4 | .ptr Devuelve un puntero al primer elemento de la matriz. |
| 5 | .dup Cree una matriz dinámica del mismo tamaño y copie el contenido de la matriz en ella. |
| 6 | .idup Cree una matriz dinámica del mismo tamaño y copie el contenido de la matriz en ella. La copia se escribe como inmutable. |
| 7 | .reverse Invierte en su lugar el orden de los elementos de la matriz. Devuelve la matriz. |
| 8 | .sort Ordena en su lugar el orden de los elementos de la matriz. Devuelve la matriz. |
Ejemplo
El siguiente ejemplo explica las diversas propiedades de una matriz:
import std.stdio;
void main() {
int n[ 5 ]; // n is an array of 5 integers
// initialize elements of array n to 0
for ( int i = 0; i < 5; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Initialized value:",n.init);
writeln("Length: ",n.length);
writeln("Size of: ",n.sizeof);
writeln("Pointer:",n.ptr);
writeln("Duplicate Array: ",n.dup);
writeln("iDuplicate Array: ",n.idup);
n = n.reverse.dup;
writeln("Reversed Array: ",n);
writeln("Sorted Array: ",n.sort);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Initialized value:[0, 0, 0, 0, 0]
Length: 5
Size of: 20
Pointer:7FFF5A373920
Duplicate Array: [100, 101, 102, 103, 104]
iDuplicate Array: [100, 101, 102, 103, 104]
Reversed Array: [104, 103, 102, 101, 100]
Sorted Array: [100, 101, 102, 103, 104]Matrices multidimensionales en D
La programación D permite matrices multidimensionales. Aquí está la forma general de una declaración de matriz multidimensional:
type name[size1][size2]...[sizeN];Ejemplo
La siguiente declaración crea un 5 tridimensional. 10. 4 matriz de enteros -
int threedim[5][10][4];Matrices bidimensionales en D
La forma más simple de la matriz multidimensional es la matriz bidimensional. Una matriz bidimensional es, en esencia, una lista de matrices unidimensionales. Para declarar una matriz de enteros bidimensionales de tamaño [x, y], escribiría la sintaxis de la siguiente manera:
type arrayName [ x ][ y ];Dónde type puede ser cualquier tipo de datos de programación D válido y arrayName será un identificador de programación D válido.
Donde tipo puede ser cualquier tipo de datos de programación D válido y arrayName es un identificador de programación D válido.
Una matriz bidimensional se puede pensar como una tabla, que tiene x número de filas y y número de columnas. Una matriz bidimensionala que contiene tres filas y cuatro columnas se puede mostrar a continuación:
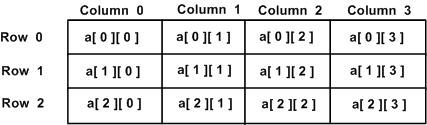
Por lo tanto, cada elemento de la matriz a es identificado por un elemento como a[ i ][ j ], dónde a es el nombre de la matriz, y i y j son los subíndices que identifican de forma única cada elemento en a.
Inicialización de matrices bidimensionales
Las matrices multidimensionales se pueden inicializar especificando valores entre corchetes para cada fila. La siguiente matriz tiene 3 filas y cada fila tiene 4 columnas.
int a[3][4] = [
[0, 1, 2, 3] , /* initializers for row indexed by 0 */
[4, 5, 6, 7] , /* initializers for row indexed by 1 */
[8, 9, 10, 11] /* initializers for row indexed by 2 */
];Las llaves anidadas, que indican la fila deseada, son opcionales. La siguiente inicialización es equivalente al ejemplo anterior:
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];Acceso a elementos de matriz bidimensionales
Se accede a un elemento en una matriz bidimensional mediante los subíndices, significa índice de fila e índice de columna de la matriz. Por ejemplo
int val = a[2][3];La declaración anterior toma el cuarto elemento de la tercera fila de la matriz. Puede verificarlo en el diagrama anterior.
import std.stdio;
void main () {
// an array with 5 rows and 2 columns.
int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]];
// output each array element's value
for ( int i = 0; i < 5; i++ ) for ( int j = 0; j < 2; j++ ) {
writeln( "a[" , i , "][" , j , "]: ",a[i][j]);
}
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8Operaciones de matriz comunes en D
Aquí hay varias operaciones realizadas en las matrices:
Rebanado de matriz
A menudo usamos parte de una matriz y la matriz en rodajas suele ser bastante útil. A continuación se muestra un ejemplo sencillo de corte de matriz.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double[] b;
b = a[1..3];
writeln(b);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
[2, 3.4]Copia de matriz
También usamos copying array. A continuación se muestra un ejemplo sencillo de copia de matrices.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double b[5];
writeln("Array a:",a);
writeln("Array b:",b);
b[] = a; // the 5 elements of a[5] are copied into b[5]
writeln("Array b:",b);
b[] = a[]; // the 5 elements of a[3] are copied into b[5]
writeln("Array b:",b);
b[1..2] = a[0..1]; // same as b[1] = a[0]
writeln("Array b:",b);
b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2]
writeln("Array b:",b);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Array a:[1000, 2, 3.4, 17, 50]
Array b:[nan, nan, nan, nan, nan]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 1000, 3.4, 17, 50]
Array b:[2, 3.4, 3.4, 17, 50]Configuración de matriz
A continuación, se muestra un ejemplo sencillo para establecer un valor en una matriz.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5];
a[] = 5;
writeln("Array a:",a);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Array a:[5, 5, 5, 5, 5]Concatenación de matrices
A continuación se muestra un ejemplo sencillo de concatenación de dos matrices.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = 5;
double b[5] = 10;
double [] c;
c = a~b;
writeln("Array c: ",c);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]Las matrices asociativas tienen un índice que no es necesariamente un número entero y pueden estar escasamente pobladas. El índice de una matriz asociativa se llamaKey, y su tipo se llama KeyType.
Las matrices asociativas se declaran colocando KeyType dentro de [] de una declaración de matriz. A continuación se muestra un ejemplo sencillo de matriz asociativa.
import std.stdio;
void main () {
int[string] e; // associative array b of ints that are
e["test"] = 3;
writeln(e["test"]);
string[string] f;
f["test"] = "Tuts";
writeln(f["test"]);
writeln(f);
f.remove("test");
writeln(f);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
3
Tuts
["test":"Tuts"]
[]Inicialización de matriz asociativa
A continuación se muestra una inicialización simple de una matriz asociativa.
import std.stdio;
void main () {
int[string] days =
[ "Monday" : 0,
"Tuesday" : 1,
"Wednesday" : 2,
"Thursday" : 3,
"Friday" : 4,
"Saturday" : 5,
"Sunday" : 6 ];
writeln(days["Tuesday"]);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
1Propiedades de la matriz asociativa
Aquí están las propiedades de una matriz asociativa:
| No Señor. | Descripción de propiedad |
|---|---|
| 1 | .sizeof Devuelve el tamaño de la referencia a la matriz asociativa; son 4 en compilaciones de 32 bits y 8 en compilaciones de 64 bits. |
| 2 | .length Devuelve el número de valores de la matriz asociativa. A diferencia de las matrices dinámicas, es de solo lectura. |
| 3 | .dup Cree una nueva matriz asociativa del mismo tamaño y copie el contenido de la matriz asociativa en ella. |
| 4 | .keys Devuelve una matriz dinámica, cuyos elementos son las claves de la matriz asociativa. |
| 5 | .values Devuelve una matriz dinámica, cuyos elementos son los valores de la matriz asociativa. |
| 6 | .rehash Reorganiza la matriz asociativa en su lugar para que las búsquedas sean más eficientes. rehash es efectivo cuando, por ejemplo, el programa ha terminado de cargar una tabla de símbolos y ahora necesita búsquedas rápidas en ella. Devuelve una referencia a la matriz reorganizada. |
| 7 | .byKey() Devuelve un delegado adecuado para su uso como agregado a un ForeachStatement que iterará sobre las claves de la matriz asociativa. |
| 8 | .byValue() Devuelve un delegado adecuado para su uso como agregado a un ForeachStatement que iterará sobre los valores de la matriz asociativa. |
| 9 | .get(Key key, lazy Value defVal) Busca clave; si existe, devuelve el valor correspondiente, de lo contrario, evalúa y devuelve defVal. |
| 10 | .remove(Key key) Elimina un objeto para la clave. |
Ejemplo
A continuación se muestra un ejemplo para utilizar las propiedades anteriores.
import std.stdio;
void main () {
int[string] array1;
array1["test"] = 3;
array1["test2"] = 20;
writeln("sizeof: ",array1.sizeof);
writeln("length: ",array1.length);
writeln("dup: ",array1.dup);
array1.rehash;
writeln("rehashed: ",array1);
writeln("keys: ",array1.keys);
writeln("values: ",array1.values);
foreach (key; array1.byKey) {
writeln("by key: ",key);
}
foreach (value; array1.byValue) {
writeln("by value ",value);
}
writeln("get value for key test: ",array1.get("test",10));
writeln("get value for key test3: ",array1.get("test3",10));
array1.remove("test");
writeln(array1);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
sizeof: 8
length: 2
dup: ["test":3, "test2":20]
rehashed: ["test":3, "test2":20]
keys: ["test", "test2"]
values: [3, 20]
by key: test
by key: test2
by value 3
by value 20
get value for key test: 3
get value for key test3: 10
["test2":20]Los indicadores de programación D son fáciles y divertidos de aprender. Algunas tareas de programación D se realizan más fácilmente con punteros y otras tareas de programación D, como la asignación de memoria dinámica, no se pueden realizar sin ellos. A continuación se muestra un puntero simple.
En lugar de apuntar directamente a la variable, el puntero apunta a la dirección de la variable. Como sabe, cada variable es una ubicación de memoria y cada ubicación de memoria tiene su dirección definida a la que se puede acceder usando el operador y comercial (&) que denota una dirección en la memoria. Considere lo siguiente que imprime la dirección de las variables definidas:
import std.stdio;
void main () {
int var1;
writeln("Address of var1 variable: ",&var1);
char var2[10];
writeln("Address of var2 variable: ",&var2);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Address of var1 variable: 7FFF52691928
Address of var2 variable: 7FFF52691930¿Qué son los punteros?
UN pointeres una variable cuyo valor es la dirección de otra variable. Como cualquier variable o constante, debe declarar un puntero antes de poder trabajar con él. La forma general de una declaración de variable de puntero es:
type *var-name;Aquí, typees el tipo base del puntero; debe ser un tipo de programación válido yvar-namees el nombre de la variable de puntero. El asterisco que usó para declarar un puntero es el mismo asterisco que usa para la multiplicación. Sin embargo; en esta declaración, el asterisco se utiliza para designar una variable como puntero. A continuación se muestra la declaración de puntero válida:
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterEl tipo de datos real del valor de todos los punteros, ya sean enteros, flotantes, de caracteres u otros, es el mismo, un número hexadecimal largo que representa una dirección de memoria. La única diferencia entre punteros de diferentes tipos de datos es el tipo de datos de la variable o constante a la que apunta el puntero.
Usando punteros en la programación D
Hay pocas operaciones importantes cuando usamos los punteros con mucha frecuencia.
definimos un puntero variables
asignar la dirección de una variable a un puntero
finalmente acceda al valor en la dirección disponible en la variable de puntero.
Esto se hace usando un operador unario *que devuelve el valor de la variable ubicada en la dirección especificada por su operando. El siguiente ejemplo hace uso de estas operaciones:
import std.stdio;
void main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
writeln("Value of var variable: ",var);
writeln("Address stored in ip variable: ",ip);
writeln("Value of *ip variable: ",*ip);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Value of var variable: 20
Address stored in ip variable: 7FFF5FB7E930
Value of *ip variable: 20Punteros nulos
Siempre es una buena práctica asignar el puntero NULL a una variable de puntero en caso de que no tenga una dirección exacta para asignar. Esto se hace en el momento de la declaración de la variable. Un puntero que se asigna nulo se llama unnull puntero.
El puntero nulo es una constante con un valor de cero definido en varias bibliotecas estándar, incluido iostream. Considere el siguiente programa:
import std.stdio;
void main () {
int *ptr = null;
writeln("The value of ptr is " , ptr) ;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The value of ptr is nullEn la mayoría de los sistemas operativos, los programas no pueden acceder a la memoria en la dirección 0 porque esa memoria está reservada por el sistema operativo. Sin embargo; la dirección de memoria 0 tiene un significado especial; indica que el puntero no está destinado a apuntar a una ubicación de memoria accesible.
Por convención, si un puntero contiene el valor nulo (cero), se supone que no apunta a nada. Para verificar si hay un puntero nulo, puede usar una declaración if de la siguiente manera:
if(ptr) // succeeds if p is not null
if(!ptr) // succeeds if p is nullPor lo tanto, si todos los punteros no utilizados reciben el valor nulo y evita el uso de un puntero nulo, puede evitar el mal uso accidental de un puntero no inicializado. Muchas veces, las variables no inicializadas contienen algunos valores basura y resulta difícil depurar el programa.
Aritmética de punteros
Hay cuatro operadores aritméticos que se pueden usar en punteros: ++, -, + y -
Para entender la aritmética de punteros, consideremos un puntero entero llamado ptr, que apunta a la dirección 1000. Suponiendo números enteros de 32 bits, realicemos la siguiente operación aritmática en el puntero:
ptr++entonces la ptrapuntará a la ubicación 1004 porque cada vez que se incrementa ptr, apunta al siguiente entero. Esta operación moverá el puntero a la siguiente ubicación de memoria sin afectar el valor real en la ubicación de memoria.
Si ptr apunta a un carácter cuya dirección es 1000, luego la operación anterior apunta a la ubicación 1001 porque el próximo carácter estará disponible en 1001.
Incrementar un puntero
Preferimos usar un puntero en nuestro programa en lugar de una matriz porque el puntero variable se puede incrementar, a diferencia del nombre de la matriz, que no se puede incrementar porque es un puntero constante. El siguiente programa incrementa el puntero de la variable para acceder a cada elemento sucesivo de la matriz:
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Address of var[0] = 18FDBC
Value of var[0] = 10
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 200Punteros vs matriz
Los punteros y las matrices están estrechamente relacionados. Sin embargo, los punteros y las matrices no son completamente intercambiables. Por ejemplo, considere el siguiente programa:
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
var.ptr[2] = 290;
ptr[0] = 220;
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}En el programa anterior, puede ver var.ptr [2] para establecer el segundo elemento y ptr [0] que se usa para establecer el elemento cero. El operador de incremento se puede utilizar con ptr pero no con var.
Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Address of var[0] = 18FDBC
Value of var[0] = 220
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 290Puntero a puntero
Un puntero a un puntero es una forma de direccionamiento indirecto múltiple o una cadena de punteros. Normalmente, un puntero contiene la dirección de una variable. Cuando definimos un puntero a un puntero, el primer puntero contiene la dirección del segundo puntero, que apunta a la ubicación que contiene el valor real como se muestra a continuación.

Una variable que es un puntero a un puntero debe declararse como tal. Esto se hace colocando un asterisco adicional delante de su nombre. Por ejemplo, a continuación se muestra la sintaxis para declarar un puntero a un puntero de tipo int:
int **var;Cuando un valor objetivo es apuntado indirectamente por un puntero a un puntero, entonces acceder a ese valor requiere que el operador de asterisco se aplique dos veces, como se muestra a continuación en el ejemplo:
import std.stdio;
const int MAX = 3;
void main () {
int var = 3000;
writeln("Value of var :" , var);
int *ptr = &var;
writeln("Value available at *ptr :" ,*ptr);
int **pptr = &ptr;
writeln("Value available at **pptr :",**pptr);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Value of var :3000
Value available at *ptr :3000
Value available at **pptr :3000Pasar puntero a funciones
D le permite pasar un puntero a una función. Para hacerlo, simplemente declara el parámetro de función como un tipo de puntero.
El siguiente ejemplo simple pasa un puntero a una función.
import std.stdio;
void main () {
// an int array with 5 elements.
int balance[5] = [1000, 2, 3, 17, 50];
double avg;
avg = getAverage( &balance[0], 5 ) ;
writeln("Average is :" , avg);
}
double getAverage(int *arr, int size) {
int i;
double avg, sum = 0;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = sum/size;
return avg;
}Cuando el código anterior se compila y se ejecuta, produce el siguiente resultado:
Average is :214.4Puntero de retorno de funciones
Considere la siguiente función, que devuelve 10 números usando un puntero, significa la dirección del primer elemento de la matriz.
import std.stdio;
void main () {
int *p = getNumber();
for ( int i = 0; i < 10; i++ ) {
writeln("*(p + " , i , ") : ",*(p + i));
}
}
int * getNumber( ) {
static int r [10];
for (int i = 0; i < 10; ++i) {
r[i] = i;
}
return &r[0];
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
*(p + 0) : 0
*(p + 1) : 1
*(p + 2) : 2
*(p + 3) : 3
*(p + 4) : 4
*(p + 5) : 5
*(p + 6) : 6
*(p + 7) : 7
*(p + 8) : 8
*(p + 9) : 9Puntero a una matriz
Un nombre de matriz es un puntero constante al primer elemento de la matriz. Por lo tanto, en la declaración:
double balance[50];balancees un puntero a & balance [0], que es la dirección del primer elemento de la matriz balance. Por lo tanto, el siguiente fragmento de programa asignap la dirección del primer elemento de balance -
double *p;
double balance[10];
p = balance;Es legal usar nombres de matrices como punteros constantes y viceversa. Por tanto, * (saldo + 4) es una forma legítima de acceder a los datos en saldo [4].
Una vez que almacena la dirección del primer elemento en p, puede acceder a los elementos de la matriz usando * p, * (p + 1), * (p + 2) y así sucesivamente. El siguiente ejemplo muestra todos los conceptos discutidos anteriormente:
import std.stdio;
void main () {
// an array with 5 elements.
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double *p;
p = &balance[0];
// output each array element's value
writeln("Array values using pointer " );
for ( int i = 0; i < 5; i++ ) {
writeln( "*(p + ", i, ") : ", *(p + i));
}
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Array values using pointer
*(p + 0) : 1000
*(p + 1) : 2
*(p + 2) : 3.4
*(p + 3) : 17
*(p + 4) : 50Las tuplas se utilizan para combinar varios valores como un solo objeto. Tuples contiene una secuencia de elementos. Los elementos pueden ser tipos, expresiones o alias. El número y los elementos de una tupla se fijan en tiempo de compilación y no se pueden cambiar en tiempo de ejecución.
Las tuplas tienen características tanto de estructuras como de matrices. Los elementos de tupla pueden ser de diferentes tipos, como estructuras. Se puede acceder a los elementos mediante indexación como matrices. Se implementan como una función de biblioteca mediante la plantilla Tuple del módulo std.typecons. Tuple hace uso de TypeTuple del módulo std.typetuple para algunas de sus operaciones.
Tupla usando tupla ()
Las tuplas se pueden construir mediante la función tuple (). Se accede a los miembros de una tupla mediante valores de índice. A continuación se muestra un ejemplo.
Ejemplo
import std.stdio;
import std.typecons;
void main() {
auto myTuple = tuple(1, "Tuts");
writeln(myTuple);
writeln(myTuple[0]);
writeln(myTuple[1]);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Tuple!(int, string)(1, "Tuts")
1
TutsTupla usando la plantilla de tupla
Tuple también se puede construir directamente con la plantilla Tuple en lugar de la función tuple (). El tipo y el nombre de cada miembro se especifican como dos parámetros de plantilla consecutivos. Es posible acceder a los miembros por propiedades cuando se crean usando plantillas.
import std.stdio;
import std.typecons;
void main() {
auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts");
writeln(myTuple);
writeln("by index 0 : ", myTuple[0]);
writeln("by .id : ", myTuple.id);
writeln("by index 1 : ", myTuple[1]);
writeln("by .value ", myTuple.value);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado
Tuple!(int, "id", string, "value")(1, "Tuts")
by index 0 : 1
by .id : 1
by index 1 : Tuts
by .value TutsAmpliación de parámetros de función y propiedad
Los miembros de Tuple se pueden expandir mediante la propiedad .expand o mediante la división. Este valor expandido / dividido se puede pasar como lista de argumentos de función. A continuación se muestra un ejemplo.
Ejemplo
import std.stdio;
import std.typecons;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(int a, float b, char c) {
writeln("method 2 ",a,"\t",b,"\t",c);
}
void main() {
auto myTuple = tuple(5, "my string", 3.3, 'r');
writeln("method1 call 1");
method1(myTuple[]);
writeln("method1 call 2");
method1(myTuple.expand);
writeln("method2 call 1");
method2(myTuple[0], myTuple[$-2..$]);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
method1 call 1
method 1 5 my string 3.3 r
method1 call 2
method 1 5 my string 3.3 r
method2 call 1
method 2 5 3.3 rTipoTupla
TypeTuple se define en el módulo std.typetuple. Una lista de valores y tipos separados por comas. A continuación se ofrece un ejemplo sencillo con TypeTuple. TypeTuple se usa para crear una lista de argumentos, una lista de plantillas y una lista literal de matriz.
import std.stdio;
import std.typecons;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
auto arguments = TypeTuple!(5, "my string", 3.3,'r');
method1(arguments);
method2(5, 6L);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
method 1 5 my string 3.3 r
5 6los structure es otro tipo de datos definido por el usuario disponible en la programación D, que le permite combinar elementos de datos de diferentes tipos.
Las estructuras se utilizan para representar un registro. Suponga que desea realizar un seguimiento de sus libros en una biblioteca. Es posible que desee realizar un seguimiento de los siguientes atributos sobre cada libro:
- Title
- Author
- Subject
- ID del libro
Definición de una estructura
Para definir una estructura, debe utilizar el structdeclaración. La declaración de estructura define un nuevo tipo de datos, con más de un miembro para su programa. El formato de la declaración de estructura es este:
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];los structure tages opcional y cada definición de miembro es una definición de variable normal, como int i; o flotar f; o cualquier otra definición de variable válida. Al final de la definición de la estructura antes del punto y coma, puede especificar una o más variables de estructura que son opcionales. Esta es la forma en que declararía la estructura de Libros:
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};Acceso a miembros de estructura
Para acceder a cualquier miembro de una estructura, usa el member access operator (.). El operador de acceso a miembros se codifica como un punto entre el nombre de la variable de estructura y el miembro de estructura al que deseamos acceder. Usaríasstructpalabra clave para definir variables de tipo de estructura. El siguiente ejemplo explica el uso de la estructura:
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
writeln( "Book 1 title : ", Book1.title);
writeln( "Book 1 author : ", Book1.author);
writeln( "Book 1 subject : ", Book1.subject);
writeln( "Book 1 book_id : ", Book1.book_id);
/* print Book2 info */
writeln( "Book 2 title : ", Book2.title);
writeln( "Book 2 author : ", Book2.author);
writeln( "Book 2 subject : ", Book2.subject);
writeln( "Book 2 book_id : ", Book2.book_id);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Book 1 title : D Programming
Book 1 author : Raj
Book 1 subject : D Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : D Programming
Book 2 author : Raj
Book 2 subject : D Programming Tutorial
Book 2 book_id : 6495700Estructuras como argumentos de función
Puede pasar una estructura como un argumento de función de forma muy similar a como pasa cualquier otra variable o puntero. Accederá a las variables de estructura de manera similar a como lo hizo en el ejemplo anterior:
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495700Inicialización de estructuras
Las estructuras se pueden inicializar de dos formas, una usando construtor y otra usando el formato {}. A continuación se muestra un ejemplo.
Ejemplo
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id = -1;
char [] author = "Raj".dup;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 );
printBook( Book1 );
Books Book2 = Books("D Programming".dup,
"D Programming Tutorial".dup, 6495407,"Raj".dup );
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id : 1001};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1001Miembros estáticos
Las variables estáticas se inicializan solo una vez. Por ejemplo, para tener los ID únicos para los libros, podemos hacer que book_id sea estático e incrementar el ID del libro. A continuación se muestra un ejemplo.
Ejemplo
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id;
char [] author = "Raj".dup;
static int id = 1000;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id );
printBook( Book1 );
Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id);
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1001
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1002
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1003UN uniones un tipo de datos especial disponible en D que le permite almacenar diferentes tipos de datos en la misma ubicación de memoria. Puede definir una unión con muchos miembros, pero solo un miembro puede contener un valor en un momento dado. Las uniones proporcionan una forma eficaz de utilizar la misma ubicación de memoria para múltiples propósitos.
Definiendo una unión en D
Para definir una unión, debe usar la declaración de unión de una manera muy similar a como lo hizo al definir la estructura. La declaración de unión define un nuevo tipo de datos, con más de un miembro para su programa. El formato de la declaración de unión es el siguiente:
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];los union tages opcional y cada definición de miembro es una definición de variable normal, como int i; o flotar f; o cualquier otra definición de variable válida. Al final de la definición de la unión, antes del punto y coma final, puede especificar una o más variables de unión, pero es opcional. Esta es la forma en que definiría un tipo de unión llamado Data que tiene los tres miembrosi, fy str -
union Data {
int i;
float f;
char str[20];
} data;Una variable de Datatype puede almacenar un entero, un número de punto flotante o una cadena de caracteres. Esto significa que se puede usar una sola variable (la misma ubicación de memoria) para almacenar múltiples tipos de datos. Puede utilizar cualquier tipo de datos integrado o definido por el usuario dentro de una unión según sus requisitos.
La memoria que ocupa un sindicato será lo suficientemente grande como para albergar al miembro más grande del sindicato. Por ejemplo, en el ejemplo anterior, el tipo de datos ocupará 20 bytes de espacio de memoria porque este es el espacio máximo que puede ocupar una cadena de caracteres. El siguiente ejemplo muestra el tamaño de memoria total ocupado por la unión anterior:
import std.stdio;
union Data {
int i;
float f;
char str[20];
};
int main( ) {
Data data;
writeln( "Memory size occupied by data : ", data.sizeof);
return 0;
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Memory size occupied by data : 20Acceso a miembros de la unión
Para acceder a cualquier miembro de un sindicato, utilizamos el member access operator (.). El operador de acceso a miembros está codificado como un punto entre el nombre de la variable de unión y el miembro de la unión al que deseamos acceder. Usaría la palabra clave union para definir variables de tipo union.
Ejemplo
El siguiente ejemplo explica el uso de union:
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
data.i = 10;
data.f = 220.5;
data.str = "D Programming".dup;
writeln( "size of : ", data.sizeof);
writeln( "data.i : ", data.i);
writeln( "data.f : ", data.f);
writeln( "data.str : ", data.str);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
size of : 16
data.i : 1917853764
data.f : 4.12236e+30
data.str : D ProgrammingAquí, puede ver que los valores de i y f miembros del sindicato se corrompieron porque el valor final asignado a la variable ha ocupado la ubicación de memoria y esta es la razón por la que el valor de str El miembro se imprime muy bien.
Ahora veamos el mismo ejemplo una vez más, donde usaremos una variable a la vez, que es el propósito principal de tener unión:
Ejemplo modificado
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
writeln( "size of : ", data.sizeof);
data.i = 10;
writeln( "data.i : ", data.i);
data.f = 220.5;
writeln( "data.f : ", data.f);
data.str = "D Programming".dup;
writeln( "data.str : ", data.str);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
size of : 16
data.i : 10
data.f : 220.5
data.str : D ProgrammingAquí, todos los miembros se imprimen muy bien porque se utiliza un miembro a la vez.
Los rangos son una abstracción del acceso a elementos. Esta abstracción permite el uso de un gran número de algoritmos sobre un gran número de tipos de contenedores. Los rangos enfatizan cómo se accede a los elementos del contenedor, a diferencia de cómo se implementan los contenedores. Rangos es un concepto muy simple que se basa en si un tipo define ciertos conjuntos de funciones miembro.
Los rangos son una parte integral de los cortes de D. D resultan ser implementaciones del rango más poderoso RandomAccessRange, y hay muchas características de rango en Phobos. Muchos algoritmos de Phobos devuelven objetos de rango temporal. Por ejemplo, filter () elige elementos que son mayores que 10 en el siguiente código en realidad devuelve un objeto de rango, no una matriz.
Rangos de números
Los rangos de números se utilizan con bastante frecuencia y estos rangos de números son de tipo int. A continuación se muestran algunos ejemplos de rangos de números:
// Example 1
foreach (value; 3..7)
// Example 2
int[] slice = array[5..10];Rangos de Phobos
Los rangos relacionados con las estructuras y las interfaces de clase son rangos de fobos. Phobos es la biblioteca estándar y en tiempo de ejecución oficial que viene con el compilador de lenguaje D.
Hay varios tipos de rangos que incluyen:
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
Rango de entrada
El rango más simple es el rango de entrada. Las otras gamas traen más requisitos además de la gama en la que se basan. Hay tres funciones que requiere InputRange:
empty- Especifica si el rango está vacío; debe devolver verdadero cuando se considera que el rango está vacío; falso de lo contrario.
front - Proporciona acceso al elemento al principio del rango.
popFront() - Acorta el rango desde el principio quitando el primer elemento.
Ejemplo
import std.stdio;
import std.string;
struct Student {
string name;
int number;
string toString() const {
return format("%s(%s)", name, number);
}
}
struct School {
Student[] students;
}
struct StudentRange {
Student[] students;
this(School school) {
this.students = school.students;
}
@property bool empty() const {
return students.length == 0;
}
@property ref Student front() {
return students[0];
}
void popFront() {
students = students[1 .. $];
}
}
void main() {
auto school = School([ Student("Raj", 1), Student("John", 2), Student("Ram", 3)]);
auto range = StudentRange(school);
writeln(range);
writeln(school.students.length);
writeln(range.front);
range.popFront;
writeln(range.empty);
writeln(range);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
[Raj(1), John(2), Ram(3)]
3
Raj(1)
false
[John(2), Ram(3)]ForwardRange
ForwardRange también requiere la función miembro de guardar parte de las otras tres funciones de InputRange y devolver una copia del rango cuando se llama a la función de guardar.
import std.array;
import std.stdio;
import std.string;
import std.range;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%s: %s", title, range.take(5));
}
void main() {
auto range = FibonacciSeries();
report("Original range", range);
range.popFrontN(2);
report("After removing two elements", range);
auto theCopy = range.save;
report("The copy", theCopy);
range.popFrontN(3);
report("After removing three more elements", range);
report("The copy", theCopy);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Original range: [0, 1, 1, 2, 3]
After removing two elements: [1, 2, 3, 5, 8]
The copy: [1, 2, 3, 5, 8]
After removing three more elements: [5, 8, 13, 21, 34]
The copy: [1, 2, 3, 5, 8]Rango bidireccional
BidirectionalRange además proporciona dos funciones miembro sobre las funciones miembro de ForwardRange. La función trasera, similar a la delantera, permite acceder al último elemento de la gama. La función popBack es similar a la función popFront y elimina el último elemento del rango.
Ejemplo
import std.array;
import std.stdio;
import std.string;
struct Reversed {
int[] range;
this(int[] range) {
this.range = range;
}
@property bool empty() const {
return range.empty;
}
@property int front() const {
return range.back; // reverse
}
@property int back() const {
return range.front; // reverse
}
void popFront() {
range.popBack();
}
void popBack() {
range.popFront();
}
}
void main() {
writeln(Reversed([ 1, 2, 3]));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
[3, 2, 1]Infinite RandomAccessRange
opIndex () es adicionalmente necesario en comparación con ForwardRange. Además, el valor de una función vacía que se conocerá en tiempo de compilación como falso. A continuación se muestra un ejemplo simple que se explica con el rango de cuadrados.
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
void main() {
auto squares = new SquaresRange();
writeln(squares[5]);
writeln(squares[10]);
squares.popFrontN(5);
writeln(squares[0]);
writeln(squares.take(50).filter!are_lastTwoDigitsSame);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
25
100
25
[100, 144, 400, 900, 1444, 1600, 2500]Rango de acceso aleatorio finito
opIndex () y la longitud son también necesarios en comparación con el rango bidireccional. Esto se explica con la ayuda de un ejemplo detallado que utiliza la serie de Fibonacci y el ejemplo de Squares Range utilizado anteriormente. Este ejemplo funciona bien en el compilador D normal, pero no en el compilador en línea.
Ejemplo
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%40s: %s", title, range.take(5));
}
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
struct Together {
const(int)[][] slices;
this(const(int)[][] slices ...) {
this.slices = slices.dup;
clearFront();
clearBack();
}
private void clearFront() {
while (!slices.empty && slices.front.empty) {
slices.popFront();
}
}
private void clearBack() {
while (!slices.empty && slices.back.empty) {
slices.popBack();
}
}
@property bool empty() const {
return slices.empty;
}
@property int front() const {
return slices.front.front;
}
void popFront() {
slices.front.popFront();
clearFront();
}
@property Together save() const {
return Together(slices.dup);
}
@property int back() const {
return slices.back.back;
}
void popBack() {
slices.back.popBack();
clearBack();
}
@property size_t length() const {
return reduce!((a, b) => a + b.length)(size_t.init, slices);
}
int opIndex(size_t index) const {
/* Save the index for the error message */
immutable originalIndex = index;
foreach (slice; slices) {
if (slice.length > index) {
return slice[index];
} else {
index -= slice.length;
}
}
throw new Exception(
format("Invalid index: %s (length: %s)", originalIndex, this.length));
}
}
void main() {
auto range = Together(FibonacciSeries().take(10).array, [ 777, 888 ],
(new SquaresRange()).take(5).array);
writeln(range.save);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]Rango de salida
OutputRange representa la salida del elemento transmitida, similar a enviar caracteres a stdout. OutputRange requiere soporte para la operación put (rango, elemento). put () es una función definida en el módulo std.range. Determina las capacidades del rango y el elemento en tiempo de compilación y usa el método más apropiado para usar para generar los elementos. A continuación se muestra un ejemplo sencillo.
import std.algorithm;
import std.stdio;
struct MultiFile {
string delimiter;
File[] files;
this(string delimiter, string[] fileNames ...) {
this.delimiter = delimiter;
/* stdout is always included */
this.files ~= stdout;
/* A File object for each file name */
foreach (fileName; fileNames) {
this.files ~= File(fileName, "w");
}
}
void put(T)(T element) {
foreach (file; files) {
file.write(element, delimiter);
}
}
}
void main() {
auto output = MultiFile("\n", "output_0", "output_1");
copy([ 1, 2, 3], output);
copy([ "red", "blue", "green" ], output);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
[1, 2, 3]
["red", "blue", "green"]Alias, como se refiere el nombre, proporciona un nombre alternativo para los nombres existentes. La sintaxis de alias se muestra a continuación.
alias new_name = existing_name;La siguiente es la sintaxis anterior, en caso de que consulte algunos ejemplos de formatos anteriores. Se desaconseja encarecidamente su uso.
alias existing_name new_name;También hay otra sintaxis que se usa con expresión y se da a continuación en la que podemos usar directamente el nombre de alias en lugar de la expresión.
alias expression alias_name ;Como sabrá, un typedef agrega la capacidad de crear nuevos tipos. Alias puede hacer el trabajo de typedef e incluso más. A continuación se muestra un ejemplo simple para usar alias que usa el encabezado std.conv que proporciona la capacidad de conversión de tipos.
import std.stdio;
import std.conv:to;
alias to!(string) toString;
void main() {
int a = 10;
string s = "Test"~toString(a);
writeln(s);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Test10En el ejemplo anterior, en lugar de usar to! String (a), lo asignamos al nombre de alias toString, lo que lo hace más conveniente y sencillo de entender.
Alias de una tupla
Echemos un vistazo a otro ejemplo en el que podemos establecer un nombre de alias para una tupla.
import std.stdio;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
method1(5, 6L);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
5 6En el ejemplo anterior, el tipo tupla se asigna a la variable de alias y simplifica la definición del método y el acceso a las variables. Este tipo de acceso es aún más útil cuando intentamos reutilizar este tipo de tuplas.
Alias para tipos de datos
Muchas veces, podemos definir tipos de datos comunes que deben usarse en toda la aplicación. Cuando varios programadores codifican una aplicación, pueden darse casos en los que una persona use int, otra double, etc. Para evitar tales conflictos, a menudo usamos tipos para tipos de datos. A continuación se muestra un ejemplo sencillo.
Ejemplo
import std.stdio;
alias int myAppNumber;
alias string myAppString;
void main() {
myAppNumber i = 10;
myAppString s = "TestString";
writeln(i,s);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
10TestStringAlias para variables de clase
A menudo existe un requisito en el que necesitamos acceder a las variables miembro de la superclase en la subclase, esto puede hacerse posible con un alias, posiblemente con un nombre diferente.
En caso de que sea nuevo en el concepto de clases y herencia, eche un vistazo al tutorial sobre clases y herencia antes de comenzar con esta sección.
Ejemplo
A continuación se muestra un ejemplo sencillo.
import std.stdio;
class Shape {
int area;
}
class Square : Shape {
string name() const @property {
return "Square";
}
alias Shape.area squareArea;
}
void main() {
auto square = new Square;
square.squareArea = 42;
writeln(square.name);
writeln(square.squareArea);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Square
42Alias This
Alias: proporciona la capacidad de conversiones automáticas de tipos de tipos definidos por el usuario. La sintaxis se muestra a continuación donde el alias de las palabras clave y esto se escriben en ambos lados de la variable miembro o función miembro.
alias member_variable_or_member_function this;Ejemplo
A continuación se muestra un ejemplo para mostrar el poder del alias this.
import std.stdio;
struct Rectangle {
long length;
long breadth;
double value() const @property {
return cast(double) length * breadth;
}
alias value this;
}
double volume(double rectangle, double height) {
return rectangle * height;
}
void main() {
auto rectangle = Rectangle(2, 3);
writeln(volume(rectangle, 5));
}En el ejemplo anterior, puede ver que el rectángulo de estructura se convierte en valor doble con la ayuda de alias de este método.
Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
30Los mixins son estructuras que permiten mezclar el código generado con el código fuente. Los mixins pueden ser de los siguientes tipos:
- Mixins de cuerdas
- Mixins de plantilla
- Mezclar espacios de nombres
Mixins de cuerdas
D tiene la capacidad de insertar código como cadena siempre que esa cadena se conozca en tiempo de compilación. La sintaxis de los mixins de cadenas se muestra a continuación:
mixin (compile_time_generated_string)Ejemplo
A continuación se muestra un ejemplo sencillo de mixins de cuerdas.
import std.stdio;
void main() {
mixin(`writeln("Hello World!");`);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello World!Aquí hay otro ejemplo en el que podemos pasar la cadena en tiempo de compilación para que los mixins puedan usar las funciones para reutilizar el código. Se muestra a continuación.
import std.stdio;
string print(string s) {
return `writeln("` ~ s ~ `");`;
}
void main() {
mixin (print("str1"));
mixin (print("str2"));
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
str1
str2Mixins de plantilla
Las plantillas D definen patrones de código comunes, para que el compilador genere instancias reales a partir de ese patrón. Las plantillas pueden generar funciones, estructuras, uniones, clases, interfaces y cualquier otro código D legal. La sintaxis de los mixins de plantilla se muestra a continuación.
mixin a_template!(template_parameters)A continuación se muestra un ejemplo simple de mixins de cadenas, donde creamos una plantilla con la clase Department y un mixin instanciando una plantilla y, por lo tanto, haciendo que las funciones setName y printNames estén disponibles para la estructura de la universidad.
Ejemplo
import std.stdio;
template Department(T, size_t count) {
T[count] names;
void setName(size_t index, T name) {
names[index] = name;
}
void printNames() {
writeln("The names");
foreach (i, name; names) {
writeln(i," : ", name);
}
}
}
struct College {
mixin Department!(string, 2);
}
void main() {
auto college = College();
college.setName(0, "name1");
college.setName(1, "name2");
college.printNames();
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The names
0 : name1
1 : name2Espacios de nombres Mixin
Los espacios de nombres de mixin se utilizan para evitar ambigüedades en los mixins de plantilla. Por ejemplo, puede haber dos variables, una definida explícitamente en main y la otra mezclada. Cuando un nombre mezclado es el mismo que un nombre que está en el alcance circundante, entonces el nombre que está en el alcance circundante obtiene usado. Este ejemplo se muestra a continuación.
Ejemplo
import std.stdio;
template Person() {
string name;
void print() {
writeln(name);
}
}
void main() {
string name;
mixin Person a;
name = "name 1";
writeln(name);
a.name = "name 2";
print();
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
name 1
name 2Los módulos son los componentes básicos de D. Se basan en un concepto simple. Cada archivo fuente es un módulo. En consecuencia, los archivos individuales en los que escribimos los programas son módulos individuales. De forma predeterminada, el nombre de un módulo es el mismo que su nombre de archivo sin la extensión .d.
Cuando se especifica explícitamente, el nombre del módulo se define mediante la palabra clave del módulo, que debe aparecer como la primera línea sin comentarios en el archivo fuente. Por ejemplo, suponga que el nombre de un archivo fuente es "employee.d". Luego, el nombre del módulo se especifica mediante la palabra clave del módulo seguida de empleado . Es como se muestra a continuación.
module employee;
class Employee {
// Class definition goes here.
}La línea de módulos es opcional. Cuando no se especifica, es el mismo que el nombre del archivo sin la extensión .d.
Nombres de archivos y módulos
D admite Unicode en el código fuente y los nombres de los módulos. Sin embargo, el soporte Unicode de los sistemas de archivos varía. Por ejemplo, aunque la mayoría de los sistemas de archivos de Linux admiten Unicode, es posible que los nombres de los archivos en los sistemas de archivos de Windows no distingan entre mayúsculas y minúsculas. Además, la mayoría de los sistemas de archivos limitan los caracteres que se pueden usar en los nombres de archivos y directorios. Por razones de portabilidad, le recomiendo que use solo letras ASCII minúsculas en los nombres de los archivos. Por ejemplo, "employee.d" sería un nombre de archivo adecuado para una clase llamada employee.
En consecuencia, el nombre del módulo también constaría de letras ASCII:
module employee; // Module name consisting of ASCII letters
class eëmployëë { }Paquetes D
Una combinación de módulos relacionados se denomina paquete. Los paquetes D también son un concepto simple: se considera que los archivos fuente que están dentro del mismo directorio pertenecen al mismo paquete. El nombre del directorio se convierte en el nombre del paquete, que también debe especificarse como las primeras partes de los nombres de los módulos.
Por ejemplo, si "employee.d" y "office.d" están dentro del directorio "empresa", especificar el nombre del directorio junto con el nombre del módulo los convierte en parte del mismo paquete:
module company.employee;
class Employee { }Del mismo modo, para el módulo de oficina:
module company.office;
class Office { }Dado que los nombres de los paquetes corresponden a los nombres de los directorios, los nombres de los paquetes de los módulos que son más profundos que un nivel de directorio deben reflejar esa jerarquía. Por ejemplo, si el directorio "empresa" incluye un directorio "sucursal", el nombre de un módulo dentro de ese directorio también incluiría sucursal.
module company.branch.employee;Uso de módulos en programas
La palabra clave de importación, que hemos estado usando en casi todos los programas hasta ahora, es para introducir un módulo en el módulo actual:
import std.stdio;El nombre del módulo también puede contener el nombre del paquete. Por ejemplo, el std. la parte anterior indica que stdio es un módulo que forma parte del paquete std.
Ubicaciones de módulos
El compilador busca los archivos del módulo convirtiendo los nombres de los paquetes y módulos directamente en nombres de archivos y directorios.
Por ejemplo, los dos módulos empleado y oficina se ubicarían como "empresa / empleado.d" y "animal / oficina.d", respectivamente (o "empresa \ empleado.d" y "empresa \ oficina.d", según el sistema de archivos) para company.employee y company.office.
Nombres de módulos largos y cortos
Los nombres que se utilizan en el programa se pueden deletrear con los nombres del módulo y del paquete como se muestra a continuación.
import company.employee;
auto employee0 = Employee();
auto employee1 = company.employee.Employee();Los nombres largos normalmente no son necesarios, pero a veces hay conflictos de nombres. Por ejemplo, cuando se hace referencia a un nombre que aparece en más de un módulo, el compilador no puede decidir a cuál se refiere. El siguiente programa explica los nombres largos para distinguir entre dos estructuras de empleados separadas que se definen en dos módulos separados: empresa y universidad. .
El primer módulo de empleados en la empresa de carpetas es el siguiente.
module company.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("Company Employee: ",str);
}
}El segundo módulo de empleados en la carpeta de la universidad es el siguiente.
module college.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("College Employee: ",str);
}
}El módulo principal de hello.d debe guardarse en la carpeta que contiene las carpetas de la universidad y la empresa. Es como sigue.
import company.employee;
import college.employee;
import std.stdio;
void main() {
auto myemployee1 = new company.employee.Employee();
myemployee1.str = "emp1";
myemployee1.print();
auto myemployee2 = new college.employee.Employee();
myemployee2.str = "emp2";
myemployee2.print();
}La palabra clave de importación no es suficiente para que los módulos se conviertan en parte del programa. Simplemente pone a disposición las características de un módulo dentro del módulo actual. Eso es necesario solo para compilar el código.
Para que se cree el programa anterior, también se deben especificar "empresa / empleado.d" y "colegio / empleado.d" en la línea de compilación.
Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
$ dmd hello.d company/employee.d college/employee.d -ofhello.amx
$ ./hello.amx
Company Employee: emp1
College Employee: emp2Las plantillas son la base de la programación genérica, que implica escribir código de una manera que es independiente de cualquier tipo en particular.
Una plantilla es un plan o fórmula para crear una clase o función genérica.
Las plantillas son la característica que permite describir el código como un patrón, para que el compilador genere el código del programa automáticamente. Algunas partes del código fuente se pueden dejar al compilador para que las complete hasta que esa parte se use realmente en el programa. El compilador completa las partes que faltan.
Plantilla de función
Definir una función como plantilla es dejar uno o más de los tipos que utiliza sin especificar, para que el compilador los deduzca más adelante. Los tipos que se dejan sin especificar se definen en la lista de parámetros de la plantilla, que se encuentra entre el nombre de la función y la lista de parámetros de la función. Por esa razón, las plantillas de funciones tienen dos listas de parámetros:
- lista de parámetros de plantilla
- lista de parámetros de función
import std.stdio;
void print(T)(T value) {
writefln("%s", value);
}
void main() {
print(42);
print(1.2);
print("test");
}Si compilamos y ejecutamos el código anterior, esto produciría el siguiente resultado:
42
1.2
testPlantilla de función con varios parámetros de tipo
Puede haber varios tipos de parámetros. Se muestran en el siguiente ejemplo.
import std.stdio;
void print(T1, T2)(T1 value1, T2 value2) {
writefln(" %s %s", value1, value2);
}
void main() {
print(42, "Test");
print(1.2, 33);
}Si compilamos y ejecutamos el código anterior, esto produciría el siguiente resultado:
42 Test
1.2 33Plantillas de clase
Así como podemos definir plantillas de funciones, también podemos definir plantillas de clases. El siguiente ejemplo define la pila de clases e implementa métodos genéricos para empujar y sacar los elementos de la pila.
import std.stdio;
import std.string;
class Stack(T) {
private:
T[] elements;
public:
void push(T element) {
elements ~= element;
}
void pop() {
--elements.length;
}
T top() const @property {
return elements[$ - 1];
}
size_t length() const @property {
return elements.length;
}
}
void main() {
auto stack = new Stack!string;
stack.push("Test1");
stack.push("Test2");
writeln(stack.top);
writeln(stack.length);
stack.pop;
writeln(stack.top);
writeln(stack.length);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Test2
2
Test1
1A menudo utilizamos variables que son mutables, pero puede haber muchas ocasiones en que no se requiera la mutabilidad. En tales casos se pueden utilizar variables inmutables. A continuación se ofrecen algunos ejemplos en los que se puede utilizar una variable inmutable.
En el caso de constantes matemáticas como pi que nunca cambian.
En el caso de arrays donde queremos retener valores y no son requisitos de mutación.
La inmutabilidad permite comprender si las variables son inmutables o mutables garantizando que determinadas operaciones no modifican determinadas variables. También reduce el riesgo de ciertos tipos de errores de programa. El concepto de inmutabilidad de D está representado por las palabras clave constante e inmutable. Aunque las dos palabras en sí mismas tienen un significado cercano, sus responsabilidades en los programas son diferentes y, a veces, son incompatibles.
El concepto de inmutabilidad de D está representado por las palabras clave constante e inmutable. Aunque las dos palabras en sí mismas tienen un significado cercano, sus responsabilidades en los programas son diferentes y, a veces, son incompatibles.
Tipos de variables inmutables en D
Hay tres tipos de variables definitorias que nunca se pueden modificar.
- constantes enum
- variables inmutables
- variables constantes
enum Constantes en D
Las constantes enum hacen posible relacionar valores constantes con nombres significativos. A continuación se muestra un ejemplo sencillo.
Ejemplo
import std.stdio;
enum Day{
Sunday = 1,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
void main() {
Day day;
day = Day.Sunday;
if (day == Day.Sunday) {
writeln("The day is Sunday");
}
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The day is SundayVariables inmutables en D
Las variables inmutables se pueden determinar durante la ejecución del programa. Simplemente indica al compilador que después de la inicialización, se vuelve inmutable. A continuación se muestra un ejemplo sencillo.
Ejemplo
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
immutable number = uniform(min, max + 1);
// cannot modify immutable expression number
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
immutable(int)4
immutable(int)100Puede ver en el ejemplo anterior cómo es posible transferir el tipo de datos a otra variable y usar stringof mientras imprime.
Variables de constante en D
Las variables constantes no se pueden modificar de forma similar a inmutables. Las variables inmutables se pueden pasar a funciones como sus parámetros inmutables y, por lo tanto, se recomienda usar inmutable sobre const. El mismo ejemplo utilizado anteriormente se modifica para const como se muestra a continuación.
Ejemplo
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
const number = uniform(min, max + 1);
// cannot modify const expression number|
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Si compilamos y ejecutamos el código anterior, esto produciría el siguiente resultado:
const(int)7
const(int)100Parámetros inmutables en D
const borra la información sobre si la variable original es mutable o inmutable y, por lo tanto, el uso de inmutable hace que le pase otras funciones con el tipo original retenido. A continuación se muestra un ejemplo sencillo.
Ejemplo
import std.stdio;
void print(immutable int[] array) {
foreach (i, element; array) {
writefln("%s: %s", i, element);
}
}
void main() {
immutable int[] array = [ 1, 2 ];
print(array);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
0: 1
1: 2Los archivos están representados por la estructura File del módulo std.stdio. Un archivo representa una secuencia de bytes, no importa si es un archivo de texto o un archivo binario.
El lenguaje de programación D proporciona acceso a funciones de alto nivel, así como llamadas de bajo nivel (nivel de SO) para manejar archivos en sus dispositivos de almacenamiento.
Abrir archivos en D
Los flujos estándar de entrada y salida stdin y stdout ya están abiertos cuando los programas comienzan a ejecutarse. Están listos para usarse. Por otro lado, los archivos deben abrirse primero especificando el nombre del archivo y los derechos de acceso necesarios.
File file = File(filepath, "mode");Aquí, filename es literal de cadena, que usa para nombrar el archivo y acceder mode puede tener uno de los siguientes valores:
| No Señor. | Modo y descripción |
|---|---|
| 1 | r Abre un archivo de texto existente con fines de lectura. |
| 2 | w Abre un archivo de texto para escribir, si no existe, se crea un nuevo archivo. Aquí, su programa comenzará a escribir contenido desde el principio del archivo. |
| 3 | a Abre un archivo de texto para escribir en modo adjunto, si no existe, se crea un nuevo archivo. Aquí su programa comenzará a agregar contenido en el contenido del archivo existente. |
| 4 | r+ Abre un archivo de texto para leer y escribir ambos. |
| 5 | w+ Abre un archivo de texto para leer y escribir ambos. Primero trunca el archivo a una longitud cero si existe; de lo contrario, crea el archivo si no existe. |
| 6 | a+ Abre un archivo de texto para leer y escribir ambos. Crea el archivo si no existe. La lectura comenzará desde el principio, pero la escritura solo se puede agregar. |
Cerrar un archivo en D
Para cerrar un archivo, use la función file.close () donde archivo contiene la referencia del archivo. El prototipo de esta función es:
file.close();Cualquier archivo que haya sido abierto por un programa debe cerrarse cuando el programa termine de usar ese archivo. En la mayoría de los casos, los archivos no necesitan cerrarse explícitamente; se cierran automáticamente cuando se terminan los objetos de archivo.
Escribir un archivo en D
file.writeln se usa para escribir en un archivo abierto.
file.writeln("hello");import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
}Cuando se compila y ejecuta el código anterior, crea un nuevo archivo test.txt en el directorio en el que se inició (en el directorio de trabajo del programa).
Leer un archivo en D
El siguiente método lee una sola línea de un archivo:
string s = file.readln();A continuación se muestra un ejemplo completo de lectura y escritura.
import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
file = File("test.txt", "r");
string s = file.readln();
writeln(s);
file.close();
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
helloAquí hay otro ejemplo para leer un archivo hasta el final del archivo.
import std.stdio;
import std.string;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.writeln("world");
file.close();
file = File("test.txt", "r");
while (!file.eof()) {
string line = chomp(file.readln());
writeln("line -", line);
}
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
line -hello
line -world
line -Puede ver en el ejemplo anterior una tercera línea vacía ya que Writeln la lleva a la siguiente línea una vez que se ejecuta.
La concurrencia es hacer que un programa se ejecute en varios subprocesos a la vez. Un ejemplo de programa concurrente es un servidor web que responde a muchos clientes al mismo tiempo. La simultaneidad es fácil con el paso de mensajes, pero muy difícil de escribir si se basan en el intercambio de datos.
Los datos que se pasan entre hilos se denominan mensajes. Los mensajes pueden estar compuestos por cualquier tipo y cantidad de variables. Cada hilo tiene una identificación, que se utiliza para especificar los destinatarios de los mensajes. Cualquier hilo que inicie otro hilo se denomina propietario del nuevo hilo.
Iniciar subprocesos en D
La función spawn () toma un puntero como parámetro e inicia un nuevo hilo desde esa función. Cualquier operación que lleve a cabo esa función, incluidas otras funciones a las que pueda llamar, se ejecutará en el nuevo hilo. Tanto el propietario como el trabajador comienzan a ejecutarse por separado como si fueran programas independientes.
Ejemplo
import std.stdio;
import std.stdio;
import std.concurrency;
import core.thread;
void worker(int a) {
foreach (i; 0 .. 4) {
Thread.sleep(1);
writeln("Worker Thread ",a + i);
}
}
void main() {
foreach (i; 1 .. 4) {
Thread.sleep(2);
writeln("Main Thread ",i);
spawn(≈worker, i * 5);
}
writeln("main is done.");
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
Main Thread 1
Worker Thread 5
Main Thread 2
Worker Thread 6
Worker Thread 10
Main Thread 3
main is done.
Worker Thread 7
Worker Thread 11
Worker Thread 15
Worker Thread 8
Worker Thread 12
Worker Thread 16
Worker Thread 13
Worker Thread 17
Worker Thread 18Identificadores de hilo en D
La variable thisTid disponible globalmente en el nivel de módulo es siempre el id del hilo actual. También puede recibir el threadId cuando se llama a spawn. A continuación se muestra un ejemplo.
Ejemplo
import std.stdio;
import std.concurrency;
void printTid(string tag) {
writefln("%s: %s, address: %s", tag, thisTid, &thisTid);
}
void worker() {
printTid("Worker");
}
void main() {
Tid myWorker = spawn(&worker);
printTid("Owner ");
writeln(myWorker);
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C
Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C
Tid(std.concurrency.MessageBox)Mensaje pasando en D
La función send () envía mensajes y la función ReceiveOnly () espera un mensaje de un tipo en particular. Hay otras funciones llamadas prioritySend (), receive () y receiveTimeout (), que se explican más adelante.
El propietario del siguiente programa envía a su trabajador un mensaje de tipo int y espera un mensaje del trabajador de tipo double. Los hilos continúan enviando mensajes de un lado a otro hasta que el propietario envía un int negativo. A continuación se muestra un ejemplo.
Ejemplo
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
int value = 0;
while (value >= 0) {
value = receiveOnly!int();
auto result = to!double(value) * 5; tid.send(result);
}
}
void main() {
Tid worker = spawn(&workerFunc,thisTid);
foreach (value; 5 .. 10) {
worker.send(value);
auto result = receiveOnly!double();
writefln("sent: %s, received: %s", value, result);
}
worker.send(-1);
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
sent: 5, received: 25
sent: 6, received: 30
sent: 7, received: 35
sent: 8, received: 40
sent: 9, received: 45Mensaje que pasa con espera en D
A continuación se muestra un ejemplo simple con el mensaje que pasa con wait.
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
Thread.sleep(dur!("msecs")( 500 ),);
tid.send("hello");
}
void main() {
spawn(&workerFunc,thisTid);
writeln("Waiting for a message");
bool received = false;
while (!received) {
received = receiveTimeout(dur!("msecs")( 100 ), (string message) {
writeln("received: ", message);
});
if (!received) {
writeln("... no message yet");
}
}
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
Waiting for a message
... no message yet
... no message yet
... no message yet
... no message yet
received: helloUna excepción es un problema que surge durante la ejecución de un programa. La excepción AD es una respuesta a una circunstancia excepcional que surge mientras se ejecuta un programa, como un intento de dividir por cero.
Las excepciones proporcionan una forma de transferir el control de una parte de un programa a otra. El manejo de excepciones D se basa en tres palabras clavetry, catchy throw.
throw- Un programa lanza una excepción cuando aparece un problema. Esto se hace usando unthrow palabra clave.
catch- Un programa detecta una excepción con un manejador de excepciones en el lugar de un programa donde desea manejar el problema. loscatch La palabra clave indica la captura de una excepción.
try - A trybloque identifica un bloque de código para el que se activan excepciones particulares. Le sigue uno o más bloques de captura.
Suponiendo que un bloque generará una excepción, un método detecta una excepción usando una combinación de try y catchpalabras clave. Se coloca un bloque try / catch alrededor del código que podría generar una excepción. El código dentro de un bloque try / catch se conoce como código protegido, y la sintaxis para usar try / catch es similar a la siguiente:
try {
// protected code
}
catch( ExceptionName e1 ) {
// catch block
}
catch( ExceptionName e2 ) {
// catch block
}
catch( ExceptionName eN ) {
// catch block
}Puede enumerar varios catch declaraciones para detectar diferentes tipos de excepciones en caso de que su try block genera más de una excepción en diferentes situaciones.
Lanzar excepciones en D
Las excepciones se pueden lanzar en cualquier lugar dentro de un bloque de código usando throwdeclaraciones. El operando de las sentencias throw determina un tipo para la excepción y puede ser cualquier expresión y el tipo del resultado de la expresión determina el tipo de excepción lanzada.
El siguiente ejemplo arroja una excepción cuando se produce la condición de división por cero:
Ejemplo
double division(int a, int b) {
if( b == 0 ) {
throw new Exception("Division by zero condition!");
}
return (a/b);
}Captura de excepciones en D
los catch bloque siguiendo el tryblock detecta cualquier excepción. Puede especificar qué tipo de excepción desea capturar y esto está determinado por la declaración de excepción que aparece entre paréntesis después de la palabra clave catch.
try {
// protected code
}
catch( ExceptionName e ) {
// code to handle ExceptionName exception
}El código anterior detecta una excepción de ExceptionNametipo. Si desea especificar que un bloque catch debe manejar cualquier tipo de excepción que se lanza en un bloque try, debe poner puntos suspensivos, ..., entre los paréntesis que encierran la declaración de excepción de la siguiente manera:
try {
// protected code
}
catch(...) {
// code to handle any exception
}El siguiente ejemplo arroja una excepción de división por cero. Está atrapado en un bloque de retención.
import std.stdio;
import std.string;
string division(int a, int b) {
string result = "";
try {
if( b == 0 ) {
throw new Exception("Cannot divide by zero!");
} else {
result = format("%s",a/b);
}
} catch (Exception e) {
result = e.msg;
}
return result;
}
void main () {
int x = 50;
int y = 0;
writeln(division(x, y));
y = 10;
writeln(division(x, y));
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
Cannot divide by zero!
5La programación por contrato en la programación D se centra en proporcionar un medio simple y comprensible de manejo de errores. La programación por contrato en D se implementa mediante tres tipos de bloques de código:
- bloque de cuerpo
- en bloque
- fuera de bloque
Bloque de cuerpo en D
El bloque de cuerpo contiene el código de ejecución de la funcionalidad real. Los bloques de entrada y salida son opcionales, mientras que el bloque de cuerpo es obligatorio. A continuación se muestra una sintaxis simple.
return_type function_name(function_params)
in {
// in block
}
out (result) {
// in block
}
body {
// actual function block
}En bloque para condiciones previas en D
En bloque es para condiciones previas simples que verifican si los parámetros de entrada son aceptables y están dentro del rango que puede manejar el código. Una ventaja de un bloque in es que todas las condiciones de entrada se pueden mantener juntas y separadas del cuerpo real de la función. A continuación se muestra una condición previa simple para validar la contraseña para su longitud mínima.
import std.stdio;
import std.string;
bool isValid(string password)
in {
assert(password.length>=5);
}
body {
// other conditions
return true;
}
void main() {
writeln(isValid("password"));
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
trueBloques de salida para condiciones posteriores en D
El bloque de salida se encarga de los valores de retorno de la función. Valida que el valor de retorno está en el rango esperado. A continuación, se muestra un ejemplo simple que contiene tanto la entrada como la salida que convierte meses y años en una forma de edad decimal combinada.
import std.stdio;
import std.string;
double getAge(double months,double years)
in {
assert(months >= 0);
assert(months <= 12);
}
out (result) {
assert(result>=years);
}
body {
return years + months/12;
}
void main () {
writeln(getAge(10,12));
}Cuando el código anterior se compila y ejecuta, lee el archivo creado en la sección anterior y produce el siguiente resultado:
12.8333La compilación condicional es el proceso de seleccionar qué código compilar y qué código no compilar de manera similar a #if / #else / #endif en C y C ++. Cualquier declaración que no esté compilada debe ser sintácticamente correcta.
La compilación condicional implica verificaciones de condición que se pueden evaluar en el momento de la compilación. Las declaraciones condicionales en tiempo de ejecución como if, for, while no son características de compilación condicional. Las siguientes características de D están destinadas a la compilación condicional:
- debug
- version
- estático si
Declaración de depuración en D
La depuración es útil durante el desarrollo del programa. Las expresiones y sentencias que están marcadas como debug se compilan en el programa solo cuando el modificador de compilador -debug está habilitado.
debug a_conditionally_compiled_expression;
debug {
// ... conditionally compiled code ...
} else {
// ... code that is compiled otherwise ...
}La cláusula else es opcional. Tanto la expresión única como el bloque de código anterior se compilan solo cuando el modificador -debug del compilador está habilitado.
En lugar de eliminarse por completo, las líneas se pueden marcar como depuradas.
debug writefln("%s debug only statement", value);Estas líneas se incluyen en el programa solo cuando el modificador -debug del compilador está habilitado.
dmd test.d -oftest -w -debugDeclaración de depuración (etiqueta) en D
Las declaraciones de depuración pueden recibir nombres (etiquetas) para que se incluyan en el programa de forma selectiva.
debug(mytag) writefln("%s not found", value);Estas líneas se incluyen en el programa solo cuando el modificador -debug del compilador está habilitado.
dmd test.d -oftest -w -debug = mytagLos bloques de depuración también pueden tener etiquetas.
debug(mytag) {
//
}Es posible habilitar más de una etiqueta de depuración a la vez.
dmd test.d -oftest -w -debug = mytag1 -debug = mytag2Declaración de depuración (nivel) en D
A veces es más útil asociar declaraciones de depuración por niveles numéricos. El aumento de los niveles puede proporcionar información más detallada.
import std.stdio;
void myFunction() {
debug(1) writeln("debug1");
debug(2) writeln("debug2");
}
void main() {
myFunction();
}Se compilarían las expresiones de depuración y los bloques que sean inferiores o iguales al nivel especificado.
$ dmd test.d -oftest -w -debug = 1 $ ./test
debug1Declaraciones de versión (etiqueta) y versión (nivel) en D
La versión es similar a debug y se usa de la misma manera. La cláusula else es opcional. Aunque la versión funciona esencialmente igual que la depuración, tener palabras clave separadas ayuda a distinguir sus usos no relacionados. Al igual que con la depuración, se puede habilitar más de una versión.
import std.stdio;
void myFunction() {
version(1) writeln("version1");
version(2) writeln("version2");
}
void main() {
myFunction();
}Se compilarían las expresiones de depuración y los bloques que sean inferiores o iguales al nivel especificado.
$ dmd test.d -oftest -w -version = 1 $ ./test
version1Estático si
Static if es el tiempo de compilación equivalente a la sentencia if. Al igual que la instrucción if, static if toma una expresión lógica y la evalúa. A diferencia de la instrucción if, static if no se trata del flujo de ejecución; más bien, determina si un fragmento de código debe incluirse en el programa o no.
La expresión if no está relacionada con el operador is que hemos visto antes, tanto sintácticamente como semánticamente. Se evalúa en tiempo de compilación. Produce un valor int, 0 o 1; dependiendo de la expresión especificada entre paréntesis. Aunque la expresión que toma no es una expresión lógica, la expresión is en sí se usa como expresión lógica en tiempo de compilación. Es especialmente útil en condicionales if estáticas y restricciones de plantilla.
import std.stdio;
enum Days {
sun,
mon,
tue,
wed,
thu,
fri,
sat
};
void myFunction(T)(T mytemplate) {
static if (is (T == class)) {
writeln("This is a class type");
} else static if (is (T == enum)) {
writeln("This is an enum type");
}
}
void main() {
Days day;
myFunction(day);
}Cuando compilamos y ejecutamos, obtendremos algunos resultados de la siguiente manera.
This is an enum typeLas clases son la característica central de la programación D que admite la programación orientada a objetos y, a menudo, se denominan tipos definidos por el usuario.
Una clase se usa para especificar la forma de un objeto y combina la representación de datos y métodos para manipular esos datos en un paquete ordenado. Los datos y funciones dentro de una clase se denominan miembros de la clase.
Definiciones de clase D
Cuando define una clase, define un plano para un tipo de datos. En realidad, esto no define ningún dato, pero define lo que significa el nombre de la clase, es decir, en qué consistirá un objeto de la clase y qué operaciones se pueden realizar en dicho objeto.
Una definición de clase comienza con la palabra clave classseguido del nombre de la clase; y el cuerpo de la clase, encerrado por un par de llaves. Una definición de clase debe ir seguida de un punto y coma o de una lista de declaraciones. Por ejemplo, definimos el tipo de datos Box usando la palabra claveclass como sigue -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}La palabra clave publicdetermina los atributos de acceso de los miembros de la clase que le siguen. Se puede acceder a un miembro público desde fuera de la clase en cualquier lugar dentro del alcance del objeto de la clase. También puede especificar los miembros de una clase comoprivate o protected que discutiremos en una subsección.
Definición de objetos D
Una clase proporciona los planos de los objetos, por lo que básicamente un objeto se crea a partir de una clase. Declaras objetos de una clase con exactamente el mismo tipo de declaración que declaras variables de tipos básicos. Las siguientes declaraciones declaran dos objetos de la clase Box:
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxAmbos objetos Box1 y Box2 tienen su propia copia de miembros de datos.
Acceso a los miembros de datos
Se puede acceder a los miembros de datos públicos de los objetos de una clase mediante el operador de acceso directo a miembros (.). Probemos con el siguiente ejemplo para aclarar las cosas:
import std.stdio;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main() {
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Volume of Box1 : 210
Volume of Box2 : 1560Es importante tener en cuenta que no se puede acceder directamente a los miembros privados y protegidos mediante el operador de acceso directo de miembros (.). En breve aprenderá cómo se puede acceder a miembros privados y protegidos.
Clases y objetos en D
Hasta ahora, tienes una idea muy básica sobre las clases D y los objetos. Hay más conceptos interesantes relacionados con las clases y objetos D que discutiremos en varias subsecciones que se enumeran a continuación:
| No Señor. | Concepto y descripción |
|---|---|
| 1 | Funciones de miembros de clase Una función miembro de una clase es una función que tiene su definición o su prototipo dentro de la definición de la clase como cualquier otra variable. |
| 2 | Modificadores de acceso a clases Un miembro de la clase puede definirse como público, privado o protegido. Por defecto, los miembros se asumirán como privados. |
| 3 | Constructor y destructor Un constructor de clase es una función especial en una clase que se llama cuando se crea un nuevo objeto de la clase. Un destructor también es una función especial que se llama cuando se elimina el objeto creado. |
| 4 | El este puntero en D Cada objeto tiene un puntero especial this que apunta al objeto en sí. |
| 5 | Puntero a clases D Un puntero a una clase se hace exactamente de la misma manera que un puntero a una estructura. De hecho, una clase es en realidad solo una estructura con funciones en ella. |
| 6 | Miembros estáticos de una clase Tanto los miembros de datos como los miembros de función de una clase se pueden declarar como estáticos. |
Uno de los conceptos más importantes de la programación orientada a objetos es la herencia. La herencia permite definir una clase en términos de otra clase, lo que facilita la creación y el mantenimiento de una aplicación. Esto también brinda la oportunidad de reutilizar la funcionalidad del código y un tiempo de implementación rápido.
Al crear una clase, en lugar de escribir miembros de datos y funciones de miembros completamente nuevos, el programador puede designar que la nueva clase herede los miembros de una clase existente. Esta clase existente se llamabase clase, y la nueva clase se conoce como el derived clase.
La idea de herencia implementa la es una relación. Por ejemplo, mamífero IS-A animal, perro IS-A mamífero y, por tanto, perro IS-A animal y así sucesivamente.
Clases base y clases derivadas en D
Una clase puede derivarse de más de una clase, lo que significa que puede heredar datos y funciones de varias clases base. Para definir una clase derivada, usamos una lista de derivación de clases para especificar la (s) clase (s) base. Una lista de derivación de clases nombra una o más clases base y tiene la forma:
class derived-class: base-classConsidere una clase base Shape y su clase derivada Rectangle como sigue -
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Total area: 35Control de acceso y herencia
Una clase derivada puede acceder a todos los miembros no privados de su clase base. Por lo tanto, los miembros de la clase base que no deberían ser accesibles para las funciones miembro de las clases derivadas deberían declararse privados en la clase base.
Una clase derivada hereda todos los métodos de la clase base con las siguientes excepciones:
- Constructores, destructores y constructores de copia de la clase base.
- Operadores sobrecargados de la clase base.
Herencia multinivel
La herencia puede ser de varios niveles y se muestra en el siguiente ejemplo.
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
class Square: Rectangle {
this(int side) {
this.setWidth(side);
this.setHeight(side);
}
}
void main() {
Square square = new Square(13);
// Print the area of the object.
writeln("Total area: ", square.getArea());
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Total area: 169D le permite especificar más de una definición para un function nombre o un operator en el mismo ámbito, que se llama function overloading y operator overloading respectivamente.
Una declaración sobrecargada es una declaración que ha sido declarada con el mismo nombre que una declaración anterior en el mismo ámbito, excepto que ambas declaraciones tienen argumentos diferentes y, obviamente, una definición (implementación) diferente.
Cuando llamas a un sobrecargado function o operator, el compilador determina la definición más apropiada para usar comparando los tipos de argumentos que usó para llamar a la función u operador con los tipos de parámetros especificados en las definiciones. El proceso de seleccionar la función o el operador sobrecargado más apropiado se llamaoverload resolution..
Sobrecarga de funciones
Puede tener varias definiciones para el mismo nombre de función en el mismo ámbito. La definición de la función debe diferir entre sí por los tipos y / o el número de argumentos en la lista de argumentos. No puede sobrecargar declaraciones de funciones que difieran solo por el tipo de retorno.
Ejemplo
El siguiente ejemplo usa la misma función print() para imprimir diferentes tipos de datos -
import std.stdio;
import std.string;
class printData {
public:
void print(int i) {
writeln("Printing int: ",i);
}
void print(double f) {
writeln("Printing float: ",f );
}
void print(string s) {
writeln("Printing string: ",s);
}
};
void main() {
printData pd = new printData();
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello D");
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Printing int: 5
Printing float: 500.263
Printing string: Hello DSobrecarga del operador
Puede redefinir o sobrecargar la mayoría de los operadores integrados disponibles en D. Por lo tanto, un programador también puede usar operadores con tipos definidos por el usuario.
Los operadores se pueden sobrecargar usando string op seguido de Add, Sub, etc., según el operador que se está sobrecargando. Podemos sobrecargar el operador + para agregar dos cuadros como se muestra a continuación.
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}El siguiente ejemplo muestra el concepto de sobrecarga de operadores utilizando una función miembro. Aquí se pasa un objeto como argumento a cuyas propiedades se accede utilizando este objeto. Se puede acceder al objeto que llama a este operador usandothis operador como se explica a continuación -
import std.stdio;
class Box {
public:
double getVolume() {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
void main( ) {
Box box1 = new Box(); // Declare box1 of type Box
Box box2 = new Box(); // Declare box2 of type Box
Box box3 = new Box(); // Declare box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.setLength(6.0);
box1.setBreadth(7.0);
box1.setHeight(5.0);
// box 2 specification
box2.setLength(12.0);
box2.setBreadth(13.0);
box2.setHeight(10.0);
// volume of box 1
volume = box1.getVolume();
writeln("Volume of Box1 : ", volume);
// volume of box 2
volume = box2.getVolume();
writeln("Volume of Box2 : ", volume);
// Add two object as follows:
box3 = box1 + box2;
// volume of box 3
volume = box3.getVolume();
writeln("Volume of Box3 : ", volume);
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Tipos de sobrecarga del operador
Básicamente, hay tres tipos de sobrecarga del operador que se enumeran a continuación.
| No Señor. | Tipos de sobrecarga |
|---|---|
| 1 | Sobrecarga de operadores unarios |
| 2 | Sobrecarga de operadores binarios |
| 3 | Sobrecarga de operadores de comparación |
Todos los programas D se componen de los siguientes dos elementos fundamentales:
Program statements (code) - Esta es la parte de un programa que realiza acciones y se llaman funciones.
Program data - Es la información del programa que se ve afectada por las funciones del programa.
La encapsulación es un concepto de programación orientada a objetos que une datos y funciones que manipulan los datos juntos, y que los mantiene a salvo de interferencias externas y uso indebido. La encapsulación de datos llevó al importante concepto de programación orientada a objetos dedata hiding.
Data encapsulation es un mecanismo para agrupar los datos y las funciones que los utilizan y data abstraction es un mecanismo para exponer solo las interfaces y ocultar al usuario los detalles de implementación.
D admite las propiedades de encapsulación y ocultación de datos mediante la creación de tipos definidos por el usuario, llamados classes. Ya hemos estudiado que una clase puede contenerprivate, protegido y publicmiembros. De forma predeterminada, todos los elementos definidos en una clase son privados. Por ejemplo
class Box {
public:
double getVolume() {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Las variables longitud, anchura y altura son private. Esto significa que solo pueden acceder a ellos otros miembros de la clase Box y no cualquier otra parte de su programa. Esta es una forma de lograr la encapsulación.
Para hacer partes de una clase public (es decir, accesibles a otras partes de su programa), debe declararlas después de la publicpalabra clave. Todas las variables o funciones definidas después del especificador público son accesibles por todas las demás funciones en su programa.
Hacer que una clase sea amiga de otra expone los detalles de implementación y reduce la encapsulación. Es ideal mantener la mayor cantidad posible de detalles de cada clase ocultos de todas las demás clases.
Encapsulación de datos en D
Cualquier programa D en el que implemente una clase con miembros públicos y privados es un ejemplo de encapsulación y abstracción de datos. Considere el siguiente ejemplo:
Ejemplo
import std.stdio;
class Adder {
public:
// constructor
this(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
}
void main( ) {
Adder a = new Adder();
a.addNum(10);
a.addNum(20);
a.addNum(30);
writeln("Total ",a.getTotal());
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Total 60La clase anterior suma números y devuelve la suma. Los miembros públicosaddNum y getTotalson las interfaces con el mundo exterior y un usuario necesita conocerlas para usar la clase. El total de miembros privados es algo que está oculto al mundo exterior, pero es necesario para que la clase funcione correctamente.
Estrategia de diseño de clases en D
La mayoría de nosotros hemos aprendido a través de una amarga experiencia a hacer que los miembros de la clase sean privados por defecto a menos que realmente necesitemos exponerlos. Eso es simplemente buenoencapsulation.
Esta sabiduría se aplica con mayor frecuencia a los miembros de datos, pero se aplica por igual a todos los miembros, incluidas las funciones virtuales.
Una interfaz es una forma de obligar a las clases que heredan de ella a implementar determinadas funciones o variables. Las funciones no deben implementarse en una interfaz porque siempre se implementan en las clases que heredan de la interfaz.
Se crea una interfaz utilizando la palabra clave de interfaz en lugar de la palabra clave de clase, aunque las dos son similares en muchos aspectos. Cuando desea heredar de una interfaz y la clase ya hereda de otra clase, debe separar el nombre de la clase y el nombre de la interfaz con una coma.
Veamos un ejemplo sencillo que explica el uso de una interfaz.
Ejemplo
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Total area: 35Interfaz con funciones estáticas y finales en D
Una interfaz puede tener un método final y estático para el cual las definiciones deben incluirse en la propia interfaz. Estas funciones no pueden ser anuladas por la clase derivada. A continuación se muestra un ejemplo sencillo.
Ejemplo
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
static void myfunction1() {
writeln("This is a static method");
}
final void myfunction2() {
writeln("This is a final method");
}
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle rect = new Rectangle();
rect.setWidth(5);
rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", rect.getArea());
rect.myfunction1();
rect.myfunction2();
}Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Total area: 35
This is a static method
This is a final methodLa abstracción se refiere a la capacidad de hacer un resumen de clase en OOP. Una clase abstracta es aquella que no se puede instanciar. Todas las demás funciones de la clase todavía existen, y se accede a sus campos, métodos y constructores de la misma manera. Simplemente no puede crear una instancia de la clase abstracta.
Si una clase es abstracta y no se puede crear una instancia, la clase no tiene mucho uso a menos que sea una subclase. Normalmente, así es como surgen las clases abstractas durante la fase de diseño. Una clase principal contiene la funcionalidad común de una colección de clases secundarias, pero la clase principal en sí es demasiado abstracta para ser utilizada por sí sola.
Usando la clase abstracta en D
Utilizar el abstractpalabra clave para declarar un resumen de clase. La palabra clave aparece en la declaración de clase en algún lugar antes de la palabra clave de clase. A continuación se muestra un ejemplo de cómo se puede heredar y usar la clase abstracta.
Ejemplo
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
}
class Employee : Person {
int empID;
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
writeln(emp.name);
writeln(emp.getAge);
}Cuando compilemos y ejecutemos el programa anterior, obtendremos el siguiente resultado.
Emp1
37Funciones abstractas
Al igual que las funciones, las clases también pueden ser abstractas. La implementación de dicha función no se da en su clase, pero debe proporcionarse en la clase que hereda la clase con función abstracta. El ejemplo anterior se actualiza con función abstracta.
Ejemplo
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
abstract void print();
}
class Employee : Person {
int empID;
override void print() {
writeln("The employee details are as follows:");
writeln("Emp ID: ", this.empID);
writeln("Emp Name: ", this.name);
writeln("Age: ",this.getAge);
}
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
emp.print();
}Cuando compilemos y ejecutemos el programa anterior, obtendremos el siguiente resultado.
The employee details are as follows:
Emp ID: 101
Emp Name: Emp1
Age: 37