DCN - Guía rápida
Un sistema de computadoras interconectadas y periféricos computarizados como impresoras se llama red de computadoras. Esta interconexión entre computadoras facilita el intercambio de información entre ellas. Las computadoras pueden conectarse entre sí mediante medios alámbricos o inalámbricos.
Clasificación de redes informáticas
Las redes de computadoras se clasifican en función de varios factores, que incluyen:
- Espacio geográfico
- Inter-connectivity
- Administration
- Architecture
Alcance geográfico
Geográficamente, una red se puede ver en una de las siguientes categorías:
- Puede extenderse a lo largo de su mesa, entre dispositivos habilitados para Bluetooth. Alcance de no más de unos pocos metros.
- Puede abarcar todo un edificio, incluidos los dispositivos intermedios para conectar todos los pisos.
- Puede abarcar toda una ciudad.
- Puede abarcar varias ciudades o provincias.
- Puede ser una red que cubra todo el mundo.
Interconectividad
Los componentes de una red se pueden conectar entre sí de manera diferente de alguna manera. Por conectividad nos referimos a lógicamente, físicamente o en ambos sentidos.
- Cada uno de los dispositivos se puede conectar a todos los demás dispositivos de la red, haciendo que la red sea en malla.
- Todos los dispositivos pueden conectarse a un solo medio pero desconectados geográficamente, creando una estructura similar a un bus.
- Cada dispositivo está conectado solo a sus pares izquierdo y derecho, creando una estructura lineal.
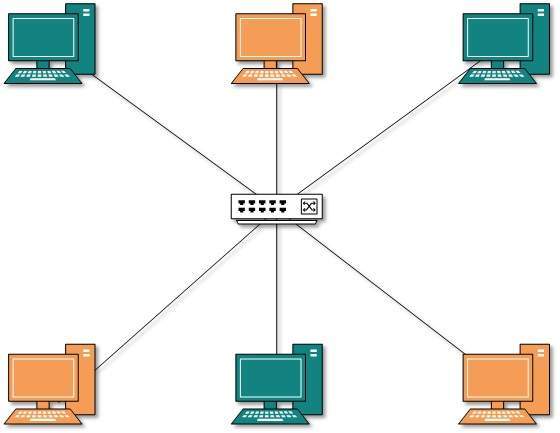
- Todos los dispositivos conectados entre sí con un solo dispositivo, creando una estructura en forma de estrella.
- Todos los dispositivos se conectaron arbitrariamente utilizando todas las formas anteriores para conectarse entre sí, lo que resultó en una estructura híbrida.
Administración
Desde el punto de vista de un administrador, una red puede ser una red privada que pertenece a un único sistema autónomo y no se puede acceder a ella fuera de su dominio físico o lógico. Una red puede ser pública a la que todos acceden.
Red de arquitectura
- Puede haber uno o más sistemas que actúen como servidor. Otro siendo el Cliente, solicita al Servidor que atienda las solicitudes. El Servidor toma y procesa las solicitudes en nombre de los Clientes.
- Se pueden conectar dos sistemas punto a punto o en forma consecutiva. Ambos residen en el mismo nivel y se llaman pares.
- Puede haber una red híbrida que implique una arquitectura de red de los dos tipos anteriores.
Las redes de computadoras se pueden discriminar en varios tipos, como cliente-servidor, peer-to-peer o híbridas, dependiendo de su arquitectura.
Aplicaciones de red
Los sistemas informáticos y los periféricos están conectados para formar una red y ofrecen numerosas ventajas:
- Uso compartido de recursos como impresoras y dispositivos de almacenamiento
- Intercambio de información mediante correos electrónicos y FTP
- Intercambio de información mediante Web o Internet
- Interacción con otros usuarios que utilizan páginas web dinámicas
- Teléfonos IP
- Videoconferencias
- Computación paralela
- Mensajería instantánea
Generalmente, las redes se distinguen según su extensión geográfica. Una red puede ser tan pequeña como la distancia entre su teléfono móvil y sus auriculares Bluetooth y tan grande como Internet, cubriendo todo el mundo geográfico.
Área de trabajo personal
Una red de área personal (PAN) es la red más pequeña que es muy personal para un usuario. Esto puede incluir dispositivos habilitados para Bluetooth o dispositivos habilitados para infrarrojos. PAN tiene un alcance de conectividad de hasta 10 metros. PAN puede incluir teclado y mouse inalámbricos para computadora, audífonos con Bluetooth, impresoras inalámbricas y controles remotos de TV.
Por ejemplo, Piconet es una red de área personal habilitada para Bluetooth que puede contener hasta 8 dispositivos conectados entre sí de forma maestro-esclavo.
Red de área local
Una red de computadoras distribuida dentro de un edificio y operada bajo un único sistema administrativo generalmente se denomina Red de área local (LAN). Por lo general, LAN cubre las oficinas, escuelas, colegios o universidades de una organización. El número de sistemas conectados en LAN puede variar desde al menos dos hasta 16 millones.
LAN proporciona una forma útil de compartir los recursos entre los usuarios finales. Los recursos como impresoras, servidores de archivos, escáneres e Internet se pueden compartir fácilmente entre computadoras.
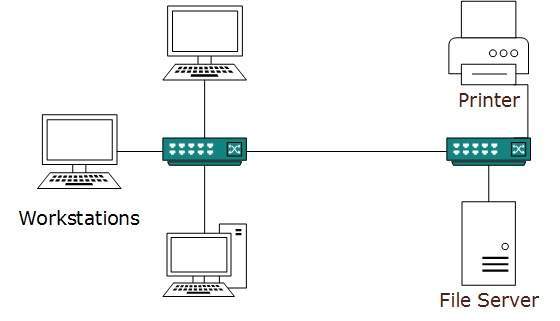
Las LAN están compuestas por equipos de enrutamiento y redes de bajo costo. Puede contener servidores locales que sirven para el almacenamiento de archivos y otras aplicaciones compartidas localmente. Opera principalmente en direcciones IP privadas y no implica un enrutamiento pesado. LAN funciona bajo su propio dominio local y se controla de forma centralizada.
LAN utiliza tecnología Ethernet o Token-ring. Ethernet es la tecnología LAN más empleada y utiliza topología en estrella, mientras que Token-ring rara vez se ve.
La LAN puede ser cableada, inalámbrica o en ambas formas a la vez.
Red de área metropolitana
La Red de Área Metropolitana (MAN) generalmente se expande por una ciudad, como una red de televisión por cable. Puede tener la forma de Ethernet, Token-ring, ATM o Interfaz de datos distribuidos por fibra (FDDI).
Metro Ethernet es un servicio proporcionado por ISP. Este servicio permite a sus usuarios expandir sus redes de área local. Por ejemplo, MAN puede ayudar a una organización a conectar todas sus oficinas en una ciudad.
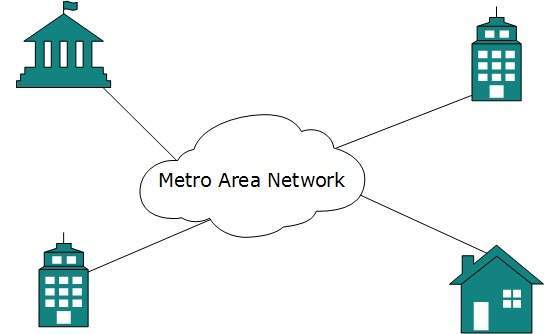
La columna vertebral de MAN es la fibra óptica de alta capacidad y alta velocidad. MAN trabaja entre la red de área local y la red de área amplia. MAN proporciona un enlace ascendente para LAN a WAN o Internet.
Red de área amplia
Como sugiere el nombre, la red de área amplia (WAN) cubre un área amplia que puede abarcar provincias e incluso todo un país. Generalmente, las redes de telecomunicaciones son redes de área amplia. Estas redes proporcionan conectividad a MAN y LAN. Dado que están equipadas con una red troncal de muy alta velocidad, las WAN utilizan equipos de red muy costosos.
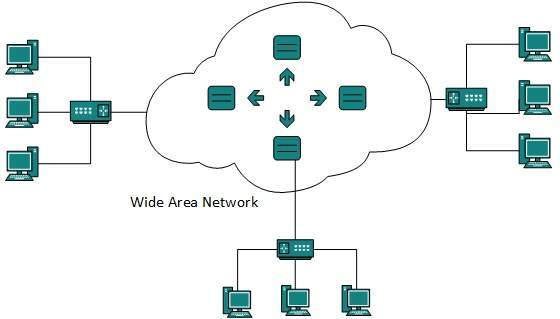
WAN puede utilizar tecnologías avanzadas como el modo de transferencia asincrónica (ATM), Frame Relay y la red óptica sincrónica (SONET). La WAN puede ser administrada por múltiples administraciones.
Internetwork
Una red de redes se llama internetwork o simplemente Internet. Es la red más grande que existe en este planeta. Internet conecta enormemente todas las WAN y puede tener conexión a LAN y redes domésticas. Internet utiliza el conjunto de protocolos TCP / IP y utiliza IP como protocolo de direccionamiento. En la actualidad, Internet se implementa ampliamente mediante IPv4. Debido a la escasez de espacios de direcciones, está migrando gradualmente de IPv4 a IPv6.
Internet permite a sus usuarios compartir y acceder a una enorme cantidad de información en todo el mundo. Utiliza WWW, FTP, servicios de correo electrónico, transmisión de audio y video, etc. A gran nivel, Internet funciona en el modelo Cliente-Servidor.
Internet utiliza una red troncal de fibra óptica de muy alta velocidad. Para interconectar varios continentes, se colocan fibras bajo el mar que conocemos como cable de comunicación submarino.
Internet se implementa ampliamente en los servicios de la World Wide Web utilizando páginas vinculadas HTML y es accesible mediante un software cliente conocido como Navegadores Web. Cuando un usuario solicita una página utilizando algún navegador web ubicado en algún servidor web en cualquier parte del mundo, el servidor web responde con la página HTML adecuada. El retraso de la comunicación es muy bajo.
Internet está al servicio de muchas propuestas y está involucrado en muchos aspectos de la vida. Algunos de ellos son:
- Sitios web
- Mensajería instantánea
- Blogging
- Redes sociales
- Marketing
- Networking
- El intercambio de recursos
- Transmisión de audio y video
Repasemos brevemente varias tecnologías LAN:
Ethernet
Ethernet es una tecnología LAN ampliamente implementada. Esta tecnología fue inventada por Bob Metcalfe y DR Boggs en el año 1970. Fue estandarizada en IEEE 802.3 en 1980.
Ethernet comparte medios. La red que utiliza medios compartidos tiene una alta probabilidad de colisión de datos. Ethernet utiliza tecnología Carrier Sense Multi Access / Collision Detection (CSMA / CD) para detectar colisiones. En caso de colisión en Ethernet, todos sus hosts retroceden, esperan una cantidad de tiempo aleatoria y luego vuelven a transmitir los datos.
El conector Ethernet es una tarjeta de interfaz de red equipada con una dirección MAC de 48 bits. Esto ayuda a otros dispositivos Ethernet a identificar y comunicarse con dispositivos remotos en Ethernet.
Ethernet tradicional utiliza especificaciones 10BASE-T. El número 10 representa una velocidad de 10 MBPS, BASE significa banda base y T significa Thick Ethernet. Ethernet 10BASE-T proporciona una velocidad de transmisión de hasta 10 MBPS y utiliza cable coaxial o cable de par trenzado Cat-5 con conector RJ-45. Ethernet sigue la topología en estrella con una longitud de segmento de hasta 100 metros. Todos los dispositivos están conectados a un concentrador / conmutador en forma de estrella.
Fast-Ethernet
Para cubrir la necesidad de tecnologías de hardware y software de rápida aparición, Ethernet se extiende como Fast-Ethernet. Puede ejecutarse en UTP, fibra óptica y también de forma inalámbrica. Puede proporcionar una velocidad de hasta 100 MBPS. Este estándar se denomina 100BASE-T en IEEE 803.2 utilizando un cable de par trenzado Cat-5. Utiliza la técnica CSMA / CD para compartir medios por cable entre los hosts Ethernet y la técnica CSMA / CA (CA significa Collision Avoidance) para LAN Ethernet inalámbrica.
Fast Ethernet en fibra se define bajo el estándar 100BASE-FX que proporciona una velocidad de hasta 100 MBPS en fibra. Ethernet sobre fibra se puede extender hasta 100 metros en modo semidúplex y puede alcanzar un máximo de 2000 metros en dúplex completo sobre fibras multimodo.
Giga-Ethernet
Después de su introducción en 1995, Fast-Ethernet pudo disfrutar de su estado de alta velocidad solo durante 3 años hasta que se introdujo Giga-Ethernet. Giga-Ethernet proporciona una velocidad de hasta 1000 mbits / segundos. IEEE802.3ab estandariza Giga-Ethernet sobre UTP utilizando cables Cat-5, Cat-5e y Cat-6. IEEE802.3ah define Giga-Ethernet sobre fibra.
LAN virtual
LAN usa Ethernet que a su vez funciona en medios compartidos. Los medios compartidos en Ethernet crean un solo dominio de difusión y un solo dominio de colisión. La introducción de conmutadores a Ethernet ha eliminado el problema del dominio de colisión único y cada dispositivo conectado al conmutador funciona en su dominio de colisión independiente. Pero incluso los Switches no pueden dividir una red en dominios de difusión separados.
Virtual LAN es una solución para dividir un solo dominio de difusión en varios dominios de difusión. El host de una VLAN no puede hablar con un host de otra. De forma predeterminada, todos los hosts se colocan en la misma VLAN.
En este diagrama, se representan diferentes VLAN en diferentes códigos de color. Los hosts en una VLAN, incluso si están conectados en el mismo conmutador, no pueden ver ni hablar con otros hosts en diferentes VLAN. VLAN es tecnología de capa 2 que trabaja en estrecha colaboración con Ethernet. Para enrutar paquetes entre dos VLAN diferentes, se requiere un dispositivo de capa 3, como un enrutador.
Una topología de red es la disposición con la que los sistemas informáticos o los dispositivos de red están conectados entre sí. Las topologías pueden definir el aspecto físico y lógico de la red. Tanto la topología lógica como la física pueden ser iguales o diferentes en una misma red.
Punto a punto
Las redes punto a punto contienen exactamente dos hosts, como una computadora, conmutadores o enrutadores, servidores conectados espalda con espalda mediante un solo cable. A menudo, el extremo de recepción de un host está conectado al extremo de envío del otro y viceversa.

Si los hosts están conectados punto a punto de manera lógica, entonces pueden tener varios dispositivos intermedios. Pero los hosts finales desconocen la red subyacente y se ven como si estuvieran conectados directamente.
Topología del bus
En el caso de la topología de bus, todos los dispositivos comparten una sola línea o cable de comunicación. La topología de bus puede tener problemas cuando varios hosts envían datos al mismo tiempo. Por lo tanto, la topología de bus utiliza tecnología CSMA / CD o reconoce un host como Bus Master para resolver el problema. Es una de las formas simples de conexión en red en las que una falla de un dispositivo no afecta a los otros dispositivos. Pero la falla de la línea de comunicación compartida puede hacer que todos los demás dispositivos dejen de funcionar.
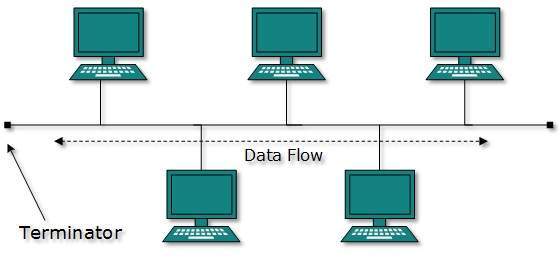
Ambos extremos del canal compartido tienen terminador de línea. Los datos se envían en una sola dirección y tan pronto como llegan al final, el terminador elimina los datos de la línea.
Topología de las estrellas
Todos los hosts en la topología en estrella están conectados a un dispositivo central, conocido como dispositivo concentrador, mediante una conexión punto a punto. Es decir, existe una conexión punto a punto entre los hosts y el concentrador. El dispositivo concentrador puede ser cualquiera de los siguientes:
- Dispositivo de capa 1 como concentrador o repetidor
- Dispositivo de capa 2 como conmutador o puente
- Dispositivo de capa 3 como enrutador o puerta de enlace
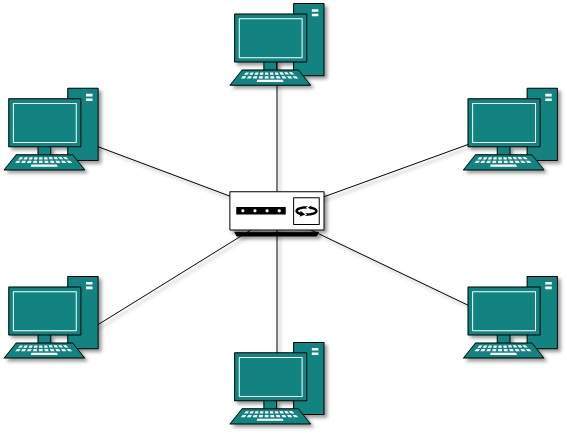
Como en la topología de bus, el concentrador actúa como un solo punto de falla. Si el concentrador falla, la conectividad de todos los hosts a todos los demás hosts falla. Cada comunicación entre hosts se realiza a través del hub. La topología en estrella no es costosa ya que conectar un host más, solo se requiere un cable y la configuración es simple.
Topología en anillo
En la topología de anillo, cada máquina host se conecta exactamente a otras dos máquinas, creando una estructura de red circular. Cuando un host intenta comunicarse o enviar un mensaje a un host que no está adyacente a él, los datos viajan a través de todos los hosts intermedios. Para conectar un host más en la estructura existente, el administrador puede necesitar solo un cable adicional más.
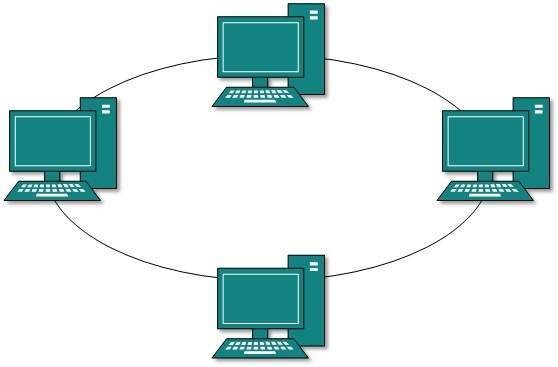
La falla de cualquier host da como resultado la falla de todo el anillo, por lo que cada conexión en el anillo es un punto de falla. Hay métodos que emplean un anillo de respaldo más.
Topología de malla
En este tipo de topología, un host está conectado a uno o varios hosts. Esta topología tiene hosts en conexión punto a punto con todos los demás hosts o también puede tener hosts que están en conexión punto a punto solo con unos pocos hosts.
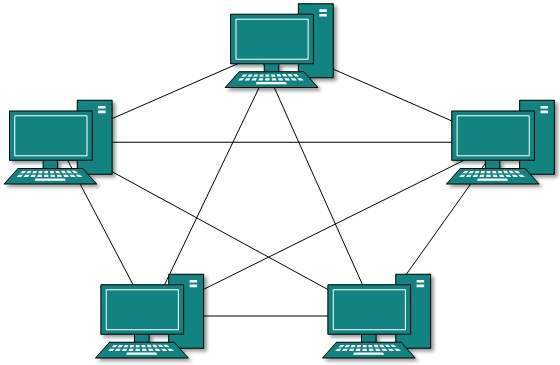
Los hosts en topología Mesh también funcionan como retransmisores para otros hosts que no tienen enlaces directos punto a punto. La tecnología de malla se divide en dos tipos:
- Full Mesh: Todos los hosts tienen una conexión punto a punto con todos los demás hosts de la red. Por lo tanto, para cada nuevo host se requieren n (n-1) / 2 conexiones. Proporciona la estructura de red más confiable entre todas las topologías de red.
- Partially Mesh: No todos los hosts tienen conexión punto a punto con todos los demás hosts. Los hosts se conectan entre sí de forma arbitraria. Esta topología existe donde necesitamos proporcionar confiabilidad a algunos hosts de todos.
Topología de árbol
También conocida como topología jerárquica, esta es la forma más común de topología de red en uso actualmente. Esta topología imita la topología en estrella extendida y hereda las propiedades de la topología de bus.
Esta topología divide la red en múltiples niveles / capas de red. Principalmente en las LAN, una red se bifurca en tres tipos de dispositivos de red. La más baja es la capa de acceso donde están conectadas las computadoras. La capa intermedia se conoce como capa de distribución, que funciona como mediadora entre la capa superior y la capa inferior. La capa más alta se conoce como capa central y es el punto central de la red, es decir, la raíz del árbol desde el que se bifurcan todos los nodos.
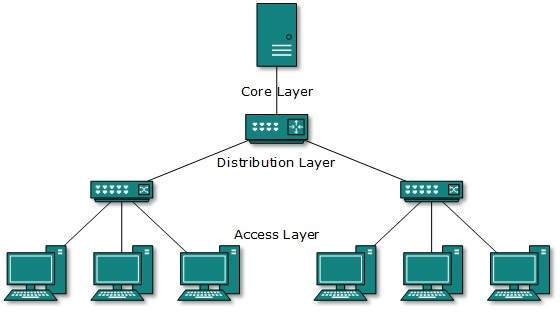
Todos los hosts vecinos tienen una conexión de punto a punto entre ellos. De manera similar a la topología de bus, si la raíz falla, toda la red sufre incluso, aunque no es el único punto de falla. Cada conexión sirve como punto de falla, cuya falla divide la red en un segmento inalcanzable.
Cadena de margaritas
Esta topología conecta todos los hosts de forma lineal. De manera similar a la topología de anillo, todos los hosts están conectados a dos hosts solamente, excepto los hosts finales. Significa que si los hosts finales en la cadena tipo margarita están conectados, entonces representa la topología de anillo.

Cada eslabón de la topología en cadena representa un solo punto de falla. Cada falla de enlace divide la red en dos segmentos. Cada host intermedio funciona como retransmisor para sus hosts inmediatos.
Topología híbrida
Una estructura de red cuyo diseño contiene más de una topología se denomina topología híbrida. La topología híbrida hereda los méritos y deméritos de todas las topologías incorporadas.
La imagen de arriba representa una topología arbitrariamente híbrida. Las topologías combinadas pueden contener atributos de topologías en estrella, anillo, bus y en cadena. La mayoría de las WAN están conectadas mediante topología de anillo dual y las redes conectadas a ellas son en su mayoría redes de topología en estrella. Internet es el mejor ejemplo de la topología híbrida más grande
La ingeniería de redes es una tarea complicada que involucra software, firmware, ingeniería de nivel de chip, hardware y pulsos eléctricos. Para facilitar la ingeniería de redes, todo el concepto de redes se divide en varias capas. Cada capa está involucrada en una tarea particular y es independiente de todas las demás capas. Pero en general, casi todas las tareas de red dependen de todas estas capas. Las capas comparten datos entre ellas y dependen unas de otras solo para recibir entrada y enviar salida.
Tareas en capas
En la arquitectura en capas del modelo de red, un proceso de red completo se divide en pequeñas tareas. A continuación, cada pequeña tarea se asigna a una capa en particular que trabaja con dedicación para procesar solo la tarea. Cada capa hace solo un trabajo específico.
En el sistema de comunicación por capas, una capa de un host se ocupa de la tarea realizada por su capa de pares en el mismo nivel en el host remoto. La tarea se inicia por capa en el nivel más bajo o en el nivel más alto. Si la tarea la inicia la capa superior, se pasa a la capa inferior para su posterior procesamiento. La capa inferior hace lo mismo, procesa la tarea y pasa a la capa inferior. Si la tarea es iniciada por la capa más baja, entonces se toma la ruta inversa.

Cada capa agrupa todos los procedimientos, protocolos y métodos que necesita para ejecutar su tarea. Todas las capas identifican a sus contrapartes mediante el encabezado y la cola de encapsulación.
Modelo OSI
Open System Interconnect es un estándar abierto para todos los sistemas de comunicación. El modelo OSI es establecido por la Organización Internacional de Normalización (ISO). Este modelo tiene siete capas:
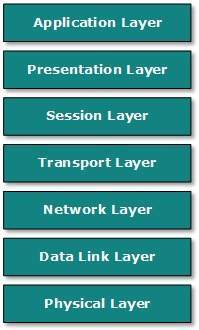
Application Layer: Esta capa es responsable de proporcionar una interfaz al usuario de la aplicación. Esta capa engloba protocolos que interactúan directamente con el usuario.
Presentation Layer: Esta capa define cómo se deben presentar los datos en el formato nativo del host remoto en el formato nativo del host.
Session Layer: Esta capa mantiene sesiones entre hosts remotos. Por ejemplo, una vez que se realiza la autenticación de usuario / contraseña, el host remoto mantiene esta sesión durante un tiempo y no vuelve a solicitar la autenticación en ese lapso de tiempo.
Transport Layer: Esta capa es responsable de la entrega de un extremo a otro entre hosts.
Network Layer: Esta capa es responsable de la asignación de direcciones y el direccionamiento exclusivo de los hosts en una red.
Data Link Layer: Esta capa es responsable de leer y escribir datos desde y hacia la línea. Los errores de enlace se detectan en esta capa.
Physical Layer: Esta capa define el hardware, cableado, potencia de salida, frecuencia de pulso, etc.
Modelo de Internet
Internet utiliza el conjunto de protocolos TCP / IP, también conocido como conjunto de Internet. Esto define el modelo de Internet que contiene una arquitectura de cuatro capas. El modelo OSI es un modelo de comunicación general, pero el modelo de Internet es lo que Internet utiliza para todas sus comunicaciones. Internet es independiente de su arquitectura de red subyacente, al igual que su modelo. Este modelo tiene las siguientes capas:

Application Layer: Esta capa define el protocolo que permite al usuario interactuar con la red, por ejemplo, FTP, HTTP, etc.
Transport Layer: Esta capa define cómo deben fluir los datos entre los hosts. El protocolo principal en esta capa es el Protocolo de control de transmisión (TCP). Esta capa garantiza que los datos entregados entre hosts estén en orden y sea responsable de la entrega de un extremo a otro.
Internet Layer: El Protocolo de Internet (IP) funciona en esta capa. Esta capa facilita el direccionamiento y el reconocimiento del host. Esta capa define el enrutamiento.
Link Layer: Esta capa proporciona un mecanismo para enviar y recibir datos reales. A diferencia de su contraparte del modelo OSI, esta capa es independiente de la arquitectura y el hardware de red subyacentes.
Durante los primeros días de Internet, su uso se limitó a militares y universidades con fines de investigación y desarrollo. Más tarde, cuando todas las redes se fusionaron y formaron Internet, los datos se utilizaron para viajar a través de la red de transporte público. Las personas comunes pueden enviar los datos que pueden ser altamente sensibles, como sus credenciales bancarias, nombre de usuario y contraseñas, documentos personales, detalles de compras en línea o información confidencial. documentos.
Todas las amenazas a la seguridad son intencionales, es decir, ocurren solo si se activan intencionalmente. Las amenazas a la seguridad se pueden dividir en las siguientes categorías:
Interruption
La interrupción es una amenaza a la seguridad en la que se ataca la disponibilidad de recursos. Por ejemplo, un usuario no puede acceder a su servidor web o el servidor web es secuestrado.
Privacy-Breach
En esta amenaza, la privacidad de un usuario se ve comprometida. Alguien, que no es la persona autorizada, está accediendo o interceptando datos enviados o recibidos por el usuario autenticado original.
Integrity
Este tipo de amenaza incluye cualquier alteración o modificación en el contexto original de comunicación. El atacante intercepta y recibe los datos enviados por el remitente y el atacante luego modifica o genera datos falsos y los envía al receptor. El receptor recibe los datos asumiendo que los envía el remitente original.
Authenticity
Esta amenaza ocurre cuando un atacante o un violador de seguridad, se hace pasar por una persona genuina y accede a los recursos o se comunica con otros usuarios genuinos.
Ninguna técnica en el mundo actual puede proporcionar un 100% de seguridad. Pero se pueden tomar medidas para proteger los datos mientras viajan en una red o Internet no segura. La técnica más utilizada es la criptografía.
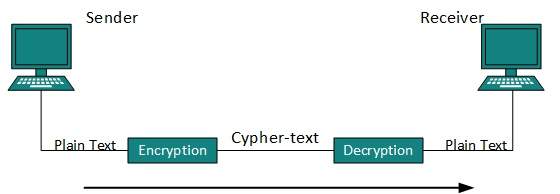
La criptografía es una técnica para cifrar los datos de texto sin formato que dificulta su comprensión e interpretación. Hay varios algoritmos criptográficos disponibles en la actualidad, como se describe a continuación:
Llave secreta
Llave pública
Resumen del mensaje
Cifrado de clave secreta
Tanto el emisor como el receptor tienen una clave secreta. Esta clave secreta se utiliza para cifrar los datos al final del remitente. Una vez que los datos están encriptados, se envían al dominio público al receptor. Debido a que el receptor conoce y tiene la clave secreta, los paquetes de datos cifrados se pueden descifrar fácilmente.
Un ejemplo de cifrado de clave secreta es el estándar de cifrado de datos (DES). En el cifrado de clave secreta, se requiere tener una clave separada para cada host en la red, lo que dificulta su administración.
Cifrado de clave pública
En este sistema de cifrado, cada usuario tiene su propia clave secreta y no está en el dominio compartido. La clave secreta nunca se revela en el dominio público. Junto con la clave secreta, cada usuario tiene su propia clave pública. La clave pública siempre se hace pública y los remitentes la utilizan para cifrar los datos. Cuando el usuario recibe los datos cifrados, puede descifrarlos fácilmente utilizando su propia clave secreta.
Un ejemplo de cifrado de clave pública es Rivest-Shamir-Adleman (RSA).
Resumen del mensaje
En este método, los datos reales no se envían, sino que se calcula y se envía un valor hash. El otro usuario final, calcula su propio valor hash y lo compara con el que acaba de recibir. Si ambos valores hash coinciden, entonces se acepta, de lo contrario, se rechaza.
Ejemplo de resumen de mensajes es el hash MD5. Se utiliza principalmente en la autenticación, donde la contraseña del usuario se verifica con la guardada en el servidor.
La capa física en el modelo OSI juega el papel de interactuar con el hardware real y el mecanismo de señalización. La capa física es la única capa del modelo de red OSI que realmente se ocupa de la conectividad física de dos estaciones diferentes. Esta capa define el equipo de hardware, cableado, cableado, frecuencias, pulsos utilizados para representar señales binarias, etc.
La capa física proporciona sus servicios a la capa de enlace de datos. La capa de enlace de datos transfiere los fotogramas a la capa física. La capa física los convierte en pulsos eléctricos, que representan datos binarios. Los datos binarios se envían a través de medios cableados o inalámbricos.
Señales
Cuando los datos se envían a través de un medio físico, primero deben convertirse en señales electromagnéticas. Los datos en sí pueden ser analógicos, como la voz humana, o digitales, como un archivo en el disco. Tanto los datos analógicos como los digitales se pueden representar en señales digitales o analógicas.
Digital Signals
Las señales digitales son de naturaleza discreta y representan una secuencia de pulsos de voltaje. Las señales digitales se utilizan dentro de los circuitos de un sistema informático.
Analog Signals
Las señales analógicas están en forma de onda continua por naturaleza y están representadas por ondas electromagnéticas continuas.
Deterioro de la transmisión
Cuando las señales viajan a través del medio, tienden a deteriorarse. Esto puede deberse a muchas razones:
Attenuation
Para que el receptor interprete los datos con precisión, la señal debe ser lo suficientemente fuerte; cuando la señal pasa por el medio, tiende a debilitarse; a medida que recorre la distancia, pierde fuerza.
Dispersion
A medida que la señal viaja a través de los medios, tiende a extenderse y superponerse. La cantidad de dispersión depende de la frecuencia utilizada.
Delay distortion
Las señales se envían a través de medios con velocidad y frecuencia predefinidas. Si la velocidad y la frecuencia de la señal no coinciden, hay posibilidades de que la señal llegue al destino de forma arbitraria. En los medios digitales, es muy importante que algunos bits lleguen antes que los enviados anteriormente.
Noise
Se dice que la alteración o fluctuación aleatoria en la señal analógica o digital es ruido en la señal, que puede distorsionar la información real que se transmite. El ruido se puede clasificar en una de las siguientes clases:
Thermal Noise
El calor agita los conductores electrónicos de un medio que puede introducir ruido en el medio. Hasta cierto nivel, el ruido térmico es inevitable.
Intermodulation
Cuando múltiples frecuencias comparten un medio, su interferencia puede causar ruido en el medio. El ruido de intermodulación ocurre si dos frecuencias diferentes comparten un medio y una de ellas tiene una fuerza excesiva o el componente en sí no funciona correctamente, entonces la frecuencia resultante puede no entregarse como se esperaba.
Crosstalk
Este tipo de ruido ocurre cuando una señal extraña ingresa al medio. Esto se debe a que la señal en un medio afecta la señal del segundo medio.
Impulse
Este ruido se introduce debido a perturbaciones irregulares como rayos, electricidad, cortocircuito o componentes defectuosos. Los datos digitales se ven afectados principalmente por este tipo de ruido.
Medios de transmisión
El medio por el cual se envía la información entre dos sistemas informáticos, llamado medio de transmisión. Los medios de transmisión vienen en dos formas.
Guided Media
Todos los alambres / cables de comunicación son medios guiados, como UTP, cables coaxiales y fibra óptica. En este medio, el remitente y el receptor están conectados directamente y la información se envía (guía) a través de él.
Unguided Media
Se dice que los espacios al aire libre o inalámbricos son medios no guiados, porque no hay conectividad entre el remitente y el receptor. La información se difunde por aire y cualquiera, incluido el destinatario real, puede recopilarla.
Capacidad del canal
Se dice que la velocidad de transmisión de información es la capacidad del canal. Lo contamos como tasa de datos en el mundo digital. Depende de numerosos factores como:
Bandwidth: La limitación física de los medios subyacentes.
Error-rate: Recepción incorrecta de información por ruido.
Encoding: El número de niveles utilizados para la señalización.
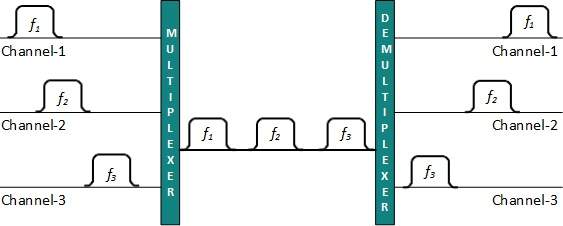
Multiplexación
La multiplexación es una técnica para mezclar y enviar múltiples flujos de datos a través de un solo medio. Esta técnica requiere hardware del sistema llamado multiplexor (MUX) para multiplexar los flujos y enviarlos por un medio, y demultiplexor (DMUX) que toma información del medio y la distribuye a diferentes destinos.
Traspuesta
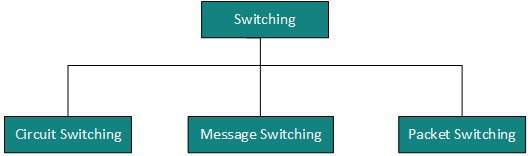
La conmutación es un mecanismo mediante el cual se envían datos / información desde el origen al destino que no están conectados directamente. Las redes tienen dispositivos de interconexión, que reciben datos de fuentes conectadas directamente, almacenan datos, los analizan y luego los reenvía al siguiente dispositivo de interconexión más cercano al destino.
El cambio se puede clasificar como:
Los datos o la información se pueden almacenar de dos formas, analógica y digital. Para que una computadora utilice los datos, debe estar en forma digital discreta. Al igual que los datos, las señales también pueden estar en forma analógica y digital. Para transmitir datos digitalmente, primero debe convertirse a formato digital.
Conversión digital a digital
Esta sección explica cómo convertir datos digitales en señales digitales. Se puede realizar de dos formas, codificación de línea y codificación de bloque. Para todas las comunicaciones, la codificación de línea es necesaria, mientras que la codificación de bloque es opcional.
Codificación de línea
El proceso para convertir datos digitales en señales digitales se denomina codificación de línea. Los datos digitales se encuentran en formato binario y se representan (almacenan) internamente como series de 1 y 0.
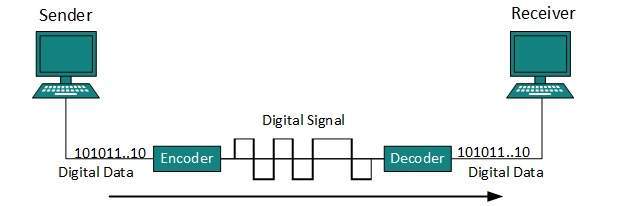
La señal digital se indica mediante una señal discreta, que representa datos digitales. Hay tres tipos de esquemas de codificación de línea disponibles:
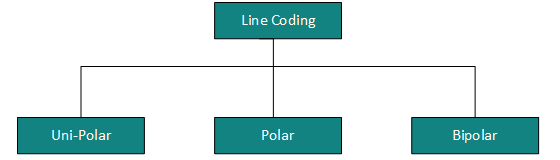
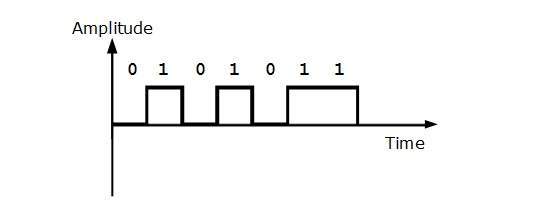
Codificación unipolar
Los esquemas de codificación unipolar utilizan un nivel de voltaje único para representar datos. En este caso, para representar el 1 binario, se transmite alto voltaje y para representar 0, no se transmite voltaje. También se llama unipolar sin retorno a cero, porque no hay una condición de reposo, es decir, representa 1 o 0.
Codificación polar
El esquema de codificación polar utiliza múltiples niveles de voltaje para representar valores binarios. Las codificaciones polares están disponibles en cuatro tipos:
Polar sin retorno a cero (Polar NRZ)
Utiliza dos niveles de voltaje diferentes para representar valores binarios. Generalmente, el voltaje positivo representa 1 y el valor negativo representa 0. También es NRZ porque no hay condición de reposo.
El esquema NRZ tiene dos variantes: NRZ-L y NRZ-I.
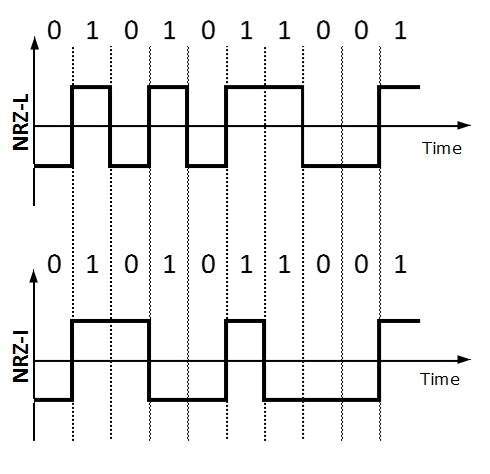
NRZ-L cambia el nivel de voltaje cuando se encuentra un bit diferente, mientras que NRZ-I cambia el voltaje cuando se encuentra un 1.
Volver a cero (RZ)
El problema con NRZ es que el receptor no puede concluir cuando finaliza un bit y cuando se inicia el siguiente bit, en caso de que el reloj del emisor y del receptor no estén sincronizados.
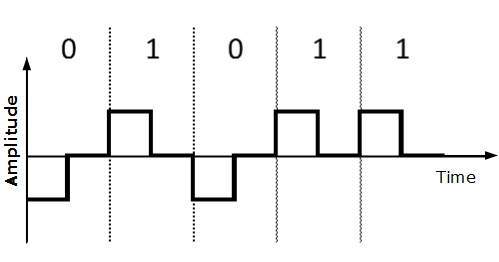
RZ usa tres niveles de voltaje, voltaje positivo para representar 1, voltaje negativo para representar 0 y voltaje cero para ninguno. Las señales cambian durante los bits, no entre bits.
Manchester
Este esquema de codificación es una combinación de RZ y NRZ-L. El tiempo de bits se divide en dos mitades. Transita en el medio del bit y cambia de fase cuando se encuentra con un bit diferente.
Manchester diferencial
Este esquema de codificación es una combinación de RZ y NRZ-I. También transita en el medio del bit, pero cambia de fase solo cuando se encuentra 1.
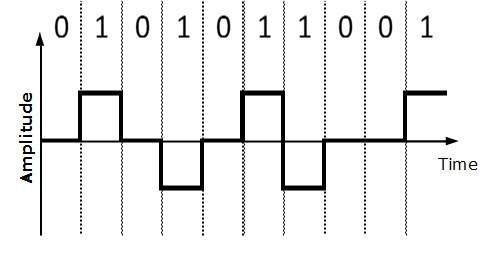
Codificación bipolar
La codificación bipolar utiliza tres niveles de voltaje, positivo, negativo y cero. El voltaje cero representa el 0 binario y el bit 1 se representa alterando los voltajes positivo y negativo.
Codificación de bloques
Para garantizar la precisión de la trama de datos recibida, se utilizan bits redundantes. Por ejemplo, en paridad par, se agrega un bit de paridad para que el recuento de unos en la trama sea par. De esta forma se incrementa el número original de bits. Se llama Codificación de bloques.
La codificación de bloque se representa mediante notación de barra oblicua, mB / nB, lo que significa que el bloque de m bits se sustituye por un bloque de n bits donde n> m. La codificación de bloques implica tres pasos:
- Division,
- Substitution
- Combination.
Una vez realizada la codificación de bloques, se codifica en línea para su transmisión.
Conversión de analógico a digital
Los micrófonos crean voz analógica y la cámara crea videos analógicos, que se tratan como datos analógicos. Para transmitir estos datos analógicos a través de señales digitales, necesitamos conversión de analógico a digital.
Los datos analógicos son un flujo continuo de datos en forma de onda, mientras que los datos digitales son discretos. Para convertir ondas analógicas en datos digitales, utilizamos Modulación de código de pulso (PCM).
PCM es uno de los métodos más utilizados para convertir datos analógicos en formato digital. Consiste en tres pasos:
- Sampling
- Quantization
- Encoding.
Muestreo
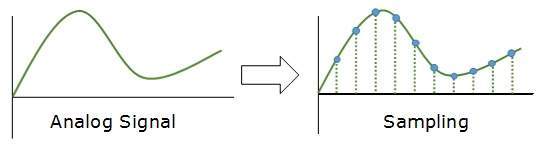
La señal analógica se muestrea cada intervalo T. El factor más importante en el muestreo es la velocidad a la que se muestrea la señal analógica. Según el Teorema de Nyquist, la frecuencia de muestreo debe ser al menos dos veces la frecuencia más alta de la señal.
Cuantificación
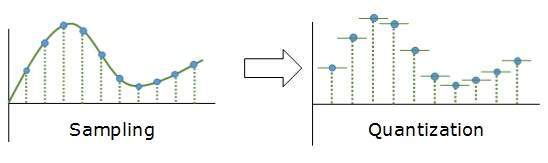
El muestreo produce una forma discreta de señal analógica continua. Cada patrón discreto muestra la amplitud de la señal analógica en ese caso. La cuantificación se realiza entre el valor de amplitud máxima y el valor de amplitud mínima. La cuantificación es una aproximación del valor analógico instantáneo.
Codificación
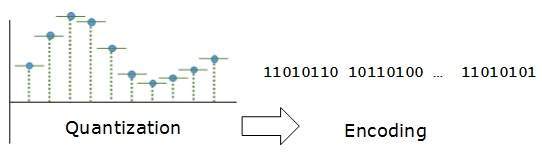
En la codificación, cada valor aproximado se convierte luego a formato binario.
Modos de transmisión
El modo de transmisión decide cómo se transmiten los datos entre dos computadoras. Los datos binarios en forma de 1 y 0 se pueden enviar en dos modos diferentes: Paralelo y Serie.
Transmisión paralela
Los bits binarios se organizan en grupos de longitud fija. Tanto el emisor como el receptor están conectados en paralelo con el mismo número de líneas de datos. Ambas computadoras distinguen entre líneas de datos de orden superior y de orden inferior. El remitente envía todos los bits a la vez en todas las líneas. Debido a que las líneas de datos son iguales al número de bits en un grupo o trama de datos, se envía un grupo completo de bits (trama de datos) de una vez. La ventaja de la transmisión en paralelo es la alta velocidad y la desventaja es el costo de los cables, ya que es igual al número de bits enviados en paralelo.
Transmisión serial
En la transmisión en serie, los bits se envían uno tras otro en forma de cola. La transmisión en serie requiere solo un canal de comunicación.
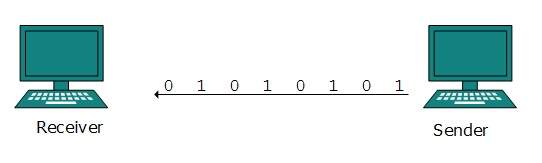
La transmisión en serie puede ser asíncrona o síncrona.
Transmisión en serie asíncrona
Se llama así porque no hay importancia de la sincronización. Los bits de datos tienen un patrón específico y ayudan al receptor a reconocer los bits de datos iniciales y finales. Por ejemplo, se antepone un 0 en cada byte de datos y se agregan uno o más unos al final.
Dos tramas de datos continuas (bytes) pueden tener un espacio entre ellas.
Transmisión en serie sincrónica
La sincronización en la transmisión síncrona tiene importancia, ya que no se sigue ningún mecanismo para reconocer los bits de datos de inicio y fin. No hay patrón o método de prefijo / sufijo. Los bits de datos se envían en modo ráfaga sin mantener un espacio entre bytes (8 bits). Una sola ráfaga de bits de datos puede contener varios bytes. Por lo tanto, la sincronización se vuelve muy importante.
Depende del receptor reconocer y separar los bits en bytes. La ventaja de la transmisión síncrona es la alta velocidad y no tiene una sobrecarga de bits adicionales de encabezado y pie de página como en la transmisión asíncrona.
Para enviar los datos digitales a través de un medio analógico, es necesario convertirlos en una señal analógica. Puede haber dos casos según el formato de los datos.
Bandpass:Los filtros se utilizan para filtrar y pasar frecuencias de interés. Un paso de banda es una banda de frecuencias que puede pasar el filtro.
Low-pass: El paso bajo es un filtro que pasa señales de baja frecuencia.
Cuando los datos digitales se convierten en una señal analógica de paso de banda, se denomina conversión de digital a analógico. Cuando la señal analógica de paso bajo se convierte en una señal analógica de paso de banda, se denomina conversión de analógico a analógico.
Conversión de digital a analógico
Cuando los datos de una computadora se envían a otra a través de alguna portadora analógica, primero se convierten en señales analógicas. Las señales analógicas se modifican para reflejar datos digitales.
Una señal analógica se caracteriza por su amplitud, frecuencia y fase. Hay tres tipos de conversiones de digital a analógico:
Amplitude Shift Keying
En esta técnica de conversión, la amplitud de la señal portadora analógica se modifica para reflejar datos binarios.
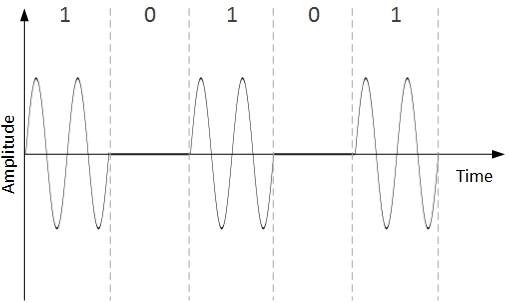
Cuando los datos binarios representan el dígito 1, se mantiene la amplitud; de lo contrario, se establece en 0. Tanto la frecuencia como la fase siguen siendo las mismas que en la señal portadora original.
Frequency Shift Keying
En esta técnica de conversión, la frecuencia de la señal portadora analógica se modifica para reflejar datos binarios.
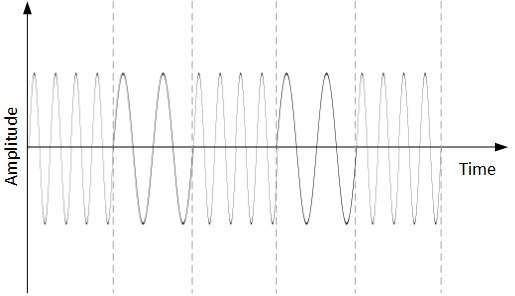
Esta técnica utiliza dos frecuencias, f1 y f2. Uno de ellos, por ejemplo f1, se elige para representar el dígito binario 1 y el otro se usa para representar el dígito binario 0. Tanto la amplitud como la fase de la onda portadora se mantienen intactas.
Phase Shift Keying
En este esquema de conversión, la fase de la señal portadora original se modifica para reflejar los datos binarios.
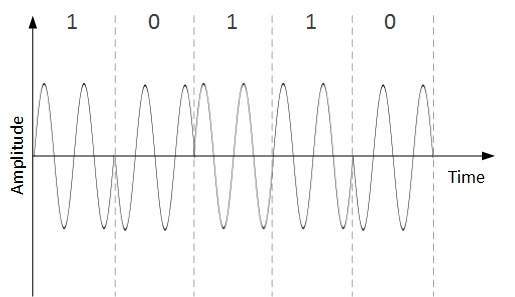
Cuando se encuentra un nuevo símbolo binario, se altera la fase de la señal. La amplitud y frecuencia de la señal portadora original se mantienen intactas.
Quadrature Phase Shift Keying
QPSK altera la fase para reflejar dos dígitos binarios a la vez. Esto se realiza en dos fases diferentes. El flujo principal de datos binarios se divide igualmente en dos subflujos. Los datos en serie se convierten en paralelo en ambos subflujos y luego cada flujo se convierte en señal digital utilizando la técnica NRZ. Posteriormente, ambas señales digitales se fusionan.
Conversión analógica a analógica
Las señales analógicas se modifican para representar datos analógicos. Esta conversión también se conoce como modulación analógica. Se requiere modulación analógica cuando se usa el paso de banda. La conversión de analógico a analógico se puede realizar de tres formas:

Amplitude Modulation
En esta modulación, la amplitud de la señal portadora se modifica para reflejar los datos analógicos.
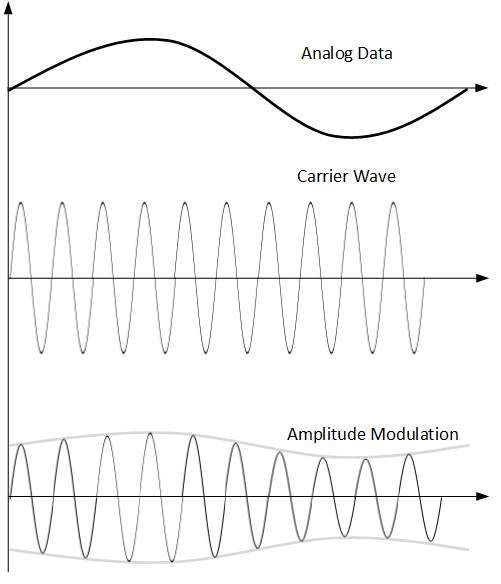
La modulación de amplitud se implementa mediante un multiplicador. La amplitud de la señal de modulación (datos analógicos) se multiplica por la amplitud de la frecuencia portadora, que luego refleja los datos analógicos.
La frecuencia y la fase de la señal portadora permanecen sin cambios.
Frequency Modulation
En esta técnica de modulación, la frecuencia de la señal portadora se modifica para reflejar el cambio en los niveles de voltaje de la señal moduladora (datos analógicos).
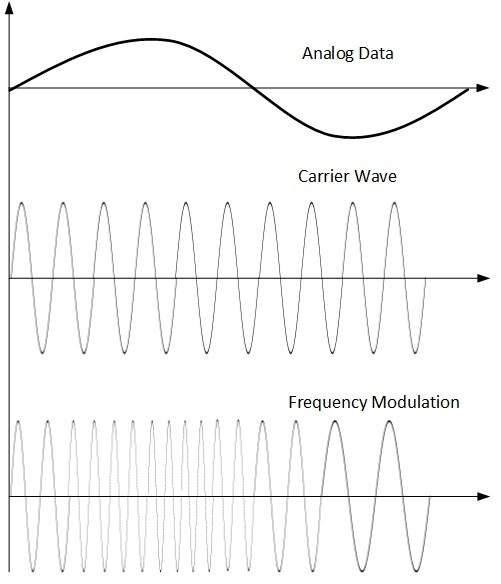
La amplitud y la fase de la señal portadora no se alteran.
Phase Modulation
En la técnica de modulación, la fase de la señal portadora se modula para reflejar el cambio de voltaje (amplitud) de la señal de datos analógicos.
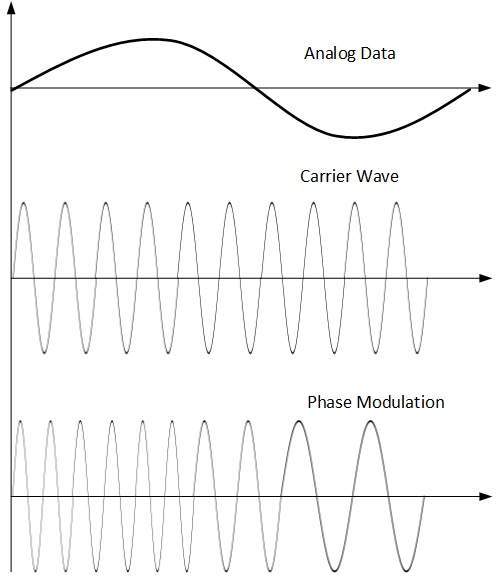
La modulación de fase es prácticamente similar a la modulación de frecuencia, pero en la modulación de fase la frecuencia de la señal portadora no aumenta. La frecuencia de la portadora se cambia (se hace densa y escasa) para reflejar el cambio de voltaje en la amplitud de la señal moduladora.
Los medios de transmisión no son más que los medios físicos a través de los cuales tiene lugar la comunicación en las redes informáticas.
Medios magnéticos
Una de las formas más convenientes de transferir datos de una computadora a otra, incluso antes del nacimiento de la red, era guardarlos en algún medio de almacenamiento y transferir datos físicos de una estación a otra. Aunque puede parecer anticuado en el mundo actual de Internet de alta velocidad, cuando el tamaño de los datos es enorme, entran en juego los medios magnéticos.
Por ejemplo, un banco tiene que manejar y transferir grandes datos de su cliente, que almacenan una copia de seguridad en algún lugar geográficamente lejano por razones de seguridad y para evitar calamidades inciertas. Si el banco necesita almacenar sus enormes datos de respaldo, entonces su transferencia a través de Internet no es factible. Es posible que los enlaces WAN no admitan una velocidad tan alta. Incluso si lo hacen; el costo es demasiado alto para pagarlo.
En estos casos, la copia de seguridad de los datos se almacena en cintas magnéticas o discos magnéticos y luego se traslada físicamente a lugares remotos.
Cable de par trenzado
Un cable de par trenzado está hecho de dos alambres de cobre aislados con plástico trenzados entre sí para formar un solo medio. De estos dos cables, solo uno transporta la señal real y el otro se usa como referencia a tierra. Los giros entre los cables son útiles para reducir el ruido (interferencia electromagnética) y la diafonía.

Hay dos tipos de cables de par trenzado:
Cable de par trenzado blindado (STP)
Cable de par trenzado sin blindaje (UTP)
Los cables STP vienen con un par de cables trenzados cubiertos con una lámina de metal. Esto lo hace más indiferente al ruido y la diafonía.
UTP tiene siete categorías, cada una adecuada para un uso específico. En las redes informáticas, se utilizan principalmente cables Cat-5, Cat-5e y Cat-6. Los cables UTP se conectan mediante conectores RJ45.
Cable coaxial
El cable coaxial tiene dos hilos de cobre. El alambre del núcleo se encuentra en el centro y está hecho de un conductor macizo, el núcleo está encerrado en una funda aislante, el segundo alambre se envuelve alrededor de la funda y, a su vez, está recubierto por una funda aislante, todo esto cubierto por una cubierta de plástico .

Debido a su estructura, el cable coaxial es capaz de transportar señales de alta frecuencia que el cable de par trenzado. La estructura envuelta le proporciona un buen blindaje contra el ruido y la diafonía. Los cables coaxiales proporcionan altas velocidades de ancho de banda de hasta 450 mbps.
Hay tres categorías de cables coaxiales, a saber, RG-59 (TV por cable), RG-58 (Thin Ethernet) y RG-11 (Thick Ethernet). RG son las siglas de Radio Government.
Los cables se conectan mediante un conector BNC y BNC-T. El terminador BNC se utiliza para terminar el cable en los extremos.
Líneas eléctricas
La comunicación por línea de alimentación (PLC) es una tecnología de capa 1 (capa física) que utiliza cables de alimentación para transmitir señales de datos. En el PLC, los datos modulados se envían a través de los cables. El receptor del otro extremo desmodula e interpreta los datos.
Debido a que las líneas eléctricas se implementan ampliamente, el PLC puede controlar y monitorear todos los dispositivos alimentados. El PLC funciona en semidúplex.
Hay dos tipos de PLC:
PLC de banda estrecha
PLC de banda ancha
El PLC de banda estrecha proporciona velocidades de datos más bajas de hasta 100 kbps, ya que funcionan a frecuencias más bajas (3-5000 kHz) y pueden extenderse a lo largo de varios kilómetros.
El PLC de banda ancha proporciona velocidades de datos más altas de hasta 100 Mbps y funciona a frecuencias más altas (1.8 - 250 MHz). No se pueden extender tanto como el PLC de banda estrecha.
Fibra óptica
La fibra óptica actúa sobre las propiedades de la luz. Cuando el rayo de luz incide en un ángulo crítico, tiende a refractarse a 90 grados. Esta propiedad se ha utilizado en fibra óptica. El núcleo del cable de fibra óptica está hecho de vidrio o plástico de alta calidad. Desde un extremo se emite luz, viaja a través de él y en el otro extremo el detector de luz detecta el flujo de luz y lo convierte en datos eléctricos.
La fibra óptica proporciona el modo de velocidad más alto. Viene en dos modos, uno es fibra monomodo y el segundo es fibra multimodo. La fibra monomodo puede transportar un solo rayo de luz, mientras que el multimodo es capaz de transportar múltiples haces de luz.

La fibra óptica también viene en capacidades unidireccionales y bidireccionales. Para conectar y acceder a la fibra óptica se utilizan conectores de tipo especial. Estos pueden ser canal de abonado (SC), punta recta (ST) o MT-RJ.
La transmisión inalámbrica es una forma de medios no guiados. La comunicación inalámbrica no implica ningún enlace físico establecido entre dos o más dispositivos que se comuniquen de forma inalámbrica. Las señales inalámbricas se esparcen por el aire y son recibidas e interpretadas por antenas apropiadas.
Cuando se conecta una antena al circuito eléctrico de una computadora o dispositivo inalámbrico, convierte los datos digitales en señales inalámbricas y se distribuye por todas partes dentro de su rango de frecuencia. El receptor del otro extremo recibe estas señales y las convierte de nuevo en datos digitales.
Una pequeña parte del espectro electromagnético se puede utilizar para la transmisión inalámbrica.

Transmision de radio
La radiofrecuencia es más fácil de generar y, debido a su gran longitud de onda, puede penetrar a través de paredes y estructuras por igual. Las ondas de radio pueden tener una longitud de onda de 1 mm a 100.000 km y una frecuencia que va desde 3 Hz (frecuencia extremadamente baja) a 300 GHz (extremadamente alta). Frecuencia). Las frecuencias de radio se subdividen en seis bandas.
Las ondas de radio a frecuencias más bajas pueden viajar a través de las paredes, mientras que las RF más altas pueden viajar en línea recta y rebotar. La potencia de las ondas de baja frecuencia disminuye drásticamente a medida que cubren largas distancias. Las ondas de radio de alta frecuencia tienen más potencia.
Las frecuencias más bajas, como las bandas VLF, LF, MF, pueden viajar por el suelo hasta 1000 kilómetros, sobre la superficie terrestre.
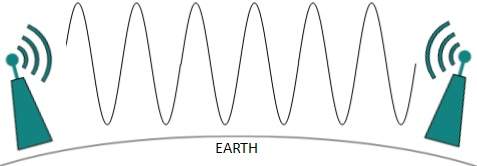
Las ondas de radio de alta frecuencia son propensas a ser absorbidas por la lluvia y otros obstáculos. Usan la ionosfera de la atmósfera terrestre. Las ondas de radio de alta frecuencia, como las bandas de HF y VHF, se propagan hacia arriba. Cuando llegan a la ionosfera, se refractan de nuevo a la tierra.
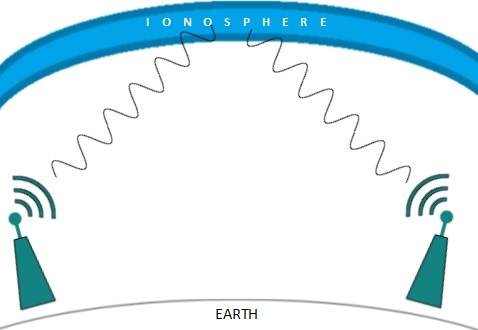
Transmisión por microondas
Las ondas electromagnéticas por encima de 100 MHz tienden a viajar en línea recta y las señales sobre ellas se pueden enviar transmitiendo esas ondas hacia una estación en particular. Debido a que las microondas viajan en línea recta, tanto el emisor como el receptor deben estar alineados para estar estrictamente en la línea de visión.
Las microondas pueden tener una longitud de onda de 1 mm a 1 metro y una frecuencia de 300 MHz a 300 GHz.
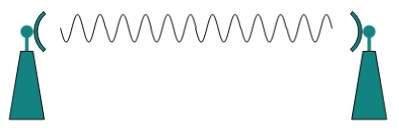
Las antenas de microondas concentran las ondas formando un haz de ellas. Como se muestra en la imagen de arriba, se pueden alinear múltiples antenas para llegar más lejos. Las microondas tienen frecuencias más altas y no atraviesan la pared como obstáculos.
La transmisión de microondas depende en gran medida de las condiciones climáticas y de la frecuencia que utiliza.
Transmisión infrarroja
La onda infrarroja se encuentra entre el espectro de luz visible y las microondas. Tiene una longitud de onda de 700 nm a 1 mm y rangos de frecuencia de 300 GHz a 430 THz.
La onda infrarroja se utiliza para fines de comunicación de muy corto alcance, como la televisión y su control remoto. El infrarrojo viaja en línea recta, por lo que es direccional por naturaleza. Debido al rango de alta frecuencia, los infrarrojos no pueden atravesar obstáculos parecidos a paredes.
Transmision de luz
El espectro electromagnético más alto que se puede utilizar para la transmisión de datos es la señalización óptica o luminosa. Esto se logra mediante LASER.
Debido a los usos de la luz de frecuencia, tiende a viajar estrictamente en línea recta, por lo que el emisor y el receptor deben estar en la línea de visión. Debido a que la transmisión láser es unidireccional, en ambos extremos de la comunicación es necesario instalar el láser y el fotodetector. El rayo láser generalmente tiene 1 mm de ancho, por lo que es un trabajo de precisión alinear dos receptores lejanos, cada uno apuntando a la fuente del láser.
El láser funciona como Tx (transmisor) y los fotodetectores funcionan como Rx (receptor).
Los láseres no pueden atravesar obstáculos como paredes, lluvia y niebla espesa. Además, el rayo láser se distorsiona por el viento, la temperatura de la atmósfera o la variación de temperatura en el camino.
El láser es seguro para la transmisión de datos, ya que es muy difícil tocar un láser de 1 mm de ancho sin interrumpir el canal de comunicación.
La multiplexación es una técnica mediante la cual se pueden procesar simultáneamente diferentes flujos de transmisión analógicos y digitales a través de un enlace compartido. La multiplexación divide el medio de alta capacidad en un medio lógico de baja capacidad que luego es compartido por diferentes flujos.
La comunicación es posible por aire (radiofrecuencia), utilizando un medio físico (cable) y luz (fibra óptica). Todos los medios son capaces de multiplexar.
Cuando varios remitentes intentan enviar a través de un solo medio, un dispositivo llamado Multiplexor divide el canal físico y asigna uno a cada uno. En el otro extremo de la comunicación, un demultiplexor recibe datos de un solo medio, identifica cada uno y envía a diferentes receptores.
Multiplexación por división de frecuencia
Cuando la portadora es frecuencia, se usa FDM. FDM es una tecnología analógica. FDM divide el espectro o el ancho de banda de la portadora en canales lógicos y asigna un usuario a cada canal. Cada usuario puede utilizar la frecuencia del canal de forma independiente y tiene acceso exclusivo al mismo. Todos los canales están divididos de tal manera que no se superpongan entre sí. Los canales están separados por bandas de guarda. La banda de guarda es una frecuencia que no utiliza ninguno de los canales.
Multiplexación por división de tiempo
TDM se aplica principalmente a señales digitales, pero también se puede aplicar a señales analógicas. En TDM, el canal compartido se divide entre sus usuarios por medio de un intervalo de tiempo. Cada usuario puede transmitir datos solo dentro del intervalo de tiempo proporcionado. Las señales digitales se dividen en cuadros, lo que equivale a un intervalo de tiempo, es decir, un cuadro de un tamaño óptimo que se puede transmitir en un intervalo de tiempo determinado.
TDM funciona en modo sincronizado. Ambos extremos, es decir, multiplexor y demultiplexor, se sincronizan oportunamente y ambos cambian al siguiente canal simultáneamente.
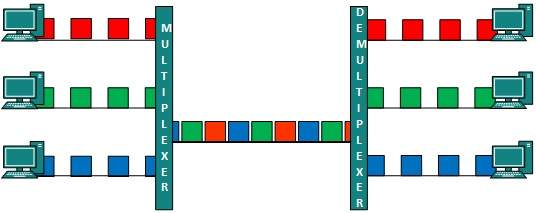
Cuando el canal A transmite su trama en un extremo, el demultiplexor proporciona medios al canal A en el otro extremo. Tan pronto como expira el intervalo de tiempo del canal A, este lado cambia al canal B. En el otro extremo, el demultiplexor funciona de manera sincronizada y proporciona medios al canal B. Las señales de diferentes canales viajan por la ruta de manera intercalada.
Multiplexación por División de Longitud de Onda
La luz tiene diferentes longitudes de onda (colores). En el modo de fibra óptica, múltiples señales portadoras ópticas se multiplexan en una fibra óptica utilizando diferentes longitudes de onda. Esta es una técnica de multiplexación analógica y se realiza conceptualmente de la misma manera que FDM pero utiliza luz como señales.

Además, en cada longitud de onda se puede incorporar multiplexación por división de tiempo para acomodar más señales de datos.
Multiplexación por división de código
Se pueden transmitir múltiples señales de datos en una sola frecuencia mediante el uso de multiplexación por división de código. FDM divide la frecuencia en canales más pequeños, pero CDM permite a sus usuarios utilizar un ancho de banda completo y transmitir señales todo el tiempo utilizando un código único. CDM utiliza códigos ortogonales para difundir señales.
A cada estación se le asigna un código único, llamado chip. Las señales viajan con estos códigos de forma independiente, dentro de todo el ancho de banda. El receptor conoce de antemano la señal del código de chip que tiene que recibir.
La conmutación es un proceso para reenviar paquetes que vienen de un puerto a un puerto que conduce hacia el destino. Cuando los datos llegan a un puerto se llama entrada, y cuando los datos salen de un puerto o salen, se llama salida. Un sistema de comunicación puede incluir varios conmutadores y nodos. En general, el cambio se puede dividir en dos categorías principales:
Connectionless: Los datos se reenvían en nombre de las tablas de reenvío. No se requiere un apretón de manos previo y los reconocimientos son opcionales.
Connection Oriented: Antes de cambiar los datos para que se reenvíen al destino, es necesario preestablecer un circuito a lo largo de la ruta entre ambos puntos finales. Luego, los datos se envían por ese circuito. Una vez completada la transferencia, los circuitos se pueden conservar para uso futuro o se pueden apagar de inmediato.
Cambio de circuito
Cuando dos nodos se comunican entre sí a través de una ruta de comunicación dedicada, se denomina conmutación de circuitos. Existe la necesidad de una ruta preespecificada desde la cual viajarán los datos y no se permiten otros datos. En la conmutación de circuitos, para transferir los datos, Se debe establecer un circuito para que pueda tener lugar la transferencia de datos.
Los circuitos pueden ser permanentes o temporales. Las aplicaciones que utilizan conmutación de circuitos pueden tener que pasar por tres fases:
Establecer un circuito
Transferir los datos
Desconecta el circuito

La conmutación de circuitos se diseñó para aplicaciones de voz. El teléfono es el mejor ejemplo adecuado de conmutación de circuitos. Antes de que un usuario pueda realizar una llamada, se establece una ruta virtual entre la persona que llama y la persona que llama a través de la red.
Conmutación de mensajes
Esta técnica estaba en algún lugar en medio de la conmutación de circuitos y la conmutación de paquetes. En la conmutación de mensajes, todo el mensaje se trata como una unidad de datos y se conmuta / transfiere en su totalidad.
Un conmutador que trabaja en la conmutación de mensajes, primero recibe el mensaje completo y lo almacena en búfer hasta que haya recursos disponibles para transferirlo al siguiente salto. Si el siguiente salto no tiene suficientes recursos para acomodar un mensaje de gran tamaño, el mensaje se almacena y el interruptor espera.

Esta técnica se consideró un sustituto de la conmutación de circuitos. Al igual que en la conmutación de circuitos, todo el camino está bloqueado solo para dos entidades. La conmutación de mensajes se reemplaza por la conmutación de paquetes. La conmutación de mensajes tiene los siguientes inconvenientes:
Cada conmutador en la ruta de tránsito necesita suficiente almacenamiento para acomodar todo el mensaje.
Debido a la técnica de almacenamiento y reenvío y las esperas incluidas hasta que los recursos estén disponibles, la conmutación de mensajes es muy lenta.
La conmutación de mensajes no era una solución para la transmisión de medios y aplicaciones en tiempo real.
Conmutación de paquetes
Las deficiencias de la conmutación de mensajes dieron origen a la idea de la conmutación de paquetes. El mensaje completo se divide en trozos más pequeños llamados paquetes. La información de conmutación se agrega en el encabezado de cada paquete y se transmite de forma independiente.
Es más fácil para los dispositivos de red intermedios almacenar paquetes de tamaño pequeño y no consumen muchos recursos ni en la ruta del operador ni en la memoria interna de los conmutadores.

La conmutación de paquetes mejora la eficiencia de la línea ya que los paquetes de múltiples aplicaciones se pueden multiplexar a través de la portadora. Internet utiliza la técnica de conmutación de paquetes. La conmutación de paquetes permite al usuario diferenciar los flujos de datos según las prioridades. Los paquetes se almacenan y reenvían de acuerdo con su prioridad para brindar calidad de servicio.
La capa de enlace de datos es la segunda capa del modelo en capas OSI. Esta capa es una de las más complicadas y tiene funcionalidades y responsabilidades complejas. La capa de enlace de datos oculta los detalles del hardware subyacente y se representa a sí misma en la capa superior como el medio para comunicarse.
La capa de enlace de datos funciona entre dos hosts que están conectados directamente en algún sentido. Esta conexión directa podría ser punto a punto o retransmitida. Se dice que los sistemas de la red de transmisión están en el mismo enlace. El trabajo de la capa de enlace de datos tiende a volverse más complejo cuando se trata de varios hosts en un solo dominio de colisión.
La capa de enlace de datos es responsable de convertir el flujo de datos en señales bit a bit y enviarlo a través del hardware subyacente. En el extremo de recepción, la capa de enlace de datos recoge datos del hardware que están en forma de señales eléctricas, los ensambla en un formato de trama reconocible y los entrega a la capa superior.
La capa de enlace de datos tiene dos subcapas:
Logical Link Control: Se ocupa de protocolos, control de flujo y control de errores.
Media Access Control: Se trata del control real de los medios
Funcionalidad de la capa de enlace de datos
La capa de enlace de datos realiza muchas tareas en nombre de la capa superior. Estos son:
Framing
La capa de enlace de datos toma paquetes de la capa de red y los encapsula en tramas, luego envía cada trama bit a bit en el hardware. En el extremo del receptor, la capa de enlace de datos capta señales del hardware y las ensambla en tramas.
Addressing
La capa de enlace de datos proporciona un mecanismo de direccionamiento de hardware de capa 2. Se supone que la dirección de hardware es única en el enlace. Está codificado en hardware en el momento de la fabricación.
Synchronization
Cuando se envían tramas de datos en el enlace, ambas máquinas deben sincronizarse para que la transferencia tenga lugar.
Error Control
A veces, las señales pueden haber encontrado problemas en la transición y los bits se invierten. Estos errores se detectan e intentan recuperar bits de datos reales. También proporciona un mecanismo de notificación de errores al remitente.
Flow Control
Las estaciones en el mismo enlace pueden tener diferente velocidad o capacidad. La capa de enlace de datos garantiza un control de flujo que permite que ambas máquinas intercambien datos a la misma velocidad.
Multi-Access
Cuando el host en el enlace compartido intenta transferir los datos, tiene una alta probabilidad de colisión. La capa de enlace de datos proporciona un mecanismo como CSMA / CD para equipar la capacidad de acceder a un medio compartido entre múltiples sistemas.
Hay muchas razones, como ruido, diafonía, etc., que pueden ayudar a que los datos se corrompan durante la transmisión. Las capas superiores funcionan con una visión generalizada de la arquitectura de red y no son conscientes del procesamiento de datos de hardware real, por lo que las capas superiores esperan una transmisión sin errores entre los sistemas. La mayoría de las aplicaciones no funcionarían como es de esperar si reciben datos erróneos. Es posible que las aplicaciones como voz y video no se vean tan afectadas y, con algunos errores, es posible que aún funcionen bien.
La capa de enlace de datos utiliza algún mecanismo de control de errores para garantizar que las tramas (flujos de bits de datos) se transmitan con cierto nivel de precisión. Pero para comprender cómo se controlan los errores, es fundamental saber qué tipos de errores pueden ocurrir.
Tipos de errores
Puede haber tres tipos de errores:
Single bit error

En un marco, solo hay un bit, en cualquier lugar, que está dañado.
Multiple bits error

La trama se recibe con más de un bit en estado corrupto.
Burst error

La trama contiene más de 1 bits consecutivos dañados.
El mecanismo de control de errores puede implicar dos formas posibles:
Detección de errores
Error de corrección
Detección de errores
Los errores en las tramas recibidas se detectan mediante Parity Check y Cyclic Redundancy Check (CRC). En ambos casos, se envían pocos bits adicionales junto con los datos reales para confirmar que los bits recibidos en el otro extremo son los mismos que se enviaron. Si la contracomprobación en el extremo del receptor falla, los bits se consideran corruptos.
Comprobación de paridad
Se envía un bit adicional junto con los bits originales para hacer que el número de unos sea par en caso de paridad par, o impar en caso de paridad impar.
El remitente mientras crea un marco cuenta el número de unos en él. Por ejemplo, si se usa paridad par y el número de unos es par, se agrega un bit con valor 0. De esta forma el número de unos permanece par. Si el número de unos es impar, para hacerlo par se suma un bit con el valor 1.

El receptor simplemente cuenta el número de unos en una trama. Si el recuento de unos es par y se usa paridad par, se considera que la trama no está dañada y se acepta. Si el recuento de unos es impar y se utiliza una paridad impar, la trama aún no está dañada.
Si un solo bit cambia en tránsito, el receptor puede detectarlo contando el número de unos. Pero cuando más de un bit es erróneo, es muy difícil para el receptor detectar el error.
Verificación de redundancia cíclica (CRC)
CRC es un enfoque diferente para detectar si la trama recibida contiene datos válidos. Esta técnica implica la división binaria de los bits de datos que se envían. El divisor se genera mediante polinomios. El remitente realiza una operación de división en los bits que se envían y calcula el resto. Antes de enviar los bits reales, el remitente agrega el resto al final de los bits reales. Los bits de datos reales más el resto se denominan palabra de código. El remitente transmite bits de datos como palabras de código.

En el otro extremo, el receptor realiza una operación de división en palabras de código utilizando el mismo divisor CRC. Si el resto contiene todos ceros, se aceptan los bits de datos; de lo contrario, se considera que se produjo algún daño en los datos en tránsito.
Error de corrección
En el mundo digital, la corrección de errores se puede realizar de dos formas:
Backward Error Correction Cuando el receptor detecta un error en los datos recibidos, solicita al remitente que retransmita la unidad de datos.
Forward Error Correction Cuando el receptor detecta algún error en los datos recibidos, ejecuta un código de corrección de errores, lo que le ayuda a recuperarse automáticamente y a corregir algunos tipos de errores.
El primero, Corrección de errores hacia atrás, es simple y solo se puede usar de manera eficiente cuando la retransmisión no es costosa. Por ejemplo, fibra óptica. Pero en el caso de una transmisión inalámbrica, la retransmisión puede costar demasiado. En el último caso, se utiliza la corrección de errores hacia adelante.
Para corregir el error en la trama de datos, el receptor debe saber exactamente qué bit de la trama está dañado. Para localizar el bit con error, los bits redundantes se utilizan como bits de paridad para la detección de errores.Por ejemplo, tomamos palabras ASCII (datos de 7 bits), luego podría haber 8 tipos de información que necesitamos: los primeros siete bits para decirnos qué bit es error y un bit más para indicar que no hay error.
Para m bits de datos, se utilizan r bits redundantes. r bits pueden proporcionar 2r combinaciones de información. En la palabra de código de m + r bits, existe la posibilidad de que los propios r bits se corrompan. Por lo tanto, el número de r bits utilizados debe informar sobre m + r ubicaciones de bits más información sin errores, es decir, m + r + 1.

La capa de enlace de datos es responsable de la implementación del flujo punto a punto y del mecanismo de control de errores.
Control de flujo
Cuando se envía una trama de datos (datos de capa 2) de un host a otro a través de un solo medio, se requiere que el remitente y el receptor trabajen a la misma velocidad. Es decir, el remitente envía a una velocidad en la que el receptor puede procesar y aceptar los datos. ¿Qué pasa si la velocidad (hardware / software) del remitente o del receptor es diferente? Si el remitente envía demasiado rápido, el receptor puede estar sobrecargado (inundado) y se pueden perder los datos.
Se pueden implementar dos tipos de mecanismos para controlar el flujo:
Stop and WaitEste mecanismo de control de flujo obliga al remitente después de transmitir una trama de datos a detenerse y esperar hasta que se reciba la confirmación de la trama de datos enviada.
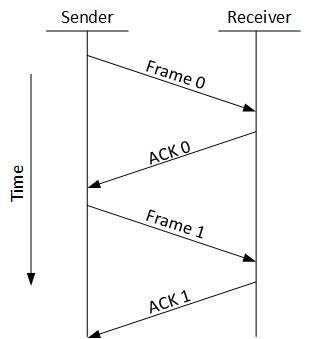
Sliding Window
En este mecanismo de control de flujo, tanto el emisor como el receptor acuerdan el número de tramas de datos después de las cuales se debe enviar el acuse de recibo. Como aprendimos, el mecanismo de control de flujo de detener y esperar desperdicia recursos, este protocolo intenta hacer uso de los recursos subyacentes tanto como sea posible.
Control de errores
Cuando se transmite una trama de datos, existe la probabilidad de que la trama de datos se pierda en el tránsito o se reciba corrupta. En ambos casos, el receptor no recibe la trama de datos correcta y el remitente no sabe nada sobre ninguna pérdida, en tal caso, tanto el emisor como el receptor están equipados con algunos protocolos que les ayudan a detectar errores de tránsito como la pérdida de datos. marco. Por tanto, el remitente retransmite la trama de datos o el receptor puede solicitar reenviar la trama de datos anterior.
Requisitos para el mecanismo de control de errores:
Error detection - El remitente y el receptor, ambos o alguno, deben cerciorarse de que existe algún error en el tránsito.
Positive ACK - Cuando el receptor recibe una trama correcta, debe reconocerla.
Negative ACK - Cuando el receptor recibe una trama dañada o una trama duplicada, envía un NACK al remitente y el remitente debe retransmitir la trama correcta.
Retransmission: El remitente mantiene un reloj y establece un período de tiempo de espera. Si un acuse de recibo de una trama de datos transmitida previamente no llega antes del tiempo de espera, el remitente retransmite la trama, pensando que la trama o su acuse de recibo se ha perdido en tránsito.
Hay tres tipos de técnicas disponibles que la capa de enlace de datos puede implementar para controlar los errores mediante solicitudes de repetición automática (ARQ):
ARQ de parar y esperar

La siguiente transición puede ocurrir en ARQ Stop-and-Wait:
- El remitente mantiene un contador de tiempo de espera.
- Cuando se envía una trama, el remitente inicia el contador de tiempo de espera.
- Si el reconocimiento de la trama llega a tiempo, el remitente transmite la siguiente trama en la cola.
- Si el acuse de recibo no llega a tiempo, el remitente asume que la trama o su acuse de recibo se han perdido en tránsito. El remitente retransmite la trama e inicia el contador de tiempo de espera.
- Si se recibe un acuse de recibo negativo, el remitente retransmite la trama.
Go-Back-N ARQ
Detener y esperar El mecanismo ARQ no utiliza los recursos al máximo. Cuando se recibe el reconocimiento, el remitente permanece inactivo y no hace nada. En el método ARQ Go-Back-N, tanto el emisor como el receptor mantienen una ventana.
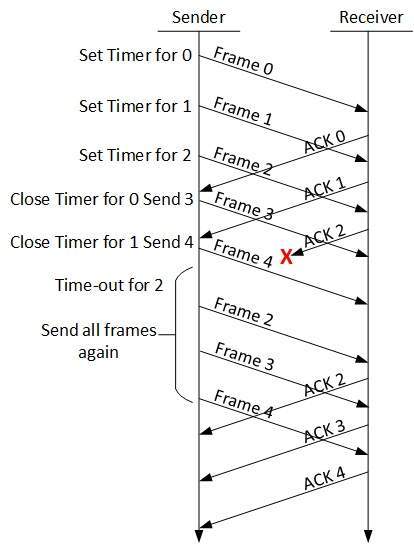
El tamaño de la ventana de envío permite al remitente enviar múltiples tramas sin recibir el reconocimiento de las anteriores. La ventana de recepción permite al receptor recibir múltiples tramas y reconocerlas. El receptor realiza un seguimiento del número de secuencia de la trama entrante.
Cuando el remitente envía todos los marcos en la ventana, verifica hasta qué número de secuencia ha recibido un reconocimiento positivo. Si todas las tramas se reconocen positivamente, el remitente envía el siguiente conjunto de tramas. Si el remitente encuentra que ha recibido NACK o no ha recibido ningún ACK para una trama en particular, retransmite todas las tramas después de las cuales no recibe ningún ACK positivo.
ARQ de repetición selectiva
En Go-back-N ARQ, se supone que el receptor no tiene ningún espacio de búfer para el tamaño de su ventana y tiene que procesar cada cuadro a medida que viene. Esto obliga al remitente a retransmitir todas las tramas que no se reconocen.
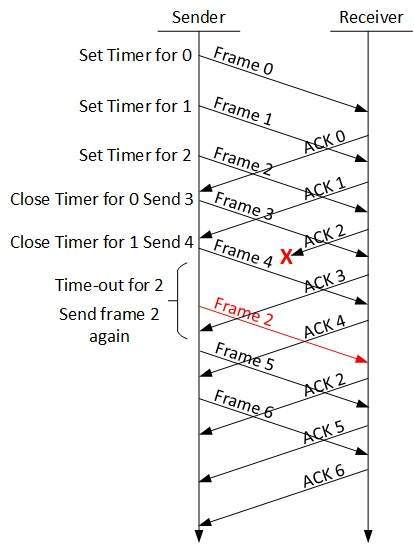
En ARQ de repetición selectiva, el receptor, mientras realiza un seguimiento de los números de secuencia, almacena los marcos en la memoria y envía NACK solo para el marco que falta o está dañado.
En este caso, el remitente envía solo el paquete para el que se recibe NACK.
La capa 3 en el modelo OSI se denomina capa de red. La capa de red gestiona las opciones relacionadas con el direccionamiento de red y host, la gestión de subredes y la interconexión de redes.
La capa de red asume la responsabilidad de enrutar los paquetes desde el origen al destino dentro o fuera de una subred. Dos subredes diferentes pueden tener diferentes esquemas de direccionamiento o tipos de direccionamiento no compatibles. Lo mismo ocurre con los protocolos, dos subredes diferentes pueden estar operando en diferentes protocolos que no son compatibles entre sí. La capa de red tiene la responsabilidad de enrutar los paquetes desde el origen al destino, mapeando diferentes esquemas y protocolos de direccionamiento.
Funcionalidades de la capa 3
Los dispositivos que funcionan en la capa de red se centran principalmente en el enrutamiento. El enrutamiento puede incluir varias tareas destinadas a lograr un solo objetivo. Estos pueden ser:
Abordar dispositivos y redes.
Poblando tablas de enrutamiento o rutas estáticas.
Poner en cola los datos entrantes y salientes y luego reenviarlos de acuerdo con las restricciones de calidad de servicio establecidas para esos paquetes.
Internetworking entre dos subredes diferentes.
Entrega de paquetes a destino con el mejor esfuerzo.
Proporciona un mecanismo orientado a la conexión y sin conexión.
Características de la capa de red
Con sus funcionalidades estándar, Layer 3 puede proporcionar varias características como:
Gestión de la calidad del servicio
Balanceo de carga y administración de enlaces
Security
Interrelación de diferentes protocolos y subredes con diferentes esquemas.
Diferente diseño de red lógica sobre el diseño de red física.
Los túneles y VPN L3 se pueden utilizar para proporcionar conectividad dedicada de extremo a extremo.
El protocolo de Internet es un protocolo de capa de red ampliamente respetado e implementado que ayuda a comunicar dispositivos de un extremo a otro a través de Internet. Viene en dos sabores. IPv4, que ha gobernado el mundo durante décadas, pero ahora se está quedando sin espacio de direcciones. IPv6 se crea para reemplazar IPv4 y, con suerte, también mitiga las limitaciones de IPv4.
El direccionamiento de red de capa 3 es una de las principales tareas de la capa de red. Las direcciones de red son siempre lógicas, es decir, se trata de direcciones basadas en software que se pueden cambiar mediante configuraciones adecuadas.
Una dirección de red siempre apunta a host / nodo / servidor o puede representar una red completa. La dirección de red siempre se configura en la tarjeta de interfaz de red y generalmente el sistema la asigna con la dirección MAC (dirección de hardware o dirección de capa 2) de la máquina para la comunicación de capa 2.
Existen diferentes tipos de direcciones de red:
IP
IPX
AppleTalk
Estamos hablando de PI aquí, ya que es la única que usamos en la práctica estos días.
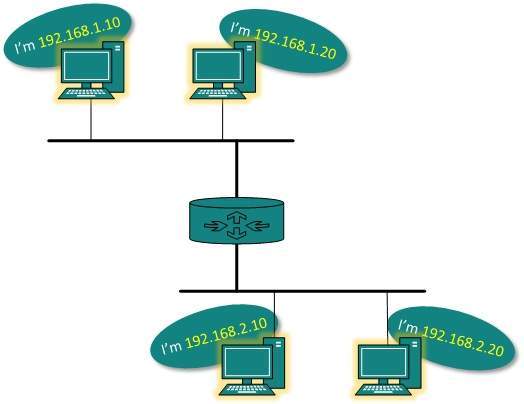
El direccionamiento IP proporciona un mecanismo para diferenciar entre hosts y red. Debido a que las direcciones IP se asignan de manera jerárquica, un host siempre reside bajo una red específica. El host que necesita comunicarse fuera de su subred, necesita saber la dirección de la red de destino, donde se enviarán los paquetes / datos.
Los hosts en diferentes subredes necesitan un mecanismo para ubicarse entre sí. Esta tarea la puede realizar el DNS. DNS es un servidor que proporciona la dirección de capa 3 del host remoto mapeado con su nombre de dominio o FQDN. Cuando un host adquiere la dirección de capa 3 (dirección IP) del host remoto, reenvía todo su paquete a su puerta de enlace. Una puerta de enlace es un enrutador equipado con toda la información que conduce a enrutar paquetes al host de destino.
Los enrutadores toman la ayuda de las tablas de enrutamiento, que tienen la siguiente información:
Método para llegar a la red
Los enrutadores al recibir una solicitud de reenvío, reenvían el paquete a su siguiente salto (enrutador adyacente) hacia el destino.
El siguiente enrutador de la ruta sigue lo mismo y, finalmente, el paquete de datos llega a su destino.
La dirección de red puede ser una de las siguientes:
Unicast (destinado a un host)
Multicast (destinado a grupo)
Broadcast (destinado a todos)
Anycast (destinado al más cercano)
Un enrutador nunca reenvía el tráfico de difusión de forma predeterminada. El tráfico de multidifusión utiliza un tratamiento especial, ya que se trata de una transmisión de vídeo o audio con la máxima prioridad. Anycast es similar a unicast, excepto que los paquetes se entregan al destino más cercano cuando hay varios destinos disponibles.
Cuando un dispositivo tiene varias rutas para llegar a un destino, siempre selecciona una ruta prefiriéndola sobre otras. Este proceso de selección se denomina enrutamiento. El enrutamiento se realiza mediante dispositivos de red especiales llamados enrutadores o se puede realizar mediante procesos de software. Los enrutadores basados en software tienen una funcionalidad y un alcance limitados.
Un enrutador siempre está configurado con alguna ruta predeterminada. Una ruta predeterminada le dice al enrutador dónde reenviar un paquete si no se encuentra una ruta para un destino específico. En caso de que existan varias rutas para llegar al mismo destino, el enrutador puede tomar una decisión basándose en la siguiente información:
Número de saltos
Bandwidth
Metric
Prefix-length
Delay
Las rutas se pueden configurar estáticamente o aprender dinámicamente. Se puede configurar una ruta para que sea preferida a otras.
Enrutamiento unicast
La mayor parte del tráfico en Internet e intranets conocido como datos de unidifusión o tráfico de unidifusión se envía con un destino especificado. El enrutamiento de datos de unidifusión a través de Internet se denomina enrutamiento de unidifusión. Es la forma más sencilla de enrutamiento porque ya se conoce el destino. Por lo tanto, el enrutador solo tiene que buscar la tabla de enrutamiento y reenviar el paquete al siguiente salto.
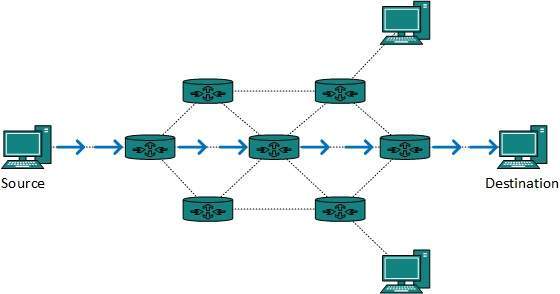
Enrutamiento de transmisión
De forma predeterminada, los paquetes de difusión no son enrutados ni reenviados por los enrutadores en ninguna red. Los enrutadores crean dominios de transmisión. Pero se puede configurar para reenviar transmisiones en algunos casos especiales. Un mensaje de difusión está destinado a todos los dispositivos de la red.
El enrutamiento de difusión se puede realizar de dos formas (algoritmo):
Un enrutador crea un paquete de datos y luego lo envía a cada host uno por uno. En este caso, el enrutador crea múltiples copias de un solo paquete de datos con diferentes direcciones de destino. Todos los paquetes se envían como unidifusión, pero debido a que se envían a todos, simula como si el enrutador estuviera transmitiendo.
Este método consume mucho ancho de banda y el enrutador debe tener la dirección de destino de cada nodo.
En segundo lugar, cuando el enrutador recibe un paquete que se va a transmitir, simplemente desborda esos paquetes de todas las interfaces. Todos los enrutadores están configurados de la misma manera.
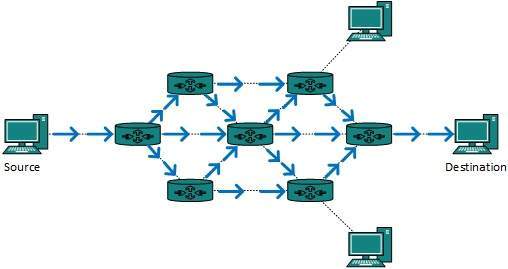
Este método es fácil para la CPU del enrutador, pero puede causar el problema de los paquetes duplicados recibidos de los enrutadores del mismo nivel.
El reenvío de ruta inversa es una técnica en la que el enrutador conoce de antemano sobre su predecesor desde donde debe recibir la transmisión. Esta técnica se utiliza para detectar y descartar duplicados.
Enrutamiento de multidifusión
El enrutamiento de multidifusión es un caso especial de enrutamiento de transmisión con diferencias significativas y desafíos. En el enrutamiento de difusión, los paquetes se envían a todos los nodos incluso si no lo desean. Pero en el enrutamiento de multidifusión, los datos se envían solo a los nodos que desean recibir los paquetes.
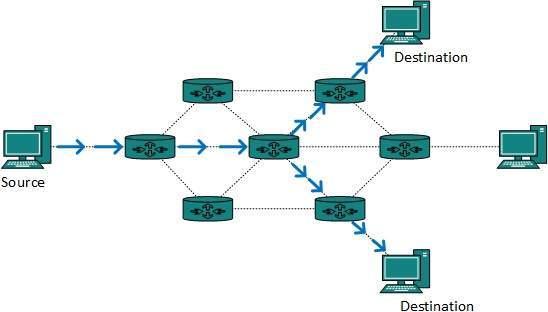
El enrutador debe saber que hay nodos que desean recibir paquetes de multidifusión (o flujo), entonces solo debe reenviarlos. El enrutamiento de multidifusión funciona con el protocolo de árbol de expansión para evitar bucles.
El enrutamiento de multidifusión también utiliza la técnica de reenvío de ruta inversa, para detectar y descartar duplicados y bucles.
Enrutamiento Anycast
El reenvío de paquetes Anycast es un mecanismo en el que varios hosts pueden tener la misma dirección lógica. Cuando se recibe un paquete destinado a esta dirección lógica, se envía al host más cercano en la topología de enrutamiento.
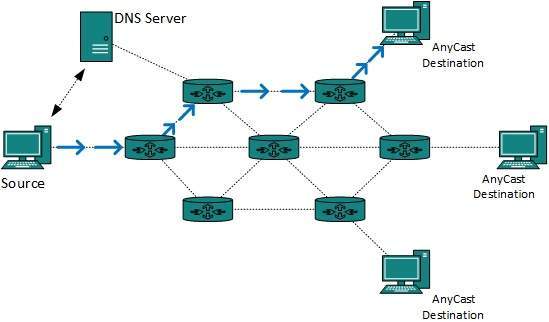
El enrutamiento Anycast se realiza con la ayuda del servidor DNS. Siempre que se recibe un paquete Anycast, se pregunta al DNS a dónde enviarlo. DNS proporciona la dirección IP que es la IP más cercana configurada en él.
Protocolos de enrutamiento unicast
Hay dos tipos de protocolos de enrutamiento disponibles para enrutar paquetes de unidifusión:
Protocolo de enrutamiento por vector de distancia
El vector de distancia es un protocolo de enrutamiento simple que toma decisiones de enrutamiento sobre el número de saltos entre el origen y el destino. Una ruta con menor número de saltos se considera la mejor ruta. Cada enrutador anuncia sus mejores rutas establecidas a otros enrutadores. En última instancia, todos los enrutadores construyen su topología de red basándose en los anuncios de sus enrutadores pares,
Por ejemplo, Routing Information Protocol (RIP).
Protocolo de enrutamiento de estado de enlace
El protocolo de estado de enlace es un protocolo un poco complicado que el vector de distancia. Tiene en cuenta los estados de los enlaces de todos los enrutadores de una red. Esta técnica ayuda a que las rutas construyan un gráfico común de toda la red. Luego, todos los enrutadores calculan su mejor ruta para propósitos de enrutamiento, por ejemplo, Abrir la ruta más corta primero (OSPF) e Intermediate System to Intermediate System (ISIS).
Protocolos de enrutamiento de multidifusión
Los protocolos de enrutamiento de unidifusión usan gráficos, mientras que los protocolos de enrutamiento de multidifusión usan árboles, es decir, árbol de expansión para evitar bucles. El árbol óptimo se denomina árbol de expansión de la ruta más corta.
DVMRP - Protocolo de enrutamiento de multidifusión por vector de distancia
MOSPF - Multicast Abrir la ruta más corta primero
CBT - Árbol basado en el núcleo
PIM - Protocolo de multidifusión independiente
La multidifusión independiente del protocolo se usa comúnmente ahora. Tiene dos sabores:
PIM Dense Mode
Este modo utiliza árboles basados en fuentes. Se utiliza en entornos densos como LAN.
PIM Sparse Mode
Este modo utiliza árboles compartidos. Se utiliza en entornos dispersos como WAN.
Algoritmos de enrutamiento
Los algoritmos de enrutamiento son los siguientes:
Inundación
Flooding es el método más simple de reenvío de paquetes. Cuando se recibe un paquete, los enrutadores lo envían a todas las interfaces excepto a aquella en la que se recibió. Esto crea demasiada carga en la red y muchos paquetes duplicados deambulan por la red.
Time to Live (TTL) se puede utilizar para evitar un bucle infinito de paquetes. Existe otro enfoque para las inundaciones, que se denomina inundación selectiva para reducir la sobrecarga en la red. En este método, el enrutador no se desborda en todas las interfaces, sino en las selectivas.
Ruta más corta
Las decisiones de enrutamiento en las redes se toman principalmente sobre la base del costo entre el origen y el destino. El conteo de lúpulos juega un papel importante aquí. La ruta más corta es una técnica que utiliza varios algoritmos para decidir una ruta con un número mínimo de saltos.
Los algoritmos de ruta más corta comunes son:
Algoritmo de Dijkstra
Algoritmo de Bellman Ford
Algoritmo de Floyd Warshall
En el escenario del mundo real, las redes bajo la misma administración generalmente están dispersas geográficamente. Puede existir el requisito de conectar dos redes diferentes del mismo tipo, así como de diferentes tipos. El enrutamiento entre dos redes se denomina interconexión de redes.
Las redes se pueden considerar diferentes en función de varios parámetros, como el protocolo, la topología, la red de capa 2 y el esquema de direccionamiento.
En la interconexión de redes, los enrutadores conocen la dirección de los demás y las direcciones más allá de ellos. Pueden configurarse estáticamente en diferentes redes o pueden aprender utilizando el protocolo de enrutamiento entre redes.
Los protocolos de enrutamiento que se utilizan dentro de una organización o administración se denominan Protocolos de puerta de enlace interior o IGP. RIP, OSPF son ejemplos de IGP. El enrutamiento entre diferentes organizaciones o administraciones puede tener un protocolo de puerta de enlace exterior y solo hay un EGP, es decir, el protocolo de puerta de enlace fronteriza.
Tunelización
Si son dos redes geográficamente separadas, que quieren comunicarse entre sí, pueden implementar una línea dedicada entre ellas o tienen que pasar sus datos a través de redes intermedias.
La tunelización es un mecanismo mediante el cual dos o más redes iguales se comunican entre sí, pasando por complejidades de redes intermedias. La tunelización está configurada en ambos extremos.
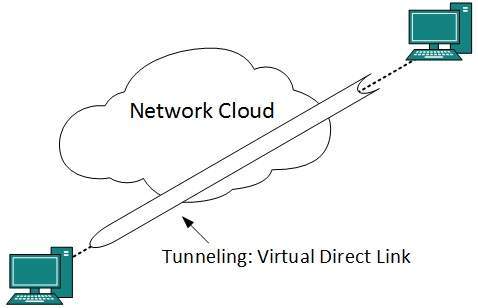
Cuando los datos ingresan desde un extremo del túnel, se etiquetan. Estos datos etiquetados luego se enrutan dentro de la red intermedia o de tránsito para llegar al otro extremo del túnel. Cuando existen datos, el túnel se quita su etiqueta y se envía a la otra parte de la red.
Ambos extremos parecen estar conectados directamente y el etiquetado hace que los datos viajen a través de la red de tránsito sin modificaciones.
Fragmentación de paquetes
La mayoría de los segmentos Ethernet tienen su unidad de transmisión máxima (MTU) fijada en 1500 bytes. Un paquete de datos puede tener más o menos longitud de paquete dependiendo de la aplicación. Los dispositivos en la ruta de tránsito también tienen sus capacidades de hardware y software que indican qué cantidad de datos puede manejar ese dispositivo y qué tamaño de paquete puede procesar.
Si el tamaño del paquete de datos es menor o igual que el tamaño del paquete que la red de tránsito puede manejar, se procesa de manera neutral. Si el paquete es más grande, se divide en pedazos más pequeños y luego se reenvía. Esto se llama fragmentación de paquetes. Cada fragmento contiene la misma dirección de origen y destino y se enruta fácilmente a través de la ruta de tránsito. En el extremo receptor se vuelve a montar.
Si un paquete con el bit DF (no fragmentar) establecido en 1 llega a un enrutador que no puede manejar el paquete debido a su longitud, el paquete se descarta.
Cuando un enrutador recibe un paquete y su bit MF (más fragmentos) se establece en 1, el enrutador sabe que se trata de un paquete fragmentado y que partes del paquete original están en camino.
Si el paquete está fragmentado demasiado pequeño, la sobrecarga aumenta. Si el paquete está demasiado fragmentado, es posible que el enrutador intermedio no pueda procesarlo y se descarte.
Cada computadora en una red tiene una dirección IP mediante la cual se puede identificar y direccionar de manera única. Una dirección IP es una dirección lógica de capa 3 (capa de red). Esta dirección puede cambiar cada vez que se reinicia una computadora. Una computadora puede tener una IP en un momento determinado y otra IP en un momento diferente.
Protocolo de resolución de direcciones (ARP)
Mientras se comunica, un host necesita la dirección de capa 2 (MAC) de la máquina de destino que pertenece al mismo dominio de transmisión o red. Una dirección MAC se graba físicamente en la tarjeta de interfaz de red (NIC) de una máquina y nunca cambia.
Por otro lado, la dirección IP en el dominio público rara vez se cambia. Si se cambia la NIC en caso de alguna falla, la dirección MAC también cambia. De esta manera, para que se produzca la comunicación de Capa 2, se requiere un mapeo entre los dos.
Para conocer la dirección MAC de un host remoto en un dominio de transmisión, una computadora que desee iniciar la comunicación envía un mensaje de transmisión ARP preguntando: "¿Quién tiene esta dirección IP?" Debido a que es una transmisión, todos los hosts del segmento de red (dominio de transmisión) reciben este paquete y lo procesan. El paquete ARP contiene la dirección IP del host de destino, con el que el host de envío desea hablar. Cuando un host recibe un paquete ARP destinado a él, responde con su propia dirección MAC.
Una vez que el host obtiene la dirección MAC de destino, puede comunicarse con el host remoto utilizando el protocolo de enlace de Capa 2. Esta asignación de MAC a IP se guarda en la caché ARP de los hosts emisores y receptores. La próxima vez, si necesitan comunicarse, pueden consultar directamente su caché ARP respectiva.
ARP inverso es un mecanismo en el que el host conoce la dirección MAC del host remoto, pero requiere conocer la dirección IP para comunicarse.
Protocolo de mensajes de control de Internet (ICMP)
ICMP es un protocolo de informe de errores y diagnóstico de red. ICMP pertenece al conjunto de protocolos IP y utiliza IP como protocolo de operador. Después de construir el paquete ICMP, se encapsula en el paquete IP. Dado que la IP en sí misma es un protocolo no confiable de mejor esfuerzo, también lo es ICMP.
Cualquier comentario sobre la red se envía al host de origen. Si ocurre algún error en la red, se informa mediante ICMP. ICMP contiene docenas de mensajes de diagnóstico y notificación de errores.
ICMP-echo e ICMP-echo-reply son los mensajes ICMP más utilizados para comprobar la accesibilidad de los hosts de un extremo a otro. Cuando un host recibe una solicitud de eco ICMP, está obligado a devolver una respuesta de eco ICMP. Si hay algún problema en la red de tránsito, el ICMP informará ese problema.
Protocolo de Internet versión 4 (IPv4)
IPv4 es un esquema de direccionamiento de 32 bits que se utiliza como mecanismo de direccionamiento de host TCP / IP. El direccionamiento IP permite que cada host de la red TCP / IP sea identificable de forma única.
IPv4 proporciona un esquema de direccionamiento jerárquico que le permite dividir la red en subredes, cada una con un número bien definido de hosts. Las direcciones IP se dividen en muchas categorías:
Class A - utiliza el primer octeto para las direcciones de red y los últimos tres octetos para el direccionamiento del host
Class B - utiliza los dos primeros octetos para las direcciones de red y los dos últimos para el direccionamiento del host
Class C - utiliza los primeros tres octetos para las direcciones de red y el último para el direccionamiento del host
Class D - Proporciona un esquema de direccionamiento IP plano en contraste con la estructura jerárquica de los tres anteriores.
Class E - Se utiliza como experimental.
IPv4 también tiene espacios de direcciones bien definidos para ser utilizados como direcciones privadas (no enrutables en Internet) y direcciones públicas (proporcionadas por ISP y son enrutables en Internet).
Aunque la propiedad intelectual no es confiable; proporciona un mecanismo de "mejor esfuerzo-entrega".
Protocolo de Internet versión 6 (IPv6)
El agotamiento de las direcciones IPv4 dio lugar a una versión 6 del Protocolo de Internet de próxima generación. IPv6 direcciona sus nodos con una dirección de 128 bits que proporciona suficiente espacio de direcciones para que se pueda utilizar en el futuro en todo el planeta o más allá.
IPv6 ha introducido el direccionamiento Anycast pero ha eliminado el concepto de transmisión. IPv6 permite a los dispositivos adquirir por sí mismos una dirección IPv6 y comunicarse dentro de esa subred. Esta configuración automática elimina la confiabilidad de los servidores de Protocolo de configuración dinámica de host (DHCP). De esta manera, incluso si el servidor DHCP en esa subred está inactivo, los hosts pueden comunicarse entre sí.
IPv6 proporciona una nueva característica de movilidad IPv6. Las máquinas equipadas con IPv6 móviles pueden moverse sin necesidad de cambiar sus direcciones IP.
IPv6 aún se encuentra en fase de transición y se espera que reemplace completamente a IPv4 en los próximos años. En la actualidad, hay pocas redes que se ejecuten en IPv6. Hay algunos mecanismos de transición disponibles para que las redes habilitadas para IPv6 hablen y se muevan por diferentes redes fácilmente en IPv4. Estos son:
- Implementación de doble pila
- Tunneling
- NAT-PT
La siguiente capa en el modelo OSI se reconoce como capa de transporte (capa 4). Todos los módulos y procedimientos relacionados con el transporte de datos o flujo de datos se clasifican en esta capa. Como todas las demás capas, esta capa se comunica con su capa de transporte de pares del host remoto.
La capa de transporte ofrece una conexión punto a punto y de un extremo a otro entre dos procesos en hosts remotos. La capa de transporte toma los datos de la capa superior (es decir, la capa de aplicación) y luego los divide en segmentos de menor tamaño, numera cada byte y los entrega a la capa inferior (capa de red) para su entrega.
Funciones
Esta capa es la primera que divide los datos de información, suministrados por la capa de aplicación, en unidades más pequeñas llamadas segmentos. Numera cada byte del segmento y mantiene su contabilidad.
Esta capa garantiza que los datos se reciban en la misma secuencia en la que se enviaron.
Esta capa proporciona una entrega de datos de un extremo a otro entre hosts que pueden pertenecer o no a la misma subred.
Todos los procesos del servidor que pretenden comunicarse a través de la red están equipados con puntos de acceso al servicio de transporte (TSAP) conocidos también como números de puerto.
Comunicación de extremo a extremo
Un proceso en un host identifica a su host par en la red remota mediante TSAP, también conocidos como números de puerto. Los TSAP están muy bien definidos y un proceso que intenta comunicarse con sus pares lo sabe de antemano.
Por ejemplo, cuando un cliente DHCP desea comunicarse con un servidor DHCP remoto, siempre solicita el número de puerto 67. Cuando un cliente DNS desea comunicarse con el servidor DNS remoto, siempre solicita el número de puerto 53 (UDP).
Los dos protocolos principales de la capa de transporte son:
Transmission Control Protocol
Proporciona una comunicación confiable entre dos hosts.
User Datagram Protocol
Proporciona una comunicación poco fiable entre dos hosts.
El Protocolo de control de transmisión (TCP) es uno de los protocolos más importantes del conjunto de protocolos de Internet. Es el protocolo más utilizado para la transmisión de datos en redes de comunicación como Internet.
Caracteristicas
TCP es un protocolo confiable. Es decir, el receptor siempre envía un acuse de recibo positivo o negativo sobre el paquete de datos al remitente, de modo que el remitente siempre tiene una pista clara sobre si el paquete de datos llegó al destino o si necesita reenviarlo.
TCP garantiza que los datos lleguen al destino previsto en el mismo orden en que se enviaron.
TCP está orientado a la conexión. TCP requiere que se establezca una conexión entre dos puntos remotos antes de enviar datos reales.
TCP proporciona un mecanismo de recuperación y verificación de errores.
TCP proporciona comunicación de un extremo a otro.
TCP proporciona control de flujo y calidad de servicio.
TCP opera en modo punto a punto Cliente / Servidor.
TCP proporciona un servidor full duplex, es decir, puede realizar funciones tanto de receptor como de remitente.
Encabezamiento
La longitud del encabezado TCP es de un mínimo de 20 bytes y un máximo de 60 bytes.
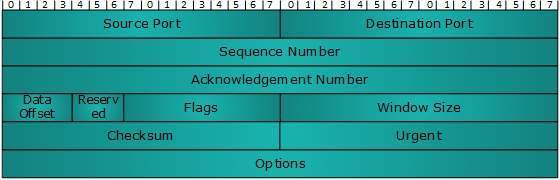
Source Port (16-bits) - Identifica el puerto de origen del proceso de aplicación en el dispositivo de envío.
Destination Port (16-bits) - Identifica el puerto de destino del proceso de aplicación en el dispositivo receptor.
Sequence Number (32-bits) - Número de secuencia de bytes de datos de un segmento en una sesión.
Acknowledgement Number (32-bits) - Cuando se establece el indicador ACK, este número contiene el siguiente número de secuencia del byte de datos esperado y funciona como reconocimiento de los datos recibidos anteriormente.
Data Offset (4-bits) - Este campo implica tanto el tamaño del encabezado TCP (palabras de 32 bits) como el desplazamiento de los datos en el paquete actual en todo el segmento TCP.
Reserved (3-bits) - Reservado para uso futuro y todos se establecen en cero de forma predeterminada.
Flags (1-bit each)
NS - El proceso de señalización de notificación de congestión explícita utiliza el bit Nonce Sum.
CWR - Cuando un host recibe un paquete con el bit ECE establecido, establece Congestion Windows Reduced para reconocer que ECE recibió.
ECE -Tiene dos significados:
Si el bit SYN está claro a 0, entonces ECE significa que el paquete IP tiene su bit CE (experiencia de congestión) establecido.
Si el bit SYN se establece en 1, ECE significa que el dispositivo es compatible con ECT.
URG - Indica que el campo de puntero urgente tiene datos importantes y debe procesarse.
ACK- Indica que el campo Reconocimiento tiene importancia. Si ACK se pone a 0, indica que el paquete no contiene ningún reconocimiento.
PSH - Cuando se establece, es una solicitud a la estación receptora para PUSH data (tan pronto como llegue) a la aplicación receptora sin almacenarlos en búfer.
RST - La bandera de reinicio tiene las siguientes características:
Se utiliza para rechazar una conexión entrante.
Se utiliza para rechazar un segmento.
Se utiliza para reiniciar una conexión.
SYN - Esta bandera se utiliza para configurar una conexión entre hosts.
FIN- Esta bandera se utiliza para liberar una conexión y no se intercambian más datos a partir de entonces. Dado que los paquetes con indicadores SYN y FIN tienen números de secuencia, se procesan en el orden correcto.
Windows Size - Este campo se utiliza para el control de flujo entre dos estaciones e indica la cantidad de búfer (en bytes) que el receptor ha asignado para un segmento, es decir, cuántos datos espera el receptor.
Checksum - Este campo contiene la suma de comprobación de encabezados, datos y pseudo encabezados.
Urgent Pointer - Apunta al byte de datos urgentes si el indicador URG se establece en 1.
Options - Facilita opciones adicionales que no están cubiertas por el encabezado regular. El campo de opción siempre se describe en palabras de 32 bits. Si este campo contiene datos de menos de 32 bits, el relleno se utiliza para cubrir los bits restantes para alcanzar el límite de 32 bits.
Direccionamiento
La comunicación TCP entre dos hosts remotos se realiza mediante números de puerto (TSAP). Los números de puertos pueden oscilar entre 0 y 65535, que se dividen como:
- Puertos del sistema (0 - 1023)
- Puertos de usuario (1024 - 49151)
- Puertos privados / dinámicos (49152 - 65535)
Gestión de conexiones
La comunicación TCP funciona en el modelo Servidor / Cliente. El cliente inicia la conexión y el servidor la acepta o la rechaza. El protocolo de enlace de tres vías se utiliza para la gestión de la conexión.
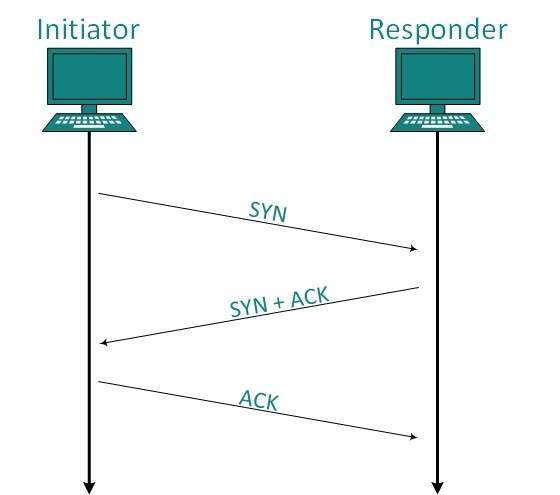
Establecimiento
El cliente inicia la conexión y envía el segmento con un número de secuencia. El servidor lo reconoce con su propio número de secuencia y ACK del segmento del cliente, que es uno más que el número de secuencia del cliente. El cliente después de recibir un ACK de su segmento envía un acuse de recibo de la respuesta del servidor.
Lanzamiento
Tanto el servidor como el cliente pueden enviar el segmento TCP con el indicador FIN establecido en 1. Cuando el extremo receptor responde con ACKnowledging FIN, esa dirección de comunicación TCP se cierra y se libera la conexión.
Gestión de ancho de banda
TCP utiliza el concepto de tamaño de ventana para adaptarse a la necesidad de gestión del ancho de banda. El tamaño de la ventana le dice al remitente en el extremo remoto, el número de segmentos de bytes de datos que el receptor en este extremo puede recibir. TCP usa la fase de inicio lento usando el tamaño de ventana 1 y aumenta el tamaño de la ventana exponencialmente después de cada comunicación exitosa.
Por ejemplo, el cliente usa ventanas de tamaño 2 y envía 2 bytes de datos. Cuando se recibe el acuse de recibo de este segmento, el tamaño de la ventana se duplica a 4 y el siguiente segmento enviado tendrá una longitud de 4 bytes de datos. Cuando se recibe el acuse de recibo del segmento de datos de 4 bytes, el cliente establece el tamaño de la ventana en 8 y así sucesivamente.
Si se pierde un acuse de recibo, es decir, se pierden datos en la red de tránsito o se recibe NACK, el tamaño de la ventana se reduce a la mitad y la fase de inicio lento comienza de nuevo.
Control de errores y control de flujo
TCP utiliza números de puerto para saber qué proceso de aplicación necesita para transferir el segmento de datos. Junto con eso, utiliza números de secuencia para sincronizarse con el host remoto. Todos los segmentos de datos se envían y reciben con números de secuencia. El remitente sabe qué último segmento de datos recibió el receptor cuando recibe ACK. El receptor conoce el último segmento enviado por el remitente refiriéndose al número de secuencia del paquete recibido recientemente.
Si el número de secuencia de un segmento recibido recientemente no coincide con el número de secuencia que el receptor esperaba, entonces se descarta y se envía NACK. Si llegan dos segmentos con el mismo número de secuencia, el valor de la marca de tiempo de TCP se compara para tomar una decisión.
Multiplexación
La técnica para combinar dos o más flujos de datos en una sesión se denomina multiplexación. Cuando un cliente TCP inicializa una conexión con el servidor, siempre se refiere a un número de puerto bien definido que indica el proceso de aplicación. El propio cliente utiliza un número de puerto generado aleatoriamente de grupos de números de puerto privados.
Con la multiplexación TCP, un cliente puede comunicarse con varios procesos de aplicación diferentes en una sola sesión. Por ejemplo, un cliente solicita una página web que a su vez contiene diferentes tipos de datos (HTTP, SMTP, FTP, etc.), el tiempo de espera de la sesión TCP aumenta y la sesión se mantiene abierta durante más tiempo para que la sobrecarga del protocolo de enlace de tres vías pueda ser evitado.
Esto permite que el sistema cliente reciba múltiples conexiones a través de una sola conexión virtual. Estas conexiones virtuales no son buenas para los servidores si el tiempo de espera es demasiado largo.
Control de congestión
Cuando se envía una gran cantidad de datos al sistema que no es capaz de manejarlos, se produce una congestión. TCP controla la congestión mediante un mecanismo de ventana. TCP establece un tamaño de ventana que le dice al otro extremo cuánto segmento de datos enviar. TCP puede utilizar tres algoritmos para el control de la congestión:
Aumento aditivo, disminución multiplicativa
Comienzo lento
Reacción del tiempo de espera
Gestión del temporizador
TCP utiliza diferentes tipos de temporizadores para controlar y gestionar varias tareas:
Temporizador para mantener vivo:
Este temporizador se utiliza para verificar la integridad y validez de una conexión.
Cuando expira el tiempo de mantenimiento, el host envía una sonda para verificar si la conexión aún existe.
Temporizador de retransmisión:
Este temporizador mantiene la sesión con estado de los datos enviados.
Si el acuse de recibo de los datos enviados no se recibe dentro del tiempo de retransmisión, el segmento de datos se envía de nuevo.
Temporizador de persistencia:
La sesión TCP puede ser pausada por cualquier host enviando Tamaño de ventana 0.
Para reanudar la sesión, un anfitrión debe enviar Tamaño de ventana con un valor mayor.
Si este segmento nunca llega al otro extremo, ambos extremos pueden esperar el uno al otro durante un tiempo infinito.
Cuando el temporizador de persistencia expira, el host reenvía el tamaño de su ventana para informar al otro extremo.
Persist Timer ayuda a evitar interbloqueos en la comunicación.
Espera temporizada:
Después de liberar una conexión, cualquiera de los hosts espera un tiempo de espera temporizada para terminar la conexión por completo.
Esto es para asegurarse de que el otro extremo haya recibido el acuse de recibo de su solicitud de terminación de conexión.
El tiempo de espera puede ser de un máximo de 240 segundos (4 minutos).
Recuperación de accidentes
TCP es un protocolo muy confiable. Proporciona un número de secuencia a cada byte enviado en segmento. Proporciona el mecanismo de retroalimentación, es decir, cuando un host recibe un paquete, está vinculado a ACK que el paquete tiene el siguiente número de secuencia esperado (si no es el último segmento).
Cuando un servidor TCP bloquea la comunicación a mitad de camino y reinicia su proceso, envía una transmisión TPDU a todos sus hosts. A continuación, los hosts pueden enviar el último segmento de datos que nunca se dejó de reconocer y continuar.
El Protocolo de datagramas de usuario (UDP) es el protocolo de comunicación de la capa de transporte más simple disponible del conjunto de protocolos TCP / IP. Implica una cantidad mínima de mecanismo de comunicación. Se dice que UDP es un protocolo de transporte poco confiable, pero utiliza servicios IP que proporcionan el mejor mecanismo de entrega.
En UDP, el receptor no genera un acuse de recibo del paquete recibido y, a su vez, el remitente no espera ningún acuse de recibo del paquete enviado. Esta deficiencia hace que este protocolo sea poco confiable y más fácil de procesar.
Requisito de UDP
Puede surgir una pregunta, ¿por qué necesitamos un protocolo poco confiable para transportar los datos? Implementamos UDP donde los paquetes de reconocimiento comparten una cantidad significativa de ancho de banda junto con los datos reales. Por ejemplo, en el caso de la transmisión de video, se envían miles de paquetes a sus usuarios. Reconocer todos los paquetes es problemático y puede contener una gran cantidad de desperdicio de ancho de banda. El mejor mecanismo de entrega del protocolo IP subyacente asegura los mejores esfuerzos para entregar sus paquetes, pero incluso si se pierden algunos paquetes en la transmisión de video, el impacto no es calamitoso y puede ignorarse fácilmente. La pérdida de algunos paquetes en el tráfico de video y voz a veces pasa desapercibida.
Caracteristicas
UDP se utiliza cuando el reconocimiento de datos no tiene ninguna importancia.
UDP es un buen protocolo para que los datos fluyan en una dirección.
UDP es simple y adecuado para comunicaciones basadas en consultas.
UDP no está orientado a la conexión.
UDP no proporciona un mecanismo de control de congestión.
UDP no garantiza la entrega ordenada de datos.
UDP es apátrida.
UDP es un protocolo adecuado para aplicaciones de transmisión como VoIP, transmisión multimedia.
Encabezado UDP
El encabezado UDP es tan simple como su función.

El encabezado UDP contiene cuatro parámetros principales:
Source Port - Esta información de 16 bits se utiliza para identificar el puerto de origen del paquete.
Destination Port - Esta información de 16 bits se utiliza para identificar el servicio de nivel de aplicación en la máquina de destino.
Length - El campo de longitud especifica la longitud completa del paquete UDP (incluido el encabezado). Es un campo de 16 bits y el valor mínimo es de 8 bytes, es decir, el tamaño del encabezado UDP en sí.
Checksum - Este campo almacena el valor de la suma de control generado por el remitente antes de enviar. IPv4 tiene este campo como opcional, por lo que cuando el campo de suma de verificación no contiene ningún valor, se convierte en 0 y todos sus bits se establecen en cero.
Aplicación UDP
Aquí hay algunas aplicaciones donde se usa UDP para transmitir datos:
Servicios de nombres de dominio
Protocolo Simple de Manejo de Red
Protocolo de transferencia de archivos trivial
Protocolo de información de enrutamiento
Kerberos
La capa de aplicación es la capa superior en el modelo en capas OSI y TCP / IP. Esta capa existe en ambos modelos en capas debido a su importancia, de interactuar con el usuario y las aplicaciones del usuario. Esta capa es para aplicaciones que están involucradas en el sistema de comunicación.
Un usuario puede o no interactuar directamente con las aplicaciones. La capa de aplicación es donde se inicia y refleja la comunicación real. Debido a que esta capa está en la parte superior de la pila de capas, no sirve a ninguna otra capa. La capa de aplicación toma la ayuda de Transporte y todas las capas debajo de ella para comunicarse o transferir sus datos al host remoto.
Cuando un protocolo de la capa de aplicación desea comunicarse con su protocolo de la capa de aplicación del mismo nivel en un host remoto, entrega los datos o la información a la capa de transporte. La capa de transporte hace el resto con la ayuda de todas las capas debajo de ella.

Existe una ambigüedad en la comprensión de la capa de aplicación y su protocolo. No todas las aplicaciones de usuario pueden colocarse en la capa de aplicación. excepto aquellas aplicaciones que interactúan con el sistema de comunicación. Por ejemplo, el diseño de software o editor de texto no puede considerarse como programas de capa de aplicación.
Por otro lado, cuando usamos un navegador web, que en realidad usa el Protocolo de transferencia de hipertexto (HTTP) para interactuar con la red. HTTP es el protocolo de capa de aplicación.
Otro ejemplo es el Protocolo de transferencia de archivos, que ayuda al usuario a transferir archivos binarios o basados en texto a través de la red. Un usuario puede usar este protocolo en cualquier software basado en GUI como FileZilla o CuteFTP y el mismo usuario puede usar FTP en el modo de línea de comandos.
Por lo tanto, independientemente del software que utilice, es el protocolo el que se considera en la capa de aplicación utilizada por ese software. DNS es un protocolo que ayuda a los protocolos de aplicación de usuario, como HTTP, a realizar su trabajo.
Dos procesos de aplicación remota pueden comunicarse principalmente de dos formas diferentes:
Peer-to-peer: Ambos procesos remotos se ejecutan al mismo nivel e intercambian datos utilizando algún recurso compartido.
Client-Server: Un proceso remoto actúa como Cliente y solicita algún recurso de otro proceso de aplicación que actúa como Servidor.
En el modelo cliente-servidor, cualquier proceso puede actuar como servidor o cliente. No es el tipo de máquina, el tamaño de la máquina o su potencia informática lo que lo convierte en servidor; es la capacidad de atender solicitudes lo que convierte a una máquina en un servidor.
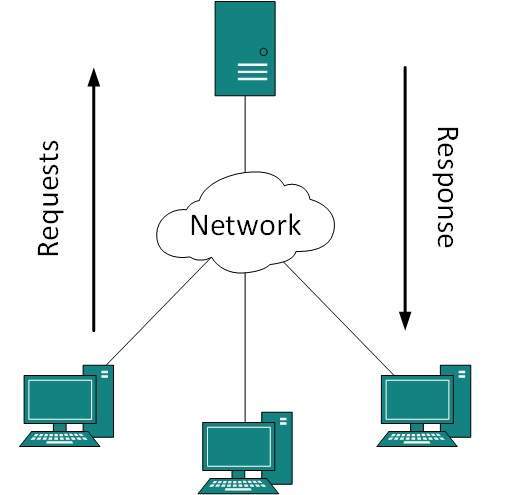
Un sistema puede actuar como servidor y cliente simultáneamente. Es decir, un proceso actúa como servidor y otro como cliente. Esto también puede suceder que los procesos de cliente y servidor residan en la misma máquina.
Comunicación
Dos procesos en el modelo cliente-servidor pueden interactuar de varias formas:
Sockets
Llamadas a procedimiento remoto (RPC)
Enchufes
En este paradigma, el proceso que actúa como servidor abre un socket utilizando un puerto conocido (o conocido por el cliente) y espera hasta que llegue alguna solicitud del cliente. El segundo proceso que actúa como Cliente también abre un socket, pero en lugar de esperar una solicitud entrante, el cliente procesa 'solicitudes primero'.
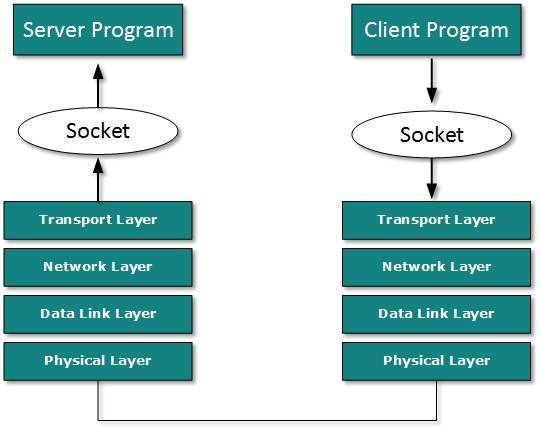
Cuando se llega a la solicitud al servidor, se atiende. Puede ser un intercambio de información o una solicitud de recursos.
Llamada a procedimiento remoto
Este es un mecanismo en el que un proceso interactúa con otro mediante llamadas a procedimientos. Un proceso (cliente) llama al procedimiento que se encuentra en un host remoto. Se dice que el proceso en el host remoto es Server. Ambos procesos son stubs asignados. Esta comunicación ocurre de la siguiente manera:
El proceso del cliente llama al stub del cliente. Pasa todos los parámetros pertenecientes al programa local.
Luego, todos los parámetros se empaquetan (ordenan) y se realiza una llamada al sistema para enviarlos al otro lado de la red.
Kernel envía los datos a través de la red y el otro extremo los recibe.
El host remoto pasa los datos al stub del servidor donde no se ordena.
Los parámetros se pasan al procedimiento y luego se ejecuta el procedimiento.
El resultado se envía de vuelta al cliente de la misma manera.
Hay varios protocolos que funcionan para los usuarios en la capa de aplicación. Los protocolos de la capa de aplicación se pueden dividir en dos categorías:
Protocolos que utilizan los usuarios, como correo electrónico, por ejemplo, eMail.
Protocolos que ayudan y dan soporte a los protocolos utilizados por los usuarios, por ejemplo DNS.
A continuación se describen algunos protocolos de la capa de aplicación:
sistema de nombres de dominio
El sistema de nombres de dominio (DNS) funciona en el modelo de servidor cliente. Utiliza el protocolo UDP para la comunicación de la capa de transporte. DNS utiliza un esquema de nombres jerárquico basado en dominios. El servidor DNS está configurado con nombres de dominio completos (FQDN) y direcciones de correo electrónico asignadas con sus respectivas direcciones de protocolo de Internet.
Se solicita un servidor DNS con FQDN y este responde con la dirección IP asignada. DNS usa el puerto UDP 53.
Protocolo simple de transferencia de correo
El Protocolo simple de transferencia de correo (SMTP) se utiliza para transferir correo electrónico de un usuario a otro. Esta tarea se realiza mediante el software cliente de correo electrónico (agentes de usuario) que utiliza el usuario. Los agentes de usuario ayudan al usuario a escribir y formatear el correo electrónico y almacenarlo hasta que Internet esté disponible. Cuando se envía un correo electrónico para enviar, el proceso de envío lo maneja el Agente de transferencia de mensajes, que normalmente viene incorporado en el software del cliente de correo electrónico.
El Agente de transferencia de mensajes utiliza SMTP para reenviar el correo electrónico a otro Agente de transferencia de mensajes (lado del servidor). Mientras que SMTP es utilizado por el usuario final solo para enviar correos electrónicos, los servidores normalmente usan SMTP para enviar y recibir correos electrónicos. SMTP utiliza los puertos TCP número 25 y 587.
El software cliente utiliza el Protocolo de acceso a mensajes de Internet (IMAP) o los protocolos POP para recibir correos electrónicos.
Protocolo de transferencia de archivos
El Protocolo de transferencia de archivos (FTP) es el protocolo más utilizado para la transferencia de archivos a través de la red. FTP utiliza TCP / IP para la comunicación y funciona en el puerto TCP 21. FTP funciona en el modelo Cliente / Servidor donde un cliente solicita un archivo del servidor y el servidor envía el recurso solicitado de vuelta al cliente.
FTP utiliza control fuera de banda, es decir, FTP utiliza el puerto TCP 20 para intercambiar información de control y los datos reales se envían a través del puerto TCP 21.
El cliente solicita al servidor un archivo. Cuando el servidor recibe una solicitud de un archivo, abre una conexión TCP para el cliente y transfiere el archivo. Una vez completada la transferencia, el servidor cierra la conexión. Para un segundo archivo, el cliente vuelve a solicitar y el servidor vuelve a abrir una nueva conexión TCP.
Protocolo de oficina postal (POP)
El Protocolo de oficina de correos versión 3 (POP 3) es un protocolo simple de recuperación de correo utilizado por los agentes de usuario (software de correo electrónico del cliente) para recuperar correos del servidor de correo.
Cuando un cliente necesita recuperar correos del servidor, abre una conexión con el servidor en el puerto TCP 110. El usuario puede acceder a sus correos y descargarlos en la computadora local. POP3 funciona en dos modos. El modo más común, el modo de eliminación, es eliminar los correos electrónicos del servidor remoto después de que se descargan en las máquinas locales. El segundo modo, el modo de conservación, no elimina el correo electrónico del servidor de correo y le da al usuario la opción de acceder a los correos posteriormente en el servidor de correo.
Protocolo de transferencia de hipertexto (HTTP)
El Protocolo de transferencia de hipertexto (HTTP) es la base de World Wide Web. El hipertexto es un sistema de documentación bien organizado que utiliza hipervínculos para vincular las páginas de los documentos de texto. HTTP funciona en el modelo cliente-servidor. Cuando un usuario desea acceder a cualquier página HTTP en Internet, la máquina cliente en el extremo del usuario inicia una conexión TCP al servidor en el puerto 80. Cuando el servidor acepta la solicitud del cliente, el cliente está autorizado para acceder a las páginas web.
Para acceder a las páginas web, un cliente normalmente utiliza navegadores web, que son responsables de iniciar, mantener y cerrar las conexiones TCP. HTTP es un protocolo sin estado, lo que significa que el servidor no mantiene información sobre solicitudes anteriores de los clientes.
Versiones HTTP
HTTP 1.0 utiliza HTTP no persistente. Como máximo, se puede enviar un objeto a través de una única conexión TCP.
HTTP 1.1 utiliza HTTP persistente. En esta versión, se pueden enviar varios objetos a través de una única conexión TCP.
Los sistemas informáticos y los sistemas computarizados ayudan a los seres humanos a trabajar de manera eficiente y explorar lo impensable. Cuando estos dispositivos se conectan entre sí para formar una red, las capacidades se mejoran varias veces. Algunos servicios básicos que la red informática puede ofrecer son.
Directorio de Servicios
Estos servicios están mapeando entre el nombre y su valor, que puede ser de valor variable o fijo. Este sistema de software ayuda a almacenar la información, organizarla y proporciona varios medios para acceder a ella.
Accounting
En una organización, varios usuarios tienen asignados sus nombres de usuario y contraseñas. Los servicios de directorio proporcionan medios para almacenar esta información en forma críptica y poner a disposición cuando se solicite.
Authentication and Authorization
Las credenciales de usuario se verifican para autenticar a un usuario en el momento del inicio de sesión y / o periódicamente. Las cuentas de usuario se pueden configurar en una estructura jerárquica y su acceso a los recursos se puede controlar mediante esquemas de autorización.
Domain Name Services
El DNS es muy utilizado y es uno de los servicios esenciales en los que funciona Internet. Este sistema asigna direcciones IP a nombres de dominio, que son más fáciles de recordar y recuperar que las direcciones IP. Debido a que la red opera con la ayuda de direcciones IP y los humanos tienden a recordar los nombres de los sitios web, el DNS proporciona la dirección IP del sitio web que se asigna a su nombre desde el back-end cuando el usuario solicita un nombre de sitio web.
Servicios de archivo
Los servicios de archivos incluyen compartir y transferir archivos a través de la red.
File Sharing
Una de las razones que dio origen a la creación de redes fue el intercambio de archivos. El intercambio de archivos permite a sus usuarios compartir sus datos con otros usuarios. El usuario puede cargar el archivo en un servidor específico, al que pueden acceder todos los usuarios previstos. Como alternativa, el usuario puede compartir su archivo en su propia computadora y proporciona acceso a los usuarios previstos.
File Transfer
Esta es una actividad para copiar o mover archivos de una computadora a otra o a varias computadoras, con la ayuda de la red subyacente. La red permite a su usuario localizar a otros usuarios en la red y transferir archivos.
Servicios de comunicación
Email
El correo electrónico es un método de comunicación y un usuario de computadora no puede trabajar sin él. Ésta es la base de las funciones de Internet actuales. El sistema de correo electrónico tiene uno o más servidores de correo electrónico. Todos sus usuarios cuentan con identificaciones únicas. Cuando un usuario envía un correo electrónico a otro usuario, en realidad se transfiere entre usuarios con la ayuda del servidor de correo electrónico.
Social Networking
Las tecnologías recientes han hecho social la vida técnica. Las personas conocedoras de la informática pueden encontrar otras personas o amigos conocidos, pueden conectarse con ellos y pueden compartir pensamientos, imágenes y videos.
Internet Chat
El chat de Internet proporciona servicios de transferencia de texto instantáneo entre dos hosts. Dos o más personas pueden comunicarse entre sí mediante los servicios de chat de retransmisión de Internet basados en texto. En estos días, el chat de voz y el chat de video son muy comunes.
Discussion Boards
Los foros de discusión proporcionan un mecanismo para conectar a varias personas con los mismos intereses. Permite a los usuarios realizar consultas, preguntas, sugerencias, etc., que pueden ser vistas por todos los demás usuarios. Otros también pueden responder.
Remote Access
Este servicio permite al usuario acceder a los datos que residen en la computadora remota. Esta función se conoce como escritorio remoto. Esto se puede hacer a través de algún dispositivo remoto, por ejemplo, un teléfono móvil o una computadora en casa.
Servicios de aplicación
Estos no son más que proporcionar servicios basados en la red a los usuarios, como servicios web, administración de bases de datos y uso compartido de recursos.
Resource Sharing
Para utilizar los recursos de manera eficiente y económica, la red proporciona un medio para compartirlos. Esto puede incluir servidores, impresoras y medios de almacenamiento, etc.
Databases
Este servicio de aplicaciones es uno de los servicios más importantes. Almacena datos e información, los procesa y permite a los usuarios recuperarlos de manera eficiente mediante consultas. Las bases de datos ayudan a las organizaciones a tomar decisiones basadas en estadísticas.
Web Services
World Wide Web se ha convertido en sinónimo de Internet y se utiliza para conectarse a Internet y acceder a archivos y servicios de información proporcionados por los servidores de Internet.