Técnicas de estimación - Guía rápida
Estimation es el proceso de encontrar una estimación o aproximación, que es un valor que puede usarse para algún propósito, incluso si los datos de entrada pueden ser incompletos, inciertos o inestables.
La estimación determina cuánto dinero, esfuerzo, recursos y tiempo tomará construir un sistema o producto específico. La estimación se basa en:
- Datos pasados / experiencia pasada
- Documentos / conocimientos disponibles
- Assumptions
- Riesgos identificados
Los cuatro pasos básicos en la estimación de proyectos de software son:
- Estime el tamaño del producto de desarrollo.
- Estime el esfuerzo en meses-persona u horas-persona.
- Estime el horario en meses calendario.
- Estime el costo del proyecto en la moneda acordada.
Observaciones sobre estimación
La estimación no tiene por qué ser una tarea única en un proyecto. Puede tener lugar durante:
- Adquirir un proyecto.
- Planificación del proyecto.
- Ejecución del Proyecto según surja la necesidad.
El alcance del proyecto debe entenderse antes de que comience el proceso de estimación. Será útil tener datos históricos del proyecto.
Las métricas del proyecto pueden proporcionar una perspectiva histórica y una valiosa información para la generación de estimaciones cuantitativas.
La planificación requiere que los gerentes técnicos y el equipo de software asuman un compromiso inicial, ya que conduce a la responsabilidad y la rendición de cuentas.
La experiencia pasada puede ayudar mucho.
Utilice al menos dos técnicas de estimación para llegar a las estimaciones y conciliar los valores resultantes. Consulte Técnicas de descomposición en la siguiente sección para obtener información sobre la conciliación de estimaciones.
Los planes deben ser iterativos y permitir ajustes a medida que pasa el tiempo y se conocen más detalles.
Enfoque general de estimación de proyectos
El enfoque de estimación de proyectos que se utiliza ampliamente es Decomposition Technique. Las técnicas de descomposición adoptan un enfoque de divide y vencerás. La estimación del tamaño, el esfuerzo y el costo se realiza de manera escalonada dividiendo un proyecto en funciones principales o actividades de ingeniería de software relacionadas.
Step 1 - Comprender el alcance del software a construir.
Step 2 - Genere una estimación del tamaño del software.
Comience con la declaración de alcance.
Descomponga el software en funciones que puedan estimarse individualmente.
Calcula el tamaño de cada función.
Obtenga estimaciones de esfuerzo y costos aplicando los valores de tamaño a sus métricas de productividad de línea base.
Combine estimaciones de funciones para producir una estimación general de todo el proyecto.
Step 3- Generar una estimación del esfuerzo y costo. Puede llegar a las estimaciones de esfuerzo y costos dividiendo un proyecto en actividades de ingeniería de software relacionadas.
Identifique la secuencia de actividades que deben realizarse para que se complete el proyecto.
Divida las actividades en tareas que se puedan medir.
Estime el esfuerzo (horas / días en persona) requerido para completar cada tarea.
Combine estimaciones de esfuerzo de las tareas de actividad para producir una estimación de la actividad.
Obtenga unidades de costo (es decir, costo / esfuerzo unitario) para cada actividad de la base de datos.
Calcule el esfuerzo total y el costo de cada actividad.
Combine estimaciones de esfuerzo y costo para cada actividad para producir una estimación de esfuerzo y costo general para todo el proyecto.
Step 4- Conciliar estimaciones: compare los valores resultantes del Paso 3 con los obtenidos en el Paso 2. Si ambos conjuntos de estimaciones coinciden, sus números son altamente confiables. De lo contrario, si ocurren estimaciones muy divergentes, lleve a cabo una investigación adicional sobre si:
El alcance del proyecto no se comprende adecuadamente o se ha malinterpretado.
El desglose de funciones y / o actividades no es exacto.
Los datos históricos utilizados para las técnicas de estimación no son adecuados para la aplicación, están obsoletos o se han aplicado incorrectamente.
Step 5 - Determine la causa de la divergencia y luego concilie las estimaciones.
Exactitud de la estimación
La precisión es una indicación de qué tan cerca está algo de la realidad. Siempre que genere una estimación, todos quieren saber qué tan cerca están los números de la realidad. Querrá que cada estimación sea lo más precisa posible, dados los datos que tiene en el momento de generarla. Y, por supuesto, no desea presentar una estimación de una manera que inspire una falsa sensación de confianza en los números.
Los factores importantes que afectan la precisión de las estimaciones son:
La precisión de todos los datos de entrada de la estimación.
La precisión de cualquier cálculo estimado.
Qué tan cerca los datos históricos o los datos de la industria utilizados para calibrar el modelo coinciden con el proyecto que está estimando.
La previsibilidad del proceso de desarrollo de software de su organización.
La estabilidad tanto de los requisitos del producto como del entorno que respalda el esfuerzo de ingeniería de software.
Si el proyecto real se planeó, monitoreó y controló cuidadosamente o no, y no ocurrieron sorpresas importantes que causaron retrasos inesperados.
A continuación se presentan algunas pautas para lograr estimaciones confiables:
- Basar las estimaciones en proyectos similares que ya se hayan completado.
- Utilice técnicas de descomposición relativamente simples para generar estimaciones de costos y esfuerzos del proyecto.
- Utilice uno o más modelos de estimación empíricos para la estimación de costos y esfuerzos de software.
Consulte la sección sobre Pautas de estimación en este capítulo.
Para garantizar la precisión, siempre se recomienda realizar una estimación utilizando al menos dos técnicas y comparar los resultados.
Problemas de estimación
A menudo, los gerentes de proyecto recurren a la estimación de horarios saltando al tamaño estimado. Esto puede deberse a los plazos establecidos por la alta dirección o el equipo de marketing. Sin embargo, cualquiera que sea el motivo, si se hace esto, en una etapa posterior sería difícil estimar los programas para adaptarse a los cambios de alcance.
Al realizar la estimación, se pueden hacer ciertas suposiciones. Es importante tener en cuenta todos estos supuestos en la hoja de estimación, ya que algunos todavía no documentan los supuestos en las hojas de estimación.
Incluso las buenas estimaciones tienen supuestos, riesgos e incertidumbre inherentes y, sin embargo, a menudo se tratan como si fueran precisas.
La mejor manera de expresar estimaciones es como un rango de resultados posibles diciendo, por ejemplo, que el proyecto tomará de 5 a 7 meses en lugar de indicar que estará completo en una fecha particular o estará completo en un no fijo. de meses. Tenga cuidado con comprometerse con un rango demasiado estrecho, ya que equivale a comprometerse con una fecha definida.
También puede incluir la incertidumbre como un valor de probabilidad acompañante. Por ejemplo, existe un 90% de probabilidad de que el proyecto se complete en una fecha definida o antes.
Las organizaciones no recopilan datos de proyectos precisos. Dado que la precisión de las estimaciones depende de los datos históricos, sería un problema.
Para cualquier proyecto, existe un cronograma más corto posible que le permitirá incluir la funcionalidad requerida y producir resultados de calidad. Si existe una restricción de programación por parte de la administración y / o el cliente, puede negociar el alcance y la funcionalidad que se entregarán.
Acuerde con el cliente el manejo de los cambios de alcance para evitar sobrecostos.
La falta de acomodación de la contingencia en la estimación final causa problemas. Por ejemplo, reuniones, eventos organizacionales.
La utilización de recursos debe considerarse inferior al 80%. Esto se debe a que los recursos serían productivos solo durante el 80% de su tiempo. Si asigna recursos con más del 80% de utilización, es probable que haya errores.
Directrices de estimación
Uno debe tener en cuenta las siguientes pautas al estimar un proyecto:
Durante la estimación, pregunte las experiencias de otras personas. Además, ponga en práctica sus propias experiencias.
Suponga que los recursos serán productivos solo el 80 por ciento de su tiempo. Por lo tanto, durante la estimación, considere la utilización de recursos como menos del 80%.
Los recursos que trabajan en varios proyectos tardan más en completar las tareas debido al tiempo perdido para cambiar entre ellos.
Incluya el tiempo de gestión en cualquier estimación.
Siempre incorpore la contingencia para la resolución de problemas, reuniones y otros eventos inesperados.
Deje suficiente tiempo para hacer una estimación adecuada del proyecto. Las estimaciones apresuradas son estimaciones inexactas y de alto riesgo. Para grandes proyectos de desarrollo, el paso de estimación debería considerarse realmente como un mini proyecto.
Siempre que sea posible, utilice datos documentados de proyectos anteriores similares de su organización. Dará como resultado la estimación más precisa. Si su organización no ha mantenido datos históricos, ahora es un buen momento para comenzar a recopilarlos.
Utilice estimaciones basadas en desarrolladores, ya que las estimaciones preparadas por personas distintas de las que harán el trabajo serán menos precisas.
Use varias personas diferentes para estimar y use varias técnicas de estimación diferentes.
Concilie las estimaciones. Observe la convergencia o dispersión entre las estimaciones. Convergencia significa que tiene una buena estimación. La técnica de banda ancha-Delphi se puede utilizar para recopilar y discutir estimaciones utilizando un grupo de personas, con la intención de producir una estimación precisa e imparcial.
Vuelva a estimar el proyecto varias veces a lo largo de su ciclo de vida.
UN Function Point(FP) es una unidad de medida para expresar la cantidad de funcionalidad empresarial que un sistema de información (como producto) proporciona a un usuario. Los FP miden el tamaño del software. Son ampliamente aceptados como estándar de la industria para el dimensionamiento funcional.
Para el software de dimensionamiento basado en FP, han surgido varios estándares reconocidos y / o especificaciones públicas. A partir de 2013, estos son:
Normas ISO
COSMIC- ISO / IEC 19761: 2011 Ingeniería de software. Un método de medición de tamaño funcional.
FiSMA - ISO / IEC 29881: 2008 Tecnología de la información - Ingeniería de sistemas y software - Método de medición de tamaño funcional FiSMA 1.1.
IFPUG - ISO / IEC 20926: 2009 Ingeniería de software y sistemas - Medición de software - Método de medición de tamaño funcional IFPUG.
Mark-II - ISO / IEC 20968: 2002 Ingeniería de software - Análisis de puntos de función Ml II - Manual de prácticas de conteo.
NESMA - ISO / IEC 24570: 2005 Ingeniería de software - Método de medición de tamaño de función NESMA versión 2.1 - Definiciones y pautas de conteo para la aplicación del Análisis de puntos de función.
Especificación del grupo de administración de objetos para el punto de función automatizado
Object Management Group (OMG), un consorcio de estándares de la industria informática sin fines de lucro y de membresía abierta, ha adoptado la especificación Automated Function Point (AFP) dirigida por el Consortium for IT Software Quality. Proporciona un estándar para automatizar el recuento de FP de acuerdo con las directrices del International Function Point User Group (IFPUG).
Function Point Analysis (FPA) techniquecuantifica las funciones contenidas en el software en términos significativos para los usuarios del software. Los FP consideran el número de funciones que se están desarrollando en función de la especificación de requisitos.
Function Points (FP) Countingse rige por un conjunto estándar de reglas, procesos y directrices definidos por el Grupo Internacional de Usuarios de Puntos de Función (IFPUG). Estos se publican en el Manual de prácticas de recuento (CPM).
Historia del análisis de puntos de función
El concepto de Puntos de Función fue introducido por Alan Albrecht de IBM en 1979. En 1984, Albrecht refinó el método. Las primeras Directrices de puntos de función se publicaron en 1984. El Grupo internacional de usuarios de puntos de función (IFPUG) es una organización mundial de usuarios de software de métricas de análisis de puntos de función con sede en EE.UU. losInternational Function Point Users Group (IFPUG)es una organización sin fines de lucro, gobernada por miembros fundada en 1986. IFPUG posee el Análisis de Puntos de Función (FPA) como se define en la norma ISO 20296: 2009 que especifica las definiciones, reglas y pasos para aplicar el método de medición de tamaño funcional (FSM) de IFPUG. IFPUG mantiene el Manual de prácticas de recuento de puntos de función (CPM). CPM 2.0 se lanzó en 1987 y desde entonces ha habido varias iteraciones. La versión 4.3 de CPM fue en 2010.
La versión 4.3.1 de CPM con revisiones editoriales de ISO incorporadas fue en 2010. La Norma ISO (IFPUG FSM) - Medición de tamaño funcional que forma parte de CPM 4.3.1 es una técnica para medir el software en términos de la funcionalidad que ofrece. El CPM es un estándar aprobado internacionalmente según ISO / IEC 14143-1 Tecnología de la información - Medición de software.
Proceso elemental (EP)
El proceso elemental es la unidad más pequeña de requisito de usuario funcional que:
- Es significativo para el usuario.
- Constituye una transacción completa.
- Es autónomo y deja el negocio de la aplicación contado en un estado consistente.
Funciones
Hay dos tipos de funciones:
- Funciones de datos
- Funciones de transacción
Funciones de datos
Hay dos tipos de funciones de datos:
- Archivos lógicos internos
- Archivos de interfaz externa
Las funciones de datos se componen de recursos internos y externos que afectan al sistema.
Internal Logical Files
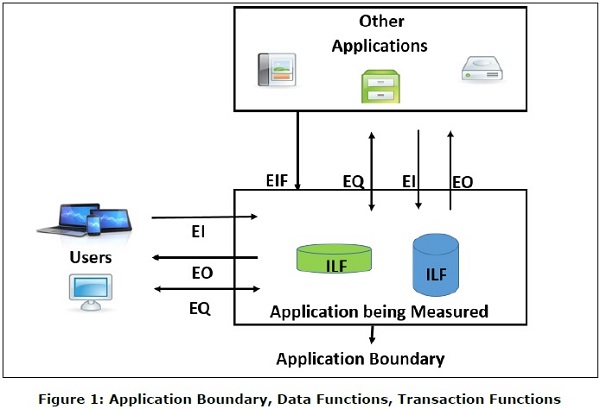
El archivo lógico interno (ILF) es un grupo identificable por el usuario de datos relacionados lógicamente o información de control que reside por completo dentro de los límites de la aplicación. La intención principal de un ILF es mantener los datos mantenidos a través de uno o más procesos elementales de la aplicación que se cuenta. Un ILF tiene el significado inherente de que se mantiene internamente, tiene alguna estructura lógica y se almacena en un archivo. (Consulte la Figura 1)
External Interface Files
El archivo de interfaz externa (EIF) es un grupo identificable por el usuario de datos relacionados lógicamente o información de control que la aplicación utiliza solo con fines de referencia. Los datos residen completamente fuera del límite de la aplicación y otra aplicación los mantiene en un ILF. Un EIF tiene el significado inherente de que se mantiene externamente, se debe desarrollar una interfaz para obtener los datos del archivo. (Consulte la Figura 1)
Funciones de transacción
Hay tres tipos de funciones de transacción.
- Entradas externas
- Salidas externas
- Consultas externas
Las funciones de transacción se componen de los procesos que se intercambian entre el usuario, las aplicaciones externas y la aplicación que se mide.
External Inputs
La entrada externa (EI) es una función de transacción en la que los datos "ingresan" a la aplicación desde fuera del límite hacia adentro. Estos datos son externos a la aplicación.
- Los datos pueden provenir de una pantalla de entrada de datos u otra aplicación.
- Una EI es la forma en que una aplicación obtiene información.
- Los datos pueden ser información de control o información comercial.
- Los datos se pueden utilizar para mantener uno o más archivos lógicos internos.
- Si los datos son información de control, no es necesario actualizar un archivo lógico interno. (Consulte la Figura 1)
External Outputs
La salida externa (EO) es una función de transacción en la que los datos "salen" del sistema. Además, un EO puede actualizar un ILF. Los datos crean informes o archivos de salida enviados a otras aplicaciones. (Consulte la Figura 1)
External Inquiries
La consulta externa (EQ) es una función de transacción con componentes de entrada y salida que dan como resultado la recuperación de datos. (Consulte la Figura 1)
Definición de RET, DET, FTR
Tipo de elemento de registro
Un tipo de elemento de registro (RET) es el subgrupo más grande de elementos identificables por el usuario dentro de un ILF o un EIF. Es mejor observar agrupaciones lógicas de datos para ayudar a identificarlos.
Tipo de elemento de datos
El tipo de elemento de datos (DET) es el subgrupo de datos dentro de un FTR. Son únicos e identificables por el usuario.
Tipo de archivo al que se hace referencia
El tipo de archivo referenciado (FTR) es el subgrupo identificable de usuario más grande dentro del EI, EO o EQ al que se hace referencia.
Las funciones de transacción EI, EO, EQ se miden contando los FTR y DET que contienen siguiendo las reglas de recuento. Asimismo, las funciones de datos ILF y EIF se miden contando los DET y RET que contienen siguiendo las reglas de recuento. Las medidas de las funciones de transacción y las funciones de datos se utilizan en el recuento FP que da como resultado el tamaño funcional o los puntos de función.
El proceso de conteo de FP incluye los siguientes pasos:
Step 1 - Determinar el tipo de conteo.
Step 2 - Determinar el límite del conteo.
Step 3 - Identificar cada Proceso Elemental (EP) requerido por el usuario.
Step 4 - Determinar los EP únicos.
Step 5 - Funciones de datos de medida.
Step 6 - Medir funciones transaccionales.
Step 7 - Calcular el tamaño funcional (cuenta de puntos de función no ajustada).
Step 8 - Determinar el factor de ajuste de valor (VAF).
Step 9 - Calcular el recuento de puntos de función ajustados.
Note- Las características generales del sistema (GSC) se hacen opcionales en la RPC 4.3.1 y se trasladan al Apéndice. Por lo tanto, se pueden omitir los pasos 8 y 9.
Paso 1: determinar el tipo de conteo
Hay tres tipos de recuentos de puntos de función:
- Cuenta de puntos de la función de desarrollo
- Cuenta de puntos de función de aplicación
- Cuenta de puntos de función de mejora
Cuenta de puntos de la función de desarrollo
Los puntos de función se pueden contar en todas las fases de un proyecto de desarrollo, desde el requisito hasta la etapa de implementación. Este tipo de recuento está asociado con un nuevo trabajo de desarrollo y puede incluir los prototipos, que pueden haber sido necesarios como solución temporal, que respalda el esfuerzo de conversión. Este tipo de recuento se denomina recuento de puntos de función de línea base.
Cuenta de puntos de función de aplicación
Los recuentos de aplicaciones se calculan como los puntos de función entregados y excluyen cualquier esfuerzo de conversión (prototipos o soluciones temporales) y la funcionalidad existente que pueda haber existido.
Cuenta de puntos de función de mejora
Cuando se realizan cambios en el software después de la producción, se consideran mejoras. Para dimensionar dichos proyectos de mejora, el recuento de puntos de función se agrega, cambia o elimina en la aplicación.
Paso 2: determinar el límite del conteo
El límite indica el límite entre la aplicación que se mide y las aplicaciones externas o el dominio del usuario. (Consulte la Figura 1)
Para determinar el límite, comprenda:
- El propósito del recuento de puntos de función
- Alcance de la aplicación que se mide
- Cómo y qué aplicaciones mantienen qué datos
- Las áreas de negocio que dan soporte a las aplicaciones
Paso 3: identificar cada proceso elemental requerido por el usuario
Componga y / o descomponga los requisitos funcionales del usuario en la unidad más pequeña de actividad, que satisfaga todos los siguientes criterios:
- Es significativo para el usuario.
- Constituye una transacción completa.
- Es autónomo.
- Deja que el negocio de la aplicación se cuente en un estado coherente.
Por ejemplo, el Requisito de usuario funcional: "Mantener la información del empleado" se puede descomponer en actividades más pequeñas, como agregar empleado, cambiar empleado, eliminar empleado y preguntar sobre empleado.
Cada unidad de actividad así identificada es un Proceso Elemental (EP).
Paso 4: Determine los procesos elementales únicos
Comparando dos EP ya identificados, cuéntelos como un EP (mismo EP) si:
- Requiere el mismo conjunto de DET.
- Requiere el mismo conjunto de FTR.
- Requiere el mismo conjunto de lógica de procesamiento para completar el EP.
No divida un EP con múltiples formas de lógica de procesamiento en múltiples Eps.
Por ejemplo, si ha identificado 'Agregar empleado' como un EP, no debe dividirse en dos EP para tener en cuenta el hecho de que un empleado puede tener o no dependientes. El EP sigue siendo 'Agregar empleado', y hay variaciones en la lógica de procesamiento y los DET para contabilizar a los dependientes.
Paso 5: Funciones de datos de medición
Clasifique cada función de datos como ILF o EIF.
Una función de datos se clasificará como:
Archivo lógico interno (ILF), si lo mantiene la aplicación que se mide.
Archivo de interfaz externa (EIF) si se hace referencia a él, pero no lo mantiene la aplicación que se mide.
Los ILF y EIF pueden contener datos comerciales, datos de control y datos basados en reglas. Por ejemplo, la conmutación telefónica se compone de los tres tipos: datos comerciales, datos de reglas y datos de control. Los datos comerciales son la llamada real. Los datos de reglas son cómo se debe enrutar la llamada a través de la red y los datos de control son cómo los conmutadores se comunican entre sí.
Considere la siguiente documentación para contar ILF y EIF:
- Objetivos y limitaciones del sistema propuesto.
- Documentación sobre el sistema actual, si existe.
- Documentación de los objetivos, problemas y necesidades percibidos por los usuarios.
- Modelos de datos.
Paso 5.1: Cuente los DET para cada función de datos
Aplique las siguientes reglas para contar DET para ILF / EIF -
Cuente un DET para cada campo no repetido identificable de usuario único mantenido o recuperado de ILF o EIF a través de la ejecución de un EP.
Cuente solo los DET que utiliza la aplicación que se miden cuando dos o más aplicaciones mantienen y / o hacen referencia a la misma función de datos.
Cuente un DET por cada atributo requerido por el usuario para establecer una relación con otro ILF o EIF.
Revise los atributos relacionados para determinar si están agrupados y contados como un DET único o si se cuentan como varios DET. La agrupación dependerá de cómo los EP utilicen los atributos dentro de la aplicación.
Paso 5.2: Cuente los RET para cada función de datos
Aplique las siguientes reglas para contar RET para ILF / EIF -
- Cuente un RET para cada función de datos.
- Cuente un RET adicional para cada uno de los siguientes subgrupos lógicos adicionales de DET.
- Entidad asociativa con atributos no clave.
- Subtipo (distinto del primer subtipo).
- Entidad atributiva, en una relación distinta a la obligatoria 1: 1.
Paso 5.3: Determine la complejidad funcional de cada función de datos
| RETS | Tipos de elementos de datos (DET) | ||
|---|---|---|---|
| 1-19 | 20-50 | >50 | |
| 1 | L | L | UN |
| 2 hasta 5 | L | UN | H |
| > 5 | UN | H | H |
Complejidad funcional: L = Bajo; A = Promedio; H = Alto
Paso 5.4: medir el tamaño funcional de cada función de datos
| Complejidad funcional | Recuento de FP para ILF | Recuento de FP para EIF |
|---|---|---|
| Bajo | 7 | 5 |
| Promedio | 10 | 7 |
| Alto | 15 | 10 |
Paso 6: medir las funciones transaccionales
Para medir las funciones transaccionales, los siguientes son los pasos necesarios:
Paso 6.1: Clasifique cada función transaccional
Las funciones transaccionales deben clasificarse como una entrada externa, una salida externa o una consulta externa.
Entrada externa
La entrada externa (EI) es un proceso elemental que procesa datos o información de control que proviene de fuera del límite. La intención principal de un EI es mantener uno o más ILF y / o alterar el comportamiento del sistema.
Deben aplicarse todas las siguientes reglas:
Los datos o la información de control se reciben desde fuera del límite de la aplicación.
Se mantiene al menos un ILF si los datos que ingresan al límite no son información de control que altera el comportamiento del sistema.
Para el PE identificado, debe aplicarse una de las tres declaraciones:
La lógica de procesamiento es única de la lógica de procesamiento realizada por otros EI para la aplicación.
El conjunto de elementos de datos identificados es diferente de los conjuntos identificados para otras IE en la aplicación.
Los ILF o EIF a los que se hace referencia son diferentes de los archivos a los que hacen referencia los otros EI en la aplicación.
Salida externa
La salida externa (EO) es un proceso elemental que envía datos o información de control fuera de los límites de la aplicación. EO incluye procesamiento adicional más allá del de una consulta externa.
La intención principal de una EO es presentar información a un usuario a través de una lógica de procesamiento que no sea o además de la recuperación de datos o información de control.
La lógica de procesamiento debe:
- Contener al menos una fórmula matemática o cálculo.
- Crea datos derivados.
- Mantenga uno o más ILF.
- Altere el comportamiento del sistema.
Deben aplicarse todas las siguientes reglas:
- Envía datos o información de control externa al límite de la aplicación.
- Para el PE identificado, debe aplicarse una de las tres declaraciones:
- La lógica de procesamiento es única de la lógica de procesamiento realizada por otros EO para la aplicación.
- El conjunto de elementos de datos identificados es diferente de otros EO en la aplicación.
- Los ILF o EIF a los que se hace referencia son diferentes de los archivos a los que hacen referencia otros EO en la aplicación.
Además, se debe aplicar una de las siguientes reglas:
- La lógica de procesamiento contiene al menos una fórmula matemática o cálculo.
- La lógica de procesamiento mantiene al menos un ILF.
- La lógica de procesamiento altera el comportamiento del sistema.
Consulta externa
La consulta externa (EQ) es un proceso elemental que envía datos o información de control fuera de los límites. La intención principal de un EQ es presentar información al usuario mediante la recuperación de datos o información de control.
La lógica de procesamiento no contiene fórmulas ni cálculos matemáticos y no crea datos derivados. No se mantiene ILF durante el procesamiento, ni se altera el comportamiento del sistema.
Deben aplicarse todas las siguientes reglas:
- Envía datos o información de control externa al límite de la aplicación.
- Para el PE identificado, debe aplicarse una de las tres declaraciones:
- La lógica de procesamiento es única de la lógica de procesamiento realizada por otros EQ para la aplicación.
- El conjunto de elementos de datos identificados es diferente de otros EQ en la aplicación.
- Los ILF o EIF a los que se hace referencia son diferentes de los archivos a los que hacen referencia otros EQ en la aplicación.
Además, se deben aplicar todas las siguientes reglas:
- La lógica de procesamiento recupera datos o información de control de un ILF o EIF.
- La lógica de procesamiento no contiene fórmulas matemáticas ni cálculos.
- La lógica de procesamiento no altera el comportamiento del sistema.
- La lógica de procesamiento no mantiene un ILF.
Paso 6.2: Cuente los DET para cada función transaccional
Aplique las siguientes reglas para contar DET para EI:
Revise todo lo que cruza (entra y / o sale) del límite.
Cuente un DET por cada atributo no repetido, identificable de usuario único que cruza (entra y / o sale) del límite durante el procesamiento de la función transaccional.
Cuente solo un DET por función transaccional para poder enviar un mensaje de respuesta de la aplicación, incluso si hay varios mensajes.
Cuente solo un DET por función transaccional para la capacidad de iniciar acciones, incluso si hay varios medios para hacerlo.
No cuente los siguientes elementos como DET:
Atributos generados dentro del límite por una función transaccional y guardados en un ILF sin salir del límite.
Literales como títulos de informes, identificadores de pantallas o paneles, encabezados de columnas y títulos de atributos.
Sellos generados por la aplicación, como atributos de fecha y hora.
Variables de paginación, números de página e información de posicionamiento, por ejemplo, 'Filas 37 a 54 de 211'.
Ayudas a la navegación, como la capacidad de navegar dentro de una lista usando "anterior", "siguiente", "primero", "último" y sus equivalentes gráficos.
Aplique las siguientes reglas para contar DET para EO / EQ:
Revise todo lo que cruza (entra y / o sale) del límite.
Cuente un DET por cada atributo no repetido, identificable de usuario único que cruza (entra y / o sale) del límite durante el procesamiento de la función transaccional.
Cuente solo un DET por función transaccional para poder enviar un mensaje de respuesta de la aplicación, incluso si hay varios mensajes.
Cuente solo un DET por función transaccional para la capacidad de iniciar acciones, incluso si hay varios medios para hacerlo.
No cuente los siguientes elementos como DET:
Atributos generados dentro del límite sin cruzar el límite.
Literales como títulos de informes, identificadores de pantallas o paneles, encabezados de columnas y títulos de atributos.
Sellos generados por la aplicación, como atributos de fecha y hora.
Variables de paginación, números de página e información de posicionamiento, por ejemplo, 'Filas 37 a 54 de 211'.
Ayudas a la navegación, como la capacidad de navegar dentro de una lista usando "anterior", "siguiente", "primero", "último" y sus equivalentes gráficos.
Paso 6.3: Cuente los FTR para cada función transaccional
Aplique las siguientes reglas para contar FTR para EI:
- Cuente un FTR por cada ILF mantenido.
- Cuente un FTR por cada ILF o EIF leído durante el procesamiento del EI.
- Cuente solo un FTR por cada ILF que se mantenga y se lea.
Aplique la siguiente regla para contar FTR para EO / EQ:
- Cuente un FTR por cada ILF o EIF leído durante el procesamiento de EP.
Además, aplique las siguientes reglas para contar FTR para EO:
- Cuente un FTR por cada ILF mantenido durante el procesamiento de EP.
- Cuente solo un FTR por cada ILF que EP mantiene y lee.
Paso 6.4: Determine la complejidad funcional de cada función transaccional
| FTR | Tipos de elementos de datos (DET) | ||
|---|---|---|---|
| 1-4 | 5-15 | >=16 | |
| 0-1 | L | L | UN |
| 2 | L | UN | H |
| > = 3 | UN | H | H |
Complejidad funcional: L = Bajo; A = Promedio; H = Alto
Determine la complejidad funcional de cada EO / EQ, con la excepción de que el EQ debe tener un mínimo de 1 FTR -
EQ debe tener un mínimo de 1 FTR FTR |
Tipos de elementos de datos (DET) | ||
|---|---|---|---|
| 1-4 | 5-15 | > = 16 | |
| 0-1 | L | L | UN |
| 2 | L | UN | H |
| > = 3 | UN | H | H |
Complejidad funcional: L = Bajo; A = Promedio; H = Alto
Paso 6.5: Medir el tamaño funcional de cada función transaccional
Mida el tamaño funcional de cada IE a partir de su complejidad funcional.
| Complejidad | Cuenta FP |
|---|---|
| Bajo | 3 |
| Promedio | 4 |
| Alto | 6 |
Mida el tamaño funcional de cada EO / EQ a partir de su complejidad funcional.
| Complejidad | Recuento de FP para EO | FP Count para EQ |
|---|---|---|
| Bajo | 4 | 3 |
| Promedio | 5 | 4 |
| Alto | 6 | 6 |
Paso 7: Calcule el tamaño funcional (recuento de puntos de función no ajustados)
Para calcular el tamaño funcional, se deben seguir los pasos que se detallan a continuación:
Paso 7.1
Recuerde lo que encontró en el Paso 1. Determine el tipo de conteo.
Paso 7.2
Calcule el tamaño funcional o el recuento de puntos de función según el tipo.
- Para el recuento de puntos de la función de desarrollo, vaya al paso 7.3.
- Para el recuento de puntos de función de la aplicación, vaya al paso 7.4.
- Para el recuento de puntos de la función de mejora, vaya al paso 7.5.
Paso 7.3
El recuento de puntos de la función de desarrollo consta de dos componentes de funcionalidad:
Funcionalidad de la aplicación incluida en los requisitos del usuario para el proyecto.
Funcionalidad de conversión incluida en los requisitos del usuario para el proyecto. La funcionalidad de conversión consta de funciones proporcionadas solo en la instalación para convertir datos y / o proporcionar otros requisitos de conversión especificados por el usuario, como informes de conversión especiales. Por ejemplo, una aplicación existente puede ser reemplazada por un nuevo sistema.
DFP = ADD + CFP
Dónde,
DFP = Cuenta de puntos de la función de desarrollo
ADD = Tamaño de las funciones entregadas al usuario por el proyecto de desarrollo
CFP = Tamaño de la función de conversión
ADD = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
CFP = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
Paso 7.4
Calcular el recuento de puntos de la función de aplicación
AFP = ADD
Dónde,
AFP = Cuenta de puntos de la función de aplicación
ADD = Tamaño de las funciones entregadas al usuario por el proyecto de desarrollo (excluyendo el tamaño de cualquier funcionalidad de conversión), o la funcionalidad que existe cada vez que se cuenta la aplicación.
ADD = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
Paso 7.5
El recuento de puntos de la función de mejora considera los siguientes cuatro componentes de funcionalidad:
- Funcionalidad que se agrega a la aplicación.
- Funcionalidad que se modifica en la Aplicación.
- Funcionalidad de conversión.
- Funcionalidad que se elimina de la aplicación.
EFP = ADD + CHGA + CFP + DEL
Dónde,
EFP = Cuenta de puntos de función de mejora
ADD = Tamaño de las funciones agregadas por el proyecto de mejora
CHGA = Tamaño de las funciones que cambia el proyecto de mejora
CFP = Tamaño de la función de conversión
DEL = Tamaño de las funciones eliminadas por el proyecto de mejora
ADD = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
CHGA = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
CFP = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
DEL = Conteo FP (ILF) + Conteo FP (EIF) + Conteo FP (EI) + Conteo FP (EO) + Conteo FP (EQ)
Paso 8: Determine el factor de ajuste del valor
Las GSC se hacen opcionales en la RPC 4.3.1 y se trasladan al Apéndice. Por lo tanto, se pueden omitir los pasos 8 y 9.
El factor de ajuste de valor (VAF) se basa en 14 GSC que califican la funcionalidad general de la aplicación que se cuenta. Las GSC son restricciones comerciales de los usuarios independientes de la tecnología. Cada característica tiene descripciones asociadas para determinar el grado de influencia.
| Característica general del sistema | Breve descripción |
|---|---|
| Transmisión de datos | ¿Cuántas facilidades de comunicación existen para ayudar en la transferencia o intercambio de información con la aplicación o sistema? |
| Procesamiento de datos distribuidos | ¿Cómo se manejan los datos distribuidos y las funciones de procesamiento? |
| Actuación | ¿El usuario requirió tiempo de respuesta o rendimiento? |
| Configuración muy utilizada | ¿Qué tan utilizada es la plataforma de hardware actual donde se ejecutará la aplicación? |
| Tasa de transacción | ¿Con qué frecuencia se ejecutan las transacciones diaria, semanal, mensual, etc.? |
| Entrada de datos en línea | ¿Qué porcentaje de la información se ingresa en línea? |
| Eficiencia del usuario final | ¿La aplicación fue diseñada para la eficiencia del usuario final? |
| Actualización en línea | ¿Cuántos ILF se actualizan mediante transacción en línea? |
| Procesamiento complejo | ¿La aplicación tiene un procesamiento lógico o matemático extenso? |
| Reutilización | ¿Se desarrolló la aplicación para satisfacer las necesidades de uno o varios usuarios? |
| Facilidad de instalación | ¿Qué tan difícil es la conversión y la instalación? |
| Facilidad operativa | ¿Qué tan efectivos y / o automatizados son los procedimientos de puesta en marcha, respaldo y recuperación? |
| Varios sitios | ¿La aplicación fue diseñada, desarrollada y soportada específicamente para ser instalada en múltiples sitios para múltiples organizaciones? |
| Facilitar el cambio | ¿La aplicación fue diseñada, desarrollada y respaldada específicamente para facilitar el cambio? |
El rango del grado de influencia está en una escala de cero a cinco, desde ninguna influencia hasta una influencia fuerte.
| Clasificación | Grado de influencia |
|---|---|
| 0 | No presente o sin influencia |
| 1 | Influencia incidental |
| 2 | Influencia moderada |
| 3 | Influencia media |
| 4 | Influencia significativa |
| 5 | Fuerte influencia en todo |
Determine el grado de influencia de cada una de las 14 CMS.
La suma de los valores de las 14 GSC así obtenidas se denomina Grado total de influencia (TDI).
TDI = ∑14 Degrees of Influence
A continuación, calcule el factor de ajuste de valor (VAF) como
VAF = (TDI × 0.01) + 0.65
Cada GSC puede variar de 0 a 5, el TDI puede variar de (0 × 14) a (5 × 14), es decir, 0 (cuando todas las GSC son bajas) a 70 (cuando todas las GSC son altas) es decir, 0 ≤ TDI ≤ 70. Por lo tanto, VAF puede variar en el rango de 0.65 (cuando todas las GSC son bajas) a 1.35 (cuando todas las GSC son altas), es decir, 0.65 ≤ VAF ≤ 1.35.
Paso 9: Calcular el recuento de puntos de la función ajustada
Según el enfoque de FPA que utiliza VAF (versiones de CPM antes de V4.3.1), esto está determinado por,
Adjusted FP Count = Unadjusted FP Count × VAF
Donde, el recuento de FP no ajustado es el tamaño funcional que ha calculado en el Paso 7.
Como la VAF puede variar de 0,65 a 1,35, la VAF ejerce una influencia de ± 35% en el recuento final ajustado de FP.
Beneficios de los puntos de función
Los puntos de función son útiles:
Al medir el tamaño de la solución en lugar del tamaño del problema.
Los requisitos son lo único que se necesita para que los puntos de función cuenten.
Ya que es independiente de la tecnología.
Ya que es independiente de los lenguajes de programación.
En la estimación de proyectos de prueba.
Al estimar los costos, el cronograma y el esfuerzo generales del proyecto.
En negociaciones de contratos, ya que proporciona un método de comunicación más fácil con grupos empresariales.
Como cuantifica y asigna un valor a los usos, interfaces y propósitos reales de las funciones en el software.
Al crear ratios con otras métricas, como horas, costo, plantilla, duración y otras métricas de la aplicación.
Repositorios FP
International Software Benchmarking Standards Group (ISBSG) crece y mantiene dos repositorios de datos de TI.
- Proyectos de desarrollo y mejora
- Aplicaciones de mantenimiento y soporte
Hay más de 6.000 proyectos en el repositorio de Proyectos de Desarrollo y Mejora.
Los datos se entregan en formato Microsoft Excel, lo que facilita el análisis posterior que desee realizar con ellos, o incluso puede utilizar los datos para algún otro propósito.
La licencia del repositorio de ISBSG se puede adquirir en: http://www.isbsg.com/
ISBSG ofrece un 10% de descuento para los miembros de IFPUG para compras en línea cuando se utiliza el código de descuento "IFPUGMembers".
Las actualizaciones de la versión de datos del proyecto de software de ISBSG se pueden encontrar en: http://www.ifpug.org/isbsg/
COSMIC e IFPUG colaboraron para producir un glosario de términos para software no funcional y requisitos del proyecto. Se puede descargar de - cosmic-sizing.org
UN Use-Case es una serie de interacciones relacionadas entre un usuario y un sistema que permite al usuario alcanzar un objetivo.
Los casos de uso son una forma de capturar los requisitos funcionales de un sistema. El usuario del sistema se denomina "Actor". Los casos de uso están fundamentalmente en forma de texto.
Puntos de casos de uso: definición
Use-Case Points (UCP)es una técnica de estimación de software que se utiliza para medir el tamaño del software con casos de uso. El concepto de UCP es similar a los FP.
El número de UCP en un proyecto se basa en lo siguiente:
- El número y la complejidad de los casos de uso en el sistema.
- El número y complejidad de los actores del sistema.
Varios requisitos no funcionales (como portabilidad, rendimiento, mantenibilidad) que no están escritos como casos de uso.
El entorno en el que se desarrollará el proyecto (como el idioma, la motivación del equipo, etc.)
La estimación con UCP requiere que todos los casos de uso se escriban con un objetivo y aproximadamente al mismo nivel, dando la misma cantidad de detalles. Por lo tanto, antes de la estimación, el equipo del proyecto debe asegurarse de haber escrito sus casos de uso con objetivos definidos y en un nivel detallado. El caso de uso normalmente se completa en una sola sesión y una vez que se logra el objetivo, el usuario puede continuar con alguna otra actividad.
Historial de puntos de casos de uso
Gustav Karner introdujo el método de estimación de puntos de casos de uso en 1993. Posteriormente, el trabajo obtuvo la licencia de Rational Software que se fusionó con IBM.
Proceso de recuento de puntos de casos de uso
El proceso de recuento de puntos de casos de uso tiene los siguientes pasos:
- Calcular UCP no ajustados
- Ajuste para la complejidad técnica
- Ajuste para la complejidad ambiental
- Calcular UCP ajustados
Paso 1: Calcule los puntos de casos de uso no ajustados.
Primero calcula los puntos de casos de uso no ajustados mediante los siguientes pasos:
- Determine el peso del caso de uso no ajustado
- Determine el peso del actor no ajustado
- Calcular puntos de casos de uso no ajustados
Step 1.1 - Determine el peso de caso de uso no ajustado.
Step 1.1.1 - Encuentre el número de transacciones en cada caso de uso.
Si los casos de uso se escriben con niveles de objetivo de usuario, una transacción equivale a un paso en el caso de uso. Encuentre el número de transacciones contando los pasos en el caso de uso.
Step 1.1.2- Clasifique cada caso de uso como simple, promedio o complejo en función del número de transacciones en el caso de uso. Además, asigne el peso del caso de uso como se muestra en la siguiente tabla:
| Complejidad de casos de uso | Numero de transacciones | Peso del caso de uso |
|---|---|---|
| Simple | ≤3 | 5 |
| Promedio | 4 a 7 | 10 |
| Complejo | > 7 | 15 |
Step 1.1.3- Repita para cada caso de uso y obtenga todos los pesos de los casos de uso. El peso de caso de uso no ajustado (UUCW) es la suma de todos los pesos de caso de uso.
Step 1.1.4 - Busque el peso de caso de uso no ajustado (UUCW) utilizando la siguiente tabla -
| Complejidad de casos de uso | Peso del caso de uso | Número de casos de uso | Producto |
|---|---|---|---|
| Simple | 5 | NSUC | 5 × NSUC |
| Promedio | 10 | NAUC | 10 × NAUC |
| Complejo | 15 | NCUC | 15 × NCUC |
| Unadjusted Use-Case Weight (UUCW) | 5 × NSUC + 10 × NAUC + 15 × NCUC | ||
Dónde,
NSUC es el no. de casos de uso simples.
NAUC es el no. de casos de uso promedio.
NCUC es el no. de casos de uso complejos.
Step 1.2 - Determine el peso del actor no ajustado.
Un actor en un caso de uso puede ser una persona, otro programa, etc. Algunos actores, como un sistema con API definida, tienen necesidades muy simples y aumentan la complejidad de un caso de uso solo ligeramente.
Algunos actores, como un sistema que interactúa a través de un protocolo, tienen más necesidades y aumentan la complejidad de un caso de uso hasta cierto punto.
Otros actores, como un usuario que interactúa a través de la GUI, tienen un impacto significativo en la complejidad de un caso de uso. Con base en estas diferencias, puede clasificar a los actores como simples, promedio y complejos.
Step 1.2.1 - Clasifique a los actores como simples, promedio y complejos y asigne pesos de actores como se muestra en la siguiente tabla -
| Complejidad del actor | Ejemplo | Peso del actor |
|---|---|---|
| Simple | Un sistema con API definida | 1 |
| Promedio | Un sistema que interactúa a través de un protocolo | 2 |
| Complejo | Un usuario que interactúa a través de la GUI | 3 |
Step 1.2.2- Repita para cada actor y obtenga todos los pesos de actor. El peso de actor no ajustado (UAW) es la suma de todos los pesos de actor.
Step 1.2.3 - Encuentre el peso del actor no ajustado (UAW) usando la siguiente tabla -
| Complejidad del actor | Peso del actor | Número de actores | Producto |
|---|---|---|---|
| Simple | 1 | NSA | 1 × NSA |
| Promedio | 2 | NAA | 2 × NAA |
| Complejo | 3 | NCA | 3 × NCA |
| Unadjusted Actor Weight (UAW) | 1 × NSA + 2 × NAA + 3 × NCA | ||
Dónde,
NSA es el no. de actores simples.
NAA es el no. de actores promedio.
NCA es el no. de actores complejos.
Step 1.3 - Calcular puntos de casos de uso no ajustados.
El peso del caso de uso no ajustado (UUCW) y el peso del actor no ajustado (UAW) juntos dan el tamaño no ajustado del sistema, lo que se conoce como puntos de caso de uso no ajustados.
Unadjusted Use-Case Points (UUCP) = UUCW + UAW
Los siguientes pasos son ajustar los puntos de casos de uso no ajustados (UUCP) para la complejidad técnica y la complejidad ambiental.
Paso 2: ajuste para la complejidad técnica
Step 2.1 - Considere los 13 factores que contribuyen al impacto de la complejidad técnica de un proyecto en los puntos de casos de uso y sus correspondientes ponderaciones, como se indica en la siguiente tabla -
| Factor | Descripción | Peso |
|---|---|---|
| T1 | Sistema distribuido | 2.0 |
| T2 | Objetivos de rendimiento de rendimiento o tiempo de respuesta | 1.0 |
| T3 | Eficiencia del usuario final | 1.0 |
| T4 | Procesamiento interno complejo | 1.0 |
| T5 | El código debe ser reutilizable | 1.0 |
| T6 | Fácil de instalar | .5 |
| T7 | Fácil de usar | .5 |
| T8 | Portátil | 2.0 |
| T9 | Fácil de cambiar | 1.0 |
| T10 | Concurrente | 1.0 |
| T11 | Incluye objetivos de seguridad especiales | 1.0 |
| T12 | Proporciona acceso directo a terceros | 1.0 |
| T13 | Se requieren instalaciones especiales para la formación de usuarios | 1.0 |
Muchos de estos factores representan los requisitos no funcionales del proyecto.
Step 2.2 - Para cada uno de los 13 Factores, evalúe el proyecto y califíquelo de 0 (irrelevante) a 5 (muy importante).
Step 2.3 - Calcule el impacto del factor a partir del peso de impacto del factor y el valor nominal del proyecto como
Impact of the Factor = Impact Weight × Rated Value
Step (2.4)- Calcular la suma del Impacto de todos los Factores. Esto da el factor técnico total (TFactor) como se indica en la tabla a continuación:
| Factor | Descripción | Peso (W) | Valor nominal (0 a 5) (RV) | Impacto (I = W × RV) |
|---|---|---|---|---|
| T1 | Sistema distribuido | 2.0 | ||
| T2 | Objetivos de rendimiento de rendimiento o tiempo de respuesta | 1.0 | ||
| T3 | Eficiencia del usuario final | 1.0 | ||
| T4 | Procesamiento interno complejo | 1.0 | ||
| T5 | El código debe ser reutilizable | 1.0 | ||
| T6 | Fácil de instalar | .5 | ||
| T7 | Fácil de usar | .5 | ||
| T8 | Portátil | 2.0 | ||
| T9 | Fácil de cambiar | 1.0 | ||
| T10 | Concurrente | 1.0 | ||
| T11 | Incluye objetivos de seguridad especiales | 1.0 | ||
| T12 | Proporciona acceso directo a terceros | 1.0 | ||
| T13 | Se requieren instalaciones especiales para la formación de usuarios | 1.0 | ||
| Total Technical Factor (TFactor) | ||||
Step 2.5 - Calcule el factor de complejidad técnica (TCF) como -
TCF = 0.6 + (0.01 × TFactor)
Paso 3: ajuste para la complejidad ambiental
Step 3.1 - Considere los 8 Factores Ambientales que podrían afectar la ejecución del proyecto y sus correspondientes Pesos como se indica en la siguiente tabla -
| Factor | Descripción | Peso |
|---|---|---|
| F1 | Familiarizado con el modelo de proyecto que se utiliza | 1,5 |
| F2 | Experiencia de aplicación | .5 |
| F3 | Experiencia orientada a objetos | 1.0 |
| F4 | Capacidad de analista principal | .5 |
| F5 | Motivación | 1.0 |
| F6 | Requisitos estables | 2.0 |
| F7 | Personal a tiempo parcial | -1,0 |
| F8 | Lenguaje de programación difícil | -1,0 |
Step 3.2 - Para cada uno de los 8 Factores, evalúe el proyecto y califíquelo de 0 (irrelevante) a 5 (muy importante).
Step 3.3 - Calcule el impacto del factor a partir del peso de impacto del factor y el valor nominal del proyecto como
Impact of the Factor = Impact Weight × Rated Value
Step 3.4- Calcular la suma del Impacto de todos los Factores. Esto da el factor ambiental total (EFactor) como se indica en la siguiente tabla:
| Factor | Descripción | Peso (W) | Valor nominal (0 a 5) (RV) | Impacto (I = W × RV) |
|---|---|---|---|---|
| F1 | Familiarizado con el modelo de proyecto que se utiliza | 1,5 | ||
| F2 | Experiencia de aplicación | .5 | ||
| F3 | Experiencia orientada a objetos | 1.0 | ||
| F4 | Capacidad de analista principal | .5 | ||
| F5 | Motivación | 1.0 | ||
| F6 | Requisitos estables | 2.0 | ||
| F7 | Personal a tiempo parcial | -1,0 | ||
| F8 | Lenguaje de programación difícil | -1,0 | ||
| Total Environment Factor (EFactor) | ||||
Step 3.5 - Calcule el factor ambiental (EF) como -
1.4 + (-0.03 × EFactor)
Paso 4: Calcule los puntos de casos de uso ajustados (UCP)
Calcule los puntos de casos de uso ajustados (UCP) como:
UCP = UUCP × TCF × EF
Ventajas y desventajas de los puntos de casos de uso
Ventajas de los puntos de casos de uso
Los UCP se basan en casos de uso y se pueden medir muy temprano en el ciclo de vida del proyecto.
UCP (estimación de tamaño) será independiente del tamaño, habilidad y experiencia del equipo que implementa el proyecto.
Se encuentra que las estimaciones basadas en UCP son cercanas a las reales cuando la estimación es realizada por personas experimentadas.
UCP es fácil de usar y no requiere análisis adicionales.
Los casos de uso se utilizan ampliamente como método de elección para describir los requisitos. En tales casos, UCP es la técnica de estimación más adecuada.
Desventajas de los puntos de casos de uso
UCP se puede usar solo cuando los requisitos están escritos en forma de casos de uso.
Depende de casos de uso bien redactados y orientados a objetivos. Si los casos de uso no están bien estructurados o de manera uniforme, es posible que el UCP resultante no sea preciso.
Los factores técnicos y ambientales tienen un alto impacto en UCP. Se debe tener cuidado al asignar valores a los factores técnicos y ambientales.
UCP es útil para la estimación inicial del tamaño total del proyecto, pero son mucho menos útiles para impulsar el trabajo de iteración a iteración de un equipo.
Delphi Methodes una técnica de comunicación estructurada, desarrollada originalmente como un método de pronóstico interactivo y sistemático que se basa en un panel de expertos. Los expertos responden cuestionarios en dos o más rondas. Después de cada ronda, un facilitador proporciona un resumen anónimo de los pronósticos de los expertos de la ronda anterior con las razones de sus juicios. Luego, se alienta a los expertos a revisar sus respuestas anteriores a la luz de las respuestas de otros miembros del panel.
Se cree que durante este proceso el rango de respuestas disminuirá y el grupo convergerá hacia la respuesta "correcta". Finalmente, el proceso se detiene después de un criterio de parada predefinido (por ejemplo, número de rondas, logro del consenso y estabilidad de los resultados) y las puntuaciones medias o medianas de las rondas finales determinan los resultados.
El método Delphi se desarrolló en la década de 1950-1960 en RAND Corporation.
Técnica Delphi de banda ancha
En la década de 1970, Barry Boehm y John A. Farquhar crearon la variante de banda ancha del método Delphi. El término "banda ancha" se utiliza porque, en comparación con el método Delphi, la técnica Delphi de banda ancha implicaba una mayor interacción y más comunicación entre los participantes.
En Wideband Delphi Technique, el equipo de estimación está formado por el director del proyecto, el moderador, los expertos y los representantes del equipo de desarrollo, constituyendo un equipo de 3-7 miembros. Hay dos reuniones:
- Reunión inicial
- Reunión de estimación
Técnica Delphi de banda ancha - Pasos
Step 1 - Elija el equipo de Estimación y un moderador.
Step 2- El moderador conduce la reunión inicial, en la que se presenta al equipo la especificación del problema y una lista de tareas de alto nivel, cualquier suposición o limitación del proyecto. El equipo analiza el problema y las cuestiones de estimación, si las hubiera. También deciden las unidades de estimación. El moderador guía toda la discusión, monitorea el tiempo y después de la reunión inicial, prepara un documento estructurado que contiene la especificación del problema, la lista de tareas de alto nivel, suposiciones y las unidades de estimación que se deciden. Luego envía copias de este documento para el siguiente paso.
Step 3 - Cada miembro del equipo de Estimación luego genera individualmente una EDT detallada, estima cada tarea en la EDT y documenta las suposiciones hechas.

Step 4- El moderador llama al equipo de Estimación para la reunión de Estimación. Si alguno de los miembros del equipo de Estimación responde diciendo que las estimaciones no están listas, el moderador da más tiempo y vuelve a enviar la Invitación a la reunión.
Step 5 - Todo el equipo de Estimación se reúne para la reunión de estimación.
Step 5.1 - Al comienzo de la reunión de Estimación, el moderador recopila las estimaciones iniciales de cada uno de los miembros del equipo.
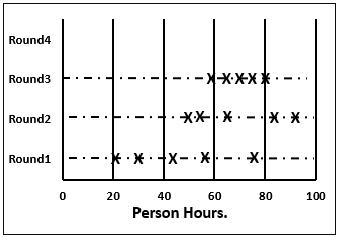
Step 5.2- Luego traza un gráfico en la pizarra. Traza la estimación total del proyecto de cada miembro como una X en la línea de la Ronda 1, sin revelar los nombres correspondientes. El equipo de Estimación tiene una idea del rango de estimaciones, que inicialmente puede ser grande.

Step 5.3- Cada miembro del equipo lee en voz alta la lista de tareas detallada que hizo, identificando las suposiciones hechas y planteando preguntas o problemas. Las estimaciones de tareas no se divulgan.
Las listas de tareas detalladas individuales contribuyen a una lista de tareas más completa cuando se combinan.
Step 5.4 - Luego, el equipo discute cualquier duda / problema que tengan sobre las tareas a las que han llegado, las suposiciones hechas y los problemas de estimación.
Step 5.5- Luego, cada miembro del equipo revisa su lista de tareas y suposiciones, y hace cambios si es necesario. Las estimaciones de tareas también pueden requerir ajustes basados en la discusión, que se indican como + N horas. para más esfuerzo y –N Hrs. por menos esfuerzo.
Luego, los miembros del equipo combinan los cambios en las estimaciones de tareas para llegar a la estimación total del proyecto.

Step 5.6 - El moderador recopila las estimaciones modificadas de todos los miembros del equipo y las traza en la línea de la Ronda 2.
En esta ronda, el rango será más estrecho en comparación con la anterior, ya que se basa más en el consenso.

Step 5.7 - El equipo luego analiza las modificaciones de tareas que han realizado y las suposiciones.
Step 5.8- Luego, cada miembro del equipo revisa su lista de tareas y suposiciones, y hace cambios si es necesario. Las estimaciones de tareas también pueden requerir ajustes basados en la discusión.
Luego, los miembros del equipo combinan nuevamente los cambios en la estimación de la tarea para llegar a la estimación total del proyecto.
Step 5.9 - El moderador vuelve a recopilar las estimaciones modificadas de todos los miembros y las traza en la línea de la Ronda 3.
Nuevamente, en esta ronda, el rango será más estrecho en comparación con el anterior.
Step 5.10 - Los pasos 5.7, 5.8, 5.9 se repiten hasta que se cumple uno de los siguientes criterios:
- Los resultados convergen en un rango aceptablemente estrecho.
- Todos los miembros del equipo no están dispuestos a cambiar sus últimas estimaciones.
- El tiempo asignado para la reunión de Estimación ha terminado.
Step 6 - El Project Manager luego reúne los resultados de la reunión de Estimación.
Step 6.1 - Compila las listas de tareas individuales y las estimaciones correspondientes en una única lista de tareas maestra.
Step 6.2 - También combina las listas individuales de supuestos.
Step 6.3 - Luego revisa la lista de tareas final con el equipo de Estimación.
Ventajas y desventajas de la técnica Delphi de banda ancha
Ventajas
- La técnica Delphi de banda ancha es una técnica de estimación basada en consenso para estimar el esfuerzo.
- Útil al estimar el tiempo para realizar una tarea.
- La participación de personas con experiencia y su estimación individual conduciría a resultados fiables.
- Las personas que harían el trabajo están haciendo estimaciones, por lo que son estimaciones válidas.
- El anonimato mantenido en todo momento hace posible que todos puedan expresar sus resultados con confianza.
- Una técnica muy sencilla.
- Los supuestos se documentan, discuten y acuerdan.
Desventajas
- Se requiere apoyo administrativo.
- Es posible que los resultados de la estimación no sean los que la gerencia quiere escuchar.
La estimación de tres puntos analiza tres valores:
- la estimación más optimista (O),
- una estimación más probable (M), y
- una estimación pesimista (estimación menos probable (L)).
Ha habido cierta confusión con respecto a la estimación de tres puntos y PERT en la industria. Sin embargo, las técnicas son diferentes. Verá las diferencias a medida que aprenda las dos técnicas. Además, al final de la técnica PERT, se recopilan y presentan las diferencias. Si quiere mirarlos primero, puede hacerlo.
La estimación de tres puntos (E) se basa en el promedio simple y sigue una distribución triangular.
E = (O + M + L) / 3

Desviación Estándar
En distribución triangular,
Media = (O + M + L) / 3
Desviación estándar = √ [((O - E) 2 + (M - E) 2 + (L - E) 2 ) / 2]
Pasos de estimación de tres puntos
Step 1 - Llegada a la WBS.
Step 2 - Para cada tarea, encuentre tres valores: la estimación más optimista (O), una estimación más probable (M) y una estimación pesimista (L).
Step 3 - Calcular la Media de los tres valores.
Mean = (O + M + L) / 3
Step 4- Calcular la estimación de tres puntos de la tarea. La estimación de tres puntos es la media. Por lo tanto,
E = Mean = (O + M + L) / 3
Step 5 - Calcular la desviación estándar de la tarea.
Standard Deviation (SD) = √ [((O − E)2 + (M − E)2 + (L - E)2)/2]
Step 6 - Repita los pasos 2, 3, 4 para todas las tareas de la WBS.
Step 7 - Calcular la estimación de tres puntos del proyecto.
E (Project) = ∑ E (Task)
Step 8 - Calcular la Desviación Estándar del proyecto.
SD (Project) = √ (∑SD (Task)2)
Convertir las estimaciones del proyecto en niveles de confianza
La estimación de tres puntos (E) y la desviación estándar (SD) así calculadas se utilizan para convertir las estimaciones del proyecto a "niveles de confianza".
La conversión se basa en que:
- El nivel de confianza en E +/– SD es aproximadamente del 68%.
- El nivel de confianza en el valor E +/– 1,645 × SD es aproximadamente del 90%.
- El nivel de confianza en el valor E +/– 2 × SD es aproximadamente del 95%.
- El nivel de confianza en el valor E +/– 3 × SD es aproximadamente del 99,7%.
Por lo general, el nivel de confianza del 95%, es decir, el valor E + 2 × DE, se utiliza para todas las estimaciones de proyectos y tareas.
La estimación de la técnica de evaluación y revisión de proyectos (PERT) considera tres valores: la estimación más optimista (O), una estimación más probable (M) y una estimación pesimista (estimación menos probable (L)). Ha habido cierta confusión con respecto a la estimación de tres puntos y PERT en la industria. Sin embargo, las técnicas son diferentes. Verá las diferencias a medida que aprenda las dos técnicas. Además, al final de este capítulo, se recopilan y presentan las diferencias.
PERT se basa en tres valores: la estimación más optimista (O), una estimación más probable (M) y una estimación pesimista (la estimación menos probable (L)). La estimación más probable se pondera 4 veces más que las otras dos estimaciones (optimista y pesimista).
La estimación PERT (E) se basa en el promedio ponderado y sigue la distribución beta.
E = (O + 4 × M + L)/6

PERT se utiliza con frecuencia junto con el método de ruta crítica (CPM). CPM informa sobre las tareas que son críticas en el proyecto. Si hay un retraso en estas tareas, el proyecto se retrasa.
Desviación Estándar
La desviación estándar (SD) mide la variabilidad o incertidumbre en la estimación.
En distribución beta,
Media = (O + 4 × M + L) / 6
Desviación estándar (SD) = (L - O) / 6
Pasos para la estimación PERT
Step (1) - Llegada a la WBS.
Step (2) - Para cada tarea, encuentre tres valores de estimación más optimista (O), una estimación más probable (M) y una estimación pesimista (L).
Step (3) - Promedio PERT = (O + 4 × M + L) / 6
PERT Media = (O + 4 × M + L) / 3
Step (4) - Calcular la desviación estándar de la tarea.
Desviación estándar (SD) = (L - O) / 6
Step (6) - Repita los pasos 2, 3, 4 para todas las tareas en la WBS.
Step (7) - Calcular la estimación PERT del proyecto.
E (Proyecto) = ∑ E (Tarea)
Step (8) - Calcular la Desviación Estándar del proyecto.
SD (Proyecto) = √ (ΣSD (Tarea) 2 )
Convertir las estimaciones del proyecto en niveles de confianza
La estimación PERT (E) y la desviación estándar (SD) así calculadas se utilizan para convertir las estimaciones del proyecto a niveles de confianza.
La conversión se basa en que
- El nivel de confianza en E +/– SD es aproximadamente del 68%.
- El nivel de confianza en el valor E +/– 1,645 × SD es aproximadamente del 90%.
- El nivel de confianza en el valor E +/– 2 × SD es aproximadamente del 95%.
- El nivel de confianza en el valor E +/– 3 × SD es aproximadamente del 99,7%.
Comúnmente, el nivel de confianza del 95%, es decir, Valor E + 2 × SD, se utiliza para todas las estimaciones de proyectos y tareas.
Diferencias entre la estimación de tres puntos y PERT
A continuación se muestran las diferencias entre la estimación de tres puntos y PERT:
| Estimación de tres puntos | IMPERTINENTE |
|---|---|
| Promedio simple | Peso promedio |
| Sigue la distribución triangular | Sigue la distribución beta |
| Utilizado para pequeños proyectos repetitivos | Se utiliza para grandes proyectos no repetitivos, generalmente proyectos de I + D. Se utiliza junto con el método de ruta crítica (CPM) |
E = Media = (O + M + L) / 3 Este es un promedio simple |
E = Media = (O + 4 × M + L) / 6 Este es el promedio ponderado |
| SD = √ [((O - E) 2 + (M - E) 2 + (L - E) 2 ) / 2] | SD = (L - O) / 6 |
Analogous Estimationutiliza una información de proyecto anterior similar para estimar la duración o el costo de su proyecto actual, de ahí la palabra "analogía". Puede utilizar una estimación análoga cuando hay información limitada sobre su proyecto actual.
Muy a menudo, habrá situaciones en las que se les pedirá a los gerentes de proyecto que brinden estimaciones de costo y duración para un nuevo proyecto, ya que los ejecutivos necesitan datos de toma de decisiones para decidir si vale la pena realizar el proyecto. Por lo general, ni el gerente de proyecto ni nadie más en la organización ha realizado un proyecto como el nuevo, pero los ejecutivos aún quieren estimaciones precisas de costos y duración.
En tales casos, la estimación análoga es la mejor solución. Puede que no sea perfecto, pero es preciso, ya que se basa en datos anteriores. La estimación análoga es una técnica fácil de implementar. La tasa de éxito del proyecto puede ser de hasta un 60% en comparación con las estimaciones iniciales.
Estimación análoga - Definición
La estimación análoga es una técnica que utiliza los valores de parámetros de datos históricos como base para estimar un parámetro similar para una actividad futura. Ejemplos de parámetros: alcance, costo y duración. Ejemplos de medidas de escala: tamaño, peso y complejidad.
Debido a que la experiencia y el juicio del director del proyecto, y posiblemente del equipo, se aplican al proceso de estimación, se considera una combinación de información histórica y juicio de expertos.
Requisitos de estimación análogos
Para una estimación análoga, el siguiente es el requisito:
- Datos de proyectos anteriores y en curso
- Horas de trabajo por semana de cada miembro del equipo
- Costos involucrados para completar el proyecto
- Proyecto cercano al proyecto actual
- En caso de que el proyecto actual sea nuevo y ningún proyecto anterior sea similar
- Módulos de proyectos anteriores que son similares a los del proyecto actual
- Actividades de proyectos anteriores que son similares a las del proyecto actual
- Datos de estos seleccionados
- Participación del director del proyecto y del equipo de estimación para garantizar un juicio experimentado sobre las estimaciones.
Pasos de estimación análogos
El director del proyecto y el equipo deben realizar una estimación análoga de forma colectiva.
Step 1 - Identificar el dominio del proyecto actual.
Step 2 - Identificar la tecnología del proyecto actual.
Step 3- Busque en la base de datos de la organización si hay datos de proyectos similares disponibles. Si está disponible, vaya al paso (4). De lo contrario, vaya al paso (6).
Step 4 - Compare el proyecto actual con los datos identificados del proyecto pasado.
Step 5- Llegar a las estimaciones de duración y costo del proyecto actual. Con esto finaliza la estimación análoga del proyecto.
Step 6 - Busque en la base de datos de la organización si algún proyecto anterior tiene módulos similares a los del proyecto actual.
Step 7 - Busque en la base de datos de la organización si algún proyecto anterior tiene actividades similares a las del proyecto actual.
Step 8 - Recopile todos esos y utilice el juicio de expertos para llegar a la duración y estimaciones de costos del proyecto actual.
Ventajas de la estimación análoga
La estimación análoga es una mejor forma de estimación en las etapas iniciales del proyecto cuando se conocen muy pocos detalles.
La técnica es sencilla y el tiempo necesario para la estimación es muy inferior.
Se puede esperar que la tasa de éxito de la organización sea alta ya que la técnica se basa en los datos de proyectos anteriores de la organización.
También se puede utilizar una estimación análoga para estimar el esfuerzo y la duración de las tareas individuales. Por lo tanto, en WBS cuando estima las tareas, puede usar Analogy.
La estructura de desglose del trabajo (WBS), en la gestión de proyectos y la ingeniería de sistemas, es una descomposición orientada a la entrega de un proyecto en componentes más pequeños. WBS es un entregable clave del proyecto que organiza el trabajo del equipo en secciones manejables. El Cuerpo de Conocimiento de Gestión de Proyectos (PMBOK) define WBS como una "descomposición jerárquica orientada a entregable del trabajo a ser ejecutado por el equipo del proyecto".
El elemento WBS puede ser un producto, datos, servicio o cualquier combinación de los mismos. WBS también proporciona el marco necesario para la estimación y el control detallados de costos junto con una guía para el desarrollo y control del cronograma.
Representación de WBS
WBS se representa como una lista jerárquica de las actividades de trabajo del proyecto. Hay dos formatos de WBS:
- Vista de esquema (formato sangrado)
- Vista de estructura de árbol (organigrama)
Primero, analicemos cómo utilizar la vista de esquema para preparar una EDT.
Vista exterior
La vista de esquema es un diseño muy fácil de usar. Presenta una buena vista de todo el proyecto y también permite modificaciones fáciles. Utiliza números para registrar las distintas etapas de un proyecto. Parece algo similar a lo siguiente:
Software Development
Scope
- Determinar el alcance del proyecto
- Patrocinio seguro de proyectos
- Definir recursos preliminares
- Asegure los recursos básicos
- Alcance completo
Analysis/Software Requirements
- Realizar análisis de necesidades
- Proyecto de especificaciones de software preliminares
- Desarrollar presupuesto preliminar
- Revise las especificaciones / presupuesto del software con el equipo
- Incorporar comentarios sobre las especificaciones del software
- Desarrollar un cronograma de entrega
- Obtenga aprobaciones para continuar (concepto, cronograma y presupuesto)
- Asegure los recursos necesarios
- Análisis completo
Design
- Revise las especificaciones preliminares del software
- Desarrollar especificaciones funcionales
- Obtenga la aprobación para continuar
- Diseño completo
Development
- Revise las especificaciones funcionales
- Identificar parámetros de diseño modular / escalonado
- Desarrollar código
- Prueba de desarrollador (depuración primaria)
- Desarrollo completo
Testing
- Desarrollar planes de prueba unitaria utilizando especificaciones de producto
- Desarrollar planes de prueba de integración utilizando especificaciones de producto
Training
- Desarrollar especificaciones de formación para usuarios finales.
- Identificar la metodología de impartición de la formación (online, presencial, etc.)
- Desarrollar materiales de formación
- Finalizar los materiales de formación
- Desarrollar un mecanismo de impartición de formación
- Materiales de formación completos
Deployment
- Determinar la estrategia de implementación final
- Desarrollar metodología de implementación
- Recursos de implementación seguros
- Capacitar al personal de apoyo
- Implementar software
- Implementación completa
Echemos ahora un vistazo a la vista de estructura de árbol.
Vista de estructura de árbol
La Vista de estructura de árbol presenta una vista muy fácil de entender de todo el proyecto. La siguiente ilustración muestra cómo se ve una vista de estructura de árbol. Este tipo de estructura de organigrama se puede dibujar fácilmente con las funciones disponibles en MS-Word.

Tipos de WBS
Hay dos tipos de WBS:
Functional WBS- En WBS funcional, el sistema se descompone en función de las funciones en la aplicación a desarrollar. Esto es útil para estimar el tamaño del sistema.
Activity WBS- En la actividad WBS, el sistema se rompe en función de las actividades en el sistema. Las actividades se dividen además en tareas. Esto es útil para estimar el esfuerzo y el programa en el sistema.
Tamaño estimado
Step 1 - Comience con WBS funcional.
Step 2 - Considere los nodos de hojas.
Step 3 - Utilice Analogy o Wideband Delphi para llegar a las estimaciones de tamaño.
Estimar el esfuerzo
Step 1- Utilice la técnica Delphi de banda ancha para construir WBS. Sugerimos que las tareas no sean más de 8 hrs. Si una tarea es de mayor duración, divídala.
Step 2 - Utilice la técnica Delphi de banda ancha o la estimación de tres puntos para llegar a las estimaciones de esfuerzo para las tareas.
Planificación
Una vez que la WBS esté lista y se conozcan las estimaciones de tamaño y esfuerzo, estará listo para programar las tareas.
Al programar las tareas, se deben tener en cuenta ciertas cosas:
Precedence - Se dice que una tarea que debe ocurrir antes que otra tenga precedencia sobre la otra.
Concurrence - Las tareas concurrentes son aquellas que pueden ocurrir al mismo tiempo (en paralelo).
Critical Path - Conjunto específico de tareas secuenciales de las que depende la fecha de finalización del proyecto.
- Todos los proyectos tienen un camino crítico.
- Acelerar las tareas no críticas no acorta directamente el cronograma.
Método del camino crítico
El método de ruta crítica (CPM) es el proceso para determinar y optimizar la ruta crítica. Las tareas de ruta no críticas pueden comenzar antes o después sin afectar la fecha de finalización.
Tenga en cuenta que la ruta crítica puede cambiar a otra a medida que acorta la actual. Por ejemplo, para WBS en la figura anterior, la ruta crítica sería la siguiente:

Como la fecha de finalización del proyecto se basa en un conjunto de tareas secuenciales, estas tareas se denominan tareas críticas.
La fecha de finalización del proyecto no se basa en la formación, la documentación y el despliegue. Estas tareas se denominan tareas no críticas.
Relaciones de dependencia de tareas
Ciertas veces, al programar, es posible que deba considerar las relaciones de dependencia de tareas. Las relaciones de dependencia de tareas importantes son:
- Fin al comienzo (FS)
- De acabado a acabado (FF)
Fin al comienzo (FS)
En la relación de dependencia de la tarea Fin-a-Inicio (FS), la Tarea B no puede iniciarse hasta que la Tarea A se complete.

De acabado a acabado (FF)
En la relación de dependencia de tareas de Finalizar-a-Finalizar (FF), la Tarea B no puede finalizar hasta que se complete la Tarea A.

Gráfico de gantt
Un diagrama de Gantt es un tipo de diagrama de barras, adaptado por Karol Adamiecki en 1896 e independientemente por Henry Gantt en la década de 1910, que ilustra el cronograma de un proyecto. Los diagramas de Gantt ilustran las fechas de inicio y finalización de los elementos terminales y los elementos de resumen de un proyecto.
Puede llevar el formato de esquema de la figura 2 a Microsoft Project para obtener una vista de diagrama de Gantt.

Hitos
Los hitos son las etapas críticas de su programa. Tendrán una duración de cero y se utilizan para indicar que ha completado cierto conjunto de tareas. Los hitos generalmente se muestran como un diamante.
Por ejemplo, en el diagrama de Gantt anterior, Diseño completo y Desarrollo completo se muestran como hitos, representados con una forma de diamante.
Los hitos se pueden vincular a los términos del contrato.
Ventajas de la estimación utilizando WBS
WBS simplifica en gran medida el proceso de estimación de proyectos. Ofrece las siguientes ventajas sobre otras técnicas de estimación:
En WBS, se identifica todo el trabajo a realizar por el proyecto. Por lo tanto, al revisar la EDT con las partes interesadas del proyecto, será menos probable que omita cualquier trabajo necesario para entregar los entregables deseados del proyecto.
WBS da como resultado estimaciones de costos y cronogramas más precisas.
El director del proyecto obtiene la participación del equipo para finalizar la WBS. Esta implicación del equipo genera ilusión y responsabilidad en el proyecto.
WBS proporciona una base para la asignación de tareas. Como una tarea precisa se asigna a un miembro del equipo en particular que sería responsable de su realización.
WBS permite monitorear y controlar a nivel de tarea. Esto le permite medir el progreso y asegurarse de que su proyecto se entregue a tiempo.
Planificación de la estimación del póquer
Planning Poker es una técnica de estimación basada en el consenso, que se utiliza principalmente para estimar el esfuerzo o el tamaño relativo de las historias de usuario en Scrum.
Planning Poker combina tres técnicas de estimación: técnica Delphi de banda ancha, estimación análoga y estimación utilizando WBS.
Planning Poker fue definido y nombrado por primera vez por James Grenning en 2002 y luego popularizado por Mike Cohn en su libro "Agile Estimación y Planificación", cuyo comercio de empresa marcó el término.
Planificación de la técnica de estimación de póquer
En la técnica de estimación de Planning Poker, las estimaciones de las historias de usuario se obtienen jugando al Planning Poker. Todo el equipo de Scrum está involucrado y da como resultado estimaciones rápidas pero confiables.
Planning Poker se juega con una baraja de cartas. A medida que se usa la secuencia de Fibonacci, las tarjetas tienen números: 1, 2, 3, 5, 8, 13, 21, 34, etc. Estos números representan los “Puntos de la historia”. Cada estimador tiene una baraja de cartas. Los números de las tarjetas deben ser lo suficientemente grandes para que todos los miembros del equipo puedan verlos cuando uno de los miembros del equipo muestre una tarjeta.
Uno de los miembros del equipo es seleccionado como moderador. El moderador lee la descripción de la historia de usuario para la que se está haciendo la estimación. Si los estimadores tienen alguna pregunta, el propietario del producto las responde.
Cada estimador selecciona de forma privada una tarjeta que representa su estimación. Las tarjetas no se muestran hasta que todos los estimadores hayan realizado una selección. En ese momento, todas las tarjetas se dan la vuelta y se sostienen simultáneamente para que todos los miembros del equipo puedan ver cada estimación.
En la primera ronda, es muy probable que las estimaciones varíen. Los estimadores alto y bajo explican el motivo de sus estimaciones. Se debe tener cuidado de que todas las discusiones estén destinadas únicamente a la comprensión y nada debe tomarse como algo personal. El moderador debe garantizar lo mismo.
El equipo puede discutir la historia y sus estimaciones durante unos minutos más.
El moderador puede tomar notas sobre la discusión que serán útiles cuando se desarrolle la historia específica. Después de la discusión, cada estimador vuelve a estimar seleccionando nuevamente una tarjeta. Una vez más, las tarjetas se mantienen en privado hasta que todos hayan estimado, momento en el que se entregan al mismo tiempo.
Repita el proceso hasta que las estimaciones converjan en una sola estimación que pueda usarse para la historia. El número de rondas de estimación puede variar de una historia de usuario a otra.
Beneficios de planificar la estimación del póquer
Planning Poker combina tres métodos de estimación:
Expert Opinion- En el enfoque de estimación basado en la opinión de un experto, se le pregunta a un experto cuánto tiempo tomará algo o qué tamaño tendrá. El experto proporciona una estimación basándose en su experiencia, intuición o instinto. La estimación de la opinión de expertos no suele llevar mucho tiempo y es más precisa en comparación con algunos de los métodos analíticos.
Analogy- La estimación de analogía utiliza la comparación de historias de usuarios. La historia de usuario subestimada se compara con historias de usuario similares implementadas anteriormente, dando resultados precisos ya que la estimación se basa en datos probados.
Disaggregation- La estimación de desagregación se realiza dividiendo una historia de usuario en historias de usuario más pequeñas y fáciles de estimar. Las historias de usuario que se incluirán en un sprint normalmente están en el rango de dos a cinco días para desarrollarse. Por lo tanto, las historias de usuario que posiblemente requieran una mayor duración deben dividirse en Casos de uso más pequeños. Este enfoque también asegura que habrá muchas historias que sean comparables.
Los esfuerzos de prueba no se basan en un período de tiempo definitivo. Los esfuerzos continúan hasta que se establece un cronograma predeterminado, independientemente de la finalización de las pruebas.
Esto se debe principalmente al hecho de que, convencionalmente, test effort estimation es parte del development estimation. Solo en el caso de técnicas de estimación que utilizan WBS, como Wideband Delphi, Three-point Estimation, PERT y WBS, puede obtener los valores para las estimaciones de las actividades de prueba.
Si ha obtenido las estimaciones como Puntos de función (FP), según Caper Jones,
Number of Test Cases = (Number of Function Points) × 1.2
Una vez que tenga el número de casos de prueba, puede tomar los datos de productividad de la base de datos de la organización y calcular el esfuerzo requerido para las pruebas.
Método de porcentaje de esfuerzo de desarrollo
El esfuerzo de prueba requerido es una proporción directa o un porcentaje del esfuerzo de desarrollo. El esfuerzo de desarrollo se puede estimar utilizando líneas de código (LOC) o puntos de función (FP). Luego, el porcentaje de esfuerzo para las pruebas se obtiene de la base de datos de la organización. El porcentaje así obtenido se utiliza para llegar a la estimación de esfuerzo para la prueba.
Estimación de proyectos de prueba
Varias organizaciones ahora brindan servicios independientes de verificación y validación a sus clientes y eso significaría que las actividades del proyecto serían completamente actividades de prueba.
La estimación de proyectos de prueba requiere experiencia en proyectos variados para el ciclo de vida de prueba de software. Cuando esté estimando un proyecto de prueba, considere:
- Habilidades de equipo
- Conocimiento del dominio
- Complejidad de la aplicación
- Información histórica
- Ciclos de errores para el proyecto
- Disponibilidad de recursos
- Variaciones de productividad
- Entorno del sistema y tiempo de inactividad
Prueba de técnicas de estimación
Se ha demostrado que las siguientes técnicas de estimación de pruebas son precisas y se utilizan ampliamente:
- Técnica de estimación de pruebas de software PERT
- Método UCP
- WBS
- Técnica Delphi de banda ancha
- Análisis de punto de función / punto de prueba
- Distribución porcentual
- Técnica de estimación de pruebas basada en la experiencia
Técnica de estimación de pruebas de software PERT
La técnica de estimación de pruebas de software PERT se basa en métodos estadísticos en los que cada tarea de prueba se divide en subtareas y luego se realizan tres tipos de estimación en cada subtarea.
La fórmula utilizada por esta técnica es:
Test Estimate = (O + (4 × M) + E)/6
Dónde,
O = Estimación optimista (mejor escenario en el que nada sale mal y todas las condiciones son óptimas).
M = Estimación más probable (duración más probable y puede haber algún problema, pero la mayoría de las cosas saldrán bien).
L = Estimación pesimista (peor escenario en el que todo sale mal).
La desviación estándar de la técnica se calcula como:
Standard Deviation (SD) = (E − O)/6
Método de punto de caso de uso
El método UCP se basa en los casos de uso en los que calculamos los pesos de los actores no ajustados y los pesos de los casos de uso no ajustados para determinar la estimación de las pruebas de software.
El caso de uso es un documento que especifica diferentes usuarios, sistemas u otras partes interesadas que interactúan con la aplicación en cuestión. Se denominan "Actores". Las interacciones logran algunos objetivos definidos que protegen el interés de todas las partes interesadas a través de diferentes comportamientos o flujos denominados escenarios.
Step 1- Cuente el no. de actores. Los actores incluyen positivos, negativos y excepcionales.
Step 2 - Calcule los pesos de los actores no ajustados como
Unadjusted Actor Weights = Total no. of Actors
Step 3 - Cuente el número de casos de uso.
Step 4 - Calcule los pesos de casos de uso no ajustados como
Unadjusted Use-Case Weights = Total no. of Use-Cases
Step 5 - Calcule los puntos de casos de uso no ajustados como
Unadjusted Use-Case Points = (Unadjusted Actor Weights + Unadjusted Use-Case Weights)
Step 6- Determinar el factor técnico / ambiental (TEF). Si no está disponible, tómelo como 0.50.
Step 7 - Calcular el punto de caso de uso ajustado como
Adjusted Use-Case Point = Unadjusted Use-Case Points × [0.65 + (0.01 × TEF]
Step 8 - Calcule el esfuerzo total como
Total Effort = Adjusted Use-Case Point × 2
Estructura de desglose del trabajo
Step 1 - Cree WBS dividiendo el proyecto de prueba en partes pequeñas.
Step 2 - Divida los módulos en submódulos.
Step 3 Divida los submódulos en funcionalidades.
Step 4 - Dividir funcionalidades en subfuncionalidades.
Step 5 - Revise todos los requisitos de prueba para asegurarse de que se agreguen en WBS.
Step 6 - Calcule la cantidad de tareas que su equipo debe completar.
Step 7 - Estimar el esfuerzo de cada tarea.
Step 8 - Estimar la duración de cada tarea.
Técnica Delphi de banda ancha
En el método Delphi de banda ancha, WBS se distribuye a un equipo compuesto por 3-7 miembros para volver a estimar las tareas. La estimación final es el resultado de las estimaciones resumidas basadas en el consenso del equipo.
Este método habla más de la experiencia que de una fórmula estadística. Este método fue popularizado por Barry Boehm para enfatizar en la iteración del grupo para llegar a un consenso donde el equipo visualizó diferentes aspectos de los problemas mientras estimaba el esfuerzo de la prueba.
Análisis de punto de función / punto de prueba
Los FP indican la funcionalidad de la aplicación de software desde la perspectiva del usuario y se utilizan como técnica para estimar el tamaño de un proyecto de software.
En las pruebas, la estimación se basa en un documento de especificación de requisitos o en un prototipo de la aplicación creado previamente. Para calcular FP para un proyecto, se requieren algunos componentes principales. Ellos son -
Unadjusted Data Function Points - i) Archivos internos, ii) Interfaces externas
Unadjusted Transaction Function Points - i) Entradas de usuario, ii) Salidas de usuario y iii) Consultas de usuario
Capers Jones basic formula -
Número de casos de prueba = (Número de puntos de función) × 1,2
Total Actual Effort (TAE) -
(Número de casos de prueba) × (Porcentaje de esfuerzo de desarrollo / 100)
Distribución porcentual
En esta técnica, todas las fases del Ciclo de vida del desarrollo de software (SDLC) tienen asignado el esfuerzo en%. Esto puede basarse en datos anteriores de proyectos similares. Por ejemplo
| Fase | % de esfuerzo |
|---|---|
| Gestión de proyectos | 7% |
| Requisitos | 9% |
| Diseño | dieciséis% |
| Codificación | 26% |
| Prueba (todas las fases de prueba) | 27% |
| Documentación | 9% |
| Instalación y formación | 6% |
A continuación, el% del esfuerzo para las pruebas (todas las fases de prueba) se distribuye aún más para todas las Fases de prueba:
| Todas las fases de prueba | % de esfuerzo |
|---|---|
| Prueba de componentes | dieciséis |
| Pruebas independientes | 84 |
| Total | 100 |
| Pruebas independientes | % de esfuerzo |
|---|---|
| Pruebas de integración | 24 |
| Prueba del sistema | 52 |
| Test de aceptación | 24 |
| Total | 100 |
| Prueba del sistema | % de esfuerzo |
|---|---|
| Prueba de sistema funcional | sesenta y cinco |
| Prueba de sistema no funcional | 35 |
| Total | 100 |
| Arquitectura de diseño y planificación de pruebas | 50% |
| Fase de revisión | 50% |
Técnica de estimación de pruebas basada en la experiencia
Esta técnica se basa en analogías y expertos. La técnica asume que ya probó aplicaciones similares en proyectos anteriores y recopiló métricas de esos proyectos. También recopiló métricas de pruebas anteriores. Tome las aportaciones de expertos en la materia que conocen muy bien la aplicación (así como las pruebas) y use las métricas que ha recopilado y llegue al esfuerzo de prueba.