HCatalog - Guía rápida
¿Qué es HCatalog?
HCatalog es una herramienta de gestión de almacenamiento de tablas para Hadoop. Expone los datos tabulares de Hive metastore a otras aplicaciones de Hadoop. Permite a los usuarios con diferentes herramientas de procesamiento de datos (Pig, MapReduce) escribir datos fácilmente en una cuadrícula. Garantiza que los usuarios no tengan que preocuparse por dónde o en qué formato se almacenan sus datos.
HCatalog funciona como un componente clave de Hive y permite a los usuarios almacenar sus datos en cualquier formato y estructura.
¿Por qué HCatalog?
Habilitación de la herramienta adecuada para el trabajo adecuado
El ecosistema de Hadoop contiene diferentes herramientas para el procesamiento de datos como Hive, Pig y MapReduce. Aunque estas herramientas no requieren metadatos, aún pueden beneficiarse de ellos cuando están presentes. Compartir un almacén de metadatos también permite a los usuarios de todas las herramientas compartir datos con mayor facilidad. Es muy común un flujo de trabajo donde los datos se cargan y normalizan usando MapReduce o Pig y luego se analizan a través de Hive. Si todas estas herramientas comparten una tienda de metadatos, los usuarios de cada herramienta tienen acceso inmediato a los datos creados con otra herramienta. No se requieren pasos de carga o transferencia.
Capturar estados de procesamiento para permitir compartir
HCatalog puede publicar sus resultados analíticos. Para que el otro programador pueda acceder a su plataforma de análisis a través de "REST". Los esquemas publicados por usted también son útiles para otros científicos de datos. Los otros científicos de datos utilizan sus descubrimientos como entradas para un descubrimiento posterior.
Integra Hadoop con todo
Hadoop como entorno de procesamiento y almacenamiento abre muchas oportunidades para la empresa; sin embargo, para impulsar la adopción, debe trabajar con las herramientas existentes y mejorarlas. Hadoop debe servir como entrada en su plataforma de análisis o integrarse con sus almacenes de datos operativos y aplicaciones web. La organización debería disfrutar del valor de Hadoop sin tener que aprender un conjunto de herramientas completamente nuevo. Los servicios REST abren la plataforma a la empresa con una API familiar y un lenguaje similar a SQL. Los sistemas de gestión de datos empresariales utilizan HCatalog para integrarse más profundamente con la plataforma Hadoop.
Arquitectura de HCatalog
La siguiente ilustración muestra la arquitectura general de HCatalog.
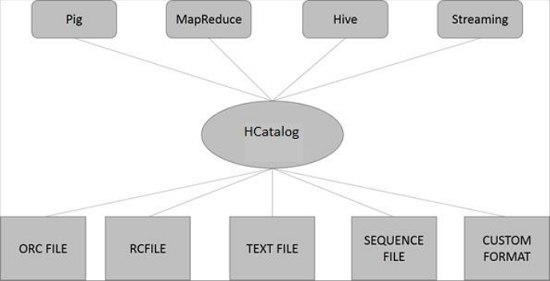
HCatalog admite la lectura y escritura de archivos en cualquier formato para el que SerDe(serializador-deserializador) se puede escribir. De forma predeterminada, HCatalog admite los formatos de archivo RCFile, CSV, JSON, SequenceFile y ORC. Para usar un formato personalizado, debe proporcionar InputFormat, OutputFormat y SerDe.
HCatalog se basa en la tienda de metadatos de Hive e incorpora el DDL de Hive. HCatalog proporciona interfaces de lectura y escritura para Pig y MapReduce y utiliza la interfaz de línea de comandos de Hive para emitir comandos de exploración de metadatos y definición de datos.
Todos los subproyectos de Hadoop, como Hive, Pig y HBase, son compatibles con el sistema operativo Linux. Por lo tanto, necesita instalar una versión de Linux en su sistema. HCatalog se fusionó con la instalación de Hive el 26 de marzo de 2013. Desde la versión Hive-0.11.0 en adelante, HCatalog viene con la instalación de Hive. Por lo tanto, siga los pasos que se indican a continuación para instalar Hive, que a su vez instalará automáticamente HCatalog en su sistema.
Paso 1: Verificación de la instalación de JAVA
Java debe estar instalado en su sistema antes de instalar Hive. Puede usar el siguiente comando para verificar si ya tiene Java instalado en su sistema:
$ java –versionSi Java ya está instalado en su sistema, puede ver la siguiente respuesta:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Si no tiene Java instalado en su sistema, debe seguir los pasos que se indican a continuación.
Paso 2: instalar Java
Descargue Java (JDK <última versión> - X64.tar.gz) visitando el siguiente enlace http://www.oracle.com/
Luego jdk-7u71-linux-x64.tar.gz se descargará en su sistema.
Generalmente, encontrará el archivo Java descargado en la carpeta Descargas. Verifíquelo y extraiga eljdk-7u71-linux-x64.gz archivo usando los siguientes comandos.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzPara que Java esté disponible para todos los usuarios, debe moverlo a la ubicación “/ usr / local /”. Abra root y escriba los siguientes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitPara configurar PATH y JAVA_HOME variables, agregue los siguientes comandos a ~/.bashrc archivo.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/binAhora verifique la instalación usando el comando java -version desde la terminal como se explicó anteriormente.
Paso 3: verificar la instalación de Hadoop
Hadoop debe estar instalado en su sistema antes de instalar Hive. Verifiquemos la instalación de Hadoop usando el siguiente comando:
$ hadoop versionSi Hadoop ya está instalado en su sistema, obtendrá la siguiente respuesta:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Si Hadoop no está instalado en su sistema, proceda con los siguientes pasos:
Paso 4: descarga de Hadoop
Descargue y extraiga Hadoop 2.4.1 de Apache Software Foundation usando los siguientes comandos.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitPaso 5: Instalación de Hadoop en modo pseudo distribuido
Los siguientes pasos se utilizan para instalar Hadoop 2.4.1 en modo pseudodistribuido.
Configurando Hadoop
Puede configurar las variables de entorno de Hadoop agregando los siguientes comandos a ~/.bashrc archivo.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binAhora aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcConfiguración de Hadoop
Puede encontrar todos los archivos de configuración de Hadoop en la ubicación "$ HADOOP_HOME / etc / hadoop". Debe realizar los cambios adecuados en esos archivos de configuración de acuerdo con su infraestructura de Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desarrollar programas Hadoop usando Java, debe restablecer las variables de entorno de Java en hadoop-env.sh archivo reemplazando JAVA_HOME valor con la ubicación de Java en su sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71A continuación se muestra la lista de archivos que debe editar para configurar Hadoop.
core-site.xml
los core-site.xml El archivo contiene información como el número de puerto utilizado para la instancia de Hadoop, la memoria asignada para el sistema de archivos, el límite de memoria para almacenar los datos y el tamaño de los búferes de lectura / escritura.
Abra core-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration> y </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
los hdfs-site.xmlEl archivo contiene información como el valor de los datos de replicación, la ruta del nodo de nombre y la ruta del nodo de datos de sus sistemas de archivos locales. Significa el lugar donde desea almacenar la infraestructura de Hadoop.
Asumamos los siguientes datos.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este archivo y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - En el archivo anterior, todos los valores de propiedad están definidos por el usuario y puede realizar cambios de acuerdo con su infraestructura de Hadoop.
yarn-site.xml
Este archivo se utiliza para configurar hilo en Hadoop. Abra el archivo yarn-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este archivo se usa para especificar qué marco MapReduce estamos usando. De forma predeterminada, Hadoop contiene una plantilla de yarn-site.xml. En primer lugar, debe copiar el archivo demapred-site,xml.template a mapred-site.xml archivo usando el siguiente comando.
$ cp mapred-site.xml.template mapred-site.xmlAbra el archivo mapred-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Paso 6: verificar la instalación de Hadoop
Los siguientes pasos se utilizan para verificar la instalación de Hadoop.
Configuración de Namenode
Configure el nodo de nombre utilizando el comando "hdfs namenode -format" de la siguiente manera:
$ cd ~ $ hdfs namenode -formatEl resultado esperado es el siguiente:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Verificación de Hadoop DFS
El siguiente comando se utiliza para iniciar el DFS. La ejecución de este comando iniciará su sistema de archivos Hadoop.
$ start-dfs.shEl resultado esperado es el siguiente:
10/24/14 21:37:56 Starting namenodes on [localhost]
localhost: starting namenode, logging to
/home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost:
starting datanode, logging to
/home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Verificación del guión de hilo
El siguiente comando se utiliza para iniciar el script de Yarn. La ejecución de este comando iniciará sus demonios Yarn.
$ start-yarn.shEl resultado esperado es el siguiente:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/
yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to
/home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.outAccediendo a Hadoop en el navegador
El número de puerto predeterminado para acceder a Hadoop es 50070. Utilice la siguiente URL para obtener los servicios de Hadoop en su navegador.
http://localhost:50070/
Verificar todas las aplicaciones para el clúster
El número de puerto predeterminado para acceder a todas las aplicaciones del clúster es 8088. Utilice la siguiente URL para visitar este servicio.
http://localhost:8088/
Una vez que haya terminado con la instalación de Hadoop, continúe con el siguiente paso e instale Hive en su sistema.
Paso 7: descarga de Hive
Usamos hive-0.14.0 en este tutorial. Puedes descargarlo visitando el siguiente enlacehttp://apache.petsads.us/hive/hive-0.14.0/. Supongamos que se descarga en el/Downloadsdirectorio. Aquí, descargamos el archivo de Hive llamado "apache-hive-0.14.0-bin.tar.gz”Para este tutorial. El siguiente comando se utiliza para verificar la descarga:
$ cd Downloads $ lsEn la descarga exitosa, puede ver la siguiente respuesta:
apache-hive-0.14.0-bin.tar.gzPaso 8: Instalación de Hive
Los siguientes pasos son necesarios para instalar Hive en su sistema. Supongamos que el archivo de Hive se descarga en el/Downloads directorio.
Extraer y verificar el archivo de Hive
El siguiente comando se utiliza para verificar la descarga y extraer el archivo de Hive:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ lsEn la descarga exitosa, puede ver la siguiente respuesta:
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gzCopiando archivos al directorio / usr / local / hive
Necesitamos copiar los archivos del superusuario "su -". Los siguientes comandos se utilizan para copiar los archivos del directorio extraído al/usr/local/hive”Directorio.
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exitConfiguración del entorno para Hive
Puede configurar el entorno de Hive agregando las siguientes líneas a ~/.bashrc archivo -
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.El siguiente comando se usa para ejecutar el archivo ~ / .bashrc.
$ source ~/.bashrcPaso 9: configurar Hive
Para configurar Hive con Hadoop, debe editar el hive-env.sh archivo, que se coloca en el $HIVE_HOME/confdirectorio. Los siguientes comandos redirigen a Hiveconfig carpeta y copie el archivo de plantilla -
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.shEdite el hive-env.sh archivo agregando la siguiente línea -
export HADOOP_HOME=/usr/local/hadoopCon esto, la instalación de Hive está completa. Ahora necesita un servidor de base de datos externo para configurar Metastore. Usamos la base de datos Apache Derby.
Paso 10: descarga e instalación de Apache Derby
Siga los pasos que se indican a continuación para descargar e instalar Apache Derby:
Descargando Apache Derby
El siguiente comando se usa para descargar Apache Derby. La descarga lleva algún tiempo.
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gzEl siguiente comando se utiliza para verificar la descarga:
$ lsEn la descarga exitosa, puede ver la siguiente respuesta:
db-derby-10.4.2.0-bin.tar.gzExtracción y verificación del archivo Derby
Los siguientes comandos se utilizan para extraer y verificar el archivo Derby:
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
$ lsEn la descarga exitosa, puede ver la siguiente respuesta:
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gzCopiar archivos en el directorio / usr / local / derby
Necesitamos copiar desde el superusuario "su -". Los siguientes comandos se utilizan para copiar los archivos del directorio extraído al/usr/local/derby directorio -
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exitPreparando el entorno para Derby
Puede configurar el entorno Derby añadiendo las siguientes líneas a ~/.bashrc archivo -
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jarEl siguiente comando se usa para ejecutar ~/.bashrc file -
$ source ~/.bashrcCrear un directorio para Metastore
Crea un directorio llamado data en el directorio $ DERBY_HOME para almacenar datos de Metastore.
$ mkdir $DERBY_HOME/dataLa instalación de Derby y la configuración ambiental ahora están completas.
Paso 11: Configurar el Metastore de Hive
Configurar Metastore significa especificar a Hive dónde se almacena la base de datos. Puede hacer esto editando elhive-site.xml archivo, que está en el $HIVE_HOME/confdirectorio. En primer lugar, copie el archivo de plantilla con el siguiente comando:
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xmlEditar hive-site.xml y agregue las siguientes líneas entre las etiquetas <configuration> y </configuration> -
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create = true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>Crea un archivo llamado jpox.properties y agregue las siguientes líneas en él:
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = minePaso 12: Verificación de la instalación de Hive
Antes de ejecutar Hive, debe crear el /tmpcarpeta y una carpeta separada de Hive en HDFS. Aquí, usamos el/user/hive/warehousecarpeta. Debe establecer el permiso de escritura para estas carpetas recién creadas como se muestra a continuación:
chmod g+wAhora configúrelos en HDFS antes de verificar Hive. Utilice los siguientes comandos:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouseLos siguientes comandos se utilizan para verificar la instalación de Hive:
$ cd $HIVE_HOME $ bin/hiveEn la instalación exitosa de Hive, puede ver la siguiente respuesta:
Logging initialized using configuration in
jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/
hive-log4j.properties Hive history
=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>Puede ejecutar el siguiente comando de muestra para mostrar todas las tablas:
hive> show tables;
OK Time taken: 2.798 seconds
hive>Paso 13: Verificar la instalación de HCatalog
Utilice el siguiente comando para establecer una variable del sistema HCAT_HOME para HCatalog Home.
export HCAT_HOME = $HiVE_HOME/HCatalogUtilice el siguiente comando para verificar la instalación de HCatalog.
cd $HCAT_HOME/bin
./hcatSi la instalación es exitosa, verá el siguiente resultado:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statementLa interfaz de línea de comandos (CLI) de HCatalog se puede invocar desde el comando $HIVE_HOME/HCatalog/bin/hcat donde $ HIVE_HOME es el directorio de inicio de Hive. hcat es un comando que se utiliza para inicializar el servidor HCatalog.
Utilice el siguiente comando para inicializar la línea de comandos de HCatalog.
cd $HCAT_HOME/bin
./hcatSi la instalación se ha realizado correctamente, obtendrá el siguiente resultado:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statementLa CLI de HCatalog admite estas opciones de línea de comandos:
| No Señor | Opción | Ejemplo y descripción |
|---|---|---|
| 1 | -gramo | hcat -g mygroup ... La tabla a crear debe tener el grupo "mygroup". |
| 2 | -pags | hcat -p rwxr-xr-x ... La tabla que se creará debe tener permisos de lectura, escritura y ejecución. |
| 3 | -F | hcat -f myscript.HCatalog ... myscript.HCatalog es un archivo de script que contiene comandos DDL para ejecutar. |
| 4 | -mi | hcat -e 'create table mytable(a int);' ... Trate la siguiente cadena como un comando DDL y ejecútelo. |
| 5 | -RE | hcat -Dkey = value ... Pasa el par clave-valor a HCatalog como una propiedad del sistema Java. |
| 6 | - | hcat Imprime un mensaje de uso. |
Nota -
los -g y -p las opciones no son obligatorias.
En un momento, ya sea -e o -f Se puede proporcionar la opción, no ambas.
El orden de las opciones es irrelevante; puede especificar las opciones en cualquier orden.
| No Señor | Comando y descripción de DDL |
|---|---|
| 1 | CREATE TABLE Cree una tabla usando HCatalog. Si crea una tabla con una cláusula CLUSjected BY, no podrá escribir en ella con Pig o MapReduce. |
| 2 | ALTER TABLE Compatible excepto para las opciones RECONSTRUIR y CONCATENAR. Su comportamiento sigue siendo el mismo que en Hive. |
| 3 | DROP TABLE Soportado. El comportamiento es el mismo que Hive (eliminar la tabla y la estructura completa). |
| 4 | CREATE/ALTER/DROP VIEW Soportado. Comportamiento igual que Hive. Note - Pig y MapReduce no pueden leer ni escribir en las vistas. |
| 5 | SHOW TABLES Muestra una lista de tablas. |
| 6 | SHOW PARTITIONS Muestra una lista de particiones. |
| 7 | Create/Drop Index Las operaciones CREATE y DROP FUNCTION son compatibles, pero las funciones creadas aún deben registrarse en Pig y colocarse en CLASSPATH para MapReduce. |
| 8 | DESCRIBE Soportado. Comportamiento igual que Hive. Describe la estructura. |
Algunos de los comandos de la tabla anterior se explican en los capítulos siguientes.
Este capítulo explica cómo crear una tabla y cómo insertar datos en ella. Las convenciones de crear una tabla en HCatalog son bastante similares a crear una tabla con Hive.
Crear declaración de tabla
Create Table es una declaración que se usa para crear una tabla en Hive metastore usando HCatalog. Su sintaxis y ejemplo son los siguientes:
Sintaxis
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]Ejemplo
Supongamos que necesita crear una tabla llamada employee utilizando CREATE TABLEdeclaración. La siguiente tabla enumera los campos y sus tipos de datos en laemployee mesa -
| No Señor | Nombre del campo | Tipo de datos |
|---|---|---|
| 1 | Eid | En t |
| 2 | Nombre | Cuerda |
| 3 | Salario | Flotador |
| 4 | Designacion | cuerda |
Los siguientes datos definen los campos admitidos como Comment, Campos con formato de fila como Field terminator, Lines terminatory Stored File type.
COMMENT ‘Employee details’
FIELDS TERMINATED BY ‘\t’
LINES TERMINATED BY ‘\n’
STORED IN TEXT FILELa siguiente consulta crea una tabla llamada employee utilizando los datos anteriores.
./hcat –e "CREATE TABLE IF NOT EXISTS employee ( eid int, name String,
salary String, destination String) \
COMMENT 'Employee details' \
ROW FORMAT DELIMITED \
FIELDS TERMINATED BY ‘\t’ \
LINES TERMINATED BY ‘\n’ \
STORED AS TEXTFILE;"Si agrega la opción IF NOT EXISTS, HCatalog ignora la declaración en caso de que la tabla ya exista.
En la creación exitosa de la tabla, puede ver la siguiente respuesta:
OK
Time taken: 5.905 secondsDeclaración de carga de datos
Generalmente, después de crear una tabla en SQL, podemos insertar datos usando la instrucción Insert. Pero en HCatalog, insertamos datos usando la instrucción LOAD DATA.
Al insertar datos en HCatalog, es mejor usar LOAD DATA para almacenar registros masivos. Hay dos formas de cargar datos: una es desdelocal file system y el segundo es de Hadoop file system.
Sintaxis
La sintaxis de LOAD DATA es la siguiente:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]- LOCAL es el identificador para especificar la ruta local. Es opcional.
- OVERWRITE es opcional para sobrescribir los datos en la tabla.
- La PARTICIÓN es opcional.
Ejemplo
Insertaremos los siguientes datos en la tabla. Es un archivo de texto llamadosample.txt en /home/user directorio.
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Kiran 40000 Hr Admin
1205 Kranthi 30000 Op AdminLa siguiente consulta carga el texto dado en la tabla.
./hcat –e "LOAD DATA LOCAL INPATH '/home/user/sample.txt'
OVERWRITE INTO TABLE employee;"En la descarga exitosa, puede ver la siguiente respuesta:
OK
Time taken: 15.905 secondsEste capítulo explica cómo modificar los atributos de una tabla, como cambiar el nombre de la tabla, cambiar los nombres de las columnas, agregar columnas y eliminar o reemplazar columnas.
Declaración de alteración de la tabla
Puede utilizar la instrucción ALTER TABLE para modificar una tabla en Hive.
Sintaxis
La declaración toma cualquiera de las siguientes sintaxis según los atributos que deseamos modificar en una tabla.
ALTER TABLE name RENAME TO new_name
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])Algunos de los escenarios se explican a continuación.
Cambiar nombre a ... Declaración
La siguiente consulta cambia el nombre de una tabla de employee a emp.
./hcat –e "ALTER TABLE employee RENAME TO emp;"Declaración de cambio
La siguiente tabla contiene los campos de employee tabla y muestra los campos a cambiar (en negrita).
| Nombre del campo | Convertir de tipo de datos | Cambiar nombre de campo | Convertir a tipo de datos |
|---|---|---|---|
| eid | En t | eid | En t |
| nombre | Cuerda | esmalte | Cuerda |
| salario | Flotador | salario | Doble |
| designacion | Cuerda | designacion | Cuerda |
Las siguientes consultas cambian el nombre del nombre de la columna y el tipo de datos de la columna utilizando los datos anteriores:
./hcat –e "ALTER TABLE employee CHANGE name ename String;"
./hcat –e "ALTER TABLE employee CHANGE salary salary Double;"Agregar declaración de columnas
La siguiente consulta agrega una columna llamada dept al employee mesa.
./hcat –e "ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name');"Reemplazar declaración
La siguiente consulta elimina todas las columnas de la employee tabla y la reemplaza con emp y name columnas -
./hcat – e "ALTER TABLE employee REPLACE COLUMNS ( eid INT empid Int, ename STRING name String);"Declaración de Drop Table
Este capítulo describe cómo colocar una tabla en HCatalog. Cuando quita una tabla de la tienda de metadatos, elimina los datos de la tabla / columna y sus metadatos. Puede ser una tabla normal (almacenada en metastore) o una tabla externa (almacenada en el sistema de archivos local); HCatalog trata a ambos de la misma manera, independientemente de su tipo.
La sintaxis es la siguiente:
DROP TABLE [IF EXISTS] table_name;La siguiente consulta descarta una tabla llamada employee -
./hcat –e "DROP TABLE IF EXISTS employee;"En la ejecución exitosa de la consulta, puede ver la siguiente respuesta:
OK
Time taken: 5.3 secondsEste capítulo describe cómo crear y administrar un viewen HCatalog. Las vistas de la base de datos se crean utilizandoCREATE VIEWdeclaración. Las vistas se pueden crear a partir de una sola tabla, varias tablas u otra vista.
Para crear una vista, un usuario debe tener los privilegios del sistema adecuados de acuerdo con la implementación específica.
Crear declaración de vista
CREATE VIEWcrea una vista con el nombre de pila. Se produce un error si ya existe una tabla o vista con el mismo nombre. Puedes usarIF NOT EXISTS para omitir el error.
Si no se proporcionan nombres de columna, los nombres de las columnas de la vista se derivarán automáticamente de la defining SELECT expression.
Note - Si SELECT contiene expresiones escalares sin alias como x + y, los nombres de columna de la vista resultante se generarán en la forma _C0, _C1, etc.
Al cambiar el nombre de las columnas, también se pueden proporcionar comentarios de columna. Los comentarios no se heredan automáticamente de las columnas subyacentes.
Una sentencia CREATE VIEW fallará si la vista defining SELECT expression es inválido.
Sintaxis
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ...;Ejemplo
Los siguientes son los datos de la tabla de empleados. Ahora veamos cómo crear una vista llamadaEmp_Deg_View que contiene los campos id, nombre, designación y salario de un empleado que tiene un salario superior a 35.000.
+------+-------------+--------+-------------------+-------+
| ID | Name | Salary | Designation | Dept |
+------+-------------+--------+-------------------+-------+
| 1201 | Gopal | 45000 | Technical manager | TP |
| 1202 | Manisha | 45000 | Proofreader | PR |
| 1203 | Masthanvali | 30000 | Technical writer | TP |
| 1204 | Kiran | 40000 | Hr Admin | HR |
| 1205 | Kranthi | 30000 | Op Admin | Admin |
+------+-------------+--------+-------------------+-------+El siguiente es el comando para crear una vista basada en los datos dados anteriormente.
./hcat –e "CREATE VIEW Emp_Deg_View (salary COMMENT ' salary more than 35,000')
AS SELECT id, name, salary, designation FROM employee WHERE salary ≥ 35000;"Salida
OK
Time taken: 5.3 secondsDeclaración de Drop View
DROP VIEW elimina los metadatos de la vista especificada. Al eliminar una vista a la que hacen referencia otras vistas, no se da ninguna advertencia (las vistas dependientes quedan colgando como inválidas y el usuario debe eliminarlas o recrearlas).
Sintaxis
DROP VIEW [IF EXISTS] view_name;Ejemplo
El siguiente comando se usa para quitar una vista llamada Emp_Deg_View.
DROP VIEW Emp_Deg_View;A menudo, desea enumerar todas las tablas en una base de datos o enumerar todas las columnas en una tabla. Obviamente, cada base de datos tiene su propia sintaxis para listar las tablas y columnas.
Show Tablesdeclaración muestra los nombres de todas las tablas. De forma predeterminada, enumera las tablas de la base de datos actual o con laIN cláusula, en una base de datos especificada.
Este capítulo describe cómo enumerar todas las tablas de la base de datos actual en HCatalog.
Mostrar declaración de tablas
La sintaxis de SHOW TABLES es la siguiente:
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];La siguiente consulta muestra una lista de tablas:
./hcat –e "Show tables;"En la ejecución exitosa de la consulta, puede ver la siguiente respuesta:
OK
emp
employee
Time taken: 5.3 secondsUna partición es una condición para los datos tabulares que se utilizan para crear una tabla o vista separada. SHOW PARTITIONS enumera todas las particiones existentes para una tabla base determinada. Las particiones se enumeran en orden alfabético. Después de Hive 0.6, también es posible especificar partes de una especificación de partición para filtrar la lista resultante.
Puede usar el comando SHOW PARTITIONS para ver las particiones que existen en una tabla en particular. Este capítulo describe cómo enumerar las particiones de una tabla en particular en HCatalog.
Mostrar declaración de particiones
La sintaxis es la siguiente:
SHOW PARTITIONS table_name;La siguiente consulta descarta una tabla llamada employee -
./hcat –e "Show partitions employee;"En la ejecución exitosa de la consulta, puede ver la siguiente respuesta:
OK
Designation = IT
Time taken: 5.3 secondsPartición dinámica
HCatalog organiza las tablas en particiones. Es una forma de dividir una tabla en partes relacionadas según los valores de las columnas divididas, como la fecha, la ciudad y el departamento. Al usar particiones, es fácil consultar una parte de los datos.
Por ejemplo, una tabla llamada Tab1contiene datos del empleado como id, nombre, departamento y yoj (es decir, año de incorporación). Suponga que necesita recuperar los detalles de todos los empleados que se unieron en 2012. Una consulta busca en toda la tabla la información requerida. Sin embargo, si divide los datos de los empleados con el año y los almacena en un archivo separado, se reduce el tiempo de procesamiento de la consulta. El siguiente ejemplo muestra cómo particionar un archivo y sus datos:
El siguiente archivo contiene employeedata mesa.
/ tab1 / employeedata / file1
id, name, dept, yoj
1, gopal, TP, 2012
2, kiran, HR, 2012
3, kaleel, SC, 2013
4, Prasanth, SC, 2013Los datos anteriores se dividen en dos archivos usando year.
/ tab1 / employeedata / 2012 / file2
1, gopal, TP, 2012
2, kiran, HR, 2012/ tab1 / employeedata / 2013 / file3
3, kaleel, SC, 2013
4, Prasanth, SC, 2013Agregar una partición
Podemos agregar particiones a una tabla alterando la tabla. Supongamos que tenemos una tabla llamadaemployee con campos como Id, Nombre, Salario, Designación, Departamento y Yoj.
Sintaxis
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec
[LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...;
partition_spec:
: (p_column = p_col_value, p_column = p_col_value, ...)La siguiente consulta se utiliza para agregar una partición al employee mesa.
./hcat –e "ALTER TABLE employee ADD PARTITION (year = '2013') location '/2012/part2012';"Cambiar el nombre de una partición
Puede utilizar el comando RENAME-TO para cambiar el nombre de una partición. Su sintaxis es la siguiente:
./hact –e "ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;"La siguiente consulta se utiliza para cambiar el nombre de una partición:
./hcat –e "ALTER TABLE employee PARTITION (year=’1203’) RENAME TO PARTITION (Yoj='1203');"Dejar caer una partición
La sintaxis del comando que se usa para eliminar una partición es la siguiente:
./hcat –e "ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,.
PARTITION partition_spec,...;"La siguiente consulta se utiliza para eliminar una partición:
./hcat –e "ALTER TABLE employee DROP [IF EXISTS] PARTITION (year=’1203’);"Crear un índice
Un índice no es más que un puntero en una columna particular de una tabla. Crear un índice significa crear un puntero en una columna particular de una tabla. Su sintaxis es la siguiente:
CREATE INDEX index_name
ON TABLE base_table_name (col_name, ...)
AS 'index.handler.class.name'
[WITH DEFERRED REBUILD]
[IDXPROPERTIES (property_name = property_value, ...)]
[IN TABLE index_table_name]
[PARTITIONED BY (col_name, ...)][
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
]
[LOCATION hdfs_path]
[TBLPROPERTIES (...)]Ejemplo
Tomemos un ejemplo para entender el concepto de índice. Usa el mismoemployee tabla que hemos usado anteriormente con los campos Id, Nombre, Salario, Designación y Departamento. Cree un índice llamado index_salary sobre el salary columna de la employee mesa.
La siguiente consulta crea un índice:
./hcat –e "CREATE INDEX inedx_salary ON TABLE employee(salary)
AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';"Es un puntero al salarycolumna. Si se modifica la columna, los cambios se almacenan utilizando un valor de índice.
Dejar caer un índice
La siguiente sintaxis se utiliza para eliminar un índice:
DROP INDEX <index_name> ON <table_name>La siguiente consulta elimina el índice index_salary -
./hcat –e "DROP INDEX index_salary ON employee;"HCatalog contiene una API de transferencia de datos para entrada y salida en paralelo sin usar MapReduce. Esta API utiliza una abstracción de almacenamiento básica de tablas y filas para leer datos del clúster de Hadoop y escribir datos en él.
La API de transferencia de datos contiene principalmente tres clases; esos son -
HCatReader - Lee datos de un clúster de Hadoop.
HCatWriter - Escribe datos en un clúster de Hadoop.
DataTransferFactory - Genera instancias de lector y escritor.
Esta API es adecuada para la configuración del nodo maestro-esclavo. Discutamos más sobreHCatReader y HCatWriter.
HCatReader
HCatReader es una clase abstracta interna de HCatalog y abstrae las complejidades del sistema subyacente desde donde se recuperarán los registros.
| S. No. | Nombre y descripción del método |
|---|---|
| 1 | Public abstract ReaderContext prepareRead() throws HCatException Esto debe llamarse en el nodo maestro para obtener ReaderContext que luego debe serializarse y enviarse a los nodos esclavos. |
| 2 | Public abstract Iterator <HCatRecorder> read() throws HCaException Esto se debe llamar en los nodos esclavos para leer HCatRecords. |
| 3 | Public Configuration getConf() Devolverá el objeto de clase de configuración. |
La clase HCatReader se utiliza para leer los datos de HDFS. La lectura es un proceso de dos pasos en el que el primer paso ocurre en el nodo maestro de un sistema externo. El segundo paso se lleva a cabo en paralelo en varios nodos esclavos.
Las lecturas se realizan en un ReadEntity. Antes de comenzar a leer, debe definir una ReadEntity desde la que leer. Esto se puede hacer a través deReadEntity.Builder. Puede especificar un nombre de base de datos, un nombre de tabla, una partición y una cadena de filtro. Por ejemplo
ReadEntity.Builder builder = new ReadEntity.Builder();
ReadEntity entity = builder.withDatabase("mydb").withTable("mytbl").build(); 10.El fragmento de código anterior define un objeto ReadEntity ("entidad"), que comprende una tabla llamada mytbl en una base de datos llamada mydb, que se puede utilizar para leer todas las filas de esta tabla. Tenga en cuenta que esta tabla debe existir en HCatalog antes del inicio de esta operación.
Después de definir un ReadEntity, obtiene una instancia de HCatReader usando ReadEntity y la configuración del clúster:
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);El siguiente paso es obtener un ReaderContext del lector de la siguiente manera:
ReaderContext cntxt = reader.prepareRead();HCatWriter
Esta abstracción es interna de HCatalog. Esto es para facilitar la escritura en HCatalog desde sistemas externos. No intente crear una instancia de esto directamente. En su lugar, use DataTransferFactory.
| No Señor. | Nombre y descripción del método |
|---|---|
| 1 | Public abstract WriterContext prepareRead() throws HCatException El sistema externo debe invocar este método exactamente una vez desde un nodo maestro. Devuelve unWriterContext. Esto debe serializarse y enviarse a los nodos esclavos para construirHCatWriter allí. |
| 2 | Public abstract void write(Iterator<HCatRecord> recordItr) throws HCaException Este método debe usarse en los nodos esclavos para realizar escrituras. RecordItr es un objeto iterador que contiene la colección de registros que se escribirán en HCatalog. |
| 3 | Public abstract void abort(WriterContext cntxt) throws HCatException Este método debe llamarse en el nodo principal. El propósito principal de este método es realizar limpiezas en caso de fallas. |
| 4 | public abstract void commit(WriterContext cntxt) throws HCatException Este método debe llamarse en el nodo principal. El propósito de este método es confirmar los metadatos. |
Similar a la lectura, la escritura también es un proceso de dos pasos en el cual el primer paso ocurre en el nodo maestro. Posteriormente, el segundo paso ocurre en paralelo en los nodos esclavos.
Las escrituras se realizan en un WriteEntity que se puede construir de una manera similar a las lecturas:
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withDatabase("mydb").withTable("mytbl").build();El código anterior crea un objeto WriteEntity entityque se puede usar para escribir en una tabla llamadamytbl en la base de datos mydb.
Después de crear WriteEntity, el siguiente paso es obtener un WriterContext -
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();Todos los pasos anteriores ocurren en el nodo principal. El nodo maestro luego serializa el objeto WriterContext y lo pone a disposición de todos los esclavos.
En los nodos esclavos, debe obtener un HCatWriter usando WriterContext de la siguiente manera:
HCatWriter writer = DataTransferFactory.getHCatWriter(context);Entonces la writertoma un iterador como argumento para el writemétodo -
writer.write(hCatRecordItr);los writer luego llama getNext() en este iterador en un bucle y escribe todos los registros adjuntos al iterador.
los TestReaderWriter.javaEl archivo se utiliza para probar las clases HCatreader y HCatWriter. El siguiente programa demuestra cómo usar HCatReader y la API de HCatWriter para leer datos de un archivo fuente y luego escribirlos en un archivo de destino.
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.ql.CommandNeedRetryException;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hive.HCatalog.common.HCatException;
import org.apache.hive.HCatalog.data.transfer.DataTransferFactory;
import org.apache.hive.HCatalog.data.transfer.HCatReader;
import org.apache.hive.HCatalog.data.transfer.HCatWriter;
import org.apache.hive.HCatalog.data.transfer.ReadEntity;
import org.apache.hive.HCatalog.data.transfer.ReaderContext;
import org.apache.hive.HCatalog.data.transfer.WriteEntity;
import org.apache.hive.HCatalog.data.transfer.WriterContext;
import org.apache.hive.HCatalog.mapreduce.HCatBaseTest;
import org.junit.Assert;
import org.junit.Test;
public class TestReaderWriter extends HCatBaseTest {
@Test
public void test() throws MetaException, CommandNeedRetryException,
IOException, ClassNotFoundException {
driver.run("drop table mytbl");
driver.run("create table mytbl (a string, b int)");
Iterator<Entry<String, String>> itr = hiveConf.iterator();
Map<String, String> map = new HashMap<String, String>();
while (itr.hasNext()) {
Entry<String, String> kv = itr.next();
map.put(kv.getKey(), kv.getValue());
}
WriterContext cntxt = runsInMaster(map);
File writeCntxtFile = File.createTempFile("hcat-write", "temp");
writeCntxtFile.deleteOnExit();
// Serialize context.
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(writeCntxtFile));
oos.writeObject(cntxt);
oos.flush();
oos.close();
// Now, deserialize it.
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(writeCntxtFile));
cntxt = (WriterContext) ois.readObject();
ois.close();
runsInSlave(cntxt);
commit(map, true, cntxt);
ReaderContext readCntxt = runsInMaster(map, false);
File readCntxtFile = File.createTempFile("hcat-read", "temp");
readCntxtFile.deleteOnExit();
oos = new ObjectOutputStream(new FileOutputStream(readCntxtFile));
oos.writeObject(readCntxt);
oos.flush();
oos.close();
ois = new ObjectInputStream(new FileInputStream(readCntxtFile));
readCntxt = (ReaderContext) ois.readObject();
ois.close();
for (int i = 0; i < readCntxt.numSplits(); i++) {
runsInSlave(readCntxt, i);
}
}
private WriterContext runsInMaster(Map<String, String> config) throws HCatException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();
return info;
}
private ReaderContext runsInMaster(Map<String, String> config,
boolean bogus) throws HCatException {
ReadEntity entity = new ReadEntity.Builder().withTable("mytbl").build();
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
ReaderContext cntxt = reader.prepareRead();
return cntxt;
}
private void runsInSlave(ReaderContext cntxt, int slaveNum) throws HCatException {
HCatReader reader = DataTransferFactory.getHCatReader(cntxt, slaveNum);
Iterator<HCatRecord> itr = reader.read();
int i = 1;
while (itr.hasNext()) {
HCatRecord read = itr.next();
HCatRecord written = getRecord(i++);
// Argh, HCatRecord doesnt implement equals()
Assert.assertTrue("Read: " + read.get(0) + "Written: " + written.get(0),
written.get(0).equals(read.get(0)));
Assert.assertTrue("Read: " + read.get(1) + "Written: " + written.get(1),
written.get(1).equals(read.get(1)));
Assert.assertEquals(2, read.size());
}
//Assert.assertFalse(itr.hasNext());
}
private void runsInSlave(WriterContext context) throws HCatException {
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
writer.write(new HCatRecordItr());
}
private void commit(Map<String, String> config, boolean status,
WriterContext context) throws IOException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
if (status) {
writer.commit(context);
} else {
writer.abort(context);
}
}
private static HCatRecord getRecord(int i) {
List<Object> list = new ArrayList<Object>(2);
list.add("Row #: " + i);
list.add(i);
return new DefaultHCatRecord(list);
}
private static class HCatRecordItr implements Iterator<HCatRecord> {
int i = 0;
@Override
public boolean hasNext() {
return i++ < 100 ? true : false;
}
@Override
public HCatRecord next() {
return getRecord(i);
}
@Override
public void remove() {
throw new RuntimeException();
}
}
}El programa anterior lee los datos del HDFS en forma de registros y escribe los datos del registro en mytable
los HCatInputFormat y HCatOutputFormatLas interfaces se utilizan para leer datos de HDFS y, después del procesamiento, escribir los datos resultantes en HDFS utilizando el trabajo MapReduce. Elaboremos las interfaces de formato de entrada y salida.
HCatInputFormat
los HCatInputFormatse usa con trabajos de MapReduce para leer datos de tablas administradas por HCatalog. HCatInputFormat expone una API MapReduce de Hadoop 0.20 para leer datos como si se hubieran publicado en una tabla.
| No Señor. | Nombre y descripción del método |
|---|---|
| 1 | public static HCatInputFormat setInput(Job job, String dbName, String tableName)throws IOException Configure las entradas que se utilizarán para el trabajo. Consulta la tienda de metadatos con la especificación de entrada dada y serializa las particiones coincidentes en la configuración del trabajo para las tareas de MapReduce. |
| 2 | public static HCatInputFormat setInput(Configuration conf, String dbName, String tableName) throws IOException Configure las entradas que se utilizarán para el trabajo. Consulta la tienda de metadatos con la especificación de entrada dada y serializa las particiones coincidentes en la configuración del trabajo para las tareas de MapReduce. |
| 3 | public HCatInputFormat setFilter(String filter)throws IOException Establezca un filtro en la tabla de entrada. |
| 4 | public HCatInputFormat setProperties(Properties properties) throws IOException Establecer propiedades para el formato de entrada. |
La API HCatInputFormat incluye los siguientes métodos:
- setInput
- setOutputSchema
- getTableSchema
Usar HCatInputFormat para leer datos, primero cree una instancia InputJobInfo con la información necesaria de la tabla que se está leyendo y luego llame setInput con el InputJobInfo.
Puedes usar el setOutputSchema método para incluir un projection schema, para especificar los campos de salida. Si no se especifica un esquema, se devolverán todas las columnas de la tabla. Puede utilizar el método getTableSchema para determinar el esquema de tabla para una tabla de entrada especificada.
HCatOutputFormat
HCatOutputFormat se usa con trabajos de MapReduce para escribir datos en tablas administradas por HCatalog. HCatOutputFormat expone una API MapReduce de Hadoop 0.20 para escribir datos en una tabla. Cuando un trabajo de MapReduce usa HCatOutputFormat para escribir la salida, se usa el OutputFormat predeterminado configurado para la tabla y la nueva partición se publica en la tabla una vez que se completa el trabajo.
| No Señor. | Nombre y descripción del método |
|---|---|
| 1 | public static void setOutput (Configuration conf, Credentials credentials, OutputJobInfo outputJobInfo) throws IOException Configure la información sobre la salida para escribir para el trabajo. Consulta al servidor de metadatos para encontrar el StorageHandler que se utilizará para la tabla. Lanza un error si la partición ya está publicada. |
| 2 | public static void setSchema (Configuration conf, HCatSchema schema) throws IOException Establezca el esquema para los datos que se escriben en la partición. El esquema de tabla se usa de forma predeterminada para la partición si no se llama. |
| 3 | public RecordWriter <WritableComparable<?>, HCatRecord > getRecordWriter (TaskAttemptContext context)throws IOException, InterruptedException Consiga al escritor de discos para el trabajo. Utiliza el OutputFormat predeterminado de StorageHandler para obtener el escritor de registros. |
| 4 | public OutputCommitter getOutputCommitter (TaskAttemptContext context) throws IOException, InterruptedException Obtenga el confirmador de salida para este formato de salida. Asegura que la salida se confirme correctamente. |
los HCatOutputFormat API incluye los siguientes métodos:
- setOutput
- setSchema
- getTableSchema
La primera llamada en HCatOutputFormat debe ser setOutput; cualquier otra llamada lanzará una excepción diciendo que el formato de salida no está inicializado.
El esquema de los datos que se escriben lo especifica el setSchemamétodo. Debe llamar a este método, proporcionando el esquema de datos que está escribiendo. Si sus datos tienen el mismo esquema que el esquema de la tabla, puede usarHCatOutputFormat.getTableSchema() para obtener el esquema de la tabla y luego pasarlo a setSchema().
Ejemplo
El siguiente programa MapReduce lee datos de una tabla que asume que tiene un número entero en la segunda columna ("columna 1") y cuenta cuántas instancias de cada valor distinto encuentra. Es decir, hace el equivalente de "select col1, count(*) from $table group by col1;".
Por ejemplo, si los valores de la segunda columna son {1, 1, 1, 3, 3, 5}, el programa producirá la siguiente salida de valores y recuentos:
1, 3
3, 2
5, 1Echemos ahora un vistazo al código del programa:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.HCatalog.common.HCatConstants;
import org.apache.HCatalog.data.DefaultHCatRecord;
import org.apache.HCatalog.data.HCatRecord;
import org.apache.HCatalog.data.schema.HCatSchema;
import org.apache.HCatalog.mapreduce.HCatInputFormat;
import org.apache.HCatalog.mapreduce.HCatOutputFormat;
import org.apache.HCatalog.mapreduce.InputJobInfo;
import org.apache.HCatalog.mapreduce.OutputJobInfo;
public class GroupByAge extends Configured implements Tool {
public static class Map extends Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable> {
int age;
@Override
protected void map(
WritableComparable key, HCatRecord value,
org.apache.hadoop.mapreduce.Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable>.Context context
)throws IOException, InterruptedException {
age = (Integer) value.get(1);
context.write(new IntWritable(age), new IntWritable(1));
}
}
public static class Reduce extends Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord> {
@Override
protected void reduce(
IntWritable key, java.lang.Iterable<IntWritable> values,
org.apache.hadoop.mapreduce.Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord>.Context context
)throws IOException ,InterruptedException {
int sum = 0;
Iterator<IntWritable> iter = values.iterator();
while (iter.hasNext()) {
sum++;
iter.next();
}
HCatRecord record = new DefaultHCatRecord(2);
record.set(0, key.get());
record.set(1, sum);
context.write(null, record);
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
args = new GenericOptionsParser(conf, args).getRemainingArgs();
String serverUri = args[0];
String inputTableName = args[1];
String outputTableName = args[2];
String dbName = null;
String principalID = System
.getProperty(HCatConstants.HCAT_METASTORE_PRINCIPAL);
if (principalID != null)
conf.set(HCatConstants.HCAT_METASTORE_PRINCIPAL, principalID);
Job job = new Job(conf, "GroupByAge");
HCatInputFormat.setInput(job, InputJobInfo.create(dbName, inputTableName, null));
// initialize HCatOutputFormat
job.setInputFormatClass(HCatInputFormat.class);
job.setJarByClass(GroupByAge.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(WritableComparable.class);
job.setOutputValueClass(DefaultHCatRecord.class);
HCatOutputFormat.setOutput(job, OutputJobInfo.create(dbName, outputTableName, null));
HCatSchema s = HCatOutputFormat.getTableSchema(job);
System.err.println("INFO: output schema explicitly set for writing:" + s);
HCatOutputFormat.setSchema(job, s);
job.setOutputFormatClass(HCatOutputFormat.class);
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new GroupByAge(), args);
System.exit(exitCode);
}
}Antes de compilar el programa anterior, debe descargar algunos jars y agregarlos al classpathpara esta aplicación. Necesita descargar todos los archivos de Hive y HCatalog (HCatalog-core-0.5.0.jar, hive-metastore-0.10.0.jar, libthrift-0.7.0.jar, hive-exec-0.10.0.jar, libfb303-0.7.0.jar, jdo2-api-2.3-ec.jar, slf4j-api-1.6.1.jar).
Utilice los siguientes comandos para copiar esos jar archivos de local a HDFS y agregarlos al classpath.
bin/hadoop fs -copyFromLocal $HCAT_HOME/share/HCatalog/HCatalog-core-0.5.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-metastore-0.10.0.jar /tmp
bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libthrift-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-exec-0.10.0.jar /tmp
bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libfb303-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/jdo2-api-2.3-ec.jar /tmp
bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/slf4j-api-1.6.1.jar /tmp
export LIB_JARS=hdfs:///tmp/HCatalog-core-0.5.0.jar,
hdfs:///tmp/hive-metastore-0.10.0.jar,
hdfs:///tmp/libthrift-0.7.0.jar,
hdfs:///tmp/hive-exec-0.10.0.jar,
hdfs:///tmp/libfb303-0.7.0.jar,
hdfs:///tmp/jdo2-api-2.3-ec.jar,
hdfs:///tmp/slf4j-api-1.6.1.jarUtilice el siguiente comando para compilar y ejecutar el programa dado.
$HADOOP_HOME/bin/hadoop jar GroupByAge tmp/hiveAhora, verifique su directorio de salida (hdfs: user / tmp / hive) para ver la salida (part_0000, part_0001).
los HCatLoader y HCatStorerLas API se utilizan con scripts de Pig para leer y escribir datos en tablas administradas por HCatalog. No se requiere ninguna configuración específica de HCatalog para estas interfaces.
Es mejor tener algunos conocimientos sobre los scripts de Apache Pig para comprender mejor este capítulo. Para obtener más información, consulte nuestro tutorial de Apache Pig .
HCatloader
HCatLoader se usa con scripts Pig para leer datos de tablas administradas por HCatalog. Utilice la siguiente sintaxis para cargar datos en HDFS con HCatloader.
A = LOAD 'tablename' USING org.apache.HCatalog.pig.HCatLoader();Debe especificar el nombre de la tabla entre comillas simples: LOAD 'tablename'. Si está utilizando una base de datos no predeterminada, debe especificar su entrada como 'dbname.tablename'.
El metastore de Hive le permite crear tablas sin especificar una base de datos. Si creó tablas de esta manera, entonces el nombre de la base de datos es'default' y no es necesario al especificar la tabla para HCatLoader.
La siguiente tabla contiene los métodos importantes y la descripción de la clase HCatloader.
| No Señor. | Nombre y descripción del método |
|---|---|
| 1 | public InputFormat<?,?> getInputFormat()throws IOException Lea el formato de entrada de los datos de carga utilizando la clase HCatloader. |
| 2 | public String relativeToAbsolutePath(String location, Path curDir) throws IOException Devuelve el formato String del Absolute path. |
| 3 | public void setLocation(String location, Job job) throws IOException Establece la ubicación donde se puede ejecutar el trabajo. |
| 4 | public Tuple getNext() throws IOException Devuelve la tupla actual (key y value) del bucle. |
HCatStorer
HCatStorer se utiliza con scripts Pig para escribir datos en tablas administradas por HCatalog. Utilice la siguiente sintaxis para la operación de almacenamiento.
A = LOAD ...
B = FOREACH A ...
...
...
my_processed_data = ...
STORE my_processed_data INTO 'tablename' USING org.apache.HCatalog.pig.HCatStorer();Debe especificar el nombre de la tabla entre comillas simples: LOAD 'tablename'. Tanto la base de datos como la tabla deben crearse antes de ejecutar su script Pig. Si está utilizando una base de datos no predeterminada, debe especificar su entrada como'dbname.tablename'.
El metastore de Hive le permite crear tablas sin especificar una base de datos. Si creó tablas de esta manera, entonces el nombre de la base de datos es'default' y no es necesario especificar el nombre de la base de datos en el store declaración.
Para el USINGcláusula, puede tener un argumento de cadena que represente pares clave / valor para particiones. Este es un argumento obligatorio cuando está escribiendo en una tabla particionada y la columna de partición no está en la columna de salida. Los valores de las claves de partición NO se deben citar.
La siguiente tabla contiene los métodos importantes y la descripción de la clase HCatStorer.
| No Señor. | Nombre y descripción del método |
|---|---|
| 1 | public OutputFormat getOutputFormat() throws IOException Lea el formato de salida de los datos almacenados utilizando la clase HCatStorer. |
| 2 | public void setStoreLocation (String location, Job job) throws IOException Establece la ubicación donde ejecutar esto store solicitud. |
| 3 | public void storeSchema (ResourceSchema schema, String arg1, Job job) throws IOException Almacene el esquema. |
| 4 | public void prepareToWrite (RecordWriter writer) throws IOException Ayuda a escribir datos en un archivo particular usando RecordWriter. |
| 5 | public void putNext (Tuple tuple) throws IOException Escribe los datos de la tupla en el archivo. |
Ejecutando Pig con HCatalog
Pig no recoge automáticamente los frascos de HCatalog. Para traer los frascos necesarios, puede usar una bandera en el comando Pig o establecer las variables de entornoPIG_CLASSPATH y PIG_OPTS como se describe abajo.
Para traer los frascos apropiados para trabajar con HCatalog, simplemente incluya la siguiente bandera:
pig –useHCatalog <Sample pig scripts file>Configuración de CLASSPATH para ejecución
Utilice la siguiente configuración de CLASSPATH para sincronizar HCatalog con Apache Pig.
export HADOOP_HOME = <path_to_hadoop_install>
export HIVE_HOME = <path_to_hive_install>
export HCAT_HOME = <path_to_hcat_install>
export PIG_CLASSPATH = $HCAT_HOME/share/HCatalog/HCatalog-core*.jar:\ $HCAT_HOME/share/HCatalog/HCatalog-pig-adapter*.jar:\
$HIVE_HOME/lib/hive-metastore-*.jar:$HIVE_HOME/lib/libthrift-*.jar:\
$HIVE_HOME/lib/hive-exec-*.jar:$HIVE_HOME/lib/libfb303-*.jar:\
$HIVE_HOME/lib/jdo2-api-*-ec.jar:$HIVE_HOME/conf:$HADOOP_HOME/conf:\ $HIVE_HOME/lib/slf4j-api-*.jarEjemplo
Supongamos que tenemos un archivo student_details.txt en HDFS con el siguiente contenido.
student_details.txt
001, Rajiv, Reddy, 21, 9848022337, Hyderabad
002, siddarth, Battacharya, 22, 9848022338, Kolkata
003, Rajesh, Khanna, 22, 9848022339, Delhi
004, Preethi, Agarwal, 21, 9848022330, Pune
005, Trupthi, Mohanthy, 23, 9848022336, Bhuwaneshwar
006, Archana, Mishra, 23, 9848022335, Chennai
007, Komal, Nayak, 24, 9848022334, trivendram
008, Bharathi, Nambiayar, 24, 9848022333, ChennaiTambién tenemos un script de muestra con el nombre sample_script.pig, en el mismo directorio HDFS. Este archivo contiene declaraciones que realizan operaciones y transformaciones en elstudent relación, como se muestra a continuación.
student = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING
PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,
phone:chararray, city:chararray);
student_order = ORDER student BY age DESC;
STORE student_order INTO 'student_order_table' USING org.apache.HCatalog.pig.HCatStorer();
student_limit = LIMIT student_order 4;
Dump student_limit;La primera declaración del script cargará los datos en el archivo llamado student_details.txt como una relación llamada student.
La segunda declaración del guión organizará las tuplas de la relación en orden descendente, según la edad, y la almacenará como student_order.
La tercera declaración almacena los datos procesados. student_order da como resultado una tabla separada llamada student_order_table.
La cuarta declaración del script almacenará las primeras cuatro tuplas de student_order como student_limit.
Finalmente, la quinta declaración volcará el contenido de la relación student_limit.
Ejecutemos ahora el sample_script.pig Como se muestra abajo.
$./pig -useHCatalog hdfs://localhost:9000/pig_data/sample_script.pigAhora, verifique su directorio de salida (hdfs: user / tmp / hive) para ver la salida (part_0000, part_0001).