KNIME - Construyendo su propio modelo
En este capítulo, creará su propio modelo de aprendizaje automático para clasificar las plantas en función de algunas características observadas. Usaremos el conocidoiris conjunto de datos de UCI Machine Learning Repositorypara este propósito. El conjunto de datos contiene tres clases diferentes de plantas. Entrenaremos nuestro modelo para clasificar una planta desconocida en una de estas tres clases.
Comenzaremos creando un nuevo flujo de trabajo en KNIME para crear nuestros modelos de aprendizaje automático.
Crear flujo de trabajo
Para crear un nuevo flujo de trabajo, seleccione la siguiente opción de menú en el banco de trabajo KNIME.
File → NewVerá la siguiente pantalla:

Selecciona el New KNIME Workflow opción y haga clic en la Nextbotón. En la siguiente pantalla, se le pedirá el nombre deseado para el flujo de trabajo y la carpeta de destino para guardarlo. Ingrese esta información como desee y haga clic enFinish para crear un nuevo espacio de trabajo.
Se agregaría un nuevo espacio de trabajo con el nombre dado al Workspace ver como se ve aquí -
Ahora agregará varios nodos en este espacio de trabajo para crear su modelo. Antes, agrega nodos, debe descargar y preparar eliris conjunto de datos para nuestro uso.
Preparando conjunto de datos
Descargue el conjunto de datos de iris del sitio del repositorio de aprendizaje automático de UCI Descargar el conjunto de datos de iris . El archivo iris.data descargado está en formato CSV. Haremos algunos cambios en él para agregar los nombres de las columnas.
Abra el archivo descargado en su editor de texto favorito y agregue la siguiente línea al principio.
sepal length, petal length, sepal width, petal width, classCuando nuestro File Reader nodo lee este archivo, automáticamente tomará los campos anteriores como nombres de columna.
Ahora, comenzará a agregar varios nodos.
Agregar lector de archivos
Ve a la Node Repository ver, escriba "archivo" en el cuadro de búsqueda para localizar el File Readernodo. Esto se ve en la captura de pantalla a continuación:

Seleccione y haga doble clic en el File Readerpara agregar el nodo al espacio de trabajo. Alternativamente, puede usar la función de arrastrar y soltar para agregar el nodo al espacio de trabajo. Una vez agregado el nodo, deberá configurarlo. Haga clic derecho en el nodo y seleccione elConfigureopción de menú. Ha hecho esto en la lección anterior.
La pantalla de configuración se parece a la siguiente después de cargar el archivo de datos.

Para cargar su conjunto de datos, haga clic en el Browsey seleccione la ubicación de su archivo iris.data. El nodo cargará el contenido del archivo que se muestra en la parte inferior del cuadro de configuración. Una vez que esté satisfecho de que el archivo de datos está ubicado correctamente y cargado, haga clic en elOK para cerrar el cuadro de diálogo de configuración.
Ahora agregará alguna anotación a este nodo. Haga clic derecho en el nodo y seleccioneNew Workflow Annotationopción de menú. Aparecería un cuadro de anotación en la pantalla como se muestra en la captura de pantalla aquí:
Haga clic dentro del cuadro y agregue la siguiente anotación:
Reads iris.dataHaga clic en cualquier lugar fuera del cuadro para salir del modo de edición. Cambie el tamaño y coloque el cuadro alrededor del nodo como desee. Finalmente, haga doble clic en elNode 1 texto debajo del nodo para cambiar esta cadena a lo siguiente:
Loads dataEn este punto, su pantalla se vería así:
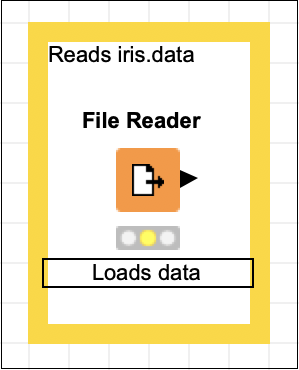
Ahora agregaremos un nuevo nodo para dividir nuestro conjunto de datos cargado en entrenamiento y prueba.
Agregar nodo de particionamiento
En el Node Repository ventana de búsqueda, escriba algunos caracteres para localizar el Partitioning nodo, como se ve en la captura de pantalla a continuación:
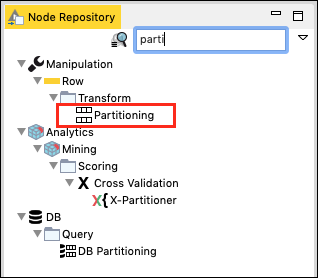
Agregue el nodo a nuestro espacio de trabajo. Establezca su configuración de la siguiente manera:
Relative (%) : 95
Draw RandomlyLa siguiente captura de pantalla muestra los parámetros de configuración.

A continuación, realice la conexión entre los dos nodos. Para hacerlo, haga clic en la salida delFile Reader nodo, mantenga pulsado el botón del ratón, aparecerá una línea de goma elástica, arrástrelo a la entrada de Partitioningnodo, suelte el botón del ratón. Ahora se establece una conexión entre los dos nodos.
Agregue la anotación, cambie la descripción, coloque el nodo y la vista de anotación como desee. Su pantalla debería verse como la siguiente en esta etapa:

A continuación, agregaremos el k-Means nodo.
Adición del nodo k-medias
Selecciona el k-Meansnodo del repositorio y agréguelo al espacio de trabajo. Si desea actualizar su conocimiento sobre el algoritmo k-Means, simplemente busque su descripción en la vista de descripción del banco de trabajo. Esto se muestra en la captura de pantalla a continuación:

Por cierto, puede buscar la descripción de diferentes algoritmos en la ventana de descripción antes de tomar una decisión final sobre cuál utilizar.
Abra el cuadro de diálogo de configuración del nodo. Usaremos los valores predeterminados para todos los campos como se muestra aquí:

Hacer clic OK para aceptar los valores predeterminados y cerrar el diálogo.
Establezca la anotación y la descripción en lo siguiente:
Anotación: Clasificar clústeres
Descripción: realizar agrupaciones
Conecte la salida superior del Partitioning nodo a la entrada de k-Meansnodo. Cambie la posición de sus elementos y su pantalla debería verse así:

A continuación, agregaremos un Cluster Assigner nodo.
Agregar asignador de clúster
los Cluster Assignerasigna nuevos datos a un conjunto existente de prototipos. Se necesitan dos entradas: el modelo prototipo y la tabla de datos que contiene los datos de entrada. Busque la descripción del nodo en la ventana de descripción que se muestra en la captura de pantalla a continuación:

Por lo tanto, para este nodo debe realizar dos conexiones:
El resultado del modelo de clúster PMML de Partitioning nodo → Prototipos Entrada de Cluster Assigner
Salida de la segunda partición de Partitioning nodo → Datos de entrada de Cluster Assigner
Estas dos conexiones se muestran en la siguiente captura de pantalla:

los Cluster Assignerno necesita ninguna configuración especial. Simplemente acepte los valores predeterminados.
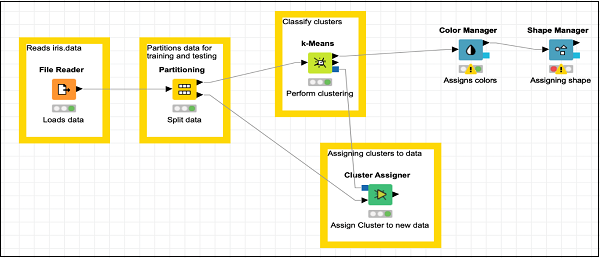
Ahora, agregue alguna anotación y descripción a este nodo. Reorganiza tus nodos. Su pantalla debería verse como la siguiente:

En este punto, nuestra agrupación está completa. Necesitamos visualizar la salida gráficamente. Para esto, agregaremos un diagrama de dispersión. Estableceremos los colores y formas para tres clases de manera diferente en el diagrama de dispersión. Por lo tanto, filtraremos la salida delk-Means nodo primero a través del Color Manager nodo y luego a través Shape Manager nodo.
Agregar Administrador de color
Busque el Color Managernodo en el repositorio. Agréguelo al espacio de trabajo. Deje la configuración a sus valores predeterminados. Tenga en cuenta que debe abrir el diálogo de configuración y presionarOKpara aceptar los valores predeterminados. Establezca el texto de descripción del nodo.
Haga una conexión desde la salida de k-Means a la entrada de Color Manager. Su pantalla se vería como la siguiente en esta etapa:

Agregar administrador de formas
Busque el Shape Manageren el repositorio y agréguelo al espacio de trabajo. Deje su configuración a los valores predeterminados. Como el anterior, debes abrir el diálogo de configuración y presionarOKpara establecer valores predeterminados. Establecer la conexión desde la salida deColor Manager a la entrada de Shape Manager. Establezca la descripción del nodo.
Su pantalla debería verse como la siguiente:
Ahora, agregará el último nodo en nuestro modelo y ese es el diagrama de dispersión.
Agregar gráfico de dispersión
Localizar Scatter Plotnodo en el repositorio y agréguelo al espacio de trabajo. Conecte la salida deShape Manager a la entrada de Scatter Plot. Deje la configuración por defecto. Establezca la descripción.
Finalmente, agregue una anotación de grupo a los tres nodos recientemente agregados
Anotación: Visualización
Vuelva a colocar los nodos como desee. Su pantalla debería verse como la siguiente en esta etapa.
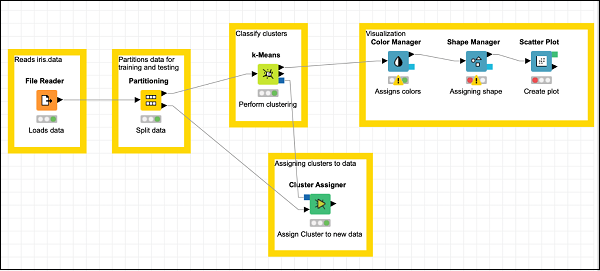
Esto completa la tarea de construcción de modelos.