Kubernetes - Guía rápida
Kubernetes en una herramienta de gestión de contenedores de código abierto alojada por Cloud Native Computing Foundation (CNCF). Esto también se conoce como la versión mejorada de Borg que fue desarrollada en Google para administrar tanto los procesos de larga ejecución como los trabajos por lotes, que anteriormente se manejaba mediante sistemas separados.
Kubernetes viene con la capacidad de automatizar la implementación, el escalado de la aplicación y las operaciones de los contenedores de aplicaciones en los clústeres. Es capaz de crear una infraestructura centrada en contenedores.
Características de Kubernetes
A continuación, se muestran algunas de las características importantes de Kubernetes.
Continúa el desarrollo, la integración y la implementación
Infraestructura en contenedores
Gestión centrada en aplicaciones
Infraestructura auto escalable
Consistencia del entorno en las pruebas de desarrollo y producción
Infraestructura débilmente acoplada, donde cada componente puede actuar como una unidad separada
Mayor densidad de utilización de recursos
Infraestructura predecible que se va a crear
Uno de los componentes clave de Kubernetes es que puede ejecutar aplicaciones en clústeres de infraestructura de máquinas virtuales y físicas. También tiene la capacidad de ejecutar aplicaciones en la nube.It helps in moving from host-centric infrastructure to container-centric infrastructure.
En este capítulo, analizaremos la arquitectura básica de Kubernetes.
Kubernetes: arquitectura de clúster
Como se ve en el siguiente diagrama, Kubernetes sigue la arquitectura cliente-servidor. En donde, tenemos master instalado en una máquina y el nodo en máquinas Linux separadas.
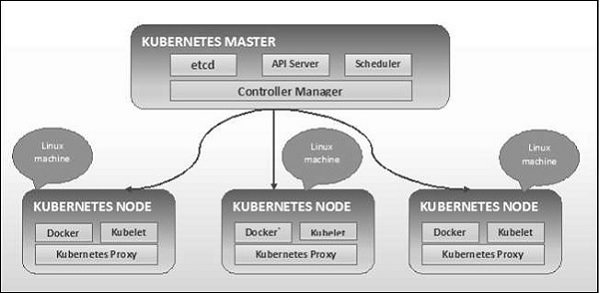
Los componentes clave de maestro y nodo se definen en la siguiente sección.
Kubernetes: componentes de la máquina maestra
Los siguientes son los componentes de Kubernetes Master Machine.
etcd
Almacena la información de configuración que puede utilizar cada uno de los nodos del clúster. Es un almacén de valor clave de alta disponibilidad que se puede distribuir entre varios nodos. Solo es accesible por el servidor de API de Kubernetes, ya que puede tener información confidencial. Es una tienda de valor clave distribuida accesible para todos.
Servidor API
Kubernetes es un servidor de API que proporciona todas las operaciones en el clúster utilizando la API. El servidor API implementa una interfaz, lo que significa que diferentes herramientas y bibliotecas pueden comunicarse fácilmente con él.Kubeconfiges un paquete junto con las herramientas del lado del servidor que se pueden utilizar para la comunicación. Expone la API de Kubernetes.
Administrador del controlador
Este componente es responsable de la mayoría de los recolectores que regula el estado del clúster y realiza una tarea. En general, se puede considerar como un demonio que se ejecuta en un bucle no terminal y es responsable de recopilar y enviar información al servidor API. Trabaja para obtener el estado compartido del clúster y luego realizar cambios para llevar el estado actual del servidor al estado deseado. Los controladores clave son controlador de replicación, controlador de punto final, controlador de espacio de nombres y controlador de cuenta de servicio. El administrador del controlador ejecuta diferentes tipos de controladores para manejar nodos, puntos finales, etc.
Programador
Este es uno de los componentes clave del maestro de Kubernetes. Es un servicio en master encargado de distribuir la carga de trabajo. Es responsable de realizar un seguimiento de la utilización de la carga de trabajo en los nodos del clúster y luego colocar la carga de trabajo en qué recursos están disponibles y aceptar la carga de trabajo. En otras palabras, este es el mecanismo responsable de asignar pods a los nodos disponibles. El programador es responsable de la utilización de la carga de trabajo y de la asignación del pod al nuevo nodo.
Kubernetes: componentes de nodo
A continuación se muestran los componentes clave del servidor de nodo que son necesarios para comunicarse con el maestro de Kubernetes.
Estibador
El primer requisito de cada nodo es Docker, que ayuda a ejecutar los contenedores de aplicaciones encapsulados en un entorno operativo relativamente aislado pero ligero.
Servicio Kubelet
Este es un pequeño servicio en cada nodo responsable de transmitir información desde y hacia el servicio del plano de control. Interactúa conetcdstore para leer los detalles de configuración y los valores de escritura. Este se comunica con el componente maestro para recibir comandos y trabajar. loskubeletEl proceso entonces asume la responsabilidad de mantener el estado de trabajo y el servidor de nodo. Gestiona reglas de red, reenvío de puertos, etc.
Servicio de proxy de Kubernetes
Este es un servicio de proxy que se ejecuta en cada nodo y ayuda a que los servicios estén disponibles para el host externo. Ayuda a reenviar la solicitud a los contenedores correctos y es capaz de realizar un equilibrio de carga primitivo. Se asegura de que el entorno de red sea predecible y accesible y, al mismo tiempo, también esté aislado. Gestiona pods en nodos, volúmenes, secretos, creando nuevos controles de salud de contenedores, etc.
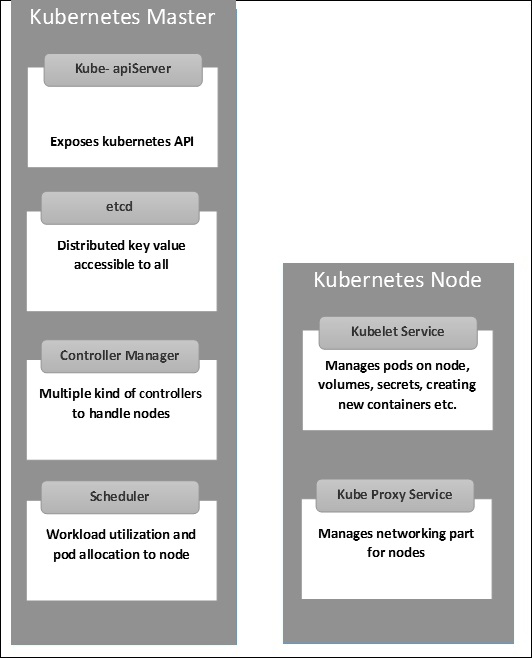
Kubernetes: estructura maestra y de nodo
Las siguientes ilustraciones muestran la estructura de Kubernetes Master y Node.
Es importante configurar el centro de datos virtual (vDC) antes de configurar Kubernetes. Esto puede considerarse como un conjunto de máquinas donde pueden comunicarse entre sí a través de la red. Para un enfoque práctico, puede configurar vDC enPROFITBRICKS si no tiene configurada una infraestructura física o en la nube.
Una vez que se completa la configuración de IaaS en cualquier nube, debe configurar el Master y el Node.
Note- La configuración se muestra para máquinas Ubuntu. Lo mismo se puede configurar en otras máquinas Linux.
Prerrequisitos
Installing Docker- Se requiere Docker en todas las instancias de Kubernetes. Los siguientes son los pasos para instalar Docker.
Step 1 - Inicie sesión en la máquina con la cuenta de usuario root.
Step 2- Actualiza la información del paquete. Asegúrese de que el paquete apt esté funcionando.
Step 3 - Ejecute los siguientes comandos.
$ sudo apt-get update $ sudo apt-get install apt-transport-https ca-certificatesStep 4 - Agregue la nueva clave GPG.
$ sudo apt-key adv \ --keyserver hkp://ha.pool.sks-keyservers.net:80 \ --recv-keys 58118E89F3A912897C070ADBF76221572C52609D $ echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main" | sudo tee
/etc/apt/sources.list.d/docker.listStep 5 - Actualiza la imagen del paquete de API.
$ sudo apt-get updateUna vez que se completen todas las tareas anteriores, puede comenzar con la instalación real del motor Docker. Sin embargo, antes de esto, debe verificar que la versión del kernel que está utilizando sea correcta.
Instalar Docker Engine
Ejecute los siguientes comandos para instalar el motor Docker.
Step 1 - Inicie sesión en la máquina.
Step 2 - Actualiza el índice del paquete.
$ sudo apt-get updateStep 3 - Instale Docker Engine con el siguiente comando.
$ sudo apt-get install docker-engineStep 4 - Inicie el demonio de Docker.
$ sudo apt-get install docker-engineStep 5 - Para saber si Docker está instalado, use el siguiente comando.
$ sudo docker run hello-worldInstalar etcd 2.0
Esto debe instalarse en Kubernetes Master Machine. Para instalarlo, ejecute los siguientes comandos.
$ curl -L https://github.com/coreos/etcd/releases/download/v2.0.0/etcd
-v2.0.0-linux-amd64.tar.gz -o etcd-v2.0.0-linux-amd64.tar.gz ->1
$ tar xzvf etcd-v2.0.0-linux-amd64.tar.gz ------>2 $ cd etcd-v2.0.0-linux-amd64 ------------>3
$ mkdir /opt/bin ------------->4 $ cp etcd* /opt/bin ----------->5En el conjunto de comandos anterior:
- Primero, descargamos el etcd. Guarde esto con el nombre especificado.
- Luego, tenemos que eliminar el alquitrán del paquete tar.
- Hacemos un dir. dentro del contenedor con nombre / opt.
- Copie el archivo extraído en la ubicación de destino.
Ahora estamos listos para construir Kubernetes. Necesitamos instalar Kubernetes en todas las máquinas del clúster.
$ git clone https://github.com/GoogleCloudPlatform/kubernetes.git $ cd kubernetes
$ make releaseEl comando anterior creará un _outputdir en la raíz de la carpeta kubernetes. A continuación, podemos extraer el directorio en cualquiera de los directorios de nuestra elección / opt / bin, etc.
A continuación, viene la parte de la red en la que debemos comenzar con la configuración del maestro y el nodo de Kubernetes. Para hacer esto, haremos una entrada en el archivo host que se puede hacer en la máquina del nodo.
$ echo "<IP address of master machine> kube-master
< IP address of Node Machine>" >> /etc/hostsLo siguiente será el resultado del comando anterior.
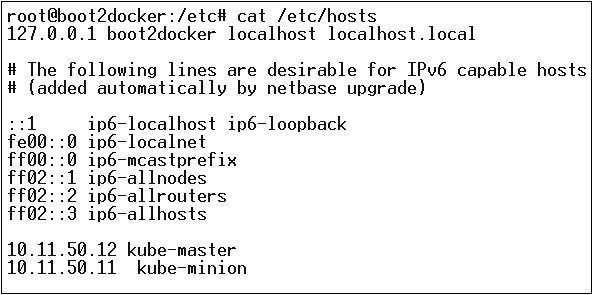
Ahora, comenzaremos con la configuración real en Kubernetes Master.
Primero, comenzaremos a copiar todos los archivos de configuración a su ubicación correcta.
$ cp <Current dir. location>/kube-apiserver /opt/bin/ $ cp <Current dir. location>/kube-controller-manager /opt/bin/
$ cp <Current dir. location>/kube-kube-scheduler /opt/bin/ $ cp <Current dir. location>/kubecfg /opt/bin/
$ cp <Current dir. location>/kubectl /opt/bin/ $ cp <Current dir. location>/kubernetes /opt/bin/El comando anterior copiará todos los archivos de configuración en la ubicación requerida. Ahora volveremos al mismo directorio donde hemos creado la carpeta Kubernetes.
$ cp kubernetes/cluster/ubuntu/init_conf/kube-apiserver.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-controller-manager.conf /etc/init/
$ cp kubernetes/cluster/ubuntu/init_conf/kube-kube-scheduler.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-apiserver /etc/init.d/
$ cp kubernetes/cluster/ubuntu/initd_scripts/kube-controller-manager /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-kube-scheduler /etc/init.d/
$ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/
$ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/El siguiente paso es actualizar el archivo de configuración copiado en / etc. dir.
Configure etcd en master usando el siguiente comando.
$ ETCD_OPTS = "-listen-client-urls = http://kube-master:4001"Configurar kube-apiserver
Para esto en el maestro, necesitamos editar el /etc/default/kube-apiserver archivo que copiamos anteriormente.
$ KUBE_APISERVER_OPTS = "--address = 0.0.0.0 \
--port = 8080 \
--etcd_servers = <The path that is configured in ETCD_OPTS> \
--portal_net = 11.1.1.0/24 \
--allow_privileged = false \
--kubelet_port = < Port you want to configure> \
--v = 0"Configurar el administrador del controlador de kube
Necesitamos agregar el siguiente contenido en /etc/default/kube-controller-manager.
$ KUBE_CONTROLLER_MANAGER_OPTS = "--address = 0.0.0.0 \
--master = 127.0.0.1:8080 \
--machines = kube-minion \ -----> #this is the kubernatics node
--v = 0A continuación, configure el programador de kube en el archivo correspondiente.
$ KUBE_SCHEDULER_OPTS = "--address = 0.0.0.0 \
--master = 127.0.0.1:8080 \
--v = 0"Una vez que se hayan completado todas las tareas anteriores, podemos seguir adelante y abrir el Kubernetes Master. Para hacer esto, reiniciaremos Docker.
$ service docker restartConfiguración del nodo de Kubernetes
El nodo de Kubernetes ejecutará dos servicios kubelet and the kube-proxy. Antes de seguir adelante, necesitamos copiar los binarios que descargamos en sus carpetas requeridas donde queremos configurar el nodo de kubernetes.
Utilice el mismo método para copiar los archivos que hicimos para kubernetes master. Como solo ejecutará kubelet y kube-proxy, los configuraremos.
$ cp <Path of the extracted file>/kubelet /opt/bin/ $ cp <Path of the extracted file>/kube-proxy /opt/bin/
$ cp <Path of the extracted file>/kubecfg /opt/bin/ $ cp <Path of the extracted file>/kubectl /opt/bin/
$ cp <Path of the extracted file>/kubernetes /opt/bin/Ahora, copiaremos el contenido en el directorio apropiado.
$ cp kubernetes/cluster/ubuntu/init_conf/kubelet.conf /etc/init/
$ cp kubernetes/cluster/ubuntu/init_conf/kube-proxy.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kubelet /etc/init.d/
$ cp kubernetes/cluster/ubuntu/initd_scripts/kube-proxy /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/
$ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/Configuraremos el kubelet y kube-proxy conf archivos.
Configuraremos el /etc/init/kubelet.conf.
$ KUBELET_OPTS = "--address = 0.0.0.0 \
--port = 10250 \
--hostname_override = kube-minion \
--etcd_servers = http://kube-master:4001 \
--enable_server = true
--v = 0"
/Para kube-proxy, lo configuraremos usando el siguiente comando.
$ KUBE_PROXY_OPTS = "--etcd_servers = http://kube-master:4001 \
--v = 0"
/etc/init/kube-proxy.confFinalmente, reiniciaremos el servicio Docker.
$ service docker restartAhora hemos terminado con la configuración. Puede verificar ejecutando los siguientes comandos.
$ /opt/bin/kubectl get minionsLas imágenes de Kubernetes (Docker) son los componentes clave de la infraestructura en contenedores. A partir de ahora, solo admitimos Kubernetes para admitir imágenes de Docker. Cada contenedor de un pod tiene su imagen de Docker ejecutándose en su interior.
Cuando configuramos un pod, la propiedad de la imagen en el archivo de configuración tiene la misma sintaxis que el comando Docker. El archivo de configuración tiene un campo para definir el nombre de la imagen, que estamos planeando extraer del registro.
A continuación se muestra la estructura de configuración común que extraerá la imagen del registro de Docker y la implementará en el contenedor de Kubernetes.
apiVersion: v1
kind: pod
metadata:
name: Tesing_for_Image_pull -----------> 1
spec:
containers:
- name: neo4j-server ------------------------> 2
image: <Name of the Docker image>----------> 3
imagePullPolicy: Always ------------->4
command: ["echo", "SUCCESS"] ------------------->En el código anterior, hemos definido:
name: Tesing_for_Image_pull - Este nombre se proporciona para identificar y verificar cuál es el nombre del contenedor que se crearía después de extraer las imágenes del registro de Docker.
name: neo4j-server- Este es el nombre que se le da al contenedor que estamos intentando crear. Como le hemos dado a neo4j-server.
image: <Name of the Docker image>- Este es el nombre de la imagen que estamos intentando extraer del Docker o del registro interno de imágenes. Necesitamos definir una ruta de registro completa junto con el nombre de la imagen que estamos tratando de extraer.
imagePullPolicy - Siempre: esta política de extracción de imágenes define que cada vez que ejecutamos este archivo para crear el contenedor, volverá a extraer el mismo nombre.
command: [“echo”, “SUCCESS”] - Con esto, cuando creemos el contenedor y si todo va bien, mostrará un mensaje cuando accedamos al contenedor.
Para extraer la imagen y crear un contenedor, ejecutaremos el siguiente comando.
$ kubectl create –f Tesing_for_Image_pullUna vez que obtengamos el registro, obtendremos el resultado exitoso.
$ kubectl log Tesing_for_Image_pullEl comando anterior producirá una salida exitosa o obtendremos una salida como falla.
Note - Se recomienda que pruebe todos los comandos usted mismo.
La función principal de un trabajo es crear uno o más pods y pistas sobre el éxito de los pods. Se aseguran de que el número especificado de pods se complete correctamente. Cuando se completa un número específico de ejecuciones exitosas de pods, el trabajo se considera completo.
Crear un trabajo
Utilice el siguiente comando para crear un trabajo:
apiVersion: v1
kind: Job ------------------------> 1
metadata:
name: py
spec:
template:
metadata
name: py -------> 2
spec:
containers:
- name: py ------------------------> 3
image: python----------> 4
command: ["python", "SUCCESS"]
restartPocliy: Never --------> 5En el código anterior, hemos definido:
kind: Job → Hemos definido el tipo como Job que dirá kubectl que el yaml El archivo que se utiliza es para crear un pod de tipo de trabajo.
Name:py → Este es el nombre de la plantilla que estamos usando y la especificación define la plantilla.
name: py → hemos dado un nombre como py bajo la especificación del contenedor que ayuda a identificar el Pod que se creará a partir de él.
Image: python → la imagen que vamos a extraer para crear el contenedor que se ejecutará dentro del pod.
restartPolicy: Never →Esta condición de reinicio de la imagen se da como nunca, lo que significa que si el contenedor se mata o si es falso, entonces no se reiniciará.
Crearemos el trabajo usando el siguiente comando con yaml que se guarda con el nombre py.yaml.
$ kubectl create –f py.yamlEl comando anterior creará un trabajo. Si desea verificar el estado de un trabajo, use el siguiente comando.
$ kubectl describe jobs/pyEl comando anterior creará un trabajo. Si desea verificar el estado de un trabajo, use el siguiente comando.
Trabajo programado
Trabajo programado en usos de Kubernetes Cronetes, que toma el trabajo de Kubernetes y lo lanza en el clúster de Kubernetes.
- Al programar un trabajo, se ejecutará un pod en un momento específico.
- Se crea para él un trabajo paródico que se invoca automáticamente.
Note - La función de un trabajo programado es compatible con la versión 1.4 y la API betch / v2alpha 1 se activa al pasar el –runtime-config=batch/v2alpha1 al abrir el servidor API.
Usaremos el mismo yaml que usamos para crear el trabajo y convertirlo en un trabajo programado.
apiVersion: v1
kind: Job
metadata:
name: py
spec:
schedule: h/30 * * * * ? -------------------> 1
template:
metadata
name: py
spec:
containers:
- name: py
image: python
args:
/bin/sh -------> 2
-c
ps –eaf ------------> 3
restartPocliy: OnFailureEn el código anterior, hemos definido:
schedule: h/30 * * * * ? → Para programar el trabajo para que se ejecute cada 30 minutos.
/bin/sh: Esto entrará en el contenedor con / bin / sh
ps –eaf → Ejecutará el comando ps -eaf en la máquina y enumerará todo el proceso en ejecución dentro de un contenedor.
Este concepto de trabajo programado es útil cuando intentamos crear y ejecutar un conjunto de tareas en un momento específico y luego completar el proceso.
Etiquetas
Las etiquetas son pares clave-valor que se adjuntan a los pods, el controlador de replicación y los servicios. Se utilizan como atributos de identificación para objetos como pods y controlador de replicación. Se pueden agregar a un objeto en el momento de la creación y se pueden agregar o modificar en el tiempo de ejecución.
Selectores
Las etiquetas no proporcionan unicidad. En general, podemos decir que muchos objetos pueden llevar las mismas etiquetas. El selector de etiquetas es un elemento básico de agrupación en Kubernetes. Los usuarios los utilizan para seleccionar un conjunto de objetos.
La API de Kubernetes admite actualmente dos tipos de selectores:
- Selectores basados en la igualdad
- Selectores basados en conjuntos
Selectores basados en la igualdad
Permiten filtrar por clave y valor. Los objetos coincidentes deben satisfacer todas las etiquetas especificadas.
Selectores basados en conjuntos
Los selectores basados en conjuntos permiten el filtrado de claves según un conjunto de valores.
apiVersion: v1
kind: Service
metadata:
name: sp-neo4j-standalone
spec:
ports:
- port: 7474
name: neo4j
type: NodePort
selector:
app: salesplatform ---------> 1
component: neo4j -----------> 2En el código anterior, estamos usando el selector de etiquetas como app: salesplatform y componente como component: neo4j.
Una vez que ejecutamos el archivo usando el kubectl comando, creará un servicio con el nombre sp-neo4j-standalone que se comunicará en el puerto 7474. El ype es NodePort con el nuevo selector de etiquetas como app: salesplatform y component: neo4j.
El espacio de nombres proporciona una calificación adicional al nombre de un recurso. Esto es útil cuando varios equipos utilizan el mismo clúster y existe la posibilidad de una colisión de nombres. Puede ser como un muro virtual entre múltiples clústeres.
Funcionalidad del espacio de nombres
A continuación se muestran algunas de las funcionalidades importantes de un espacio de nombres en Kubernetes:
Los espacios de nombres ayudan a la comunicación de pod a pod utilizando el mismo espacio de nombres.
Los espacios de nombres son clústeres virtuales que pueden ubicarse encima del mismo clúster físico.
Proporcionan una separación lógica entre los equipos y sus entornos.
Crear un espacio de nombres
El siguiente comando se usa para crear un espacio de nombres.
apiVersion: v1
kind: Namespce
metadata
name: elkControlar el espacio de nombres
El siguiente comando se usa para controlar el espacio de nombres.
$ kubectl create –f namespace.yml ---------> 1
$ kubectl get namespace -----------------> 2 $ kubectl get namespace <Namespace name> ------->3
$ kubectl describe namespace <Namespace name> ---->4 $ kubectl delete namespace <Namespace name>En el código anterior,
- Estamos usando el comando para crear un espacio de nombres.
- Esto mostrará una lista de todos los espacios de nombres disponibles.
- Esto obtendrá un espacio de nombres particular cuyo nombre se especifica en el comando.
- Esto describirá los detalles completos sobre el servicio.
- Esto eliminará un espacio de nombres particular presente en el clúster.
Uso del espacio de nombres en el servicio: ejemplo
A continuación se muestra un ejemplo de un archivo de muestra para usar el espacio de nombres en el servicio.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCPEn el código anterior, estamos usando el mismo espacio de nombres en los metadatos del servicio con el nombre de elk.
Un nodo es una máquina en funcionamiento en el clúster de Kubernetes que también se conoce como minion. Son unidades de trabajo que pueden ser físicas, VM o una instancia en la nube.
Cada nodo tiene toda la configuración necesaria para ejecutar un pod en él, como el servicio proxy y el servicio kubelet junto con Docker, que se utiliza para ejecutar los contenedores de Docker en el pod creado en el nodo.
No los crea Kubernetes, pero los crea externamente el proveedor de servicios en la nube o el administrador del clúster de Kubernetes en máquinas físicas o VM.
El componente clave de Kubernetes para manejar múltiples nodos es el administrador del controlador, que ejecuta varios tipos de controladores para administrar los nodos. Para administrar los nodos, Kubernetes crea un objeto de tipo nodo que validará que el objeto que se crea es un nodo válido.
Servicio con Selector
apiVersion: v1
kind: node
metadata:
name: < ip address of the node>
labels:
name: <lable name>En formato JSON, se crea el objeto real que tiene el siguiente aspecto:
{
Kind: node
apiVersion: v1
"metadata":
{
"name": "10.01.1.10",
"labels"
{
"name": "cluster 1 node"
}
}
}Controlador de nodo
Son la colección de servicios que se ejecutan en el maestro de Kubernetes y monitorean continuamente el nodo en el clúster sobre la base de metadata.name. Si todos los servicios requeridos están en ejecución, el nodo se valida y el controlador asignará un pod recién creado a ese nodo. Si no es válido, el maestro no le asignará ningún pod y esperará hasta que sea válido.
El maestro de Kubernetes registra el nodo automáticamente, si –register-node bandera es verdadera.
–register-node = trueSin embargo, si el administrador del clúster desea administrarlo manualmente, puede hacerlo girando el plano de:
–register-node = falseUn servicio se puede definir como un conjunto lógico de pods. Se puede definir como una abstracción en la parte superior del pod que proporciona una única dirección IP y un nombre DNS mediante el cual se puede acceder a los pods. Con Service, es muy fácil administrar la configuración del equilibrio de carga. Ayuda a las vainas a escalar muy fácilmente.
Un servicio es un objeto REST en Kubernetes cuya definición se puede publicar en Kubernetes apiServer en el maestro de Kubernetes para crear una nueva instancia.
Servicio sin selector
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
ports:
- port: 8080
targetPort: 31999La configuración anterior creará un servicio con el nombre Tutorial_point_service.
Archivo de configuración de servicio con selector
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: "My Application" -------------------> (Selector)
ports:
- port: 8080
targetPort: 31999En este ejemplo, tenemos un selector; así que para transferir tráfico, necesitamos crear un punto final manualmente.
apiVersion: v1
kind: Endpoints
metadata:
name: Tutorial_point_service
subnets:
address:
"ip": "192.168.168.40" -------------------> (Selector)
ports:
- port: 8080En el código anterior, hemos creado un punto final que enrutará el tráfico al punto final definido como "192.168.168.40:8080".
Creación de servicios multipuerto
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: “My Application” -------------------> (Selector)
ClusterIP: 10.3.0.12
ports:
-name: http
protocol: TCP
port: 80
targetPort: 31999
-name:https
Protocol: TCP
Port: 443
targetPort: 31998Tipos de servicios
ClusterIP- Esto ayuda a restringir el servicio dentro del clúster. Expone el servicio dentro del clúster de Kubernetes definido.
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: NodeportServiceNodePort- Expondrá el servicio en un puerto estático en el nodo implementado. UNClusterIP servicio, al cual NodePortel servicio se enrutará, se crea automáticamente. Se puede acceder al servicio desde fuera del clúster mediante elNodeIP:nodePort.
spec:
ports:
- port: 8080
nodePort: 31999
name: NodeportService
clusterIP: 10.20.30.40Load Balancer - Utiliza el equilibrador de carga de los proveedores de la nube. NodePort y ClusterIP Los servicios se crean automáticamente a los que se enrutará el equilibrador de carga externo.
Un servicio completo yamlarchivo con el tipo de servicio como puerto de nodo. Intente crear uno usted mismo.
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: env_nameUn pod es una colección de contenedores y su almacenamiento dentro de un nodo de un clúster de Kubernetes. Es posible crear una vaina con varios contenedores en su interior. Por ejemplo, mantener un contenedor de base de datos y un contenedor de datos en el mismo pod.
Tipos de vaina
Hay dos tipos de Pods:
- Vaina de un solo contenedor
- Vaina de contenedores múltiples
Vaina de contenedor individual
Se pueden crear simplemente con el comando kubctl run, donde tiene una imagen definida en el registro de Docker que extraeremos mientras creamos un pod.
$ kubectl run <name of pod> --image=<name of the image from registry>Example - Crearemos un pod con una imagen de Tomcat que está disponible en el hub de Docker.
$ kubectl run tomcat --image = tomcat:8.0Esto también se puede hacer creando el yaml archivo y luego ejecutando el kubectl create mando.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: AlwaysUna vez que lo anterior yaml se crea el archivo, guardaremos el archivo con el nombre de tomcat.yml y ejecute el comando create para ejecutar el documento.
$ kubectl create –f tomcat.ymlCreará una vaina con el nombre de tomcat. Podemos usar el comando describe junto conkubectl para describir la vaina.
Vaina de contenedores múltiples
Las vainas de contenedores múltiples se crean usando yaml mail con la definición de los contenedores.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
-name: Database
Image: mongoDB
Ports:
containerPort: 7501
imagePullPolicy: AlwaysEn el código anterior, hemos creado un pod con dos contenedores dentro, uno para tomcat y otro para MongoDB.
El controlador de replicación es una de las características clave de Kubernetes, que es responsable de administrar el ciclo de vida del pod. Es responsable de asegurarse de que el número especificado de réplicas de pod se esté ejecutando en cualquier momento. Se usa en el momento en que uno quiere asegurarse de que se esté ejecutando el número especificado de pod o al menos un pod. Tiene la capacidad de subir o bajar el número especificado de pod.
Es una buena práctica utilizar el controlador de replicación para administrar el ciclo de vida del pod en lugar de crear un pod una y otra vez.
apiVersion: v1
kind: ReplicationController --------------------------> 1
metadata:
name: Tomcat-ReplicationController --------------------------> 2
spec:
replicas: 3 ------------------------> 3
template:
metadata:
name: Tomcat-ReplicationController
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat- -----------------------> 4
image: tomcat: 8.0
ports:
- containerPort: 7474 ------------------------> 5Detalles de configuración
Kind: ReplicationController → En el código anterior, hemos definido el tipo como controlador de replicación que le dice al kubectl que el yaml el archivo se utilizará para crear el controlador de replicación.
name: Tomcat-ReplicationController→ Esto ayuda a identificar el nombre con el que se creará el controlador de replicación. Si ejecutamos el kubctl, obtenemosrc < Tomcat-ReplicationController > mostrará los detalles del controlador de replicación.
replicas: 3 → Esto ayuda al controlador de replicación a comprender que necesita mantener tres réplicas de un pod en cualquier momento del ciclo de vida del pod.
name: Tomcat → En la sección de especificaciones, hemos definido el nombre como tomcat que le dirá al controlador de replicación que el contenedor presente dentro de los pods es tomcat.
containerPort: 7474 → Ayuda a asegurarse de que todos los nodos del clúster donde el pod está ejecutando el contenedor dentro del pod estarán expuestos en el mismo puerto 7474.

Aquí, el servicio de Kubernetes funciona como un equilibrador de carga para tres réplicas de Tomcat.
El conjunto de réplicas asegura cuántas réplicas de pod se deben ejecutar. Puede considerarse como un reemplazo del controlador de replicación. La diferencia clave entre el conjunto de réplicas y el controlador de réplica es que el controlador de réplica solo admite el selector basado en igualdad, mientras que el conjunto de réplicas admite el selector basado en conjuntos.
apiVersion: extensions/v1beta1 --------------------->1
kind: ReplicaSet --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
selector:
matchLables:
tier: Backend ------------------> 3
matchExpression:
{ key: tier, operation: In, values: [Backend]} --------------> 4
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
- containerPort: 7474Detalles de configuración
apiVersion: extensions/v1beta1 → En el código anterior, la versión de API es la versión beta avanzada de Kubernetes que admite el concepto de conjunto de réplicas.
kind: ReplicaSet → Hemos definido el tipo como el conjunto de réplicas que ayuda a kubectl a comprender que el archivo se utiliza para crear un conjunto de réplicas.
tier: Backend → Hemos definido el nivel de etiqueta como backend que crea un selector coincidente.
{key: tier, operation: In, values: [Backend]} → Esto ayudará matchExpression para comprender la condición de coincidencia que hemos definido y en la operación que utiliza matchlabel para encontrar detalles.
Ejecute el archivo anterior usando kubectl y cree el conjunto de réplicas de backend con la definición proporcionada en el yaml archivo.

Las implementaciones se actualizan y una versión superior del controlador de replicación. Administran la implementación de conjuntos de réplicas, que también es una versión mejorada del controlador de réplica. Tienen la capacidad de actualizar el conjunto de réplicas y también pueden retroceder a la versión anterior.
Proporcionan muchas características actualizadas de matchLabels y selectors. Tenemos un nuevo controlador en el maestro de Kubernetes llamado controlador de implementación que lo hace posible. Tiene la capacidad de cambiar la implementación a mitad de camino.
Cambiar la implementación
Updating- El usuario puede actualizar la implementación en curso antes de que se complete. En esto, se resolverá la implementación existente y se creará una nueva implementación.
Deleting- El usuario puede pausar / cancelar la implementación eliminándola antes de que se complete. La recreación de la misma implementación la reanudará.
Rollback- Podemos revertir la implementación o la implementación en curso. El usuario puede crear o actualizar la implementación usandoDeploymentSpec.PodTemplateSpec = oldRC.PodTemplateSpec.
Estrategias de implementación
Las estrategias de implementación ayudan a definir cómo el nuevo RC debe reemplazar al RC existente.
Recreate- Esta característica matará a todos los RC existentes y luego mostrará los nuevos. Esto da como resultado una implementación rápida, sin embargo, dará lugar a un tiempo de inactividad cuando los módulos antiguos estén inactivos y los módulos nuevos no aparezcan.
Rolling Update- Esta función baja gradualmente el antiguo RC y muestra el nuevo. Esto da como resultado una implementación lenta, sin embargo, no hay implementación. En todo momento, en este proceso hay disponibles pocos pods antiguos y pocos pods nuevos.
El archivo de configuración de Implementación tiene este aspecto.
apiVersion: extensions/v1beta1 --------------------->1
kind: Deployment --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
spec:
containers:
- name: Tomcatimage:
tomcat: 8.0
ports:
- containerPort: 7474En el código anterior, lo único que es diferente del conjunto de réplicas es que hemos definido el tipo como implementación.
Crear despliegue
$ kubectl create –f Deployment.yaml -–record
deployment "Deployment" created Successfully.Obtener la implementación
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVILABLE AGE
Deployment 3 3 3 3 20sVerificar el estado de la implementación
$ kubectl rollout status deployment/DeploymentActualización de la implementación
$ kubectl set image deployment/Deployment tomcat=tomcat:6.0Retroceder a la implementación anterior
$ kubectl rollout undo deployment/Deployment –to-revision=2En Kubernetes, un volumen se puede considerar como un directorio al que pueden acceder los contenedores de un pod. Tenemos diferentes tipos de volúmenes en Kubernetes y el tipo define cómo se crea el volumen y su contenido.
El concepto de volumen estaba presente con el Docker, sin embargo, el único problema era que el volumen estaba muy limitado a un módulo en particular. Tan pronto como terminó la vida de una cápsula, también se perdió el volumen.
Por otro lado, los volúmenes que se crean a través de Kubernetes no se limitan a ningún contenedor. Admite cualquiera o todos los contenedores implementados dentro del pod de Kubernetes. Una ventaja clave del volumen de Kubernetes es que admite diferentes tipos de almacenamiento en los que el pod puede usar varios de ellos al mismo tiempo.
Tipos de volumen de Kubernetes
Aquí hay una lista de algunos volúmenes populares de Kubernetes:
emptyDir- Es un tipo de volumen que se crea cuando un Pod se asigna por primera vez a un Nodo. Permanece activo mientras el Pod se esté ejecutando en ese nodo. El volumen está inicialmente vacío y los contenedores del pod pueden leer y escribir los archivos en el volumen emptyDir. Una vez que se quita el Pod del nodo, se borran los datos en emptyDir.
hostPath - Este tipo de volumen monta un archivo o directorio desde el sistema de archivos del nodo host en su pod.
gcePersistentDisk- Este tipo de volumen monta un disco persistente de Google Compute Engine (GCE) en su pod. Los datos en ungcePersistentDisk permanece intacto cuando el Pod se retira del nodo.
awsElasticBlockStore- Este tipo de volumen monta un almacén de bloques elásticos de Amazon Web Services (AWS) en su pod. Al igual quegcePersistentDisk, los datos en un awsElasticBlockStore permanece intacto cuando el Pod se retira del nodo.
nfs - un nfsvolume permite montar un NFS (Network File System) existente en su pod. Los datos en unnfsel volumen no se borra cuando el Pod se quita del nodo. El volumen solo está desmontado.
iscsi - un iscsi volume permite montar un volumen iSCSI (SCSI sobre IP) existente en su pod.
flocker- Es un administrador de volumen de datos de contenedor agrupado de código abierto. Se utiliza para administrar volúmenes de datos. UNflockervolume permite montar un conjunto de datos Flocker en un pod. Si el conjunto de datos no existe en Flocker, primero debe crearlo utilizando la API de Flocker.
glusterfs- Glusterfs es un sistema de archivos en red de código abierto. Un volumen glusterfs permite montar un volumen glusterfs en su pod.
rbd- RBD son las siglas de Rados Block Device. Unrbdvolume permite montar un volumen de dispositivo de bloque Rados en su pod. Los datos permanecen conservados después de que el Pod se elimina del nodo.
cephfs - A cephfsvolume permite montar un volumen CephFS existente en su pod. Los datos permanecen intactos después de que el Pod se elimina del nodo.
gitRepo - A gitRepo volumen monta un directorio vacío y clona un git repositorio en él para que lo use su pod.
secret - A secret el volumen se utiliza para pasar información confidencial, como contraseñas, a los pods.
persistentVolumeClaim - A persistentVolumeClaimvolume se utiliza para montar un PersistentVolume en un pod. PersistentVolumes es una forma para que los usuarios "reclamen" almacenamiento duradero (como un GCE PersistentDisk o un volumen iSCSI) sin conocer los detalles del entorno de nube en particular.
downwardAPI - A downwardAPIEl volumen se utiliza para hacer que los datos API descendentes estén disponibles para las aplicaciones. Monta un directorio y escribe los datos solicitados en archivos de texto sin formato.
azureDiskVolume - un AzureDiskVolume se utiliza para montar un disco de datos de Microsoft Azure en un pod.
Volumen persistente y reclamo de volumen persistente
Persistent Volume (PV)- Es una pieza de almacenamiento de red que ha sido aprovisionada por el administrador. Es un recurso en el clúster que es independiente de cualquier pod individual que use el PV.
Persistent Volume Claim (PVC)- El almacenamiento solicitado por Kubernetes para sus pods se conoce como PVC. El usuario no necesita conocer el aprovisionamiento subyacente. Las notificaciones deben crearse en el mismo espacio de nombres donde se crea el pod.
Creación de volumen persistente
kind: PersistentVolume ---------> 1
apiVersion: v1
metadata:
name: pv0001 ------------------> 2
labels:
type: local
spec:
capacity: -----------------------> 3
storage: 10Gi ----------------------> 4
accessModes:
- ReadWriteOnce -------------------> 5
hostPath:
path: "/tmp/data01" --------------------------> 6En el código anterior, hemos definido:
kind: PersistentVolume → Hemos definido el tipo como PersistentVolume que le dice a kubernetes que el archivo yaml que se está utilizando es para crear el volumen persistente.
name: pv0001 → Nombre del PersistentVolume que estamos creando.
capacity: → Esta especificación definirá la capacidad de PV que estamos tratando de crear.
storage: 10Gi → Esto le dice a la infraestructura subyacente que estamos tratando de reclamar espacio 10Gi en la ruta definida.
ReadWriteOnce → Esto indica los derechos de acceso del volumen que estamos creando.
path: "/tmp/data01" → Esta definición le dice a la máquina que estamos tratando de crear un volumen bajo esta ruta en la infraestructura subyacente.
Creando PV
$ kubectl create –f local-01.yaml
persistentvolume "pv0001" createdComprobación de PV
$ kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 10Gi RWO Available 14sDescribiendo PV
$ kubectl describe pv pv0001Crear reclamo de volumen persistente
kind: PersistentVolumeClaim --------------> 1
apiVersion: v1
metadata:
name: myclaim-1 --------------------> 2
spec:
accessModes:
- ReadWriteOnce ------------------------> 3
resources:
requests:
storage: 3Gi ---------------------> 4En el código anterior, hemos definido:
kind: PersistentVolumeClaim → Indica a la infraestructura subyacente que estamos tratando de reclamar una cantidad específica de espacio.
name: myclaim-1 → Nombre del reclamo que estamos intentando crear.
ReadWriteOnce → Esto especifica el modo del reclamo que estamos tratando de crear.
storage: 3Gi → Esto le dirá a Kubernetes sobre la cantidad de espacio que estamos tratando de reclamar.
Creando PVC
$ kubectl create –f myclaim-1
persistentvolumeclaim "myclaim-1" createdObtener detalles sobre el PVC
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
myclaim-1 Bound pv0001 10Gi RWO 7sDescribe PVC
$ kubectl describe pv pv0001Uso de PV y PVC con POD
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
name: frontendhttp
spec:
containers:
- name: myfrontend
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts: ----------------------------> 1
- mountPath: "/usr/share/tomcat/html"
name: mypd
volumes: -----------------------> 2
- name: mypd
persistentVolumeClaim: ------------------------->3
claimName: myclaim-1En el código anterior, hemos definido:
volumeMounts: → Este es el camino en el contenedor en el que se realizará el montaje.
Volume: → Esta definición define la definición de volumen que vamos a reclamar.
persistentVolumeClaim: → Debajo de esto, definimos el nombre del volumen que vamos a utilizar en el pod definido.
Los secretos se pueden definir como objetos de Kubernetes que se utilizan para almacenar datos confidenciales como el nombre de usuario y las contraseñas con cifrado.
Hay varias formas de crear secretos en Kubernetes.
- Creando a partir de archivos txt.
- Creando desde el archivo yaml.
Crear desde archivo de texto
Para crear secretos a partir de un archivo de texto, como el nombre de usuario y la contraseña, primero debemos almacenarlos en un archivo txt y usar el siguiente comando.
$ kubectl create secret generic tomcat-passwd –-from-file = ./username.txt –fromfile = ./.
password.txtCrear desde archivo Yaml
apiVersion: v1
kind: Secret
metadata:
name: tomcat-pass
type: Opaque
data:
password: <User Password>
username: <User Name>Creando el secreto
$ kubectl create –f Secret.yaml
secrets/tomcat-passUsando secretos
Una vez que hemos creado los secretos, se puede consumir en un pod o en el controlador de replicación como:
- Variable ambiental
- Volume
Como variable de entorno
Para usar el secreto como variable de entorno, usaremos env en la sección de especificaciones del archivo pod yaml.
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: tomcat-passComo volumen
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat:7.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"Configuración secreta como variable de entorno
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
spec:
nodeSelector:
resource-group:
containers:
- name: appname
image:
imagePullPolicy: Always
ports:
- containerPort: 3000
env: -----------------------------> 1
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: tomcat-secretsEn el código anterior, bajo el env definición, estamos usando secretos como variable de entorno en el controlador de replicación.
Secretos como montaje de volumen
apiVersion: v1
kind: pod
metadata:
name: appname
spec:
metadata:
name: appname
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat: 8.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"La política de red define cómo los pods del mismo espacio de nombres se comunicarán entre sí y con el extremo de la red. Requiereextensions/v1beta1/networkpoliciespara ser habilitado en la configuración del tiempo de ejecución en el servidor API. Sus recursos usan etiquetas para seleccionar los pods y definir reglas para permitir el tráfico a un pod específico además del definido en el espacio de nombres.
Primero, necesitamos configurar la Política de aislamiento del espacio de nombres. Básicamente, este tipo de políticas de red son necesarias en los balanceadores de carga.
kind: Namespace
apiVersion: v1
metadata:
annotations:
net.beta.kubernetes.io/network-policy: |
{
"ingress":
{
"isolation": "DefaultDeny"
}
}$ kubectl annotate ns <namespace> "net.beta.kubernetes.io/network-policy =
{\"ingress\": {\"isolation\": \"DefaultDeny\"}}"Una vez que se crea el espacio de nombres, debemos crear la Política de red.
Política de red Yaml
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: allow-frontend
namespace: myns
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379La API de Kubernetes sirve como base para el esquema de configuración declarativo del sistema. KubectlLa herramienta de línea de comandos se puede utilizar para crear, actualizar, eliminar y obtener un objeto API. La API de Kubernetes actúa como un comunicador entre los diferentes componentes de Kubernetes.
Agregar API a Kubernetes
Agregar una nueva API a Kubernetes agregará nuevas funciones a Kubernetes, lo que aumentará la funcionalidad de Kubernetes. Sin embargo, al mismo tiempo también aumentará el costo y la capacidad de mantenimiento del sistema. Para crear un equilibrio entre el costo y la complejidad, existen algunos conjuntos definidos para ello.
La API que se está agregando debería ser útil para más del 50% de los usuarios. No hay otra forma de implementar la funcionalidad en Kubernetes. Las circunstancias excepcionales se discuten en la reunión de la comunidad de Kubernetes y luego se agrega la API.
Cambios de API
Para aumentar la capacidad de Kubernetes, se introducen cambios continuamente en el sistema. Lo hace el equipo de Kubernetes para agregar la funcionalidad a Kubernetes sin eliminar ni afectar la funcionalidad existente del sistema.
Para demostrar el proceso general, aquí hay un ejemplo (hipotético):
Un usuario envía un objeto Pod a /api/v7beta1/...
El JSON se descompone en un v7beta1.Pod estructura
Los valores predeterminados se aplican a v7beta1.Pod
los v7beta1.Pod se convierte en un api.Pod estructura
los api.Pod se valida y los errores se devuelven al usuario
los api.Pod se convierte en un v6.Pod (porque v6 es la última versión estable)
los v6.Pod se ordena en JSON y se escribe en etcd
Ahora que tenemos el objeto Pod almacenado, un usuario puede OBTENER ese objeto en cualquier versión de API compatible. Por ejemplo
Un usuario OBTIENE el Pod de /api/v5/...
El JSON se lee desde etcd y unmarshalled en una v6.Pod estructura
Los valores predeterminados se aplican a v6.Pod
los v6.Pod se convierte en una estructura api.Pod
los api.Pod se convierte en un v5.Pod estructura
los v5.Pod se ordena en JSON y se envía al usuario
La implicación de este proceso es que los cambios de API deben realizarse con cuidado y de manera compatible con versiones anteriores.
Control de versiones de API
Para facilitar la compatibilidad con varias estructuras, Kubernetes admite varias versiones de API, cada una en una ruta de API diferente, como /api/v1 o /apsi/extensions/v1beta1
Los estándares de control de versiones en Kubernetes se definen en varios estándares.
Nivel alfa
Esta versión contiene alfa (por ejemplo, v1alpha1)
Esta versión puede tener errores; la versión habilitada puede tener errores
El soporte para errores se puede eliminar en cualquier momento.
Recomendado para ser utilizado en pruebas a corto plazo solo ya que el soporte puede no estar presente todo el tiempo.
Nivel Beta
El nombre de la versión contiene beta (por ejemplo, v2beta3)
El código está completamente probado y se supone que la versión habilitada es estable.
El soporte de la función no se eliminará; puede haber algunos pequeños cambios.
Recomendado solo para usos no críticos para el negocio debido a la posibilidad de cambios incompatibles en versiones posteriores.
Nivel estable
El nombre de la versión es vX dónde X es un número entero.
Las versiones estables de las funciones aparecerán en el software publicado para muchas versiones posteriores.
Kubectl es la utilidad de línea de comandos para interactuar con la API de Kubernetes. Es una interfaz que se utiliza para comunicarse y administrar pods en el clúster de Kubernetes.
Es necesario configurar kubectl en local para interactuar con el clúster de Kubernetes.
Configuración de Kubectl
Descargue el ejecutable a la estación de trabajo local usando el comando curl.
En Linux
$ curl -O https://storage.googleapis.com/kubernetesrelease/
release/v1.5.2/bin/linux/amd64/kubectlEn la estación de trabajo OS X
$ curl -O https://storage.googleapis.com/kubernetesrelease/
release/v1.5.2/bin/darwin/amd64/kubectlUna vez completada la descarga, mueva los binarios en la ruta del sistema.
$ chmod +x kubectl
$ mv kubectl /usr/local/bin/kubectlConfigurando Kubectl
A continuación se muestran los pasos para realizar la operación de configuración.
$ kubectl config set-cluster default-cluster --server = https://${MASTER_HOST} -- certificate-authority = ${CA_CERT}
$ kubectl config set-credentials default-admin --certificateauthority = ${
CA_CERT} --client-key = ${ADMIN_KEY} --clientcertificate = ${
ADMIN_CERT}
$ kubectl config set-context default-system --cluster = default-cluster -- user = default-admin $ kubectl config use-context default-systemReemplazar ${MASTER_HOST} con la dirección o el nombre del nodo principal utilizado en los pasos anteriores.
Reemplazar ${CA_CERT} con el camino absoluto al ca.pem creado en los pasos anteriores.
Reemplazar ${ADMIN_KEY} con el camino absoluto al admin-key.pem creado en los pasos anteriores.
Reemplazar ${ADMIN_CERT} con el camino absoluto al admin.pem creado en los pasos anteriores.
Verificación de la configuración
Para verificar si el kubectl funciona bien o no, compruebe si el cliente de Kubernetes está configurado correctamente.
$ kubectl get nodes
NAME LABELS STATUS
Vipin.com Kubernetes.io/hostname = vipin.mishra.com ReadyKubectlcontrola el clúster de Kubernetes. Es uno de los componentes clave de Kubernetes que se ejecuta en la estación de trabajo de cualquier máquina cuando se realiza la configuración. Tiene la capacidad de administrar los nodos del clúster.
KubectlLos comandos se utilizan para interactuar y administrar los objetos de Kubernetes y el clúster. En este capítulo, analizaremos algunos comandos utilizados en Kubernetes a través de kubectl.
kubectl annotate - Actualiza la anotación de un recurso.
$kubectl annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ...
KEY_N = VAL_N [--resource-version = version]Por ejemplo,
kubectl annotate pods tomcat description = 'my frontend'kubectl api-versions - Imprime las versiones compatibles de API en el clúster.
$ kubectl api-version;kubectl apply - Tiene la capacidad de configurar un recurso por archivo o stdin.
$ kubectl apply –f <filename>kubectl attach - Esto adjunta cosas al contenedor en ejecución.
$ kubectl attach <pod> –c <container> $ kubectl attach 123456-7890 -c tomcat-conatinerkubectl autoscale - Se utiliza para escalar automáticamente los pods que se definen como Implementación, conjunto de réplicas, Controlador de réplica.
$ kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min = MINPODS] -- max = MAXPODS [--cpu-percent = CPU] [flags] $ kubectl autoscale deployment foo --min = 2 --max = 10kubectl cluster-info - Muestra la información del clúster.
$ kubectl cluster-infokubectl cluster-info dump - Descarga información relevante sobre el clúster para depuración y diagnóstico.
$ kubectl cluster-info dump
$ kubectl cluster-info dump --output-directory = /path/to/cluster-statekubectl config - Modifica el archivo kubeconfig.
$ kubectl config <SUBCOMMAD>
$ kubectl config –-kubeconfig <String of File name>kubectl config current-context - Muestra el contexto actual.
$ kubectl config current-context
#deploys the current contextkubectl config delete-cluster - Elimina el clúster especificado de kubeconfig.
$ kubectl config delete-cluster <Cluster Name>kubectl config delete-context - Elimina un contexto específico de kubeconfig.
$ kubectl config delete-context <Context Name>kubectl config get-clusters - Muestra el clúster definido en kubeconfig.
$ kubectl config get-cluster $ kubectl config get-cluster <Cluser Name>kubectl config get-contexts - Describe uno o varios contextos.
$ kubectl config get-context <Context Name>kubectl config set-cluster : Establece la entrada del clúster en Kubernetes.
$ kubectl config set-cluster NAME [--server = server] [--certificateauthority =
path/to/certificate/authority] [--insecure-skip-tls-verify = true]kubectl config set-context - Establece una entrada de contexto en el punto de entrada de kubernetes.
$ kubectl config set-context NAME [--cluster = cluster_nickname] [-- user = user_nickname] [--namespace = namespace] $ kubectl config set-context prod –user = vipin-mishrakubectl config set-credentials - Establece una entrada de usuario en kubeconfig.
$ kubectl config set-credentials cluster-admin --username = vipin --
password = uXFGweU9l35qcifkubectl config set - Establece un valor individual en el archivo kubeconfig.
$ kubectl config set PROPERTY_NAME PROPERTY_VALUEkubectl config unset - Desarma un componente específico en kubectl.
$ kubectl config unset PROPERTY_NAME PROPERTY_VALUEkubectl config use-context - Establece el contexto actual en el archivo kubectl.
$ kubectl config use-context <Context Name>kubectl config view
$ kubectl config view $ kubectl config view –o jsonpath='{.users[?(@.name == "e2e")].user.password}'kubectl cp - Copie archivos y directorios desde y hacia contenedores.
$ kubectl cp <Files from source> <Files to Destinatiion> $ kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container>kubectl create- Para crear recursos por nombre de archivo o stdin. Para ello, se aceptan los formatos JSON o YAML.
$ kubectl create –f <File Name> $ cat <file name> | kubectl create –f -De la misma manera, podemos crear varias cosas como se enumeran usando el create comando junto con kubectl.
- deployment
- namespace
- quota
- Docker-registro secreto
- secret
- secreto genérico
- tls secretos
- serviceaccount
- servicio clusterip
- equilibrador de carga de servicio
- servicio nodeport
kubectl delete - Elimina recursos por nombre de archivo, stdin, recurso y nombres.
$ kubectl delete –f ([-f FILENAME] | TYPE [(NAME | -l label | --all)])kubectl describe- Describe cualquier recurso en particular en kubernetes. Muestra detalles de un recurso o un grupo de recursos.
$ kubectl describe <type> <type name>
$ kubectl describe pod tomcatkubectl drain- Se utiliza para drenar un nodo con fines de mantenimiento. Prepara el nodo para el mantenimiento. Esto marcará el nodo como no disponible para que no se le asigne un nuevo contenedor que se creará.
$ kubectl drain tomcat –forcekubectl edit- Se utiliza para finalizar los recursos en el servidor. Esto permite editar directamente un recurso que se puede recibir a través de la herramienta de línea de comandos.
$ kubectl edit <Resource/Name | File Name) Ex. $ kubectl edit rc/tomcatkubectl exec - Esto ayuda a ejecutar un comando en el contenedor.
$ kubectl exec POD <-c CONTAINER > -- COMMAND < args...> $ kubectl exec tomcat 123-5-456 datekubectl expose- Se utiliza para exponer los objetos de Kubernetes, como el pod, el controlador de replicación y el servicio, como un nuevo servicio de Kubernetes. Esto tiene la capacidad de exponerlo a través de un contenedor en ejecución o desde unyaml archivo.
$ kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol = TCP|UDP] [--target-port = number-or-name] [--name = name] [--external-ip = external-ip-ofservice] [--type = type] $ kubectl expose rc tomcat –-port=80 –target-port = 30000
$ kubectl expose –f tomcat.yaml –port = 80 –target-port =kubectl get - Este comando es capaz de obtener datos en el clúster sobre los recursos de Kubernetes.
$ kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columnsfile=...|
go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...]
(TYPE [NAME | -l label] | TYPE/NAME ...) [flags]Por ejemplo,
$ kubectl get pod <pod name> $ kubectl get service <Service name>kubectl logs- Se utilizan para meter los troncos del contenedor en una vaina. La impresión de los registros puede ser la definición del nombre del contenedor en el pod. Si el POD solo tiene un contenedor, no es necesario definir su nombre.
$ kubectl logs [-f] [-p] POD [-c CONTAINER] Example $ kubectl logs tomcat.
$ kubectl logs –p –c tomcat.8kubectl port-forward - Se utilizan para reenviar uno o más puertos locales a los pods.
$ kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT
[...[LOCAL_PORT_N:]REMOTE_PORT_N]
$ kubectl port-forward tomcat 3000 4000 $ kubectl port-forward tomcat 3000:5000kubectl replace - Capaz de reemplazar un recurso por nombre de archivo o stdin.
$ kubectl replace -f FILENAME $ kubectl replace –f tomcat.yml
$ cat tomcat.yml | kubectl replace –f -kubectl rolling-update- Realiza una actualización continua en un controlador de replicación. Reemplaza el controlador de replicación especificado por un nuevo controlador de replicación actualizando un POD a la vez.
$ kubectl rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] --
image = NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
$ kubectl rolling-update frontend-v1 –f freontend-v2.yamlkubectl rollout - Es capaz de gestionar el despliegue de la implementación.
$ Kubectl rollout <Sub Command>
$ kubectl rollout undo deployment/tomcatAparte de lo anterior, podemos realizar varias tareas utilizando el lanzamiento, como:
- historial de despliegue
- pausa de lanzamiento
- reanudar el lanzamiento
- estado de lanzamiento
- despliegue deshacer
kubectl run - El comando Ejecutar tiene la capacidad de ejecutar una imagen en el clúster de Kubernetes.
$ kubectl run NAME --image = image [--env = "key = value"] [--port = port] [--
replicas = replicas] [--dry-run = bool] [--overrides = inline-json] [--command] --
[COMMAND] [args...]
$ kubectl run tomcat --image = tomcat:7.0 $ kubectl run tomcat –-image = tomcat:7.0 –port = 5000kubectl scale - Escalará el tamaño de las implementaciones de Kubernetes, ReplicaSet, Replication Controller o trabajo.
$ kubectl scale [--resource-version = version] [--current-replicas = count] -- replicas = COUNT (-f FILENAME | TYPE NAME ) $ kubectl scale –-replica = 3 rs/tomcat
$ kubectl scale –replica = 3 tomcat.yamlkubectl set image - Actualiza la imagen de una plantilla de pod.
$ kubectl set image (-f FILENAME | TYPE NAME)
CONTAINER_NAME_1 = CONTAINER_IMAGE_1 ... CONTAINER_NAME_N = CONTAINER_IMAGE_N
$ kubectl set image deployment/tomcat busybox = busybox ngnix = ngnix:1.9.1 $ kubectl set image deployments, rc tomcat = tomcat6.0 --allkubectl set resources- Se utiliza para establecer el contenido del recurso. Actualiza recursos / límites en el objeto con la plantilla de pod.
$ kubectl set resources (-f FILENAME | TYPE NAME) ([--limits = LIMITS & -- requests = REQUESTS] $ kubectl set resources deployment tomcat -c = tomcat --
limits = cpu = 200m,memory = 512Mikubectl top node- Muestra el uso de CPU / Memoria / Almacenamiento. El comando superior le permite ver el consumo de recursos de los nodos.
$ kubectl top node [node Name]El mismo comando también se puede utilizar con un pod.
Para crear una aplicación para la implementación de Kubernetes, primero debemos crear la aplicación en Docker. Esto se puede hacer de dos formas:
- Descargando
- Desde el archivo Docker
Descargando
La imagen existente se puede descargar desde el concentrador de Docker y se puede almacenar en el registro de Docker local.
Para hacer eso, ejecute Docker pull mando.
$ docker pull --help
Usage: docker pull [OPTIONS] NAME[:TAG|@DIGEST]
Pull an image or a repository from the registry
-a, --all-tags = false Download all tagged images in the repository
--help = false Print usageLo siguiente será el resultado del código anterior.

La captura de pantalla anterior muestra un conjunto de imágenes que se almacenan en nuestro registro local de Docker.
Si queremos construir un contenedor a partir de la imagen que consiste en una aplicación a probar, podemos hacerlo usando el comando run de Docker.
$ docker run –i –t unbunt /bin/bashDesde archivo Docker
Para crear una aplicación a partir del archivo Docker, primero debemos crear un archivo Docker.
A continuación se muestra un ejemplo de archivo Jenkins Docker.
FROM ubuntu:14.04
MAINTAINER [email protected]
ENV REFRESHED_AT 2017-01-15
RUN apt-get update -qq && apt-get install -qqy curl
RUN curl https://get.docker.io/gpg | apt-key add -
RUN echo deb http://get.docker.io/ubuntu docker main > /etc/apt/↩
sources.list.d/docker.list
RUN apt-get update -qq && apt-get install -qqy iptables ca-↩
certificates lxc openjdk-6-jdk git-core lxc-docker
ENV JENKINS_HOME /opt/jenkins/data
ENV JENKINS_MIRROR http://mirrors.jenkins-ci.org
RUN mkdir -p $JENKINS_HOME/plugins
RUN curl -sf -o /opt/jenkins/jenkins.war -L $JENKINS_MIRROR/war-↩ stable/latest/jenkins.war RUN for plugin in chucknorris greenballs scm-api git-client git ↩ ws-cleanup ;\ do curl -sf -o $JENKINS_HOME/plugins/${plugin}.hpi \ -L $JENKINS_MIRROR/plugins/${plugin}/latest/${plugin}.hpi ↩
; done
ADD ./dockerjenkins.sh /usr/local/bin/dockerjenkins.sh
RUN chmod +x /usr/local/bin/dockerjenkins.sh
VOLUME /var/lib/docker
EXPOSE 8080
ENTRYPOINT [ "/usr/local/bin/dockerjenkins.sh" ]Una vez que se crea el archivo anterior, guárdelo con el nombre de Dockerfile y cd a la ruta del archivo. Luego, ejecute el siguiente comando.

$ sudo docker build -t jamtur01/Jenkins .Una vez que se crea la imagen, podemos probar si la imagen funciona bien y se puede convertir en un contenedor.
$ docker run –i –t jamtur01/Jenkins /bin/bashLa implementación es un método para convertir imágenes en contenedores y luego asignar esas imágenes a pods en el clúster de Kubernetes. Esto también ayuda a configurar el clúster de aplicaciones que incluye la implementación del servicio, el módulo, el controlador de replicación y el conjunto de réplicas. El clúster se puede configurar de tal manera que las aplicaciones implementadas en el pod puedan comunicarse entre sí.
En esta configuración, podemos tener una configuración de equilibrador de carga en la parte superior de una aplicación que desvía el tráfico a un conjunto de pods y luego se comunican con los pods de backend. La comunicación entre los pods se produce a través del objeto de servicio integrado en Kubernetes.
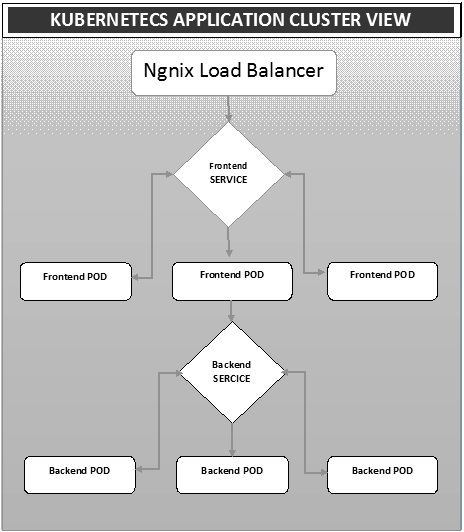
Archivo Yaml del equilibrador de carga de Ngnix
apiVersion: v1
kind: Service
metadata:
name: oppv-dev-nginx
labels:
k8s-app: omni-ppv-api
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: devControlador de replicación Ngnix Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
labels:
k8s-app: appname
component: nginx
env: env_name
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: BACKEND_HOST
value: oppv-env_name-node:3000Archivo Yaml del servicio frontend
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- name: http
port: 3000
protocol: TCP
targetPort: 3000
selector:
k8s-app: appname
component: nodejs
env: devArchivo Yaml del controlador de replicación de frontend
apiVersion: v1
kind: ReplicationController
metadata:
name: Frontend
spec:
replicas: 3
template:
metadata:
name: frontend
labels:
k8s-app: Frontend
component: nodejs
env: Dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 3000
resources:
requests:
memory: "request_mem"
cpu: "limit_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: config-envArchivo Yaml del servicio de backend
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
k8s-app: backend
spec:
type: NodePort
ports:
- name: http
port: 9010
protocol: TCP
targetPort: 9000
selector:
k8s-app: appname
component: play
env: devArchivo Yaml del controlador de replicación respaldado
apiVersion: v1
kind: ReplicationController
metadata:
name: backend
spec:
replicas: 3
template:
metadata:
name: backend
labels:
k8s-app: beckend
component: play
env: dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 9000
command: [ "./docker-entrypoint.sh" ]
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
volumeMounts:
- name: config-volume
mountPath: /app/vipin/play/conf
volumes:
- name: config-volume
configMap:
name: appnameAutoscalinges una de las características clave del clúster de Kubernetes. Es una característica en la que el clúster es capaz de aumentar la cantidad de nodos a medida que aumenta la demanda de respuesta del servicio y disminuir la cantidad de nodos a medida que disminuye el requisito. Esta función de escalado automático se admite actualmente en Google Cloud Engine (GCE) y Google Container Engine (GKE) y comenzará con AWS muy pronto.
Para configurar una infraestructura escalable en GCE, primero debemos tener un proyecto de GCE activo con funciones de monitoreo en la nube de Google, registro en la nube de Google y stackdriver habilitado.
Primero, configuraremos el clúster con pocos nodos ejecutándose en él. Una vez hecho esto, necesitamos configurar la siguiente variable de entorno.
Variable ambiental
export NUM_NODES = 2
export KUBE_AUTOSCALER_MIN_NODES = 2
export KUBE_AUTOSCALER_MAX_NODES = 5
export KUBE_ENABLE_CLUSTER_AUTOSCALER = trueUna vez hecho esto, iniciaremos el clúster ejecutando kube-up.sh. Esto creará un clúster junto con el complemento autoescalar del clúster.
./cluster/kube-up.shEn la creación del clúster, podemos verificar nuestro clúster usando el siguiente comando kubectl.
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 10m
kubernetes-minion-group-de5q Ready 10m
kubernetes-minion-group-yhdx Ready 8mAhora, podemos implementar una aplicación en el clúster y luego habilitar el escalador automático de pod horizontal. Esto se puede hacer usando el siguiente comando.
$ kubectl autoscale deployment <Application Name> --cpu-percent = 50 --min = 1 --
max = 10El comando anterior muestra que mantendremos al menos una y un máximo de 10 réplicas del POD a medida que aumenta la carga de la aplicación.
Podemos comprobar el estado del escalador automático ejecutando el $kubclt get hpamando. Aumentaremos la carga en los pods usando el siguiente comando.
$ kubectl run -i --tty load-generator --image = busybox /bin/sh
$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; donePodemos comprobar el hpa mediante la ejecución $ kubectl get hpa mando.
$ kubectl get hpa NAME REFERENCE TARGET CURRENT php-apache Deployment/php-apache/scale 50% 310% MINPODS MAXPODS AGE 1 20 2m $ kubectl get deployment php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 7 7 7 3 4mPodemos verificar la cantidad de pods en ejecución usando el siguiente comando.
jsz@jsz-desk2:~/k8s-src$ kubectl get pods
php-apache-2046965998-3ewo6 0/1 Pending 0 1m
php-apache-2046965998-8m03k 1/1 Running 0 1m
php-apache-2046965998-ddpgp 1/1 Running 0 5m
php-apache-2046965998-lrik6 1/1 Running 0 1m
php-apache-2046965998-nj465 0/1 Pending 0 1m
php-apache-2046965998-tmwg1 1/1 Running 0 1m
php-apache-2046965998-xkbw1 0/1 Pending 0 1mY finalmente, podemos obtener el estado del nodo.
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 9m
kubernetes-minion-group-6z5i Ready 43s
kubernetes-minion-group-de5q Ready 9m
kubernetes-minion-group-yhdx Ready 9mLa configuración del panel de Kubernetes implica varios pasos con un conjunto de herramientas necesarias como requisitos previos para configurarlo.
- Docker (1.3 o superior)
- ir (1.5+)
- nodejs (4.2.2+)
- npm (1.3+)
- java (7+)
- trago (3.9+)
- Kubernetes (1.1.2+)
Configuración del tablero
$ sudo apt-get update && sudo apt-get upgrade Installing Python $ sudo apt-get install python
$ sudo apt-get install python3 Installing GCC $ sudo apt-get install gcc-4.8 g++-4.8
Installing make
$ sudo apt-get install make Installing Java $ sudo apt-get install openjdk-7-jdk
Installing Node.js
$ wget https://nodejs.org/dist/v4.2.2/node-v4.2.2.tar.gz $ tar -xzf node-v4.2.2.tar.gz
$ cd node-v4.2.2 $ ./configure
$ make $ sudo make install
Installing gulp
$ npm install -g gulp $ npm install gulpVerificación de versiones
Java Version
$ java –version java version "1.7.0_91" OpenJDK Runtime Environment (IcedTea 2.6.3) (7u91-2.6.3-1~deb8u1+rpi1) OpenJDK Zero VM (build 24.91-b01, mixed mode) $ node –v
V4.2.2
$ npn -v 2.14.7 $ gulp -v
[09:51:28] CLI version 3.9.0
$ sudo gcc --version
gcc (Raspbian 4.8.4-1) 4.8.4
Copyright (C) 2013 Free Software Foundation, Inc. This is free software;
see the source for copying conditions. There is NO warranty; not even for
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.Instalación de GO
$ git clone https://go.googlesource.com/go
$ cd go $ git checkout go1.4.3
$ cd src Building GO $ ./all.bash
$ vi /root/.bashrc In the .bashrc export GOROOT = $HOME/go
export PATH = $PATH:$GOROOT/bin
$ go version
go version go1.4.3 linux/armInstalación del panel de Kubernetes
$ git clone https://github.com/kubernetes/dashboard.git
$ cd dashboard $ npm install -g bowerEjecutando el tablero
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard
$ npm install -g bower $ gulp serve
[11:19:12] Requiring external module babel-core/register
[11:20:50] Using gulpfile ~/dashboard/gulpfile.babel.js
[11:20:50] Starting 'package-backend-source'...
[11:20:50] Starting 'kill-backend'...
[11:20:50] Finished 'kill-backend' after 1.39 ms
[11:20:50] Starting 'scripts'...
[11:20:53] Starting 'styles'...
[11:21:41] Finished 'scripts' after 50 s
[11:21:42] Finished 'package-backend-source' after 52 s
[11:21:42] Starting 'backend'...
[11:21:43] Finished 'styles' after 49 s
[11:21:43] Starting 'index'...
[11:21:44] Finished 'index' after 1.43 s
[11:21:44] Starting 'watch'...
[11:21:45] Finished 'watch' after 1.41 s
[11:23:27] Finished 'backend' after 1.73 min
[11:23:27] Starting 'spawn-backend'...
[11:23:27] Finished 'spawn-backend' after 88 ms
[11:23:27] Starting 'serve'...
2016/02/01 11:23:27 Starting HTTP server on port 9091
2016/02/01 11:23:27 Creating API client for
2016/02/01 11:23:27 Creating Heapster REST client for http://localhost:8082
[11:23:27] Finished 'serve' after 312 ms
[BS] [BrowserSync SPA] Running...
[BS] Access URLs:
--------------------------------------
Local: http://localhost:9090/
External: http://192.168.1.21:9090/
--------------------------------------
UI: http://localhost:3001
UI External: http://192.168.1.21:3001
--------------------------------------
[BS] Serving files from: /root/dashboard/.tmp/serve
[BS] Serving files from: /root/dashboard/src/app/frontend
[BS] Serving files from: /root/dashboard/src/appEl panel de Kubernetes
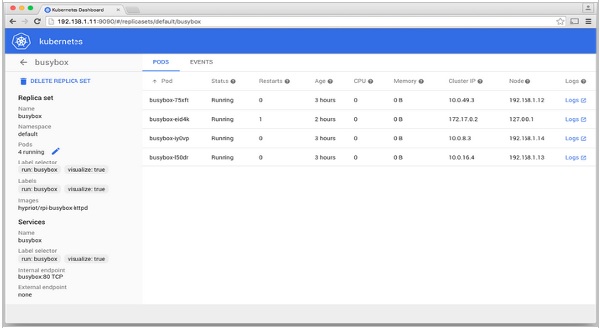
El monitoreo es uno de los componentes clave para administrar grandes clústeres. Para ello disponemos de una serie de herramientas.
Monitoreo con Prometheus
Es un sistema de vigilancia y alerta. Fue construido en SoundCloud y fue de código abierto en 2012. Maneja muy bien los datos multidimensionales.
Prometheus tiene múltiples componentes para participar en el monitoreo:
Prometheus - Es el componente principal que elimina y almacena datos.
Prometheus node explore - Obtiene las matrices de nivel de host y las expone a Prometheus.
Ranch-eye - es un haproxy y expone cAdvisor estadísticas a Prometheus.
Grafana - Visualización de datos.
InfuxDB - Base de datos de series de tiempo utilizada específicamente para almacenar datos del ganadero.
Prom-ranch-exporter - Es una aplicación simple de node.js, que ayuda a consultar al servidor Rancher sobre el estado de la pila de servicio.
Agente de Docker de Sematext
Es un agente moderno de recopilación de registros, eventos y métricas compatibles con Docker. Se ejecuta como un contenedor pequeño en cada host de Docker y recopila registros, métricas y eventos para todos los contenedores y nodos del clúster. Descubre todos los contenedores (un pod puede contener varios contenedores), incluidos los contenedores para los servicios centrales de Kubernetes, si los servicios centrales se implementan en contenedores Docker. Después de su implementación, todos los registros y métricas están disponibles de inmediato.
Implementación de agentes en nodos
Kubernetes proporciona DeamonSets que garantiza que los pods se agreguen al clúster.
Configuración del agente de Docker de SemaText
Se configura mediante variables de entorno.
Obtenga una cuenta gratuita en apps.sematext.com , si aún no tiene una.
Cree una aplicación de SPM de tipo "Docker" para obtener el token de la aplicación de SPM. La aplicación SPM contendrá su evento y métricas de rendimiento de Kubernetes.
Cree una aplicación Logsene para obtener el token de la aplicación Logsene. La aplicación Logsene mantendrá sus registros de Kubernetes.
Edite los valores de LOGSENE_TOKEN y SPM_TOKEN en la definición de DaemonSet como se muestra a continuación.
Coge la última plantilla sematext-agent-daemonset.yml (texto plano sin formato) (que también se muestra a continuación).
Guárdelo en algún lugar del disco.
Reemplace los marcadores de posición SPM_TOKEN y LOGSENE_TOKEN con sus tokens de la aplicación SPM y Logsene.
Crear objeto DaemonSet
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: sematext-agent
spec:
template:
metadata:
labels:
app: sematext-agent
spec:
selector: {}
dnsPolicy: "ClusterFirst"
restartPolicy: "Always"
containers:
- name: sematext-agent
image: sematext/sematext-agent-docker:latest
imagePullPolicy: "Always"
env:
- name: SPM_TOKEN
value: "REPLACE THIS WITH YOUR SPM TOKEN"
- name: LOGSENE_TOKEN
value: "REPLACE THIS WITH YOUR LOGSENE TOKEN"
- name: KUBERNETES
value: "1"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
- mountPath: /etc/localtime
name: localtime
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: localtime
hostPath:
path: /etc/localtimeEjecución de Sematext Agent Docker con kubectl
$ kubectl create -f sematext-agent-daemonset.yml
daemonset "sematext-agent-daemonset" createdRegistro de Kubernetes
Los registros de contenedores de Kubernetes no son muy diferentes de los registros de contenedores de Docker. Sin embargo, los usuarios de Kubernetes deben ver los registros de los pods implementados. Por lo tanto, es muy útil tener información específica de Kubernetes disponible para la búsqueda de registros, como:
- Espacio de nombres de Kubernetes
- Nombre del pod de Kubernetes
- Nombre del contenedor de Kubernetes
- Nombre de la imagen de Docker
- UID de Kubernetes
Uso de ELK Stack y LogSpout
La pila ELK incluye Elasticsearch, Logstash y Kibana. Para recopilar y reenviar los registros a la plataforma de registro, usaremos LogSpout (aunque hay otras opciones como FluentD).
El siguiente código muestra cómo configurar el clúster ELK en Kubernetes y crear un servicio para ElasticSearch:
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCPCreación de un controlador de replicación
apiVersion: v1
kind: ReplicationController
metadata:
name: es
namespace: elk
labels:
component: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
spec:
serviceAccount: elasticsearch
containers:
- name: es
securityContext:
capabilities:
add:
- IPC_LOCK
image: quay.io/pires/docker-elasticsearch-kubernetes:1.7.1-4
env:
- name: KUBERNETES_CA_CERTIFICATE_FILE
value: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "CLUSTER_NAME"
value: "myesdb"
- name: "DISCOVERY_SERVICE"
value: "elasticsearch"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: HTTP_ENABLE
value: "true"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
volumeMounts:
- mountPath: /data
name: storage
volumes:
- name: storage
emptyDir: {}URL de Kibana
Para Kibana, proporcionamos la URL de Elasticsearch como variable de entorno.
- name: KIBANA_ES_URL
value: "http://elasticsearch.elk.svc.cluster.local:9200"
- name: KUBERNETES_TRUST_CERT
value: "true"Se podrá acceder a la interfaz de usuario de Kibana en el puerto del contenedor 5601 y en la combinación correspondiente de host / puerto de nodo. Cuando comience, no habrá ningún dato en Kibana (lo que se espera ya que no ha enviado ningún dato).