ML: Comprensión de datos con visualización
Introducción
En el capítulo anterior, discutimos la importancia de los datos para los algoritmos de Machine Learning junto con algunas recetas de Python para comprender los datos con estadísticas. Existe otra forma llamada Visualización, para comprender los datos.
Con la ayuda de la visualización de datos, podemos ver cómo se ven los datos y qué tipo de correlación mantienen los atributos de los datos. Es la forma más rápida de ver si las características corresponden a la salida. Con la ayuda de seguir las recetas de Python, podemos comprender los datos de ML con estadísticas.

Gráficas univariadas: comprensión de los atributos de forma independiente
El tipo de visualización más simple es la visualización de una sola variable o "univariante". Con la ayuda de la visualización univariada, podemos comprender cada atributo de nuestro conjunto de datos de forma independiente. Las siguientes son algunas técnicas en Python para implementar la visualización univariante:
Histogramas
Los histogramas agrupan los datos en bins y es la forma más rápida de tener una idea sobre la distribución de cada atributo en el conjunto de datos. Las siguientes son algunas de las características de los histogramas:
Nos proporciona un recuento del número de observaciones en cada contenedor creado para visualización.
A partir de la forma del contenedor, podemos observar fácilmente la distribución, es decir, si es gaussiana, sesgada o exponencial.
Los histogramas también nos ayudan a ver posibles valores atípicos.
Ejemplo
El código que se muestra a continuación es un ejemplo de la secuencia de comandos de Python que crea el histograma de los atributos del conjunto de datos Pima Indian Diabetes. Aquí, usaremos la función hist () en Pandas DataFrame para generar histogramas ymatplotlib por trazarlos.
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.hist()
pyplot.show()Salida
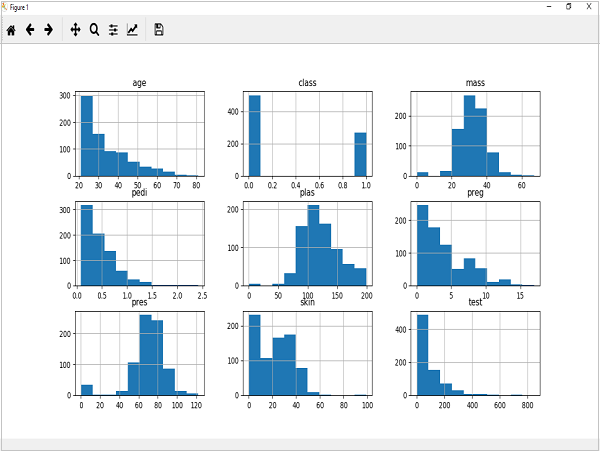
El resultado anterior muestra que creó el histograma para cada atributo en el conjunto de datos. A partir de esto, podemos observar que quizás la edad, el pedi y el atributo de prueba pueden tener una distribución exponencial, mientras que la masa y el plasma tienen una distribución gaussiana.
Gráficos de densidad
Otra técnica rápida y sencilla para obtener la distribución de cada atributo son las gráficas de densidad. También es como un histograma, pero tiene una curva suave dibujada en la parte superior de cada contenedor. Podemos llamarlos histogramas abstractos.
Ejemplo
En el siguiente ejemplo, la secuencia de comandos de Python generará diagramas de densidad para la distribución de atributos del conjunto de datos de diabetes india de Pima.
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.plot(kind='density', subplots=True, layout=(3,3), sharex=False)
pyplot.show()Salida
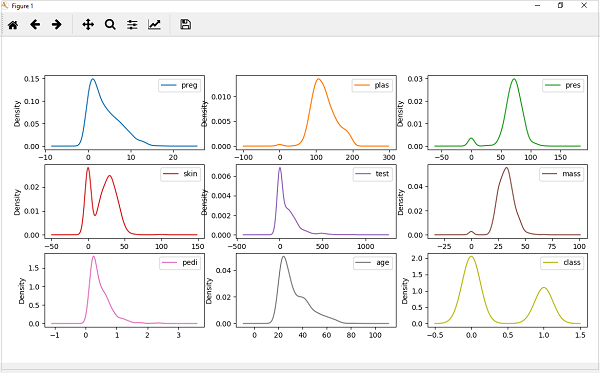
A partir del resultado anterior, la diferencia entre los gráficos de densidad y los histogramas se puede entender fácilmente.
Diagramas de caja y bigotes
Los diagramas de caja y bigotes, también llamados diagramas de caja en forma abreviada, son otra técnica útil para revisar la distribución de la distribución de cada atributo. Las siguientes son las características de esta técnica:
Es de naturaleza univariante y resume la distribución de cada atributo.
Dibuja una línea para el valor medio, es decir, para la mediana.
Dibuja una caja alrededor del 25% y 75%.
También dibuja bigotes que nos darán una idea de la difusión de los datos.
Los puntos fuera de los bigotes significan los valores atípicos. Los valores atípicos serían 1,5 veces mayores que el tamaño de la extensión de los datos intermedios.
Ejemplo
En el siguiente ejemplo, la secuencia de comandos de Python generará diagramas de densidad para la distribución de atributos del conjunto de datos de diabetes india de Pima.
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False)
pyplot.show()Salida

En el gráfico anterior de distribución de atributos, se puede observar que la edad, la prueba y la piel aparecen sesgadas hacia valores más pequeños.
Gráficos multivariados: interacción entre múltiples variables
Otro tipo de visualización es la visualización multivariable o “multivariante”. Con la ayuda de la visualización multivariante, podemos comprender la interacción entre múltiples atributos de nuestro conjunto de datos. Las siguientes son algunas técnicas en Python para implementar la visualización multivariante:
Gráfico de matriz de correlación
La correlación es una indicación de los cambios entre dos variables. En nuestros capítulos anteriores, hemos discutido los coeficientes de correlación de Pearson y también la importancia de la correlación. Podemos trazar una matriz de correlación para mostrar qué variable tiene una correlación alta o baja con respecto a otra variable.
Ejemplo
En el siguiente ejemplo, la secuencia de comandos de Python generará y trazará una matriz de correlación para el conjunto de datos Pima Indian Diabetes. Se puede generar con la ayuda de la función corr () en Pandas DataFrame y trazar con la ayuda de pyplot.
from matplotlib import pyplot
from pandas import read_csv
import numpy
Path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(Path, names=names)
correlations = data.corr()
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = numpy.arange(0,9,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
pyplot.show()Salida

De la salida anterior de la matriz de correlación, podemos ver que es simétrica, es decir, la parte inferior izquierda es la misma que la superior derecha. También se observa que cada variable se correlaciona positivamente entre sí.
Gráfico de matriz de dispersión
Los gráficos de dispersión muestran cuánto se ve afectada una variable por otra o la relación entre ellas con la ayuda de puntos en dos dimensiones. Los diagramas de dispersión son muy parecidos a los gráficos de líneas en el concepto de que utilizan ejes horizontales y verticales para trazar puntos de datos.
Ejemplo
En el siguiente ejemplo, la secuencia de comandos de Python generará y trazará una matriz de dispersión para el conjunto de datos Pima Indian Diabetes. Puede generarse con la ayuda de la función scatter_matrix () en Pandas DataFrame y trazarse con la ayuda de pyplot.
from matplotlib import pyplot
from pandas import read_csv
from pandas.tools.plotting import scatter_matrix
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
scatter_matrix(data)
pyplot.show()Salida
