Aprendizaje automático: guía rápida
La inteligencia artificial (IA) actual ha superado con creces el bombo publicitario de blockchain y la computación cuántica. Esto se debe al hecho de que el hombre común dispone fácilmente de enormes recursos informáticos. Los desarrolladores ahora aprovechan esto para crear nuevos modelos de aprendizaje automático y volver a entrenar los modelos existentes para obtener un mejor rendimiento y resultados. La fácil disponibilidad de la Computación de alto rendimiento (HPC) ha provocado un aumento repentino de la demanda de profesionales de TI con habilidades de aprendizaje automático.
En este tutorial, aprenderá en detalle sobre:
¿Cuál es el quid del aprendizaje automático?
¿Cuáles son los diferentes tipos de aprendizaje automático?
¿Cuáles son los diferentes algoritmos disponibles para desarrollar modelos de aprendizaje automático?
¿Qué herramientas están disponibles para desarrollar estos modelos?
¿Cuáles son las opciones de lenguaje de programación?
¿Qué plataformas admiten el desarrollo y la implementación de aplicaciones de aprendizaje automático?
¿Qué IDE (entorno de desarrollo integrado) están disponibles?
¿Cómo mejorar rápidamente sus habilidades en esta importante área?
Cuando etiquetas una cara en una foto de Facebook, es la IA la que se ejecuta detrás de escena e identifica las caras en una imagen. El etiquetado facial ahora está omnipresente en varias aplicaciones que muestran imágenes con rostros humanos. ¿Por qué solo rostros humanos? Existen varias aplicaciones que detectan objetos como gatos, perros, botellas, coches, etc. Disponemos de coches autónomos en marcha por nuestras carreteras que detectan objetos en tiempo real para conducir el coche. Cuando viaja, usa GoogleDirectionspara conocer las situaciones de tráfico en tiempo real y seguir el mejor camino sugerido por Google en ese momento. Esta es otra implementación más de la técnica de detección de objetos en tiempo real.
Consideremos el ejemplo de Google Translateaplicación que usamos normalmente cuando visitamos países extranjeros. La aplicación de traducción en línea de Google en su dispositivo móvil lo ayuda a comunicarse con la gente local que habla un idioma que es extranjero para usted.
Son varias las aplicaciones de la IA que usamos prácticamente en la actualidad. De hecho, cada uno de nosotros usamos la IA en muchas partes de nuestras vidas, incluso sin nuestro conocimiento. La IA actual puede realizar trabajos extremadamente complejos con gran precisión y velocidad. Analicemos un ejemplo de tarea compleja para comprender qué capacidades se esperan en una aplicación de IA que desarrollaría hoy para sus clientes.
Ejemplo
Todos usamos Google Directionsdurante nuestro viaje a cualquier lugar de la ciudad para un viaje diario al trabajo o incluso para viajes entre ciudades. La aplicación Google Directions sugiere el camino más rápido a nuestro destino en ese momento. Cuando seguimos este camino, hemos observado que Google tiene casi un 100% de acierto en sus sugerencias y nos ahorramos nuestro valioso tiempo en el viaje.
Puede imaginar la complejidad involucrada en el desarrollo de este tipo de aplicación considerando que existen múltiples rutas hacia su destino y la aplicación tiene que juzgar la situación del tráfico en cada ruta posible para darle una estimación del tiempo de viaje para cada ruta. Además, considere el hecho de que Google Directions cubre todo el mundo. Sin lugar a dudas, muchas técnicas de inteligencia artificial y aprendizaje automático se utilizan bajo el capó de tales aplicaciones.
Teniendo en cuenta la demanda continua para el desarrollo de tales aplicaciones, ahora comprenderá por qué hay una demanda repentina de profesionales de TI con habilidades de inteligencia artificial.
En nuestro próximo capítulo, aprenderemos qué se necesita para desarrollar programas de IA.
El viaje de la IA comenzó en la década de 1950 cuando la potencia informática era una fracción de lo que es hoy. La IA comenzó con las predicciones hechas por la máquina de una manera que un estadístico hace predicciones usando su calculadora. Por lo tanto, todo el desarrollo inicial de la IA se basó principalmente en técnicas estadísticas.
En este capítulo, analicemos en detalle qué son estas técnicas estadísticas.
Técnicas estadísticas
El desarrollo de las aplicaciones de IA actuales comenzó con el uso de técnicas estadísticas tradicionales ancestrales. Debe haber utilizado la interpolación en línea recta en las escuelas para predecir un valor futuro. Hay varias otras técnicas estadísticas similares que se aplican con éxito en el desarrollo de los llamados programas de IA. Decimos “así llamado” porque los programas de IA que tenemos hoy en día son mucho más complejos y utilizan técnicas mucho más allá de las técnicas estadísticas utilizadas por los primeros programas de IA.
A continuación se enumeran algunos de los ejemplos de técnicas estadísticas que se utilizan para desarrollar aplicaciones de IA en aquellos días y que todavía están en práctica:
- Regression
- Classification
- Clustering
- Teorías de probabilidad
- Árboles de decisión
Aquí hemos enumerado solo algunas técnicas primarias que son suficientes para comenzar con la IA sin asustarlo de la inmensidad que exige la IA. Si está desarrollando aplicaciones de inteligencia artificial basadas en datos limitados, estaría utilizando estas técnicas estadísticas.
Sin embargo, hoy en día los datos son abundantes. Para analizar el tipo de datos enormes que poseemos, las técnicas estadísticas no son de mucha ayuda ya que tienen algunas limitaciones propias. Por lo tanto, se desarrollan métodos más avanzados, como el aprendizaje profundo, para resolver muchos problemas complejos.
A medida que avancemos en este tutorial, entenderemos qué es el aprendizaje automático y cómo se utiliza para desarrollar aplicaciones de IA tan complejas.
Considere la siguiente figura que muestra una gráfica de los precios de la vivienda frente a su tamaño en pies cuadrados.

Después de trazar varios puntos de datos en la gráfica XY, trazamos una línea de mejor ajuste para hacer nuestras predicciones para cualquier otra casa dado su tamaño. Enviará los datos conocidos a la máquina y le pedirá que encuentre la línea que mejor se ajuste. Una vez que la máquina encuentre la línea de mejor ajuste, probará su idoneidad introduciendo un tamaño de casa conocido, es decir, el valor Y en la curva anterior. La máquina ahora devolverá el valor X estimado, es decir, el precio esperado de la casa. El diagrama se puede extrapolar para encontrar el precio de una casa de 3000 pies cuadrados o incluso más grande. Esto se llama regresión en estadística. En particular, este tipo de regresión se denomina regresión lineal ya que la relación entre los puntos de datos X e Y es lineal.
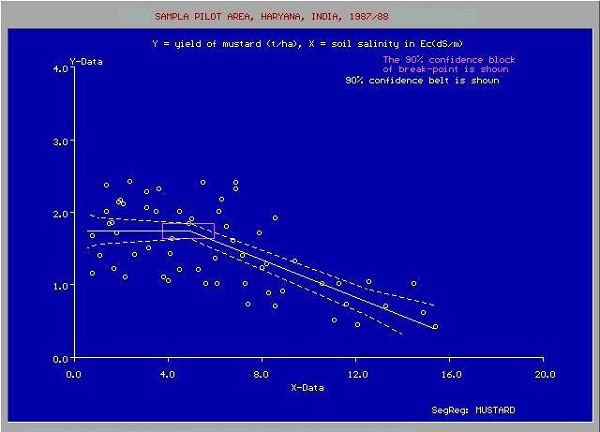
En muchos casos, la relación entre los puntos de datos X e Y puede no ser una línea recta y puede ser una curva con una ecuación compleja. Su tarea ahora sería encontrar la curva de mejor ajuste que se pueda extrapolar para predecir los valores futuros. Uno de estos gráficos de aplicación se muestra en la siguiente figura.
Fuente:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Utilizará las técnicas de optimización estadística para encontrar la ecuación de la curva de mejor ajuste aquí. Y de esto se trata exactamente el aprendizaje automático. Utiliza técnicas de optimización conocidas para encontrar la mejor solución a su problema.
A continuación, veamos las diferentes categorías de Machine Learning.
El aprendizaje automático se clasifica ampliamente en los siguientes títulos:
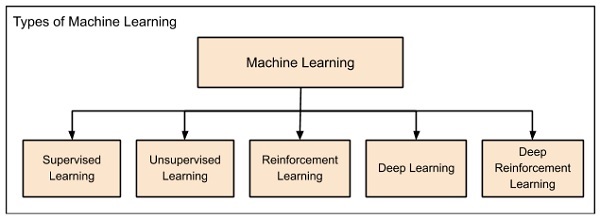
El aprendizaje automático evolucionó de izquierda a derecha como se muestra en el diagrama anterior.
Inicialmente, los investigadores comenzaron con el aprendizaje supervisado. Este es el caso de la predicción del precio de la vivienda discutida anteriormente.
A esto le siguió el aprendizaje no supervisado, en el que la máquina está diseñada para aprender por sí sola sin supervisión.
Los científicos descubrieron además que puede ser una buena idea recompensar a la máquina cuando hace el trabajo de la manera esperada y llegó el aprendizaje por refuerzo.
Muy pronto, los datos que están disponibles en estos días se han vuelto tan enormes que las técnicas convencionales desarrolladas hasta ahora no lograron analizar el big data y proporcionarnos las predicciones.
Así, llegó el aprendizaje profundo donde se simula el cerebro humano en las Redes Neuronales Artificiales (ANN) creadas en nuestras computadoras binarias.
La máquina ahora aprende por sí sola utilizando la alta potencia informática y los enormes recursos de memoria que están disponibles en la actualidad.
Ahora se observa que Deep Learning ha resuelto muchos de los problemas que antes no tenían solución.
La técnica ahora está más avanzada al otorgar incentivos a las redes de Deep Learning como premios y finalmente llega Deep Reinforcement Learning.
Estudiemos ahora cada una de estas categorías con más detalle.
Aprendizaje supervisado
El aprendizaje supervisado es análogo a enseñar a un niño a caminar. Usted tomará la mano del niño, le enseñará cómo llevar el pie hacia adelante, caminará usted mismo para una demostración, etc., hasta que el niño aprenda a caminar por sí mismo.
Regresión
De manera similar, en el caso del aprendizaje supervisado, le da ejemplos concretos conocidos a la computadora. Usted dice que para un valor de característica dado x1 la salida es y1, para x2 es y2, para x3 es y3, y así sucesivamente. Con base en estos datos, dejas que la computadora descubra una relación empírica entre xey.
Una vez que la máquina esté entrenada de esta manera con una cantidad suficiente de puntos de datos, ahora le pediría a la máquina que prediga Y para una X dada. Suponiendo que conoce el valor real de Y para esta X dada, podrá deducir si la predicción de la máquina es correcta.
Por lo tanto, probará si la máquina ha aprendido utilizando los datos de prueba conocidos. Una vez que esté satisfecho de que la máquina puede realizar las predicciones con el nivel de precisión deseado (por ejemplo, del 80 al 90%), puede dejar de entrenar la máquina.
Ahora, puede usar la máquina de manera segura para hacer las predicciones en puntos de datos desconocidos, o pedirle a la máquina que prediga Y para un X dado para el que no conoce el valor real de Y. Esta capacitación se incluye en la regresión de la que hablamos más temprano.
Clasificación
También puede utilizar técnicas de aprendizaje automático para problemas de clasificación. En los problemas de clasificación, clasifica los objetos de naturaleza similar en un solo grupo. Por ejemplo, en un conjunto de 100 estudiantes, digamos, es posible que desee agruparlos en tres grupos según sus alturas: corto, mediano y largo. Midiendo la altura de cada alumno, los colocará en un grupo adecuado.
Ahora, cuando llegue un estudiante nuevo, lo colocará en un grupo apropiado midiendo su altura. Al seguir los principios del entrenamiento de regresión, entrenará la máquina para clasificar a un estudiante en función de su característica: la altura. Cuando la máquina aprenda cómo se forman los grupos, podrá clasificar correctamente a cualquier estudiante nuevo desconocido. Una vez más, usaría los datos de prueba para verificar que la máquina haya aprendido su técnica de clasificación antes de poner en producción el modelo desarrollado.
El aprendizaje supervisado es donde la IA realmente comenzó su viaje. Esta técnica se aplicó con éxito en varios casos. Ha utilizado este modelo mientras realizaba el reconocimiento de escritura a mano en su máquina. Se han desarrollado varios algoritmos para el aprendizaje supervisado. Aprenderá sobre ellos en los siguientes capítulos.
Aprendizaje sin supervisión
En el aprendizaje no supervisado, no especificamos una variable objetivo a la máquina, sino que le preguntamos a la máquina "¿Qué me puede decir acerca de X?". Más específicamente, podemos hacer preguntas como, dado un enorme conjunto de datos X, "¿Cuáles son los cinco mejores grupos que podemos hacer con X?" o "¿Qué características ocurren juntas con mayor frecuencia en X?". Para llegar a las respuestas a tales preguntas, puede comprender que el número de puntos de datos que necesitaría la máquina para deducir una estrategia sería muy grande. En caso de aprendizaje supervisado, la máquina puede entrenarse incluso con unos pocos miles de puntos de datos. Sin embargo, en el caso del aprendizaje no supervisado, la cantidad de puntos de datos que se aceptan razonablemente para el aprendizaje comienza en unos pocos millones. En estos días, los datos generalmente están disponibles en abundancia. Idealmente, los datos requieren curación. Sin embargo, la cantidad de datos que fluye continuamente en una red de área social, en la mayoría de los casos, la curación de datos es una tarea imposible.
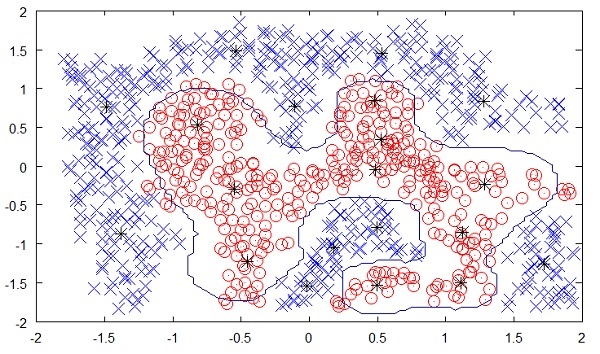
La siguiente figura muestra el límite entre los puntos amarillos y rojos según lo determinado por el aprendizaje automático no supervisado. Puede ver claramente que la máquina podría determinar la clase de cada uno de los puntos negros con una precisión bastante buena.
Fuente:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
El aprendizaje no supervisado ha mostrado un gran éxito en muchas aplicaciones modernas de IA, como la detección de rostros, la detección de objetos, etc.
Aprendizaje reforzado
Considere adiestrar a un perro mascota, entrenamos a nuestra mascota para que nos traiga una pelota. Lanzamos la pelota a cierta distancia y le pedimos al perro que nos la devuelva. Cada vez que el perro hace esto bien, lo premiamos. Lentamente, el perro aprende que hacer el trabajo correctamente le da una recompensa y luego el perro comienza a hacer el trabajo de la manera correcta en el futuro. Exactamente, este concepto se aplica en el tipo de aprendizaje “Refuerzo”. La técnica fue desarrollada inicialmente para máquinas para jugar. La máquina recibe un algoritmo para analizar todos los movimientos posibles en cada etapa del juego. La máquina puede seleccionar uno de los movimientos al azar. Si el movimiento es correcto, la máquina es recompensada; de lo contrario, puede ser penalizada. Lentamente, la máquina comenzará a diferenciar entre movimientos correctos e incorrectos y, después de varias iteraciones, aprenderá a resolver el rompecabezas del juego con mayor precisión. La precisión de ganar el juego mejoraría a medida que la máquina juegue más y más juegos.
El proceso completo se puede representar en el siguiente diagrama:
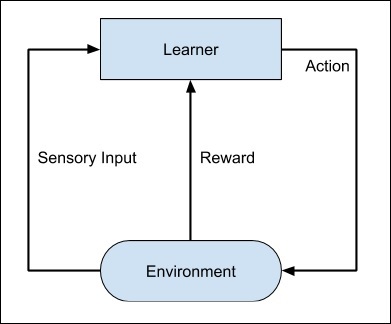
Esta técnica de aprendizaje automático se diferencia del aprendizaje supervisado en que no es necesario proporcionar los pares de entrada / salida etiquetados. La atención se centra en encontrar el equilibrio entre explorar las nuevas soluciones y explotar las soluciones aprendidas.
Aprendizaje profundo
El aprendizaje profundo es un modelo basado en Redes Neuronales Artificiales (ANN), más específicamente Redes Neuronales Convolucionales (CNN). Existen varias arquitecturas utilizadas en el aprendizaje profundo, como las redes neuronales profundas, las redes de creencias profundas, las redes neuronales recurrentes y las redes neuronales convolucionales.
Estas redes se han aplicado con éxito para resolver problemas de visión por computadora, reconocimiento de voz, procesamiento del lenguaje natural, bioinformática, diseño de fármacos, análisis de imágenes médicas y juegos. Hay varios otros campos en los que se aplica de forma proactiva el aprendizaje profundo. El aprendizaje profundo requiere una gran potencia de procesamiento y datos enormes, que generalmente están fácilmente disponibles en estos días.
Hablaremos sobre el aprendizaje profundo con más detalle en los próximos capítulos.
Aprendizaje por refuerzo profundo
El Deep Reinforcement Learning (DRL) combina las técnicas de aprendizaje profundo y reforzado. Los algoritmos de aprendizaje por refuerzo como Q-learning ahora se combinan con el aprendizaje profundo para crear un modelo de DRL potente. La técnica ha tenido un gran éxito en los campos de la robótica, los videojuegos, las finanzas y la salud. Muchos problemas que antes no tenían solución se resuelven ahora mediante la creación de modelos DRL. Se están realizando muchas investigaciones en esta área y las industrias la llevan a cabo de manera muy activa.
Hasta ahora, ha recibido una breve introducción a varios modelos de aprendizaje automático, ahora exploremos un poco más en profundidad varios algoritmos que están disponibles bajo estos modelos.
El aprendizaje supervisado es uno de los modelos importantes de aprendizaje involucrados en las máquinas de entrenamiento. Este capítulo habla en detalle sobre lo mismo.
Algoritmos para el aprendizaje supervisado
Hay varios algoritmos disponibles para el aprendizaje supervisado. Algunos de los algoritmos de aprendizaje supervisado más utilizados son los que se muestran a continuación:
- k-Vecinos más cercanos
- Árboles de decisión
- Bayes ingenuo
- Regresión logística
- Máquinas de vectores de soporte
A medida que avanzamos en este capítulo, analicemos en detalle cada uno de los algoritmos.
k-Vecinos más cercanos
Los k-vecinos más cercanos, que simplemente se denominan kNN, es una técnica estadística que se puede utilizar para resolver problemas de clasificación y regresión. Analicemos el caso de clasificar un objeto desconocido usando kNN. Considere la distribución de objetos como se muestra en la imagen que se muestra a continuación:
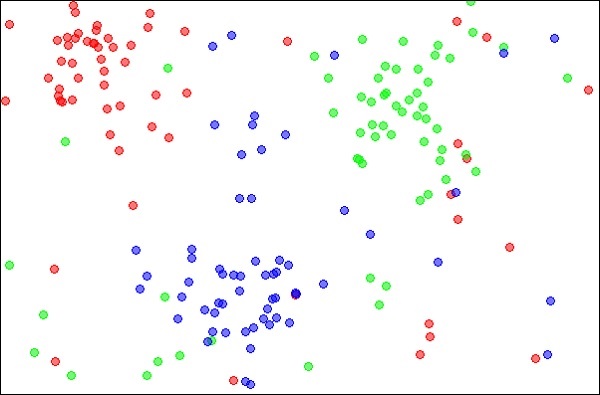
Fuente:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
El diagrama muestra tres tipos de objetos, marcados en colores rojo, azul y verde. Cuando ejecute el clasificador kNN en el conjunto de datos anterior, los límites para cada tipo de objeto se marcarán como se muestra a continuación:

Fuente:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Ahora, considere un nuevo objeto desconocido que desee clasificar como rojo, verde o azul. Esto se muestra en la siguiente figura.
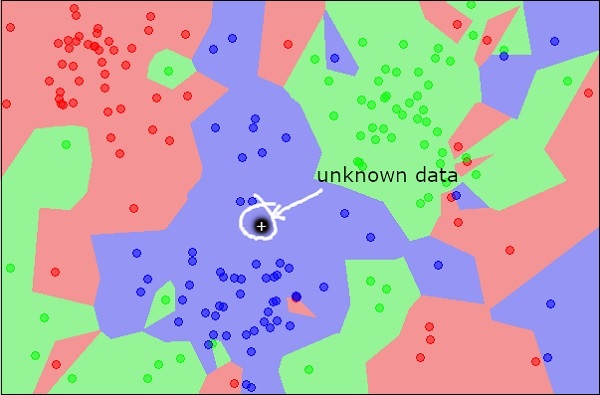
Como lo ve visualmente, el punto de datos desconocido pertenece a una clase de objetos azules. Matemáticamente, esto se puede concluir midiendo la distancia de este punto desconocido con todos los demás puntos del conjunto de datos. Cuando lo hagas, sabrás que la mayoría de sus vecinos son de color azul. La distancia promedio a los objetos rojos y verdes sería definitivamente mayor que la distancia promedio a los objetos azules. Así, este objeto desconocido se puede clasificar como perteneciente a la clase azul.
El algoritmo kNN también se puede utilizar para problemas de regresión. El algoritmo kNN está disponible como listo para usar en la mayoría de las bibliotecas ML.
Árboles de decisión
A continuación se muestra un árbol de decisiones simple en formato de diagrama de flujo:
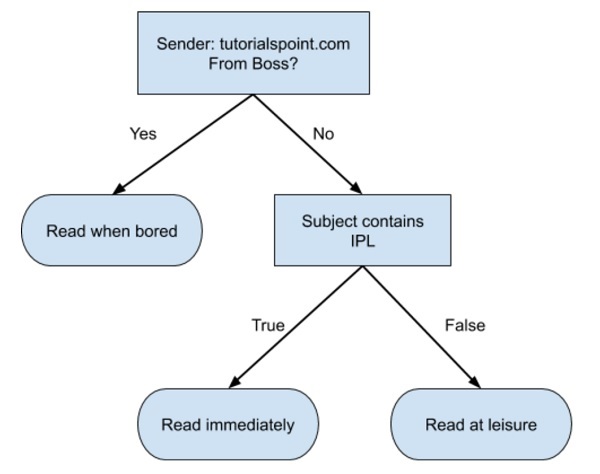
Escribiría un código para clasificar sus datos de entrada según este diagrama de flujo. El diagrama de flujo se explica por sí mismo y es trivial. En este escenario, está intentando clasificar un correo electrónico entrante para decidir cuándo leerlo.
En realidad, los árboles de decisión pueden ser grandes y complejos. Hay varios algoritmos disponibles para crear y atravesar estos árboles. Como entusiasta del aprendizaje automático, debe comprender y dominar estas técnicas para crear y atravesar árboles de decisiones.
Bayes ingenuo
Naive Bayes se utiliza para crear clasificadores. Suponga que desea separar (clasificar) frutas de diferentes tipos de una canasta de frutas. Puede utilizar características como el color, el tamaño y la forma de una fruta. Por ejemplo, cualquier fruta que sea de color rojo, de forma redonda y de unos 10 cm de diámetro puede considerarse manzana. Entonces, para entrenar el modelo, usaría estas características y probaría la probabilidad de que una característica dada coincida con las restricciones deseadas. Las probabilidades de diferentes características se combinan para llegar a una probabilidad de que una fruta determinada sea una manzana. Naive Bayes generalmente requiere una pequeña cantidad de datos de entrenamiento para la clasificación.
Regresión logística
Mira el siguiente diagrama. Muestra la distribución de puntos de datos en el plano XY.

En el diagrama, podemos inspeccionar visualmente la separación de los puntos rojos de los puntos verdes. Puede dibujar una línea de límite para separar estos puntos. Ahora, para clasificar un nuevo punto de datos, solo necesitará determinar en qué lado de la línea se encuentra el punto.
Máquinas de vectores de soporte
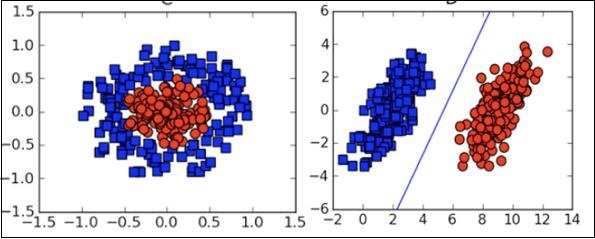
Mire la siguiente distribución de datos. Aquí las tres clases de datos no se pueden separar linealmente. Las curvas de los límites no son lineales. En tal caso, encontrar la ecuación de la curva se convierte en un trabajo complejo.
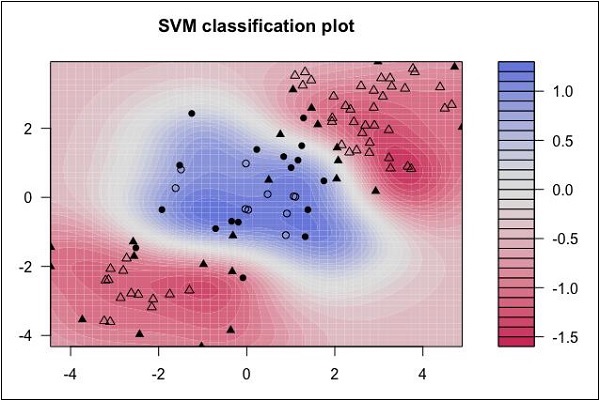
Fuente: http://uc-r.github.io/svm
Support Vector Machines (SVM) es útil para determinar los límites de separación en tales situaciones.
Afortunadamente, la mayoría de las veces no es necesario codificar los algoritmos mencionados en la lección anterior. Hay muchas bibliotecas estándar que proporcionan la implementación lista para usar de estos algoritmos. Uno de esos conjuntos de herramientas que se utiliza popularmente es scikit-learn. La siguiente figura ilustra el tipo de algoritmos que están disponibles para su uso en esta biblioteca.

Fuente: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
El uso de estos algoritmos es trivial y, dado que están bien probados en el campo, puede usarlos de manera segura en sus aplicaciones de inteligencia artificial. La mayoría de estas bibliotecas son de uso gratuito incluso con fines comerciales.
Hasta ahora lo que has visto es hacer que la máquina aprenda a encontrar la solución a nuestro objetivo. En regresión, entrenamos la máquina para predecir un valor futuro. En clasificación, entrenamos a la máquina para clasificar un objeto desconocido en una de las categorías definidas por nosotros. En resumen, hemos estado entrenando máquinas para que puedan predecir Y para nuestros datos X. Dado un conjunto de datos enorme y sin estimar las categorías, sería difícil para nosotros entrenar la máquina mediante el aprendizaje supervisado. ¿Qué pasa si la máquina puede buscar y analizar los grandes datos que se ejecutan en varios Gigabytes y Terabytes y nos dice que estos datos contienen tantas categorías distintas?
Como ejemplo, considere los datos del votante. Al considerar algunas aportaciones de cada votante (estas se denominan características en la terminología de la IA), deje que la máquina prediga que hay tantos votantes que votarían por X partido político y muchos votarían por Y, y así sucesivamente. Por lo tanto, en general, le estamos preguntando a la máquina dada un gran conjunto de puntos de datos X, "¿Qué me puede decir acerca de X?". O puede ser una pregunta como "¿Cuáles son los cinco mejores grupos que podemos hacer con X?". O podría ser incluso como "¿Qué tres características ocurren juntas con mayor frecuencia en X?".
De esto se trata exactamente el aprendizaje no supervisado.
Algoritmos para el aprendizaje no supervisado
Analicemos ahora uno de los algoritmos más utilizados para la clasificación en el aprendizaje automático no supervisado.
agrupación de k-medias
Las elecciones presidenciales de 2000 y 2004 en los Estados Unidos estuvieron cerca, muy cerca. El mayor porcentaje del voto popular que recibió cualquier candidato fue del 50,7% y el más bajo fue del 47,9%. Si un porcentaje de los votantes hubiera cambiado de bando, el resultado de la elección habría sido diferente. Hay pequeños grupos de votantes que, cuando se les solicita debidamente, cambiarán de bando. Estos grupos pueden no ser enormes, pero con carreras tan reñidas, pueden ser lo suficientemente grandes como para cambiar el resultado de las elecciones. ¿Cómo encuentras a estos grupos de personas? ¿Cómo les atrae con un presupuesto limitado? La respuesta es la agrupación.
Entendamos cómo se hace.
Primero, recopila información sobre las personas con o sin su consentimiento: cualquier tipo de información que pueda dar alguna pista sobre lo que es importante para ellos y lo que influirá en su forma de votar.
Luego, coloca esta información en una especie de algoritmo de agrupamiento.
A continuación, para cada grupo (sería inteligente elegir primero el más grande), elabora un mensaje que atraerá a estos votantes.
Finalmente, entrega la campaña y mide para ver si está funcionando.
La agrupación en clústeres es un tipo de aprendizaje no supervisado que forma automáticamente grupos de cosas similares. Es como una clasificación automática. Puede agrupar casi cualquier cosa, y cuanto más similares sean los elementos en el grupo, mejores serán los grupos. En este capítulo, vamos a estudiar un tipo de algoritmo de agrupamiento llamado k-medias. Se llama k-medias porque encuentra 'k' grupos únicos, y el centro de cada grupo es la media de los valores en ese grupo.
Identificación de clústeres
La identificación de conglomerados le dice a un algoritmo: “Aquí hay algunos datos. Ahora agrupe cosas similares y hábleme de esos grupos ". La diferencia clave con la clasificación es que en la clasificación sabes lo que estás buscando. Si bien ese no es el caso de la agrupación.
La agrupación en clústeres a veces se denomina clasificación no supervisada porque produce el mismo resultado que la clasificación pero sin tener clases predefinidas.
Ahora, nos sentimos cómodos con el aprendizaje supervisado y no supervisado. Para comprender el resto de las categorías de aprendizaje automático, primero debemos comprender las redes neuronales artificiales (ANN), que aprenderemos en el próximo capítulo.
La idea de las redes neuronales artificiales se derivó de las redes neuronales del cerebro humano. El cerebro humano es realmente complejo. Al estudiar cuidadosamente el cerebro, los científicos e ingenieros idearon una arquitectura que podría encajar en nuestro mundo digital de computadoras binarias. Una de estas arquitecturas típicas se muestra en el siguiente diagrama:
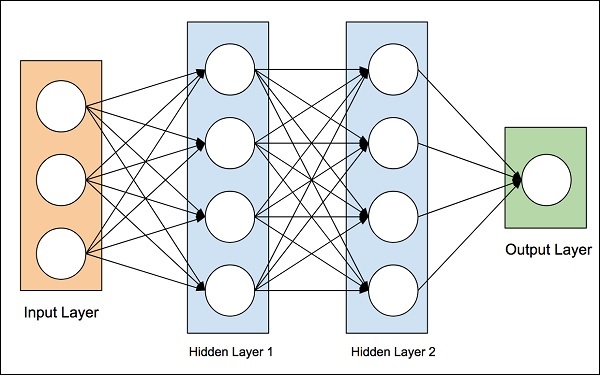
Hay una capa de entrada que tiene muchos sensores para recopilar datos del mundo exterior. En el lado derecho, tenemos una capa de salida que nos da el resultado predicho por la red. Entre estos dos, se ocultan varias capas. Cada capa adicional agrega más complejidad al entrenamiento de la red, pero proporcionaría mejores resultados en la mayoría de las situaciones. Hay varios tipos de arquitecturas diseñadas que discutiremos ahora.
Arquitecturas ANN
El siguiente diagrama muestra varias arquitecturas ANN desarrolladas durante un período de tiempo y que están en práctica hoy.
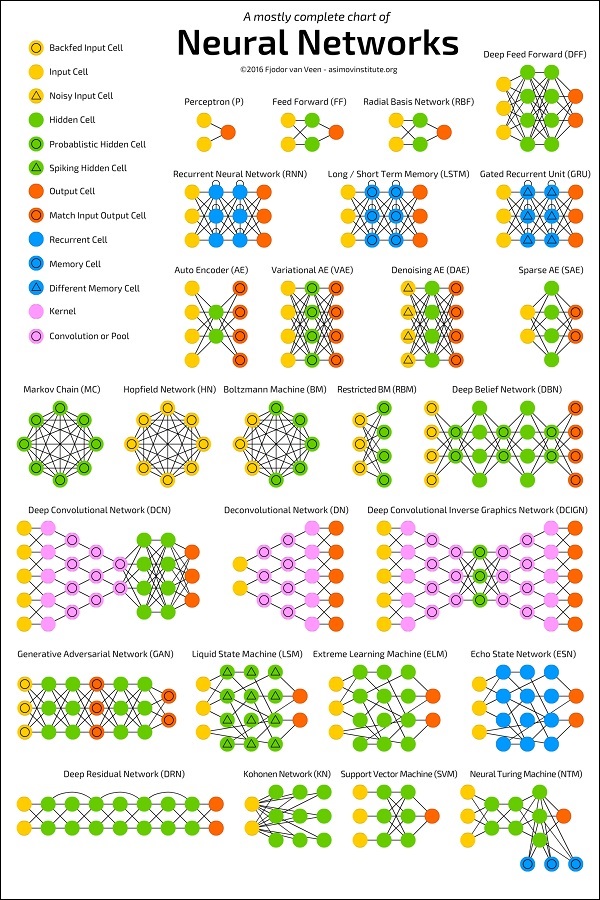
Fuente:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Cada arquitectura se desarrolla para un tipo específico de aplicación. Por lo tanto, cuando use una red neuronal para su aplicación de aprendizaje automático, tendrá que usar una arquitectura existente o diseñar la suya propia. El tipo de aplicación que finalmente decida depende de las necesidades de su aplicación. No existe una pauta única que le indique que debe utilizar una arquitectura de red específica.
El aprendizaje profundo usa ANN. Primero veremos algunas aplicaciones de aprendizaje profundo que le darán una idea de su poder.
Aplicaciones
El aprendizaje profundo ha tenido mucho éxito en varias áreas de las aplicaciones de aprendizaje automático.
Self-driving Cars- Los coches autónomos autónomos utilizan técnicas de aprendizaje profundo. Por lo general, se adaptan a las situaciones de tráfico en constante cambio y mejoran cada vez más en la conducción durante un período de tiempo.
Speech Recognition- Otra aplicación interesante del Deep Learning es el reconocimiento de voz. Todos usamos hoy en día varias aplicaciones móviles que son capaces de reconocer nuestro habla. Siri de Apple, Alexa de Amazon, Cortena de Microsoft y Asistente de Google: todos ellos utilizan técnicas de aprendizaje profundo.
Mobile Apps- Usamos varias aplicaciones móviles y basadas en la web para organizar nuestras fotos. Detección de rostros, identificación de rostros, etiquetado de rostros, identificación de objetos en una imagen: todo esto utiliza el aprendizaje profundo.
Oportunidades desaprovechadas del aprendizaje profundo
Después de observar el gran éxito que las aplicaciones de aprendizaje profundo han logrado en muchos dominios, la gente comenzó a explorar otros dominios donde el aprendizaje automático no se aplicaba hasta ahora. Existen varios dominios en los que las técnicas de aprendizaje profundo se aplican con éxito y hay muchos otros dominios que pueden explotarse. Algunos de ellos se comentan aquí.
La agricultura es una de esas industrias donde las personas pueden aplicar técnicas de aprendizaje profundo para mejorar el rendimiento de los cultivos.
La financiación al consumidor es otra área en la que el aprendizaje automático puede ayudar enormemente a proporcionar una detección temprana de fraudes y analizar la capacidad de pago del cliente.
Las técnicas de aprendizaje profundo también se aplican al campo de la medicina para crear nuevos fármacos y proporcionar una prescripción personalizada a un paciente.
Las posibilidades son infinitas y hay que seguir observando las nuevas ideas y desarrollos que surgen con frecuencia.
Qué se necesita para lograr más con el aprendizaje profundo
Para utilizar el aprendizaje profundo, la potencia de la supercomputación es un requisito obligatorio. Necesita tanto memoria como CPU para desarrollar modelos de aprendizaje profundo. Afortunadamente, hoy tenemos una fácil disponibilidad de HPC - Computación de alto rendimiento. Debido a esto, el desarrollo de las aplicaciones de aprendizaje profundo que mencionamos anteriormente se convirtió en una realidad hoy y en el futuro también podemos ver las aplicaciones en esas áreas sin explotar que discutimos anteriormente.
Ahora, veremos algunas de las limitaciones del aprendizaje profundo que debemos considerar antes de usarlo en nuestra aplicación de aprendizaje automático.
Desventajas del aprendizaje profundo
Algunos de los puntos importantes que debe considerar antes de utilizar el aprendizaje profundo se enumeran a continuación:
- Enfoque de caja negra
- Duración del desarrollo
- La cantidad de datos
- Costoso computacionalmente
Ahora estudiaremos cada una de estas limitaciones en detalle.
Enfoque de caja negra
Una ANN es como una caja negra. Le da una determinada entrada y le proporcionará una salida específica. El siguiente diagrama le muestra una de esas aplicaciones en la que alimenta una imagen de animal a una red neuronal y le dice que la imagen es de un perro.
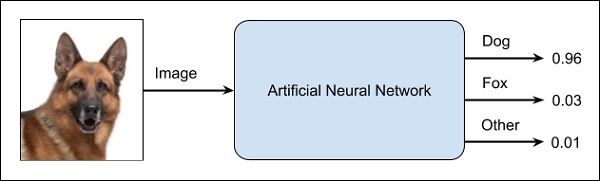
La razón por la que esto se llama enfoque de caja negra es que no sabe por qué la red obtuvo un resultado determinado. ¿No sabes cómo concluyó la red que es un perro? Ahora considere una aplicación bancaria en la que el banco quiere decidir la solvencia de un cliente. La red definitivamente le dará una respuesta a esta pregunta. Sin embargo, ¿podrá justificarlo ante un cliente? Los bancos deben explicar a sus clientes por qué no se sanciona el préstamo.
Duración del desarrollo
El proceso de entrenamiento de una red neuronal se muestra en el siguiente diagrama:

Primero, defina el problema que desea resolver, cree una especificación para él, decida las características de entrada, diseñe una red, impleméntela y pruebe la salida. Si el resultado no es el esperado, tómelo como un comentario para reestructurar su red. Este es un proceso iterativo y puede requerir varias iteraciones hasta que la red de tiempo esté completamente entrenada para producir los resultados deseados.
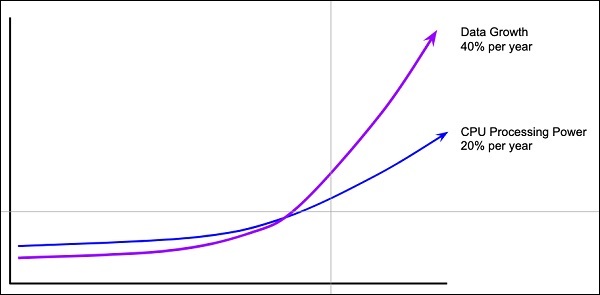
La cantidad de datos
Las redes de aprendizaje profundo generalmente requieren una gran cantidad de datos para el entrenamiento, mientras que los algoritmos tradicionales de aprendizaje automático pueden usarse con gran éxito incluso con solo unos pocos miles de puntos de datos. Afortunadamente, la abundancia de datos está creciendo al 40% por año y la potencia de procesamiento de la CPU está creciendo al 20% por año, como se ve en el diagrama que se muestra a continuación
Costoso computacionalmente
El entrenamiento de una red neuronal requiere varias veces más potencia computacional que la requerida para ejecutar algoritmos tradicionales. El entrenamiento exitoso de redes neuronales profundas puede requerir varias semanas de entrenamiento.
En contraste con esto, los algoritmos tradicionales de aprendizaje automático toman solo unos minutos / horas para entrenarse. Además, la cantidad de potencia computacional necesaria para entrenar una red neuronal profunda depende en gran medida del tamaño de sus datos y de la profundidad y complejidad de la red.
Después de tener una descripción general de lo que es el aprendizaje automático, sus capacidades, limitaciones y aplicaciones, ahora vamos a sumergirnos en el aprendizaje del "aprendizaje automático".
El aprendizaje automático tiene un ancho muy amplio y requiere habilidades en varios dominios. Las habilidades que necesita adquirir para convertirse en un experto en aprendizaje automático se enumeran a continuación:
- Statistics
- Teorías de probabilidad
- Calculus
- Técnicas de optimización
- Visualization
Necesidad de diversas habilidades de aprendizaje automático
Para darle una breve idea de las habilidades que necesita adquirir, analicemos algunos ejemplos:
Notación matemática
La mayoría de los algoritmos de aprendizaje automático se basan en gran medida en las matemáticas. El nivel de matemáticas que necesita saber es probablemente solo un nivel principiante. Lo importante es que debería poder leer la notación que usan los matemáticos en sus ecuaciones. Por ejemplo, si puede leer la notación y comprender lo que significa, está listo para aprender el aprendizaje automático. De lo contrario, es posible que deba mejorar sus conocimientos de matemáticas.
$$ f_ {AN} (net- \ theta) = \ begin {cases} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if - \ epsilon <net- \ theta <\ épsilon \\ - \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {cases} $$
$$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i, j = 1} ^ m etiqueta ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {array} {c} j \\ \ end {matriz} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {matriz} {c} i \\ \ end {matriz} \ derecha), x ^ \ izquierda (\ begin {matriz} {c} j \\ \ end {matriz} \ derecha) \ rangle \ end {bmatrix} $$
$$ f_ {AN} (net- \ theta) = \ left (\ frac {e ^ {\ lambda (net- \ theta)} - e ^ {- \ lambda (net- \ theta)}} {e ^ { \ lambda (net- \ theta)} + e ^ {- \ lambda (net- \ theta)}} \ right) \; $$
Teoría de probabilidad
Aquí hay un ejemplo para poner a prueba su conocimiento actual de la teoría de la probabilidad: Clasificación con probabilidades condicionales.
$$ p (c_ {i} | x, y) \; = \ frac {p (x, y | c_ {i}) \; p (c_ {i}) \;} {p (x, y) \ ;} $$
Con estas definiciones, podemos definir la regla de clasificación bayesiana:
- Si P (c1 | x, y)> P (c2 | x, y), la clase es c1.
- Si P (c1 | x, y) <P (c2 | x, y), la clase es c2.
Problema de optimizacion
Aquí hay una función de optimización
$$ \ displaystyle \\\ max \ limits _ {\ alpha} \ begin {bmatrix} \ displaystyle \ sum \ limits_ {i = 1} ^ m \ alpha- \ frac {1} {2} \ displaystyle \ sum \ limits_ { i, j = 1} ^ m etiqueta ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) \ cdot \: label ^ \ left (\ begin {array} {c} j \\ \ end {matriz} \ right) \ cdot \: a_ {i} \ cdot \: a_ {j} \ langle x ^ \ left (\ begin {matriz} {c} i \\ \ end {matriz} \ derecha), x ^ \ izquierda (\ begin {matriz} {c} j \\ \ end {matriz} \ derecha) \ rangle \ end {bmatrix} $$
Sujeto a las siguientes limitaciones:
$$ \ alpha \ geq0 y \: \ displaystyle \ sum \ limits_ {i-1} ^ m \ alpha_ {i} \ cdot \: label ^ \ left (\ begin {array} {c} i \\ \ end {array} \ right) = 0 $$
Si puede leer y comprender lo anterior, está listo.
Visualización
En muchos casos, deberá comprender los distintos tipos de gráficos de visualización para comprender la distribución de sus datos e interpretar los resultados de la salida del algoritmo.
Además de los aspectos teóricos anteriores del aprendizaje automático, necesita buenas habilidades de programación para codificar esos algoritmos.
Entonces, ¿qué se necesita para implementar ML? Examinemos esto en el próximo capítulo.
Para desarrollar aplicaciones de aprendizaje automático, deberá decidir la plataforma, el IDE y el lenguaje de desarrollo. Hay varias opciones disponibles. La mayoría de ellos cumplirían con sus requisitos fácilmente, ya que todos proporcionan la implementación de los algoritmos de IA discutidos hasta ahora.
Si está desarrollando el algoritmo ML por su cuenta, los siguientes aspectos deben entenderse con cuidado:
El idioma de su elección: este es esencialmente su competencia en uno de los idiomas admitidos en el desarrollo de ML.
El IDE que utiliza: esto dependerá de su familiaridad con los IDE existentes y su nivel de comodidad.
Development platform- Hay varias plataformas disponibles para desarrollo e implementación. La mayoría de estos son de uso gratuito. En algunos casos, es posible que deba incurrir en una tarifa de licencia más allá de una cierta cantidad de uso. Aquí hay una breve lista de opciones de idiomas, IDE y plataformas para su referencia inmediata.
Elección de idioma
Aquí hay una lista de idiomas que admiten el desarrollo de AA:
- Python
- R
- Matlab
- Octave
- Julia
- C++
- C
Esta lista no es esencialmente completa; sin embargo, cubre muchos lenguajes populares utilizados en el desarrollo del aprendizaje automático. Dependiendo de su nivel de comodidad, seleccione un idioma para el desarrollo, desarrolle sus modelos y pruebe.
IDE
Aquí hay una lista de IDE que admiten el desarrollo de ML:
- Estudio R
- Pycharm
- iPython / Jupyter Notebook
- Julia
- Spyder
- Anaconda
- Rodeo
- Google –Colab
La lista anterior no es esencialmente completa. Cada uno tiene sus propios méritos y deméritos. Se anima al lector a probar estos diferentes IDE antes de limitarse a uno solo.
Plataformas
Aquí hay una lista de plataformas en las que se pueden implementar aplicaciones de AA:
- IBM
- Microsoft Azure
- Google Cloud
- Amazon
- Mlflow
Una vez más, esta lista no es exhaustiva. Se anima al lector a que se registre en los servicios antes mencionados y los pruebe ellos mismos.
Este tutorial le presentó el aprendizaje automático. Ahora, sabes que el aprendizaje automático es una técnica de entrenamiento de máquinas para que realicen las actividades que puede hacer un cerebro humano, aunque un poco más rápido y mejor que un ser humano promedio. Hoy hemos visto que las máquinas pueden vencer a campeones humanos en juegos como Ajedrez, AlphaGO, que se consideran muy complejos. Ha visto que las máquinas pueden entrenarse para realizar actividades humanas en varias áreas y pueden ayudar a los humanos a vivir una vida mejor.
El aprendizaje automático puede ser supervisado o no supervisado. Si tiene una menor cantidad de datos y datos claramente etiquetados para la capacitación, opte por el aprendizaje supervisado. El aprendizaje no supervisado generalmente daría un mejor rendimiento y resultados para grandes conjuntos de datos. Si tiene un gran conjunto de datos fácilmente disponible, opte por técnicas de aprendizaje profundo. También ha aprendido Aprendizaje por refuerzo y Aprendizaje por refuerzo profundo. Ahora sabe qué son las redes neuronales, sus aplicaciones y limitaciones.
Finalmente, cuando se trata del desarrollo de sus propios modelos de aprendizaje automático, analizó las opciones de varios lenguajes de desarrollo, IDE y plataformas. Lo siguiente que debe hacer es comenzar a aprender y practicar cada técnica de aprendizaje automático. El tema es vasto, significa que hay amplitud, pero si se tiene en cuenta la profundidad, cada tema se puede aprender en pocas horas. Cada tema es independiente entre sí. Debe tener en cuenta un tema a la vez, aprenderlo, practicarlo e implementar el algoritmo o algoritmos en él utilizando el idioma que elija. Esta es la mejor manera de comenzar a estudiar Machine Learning. Practicando un tema a la vez, muy pronto adquiriría el ancho que eventualmente se requiere de un experto en aprendizaje automático.
¡Buena suerte!