Mahout - Medio ambiente
Este capítulo le enseña cómo configurar mahout. Java y Hadoop son los requisitos previos de mahout. A continuación se detallan los pasos para descargar e instalar Java, Hadoop y Mahout.
Configuración previa a la instalación
Antes de instalar Hadoop en el entorno Linux, necesitamos configurar Linux usando ssh(Cubierta segura). Siga los pasos que se mencionan a continuación para configurar el entorno Linux.
Crear un usuario
Se recomienda crear un usuario separado para Hadoop para aislar el sistema de archivos Hadoop del sistema de archivos Unix. Siga los pasos que se indican a continuación para crear un usuario:
Abra root usando el comando "su".
- Cree un usuario desde la cuenta raíz usando el comando “useradd username”.
Ahora puede abrir una cuenta de usuario existente usando el comando “su username”.
Abra la terminal de Linux y escriba los siguientes comandos para crear un usuario.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfiguración de SSH y generación de claves
La configuración de SSH es necesaria para realizar diferentes operaciones en un clúster, como iniciar, detener y distribuir operaciones de shell de demonio. Para autenticar diferentes usuarios de Hadoop, es necesario proporcionar un par de claves pública / privada para un usuario de Hadoop y compartirlo con diferentes usuarios.
Los siguientes comandos se utilizan para generar un par de clave-valor mediante SSH, copiar el formulario de claves públicas id_rsa.pub en allowed_keys y proporcionar permisos de propietario, lectura y escritura en el archivo Authorized_keys respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keysVerificando ssh
ssh localhostInstalación de Java
Java es el principal requisito previo para Hadoop y HBase. En primer lugar, debe verificar la existencia de Java en su sistema usando "java -version". La sintaxis del comando de la versión de Java se proporciona a continuación.
$ java -versionDebería producir el siguiente resultado.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Si no tiene Java instalado en su sistema, siga los pasos que se indican a continuación para instalar Java.
Step 1
Descargue java (JDK <última versión> - X64.tar.gz) visitando el siguiente enlace: Oracle
Luego jdk-7u71-linux-x64.tar.gz is downloaded en su sistema.
Step 2
Generalmente, encontrará el archivo Java descargado en la carpeta Descargas. Verifíquelo y extraiga eljdk-7u71-linux-x64.gz archivo usando los siguientes comandos.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzStep 3
Para que Java esté disponible para todos los usuarios, debe moverlo a la ubicación “/ usr / local /”. Abra root y escriba los siguientes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitStep 4
Para configurar PATH y JAVA_HOME variables, agregue los siguientes comandos a ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binAhora, verifique el java -version comando desde la terminal como se explicó anteriormente.
Descargando Hadoop
Después de instalar Java, primero debe instalar Hadoop. Verifique la existencia de Hadoop usando el comando "Versión de Hadoop" como se muestra a continuación.
hadoop versionDebería producir el siguiente resultado:
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jarSi su sistema no puede localizar Hadoop, descargue Hadoop e instálelo en su sistema. Siga los comandos que se indican a continuación para hacerlo.
Descargue y extraiga hadoop-2.6.0 de la base de software apache usando los siguientes comandos.
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitInstalación de Hadoop
Instale Hadoop en cualquiera de los modos necesarios. Aquí, estamos demostrando las funcionalidades de HBase en modo pseudodistribuido, por lo tanto, instale Hadoop en modo pseudodistribuido.
Siga los pasos que se indican a continuación para instalar Hadoop 2.4.1 en su sistema.
Paso 1: configurar Hadoop
Puede configurar las variables de entorno de Hadoop agregando los siguientes comandos a ~/.bashrc archivo.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEAhora, aplique todos los cambios en el sistema actualmente en ejecución.
$ source ~/.bashrcPaso 2: Configuración de Hadoop
Puede encontrar todos los archivos de configuración de Hadoop en la ubicación "$ HADOOP_HOME / etc / hadoop". Es necesario realizar cambios en esos archivos de configuración de acuerdo con su infraestructura de Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desarrollar programas Hadoop en Java, necesita restablecer las variables de entorno de Java en hadoop-env.sh archivo reemplazando JAVA_HOME valor con la ubicación de Java en su sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71A continuación se muestra la lista de archivos que debe editar para configurar Hadoop.
core-site.xml
los core-site.xml El archivo contiene información como el número de puerto utilizado para la instancia de Hadoop, la memoria asignada para el sistema de archivos, el límite de memoria para almacenar datos y el tamaño de los búferes de lectura / escritura.
Abra core-site.xml y agregue la siguiente propiedad entre las etiquetas <configuration>, </configuration>:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xm
los hdfs-site.xmlEl archivo contiene información como el valor de los datos de replicación, la ruta del nodo de nombre y las rutas del nodo de datos de sus sistemas de archivos locales. Significa el lugar donde desea almacenar la infraestructura de Hadoop.
Supongamos los siguientes datos:
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este archivo y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note:En el archivo anterior, todos los valores de propiedad son definidos por el usuario. Puede realizar cambios de acuerdo con su infraestructura de Hadoop.
mapred-site.xml
Este archivo se utiliza para configurar hilo en Hadoop. Abra el archivo mapred-site.xml y agregue la siguiente propiedad entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este archivo se utiliza para especificar qué marco MapReduce estamos usando. De forma predeterminada, Hadoop contiene una plantilla de mapred-site.xml. En primer lugar, es necesario copiar el archivo demapred-site.xml.template a mapred-site.xml archivo usando el siguiente comando.
$ cp mapred-site.xml.template mapred-site.xmlAbierto mapred-site.xml y agregue las siguientes propiedades entre las etiquetas <configuration>, </configuration> en este archivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificación de la instalación de Hadoop
Los siguientes pasos se utilizan para verificar la instalación de Hadoop.
Paso 1: Configuración del nodo de nombre
Configure el nodo de nombre utilizando el comando "hdfs namenode -format" de la siguiente manera:
$ cd ~
$ hdfs namenode -formatEl resultado esperado es el siguiente:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain
1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Paso 2: verificar Hadoop dfs
El siguiente comando se usa para iniciar dfs. Este comando inicia su sistema de archivos Hadoop.
$ start-dfs.shEl resultado esperado es el siguiente:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Paso 3: Verificación del guión de hilo
El siguiente comando se utiliza para iniciar el guión de hilo. La ejecución de este comando iniciará sus demonios de hilo.
$ start-yarn.shEl resultado esperado es el siguiente:
starting yarn daemons
starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outPaso 4: Acceder a Hadoop en el navegador
El número de puerto predeterminado para acceder a hadoop es 50070. Utilice la siguiente URL para obtener los servicios de Hadoop en su navegador.
http://localhost:50070/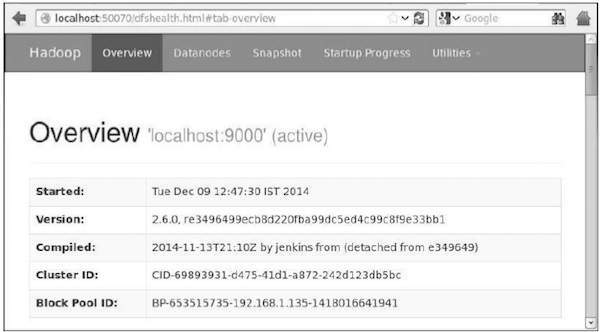
Paso 5: verificar todas las aplicaciones para el clúster
El número de puerto predeterminado para acceder a todas las aplicaciones del clúster es 8088. Utilice la siguiente URL para visitar este servicio.
http://localhost:8088/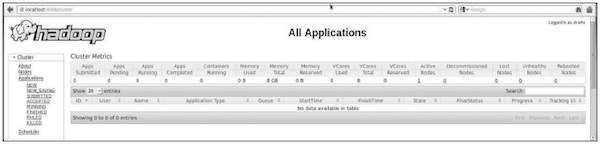
Descargando Mahout
Mahout está disponible en el sitio web Mahout . Descarga Mahout desde el enlace proporcionado en el sitio web. Aquí está la captura de pantalla del sitio web.

Paso 1
Descarga Apache mahout desde el enlace http://mirror.nexcess.net/apache/mahout/ usando el siguiente comando.
[Hadoop@localhost ~]$ wget
http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gzLuego mahout-distribution-0.9.tar.gz se descargará en su sistema.
Paso 2
Navegue por la carpeta donde mahout-distribution-0.9.tar.gz se almacena y extrae el archivo jar descargado como se muestra a continuación.
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gzRepositorio de Maven
A continuación se muestra el pom.xml para construir Apache Mahout usando Eclipse.
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>