MongoDB - Guía rápida
MongoDB es una base de datos multiplataforma orientada a documentos que proporciona alto rendimiento, alta disponibilidad y fácil escalabilidad. MongoDB trabaja en el concepto de colección y documento.
Base de datos
La base de datos es un contenedor físico para colecciones. Cada base de datos obtiene su propio conjunto de archivos en el sistema de archivos. Un solo servidor MongoDB normalmente tiene varias bases de datos.
Colección
La colección es un grupo de documentos MongoDB. Es el equivalente a una tabla RDBMS. Existe una colección dentro de una sola base de datos. Las colecciones no imponen un esquema. Los documentos de una colección pueden tener diferentes campos. Normalmente, todos los documentos de una colección tienen un propósito similar o relacionado.
Documento
Un documento es un conjunto de pares clave-valor. Los documentos tienen esquema dinámico. El esquema dinámico significa que los documentos de la misma colección no necesitan tener el mismo conjunto de campos o estructura, y los campos comunes en los documentos de una colección pueden contener diferentes tipos de datos.
La siguiente tabla muestra la relación de la terminología RDBMS con MongoDB.
| RDBMS | MongoDB |
|---|---|
| Base de datos | Base de datos |
| Mesa | Colección |
| Tupla / Fila | Documento |
| columna | Campo |
| Unión de mesa | Documentos incrustados |
| Clave primaria | Clave principal (clave predeterminada _id proporcionada por mongodb) |
| Cliente y servidor de base de datos | |
| Mysqld / Oracle | mongod |
| mysql / sqlplus | mongo |
Documento de muestra
El siguiente ejemplo muestra la estructura del documento de un sitio de blog, que es simplemente un par clave-valor separado por comas.
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}_ides un número hexadecimal de 12 bytes que asegura la unicidad de cada documento. Puede proporcionar _id al insertar el documento. Si no lo proporciona, MongoDB proporciona una identificación única para cada documento. Estos 12 bytes, los primeros 4 bytes para la marca de tiempo actual, los siguientes 3 bytes para la identificación de la máquina, los siguientes 2 bytes para la identificación del proceso del servidor MongoDB y los 3 bytes restantes son un simple VALOR incremental.
Cualquier base de datos relacional tiene un diseño de esquema típico que muestra el número de tablas y la relación entre estas tablas. Mientras que en MongoDB, no existe el concepto de relación.
Ventajas de MongoDB sobre RDBMS
Schema less- MongoDB es una base de datos de documentos en la que una colección contiene diferentes documentos. El número de campos, el contenido y el tamaño del documento pueden diferir de un documento a otro.
La estructura de un solo objeto es clara.
Sin uniones complejas.
Capacidad de consulta profunda. MongoDB admite consultas dinámicas en documentos mediante un lenguaje de consulta basado en documentos que es casi tan poderoso como SQL.
Tuning.
Ease of scale-out - MongoDB es fácil de escalar.
No se necesita conversión / mapeo de objetos de aplicación a objetos de base de datos.
Utiliza memoria interna para almacenar el conjunto de trabajo (en ventana), lo que permite un acceso más rápido a los datos.
¿Por qué utilizar MongoDB?
Document Oriented Storage - Los datos se almacenan en forma de documentos de estilo JSON.
Índice de cualquier atributo
Replicación y alta disponibilidad
Auto-sharding
Consultas enriquecidas
Actualizaciones rápidas en el lugar
Soporte profesional de MongoDB
¿Dónde usar MongoDB?
- Big Data
- Gestión y entrega de contenido
- Infraestructura móvil y social
- Gestión de datos de usuario
- Centro de datos
Veamos ahora cómo instalar MongoDB en Windows.
Instalar MongoDB en Windows
Para instalar MongoDB en Windows, primero descargue la última versión de MongoDB de https://www.mongodb.org/downloads. Asegúrese de obtener la versión correcta de MongoDB según su versión de Windows. Para obtener su versión de Windows, abra el símbolo del sistema y ejecute el siguiente comando.
C:\>wmic os get osarchitecture
OSArchitecture
64-bit
C:\>Las versiones de 32 bits de MongoDB solo admiten bases de datos de menos de 2 GB y solo son adecuadas para fines de prueba y evaluación.
Ahora extraiga el archivo descargado en c: \ drive o en cualquier otra ubicación. Asegúrese de que el nombre de la carpeta extraída sea mongodb-win32-i386- [versión] o mongodb-win32-x86_64- [versión]. Aquí [versión] es la versión de descarga de MongoDB.
A continuación, abra el símbolo del sistema y ejecute el siguiente comando.
C:\>move mongodb-win64-* mongodb
1 dir(s) moved.
C:\>En caso de que haya extraído el MongoDB en una ubicación diferente, vaya a esa ruta usando el comando cd FOLDER/DIR y ahora ejecute el proceso dado anteriormente.
MongoDB requiere una carpeta de datos para almacenar sus archivos. La ubicación predeterminada para el directorio de datos de MongoDB es c: \ data \ db. Entonces necesitas crear esta carpeta usando el símbolo del sistema. Ejecute la siguiente secuencia de comandos.
C:\>md data
C:\md data\dbSi tiene que instalar MongoDB en una ubicación diferente, debe especificar una ruta alternativa para \data\db estableciendo el camino dbpath en mongod.exe. Para lo mismo, emita los siguientes comandos.
En el símbolo del sistema, navegue hasta el directorio bin presente en la carpeta de instalación de MongoDB. Supongamos que mi carpeta de instalación esD:\set up\mongodb
C:\Users\XYZ>d:
D:\>cd "set up"
D:\set up>cd mongodb
D:\set up\mongodb>cd bin
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"Esto mostrará waiting for connections en la salida de la consola, que indica que el proceso mongod.exe se está ejecutando correctamente.
Ahora, para ejecutar MongoDB, debe abrir otro símbolo del sistema y ejecutar el siguiente comando.
D:\set up\mongodb\bin>mongo.exe
MongoDB shell version: 2.4.6
connecting to: test
>db.test.save( { a: 1 } )
>db.test.find()
{ "_id" : ObjectId(5879b0f65a56a454), "a" : 1 }
>Esto mostrará que MongoDB está instalado y se ejecuta correctamente. La próxima vez que ejecute MongoDB, solo debe emitir comandos.
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"
D:\set up\mongodb\bin>mongo.exeInstalar MongoDB en Ubuntu
Ejecute el siguiente comando para importar la clave GPG pública de MongoDB:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10Cree un archivo /etc/apt/sources.list.d/mongodb.list usando el siguiente comando.
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen'
| sudo tee /etc/apt/sources.list.d/mongodb.listAhora emita el siguiente comando para actualizar el repositorio:
sudo apt-get updateLuego instale MongoDB usando el siguiente comando:
apt-get install mongodb-10gen = 2.2.3En la instalación anterior, 2.2.3 es la versión MongoDB publicada actualmente. Asegúrese de instalar siempre la última versión. Ahora MongoDB se ha instalado correctamente.
Inicie MongoDB
sudo service mongodb startDetener MongoDB
sudo service mongodb stopReinicie MongoDB
sudo service mongodb restartPara usar MongoDB, ejecute el siguiente comando.
mongoEsto lo conectará a la ejecución de la instancia de MongoDB.
Ayuda de MongoDB
Para obtener una lista de comandos, escriba db.help()en el cliente MongoDB. Esto le dará una lista de comandos como se muestra en la siguiente captura de pantalla.

Estadísticas de MongoDB
Para obtener estadísticas sobre el servidor MongoDB, escriba el comando db.stats()en el cliente MongoDB. Esto mostrará el nombre de la base de datos, el número de colecciones y los documentos en la base de datos. La salida del comando se muestra en la siguiente captura de pantalla.

Los datos en MongoDB tienen un esquema flexible. Documentos en la misma colección. No es necesario que tengan el mismo conjunto de campos o estructura, y los campos comunes en los documentos de una colección pueden contener diferentes tipos de datos.
Algunas consideraciones al diseñar Schema en MongoDB
Diseñe su esquema de acuerdo con los requisitos del usuario.
Combine objetos en un documento si los usará juntos. De lo contrario, sepárelos (pero asegúrese de que no sea necesario unirlos).
Duplique los datos (pero limitados) porque el espacio en disco es barato en comparación con el tiempo de cálculo.
Realice uniones mientras escribe, no en lectura.
Optimice su esquema para los casos de uso más frecuentes.
Realice una agregación compleja en el esquema.
Ejemplo
Supongamos que un cliente necesita un diseño de base de datos para su blog / sitio web y ve las diferencias entre RDBMS y el diseño de esquema de MongoDB. El sitio web tiene los siguientes requisitos.
- Cada publicación tiene un título, una descripción y una URL únicos.
- Cada publicación puede tener una o más etiquetas.
- Cada publicación tiene el nombre de su editor y el número total de Me gusta.
- Cada publicación tiene comentarios proporcionados por los usuarios junto con su nombre, mensaje, tiempo de datos y me gusta.
- En cada publicación, puede haber cero o más comentarios.
En el esquema RDBMS, el diseño de los requisitos anteriores tendrá un mínimo de tres tablas.

Mientras esté en el esquema de MongoDB, el diseño tendrá una publicación de colección y la siguiente estructura:
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}Entonces, mientras muestra los datos, en RDBMS debe unir tres tablas y en MongoDB, los datos se mostrarán solo de una colección.
En este capítulo, veremos cómo crear una base de datos en MongoDB.
El comando de uso
MongoDB use DATABASE_NAMEse utiliza para crear la base de datos. El comando creará una nueva base de datos si no existe; de lo contrario, devolverá la base de datos existente.
Sintaxis
Sintaxis básica de use DATABASE declaración es la siguiente:
use DATABASE_NAMEEjemplo
Si desea utilizar una base de datos con nombre <mydb>, luego use DATABASE declaración sería la siguiente:
>use mydb
switched to db mydbPara verificar su base de datos actualmente seleccionada, use el comando db
>db
mydbSi desea verificar su lista de bases de datos, use el comando show dbs.
>show dbs
local 0.78125GB
test 0.23012GBSu base de datos creada (mydb) no está presente en la lista. Para mostrar la base de datos, debe insertar al menos un documento en ella.
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GBEn MongoDB, la base de datos predeterminada es prueba. Si no creó ninguna base de datos, las colecciones se almacenarán en la base de datos de prueba.
En este capítulo, veremos cómo soltar una base de datos usando el comando MongoDB.
El método dropDatabase ()
MongoDB db.dropDatabase() El comando se usa para eliminar una base de datos existente.
Sintaxis
Sintaxis básica de dropDatabase() El comando es el siguiente:
db.dropDatabase()Esto eliminará la base de datos seleccionada. Si no ha seleccionado ninguna base de datos, eliminará la base de datos de 'prueba' predeterminada.
Ejemplo
Primero, verifique la lista de bases de datos disponibles usando el comando, show dbs.
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
>Si desea eliminar una nueva base de datos <mydb>, luego dropDatabase() comando sería el siguiente:
>use mydb
switched to db mydb
>db.dropDatabase()
>{ "dropped" : "mydb", "ok" : 1 }
>Ahora verifique la lista de bases de datos.
>show dbs
local 0.78125GB
test 0.23012GB
>En este capítulo, veremos cómo crear una colección usando MongoDB.
El método createCollection ()
MongoDB db.createCollection(name, options) se utiliza para crear una colección.
Sintaxis
Sintaxis básica de createCollection() El comando es el siguiente:
db.createCollection(name, options)En el comando, name es el nombre de la colección que se creará. Options es un documento y se utiliza para especificar la configuración de la colección.
| Parámetro | Tipo | Descripción |
|---|---|---|
| Nombre | Cuerda | Nombre de la colección a crear |
| Opciones | Documento | (Opcional) Especifique opciones sobre el tamaño de la memoria y la indexación |
El parámetro de opciones es opcional, por lo que debe especificar solo el nombre de la colección. A continuación se muestra la lista de opciones que puede utilizar:
| Campo | Tipo | Descripción |
|---|---|---|
| tapado | Booleano | (Opcional) Si es verdadero, habilita una colección limitada. La colección limitada es una colección de tamaño fijo que sobrescribe automáticamente sus entradas más antiguas cuando alcanza su tamaño máximo.If you specify true, you need to specify size parameter also. |
| autoIndexId | Booleano | (Opcional) Si es verdadero, crea automáticamente un índice en el campo _id. El valor predeterminado es falso. |
| Talla | número | (Opcional) Especifica un tamaño máximo en bytes para una colección con límite. If capped is true, then you need to specify this field also. |
| max | número | (Opcional) Especifica el número máximo de documentos permitidos en la colección limitada. |
Al insertar el documento, MongoDB primero verifica el campo de tamaño de la colección limitada, luego verifica el campo máximo.
Ejemplos
Sintaxis básica de createCollection() El método sin opciones es el siguiente:
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>Puede verificar la colección creada usando el comando show collections.
>show collections
mycollection
system.indexesEl siguiente ejemplo muestra la sintaxis de createCollection() método con pocas opciones importantes -
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>En MongoDB, no es necesario crear una colección. MongoDB crea una colección automáticamente cuando inserta algún documento.
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>En este capítulo, veremos cómo eliminar una colección usando MongoDB.
El método drop ()
MongoDB's db.collection.drop() se utiliza para eliminar una colección de la base de datos.
Sintaxis
Sintaxis básica de drop() El comando es el siguiente:
db.COLLECTION_NAME.drop()Ejemplo
Primero, verifique las colecciones disponibles en su base de datos mydb.
>use mydb
switched to db mydb
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>Ahora suelta la colección con el nombre mycollection.
>db.mycollection.drop()
true
>Vuelva a comprobar la lista de colecciones en la base de datos.
>show collections
mycol
system.indexes
tutorialspoint
>El método drop () devolverá verdadero, si la colección seleccionada se elimina con éxito, de lo contrario, devolverá falso.
MongoDB admite muchos tipos de datos. Algunos de ellos son ...
String- Este es el tipo de datos más utilizado para almacenar los datos. La cadena en MongoDB debe ser válida para UTF-8.
Integer- Este tipo se utiliza para almacenar un valor numérico. El número entero puede ser de 32 bits o 64 bits, dependiendo de su servidor.
Boolean - Este tipo se utiliza para almacenar un valor booleano (verdadero / falso).
Double - Este tipo se utiliza para almacenar valores de coma flotante.
Min/ Max keys - Este tipo se utiliza para comparar un valor con los elementos BSON más bajos y más altos.
Arrays - Este tipo se utiliza para almacenar matrices o listas o valores múltiples en una clave.
Timestamp- marca de tiempo. Esto puede ser útil para registrar cuando se ha modificado o agregado un documento.
Object - Este tipo de datos se utiliza para documentos incrustados.
Null - Este tipo se utiliza para almacenar un valor nulo.
Symbol- Este tipo de datos se utiliza de forma idéntica a una cadena; sin embargo, generalmente está reservado para idiomas que usan un tipo de símbolo específico.
Date - Este tipo de datos se utiliza para almacenar la fecha u hora actual en formato de hora UNIX. Puede especificar su propia fecha y hora creando un objeto de Fecha y pasando día, mes y año en él.
Object ID - Este tipo de datos se utiliza para almacenar el ID del documento.
Binary data - Este tipo de datos se utiliza para almacenar datos binarios.
Code - Este tipo de datos se utiliza para almacenar código JavaScript en el documento.
Regular expression - Este tipo de datos se utiliza para almacenar expresiones regulares.
En este capítulo, aprenderemos cómo insertar un documento en la colección MongoDB.
El método insert ()
Para insertar datos en la colección de MongoDB, debe utilizar MongoDB's insert() o save() método.
Sintaxis
La sintaxis básica de insert() El comando es el siguiente:
>db.COLLECTION_NAME.insert(document)Ejemplo
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})aquí mycoles el nombre de nuestra colección, como se creó en el capítulo anterior. Si la colección no existe en la base de datos, MongoDB creará esta colección y luego insertará un documento en ella.
En el documento insertado, si no especificamos el parámetro _id, MongoDB asigna un ObjectId único para este documento.
_id es un número hexadecimal de 12 bytes único para cada documento de una colección. 12 bytes se dividen de la siguiente manera:
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id,
3 bytes incrementer)Para insertar varios documentos en una sola consulta, puede pasar una matriz de documentos en el comando insert ().
Ejemplo
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])Para insertar el documento puede utilizar db.post.save(document)además. Si no especifica_id en el documento entonces save() El método funcionará igual que insert()método. Si especifica _id, reemplazará los datos completos del documento que contiene _id como se especifica en el método save ().
En este capítulo, aprenderemos cómo consultar documentos de la colección MongoDB.
El método find ()
Para consultar datos de la colección de MongoDB, debe utilizar MongoDB's find() método.
Sintaxis
La sintaxis básica de find() El método es el siguiente:
>db.COLLECTION_NAME.find()find() El método mostrará todos los documentos de forma no estructurada.
El método pretty ()
Para mostrar los resultados de forma formateada, puede utilizar pretty() método.
Sintaxis
>db.mycol.find().pretty()Ejemplo
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>Aparte del método find (), hay findOne() método, que devuelve solo un documento.
RDBMS Equivalentes de la cláusula Where en MongoDB
Para consultar el documento sobre la base de alguna condición, puede utilizar las siguientes operaciones.
| Operación | Sintaxis | Ejemplo | Equivalente a RDBMS |
|---|---|---|---|
| Igualdad | {<clave>: <valor>} | db.mycol.find ({"por": "punto de tutoriales"}). pretty () | donde by = 'punto de tutoriales' |
| Menos que | {<clave>: {$ lt: <valor>}} | db.mycol.find ({"me gusta": {$ lt: 50}}). pretty () | donde me gusta <50 |
| Menor que igual | {<clave>: {$ lte: <valor>}} | db.mycol.find ({"me gusta": {$ lte: 50}}). pretty () | donde me gusta <= 50 |
| Mas grande que | {<clave>: {$ gt: <valor>}} | db.mycol.find ({"me gusta": {$ gt: 50}}). pretty () | donde me gusta> 50 |
| Mayor que igual | {<clave>: {$ gte: <valor>}} | db.mycol.find ({"me gusta": {$ gte: 50}}). pretty () | donde me gusta> = 50 |
| No es igual | {<clave>: {$ ne: <valor>}} | db.mycol.find ({"me gusta": {$ ne: 50}}). pretty () | donde me gusta! = 50 |
Y en MongoDB
Sintaxis
En el find() método, si pasa varias claves separándolas por ',' entonces MongoDB lo trata como ANDcondición. A continuación se muestra la sintaxis básica deAND -
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()Ejemplo
El siguiente ejemplo mostrará todos los tutoriales escritos por 'punto de tutoriales' y cuyo título es 'Descripción general de MongoDB'.
>db.mycol.find({$and:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() {
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}Para el ejemplo anterior, la cláusula where equivalente será ' where by = 'tutorials point' AND title = 'MongoDB Overview' '. Puede pasar cualquier número de pares de clave y valor en la cláusula de búsqueda.
O en MongoDB
Sintaxis
Para consultar documentos basados en la condición OR, debe usar $orpalabra clave. A continuación se muestra la sintaxis básica deOR -
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()Ejemplo
El siguiente ejemplo mostrará todos los tutoriales escritos por 'punto de tutoriales' o cuyo título es 'Descripción general de MongoDB'.
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>Usando AND y OR juntos
Ejemplo
El siguiente ejemplo mostrará los documentos que tienen gustos superiores a 10 y cuyo título es "Descripción general de MongoDB" o "punto de tutoriales". SQL equivalente donde la cláusula es'where likes>10 AND (by = 'tutorials point' OR title = 'MongoDB Overview')'
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>MongoDB's update() y save()Los métodos se utilizan para actualizar el documento en una colección. El método update () actualiza los valores en el documento existente mientras que el método save () reemplaza el documento existente con el documento pasado en el método save ().
Método de actualización de MongoDB ()
El método update () actualiza los valores en el documento existente.
Sintaxis
La sintaxis básica de update() El método es el siguiente:
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)Ejemplo
Considere que la colección mycol tiene los siguientes datos.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}El siguiente ejemplo establecerá el nuevo título 'Nuevo tutorial de MongoDB' de los documentos cuyo título es 'Descripción general de MongoDB'.
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>De forma predeterminada, MongoDB actualizará solo un documento. Para actualizar varios documentos, debe establecer un parámetro 'multi' en verdadero.
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})Método Save () de MongoDB
los save() El método reemplaza el documento existente con el nuevo documento pasado en el método save ().
Sintaxis
La sintaxis básica de MongoDB save() El método se muestra a continuación:
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})Ejemplo
El siguiente ejemplo reemplazará el documento con el _id '5983548781331adf45ec5'.
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>En este capítulo, aprenderemos cómo eliminar un documento usando MongoDB.
El método remove ()
MongoDB's remove()El método se utiliza para eliminar un documento de la colección. El método remove () acepta dos parámetros. Uno es el criterio de eliminación y el segundo es solo una bandera.
deletion criteria - Se eliminarán los criterios de eliminación (opcional) de acuerdo con los documentos.
justOne - (Opcional) si se establece en verdadero o 1, elimine solo un documento.
Sintaxis
Sintaxis básica de remove() El método es el siguiente:
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)Ejemplo
Considere que la colección mycol tiene los siguientes datos.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}El siguiente ejemplo eliminará todos los documentos cuyo título sea 'Descripción general de MongoDB'.
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>Quitar solo uno
Si hay varios registros y desea eliminar solo el primer registro, establezca justOne parámetro en remove() método.
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)Eliminar todos los documentos
Si no especifica los criterios de eliminación, MongoDB eliminará documentos completos de la colección. This is equivalent of SQL's truncate command.
>db.mycol.remove({})
>db.mycol.find()
>En MongoDB, la proyección significa seleccionar solo los datos necesarios en lugar de seleccionar todos los datos de un documento. Si un documento tiene 5 campos y necesita mostrar solo 3, seleccione solo 3 de ellos.
El método find ()
MongoDB's find(), explicado en MongoDB Query Document acepta el segundo parámetro opcional que es la lista de campos que desea recuperar. En MongoDB, cuando ejecutafind()método, luego muestra todos los campos de un documento. Para limitar esto, debe establecer una lista de campos con valor 1 o 0. Se usa 1 para mostrar el campo mientras que 0 se usa para ocultar los campos.
Sintaxis
La sintaxis básica de find() El método con proyección es el siguiente:
>db.COLLECTION_NAME.find({},{KEY:1})Ejemplo
Considere que la colección mycol tiene los siguientes datos:
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}El siguiente ejemplo mostrará el título del documento mientras consulta el documento.
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>tenga en cuenta _id El campo siempre se muestra mientras se ejecuta find() método, si no desea este campo, debe establecerlo como 0.
En este capítulo, aprenderemos cómo limitar registros usando MongoDB.
El método Limit ()
Para limitar los registros en MongoDB, debe usar limit()método. El método acepta un argumento de tipo numérico, que es el número de documentos que desea que se muestren.
Sintaxis
La sintaxis básica de limit() El método es el siguiente:
>db.COLLECTION_NAME.find().limit(NUMBER)Ejemplo
Considere la colección myycol tiene los siguientes datos.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}El siguiente ejemplo mostrará solo dos documentos al consultar el documento.
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>Si no especifica el argumento de número en limit() luego mostrará todos los documentos de la colección.
Método MongoDB Skip ()
Aparte del método limit (), hay un método más skip() que también acepta el argumento de tipo de número y se utiliza para omitir el número de documentos.
Sintaxis
La sintaxis básica de skip() El método es el siguiente:
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)Ejemplo
El siguiente ejemplo mostrará solo el segundo documento.
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>Tenga en cuenta que el valor predeterminado en skip() el método es 0.
En este capítulo, aprenderemos a ordenar registros en MongoDB.
El método sort ()
Para ordenar documentos en MongoDB, debe usar sort()método. El método acepta un documento que contiene una lista de campos junto con su orden de clasificación. Para especificar el orden de clasificación se utilizan 1 y -1. 1 se usa para orden ascendente mientras que -1 se usa para orden descendente.
Sintaxis
La sintaxis básica de sort() El método es el siguiente:
>db.COLLECTION_NAME.find().sort({KEY:1})Ejemplo
Considere la colección myycol tiene los siguientes datos.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}El siguiente ejemplo mostrará los documentos ordenados por título en orden descendente.
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
>Tenga en cuenta que si no especifica la preferencia de clasificación, sort() El método mostrará los documentos en orden ascendente.
Los índices apoyan la resolución eficiente de consultas. Sin índices, MongoDB debe escanear todos los documentos de una colección para seleccionar aquellos documentos que coincidan con la declaración de consulta. Este análisis es muy ineficaz y requiere que MongoDB procese un gran volumen de datos.
Los índices son estructuras de datos especiales que almacenan una pequeña parte del conjunto de datos en una forma fácil de recorrer. El índice almacena el valor de un campo específico o un conjunto de campos, ordenados por el valor del campo como se especifica en el índice.
El método asegurarIndex ()
Para crear un índice, debe usar el método secureIndex () de MongoDB.
Sintaxis
La sintaxis básica de ensureIndex() El método es el siguiente ().
>db.COLLECTION_NAME.ensureIndex({KEY:1})Aquí la clave es el nombre del campo en el que desea crear el índice y 1 es para el orden ascendente. Para crear un índice en orden descendente, debe usar -1.
Ejemplo
>db.mycol.ensureIndex({"title":1})
>En ensureIndex() método puede pasar varios campos, para crear un índice en varios campos.
>db.mycol.ensureIndex({"title":1,"description":-1})
>ensureIndex()El método también acepta una lista de opciones (que son opcionales). A continuación se muestra la lista:
| Parámetro | Tipo | Descripción |
|---|---|---|
| antecedentes | Booleano | Crea el índice en segundo plano para que la creación de un índice no bloquee otras actividades de la base de datos. Especifique verdadero para construir en segundo plano. El valor predeterminado esfalse. |
| único | Booleano | Crea un índice único para que la colección no acepte la inserción de documentos donde la clave o claves de índice coinciden con un valor existente en el índice. Especifique verdadero para crear un índice único. El valor predeterminado esfalse. |
| nombre | cuerda | El nombre del índice. Si no se especifica, MongoDB genera un nombre de índice concatenando los nombres de los campos indexados y el orden de clasificación. |
| dropDups | Booleano | Crea un índice único en un campo que puede tener duplicados. MongoDB indexa solo la primera aparición de una clave y elimina todos los documentos de la colección que contienen apariciones posteriores de esa clave. Especifique verdadero para crear un índice único. El valor predeterminado esfalse. |
| escaso | Booleano | Si es verdadero, el índice solo hace referencia a documentos con el campo especificado. Estos índices utilizan menos espacio pero se comportan de manera diferente en algunas situaciones (en particular, en los tipos). El valor predeterminado esfalse. |
| expireAfterSeconds | entero | Especifica un valor, en segundos, como TTL para controlar cuánto tiempo MongoDB retiene los documentos de esta colección. |
| v | versión de índice | El número de versión del índice. La versión de índice predeterminada depende de la versión de MongoDB que se esté ejecutando al crear el índice. |
| pesos | documento | El peso es un número que va de 1 a 99,999 y denota la importancia del campo en relación con los otros campos indexados en términos de puntuación. |
| idioma predeterminado | cuerda | Para un índice de texto, el idioma que determina la lista de palabras vacías y las reglas para el lematizador y el tokenizador. El valor predeterminado esenglish. |
| language_override | cuerda | Para un índice de texto, especifique el nombre del campo en el documento que contiene el idioma para reemplazar el idioma predeterminado. El valor predeterminado es el idioma. |
Las operaciones de agregaciones procesan registros de datos y devuelven resultados calculados. Las operaciones de agregación agrupan valores de varios documentos y pueden realizar una variedad de operaciones en los datos agrupados para devolver un solo resultado. En SQL count (*) y con group by es un equivalente de agregación mongodb.
El método aggregate ()
Para la agregación en MongoDB, debe usar aggregate() método.
Sintaxis
Sintaxis básica de aggregate() El método es el siguiente:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)Ejemplo
En la colección tienes los siguientes datos:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},Ahora, de la colección anterior, si desea mostrar una lista que indique cuántos tutoriales ha escrito cada usuario, utilizará lo siguiente aggregate() método -
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>La consulta equivalente a SQL para el caso de uso anterior será select by_user, count(*) from mycol group by by_user.
En el ejemplo anterior, hemos agrupado los documentos por campo. by_usery en cada ocurrencia de by_user se incrementa el valor anterior de la suma. A continuación se muestra una lista de expresiones de agregación disponibles.
| Expresión | Descripción | Ejemplo |
|---|---|---|
| $ suma | Suma el valor definido de todos los documentos de la colección. | db.mycol.aggregate ([{$ grupo: {_id: "$by_user", num_tutorial : {$suma: "$ me gusta"}}}]) |
| $ promedio | Calcula el promedio de todos los valores dados de todos los documentos de la colección. | db.mycol.aggregate ([{$group : {_id : "$por_usuario ", num_tutorial: {$avg : "$gustos"}}}]) |
| $ min | Obtiene el mínimo de los valores correspondientes de todos los documentos de la colección. | db.mycol.aggregate ([{$ grupo: {_id: "$by_user", num_tutorial : {$min: "$ me gusta"}}}]) |
| $ máx. | Obtiene el máximo de los valores correspondientes de todos los documentos de la colección. | db.mycol.aggregate ([{$group : {_id : "$por_usuario ", num_tutorial: {$max : "$gustos"}}}]) |
| $ empujar | Inserta el valor en una matriz en el documento resultante. | db.mycol.aggregate ([{$ grupo: {_id: "$by_user", url : {$empujar: "$ url"}}}]) |
| $ addToSet | Inserta el valor en una matriz en el documento resultante, pero no crea duplicados. | db.mycol.aggregate ([{$group : {_id : "$by_user ", url: {$addToSet : "$url "}}}]) |
| $ primero | Obtiene el primer documento de los documentos de origen según la agrupación. Por lo general, esto solo tiene sentido junto con alguna etapa "$ sort" aplicada previamente. | db.mycol.aggregate ([{$group : {_id : "$by_user ", first_url: {$first : "$url "}}}]) |
| $ último | Obtiene el último documento de los documentos de origen según la agrupación. Por lo general, esto solo tiene sentido junto con alguna etapa "$ sort" aplicada previamente. | db.mycol.aggregate ([{$group : {_id : "$by_user ", last_url: {$last : "$url "}}}]) |
Concepto de tubería
En el comando UNIX, la canalización de shell significa la posibilidad de ejecutar una operación en alguna entrada y usar la salida como entrada para el siguiente comando y así sucesivamente. MongoDB también admite el mismo concepto en el marco de agregación. Existe un conjunto de etapas posibles y cada una de ellas se toma como un conjunto de documentos como entrada y produce un conjunto resultante de documentos (o el documento JSON resultante final al final del proceso). Esto, a su vez, se puede utilizar para la siguiente etapa y así sucesivamente.
Las siguientes son las posibles etapas en el marco de agregación:
$project - Se utiliza para seleccionar algunos campos específicos de una colección.
$match - Esta es una operación de filtrado y, por lo tanto, puede reducir la cantidad de documentos que se dan como entrada a la siguiente etapa.
$group - Esto hace la agregación real como se discutió anteriormente.
$sort - Ordena los documentos.
$skip - Con esto, es posible saltar hacia adelante en la lista de documentos para una cantidad determinada de documentos.
$limit - Esto limita la cantidad de documentos a mirar, por el número dado a partir de las posiciones actuales.
$unwind- Se utiliza para desenrollar documentos que utilizan matrices. Cuando se usa una matriz, los datos se unen previamente y esta operación se deshará con esto para tener documentos individuales nuevamente. Así, con esta etapa aumentaremos la cantidad de documentos para la siguiente etapa.
La replicación es el proceso de sincronizar datos en varios servidores. La replicación proporciona redundancia y aumenta la disponibilidad de datos con múltiples copias de datos en diferentes servidores de bases de datos. La replicación protege una base de datos de la pérdida de un solo servidor. La replicación también le permite recuperarse de fallas de hardware e interrupciones del servicio. Con copias adicionales de los datos, puede dedicar una a la recuperación de desastres, generación de informes o respaldo.
¿Por qué la replicación?
- Para mantener sus datos seguros
- Alta disponibilidad de datos (24 * 7)
- Recuperación de desastres
- Sin tiempo de inactividad por mantenimiento (como copias de seguridad, reconstrucciones de índices, compactación)
- Escala de lectura (copias adicionales para leer)
- El conjunto de réplicas es transparente para la aplicación
Cómo funciona la replicación en MongoDB
MongoDB logra la replicación mediante el uso de un conjunto de réplicas. Un conjunto de réplicas es un grupo demongodinstancias que alojan el mismo conjunto de datos. En una réplica, un nodo es el nodo principal que recibe todas las operaciones de escritura. Todas las demás instancias, como las secundarias, aplican operaciones desde la primaria para que tengan el mismo conjunto de datos. El conjunto de réplicas solo puede tener un nodo principal.
El conjunto de réplicas es un grupo de dos o más nodos (generalmente se requiere un mínimo de 3 nodos).
En un conjunto de réplicas, un nodo es el nodo principal y los nodos restantes son secundarios.
Todos los datos se replican del nodo primario al secundario.
En el momento de la conmutación por error automática o el mantenimiento, se establece la elección para el nodo primario y se elige un nuevo nodo primario.
Después de la recuperación del nodo fallido, vuelve a unirse al conjunto de réplicas y funciona como nodo secundario.
Se muestra un diagrama típico de la replicación de MongoDB en el que la aplicación cliente siempre interactúa con el nodo principal y el nodo principal luego replica los datos en los nodos secundarios.

Funciones del conjunto de réplicas
- Un grupo de N nodos
- Cualquier nodo puede ser primario
- Todas las operaciones de escritura van al primario
- Conmutación por error automática
- Recuperación automática
- Elección de consenso de primarias
Configurar un conjunto de réplicas
En este tutorial, convertiremos una instancia de MongoDB independiente en un conjunto de réplicas. Para convertir a un conjunto de réplicas, los siguientes son los pasos:
Apague el servidor MongoDB que ya está ejecutando.
Inicie el servidor MongoDB especificando la opción - replSet. A continuación se muestra la sintaxis básica de --replSet -
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"Ejemplo
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0Comenzará una instancia mongod con el nombre rs0, en el puerto 27017.
Ahora inicie el símbolo del sistema y conéctese a esta instancia de mongod.
En el cliente Mongo, emita el comando rs.initiate() para iniciar un nuevo conjunto de réplicas.
Para verificar la configuración del conjunto de réplicas, emita el comando rs.conf(). Para comprobar el estado del conjunto de réplicas, emita el comandors.status().
Agregar miembros al conjunto de réplicas
Para agregar miembros al conjunto de réplicas, inicie instancias de mongod en varias máquinas. Ahora inicie un cliente mongo y emita un comandors.add().
Sintaxis
La sintaxis básica de rs.add() El comando es el siguiente:
>rs.add(HOST_NAME:PORT)Ejemplo
Suponga que el nombre de su instancia mongod es mongod1.net y se está ejecutando en el puerto 27017. Para agregar esta instancia al conjunto de réplicas, emita el comandors.add() en el cliente Mongo.
>rs.add("mongod1.net:27017")
>Puede agregar una instancia de mongod al conjunto de réplicas solo cuando esté conectado al nodo principal. Para verificar si está conectado al primario o no, emita el comandodb.isMaster() en cliente mongo.
Sharding es el proceso de almacenar registros de datos en múltiples máquinas y es el enfoque de MongoDB para satisfacer las demandas del crecimiento de datos. A medida que aumenta el tamaño de los datos, es posible que una sola máquina no sea suficiente para almacenar los datos ni proporcionar un rendimiento de lectura y escritura aceptable. La fragmentación resuelve el problema de la escala horizontal. Con la fragmentación, agrega más máquinas para respaldar el crecimiento de datos y las demandas de las operaciones de lectura y escritura.
¿Por qué Sharding?
- En la replicación, todas las escrituras van al nodo maestro
- Las consultas sensibles a la latencia aún van a master
- El conjunto de réplicas único tiene una limitación de 12 nodos
- La memoria no puede ser lo suficientemente grande cuando el conjunto de datos activo es grande
- El disco local no es lo suficientemente grande
- El escalado vertical es demasiado caro
Fragmentación en MongoDB
El siguiente diagrama muestra la fragmentación en MongoDB mediante un clúster fragmentado.

En el siguiente diagrama, hay tres componentes principales:
Shards- Los fragmentos se utilizan para almacenar datos. Proporcionan alta disponibilidad y consistencia de datos. En el entorno de producción, cada fragmento es un conjunto de réplicas independiente.
Config Servers- Los servidores de configuración almacenan los metadatos del clúster. Estos datos contienen una asignación del conjunto de datos del clúster a los fragmentos. El enrutador de consultas usa estos metadatos para orientar operaciones a fragmentos específicos. En el entorno de producción, los clústeres fragmentados tienen exactamente 3 servidores de configuración.
Query Routers- Los enrutadores de consultas son básicamente instancias de mongo, interactúan con las aplicaciones cliente y dirigen las operaciones al fragmento apropiado. El enrutador de consultas procesa y dirige las operaciones a fragmentos y luego devuelve los resultados a los clientes. Un clúster fragmentado puede contener más de un enrutador de consultas para dividir la carga de solicitudes del cliente. Un cliente envía solicitudes a un enrutador de consultas. Generalmente, un clúster fragmentado tiene muchos enrutadores de consultas.
En este capítulo, veremos cómo crear una copia de seguridad en MongoDB.
Volcar datos de MongoDB
Para crear una copia de seguridad de la base de datos en MongoDB, debe usar mongodumpmando. Este comando volcará todos los datos de su servidor en el directorio de volcado. Hay muchas opciones disponibles mediante las cuales puede limitar la cantidad de datos o crear una copia de seguridad de su servidor remoto.
Sintaxis
La sintaxis básica de mongodump El comando es el siguiente:
>mongodumpEjemplo
Inicie su servidor mongod. Suponiendo que su servidor mongod se está ejecutando en el localhost y el puerto 27017, abra un símbolo del sistema y vaya al directorio bin de su instancia de mongodb y escriba el comandomongodump
Considere que la colección mycol tiene los siguientes datos.
>mongodumpEl comando se conectará al servidor que se ejecuta en 127.0.0.1 y puerto 27017 y volver todos los datos del servidor al directorio /bin/dump/. A continuación se muestra la salida del comando:

A continuación se muestra una lista de opciones disponibles que se pueden utilizar con el mongodump mando.
| Sintaxis | Descripción | Ejemplo |
|---|---|---|
| mongodump --host HOST_NAME --port PORT_NUMBER | Este comando hará una copia de seguridad de todas las bases de datos de la instancia mongod especificada. | mongodump --host tutorialspoint.com --port 27017 |
| mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY | Este comando respaldará solo la base de datos especificada en la ruta especificada. | mongodump --dbpath / data / db / --out / data / backup / |
| mongodump --collection COLLECTION --db DB_NAME | Este comando respaldará solo la colección especificada de la base de datos especificada. | mongodump --collection mycol --db test |
Restaurar datos
Para restaurar los datos de respaldo de MongoDB mongorestorese utiliza el comando. Este comando restaura todos los datos del directorio de respaldo.
Sintaxis
La sintaxis básica de mongorestore el comando es -
>mongorestoreA continuación se muestra la salida del comando:

Cuando esté preparando una implementación de MongoDB, debe intentar comprender cómo su aplicación se mantendrá en producción. Es una buena idea desarrollar un enfoque coherente y repetible para administrar su entorno de implementación para que pueda minimizar las sorpresas una vez que esté en producción.
El mejor enfoque incorpora la creación de prototipos de su configuración, la realización de pruebas de carga, el monitoreo de métricas clave y el uso de esa información para escalar su configuración. La parte clave del enfoque es monitorear de manera proactiva todo su sistema; esto lo ayudará a comprender cómo se mantendrá su sistema de producción antes de la implementación y determinar dónde deberá agregar capacidad. Tener una idea de los posibles picos en el uso de la memoria, por ejemplo, podría ayudar a apagar un incendio de bloqueo de escritura antes de que comience.
Para monitorear su implementación, MongoDB proporciona algunos de los siguientes comandos:
mongostato
Este comando verifica el estado de todas las instancias de mongod en ejecución y devuelve los contadores de las operaciones de la base de datos. Estos contadores incluyen inserciones, consultas, actualizaciones, eliminaciones y cursores. El comando también muestra cuándo está alcanzando fallas de página y muestra su porcentaje de bloqueo. Esto significa que se está quedando sin memoria, agota la capacidad de escritura o tiene algún problema de rendimiento.
Para ejecutar el comando, inicie su instancia de mongod. En otro símbolo del sistema, vaya abin directorio de su instalación de mongodb y escriba mongostat.
D:\set up\mongodb\bin>mongostatA continuación se muestra la salida del comando:

mongotop
Este comando rastrea e informa la actividad de lectura y escritura de la instancia de MongoDB por colección. Por defecto,mongotopdevuelve información en cada segundo, que puede cambiar en consecuencia. Debe verificar que esta actividad de lectura y escritura coincida con la intención de su aplicación, y que no esté enviando demasiadas escrituras a la base de datos a la vez, leyendo con demasiada frecuencia desde un disco o superando el tamaño de su conjunto de trabajo.
Para ejecutar el comando, inicie su instancia de mongod. En otro símbolo del sistema, vaya abin directorio de su instalación de mongodb y escriba mongotop.
D:\set up\mongodb\bin>mongotopA continuación se muestra la salida del comando:
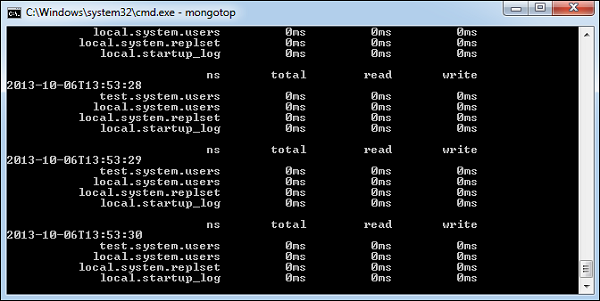
Cambiar mongotop comando para devolver información con menos frecuencia, especifique un número específico después del comando mongotop.
D:\set up\mongodb\bin>mongotop 30El ejemplo anterior devolverá valores cada 30 segundos.
Además de las herramientas de MongoDB, 10gen proporciona un servicio de monitoreo alojado gratuito, MongoDB Management Service (MMS), que proporciona un panel y le brinda una vista de las métricas de todo su clúster.
En este capítulo, aprenderemos cómo configurar el controlador JDBC de MongoDB.
Instalación
Antes de comenzar a usar MongoDB en sus programas Java, debe asegurarse de tener el controlador JDBC de MongoDB y Java configurado en la máquina. Puede consultar el tutorial de Java para la instalación de Java en su máquina. Ahora, veamos cómo configurar el controlador JDBC de MongoDB.
Necesita descargar el jar desde la ruta Descargar mongo.jar . Asegúrate de descargar la última versión.
Necesita incluir el mongo.jar en su classpath.
Conectarse a la base de datos
Para conectar la base de datos, debe especificar el nombre de la base de datos, si la base de datos no existe, MongoDB la crea automáticamente.
A continuación se muestra el fragmento de código para conectarse a la base de datos:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Credentials ::"+ credential);
}
}Ahora, compilemos y ejecutemos el programa anterior para crear nuestra base de datos myDb como se muestra a continuación.
$javac ConnectToDB.java
$java ConnectToDBAl ejecutarse, el programa anterior le da la siguiente salida.
Connected to the database successfully
Credentials ::MongoCredential{
mechanism = null,
userName = 'sampleUser',
source = 'myDb',
password = <hidden>,
mechanismProperties = {}
}Crear una colección
Para crear una colección, createCollection() método de com.mongodb.client.MongoDatabase se utiliza la clase.
A continuación se muestra el fragmento de código para crear una colección:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class CreatingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
//Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
//Creating a collection
database.createCollection("sampleCollection");
System.out.println("Collection created successfully");
}
}Al compilar, el programa anterior le da el siguiente resultado:
Connected to the database successfully
Collection created successfullyObtener / seleccionar una colección
Para obtener / seleccionar una colección de la base de datos, getCollection() método de com.mongodb.client.MongoDatabase se utiliza la clase.
A continuación se muestra el programa para obtener / seleccionar una colección:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class selectingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collection created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("myCollection");
System.out.println("Collection myCollection selected successfully");
}
}Al compilar, el programa anterior le da el siguiente resultado:
Connected to the database successfully
Collection created successfully
Collection myCollection selected successfullyInsertar un documento
Para insertar un documento en MongoDB, insert() método de com.mongodb.client.MongoCollection se utiliza la clase.
A continuación se muestra el fragmento de código para insertar un documento:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class InsertingDocument {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
Document document = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "http://www.tutorialspoint.com/mongodb/")
.append("by", "tutorials point");
collection.insertOne(document);
System.out.println("Document inserted successfully");
}
}Al compilar, el programa anterior le da el siguiente resultado:
Connected to the database successfully
Collection sampleCollection selected successfully
Document inserted successfullyRecuperar todos los documentos
Para seleccionar todos los documentos de la colección, find() método de com.mongodb.client.MongoCollectionse utiliza la clase. Este método devuelve un cursor, por lo que debe iterar este cursor.
A continuación se muestra el programa para seleccionar todos los documentos:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class RetrievingAllDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}Al compilar, el programa anterior le da el siguiente resultado:
Document{{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 100,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}
Document{{
_id = 7452239959673a32646baab8,
title = RethinkDB,
id = 2,
description = database,
likes = 200,
url = http://www.tutorialspoint.com/rethinkdb/, by = tutorials point
}}Actualizar documento
Para actualizar un documento de la colección, updateOne() método de com.mongodb.client.MongoCollection se utiliza la clase.
A continuación se muestra el programa para seleccionar el primer documento:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class UpdatingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection myCollection selected successfully");
collection.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}Al compilar, el programa anterior le da el siguiente resultado:
Document update successfully...
Document {{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 150,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}Eliminar un documento
Para eliminar un documento de la colección, debe utilizar el deleteOne() método del com.mongodb.client.MongoCollection clase.
A continuación se muestra el programa para eliminar un documento:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DeletingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Deleting the documents
collection.deleteOne(Filters.eq("id", 1));
System.out.println("Document deleted successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(it.next());
i++;
}
}
}Al compilar, el programa anterior le da el siguiente resultado:
Connected to the database successfully
Collection sampleCollection selected successfully
Document deleted successfully...Dejar caer una colección
Para eliminar una colección de una base de datos, debe utilizar el drop() método del com.mongodb.client.MongoCollection clase.
A continuación se muestra el programa para eliminar una colección:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collections created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping a Collection
collection.drop();
System.out.println("Collection dropped successfully");
}
}Al compilar, el programa anterior le da el siguiente resultado:
Connected to the database successfully
Collection sampleCollection selected successfully
Collection dropped successfullyListado de todas las colecciones
Para enumerar todas las colecciones en una base de datos, debe usar el listCollectionNames() método del com.mongodb.client.MongoDatabase clase.
A continuación se muestra el programa para enumerar todas las colecciones de una base de datos:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ListOfCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Collection created successfully");
for (String name : database.listCollectionNames()) {
System.out.println(name);
}
}
}Al compilar, el programa anterior le da el siguiente resultado:
Connected to the database successfully
Collection created successfully
myCollection
myCollection1
myCollection5Métodos restantes de MongoDB save(), limit(), skip(), sort() etc. funcionan igual que se explica en el tutorial siguiente.
Para usar MongoDB con PHP, debe usar el controlador PHP de MongoDB. Descargue el controlador de la URL Descargar controlador PHP . Asegúrate de descargar la última versión. Ahora descomprima el archivo y coloque php_mongo.dll en su directorio de extensión PHP ("ext" por defecto) y agregue la siguiente línea a su archivo php.ini -
extension = php_mongo.dllRealizar una conexión y seleccionar una base de datos
Para realizar una conexión, debe especificar el nombre de la base de datos, si la base de datos no existe, MongoDB la crea automáticamente.
A continuación se muestra el fragmento de código para conectarse a la base de datos:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
?>Cuando se ejecuta el programa, producirá el siguiente resultado:
Connection to database successfully
Database mydb selectedCrear una colección
A continuación se muestra el fragmento de código para crear una colección:
<?php
// connect to mongodb
$m = new MongoClient(); echo "Connection to database successfully"; // select a database $db = $m->mydb; echo "Database mydb selected"; $collection = $db->createCollection("mycol");
echo "Collection created succsessfully";
?>Cuando se ejecuta el programa, producirá el siguiente resultado:
Connection to database successfully
Database mydb selected
Collection created succsessfullyInsertar un documento
Para insertar un documento en MongoDB, insert() se utiliza el método.
A continuación se muestra el fragmento de código para insertar un documento:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$document = array( "title" => "MongoDB", "description" => "database", "likes" => 100, "url" => "http://www.tutorialspoint.com/mongodb/", "by" => "tutorials point" ); $collection->insert($document);
echo "Document inserted successfully";
?>Cuando se ejecuta el programa, producirá el siguiente resultado:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document inserted successfullyBuscar todos los documentos
Para seleccionar todos los documentos de la colección, se utiliza el método find ().
A continuación se muestra el fragmento de código para seleccionar todos los documentos:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$cursor = $collection->find();
// iterate cursor to display title of documents
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>Cuando se ejecuta el programa, producirá el siguiente resultado:
Connection to database successfully
Database mydb selected
Collection selected succsessfully {
"title": "MongoDB"
}Actualizar un documento
Para actualizar un documento, debe utilizar el método update ().
En el siguiente ejemplo, actualizaremos el título del documento insertado a MongoDB Tutorial. A continuación se muestra el fragmento de código para actualizar un documento:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now update the document
$collection->update(array("title"=>"MongoDB"), array('$set'=>array("title"=>"MongoDB Tutorial")));
echo "Document updated successfully";
// now display the updated document
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>Cuando se ejecuta el programa, producirá el siguiente resultado:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document updated successfully
Updated document {
"title": "MongoDB Tutorial"
}Eliminar un documento
Para eliminar un documento, debe utilizar el método remove ().
En el siguiente ejemplo, eliminaremos los documentos que tienen el título MongoDB Tutorial. A continuación se muestra el fragmento de código para eliminar un documento:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now remove the document
$collection->remove(array("title"=>"MongoDB Tutorial"),false); echo "Documents deleted successfully"; // now display the available documents $cursor = $collection->find(); // iterate cursor to display title of documents echo "Updated document"; foreach ($cursor as $document) { echo $document["title"] . "\n";
}
?>Cuando se ejecuta el programa, producirá el siguiente resultado:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Documents deleted successfullyEn el ejemplo anterior, el segundo parámetro es de tipo booleano y se utiliza para justOne campo de remove() método.
Métodos restantes de MongoDB findOne(), save(), limit(), skip(), sort() etc. funciona igual que se explicó anteriormente.
Las relaciones en MongoDB representan cómo varios documentos se relacionan lógicamente entre sí. Las relaciones se pueden modelar medianteEmbedded y Referencedenfoques. Tales relaciones pueden ser 1: 1, 1: N, N: 1 o N: N.
Consideremos el caso de almacenar direcciones para usuarios. Por lo tanto, un usuario puede tener varias direcciones, lo que hace que esta sea una relación 1: N.
A continuación se muestra la estructura del documento de muestra de user documento -
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"name": "Tom Hanks",
"contact": "987654321",
"dob": "01-01-1991"
}A continuación se muestra la estructura del documento de muestra de address documento -
{
"_id":ObjectId("52ffc4a5d85242602e000000"),
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
}Modelado de relaciones incrustadas
En el enfoque integrado, integraremos el documento de dirección dentro del documento del usuario.
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}Este enfoque mantiene todos los datos relacionados en un solo documento, lo que facilita su recuperación y mantenimiento. El documento completo se puede recuperar en una sola consulta, como:
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})Tenga en cuenta que en la consulta anterior, db y users son la base de datos y la colección respectivamente.
El inconveniente es que si el documento incrustado sigue creciendo demasiado, puede afectar el rendimiento de lectura / escritura.
Modelado de relaciones referenciadas
Este es el enfoque para diseñar una relación normalizada. En este enfoque, tanto los documentos de usuario como los de dirección se mantendrán por separado, pero el documento de usuario contendrá un campo que hará referencia al documento de dirección.id campo.
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}Como se muestra arriba, el documento de usuario contiene el campo de matriz address_idsque contiene ObjectIds de las direcciones correspondientes. Usando estos ObjectIds, podemos consultar los documentos de dirección y obtener detalles de la dirección desde allí. Con este enfoque, necesitaremos dos consultas: primero para obtener eladdress_ids campos de user documento y segundo para obtener estas direcciones de address colección.
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})Como se vio en el último capítulo de las relaciones de MongoDB, para implementar una estructura de base de datos normalizada en MongoDB, usamos el concepto de Referenced Relationships también conocido como Manual Referencesen el que almacenamos manualmente la identificación del documento referenciado dentro de otro documento. Sin embargo, en los casos en que un documento contiene referencias de diferentes colecciones, podemos usarMongoDB DBRefs.
DBRefs vs referencias manuales
Como escenario de ejemplo, donde usaríamos DBRefs en lugar de referencias manuales, considere una base de datos donde estamos almacenando diferentes tipos de direcciones (hogar, oficina, correo, etc.) en diferentes colecciones (address_home, address_office, address_mailing, etc.). Ahora, cuando unuserEl documento de la colección hace referencia a una dirección, también debe especificar qué colección buscar en función del tipo de dirección. En tales escenarios donde un documento hace referencia a documentos de muchas colecciones, deberíamos usar DBRefs.
Usando DBRefs
Hay tres campos en DBRefs:
$ref - Este campo especifica la colección del documento referenciado.
$id - Este campo especifica el campo _id del documento referenciado
$db - Este es un campo opcional y contiene el nombre de la base de datos en la que se encuentra el documento referenciado.
Considere un documento de usuario de muestra con un campo DBRef address como se muestra en el fragmento de código -
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home", "$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}los address El campo DBRef aquí especifica que el documento de dirección referenciado se encuentra en address_home colección bajo tutorialspoint base de datos y tiene una identificación de 534009e4d852427820000002.
El siguiente código busca dinámicamente en la colección especificada por $ref parámetro (address_home en nuestro caso) para un documento con id según lo especificado por $id parámetro en DBRef.
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})El código anterior devuelve el siguiente documento de dirección presente en address_home colección -
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}En este capítulo, aprenderemos acerca de las consultas cubiertas.
¿Qué es una consulta cubierta?
Según la documentación oficial de MongoDB, una consulta cubierta es una consulta en la que:
- Todos los campos de la consulta forman parte de un índice.
- Todos los campos devueltos en la consulta están en el mismo índice.
Dado que todos los campos presentes en la consulta son parte de un índice, MongoDB coincide con las condiciones de la consulta y devuelve el resultado utilizando el mismo índice sin mirar dentro de los documentos. Dado que los índices están presentes en la RAM, la obtención de datos de índices es mucho más rápida en comparación con la obtención de datos mediante el escaneo de documentos.
Usar consultas cubiertas
Para probar las consultas cubiertas, considere el siguiente documento en el users colección -
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}Primero crearemos un índice compuesto para el users colección en los campos gender y user_name usando la siguiente consulta -
>db.users.ensureIndex({gender:1,user_name:1})Ahora, este índice cubrirá la siguiente consulta:
>db.users.find({gender:"M"},{user_name:1,_id:0})Es decir, para la consulta anterior, MongoDB no buscaría documentos de base de datos. En su lugar, obtendría los datos necesarios de los datos indexados, lo que es muy rápido.
Dado que nuestro índice no incluye _id, lo hemos excluido explícitamente del conjunto de resultados de nuestra consulta, ya que MongoDB de forma predeterminada devuelve el campo _id en cada consulta. Por lo tanto, la siguiente consulta no se habría cubierto dentro del índice creado anteriormente:
>db.users.find({gender:"M"},{user_name:1})Por último, recuerde que un índice no puede cubrir una consulta si:
- Cualquiera de los campos indexados es una matriz
- Cualquiera de los campos indexados es un subdocumento
El análisis de consultas es un aspecto muy importante para medir la eficacia de la base de datos y el diseño de indexación. Aprenderemos sobre los de uso frecuente$explain y $hint consultas.
Usando $ explicar
los $explainEl operador proporciona información sobre la consulta, los índices utilizados en una consulta y otras estadísticas. Es muy útil al analizar qué tan bien están optimizados sus índices.
En el último capítulo, ya habíamos creado un índice para el users colección en campos gender y user_name usando la siguiente consulta -
>db.users.ensureIndex({gender:1,user_name:1})Ahora usaremos $explain en la siguiente consulta:
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()La consulta explica () anterior devuelve el siguiente resultado analizado:
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1 }, { "$maxElement" : 1
}
]
]
}
}Ahora veremos los campos en este conjunto de resultados:
El verdadero valor de indexOnly indica que esta consulta ha utilizado la indexación.
los cursorcampo especifica el tipo de cursor utilizado. El tipo BTreeCursor indica que se utilizó un índice y también da el nombre del índice utilizado. BasicCursor indica que se realizó un análisis completo sin utilizar ningún índice.
n indica el número de documentos que coinciden devueltos.
nscannedObjects indica el número total de documentos escaneados.
nscanned indica el número total de documentos o entradas de índice escaneados.
Usando $ hint
los $hintEl operador obliga al optimizador de consultas a utilizar el índice especificado para ejecutar una consulta. Esto es particularmente útil cuando desea probar el rendimiento de una consulta con diferentes índices. Por ejemplo, la siguiente consulta especifica el índice en los camposgender y user_name que se utilizará para esta consulta:
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})Para analizar la consulta anterior usando $ explicar:
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()Datos del modelo para operaciones atómicas
El enfoque recomendado para mantener la atomicidad sería mantener toda la información relacionada, que con frecuencia se actualiza junta en un solo documento utilizando embedded documents. Esto aseguraría que todas las actualizaciones de un solo documento sean atómicas.
Considere el siguiente documento de productos:
{
"_id":1,
"product_name": "Samsung S3",
"category": "mobiles",
"product_total": 5,
"product_available": 3,
"product_bought_by": [
{
"customer": "john",
"date": "7-Jan-2014"
},
{
"customer": "mark",
"date": "8-Jan-2014"
}
]
}En este documento, hemos incorporado la información del cliente que compra el producto en el product_bought_bycampo. Ahora, siempre que un nuevo cliente compre el producto, primero verificaremos si el producto todavía está disponible usandoproduct_availablecampo. Si está disponible, reduciremos el valor del campo product_available así como insertaremos el documento incrustado del nuevo cliente en el campo product_bought_by. UsaremosfindAndModify comando para esta funcionalidad porque busca y actualiza el documento al mismo tiempo.
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1}, $push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})Nuestro enfoque de documento incrustado y el uso de la consulta findAndModify asegura que la información de compra del producto se actualice solo si el producto está disponible. Y toda esta transacción, al estar en la misma consulta, es atómica.
En contraste con esto, considere el escenario en el que podríamos haber mantenido la disponibilidad del producto y la información sobre quién compró el producto, por separado. En este caso, primero comprobaremos si el producto está disponible mediante la primera consulta. Luego en la segunda consulta actualizaremos la información de compra. Sin embargo, es posible que entre las ejecuciones de estas dos consultas, algún otro usuario haya comprado el producto y ya no esté disponible. Sin saber esto, nuestra segunda consulta actualizará la información de compra en función del resultado de nuestra primera consulta. Esto hará que la base de datos sea inconsistente porque hemos vendido un producto que no está disponible.
Considere el siguiente documento del users colección -
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}El documento anterior contiene un address sub-document y un tags array.
Campos de matriz de indexación
Supongamos que queremos buscar documentos de usuario en función de las etiquetas del usuario. Para esto, crearemos un índice en la matriz de etiquetas en la colección.
La creación de un índice en una matriz a su vez crea entradas de índice separadas para cada uno de sus campos. Entonces, en nuestro caso, cuando creamos un índice en una matriz de etiquetas, se crearán índices separados para sus valores música, cricket y blogs.
Para crear un índice en una matriz de etiquetas, use el siguiente código:
>db.users.ensureIndex({"tags":1})Después de crear el índice, podemos buscar en el campo de etiquetas de la colección de esta manera:
>db.users.find({tags:"cricket"})Para verificar que se utiliza la indexación adecuada, utilice lo siguiente explain comando -
>db.users.find({tags:"cricket"}).explain()El comando anterior resultó en "cursor": "BtreeCursor tags_1" que confirma que se utiliza la indexación adecuada.
Indexación de campos de subdocumentos
Supongamos que queremos buscar documentos basados en campos de ciudad, estado y código PIN. Dado que todos estos campos son parte del campo del subdocumento de dirección, crearemos un índice en todos los campos del subdocumento.
Para crear un índice en los tres campos del subdocumento, use el siguiente código:
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})Una vez creado el índice, podemos buscar cualquiera de los campos del subdocumento utilizando este índice de la siguiente manera:
>db.users.find({"address.city":"Los Angeles"})Recuerde que la expresión de la consulta debe seguir el orden del índice especificado. Entonces, el índice creado anteriormente admitiría las siguientes consultas:
>db.users.find({"address.city":"Los Angeles","address.state":"California"})También admitirá la siguiente consulta:
>db.users.find({"address.city":"LosAngeles","address.state":"California",
"address.pincode":"123"})En este capítulo, aprenderemos sobre las limitaciones de indexación y sus otros componentes.
Sobrecarga adicional
Cada índice ocupa algo de espacio y provoca una sobrecarga en cada inserción, actualización y eliminación. Entonces, si rara vez usa su colección para operaciones de lectura, tiene sentido no usar índices.
Uso de RAM
Dado que los índices se almacenan en la RAM, debe asegurarse de que el tamaño total del índice no exceda el límite de RAM. Si el tamaño total aumenta el tamaño de la RAM, comenzará a eliminar algunos índices, lo que provocará una pérdida de rendimiento.
Limitaciones de consultas
La indexación no se puede utilizar en consultas que utilizan:
- Expresiones regulares u operadores de negación como $nin, $no, etc.
- Operadores aritméticos como $ mod, etc.
- $ where cláusula
Por lo tanto, siempre es recomendable verificar el uso del índice para sus consultas.
Límites de claves de índice
A partir de la versión 2.6, MongoDB no creará un índice si el valor del campo de índice existente excede el límite de la clave del índice.
Inserción de documentos que superan el límite de claves de índice
MongoDB no insertará ningún documento en una colección indexada si el valor del campo indexado de este documento excede el límite de la clave de índice. Lo mismo ocurre con las utilidades mongorestore y mongoimport.
Rangos máximos
- Una colección no puede tener más de 64 índices.
- La longitud del nombre del índice no puede superar los 125 caracteres.
- Un índice compuesto puede tener un máximo de 31 campos indexados.
Hemos estado usando Id. De objeto de MongoDB en todos los capítulos anteriores. En este capítulo, entenderemos la estructura de ObjectId.
Un ObjectId es un tipo BSON de 12 bytes que tiene la siguiente estructura:
- Los primeros 4 bytes que representan los segundos desde la época de Unix
- Los siguientes 3 bytes son el identificador de la máquina
- Los siguientes 2 bytes constan de process id
- Los últimos 3 bytes son un valor de contador aleatorio
MongoDB usa ObjectIds como el valor predeterminado de _idcampo de cada documento, que se genera durante la creación de cualquier documento. La compleja combinación de ObjectId hace que todos los campos _id sean únicos.
Creando un nuevo ObjectId
Para generar un nuevo ObjectId, use el siguiente código:
>newObjectId = ObjectId()La declaración anterior devolvió la siguiente identificación generada de forma única:
ObjectId("5349b4ddd2781d08c09890f3")En lugar de que MongoDB genere el ObjectId, también puede proporcionar una identificación de 12 bytes:
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")Creación de marca de tiempo de un documento
Dado que el _id ObjectId almacena de forma predeterminada la marca de tiempo de 4 bytes, en la mayoría de los casos no es necesario almacenar la hora de creación de ningún documento. Puede obtener la hora de creación de un documento utilizando el método getTimestamp -
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()Esto devolverá la hora de creación de este documento en formato de fecha ISO -
ISODate("2014-04-12T21:49:17Z")Conversión de ObjectId en cadena
En algunos casos, es posible que necesite el valor de ObjectId en un formato de cadena. Para convertir el ObjectId en una cadena, use el siguiente código:
>newObjectId.strEl código anterior devolverá el formato de cadena del Guid -
5349b4ddd2781d08c09890f3Según la documentación de MongoDB, Map-reducees un paradigma de procesamiento de datos para condensar grandes volúmenes de datos en resultados agregados útiles. Usos de MongoDBmapReducecomando para operaciones de reducción de mapas. MapReduce se utiliza generalmente para procesar grandes conjuntos de datos.
Comando MapReduce
A continuación se muestra la sintaxis del comando mapReduce básico:
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)La función map-reduce primero consulta la colección, luego asigna los documentos de resultado para emitir pares clave-valor, que luego se reduce en función de las claves que tienen múltiples valores.
En la sintaxis anterior:
map es una función de javascript que asigna un valor con una clave y emite un par clave-valor
reduce es una función javascript que reduce o agrupa todos los documentos que tienen la misma clave
out especifica la ubicación del resultado de la consulta de reducción de mapa
query especifica los criterios de selección opcionales para seleccionar documentos
sort especifica los criterios de clasificación opcionales
limit especifica el número máximo opcional de documentos a devolver
Usando MapReduce
Considere la siguiente estructura de documento que almacena publicaciones de usuarios. El documento almacena el nombre de usuario del usuario y el estado de la publicación.
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}Ahora, usaremos una función mapReduce en nuestro posts colección para seleccionar todas las publicaciones activas, agruparlas sobre la base de user_name y luego contar el número de publicaciones de cada usuario usando el siguiente código:
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
)La consulta de mapReduce anterior genera el siguiente resultado:
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}El resultado muestra que un total de 4 documentos coincidieron con la consulta (estado: "activo"), la función de mapa emitió 4 documentos con pares clave-valor y, finalmente, la función reducir agrupó los documentos mapeados que tienen las mismas claves en 2.
Para ver el resultado de esta consulta mapReduce, use el operador de búsqueda -
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
).find()La consulta anterior da el siguiente resultado que indica que ambos usuarios tom y mark tener dos publicaciones en estados activos -
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }De manera similar, las consultas de MapReduce se pueden utilizar para construir consultas de agregación complejas de gran tamaño. El uso de funciones personalizadas de Javascript hace uso de MapReduce, que es muy flexible y potente.
A partir de la versión 2.4, MongoDB comenzó a admitir índices de texto para buscar dentro del contenido de la cadena. losText Search utiliza técnicas de derivación para buscar palabras específicas en los campos de cadena eliminando palabras vacías derivadas como a, an, the, etc. En la actualidad, MongoDB admite alrededor de 15 idiomas.
Habilitar la búsqueda de texto
Inicialmente, la búsqueda de texto era una función experimental, pero a partir de la versión 2.6, la configuración está habilitada de forma predeterminada. Pero si está utilizando la versión anterior de MongoDB, debe habilitar la búsqueda de texto con el siguiente código:
>db.adminCommand({setParameter:true,textSearchEnabled:true})Crear índice de texto
Considere el siguiente documento en posts colección que contiene el texto de la publicación y sus etiquetas -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}Crearemos un índice de texto en el campo post_text para que podamos buscar dentro del texto de nuestras publicaciones -
>db.posts.ensureIndex({post_text:"text"})Usar índice de texto
Ahora que hemos creado el índice de texto en el campo post_text, buscaremos todas las publicaciones que tengan la palabra tutorialspoint en su texto.
>db.posts.find({$text:{$search:"tutorialspoint"}})El comando anterior devolvió los siguientes documentos de resultado con la palabra tutorialspoint en su mensaje de texto -
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on tutorialspoint",
"tags" : [ "mongodb", "tutorialspoint" ]
}
{
"_id" : ObjectId("53493d1fd852429c10000003"),
"post_text" : "writing tutorials on mongodb",
"tags" : [ "mongodb", "tutorial" ]
}Si está utilizando versiones antiguas de MongoDB, debe usar el siguiente comando:
>db.posts.runCommand("text",{search:" tutorialspoint "})El uso de la búsqueda de texto mejora en gran medida la eficiencia de la búsqueda en comparación con la búsqueda normal.
Eliminar índice de texto
Para eliminar un índice de texto existente, primero busque el nombre del índice utilizando la siguiente consulta:
>db.posts.getIndexes()Después de obtener el nombre de su índice de la consulta anterior, ejecute el siguiente comando. Aquí,post_text_text es el nombre del índice.
>db.posts.dropIndex("post_text_text")Las expresiones regulares se utilizan con frecuencia en todos los idiomas para buscar un patrón o palabra en cualquier cadena. MongoDB también proporciona la funcionalidad de expresión regular para la coincidencia de patrones de cadena utilizando el$regexoperador. MongoDB usa PCRE (Perl Compatible Regular Expression) como lenguaje de expresión regular.
A diferencia de la búsqueda de texto, no necesitamos realizar ninguna configuración o comando para usar expresiones regulares.
Considere la siguiente estructura del documento en posts colección que contiene el texto de la publicación y sus etiquetas -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}Usar expresión de expresiones regulares
La siguiente consulta de expresiones regulares busca todas las publicaciones que contienen cadenas tutorialspoint en ella -
>db.posts.find({post_text:{$regex:"tutorialspoint"}})La misma consulta también se puede escribir como:
>db.posts.find({post_text:/tutorialspoint/})Uso de expresiones regulares con mayúsculas y minúsculas
Para que la búsqueda no distinga entre mayúsculas y minúsculas, utilizamos el $options parámetro con valor $i. El siguiente comando buscará cadenas que tengan la palabratutorialspoint, independientemente del caso menor o capital -
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})Uno de los resultados devueltos por esta consulta es el siguiente documento que contiene la palabra tutorialspoint en diferentes casos -
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on TutorialsPoint",
"tags" : [ "tutorialspoint" ]
}Uso de expresiones regulares para elementos de matriz
También podemos usar el concepto de expresión regular en el campo de matriz. Esto es particularmente muy importante cuando implementamos la funcionalidad de las etiquetas. Por lo tanto, si desea buscar todas las publicaciones que tengan etiquetas a partir de la palabra tutorial (ya sea tutorial o tutoriales o tutorialpoint o tutorialphp), puede usar el siguiente código:
>db.posts.find({tags:{$regex:"tutorial"}})Optimización de consultas de expresiones regulares
Si los campos del documento son indexed, la consulta utilizará valores indexados para coincidir con la expresión regular. Esto hace que la búsqueda sea muy rápida en comparación con la expresión regular que escanea toda la colección.
Si la expresión regular es una prefix expression, todas las coincidencias deben comenzar con una determinada cadena de caracteres. Por ejemplo, si la expresión regex es^tut, entonces la consulta debe buscar solo aquellas cadenas que comienzan con tut.
RockMongo es una herramienta de administración de MongoDB con la que puede administrar su servidor, bases de datos, colecciones, documentos, índices y mucho más. Proporciona una forma muy sencilla de leer, escribir y crear documentos. Es similar a la herramienta PHPMyAdmin para PHP y MySQL.
Descargando RockMongo
Puede descargar la última versión de RockMongo desde aquí: https://github.com/iwind/rockmongo
Instalación de RockMongo
Una vez descargado, puede descomprimir el paquete en la carpeta raíz de su servidor y cambiar el nombre de la carpeta extraída a rockmongo. Abra cualquier navegador web y acceda alindex.phppágina de la carpeta rockmongo. Ingrese admin / admin como nombre de usuario / contraseña respectivamente.
Trabajando con RockMongo
Ahora veremos algunas operaciones básicas que puede realizar con RockMongo.
Crear nueva base de datos
Para crear una nueva base de datos, haga clic en Databaseslengüeta. Hacer clicCreate New Database. En la siguiente pantalla, proporcione el nombre de la nueva base de datos y haga clic enCreate. Verá que se agrega una nueva base de datos en el panel izquierdo.
Creando nueva colección
Para crear una nueva colección dentro de una base de datos, haga clic en esa base de datos en el panel izquierdo. Clickea en elNew Collectionenlace en la parte superior. Proporcione el nombre requerido de la colección. No se preocupe por los otros campos de Está limitado, Tamaño y Máx. Haga clic enCreate. Se creará una nueva colección y podrás verla en el panel izquierdo.
Crear nuevo documento
Para crear un nuevo documento, haga clic en la colección a la que desea agregar documentos. Cuando haga clic en una colección, podrá ver todos los documentos de esa colección enumerados allí. Para crear un nuevo documento, haga clic en elInsertenlace en la parte superior. Puede ingresar los datos del documento en formato JSON o de matriz y hacer clic enSave.
Exportar / Importar datos
Para importar / exportar datos de cualquier colección, haga clic en esa colección y luego haga clic en Export/Importenlace en el panel superior. Siga las siguientes instrucciones para exportar sus datos en formato zip y luego importe el mismo archivo zip para volver a importar los datos.
GridFSes la especificación de MongoDB para almacenar y recuperar archivos grandes como imágenes, archivos de audio, archivos de video, etc. Es una especie de sistema de archivos para almacenar archivos, pero sus datos se almacenan dentro de las colecciones de MongoDB. GridFS tiene la capacidad de almacenar archivos incluso mayores que su límite de tamaño de documento de 16 MB.
GridFS divide un archivo en fragmentos y almacena cada fragmento de datos en un documento separado, cada uno de un tamaño máximo de 255k.
GridFS por defecto usa dos colecciones fs.files y fs.chunkspara almacenar los metadatos del archivo y los fragmentos. Cada fragmento se identifica por su campo _id ObjectId único. Los archivos fs. sirven como documento principal. losfiles_id campo en el documento fs.chunks vincula el fragmento a su padre.
A continuación se muestra un documento de muestra de la colección fs.files:
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}El documento especifica el nombre del archivo, el tamaño del fragmento, la fecha de carga y la longitud.
A continuación se muestra un documento de muestra del documento fs.chunks:
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}Agregar archivos a GridFS
Ahora, almacenaremos un archivo mp3 usando GridFS usando el putmando. Para ello usaremos elmongofiles.exe utilidad presente en la carpeta bin de la carpeta de instalación de MongoDB.
Abra el símbolo del sistema, navegue hasta mongofiles.exe en la carpeta bin de la carpeta de instalación de MongoDB y escriba el siguiente código:
>mongofiles.exe -d gridfs put song.mp3Aquí, gridfses el nombre de la base de datos en la que se almacenará el archivo. Si la base de datos no está presente, MongoDB creará automáticamente un nuevo documento sobre la marcha. Song.mp3 es el nombre del archivo cargado. Para ver el documento del archivo en la base de datos, puede usar buscar consulta -
>db.fs.files.find()El comando anterior devolvió el siguiente documento:
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}También podemos ver todos los fragmentos presentes en la colección fs.chunks relacionados con el archivo almacenado con el siguiente código, utilizando la identificación del documento devuelta en la consulta anterior:
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})En mi caso, la consulta arrojó 40 documentos, lo que significa que todo el documento mp3 se dividió en 40 fragmentos de datos.
Capped collectionsson colecciones circulares de tamaño fijo que siguen el orden de inserción para admitir un alto rendimiento para las operaciones de creación, lectura y eliminación. Por circular, significa que cuando se agota el tamaño fijo asignado a la colección, comenzará a eliminar el documento más antiguo de la colección sin proporcionar ningún comando explícito.
Las colecciones limitadas restringen las actualizaciones de los documentos si la actualización da como resultado un mayor tamaño del documento. Dado que las colecciones limitadas almacenan documentos en el orden del almacenamiento en disco, se asegura de que el tamaño del documento no aumente el tamaño asignado en el disco. Las colecciones limitadas son las mejores para almacenar información de registro, datos de caché o cualquier otro dato de gran volumen.
Creación de una colección limitada
Para crear una colección limitada, usamos el comando normal createCollection pero con capped opción como true y especificando el tamaño máximo de colección en bytes.
>db.createCollection("cappedLogCollection",{capped:true,size:10000})Además del tamaño de la colección, también podemos limitar el número de documentos de la colección utilizando el max parámetro -
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})Si desea verificar si una colección está limitada o no, use lo siguiente isCapped comando -
>db.cappedLogCollection.isCapped()Si hay una colección existente que planea convertir a limitada, puede hacerlo con el siguiente código:
>db.runCommand({"convertToCapped":"posts",size:10000})Este código convertiría nuestra colección existente posts a una colección limitada.
Consultando colección limitada
De forma predeterminada, una consulta de búsqueda en una colección limitada mostrará los resultados en el orden de inserción. Pero si desea que los documentos se recuperen en orden inverso, utilice elsort comando como se muestra en el siguiente código -
>db.cappedLogCollection.find().sort({$natural:-1})Hay algunos otros puntos importantes con respecto a las colecciones limitadas que vale la pena conocer:
No podemos eliminar documentos de una colección limitada.
No hay índices predeterminados presentes en una colección limitada, ni siquiera en el campo _id.
Al insertar un nuevo documento, MongoDB no tiene que buscar realmente un lugar para colocar un nuevo documento en el disco. Puede insertar ciegamente el nuevo documento al final de la colección. Esto hace que las operaciones de inserción en colecciones limitadas sean muy rápidas.
De manera similar, mientras lee documentos, MongoDB devuelve los documentos en el mismo orden en que están presentes en el disco. Esto hace que la operación de lectura sea muy rápida.
MongoDB no tiene una funcionalidad de incremento automático lista para usar, como las bases de datos SQL. De forma predeterminada, utiliza el ObjectId de 12 bytes para_idcampo como la clave principal para identificar de forma exclusiva los documentos. Sin embargo, puede haber escenarios en los que queramos que el campo _id tenga algún valor autoincrementado que no sea ObjectId.
Dado que esta no es una característica predeterminada en MongoDB, lograremos esta funcionalidad mediante programación utilizando un counters colección como lo sugiere la documentación de MongoDB.
Uso de Counter Collection
Considera lo siguiente productsdocumento. Queremos que el campo _id sea unauto-incremented integer sequence desde 1,2,3,4 hasta n.
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}Para ello, cree un counters colección, que realizará un seguimiento del último valor de secuencia para todos los campos de secuencia.
>db.createCollection("counters")Ahora, insertaremos el siguiente documento en la colección de contadores con productid como su clave -
{
"_id":"productid",
"sequence_value": 0
}El campo sequence_value realiza un seguimiento del último valor de la secuencia.
Utilice el siguiente código para insertar este documento de secuencia en la colección de contadores:
>db.counters.insert({_id:"productid",sequence_value:0})Creación de la función de JavaScript
Ahora crearemos una función getNextSequenceValueque tomará el nombre de la secuencia como entrada, incrementará el número de secuencia en 1 y devolverá el número de secuencia actualizado. En nuestro caso, el nombre de la secuencia esproductid.
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}Usando la función de Javascript
Ahora usaremos la función getNextSequenceValue mientras creamos un nuevo documento y asignamos el valor de secuencia devuelto como el campo _id del documento.
Inserte dos documentos de muestra usando el siguiente código:
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"
})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"
})Como puede ver, hemos utilizado la función getNextSequenceValue para establecer el valor del campo _id.
Para verificar la funcionalidad, busquemos los documentos usando el comando buscar -
>db.products.find()La consulta anterior devolvió los siguientes documentos con el campo _id incrementado automáticamente:
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }