MS SQL Server - Guía rápida
Este capítulo presenta SQL Server, analiza su uso, ventajas, versiones y componentes.
¿Qué es SQL Server?
Es un software, desarrollado por Microsoft, que se implementa a partir de la especificación de RDBMS.
También es un ORDBMS.
Depende de la plataforma.
Es un software basado en GUI y comandos.
Es compatible con el lenguaje SQL (SEQUEL), que es un producto de IBM, sin procedimientos, base de datos común y lenguaje que no distingue entre mayúsculas y minúsculas.
Uso de SQL Server
- Crear bases de datos.
- Mantener bases de datos.
- Analizar los datos a través de SQL Server Analysis Services (SSAS).
- Generar informes a través de SQL Server Reporting Services (SSRS).
- Realizar operaciones ETL a través de SQL Server Integration Services (SSIS).
Versiones de SQL Server
| Versión | Año | Nombre clave |
|---|---|---|
| 6.0 | 1995 | SQL95 |
| 6.5 | 1996 | Hidra |
| 7.0 | 1998 | Esfinge |
| 8.0 (2000) | 2000 | Shiloh |
| 9.0 (2005) | 2005 | Yukon |
| 10.0 (2008) | 2008 | Katmai |
| 10,5 (2008 R2) | 2010 | Kilimanjaro |
| 11,0 (2012) | 2012 | Denali |
| 12 (2014) | 2014 | Hekaton (inicialmente), SQL 14 (actual) |
Componentes de SQL Server
SQL Server funciona en una arquitectura cliente-servidor, por lo que admite dos tipos de componentes: (a) Estación de trabajo y (b) Servidor.
Workstation componentsestán instalados en cada dispositivo / máquina del operador de SQL Server. Estas son solo interfaces para interactuar con los componentes del servidor. Ejemplo: SSMS, SSCM, Profiler, BIDS, SQLEM, etc.
Server componentsestán instalados en servidor centralizado. Estos son servicios. Ejemplo: SQL Server, Agente SQL Server, SSIS, SSAS, SSRS, navegador SQL, búsqueda de texto completo de SQL Server, etc.
Instancia de SQL Server
- Una instancia es una instalación de SQL Server.
- Una instancia es una copia exacta del mismo software.
- Si instalamos 'n' veces, entonces se crearán 'n' instancias.
- Hay dos tipos de instancias en SQL Server a) Predeterminado b) Con nombre.
- Solo se admitirá una instancia predeterminada en un servidor.
- Se admitirán varias instancias con nombre en un servidor.
- La instancia predeterminada tomará el nombre del servidor como Nombre de la instancia.
- El nombre del servicio de instancia predeterminado es MSSQLSERVER.
- Se admitirán 16 instancias en la versión 2000.
- Se admitirán 50 instancias en 2005 y versiones posteriores.
Ventajas de las instancias
- Para instalar diferentes versiones en una máquina.
- Reducir costos.
- Para mantener los entornos de producción, desarrollo y prueba por separado.
- Para reducir los problemas temporales de la base de datos.
- Para separar los privilegios de seguridad.
- Para mantener el servidor en espera.
SQL Server está disponible en varias ediciones. Este capítulo enumera las múltiples ediciones con sus características.
Enterprise - Esta es la edición de gama alta con un conjunto completo de funciones.
Standard - Tiene menos funciones que Enterprise, cuando no se requieren funciones avanzadas.
Workgroup - Esto es adecuado para oficinas remotas de una empresa más grande.
Web - Está diseñado para aplicaciones web.
Developer- Esto es similar a Enterprise, pero con licencia para un solo usuario para desarrollo, prueba y demostración. Se puede actualizar fácilmente a Enterprise sin reinstalarlo.
Express- Esta es una base de datos de nivel de entrada gratuita. Puede utilizar solo 1 CPU y 1 GB de memoria, el tamaño máximo de la base de datos es de 10 GB.
Compact- Esta es una base de datos integrada gratuita para el desarrollo de aplicaciones móviles. El tamaño máximo de la base de datos es de 4 GB.
Datacenter- El cambio principal en el nuevo SQL Server 2008 R2 es Datacenter Edition. La edición Datacenter no tiene limitación de memoria y ofrece soporte para más de 25 instancias.
Business Intelligence - Business Intelligence Edition es una nueva introducción en SQL Server 2012. Esta edición incluye todas las funciones de la edición Standard y compatibilidad con funciones de BI avanzadas como Power View y PowerPivot, pero carece de compatibilidad con funciones de disponibilidad avanzadas como los grupos de disponibilidad AlwaysOn y otras operaciones en línea.
Enterprise Evaluation- SQL Server Evaluation Edition es una excelente manera de obtener una instancia gratuita y completamente funcional de SQL Server para aprender y desarrollar soluciones. Esta edición tiene una caducidad incorporada de 6 meses desde el momento en que la instalas.
| 2005 | 2008 | 2008 R2 | 2012 | 2014 |
|---|---|---|---|---|
| Empresa | si | si | si | si |
| Estándar | si | si | si | si |
| Desarrollador | si | si | si | si |
| Grupo de trabajo | si | si | No | No |
| Win Compact Edition - Móvil | si | si | si | si |
| Evaluación de la empresa | si | si | si | si |
| Rápido | si | si | si | si |
| Web | si | si | si | |
| Centro de datos | No | No | ||
| Inteligencia de negocios | si |
SQL Server admite dos tipos de instalación:
- Standalone
- Basado en clústeres
Cheques
- Verifique el acceso RDP para el servidor.
- Compruebe el bit del sistema operativo, la IP, el dominio del servidor.
- Compruebe si su cuenta está en el grupo de administración para ejecutar el archivo setup.exe.
- Ubicación del software.
Requisitos
- Qué versión, edición, SP y revisión, si corresponde.
- Cuentas de servicio para motor de base de datos, agente, SSAS, SSIS, SSRS, si corresponde.
- Nombre de instancia con nombre, si corresponde.
- Ubicación de binarios, sistema, bases de datos de usuarios.
- Modo de autenticación.
- Configuración de colación.
- Lista de características.
Requisitos previos para 2005
- Configurar archivos de soporte.
- .net framework 2.0.
- Cliente nativo de SQL Server.
Requisitos previos para 2008 y 2008R2
- Configurar archivos de soporte.
- .net framework 3.5 SP1.
- Cliente nativo de SQL Server.
- Instalador de Windows 4.5 / versión posterior.
Requisitos previos para 2012 y 2014
- Configurar archivos de soporte.
- .net framework 4.0.
- Cliente nativo de SQL Server.
- Instalador de Windows 4.5 / versión posterior.
- Windows PowerShell 2.0.
Pasos de instalación
Step 1 - Descargue la edición de evaluación de http://www.microsoft.com/download/en/details.aspx?id=29066
Una vez que se descargue el software, los siguientes archivos estarán disponibles según su opción de descarga (32 o 64 bits).
ENU \ x86 \ SQLFULL_x86_ENU_Core.box
ENU \ x86 \ SQLFULL_x86_ENU_Install.exe
ENU \ x86 \ SQLFULL_x86_ENU_Lang.box
OR
ENU \ x86 \ SQLFULL_x64_ENU_Core.box
ENU \ x86 \ SQLFULL_x64_ENU_Install.exe
ENU \ x86 \ SQLFULL_x64_ENU_Lang.box
Note - X86 (32 bits) y X64 (64 bits)
Step 2 - Haga doble clic en "SQLFULL_x86_ENU_Install.exe" o "SQLFULL_x64_ENU_Install.exe", extraerá los archivos necesarios para la instalación en la carpeta "SQLFULL_x86_ENU" o "SQLFULL_x86_ENU" respectivamente.
Step 3 - Haga clic en la carpeta "SQLFULL_x86_ENU" o "SQLFULL_x64_ENU_Install.exe" y haga doble clic en la aplicación "SETUP".
Para comprender, aquí hemos utilizado el software SQLFULL_x64_ENU_Install.exe.
Step 4 - Una vez que hagamos clic en la aplicación 'configurar', se abrirá la siguiente pantalla.

Step 5 - Haga clic en Instalación que se encuentra en el lado izquierdo de la pantalla anterior.

Step 6- Haga clic en la primera opción del lado derecho que se ve en la pantalla anterior. Se abrirá la siguiente pantalla.

Step 7 - Haga clic en Aceptar y aparecerá la siguiente pantalla.
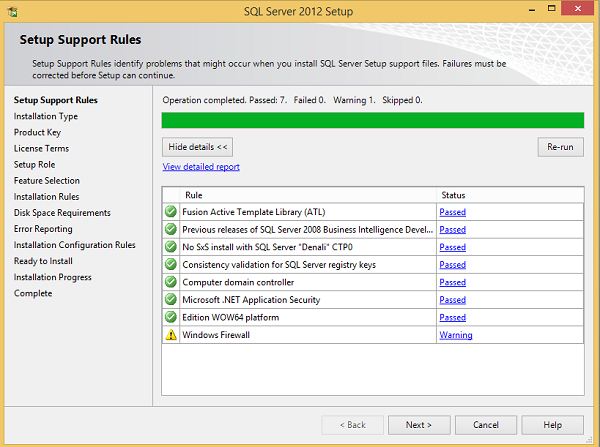
Step 8 - Haga clic en Siguiente para obtener la siguiente pantalla.

Step 9 - Asegúrese de verificar la selección de clave de producto y haga clic en Siguiente.

Step 10 - Seleccione la casilla de verificación para aceptar la opción de licencia y haga clic en Siguiente.

Step 11 - Seleccione la opción de instalación de la función de SQL Server y haga clic en Siguiente.

Step 12 - Seleccione la casilla de verificación Servicios del motor de base de datos y haga clic en Siguiente.
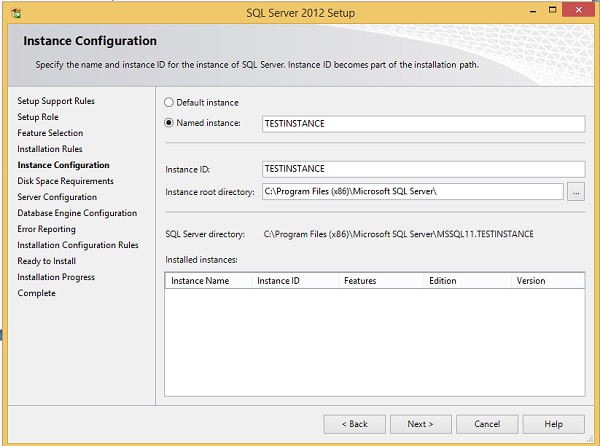
Step 13 - Ingrese la instancia nombrada (aquí usé TestInstance) y haga clic en Siguiente.

Step 14 - Haga clic en Siguiente en la pantalla anterior y aparecerá la siguiente pantalla.

Step 15 - Seleccione los nombres de las cuentas de servicio y los tipos de inicio para los servicios enumerados anteriormente y haga clic en Clasificación.

Step 16 - Asegúrese de que la selección de clasificación correcta esté marcada y haga clic en Siguiente.

Step 17 - Asegúrese de que la selección del modo de autenticación y los administradores estén marcados y haga clic en Directorios de datos.
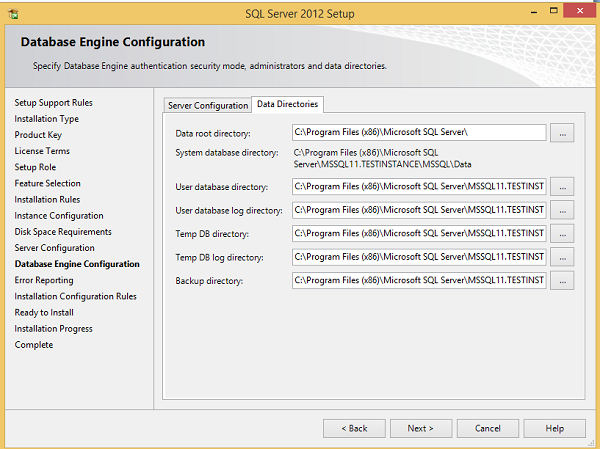
Step 18- Asegúrese de seleccionar las ubicaciones de directorio anteriores y haga clic en Siguiente. Aparece la siguiente pantalla.

Step 19 - Haga clic en Siguiente en la pantalla anterior.

Step 20 - Haga clic en Siguiente en la pantalla anterior para obtener la siguiente pantalla.

Step 21 - Asegúrese de comprobar la selección anterior correctamente y haga clic en Instalar.
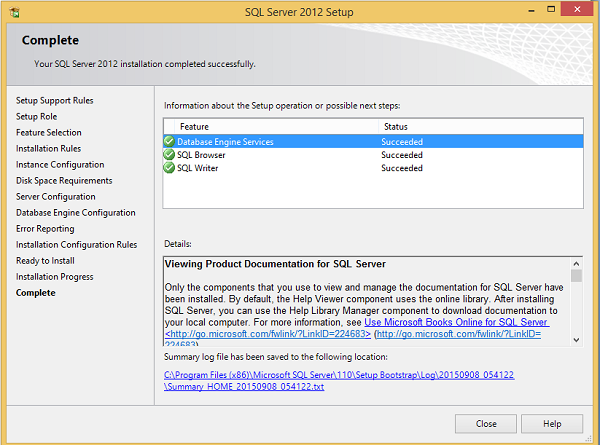
La instalación se realizó correctamente como se muestra en la pantalla anterior. Haga clic en Cerrar para finalizar.
Hemos clasificado la arquitectura de SQL Server en las siguientes partes para facilitar su comprensión:
- Arquitectura general
- Arquitectura de memoria
- Arquitectura de archivos de datos
- Arquitectura del archivo de registro
Arquitectura general
Client - Dónde se inició la solicitud.
Query - Consulta SQL que es lenguaje de alto nivel.
Logical Units - Palabras clave, expresiones y operadores, etc.
N/W Packets - Código relacionado con la red.
Protocols - En SQL Server tenemos 4 protocolos.
Memoria compartida (para conexiones locales y resolución de problemas).
Tuberías con nombre (para conexiones que están en conectividad LAN).
TCP / IP (para conexiones que están en conectividad WAN).
Adaptador de interfaz virtual VIA (requiere hardware especial para ser configurado por el proveedor y también obsoleto de la versión SQL 2012).
Server - Dónde se instalaron los servicios SQL y residen las bases de datos.
Relational Engine- Aquí es donde se realizará la ejecución real. Contiene analizador de consultas, optimizador de consultas y ejecutor de consultas.
Query Parser (Command Parser) and Compiler (Translator) - Esto verificará la sintaxis de la consulta y la convertirá a lenguaje de máquina.
Query Optimizer - Preparará el plan de ejecución como salida tomando como entrada la consulta, las estadísticas y el árbol de Algebrizer.
Execution Plan - Es como una hoja de ruta, que contiene el orden de todos los pasos a realizar como parte de la ejecución de la consulta.
Query Executor - Aquí es donde se ejecutará la consulta paso a paso con la ayuda del plan de ejecución y también se contactará con el motor de almacenamiento.
Storage Engine - Es responsable del almacenamiento y recuperación de datos en el sistema de almacenamiento (disco, SAN, etc.), manipulación de datos, bloqueo y gestión de transacciones.
SQL OS- Se encuentra entre la máquina host (sistema operativo Windows) y SQL Server. Todas las actividades realizadas en el motor de la base de datos están a cargo de SQL OS. SQL OS proporciona varios servicios del sistema operativo, como la gestión de memoria se ocupa de la agrupación de búfer, el búfer de registro y la detección de interbloqueo utilizando la estructura de bloqueo y bloqueo.
Checkpoint Process- Checkpoint es un proceso interno que escribe todas las páginas sucias (páginas modificadas) desde la memoria caché del búfer en el disco físico. Aparte de esto, también escribe los registros de registro desde el búfer de registro al archivo físico. La escritura de páginas sucias desde la memoria caché del búfer al archivo de datos también se conoce como Endurecimiento de páginas sucias.
Es un proceso dedicado y se ejecuta automáticamente por SQL Server a intervalos específicos. SQL Server ejecuta el proceso de punto de control para cada base de datos individualmente. Checkpoint ayuda a reducir el tiempo de recuperación de SQL Server en caso de un apagado inesperado o una falla o falla del sistema.
Puntos de control en SQL Server
En SQL Server 2012 hay cuatro tipos de checkpoints -
Automatic - Este es el punto de control más común que se ejecuta como un proceso en segundo plano para asegurarse de que la base de datos de SQL Server se pueda recuperar en el límite de tiempo definido por el intervalo de recuperación - Opción de configuración del servidor.
Indirect- Esto es nuevo en SQL Server 2012. También se ejecuta en segundo plano, pero para cumplir con un tiempo de recuperación objetivo especificado por el usuario para la base de datos específica donde se ha configurado la opción. Una vez que se ha seleccionado Target_Recovery_Time para una base de datos determinada, esto anulará el intervalo de recuperación especificado para el servidor y evitará el punto de control automático en dicha base de datos.
Manual- Esta se ejecuta como cualquier otra instrucción T-SQL, una vez que emita el comando de punto de control, se ejecutará hasta su finalización. El punto de control manual se ejecuta solo para su base de datos actual. También puede especificar Checkpoint_Duration, que es opcional; esta duración especifica el tiempo en el que desea que se complete su punto de control.
Internal- Como usuario, no puede controlar el control interno. Emitidos en operaciones específicas como
El apagado inicia una operación de punto de control en todas las bases de datos, excepto cuando el apagado no está limpio (apagado con nowait).
Si el modelo de recuperación cambia de Completo \ Registro masivo a Simple.
Mientras realiza una copia de seguridad de la base de datos.
Si su base de datos está en un modelo de recuperación simple, el proceso de punto de control se ejecuta automáticamente cuando el registro se llena al 70% o según la opción del servidor: intervalo de recuperación.
El comando Alterar la base de datos para agregar o quitar un archivo de registro de datos también inicia un punto de control.
El punto de control también tiene lugar cuando el modelo de recuperación de la base de datos se registra de forma masiva y se realiza una operación mínimamente registrada.
Creación de instantáneas de base de datos.
Lazy Writer Process- El escritor diferido enviará páginas sucias al disco por una razón completamente diferente, porque necesita liberar memoria en el grupo de búfer. Esto sucede cuando el servidor SQL se encuentra bajo presión de memoria. Hasta donde yo sé, esto está controlado por un proceso interno y no hay configuración para ello.
El servidor SQL monitorea constantemente el uso de la memoria para evaluar la contención (o disponibilidad) de los recursos; su trabajo es asegurarse de que haya una cierta cantidad de espacio libre disponible en todo momento. Como parte de este proceso, cuando se da cuenta de cualquier conflicto de recursos, hace que Lazy Writer libere algunas páginas en la memoria escribiendo páginas sucias en el disco. Emplea el algoritmo de uso menos reciente (LRU) para decidir qué páginas se van a descargar en el disco.
Si Lazy Writer está siempre activo, podría indicar un cuello de botella en la memoria.
Arquitectura de memoria
A continuación se presentan algunas de las características más destacadas de la arquitectura de memoria.
Uno de los principales objetivos de diseño de todo el software de base de datos es minimizar la E / S de disco porque las lecturas y escrituras de disco se encuentran entre las operaciones que consumen más recursos.
La memoria en Windows se puede llamar con el espacio de direcciones virtual, compartido por el modo Kernel (modo OS) y el modo Usuario (aplicación como SQL Server).
El "Espacio de direcciones de usuario" de SQL Server se divide en dos regiones: MemToLeave y Buffer Pool.
El tamaño de MemToLeave (MTL) y del grupo de búfer (BPool) lo determina SQL Server durante el inicio.
Buffer managementes un componente clave para lograr una E / S de alta eficiencia. El componente de gestión del búfer consta de dos mecanismos: el administrador del búfer para acceder y actualizar las páginas de la base de datos y el grupo de búfer para reducir la E / S de los archivos de la base de datos.
El grupo de amortiguadores se divide a su vez en varias secciones. Los más importantes son el caché del búfer (también denominado caché de datos) y el caché de procedimientos.Buffer cachemantiene las páginas de datos en la memoria para que los datos a los que se accede con frecuencia se puedan recuperar del caché. La alternativa sería leer las páginas de datos del disco. La lectura de páginas de datos de la memoria caché optimiza el rendimiento al minimizar el número de operaciones de E / S necesarias que son inherentemente más lentas que recuperar datos de la memoria.
Procedure cachemantiene los planes de ejecución de consultas y procedimientos almacenados para minimizar el número de veces que deben generarse planes de consulta. Puede encontrar información sobre el tamaño y la actividad dentro de la caché de procedimientos utilizando la instrucción DBCC PROCCACHE.
Otras partes del grupo de amortiguadores incluyen:
System level data structures - Contiene datos de nivel de instancia de SQL Server sobre bases de datos y bloqueos.
Log cache - Reservado para leer y escribir páginas de registro de transacciones.
Connection context- Cada conexión a la instancia tiene un área pequeña de memoria para registrar el estado actual de la conexión. Esta información incluye procedimientos almacenados y parámetros de función definidos por el usuario, posiciones del cursor y más.
Stack space - Windows asigna espacio de pila para cada hilo iniciado por SQL Server.
Arquitectura de archivos de datos
La arquitectura del archivo de datos tiene los siguientes componentes:
Grupos de archivos
Los archivos de la base de datos se pueden agrupar en grupos de archivos con fines de asignación y administración. Ningún archivo puede ser miembro de más de un grupo de archivos. Los archivos de registro nunca forman parte de un grupo de archivos. El espacio de registro se administra por separado del espacio de datos.
Hay dos tipos de grupos de archivos en SQL Server, primario y definido por el usuario. El grupo de archivos principal contiene el archivo de datos principal y cualquier otro archivo no asignado específicamente a otro grupo de archivos. Todas las páginas de las tablas del sistema se asignan en el grupo de archivos principal. Los grupos de archivos definidos por el usuario son cualquier grupo de archivos especificado mediante la palabra clave del grupo de archivos en la declaración de creación de base de datos o modificación de base de datos.
Un grupo de archivos en cada base de datos funciona como grupo de archivos predeterminado. Cuando SQL Server asigna una página a una tabla o índice para el que no se especificó ningún grupo de archivos cuando se crearon, las páginas se asignan desde el grupo de archivos predeterminado. Para cambiar el grupo de archivos predeterminado de un grupo de archivos a otro grupo de archivos, debe tener la función db fija db_owner.
De forma predeterminada, el grupo de archivos principal es el grupo de archivos predeterminado. El usuario debe tener un rol fijo de base de datos db_owner para poder realizar copias de seguridad de archivos y grupos de archivos individualmente.
Archivos
Las bases de datos tienen tres tipos de archivos: archivo de datos principal, archivo de datos secundario y archivo de registro. El archivo de datos principal es el punto de partida de la base de datos y apunta a los otros archivos de la base de datos.
Cada base de datos tiene un archivo de datos principal. Podemos dar cualquier extensión para el archivo de datos principal, pero la extensión recomendada es.mdf. El archivo de datos secundario es un archivo que no es el archivo de datos principal de esa base de datos. Algunas bases de datos pueden tener varios archivos de datos secundarios. Es posible que algunas bases de datos no tengan un solo archivo de datos secundario. La extensión recomendada para el archivo de datos secundario es.ndf.
Los archivos de registro contienen toda la información de registro utilizada para recuperar la base de datos. La base de datos debe tener al menos un archivo de registro. Podemos tener varios archivos de registro para una base de datos. La extensión recomendada para el archivo de registro es.ldf.
La ubicación de todos los archivos en una base de datos se registra tanto en la base de datos maestra como en el archivo principal de la base de datos. La mayoría de las veces, el motor de la base de datos utiliza la ubicación del archivo de la base de datos maestra.
Los archivos tienen dos nombres: lógico y físico. El nombre lógico se utiliza para hacer referencia al archivo en todas las declaraciones de T-SQL. El nombre físico es OS_file_name, debe seguir las reglas del SO. Los archivos de datos y de registro se pueden colocar en sistemas de archivos FAT o NTFS, pero no en sistemas de archivos comprimidos. Puede haber hasta 32,767 archivos en una base de datos.
Extensiones
Las extensiones son la unidad básica en la que se asigna espacio a tablas e índices. Una extensión es de 8 páginas contiguas o 64 KB. SQL Server tiene dos tipos de extensiones: uniforme y mixto. Las extensiones uniformes se componen de un solo objeto. Las extensiones mixtas son compartidas por hasta ocho objetos.
Páginas
Es la unidad fundamental de almacenamiento de datos en MS SQL Server. El tamaño de la página es de 8 KB. El inicio de cada página es un encabezado de 96 bytes que se utiliza para almacenar información del sistema, como el tipo de página, la cantidad de espacio libre en la página y la identificación del objeto que posee la página. Hay 9 tipos de páginas de datos en SQL Server.
Data - Filas de datos con todos los datos excepto texto, ntext e imagen.
Index - Entradas de índice.
Text\Image - Datos de texto, imagen y ntext.
GAM - Información sobre extensiones asignadas.
SGAM - Información sobre extensiones asignadas a nivel de sistema.
Page Free Space (PFS) - Información sobre el espacio libre disponible en páginas.
Index Allocation Map (IAM) - Información sobre las extensiones utilizadas por una tabla o índice.
Bulk Changed Map (BCM) - Información sobre extensiones modificadas por operaciones masivas desde la última declaración de registro de respaldo.
Differential Changed Map (DCM) - Información sobre extensiones que han cambiado desde la última declaración de la base de datos de respaldo.
Arquitectura de archivos de registro
El registro de transacciones de SQL Server funciona lógicamente como si el registro de transacciones fuera una cadena de registros. Cada registro de registro se identifica mediante el número de secuencia de registro (LSN). Cada registro contiene el ID de la transacción a la que pertenece.
Los registros de registro de modificaciones de datos registran la operación lógica realizada o registran las imágenes de antes y después de los datos modificados. La imagen anterior es una copia de los datos antes de que se realice la operación; la imagen posterior es una copia de los datos después de que se ha realizado la operación.
Los pasos para recuperar una operación dependen del tipo de registro:
- Operación lógica registrada.
- Para hacer avanzar la operación lógica, la operación se realiza de nuevo.
- Para revertir la operación lógica, se realiza la operación lógica inversa.
- Imagen de antes y después registrada.
- Para hacer avanzar la operación, se aplica la imagen posterior.
- Para revertir la operación, se aplica la imagen anterior.
Los diferentes tipos de operaciones se registran en el registro de transacciones. Estas operaciones incluyen:
El inicio y el final de cada transacción.
Cada modificación de datos (insertar, actualizar o eliminar). Esto incluye cambios por procedimientos almacenados del sistema o declaraciones de lenguaje de definición de datos (DDL) en cualquier tabla, incluidas las tablas del sistema.
Cada extensión y asignación o desasignación de páginas.
Crear o eliminar una tabla o índice.
También se registran las operaciones de reversión. Cada transacción reserva espacio en el registro de transacciones para asegurarse de que exista suficiente espacio de registro para admitir una reversión provocada por una declaración de reversión explícita o si se encuentra un error. Este espacio reservado se libera cuando se completa la transacción.
La sección del archivo de registro desde el primer registro de registro que debe estar presente para una reversión exitosa en toda la base de datos al último registro escrito se denomina parte activa del registro o registro activo. Esta es la sección del registro necesaria para una recuperación completa de la base de datos. Nunca se puede truncar ninguna parte del registro activo. El LSN de este primer registro de registro se conoce como el LSN de recuperación mínima (Min LSN).
El Motor de base de datos de SQL Server divide cada archivo de registro físico internamente en varios archivos de registro virtuales. Los archivos de registro virtuales no tienen un tamaño fijo y no hay un número fijo de archivos de registro virtuales para un archivo de registro físico.
El motor de base de datos elige el tamaño de los archivos de registro virtuales de forma dinámica mientras crea o amplía los archivos de registro. El motor de base de datos intenta mantener una pequeña cantidad de archivos virtuales. Los administradores no pueden configurar ni establecer el tamaño o la cantidad de archivos de registro virtuales. La única vez que los archivos de registro virtuales afectan el rendimiento del sistema es si los archivos de registro físicos se definen por valores de tamaño pequeño y crecimiento_incremento.
El valor de tamaño es el tamaño inicial del archivo de registro y el valor de growth_increment es la cantidad de espacio que se agrega al archivo cada vez que se requiere espacio nuevo. Si los archivos de registro crecen a un tamaño grande debido a muchos incrementos pequeños, tendrán muchos archivos de registro virtuales. Esto puede ralentizar el inicio de la base de datos y también registrar las operaciones de copia de seguridad y restauración.
Recomendamos que asigne a los archivos de registro un valor de tamaño cercano al tamaño final requerido y que también tenga un valor de incremento de crecimiento relativamente grande. SQL Server utiliza un registro de escritura anticipada (WAL), que garantiza que no se escriban modificaciones de datos en el disco antes de que el registro de registro asociado se escriba en el disco. Esto mantiene las propiedades ACID para una transacción.
SQL Server Management Studio es una herramienta cliente / componente de estación de trabajo que se instalará si seleccionamos el componente de estación de trabajo en los pasos de instalación. Esto le permite conectarse y administrar su servidor SQL desde una interfaz gráfica en lugar de tener que usar la línea de comandos.
Para conectarse a una instancia remota de SQL Server, necesitará este software o uno similar. Es utilizado por administradores, desarrolladores, probadores, etc.
Los siguientes métodos se utilizan para abrir SQL Server Management Studio.
Primer método
Inicio → Todos los programas → MS SQL Server 2012 → SQL Server Management Studio
Segundo método
Vaya a Ejecutar y escriba SQLWB (para la versión 2005) SSMS (para las versiones 2008 y posteriores). Luego haga clic en Enter.
SQL Server Management Studio se abrirá como se muestra en la siguiente instantánea en cualquiera de los métodos anteriores.

Un inicio de sesión es una credencial simple para acceder a SQL Server. Por ejemplo, proporciona su nombre de usuario y contraseña al iniciar sesión en Windows o incluso en su cuenta de correo electrónico. Este nombre de usuario y contraseña crean las credenciales. Por lo tanto, las credenciales son simplemente un nombre de usuario y una contraseña.
SQL Server permite cuatro tipos de inicios de sesión:
- Un inicio de sesión basado en las credenciales de Windows.
- Un inicio de sesión específico para SQL Server.
- Un inicio de sesión asignado a un certificado.
- Un inicio de sesión asignado a una clave asimétrica.
En este tutorial, estamos interesados en inicios de sesión basados en credenciales de Windows e inicios de sesión específicos de SQL Server.
Los inicios de sesión basados en las credenciales de Windows le permiten iniciar sesión en SQL Server con un nombre de usuario y una contraseña de Windows. Si necesita crear sus propias credenciales (nombre de usuario y contraseña), puede crear un inicio de sesión específico para SQL Server.
Para crear, modificar o eliminar un inicio de sesión de SQL Server, puede adoptar uno de dos enfoques:
- Utilizando SQL Server Management Studio.
- Usando sentencias T-SQL.
Los siguientes métodos se utilizan para crear un inicio de sesión:
Primer método: uso de SQL Server Management Studio
Step 1 - Después de conectarse a la instancia de SQL Server, expanda la carpeta de inicios de sesión como se muestra en la siguiente instantánea.

Step 2 - Haga clic con el botón derecho en Logins, luego haga clic en Newlogin y se abrirá la siguiente pantalla.

Step 3 - Complete las columnas Nombre de inicio de sesión, Contraseña y Confirmar contraseña como se muestra en la pantalla anterior y luego haga clic en Aceptar.
El inicio de sesión se creará como se muestra en la siguiente imagen.

Segundo método: usar el script T-SQL
Create login yourloginname with password='yourpassword'Para crear un nombre de inicio de sesión con TestLogin y la contraseña 'P @ ssword', ejecute la siguiente consulta.
Create login TestLogin with password='P@ssword'La base de datos es una colección de objetos como tabla, vista, procedimiento almacenado, función, disparador, etc.
En MS SQL Server, hay dos tipos de bases de datos disponibles.
- Bases de datos del sistema
- Bases de datos de usuario
Bases de datos del sistema
Las bases de datos del sistema se crean automáticamente cuando instalamos MS SQL Server. A continuación se muestra una lista de bases de datos del sistema:
- Master
- Model
- MSDB
- Tempdb
- Recurso (introducido en la versión 2005)
- Distribución (es solo para la función de replicación)
Bases de datos de usuario
Las bases de datos de usuario son creadas por usuarios (administradores, desarrolladores y evaluadores que tienen acceso para crear bases de datos).
Los siguientes métodos se utilizan para crear una base de datos de usuarios.
Método 1: usar el script T-SQL o restaurar la base de datos
A continuación se muestra la sintaxis básica para crear una base de datos en MS SQL Server.
Create database <yourdatabasename>O
Restore Database <Your database name> from disk = '<Backup file location + file name>Ejemplo
Para crear una base de datos llamada 'Testdb', ejecute la siguiente consulta.
Create database TestdbO
Restore database Testdb from disk = 'D:\Backup\Testdb_full_backup.bak'Note - D: \ backup es la ubicación del archivo de respaldo y Testdb_full_backup.bak es el nombre del archivo de respaldo
Método 2: uso de SQL Server Management Studio
Conéctese a la instancia de SQL Server y haga clic con el botón derecho en la carpeta de bases de datos. Haga clic en nueva base de datos y aparecerá la siguiente pantalla.

Ingrese el campo del nombre de la base de datos con el nombre de su base de datos (ejemplo: para crear una base de datos con el nombre 'Testdb') y haga clic en Aceptar. La base de datos de Testdb se creará como se muestra en la siguiente instantánea.
Seleccione su base de datos según su acción antes de continuar con cualquiera de los siguientes métodos.
Método 1: uso de SQL Server Management Studio
Ejemplo
Para ejecutar una consulta para seleccionar el historial de respaldo en la base de datos llamada 'msdb', seleccione la base de datos msdb como se muestra en la siguiente instantánea.
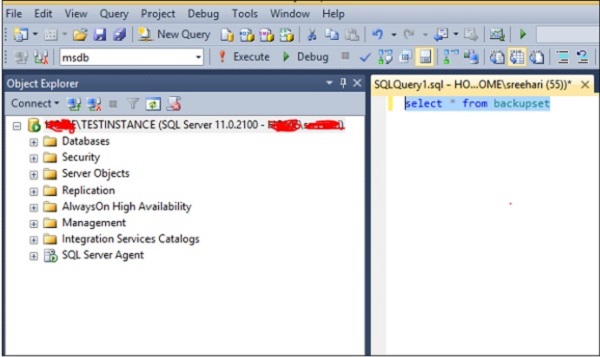
Método 2: usar el script T-SQL
Use <your database name>Ejemplo
Para ejecutar su consulta para seleccionar el historial de copias de seguridad en la base de datos llamada 'msdb', seleccione la base de datos msdb ejecutando la siguiente consulta.
Exec use msdbLa consulta abrirá la base de datos msdb. Puede ejecutar la siguiente consulta para seleccionar el historial de copias de seguridad.
Select * from backupsetPara eliminar su base de datos de MS SQL Server, use el comando drop database. Se pueden utilizar los siguientes dos métodos para este propósito.
Método 1: usar el script T-SQL
A continuación se muestra la sintaxis básica para eliminar la base de datos de MS SQL Server.
Drop database <your database name>Ejemplo
Para eliminar el nombre de la base de datos 'Testdb', ejecute la siguiente consulta.
Drop database TestdbMétodo 2: uso de MS SQL Server Management Studio
Conéctese a SQL Server y haga clic con el botón derecho en la base de datos que desea eliminar. Haga clic en eliminar comando y aparecerá la siguiente pantalla.

Haga clic en Aceptar para eliminar la base de datos (en este ejemplo, el nombre es Testdb como se muestra en la pantalla anterior) de MS SQL Server.
Backupes una copia de datos / base de datos, etc. Hacer una copia de seguridad de la base de datos de MS SQL Server es esencial para proteger los datos. Las copias de seguridad de MS SQL Server son principalmente de tres tipos: completa o base de datos, diferencial o incremental y registro transaccional o registro.
La base de datos de respaldo se puede hacer usando cualquiera de los dos métodos siguientes.
Método 1: uso de T-SQL
Tipo completo
Backup database <Your database name> to disk = '<Backup file location + file name>'Tipo diferencial
Backup database <Your database name> to
disk = '<Backup file location + file name>' with differentialTipo de registro
Backup log <Your database name> to disk = '<Backup file location + file name>'Ejemplo
El siguiente comando se usa para la base de datos de respaldo completa llamada 'TestDB' en la ubicación 'D: \' con el nombre del archivo de respaldo 'TestDB_Full.bak'
Backup database TestDB to disk = 'D:\TestDB_Full.bak'El siguiente comando se usa para la base de datos de respaldo diferencial llamada 'TestDB' a la ubicación 'D: \' con el nombre del archivo de respaldo 'TestDB_diff.bak'
Backup database TestDB to disk = 'D:\TestDB_diff.bak' with differentialEl siguiente comando se usa para la base de datos de respaldo del registro llamada 'TestDB' en la ubicación 'D: \' con el nombre del archivo de respaldo 'TestDB_log.trn'
Backup log TestDB to disk = 'D:\TestDB_log.trn'Método 2: uso de SSMS (SQL SERVER Management Studio)
Step 1 - Conéctese a la instancia de la base de datos llamada 'TESTINSTANCE' y expanda la carpeta de bases de datos como se muestra en la siguiente instantánea.

Step 2- Haga clic derecho en la base de datos 'TestDB' y seleccione las tareas. Haga clic en Copia de seguridad y aparecerá la siguiente pantalla.

Step 3- Seleccione el tipo de copia de seguridad (Full \ diff \ log) y asegúrese de verificar la ruta de destino, que es donde se creará el archivo de copia de seguridad. Seleccione las opciones en la esquina superior izquierda para ver la siguiente pantalla.

Step 4 - Haga clic en Aceptar para crear una copia de seguridad completa de la base de datos 'TestDB' como se muestra en la siguiente instantánea.


Restoringes el proceso de copiar datos de una copia de seguridad y aplicar transacciones registradas a los datos. Restaurar es lo que hace con las copias de seguridad. Tome el archivo de respaldo y conviértalo nuevamente en una base de datos.
La opción Restaurar base de datos se puede realizar mediante cualquiera de los dos métodos siguientes.
Método 1 - T-SQL
Sintaxis
Restore database <Your database name> from disk = '<Backup file location + file name>'Ejemplo
El siguiente comando se usa para restaurar la base de datos llamada 'TestDB' con el nombre del archivo de respaldo 'TestDB_Full.bak' que está disponible en la ubicación 'D: \' si está sobrescribiendo la base de datos existente.
Restore database TestDB from disk = ' D:\TestDB_Full.bak' with replaceSi está creando una nueva base de datos con este comando de restauración y no hay una ruta de datos similar, registre los archivos en el servidor de destino, luego use la opción de movimiento como el siguiente comando.
Asegúrese de que exista la ruta D: \ Data como se usa en el siguiente comando para los archivos de registro y datos.
RESTORE DATABASE TestDB FROM DISK = 'D:\ TestDB_Full.bak' WITH MOVE 'TestDB' TO
'D:\Data\TestDB.mdf', MOVE 'TestDB_Log' TO 'D:\Data\TestDB_Log.ldf'Método 2: SSMS (SQL SERVER Management Studio)
Step 1- Conéctese a la instancia de la base de datos llamada 'TESTINSTANCE' y haga clic con el botón derecho en la carpeta de la base de datos. Haga clic en Restaurar base de datos como se muestra en la siguiente instantánea.

Step 2 - Seleccione el botón de radio del dispositivo y haga clic en la elipse para seleccionar el archivo de respaldo como se muestra en la siguiente instantánea.
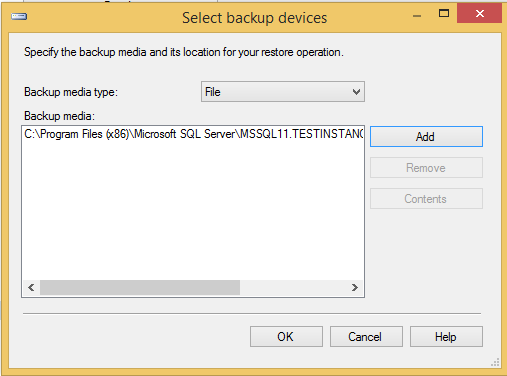
Step 3 - Haga clic en Aceptar y aparecerá la siguiente pantalla.

Step 4 - Seleccione la opción Archivos que se encuentra en la esquina superior izquierda como se muestra en la siguiente instantánea.

Step 5 - Seleccione Opciones que se encuentra en la esquina superior izquierda y haga clic en Aceptar para restaurar la base de datos 'TestDB' como se muestra en la siguiente instantánea.

Usuario se refiere a una cuenta en la base de datos de MS SQL Server que se utiliza para acceder a la base de datos.
Los usuarios se pueden crear utilizando cualquiera de los dos métodos siguientes.
Método 1: uso de T-SQL
Sintaxis
Create user <username> for login <loginname>Ejemplo
Para crear el nombre de usuario 'TestUser' con asignación al nombre de inicio de sesión 'TestLogin' en la base de datos TestDB, ejecute la siguiente consulta.
create user TestUser for login TestLoginDonde 'TestLogin' es el nombre de inicio de sesión que se creó como parte de la creación de inicio de sesión
Método 2: uso de SSMS (SQL Server Management Studio)
Note - Primero tenemos que crear Login con cualquier nombre antes de crear una cuenta de usuario.
Usemos el nombre de inicio de sesión llamado 'TestLogin'.
Step 1- Conectar SQL Server y expandir la carpeta de bases de datos. Luego expanda la base de datos llamada 'TestDB' donde vamos a crear la cuenta de usuario y expandir la carpeta de seguridad. Haga clic con el botón derecho en los usuarios y haga clic en el nuevo usuario para ver la siguiente pantalla.

Step 2 - Ingrese 'TestUser' en el campo de nombre de usuario y haga clic en la elipse para seleccionar el nombre de inicio de sesión llamado 'TestLogin' como se muestra en la siguiente instantánea.

Step 3- Haga clic en Aceptar para mostrar el nombre de inicio de sesión. De nuevo, haga clic en Aceptar para crear el usuario 'TestUser' como se muestra en la siguiente instantánea.

Permissionsconsulte las reglas que rigen los niveles de acceso que tienen los principales a los elementos protegibles. Puede otorgar, revocar y denegar permisos en MS SQL Server.
Para asignar permisos, se puede utilizar cualquiera de los dos métodos siguientes.
Método 1: uso de T-SQL
Sintaxis
Use <database name>
Grant <permission name> on <object name> to <username\principle>Ejemplo
Para asignar permiso de selección a un usuario llamado 'TestUser' en el objeto llamado 'TestTable' en la base de datos 'TestDB', ejecute la siguiente consulta.
USE TestDB
GO
Grant select on TestTable to TestUserMétodo 2: uso de SSMS (SQL Server Management Studio)
Step 1 - Conéctese a la instancia y expanda las carpetas como se muestra en la siguiente instantánea.

Step 2- Haga clic con el botón derecho en TestUser y haga clic en Propiedades. Aparece la siguiente pantalla.
Step 3Haga clic en Buscar y seleccione opciones específicas. Haga clic en Tipos de objeto, seleccione tablas y haga clic en examinar. Seleccione 'TestTable' y haga clic en Aceptar. Aparece la siguiente pantalla.

Step 4 Seleccione la casilla de verificación para la columna Otorgar en Seleccionar permiso y haga clic en Aceptar como se muestra en la instantánea anterior.

Step 5Seleccione el permiso en 'TestTable' de la base de datos TestDB otorgado a 'TestUser'. Haga clic en Aceptar.
El monitoreo se refiere a verificar el estado de la base de datos, configuraciones que pueden ser el nombre del propietario, nombres de archivos, tamaños de archivos, programas de respaldo, etc.
Las bases de datos de SQL Server se pueden monitorear principalmente a través de SQL Server Management Studio o T-SQL, y también se pueden monitorear a través de varios métodos como crear trabajos de agentes y configurar el correo de la base de datos, herramientas de terceros, etc.
El estado de la base de datos se puede verificar si está en línea o en cualquier otro estado, como se muestra en la siguiente instantánea.

Según la pantalla anterior, todas las bases de datos están en estado "En línea". Si alguna base de datos se encuentra en cualquier otro estado, ese estado se mostrará como se muestra en la siguiente instantánea.

MS SQL Server proporciona los siguientes dos servicios que son obligatorios para la creación y el mantenimiento de bases de datos. También se enumeran otros servicios complementarios disponibles para diferentes propósitos.
- servidor SQL
- Agente SQL Server
Otros servicios
- Explorador de SQL Server
- Búsqueda de texto completo de SQL Server
- Servicios de integración de SQL Server
- Servicios de informes de SQL Server
- Servicios de análisis de SQL Server
Los servicios anteriores se pueden utilizar mediante el siguiente método.
Iniciar servicios
Para iniciar cualquiera de los servicios, se puede utilizar cualquiera de los dos métodos siguientes.
Método 1: Services.msc
Step 1- Vaya a Ejecutar, escriba services.msc y haga clic en Aceptar. Aparece la siguiente pantalla.

Step 2- Para iniciar el servicio, haga clic derecho en el servicio, haga clic en el botón Inicio. Los servicios se iniciarán como se muestra en la siguiente instantánea.

Método 2: Administrador de configuración de SQL Server
Step 1 - Abra el administrador de configuración usando el siguiente proceso.
Inicio → Todos los programas → MS SQL Server 2012 → Herramientas de configuración → Administrador de configuración de SQL Server.

Step 2- Seleccione el nombre del servicio, haga clic derecho y haga clic en la opción de inicio. Los servicios se iniciarán como se muestra en la siguiente instantánea.

Detener servicios
Para detener cualquiera de los servicios, se puede utilizar cualquiera de los siguientes tres métodos.
Método 1: Services.msc
Step 1- Vaya a Ejecutar, escriba services.msc y haga clic en Aceptar. Aparece la siguiente pantalla.

Step 2- Para detener los servicios, haga clic con el botón derecho en el servicio y haga clic en Detener. El servicio seleccionado se detendrá como se muestra en la siguiente instantánea.

Método 2: Administrador de configuración de SQL Server
Step 1 - Abra el administrador de configuración usando el siguiente proceso.
Inicio → Todos los programas → MS SQL Server 2012 → Herramientas de configuración → Administrador de configuración de SQL Server.

Step 2- Seleccione el nombre del servicio, haga clic derecho y haga clic en la opción Detener. El servicio seleccionado se detendrá como se muestra en la siguiente instantánea.

Método 3: SSMS (SQL Server Management Studio)
Step 1 - Conéctese a la instancia como se muestra en la siguiente instantánea.

Step 2- Haga clic derecho en el nombre de la instancia y haga clic en la opción Detener. Aparece la siguiente pantalla.

Step 3 - Haga clic en el botón Sí y se abrirá la siguiente pantalla.

Step 4- Haga clic en la opción Sí en la pantalla anterior para detener el servicio del agente de SQL Server. Los servicios se detendrán como se muestra en la siguiente captura de pantalla.

Nota
No podemos usar el método de SQL Server Management Studio para iniciar los Servicios porque no podemos conectarnos debido al estado de los servicios ya detenido.
No podemos excluir la detención del servicio del agente del servicio SQL mientras se detiene el servicio del servidor SQL, ya que el servicio del agente del servidor SQL es un servicio dependiente.
La alta disponibilidad (HA) es la solución \ proceso \ tecnología para hacer que la aplicación \ base de datos esté disponible las 24 horas del día, los 7 días de la semana, ya sea en cortes planificados o no planificados.
Principalmente, hay cinco opciones en MS SQL Server para lograr \ configurar una solución de alta disponibilidad para las bases de datos.
Replicación
Los datos de origen se copiarán en el destino mediante agentes de replicación (trabajos). Tecnología a nivel de objeto.
Terminología
- El editor es el servidor de origen.
- El distribuidor es opcional y almacena datos replicados para el suscriptor.
- El suscriptor es el servidor de destino.
Envío de registro
Los datos de origen se copiarán al destino a través de las tareas de respaldo del Registro de transacciones. Tecnología de nivel de base de datos.
Terminología
- El servidor primario es el servidor de origen.
- El servidor secundario es el servidor de destino.
- El servidor de monitoreo es opcional y será monitoreado por el estado de envío de registros.
Reflejando
Los datos primarios se copiarán a los secundarios a través de transacciones de red con la ayuda de la duplicación del punto final y el número de puerto. Tecnología de nivel de base de datos.
Terminología
- El servidor principal es el servidor de origen.
- El servidor espejo es el servidor de destino.
- El servidor testigo es opcional y se utiliza para realizar una conmutación por error automática.
Agrupación
Los datos se almacenarán en una ubicación compartida que es utilizada por los servidores primarios y secundarios según la disponibilidad del servidor. Tecnología de nivel de instancia. Se requiere la configuración de la agrupación en clústeres de Windows con el almacenamiento compartido.
Terminología
- El nodo activo es donde se ejecutan los servicios SQL.
- El nodo pasivo es donde no se están ejecutando los servicios SQL.
Grupos de disponibilidad AlwaysON
Los datos primarios se copiarán a los secundarios mediante transacciones de red. Grupo de tecnología a nivel de base de datos. Se requiere la configuración de la agrupación en clústeres de Windows sin almacenamiento compartido.
Terminología
- La réplica principal es el servidor de origen.
- La réplica secundaria es el servidor de destino.
A continuación se muestran los pasos para configurar la tecnología HA (duplicación y envío de registros), excepto la agrupación en clústeres, los grupos de disponibilidad AlwaysON y la replicación.
Step 1 - Realice una copia de seguridad completa y una de T-log de la base de datos de origen.
Ejemplo
Para configurar la duplicación / trasvase de registros para la base de datos 'TestDB' en 'TESTINSTANCE' como principal y 'DEVINSTANCE' como servidores SQL secundarios, escriba la siguiente consulta para realizar copias de seguridad completas y de registro T en el servidor de origen (TESTINSTANCE).
Conéctese a 'TESTINSTANCE' SQL Server y abra una nueva consulta, escriba el siguiente código y ejecútelo como se muestra en la siguiente captura de pantalla.
Backup database TestDB to disk = 'D:\testdb_full.bak'
GO
Backup log TestDB to disk = 'D:\testdb_log.trn'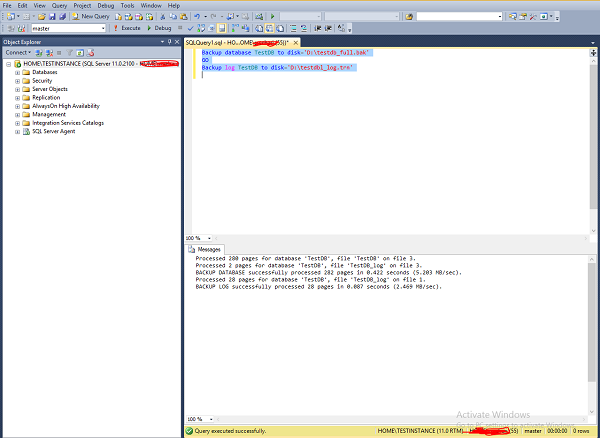
Step 2 - Copie los archivos de respaldo al servidor de destino.
En este caso, solo tenemos un servidor físico y dos Instancias de Servidores SQL instalados, por lo tanto, no hay necesidad de copiar, pero si dos instancias de SQL Server están en un servidor físico diferente, necesitamos copiar los siguientes dos archivos a cualquier ubicación del servidor secundario donde está instalada la instancia 'DEVINSTANCE'.

Step 3 - Restaurar la base de datos con archivos de respaldo en el servidor de destino con la opción 'norecovery'.
Ejemplo
Conéctese a 'DEVINSTANCE' SQL Server y abra Nueva consulta. Escriba el siguiente código para restaurar la base de datos con el nombre 'TestDB' que es el mismo nombre de la base de datos primaria ('TestDB') para la creación de reflejo de la base de datos. Sin embargo, podemos proporcionar un nombre diferente para la configuración del envío de registros. En este caso, usemos el nombre de la base de datos 'TestDB'. Utilice la opción 'norecovery' para dos restauraciones (archivos de copia de seguridad completos y t-log).
Restore database TestDB from disk = 'D:\TestDB_full.bak'
with move 'TestDB' to 'D:\DATA\TestDB_DR.mdf',
move 'TestDB_log' to 'D:\DATA\TestDB_log_DR.ldf',
norecovery
GO
Restore database TestDB from disk = 'D:\TestDB_log.trn' with norecovery
Actualice la carpeta de bases de datos en el servidor 'DEVINSTANCE' para ver la base de datos restaurada 'TestDB' con el estado de restauración como se muestra en la siguiente instantánea.
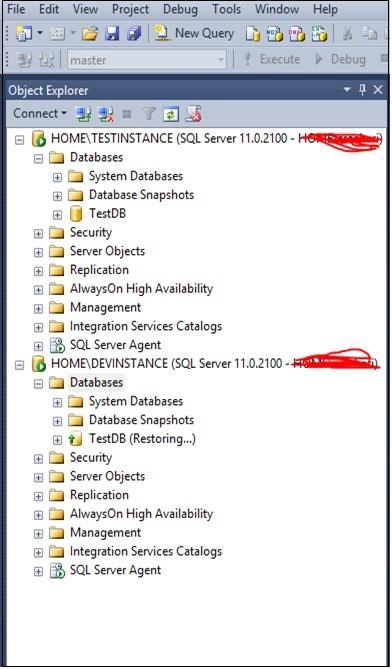
Step 4 - Configure HA (envío de registros, duplicación) según sus requisitos, como se muestra en la siguiente instantánea.
Ejemplo
Haga clic con el botón derecho en la base de datos 'TestDB' de 'TESTINSTANCE' SQL Server que es principal y haga clic en Propiedades. La siguiente pantalla aparecerá.

Step 5 - Seleccione la opción llamada 'Duplicación' o 'Envío de registro de transacciones' que están en el cuadro de color rojo como se muestra en la pantalla anterior según sus requisitos y siga los pasos del asistente guiados por el sistema para completar la configuración.
Report es un componente visualizable.
Uso
El informe se utiliza básicamente para dos propósitos: Operaciones internas de la empresa y Operaciones externas de la empresa.
Servicios de informes
Este es un servicio que se utiliza para crear y publicar varios tipos de informes.
A continuación se presentan los tres requisitos necesarios para desarrollar cualquier informe.
- Procesos de negocio
- Layout
- Query\Procedure\View
Los BIDS (Business Intelligence Studio hasta 2008 R2) y SSDT (SQL Server Data Tools desde 2012) son entornos para desarrollar informes.
A continuación se muestran los pasos para abrir el entorno BIDS \ SSDT para desarrollar informes.
Step 1- Abra BIDS \ SSDT según la versión del grupo de programas de Microsoft SQL Server. La siguiente pantalla aparecerá. En este caso, SSDT se ha abierto.
Step 2- Vaya al archivo en la esquina superior izquierda en la captura de pantalla anterior. Haga clic en Nuevo y seleccione el proyecto. Se abrirá la siguiente pantalla.

Step 3 - En la pantalla anterior, seleccione los servicios de informes en Business Intelligence en la esquina superior izquierda como se muestra en la siguiente captura de pantalla.

Step 4 - En la pantalla anterior, seleccione el asistente del proyecto del servidor de informes (lo guiará paso a paso a través de los asistentes) o el proyecto del servidor de informes (se utilizará para seleccionar la configuración personalizada) según sus requisitos para desarrollar el informe.
El plan de ejecución será generado por Query Optimizer con la ayuda de estadísticas y el árbol de procesadores de Algebrizer. Es el resultado del optimizador de consultas e indica cómo hacer \ realizar su trabajo \ requisito.
Hay dos planes de ejecución diferentes: estimado y real.
Estimated execution plan indica la vista del optimizador.
Actual execution plan indica qué ejecutó la consulta y cómo se hizo.
Los planes de ejecución se almacenan en la memoria denominada caché de planes, por lo que se pueden reutilizar. Cada plan se almacena una vez a menos que el optimizador decida el paralelismo para la ejecución de la consulta.
Hay tres formatos diferentes de planes de ejecución disponibles en SQL Server: planes gráficos, planes de texto y planes XML.
SHOWPLAN es el permiso que se requiere para el usuario que desea ver el plan de ejecución.
Ejemplo 1
A continuación se muestra el procedimiento para ver el plan de ejecución estimado.
Step 1- Conectarse a la instancia de SQL Server. En este caso, 'TESTINSTANCE' es el nombre de la instancia como se muestra en la siguiente instantánea.

Step 2- Haga clic en la opción Nueva consulta en la pantalla anterior y escriba la siguiente consulta. Antes de escribir la consulta, seleccione el nombre de la base de datos. En este caso, 'TestDB' es el nombre de la base de datos.
Select * from StudentTable
Step 3 - Haga clic en el símbolo que está resaltado en el cuadro de color rojo en la pantalla anterior para mostrar el plan de ejecución estimado como se muestra en la siguiente captura de pantalla.

Step 4- Coloque el mouse en el escaneo de la mesa, que es el segundo símbolo sobre el cuadro de color rojo en la pantalla anterior para mostrar el plan de ejecución estimado en detalle. Aparece la siguiente captura de pantalla.

Ejemplo 2
A continuación se muestra el procedimiento para ver el plan de ejecución real.
Step 1Conéctese a la instancia de SQL Server. En este caso, 'TESTINSTANCE' es el nombre de la instancia.

Step 2- Haga clic en la opción Nueva consulta que se ve en la pantalla anterior y escriba la siguiente consulta. Antes de escribir la consulta, seleccione el nombre de la base de datos. En este caso, 'TestDB' es el nombre de la base de datos.
Select * from StudentTable
Step 3 - Haga clic en el símbolo que está resaltado en el cuadro de color rojo en la pantalla anterior y luego ejecute la consulta para mostrar el plan de ejecución real junto con el resultado de la consulta como se muestra en la siguiente captura de pantalla.

Step 4- Coloque el mouse sobre el escaneo de la mesa, que es el segundo símbolo sobre el cuadro de color rojo en la pantalla para mostrar el plan de ejecución real en detalle. Aparece la siguiente captura de pantalla.

Step 5 - Haga clic en Resultados que se encuentra en la esquina superior izquierda en la pantalla anterior para obtener la siguiente pantalla.

Este servicio se utiliza para realizar ETL (Extracción, Transformación y Carga de datos) y operaciones de administración. Los BIDS (Business Intelligence Studio hasta 2008 R2) y SSDT (SQL Server Data Tools desde 2012) son los entornos para desarrollar paquetes.
Arquitectura básica SSIS
Solución (Colección de proyectos) ---> Proyecto (Colección de paquetes) ---> Paquete (Colección de tareas para ETL y operaciones administrativas)
En Paquete, están disponibles los siguientes componentes:
- Flujo de control (contenedores y tareas)
- Flujo de datos (origen, transformaciones, destinos)
- Manejador de eventos (envío de mensajes, correos electrónicos)
- Explorador de paquetes (una vista única para todos los paquetes)
- Parámetros (interacción del usuario)
Los siguientes son los pasos para abrir BIDS \ SSDT.
Step 1- Abra BIDS \ SSDT según la versión del grupo de programas de Microsoft SQL Server. Aparece la siguiente pantalla.
Step 2- La pantalla anterior muestra que SSDT se ha abierto. Vaya al archivo en la esquina superior izquierda de la imagen de arriba y haga clic en Nuevo. Seleccione el proyecto y se abre la siguiente pantalla.

Step 3 - Seleccione Servicios de integración en Business Intelligence en la esquina superior izquierda de la pantalla anterior para obtener la siguiente pantalla.

Step 4 - En la pantalla anterior, seleccione Proyecto de Integration Services o Asistente de proyecto de importación de Integration Services según sus requisitos para desarrollar / crear el paquete.
Este servicio se utiliza para analizar grandes cantidades de datos y aplicarlos a decisiones comerciales. También se utiliza para crear modelos de negocio bidimensionales o multidimensionales.
En la versión de SQL Server 2000, se llama MSAS (Microsoft Analysis Services).
Desde SQL Server 2005, se llama SSAS (SQL Server Analysis Services).
Modos
Hay dos modos: modo nativo (modo SQL Server) y modo punto compartido.
Modelos
Hay dos modelos: modelo tabular (para análisis de equipo y personal) y modelo de dimensiones múltiples (para análisis corporativo).
Los BIDS (Business Intelligence Studio hasta 2008 R2) y SSDT (SQL Server Data Tools desde 2012) son entornos para trabajar con SSAS.
Step 1- Abra BIDS \ SSDT según la versión del grupo de programas de Microsoft SQL Server. La siguiente pantalla aparecerá.

Step 2- La pantalla anterior muestra que SSDT se ha abierto. Vaya al archivo en la esquina superior izquierda en la imagen de arriba y haga clic en Nuevo. Seleccione el proyecto y se abre la siguiente pantalla.

Step 3- Seleccione Analysis Services en la pantalla anterior debajo de Business Intelligence como se ve en la esquina superior izquierda. Aparece la siguiente pantalla.
Step 4 - En la pantalla anterior, seleccione cualquier opción de las cinco opciones enumeradas en función de sus requisitos para trabajar con los servicios de análisis.