Kit de herramientas de lenguaje natural - Guía rápida
¿Qué es el procesamiento del lenguaje natural (NLP)?
El método de comunicación con la ayuda del cual los humanos pueden hablar, leer y escribir es el lenguaje. En otras palabras, los humanos podemos pensar, hacer planes, tomar decisiones en nuestro lenguaje natural. Aquí la gran pregunta es, en la era de la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo, ¿pueden los humanos comunicarse en lenguaje natural con computadoras / máquinas? El desarrollo de aplicaciones de PNL es un gran desafío para nosotros porque las computadoras requieren datos estructurados, pero, por otro lado, el habla humana no está estructurada y, a menudo, es de naturaleza ambigua.
El lenguaje natural es ese subcampo de la informática, más específicamente de la IA, que permite a las computadoras / máquinas comprender, procesar y manipular el lenguaje humano. En palabras simples, la PNL es una forma en que las máquinas analizan, comprenden y derivan el significado de los lenguajes naturales humanos como el hindi, el inglés, el francés, el holandés, etc.
¿Como funciona?
Antes de profundizar en el funcionamiento de la PNL, debemos comprender cómo los seres humanos usan el lenguaje. Todos los días, los humanos usamos cientos o miles de palabras y otros humanos las interpretan y responden en consecuencia. Es una comunicación simple para humanos, ¿no? Pero sabemos que las palabras son mucho más profundas que eso y siempre derivamos un contexto de lo que decimos y cómo lo decimos. Es por eso que podemos decir que en lugar de centrarse en la modulación de voz, la PNL se basa en patrones contextuales.
Entendamos con un ejemplo:
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.¿Cómo saben los humanos qué palabra significa qué? La respuesta a esta pregunta es que aprendemos a través de nuestra experiencia. Pero, ¿cómo aprenden lo mismo las máquinas / computadoras?
Comprendamoslo siguiendo unos sencillos pasos:
Primero, necesitamos alimentar a las máquinas con suficientes datos para que las máquinas puedan aprender de la experiencia.
Luego, la máquina creará vectores de palabras, mediante el uso de algoritmos de aprendizaje profundo, a partir de los datos que alimentamos anteriormente y de los datos circundantes.
Luego, al realizar operaciones algebraicas simples en estos vectores de palabras, la máquina podría proporcionar las respuestas como seres humanos.
Componentes de la PNL
El siguiente diagrama representa los componentes del procesamiento del lenguaje natural (NLP):
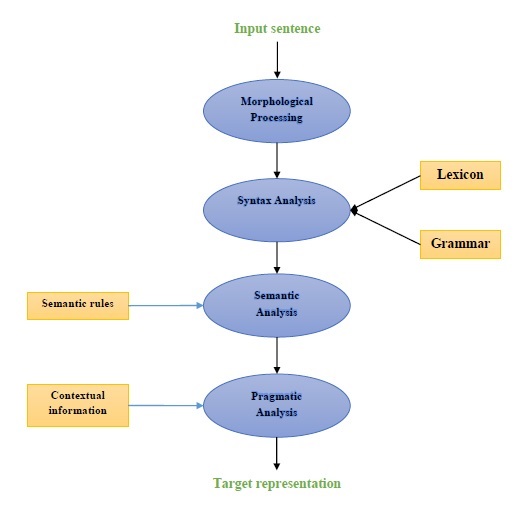
Procesamiento morfológico
El procesamiento morfológico es el primer componente de la PNL. Incluye la división de fragmentos de entrada de lenguaje en conjuntos de fichas correspondientes a párrafos, oraciones y palabras. Por ejemplo, una palabra como“everyday” se puede dividir en dos tokens de subpalabras como “every-day”.
Análisis de sintaxis
El análisis de sintaxis, el segundo componente, es uno de los componentes más importantes de la PNL. Los propósitos de este componente son los siguientes:
Para comprobar que una oración está bien formada o no.
Para dividirlo en una estructura que muestre las relaciones sintácticas entre las diferentes palabras.
Por ejemplo, las oraciones como “The school goes to the student” sería rechazado por el analizador de sintaxis.
Análisis semántico
El análisis semántico es el tercer componente de la PNL que se utiliza para comprobar la significación del texto. Incluye dibujar el significado exacto, o podemos decir el significado del diccionario del texto. Por ejemplo, frases como "Es un helado caliente". sería descartado por el analizador semántico.
Análisis pragmático
El análisis pragmático es el cuarto componente de la PNL. Incluye ajustar los objetos o eventos reales que existen en cada contexto con referencias de objetos obtenidas por el componente anterior, es decir, el análisis semántico. Por ejemplo, las oraciones como“Put the fruits in the basket on the table” puede tener dos interpretaciones semánticas, por lo tanto, el analizador pragmático elegirá entre estas dos posibilidades.
Ejemplos de aplicaciones de PNL
La PNL, una tecnología emergente, deriva varias formas de IA que solíamos ver en estos días. Para las aplicaciones cada vez más cognitivas de hoy y del mañana, el uso de la PNL en la creación de una interfaz fluida e interactiva entre humanos y máquinas seguirá siendo una prioridad absoluta. A continuación se presentan algunas de las aplicaciones muy útiles de la PNL.
Máquina traductora
La traducción automática (MT) es una de las aplicaciones más importantes del procesamiento del lenguaje natural. MT es básicamente un proceso de traducción de un idioma o texto de origen a otro idioma. El sistema de traducción automática puede ser bilingüe o multilingüe.
Lucha contra el spam
Debido al enorme aumento de correos electrónicos no deseados, los filtros de correo no deseado se han vuelto importantes porque son la primera línea de defensa contra este problema. Al considerar sus problemas de falsos positivos y falsos negativos como los problemas principales, la funcionalidad de NLP se puede utilizar para desarrollar un sistema de filtrado de spam.
El modelado de N-gramas, la derivación de palabras y la clasificación bayesiana son algunos de los modelos de PNL existentes que se pueden utilizar para el filtrado de spam.
Recuperación de información y búsqueda web
La mayoría de los motores de búsqueda como Google, Yahoo, Bing, WolframAlpha, etc., basan su tecnología de traducción automática (MT) en modelos de aprendizaje profundo de PNL. Estos modelos de aprendizaje profundo permiten a los algoritmos leer texto en una página web, interpretar su significado y traducirlo a otro idioma.
Resumen de texto automático
El resumen de texto automático es una técnica que crea un resumen breve y preciso de documentos de texto más largos. Por lo tanto, nos ayuda a obtener información relevante en menos tiempo. En esta era digital, tenemos una gran necesidad de resúmenes de texto automáticos porque tenemos una avalancha de información en Internet que no se detendrá. La PNL y sus funcionalidades juegan un papel importante en el desarrollo de un resumen de texto automático.
Corrección gramatical
La corrección ortográfica y gramatical es una característica muy útil del software de procesador de texto como Microsoft Word. El procesamiento del lenguaje natural (NLP) se usa ampliamente para este propósito.
Respuesta a preguntas
La respuesta a preguntas, otra aplicación principal del procesamiento del lenguaje natural (PNL), se centra en la construcción de sistemas que responden automáticamente a la pregunta publicada por el usuario en su lenguaje natural.
Análisis de los sentimientos
El análisis de sentimientos se encuentra entre otras aplicaciones importantes del procesamiento del lenguaje natural (NLP). Como su nombre lo indica, el análisis de sentimiento se utiliza para:
Identificar los sentimientos entre varias publicaciones y
Identifique el sentimiento donde las emociones no se expresan explícitamente.
Las empresas de comercio electrónico en línea como Amazon, eBay, etc., utilizan el análisis de sentimiento para identificar la opinión y el sentimiento de sus clientes en línea. Les ayudará a comprender lo que piensan sus clientes sobre sus productos y servicios.
Motores de voz
Los motores de voz como Siri, Google Voice, Alexa se basan en NLP para que podamos comunicarnos con ellos en nuestro lenguaje natural.
Implementación de PNL
Para construir las aplicaciones mencionadas anteriormente, necesitamos tener un conjunto de habilidades específicas con una gran comprensión del lenguaje y herramientas para procesar el lenguaje de manera eficiente. Para lograr esto, tenemos varias herramientas de código abierto disponibles. Algunos de ellos son de código abierto, mientras que otros son desarrollados por organizaciones para crear sus propias aplicaciones de PNL. A continuación se muestra la lista de algunas herramientas de PNL:
Kit de herramientas de lenguaje natural (NLTK)
Mallet
GATE
Abrir PNL
UIMA
Genism
Kit de herramientas de Stanford
La mayoría de estas herramientas están escritas en Java.
Kit de herramientas de lenguaje natural (NLTK)
Entre la herramienta de PNL mencionada anteriormente, NLTK obtiene una puntuación muy alta en lo que respecta a la facilidad de uso y la explicación del concepto. La curva de aprendizaje de Python es muy rápida y NLTK está escrito en Python, por lo que NLTK también tiene un muy buen kit de aprendizaje. NLTK ha incorporado la mayoría de las tareas como tokenización, derivación, lematización, puntuación, recuento de caracteres y recuento de palabras. Es muy elegante y fácil de trabajar.
Para instalar NLTK, debemos tener Python instalado en nuestras computadoras. Puede ir al enlace www.python.org/downloads y seleccionar la última versión para su sistema operativo, es decir, Windows, Mac y Linux / Unix. Para obtener un tutorial básico sobre Python, puede consultar el enlace www.tutorialspoint.com/python3/index.htm .
Ahora, una vez que haya instalado Python en su sistema informático, permítanos entender cómo podemos instalar NLTK.
Instalación de NLTK
Podemos instalar NLTK en varios sistemas operativos de la siguiente manera:
En Windows
Para instalar NLTK en el sistema operativo Windows, siga los pasos a continuación:
Primero, abra el símbolo del sistema de Windows y navegue hasta la ubicación del pip carpeta.
Luego, ingrese el siguiente comando para instalar NLTK -
pip3 install nltkAhora, abra PythonShell desde el menú Inicio de Windows y escriba el siguiente comando para verificar la instalación de NLTK:
Import nltkSi no obtiene ningún error, ha instalado correctamente NLTK en su sistema operativo Windows con Python3.
En Mac / Linux
Para instalar NLTK en Mac / Linux OS, escriba el siguiente comando:
sudo pip install -U nltkSi no tiene pip instalado en su computadora, siga las instrucciones que se dan a continuación para instalar primero pip -
Primero, actualice el índice del paquete siguiendo el siguiente comando:
sudo apt updateAhora, escriba el siguiente comando para instalar pip para python 3 -
sudo apt install python3-pipA través de Anaconda
Para instalar NLTK a través de Anaconda, siga los pasos a continuación:
Primero, para instalar Anaconda, vaya al enlace www.anaconda.com/distribution/#download-section y luego seleccione la versión de Python que necesita instalar.
Una vez que tenga Anaconda en su sistema informático, vaya a su símbolo del sistema y escriba el siguiente comando:
conda install -c anaconda nltk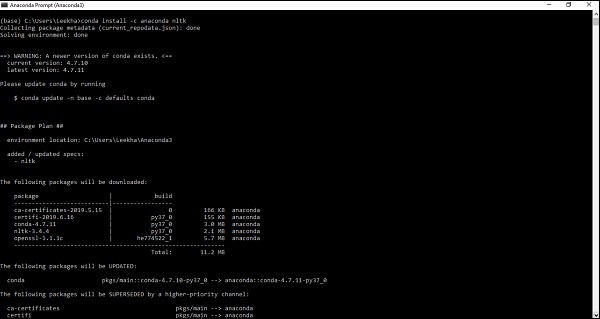
Debe revisar el resultado e ingresar 'sí'. NLTK se descargará e instalará en su paquete Anaconda.
Descarga de paquetes y conjuntos de datos de NLTK
Ahora tenemos NLTK instalado en nuestras computadoras, pero para usarlo necesitamos descargar los conjuntos de datos (corpus) disponibles en él. Algunos de los conjuntos de datos importantes disponibles sonstpwords, guntenberg, framenet_v15 y así.
Con la ayuda de los siguientes comandos, podemos descargar todos los conjuntos de datos NLTK:
import nltk
nltk.download()
Obtendrá la siguiente ventana de descarga NLTK.
Ahora, haga clic en el botón de descarga para descargar los conjuntos de datos.
¿Cómo ejecutar el script NLTK?
A continuación se muestra el ejemplo en el que estamos implementando el algoritmo Porter Stemmer utilizando PorterStemmerclase nltk. con este ejemplo podrá comprender cómo ejecutar un script NLTK.
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el PorterStemmer class para implementar el algoritmo Porter Stemmer.
from nltk.stem import PorterStemmerA continuación, cree una instancia de la clase Porter Stemmer de la siguiente manera:
word_stemmer = PorterStemmer()Ahora, ingrese la palabra que desea derivar. -
word_stemmer.stem('writing')Salida
'write'word_stemmer.stem('eating')Salida
'eat'¿Qué es Tokenizing?
Puede definirse como el proceso de dividir un fragmento de texto en partes más pequeñas, como oraciones y palabras. Estas partes más pequeñas se llaman tokens. Por ejemplo, una palabra es un símbolo en una oración y una oración es un símbolo en un párrafo.
Como sabemos, la PNL se usa para construir aplicaciones como análisis de sentimientos, sistemas de control de calidad, traducción de idiomas, chatbots inteligentes, sistemas de voz, etc., por lo que, para construirlos, es vital comprender el patrón en el texto. Los tokens, mencionados anteriormente, son muy útiles para encontrar y comprender estos patrones. Podemos considerar la tokenización como el paso base para otras recetas como la derivación y la lematización.
Paquete NLTK
nltk.tokenize es el paquete proporcionado por el módulo NLTK para lograr el proceso de tokenización.
Convertir oraciones en palabras
Dividir la oración en palabras o crear una lista de palabras a partir de una cadena es una parte esencial de toda actividad de procesamiento de texto. Vamos a entenderlo con la ayuda de varias funciones / módulos proporcionados pornltk.tokenize paquete.
módulo word_tokenize
word_tokenizeEl módulo se utiliza para la tokenización básica de palabras. El siguiente ejemplo utilizará este módulo para dividir una oración en palabras.
Ejemplo
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')Salida
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']TreebankWordTokenizer Class
word_tokenize módulo, utilizado anteriormente es básicamente una función contenedora que llama a la función tokenize () como una instancia del TreebankWordTokenizerclase. Dará el mismo resultado que obtenemos al usar el módulo word_tokenize () para dividir las oraciones en palabras. Veamos el mismo ejemplo implementado anteriormente:
Ejemplo
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el TreebankWordTokenizer clase para implementar el algoritmo de tokenizador de palabras -
from nltk.tokenize import TreebankWordTokenizerA continuación, cree una instancia de la clase TreebankWordTokenizer de la siguiente manera:
Tokenizer_wrd = TreebankWordTokenizer()Ahora, ingrese la oración que desea convertir en tokens:
Tokenizer_wrd.tokenize(
'Tutorialspoint.com provides high quality technical tutorials for free.'
)Salida
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials', 'for', 'free', '.'
]Ejemplo de implementación completo
Veamos el ejemplo de implementación completo a continuación.
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')Salida
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials','for', 'free', '.'
]La convención más importante de un tokenizador es separar las contracciones. Por ejemplo, si usamos el módulo word_tokenize () para este propósito, dará el resultado de la siguiente manera:
Ejemplo
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')Salida
['wo', "n't"]]Tal tipo de convención por TreebankWordTokenizeres inaceptable. Es por eso que tenemos dos tokenizadores de palabras alternativas, a saberPunktWordTokenizer y WordPunctTokenizer.
WordPunktTokenizer (clase)
Un tokenizador de palabras alternativo que divide toda la puntuación en tokens separados. Entendamos con el siguiente ejemplo sencillo:
Ejemplo
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")Salida
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']Tokenizar texto en oraciones
En esta sección vamos a dividir el texto / párrafo en oraciones. NLTK proporcionasent_tokenize módulo para este propósito.
¿Por qué es necesario?
Una pregunta obvia que nos vino a la mente es que cuando tenemos un tokenizador de palabras, ¿por qué necesitamos un tokenizador de oraciones o por qué tenemos que convertir el texto en oraciones? Supongamos que necesitamos contar palabras promedio en oraciones, ¿cómo podemos hacer esto? Para realizar esta tarea, necesitamos tanto la tokenización de frases como la tokenización de palabras.
Entendamos la diferencia entre el tokenizador de oración y palabra con la ayuda del siguiente ejemplo simple:
Ejemplo
import nltk
from nltk.tokenize import sent_tokenize
text = "Let us understand the difference between sentence & word tokenizer.
It is going to be a simple example."
sent_tokenize(text)Salida
[
"Let us understand the difference between sentence & word tokenizer.",
'It is going to be a simple example.'
]Tokenización de oraciones usando expresiones regulares
Si cree que la salida del tokenizador de palabras es inaceptable y desea un control completo sobre cómo tokenizar el texto, tenemos una expresión regular que se puede usar al realizar la tokenización de frases. NLTK proporcionaRegexpTokenizer clase para lograr esto.
Entendamos el concepto con la ayuda de dos ejemplos a continuación.
En el primer ejemplo, usaremos expresiones regulares para hacer coincidir tokens alfanuméricos más comillas simples para que no dividamos contracciones como “won’t”.
Ejemplo 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")Salida
["won't", 'is', 'a', 'contraction']
["can't", 'is', 'a', 'contraction']En el primer ejemplo, usaremos expresiones regulares para tokenizar en espacios en blanco.
Ejemplo 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")Salida
["won't", 'is', 'a', 'contraction']De la salida anterior, podemos ver que la puntuación permanece en los tokens. El parámetro gaps = True significa que el patrón identificará los huecos en los que se tokenizará. Por otro lado, si usamos el parámetro gaps = False, entonces el patrón se usaría para identificar los tokens que se pueden ver en el siguiente ejemplo:
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")Salida
[ ]Nos dará la salida en blanco.
¿Por qué entrenar su propio tokenizador de oraciones?
Esta es una pregunta muy importante: si tenemos el tokenizador de oraciones predeterminado de NLTK, ¿por qué necesitamos entrenar un tokenizador de oraciones? La respuesta a esta pregunta radica en la calidad del tokenizador de oraciones predeterminado de NLTK. El tokenizador predeterminado de NLTK es básicamente un tokenizador de uso general. Aunque funciona muy bien, puede que no sea una buena opción para texto no estándar, que quizás sea nuestro texto, o para un texto que tiene un formato único. Para convertir dicho texto en token y obtener los mejores resultados, debemos entrenar nuestro propio tokenizador de oraciones.
Ejemplo de implementación
Para este ejemplo, usaremos el corpus de texto web. El archivo de texto que vamos a usar de este corpus tiene el formato de texto como los cuadros de diálogo que se muestran a continuación:
Guy: How old are you?
Hipster girl: You know, I never answer that question. Because to me, it's about
how mature you are, you know? I mean, a fourteen year old could be more mature
than a twenty-five year old, right? I'm sorry, I just never answer that question.
Guy: But, uh, you're older than eighteen, right?
Hipster girl: Oh, yeah.Hemos guardado este archivo de texto con el nombre training_tokenizer. NLTK proporciona una clase llamadaPunktSentenceTokenizercon la ayuda de la cual podemos entrenar en texto sin formato para producir un tokenizador de oración personalizado. Podemos obtener texto sin procesar leyendo en un archivo o desde un corpus NLTK usando elraw() método.
Veamos el ejemplo a continuación para obtener más información sobre él:
Primero, importa PunktSentenceTokenizer clase de nltk.tokenize paquete -
from nltk.tokenize import PunktSentenceTokenizerAhora, importa webtext corpus de nltk.corpus paquete
from nltk.corpus import webtextA continuación, usando raw() método, obtenga el texto sin formato de training_tokenizer.txt archivo de la siguiente manera:
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')Ahora, crea una instancia de PunktSentenceTokenizer e imprima las oraciones de tokenizar del archivo de texto de la siguiente manera:
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Salida
White guy: So, do you have any plans for this evening?
print(sents_1[1])
Output:
Asian girl: Yeah, being angry!
print(sents_1[670])
Output:
Guy: A hundred bucks?
print(sents_1[675])
Output:
Girl: But you already have a Big Mac...Ejemplo de implementación completo
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Salida
White guy: So, do you have any plans for this evening?Para comprender la diferencia entre el tokenizador de oraciones predeterminado de NLTK y nuestro propio tokenizador de oraciones entrenado, vamos a convertir el mismo archivo en tokenizador de oración predeterminado, es decir, sent_tokenize ().
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?Con la ayuda de la diferencia en la salida, podemos entender el concepto de por qué es útil entrenar nuestro propio tokenizador de oraciones.
¿Qué son las palabras vacías?
Algunas palabras comunes que están presentes en el texto pero que no contribuyen al significado de una oración. Estas palabras no son en absoluto importantes para la recuperación de información o el procesamiento del lenguaje natural. Las palabras vacías más comunes son 'el' y 'a'.
Corpus de palabras vacías NLTK
En realidad, el kit de herramientas de lenguaje natural viene con un corpus de palabras vacías que contiene listas de palabras para muchos idiomas. Entendamos su uso con la ayuda del siguiente ejemplo:
En primer lugar, la importación de las palabras vacías Copus de nltk.corpus paquete -
from nltk.corpus import stopwordsAhora, usaremos palabras vacías de los idiomas ingleses.
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Salida
['I', 'writer']Ejemplo de implementación completo
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Salida
['I', 'writer']Encontrar la lista completa de idiomas admitidos
Con la ayuda de la siguiente secuencia de comandos de Python, también podemos encontrar la lista completa de lenguajes compatibles con el corpus de palabras vacías de NLTK:
from nltk.corpus import stopwords
stopwords.fileids()Salida
[
'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french',
'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali',
'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish',
'swedish', 'tajik', 'turkish'
]¿Qué es Wordnet?
Wordnet es una gran base de datos léxica del inglés, que fue creada por Princeton. Es parte del corpus NLTK. Los sustantivos, verbos, adjetivos y adverbios se agrupan en un conjunto de synsets, es decir, sinónimos cognitivos. Aquí, cada conjunto de synsets expresa un significado distinto. A continuación se muestran algunos casos de uso de Wordnet:
- Se puede utilizar para buscar la definición de una palabra.
- Podemos encontrar sinónimos y antónimos de una palabra.
- Las relaciones de palabras y las similitudes se pueden explorar utilizando Wordnet
- Desambiguación del sentido de las palabras para aquellas palabras que tienen múltiples usos y definiciones
¿Cómo importar Wordnet?
Wordnet se puede importar con la ayuda del siguiente comando:
from nltk.corpus import wordnetPara un comando más compacto, use lo siguiente:
from nltk.corpus import wordnet as wnInstancias de Synset
Synset son agrupaciones de palabras sinónimos que expresan el mismo concepto. Cuando utilice Wordnet para buscar palabras, obtendrá una lista de instancias de Synset.
wordnet.synsets (palabra)
Para obtener una lista de Synsets, podemos buscar cualquier palabra en Wordnet usando wordnet.synsets(word). Por ejemplo, en la próxima receta de Python, buscaremos en Synset el 'perro' junto con algunas propiedades y métodos de Synset:
Ejemplo
Primero, importe wordnet de la siguiente manera:
from nltk.corpus import wordnet as wnAhora, proporcione la palabra que desea buscar en Synset:
syn = wn.synsets('dog')[0]Aquí, estamos usando el método name () para obtener el nombre único del synset que se puede usar para obtener el Synset directamente -
syn.name()
Output:
'dog.n.01'A continuación, estamos usando el método definition () que nos dará la definición de la palabra -
syn.definition()
Output:
'a member of the genus Canis (probably descended from the common wolf) that has
been domesticated by man since prehistoric times; occurs in many breeds'Otro método es examples () que nos dará los ejemplos relacionados con la palabra -
syn.examples()
Output:
['the dog barked all night']Ejemplo de implementación completo
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()Conseguir hipernimos
Los Synsets están organizados en una estructura de árbol de herencia en la que Hypernyms representa términos más abstractos mientras Hyponymsrepresenta los términos más específicos. Una de las cosas importantes es que este árbol se puede rastrear hasta un hiperónimo raíz. Entendamos el concepto con la ayuda del siguiente ejemplo:
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()Salida
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]Aquí, podemos ver que canine y domestic_animal son los hiperónimos de 'perro'.
Ahora, podemos encontrar los hipónimos de 'perro' de la siguiente manera:
syn.hypernyms()[0].hyponyms()Salida
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]De la salida anterior, podemos ver que 'perro' es solo uno de los muchos hipónimos de 'domestic_animals'.
Para encontrar la raíz de todos estos, podemos usar el siguiente comando:
syn.root_hypernyms()Salida
[Synset('entity.n.01')]De la salida anterior, podemos ver que solo tiene una raíz.
Ejemplo de implementación completo
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()Salida
[Synset('entity.n.01')]Lemas en Wordnet
En lingüística, la forma canónica o morfológica de una palabra se llama lema. Para encontrar un sinónimo y un antónimo de una palabra, también podemos buscar lemas en WordNet. Veamos cómo.
Encontrar sinónimos
Usando el método lemma (), podemos encontrar el número de sinónimos de un Synset. Apliquemos este método en synset 'perro' -
Ejemplo
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)Salida
3La salida anterior muestra que 'perro' tiene tres lemas.
Obtener el nombre del primer lema de la siguiente manera:
lemmas[0].name()
Output:
'dog'Obteniendo el nombre del segundo lema de la siguiente manera:
lemmas[1].name()
Output:
'domestic_dog'Obteniendo el nombre del tercer lema de la siguiente manera:
lemmas[2].name()
Output:
'Canis_familiaris'En realidad, un Synset representa un grupo de lemas que tienen un significado similar, mientras que un lema representa una forma de palabra distinta.
Encontrar antónimos
En WordNet, algunos lemas también tienen antónimos. Por ejemplo, la palabra 'bueno' tiene un total de 27 synets, entre ellos, 5 tienen lemas con antónimos. Busquemos los antónimos (cuando la palabra 'bueno' se usa como sustantivo y cuando la palabra 'bueno' se usa como adjetivo).
Ejemplo 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()Salida
'evil'antonym1.synset().definition()Salida
'the quality of being morally wrong in principle or practice'El ejemplo anterior muestra que la palabra "bueno", cuando se usa como sustantivo, tiene el primer antónimo "mal".
Ejemplo 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()Salida
'bad'antonym2.synset().definition()Salida
'having undesirable or negative qualities’El ejemplo anterior muestra que la palabra 'bueno', cuando se usa como adjetivo, tiene el primer antónimo 'malo'.
¿Qué es Stemming?
Stemming es una técnica que se utiliza para extraer la forma básica de las palabras eliminando afijos de ellas. Es como cortar las ramas de un árbol hasta los tallos. Por ejemplo, la raíz de las palabraseating, eats, eaten es eat.
Los motores de búsqueda utilizan lematización para indexar las palabras. Por eso, en lugar de almacenar todas las formas de una palabra, un motor de búsqueda puede almacenar solo las raíces. De esta forma, la derivación reduce el tamaño del índice y aumenta la precisión de la recuperación.
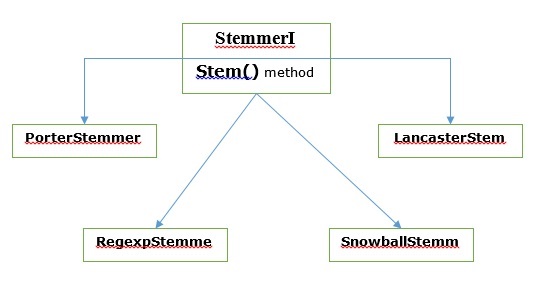
Varios algoritmos de derivación
En NLTK, stemmerI, cual tiene stem()método, la interfaz tiene todos los lematizadores que vamos a cubrir a continuación. Entendamos con el siguiente diagrama
Algoritmo de derivación de Porter
Es uno de los algoritmos de lematización más comunes que está diseñado básicamente para eliminar y reemplazar sufijos conocidos de palabras en inglés.
Clase PorterStemmer
NLTK tiene PorterStemmerclass con la ayuda de la cual podemos implementar fácilmente algoritmos de Porter Stemmer para la palabra que queremos derivar. Esta clase conoce varias formas de palabras regulares y sufijos con la ayuda de los cuales puede transformar la palabra de entrada en una raíz final. La raíz resultante es a menudo una palabra más corta que tiene el mismo significado de raíz. Veamos un ejemplo:
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el PorterStemmer class para implementar el algoritmo Porter Stemmer.
from nltk.stem import PorterStemmerA continuación, cree una instancia de la clase Porter Stemmer de la siguiente manera:
word_stemmer = PorterStemmer()Ahora, ingrese la palabra que desea derivar.
word_stemmer.stem('writing')Salida
'write'word_stemmer.stem('eating')Salida
'eat'Ejemplo de implementación completo
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Salida
'write'Algoritmo de derivación de Lancaster
Fue desarrollado en la Universidad de Lancaster y es otro algoritmo de derivación muy común.
LancasterStemmer clase
NLTK tiene LancasterStemmerclass con la ayuda de la cual podemos implementar fácilmente algoritmos de Lancaster Stemmer para la palabra que queremos derivar. Veamos un ejemplo:
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el LancasterStemmer clase para implementar el algoritmo Lancaster Stemmer
from nltk.stem import LancasterStemmerA continuación, cree una instancia de LancasterStemmer clase de la siguiente manera -
Lanc_stemmer = LancasterStemmer()Ahora, ingrese la palabra que desea derivar.
Lanc_stemmer.stem('eats')Salida
'eat'Ejemplo de implementación completo
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Salida
'eat'Algoritmo de derivación de expresiones regulares
Con la ayuda de este algoritmo de derivación, podemos construir nuestra propia derivación.
Clase RegexpStemmer
NLTK tiene RegexpStemmerclass con la ayuda de la cual podemos implementar fácilmente algoritmos de Stemmer de expresión regular. Básicamente, toma una sola expresión regular y elimina cualquier prefijo o sufijo que coincida con la expresión. Veamos un ejemplo:
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el RegexpStemmer class para implementar el algoritmo de Stemmer de expresiones regulares.
from nltk.stem import RegexpStemmerA continuación, cree una instancia de RegexpStemmer class y proporciona el sufijo o prefijo que desea eliminar de la palabra de la siguiente manera:
Reg_stemmer = RegexpStemmer(‘ing’)Ahora, ingrese la palabra que desea derivar.
Reg_stemmer.stem('eating')Salida
'eat'Reg_stemmer.stem('ingeat')Salida
'eat'
Reg_stemmer.stem('eats')Salida
'eat'Ejemplo de implementación completo
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Salida
'eat'Algoritmo de derivación de bola de nieve
Es otro algoritmo de derivación muy útil.
Clase SnowballStemmer
NLTK tiene SnowballStemmerclass con la ayuda de la cual podemos implementar fácilmente los algoritmos Snowball Stemmer. Admite 15 idiomas distintos del inglés. Para usar esta clase de vaporización, necesitamos crear una instancia con el nombre del idioma que estamos usando y luego llamar al método stem (). Veamos un ejemplo:
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el SnowballStemmer clase para implementar el algoritmo Snowball Stemmer
from nltk.stem import SnowballStemmerVeamos los idiomas que admite:
SnowballStemmer.languagesSalida
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)A continuación, cree una instancia de la clase SnowballStemmer con el idioma que desea utilizar. Aquí, estamos creando el lematizador para el idioma "francés".
French_stemmer = SnowballStemmer(‘french’)Ahora, llame al método stem () e ingrese la palabra que desea derivar.
French_stemmer.stem (‘Bonjoura’)Salida
'bonjour'Ejemplo de implementación completo
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Salida
'bonjour'¿Qué es la lematización?
La técnica de lematización es como la derivación. La salida que obtendremos después de la lematización se llama 'lema', que es una palabra raíz en lugar de raíz raíz, la salida de la raíz. Después de la lematización, obtendremos una palabra válida que significa lo mismo.
NLTK proporciona WordNetLemmatizer clase que es un envoltorio delgado alrededor del wordnetcuerpo. Esta clase usamorphy() función a la WordNet CorpusReaderclass para encontrar un lema. Entendamos con un ejemplo:
Ejemplo
Primero, necesitamos importar el kit de herramientas de lenguaje natural (nltk).
import nltkAhora, importe el WordNetLemmatizer class para implementar la técnica de lematización.
from nltk.stem import WordNetLemmatizerA continuación, cree una instancia de WordNetLemmatizer clase.
lemmatizer = WordNetLemmatizer()Ahora, llame al método lemmatize () e ingrese la palabra de la que desea encontrar el lema.
lemmatizer.lemmatize('eating')Salida
'eating'lemmatizer.lemmatize('books')Salida
'book'Ejemplo de implementación completo
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Salida
'book'Diferencia entre derivación y lematización
Entendamos la diferencia entre Stemming y Lemmatization con la ayuda del siguiente ejemplo:
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Salida
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Salida
believEl resultado de ambos programas indica la principal diferencia entre derivación y lematización. PorterStemmerla clase corta las 'es' de la palabra. Por otra parte,WordNetLemmatizerla clase encuentra una palabra válida. En palabras simples, la técnica de derivación solo mira la forma de la palabra mientras que la técnica de lematización mira el significado de la palabra. Significa que después de aplicar la lematización, siempre obtendremos una palabra válida.
La derivación y la lematización pueden considerarse como una especie de compresión lingüística. En el mismo sentido, el reemplazo de palabras se puede considerar como normalización de texto o corrección de errores.
Pero, ¿por qué necesitamos el reemplazo de palabras? Supongamos que si hablamos de tokenización, entonces está teniendo problemas con las contracciones (como no puedo, no lo haré, etc.). Entonces, para manejar estos problemas, necesitamos reemplazo de palabras. Por ejemplo, podemos reemplazar las contracciones con sus formas expandidas.
Reemplazo de palabras usando expresión regular
Primero, reemplazaremos palabras que coincidan con la expresión regular. Pero para esto debemos tener una comprensión básica de las expresiones regulares, así como del módulo python re. En el siguiente ejemplo, reemplazaremos la contracción con sus formas expandidas (por ejemplo, "no puedo" será reemplazado por "no puede"), todo eso usando expresiones regulares.
Ejemplo
Primero, importe el paquete necesario re para trabajar con expresiones regulares.
import re
from nltk.corpus import wordnetA continuación, defina los patrones de reemplazo de su elección de la siguiente manera:
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]Ahora, cree una clase que pueda usarse para reemplazar palabras:
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return sGuarde este programa de Python (digamos repRE.py) y ejecútelo desde el símbolo del sistema de Python. Después de ejecutarlo, importe la clase REReplacer cuando desee reemplazar palabras. Veamos cómo.
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'Ejemplo de implementación completo
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return sAhora, una vez que haya guardado el programa anterior y lo haya ejecutado, puede importar la clase y usarla de la siguiente manera:
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")Salida
'I will not do it'Reemplazo antes del procesamiento de texto
Una de las prácticas comunes al trabajar con procesamiento de lenguaje natural (PNL) es limpiar el texto antes de procesarlo. En esta preocupación también podemos utilizar nuestroREReplacer clase creada anteriormente en el ejemplo anterior, como paso preliminar antes del procesamiento de texto, es decir, la tokenización.
Ejemplo
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']En la receta de Python anterior, podemos comprender fácilmente la diferencia entre la salida del tokenizador de palabras sin y con el uso de reemplazo de expresiones regulares.
Eliminación de caracteres repetidos
¿Somos estrictamente gramaticales en nuestro lenguaje cotidiano? No lo estamos. Por ejemplo, a veces escribimos 'Hiiiiiiiiiiii Mohan' para enfatizar la palabra 'Hola'. Pero el sistema informático no sabe que "Hiiiiiiiiiiii" es una variación de la palabra "Hola". En el siguiente ejemplo, crearemos una clase llamadarep_word_removal que se puede utilizar para eliminar las palabras repetidas.
Ejemplo
Primero, importe el paquete necesario re para trabajar con expresiones regulares
import re
from nltk.corpus import wordnetAhora, cree una clase que se pueda usar para eliminar las palabras repetidas:
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_wordGuarde este programa de Python (por ejemplo, removerepeat.py) y ejecútelo desde el símbolo del sistema de Python. Después de ejecutarlo, importeRep_word_removalclass cuando desee eliminar las palabras repetidas. ¿Veamos cómo?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'Ejemplo de implementación completo
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_wordAhora, una vez que haya guardado el programa anterior y lo haya ejecutado, puede importar la clase y usarla de la siguiente manera:
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")Salida
'Hi'Reemplazo de palabras con sinónimos comunes
Al trabajar con PNL, especialmente en el caso del análisis de frecuencia y la indexación de texto, siempre es beneficioso comprimir el vocabulario sin perder significado porque ahorra mucha memoria. Para lograr esto, debemos definir el mapeo de una palabra con sus sinónimos. En el siguiente ejemplo, crearemos una clase llamadaword_syn_replacer que se puede utilizar para reemplazar las palabras con sus sinónimos comunes.
Ejemplo
Primero, importe el paquete necesario re para trabajar con expresiones regulares.
import re
from nltk.corpus import wordnetA continuación, cree la clase que toma una asignación de reemplazo de palabras:
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Guarde este programa de Python (digamos replacesyn.py) y ejecútelo desde el símbolo del sistema de Python. Después de ejecutarlo, importeword_syn_replacerclass cuando desee reemplazar palabras con sinónimos comunes. Veamos cómo.
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Salida
'birthday'Ejemplo de implementación completo
import re
from nltk.corpus import wordnet
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Ahora, una vez que haya guardado el programa anterior y lo haya ejecutado, puede importar la clase y usarla de la siguiente manera:
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Salida
'birthday'La desventaja del método anterior es que deberíamos tener que codificar los sinónimos en un diccionario de Python. Tenemos dos mejores alternativas en forma de archivo CSV y YAML. Podemos guardar nuestro vocabulario de sinónimos en cualquiera de los archivos mencionados anteriormente y construirword_mapdiccionario de ellos. Entendamos el concepto con la ayuda de ejemplos.
Usando archivo CSV
Para utilizar el archivo CSV para este propósito, el archivo debe tener dos columnas, la primera columna consta de una palabra y la segunda columna consta de los sinónimos destinados a reemplazarla. Guardemos este archivo comosyn.csv. En el siguiente ejemplo, crearemos una clase llamada CSVword_syn_replacer que se extiende word_syn_replacer en replacesyn.py archivo y se utilizará para construir el word_map diccionario de syn.csv archivo.
Ejemplo
Primero, importe los paquetes necesarios.
import csvA continuación, cree la clase que toma una asignación de reemplazo de palabras:
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Después de ejecutarlo, importe CSVword_syn_replacerclass cuando desee reemplazar palabras con sinónimos comunes. ¿Veamos cómo?
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Salida
'birthday'Ejemplo de implementación completo
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Ahora, una vez que haya guardado el programa anterior y lo haya ejecutado, puede importar la clase y usarla de la siguiente manera:
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Salida
'birthday'Usando archivo YAML
Como hemos usado el archivo CSV, también podemos usar el archivo YAML para este propósito (debemos tener PyYAML instalado). Guardemos el archivo comosyn.yaml. En el siguiente ejemplo, crearemos una clase llamada YAMLword_syn_replacer que se extiende word_syn_replacer en replacesyn.py archivo y se utilizará para construir el word_map diccionario de syn.yaml archivo.
Ejemplo
Primero, importe los paquetes necesarios.
import yamlA continuación, cree la clase que toma una asignación de reemplazo de palabras:
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Después de ejecutarlo, importe YAMLword_syn_replacerclass cuando desee reemplazar palabras con sinónimos comunes. ¿Veamos cómo?
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Salida
'birthday'Ejemplo de implementación completo
import yaml
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Ahora, una vez que haya guardado el programa anterior y lo haya ejecutado, puede importar la clase y usarla de la siguiente manera:
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Salida
'birthday'Reemplazo de antónimo
Como sabemos, un antónimo es una palabra que tiene el significado opuesto de otra palabra, y lo opuesto del reemplazo de sinónimos se llama reemplazo de antónimo. En esta sección, trataremos con el reemplazo de antónimos, es decir, reemplazando palabras con antónimos inequívocos usando WordNet. En el siguiente ejemplo, crearemos una clase llamadaword_antonym_replacer que tienen dos métodos, uno para reemplazar la palabra y otro para eliminar las negaciones.
Ejemplo
Primero, importe los paquetes necesarios.
from nltk.corpus import wordnetA continuación, cree la clase llamada word_antonym_replacer -
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsGuarde este programa de Python (por ejemplo, replaceantonym.py) y ejecútelo desde el símbolo del sistema de Python. Después de ejecutarlo, importeword_antonym_replacerclass cuando desee reemplazar palabras con sus antónimos inequívocos. Veamos cómo.
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)Salida
['beautify'']
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Salida
["Let us", 'beautify', 'our', 'country']Ejemplo de implementación completo
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsAhora, una vez que haya guardado el programa anterior y lo haya ejecutado, puede importar la clase y usarla de la siguiente manera:
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Salida
["Let us", 'beautify', 'our', 'country']¿Qué es un corpus?
Un corpus es una gran colección, en formato estructurado, de textos legibles por máquina que han sido producidos en un entorno comunicativo natural. La palabra Corpora es el plural de Corpus. Corpus se puede derivar de muchas formas como sigue:
- Del texto que originalmente era electrónico
- De las transcripciones del lenguaje hablado
- Desde el reconocimiento óptico de caracteres, etc.
La representatividad del corpus, el balance del corpus, el muestreo, el tamaño del corpus son los elementos que juegan un papel importante en el diseño del corpus. Algunos de los corpus más populares para tareas de PNL son TreeBank, PropBank, VarbNet y WordNet.
¿Cómo construir un corpus personalizado?
Al descargar NLTK, también instalamos el paquete de datos NLTK. Entonces, ya tenemos el paquete de datos NLTK instalado en nuestra computadora. Si hablamos de Windows, asumiremos que este paquete de datos está instalado enC:\natural_language_toolkit_data y si hablamos de Linux, Unix y Mac OS X, asumiremos que este paquete de datos está instalado en /usr/share/natural_language_toolkit_data.
En la siguiente receta de Python, crearemos corpus personalizados que deben estar dentro de una de las rutas definidas por NLTK. Es así porque NLTK puede encontrarlo. Para evitar conflictos con el paquete de datos oficial NLTK, permítanos crear un directorio natural_language_toolkit_data personalizado en nuestro directorio de inicio.
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)Salida
TrueAhora, comprobemos si tenemos el directorio natural_language_toolkit_data en nuestro directorio de inicio o no -
import nltk.data
path in nltk.data.pathSalida
TrueComo tenemos la salida Verdadero, significa que tenemos nltk_data directorio en nuestro directorio de inicio.
Ahora crearemos un archivo de lista de palabras, llamado wordfile.txt y ponerlo en una carpeta, llamada corpus en nltk_data directorio (~/nltk_data/corpus/wordfile.txt) y lo cargará usando nltk.data.load -
import nltk.data
nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)Salida
b’tutorialspoint\n’Lectores de corpus
NLTK proporciona varias clases de CorpusReader. Los vamos a cubrir en las siguientes recetas de Python.
Crear corpus de listas de palabras
NLTK tiene WordListCorpusReaderclase que proporciona acceso al archivo que contiene una lista de palabras. Para la siguiente receta de Python, necesitamos crear un archivo de lista de palabras que puede ser CSV o un archivo de texto normal. Por ejemplo, hemos creado un archivo llamado 'lista' que contiene los siguientes datos:
tutorialspoint
Online
Free
TutorialsAhora creemos una instancia WordListCorpusReader clase que produce la lista de palabras de nuestro archivo creado ‘list’.
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()Salida
['tutorialspoint', 'Online', 'Free', 'Tutorials']Creación de un corpus de palabras con etiquetas POS
NLTK tiene TaggedCorpusReaderclass con la ayuda de la cual podemos crear un corpus de palabras etiquetadas POS. En realidad, el etiquetado de POS es el proceso de identificar la etiqueta de la parte del discurso de una palabra.
Uno de los formatos más simples para un corpus etiquetado es de la forma 'palabra / etiqueta' como el siguiente extracto del corpus marrón:
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber
astronomical/jj ./.En el extracto anterior, cada palabra tiene una etiqueta que denota su POS. Por ejemplo,vb se refiere a un verbo.
Ahora creemos una instancia TaggedCorpusReaderclase que produce palabras etiquetadas POS forman el archivo ‘list.pos’, que tiene el extracto anterior.
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()Salida
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]Crear corpus de frases fragmentadas
NLTK tiene ChnkedCorpusReaderclass con la ayuda de la cual podemos crear un corpus de frases fragmentadas. En realidad, un fragmento es una frase corta en una oración.
Por ejemplo, tenemos el siguiente extracto del etiquetado treebank corpus -
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/
IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.En el extracto anterior, cada fragmento es un sintagma nominal, pero las palabras que no están entre corchetes son parte del árbol de oraciones y no parte de ningún subárbol de sintagma nominal.
Ahora creemos una instancia ChunkedCorpusReader clase que produce una frase fragmentada del archivo ‘list.chunk’, que tiene el extracto anterior.
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()Salida
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]Creación de corpus de texto categorizado
NLTK tiene CategorizedPlaintextCorpusReaderclass con la ayuda de la cual podemos crear un corpus de texto categorizado. Es muy útil en caso de que tengamos un gran corpus de texto y deseamos categorizarlo en secciones separadas.
Por ejemplo, el cuerpo marrón tiene varias categorías diferentes. Descubrámoslos con la ayuda del siguiente código de Python:
from nltk.corpus import brown^M
brown.categories()Salida
[
'adventure', 'belles_lettres', 'editorial', 'fiction', 'government',
'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion',
'reviews', 'romance', 'science_fiction'
]Una de las formas más fáciles de categorizar un corpus es tener un archivo para cada categoría. Por ejemplo, veamos los dos extractos delmovie_reviews corpus -
movie_pos.txt
La delgada línea roja es defectuosa pero provoca.
movie_neg.txt
Una producción brillante y de gran presupuesto no puede compensar la falta de espontaneidad que impregna su programa de televisión.
Entonces, de los dos archivos anteriores, tenemos dos categorías a saber pos y neg.
Ahora creemos una instancia CategorizedPlaintextCorpusReader clase.
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])Salida
['neg', 'pos']
['movie_neg.txt']
['movie_pos.txt']¿Qué es el etiquetado POS?
El etiquetado, una especie de clasificación, es la asignación automática de la descripción de los tokens. Al descriptor lo llamamos 'etiqueta', que representa una de las partes del discurso (sustantivos, verbos, adverbios, adjetivos, pronombres, conjunción y sus subcategorías), información semántica, etc.
Por otro lado, si hablamos de etiquetado de parte de la oración (POS), se puede definir como el proceso de convertir una oración en forma de lista de palabras en una lista de tuplas. Aquí, las tuplas tienen la forma de (palabra, etiqueta). También podemos llamar al etiquetado POS al proceso de asignar una de las partes del discurso a la palabra dada.
La siguiente tabla representa la notificación POS más frecuente utilizada en el corpus de Penn Treebank:
| No Señor | Etiqueta | Descripción |
|---|---|---|
| 1 | NNP | Nombre propio, singular |
| 2 | NNPS | Sustantivo propio, plural |
| 3 | PDT | Predeterminador |
| 4 | POS | Final posesivo |
| 5 | PRP | Pronombre personal |
| 6 | PRP $ | Pronombre posesivo |
| 7 | RB | Adverbio |
| 8 | RBR | Adverbio, comparativo |
| 9 | RBS | Adverbio, superlativo |
| 10 | RP | Partícula |
| 11 | SYM | Símbolo (matemático o científico) |
| 12 | A | a |
| 13 | UH | Interjección |
| 14 | VB | Verbo, forma base |
| 15 | VBD | Verbo, pasado |
| dieciséis | VBG | Verbo, gerundio / participio presente |
| 17 | VBN | Verbo, pasado |
| 18 | WP | Pronombre Wh |
| 19 | WP $ | Pronombre-wh posesivo |
| 20 | WRB | Wh-adverbio |
| 21 | # | Signo de Libra |
| 22 | PS | Signo de dólar |
| 23 | . | Puntuación final de la oración |
| 24 | , | Coma |
| 25 | : | Colon, punto y coma |
| 26 | ( | Carácter de corchete izquierdo |
| 27 | ) | Carácter de corchete derecho |
| 28 | " | Comilla doble recta |
| 29 | ' | Comillas simples abiertas |
| 30 | " | Comillas dobles abiertas a la izquierda |
| 31 | ' | Comilla simple de cierre derecho |
| 32 | " | Comillas dobles abiertas a la derecha |
Ejemplo
Entendamos esto con un experimento de Python:
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Salida
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]¿Por qué etiquetado POS?
El etiquetado POS es una parte importante de la PNL porque funciona como requisito previo para un análisis posterior de la PNL de la siguiente manera:
- Chunking
- Análisis de sintaxis
- Extracción de información
- Máquina traductora
- Análisis de los sentimientos
- Análisis gramatical y desambiguación del sentido de las palabras
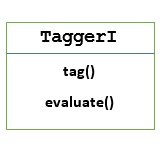
TaggerI - Clase base
Todos los etiquetadores residen en el paquete nltk.tag de NLTK. La clase base de estos etiquetadores esTaggerI, significa que todos los etiquetadores heredan de esta clase.
Methods - La clase TaggerI tiene los siguientes dos métodos que deben ser implementados por todas sus subclases -
tag() method - Como su nombre lo indica, este método toma una lista de palabras como entrada y devuelve una lista de palabras etiquetadas como salida.
evaluate() method - Con la ayuda de este método, podemos evaluar la precisión del etiquetador.
La línea de base del etiquetado POS
La línea de base o el paso básico del etiquetado POS es Default Tagging, que se puede realizar utilizando la clase DefaultTagger de NLTK. El etiquetado predeterminado simplemente asigna la misma etiqueta POS a cada token. El etiquetado predeterminado también proporciona una línea de base para medir las mejoras de precisión.
Clase DefaultTagger
El etiquetado predeterminado se realiza mediante DefaultTagging class, que toma el único argumento, es decir, la etiqueta que queremos aplicar.
¿Como funciona?
Como se dijo anteriormente, todos los etiquetadores se heredan de TaggerIclase. losDefaultTagger es heredado de SequentialBackoffTagger que es una subclase de TaggerI class. Entendamos con el siguiente diagrama -
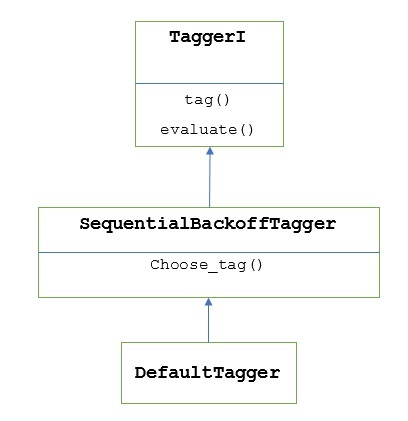
Como parte de SeuentialBackoffTagger, la DefaultTagger debe implementar el método choose_tag () que toma los siguientes tres argumentos.
- Lista de tokens
- Índice del token actual
- Lista del token anterior, es decir, el historial
Ejemplo
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Salida
[('Tutorials', 'NN'), ('Point', 'NN')]En este ejemplo, elegimos una etiqueta nominal porque es el tipo de palabras más común. Además,DefaultTagger También es más útil cuando elegimos la etiqueta POS más común.
Evaluación de precisión
los DefaultTaggertambién es la línea de base para evaluar la precisión de los etiquetadores. Esa es la razón por la que podemos usarlo junto conevaluate()método para medir la precisión. losevaluate() El método toma una lista de tokens etiquetados como estándar de oro para evaluar al etiquetador.
A continuación se muestra un ejemplo en el que usamos nuestro etiquetador predeterminado, llamado exptagger, creado anteriormente, para evaluar la precisión de un subconjunto de treebank oraciones etiquetadas corpus -
Ejemplo
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Salida
0.13198749536374715El resultado anterior muestra que al elegir NN para cada etiqueta, podemos lograr pruebas de precisión de alrededor del 13% en 1000 entradas del treebank cuerpo.
Etiquetar una lista de oraciones
En lugar de etiquetar una sola oración, el NLTK TaggerI la clase también nos proporciona un tag_sents()método con la ayuda del cual podemos etiquetar una lista de oraciones. A continuación se muestra el ejemplo en el que etiquetamos dos oraciones simples
Ejemplo
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Salida
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]En el ejemplo anterior, usamos nuestro etiquetador predeterminado creado anteriormente llamado exptagger.
Desmarcar una oración
También podemos quitar la etiqueta de una oración. NLTK proporciona el método nltk.tag.untag () para este propósito. Tomará una oración etiquetada como entrada y proporcionará una lista de palabras sin etiquetas. Veamos un ejemplo:
Ejemplo
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Salida
['Tutorials', 'Point']¿Qué es Unigram Tagger?
Como su nombre lo indica, el etiquetador unigram es un etiquetador que solo usa una sola palabra como contexto para determinar la etiqueta POS (parte del discurso). En palabras simples, Unigram Tagger es un etiquetador basado en el contexto cuyo contexto es una sola palabra, es decir, Unigram.
¿Como funciona?
NLTK proporciona un módulo llamado UnigramTaggerpara este propósito. Pero antes de profundizar en su funcionamiento, comprendamos la jerarquía con la ayuda del siguiente diagrama:
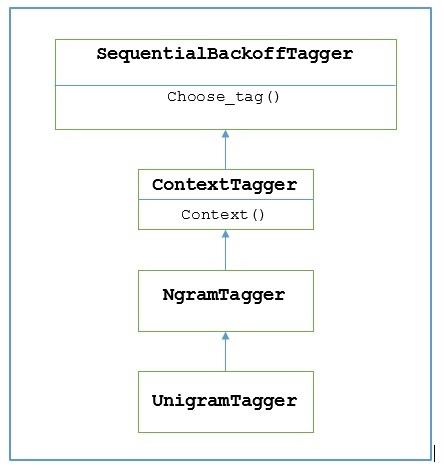
Del diagrama anterior, se entiende que UnigramTagger es heredado de NgramTagger que es una subclase de ContextTagger, que hereda de SequentialBackoffTagger.
El funcionamiento de UnigramTagger se explica con la ayuda de los siguientes pasos:
Como hemos visto, UnigramTagger hereda de ContextTagger, implementa un context()método. Estacontext() El método toma los mismos tres argumentos que choose_tag() método.
El resultado de context()método será la palabra token que se utilizará para crear el modelo. Una vez que se crea el modelo, la palabra token también se usa para buscar la mejor etiqueta.
De este modo, UnigramTagger construirá un modelo de contexto a partir de la lista de oraciones etiquetadas.
Entrenamiento de un etiquetador Unigram
NLTK's UnigramTaggerse puede entrenar proporcionando una lista de oraciones etiquetadas en el momento de la inicialización. En el siguiente ejemplo, usaremos las oraciones etiquetadas del corpus del banco de árboles. Usaremos las primeras 2500 oraciones de ese corpus.
Ejemplo
Primero importe el módulo UniframTagger desde nltk -
from nltk.tag import UnigramTaggerA continuación, importe el corpus que desee utilizar. Aquí estamos usando el corpus de treebank -
from nltk.corpus import treebankAhora, tome las oraciones con fines de entrenamiento. Estamos tomando las primeras 2500 oraciones con fines de capacitación y las etiquetaremos:
train_sentences = treebank.tagged_sents()[:2500]A continuación, aplique UnigramTagger en las oraciones utilizadas con fines de entrenamiento:
Uni_tagger = UnigramTagger(train_sentences)Tome algunas oraciones, ya sean iguales o menos tomadas con fines de capacitación, es decir, 2500, con fines de prueba. Aquí tomamos los primeros 1500 para fines de prueba:
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Salida
0.8942306156033808Aquí, obtuvimos alrededor del 89 por ciento de precisión para un etiquetador que usa la búsqueda de una sola palabra para determinar la etiqueta POS.
Ejemplo de implementación completo
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Salida
0.8942306156033808Anulando el modelo de contexto
Del diagrama anterior que muestra la jerarquía de UnigramTagger, conocemos todos los etiquetadores que heredan de ContextTagger, en lugar de entrenar a los suyos, pueden tomar un modelo prediseñado. Este modelo prediseñado es simplemente una asignación de diccionario de Python de una clave de contexto a una etiqueta. Y paraUnigramTagger, las claves de contexto son palabras individuales mientras que para otras NgramTagger subclases, serán tuplas.
Podemos anular este modelo de contexto pasando otro modelo simple al UnigramTaggerclase en lugar de aprobar el conjunto de entrenamiento. Entendamos esto con la ayuda de un sencillo ejemplo a continuación:
Ejemplo
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Salida
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Como nuestro modelo contiene 'Vinken' como la única clave de contexto, puede observar en el resultado anterior que solo esta palabra tiene etiqueta y todas las demás palabras tienen None como etiqueta.
Establecer un umbral de frecuencia mínima
Para decidir qué etiqueta es más probable para un contexto dado, el ContextTaggerla clase usa la frecuencia de ocurrencia. Lo hará de forma predeterminada incluso si la palabra de contexto y la etiqueta ocurren solo una vez, pero podemos establecer un umbral de frecuencia mínima pasando uncutoff valor para el UnigramTaggerclase. En el siguiente ejemplo, estamos pasando el valor de corte en la receta anterior en la que entrenamos un UnigramTagger -
Ejemplo
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Salida
0.7357651629613641Combinando etiquetadores
Combinar etiquetadores o encadenar etiquetadores entre sí es una de las características importantes de NLTK. El concepto principal detrás de la combinación de etiquetadores es que, en caso de que un etiquetador no sepa cómo etiquetar una palabra, se pasará al etiquetador encadenado. Para lograr este propósito,SequentialBackoffTagger nos proporciona el Backoff tagging característica.
Etiquetado de retroceso
Como se dijo anteriormente, el etiquetado de retroceso es una de las características importantes de SequentialBackoffTagger, que nos permite combinar etiquetadores de una manera que si un etiquetador no sabe cómo etiquetar una palabra, la palabra se pasará al siguiente etiquetador y así sucesivamente hasta que no queden etiquetadores de retroceso para verificar.
¿Como funciona?
En realidad, cada subclase de SequentialBackoffTaggerpuede tomar un argumento de palabra clave 'retroceso'. El valor de este argumento de palabra clave es otra instancia de unSequentialBackoffTagger. Ahora, siempre que estoSequentialBackoffTaggerse inicializa la clase, se creará una lista interna de etiquetadores de retroceso (con él mismo como primer elemento). Además, si se proporciona un etiquetador de retroceso, se agregará la lista interna de estos etiquetadores de retroceso.
En el siguiente ejemplo, tomamos DefaulTagger como etiquetador de retroceso en la receta de Python anterior con la que hemos entrenado UnigramTagger.
Ejemplo
En este ejemplo, estamos usando DefaulTaggercomo etiquetador de retroceso. Siempre que elUnigramTagger no puede etiquetar una palabra, etiquetador de retroceso, es decir DefaulTagger, en nuestro caso, lo etiquetará con 'NN'.
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Salida
0.9061975746536931De la salida anterior, puede observar que al agregar un etiquetador de retroceso, la precisión aumenta en aproximadamente un 2%.
Salvando a los etiquetadores con pepinillo
Como hemos visto, entrenar a un etiquetador es muy engorroso y también lleva tiempo. Para ahorrar tiempo, podemos elegir un etiquetador entrenado para usarlo más tarde. En el siguiente ejemplo, vamos a hacer esto con nuestro etiquetador ya entrenado llamado‘Uni_tagger’.
Ejemplo
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)Clase NgramTagger
Del diagrama de jerarquía discutido en la unidad anterior, UnigramTagger es heredado de NgarmTagger clase pero tenemos dos subclases más de NgarmTagger clase -
Subclase BigramTagger
En realidad, un ngram es una subsecuencia de n elementos, por lo tanto, como su nombre lo indica, BigramTaggerla subclase examina los dos elementos. El primer elemento es la palabra etiquetada anteriormente y el segundo elemento es la palabra etiquetada actual.
TrigramTagger subclase
En la misma nota de BigramTagger, TrigramTagger La subclase analiza los tres elementos, es decir, dos palabras etiquetadas anteriormente y una palabra etiquetada actual.
Prácticamente si aplicamos BigramTagger y TrigramTaggersubclases individualmente como hicimos con la subclase UnigramTagger, ambas funcionan muy mal. Veamos en los ejemplos a continuación:
Uso de la subclase BigramTagger
from nltk.tag import BigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Bi_tagger = BigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Bi_tagger.evaluate(test_sentences)Salida
0.44669191071913594Uso de la subclase TrigramTagger
from nltk.tag import TrigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Tri_tagger = TrigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Tri_tagger.evaluate(test_sentences)Salida
0.41949863394526193Puede comparar el rendimiento de UnigramTagger, que usamos anteriormente (dio alrededor del 89% de precisión) con BigramTagger (dio alrededor de 44% de precisión) y TrigramTagger (dio alrededor de 41% de precisión). La razón es que los etiquetadores de Bigram y Trigram no pueden aprender el contexto de la (s) primera (s) palabra (s) en una oración. Por otro lado, la clase UnigramTagger no se preocupa por el contexto anterior y adivina la etiqueta más común para cada palabra, por lo que puede tener una alta precisión de referencia.
Combinando etiquetadores ngram
A partir de los ejemplos anteriores, es obvio que los etiquetadores Bigram y Trigram pueden contribuir cuando los combinamos con el etiquetado de retroceso. En el siguiente ejemplo, estamos combinando etiquetadores Unigram, Bigram y Trigram con etiquetado de retroceso. El concepto es el mismo que el de la receta anterior mientras combina UnigramTagger con etiquetador de retroceso. La única diferencia es que estamos usando la función denominada backoff_tagger () de tagger_util.py, que se muestra a continuación, para la operación de retroceso.
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoffEjemplo
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Salida
0.9234530029238365A partir de la salida anterior, podemos ver que aumenta la precisión en aproximadamente un 3%.
Fijar etiquetador
Otra clase importante de la subclase ContextTagger es AffixTagger. En la clase AffixTagger, el contexto es prefijo o sufijo de una palabra. Esa es la razón por la que la clase AffixTagger puede aprender etiquetas basadas en subcadenas de longitud fija al principio o al final de una palabra.
¿Como funciona?
Su funcionamiento depende del argumento llamado affix_length que especifica la longitud del prefijo o sufijo. El valor predeterminado es 3. ¿Pero cómo distingue si la clase AffixTagger aprendió el prefijo o el sufijo de la palabra?
affix_length=positive - Si el valor de affix_lenght es positivo, significa que la clase AffixTagger aprenderá los prefijos de las palabras.
affix_length=negative - Si el valor de affix_lenght es negativo, significa que la clase AffixTagger aprenderá los sufijos de las palabras.
Para hacerlo más claro, en el siguiente ejemplo, usaremos la clase AffixTagger en oraciones de bancos de árboles etiquetadas.
Ejemplo
En este ejemplo, AffixTagger aprenderá el prefijo de la palabra porque no estamos especificando ningún valor para el argumento affix_length. El argumento tomará el valor predeterminado 3 -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Salida
0.2800492099250667Veamos en el siguiente ejemplo cuál será la precisión cuando proporcionemos el valor 4 al argumento affix_length -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Salida
0.18154947354966527Ejemplo
En este ejemplo, AffixTagger aprenderá el sufijo de la palabra porque especificaremos un valor negativo para el argumento affix_length.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Salida
0.2800492099250667Brill Tagger
Brill Tagger es un etiquetador basado en transformación. NLTK proporcionaBrillTagger clase que es el primer etiquetador que no es una subclase de SequentialBackoffTagger. Frente a él, una serie de reglas para corregir los resultados de un etiquetador inicial es utilizada porBrillTagger.
¿Como funciona?
Para entrenar a un BrillTagger clase usando BrillTaggerTrainer definimos la siguiente función -
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)Como podemos ver, esta función requiere initial_tagger y train_sentences. Se necesita uninitial_tagger argumento y una lista de plantillas, que implementa el BrillTemplateinterfaz. losBrillTemplate La interfaz se encuentra en el nltk.tbl.templatemódulo. Una de esas implementaciones esbrill.Template clase.
El papel principal del etiquetador basado en transformación es generar reglas de transformación que corrijan la salida del etiquetador inicial para que esté más en línea con las oraciones de entrenamiento. Veamos el flujo de trabajo a continuación:
Ejemplo
Para este ejemplo, usaremos combine_tagger que creamos mientras combinábamos etiquetadores (en la receta anterior) de una cadena de retroceso de NgramTagger clases, como initial_tagger. Primero, evaluemos el resultado usandoCombine.tagger y luego usar eso como initial_tagger entrenar al brillante etiquetador.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Salida
0.9234530029238365Ahora, veamos el resultado de la evaluación cuando Combine_tagger se usa como initial_tagger entrenar al etiquetador brillante -
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Salida
0.9246832510505041Podemos notar que BrillTagger La clase tiene una precisión ligeramente mayor que la Combine_tagger.
Ejemplo de implementación completo
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Salida
0.9234530029238365
0.9246832510505041Etiquetador TnT
TnT Tagger, siglas de Trigrams'nTags, es un etiquetador estadístico que se basa en modelos de Markov de segundo orden.
¿Como funciona?
Podemos entender el funcionamiento del etiquetador TnT con la ayuda de los siguientes pasos:
Primero basado en datos de entrenamiento, TnT tegger mantiene varios FreqDist y ConditionalFreqDist instancias.
Después de eso, los unigramas, bigramas y trigramas serán contados por estas distribuciones de frecuencia.
Ahora, durante el etiquetado, mediante el uso de frecuencias, calculará las probabilidades de posibles etiquetas para cada palabra.
Es por eso que en lugar de construir una cadena de retroceso de NgramTagger, usa todos los modelos de ngram juntos para elegir la mejor etiqueta para cada palabra. Evaluemos la precisión con el etiquetador TnT en el siguiente ejemplo:
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Salida
0.9165508316157791Tenemos un poco menos de precisión que con Brill Tagger.
Tenga en cuenta que tenemos que llamar train() antes de evaluate() de lo contrario, obtendremos un 0% de precisión.
Análisis y su relevancia en PNL
La palabra 'Parsing' cuyo origen es de palabra latina ‘pars’ (lo que significa ‘part’), se utiliza para extraer el significado exacto o el significado del diccionario del texto. También se llama análisis sintáctico o análisis de sintaxis. Al comparar las reglas de la gramática formal, el análisis de sintaxis comprueba el significado del texto. La oración como "Dame un helado caliente", por ejemplo, sería rechazada por el analizador sintáctico o el analizador sintáctico.
En este sentido, podemos definir parsing o análisis sintáctico o análisis de sintaxis de la siguiente manera:
Puede definirse como el proceso de analizar las cadenas de símbolos en el lenguaje natural conforme a las reglas de la gramática formal.
Podemos entender la relevancia del análisis sintáctico en PNL con la ayuda de los siguientes puntos:
El analizador se utiliza para informar cualquier error de sintaxis.
Ayuda a recuperarse de errores que ocurren comúnmente para que el procesamiento del resto del programa pueda continuar.
El árbol de análisis se crea con la ayuda de un analizador.
El analizador se utiliza para crear una tabla de símbolos, que juega un papel importante en la PNL.
El analizador también se utiliza para producir representaciones intermedias (IR).
Análisis profundo versus poco profundo
| Análisis profundo | Análisis superficial |
|---|---|
| En el análisis profundo, la estrategia de búsqueda dará una estructura sintáctica completa a una oración. | Es la tarea de analizar una parte limitada de la información sintáctica de la tarea dada. |
| Es adecuado para aplicaciones complejas de PNL. | Se puede utilizar para aplicaciones de PNL menos complejas. |
| Los sistemas de diálogo y el resumen son ejemplos de aplicaciones de PNL en las que se utiliza el análisis profundo. | La extracción de información y la minería de texto son ejemplos de aplicaciones de PNL en las que se utiliza el análisis profundo. |
| También se llama análisis completo. | También se llama fragmentación. |
Varios tipos de analizadores
Como se discutió, un analizador es básicamente una interpretación procedimental de la gramática. Encuentra un árbol óptimo para la oración dada después de buscar en el espacio de una variedad de árboles. Veamos algunos de los analizadores disponibles a continuación:
Analizador sintáctico de descenso recursivo
El análisis sintáctico de descenso recursivo es una de las formas más sencillas de análisis sintáctico. A continuación se presentan algunos puntos importantes sobre el analizador de descenso recursivo:
Sigue un proceso de arriba hacia abajo.
Intenta verificar que la sintaxis del flujo de entrada sea correcta o no.
Lee la oración de entrada de izquierda a derecha.
Una operación necesaria para el analizador sintáctico descendente recursivo es leer caracteres del flujo de entrada y hacerlos coincidir con los terminales de la gramática.
Analizador de cambio-reducción
A continuación se presentan algunos puntos importantes sobre el analizador sintáctico shift-reduce:
Sigue un proceso simple de abajo hacia arriba.
Intenta encontrar una secuencia de palabras y frases que correspondan al lado derecho de una producción gramatical y las reemplaza con el lado izquierdo de la producción.
El intento anterior de encontrar una secuencia de palabras continúa hasta que se reduce toda la oración.
En otras palabras simples, el analizador shift-reduce comienza con el símbolo de entrada e intenta construir el árbol del analizador hasta el símbolo de inicio.
Analizador de gráficos
A continuación se presentan algunos puntos importantes sobre el analizador de gráficos:
Es principalmente útil o adecuado para gramáticas ambiguas, incluidas gramáticas de lenguajes naturales.
Aplica programación dinámica a los problemas de análisis.
Debido a la programación dinámica, los resultados hipotéticos parciales se almacenan en una estructura denominada "gráfico".
El 'gráfico' también se puede reutilizar.
Analizador de expresiones regulares
El análisis de expresiones regulares es una de las técnicas de análisis más utilizadas. A continuación se presentan algunos puntos importantes sobre el analizador Regexp:
Como su nombre lo indica, utiliza una expresión regular definida en forma de gramática encima de una cadena con etiqueta POS.
Básicamente utiliza estas expresiones regulares para analizar las oraciones de entrada y generar un árbol de análisis a partir de esto.
Ejemplo
A continuación se muestra un ejemplo funcional de Regexp Parser:
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Salida
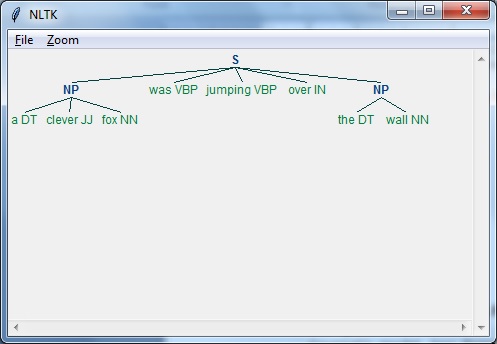
Análisis de dependencias
Análisis de dependencias (DP), un mecanismo de análisis moderno, cuyo concepto principal es que cada unidad lingüística, es decir, palabras, se relaciona entre sí mediante un vínculo directo. Estos enlaces directos son en realidad‘dependencies’en lingüística. Por ejemplo, el siguiente diagrama muestra la gramática de dependencia para la oración“John can hit the ball”.

Paquete NLTK
Hemos seguido las dos formas de realizar análisis de dependencia con NLTK:
Analizador probabilístico de dependencia proyectiva
Esta es la primera forma en que podemos hacer análisis de dependencia con NLTK. Pero este analizador tiene la restricción de entrenamiento con un conjunto limitado de datos de entrenamiento.
Analizador de Stanford
Esta es otra forma en que podemos hacer análisis de dependencia con NLTK. El analizador de Stanford es un analizador de dependencias de última generación. NLTK tiene un envoltorio alrededor. Para usarlo, necesitamos descargar las siguientes dos cosas:
El analizador de Stanford CoreNLP .
Modelo de idioma para el idioma deseado. Por ejemplo, modelo de idioma inglés.
Ejemplo
Una vez que descargó el modelo, podemos usarlo a través de NLTK de la siguiente manera:
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Salida
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]¿Qué es Chunking?
La fragmentación, uno de los procesos importantes en el procesamiento del lenguaje natural, se utiliza para identificar partes del habla (POS) y frases cortas. En otras palabras simples, con fragmentación, podemos obtener la estructura de la oración. También es llamadopartial parsing.
Patrones de trozos y grietas
Chunk patternsson los patrones de las etiquetas de parte del discurso (POS) que definen qué tipo de palabras componen un fragmento. Podemos definir patrones de fragmentos con la ayuda de expresiones regulares modificadas.
Además, también podemos definir patrones para qué tipo de palabras no deben estar en un fragmento y estas palabras sin fragmentar se conocen como chinks.
Ejemplo de implementación
En el siguiente ejemplo, junto con el resultado de analizar la oración “the book has many chapters”, Hay una gramática para las frases nominales que combina un patrón de fragmentos y un patrón de grietas.
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Salida
Como se vio anteriormente, el patrón para especificar un fragmento es usar llaves de la siguiente manera:
{<DT><NN>}Y para especificar una grieta, podemos voltear las llaves de la siguiente manera:
}<VB>{.Ahora, para un tipo de frase en particular, estas reglas se pueden combinar en una gramática.
Extracción de información
Hemos pasado por etiquetadores y analizadores que se pueden utilizar para construir un motor de extracción de información. Veamos una canalización básica de extracción de información:
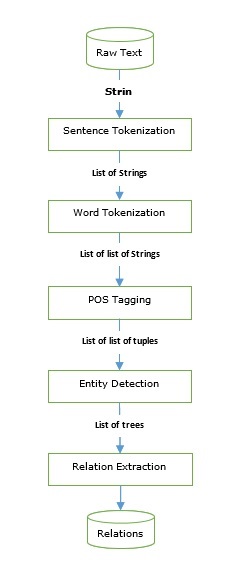
La extracción de información tiene muchas aplicaciones que incluyen:
- Inteligencia de negocios
- Reanudar la recolección
- Análisis de medios
- Detección de sentimiento
- Búsqueda de patentes
- Escaneo de correo electrónico
Reconocimiento de entidad designada (NER)
El reconocimiento de entidad con nombre (NER) es en realidad una forma de extraer algunas de las entidades más comunes como nombres, organizaciones, ubicación, etc. Veamos un ejemplo que tomó todos los pasos de preprocesamiento, como la tokenización de oraciones, etiquetado POS, fragmentación, NER, y sigue la tubería provista en la figura anterior.
Ejemplo
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Algunos de los reconocimientos de entidades nombradas (NER) modificados también se pueden utilizar para extraer entidades como nombres de productos, entidades biomédicas, marcas y mucho más.
Extracción de relaciones
La extracción de relaciones, otra operación de extracción de información comúnmente utilizada, es el proceso de extraer las diferentes relaciones entre varias entidades. Pueden existir diferentes relaciones como herencia, sinónimos, análogos, etc., cuya definición depende de la necesidad de información. Por ejemplo, supongamos que si queremos buscar la escritura de un libro, la autoría sería una relación entre el nombre del autor y el nombre del libro.
Ejemplo
En el siguiente ejemplo, usamos la misma canalización de IE, como se muestra en el diagrama anterior, que usamos hasta la relación de entidad nombrada (NER) y la ampliamos con un patrón de relación basado en las etiquetas NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Salida
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']En el código anterior, hemos utilizado un corpus incorporado llamado ieer. En este corpus, las oraciones se etiquetan hasta Relación entidad con nombre (NER). Aquí solo necesitamos especificar el patrón de relación que queremos y el tipo de NER que queremos que defina la relación. En nuestro ejemplo, definimos la relación entre una organización y una ubicación. Extrajimos todas las combinaciones de estos patrones.
¿Por qué transformar Chunks?
Hasta ahora tenemos fragmentos o frases de oraciones, pero ¿qué se supone que debemos hacer con ellas? Una de las tareas importantes es transformarlos. ¿Pero por qué? Es hacer lo siguiente:
- corrección gramatical y
- reordenando frases
Filtrar palabras insignificantes / inútiles
Suponga que si desea juzgar el significado de una frase, hay muchas palabras de uso común, como "la", "a", que son insignificantes o inútiles. Por ejemplo, vea la siguiente frase:
'La película fue buena'.
Aquí las palabras más significativas son "película" y "bueno". Otras palabras, "el" y "era" son inútiles o insignificantes. Es porque sin ellos también podemos obtener el mismo significado de la frase. 'Buena película'.
En la siguiente receta de Python, aprenderemos cómo eliminar palabras inútiles / insignificantes y mantener las palabras significativas con la ayuda de etiquetas POS.
Ejemplo
Primero, mirando a través treebankcorpus para palabras vacías, necesitamos decidir qué etiquetas de parte del discurso son significativas y cuáles no. Veamos la siguiente tabla de palabras y etiquetas insignificantes:
| Palabra | Etiqueta |
|---|---|
| un | DT |
| Todas | PDT |
| Un | DT |
| Y | CC |
| O | CC |
| Ese | WDT |
| los | DT |
En la tabla anterior, podemos ver además de CC, todas las demás etiquetas terminan con DT, lo que significa que podemos filtrar palabras insignificantes mirando el sufijo de la etiqueta.
Para este ejemplo, usaremos una función llamada filter()que toma un solo fragmento y devuelve un nuevo fragmento sin ninguna palabra etiquetada insignificante. Esta función filtra las etiquetas que terminan en DT o CC.
Ejemplo
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)Ahora, usemos esta función filter () en nuestra receta de Python para eliminar palabras insignificantes -
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])Salida
[('good', 'JJ'), ('movie', 'NN')]Corrección de verbos
Muchas veces, en el lenguaje del mundo real vemos formas verbales incorrectas. Por ejemplo, '¿estás bien?' no es correcto. La forma verbal no es correcta en esta oración. La oración debería ser '¿estás bien?' NLTK nos proporciona la forma de corregir tales errores mediante la creación de asignaciones de corrección de verbos. Estos mapeos de corrección se utilizan dependiendo de si hay un sustantivo plural o singular en el fragmento.
Ejemplo
Para implementar la receta de Python, primero necesitamos definir asignaciones de corrección de verbos. Creemos dos mapas de la siguiente manera:
Plural to Singular mappings
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}Singular to Plural mappings
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}Como se vio arriba, cada mapeo tiene un verbo etiquetado que se asigna a otro verbo etiquetado. Las asignaciones iniciales en nuestro ejemplo cubren lo básico de las asignacionesis to are, was to were, y viceversa.
A continuación, definiremos una función llamada verbs(), en el que puedes pasar una grieta con la forma verbal incorrecta y obtendrás una parte corregida. Para hacerloverb() La función usa una función auxiliar llamada index_chunk() que buscará en el fragmento la posición de la primera palabra etiquetada.
Veamos estas funciones -
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunkGuarde estas funciones en un archivo de Python en su directorio local donde está instalado Python o Anaconda y ejecútelo. Lo he guardado comoverbcorrect.py.
Ahora, llamemos verbs() función en un POS etiquetado is you fine trozo -
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])Salida
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]Eliminando la voz pasiva de las frases
Otra tarea útil es eliminar la voz pasiva de las frases. Esto se puede hacer con la ayuda de intercambiar las palabras alrededor de un verbo. Por ejemplo,‘the tutorial was great’ se puede transformar en ‘the great tutorial’.
Ejemplo
Para lograr esto, estamos definiendo una función llamada eliminate_passive()que intercambiará el lado derecho del fragmento con el lado izquierdo usando el verbo como punto de pivote. Para encontrar el verbo pivotar, también usará elindex_chunk() función definida anteriormente.
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]Ahora, llamemos eliminate_passive() función en un POS etiquetado the tutorial was great trozo -
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)Salida
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]Intercambio de cardenales sustantivos
Como sabemos, una palabra cardinal como 5 se etiqueta como CD en un fragmento. Estas palabras cardinales suelen aparecer antes o después de un sustantivo, pero para fines de normalización es útil colocarlas siempre antes del sustantivo. Por ejemplo, la fechaJanuary 5 Se puede escribir como 5 January. Entendamos con el siguiente ejemplo.
Ejemplo
Para lograr esto, estamos definiendo una función llamada swapping_cardinals()que cambiará cualquier cardenal que ocurra inmediatamente después de un sustantivo con el sustantivo. Con esto, el cardenal aparecerá inmediatamente antes del sustantivo. Para hacer una comparación de igualdad con la etiqueta dada, usa una función auxiliar que nombramos comotag_eql().
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return fAhora podemos definir swapping_cardinals () -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunkAhora, llamemos swapping_cardinals() funcionar en una cita “January 5” -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])Salida
[('10', 'CD'), ('January', 'NNP')]
10 JanuaryLas siguientes son las dos razones para transformar los árboles:
- Para modificar el árbol de análisis profundo y
- Para aplanar árboles de análisis profundo
Conversión de árbol o subárbol en oración
La primera receta que vamos a discutir aquí es convertir un árbol o subárbol de nuevo en una oración o cadena de bloques. Esto es muy simple, veamos en el siguiente ejemplo:
Ejemplo
from nltk.corpus import treebank_chunk
tree = treebank_chunk.chunked_sents()[2]
' '.join([w for w, t in tree.leaves()])Salida
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields
PLC , was named a nonexecutive director of this British industrial
conglomerate .'Aplanamiento profundo de árboles
Los árboles profundos de frases anidadas no se pueden usar para entrenar un fragmento, por lo tanto, debemos aplanarlos antes de usarlos. En el siguiente ejemplo, usaremos la tercera oración analizada, que es un árbol profundo de frases anidadas, de latreebank cuerpo.
Ejemplo
Para lograr esto, estamos definiendo una función llamada deeptree_flat()que tomará un solo árbol y devolverá un nuevo árbol que mantiene solo los árboles del nivel más bajo. Para hacer la mayor parte del trabajo, utiliza una función auxiliar que nombramos comochildtree_flat().
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))Ahora, llamemos deeptree_flat() función en la tercera oración analizada, que es un árbol profundo de frases anidadas, de la treebankcuerpo. Guardamos estas funciones en un archivo llamado deeptree.py.
from deeptree import deeptree_flat
from nltk.corpus import treebank
deeptree_flat(treebank.parsed_sents()[2])Salida
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Construcción de árbol poco profundo
En la sección anterior, aplanamos un árbol profundo de frases anidadas manteniendo solo los subárboles de nivel más bajo. En esta sección, vamos a mantener solo los subárboles de más alto nivel, es decir, para construir el árbol poco profundo. En el siguiente ejemplo usaremos la tercera oración analizada, que es un árbol profundo de frases anidadas, de latreebank cuerpo.
Ejemplo
Para lograr esto, estamos definiendo una función llamada tree_shallow() que eliminará todos los subárboles anidados manteniendo solo las etiquetas del subárbol superior.
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)Ahora, llamemos tree_shallow()función el 3 rd frase analizada, que es profunda árbol de frases anidadas, desde eltreebankcuerpo. Guardamos estas funciones en un archivo llamado shallowtree.py.
from shallowtree import shallow_tree
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2])Salida
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Podemos ver la diferencia con la ayuda de obtener la altura de los árboles:
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2]).height()Salida
3from nltk.corpus import treebank
treebank.parsed_sents()[2].height()Salida
9Conversión de etiquetas de árbol
En los árboles de análisis hay variedad de Treetipos de etiquetas que no están presentes en los árboles de trozos. Pero mientras usamos el árbol de análisis para entrenar un fragmento, nos gustaría reducir esta variedad convirtiendo algunas de las etiquetas de árbol en tipos de etiquetas más comunes. Por ejemplo, tenemos dos subárboles NP alternativos, a saber, NP-SBL y NP-TMP. Podemos convertir ambos en NP. Veamos cómo hacerlo en el siguiente ejemplo.
Ejemplo
Para lograr esto, estamos definiendo una función llamada tree_convert() que toma los siguientes dos argumentos:
- Árbol para convertir
- Un mapeo de conversión de etiquetas
Esta función devolverá un nuevo árbol con todas las etiquetas coincidentes reemplazadas según los valores del mapeo.
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)Ahora, llamemos tree_convert() función en la tercera oración analizada, que es un árbol profundo de frases anidadas, de la treebankcuerpo. Guardamos estas funciones en un archivo llamadoconverttree.py.
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)Salida
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])¿Qué es la clasificación de texto?
La clasificación de texto, como su nombre lo indica, es la forma de clasificar fragmentos de texto o documentos. Pero aquí surge la pregunta de que ¿por qué necesitamos usar clasificadores de texto? Una vez examinado el uso de palabras en un documento o fragmento de texto, los clasificadores podrán decidir qué etiqueta de clase se le debe asignar.
Clasificador binario
Como su nombre lo indica, el clasificador binario decidirá entre dos etiquetas. Por ejemplo, positivo o negativo. En este, el fragmento de texto o documento puede ser una etiqueta u otra, pero no ambas.
Clasificador de etiquetas múltiples
A diferencia del clasificador binario, el clasificador de etiquetas múltiples puede asignar una o más etiquetas a un fragmento de texto o documento.
Conjunto de funciones etiquetadas versus no etiquetadas
Un mapeo de valores clave de nombres de características a valores de características se denomina conjunto de características. Los conjuntos de características etiquetadas o los datos de entrenamiento son muy importantes para el entrenamiento de clasificación, de modo que luego pueda clasificar el conjunto de características sin etiquetar.
| Conjunto de funciones etiquetadas | Conjunto de funciones sin etiquetar |
|---|---|
| Es una tupla que se parece a (hazaña, etiqueta). | Es una hazaña en sí misma. |
| Es una instancia con una etiqueta de clase conocida. | Sin etiqueta asociada, podemos llamarlo instancia. |
| Se utiliza para entrenar un algoritmo de clasificación. | Una vez entrenado, el algoritmo de clasificación puede clasificar un conjunto de características sin etiquetar. |
Extracción de características de texto
La extracción de características de texto, como su nombre lo indica, es el proceso de transformar una lista de palabras en un conjunto de características que puede utilizar un clasificador. Debemos tener que transformar nuestro texto en‘dict’ conjuntos de características de estilo porque el Kit de herramientas de lenguaje natural (NLTK) espera ‘dict’ conjuntos de características de estilo.
Modelo de bolsa de palabras (BoW)
BoW, uno de los modelos más simples en PNL, se utiliza para extraer las características de un texto o documento para que pueda usarse en el modelado, como en los algoritmos de ML. Básicamente, construye un conjunto de características de presencia de palabras a partir de todas las palabras de una instancia. El concepto detrás de este método es que no le importa cuántas veces aparece una palabra o el orden de las palabras, solo le importa si la palabra está presente en una lista de palabras o no.
Ejemplo
Para este ejemplo, vamos a definir una función llamada bow () -
def bow(words):
return dict([(word, True) for word in words])Ahora, llamemos bow()función en palabras. Guardamos estas funciones en un archivo llamado bagwords.py.
from bagwords import bow
bow(['we', 'are', 'using', 'tutorialspoint'])Salida
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}Clasificadores de entrenamiento
En secciones anteriores, aprendimos cómo extraer características del texto. Entonces ahora podemos entrenar a un clasificador. El primer clasificador y el más sencillo esNaiveBayesClassifier clase.
Clasificador Naïve Bayes
Para predecir la probabilidad de que un conjunto de características dado pertenezca a una etiqueta particular, utiliza el teorema de Bayes. La fórmula del teorema de Bayes es la siguiente.
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$Aquí,
P(A|B) - También se denomina probabilidad posterior, es decir, la probabilidad de que ocurra el primer evento, es decir, A, dado que ocurrió el segundo evento, es decir, B.
P(B|A) - Es la probabilidad de que el segundo evento, es decir, B ocurra después del primer evento, es decir, A ocurrió.
P(A), P(B) - También se denomina probabilidad previa, es decir, la probabilidad de que ocurra el primer evento, es decir, A o el segundo, es decir, B.
Para entrenar el clasificador Naïve Bayes, usaremos el movie_reviewscorpus de NLTK. Este corpus tiene dos categorías de texto, a saber:pos y neg. Estas categorías hacen que un clasificador entrenado en ellas sea un clasificador binario. Cada archivo del corpus se compone de dos, uno es una reseña de película positiva y otro es una reseña de película negativa. En nuestro ejemplo, utilizaremos cada archivo como una única instancia tanto para entrenar como para probar el clasificador.
Ejemplo
Para el clasificador de entrenamiento, necesitamos una lista de conjuntos de características etiquetados, que tendrá el formato [(featureset, label)]. Aquí elfeatureset variable es una dict y la etiqueta es la etiqueta de clase conocida para el featureset. Vamos a crear una función llamadalabel_corpus() que tomará un corpus llamado movie_reviewsy también una función llamada feature_detector, que por defecto es bag of words. Construirá y devolverá un mapeo del formulario, {etiqueta: [conjunto de características]}. Después de eso, utilizaremos este mapeo para crear una lista de instancias de entrenamiento etiquetadas e instancias de prueba.
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_featsCon la ayuda de la función anterior obtendremos un mapeo {label:fetaureset}. Ahora vamos a definir una función más llamadasplit que tomará un mapeo devuelto por label_corpus() función y divide cada lista de conjuntos de características en entrenamiento etiquetado, así como en instancias de prueba.
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_featsAhora, usemos estas funciones en nuestro corpus, es decir, movietitis -
from nltk.corpus import movie_reviews
from featx import label_feats_from_corpus, split_label_feats
movie_reviews.categories()Salida
['neg', 'pos']Ejemplo
lfeats = label_feats_from_corpus(movie_reviews)
lfeats.keys()Salida
dict_keys(['neg', 'pos'])Ejemplo
train_feats, test_feats = split_label_feats(lfeats, split = 0.75)
len(train_feats)Salida
1500Ejemplo
len(test_feats)Salida
500Lo hemos visto en movie_reviewscorpus, hay 1000 archivos pos y 1000 archivos neg. También terminamos con 1500 instancias de capacitación etiquetadas y 500 instancias de prueba etiquetadas.
Ahora entrenemos NaïveBayesClassifier usando su train() método de clase -
from nltk.classify import NaiveBayesClassifier
NBC = NaiveBayesClassifier.train(train_feats)
NBC.labels()Salida
['neg', 'pos']Clasificador de árbol de decisión
Otro clasificador importante es el clasificador de árbol de decisión. Aquí para entrenarloDecisionTreeClassifierclase creará una estructura de árbol. En esta estructura de árbol, cada nodo corresponde a un nombre de característica y las ramas corresponden a los valores de característica. Y bajando las ramas llegaremos a las hojas del árbol, es decir, las etiquetas de clasificación.
Para entrenar el clasificador del árbol de decisión, usaremos las mismas funciones de entrenamiento y prueba, es decir train_feats y test_feats, variables que hemos creado a partir de movie_reviews cuerpo.
Ejemplo
Para entrenar este clasificador, llamaremos DecisionTreeClassifier.train() método de clase de la siguiente manera:
from nltk.classify import DecisionTreeClassifier
decisiont_classifier = DecisionTreeClassifier.train(
train_feats, binary = True, entropy_cutoff = 0.8,
depth_cutoff = 5, support_cutoff = 30
)
accuracy(decisiont_classifier, test_feats)Salida
0.725Clasificador de máxima entropía
Otro clasificador importante es MaxentClassifier que también se conoce como conditional exponential classifier o logistic regression classifier. Aquí para entrenarlo, elMaxentClassifier class convertirá conjuntos de características etiquetados en vectores usando codificación.
Para entrenar el clasificador del árbol de decisión, usaremos las mismas funciones de entrenamiento y prueba, es decir train_featsy test_feats, variables que hemos creado a partir de movie_reviews cuerpo.
Ejemplo
Para entrenar este clasificador, llamaremos MaxentClassifier.train() método de clase de la siguiente manera:
from nltk.classify import MaxentClassifier
maxent_classifier = MaxentClassifier
.train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5)
accuracy(maxent_classifier, test_feats)Salida
0.786Clasificador de Scikit-learn
Una de las mejores bibliotecas de aprendizaje automático (ML) es Scikit-learn. En realidad, contiene todo tipo de algoritmos ML para varios propósitos, pero todos tienen el mismo patrón de diseño de ajuste de la siguiente manera:
- Ajustar el modelo a los datos
- Y usa ese modelo para hacer predicciones
En lugar de acceder directamente a los modelos de scikit-learn, aquí usaremos NLTK's SklearnClassifierclase. Esta clase es una clase contenedora alrededor de un modelo scikit-learn para que se ajuste a la interfaz Classifier de NLTK.
Seguiremos los siguientes pasos para capacitar a un SklearnClassifier clase -
Step 1 - Primero crearemos funciones de entrenamiento como hicimos en recetas anteriores.
Step 2 - Ahora, elija e importe un algoritmo de Scikit-learn.
Step 3 - A continuación, necesitamos construir un SklearnClassifier class con el algoritmo elegido.
Step 4 - Por último, entrenaremos SklearnClassifier clase con nuestras funciones de entrenamiento.
Implementemos estos pasos en la siguiente receta de Python:
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import MultinomialNB
sklearn_classifier = SklearnClassifier(MultinomialNB())
sklearn_classifier.train(train_feats)
<SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))>
accuracy(sk_classifier, test_feats)Salida
0.885Medición de precisión y recuperación
Al entrenar varios clasificadores, también hemos medido su precisión. Pero además de la precisión, hay otras métricas que se utilizan para evaluar los clasificadores. Dos de estas métricas sonprecision y recall.
Ejemplo
En este ejemplo, vamos a calcular la precisión y la recuperación de la clase NaiveBayesClassifier que entrenamos anteriormente. Para lograr esto, crearemos una función llamada metrics_PR () que tomará dos argumentos, uno es el clasificador entrenado y el otro son las características de prueba etiquetadas. Ambos argumentos son los mismos que pasamos al calcular la precisión de los clasificadores:
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recallsLlamemos a esta función para encontrar la precisión y recordar:
from metrics_classification import metrics_PR
nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats)
nb_precisions['pos']Salida
0.6713532466435213Ejemplo
nb_precisions['neg']Salida
0.9676271186440678Ejemplo
nb_recalls['pos']Salida
0.96Ejemplo
nb_recalls['neg']Salida
0.478Combinación de clasificador y votación
La combinación de clasificadores es una de las mejores formas de mejorar el rendimiento de la clasificación. Y votar es una de las mejores formas de combinar múltiples clasificadores. Para votar necesitamos tener un número impar de clasificadores. En la siguiente receta de Python vamos a combinar tres clasificadores, a saber, la clase NaiveBayesClassifier, la clase DecisionTreeClassifier y la clase MaxentClassifier.
Para lograr esto, vamos a definir una función llamada vote_classifiers () de la siguiente manera.
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()Llamemos a esta función para combinar tres clasificadores y encontrar la precisión:
from vote_classification import Voting_classifiers
combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier)
combined_classifier.labels()Salida
['neg', 'pos']Ejemplo
accuracy(combined_classifier, test_feats)Salida
0.948De la salida anterior, podemos ver que los clasificadores combinados obtuvieron la mayor precisión que los clasificadores individuales.