Python Web Scraping - Guía rápida
El web scraping es un proceso automático de extracción de información de la web. Este capítulo le dará una idea en profundidad del raspado web, su comparación con el rastreo web y por qué debería optar por el raspado web. También aprenderá sobre los componentes y el funcionamiento de un web scraper.
¿Qué es Web Scraping?
El significado del diccionario de la palabra "Desguace" implica obtener algo de la web. Aquí surgen dos preguntas: qué podemos obtener de la web y cómo obtenerlo.
La respuesta a la primera pregunta es ‘data’. Los datos son indispensables para cualquier programador y el requisito básico de todo proyecto de programación es la gran cantidad de datos útiles.
La respuesta a la segunda pregunta es un poco complicada, porque hay muchas formas de obtener datos. En general, podemos obtener datos de una base de datos o archivo de datos y otras fuentes. Pero, ¿y si necesitamos una gran cantidad de datos disponibles en línea? Una forma de obtener este tipo de datos es buscar manualmente (haciendo clic en un navegador web) y guardar (copiar y pegar en una hoja de cálculo o archivo) los datos necesarios. Este método es bastante tedioso y requiere mucho tiempo. Otra forma de obtener estos datos es utilizandoweb scraping.
Web scraping, también llamado web data mining o web harvesting, es el proceso de construcción de un agente que puede extraer, analizar, descargar y organizar información útil de la web automáticamente. En otras palabras, podemos decir que en lugar de guardar manualmente los datos de los sitios web, el software de raspado web cargará y extraerá automáticamente datos de varios sitios web según nuestro requisito.
Origen del web scraping
El origen del web scraping es el screen scraping, que se utilizó para integrar aplicaciones no basadas en web o aplicaciones nativas de Windows. Originalmente, el raspado de pantalla se usaba antes del amplio uso de World Wide Web (WWW), pero no se podía escalar WWW expandido. Esto hizo necesario automatizar el enfoque del raspado de pantalla y la técnica llamada‘Web Scraping’ llego a existir.
Rastreo web frente a raspado web
Los términos rastreo web y raspado a menudo se usan indistintamente, ya que el concepto básico de ellos es extraer datos. Sin embargo, son diferentes entre sí. Podemos entender la diferencia básica de sus definiciones.
El rastreo web se utiliza básicamente para indexar la información en la página utilizando bots, también conocidos como rastreadores. También es llamadoindexing. Por otro lado, el web scraping es una forma automatizada de extraer la información utilizando bots, también conocidos como scrapers. También es llamadodata extraction.
Para comprender la diferencia entre estos dos términos, echemos un vistazo a la tabla de comparación que se proporciona a continuación:
| Rastreo web | Raspado web |
|---|---|
| Se refiere a descargar y almacenar los contenidos de un gran número de sitios web. | Se refiere a la extracción de elementos de datos individuales del sitio web mediante el uso de una estructura específica del sitio. |
| Principalmente hecho a gran escala. | Se puede implementar a cualquier escala. |
| Produce información genérica. | Proporciona información específica. |
| Utilizado por los principales motores de búsqueda como Google, Bing, Yahoo. Googlebot es un ejemplo de un rastreador web. | La información extraída mediante web scraping se puede utilizar para replicar en algún otro sitio web o se puede utilizar para realizar análisis de datos. Por ejemplo, los elementos de datos pueden ser nombres, dirección, precio, etc. |
Usos del web scraping
Los usos y razones para usar el web scraping son tan infinitos como los usos de la World Wide Web. Los web scrapers pueden hacer cualquier cosa como pedir comida en línea, escanear el sitio web de compras en línea para usted y comprar el boleto de un partido en el momento en que estén disponibles, etc. Aquí se analizan algunos de los usos importantes del web scraping:
E-commerce Websites - Los web scrapers pueden recopilar los datos especialmente relacionados con el precio de un producto específico de varios sitios web de comercio electrónico para su comparación.
Content Aggregators - Los agregadores de contenido como los agregadores de noticias y los agregadores de trabajos utilizan ampliamente el web scraping para proporcionar datos actualizados a sus usuarios.
Marketing and Sales Campaigns - Los raspadores web se pueden utilizar para obtener datos como correos electrónicos, números de teléfono, etc. para campañas de ventas y marketing.
Search Engine Optimization (SEO) - El raspado web es ampliamente utilizado por herramientas de SEO como SEMRush, Majestic, etc. para indicar a las empresas cómo se clasifican para las palabras clave de búsqueda que les interesan.
Data for Machine Learning Projects - La recuperación de datos para proyectos de aprendizaje automático depende del raspado web.
Data for Research - Los investigadores pueden recopilar datos útiles para su trabajo de investigación ahorrando tiempo mediante este proceso automatizado.
Componentes de un Web Scraper
Un raspador de banda consta de los siguientes componentes:
Módulo de rastreador web
Un componente muy necesario del raspador web, el módulo del rastreador web, se utiliza para navegar por el sitio web de destino realizando una solicitud HTTP o HTTPS a las URL. El rastreador descarga los datos no estructurados (contenido HTML) y los pasa al extractor, el siguiente módulo.
Extractor
El extractor procesa el contenido HTML obtenido y extrae los datos en formato semiestructurado. Esto también se denomina módulo analizador y utiliza diferentes técnicas de análisis como expresión regular, análisis HTML, análisis DOM o Inteligencia Artificial para su funcionamiento.
Módulo de limpieza y transformación de datos
Los datos extraídos anteriormente no son adecuados para su uso inmediato. Debe pasar por algún módulo de limpieza para que podamos utilizarlo. Los métodos como la manipulación de cadenas o la expresión regular se pueden utilizar para este propósito. Tenga en cuenta que la extracción y la transformación también se pueden realizar en un solo paso.
Módulo de almacenamiento
Después de extraer los datos, debemos almacenarlos según nuestro requisito. El módulo de almacenamiento generará los datos en un formato estándar que se puede almacenar en una base de datos o en formato JSON o CSV.
Funcionamiento de un Web Scraper
El web scraper puede definirse como un software o un script que se utiliza para descargar el contenido de varias páginas web y extraer datos de ellas.
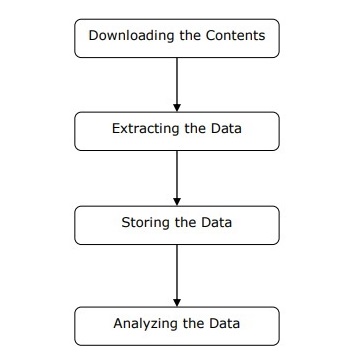
Podemos entender el funcionamiento de un raspador web en pasos simples como se muestra en el diagrama que se muestra arriba.
Paso 1: descarga de contenido de páginas web
En este paso, un raspador web descargará el contenido solicitado de varias páginas web.
Paso 2: extracción de datos
Los datos de los sitios web son HTML y en su mayoría no están estructurados. Por lo tanto, en este paso, web scraper analizará y extraerá datos estructurados de los contenidos descargados.
Paso 3: almacenar los datos
Aquí, un raspador web almacenará y guardará los datos extraídos en cualquiera de los formatos como CSV, JSON o en la base de datos.
Paso 4: analizar los datos
Después de que todos estos pasos se hayan realizado con éxito, el web scraper analizará los datos así obtenidos.
En el primer capítulo, hemos aprendido de qué se trata el web scraping. En este capítulo, veamos cómo implementar web scraping usando Python.
¿Por qué Python para Web Scraping?
Python es una herramienta popular para implementar web scraping. El lenguaje de programación Python también se utiliza para otros proyectos útiles relacionados con la seguridad cibernética, las pruebas de penetración y las aplicaciones forenses digitales. Usando la programación base de Python, el web scraping se puede realizar sin usar ninguna otra herramienta de terceros.
El lenguaje de programación Python está ganando gran popularidad y las razones que hacen que Python sea una buena opción para proyectos de raspado web son las siguientes:
Simplicidad de sintaxis
Python tiene la estructura más simple en comparación con otros lenguajes de programación. Esta característica de Python facilita las pruebas y el desarrollador puede centrarse más en la programación.
Módulos incorporados
Otra razón para usar Python para web scraping son las bibliotecas útiles integradas y externas que posee. Podemos realizar muchas implementaciones relacionadas con el web scraping utilizando Python como base para la programación.
Lenguaje de programación de código abierto
Python tiene un gran apoyo de la comunidad porque es un lenguaje de programación de código abierto.
Amplia gama de aplicaciones
Python se puede utilizar para varias tareas de programación que van desde pequeños scripts de shell hasta aplicaciones web empresariales.
Instalación de Python
La distribución de Python está disponible para plataformas como Windows, MAC y Unix / Linux. Necesitamos descargar solo el código binario aplicable a nuestra plataforma para instalar Python. Pero en caso de que el código binario de nuestra plataforma no esté disponible, debemos tener un compilador C para que el código fuente se pueda compilar manualmente.
Podemos instalar Python en varias plataformas de la siguiente manera:
Instalación de Python en Unix y Linux
Debe seguir los pasos que se indican a continuación para instalar Python en máquinas Unix / Linux:
Step 1 - Ir al enlace https://www.python.org/downloads/
Step 2 - Descargue el código fuente comprimido disponible para Unix / Linux en el enlace anterior.
Step 3 - Extrae los archivos a tu computadora.
Step 4 - Utilice los siguientes comandos para completar la instalación -
run ./configure script
make
make installPuede encontrar Python instalado en la ubicación estándar /usr/local/bin y sus bibliotecas en /usr/local/lib/pythonXX, donde XX es la versión de Python.
Instalación de Python en Windows
Debe seguir los pasos que se indican a continuación para instalar Python en máquinas con Windows:
Step 1 - Ir al enlace https://www.python.org/downloads/
Step 2 - Descarga el instalador de Windows python-XYZ.msi archivo, donde XYZ es la versión que necesitamos instalar.
Step 3 - Ahora, guarde el archivo de instalación en su máquina local y ejecute el archivo MSI.
Step 4 - Por último, ejecute el archivo descargado para que aparezca el asistente de instalación de Python.
Instalación de Python en Macintosh
Debemos usar Homebrew para instalar Python 3 en Mac OS X. Homebrew es fácil de instalar y un gran instalador de paquetes.
Homebrew también se puede instalar usando el siguiente comando:
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"Para actualizar el administrador de paquetes, podemos usar el siguiente comando:
$ brew updateCon la ayuda del siguiente comando, podemos instalar Python3 en nuestra máquina MAC:
$ brew install python3Configuración de PATH
Puede utilizar las siguientes instrucciones para configurar la ruta en varios entornos:
Configuración de la ruta en Unix / Linux
Utilice los siguientes comandos para configurar rutas utilizando varios shells de comandos:
Para csh shell
setenv PATH "$PATH:/usr/local/bin/python".Para bash shell (Linux)
ATH="$PATH:/usr/local/bin/python".Para sh o ksh shell
PATH="$PATH:/usr/local/bin/python".Configurar la ruta en Windows
Para configurar la ruta en Windows, podemos usar la ruta %path%;C:\Python en el símbolo del sistema y luego presione Entrar.
Ejecutando Python
Podemos iniciar Python usando cualquiera de las siguientes tres formas:
Intérprete interactivo
Se puede utilizar un sistema operativo como UNIX y DOS que proporciona un intérprete de línea de comandos o shell para iniciar Python.
Podemos comenzar a codificar en un intérprete interactivo de la siguiente manera:
Step 1 - Entrar python en la línea de comando.
Step 2 - Entonces, podemos comenzar a codificar de inmediato en el intérprete interactivo.
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSScript de la línea de comandos
Podemos ejecutar un script de Python en la línea de comando invocando al intérprete. Se puede entender de la siguiente manera:
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSEntorno de desarrollo integrado
También podemos ejecutar Python desde el entorno GUI si el sistema tiene una aplicación GUI que admita Python. A continuación se muestran algunos IDE que admiten Python en varias plataformas:
IDE for UNIX - UNIX, para Python, tiene IDE IDE.
IDE for Windows - Windows tiene PythonWin IDE que también tiene GUI.
IDE for Macintosh - Macintosh tiene IDLE IDE que se puede descargar como archivos MacBinary o BinHex'd desde el sitio web principal.
En este capítulo, aprendamos varios módulos de Python que podemos usar para web scraping.
Entornos de desarrollo de Python usando virtualenv
Virtualenv es una herramienta para crear entornos Python aislados. Con la ayuda de virtualenv, podemos crear una carpeta que contenga todos los ejecutables necesarios para usar los paquetes que requiere nuestro proyecto Python. También nos permite agregar y modificar módulos de Python sin acceso a la instalación global.
Puede usar el siguiente comando para instalar virtualenv -
(base) D:\ProgramData>pip install virtualenv
Collecting virtualenv
Downloading
https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3
5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl
(1.9MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s
Installing collected packages: virtualenv
Successfully installed virtualenv-16.0.0Ahora, necesitamos crear un directorio que represente el proyecto con la ayuda del siguiente comando:
(base) D:\ProgramData>mkdir webscrapAhora, ingrese a ese directorio con la ayuda de este siguiente comando:
(base) D:\ProgramData>cd webscrapAhora, necesitamos inicializar la carpeta del entorno virtual de nuestra elección de la siguiente manera:
(base) D:\ProgramData\webscrap>virtualenv websc
Using base prefix 'd:\\programdata'
New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe
Installing setuptools, pip, wheel...done.Ahora, active el entorno virtual con el comando que se proporciona a continuación. Una vez activado con éxito, verá su nombre en el lado izquierdo entre paréntesis.
(base) D:\ProgramData\webscrap>websc\scripts\activatePodemos instalar cualquier módulo en este entorno de la siguiente manera:
(websc) (base) D:\ProgramData\webscrap>pip install requests
Collecting requests
Downloading
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9
1kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading
https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca
55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133
kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading
https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364
4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl
(147kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s
Collecting urllib3<1.24,>=1.21.1 (from requests)
Downloading
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k
B)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s
Collecting idna<2.8,>=2.5 (from requests)
Downloading
https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746
a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s
Installing collected packages: chardet, certifi, urllib3, idna, requests
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1
urllib3-1.23Para desactivar el entorno virtual, podemos usar el siguiente comando:
(websc) (base) D:\ProgramData\webscrap>deactivate
(base) D:\ProgramData\webscrap>Puede ver que (websc) se ha desactivado.
Módulos de Python para web scraping
Web scraping es el proceso de construcción de un agente que puede extraer, analizar, descargar y organizar información útil de la web automáticamente. En otras palabras, en lugar de guardar manualmente los datos de los sitios web, el software de raspado web cargará y extraerá automáticamente datos de varios sitios web según nuestro requisito.
En esta sección, vamos a discutir acerca de las bibliotecas Python útiles para el raspado web.
Peticiones
Es una biblioteca de raspado web de Python simple. Es una biblioteca HTTP eficiente que se utiliza para acceder a páginas web. Con la ayuda deRequests, podemos obtener el HTML sin procesar de las páginas web que luego se pueden analizar para recuperar los datos. Antes de usarrequests, entendamos su instalación.
Instalación de solicitudes
Podemos instalarlo en nuestro entorno virtual o en la instalación global. Con la ayuda depip comando, podemos instalarlo fácilmente de la siguiente manera:
(base) D:\ProgramData> pip install requests
Collecting requests
Using cached
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl
Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages
(from requests) (2.6)
Requirement already satisfied: urllib3<1.24,>=1.21.1 in
d:\programdata\lib\site-packages (from requests) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages
(from requests) (2018.1.18)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in
d:\programdata\lib\site-packages (from requests) (3.0.4)
Installing collected packages: requests
Successfully installed requests-2.19.1Ejemplo
En este ejemplo, estamos realizando una solicitud GET HTTP para una página web. Para esto, primero debemos importar la biblioteca de solicitudes de la siguiente manera:
In [1]: import requestsEn esta siguiente línea de código, utilizamos solicitudes para realizar solicitudes GET HTTP para la URL: https://authoraditiagarwal.com/ haciendo una solicitud GET.
In [2]: r = requests.get('https://authoraditiagarwal.com/')Ahora podemos recuperar el contenido usando .text propiedad de la siguiente manera:
In [5]: r.text[:200]Observe que en la siguiente salida, obtuvimos los primeros 200 caracteres.
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope
\n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#"
>\n<head>\n\t<meta charset
="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'Urllib3
Es otra biblioteca de Python que se puede usar para recuperar datos de URL similares a requestsbiblioteca. Puede leer más sobre esto en su documentación técnica enhttps://urllib3.readthedocs.io/en/latest/.
Instalación de Urllib3
Utilizando el pip comando, podemos instalar urllib3 ya sea en nuestro entorno virtual o en una instalación global.
(base) D:\ProgramData>pip install urllib3
Collecting urllib3
Using cached
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl
Installing collected packages: urllib3
Successfully installed urllib3-1.23Ejemplo: raspado usando Urllib3 y BeautifulSoup
En el siguiente ejemplo, estamos raspando la página web usando Urllib3 y BeautifulSoup. Estamos usandoUrllib3en el lugar de la biblioteca de solicitudes para obtener los datos brutos (HTML) de la página web. Entonces estamos usandoBeautifulSoup para analizar esos datos HTML.
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)Esta es la salida que observará cuando ejecute este código:
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalSelenio
Es un conjunto de pruebas automatizadas de código abierto para aplicaciones web en diferentes navegadores y plataformas. No es una sola herramienta, sino un conjunto de software. Tenemos enlaces de selenio para Python, Java, C #, Ruby y JavaScript. Aquí vamos a realizar web scraping usando selenium y sus enlaces Python. Puede obtener más información sobre Selenium con Java en el enlace Selenium .
Los enlaces Selenium Python proporcionan una API conveniente para acceder a Selenium WebDrivers como Firefox, IE, Chrome, Remote, etc. Las versiones actuales de Python compatibles son 2.7, 3.5 y superiores.
Instalación de selenio
Utilizando el pip comando, podemos instalar urllib3 ya sea en nuestro entorno virtual o en una instalación global.
pip install seleniumComo selenium requiere un controlador para interactuar con el navegador elegido, necesitamos descargarlo. La siguiente tabla muestra diferentes navegadores y sus enlaces para descargar el mismo.
Chrome |
https://sites.google.com/a/chromium.org/ |
Edge |
https://developer.microsoft.com/ |
Firefox |
https://github.com/ |
Safari |
https://webkit.org/ |
Ejemplo
Este ejemplo muestra el web scraping con selenio. También se puede utilizar para pruebas que se denominan pruebas de selenio.
Después de descargar el controlador particular para la versión especificada del navegador, necesitamos programar en Python.
Primero, necesito importar webdriver de selenio de la siguiente manera:
from selenium import webdriverAhora, proporcione la ruta del controlador web que hemos descargado según nuestro requisito:
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)Ahora, proporcione la URL que queremos abrir en ese navegador web ahora controlado por nuestro script Python.
browser.get('https://authoraditiagarwal.com/leadershipmanagement')También podemos raspar un elemento en particular proporcionando el xpath como se proporciona en lxml.
browser.find_element_by_xpath('/html/body').click()Puede comprobar el resultado del navegador, controlado por la secuencia de comandos de Python.
Scrapy
Scrapy es un marco de rastreo web rápido y de código abierto escrito en Python, que se utiliza para extraer los datos de la página web con la ayuda de selectores basados en XPath. Scrapy se lanzó por primera vez el 26 de junio de 2008 con licencia BSD, con un hito 1.0 lanzado en junio de 2015. Nos proporciona todas las herramientas que necesitamos para extraer, procesar y estructurar los datos de los sitios web.
Instalación de Scrapy
Utilizando el pip comando, podemos instalar urllib3 ya sea en nuestro entorno virtual o en una instalación global.
pip install scrapyPara un estudio más detallado de Scrapy puedes ir al enlace Scrapy
Con Python, podemos raspar cualquier sitio web o elementos particulares de una página web, pero ¿tiene alguna idea de si es legal o no? Antes de raspar cualquier sitio web debemos tener que conocer la legalidad del raspado web. Este capítulo explicará los conceptos relacionados con la legalidad del web scraping.
Introducción
Generalmente, si va a utilizar los datos extraídos para uso personal, es posible que no haya ningún problema. Pero si va a volver a publicar esos datos, antes de hacer lo mismo, debe realizar una solicitud de descarga al propietario o realizar una investigación de antecedentes sobre las políticas y los datos que va a recopilar.
Investigación necesaria antes del raspado
Si apunta a un sitio web para extraer datos de él, debemos comprender su escala y estructura. A continuación se muestran algunos de los archivos que debemos analizar antes de comenzar con el web scraping.
Analizando robots.txt
En realidad, la mayoría de los editores permiten a los programadores rastrear sus sitios web hasta cierto punto. En otro sentido, los editores quieren que se rastreen partes específicas de los sitios web. Para definir esto, los sitios web deben establecer algunas reglas para indicar qué partes se pueden rastrear y cuáles no. Estas reglas se definen en un archivo llamadorobots.txt.
robots.txtes un archivo legible por humanos que se utiliza para identificar las partes del sitio web que los rastreadores pueden y no pueden rastrear. No existe un formato estándar de archivo robots.txt y los editores del sitio web pueden hacer modificaciones según sus necesidades. Podemos comprobar el archivo robots.txt de un sitio web en particular proporcionando una barra y un archivo robots.txt después de la URL de ese sitio web. Por ejemplo, si queremos verificarlo para Google.com, entonces debemos escribirhttps://www.google.com/robots.txt y obtendremos algo de la siguiente manera:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..Algunas de las reglas más comunes que se definen en el archivo robots.txt de un sitio web son las siguientes:
User-agent: BadCrawler
Disallow: /La regla anterior significa que el archivo robots.txt pregunta a un rastreador con BadCrawler agente de usuario para no rastrear su sitio web.
User-agent: *
Crawl-delay: 5
Disallow: /trapLa regla anterior significa que el archivo robots.txt retrasa al rastreador durante 5 segundos entre las solicitudes de descarga de todos los agentes de usuario para evitar la sobrecarga del servidor. los/traplink intentará bloquear los rastreadores maliciosos que siguen enlaces no permitidos. Hay muchas más reglas que puede definir el editor del sitio web según sus requisitos. Algunos de ellos se discuten aquí:
Analizar archivos de sitemaps
¿Qué se supone que debe hacer si desea rastrear un sitio web para obtener información actualizada? Rastreará todas las páginas web para obtener esa información actualizada, pero esto aumentará el tráfico del servidor de ese sitio web en particular. Es por eso que los sitios web proporcionan archivos de mapas del sitio para ayudar a los rastreadores a localizar el contenido actualizado sin necesidad de rastrear todas las páginas web. El estándar del mapa del sitio se define enhttp://www.sitemaps.org/protocol.html.
Contenido del archivo de mapa del sitio
El siguiente es el contenido del archivo de mapa del sitio de https://www.microsoft.com/robots.txt que se descubre en el archivo robot.txt -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlEl contenido anterior muestra que el mapa del sitio enumera las URL en el sitio web y además permite que un webmaster especifique información adicional como la última fecha de actualización, cambio de contenido, importancia de la URL en relación con otros, etc.sobre cada URL.
¿Cuál es el tamaño del sitio web?
¿El tamaño de un sitio web, es decir, el número de páginas web de un sitio web, afecta la forma en que rastreamos? Ciertamente si. Porque si tenemos menos páginas web para rastrear, entonces la eficiencia no sería un problema serio, pero supongamos que si nuestro sitio web tiene millones de páginas web, por ejemplo Microsoft.com, descargar cada página web secuencialmente tomaría varios meses y entonces la eficiencia sería una seria preocupación.
Comprobación del tamaño del sitio web
Al verificar el tamaño del resultado del rastreador de Google, podemos tener una estimación del tamaño de un sitio web. Nuestro resultado se puede filtrar usando la palabra clavesitemientras realiza la búsqueda en Google. Por ejemplo, estimar el tamaño dehttps://authoraditiagarwal.com/ se da a continuación -
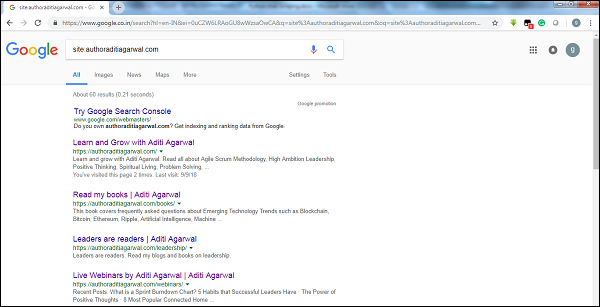
Puede ver que hay alrededor de 60 resultados, lo que significa que no es un sitio web grande y que el rastreo no conduciría al problema de la eficiencia.
¿Qué tecnología utiliza el sitio web?
Otra pregunta importante es si la tecnología utilizada por el sitio web afecta la forma en que rastreamos. Sí, afecta. Pero, ¿cómo podemos comprobar la tecnología que utiliza un sitio web? Hay una biblioteca de Python llamadabuiltwith con la ayuda del cual podemos conocer la tecnología que utiliza un sitio web.
Ejemplo
En este ejemplo vamos a comprobar la tecnología utilizada por el sitio web. https://authoraditiagarwal.com con la ayuda de la biblioteca Python builtwith. Pero antes de usar esta biblioteca, debemos instalarla de la siguiente manera:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3Ahora, con la ayuda de seguir una línea simple de códigos, podemos verificar la tecnología utilizada por un sitio web en particular:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}¿Quién es el propietario del sitio web?
El propietario del sitio web también es importante porque si el propietario es conocido por bloquear los rastreadores, los rastreadores deben tener cuidado al extraer los datos del sitio web. Hay un protocolo llamadoWhois con la ayuda de la cual podemos averiguar sobre el propietario del sitio web.
Ejemplo
En este ejemplo, vamos a comprobar si el propietario del sitio web dice microsoft.com con la ayuda de Whois. Pero antes de usar esta biblioteca, debemos instalarla de la siguiente manera:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0Ahora, con la ayuda de seguir una línea simple de códigos, podemos verificar la tecnología utilizada por un sitio web en particular:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}Analizar una página web significa comprender su estructura. Ahora, surge la pregunta de por qué es importante para el web scraping. En este capítulo, comprendamos esto en detalle.
Análisis de páginas web
El análisis de la página web es importante porque sin analizar no podemos saber en qué forma vamos a recibir los datos (estructurados o no) de esa página web después de la extracción. Podemos hacer análisis de páginas web de las siguientes formas:
Ver fuente de página
Esta es una forma de comprender cómo está estructurada una página web examinando su código fuente. Para implementar esto, necesitamos hacer clic derecho en la página y luego debemos seleccionar elView page sourceopción. Luego, obtendremos los datos de nuestro interés de esa página web en forma de HTML. Pero la principal preocupación son los espacios en blanco y el formato que nos resulta difícil de formatear.
Inspeccionar el origen de la página haciendo clic en la opción Inspeccionar elemento
Esta es otra forma de analizar la página web. Pero la diferencia es que resolverá el problema del formato y los espacios en blanco en el código fuente de la página web. Puede implementar esto haciendo clic derecho y luego seleccionando elInspect o Inspect elementopción del menú. Proporcionará la información sobre un área o elemento particular de esa página web.
Diferentes formas de extraer datos de una página web
Los siguientes métodos se utilizan principalmente para extraer datos de una página web:
Expresión regular
Son lenguajes de programación altamente especializados integrados en Python. Podemos usarlo a través deremódulo de Python. También se le llama RE o regexes o patrones de regex. Con la ayuda de expresiones regulares, podemos especificar algunas reglas para el posible conjunto de cadenas que queremos hacer coincidir a partir de los datos.
Si desea obtener más información sobre las expresiones regulares en general, vaya al enlace https://www.tutorialspoint.com/automata_theory/regular_expressions.htmy si desea saber más sobre el módulo re o la expresión regular en Python, puede seguir el enlace https://www.tutorialspoint.com/python/python_reg_expressions.htm .
Ejemplo
En el siguiente ejemplo, vamos a extraer datos sobre India de http://example.webscraping.com después de hacer coincidir el contenido de <td> con la ayuda de una expresión regular.
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)Salida
La salida correspondiente será como se muestra aquí:
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]Observe que en el resultado anterior puede ver los detalles sobre el país India utilizando expresiones regulares.
Hermosa sopa
Supongamos que queremos recopilar todos los hipervínculos de una página web, luego podemos usar un analizador llamado BeautifulSoup que se puede conocer con más detalle en https://www.crummy.com/software/BeautifulSoup/bs4/doc/.En palabras simples, BeautifulSoup es una biblioteca de Python para extraer datos de archivos HTML y XML. Se puede usar con solicitudes, porque necesita una entrada (documento o url) para crear un objeto de sopa, ya que no puede recuperar una página web por sí mismo. Puede utilizar la siguiente secuencia de comandos de Python para recopilar el título de la página web y los hipervínculos.
Instalación de Beautiful Soup
Utilizando el pip comando, podemos instalar beautifulsoup ya sea en nuestro entorno virtual o en una instalación global.
(base) D:\ProgramData>pip install bs4
Collecting bs4
Downloading
https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89
a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages
(from bs4) (4.6.0)
Building wheels for collected packages: bs4
Running setup.py bdist_wheel for bs4 ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d
52235414c3467d8889be38dd472
Successfully built bs4
Installing collected packages: bs4
Successfully installed bs4-0.0.1Ejemplo
Tenga en cuenta que en este ejemplo, estamos ampliando el ejemplo anterior implementado con el módulo de solicitudes de Python. estamos usandor.text para crear un objeto de sopa que luego se usará para obtener detalles como el título de la página web.
Primero, necesitamos importar los módulos de Python necesarios:
import requests
from bs4 import BeautifulSoupEn la siguiente línea de código, usamos solicitudes para realizar solicitudes GET HTTP para la URL: https://authoraditiagarwal.com/ haciendo una solicitud GET.
r = requests.get('https://authoraditiagarwal.com/')Ahora necesitamos crear un objeto Soup de la siguiente manera:
soup = BeautifulSoup(r.text, 'lxml')
print (soup.title)
print (soup.title.text)Salida
La salida correspondiente será como se muestra aquí:
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalLxml
Otra biblioteca de Python que vamos a discutir para web scraping es lxml. Es una biblioteca de análisis HTML y XML de alto rendimiento. Es comparativamente rápido y sencillo. Puedes leer más sobre esto enhttps://lxml.de/.
Instalación de lxml
Usando el comando pip, podemos instalar lxml ya sea en nuestro entorno virtual o en una instalación global.
(base) D:\ProgramData>pip install lxml
Collecting lxml
Downloading
https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e
3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl
(3.
6MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s
Installing collected packages: lxml
Successfully installed lxml-4.2.5Ejemplo: extracción de datos usando lxml y solicitudes
En el siguiente ejemplo, extraemos un elemento particular de la página web de authoraditiagarwal.com mediante el uso de lxml y solicitudes -
Primero, necesitamos importar las solicitudes y html de la biblioteca lxml de la siguiente manera:
import requests
from lxml import htmlAhora debemos proporcionar la URL de la página web para eliminar
url = 'https://authoraditiagarwal.com/leadershipmanagement/'Ahora necesitamos proporcionar el camino (Xpath) a un elemento particular de esa página web -
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]'
response = requests.get(url)
byte_string = response.content
source_code = html.fromstring(byte_string)
tree = source_code.xpath(path)
print(tree[0].text_content())Salida
La salida correspondiente será como se muestra aquí:
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate
daily progress to the stakeholders. It tracks the completion of work for a given sprint
or an iteration. The horizontal axis represents the days within a Sprint. The vertical
axis represents the hours remaining to complete the committed work.En capítulos anteriores, aprendimos sobre la extracción de datos de páginas web o el web scraping mediante varios módulos de Python. En este capítulo, veamos varias técnicas para procesar los datos que se han extraído.
Introducción
Para procesar los datos que se han extraído, debemos almacenar los datos en nuestra máquina local en un formato particular como hoja de cálculo (CSV), JSON o, a veces, en bases de datos como MySQL.
Procesamiento de datos CSV y JSON
Primero, vamos a escribir la información, después de tomarla de la página web, en un archivo CSV o una hoja de cálculo. Primero entendamos a través de un ejemplo simple en el que primero tomaremos la información usandoBeautifulSoup módulo, como se hizo anteriormente, y luego, usando el módulo Python CSV, escribiremos esa información textual en un archivo CSV.
Primero, necesitamos importar las bibliotecas de Python necesarias de la siguiente manera:
import requests
from bs4 import BeautifulSoup
import csvEn esta siguiente línea de código, utilizamos solicitudes para realizar solicitudes GET HTTP para la URL: https://authoraditiagarwal.com/ haciendo una solicitud GET.
r = requests.get('https://authoraditiagarwal.com/')Ahora, necesitamos crear un objeto Soup de la siguiente manera:
soup = BeautifulSoup(r.text, 'lxml')Ahora, con la ayuda de las siguientes líneas de código, escribiremos los datos capturados en un archivo CSV llamado dataprocessing.csv.
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])Después de ejecutar este script, la información textual o el título de la página web se guardarán en el archivo CSV mencionado anteriormente en su máquina local.
Del mismo modo, podemos guardar la información recopilada en un archivo JSON. El siguiente es un script de Python fácil de entender para hacer lo mismo en el que estamos obteniendo la misma información que hicimos en el último script de Python, pero esta vez la información obtenida se guarda en JSONfile.txt mediante el módulo JSON Python.
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)Después de ejecutar este script, la información capturada, es decir, el título de la página web, se guardará en el archivo de texto mencionado anteriormente en su máquina local.
Procesamiento de datos con AWS S3
A veces, es posible que deseemos guardar datos extraídos en nuestro almacenamiento local con fines de archivo. Pero, ¿qué pasa si necesitamos almacenar y analizar estos datos a una escala masiva? La respuesta es un servicio de almacenamiento en la nube llamado Amazon S3 o AWS S3 (Simple Storage Service). Básicamente, AWS S3 es un almacenamiento de objetos creado para almacenar y recuperar cualquier cantidad de datos desde cualquier lugar.
Podemos seguir los siguientes pasos para almacenar datos en AWS S3:
Step 1- Primero necesitamos una cuenta de AWS que nos proporcione las claves secretas para usar en nuestro script de Python mientras almacenamos los datos. Creará un bucket de S3 en el que podremos almacenar nuestros datos.
Step 2 - A continuación, necesitamos instalar boto3Biblioteca de Python para acceder al depósito de S3. Se puede instalar con la ayuda del siguiente comando:
pip install boto3Step 3 - A continuación, podemos usar el siguiente script de Python para extraer datos de la página web y guardarlos en el bucket de AWS S3.
Primero, necesitamos importar bibliotecas Python para scraping, aquí estamos trabajando con requestsy boto3 guardar datos en el depósito S3.
import requests
import boto3Ahora podemos extraer los datos de nuestra URL.
data = requests.get("Enter the URL").textAhora, para almacenar datos en el depósito S3, necesitamos crear el cliente S3 de la siguiente manera:
s3 = boto3.client('s3')
bucket_name = "our-content"La siguiente línea de código creará el depósito S3 de la siguiente manera:
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read')
s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")Ahora puede verificar el depósito con el nombre our-content de su cuenta de AWS.
Procesamiento de datos usando MySQL
Aprendamos a procesar datos usando MySQL. Si desea obtener más información sobre MySQL, puede seguir el enlacehttps://www.tutorialspoint.com/mysql/.
Con la ayuda de los siguientes pasos, podemos extraer y procesar datos en la tabla MySQL:
Step 1- Primero, al usar MySQL necesitamos crear una base de datos y una tabla en la que queremos guardar nuestros datos extraídos. Por ejemplo, estamos creando la tabla con la siguiente consulta:
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));Step 2- A continuación, debemos ocuparnos de Unicode. Tenga en cuenta que MySQL no maneja Unicode por defecto. Necesitamos activar esta función con la ayuda de los siguientes comandos que cambiarán el juego de caracteres predeterminado para la base de datos, para la tabla y para ambas columnas:
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;Step 3- Ahora, integre MySQL con Python. Para ello, necesitaremos PyMySQL que se puede instalar con la ayuda del siguiente comando
pip install PyMySQLStep 4- Ahora, nuestra base de datos llamada Scrap, creada anteriormente, está lista para guardar los datos, después de extraerlos de la web, en una tabla llamada Scrap_pages. Aquí, en nuestro ejemplo, vamos a extraer datos de Wikipedia y se guardarán en nuestra base de datos.
Primero, necesitamos importar los módulos de Python requeridos.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import pymysql
import reAhora, haga una conexión, es decir, integre esto con Python.
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()Ahora, conéctese con Wikipedia y obtenga datos de ella.
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)Por último, debemos cerrar tanto el cursor como la conexión.
finally:
cur.close()
conn.close()Esto guardará los datos recopilados de Wikipedia en una tabla llamada scrap_pages. Si está familiarizado con MySQL y web scraping, entonces el código anterior no sería difícil de entender.
Procesamiento de datos usando PostgreSQL
PostgreSQL, desarrollado por un equipo mundial de voluntarios, es un sistema de gestión de bases de datos relacionales (RDMS) de código abierto. El proceso de procesamiento de los datos extraídos mediante PostgreSQL es similar al de MySQL. Habría dos cambios: Primero, los comandos serían diferentes a MySQL y segundo, aquí usaremospsycopg2 Librería Python para realizar su integración con Python.
Si no está familiarizado con PostgreSQL, puede aprenderlo en https://www.tutorialspoint.com/postgresql/. Y con la ayuda del siguiente comando podemos instalar la biblioteca Python psycopg2 -
pip install psycopg2El web scraping generalmente implica descargar, almacenar y procesar el contenido de los medios web. En este capítulo, entendamos cómo procesar el contenido descargado de la web.
Introducción
El contenido de los medios web que obtenemos durante el scraping pueden ser imágenes, archivos de audio y video, en forma de páginas que no son web, así como archivos de datos. Pero, ¿podemos confiar en los datos descargados especialmente en la extensión de datos que vamos a descargar y almacenar en la memoria de nuestra computadora? Esto hace que sea fundamental conocer el tipo de datos que vamos a almacenar localmente.
Obtener contenido multimedia de la página web
En esta sección, vamos a aprender cómo podemos descargar contenido multimedia que represente correctamente el tipo de medio en función de la información del servidor web. Podemos hacerlo con la ayuda de Pythonrequests módulo como hicimos en el capítulo anterior.
Primero, necesitamos importar los módulos de Python necesarios de la siguiente manera:
import requestsAhora, proporcione la URL del contenido multimedia que queremos descargar y almacenar localmente.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Utilice el siguiente código para crear un objeto de respuesta HTTP.
r = requests.get(url)Con la ayuda de la siguiente línea de código, podemos guardar el contenido recibido como archivo .png.
with open("ThinkBig.png",'wb') as f:
f.write(r.content)Después de ejecutar el script de Python anterior, obtendremos un archivo llamado ThinkBig.png, que tendría la imagen descargada.
Extrayendo el nombre de archivo de la URL
Después de descargar el contenido del sitio web, también queremos guardarlo en un archivo con un nombre de archivo que se encuentra en la URL. Pero también podemos verificar si también existen números de fragmentos adicionales en la URL. Para esto, necesitamos encontrar el nombre de archivo real de la URL.
Con la ayuda de la siguiente secuencia de comandos de Python, use urlparse, podemos extraer el nombre del archivo de la URL -
import urllib3
import os
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
a = urlparse(url)
a.pathPuede observar la salida como se muestra a continuación:
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg'
os.path.basename(a.path)Puede observar la salida como se muestra a continuación:
'MetaSlider_ThinkBig-1080x180.jpg'Una vez que ejecute el script anterior, obtendremos el nombre de archivo de la URL.
Información sobre el tipo de contenido de la URL
Mientras extraemos los contenidos del servidor web, mediante solicitud GET, también podemos verificar su información proporcionada por el servidor web. Con la ayuda de la siguiente secuencia de comandos de Python, podemos determinar qué significa servidor web con el tipo de contenido:
Primero, necesitamos importar los módulos de Python necesarios de la siguiente manera:
import requestsAhora, debemos proporcionar la URL del contenido multimedia que queremos descargar y almacenar localmente.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"La siguiente línea de código creará un objeto de respuesta HTTP.
r = requests.get(url, allow_redirects=True)Ahora, podemos obtener qué tipo de información sobre el contenido puede proporcionar el servidor web.
for headers in r.headers: print(headers)Puede observar la salida como se muestra a continuación:
Date
Server
Upgrade
Connection
Last-Modified
Accept-Ranges
Content-Length
Keep-Alive
Content-TypeCon la ayuda de la siguiente línea de código, podemos obtener la información particular sobre el tipo de contenido, digamos tipo de contenido -
print (r.headers.get('content-type'))Puede observar la salida como se muestra a continuación:
image/jpegCon la ayuda de la siguiente línea de código, podemos obtener la información particular sobre el tipo de contenido, digamos EType -
print (r.headers.get('ETag'))Puede observar la salida como se muestra a continuación:
NoneObserve el siguiente comando:
print (r.headers.get('content-length'))Puede observar la salida como se muestra a continuación:
12636Con la ayuda de la siguiente línea de código podemos obtener la información particular sobre el tipo de contenido, digamos Servidor -
print (r.headers.get('Server'))Puede observar la salida como se muestra a continuación:
ApacheGeneración de miniaturas para imágenes
Miniatura es una descripción o representación muy pequeña. Un usuario puede querer guardar solo la miniatura de una imagen grande o guardar tanto la imagen como la miniatura. En esta sección vamos a crear una miniatura de la imagen llamadaThinkBig.png descargado en la sección anterior “Obtención de contenido multimedia desde una página web”.
Para este script de Python, necesitamos instalar la biblioteca de Python llamada Pillow, una bifurcación de la biblioteca de imágenes de Python que tiene funciones útiles para manipular imágenes. Se puede instalar con la ayuda del siguiente comando:
pip install pillowLa siguiente secuencia de comandos de Python creará una miniatura de la imagen y la guardará en el directorio actual con el prefijo del archivo de miniatura con Th_
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")El código anterior es muy fácil de entender y puede buscar el archivo en miniatura en el directorio actual.
Captura de pantalla del sitio web
En web scraping, una tarea muy común es realizar capturas de pantalla de un sitio web. Para implementar esto, usaremos selenium y webdriver. La siguiente secuencia de comandos de Python tomará la captura de pantalla del sitio web y la guardará en el directorio actual.
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.com/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quitPuede observar la salida como se muestra a continuación:
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0-
a571-892dc4c90eb7
<bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver
(session="37e8e440e2f7807ef41ca7aa20ce7c97")>>Después de ejecutar el script, puede verificar su directorio actual para screenshot.png archivo.
Generación de miniaturas para video
Supongamos que hemos descargado videos del sitio web y queremos generar miniaturas para ellos, de modo que se pueda hacer clic en un video específico, basado en su miniatura. Para generar miniaturas para videos, necesitamos una herramienta simple llamadaffmpeg que se puede descargar desde www.ffmpeg.org. Después de la descarga, debemos instalarlo según las especificaciones de nuestro sistema operativo.
El siguiente script de Python generará una miniatura del video y lo guardará en nuestro directorio local:
import subprocess
video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4
thumbnail_image_file = 'thumbnail_solar_video.jpg'
subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '-
vframes', '1', thumbnail_image_file, "-y"])Después de ejecutar el script anterior, obtendremos la miniatura llamada thumbnail_solar_video.jpg guardado en nuestro directorio local.
Extraer un video MP4 a MP3
Suponga que ha descargado algún archivo de video de un sitio web, pero solo necesita el audio de ese archivo para cumplir con su propósito, luego puede hacerlo en Python con la ayuda de la biblioteca de Python llamada moviepy que se puede instalar con la ayuda del siguiente comando:
pip install moviepyAhora, después de instalar con éxito moviepy con la ayuda del siguiente script, podemos convertir MP4 a MP3.
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")Puede observar la salida como se muestra a continuación:
[MoviePy] Writing audio in movie_audio.mp3
100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦
¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00,
476.30it/s]
[MoviePy] Done.El script anterior guardará el archivo MP3 de audio en el directorio local.
En el capítulo anterior, hemos visto cómo lidiar con videos e imágenes que obtenemos como parte del contenido de web scraping. En este capítulo nos ocuparemos del análisis de texto utilizando la biblioteca Python y aprenderemos sobre esto en detalle.
Introducción
Puede realizar análisis de texto utilizando la biblioteca de Python llamada Kit de herramientas de lenguaje natural (NLTK). Antes de pasar a los conceptos de NLTK, comprendamos la relación entre el análisis de texto y el web scraping.
El análisis de las palabras en el texto puede llevarnos a saber qué palabras son importantes, qué palabras son inusuales y cómo se agrupan las palabras. Este análisis facilita la tarea del web scraping.
Empezando con NLTK
El kit de herramientas de lenguaje natural (NLTK) es una colección de bibliotecas de Python que está diseñada especialmente para identificar y etiquetar partes del habla que se encuentran en el texto del lenguaje natural como el inglés.
Instalación de NLTK
Puede usar el siguiente comando para instalar NLTK en Python:
pip install nltkSi está usando Anaconda, entonces se puede construir un paquete conda para NLTK usando el siguiente comando:
conda install -c anaconda nltkDescarga de datos de NLTK
Después de instalar NLTK, tenemos que descargar repositorios de texto preestablecidos. Pero antes de descargar repositorios preestablecidos de texto, necesitamos importar NLTK con la ayuda deimport comando de la siguiente manera:
mport nltkAhora, con la ayuda del siguiente comando, se pueden descargar datos NLTK:
nltk.download()La instalación de todos los paquetes disponibles de NLTK llevará algún tiempo, pero siempre se recomienda instalar todos los paquetes.
Instalación de otros paquetes necesarios
También necesitamos algunos otros paquetes de Python como gensim y pattern para realizar análisis de texto, así como para crear aplicaciones de procesamiento de lenguaje natural utilizando NLTK.
gensim- Una biblioteca robusta de modelado semántico que es útil para muchas aplicaciones. Se puede instalar con el siguiente comando:
pip install gensimpattern - Solía hacer gensimel paquete funciona correctamente. Se puede instalar con el siguiente comando:
pip install patternTokenización
El proceso de dividir el texto dado, en unidades más pequeñas llamadas tokens, se llama tokenización. Estos tokens pueden ser palabras, números o signos de puntuación. También es llamadoword segmentation.
Ejemplo

El módulo NLTK proporciona diferentes paquetes de tokenización. Podemos utilizar estos paquetes según nuestro requisito. Algunos de los paquetes se describen aquí:
sent_tokenize package- Este paquete dividirá el texto de entrada en oraciones. Puede usar el siguiente comando para importar este paquete:
from nltk.tokenize import sent_tokenizeword_tokenize package- Este paquete dividirá el texto de entrada en palabras. Puede usar el siguiente comando para importar este paquete:
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Este paquete dividirá el texto de entrada y los signos de puntuación en palabras. Puede usar el siguiente comando para importar este paquete:
from nltk.tokenize import WordPuncttokenizerDerivado
En cualquier idioma, existen diferentes formas de palabras. Un idioma incluye muchas variaciones debido a razones gramaticales. Por ejemplo, considere las palabrasdemocracy, democraticy democratization. Tanto para el aprendizaje automático como para los proyectos de raspado web, es importante que las máquinas comprendan que estas palabras diferentes tienen la misma forma base. De ahí que podamos decir que puede resultar útil extraer las formas base de las palabras mientras se analiza el texto.
Esto se puede lograr mediante la derivación, que puede definirse como el proceso heurístico de extraer las formas básicas de las palabras cortando los extremos de las palabras.
El módulo NLTK proporciona diferentes paquetes para derivar. Podemos utilizar estos paquetes según nuestro requisito. Algunos de estos paquetes se describen aquí:
PorterStemmer package- El algoritmo de Porter es utilizado por este paquete derivado de Python para extraer la forma base. Puede usar el siguiente comando para importar este paquete:
from nltk.stem.porter import PorterStemmerPor ejemplo, después de dar la palabra ‘writing’ como entrada a este lematizador, la salida sería la palabra ‘write’ después de la derivación.
LancasterStemmer package- El algoritmo de Lancaster es utilizado por este paquete derivado de Python para extraer la forma base. Puede usar el siguiente comando para importar este paquete:
from nltk.stem.lancaster import LancasterStemmerPor ejemplo, después de dar la palabra ‘writing’ como entrada a este lematizador, la salida sería la palabra ‘writ’ después de la derivación.
SnowballStemmer package- Este paquete derivado de Python utiliza el algoritmo de Snowball para extraer la forma base. Puede usar el siguiente comando para importar este paquete:
from nltk.stem.snowball import SnowballStemmerPor ejemplo, después de dar la palabra "escritura" como entrada a esta lematización, la salida sería la palabra "escribir" después de la lematización.
Lematización
Otra forma de extraer la forma básica de las palabras es mediante lematización, normalmente con el objetivo de eliminar las terminaciones flexivas mediante el uso de vocabulario y análisis morfológico. La forma básica de cualquier palabra después de la lematización se llama lema.
El módulo NLTK proporciona los siguientes paquetes para lematización:
WordNetLemmatizer package- Extraerá la forma base de la palabra dependiendo de si se usa como sustantivo o como verbo. Puede usar el siguiente comando para importar este paquete:
from nltk.stem import WordNetLemmatizerFragmentación
Chunking, que significa dividir los datos en pequeños fragmentos, es uno de los procesos importantes en el procesamiento del lenguaje natural para identificar las partes del habla y frases cortas como frases nominales. Chunking consiste en etiquetar los tokens. Podemos obtener la estructura de la oración con la ayuda del proceso de fragmentación.
Ejemplo
En este ejemplo, vamos a implementar la fragmentación de frases sustantivas mediante el módulo NLTK Python. NP chunking es una categoría de chunking que encontrará los fragmentos de frases nominales en la oración.
Pasos para implementar la fragmentación de frases nominales
Necesitamos seguir los pasos que se dan a continuación para implementar la fragmentación de frases nominales:
Paso 1 - Definición de gramática de fragmentos
En el primer paso, definiremos la gramática para fragmentar. Consistiría en las reglas que debemos seguir.
Paso 2: creación del analizador de fragmentos
Ahora, crearemos un analizador de fragmentos. Analizaría la gramática y daría la salida.
Paso 3 - La salida
En este último paso, la salida se produciría en formato de árbol.
Primero, necesitamos importar el paquete NLTK de la siguiente manera:
import nltkA continuación, necesitamos definir la oración. Aquí DT: el determinante, VBP: el verbo, JJ: el adjetivo, IN: la preposición y NN: el sustantivo.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]A continuación, damos la gramática en forma de expresión regular.
grammar = "NP:{<DT>?<JJ>*<NN>}"Ahora, la siguiente línea de código definirá un analizador para analizar la gramática.
parser_chunking = nltk.RegexpParser(grammar)Ahora, el analizador analizará la oración.
parser_chunking.parse(sentence)A continuación, damos nuestra salida en la variable.
Output = parser_chunking.parse(sentence)Con la ayuda del siguiente código, podemos dibujar nuestra salida en forma de árbol como se muestra a continuación.
output.draw()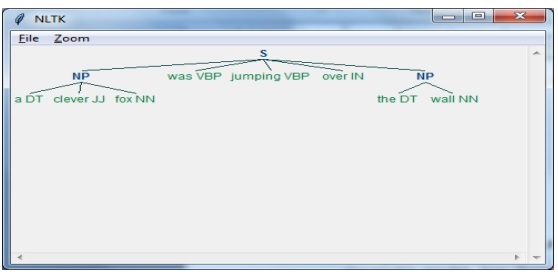
Modelo de bolsa de palabras (BoW) Extracción y conversión del texto en forma numérica
Bag of Word (BoW), un modelo útil en el procesamiento del lenguaje natural, se utiliza básicamente para extraer las características del texto. Después de extraer las características del texto, se puede usar en el modelado en algoritmos de aprendizaje automático porque los datos sin procesar no se pueden usar en aplicaciones de aprendizaje automático.
Funcionamiento del modelo BoW
Inicialmente, el modelo extrae un vocabulario de todas las palabras del documento. Más tarde, utilizando una matriz de términos de documento, construiría un modelo. De esta forma, el modelo BoW representa el documento como una bolsa de palabras únicamente y se descarta el orden o estructura.
Ejemplo
Supongamos que tenemos las siguientes dos oraciones:
Sentence1 - Este es un ejemplo del modelo Bag of Words.
Sentence2 - Podemos extraer características usando el modelo Bag of Words.
Ahora, al considerar estas dos oraciones, tenemos las siguientes 14 palabras distintas:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Construyendo un modelo de bolsa de palabras en NLTK
Veamos el siguiente script de Python que construirá un modelo BoW en NLTK.
Primero, importe el siguiente paquete:
from sklearn.feature_extraction.text import CountVectorizerA continuación, defina el conjunto de oraciones:
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Salida
Muestra que tenemos 14 palabras distintas en las dos oraciones anteriores:
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Modelado de temas: identificación de patrones en datos de texto
Generalmente, los documentos se agrupan en temas y el modelado de temas es una técnica para identificar los patrones en un texto que corresponde a un tema en particular. En otras palabras, el modelado de temas se utiliza para descubrir temas abstractos o estructuras ocultas en un conjunto de documentos determinado.
Puede utilizar el modelado de temas en los siguientes escenarios:
Clasificación de texto
La clasificación se puede mejorar mediante el modelado de temas porque agrupa palabras similares en lugar de usar cada palabra por separado como una característica.
Sistemas de recomendación
Podemos construir sistemas de recomendación usando medidas de similitud.
Algoritmos de modelado de temas
Podemos implementar el modelado de temas utilizando los siguientes algoritmos:
Latent Dirichlet Allocation(LDA) - Es uno de los algoritmos más populares que utiliza los modelos gráficos probabilísticos para implementar el modelado de temas.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Se basa en Álgebra lineal y utiliza el concepto de SVD (Descomposición de valores singulares) en la matriz de términos del documento.
Non-Negative Matrix Factorization (NMF) - También se basa en Álgebra lineal como LDA.
Los algoritmos mencionados anteriormente tendrían los siguientes elementos:
- Número de temas: parámetro
- Matriz documento-palabra: entrada
- WTM (Word Topic Matrix) y TDM (Topic Document Matrix): Salida
Introducción
El web scraping es una tarea compleja y la complejidad se multiplica si el sitio web es dinámico. Según la Auditoría Global de Accesibilidad Web de las Naciones Unidas, más del 70% de los sitios web son de naturaleza dinámica y se basan en JavaScript para sus funcionalidades.
Ejemplo de sitio web dinámico
Veamos un ejemplo de un sitio web dinámico y sepamos por qué es difícil de raspar. Aquí vamos a tomar un ejemplo de búsqueda desde un sitio web llamadohttp://example.webscraping.com/places/default/search.Pero, ¿cómo podemos decir que este sitio web es de naturaleza dinámica? Se puede juzgar por la salida del siguiente script de Python que intentará extraer datos de la página web mencionada anteriormente:
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)Salida
[ ]El resultado anterior muestra que el raspador de ejemplo no pudo extraer información porque el elemento <div> que estamos tratando de encontrar está vacío.
Enfoques para extraer datos de sitios web dinámicos
Hemos visto que el raspador no puede raspar la información de un sitio web dinámico porque los datos se cargan dinámicamente con JavaScript. En tales casos, podemos utilizar las siguientes dos técnicas para extraer datos de sitios web dinámicos dependientes de JavaScript:
- JavaScript de ingeniería inversa
- Representación de JavaScript
JavaScript de ingeniería inversa
El proceso llamado ingeniería inversa sería útil y nos permite comprender cómo las páginas web cargan los datos de forma dinámica.
Para hacer esto, necesitamos hacer clic en el inspect elementpestaña para una URL especificada. A continuación, haremos clic enNETWORK pestaña para encontrar todas las solicitudes realizadas para esa página web, incluido search.json con una ruta de /ajax. En lugar de acceder a los datos AJAX desde el navegador o mediante la pestaña RED, también podemos hacerlo con la ayuda del siguiente script de Python:
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()Ejemplo
El script anterior nos permite acceder a la respuesta JSON mediante el método Python json. De manera similar, podemos descargar la respuesta de cadena sin procesar y, al usar el método json.loads de python, también podemos cargarla. Estamos haciendo esto con la ayuda del siguiente script de Python. Básicamente, raspará todos los países buscando la letra del alfabeto 'a' y luego iterando las páginas resultantes de las respuestas JSON.
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))Después de ejecutar el script anterior, obtendremos el siguiente resultado y los registros se guardarán en el archivo llamado countries.txt.
Salida
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...Representación de JavaScript
En la sección anterior, hicimos ingeniería inversa en la página web sobre cómo funcionaba la API y cómo podemos usarla para recuperar los resultados en una sola solicitud. Sin embargo, podemos enfrentar las siguientes dificultades al hacer ingeniería inversa:
A veces, los sitios web pueden ser muy difíciles. Por ejemplo, si el sitio web está creado con una herramienta de navegador avanzada como Google Web Toolkit (GWT), entonces el código JS resultante sería generado por una máquina y sería difícil de entender y realizar ingeniería inversa.
Algunos marcos de nivel superior como React.js puede dificultar la ingeniería inversa al abstraer la ya compleja lógica de JavaScript.
La solución a las dificultades anteriores es utilizar un motor de renderizado de navegador que analiza HTML, aplica el formato CSS y ejecuta JavaScript para mostrar una página web.
Ejemplo
En este ejemplo, para renderizar Java Script usaremos un módulo de Python conocido, Selenium. El siguiente código de Python representará una página web con la ayuda de Selenium:
Primero, necesitamos importar webdriver desde selenium de la siguiente manera:
from selenium import webdriverAhora, proporcione la ruta del controlador web que hemos descargado según nuestro requisito:
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)Ahora, proporcione la URL que queremos abrir en ese navegador web ahora controlado por nuestro script Python.
driver.get('http://example.webscraping.com/search')Ahora, podemos usar el ID de la caja de herramientas de búsqueda para configurar el elemento a seleccionar.
driver.find_element_by_id('search_term').send_keys('.')A continuación, podemos usar el script java para configurar el contenido del cuadro de selección de la siguiente manera:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)La siguiente línea de código muestra que la búsqueda está lista para hacer clic en la página web:
driver.find_element_by_id('search').click()La siguiente línea de código muestra que esperará 45 segundos para completar la solicitud AJAX.
driver.implicitly_wait(45)Ahora, para seleccionar enlaces de países, podemos usar el selector CSS de la siguiente manera:
links = driver.find_elements_by_css_selector('#results a')Ahora se puede extraer el texto de cada enlace para crear la lista de países:
countries = [link.text for link in links]
print(countries)
driver.close()En el capítulo anterior, hemos visto cómo raspar sitios web dinámicos. En este capítulo, entendamos el raspado de sitios web que funcionan con entradas basadas en usuarios, es decir, sitios web basados en formularios.
Introducción
En estos días, WWW (World Wide Web) se está moviendo hacia las redes sociales, así como hacia los contenidos generados por los usuarios. Entonces, surge la pregunta de cómo podemos acceder a ese tipo de información que está más allá de la pantalla de inicio de sesión. Para ello tenemos que lidiar con formularios e inicios de sesión.
En capítulos anteriores, trabajamos con el método HTTP GET para solicitar información, pero en este capítulo trabajaremos con el método HTTP POST que envía información a un servidor web para su almacenamiento y análisis.
Interactuar con formularios de inicio de sesión
Mientras trabajaba en Internet, debe haber interactuado con los formularios de inicio de sesión muchas veces. Pueden ser muy simples, como incluir solo unos pocos campos HTML, un botón de envío y una página de acción, o pueden ser complicados y tener algunos campos adicionales como correo electrónico, dejar un mensaje junto con el captcha por razones de seguridad.
En esta sección, vamos a tratar con un formulario de envío simple con la ayuda de la biblioteca de solicitudes de Python.
Primero, necesitamos importar la biblioteca de solicitudes de la siguiente manera:
import requestsAhora, debemos proporcionar la información para los campos del formulario de inicio de sesión.
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}En la siguiente línea de código, debemos proporcionar la URL en la que se realizaría la acción del formulario.
r = requests.post(“enter the URL”, data = parameters)
print(r.text)Después de ejecutar el script, devolverá el contenido de la página donde ocurrió la acción.
Suponga que si desea enviar cualquier imagen con el formulario, entonces es muy fácil con request.post (). Puede entenderlo con la ayuda de la siguiente secuencia de comandos de Python:
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)Carga de cookies desde el servidor web
Una cookie, a veces llamada cookie web o cookie de Internet, es un pequeño fragmento de datos enviado desde un sitio web y nuestra computadora lo almacena en un archivo ubicado dentro de nuestro navegador web.
En el contexto del trato con los formularios de inicio de sesión, las cookies pueden ser de dos tipos. Uno, lo tratamos en la sección anterior, que nos permite enviar información a un sitio web y el segundo, que nos permite permanecer en un estado permanente de “sesión iniciada” durante nuestra visita al sitio web. Para el segundo tipo de formularios, los sitios web utilizan cookies para realizar un seguimiento de quién está conectado y quién no.
¿Qué hacen las cookies?
En estos días, la mayoría de los sitios web utilizan cookies para realizar un seguimiento. Podemos comprender el funcionamiento de las cookies con la ayuda de los siguientes pasos:
Step 1- Primero, el sitio autenticará nuestras credenciales de inicio de sesión y las almacenará en la cookie de nuestro navegador. Esta cookie generalmente contiene información de seguimiento, tiempo de espera y toke generado por el servidor.
Step 2- A continuación, el sitio web utilizará la cookie como prueba de autenticación. Esta autenticación siempre se muestra cada vez que visitamos el sitio web.
Las cookies son muy problemáticas para los web scrapers porque si los web scrapers no realizan un seguimiento de las cookies, el formulario enviado se devuelve y, en la página siguiente, parece que nunca iniciaron sesión. Es muy fácil rastrear las cookies con la ayuda de Pitón requests biblioteca, como se muestra a continuación -
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)En la línea de código anterior, la URL sería la página que actuará como procesador para el formulario de inicio de sesión.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Después de ejecutar el script anterior, recuperaremos las cookies del resultado de la última solicitud.
Existe otro problema con las cookies: a veces, los sitios web modifican las cookies sin previo aviso. Este tipo de situación puede resolverserequests.Session() como sigue -
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)En la línea de código anterior, la URL sería la página que actuará como procesador para el formulario de inicio de sesión.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Observe que puede comprender fácilmente la diferencia entre un guión con sesión y sin sesión.
Automatizar formularios con Python
En esta sección vamos a tratar un módulo de Python llamado Mechanize que reducirá nuestro trabajo y automatizará el proceso de llenado de formularios.
Módulo de mecanizado
El módulo Mechanize nos proporciona una interfaz de alto nivel para interactuar con formularios. Antes de comenzar a usarlo necesitamos instalarlo con el siguiente comando:
pip install mechanizeTenga en cuenta que solo funcionaría en Python 2.x.
Ejemplo
En este ejemplo, vamos a automatizar el proceso de completar un formulario de inicio de sesión que tiene dos campos, a saber, correo electrónico y contraseña:
import mechanize
brwsr = mechanize.Browser()
brwsr.open(Enter the URL of login)
brwsr.select_form(nr = 0)
brwsr['email'] = ‘Enter email’
brwsr['password'] = ‘Enter password’
response = brwsr.submit()
brwsr.submit()El código anterior es muy fácil de entender. Primero, importamos el módulo de mecanizado. Luego, se ha creado un objeto de navegador Mechanize. Luego, navegamos a la URL de inicio de sesión y seleccionamos el formulario. Después de eso, los nombres y valores se pasan directamente al objeto del navegador.
En este capítulo, entendamos cómo realizar el raspado web y el procesamiento de CAPTCHA que se utiliza para probar a un usuario como humano o robot.
¿Qué es CAPTCHA?
La forma completa de CAPTCHA es Completely Automated Public Turing test to tell Computers and Humans Apart, lo que sugiere claramente que se trata de una prueba para determinar si el usuario es humano o no.
Un CAPTCHA es una imagen distorsionada que generalmente no es fácil de detectar mediante un programa de computadora, pero un humano de alguna manera puede lograr entenderla. La mayoría de los sitios web utilizan CAPTCHA para evitar que los bots interactúen.
Cargando CAPTCHA con Python
Supongamos que queremos hacer el registro en un sitio web y hay un formulario con CAPTCHA, entonces antes de cargar la imagen CAPTCHA necesitamos conocer la información específica requerida por el formulario. Con la ayuda del siguiente script de Python, podemos comprender los requisitos del formulario de registro en el sitio web llamadohttp://example.webscrapping.com.
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)En el script de Python anterior, primero definimos una función que analizará el formulario utilizando el módulo lxml python y luego imprimirá los requisitos del formulario de la siguiente manera:
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}Puede comprobar en la salida anterior que toda la información excepto recpatcha_response_fieldson comprensibles y sencillos. Ahora surge la pregunta de cómo podemos manejar esta compleja información y descargar CAPTCHA. Se puede hacer con la ayuda de la biblioteca Python de almohada de la siguiente manera;
Paquete Pillow Python
Pillow es una bifurcación de la biblioteca de imágenes de Python que tiene funciones útiles para manipular imágenes. Se puede instalar con la ayuda del siguiente comando:
pip install pillowEn el siguiente ejemplo lo usaremos para cargar el CAPTCHA -
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return imgEl script de Python anterior está usando pillowpython y definir una función para cargar la imagen CAPTCHA. Debe usarse con la función denominadaform_parser()que se define en el script anterior para obtener información sobre el formulario de registro. Este script guardará la imagen CAPTCHA en un formato útil que además se puede extraer como cadena.
OCR: extracción de texto de una imagen con Python
Después de cargar el CAPTCHA en un formato útil, podemos extraerlo con la ayuda del Reconocimiento óptico de caracteres (OCR), un proceso de extracción de texto de las imágenes. Para este propósito, vamos a utilizar el motor Tesseract OCR de código abierto. Se puede instalar con la ayuda del siguiente comando:
pip install pytesseractEjemplo
Aquí ampliaremos el script de Python anterior, que cargó el CAPTCHA usando el paquete Pillow Python, de la siguiente manera:
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')El script de Python anterior leerá el CAPTCHA en modo blanco y negro, lo que sería claro y fácil de pasar a tesseract de la siguiente manera:
pytesseract.image_to_string(bw)Después de ejecutar el script anterior, obtendremos el CAPTCHA del formulario de registro como salida.
Este capítulo explica cómo realizar pruebas usando web scrapers en Python.
Introducción
En proyectos web grandes, las pruebas automatizadas del backend del sitio web se realizan con regularidad, pero las pruebas de frontend se omiten con frecuencia. La razón principal detrás de esto es que la programación de sitios web es como una red de varios lenguajes de programación y marcado. Podemos escribir una prueba de unidad para un idioma, pero se vuelve un desafío si la interacción se realiza en otro idioma. Es por eso que debemos tener un conjunto de pruebas para asegurarnos de que nuestro código esté funcionando según nuestras expectativas.
Probando usando Python
Cuando hablamos de pruebas, significa pruebas unitarias. Antes de profundizar en las pruebas con Python, debemos conocer las pruebas unitarias. A continuación se presentan algunas de las características de las pruebas unitarias:
Al menos un aspecto de la funcionalidad de un componente se probaría en cada prueba unitaria.
Cada prueba unitaria es independiente y también se puede ejecutar de forma independiente.
La prueba unitaria no interfiere con el éxito o el fracaso de ninguna otra prueba.
Las pruebas unitarias pueden ejecutarse en cualquier orden y deben contener al menos una afirmación.
Unittest - Módulo Python
El módulo de Python llamado Unittest para pruebas unitarias viene con toda la instalación estándar de Python. Solo tenemos que importarlo y el resto es tarea de unittest.TestCase class que hará lo siguiente:
Las funciones SetUp y tearDown son proporcionadas por unittest.TestCase class. Estas funciones pueden ejecutarse antes y después de cada prueba unitaria.
También proporciona declaraciones de aserción para permitir que las pruebas pasen o fallen.
Ejecuta todas las funciones que comienzan con test_ como prueba unitaria.
Ejemplo
En este ejemplo, combinaremos el web scraping con unittest. Probaremos la página de Wikipedia para buscar la cadena 'Python'. Básicamente hará dos pruebas, primero si la página de título es la misma que la cadena de búsqueda, es decir, 'Python' o no, y la segunda prueba se asegura de que la página tenga un div de contenido.
Primero, importaremos los módulos de Python requeridos. Estamos usando BeautifulSoup para web scraping y, por supuesto, unittest para realizar pruebas.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import unittestAhora necesitamos definir una clase que extenderá unittest.TestCase. Los objetos globales bs se compartirían entre todas las pruebas. Una función especificada de unittest setUpClass lo logrará. Aquí definiremos dos funciones, una para probar la página de título y otra para probar el contenido de la página.
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()Después de ejecutar el script anterior, obtendremos el siguiente resultado:
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)Pruebas con selenio
Analicemos cómo usar Python Selenium para realizar pruebas. También se llama prueba de selenio. Ambos Pythonunittest y Seleniumno tienen mucho en común. Sabemos que Selenium envía los comandos estándar de Python a diferentes navegadores, a pesar de la variación en el diseño de su navegador. Recuerde que ya instalamos y trabajamos con Selenium en capítulos anteriores. Aquí crearemos scripts de prueba en Selenium y los usaremos para la automatización.
Ejemplo
Con la ayuda del próximo script de Python, estamos creando un script de prueba para la automatización de la página de inicio de sesión de Facebook. Puede modificar el ejemplo para automatizar otros formularios e inicios de sesión de su elección, sin embargo, el concepto sería el mismo.
Primero, para conectarse al navegador web, importaremos el controlador web desde el módulo selenium -
from selenium import webdriverAhora, necesitamos importar claves del módulo de selenio.
from selenium.webdriver.common.keys import KeysA continuación, debemos proporcionar el nombre de usuario y la contraseña para iniciar sesión en nuestra cuenta de Facebook.
user = "[email protected]"
pwd = ""A continuación, proporcione la ruta al controlador web para Chrome.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("http://www.facebook.com")Ahora verificaremos las condiciones usando la palabra clave assert.
assert "Facebook" in driver.titleCon la ayuda de la siguiente línea de código, enviamos valores a la sección de correo electrónico. Aquí lo estamos buscando por su id, pero podemos hacerlo buscándolo por su nombre comodriver.find_element_by_name("email").
element = driver.find_element_by_id("email")
element.send_keys(user)Con la ayuda de la siguiente línea de código, enviamos valores a la sección de contraseña. Aquí lo estamos buscando por su id, pero podemos hacerlo buscándolo por su nombre comodriver.find_element_by_name("pass").
element = driver.find_element_by_id("pass")
element.send_keys(pwd)La siguiente línea de código se usa para presionar enter / login después de insertar los valores en el campo de correo electrónico y contraseña.
element.send_keys(Keys.RETURN)Ahora cerraremos el navegador.
driver.close()Después de ejecutar la secuencia de comandos anterior, se abrirá el navegador web Chrome y podrá ver que se inserta el correo electrónico y la contraseña y se hace clic en el botón de inicio de sesión.
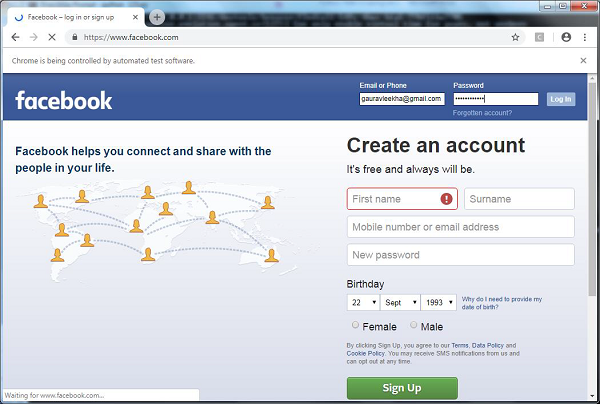
Comparación: unittest o Selenium
La comparación de unittest y selenium es difícil porque si desea trabajar con grandes conjuntos de pruebas, se requiere la rigidez sintáctica de unites. Por otro lado, si va a probar la flexibilidad del sitio web, la prueba de selenio sería nuestra primera opción. Pero, ¿y si pudiéramos combinar ambos? Podemos importar selenio a unittest de Python y obtener lo mejor de ambos. El selenio se puede utilizar para obtener información sobre un sitio web y unittest puede evaluar si esa información cumple con los criterios para aprobar la prueba o no.
Por ejemplo, estamos reescribiendo la secuencia de comandos de Python anterior para la automatización del inicio de sesión de Facebook combinando ambos de la siguiente manera:
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "[email protected]"
pwd = ""
pageUrl = "http://www.facebook.com"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()