SAP BODS - Guía rápida
Un almacén de datos se conoce como un repositorio central para almacenar los datos de una o varias fuentes de datos heterogéneas. El almacén de datos se utiliza para informar y analizar información y almacena tanto datos históricos como actuales. Los datos en el sistema DW se utilizan para informes analíticos, que luego los analistas comerciales, gerentes de ventas o trabajadores del conocimiento utilizan para la toma de decisiones.
Los datos en el sistema DW se cargan desde un sistema de transacciones operativas como Ventas, Marketing, RR.HH., SCM, etc. Pueden pasar por el almacén de datos operativos u otras transformaciones antes de cargarse en el sistema DW para el procesamiento de la información.
Almacén de datos: características clave
Las características clave de un sistema DW son:
Es un repositorio de datos central donde los datos se almacenan de una o más fuentes de datos heterogéneas.
Un sistema DW almacena tanto datos actuales como históricos. Normalmente, un sistema DW almacena de 5 a 10 años de datos históricos.
Un sistema DW siempre se mantiene separado de un sistema de transacciones operativas.
Los datos en el sistema DW se utilizan para diferentes tipos de informes analíticos que van desde la comparación trimestral hasta la anual.
Necesidad de un sistema DW
Suponga que tiene una agencia de préstamos hipotecarios donde los datos provienen de múltiples aplicaciones como marketing, ventas, ERP, HRM, MM, etc. Estos datos se extraen, transforman y cargan en Data Warehouse.
Por ejemplo, si tiene que comparar las ventas trimestrales / anuales de un producto, no puede usar una base de datos transaccional operativa, ya que esto colgará el sistema de transacciones. Por lo tanto, se utiliza un almacén de datos para este propósito.
Diferencia entre DW y ODB
Las diferencias entre un almacén de datos y una base de datos operativa (base de datos transaccional) son las siguientes:
Un sistema transaccional está diseñado para cargas de trabajo y transacciones conocidas, como actualizar un registro de usuario, buscar un registro, etc. Sin embargo, las transacciones del almacén de datos son más complejas y presentan una forma general de datos.
Un sistema transaccional contiene los datos actuales de una organización y el almacén de datos normalmente contiene los datos históricos.
El sistema transaccional admite el procesamiento paralelo de múltiples transacciones. Se requieren mecanismos de recuperación y control de concurrencia para mantener la coherencia de la base de datos.
Una consulta de base de datos operativa permite leer y modificar operaciones (eliminar y actualizar), mientras que una consulta OLAP solo necesita acceso de solo lectura a los datos almacenados (instrucción Select).
Arquitectura DW
El almacenamiento de datos implica la limpieza de datos, la integración de datos y la consolidación de datos.

Un almacén de datos tiene una arquitectura de 3 capas: Data Source Layer, Integration Layer, y Presentation Layer. La ilustración proporcionada anteriormente muestra la arquitectura común de un sistema de almacenamiento de datos.
Hay cuatro tipos de sistemas de almacenamiento de datos.
- Data Mart
- Procesamiento analítico en línea (OLAP)
- Procesamiento transaccional en línea (OLTP)
- Análisis predictivo (PA)
Data Mart
Un Data Mart se conoce como la forma más simple de un sistema de almacenamiento de datos y normalmente consta de un área funcional única en una organización como ventas, finanzas o marketing, etc.
Data Mart en una organización y es creado y administrado por un solo departamento. Como pertenece a un solo departamento, el departamento generalmente obtiene datos de solo unas pocas o un tipo de fuentes / aplicaciones. Esta fuente podría ser un sistema operativo interno, un almacén de datos o un sistema externo.
Procesamiento analítico en línea
En un sistema OLAP, hay menos número de transacciones en comparación con un sistema transaccional. Las consultas ejecutadas son de naturaleza compleja e implican agregaciones de datos.
¿Qué es una agregación?
Guardamos tablas con datos agregados como anual (1 fila), trimestral (4 filas), mensual (12 filas) más o menos, si alguien tiene que hacer una comparación de año a año, solo se procesará una fila. Sin embargo, en una tabla no agregada comparará todas las filas.
SELECT SUM(salary)
FROM employee
WHERE title = 'Programmer';Medidas efectivas en un sistema OLAP
El tiempo de respuesta es conocido como una de las medidas más efectivas y clave en un OLAPsistema. Los datos almacenados agregados se mantienen en esquemas multidimensionales como los esquemas en estrella (cuando los datos se organizan en grupos jerárquicos, a menudo llamados dimensiones y en hechos y hechos agregados, se denominan esquemas).
La latencia de un sistema OLAP es de unas pocas horas en comparación con los data marts donde se espera una latencia más cercana a un día.
Procesamiento de transacciones en línea
En un sistema OLTP, hay una gran cantidad de transacciones breves en línea, como INSERT, UPDATE y DELETE.
En un sistema OLTP, una medida eficaz es el tiempo de procesamiento de transacciones cortas y es muy inferior. Controla la integridad de los datos en entornos de acceso múltiple. Para un sistema OLTP, el número de transacciones por segundo mide laeffectiveness. Un sistema de almacenamiento de datos OLTP contiene datos actuales y detallados y se mantiene en los esquemas del modelo de entidad (3NF).
Ejemplo
Sistema de transacciones del día a día en una tienda minorista, donde los registros de los clientes se insertan, actualizan y eliminan a diario. Proporciona un procesamiento de consultas muy rápido. Las bases de datos OLTP contienen datos detallados y actualizados. El esquema utilizado para almacenar la base de datos OLTP es el modelo de entidad.
Diferencias entre OLTP y OLAP
Las siguientes ilustraciones muestran las diferencias clave entre un OLTP y OLAP sistema.

Indexes - El sistema OLTP tiene solo unos pocos índices, mientras que en un sistema OLAP hay muchos índices para optimizar el rendimiento.
Joins- En un sistema OLTP, se normalizan un gran número de uniones y datos. Sin embargo, en un sistema OLAP hay menos uniones y están desnormalizadas.
Aggregation - En un sistema OLTP, los datos no se agregan mientras que en una base de datos OLAP se utilizan más agregaciones.
Análisis predictivo
El análisis predictivo se conoce como encontrar patrones ocultos en los datos almacenados en el sistema DW mediante el uso de diferentes funciones matemáticas para predecir resultados futuros.
El sistema de Análisis Predictivo es diferente de un sistema OLAP en términos de su uso. Se utiliza para centrarse en resultados futuros. Un sistema OALP se enfoca en el procesamiento de datos actuales e históricos para informes analíticos.
Hay varios sistemas de almacenamiento de datos / bases de datos disponibles en el mercado que cumplen con las capacidades de un sistema DW. Los proveedores más comunes de sistemas de almacenamiento de datos son:
- Microsoft SQL Server
- Oracle Exadata
- IBM Netezza
- Teradata
- Sybase IQ
- SAP Business Warehouse (SAP BW)
SAP Business Warehouse
SAP Business Warehousees parte de la plataforma de lanzamiento de SAP NetWeaver. Antes de NetWeaver 7.4, se lo conocía como SAP NetWeaver Business Warehouse.
El almacenamiento de datos en SAP BW significa integración, transformación, limpieza de datos, almacenamiento y almacenamiento de datos. El proceso de DW incluye el modelado de datos en el sistema BW, la puesta en escena y la administración. La herramienta principal, que se utiliza para administrar las tareas de DW en el sistema BW, es el banco de trabajo de administración.
Características clave
SAP BW proporciona capacidades como Business Intelligence, que incluye servicios analíticos y planificación empresarial, informes analíticos, procesamiento e información de consultas y almacenamiento de datos empresariales.
Proporciona una combinación de bases de datos y herramientas de administración de bases de datos que ayuda a tomar decisiones.
Otras características clave del sistema BW incluyen la Interfaz de programación de aplicaciones comerciales (BAPI) que admite la conexión a aplicaciones que no son de SAP R / 3, extracción y carga automatizada de datos, un procesador OLAP integrado, repositorio de metadatos, herramientas de administración, soporte en varios idiomas y un interfaz habilitada para web.
SAP BW fue introducido por primera vez en 1998 por SAP, una empresa alemana. El sistema SAP BW se basó en un enfoque basado en modelos para hacer que Enterprise Data Warehouse sea fácil, simple y más eficiente para los datos de SAP R3.
Desde los últimos 16 años, SAP BW ha evolucionado como uno de los sistemas clave para que muchas empresas gestionen sus necesidades de almacenamiento de datos empresariales.
El Explorador de Negocios (BEx) brinda una opción para informes flexibles, análisis estratégicos y reportes operativos en la empresa.
Se utiliza para realizar informes, ejecución de consultas y funciones de análisis en el sistema de BI. También puede procesar datos actuales e históricos con varios grados de detalles en la Web y en formato Excel.
Utilizando BEx difusión de información, el contenido de BI se puede compartir por correo electrónico como documento o en forma de enlaces como datos en vivo o también se puede publicar utilizando las funciones de SAP EP.
Productos y objetos comerciales
SAP Business Objects se conoce como la herramienta de Business Intelligence más común y se utiliza para manipular datos, acceder a usuarios, analizar, formatear y publicar información en diferentes plataformas. Es un conjunto de herramientas basadas en el front-end, que permite a los usuarios comerciales y los tomadores de decisiones mostrar, clasificar y analizar datos actuales e históricos de inteligencia comercial.
Consta de las siguientes herramientas:
Inteligencia web
Web Intelligence (WebI) se denomina como la herramienta de informes detallados de Business Objects más común que admite varias funciones de análisis de datos como exploración, jerarquías, gráficos, medidas calculadas, etc. Permite a los usuarios finales crear consultas ad-hoc en el panel de consultas y para realizar análisis de datos tanto en línea como fuera de línea.
SAP Business Objects Xcelsius / Dashboards
Los paneles proporcionan visualización de datos y capacidades de creación de paneles para los usuarios finales y puede crear paneles interactivos con esta herramienta.
También puede agregar varios tipos de cuadros y gráficos y crear cuadros de mando dinámicos para visualizaciones de datos, que se utilizan principalmente en reuniones financieras en una organización.
Reportes de cristal
Crystal Reports se utiliza para informes perfectos en píxeles. Esto permite a los usuarios crear y diseñar informes y luego utilizarlos para imprimir.
Explorador
El Explorador permite al usuario buscar el contenido en el repositorio de BI y las mejores coincidencias se muestran en forma de gráficos. No es necesario anotar las consultas para realizar la búsqueda.
Varios otros componentes y herramientas introducidos para informes detallados, visualización de datos y propósitos de tablero de instrumentos son Design Studio, la edición Analysis para Microsoft Office, BI Repository y la plataforma Business Objects Mobile.
ETL son las siglas de Extract, Transform and Load. Una herramienta ETL extrae los datos de diferentes sistemas de origen RDBMS, transforma los datos como aplicar cálculos, concatenar, etc. y luego cargar los datos en el sistema de almacenamiento de datos. Los datos se cargan en el sistema DW en forma de tablas de hechos y dimensiones.
Extracción
Se requiere un área de preparación durante la carga ETL. Hay varias razones por las que se requiere un área de preparación.
Los sistemas de origen solo están disponibles durante un período de tiempo específico para extraer datos. Este período de tiempo es menor que el tiempo total de carga de datos. Por lo tanto, el área de preparación le permite extraer los datos del sistema de origen y los mantiene en el área de preparación antes de que finalice el intervalo de tiempo.
El área de preparación es necesaria cuando desea obtener los datos de varias fuentes de datos juntos o si desea unir dos o más sistemas. Por ejemplo, no podrá realizar una consulta SQL uniendo dos tablas de dos bases de datos físicamente diferentes.
La franja horaria de las extracciones de datos para diferentes sistemas varía según la zona horaria y las horas de funcionamiento.
Los datos extraídos de los sistemas de origen se pueden utilizar en varios sistemas de almacenamiento de datos, almacenes de datos operativos, etc.
ETL le permite realizar transformaciones complejas y requiere un área adicional para almacenar los datos.

Transformar
En la transformación de datos, aplica un conjunto de funciones a los datos extraídos para cargarlos en el sistema de destino. Los datos, que no requieren ninguna transformación, se conocen como movimiento directo o transferencia de datos.
Puede aplicar diferentes transformaciones en datos extraídos del sistema de origen. Por ejemplo, puede realizar cálculos personalizados. Si desea ingresos por suma de ventas y esto no está en la base de datos, puede aplicar elSUM fórmula durante la transformación y cargue los datos.
Por ejemplo, si tiene el nombre y el apellido en una tabla en diferentes columnas, puede usar concatenar antes de cargar.
Carga
Durante la fase de carga, los datos se cargan en el sistema de destino final y pueden ser un archivo plano o un sistema de almacenamiento de datos.
SAP BO Data Services es una herramienta ETL utilizada para la integración de datos, la calidad de los datos, la elaboración de perfiles de datos y el procesamiento de datos. Le permite integrar y transformar un sistema confiable de almacenamiento de datos en datos para informes analíticos.
BO Data Services consta de una interfaz de desarrollo de interfaz de usuario, un repositorio de metadatos, conectividad de datos al sistema de origen y destino y una consola de gestión para la programación de trabajos.
Integración de datos y gestión de datos
SAP BO Data Services es una herramienta de gestión e integración de datos y consta de Data Integrator Job Server y Data Integrator Designer.
Características clave
Puede aplicar varias transformaciones de datos utilizando el lenguaje del integrador de datos para aplicar transformaciones de datos complejas y crear funciones personalizadas.
Data Integrator Designer se utiliza para almacenar trabajos por lotes y en tiempo real y nuevos proyectos en el repositorio.
DI Designer también ofrece una opción para el desarrollo ETL basado en equipo al proporcionar un repositorio central con todas las funciones básicas.
El servidor de trabajos de Data Integrator es responsable de procesar los trabajos que se crean con DI Designer.
Administrador web
El administrador web de Data Integrator es utilizado por los administradores del sistema y el administrador de la base de datos para mantener los repositorios en los servicios de datos. Los servicios de datos incluyen el repositorio de metadatos, el repositorio central para el desarrollo basado en equipos, el servidor de trabajos y los servicios web.
Funciones clave de DI Web Administrator
- Se utiliza para programar, monitorear y ejecutar trabajos por lotes.
- Se utiliza para configurar e iniciar y detener servidores en tiempo real.
- Se utiliza para configurar Job Server, Access Server y el uso del repositorio.
- Se utiliza para configurar adaptadores.
- Se utiliza para configurar y controlar todas las herramientas en BO Data Services.
La función de gestión de datos hace hincapié en la calidad de los datos. Implica la limpieza de datos, la mejora y la consolidación de los datos para obtener datos correctos en el sistema DW.
En este capítulo, aprenderemos sobre la arquitectura SAP BODS. La ilustración muestra la arquitectura del sistema BODS con área de preparación.
Capa de origen
La capa de origen incluye diferentes fuentes de datos como aplicaciones de SAP y un sistema RDBMS que no es de SAP, y la integración de datos tiene lugar en el área de preparación.
SAP Business Objects Data Services incluye diferentes componentes como Data Service Designer, Data Services Management Console, Repository Manager, Data Services Server Manager, Work bench, etc. El sistema de destino puede ser un sistema DW como SAP HANA, SAP BW o no SAP. Sistema de almacenamiento de datos.

La siguiente captura de pantalla muestra los diferentes componentes de SAP BODS.

También puede dividir la arquitectura BODS en las siguientes capas:
- Capa de aplicación web
- Capa de servidor de base de datos
- Capa de servicio de servicios de datos
La siguiente ilustración muestra la arquitectura BODS.

Evolución del producto: ATL, DI y DQ
Acta Technology Inc. desarrolló SAP Business Objects Data Services y, posteriormente, Business Objects Company lo adquirió. Acta Technology Inc. es una empresa con sede en EE. UU. Y fue responsable del desarrollo de la plataforma de integración de primeros datos. Los dos productos de software ETL desarrollados por Acta Inc. fue elData Integration (DI) herramienta y la Data Management o Data Quality (DQ) herramienta.
Business Objects, una empresa francesa adquirió Acta Technology Inc. en 2002 y posteriormente, ambos productos pasaron a llamarse Business Objects Data Integration (BODI) herramienta y Business Objects Data Quality (BODQ) herramienta.
SAP adquirió Business Objects en 2007 y ambos productos pasaron a llamarse SAP BODI y SAP BODQ. En 2008, SAP integró ambos productos en un único producto de software denominado SAP Business Objects Data Services (BODS).
SAP BODS proporciona una solución de integración y gestión de datos y, en la versión anterior de BODS, se incluyó la solución de procesamiento de datos de texto.
BODS - Objetos
Todas las entidades que se utilizan en BO Data Services Designer se denominan Objects. Todos los objetos como proyectos, trabajos, metadatos y funciones del sistema se almacenan en la biblioteca de objetos local. Todos los objetos son de naturaleza jerárquica.
Los objetos contienen principalmente lo siguiente:
Properties- Se utilizan para describir un objeto y no afectan su funcionamiento. Ejemplo: nombre de un objeto, fecha de creación, etc.
Options - Que controlan el funcionamiento de los objetos.
Tipos de objetos
Hay dos tipos de objetos en el sistema: objetos reutilizables y objetos de un solo uso. El tipo de objeto determina cómo se utiliza y se recupera ese objeto.
Objetos reutilizables
La mayoría de los objetos que se almacenan en el repositorio se pueden reutilizar. Cuando un objeto reutilizable se define y guarda en el repositorio local, puede reutilizar el objeto creando llamadas a la definición. Cada objeto reutilizable tiene solo una definición y todas las llamadas a ese objeto se refieren a esa definición. Ahora, si la definición de un objeto se cambia en un lugar, está cambiando la definición del objeto en todos los lugares donde aparece ese objeto.
Una biblioteca de objetos se utiliza para contener la definición de objeto y cuando un objeto se arrastra y suelta de la biblioteca, se crea una nueva referencia a un objeto existente.
Objetos de un solo uso
Todos los objetos que se definen específicamente para un trabajo o flujo de datos se conocen como objetos de un solo uso. Por ejemplo, transformación específica utilizada en cualquier carga de datos.
BODS - Jerarquía de objetos
Todos los objetos son de naturaleza jerárquica. El siguiente diagrama muestra la jerarquía de objetos en el sistema SAP BODS:

BODS: herramientas y funciones
Según la arquitectura que se ilustra a continuación, tenemos muchas herramientas definidas en SAP Business Objects Data Services. Cada herramienta tiene su propia función según el panorama del sistema.

En la parte superior, tiene los Servicios de plataforma de información instalados para la administración de seguridad de derechos y usuarios. BODS depende de la consola de administración central (CMC) para el acceso del usuario y la función de seguridad. Esto es aplicable a la versión 4.x. En la versión anterior, se hacía en Management Console.
El Diseñador de servicios de datos es una herramienta de desarrollo que se utiliza para crear objetos que constan de asignación de datos, transformación y lógica. Está basado en GUI y funciona como diseñador para servicios de datos.
Repositorio
El repositorio se utiliza para almacenar metadatos de objetos utilizados en BO Data Services. Cada repositorio debe registrarse en la Consola de administración central y estar vinculado con uno o varios servidores de trabajo, que son responsables de ejecutar los trabajos que usted crea.
Tipos de repositorios
Hay tres tipos de repositorios.
Local Repository - Se utiliza para almacenar los metadatos de todos los objetos creados en Data Services Designer como proyectos, trabajos, flujo de datos, flujo de trabajo, etc.
Central Repository- Se utiliza para controlar la gestión de versiones de los objetos y se utiliza para el desarrollo multiusos. El repositorio central almacena todas las versiones de un objeto de aplicación. Por lo tanto, le permite pasar a versiones anteriores.
Profiler Repository- Se utiliza para gestionar todos los metadatos relacionados con las tareas del generador de perfiles realizadas en SAP BODS Designer. El repositorio CMS almacena metadatos de todas las tareas realizadas en CMC en la plataforma de BI. Information Steward Repository almacena todos los metadatos de las tareas de creación de perfiles y los objetos creados en Information Steward.
Servidor de trabajo
El servidor de trabajos se utiliza para ejecutar los trabajos por lotes y en tiempo real creados por usted. Obtiene la información del trabajo de los repositorios respectivos e inicia el motor de datos para ejecutar el trabajo. El servidor de trabajos puede ejecutar los trabajos en tiempo real o programados y utiliza subprocesos múltiples en la memoria caché y procesamiento paralelo para optimizar el rendimiento.
Acceder al servidor
Access Server en Data Services se conoce como sistema de intermediario de mensajes en tiempo real, que toma las solicitudes de mensajes, pasa al servicio en tiempo real y muestra un mensaje en un período de tiempo específico.
Consola de gestión de servicios de datos
La consola de gestión de servicios de datos se utiliza para realizar actividades de administración como programar los trabajos, generar informes de calidad en el sistema DS, validación de datos, documentación, etc.
BODS - Estándares de denominación
Es recomendable utilizar convenciones de nomenclatura estándar para todos los objetos en todos los sistemas, ya que esto le permite identificar los objetos en los repositorios fácilmente.
La tabla muestra la lista de convenciones de nomenclatura recomendadas que deben usarse para todos los trabajos y otros objetos.
| Prefijo | Sufijo | Objeto |
|---|---|---|
| DF_ | n / A | Flujo de datos |
| EDF_ | _Entrada | Flujo de datos integrado |
| EDF_ | _Salida | Flujo de datos integrado |
| RTJob_ | n / A | Trabajo en tiempo real |
| WF_ | n / A | Flujo de trabajo |
| TRABAJO_ | n / A | Trabajo |
| n / A | _DS | Almacén de datos |
| CORRIENTE CONTINUA_ | n / A | Configuración de datos |
| CAROLINA DEL SUR_ | n / A | Configuración del sistema |
| n / A | _Memory_DS | Almacén de datos de memoria |
| PROC_ | n / A | Procedimiento almacenado |
Los conceptos básicos de BO Data Service incluyen objetos clave en el diseño del flujo de trabajo como proyecto, trabajo, flujo de trabajo, flujo de datos, repositorios.
BODS: repositorio y tipos
El repositorio se utiliza para almacenar metadatos de objetos utilizados en BO Data Services. Cada repositorio debe registrarse en la Consola de administración central, CMC, y debe estar vinculado con uno o varios servidores de trabajos, que son responsables de ejecutar los trabajos que usted crea.
Tipos de repositorios
Hay tres tipos de repositorios.
Local Repository - Se utiliza para almacenar los metadatos de todos los objetos creados en Data Services Designer como proyectos, trabajos, flujo de datos, flujo de trabajo, etc.
Central Repository- Se utiliza para controlar la gestión de versiones de los objetos y se utiliza para el desarrollo multiusos. El repositorio central almacena todas las versiones de un objeto de aplicación. Por lo tanto, le permite pasar a versiones anteriores.
Profiler Repository- Se utiliza para gestionar todos los metadatos relacionados con las tareas del generador de perfiles realizadas en SAP BODS Designer. El repositorio CMS almacena metadatos de todas las tareas realizadas en CMC en la plataforma de BI. Information Steward Repository almacena todos los metadatos de las tareas de creación de perfiles y los objetos creados en Information Steward.
Para crear un repositorio de BODS, debe tener instalada una base de datos. Puede utilizar SQL Server, la base de datos Oracle, My SQL, SAP HANA, Sybase, etc.
Creando repositorio
Debe crear los siguientes usuarios en la base de datos al instalar BODS y crear repositorios. Estos usuarios deben iniciar sesión en diferentes servidores, como el servidor CMS, el servidor de auditoría, etc.
Crear BODS de usuario identificados por Bodsserver1
- Grant Connect to BODS;
- Otorgar Crear sesión a BODS;
- Otorgar DBA a BODS;
- Otorgue Crear cualquier tabla a BODS;
- Otorgar Crear cualquier vista a BODS;
- Otorgar Drop Any Table a BODS;
- Otorgar Drop Any View a BODS;
- Otorgar Insertar cualquier tabla a BODS;
- Otorgar Actualizar cualquier tabla a BODS;
- Otorgar Eliminar cualquier tabla a BODS;
- Alterar CUOTA DE BODS DE USUARIO ILIMITADA EN USUARIOS;
Crear usuario CMS identificado por CMSserver1
- Otorgar conexión a CMS;
- Otorgar Crear sesión a CMS;
- Otorgar DBA a CMS;
- Otorgue Crear cualquier tabla a CMS;
- Otorgue Crear cualquier vista a CMS;
- Otorgar Drop Any Table a CMS;
- Otorgar Drop Any View a CMS;
- Otorgar Insertar cualquier tabla a CMS;
- Otorgar actualización de cualquier tabla a CMS;
- Otorgar Eliminar cualquier tabla a CMS;
- Alterar la CUOTA DE USUARIO CMS ILIMITADA EN USUARIOS;
Crear usuario CMSAUDIT identificado por CMSAUDITserver1
- Otorgar conexión a CMSAUDIT;
- Otorgar Crear sesión a CMSAUDIT;
- Otorgar DBA a CMSAUDIT;
- Otorgue Crear cualquier tabla a CMSAUDIT;
- Otorgue Crear cualquier vista a CMSAUDIT;
- Otorgar Drop Any Table a CMSAUDIT;
- Otorgar Drop Any View a CMSAUDIT;
- Otorgue Insertar cualquier tabla a CMSAUDIT;
- Otorgar Actualizar cualquier tabla a CMSAUDIT;
- Otorgar Eliminar cualquier tabla a CMSAUDIT;
- Alterar USUARIO CMSAUDIT CUOTA ILIMITADA EN USUARIOS;
Para crear un nuevo repositorio después de la instalación
Step 1 - Crea una base de datos Local_Repoy vaya a Data Services Repository Manager. Configure la base de datos como repositorio local.

Una nueva ventana se abrirá.
Step 2 - Ingrese los detalles en los siguientes campos -
Tipo de repositorio, tipo de base de datos, nombre del servidor de la base de datos, puerto, nombre de usuario y contraseña.

Step 3 - Haga clic en el Createbotón. Recibirá el siguiente mensaje:

Step 4 - Ahora inicie sesión en la Consola de administración central CMC en SAP BI Platform con nombre de usuario y contraseña.
Step 5 - En la página de inicio de CMC, haga clic en Data Services.

Step 6 - Desde el Data Services menú, haga clic en Configure a new Data Services Repositorio.

Step 7 - Ingrese los detalles como se indica en la nueva ventana.
- Nombre del repositorio: Local_Repo
- Tipo de base de datos: SAP HANA
- Nombre del servidor de base de datos: mejor
- Nombre de la base de datos: LOCAL_REPO
- Nombre de usuario:
- Password:*****

Step 8 - Haga clic en el botón Test Connection y si tiene éxito, haga clic en Save. Una vez que guarde, aparecerá en la pestaña Repositorio en CMC.
Step 9 - Aplicar derechos de acceso y seguridad en el repositorio local en CMC → User and Groups.
Step 10 - Una vez otorgado el acceso, vaya a Diseñador de servicios de datos → Seleccione Repositorio → Ingrese el nombre de usuario y la contraseña para iniciar sesión.

Actualización del repositorio
Para actualizar un repositorio, siga los pasos dados.
Step 1 - Para actualizar un repositorio después de la instalación, cree una base de datos Local_Repo y vaya a Data Services Repository Manager.
Step 2 - Configurar la base de datos como repositorio local.

Una nueva ventana se abrirá.
Step 3 - Ingrese los detalles para los siguientes campos.
Tipo de repositorio, tipo de base de datos, nombre del servidor de la base de datos, puerto, nombre de usuario y contraseña.

Verá la salida como se muestra en la captura de pantalla que se muestra a continuación.

La Consola de gestión de servicios de datos (DSMC) se utiliza para realizar actividades de administración como programar los trabajos, generar informes de calidad en el sistema DS, validación de datos, documentación, etc.
Puede acceder a la Consola de administración de servicios de datos de las siguientes maneras:
Puede acceder a la Consola de administración de servicios de datos yendo a Start → All Programs → Data Services → Data Service Management Console.
También puede acceder a la consola de administración de servicios de datos a través de Designer si ya ha iniciado sesión.
Para acceder a la consola de administración de servicios de datos a través de Designer Home Page siga los pasos que se indican a continuación.

Para acceder a la consola de administración de servicios de datos a través de Herramientas, siga los pasos dados:
Step 1 - Ir a Tools → Data Services Management Console como se muestra en la siguiente imagen.

Step 2 - Una vez que inicie sesión en Data Services Management Console, la pantalla de inicio se abrirá como se muestra en la captura de pantalla que se muestra a continuación. En la parte superior, puede ver el nombre de usuario a través del cual inició sesión.
En la página de inicio, verá las siguientes opciones:
- Administrator
- Documentación automática
- Validación de datos
- Análisis de impacto y linaje
- Tablero operativo
- Informes de calidad de datos

Las funciones clave de cada módulo de la Consola de administración de servicios de datos se explican en este capítulo.
Módulo de administrador
Se utiliza una opción de administrador para administrar:
- Usuarios y roles
- Para agregar conexiones para acceder a servidores y repositorios
- Para acceder a los datos del trabajo publicados para servicios web
- Para programar y monitorear trabajos por lotes
- Para comprobar el estado del servidor de acceso y los servicios en tiempo real.
Una vez que haga clic en el Administratorpestaña, puede ver muchos enlaces en el panel izquierdo. Son: estado, lote, servicios web, conexiones SAP, grupos de servidores, gestión de repositorios de perfiles e historial de ejecución de trabajos.

Nodos
Los distintos nodos que se encuentran en el módulo Administrador se describen a continuación.
Estado
El nodo Estado se utiliza para comprobar el estado de los trabajos por lotes y en tiempo real, el estado del servidor de acceso, los repositorios de adaptadores y perfiladores, y otros estados del sistema.
Haga clic en Estado → Seleccionar un repositorio
En el panel derecho, verá las pestañas de las siguientes opciones:
Batch Job Status- Se utiliza para comprobar el estado del trabajo por lotes. Puede comprobar la información del trabajo, como seguimiento, monitorización, error y monitor de rendimiento, hora de inicio, hora de finalización, duración, etc.

Batch Job Configuration - La configuración de trabajos por lotes se utiliza para verificar la programación de trabajos individuales o puede agregar una acción como Ejecutar, Agregar programación, Exportar comando de ejecución.
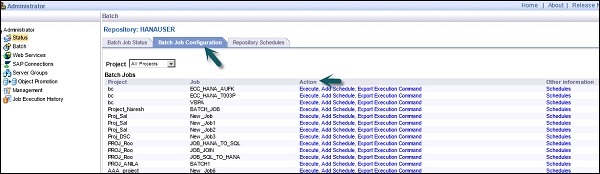
Repositories Schedules - Se utiliza para ver y configurar horarios para todos los trabajos en el repositorio.
Nodo de lote
En el nodo Trabajo por lotes, verá las mismas opciones que las anteriores.
| No Señor. | Opción y descripción |
|---|---|
| 1 | Batch Job Status Vea el estado de la última ejecución e información detallada sobre cada trabajo. |
| 2 | Batch Job Configuration Configure las opciones de ejecución y programación para trabajos individuales. |
| 3 | Repository Schedules Ver y configurar horarios para todos los trabajos en el repositorio. |
Nodo de servicios web
Los servicios web se utilizan para publicar trabajos en tiempo real y trabajos por lotes como operación de servicio web y para verificar el estado de estas operaciones. También se utiliza para mantener la seguridad de los trabajos publicados como servicio web y para verWSDL archivo.

Conexiones SAP
SAP Connections se utiliza para verificar el estado o para configurar RFC server interface en la Consola de administración de servicios de datos.
Para comprobar el estado de la interfaz del servidor RFC, vaya a la pestaña Estado de la interfaz del servidor RFC. Para agregar una nueva interfaz de servidor RFC, en la pestaña de configuración, haga clic enAdd.
Cuando se abra una nueva ventana, ingrese los detalles de configuración del servidor RFC, haga clic en Apply.

Grupos de servidores
Esto se usa para agrupar todos los servidores de trabajos que están asociados con el mismo repositorio en un grupo de servidores. Esta pestaña se utiliza para equilibrar la carga mientras se ejecutan los trabajos en los servicios de datos.
Cuando se ejecuta un trabajo, comprueba el servidor de trabajos correspondiente y, si está inactivo, mueve el trabajo a otro servidor de trabajos del mismo grupo. Se utiliza principalmente en producción para equilibrar la carga.

Repositorios de perfiles
Cuando conecta el repositorio de perfiles al administrador, le permite expandir el nodo del repositorio de perfiles. Puede ir a la página de estado de Tareas de perfil.
Nodo de gestión
Para utilizar la función de la pestaña Administrador, debe agregar conexiones a los servicios de datos mediante el nodo de gestión. El nodo de administración consta de diferentes opciones de configuración para la aplicación de administración.

Historial de ejecución de trabajos
Se utiliza para comprobar el historial de ejecución de un trabajo o un flujo de datos. Con esta opción, puede verificar el historial de ejecución de un trabajo por lotes o todos los trabajos por lotes creados por usted.
Cuando selecciona un trabajo, la información se muestra en forma de tabla, que consta de nombre del repositorio, nombre del trabajo, hora de inicio, hora de finalización, hora de ejecución, estado, etc.

El Diseñador de servicios de datos es una herramienta de desarrollo que se utiliza para crear objetos que consisten en mapeo de datos, transformación y lógica. Está basado en GUI y funciona como diseñador para servicios de datos.
Puede crear varios objetos utilizando el Diseñador de servicios de datos como proyectos, trabajos, flujos de trabajo, flujos de datos, mapeo, transformaciones, etc.
Para iniciar el Diseñador de servicios de datos, siga los pasos que se indican a continuación.
Step 1 - Apunte a Inicio → Todos los programas → SAP Data Services 4.2 → Data Services Designer.

Step 2 - Seleccione el Repositorio e ingrese la contraseña para iniciar sesión.

Una vez que seleccione el repositorio e inicie sesión en el diseñador de servicios de datos, aparecerá una pantalla de inicio como se muestra en la imagen a continuación.

En el panel izquierdo, tiene el área del proyecto, donde puede crear un nuevo proyecto, trabajo, flujo de datos, flujo de trabajo, etc. En el área del proyecto, tiene la biblioteca de objetos locales, que consta de todos los objetos creados en los servicios de datos.
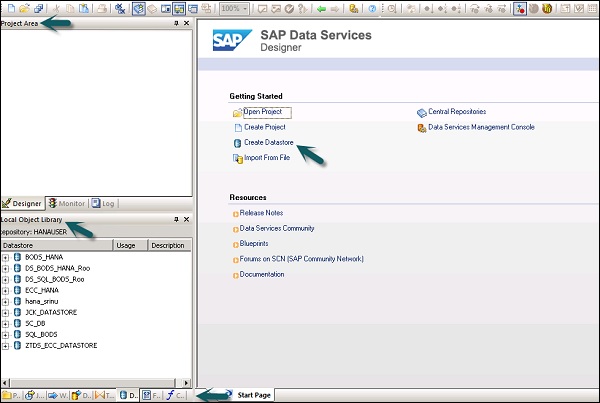
En el panel inferior, puede abrir los objetos existentes yendo a opciones específicas como Proyecto, Trabajos, Flujo de datos, Flujo de trabajo, etc. Una vez que seleccione cualquiera de los objetos del panel inferior, le mostrará todos los objetos similares que ya existen. creado en el repositorio en la biblioteca de objetos local.
En el lado derecho, tiene una pantalla de inicio, que puede usarse para:
- Crear proyecto
- Proyecto abierto
- Crear almacenes de datos
- Crear repositorios
- Importar desde archivo plano
- Consola de gestión de servicios de datos
Para desarrollar un flujo ETL, primero debe crear almacenes de datos para el sistema de origen y destino. Siga los pasos dados para desarrollar un flujo ETL:
Step 1 - Click Create Data Stores.

Una nueva ventana se abrirá.
Step 2 - Ingrese el Datastore nombre, Datastoretype y tipo de base de datos como se muestra a continuación. Puede seleccionar una base de datos diferente como sistema de origen, como se muestra en la captura de pantalla a continuación.

Step 3- Para utilizar el sistema ECC como fuente de datos, seleccione Aplicaciones SAP como tipo de almacén de datos. Introduzca el nombre de usuario y la contraseña y en elAdvance pestaña, ingrese el número de sistema y el número de cliente.

Step 4- Haga clic en Aceptar y el almacén de datos se agregará a la lista de bibliotecas de objetos locales. Si expande Datastore, no muestra ninguna tabla.

Step 5 - Para extraer cualquier tabla del sistema ECC para cargarla en el sistema de destino, haga clic con el botón derecho en Tablas → Importar por nombres.

Step 6 - Ingrese el nombre de la tabla y haga clic en Import. Aquí, se utiliza Table-Mara, que es una tabla predeterminada en el sistema ECC.
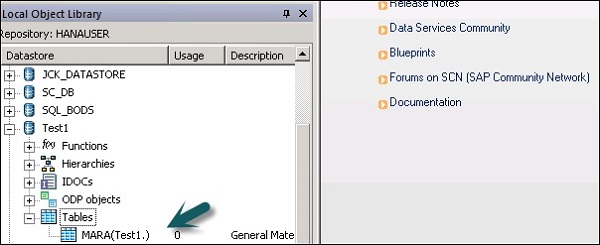
Step 7 - De forma similar, cree un Datastorepara el sistema de destino. En este ejemplo, HANA se utiliza como sistema de destino.

Una vez que haga clic en Aceptar, Datastore se agregará a la biblioteca de objetos local y no habrá ninguna tabla dentro de ella.
Crear un flujo ETL
Para crear un flujo ETL, cree un nuevo proyecto.
Step 1 - Haga clic en la opción, Create Project. Ingrese el nombre del proyecto y haga clic enCreate. Se agregará al área del proyecto.

Step 2 - Haga clic derecho en el nombre del proyecto y cree un nuevo trabajo por lotes / trabajo en tiempo real.

Step 3- Ingrese el nombre del trabajo y presione Enter. Tienes que agregar flujo de trabajo y flujo de datos a esto. Seleccione un flujo de trabajo y haga clic en el área de trabajo para agregarlo al trabajo. Ingrese el nombre del flujo de trabajo y haga doble clic en él para agregarlo al área de Proyecto.
Step 4- De manera similar, seleccione el flujo de datos y llévelo al área de Proyecto. Ingrese el nombre del flujo de datos y haga doble clic para agregarlo al nuevo proyecto.

Step 5- Ahora arrastre la tabla de origen debajo del almacén de datos al área de trabajo. Ahora puede arrastrar la tabla de destino con un tipo de datos similar al área de trabajo o puede crear una nueva tabla de plantilla.
Para crear una nueva tabla de plantilla, haga clic con el botón derecho en la tabla de origen, Agregar nueva → Tabla de plantilla.

Step 6- Ingrese el nombre de la tabla y seleccione el almacén de datos de la lista como almacén de datos de destino. El nombre del propietario representa el nombre del esquema donde se debe crear la tabla.

La tabla se agregará al área de trabajo con este nombre de tabla.
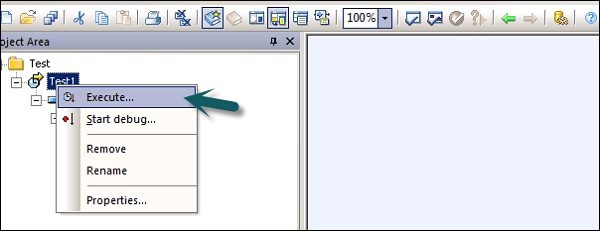
Step 7- Arrastre la línea de la tabla de origen a la tabla de destino. Haga clic en elSave All opción en la parte superior.

Ahora puede programar el trabajo usando la Consola de administración del servicio de datos o puede ejecutarlo manualmente haciendo clic derecho en el nombre del trabajo y Ejecutar.
Los almacenes de datos se utilizan para configurar la conexión entre una aplicación y la base de datos. Puede crear directamente Datastore o puede crearse con la ayuda de adaptadores. Datastore permite que una aplicación / software lea o escriba metadatos de una aplicación o base de datos y escriba en esa base de datos o aplicación.
En Business Objects Data Services, puede conectarse a los siguientes sistemas mediante Datastore:
- Sistemas de mainframe y base de datos
- Aplicaciones y software con adaptadores escritos por el usuario
- Aplicaciones SAP, SAP BW, Oracle Apps, Siebel, etc.
Los servicios de datos de SAP Business Objects ofrecen una opción para conectarse a las interfaces de Mainframe mediante AttunityConector. UtilizandoAttunity, conecte el almacén de datos a la lista de fuentes que se proporciona a continuación:
- DB2 UDB para OS / 390
- DB2 UDB para OS / 400
- IMS/DB
- VSAM
- Adabas
- Archivos planos en OS / 390 y OS / 400

Con el conector Attunity, puede conectarse a los datos del mainframe con la ayuda de un software. Este software debe instalarse manualmente en el servidor de mainframe y en el servidor de trabajo del cliente local mediante una interfaz ODBC.
Ingrese los detalles como la ubicación del host, el puerto, el espacio de trabajo de Attunity, etc.
Crear almacén de datos para una base de datos
Para crear un almacén de datos para una base de datos, siga los pasos que se indican a continuación.
Step 1- Ingrese el nombre del almacén de datos, el tipo de almacén de datos y el tipo de base de datos como se muestra en la imagen que se muestra a continuación. Puede seleccionar una base de datos diferente como sistema de origen en la lista.

Step 2- Para utilizar el sistema ECC como fuente de datos, seleccione Aplicaciones SAP como el tipo de almacén de datos. Ingrese el nombre de usuario y la contraseña. Haga clic en elAdvance pestaña e ingrese el número de sistema y el número de cliente.

Step 3- Haga clic en Aceptar y el almacén de datos se agregará a la lista de bibliotecas de objetos locales. Si expande el almacén de datos, no hay ninguna tabla para mostrar.
En este capítulo, aprenderemos cómo editar o cambiar el almacén de datos. Para cambiar o editar el almacén de datos, siga los pasos que se indican a continuación.
Step 1- Para editar un almacén de datos, haga clic derecho en el nombre del almacén de datos y haga clic en Editar. Abrirá el editor de Datastore.

Puede editar la información de conexión para la configuración actual de Datastore.
Step 2 - Haga clic en el Advance y puede editar el número de cliente, la identificación del sistema y otras propiedades.
Step 3 - Haga clic en el Edit opción para agregar, editar y eliminar las configuraciones.

Step 4 - Haga clic en Aceptar y se aplicarán los cambios.
Puede crear un almacén de datos utilizando la memoria como tipo de base de datos. Los almacenes de datos de memoria se utilizan para mejorar el rendimiento de los flujos de datos en trabajos en tiempo real, ya que almacena los datos en la memoria para facilitar el acceso rápido y no requiere ir a la fuente de datos original.
Un almacén de datos de memoria se usa para almacenar esquemas de tablas de memoria en el repositorio. Estas tablas de memoria obtienen datos de tablas en la base de datos relacional o usando archivos de datos jerárquicos como mensajes XML e IDOC. Las tablas de memoria permanecen activas hasta que se ejecuta el trabajo y los datos de las tablas de memoria no se pueden compartir entre diferentes trabajos en tiempo real.
Creación de un almacén de datos de memoria
Para crear Memory Datastore, siga los pasos que se indican a continuación.
Step 1 - Haga clic en Crear almacén de datos e ingrese el nombre del almacén de datos “Memory_DS_TEST”. Las tablas de memoria se presentan con tablas RDBMS normales y se pueden identificar con convenciones de nomenclatura.
Step 2 - En Tipo de almacén de datos, seleccione Base de datos y en el tipo de base de datos seleccione Memory. Haga clic en Aceptar.

Step 3 - Ahora vaya a Proyecto → Nuevo → Proyecto como se muestra en la captura de pantalla que se muestra a continuación.

Step 4- Cree un nuevo trabajo haciendo clic derecho. Agregue flujo de trabajo y flujo de datos como se muestra a continuación.
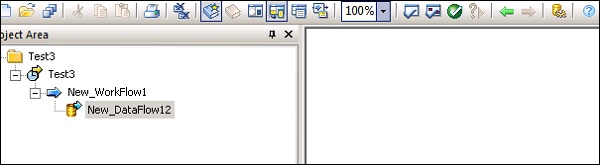
Step 5- Seleccione una tabla de Plantilla y arrástrela y suéltela en el área de trabajo. Se abrirá una ventana Crear tabla.

Step 6- Ingrese el nombre de la tabla y en Datastore, seleccione Memory Datastore. Si desea un ID de fila generado por el sistema, seleccione elcreate row idcasilla de verificación. Haga clic en Aceptar.
Step 7 - Conecte esta tabla de memoria al flujo de datos y haga clic en Save All en la cima.

Tabla de memoria como origen y destino
Para usar una tabla de memoria como objetivo:
Step 1- Vaya a la biblioteca de objetos local, haga clic en la pestaña Datastore. Expanda el almacén de datos de memoria → Expandir tablas.
Step 2- Seleccione la tabla de memoria que desea utilizar como tabla de origen o de destino y arrástrela al flujo de trabajo. Conecte esta tabla de memoria como origen o destino en el flujo de datos.
Step 3 - Haga clic en el save para guardar el trabajo.
Hay varios proveedores de bases de datos, que solo proporcionan una ruta de comunicación unidireccional desde una base de datos a otra. Estas rutas se conocen como enlaces a bases de datos. En SQL Server, el servidor vinculado permite una ruta de comunicación unidireccional de una base de datos a otra.
Ejemplo
Considere un servidor de base de datos local llamado “Product” almacena el enlace de la base de datos para acceder a la información en el servidor de base de datos remoto llamado Customer. Ahora, los usuarios que están conectados al servidor de base de datos remoto Cliente no pueden utilizar el mismo enlace para acceder a los datos en el servidor de base de datos Producto. Usuarios que están conectados a“Customer” debe tener un enlace separado en el diccionario de datos del servidor para acceder a los datos en el servidor de la base de datos del Producto.
Esta ruta de comunicación entre las dos bases de datos se denomina enlace de base de datos. Los almacenes de datos, que se crean entre estas relaciones de bases de datos vinculadas, se conocen como almacenes de datos vinculados.
Existe la posibilidad de conectar un Datastore a otro Datastore e importar un enlace de base de datos externa como opción de Datastore.

Adapter Datastore te permite importar metadatos de aplicaciones al repositorio. Puede acceder a los metadatos de la aplicación y mover los datos por lotes y en tiempo real entre diferentes aplicaciones y software.
Hay un kit de desarrollo de software de adaptador: SDK proporcionado por SAP que se puede utilizar para desarrollar adaptadores personalizados. Estos adaptadores se muestran en el diseñador de servicios de datos por los almacenes de datos de adaptadores.
Para extraer o cargar los datos con un adaptador, debe definir al menos un almacén de datos para este propósito.
Almacén de datos del adaptador: definición
Para definir Adaptive Datastore, siga los pasos dados:
Step 1 - Click Create Datastore→ Ingrese el nombre de Datastore. Seleccione el tipo de almacén de datos como adaptador. Selecciona elJob Server de la lista y el nombre de la instancia del adaptador y haga clic en OK.

Para examinar los metadatos de la aplicación
Haga clic derecho en el nombre del almacén de datos y haga clic en Open. Se abrirá una nueva ventana que muestra los metadatos de origen. Haga clic en el signo + para verificar los objetos y haga clic con el botón derecho en el objeto para importar.
El formato de archivo se define como un conjunto de propiedades para presentar la estructura de archivos planos. Define la estructura de los metadatos. El formato de archivo se utiliza para conectarse a la base de datos de origen y destino cuando los datos se almacenan en los archivos y no en la base de datos.
El formato de archivo se utiliza para las siguientes funciones:
- Cree una plantilla de formato de archivo para definir la estructura de un archivo.
- Cree un formato de archivo de origen y destino específico en el flujo de datos.
Los siguientes tipos de archivos se pueden usar como archivo de origen o de destino usando el formato de archivo:
- Delimited
- Transporte SAP
- Texto no estructurado
- Binario no estructurado
- Ancho fijo
Editor de formato de archivo
El Editor de formato de archivo se utiliza para establecer las propiedades de las plantillas de formato de archivo y los formatos de archivo de origen y destino.
Los siguientes modos están disponibles en el editor de formato de archivo:
New mode - Le permite crear una nueva plantilla de formato de archivo.
Edit mode - Le permite editar una plantilla de formato de archivo existente.
Source mode - Le permite editar el formato de archivo de un archivo fuente en particular.
Target mode - Le permite editar el formato de archivo de un archivo de destino en particular.
Hay tres áreas de trabajo para el Editor de formato de archivo:
Properties Values - Se utiliza para editar los valores de las propiedades del formato de archivo.
Column Attributes - Se utiliza para editar y definir las columnas o campos del archivo.
Data Preview - Se utiliza para ver cómo afectan los ajustes a los datos de muestra.
Crear un formato de archivo
Para crear un formato de archivo, siga los pasos que se indican a continuación.
Step 1 - Vaya a Biblioteca de objetos locales → Archivos planos.

Step 2 - Haga clic derecho en la opción Archivos planos → Nuevo.

Se abrirá una nueva ventana del Editor de formato de archivo.
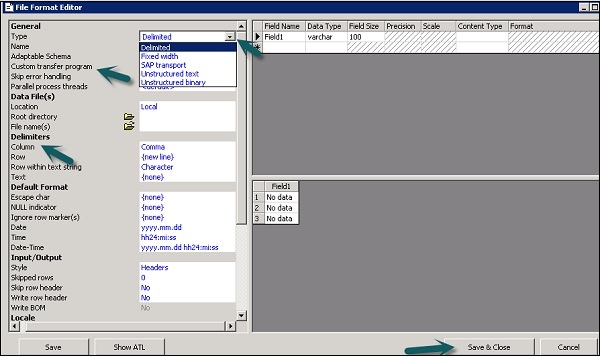
Step 3- Seleccione el tipo de formato de archivo. Ingrese el nombre que describe la plantilla de formato de archivo. Para archivos de ancho fijo y delimitado, puede leer y cargar usando el programa de transferencia personalizado. Ingrese las otras propiedades para describir los archivos que representa esta plantilla.
También puede especificar la estructura de las columnas en el área de trabajo de los atributos de columna para algunos formatos de archivo específicos. Una vez definidas todas las propiedades, haga clic en elSave botón.
Editar un formato de archivo
Para editar los formatos de archivo, siga los pasos que se indican a continuación.
Step 1 - En la biblioteca de objetos locales, vaya a la Format lengüeta.
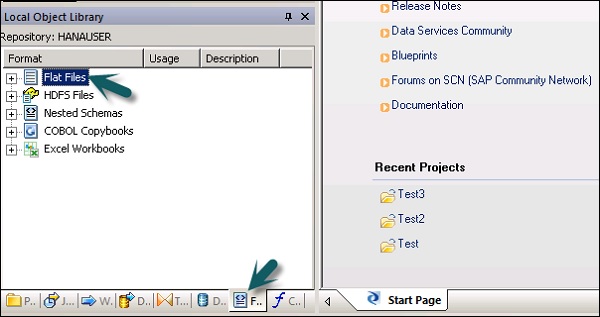
Step 2- Seleccione el formato de archivo que desea editar. Haga clic derecho en elEdit opción.

Realice cambios en el editor de formato de archivo y haga clic en el Save botón.
Puede crear un formato de archivo de libro de copias COBOL que le ralentice para crear solo el formato. Puede configurar la fuente más tarde una vez que agregue el formato al flujo de datos.
Puede crear el formato de archivo y conectarlo al archivo de datos al mismo tiempo. Siga los pasos que se indican a continuación.
Step 1 - Vaya a Biblioteca de objetos locales → Formato de archivo → Cuadernos COBOL.

Step 2 - Haga clic derecho en el New opción.

Step 3- Ingrese el nombre del formato. Vaya a la pestaña Formato → Seleccione el cuaderno COBOL para importar. La extensión del archivo es.cpy.
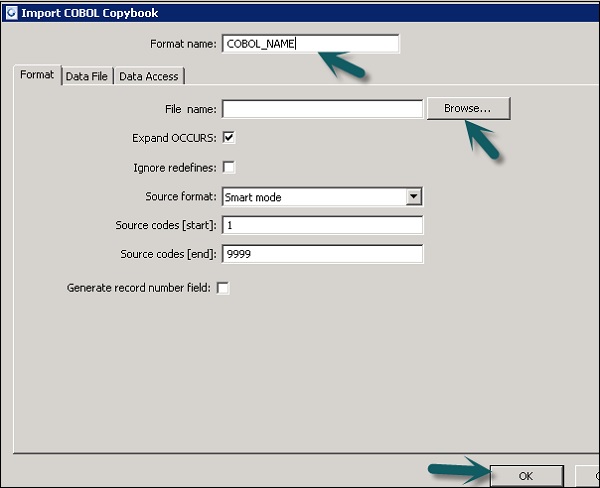
Step 4 - Click OK. Este formato de archivo se agrega a la biblioteca de objetos locales. Se abre el cuadro de diálogo COBOL Copybook Schema name. Si es necesario, cambie el nombre del esquema y haga clic enOK.
Al utilizar los almacenes de datos de la base de datos, puede extraer los datos de las tablas y funciones de la base de datos. Cuando realiza la importación de datos para metadatos,Tool le permite editar los nombres de las columnas, tipos de datos, descripción, etc.
Puede editar los siguientes objetos:
- Nombre de la tabla
- Nombre de columna
- Descripción de la tabla
- Descripción de la columna
- Tipo de datos de columna
- Tipo de contenido de columna
- Atributos de tabla
- Clave primaria
- Nombre del dueño
Importación de metadatos
Para importar metadatos, siga los pasos que se indican a continuación:
Step 1 - Vaya a Biblioteca de objetos locales → vaya al almacén de datos que desea utilizar.

Step 2 - Haga clic con el botón derecho en Datastore → Abrir.
En el espacio de trabajo, se mostrarán todos los elementos que están disponibles para importar. Seleccione los elementos para los que desea importar los metadatos.

En la biblioteca de objetos, vaya al almacén de datos para ver la lista de objetos importados.
Puede usar el libro de trabajo de Microsoft Excel como fuente de datos usando los formatos de archivo en Servicios de datos. El libro de Excel debe estar disponible en el sistema de archivos de Windows o en el sistema de archivos Unix.
| No Señor. | Acceso y descripción |
|---|---|
| 1 | In the object library, click the Formats tab. Un libro de Excel formal describe la estructura definida en un libro de Excel (denotado con una extensión .xls). Almacena plantillas de formato para rangos de datos de Excel en la biblioteca de objetos. Utiliza la plantilla para definir el formato de una fuente en particular en un flujo de datos. SAP Data Services accede a los libros de trabajo de Excel solo como fuente (no como destinos). |
Haga clic derecho en el New opción y seleccione Excel Workbook como se muestra en la captura de pantalla a continuación.

Extracción de datos de archivos XML DTD, XSD
También puede importar formato de archivo de esquema XML o DTD.
Step 1 - Vaya a Biblioteca de objetos locales → pestaña Formato → Esquema anidado.
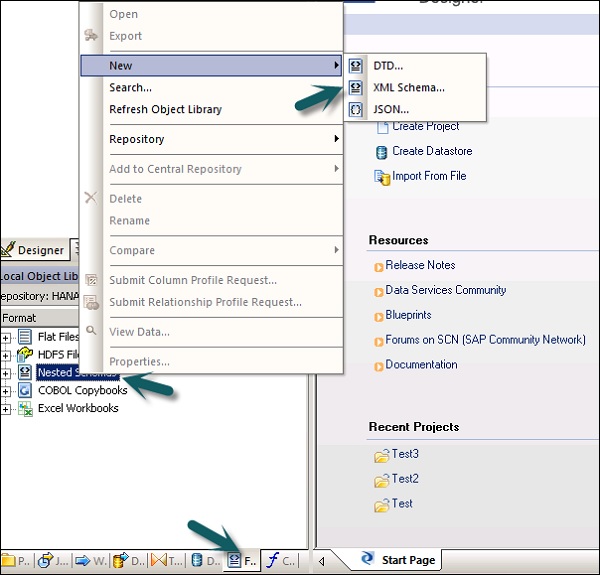
Step 2 - Señalar New(Puede seleccionar un archivo DTD o un esquema XML o formato de archivo JSON). Ingrese el nombre del formato de archivo y seleccione el archivo que desea importar. Haga clic en Aceptar.
Extracción de datos de los cuadernos COBOL
También puede importar formato de archivo en libros de copias COBOL. Vaya a Biblioteca de objetos locales → Formato → Cuadernos COBOL.

El flujo de datos se utiliza para extraer, transformar y cargar datos desde el sistema de origen al de destino. Todas las transformaciones, carga y formateo ocurren en el flujo de datos.
Una vez que defina un flujo de datos en un proyecto, este se puede agregar a un flujo de trabajo o un trabajo ETL. El flujo de datos puede enviar o recibir objetos / información usando parámetros. El flujo de datos se nombra en formatoDF_Name.

Ejemplo de flujo de datos
Supongamos que desea cargar una tabla de hechos en el sistema DW con datos de dos tablas en el sistema fuente.
Data Flow contiene los siguientes objetos:
- Tabla de dos fuentes
- Unir entre dos tablas y definir en Query transform
- Tabla de destino

Hay tres tipos de objetos que se pueden agregar a un flujo de datos. Ellos son -
- Source
- Target
- Transforms
Step 1 - Vaya a la Biblioteca de objetos locales y arrastre ambas tablas al espacio de trabajo.

Step 2 - Para agregar una Transformación de consulta, arrastre desde la barra de herramientas derecha.
Step 3 - Únase a ambas tablas y cree una tabla de destino de plantilla haciendo clic con el botón derecho en el cuadro Consulta → Agregar nuevo → Nueva tabla de plantilla.

Step 4 - Introduzca el nombre de la tabla de destino, el nombre del almacén de datos y el propietario (nombre del esquema) bajo el cual se creará la tabla.
Step 5 - Arrastre la tabla de destino al frente y únala a la transformación de consulta.
Pasar parámetros
También puede pasar diferentes parámetros dentro y fuera del flujo de datos. Al pasar un parámetro a un flujo de datos, los objetos en el flujo de datos hacen referencia a esos parámetros. Usando parámetros, puede pasar diferentes operaciones a un flujo de datos.
Ejemplo: suponga que ha introducido un parámetro en una tabla sobre la última actualización. Le permite extraer solo las filas modificadas desde la última actualización.
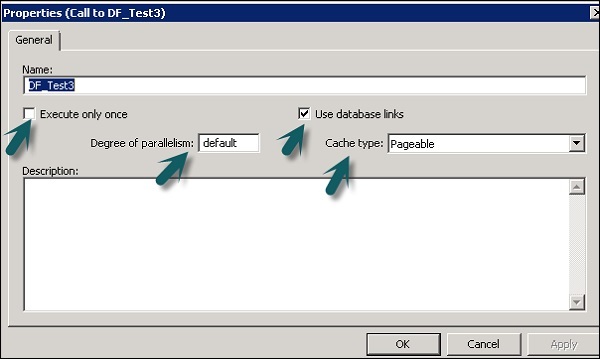
Puede cambiar las propiedades de un flujo de datos como Ejecutar una vez, tipo de caché, enlace de base de datos, paralelismo, etc.
Step 1 - Para cambiar las propiedades del flujo de datos, haga clic derecho en Flujo de datos → Propiedades
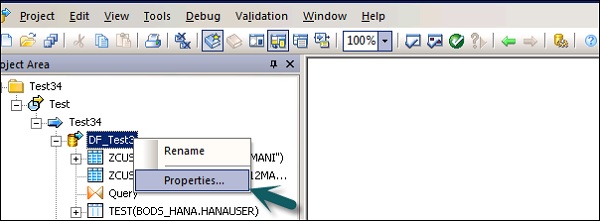
Puede establecer varias propiedades para un flujo de datos. Las propiedades se dan a continuación.
| No Señor. | Propiedades y descripción |
|---|---|
| 1 | Execute only once Cuando especifica que un flujo de datos solo debe ejecutarse una vez, un trabajo por lotes nunca volverá a ejecutar ese flujo de datos después de que el flujo de datos se complete correctamente, excepto si el flujo de datos está contenido en un flujo de trabajo que es una unidad de recuperación que se vuelve a ejecutar y no se ha completado con éxito en otro lugar fuera de la unidad de recuperación. Se recomienda que no marque un flujo de datos como Ejecutar solo una vez si un flujo de trabajo principal es una unidad de recuperación. |
| 2 | Use database links Los enlaces de bases de datos son rutas de comunicación entre un servidor de base de datos y otro. Los enlaces de bases de datos permiten a los usuarios locales acceder a los datos de una base de datos remota, que puede estar en la computadora local o remota del mismo tipo de base de datos o diferente. |
| 3 | Degree of parallelism El grado de paralelismo (DOP) es una propiedad de un flujo de datos que define cuántas veces se replica cada transformación dentro de un flujo de datos para procesar un subconjunto paralelo de datos. |
| 4 | Cache type Puede almacenar en caché los datos para mejorar el rendimiento de operaciones como combinaciones, grupos, ordenaciones, filtrado, búsquedas y comparaciones de tablas. Puede seleccionar uno de los siguientes valores para la opción Tipo de caché en la ventana Propiedades del flujo de datos:
|
Step 2 - Cambie las propiedades como Ejecutar solo una vez, Grado de paralelismo y tipos de caché.
Objetos de origen y destino
Un flujo de datos puede extraer o cargar datos directamente utilizando los siguientes objetos:
Source objects - Los objetos fuente definen la fuente de la que se extraen los datos o se leen los datos.
Target objects - Objetos de destino define el destino en el que carga o escribe los datos.
Se puede utilizar el siguiente tipo de objeto de origen y se utilizan diferentes métodos de acceso para los objetos de origen.
| Mesa | Un archivo formateado con columnas y filas como se usa en bases de datos relacionales | Directo o mediante adaptador |
| Tabla de plantillas | Una tabla de plantilla que se ha creado y guardado en otro flujo de datos (utilizado en desarrollo) | Directo |
| Archivo | Un archivo plano delimitado o de ancho fijo | Directo |
| Documento | Un archivo con un formato específico de la aplicación (no legible por el analizador SQL o XML) | A través del adaptador |
| Archivo XML | Un archivo formateado con etiquetas XML | Directo |
| Mensaje XML | Utilizado como fuente en trabajos en tiempo real | Directo |
Se pueden utilizar los siguientes objetos de destino y se pueden aplicar diferentes métodos de acceso.
| Mesa | Un archivo formateado con columnas y filas como se usa en bases de datos relacionales | Directo o mediante adaptador |
| Tabla de plantillas | Una tabla cuyo formato se basa en la salida de la transformación anterior (utilizada en desarrollo) | Directo |
| Archivo | Un archivo plano delimitado o de ancho fijo | Directo |
| Documento | Un archivo con un formato específico de la aplicación (no legible por el analizador SQL o XML) | A través del adaptador |
| Archivo XML | Un archivo formateado con etiquetas XML | Directo |
| Archivo de plantilla XML | Un archivo XML cuyo formato se basa en la salida de transformación anterior (utilizado en desarrollo, principalmente para depurar flujos de datos) | Directo |
Los flujos de trabajo se utilizan para determinar el proceso de ejecución. El propósito principal del flujo de trabajo es prepararse para ejecutar los flujos de datos y establecer el estado del sistema, una vez que se completa la ejecución del flujo de datos.
Los trabajos por lotes en proyectos ETL son similares a los flujos de trabajo con la única diferencia de que el trabajo no tiene parámetros.
Se pueden agregar varios objetos a un flujo de trabajo. Ellos son -
- Flujo de trabajo
- Flujo de datos
- Scripts
- Loops
- Conditions
- Probar o atrapar bloques
También puede hacer que un flujo de trabajo llame a otro flujo de trabajo o un flujo de trabajo se pueda llamar a sí mismo.
Note - En el flujo de trabajo, los pasos se ejecutan en una secuencia de izquierda a derecha.
Ejemplo de flujo de trabajo
Suponga que hay una tabla de hechos que desea actualizar y ha creado un flujo de datos con la transformación. Ahora, si desea mover los datos del sistema de origen, debe verificar la última modificación de la tabla de hechos para extraer solo las filas que se agregan después de la última actualización.
Para lograr esto, debe crear un script, que determina la fecha de la última actualización y luego pasar esto como parámetro de entrada al flujo de datos.
También debe verificar si la conexión de datos a una tabla de hechos en particular está activa o no. Si no está activo, debe configurar un bloque de captura, que envía automáticamente un correo electrónico al administrador para notificar sobre este problema.
Los flujos de trabajo se pueden crear utilizando los siguientes métodos:
- Biblioteca de objetos
- Paleta de herramientas
Crear un flujo de trabajo usando la biblioteca de objetos
Para crear un flujo de trabajo utilizando la biblioteca de objetos, siga los pasos que se indican a continuación.
Step 1 - Vaya a la pestaña Biblioteca de objetos → Flujo de trabajo.

Step 2 - Haga clic derecho en el New opción.

Step 3 - Ingrese el nombre del flujo de trabajo.
Crear un flujo de trabajo usando la paleta de herramientas
Para crear un flujo de trabajo usando la paleta de herramientas, haga clic en el icono en el lado derecho y arrastre el flujo de trabajo en el espacio de trabajo.
También puede configurar la ejecución del flujo de trabajo solo una vez accediendo a las propiedades del flujo de trabajo.
Condicionales
También puede agregar condicionales al flujo de trabajo. Esto le permite implementar la lógica If / Else / Then en los flujos de trabajo.
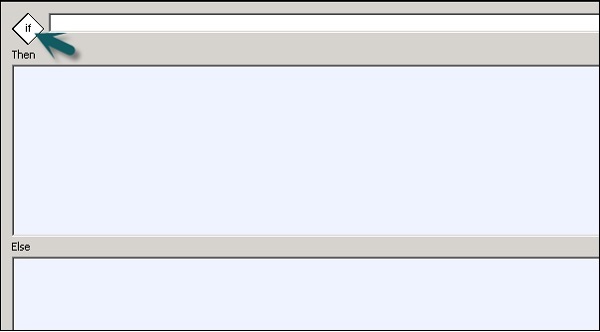
| No Señor. | Condicional y descripción |
|---|---|
| 1 | If Una expresión booleana que se evalúa como VERDADERO o FALSO. Puede utilizar funciones, variables y operadores estándar para construir la expresión. |
| 2 | Then Elementos de flujo de trabajo para ejecutar si el If expresión se evalúa como VERDADERO. |
| 3 | Else (Opcional) Elementos de flujo de trabajo para ejecutar si el If expresión se evalúa como FALSO. |
Para definir un condicional
Step 1 - Vaya a Flujo de trabajo → Haga clic en el icono Condicional en la paleta de herramientas del lado derecho.
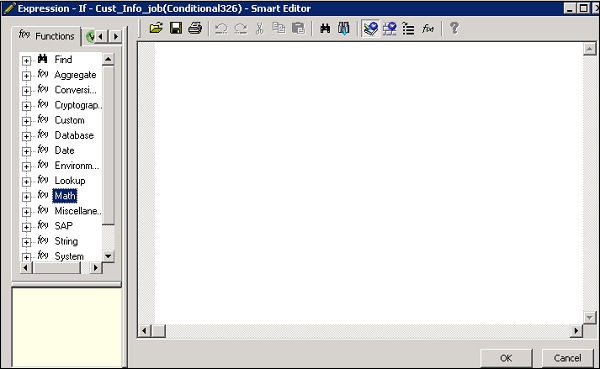
Step 2 - Haga doble clic en el nombre de Condicional para abrir el If-Then–Else editor condicional.
Step 3- Ingrese la expresión booleana que controla el condicional. Haga clic en Aceptar.
Step 4 - Arrastre el flujo de datos que desea ejecutar Then and Else ventana según la expresión en la condición IF.

Una vez que complete la condición, puede depurar y validar el condicional.
Las transformaciones se utilizan para manipular los conjuntos de datos como entradas y crear una o varias salidas. Hay varias transformaciones que se pueden utilizar en los servicios de datos. El tipo de transformaciones depende de la versión y el producto adquirido.
Los siguientes tipos de transformaciones están disponibles:
Integración de datos
Las transformaciones de integración de datos se utilizan para la extracción, transformación y carga de datos en el sistema DW. Asegura la integridad de los datos y mejora la productividad de los desarrolladores.
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Comparación de tablas, etc.
Calidad de los datos
Las transformaciones de calidad de datos se utilizan para mejorar la calidad de los datos. Puede aplicar analizar, corregir, estandarizar y enriquecer el conjunto de datos del sistema de origen.
- Associate
- Limpieza de datos
- Secuenciador de paseo DSF2, etc.
Plataforma
La plataforma se utiliza para el movimiento de conjuntos de datos. Con esto, puede generar, mapear y fusionar filas de dos o más fuentes de datos.
- Case
- Merge
- Consulta, etc.
Procesamiento de datos de texto
El procesamiento de datos de texto le permite procesar un gran volumen de datos de texto.
En este capítulo, verá cómo agregar Transform a un flujo de datos.
Step 1 - Vaya a Biblioteca de objetos → pestaña Transformar.
Step 2- Seleccione la transformación que desea agregar al flujo de datos. Si agrega una transformación que tiene la opción de seleccionar la configuración, se abrirá un mensaje.
Step 3 - Dibuje la conexión del flujo de datos para conectar la fuente a una transformación.
Step 4 - Haga doble clic en el nombre de la transformación para abrir el editor de transformación.
Una vez que la definición esté completa, haga clic en OK para cerrar el editor.
Esta es la transformación más común utilizada en los servicios de datos y puede realizar las siguientes funciones:
- Filtrado de datos de fuentes
- Uniendo datos de múltiples fuentes
- Realizar funciones y transformaciones en datos
- Mapeo de columnas de esquemas de entrada a salida
- Asignación de claves primarias
- Agregar nuevas columnas, esquemas y funciones como resultado de los esquemas de salida
Como la transformación de consulta es la transformación más utilizada, se proporciona un acceso directo para esta consulta en la paleta de herramientas.
Para agregar la transformación de consulta, siga los pasos que se indican a continuación:
Step 1- Haga clic en la paleta de herramientas de transformación de consultas. Haga clic en cualquier lugar del espacio de trabajo Flujo de datos. Conéctelo a las entradas y salidas.

Cuando hace doble clic en el icono de transformación de consultas, se abre un editor de consultas que se utiliza para realizar operaciones de consulta.
Las siguientes áreas están presentes en la transformación de consultas:
- Esquema de entrada
- Esquema de salida
- Parameters
Los esquemas de entrada y salida contienen columnas, esquemas anidados y funciones. Schema In y Schema Out muestra el esquema seleccionado actualmente en transformación.
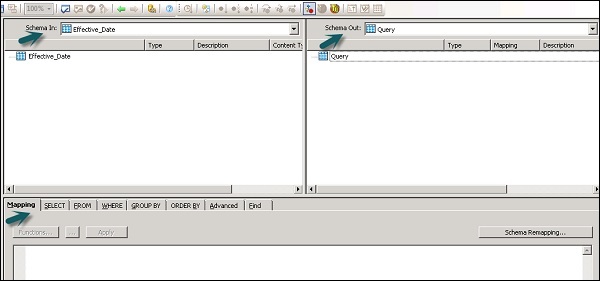
Para cambiar el esquema de salida, seleccione el esquema en la lista, haga clic con el botón derecho y seleccione Convertir en actual.

Transformación de la calidad de los datos
Las transformaciones de calidad de datos no se pueden conectar directamente a la transformación ascendente, que contiene tablas anidadas. Para conectar estas transformaciones, debe agregar una transformación de consulta o una transformación de canalización XML entre la transformación de la tabla anidada y la transformación de calidad de datos.
¿Cómo utilizar la transformación de la calidad de datos?
Step 1 - Ir a Biblioteca de objetos → pestaña Transformar
Step 2 - Expanda la transformación de Calidad de datos y agregue la transformación o la configuración de transformación que desea agregar al flujo de datos.
Step 3- Dibujar las conexiones del flujo de datos. Haga doble clic en el nombre de la transformación, se abre el editor de transformación. En el esquema de entrada, seleccione los campos de entrada que desea asignar.
Note - Para usar Associate Transform, puede agregar campos definidos por el usuario a la pestaña de entrada.
Transformación de procesamiento de datos de texto
Transformación de procesamiento de datos de texto le permite extraer la información específica de un gran volumen de texto. Puede buscar hechos y entidades como clientes, productos y hechos financieros, específicos de una organización.
Esta transformación también verifica la relación entre entidades y permite la extracción. Los datos extraídos mediante el procesamiento de datos de texto se pueden utilizar en inteligencia empresarial, informes, consultas y análisis.
Transformación de extracción de entidad
En los servicios de datos, el procesamiento de datos de texto se realiza con la ayuda de Entity Extraction, que extrae entidades y hechos de datos no estructurados.
Esto implica analizar y procesar un gran volumen de datos de texto, buscar entidades, asignarlas al tipo apropiado y presentar metadatos en formato estándar.
La transformación Entity Extraction puede extraer información de cualquier texto, HTML, XML o cierto contenido de formato binario (como PDF) y generar una salida estructurada. Puede utilizar la salida de varias formas según su flujo de trabajo. Puede usarlo como entrada para otra transformación o escribir en múltiples fuentes de salida, como una tabla de base de datos o un archivo plano. La salida se genera en codificación UTF-16.
Entity Extract Transform can be used in the following scenarios −
Encontrar una información específica a partir de una gran cantidad de texto.
Encontrar información estructurada a partir de texto no estructurado con información existente para establecer nuevas conexiones.
Informes y análisis de la calidad del producto.
Diferencias entre TDP y limpieza de datos
El procesamiento de datos de texto se utiliza para encontrar información relevante a partir de datos de texto no estructurados. Sin embargo, la limpieza de datos se utiliza para estandarizar y limpiar datos estructurados.
| Parámetros | Procesamiento de datos de texto | Limpieza de datos |
|---|---|---|
| Tipo de entrada | Datos no estructurados | Datos estructurados |
| Tamaño de entrada | Más de 5 KB | Menos de 5 KB |
| Alcance de entrada | Dominio amplio con muchas variaciones | Variaciones limitadas |
| Uso potencial | Información significativa potencial de datos no estructurados | Calidad de los datos para almacenar en el repositorio |
| Salida | Cree anotaciones en forma de entidades, tipo, etc. La entrada no se modifica | Crear campos estandarizados, la entrada se cambia |
La administración de los servicios de datos incluye la creación de trabajos por lotes y en tiempo real, la programación de trabajos, el flujo de datos integrados, las variables y parámetros, el mecanismo de recuperación, la creación de perfiles de datos, el ajuste del rendimiento, etc.
Trabajos en tiempo real
Puede crear trabajos en tiempo real para procesar mensajes en tiempo real en el diseñador de servicios de datos. Como un trabajo por lotes, el trabajo en tiempo real extrae los datos, los transforma y los carga.
Cada trabajo en tiempo real puede extraer datos de un solo mensaje. También puede extraer datos de otras fuentes como tablas o archivos.
Los trabajos en tiempo real no se ejecutan con la ayuda de activadores a diferencia de los trabajos por lotes. Los administradores los ejecutan como servicios en tiempo real. Los servicios en tiempo real esperan mensajes del servidor de acceso. El servidor de acceso recibe este mensaje y lo pasa a los servicios en tiempo real, que está configurado para procesar el tipo de mensaje. Los servicios en tiempo real ejecutan el mensaje y devuelven el resultado y continúan procesando los mensajes hasta que reciben una instrucción para detener la ejecución.
Trabajos en tiempo real frente a por lotes
Las transformaciones como las ramas y la lógica de control se utilizan con más frecuencia en trabajos en tiempo real, lo que no es el caso de los trabajos por lotes en el diseñador.
Los trabajos en tiempo real no se ejecutan en respuesta a una programación o desencadenante interno a diferencia de los trabajos por lotes.
Creación de trabajos en tiempo real
Se pueden crear trabajos en tiempo real utilizando los mismos objetos como flujos de datos, flujos de trabajo, bucles, condicionales, scripts, etc.
Puede utilizar los siguientes modelos de datos para crear trabajos en tiempo real:
- Modelo de flujo de datos único
- Modelo de flujo de datos múltiples
Modelo de flujo de datos único
Puede crear un trabajo en tiempo real con un solo flujo de datos en su ciclo de procesamiento en tiempo real e incluye un solo origen de mensaje y un solo destino de mensaje.
Creating Real Time job using single data model −
Para crear un trabajo en tiempo real utilizando un modelo de datos único, siga los pasos indicados.
Step 1 - Vaya a Diseñador de servicios de datos → Proyecto nuevo → Proyecto → Ingrese el nombre del proyecto

Step 2 - Haga clic derecho en el espacio en blanco en el área Proyecto → Nuevo trabajo en tiempo real.

El espacio de trabajo muestra dos componentes del trabajo en tiempo real:
- RT_Process_begins
- Step_ends
Muestra el comienzo y el final del trabajo en tiempo real.

Step 3 - Para crear un trabajo en tiempo real con un solo flujo de datos, seleccione el flujo de datos de la paleta de herramientas en el panel derecho y arrástrelo al espacio de trabajo.
Haga clic dentro del ciclo, puede utilizar un origen de mensaje y un destino de mensaje en ciclo de procesamiento en tiempo real. Conecte las marcas inicial y final al flujo de datos.

Step 4 - Agregue configurar objetos en el flujo de datos según sea necesario y guarde el trabajo.
Modelo de flujo de datos múltiples
Esto le permite crear un trabajo en tiempo real con múltiples flujos de datos en su ciclo de procesamiento en tiempo real. También debe asegurarse de que los datos de cada modelo de datos se procesen por completo antes de pasar al siguiente mensaje.
Prueba de trabajos en tiempo real
Puede probar el trabajo en tiempo real pasando el mensaje de muestra como mensaje de origen desde el archivo. Puede comprobar si los servicios de datos generan el mensaje de destino esperado.
Para asegurarse de que su trabajo le dé el resultado esperado, puede ejecutar el trabajo en el modo de visualización de datos. Con este modo, puede capturar datos de salida para asegurarse de que su trabajo en tiempo real funcione correctamente.
Flujos de datos integrados
El flujo de datos incorporado se conoce como flujos de datos, que se llaman desde otro flujo de datos en el diseño. El flujo de datos incrustado puede contener múltiples fuentes y destinos, pero solo una entrada o salida transfiere datos al flujo de datos principal.
Se pueden utilizar los siguientes tipos de flujos de datos integrados:
One Input - El flujo de datos integrado se agrega al final del flujo de datos.
One Output - El flujo de datos incrustado se agrega al comienzo de un flujo de datos.
No input or output - Replica un flujo de datos existente.
El flujo de datos integrado se puede utilizar para el siguiente propósito:
Para simplificar la visualización del flujo de datos.
Si desea guardar la lógica del flujo y reutilizarla en otros flujos de datos.
Para la depuración, en la que crea secciones de flujo de datos como flujo de datos incrustado y las ejecuta por separado.
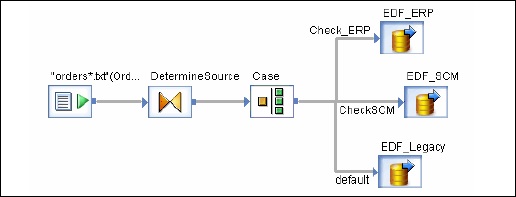
Puede seleccionar un objeto en el flujo de datos existente. Hay dos formas de crear un flujo de datos integrado.
Opción 1
Haga clic derecho en el objeto y seleccione para convertirlo en flujo de datos integrados.

opcion 2
Arrastre el flujo de datos completo y validado de la biblioteca de objetos a un flujo de datos abierto en el espacio de trabajo. A continuación, abra el flujo de datos que se ha creado. Seleccione el objeto que desea utilizar como puerto de entrada y salida y haga clic enmake port para ese objeto.

Los servicios de datos agregan ese objeto como punto de conexión para el flujo de datos integrado.
Variables y parámetros
Puede utilizar variables locales y globales con flujo de datos y flujo de trabajo, lo que proporciona más flexibilidad en el diseño de trabajos.
Las características clave son:
El tipo de datos de una variable puede ser un número, entero, decimal, fecha o una cadena de texto como un carácter.
Las variables se pueden utilizar en los flujos de datos y flujos de trabajo como función en el Where cláusula.
Las variables locales en los servicios de datos están restringidas al objeto en el que se crean.
Las variables globales están restringidas a los trabajos en los que se crean. Con las variables globales, puede cambiar los valores de las variables globales predeterminadas en tiempo de ejecución.
Las expresiones que se utilizan en el flujo de trabajo y el flujo de datos se conocen como parameters.
Todas las variables y parámetros en el flujo de trabajo y los flujos de datos se muestran en la ventana de variables y parámetros.
Para ver variables y parámetros, siga los pasos que se indican a continuación:
Vaya a Herramientas → Variables.

Una nueva ventana Variables and parametersse visualiza. Tiene dos pestañas: Definiciones y Llamadas.
los DefinitionsLa pestaña le permite crear y ver variables y parámetros. Puede utilizar variables y parámetros locales a nivel de flujo de trabajo y de flujo de datos. Las variables globales se pueden utilizar a nivel de trabajo.
Trabajo |
Variables locales Variables globales |
Un guión o condicional en el trabajo. Cualquier objeto en el trabajo |
Flujo de trabajo |
Variables locales Parámetros |
Este flujo de trabajo o se transmite a otros flujos de trabajo o flujos de datos mediante un parámetro. Objetos padre para pasar variables locales. Los flujos de trabajo también pueden devolver variables o parámetros a los objetos principales. |
Flujo de datos |
Parámetros |
Una cláusula WHERE, mapeo de columnas o una función en el flujo de datos. Flujo de datos. Los flujos de datos no pueden devolver valores de salida. |
En la pestaña de llamada, puede ver el nombre del parámetro definido para todos los objetos en la definición de un objeto principal.
Definición de variable local
Para definir la variable local, abra el trabajo en tiempo real.
Step 1- Vaya a Herramientas → Variables. Un nuevoVariables and Parameters se abrirá la ventana.
Step 2 - Ir a Variable → Clic derecho → Insertar

Creará un nuevo parámetro $NewVariable0.
Step 3- Ingrese el nombre de la nueva variable. Seleccione el tipo de datos de la lista.

Una vez definido, cierre la ventana. De manera similar, puede definir los parámetros para el flujo de datos y el flujo de trabajo.

En caso de que su trabajo no se ejecute correctamente, debe corregir el error y volver a ejecutar el trabajo. En caso de trabajos fallidos, existe la posibilidad de que algunas tablas se hayan cargado, alterado o cargado parcialmente. Debe volver a ejecutar el trabajo para obtener todos los datos y eliminar los datos duplicados o faltantes.
Dos técnicas que se pueden utilizar para la recuperación son las siguientes:
Automatic Recovery - Esto le permite ejecutar trabajos fallidos en modo de recuperación.
Manually Recovery - Esto le permite volver a ejecutar los trabajos sin considerar la repetición parcial del tiempo anterior.
To run a job with Recovery option enabled in Designer
Step 1 - Haga clic derecho en el nombre del trabajo → Ejecutar.

Step 2 - Guarde todos los cambios y Ejecute → Sí.
Step 3- Vaya a la pestaña Ejecución → casilla de verificación Habilitar recuperación. Si esta casilla no está marcada, los servicios de datos no recuperarán el trabajo, si falla.

To run a job in Recovery mode from Designer
Step 1- Haga clic derecho y ejecute el trabajo como arriba. Guardar cambios.
Step 2- Vaya a las Opciones de ejecución. Tienes que asegurarte de que la opciónRecover from last failed execution la casilla está marcada.
Note- Esta opción no está habilitada si un trabajo aún no se ha ejecutado. Esto se conoce como recuperación automática de un trabajo fallido.

El Diseñador de servicios de datos proporciona una función de creación de perfiles de datos para garantizar y mejorar la calidad y estructura de los datos de origen.
Data Profiler le permite:
Encuentre anomalías en los datos de origen, validación y acción correctiva y calidad de los datos de origen.
Defina la estructura y la relación de los datos de origen para una mejor ejecución de trabajos, flujos de trabajo y flujos de datos.
Busque el contenido del sistema de origen y destino para determinar que su trabajo devuelve un resultado esperado.
Data Profiler proporciona la siguiente información sobre la ejecución del servidor Profiler:
Análisis de columna
Basic Profiling - Incluye información como mínimo, máximo, promedio, etc.
Detailed Profiling - Incluye información como recuento distinto, porcentaje distinto, mediana, etc.
Análisis de relaciones
Anomalías de datos entre dos columnas para las que define una relación.
La función de creación de perfiles de datos se puede utilizar en datos de las siguientes fuentes de datos:
- servidor SQL
- Oracle
- DB2
- Conector de sintonía
- Sybase IQ
- Teradata
Conexión a Profiler Server
Para conectarse a un servidor de perfiles:
Step 1 - Vaya a Herramientas → Iniciar sesión en el servidor de perfiles

Step 2 - Ingrese los detalles como Sistema, Nombre de usuario, Contraseña y Autenticación.
Step 3 - Haga clic en el Log on botón.
Cuando esté conectado, se mostrará una lista de repositorios de perfiladores. SeleccioneRepository y haga clic en Connect.
El rendimiento de un trabajo ETL depende del sistema en el que esté utilizando el software de servicios de datos, el número de movimientos, etc.
Hay varios otros factores que contribuyen al desempeño en una tarea ETL. Ellos son -
Source Data Base - La base de datos de origen debe configurarse para realizar Selectdeclaraciones rápidamente. Esto se puede hacer aumentando el tamaño de la E / S de la base de datos, aumentando el tamaño del búfer compartido para almacenar en caché más datos y no permitiendo el paralelo para tablas pequeñas, etc.
Source Operating System- El sistema operativo de origen debe configurarse para leer los datos rápidamente de los discos. Establezca el protocolo de lectura anticipada en 64 KB.
Target Database - La base de datos de destino debe estar configurada para realizar INSERT y UPDATEcon rapidez. Esto se puede hacer mediante:
- Deshabilitar el registro de archivo.
- Deshabilitar el registro de rehacer para todas las tablas.
- Maximización del tamaño del búfer compartido.
Target Operating System- El sistema operativo de destino debe configurarse para escribir los datos en los discos rápidamente. Puede activar la E / S asíncrona para que las operaciones de entrada / salida sean lo más rápidas posible.
Network - El ancho de banda de la red debería ser suficiente para transferir los datos del sistema de origen al de destino.
BODS Repository Database - Para mejorar el rendimiento de los trabajos BODS, se puede realizar lo siguiente:
Monitor Sample Rate - En caso de que esté procesando una gran cantidad de datos establecidos en un trabajo ETL, controle la frecuencia de muestreo a un valor más alto para reducir el número de llamadas de E / S al archivo de registro y mejorar así el rendimiento.
También puede excluir los registros de servicios de datos del análisis de virus si el análisis de virus está configurado en el servidor de trabajo, ya que puede causar una degradación del rendimiento.
Job Server OS - En Servicios de datos, un flujo de datos en un trabajo inicia uno ‘al_engine’proceso, que inicia cuatro subprocesos. Para obtener el máximo rendimiento, considere un diseño que ejecute uno‘al_engine’proceso por CPU a la vez. El sistema operativo del servidor de trabajos debe ajustarse de tal manera que todos los subprocesos se distribuyan a todas las CPU disponibles.
SAP BO Data Services admite el desarrollo multiusuario donde cada usuario puede trabajar en una aplicación en su propio repositorio local. Cada equipo utiliza un repositorio central para guardar la copia principal de una aplicación y todas las versiones de los objetos en la aplicación.
Las características clave son:
En SAP Data Services, puede crear un repositorio central para almacenar una copia del equipo de una aplicación. Contiene toda la información que también está disponible en el repositorio local. Sin embargo, solo proporciona una ubicación de almacenamiento para la información del objeto. Para realizar cambios, debe trabajar en el repositorio local.
Puede copiar objetos del repositorio central al repositorio local. Sin embargo, si tiene que realizar algún cambio, debe verificar ese objeto en el repositorio central. Debido a esto, los otros usuarios no pueden verificar ese objeto en el repositorio central y, por lo tanto, no pueden realizar cambios en el mismo objeto.
Una vez que realice los cambios en el objeto, debe registrar el objeto. Permite a los servicios de datos guardar nuevos objetos modificados en el repositorio central.
Los servicios de datos permiten que varios usuarios con repositorios locales se conecten al repositorio central al mismo tiempo, pero solo un usuario puede verificar y realizar cambios en un objeto específico.
El repositorio central también mantiene el historial de cada objeto. Le permite volver a la versión anterior de un objeto, si los cambios no resultan como se requiere.
Múltiples usuarios
Los servicios de datos SAP BO permiten que varios usuarios trabajen en la misma aplicación al mismo tiempo. Los siguientes términos deben considerarse en un entorno multiusuario:
| No Señor. | Multiusuario y descripción |
|---|---|
| 1 | Highest level object El objeto de nivel más alto es el objeto que no depende de ningún objeto en la jerarquía de objetos. Por ejemplo, si el trabajo 1 está compuesto por el flujo de trabajo 1 y el flujo de datos 1, el trabajo 1 es el objeto de nivel más alto. |
| 2 | Object dependents Los dependientes de objetos son objetos asociados debajo del objeto de nivel más alto en la jerarquía. Por ejemplo, si el trabajo 1 está compuesto por el flujo de trabajo 1 que contiene el flujo de datos 1, entonces tanto el flujo de trabajo 1 como el flujo de datos 1 son dependientes del trabajo 1. Además, el flujo de datos 1 depende del flujo de trabajo 1. |
| 3 | Object version Una versión de objeto es una instancia de un objeto. Cada vez que agrega o registra un objeto en el repositorio central, el software crea una nueva versión del objeto. La última versión de un objeto es la última o la versión más reciente creada. |
Para actualizar el repositorio local en un entorno multiusuario, puede obtener la última copia de cada objeto del repositorio central. Para editar un objeto, puede utilizar la opción de check out y check in.
Hay varios parámetros de seguridad que se pueden aplicar en un repositorio central para que sea seguro.
Varios parámetros de seguridad son:
Authentication - Esto permite que solo los usuarios auténticos inicien sesión en el repositorio central.
Authorization - Esto permite al usuario asignar diferentes niveles de permisos para cada objeto.
Auditing- Se utiliza para mantener el historial de todos los cambios realizados en un objeto. Puede comprobar todas las versiones anteriores y volver a las versiones anteriores.
Creación de un repositorio central no seguro
En un entorno de desarrollo multiusuario, siempre es recomendable trabajar en el método de repositorio central.
Para crear un repositorio central no seguro, siga los pasos dados:
Step 1 - Crear una base de datos, utilizando el sistema de gestión de bases de datos, que actuará como repositorio central.
Step 2 - Vaya a un administrador de repositorio.

Step 3- Seleccione el tipo de repositorio como Central. Ingrese los detalles de la base de datos, como el nombre de usuario y la contraseña, y haga clic enCreate.

Step 4 - Para definir una conexión al Repositorio Central, Tools → Central Repository.

Step 5 - Seleccione la conexión Repository in Central Repository y haga clic en el Add icono.

Step 6 - Introduzca la contraseña del repositorio central y haga clic en el Activate botón.
Creación de un repositorio central seguro
Para crear un repositorio central seguro, vaya al administrador del repositorio. Seleccione el tipo de repositorio como Central. Haga clic en elEnable Security Marque la casilla.

Para un desarrollo exitoso en el entorno multiusuario, es recomendable implementar algunos procesos como check in y check out.
Puede utilizar los siguientes procesos en un entorno multiusuario:
- Filtering
- Comprobando objetos
- Deshaciendo el pago y envío
- Registrando objetos
- Etiquetado de objetos
El filtrado es aplicable cuando agrega cualquier objeto, registra, retira y etiqueta objetos en el repositorio central.
Migración de trabajos multiusuario
En SAP Data Services, la migración de trabajos se puede aplicar en diferentes niveles, es decir, nivel de aplicación, nivel de repositorio, nivel de actualización.
No puede copiar el contenido de un repositorio central a otro repositorio central directamente; necesita hacer uso del repositorio local.
El primer paso es obtener la última versión de todos los objetos del repositorio central al repositorio local. Active el repositorio central en el que desea copiar los contenidos. Agregue todos los objetos que desea copiar del repositorio local al repositorio central.
Migración del repositorio central
Si actualiza la versión de SAP Data Services, también debe actualizar la versión de Repository.
Se deben considerar los siguientes puntos al migrar un repositorio central para actualizar la versión:
Realice una copia de seguridad del repositorio central de todas las tablas y objetos.
Para mantener la versión de los objetos en los servicios de datos, mantenga un repositorio central para cada versión. Cree un nuevo historial central con la nueva versión del software Data Services y copie todos los objetos en este repositorio.
Si instala una nueva versión de Data Services, siempre se recomienda que actualice su repositorio central a una nueva versión de objetos.
Actualice su repositorio local a la misma versión, ya que es posible que las diferentes versiones del repositorio central y local no funcionen al mismo tiempo.
Antes de migrar el repositorio central, registre todos los objetos. Como no actualiza el repositorio central y local simultáneamente, es necesario registrar todos los objetos. Una vez que haya actualizado su repositorio central a una versión más reciente, no podrá registrar objetos del repositorio local, que tiene una versión anterior de los Servicios de datos.