Ingeniería de software - Guía rápida
Primero entendamos qué significa la ingeniería de software. El término está compuesto por dos palabras, software e ingeniería.
Software es más que un código de programa. Un programa es un código ejecutable que tiene algún propósito computacional. El software se considera una colección de código de programación ejecutable, bibliotecas asociadas y documentación. El software, cuando se crea para un requisito específico, se denominasoftware product.
Engineering por otro lado, se trata de desarrollar productos, utilizando principios y métodos científicos bien definidos.
Software engineeringes una rama de la ingeniería asociada con el desarrollo de productos de software utilizando principios, métodos y procedimientos científicos bien definidos. El resultado de la ingeniería de software es un producto de software eficiente y confiable.
Definiciones
IEEE define la ingeniería de software como:
(1) La aplicación de un enfoque sistemático, disciplinado y cuantificable para el desarrollo, operación y mantenimiento de software; es decir, la aplicación de la ingeniería al software.
(2) El estudio de enfoques como en la declaración anterior.
Fritz Bauer, un informático alemán, define la ingeniería de software como:
La ingeniería de software es el establecimiento y uso de principios de ingeniería sólidos para obtener un software económico que sea confiable y funcione de manera eficiente en máquinas reales.
Evolución del software
El proceso de desarrollo de un producto de software utilizando principios y métodos de ingeniería de software se denomina software evolution. Esto incluye el desarrollo inicial del software y su mantenimiento y actualizaciones, hasta que se desarrolle el producto de software deseado, que satisfaga los requisitos esperados.

La evolución comienza con el proceso de recopilación de requisitos. Después, los desarrolladores crean un prototipo del software previsto y se lo muestran a los usuarios para obtener sus comentarios en la etapa inicial del desarrollo del producto de software. Los usuarios sugieren cambios, en los que también cambian varias actualizaciones y mantenimiento consecutivos. Este proceso cambia al software original, hasta que se logra el software deseado.
Incluso después de que el usuario ha deseado el software en la mano, la tecnología avanzada y los requisitos cambiantes obligan al producto de software a cambiar en consecuencia. No es factible volver a crear software desde cero e ir uno a uno con los requisitos. La única solución viable y económica es actualizar el software existente para que cumpla con los requisitos más recientes.
Leyes de evolución del software
Lehman ha dado leyes para la evolución del software. Dividió el software en tres categorías diferentes:
- S-type (static-type) - Este es un software que funciona estrictamente de acuerdo con especificaciones y soluciones definidas . La solución y el método para lograrlo, ambos se entienden inmediatamente antes de codificar. El software de tipo s está menos sujeto a cambios, por lo que este es el más simple de todos. Por ejemplo, programa de calculadora para cálculos matemáticos.
- P-type (practical-type) - Este es un software con una colección de procedimientos. Esto se define exactamente por lo que pueden hacer los procedimientos. En este software, las especificaciones se pueden describir pero la solución no es obvia al instante. Por ejemplo, software de juegos.
- E-type (embedded-type) - Este software funciona estrechamente como requisito del entorno del mundo real . Este software tiene un alto grado de evolución ya que hay varios cambios en las leyes, impuestos, etc. en situaciones del mundo real. Por ejemplo, software de comercio en línea.
Evolución del software E-Type
Lehman ha dado ocho leyes para la evolución del software E-Type:
- Continuing change - Un sistema de software de tipo E debe continuar adaptándose a los cambios del mundo real, de lo contrario se vuelve cada vez menos útil.
- Increasing complexity - A medida que evoluciona un sistema de software de tipo E, su complejidad tiende a aumentar a menos que se trabaje para mantenerlo o reducirlo.
- Conservation of familiarity - La familiaridad con el software o el conocimiento sobre cómo se desarrolló, por qué se desarrolló de esa manera en particular, etc. debe conservarse a cualquier costo, para implementar los cambios en el sistema.
- Continuing growth- Para que un sistema de tipo E destinado a resolver algún problema comercial, su tamaño de implementación de los cambios crece de acuerdo con los cambios de estilo de vida de la empresa.
- Reducing quality - Un sistema de software tipo E pierde calidad a menos que se mantenga y se adapte rigurosamente a un entorno operativo cambiante.
- Feedback systems- Los sistemas de software de tipo E constituyen sistemas de retroalimentación de varios niveles y bucles y deben tratarse como tales para poder modificarlos o mejorarlos con éxito.
- Self-regulation - Los procesos de evolución del sistema de tipo E se autorregulan con la distribución del producto y las medidas del proceso casi normales.
- Organizational stability - La tasa de actividad global efectiva promedio en un sistema de tipo E en evolución es invariable durante la vida útil del producto.
Paradigmas de software
Los paradigmas de software se refieren a los métodos y pasos que se toman al diseñar el software. Hay muchos métodos propuestos y están en funcionamiento en la actualidad, pero necesitamos ver en qué parte de la ingeniería de software se encuentran estos paradigmas. Estos se pueden combinar en varias categorías, aunque cada uno de ellos está contenido entre sí:

El paradigma de programación es un subconjunto del paradigma de diseño de software que es además un subconjunto del paradigma de desarrollo de software.
Paradigma de desarrollo de software
Este Paradigma se conoce como paradigmas de ingeniería de software donde se aplican todos los conceptos de ingeniería pertenecientes al desarrollo de software. Incluye varias investigaciones y recopilación de requisitos que ayudan a construir el producto de software. Consiste en -
- Recopilación de requisitos
- Diseño de software
- Programming
Paradigma de diseño de software
Este paradigma es parte del desarrollo de software e incluye:
- Design
- Maintenance
- Programming
Paradigma de programación
Este paradigma está estrechamente relacionado con el aspecto de programación del desarrollo de software. Esto incluye -
- Coding
- Testing
- Integration
Necesidad de ingeniería de software
La necesidad de ingeniería de software surge debido a la mayor tasa de cambio en los requisitos del usuario y el entorno en el que funciona el software.
- Large software - Es más fácil construir un muro que una casa o un edificio, así mismo, a medida que el tamaño del software se vuelve grande, la ingeniería tiene que dar un paso para darle un proceso científico.
- Scalability- Si el proceso de software no se basara en conceptos científicos y de ingeniería, sería más fácil volver a crear software nuevo que escalar uno existente.
- Cost- A medida que la industria del hardware ha demostrado sus habilidades y la enorme fabricación, ha bajado el precio del hardware informático y electrónico. Pero el costo del software sigue siendo alto si no se adapta el proceso adecuado.
- Dynamic Nature- La naturaleza siempre creciente y adaptable del software depende en gran medida del entorno en el que trabaja el usuario. Si la naturaleza del software siempre cambia, es necesario realizar nuevas mejoras en el existente. Aquí es donde la ingeniería de software juega un buen papel.
- Quality Management- Un mejor proceso de desarrollo de software proporciona un producto de software mejor y de calidad.
Características de un buen software
Un producto de software se puede juzgar por lo que ofrece y lo bien que se puede utilizar. Este software debe cumplir con los siguientes motivos:
- Operational
- Transitional
- Maintenance
Se espera que el software bien diseñado y elaborado tenga las siguientes características:
Operacional
Esto nos dice qué tan bien funciona el software en las operaciones. Se puede medir en:
- Budget
- Usability
- Efficiency
- Correctness
- Functionality
- Dependability
- Security
- Safety
Transicional
Este aspecto es importante cuando el software se traslada de una plataforma a otra:
- Portability
- Interoperability
- Reusability
- Adaptability
Mantenimiento
Este aspecto describe qué tan bien un software tiene las capacidades para mantenerse en un entorno en constante cambio:
- Modularity
- Maintainability
- Flexibility
- Scalability
En resumen, la ingeniería de software es una rama de la informática que utiliza conceptos de ingeniería bien definidos necesarios para producir productos de software eficientes, duraderos, escalables, dentro del presupuesto y a tiempo.
El ciclo de vida del desarrollo de software, SDLC para abreviar, es una secuencia estructurada y bien definida de etapas en la ingeniería de software para desarrollar el producto de software deseado.
Actividades SDLC
SDLC proporciona una serie de pasos a seguir para diseñar y desarrollar un producto de software de manera eficiente. El marco SDLC incluye los siguientes pasos:
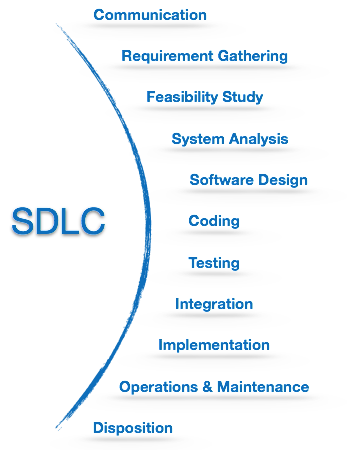
Comunicación
Este es el primer paso en el que el usuario inicia la solicitud de un producto de software deseado. Se pone en contacto con el proveedor de servicios e intenta negociar los términos. Presenta su solicitud a la organización proveedora de servicios por escrito.
Reunión de requisitos
Este paso en adelante, el equipo de desarrollo de software trabaja para llevar a cabo el proyecto. El equipo mantiene conversaciones con varias partes interesadas del dominio del problema e intenta obtener la mayor cantidad de información posible sobre sus requisitos. Los requisitos se contemplan y se separan en requisitos de usuario, requisitos del sistema y requisitos funcionales. Los requisitos se recopilan utilizando una serie de prácticas como se indica:
- estudiar el sistema y el software existentes u obsoletos,
- realizar entrevistas a usuarios y desarrolladores,
- refiriéndose a la base de datos o
- recolectando respuestas de los cuestionarios.
Estudio de factibilidad
Después de recopilar los requisitos, el equipo elabora un plan aproximado del proceso de software. En este paso, el equipo analiza si se puede hacer un software que cumpla con todos los requisitos del usuario y si existe alguna posibilidad de que el software deje de ser útil. Se averigua si el proyecto es económica, práctica y tecnológicamente viable para que la organización lo emprenda. Hay muchos algoritmos disponibles que ayudan a los desarrolladores a concluir la viabilidad de un proyecto de software.
Análisis del sistema
En este paso, los desarrolladores deciden una hoja de ruta de su plan y tratan de presentar el mejor modelo de software adecuado para el proyecto. El análisis del sistema incluye la comprensión de las limitaciones del producto de software, el aprendizaje de problemas relacionados con el sistema o los cambios que deben realizarse en los sistemas existentes de antemano, la identificación y el tratamiento del impacto del proyecto en la organización y el personal, etc. El equipo del proyecto analiza el alcance del proyecto y planifica el cronograma y recursos en consecuencia.
Diseño de software
El siguiente paso es poner todo el conocimiento de los requisitos y análisis en el escritorio y diseñar el producto de software. Los aportes de los usuarios y la información recopilada en la fase de recopilación de requisitos son los aportes de este paso. El resultado de este paso viene en forma de dos diseños; diseño lógico y diseño físico. Los ingenieros producen diccionarios de datos y metadatos, diagramas lógicos, diagramas de flujo de datos y, en algunos casos, pseudocódigos.
Codificación
Este paso también se conoce como fase de programación. La implementación del diseño de software comienza en términos de escribir código de programa en el lenguaje de programación adecuado y desarrollar programas ejecutables sin errores de manera eficiente.
Pruebas
Una estimación dice que se debe probar el 50% de todo el proceso de desarrollo de software. Los errores pueden arruinar el software desde un nivel crítico hasta su propia eliminación. Los desarrolladores realizan pruebas de software mientras codifican y expertos en pruebas en varios niveles de código, como pruebas de módulos, pruebas de programas, pruebas de productos, pruebas internas y pruebas del producto al final del usuario. El descubrimiento temprano de errores y su solución es la clave para un software confiable.
Integración
Es posible que el software deba integrarse con las bibliotecas, bases de datos y otros programas. Esta etapa de SDLC está involucrada en la integración de software con entidades del mundo exterior.
Implementación
Esto significa instalar el software en las máquinas de los usuarios. A veces, el software necesita configuraciones posteriores a la instalación por parte del usuario. Se prueba la portabilidad y adaptabilidad del software, y los problemas relacionados con la integración se resuelven durante la implementación.
Operación y mantenimiento
Esta fase confirma el funcionamiento del software en términos de mayor eficiencia y menos errores. Si es necesario, los usuarios reciben capacitación o se les ayuda con la documentación sobre cómo operar el software y cómo mantenerlo operativo. El software se mantiene actualizado actualizando el código de acuerdo con los cambios que tienen lugar en el entorno o la tecnología del usuario final. Esta fase puede enfrentar desafíos por errores ocultos y problemas no identificados del mundo real.
Disposición
A medida que pasa el tiempo, el software puede disminuir en el frente del rendimiento. Puede volverse completamente obsoleto o puede necesitar una actualización intensa. Por tanto, surge una necesidad imperiosa de eliminar una parte importante del sistema. Esta fase incluye el archivo de datos y los componentes de software necesarios, el cierre del sistema, la planificación de la actividad de disposición y la terminación del sistema en el momento adecuado al final del sistema.
Paradigma de desarrollo de software
El paradigma de desarrollo de software ayuda al desarrollador a seleccionar una estrategia para desarrollar el software. Un paradigma de desarrollo de software tiene su propio conjunto de herramientas, métodos y procedimientos, que se expresan claramente y definen el ciclo de vida del desarrollo de software. Algunos paradigmas de desarrollo de software o modelos de proceso se definen de la siguiente manera:
Modelo de cascada
El modelo de cascada es el modelo más simple de paradigma de desarrollo de software. Dice que todas las fases de SDLC funcionarán una tras otra de manera lineal. Es decir, cuando finalice la primera fase, solo comenzará la segunda fase y así sucesivamente.

Este modelo asume que todo se lleva a cabo y transcurre perfectamente como estaba previsto en la etapa anterior y no hay necesidad de pensar en las cuestiones pasadas que puedan surgir en la siguiente etapa. Este modelo no funciona correctamente si quedan algunos problemas en el paso anterior. La naturaleza secuencial del modelo no nos permite retroceder y deshacer o rehacer nuestras acciones.
Este modelo es más adecuado cuando los desarrolladores ya han diseñado y desarrollado software similar en el pasado y conocen todos sus dominios.
Modelo iterativo
Este modelo lidera el proceso de desarrollo de software en iteraciones. Proyecta el proceso de desarrollo de manera cíclica repitiendo cada paso después de cada ciclo del proceso SDLC.

El software se desarrolla primero a muy pequeña escala y se siguen todos los pasos que se tienen en cuenta. Luego, en cada iteración siguiente, se diseñan, codifican, prueban y agregan más funciones y módulos al software. Cada ciclo produce un software, que es completo en sí mismo y tiene más características y capacidades que el anterior.
Después de cada iteración, el equipo de gestión puede trabajar en la gestión de riesgos y prepararse para la siguiente iteración. Debido a que un ciclo incluye una pequeña parte de todo el proceso de software, es más fácil administrar el proceso de desarrollo pero consume más recursos.
Modelo espiral
El modelo en espiral es una combinación de ambos, modelo iterativo y uno del modelo SDLC. Puede verse como si eligiera un modelo SDLC y lo combinara con un proceso cíclico (modelo iterativo).

Este modelo considera el riesgo, que a menudo pasa desapercibido para la mayoría de los otros modelos. El modelo comienza con la determinación de los objetivos y las limitaciones del software al comienzo de una iteración. La siguiente fase es la creación de un prototipo del software. Esto incluye análisis de riesgo. Luego, se usa un modelo SDLC estándar para construir el software. En la cuarta fase se prepara el plan de la próxima iteración.
V - modelo
El mayor inconveniente del modelo de cascada es que pasamos a la siguiente etapa solo cuando la anterior está terminada y no había posibilidad de retroceder si algo se encuentra mal en etapas posteriores. V-Model proporciona medios para probar el software en cada etapa de manera inversa.

En cada etapa, se crean planes de prueba y casos de prueba para verificar y validar el producto de acuerdo con los requisitos de esa etapa. Por ejemplo, en la etapa de recopilación de requisitos, el equipo de prueba prepara todos los casos de prueba en correspondencia con los requisitos. Más tarde, cuando el producto se desarrolla y está listo para la prueba, los casos de prueba de esta etapa verifican el software con respecto a su validez para los requisitos en esta etapa.
Esto hace que tanto la verificación como la validación vayan en paralelo. Este modelo también se conoce como modelo de verificación y validación.
Modelo Big Bang
Este modelo es el modelo más simple en su forma. Requiere poca planificación, mucha programación y muchos fondos. Este modelo se conceptualiza en torno al big bang del universo. Como dicen los científicos, después del Big Bang, muchas galaxias, planetas y estrellas evolucionaron simplemente como un evento. Del mismo modo, si juntamos mucha programación y fondos, puede lograr el mejor producto de software.

Para este modelo, se requiere muy poca planificación. No sigue ningún proceso, o en ocasiones el cliente no está seguro de los requisitos y necesidades futuras. Entonces, los requisitos de entrada son arbitrarios.
Este modelo no es adecuado para grandes proyectos de software, pero es bueno para aprender y experimentar.
Para una lectura en profundidad sobre SDLC y sus diversos modelos, haga clic aquí.
El patrón de trabajo de una empresa de TI dedicada al desarrollo de software se puede dividir en dos partes:
- Creación de software
- Gestión de proyectos de software
Un proyecto es una tarea bien definida, que es una colección de varias operaciones realizadas para lograr un objetivo (por ejemplo, desarrollo y entrega de software). Un proyecto se puede caracterizar como:
- Cada proyecto puede tener un objetivo único y distinto.
- El proyecto no es una actividad rutinaria ni una operación diaria.
- El proyecto viene con una hora de inicio y una hora de finalización.
- El proyecto finaliza cuando se logra su objetivo, por lo tanto, es una fase temporal en la vida de una organización.
- El proyecto necesita recursos adecuados en términos de tiempo, mano de obra, finanzas, material y banco de conocimientos.
Proyecto de software
Un proyecto de software es el procedimiento completo de desarrollo de software desde la recopilación de requisitos hasta la prueba y el mantenimiento, realizado de acuerdo con las metodologías de ejecución, en un período de tiempo específico para lograr el producto de software previsto.
Necesidad de gestión de proyectos de software
Se dice que el software es un producto intangible. El desarrollo de software es una especie de corriente completamente nueva en los negocios mundiales y hay muy poca experiencia en la creación de productos de software. La mayoría de los productos de software están hechos a medida para adaptarse a los requisitos del cliente. El más importante es que la tecnología subyacente cambia y avanza con tanta frecuencia y rapidez que la experiencia de un producto puede no aplicarse al otro. Todas estas limitaciones comerciales y ambientales conllevan riesgos en el desarrollo de software, por lo que es esencial administrar los proyectos de software de manera eficiente.

La imagen de arriba muestra restricciones triples para proyectos de software. Es una parte esencial de la organización del software entregar un producto de calidad, manteniendo el costo dentro de las restricciones presupuestarias del cliente y entregar el proyecto según lo programado. Hay varios factores, tanto internos como externos, que pueden afectar este triángulo de triple restricción. Cualquiera de los tres factores puede afectar gravemente a los otros dos.
Por lo tanto, la gestión de proyectos de software es fundamental para incorporar los requisitos del usuario junto con las limitaciones de tiempo y presupuesto.
Gerente de proyectos de software
Un gerente de proyecto de software es una persona que asume la responsabilidad de ejecutar el proyecto de software. El gerente de proyectos de software está al tanto de todas las fases de SDLC por las que pasaría el software. Es posible que el gerente de proyecto nunca participe directamente en la producción del producto final, pero controla y administra las actividades involucradas en la producción.
Un gerente de proyecto monitorea de cerca el proceso de desarrollo, prepara y ejecuta varios planes, organiza los recursos necesarios y adecuados, mantiene la comunicación entre todos los miembros del equipo para abordar cuestiones de costo, presupuesto, recursos, tiempo, calidad y satisfacción del cliente.
Veamos algunas responsabilidades que asume un director de proyecto:
La gestión de personas
- Actuar como líder del proyecto
- Lesión con stakeholders
- Gestión de recursos humanos
- Configurar la jerarquía de informes, etc.
Proyecto de gestión
- Definición y configuración del alcance del proyecto
- Gestión de actividades de gestión de proyectos
- Seguimiento del progreso y el desempeño
- Análisis de riesgos en cada fase
- Dar los pasos necesarios para evitar o salir de problemas
- Actuar como portavoz del proyecto
Actividades de gestión de software
La gestión de proyectos de software comprende una serie de actividades, que incluyen la planificación del proyecto, la determinación del alcance del producto de software, la estimación del costo en varios términos, la programación de tareas y eventos y la gestión de recursos. Las actividades de gestión de proyectos pueden incluir:
- Project Planning
- Scope Management
- Project Estimation
Planificación de proyectos
La planificación de proyectos de software es una tarea que se realiza antes de que comience realmente la producción de software. Está ahí para la producción de software, pero no involucra ninguna actividad concreta que tenga alguna conexión directa con la producción de software; más bien es un conjunto de múltiples procesos, lo que facilita la producción de software. La planificación del proyecto puede incluir lo siguiente:
Gestión del alcance
Define el alcance del proyecto; esto incluye todas las actividades, el proceso debe realizarse para hacer un producto de software entregable. La gestión del alcance es esencial porque crea límites del proyecto al definir claramente qué se haría en el proyecto y qué no se haría. Esto hace que el proyecto contenga tareas limitadas y cuantificables, que se pueden documentar fácilmente y, a su vez, evita el sobrecoste y el tiempo.
Durante la gestión del Alcance del Proyecto, es necesario:
- Definir el alcance
- Decidir su verificación y control
- Divida el proyecto en varias partes más pequeñas para facilitar la gestión.
- Verificar el alcance
- Controle el alcance incorporando cambios al alcance
Estimación del proyecto
Para una gestión eficaz es imprescindible una estimación precisa de varias medidas. Con una estimación correcta, los gerentes pueden administrar y controlar el proyecto de manera más eficiente y efectiva.
La estimación del proyecto puede involucrar lo siguiente:
- Software size estimation
El tamaño del software puede estimarse en términos de KLOC (Kilo Line of Code) o calculando el número de puntos de función en el software. Las líneas de código dependen de las prácticas de codificación y los puntos de función varían según los requisitos del usuario o del software.
- Effort estimation
Los gerentes estiman los esfuerzos en términos de requisitos de personal y horas hombre requeridas para producir el software. Para la estimación del esfuerzo, se debe conocer el tamaño del software. Esto puede derivarse de la experiencia de los gerentes, los datos históricos de la organización o el tamaño del software se pueden convertir en esfuerzos mediante el uso de algunas fórmulas estándar.
- Time estimation
Una vez que se estiman el tamaño y los esfuerzos, se puede estimar el tiempo requerido para producir el software. Los esfuerzos necesarios se segregan en subcategorías según las especificaciones de requisitos y la interdependencia de varios componentes del software. Las tareas de software se dividen en tareas, actividades o eventos más pequeños por Work Breakthrough Structure (WBS). Las tareas se programan en el día a día o en meses naturales.
La suma del tiempo necesario para completar todas las tareas en horas o días es el tiempo total invertido para completar el proyecto.
- Cost estimation
Este podría considerarse como el más difícil de todos porque depende de más elementos que cualquiera de los anteriores. Para estimar el costo del proyecto, se requiere considerar:
- Tamaño del software
- Calidad del software
- Hardware
- Software o herramientas adicionales, licencias, etc.
- Personal calificado con habilidades específicas para tareas
- Viaje involucrado
- Communication
- Capacitación y apoyo
Técnicas de estimación de proyectos
Discutimos varios parámetros relacionados con la estimación del proyecto, como el tamaño, el esfuerzo, el tiempo y el costo.
El gerente de proyecto puede estimar los factores enumerados utilizando dos técnicas ampliamente reconocidas:
Técnica de descomposición
Esta técnica asume el software como producto de varias composiciones.
Hay dos modelos principales:
- Line of Code La estimación se realiza en nombre del número de líneas de códigos en el producto de software.
- Function Points La estimación se realiza en nombre del número de puntos de función en el producto de software.
Técnica de estimación empírica
Esta técnica utiliza fórmulas derivadas empíricamente para realizar estimaciones. Estas fórmulas se basan en LOC o FP.
- Putnam Model
Este modelo está hecho por Lawrence H. Putnam, que se basa en la distribución de frecuencia de Norden (curva de Rayleigh). El modelo de Putnam mapea el tiempo y los esfuerzos necesarios con el tamaño del software.
- COCOMO
COCOMO son las siglas de COnstructive COst MODdel, desarrollado por Barry W. Boehm. Divide el producto de software en tres categorías de software: orgánico, adosado e integrado.
Programación de proyectos
La programación del proyecto en un proyecto se refiere a la hoja de ruta de todas las actividades que se realizarán con un orden específico y dentro del intervalo de tiempo asignado a cada actividad. Los gerentes de proyecto tienden a definir varias tareas e hitos del proyecto y organizarlos teniendo en cuenta varios factores. Buscan tareas que se encuentran en una ruta crítica en el cronograma, que es necesario completar de manera específica (debido a la interdependencia de tareas) y estrictamente dentro del tiempo asignado. Es menos probable que la disposición de las tareas que se encuentran fuera de la ruta crítica afecte a todo el cronograma del proyecto.
Para programar un proyecto, es necesario:
- Divida las tareas del proyecto en una forma más pequeña y manejable
- Descubra varias tareas y correlacione
- Estimar el marco de tiempo requerido para cada tarea
- Divida el tiempo en unidades de trabajo
- Asignar un número adecuado de unidades de trabajo para cada tarea.
- Calcule el tiempo total requerido para el proyecto de principio a fin
Administracion de recursos
Todos los elementos utilizados para desarrollar un producto de software pueden asumirse como recursos para ese proyecto. Esto puede incluir recursos humanos, herramientas productivas y bibliotecas de software.
Los recursos están disponibles en cantidades limitadas y permanecen en la organización como un conjunto de activos. La escasez de recursos dificulta el desarrollo del proyecto y puede retrasarse en el cronograma. La asignación de recursos adicionales aumenta el costo de desarrollo al final. Por tanto, es necesario estimar y asignar recursos adecuados para el proyecto.
La gestión de recursos incluye:
- Definir el proyecto de organización adecuado mediante la creación de un equipo de proyecto y la asignación de responsabilidades a cada miembro del equipo.
- Determinar los recursos necesarios en una etapa particular y su disponibilidad.
- Administre los recursos generando solicitudes de recursos cuando sean necesarios y desasignándolos cuando ya no sean necesarios.
Gestión de riesgos del proyecto
La gestión de riesgos incluye todas las actividades relacionadas con la identificación, el análisis y la provisión de riesgos predecibles y no predecibles en el proyecto. El riesgo puede incluir lo siguiente:
- Personal experimentado que abandona el proyecto y nuevo personal que ingresa.
- Cambio en la gestión organizacional.
- Requisito cambio o malinterpretación del requisito.
- Subestimación del tiempo y los recursos necesarios.
- Cambios tecnológicos, cambios ambientales, competencia empresarial.
Proceso de gestión de riesgos
Hay las siguientes actividades involucradas en el proceso de gestión de riesgos:
- Identification - Tome nota de todos los posibles riesgos que puedan ocurrir en el proyecto.
- Categorize - Clasifique los riesgos conocidos en intensidad de riesgo alta, media y baja según su posible impacto en el proyecto.
- Manage - Analizar la probabilidad de ocurrencia de riesgos en varias fases. Haga un plan para evitar o enfrentar riesgos. Intente minimizar sus efectos secundarios.
- Monitor - Controle de cerca los riesgos potenciales y sus primeros síntomas. También supervise los efectos de las medidas adoptadas para mitigarlos o evitarlos.
Ejecución y seguimiento de proyectos
En esta fase, las tareas descritas en los planes del proyecto se ejecutan de acuerdo con sus cronogramas.
La ejecución necesita un seguimiento para comprobar si todo va de acuerdo con el plan. Monitorear es observar para verificar la probabilidad de riesgo y tomar medidas para abordar el riesgo o informar el estado de varias tareas.
Estas medidas incluyen:
- Activity Monitoring - Todas las actividades programadas dentro de alguna tarea se pueden monitorear en el día a día. Cuando se completan todas las actividades de una tarea, se considera completa.
- Status Reports - Los informes contienen el estado de las actividades y tareas completadas dentro de un período de tiempo determinado, generalmente una semana. El estado se puede marcar como terminado, pendiente o en progreso, etc.
- Milestones Checklist - Cada proyecto se divide en múltiples fases donde se realizan las principales tareas (hitos) en función de las fases de SDLC. Esta lista de verificación de hitos se prepara una vez cada pocas semanas e informa el estado de los hitos.
Gestión de comunicación de proyectos
La comunicación eficaz juega un papel vital en el éxito de un proyecto. Sirve de puente entre el cliente y la organización, entre los miembros del equipo y otras partes interesadas en el proyecto, como los proveedores de hardware.
La comunicación puede ser oral o escrita. El proceso de gestión de la comunicación puede tener los siguientes pasos:
- Planning - Este paso incluye la identificación de todos los interesados en el proyecto y el modo de comunicación entre ellos. También considera si se requieren instalaciones de comunicación adicionales.
- Sharing - Después de determinar varios aspectos de la planificación, el gerente se enfoca en compartir la información correcta con la persona correcta en el momento correcto. Esto mantiene a todos los involucrados en el proyecto al día con el progreso del proyecto y su estado.
- Feedback - Los gerentes de proyecto utilizan diversas medidas y mecanismos de retroalimentación y crean informes de estado y desempeño. Este mecanismo asegura que los aportes de las diversas partes interesadas lleguen al director del proyecto como retroalimentación.
- Closure - Al final de cada gran evento, final de una fase de SDLC o finalización del propio proyecto, se anuncia formalmente el cierre administrativo para actualizar a todos los interesados mediante el envío de correo electrónico, la distribución de una copia impresa del documento o por otro medio de comunicación eficaz.
Después del cierre, el equipo pasa a la siguiente fase o proyecto.
Gestión de la configuración
La gestión de la configuración es un proceso de seguimiento y control de los cambios en el software en términos de requisitos, diseño, funciones y desarrollo del producto.
IEEE lo define como “el proceso de identificar y definir los elementos en el sistema, controlar el cambio de estos elementos a lo largo de su ciclo de vida, registrar y reportar el estado de los elementos y las solicitudes de cambio, y verificar la integridad y corrección de los elementos”.
En general, una vez finalizado el SRS, hay menos posibilidades de que el usuario requiera cambios. Si ocurren, los cambios se abordan solo con la aprobación previa de la gerencia superior, ya que existe la posibilidad de que se excedan los costos y el tiempo.
Base
Una fase de SDLC se asume como finalizada si es de línea base, es decir, la línea base es una medida que define la completitud de una fase. Una fase se basa en la línea de base cuando todas las actividades relacionadas con ella están terminadas y bien documentadas. Si no fuera la fase final, su salida se utilizaría en la siguiente fase inmediata.
La gestión de la configuración es una disciplina de la administración de la organización, que se encarga de la ocurrencia de cualquier cambio (proceso, requisito, tecnológico, estratégico, etc.) después de que una fase es la línea base. CM controla los cambios realizados en el software.
Cambio de control
El control de cambios es una función de la gestión de la configuración, lo que garantiza que todos los cambios realizados en el sistema de software sean coherentes y se realicen según las normas y reglamentos de la organización.
Un cambio en la configuración del producto pasa por los siguientes pasos:
Identification- Llega una solicitud de cambio de una fuente interna o externa. Cuando la solicitud de cambio se identifica formalmente, está debidamente documentada.
Validation - Se comprueba la validez de la solicitud de cambio y se confirma su procedimiento de tramitación.
Analysis- El impacto de la solicitud de cambio se analiza en términos de cronograma, costo y esfuerzos requeridos. Se analiza el impacto general del cambio prospectivo en el sistema.
Control- Si el cambio prospectivo impacta a demasiadas entidades en el sistema o es inevitable, es obligatorio contar con la aprobación de las altas autoridades antes de que el cambio se incorpore al sistema. Se decide si vale la pena incorporar el cambio o no. Si no es así, la solicitud de cambio se rechaza formalmente.
Execution - Si la fase anterior determina ejecutar la solicitud de cambio, esta fase toma las acciones apropiadas para ejecutar el cambio, hace una revisión completa si es necesario.
Close request- Se verifica el cambio para su correcta implementación y fusión con el resto del sistema. Este cambio recién incorporado en el software está debidamente documentado y la solicitud se cierra formalmente.
Herramientas de gestión de proyectos
El riesgo y la incertidumbre se multiplican con respecto al tamaño del proyecto, incluso cuando el proyecto se desarrolla de acuerdo con metodologías establecidas.
Hay herramientas disponibles que ayudan a una gestión eficaz del proyecto. Se describen algunos:
Gráfico de gantt
Los diagramas de Gantt fueron ideados por Henry Gantt (1917). Representa el cronograma del proyecto con respecto a los períodos de tiempo. Es un gráfico de barras horizontales con barras que representan las actividades y el tiempo programado para las actividades del proyecto.

Gráfico PERT
El gráfico PERT (técnica de evaluación y revisión de programas) es una herramienta que describe el proyecto como un diagrama de red. Es capaz de representar gráficamente los principales eventos del proyecto tanto de forma paralela como consecutiva. Los eventos, que ocurren uno tras otro, muestran la dependencia del evento posterior sobre el anterior.

Los eventos se muestran como nodos numerados. Están conectados por flechas etiquetadas que representan la secuencia de tareas del proyecto.
Histograma de recursos
Esta es una herramienta gráfica que contiene una barra o un gráfico que representa la cantidad de recursos (generalmente personal capacitado) necesarios a lo largo del tiempo para un evento (o fase) del proyecto. El histograma de recursos es una herramienta eficaz para la planificación y coordinación del personal.


Análisis de ruta crítica
Esta herramienta es útil para reconocer tareas interdependientes en el proyecto. También ayuda a encontrar la ruta más corta o la ruta crítica para completar el proyecto con éxito. Como el diagrama PERT, a cada evento se le asigna un marco de tiempo específico. Esta herramienta muestra la dependencia del evento asumiendo que un evento puede pasar al siguiente solo si se completa el anterior.
Los eventos se organizan de acuerdo con su hora de inicio más temprana posible. La ruta entre el nodo inicial y final es una ruta crítica que no se puede reducir más y todos los eventos deben ejecutarse en el mismo orden.
Los requisitos de software son una descripción de las características y funcionalidades del sistema de destino. Los requisitos transmiten las expectativas de los usuarios del producto de software. Los requisitos pueden ser obvios u ocultos, conocidos o desconocidos, esperados o inesperados desde el punto de vista del cliente.
Ingeniería de requisitos
El proceso para recopilar los requisitos de software del cliente, analizarlos y documentarlos se conoce como ingeniería de requisitos.
El objetivo de la ingeniería de requisitos es desarrollar y mantener un documento de 'Especificación de requisitos del sistema' sofisticado y descriptivo.
Proceso de ingeniería de requisitos
Es un proceso de cuatro pasos, que incluye:
- Estudio de factibilidad
- Reunión de requisitos
- Especificación de requisitos de software
- Validación de requisitos de software
Veamos el proceso brevemente -
Estudio de factibilidad
Cuando el cliente se acerca a la organización para desarrollar el producto deseado, se le ocurre una idea aproximada acerca de qué funciones debe realizar el software y qué características se esperan del software.
Haciendo referencia a esta información, los analistas hacen un estudio detallado sobre si el sistema deseado y su funcionalidad son factibles de desarrollar.
Este estudio de viabilidad está enfocado hacia el objetivo de la organización. Este estudio analiza si el producto de software se puede materializar prácticamente en términos de implementación, contribución del proyecto a la organización, restricciones de costos y según los valores y objetivos de la organización. Explora los aspectos técnicos del proyecto y el producto, como la usabilidad, la capacidad de mantenimiento, la productividad y la capacidad de integración.
El resultado de esta fase debe ser un informe de estudio de factibilidad que debe contener comentarios adecuados y recomendaciones para la administración sobre si el proyecto debe emprenderse o no.
Reunión de requisitos
Si el informe de viabilidad es positivo para emprender el proyecto, la siguiente fase comienza con la recopilación de requisitos del usuario. Los analistas e ingenieros se comunican con el cliente y los usuarios finales para conocer sus ideas sobre lo que debe proporcionar el software y qué características quieren que incluya.
Especificación de requisitos de software
SRS es un documento creado por el analista de sistemas después de que se recopilan los requisitos de varias partes interesadas.
SRS define cómo el software previsto interactuará con el hardware, las interfaces externas, la velocidad de operación, el tiempo de respuesta del sistema, la portabilidad del software en varias plataformas, la capacidad de mantenimiento, la velocidad de recuperación después de fallar, la seguridad, la calidad, las limitaciones, etc.
Los requisitos recibidos del cliente están escritos en lenguaje natural. Es responsabilidad del analista de sistemas documentar los requisitos en lenguaje técnico para que puedan ser comprendidos y útiles por el equipo de desarrollo de software.
SRS debería presentar las siguientes características:
- Los requisitos del usuario se expresan en lenguaje natural.
- Los requisitos técnicos se expresan en un lenguaje estructurado, que se utiliza dentro de la organización.
- La descripción del diseño debe estar escrita en pseudocódigo.
- Formato de formularios y serigrafías GUI.
- Notaciones condicionales y matemáticas para DFD, etc.
Validación de requisitos de software
Una vez que se desarrollan las especificaciones de los requisitos, se validan los requisitos mencionados en este documento. El usuario puede solicitar una solución ilegal y poco práctica o los expertos pueden interpretar los requisitos incorrectamente. Esto da como resultado un enorme aumento en el costo si no se corta de raíz. Los requisitos se pueden comparar con las siguientes condiciones:
- Si se pueden implementar de manera práctica
- Si son válidos y según la funcionalidad y el dominio del software.
- Si hay ambigüedades
- Si estan completos
- Si se pueden demostrar
Proceso de obtención de requisitos
El proceso de obtención de requisitos se puede representar mediante el siguiente diagrama:

- Requirements gathering - Los desarrolladores discuten con el cliente y los usuarios finales y conocen sus expectativas del software.
- Organizing Requirements - Los desarrolladores priorizan y organizan los requisitos en orden de importancia, urgencia y conveniencia.
Negotiation & discussion - Si los requisitos son ambiguos o existen algunos conflictos en los requisitos de varios interesados, si lo son, se negocia y discute con los interesados. Luego, los requisitos pueden priorizarse y comprometerse razonablemente.
Los requisitos provienen de varias partes interesadas. Para eliminar la ambigüedad y los conflictos, se discuten para mayor claridad y corrección. Los requisitos poco realistas se ven comprometidos razonablemente.
- Documentation - Todos los requisitos formales e informales, funcionales y no funcionales se documentan y se ponen a disposición para el procesamiento de la siguiente fase.
Técnicas de obtención de requisitos
La obtención de requisitos es el proceso para averiguar los requisitos de un sistema de software previsto mediante la comunicación con el cliente, los usuarios finales, los usuarios del sistema y otras personas que tienen interés en el desarrollo del sistema de software.
Hay varias formas de descubrir los requisitos.
Entrevistas
Las entrevistas son un medio sólido para recopilar requisitos. La organización puede realizar varios tipos de entrevistas como:
- Las entrevistas estructuradas (cerradas), en las que se decide de antemano toda la información a recopilar, siguen el patrón y el tema de la discusión con firmeza.
- Entrevistas no estructuradas (abiertas), donde la información a recopilar no se decide de antemano, más flexibles y menos sesgadas.
- Entrevistas orales
- Entrevistas escritas
- Entrevistas uno a uno que se llevan a cabo entre dos personas al otro lado de la mesa.
- Entrevistas grupales que se realizan entre grupos de participantes. Ayudan a descubrir cualquier requisito que falte, ya que hay muchas personas involucradas.
Encuestas
La organización puede realizar encuestas entre varias partes interesadas al consultar sobre sus expectativas y requisitos del próximo sistema.
Cuestionarios
Se entrega a todas las partes interesadas un documento con un conjunto predefinido de preguntas objetivas y sus respectivas opciones, que se recopilan y compilan.
Una deficiencia de esta técnica es que, si no se menciona una opción para algún problema en el cuestionario, el problema podría quedar desatendido.
Análisis de tareas
El equipo de ingenieros y desarrolladores puede analizar la operación para la que se requiere el nuevo sistema. Si el cliente ya dispone de algún software para realizar determinada operación, se estudia y se recogen los requisitos del sistema propuesto.
Análisis de dominio
Cada software pertenece a alguna categoría de dominio. Las personas expertas en el dominio pueden ser de gran ayuda para analizar requisitos generales y específicos.
Lluvia de ideas
Se lleva a cabo un debate informal entre varias partes interesadas y todas sus aportaciones se registran para un análisis de requisitos adicional.
Creación de prototipos
La creación de prototipos consiste en crear una interfaz de usuario sin agregar funcionalidad detallada para que el usuario interprete las características del producto de software previsto. Ayuda a dar una mejor idea de los requisitos. Si no hay ningún software instalado en el cliente para referencia del desarrollador y el cliente no conoce sus propios requisitos, el desarrollador crea un prototipo basado en los requisitos mencionados inicialmente. El prototipo se muestra al cliente y se anotan los comentarios. La retroalimentación del cliente sirve como entrada para la recopilación de requisitos.
Observación
Equipo de expertos visita la organización o el lugar de trabajo del cliente. Observan el funcionamiento real de los sistemas instalados existentes. Observan el flujo de trabajo al final del cliente y cómo se tratan los problemas de ejecución. El equipo mismo saca algunas conclusiones que ayudan a formar los requisitos esperados del software.
Características de los requisitos de software
La recopilación de requisitos de software es la base de todo el proyecto de desarrollo de software. Por tanto, deben ser claros, correctos y bien definidos.
Las especificaciones de requisitos de software completas deben ser:
- Clear
- Correct
- Consistent
- Coherent
- Comprehensible
- Modifiable
- Verifiable
- Prioritized
- Unambiguous
- Traceable
- Fuente creíble
Requisitos de Software
Debemos intentar comprender qué tipo de requisitos pueden surgir en la fase de obtención de requisitos y qué tipos de requisitos se esperan del sistema de software.
En términos generales, los requisitos de software deben clasificarse en dos categorías:
Requerimientos funcionales
Los requisitos, que están relacionados con el aspecto funcional del software, entran en esta categoría.
Definen funciones y funcionalidades dentro y desde el sistema de software.
Ejemplos:
- Opción de búsqueda dada al usuario para buscar entre varias facturas.
- El usuario debe poder enviar cualquier informe a la gerencia.
- Los usuarios se pueden dividir en grupos y los grupos pueden tener derechos separados.
- Debe cumplir con las reglas comerciales y las funciones administrativas.
- El software se desarrolla manteniendo intacta la compatibilidad con versiones anteriores.
Requerimientos no funcionales
Los requisitos, que no están relacionados con el aspecto funcional del software, entran en esta categoría. Son características implícitas o esperadas del software, que los usuarios asumen.
Los requisitos no funcionales incluyen:
- Security
- Logging
- Storage
- Configuration
- Performance
- Cost
- Interoperability
- Flexibility
- Recuperación de desastres
- Accessibility
Los requisitos se clasifican lógicamente como
- Must Have : El software no puede decirse operativo sin ellos.
- Should have : Mejora de la funcionalidad del software.
- Could have : El software aún puede funcionar correctamente con estos requisitos.
- Wish list : Estos requisitos no se corresponden con ningún objetivo del software.
Mientras se desarrolla software, se debe implementar 'Must have', 'Should have' es un tema de debate con las partes interesadas y la negación, mientras que 'podría tener' y 'lista de deseos' se pueden mantener para actualizaciones de software.
Requisitos de la interfaz de usuario
La interfaz de usuario es una parte importante de cualquier software, hardware o sistema híbrido. Un software es ampliamente aceptado si es:
- fácil de operar
- rápida en respuesta
- Manejo eficaz de errores operativos
- proporcionando una interfaz de usuario simple pero consistente
La aceptación del usuario depende principalmente de cómo el usuario puede utilizar el software. La interfaz de usuario es la única forma que tienen los usuarios de percibir el sistema. Un sistema de software de buen rendimiento también debe estar equipado con una interfaz de usuario atractiva, clara, coherente y receptiva. De lo contrario, las funcionalidades del sistema de software no se pueden utilizar de manera conveniente. Se dice que un sistema es bueno si proporciona los medios para utilizarlo de manera eficiente. Los requisitos de la interfaz de usuario se mencionan brevemente a continuación:
- Presentación de contenido
- Navegación fácil
- Interfaz simple
- Responsive
- Elementos de IU consistentes
- Mecanismo de retroalimentación
- Configuración por defecto
- Disposición intencionada
- Uso estratégico del color y la textura.
- Proporcionar información de ayuda
- Enfoque centrado en el usuario
- Configuración de vista basada en grupos.
Analista de sistemas de software
El analista de sistemas en una organización de TI es una persona que analiza los requisitos del sistema propuesto y se asegura de que los requisitos se conciban y documenten de manera adecuada y correcta. El rol de un analista comienza durante la Fase de análisis de software de SDLC. Es responsabilidad del analista asegurarse de que el software desarrollado cumpla con los requisitos del cliente.
Los analistas de sistemas tienen las siguientes responsabilidades:
- Analizar y comprender los requisitos del software previsto
- Entender cómo el proyecto contribuirá a los objetivos de la organización.
- Identificar las fuentes de los requisitos
- Validación de requisito
- Desarrollar e implementar un plan de gestión de requisitos
- Documentación de los requisitos comerciales, técnicos, de procesos y de productos.
- Coordinación con clientes para priorizar requisitos y eliminar y ambigüedad
- Finalización de los criterios de aceptación con el cliente y otras partes interesadas.
Métricas y medidas de software
Las medidas de software pueden entenderse como un proceso de cuantificación y simbolización de varios atributos y aspectos del software.
Las métricas de software proporcionan medidas para varios aspectos del proceso de software y del producto de software.
Las medidas de software son un requisito fundamental de la ingeniería de software. No solo ayudan a controlar el proceso de desarrollo de software, sino que también ayudan a mantener excelente la calidad del producto final.
Según Tom DeMarco, un (ingeniero de software), "No se puede controlar lo que no se puede medir". Según su dicho, está muy claro cuán importantes son las medidas de software.
Veamos algunas métricas de software:
Size Metrics - LOC (líneas de código), calculado principalmente en miles de líneas de código fuente entregadas, denotado como KLOC.
Function Point Count es una medida de la funcionalidad proporcionada por el software. El recuento de puntos de función define el tamaño del aspecto funcional del software.
- Complexity Metrics - La complejidad ciclomática de McCabe cuantifica el límite superior del número de rutas independientes en un programa, que se percibe como la complejidad del programa o sus módulos. Se representa en términos de conceptos de teoría de grafos mediante el uso de un diagrama de flujo de control.
Quality Metrics - Los defectos, sus tipos y causas, las consecuencias, la intensidad de la gravedad y sus implicaciones definen la calidad del producto.
El número de defectos encontrados en el proceso de desarrollo y el número de defectos informados por el cliente después de que el producto se instala o se entrega al cliente definen la calidad del producto.
- Process Metrics - En varias fases de SDLC, los métodos y herramientas utilizados, los estándares de la empresa y el desempeño del desarrollo son métricas de procesos de software.
- Resource Metrics - El esfuerzo, el tiempo y los diversos recursos utilizados representan métricas para la medición de recursos.
El diseño de software es un proceso para transformar los requisitos del usuario en alguna forma adecuada, lo que ayuda al programador en la codificación e implementación del software.
Para evaluar los requisitos del usuario, se crea un documento SRS (Especificación de requisitos de software), mientras que para la codificación y la implementación, se necesitan requisitos más específicos y detallados en términos de software. La salida de este proceso se puede utilizar directamente en la implementación en lenguajes de programación.
El diseño de software es el primer paso en SDLC (ciclo de vida del diseño de software), que mueve la concentración del dominio del problema al dominio de la solución. Intenta especificar cómo cumplir con los requisitos mencionados en SRS.
Niveles de diseño de software
El diseño de software produce tres niveles de resultados:
- Architectural Design - El diseño arquitectónico es la versión abstracta más alta del sistema. Identifica el software como un sistema con muchos componentes que interactúan entre sí. En este nivel, los diseñadores tienen la idea del dominio de solución propuesto.
- High-level Design- El diseño de alto nivel rompe el concepto de diseño arquitectónico de “entidad única-componente múltiple” en una vista menos abstraída de subsistemas y módulos y describe su interacción entre sí. El diseño de alto nivel se centra en cómo el sistema junto con todos sus componentes se pueden implementar en forma de módulos. Reconoce la estructura modular de cada subsistema y su relación e interacción entre sí.
- Detailed Design- El diseño detallado se ocupa de la parte de implementación de lo que se ve como un sistema y sus subsistemas en los dos diseños anteriores. Es más detallado sobre los módulos y sus implementaciones. Define la estructura lógica de cada módulo y sus interfaces para comunicarse con otros módulos.
Modularización
La modularización es una técnica para dividir un sistema de software en varios módulos discretos e independientes, que se espera que sean capaces de realizar tareas de forma independiente. Estos módulos pueden funcionar como construcciones básicas para todo el software. Los diseñadores tienden a diseñar módulos de manera que se puedan ejecutar y / o compilar por separado e independientemente.
El diseño modular sigue involuntariamente las reglas de la estrategia de resolución de problemas "divide y vencerás", esto se debe a que hay muchos otros beneficios asociados con el diseño modular de un software.
Ventaja de la modularización:
- Los componentes más pequeños son más fáciles de mantener
- El programa se puede dividir en función de los aspectos funcionales
- El nivel de abstracción deseado se puede incorporar al programa.
- Los componentes con alta cohesión se pueden volver a utilizar
- La ejecución concurrente puede ser posible
- Deseado desde el punto de vista de la seguridad
Concurrencia
En el pasado, todo el software debe ejecutarse de forma secuencial. Por ejecución secuencial queremos decir que la instrucción codificada se ejecutará una tras otra, lo que implica que solo se activa una parte del programa en un momento dado. Digamos que un software tiene varios módulos, entonces solo uno de todos los módulos se puede encontrar activo en cualquier momento de ejecución.
En el diseño de software, la concurrencia se implementa dividiendo el software en múltiples unidades de ejecución independientes, como módulos, y ejecutándolos en paralelo. En otras palabras, la concurrencia proporciona la capacidad al software para ejecutar más de una parte del código en paralelo entre sí.
Es necesario que los programadores y diseñadores reconozcan esos módulos, que se pueden realizar en ejecución paralela.
Ejemplo
La función de revisión ortográfica del procesador de texto es un módulo de software que se ejecuta junto con el procesador de texto.
Acoplamiento y cohesión
Cuando un programa de software está modularizado, sus tareas se dividen en varios módulos en función de algunas características. Como sabemos, los módulos son un conjunto de instrucciones que se juntan para lograr algunas tareas. Sin embargo, se consideran como una entidad única, pero pueden referirse entre sí para trabajar juntos. Existen medidas mediante las cuales se puede medir la calidad de un diseño de módulos y su interacción entre ellos. Estas medidas se denominan acoplamiento y cohesión.
Cohesión
La cohesión es una medida que define el grado de intradependencia dentro de los elementos de un módulo. Cuanto mayor sea la cohesión, mejor será el diseño del programa.
Hay siete tipos de cohesión, a saber:
- Co-incidental cohesion -Es una cohesión aleatoria y no planificada, que podría ser el resultado de dividir el programa en módulos más pequeños por el bien de la modularización. Debido a que no está planificado, puede causar confusión a los programadores y, en general, no se acepta.
- Logical cohesion - Cuando los elementos categorizados lógicamente se agrupan en un módulo, se denomina cohesión lógica.
- emporal Cohesion - Cuando los elementos del módulo se organizan de manera que se procesan en un momento similar en el tiempo, se denomina cohesión temporal.
- Procedural cohesion - Cuando se agrupan elementos del módulo, que se ejecutan secuencialmente para realizar una tarea, se denomina cohesión procedimental.
- Communicational cohesion - Cuando se agrupan elementos del módulo, que se ejecutan secuencialmente y trabajan sobre los mismos datos (información), se denomina cohesión comunicacional.
- Sequential cohesion - Cuando los elementos del módulo se agrupan porque la salida de un elemento sirve como entrada a otro y así sucesivamente, se denomina cohesión secuencial.
- Functional cohesion - Se considera que es el grado más alto de cohesión y es muy esperado. Los elementos del módulo en cohesión funcional se agrupan porque todos contribuyen a una única función bien definida. También se puede reutilizar.
Acoplamiento
El acoplamiento es una medida que define el nivel de interdependencia entre los módulos de un programa. Indica a qué nivel los módulos interfieren e interactúan entre sí. Cuanto menor sea el acoplamiento, mejor será el programa.
Hay cinco niveles de acoplamiento, a saber:
- Content coupling - Cuando un módulo puede acceder directamente o modificar o hacer referencia al contenido de otro módulo, se denomina acoplamiento a nivel de contenido.
- Common coupling- Cuando varios módulos tienen acceso de lectura y escritura a algunos datos globales, se denomina acoplamiento común o global.
- Control coupling- Dos módulos se denominan acoplados por control si uno de ellos decide la función del otro módulo o cambia su flujo de ejecución.
- Stamp coupling- Cuando varios módulos comparten una estructura de datos común y trabajan en diferentes partes de ella, se denomina acoplamiento de sellos.
- Data coupling- El acoplamiento de datos es cuando dos módulos interactúan entre sí mediante el paso de datos (como parámetro). Si un módulo pasa la estructura de datos como parámetro, entonces el módulo receptor debe usar todos sus componentes.
Idealmente, ningún acoplamiento se considera el mejor.
Verificación de diseño
El resultado del proceso de diseño de software es la documentación de diseño, pseudocódigos, diagramas lógicos detallados, diagramas de proceso y una descripción detallada de todos los requisitos funcionales o no funcionales.
La siguiente fase, que es la implementación del software, depende de todos los resultados mencionados anteriormente.
Entonces es necesario verificar la salida antes de pasar a la siguiente fase. Cuanto antes se detecte un error, mejor será o es posible que no se detecte hasta que se pruebe el producto. Si los resultados de la fase de diseño están en forma de notación formal, entonces se deben usar sus herramientas asociadas para la verificación; de lo contrario, se puede usar una revisión completa del diseño para la verificación y validación.
Mediante un enfoque de verificación estructurado, los revisores pueden detectar defectos que podrían deberse a pasar por alto algunas condiciones. Una buena revisión del diseño es importante para un buen diseño, precisión y calidad del software.
El análisis y diseño de software incluye todas las actividades que ayudan a transformar la especificación de requisitos en implementación. Las especificaciones de requisitos especifican todas las expectativas funcionales y no funcionales del software. Estas especificaciones de requisitos vienen en forma de documentos legibles y comprensibles por humanos, a los que una computadora no tiene nada que ver.
El análisis y el diseño de software es la etapa intermedia, que ayuda a que los requisitos legibles por humanos se transformen en código real.
Veamos algunas herramientas de análisis y diseño utilizadas por los diseñadores de software:
Diagrama de flujo de datos
El diagrama de flujo de datos es una representación gráfica del flujo de datos en un sistema de información. Es capaz de representar el flujo de datos entrantes, el flujo de datos salientes y los datos almacenados. El DFD no menciona nada sobre cómo fluyen los datos a través del sistema.
Existe una diferencia importante entre DFD y Diagrama de flujo. El diagrama de flujo muestra el flujo de control en los módulos del programa. Los DFD representan el flujo de datos en el sistema en varios niveles. DFD no contiene ningún elemento de control o rama.
Tipos de DFD
Los diagramas de flujo de datos son lógicos o físicos.
- Logical DFD - Este tipo de DFD se concentra en el proceso del sistema y el flujo de datos en el sistema. Por ejemplo, en un sistema de software bancario, cómo se mueven los datos entre diferentes entidades.
- Physical DFD- Este tipo de DFD muestra cómo se implementa realmente el flujo de datos en el sistema. Es más específico y cercano a la implementación.
Componentes DFD
DFD puede representar el origen, el destino, el almacenamiento y el flujo de datos utilizando el siguiente conjunto de componentes:

- Entities- Las entidades son fuente y destino de datos de información. Las entidades están representadas por rectángulos con sus respectivos nombres.
- Process - Las actividades y acciones tomadas sobre los datos se representan mediante un círculo o rectángulos de borde redondeado.
- Data Storage - Hay dos variantes de almacenamiento de datos: puede representarse como un rectángulo sin ambos lados más pequeños o como un rectángulo de lados abiertos al que le falta un solo lado.
- Data Flow- El movimiento de datos se muestra mediante flechas puntiagudas. El movimiento de datos se muestra desde la base de la flecha como su origen hacia la punta de la flecha como destino.
Niveles de DFD
- Level 0- El DFD de nivel de abstracción más alto se conoce como DFD de nivel 0, que describe todo el sistema de información como un diagrama que oculta todos los detalles subyacentes. Los DFD de nivel 0 también se conocen como DFD de nivel de contexto.
- Level 1- El DFD de nivel 0 se divide en DFD de nivel 1 más específico. El DFD de nivel 1 describe los módulos básicos del sistema y el flujo de datos entre varios módulos. El DFD de nivel 1 también menciona procesos básicos y fuentes de información.
Level 2 - En este nivel, DFD muestra cómo fluyen los datos dentro de los módulos mencionados en el Nivel 1.
Los DFD de nivel superior se pueden transformar en DFD de nivel inferior más específicos con un nivel más profundo de comprensión, a menos que se alcance el nivel de especificación deseado.


Gráficos de estructura
El diagrama de estructura es un diagrama derivado del diagrama de flujo de datos. Representa el sistema con más detalle que DFD. Desglosa todo el sistema en módulos funcionales más bajos, describe las funciones y subfunciones de cada módulo del sistema con mayor detalle que DFD.
El diagrama de estructura representa la estructura jerárquica de los módulos. En cada capa se realiza una tarea específica.
Estos son los símbolos utilizados en la construcción de gráficos de estructura:
- Module- Representa proceso o subrutina o tarea. Un módulo de control se ramifica a más de un submódulo. Los módulos de la biblioteca son reutilizables e invocables desde cualquier módulo.

- Condition- Está representado por un pequeño diamante en la base del módulo. Muestra que el módulo de control puede seleccionar cualquiera de las subrutinas en función de alguna condición.

- Jump - Se muestra una flecha apuntando dentro del módulo para representar que el control saltará en el medio del submódulo.

- Loop- Una flecha curva representa un bucle en el módulo. Todos los submódulos cubiertos por el ciclo repiten la ejecución del módulo.

- Data flow - Una flecha dirigida con un círculo vacío al final representa el flujo de datos.

- Control flow - Una flecha dirigida con un círculo relleno al final representa el flujo de control.

Diagrama HIPO
El diagrama HIPO (Hierarchical Input Process Output) es una combinación de dos métodos organizados para analizar el sistema y proporcionar los medios de documentación. El modelo HIPO fue desarrollado por IBM en el año 1970.
El diagrama HIPO representa la jerarquía de módulos en el sistema de software. El analista utiliza el diagrama HIPO para obtener una vista de alto nivel de las funciones del sistema. Descompone funciones en subfunciones de manera jerárquica. Describe las funciones realizadas por el sistema.
Los diagramas HIPO son buenos para fines de documentación. Su representación gráfica hace que sea más fácil para los diseñadores y gerentes tener una idea pictórica de la estructura del sistema.

A diferencia del diagrama IPO (Input Process Output), que representa el flujo de control y datos en un módulo, HIPO no proporciona ninguna información sobre el flujo de datos o el flujo de control.

Ejemplo
Ambas partes del diagrama HIPO, la presentación jerárquica y el gráfico IPO se utilizan para el diseño de la estructura del programa de software, así como para la documentación del mismo.
Ingles estructurado
La mayoría de los programadores desconocen el panorama general del software, por lo que solo confían en lo que sus gerentes les dicen que hagan. Es responsabilidad de la administración de software superior proporcionar información precisa a los programadores para desarrollar un código preciso pero rápido.
Otras formas de métodos, que utilizan gráficos o diagramas, a veces pueden ser interpretadas de manera diferente por diferentes personas.
Por lo tanto, los analistas y diseñadores del software crean herramientas como el inglés estructurado. No es más que la descripción de lo que se requiere para codificar y cómo codificarlo. El inglés estructurado ayuda al programador a escribir código sin errores.
Otras formas de métodos, que utilizan gráficos o diagramas, a veces pueden ser interpretadas de manera diferente por diferentes personas. Aquí, tanto el inglés estructurado como el pseudocódigo intentan mitigar esa brecha de comprensión.
El inglés estructurado es el paradigma de programación estructurada que utiliza palabras en inglés simple. No es el código definitivo, sino una especie de descripción de lo que se requiere para codificar y cómo codificarlo. Los siguientes son algunos tokens de programación estructurada.
IF-THEN-ELSE,
DO-WHILE-UNTILAnalyst utiliza la misma variable y el mismo nombre de datos, que se almacenan en el Diccionario de datos, lo que hace que sea mucho más sencillo escribir y comprender el código.
Ejemplo
Tomamos el mismo ejemplo de autenticación de cliente en el entorno de compras en línea. Este procedimiento para autenticar al cliente se puede escribir en inglés estructurado como:
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIFEl código escrito en inglés estructurado se parece más al inglés hablado del día a día. No se puede implementar directamente como un código de software. El inglés estructurado es independiente del lenguaje de programación.
Pseudocódigo
El pseudocódigo se escribe más parecido al lenguaje de programación. Puede considerarse como un lenguaje de programación aumentado, lleno de comentarios y descripciones.
El pseudocódigo evita la declaración de variables, pero se escriben utilizando algunas construcciones reales del lenguaje de programación, como C, Fortran, Pascal, etc.
El pseudocódigo contiene más detalles de programación que el inglés estructurado. Proporciona un método para realizar la tarea, como si una computadora estuviera ejecutando el código.
Ejemplo
Programa para imprimir Fibonacci hasta n números.
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}Tablas de decisiones
Una tabla de decisiones representa las condiciones y las acciones respectivas que se deben tomar para abordarlas, en un formato tabular estructurado.
Es una herramienta poderosa para depurar y prevenir errores. Ayuda a agrupar información similar en una sola tabla y luego, al combinar tablas, brinda una toma de decisiones fácil y conveniente.
Crear tabla de decisiones
Para crear la tabla de decisiones, el desarrollador debe seguir cuatro pasos básicos:
- Identificar todas las posibles condiciones a abordar
- Determinar acciones para todas las condiciones identificadas
- Crear reglas máximas posibles
- Definir acción para cada regla
Las tablas de decisiones deben ser verificadas por los usuarios finales y últimamente se pueden simplificar eliminando reglas y acciones duplicadas.
Ejemplo
Tomemos un ejemplo sencillo del problema diario con nuestra conectividad a Internet. Comenzamos identificando todos los problemas que pueden surgir al iniciar Internet y sus respectivas posibles soluciones.
Enumeramos todos los posibles problemas en las condiciones de la columna y las posibles acciones en la columna Acciones.
| Condiciones / Acciones | Reglas | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Condiciones | Muestra conectado | norte | norte | norte | norte | Y | Y | Y | Y |
| Ping está funcionando | norte | norte | Y | Y | norte | norte | Y | Y | |
| Abre el sitio web | Y | norte | Y | norte | Y | norte | Y | norte | |
| Comportamiento | Compruebe el cable de red | X | |||||||
| Compruebe el enrutador de Internet | X | X | X | X | |||||
| Reiniciar el navegador web | X | ||||||||
| Póngase en contacto con el proveedor de servicios | X | X | X | X | X | X | |||
| No hacer nada | |||||||||
Modelo entidad-relación
El modelo Entidad-Relación es un tipo de modelo de base de datos basado en la noción de entidades del mundo real y la relación entre ellas. Podemos mapear el escenario del mundo real en el modelo de base de datos ER. ER Model crea un conjunto de entidades con sus atributos, un conjunto de restricciones y relación entre ellos.
El modelo ER se utiliza mejor para el diseño conceptual de bases de datos. El modelo ER se puede representar de la siguiente manera:

Entity - Una entidad en el modelo ER es un ser del mundo real, que tiene algunas propiedades llamadas attributes. Cada atributo está definido por su correspondiente conjunto de valores, llamadodomain.
Por ejemplo, considere la base de datos de una escuela. Aquí, un estudiante es una entidad. El estudiante tiene varios atributos como nombre, identificación, edad y clase, etc.
Relationship - La asociación lógica entre entidades se llama relationship. Las relaciones se asignan con entidades de varias formas. Las cardinalidades de mapeo definen el número de asociaciones entre dos entidades.
Mapeo de cardinalidades:
- doce y cincuenta y nueve de la noche
- uno a muchos
- muchos a uno
- muchos a muchos
Diccionario de datos
El diccionario de datos es la recopilación centralizada de información sobre datos. Almacena el significado y el origen de los datos, su relación con otros datos, el formato de datos para su uso, etc. El diccionario de datos tiene definiciones rigurosas de todos los nombres para facilitar al usuario y a los diseñadores de software.
El diccionario de datos a menudo se denomina repositorio de metadatos (datos sobre datos). Se crea junto con el modelo DFD (Diagrama de flujo de datos) del programa de software y se espera que se actualice siempre que se cambie o actualice DFD.
Requisito del diccionario de datos
Se hace referencia a los datos a través del diccionario de datos mientras se diseña e implementa el software. El diccionario de datos elimina cualquier posibilidad de ambigüedad. Ayuda a mantener sincronizado el trabajo de los programadores y diseñadores mientras se usa la misma referencia de objeto en todas partes del programa.
El diccionario de datos proporciona una forma de documentación para el sistema de base de datos completo en un solo lugar. La validación de DFD se realiza mediante un diccionario de datos.
Contenido
El diccionario de datos debe contener información sobre lo siguiente
- Flujo de datos
- Estructura de datos
- Elementos de datos
- Almacenes de datos
- Procesamiento de datos
El flujo de datos se describe mediante DFD como se estudió anteriormente y se representa en forma algebraica como se describe.
| = | Compuesto de |
|---|---|
| {} | Repetición |
| () | Opcional |
| + | Y |
| [/] | O |
Ejemplo
Dirección = Número de casa + (Calle / Área) + Ciudad + Estado
ID del curso = Número del curso + Nombre del curso + Nivel del curso + Calificaciones del curso
Elementos de datos
Los elementos de datos consisten en el nombre y las descripciones de los elementos de control y datos, almacenes de datos internos o externos, etc.con los siguientes detalles:
- Nombre principal
- Nombre secundario (alias)
- Caso de uso (cómo y dónde usarlo)
- Descripción del contenido (notación, etc.)
- Información adicional (valores predeterminados, restricciones, etc.)
Almacén de datos
Almacena la información desde donde los datos ingresan al sistema y existen fuera del sistema. El almacén de datos puede incluir:
- Files
- Interna al software.
- Externo al software pero en la misma máquina.
- Externo al software y al sistema, ubicado en una máquina diferente.
- Tables
- Convenio de denominación
- Propiedad de indexación
Procesamiento de datos
Hay dos tipos de procesamiento de datos:
- Logical: Como lo ve el usuario
- Physical: Como lo ve el software
El diseño de software es un proceso para conceptualizar los requisitos del software en la implementación del software. El diseño de software toma los requisitos del usuario como desafíos y trata de encontrar una solución óptima. Mientras se conceptualiza el software, se traza un plan para encontrar el mejor diseño posible para implementar la solución deseada.
Existen múltiples variantes de diseño de software. Estudiémoslos brevemente:
Diseño estructurado
El diseño estructurado es una conceptualización del problema en varios elementos de solución bien organizados. Se trata básicamente del diseño de la solución. El beneficio del diseño estructurado es que brinda una mejor comprensión de cómo se está resolviendo el problema. El diseño estructurado también facilita que el diseñador se concentre en el problema con mayor precisión.
El diseño estructurado se basa principalmente en la estrategia de "divide y vencerás" en la que un problema se divide en varios problemas pequeños y cada problema pequeño se resuelve individualmente hasta que se resuelve todo el problema.
Los pequeños problemas se resuelven mediante módulos de solución. El diseño estructurado enfatiza que estos módulos estén bien organizados para lograr una solución precisa.
Estos módulos están organizados en jerarquía. Se comunican entre sí. Un buen diseño estructurado siempre sigue algunas reglas para la comunicación entre múltiples módulos, a saber:
Cohesion - agrupación de todos los elementos relacionados funcionalmente.
Coupling - comunicación entre diferentes módulos.
Un buen diseño estructurado tiene una alta cohesión y bajos arreglos de acoplamiento.
Diseño orientado a funciones
En el diseño orientado a funciones, el sistema se compone de muchos subsistemas más pequeños conocidos como funciones. Estas funciones son capaces de realizar tareas importantes en el sistema. El sistema se considera una vista superior de todas las funciones.
El diseño orientado a funciones hereda algunas propiedades del diseño estructurado donde se utiliza la metodología de dividir y conquistar.
Este mecanismo de diseño divide todo el sistema en funciones más pequeñas, lo que proporciona medios de abstracción ocultando la información y su funcionamiento. Estos módulos funcionales pueden compartir información entre sí mediante el paso de información y el uso de información disponible globalmente.
Otra característica de las funciones es que cuando un programa llama a una función, la función cambia el estado del programa, lo que a veces no es aceptable para otros módulos. El diseño orientado a funciones funciona bien donde el estado del sistema no importa y el programa / funciones trabajan en la entrada en lugar de en un estado.
Proceso de diseño
- Todo el sistema se ve como cómo fluyen los datos en el sistema por medio de un diagrama de flujo de datos.
- DFD describe cómo las funciones cambian los datos y el estado de todo el sistema.
- Todo el sistema se divide lógicamente en unidades más pequeñas conocidas como funciones sobre la base de su funcionamiento en el sistema.
- Luego, cada función se describe en su totalidad.
Diseño orientado a objetos
El diseño orientado a objetos trabaja alrededor de las entidades y sus características en lugar de funciones involucradas en el sistema de software. Esta estrategia de diseño se centra en las entidades y sus características. Todo el concepto de solución de software gira en torno a las entidades comprometidas.
Veamos los conceptos importantes del Diseño Orientado a Objetos:
- Objects - Todas las entidades involucradas en el diseño de la solución se conocen como objetos. Por ejemplo, la persona, los bancos, la empresa y los clientes se tratan como objetos. Cada entidad tiene algunos atributos asociados y tiene algunos métodos para actuar sobre los atributos.
Classes - Una clase es una descripción generalizada de un objeto. Un objeto es una instancia de una clase. La clase define todos los atributos que puede tener un objeto y los métodos que definen la funcionalidad del objeto.
En el diseño de la solución, los atributos se almacenan como variables y las funcionalidades se definen mediante métodos o procedimientos.
- Encapsulation - En OOD, los atributos (variables de datos) y los métodos (operación sobre los datos) que se agrupan juntos se denomina encapsulación. La encapsulación no solo agrupa la información importante de un objeto, sino que también restringe el acceso a los datos y métodos del mundo exterior. A esto se le llama ocultación de información.
- Inheritance - OOD permite que clases similares se apilen de manera jerárquica donde las subclases inferiores pueden importar, implementar y reutilizar variables y métodos permitidos de sus superclases inmediatas. Esta propiedad de OOD se conoce como herencia. Esto facilita la definición de clases específicas y la creación de clases generalizadas a partir de clases específicas.
- Polymorphism - Los lenguajes OOD proporcionan un mecanismo en el que se puede asignar el mismo nombre a métodos que realizan tareas similares pero varían en argumentos. Esto se llama polimorfismo, que permite que una sola interfaz realice tareas para diferentes tipos. Dependiendo de cómo se invoque la función, se ejecuta la porción respectiva del código.
Proceso de diseño
El proceso de diseño de software puede percibirse como una serie de pasos bien definidos. Aunque varía según el enfoque de diseño (orientado a funciones u orientado a objetos, puede tener los siguientes pasos involucrados:
- El diseño de una solución se crea a partir del requisito o del sistema utilizado anteriormente y / o del diagrama de secuencia del sistema.
- Los objetos se identifican y agrupan en clases en nombre de la similitud en las características de los atributos.
- Se define la jerarquía de clases y la relación entre ellas.
- Se define el marco de aplicación.
Enfoques de diseño de software
Aquí hay dos enfoques genéricos para el diseño de software:
Diseño de arriba hacia abajo
Sabemos que un sistema se compone de más de un subsistema y contiene varios componentes. Además, estos subsistemas y componentes pueden tener su propio conjunto de subsistemas y componentes y crean una estructura jerárquica en el sistema.
El diseño de arriba hacia abajo toma todo el sistema de software como una entidad y luego lo descompone para lograr más de un subsistema o componente en función de algunas características. Luego, cada subsistema o componente se trata como un sistema y se descompone aún más. Este proceso continúa ejecutándose hasta que se alcanza el nivel más bajo del sistema en la jerarquía de arriba hacia abajo.
El diseño de arriba hacia abajo comienza con un modelo generalizado de sistema y continúa definiendo la parte más específica del mismo. Cuando todos los componentes están compuestos, todo el sistema entra en existencia.
El diseño de arriba hacia abajo es más adecuado cuando la solución de software debe diseñarse desde cero y se desconocen detalles específicos.
Diseño de abajo hacia arriba
El modelo de diseño de abajo hacia arriba comienza con los componentes más específicos y básicos. Continúa componiendo componentes de nivel superior utilizando componentes de nivel básico o inferior. Sigue creando componentes de nivel superior hasta que el sistema deseado no evoluciona como un solo componente. Con cada nivel superior, aumenta la cantidad de abstracción.
La estrategia de abajo hacia arriba es más adecuada cuando se necesita crear un sistema a partir de algún sistema existente, donde las primitivas básicas se pueden usar en el sistema más nuevo.
Ambos enfoques, de arriba hacia abajo y de abajo hacia arriba, no son prácticos individualmente. En cambio, se utiliza una buena combinación de ambos.
La interfaz de usuario es la vista de la aplicación de front-end con la que el usuario interactúa para utilizar el software. El usuario puede manipular y controlar el software y el hardware mediante la interfaz de usuario. Hoy en día, la interfaz de usuario se encuentra en casi todos los lugares donde existe la tecnología digital, desde computadoras, teléfonos móviles, automóviles, reproductores de música, aviones, barcos, etc.
La interfaz de usuario es parte del software y está diseñada de tal manera que se espera que proporcione al usuario información sobre el software. La interfaz de usuario proporciona una plataforma fundamental para la interacción persona-computadora.
La interfaz de usuario puede ser gráfica, basada en texto, audio-video, dependiendo de la combinación de hardware y software subyacente. La interfaz de usuario puede ser hardware o software o una combinación de ambos.
El software se vuelve más popular si su interfaz de usuario es:
- Attractive
- Fácil de usar
- Responde en poco tiempo
- Claro para entender
- Consistente en todas las pantallas de interfaz
La interfaz de usuario se divide ampliamente en dos categorías:
- Interfaz de línea de comandos
- Interfaz gráfica del usuario
Interfaz de línea de comandos (CLI)
CLI ha sido una gran herramienta de interacción con las computadoras hasta que surgieron los monitores de visualización de video. CLI es la primera opción de muchos usuarios técnicos y programadores. CLI es la interfaz mínima que un software puede proporcionar a sus usuarios.
CLI proporciona un símbolo del sistema, el lugar donde el usuario escribe el comando y lo alimenta al sistema. El usuario debe recordar la sintaxis del comando y su uso. Las CLI anteriores no estaban programadas para manejar los errores del usuario de manera efectiva.
Un comando es una referencia basada en texto a un conjunto de instrucciones, que se espera que el sistema ejecute. Existen métodos como macros, scripts que facilitan la operación del usuario.
CLI utiliza menos recursos informáticos en comparación con GUI.
Elementos CLI

Una interfaz de línea de comandos basada en texto puede tener los siguientes elementos:
Command Prompt- Es un notificador basado en texto que muestra principalmente el contexto en el que está trabajando el usuario. Es generado por el sistema de software.
Cursor- Es una pequeña línea horizontal o una barra vertical de la altura de la línea, para representar la posición del carácter mientras escribe. El cursor se encuentra principalmente en estado parpadeante. Se mueve cuando el usuario escribe o borra algo.
Command- Un comando es una instrucción ejecutable. Puede tener uno o más parámetros. La salida en la ejecución del comando se muestra en línea en la pantalla. Cuando se produce la salida, el símbolo del sistema se muestra en la siguiente línea.
Interfaz gráfica del usuario
La interfaz gráfica de usuario proporciona al usuario medios gráficos para interactuar con el sistema. La GUI puede ser una combinación de hardware y software. Usando GUI, el usuario interpreta el software.
Normalmente, la GUI consume más recursos que la CLI. Con el avance de la tecnología, los programadores y diseñadores crean diseños de GUI complejos que funcionan con más eficiencia, precisión y velocidad.
Elementos GUI
La GUI proporciona un conjunto de componentes para interactuar con software o hardware.
Cada componente gráfico proporciona una forma de trabajar con el sistema. Un sistema de GUI tiene los siguientes elementos, como:

Window- Un área donde se muestran los contenidos de la aplicación. El contenido de una ventana se puede mostrar en forma de iconos o listas, si la ventana representa la estructura del archivo. Es más fácil para un usuario navegar en el sistema de archivos en una ventana de exploración. Las ventanas se pueden minimizar, cambiar de tamaño o maximizar al tamaño de la pantalla. Se pueden mover a cualquier lugar de la pantalla. Una ventana puede contener otra ventana de la misma aplicación, llamada ventana secundaria.
Tabs - Si una aplicación permite ejecutar varias instancias de sí misma, aparecen en la pantalla como ventanas independientes. Tabbed Document Interfaceha aparecido para abrir varios documentos en la misma ventana. Esta interfaz también ayuda a ver el panel de preferencias en la aplicación. Todos los navegadores web modernos utilizan esta función.
Menu- Menú es una serie de comandos estándar, agrupados y colocados en un lugar visible (generalmente en la parte superior) dentro de la ventana de la aplicación. El menú se puede programar para que aparezca u oculte con los clics del mouse.
Icon- Un icono es una imagen pequeña que representa una aplicación asociada. Cuando se hace clic en estos iconos o se hace doble clic en ellos, se abre la ventana de la aplicación. El icono muestra la aplicación y los programas instalados en un sistema en forma de imágenes pequeñas.
Cursor- Los dispositivos interactivos como el mouse, el panel táctil y el lápiz digital se representan en la GUI como cursores. El cursor en pantalla sigue las instrucciones del hardware casi en tiempo real. Los cursores también se denominan punteros en los sistemas GUI. Se utilizan para seleccionar menús, ventanas y otras funciones de la aplicación.
Componentes GUI específicos de la aplicación
Una GUI de una aplicación contiene uno o más de los elementos GUI enumerados:
Application Window - La mayoría de las ventanas de aplicaciones utilizan las construcciones proporcionadas por los sistemas operativos, pero muchas utilizan sus propias ventanas creadas por el cliente para contener el contenido de la aplicación.
Dialogue Box - Es una ventana secundaria que contiene un mensaje para el usuario y una solicitud para realizar alguna acción. Por ejemplo: la aplicación genera un diálogo para obtener la confirmación del usuario para eliminar un archivo.
Text-Box - Proporciona un área para que el usuario escriba e ingrese datos basados en texto.
Buttons - Imitan botones de la vida real y se utilizan para enviar entradas al software.

Radio-button- Muestra las opciones disponibles para la selección. Solo se puede seleccionar uno entre todos los ofrecidos.
Check-box- Funciones similares a list-box. Cuando se selecciona una opción, la casilla se marca como marcada. Se pueden seleccionar varias opciones representadas por casillas de verificación.
List-box - Proporciona una lista de elementos disponibles para su selección. Se puede seleccionar más de un elemento.

Otros componentes GUI impresionantes son:
- Sliders
- Combo-box
- Data-grid
- La lista desplegable
Actividades de diseño de interfaz de usuario
Hay una serie de actividades realizadas para diseñar la interfaz de usuario. El proceso de diseño e implementación de GUI es similar al SDLC. Se puede utilizar cualquier modelo para la implementación de GUI entre el modelo Waterfall, Iterative o Spiral.
Un modelo utilizado para el diseño y desarrollo de GUI debe cumplir con estos pasos específicos de GUI.

GUI Requirement Gathering- Los diseñadores pueden querer tener una lista de todos los requisitos funcionales y no funcionales de la GUI. Esto se puede tomar del usuario y su solución de software existente.
User Analysis- El diseñador estudia quién va a utilizar la GUI del software. El público objetivo es importante, ya que los detalles del diseño cambian de acuerdo con el nivel de conocimiento y competencia del usuario. Si el usuario tiene conocimientos técnicos, se puede incorporar una GUI avanzada y compleja. Para un usuario novato, se incluye más información sobre los procedimientos del software.
Task Analysis- Los diseñadores deben analizar qué tarea debe realizar la solución de software. Aquí en GUI, no importa cómo se haga. Las tareas se pueden representar de manera jerárquica tomando una tarea principal y dividiéndola en subtareas más pequeñas. Las tareas proporcionan objetivos para la presentación de la GUI. El flujo de información entre las subtareas determina el flujo de los contenidos de la GUI en el software.
GUI Design & implementation- Los diseñadores, después de tener información sobre los requisitos, las tareas y el entorno del usuario, diseñan la GUI y las implementa en el código e integran la GUI con software funcional o ficticio en segundo plano. Luego, los desarrolladores lo autoprueban.
Testing- Las pruebas de GUI se pueden realizar de varias formas. La organización puede tener inspección interna, la participación directa de los usuarios y el lanzamiento de la versión beta son algunos de ellos. Las pruebas pueden incluir usabilidad, compatibilidad, aceptación del usuario, etc.
Herramientas de implementación de GUI
Hay varias herramientas disponibles con las que los diseñadores pueden crear una GUI completa con un clic del mouse. Algunas herramientas pueden integrarse en el entorno de software (IDE).
Las herramientas de implementación de GUI proporcionan una poderosa variedad de controles de GUI. Para la personalización del software, los diseñadores pueden cambiar el código en consecuencia.
Hay diferentes segmentos de herramientas GUI según su diferente uso y plataforma.
Ejemplo
GUI móvil, GUI de computadora, GUI de pantalla táctil, etc. Aquí hay una lista de algunas herramientas que son útiles para construir GUI:
- FLUID
- AppInventor (Android)
- LucidChart
- Wavemaker
- Estudio visual
Interfaz de usuario Reglas de oro
Las siguientes reglas se mencionan como las reglas de oro para el diseño de GUI, descritas por Shneiderman y Plaisant en su libro (Designing the User Interface).
Strive for consistency- Deben requerirse secuencias consistentes de acciones en situaciones similares. Se debe utilizar terminología idéntica en las indicaciones, los menús y las pantallas de ayuda. Se deben emplear comandos consistentes en todo momento.
Enable frequent users to use short-cuts- El deseo del usuario de reducir el número de interacciones aumenta con la frecuencia de uso. Las abreviaturas, las teclas de función, los comandos ocultos y las funciones de macros son muy útiles para un usuario experto.
Offer informative feedback- Para cada acción del operador, debe haber alguna retroalimentación del sistema. Para las acciones frecuentes y menores, la respuesta debe ser modesta, mientras que para las acciones mayores y poco frecuentes, la respuesta debe ser más sustancial.
Design dialog to yield closure- Las secuencias de acciones deben organizarse en grupos con un comienzo, un desarrollo y un final. La retroalimentación informativa al completar un grupo de acciones les da a los operadores la satisfacción del logro, una sensación de alivio, la señal para dejar de lado los planes de contingencia y las opciones de sus mentes, y esto indica que el camino a seguir es claro para prepararse para el próximo. grupo de acciones.
Offer simple error handling- En la medida de lo posible, diseñe el sistema para que el usuario no cometa un error grave. Si se comete un error, el sistema debe poder detectarlo y ofrecer mecanismos simples y comprensibles para manejar el error.
Permit easy reversal of actions- Esta función alivia la ansiedad, ya que el usuario sabe que los errores se pueden deshacer. La fácil reversión de acciones fomenta la exploración de opciones desconocidas. Las unidades de reversibilidad pueden ser una sola acción, una entrada de datos o un grupo completo de acciones.
Support internal locus of control- Los operadores experimentados desean fuertemente la sensación de que están a cargo del sistema y que el sistema responde a sus acciones. Diseñe el sistema para que los usuarios sean los iniciadores de las acciones en lugar de los respondedores.
Reduce short-term memory load - La limitación del procesamiento de información humana en la memoria a corto plazo requiere que las pantallas se mantengan simples, se consoliden las pantallas de múltiples páginas, se reduzca la frecuencia de movimiento de las ventanas y se asigne suficiente tiempo de entrenamiento para códigos, mnemotécnicos y secuencias de acciones.
El término complejidad significa el estado de eventos o cosas, que tienen múltiples enlaces interconectados y estructuras muy complicadas. En la programación de software, a medida que se realiza el diseño del software, la cantidad de elementos y sus interconexiones gradualmente se vuelven enormes, lo que se vuelve demasiado difícil de entender a la vez.
La complejidad del diseño de software es difícil de evaluar sin utilizar métricas y medidas de complejidad. Veamos tres medidas importantes de complejidad del software.
Medidas de complejidad de Halstead
En 1977, Maurice Howard Halstead introdujo métricas para medir la complejidad del software. Las métricas de Halstead dependen de la implementación real del programa y sus medidas, que se calculan directamente a partir de los operadores y operandos del código fuente, de manera estática. Permite evaluar el tiempo de prueba, vocabulario, tamaño, dificultad, errores y esfuerzos para el código fuente C / C ++ / Java.
Según Halstead, “un programa informático es una implementación de un algoritmo que se considera una colección de tokens que se pueden clasificar como operadores u operandos”. Las métricas de Halstead piensan en un programa como una secuencia de operadores y sus operandos asociados.
Define varios indicadores para verificar la complejidad del módulo.
| Parámetro | Sentido |
|---|---|
| n1 | Número de operadores únicos |
| n2 | Número de operandos únicos |
| N1 | Número de ocurrencia total de operadores |
| N2 | Número de ocurrencia total de operandos |
Cuando seleccionamos el archivo de origen para ver sus detalles de complejidad en Metric Viewer, se ve el siguiente resultado en Metric Report:
| Métrico | Sentido | Representación matemática |
|---|---|---|
| norte | Vocabulario | n1 + n2 |
| norte | Talla | N1 + N2 |
| V | Volumen | Longitud * Vocabulario Log2 |
| re | Dificultad | (n1 / 2) * (N1 / n2) |
| mi | Esfuerzos | Dificultad * Volumen |
| segundo | Errores | Volumen / 3000 |
| T | Tiempo de prueba | Tiempo = Esfuerzos / S, donde S = 18 segundos. |
Medidas de complejidad ciclomática
Cada programa incluye declaraciones para ejecutar con el fin de realizar alguna tarea y otras declaraciones de toma de decisiones que deciden qué declaraciones deben ejecutarse. Estos constructos de toma de decisiones cambian el flujo del programa.
Si comparamos dos programas del mismo tamaño, el que tenga más declaraciones de toma de decisiones será más complejo ya que el control del programa salta con frecuencia.
McCabe, en 1976, propuso Cyclomatic Complexity Measure para cuantificar la complejidad de un software dado. Es un modelo basado en gráficos que se basa en las construcciones de toma de decisiones del programa, como las declaraciones if-else, do-while, repeat-until, switch-case y goto.
Proceso para hacer el gráfico de control de flujo:
- Divida el programa en bloques más pequeños, delimitados por constructos de toma de decisiones.
- Cree nodos que representen cada uno de estos nodos.
- Conecte los nodos de la siguiente manera:
Si el control puede ramificarse del bloque i al bloque j
Dibuja un arco
De nodo de salida a nodo de entrada
Dibuja un arco.
Para calcular la complejidad ciclomática de un módulo de programa, usamos la fórmula:
V(G) = e – n + 2
Where
e is total number of edges
n is total number of nodes
La complejidad ciclomática del módulo anterior es
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4Según P. Jorgensen, la Complejidad Ciclomática de un módulo no debe exceder 10.
Punto de función
Se usa ampliamente para medir el tamaño del software. Function Point se concentra en la funcionalidad proporcionada por el sistema. Las características y la funcionalidad del sistema se utilizan para medir la complejidad del software.
El punto de función cuenta con cinco parámetros, denominados Entrada externa, Salida externa, Archivos internos lógicos, Archivos de interfaz externa y Consulta externa. Para considerar la complejidad del software, cada parámetro se clasifica además como simple, promedio o complejo.
Veamos los parámetros del punto de función:
Entrada externa
Cada entrada única al sistema, desde el exterior, se considera entrada externa. Se mide la unicidad de la entrada, ya que dos entradas no deben tener los mismos formatos. Estas entradas pueden ser datos o parámetros de control.
Simple - si el recuento de entrada es bajo y afecta a menos archivos internos
Complex - si el recuento de entrada es alto y afecta a más archivos internos
Average - entre simple y complejo.
Salida externa
Todos los tipos de salida proporcionados por el sistema se cuentan en esta categoría. La salida se considera única si su formato de salida y / o procesamiento son únicos.
Simple - si el recuento de salida es bajo
Complex - si el recuento de salida es alto
Average - entre simple y complejo.
Archivos internos lógicos
Cada sistema de software mantiene archivos internos para mantener su información funcional y funcionar correctamente. Estos archivos contienen datos lógicos del sistema. Estos datos lógicos pueden contener tanto datos funcionales como datos de control.
Simple - si el número de tipos de registros es bajo
Complex - si el número de tipos de registros es alto
Average - entre simple y complejo.
Archivos de interfaz externa
El sistema de software puede necesitar compartir sus archivos con algún software externo o puede necesitar pasar el archivo para su procesamiento o como parámetro para alguna función. Todos estos archivos se cuentan como archivos de interfaz externos.
Simple - si el número de tipos de registro en el archivo compartido es bajo
Complex - si el número de tipos de registros en el archivo compartido es alto
Average - entre simple y complejo.
Consulta externa
Una consulta es una combinación de entrada y salida, donde el usuario envía algunos datos para consultar como entrada y el sistema responde al usuario con la salida de la consulta procesada. La complejidad de una consulta es más que una entrada externa y una salida externa. Se dice que la consulta es única si su entrada y salida son únicas en términos de formato y datos.
Simple - si la consulta necesita un procesamiento bajo y produce una pequeña cantidad de datos de salida
Complex - si la consulta necesita un proceso alto y produce una gran cantidad de datos de salida
Average - entre simple y complejo.
A cada uno de estos parámetros del sistema se le asigna un peso de acuerdo con su clase y complejidad. La siguiente tabla menciona el peso dado a cada parámetro:
| Parámetro | Simple | Promedio | Complejo |
|---|---|---|---|
| Entradas | 3 | 4 | 6 |
| Salidas | 4 | 5 | 7 |
| Investigación | 3 | 4 | 6 |
| Archivos | 7 | 10 | 15 |
| Interfaces | 5 | 7 | 10 |
La tabla anterior produce puntos de función sin procesar. Estos puntos de función se ajustan según la complejidad del entorno. El sistema se describe utilizando catorce características diferentes:
- Transmisión de datos
- Procesamiento distribuido
- Objetivos de rendimiento
- Carga de configuración de operación
- Tasa de transacción
- Entrada de datos en línea,
- Eficiencia del usuario final
- Actualización en línea
- Lógica de procesamiento compleja
- Re-usability
- Facilidad de instalación
- Facilidad operativa
- Varios sitios
- Deseo de facilitar cambios
A continuación, estos factores de características se clasifican de 0 a 5, como se menciona a continuación:
- Sin influencia
- Incidental
- Moderate
- Average
- Significant
- Essential
Luego, todas las calificaciones se resumen como N. El valor de N varía de 0 a 70 (14 tipos de características x 5 tipos de calificaciones). Se utiliza para calcular los factores de ajuste de complejidad (CAF), utilizando las siguientes fórmulas:
CAF = 0.65 + 0.01NLuego,
Delivered Function Points (FP)= CAF x Raw FPEste FP se puede utilizar en varias métricas, como:
Cost = $ / FP
Quality = Errores / FP
Productivity = FP / persona-mes
En este capítulo, estudiaremos sobre métodos de programación, documentación y desafíos en la implementación de software.
Programación estructurada
En el proceso de codificación, las líneas de código se siguen multiplicando, por lo que aumenta el tamaño del software. Gradualmente, se vuelve casi imposible recordar el flujo del programa. Si uno olvida cómo se construyen el software y sus programas, archivos y procedimientos subyacentes, entonces se vuelve muy difícil compartir, depurar y modificar el programa. La solución a esto es la programación estructurada. Anima al desarrollador a utilizar subrutinas y bucles en lugar de utilizar saltos simples en el código, lo que aporta claridad al código y mejora su eficiencia. La programación estructurada también ayuda al programador a reducir el tiempo de codificación y organizar el código correctamente.
La programación estructurada establece cómo se codificará el programa. La programación estructurada utiliza tres conceptos principales:
Top-down analysis- Siempre se hace un software para realizar algún trabajo racional. Este trabajo racional se conoce como problema en el lenguaje del software. Por tanto, es muy importante que entendamos cómo solucionar el problema. Bajo un análisis de arriba hacia abajo, el problema se divide en pequeños fragmentos donde cada uno tiene algún significado. Cada problema se resuelve individualmente y los pasos se indican claramente sobre cómo resolver el problema.
Modular Programming- Durante la programación, el código se divide en grupos más pequeños de instrucciones. Estos grupos se conocen como módulos, subprogramas o subrutinas. Programación modular basada en la comprensión del análisis de arriba hacia abajo. Desalienta los saltos usando declaraciones 'goto' en el programa, lo que a menudo hace que el flujo del programa no sea rastreable. Los saltos están prohibidos y se recomienda el formato modular en la programación estructurada.
Structured Coding - En referencia con el análisis de arriba hacia abajo, la codificación estructurada subdivide los módulos en unidades de código más pequeñas en el orden de su ejecución. La programación estructurada usa una estructura de control, que controla el flujo del programa, mientras que la codificación estructurada usa una estructura de control para organizar sus instrucciones en patrones definibles.
Programación funcional
La programación funcional es un estilo de lenguaje de programación, que utiliza los conceptos de funciones matemáticas. Una función en matemáticas siempre debería producir el mismo resultado al recibir el mismo argumento. En los lenguajes de procedimiento, el flujo del programa se ejecuta a través de procedimientos, es decir, el control del programa se transfiere al procedimiento llamado. Mientras el flujo de control se transfiere de un procedimiento a otro, el programa cambia de estado.
En la programación por procedimientos, es posible que un procedimiento produzca resultados diferentes cuando se lo llama con el mismo argumento, ya que el programa en sí puede estar en un estado diferente al llamarlo. Esta es una propiedad y también un inconveniente de la programación de procedimientos, en la que la secuencia o el tiempo de ejecución del procedimiento se vuelve importante.
La programación funcional proporciona medios de cálculo como funciones matemáticas, que producen resultados independientemente del estado del programa. Esto hace posible predecir el comportamiento del programa.
La programación funcional utiliza los siguientes conceptos:
First class and High-order functions - Estas funciones tienen la capacidad de aceptar otra función como argumento o devuelven otras funciones como resultados.
Pure functions - Estas funciones no incluyen actualizaciones destructivas, es decir, no afectan a ninguna E / S ni a la memoria y si no están en uso se pueden eliminar fácilmente sin obstaculizar el resto del programa.
Recursion- La recursividad es una técnica de programación en la que una función se llama a sí misma y repite el código del programa en ella a menos que coincida alguna condición predefinida. La recursividad es la forma de crear bucles en la programación funcional.
Strict evaluation- Es un método para evaluar la expresión pasada a una función como argumento. La programación funcional tiene dos tipos de métodos de evaluación, estrictos (ansiosos) o no estrictos (vagos). La evaluación estricta siempre evalúa la expresión antes de invocar la función. La evaluación no estricta no evalúa la expresión a menos que sea necesaria.
λ-calculus- La mayoría de los lenguajes de programación funcionales utilizan λ-cálculo como sus sistemas de tipos. Las expresiones λ se ejecutan evaluándolas a medida que ocurren.
Common Lisp, Scala, Haskell, Erlang y F # son algunos ejemplos de lenguajes de programación funcionales.
Estilo de programación
El estilo de programación es un conjunto de reglas de codificación seguidas por todos los programadores para escribir el código. Cuando varios programadores trabajan en el mismo proyecto de software, con frecuencia necesitan trabajar con el código del programa escrito por otro desarrollador. Esto se vuelve tedioso o, en ocasiones, imposible, si todos los desarrolladores no siguen algún estilo de programación estándar para codificar el programa.
Un estilo de programación apropiado incluye el uso de nombres de funciones y variables relevantes para la tarea prevista, uso de sangrías bien ubicadas, código de comentarios para la conveniencia del lector y presentación general del código. Esto hace que el código del programa sea legible y comprensible para todos, lo que a su vez facilita la depuración y la resolución de errores. Además, el estilo de codificación adecuado ayuda a facilitar la documentación y la actualización.
Directrices de codificación
La práctica del estilo de codificación varía según las organizaciones, los sistemas operativos y el lenguaje de codificación en sí.
Los siguientes elementos de codificación pueden definirse según las directrices de codificación de una organización:
Naming conventions - Esta sección define cómo nombrar funciones, variables, constantes y variables globales.
Indenting - Este es el espacio que queda al principio de la línea, generalmente de 2 a 8 espacios en blanco o una sola pestaña.
Whitespace - Generalmente se omite al final de la línea.
Operators- Define las reglas de escritura de operadores matemáticos, de asignación y lógicos. Por ejemplo, el operador de asignación '=' debe tener un espacio antes y después, como en "x = 2".
Control Structures - Las reglas de escritura if-then-else, case-switch, while-until y para las declaraciones de flujo de control únicamente y de forma anidada.
Line length and wrapping- Define cuántos caracteres debe haber en una línea, la mayoría de las veces una línea tiene 80 caracteres. Envolver define cómo se debe envolver una línea, si es demasiado larga.
Functions - Esto define cómo se deben declarar e invocar las funciones, con y sin parámetros.
Variables - Esto menciona cómo se declaran y definen variables de diferentes tipos de datos.
Comments- Este es uno de los componentes de codificación importantes, ya que los comentarios incluidos en el código describen lo que realmente hace el código y todas las demás descripciones asociadas. Esta sección también ayuda a crear documentación de ayuda para otros desarrolladores.
Documentación de software
La documentación del software es una parte importante del proceso del software. Un documento bien escrito proporciona una gran herramienta y un medio de repositorio de información necesario para conocer el proceso del software. La documentación del software también proporciona información sobre cómo utilizar el producto.
Una documentación bien mantenida debe incluir los siguientes documentos:
Requirement documentation - Esta documentación funciona como herramienta clave para que el diseñador de software, el desarrollador y el equipo de pruebas lleven a cabo sus respectivas tareas. Este documento contiene toda la descripción funcional, no funcional y de comportamiento del software previsto.
La fuente de este documento pueden ser datos almacenados previamente sobre el software, software que ya se está ejecutando al final del cliente, entrevista del cliente, cuestionarios e investigación. Generalmente se almacena en forma de hoja de cálculo o documento de procesamiento de texto con el equipo de administración de software de alta gama.
Esta documentación sirve como base para el desarrollo del software y se utiliza principalmente en las fases de verificación y validación. La mayoría de los casos de prueba se crean directamente a partir de la documentación de requisitos.
Software Design documentation - Esta documentación contiene toda la información necesaria, que se necesita para construir el software. Contiene:(a) Arquitectura de software de alto nivel, (b) Detalles de diseño de software, (c) Diagramas de flujo de datos, (d) Diseño de base de datos
Estos documentos funcionan como repositorio para que los desarrolladores implementen el software. Aunque estos documentos no brindan detalles sobre cómo codificar el programa, brindan toda la información necesaria que se requiere para la codificación y la implementación.
Technical documentation- Esta documentación es mantenida por los desarrolladores y codificadores reales. Estos documentos, en su conjunto, representan información sobre el código. Al escribir el código, los programadores también mencionan el objetivo del código, quién lo escribió, dónde se requerirá, qué hace y cómo lo hace, qué otros recursos usa el código, etc.
La documentación técnica aumenta la comprensión entre varios programadores que trabajan en el mismo código. Mejora la capacidad de reutilización del código. Hace que la depuración sea fácil y rastreable.
Hay varias herramientas automatizadas disponibles y algunas vienen con el propio lenguaje de programación. Por ejemplo, java viene con la herramienta JavaDoc para generar documentación técnica de código.
User documentation- Esta documentación es diferente a todas las explicadas anteriormente. Toda la documentación previa se mantiene para brindar información sobre el software y su proceso de desarrollo. Pero la documentación del usuario explica cómo debería funcionar el producto de software y cómo debería utilizarse para obtener los resultados deseados.
Esta documentación puede incluir procedimientos de instalación de software, guías prácticas, guías de usuario, método de desinstalación y referencias especiales para obtener más información, como actualización de licencias, etc.
Desafíos de implementación de software
Hay algunos desafíos que enfrenta el equipo de desarrollo al implementar el software. Algunos de ellos se mencionan a continuación:
Code-reuse- Las interfaces de programación de los lenguajes actuales son muy sofisticadas y están equipadas con enormes funciones de biblioteca. Aún así, para reducir el costo del producto final, la administración de la organización prefiere reutilizar el código, que se creó anteriormente para algún otro software. Los programadores enfrentan grandes problemas para verificar la compatibilidad y decidir cuánto código reutilizar.
Version Management- Cada vez que se envía un nuevo software al cliente, los desarrolladores deben mantener la documentación relacionada con la versión y la configuración. Esta documentación debe ser muy precisa y estar disponible a tiempo.
Target-Host- El programa de software, que se está desarrollando en la organización, debe diseñarse para máquinas host en el extremo del cliente. Pero a veces, es imposible diseñar un software que funcione en las máquinas de destino.
La prueba de software es la evaluación del software contra los requisitos recopilados de los usuarios y las especificaciones del sistema. Las pruebas se realizan a nivel de fase en el ciclo de vida del desarrollo de software o a nivel de módulo en el código del programa. Las pruebas de software se componen de validación y verificación.
Validación de software
La validación es el proceso de examinar si el software satisface o no los requisitos del usuario. Se realiza al final del SDLC. Si el software cumple con los requisitos para los que se creó, se valida.
- La validación garantiza que el producto en desarrollo cumpla con los requisitos del usuario.
- La validación responde a la pregunta: "¿Estamos desarrollando el producto que intenta todo lo que el usuario necesita de este software?".
- La validación enfatiza los requisitos del usuario.
Verificación de software
La verificación es el proceso de confirmar si el software cumple con los requisitos comerciales y se desarrolla de acuerdo con las especificaciones y metodologías adecuadas.
- La verificación garantiza que el producto que se está desarrollando cumple con las especificaciones de diseño.
- La verificación responde a la pregunta: "¿Estamos desarrollando este producto siguiendo firmemente todas las especificaciones de diseño?"
- Las verificaciones se concentran en el diseño y las especificaciones del sistema.
El objetivo de la prueba son:
Errors- Estos son errores de codificación reales cometidos por desarrolladores. Además, existe una diferencia en la salida del software y la salida deseada se considera un error.
Fault- Cuando existe un error, se produce una falla. Una falla, también conocida como error, es el resultado de un error que puede hacer que el sistema falle.
Failure - Se dice que falla la incapacidad del sistema para realizar la tarea deseada. La falla ocurre cuando existe una falla en el sistema.
Pruebas manuales frente a pruebas automatizadas
Las pruebas se pueden realizar manualmente o con una herramienta de prueba automatizada:
Manual- Esta prueba se realiza sin la ayuda de herramientas de prueba automatizadas. El probador de software prepara casos de prueba para diferentes secciones y niveles del código, ejecuta las pruebas e informa el resultado al administrador.
Las pruebas manuales consumen tiempo y recursos. El evaluador debe confirmar si se utilizan o no los casos de prueba correctos. La mayor parte de las pruebas implica pruebas manuales.
AutomatedEsta prueba es un procedimiento de prueba que se realiza con la ayuda de herramientas de prueba automatizadas. Las limitaciones de las pruebas manuales se pueden superar utilizando herramientas de prueba automatizadas.
Es necesario realizar una prueba para comprobar si se puede abrir una página web en Internet Explorer. Esto se puede hacer fácilmente con pruebas manuales. Pero para comprobar si el servidor web puede soportar la carga de 1 millón de usuarios, es bastante imposible probarlo manualmente.
Existen herramientas de software y hardware que ayudan al evaluador a realizar pruebas de carga, pruebas de estrés y pruebas de regresión.
Enfoques de prueba
Las pruebas se pueden realizar según dos enfoques:
- Prueba de funcionalidad
- Prueba de implementación
Cuando se prueba la funcionalidad sin tener en cuenta la implementación real, se conoce como prueba de caja negra. El otro lado se conoce como prueba de caja blanca, donde no solo se prueba la funcionalidad, sino que también se analiza la forma en que se implementa.
Las pruebas exhaustivas son el método mejor deseado para una prueba perfecta. Se prueba cada uno de los valores posibles en el rango de los valores de entrada y salida. No es posible probar todos y cada uno de los valores en un escenario del mundo real si el rango de valores es grande.
Prueba de caja negra
Se lleva a cabo para probar la funcionalidad del programa. También se llama prueba 'conductual'. El probador en este caso, tiene un conjunto de valores de entrada y los respectivos resultados deseados. Al proporcionar la entrada, si la salida coincide con los resultados deseados, el programa se prueba 'bien' y, en caso contrario, es problemático.

En este método de prueba, el probador no conoce el diseño y la estructura del código, y los ingenieros de prueba y los usuarios finales realizan esta prueba en el software.
Técnicas de prueba de caja negra:
Equivalence class- La entrada se divide en clases similares. Si un elemento de una clase pasa la prueba, se supone que se pasa toda la clase.
Boundary values- La entrada se divide en valores finales superior e inferior. Si estos valores pasan la prueba, se supone que todos los valores intermedios también pueden pasar.
Cause-effect graphing- En los dos métodos anteriores, solo se prueba un valor de entrada a la vez. Causa (entrada): el efecto (salida) es una técnica de prueba en la que las combinaciones de valores de entrada se prueban de forma sistemática.
Pair-wise Testing- El comportamiento del software depende de múltiples parámetros. En la prueba por pares, los múltiples parámetros se prueban por pares para sus diferentes valores.
State-based testing- El sistema cambia de estado al proporcionar la entrada. Estos sistemas se prueban en función de sus estados y entradas.
Prueba de caja blanca
Se lleva a cabo para probar el programa y su implementación, con el fin de mejorar la eficiencia o la estructura del código. También se conoce como prueba 'estructural'.

En este método de prueba, el probador conoce el diseño y la estructura del código. Los programadores del código realizan esta prueba en el código.
Las siguientes son algunas técnicas de prueba de caja blanca:
Control-flow testing- El propósito de las pruebas de flujo de control para configurar casos de prueba que cubran todas las declaraciones y condiciones de rama. Las condiciones de la rama se prueban para determinar si son verdaderas y falsas, de modo que se puedan cubrir todas las declaraciones.
Data-flow testing- Esta técnica de prueba hace hincapié en cubrir todas las variables de datos incluidas en el programa. Prueba dónde se declararon y definieron las variables y dónde se utilizaron o cambiaron.
Niveles de prueba
Las pruebas en sí pueden definirse en varios niveles de SDLC. El proceso de prueba se ejecuta en paralelo al desarrollo de software. Antes de saltar a la siguiente etapa, se prueba, valida y verifica una etapa.
Las pruebas se realizan por separado solo para asegurarse de que no queden errores o problemas ocultos en el software. El software se prueba en varios niveles:
Examen de la unidad
Mientras codifica, el programador realiza algunas pruebas en esa unidad de programa para saber si está libre de errores. Las pruebas se realizan con un enfoque de prueba de caja blanca. Las pruebas unitarias ayudan a los desarrolladores a decidir que las unidades individuales del programa funcionan según los requisitos y no presentan errores.
Pruebas de integración
Incluso si las unidades de software funcionan bien individualmente, es necesario averiguar si las unidades, si se integran juntas, también funcionarían sin errores. Por ejemplo, paso de argumentos y actualización de datos, etc.
Prueba del sistema
El software se compila como producto y luego se prueba como un todo. Esto se puede lograr mediante una o más de las siguientes pruebas:
Functionality testing - Prueba todas las funcionalidades del software contra el requisito.
Performance testing- Esta prueba demuestra la eficacia del software. Prueba la eficacia y el tiempo medio que tarda el software en realizar la tarea deseada. Las pruebas de rendimiento se realizan mediante pruebas de carga y pruebas de estrés en las que el software se somete a una gran carga de usuarios y datos en diversas condiciones ambientales.
Security & Portability - Estas pruebas se realizan cuando el software está destinado a funcionar en varias plataformas y se accede por varias personas.
Test de aceptación
Cuando el software está listo para entregarse al cliente, debe pasar por la última fase de prueba en la que se prueba la interacción y respuesta del usuario. Esto es importante porque incluso si el software cumple con todos los requisitos del usuario y si al usuario no le gusta la forma en que aparece o funciona, puede ser rechazado.
Alpha testing- El propio equipo de desarrolladores realiza pruebas alfa utilizando el sistema como si se estuviera utilizando en un entorno de trabajo. Intentan averiguar cómo reaccionaría el usuario a alguna acción en el software y cómo debería responder el sistema a las entradas.
Beta testing- Una vez que el software se prueba internamente, se entrega a los usuarios para que lo utilicen en su entorno de producción solo con fines de prueba. Este no es todavía el producto entregado. Los desarrolladores esperan que los usuarios en esta etapa traigan problemas mínimos, que se omitieron para atender.
Pruebas de regresión
Siempre que un producto de software se actualiza con un nuevo código, característica o funcionalidad, se prueba a fondo para detectar si hay algún impacto negativo del código agregado. Esto se conoce como prueba de regresión.
Documentación de prueba
Los documentos de prueba se preparan en diferentes etapas:
Antes de la prueba
La prueba comienza con la generación de casos de prueba. Se necesitan los siguientes documentos como referencia:
SRS document - Documento de requisitos funcionales
Test Policy document - Describe hasta qué punto deben realizarse las pruebas antes de lanzar el producto.
Test Strategy document - Esto menciona aspectos detallados del equipo de prueba, la matriz de responsabilidad y los derechos / responsabilidad del gerente de prueba y el ingeniero de prueba.
Traceability Matrix document- Este es un documento SDLC, que está relacionado con el proceso de recopilación de requisitos. A medida que surgen nuevos requisitos, se agregan a esta matriz. Estas matrices ayudan a los evaluadores a conocer la fuente de los requisitos. Se pueden rastrear hacia adelante y hacia atrás.
Mientras se prueba
Es posible que se requieran los siguientes documentos mientras se inician y se realizan las pruebas:
Test Case document- Este documento contiene una lista de las pruebas que deben realizarse. Incluye plan de prueba de la unidad, plan de prueba de integración, plan de prueba del sistema y plan de prueba de aceptación.
Test description - Este documento es una descripción detallada de todos los casos de prueba y procedimientos para ejecutarlos.
Test case report - Este documento contiene un informe de caso de prueba como resultado de la prueba.
Test logs - Este documento contiene registros de prueba para cada informe de caso de prueba.
Después de la prueba
Los siguientes documentos se pueden generar después de la prueba:
Test summary- Este resumen de prueba es un análisis colectivo de todos los informes y registros de prueba. Resume y concluye si el software está listo para ser lanzado. El software se lanza bajo el sistema de control de versiones si está listo para ejecutarse.
Pruebas frente a control de calidad, garantía de calidad y auditoría
Necesitamos entender que las pruebas de software son diferentes del aseguramiento de la calidad del software, el control de calidad del software y la auditoría del software.
Software quality assurance- Se trata de medios de seguimiento del proceso de desarrollo de software, mediante los cuales se asegura que todas las medidas se toman según los estándares de la organización. Esta supervisión se realiza para asegurarse de que se siguieron los métodos de desarrollo de software adecuados.
Software quality control- Este es un sistema para mantener la calidad del producto de software. Puede incluir aspectos funcionales y no funcionales del producto de software, que mejoran la buena voluntad de la organización. Este sistema asegura que el cliente esté recibiendo un producto de calidad para sus necesidades y el producto certificado como "apto para su uso".
Software audit- Esta es una revisión del procedimiento utilizado por la organización para desarrollar el software. Un equipo de auditores, independiente del equipo de desarrollo, examina el proceso, el procedimiento, los requisitos y otros aspectos del software SDLC. El propósito de la auditoría de software es verificar que el software y su proceso de desarrollo cumplen con los estándares, reglas y regulaciones.
El mantenimiento de software es una parte ampliamente aceptada de SDLC hoy en día. Representa todas las modificaciones y actualizaciones realizadas después de la entrega del producto de software. Hay varias razones por las que se requieren modificaciones, algunas de ellas se mencionan brevemente a continuación:
Market Conditions - Las políticas, que cambian con el tiempo, como los impuestos y las restricciones introducidas recientemente, como la forma de llevar la contabilidad, pueden generar la necesidad de modificaciones.
Client Requirements - Con el tiempo, el cliente puede solicitar nuevas características o funciones en el software.
Host Modifications - Si cambia el hardware y / o la plataforma (como el sistema operativo) del host de destino, se necesitan cambios de software para mantener la adaptabilidad.
Organization Changes - Si hay algún cambio en el nivel de negocio en el extremo del cliente, como la reducción de la fuerza de la organización, la adquisición de otra empresa, la organización que se aventura en nuevos negocios, puede surgir la necesidad de modificar el software original.
Tipos de mantenimiento
Durante la vida útil del software, el tipo de mantenimiento puede variar según su naturaleza. Puede ser solo una tarea de mantenimiento de rutina como algún error descubierto por algún usuario o puede ser un gran evento en sí mismo basado en el tamaño o la naturaleza del mantenimiento. A continuación se muestran algunos tipos de mantenimiento en función de sus características:
Corrective Maintenance - Esto incluye modificaciones y actualizaciones realizadas para corregir o solucionar problemas, que son descubiertos por el usuario o concluidos por informes de errores del usuario.
Adaptive Maintenance - Esto incluye modificaciones y actualizaciones aplicadas para mantener el producto de software actualizado y sintonizado con el cambiante mundo de la tecnología y el entorno empresarial.
Perfective Maintenance- Esto incluye modificaciones y actualizaciones realizadas para mantener el software utilizable durante un largo período de tiempo. Incluye nuevas funciones, nuevos requisitos de usuario para refinar el software y mejorar su confiabilidad y rendimiento.
Preventive Maintenance- Esto incluye modificaciones y actualizaciones para evitar problemas futuros del software. Tiene como objetivo atender problemas, que no son importantes en este momento pero que pueden causar problemas graves en el futuro.
Costo de mantenimiento
Los informes sugieren que el costo de mantenimiento es alto. Un estudio sobre la estimación del mantenimiento de software encontró que el costo de mantenimiento es tan alto como el 67% del costo de todo el ciclo del proceso del software.
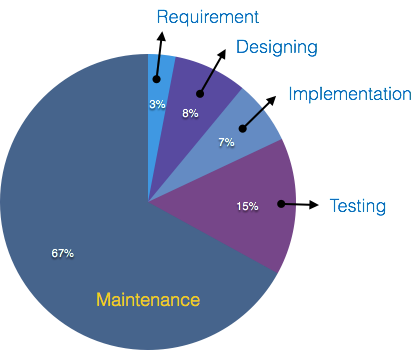
En promedio, el costo del mantenimiento del software es más del 50% de todas las fases de SDLC. Hay varios factores que provocan que el costo de mantenimiento sea elevado, tales como:
Factores del mundo real que afectan el costo de mantenimiento
- La edad estándar de cualquier software se considera de 10 a 15 años.
- Los softwares más antiguos, que estaban destinados a funcionar en máquinas lentas con menos memoria y capacidad de almacenamiento, no pueden seguir desafiando a los nuevos softwares mejorados en hardware moderno.
- A medida que avanza la tecnología, resulta costoso mantener el software antiguo.
- La mayoría de los ingenieros de mantenimiento son novatos y utilizan el método de prueba y error para corregir el problema.
- A menudo, los cambios realizados pueden dañar fácilmente la estructura original del software, dificultando los cambios posteriores.
- Los cambios a menudo quedan indocumentados, lo que puede causar más conflictos en el futuro.
Factores finales del software que afectan el costo de mantenimiento
- Estructura del programa de software
- Lenguaje de programación
- Dependencia del entorno externo
- Confiabilidad y disponibilidad del personal
Actividades de mantenimiento
IEEE proporciona un marco para las actividades del proceso de mantenimiento secuencial. Se puede utilizar de manera iterativa y se puede ampliar para que se puedan incluir elementos y procesos personalizados.

Estas actividades van de la mano con cada una de las siguientes fases:
Identification & Tracing- Implica actividades relativas a la identificación de requisitos de modificación o mantenimiento. Lo genera el usuario o el propio sistema puede informar mediante logs o mensajes de error. Aquí también se clasifica el tipo de mantenimiento.
Analysis- La modificación se analiza por su impacto en el sistema, incluidas las implicaciones de seguridad y protección. Si el impacto probable es severo, se busca una solución alternativa. Luego, un conjunto de modificaciones necesarias se materializa en especificaciones de requisitos. Se analiza el costo de modificación / mantenimiento y se concluye la estimación.
Design- Los módulos nuevos, que necesitan ser reemplazados o modificados, se diseñan contra las especificaciones de requisitos establecidas en la etapa anterior. Los casos de prueba se crean para validación y verificación.
Implementation - Los nuevos módulos se codifican con la ayuda del diseño estructurado creado en el paso de diseño. Se espera que cada programador realice pruebas unitarias en paralelo.
System Testing- Las pruebas de integración se realizan entre módulos recién creados. También se realizan pruebas de integración entre los nuevos módulos y el sistema. Finalmente, el sistema se prueba como un todo, siguiendo procedimientos de prueba regresivos.
Acceptance Testing- Después de probar el sistema internamente, se prueba su aceptación con la ayuda de los usuarios. Si en este estado, el usuario se queja de algunos problemas, se abordarán o se indicará que se abordarán en la próxima iteración.
Delivery- Después de la prueba de aceptación, el sistema se implementa en toda la organización, ya sea mediante un pequeño paquete de actualización o una nueva instalación del sistema. La prueba final se lleva a cabo en el cliente después de la entrega del software.
Se proporciona un servicio de capacitación si es necesario, además de la copia impresa del manual del usuario.
Maintenance management- La gestión de la configuración es una parte esencial del mantenimiento del sistema. Cuenta con herramientas de control de versiones para controlar versiones, semi-versiones o administración de parches.
Reingeniería de software
Cuando necesitamos actualizar el software para mantenerlo en el mercado actual, sin afectar su funcionalidad, se llama reingeniería de software. Es un proceso minucioso en el que se cambia el diseño del software y se reescriben los programas.
El software heredado no puede seguir sintonizándose con la última tecnología disponible en el mercado. A medida que el hardware se vuelve obsoleto, la actualización del software se convierte en un dolor de cabeza. Incluso si el software envejece con el tiempo, su funcionalidad no lo hace.
Por ejemplo, inicialmente Unix se desarrolló en lenguaje ensamblador. Cuando surgió el lenguaje C, Unix fue rediseñado en C, porque trabajar en lenguaje ensamblador era difícil.
Aparte de esto, a veces los programadores notan que pocas partes del software necesitan más mantenimiento que otras y también necesitan reingeniería.

Proceso de reingeniería
- Decidequé rediseñar. ¿Es un software completo o una parte de él?
- Perform Ingeniería inversa, para obtener especificaciones de software existente.
- Restructure Programsi es requerido. Por ejemplo, cambiar programas orientados a funciones en programas orientados a objetos.
- Re-structure data según sea necesario.
- Apply Forward engineering conceptos para obtener software rediseñado.
Hay algunos términos importantes que se utilizan en la reingeniería de software
Ingeniería inversa
Es un proceso para lograr la especificación del sistema mediante el análisis a fondo y la comprensión del sistema existente. Este proceso puede verse como un modelo SDLC inverso, es decir, intentamos obtener un nivel de abstracción más alto analizando niveles de abstracción más bajos.
Un sistema existente es un diseño implementado previamente, del que no sabemos nada. Luego, los diseñadores realizan ingeniería inversa mirando el código e intentan obtener el diseño. Con el diseño en la mano, intentan concluir las especificaciones. Por lo tanto, ir a la inversa del código a la especificación del sistema.

Reestructuración del programa
Es un proceso para reestructurar y reconstruir el software existente. Se trata de reorganizar el código fuente, ya sea en el mismo lenguaje de programación o de un lenguaje de programación a otro diferente. La reestructuración puede tener una reestructuración del código fuente y una reestructuración de datos o ambas.
La reestructuración no afecta la funcionalidad del software, pero mejora la confiabilidad y el mantenimiento. Los componentes del programa, que provocan errores con mucha frecuencia, pueden modificarse o actualizarse con una reestructuración.
La confiabilidad del software en una plataforma de hardware obsoleta se puede eliminar mediante una reestructuración.
Ingeniería avanzada
La ingeniería avanzada es un proceso de obtención del software deseado a partir de las especificaciones disponibles que se redujeron mediante ingeniería inversa. Se asume que ya se hizo algo de ingeniería de software en el pasado.
La ingeniería avanzada es lo mismo que el proceso de ingeniería de software con una sola diferencia: se lleva a cabo siempre después de la ingeniería inversa.

Reutilización de componentes
Un componente es parte del código del programa de software, que ejecuta una tarea independiente en el sistema. Puede ser un módulo pequeño o un subsistema en sí.
Ejemplo
Los procedimientos de inicio de sesión utilizados en la web se pueden considerar como componentes, el sistema de impresión en software puede verse como un componente del software.
Los componentes tienen una alta cohesión de funcionalidad y una menor tasa de acoplamiento, es decir, funcionan de forma independiente y pueden realizar tareas sin depender de otros módulos.
En OOP, los objetos que se diseñan son muy específicos para su interés y tienen menos posibilidades de ser utilizados en algún otro software.
En la programación modular, los módulos están codificados para realizar tareas específicas que se pueden utilizar en varios otros programas de software.
Existe una vertical completamente nueva, que se basa en la reutilización de componentes de software y se conoce como Ingeniería de software basada en componentes (CBSE).

La reutilización se puede realizar en varios niveles
Application level - Donde se utiliza una aplicación completa como subsistema de nuevo software.
Component level - Dónde se utiliza el subsistema de una aplicación.
Modules level - Donde se reutilizan módulos funcionales.
Los componentes de software proporcionan interfaces que se pueden utilizar para establecer la comunicación entre diferentes componentes.
Proceso de reutilización
Se pueden adoptar dos tipos de métodos: manteniendo los mismos requisitos y ajustando los componentes o manteniendo los mismos componentes y modificando los requisitos.

Requirement Specification - Se especifican los requisitos funcionales y no funcionales, que debe cumplir un producto de software, con la ayuda del sistema existente, la entrada del usuario o ambos.
Design- Este también es un paso del proceso SDLC estándar, donde los requisitos se definen en términos de lenguaje de software. Se crea la arquitectura básica del sistema en su conjunto y sus subsistemas.
Specify Components - Al estudiar el diseño del software, los diseñadores segregan todo el sistema en componentes o subsistemas más pequeños. Un diseño de software completo se convierte en una colección de un gran conjunto de componentes que trabajan juntos.
Search Suitable Components - Los diseñadores remiten al repositorio de componentes de software para buscar el componente correspondiente, en función de la funcionalidad y los requisitos de software previstos.
Incorporate Components - Todos los componentes combinados se empaquetan juntos para darles forma como software completo.
CASE significa Ccomputadora Aided Software Eningeniería. Significa, desarrollo y mantenimiento de proyectos de software con la ayuda de varias herramientas de software automatizadas.
Herramientas CASE
Las herramientas CASE son un conjunto de programas de aplicación de software que se utilizan para automatizar las actividades de SDLC. Las herramientas CASE son utilizadas por administradores de proyectos de software, analistas e ingenieros para desarrollar sistemas de software.
Hay varias herramientas CASE disponibles para simplificar varias etapas del ciclo de vida del desarrollo de software, como herramientas de análisis, herramientas de diseño, herramientas de gestión de proyectos, herramientas de gestión de bases de datos y herramientas de documentación, por nombrar algunas.
El uso de herramientas CASE acelera el desarrollo del proyecto para producir el resultado deseado y ayuda a descubrir fallas antes de continuar con la siguiente etapa en el desarrollo de software.
Componentes de las herramientas CASE
Las herramientas CASE se pueden dividir ampliamente en las siguientes partes según su uso en una etapa SDLC particular:
Central Repository- Las herramientas CASE requieren un repositorio central, que puede servir como fuente de información común, integrada y consistente. El depósito central es un lugar central de almacenamiento donde se almacenan las especificaciones del producto, los documentos de requisitos, los informes y diagramas relacionados y otra información útil relacionada con la gestión. El repositorio central también sirve como diccionario de datos.

Upper Case Tools - Las herramientas de CASE superior se utilizan en las etapas de planificación, análisis y diseño de SDLC.
Lower Case Tools - Se utilizan herramientas de CASE inferior en implementación, prueba y mantenimiento.
Integrated Case Tools - Las herramientas CASE integradas son útiles en todas las etapas de SDLC, desde la recopilación de requisitos hasta las pruebas y la documentación.
Las herramientas CASE se pueden agrupar si tienen una funcionalidad, actividades de proceso y capacidad de integración similares con otras herramientas.
Alcance de las herramientas de caso
El alcance de las herramientas CASE abarca todo el SDLC.
Tipos de herramientas de caja
Ahora repasaremos brevemente varias herramientas CASE
Herramientas de diagrama
Estas herramientas se utilizan para representar los componentes del sistema, los datos y el flujo de control entre varios componentes de software y la estructura del sistema en forma gráfica. Por ejemplo, la herramienta Flow Chart Maker para crear diagramas de flujo de última generación.
Herramientas de modelado de procesos
El modelado de procesos es un método para crear un modelo de proceso de software, que se utiliza para desarrollar el software. Las herramientas de modelado de procesos ayudan a los gerentes a elegir un modelo de proceso o modificarlo según los requisitos del producto de software. Por ejemplo, EPF Composer
Herramientas de gestión de proyectos
Estas herramientas se utilizan para la planificación de proyectos, la estimación de costes y esfuerzos, la programación de proyectos y la planificación de recursos. Los gerentes deben cumplir estrictamente la ejecución del proyecto con cada paso mencionado en la gestión de proyectos de software. Las herramientas de gestión de proyectos ayudan a almacenar y compartir información del proyecto en tiempo real en toda la organización. Por ejemplo, Creative Pro Office, Trac Project, Basecamp.
Herramientas de documentación
La documentación en un proyecto de software comienza antes del proceso de software, pasa por todas las fases de SDLC y después de la finalización del proyecto.
Las herramientas de documentación generan documentos para usuarios técnicos y usuarios finales. Los usuarios técnicos son en su mayoría profesionales internos del equipo de desarrollo que consultan el manual del sistema, el manual de referencia, el manual de formación, los manuales de instalación, etc. Los documentos del usuario final describen el funcionamiento y los procedimientos del sistema, como el manual del usuario. Por ejemplo, Doxygen, DrExplain, Adobe RoboHelp para documentación.
Herramientas de análisis
Estas herramientas ayudan a recopilar requisitos, verifican automáticamente cualquier inconsistencia, inexactitud en los diagramas, redundancias de datos u omisiones erróneas. Por ejemplo, Accept 360, Accompa, CaseComplete para análisis de requisitos, Visible Analyst para análisis total.
Herramientas de diseño
Estas herramientas ayudan a los diseñadores de software a diseñar la estructura de bloques del software, que se puede dividir en módulos más pequeños utilizando técnicas de refinamiento. Estas herramientas proporcionan detalles de cada módulo e interconexiones entre módulos. Por ejemplo, diseño de software animado
Herramientas de gestión de la configuración
Una instancia de software se publica en una versión. Las herramientas de gestión de la configuración se ocupan de:
- Gestión de versiones y revisiones
- Gestión de la configuración básica
- Gestión del control de cambios
Las herramientas CASE ayudan en esto mediante el seguimiento automático, la gestión de versiones y la gestión de versiones. Por ejemplo, Fossil, Git, Accu REV.
Herramientas de control de cambios
Estas herramientas se consideran parte de las herramientas de gestión de la configuración. Se ocupan de los cambios realizados en el software después de que se fija su línea de base o cuando el software se lanza por primera vez. Las herramientas CASE automatizan el seguimiento de cambios, la gestión de archivos, la gestión de códigos y más. También ayuda a hacer cumplir la política de cambio de la organización.
Herramientas de programación
Estas herramientas constan de entornos de programación como IDE (entorno de desarrollo integrado), biblioteca de módulos incorporada y herramientas de simulación. Estas herramientas proporcionan una ayuda completa para crear productos de software e incluyen funciones para simulación y pruebas. Por ejemplo, Cscope para buscar código en C, Eclipse.
Herramientas de creación de prototipos
El prototipo de software es una versión simulada del producto de software previsto. El prototipo proporciona la apariencia inicial del producto y simula algunos aspectos del producto real.
Las herramientas CASE de creación de prototipos vienen esencialmente con bibliotecas gráficas. Pueden crear interfaces de usuario y diseño independientes del hardware. Estas herramientas nos ayudan a construir prototipos rápidos basados en información existente. Además, proporcionan simulación de prototipo de software. Por ejemplo, el prototipo de compositor de Serena, Mockup Builder.
Herramientas de desarrollo web
Estas herramientas ayudan a diseñar páginas web con todos los elementos relacionados, como formularios, texto, guiones, gráficos, etc. Las herramientas web también brindan una vista previa en vivo de lo que se está desarrollando y cómo se verá una vez terminado. Por ejemplo, Fontello, Adobe Edge Inspect, Foundation 3, Brackets.
Herramientas de aseguramiento de la calidad
La garantía de calidad en una organización de software consiste en monitorear el proceso de ingeniería y los métodos adoptados para desarrollar el producto de software con el fin de garantizar el cumplimiento de la calidad según los estándares de la organización. Las herramientas de control de calidad constan de herramientas de configuración y control de cambios y herramientas de prueba de software. Por ejemplo, SoapTest, AppsWatch, JMeter.
Herramientas de mantenimiento
El mantenimiento del software incluye modificaciones en el producto de software después de su entrega. Las técnicas de registro automático y notificación de errores, la generación automática de tickets de error y el análisis de la causa raíz son algunas de las herramientas CASE que ayudan a la organización del software en la fase de mantenimiento de SDLC. Por ejemplo, Bugzilla para seguimiento de defectos, HP Quality Center.