Talend - Guía rápida
Talend es una plataforma de integración de software que proporciona soluciones para integración de datos, calidad de datos, gestión de datos, preparación de datos y Big Data. La demanda de profesionales ETL con conocimientos sobre Talend es alta. Además, es la única herramienta ETL con todos los complementos para integrarse fácilmente con el ecosistema de Big Data.
Según Gartner, Talend se encuentra en el cuadrante mágico de Líderes para las herramientas de integración de datos.
Talend ofrece varios productos comerciales que se enumeran a continuación:
- Calidad de datos de Talend
- Integración de datos de Talend
- Preparación de datos de Talend
- Talend Cloud
- Talend Big Data
- Plataforma Talend MDM (gestión de datos maestros)
- Plataforma de servicios de datos de Talend
- Administrador de metadatos de Talend
- Talend Data Fabric
Talend también ofrece Open Studio, que es una herramienta gratuita de código abierto que se utiliza ampliamente para la integración de datos y Big Data.
Los siguientes son los requisitos del sistema para descargar y trabajar en Talend Open Studio:
Sistema operativo recomendado
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
Requisito de memoria
- Memoria: mínimo 4 GB, recomendado 8 GB
- Espacio de almacenamiento: 30 GB
Además, también necesita un clúster Hadoop en funcionamiento (preferiblemente Cloudera.
Note - Java 8 debe estar disponible con las variables de entorno ya configuradas.
Para descargar Talend Open Studio para Big Data e integración de datos, siga los pasos que se indican a continuación:
Step 1 - Ir a la página: https://www.talend.com/products/big-data/big-data-open-studio/y haga clic en el botón de descarga. Puede ver que el archivo TOS_BD_xxxxxxx.zip comienza a descargarse.
Step 2 - Una vez finalizada la descarga, extraiga el contenido del archivo zip, creará una carpeta con todos los archivos de Talend.
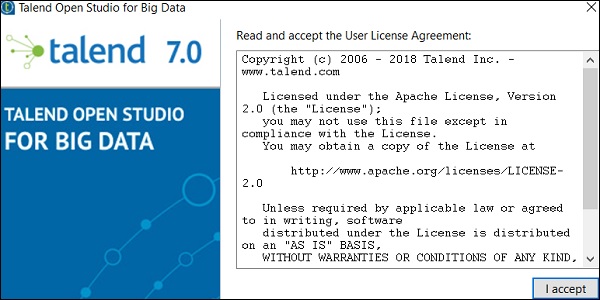
Step 3- Abra la carpeta Talend y haga doble clic en el archivo ejecutable: TOS_BD-win-x86_64.exe. Acepte el Acuerdo de licencia de usuario.
Step 4 - Cree un nuevo proyecto y haga clic en Finalizar.
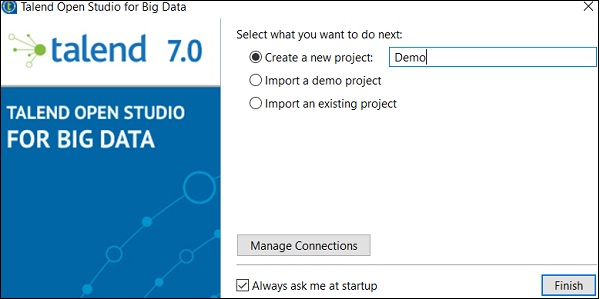
Step 5 - Haga clic en Permitir acceso en caso de que reciba la alerta de seguridad de Windows.
Step 6 - Ahora, se abrirá la página de bienvenida de Talend Open Studio.
Step 7 - Haga clic en Finalizar para instalar las bibliotecas de terceros necesarias.
Step 8 - Acepte los términos y haga clic en Finalizar.
Step 9 - Haga clic en Sí.
Ahora su Talend Open Studio está listo con las bibliotecas necesarias.
Talend Open Studio es una herramienta ETL gratuita de código abierto para la integración de datos y Big Data. Es una herramienta de desarrollo y diseñador de trabajos basada en Eclipse. Solo necesita arrastrar y soltar componentes y conectarlos para crear y ejecutar ETL o trabajos ETL. La herramienta creará el código Java para el trabajo automáticamente y no es necesario que escriba una sola línea de código.
Hay múltiples opciones para conectarse con fuentes de datos como RDBMS, Excel, ecosistema de Big Data SaaS, así como aplicaciones y tecnologías como SAP, CRM, Dropbox y muchas más.
Algunos beneficios importantes que ofrece Talend Open Studio son los siguientes:
Proporciona todas las funciones necesarias para la integración y sincronización de datos con 900 componentes, conectores integrados, conversión automática de trabajos a código Java y mucho más.
La herramienta es completamente gratuita, por lo que hay grandes ahorros de costos.
En los últimos 12 años, varias organizaciones gigantes han adoptado TOS para la integración de datos, lo que muestra un factor de confianza muy alto en esta herramienta.
La comunidad de Talend para la integración de datos es muy activa.
Talend sigue agregando funciones a estas herramientas y la documentación está bien estructurada y es muy fácil de seguir.
La mayoría de las organizaciones obtienen datos de varios lugares y los almacenan por separado. Ahora bien, si la organización tiene que tomar decisiones, debe tomar datos de diferentes fuentes, ponerlos en una vista unificada y luego analizarlos para obtener un resultado. Este proceso se denomina Integración de datos.
Beneficios
La integración de datos ofrece muchos beneficios, como se describe a continuación:
Mejora la colaboración entre diferentes equipos de la organización que intentan acceder a los datos de la organización.
Ahorra tiempo y facilita el análisis de datos, ya que los datos se integran de forma eficaz.
El proceso de integración de datos automatizado sincroniza los datos y facilita la generación de informes periódicos y en tiempo real, lo que de otra manera lleva mucho tiempo si se hace manualmente.
Los datos que se integran de varias fuentes maduran y mejoran con el tiempo, lo que eventualmente ayuda a mejorar la calidad de los datos.
Trabajar con proyectos
En esta sección, entendamos cómo trabajar en proyectos de Talend:
Crear un proyecto
Haga doble clic en el archivo ejecutable TOS Big Data, se abrirá la ventana que se muestra a continuación.
Seleccione la opción Crear un nuevo proyecto, mencione el nombre del proyecto y haga clic en Crear.

Seleccione el proyecto que creó y haga clic en Finalizar.

Importar un proyecto
Haga doble clic en el archivo ejecutable TOS Big Data, puede ver la ventana como se muestra a continuación. Seleccione la opción Importar un proyecto de demostración y haga clic en Seleccionar.

Puede elegir entre las opciones que se muestran a continuación. Aquí estamos eligiendo demostraciones de integración de datos. Ahora, haz clic en Finalizar.

Ahora, proporcione el nombre y la descripción del proyecto. Haga clic en Finalizar.

Puede ver su proyecto importado en la lista de proyectos existentes.
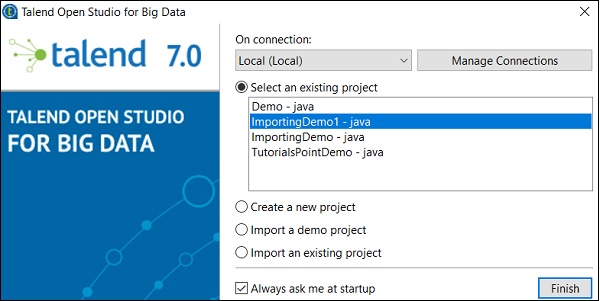
Ahora, comprendamos cómo importar un proyecto Talend existente.
Seleccione la opción Importar un proyecto existente y haga clic en Seleccionar.

Dé el nombre del proyecto y seleccione la opción "Seleccionar directorio raíz".

Examine el directorio de inicio de su proyecto Talend existente y haga clic en Finalizar.

Su proyecto Talend existente se importará.
Abrir un proyecto
Seleccione un proyecto del proyecto existente y haga clic en Finalizar. Esto abrirá ese proyecto de Talend.

Eliminar un proyecto
Para eliminar un proyecto, haga clic en Administrar conexiones.

Haga clic en Eliminar proyecto (s) existente (s)

Seleccione el proyecto que desea eliminar y haga clic en Aceptar.
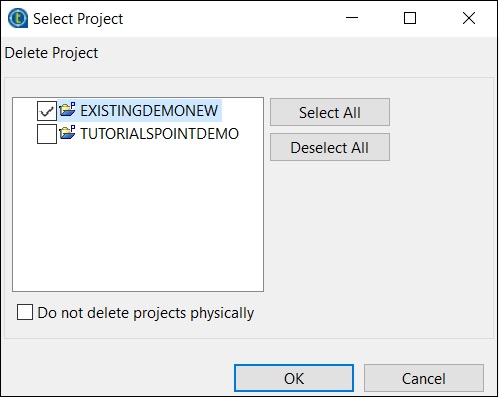
Haga clic en Aceptar nuevamente.
Exportar un proyecto
Haga clic en la opción Exportar proyecto.

Seleccione el proyecto que desea exportar y proporcione una ruta hacia donde se debe exportar. Haga clic en Finalizar.

El modelo de negocio es una representación gráfica de un proyecto de integración de datos. Es una representación no técnica del flujo de trabajo del negocio.
¿Por qué necesitas un modelo de negocio?
Un modelo de negocio se construye para mostrarle a la alta dirección lo que está haciendo y también hace que su equipo comprenda lo que está tratando de lograr. El diseño de un modelo de negocio se considera una de las mejores prácticas que adoptan las organizaciones al inicio de su proyecto de integración de datos. Además, ayudando a reducir costos, encuentra y resuelve los cuellos de botella en su proyecto. El modelo se puede modificar durante y después de la implementación del proyecto, si es necesario.
Creación de modelo de negocio en Talend Open Studio
Talend open studio proporciona múltiples formas y conectores para crear y diseñar un modelo de negocio. Cada módulo de un modelo de negocio puede tener una documentación adjunta.
Talend Open Studio ofrece las siguientes formas y opciones de conectores para crear un modelo de negocio:
Decision - Esta forma se utiliza para poner una condición en el modelo.
Action - Esta forma se utiliza para mostrar cualquier transformación, traducción o formato.
Terminal - Esta forma muestra el tipo de terminal de salida.
Data - Esta forma se utiliza para mostrar el tipo de datos.
Document - Esta forma se utiliza para insertar un objeto de documento que se puede utilizar para la entrada / salida de los datos procesados.
Input - Esta forma se utiliza para insertar un objeto de entrada mediante el cual el usuario puede pasar los datos manualmente.
List - Esta forma contiene los datos extraídos y se puede definir para contener solo cierto tipo de datos en la lista.
Database - Esta forma se utiliza para contener los datos de entrada / salida.
Actor - Esta forma simboliza a las personas involucradas en la toma de decisiones y los procesos técnicos.
Ellipse - Inserta una forma de elipse.
Gear - Esta forma muestra los programas manuales que deben sustituirse por trabajos de Talend.
Todas las operaciones en Talend se realizan mediante conectores y componentes. Talend ofrece más de 800 conectores y componentes para realizar varias operaciones. Estos componentes están presentes en la paleta y hay 21 categorías principales a las que pertenecen los componentes. Puede elegir los conectores y simplemente arrastrarlos y soltarlos en el panel del diseñador, creará código Java automáticamente que se compilará cuando guarde el código Talend.
Las categorías principales que contienen componentes se muestran a continuación:
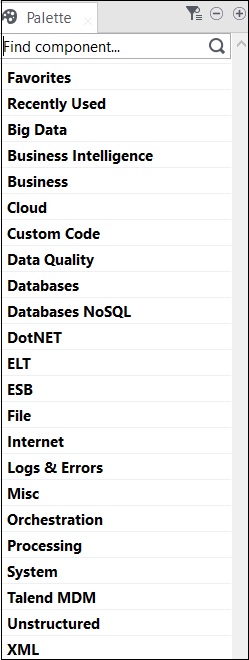
La siguiente es la lista de conectores y componentes ampliamente utilizados para la integración de datos en Talend Open Studio:
tMysqlConnection - Se conecta a la base de datos MySQL definida en el componente.
tMysqlInput - Ejecuta la consulta de la base de datos para leer una base de datos y extraer campos (tablas, vistas, etc.) según la consulta.
tMysqlOutput - Se utiliza para escribir, actualizar, modificar datos en una base de datos MySQL.
tFileInputDelimited - Lee un archivo delimitado fila por fila, lo divide en campos separados y lo pasa al siguiente componente.
tFileInputExcel - Lee un archivo de Excel fila por fila y los divide en campos separados y lo pasa al siguiente componente.
tFileList - Obtiene todos los archivos y directorios de un patrón de máscara de archivo determinado.
tFileArchive - Comprime un conjunto de archivos o carpetas en un archivo zip, gzip o tar.gz.
tRowGenerator - Proporciona un editor donde puede escribir funciones o elegir expresiones para generar sus datos de muestra.
tMsgBox - Devuelve un cuadro de diálogo con el mensaje especificado y un botón Aceptar.
tLogRow- Supervisa los datos que se procesan. Muestra datos / salida en la consola de ejecución.
tPreJob - Define los trabajos secundarios que se ejecutarán antes de que comience su trabajo real.
tMap- Actúa como un complemento en Talend Studio. Toma datos de una o más fuentes, los transforma y luego envía los datos transformados a uno o más destinos.
tJoin - Une 2 tablas realizando uniones internas y externas entre el flujo principal y el flujo de búsqueda.
tJava - Le permite utilizar código Java personalizado en el programa Talend.
tRunJob - Gestiona sistemas de trabajos complejos ejecutando un trabajo de Talend tras otro.
Esta es la implementación técnica / representación gráfica del modelo de negocio. En este diseño, uno o más componentes están conectados entre sí para ejecutar un proceso de integración de datos. Por lo tanto, cuando arrastra y suelta componentes en el panel de diseño y luego los conecta con conectores, el diseño de un trabajo convierte todo en código y crea un programa ejecutable completo que forma el flujo de datos.
Crear un trabajo
En la ventana del repositorio, haga clic con el botón derecho en el Diseño del trabajo y haga clic en Crear trabajo.
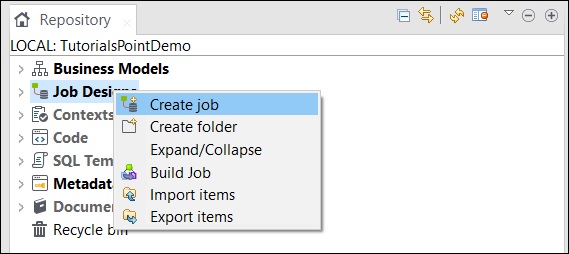
Proporcione el nombre, el propósito y la descripción del trabajo y haga clic en Finalizar.
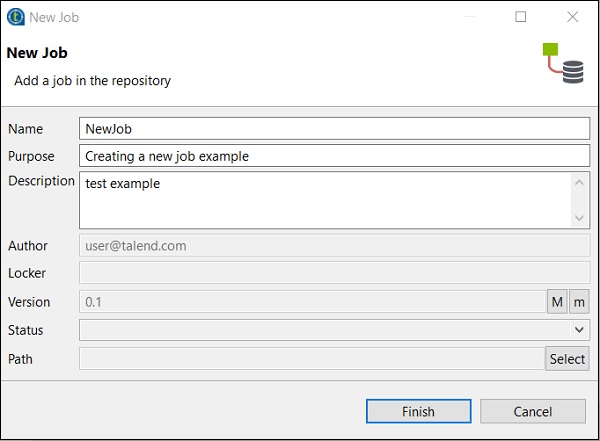
Puede ver que su trabajo se ha creado en Diseño de trabajo.
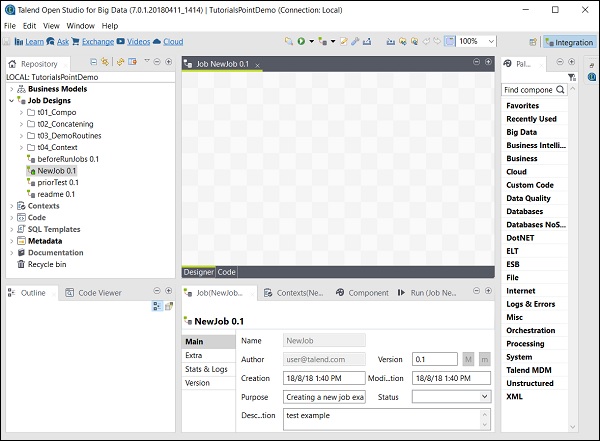
Ahora, usemos este trabajo para agregar componentes, conectarlos y configurarlos. Aquí, tomaremos un archivo de Excel como entrada y produciremos un archivo de Excel como salida con los mismos datos.
Agregar componentes a un trabajo
Hay varios componentes en la paleta para elegir. También hay una opción de búsqueda, en la que puede ingresar el nombre del componente para seleccionarlo.
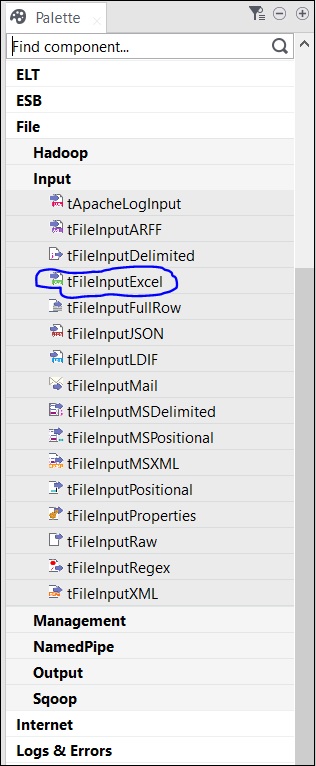
Dado que, aquí estamos tomando un archivo de Excel como entrada, arrastraremos y soltaremos el componente tFileInputExcel desde la paleta a la ventana del Diseñador.

Ahora, si hace clic en cualquier lugar de la ventana del diseñador, aparecerá un cuadro de búsqueda. Busque tLogRow y selecciónelo para traerlo a la ventana del diseñador.

Finalmente, seleccione el componente tFileOutputExcel de la paleta y arrástrelo y suéltelo en la ventana del diseñador.
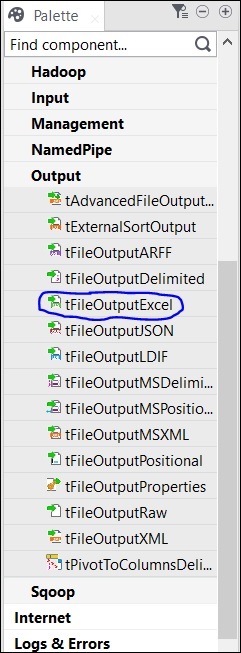
Ahora, la adición de los componentes está lista.
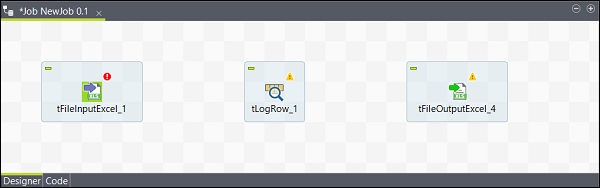
Conexión de los componentes
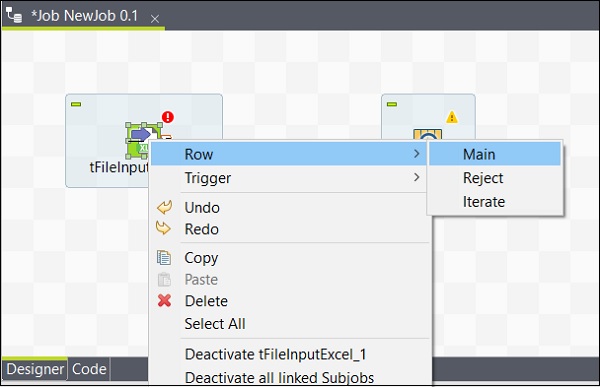
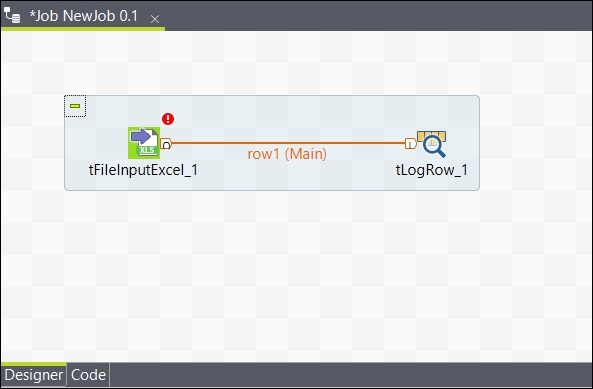
Después de agregar componentes, debe conectarlos. Haga clic con el botón derecho en el primer componente tFileInputExcel y dibuje una línea principal en tLogRow como se muestra a continuación.
Del mismo modo, haga clic con el botón derecho en tLogRow y dibuje una línea principal en tFileOutputExcel. Ahora, sus componentes están conectados.
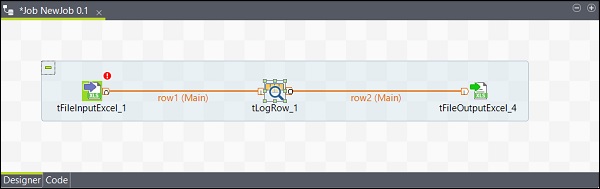
Configurar los componentes
Después de agregar y conectar los componentes en el trabajo, debe configurarlos. Para ello, haga doble clic en el primer componente tFileInputExcel para configurarlo. Proporcione la ruta de su archivo de entrada en Nombre de archivo / flujo como se muestra a continuación.
Si su primera fila en Excel tiene los nombres de las columnas, coloque 1 en la opción Encabezado.
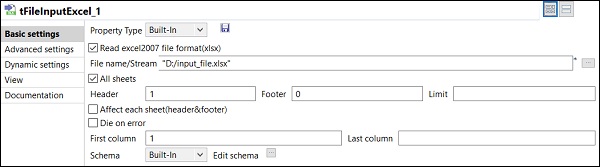
Haga clic en Editar esquema y agregue las columnas y su tipo de acuerdo con su archivo de Excel de entrada. Haga clic en Aceptar después de agregar el esquema.
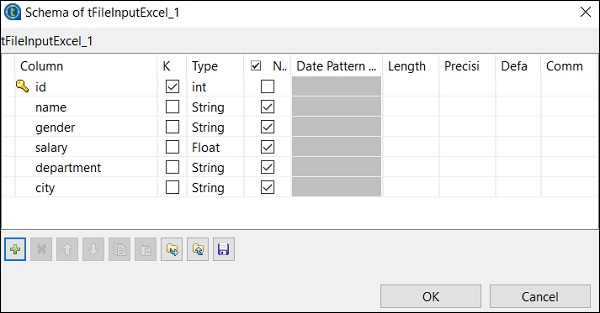
Haga clic en Sí.
En el componente tLogRow, haga clic en sincronizar columnas y seleccione el modo en el que desea generar las filas a partir de su entrada. Aquí hemos seleccionado el modo básico con "," como separador de campo.
Finalmente, en el componente tFileOutputExcel, proporcione la ruta del nombre del archivo donde desea almacenar
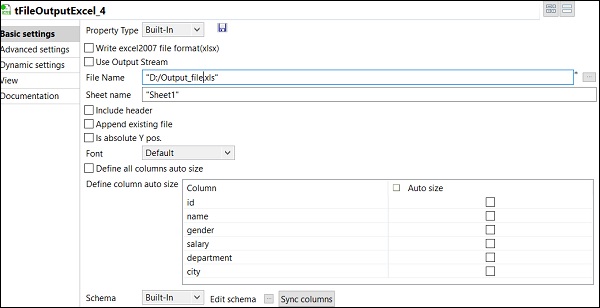
su archivo de Excel de salida con el nombre de la hoja. Click on sync columns.
Ejecutando el trabajo
Una vez que haya terminado de agregar, conectar y configurar sus componentes, estará listo para ejecutar su trabajo de Talend. Haga clic en el botón Ejecutar para comenzar la ejecución.

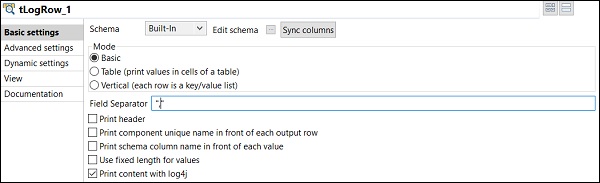
Verá la salida en el modo básico con "," separador.
También puede ver que su salida se guarda como un Excel en la ruta de salida que mencionó.
Los metadatos básicamente significan datos sobre datos. Indica qué, cuándo, por qué, quién, dónde, cuál y cómo de los datos. En Talend, los metadatos tienen toda la información sobre los datos que están presentes en Talend Studio. La opción de metadatos está presente dentro del panel Repositorio de Talend Open Studio.
Varias fuentes como DB Connections, diferentes tipos de archivos, LDAP, Azure, Salesforce, Web Services FTP, Hadoop Cluster y muchas más opciones están presentes en Talend Metadata.
El uso principal de los metadatos en Talend Open Studio es que puede utilizar estas fuentes de datos en varios trabajos con solo arrastrar y soltar desde el panel de Metadatos en el repositorio.
Las variables de contexto son las variables que pueden tener diferentes valores en diferentes entornos. Puede crear un grupo de contexto que pueda contener múltiples variables de contexto. No es necesario agregar cada variable de contexto una por una a un trabajo, simplemente puede agregar el grupo de contexto al trabajo.
Estas variables se utilizan para preparar la producción de código. Significa que mediante el uso de variables de contexto, puede mover el código en entornos de desarrollo, prueba o producción, se ejecutará en todos los entornos.
En cualquier trabajo, puede ir a la pestaña Contextos como se muestra a continuación y agregar variables de contexto.
En este capítulo, analicemos la gestión de trabajos y las funcionalidades correspondientes incluidas en Talend.
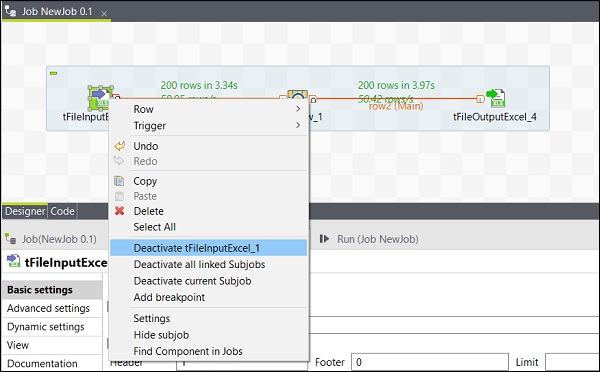
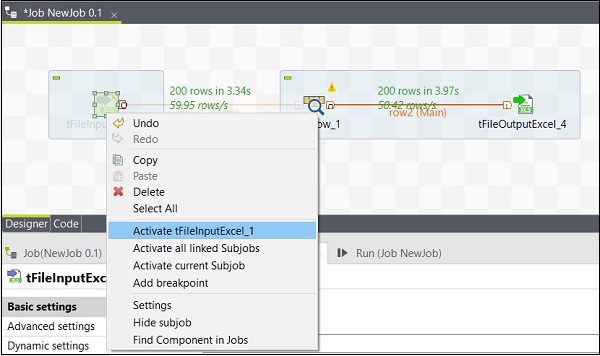
Activar / desactivar un componente
Activar / Desactivar un componente es muy simple. Solo necesita seleccionar el componente, hacer clic derecho sobre él y elegir la opción de desactivar o activar ese componente.
Importación / exportación de elementos y trabajos de construcción
Para exportar un elemento del trabajo, haga clic con el botón derecho en el trabajo en Diseños de trabajo y haga clic en Exportar elementos.
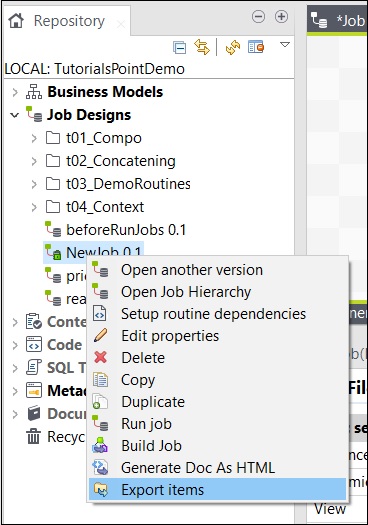
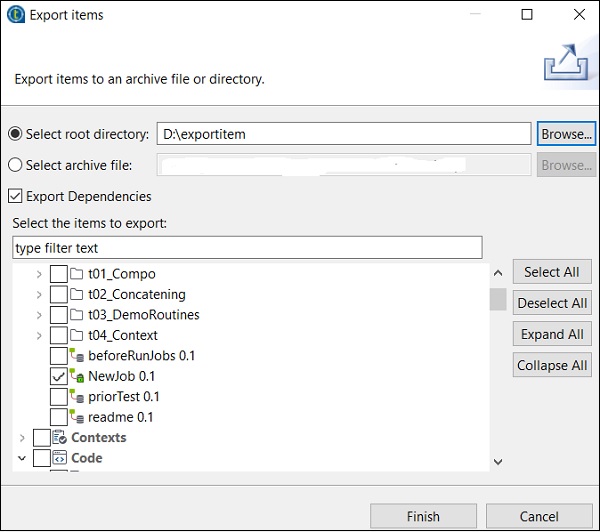
Ingrese la ruta donde desea exportar el artículo y haga clic en Finalizar.
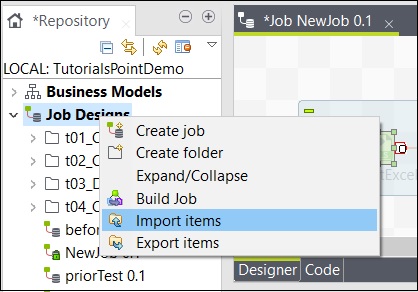
Para importar un elemento del trabajo, haga clic con el botón derecho en el trabajo en Diseños de trabajo y haga clic en Importar elementos.
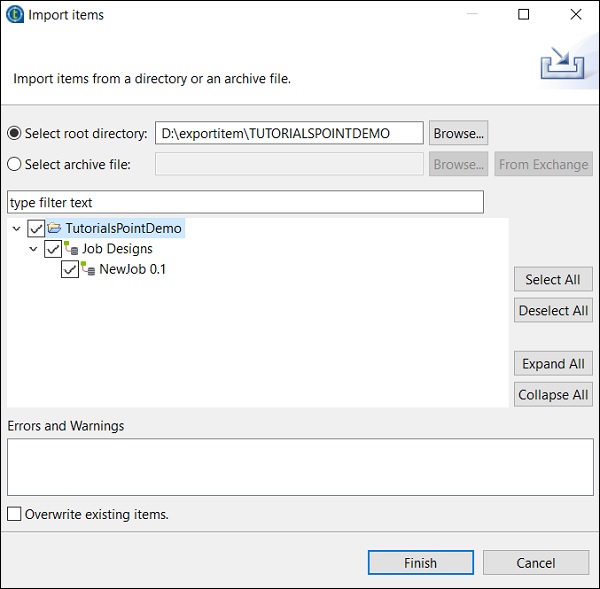
Busque el directorio raíz desde donde desea importar los elementos.
Seleccione todas las casillas de verificación y haga clic en Finalizar.
En este capítulo, comprendamos el manejo de la ejecución de un trabajo en Talend.
Para crear un trabajo, haga clic con el botón derecho en el trabajo y seleccione la opción Crear trabajo.
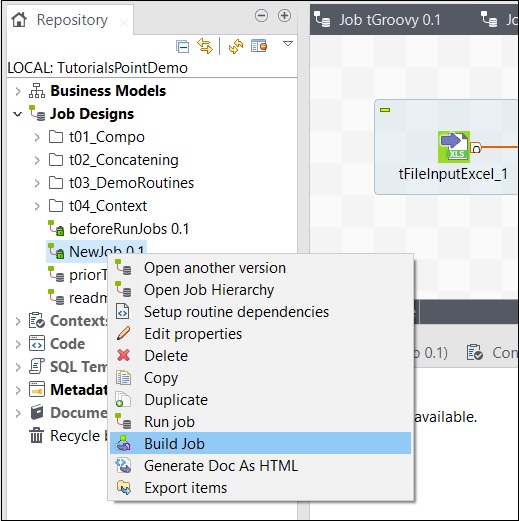
Mencione la ruta donde desea archivar el trabajo, seleccione la versión del trabajo y el tipo de compilación, luego haga clic en Finalizar.
Cómo ejecutar un trabajo en modo normal
Para ejecutar un trabajo en un nodo normal, debe seleccionar "Ejecución básica" y hacer clic en el botón Ejecutar para que comience la ejecución.
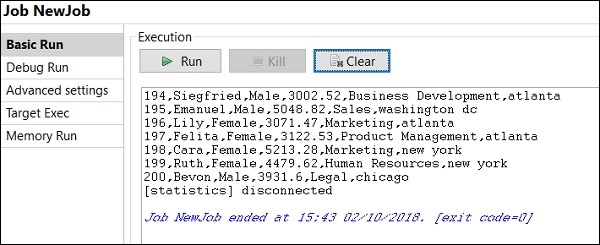
Cómo ejecutar un trabajo en modo de depuración
Para ejecutar el trabajo en modo de depuración, agregue un punto de interrupción a los componentes que desea depurar.
Luego, seleccione y haga clic derecho en el componente, haga clic en la opción Agregar punto de interrupción. Observe que aquí hemos agregado puntos de interrupción a los componentes tFileInputExcel y tLogRow. Luego, vaya a Debug Run y haga clic en el botón Java Debug.
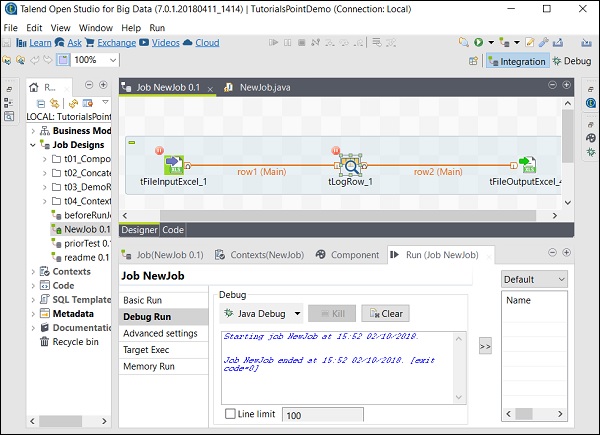
Puede observar en la siguiente captura de pantalla que el trabajo ahora se ejecutará en modo de depuración y de acuerdo con los puntos de interrupción que hemos mencionado.
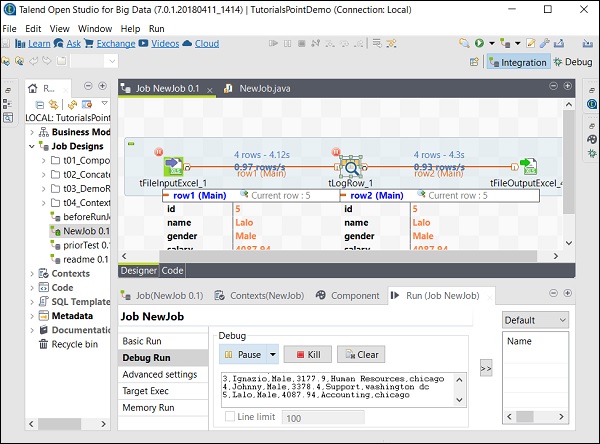
Ajustes avanzados
En la configuración avanzada, puede seleccionar entre Estadísticas, Tiempo de ejecución, Guardar trabajo antes de la ejecución, Borrar antes de ejecutar y configuración de JVM. Cada una de estas opciones tiene la funcionalidad que se explica aquí:
Statistics - Muestra la tasa de rendimiento del procesamiento;
Exec Time - El tiempo necesario para ejecutar el trabajo.
Save Job before Execution - Guarda automáticamente el trabajo antes de que comience la ejecución.
Clear before Run - Elimina todo de la consola de salida.
JVM Settings - Nos ayuda a configurar los propios argumentos de Java.
El lema de Open Studio con Big Data es "Simplifique ETL y ELT con la herramienta ETL de código abierto líder y gratuita para Big Data". En este capítulo, analicemos el uso de Talend como herramienta para procesar datos en un entorno de big data.
Introducción
Talend Open Studio - Big Data es una herramienta gratuita y de código abierto para procesar sus datos muy fácilmente en un entorno de big data. Tiene muchos componentes de big data disponibles en Talend Open Studio, que le permiten crear y ejecutar trabajos de Hadoop con solo arrastrar y soltar algunos componentes de Hadoop.
Además, no necesitamos escribir grandes líneas de códigos MapReduce; Talend Open Studio Big Data le ayuda a hacer esto con los componentes presentes en él. Genera automáticamente el código de MapReduce para usted, solo necesita arrastrar y soltar los componentes y configurar algunos parámetros.
También le brinda la opción de conectarse con varias distribuciones de Big Data como Cloudera, HortonWorks, MapR, Amazon EMR e incluso Apache.
Componentes de Talend para Big Data
La lista de categorías con componentes para ejecutar un trabajo en el entorno de Big Data incluido en Big Data se muestra a continuación:
La lista de conectores y componentes de Big Data en Talend Open Studio se muestra a continuación:
tHDFSConnection - Se utiliza para conectarse a HDFS (sistema de archivos distribuido Hadoop).
tHDFSInput - Lee los datos de la ruta hdfs dada, los coloca en el esquema de talend y luego los pasa al siguiente componente del trabajo.
tHDFSList - Recupera todos los archivos y carpetas en la ruta hdfs dada.
tHDFSPut - Copia archivo / carpeta del sistema de archivos local (definido por el usuario) a hdfs en la ruta dada.
tHDFSGet - Copia el archivo / carpeta de hdfs al sistema de archivos local (definido por el usuario) en la ruta indicada.
tHDFSDelete - Elimina el archivo de HDFS
tHDFSExist - Comprueba si un archivo está presente en HDFS o no.
tHDFSOutput - Escribe flujos de datos en HDFS.
tCassandraConnection - Abre la conexión al servidor Cassandra.
tCassandraRow - Ejecuta consultas CQL (lenguaje de consulta Cassandra) en la base de datos especificada.
tHBaseConnection - Abre la conexión a la base de datos HBase.
tHBaseInput - lee datos de la base de datos HBase.
tHiveConnection - Abre la conexión a la base de datos de Hive.
tHiveCreateTable - Crea una tabla dentro de una base de datos de colmena.
tHiveInput - Lee datos de la base de datos de la colmena.
tHiveLoad - Escribe datos en una tabla de colmena o en un directorio específico.
tHiveRow : Ejecuta consultas HiveQL en la base de datos especificada.
tPigLoad - Carga datos de entrada al flujo de salida.
tPigMap - Se utiliza para transformar y enrutar los datos en un proceso de cerdo.
tPigJoin - Realiza la operación de unión de 2 archivos basada en claves de unión.
tPigCoGroup - Agrupa y agrega los datos provenientes de múltiples entradas.
tPigSort - Ordena los datos proporcionados en función de una o más claves de clasificación definidas.
tPigStoreResult - Almacena el resultado de la operación porcina en un espacio de almacenamiento definido.
tPigFilterRow - Filtra las columnas especificadas para dividir los datos según la condición dada.
tPigDistinct - Elimina las tuplas duplicadas de la relación.
tSqoopImport - Transfiere datos de bases de datos relacionales como MySQL, Oracle DB a HDFS.
tSqoopExport - Transfiere datos de HDFS a bases de datos relacionales como MySQL, Oracle DB
En este capítulo, aprendamos en detalle cómo funciona Talend con el sistema de archivos distribuido Hadoop.
Configuración y requisitos previos
Antes de continuar con Talend con HDFS, debemos conocer la configuración y los requisitos previos que se deben cumplir para este propósito.
Aquí estamos ejecutando Cloudera Quickstart 5.10 VM en una caja virtual. Se debe utilizar una red de solo host en esta máquina virtual.
IP de red solo de host: 192.168.56.101

También debe tener el mismo host ejecutándose en cloudera Manager.

Ahora en su sistema Windows, vaya a c: \ Windows \ System32 \ Drivers \ etc \ hosts y edite este archivo usando el Bloc de notas como se muestra a continuación.

Del mismo modo, en su máquina virtual de inicio rápido de cloudera, edite su archivo / etc / hosts como se muestra a continuación.
sudo gedit /etc/hosts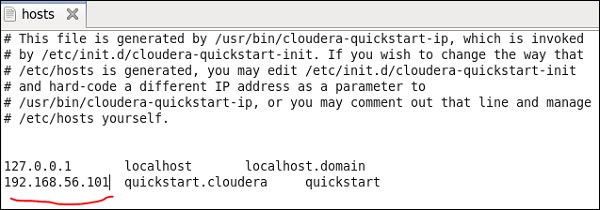
Configuración de la conexión Hadoop
En el panel del repositorio, vaya a Metadatos. Haga clic con el botón derecho en Hadoop Cluster y cree un nuevo clúster. Proporcione el nombre, el propósito y la descripción de esta conexión de clúster de Hadoop.
Haga clic en Siguiente.

Seleccione la distribución como cloudera y elija la versión que está utilizando. Seleccione la opción de recuperación de configuración y haga clic en Siguiente.

Ingrese las credenciales del administrador (URI con puerto, nombre de usuario, contraseña) como se muestra a continuación y haga clic en Conectar. Si los detalles son correctos, obtendrá Cloudera QuickStart en clústeres descubiertos.
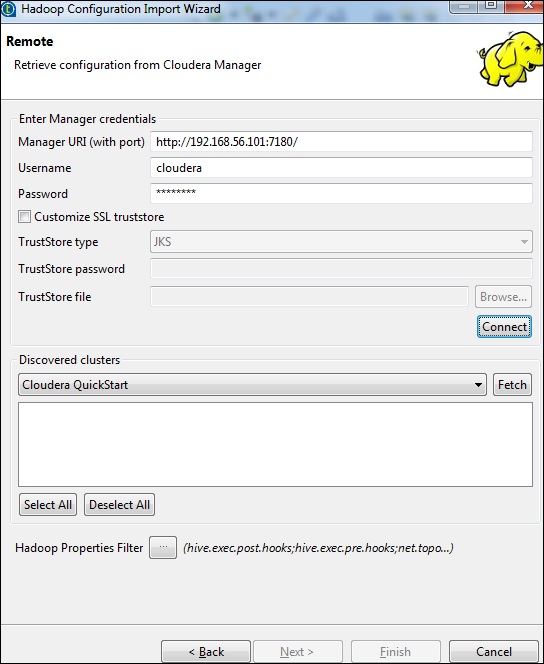
Haga clic en Obtener. Esto buscará todas las conexiones y configuraciones para HDFS, YARN, HBASE, HIVE.
Seleccione Todo y haga clic en Finalizar.

Tenga en cuenta que todos los parámetros de conexión se completarán automáticamente. Mencione cloudera en el nombre de usuario y haga clic en Finalizar.

Con esto, se ha conectado correctamente a un clúster de Hadoop.

Conexión a HDFS
En este trabajo, enumeraremos todos los directorios y archivos que están presentes en HDFS.
En primer lugar, crearemos un trabajo y luego le agregaremos componentes HDFS. Haga clic con el botón derecho en el diseño del trabajo y cree un nuevo trabajo: hadoopjob.
Ahora agregue 2 componentes de la paleta: tHDFSConnection y tHDFSList. Haga clic derecho en tHDFSConnection y conecte estos 2 componentes usando el disparador 'OnSubJobOk'.
Ahora, configure ambos componentes de talend hdfs.

En tHDFSConnection, elija Repositorio como Tipo de propiedad y seleccione el clúster de cloudera de Hadoop que creó anteriormente. Completará automáticamente todos los detalles necesarios para este componente.

En tHDFSList, seleccione "Usar una conexión existente" y en la lista de componentes elija la tHDFSConnection que configuró.
Proporcione la ruta de inicio de HDFS en la opción HDFS Directory y haga clic en el botón Examinar a la derecha.

Si ha establecido la conexión correctamente con las configuraciones mencionadas anteriormente, verá una ventana como se muestra a continuación. Enumerará todos los directorios y archivos presentes en el inicio de HDFS.

Puede verificar esto verificando su HDFS en cloudera.

Leyendo archivo desde HDFS
En esta sección, entendamos cómo leer un archivo de HDFS en Talend. Puede crear un nuevo trabajo para este propósito, sin embargo, aquí estamos usando el existente.
Arrastra y suelta 3 componentes: tHDFSConnection, tHDFSInput y tLogRow desde la paleta a la ventana del diseñador.
Haga clic derecho en tHDFSConnection y conecte el componente tHDFSInput usando el disparador 'OnSubJobOk'.
Haga clic con el botón derecho en tHDFSInput y arrastre un enlace principal a tLogRow.

Tenga en cuenta que tHDFSConnection tendrá una configuración similar a la anterior. En tHDFSInput, seleccione "Usar una conexión existente" y de la lista de componentes, elija tHDFSConnection.
En el Nombre de archivo, ingrese la ruta HDFS del archivo que desea leer. Aquí estamos leyendo un archivo de texto simple, por lo que nuestro tipo de archivo es Archivo de texto. De manera similar, según su entrada, complete el separador de fila, el separador de campo y los detalles del encabezado como se menciona a continuación. Finalmente, haga clic en el botón Editar esquema.

Dado que nuestro archivo solo tiene texto sin formato, estamos agregando solo una columna de tipo String. Ahora, haz clic en Aceptar.
Note - Cuando su entrada tiene múltiples columnas de diferentes tipos, debe mencionar el esquema aquí en consecuencia.

En el componente tLogRow, haga clic en Sincronizar columnas en editar esquema.
Seleccione el modo en el que desea que se imprima su salida.

Finalmente, haga clic en Ejecutar para ejecutar el trabajo.
Una vez que haya leído correctamente un archivo HDFS, podrá ver el siguiente resultado.

Escribir archivo en HDFS
Veamos cómo escribir un archivo desde HDFS en Talend. Arrastra y suelta 3 componentes: tHDFSConnection, tFileInputDelimited y tHDFSOutput de la paleta a la ventana del diseñador.
Haga clic con el botón derecho en tHDFSConnection y conecte el componente tFileInputDelimited usando el disparador 'OnSubJobOk'.
Haga clic con el botón derecho en tFileInputDelimited y arrastre un enlace principal a tHDFSOutput.

Tenga en cuenta que tHDFSConnection tendrá una configuración similar a la anterior.
Ahora, en tFileInputDelimited, proporcione la ruta del archivo de entrada en la opción Nombre de archivo / Transmisión. Aquí estamos usando un archivo csv como entrada, por lo tanto, el separador de campo es ",".
Seleccione el encabezado, pie de página, límite de acuerdo con su archivo de entrada. Tenga en cuenta que aquí nuestro encabezado es 1 porque la fila 1 contiene los nombres de las columnas y el límite es 3 porque estamos escribiendo solo las primeras 3 filas en HDFS.
Ahora, haga clic en editar esquema.
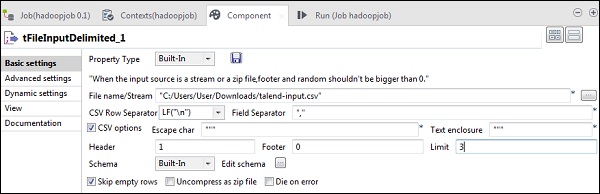
Ahora, según nuestro archivo de entrada, defina el esquema. Nuestro archivo de entrada tiene 3 columnas como se menciona a continuación.

En el componente tHDFSOutput, haga clic en sincronizar columnas. Luego, seleccione tHDFSConnection en Usar una conexión existente. Además, en Nombre de archivo, proporcione una ruta HDFS donde desea escribir su archivo.
Tenga en cuenta que el tipo de archivo será archivo de texto, la acción será "crear", el separador de filas será "\ n" y el separador de campo es ";"

Finalmente, haga clic en Ejecutar para ejecutar su trabajo. Una vez que el trabajo se haya ejecutado correctamente, verifique si su archivo está en HDFS.

Ejecute el siguiente comando hdfs con la ruta de salida que mencionó en su trabajo.
hdfs dfs -cat /input/talendwriteVerá el siguiente resultado si tiene éxito al escribir en HDFS.

En el capítulo anterior, hemos visto cómo Talend trabaja con Big Data. En este capítulo, entenderemos cómo utilizar map Reduce con Talend.
Creación de un trabajo de Talend MapReduce
Aprendamos a ejecutar un trabajo MapReduce en Talend. Aquí ejecutaremos un ejemplo de recuento de palabras de MapReduce.
Para ello, haga clic con el botón derecho en Diseño de trabajo y cree un nuevo trabajo: MapreduceJob. Mencione los detalles del trabajo y haga clic en Finalizar.
Adición de componentes al trabajo MapReduce
Para agregar componentes a un trabajo de MapReduce, arrastre y suelte cinco componentes de Talend: tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput desde la paleta a la ventana del diseñador. Haga clic derecho en tHDFSInput y cree el enlace principal para tNormalize.
Haga clic derecho en tNormalize y cree el enlace principal a tAggregateRow. Luego, haga clic derecho en tAggregateRow y cree el enlace principal a tMap. Ahora, haga clic derecho en tMap y cree el enlace principal a tHDFSOutput.
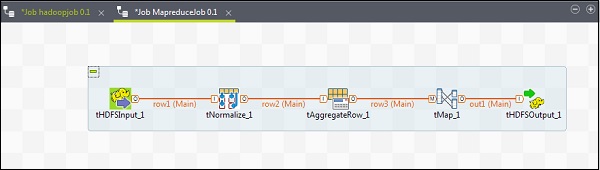
Configurar componentes y transformaciones
En tHDFSInput, seleccione la distribución cloudera y su versión. Tenga en cuenta que el URI de Namenode debe ser "hdfs: //quickstart.cloudera: 8020" y el nombre de usuario debe ser "cloudera". En la opción de nombre de archivo, proporcione la ruta de su archivo de entrada al trabajo MapReduce. Asegúrese de que este archivo de entrada esté presente en HDFS.
Ahora, seleccione el tipo de archivo, el separador de filas, el separador de archivos y el encabezado de acuerdo con su archivo de entrada.
Haga clic en editar esquema y agregue el campo "línea" como tipo de cadena.
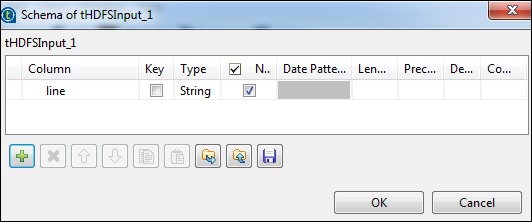
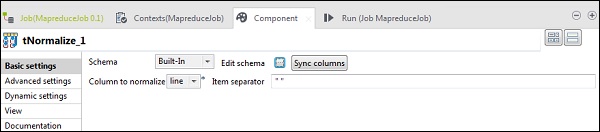
En tNomalize, la columna a normalizar será la línea y el separador de elementos será un espacio en blanco -> "". Ahora, haga clic en editar esquema. tNormalize tendrá una columna de línea y tAggregateRow tendrá 2 columnas de palabras y recuento de palabras como se muestra a continuación.
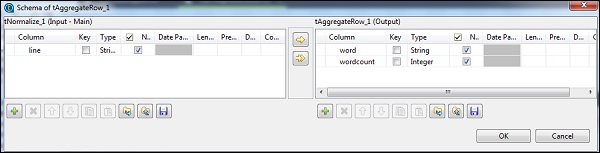
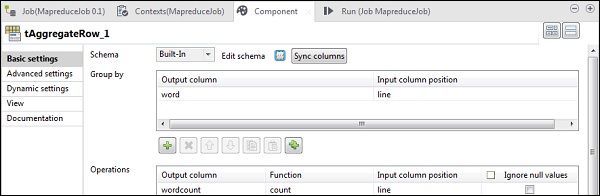
En tAggregateRow, ponga palabra como columna de salida en la opción Agrupar por. En operaciones, ponga el recuento de palabras como columna de salida, la función como recuento y la posición de la columna de entrada como línea.
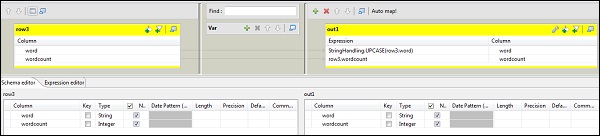
Ahora haga doble clic en el componente tMap para ingresar al editor de mapas y mapear la entrada con la salida requerida. En este ejemplo, la palabra se asigna con la palabra y el recuento de palabras se asigna con el recuento de palabras. En la columna de expresiones, haga clic en […] para ingresar al generador de expresiones.
Ahora, seleccione StringHandling de la lista de categorías y la función UPCASE. Edite la expresión a "StringHandling.UPCASE (fila3.word)" y haga clic en Aceptar. Mantenga row3.wordcount en la columna de expresión correspondiente al recuento de palabras como se muestra a continuación.
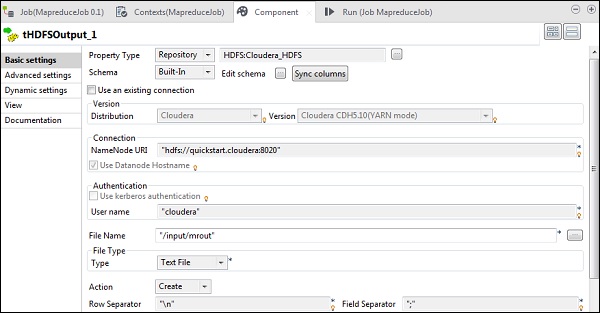
En tHDFSOutput, conéctese al clúster de Hadoop que creamos a partir del tipo de propiedad como repositorio. Observe que los campos se completarán automáticamente. En Nombre de archivo, proporcione la ruta de salida donde desea almacenar la salida. Mantenga la Acción, el separador de filas y el separador de campos como se muestra a continuación.
Ejecución del trabajo MapReduce
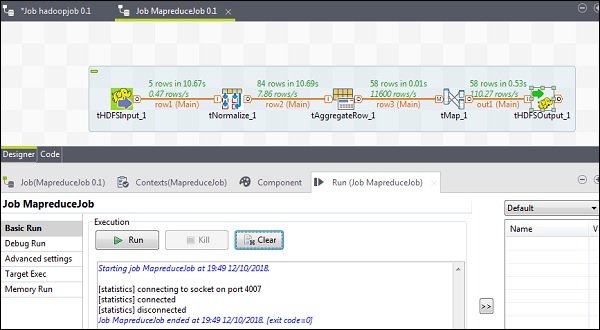
Una vez que su configuración se haya completado con éxito, haga clic en Ejecutar y ejecute su trabajo MapReduce.
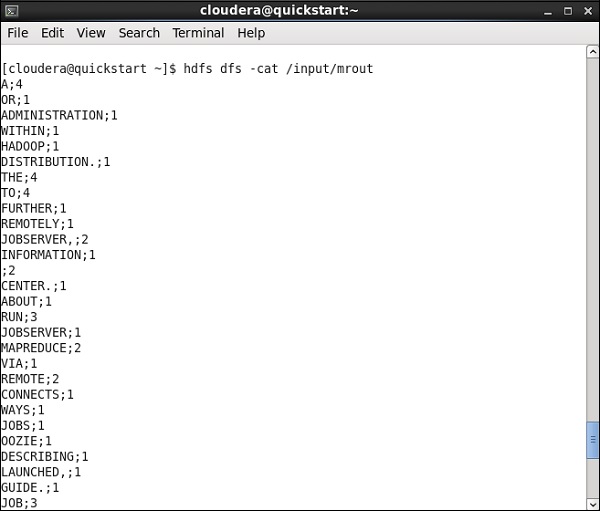
Vaya a su ruta HDFS y verifique la salida. Tenga en cuenta que todas las palabras estarán en mayúsculas con su recuento de palabras.
En este capítulo, aprendamos a trabajar con un trabajo de Cerdo en Talend.
Creación de un trabajo de Talend Pig
En esta sección, aprendamos a ejecutar un trabajo de Pig en Talend. Aquí, procesaremos los datos de la NYSE para averiguar el volumen promedio de acciones de IBM.
Para ello, haga clic con el botón derecho en Diseño de trabajo y cree un nuevo trabajo: pigjob. Mencione los detalles del trabajo y haga clic en Finalizar.
Agregar componentes a Pig Job
Para agregar componentes al trabajo de Pig, arrastre y suelte cuatro componentes de Talend: tPigLoad, tPigFilterRow, tPigAggregate, tPigStoreResult, desde la paleta a la ventana del diseñador.
Luego, haga clic derecho en tPigLoad y cree la línea Pig Combine en tPigFilterRow. A continuación, haga clic con el botón derecho en tPigFilterRow y cree la línea Pig Combine en tPigAggregate. Haga clic con el botón derecho en tPigAggregate y cree la línea de combinación de Pig en tPigStoreResult.
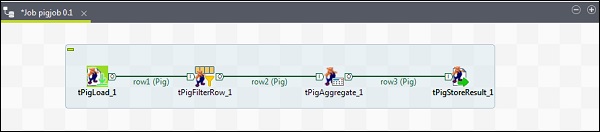
Configurar componentes y transformaciones
En tPigLoad, mencione la distribución como cloudera y la versión de cloudera. Tenga en cuenta que el URI de Namenode debe ser "hdfs: //quickstart.cloudera: 8020" y Resource Manager debe ser "quickstart.cloudera: 8020". Además, el nombre de usuario debe ser "cloudera".
En el URI del archivo de entrada, proporcione la ruta de su archivo de entrada NYSE al trabajo porcino. Tenga en cuenta que este archivo de entrada debe estar presente en HDFS.
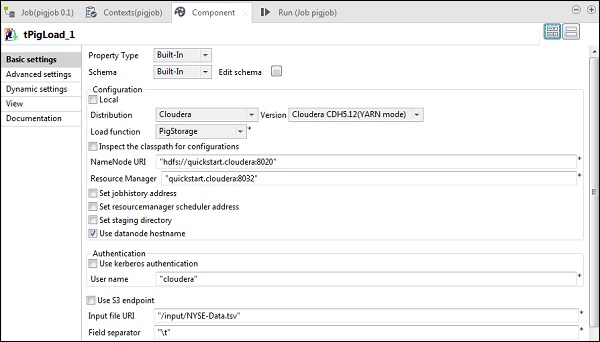
Haga clic en editar esquema, agregue las columnas y su tipo como se muestra a continuación.
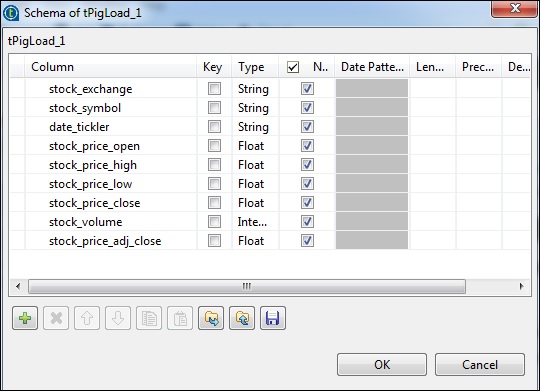
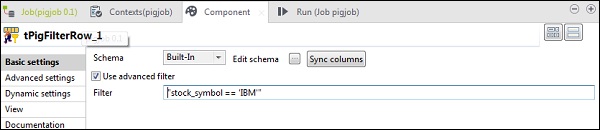
En tPigFilterRow, seleccione la opción “Usar filtro avanzado” y ponga “stock_symbol = = 'IBM'” en la opción Filtro.
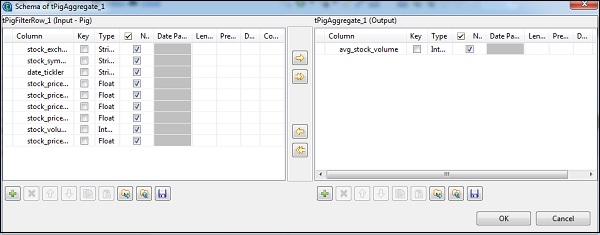
En tAggregateRow, haga clic en editar esquema y agregue la columna avg_stock_volume en la salida como se muestra a continuación.
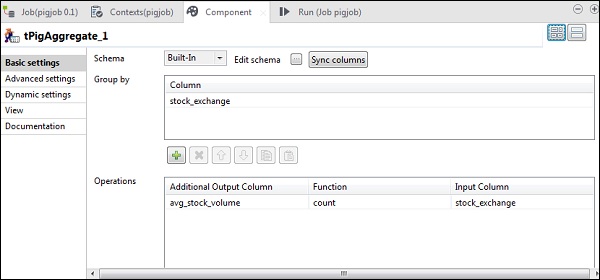
Ahora, ponga la columna stock_exchange en Agrupar por opción. Agregue la columna avg_stock_volume en el campo Operaciones con función de recuento y stock_exchange como columna de entrada.
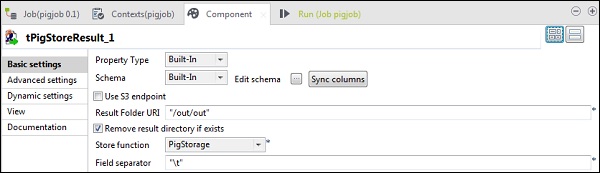
En tPigStoreResult, proporcione la ruta de salida en el URI de la carpeta de resultados donde desea almacenar el resultado del trabajo Pig. Seleccione la función de almacenamiento como PigStorage y el separador de campo (no obligatorio) como "\ t".
Ejecutando el trabajo de cerdo
Ahora haga clic en Ejecutar para ejecutar su trabajo de Pig. (Ignore las advertencias)
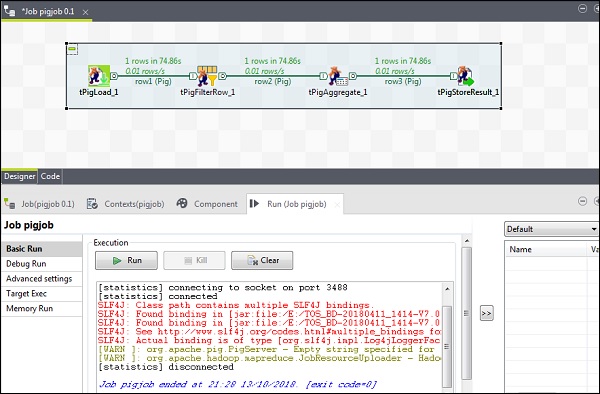
Una vez que finalice el trabajo, vaya y verifique su salida en la ruta HDFS que mencionó para almacenar el resultado del trabajo de cerdo. El volumen de stock medio de IBM es de 500.
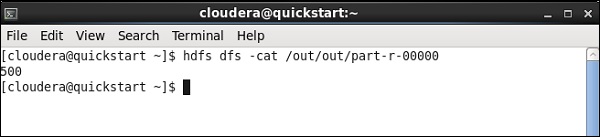
En este capítulo, entendamos cómo trabajar con el trabajo de Hive en Talend.
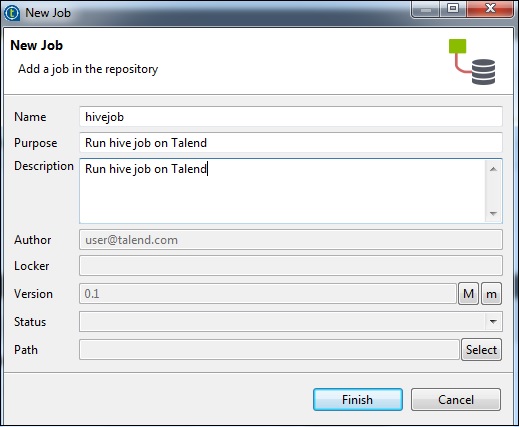
Creación de un trabajo de Talend Hive
Como ejemplo, cargaremos los datos de NYSE en una tabla de colmena y ejecutaremos una consulta básica de colmena. Haga clic derecho en Job Design y cree un nuevo trabajo: hivejob. Mencione los detalles del trabajo y haga clic en Finalizar.
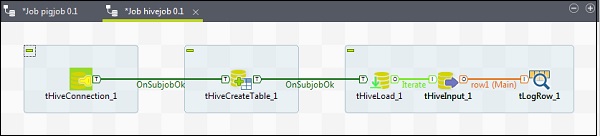
Agregar componentes al trabajo de Hive
Para asignar componentes a un trabajo de Hive, arrastre y suelte cinco componentes de talend: tHiveConnection, tHiveCreateTable, tHiveLoad, tHiveInput y tLogRow desde la paleta a la ventana del diseñador. Luego, haga clic con el botón derecho en tHiveConnection y cree el disparador OnSubjobOk en tHiveCreateTable. Ahora, haga clic con el botón derecho en tHiveCreateTable y cree el disparador OnSubjobOk para tHiveLoad. Haga clic con el botón derecho en tHiveLoad y cree un disparador iterativo en tHiveInput. Finalmente, haga clic derecho en tHiveInput y cree una línea principal para tLogRow.
Configurar componentes y transformaciones
En tHiveConnection, seleccione la distribución como cloudera y la versión que está utilizando. Tenga en cuenta que el modo de conexión será independiente y el servicio Hive será Hive 2. También compruebe si los siguientes parámetros están configurados en consecuencia:
- Anfitrión: "quickstart.cloudera"
- Puerto: "10000"
- Base de datos: "predeterminada"
- Nombre de usuario: "colmena"
Tenga en cuenta que la contraseña se completará automáticamente, no es necesario editarla. Además, otras propiedades de Hadoop estarán predeterminadas y configuradas de forma predeterminada.
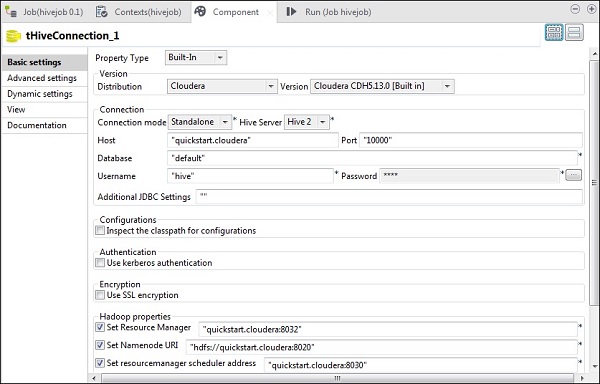
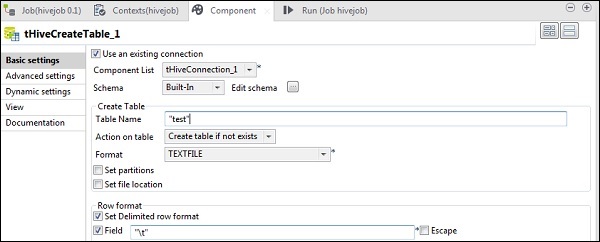
En tHiveCreateTable, seleccione Usar una conexión existente y coloque tHiveConnection en la lista de componentes. Dé el nombre de la tabla que desea crear en la base de datos predeterminada. Mantenga los otros parámetros como se muestra a continuación.
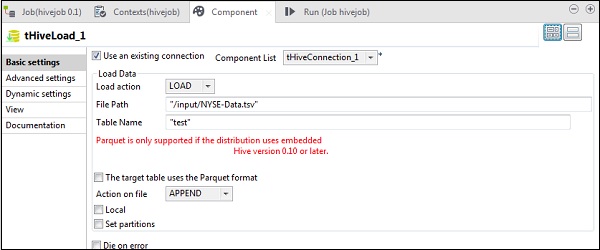
En tHiveLoad, seleccione "Usar una conexión existente" y ponga tHiveConnection en la lista de componentes. Seleccione CARGAR en la acción Cargar. En Ruta de archivo, proporcione la ruta HDFS de su archivo de entrada NYSE. Mencione la tabla en Nombre de la tabla, en la que desea cargar la entrada. Mantenga los otros parámetros como se muestra a continuación.
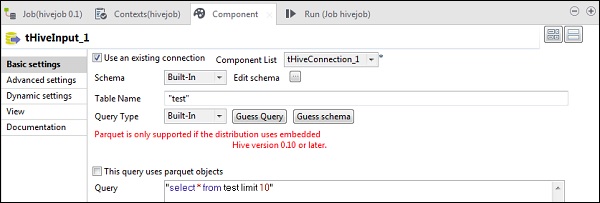
En tHiveInput, seleccione Usar una conexión existente y coloque tHiveConnection en la lista de componentes. Haga clic en editar esquema, agregue las columnas y su tipo como se muestra en la instantánea del esquema a continuación. Ahora dé el nombre de la tabla que creó en tHiveCreateTable.
Coloque su consulta en la opción de consulta que desea ejecutar en la tabla de Hive. Aquí estamos imprimiendo todas las columnas de las primeras 10 filas en la tabla del subárbol de prueba.
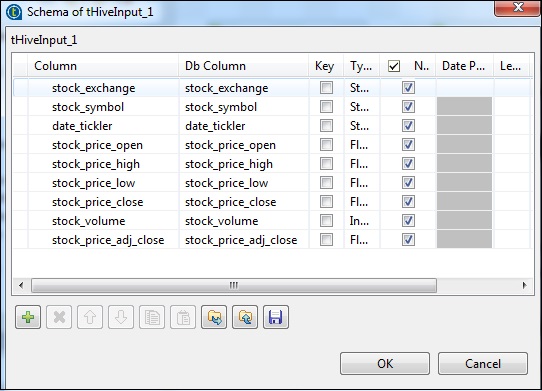
En tLogRow, haga clic en sincronizar columnas y seleccione el modo Tabla para mostrar la salida.
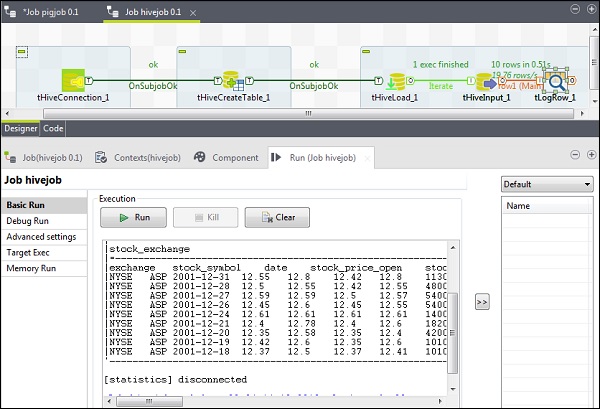
Ejecutando el trabajo de Hive
Haga clic en Ejecutar para comenzar la ejecución. Si toda la conexión y los parámetros se configuraron correctamente, verá el resultado de su consulta como se muestra a continuación.