Unix / Linux - Guía rápida
¿Qué es Unix?
El sistema operativo Unix es un conjunto de programas que actúan como enlace entre la computadora y el usuario.
Los programas de computadora que asignan los recursos del sistema y coordinan todos los detalles de los componentes internos de la computadora se denominan operating system o la kernel.
Los usuarios se comunican con el kernel a través de un programa conocido como shell. El shell es un intérprete de línea de comandos; traduce los comandos ingresados por el usuario y los convierte a un idioma que es entendido por el kernel.
Unix fue desarrollado originalmente en 1969 por un grupo de empleados de AT&T, Ken Thompson, Dennis Ritchie, Douglas McIlroy y Joe Ossanna en Bell Labs.
Hay varias variantes de Unix disponibles en el mercado. Solaris Unix, AIX, HP Unix y BSD son algunos ejemplos. Linux también es una versión de Unix que está disponible gratuitamente.
Varias personas pueden usar una computadora Unix al mismo tiempo; por lo tanto, Unix se denomina sistema multiusuario.
Un usuario también puede ejecutar varios programas al mismo tiempo; por tanto, Unix es un entorno multitarea.
Arquitectura Unix
Aquí hay un diagrama de bloques básico de un sistema Unix:
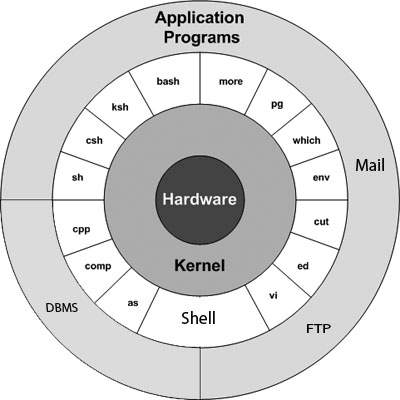
El concepto principal que une todas las versiones de Unix son los siguientes cuatro conceptos básicos:
Kernel- El kernel es el corazón del sistema operativo. Interactúa con el hardware y la mayoría de las tareas, como la administración de memoria, la programación de tareas y la administración de archivos.
Shell- El shell es la utilidad que procesa sus solicitudes. Cuando escribe un comando en su terminal, el shell interpreta el comando y llama al programa que desea. El shell usa sintaxis estándar para todos los comandos. C Shell, Bourne Shell y Korn Shell son los shells más famosos que están disponibles con la mayoría de las variantes de Unix.
Commands and Utilities - Hay varios comandos y utilidades que puede utilizar en sus actividades diarias. cp, mv, cat y grep, etc. son algunos ejemplos de comandos y utilidades. Hay más de 250 comandos estándar, además de numerosas otras dispuestas a 3 rd software de otros fabricantes. Todos los comandos vienen con varias opciones.
Files and Directories- Todos los datos de Unix están organizados en archivos. Luego, todos los archivos se organizan en directorios. Estos directorios se organizan además en una estructura en forma de árbol llamadafilesystem.
Arranque del sistema
Si tiene una computadora que tiene el sistema operativo Unix instalado, entonces simplemente necesita encender el sistema para que funcione.
Tan pronto como enciende el sistema, comienza a arrancar y finalmente le pide que inicie sesión en el sistema, que es una actividad para iniciar sesión en el sistema y usarlo para sus actividades diarias.
Iniciar sesión Unix
Cuando se conecta por primera vez a un sistema Unix, normalmente ve un mensaje como el siguiente:
login:Iniciar sesión
Tenga a mano su ID de usuario (identificación de usuario) y contraseña. Comuníquese con el administrador del sistema si aún no los tiene.
Escriba su ID de usuario en el indicador de inicio de sesión, luego presione ENTER. Tu ID de usuario escase-sensitive, así que asegúrese de escribirlo exactamente como le indicó el administrador del sistema.
Escriba su contraseña cuando se le solicite la contraseña, luego presione ENTER. Su contraseña también distingue entre mayúsculas y minúsculas.
Si proporciona el ID de usuario y la contraseña correctos, se le permitirá ingresar al sistema. Lea la información y los mensajes que aparecen en la pantalla, que es la siguiente.
login : amrood
amrood's password:
Last login: Sun Jun 14 09:32:32 2009 from 62.61.164.73
$Se le proporcionará un símbolo del sistema (en ocasiones llamado $indicador) donde escribe todos sus comandos. Por ejemplo, para consultar el calendario, debe escribir elcal comando de la siguiente manera:
$ cal June 2009 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 $Cambia la contraseña
Todos los sistemas Unix requieren contraseñas para ayudar a garantizar que sus archivos y datos sigan siendo suyos y que el sistema en sí esté protegido contra piratas informáticos y piratas informáticos. Los siguientes son los pasos para cambiar su contraseña:
Step 1 - Para comenzar, escriba la contraseña en el símbolo del sistema como se muestra a continuación.
Step 2 - Ingrese su contraseña anterior, la que está usando actualmente.
Step 3- Escriba su nueva contraseña. Mantenga siempre su contraseña lo suficientemente compleja para que nadie pueda adivinarla. Pero asegúrate de recordarlo.
Step 4 - Debe verificar la contraseña escribiéndola nuevamente.
$ passwd Changing password for amrood (current) Unix password:****** New UNIX password:******* Retype new UNIX password:******* passwd: all authentication tokens updated successfully $Note- Hemos agregado un asterisco (*) aquí solo para mostrar la ubicación donde debe ingresar la contraseña actual y la nueva en su sistema. No muestra ningún carácter cuando escribe.
Listado de directorios y archivos
Todos los datos en Unix están organizados en archivos. Todos los archivos están organizados en directorios. Estos directorios están organizados en una estructura en forma de árbol llamada sistema de archivos.
Puedes usar el lscomando para enumerar todos los archivos o directorios disponibles en un directorio. A continuación se muestra el ejemplo de usols comando con -l opción.
$ ls -l total 19621 drwxrwxr-x 2 amrood amrood 4096 Dec 25 09:59 uml -rw-rw-r-- 1 amrood amrood 5341 Dec 25 08:38 uml.jpg drwxr-xr-x 2 amrood amrood 4096 Feb 15 2006 univ drwxr-xr-x 2 root root 4096 Dec 9 2007 urlspedia -rw-r--r-- 1 root root 276480 Dec 9 2007 urlspedia.tar drwxr-xr-x 8 root root 4096 Nov 25 2007 usr -rwxr-xr-x 1 root root 3192 Nov 25 2007 webthumb.php -rw-rw-r-- 1 amrood amrood 20480 Nov 25 2007 webthumb.tar -rw-rw-r-- 1 amrood amrood 5654 Aug 9 2007 yourfile.mid -rw-rw-r-- 1 amrood amrood 166255 Aug 9 2007 yourfile.swf $Aquí las entradas que comienzan con d.....representar directorios. Por ejemplo, uml, univ y urlspedia son directorios y el resto de las entradas son archivos.
¿Quién eres tú?
Mientras está conectado al sistema, es posible que desee saber: Who am I?
La forma más sencilla de averiguar "quién es" es ingresar al whoami comando -
$ whoami amrood $Pruébelo en su sistema. Este comando enumera el nombre de la cuenta asociada con el inicio de sesión actual. Puedes probarwho am i comando también para obtener información sobre usted.
¿Quién está conectado?
En algún momento, es posible que le interese saber quién está conectado a la computadora al mismo tiempo.
Hay tres comandos disponibles para obtener esta información, en función de cuánto desea saber sobre los otros usuarios: users, whoy w.
$ users amrood bablu qadir $ who
amrood ttyp0 Oct 8 14:10 (limbo)
bablu ttyp2 Oct 4 09:08 (calliope)
qadir ttyp4 Oct 8 12:09 (dent)
$Prueba el wcomando en su sistema para verificar la salida. Esto enumera la información asociada con los usuarios registrados en el sistema.
Saliendo de tu cuenta
Cuando termine su sesión, debe cerrar la sesión del sistema. Esto es para asegurar que nadie más acceda a sus archivos.
To log out
Solo escribe el logout comando en el símbolo del sistema, y el sistema limpiará todo y romperá la conexión.
Apagado del sistema
La forma más consistente de apagar un sistema Unix correctamente a través de la línea de comandos es usar uno de los siguientes comandos:
| No Señor. | Comando y descripción |
|---|---|
| 1 | halt Desconecta el sistema inmediatamente |
| 2 | init 0 Apaga el sistema mediante secuencias de comandos predefinidas para sincronizar y limpiar el sistema antes de apagarlo |
| 3 | init 6 Reinicia el sistema apagándolo por completo y luego reiniciándolo |
| 4 | poweroff Apaga el sistema apagándolo |
| 5 | reboot Reinicia el sistema |
| 6 | shutdown Apaga el sistema |
Por lo general, debe ser el superusuario o root (la cuenta con más privilegios en un sistema Unix) para apagar el sistema. Sin embargo, en algunos equipos Unix independientes o de propiedad personal, un usuario administrativo y, a veces, los usuarios habituales pueden hacerlo.
En este capítulo, discutiremos en detalle sobre la administración de archivos en Unix. Todos los datos en Unix están organizados en archivos. Todos los archivos están organizados en directorios. Estos directorios están organizados en una estructura en forma de árbol llamada sistema de archivos.
Cuando trabaja con Unix, de una forma u otra, pasa la mayor parte del tiempo trabajando con archivos. Este tutorial lo ayudará a comprender cómo crear y eliminar archivos, copiarlos y cambiarles el nombre, crear enlaces a ellos, etc.
En Unix, hay tres tipos básicos de archivos:
Ordinary Files- Un archivo ordinario es un archivo del sistema que contiene datos, texto o instrucciones del programa. En este tutorial, verá cómo trabajar con archivos normales.
Directories- Los directorios almacenan archivos especiales y ordinarios. Para los usuarios familiarizados con Windows o Mac OS, los directorios de Unix son equivalentes a carpetas.
Special Files- Algunos archivos especiales proporcionan acceso a hardware como discos duros, unidades de CD-ROM, módems y adaptadores Ethernet. Otros archivos especiales son similares a los alias o accesos directos y le permiten acceder a un solo archivo con diferentes nombres.
Listado de archivos
Para enumerar los archivos y directorios almacenados en el directorio actual, use el siguiente comando:
$lsAquí está la salida de muestra del comando anterior:
$ls
bin hosts lib res.03
ch07 hw1 pub test_results
ch07.bak hw2 res.01 users
docs hw3 res.02 workEl comando ls apoya el -l opción que le ayudaría a obtener más información sobre los archivos enumerados -
$ls -l
total 1962188
drwxrwxr-x 2 amrood amrood 4096 Dec 25 09:59 uml
-rw-rw-r-- 1 amrood amrood 5341 Dec 25 08:38 uml.jpg
drwxr-xr-x 2 amrood amrood 4096 Feb 15 2006 univ
drwxr-xr-x 2 root root 4096 Dec 9 2007 urlspedia
-rw-r--r-- 1 root root 276480 Dec 9 2007 urlspedia.tar
drwxr-xr-x 8 root root 4096 Nov 25 2007 usr
drwxr-xr-x 2 200 300 4096 Nov 25 2007 webthumb-1.01
-rwxr-xr-x 1 root root 3192 Nov 25 2007 webthumb.php
-rw-rw-r-- 1 amrood amrood 20480 Nov 25 2007 webthumb.tar
-rw-rw-r-- 1 amrood amrood 5654 Aug 9 2007 yourfile.mid
-rw-rw-r-- 1 amrood amrood 166255 Aug 9 2007 yourfile.swf
drwxr-xr-x 11 amrood amrood 4096 May 29 2007 zlib-1.2.3
$Aquí está la información sobre todas las columnas enumeradas:
First Column- Representa el tipo de archivo y el permiso otorgado en el archivo. A continuación se muestra la descripción de todo tipo de archivos.
Second Column - Representa el número de bloques de memoria que ocupa el archivo o directorio.
Third Column- Representa al propietario del archivo. Este es el usuario de Unix que creó este archivo.
Fourth Column- Representa al grupo del propietario. Cada usuario de Unix tendrá un grupo asociado.
Fifth Column - Representa el tamaño del archivo en bytes.
Sixth Column - Representa la fecha y la hora en que este archivo fue creado o modificado por última vez.
Seventh Column - Representa el nombre del archivo o directorio.
En el ls -l ejemplo de lista, cada línea de archivo comienza con un d, -o l. Estos caracteres indican el tipo de archivo que se muestra.
| No Señor. | Prefijo y descripción |
|---|---|
| 1 | - Archivo normal, como un archivo de texto ASCII, un ejecutable binario o un vínculo físico. |
| 2 | b Bloquear archivo especial. Bloquear archivo de dispositivo de entrada / salida, como un disco duro físico. |
| 3 | c Archivo especial de caracteres. Archivo de dispositivo de entrada / salida sin formato, como un disco duro físico. |
| 4 | d Archivo de directorio que contiene una lista de otros archivos y directorios. |
| 5 | l Archivo de enlace simbólico. Enlaces en cualquier archivo normal. |
| 6 | p Pipa con nombre. Un mecanismo para comunicaciones entre procesos. |
| 7 | s Toma utilizada para la comunicación entre procesos. |
Metacaracteres
Los metacaracteres tienen un significado especial en Unix. Por ejemplo,* y ?son metacaracteres. Usamos* para que coincida con 0 o más caracteres, un signo de interrogación (?) coincide con un solo carácter.
Por ejemplo:
$ls ch*.docMuestra todos los archivos, cuyos nombres comienzan con ch y terminar con .doc -
ch01-1.doc ch010.doc ch02.doc ch03-2.doc
ch04-1.doc ch040.doc ch05.doc ch06-2.doc
ch01-2.doc ch02-1.doc cAquí, *funciona como meta personaje que coincide con cualquier personaje. Si desea mostrar todos los archivos que terminan con solo.doc, entonces puede usar el siguiente comando:
$ls *.docArchivos ocultos
Un archivo invisible es uno, cuyo primer carácter es el punto o el punto (.). Los programas Unix (incluido el shell) utilizan la mayoría de estos archivos para almacenar información de configuración.
Algunos ejemplos comunes de archivos ocultos incluyen los archivos:
.profile - El script de inicialización de Bourne shell (sh)
.kshrc - El script de inicialización del shell Korn (ksh)
.cshrc - El script de inicialización de C shell (csh)
.rhosts - El archivo de configuración de shell remoto
Para enumerar los archivos invisibles, especifique el -a opción a ls -
$ ls -a
. .profile docs lib test_results
.. .rhosts hosts pub users
.emacs bin hw1 res.01 work
.exrc ch07 hw2 res.02
.kshrc ch07.bak hw3 res.03
$Single dot (.) - Esto representa el directorio actual.
Double dot (..) - Esto representa el directorio principal.
Crear archivos
Puedes usar el vieditor para crear archivos ordinarios en cualquier sistema Unix. Simplemente necesita dar el siguiente comando:
$ vi filenameEl comando anterior abrirá un archivo con el nombre de archivo dado. Ahora, presione la teclaipara entrar en el modo de edición. Una vez que esté en el modo de edición, puede comenzar a escribir su contenido en el archivo como en el siguiente programa:
This is unix file....I created it for the first time.....
I'm going to save this content in this file.Una vez que haya terminado con el programa, siga estos pasos:
Presione la tecla esc para salir del modo de edición.
Presione dos teclas Shift + ZZ juntos para salir completamente del archivo.
Ahora tendrá un archivo creado con filename en el directorio actual.
$ vi filename $Editar archivos
Puede editar un archivo existente usando el vieditor. Discutiremos brevemente cómo abrir un archivo existente:
$ vi filenameUna vez que se abre el archivo, puede entrar en el modo de edición presionando la tecla iy luego puede continuar editando el archivo. Si desea moverse aquí y allá dentro de un archivo, primero debe salir del modo de edición presionando la teclaEsc. Después de esto, puede usar las siguientes teclas para moverse dentro de un archivo:
l tecla para moverse hacia el lado derecho.
h tecla para moverse hacia el lado izquierdo.
k clave para moverse hacia arriba en el archivo.
j clave para mover hacia abajo en el archivo.
Entonces, usando las teclas anteriores, puede colocar el cursor donde desee editar. Una vez que esté posicionado, puede usar elipara entrar en el modo de edición. Una vez que haya terminado con la edición en su archivo, presioneEsc y finalmente dos llaves Shift + ZZ juntos para salir completamente del archivo.
Mostrar contenido de un archivo
Puedes usar el catcomando para ver el contenido de un archivo. A continuación se muestra un ejemplo simple para ver el contenido del archivo creado anteriormente:
$ cat filename
This is unix file....I created it for the first time.....
I'm going to save this content in this file.
$Puede mostrar los números de línea utilizando el -b opción junto con la cat comando de la siguiente manera:
$ cat -b filename
1 This is unix file....I created it for the first time.....
2 I'm going to save this content in this file.
$Contar palabras en un archivo
Puedes usar el wccomando para obtener un recuento del número total de líneas, palabras y caracteres contenidos en un archivo. A continuación se muestra un ejemplo simple para ver la información sobre el archivo creado anteriormente:
$ wc filename
2 19 103 filename
$Aquí está el detalle de las cuatro columnas:
First Column : Representa el número total de líneas del archivo.
Second Column - Representa el número total de palabras en el archivo.
Third Column: Representa el número total de bytes del archivo. Este es el tamaño real del archivo.
Fourth Column : Representa el nombre del archivo.
Puede proporcionar varios archivos y obtener información sobre esos archivos a la vez. La siguiente es una sintaxis simple:
$ wc filename1 filename2 filename3Copiando documentos
Para hacer una copia de un archivo use el cpmando. La sintaxis básica del comando es:
$ cp source_file destination_fileA continuación se muestra el ejemplo para crear una copia del archivo existente filename.
$ cp filename copyfile
$Ahora encontrará un archivo más copyfileen su directorio actual. Este archivo será exactamente el mismo que el archivo original.filename.
Cambio de nombre de archivos
Para cambiar el nombre de un archivo, use el mvmando. A continuación se muestra la sintaxis básica:
$ mv old_file new_fileEl siguiente programa cambiará el nombre del archivo existente filename a newfile.
$ mv filename newfile $los mvEl comando moverá el archivo existente completamente al nuevo archivo. En este caso, solo encontraránewfile en su directorio actual.
Eliminar archivos
Para eliminar un archivo existente, use el rmmando. A continuación se muestra la sintaxis básica:
$ rm filenameCaution- Un archivo puede contener información útil. Siempre se recomienda tener cuidado al usar esteDeletemando. Es mejor usar el-i opción junto con rm mando.
A continuación se muestra el ejemplo que muestra cómo eliminar completamente el archivo existente filename.
$ rm filename
$Puede eliminar varios archivos a la vez con el comando que se proporciona a continuación:
$ rm filename1 filename2 filename3
$Secuencias de Unix estándar
En circunstancias normales, cada programa Unix tiene tres flujos (archivos) abiertos cuando se inicia:
stdin- Esto se conoce como entrada estándar y el descriptor de archivo asociado es 0. También se representa como STDIN. El programa Unix leerá la entrada predeterminada de STDIN.
stdout- Esto se conoce como salida estándar y el descriptor de archivo asociado es 1. También se representa como STDOUT. El programa Unix escribirá la salida predeterminada en STDOUT
stderr- Esto se conoce como error estándar y el descriptor de archivo asociado es 2. También se representa como STDERR. El programa Unix escribirá todos los mensajes de error en STDERR.
En este capítulo, discutiremos en detalle sobre la administración de directorios en Unix.
Un directorio es un archivo cuyo trabajo individual es almacenar los nombres de los archivos y la información relacionada. Todos los archivos, ya sean ordinarios, especiales o de directorio, están contenidos en directorios.
Unix usa una estructura jerárquica para organizar archivos y directorios. Esta estructura se denomina a menudo árbol de directorios. El árbol tiene un solo nodo raíz, el carácter de barra (/), y todos los demás directorios se encuentran debajo.
Directorio de inicio
El directorio en el que se encuentra cuando inicia sesión por primera vez se denomina directorio de inicio.
Hará gran parte de su trabajo en su directorio personal y en los subdirectorios que creará para organizar sus archivos.
Puede ingresar a su directorio de inicio en cualquier momento usando el siguiente comando:
$cd ~
$aquí ~indica el directorio de inicio. Suponga que tiene que ir al directorio de inicio de cualquier otro usuario, use el siguiente comando:
$cd ~username
$Para ir a su último directorio, puede usar el siguiente comando:
$cd -
$Nombres de ruta absolutos / relativos
Los directorios se organizan en una jerarquía con la raíz (/) en la parte superior. La posición de cualquier archivo dentro de la jerarquía se describe mediante su nombre de ruta.
Los elementos de un nombre de ruta están separados por una /. Un nombre de ruta es absoluto, si se describe en relación con la raíz, por lo que los nombres de ruta absolutos siempre comienzan con una /.
A continuación se muestran algunos ejemplos de nombres de archivo absolutos.
/etc/passwd
/users/sjones/chem/notes
/dev/rdsk/Os3Un nombre de ruta también puede ser relativo a su directorio de trabajo actual. Los nombres de ruta relativos nunca comienzan con /. En relación con el directorio de inicio del usuario amrood, algunos nombres de ruta pueden verse así:
chem/notes
personal/resPara determinar dónde se encuentra dentro de la jerarquía del sistema de archivos en cualquier momento, ingrese el comando pwd para imprimir el directorio de trabajo actual -
$pwd
/user0/home/amrood
$Listado de directorios
Para listar los archivos en un directorio, puede usar la siguiente sintaxis:
$ls dirnameA continuación se muestra el ejemplo para enumerar todos los archivos contenidos en /usr/local directorio -
$ls /usr/local
X11 bin gimp jikes sbin
ace doc include lib share
atalk etc info man amiCreando Directorios
Ahora entenderemos cómo crear directorios. Los directorios se crean con el siguiente comando:
$mkdir dirnameAquí, directorio es la ruta absoluta o relativa del directorio que desea crear. Por ejemplo, el comando -
$mkdir mydir $Crea el directorio mydiren el directorio actual. Aquí hay otro ejemplo:
$mkdir /tmp/test-dir $Este comando crea el directorio test-dir en el /tmpdirectorio. losmkdir El comando no produce salida si crea con éxito el directorio solicitado.
Si da más de un directorio en la línea de comando, mkdircrea cada uno de los directorios. Por ejemplo,
$mkdir docs pub $Crea los directorios docs y pub en el directorio actual.
Creación de directorios principales
Ahora entenderemos cómo crear directorios principales. A veces, cuando desea crear un directorio, es posible que su directorio o directorios principales no existan. En este caso,mkdir emite un mensaje de error de la siguiente manera:
$mkdir /tmp/amrood/test mkdir: Failed to make directory "/tmp/amrood/test"; No such file or directory $En tales casos, puede especificar el -p opción a la mkdirmando. Crea todos los directorios necesarios para ti. Por ejemplo
$mkdir -p /tmp/amrood/test $El comando anterior crea todos los directorios principales necesarios.
Eliminar directorios
Los directorios se pueden eliminar usando el rmdir comando de la siguiente manera:
$rmdir dirname $Note - Para eliminar un directorio, asegúrese de que esté vacío, lo que significa que no debe haber ningún archivo o subdirectorio dentro de este directorio.
Puede eliminar varios directorios a la vez de la siguiente manera:
$rmdir dirname1 dirname2 dirname3 $El comando anterior elimina los directorios dirname1, dirname2 y dirname3, si están vacíos. losrmdir El comando no produce salida si tiene éxito.
Cambio de directorios
Puedes usar el cdcomando para hacer más que simplemente cambiar a un directorio de inicio. Puede usarlo para cambiar a cualquier directorio especificando una ruta de acceso absoluta o relativa válida. La sintaxis es la siguiente:
$cd dirname $Aquí, dirnamees el nombre del directorio al que desea cambiar. Por ejemplo, el comando -
$cd /usr/local/bin $Cambios en el directorio /usr/local/bin. Desde este directorio, puedecd al directorio /usr/home/amrood usando la siguiente ruta relativa -
$cd ../../home/amrood $Cambio de nombre de directorios
los mv (move)El comando también se puede utilizar para cambiar el nombre de un directorio. La sintaxis es la siguiente:
$mv olddir newdir $Puede cambiar el nombre de un directorio mydir a yourdir como sigue -
$mv mydir yourdir $Los directorios. (punto) y .. (punto punto)
los filename .(punto) representa el directorio de trabajo actual; y elfilename .. (punto punto) representa el directorio un nivel por encima del directorio de trabajo actual, a menudo denominado directorio padre.
Si ingresamos el comando para mostrar una lista de los directorios / archivos de trabajo actuales y usamos el -a option para listar todos los archivos y el -l option para proporcionar la lista larga, recibiremos el siguiente resultado.
$ls -la drwxrwxr-x 4 teacher class 2048 Jul 16 17.56 . drwxr-xr-x 60 root 1536 Jul 13 14:18 .. ---------- 1 teacher class 4210 May 1 08:27 .profile -rwxr-xr-x 1 teacher class 1948 May 12 13:42 memo $En este capítulo, discutiremos en detalle acerca de los modos de acceso y permisos de archivos en Unix. La propiedad de los archivos es un componente importante de Unix que proporciona un método seguro para almacenar archivos. Cada archivo en Unix tiene los siguientes atributos:
Owner permissions - Los permisos del propietario determinan qué acciones puede realizar el propietario del archivo en el archivo.
Group permissions - Los permisos del grupo determinan qué acciones puede realizar un usuario, que es miembro del grupo al que pertenece un archivo, en el archivo.
Other (world) permissions - Los permisos para otros indican qué acción pueden realizar todos los demás usuarios en el archivo.
Los indicadores de permisos
Durante el uso ls -l comando, muestra diversa información relacionada con el permiso del archivo de la siguiente manera:
$ls -l /home/amrood
-rwxr-xr-- 1 amrood users 1024 Nov 2 00:10 myfile
drwxr-xr--- 1 amrood users 1024 Nov 2 00:10 mydirAquí, la primera columna representa diferentes modos de acceso, es decir, el permiso asociado con un archivo o directorio.
Los permisos se dividen en grupos de tres, y cada posición en el grupo denota un permiso específico, en este orden: leer (r), escribir (w), ejecutar (x) -
Los primeros tres caracteres (2-4) representan los permisos del propietario del archivo. Por ejemplo,-rwxr-xr-- representa que el propietario tiene permiso de lectura (r), escritura (w) y ejecución (x).
El segundo grupo de tres caracteres (5-7) consiste en los permisos para el grupo al que pertenece el archivo. Por ejemplo,-rwxr-xr-- representa que el grupo tiene permiso de lectura (r) y ejecución (x), pero no de escritura.
El último grupo de tres caracteres (8-10) representa los permisos para todos los demás. Por ejemplo,-rwxr-xr-- representa que hay read (r) solo permiso.
Modos de acceso a archivos
Los permisos de un archivo son la primera línea de defensa en la seguridad de un sistema Unix. Los bloques de construcción básicos de los permisos de Unix son losread, writey execute permisos, que se describen a continuación:
Leer
Otorga la capacidad de leer, es decir, ver el contenido del archivo.
Escribir
Otorga la capacidad de modificar o eliminar el contenido del archivo.
Ejecutar
El usuario con permisos de ejecución puede ejecutar un archivo como programa.
Modos de acceso al directorio
Los modos de acceso al directorio se enumeran y organizan de la misma manera que cualquier otro archivo. Hay algunas diferencias que deben mencionarse:
Leer
El acceso a un directorio significa que el usuario puede leer el contenido. El usuario puede mirar elfilenames dentro del directorio.
Escribir
Acceso significa que el usuario puede agregar o eliminar archivos del directorio.
Ejecutar
La ejecución de un directorio no tiene mucho sentido, así que piense en esto como un permiso de desplazamiento.
Un usuario debe tener execute acceso al bin directorio para ejecutar el ls o la cd mando.
Cambiar permisos
Para cambiar el archivo o los permisos del directorio, utilice el chmodcomando (cambiar modo). Hay dos formas de usar chmod: el modo simbólico y el modo absoluto.
Usando chmod en modo simbólico
La forma más fácil para que un principiante modifique los permisos de archivos o directorios es usar el modo simbólico. Con los permisos simbólicos, puede agregar, eliminar o especificar el conjunto de permisos que desee mediante los operadores de la siguiente tabla.
| No Señor. | Operador y descripción de Chmod |
|---|---|
| 1 | + Agrega los permisos designados a un archivo o directorio. |
| 2 | - Elimina los permisos designados de un archivo o directorio. |
| 3 | = Establece los permisos designados. |
Aquí hay un ejemplo usando testfile. Corriendols -1 en el archivo de prueba muestra que los permisos del archivo son los siguientes:
$ls -l testfile
-rwxrwxr-- 1 amrood users 1024 Nov 2 00:10 testfileEntonces cada ejemplo chmod El comando de la tabla anterior se ejecuta en el archivo de prueba, seguido de ls –l, para que pueda ver los cambios de permisos -
$chmod o+wx testfile $ls -l testfile
-rwxrwxrwx 1 amrood users 1024 Nov 2 00:10 testfile
$chmod u-x testfile $ls -l testfile
-rw-rwxrwx 1 amrood users 1024 Nov 2 00:10 testfile
$chmod g = rx testfile $ls -l testfile
-rw-r-xrwx 1 amrood users 1024 Nov 2 00:10 testfileAsí es como puede combinar estos comandos en una sola línea:
$chmod o+wx,u-x,g = rx testfile $ls -l testfile
-rw-r-xrwx 1 amrood users 1024 Nov 2 00:10 testfileUsando chmod con permisos absolutos
La segunda forma de modificar los permisos con el comando chmod es usar un número para especificar cada conjunto de permisos para el archivo.
A cada permiso se le asigna un valor, como muestra la siguiente tabla, y el total de cada conjunto de permisos proporciona un número para ese conjunto.
| Número | Representación de permiso octal | Árbitro |
|---|---|---|
| 0 | Sin autorización | --- |
| 1 | Permiso de ejecución | --X |
| 2 | Permiso de escritura | -w- |
| 3 | Permiso de ejecución y escritura: 1 (ejecutar) + 2 (escribir) = 3 | -wx |
| 4 | Leer permiso | r-- |
| 5 | Permiso de lectura y ejecución: 4 (lectura) + 1 (ejecución) = 5 | rx |
| 6 | Permiso de lectura y escritura: 4 (lectura) + 2 (escritura) = 6 | rw- |
| 7 | Todos los permisos: 4 (lectura) + 2 (escritura) + 1 (ejecutar) = 7 | rwx |
Aquí hay un ejemplo usando el archivo de prueba. Corriendols -1 en el archivo de prueba muestra que los permisos del archivo son los siguientes:
$ls -l testfile
-rwxrwxr-- 1 amrood users 1024 Nov 2 00:10 testfileEntonces cada ejemplo chmod El comando de la tabla anterior se ejecuta en el archivo de prueba, seguido de ls –l, para que pueda ver los cambios de permisos -
$ chmod 755 testfile
$ls -l testfile -rwxr-xr-x 1 amrood users 1024 Nov 2 00:10 testfile $chmod 743 testfile
$ls -l testfile -rwxr---wx 1 amrood users 1024 Nov 2 00:10 testfile $chmod 043 testfile
$ls -l testfile
----r---wx 1 amrood users 1024 Nov 2 00:10 testfileCambio de propietarios y grupos
Al crear una cuenta en Unix, asigna un owner ID y un group IDa cada usuario. Todos los permisos mencionados anteriormente también se asignan según el propietario y los grupos.
Hay dos comandos disponibles para cambiar el propietario y el grupo de archivos:
chown - el chown comando significa "change owner" y se utiliza para cambiar el propietario de un archivo.
chgrp - el chgrp comando significa "change group" y se utiliza para cambiar el grupo de un archivo.
Cambio de propiedad
los chowncomando cambia la propiedad de un archivo. La sintaxis básica es la siguiente:
$ chown user filelistEl valor del usuario puede ser el name of a user en el sistema o en el user id (uid) de un usuario en el sistema.
El siguiente ejemplo le ayudará a comprender el concepto:
$ chown amrood testfile $Cambia el propietario del archivo dado al usuario. amrood.
NOTE - El superusuario, root, tiene la capacidad ilimitada de cambiar la propiedad de cualquier archivo, pero los usuarios normales pueden cambiar la propiedad solo de los archivos que poseen.
Cambiar la propiedad del grupo
los chgrpEl comando cambia la propiedad del grupo de un archivo. La sintaxis básica es la siguiente:
$ chgrp group filelistEl valor del grupo puede ser el name of a group en el sistema o the group ID (GID) de un grupo en el sistema.
El siguiente ejemplo le ayuda a comprender el concepto:
$ chgrp special testfile
$Cambia el grupo del archivo dado a special grupo.
Permiso de archivos SUID y SGID
A menudo, cuando se ejecuta un comando, tendrá que ejecutarse con privilegios especiales para realizar su tarea.
Por ejemplo, cuando cambia su contraseña con el passwd comando, su nueva contraseña se almacena en el archivo /etc/shadow.
Como usuario habitual, no tiene read o writeacceso a este archivo por razones de seguridad, pero cuando cambia su contraseña, necesita tener permiso de escritura en este archivo. Esto significa que elpasswd El programa tiene que otorgarle permisos adicionales para que pueda escribir en el archivo. /etc/shadow.
Se otorgan permisos adicionales a los programas a través de un mecanismo conocido como Set User ID (SUID) y Set Group ID (SGID) bits.
Cuando ejecuta un programa que tiene habilitado el bit SUID, hereda los permisos del propietario de ese programa. Los programas que no tienen el bit SUID establecido se ejecutan con los permisos del usuario que inició el programa.
Este también es el caso de SGID. Normalmente, los programas se ejecutan con los permisos de su grupo, pero su grupo se cambiará solo para este programa al propietario del grupo del programa.
Los bits SUID y SGID aparecerán como la letra "s"si el permiso está disponible. El SUID"s" bit se ubicará en los bits de permiso donde los propietarios execute el permiso normalmente reside.
Por ejemplo, el comando -
$ ls -l /usr/bin/passwd
-r-sr-xr-x 1 root bin 19031 Feb 7 13:47 /usr/bin/passwd*
$Muestra que el bit SUID está establecido y que el comando es propiedad de la raíz. Una letra mayúsculaS en la posición de ejecución en lugar de minúsculas s indica que el bit de ejecución no está establecido.
Si el bit adhesivo está habilitado en el directorio, los archivos solo se pueden eliminar si usted es uno de los siguientes usuarios:
- El propietario del directorio fijo
- El propietario del archivo que se elimina
- El superusuario, root
Para configurar los bits SUID y SGID para cualquier directorio, intente con el siguiente comando:
$ chmod ug+s dirname
$ ls -l drwsr-sr-x 2 root root 4096 Jun 19 06:45 dirname $En este capítulo, discutiremos en detalle sobre el entorno Unix. Un concepto importante de Unix es elenvironment, que se define mediante variables de entorno. Algunos son configurados por el sistema, otros por usted, otros por el shell o cualquier programa que cargue otro programa.
Una variable es una cadena de caracteres a la que le asignamos un valor. El valor asignado puede ser un número, texto, nombre de archivo, dispositivo o cualquier otro tipo de datos.
Por ejemplo, primero establecemos una variable TEST y luego accedemos a su valor usando el echo comando -
$TEST="Unix Programming" $echo $TESTProduce el siguiente resultado.
Unix ProgrammingTenga en cuenta que las variables de entorno se establecen sin utilizar el $sign pero al acceder a ellos usamos el signo $ como prefijo. Estas variables conservan sus valores hasta que salimos del caparazón.
Cuando inicia sesión en el sistema, el shell pasa por una fase llamada initializationpara configurar el medio ambiente. Este suele ser un proceso de dos pasos que implica que el shell lea los siguientes archivos:
- /etc/profile
- profile
El proceso es el siguiente:
El shell comprueba si el archivo /etc/profile existe.
Si existe, el shell lo lee. De lo contrario, este archivo se omite. No se muestra ningún mensaje de error.
El shell comprueba si el archivo .profileexiste en su directorio personal. Su directorio de inicio es el directorio en el que comienza después de iniciar sesión.
Si existe, el shell lo lee; de lo contrario, el caparazón lo salta. No se muestra ningún mensaje de error.
Tan pronto como se hayan leído ambos archivos, el shell muestra un mensaje:
$Este es el indicador donde puede ingresar comandos para ejecutarlos.
Note - El proceso de inicialización de shell detallado aquí se aplica a todos Bourne tipo shells, pero algunos archivos adicionales son usados por bash y ksh.
El archivo .profile
El archivo /etc/profile es mantenido por el administrador del sistema de su máquina Unix y contiene la información de inicialización de shell requerida por todos los usuarios en un sistema.
El archivo .profileestá bajo tu control. Puede agregar tanta información de personalización de shell como desee a este archivo. El conjunto mínimo de información que necesita configurar incluye:
- El tipo de terminal que está utilizando.
- Una lista de directorios en los que ubicar los comandos.
- Una lista de variables que afectan la apariencia de su terminal.
Puedes comprobar tu .profiledisponible en su directorio personal. Ábralo usando el editor vi y verifique todas las variables establecidas para su entorno.
Configuración del tipo de terminal
Por lo general, el tipo de terminal que está utilizando lo configura automáticamente el login o gettyprogramas. A veces, el proceso de configuración automática adivina su terminal incorrectamente.
Si su terminal está configurado incorrectamente, la salida de los comandos puede parecer extraña, o es posible que no pueda interactuar con el shell correctamente.
Para asegurarse de que este no sea el caso, la mayoría de los usuarios configuran su terminal al mínimo común denominador de la siguiente manera:
$TERM=vt100 $Establecer la RUTA
Cuando escribe cualquier comando en el símbolo del sistema, el shell debe ubicar el comando antes de que pueda ejecutarse.
La variable PATH especifica las ubicaciones en las que el shell debe buscar comandos. Por lo general, la variable Path se establece de la siguiente manera:
$PATH=/bin:/usr/bin $Aquí, cada una de las entradas individuales separadas por dos puntos (:)son directorios. Si solicita al shell que ejecute un comando y no puede encontrarlo en ninguno de los directorios dados en la variable PATH, aparece un mensaje similar al siguiente:
$hello hello: not found $Hay variables como PS1 y PS2 que se analizan en la siguiente sección.
Variables PS1 y PS2
Los caracteres que muestra el shell como símbolo del sistema se almacenan en la variable PS1. Puede cambiar esta variable para que sea lo que desee. Tan pronto como lo cambie, el shell lo usará a partir de ese momento.
Por ejemplo, si emitió el comando:
$PS1='=>'
=>
=>
=>Su mensaje se convertirá en =>. Para establecer el valor dePS1 para que muestre el directorio de trabajo, emita el comando -
=>PS1="[\u@\h \w]\$"
[root@ip-72-167-112-17 /var/www/tutorialspoint/unix]$ [root@ip-72-167-112-17 /var/www/tutorialspoint/unix]$El resultado de este comando es que el indicador muestra el nombre de usuario del usuario, el nombre de la máquina (nombre de host) y el directorio de trabajo.
Hay unos cuantos escape sequencesque se pueden utilizar como argumentos de valor para PS1; trate de limitarse a lo más crítico para que el mensaje no lo abrume con información.
| No Señor. | Secuencia de escape y descripción |
|---|---|
| 1 | \t Hora actual, expresada como HH: MM: SS |
| 2 | \d Fecha actual, expresada como día de la semana Mes Fecha |
| 3 | \n Nueva línea |
| 4 | \s Entorno de shell actual |
| 5 | \W Directorio de trabajo |
| 6 | \w Ruta completa del directorio de trabajo |
| 7 | \u Nombre de usuario del usuario actual |
| 8 | \h Nombre de host de la máquina actual |
| 9 | \# Número de comando del comando actual. Aumenta cuando se ingresa un nuevo comando |
| 10 | \$ Si el UID efectivo es 0 (es decir, si ha iniciado sesión como root), finalice el mensaje con el carácter #; de lo contrario, use el signo $ |
Puede realizar el cambio usted mismo cada vez que inicie sesión, o puede hacer que el cambio se realice automáticamente en PS1 agregándolo a su .profile archivo.
Cuando emite un comando que está incompleto, el shell mostrará un indicador secundario y esperará a que complete el comando y presione Enter otra vez.
El indicador secundario predeterminado es > (el signo mayor que), pero se puede cambiar redefiniendo el PS2 variable de shell -
A continuación se muestra el ejemplo que utiliza el indicador secundario predeterminado:
$ echo "this is a > test" this is a test $El ejemplo que se muestra a continuación redefine PS2 con un mensaje personalizado:
$ PS2="secondary prompt->" $ echo "this is a
secondary prompt->test"
this is a
test
$Variables de entorno
A continuación se muestra la lista parcial de variables de entorno importantes. Estas variables se configuran y se accede a ellas como se menciona a continuación:
| No Señor. | Variable y descripción |
|---|---|
| 1 | DISPLAY Contiene el identificador de la pantalla que X11 los programas deben usar por defecto. |
| 2 | HOME Indica el directorio de inicio del usuario actual: el argumento predeterminado para el cd built-in mando. |
| 3 | IFS Indica el Internal Field Separator que utiliza el analizador para la división de palabras después de la expansión. |
| 4 | LANG LANG se expande a la configuración regional predeterminada del sistema; LC_ALL se puede utilizar para anular esto. Por ejemplo, si su valor espt_BR, el idioma se establece en portugués (brasileño) y la configuración regional en Brasil. |
| 5 | LD_LIBRARY_PATH Un sistema Unix con un enlazador dinámico, contiene una lista separada por dos puntos de directorios en los que el enlazador dinámico debe buscar objetos compartidos cuando construye una imagen de proceso después de exec, antes de buscar en cualquier otro directorio. |
| 6 | PATH Indica la ruta de búsqueda de comandos. Es una lista de directorios separados por dos puntos en los que el shell busca comandos. |
| 7 | PWD Indica el directorio de trabajo actual según lo establecido por el comando cd. |
| 8 | RANDOM Genera un número entero aleatorio entre 0 y 32.767 cada vez que se hace referencia a él. |
| 9 | SHLVL Se incrementa en uno cada vez que se inicia una instancia de bash. Esta variable es útil para determinar si el comando de salida integrado finaliza la sesión actual. |
| 10 | TERM Se refiere al tipo de pantalla. |
| 11 | TZ Se refiere a la zona horaria. Puede tomar valores como GMT, AST, etc. |
| 12 | UID Se expande al ID de usuario numérico del usuario actual, inicializado al inicio del shell. |
A continuación se muestra el ejemplo de muestra que muestra algunas variables de entorno:
$ echo $HOME /root ]$ echo $DISPLAY $ echo $TERM xterm $ echo $PATH /usr/local/bin:/bin:/usr/bin:/home/amrood/bin:/usr/local/bin $En este capítulo, discutiremos en detalle sobre la impresión y el correo electrónico como las utilidades básicas de Unix. Hasta ahora, hemos intentado comprender el sistema operativo Unix y la naturaleza de sus comandos básicos. En este capítulo, aprenderemos algunas utilidades importantes de Unix que pueden usarse en nuestra vida diaria.
Impresión de archivos
Antes de imprimir un archivo en un sistema Unix, es posible que desee volver a formatearlo para ajustar los márgenes, resaltar algunas palabras, etc. La mayoría de los archivos también se pueden imprimir sin reformatear, pero la impresión sin formato puede no ser tan atractiva.
Muchas versiones de Unix incluyen dos potentes formateadores de texto, nroff y troff.
El comando pr
los prEl comando realiza un formato menor de archivos en la pantalla del terminal o para una impresora. Por ejemplo, si tiene una lista larga de nombres en un archivo, puede formatearlo en pantalla en dos o más columnas.
A continuación se muestra la sintaxis de pr comando -
pr option(s) filename(s)los prcambia el formato del archivo solo en la pantalla o en la copia impresa; no modifica el archivo original. La siguiente tabla enumera algunospr opciones -
| No Señor. | Opción y descripción |
|---|---|
| 1 | -k Produce k columnas de salida |
| 2 | -d Haga doble espacio en la salida (no en todos pr versiones) |
| 3 | -h "header" Toma el siguiente elemento como encabezado de informe |
| 4 | -t Elimina la impresión del encabezado y los márgenes superior / inferior |
| 5 | -l PAGE_LENGTH Establece la longitud de la página en PAGE_LENGTH (66) líneas. El número predeterminado de líneas de texto es 56 |
| 6 | -o MARGIN Desplaza cada línea con espacios MARGIN (cero) |
| 7 | -w PAGE_WIDTH Establece el ancho de la página en PAGE_WIDTH (72) caracteres solo para la salida de varias columnas de texto |
Antes de usar pr, aquí está el contenido de un archivo de muestra llamado comida.
$cat food Sweet Tooth Bangkok Wok Mandalay Afghani Cuisine Isle of Java Big Apple Deli Sushi and Sashimi Tio Pepe's Peppers ........ $Usemos el prcomando para hacer un informe de dos columnas con el encabezado Restaurantes -
$pr -2 -h "Restaurants" food Nov 7 9:58 1997 Restaurants Page 1 Sweet Tooth Isle of Java Bangkok Wok Big Apple Deli Mandalay Sushi and Sashimi Afghani Cuisine Tio Pepe's Peppers ........ $Los comandos lp y lpr
El comando lp o lprimprime un archivo en papel en lugar de la visualización en pantalla. Una vez que esté listo para formatear con elpr comando, puede utilizar cualquiera de estos comandos para imprimir su archivo en la impresora conectada a su computadora.
El administrador del sistema probablemente haya configurado una impresora predeterminada en su sitio. Para imprimir un archivo llamadofood en la impresora predeterminada, utilice el lp o lpr comando, como en el siguiente ejemplo:
$lp food request id is laserp-525 (1 file) $los lp El comando muestra un ID que puede utilizar para cancelar el trabajo de impresión o comprobar su estado.
Si está utilizando el lp comando, puede usar el -nNumopción para imprimir Num número de copias. Junto con el comandolpr, puedes usar -Num por lo mismo.
Si hay varias impresoras conectadas a la red compartida, puede elegir una impresora usando -dprinter opción junto con el comando lp y para el mismo propósito puede usar -Pprinteropción junto con el comando lpr. Aquí impresora es el nombre de la impresora.
Los comandos lpstat y lpq
los lpstat El comando muestra qué hay en la cola de la impresora: ID de solicitud, propietarios, tamaños de archivo, cuándo se enviaron los trabajos para imprimir y el estado de las solicitudes.
Utilizar lpstat -osi desea ver todas las solicitudes de salida que no sean solo las suyas. Las solicitudes se muestran en el orden en que se imprimirán:
$lpstat -o laserp-573 john 128865 Nov 7 11:27 on laserp laserp-574 grace 82744 Nov 7 11:28 laserp-575 john 23347 Nov 7 11:35 $los lpq da información ligeramente diferente a la lpstat -o -
$lpq laserp is ready and printing Rank Owner Job Files Total Size active john 573 report.ps 128865 bytes 1st grace 574 ch03.ps ch04.ps 82744 bytes 2nd john 575 standard input 23347 bytes $Aquí la primera línea muestra el estado de la impresora. Si la impresora está desactivada o se está quedando sin papel, es posible que vea diferentes mensajes en esta primera línea.
Los comandos cancel y lprm
los cancel comando termina una solicitud de impresión desde el lp command. loslprm el comando termina todo lpr requests. Puede especificar el ID de la solicitud (mostrado por lp o lpq) o el nombre de la impresora.
$cancel laserp-575 request "laserp-575" cancelled $Para cancelar cualquier solicitud que se esté imprimiendo actualmente, independientemente de su ID, simplemente ingrese cancelar y el nombre de la impresora -
$cancel laserp request "laserp-573" cancelled $los lprmEl comando cancelará el trabajo activo si le pertenece. De lo contrario, puede dar números de trabajo como argumentos o usar undash (-) para eliminar todos sus trabajos -
$lprm 575 dfA575diamond dequeued cfA575diamond dequeued $los lprm El comando le dice los nombres de archivo reales eliminados de la cola de impresión.
Envío de correo electrónico
Utiliza el comando de correo de Unix para enviar y recibir correo. Aquí está la sintaxis para enviar un correo electrónico:
$mail [-s subject] [-c cc-addr] [-b bcc-addr] to-addrAquí hay opciones importantes relacionadas con el comando de correo -s
| No Señor. | Opción y descripción |
|---|---|
| 1 | -s Especifica el asunto en la línea de comando. |
| 2 | -c Envía copias carbón a la lista de usuarios. La lista debe ser una lista de nombres separados por comas. |
| 3 | -b Envía copias en carbón ocultas a la lista. La lista debe ser una lista de nombres separados por comas. |
A continuación se muestra un ejemplo para enviar un mensaje de prueba a [email protected].
$mail -s "Test Message" [email protected]Luego se espera que ingrese su mensaje, seguido de "control-D"al principio de una línea. Para detener, simplemente escriba punto(.) como sigue -
Hi,
This is a test
.
Cc:Puede enviar un archivo completo utilizando un redirect < operator como sigue -
$mail -s "Report 05/06/07" [email protected] < demo.txtPara verificar el correo electrónico entrante en su sistema Unix, simplemente escriba el correo electrónico de la siguiente manera:
$mail
no emailEn este capítulo, discutiremos en detalle sobre tuberías y filtros en Unix. Puede conectar dos comandos juntos para que la salida de un programa se convierta en la entrada del siguiente programa. Dos o más comandos conectados de esta manera forman una tubería.
Para hacer una tubería, coloque una barra vertical (|) en la línea de comando entre dos comandos.
Cuando un programa toma su entrada de otro programa, realiza alguna operación en esa entrada y escribe el resultado en la salida estándar. Se lo conoce comofilter.
El comando grep
El comando grep busca en un archivo o archivos líneas que tengan un patrón determinado. La sintaxis es -
$grep pattern file(s)El nombre "grep" viene del comando ed (un editor de línea de Unix) g/re/p que significa "buscar globalmente una expresión regular e imprimir todas las líneas que la contengan".
Una expresión regular es un texto sin formato (una palabra, por ejemplo) y / o caracteres especiales utilizados para la coincidencia de patrones.
El uso más simple de grep es buscar un patrón que consta de una sola palabra. Se puede usar en una tubería para que solo aquellas líneas de los archivos de entrada que contienen una cadena determinada se envíen a la salida estándar. Si no le da a grep un nombre de archivo para leer, leerá su entrada estándar; así es como funcionan todos los programas de filtrado:
$ls -l | grep "Aug"
-rw-rw-rw- 1 john doc 11008 Aug 6 14:10 ch02
-rw-rw-rw- 1 john doc 8515 Aug 6 15:30 ch07
-rw-rw-r-- 1 john doc 2488 Aug 15 10:51 intro
-rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros
$Hay varias opciones que puede utilizar junto con el grep comando -
| No Señor. | Opción y descripción |
|---|---|
| 1 | -v Imprime todas las líneas que no coinciden con el patrón. |
| 2 | -n Imprime la línea coincidente y su número de línea. |
| 3 | -l Imprime solo los nombres de los archivos con líneas coincidentes (letra "l") |
| 4 | -c Imprime solo el recuento de líneas coincidentes. |
| 5 | -i Coincide con mayúsculas o minúsculas. |
Usemos ahora una expresión regular que le dice a grep que busque líneas con "carol", seguido de cero u otros caracteres abreviados en una expresión regular como ". *"), seguido de "Ago" .−
Aquí, estamos usando el -i opción para tener una búsqueda que no distinga entre mayúsculas y minúsculas -
$ls -l | grep -i "carol.*aug"
-rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros
$El comando sort
los sortEl comando organiza las líneas de texto alfabéticamente o numéricamente. El siguiente ejemplo ordena las líneas en el archivo de alimentos:
$sort food
Afghani Cuisine
Bangkok Wok
Big Apple Deli
Isle of Java
Mandalay
Sushi and Sashimi
Sweet Tooth
Tio Pepe's Peppers
$los sortEl comando organiza las líneas de texto alfabéticamente de forma predeterminada. Hay muchas opciones que controlan la clasificación:
| No Señor. | Descripción |
|---|---|
| 1 | -n Ordena numéricamente (ejemplo: 10 se ordenará después de 2), ignora los espacios en blanco y las pestañas. |
| 2 | -r Invierte el orden de clasificación. |
| 3 | -f Ordena mayúsculas y minúsculas juntas. |
| 4 | +x Ignora primero x campos al ordenar. |
Se pueden vincular más de dos comandos en una tubería. Tomando un ejemplo de tubería anterior usandogrep, podemos ordenar los archivos modificados en agosto por orden de tamaño.
La siguiente tubería consta de los comandos ls, grepy sort -
$ls -l | grep "Aug" | sort +4n
-rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros
-rw-rw-r-- 1 john doc 2488 Aug 15 10:51 intro
-rw-rw-rw- 1 john doc 8515 Aug 6 15:30 ch07
-rw-rw-rw- 1 john doc 11008 Aug 6 14:10 ch02
$Esta tubería clasifica todos los archivos de su directorio modificados en agosto por orden de tamaño y los imprime en la pantalla del terminal. La opción de clasificación + 4n omite cuatro campos (los campos están separados por espacios en blanco) y luego clasifica las líneas en orden numérico.
Los comandos pg y más
Normalmente, puede comprimir una salida larga en la pantalla, pero si pasa más texto o usa el pgcomando como filtro; la pantalla se detiene una vez que la pantalla está llena de texto.
Supongamos que tiene una lista de directorios larga. Para facilitar la lectura de la lista ordenada, canalice la salida a través demore como sigue -
$ls -l | grep "Aug" | sort +4n | more
-rw-rw-r-- 1 carol doc 1605 Aug 23 07:35 macros
-rw-rw-r-- 1 john doc 2488 Aug 15 10:51 intro
-rw-rw-rw- 1 john doc 8515 Aug 6 15:30 ch07
-rw-rw-r-- 1 john doc 14827 Aug 9 12:40 ch03
.
.
.
-rw-rw-rw- 1 john doc 16867 Aug 6 15:56 ch05
--More--(74%)La pantalla se llenará una vez que esté llena de texto que consta de líneas ordenadas por el orden del tamaño del archivo. En la parte inferior de la pantalla está elmore indicador, donde puede escribir un comando para moverse por el texto ordenado.
Una vez que haya terminado con esta pantalla, puede usar cualquiera de los comandos enumerados en la discusión del programa más.
En este capítulo, analizaremos en detalle la gestión de procesos en Unix. Cuando ejecuta un programa en su sistema Unix, el sistema crea un entorno especial para ese programa. Este entorno contiene todo lo necesario para que el sistema ejecute el programa como si no se estuviera ejecutando ningún otro programa en el sistema.
Siempre que emite un comando en Unix, crea o inicia un nuevo proceso. Cuando probaste ellscomando para listar el contenido del directorio, inició un proceso. Un proceso, en términos simples, es una instancia de un programa en ejecución.
El sistema operativo rastrea los procesos a través de un número de identificación de cinco dígitos conocido como pid o la process ID. Cada proceso del sistema tiene unpid.
Los pids eventualmente se repiten porque todos los números posibles se agotan y el siguiente pid vuelve o comienza de nuevo. En cualquier momento, no existen dos procesos con el mismo pid en el sistema porque es el pid que Unix usa para rastrear cada proceso.
Iniciar un proceso
Cuando inicia un proceso (ejecuta un comando), hay dos formas de ejecutarlo:
- Procesos de primer plano
- Procesos de fondo
Procesos de primer plano
De forma predeterminada, todos los procesos que inicias se ejecutan en primer plano. Obtiene su entrada del teclado y envía su salida a la pantalla.
Puedes ver que esto sucede con el lsmando. Si desea enumerar todos los archivos en su directorio actual, puede usar el siguiente comando:
$ls ch*.docEsto mostraría todos los archivos, cuyos nombres comienzan con ch y terminar con .doc -
ch01-1.doc ch010.doc ch02.doc ch03-2.doc
ch04-1.doc ch040.doc ch05.doc ch06-2.doc
ch01-2.doc ch02-1.docEl proceso se ejecuta en primer plano, la salida se dirige a mi pantalla, y si el ls comando quiere cualquier entrada (que no es así), la espera desde el teclado.
Mientras un programa se está ejecutando en primer plano y requiere mucho tiempo, no se pueden ejecutar otros comandos (iniciar otros procesos) porque el indicador no estará disponible hasta que el programa termine de procesarse y salga.
Procesos de fondo
Un proceso en segundo plano se ejecuta sin estar conectado a su teclado. Si el proceso en segundo plano requiere alguna entrada de teclado, espera.
La ventaja de ejecutar un proceso en segundo plano es que puede ejecutar otros comandos; ¡no tiene que esperar hasta que se complete para iniciar otro!
La forma más sencilla de iniciar un proceso en segundo plano es agregar un ampersand (&) al final del comando.
$ls ch*.doc &Esto muestra todos los archivos cuyos nombres comienzan con ch y terminar con .doc -
ch01-1.doc ch010.doc ch02.doc ch03-2.doc
ch04-1.doc ch040.doc ch05.doc ch06-2.doc
ch01-2.doc ch02-1.docAquí, si el ls comando quiere cualquier entrada (que no lo hace), entra en un estado de parada hasta que lo movimos al primer plano y le damos los datos del teclado.
Esa primera línea contiene información sobre el proceso en segundo plano: el número de trabajo y la identificación del proceso. Necesita saber el número de trabajo para manipularlo entre el fondo y el primer plano.
Presione la tecla Enter y verá lo siguiente:
[1] + Done ls ch*.doc &
$La primera línea te dice que el lsEl proceso en segundo plano del comando finaliza correctamente. El segundo es un mensaje para otro comando.
Listado de procesos en ejecución
Es fácil ver sus propios procesos ejecutando el ps (estado del proceso) comando de la siguiente manera -
$ps
PID TTY TIME CMD
18358 ttyp3 00:00:00 sh
18361 ttyp3 00:01:31 abiword
18789 ttyp3 00:00:00 psUno de los indicadores más utilizados para ps es el -f (f para completa), que proporciona más información, como se muestra en el siguiente ejemplo:
$ps -f
UID PID PPID C STIME TTY TIME CMD
amrood 6738 3662 0 10:23:03 pts/6 0:00 first_one
amrood 6739 3662 0 10:22:54 pts/6 0:00 second_one
amrood 3662 3657 0 08:10:53 pts/6 0:00 -ksh
amrood 6892 3662 4 10:51:50 pts/6 0:00 ps -fAquí está la descripción de todos los campos mostrados por ps -f comando -
| No Señor. | Columna y descripción |
|---|---|
| 1 | UID ID de usuario al que pertenece este proceso (la persona que lo ejecuta) |
| 2 | PID Identificacion de proceso |
| 3 | PPID ID del proceso principal (el ID del proceso que lo inició) |
| 4 | C Utilización de CPU del proceso |
| 5 | STIME Hora de inicio del proceso |
| 6 | TTY Tipo de terminal asociado al proceso |
| 7 | TIME Tiempo de CPU que toma el proceso |
| 8 | CMD El comando que inició este proceso |
Hay otras opciones que se pueden utilizar junto con ps comando -
| No Señor. | Opción y descripción |
|---|---|
| 1 | -a Muestra información sobre todos los usuarios. |
| 2 | -x Muestra información sobre procesos sin terminales |
| 3 | -u Muestra información adicional como la opción -f |
| 4 | -e Muestra información ampliada |
Detener procesos
La finalización de un proceso se puede realizar de varias formas diferentes. A menudo, desde un comando basado en consola, al enviar una pulsación de tecla CTRL + C (el carácter de interrupción predeterminado) saldrá del comando. Esto funciona cuando el proceso se ejecuta en modo de primer plano.
Si un proceso se está ejecutando en segundo plano, debe obtener su ID de trabajo usando el psmando. Después de eso, puede usar elkill comando para matar el proceso de la siguiente manera:
$ps -f
UID PID PPID C STIME TTY TIME CMD
amrood 6738 3662 0 10:23:03 pts/6 0:00 first_one
amrood 6739 3662 0 10:22:54 pts/6 0:00 second_one
amrood 3662 3657 0 08:10:53 pts/6 0:00 -ksh
amrood 6892 3662 4 10:51:50 pts/6 0:00 ps -f
$kill 6738
TerminatedAquí el kill comando termina el first_oneproceso. Si un proceso ignora un comando de interrupción regular, puede usarkill -9 seguido del ID del proceso de la siguiente manera:
$kill -9 6738
TerminatedProcesos padre e hijo
Cada proceso de Unix tiene dos números de identificación asignados: la identificación del proceso (pid) y la identificación del proceso principal (ppid). Cada proceso de usuario en el sistema tiene un proceso principal.
La mayoría de los comandos que ejecuta tienen el shell como padre. Comprobar elps -f ejemplo donde este comando enumera tanto el ID del proceso como el ID del proceso principal.
Procesos zombis y huérfanos
Normalmente, cuando se mata un proceso hijo, el proceso padre se actualiza mediante un SIGCHLDseñal. Luego, el padre puede hacer otra tarea o reiniciar a un nuevo niño según sea necesario. Sin embargo, a veces el proceso padre se mata antes de que se mata a su hijo. En este caso, el "padre de todos los procesos", elinitproceso, se convierte en el nuevo PPID (ID de proceso principal). En algunos casos, estos procesos se denominan procesos huérfanos.
Cuando se mata un proceso, un ps La lista aún puede mostrar el proceso con un Zestado. Este es un proceso zombi o desaparecido. El proceso está muerto y no se está utilizando. Estos procesos son diferentes de los procesos huérfanos. Han completado la ejecución, pero aún encuentran una entrada en la tabla de procesos.
Procesos de demonio
Los demonios son procesos en segundo plano relacionados con el sistema que a menudo se ejecutan con los permisos de raíz y solicitudes de servicios de otros procesos.
Un demonio no tiene una terminal de control. No se puede abrir/dev/tty. Si haces un"ps -ef" y mira el tty campo, todos los demonios tendrán un ? Para el tty.
Para ser precisos, un demonio es un proceso que se ejecuta en segundo plano, generalmente esperando que suceda algo con lo que es capaz de trabajar. Por ejemplo, un demonio de impresora esperando comandos de impresión.
Si tiene un programa que requiere un procesamiento prolongado, entonces vale la pena convertirlo en un demonio y ejecutarlo en segundo plano.
El mando superior
los top El comando es una herramienta muy útil para mostrar rápidamente los procesos ordenados por varios criterios.
Es una herramienta de diagnóstico interactiva que se actualiza con frecuencia y muestra información sobre la memoria física y virtual, el uso de la CPU, los promedios de carga y sus procesos ocupados.
Aquí está la sintaxis simple para ejecutar el comando superior y ver las estadísticas de utilización de la CPU por diferentes procesos:
$topID de trabajo versus ID de proceso
Los procesos en segundo plano y suspendidos generalmente se manipulan mediante job number (job ID). Este número es diferente del ID del proceso y se usa porque es más corto.
Además, un trabajo puede constar de varios procesos que se ejecutan en serie o al mismo tiempo, en paralelo. Usar la identificación del trabajo es más fácil que rastrear procesos individuales.
En este capítulo, discutiremos en detalle sobre las utilidades de comunicación de red en Unix. Cuando trabaja en un entorno distribuido, necesita comunicarse con usuarios remotos y también necesita acceder a máquinas Unix remotas.
Hay varias utilidades de Unix que ayudan a los usuarios a realizar cálculos en un entorno distribuido en red. Este capítulo enumera algunos de ellos.
La utilidad ping
los pingEl comando envía una solicitud de eco a un host disponible en la red. Con este comando, puede verificar si su host remoto responde bien o no.
El comando ping es útil para lo siguiente:
- Seguimiento y aislamiento de problemas de hardware y software.
- Determinación del estado de la red y varios hosts externos.
- Prueba, medición y gestión de redes.
Sintaxis
A continuación se muestra la sintaxis simple para usar el comando ftp:
$ping hostname or ip-addressEl comando anterior comienza a imprimir una respuesta cada segundo. Para salir del comando, puede terminarlo presionandoCNTRL + C llaves.
Ejemplo
A continuación se muestra un ejemplo para verificar la disponibilidad de un host disponible en la red:
$ping google.com PING google.com (74.125.67.100) 56(84) bytes of data. 64 bytes from 74.125.67.100: icmp_seq = 1 ttl = 54 time = 39.4 ms 64 bytes from 74.125.67.100: icmp_seq = 2 ttl = 54 time = 39.9 ms 64 bytes from 74.125.67.100: icmp_seq = 3 ttl = 54 time = 39.3 ms 64 bytes from 74.125.67.100: icmp_seq = 4 ttl = 54 time = 39.1 ms 64 bytes from 74.125.67.100: icmp_seq = 5 ttl = 54 time = 38.8 ms --- google.com ping statistics --- 22 packets transmitted, 22 received, 0% packet loss, time 21017ms rtt min/avg/max/mdev = 38.867/39.334/39.900/0.396 ms $Si no existe un host, recibirá el siguiente resultado:
$ping giiiiiigle.com ping: unknown host giiiiigle.com $La utilidad ftp
Aquí, ftp representa File Ttransferir Protocol. Esta utilidad le ayuda a cargar y descargar su archivo de una computadora a otra.
La utilidad ftp tiene su propio conjunto de comandos similares a Unix. Estos comandos lo ayudan a realizar tareas como:
Conéctese e inicie sesión en un host remoto.
Navegar por directorios.
Muestra el contenido del directorio.
Coloque y obtenga archivos.
Transferir archivos como ascii, ebcdic o binary.
Sintaxis
A continuación se muestra la sintaxis simple para usar el comando ftp:
$ftp hostname or ip-addressEl comando anterior le pedirá el ID de inicio de sesión y la contraseña. Una vez que esté autenticado, puede acceder al directorio de inicio de la cuenta de inicio de sesión y podrá ejecutar varios comandos.
Las siguientes tablas enumeran algunos comandos importantes:
| No Señor. | Comando y descripción |
|---|---|
| 1 | put filename Carga el nombre de archivo de la máquina local a la máquina remota. |
| 2 | get filename Descarga el nombre de archivo de la máquina remota a la máquina local. |
| 3 | mput file list Carga más de un archivo desde la máquina local a la máquina remota. |
| 4 | mget file list Descarga más de un archivo de la máquina remota a la máquina local. |
| 5 | prompt off Desactiva la indicación. De forma predeterminada, recibirá un mensaje para cargar o descargar archivos usandomput o mget comandos. |
| 6 | prompt on Activa la indicación. |
| 7 | dir Enumera todos los archivos disponibles en el directorio actual de la máquina remota. |
| 8 | cd dirname Cambia el directorio a dirname en la máquina remota. |
| 9 | lcd dirname Cambia el directorio a dirname en la máquina local. |
| 10 | quit Ayuda a cerrar sesión desde el inicio de sesión actual. |
Cabe señalar que todos los archivos se descargarían o cargarían desde o hacia los directorios actuales. Si desea cargar sus archivos en un directorio en particular, primero debe cambiar a ese directorio y luego cargar los archivos requeridos.
Ejemplo
A continuación se muestra el ejemplo para mostrar el funcionamiento de algunos comandos:
$ftp amrood.com
Connected to amrood.com.
220 amrood.com FTP server (Ver 4.9 Thu Sep 2 20:35:07 CDT 2009)
Name (amrood.com:amrood): amrood
331 Password required for amrood.
Password:
230 User amrood logged in.
ftp> dir
200 PORT command successful.
150 Opening data connection for /bin/ls.
total 1464
drwxr-sr-x 3 amrood group 1024 Mar 11 20:04 Mail
drwxr-sr-x 2 amrood group 1536 Mar 3 18:07 Misc
drwxr-sr-x 5 amrood group 512 Dec 7 10:59 OldStuff
drwxr-sr-x 2 amrood group 1024 Mar 11 15:24 bin
drwxr-sr-x 5 amrood group 3072 Mar 13 16:10 mpl
-rw-r--r-- 1 amrood group 209671 Mar 15 10:57 myfile.out
drwxr-sr-x 3 amrood group 512 Jan 5 13:32 public
drwxr-sr-x 3 amrood group 512 Feb 10 10:17 pvm3
226 Transfer complete.
ftp> cd mpl
250 CWD command successful.
ftp> dir
200 PORT command successful.
150 Opening data connection for /bin/ls.
total 7320
-rw-r--r-- 1 amrood group 1630 Aug 8 1994 dboard.f
-rw-r----- 1 amrood group 4340 Jul 17 1994 vttest.c
-rwxr-xr-x 1 amrood group 525574 Feb 15 11:52 wave_shift
-rw-r--r-- 1 amrood group 1648 Aug 5 1994 wide.list
-rwxr-xr-x 1 amrood group 4019 Feb 14 16:26 fix.c
226 Transfer complete.
ftp> get wave_shift
200 PORT command successful.
150 Opening data connection for wave_shift (525574 bytes).
226 Transfer complete.
528454 bytes received in 1.296 seconds (398.1 Kbytes/s)
ftp> quit
221 Goodbye.
$La utilidad telnet
Hay ocasiones en las que debemos conectarnos a una máquina Unix remota y trabajar en esa máquina de forma remota. Telnet es una utilidad que permite al usuario de una computadora en un sitio establecer una conexión, iniciar sesión y luego trabajar en una computadora en otro sitio.
Una vez que inicie sesión con Telnet, puede realizar todas las actividades en su máquina conectada de forma remota. El siguiente es un ejemplo de sesión Telnet:
C:>telnet amrood.com
Trying...
Connected to amrood.com.
Escape character is '^]'.
login: amrood
amrood's Password:
*****************************************************
* *
* *
* WELCOME TO AMROOD.COM *
* *
* *
*****************************************************
Last unsuccessful login: Fri Mar 3 12:01:09 IST 2009
Last login: Wed Mar 8 18:33:27 IST 2009 on pts/10
{ do your work }
$ logout
Connection closed.
C:>La utilidad del dedo
los fingerEl comando muestra información sobre los usuarios en un host determinado. El host puede ser local o remoto.
Finger puede estar desactivado en otros sistemas por razones de seguridad.
A continuación se muestra la sintaxis simple para usar el comando finger:
Verifique todos los usuarios registrados en la máquina local -
$ finger
Login Name Tty Idle Login Time Office
amrood pts/0 Jun 25 08:03 (62.61.164.115)Obtenga información sobre un usuario específico disponible en la máquina local:
$ finger amrood
Login: amrood Name: (null)
Directory: /home/amrood Shell: /bin/bash
On since Thu Jun 25 08:03 (MST) on pts/0 from 62.61.164.115
No mail.
No Plan.Verifique todos los usuarios registrados en la máquina remota -
$ finger @avtar.com
Login Name Tty Idle Login Time Office
amrood pts/0 Jun 25 08:03 (62.61.164.115)Obtenga la información sobre un usuario específico disponible en la máquina remota:
$ finger [email protected]
Login: amrood Name: (null)
Directory: /home/amrood Shell: /bin/bash
On since Thu Jun 25 08:03 (MST) on pts/0 from 62.61.164.115
No mail.
No Plan.En este capítulo, entenderemos cómo funciona el editor vi en Unix. Hay muchas formas de editar archivos en Unix. Editar archivos usando el editor de texto orientado a pantallavies una de las mejores formas. Este editor le permite editar líneas en contexto con otras líneas en el archivo.
Una versión mejorada del editor vi que se llama VIMtambién está disponible ahora. Aquí, VIM significaVi IMdemostrado.
vi generalmente se considera el estándar de facto en los editores de Unix porque:
Por lo general, está disponible en todas las versiones del sistema Unix.
Sus implementaciones son muy similares en todos los ámbitos.
Requiere muy pocos recursos.
Es más fácil de usar que otros editores como el ed o la ex.
Puedes usar el vieditor para editar un archivo existente o crear un nuevo archivo desde cero. También puede usar este editor para leer un archivo de texto.
Iniciar el editor vi
La siguiente tabla enumera los comandos básicos para usar el editor vi:
| No Señor. | Comando y descripción |
|---|---|
| 1 | vi filename Crea un archivo nuevo si ya no existe; de lo contrario, abre un archivo existente. |
| 2 | vi -R filename Abre un archivo existente en modo de solo lectura. |
| 3 | view filename Abre un archivo existente en modo de solo lectura. |
A continuación se muestra un ejemplo para crear un nuevo archivo. testfile si ya no existe en el directorio de trabajo actual -
$vi testfileEl comando anterior generará la siguiente salida:
|
~
~
~
~
~
~
~
~
~
~
~
~
"testfile" [New File]Notarás un tilde(~) en cada línea que sigue al cursor. Una tilde representa una línea no utilizada. Si una línea no comienza con una tilde y parece estar en blanco, hay un espacio, tabulación, nueva línea o algún otro carácter no visible presente.
Ahora tiene un archivo abierto para comenzar a trabajar. Antes de continuar, comprendamos algunos conceptos importantes.
Modos de operación
Mientras trabajamos con el editor vi, generalmente nos encontramos con los siguientes dos modos:
Command mode- Este modo le permite realizar tareas administrativas como guardar los archivos, ejecutar los comandos, mover el cursor, cortar (tirar) y pegar las líneas o palabras, así como buscar y reemplazar. En este modo, todo lo que escriba se interpreta como un comando.
Insert mode- Este modo le permite insertar texto en el archivo. Todo lo que se escribe en este modo se interpreta como entrada y se coloca en el archivo.
vi siempre comienza en el command mode. Para ingresar texto, debe estar en el modo de inserción para lo cual simplemente escribai. Para salir del modo de inserción, presione elEsc , que lo llevará de regreso al modo de comando.
Hint- Si no está seguro en qué modo se encuentra, presione la tecla Esc dos veces; esto lo llevará al modo de comando. Abre un archivo usando el editor vi. Comience escribiendo algunos caracteres y luego pase al modo de comando para comprender la diferencia.
Salir de vi
El comando para salir de vi es :q. Una vez en el modo de comando, escriba dos puntos y 'q', seguido de return. Si su archivo ha sido modificado de alguna manera, el editor le advertirá de esto y no le permitirá salir. Para ignorar este mensaje, el comando para salir de vi sin guardar es:q!. Esto le permite salir de vi sin guardar ninguno de los cambios.
El comando para guardar el contenido del editor es :w. Puede combinar el comando anterior con el comando quit, o usar:wq y volver.
La forma más fácil de save your changes and exit viestá con el comando ZZ. Cuando esté en el modo de comando, escribaZZ. losZZ El comando funciona de la misma manera que el :wq mando.
Si desea especificar / indicar un nombre en particular para el archivo, puede hacerlo especificándolo después de la :w. Por ejemplo, si desea guardar el archivo en el que está trabajando con otro nombre de archivo llamadofilename2, escribirías :w filename2 y volver.
Moverse dentro de un archivo
Para moverse dentro de un archivo sin afectar su texto, debe estar en el modo de comando (presione Esc dos veces). La siguiente tabla enumera algunos comandos que puede usar para moverse un carácter a la vez:
| No Señor. | Comando y descripción |
|---|---|
| 1 | k Mueve el cursor una línea hacia arriba |
| 2 | j Mueve el cursor una línea hacia abajo |
| 3 | h Mueve el cursor a la posición de un carácter a la izquierda |
| 4 | l Mueve el cursor a la derecha una posición de carácter |
Los siguientes puntos deben tenerse en cuenta para moverse dentro de un archivo:
vi distingue entre mayúsculas y minúsculas. Debe prestar atención a las mayúsculas al usar los comandos.
La mayoría de los comandos en vi pueden estar precedidos por la cantidad de veces que desea que ocurra la acción. Por ejemplo,2j mueve el cursor dos líneas hacia abajo en la ubicación del cursor.
Hay muchas otras formas de moverse dentro de un archivo en vi. Recuerda que debes estar en modo comando (press Esc twice). La siguiente tabla enumera algunos comandos para moverse por el archivo:
| No Señor. | Comando y descripción |
|---|---|
| 1 | 0 or | Coloca el cursor al principio de una línea. |
| 2 | $ Coloca el cursor al final de una línea. |
| 3 | w Coloca el cursor en la siguiente palabra |
| 4 | b Coloca el cursor en la palabra anterior. |
| 5 | ( Coloca el cursor al comienzo de la oración actual |
| 6 | ) Coloca el cursor al principio de la siguiente oración. |
| 7 | E Va al final de la palabra delimitada en blanco. |
| 8 | { Mueve un párrafo hacia atrás |
| 9 | } Avanza un párrafo |
| 10 | [[ Mueve una sección hacia atrás |
| 11 | ]] Mueve una sección hacia adelante |
| 12 | n| Se mueve a la columna n en la línea actual |
| 13 | 1G Pasa a la primera línea del archivo. |
| 14 | G Va a la última línea del archivo. |
| 15 | nG Se mueve al nth línea del archivo |
| dieciséis | :n Se mueve al nth línea del archivo |
| 17 | fc Avanza a c |
| 18 | Fc Vuelve a c |
| 19 | H Se mueve a la parte superior de la pantalla. |
| 20 | nH Se mueve al nth línea desde la parte superior de la pantalla |
| 21 | M Se mueve al centro de la pantalla. |
| 22 | L Mover a la parte inferior de la pantalla |
| 23 | nL Se mueve al nth línea desde la parte inferior de la pantalla |
| 24 | :x Los dos puntos seguidos de un número colocarían el cursor en el número de línea representado por x |
Comandos de control
Los siguientes comandos se pueden utilizar con la tecla de control para realizar las funciones que se indican en la siguiente tabla:
| No Señor. | Comando y descripción |
|---|---|
| 1 | CTRL+d Avanza 1/2 pantalla |
| 2 | CTRL+f Avanza una pantalla completa |
| 3 | CTRL+u Se mueve hacia atrás 1/2 pantalla |
| 4 | CTRL+b Retrocede una pantalla completa |
| 5 | CTRL+e Mueve la pantalla una línea hacia arriba |
| 6 | CTRL+y Mueve la pantalla una línea hacia abajo |
| 7 | CTRL+u Mueve la pantalla 1/2 página hacia arriba |
| 8 | CTRL+d Mueve la pantalla 1/2 página hacia abajo |
| 9 | CTRL+b Mueve la pantalla una página hacia arriba |
| 10 | CTRL+f Mueve la pantalla una página hacia abajo |
| 11 | CTRL+I Vuelve a dibujar la pantalla |
Editar archivos
Para editar el archivo, debe estar en el modo de inserción. Hay muchas formas de ingresar al modo de inserción desde el modo de comando:
| No Señor. | Comando y descripción |
|---|---|
| 1 | i Inserta texto antes de la ubicación actual del cursor |
| 2 | I Inserta texto al principio de la línea actual |
| 3 | a Inserta texto después de la ubicación actual del cursor |
| 4 | A Inserta texto al final de la línea actual |
| 5 | o Crea una nueva línea para la entrada de texto debajo de la ubicación del cursor |
| 6 | O Crea una nueva línea para la entrada de texto sobre la ubicación del cursor |
Eliminar personajes
Aquí hay una lista de comandos importantes, que se pueden usar para eliminar caracteres y líneas en un archivo abierto:
| No Señor. | Comando y descripción |
|---|---|
| 1 | x Elimina el carácter debajo de la ubicación del cursor |
| 2 | X Elimina el carácter antes de la ubicación del cursor. |
| 3 | dw Elimina de la ubicación actual del cursor a la siguiente palabra |
| 4 | d^ Elimina desde la posición actual del cursor hasta el principio de la línea. |
| 5 | d$ Elimina desde la posición actual del cursor hasta el final de la línea |
| 6 | D Elimina desde la posición del cursor hasta el final de la línea actual |
| 7 | dd Elimina la línea en la que está el cursor |
Como se mencionó anteriormente, la mayoría de los comandos en vi pueden estar precedidos por la cantidad de veces que desea que ocurra la acción. Por ejemplo,2x elimina dos caracteres debajo de la ubicación del cursor y 2dd elimina dos líneas en las que se encuentra el cursor.
Se recomienda que practique los comandos antes de continuar.
Cambiar comandos
También tiene la capacidad de cambiar caracteres, palabras o líneas en vi sin eliminarlos. Aquí están los comandos relevantes:
| No Señor. | Comando y descripción |
|---|---|
| 1 | cc Elimina el contenido de la línea, dejándolo en modo de inserción. |
| 2 | cw Cambia la palabra en la que se encuentra el cursor del cursor a minúscula w fin de la palabra. |
| 3 | r Reemplaza el carácter debajo del cursor. vi vuelve al modo de comando después de que se ingresa el reemplazo. |
| 4 | R Sobrescribe varios caracteres que comienzan con el carácter que se encuentra actualmente debajo del cursor. Debes usarEsc para detener la sobrescritura. |
| 5 | s Reemplaza el carácter actual con el carácter que escribe. Posteriormente, queda en el modo de inserción. |
| 6 | S Elimina la línea en la que se encuentra el cursor y la reemplaza con el nuevo texto. Después de ingresar el nuevo texto, vi permanece en el modo de inserción. |
Copiar y pegar comandos
Puede copiar líneas o palabras de un lugar y luego puede pegarlas en otro lugar usando los siguientes comandos:
| No Señor. | Comando y descripción |
|---|---|
| 1 | yy Copia la línea actual. |
| 2 | yw Copia la palabra actual desde el carácter en el que se encuentra el cursor w minúscula, hasta el final de la palabra. |
| 3 | p Coloca el texto copiado después del cursor. |
| 4 | P Coloca el texto tirado antes del cursor. |
Comandos avanzados
Hay algunos comandos avanzados que simplifican la edición diaria y permiten un uso más eficiente de vi -
| No Señor. | Comando y descripción |
|---|---|
| 1 | J Une la línea actual con la siguiente. Un recuento de j comandos une muchas líneas. |
| 2 | << Desplaza la línea actual hacia la izquierda en un ancho de turno. |
| 3 | >> Desplaza la línea actual a la derecha en un ancho de turno. |
| 4 | ~ Cambia el caso del carácter debajo del cursor. |
| 5 | ^G Presione las teclas Ctrl y G al mismo tiempo para mostrar el nombre del archivo actual y el estado. |
| 6 | U Restaura la línea actual al estado en el que estaba antes de que el cursor entrara en la línea. |
| 7 | u Esto ayuda a deshacer el último cambio que se hizo en el archivo. Si escribe "u" de nuevo, se volverá a realizar el cambio. |
| 8 | J Une la línea actual con la siguiente. Un recuento se suma a tantas líneas. |
| 9 | :f Muestra la posición actual en el archivo en% y el nombre del archivo, el número total de archivos. |
| 10 | :f filename Cambia el nombre del archivo actual a nombre de archivo. |
| 11 | :w filename Escribe en el archivo nombre de archivo. |
| 12 | :e filename Abre otro archivo con nombre de archivo. |
| 13 | :cd dirname Cambia el directorio de trabajo actual a dirname. |
| 14 | :e # Alterna entre dos archivos abiertos. |
| 15 | :n En caso de que abra varios archivos usando vi, use :n para ir al siguiente archivo de la serie. |
| dieciséis | :p En caso de que abra varios archivos usando vi, use :p para ir al archivo anterior de la serie. |
| 17 | :N En caso de que abra varios archivos usando vi, use :N para ir al archivo anterior de la serie. |
| 18 | :r file Lee el archivo y lo inserta después de la línea actual. |
| 19 | :nr file Lee el archivo y lo inserta después de la línea n. |
Búsqueda de palabras y caracteres
El editor vi tiene dos tipos de búsquedas: string y character. Para una búsqueda de cadenas, el/ y ?se utilizan comandos. Cuando inicie estos comandos, el comando que acaba de escribir se mostrará en la última línea de la pantalla, donde escribe la cadena en particular que debe buscar.
Estos dos comandos difieren solo en la dirección donde se realiza la búsqueda:
los / El comando busca hacia adelante (hacia abajo) en el archivo.
los ? El comando busca hacia atrás (hacia arriba) en el archivo.
los n y NLos comandos repiten el comando de búsqueda anterior en la misma dirección o en la opuesta, respectivamente. Algunos personajes tienen significados especiales. Estos caracteres deben ir precedidos de una barra invertida (\) que se incluirá como parte de la expresión de búsqueda.
| No Señor. | Descripción del personaje |
|---|---|
| 1 | ^ Busca al principio de la línea (utilizar al principio de una expresión de búsqueda). |
| 2 | . Coincide con un solo carácter. |
| 3 | * Coincide con cero o más del carácter anterior. |
| 4 | $ Fin de la línea (Úselo al final de la expresión de búsqueda). |
| 5 | [ Inicia un conjunto de expresiones coincidentes o no coincidentes. |
| 6 | < Esto se pone en una expresión escapada con la barra invertida para encontrar el final o el comienzo de una palabra. |
| 7 | > Esto ayuda a ver el '<'descripción del personaje arriba. |
La búsqueda de caracteres busca dentro de una línea para encontrar un carácter ingresado después del comando. losf y F los comandos buscan un carácter en la línea actual solamente. f busca hacia adelante y F busca hacia atrás y el cursor se mueve a la posición del carácter encontrado.
los t y T Los comandos buscan un carácter en la línea actual solamente, pero para t, el cursor se mueve a la posición antes del carácter, y T busca la línea hacia atrás a la posición después del carácter.
Establecer comandos
Puede cambiar la apariencia de su pantalla vi usando lo siguiente :setcomandos. Una vez que esté en el modo de comando, escriba:set seguido de cualquiera de los siguientes comandos.
| No Señor. | Comando y descripción |
|---|---|
| 1 | :set ic Ignora el caso al buscar |
| 2 | :set ai Establece sangría automática |
| 3 | :set noai Elimina la sangría automática |
| 4 | :set nu Muestra líneas con números de línea en el lado izquierdo |
| 5 | :set sw Establece el ancho de una pestaña de software. Por ejemplo, establecería un ancho de turno de 4 con este comando::set sw = 4 |
| 6 | :set ws Si Wrapscan está configurado y la palabra no se encuentra al final del archivo, intentará buscarla al principio. |
| 7 | :set wm Si esta opción tiene un valor mayor que cero, el editor automáticamente "ajustará la palabra". Por ejemplo, para establecer el margen de ajuste en dos caracteres, debe escribir esto::set wm = 2 |
| 8 | :set ro Cambia el tipo de archivo a "solo lectura" |
| 9 | :set term Imprime el tipo de terminal |
| 10 | :set bf Descarta los caracteres de control de la entrada |
Ejecución de comandos
El vi tiene la capacidad de ejecutar comandos desde dentro del editor. Para ejecutar un comando, solo necesita ir al modo de comando y escribir:! mando.
Por ejemplo, si desea comprobar si existe un archivo antes de intentar guardar su archivo con ese nombre de archivo, puede escribir :! ls y verá la salida de ls en la pantalla.
Puede presionar cualquier tecla (o la secuencia de escape del comando) para regresar a su sesión de vi.
Reemplazo de texto
El comando de sustitución (:s/) le permite reemplazar rápidamente palabras o grupos de palabras dentro de sus archivos. A continuación se muestra la sintaxis para reemplazar el texto:
:s/search/replace/glos grepresenta globalmente. El resultado de este comando es que se cambian todas las ocurrencias en la línea del cursor.
Puntos importantes a tener en cuenta
Los siguientes puntos se sumarán a su éxito con vi:
Debe estar en modo comando para usar los comandos. (Presione Esc dos veces en cualquier momento para asegurarse de que está en modo de comando).
Debes tener cuidado con los comandos. Éstos distinguen entre mayúsculas y minúsculas.
Debe estar en modo insertar para ingresar texto.
UN Shellle proporciona una interfaz para el sistema Unix. Recopila información de usted y ejecuta programas basados en esa entrada. Cuando un programa termina de ejecutarse, muestra la salida de ese programa.
Shell es un entorno en el que podemos ejecutar nuestros comandos, programas y scripts de shell. Hay diferentes sabores de un shell, al igual que hay diferentes sabores de sistemas operativos. Cada versión de shell tiene su propio conjunto de funciones y comandos reconocidos.
Indicador de Shell
El aviso, $, que se llama command prompt, es emitido por el shell. Mientras se muestra el indicador, puede escribir un comando.
Shell lee su entrada después de presionar Enter. Determina el comando que desea ejecutar mirando la primera palabra de su entrada. Una palabra es un conjunto ininterrumpido de caracteres. Los espacios y las tabulaciones separan las palabras.
A continuación se muestra un ejemplo sencillo de date comando, que muestra la fecha y hora actuales -
$date
Thu Jun 25 08:30:19 MST 2009Puede personalizar su símbolo del sistema utilizando la variable de entorno PS1 explicada en el tutorial de entorno.
Tipos de conchas
En Unix, hay dos tipos principales de shells:
Bourne shell - Si está utilizando un shell de tipo Bourne, el $ carácter es el mensaje predeterminado.
C shell - Si está utilizando un shell de tipo C, el carácter% es el indicador predeterminado.
Bourne Shell tiene las siguientes subcategorías:
- Concha de Bourne (sh)
- Cáscara de Korn (ksh)
- Bourne Again shell (bash)
- Cáscara POSIX (sh)
Siguen las diferentes carcasas de tipo C:
- C shell (csh)
- Carcasa TENEX / TOPS C (tcsh)
El shell original de Unix fue escrito a mediados de la década de 1970 por Stephen R. Bourne mientras estaba en AT&T Bell Labs en Nueva Jersey.
Bourne shell fue el primer shell que apareció en los sistemas Unix, por lo que se conoce como "el shell".
El shell Bourne generalmente se instala como /bin/shen la mayoría de las versiones de Unix. Por esta razón, es el shell preferido para escribir scripts que se pueden usar en diferentes versiones de Unix.
En este capítulo, cubriremos la mayoría de los conceptos de Shell que se basan en Borne Shell.
Scripts de Shell
El concepto básico de un script de shell es una lista de comandos, que se enumeran en el orden de ejecución. Un buen script de shell tendrá comentarios, precedidos por# firmar, describiendo los pasos.
Hay pruebas condicionales, como que el valor A es mayor que el valor B, bucles que nos permiten pasar por grandes cantidades de datos, archivos para leer y almacenar datos y variables para leer y almacenar datos, y el script puede incluir funciones.
Vamos a escribir muchos guiones en las siguientes secciones. Sería un archivo de texto simple en el que pondríamos todos nuestros comandos y varias otras construcciones requeridas que le dicen al entorno del shell qué hacer y cuándo hacerlo.
Los scripts y las funciones de Shell se interpretan. Esto significa que no se compilan.
Script de ejemplo
Supongamos que creamos un test.shguión. Tenga en cuenta que todos los scripts tendrían el.shextensión. Antes de agregar algo más a su secuencia de comandos, debe alertar al sistema de que se está iniciando una secuencia de comandos de shell. Esto se hace usando elshebangconstruir. Por ejemplo
#!/bin/shEsto le dice al sistema que los comandos que siguen deben ser ejecutados por el shell Bourne. Se llama shebang porque el#El símbolo se llama hash y el! El símbolo se llama explosión .
Para crear un script que contenga estos comandos, primero coloque la línea shebang y luego agregue los comandos:
#!/bin/bash
pwd
lsComentarios de Shell
Puede poner sus comentarios en su guión de la siguiente manera:
#!/bin/bash
# Author : Zara Ali
# Copyright (c) Tutorialspoint.com
# Script follows here:
pwd
lsGuarde el contenido anterior y haga que el script sea ejecutable -
$chmod +x test.shEl script de shell ahora está listo para ejecutarse.
$./test.shTras la ejecución, recibirá el siguiente resultado:
/home/amrood
index.htm unix-basic_utilities.htm unix-directories.htm
test.sh unix-communication.htm unix-environment.htmNote - Para ejecutar un programa disponible en el directorio actual, use ./program_name
Scripts de shell extendidos
Los scripts de shell tienen varias construcciones necesarias que le indican al entorno de shell qué hacer y cuándo hacerlo. Por supuesto, la mayoría de los scripts son más complejos que el anterior.
El shell es, después de todo, un lenguaje de programación real, completo con variables, estructuras de control, etc. No importa lo complicado que se vuelva un script, sigue siendo solo una lista de comandos ejecutados secuencialmente.
El siguiente script usa el read comando que toma la entrada del teclado y la asigna como el valor de la variable PERSON y finalmente la imprime en STDOUT.
#!/bin/sh
# Author : Zara Ali
# Copyright (c) Tutorialspoint.com
# Script follows here:
echo "What is your name?"
read PERSON
echo "Hello, $PERSON"Aquí hay una ejecución de muestra del script:
$./test.sh What is your name? Zara Ali Hello, Zara Ali $En este capítulo, aprenderemos cómo usar las variables de Shell en Unix. Una variable es una cadena de caracteres a la que le asignamos un valor. El valor asignado puede ser un número, texto, nombre de archivo, dispositivo o cualquier otro tipo de datos.
Una variable no es más que un puntero a los datos reales. El shell le permite crear, asignar y eliminar variables.
Nombres de variables
El nombre de una variable solo puede contener letras (de la A a la Z o de la A a la Z), números (0 a 9) o el carácter de subrayado (_).
Por convención, las variables de shell de Unix tendrán sus nombres en MAYÚSCULAS.
Los siguientes ejemplos son nombres de variables válidos:
_ALI
TOKEN_A
VAR_1
VAR_2A continuación se muestran ejemplos de nombres de variables no válidos:
2_VAR
-VARIABLE
VAR1-VAR2
VAR_A!La razón por la que no puede utilizar otros caracteres como !, *o - es que estos caracteres tienen un significado especial para el caparazón.
Definición de variables
Las variables se definen de la siguiente manera:
variable_name=variable_valuePor ejemplo
NAME="Zara Ali"El ejemplo anterior define la variable NOMBRE y le asigna el valor "Zara Ali". Las variables de este tipo se denominanscalar variables. Una variable escalar solo puede contener un valor a la vez.
Shell le permite almacenar cualquier valor que desee en una variable. Por ejemplo
VAR1="Zara Ali"
VAR2=100Acceder a valores
Para acceder al valor almacenado en una variable, anteponga su nombre con el signo de dólar ($) -
Por ejemplo, el siguiente script accederá al valor de la variable definida NAME y la imprimirá en STDOUT -
#!/bin/sh
NAME="Zara Ali"
echo $NAMEEl script anterior producirá el siguiente valor:
Zara AliVariables de solo lectura
Shell proporciona una forma de marcar variables como de solo lectura mediante el comando de solo lectura. Una vez que una variable se marca como de solo lectura, su valor no se puede cambiar.
Por ejemplo, el siguiente script genera un error al intentar cambiar el valor de NAME -
#!/bin/sh
NAME="Zara Ali"
readonly NAME
NAME="Qadiri"El script anterior generará el siguiente resultado:
/bin/sh: NAME: This variable is read only.Desarmar variables
Desarmar o eliminar una variable indica al shell que elimine la variable de la lista de variables que rastrea. Una vez que desarma una variable, no puede acceder al valor almacenado en la variable.
A continuación se muestra la sintaxis para desarmar una variable definida utilizando el unset comando -
unset variable_nameEl comando anterior desarma el valor de una variable definida. Aquí hay un ejemplo simple que demuestra cómo funciona el comando:
#!/bin/sh
NAME="Zara Ali"
unset NAME
echo $NAMEEl ejemplo anterior no imprime nada. No puede utilizar el comando unset paraunset variables que están marcadas readonly.
Tipos de variables
Cuando se ejecuta un shell, existen tres tipos principales de variables:
Local Variables- Una variable local es una variable que está presente dentro de la instancia actual del shell. No está disponible para programas iniciados por el shell. Se establecen en el símbolo del sistema.
Environment Variables- Una variable de entorno está disponible para cualquier proceso hijo del shell. Algunos programas necesitan variables de entorno para funcionar correctamente. Por lo general, un script de shell define solo las variables de entorno que necesitan los programas que ejecuta.
Shell Variables- Una variable de shell es una variable especial establecida por el shell y requerida por el shell para funcionar correctamente. Algunas de estas variables son variables de entorno, mientras que otras son variables locales.
En este capítulo, discutiremos en detalle acerca de las variables especiales en Unix. En uno de nuestros capítulos anteriores, entendimos cómo tener cuidado cuando usamos ciertos caracteres no alfanuméricos en los nombres de las variables. Esto se debe a que esos caracteres se utilizan en los nombres de variables especiales de Unix. Estas variables están reservadas para funciones específicas.
Por ejemplo, el $ carácter representa el número de identificación del proceso, o PID, del shell actual -
$echo $$
El comando anterior escribe el PID del shell actual:
29949La siguiente tabla muestra una serie de variables especiales que puede utilizar en sus scripts de shell:
| No Señor. | Variable y descripción |
|---|---|
| 1 | $0 El nombre de archivo del script actual. |
| 2 | $n Estas variables corresponden a los argumentos con los que se invocó un script. aquín es un número decimal positivo correspondiente a la posición de un argumento (el primer argumento es $1, the second argument is $2, y así sucesivamente). |
| 3 | $# El número de argumentos proporcionados a un script. |
| 4 | $* Todos los argumentos se citan dos veces. Si un script recibe dos argumentos,$* is equivalent to $1 $ 2. |
| 5 | $@ Todos los argumentos se citan individualmente por partida doble. Si un script recibe dos argumentos,$@ is equivalent to $1 $ 2. |
| 6 | $? El estado de salida del último comando ejecutado. |
| 7 | $$ El número de proceso del shell actual. En el caso de los scripts de shell, este es el ID de proceso con el que se ejecutan. |
| 8 | $! El número de proceso del último comando en segundo plano. |
Argumentos de la línea de comandos
Los argumentos de la línea de comandos $1, $2, $3, ...$9 son parámetros posicionales, con $0 pointing to the actual command, program, shell script, or function and $1, $2, $3, ... $ 9 como argumentos del comando.
El siguiente script utiliza varias variables especiales relacionadas con la línea de comando:
#!/bin/sh
echo "File Name: $0"
echo "First Parameter : $1" echo "Second Parameter : $2"
echo "Quoted Values: $@" echo "Quoted Values: $*"
echo "Total Number of Parameters : $#"Aquí hay una ejecución de muestra para el script anterior:
$./test.sh Zara Ali
File Name : ./test.sh
First Parameter : Zara
Second Parameter : Ali
Quoted Values: Zara Ali
Quoted Values: Zara Ali
Total Number of Parameters : 2Parámetros especiales $* and $@
Hay parámetros especiales que permiten acceder a todos los argumentos de la línea de comandos a la vez. $* y $@ ambos actuarán de la misma manera a menos que estén entre comillas dobles, "".
Ambos parámetros especifican los argumentos de la línea de comandos. Sin embargo, el "$*" special parameter takes the entire list as one argument with spaces between and the "$El parámetro especial @ "toma la lista completa y la separa en argumentos separados.
Podemos escribir el script de shell como se muestra a continuación para procesar un número desconocido de argumentos de línea de comando con el $* or $@ parámetros especiales -
#!/bin/sh
for TOKEN in $* do echo $TOKEN
doneAquí hay una ejecución de muestra para el script anterior:
$./test.sh Zara Ali 10 Years Old
Zara
Ali
10
Years
OldNote - aquí do...done es una especie de bucle que se tratará en un tutorial posterior.
Estado de salida
los $? La variable representa el estado de salida del comando anterior.
El estado de salida es un valor numérico devuelto por cada comando una vez completado. Como regla general, la mayoría de los comandos devuelven un estado de salida de 0 si tuvieron éxito y 1 si no tuvieron éxito.
Algunos comandos devuelven estados de salida adicionales por motivos particulares. Por ejemplo, algunos comandos diferencian entre los tipos de errores y devolverán varios valores de salida según el tipo específico de falla.
A continuación se muestra el ejemplo de un comando exitoso:
$./test.sh Zara Ali File Name : ./test.sh First Parameter : Zara Second Parameter : Ali Quoted Values: Zara Ali Quoted Values: Zara Ali Total Number of Parameters : 2 $echo $? 0 $En este capítulo, discutiremos cómo usar matrices de shell en Unix. Una variable de shell es lo suficientemente capaz de contener un solo valor. Estas variables se denominan variables escalares.
Shell admite un tipo diferente de variable llamada array variable. Esto puede contener varios valores al mismo tiempo. Las matrices proporcionan un método para agrupar un conjunto de variables. En lugar de crear un nombre nuevo para cada variable necesaria, puede utilizar una única variable de matriz que almacene todas las demás variables.
Todas las reglas de nomenclatura discutidas para las Variables de Shell serían aplicables al nombrar matrices.
Definición de valores de matriz
La diferencia entre una variable de matriz y una variable escalar se puede explicar de la siguiente manera.
Suponga que está intentando representar los nombres de varios estudiantes como un conjunto de variables. Cada una de las variables individuales es una variable escalar de la siguiente manera:
NAME01="Zara"
NAME02="Qadir"
NAME03="Mahnaz"
NAME04="Ayan"
NAME05="Daisy"Podemos usar una sola matriz para almacenar todos los nombres mencionados anteriormente. A continuación se muestra el método más simple para crear una variable de matriz. Esto ayuda a asignar un valor a uno de sus índices.
array_name[index]=valueAquí array_name es el nombre de la matriz, índice es el índice del elemento en la matriz que desea establecer y valor es el valor que desea establecer para ese elemento.
Como ejemplo, los siguientes comandos:
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"Si está utilizando el ksh shell, aquí está la sintaxis de inicialización de matriz:
set -A array_name value1 value2 ... valuenSi está utilizando el bash shell, aquí está la sintaxis de inicialización de matriz:
array_name=(value1 ... valuen)Acceso a los valores de matriz
Después de haber establecido cualquier variable de matriz, acceda a ella de la siguiente manera:
${array_name[index]}Aquí array_name es el nombre de la matriz e index es el índice del valor al que se accede. A continuación se muestra un ejemplo para comprender el concepto:
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Index: ${NAME[0]}"
echo "Second Index: ${NAME[1]}"El ejemplo anterior generará el siguiente resultado:
$./test.sh
First Index: Zara
Second Index: QadirPuede acceder a todos los elementos de una matriz de una de las siguientes formas:
${array_name[*]} ${array_name[@]}aquí array_name es el nombre de la matriz que le interesa. El siguiente ejemplo le ayudará a comprender el concepto:
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Method: ${NAME[*]}" echo "Second Method: ${NAME[@]}"El ejemplo anterior generará el siguiente resultado:
$./test.sh
First Method: Zara Qadir Mahnaz Ayan Daisy
Second Method: Zara Qadir Mahnaz Ayan DaisyHay varios operadores compatibles con cada shell. Discutiremos en detalle sobre el shell Bourne (shell predeterminado) en este capítulo.
Ahora discutiremos los siguientes operadores:
- Operadores aritméticos
- Operadores relacionales
- Operadores booleanos
- Operadores de cadenas
- Operadores de prueba de archivos
El shell Bourne no tenía originalmente ningún mecanismo para realizar operaciones aritméticas simples, pero también usa programas externos awk o expr.
El siguiente ejemplo muestra cómo sumar dos números:
#!/bin/sh
val=`expr 2 + 2`
echo "Total value : $val"El script anterior generará el siguiente resultado:
Total value : 4Los siguientes puntos deben tenerse en cuenta al agregar:
Debe haber espacios entre operadores y expresiones. Por ejemplo, 2 + 2 no es correcto; debe escribirse como 2 + 2.
La expresión completa debe incluirse entre ‘ ‘, llamado la tilde.
Operadores aritméticos
Bourne Shell admite los siguientes operadores aritméticos.
Asumir variable a tiene 10 y variable b sostiene 20 entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| + (Adición) | Agrega valores a ambos lados del operador | expr $a + $b` dará 30 |
| - (Resta) | Resta el operando de la mano derecha del operando de la mano izquierda | expr $a - $b` dará -10 |
| * (Multiplicación) | Multiplica los valores a ambos lados del operador | expr $a \* $b` dará 200 |
| / (División) | Divide el operando de la izquierda por el operando de la derecha | expr $b / $a` dará 2 |
| % (Módulo) | Divide el operando de la izquierda por el operando de la derecha y devuelve el resto | expr $b % $a` dará 0 |
| = (Asignación) | Asigna operando derecho en operando izquierdo | a = $ b asignaría el valor de b en a |
| == (Igualdad) | Compara dos números, si ambos son iguales, devuelve verdadero. | [$ a == $ b] devolvería falso. |
| ! = (No igualdad) | Compara dos números, si ambos son diferentes, devuelve verdadero. | [$ a! = $ b] devolvería verdadero. |
Es muy importante entender que todas las expresiones condicionales deben estar dentro de llaves cuadradas con espacios alrededor, por ejemplo [ $a == $b ] es correcto mientras que, [$a==$b] Es incorrecto.
Todos los cálculos aritméticos se realizan utilizando números enteros largos.
Operadores relacionales
Bourne Shell admite los siguientes operadores relacionales que son específicos de valores numéricos. Estos operadores no funcionan para valores de cadena a menos que su valor sea numérico.
Por ejemplo, los siguientes operadores funcionarán para comprobar una relación entre 10 y 20, así como entre "10" y "20", pero no entre "diez" y "veinte".
Asumir variable a tiene 10 y variable b sostiene 20 entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| -eq | Comprueba si el valor de dos operandos es igual o no; si es así, entonces la condición se vuelve verdadera. | [$ a -eq $ b] no es cierto. |
| -ne | Comprueba si el valor de dos operandos es igual o no; si los valores no son iguales, la condición se cumple. | [$ a -ne $ b] es cierto. |
| -gt | Comprueba si el valor del operando izquierdo es mayor que el valor del operando derecho; si es así, entonces la condición se vuelve verdadera. | [$ a -gt $ b] no es cierto. |
| -lt | Comprueba si el valor del operando izquierdo es menor que el valor del operando derecho; si es así, entonces la condición se vuelve verdadera. | [$ a -lt $ b] es cierto. |
| -ge | Comprueba si el valor del operando izquierdo es mayor o igual que el valor del operando derecho; si es así, entonces la condición se vuelve verdadera. | [$ a -ge $ b] no es cierto. |
| -le | Comprueba si el valor del operando izquierdo es menor o igual que el valor del operando derecho; si es así, entonces la condición se vuelve verdadera. | [$ a -le $ b] es cierto. |
Es muy importante comprender que todas las expresiones condicionales deben colocarse entre llaves con espacios alrededor. Por ejemplo,[ $a <= $b ] es correcto mientras que, [$a <= $b] Es incorrecto.
Operadores booleanos
Los siguientes operadores booleanos son compatibles con Bourne Shell.
Asumir variable a tiene 10 y variable b sostiene 20 entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| ! | Esta es la negación lógica. Esto invierte una condición verdadera en falsa y viceversa. | [! falso] es verdadero. |
| -o | Esto es lógico OR. Si uno de los operandos es verdadero, entonces la condición se vuelve verdadera. | [$ a -lt 20 -o $ b -gt 100] es cierto. |
| -a | Esto es lógico AND. Si ambos operandos son verdaderos, entonces la condición se vuelve verdadera en caso contrario es falsa. | [$ a -lt 20 -a $ b -gt 100] es falso. |
Operadores de cadenas
Los siguientes operadores de cadena son compatibles con Bourne Shell.
Asumir variable a contiene "abc" y variable b sostiene "efg" entonces -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| = | Comprueba si el valor de dos operandos es igual o no; si es así, entonces la condición se vuelve verdadera. | [$ a = $ b] no es cierto. |
| != | Comprueba si el valor de dos operandos es igual o no; si los valores no son iguales, la condición se cumple. | [$ a! = $ b] es cierto. |
| -z | Comprueba si el tamaño del operando de cadena dado es cero; si es de longitud cero, devuelve verdadero. | [-z $ a] no es cierto. |
| -n | Comprueba si el tamaño del operando de cadena dado es distinto de cero; si tiene una longitud distinta de cero, devuelve verdadero. | [-n $ a] no es falso. |
| str | Comprueba si strno es la cadena vacía; si está vacío, devuelve falso. | [$ a] no es falso. |
Operadores de prueba de archivos
Tenemos algunos operadores que se pueden utilizar para probar varias propiedades asociadas con un archivo Unix.
Asume una variable file contiene una "prueba" de nombre de archivo existente cuyo tamaño es de 100 bytes y tiene read, write y execute permiso en -
Mostrar ejemplos
| Operador | Descripción | Ejemplo |
|---|---|---|
| -b file | Comprueba si el archivo es un archivo especial de bloque; si es así, entonces la condición se vuelve verdadera. | [-b $ archivo] es falso. |
| -c file | Comprueba si el archivo es un archivo especial de carácter; si es así, entonces la condición se vuelve verdadera. | [-c $ archivo] es falso. |
| -d file | Comprueba si el archivo es un directorio; si es así, entonces la condición se vuelve verdadera. | [-d $ archivo] no es cierto. |
| -f file | Comprueba si el archivo es un archivo normal en lugar de un directorio o un archivo especial; si es así, entonces la condición se vuelve verdadera. | [-f $ archivo] es verdadero. |
| -g file | Comprueba si el archivo tiene su bit de identificación de grupo establecido (SGID) establecido; si es así, entonces la condición se vuelve verdadera. | [-g $ archivo] es falso. |
| -k file | Comprueba si el archivo tiene su bit adhesivo establecido; si es así, entonces la condición se vuelve verdadera. | [-k $ archivo] es falso. |
| -p file | Comprueba si el archivo es una tubería con nombre; si es así, entonces la condición se vuelve verdadera. | [-p $ archivo] es falso. |
| -t file | Comprueba si el descriptor de archivo está abierto y asociado con un terminal; si es así, entonces la condición se vuelve verdadera. | [-t $ archivo] es falso. |
| -u file | Comprueba si el archivo tiene su bit Set User ID (SUID) establecido; si es así, entonces la condición se vuelve verdadera. | [-u $ archivo] es falso. |
| -r file | Comprueba si el archivo es legible; si es así, entonces la condición se vuelve verdadera. | [-r $ archivo] es verdadero. |
| -w file | Comprueba si el archivo se puede escribir; si es así, entonces la condición se vuelve verdadera. | [-w $ archivo] es verdadero. |
| -x file | Comprueba si el archivo es ejecutable; si es así, entonces la condición se vuelve verdadera. | [-x $ archivo] es verdadero. |
| -s file | Comprueba si el archivo tiene un tamaño superior a 0; si es así, la condición se vuelve verdadera. | [-s $ file] es verdadero. |
| -e file | Comprueba si el archivo existe; es verdadero incluso si el archivo es un directorio pero existe. | [-e $ archivo] es verdadero. |
Operadores de Shell C
El siguiente enlace le dará una breve idea sobre los operadores de C Shell:
Operadores de Shell C
Operadores de Shell Korn
El siguiente enlace lo ayuda a comprender los operadores de Korn Shell:
Operadores de Shell Korn
En este capítulo, entenderemos la toma de decisiones de shell en Unix. Mientras escribe un script de shell, puede haber una situación en la que necesite adoptar una ruta de las dos rutas dadas. Por lo tanto, debe utilizar declaraciones condicionales que permitan a su programa tomar decisiones correctas y realizar las acciones correctas.
Unix Shell admite declaraciones condicionales que se utilizan para realizar diferentes acciones basadas en diferentes condiciones. Ahora entenderemos aquí dos declaraciones de toma de decisiones:
los if...else declaración
los case...esac declaración
Las declaraciones if ... else
Las declaraciones if else son declaraciones útiles para la toma de decisiones que se pueden usar para seleccionar una opción de un conjunto dado de opciones.
Unix Shell admite las siguientes formas de if…else declaración -
- si ... declaración fi
- if ... else ... declaración fi
- if ... elif ... else ... declaración fi
La mayoría de los enunciados if verifican las relaciones utilizando operadores relacionales discutidos en el capítulo anterior.
El caso ... Declaración de esac
Puede utilizar varios if...elifdeclaraciones para realizar una rama de múltiples vías. Sin embargo, esta no es siempre la mejor solución, especialmente cuando todas las ramas dependen del valor de una sola variable.
Soporta Unix Shell case...esac declaración que maneja exactamente esta situación, y lo hace de manera más eficiente que la repetida if...elif declaraciones.
Solo hay una forma de case...esac declaración que se ha descrito en detalle aquí -
- caso ... declaración esac
los case...esac declaración en el shell de Unix es muy similar a la switch...case declaración que tenemos en otros lenguajes de programación como C o C++ y PERLetc.
En este capítulo, discutiremos los bucles de shell en Unix. Un bucle es una poderosa herramienta de programación que le permite ejecutar un conjunto de comandos repetidamente. En este capítulo, examinaremos los siguientes tipos de bucles disponibles para los programadores de shell:
- El bucle while
- El bucle for
- El bucle hasta
- El bucle de selección
Utilizará diferentes bucles según la situación. Por ejemplo, elwhileloop ejecuta los comandos dados hasta que la condición dada permanece verdadera; launtil El bucle se ejecuta hasta que se cumple una condición determinada.
Una vez que tenga una buena práctica de programación, obtendrá la experiencia y, por lo tanto, comenzará a utilizar el bucle adecuado según la situación. Aquí,while y for los bucles están disponibles en la mayoría de los otros lenguajes de programación como C, C++ y PERLetc.
Bucles de anidación
Todos los bucles admiten el concepto de anidación, lo que significa que puede colocar un bucle dentro de otro similar o bucles diferentes. Este anidamiento puede aumentar hasta un número ilimitado de veces según sus necesidades.
Aquí hay un ejemplo de anidación whilelazo. Los otros bucles se pueden anidar según los requisitos de programación de una manera similar:
Anidando bucles while
Es posible utilizar un bucle while como parte del cuerpo de otro bucle while.
Sintaxis
while command1 ; # this is loop1, the outer loop
do
Statement(s) to be executed if command1 is true
while command2 ; # this is loop2, the inner loop
do
Statement(s) to be executed if command2 is true
done
Statement(s) to be executed if command1 is true
doneEjemplo
A continuación, se muestra un ejemplo sencillo de anidación de bucles. Agreguemos otro bucle de cuenta regresiva dentro del bucle que solía contar hasta nueve:
#!/bin/sh
a=0
while [ "$a" -lt 10 ] # this is loop1 do b="$a"
while [ "$b" -ge 0 ] # this is loop2 do echo -n "$b "
b=`expr $b - 1` done echo a=`expr $a + 1`
doneEsto producirá el siguiente resultado. Es importante notar cómoecho -ntrabaja aquí. aquí-n La opción permite que echo evite imprimir un carácter de nueva línea.
0
1 0
2 1 0
3 2 1 0
4 3 2 1 0
5 4 3 2 1 0
6 5 4 3 2 1 0
7 6 5 4 3 2 1 0
8 7 6 5 4 3 2 1 0
9 8 7 6 5 4 3 2 1 0En este capítulo, discutiremos el control de bucle de shell en Unix. Hasta ahora, ha estudiado la creación de bucles y el trabajo con bucles para realizar diferentes tareas. A veces es necesario detener un bucle u omitir iteraciones del bucle.
En este capítulo, aprenderemos a seguir dos declaraciones que se utilizan para controlar los bucles de shell:
los break declaración
los continue declaración
El bucle infinito
Todos los bucles tienen una vida limitada y salen una vez que la condición es falsa o verdadera según el bucle.
Un bucle puede continuar para siempre si no se cumple la condición requerida. Un bucle que se ejecuta para siempre sin terminar se ejecuta un número infinito de veces. Por esta razón, estos bucles se denominan bucles infinitos.
Ejemplo
Aquí hay un ejemplo simple que usa while bucle para mostrar los números del cero al nueve -
#!/bin/sh
a=10
until [ $a -lt 10 ] do echo $a
a=`expr $a + 1`
doneEste bucle continúa para siempre porque a es siempre greater than o equal to 10 y nunca es menos de 10.
La declaración de descanso
los breakLa instrucción se usa para terminar la ejecución de todo el ciclo, después de completar la ejecución de todas las líneas de código hasta la instrucción break. Luego desciende al código que sigue al final del ciclo.
Sintaxis
El seguimiento break La declaración se usa para salir de un bucle -
breakEl comando break también se puede usar para salir de un bucle anidado usando este formato:
break naquí n especifica el nth bucle envolvente a la salida de.
Ejemplo
Aquí hay un ejemplo simple que muestra que el ciclo termina tan pronto como a se convierte en 5 -
#!/bin/sh
a=0
while [ $a -lt 10 ]
do
echo $a if [ $a -eq 5 ]
then
break
fi
a=`expr $a + 1`
doneTras la ejecución, recibirá el siguiente resultado:
0
1
2
3
4
5Aquí hay un ejemplo simple de bucle for anidado. Este script sale de ambos bucles sivar1 equals 2 y var2 equals 0 -
#!/bin/sh
for var1 in 1 2 3
do
for var2 in 0 5
do
if [ $var1 -eq 2 -a $var2 -eq 0 ] then break 2 else echo "$var1 $var2"
fi
done
doneTras la ejecución, recibirá el siguiente resultado. En el ciclo interno, tiene un comando de interrupción con el argumento 2. Esto indica que si se cumple una condición, debe salir del ciclo externo y, en última instancia, también del ciclo interno.
1 0
1 5La declaración de continuar
los continue declaración es similar a la break comando, excepto que hace que salga la iteración actual del ciclo, en lugar de todo el ciclo.
Esta declaración es útil cuando se ha producido un error, pero desea intentar ejecutar la siguiente iteración del bucle.
Sintaxis
continueAl igual que con la instrucción break, se puede proporcionar un argumento entero al comando continue para omitir comandos de bucles anidados.
continue naquí n especifica el nth bucle adjunto desde el que continuar.
Ejemplo
El siguiente bucle hace uso del continue instrucción que regresa de la instrucción continue y comienza a procesar la siguiente instrucción -
#!/bin/sh
NUMS="1 2 3 4 5 6 7"
for NUM in $NUMS
do
Q=`expr $NUM % 2` if [ $Q -eq 0 ]
then
echo "Number is an even number!!"
continue
fi
echo "Found odd number"
doneTras la ejecución, recibirá el siguiente resultado:
Found odd number
Number is an even number!!
Found odd number
Number is an even number!!
Found odd number
Number is an even number!!
Found odd number¿Qué es la sustitución?
El shell realiza una sustitución cuando encuentra una expresión que contiene uno o más caracteres especiales.
Ejemplo
Aquí, el valor de impresión de la variable se sustituye por su valor. Mismo tiempo,"\n" se sustituye por una nueva línea -
#!/bin/sh
a=10
echo -e "Value of a is $a \n"Recibirás el siguiente resultado. Aquí el-e La opción habilita la interpretación de los escapes de barra invertida.
Value of a is 10A continuación se muestra el resultado sin -e opción -
Value of a is 10\nAquí están las siguientes secuencias de escape que se pueden usar en el comando echo:
| No Señor. | Escape y descripción |
|---|---|
| 1 | \\ barra invertida |
| 2 | \a alerta (BEL) |
| 3 | \b retroceso |
| 4 | \c suprimir nueva línea final |
| 5 | \f formulario de alimentación |
| 6 | \n nueva línea |
| 7 | \r retorno de carro |
| 8 | \t pestaña horizontal |
| 9 | \v pestaña vertical |
Puedes usar el -E opción para deshabilitar la interpretación de los escapes de barra invertida (predeterminado).
Puedes usar el -n opción para deshabilitar la inserción de una nueva línea.
Sustitución de comandos
La sustitución de comandos es el mecanismo mediante el cual el shell ejecuta un conjunto determinado de comandos y luego sustituye su salida en lugar de los comandos.
Sintaxis
La sustitución del comando se realiza cuando un comando se da como:
`command`Al realizar la sustitución del comando, asegúrese de utilizar la comilla inversa, no el carácter de comilla simple.
Ejemplo
La sustitución de comandos se usa generalmente para asignar la salida de un comando a una variable. Cada uno de los siguientes ejemplos demuestra la sustitución de comandos:
#!/bin/sh
DATE=`date`
echo "Date is $DATE"
USERS=`who | wc -l`
echo "Logged in user are $USERS" UP=`date ; uptime` echo "Uptime is $UP"Tras la ejecución, recibirá el siguiente resultado:
Date is Thu Jul 2 03:59:57 MST 2009
Logged in user are 1
Uptime is Thu Jul 2 03:59:57 MST 2009
03:59:57 up 20 days, 14:03, 1 user, load avg: 0.13, 0.07, 0.15Sustitución de variables
La sustitución de variables permite al programador de shell manipular el valor de una variable en función de su estado.
Aquí está la siguiente tabla para todas las posibles sustituciones:
| No Señor. | Forma y descripción |
|---|---|
| 1 | ${var} Sustituye el valor de var . |
| 2 | ${var:-word} Si var es nulo o no establecido, palabra se sustituye porvar. El valor de var no cambia. |
| 3 | ${var:=word} Si var es nulo o no establecido, var se establece en el valor deword. |
| 4 | ${var:?message} Si var es nulo o no se establece, el mensaje se imprime con el error estándar. Esto verifica que las variables estén configuradas correctamente. |
| 5 | ${var:+word} Si se establece var , word se sustituye por var. El valor de var no cambia. |
Ejemplo
A continuación se muestra el ejemplo para mostrar varios estados de la sustitución anterior:
#!/bin/sh
echo ${var:-"Variable is not set"}
echo "1 - Value of var is ${var}" echo ${var:="Variable is not set"}
echo "2 - Value of var is ${var}" unset var echo ${var:+"This is default value"}
echo "3 - Value of var is $var" var="Prefix" echo ${var:+"This is default value"}
echo "4 - Value of var is $var" echo ${var:?"Print this message"}
echo "5 - Value of var is ${var}"Tras la ejecución, recibirá el siguiente resultado:
Variable is not set
1 - Value of var is
Variable is not set
2 - Value of var is Variable is not set
3 - Value of var is
This is default value
4 - Value of var is Prefix
Prefix
5 - Value of var is PrefixEn este capítulo, analizaremos en detalle los mecanismos de cotización de Shell. Comenzaremos discutiendo los metacaracteres.
Los metacaracteres
Unix Shell proporciona varios metacaracteres que tienen un significado especial al usarlos en cualquier script de Shell y provocan la terminación de una palabra a menos que se cite.
Por ejemplo, ? coincide con un solo carácter mientras enumera archivos en un directorio y un *coincide con más de un carácter. Aquí hay una lista de la mayoría de los caracteres especiales de shell (también llamados metacaracteres):
* ? [ ] ' " \ $ ; & ( ) | ^ < > new-line space tabUn carácter puede ser citado (es decir, hecho que se represente a sí mismo) precediéndolo con un \.
Ejemplo
El siguiente ejemplo muestra cómo imprimir un * o un ? -
#!/bin/sh
echo Hello; WordTras la ejecución, recibirá el siguiente resultado:
Hello
./test.sh: line 2: Word: command not found
shell returned 127Intentemos ahora usar un carácter entre comillas:
#!/bin/sh
echo Hello\; WordTras la ejecución, recibirá el siguiente resultado:
Hello; Wordlos $ El signo es uno de los metacaracteres, por lo que debe citarse para evitar un manejo especial por parte del shell.
#!/bin/sh
echo "I have \$1200"Tras la ejecución, recibirá el siguiente resultado:
I have $1200La siguiente tabla enumera las cuatro formas de cotización:
| No Señor. | Cotización y descripción |
|---|---|
| 1 | Single quote Todos los caracteres especiales entre estas comillas pierden su significado especial. |
| 2 | Double quote La mayoría de los caracteres especiales entre estas citas pierden su significado especial con estas excepciones:
|
| 3 | Backslash Cualquier carácter que siga inmediatamente a la barra invertida pierde su significado especial. |
| 4 | Back quote Cualquier cosa entre comillas inversas se trataría como un comando y se ejecutaría. |
Las citas individuales
Considere un comando echo que contiene muchos caracteres especiales de shell:
echo <-$1500.**>; (update?) [y|n]Poner una barra invertida delante de cada carácter especial es tedioso y dificulta la lectura de la línea.
echo \<-\$1500.\*\*\>\; \(update\?\) \[y\|n\]Existe una manera fácil de citar un gran grupo de personajes. Ponga una comilla simple (') al principio y al final de la cadena -
echo '<-$1500.**>; (update?) [y|n]'Los caracteres entre comillas simples se citan como si hubiera una barra invertida delante de cada carácter. Con esto, el comando echo se muestra de manera adecuada.
Si aparece una comilla simple dentro de una cadena que se va a generar, no debe poner toda la cadena entre comillas simples, sino que debe precederla usando una barra invertida (\) como sigue:
echo 'It\'s Shell ProgrammingLas citas dobles
Intente ejecutar el siguiente script de shell. Este script de shell hace uso de comillas simples:
VAR=ZARA
echo '$VAR owes <-$1500.**>; [ as of (`date +%m/%d`) ]'Tras la ejecución, recibirá el siguiente resultado:
$VAR owes <-$1500.**>; [ as of (`date +%m/%d`) ]Esto no es lo que tenía que mostrarse. Es obvio que las comillas simples evitan la sustitución de variables. Si desea sustituir los valores de las variables y hacer que las comillas funcionen como se espera, entonces deberá poner sus comandos entre comillas dobles de la siguiente manera:
VAR=ZARA
echo "$VAR owes <-\$1500.**>; [ as of (`date +%m/%d`) ]"Tras la ejecución, recibirá el siguiente resultado:
ZARA owes <-$1500.**>; [ as of (07/02) ]Las comillas dobles eliminan el significado especial de todos los caracteres excepto los siguientes:
$ para sustitución de parámetros
Citas inversas para sustitución de comandos
\$ para habilitar signos de dólar literal
\` para habilitar comillas inversas literales
\" para habilitar comillas dobles incrustadas
\\ para habilitar barras invertidas incrustadas
Todos los demás \ los caracteres son literales (no especiales)
Los caracteres entre comillas simples se citan como si hubiera una barra invertida delante de cada carácter. Esto ayuda a que el comando echo se muestre correctamente.
Si aparece una comilla simple dentro de una cadena que se va a generar, no debe poner toda la cadena entre comillas simples, sino que debe precederla usando una barra invertida (\) como sigue:
echo 'It\'s Shell Programming'Las comillas
Poner cualquier comando de Shell en el medio backquotes ejecuta el comando.
Sintaxis
Aquí está la sintaxis simple para poner cualquier Shell command entre comillas inversas -
var=`command`Ejemplo
los date El comando se ejecuta en el siguiente ejemplo y el resultado producido se almacena en la variable DATA.
DATE=`date`
echo "Current Date: $DATE"Tras la ejecución, recibirá el siguiente resultado:
Current Date: Thu Jul 2 05:28:45 MST 2009En este capítulo, analizaremos en detalle las redirecciones de entrada / salida de Shell. La mayoría de los comandos del sistema Unix toman la entrada de su terminal y envían la salida resultante a su terminal. Un comando normalmente lee su entrada desde la entrada estándar, que resulta ser su terminal por defecto. De manera similar, un comando normalmente escribe su salida en la salida estándar, que nuevamente es su terminal por defecto.
Redirección de salida
En su lugar, la salida de un comando normalmente destinado a la salida estándar se puede desviar fácilmente a un archivo. Esta capacidad se conoce como redirección de salida.
Si el archivo de notación> se agrega a cualquier comando que normalmente escribe su salida en la salida estándar, la salida de ese comando se escribirá en el archivo en lugar de en su terminal.
Compruebe lo siguiente who comando que redirige la salida completa del comando en el archivo de usuarios.
$ who > usersObserve que no aparece ninguna salida en el terminal. Esto se debe a que la salida se ha redirigido desde el dispositivo de salida estándar predeterminado (el terminal) al archivo especificado. Puede consultar el archivo de usuarios para ver el contenido completo:
$ cat users
oko tty01 Sep 12 07:30
ai tty15 Sep 12 13:32
ruth tty21 Sep 12 10:10
pat tty24 Sep 12 13:07
steve tty25 Sep 12 13:03
$Si un comando tiene su salida redirigida a un archivo y el archivo ya contiene algunos datos, esos datos se perderán. Considere el siguiente ejemplo:
$ echo line 1 > users
$ cat users line 1 $Puede usar el operador >> para agregar la salida en un archivo existente de la siguiente manera:
$ echo line 2 >> users $ cat users
line 1
line 2
$Redirección de entrada
Así como la salida de un comando se puede redirigir a un archivo, también se puede redirigir la entrada de un comando desde un archivo. Como elgreater-than character > se utiliza para la redirección de salida, el less-than character < se utiliza para redirigir la entrada de un comando.
Los comandos que normalmente toman su entrada de la entrada estándar pueden tener su entrada redirigida desde un archivo de esta manera. Por ejemplo, para contar el número de líneas en el archivo que los usuarios generaron anteriormente, puede ejecutar el comando de la siguiente manera:
$ wc -l users
2 users
$Tras la ejecución, recibirá el siguiente resultado. Puede contar el número de líneas en el archivo redirigiendo la entrada estándar delwccomando de los usuarios del archivo -
$ wc -l < users
2
$Tenga en cuenta que existe una diferencia en la salida producida por las dos formas del comando wc. En el primer caso, el nombre de los usuarios del archivo se enumera con el recuento de líneas; en el segundo caso, no lo es.
En el primer caso, wc sabe que está leyendo su entrada de los usuarios del archivo. En el segundo caso, solo sabe que está leyendo su entrada desde la entrada estándar, por lo que no muestra el nombre del archivo.
Aquí Documento
UN here document se utiliza para redirigir la entrada a un programa o script de shell interactivo.
Podemos ejecutar un programa interactivo dentro de un script de shell sin la acción del usuario proporcionando la entrada requerida para el programa interactivo o script de shell interactivo.
La forma general de un here el documento es -
command << delimiter
document
delimiterAquí la cáscara interpreta el <<operador como una instrucción para leer la entrada hasta que encuentre una línea que contenga el delimitador especificado. Todas las líneas de entrada hasta la línea que contiene el delimitador se introducen en la entrada estándar del comando.
El delimitador le dice al shell que el hereel documento se ha completado. Sin él, el shell continúa leyendo la entrada para siempre. El delimitador debe ser una sola palabra que no contenga espacios ni tabulaciones.
A continuación se muestra la entrada al comando wc -l para contar el número total de líneas -
$wc -l << EOF
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.
EOF
3
$Puedes usar el here document para imprimir varias líneas usando su secuencia de comandos de la siguiente manera:
#!/bin/sh
cat << EOF
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.
EOFTras la ejecución, recibirá el siguiente resultado:
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.El siguiente script ejecuta una sesión con el vi editor de texto y guarda la entrada en el archivo test.txt.
#!/bin/sh
filename=test.txt
vi $filename <<EndOfCommands
i
This file was created automatically from
a shell script
^[
ZZ
EndOfCommandsSi ejecuta este script con vim actuando como vi, es probable que vea un resultado como el siguiente:
$ sh test.sh Vim: Warning: Input is not from a terminal $Después de ejecutar el script, debería ver lo siguiente agregado al archivo test.txt -
$ cat test.txt This file was created automatically from a shell script $Descartar la salida
A veces, necesitará ejecutar un comando, pero no desea que la salida se muestre en la pantalla. En tales casos, puede descartar la salida redirigiéndola al archivo/dev/null -
$ command > /dev/nullAquí comando es el nombre del comando que desea ejecutar. El archivo/dev/null es un archivo especial que descarta automáticamente todas sus entradas.
Para descartar tanto la salida de un comando como su salida de error, use la redirección estándar para redirigir STDERR a STDOUT -
$ command > /dev/null 2>&1aquí 2 representa STDERR y 1 representa STDOUT. Puede mostrar un mensaje en STDERR redirigiendo STDOUT a STDERR de la siguiente manera:
$ echo message 1>&2Comandos de redireccionamiento
A continuación se muestra una lista completa de comandos que puede usar para la redirección:
| No Señor. | Comando y descripción |
|---|---|
| 1 | pgm > file La salida de pgm se redirige al archivo |
| 2 | pgm < file El programa pgm lee su entrada del archivo |
| 3 | pgm >> file La salida de pgm se adjunta al archivo |
| 4 | n > file Salida de flujo con descriptor n redirigido al archivo |
| 5 | n >> file Salida de flujo con descriptor n adjunto al archivo |
| 6 | n >& m Fusiona la salida de la secuencia n con corriente m |
| 7 | n <& m Fusiona la entrada de la secuencia n con corriente m |
| 8 | << tag La entrada estándar viene desde aquí hasta la siguiente etiqueta al principio de la línea |
| 9 | | Toma la salida de un programa o proceso y la envía a otro |
Tenga en cuenta que el descriptor de archivo 0 es normalmente entrada estándar (STDIN), 1 es salida estándar (STDOUT), y 2 es la salida de error estándar (STDERR).
En este capítulo, discutiremos en detalle sobre las funciones de shell. Las funciones le permiten dividir la funcionalidad general de un script en subsecciones lógicas más pequeñas, a las que luego se les puede llamar para realizar sus tareas individuales cuando sea necesario.
El uso de funciones para realizar tareas repetitivas es una excelente manera de crear code reuse. Ésta es una parte importante de los principios modernos de programación orientada a objetos.
Las funciones de shell son similares a las subrutinas, procedimientos y funciones de otros lenguajes de programación.
Creando funciones
Para declarar una función, simplemente use la siguiente sintaxis:
function_name () {
list of commands
}El nombre de su función es function_name, y eso es lo que usará para llamarlo desde otra parte de sus scripts. El nombre de la función debe ir seguido de paréntesis, seguido de una lista de comandos entre llaves.
Ejemplo
El siguiente ejemplo muestra el uso de la función -
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World"
}
# Invoke your function
HelloTras la ejecución, recibirá el siguiente resultado:
$./test.sh
Hello WorldPasar parámetros a una función
Puede definir una función que acepte parámetros mientras llama a la función. Estos parámetros estarían representados por$1, $2 y así.
A continuación se muestra un ejemplo en el que pasamos dos parámetros Zara y Ali y luego capturamos e imprimimos estos parámetros en la función.
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World $1 $2"
}
# Invoke your function
Hello Zara AliTras la ejecución, recibirá el siguiente resultado:
$./test.sh
Hello World Zara AliDevolver valores de funciones
Si ejecuta un exit comando desde dentro de una función, su efecto no es solo terminar la ejecución de la función sino también del programa de shell que llamó a la función.
Si, en cambio, solo desea terminar la ejecución de la función, entonces hay una forma de salir de una función definida.
Según la situación, puede devolver cualquier valor de su función utilizando el return comando cuya sintaxis es la siguiente:
return codeaquí code puede ser cualquier cosa que elija aquí, pero obviamente debe elegir algo que sea significativo o útil en el contexto de su script como un todo.
Ejemplo
La siguiente función devuelve un valor 10 -
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World $1 $2" return 10 } # Invoke your function Hello Zara Ali # Capture value returnd by last command ret=$?
echo "Return value is $ret"Tras la ejecución, recibirá el siguiente resultado:
$./test.sh
Hello World Zara Ali
Return value is 10Funciones anidadas
Una de las características más interesantes de las funciones es que pueden llamarse a sí mismas y también a otras funciones. Una función que se llama a sí misma se conoce comorecursive function.
El siguiente ejemplo demuestra el anidamiento de dos funciones:
#!/bin/sh
# Calling one function from another
number_one () {
echo "This is the first function speaking..."
number_two
}
number_two () {
echo "This is now the second function speaking..."
}
# Calling function one.
number_oneTras la ejecución, recibirá el siguiente resultado:
This is the first function speaking...
This is now the second function speaking...Llamada de función desde el indicador
Puede poner definiciones para funciones de uso común dentro de su .profile. Estas definiciones estarán disponibles siempre que inicie sesión y podrá usarlas en el símbolo del sistema.
Alternativamente, puede agrupar las definiciones en un archivo, digamos test.shy luego ejecute el archivo en el shell actual escribiendo -
$. test.shEsto tiene el efecto de causar funciones definidas dentro test.sh para ser leído y definido en el shell actual de la siguiente manera:
$ number_one
This is the first function speaking...
This is now the second function speaking...
$Para eliminar la definición de una función del shell, use el comando unset con el .fopción. Este comando también se usa para eliminar la definición de una variable en el shell.
$ unset -f function_nameTodos los comandos de Unix vienen con una serie de opciones opcionales y obligatorias. Es muy común olvidar la sintaxis completa de estos comandos.
Debido a que nadie puede recordar cada comando de Unix y todas sus opciones, tenemos ayuda en línea disponible para mitigar esto desde que Unix estaba en su etapa de desarrollo.
La versión de Unix de Help files son llamados man pages. Si hay un nombre de comando y no está seguro de cómo usarlo, Man Pages le ayudará con cada paso.
Sintaxis
Aquí está el comando simple que lo ayuda a obtener los detalles de cualquier comando de Unix mientras trabaja con el sistema:
$man commandEjemplo
Suponga que hay un comando que requiere que obtenga ayuda; suponga que quiere saber sobrepwd entonces simplemente necesita usar el siguiente comando:
$man pwdEl comando anterior le ayuda con la información completa sobre el pwdmando. Pruébelo usted mismo en el símbolo del sistema para obtener más detalles.
Puede obtener detalles completos sobre man comando en sí mismo usando el siguiente comando:
$man manSecciones de la página de manual
Las páginas de manual generalmente se dividen en secciones, que generalmente varían según la preferencia del autor de la página de manual. La siguiente tabla enumera algunas secciones comunes:
| No Señor. | Sección y descripción |
|---|---|
| 1 | NAME Nombre del comando |
| 2 | SYNOPSIS Parámetros de uso general del comando |
| 3 | DESCRIPTION Describe lo que hace el comando |
| 4 | OPTIONS Describe todos los argumentos u opciones del comando |
| 5 | SEE ALSO Enumera otros comandos que están directamente relacionados con el comando en la página de manual o que se parecen mucho a su funcionalidad. |
| 6 | BUGS Explica cualquier problema o error conocido que exista con el comando o su salida. |
| 7 | EXAMPLES Ejemplos de uso común que le dan al lector una idea de cómo se puede usar el comando. |
| 8 | AUTHORS El autor de la página de manual / comando |
En resumen, las páginas de manual son un recurso vital y la primera vía de investigación cuando se necesita información sobre comandos o archivos en un sistema Unix.
Comandos de shell útiles
El siguiente enlace le ofrece una lista de los comandos de Unix Shell más importantes y más utilizados.
Si no sabe cómo usar ningún comando, utilice la página de manual para obtener detalles completos sobre el comando.
Aquí está la lista de Unix Shell: comandos útiles
En este capítulo, discutiremos en detalle sobre las expresiones regulares con SED en Unix.
Una expresión regular es una cadena que se puede utilizar para describir varias secuencias de caracteres. Las expresiones regulares son utilizadas por varios comandos Unix diferentes, incluyendoed, sed, awk, grep, y en una medida más limitada, vi.
aquí SED representa stream editor. Este editor orientado a flujos fue creado exclusivamente para ejecutar scripts. Por lo tanto, toda la entrada que ingresa pasa a través y va a STDOUT y no cambia el archivo de entrada.
Invocando sed
Antes de comenzar, asegurémonos de tener una copia local de /etc/passwd archivo de texto para trabajar sed.
Como se mencionó anteriormente, sed se puede invocar enviándole datos a través de una tubería de la siguiente manera:
$ cat /etc/passwd | sed
Usage: sed [OPTION]... {script-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression = script
...............................los cat comando vuelca el contenido de /etc/passwd a seda través de la tubería en el espacio del patrón de sed. El espacio de patrón es el búfer de trabajo interno que sed usa para sus operaciones.
La sintaxis general de sed
A continuación se muestra la sintaxis general de sed:
/pattern/actionAquí, pattern es una expresión regular y actiones uno de los comandos dados en la siguiente tabla. Sipattern se omite, action se realiza para cada línea como hemos visto anteriormente.
El carácter de barra (/) que rodea el patrón es obligatorio porque se utilizan como delimitadores.
| No Señor. | Rango y descripción |
|---|---|
| 1 | p Imprime la linea |
| 2 | d Elimina la línea |
| 3 | s/pattern1/pattern2/ Sustituye la primera aparición de patrón1 con patrón2 |
Eliminar todas las líneas con sed
Ahora entenderemos cómo eliminar todas las líneas con sed. Invoque sed nuevamente; pero ahora se supone que el sed usa elediting command delete line, denotado por una sola letra d -
$ cat /etc/passwd | sed 'd' $En lugar de invocar sed enviándole un archivo a través de una tubería, se puede indicar al sed que lea los datos de un archivo, como en el siguiente ejemplo.
El siguiente comando hace exactamente lo mismo que en el ejemplo anterior, sin el comando cat:
$ sed -e 'd' /etc/passwd $Las direcciones sed
El sed también admite direcciones. Las direcciones son ubicaciones particulares en un archivo o un rango donde se debe aplicar un comando de edición en particular. Cuando el sed no encuentra direcciones, realiza sus operaciones en cada línea del archivo.
El siguiente comando agrega una dirección básica al comando sed que ha estado usando:
$ cat /etc/passwd | sed '1d' |more daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh $Observe que el número 1 se agrega antes del delete editmando. Esto le indica al sed que realice el comando de edición en la primera línea del archivo. En este ejemplo, sed eliminará la primera línea de/etc/password e imprima el resto del archivo.
Los rangos de direcciones sed
Ahora entenderemos cómo trabajar con the sed address ranges. Entonces, ¿qué sucede si desea eliminar más de una línea de un archivo? Puede especificar un rango de direcciones con sed de la siguiente manera:
$ cat /etc/passwd | sed '1, 5d' |more games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh $El comando anterior se aplicará en todas las líneas desde 1 hasta 5. Esto elimina las primeras cinco líneas.
Pruebe los siguientes rangos de direcciones:
| No Señor. | Rango y descripción |
|---|---|
| 1 | '4,10d' Las líneas que comienzan a partir de la 4 º hasta el 10 º se eliminan |
| 2 | '10,4d' Solo se elimina la décima línea, porque el sed no funciona en dirección inversa |
| 3 | '4,+5d' Esto coincide con la línea 4 del archivo, elimina esa línea, continúa eliminando las siguientes cinco líneas y luego deja de eliminarse e imprime el resto. |
| 4 | '2,5!d' Esto elimina todo excepto desde la 2ª hasta la 5ª línea |
| 5 | '1~3d' Esto elimina la primera línea, pasa a las siguientes tres líneas y luego elimina la cuarta línea. Sed continúa aplicando este patrón hasta el final del archivo. |
| 6 | '2~2d' Esto le dice a sed que elimine la segunda línea, pase a la siguiente línea, elimine la siguiente línea y repita hasta llegar al final del archivo. |
| 7 | '4,10p' Se imprimen líneas desde la 4ª hasta la 10ª |
| 8 | '4,d' Esto genera el error de sintaxis |
| 9 | ',10d' Esto también generaría un error de sintaxis |
Note - Mientras usa el p acción, debes usar la -nopción para evitar la repetición de la impresión de líneas. Compruebe la diferencia entre los siguientes dos comandos:
$ cat /etc/passwd | sed -n '1,3p' Check the above command without -n as follows − $ cat /etc/passwd | sed '1,3p'El comando de sustitución
El comando de sustitución, denotado por s, sustituirá cualquier cadena que especifique con cualquier otra cadena que especifique.
Para sustituir una cadena por otra, sed necesita tener la información sobre dónde termina la primera cadena y comienza la cadena de sustitución. Para ello, procedemos a sujetar las dos cadenas con la barra inclinada (/) personaje.
El siguiente comando sustituye la primera aparición en una línea de la cadena root con la cuerda amrood.
$ cat /etc/passwd | sed 's/root/amrood/'
amrood:x:0:0:root user:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
..........................Es muy importante tener en cuenta que sed sustituye solo la primera aparición en una línea. Si la raíz de la cadena aparece más de una vez en una línea, solo se reemplazará la primera coincidencia.
Para que sed realice una sustitución global, agregue la letra g hasta el final del comando de la siguiente manera:
$ cat /etc/passwd | sed 's/root/amrood/g'
amrood:x:0:0:amrood user:/amrood:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
...........................Banderas de sustitución
Hay una serie de otros indicadores útiles que se pueden pasar además del g flag, y puede especificar más de uno a la vez.
| No Señor. | Bandera y descripción |
|---|---|
| 1 | g Reemplaza todos los partidos, no solo el primer partido |
| 2 | NUMBER Reemplaza solo NUMBER th partido |
| 3 | p Si se realizó una sustitución, imprime el espacio del patrón |
| 4 | w FILENAME Si se realizó una sustitución, escribe el resultado en FILENAME |
| 5 | I or i Coincidencias sin distinción entre mayúsculas y minúsculas |
| 6 | M or m Además del comportamiento normal de los caracteres especiales de expresión regular ^ y $, this flag causes ^ to match the empty string after a newline and $ para hacer coincidir la cadena vacía antes de una nueva línea |
Usar un separador de cadenas alternativo
Suponga que tiene que hacer una sustitución en una cadena que incluye el carácter de barra diagonal. En este caso, puede especificar un separador diferente proporcionando el carácter designado después dels.
$ cat /etc/passwd | sed 's:/root:/amrood:g'
amrood:x:0:0:amrood user:/amrood:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/shEn el ejemplo anterior, hemos utilizado : como el delimiter en lugar de barra oblicua / porque estábamos intentando buscar /root en lugar de la raíz simple.
Reemplazo con espacio vacío
Utilice una cadena de sustitución vacía para eliminar la cadena raíz de la /etc/passwd archivo completo -
$ cat /etc/passwd | sed 's/root//g'
:x:0:0::/:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/shSustitución de direcciones
Si quieres sustituir la cuerda sh con la cuerda quiet solo en la línea 10, puede especificarlo de la siguiente manera:
$ cat /etc/passwd | sed '10s/sh/quiet/g'
root:x:0:0:root user:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/quietDe manera similar, para hacer una sustitución de rango de direcciones, puede hacer algo como lo siguiente:
$ cat /etc/passwd | sed '1,5s/sh/quiet/g'
root:x:0:0:root user:/root:/bin/quiet
daemon:x:1:1:daemon:/usr/sbin:/bin/quiet
bin:x:2:2:bin:/bin:/bin/quiet
sys:x:3:3:sys:/dev:/bin/quiet
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/shComo puede ver en la salida, las primeras cinco líneas tenían la cadena sh cambiado a quiet, pero el resto de las líneas quedaron intactas.
El comando de emparejamiento
Usarías el p opción junto con la -n opción para imprimir todas las líneas coincidentes de la siguiente manera:
$ cat testing | sed -n '/root/p'
root:x:0:0:root user:/root:/bin/sh
[root@ip-72-167-112-17 amrood]# vi testing
root:x:0:0:root user:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/shUsar expresión regular
Al hacer coincidir patrones, puede utilizar la expresión regular que proporciona más flexibilidad.
Verifique el siguiente ejemplo que coincide con todas las líneas que comienzan con daemon y luego las elimina:
$ cat testing | sed '/^daemon/d'
root:x:0:0:root user:/root:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/shA continuación se muestra el ejemplo que elimina todas las líneas que terminan con sh -
$ cat testing | sed '/sh$/d'
sync:x:4:65534:sync:/bin:/bin/syncLa siguiente tabla enumera cuatro caracteres especiales que son muy útiles en expresiones regulares.
| No Señor. | Descripción del personaje |
|---|---|
| 1 | ^ Coincide con el comienzo de las líneas |
| 2 | $ Coincide con el final de las líneas |
| 3 | . Coincide con cualquier carácter individual |
| 4 | * Coincide con cero o más ocurrencias del carácter anterior |
| 5 | [chars] Coincide con cualquiera de los caracteres dados en chars, donde chars es una secuencia de caracteres. Puede utilizar el carácter - para indicar un rango de caracteres. |
Personajes a juego
Mira algunas expresiones más para demostrar el uso de metacharacters. Por ejemplo, el siguiente patrón:
| No Señor. | Expresión y descripción |
|---|---|
| 1 | /a.c/ Coincide con líneas que contienen cadenas como a+c, a-c, abc, matchy a3c |
| 2 | /a*c/ Coincide con las mismas cadenas junto con cadenas como ace, yaccy arctic |
| 3 | /[tT]he/ Coincide con la cuerda The y the |
| 4 | /^$/ Coincide con líneas en blanco |
| 5 | /^.*$/ Coincide con una línea completa, sea lo que sea |
| 6 | / */ Coincide con uno o más espacios |
| 7 | /^$/ Partidos blank líneas |
La siguiente tabla muestra algunos conjuntos de caracteres de uso frecuente:
| No Señor. | Conjunto y descripción |
|---|---|
| 1 | [a-z] Coincide con una sola letra minúscula |
| 2 | [A-Z] Coincide con una sola letra mayúscula |
| 3 | [a-zA-Z] Coincide con una sola letra |
| 4 | [0-9] Coincide con un solo número |
| 5 | [a-zA-Z0-9] Coincide con una sola letra o número |
Palabras clave de clase de personaje
Algunas palabras clave especiales están comúnmente disponibles para regexps, especialmente las utilidades GNU que emplean regexps. Son muy útiles para las expresiones regulares sed, ya que simplifican las cosas y mejoran la legibilidad.
Por ejemplo, los personajes a through z y los personajes A through Z, constituyen una de esas clases de caracteres que tiene la palabra clave [[:alpha:]]
Usando la palabra clave de la clase de caracteres alfabéticos, este comando imprime solo aquellas líneas en el /etc/syslog.conf archivo que comienza con una letra del alfabeto -
$ cat /etc/syslog.conf | sed -n '/^[[:alpha:]]/p'
authpriv.* /var/log/secure
mail.* -/var/log/maillog
cron.* /var/log/cron
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.logLa siguiente tabla es una lista completa de las palabras clave de clase de caracteres disponibles en GNU sed.
| No Señor. | Clase de personaje y descripción |
|---|---|
| 1 | [[:alnum:]] Alfanumérico [az AZ 0-9] |
| 2 | [[:alpha:]] Alfabético [az AZ] |
| 3 | [[:blank:]] Caracteres en blanco (espacios o tabulaciones) |
| 4 | [[:cntrl:]] Personajes de control |
| 5 | [[:digit:]] Números [0-9] |
| 6 | [[:graph:]] Cualquier carácter visible (excluye los espacios en blanco) |
| 7 | [[:lower:]] Letras minúsculas [az] |
| 8 | [[:print:]] Caracteres imprimibles (caracteres sin control) |
| 9 | [[:punct:]] Caracteres de puntuación |
| 10 | [[:space:]] Espacio en blanco |
| 11 | [[:upper:]] Letras mayúsculas [AZ] |
| 12 | [[:xdigit:]] Dígitos hexadecimales [0-9 af AF] |
Aampersand referencias
los sed metacharacter &representa el contenido del patrón que se emparejó. Por ejemplo, digamos que tiene un archivo llamadophone.txt lleno de números de teléfono, como los siguientes:
5555551212
5555551213
5555551214
6665551215
6665551216
7775551217Quieres hacer el area code(los primeros tres dígitos) entre paréntesis para facilitar la lectura. Para hacer esto, puede usar el carácter de reemplazo comercial:
$ sed -e 's/^[[:digit:]][[:digit:]][[:digit:]]/(&)/g' phone.txt
(555)5551212
(555)5551213
(555)5551214
(666)5551215
(666)5551216
(777)5551217Aquí, en la parte del patrón, está haciendo coincidir los primeros 3 dígitos y luego usando & está reemplazando esos 3 dígitos con los alrededores parentheses.
Uso de varios comandos sed
Puede usar varios comandos sed en un solo comando sed de la siguiente manera:
$ sed -e 'command1' -e 'command2' ... -e 'commandN' filesaquí command1 mediante commandNson comandos sed del tipo discutido anteriormente. Estos comandos se aplican a cada una de las líneas de la lista de archivos proporcionada por archivos.
Usando el mismo mecanismo, podemos escribir el ejemplo de número de teléfono anterior de la siguiente manera:
$ sed -e 's/^[[:digit:]]\{3\}/(&)/g' \
-e 's/)[[:digit:]]\{3\}/&-/g' phone.txt
(555)555-1212
(555)555-1213
(555)555-1214
(666)555-1215
(666)555-1216
(777)555-1217Note - En el ejemplo anterior, en lugar de repetir la palabra clave de clase de carácter [[:digit:]] tres veces, lo reemplazamos con \{3\}, lo que significa que la expresión regular anterior coincide tres veces. También hemos utilizado\ para dar un salto de línea y esto debe eliminarse antes de ejecutar el comando.
Volver Referencias
los ampersand metacharacteres útil, pero aún más útil es la capacidad de definir regiones específicas en expresiones regulares. Estas regiones especiales se pueden usar como referencia en sus cadenas de reemplazo. Al definir partes específicas de una expresión regular, puede volver a referirse a esas partes con un carácter de referencia especial.
Que hacer back references, primero debe definir una región y luego volver a referirse a esa región. Para definir una región, insertabackslashed parenthesesalrededor de cada región de interés. La primera región que rodea con barras invertidas se hace referencia a continuación mediante\1, la segunda región por \2, y así.
Asumiendo phone.txt tiene el siguiente texto:
(555)555-1212
(555)555-1213
(555)555-1214
(666)555-1215
(666)555-1216
(777)555-1217Prueba el siguiente comando:
$ cat phone.txt | sed 's/\(.*)\)\(.*-\)\(.*$\)/Area \
code: \1 Second: \2 Third: \3/'
Area code: (555) Second: 555- Third: 1212
Area code: (555) Second: 555- Third: 1213
Area code: (555) Second: 555- Third: 1214
Area code: (666) Second: 555- Third: 1215
Area code: (666) Second: 555- Third: 1216
Area code: (777) Second: 555- Third: 1217Note - En el ejemplo anterior, cada expresión regular dentro del paréntesis sería referenciada por \1, \2y así. Hemos usado\para dar salto de línea aquí. Esto debe eliminarse antes de ejecutar el comando.
Un sistema de archivos es una colección lógica de archivos en una partición o un disco. Una partición es un contenedor de información y puede abarcar todo un disco duro si se desea.
Su disco duro puede tener varias particiones que generalmente contienen un solo sistema de archivos, como un sistema de archivos que aloja el /file system u otro que contenga el /home file system.
Un sistema de archivos por partición permite el mantenimiento lógico y la gestión de diferentes sistemas de archivos.
Todo en Unix se considera un archivo, incluidos los dispositivos físicos como DVD-ROM, dispositivos USB y unidades de disquete.
Estructura de directorios
Unix usa una estructura de sistema de archivos jerárquica, muy parecida a un árbol al revés, con la raíz (/) en la base del sistema de archivos y todos los demás directorios extendiéndose desde allí.
Un sistema de archivos Unix es una colección de archivos y directorios que tiene las siguientes propiedades:
Tiene un directorio raíz (/) que contiene otros archivos y directorios.
Cada archivo o directorio se identifica de forma única por su nombre, el directorio en el que reside y un identificador único, normalmente llamado inode.
Por convención, el directorio raíz tiene un inode número de 2 y el lost+found el directorio tiene un inode número de 3. Números de inode0 y 1no se utilizan. Los números de inodo de archivo se pueden ver especificando el-i option a ls command.
Es autónomo. No hay dependencias entre un sistema de archivos y otro.
Los directorios tienen propósitos específicos y generalmente contienen los mismos tipos de información para localizar archivos fácilmente. A continuación se muestran los directorios que existen en las versiones principales de Unix:
| No Señor. | Directorio y descripción |
|---|---|
| 1 | / Este es el directorio raíz que debe contener solo los directorios necesarios en el nivel superior de la estructura de archivos. |
| 2 | /bin Aquí es donde se encuentran los archivos ejecutables. Estos archivos están disponibles para todos los usuarios. |
| 3 | /dev Estos son controladores de dispositivo |
| 4 | /etc Comandos de directorio del supervisor, archivos de configuración, archivos de configuración de disco, listas de usuarios válidas, grupos, ethernet, hosts, dónde enviar mensajes críticos |
| 5 | /lib Contiene archivos de biblioteca compartidos y, a veces, otros archivos relacionados con el kernel |
| 6 | /boot Contiene archivos para arrancar el sistema. |
| 7 | /home Contiene el directorio de inicio para usuarios y otras cuentas. |
| 8 | /mnt Se utiliza para montar otros sistemas de archivos temporales, como cdrom y floppy Para el CD-ROM conducir y floppy diskette drive, respectivamente |
| 9 | /proc Contiene todos los procesos marcados como archivo por process number u otra información que sea dinámica para el sistema |
| 10 | /tmp Contiene archivos temporales utilizados entre los inicios del sistema |
| 11 | /usr Se utiliza para diversos fines y puede ser utilizado por muchos usuarios. Incluye comandos administrativos, archivos compartidos, archivos de biblioteca y otros |
| 12 | /var Normalmente contiene archivos de longitud variable, como archivos de registro e impresión y cualquier otro tipo de archivo que pueda contener una cantidad variable de datos. |
| 13 | /sbin Contiene archivos binarios (ejecutables), generalmente para la administración del sistema. Por ejemplo,fdisk y ifconfig utlities |
| 14 | /kernel Contiene archivos del kernel |
Navegar por el sistema de archivos
Ahora que comprende los conceptos básicos del sistema de archivos, puede comenzar a navegar hasta los archivos que necesita. Los siguientes comandos se utilizan para navegar por el sistema:
| No Señor. | Comando y descripción |
|---|---|
| 1 | cat filename Muestra un nombre de archivo |
| 2 | cd dirname Lo lleva al directorio identificado |
| 3 | cp file1 file2 Copia un archivo / directorio en la ubicación especificada |
| 4 | file filename Identifica el tipo de archivo (binario, texto, etc.) |
| 5 | find filename dir Encuentra un archivo / directorio |
| 6 | head filename Muestra el comienzo de un archivo. |
| 7 | less filename Navega por un archivo desde el final o el principio |
| 8 | ls dirname Muestra el contenido del directorio especificado. |
| 9 | mkdir dirname Crea el directorio especificado |
| 10 | more filename Navega por un archivo desde el principio hasta el final |
| 11 | mv file1 file2 Mueve la ubicación o cambia el nombre de un archivo / directorio |
| 12 | pwd Muestra el directorio actual en el que se encuentra el usuario |
| 13 | rm filename Elimina un archivo |
| 14 | rmdir dirname Elimina un directorio |
| 15 | tail filename Muestra el final de un archivo. |
| dieciséis | touch filename Crea un archivo en blanco o modifica un archivo existente o sus atributos |
| 17 | whereis filename Muestra la ubicación de un archivo. |
| 18 | which filename Muestra la ubicación de un archivo si está en su RUTA |
Puede utilizar la Ayuda de la página de manual para comprobar la sintaxis completa de cada comando mencionado aquí.
El comando df
La primera forma de administrar su espacio de partición es con el df (disk free)mando. El comandodf -k (disk free) muestra el disk space usage in kilobytes, como se muestra a continuación -
$df -k Filesystem 1K-blocks Used Available Use% Mounted on /dev/vzfs 10485760 7836644 2649116 75% / /devices 0 0 0 0% /devices $Algunos de los directorios, como /devices, muestra 0 en las columnas de kbytes, usado y disponible, así como 0% para la capacidad. Estos son sistemas de archivos especiales (o virtuales) y, aunque residen en el disco debajo de /, por sí mismos no consumen espacio en disco.
los df -kla salida es generalmente la misma en todos los sistemas Unix. Esto es lo que generalmente incluye:
| No Señor. | Columna y descripción |
|---|---|
| 1 | Filesystem El nombre del sistema de archivos físico |
| 2 | kbytes Total de kilobytes de espacio disponible en el medio de almacenamiento |
| 3 | used Total de kilobytes de espacio utilizado (por archivos) |
| 4 | avail Total de kilobytes disponibles para su uso |
| 5 | capacity Porcentaje del espacio total utilizado por archivos |
| 6 | Mounted on En qué está montado el sistema de archivos |
Puedes usar el -h (human readable) option para mostrar la salida en un formato que muestre el tamaño en una notación más fácil de entender.
El du Command
los du (disk usage) command le permite especificar directorios para mostrar el uso de espacio en disco en un directorio en particular.
Este comando es útil si desea determinar cuánto espacio ocupa un directorio en particular. El siguiente comando muestra el número de bloques consumidos por cada directorio. Un solo bloque puede tomar 512 Bytes o 1 Kilo Byte dependiendo de su sistema.
$du /etc 10 /etc/cron.d 126 /etc/default 6 /etc/dfs ... $los -h La opción hace que la salida sea más fácil de comprender -
$du -h /etc 5k /etc/cron.d 63k /etc/default 3k /etc/dfs ... $Montaje del sistema de archivos
Se debe montar un sistema de archivos para que el sistema pueda utilizarlo. Para ver lo que está actualmente montado (disponible para su uso) en su sistema, use el siguiente comando:
$ mount /dev/vzfs on / type reiserfs (rw,usrquota,grpquota) proc on /proc type proc (rw,nodiratime) devpts on /dev/pts type devpts (rw) $los /mntEl directorio, según la convención de Unix, es donde se encuentran los montajes temporales (como unidades de CDROM, unidades de red remotas y unidades de disquete). Si necesita montar un sistema de archivos, puede utilizar el comando mount con la siguiente sintaxis:
mount -t file_system_type device_to_mount directory_to_mount_toPor ejemplo, si desea montar un CD-ROM al directorio /mnt/cdrom, puede escribir -
$ mount -t iso9660 /dev/cdrom /mnt/cdromEsto supone que su dispositivo de CD-ROM se llama /dev/cdrom y que quieres montarlo /mnt/cdrom. Consulte la página de manual de mount para obtener información más específica o escriba mount-h en la línea de comandos para obtener información de ayuda.
Después del montaje, puede usar el comando cd para navegar por el nuevo sistema de archivos disponible a través del punto de montaje que acaba de crear.
Desmontar el sistema de archivos
Para desmontar (eliminar) el sistema de archivos de su sistema, utilice el umount comando identificando el punto de montaje o dispositivo.
Por ejemplo, to unmount cdrom, use el siguiente comando -
$ umount /dev/cdromlos mount command le permite acceder a sus sistemas de archivos, pero en la mayoría de los sistemas Unix modernos, el automount function hace que este proceso sea invisible para el usuario y no requiere ninguna intervención.
Cuotas de usuarios y grupos
Las cuotas de usuario y grupo proporcionan los mecanismos mediante los cuales la cantidad de espacio utilizado por un solo usuario o todos los usuarios dentro de un grupo específico puede limitarse a un valor definido por el administrador.
Las cuotas operan alrededor de dos límites que permiten al usuario tomar alguna acción si la cantidad de espacio o la cantidad de bloques de disco comienzan a exceder los límites definidos por el administrador:
Soft Limit - Si el usuario supera el límite definido, existe un período de gracia que permite al usuario liberar espacio.
Hard Limit - Cuando se alcanza el límite estricto, independientemente del período de gracia, no se pueden asignar más archivos o bloques.
Hay varios comandos para administrar cuotas:
| No Señor. | Comando y descripción |
|---|---|
| 1 | quota Muestra el uso del disco y los límites para un usuario del grupo. |
| 2 | edquota Este es un editor de cuotas. La cuota de usuarios o grupos se puede editar usando este comando |
| 3 | quotacheck Escanea un sistema de archivos para el uso del disco, crea, verifica y repara archivos de cuotas |
| 4 | setquota Este es un editor de cuotas de línea de comandos |
| 5 | quotaon Esto anuncia al sistema que las cuotas de disco deben habilitarse en uno o más sistemas de archivos. |
| 6 | quotaoff Esto le anuncia al sistema que las cuotas de disco deben deshabilitarse para uno o más sistemas de archivos. |
| 7 | repquota Esto imprime un resumen del uso del disco y las cuotas para los sistemas de archivos especificados. |
Puede utilizar la Ayuda de la página de manual para comprobar la sintaxis completa de cada comando mencionado aquí.
En este capítulo, discutiremos en detalle sobre la administración de usuarios en Unix.
Hay tres tipos de cuentas en un sistema Unix:
Cuenta raíz
Esto también se llama superusery tendría un control completo y sin restricciones del sistema. Un superusuario puede ejecutar cualquier comando sin ninguna restricción. Este usuario debe asumirse como administrador del sistema.
Cuentas del sistema
Las cuentas del sistema son las necesarias para el funcionamiento de componentes específicos del sistema, por ejemplo, cuentas de correo y sshdcuentas. Estas cuentas suelen ser necesarias para alguna función específica en su sistema, y cualquier modificación a ellas podría afectar negativamente al sistema.
Cuentas de usuario
Las cuentas de usuario proporcionan acceso interactivo al sistema para usuarios y grupos de usuarios. Los usuarios generales generalmente se asignan a estas cuentas y generalmente tienen acceso limitado a los archivos y directorios críticos del sistema.
Unix admite un concepto de cuenta de grupo que agrupa lógicamente varias cuentas. Cada cuenta sería parte de otra cuenta grupal. Un grupo Unix juega un papel importante en el manejo de permisos de archivos y administración de procesos.
Gestión de usuarios y grupos
Hay cuatro archivos principales de administración de usuarios:
/etc/passwd- Mantiene la información de la cuenta de usuario y la contraseña. Este archivo contiene la mayor parte de la información sobre las cuentas del sistema Unix.
/etc/shadow- Contiene la contraseña cifrada de la cuenta correspondiente. No todos los sistemas admiten este archivo.
/etc/group - Este archivo contiene la información del grupo para cada cuenta.
/etc/gshadow - Este archivo contiene información segura de la cuenta del grupo.
Verifique todos los archivos anteriores usando el cat mando.
La siguiente tabla enumera los comandos que están disponibles en la mayoría de los sistemas Unix para crear y administrar cuentas y grupos:
| No Señor. | Comando y descripción |
|---|---|
| 1 | useradd Agrega cuentas al sistema |
| 2 | usermod Modifica los atributos de la cuenta |
| 3 | userdel Elimina cuentas del sistema |
| 4 | groupadd Agrega grupos al sistema |
| 5 | groupmod Modifica los atributos del grupo |
| 6 | groupdel Elimina grupos del sistema |
Puede utilizar la Ayuda de la página de manual para comprobar la sintaxis completa de cada comando mencionado aquí.
Crear un grupo
Ahora entenderemos cómo crear un grupo. Para esto, necesitamos crear grupos antes de crear cualquier cuenta, de lo contrario, podemos hacer uso de los grupos existentes en nuestro sistema. Tenemos todos los grupos listados en/etc/groups archivo.
Todos los grupos predeterminados son grupos específicos de cuentas del sistema y no se recomienda usarlos para cuentas normales. Entonces, la siguiente es la sintaxis para crear una nueva cuenta de grupo:
groupadd [-g gid [-o]] [-r] [-f] groupnameLa siguiente tabla enumera los parámetros:
| No Señor. | Opción y descripción |
|---|---|
| 1 | -g GID El valor numérico de la identificación del grupo. |
| 2 | -o Esta opción permite agregar un grupo con un GID no único |
| 3 | -r Esta bandera instruye groupadd para agregar una cuenta del sistema |
| 4 | -f Esta opción hace que se salga con el estado de éxito, si el grupo especificado ya existe. Con -g, si el GID especificado ya existe, se elige otro GID (único) |
| 5 | groupname Nombre del grupo real que se creará |
Si no especifica ningún parámetro, el sistema utiliza los valores predeterminados.
El siguiente ejemplo crea un grupo de desarrolladores con valores predeterminados, que es muy aceptable para la mayoría de los administradores.
$ groupadd developersModificar un grupo
Para modificar un grupo, use el groupmod sintaxis -
$ groupmod -n new_modified_group_name old_group_namePara cambiar el nombre del grupo developers_2 a desarrollador, escriba -
$ groupmod -n developer developer_2Así es como cambiará el GID financiero a 545:
$ groupmod -g 545 developerEliminar un grupo
Ahora entenderemos cómo eliminar un grupo. Para eliminar un grupo existente, todo lo que necesita es elgroupdel command y el group name. Para eliminar el grupo financiero, el comando es:
$ groupdel developerEsto elimina solo el grupo, no los archivos asociados con ese grupo. Sus propietarios aún pueden acceder a los archivos.
Crea una cuenta
Veamos cómo crear una nueva cuenta en su sistema Unix. A continuación se muestra la sintaxis para crear una cuenta de usuario:
useradd -d homedir -g groupname -m -s shell -u userid accountnameLa siguiente tabla enumera los parámetros:
| No Señor. | Opción y descripción |
|---|---|
| 1 | -d homedir Especifica el directorio de inicio de la cuenta. |
| 2 | -g groupname Especifica una cuenta de grupo para esta cuenta |
| 3 | -m Crea el directorio de inicio si no existe |
| 4 | -s shell Especifica el shell predeterminado para esta cuenta. |
| 5 | -u userid Puede especificar una identificación de usuario para esta cuenta |
| 6 | accountname Nombre de cuenta real que se creará |
Si no especifica ningún parámetro, el sistema utiliza los valores predeterminados. losuseradd comando modifica el /etc/passwd, /etc/shadowy /etc/group archivos y crea un directorio de inicio.
A continuación se muestra el ejemplo que crea una cuenta mcmohd, configurando su directorio de inicio en /home/mcmohd y el grupo como developers. Este usuario tendría asignado Korn Shell.
$ useradd -d /home/mcmohd -g developers -s /bin/ksh mcmohdAntes de emitir el comando anterior, asegúrese de que ya haya creado el grupo de desarrolladores con elgroupadd mando.
Una vez que se crea una cuenta, puede establecer su contraseña utilizando el passwd comando de la siguiente manera:
$ passwd mcmohd20
Changing password for user mcmohd20.
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.Cuando escribes passwd accountname, le da la opción de cambiar la contraseña, siempre que sea un superusuario. De lo contrario, puede cambiar solo su contraseña usando el mismo comando pero sin especificar el nombre de su cuenta.
Modificar una cuenta
los usermodEl comando le permite realizar cambios en una cuenta existente desde la línea de comando. Utiliza los mismos argumentos que eluseradd comando, más el argumento -l, que le permite cambiar el nombre de la cuenta.
Por ejemplo, para cambiar el nombre de la cuenta mcmohd a mcmohd20 y para cambiar el directorio de inicio en consecuencia, deberá ejecutar el siguiente comando:
$ usermod -d /home/mcmohd20 -m -l mcmohd mcmohd20Eliminar una cuenta
los userdelEl comando se puede utilizar para eliminar un usuario existente. Este es un comando muy peligroso si no se usa con precaución.
Solo hay un argumento u opción disponible para el comando .r, para eliminar el directorio de inicio y el archivo de correo de la cuenta.
Por ejemplo, para eliminar la cuenta mcmohd20 , ejecute el siguiente comando:
$ userdel -r mcmohd20Si desea conservar el directorio de inicio para realizar copias de seguridad, omita el -ropción. Puede eliminar el directorio de inicio según sea necesario más adelante.
En este capítulo, discutiremos en detalle sobre el rendimiento del sistema en Unix.
Le presentaremos algunas herramientas gratuitas que están disponibles para monitorear y administrar el rendimiento en sistemas Unix. Estas herramientas también proporcionan pautas sobre cómo diagnosticar y solucionar problemas de rendimiento en el entorno Unix.
Unix tiene los siguientes tipos de recursos principales que deben monitorearse y ajustarse:
CPU
Memory
Disk space
Communications lines
I/O Time
Network Time
Applications programs
Componentes de rendimiento
La siguiente tabla enumera cinco componentes principales que ocupan el tiempo del sistema:
| No Señor. | Descripción de Componente |
|---|---|
| 1 | User State CPU La cantidad real de tiempo que la CPU dedica a ejecutar el programa del usuario en el estado de usuario. Incluye el tiempo dedicado a ejecutar llamadas a la biblioteca, pero no incluye el tiempo invertido en el kernel en su nombre. |
| 2 | System State CPU Esta es la cantidad de tiempo que la CPU pasa en el estado del sistema en nombre de este programa. TodasI/O routinesrequieren servicios del kernel. El programador puede afectar este valor bloqueando las transferencias de E / S |
| 3 | I/O Time and Network Time Esta es la cantidad de tiempo dedicado a mover datos y atender solicitudes de E / S |
| 4 | Virtual Memory Performance Esto incluye cambio de contexto e intercambio |
| 5 | Application Program Tiempo dedicado a ejecutar otros programas: cuando el sistema no está dando servicio a esta aplicación porque otra aplicación tiene actualmente la CPU |
Herramientas de rendimiento
Unix proporciona las siguientes herramientas importantes para medir y ajustar el rendimiento del sistema Unix:
| No Señor. | Comando y descripción |
|---|---|
| 1 | nice/renice Ejecuta un programa con prioridad de programación modificada |
| 2 | netstat Imprime conexiones de red, tablas de enrutamiento, estadísticas de interfaz, conexiones de enmascaramiento y membresías de multidifusión |
| 3 | time Ayuda a cronometrar un comando simple o dar uso de recursos |
| 4 | uptime Este es el promedio de carga del sistema |
| 5 | ps Reporta una instantánea de los procesos actuales |
| 6 | vmstat Reporta estadísticas de memoria virtual |
| 7 | gprof Muestra los datos del perfil del gráfico de llamadas |
| 8 | prof Facilita la elaboración de perfiles de procesos |
| 9 | top Muestra las tareas del sistema |
Puede utilizar la Ayuda de la página de manual para comprobar la sintaxis completa de cada comando mencionado aquí.
En este capítulo, discutiremos en detalle sobre el registro del sistema en Unix.
Los sistemas Unix tienen un sistema de registro muy flexible y potente, que le permite registrar casi cualquier cosa que pueda imaginar y luego manipular los registros para recuperar la información que necesita.
Muchas versiones de Unix proporcionan una función de registro de propósito general llamada syslog. Los programas individuales que necesitan tener información registrada, envían la información a syslog.
Unix syslog es una función de registro del sistema uniforme y configurable por host. El sistema utiliza un proceso de registro del sistema centralizado que ejecuta el programa./etc/syslogd o /etc/syslog.
El funcionamiento del registrador del sistema es bastante sencillo. Los programas envían sus entradas de registro a syslogd , que consulta el archivo de configuración/etc/syslogd.conf o /etc/syslog y, cuando se encuentra una coincidencia, escribe el mensaje de registro en el archivo de registro deseado.
Hay cuatro términos básicos de Syslog que debe comprender:
| No Señor. | Término y descripción |
|---|---|
| 1 | Facility El identificador utilizado para describir la aplicación o proceso que envió el mensaje de registro. Por ejemplo, correo, kernel y ftp. |
| 2 | Priority Un indicador de la importancia del mensaje. Los niveles se definen dentro de syslog como pautas, desde la información de depuración hasta los eventos críticos. |
| 3 | Selector Una combinación de una o más instalaciones y niveles. Cuando un evento entrante coincide con un selector, se realiza una acción. |
| 4 | Action Qué sucede con un mensaje entrante que coincide con un selector: las acciones pueden escribir el mensaje en un archivo de registro, enviar el mensaje a una consola u otro dispositivo, escribir el mensaje a un usuario que haya iniciado sesión o enviar el mensaje a otro servidor syslog. |
Instalaciones de Syslog
Ahora entenderemos acerca de las instalaciones de syslog. Aquí están las facilidades disponibles para el selector. No todas las funciones están presentes en todas las versiones de Unix.
| Instalaciones | Descripción |
|---|---|
| 1 | auth Actividad relacionada con la solicitud de nombre y contraseña (getty, su, login) |
| 2 | authpriv Igual que la autenticación, pero se registra en un archivo que solo pueden leer los usuarios seleccionados |
| 3 | console Se utiliza para capturar mensajes que generalmente se dirigen a la consola del sistema. |
| 4 | cron Mensajes del programador del sistema cron |
| 5 | daemon Demonio del sistema atrapa todo |
| 6 | ftp Mensajes relacionados con el demonio ftp |
| 7 | kern Mensajes del kernel |
| 8 | local0.local7 Instalaciones locales definidas por sitio |
| 9 | lpr Mensajes del sistema de impresión de líneas |
| 10 | Mensajes relacionados con el sistema de correo |
| 11 | mark Pseudoevento utilizado para generar marcas de tiempo en archivos de registro |
| 12 | news Mensajes relacionados con el protocolo de noticias de red (nntp) |
| 13 | ntp Mensajes relacionados con el protocolo de tiempo de la red |
| 14 | user Procesos de usuario habituales |
| 15 | uucp Subsistema UUCP |
Prioridades de Syslog
Las prioridades de syslog se resumen en la siguiente tabla:
| No Señor. | Prioridad y descripción |
|---|---|
| 1 | emerg Condición de emergencia, como una caída inminente del sistema, generalmente se transmite a todos los usuarios |
| 2 | alert Condición que debe corregirse de inmediato, como una base de datos del sistema dañada |
| 3 | crit Condición crítica, como un error de hardware |
| 4 | err Error ordinario |
| 5 | Warning Advertencia |
| 6 | notice Condición que no es un error, pero que posiblemente deba manejarse de una manera especial |
| 7 | info Mensaje informativo |
| 8 | debug Mensajes que se utilizan al depurar programas |
| 9 | none Pseudo nivel utilizado para especificar que no se registren mensajes |
La combinación de instalaciones y niveles le permite discernir qué se registra y adónde va esa información.
A medida que cada programa envía sus mensajes debidamente al registrador del sistema, el registrador toma decisiones sobre qué hacer un seguimiento y qué descartar en función de los niveles definidos en el selector.
Cuando especifica un nivel, el sistema hará un seguimiento de todo en ese nivel y más alto.
El archivo /etc/syslog.conf
los /etc/syslog.confel archivo controla dónde se registran los mensajes. Un típicosyslog.conf el archivo podría verse así:
*.err;kern.debug;auth.notice /dev/console
daemon,auth.notice /var/log/messages
lpr.info /var/log/lpr.log
mail.* /var/log/mail.log
ftp.* /var/log/ftp.log
auth.* @prep.ai.mit.edu
auth.* root,amrood
netinfo.err /var/log/netinfo.log
install.* /var/log/install.log
*.emerg *
*.alert |program_name
mark.* /dev/consoleCada línea del archivo contiene dos partes:
UN message selectorque especifica qué tipo de mensajes registrar. Por ejemplo, todos los mensajes de error o todos los mensajes de depuración del kernel.
Un action fieldque dice lo que se debe hacer con el mensaje. Por ejemplo, póngalo en un archivo o envíe el mensaje al terminal de un usuario.
A continuación se muestran los puntos notables para la configuración anterior:
Los selectores de mensajes tienen dos partes: a facility y a priority. Por ejemplo, kern.debug selecciona todos los mensajes de depuración (la prioridad) generados por el kernel (la instalación).
El selector de mensajes kern.debug selecciona todas las prioridades que son mayores que debug.
Un asterisco en lugar de la instalación o la prioridad indica "todos". Por ejemplo,*.debug significa todos los mensajes de depuración, mientras que kern.* significa todos los mensajes generados por el kernel.
También puede utilizar comas para especificar varias instalaciones. Se pueden agrupar dos o más selectores mediante un punto y coma.
Acciones de registro
El campo de acción especifica una de las cinco acciones:
Registrar mensaje en un archivo o dispositivo. Por ejemplo,/var/log/lpr.log o /dev/console.
Envíe un mensaje a un usuario. Puede especificar varios nombres de usuario separándolos con comas; por ejemplo, root, amrood.
Envíe un mensaje a todos los usuarios. En este caso, el campo de acción consta de un asterisco; por ejemplo, *.
Canalice el mensaje a un programa. En este caso, el programa se especifica después del símbolo de tubería Unix (|).
Envíe el mensaje al syslog en otro host. En este caso, el campo de acción consta de un nombre de host, precedido por una arroba; por ejemplo, @ tutorialspoint.com.
El comando logger
Unix proporciona el loggercomando, que es un comando extremadamente útil para lidiar con el registro del sistema. loslogger El comando envía mensajes de registro al demonio syslogd y, en consecuencia, provoca el registro del sistema.
Esto significa que podemos verificar desde la línea de comando en cualquier momento syslogddaemon y su configuración. El comando del registrador proporciona un método para agregar entradas de una línea al archivo de registro del sistema desde la línea de comandos.
El formato del comando es:
logger [-i] [-f file] [-p priority] [-t tag] [message]...Aquí está el detalle de los parámetros:
| No Señor. | Opción y descripción |
|---|---|
| 1 | -f filename Utiliza el contenido del archivo nombre de archivo como mensaje para registrar. |
| 2 | -i Registra el ID de proceso del proceso del registrador con cada línea. |
| 3 | -p priority Ingresa el mensaje con la prioridad especificada (entrada de selector especificada); la prioridad del mensaje se puede especificar numéricamente o como un par de facilidad.prioridad. La prioridad predeterminada es user.notice. |
| 4 | -t tag Marca cada línea agregada al registro con la etiqueta especificada. |
| 5 | message Los argumentos de cadena cuyo contenido se concatenan juntos en el orden especificado, separados por el espacio. |
Puede utilizar la Ayuda de la página de manual para comprobar la sintaxis completa de este comando.
Rotación de registros
Los archivos de registro tienden a crecer muy rápido y consumen grandes cantidades de espacio en disco. Para habilitar las rotaciones de registros, la mayoría de las distribuciones utilizan herramientas comonewsyslog o logrotate.
Estas herramientas deben llamarse en un intervalo de tiempo frecuente utilizando el cron daemon. Consulte las páginas de manual de newsyslog o logrotate para obtener más detalles.
Ubicaciones importantes de registros
Todas las aplicaciones del sistema crean sus archivos de registro en /var/logy sus subdirectorios. Aquí hay algunas aplicaciones importantes y sus directorios de registro correspondientes:
| Solicitud | Directorio |
|---|---|
| httpd | / var / log / httpd |
| samba | / var / log / samba |
| cron | / var / log / |
| correo | / var / log / |
| mysql | / var / log / |
En este capítulo, discutiremos en detalle sobre señales y trampas en Unix.
Las señales son interrupciones de software enviadas a un programa para indicar que ha ocurrido un evento importante. Los eventos pueden variar desde solicitudes de usuarios hasta errores de acceso ilegal a la memoria. Algunas señales, como la señal de interrupción, indican que un usuario le ha pedido al programa que haga algo que no está en el flujo de control habitual.
La siguiente tabla enumera las señales comunes que puede encontrar y desea utilizar en sus programas:
| Nombre de la señal | Número de señal | Descripción |
|---|---|---|
| SIGHUP | 1 | Cuelgue detectado en el terminal de control o muerte del proceso de control |
| SIGNO | 2 | Emitido si el usuario envía una señal de interrupción (Ctrl + C) |
| SIGQUIT | 3 | Emitido si el usuario envía una señal de salida (Ctrl + D) |
| SIGFPE | 8 | Emitido si se intenta una operación matemática ilegal |
| SIGKILL | 9 | Si un proceso recibe esta señal, debe salir de inmediato y no realizará ninguna operación de limpieza. |
| SIGALRM | 14 | Señal de alarma (usada para temporizadores) |
| SIGTERM | 15 | Señal de terminación del software (enviada por kill de forma predeterminada) |
Lista de señales
Existe una manera fácil de enumerar todas las señales admitidas por su sistema. Solo emita elkill -l comando y mostraría todas las señales admitidas -
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT
17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN
35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4
39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12
47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14
51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10
55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6
59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAXLa lista real de señales varía entre Solaris, HP-UX y Linux.
Acciones predeterminadas
Cada señal tiene una acción predeterminada asociada. La acción predeterminada para una señal es la acción que realiza un script o programa cuando recibe una señal.
Algunas de las posibles acciones predeterminadas son:
Termina el proceso.
Ignora la señal.
Volcado de núcleo. Esto crea un archivo llamadocore que contiene la imagen de memoria del proceso cuando recibió la señal.
Detén el proceso.
Continuar con un proceso detenido.
Envío de señales
Hay varios métodos para enviar señales a un programa o script. Uno de los más comunes es que un usuario escribaCONTROL-C o la INTERRUPT key mientras se ejecuta un script.
Cuando presiona el Ctrl+C clave, una SIGINT se envía al script y, según se define, el script de acción predeterminado finaliza.
El otro método común para enviar señales es utilizar el kill command, cuya sintaxis es la siguiente:
$ kill -signal pidaquí signal es el número o el nombre de la señal a entregar y pides el ID de proceso al que se debe enviar la señal. Por ejemplo:
$ kill -1 1001El comando anterior envía el HUP o la señal de colgar al programa que se está ejecutando con process ID 1001. Para enviar una señal de interrupción al mismo proceso, use el siguiente comando:
$ kill -9 1001Esto mata el proceso que se ejecuta con process ID 1001.
Señales de captura
Cuando presiona la tecla Ctrl + C o Break en su terminal durante la ejecución de un programa de shell, normalmente ese programa se termina inmediatamente y su símbolo del sistema regresa. Puede que esto no siempre sea deseable. Por ejemplo, puede terminar dejando un montón de archivos temporales que no se limpiarán.
Capturar estas señales es bastante fácil, y el comando trap tiene la siguiente sintaxis:
$ trap commands signalsAquí, el comando puede ser cualquier comando Unix válido, o incluso una función definida por el usuario, y la señal puede ser una lista de cualquier número de señales que desee atrapar.
Hay dos usos comunes para trap en scripts de shell:
- Limpiar archivos temporales
- Ignorar señales
Limpieza de archivos temporales
Como ejemplo del comando trap, a continuación se muestra cómo puede eliminar algunos archivos y luego salir si alguien intenta abortar el programa desde la terminal:
$ trap "rm -f $WORKDIR/work1$$ $WORKDIR/dataout$$; exit" 2Desde el punto en el programa de shell en el que se ejecuta esta trampa, los dos archivos work1$$ y dataout$$ se eliminará automáticamente si el programa recibe la señal número 2.
Por lo tanto, si el usuario interrumpe la ejecución del programa después de que se ejecute esta trampa, puede estar seguro de que estos dos archivos se limpiarán. losexit comando que sigue al rm es necesario porque sin él, la ejecución continuaría en el programa en el punto en que se detuvo cuando se recibió la señal.
La señal número 1 se genera para hangup. O alguien cuelga intencionalmente la línea o la línea se desconecta accidentalmente.
Puede modificar la trampa anterior para eliminar también los dos archivos especificados en este caso agregando la señal número 1 a la lista de señales:
$ trap "rm $WORKDIR/work1$$ $WORKDIR/dataout$$; exit" 1 2Ahora bien, estos archivos serán eliminados si la línea se colgó o si el Ctrl + C pulsador hace presionados.
Los comandos especificados para capturar deben ir entre comillas, si contienen más de un comando. También tenga en cuenta que el shell escanea la línea de comandos en el momento en que se ejecuta el comando trap y también cuando se recibe una de las señales enumeradas.
Por tanto, en el ejemplo anterior, el valor de WORKDIR y $$se sustituirá en el momento en que se ejecute el comando trap. Si desea que esta sustitución ocurra en el momento en que se recibió la señal 1 o 2, puede poner los comandos entre comillas simples:
$ trap 'rm $WORKDIR/work1$$ $WORKDIR/dataout$$; exit' 1 2Ignorando señales
Si el comando enumerado para trampa es nulo, la señal especificada se ignorará cuando se reciba. Por ejemplo, el comando -
$ trap '' 2Esto especifica que la señal de interrupción debe ignorarse. Es posible que desee ignorar ciertas señales al realizar una operación que no desea que se interrumpa. Puede especificar que se ignoren varias señales de la siguiente manera:
$ trap '' 1 2 3 15Tenga en cuenta que el primer argumento debe especificarse para que se ignore una señal y no es equivalente a escribir lo siguiente, que tiene un significado separado propio:
$ trap 2Si ignora una señal, todas las subcapas también ignoran esa señal. Sin embargo, si especifica que se debe tomar una acción al recibir una señal, todas las subcapas seguirán tomando la acción predeterminada al recibir esa señal.
Restablecimiento de trampas
Una vez que haya cambiado la acción predeterminada que se tomará al recibir una señal, puede volver a cambiarla con la trampa si simplemente omite el primer argumento; entonces -
$ trap 1 2Esto restablece la acción que se debe tomar al recibir las señales 1 o 2 a los valores predeterminados.