VSAM - Guía rápida
El método de acceso al almacenamiento virtual (VSAM) es un método de acceso de alto rendimiento y una organización de conjuntos de datos, que organiza y mantiene los datos a través de una estructura de catálogo. Utiliza el concepto de almacenamiento virtual y puede proteger conjuntos de datos en varios niveles dando contraseñas. VSAM se puede utilizar en programas COBOL como archivos secuenciales físicos. VSAM son los conjuntos de datos lógicos para almacenar registros. Los archivos se pueden leer de forma secuencial y aleatoria en VSAM. Es una forma mejorada de almacenar datos que supera algunas de las limitaciones de los sistemas de archivos convencionales como los archivos secuenciales.
Características de VSAM
Las siguientes son las características de VSAM:
VSAM protege los datos contra el acceso no autorizado mediante el uso de contraseñas.
VSAM proporciona acceso rápido a conjuntos de datos.
VSAM tiene opciones para optimizar el rendimiento.
VSAM permite el intercambio de conjuntos de datos en entornos por lotes y en línea.
Los VSAM están más estructurados y organizados para almacenar datos.
El espacio libre se reutiliza automáticamente en los archivos VSAM.
Limitaciones de VSAM
La única limitación de VSAM es que no se puede almacenar en el volumen TAPE. Siempre se almacena en el espacio DASD. Requiere una serie de cilindros para almacenar los datos, lo que no es rentable.
VSAM consta de los siguientes componentes:
- Clúster VSAM
- Área de control
- Intervalo de control
Clúster VSAM
VSAM son los conjuntos de datos lógicos para almacenar registros y se conocen como clústeres. Un grupo es una asociación del índice, el conjunto de secuencias y las partes de datos del conjunto de datos. El espacio ocupado por un clúster VSAM se divide en áreas contiguas denominadas Intervalos de control. Discutiremos sobre los intervalos de control más adelante en este módulo.
Hay dos componentes principales en un clúster VSAM:
Index Componentcontiene la parte del índice. Los registros de índice están presentes en el componente de índice. El uso del componente de índice VSAM puede recuperar registros del componente de datos.
Data Componentcontiene la parte de datos. Los registros de datos reales están presentes en el componente de datos.
Intervalo de control
Los intervalos de control (CI) en VSAM son equivalentes a bloques para conjuntos de datos que no son VSAM. En los métodos que no son VSAM, la unidad de datos la define el bloque. VSAM trabaja con el área de datos lógicos que se conoce como Intervalos de control.
Los intervalos de control son la unidad más pequeña de transferencia entre un disco y el sistema operativo. Siempre que se recupera un registro directamente del almacenamiento, todo el CI que contiene el registro se lee en el búfer de entrada y salida de VSAM. Luego, el registro deseado se transfiere al área de trabajo desde el búfer VSAM.
El intervalo de control consta de:
- Registros lógicos
- Campos de información de control
- Espacio libre
Cuando se carga un conjunto de datos VSAM, se crean intervalos de control. El tamaño del intervalo de control predeterminado es de 4 KB y puede extenderse hasta 32 KB.
Análisis del intervalo de control
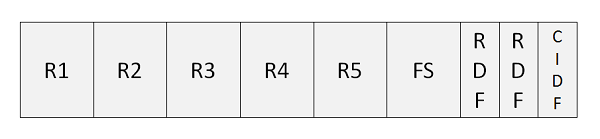
A continuación se muestra la descripción de los términos utilizados en el programa anterior:
R1..R5 - Registros que se almacenan en Intervalo de control.
FS - FS es espacio libre, que se puede utilizar para una mayor expansión del conjunto de datos.
RDF- RDF se conoce como campos de definición de registros. Los RDF tienen una longitud de 3 bytes. Describe la longitud de los registros e indica cuántos registros adyacentes tienen la misma longitud.
CIDF- CIDF se conoce como campos de definición de intervalo de control. Los CIDF tienen 4 bytes de longitud y contienen información sobre el intervalo de control.
Área de control
Un área de control (CA) se forma juntando dos o más intervalos de control. Un conjunto de datos VSAM se compone de una o más áreas de control. El tamaño de VSAM es siempre un múltiplo de su Área de control. Los archivos VSAM se extienden en unidades de áreas de control.
A continuación se muestra el ejemplo del área de control:

El clúster VSAM se define en JCL. Usos de JCLIDCAMSutilidad para crear un clúster. IDCAMS es una utilidad, desarrollada por IBM, para servicios de métodos de acceso. Se utiliza para definir principalmente conjuntos de datos VSAM.
Definición de un clúster
La siguiente sintaxis muestra los principales parámetros que se agrupan en Define Cluster, Data y Index.
.DEFINE CLUSTER (NAME(vsam-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
[INDEXED / NONINDEXED / NUMBERED / LINEAR] -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[KEYS(length offset)] -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE] ) -
DATA -
(NAME(vsam-file-name.data)) -
INDEX -
(NAME(vsam-file-name.index)) -
CATALOG(catalog-name[/password]))Los parámetros en el nivel CLUSTER se aplican a todo el clúster. Los parámetros a nivel de DATOS o ÍNDICE se aplican solo al componente de datos o índice.
Discutiremos cada parámetro en detalle en la siguiente tabla:
| No Señor | Parámetros con descripción |
|---|---|
| 1 | DEFINE CLUSTER El comando Definir clúster se utiliza para definir un clúster y especificar atributos de parámetros para el clúster y sus componentes. |
| 2 | NAME NAME especifica el nombre del archivo VSAM para el que estamos definiendo el clúster. |
| 3 | BLOCKS Bloques especifica la cantidad de bloques asignados para el clúster. |
| 4 | VOLUMES Volúmenes especifica uno o más volúmenes que contendrán el clúster o componente. |
| 5 | INDEXED / NONINDEXED / NUMBERED / LINEAR Este parámetro puede tomar tres valores INDEXED, NONINDEXED o NUMBERED dependiendo del tipo de conjunto de datos que estamos creando. Para archivos de secuencia de clave (KSDS), se utiliza la opción INDEXED. Para archivos de secuencia de entrada (ESDS), se utiliza la opción NONINDEXED. Para archivos de registro relativo (RRDS), se requiere la opción NUMBERED. Para archivos lineales (LDS), se requiere la opción LINEAR. El valor predeterminado de este parámetro es INDEXADO. Discutiremos más sobre KSDS, ESDS, RRDS y LDS en los próximos módulos. |
| 6 | RECSZ El parámetro Tamaño de registro tiene dos valores que son Tamaño de registro promedio y máximo. El Promedio especifica la longitud promedio de los registros lógicos en el archivo y el Máximo denota la longitud de los registros. |
| 7 | FREESPACE Freespace especifica el porcentaje de espacio libre a reservar para los intervalos de control (CI) y las áreas de control (CA) del componente de datos. El valor predeterminado de este parámetro es cero porcentaje. |
| 8 | CISZ CISZ se conoce como tamaño de intervalo de control. Especifica el tamaño de los intervalos de control. |
| 9 | KEYS El parámetro de claves se define solo en archivos de secuencia de claves (KSDS). Especifica la longitud y el desplazamiento de la clave principal desde la primera columna. El rango de valor de este parámetro es de 1 a 255 bytes. |
| 10 | READPW El valor del parámetro READPW especifica la contraseña del nivel de lectura. |
| 11 | FOR/TO El valor de este parámetro especifica la cantidad de tiempo en términos de fecha y días para retener el archivo. El valor predeterminado de este parámetro es cero días. |
| 12 | UPDATEPW El valor en el parámetro UPDATEPW especifica la contraseña del nivel de actualización. |
| 13 | REUSE / NOREUSE El parámetro REUSE permite definir clústeres que se pueden restablecer a estado vacío sin eliminarlos y redefinirlos. |
| 14 | DATA - NAME La parte de DATOS del clúster contiene el nombre del conjunto de datos que contiene los datos reales del archivo. |
| 15 | INDEX-NAME La parte INDICE del clúster contiene la clave principal y el puntero de memoria para el registro correspondiente en la parte de datos. Se define cuando se utiliza un clúster secuenciado por claves. |
| dieciséis | CATALOG El parámetro de catálogo denota el catálogo bajo el cual se definirá el archivo. Discutiremos sobre el catálogo por separado en los próximos módulos. |
Ejemplo
A continuación se muestra un ejemplo básico para mostrar cómo definir un clúster en JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) -
INDEXED -
RECSZ(80 80) -
TRACKS(1,1) -
KEYS(5 0) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.KSDSFILE.DATA)) -
INDEX (NAME(MY.VSAM.KSDSFILE.INDEX))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará el archivo MY.VSAM.KSDSFILE VSAM.
Eliminar un clúster
Para eliminar un archivo VSAM, el clúster VSAM debe eliminarse mediante la utilidad IDCAMS. El comando DELETE elimina la entrada del clúster VSAM del catálogo y, opcionalmente, elimina el archivo, liberando así el espacio ocupado por el objeto. Si el conjunto de datos de VSAM no está vencido, no se eliminará. Para eliminar este tipo de conjuntos de datos, utilice la opción PURGA.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]La sintaxis anterior muestra los parámetros que podemos usar con la instrucción Delete. Discutiremos cada uno de ellos en detalle en la siguiente tabla:
| No Señor | Parámetros con descripción |
|---|---|
| 1 | ERASE / NOERASE La opción ERASE se especifica para anular el atributo ERASE especificado para el objeto en el catálogo. La opción NOERASE se toma por defecto. |
| 2 | FORCE / NOFORCE La opción FORCE se especifica para eliminar SPACE y USERCATALOG incluso si no están vacíos. La opción NOFORCE se toma por defecto. |
| 3 | PURGE / NOPURGE La opción PURGE se usa para eliminar el conjunto de datos VSAM si el conjunto de datos no ha expirado. La opción NOPURGA se toma por defecto. |
| 4 | SCRATCH / NOSCRATCH La opción SCRATCH se especifica para eliminar la entrada asociada para el objeto de la Tabla de contenido del volumen. Se utiliza principalmente para conjuntos de datos que no son de vsam, como los GDG. La opción NOSCRATCH se toma por defecto. |
Ejemplo
A continuación, se muestra un ejemplo básico para mostrar cómo eliminar un clúster en JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.KSDSFILE CLUSTER
PURGE
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y eliminará el archivo VSAM MY.VSAM.KSDSFILE.
ESDS se conoce como conjunto de datos secuenciados de entrada. Un conjunto de datos con secuencia de entrada se comporta como una organización secuencial de archivos con algunas características más incluidas. Podemos acceder a los registros directamente y, por motivos de seguridad, también podemos utilizar contraseñas. Debemos codificarNONINDEXEDdentro del comando DEFINE CLUSTER para conjuntos de datos ESDS. Las siguientes son las características clave de ESDS:
Los registros del clúster ESDS se almacenan en el orden en que se insertaron en el conjunto de datos.
Los registros se referencian por la dirección física que se conoce como Relative Byte Address (RBA). Suponga que si en un conjunto de datos ESDS, tenemos registros de 80 bytes, el RBA del primer registro será 0, el RBA para el segundo registro será 80, para el tercer registro será 160 y así sucesivamente.
Se puede acceder a los registros secuencialmente por RBA, que se conoce como addressed access.
Los registros se mantienen en el orden en que se insertaron. Los nuevos registros se insertan al final.
La eliminación de registros no es posible en el conjunto de datos ESDS. Pero pueden marcarse como inactivos.
Los registros del conjunto de datos ESDS pueden tener una longitud fija o variable.
ESDS no está indexado. Las claves no están presentes en el conjunto de datos ESDS, por lo que pueden contener registros duplicados.
ESDS se puede utilizar en programas COBOL como cualquier otro archivo. Especificaremos el nombre del archivo en JCL y podemos usar el archivo ESDS para procesarlo dentro del programa. En el programa COBOL, especifique la organización de archivos comoSequential y modo de acceso como Sequential con el conjunto de datos ESDS.
Definición de clúster ESDS
La siguiente sintaxis muestra qué parámetros podemos usar al crear un clúster ESDS. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
DEFINE CLUSTER (NAME(esds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
NONINDEXED -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(esds-file-name.data))Ejemplo
El siguiente ejemplo muestra cómo crear un clúster ESDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.ESDSFILE) -
NONINDEXED -
RECSZ(80 80) -
TRACKS(1,1) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.ESDSFILE.DATA))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará el archivo MY.VSAM.ESDSFILE VSAM.
Eliminación del clúster ESDS
El clúster de ESDS se elimina mediante la utilidad IDCAMS. El comando DELETE elimina la entrada del clúster VSAM del catálogo y, opcionalmente, elimina el archivo, liberando así el espacio ocupado por el objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]La sintaxis anterior muestra qué parámetros podemos usar al eliminar el clúster ESDS. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
Ejemplo
El siguiente ejemplo muestra cómo eliminar un clúster ESDS en JCL mediante la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.ESDSFILE CLUSTER
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y eliminará MY.VSAM.ESDSFILE VSAM Cluster.
KSDS se conoce como conjunto de datos secuenciados clave. Un conjunto de datos en secuencia de claves (KSDS) es más complejo que ESDS y RRDS, pero es más útil y versátil. Debemos codificarINDEXEDdentro del comando DEFINE CLUSTER para conjuntos de datos KSDS. El clúster de KSDS consta de los siguientes dos componentes:
Index- El componente de índice del clúster KSDS contiene la lista de valores clave para los registros en el clúster con punteros a los registros correspondientes en el componente de datos. El componente de índice se refiere a la dirección física de un registro KSDS. Esto relaciona la clave de cada registro con la ubicación relativa del registro en el conjunto de datos. Cuando se agrega o elimina un registro, este índice se actualiza en consecuencia.
Data- El componente de datos del clúster KSDS contiene los datos reales. Cada registro en el componente de datos de un clúster KSDS contiene un campo clave con el mismo número de caracteres y ocurre en la misma posición relativa en cada registro.
Las siguientes son las características clave de KSDS:
Los registros dentro del conjunto de datos de KSDS siempre se mantienen ordenados por campo clave. Los registros se almacenan en orden ascendente, clasificando secuencia por tecla.
Se puede acceder a los registros de forma secuencial y también es posible el acceso directo.
Los registros se identifican mediante una clave. La clave de cada registro es un campo en una posición predefinida dentro del registro. Cada clave debe ser única en el conjunto de datos de KSDS. De modo que no es posible la duplicación de registros.
Cuando se insertan nuevos registros, el orden lógico de los registros depende de la secuencia de clasificación del campo clave.
Los registros en el conjunto de datos KSDS pueden tener una longitud fija o variable.
KSDS se puede utilizar en COBOLprogramas como cualquier otro archivo. Especificaremos el nombre del archivo en JCL y podemos usar el archivo KSDS para procesarlo dentro del programa. En el programa COBOL, especifique la organización de archivos comoIndexed y puedes usar cualquier modo de acceso (Sequential, Random or Dynamic) con el conjunto de datos KSDS.
Estructura de archivo KSDS
Para buscar un registro en particular, le damos un valor de clave único. El valor clave se busca en el componente de índice. Una vez que se encuentra la clave, se recupera la dirección de memoria correspondiente que se refiere al componente de datos. A partir de la dirección de la memoria podemos obtener los datos reales que se almacenan en el componente de datos. El siguiente ejemplo muestra la estructura básica del índice y el archivo de datos:
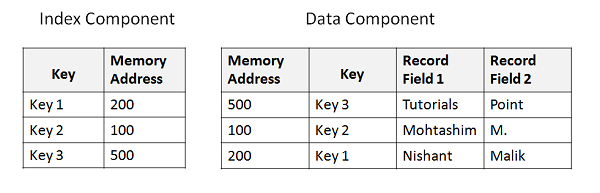
Definición de clúster de KSDS
La siguiente sintaxis muestra qué parámetros podemos usar al crear un clúster KSDS.
La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
DEFINE CLUSTER (NAME(ksds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
INDEXED -
KEYS(length offset) -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(ksds-file-name.data)) -
INDEX -
(NAME(ksds-file-name.index))Ejemplo
El siguiente ejemplo muestra cómo crear un clúster KSDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) -
INDEXED -
KEYS(6 1) -
RECSZ(80 80) -
TRACKS(1,1) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.KSDSFILE.DATA)) -
INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) -
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará el archivo MY.VSAM.KSDSFILE VSAM.
Eliminar el clúster de KSDS
El clúster de KSDS se elimina mediante la utilidad IDCAMS. El comando DELETE elimina la entrada del clúster VSAM del catálogo y, opcionalmente, elimina el archivo, liberando así el espacio ocupado por el objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]La sintaxis anterior muestra qué parámetros podemos usar al eliminar el clúster KSDS. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
Ejemplo
El siguiente ejemplo muestra cómo eliminar un clúster de KSDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.KSDSFILE CLUSTER
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y eliminará MY.VSAM.KSDSFILE VSAM Cluster.
RRDS se conoce como conjunto de datos de registro relativo. El clúster RRDS es similar a un clúster ESDS. La única diferencia es que se accede a los registros RRDS porRelative Record Number (RRN), debemos codificar NUMBEREDdentro del comando DEFINE CLUSTER. Las siguientes son las características clave de RRDS:
Un conjunto de datos de registro relativo tiene registros que son identificados por Relative Record Number (RRN), que es el número de secuencia relativo al primer registro.
RRDS permite el acceso de registros por número como registro 1, registro 2, etc. Esto proporciona acceso aleatorio y asume que el programa de aplicación tiene una forma de obtener los números de registro deseados.
Se puede acceder a los registros de un conjunto de datos RRDS de forma secuencial, en orden de número de registro relativo, o directamente, proporcionando el número de registro relativo del registro deseado.
Los registros en un conjunto de datos RRDS se almacenan en ranuras de longitud fija. Cada registro está referenciado por el número de su ranura, el número puede variar desde 1 hasta el número máximo de registros en el conjunto de datos.
Los registros en un RRDS se pueden escribir insertando un nuevo registro en una ranura vacía.
Los registros se pueden eliminar de un clúster RRDS, dejando un espacio vacío.
Aplicaciones que usan registros de longitud fija o un número de registro con significado contextual que pueden usar conjuntos de datos RRDS.
RRDS se puede utilizar en COBOLprogramas como cualquier otro archivo. Especificaremos el nombre del archivo en JCL y podemos usar el archivo KSDS para procesarlo dentro del programa. En el programa COBOL, especifique la organización de archivos comoRELATIVE y puedes usar cualquier modo de acceso (Sequential, Random or Dynamic) con el conjunto de datos RRDS.
Estructura de archivo RRDS
El espacio se divide en ranuras de longitud fija en la estructura de archivos RRDS. Una ranura puede estar completamente vacía o completamente llena. Por lo tanto, se pueden agregar nuevos registros a los espacios vacíos y los registros existentes se pueden eliminar de los espacios que se llenan. Podemos acceder a cualquier registro directamente dando Número de registro relativo. El siguiente ejemplo muestra la estructura básica del archivo de datos:
Componente de datos
| Número de registro relativo | Campo de registro 1 | Campo de registro 2 |
|---|---|---|
| 1 | Tutorial | Punto |
| 2 | Mohtashim | METRO. |
| 3 | Nishant | Malik |
Definición de clúster RRDS
La siguiente sintaxis muestra qué parámetros podemos usar al crear un clúster RRDS.
La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
DEFINE CLUSTER (NAME(rrds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
NUMBERED -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(rrds-file-name.data))Ejemplo
El siguiente ejemplo muestra cómo crear un clúster RRDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.RRDSFILE) -
NUMBERED -
RECSZ(80 80) -
TRACKS(1,1) -
REUSE -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.RRDSFILE.DATA))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará el archivo MY.VSAM.RRDSFILE VSAM.
Eliminar el clúster RRDS
El clúster RRDS se elimina mediante la utilidad IDCAMS. El comando DELETE elimina la entrada del clúster VSAM del catálogo y, opcionalmente, elimina el archivo, liberando así el espacio ocupado por el objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]La sintaxis anterior muestra qué parámetros podemos usar al eliminar el clúster RRDS. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
Ejemplo
El siguiente ejemplo muestra cómo eliminar un clúster RRDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.RRDSFILE CLUSTER
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y eliminará MY.VSAM.RRDSFILE VSAM Cluster.
LDS se conoce como conjunto de datos lineales. El conjunto de datos lineal es la única forma de conjunto de datos de flujo de bytes que se utiliza en los archivos del sistema operativo tradicional. Los conjuntos de datos lineales rara vez se utilizan. Las siguientes son las características clave de LDS:
Los conjuntos de datos lineales no contienen RDF ni CIDF, ya que no tienen información de control incorporada en su CI.
Datos a los que se puede acceder como cadenas direccionables por bytes en el almacenamiento virtual en conjuntos de datos lineales.
Los conjuntos de datos lineales tienen un tamaño de intervalo de control de 4 KB.
LDS es una especie de archivo que no es vsam con algunas funciones de VSAM como el uso de IDCAMS e información específica de VSAM en el catálogo.
DB2 es actualmente el mayor usuario de conjuntos de datos lineales.
IDCAMS se utiliza para definir una LDS, pero se accede a ella mediante una macro de datos en virtual (DIV).
El conjunto de datos lineal no tiene conceptos de registros. Todos los bytes LDS son bytes de datos.
Definición de clúster LDS
La siguiente sintaxis muestra qué parámetros podemos usar al crear un clúster LDS. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
DEFINE CLUSTER (NAME(lds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
LINEAR -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(lds-file-name.data))Ejemplo
El siguiente ejemplo muestra cómo crear un clúster LDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.LDSFILE) -
LINEAR -
TRACKS(1,1) -
CISZ(4096) ) -
DATA (NAME(MY.VSAM.LDSFILE.DATA))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará el archivo MY.VSAM.LDSFILE VSAM.
Eliminar clúster LDS
El clúster LDS se elimina mediante la utilidad IDCAMS. El comando DELETE elimina la entrada del clúster VSAM del catálogo y, opcionalmente, elimina el archivo, liberando así el espacio ocupado por el objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]La sintaxis anterior muestra qué parámetros podemos usar al eliminar el clúster LDS. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
Ejemplo
El siguiente ejemplo muestra cómo eliminar un clúster LDS en JCL utilizando la utilidad IDCAMS:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.LDSFILE CLUSTER
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y eliminará MY.VSAM.LDSFILE VSAM Cluster.
Los comandos VSAM se utilizan para realizar determinadas operaciones en conjuntos de datos VSAM. Los siguientes son los comandos VSAM más útiles:
- Alter
- Repro
- Listcat
- Examine
- Verify
Alterar
El comando ALTER se utiliza para modificar los atributos del archivo VSAM. Podemos cambiar los atributos del archivo VSAM que hemos mencionado en la definición del clúster VSAM. A continuación se muestra la sintaxis para cambiar los atributos:
ALTER file-cluster-name [password]
[ADDVOLUMES(volume-serial)]
[BUFFERSPACE(size)]
[EMPTY / NOEMPTY]
[ERASE / NOERASE]
[FREESPACE(CI-percentage CA-percentage)]
[KEYS(length offset)]
[NEWNAME(new-name)]
[RECORDSIZE(average maximum)]
[REMOVEVOLUMES(volume-serial)]
[SCRATCH / NOSCRATCH]
[TO(date) / FOR(days)]
[UPGRADE / NOUPGRADE]
[CATALOG(catalog-name [password]]La sintaxis anterior muestra qué parámetros podemos modificar en un clúster VSAM existente. La descripción del parámetro sigue siendo la misma que se menciona en VSAM - Módulo de clúster.
Ejemplo
El siguiente ejemplo muestra cómo usar el comando ALTER para aumentar el espacio libre, para agregar más volúmenes y para Alter Keys:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
ALTER MY.VSAM.KSDSFILE
[ADDVOLUMES(2)]
[FREESPACE(6 6)]
[KEYS(10 2)]
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y alterará el espacio libre, los volúmenes y las claves.
Repro
El comando REPRO se usa para cargar datos en el conjunto de datos VSAM. También se utiliza para copiar datos de un conjunto de datos VSAM a otro. Podemos usar este comando para copiar datos de un archivo secuencial a un archivo VSAM. La utilidad IDCAMS usa el comando REPRO para cargar los conjuntos de datos.
REPRO INFILE(in-ddname)
OUTFILE(out-ddname)En la sintaxis anterior, in-ddname es el nombre DD para el conjunto de datos de entrada que tiene registros. Out-ddname es el nombre DD para el conjunto de datos de salida, donde se copiarán los registros de los conjuntos de datos de entrada.
Ejemplo
El siguiente ejemplo muestra cómo copiar registros de un conjunto de datos a otro conjunto de datos VSAM:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//IN DD DSN = MY.VSAM.KSDSFILE,DISP = SHR
//OUT DD DSN = MY.VSAM1.KSDSFILE,DISP = SHR
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
REPRO INFILE(IN)
OUTFILE(OUT)
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y copiará todos los registros de MY.VSAM.KSDSFILE al archivo MY.VSAM1.KSDSFILE VSAM.
Listcat
El comando LISTCAT se usa para obtener los detalles del catálogo de un conjunto de datos VSAM. El comando Listcat proporciona la siguiente información sobre los conjuntos de datos VSAM:
- Información SMS
- Información de RLS
- Información de volumen
- Información de la esfera
- Información de asignación
- Atributos del conjunto de datos
LISTCAT ENTRY(vsam-file-name) ALLEn la sintaxis anterior, vsam-file-name es el nombre del conjunto de datos VSAM para el que necesitamos toda la información. Se especifica la palabra clave ALL para obtener todos los detalles del catálogo.
Ejemplo
El siguiente ejemplo muestra cómo obtener todos los detalles mediante el comando Listcat para un conjunto de datos VSAM:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
LISTCAT ENTRY(MY.VSAM.KSDSFILE)
ALL
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y mostrará todos los detalles del catálogo sobre el conjunto de datos MY.VSAM.KSDSFILE.
Examinar
El comando Examinar se utiliza para verificar la integridad estructural de un grupo de conjuntos de datos secuenciados por clave. Comprueba los componentes de índice y datos y, si se encuentra algún problema, los mensajes de error se envían en cola. Puede consultar cualquiera de los mensajes IDCxxxxx.
EXAMINE NAME(vsam-ksds-name) -
INDEXTEST DATATEST -
ERRORLIMIT(50)En la sintaxis anterior, vsam-ksds-name es el nombre del conjunto de datos VSAM para el que necesitamos examinar el índice y la parte de datos del clúster VSAM.
Ejemplo
El siguiente ejemplo muestra cómo verificar si el índice y la parte de datos del conjunto de datos KSDS están sincronizados o no:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
EXAMINE NAME(MY.VSAM.KSDSFILE) -
INDEXTEST DATATEST -
ERRORLIMIT(50)
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y mostrará todos los problemas con el conjunto de datos VSAM en uno de los mensajes IDCxxxxx en spool.
Verificar
El comando Verify se usa para verificar y reparar archivos VSAM que no se han cerrado correctamente después de un error. El comando agrega registros correctos de fin de datos al archivo.
VERIFY DS(vsam-file-name)En la sintaxis anterior, vsam-file-name es el nombre del conjunto de datos VSAM para el que necesitamos verificar los errores.
Ejemplo
El siguiente ejemplo muestra cómo verificar y corregir errores en el conjunto de datos VSAM:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
VERIFY DS(MY.VSAM.KSDSFILE)
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y solucionará los errores en el conjunto de datos VSAM.
El índice alternativo es el índice adicional que se crea para los conjuntos de datos KSDS / ESDS además de su índice principal. Un índice alternativo proporciona acceso a los registros mediante el uso de más de una clave. La clave del índice alternativo puede ser una clave no única, puede tener duplicados.
Creación de índice alternativo
Los siguientes pasos se utilizan para crear un índice alternativo:
- Definir índice alternativo
- Definir ruta
- Índice de construcción
Definir índice alternativo
El índice alternativo se define mediante DEFINE AIX mando.
DEFINE AIX -
(NAME(alternate-index-name) -
RELATE(vsam-file-name) -
CISZ(number) -
FREESPACE(CI-Percentage,CA-Percentage) -
KEYS(length offset) -
NONUNIQUEKEY / UNIQUEKEY -
UPGRADE / NOUPGRADE -
RECORDSIZE(average maximum)) -
DATA -
(NAME(vsam-file-name.data)) -
INDEX -
(NAME(vsam-file-name.index))La sintaxis anterior muestra los parámetros que se utilizan al definir el índice alternativo. Ya hemos discutido algunos parámetros en Definir módulo de clúster y algunos de los nuevos parámetros se utilizan para definir el índice alternativo que discutiremos aquí:
| No Señor | Parámetros con descripción |
|---|---|
| 1 | DEFINE AIX El comando Definir AIX se utiliza para definir el índice alternativo y especificar atributos de parámetros para sus componentes. |
| 2 | NAME NAME especifica el nombre del índice alternativo. |
| 3 | RELATE RELATE especifica el nombre del clúster VSAM para el que se crea el índice alternativo. |
| 4 | NONUNIQUEKEY / UNIQUEKEY UNIQUEKEY especifica que el índice alternativo es único y NONUNIQUEKEY especifica que pueden existir duplicados. |
| 5 | UPGRADE / NOUPGRADE UPGRADE especifica que el índice alternativo debe modificarse si se modifica el clúster base y NOUPGRADE especifica que los índices alternativos deben dejarse solo si se modifica el clúster base. |
Ejemplo
A continuación se muestra un ejemplo básico para mostrar cómo definir un índice alternativo en JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE AIX (NAME(MY.VSAM.KSDSAIX) -
RELATE(MY.VSAM.KSDSFILE) -
CISZ(4096) -
FREESPACE(20,20) -
KEYS(20,7) -
NONUNIQUEKEY -
UPGRADE -
RECORDSIZE(80,80)) -
DATA(NAME(MY.VSAM.KSDSAIX.DATA)) -
INDEX(NAME(MY.VSAM.KSDSAIX.INDEX))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará MY.VSAM.KSDSAIX Alternate Index.
Definir ruta
Definir ruta se utiliza para relacionar el índice alternativo con el clúster base. Al definir la ruta, especificamos el nombre de la ruta y el índice alternativo con el que está relacionada esta ruta.
DEFINE PATH -
NAME(alternate-index-path-name) -
PATHENTRY(alternate-index-name))La sintaxis anterior tiene dos parámetros. NAME se utiliza para especificar el nombre de ruta de índice alternativo y PATHENTRY se utiliza para especificar el nombre de índice alternativo.
Ejemplo
A continuación se muestra un ejemplo básico para definir la ruta en JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE PATH -
NAME(MY.VSAM.KSDSAIX.PATH) -
PATHENTRY(MY.VSAM.KSDSAIX))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y creará una ruta entre el índice alternativo y el clúster base.
Índice de construcción
El comando BLDINDEX se usa para construir el índice alternativo. BLDINDEX lee todos los registros en el conjunto de datos indexados VSAM (o grupo base) y extrae los datos necesarios para construir el índice alternativo.
BLDINDEX -
INDATASET(vsam-cluster-name) -
OUTDATASET(alternate-index-name))La sintaxis anterior tiene dos parámetros. INDATASET se utiliza para especificar el nombre del clúster VSAM y OUTDATASET se utiliza para especificar el nombre de índice alternativo.
Ejemplo
A continuación se muestra un ejemplo básico para crear índices en JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
BLDINDEX -
INDATASET(MY.VSAM.KSDSFILE) -
OUTDATASET(MY.VSAM.KSDSAIX))
/*Si va a ejecutar el JCL anterior en el servidor Mainframes. Debería ejecutarse con MAXCC = 0 y construirá el índice.
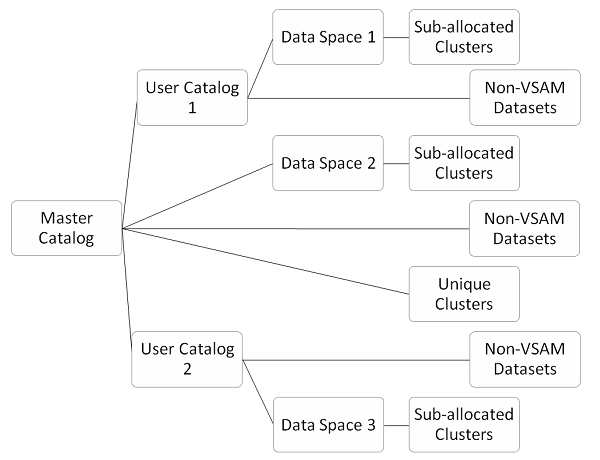
El catálogo mantiene la unidad y el volumen donde reside el conjunto de datos. El catálogo se utiliza para la recuperación de conjuntos de datos. Los conjuntos de datos que no son de VSAM crean una entrada de catálogo mediante el parámetro Disposition en JCL. Los conjuntos de datos de VSAM mantienen su propio catálogo en forma de clúster KSDS. En la siguiente imagen se puede ver el tipo de catálogos VSAM -
Catálogo maestro
El catálogo maestro es en sí mismo un archivo que monitorea y administra las operaciones de VSAM. Solo hay un catálogo maestro en cualquier sistema que contiene entradas sobre conjuntos de datos del sistema y conjuntos de datos VSAM. Los conjuntos de datos VSAM y no VSAM pueden tener una entrada en el catálogo maestro, pero esta no es una buena práctica. El catálogo maestro se crea durante el proceso de generación del sistema y reside en el volumen del sistema. El catálogo maestro posee todos los recursos VSAM en el sistema operativo. Todos los archivos utilizados en VSAM están controlados por el catálogo maestro. El catálogo maestro es responsable de las siguientes operaciones:
- Autorización de contraseña para archivos
- Mejorando la seguridad
- Acceso VSAM para archivos
- Gestión de espacio de archivo
- Ubicación del archivo
- Espacio libre disponible en archivo
Cuando cambia cualquiera de los atributos de archivo anteriores, se actualizan automáticamente en el catálogo maestro. El catálogo maestro se define mediante programas IDCAMS.
Catálogo de usuario
El catálogo de usuario tiene la misma estructura y conceptos que el catálogo maestro. Está presente en el siguiente nivel jerárquico después del catálogo maestro. El catálogo de usuarios no es obligatorio en el sistema, pero se utiliza para mejorar la seguridad del sistema VSAM. El catálogo maestro apunta a archivos VSAM, pero si el catálogo de usuario está presente, el catálogo maestro apunta al catálogo de usuario. Los catálogos de usuario pueden ser numerosos según los requisitos del sistema. En la estructura de VSAM, si se elimina el catálogo maestro, no afectará al catálogo de usuarios. El catálogo de usuario contiene entradas sobre conjuntos de datos específicos de la aplicación. La información del catálogo de usuarios se almacena en el catálogo maestro.
Espacio de datos
El espacio de datos es un área del dispositivo de almacenamiento de acceso directo que se asigna exclusivamente para el uso de VSAM. Se debe crear un espacio de datos antes de crear clústeres VSAM. El área ocupada por el espacio de datos se registra en la Tabla de Contenido del Volumen (VTOC), por lo que el espacio no estará disponible para su asignación a ningún otro uso, ya sea VSAM o no VSAM. VTOC tiene entrada de área ocupada por espacio. VSAM crea un espacio de datos para contener las entradas del catálogo de usuarios. VSAM toma el control de este espacio y monitorea y mantiene este espacio según lo necesiten los archivos VSAM.
Clústeres únicos
Los clústeres únicos consisten en un espacio de datos separado que es utilizado completamente por el clúster creado dentro de él. Los clústeres únicos se crean a partir del espacio no asignado en el almacenamiento de acceso directo.
Clústeres subasignados
Un archivo VSAM subasignado comparte el espacio VSAM con otros archivos subasignados. Especifica que el archivo debe subasignarse dentro del espacio VSAM existente. La subasignación se utiliza para facilitar la gestión y el control de los espacios VSAM.
Conjuntos de datos que no son VSAM
Los conjuntos de datos que no son de VSAM residen tanto en cinta como en almacenamiento de acceso directo. Los conjuntos de datos que no son de VSAM pueden tener entradas tanto en el catálogo maestro como en los catálogos de usuario. La función principal de catalogar conjuntos de datos que no son de VSAM es retener la información de serie de unidades y volúmenes.
Mientras trabaja con conjuntos de datos VSAM, puede encontrar terminaciones anómalas. A continuación se muestran los códigos de estado de archivos comunes con su descripción que lo ayudarán a resolver los problemas:
| Código | Descripción |
|---|---|
| 00 | La operación se realizó con éxito |
| 02 | Se encontró una clave duplicada de índice alternativo no único |
| 04 | Registro de longitud fija no válido |
| 05 | Mientras realiza OPEN, el archivo y el archivo no está presente |
| 10 | Fin de archivo encontrado |
| 14 | Intentó LEER un registro relativo fuera del límite del archivo |
| 20 | Clave no válida para VSAM KSDS o RRDS |
| 21 | Error de secuencia al realizar WRITE o al cambiar de clave en REWRITE |
| 22 | Se encontró la clave principal duplicada |
| 23 | Registro no encontrado o Archivo no encontrado |
| 24 | Clave fuera del límite del archivo |
| 30 | Error de E / S permanente |
| 34 | Grabar fuera del límite del archivo |
| 35 | Mientras realiza OPEN, el archivo y el archivo no está presente |
| 37 | ABRIR archivo con modo incorrecto |
| 38 | Intenté ABRIR un archivo bloqueado |
| 39 | OPEN falló debido a atributos de archivo en conflicto |
| 41 | Intenté ABRIR un archivo que ya está abierto |
| 42 | Intenté CERRAR un archivo que no está ABIERTO |
| 43 | Intenté REESCRIBIR sin LEER un registro primero |
| 44 | Intenté REESCRIBIR un registro de diferente longitud |
| 46 | Intenté LEER más allá del final del archivo |
| 47 | Intenté LEER de un archivo que no se abrió IO o INPUT |
| 48 | Intenté ESCRIBIR en un archivo que no se abrió IO o OUTPUT |
| 49 | Intenté BORRAR o REESCRIBIR en un archivo que no se abrió IO |
| 91 | Error de contraseña o autorización |
| 92 | Error de lógica |
| 93 | Los recursos no están disponibles |
| 94 | Registro secuencial no disponible o error OPEN concurrente |
| 95 | Información de archivo no válida o incompleta |
| 96 | Sin declaración DD para el archivo |
| 97 | ABRIR correctamente y verificar la integridad del archivo |
| 98 | El archivo está bloqueado - OPEN falló |
| 99 | Registro bloqueado: error en el acceso al registro |