Zookeeper - Guía rápida
ZooKeeper es un servicio de coordinación distribuida para administrar un gran conjunto de hosts. Coordinar y gestionar un servicio en un entorno distribuido es un proceso complicado. ZooKeeper resuelve este problema con su arquitectura y API simples. ZooKeeper permite a los desarrolladores centrarse en la lógica de la aplicación principal sin preocuparse por la naturaleza distribuida de la aplicación.
El marco de ZooKeeper se creó originalmente en "Yahoo!" para acceder a sus aplicaciones de una manera fácil y robusta. Más tarde, Apache ZooKeeper se convirtió en un estándar para el servicio organizado utilizado por Hadoop, HBase y otros marcos distribuidos. Por ejemplo, Apache HBase usa ZooKeeper para rastrear el estado de los datos distribuidos.
Antes de seguir adelante, es importante que sepamos un par de cosas sobre aplicaciones distribuidas. Entonces, comencemos la discusión con una descripción general rápida de las aplicaciones distribuidas.
Aplicación distribuida
Una aplicación distribuida puede ejecutarse en múltiples sistemas en una red en un momento dado (simultáneamente) coordinándose entre sí para completar una tarea particular de una manera rápida y eficiente. Normalmente, las tareas complejas y lentas, que tardarán horas en completarse con una aplicación no distribuida (que se ejecuta en un solo sistema), se pueden realizar en minutos mediante una aplicación distribuida utilizando las capacidades informáticas de todo el sistema involucrado.
El tiempo para completar la tarea se puede reducir aún más configurando la aplicación distribuida para que se ejecute en más sistemas. Un grupo de sistemas en los que se ejecuta una aplicación distribuida se denominaCluster y cada máquina que se ejecuta en un clúster se llama Node.
Una aplicación distribuida tiene dos partes, Server y Clientsolicitud. Las aplicaciones de servidor en realidad están distribuidas y tienen una interfaz común para que los clientes puedan conectarse a cualquier servidor del clúster y obtener el mismo resultado. Las aplicaciones cliente son las herramientas para interactuar con una aplicación distribuida.

Beneficios de las aplicaciones distribuidas
Reliability - La falla de uno o varios sistemas no hace que todo el sistema falle.
Scalability - El rendimiento se puede aumentar cuando sea necesario agregando más máquinas con cambios menores en la configuración de la aplicación sin tiempo de inactividad.
Transparency - Oculta la complejidad del sistema y se muestra como una sola entidad / aplicación.
Desafíos de las aplicaciones distribuidas
Race condition- Dos o más máquinas que intentan realizar una tarea en particular, que en realidad solo debe realizarla una sola máquina en un momento dado. Por ejemplo, los recursos compartidos solo deben ser modificados por una sola máquina en un momento dado.
Deadlock - Dos o más operaciones esperando que la otra se complete indefinidamente.
Inconsistency - Fallo parcial de datos.
¿Para qué sirve Apache ZooKeeper?
Apache ZooKeeper es un servicio utilizado por un clúster (grupo de nodos) para coordinarse entre sí y mantener los datos compartidos con técnicas de sincronización sólidas. ZooKeeper es en sí mismo una aplicación distribuida que proporciona servicios para escribir una aplicación distribuida.
Los servicios comunes proporcionados por ZooKeeper son los siguientes:
Naming service- Identificar los nodos de un clúster por nombre. Es similar al DNS, pero para nodos.
Configuration management - Información de configuración más reciente y actualizada del sistema para un nodo de unión.
Cluster management - Entrada / salida de un nodo en un cluster y estado del nodo en tiempo real.
Leader election - Elección de un nodo como líder con fines de coordinación.
Locking and synchronization service- Bloquear los datos mientras los modifica. Este mecanismo lo ayuda en la recuperación automática de fallas mientras conecta otras aplicaciones distribuidas como Apache HBase.
Highly reliable data registry - Disponibilidad de datos incluso cuando uno o varios nodos están inactivos.
Las aplicaciones distribuidas ofrecen muchos beneficios, pero también presentan algunos desafíos complejos y difíciles de resolver. El marco de ZooKeeper proporciona un mecanismo completo para superar todos los desafíos. La condición de carrera y el interbloqueo se manejan usandofail-safe synchronization approach. Otro inconveniente principal es la inconsistencia de los datos, que ZooKeeper resuelve conatomicity.
Beneficios de ZooKeeper
Estos son los beneficios de usar ZooKeeper:
Simple distributed coordination process
Synchronization- Exclusión mutua y cooperación entre procesos del servidor. Este proceso ayuda en Apache HBase para la gestión de la configuración.
Ordered Messages
Serialization- Codifica los datos según reglas específicas. Asegúrese de que su aplicación se ejecute de forma coherente. Este enfoque se puede utilizar en MapReduce para coordinar la cola para ejecutar subprocesos en ejecución.
Reliability
Atomicity - La transferencia de datos tiene éxito o falla por completo, pero ninguna transacción es parcial.
Antes de profundizar en el funcionamiento de ZooKeeper, echemos un vistazo a los conceptos fundamentales de ZooKeeper. Discutiremos los siguientes temas en este capítulo:
- Architecture
- Espacio de nombres jerárquico
- Session
- Watches
Arquitectura de ZooKeeper
Eche un vistazo al siguiente diagrama. Representa la “Arquitectura Cliente-Servidor” de ZooKeeper.
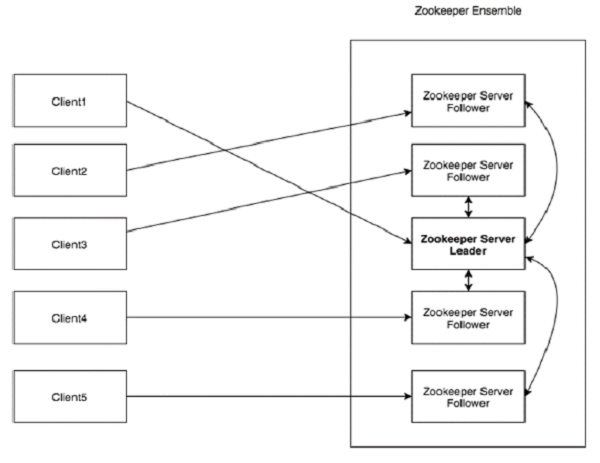
Cada uno de los componentes que forman parte de la arquitectura de ZooKeeper se ha explicado en la siguiente tabla.
| Parte | Descripción |
|---|---|
| Cliente | Los clientes, uno de los nodos de nuestro clúster de aplicaciones distribuidas, acceden a la información desde el servidor. Durante un intervalo de tiempo particular, cada cliente envía un mensaje al servidor para informarle al servidor que el cliente está vivo. Del mismo modo, el servidor envía un acuse de recibo cuando un cliente se conecta. Si no hay respuesta del servidor conectado, el cliente redirige automáticamente el mensaje a otro servidor. |
| Servidor | Server, uno de los nodos de nuestro conjunto ZooKeeper, proporciona todos los servicios a los clientes. Da reconocimiento al cliente para informar que el servidor está activo. |
| Conjunto | Grupo de servidores de ZooKeeper. El número mínimo de nodos que se requiere para formar un conjunto es 3. |
| Líder | Nodo del servidor que realiza la recuperación automática si falla alguno de los nodos conectados. Los líderes se eligen al inicio del servicio. |
| Seguidor | Nodo del servidor que sigue las instrucciones del líder. |
Espacio de nombres jerárquico
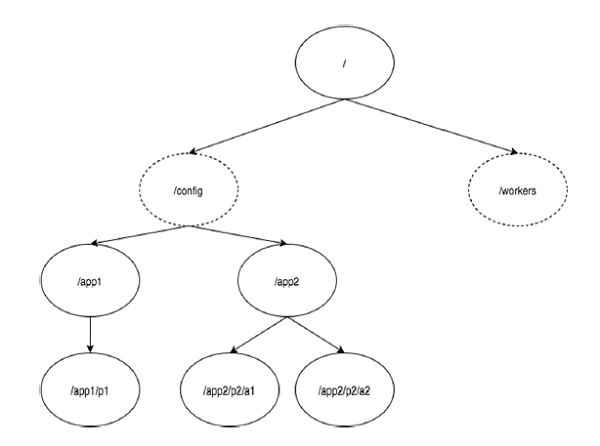
El siguiente diagrama muestra la estructura de árbol del sistema de archivos de ZooKeeper utilizado para la representación de la memoria. El nodo ZooKeeper se denominaznode. Cada znode está identificado por un nombre y separado por una secuencia de ruta (/).
En el diagrama, primero tienes una raíz znodeseparado por "/". En root, tiene dos espacios de nombres lógicosconfig y workers.
los config El espacio de nombres se utiliza para la gestión de la configuración centralizada y workers el espacio de nombres se utiliza para nombrar.
Debajo configespacio de nombres, cada znode puede almacenar hasta 1 MB de datos. Esto es similar al sistema de archivos UNIX excepto que el znode padre también puede almacenar datos. El propósito principal de esta estructura es almacenar datos sincronizados y describir los metadatos del znode. Esta estructura se llama comoZooKeeper Data Model.
Cada znode del modelo de datos de ZooKeeper mantiene un statestructura. Una estadística simplemente proporcionametadatade un znode. Consiste en el número de versión, la lista de control de acciones (ACL), la marca de tiempo y la longitud de los datos.
Version number- Cada znode tiene un número de versión, lo que significa que cada vez que cambian los datos asociados con el znode, su número de versión correspondiente también aumentará. El uso del número de versión es importante cuando varios clientes del zookeeper intentan realizar operaciones en el mismo znode.
Action Control List (ACL)- ACL es básicamente un mecanismo de autenticación para acceder al znode. Gobierna todas las operaciones de lectura y escritura de znode.
Timestamp- La marca de tiempo representa el tiempo transcurrido desde la creación y modificación de znode. Suele representarse en milisegundos. ZooKeeper identifica todos los cambios en los znodes desde “ID de transacción” (zxid).Zxid es único y mantiene el tiempo para cada transacción para que pueda identificar fácilmente el tiempo transcurrido entre una solicitud y otra.
Data length- La cantidad total de datos almacenados en un znode es la longitud de los datos. Puede almacenar un máximo de 1 MB de datos.
Tipos de Znodes
Los Znodes se clasifican como persistentes, secuenciales y efímeros.
Persistence znode- El znode de persistencia está vivo incluso después de que el cliente, que creó ese znode en particular, se desconecta. De forma predeterminada, todos los znodes son persistentes a menos que se especifique lo contrario.
Ephemeral znode- Los znodes efímeros están activos hasta que el cliente está vivo. Cuando un cliente se desconecta del conjunto ZooKeeper, los znodes efímeros se eliminan automáticamente. Por esta razón, solo los znodes efímeros no pueden tener más hijos. Si se elimina un znode efímero, el siguiente nodo adecuado ocupará su posición. Los znodes efímeros juegan un papel importante en la elección del líder.
Sequential znode- Los znodes secuenciales pueden ser persistentes o efímeros. Cuando se crea un nuevo znode como un znode secuencial, ZooKeeper establece la ruta del znode adjuntando un número de secuencia de 10 dígitos al nombre original. Por ejemplo, si un znode con ruta/myapp se crea como un znode secuencial, ZooKeeper cambiará la ruta a /myapp0000000001y establezca el siguiente número de secuencia como 0000000002. Si dos znodes secuenciales se crean simultáneamente, ZooKeeper nunca usa el mismo número para cada znode. Los znodes secuenciales juegan un papel importante en el bloqueo y la sincronización.
Sesiones
Las sesiones son muy importantes para el funcionamiento de ZooKeeper. Las solicitudes de una sesión se ejecutan en orden FIFO. Una vez que un cliente se conecta a un servidor, la sesión se establecerá ysession id se asigna al cliente.
El cliente envía heartbeatsen un intervalo de tiempo particular para mantener la sesión válida. Si el conjunto ZooKeeper no recibe latidos de un cliente por más del período (tiempo de espera de sesión) especificado al inicio del servicio, decide que el cliente murió.
Los tiempos de espera de las sesiones se suelen representar en milisegundos. Cuando una sesión finaliza por cualquier motivo, los znodes efímeros creados durante esa sesión también se eliminan.
Relojes
Los relojes son un mecanismo simple para que el cliente reciba notificaciones sobre los cambios en el conjunto ZooKeeper. Los clientes pueden configurar relojes mientras leen un znode en particular. Los relojes envían una notificación al cliente registrado para cualquier cambio de znode (en el que se registra el cliente).
Los cambios de Znode son modificaciones de los datos asociados con el znode o cambios en los hijos de znode. Los relojes se activan solo una vez. Si un cliente quiere una notificación nuevamente, debe hacerlo a través de otra operación de lectura. Cuando expira una sesión de conexión, el cliente se desconectará del servidor y los relojes asociados también se eliminarán.
Una vez que se inicia un conjunto de ZooKeeper, esperará a que los clientes se conecten. Los clientes se conectarán a uno de los nodos del conjunto ZooKeeper. Puede ser un nodo líder o seguidor. Una vez que un cliente está conectado, el nodo asigna una ID de sesión al cliente en particular y envía un acuse de recibo al cliente. Si el cliente no recibe una confirmación, simplemente intenta conectar otro nodo en el conjunto de ZooKeeper. Una vez conectado a un nodo, el cliente enviará latidos al nodo en un intervalo regular para asegurarse de que no se pierda la conexión.
If a client wants to read a particular znode, envía un read requestal nodo con la ruta de znode y el nodo devuelve el znode solicitado obteniéndolo de su propia base de datos. Por esta razón, las lecturas son rápidas en el conjunto ZooKeeper.
If a client wants to store data in the ZooKeeper ensemble, envía la ruta de znode y los datos al servidor. El servidor conectado enviará la solicitud al líder y luego el líder volverá a emitir la solicitud por escrito a todos los seguidores. Si solo la mayoría de los nodos responde correctamente, la solicitud de escritura se realizará correctamente y se enviará un código de retorno al cliente. De lo contrario, la solicitud de escritura fallará. La estricta mayoría de nodos se denominaQuorum.
Nodos en un conjunto ZooKeeper
Analicemos el efecto de tener un número diferente de nodos en el conjunto ZooKeeper.
Si tenemos a single node, entonces el conjunto ZooKeeper falla cuando falla ese nodo. Contribuye al "punto único de falla" y no se recomienda en un entorno de producción.
Si tenemos two nodes y falla un nodo, tampoco tenemos mayoría, ya que uno de cada dos no es mayoría.
Si tenemos three nodesy un nodo falla, tenemos mayoría y, por tanto, es el requisito mínimo. Es obligatorio que un conjunto de ZooKeeper tenga al menos tres nodos en un entorno de producción en vivo.
Si tenemos four nodesy dos nodos fallan, vuelve a fallar y es similar a tener tres nodos. El nodo adicional no tiene ningún propósito y, por lo tanto, es mejor agregar nodos en números impares, por ejemplo, 3, 5, 7.
Sabemos que un proceso de escritura es caro que un proceso de lectura en el conjunto ZooKeeper, ya que todos los nodos necesitan escribir los mismos datos en su base de datos. Por tanto, es mejor tener menos nodos (3, 5 o 7) que tener una gran cantidad de nodos para un entorno equilibrado.
El siguiente diagrama muestra ZooKeeper WorkFlow y la siguiente tabla explica sus diferentes componentes.
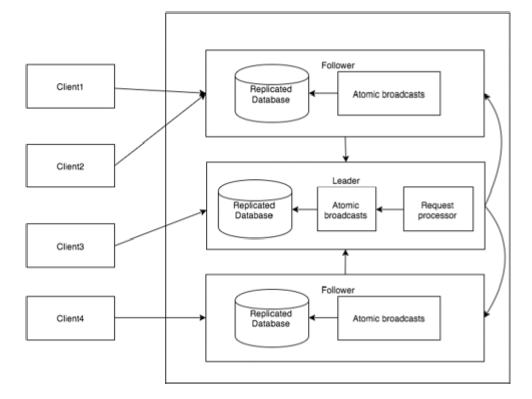
| Componente | Descripción |
|---|---|
| Escribir | El proceso de escritura lo maneja el nodo líder. El líder reenvía la solicitud de escritura a todos los znodes y espera las respuestas de los znodes. Si la mitad de los znodes responden, el proceso de escritura está completo. |
| Leer | Las lecturas se realizan internamente mediante un znode conectado específico, por lo que no es necesario interactuar con el clúster. |
| Base de datos replicada | Se utiliza para almacenar datos en zookeeper. Cada znode tiene su propia base de datos y cada znode tiene los mismos datos en todo momento con la ayuda de la coherencia. |
| Líder | Líder es el Znode que se encarga de procesar las solicitudes de escritura. |
| Seguidor | Los seguidores reciben solicitudes de escritura de los clientes y las reenvían al líder znode. |
| Procesador de solicitudes | Presente solo en el nodo líder. Gobierna las solicitudes de escritura del nodo seguidor. |
| Transmisiones atómicas | Responsable de transmitir los cambios desde el nodo líder a los nodos seguidores. |
Analicemos cómo se puede elegir un nodo líder en un conjunto ZooKeeper. Considere que hayNnúmero de nodos en un clúster. El proceso de elección de líder es el siguiente:
Todos los nodos crean un znodo secuencial y efímero con la misma ruta, /app/leader_election/guid_.
El conjunto ZooKeeper agregará el número de secuencia de 10 dígitos a la ruta y el znode creado será /app/leader_election/guid_0000000001, /app/leader_election/guid_0000000002, etc.
Para una instancia determinada, el nodo que crea el número más pequeño en el znode se convierte en el líder y todos los demás nodos son seguidores.
Cada nodo seguidor observa el znode que tiene el siguiente número más pequeño. Por ejemplo, el nodo que crea znode/app/leader_election/guid_0000000008 mirará el znode /app/leader_election/guid_0000000007 y el nodo que crea el znode /app/leader_election/guid_0000000007 mirará el znode /app/leader_election/guid_0000000006.
Si el líder cae, entonces su correspondiente znode /app/leader_electionN se elimina.
El siguiente nodo seguidor en línea recibirá la notificación a través del observador sobre la eliminación del líder.
El siguiente nodo seguidor de la línea comprobará si hay otros znodes con el número más pequeño. Si no hay ninguno, asumirá el papel de líder. De lo contrario, encuentra el nodo que creó el znode con el número más pequeño como líder.
De manera similar, todos los demás nodos seguidores eligen el nodo que creó el znode con el número más pequeño como líder.
La elección de un líder es un proceso complejo cuando se hace desde cero. Pero el servicio ZooKeeper lo hace muy simple. Pasemos a la instalación de ZooKeeper con fines de desarrollo en el siguiente capítulo.
Antes de instalar ZooKeeper, asegúrese de que su sistema se esté ejecutando en cualquiera de los siguientes sistemas operativos:
Any of Linux OS- Apoya el desarrollo y la implementación. Se prefiere para aplicaciones de demostración.
Windows OS - Apoya solo el desarrollo.
Mac OS - Apoya solo el desarrollo.
El servidor ZooKeeper se crea en Java y se ejecuta en JVM. Necesita utilizar JDK 6 o superior.
Ahora, siga los pasos que se indican a continuación para instalar el marco de ZooKeeper en su máquina.
Paso 1: verificar la instalación de Java
Creemos que ya tiene un entorno Java instalado en su sistema. Simplemente verifíquelo usando el siguiente comando.
$ java -versionSi tiene Java instalado en su máquina, entonces podría ver la versión de Java instalada. De lo contrario, siga los sencillos pasos que se indican a continuación para instalar la última versión de Java.
Paso 1.1: Descarga JDK
Descargue la última versión de JDK visitando el siguiente enlace y descargue la última versión. Java
La última versión (mientras se escribe este tutorial) es JDK 8u 60 y el archivo es “jdk-8u60-linuxx64.tar.gz”. Descargue el archivo en su máquina.
Paso 1.2: extrae los archivos
Generalmente, los archivos se descargan al downloadscarpeta. Verifíquelo y extraiga la configuración de tar usando los siguientes comandos.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzPaso 1.3: muévase al directorio de opciones
Para que Java esté disponible para todos los usuarios, mueva el contenido java extraído a la carpeta “/ usr / local / java”.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Paso 1.4: Establecer ruta
Para establecer la ruta y las variables JAVA_HOME, agregue los siguientes comandos al archivo ~ / .bashrc.
export JAVA_HOME = /usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binAhora, aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcPaso 1.5: alternativas de Java
Utilice el siguiente comando para cambiar las alternativas de Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Paso 1.6
Verifique la instalación de Java usando el comando de verificación (java -version) explicado en el Paso 1.
Paso 2: Instalación de ZooKeeper Framework
Paso 2.1: Descarga ZooKeeper
Para instalar el framework ZooKeeper en su máquina, visite el siguiente enlace y descargue la última versión de ZooKeeper. http://zookeeper.apache.org/releases.html
A partir de ahora, la última versión de ZooKeeper es 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Paso 2.2: extraiga el archivo tar
Extraiga el archivo tar usando los siguientes comandos:
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataPaso 2.3: crear archivo de configuración
Abra el archivo de configuración llamado conf/zoo.cfg usando el comando vi conf/zoo.cfg y todos los siguientes parámetros para establecer como punto de partida.
$ vi conf/zoo.cfg
tickTime = 2000
dataDir = /path/to/zookeeper/data
clientPort = 2181
initLimit = 5
syncLimit = 2Una vez que el archivo de configuración se haya guardado correctamente, vuelva a la terminal. Ahora puede iniciar el servidor del guardián del zoológico.
Paso 2.4: Inicie el servidor de ZooKeeper
Ejecute el siguiente comando:
$ bin/zkServer.sh startDespués de ejecutar este comando, obtendrá una respuesta de la siguiente manera:
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDPaso 2.5: Inicie CLI
Escriba el siguiente comando:
$ bin/zkCli.shDespués de escribir el comando anterior, se conectará al servidor de ZooKeeper y debería obtener la siguiente respuesta.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Detener el servidor de ZooKeeper
Después de conectar el servidor y realizar todas las operaciones, puede detener el servidor del guardián del zoológico usando el siguiente comando.
$ bin/zkServer.sh stopLa interfaz de línea de comandos (CLI) de ZooKeeper se utiliza para interactuar con el conjunto de ZooKeeper con fines de desarrollo. Es útil para depurar y trabajar con diferentes opciones.
Para realizar operaciones CLI de ZooKeeper, primero encienda su servidor ZooKeeper ( “bin / zkServer.sh start” ) y luego, el cliente ZooKeeper ( “bin / zkCli.sh” ). Una vez que el cliente se inicia, puede realizar la siguiente operación:
- Crear znodes
- Obtener datos
- Observe los cambios de znode
- Establecer datos
- Crear hijos de un znode
- Lista de hijos de un znode
- Comprobar estado
- Eliminar / Eliminar un znode
Ahora veamos el comando anterior uno por uno con un ejemplo.
Crear Znodes
Crea un znode con la ruta dada. losflagEl argumento especifica si el znode creado será efímero, persistente o secuencial. De forma predeterminada, todos los znodes son persistentes.
Ephemeral znodes (bandera: e) se eliminará automáticamente cuando expire una sesión o cuando el cliente se desconecte.
Sequential znodes garantía de que la ruta de znode será única.
El conjunto ZooKeeper agregará un número de secuencia junto con un relleno de 10 dígitos a la ruta de znode. Por ejemplo, la ruta de znode / myapp se convertirá a / myapp0000000001 y el siguiente número de secuencia será / myapp0000000002 . Si no se especifican banderas, entonces el znode se considera comopersistent.
Sintaxis
create /path /dataMuestra
create /FirstZnode “Myfirstzookeeper-app”Salida
[zk: localhost:2181(CONNECTED) 0] create /FirstZnode “Myfirstzookeeper-app”
Created /FirstZnodePara crear un Sequential znode, agregar -s flag Como se muestra abajo.
Sintaxis
create -s /path /dataMuestra
create -s /FirstZnode second-dataSalida
[zk: localhost:2181(CONNECTED) 2] create -s /FirstZnode “second-data”
Created /FirstZnode0000000023Para crear un Ephemeral Znode, agregar -e flag Como se muestra abajo.
Sintaxis
create -e /path /dataMuestra
create -e /SecondZnode “Ephemeral-data”Salida
[zk: localhost:2181(CONNECTED) 2] create -e /SecondZnode “Ephemeral-data”
Created /SecondZnodeRecuerde que cuando se pierde la conexión de un cliente, el znode efímero se eliminará. Puede intentarlo saliendo de la CLI de ZooKeeper y luego volviendo a abrir la CLI.
Obtener datos
Devuelve los datos asociados del znode y los metadatos del znode especificado. Obtendrá información como cuándo se modificaron por última vez los datos, dónde se modificaron e información sobre los datos. Esta CLI también se usa para asignar relojes para mostrar notificaciones sobre los datos.
Sintaxis
get /pathMuestra
get /FirstZnodeSalida
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode
“Myfirstzookeeper-app”
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0Para acceder a un znode secuencial, debe ingresar la ruta completa del znode.
Muestra
get /FirstZnode0000000023Salida
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode0000000023
“Second-data”
cZxid = 0x80
ctime = Tue Sep 29 16:25:47 IST 2015
mZxid = 0x80
mtime = Tue Sep 29 16:25:47 IST 2015
pZxid = 0x80
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 0Reloj
Los relojes muestran una notificación cuando los datos secundarios de znode o znode especificados cambian. Puede establecer unwatch solo en get mando.
Sintaxis
get /path [watch] 1Muestra
get /FirstZnode 1Salida
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode 1
“Myfirstzookeeper-app”
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0La salida es similar a la normal. getcomando, pero esperará los cambios de znode en segundo plano. <Empiece aquí>
Establecer datos
Configure los datos del znode especificado. Una vez que termine esta operación configurada, puede verificar los datos usando elget Comando CLI.
Sintaxis
set /path /dataMuestra
set /SecondZnode Data-updatedSalida
[zk: localhost:2181(CONNECTED) 1] get /SecondZnode “Data-updated”
cZxid = 0x82
ctime = Tue Sep 29 16:29:50 IST 2015
mZxid = 0x83
mtime = Tue Sep 29 16:29:50 IST 2015
pZxid = 0x82
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x15018b47db00000
dataLength = 14
numChildren = 0Si asignaste watch opción en get comando (como en el comando anterior), entonces la salida será similar a la que se muestra a continuación:
Salida
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Mysecondzookeeper-app”
WATCHER: :
WatchedEvent state:SyncConnected type:NodeDataChanged path:/FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x84
mtime = Tue Sep 29 17:14:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0Crear hijos / Sub-znode
Crear hijos es similar a crear nuevos znodes. La única diferencia es que la ruta del znode secundario también tendrá la ruta principal.
Sintaxis
create /parent/path/subnode/path /dataMuestra
create /FirstZnode/Child1 firstchildrenSalida
[zk: localhost:2181(CONNECTED) 16] create /FirstZnode/Child1 “firstchildren”
created /FirstZnode/Child1
[zk: localhost:2181(CONNECTED) 17] create /FirstZnode/Child2 “secondchildren”
created /FirstZnode/Child2Lista de niños
Este comando se usa para listar y mostrar children de un znode.
Sintaxis
ls /pathMuestra
ls /MyFirstZnodeSalida
[zk: localhost:2181(CONNECTED) 2] ls /MyFirstZnode
[mysecondsubnode, myfirstsubnode]Comprobar estado
Statusdescribe los metadatos de un znode especificado. Contiene detalles como marca de tiempo, número de versión, ACL, longitud de los datos y znode secundario.
Sintaxis
stat /pathMuestra
stat /FirstZnodeSalida
[zk: localhost:2181(CONNECTED) 1] stat /FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 17:14:24 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0Eliminar un Znode
Elimina un znode especificado y de forma recursiva todos sus elementos secundarios. Esto sucedería solo si tal znode está disponible.
Sintaxis
rmr /pathMuestra
rmr /FirstZnodeSalida
[zk: localhost:2181(CONNECTED) 10] rmr /FirstZnode
[zk: localhost:2181(CONNECTED) 11] get /FirstZnode
Node does not exist: /FirstZnodeEliminar (delete /path) comando es similar a remove comando, excepto el hecho de que funciona solo en znodes sin hijos.
ZooKeeper tiene un enlace API oficial para Java y C. La comunidad ZooKeeper proporciona API no oficial para la mayoría de los lenguajes (.NET, python, etc.). Usando la API de ZooKeeper, una aplicación puede conectarse, interactuar, manipular datos, coordinar y finalmente desconectarse de un conjunto de ZooKeeper.
La API de ZooKeeper tiene un amplio conjunto de características para obtener toda la funcionalidad del conjunto ZooKeeper de una manera simple y segura. La API de ZooKeeper proporciona métodos sincrónicos y asincrónicos.
El conjunto ZooKeeper y la API ZooKeeper se complementan completamente en todos los aspectos y beneficia a los desarrolladores de una manera excelente. Analicemos el enlace de Java en este capítulo.
Conceptos básicos de la API de ZooKeeper
La aplicación que interactúa con el conjunto ZooKeeper se denomina ZooKeeper Client o simplemente Client.
Znode es el componente principal del conjunto ZooKeeper y la API de ZooKeeper proporciona un pequeño conjunto de métodos para manipular todos los detalles de znode con el conjunto ZooKeeper.
El cliente debe seguir los pasos que se indican a continuación para tener una interacción clara y limpia con el conjunto ZooKeeper.
Conéctese al conjunto ZooKeeper. El conjunto ZooKeeper asigna un ID de sesión para el cliente.
Envíe latidos al servidor periódicamente. De lo contrario, el conjunto de ZooKeeper expira la ID de sesión y el cliente debe volver a conectarse.
Obtenga / configure los znodes siempre que haya una ID de sesión activa.
Desconéctese del conjunto ZooKeeper, una vez que haya completado todas las tareas. Si el cliente está inactivo por un tiempo prolongado, entonces el conjunto ZooKeeper desconectará automáticamente al cliente.
Enlace de Java
Entendamos el conjunto más importante de API de ZooKeeper en este capítulo. La parte central de la API de ZooKeeper esZooKeeper class. Proporciona opciones para conectar el conjunto ZooKeeper en su constructor y tiene los siguientes métodos:
connect - conectarse al conjunto ZooKeeper
create - crear un znode
exists - comprobar si existe un znode y su información
getData - obtener datos de un znode en particular
setData - establecer datos en un znode particular
getChildren - obtener todos los subnodos disponibles en un znode particular
delete - obtener un znode particular y todos sus hijos
close - cerrar una conexión
Conéctese al conjunto ZooKeeper
La clase ZooKeeper proporciona funcionalidad de conexión a través de su constructor. La firma del constructor es la siguiente:
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)Dónde,
connectionString - Anfitrión del conjunto ZooKeeper.
sessionTimeout - tiempo de espera de la sesión en milisegundos.
watcher- un objeto que implementa la interfaz "Watcher". El conjunto ZooKeeper devuelve el estado de la conexión a través del objeto observador.
Creemos una nueva clase de ayuda ZooKeeperConnection y agrega un método connect. losconnect El método crea un objeto ZooKeeper, se conecta al conjunto ZooKeeper y luego devuelve el objeto.
aquí CountDownLatch se utiliza para detener (esperar) el proceso principal hasta que el cliente se conecta con el conjunto ZooKeeper.
El conjunto ZooKeeper responde el estado de la conexión a través del Watcher callback. La devolución de llamada de Watcher se llamará una vez que el cliente se conecte con el conjunto ZooKeeper y la devolución de llamada de Watcher llame alcountDown método del CountDownLatch para abrir la cerradura, await en el proceso principal.
Aquí está el código completo para conectarse con un conjunto ZooKeeper.
Codificación: ZooKeeperConnection.java
// import java classes
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
// import zookeeper classes
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.AsyncCallback.StatCallback;
import org.apache.zookeeper.KeeperException.Code;
import org.apache.zookeeper.data.Stat;
public class ZooKeeperConnection {
// declare zookeeper instance to access ZooKeeper ensemble
private ZooKeeper zoo;
final CountDownLatch connectedSignal = new CountDownLatch(1);
// Method to connect zookeeper ensemble.
public ZooKeeper connect(String host) throws IOException,InterruptedException {
zoo = new ZooKeeper(host,5000,new Watcher() {
public void process(WatchedEvent we) {
if (we.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
});
connectedSignal.await();
return zoo;
}
// Method to disconnect from zookeeper server
public void close() throws InterruptedException {
zoo.close();
}
}Guarde el código anterior y se utilizará en la siguiente sección para conectar el conjunto ZooKeeper.
Crea un Znode
La clase ZooKeeper proporciona create methodpara crear un nuevo znode en el conjunto ZooKeeper. La firma delcreate El método es el siguiente:
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)Dónde,
path- Ruta de Znode. Por ejemplo, / myapp1, / myapp2, / myapp1 / mydata1, myapp2 / mydata1 / myanothersubdata
data - datos para almacenar en una ruta de znode especificada
acl- lista de control de acceso del nodo a crear. La API de ZooKeeper proporciona una interfaz estáticaZooDefs.Idspara obtener algunas de las listas de acl básicas. Por ejemplo, ZooDefs.Ids.OPEN_ACL_UNSAFE devuelve una lista de acl para znodes abiertos.
createMode- el tipo de nodo, ya sea efímero, secuencial o ambos. Esto es unenum.
Creemos una nueva aplicación Java para comprobar el createfuncionalidad de la API de ZooKeeper. Crea un archivoZKCreate.java. En el método principal, crea un objeto de tipoZooKeeperConnection y llama al connect método para conectarse al conjunto ZooKeeper.
El método de conexión devolverá el objeto ZooKeeper zk. Ahora, llame alcreate método de zk objeto con personalizado path y data.
El código completo del programa para crear un znode es el siguiente:
Codificación: ZKCreate.java
import java.io.IOException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
public class ZKCreate {
// create static instance for zookeeper class.
private static ZooKeeper zk;
// create static instance for ZooKeeperConnection class.
private static ZooKeeperConnection conn;
// Method to create znode in zookeeper ensemble
public static void create(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
public static void main(String[] args) {
// znode path
String path = "/MyFirstZnode"; // Assign path to znode
// data in byte array
byte[] data = "My first zookeeper app”.getBytes(); // Declare data
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
create(path, data); // Create the data to the specified path
conn.close();
} catch (Exception e) {
System.out.println(e.getMessage()); //Catch error message
}
}
}Una vez compilada y ejecutada la aplicación, se creará un znode con los datos especificados en el conjunto de ZooKeeper. Puede verificarlo usando la CLI de ZooKeeperzkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnodeExiste: compruebe la existencia de un Znode
La clase ZooKeeper proporciona la exists methodpara comprobar la existencia de un znode. Devuelve los metadatos de un znode, si existe el znode especificado. La firma delexists El método es el siguiente:
exists(String path, boolean watcher)Dónde,
path - Ruta de Znode
watcher - valor booleano para especificar si se debe observar un znode especificado o no
Creemos una nueva aplicación Java para comprobar la funcionalidad "existente" de la API de ZooKeeper. Cree un archivo "ZKExists.java" . En el método principal, cree el objeto ZooKeeper, "zk" utilizando el objeto "ZooKeeperConnection" . Luego, llame al método "existe" del objeto "zk" con una "ruta" personalizada . La lista completa es la siguiente:
Codificación: ZKExists.java
import java.io.IOException;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKExists {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path, true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign znode to the specified path
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path of the znode
if(stat != null) {
System.out.println("Node exists and the node version is " +
stat.getVersion());
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage()); // Catches error messages
}
}
}Una vez que la aplicación esté compilada y ejecutada, obtendrá el siguiente resultado.
Node exists and the node version is 1.Método getData
La clase ZooKeeper proporciona getDatamétodo para obtener los datos adjuntos en un znode especificado y su estado. La firma delgetData El método es el siguiente:
getData(String path, Watcher watcher, Stat stat)Dónde,
path - Ruta de Znode.
watcher - Función de devolución de llamada de tipo Watcher. El conjunto ZooKeeper notificará a través de la devolución de llamada de Watcher cuando cambien los datos del znode especificado. Esta es una notificación única.
stat - Devuelve los metadatos de un znode.
Creemos una nueva aplicación Java para comprender la getDatafuncionalidad de la API de ZooKeeper. Crea un archivoZKGetData.java. En el método principal, cree un objeto ZooKeeperzk usando él ZooKeeperConnectionobjeto. Entonces, llame algetData método de objeto zk con ruta personalizada.
Aquí está el código del programa completo para obtener los datos de un nodo específico:
Codificación: ZKGetData.java
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException, KeeperException {
String path = "/MyFirstZnode";
final CountDownLatch connectedSignal = new CountDownLatch(1);
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path);
if(stat != null) {
byte[] b = zk.getData(path, new Watcher() {
public void process(WatchedEvent we) {
if (we.getType() == Event.EventType.None) {
switch(we.getState()) {
case Expired:
connectedSignal.countDown();
break;
}
} else {
String path = "/MyFirstZnode";
try {
byte[] bn = zk.getData(path,
false, null);
String data = new String(bn,
"UTF-8");
System.out.println(data);
connectedSignal.countDown();
} catch(Exception ex) {
System.out.println(ex.getMessage());
}
}
}
}, null);
String data = new String(b, "UTF-8");
System.out.println(data);
connectedSignal.await();
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}Una vez que la aplicación esté compilada y ejecutada, obtendrá el siguiente resultado
My first zookeeper appY la aplicación esperará nuevas notificaciones del conjunto ZooKeeper. Cambiar los datos del znode especificado usando ZooKeeper CLIzkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> set /MyFirstZnode HelloAhora, la aplicación imprimirá la siguiente salida y saldrá.
HelloMétodo setData
La clase ZooKeeper proporciona setDatamétodo para modificar los datos adjuntos en un znode especificado. La firma delsetData El método es el siguiente:
setData(String path, byte[] data, int version)Dónde,
path - Ruta de Znode
data - datos para almacenar en una ruta de znode especificada.
version- Versión actual del znode. ZooKeeper actualiza el número de versión del znode cada vez que se modifican los datos.
Creemos ahora una nueva aplicación Java para comprender la setDatafuncionalidad de la API de ZooKeeper. Crea un archivoZKSetData.java. En el método principal, cree un objeto ZooKeeperzk utilizando el ZooKeeperConnectionobjeto. Entonces, llame alsetData método de zk objeto con la ruta especificada, nuevos datos y versión del nodo.
Aquí está el código del programa completo para modificar los datos adjuntos en un znode específico.
Código: ZKSetData.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import java.io.IOException;
public class ZKSetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to update the data in a znode. Similar to getData but without watcher.
public static void update(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.setData(path, data, zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path= "/MyFirstZnode";
byte[] data = "Success".getBytes(); //Assign data which is to be updated.
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
update(path, data); // Update znode data to the specified path
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}Una vez que la aplicación se compila y ejecuta, los datos del znode especificado se cambiarán y se pueden verificar usando la CLI de ZooKeeper, zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnodegetChildrenMethod
La clase ZooKeeper proporciona getChildrenmétodo para obtener todos los subnodos de un znode en particular. La firma delgetChildren El método es el siguiente:
getChildren(String path, Watcher watcher)Dónde,
path - Ruta de Znode.
watcher- Función de devolución de llamada de tipo "Watcher". El conjunto de ZooKeeper notificará cuando se elimine el znode especificado o cuando se cree / elimine un niño bajo el znode. Esta es una notificación única.
Codificación: ZKGetChildren.java
import java.io.IOException;
import java.util.*;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetChildren {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path
if(stat!= null) {
//“getChildren” method- get all the children of znode.It has two
args, path and watch
List <String> children = zk.getChildren(path, false);
for(int i = 0; i < children.size(); i++)
System.out.println(children.get(i)); //Print children's
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}Antes de ejecutar el programa, creemos dos subnodos para /MyFirstZnode utilizando la CLI de ZooKeeper, zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> create /MyFirstZnode/myfirstsubnode Hi
>>> create /MyFirstZnode/mysecondsubmode HiAhora, compilar y ejecutar el programa generará los znodes creados anteriormente.
myfirstsubnode
mysecondsubnodeEliminar un Znode
La clase ZooKeeper proporciona deletemétodo para eliminar un znode especificado. La firma deldelete El método es el siguiente:
delete(String path, int version)Dónde,
path - Ruta de Znode.
version - Versión actual del znode.
Creemos una nueva aplicación Java para comprender la deletefuncionalidad de la API de ZooKeeper. Crea un archivoZKDelete.java. En el método principal, cree un objeto ZooKeeperzk utilizando ZooKeeperConnectionobjeto. Entonces, llame aldelete método de zk objeto con el especificado path y versión del nodo.
El código de programa completo para eliminar un znode es el siguiente:
Codificación: ZKDelete.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
public class ZKDelete {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static void delete(String path) throws KeeperException,InterruptedException {
zk.delete(path,zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; //Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
delete(path); //delete the node with the specified path
} catch(Exception e) {
System.out.println(e.getMessage()); // catches error messages
}
}
}Zookeeper proporciona una infraestructura de coordinación flexible para entornos distribuidos. El framework ZooKeeper es compatible con muchas de las mejores aplicaciones industriales de la actualidad. Discutiremos algunas de las aplicaciones más notables de ZooKeeper en este capítulo.
Yahoo!
El marco de ZooKeeper se creó originalmente en “Yahoo!”. Una aplicación distribuida bien diseñada debe cumplir requisitos tales como transparencia de datos, mejor rendimiento, solidez, configuración centralizada y coordinación. Entonces, diseñaron el marco de ZooKeeper para cumplir con estos requisitos.
Apache Hadoop
Apache Hadoop es la fuerza impulsora detrás del crecimiento de la industria de Big Data. Hadoop confía en ZooKeeper para la gestión y coordinación de la configuración. Tomemos un escenario para comprender el papel de ZooKeeper en Hadoop.
Suponga que un Hadoop cluster puentes 100 or more commodity servers. Por lo tanto, se necesitan servicios de coordinación y denominación. Como está involucrado el cálculo de una gran cantidad de nodos, cada nodo debe sincronizarse entre sí, saber dónde acceder a los servicios y saber cómo deben configurarse. En este momento, los clústeres de Hadoop requieren servicios entre nodos. ZooKeeper proporciona las instalaciones paracross-node synchronization y asegura que las tareas en los proyectos de Hadoop se serialicen y sincronicen.
Varios servidores de ZooKeeper admiten grandes clústeres de Hadoop. Cada máquina cliente se comunica con uno de los servidores de ZooKeeper para recuperar y actualizar su información de sincronización. Algunos de los ejemplos en tiempo real son:
Human Genome Project- El Proyecto Genoma Humano contiene terabytes de datos. El marco Hadoop MapReduce se puede utilizar para analizar el conjunto de datos y encontrar datos interesantes para el desarrollo humano.
Healthcare - Los hospitales pueden almacenar, recuperar y analizar grandes conjuntos de registros médicos de pacientes, que normalmente están en terabytes.
Apache HBase
Apache HBase es una base de datos NoSQL distribuida de código abierto que se utiliza para el acceso de lectura / escritura en tiempo real de grandes conjuntos de datos y se ejecuta en la parte superior de HDFS. HBase siguemaster-slave architecturedonde el Maestro HBase gobierna a todos los esclavos. Los esclavos se conocen comoRegion servers.
La instalación de la aplicación distribuida HBase depende de un clúster de ZooKeeper en ejecución. Apache HBase usa ZooKeeper para rastrear el estado de los datos distribuidos en los servidores maestros y regionales con la ayuda decentralized configuration management y distributed mutexmecanismos. Estos son algunos de los casos de uso de HBase:
Telecom- La industria de las telecomunicaciones almacena miles de millones de registros de llamadas móviles (alrededor de 30 TB / mes) y acceder a estos registros de llamadas en tiempo real se convierte en una tarea enorme. HBase se puede utilizar para procesar todos los registros en tiempo real, de manera fácil y eficiente.
Social network- Al igual que en la industria de las telecomunicaciones, sitios como Twitter, LinkedIn y Facebook reciben grandes volúmenes de datos a través de las publicaciones creadas por los usuarios. HBase se puede utilizar para encontrar tendencias recientes y otros datos interesantes.
Apache Solr
Apache Solr es una plataforma de búsqueda de código abierto rápida escrita en Java. Es un motor de búsqueda distribuido ultrarrápido y tolerante a fallos. Construido sobreLucene, es un motor de búsqueda de texto de alto rendimiento y con todas las funciones.
Solr utiliza ampliamente todas las funciones de ZooKeeper, como la gestión de la configuración, la elección de líderes, la gestión de nodos, el bloqueo y la sincronización de datos.
Solr tiene dos partes distintas, indexing y searching. La indexación es un proceso de almacenamiento de datos en un formato adecuado para que se puedan buscar más tarde. Solr usa ZooKeeper tanto para indexar los datos en múltiples nodos como para buscar desde múltiples nodos. ZooKeeper aporta las siguientes características:
Agregue / elimine nodos cuando sea necesario
Replicación de datos entre nodos y, posteriormente, minimización de la pérdida de datos.
Compartir datos entre varios nodos y, posteriormente, buscar desde varios nodos para obtener resultados de búsqueda más rápidos
Algunos de los casos de uso de Apache Solr incluyen comercio electrónico, búsqueda de empleo, etc.