Apache Flume - Source du générateur de séquence
Dans le chapitre précédent, nous avons vu comment récupérer des données de la source Twitter vers HDFS. Ce chapitre explique comment récupérer des données depuisSequence generator.
Conditions préalables
Pour exécuter l'exemple fourni dans ce chapitre, vous devez installer HDFS de même que Flume. Par conséquent, vérifiez l'installation de Hadoop et démarrez le HDFS avant de continuer. (Reportez-vous au chapitre précédent pour savoir comment démarrer le HDFS).
Configurer Flume
Nous devons configurer la source, le canal et le puits en utilisant le fichier de configuration dans le confdossier. L'exemple donné dans ce chapitre utilise unsequence generator source, une memory channel, Et un HDFS sink.
Source du générateur de séquence
C'est la source qui génère les événements en continu. Il maintient un compteur qui commence à 0 et incrémente de 1. Il est utilisé à des fins de test. Lors de la configuration de cette source, vous devez fournir des valeurs aux propriétés suivantes -
Channels
Source type - seq
Canal
Nous utilisons le memorycanal. Pour configurer le canal mémoire, vous devez fournir une valeur au type du canal. Vous trouverez ci-dessous la liste des propriétés que vous devez fournir lors de la configuration du canal mémoire -
type- Il contient le type de chaîne. Dans notre exemple, le type est MemChannel.
Capacity- C'est le nombre maximum d'événements stockés dans le canal. Sa valeur par défaut est 100. (facultatif)
TransactionCapacity- C'est le nombre maximum d'événements que le canal accepte ou envoie. Sa valeur par défaut est 100. (facultatif).
Évier HDFS
Ce récepteur écrit des données dans le HDFS. Pour configurer ce récepteur, vous devez fournir les détails suivants.
Channel
type - hdfs
hdfs.path - le chemin du répertoire dans HDFS où les données doivent être stockées.
Et nous pouvons fournir des valeurs facultatives basées sur le scénario. Vous trouverez ci-dessous les propriétés facultatives du récepteur HDFS que nous configurons dans notre application.
fileType - C'est le format de fichier requis de notre fichier HDFS. SequenceFile, DataStream et CompressedStreamsont les trois types disponibles avec ce flux. Dans notre exemple, nous utilisons leDataStream.
writeFormat - Peut être texte ou inscriptible.
batchSize- Il s'agit du nombre d'événements écrits dans un fichier avant qu'il ne soit vidé dans le HDFS. Sa valeur par défaut est 100.
rollsize- C'est la taille du fichier pour déclencher un roulement. Sa valeur par défaut est 100.
rollCount- C'est le nombre d'événements écrits dans le fichier avant qu'il ne soit lancé. Sa valeur par défaut est 10.
Exemple - Fichier de configuration
Ci-dessous est un exemple du fichier de configuration. Copiez ce contenu et enregistrez-le sousseq_gen .conf dans le dossier conf de Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelExécution
Parcourez le répertoire de base de Flume et exécutez l'application comme indiqué ci-dessous.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentSi tout se passe bien, la source commence à générer des numéros de séquence qui seront poussés dans le HDFS sous la forme de fichiers journaux.
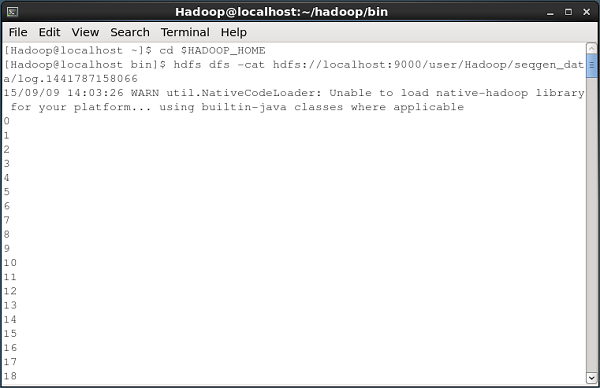
Ci-dessous, un instantané de la fenêtre d'invite de commande récupérant les données générées par le générateur de séquence dans le HDFS.

Vérification du HDFS
Vous pouvez accéder à l'interface Web d'administration Hadoop à l'aide de l'URL suivante:
http://localhost:50070/Cliquez sur le menu déroulant nommé Utilitiessur le côté droit de la page. Vous pouvez voir deux options comme indiqué dans le diagramme ci-dessous.
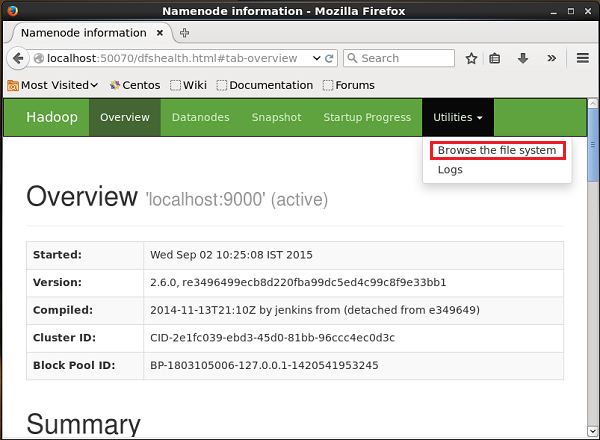
Cliquer sur Browse the file system et entrez le chemin du répertoire HDFS dans lequel vous avez stocké les données générées par le générateur de séquence.
Dans notre exemple, le chemin sera /user/Hadoop/ seqgen_data /. Ensuite, vous pouvez voir la liste des fichiers journaux générés par le générateur de séquence, stockés dans le HDFS comme indiqué ci-dessous.

Vérification du contenu du fichier
Tous ces fichiers journaux contiennent des nombres au format séquentiel. Vous pouvez vérifier le contenu de ces fichiers dans le système de fichiers en utilisant lecat comme indiqué ci-dessous.