Apache NiFi - Guide rapide
Apache NiFi est un système puissant, facile à utiliser et fiable pour traiter et distribuer des données entre des systèmes disparates. Il est basé sur la technologie Niagara Files développée par la NSA puis, après 8 ans, donné à la fondation Apache Software. Il est distribué sous licence Apache Version 2.0, janvier 2004. La dernière version pour Apache NiFi est 1.7.1.
Apache NiFi est une plate-forme d'ingestion de données en temps réel, qui peut transférer et gérer le transfert de données entre différentes sources et systèmes de destination. Il prend en charge une grande variété de formats de données tels que les journaux, les données de géolocalisation, les flux sociaux, etc. Il prend également en charge de nombreux protocoles tels que SFTP, HDFS et KAFKA, etc. de nombreuses organisations informatiques.
Apache NiFi - Caractéristiques générales
Les caractéristiques générales d'Apache NiFi sont les suivantes -
Apache NiFi fournit une interface utilisateur Web, qui offre une expérience transparente entre la conception, le contrôle, les commentaires et la surveillance.
Il est hautement configurable. Cela aide les utilisateurs avec une livraison garantie, une faible latence, un débit élevé, une priorisation dynamique, une contre-pression et modifie les flux lors de l'exécution.
Il fournit également un module de provenance des données pour suivre et surveiller les données du début à la fin du flux.
Les développeurs peuvent créer leurs propres processeurs personnalisés et tâches de reporting en fonction de leurs besoins.
NiFi prend également en charge des protocoles sécurisés tels que SSL, HTTPS, SSH et d'autres cryptages.
Il prend également en charge la gestion des utilisateurs et des rôles et peut également être configuré avec LDAP pour l'autorisation.
Apache NiFi - Concepts clés
Les concepts clés d'Apache NiFi sont les suivants -
Process Group - C'est un groupe de flux NiFi, qui aide un utilisateur à gérer et à maintenir les flux de manière hiérarchique.
Flow - Il est créé en connectant différents processeurs pour transférer et modifier les données si nécessaire d'une ou plusieurs sources de données vers une autre source de données de destination.
Processor- Un processeur est un module Java chargé de récupérer les données du système d'approvisionnement ou de les stocker dans le système de destination. D'autres processeurs sont également utilisés pour ajouter des attributs ou modifier le contenu dans flowfile.
Flowfile- C'est l'utilisation de base de NiFi, qui représente le seul objet des données extraites du système source dans NiFi. NiFiprocessormodifie le fichier de flux pendant qu'il se déplace du processeur source vers la destination. Différents événements tels que CREATE, CLONE, RECEIVE, etc. sont exécutés sur le fichier de flux par différents processeurs dans un flux.
Event- Les événements représentent la modification du fichier de flux lors de la traversée d'un flux NiFi. Ces événements sont suivis dans la provenance des données.
Data provenance - Il s'agit d'un référentiel.Il dispose également d'une interface utilisateur, qui permet aux utilisateurs de vérifier les informations sur un fichier de flux et aide à résoudre les problèmes qui surviennent lors du traitement d'un fichier de flux.
Avantages d'Apache NiFi
Apache NiFi permet la récupération de données à partir de machines distantes en utilisant SFTP et garantit le lignage des données.
Apache NiFi prend en charge le clustering, de sorte qu'il peut fonctionner sur plusieurs nœuds avec le même flux traitant différentes données, ce qui augmente les performances du traitement des données.
Il fournit également des politiques de sécurité au niveau de l'utilisateur, au niveau du groupe de processus et d'autres modules.
Son interface utilisateur peut également fonctionner sur HTTPS, ce qui sécurise l'interaction des utilisateurs avec NiFi.
NiFi prend en charge environ 188 processeurs et un utilisateur peut également créer des plugins personnalisés pour prendre en charge une grande variété de systèmes de données.
Inconvénients d'Apache NiFi
Lorsque le nœud est déconnecté du cluster NiFi alors qu'un utilisateur y apporte des modifications, le flow.xml devient invalide.Anode ne peut pas se reconnecter au cluster à moins que l'administrateur ne copie manuellement flow.xml à partir du nœud connecté.
Apache NiFi a un problème de persistance de l'état en cas de changement de nœud principal, ce qui empêche parfois les processeurs de récupérer les données des systèmes d'approvisionnement.
Apache NiFi se compose d'un serveur Web, d'un contrôleur de flux et d'un processeur, qui s'exécute sur Java Virtual Machine. Il dispose également de 3 référentiels Flowfile Repository, Content Repository et Provenance Repository, comme illustré dans la figure ci-dessous.

Référentiel Flowfile
Ce référentiel stocke l'état actuel et les attributs de chaque fichier de flux qui passe par les flux de données d'Apache NiFi. L'emplacement par défaut de ce référentiel est dans le répertoire racine d'apache NiFi. L'emplacement de ce référentiel peut être modifié en modifiant la propriété nommée "nifi.flowfile.repository.directory".
Référentiel de contenu
Ce référentiel contient tout le contenu présent dans tous les flowfiles de NiFi. Son répertoire par défaut se trouve également dans le répertoire racine de NiFi et il peut être modifié à l'aide de la propriété "org.apache.nifi.controller.repository.FileSystemRepository". Ce répertoire utilise un grand espace sur le disque, il est donc conseillé de disposer de suffisamment d'espace sur le disque d'installation.
Référentiel de provenance
Le référentiel suit et stocke tous les événements de tous les fichiers de flux qui circulent dans NiFi. Il existe deux référentiels de provenance -volatile provenance repository (dans ce référentiel, toutes les données de provenance sont perdues après le redémarrage) et persistent provenance repository. Son répertoire par défaut se trouve également dans le répertoire racine de NiFi et il peut être modifié à l'aide des propriétés "org.apache.nifi.provenance.PersistentProvenanceRepository" et "org.apache.nifi.provenance.VolatileProvenanceRepositor" pour les référentiels respectifs.

Dans ce chapitre, nous allons découvrir la configuration de l'environnement d'Apache NiFi. Les étapes d'installation d'Apache NiFi sont les suivantes -
Step 1- Installez la version actuelle de Java sur votre ordinateur. Veuillez définir leJAVA_HOME dans votre machine. Vous pouvez vérifier la version comme indiqué ci-dessous:
Dans le système d'exploitation Windows (OS) (à l'aide de l'invite de commande) -
> java -versionSous UNIX OS (à l'aide du terminal):
$ echo $JAVA_HOME
Step 2 - TéléchargerApache NiFi depuis https://nifi.apache.org/download.html
Pour Windows OS, téléchargez le fichier ZIP.
Pour UNIX OS, téléchargez le fichier TAR.
Pour les images du docker, accédez au lien suivant https://hub.docker.com/r/apache/nifi/.
Step 3- Le processus d'installation d'Apache NiFi est très simple. Le processus diffère selon le système d'exploitation -
Windows OS - Décompressez le package zip et Apache NiFi est installé.
UNIX OS - Extrayez le fichier tar dans n'importe quel emplacement et le Logstash est installé.
$tar -xvf nifi-1.6.0-bin.tar.gzStep 4- Ouvrez l'invite de commande, accédez au répertoire bin de NiFi. Par exemple, C: \ nifi-1.7.1 \ bin et exécutez le fichier run-nifi.bat.
C:\nifi-1.7.1\bin>run-nifi.batStep 5- La mise en place de l'interface NiFi prendra quelques minutes. Un utilisateur peut vérifier nifi-app.log, une fois l'interface NiFi activée, un utilisateur peut entrerhttp://localhost:8080/nifi/ pour accéder à l'interface utilisateur.
Apache est une plate-forme Web accessible par un utilisateur à l'aide de l'interface utilisateur Web. L'interface utilisateur NiFi est très interactive et fournit une grande variété d'informations sur NiFi. Comme le montre l'image ci-dessous, un utilisateur peut accéder aux informations sur les attributs suivants -
- Threads actifs
- Total des données en file d'attente
- Transmission de groupes de processus distants
- Ne pas transmettre de groupes de processus distants
- Composants en cours d'exécution
- Composants arrêtés
- Composants non valides
- Composants désactivés
- Groupes de processus versionnés à jour
- Groupes de processus versionnés modifiés localement
- Groupes de processus versionnés obsolètes
- Groupes de processus modifiés localement et périmés
- Échec de synchronisation Groupes de processus versionnés

Composants d'Apache NiFi
L'interface utilisateur Apache NiFi comprend les composants suivants -
Processeurs
L'utilisateur peut faire glisser l'icône de processus sur le canevas et sélectionner le processeur souhaité pour le flux de données dans NiFi.

Port d'entrée
L'icône ci-dessous est déplacée vers le canevas pour ajouter le port d'entrée dans n'importe quel flux de données.
Le port d'entrée est utilisé pour obtenir des données du processeur, qui ne sont pas présentes dans ce groupe de processus.

Après avoir fait glisser cette icône, NiFi demande d'entrer le nom du port d'entrée, puis il est ajouté au canevas NiFi.
Port de sortie
L'icône ci-dessous est déplacée vers le canevas pour ajouter le port de sortie dans n'importe quel flux de données.
Le port de sortie est utilisé pour transférer des données vers le processeur, qui n'est pas présent dans ce groupe de processus.

Après avoir fait glisser cette icône, NiFi demande à entrer le nom du port de sortie, puis il est ajouté au canevas NiFi.

Groupe de processus
Un utilisateur utilise l'icône ci-dessous pour ajouter un groupe de processus dans le canevas NiFi.
Après avoir fait glisser cette icône, NiFi demande d'entrer le nom du groupe de processus, puis il est ajouté au canevas NiFi.

Groupe de processus distant
Ceci est utilisé pour ajouter un groupe de processus distant dans le canevas NiFi.

Entonnoir
L'entonnoir est utilisé pour transférer la sortie d'un processeur vers plusieurs processeurs. L'utilisateur peut utiliser l'icône ci-dessous pour ajouter l'entonnoir dans un flux de données NiFi.
Modèle
Cette icône est utilisée pour ajouter un modèle de flux de données au canevas NiFi. Cela permet de réutiliser le flux de données dans la même instance NiFi ou dans différentes instances.
Après avoir fait glisser, un utilisateur peut sélectionner les modèles déjà ajoutés dans le NiFi.
Étiquette
Ceux-ci sont utilisés pour ajouter du texte sur la toile NiFi à propos de n'importe quel composant présent dans NiFi. Il offre une gamme de couleurs utilisées par un utilisateur pour ajouter un sens esthétique.
Les processeurs Apache NiFi sont les blocs de base pour créer un flux de données. Chaque processeur a des fonctionnalités différentes, ce qui contribue à la création d'un fichier de flux de sortie. Le flux de données montré dans l'image ci-dessous extrait le fichier d'un répertoire à l'aide du processeur GetFile et le stocke dans un autre répertoire à l'aide du processeur PutFile.
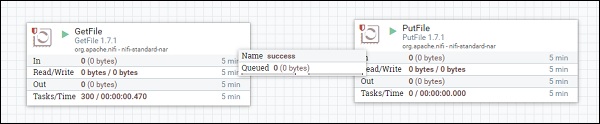
GetFile
Le processus GetFile est utilisé pour récupérer des fichiers d'un format spécifique à partir d'un répertoire spécifique. Il fournit également d'autres options à l'utilisateur pour plus de contrôle sur la récupération. Nous en discuterons dans la section des propriétés ci-dessous.
Paramètres GetFile
Voici les différents paramètres du processeur GetFile -
Nom
Dans le paramètre Nom, un utilisateur peut définir n'importe quel nom pour les processeurs en fonction du projet ou de celui-ci, ce qui rend le nom plus significatif.
Activer
Un utilisateur peut activer ou désactiver le processeur à l'aide de ce paramètre.
Durée de la pénalité
Ce paramètre permet à un utilisateur d'ajouter la durée du temps de pénalité, en cas d'échec du fichier de flux.
Durée du rendement
Ce paramètre est utilisé pour spécifier le temps de rendement du processeur. Pendant cette durée, le processus n'est pas de nouveau planifié.
Niveau du bulletin
Ce paramètre est utilisé pour spécifier le niveau de journalisation de ce processeur.
Mettre fin automatiquement aux relations
Cela a une liste de contrôle de toutes les relations disponibles de ce processus particulier. En cochant les cases, un utilisateur peut programmer le processeur pour terminer le fichier de flux sur cet événement et ne pas l'envoyer plus loin dans le flux.

Planification GetFile
Voici les options de planification suivantes offertes par le processeur GetFile -
Stratégie de planification
Vous pouvez planifier le processus en fonction du temps en sélectionnant piloté par le temps ou une chaîne CRON spécifiée en sélectionnant une option de pilote CRON.
Tâches simultanées
Cette option est utilisée pour définir la planification des tâches simultanées pour ce processeur.
Exécution
Un utilisateur peut définir s'il doit exécuter le processeur dans tous les nœuds ou uniquement dans le nœud principal à l'aide de cette option.
Calendrier d'exécution
Il est utilisé pour définir le temps pour la stratégie pilotée par le temps ou l'expression CRON pour la stratégie pilotée par CRON.

Propriétés GetFile
GetFile offre plusieurs propriétés comme indiqué dans l'image ci-dessous qui fait rage des propriétés obligatoires telles que le répertoire d'entrée et le filtre de fichiers à des propriétés facultatives telles que le filtre de chemin et la taille maximale du fichier. Un utilisateur peut gérer le processus de récupération de fichiers à l'aide de ces propriétés.

Commentaires GetFile
Cette section est utilisée pour spécifier toute information sur le processeur.

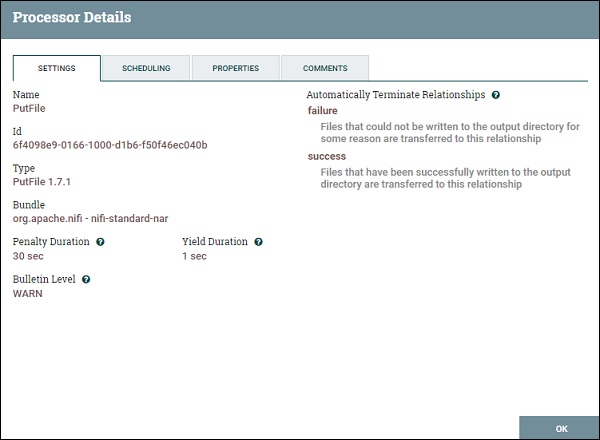
PutFile
Le processeur PutFile est utilisé pour stocker le fichier du flux de données vers un emplacement spécifique.

Paramètres PutFile
Le processeur PutFile a les paramètres suivants -
Nom
Dans le paramètre Nom, un utilisateur peut définir n'importe quel nom pour les processeurs en fonction du projet ou de ce qui rend le nom plus significatif.
Activer
Un utilisateur peut activer ou désactiver le processeur à l'aide de ce paramètre.
Durée de la pénalité
Ce paramètre permet à un utilisateur d'ajouter la durée du temps de pénalité, en cas d'échec du fichier de flux.
Durée du rendement
Ce paramètre est utilisé pour spécifier le temps de rendement du processeur. Pendant cette durée, le processus n'est pas programmé à nouveau.
Niveau du bulletin
Ce paramètre est utilisé pour spécifier le niveau de journalisation de ce processeur.
Mettre fin automatiquement aux relations
Ce paramètre a une liste de vérification de toutes les relations disponibles de ce processus particulier. En cochant les cases, l'utilisateur peut programmer le processeur pour terminer le fichier de flux sur cet événement et ne pas l'envoyer plus loin dans le flux.
Planification PutFile
Voici les options de planification suivantes offertes par le processeur PutFile -
Stratégie de planification
Vous pouvez planifier le processus sur la base du temps en sélectionnant piloté par minuterie ou une chaîne CRON spécifiée en sélectionnant l'option de pilote CRON. Il existe également une stratégie expérimentale Event Driven, qui déclenchera le processeur sur un événement spécifique.
Tâches simultanées
Cette option est utilisée pour définir la planification des tâches simultanées pour ce processeur.
Exécution
Un utilisateur peut définir s'il doit exécuter le processeur dans tous les nœuds ou uniquement dans le nœud principal à l'aide de cette option.
Calendrier d'exécution
Il est utilisé pour définir le temps pour la stratégie pilotée par la minuterie ou l'expression CRON pour la stratégie pilotée par CRON.

Propriétés PutFile
Le processeur PutFile fournit des propriétés telles que Directory pour spécifier le répertoire de sortie à des fins de transfert de fichiers et d'autres pour gérer le transfert comme indiqué dans l'image ci-dessous.

Commentaires PutFile
Cette section est utilisée pour spécifier toute information sur le processeur.

Dans ce chapitre, nous aborderons la catégorisation des processus dans Apache NiFi.
Processeurs d'ingestion de données
Les processeurs de la catégorie Ingestion de données sont utilisés pour ingérer des données dans le flux de données NiFi. Ce sont principalement le point de départ de tout flux de données dans apache NiFi. Certains des processeurs qui appartiennent à ces catégories sont GetFile, GetHTTP, GetFTP, GetKAFKA, etc.
Processeurs de routage et de médiation
Les processeurs de routage et de médiation sont utilisés pour acheminer les fichiers de flux vers différents processeurs ou flux de données en fonction des informations contenues dans les attributs ou du contenu de ces fichiers de flux. Ces processeurs sont également chargés de contrôler les flux de données NiFi. Certains des processeurs qui appartiennent à cette catégorie sont RouteOnAttribute, RouteOnContent, ControlRate, RouteText, etc.
Processeurs d'accès aux bases de données
Les processeurs de cette catégorie d'accès à la base de données sont capables de sélectionner ou d'insérer des données ou d'exécuter et de préparer d'autres instructions SQL à partir de la base de données. Ces processeurs utilisent principalement le paramètre de contrôleur de pool de connexion de données d'Apache NiFi. Certains des processeurs appartenant à cette catégorie sont ExecuteSQL, PutSQL, PutDatabaseRecord, ListDatabaseTables, etc.
Processeurs d'extraction d'attributs
Les processeurs d'extraction d'attributs sont chargés d'extraire, d'analyser et de modifier le traitement des attributs du fichier de flux dans le flux de données NiFi. Certains des processeurs appartenant à cette catégorie sont UpdateAttribute, EvaluateJSONPath, ExtractText, AttributesToJSON, etc.
Processeurs d'interaction système
Les processeurs d'interaction système sont utilisés pour exécuter des processus ou des commandes dans n'importe quel système d'exploitation. Ces processeurs exécutent également des scripts dans de nombreuses langues pour interagir avec une variété de systèmes. Certains des processeurs appartenant à cette catégorie sont ExecuteScript, ExecuteProcess, ExecuteGroovyScript, ExecuteStreamCommand, etc.
Processeurs de transformation de données
Les processeurs appartenant à Data Transformation sont capables de modifier le contenu des fichiers de flux. Ceux-ci peuvent être utilisés pour remplacer complètement les données d'un fichier de flux normalement utilisé lorsqu'un utilisateur doit envoyer un fichier de flux en tant que corps HTTP pour appeler le processeurHTTP. Certains des processeurs appartenant à cette catégorie sont ReplaceText, JoltTransformJSON, etc.
Envoi de processeurs de données
Les processeurs de données d'envoi sont généralement le processeur final d'un flux de données. Ces processeurs sont responsables du stockage ou de l'envoi des données au serveur de destination. Après avoir réussi à stocker ou à envoyer les données, ces processeurs DROP le fichier de flux avec la relation de succès. Certains des processeurs appartenant à cette catégorie sont PutEmail, PutKafka, PutSFTP, PutFile, PutFTP, etc.
Processeurs de fractionnement et d'agrégation
Ces processeurs sont utilisés pour fractionner et fusionner le contenu présent dans un fichier de flux. Certains des processeurs appartenant à cette catégorie sont SplitText, SplitJson, SplitXml, MergeContent, SplitContent, etc.
Processeurs HTTP
Ces processeurs traitent les appels HTTP et HTTPS. Certains des processeurs appartenant à cette catégorie sont InvokeHTTP, PostHTTP, ListenHTTP, etc.
Processeurs AWS
Les processeurs AWS sont responsables de l'interaction avec le système de services Web d'Amazon. Certains des processeurs appartenant à cette catégorie sont GetSQS, PutSNS, PutS3Object, FetchS3Object, etc.
Dans un flux de données Apache NiFi, les fichiers de flux passent d'un processeur à un autre via une connexion qui est validée à l'aide d'une relation entre processeurs. Chaque fois qu'une connexion est créée, un développeur sélectionne une ou plusieurs relations entre ces processeurs.

Comme vous pouvez le voir dans l'image ci-dessus, les cases à cocher dans le rectangle noir sont des relations. Si un développeur sélectionne ces cases à cocher, le fichier de flux se terminera dans ce processeur particulier, lorsque la relation réussit ou échoue, ou les deux.
Succès
Lorsqu'un processeur traite avec succès un fichier de flux comme stocker ou extrait des données à partir de n'importe quelle source de données sans obtenir de connexion, d'authentification ou toute autre erreur, le fichier de flux passe en relation de réussite.
Échec
Lorsqu'un processeur n'est pas en mesure de traiter un fichier de flux sans erreurs telles qu'une erreur d'authentification ou un problème de connexion, etc., le fichier de flux passe à une relation d'échec.
Un développeur peut également transférer les fichiers de flux vers d'autres processeurs à l'aide de connexions. Le développeur peut le sélectionner et également l'équilibrer de charge, mais l'équilibrage de charge vient d'être publié dans la version 1.8, qui ne sera pas abordée dans ce didacticiel.

Comme vous pouvez le voir dans l'image ci-dessus, la connexion marquée en rouge a une relation d'échec, ce qui signifie que tous les fichiers de flux avec des erreurs iront au processeur à gauche et respectivement tous les fichiers de flux sans erreurs seront transférés à la connexion marquée en vert.
Passons maintenant aux autres relations.
comms.failure
Cette relation est satisfaite lorsqu'un Flowfile n'a pas pu être extrait du serveur distant en raison d'un échec de communication.
pas trouvé
Tout Flowfile pour lequel nous recevons un message «Not Found» du serveur distant sera déplacé vers not.found relation.
permission refusée
Lorsque NiFi ne parvient pas à récupérer un fichier de flux sur le serveur distant en raison d'une autorisation insuffisante, il se déplace à travers cette relation.
Un fichier de flux est une entité de traitement de base dans Apache NiFi. Il contient des contenus et des attributs de données, qui sont utilisés par les processeurs NiFi pour traiter les données. Le contenu du fichier contient normalement les données extraites des systèmes source. Les attributs les plus courants d'un Apache NiFi FlowFile sont -

UUID
Cela signifie Universally Unique Identifier, qui est une identité unique d'un fichier de flux généré par NiFi.
Nom de fichier
Cet attribut contient le nom de fichier de ce fichier de flux et il ne doit contenir aucune structure de répertoire.
Taille du fichier
Il contient la taille d'un fichier Apache NiFi FlowFile.
mime.type
Il spécifie le type MIME de ce FlowFile.
chemin
Cet attribut contient le chemin d'accès relatif d'un fichier auquel appartient un fichier de flux et ne contient pas le nom de fichier.
La connexion de flux de données Apache NiFi dispose d'un système de mise en file d'attente pour gérer la grande quantité de données entrantes. Ces files d'attente peuvent gérer une très grande quantité de FlowFiles pour permettre au processeur de les traiter en série.

La file d'attente dans l'image ci-dessus a 1 fichier de flux transféré via une relation de réussite. Un utilisateur peut vérifier le fichier de flux en sélectionnant leList queueoption dans la liste déroulante. En cas de surcharge ou d'erreur, un utilisateur peut également effacer la file d'attente en sélectionnant leempty queue puis l'utilisateur peut redémarrer le flux pour récupérer ces fichiers dans le flux de données.

La liste des fichiers de flux dans une file d'attente comprend la position, l'UUID, le nom de fichier, la taille du fichier, la durée de la file d'attente et la durée du lignage. Un utilisateur peut voir tous les attributs et le contenu d'un fichier de flux en cliquant sur l'icône d'informations présente dans la première colonne de la liste de fichiers de flux.

Dans Apache NiFi, un utilisateur peut gérer différents flux de données dans différents groupes de processus. Ces groupes peuvent être basés sur différents projets ou organisations pris en charge par l'instance Apache NiFi.
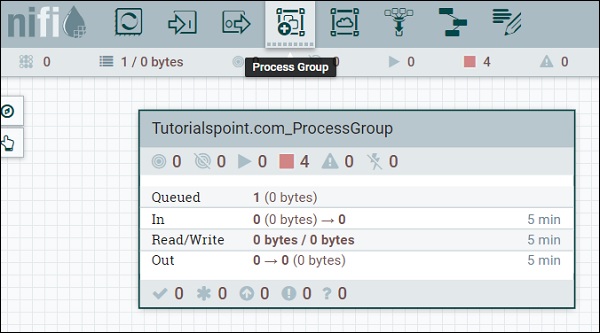
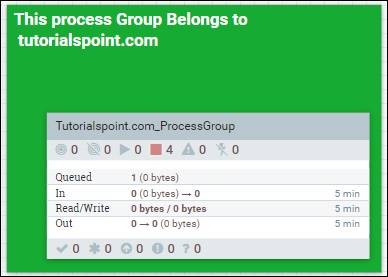
Le quatrième symbole dans le menu en haut de l'interface utilisateur NiFi, comme illustré dans l'image ci-dessus, est utilisé pour ajouter un groupe de processus dans le canevas NiFi. Le groupe de processus nommé «Tutorialspoint.com_ProcessGroup» contient un flux de données avec quatre processeurs actuellement en phase d'arrêt, comme vous pouvez le voir dans l'image ci-dessus. Des groupes de processus peuvent être créés de manière hiérarchique pour gérer les flux de données dans une meilleure structure, ce qui est facile à comprendre.

Dans le pied de page de NiFi UI, vous pouvez voir les groupes de processus et revenir en haut du groupe de processus dans lequel un utilisateur est actuellement présent.
Pour voir la liste complète des groupes de processus présents dans NiFi, un utilisateur peut accéder au résumé en utilisant le menu présent en haut à gauche de l'interface NiFi. En résumé, il existe un onglet des groupes de processus où tous les groupes de processus sont répertoriés avec des paramètres tels que l'état de la version, transféré / taille, entrée / taille, lecture / écriture, sortie / taille, etc., comme indiqué dans l'image ci-dessous.

Apache NiFi propose des étiquettes pour permettre à un développeur d'écrire des informations sur les composants présents dans le canevas NiFI. L'icône la plus à gauche dans le menu supérieur de NiFi UI est utilisée pour ajouter l'étiquette dans le canevas NiFi.

Un développeur peut changer la couleur de l'étiquette et la taille du texte avec un clic droit sur l'étiquette et choisir l'option appropriée dans le menu.
Apache NiFi est une plate-forme hautement configurable. Le fichier nifi.properties dans le répertoire conf
contient la majeure partie de la configuration.
Les propriétés couramment utilisées d'Apache NiFi sont les suivantes -
Propriétés principales
Cette section contient les propriétés, qui sont obligatoires pour exécuter une instance NiFi.
| S.No. | Nom de la propriété | Valeur par défaut | la description |
|---|---|---|---|
| 1 | nifi.flow.configuration.file | ./conf/flow.xml.gz | Cette propriété contient le chemin d'accès au fichier flow.xml. Ce fichier contient tous les flux de données créés en NiFi. |
| 2 | nifi.flow.configuration.archive.enabled | vrai | Cette propriété est utilisée pour activer ou désactiver l'archivage dans NiFi. |
| 3 | nifi.flow.configuration.archive.dir | ./conf/archive/ | Cette propriété est utilisée pour spécifier le répertoire d'archive. |
| 4 | nifi.flow.configuration.archive.max.time | 30 jours | Ceci est utilisé pour spécifier la durée de conservation pour l'archivage du contenu. |
| 5 | nifi.flow.configuration.archive.max.storage | 500 Mo | il contient la taille maximale du répertoire d'archivage pouvant augmenter. |
| 6 | nifi.authorizer.configuration.file | ./conf/authorizers.xml | Pour spécifier le fichier de configuration de l'autorisation, qui est utilisé pour l'autorisation utilisateur. |
| sept | nifi.login.identity.provider.configuration.file | ./conf/login-identity-providers.xml | Cette propriété contient la configuration des fournisseurs d'identité de connexion, |
| 8 | nifi.templates.directory | ./conf/templates | Cette propriété est utilisée pour spécifier le répertoire dans lequel les modèles NiFi seront stockés. |
| 9 | nifi.nar.library.directory | ./lib | Cette propriété contient le chemin d'accès à la bibliothèque, que NiFi utilisera pour charger tous les composants à l'aide des fichiers NAR présents dans ce dossier lib. |
| dix | nifi.nar.working.directory | ./work/nar/ | Ce répertoire stockera les fichiers nar décompressés, une fois que NiFi les aura traités. |
| 11 | nifi.documentation.working.directory | ./work/docs/components | Ce répertoire contient la documentation de tous les composants. |
Gestion d'état
Ces propriétés sont utilisées pour stocker l'état des composants utiles pour démarrer le traitement, là où les composants sont restés après un redémarrage et dans la prochaine planification en cours d'exécution.
| S.No. | Nom de la propriété | Valeur par défaut | la description |
|---|---|---|---|
| 1 | nifi.state.management.configuration.file | ./conf/state-management.xml | Cette propriété contient le chemin d'accès au fichier state-management.xml. Ce fichier contient tous les états des composants présents dans les flux de données de cette instance NiFi. |
| 2 | nifi.state.management.provider.local | fournisseur local | Il contient l'ID du fournisseur local de l'État. |
| 3 | nifi.state.management.provider.cluster | fournisseur zk | Cette propriété contient l'ID du fournisseur d'état à l'échelle du cluster. Cela sera ignoré si NiFi n'est pas en cluster mais doit être rempli s'il est exécuté dans un cluster. |
| 4 | nifi.state.management. intégré. gardien de zoo. début | faux | Cette propriété spécifie si cette instance de NiFi doit exécuter ou non un serveur ZooKeeper intégré. |
| 5 | nifi.state.management. intégré. zookeeper.properties | ./conf/zookeeper.properties | Cette propriété contient le chemin du fichier de propriétés qui fournit les propriétés ZooKeeper à utiliser si <nifi.state.management. intégré. gardien de zoo. start> est défini sur true. |
Référentiel FlowFile
Examinons maintenant les détails importants du référentiel FlowFile -
| S.No. | Nom de la propriété | Valeur par défaut | la description |
|---|---|---|---|
| 1 | nifi.flowfile.repository. la mise en oeuvre | org.apache.nifi. manette. dépôt. WriteAhead FlowFileRepository | Cette propriété est utilisée pour spécifier le stockage des fichiers de flux en mémoire ou sur disque. Si un utilisateur souhaite stocker les fichiers de flux en mémoire, passez à "org.apache.nifi.controller. Repository.VolatileFlowFileRepository". |
| 2 | nifi.flowfile.repository.directory | ./flowfile_repository | Pour spécifier le répertoire du référentiel de fichiers de flux. |
Apache NiFi prend en charge plusieurs outils tels que ambari, le gardien de zoo à des fins d'administration. NiFi fournit également la configuration dans le fichier nifi.properties pour configurer HTTPS et d'autres choses pour les administrateurs.
gardien de zoo
NiFi lui-même ne gère pas le processus de vote en cluster. Cela signifie que lorsqu'un cluster est créé, tous les nœuds sont principaux et coordinateurs. Ainsi, zookeeper est configuré pour gérer le vote du nœud principal et du coordinateur. Le fichier nifi.properties contient certaines propriétés pour configurer le gardien de zoo.
| S.No. | Nom de la propriété | Valeur par défaut | la description |
|---|---|---|---|
| 1 | nifi.state.management.embedded.zookeeper. Propriétés | ./conf/zookeeper.properties | Pour spécifier le chemin et le nom du fichier de propriétés de gardien de zoo. |
| 2 | nifi.zookeeper.connect.string | vide | Pour spécifier la chaîne de connexion du gardien de zoo. |
| 3 | nifi.zookeeper.connect.timeout | 3 secondes | Pour spécifier le délai d'expiration de la connexion du gardien de zoo avec NiFi. |
| 4 | nifi.zookeeper.session.timeout | 3 secondes | Pour spécifier le délai d'expiration de la session du gardien de zoo avec NiFi. |
| 5 | nifi.zookeeper.root.node | / nifi | Pour spécifier le nœud racine pour le gardien de zoo. |
| 6 | nifi.zookeeper.auth.type | vide | Pour spécifier le type d'authentification pour le gardien de zoo. |
Activer HTTPS
Pour utiliser NiFi sur HTTPS, les administrateurs doivent générer un keystore et un truststore et définir certaines propriétés dans le fichier nifi.properties. La boîte à outils TLS peut être utilisée pour générer toutes les clés nécessaires pour activer HTTPS dans apache NiFi.
| S.No. | Nom de la propriété | Valeur par défaut | la description |
|---|---|---|---|
| 1 | nifi.web.https.port | vide | Pour spécifier le numéro de port https. |
| 2 | nifi.web.https.network.interface.default | vide | Interface par défaut pour https en NiFi. |
| 3 | nifi.security.keystore | vide | Pour spécifier le chemin et le nom de fichier du keystore. |
| 4 | nifi.security.keystoreType | vide | Pour spécifier le type de type de fichier de clés comme JKS. |
| 5 | nifi.security.keystorePasswd | vide | Pour spécifier le mot de passe du fichier de clés. |
| 6 | nifi.security.truststore | vide | Pour spécifier le chemin et le nom de fichier du truststore. |
| sept | nifi.security.truststoreType | vide | Pour spécifier le type de type truststore comme JKS. |
| 8 | nifi.security.truststorePasswd | vide | Pour spécifier le mot de passe du truststore. |
Autres propriétés pour l'administration
Il existe d'autres propriétés, qui sont utilisées par les administrateurs pour gérer le NiFi et pour sa continuité de service.
| S.No. | Nom de la propriété | Valeur par défaut | la description |
|---|---|---|---|
| 1 | nifi.flowcontroller.graceful.shutdown.period | 10 secondes | Pour spécifier l'heure d'arrêt normal du contrôleur de flux NiFi. |
| 2 | nifi.administrative.yield.duration | 30 secondes | Pour spécifier la durée de rendement administratif pour NiFi. |
| 3 | nifi.authorizer.configuration.file | ./conf/authorizers.xml | Pour spécifier le chemin et le nom de fichier du fichier de configuration de l'autorisation. |
| 4 | nifi.login.identity.provider.configuration.file | ./conf/login-identity-providers.xml | Pour spécifier le chemin et le nom de fichier du fichier de configuration du fournisseur d'identité de connexion. |
Apache NiFi propose un grand nombre de composants pour aider les développeurs à créer des flux de données pour tout type de protocoles ou sources de données. Pour créer un flux, un développeur fait glisser les composants de la barre de menus vers le canevas et les connecte en cliquant et en faisant glisser la souris d'un composant à l'autre.
Généralement, un NiFi a un composant écouteur au début du flux comme getfile, qui récupère les données du système source. À l'autre extrémité, il y a un composant émetteur comme putfile et il y a des composants entre les deux, qui traitent les données.
Par exemple, créons un flux, qui prend un fichier vide dans un répertoire et ajoute du texte dans ce fichier et le place dans un autre répertoire.

Pour commencer, faites glisser l'icône du processeur sur le canevas NiFi et sélectionnez le processeur GetFile dans la liste.
Créez un répertoire d'entrée comme c:\inputdir.
Cliquez avec le bouton droit sur le processeur et sélectionnez configurer et dans l'onglet Propriétés ajouter Input Directory (c:\inputdir) et cliquez sur Appliquer et revenez au canevas.
Faites glisser l'icône du processeur sur le canevas et sélectionnez le processeur ReplaceText dans la liste.
Cliquez avec le bouton droit sur le processeur et sélectionnez configurer. dans leproperties onglet, ajoutez du texte comme “Hello tutorialspoint.com” dans la zone de texte Valeur de remplacement et cliquez sur Appliquer.
Accédez à l'onglet Paramètres, cochez la case d'échec sur le côté droit, puis revenez au canevas.
Connectez le processeur GetFIle à ReplaceText sur la relation de réussite.
Faites glisser l'icône du processeur sur le canevas et sélectionnez le processeur PutFile dans la liste.
Créez un répertoire de sortie comme c:\outputdir.
Cliquez avec le bouton droit sur le processeur et sélectionnez configurer. Dans l'onglet des propriétés, ajoutezDirectory (c:\outputdir) et cliquez sur Appliquer et revenez au canevas.
Accédez à l'onglet Paramètres et cochez la case Échec et réussite sur le côté droit, puis revenez au canevas.
Connectez le processeur ReplaceText à PutFile sur la relation de réussite.
Maintenant, démarrez le flux et ajoutez un fichier vide dans le répertoire d'entrée et vous verrez que, il se déplacera vers le répertoire de sortie et le texte sera ajouté au fichier.
En suivant les étapes ci-dessus, les développeurs peuvent choisir n'importe quel processeur et autre composant NiFi pour créer un flux adapté à leur organisation ou client.
Apache NiFi propose le concept de Templates, ce qui facilite la réutilisation et la distribution des flux NiFi. Les flux peuvent être utilisés par d'autres développeurs ou dans d'autres clusters NiFi. Cela aide également les développeurs NiFi à partager leur travail dans des référentiels comme GitHub.
Créer un modèle
Créons un modèle pour le flux, que nous avons créé dans le chapitre n ° 15 «Apache NiFi - Création de flux».

Sélectionnez tous les composants du flux à l'aide de la touche Maj, puis cliquez sur l'icône de création de modèle sur le côté gauche du canevas NiFi. Vous pouvez également voir une boîte à outils comme indiqué dans l'image ci-dessus. Cliquez sur l'icônecreate templatemarqué en bleu comme sur l'image ci-dessus. Saisissez le nom du modèle. Un développeur peut également ajouter une description, qui est facultative.
Télécharger le modèle
Ensuite, allez à l'option Modèles NiFi dans le menu présent dans le coin supérieur droit de NiFi UI comme le montre l'image ci-dessous.

Cliquez maintenant sur l'icône de téléchargement (présente à droite dans la liste) du modèle que vous souhaitez télécharger. Un fichier XML avec le nom du modèle sera téléchargé.
Télécharger un modèle
Pour utiliser un modèle dans NiFi, un développeur devra télécharger son fichier xml sur NiFi à l'aide de l'interface utilisateur. Il y a une icône de téléchargement de modèle (marquée en bleu dans l'image ci-dessous) à côté de l'icône Créer un modèle, cliquez dessus et parcourez le xml.

Ajouter un modèle
Dans la barre d'outils supérieure de NiFi UI, l'icône du modèle se trouve avant l'icône d'étiquette. L'icône est marquée en bleu comme indiqué dans l'image ci-dessous.

Faites glisser l'icône du modèle et choisissez le modèle dans la liste déroulante et cliquez sur Ajouter. Il ajoutera le modèle au canevas NiFi.
NiFi propose un grand nombre d'API, qui aident les développeurs à apporter des modifications et à obtenir des informations sur NiFi à partir de tout autre outil ou applications développées sur mesure. Dans ce tutoriel, nous utiliserons l'application Postman dans Google Chrome pour expliquer quelques exemples.
Pour ajouter postmantoyour Google Chrome, accédez à l'URL mentionnée ci-dessous et cliquez sur le bouton Ajouter au chrome. Vous verrez maintenant une nouvelle application ajoutée à votre Google Chrome.
boutique en ligne chrome
La version actuelle de l'API NiFi rest est la 1.8.0 et la documentation est présente dans l'URL mentionnée ci-dessous.
https://nifi.apache.org/docs/nifi-docs/rest-api/index.html
Voici les modules d'API NiFi rest les plus utilisés -
http: // <url nifi>: <port nifi> / nifi-api / <api-path>
Si HTTPS est activé https: // <nifi url>: <nifi port> / nifi-api / <api-path>
| S.No. | Nom du module API | api-path | La description |
|---|---|---|---|
| 1 | Accès | /accès | Pour authentifier l'utilisateur et obtenir un jeton d'accès de NiFi. |
| 2 | Manette | /manette | Pour gérer le cluster et créer une tâche de rapport. |
| 3 | Services de contrôleur | / controller-services | Il est utilisé pour gérer les services du contrôleur et mettre à jour les références de service du contrôleur. |
| 4 | Tâches de rapport | / reporting-tâches | Pour gérer les tâches de reporting. |
| 5 | Couler | /couler | Pour obtenir les métadonnées du flux de données, l'état des composants et l'historique des requêtes |
| 6 | Groupes de processus | / process-groups | Pour télécharger et instancier un modèle et créer des composants. |
| sept | Processeurs | / processeurs | Pour créer et planifier un processeur et définir ses propriétés. |
| 8 | Connexions | /Connexions | Pour créer une connexion, définir la priorité de la file d'attente et mettre à jour la destination de connexion |
| 9 | Files d'attente FlowFile | / flowfile-queues | Pour afficher le contenu de la file d'attente, téléchargez le contenu du fichier de flux et videz la file d'attente. |
| dix | Groupes de processus distants | / remote-process-groups | Pour créer un groupe distant et activer la transmission. |
| 11 | Provenance | /provenance | Pour interroger la provenance et rechercher le lignage des événements. |
Considérons maintenant un exemple et exécutons sur postman pour obtenir les détails sur l'instance NiFi en cours d'exécution.
Demande
GET http://localhost:8080/nifi-api/flow/aboutRéponse
{
"about": {
"title": "NiFi",
"version": "1.7.1",
"uri": "http://localhost:8080/nifi-api/",
"contentViewerUrl": "../nifi-content-viewer/",
"timezone": "SGT",
"buildTag": "nifi-1.7.1-RC1",
"buildTimestamp": "07/12/2018 12:54:43 SGT"
}
}Apache NiFi enregistre et stocke toutes les informations sur les événements qui se produisent sur les données ingérées dans le flux. Le référentiel de provenance des données stocke ces informations et fournit une interface utilisateur pour rechercher ces informations d'événement. La provenance des données est également accessible pour le niveau NiFi complet et le niveau du processeur.
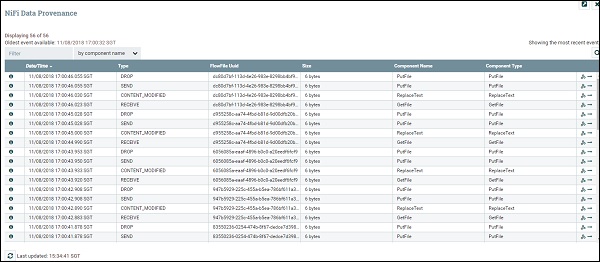
Le tableau suivant répertorie les différents champs de la liste d'événements NiFi Data Provenance avec les champs suivants:
| S.No. | Nom de domaine | La description |
|---|---|---|
| 1 | Date / heure | Date et heure de l'événement. |
| 2 | Type | Type d'événement comme «CRÉER». |
| 3 | FlowFileUuid | UUID du fichier de flux sur lequel l'événement est exécuté. |
| 4 | Taille | Taille du fichier de flux. |
| 5 | Nom du composant | Nom du composant qui a exécuté l'événement. |
| 6 | Type de composant | Type de composant. |
| sept | Afficher la lignée | La dernière colonne a l'icône Afficher la lignée, qui est utilisée pour voir la lignée du fichier de flux, comme indiqué dans l'image ci-dessous. |
Pour obtenir plus d'informations sur l'événement, un utilisateur peut cliquer sur l'icône d'information présente dans la première colonne de l'interface de Provenance des données NiFi.
Il existe certaines propriétés dans le fichier nifi.properties, qui sont utilisées pour gérer le référentiel NiFi Data Provenance.
| S.No. | Nom de la propriété | Valeur par défaut | La description |
|---|---|---|---|
| 1 | nifi.provenance.repository.directory.default | ./provenance_repository | Pour spécifier le chemin par défaut de la provenance des données NiFi. |
| 2 | nifi.provenance.repository.max.storage.time | 24 heures | Pour spécifier la durée de conservation maximale de la provenance des données NiFi. |
| 3 | nifi.provenance.repository.max.storage.size | 1 Go | Pour spécifier le stockage maximal de la provenance des données NiFi. |
| 4 | nifi.provenance.repository.rollover.time | 30 secondes | Pour spécifier le temps de roulement de la provenance des données NiFi. |
| 5 | nifi.provenance.repository.rollover.size | 100 Mo | Pour spécifier la taille de survol de la provenance des données NiFi. |
| 6 | nifi.provenance.repository.indexed.fields | EventType, FlowFileUUID, Nom de fichier, ProcessorID, Relation | Pour spécifier les champs utilisés pour rechercher et indexer la provenance des données NiFi. |
Dans Apache NiFi, il existe plusieurs façons de surveiller les différentes statistiques du système telles que les erreurs, l'utilisation de la mémoire, l'utilisation du processeur, les statistiques de flux de données, etc. Nous discuterons des plus populaires dans ce tutoriel.
Surveillance intégrée
Dans cette section, nous en apprendrons plus sur la surveillance intégrée dans Apache NiFi.
Tableau d'affichage
Le babillard affiche les dernières ERREURS et AVERTISSEMENTS générés par les processeurs NiFi en temps réel. Pour accéder au tableau d'affichage, un utilisateur devra aller dans le menu déroulant de droite et sélectionner l'option Tableau d'affichage. Il s'actualise automatiquement et un utilisateur peut également le désactiver. Un utilisateur peut également accéder au processeur réel en double-cliquant sur l'erreur. Un utilisateur peut également filtrer les bulletins en travaillant avec les éléments suivants:
- par message
- de nom
- par identifiant
- par identifiant de groupe
Interface utilisateur de provenance des données
Pour surveiller les événements survenant sur n'importe quel processeur spécifique ou tout au long de NiFi, un utilisateur peut accéder à la provenance des données à partir du même menu que le tableau d'affichage. Un utilisateur peut également filtrer les événements dans le référentiel de provenance des données en travaillant avec les champs suivants -
- par nom de composant
- par type de composant
- par type
Interface utilisateur récapitulative NiFi
Le résumé Apache NiFi est également accessible à partir du même menu que le tableau d'affichage. Cette interface utilisateur contient des informations sur tous les composants de cette instance ou cluster NiFi particulier. Ils peuvent être filtrés par nom, par type ou par URI. Il existe différents onglets pour différents types de composants. Voici les composants qui peuvent être surveillés dans l'interface utilisateur du résumé NiFi -
- Processors
- Ports d'entrée
- Ports de sortie
- Groupes de processus distants
- Connections
- Groupes de processus
Dans cette interface utilisateur, il existe un lien en bas à droite nommé Diagnostics système pour vérifier les statistiques JVM.
Tâches de rapport
Apache NiFi fournit plusieurs tâches de reporting pour prendre en charge les systèmes de surveillance externes tels qu'Ambari, Grafana, etc. Un développeur peut créer une tâche de rapport personnalisée ou peut configurer les tâches intégrées pour envoyer les métriques de NiFi aux systèmes de surveillance externes. Le tableau suivant répertorie les tâches de reporting proposées par NiFi 1.7.1.
| S.No. | Nom de la tâche de rapport | La description |
|---|---|---|
| 1 | AmbariReportingTask | Pour configurer le service de métriques Ambari pour NiFi. |
| 2 | ControllerStatusReportingTask | Pour rapporter les informations de l'interface utilisateur de résumé NiFi pour les 5 dernières minutes. |
| 3 | MonitorDiskUsage | Pour signaler et avertir de l'utilisation du disque d'un répertoire spécifique. |
| 4 | MonitorMemory | Pour surveiller la quantité de tas Java utilisée dans un pool de mémoire Java de JVM. |
| 5 | SiteToSiteBulletinReportingTask | Pour signaler les erreurs et les avertissements dans les bulletins à l'aide du protocole site à site. |
| 6 | SiteToSiteProvenanceReportingTask | Pour signaler les événements de provenance des données NiFi à l'aide du protocole site à site. |
API NiFi
Il existe une API nommée diagnostics système, qui peut être utilisée pour surveiller les statistiques NiFI dans n'importe quelle application développée sur mesure. Laissez-nous vérifier l'API dans postman.
Demande
http://localhost:8080/nifi-api/system-diagnosticsRéponse
{
"systemDiagnostics": {
"aggregateSnapshot": {
"totalNonHeap": "183.89 MB",
"totalNonHeapBytes": 192819200,
"usedNonHeap": "173.47 MB",
"usedNonHeapBytes": 181894560,
"freeNonHeap": "10.42 MB",
"freeNonHeapBytes": 10924640,
"maxNonHeap": "-1 bytes",
"maxNonHeapBytes": -1,
"totalHeap": "512 MB",
"totalHeapBytes": 536870912,
"usedHeap": "273.37 MB",
"usedHeapBytes": 286652264,
"freeHeap": "238.63 MB",
"freeHeapBytes": 250218648,
"maxHeap": "512 MB",
"maxHeapBytes": 536870912,
"heapUtilization": "53.0%",
"availableProcessors": 4,
"processorLoadAverage": -1,
"totalThreads": 71,
"daemonThreads": 31,
"uptime": "17:30:35.277",
"flowFileRepositoryStorageUsage": {
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
},
"contentRepositoryStorageUsage": [
{
"identifier": "default",
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
}
],
"provenanceRepositoryStorageUsage": [
{
"identifier": "default",
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
}
],
"garbageCollection": [
{
"name": "G1 Young Generation",
"collectionCount": 344,
"collectionTime": "00:00:06.239",
"collectionMillis": 6239
},
{
"name": "G1 Old Generation",
"collectionCount": 0,
"collectionTime": "00:00:00.000",
"collectionMillis": 0
}
],
"statsLastRefreshed": "09:30:20 SGT",
"versionInfo": {
"niFiVersion": "1.7.1",
"javaVendor": "Oracle Corporation",
"javaVersion": "1.8.0_151",
"osName": "Windows 7",
"osVersion": "6.1",
"osArchitecture": "amd64",
"buildTag": "nifi-1.7.1-RC1",
"buildTimestamp": "07/12/2018 12:54:43 SGT"
}
}
}
}Avant de commencer la mise à niveau d'Apache NiFi, lisez les notes de publication pour connaître les modifications et les ajouts. Un utilisateur doit évaluer l'impact de ces ajouts et changements dans son installation NiFi actuelle. Vous trouverez ci-dessous le lien pour obtenir les notes de publication des nouvelles versions d'Apache NiFi.
https://cwiki.apache.org/confluence/display/NIFI/Release+Notes
Dans une configuration de cluster, un utilisateur doit mettre à niveau l'installation NiFi de chaque nœud d'un cluster. Suivez les étapes ci-dessous pour mettre à niveau Apache NiFi.
Sauvegardez tous les NAR personnalisés présents dans votre NiFi ou lib actuel ou dans tout autre dossier.
Téléchargez la nouvelle version d'Apache NiFi. Vous trouverez ci-dessous le lien pour télécharger la source et les binaires de la dernière version NiFi.
https://nifi.apache.org/download.html
Créez un nouveau répertoire dans le même répertoire d'installation du NiFi actuel et extrayez la nouvelle version d'Apache NiFi.
Arrêtez le NiFi gracieusement. Arrêtez d'abord tous les processeurs et laissez tous les fichiers de flux présents dans le flux être traités. Une fois qu'il n'y a plus de fichier de flux, arrêtez le NiFi.
Copiez la configuration de authorizers.xml de l'installation NiFi actuelle vers la nouvelle version.
Mettez à jour les valeurs dans bootstrap-notification-services.xml et bootstrap.conf de la nouvelle version NiFi à partir de la version actuelle.
Ajoutez la journalisation personnalisée de logback.xml à la nouvelle installation NiFi.
Configurez le fournisseur d'identité de connexion dans login-identity-providers.xml à partir de la version actuelle.
Mettez à jour toutes les propriétés dans nifi.properties de la nouvelle installation NiFi à partir de la version actuelle.
Veuillez vous assurer que le groupe et l'utilisateur de la nouvelle version sont identiques à la version actuelle, pour éviter toute erreur de refus d'autorisation.
Copiez la configuration de state-management.xml de la version actuelle vers la nouvelle version.
Copiez le contenu des répertoires suivants de la version actuelle de l'installation NiFi dans les mêmes répertoires de la nouvelle version.
./conf/flow.xml.gz
Aussi flow.xml.gz du répertoire d'archives.
Pour les référentiels de provenance et de contenu, modifiez les valeurs dans nifi. properties dans les référentiels actuels.
copier l'état de ./state/local ou changer dans nifi.properties si un autre répertoire externe est spécifié.
Revérifiez toutes les modifications effectuées et vérifiez si elles ont un impact sur les nouvelles modifications ajoutées dans la nouvelle version NiFi. S'il y a un impact, recherchez les solutions.
Démarrez tous les nœuds NiFi et vérifiez si tous les flux fonctionnent correctement et si les référentiels stockent des données et que Ui les récupère avec des erreurs.
Surveillez les bulletins pendant un certain temps pour rechercher de nouvelles erreurs.
Si la nouvelle version fonctionne correctement, la version actuelle peut être archivée et supprimée des répertoires.
Apache NiFi Remote Process Group ou RPG permet au flux de diriger les FlowFiles d'un flux vers différentes instances NiFi à l'aide du protocole Site-to-Site. Depuis la version 1.7.1, NiFi n'offre pas de relations équilibrées, donc RPG est utilisé pour l'équilibrage de charge dans un flux de données NiFi.

Un développeur peut ajouter le RPG à partir de la barre d'outils supérieure de NiFi UI en faisant glisser l'icône comme indiqué dans l'image ci-dessus sur le canevas. Pour configurer un RPG, un développeur doit ajouter les champs suivants -
| S.No. | Nom de domaine | La description |
|---|---|---|
| 1 | URL | Pour spécifier des URL NiFi cibles distantes séparées par des virgules. |
| 2 | Protocole de transport | Pour spécifier le protocole de transport pour les instances NiFi distantes. C'est soit RAW, soit HTTP. |
| 3 | Interface réseau locale | Pour spécifier l'interface réseau locale pour envoyer / recevoir des données. |
| 4 | Nom d'hôte du serveur proxy HTTP | Pour spécifier le nom d'hôte du serveur proxy à des fins de transport dans RPG. |
| 5 | Port du serveur proxy HTTP | Pour spécifier le port du serveur proxy à des fins de transport dans RPG. |
| 6 | Utilisateur proxy HTTP | C'est un champ facultatif pour spécifier le nom d'utilisateur du proxy HTTP. |
| sept | Mot de passe du proxy HTTP | C'est un champ facultatif pour spécifier le mot de passe du nom d'utilisateur ci-dessus. |
Un développeur doit l'activer, avant de l'utiliser comme nous démarrons des processeurs avant de les utiliser.
Apache NiFi propose des services partagés, qui peuvent être partagés par les processeurs et la tâche de rapport est appelée paramètres du contrôleur. Ce sont comme le pool de connexion de base de données, qui peut être utilisé par les processeurs accédant à la même base de données.
Pour accéder aux paramètres du contrôleur, utilisez le menu déroulant dans le coin supérieur droit de NiFi UI comme indiqué dans l'image ci-dessous.
Il existe de nombreux paramètres de contrôleur proposés par Apache NiFi, nous discuterons d'un paramètre couramment utilisé et de la manière dont nous le configurons dans NiFi.
DBCPConnectionPool
Ajoutez le signe plus dans la page Paramètres Nifi après avoir cliqué sur l'option Paramètres du contrôleur. Sélectionnez ensuite le DBCPConnectionPool dans la liste des paramètres du contrôleur. DBCPConnectionPool sera ajouté dans la page principale des paramètres NiFi comme indiqué dans l'image ci-dessous.

Il contient les informations suivantes sur le contrôleur setting:Name
- Type
- Bundle
- State
- Scope
- Icône Configurer et supprimer
Cliquez sur l'icône de configuration et remplissez les champs requis. Les champs sont listés dans le tableau ci-dessous -
| S.No. | Nom de domaine | Valeur par défaut | la description |
|---|---|---|---|
| 1 | URL de connexion à la base de données | vide | Pour spécifier l'URL de connexion à la base de données. |
| 2 | Nom de classe du pilote de base de données | vide | Pour spécifier le nom de classe du pilote pour la base de données comme com.mysql.jdbc.Driver pour mysql. |
| 3 | Temps d'attente maximum | 500 millis | Pour spécifier le temps d'attente des données d'une connexion à la base de données. |
| 4 | Nombre total maximum de connexions | 8 | Pour spécifier le nombre maximal de connexions allouées dans le pool de connexions de base de données. |
Pour arrêter ou configurer un paramètre de contrôleur, tous les composants NiFi connectés doivent d'abord être arrêtés. NiFi ajoute également de la portée dans les paramètres du contrôleur pour en gérer la configuration. Par conséquent, seuls ceux qui partagent les mêmes paramètres ne seront pas affectés et utiliseront les mêmes paramètres de contrôleur.
Les tâches de rapport Apache NiFi sont similaires aux services de contrôleur, qui s'exécutent en arrière-plan et envoient ou enregistrent les statistiques de l'instance NiFi. La tâche de rapport NiFi est également accessible à partir de la même page que les paramètres du contrôleur, mais dans un onglet différent.

Pour ajouter une tâche de reporting, un développeur doit cliquer sur le bouton plus présent en haut à droite de la page des tâches de reporting. Ces tâches de reporting sont principalement utilisées pour surveiller les activités d'une instance NiFi, soit dans les bulletins, soit dans la provenance. Ces tâches de rapport utilisent principalement le site à site pour transporter les données statistiques NiFi vers un autre nœud ou un système externe.
Ajoutons maintenant une tâche de rapport configurée pour plus de compréhension.
MonitorMemory
Cette tâche de rapport est utilisée pour générer des communiqués, lorsqu'un pool de mémoire croise le pourcentage spécifié. Suivez ces étapes pour configurer la tâche de rapport MonitorMemory -
Ajoutez le signe plus et recherchez MonitorMemory dans la liste.
Sélectionnez MonitorMemory et cliquez sur AJOUTER.
Une fois qu'il est ajouté dans la page principale de la page principale des tâches de rapport, cliquez sur l'icône de configuration.
Dans l'onglet des propriétés, sélectionnez le pool de mémoire que vous souhaitez surveiller.
Sélectionnez le pourcentage après lequel vous souhaitez que les bulletins alertent les utilisateurs.
Démarrez la tâche de rapport.
Apache NiFi - Processeur personnalisé
Apache NiFi est une plate-forme open source et donne aux développeurs la possibilité d'ajouter leur processeur personnalisé dans la bibliothèque NiFi. Suivez ces étapes pour créer un processeur personnalisé.
Téléchargez la dernière version de Maven à partir du lien ci-dessous.
https://maven.apache.org/download.cgi
Ajoutez une variable d'environnement nommée M2_HOME et définissez la valeur comme répertoire d'installation de maven.
Téléchargez Eclipse IDE à partir du lien ci-dessous.
https://www.eclipse.org/downloads/download.php
Ouvrez l'invite de commande et exécutez la commande Maven Archetype.
> mvn archetype:generateRecherchez le type nifi dans les projets d'archétype.
Sélectionnez org.apache.nifi: projet nifi-processor-bundle-archetype.
Ensuite, dans la liste des versions, sélectionnez la dernière version à savoir 1.7.1 pour ce tutoriel.
Entrez le groupId, artifactId, version, package et artifactBaseName etc.
Ensuite, un projet maven sera créé avec des répertoires.
nifi-<artifactBaseName>-processors
nifi-<artifactBaseName>-nar
Exécutez la commande ci-dessous dans le répertoire nifi- <artifactBaseName> -processors pour ajouter le projet dans l'éclipse.
mvn install eclipse:eclipseOuvrez Eclipse et sélectionnez Importer dans le menu Fichier.
Sélectionnez ensuite «Projets existants dans l'espace de travail» et ajoutez le projet à partir du répertoire nifi- <artifactBaseName> -processors dans eclipse.
Ajoutez votre code dans la fonction publique void onTrigger (contexte ProcessContext, session ProcessSession), qui s'exécute chaque fois qu'un processeur est planifié pour s'exécuter.
Emballez ensuite le code dans un fichier NAR en exécutant la commande mentionnée ci-dessous.
mvn clean installUn fichier NAR sera créé à nifi-
-nar / répertoire cible. Copiez le fichier NAR dans le dossier lib d'Apache NiFi et redémarrez le NiFi.
Après le redémarrage réussi de NiFi, vérifiez la liste des processeurs pour le nouveau processeur personnalisé.
Pour toute erreur, vérifiez le fichier ./logs/nifi.log.
Apache NiFi - Service de contrôleurs personnalisés
Apache NiFi est une plate-forme open source et donne aux développeurs la possibilité d'ajouter leur service de contrôleurs personnalisés dans Apache NiFi. Les étapes et les outils sont presque les mêmes que ceux utilisés pour créer un processeur personnalisé.
Ouvrez l'invite de commande et exécutez la commande Maven Archetype.
> mvn archetype:generateRecherchez le type nifi dans les projets d'archétype.
Sélectionner org.apache.nifi:nifi-service-bundle-archetype projet.
Ensuite, dans la liste des versions, sélectionnez la dernière version - 1.7.1 pour ce tutoriel.
Entrez le groupId, artifactId, version, package et artifactBaseName, etc.
Un projet maven sera créé avec des répertoires.
nifi-<artifactBaseName>
nifi-<artifactBaseName>-nar
nifi-<artifactBaseName>-api
nifi-<artifactBaseName>-api-nar
Exécutez la commande ci-dessous dans les répertoires nifi- <artifactBaseName> et nifi- <artifactBaseName> -api pour ajouter ces deux projets dans l'éclipse.
mvn install eclipse: eclipse
Ouvrez Eclipse et sélectionnez Importer dans le menu Fichier.
Sélectionnez ensuite «Projets existants dans l'espace de travail» et ajoutez le projet des répertoires nifi- <artifactBaseName> et nifi- <artifactBaseName> -api dans eclipse.
Ajoutez votre code dans les fichiers source.
Emballez ensuite le code dans un fichier NAR en exécutant la commande mentionnée ci-dessous.
installation propre mvn
Deux fichiers NAR seront créés dans chaque répertoire nifi- <artifactBaseName> / target et nifi- <artifactBaseName> -api / target.
Copiez ces fichiers NAR dans le dossier lib d'Apache NiFi et redémarrez le NiFi.
Après le redémarrage réussi de NiFi, vérifiez la liste des processeurs pour le nouveau processeur personnalisé.
Pour toute erreur, vérifiez ./logs/nifi.log fichier.
Apache NiFi - Journalisation
Apache NiFi utilise la bibliothèque de retour pour gérer sa journalisation. Il existe un fichier logback.xml présent dans le répertoire conf de NiFi, qui permet de configurer la journalisation dans NiFi. Les journaux sont générés dans le dossier logs de NiFi et les fichiers journaux sont décrits ci-dessous.
nifi-app.log
Il s'agit du fichier journal principal de nifi, qui enregistre toutes les activités de l'application apache NiFi allant du chargement des fichiers NAR aux erreurs d'exécution ou aux bulletins rencontrés par les composants NiFi. Vous trouverez ci-dessous l'appender par défaut danslogback.xml déposer pour nifi-app.log fichier.
<appender name="APP_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-app.log</file>
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/
nifi-app_%d{yyyy-MM-dd_HH}.%i.log
</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<immediateFlush>true</immediateFlush>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>Le nom de l'appender est APP_FILE et la classe est RollingFileAppender, ce qui signifie que l'enregistreur utilise la politique de restauration. Par défaut, la taille maximale du fichier est de 100 Mo et peut être remplacée par la taille requise. La rétention maximale pour APP_FILE est de 30 fichiers journaux et peut être modifiée selon les besoins de l'utilisateur.
nifi-user.log
Ce journal contient les événements utilisateur tels que la sécurité Web, la configuration de l'API Web, l'autorisation de l'utilisateur, etc. Ci-dessous se trouve l'appender pour nifi-user.log dans le fichier logback.xml.
<appender name="USER_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-user.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/
nifi-user_%d.log
</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>Le nom de l'appender est USER_FILE. Il suit la politique de roulement. La période de rétention maximale pour USER_FILE est de 30 fichiers journaux. Vous trouverez ci-dessous les enregistreurs par défaut pour l'appender USER_FILE présents dans nifi-user.log.
<logger name="org.apache.nifi.web.security" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.web.api.config" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.authorization" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.cluster.authorization" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>
<logger name="org.apache.nifi.web.filter.RequestLogger" level="INFO" additivity="false">
<appender-ref ref="USER_FILE"/>
</logger>nifi-bootstrap.log
Ce journal contient les journaux d'amorçage, la sortie standard d'Apache NiFi (tout system.out écrit dans le code principalement pour le débogage) et l'erreur standard (tout system.err écrit dans le code). Vous trouverez ci-dessous l'appender par défaut pour le nifi-bootstrap.log dans logback.log.
<appender name="BOOTSTRAP_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-bootstrap.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/nifi-bootstrap_%d.log
</fileNamePattern>
<maxHistory>5</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>nifi-bootstrap.log, le nom de l'appender est BOOTSTRAP_FILE, qui suit également la politique de restauration. La rétention maximale pour l'appender BOOTSTRAP_FILE est de 5 fichiers journaux. Vous trouverez ci-dessous les enregistreurs par défaut pour le fichier nifi-bootstrap.log.
<logger name="org.apache.nifi.bootstrap" level="INFO" additivity="false">
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<logger name="org.apache.nifi.bootstrap.Command" level="INFO" additivity="false">
<appender-ref ref="CONSOLE" />
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<logger name="org.apache.nifi.StdOut" level="INFO" additivity="false">
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>
<logger name="org.apache.nifi.StdErr" level="ERROR" additivity="false">
<appender-ref ref="BOOTSTRAP_FILE" />
</logger>