Apache Presto - Guide rapide
L'analyse de données est le processus d'analyse des données brutes pour recueillir des informations pertinentes pour une meilleure prise de décision. Il est principalement utilisé dans de nombreuses organisations pour prendre des décisions commerciales. Eh bien, l'analyse des mégadonnées implique une grande quantité de données et ce processus est assez complexe, les entreprises utilisent donc différentes stratégies.
Par exemple, Facebook est l'une des plus grandes sociétés d'entrepôt de données au monde et basée sur les données. Les données de l'entrepôt Facebook sont stockées dans Hadoop pour des calculs à grande échelle. Plus tard, lorsque les données d'entrepôt sont devenues des pétaoctets, ils ont décidé de développer un nouveau système à faible latence. En 2012, les membres de l'équipe Facebook ont conçu“Presto” pour des analyses de requêtes interactives qui fonctionneraient rapidement même avec des pétaoctets de données.
Qu'est-ce qu'Apache Presto?
Apache Presto est un moteur d'exécution de requêtes parallèle distribué, optimisé pour une faible latence et une analyse interactive des requêtes. Presto exécute les requêtes facilement et évolue sans temps d'arrêt, même de gigaoctets à pétaoctets.
Une seule requête Presto peut traiter les données de plusieurs sources telles que HDFS, MySQL, Cassandra, Hive et bien d'autres sources de données. Presto est construit en Java et facile à intégrer avec d'autres composants d'infrastructure de données. Presto est puissant et des entreprises de premier plan comme Airbnb, DropBox, Groupon, Netflix l'adoptent.
Presto - Caractéristiques
Presto contient les fonctionnalités suivantes -
- Architecture simple et extensible.
- Connecteurs enfichables - Presto prend en charge les connecteurs enfichables pour fournir des métadonnées et des données pour les requêtes.
- Exécutions en pipeline: évite la surcharge de latence d'E / S inutile.
- Fonctions définies par l'utilisateur - Les analystes peuvent créer des fonctions personnalisées définies par l'utilisateur pour migrer facilement.
- Traitement colonnaire vectorisé.
Presto - Avantages
Voici une liste des avantages qu'offre Apache Presto -
- Opérations SQL spécialisées
- Facile à installer et à déboguer
- Abstraction de stockage simple
- Met rapidement à l'échelle les données de pétaoctets avec une faible latence
Presto - Applications
Presto prend en charge la plupart des meilleures applications industrielles d'aujourd'hui. Jetons un coup d'œil à certaines des applications notables.
Facebook- Facebook a construit Presto pour les besoins d'analyse de données. Presto met facilement à l'échelle une grande vitesse de données.
Teradata- Teradata fournit des solutions de bout en bout dans l'analyse Big Data et l'entreposage de données. La contribution de Teradata à Presto permet à davantage d'entreprises de répondre à tous les besoins analytiques.
Airbnb- Presto fait partie intégrante de l'infrastructure de données Airbnb. Eh bien, des centaines d'employés exécutent des requêtes chaque jour avec la technologie.
Pourquoi Presto?
Presto prend en charge la norme ANSI SQL, ce qui a rendu la tâche très facile pour les analystes de données et les développeurs. Bien qu'il soit construit en Java, il évite les problèmes typiques de code Java liés à l'allocation de mémoire et au garbage collection. Presto a une architecture de connecteur compatible avec Hadoop. Il permet de brancher facilement des systèmes de fichiers.
Presto fonctionne sur plusieurs distributions Hadoop. De plus, Presto peut accéder à partir d'une plateforme Hadoop pour interroger Cassandra, des bases de données relationnelles ou d'autres magasins de données. Cette capacité d'analyse multiplateforme permet aux utilisateurs de Presto d'extraire une valeur commerciale maximale de gigaoctets à pétaoctets de données.
L'architecture de Presto est presque similaire à l'architecture SGBD MPP (traitement massivement parallèle) classique. Le diagramme suivant illustre l'architecture de Presto.

Le diagramme ci-dessus se compose de différents composants. Le tableau suivant décrit chacun des composants en détail.
| S. Non | Composant et description |
|---|---|
| 1. | Client Le client (Presto CLI) soumet des instructions SQL à un coordinateur pour obtenir le résultat. |
| 2. | Coordinator Le coordinateur est un démon maître. Le coordinateur analyse d'abord les requêtes SQL, puis analyse et planifie l'exécution de la requête. Scheduler exécute le pipeline, attribue le travail au nœud le plus proche et surveille la progression. |
| 3. | Connector Les plugins de stockage sont appelés connecteurs. Hive, HBase, MySQL, Cassandra et bien d'autres font office de connecteur; sinon, vous pouvez également en implémenter un personnalisé. Le connecteur fournit des métadonnées et des données pour les requêtes. Le coordinateur utilise le connecteur pour obtenir des métadonnées afin de créer un plan de requête. |
| 4. | Worker Le coordinateur affecte la tâche aux nœuds de calcul. Les travailleurs obtiennent les données réelles du connecteur. Enfin, le nœud worker fournit le résultat au client. |
Presto - Flux de travail
Presto est un système distribué qui s'exécute sur un cluster de nœuds. Le moteur de requête distribué de Presto est optimisé pour l'analyse interactive et prend en charge le SQL ANSI standard, y compris les requêtes complexes, les agrégations, les jointures et les fonctions de fenêtre. L'architecture Presto est simple et extensible. Le client Presto (CLI) soumet des instructions SQL à un coordinateur de démon maître.
Le planificateur se connecte via le pipeline d'exécution. Le planificateur affecte le travail aux nœuds les plus proches des données et surveille la progression. Le coordinateur affecte la tâche à plusieurs nœuds de travail et enfin le nœud de travail renvoie le résultat au client. Le client extrait les données du processus de sortie. L'extensibilité est la conception clé. Les connecteurs enfichables tels que Hive, HBase, MySQL, etc., fournissent des métadonnées et des données pour les requêtes. Presto a été conçu avec une «abstraction de stockage simple» qui permet de fournir facilement une capacité de requête SQL sur ces différents types de sources de données.
Modèle d'exécution
Presto prend en charge le moteur de requête et d'exécution personnalisé avec des opérateurs conçus pour prendre en charge la sémantique SQL. Outre une planification améliorée, tous les traitements sont en mémoire et acheminés sur le réseau entre les différentes étapes. Cela évite une surcharge de latence d'E / S inutile.
Ce chapitre explique comment installer Presto sur votre machine. Passons en revue les exigences de base de Presto,
- Linux ou Mac OS
- Java version 8
Maintenant, continuons les étapes suivantes pour installer Presto sur votre machine.
Vérification de l'installation de Java
Espérons que vous avez déjà installé la version 8 de Java sur votre ordinateur, vous n'avez donc qu'à le vérifier à l'aide de la commande suivante.
$ java -versionSi Java est correctement installé sur votre ordinateur, vous pouvez voir la version de Java installé. Si Java n'est pas installé, suivez les étapes suivantes pour installer Java 8 sur votre machine.
Téléchargez JDK. Téléchargez la dernière version de JDK en visitant le lien suivant.
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
La dernière version est JDK 8u 92 et le fichier est «jdk-8u92-linux-x64.tar.gz». Veuillez télécharger le fichier sur votre machine.
Après cela, extrayez les fichiers et déplacez-vous vers le répertoire spécifique.
Ensuite, définissez des alternatives Java. Enfin Java sera installé sur votre machine.
Installation d'Apache Presto
Téléchargez la dernière version de Presto en visitant le lien suivant,
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.149/
Maintenant, la dernière version de «presto-server-0.149.tar.gz» sera téléchargée sur votre machine.
Extraire les fichiers tar
Extraire le tar fichier à l'aide de la commande suivante -
$ tar -zxf presto-server-0.149.tar.gz
$ cd presto-server-0.149Paramètres de configuration
Créer un répertoire «data»
Créez un répertoire de données en dehors du répertoire d'installation, qui sera utilisé pour stocker les journaux, les métadonnées, etc., afin qu'il soit facilement préservé lors de la mise à niveau de Presto. Il est défini à l'aide du code suivant -
$ cd
$ mkdir dataPour afficher le chemin où il se trouve, utilisez la commande «pwd». Cet emplacement sera attribué dans le fichier node.properties suivant.
Créer le répertoire «etc»
Créez un répertoire etc dans le répertoire d'installation de Presto en utilisant le code suivant -
$ cd presto-server-0.149
$ mkdir etcCe répertoire contiendra les fichiers de configuration. Créons chaque fichier un par un.
Propriétés du nœud
Le fichier de propriétés du nœud Presto contient la configuration environnementale spécifique à chaque nœud. Il est créé dans le répertoire etc (etc / node.properties) en utilisant le code suivant -
$ cd etc
$ vi node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/../workspace/PrestoAprès avoir effectué toutes les modifications, enregistrez le fichier et quittez le terminal. Icinode.data est le chemin de l'emplacement du répertoire de données créé ci-dessus. node.id représente l'identifiant unique de chaque nœud.
Configuration JVM
Créez un fichier «jvm.config» dans le répertoire etc (etc / jvm.config). Ce fichier contient une liste d'options de ligne de commande utilisées pour lancer la machine virtuelle Java.
$ cd etc
$ vi jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize = 32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError = kill -9 %pAprès avoir effectué toutes les modifications, enregistrez le fichier et quittez le terminal.
Propriétés de configuration
Créez un fichier «config.properties» dans le répertoire etc (etc / config.properties). Ce fichier contient la configuration du serveur Presto. Si vous configurez une seule machine pour les tests, le serveur Presto ne peut fonctionner que comme processus de coordination tel que défini à l'aide du code suivant -
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Ici,
coordinator - nœud maître.
node-scheduler.include-coordinator - Permet de planifier le travail sur le coordinateur.
http-server.http.port - Spécifie le port du serveur HTTP.
query.max-memory=5GB - La quantité maximale de mémoire distribuée.
query.max-memory-per-node=1GB - La quantité maximale de mémoire par nœud.
discovery-server.enabled - Presto utilise le service Discovery pour trouver tous les nœuds du cluster.
discovery.uri - l'URI du serveur Discovery.
Si vous configurez plusieurs serveurs Presto de machines, Presto fonctionnera à la fois comme processus de coordination et de travail. Utilisez ce paramètre de configuration pour tester le serveur Presto sur plusieurs machines.
Configuration pour le coordinateur
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Configuration pour le travailleur
$ cd etc
$ vi config.properties
coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery.uri = http://localhost:8080Propriétés du journal
Créez un fichier «log.properties» dans le répertoire etc (etc / log.properties). Ce fichier contient le niveau de journalisation minimum pour les hiérarchies de journalisation nommées. Il est défini à l'aide du code suivant -
$ cd etc
$ vi log.properties
com.facebook.presto = INFOEnregistrez le fichier et quittez le terminal. Ici, quatre niveaux de journalisation sont utilisés tels que DEBUG, INFO, WARN et ERROR. Le niveau de journal par défaut est INFO.
Propriétés du catalogue
Créez un répertoire «catalogue» dans le répertoire etc (etc / catalog). Cela sera utilisé pour le montage des données. Par exemple, créezetc/catalog/jmx.properties avec le contenu suivant pour monter le jmx connector comme le catalogue jmx -
$ cd etc
$ mkdir catalog $ cd catalog
$ vi jmx.properties
connector.name = jmxDémarrez Presto
Presto peut être démarré à l'aide de la commande suivante,
$ bin/launcher startEnsuite, vous verrez la réponse similaire à celle-ci,
Started as 840Exécutez Presto
Pour lancer le serveur Presto, utilisez la commande suivante -
$ bin/launcher runAprès avoir lancé avec succès le serveur Presto, vous pouvez trouver les fichiers journaux dans le répertoire «var / log».
launcher.log - Ce journal est créé par le lanceur et est connecté aux flux stdout et stderr du serveur.
server.log - Il s'agit du fichier journal principal utilisé par Presto.
http-request.log - Requête HTTP reçue par le serveur.
À partir de maintenant, vous avez installé avec succès les paramètres de configuration Presto sur votre machine. Continuons les étapes pour installer Presto CLI.
Installez Presto CLI
La CLI Presto fournit un shell interactif basé sur un terminal pour exécuter des requêtes.
Téléchargez la CLI Presto en visitant le lien suivant,
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.149/
Maintenant, «presto-cli-0.149-executable.jar» sera installé sur votre machine.
Exécutez CLI
Après avoir téléchargé le presto-cli, copiez-le vers l'emplacement à partir duquel vous souhaitez l'exécuter. Cet emplacement peut être n'importe quel nœud ayant un accès réseau au coordinateur. Commencez par changer le nom du fichier Jar en Presto. Ensuite, rendez-le exécutable avecchmod + x commande en utilisant le code suivant -
$ mv presto-cli-0.149-executable.jar presto
$ chmod +x prestoExécutez maintenant CLI à l'aide de la commande suivante,
./presto --server localhost:8080 --catalog jmx --schema default
Here jmx(Java Management Extension) refers to catalog and default referes to schema.Vous verrez la réponse suivante,
presto:default>Tapez maintenant la commande «jps» sur votre terminal et vous verrez les démons en cours d'exécution.
Arrêtez Presto
Après avoir effectué toutes les exécutions, vous pouvez arrêter le serveur presto à l'aide de la commande suivante -
$ bin/launcher stopCe chapitre abordera les paramètres de configuration de Presto.
Vérificateur Presto
Le Presto Verifier peut être utilisé pour tester Presto par rapport à une autre base de données (telle que MySQL), ou pour tester deux clusters Presto l'un par rapport à l'autre.
Créer une base de données dans MySQL
Ouvrez le serveur MySQL et créez une base de données à l'aide de la commande suivante.
create database testVous avez maintenant créé la base de données «test» sur le serveur. Créez la table et chargez-la avec la requête suivante.
CREATE TABLE verifier_queries(
id INT NOT NULL AUTO_INCREMENT,
suite VARCHAR(256) NOT NULL,
name VARCHAR(256),
test_catalog VARCHAR(256) NOT NULL,
test_schema VARCHAR(256) NOT NULL,
test_prequeries TEXT,
test_query TEXT NOT NULL,
test_postqueries TEXT,
test_username VARCHAR(256) NOT NULL default 'verifier-test',
test_password VARCHAR(256),
control_catalog VARCHAR(256) NOT NULL,
control_schema VARCHAR(256) NOT NULL,
control_prequeries TEXT,
control_query TEXT NOT NULL,
control_postqueries TEXT,
control_username VARCHAR(256) NOT NULL default 'verifier-test',
control_password VARCHAR(256),
session_properties_json TEXT,
PRIMARY KEY (id)
);Ajouter des paramètres de configuration
Créez un fichier de propriétés pour configurer le vérificateur -
$ vi config.properties
suite = mysuite
query-database = jdbc:mysql://localhost:3306/tutorials?user=root&password=pwd
control.gateway = jdbc:presto://localhost:8080
test.gateway = jdbc:presto://localhost:8080
thread-count = 1Ici, dans le query-database champ, entrez les détails suivants - nom de la base de données mysql, nom d'utilisateur et mot de passe.
Télécharger le fichier JAR
Téléchargez le fichier jar Presto-verifier en visitant le lien suivant,
https://repo1.maven.org/maven2/com/facebook/presto/presto-verifier/0.149/
Maintenant la version “presto-verifier-0.149-executable.jar” est téléchargé sur votre machine.
Exécuter le JAR
Exécutez le fichier JAR à l'aide de la commande suivante,
$ mv presto-verifier-0.149-executable.jar verifier
$ chmod+x verifierExécuter le vérificateur
Exécutez le vérificateur à l'aide de la commande suivante,
$ ./verifier config.propertiesCréer une table
Créons un tableau simple dans “test” base de données à l'aide de la requête suivante.
create table product(id int not null, name varchar(50))Insérer un tableau
Après avoir créé une table, insérez deux enregistrements à l'aide de la requête suivante,
insert into product values(1,’Phone')
insert into product values(2,’Television’)Exécuter la requête du vérificateur
Exécutez l'exemple de requête suivant dans le terminal du vérificateur (./verifier config.propeties) pour vérifier le résultat du vérificateur.
Exemple de requête
insert into verifier_queries (suite, test_catalog, test_schema, test_query,
control_catalog, control_schema, control_query) values
('mysuite', 'mysql', 'default', 'select * from mysql.test.product',
'mysql', 'default', 'select * from mysql.test.product');Ici, select * from mysql.test.product la requête fait référence au catalogue mysql, test est le nom de la base de données et productest le nom de la table. De cette façon, vous pouvez accéder au connecteur mysql en utilisant le serveur Presto.
Ici, deux mêmes requêtes de sélection sont testées l'une par rapport à l'autre pour voir les performances. De même, vous pouvez exécuter d'autres requêtes pour tester les résultats de performances. Vous pouvez également connecter deux clusters Presto pour vérifier les résultats de performances.
Dans ce chapitre, nous aborderons les outils d'administration utilisés dans Presto. Commençons par l'interface Web de Presto.
Interface Web
Presto fournit une interface Web pour surveiller et gérer les requêtes. Il est accessible à partir du numéro de port spécifié dans les propriétés de configuration du coordinateur.
Démarrez le serveur Presto et la CLI Presto. Ensuite, vous pouvez accéder à l'interface Web à partir de l'url suivante -http://localhost:8080/
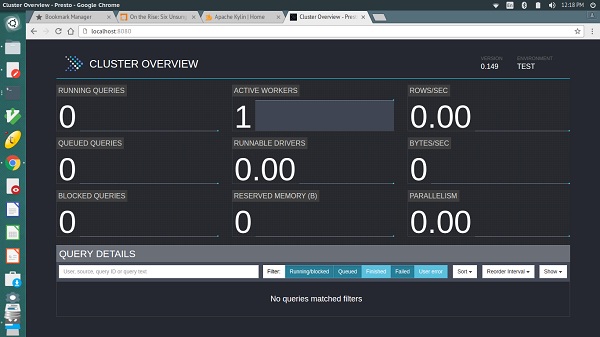
La sortie sera similaire à l'écran ci-dessus.
Ici, la page principale contient une liste de requêtes ainsi que des informations telles que l'ID de requête unique, le texte de la requête, l'état de la requête, le pourcentage achevé, le nom d'utilisateur et la source d'où provient cette requête. Les dernières requêtes s'exécutent en premier, puis les requêtes terminées ou non terminées sont affichées en bas.
Réglage des performances sur Presto
Si le cluster Presto rencontre des problèmes de performances, modifiez vos paramètres de configuration par défaut pour les paramètres suivants.
Propriétés de configuration
task. info -refresh-max-wait - Réduit la charge de travail du coordinateur.
task.max-worker-threads - Divise le processus et affecte à chaque nœud de travail.
distributed-joins-enabled - Jointures distribuées basées sur le hachage.
node-scheduler.network-topology - Définit la topologie du réseau sur le planificateur.
Paramètres JVM
Modifiez vos paramètres JVM par défaut pour les paramètres suivants. Cela sera utile pour diagnostiquer les problèmes de garbage collection.
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics = 2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount = 1Dans ce chapitre, nous verrons comment créer et exécuter des requêtes sur Presto. Passons en revue les types de données de base pris en charge par Presto.
Types de données de base
Le tableau suivant décrit les types de données de base de Presto.
| S. Non | Type de données et description |
|---|---|
| 1. | VARCHAR Données de caractères de longueur variable |
| 2. | BIGINT Un entier signé 64 bits |
| 3. | DOUBLE Une valeur de double précision à virgule flottante 64 bits |
| 4. | DECIMAL Un nombre décimal de précision fixe. Par exemple, DECIMAL (10,3) - 10 est la précision, c'est-à-dire le nombre total de chiffres et 3 est la valeur d'échelle représentée sous forme de point fractionnaire. L'échelle est facultative et la valeur par défaut est 0 |
| 5. | BOOLEAN Valeurs booléennes true et false |
| 6. | VARBINARY Données binaires de longueur variable |
| sept. | JSON Données JSON |
| 8. | DATE Type de données de date représenté par année-mois-jour |
| 9. | TIME, TIMESTAMP, TIMESTAMP with TIME ZONE TIME - Heure de la journée (heure-min-sec-milliseconde) TIMESTAMP - Date et heure du jour TIMESTAMP with TIME ZONE - Date et heure du jour avec fuseau horaire de la valeur |
| dix. | INTERVAL Étirer ou prolonger les types de données de date et d'heure |
| 11. | ARRAY Tableau du type de composant donné. Par exemple, ARRAY [5,7] |
| 12. | MAP Mapper entre les types de composants donnés. Par exemple, MAP (ARRAY ['one', 'two'], ARRAY [5,7]) |
| 13. | ROW Structure de ligne composée de champs nommés |
Presto - Opérateurs
Les opérateurs Presto sont répertoriés dans le tableau suivant.
| S. Non | Opérateur et description |
|---|---|
| 1. | Opérateur arithmétique Presto prend en charge les opérateurs arithmétiques tels que +, -, *, /,% |
| 2. | Opérateur relationnel <,>, <=,> =, =, <> |
| 3. | Opérateur logique ET, OU, PAS |
| 4. | Opérateur de gamme L'opérateur de plage est utilisé pour tester la valeur dans une plage spécifique. Presto prend en charge BETWEEN, IS NULL, IS NOT NULL, GREATEST and MOINS |
| 5. | Opérateur décimal Opérateur décimal arithmétique binaire effectue une opération arithmétique binaire pour le type décimal Opérateur décimal unaire - Le - operator effectue la négation |
| 6. | Opérateur de chaîne le ‘||’ operator effectue la concaténation de chaînes |
| sept. | Opérateur de date et d'heure Effectue des opérations d'addition et de soustraction arithmétiques sur les types de données de date et d'heure |
| 8. | Opérateur de tableau Opérateur d'indice [] - accéder à un élément d'un tableau Opérateur de concaténation || - concaténer un tableau avec un tableau ou un élément du même type |
| 9. | Opérateur de carte Opérateur d'indice de carte [] - récupère la valeur correspondant à une clé donnée à partir d'une carte |
À partir de maintenant, nous discutions d'exécuter quelques requêtes de base simples sur Presto. Ce chapitre abordera les fonctions SQL importantes.
Fonctions mathématiques
Les fonctions mathématiques fonctionnent sur des formules mathématiques. Le tableau suivant décrit la liste des fonctions en détail.
| S.No. | Description de la fonction |
|---|---|
| 1. | abs (x) Renvoie la valeur absolue de x |
| 2. | cbrt (x) Renvoie la racine cubique de x |
| 3. | plafond (x) Renvoie le x valeur arrondie à l'entier supérieur le plus proche |
| 4. | ceil(x) Alias pour plafond (x) |
| 5. | degrés (x) Renvoie la valeur du degré pour x |
| 6. | ex) Renvoie la valeur double du nombre d'Euler |
| sept. | exp(x) Renvoie la valeur de l'exposant pour le nombre d'Euler |
| 8. | plancher (x) Retour x arrondi à l'entier inférieur le plus proche |
| 9. | from_base(string,radix) Renvoie la valeur de la chaîne interprétée comme un nombre de base de base |
| dix. | ln(x) Renvoie le logarithme naturel de x |
| 11. | log2 (x) Renvoie le logarithme de base 2 de x |
| 12. | log10(x) Renvoie le logarithme en base 10 de x |
| 13. | log(x,y) Renvoie la base y logarithme de x |
| 14. | mod (n, m) Renvoie le module (reste) de n divisé par m |
| 15. | pi() Renvoie la valeur pi. Le résultat sera renvoyé sous forme de valeur double |
| 16. | puissance (x, p) Renvoie la puissance de la valeur ‘p’ à la x valeur |
| 17. | pow(x,p) Alias pour le pouvoir (x, p) |
| 18. | radians (x) convertit l'angle x en degrés radians |
| 19. | rand() Alias pour radians () |
| 20. | Aléatoire() Renvoie la valeur pseudo-aléatoire |
| 21. | rand(n) Alias pour aléatoire () |
| 22. | rond (x) Renvoie la valeur arrondie pour x |
| 23. | round(x,d) x valeur arrondie pour le ‘d’ décimales |
| 24. | sign(x) Renvoie la fonction signum de x, c'est-à-dire 0 si l'argument est 0 1 si l'argument est supérieur à 0 -1 si l'argument est inférieur à 0 Pour les arguments doubles, la fonction renvoie en plus - NaN si l'argument est NaN 1 si l'argument est + Infinity -1 si l'argument est -Infinity |
| 25. | sqrt (x) Renvoie la racine carrée de x |
| 26. | to_base (x, base) Le type de retour est archer. Le résultat est renvoyé comme base de base pourx |
| 27. | tronquer (x) Tronque la valeur de x |
| 28. | width_bucket (x, borne1, borne2, n) Renvoie le numéro de casier de x limites bound1 et bound2 spécifiées et nombre n de compartiments |
| 29. | width_bucket (x, bacs) Renvoie le numéro de casier de x selon les bins spécifiés par les bins du tableau |
Fonctions trigonométriques
Les arguments des fonctions trigonométriques sont représentés par des radians (). Le tableau suivant répertorie les fonctions.
| S. Non | Fonctions et description |
|---|---|
| 1. | acos (x) Renvoie la valeur du cosinus inverse (x) |
| 2. | asin(x) Renvoie la valeur sinusoïdale inverse (x) |
| 3. | atan(x) Renvoie la valeur de la tangente inverse (x) |
| 4. | atan2 (y, x) Renvoie la valeur de la tangente inverse (y / x) |
| 5. | cos(x) Renvoie la valeur cosinus (x) |
| 6. | cosh (x) Renvoie la valeur du cosinus hyperbolique (x) |
| sept. | sin (x) Renvoie la valeur sinusoïdale (x) |
| 8. | tan(x) Renvoie la valeur tangente (x) |
| 9. | tanh(x) Renvoie la valeur de tangente hyperbolique (x) |
Fonctions au niveau du bit
Le tableau suivant répertorie les fonctions Bitwise.
| S. Non | Fonctions et description |
|---|---|
| 1. | nombre_bits (x, bits) Comptez le nombre de bits |
| 2. | bitwise_and (x, y) Effectuer une opération ET au niveau du bit pour deux bits, x et y |
| 3. | bitwise_or (x, y) Opération OR au niveau du bit entre deux bits x, y |
| 4. | bitwise_not (x) Bitwise Pas d'opération pour bit x |
| 5. | bitwise_xor (x, y) Opération XOR pour les bits x, y |
Fonctions de chaîne
Le tableau suivant répertorie les fonctions de chaîne.
| S. Non | Fonctions et description |
|---|---|
| 1. | concat (chaîne1, ..., chaîneN) Concaténer les chaînes données |
| 2. | longueur (chaîne) Renvoie la longueur de la chaîne donnée |
| 3. | inférieur (chaîne) Renvoie le format minuscule de la chaîne |
| 4. | supérieur (chaîne) Renvoie le format en majuscules pour la chaîne donnée |
| 5. | lpad (chaîne, taille, padstring) Remplissage à gauche pour la chaîne donnée |
| 6. | ltrim (chaîne) Supprime le premier espace blanc de la chaîne |
| sept. | replace (chaîne, recherche, remplacement) Remplace la valeur de chaîne |
| 8. | reverse (chaîne) Inverse l'opération effectuée pour la chaîne |
| 9. | rpad (chaîne, taille, padstring) Remplissage droit pour la chaîne donnée |
| dix. | rtrim (chaîne) Supprime l'espace blanc de fin de la chaîne |
| 11. | split (chaîne, délimiteur) Divise la chaîne sur le délimiteur et renvoie un tableau de taille au maximum |
| 12. | split_part (chaîne, délimiteur, index) Divise la chaîne sur le délimiteur et renvoie l'index du champ |
| 13. | strpos (chaîne, sous-chaîne) Renvoie la position de départ de la sous-chaîne dans la chaîne |
| 14. | substr (chaîne, début) Renvoie la sous-chaîne de la chaîne donnée |
| 15. | substr (chaîne, début, longueur) Renvoie la sous-chaîne de la chaîne donnée avec la longueur spécifique |
| 16. | trim (chaîne) Supprime les espaces de début et de fin de la chaîne |
Fonctions de date et d'heure
Le tableau suivant répertorie les fonctions de date et d'heure.
| S. Non | Fonctions et description |
|---|---|
| 1. | date actuelle Renvoie la date actuelle |
| 2. | heure actuelle Renvoie l'heure actuelle |
| 3. | current_timestamp Renvoie l'horodatage actuel |
| 4. | current_timezone () Renvoie le fuseau horaire actuel |
| 5. | maintenant() Renvoie la date actuelle, l'horodatage avec le fuseau horaire |
| 6. | heure locale Renvoie l'heure locale |
| sept. | horodatage local Renvoie l'horodatage local |
Fonctions d'expression régulière
Le tableau suivant répertorie les fonctions d'expressions régulières.
| S. Non | Fonctions et description |
|---|---|
| 1. | regexp_extract_all (chaîne, modèle) Renvoie la chaîne correspondant à l'expression régulière du modèle |
| 2. | regexp_extract_all (chaîne, modèle, groupe) Renvoie la chaîne correspondant à l'expression régulière pour le modèle et le groupe |
| 3. | regexp_extract (chaîne, modèle) Renvoie la première sous-chaîne correspondant à l'expression régulière du modèle |
| 4. | regexp_extract (chaîne, modèle, groupe) Renvoie la première sous-chaîne correspondant à l'expression régulière pour le modèle et le groupe |
| 5. | regexp_like (chaîne, modèle) Renvoie la chaîne correspondant au modèle. Si la chaîne est retournée, la valeur sera true sinon false |
| 6. | regexp_replace (chaîne, modèle) Remplace l'instance de la chaîne correspondant à l'expression par le modèle |
| sept. | regexp_replace (chaîne, modèle, remplacement) Remplacez l'instance de la chaîne correspondant à l'expression par le modèle et le remplacement |
| 8. | regexp_split (chaîne, modèle) Divise l'expression régulière pour le modèle donné |
Fonctions JSON
Le tableau suivant répertorie les fonctions JSON.
| S. Non | Fonctions et description |
|---|---|
| 1. | json_array_contains (json, valeur) Vérifiez que la valeur existe dans un tableau json. Si la valeur existe, elle retournera vrai, sinon faux |
| 2. | json_array_get (json_array, index) Récupère l'élément pour l'index dans le tableau json |
| 3. | json_array_length (json) Renvoie la longueur dans le tableau json |
| 4. | json_format (json) Renvoie le format de structure json |
| 5. | json_parse (chaîne) Analyse la chaîne en tant que json |
| 6. | json_size (json, json_path) Renvoie la taille de la valeur |
Fonctions URL
Le tableau suivant répertorie les fonctions URL.
| S. Non | Fonctions et description |
|---|---|
| 1. | url_extract_host (url) Renvoie l'hôte de l'URL |
| 2. | url_extract_path (url) Renvoie le chemin de l'URL |
| 3. | url_extract_port (url) Renvoie le port de l'URL |
| 4. | url_extract_protocol (url) Renvoie le protocole de l'URL |
| 5. | url_extract_query (url) Renvoie la chaîne de requête de l'URL |
Fonctions d'agrégation
Le tableau suivant répertorie les fonctions d'agrégation.
| S. Non | Fonctions et description |
|---|---|
| 1. | avg(x) Renvoie la moyenne pour la valeur donnée |
| 2. | min (x, n) Renvoie la valeur minimale de deux valeurs |
| 3. | max (x, n) Renvoie la valeur maximale de deux valeurs |
| 4. | somme (x) Renvoie la somme de la valeur |
| 5. | compter(*) Renvoie le nombre de lignes d'entrée |
| 6. | compter (x) Renvoie le nombre de valeurs d'entrée |
| sept. | somme de contrôle (x) Renvoie la somme de contrôle pour x |
| 8. | arbitraire (x) Renvoie la valeur arbitraire de x |
Fonctions de couleur
Le tableau suivant répertorie les fonctions de couleur.
| S. Non | Fonctions et description |
|---|---|
| 1. | barre (x, largeur) Rend une seule barre en utilisant rgb low_color et high_color |
| 2. | barre (x, largeur, low_color, high_color) Rend une seule barre pour la largeur spécifiée |
| 3. | couleur (chaîne) Renvoie la valeur de couleur pour la chaîne saisie |
| 4. | rendu (x, couleur) Rend la valeur x en utilisant la couleur spécifique à l'aide des codes de couleur ANSI |
| 5. | rendre (b) Accepte la valeur booléenne b et rend un vert vrai ou un rouge faux à l'aide des codes de couleur ANSI |
| 6. | rgb(red, green, blue) Renvoie une valeur de couleur capturant la valeur RVB de trois valeurs de couleur de composant fournies en tant que paramètres int allant de 0 à 255 |
Fonctions de tableau
Le tableau suivant répertorie les fonctions Array.
| S. Non | Fonctions et description |
|---|---|
| 1. | array_max (x) Recherche l'élément max dans un tableau |
| 2. | array_min (x) Recherche l'élément min dans un tableau |
| 3. | array_sort (x) Trie les éléments dans un tableau |
| 4. | array_remove (x, élément) Supprime l'élément spécifique d'un tableau |
| 5. | concat (x, y) Concatène deux tableaux |
| 6. | contient (x, élément) Recherche les éléments donnés dans un tableau. True sera retourné s'il est présent, sinon faux |
| sept. | array_position (x, élément) Trouvez la position de l'élément donné dans un tableau |
| 8. | array_intersect (x, y) Effectue une intersection entre deux tableaux |
| 9. | element_at (tableau, index) Renvoie la position de l'élément du tableau |
| dix. | tranche (x, début, longueur) Découpe les éléments du tableau avec la longueur spécifique |
Fonctions Teradata
Le tableau suivant répertorie les fonctions Teradata.
| S. Non | Fonctions et description |
|---|---|
| 1. | index (chaîne, sous-chaîne) Renvoie l'index de la chaîne avec la sous-chaîne donnée |
| 2. | sous-chaîne (chaîne, début) Renvoie la sous-chaîne de la chaîne donnée. Vous pouvez spécifier ici l'index de départ |
| 3. | sous-chaîne (chaîne, début, longueur) Renvoie la sous-chaîne de la chaîne donnée pour l'index de début spécifique et la longueur de la chaîne |
Le connecteur MySQL est utilisé pour interroger une base de données MySQL externe.
Conditions préalables
Installation du serveur MySQL.
Paramètres de configuration
J'espère que vous avez installé le serveur mysql sur votre machine. Pour activer les propriétés mysql sur le serveur Presto, vous devez créer un fichier“mysql.properties” dans “etc/catalog”annuaire. Exécutez la commande suivante pour créer un fichier mysql.properties.
$ cd etc $ cd catalog
$ vi mysql.properties
connector.name = mysql
connection-url = jdbc:mysql://localhost:3306
connection-user = root
connection-password = pwdEnregistrez le fichier et quittez le terminal. Dans le fichier ci-dessus, vous devez entrer votre mot de passe mysql dans le champ login-password.
Créer une base de données dans MySQL Server
Ouvrez le serveur MySQL et créez une base de données à l'aide de la commande suivante.
create database tutorialsVous avez maintenant créé une base de données «didacticiels» sur le serveur. Pour activer le type de base de données, utilisez la commande «utiliser des didacticiels» dans la fenêtre de requête.
Créer une table
Créons un tableau simple sur la base de données «tutoriels».
create table author(auth_id int not null, auth_name varchar(50),topic varchar(100))Insérer un tableau
Après avoir créé une table, insérez trois enregistrements à l'aide de la requête suivante.
insert into author values(1,'Doug Cutting','Hadoop')
insert into author values(2,’James Gosling','java')
insert into author values(3,'Dennis Ritchie’,'C')Sélectionner des enregistrements
Pour récupérer tous les enregistrements, tapez la requête suivante.
Requete
select * from authorRésultat
auth_id auth_name topic
1 Doug Cutting Hadoop
2 James Gosling java
3 Dennis Ritchie CÀ partir de maintenant, vous avez interrogé des données à l'aide du serveur MySQL. Connectons le plugin de stockage Mysql au serveur Presto.
Connectez Presto CLI
Tapez la commande suivante pour connecter le plugin MySql sur Presto CLI.
./presto --server localhost:8080 --catalog mysql --schema tutorialsVous recevrez la réponse suivante.
presto:tutorials>Ici “tutorials” fait référence au schéma du serveur mysql.
Répertorier les schémas
Pour lister tous les schémas de mysql, tapez la requête suivante sur le serveur Presto.
Requete
presto:tutorials> show schemas from mysql;Résultat
Schema
--------------------
information_schema
performance_schema
sys
tutorialsDe ce résultat, nous pouvons conclure les trois premiers schémas comme prédéfinis et le dernier comme créé par vous-même.
Lister les tables à partir du schéma
La requête suivante répertorie toutes les tables du schéma des didacticiels.
Requete
presto:tutorials> show tables from mysql.tutorials;Résultat
Table
--------
authorNous n'avons créé qu'une seule table dans ce schéma. Si vous avez créé plusieurs tables, toutes les tables seront répertoriées.
Décrire le tableau
Pour décrire les champs de la table, saisissez la requête suivante.
Requete
presto:tutorials> describe mysql.tutorials.author;Résultat
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Afficher les colonnes de la table
Requete
presto:tutorials> show columns from mysql.tutorials.author;Résultat
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Accéder aux enregistrements de la table
Pour récupérer tous les enregistrements de la table mysql, lancez la requête suivante.
Requete
presto:tutorials> select * from mysql.tutorials.author;Résultat
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CÀ partir de ce résultat, vous pouvez récupérer les enregistrements du serveur mysql dans Presto.
Créer une table en utilisant comme commande
Le connecteur Mysql ne prend pas en charge la requête de création de table, mais vous pouvez créer une table en utilisant la commande as.
Requete
presto:tutorials> create table mysql.tutorials.sample as
select * from mysql.tutorials.author;Résultat
CREATE TABLE: 3 rowsVous ne pouvez pas insérer de lignes directement car ce connecteur présente certaines limitations. Il ne peut pas prendre en charge les requêtes suivantes -
- create
- insert
- update
- delete
- drop
Pour afficher les enregistrements de la table nouvellement créée, tapez la requête suivante.
Requete
presto:tutorials> select * from mysql.tutorials.sample;Résultat
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CLes extensions de gestion Java (JMX) fournissent des informations sur la machine virtuelle Java et les logiciels exécutés dans JVM. Le connecteur JMX est utilisé pour interroger les informations JMX dans le serveur Presto.
Comme nous l'avons déjà activé “jmx.properties” fichier sous “etc/catalog”annuaire. Connectez maintenant la CLI Prest pour activer le plugin JMX.
CLI Presto
Requete
$ ./presto --server localhost:8080 --catalog jmx --schema jmxRésultat
Vous recevrez la réponse suivante.
presto:jmx>Schéma JMX
Pour lister tous les schémas dans «jmx», tapez la requête suivante.
Requete
presto:jmx> show schemas from jmx;Résultat
Schema
--------------------
information_schema
currentAfficher les tableaux
Pour afficher les tables dans le schéma «actuel», utilisez la commande suivante.
Requête 1
presto:jmx> show tables from jmx.current;Résultat
Table
------------------------------------------------------------------------------
com.facebook.presto.execution.scheduler:name = nodescheduler
com.facebook.presto.execution:name = queryexecution
com.facebook.presto.execution:name = querymanager
com.facebook.presto.execution:name = remotetaskfactory
com.facebook.presto.execution:name = taskexecutor
com.facebook.presto.execution:name = taskmanager
com.facebook.presto.execution:type = queryqueue,name = global,expansion = global
………………
……………….Requête 2
presto:jmx> select * from jmx.current.”java.lang:type = compilation";Résultat
node | compilationtimemonitoringsupported | name | objectname | totalcompilationti
--------------------------------------+------------------------------------+--------------------------------+----------------------------+-------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | true | HotSpot 64-Bit Tiered Compilers | java.lang:type=Compilation | 1276Requête 3
presto:jmx> select * from jmx.current."com.facebook.presto.server:name = taskresource";Résultat
node | readfromoutputbuffertime.alltime.count
| readfromoutputbuffertime.alltime.max | readfromoutputbuffertime.alltime.maxer
--------------------------------------+---------------------------------------+--------------------------------------+---------------------------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | 92.0 | 1.009106149 |Le connecteur Hive permet d'interroger les données stockées dans un entrepôt de données Hive.
Conditions préalables
- Hadoop
- Hive
J'espère que vous avez installé Hadoop et Hive sur votre machine. Démarrez tous les services un par un dans le nouveau terminal. Ensuite, démarrez Hive Metastore à l'aide de la commande suivante,
hive --service metastorePresto utilise le service de métastore Hive pour obtenir les détails de la table Hive.
Paramètres de configuration
Créer un fichier “hive.properties” en dessous de “etc/catalog”annuaire. Utilisez la commande suivante.
$ cd etc $ cd catalog
$ vi hive.properties
connector.name = hive-cdh4
hive.metastore.uri = thrift://localhost:9083Après avoir effectué toutes les modifications, enregistrez le fichier et quittez le terminal.
Créer une base de données
Créez une base de données dans Hive à l'aide de la requête suivante -
Requete
hive> CREATE SCHEMA tutorials;Une fois la base de données créée, vous pouvez la vérifier à l'aide du “show databases” commander.
Créer une table
Create Table est une instruction utilisée pour créer une table dans Hive. Par exemple, utilisez la requête suivante.
hive> create table author(auth_id int, auth_name varchar(50),
topic varchar(100) STORED AS SEQUENCEFILE;Insérer un tableau
La requête suivante est utilisée pour insérer des enregistrements dans la table de la ruche.
hive> insert into table author values (1,’ Doug Cutting’,Hadoop),
(2,’ James Gosling’,java),(3,’ Dennis Ritchie’,C);Démarrez Presto CLI
Vous pouvez démarrer Presto CLI pour connecter le plugin de stockage Hive à l'aide de la commande suivante.
$ ./presto --server localhost:8080 --catalog hive —schema tutorials;Vous recevrez la réponse suivante.
presto:tutorials >Répertorier les schémas
Pour répertorier tous les schémas du connecteur Hive, saisissez la commande suivante.
Requete
presto:tutorials > show schemas from hive;Résultat
default
tutorialsTables de liste
Pour lister toutes les tables dans le schéma «tutoriels», utilisez la requête suivante.
Requete
presto:tutorials > show tables from hive.tutorials;Résultat
authorRécupérer la table
La requête suivante est utilisée pour récupérer tous les enregistrements de la table de la ruche.
Requete
presto:tutorials > select * from hive.tutorials.author;Résultat
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CLe connecteur Kafka pour Presto permet d'accéder aux données d'Apache Kafka en utilisant Presto.
Conditions préalables
Téléchargez et installez la dernière version des projets Apache suivants.
- Apache ZooKeeper
- Apache Kafka
Démarrez ZooKeeper
Démarrez le serveur ZooKeeper à l'aide de la commande suivante.
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesMaintenant, ZooKeeper démarre le port sur 2181.
Démarrez Kafka
Démarrez Kafka dans un autre terminal à l'aide de la commande suivante.
$ bin/kafka-server-start.sh config/server.propertiesAprès le démarrage de kafka, il utilise le numéro de port 9092.
Données TPCH
Télécharger tpch-kafka
$ curl -o kafka-tpch
https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_
0811-1.0.shVous avez maintenant téléchargé le chargeur depuis Maven central en utilisant la commande ci-dessus. Vous obtiendrez une réponse similaire à la suivante.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
5 21.6M 5 1279k 0 0 83898 0 0:04:30 0:00:15 0:04:15 129k
6 21.6M 6 1407k 0 0 86656 0 0:04:21 0:00:16 0:04:05 131k
24 21.6M 24 5439k 0 0 124k 0 0:02:57 0:00:43 0:02:14 175k
24 21.6M 24 5439k 0 0 124k 0 0:02:58 0:00:43 0:02:15 160k
25 21.6M 25 5736k 0 0 128k 0 0:02:52 0:00:44 0:02:08 181k
………………………..Ensuite, rendez-le exécutable à l'aide de la commande suivante,
$ chmod 755 kafka-tpchExécutez tpch-kafka
Exécutez le programme kafka-tpch pour précharger un certain nombre de rubriques avec des données tpch à l'aide de la commande suivante.
Requete
$ ./kafka-tpch load --brokers localhost:9092 --prefix tpch. --tpch-type tinyRésultat
2016-07-13T16:15:52.083+0530 INFO main io.airlift.log.Logging Logging
to stderr
2016-07-13T16:15:52.124+0530 INFO main de.softwareforge.kafka.LoadCommand
Processing tables: [customer, orders, lineitem, part, partsupp, supplier,
nation, region]
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-1
de.softwareforge.kafka.LoadCommand Loading table 'customer' into topic 'tpch.customer'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-2
de.softwareforge.kafka.LoadCommand Loading table 'orders' into topic 'tpch.orders'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-3
de.softwareforge.kafka.LoadCommand Loading table 'lineitem' into topic 'tpch.lineitem'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-4
de.softwareforge.kafka.LoadCommand Loading table 'part' into topic 'tpch.part'...
………………………
……………………….Désormais, les clients, commandes, fournisseurs, etc. des tables Kafka sont chargés à l'aide de tpch.
Ajouter des paramètres de configuration
Ajoutons les paramètres de configuration du connecteur Kafka suivants sur le serveur Presto.
connector.name = kafka
kafka.nodes = localhost:9092
kafka.table-names = tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,
tpch.supplier,tpch.nation,tpch.region
kafka.hide-internal-columns = falseDans la configuration ci-dessus, les tables Kafka sont chargées à l'aide du programme Kafka-tpch.
Démarrez Presto CLI
Démarrez Presto CLI à l'aide de la commande suivante,
$ ./presto --server localhost:8080 --catalog kafka —schema tpch;Ici “tpch" est un schéma pour le connecteur Kafka et vous recevrez une réponse comme suit.
presto:tpch>Tables de liste
La requête suivante répertorie toutes les tables de “tpch” schéma.
Requete
presto:tpch> show tables;Résultat
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplierDécrire la table des clients
La requête suivante décrit “customer” table.
Requete
presto:tpch> describe customer;Résultat
Column | Type | Comment
-------------------+---------+---------------------------------------------
_partition_id | bigint | Partition Id
_partition_offset | bigint | Offset for the message within the partition
_segment_start | bigint | Segment start offset
_segment_end | bigint | Segment end offset
_segment_count | bigint | Running message count per segment
_key | varchar | Key text
_key_corrupt | boolean | Key data is corrupt
_key_length | bigint | Total number of key bytes
_message | varchar | Message text
_message_corrupt | boolean | Message data is corrupt
_message_length | bigint | Total number of message bytesL'interface JDBC de Presto est utilisée pour accéder à l'application Java.
Conditions préalables
Installez presto-jdbc-0.150.jar
Vous pouvez télécharger le fichier JDBC jar en visitant le lien suivant,
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.150/
Une fois le fichier jar téléchargé, ajoutez-le au chemin de classe de votre application Java.
Créer une application simple
Créons une application Java simple en utilisant l'interface JDBC.
Codage - PrestoJdbcSample.java
import java.sql.*;
import com.facebook.presto.jdbc.PrestoDriver;
//import presto jdbc driver packages here.
public class PrestoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
connection = DriverManager.getConnection(
"jdbc:presto://localhost:8080/mysql/tutorials", "tutorials", “");
//connect mysql server tutorials database here
statement = connection.createStatement();
String sql;
sql = "select auth_id, auth_name from mysql.tutorials.author”;
//select mysql table author table two columns
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("auth_id");
String name = resultSet.getString(“auth_name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Enregistrez le fichier et quittez l'application. Maintenant, démarrez le serveur Presto dans un terminal et ouvrez un nouveau terminal pour compiler et exécuter le résultat. Voici les étapes -
Compilation
~/Workspace/presto/presto-jdbc $ javac -cp presto-jdbc-0.149.jar PrestoJdbcSample.javaExécution
~/Workspace/presto/presto-jdbc $ java -cp .:presto-jdbc-0.149.jar PrestoJdbcSampleProduction
INFO: Logging initialized @146ms
ID: 1;
Name: Doug Cutting
ID: 2;
Name: James Gosling
ID: 3;
Name: Dennis RitchieCréez un projet Maven pour développer la fonction personnalisée Presto.
SimpleFunctionsFactory.java
Créez la classe SimpleFunctionsFactory pour implémenter l'interface FunctionFactory.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.metadata.FunctionListBuilder;
import com.facebook.presto.metadata.SqlFunction;
import com.facebook.presto.spi.type.TypeManager;
import java.util.List;
public class SimpleFunctionFactory implements FunctionFactory {
private final TypeManager typeManager;
public SimpleFunctionFactory(TypeManager typeManager) {
this.typeManager = typeManager;
}
@Override
public List<SqlFunction> listFunctions() {
return new FunctionListBuilder(typeManager)
.scalar(SimpleFunctions.class)
.getFunctions();
}
}SimpleFunctionsPlugin.java
Créez une classe SimpleFunctionsPlugin pour implémenter l'interface Plugin.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.spi.Plugin;
import com.facebook.presto.spi.type.TypeManager;
import com.google.common.collect.ImmutableList;
import javax.inject.Inject;
import java.util.List;
import static java.util.Objects.requireNonNull;
public class SimpleFunctionsPlugin implements Plugin {
private TypeManager typeManager;
@Inject
public void setTypeManager(TypeManager typeManager) {
this.typeManager = requireNonNull(typeManager, "typeManager is null”);
//Inject TypeManager class here
}
@Override
public <T> List<T> getServices(Class<T> type){
if (type == FunctionFactory.class) {
return ImmutableList.of(type.cast(new SimpleFunctionFactory(typeManager)));
}
return ImmutableList.of();
}
}Ajouter un fichier de ressources
Créez un fichier de ressources spécifié dans le package d'implémentation.
(com.tutorialspoint.simple.functions.SimpleFunctionsPlugin)Maintenant, déplacez-vous vers l'emplacement du fichier de ressources @ / chemin / vers / ressource /
Puis ajoutez les modifications,
com.facebook.presto.spi.Pluginpom.xml
Ajoutez les dépendances suivantes au fichier pom.xml.
<?xml version = "1.0"?>
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorialspoint.simple.functions</groupId>
<artifactId>presto-simple-functions</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>presto-simple-functions</name>
<description>Simple test functions for Presto</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-spi</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-main</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
<build>
<finalName>presto-simple-functions</finalName>
<plugins>
<!-- Make this jar executable -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.3.2</version>
</plugin>
</plugins>
</build>
</project>SimpleFunctions.java
Créez une classe SimpleFunctions à l'aide des attributs Presto.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.operator.Description;
import com.facebook.presto.operator.scalar.ScalarFunction;
import com.facebook.presto.operator.scalar.StringFunctions;
import com.facebook.presto.spi.type.StandardTypes;
import com.facebook.presto.type.LiteralParameters;
import com.facebook.presto.type.SqlType;
public final class SimpleFunctions {
private SimpleFunctions() {
}
@Description("Returns summation of two numbers")
@ScalarFunction(“mysum")
//function name
@SqlType(StandardTypes.BIGINT)
public static long sum(@SqlType(StandardTypes.BIGINT) long num1,
@SqlType(StandardTypes.BIGINT) long num2) {
return num1 + num2;
}
}Une fois l'application créée, compilez et exécutez l'application. Il produira le fichier JAR. Copiez le fichier et déplacez le fichier JAR dans le répertoire du plugin du serveur Presto cible.
Compilation
mvn compileExécution
mvn packageMaintenant, redémarrez le serveur Presto et connectez le client Presto. Exécutez ensuite l'application de fonction personnalisée comme expliqué ci-dessous,
$ ./presto --catalog mysql --schema defaultRequete
presto:default> select mysum(10,10);Résultat
_col0
-------
20