Cognos - Guide rapide
Un entrepôt de données se compose de données provenant multiple heterogeneous data sourceset est utilisé pour les rapports analytiques et la prise de décision. L'entrepôt de données est un endroit central où les données sont stockées à partir de différentes sources de données et applications.
Le terme Data Warehouse a été inventé pour la première fois par Bill Inmom en 1990. Un Data Warehouse est toujours séparé d'une base de données opérationnelle.
Les données d'un système DW sont chargées à partir de systèmes de transaction opérationnels tels que -
- Sales
- Marketing
- HR
- SCM, etc.
Il peut passer par le stockage de données opérationnelles ou d'autres transformations avant d'être chargé dans le système DW pour le traitement de l'information.
Un entrepôt de données est utilisé pour le reporting et l'analyse d'informations et stocke les données historiques et actuelles. Les données du système DW sont utilisées pour les rapports analytiques, qui sont ensuite utilisés par les analystes commerciaux, les directeurs des ventes ou les travailleurs du savoir pour la prise de décision.

Dans l'image ci-dessus, vous pouvez voir que les données proviennent de multiple heterogeneous datasources vers un entrepôt de données. Les sources de données courantes pour un entrepôt de données comprennent:
- Bases de données opérationnelles
- Applications SAP et non-SAP
- Fichiers plats (fichiers xls, csv, txt)
Les utilisateurs de BI (Business Intelligence) accèdent aux données de l'entrepôt de données pour les rapports analytiques, l'exploration de données et l'analyse. Ceci est utilisé pour la prise de décision par les utilisateurs professionnels, le directeur des ventes, les analystes pour définir la stratégie future.
Caractéristiques d'un entrepôt de données
Il s'agit d'un référentiel de données central où les données sont stockées à partir d'une ou plusieurs sources de données hétérogènes. Un système DW stocke les données actuelles et historiques. Normalement, un système DW stocke 5 à 10 ans de données historiques. Un système DW est toujours séparé d'un système de transaction opérationnel.
Les données d'un système DW sont utilisées pour différents types de rapports analytiques allant de la comparaison trimestrielle à la comparaison annuelle.
Entrepôt de données et base de données opérationnelle
Les différences entre un entrepôt de données et une base de données opérationnelle sont les suivantes:
Un Operational System est conçu pour les charges de travail et les transactions connues telles que la mise à jour d'un enregistrement utilisateur, la recherche d'un enregistrement, etc. Cependant, les transactions de l'entrepôt de données sont plus complexes et présentent une forme générale de données.
Un Operational System contient les données actuelles d'une organisation et l'entrepôt de données contient normalement les données historiques.
Un Operational Databaseprend en charge le traitement parallèle de plusieurs transactions. Des mécanismes de contrôle d'accès et de récupération sont nécessaires pour maintenir la cohérence de la base de données.
Un Operational Database query permet de lire et de modifier les opérations (insérer, supprimer et mettre à jour) alors qu'une requête OLAP ne nécessite qu'un accès en lecture seule aux données stockées (instruction Select).
Architecture de l'entrepôt de données
L'entreposage de données implique le nettoyage des données, l'intégration des données et la consolidation des données. Un entrepôt de données a une architecture à 3 couches -
Couche de source de données
Il définit comment les données arrivent dans un entrepôt de données. Il implique diverses sources de données et systèmes de transaction opérationnels, fichiers plats, applications, etc.
Couche d'intégration
Il se compose d'un magasin de données opérationnelles et d'une zone de préparation. La zone de transit est utilisée pour effectuer le nettoyage des données, la transformation des données et le chargement des données de différentes sources vers un entrepôt de données. Comme plusieurs sources de données sont disponibles pour l'extraction à différents fuseaux horaires, la zone de transit est utilisée pour stocker les données et plus tard pour appliquer des transformations aux données.
Couche de présentation
Ceci est utilisé pour effectuer des rapports BI par les utilisateurs finaux. Les données d'un système DW sont accessibles par les utilisateurs BI et utilisées pour le reporting et l'analyse.
L'illustration suivante montre l'architecture commune d'un système d'entrepôt de données.

Caractéristiques d'un entrepôt de données
Voici les principales caractéristiques d'un entrepôt de données:
Subject Oriented - Dans un système DW, les données sont catégorisées et stockées par un sujet commercial plutôt que par une application comme les plans d'équité, les actions, les prêts, etc.
Integrated - Les données provenant de plusieurs sources de données sont intégrées dans un entrepôt de données.
Non Volatile- Les données de l'entrepôt de données sont non volatiles. Cela signifie que lorsque les données sont chargées dans le système DW, elles ne sont pas modifiées.
Time Variant- Un système DW contient des données historiques par rapport au système transactionnel qui ne contient que des données actuelles. Dans un entrepôt de données, vous pouvez voir les données pour 3 mois, 6 mois, 1 an, 5 ans, etc.
OLTP contre OLAP
Premièrement, OLTP signifie Online Transaction Processing, tandis que OLAP signifie Online Analytical Processing
Dans un système OLTP, il existe un grand nombre de transactions en ligne courtes telles que INSERT, UPDATE et DELETE.
Alors que, dans un système OLTP, une mesure efficace est le temps de traitement des transactions courtes et est très inférieur. Il contrôle l'intégrité des données dans les environnements multi-accès. Pour un système OLTP, le nombre de transactions par seconde mesure l'efficacité. Un système d'entrepôt de données OLTP contient des données actuelles et détaillées et est conservé dans les schémas du modèle d'entité (3NF).
For Example -
Un système de transaction au jour le jour dans un magasin de détail, où les enregistrements des clients sont insérés, mis à jour et supprimés quotidiennement. Il permet un traitement des requêtes plus rapide. Les bases de données OLTP contiennent des données détaillées et actuelles. Le schéma utilisé pour stocker la base de données OLTP est le modèle Entity.
Dans un système OLAP, le nombre de transactions est inférieur à celui d'un système transactionnel. Les requêtes exécutées sont de nature complexe et impliquent des agrégations de données.
Qu'est-ce qu'une agrégation?
Nous sauvegardons des tableaux avec des données agrégées telles que annuelle (1 ligne), trimestrielle (4 lignes), mensuelle (12 lignes) ou plus, si quelqu'un doit faire une comparaison d'année en année, une seule ligne sera traitée. Cependant, dans un tableau non agrégé, il comparera toutes les lignes. C'est ce qu'on appelle l'agrégation.
Il existe diverses fonctions d'agrégation qui peuvent être utilisées dans un système OLAP telles que Sum, Avg, Max, Min, etc.
For Example -
SELECT Avg(salary)
FROM employee
WHERE title = 'Programmer';Différences clés
Ce sont les principales différences entre un système OLAP et un système OLTP.
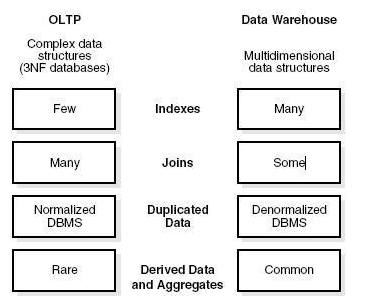
Indexes - Un système OLTP n'a que quelques index tandis que dans un système OLAP, il existe de nombreux index pour l'optimisation des performances.
Joins- Dans un système OLTP, un grand nombre de jointures et de données sont normalisées. Cependant, dans un système OLAP, il y a moins de jointures et sont dé-normalisées.
Aggregation - Dans un système OLTP, les données ne sont pas agrégées alors que dans une base de données OLAP, davantage d'agrégations sont utilisées.
Normalization - Un système OLTP contient des données normalisées, mais les données ne sont pas normalisées dans un système OLAP.
Data Mart Vs Data Warehouse
Le magasin de données se concentre sur un seul domaine fonctionnel et représente la forme la plus simple d'un entrepôt de données. Considérez un entrepôt de données contenant des données pour les ventes, le marketing, les ressources humaines et les finances. Un Data Mart se concentre sur un seul domaine fonctionnel comme les ventes ou le marketing.

Dans l'image ci-dessus, vous pouvez voir la différence entre un entrepôt de données et un magasin de données.
Tableau des faits vs dimensions
Une table de faits représente les mesures sur lesquelles l'analyse est effectuée. Il contient également des clés étrangères pour les clés de dimension.
For example - Chaque vente est un fait.
| Identifiant du client | ID de produit | ID de l'heure | Qté vendue |
|---|---|---|---|
| 1110 | 25 | 2 | 125 |
| 1210 | 28 | 4 | 252 |
La table Dimension représente les caractéristiques d'une dimension. Une dimension Client peut avoir Customer_Name, Phone_No, Sex, etc.
| Identifiant du client | Cust_Name | Téléphone | Sexe |
|---|---|---|---|
| 1110 | Sortie | 1113334444 | F |
| 1210 | Adam | 2225556666 | M |
Un schéma est défini comme une description logique de la base de données où les tables de faits et de dimension sont jointes de manière logique. L'entrepôt de données est géré sous la forme de schémas Star, Snowflakes et Fact Constellation.
Schéma en étoile
Un schéma en étoile contient une table de faits et plusieurs tables de dimension. Chaque dimension est représentée avec une seule table à une dimension et elles ne sont pas normalisées. La table Dimension contient un ensemble d'attributs.
Caractéristiques
- Dans un schéma Star, il n'y a qu'une seule table de faits et plusieurs tables de dimension.
- Dans un schéma en étoile, chaque dimension est représentée par une table à une dimension.
- Les tables de dimension ne sont pas normalisées dans un schéma en étoile.
- Chaque table de dimension est jointe à une clé dans une table de faits.
L'illustration suivante montre les données de vente d'une entreprise par rapport aux quatre dimensions, à savoir le temps, l'article, la succursale et l'emplacement.
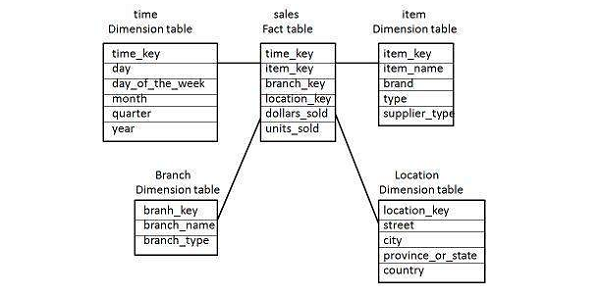
Il y a une table de faits au centre. Il contient les clés de chacune des quatre dimensions. La table de faits contient également les attributs, à savoir les dollars vendus et les unités vendues.
Note- Chaque dimension n'a qu'une table à une dimension et chaque table contient un ensemble d'attributs. Par exemple, la table de dimension d'emplacement contient l'ensemble d'attributs {location_key, street, city, province_or_state, country}. Cette contrainte peut entraîner une redondance des données.
For example- «Vancouver» et «Victoria», les deux villes se trouvent dans la province canadienne de la Colombie-Britannique. Les entrées pour ces villes peuvent entraîner une redondance des données le long des attributs province_or_state et country.
Schéma de flocons de neige
Certaines tables de dimension du schéma Snowflake sont normalisées. La normalisation divise les données en tableaux supplémentaires, comme indiqué dans l'illustration suivante.
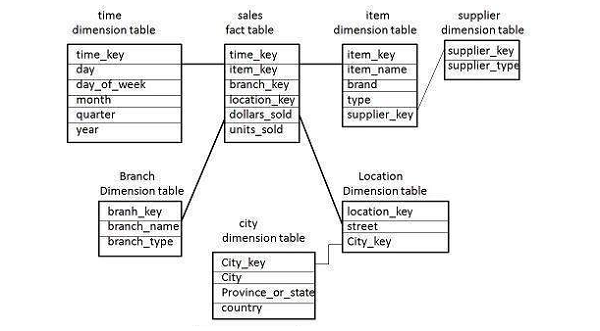
Contrairement au schéma Star, la table de dimension dans un schéma en flocon de neige est normalisée.
For example- La table de dimension article dans un schéma en étoile est normalisée et divisée en deux tables de dimension, à savoir la table article et fournisseur. Désormais, la table de dimension d'article contient les attributs item_key, item_name, type, brand et supplier-key.
La clé fournisseur est liée à la table de dimension fournisseur. La table de dimension fournisseur contient les attributs clé_fournisseur et type_fournisseur.
Note - En raison de la normalisation dans le schéma Snowflake, la redondance est réduite et par conséquent, il devient facile à entretenir et à économiser de l'espace de stockage.
Schéma de constellation des faits (schéma de la galaxie)
Une constellation de faits a plusieurs tables de faits. Il est également connu sous le nom de schéma Galaxy.
L'illustration suivante montre deux tables de faits, à savoir Ventes et Expédition -

La table de faits sur les ventes est la même que celle du schéma en étoile. La table de faits d'expédition a cinq dimensions, à savoir item_key, time_key, shipper_key, from_location, to_location. Le tableau des données d'expédition contient également deux mesures, à savoir les dollars vendus et les unités vendues. Il est également possible de partager des tables de dimension entre des tables de faits.
For example - Les tables de dimension de temps, d'article et d'emplacement sont partagées entre la table de faits sur les ventes et l'expédition.
Un outil ETL extrait les données de toutes ces sources de données hétérogènes, transforme les données (comme appliquer des calculs, joindre des champs, des clés, supprimer des champs de données incorrects, etc.) et les charger dans un entrepôt de données.
Extraction
Une zone de transit est nécessaire pendant le chargement ETL. Il y a plusieurs raisons pour lesquelles une zone de rassemblement est nécessaire. Les systèmes sources ne sont disponibles que pendant une période spécifique pour extraire les données. Cette période est inférieure au temps total de chargement des données. Par conséquent, la zone de transit vous permet d'extraire les données du système source et de les conserver dans la zone de transit avant la fin de la plage horaire.
La zone de préparation est requise lorsque vous souhaitez rassembler les données de plusieurs sources de données ou si vous souhaitez joindre deux ou plusieurs systèmes ensemble.
For example - Vous ne pourrez pas exécuter une requête SQL joignant deux tables de deux bases de données physiquement différentes.
Le créneau horaire des extractions de données pour différents systèmes varie en fonction du fuseau horaire et des heures de fonctionnement. Les données extraites des systèmes sources peuvent être utilisées dans plusieurs systèmes d'entrepôt de données, magasins de données d'exploitation, etc.
ETL vous permet d'effectuer des transformations complexes et nécessite une zone supplémentaire pour stocker les données.

Transformer
Dans la transformation de données, vous appliquez un ensemble de fonctions sur les données extraites pour les charger dans le système cible. Les données qui ne nécessitent aucune transformation sont appelées déplacement direct ou transfert de données.
Vous pouvez appliquer différentes transformations aux données extraites du système source. Par exemple, vous pouvez effectuer des calculs personnalisés. Si vous voulez un revenu de somme des ventes et que celui-ci ne figure pas dans la base de données, vous pouvez appliquer la formule SOMME lors de la transformation et charger les données.
For example - Si vous avez le prénom et le nom dans une table dans différentes colonnes, vous pouvez utiliser concaténer avant le chargement.
Charge
Pendant la phase de chargement, les données sont chargées dans le système cible final et il peut s'agir d'un fichier plat ou d'un système Data Warehouse.
Outil de reporting BI
Les outils BI (Business Intelligence) sont utilisés par les utilisateurs métier pour créer des rapports de base, moyens et complexes à partir des données transactionnelles dans l'entrepôt de données et en créant des univers à l'aide du Information Design Tool/UDT. Diverses sources de données SAP et non SAP peuvent être utilisées pour créer des rapports.
Il existe de nombreux outils de reporting BI, de tableau de bord et de visualisation de données disponibles sur le marché. Certains d'entre eux sont les suivants -
- SAP Business Objects Web Intelligence (WebI)
- Rapports Crystal
- SAP Lumira
- Concepteur de tableau de bord
- IBM Cognos
- Plateforme Microsoft BI
- Intelligence économique Tableau
- JasperSoft
- Oracle BI OBIEE
- Pentaho
- QlickView
- SAP BW
- Intelligence d'affaires SAS
- Necto
- Tibco Spotfire
IBM Cognos Business Intelligence est un web based reporting and analytic tool. Il est utilisé pour effectuer une agrégation de données et créer des rapports détaillés conviviaux. Les rapports peuvent contenir des graphiques, plusieurs pages, différents onglets et des invites interactives. Ces rapports peuvent être consultés sur des navigateurs Web ou sur des appareils portables tels que des tablettes et des smartphones.
Cognos vous offre également la possibilité d'exporter le rapport au format XML ou PDF ou vous pouvez afficher les rapports au format XML. Vous pouvez également planifier le rapport pour qu'il s'exécute en arrière-plan à une période spécifique afin de gagner du temps pour afficher le rapport quotidien car vous n'avez pas besoin d'exécuter le rapport à chaque fois.
IBM Cognos fournit un large éventail de fonctionnalités et peut être considéré comme un logiciel d'entreprise pour fournir un environnement de reporting flexible et can be used for large and medium enterprises. Il répond aux besoins des utilisateurs expérimentés, des analystes, des chefs d'entreprise et des dirigeants d'entreprise. Les utilisateurs expérimentés et les analystes souhaitent créer des rapports ad hoc et peuvent créer plusieurs vues des mêmes données. Les dirigeants d'entreprise veulent voir des données de synthèse dans des styles de tableau de bord, des onglets croisés et des visualisations. Cognos autorise les deux options pour tous les groupes d'utilisateurs.
Principales fonctionnalités d'IBM Cognos
Les rapports Cognos BI vous permettent de regrouper les données de plusieurs bases de données dans un seul ensemble de rapports. IBM Cognos propose une large gamme de fonctionnalités par rapport aux autres outils de BI du marché. Vous pouvez créer et planifier les rapports et les rapports complexes peuvent être facilement conçus dans l'outil de rapport Cognos BI.
L'outil de rapport Cognos BI permet de créer un rapport pour un ensemble d'utilisateurs tels que: les utilisateurs expérimentés, les analystes et les dirigeants d'entreprise, etc. IBM Cognos peut gérer un grand volume de données et convient aux moyennes et grandes entreprises pour répondre aux besoins de BI.
Cognos d'architecture à 3 niveaux
Cognos BI est considéré comme une mise en page d'architecture à 3 niveaux. En haut, il y a un client Web ou un serveur Web. Le 2 e niveau se compose d'un serveur d'applications Web. Alors que le niveau inférieur se compose d'une couche de données.
Ces niveaux sont séparés par des pare-feu et la communication entre ces niveaux s'effectue à l'aide des protocoles SOAP et HTTP.

Clients Web de niveau 1
Le client Web permet aux utilisateurs BI d'accéder aux données TM1 et d'interagir avec les données dans l'un des navigateurs pris en charge. Le niveau 1 est chargé de gérer la passerelle et est utilisé pour le chiffrement et le déchiffrement des mots de passe, l'extraction des informations nécessaires pour soumettre une demande au serveur de BI, l'authentification du serveur et pour transmettre la demande au répartiteur Cognos BI pour traitement.
Serveur d'applications Web de niveau 2
Ce niveau héberge le serveur Cognos BI et ses services associés. Le serveur d'applications contient des composants d'application, Content Manager et le service Bootstrap.
Le serveur d'applications Web Cognos TM1 s'exécute sur un serveur Apache Tomcat basé sur Java. En utilisant ce niveau, les feuilles de calcul Microsoft Excel peuvent être converties en feuilles Web TM1 et permettent également d'exporter des feuilles Web au format Excel et PDF.
Données de niveau 3
Ce niveau contient du contenu et des sources de données. Il contient le serveur Admin TM1 et au moins un serveur TM1.
Le serveur Admin TM1 peut être installé sur n'importe quel ordinateur de votre réseau local et doit résider sur le même réseau que le serveur TM1. La version du serveur TM1 doit être égale ou la plus récente à la version de Cognos TM1 web.
Versions de Cognos
Dans cette section, nous aborderons les différentes versions de Cognos.
Cognos Query version 7
| 7.4 | Inactif (au 30 septembre 2012) | Indisponible (depuis le 30 sept. 2012) | |
| 7,3 | Inactif (au 1er janvier 2008) | Indisponible (depuis le 30 juin 2012) | 7.4 |
| 7,1 | Inactif (au 31 décembre 2005) | Indisponible (depuis le 30 nov.2011) | 7.3 ou 7.4 |
| 7,0 | Inactif (au 31 décembre 2004) | Indisponible (depuis le 30 nov.2011) | 7.1 ou 7.3 |
Cognos 8 BI
| 8.4.0 | Support IBM standard (3), inactif (au 30 septembre 2012) | Indisponible (depuis le 30 sept. 2012) | 8.4.1 |
| 8.4 FCS (premier envoi client) | Inactif (au 27 février 2009) | Indisponible | 8.4.1 |
| 8.3 | Inactif (au 30 avril 2012) | Indisponible (depuis le 30 avril 2013) | 8.4.1 |
| 8,2 | Inactif (au 31 mars 2010) | Indisponible (depuis le 30 juin 2012) | 8.4.1 |
| 8.1.2 MR2 | Inactif (au 31 mars 2009) | Indisponible (depuis le 30 nov.2011) | 8.4.1 |
| 8.1.2 MR1 | Inactif (au 31 mars 2009) | Indisponible (depuis le 30 nov.2011) | 8.4.1 |
| 8.1.1 | Inactif (au 31 décembre 2004) | Indisponible (depuis le 30 nov.2011) | 8.4.1 |
Cognos tm1
| 9.4 MR1 | Inactif (au 30 septembre 2012) | Indisponible (depuis le 30 sept. 2012) | 9.5.2 |
| 9.4 | Inactif (au 30 septembre 2012) | Indisponible (depuis le 30 sept. 2012) | 9.5.2 |
| 9.1 SP4 | Inactif (au 31 décembre 2010) | Indisponible (depuis le 30 nov.2011) | 9.5.2 |
| 9.1 SP3 | Inactif (au 31 décembre 2010) | Indisponible (depuis le 30 nov.2011) | 9.5.2 |
Et puis il y avait différentes sous-versions de - Cognos Business Intelligence 10, qui étaient -
- IBM Cognos Business Intelligence 10.1
- IBM Cognos Business Intelligence 10.1.1
- IBM Cognos Business Intelligence 10.2
- IBM Cognos Business Intelligence 10.2.1
- IBM Cognos Business Intelligence 10.2.2
- IBM Cognos Business Intelligence 11.0.0
Cognos vs autres outils de reporting BI
Il existe divers autres outils de reporting BI sur le marché qui sont utilisés dans les moyennes et grandes entreprises à des fins d'analyse et de reporting. Certains d'entre eux sont décrits ici avec ses principales caractéristiques.
Cognos vs Microsoft BI (Source: www.trustradius.com)
Voici les principales fonctionnalités prises en charge par les deux outils:
- Rapports standard
- Rapports ad hoc
- Sortie de rapport et planification
- Découverte et visualisation des données
- Contrôle d'accès et sécurité
- Capacités mobiles

Cognos peut être considéré comme une solution robuste qui vous permet de créer une variété de rapports tels que des onglets croisés, des rapports actifs (dernière fonctionnalité de Cognos 10) et d'autres structures de rapports. Vous pouvez créer des invites utilisateur, la planification du rapport est facile et vous pouvez exporter et afficher des rapports dans différents formats. Microsoft BI offre une visualisation facile des données d'entreprise ainsi qu'une intégration facile avec Microsoft Excel.
IBM Cognos vs SAP Business Objects
SAP BO prend en charge son propre outil ETL SAP Data Services. IBM Cognos ne prend pas en charge son propre outil ETL. IBM Cognos 8 ne fournit pas de fonctionnalités de rapport hors ligne, mais il est présent dans les outils de rapport SAP Business Objects.
Dans Cognos, toute la fonctionnalité est divisée en plusieurs outils Query Studio, Analysis Studio, Event Studio, etc. C'est une tâche difficile d'apprendre tous les outils. Dans SAP Business Objects, vous disposez de plusieurs outils tels que Web Intelligence pour la création de rapports, IDT pour Universe Designer, Dashboard Designer afin que les utilisateurs aient le sentiment qu'il est difficile de gérer et d'apprendre tous les outils.
Dans IBM Cognos, les données générées peuvent être transformées dans différents formats (par exemple, HTML, PDF, etc.) et peuvent également être consultées à partir de plusieurs emplacements (e-mail, mobile, bureau, etc.). IBM fournit plusieurs fonctionnalités de planification telles que les prévisions, les budgets, la modélisation de scénarios avancés, etc. La sélection de l'outil BI dépend de divers facteurs tels que les besoins de l'entreprise, la version du logiciel, les fonctionnalités prises en charge et le coût de la licence.
Différents composants de Cognos communiquent entre eux à l'aide du bus BI et sont connus sous le nom de protocole SOAP (Simple Object Access Protocol) et prennent en charge WSDL. Le bus BI dans l'architecture Cognos n'est pas un composant logiciel mais consiste en un ensemble de protocoles permettant la communication entre Cognos Services.
Les processus activés par le protocole BI Bus comprennent:
- Messagerie et répartition
- Traitement des messages du journal
- Gestion des connexions à la base de données
- Interactions avec Microsoft .NET Framework
- Utilisation du port
- Demande de traitement de flux
- Pages du portail
Lorsque vous installez Cognos 8 à l'aide de l'assistant d'installation, vous spécifiez où installer chacun de ces composants -
Passerelles
Le niveau Serveur Web Cognos 8 contient une ou plusieurs passerelles Cognos 8. La communication Web dans Cognos 8 se fait généralement via des passerelles, qui résident sur un ou plusieurs serveurs Web. Une passerelle est une extension d'un programme de serveur Web qui transfère des informations du serveur Web à un autre serveur. La communication Web peut également avoir lieu directement avec un répartiteur Cognos 8, mais cette option est moins courante.
Cognos 8 prend en charge plusieurs types de passerelles Web, notamment:
- CGI- La passerelle par défaut, CGI peut être utilisée pour tous les serveurs Web pris en charge. Toutefois, pour des performances ou un débit améliorés, vous pouvez choisir l'un des autres types de passerelle pris en charge.
- ISAPI- Cela peut être utilisé pour le serveur Web Microsoft Internet Information Services (IIS). Il offre des performances plus rapides pour IIS.
- apache_mod - Vous pouvez utiliser une passerelle apache_mod avec le serveur Web Apache.
- Servlet - Si votre infrastructure de serveur Web prend en charge les servlets ou si vous utilisez un serveur d'applications, vous pouvez utiliser une passerelle de servlet.
Composants d'application
Ce composant se compose d'un répartiteur chargé d'exploiter les services et d'acheminer les demandes. Le répartiteur est une application multithread qui utilise un ou plusieurs threads par demande. Les modifications de configuration sont communiquées régulièrement à tous les répartiteurs en cours d'exécution. Ce répartiteur inclut Cognos Application Firewall pour assurer la sécurité de Cognos 8.
Le répartiteur peut acheminer les demandes vers un service local, tel que le service de rapport, le service de présentation, le service de travail ou le service de surveillance. Un répartiteur peut également acheminer les demandes vers un répartiteur spécifique pour exécuter une demande donnée. Ces demandes peuvent être acheminées vers des répartiteurs spécifiques en fonction des besoins d'équilibrage de charge ou des exigences du package ou du groupe d'utilisateurs.
Gestionnaire de contenu
Content Manager contient Access Manager, le composant de sécurité principal de Cognos 8. Access Manager exploite vos fournisseurs de sécurité existants pour une utilisation avec Cognos 8. Il fournit à Cognos 8 un ensemble cohérent de fonctionnalités de sécurité et d'API, y compris l'authentification, l'autorisation et le chiffrement des utilisateurs. Il prend également en charge l'espace de noms Cognos.
Vous pouvez créer des rapports utilisateur interactifs dans Cognos Studio au-dessus de diverses sources de données en créant des connexions relationnelles et OLAP dans l'interface d'administration Web qui sont ensuite utilisées pour la modélisation des données dans Framework Manager, appelées packages. Tous les rapports et tableaux de bord créés dans Cognos Studio sont publiés sur Cognos Connection et sur le portail pour distribution. Le studio de rapports peut être utilisé pour exécuter le rapport complexe et pour afficher les informations de Business Intelligence ou cela peut également être consulté à partir de différents portails où ils sont publiés.
Cognos Connections permet d'accéder aux rapports, aux requêtes, aux analyses et aux packages. Ils peuvent également être utilisés pour créer des raccourcis de rapport, des URL et des pages et pour organiser les entrées et ils peuvent également être personnalisés pour une autre utilisation.

Connexion de différentes sources de données
Une source de données définit la connexion physique à une base de données et différents paramètres de connexion tels que le délai de connexion, l'emplacement de la base de données, etc. Une connexion à une source de données contient des informations d'identification et de connexion. Vous pouvez créer une nouvelle connexion à la base de données ou modifier une connexion à une source de données existante.
Vous pouvez également combiner une ou plusieurs connexions de source de données et créer des packages et les publier à l'aide du gestionnaire de cadre.
Mode de requête dynamique
Le mode de requête dynamique est utilisé pour fournir une communication à la source de données à l'aide de connexions XMLA / Java. Pour vous connecter à la base de données Relation, vous pouvez utiliser une connexion JDBC de type 4 qui convertit les appels JDBC dans un format spécifique au fournisseur. Il offre des performances améliorées par rapport aux pilotes de type 2 car il n'est pas nécessaire de convertir les appels en ODBC ou en API de base de données. Le mode de requête dynamique dans la connexion Cognos peut prendre en charge les types suivants de bases de données relationnelles:
- Microsoft SQL Server
- Oracle
- IBM DB2
- Teradata
- Netezza
Pour prendre en charge les sources de données OLAP, la connectivité Java / XMLA fournit un MDX optimisé et amélioré pour différentes versions et technologies OLAP. Le mode de requête dynamique de Cognos peut être utilisé avec les sources de données OLAP suivantes:
- Entrepôt d'informations commerciales SAP (SAP BW)
- Oracle Essbase
- Services d'analyse Microsoft
- IBM Cognos TM1
- Surveillance en temps réel d'IBM Cognos
Sources de données DB2
Le type de connexion DB2 est utilisé pour se connecter à DB2 Windows, Unix et Linux, Db2 zOS, etc.
Les paramètres de connexion courants utilisés dans la source de données DB2 comprennent:
- Nom de la base de données
- Timeouts
- Signon
- Chaîne de connexion DB2
- Séquence de classement
Création d'une connexion à une source de données dans IBM Cognos
Pour créer des modèles dans IBM Cognos Framework Manager, il est nécessaire de créer une connexion à la source de données. Lors de la définition de la connexion à la source de données, vous devez entrer les paramètres de connexion - emplacement de la base de données, délai d'expiration, connexion, etc.
Dans IBM Cognos Connection → cliquez sur le Launch IBM Cognos Administration

In the Configuration tab, click Data Source Connections. In this window, navigate to the New Data Source button.


Enter the unique connection name and description.
You can add a description related to the data source to uniquely identify the connection and click the next button.

Select the type of connection from the drop down list and click on the next button as shown in the following screenshot.

In the next screen that appears, enter the connection details as shown in the following screenshot.

You can use the Test connection to test the connectivity to the data source using connection parameters that you have defined. Click on the finish button once done.
Data Source Security Setup
Data Source Security can be defined using IBM Cognos authentication. As per the data source, different types of authentication can be configured in the Cognos connection −
No Authentication − This allows login to the data source without using any sign-on credentials. This type of connection doesn’t provide data source security in connection.
IBM Cognos Software Service Credential − In this type of a sign-on, you log in to the data source using a logon specified for the IBM Cognos Service and the user does not require a separate database sign-on. In a live environment, it is advisable to use individual database sign on.
External Name Space − It requires the same BI logon credentials that are used to authenticate the external authentication namespace. The user must be logged into the name space before logging in to the data source and it should be active.

All the data sources also support data source sign-on defined for everyone in the group or for individual users, group or roles. If the data source requires a data source sign-on, but you don't have the access to a sign-on for this data source, you will be prompted to log on each time you access the data source.
IBM Cognos also supports security at cube level. If you are using cubes, security may be set at the cube level. For Microsoft Analysis Service, security is defined at the cube level roles.
In this chapter, we will discuss how to create a package using COGNOS.
How to Create a Package?
In IBM Cognos, you can create packages for SAP BW or power cube data sources. Packages are available in the Public folder or in My folder as shown in the following screenshot.

Once a package is deployed, the default configuration is applied on the package. You can configure a package to use different settings or you can modify the settings of the existing package.
To configure a package, you should have administrator privilege.
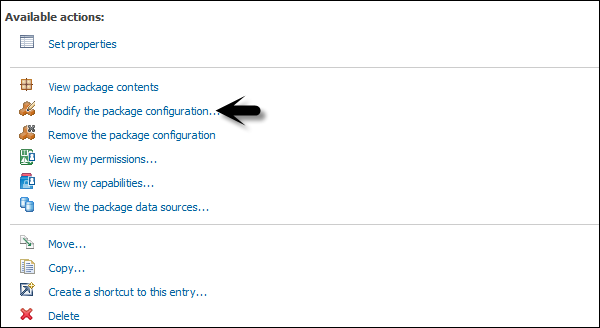
Locate the package in the Public folder, click on More button under the Action tab as shown in the following screenshot.

Click on Modify the package configuration and Click Select an analysis. Select the default analysis to be used for this package when a new analysis is created. Click OK and change the package settings as required and click Finish.
Creating a New Package
In the Package tab, Public folder, you can also create a new Package using the IBM Cognos connection.

Select the data source that you want to use in the package and click OK.
Scheduling Reports in IBM Cognos
You can also schedule the reports in IBM Cognos as per your business requirements. Scheduling a report allows you to save the refresh time. You can define various scheduling properties like frequency, time zone, start and end date, etc.
To schedule a report, select the report and go to More button as shown in the following screenshot.

You have an option to add a new schedule. Select the New Schedule button as shown in the following screenshot.
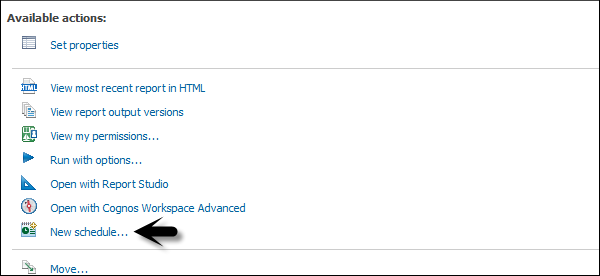
You can select the following options under the Schedule tab −
- Frequency
- Start and End
- Priority
- Daily Frequency, etc.
When the scheduling properties are defined, you can save it by clicking the OK button at the bottom. Disabling the Schedule options allows you to make the schedule inactive but the schedule will be saved for the report. You can remove this option any time to enable the schedule again.

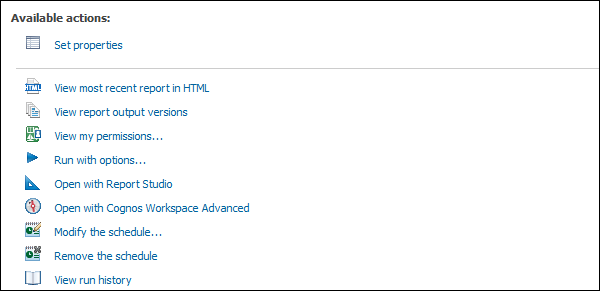
To edit an existing schedule, select the report and go to More. You can modify an existing schedule or remove the schedule permanently.
In this chapter, we will discuss regarding what a Framework Manager is and about its various other components.
What is a Framework Manager?
IBM Cognos Framework Manager is used to create business model of metadata derived from one or more data sources. It is a Windows based tool which is used to publish the business models to Cognos BI in the form of packages which can be used for analytical reporting and analysis.
Before you start a new project in Framework Manager, it is necessary that you go through BI reporting requirements that helps you to identify data strategies, metadata, report package delivery, etc. This helps you to identify which data sources are required in the Framework Manager to get the required data in the BI report. You should consider the following factors before starting a new project in the Framework manager.
- Data Sources required to meet BI needs.
- Types of DW system
- Data refresh in Data Warehouse
- BI Reporting- Daily, Weekly, or monthly.
Metadata Modeling
A Metadata model is defined as the collection of database objects (tables, columns and relationship between objects) imported from the database. When you run the report, metadata published in BI Cognos portal generates a SQL statement according to the query.

The IBM Cognos Framework manager can hide the complexity of data in the data source and also alter the way how data is shown to users. It provides a view that is easy for BI users to understand and perform analysis and reporting.
IBM Cognos Framework Manager User Interface
The following screenshot shows the IBM Cognos BI Framework Manager User Interface.

Following are the various components of the above screenshot that are explained in detail for better understanding −
Project Viewer − This pane on left side allows you to access all the existing projects in a tree format.
Project Info − This is the center pane that is used to manage objects of an existing project. This has three tabs: Explorer, Diagram and Dimension.
Properties − This pane at the bottom is used to set the value of different properties of an object in a project.
Tools − This pane on the right side provides you various important useful tools. You can perform a search, or display an object and its dependent objects, changing project language, etc.
Importing Metadata from a Relational Database
For importing Metadata from a Relational Database, you map the database objects to the Framework manager objects. In the Framework Manager, you can import all the objects or you can select particular objects like tables, columns, functions, stored procedures, views, etc.
Only user defined Stored procedures are supported.
| Database Objects | Framework Manager Objects |
|---|---|
| Column | Query Item |
| View | Query Subject |
| Synonym | Query Subject |
| Procedure | Query Subject |
| Table | Query Subject |
| Function | Project Function |
To create a metadata model, run metadata wizard from the Action menu. Select a data source connection and click the Next button. Select the check boxes for the objects you want to import.
Specify how the import should handle duplicate object names. Choose either to import and create a unique name, or not to import. If you choose to create a unique name, the imported object appears with a number.
For example − When you see QuerySubject and QuerySubject1 in your project. Then click Import.

Import statistics including a list of objects that could not be imported and a count of objects that were imported are shown.
The next step is to click on the Finish button.
After importing Metadata, you must check the imported Metadata for the following areas −
- Relationships and Cardinality
- Determinants
- Usage property for query items
- Regular Aggregate property for query items
Importing Metadata from Cognos 8 Model
In the Framework Manager, you can also import metadata from an existing Cognos 8 Model. To import Metadata from the Cognos 8 model, go to Actions → Run Metadata wizard.
Click on the Cognos 8 Model and then the Next button. Navigate to the .cpf file from Cognos 8 Model and the click on Next.
Select the check boxes for objects you want to import and then click on Next and then on Finish.
Modeling Relational Metadata
Once you import the metadata, next is to validate the objects for reporting requirement. You can select the objects that appear in the report and test them. You can create two views of the Metadata Model −
- Import View
- Business View
The Import view shows you the metadata imported from the data source. To validate the data as per your BI reporting, you can perform the following steps −
Ensure that the relationships reflect the reporting requirements.
Optimize and customize the data retrieved by the query subjects.
Optimize and customize the data retrieved by dimensions. You may want to store dimensions in a separate dimensional view.
Handle support for multilingual metadata.
Control how data is used and formatted by checking query item properties.
Business view is used to provide the information in metadata. You can perform calculations, aggregations and apply filters in Business view and easily allow users to build the report. You can add business rules such as custom calculations and filters that define the information users can retrieve.
Organize the model by creating separate views for each user group that reflect the business concepts familiar to your users.
Relationships are used to create queries on multiple objects in a metadata model. Relationships can be bidirectional and without creating relationship, objects are individual entities with no use in metadata model.
Each object in metadata model is connected using primary or foreign key in the data source. You can create or remove relationships in the metadata model to meet the business requirements.
There are different relationships which are possible, some of them are −
One to One − When an instance of one query subject is related to another instance. For example: Each customer has one customer id.
One to Many − This relationship occurs when one instance of query subject relates to multiple instances. For example: Each doctor has many patients.
Many to Many − This relationship occurs when many instances of a query subject relates to multiple instances. For example: Each patient has many doctors.
Cardinality Concept
It is defined as the number of related rows for each of the two query subjects. Cardinality is used in the following ways −
- Loop Joins in Star schema
- Optimized access to data source
- Avoid double counting fact data
While using the Relational database as a data source, Cardinality can be defined considering the following rules −
- Primary and Foreign keys
- Match query item names represent uniquely indexed columns
- Matching query item names
The most common ways to define Cardinality is by using the primary and foreign key. To view the key information that was imported, right click on the query subject → Edit Definition. You can import many to many relationships, optional relationships, and outer joins from the data source.
Relationship Notation in Metadata Model
In the Framework manager, a relation is represented by Merise notation. The first part of this notation represents the type of join for this relationship.
- 0..1 represents zero or one match
- 1..1 represents one to one match
- 0..n represents Zero or no matches
- 1..n represents One or more matches
- 1 − An inner join with all matching rows from both objects.
- 0 − An Outer join with all objects from both, including the items that don’t match.
Creating or Modifying the Relationships
To create a Relationship or to combine logically related objects which are not joined in metadata import. You can manually create relationship between objects or can automatically define relationship between objects based on selected criteria.
To create a Relationship, use CTRL key to select one or more query items, subjects or dimensions. Then go to Action Menu → Create Relationship.
If this is a valid Relationship, the Framework manager wants to create a shortcut to the relationship. You can then click on the OK button.

Once you create a relationship after the metadata import, you can also modify the relationship or Cardinality in the Framework manager.
To edit a Relationship, click a relationship and from Action menu → click Edit Definition.
From the Relationship Expression tab → Select Query items, Cardinalities and Operators.

To create an additional Join, go to the Relationship Expression tab → New Link and Define New Relationship.
To test this Relationship, go to Relationship SQL tab → rows to be returned → Test.

Click on OK button.
Creating a Relationship Shortcut
A Relationship shortcut is defined as the pointer to an existing relationship and to reuse the definition of an existing relationship. When you make any change to the source Relationship, they are automatically updated in shortcuts. Relationship shortcuts are also used to resolve ambiguous relationship between query subjects.
The Framework Manager asks whether you want to create a relationship shortcut whenever you create a relationship and both these conditions are true.
- At least one end for the new relationship is a shortcut.
- A relationship exists between the original objects.
Go to Action Menu → Create Relationship.
If this is a valid Relationship, Framework manager wants to create a shortcut to the relationship. Click YES. A list appears of all relationships in which one end is a model object and the other end is either another model object or a shortcut to another model object.
Click OK.
Create a Query Subject
A query subject is defined as a set of query items that have an inherent relationship. A query subject can be used to customize the data they retrieve using a Framework Manager.
The following are the query subject types in a Framework Manager −
Data Source Query Subject − These are based on the Relational metadata defined by the SQL statements and are automatically created for each table and view when you import metadata into model.
Note − The data source query subject references the data from only one data source at a time, but you can directly edit the SQL that defines the retrieve data to edit the query subject.
Model Query Subjects − They are not directly created from a data source but are based on the query items defined in other query subjects or dimensions. Using the model query subject, it allows you to create more abstract and business view of data source.
Stored Procedure Query Subjects − They are created when a Procedure is imported from a Relational data source. IBM Cognos Framework Manager only supports user defined Stored Procedures and system stored procedures are not supported.

Comment créer un sujet de requête de source de données?
De Actions Menu → Create → Query Subject.
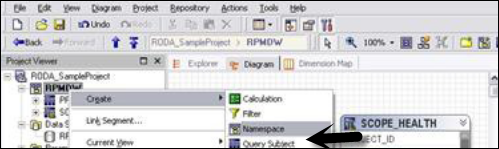
Entrez le nom d'un nouvel objet de requête.
Cliquer sur Data Source → OK to open new Query Subject wizard.

Suivez les étapes jusqu'à ce que le bouton Terminer apparaisse → Terminer
Faites un clic droit sur Query Subject → Edit Definition. Clique sur leSQL tab → Available database objects box, drag objects to the SQL box.
Vous pouvez également insérer une référence de source de données, insérer une macro, incorporer un calcul et incorporer un filtre.
Sélectionnez les actions dans la liste et cliquez sur OK.

| Objectif | action |
|---|---|
| Contrôle de la granularité | Onglet Déterminants |
| Pour tester le sujet de la requête | Onglet Test |
| Pour afficher SQL | Onglet Informations sur la requête |
| Pour afficher les tables système à partir de la source de données | Case à cocher Afficher les objets système |
Modifier SQL
Lorsque vous modifiez une source de base de données Relation, créez ou interrogez une base de données Relation, SQL est utilisé en arrière-plan. Vous pouvez utiliser les options suivantes -
- Cognos SQL
- SQL natif
- Passer par SQL
Pour modifier le SQL du sujet de requête de modèle, copiez le SQL de l'onglet Informations de requête et collez-le dans le nouveau sujet de requête de source de données. Il est possible de convertir un sujet de requête de modèle en sujet de requête de source de données.
- Cliquez sur Objet de la requête de la source de données et Action menu → Edit Definition.
- Cliquez sur le bouton SQL, faites glisser les objets ou tapez SQL que vous voulez.
- Cliquez sur OK.

Changer le type de SQL
Vous pouvez sélectionner le type de SQL à utiliser lorsque vous définissez le sujet de requête de source de données. Ces facteurs doivent être pris en compte lors de l'examen du type de SQL -
| Type SQL | Avantage | Désavantage |
|---|---|---|
| Cognos SQL | Performance améliorée Travailler sur toutes les bases de données prises en charge |
SQL non standard non pris en charge |
| SQL natif | Optimisation des performances Spécifique à la base de données |
SQL ne fonctionne pas sur une base de données différente. Vous ne pouvez pas utiliser SQL que la source de données ne prend pas en charge pour les sous-requêtes. |
| Passer par SQL | Tout SQL pris en charge par la base de données | Aucune option pour Framework Manager à optimiser performances automatiquement |
Notez également qu'il n'est pas possible de modifier le type de SQL pour les sujets de requête en fonction des sources de données OLAP.
Pour modifier le type SQL, accédez à Sujet de la requête que vous souhaitez modifier.
Aller à Actions menu → Edit Definition and go to Query Information button.

Aller à Options → SQL Settings tab.
Pour changer le type de SQL, cliquez sur Liste des types de SQL. Cliquez ensuite sur OK.
Query Studio est défini comme un outil Web permettant de créer des requêtes et des rapports dans Cognos 8. Il est également utilisé pour exécuter des requêtes et des rapports simples.
Dans Query Studio, les fonctions suivantes peuvent être exécutées -
Viewing Data- À l'aide de Query Studio, vous pouvez vous connecter à la source de données pour afficher les données dans une arborescence. Vous pouvez voir le sujet de la requête, les détails de l'élément de requête, etc.
Creating BI Reports- Vous pouvez utiliser Query Studio pour créer des rapports simples en utilisant la source de données. Vous pouvez également faire référence à des rapports existants pour créer un nouveau rapport.
Changing Existing Reports - Vous pouvez également modifier les rapports existants en modifiant la mise en page du rapport - Ajouter des graphiques, des titres, des en-têtes, des styles de bordure, etc.
Data Customization in Report - Vous pouvez appliquer diverses personnalisations dans les rapports - Filtres, calculs et agrégations pour effectuer l'analyse des données, explorer en avant et en arrière, etc.
À l'aide de rapports ad hoc, un utilisateur peut créer des requêtes ou des rapports pour une analyse ad hoc. La fonction de création de rapports ad hoc permet aux utilisateurs professionnels de créer des requêtes et des rapports simples en haut du tableau des faits et des dimensions dans l'entrepôt de données.
Query Studio dans Cognos BI propose les fonctionnalités suivantes:
- Affichez les données et effectuez une analyse de données ad hoc.
- Enregistrez le rapport pour une utilisation future.
- Utilisez les données du rapport en appliquant des filtres, des résumés et des calculs.
- Pour créer un rapport ad hoc à l'aide de query studio, connectez-vous au logiciel IBM Cognos et cliquez sur Interroger mes données.

Sélectionnez le package de rapports. La prochaine fois que vous visiterez cette page; vous verrez votre sélection sous les packages récemment utilisés. Cliquez sur le nom du package.

Dans l'écran suivant, vous pouvez ajouter des éléments de dimension, des filtres et des invites, des faits et des calculs, etc.

Vous devez insérer les objets dans cet ordre. Pour insérer un objet dans le rapport, vous pouvez utiliser le bouton Insérer en bas.
- Insérer et filtrer des éléments de dimension
- Insérer des filtres et des invites
- Insérer des faits et des calculs
- Appliquer les touches de finition
- Enregistrez, exécutez, collaborez et partagez
En haut, vous avez la barre d'outils, où vous pouvez créer un nouveau rapport, enregistrer un rapport existant, couper, coller, insérer des graphiques, explorer de haut en bas, etc.

Lorsque vous insérez tous les objets dans un rapport, vous pouvez cliquer sur l'option Exécuter (

Vous pouvez utiliser différents types de rapport dans Cognos Query Studio pour répondre aux besoins de l'entreprise. Vous pouvez créer les types de rapport suivants dans Query Studio -
List Reports - Ces rapports sont utilisés pour afficher l'ensemble de votre clientèle, comme indiqué dans la capture d'écran suivante.
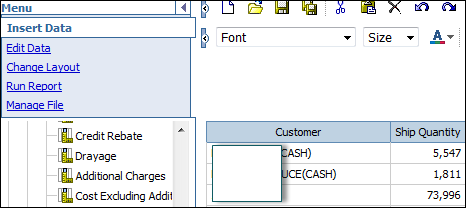
Crosstab Reports - Ils sont utilisés pour afficher la quantité vendue avec le produit et la région sur différents axes.
Charts- Vous pouvez insérer des graphiques pour afficher les données graphiquement. Vous pouvez combiner un graphique avec un tableau croisé ou également avec un rapport de liste.
Vous pouvez créer un nouveau rapport en insérant des objets de la source de données dans Query Studio. Vous pouvez également modifier un rapport existant et l'enregistrer sous un nom différent.
Vous pouvez ouvrir Query Studio en accédant à l'option Interroger mes données sur la page d'accueil ou en accédant à Launch → Query Studio.

Dans l'écran suivant, vous serez invité à sélectionner un package pour ajouter des objets dans les rapports. Vous pouvez sélectionner un package récemment utilisé ou tout autre package créé dans Framework Manager.

Vous pouvez voir les éléments de requête répertoriés sur le côté gauche. Vous pouvez ajouter des données et enregistrer le rapport.

Vous pouvez ouvrir un rapport existant dans Query Studio et l'enregistrer sous un nom différent après avoir effectué des modifications.
Pour ouvrir un rapport existant, recherchez et cliquez sur le nom du rapport que vous souhaitez ouvrir.
Le rapport s'ouvre dans Query Studio. Vous pouvez utiliser Ouvrir avec Query Studio

Ou vous pouvez lancer Query Studio et ouvrir l'option en haut.
Rechercher le rapport dans la liste des dossiers disponibles → OK

Vous pouvez ajouter des objets à partir d'une source de données. Chaque objet possède une icône représentative et peut insérer tous les objets suivants dans un rapport.


Lorsque vous enregistrez un rapport dans Query Studio, il enregistre la définition de requête. Il n'enregistre pas les données lors de l'enregistrement du rapport. Lorsque vous exécutez un rapport enregistré il y a une semaine, les données de ce rapport reflètent les modifications récentes de la source de données.
Pour enregistrer un rapport, cliquez sur l'icône Enregistrer en haut.

Dans l'écran suivant, entrez le nom, la description et l'emplacement où vous souhaitez enregistrer le rapport → OK.

Enregistrer un rapport avec un nom et un emplacement différents
Vous pouvez utiliser l'option Enregistrer sous pour enregistrer un rapport avec un nom différent ou à un emplacement différent, comme illustré dans la capture d'écran suivante.

Specify a name and location - Pour inclure une description, saisissez les informations que vous souhaitez ajouter dans la zone Description.
Cliquez sur OK.
Un rapport dans Query Studio s'exécute lorsque vous mettez à jour des données à partir de la source de données dans le rapport. Lorsque vous ouvrez un rapport existant ou apportez des modifications à un rapport, Query Studio exécute à nouveau le rapport.
Vous pouvez utiliser les options suivantes pour exécuter un rapport -
Run with Prompt- Vous pouvez exécuter un rapport à l'aide d'une invite utilisateur. Lorsque vous exécutez le rapport, vous êtes invité à sélectionner la valeur.
Run with all Data- La commande Exécuter avec toutes les données exécute le rapport en utilisant la source de données complète. L'exécution d'un rapport peut prendre du temps. Si vous prévoyez d'apporter plusieurs modifications à un rapport, exécutez le rapport en mode aperçu pour économiser du temps et des ressources informatiques en limitant les lignes de données que votre rapport récupère.
Preview Report with no Data- Vous pouvez utiliser l'option d'aperçu lorsque vous souhaitez voir à quoi ressemblera le rapport. Ceci est utile lorsque vous souhaitez apporter des modifications de mise en forme.
Ouvrez le rapport souhaité dans Query Studio. Dans le menu Exécuter le rapport, choisissez comment exécuter le rapport -
Pour exécuter le rapport en utilisant toutes les données, cliquez sur Exécuter avec toutes les données, comme illustré dans la capture d'écran suivante.

Pour exécuter le rapport en utilisant des données limitées, cliquez sur Aperçu avec des données limitées.
Si le package sur lequel le rapport est basé contient un filtre de conception, les performances sont améliorées.
Pour exécuter le rapport sans données, cliquez sur Aperçu sans données.
Exécuter un rapport au format PDF, XML et CSV
Vous pouvez exécuter un rapport au format PDF, XML ou au format CSV. Pour exécuter un rapport dans différents formats, sélectionnez le rapport et cliquez sur Exécuter avec les options.

Sélectionnez le format dans lequel vous souhaitez exécuter le rapport. Vous pouvez choisir parmi les formats suivants. Sélectionnez le format et cliquez sur Exécuter en bas comme indiqué dans la capture d'écran suivante.
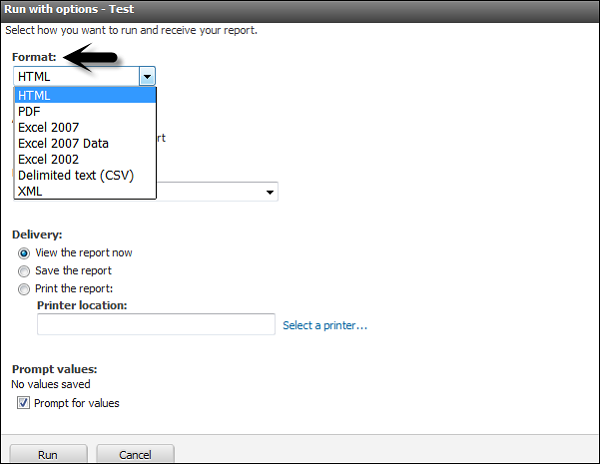
Vous pouvez également imprimer un rapport pour en obtenir une copie sur papier. Vous pouvez entrer directement l'emplacement de l'imprimante lors de l'exécution du rapport ou vous pouvez exécuter le rapport au format PDF et plus tard, vous pouvez imprimer le rapport.
Pour prendre directement l'impression du rapport, sélectionnez le rapport et cliquez sur Exécuter avec options.
Dans le mode de livraison, sélectionnez imprimer le rapport et entrez l'emplacement comme indiqué dans la capture d'écran suivante.

Report Studio est un outil Web utilisé par les développeurs de rapports pour créer plusieurs pages, des rapports complexes en plus de plusieurs sources de données. Vous pouvez créer des rapports de ventes, des rapports d'inventaire, des relevés de compte, des bilans, etc.
Comment créer un rapport dans Report Studio?
Pour créer des rapports dans Report Studio, vous devez avoir une bonne compréhension de l'interface utilisateur. L'interface utilisateur de Report Studio est divisée en deux parties -
- Barre d'explorateur sur le côté gauche.
- Zone de travail pour la conception de rapports.

La capture d'écran ci-dessus comporte trois blocs principaux, qui sont les suivants -
Insertable Object Pane- Le volet Objets insérables contient des objets que vous pouvez ajouter à un rapport. Ces objets peuvent être ajoutés en les faisant glisser vers la zone de travail. Il peut contenir -
Onglet Source (qui contient l'élément du package).
Éléments de données (requêtes créées dans le rapport).
Boîte à outils (différents objets comme des graphiques qui peuvent être ajoutés au rapport)
Properties Pane- Le volet Propriétés répertorie les propriétés que vous pouvez définir pour un objet dans un rapport. Pour obtenir de l'aide, sélectionnez la propriété et utilisez la touche F1 du clavier.
Work Area - La zone de travail est appelée zone où le rapport est conçu.
Comment ouvrir Report Studio?
Sur la page d'accueil, accédez à Launch → Report Studio → Select a Package ou dans la page d'accueil d'IBM Cognos, cliquez sur Créer des rapports avancés pour ouvrir Report Studio.


Sur l'écran d'accueil de Report Studio, vous avez la possibilité de créer un nouveau rapport ou d'ouvrir un rapport existant.

Vous serez invité à sélectionner le type de rapport que vous souhaitez créer. Vous avez la possibilité de sélectionner différents types de rapports.
Dans Report Studio, vous pouvez créer différents types de rapports. Ils vous permettent de présenter les données dans différents formats, comme un rapport de liste peut être utilisé pour afficher les informations client.
The following reports can be created in Report Studio -
Rapport de liste
Ce rapport est utilisé pour afficher les données dans un format détaillé. Les données sont affichées dans des lignes et des colonnes et chaque colonne contient toutes les valeurs d'un élément de données.
| Trimestre | Numéro de commande | Quantité | Revenu |
|---|---|---|---|
| T4 | 101035 | 105 | 4 200,00 $ |
| 101037 | 90 | 8 470,80 $ | |
| 101044 | 124 | 11 479,92 $ | |
| 101052 | 193 | 15 952,42 $ | |
| 101064 | 58 | 5 458,96 $ | |
| 101065 | 78 | 7 341,36 $ | |
| 101081 | 145 | 5 800,00 $ | |
| 101092 | 81 | 7 623,72 $ | |
| 101093 | 50 | 4 706,00 $ | |
| 101103 | 139 | 5 560,00 $ |
Tableau croisé
Comme le rapport de liste, un rapport à onglets croisés affiche également les données en ligne et en colonnes, mais les données sont compactes et non détaillées. Aux points d'intersection des lignes et des colonnes, vous affichez les données résumées.

Graphique
Vous pouvez utiliser Report Studio pour créer de nombreux types de graphiques, notamment des graphiques à colonnes, à barres, à aires et à courbes. Vous pouvez également créer des graphiques personnalisés qui combinent ces types de graphiques.
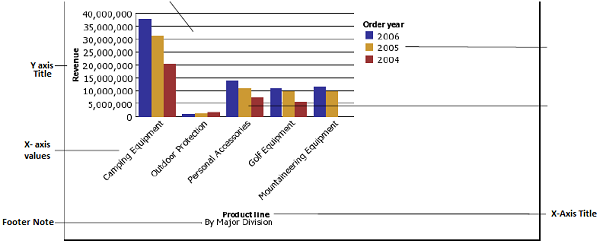
Carte
Vous pouvez également utiliser des cartes dans Report Studio pour présenter des données pour une région, un pays ou un emplacement particulier.
A map report consists of three parts -
- Couche de région
- Couche de points
- Afficher le calque

Répétiteur
Les répéteurs sont utilisés pour ajouter des éléments répétés dans un rapport lors de l'exécution du rapport. Pour ajouter un répéteur, faites glisser un répéteur de la boîte à outils vers la zone de travail.

Un rapport de liste qui affiche les données dans des lignes et des colonnes et chaque cellule affiche les données de la base de données ou vous pouvez également ajouter des calculs personnalisés dans un rapport de liste.
Pour créer un nouveau rapport de liste, accédez à Nouveau → Vide comme indiqué dans la capture d'écran suivante.
Lorsque vous sélectionnez un rapport de liste, vous obtenez la structure suivante du rapport dans Report Studio. Vous devez faire glisser les objets du package sur le côté gauche vers la structure du rapport.
Vous pouvez également modifier le titre du rapport qui apparaîtra une fois le rapport exécuté.

Vous pouvez utiliser différents outils en haut pour la mise en forme du rapport. Pour enregistrer un rapport, cliquez sur le bouton Enregistrer. Pour exécuter un rapport, cliquez sur Exécuter le

Une fois que vous avez enregistré le rapport, vous avez la possibilité de l'enregistrer dans le dossier Public ou Mon dossier.

Lorsque vous cliquez sur l'option Exécuter, vous pouvez sélectionner différents formats pour exécuter le rapport.



Vous serez invité à sélectionner le type de rapport que vous souhaitez créer. Vous avez la possibilité de choisir parmi différents types de rapports.
Sélectionnez Tableau croisé comme type de rapport et cliquez sur OK.
La structure d'un rapport Crosstab s'ouvre comme illustré dans la capture d'écran suivante.

Dans le volet Objets insérables, sous l'onglet Source, cliquez sur l'élément de données que vous souhaitez ajouter au tableau croisé et faites-le glisser vers les lignes ou les colonnes.

Une barre noire indique où vous pouvez déposer l'élément de données. Répétez les étapes ci-dessus pour insérer des éléments de données supplémentaires.
Vous ajoutez des dimensions aux lignes ou aux colonnes et pour ajouter des mesures au tableau croisé, faites glisser les mesures souhaitées vers Mesures.

Lorsque vous exécutez le rapport, un rapport de tableau croisé est généré avec un bord.
Formatage d'un tableau croisé
Vous pouvez également formater le tableau croisé pour lui donner l'apparence selon l'exigence. Lorsque vous spécifiez la mise en forme de toutes les lignes, colonnes, cellules de faits ou du tableau croisé, la mise en forme est automatiquement appliquée à tous les nouveaux éléments que vous ajoutez.
Ordre des styles de tableau croisé
Lorsque vous appliquez des styles tels que la couleur de la police, les lignes et les colonnes, les intersections sont appliquées dans l'ordre suivant.
- Cellules de faits du tableau croisé
- Cellules de faits dans les rangées les plus externes
- Cellules de faits dans les rangées les plus internes
- Cellules de faits dans les colonnes les plus externes
- Cellules de faits dans les colonnes les plus internes
- Intersections de tableaux croisés
Pour mettre en forme le tableau croisé, cliquez n'importe où dans le tableau croisé. Cliquez sur le bouton Sélectionner l'ancêtre dans la barre de titre du volet Propriétés, puis sur Tableau croisé comme illustré dans la capture d'écran suivante.

Dans le volet Propriétés, cliquez sur la propriété souhaitée, puis spécifiez une valeur. Par exemple, si vous souhaitez spécifier une couleur d'arrière-plan, cliquez sur Couleur d'arrière-plan et choisissez la couleur que vous souhaitez utiliser.

Vous pouvez également cliquer avec le bouton droit sur la ligne ou la colonne et cliquer sur Sélectionner les cellules de faits des membres. Dans le volet Propriétés, cliquez sur la propriété souhaitée, puis spécifiez une valeur.
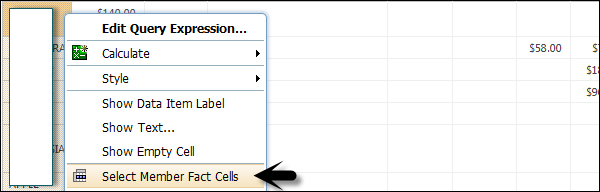
Dans Report Studio, vous pouvez créer de nombreux types de graphiques tels que des graphiques à colonnes, à barres, à aires, à courbes ou un graphique personnalisé qui combine ces types de graphiques.


Dans l'onglet Source, développez la requête.
- Faites glisser Revenue vers la zone de dépôt Mesure (axe y).
- Faites glisser Année en cours vers la zone de dépôt Série.
- Faites glisser Ordre vers la zone de dépôt Catégories (axe des x).

Faites glisser les objets comme indiqué dans la capture d'écran ci-dessus.

Enregistrez le graphique en utilisant la barre d'outils en haut. Enregistrez-le dans Public ou My Folder comme indiqué dans la rubrique précédente. Exécutez le rapport pour voir le résultat dans un format de graphique.
Vous pouvez également créer une table Répéteur ou un rapport cartographique dans Cognos Report Studio.
Plusieurs fonctions de rapport peuvent être utilisées dans un rapport Cognos.
Certaines de ces différentes fonctions de rapport incluent:
_jours_entre
Cette fonction est utilisée pour renvoyer un nombre positif ou négatif représentant le nombre de jours entre les deux expressions datetime. Si une exp_horodatage1 <exp_horodatage2, le résultat sera un nombre –ve.
Comment utiliser
_days_between(timestamp_exp1, timestamp_exp2)_days_to_end_of_month
Cette fonction est utilisée pour renvoyer un nombre représentant le nombre de jours restants dans le mois représenté par l'expression datetime timestamp_exp.
Comment utiliser
_days_to_end_of_month(timestamp_exp)_premier_du_mois
Cette fonction est utilisée pour renvoyer une date / heure qui est le premier jour du mois représenté par timestamp_exp.
_add_days
Cette fonction est utilisée pour renvoyer le datetime résultant de l'ajout de jours integer_exp à timestamp_exp.
Comment utiliser
_add_days(timestamp_exp, integer_exp)_add_months
Cette fonction est utilisée pour renvoyer le datetime résultant de l'ajout de mois integer_exp à timestamp_exp.
Comment utiliser
_add_months(timestamp_exp, integer_exp)_add_years
Cette fonction est utilisée pour renvoyer la date / heure résultant de l'ajout d'années integer_exp à timestamp_exp.
Comment utiliser
_add_years(timestamp_exp, integer_exp)_âge
Cette fonction est utilisée pour renvoyer un nombre obtenu en soustrayant exp_horodatage de la date du jour au format AAAAMMJJ (années, mois, jours).
Comment utiliser
_age(timestamp_exp)_jour de la semaine
Cette fonction est utilisée pour renvoyer le jour de la semaine (entre 1 et 7), où 1 est le premier jour de la semaine comme indiqué par integer_exp (entre 1 et 7, 1 étant lundi et 7 étant dimanche). Notez que dans la norme ISO 8601, une semaine commence par le lundi étant le jour 1. En Amérique du Nord où le dimanche est le premier jour de la semaine étant le jour 7.
Comment utiliser
_day_of_week(timestamp_exp, integer_exp)_day_of_year
Cette fonction est utilisée pour renvoyer l'ordinal du jour de l'année dans date_ exp (1 à 366). Aussi connu sous le nom de jour julien.
Comment utiliser
_day_of_year(timestamp_exp)Comme ceux-ci, il existe également diverses autres fonctions de rapport qui peuvent être utilisées.
Ceci est utilisé pour garantir que votre rapport ne contient aucune erreur. Lorsqu'un rapport créé dans l'ancienne version de Cognos est mis à niveau, il est automatiquement validé.
Pour valider un rapport, allez dans le menu Outils et cliquez sur le bouton Valider comme indiqué dans la capture d'écran suivante.


Il existe différents niveaux de validation -
Error - Pour récupérer toutes les erreurs renvoyées par la requête.
Warning - Pour récupérer toutes les erreurs et avertissements renvoyés par la requête.
Key Transformation - Pour récupérer les étapes de transformation importantes.
Information - Pour récupérer d'autres informations relatives à la planification et à l'exécution des requêtes.

Vous pouvez exécuter le rapport avec différentes options. Pour définir les options du rapport, accédez aux options d'exécution.
You get different options -
Format - Vous pouvez sélectionner un format différent.

To select Paper size - Vous pouvez choisir parmi différents formats de papier, orientation.
Select Data mode - Toutes les données, données limitées et aucune donnée.
Language - Sélectionnez la langue dans laquelle vous souhaitez exécuter le rapport.
Lignes par page et option d'invite, etc.

L'administration des rapports vous permet d'accorder des autorisations à différents utilisateurs au niveau du rapport. Vous pouvez définir diverses autres propriétés telles que les versions de sortie, les autorisations, les propriétés générales, etc.
Pour ouvrir les propriétés du rapport et l'onglet des autorisations, accédez à Plus d'options sur la page d'accueil d'IBM Cognos.

Vous pouvez sélectionner les actions suivantes dans plus d'options -
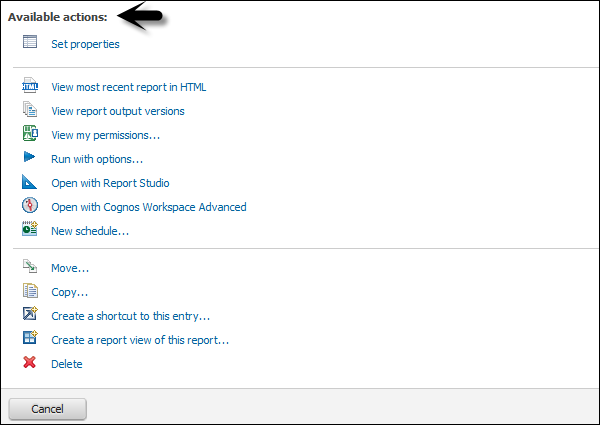
Dans l'onglet d'autorisation, vous pouvez spécifier les autorisations d'accès pour cette entrée. Par défaut, une entrée acquiert ses autorisations d'accès auprès d'un parent. Vous pouvez remplacer ces autorisations avec les autorisations définies explicitement pour cette entrée.

Vous pouvez également déplacer, copier ou supprimer un rapport dans Plus d'options. Vous pouvez créer une entrée de raccourci ou une vue de rapport du rapport.
Les filtres sont utilisés pour limiter les données que vous souhaitez dans votre rapport. Vous pouvez appliquer un ou plusieurs filtres dans un rapport Cognos et le rapport renvoie les données qui remplissent les conditions de filtre. Vous pouvez créer divers filtres personnalisés dans un rapport selon l'exigence.
- Sélectionnez la colonne sur laquelle filtrer.
- Cliquez sur la liste déroulante du bouton Filtrer.
- Choisissez Créer un filtre personnalisé.
- La boîte de dialogue Condition de filtre s'affiche.

Dans la fenêtre suivante, définissez les paramètres du filtre.
Condition - cliquez sur la flèche de la liste pour voir vos choix (Afficher ou Ne pas afficher les valeurs suivantes).
Values - cliquez sur la flèche de la liste pour voir vos choix.
Keywords - vous permet de rechercher des valeurs spécifiques dans la liste de valeurs.
Values List- affiche les valeurs de champ que vous pouvez utiliser comme valeurs de filtre. Vous pouvez en sélectionner un ou plusieurs. Utilisez le bouton fléché pour ajouter plusieurs valeurs.
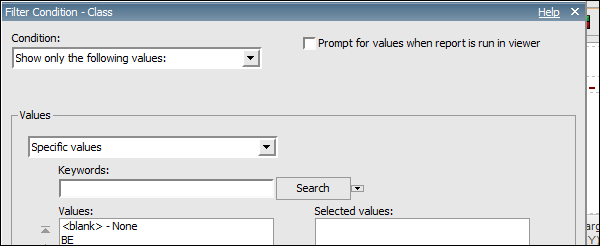
Sélectionnez une valeur et cliquez sur la flèche pointant vers la droite pour déplacer la valeur dans la colonne sélectionnée. Vous pouvez utiliser la touche Ctrl pour ajouter plusieurs valeurs à la fois. Cliquez sur OK lorsque le filtre est défini.
Note- Vous pouvez afficher les filtres dans la page Explorateur de requêtes et non dans l'explorateur de pages. Vous pouvez accéder à l'explorateur de requêtes et afficher les filtres.

Supprimer un filtre
Un filtre peut être supprimé en suivant les étapes suivantes -
Accédez à l'explorateur de requêtes comme indiqué dans la capture d'écran ci-dessus
Cliquez sur Requête et localisez le volet Filtres détaillés dans le coin supérieur droit de la fenêtre, comme indiqué dans la capture d'écran ci-dessus
Sélectionnez le filtre que vous souhaitez supprimer et appuyez sur le bouton Supprimer
Vous pouvez également couper / copier un filtre

Vous pouvez ajouter des calculs personnalisés à votre rapport selon les besoins de l'entreprise. Avec l'aide des opérateurs, différents calculs peuvent être ajoutés comme si vous souhaitez ajouter une nouvelle valeur de salaire * 0,2 en bonus.
Pour créer des calculs dans un rapport -
- Sélectionnez l'élément dans le rapport.
- Cliquez sur le bouton Insérer un calcul et sélectionnez le calcul à effectuer.
Note - Les calculs qui ne s'appliquent pas aux éléments que vous avez sélectionnés sont grisés.

Pour modifier l'ordre des opérandes ou le nom de l'élément calculé ajouté au rapport, cliquez sur Personnalisé. Le calcul apparaît sous forme de nouvelle ligne ou colonne dans votre rapport.

Forage
L'exploration vers le haut et vers le bas permet d'effectuer une analyse en se déplaçant entre les niveaux d'informations. L'exploration vers le bas est utilisée pour afficher des informations plus détaillées jusqu'au niveau le plus bas et l'exploration vers le haut est utilisée pour comparer les résultats.
Pour explorer vers le bas ou vers le haut dans une seule ligne ou colonne, placez le pointeur sur le texte de l'étiquette jusqu'à ce que l'icône avec le signe plus (+) et l'icône d'exploration vers le bas du curseur s'affiche et le texte est souligné, puis cliquez sur.
Pour explorer simultanément une ligne et une colonne vers le bas ou vers le haut, cliquez sur la valeur à l'intersection de la ligne et de la colonne, puis cliquez à nouveau.
Analysis Studio est utilisé pour se concentrer sur les éléments importants pour l'entreprise. Vous pouvez faire des comparaisons, des analyses de tendances et des analyses comme les meilleurs et les moins performants et vous permettre également de partager votre analyse avec d'autres.
Analysis Studio n'est pas seulement utilisé par les analystes BI, mais également par les utilisateurs professionnels qui comprennent les affaires et souhaitent trouver des réponses aux requêtes commerciales à l'aide de données historiques.
Vous pouvez utiliser Analysis Studio pour comparer et manipuler des données afin de comprendre les relations entre les données et leur importance relative. Que vous souhaitiez évaluer la croissance des revenus ou identifier les plus performants, Analysis Studio fournit l'assistance de filtrage, de calcul et de tri dont vous avez besoin pour l'analyse.
Interface
Analysis Studio se compose de plusieurs zones qui sont présentées dans les zones suivantes et sont également expliquées en détail.

Insertable Object Pane - L'onglet Source du volet Objets insérables contient l'arborescence source du package sélectionné pour l'analyse.
Information Pane - Le volet Informations affiche le nom, le niveau, les attributs (le cas échéant) et l'agrégation associés à l'élément sélectionné dans l'arborescence source, ainsi que toute information supplémentaire fournie par le modélisateur de données.
Properties Pane - Vous pouvez utiliser le volet Propriétés pour apporter plusieurs modifications et les appliquer en même temps, au lieu d'exécuter différentes commandes.
Work Area- Cette zone contient le tableau croisé ou les graphiques pour effectuer l'analyse. Vous pouvez afficher l'analyse sous la forme d'un tableau croisé, d'un graphique ou d'une combinaison des deux.
Et enfin il y a le Overview Area ainsi que.
Pour créer une analyse dans le studio d'analyse, vous devez sélectionner un package comme source de données. Vous pouvez créer une nouvelle analyse ou utiliser une analyse existante comme référence pour créer une nouvelle analyse en modifiant son nom avant de l'enregistrer.
Pour créer une analyse - Sélectionnez le package que vous souhaitez utiliser dans le dossier Public. Accédez à Report Studio comme indiqué dans la capture d'écran suivante.

Dans une nouvelle fenêtre de dialogue, sélectionnez une analyse vide ou une analyse par défaut.
Blank Analysis - Une analyse des blancs commence par un tableau croisé vierge dans la zone de travail.
Default Analysis - Une analyse par défaut utilise l'analyse par défaut du package telle que définie dans Cognos Connection ou les deux premières dimensions de la source de données pour les lignes et colonnes du tableau croisé et la première mesure de la source de données pour la mesure du tableau croisé.
Après avoir sélectionné, cliquez sur OK. Analysis Studio démarre. Les éléments que vous pouvez utiliser dans l'analyse sont répertoriés dans le volet Objets insérables.

Pour enregistrer une analyse, vous pouvez cliquer sur le bouton Enregistrer en haut comme indiqué dans la capture d'écran suivante.

Entrez le nom de l'analyse et l'emplacement → puis cliquez sur OK.
Pour ouvrir une analyse existante, recherchez le nom de l'analyse que vous souhaitez ouvrir et cliquez dessus. Il est ouvert dans Analysis Studio.

Vous pouvez apporter des modifications selon l'exigence. Enregistrez l'analyse.
Vous pouvez également ouvrir une nouvelle analyse tout en travaillant dans une analyse existante, cliquez sur le nouveau bouton dans la barre d'outils. La nouvelle analyse conserve l'état de l'arborescence source dans le volet Objets insérables et conserve tous les éléments de l'onglet Éléments d'analyse.
Cognos Event Studio est un outil Web qui vous permet de créer et de gérer des agents pour surveiller les données et effectuer des tâches lorsque les données atteignent des seuils prédéfinis.
Événements
Vous pouvez spécifier une condition d'événement pour exécuter une tâche. Un événement est défini comme une expression de requête dans un package de données.
Lorsqu'un enregistrement correspond à la condition de l'événement, un agent exécute des tâches. Lorsqu'un agent s'exécute, il vérifie les données pour toutes les instances d'événement.
Instance d'événement
Un agent surveille les données, chaque instance d'événement est détectée. Les règles d'exécution des tâches sont suivies pour déterminer si un agent exécutera la tâche. La fréquence des tâches définit qu'une tâche doit être exécutée une fois ou répétée pour chaque instance d'événement.

Liste des événements
Vous pouvez classer l'événement en fonction de la tâche effectuée. La liste des événements affiche tous les événements exécutés par un agent. Différentes catégories d'événements incluent -
- New
- En cours et changé
- En cours et inchangé
- Ceased
Une clé d'événement est utilisée pour déterminer si un événement est nouveau, en cours mais modifié, en cours et inchangé, ou a cessé. Event Studio compare les instances d'événement détectées dans chaque exécution d'agent avec celles détectées lors de l'exécution précédente. Pour vous assurer qu'il correspond correctement aux instances d'événement à comparer, vous devez définir une clé d'événement. La clé d'événement est la combinaison d'éléments de données qui définissent de manière unique une instance d'événement.
Agent
Un agent s'exécute pour vérifier les occurrences de l'événement. Un agent exécute une tâche pour les événements qui répondent aux règles d'exécution.
Tâches
Une tâche peut être utilisée pour informer les utilisateurs d'un changement d'événement professionnel. Les utilisateurs peuvent prendre les mesures appropriées selon l'événement.
Vous pouvez créer une tâche pour les fonctions suivantes -
- Ajouter un élément
- Envoyer un e-mail
- Publier un nouvel élément
- Exécuter un travail
- Lancer une importation
- Exécutez une exportation et bien d'autres.
Un agent peut utiliser différentes méthodes de notification pour notifier les utilisateurs professionnels. Un agent peut notifier les utilisateurs professionnels en:
- Un e-mail aux utilisateurs professionnels.
- Publication d'une actualité dans un dossier fréquemment utilisé par les utilisateurs.
E-mail aux utilisateurs professionnels
Vous pouvez notifier les personnes par e-mail à l'aide d'une tâche de rapport ou d'une tâche d'e-mail. Pour vous aider à choisir la méthode à utiliser, vous devez comprendre en quoi elles diffèrent.
Vous pouvez utiliser une tâche de rapport ou une tâche de courrier électronique -
- Pour envoyer un seul message texte par e-mail.
- Pour attacher un seul rapport dans les formats de sortie spécifiés.
- Si vous joignez un seul rapport HTML et laissez le champ de corps vide, le rapport apparaît dans le corps du message.
- Pour ajouter des liens vers un seul rapport pour les formats de sortie spécifiés.
Article d'actualité publié
Dans ce cas, vous pouvez publier une actualité / un titre dans un dossier dont le contenu peut être affiché dans un portlet Cognos Navigator et dans n'importe quelle vue de dossier. Lorsqu'un utilisateur professionnel clique sur le titre, il peut ouvrir le contenu ou l'afficher sous forme de page Web.