SGBD - Normalisation
Dépendance fonctionnelle
La dépendance fonctionnelle (FD) est un ensemble de contraintes entre deux attributs dans une relation. La dépendance fonctionnelle dit que si deux tuples ont les mêmes valeurs pour les attributs A1, A2, ..., An, alors ces deux tuples doivent avoir les mêmes valeurs pour les attributs B1, B2, ..., Bn.
La dépendance fonctionnelle est représentée par un signe de flèche (→), c'est-à-dire X → Y, où X détermine fonctionnellement Y. Les attributs de gauche déterminent les valeurs des attributs de droite.
Axiomes d'Armstrong
Si F est un ensemble de dépendances fonctionnelles, alors la fermeture de F, notée F + , est l'ensemble de toutes les dépendances fonctionnelles impliquées logiquement par F. .
Reflexive rule - Si alpha est un ensemble d'attributs et beta is_subset_of alpha, alors alpha détient beta.
Augmentation rule- Si a → b vaut et y est un ensemble d'attributs, alors ay → by est également valable. Cela ajoute des attributs dans les dépendances, ne change pas les dépendances de base.
Transitivity rule- Identique à la règle transitive en algèbre, si a → b est vrai et que b → c est vrai, alors a → c est également vrai. a → b est appelé comme un fonctionnellement qui détermine b.
Dépendance fonctionnelle triviale
Trivial- Si une dépendance fonctionnelle (FD) X → Y est vérifiée, où Y est un sous-ensemble de X, alors on l'appelle un FD trivial. Les FD triviaux tiennent toujours.
Non-trivial - Si un FD X → Y tient, où Y n'est pas un sous-ensemble de X, alors on l'appelle un FD non trivial.
Completely non-trivial - Si une FD X → Y est vérifiée, où x intersecte Y = it, on dit qu'elle est une FD complètement non triviale.
Normalisation
Si la conception d'une base de données n'est pas parfaite, elle peut contenir des anomalies, qui sont comme un mauvais rêve pour tout administrateur de base de données. Gérer une base de données avec des anomalies est quasiment impossible.
Update anomalies- Si les éléments de données sont dispersés et ne sont pas correctement liés les uns aux autres, cela peut conduire à des situations étranges. Par exemple, lorsque nous essayons de mettre à jour un élément de données avec ses copies dispersées à plusieurs endroits, quelques instances sont mises à jour correctement tandis que quelques autres se retrouvent avec d'anciennes valeurs. De telles instances laissent la base de données dans un état incohérent.
Deletion anomalies - Nous avons essayé de supprimer un enregistrement, mais certaines parties n'ont pas été supprimées en raison de l'inconscience, les données sont également enregistrées ailleurs.
Insert anomalies - Nous avons essayé d'insérer des données dans un enregistrement qui n'existe pas du tout.
La normalisation est une méthode pour supprimer toutes ces anomalies et amener la base de données à un état cohérent.
Première forme normale
La première forme normale est définie dans la définition des relations (tables) elle-même. Cette règle définit que tous les attributs d'une relation doivent avoir des domaines atomiques. Les valeurs d'un domaine atomique sont des unités indivisibles.

Nous réorganisons la relation (table) comme ci-dessous, pour la convertir en première forme normale.
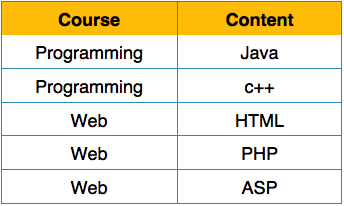
Chaque attribut ne doit contenir qu'une seule valeur de son domaine prédéfini.
Deuxième forme normale
Avant d'en apprendre davantage sur la deuxième forme normale, nous devons comprendre ce qui suit -
Prime attribute - Un attribut, qui fait partie de la clé candidate, est appelé attribut principal.
Non-prime attribute - Un attribut, qui ne fait pas partie de la clé principale, est dit être un attribut non principal.
Si nous suivons la deuxième forme normale, alors chaque attribut non premier devrait être entièrement fonctionnellement dépendant de l'attribut clé principal. Autrement dit, si X → A est vrai, alors il ne devrait y avoir aucun sous-ensemble propre Y de X, pour lequel Y → A est également vrai.

Nous voyons ici dans la relation Student_Project que les principaux attributs clés sont Stu_ID et Proj_ID. Selon la règle, les attributs non clés, c'est-à-dire Stu_Name et Proj_Name, doivent être dépendants des deux et non de l'un des attributs de clé principale individuellement. Mais nous trouvons que Stu_Name peut être identifié par Stu_ID et Proj_Name peut être identifié par Proj_ID indépendamment. C'est appelépartial dependency, ce qui n'est pas autorisé dans la deuxième forme normale.
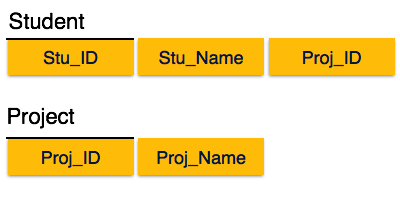
Nous avons brisé la relation en deux comme le montre l'image ci-dessus. Il n'existe donc pas de dépendance partielle.
Troisième forme normale
Pour qu'une relation soit dans la troisième forme normale, elle doit être dans la deuxième forme normale et ce qui suit doit satisfaire:
- Aucun attribut non principal ne dépend de manière transitoire de l'attribut clé principal.
- Pour toute dépendance fonctionnelle non triviale, X → A, alors soit -
-
X est une super-clé ou,
- A est l'attribut principal.

Nous trouvons que dans la relation Student_detail ci-dessus, Stu_ID est la clé et le seul attribut clé principal. Nous constatons que City peut être identifié par Stu_ID ainsi que par Zip lui-même. Ni Zip n'est une super-clé, ni City n'est un attribut principal. De plus, Stu_ID → Zip → City, il existe donctransitive dependency.
Pour amener cette relation dans la troisième forme normale, nous divisons la relation en deux relations comme suit -
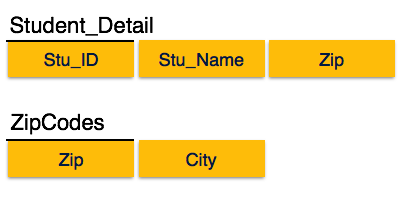
Forme normale de Boyce-Codd
Boyce-Codd Normal Form (BCNF) est une extension de la troisième forme normale à des conditions strictes. BCNF déclare que -
- Pour toute dépendance fonctionnelle non triviale, X → A, X doit être une super-clé.
Dans l'image ci-dessus, Stu_ID est la super-clé dans la relation Student_Detail et Zip est la super-clé dans la relation ZipCodes. Alors,
Stu_ID → Stu_Name, Zip
et
Zip → Ville
Ce qui confirme que les deux relations sont en BCNF.