Deep Learning avec Keras - Guide rapide
Le Deep Learning est devenu un mot à la mode ces derniers jours dans le domaine de l'intelligence artificielle (IA). Pendant de nombreuses années, nous avons utilisé le Machine Learning (ML) pour transmettre de l'intelligence aux machines. Ces derniers jours, l'apprentissage en profondeur est devenu plus populaire en raison de sa suprématie dans les prédictions par rapport aux techniques de ML traditionnelles.
Le Deep Learning signifie essentiellement former un réseau neuronal artificiel (ANN) avec une énorme quantité de données. En apprentissage profond, le réseau apprend par lui-même et nécessite donc d'énormes données pour apprendre. Alors que l'apprentissage automatique traditionnel est essentiellement un ensemble d'algorithmes qui analysent les données et en tirent des leçons. Ils ont ensuite utilisé cet apprentissage pour prendre des décisions intelligentes.
Désormais, pour Keras, il s'agit d'une API de réseaux neuronaux de haut niveau qui s'exécute sur TensorFlow - une plate-forme d'apprentissage automatique open source de bout en bout. Grâce à Keras, vous définissez facilement des architectures ANN complexes pour expérimenter vos Big Data. Keras prend également en charge le GPU, qui devient essentiel pour traiter d'énormes quantités de données et développer des modèles d'apprentissage automatique.
Dans ce didacticiel, vous apprendrez à utiliser Keras pour créer des réseaux de neurones profonds. Nous examinerons les exemples pratiques d'enseignement. Le problème à résoudre est de reconnaître les chiffres manuscrits à l'aide d'un réseau neuronal formé par l'apprentissage en profondeur.
Juste pour vous enthousiasmer davantage dans l'apprentissage en profondeur, voici une capture d'écran des tendances de Google en matière d'apprentissage en profondeur ici -

Comme vous pouvez le voir sur le diagramme, l'intérêt pour l'apprentissage en profondeur ne cesse de croître au cours des dernières années. Il existe de nombreux domaines tels que la vision par ordinateur, le traitement du langage naturel, la reconnaissance vocale, la bioinformatique, la conception de médicaments, etc., dans lesquels l'apprentissage en profondeur a été appliqué avec succès. Ce didacticiel vous permettra de démarrer rapidement l'apprentissage en profondeur.
Alors continuez à lire!
Comme indiqué dans l'introduction, l'apprentissage en profondeur est un processus d'entraînement d'un réseau neuronal artificiel avec une énorme quantité de données. Une fois formé, le réseau pourra nous donner des prédictions sur des données invisibles. Avant d'aller plus loin en expliquant ce qu'est le deep learning, passons rapidement en revue quelques termes utilisés dans la formation d'un réseau neuronal.
Les réseaux de neurones
L'idée de réseau neuronal artificiel est dérivée des réseaux neuronaux de notre cerveau. Un réseau neuronal typique se compose de trois couches - entrée, sortie et couche cachée, comme indiqué dans l'image ci-dessous.

Ceci est également appelé un shallowréseau neuronal, car il ne contient qu'une seule couche cachée. Vous ajoutez plus de couches cachées dans l'architecture ci-dessus pour créer une architecture plus complexe.
Réseaux profonds
Le diagramme suivant montre un réseau profond composé de quatre couches cachées, une couche d'entrée et une couche de sortie.
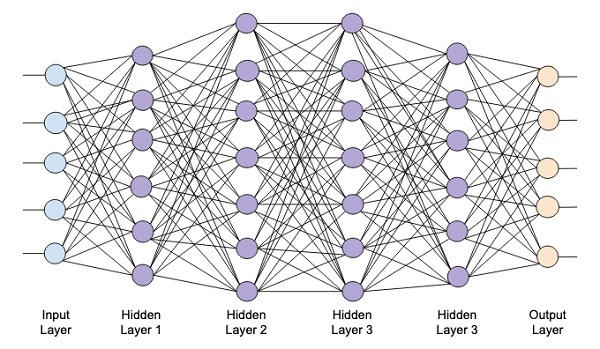
Au fur et à mesure que le nombre de couches cachées est ajouté au réseau, sa formation devient plus complexe en termes de ressources requises et de temps nécessaire pour former complètement le réseau.
Formation réseau
Une fois que vous avez défini l'architecture du réseau, vous l'entraînez à effectuer certains types de prédictions. La formation d'un réseau est un processus consistant à trouver les pondérations appropriées pour chaque lien du réseau. Pendant l'entraînement, les données circulent des couches d'entrée aux couches de sortie via diverses couches masquées. Comme les données se déplacent toujours dans une direction de l'entrée à la sortie, nous appelons ce réseau en tant que réseau à réaction et nous appelons la propagation des données en tant que propagation en avant.
Fonction d'activation
À chaque couche, nous calculons la somme pondérée des entrées et la transmettons à une fonction d'activation. La fonction d'activation apporte la non-linéarité au réseau. C'est simplement une fonction mathématique qui discrétise la sortie. Certaines des fonctions d'activation les plus couramment utilisées sont sigmoïde, hyperbolique, tangente (tanh), ReLU et Softmax.
Rétropropagation
La rétropropagation est un algorithme d'apprentissage supervisé. Dans Backpropagation, les erreurs se propagent vers l'arrière de la sortie à la couche d'entrée. Étant donné une fonction d'erreur, nous calculons le gradient de la fonction d'erreur par rapport aux poids attribués à chaque connexion. Le calcul du gradient procède à l'envers à travers le réseau. Le gradient de la couche finale de poids est calculé en premier et le gradient de la première couche de poids est calculé en dernier.
A chaque couche, les calculs partiels du gradient sont réutilisés dans le calcul du gradient pour la couche précédente. C'est ce qu'on appelle la descente de gradient.
Dans ce didacticiel basé sur un projet, vous allez définir un réseau de neurones profonds à feed-forward et l'entraîner avec des techniques de rétropropagation et de descente de gradient. Heureusement, Keras nous fournit toutes les API de haut niveau pour définir l'architecture réseau et l'entraîner à l'aide de la descente de gradient. Ensuite, vous apprendrez comment faire cela dans Keras.
Système de reconnaissance des chiffres manuscrits
Dans ce mini projet, vous appliquerez les techniques décrites précédemment. Vous allez créer un réseau de neurones d'apprentissage en profondeur qui sera formé pour reconnaître les chiffres manuscrits. Dans tout projet d'apprentissage automatique, le premier défi consiste à collecter les données. En particulier, pour les réseaux d'apprentissage profond, vous avez besoin d'énormes données. Heureusement, pour le problème que nous essayons de résoudre, quelqu'un a déjà créé un ensemble de données pour la formation. Cela s'appelle mnist, qui est disponible dans le cadre des bibliothèques Keras. L'ensemble de données se compose de plusieurs images de 28 x 28 pixels de chiffres manuscrits. Vous entraînerez votre modèle sur la majeure partie de cet ensemble de données et le reste des données sera utilisé pour valider votre modèle entraîné.
Description du projet
le mnistl'ensemble de données se compose de 70000 images de chiffres manuscrits. Quelques exemples d'images sont reproduits ici pour votre référence

Chaque image a une taille de 28 x 28 pixels, ce qui en fait un total de 768 pixels de différents niveaux de gris. La plupart des pixels tendent vers l'ombre noire tandis que seuls quelques-uns d'entre eux sont vers le blanc. Nous mettrons la distribution de ces pixels dans un tableau ou un vecteur. Par exemple, la distribution des pixels pour une image typique des chiffres 4 et 5 est illustrée dans la figure ci-dessous.
Chaque image a une taille de 28 x 28 pixels, ce qui en fait un total de 768 pixels de différents niveaux de gris. La plupart des pixels tendent vers l'ombre noire tandis que seuls quelques-uns d'entre eux sont vers le blanc. Nous mettrons la distribution de ces pixels dans un tableau ou un vecteur. Par exemple, la distribution des pixels pour une image typique des chiffres 4 et 5 est illustrée dans la figure ci-dessous.

En clair, vous pouvez voir que la distribution des pixels (en particulier ceux tendant vers les tons blancs) diffère, cela distingue les chiffres qu'ils représentent. Nous alimenterons cette distribution de 784 pixels à notre réseau en entrée. La sortie du réseau se composera de 10 catégories représentant un chiffre entre 0 et 9.
Notre réseau sera composé de 4 couches - une couche d'entrée, une couche de sortie et deux couches cachées. Chaque couche cachée contiendra 512 nœuds. Chaque couche est entièrement connectée à la couche suivante. Lorsque nous formerons le réseau, nous calculerons les poids pour chaque connexion. Nous formons le réseau en appliquant la rétropropagation et la descente de gradient dont nous avons parlé précédemment.
Dans ce contexte, commençons maintenant à créer le projet.
Configuration du projet
Nous utiliserons Jupyter à travers Anacondanavigateur pour notre projet. Comme notre projet utilise TensorFlow et Keras, vous devrez les installer dans la configuration d'Anaconda. Pour installer Tensorflow, exécutez la commande suivante dans la fenêtre de votre console:
>conda install -c anaconda tensorflowPour installer Keras, utilisez la commande suivante -
>conda install -c anaconda kerasVous êtes maintenant prêt à démarrer Jupyter.
Démarrer Jupyter
Lorsque vous démarrez le navigateur Anaconda, vous verrez l'écran d'ouverture suivant.

Cliquez sur ‘Jupyter’pour le démarrer. L'écran affichera les projets existants, le cas échéant, sur votre lecteur.
Démarrer un nouveau projet
Démarrez un nouveau projet Python 3 dans Anaconda en sélectionnant l'option de menu suivante -
File | New Notebook | Python 3La capture d'écran de la sélection de menu est affichée pour votre référence rapide -

Un nouveau projet vierge apparaîtra sur votre écran comme indiqué ci-dessous -
Remplacez le nom du projet par DeepLearningDigitRecognition en cliquant et en modifiant le nom par défaut “UntitledXX”.
Nous importons d'abord les différentes bibliothèques requises par le code dans notre projet.
Gestion et traçage des tableaux
Comme d'habitude, nous utilisons numpy pour la gestion des tableaux et matplotlibpour le traçage. Ces bibliothèques sont importées dans notre projet en utilisant les éléments suivantsimport déclarations
import numpy as np
import matplotlib
import matplotlib.pyplot as plotSuppression des avertissements
Comme Tensorflow et Keras continuent de se réviser, si vous ne synchronisez pas leurs versions appropriées dans le projet, au moment de l'exécution, vous verrez de nombreuses erreurs d'avertissement. Comme ils détournent votre attention de l'apprentissage, nous supprimerons tous les avertissements de ce projet. Ceci est fait avec les lignes de code suivantes -
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = FalseKeras
Nous utilisons les bibliothèques Keras pour importer des ensembles de données. Nous utiliserons lemnistensemble de données pour les chiffres manuscrits. Nous importons le package requis en utilisant la déclaration suivante
from keras.datasets import mnistNous définirons notre réseau de neurones d'apprentissage profond à l'aide de packages Keras. Nous importons leSequential, Dense, Dropout et Activationpackages pour définir l'architecture du réseau. Nous utilisonsload_modelpackage pour enregistrer et récupérer notre modèle. Nous utilisons égalementnp_utilspour quelques utilitaires dont nous avons besoin dans notre projet. Ces importations sont effectuées avec les instructions de programme suivantes -
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utilsLorsque vous exécutez ce code, vous verrez un message sur la console indiquant que Keras utilise TensorFlow au niveau du backend. La capture d'écran à ce stade est affichée ici -

Maintenant que nous avons toutes les importations requises par notre projet, nous allons procéder à la définition de l'architecture de notre réseau Deep Learning.
Notre modèle de réseau neuronal consistera en une pile linéaire de couches. Pour définir un tel modèle, nous appelons leSequential fonction -
model = Sequential()Couche d'entrée
Nous définissons la couche d'entrée, qui est la première couche de notre réseau à l'aide de l'instruction de programme suivante -
model.add(Dense(512, input_shape=(784,)))Cela crée une couche avec 512 nœuds (neurones) avec 784 nœuds d'entrée. Ceci est illustré dans la figure ci-dessous -

Notez que tous les nœuds d'entrée sont entièrement connectés à la couche 1, c'est-à-dire que chaque nœud d'entrée est connecté aux 512 nœuds de la couche 1.
Ensuite, nous devons ajouter la fonction d'activation pour la sortie de la couche 1. Nous utiliserons ReLU comme activation. La fonction d'activation est ajoutée à l'aide de l'instruction de programme suivante -
model.add(Activation('relu'))Ensuite, nous ajoutons un abandon de 20% en utilisant la déclaration ci-dessous. Le décrochage est une technique utilisée pour empêcher le modèle de surajustement.
model.add(Dropout(0.2))À ce stade, notre couche d'entrée est entièrement définie. Ensuite, nous ajouterons un calque caché.
Couche cachée
Notre couche cachée sera composée de 512 nœuds. L'entrée de la couche masquée provient de notre couche d'entrée précédemment définie. Tous les nœuds sont entièrement connectés comme dans le cas précédent. La sortie de la couche cachée ira à la couche suivante du réseau, qui sera notre couche finale et de sortie. Nous utiliserons la même activation ReLU que pour la couche précédente et un abandon de 20%. Le code pour ajouter cette couche est donné ici -
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))Le réseau à ce stade peut être visualisé comme suit -

Ensuite, nous ajouterons la couche finale à notre réseau, qui est la couche de sortie. Notez que vous pouvez ajouter n'importe quel nombre de couches cachées en utilisant le code similaire à celui que vous avez utilisé ici. L'ajout de couches supplémentaires rendrait le réseau complexe pour la formation; cependant, ce qui donne un avantage certain de meilleurs résultats dans de nombreux cas, mais pas tous.
Couche de sortie
La couche de sortie se compose de seulement 10 nœuds car nous voulons classer les images données en 10 chiffres distincts. Nous ajoutons cette couche, en utilisant l'instruction suivante -
model.add(Dense(10))Comme nous voulons classer la sortie en 10 unités distinctes, nous utilisons l'activation softmax. Dans le cas de ReLU, la sortie est binaire. Nous ajoutons l'activation en utilisant la déclaration suivante -
model.add(Activation('softmax'))À ce stade, notre réseau peut être visualisé comme indiqué dans le diagramme ci-dessous -

À ce stade, notre modèle de réseau est entièrement défini dans le logiciel. Exécutez la cellule de code et s'il n'y a pas d'erreur, vous obtiendrez un message de confirmation à l'écran comme indiqué dans la capture d'écran ci-dessous -

Ensuite, nous devons compiler le modèle.
La compilation est effectuée à l'aide d'un seul appel de méthode appelé compile.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')le compileLa méthode nécessite plusieurs paramètres. Le paramètre de perte est spécifié pour avoir le type'categorical_crossentropy'. Le paramètre metrics est défini sur'accuracy' et enfin nous utilisons le adamoptimiseur pour la formation du réseau. La sortie à ce stade est indiquée ci-dessous -

Maintenant, nous sommes prêts à alimenter les données de notre réseau.
Chargement des données
Comme dit précédemment, nous utiliserons le mnistensemble de données fourni par Keras. Lorsque nous chargeons les données dans notre système, nous les diviserons dans les données d'entraînement et de test. Les données sont chargées en appelant leload_data méthode comme suit -
(X_train, y_train), (X_test, y_test) = mnist.load_data()La sortie à ce stade ressemble à ce qui suit -

Maintenant, nous allons apprendre la structure de l'ensemble de données chargé.
Les données qui nous sont fournies sont les images graphiques de taille 28 x 28 pixels, contenant chacune un seul chiffre entre 0 et 9. Nous afficherons les dix premières images sur la console. Le code pour cela est donné ci-dessous -
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])Dans une boucle itérative de 10 points, nous créons un sous-tracé à chaque itération et montrons une image de X_trainvecteur dedans. Nous intitulons chaque image à partir duy_trainvecteur. Notez que ley_train vecteur contient les valeurs réelles de l'image correspondante dans X_trainvecteur. Nous supprimons les marquages des axes x et y en appelant les deux méthodesxticks et yticksavec un argument nul. Lorsque vous exécutez le code, vous verrez la sortie suivante -

Ensuite, nous préparerons les données pour les alimenter dans notre réseau.
Avant de transmettre les données à notre réseau, elles doivent être converties au format requis par le réseau. C'est ce qu'on appelle la préparation des données pour le réseau. Il consiste généralement à convertir une entrée multidimensionnelle en un vecteur à une seule dimension et à normaliser les points de données.
Remodeler le vecteur d'entrée
Les images de notre ensemble de données sont constituées de 28 x 28 pixels. Cela doit être converti en un vecteur unidimensionnel de taille 28 * 28 = 784 pour le nourrir dans notre réseau. Nous le faisons en appelant lereshape méthode sur le vecteur.
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)Désormais, notre vecteur d'apprentissage sera composé de 60000 points de données, chacun étant constitué d'un vecteur de dimension unique de taille 784. De même, notre vecteur de test sera constitué de 10000 points de données d'un vecteur monodimensionnel de taille 784.
Normalisation des données
Les données que le vecteur d'entrée contient actuellement ont une valeur discrète entre 0 et 255 - les niveaux d'échelle de gris. La normalisation de ces valeurs de pixels entre 0 et 1 contribue à accélérer la formation. Comme nous allons utiliser la descente de gradient stochastique, la normalisation des données aidera également à réduire le risque de rester coincé dans les optima locaux.
Pour normaliser les données, nous les représentons en tant que type float et les divisons par 255 comme indiqué dans l'extrait de code suivant -
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255Voyons maintenant à quoi ressemblent les données normalisées.
Examen des données normalisées
Pour afficher les données normalisées, nous appellerons la fonction d'histogramme comme indiqué ici -
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))Ici, nous traçons l'histogramme du premier élément du X_trainvecteur. Nous imprimons également le chiffre représenté par ce point de données. La sortie de l'exécution du code ci-dessus est affichée ici -

Vous remarquerez une densité épaisse de points ayant une valeur proche de zéro. Ce sont les points noirs de l'image, qui constituent évidemment la partie principale de l'image. Le reste des points d'échelle de gris, qui sont proches de la couleur blanche, représentent le chiffre. Vous pouvez vérifier la distribution des pixels pour un autre chiffre. Le code ci-dessous imprime l'histogramme d'un chiffre à l'index de 2 dans l'ensemble de données d'apprentissage.
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])La sortie de l'exécution du code ci-dessus est indiquée ci-dessous -

En comparant les deux chiffres ci-dessus, vous remarquerez que la distribution des pixels blancs dans deux images diffère indiquant une représentation d'un chiffre différent - «5» et «4» dans les deux images ci-dessus.
Ensuite, nous examinerons la distribution des données dans notre ensemble de données d'entraînement complet.
Examen de la distribution des données
Avant d'entraîner notre modèle d'apprentissage automatique sur notre ensemble de données, nous devons connaître la distribution des chiffres uniques dans notre ensemble de données. Nos images représentent 10 chiffres distincts allant de 0 à 9. Nous aimerions connaître le nombre de chiffres 0, 1, etc., dans notre jeu de données. Nous pouvons obtenir ces informations en utilisant leunique méthode de Numpy.
Utilisez la commande suivante pour imprimer le nombre de valeurs uniques et le nombre d'occurrences de chacune
print(np.unique(y_train, return_counts=True))Lorsque vous exécutez la commande ci-dessus, vous verrez la sortie suivante -
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))Il montre qu'il existe 10 valeurs distinctes - 0 à 9. Il y a 5923 occurrences du chiffre 0, 6742 occurrences du chiffre 1, et ainsi de suite. La capture d'écran de la sortie est affichée ici -

Comme dernière étape de la préparation des données, nous devons encoder nos données.
Codage des données
Nous avons dix catégories dans notre ensemble de données. Nous allons donc encoder notre sortie dans ces dix catégories en utilisant un encodage one-hot. Nous utilisons la méthode to_categorial des utilitaires Numpy pour effectuer l'encodage. Une fois les données de sortie codées, chaque point de données serait converti en un vecteur dimensionnel unique de taille 10. Par exemple, le chiffre 5 sera maintenant représenté par [0,0,0,0,0,1,0,0,0 , 0].
Encodez les données en utilisant le morceau de code suivant -
n_classes = 10
Y_train = np_utils.to_categorical(y_train, n_classes)Vous pouvez vérifier le résultat du codage en imprimant les 5 premiers éléments du vecteur Y_train catégorisé.
Utilisez le code suivant pour imprimer les 5 premiers vecteurs -
for i in range(5):
print (Y_train[i])Vous verrez la sortie suivante -
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]Le premier élément représente le chiffre 5, le second représente le chiffre 0, et ainsi de suite.
Enfin, vous devrez également catégoriser les données de test, ce qui est fait à l'aide de l'instruction suivante -
Y_test = np_utils.to_categorical(y_test, n_classes)À ce stade, vos données sont entièrement préparées pour alimenter le réseau.
Ensuite, vient la partie la plus importante et c'est la formation de notre modèle de réseau.
L'entraînement du modèle est effectué en un seul appel de méthode appelé fit qui prend peu de paramètres, comme indiqué dans le code ci-dessous -
history = model.fit(X_train, Y_train,
batch_size=128, epochs=20,
verbose=2,
validation_data=(X_test, Y_test)))Les deux premiers paramètres de la méthode d'ajustement spécifient les caractéristiques et la sortie de l'ensemble de données d'entraînement.
le epochsest réglé sur 20; nous supposons que la formation convergera dans un maximum de 20 époques - les itérations. Le modèle entraîné est validé sur les données de test comme spécifié dans le dernier paramètre.
La sortie partielle de l'exécution de la commande ci-dessus est affichée ici -
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
- 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665
Epoch 2/20
- 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715
Epoch 3/20
- 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765
Epoch 4/20
- 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795
Epoch 5/20
- 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792La capture d'écran de la sortie est donnée ci-dessous pour votre référence rapide -

Maintenant, au fur et à mesure que le modèle est formé sur nos données d'entraînement, nous évaluerons ses performances.
Pour évaluer les performances du modèle, nous appelons evaluate méthode comme suit -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)Pour évaluer les performances du modèle, nous appelons evaluate méthode comme suit -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)Nous imprimerons la perte et l'exactitude en utilisant les deux déclarations suivantes -
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])Lorsque vous exécutez les instructions ci-dessus, vous verrez la sortie suivante -
Test Loss 0.08041584826191042
Test Accuracy 0.9837Cela montre une précision de test de 98%, ce qui devrait être acceptable pour nous. Ce que cela signifie pour nous que dans 2% des cas, les chiffres manuscrits ne seraient pas classés correctement. Nous allons également tracer des métriques de précision et de perte pour voir comment le modèle fonctionne sur les données de test.
Tracer des mesures de précision
Nous utilisons l'enregistrement historypendant notre formation pour obtenir un graphique des mesures de précision. Le code suivant tracera la précision à chaque époque. Nous prenons la précision des données d'entraînement («acc») et la précision des données de validation («val_acc») pour le traçage.
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')Le tracé de sortie est illustré ci-dessous -

Comme vous pouvez le voir sur le diagramme, la précision augmente rapidement au cours des deux premières époques, indiquant que le réseau apprend rapidement. Ensuite, la courbe s'aplatit, indiquant qu'il ne faut pas trop d'époques pour entraîner davantage le modèle. En général, si la précision des données d'entraînement («acc») continue de s'améliorer alors que la précision des données de validation («val_acc») s'aggrave, vous rencontrez un surajustement. Cela indique que le modèle commence à mémoriser les données.
Nous allons également tracer les métriques de perte pour vérifier les performances de notre modèle.
Tracer des mesures de perte
Encore une fois, nous représentons la perte sur les données d'apprentissage («perte») et de test («val_loss»). Ceci est fait en utilisant le code suivant -
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')La sortie de ce code est indiquée ci-dessous -

Comme vous pouvez le voir sur le diagramme, la perte sur l'ensemble d'apprentissage diminue rapidement pour les deux premières époques. Pour l'ensemble de test, la perte ne diminue pas au même rythme que l'ensemble d'apprentissage, mais reste presque stable pour plusieurs époques. Cela signifie que notre modèle se généralise bien aux données invisibles.
Maintenant, nous allons utiliser notre modèle entraîné pour prédire les chiffres de nos données de test.
Il est très facile de prédire les chiffres dans des données invisibles. Il vous suffit d'appeler lepredict_classes méthode de la model en le passant à un vecteur constitué de vos points de données inconnus.
predictions = model.predict_classes(X_test)L'appel de méthode renvoie les prédictions dans un vecteur qui peut être testé pour les 0 et les 1 par rapport aux valeurs réelles. Ceci est fait en utilisant les deux instructions suivantes -
correct_predictions = np.nonzero(predictions == y_test)[0]
incorrect_predictions = np.nonzero(predictions != y_test)[0]Enfin, nous imprimerons le nombre de prédictions correctes et incorrectes en utilisant les deux instructions de programme suivantes -
print(len(correct_predictions)," classified correctly")
print(len(incorrect_predictions)," classified incorrectly")Lorsque vous exécutez le code, vous obtiendrez la sortie suivante -
9837 classified correctly
163 classified incorrectlyMaintenant que vous avez formé le modèle de manière satisfaisante, nous le conserverons pour une utilisation future.
Nous enregistrerons le modèle entraîné sur notre lecteur local dans le dossier models de notre répertoire de travail actuel. Pour enregistrer le modèle, exécutez le code suivant -
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)La sortie après l'exécution du code est indiquée ci-dessous -

Maintenant que vous avez enregistré un modèle entraîné, vous pouvez l'utiliser plus tard pour traiter vos données inconnues.
Pour prédire les données invisibles, vous devez d'abord charger le modèle entraîné dans la mémoire. Cela se fait à l'aide de la commande suivante -
model = load_model ('./models/handwrittendigitrecognition.h5')Notez que nous chargeons simplement le fichier .h5 en mémoire. Cela configure l'ensemble du réseau neuronal en mémoire avec les poids attribués à chaque couche.
Maintenant, pour faire vos prédictions sur des données invisibles, chargez les données, que ce soit un ou plusieurs éléments, dans la mémoire. Prétraitez les données pour répondre aux exigences d'entrée de notre modèle comme ce que vous avez fait sur vos données d'entraînement et de test ci-dessus. Après le prétraitement, alimentez-le sur votre réseau. Le modèle sortira sa prédiction.
Keras fournit une API de haut niveau pour créer un réseau neuronal profond. Dans ce didacticiel, vous avez appris à créer un réseau de neurones profond qui a été formé pour trouver les chiffres dans un texte manuscrit. Un réseau multicouche a été créé à cet effet. Keras vous permet de définir une fonction d'activation de votre choix à chaque couche. En utilisant la descente de gradient, le réseau a été formé sur les données d'entraînement. La précision du réseau formé dans la prédiction des données invisibles a été testée sur les données de test. Vous avez appris à tracer les métriques de précision et d'erreur. Une fois le réseau entièrement formé, vous avez enregistré le modèle de réseau pour une utilisation future.