DocumentDB SQL - Guide rapide
DocumentDB est la dernière plate-forme de base de données de documents NoSQL de Microsoft qui s'exécute sur Azure. Dans ce didacticiel, nous allons tout apprendre sur l'interrogation de documents à l'aide de la version spéciale de SQL prise en charge par DocumentDB.
Base de données de documents NoSQL
DocumentDB est la dernière base de données de documents NoSQL de Microsoft, cependant, quand nous parlons de base de données de documents NoSQL, qu'entendons-nous précisément par NoSQL et base de données de documents?
SQL signifie langage de requête structuré qui est un langage de requête traditionnel des bases de données relationnelles. SQL est souvent assimilé à des bases de données relationnelles.
Il est vraiment plus utile de considérer une base de données NoSQL comme une base de données non relationnelle, donc NoSQL signifie vraiment non relationnelle.
Il existe différents types de bases de données NoSQL qui incluent des magasins de valeurs clés tels que -
- Stockage de table Azure
- Magasins basés sur des colonnes, comme Cassandra
- Bases de données graphiques, comme NEO4
- Bases de données de documents, comme MongoDB et Azure DocumentDB
Pourquoi la syntaxe SQL?
Cela peut sembler étrange au début, mais dans DocumentDB qui est une base de données NoSQL, nous interrogeons en utilisant SQL. Comme mentionné ci-dessus, il s'agit d'une version spéciale de SQL enracinée dans la sémantique JSON et JavaScript.
SQL n'est qu'un langage, mais c'est aussi un langage très populaire, riche et expressif. Ainsi, il semble définitivement être une bonne idée d'utiliser un dialecte de SQL plutôt que de proposer une toute nouvelle façon d'exprimer des requêtes que nous aurions besoin d'apprendre si vous vouliez extraire des documents de votre base de données.
SQL est conçu pour les bases de données relationnelles et DocumentDB est une base de données de documents non relationnelle. L'équipe DocumentDB a en fait adapté la syntaxe SQL pour le monde non relationnel des bases de données documentaires, et c'est ce que signifie l'enracinement de SQL en JSON et JavaScript.
Le langage se lit toujours comme du SQL familier, mais la sémantique est basée sur des documents JSON sans schéma plutôt que sur des tables relationnelles. Dans DocumentDB, nous travaillerons avec des types de données JavaScript plutôt qu'avec des types de données SQL. Nous connaîtrons SELECT, FROM, WHERE, etc., mais avec les types JavaScript, qui sont limités aux nombres et aux chaînes, les objets, les tableaux, les valeurs booléennes et nulles sont bien moins nombreux que le large éventail de types de données SQL.
De même, les expressions sont évaluées comme des expressions JavaScript plutôt que comme une forme de T-SQL. Par exemple, dans un monde de données dénormalisées, nous ne traitons pas les lignes et les colonnes, mais des documents sans schéma avec des structures hiérarchiques qui contiennent des tableaux et des objets imbriqués.
Comment fonctionne SQL?
L'équipe DocumentDB a répondu à cette question de plusieurs manières innovantes. Peu d'entre eux sont répertoriés comme suit -
Tout d'abord, en supposant que vous n'ayez pas changé le comportement par défaut pour indexer automatiquement chaque propriété d'un document, vous pouvez utiliser la notation en pointillé dans vos requêtes pour naviguer dans un chemin vers n'importe quelle propriété, quelle que soit son imbrication dans le document.
Vous pouvez également effectuer une jointure intra-document dans laquelle des éléments de tableau imbriqués sont joints à leur élément parent dans un document d'une manière très similaire à la manière dont une jointure est effectuée entre deux tables dans le monde relationnel.
Vos requêtes peuvent renvoyer des documents de la base de données tels quels, ou vous pouvez projeter n'importe quelle forme JSON personnalisée de votre choix en fonction de la quantité ou du minimum de données de document que vous souhaitez.
SQL dans DocumentDB prend en charge de nombreux opérateurs courants, notamment -
Opérations arithmétiques et au niveau du bit
Logique ET et OU
Comparaisons d'égalité et de plage
Concaténation de chaînes
Le langage de requête prend également en charge une multitude de fonctions intégrées.
Le portail Azure dispose d'un explorateur de requêtes qui nous permet d'exécuter n'importe quelle requête SQL sur notre base de données DocumentDB. Nous utiliserons l'explorateur de requêtes pour démontrer les nombreuses capacités et fonctionnalités du langage de requête en commençant par la requête la plus simple possible.
Step 1 - Ouvrez le portail Azure et dans le panneau de base de données, cliquez sur le panneau Explorateur de requêtes.
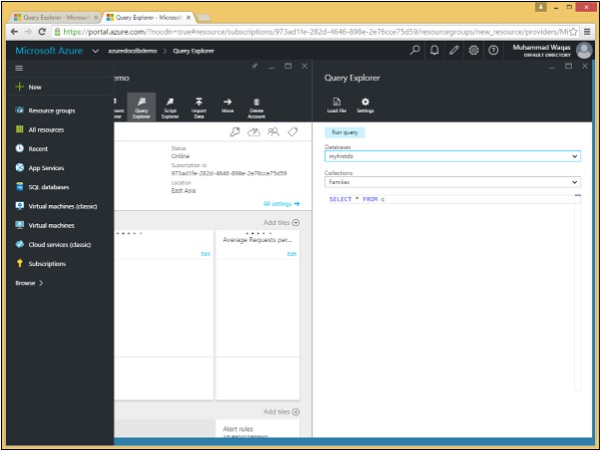
N'oubliez pas que les requêtes s'exécutent dans le cadre d'une collection, et donc l'explorateur de requêtes nous permet de choisir la collection dans cette liste déroulante. Nous le laisserons à notre collection Familles qui contient les trois documents. Considérons ces trois documents dans cet exemple.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
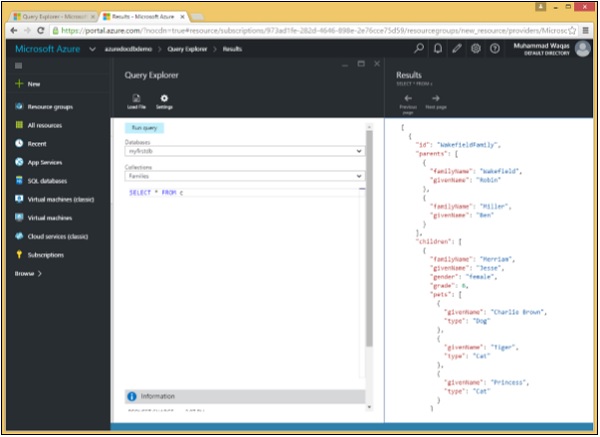
}L'Explorateur de requêtes s'ouvre avec cette simple requête SELECT * FROM c, qui récupère simplement tous les documents de la collection. Bien que simple, elle est tout de même assez différente de la requête équivalente dans une base de données relationnelle.
Step 2- Dans les bases de données relationnelles, SELECT * signifie retourner toutes les colonnes dans DocumentDB. Cela signifie que vous souhaitez que chaque document de votre résultat soit renvoyé exactement tel qu'il est stocké dans la base de données.
Mais lorsque vous sélectionnez des propriétés et des expressions spécifiques au lieu de simplement émettre un SELECT *, vous projetez une nouvelle forme que vous souhaitez pour chaque document dans le résultat.
Step 3 - Cliquez sur «Exécuter» pour exécuter la requête et ouvrir le panneau Résultats.

Comme on peut le voir, la WakefieldFamily, la SmithFamily et la AndersonFamily sont récupérées.
Voici les trois documents qui sont récupérés à la suite de la SELECT * FROM c requete.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
"givenName": "Fluffy",
"type": "Rabbit"
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Cependant, ces résultats incluent également les propriétés générées par le système qui sont toutes précédées du caractère de soulignement.
Dans ce chapitre, nous aborderons la clause FROM, qui ne fonctionne en rien comme une clause FROM standard en SQL standard.
Les requêtes s'exécutent toujours dans le contexte d'une collection spécifique et ne peuvent pas se joindre à des documents de la collection, ce qui nous amène à nous demander pourquoi nous avons besoin d'une clause FROM. En fait, nous ne le faisons pas, mais si nous ne l'incluons pas, nous n'interrogerons pas les documents de la collection.
Le but de cette clause est de spécifier la source de données sur laquelle la requête doit fonctionner. Généralement, toute la collection est la source, mais on peut spécifier un sous-ensemble de la collection à la place. La clause FROM <from_specification> est facultative, sauf si la source est filtrée ou projetée plus tard dans la requête.
Regardons à nouveau le même exemple. Voici leAndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
Dans la requête ci-dessus, "SELECT * FROM c»Indique que toute la collection Families est la source sur laquelle énumérer.
Sous-documents
La source peut également être réduite à un sous-ensemble plus petit. Lorsque nous voulons récupérer uniquement un sous-arbre dans chaque document, la sous-racine pourrait alors devenir la source, comme illustré dans l'exemple suivant.
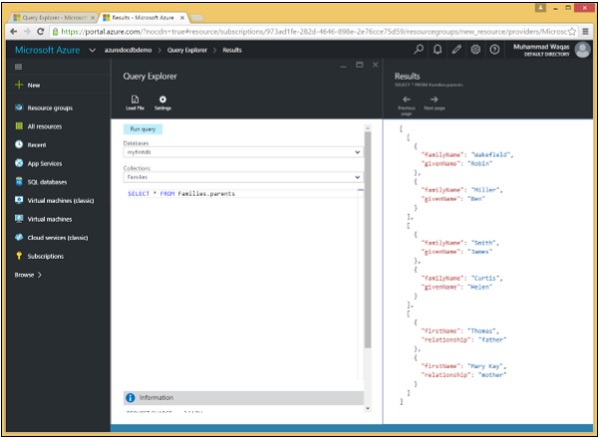
Lorsque nous exécutons la requête suivante -
SELECT * FROM Families.parentsLes sous-documents suivants seront récupérés.
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]À la suite de cette requête, nous pouvons voir que seuls les sous-documents parents sont récupérés.
Dans ce chapitre, nous aborderons la clause WHERE, qui est également facultative comme la clause FROM. Il est utilisé pour spécifier une condition lors de la récupération des données sous la forme de documents JSON fournis par la source. Tout document JSON doit évaluer les conditions spécifiées comme étant «vraies» pour être pris en compte pour le résultat. Si la condition donnée est satisfaite, alors seulement elle renvoie des données spécifiques sous la forme de document (s) JSON. Nous pouvons utiliser la clause WHERE pour filtrer les enregistrements et récupérer uniquement les enregistrements nécessaires.
Nous considérerons les trois mêmes documents dans cet exemple. Voici leAndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple simple dans lequel la clause WHERE est utilisée.
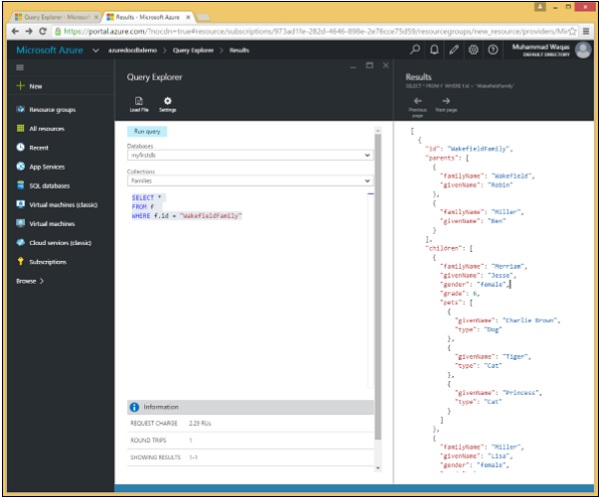
Dans cette requête, dans la clause WHERE, la condition (WHERE f.id = "WakefieldFamily") est spécifiée.
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"Lorsque la requête ci-dessus est exécutée, elle renvoie le document JSON complet pour WakefieldFamily, comme indiqué dans la sortie suivante.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]Un opérateur est un mot réservé ou un caractère utilisé principalement dans une clause SQL WHERE pour effectuer des opérations, telles que des comparaisons et des opérations arithmétiques. DocumentDB SQL prend également en charge diverses expressions scalaires. Les plus couramment utilisés sontbinary and unary expressions.
Les opérateurs SQL suivants sont actuellement pris en charge et peuvent être utilisés dans les requêtes.
Opérateurs de comparaison SQL
Voici une liste de tous les opérateurs de comparaison disponibles dans la grammaire SQL DocumentDB.
| S.No. | Opérateurs et description |
|---|---|
| 1 | = Vérifie si les valeurs de deux opérandes sont égales ou non. Si oui, alors la condition devient vraie. |
| 2 | != Vérifie si les valeurs de deux opérandes sont égales ou non. Si les valeurs ne sont pas égales, la condition devient vraie. |
| 3 | <> Vérifie si les valeurs de deux opérandes sont égales ou non. Si les valeurs ne sont pas égales, la condition devient vraie. |
| 4 | > Vérifie si la valeur de l'opérande gauche est supérieure à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. |
| 5 | < Vérifie si la valeur de l'opérande gauche est inférieure à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. |
| 6 | >= Vérifie si la valeur de l'opérande gauche est supérieure ou égale à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. |
| sept | <= Vérifie si la valeur de l'opérande gauche est inférieure ou égale à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. |
Opérateurs logiques SQL
Voici une liste de tous les opérateurs logiques disponibles dans la grammaire SQL DocumentDB.
| S.No. | Opérateurs et description |
|---|---|
| 1 | AND L'opérateur AND permet l'existence de plusieurs conditions dans la clause WHERE d'une instruction SQL. |
| 2 | BETWEEN L'opérateur BETWEEN est utilisé pour rechercher des valeurs qui se trouvent dans un ensemble de valeurs, étant donné la valeur minimale et la valeur maximale. |
| 3 | IN L'opérateur IN est utilisé pour comparer une valeur à une liste de valeurs littérales qui ont été spécifiées. |
| 4 | OR L'opérateur OR est utilisé pour combiner plusieurs conditions dans la clause WHERE d'une instruction SQL. |
| 5 | NOT L'opérateur NOT inverse la signification de l'opérateur logique avec lequel il est utilisé. Par exemple, NOT EXISTS, NOT BETWEEN, NOT IN, etc. Il s'agit d'un opérateur de négation. |
Opérateurs arithmétiques SQL
Voici une liste de tous les opérateurs arithmétiques disponibles dans la grammaire SQL DocumentDB.
| S.No. | Opérateurs et description |
|---|---|
| 1 | + Addition - Ajoute des valeurs de chaque côté de l'opérateur. |
| 2 | - Subtraction - Soustrait l'opérande de droite de l'opérande de gauche. |
| 3 | * Multiplication - Multiplie les valeurs de chaque côté de l'opérateur. |
| 4 | / Division - Divise l'opérande de gauche par l'opérande de droite. |
| 5 | % Modulus - Divise l'opérande de gauche par l'opérande de droite et renvoie le reste. |
Nous considérerons également les mêmes documents dans cet exemple. Voici leAndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple simple dans lequel un opérateur de comparaison est utilisé dans la clause WHERE.
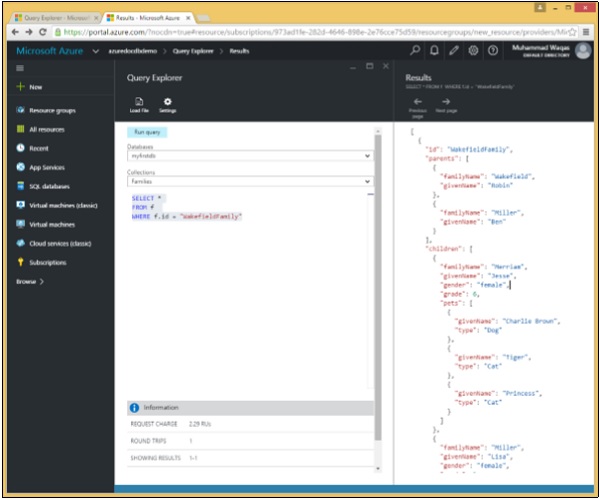
Dans cette requête, dans la clause WHERE, la condition (WHERE f.id = "WakefieldFamily") est spécifiée et elle récupérera le document dont l'id est égal à WakefieldFamily.
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"Lorsque la requête ci-dessus est exécutée, elle renvoie le document JSON complet pour WakefieldFamily, comme indiqué dans la sortie suivante.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]Jetons un œil à un autre exemple dans lequel la requête récupérera les données enfants dont la note est supérieure à 5.
SELECT *
FROM Families.children[0] c
WHERE (c.grade > 5)Lorsque la requête ci-dessus est exécutée, elle récupère le sous-document suivant comme indiqué dans la sortie.
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]Le mot clé BETWEEN est utilisé pour exprimer des requêtes sur des plages de valeurs comme dans SQL. BETWEEN peut être utilisé contre des chaînes ou des nombres. La principale différence entre l'utilisation de BETWEEN dans DocumentDB et ANSI SQL est que vous pouvez exprimer des requêtes de plage par rapport à des propriétés de types mixtes.
Par exemple, dans certains documents, il est possible que vous ayez "note" comme nombre et dans d'autres documents, il peut s'agir de chaînes. Dans ces cas, une comparaison entre deux types de résultats différents est "indéfinie" et le document sera ignoré.
Considérons les trois documents de l'exemple précédent. Voici leAndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un œil à un exemple, où la requête renvoie tous les documents familiaux dans lesquels la note du premier enfant est comprise entre 1 et 5 (les deux inclus).
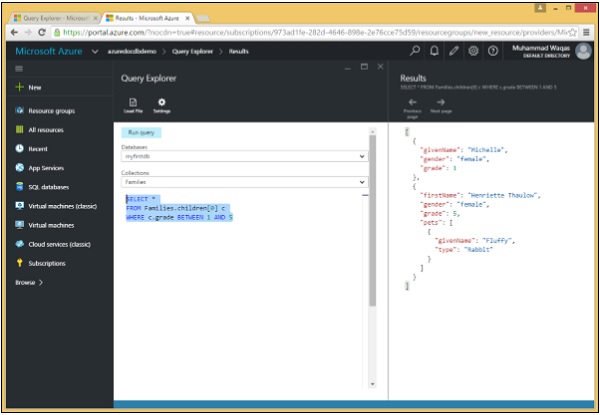
Voici la requête dans laquelle le mot clé BETWEEN est utilisé, puis l'opérateur logique ET.
SELECT *
FROM Families.children[0] c
WHERE c.grade BETWEEN 1 AND 5Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
]Pour afficher les notes en dehors de la plage de l'exemple précédent, utilisez NOT BETWEEN comme indiqué dans la requête suivante.
SELECT *
FROM Families.children[0] c
WHERE c.grade NOT BETWEEN 1 AND 5Lorsque cette requête est exécutée. Il produit la sortie suivante.
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]Le mot clé IN peut être utilisé pour vérifier si une valeur spécifiée correspond à une valeur dans une liste. L'opérateur IN vous permet de spécifier plusieurs valeurs dans une clause WHERE. IN équivaut à enchaîner plusieurs clauses OR.
Les trois documents similaires sont considérés comme réalisés dans les exemples précédents. Voici leAndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple simple.
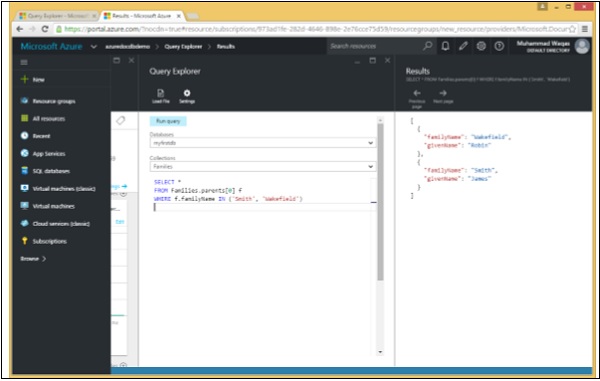
Voici la requête qui récupérera les données dont le nom de famille est «Smith» ou Wakefield.
SELECT *
FROM Families.parents[0] f
WHERE f.familyName IN ('Smith', 'Wakefield')Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Smith",
"givenName": "James"
}
]Considérons un autre exemple simple dans lequel tous les documents de famille seront récupérés où l'identifiant est l'un de "SmithFamily" ou "AndersenFamily". Voici la requête.
SELECT *
FROM Families
WHERE Families.id IN ('SmithFamily', 'AndersenFamily')Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Lorsque vous savez que vous ne renvoyez qu'une seule valeur, le mot clé VALUE peut vous aider à produire un ensemble de résultats plus léger en évitant la surcharge liée à la création d'un objet à part entière. Le mot clé VALUE permet de renvoyer une valeur JSON.
Jetons un coup d'œil à un exemple simple.
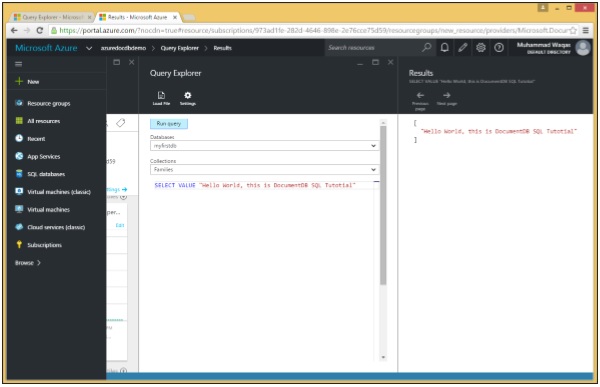
Voici la requête avec le mot clé VALUE.
SELECT VALUE "Hello World, this is DocumentDB SQL Tutorial"Lorsque cette requête est exécutée, elle renvoie le scalaire "Hello World, c'est DocumentDB SQL Tutorial".
[
"Hello World, this is DocumentDB SQL Tutorial"
]Dans un autre exemple, considérons les trois documents des exemples précédents.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Voici la requête.
SELECT VALUE f.location
FROM Families fLorsque cette requête est exécutée, elle retourne l'adresse sans l'étiquette d'emplacement.
[
{
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
{
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
{
"state": "WA",
"county": "King",
"city": "Seattle"
}
]Si nous spécifions maintenant la même requête sans mot-clé VALUE, elle renverra l'adresse avec l'étiquette d'emplacement. Voici la requête.
SELECT f.location
FROM Families fLorsque cette requête est exécutée, elle produit la sortie suivante.
[
{
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
}
},
{
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
},
{
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
}
}
]Microsoft Azure DocumentDB prend en charge l'interrogation de documents à l'aide de SQL sur des documents JSON. Vous pouvez trier les documents de la collection sur des nombres et des chaînes à l'aide d'une clause ORDER BY dans votre requête. La clause peut inclure un argument ASC / DESC facultatif pour spécifier l'ordre dans lequel les résultats doivent être récupérés.
Nous considérerons les mêmes documents que dans les exemples précédents.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple simple.
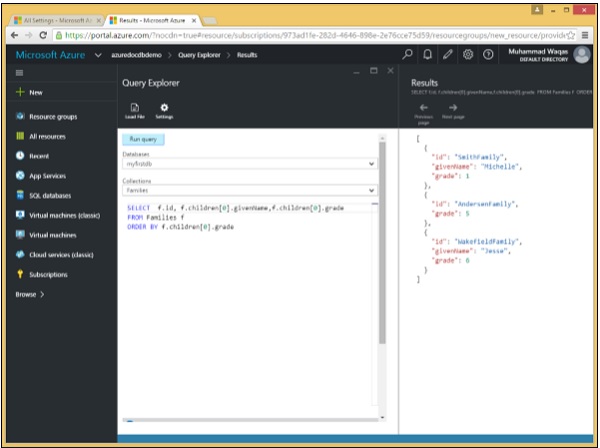
Voici la requête qui contient le mot clé ORDER BY.
SELECT f.id, f.children[0].givenName,f.children[0].grade
FROM Families f
ORDER BY f.children[0].gradeLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"id": "SmithFamily",
"givenName": "Michelle",
"grade": 1
},
{
"id": "AndersenFamily",
"grade": 5
},
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]Prenons un autre exemple simple.
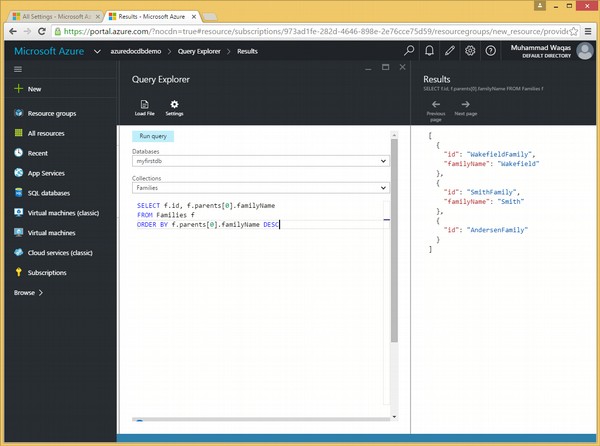
Voici la requête qui contient le mot clé ORDER BY et le mot clé facultatif DESC.
SELECT f.id, f.parents[0].familyName
FROM Families f
ORDER BY f.parents[0].familyName DESCLorsque la requête ci-dessus est exécutée, elle produira la sortie suivante.
[
{
"id": "WakefieldFamily",
"familyName": "Wakefield"
},
{
"id": "SmithFamily",
"familyName": "Smith"
},
{
"id": "AndersenFamily"
}
]Dans DocumentDB SQL, Microsoft a ajouté une nouvelle construction qui peut être utilisée avec le mot clé IN pour prendre en charge l'itération sur des tableaux JSON. La prise en charge de l'itération est fournie dans la clause FROM.
Nous examinerons à nouveau trois documents similaires des exemples précédents.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple simple sans mot clé IN dans la clause FROM.
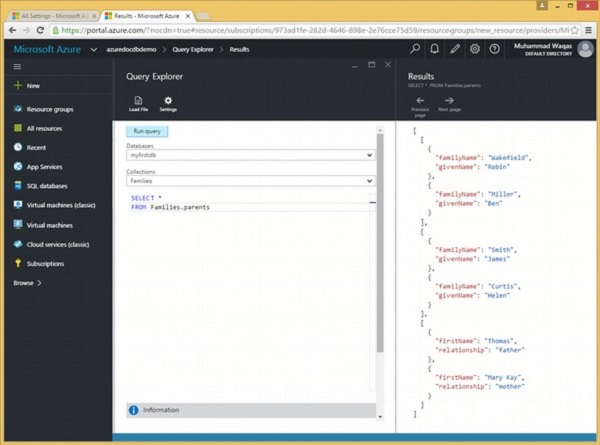
Voici la requête qui retournera tous les parents de la collection Families.
SELECT *
FROM Families.parentsLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]Comme on peut le voir dans la sortie ci-dessus, les parents de chaque famille sont affichés dans un tableau JSON distinct.
Jetons un œil au même exemple, mais cette fois, nous utiliserons le mot clé IN dans la clause FROM.
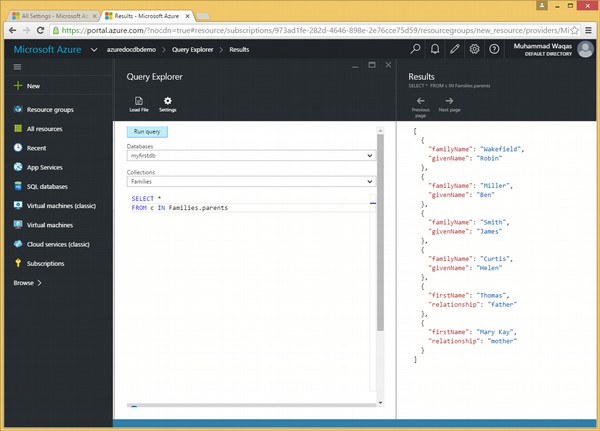
Voici la requête qui contient le mot clé IN.
SELECT *
FROM c IN Families.parentsLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
},
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
},
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]Dans l'exemple ci-dessus, on peut voir qu'avec l'itération, la requête qui effectue l'itération sur les parents dans la collection a un tableau de sortie différent. Par conséquent, tous les parents de chaque famille sont ajoutés dans un seul tableau.
Dans les bases de données relationnelles, la clause Joins est utilisée pour combiner les enregistrements de deux tables ou plus dans une base de données, et la nécessité de joindre des tables est très importante lors de la conception de schémas normalisés. Puisque DocumentDB traite le modèle de données dénormalisé de documents sans schéma, le JOIN dans DocumentDB SQL est l'équivalent logique d'un "selfjoin".
Considérons les trois documents comme dans les exemples précédents.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple pour comprendre le fonctionnement de la clause JOIN.
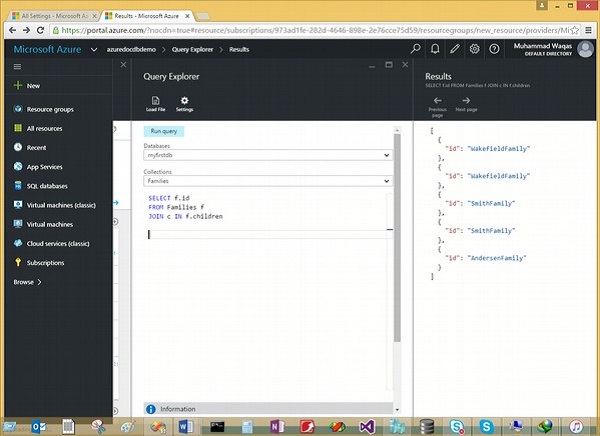
Voici la requête qui joindra le sous-document racine aux enfants.
SELECT f.id
FROM Families f
JOIN c IN f.childrenLorsque la requête ci-dessus est exécutée, elle produira la sortie suivante.
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]Dans l'exemple ci-dessus, la jointure se situe entre la racine du document et la sous-racine des enfants, ce qui crée un produit croisé entre deux objets JSON. Voici certains points à noter -
Dans la clause FROM, la clause JOIN est un itérateur.
Les deux premiers documents WakefieldFamily et SmithFamily contiennent deux enfants. Par conséquent, le jeu de résultats contient également le produit croisé qui produit un objet distinct pour chaque enfant.
Le troisième document AndersenFamily ne contient qu'un seul enfant, il n'y a donc qu'un seul objet correspondant à ce document.
Jetons un coup d'œil au même exemple, mais cette fois, nous récupérons également le nom de l'enfant pour une meilleure compréhension de la clause JOIN.
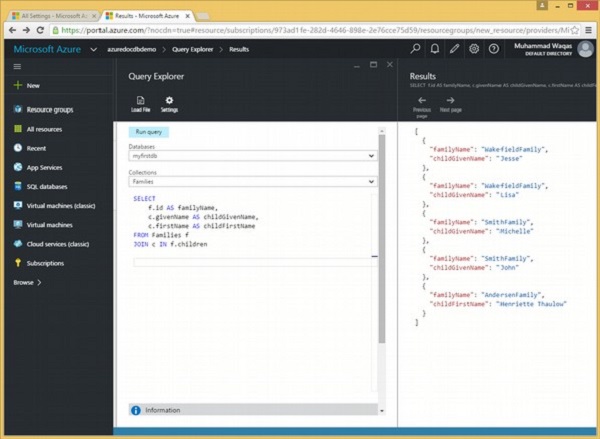
Voici la requête qui joindra le sous-document racine aux enfants.
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]Dans les bases de données relationnelles, les alias SQL sont utilisés pour renommer temporairement une table ou un en-tête de colonne. De même, dans DocumentDB, les alias sont utilisés pour renommer temporairement un document JSON, un sous-document, un objet ou tout autre champ.
Le changement de nom est une modification temporaire et le document réel ne change pas. Fondamentalement, les alias sont créés pour rendre les noms de champs / documents plus lisibles. Pour l'alias, le mot clé AS est utilisé, ce qui est facultatif.
Considérons trois documents similaires à ceux utilisés dans les exemples précédents.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un œil à un exemple pour discuter des alias.
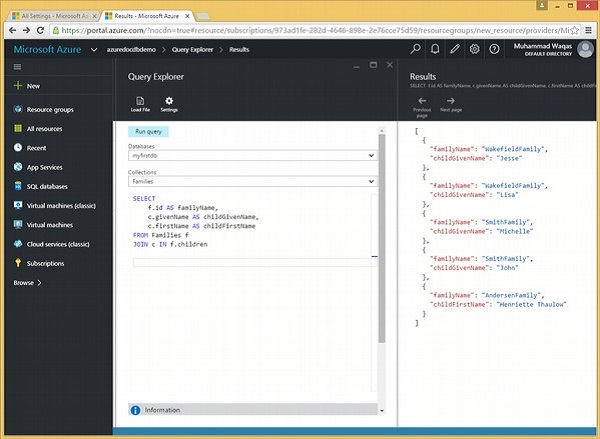
Voici la requête qui joindra le sous-document racine aux enfants. Nous avons des alias tels que f.id AS familyName, c.givenName AS childGivenName et c.firstName AS childFirstName.
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]La sortie ci-dessus montre que les noms de fichiers sont modifiés, mais il s'agit d'un changement temporaire et les documents d'origine ne sont pas modifiés.
Dans DocumentDB SQL, Microsoft a ajouté une fonctionnalité clé à l'aide de laquelle nous pouvons facilement créer un tableau. Cela signifie que lorsque nous exécutons une requête, cela crée un tableau de collection similaire à un objet JSON à la suite d'une requête.
Considérons les mêmes documents que dans les exemples précédents.
Voici le AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Voici le SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Voici le WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un œil à un exemple.
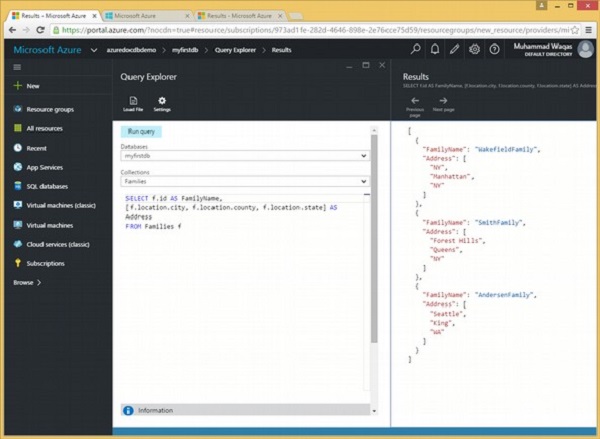
Voici la requête qui renverra le nom de famille et l'adresse de chaque famille.
SELECT f.id AS FamilyName,
[f.location.city, f.location.county, f.location.state] AS Address
FROM Families fComme on peut le voir, les champs de ville, de comté et d'état sont placés entre crochets, ce qui crée un tableau et ce tableau est nommé Address. Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"FamilyName": "WakefieldFamily",
"Address": [
"NY",
"Manhattan",
"NY"
]
},
{
"FamilyName": "SmithFamily",
"Address": [
"Forest Hills",
"Queens",
"NY"
]
},
{
"FamilyName": "AndersenFamily",
"Address": [
"Seattle",
"King",
"WA"
]
}
]Les informations sur la ville, le comté et l'état sont ajoutées dans le tableau d'adresses dans la sortie ci-dessus.
Dans DocumentDB SQL, la clause SELECT prend également en charge les expressions scalaires telles que les constantes, les expressions arithmétiques, les expressions logiques, etc. Normalement, les requêtes scalaires sont rarement utilisées, car elles n'interrogent pas réellement les documents de la collection, elles évaluent simplement les expressions. Mais il est toujours utile d'utiliser des requêtes d'expressions scalaires pour apprendre les bases, comment utiliser des expressions et mettre en forme JSON dans une requête, et ces concepts s'appliquent directement aux requêtes réelles que vous exécuterez sur les documents d'une collection.
Jetons un coup d'œil à un exemple qui contient plusieurs requêtes scalaires.
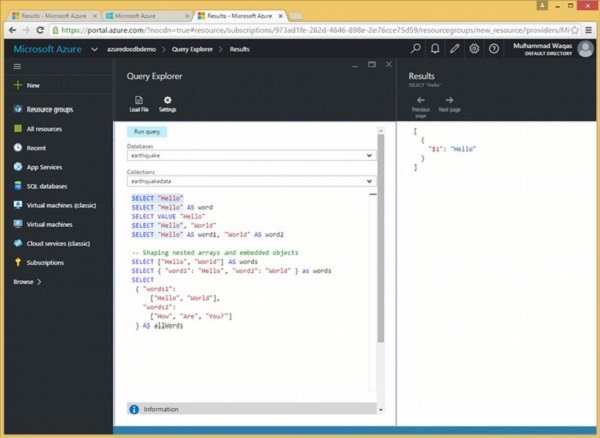
Dans l'explorateur de requêtes, sélectionnez uniquement le texte à exécuter et cliquez sur «Exécuter». Lançons ce premier.
SELECT "Hello"Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"$1": "Hello"
}
]Cette sortie peut sembler un peu déroutante, alors décomposons-la.
Tout d'abord, comme nous l'avons vu dans la dernière démo, les résultats des requêtes sont toujours contenus entre crochets car ils sont renvoyés sous forme de tableau JSON, même les résultats de requêtes d'expressions scalaires comme celle-ci qui ne renvoie qu'un seul document.
Nous avons un tableau avec un document, et ce document contient une seule propriété pour l'expression unique dans l'instruction SELECT.
L'instruction SELECT ne fournit pas de nom pour cette propriété, donc DocumentDB en génère automatiquement un en utilisant $ 1.
Ce n'est généralement pas ce que nous voulons, c'est pourquoi nous pouvons utiliser AS pour alias l'expression dans la requête, qui définit le nom de la propriété dans le document généré comme vous le souhaitez, mot, dans cet exemple.
SELECT "Hello" AS wordLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"word": "Hello"
}
]De même, voici une autre requête simple.
SELECT ((2 + 11 % 7)-2)/3La requête récupère la sortie suivante.
[
{
"$1": 1.3333333333333333
}
]Jetons un coup d'œil à un autre exemple de mise en forme de tableaux imbriqués et d'objets incorporés.
SELECT
{
"words1":
["Hello", "World"],
"words2":
["How", "Are", "You?"]
} AS allWordsLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"allWords": {
"words1": [
"Hello",
"World"
],
"words2": [
"How",
"Are",
"You?"
]
}
}
]Dans les bases de données relationnelles, une requête paramétrée est une requête dans laquelle des espaces réservés sont utilisés pour les paramètres et les valeurs de paramètre sont fournies au moment de l'exécution. DocumentDB prend également en charge les requêtes paramétrées, et les paramètres des requêtes paramétrées peuvent être exprimés avec la notation @ familière. La raison la plus importante d'utiliser des requêtes paramétrées est d'éviter les attaques par injection SQL. Il peut également fournir une gestion robuste et un échappement des entrées utilisateur.
Jetons un coup d'œil à un exemple où nous utiliserons le SDK .Net. Voici le code qui supprimera la collection.
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine(">>> Delete Collection {0} in {1} <<<",
collectionId, _database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}",
collectionId, _database.Id);
}La construction d'une requête paramétrée est la suivante.
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};Nous ne codons pas en dur la collectionId, donc cette méthode peut être utilisée pour supprimer n'importe quelle collection. Nous pouvons utiliser le symbole «@» pour préfixer les noms de paramètres, similaire à SQL Server.
Dans l'exemple ci-dessus, nous recherchons une collection spécifique par Id où le paramètre Id est défini dans ce SqlParameterCollection affecté à la propriété du paramètre de ce SqlQuerySpec. Le SDK effectue ensuite le travail de construction de la chaîne de requête finale pour DocumentDB avec l'ID collection incorporé à l'intérieur. Nous exécutons la requête et utilisons ensuite son SelfLink pour supprimer la collection.
Voici l'implémentation de la tâche CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM
c WHERE c.id = 'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "MyCollection1");
await DeleteCollection(client, "MyCollection2");
}
}Lorsque le code est exécuté, il produit la sortie suivante.
**** Delete Collection MyCollection1 in mydb ****
Deleted collection MyCollection1 from database myfirstdb
**** Delete Collection MyCollection2 in mydb ****
Deleted collection MyCollection2 from database myfirstdbJetons un œil à un autre exemple. Nous pouvons écrire une requête qui prend le nom et l'état de l'adresse comme paramètres, puis l'exécute pour diverses valeurs de lastname et location.state en fonction de l'entrée de l'utilisateur.
SELECT *
FROM Families f
WHERE f.lastName = @lastName AND f.location.state = @addressStateCette demande peut ensuite être envoyée à DocumentDB en tant que requête JSON paramétrée, comme indiqué dans le code suivant.
{
"query": "SELECT * FROM Families f WHERE f.lastName = @lastName AND
f.location.state = @addressState",
"parameters": [
{"name": "@lastName", "value": "Wakefield"},
{"name": "@addressState", "value": "NY"},
]
}DocumentDB prend en charge une multitude de fonctions intégrées pour les opérations courantes qui peuvent être utilisées dans les requêtes. Il existe de nombreuses fonctions pour effectuer des calculs mathématiques, ainsi que des fonctions de vérification de type extrêmement utiles lorsque vous travaillez avec différents schémas. Ces fonctions peuvent tester si une certaine propriété existe et s'il s'agit d'un nombre ou d'une chaîne, d'un booléen ou d'un objet.
Nous obtenons également ces fonctions pratiques pour analyser et manipuler des chaînes, ainsi que plusieurs fonctions pour travailler avec des tableaux vous permettant de faire des choses comme concaténer des tableaux et tester pour voir si un tableau contient un élément particulier.
Voici les différents types de fonctions intégrées -
| S.No. | Fonctions et description intégrées |
|---|---|
| 1 | Fonctions mathématiques Les fonctions mathématiques effectuent un calcul, généralement basé sur des valeurs d'entrée fournies sous forme d'arguments, et renvoient une valeur numérique. |
| 2 | Fonctions de vérification de type Les fonctions de vérification de type vous permettent de vérifier le type d'une expression dans les requêtes SQL. |
| 3 | Fonctions de chaîne Les fonctions de chaîne effectuent une opération sur une valeur d'entrée de chaîne et renvoient une valeur de chaîne, numérique ou booléenne. |
| 4 | Fonctions de tableau Les fonctions de tableau effectuent une opération sur une valeur d'entrée de tableau et retournent sous la forme d'une valeur numérique, booléenne ou de tableau. |
| 5 | Fonctions spatiales DocumentDB prend également en charge les fonctions intégrées de l'Open Geospatial Consortium (OGC) pour les requêtes géospatiales. |
Dans DocumentDB, nous utilisons en fait SQL pour interroger des documents. Si nous faisons du développement .NET, il existe également un fournisseur LINQ qui peut être utilisé et qui peut générer le SQL approprié à partir d'une requête LINQ.
Types de données pris en charge
Dans DocumentDB, tous les types primitifs JSON sont pris en charge dans le fournisseur LINQ inclus avec le SDK DocumentDB .NET, qui sont les suivants:
- Numeric
- Boolean
- String
- Null
Expression prise en charge
Les expressions scalaires suivantes sont prises en charge dans le fournisseur LINQ inclus avec le SDK DocumentDB .NET.
Constant Values - Inclut les valeurs constantes des types de données primitifs.
Property/Array Index Expressions - Les expressions font référence à la propriété d'un objet ou d'un élément de tableau.
Arithmetic Expressions - Inclut les expressions arithmétiques courantes sur les valeurs numériques et booléennes.
String Comparison Expression - Comprend la comparaison d'une valeur de chaîne à une valeur de chaîne constante.
Object/Array Creation Expression- Renvoie un objet de type valeur composée ou de type anonyme ou un tableau de ces objets. Ces valeurs peuvent être imbriquées.
Opérateurs LINQ pris en charge
Voici une liste des opérateurs LINQ pris en charge dans le fournisseur LINQ inclus avec le SDK DocumentDB .NET.
Select - Les projections se traduisent par SQL SELECT, y compris la construction d'objets.
Where- Les filtres se traduisent en SQL WHERE et prennent en charge la traduction entre &&, || et ! aux opérateurs SQL.
SelectMany- Permet le déroulement des tableaux à la clause SQL JOIN. Peut être utilisé pour chaîner / imbriquer des expressions pour filtrer les éléments du tableau.
OrderBy and OrderByDescending - Se traduit par ORDER BY croissant / décroissant.
CompareTo- Se traduit par des comparaisons de gamme. Couramment utilisé pour les chaînes car elles ne sont pas comparables dans .NET.
Take - Traduit en SQL TOP pour limiter les résultats d'une requête.
Math Functions - Prend en charge la traduction de .NET Abs, Acos, Asin, Atan, Ceiling, Cos, Exp, Floor, Log, Log10, Pow, Round, Sign, Sin, Sqrt, Tan, Truncate vers les fonctions intégrées SQL équivalentes.
String Functions - Prend en charge la traduction de .NET Concat, Contains, EndsWith, IndexOf, Count, ToLower, TrimStart, Replace, Reverse, TrimEnd, StartsWith, SubString, ToUpper vers les fonctions intégrées SQL équivalentes.
Array Functions - Prend en charge la traduction de Concat, Contains et Count de .NET vers les fonctions intégrées SQL équivalentes.
Geospatial Extension Functions - Prend en charge la traduction des méthodes de stub Distance, Within, IsValid et IsValidDetailed vers les fonctions intégrées SQL équivalentes.
User-Defined Extension Function - Prend en charge la traduction de la méthode de stub UserDefinedFunctionProvider.Invoke vers la fonction définie par l'utilisateur correspondante.
Miscellaneous- Prend en charge la traduction des opérateurs de coalescence et conditionnels. Peut traduire Contains en String CONTAINS, ARRAY_CONTAINS ou SQL IN selon le contexte.
Jetons un coup d'œil à un exemple où nous utiliserons le SDK .Net. Voici les trois documents que nous allons considérer pour cet exemple.
Nouveau client 1
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}Nouveau client 2
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "678 Main Street",
"location": {
"city": "London",
"stateProvinceName": " London "
},
"postalCode": "11229",
"countryRegionName": "United Kingdom"
},
}Nouveau client 3
{
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "12 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}Voici le code dans lequel nous interrogeons à l'aide de LINQ. Nous avons défini une requête LINQ dansq, mais il ne s'exécutera pas tant que nous n'exécuterons pas .ToList dessus.
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == "United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} US customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}Le SDK convertira notre requête LINQ en syntaxe SQL pour DocumentDB, générant une clause SELECT et WHERE basée sur notre syntaxe LINQ.
Appelons les requêtes ci-dessus à partir de la tâche CreateDocumentClient.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
QueryDocumentsWithLinq(client);
}
}Lorsque le code ci-dessus est exécuté, il produit la sortie suivante.
**** Query Documents (LINQ) ****
Quering for US customers (LINQ)
Found 2 US customers
Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn
Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: BrooklynDe nos jours, JavaScript est partout, et pas seulement dans les navigateurs. DocumentDB embrasse JavaScript comme une sorte de T-SQL moderne et prend en charge l'exécution transactionnelle de la logique JavaScript de manière native, directement dans le moteur de base de données. DocumentDB fournit un modèle de programmation pour exécuter la logique d'application basée sur JavaScript directement sur les collections en termes de procédures stockées et de déclencheurs.
Jetons un coup d'œil à un exemple où nous créons une procédure de stockage simple. Voici les étapes -
Step 1 - Créez de nouvelles applications de console.
Step 2- Ajoutez le SDK .NET de NuGet. Nous utilisons le SDK .NET ici, ce qui signifie que nous allons écrire du code C # pour créer, exécuter, puis supprimer notre procédure stockée, mais la procédure stockée elle-même est écrite en JavaScript.
Step 3 - Cliquez avec le bouton droit sur le projet dans l'explorateur de solutions.
Step 4 - Ajoutez un nouveau fichier JavaScript pour la procédure stockée et appelez-le HelloWorldStoreProce.js
Chaque procédure stockée n'est qu'une fonction JavaScript, nous allons donc créer une nouvelle fonction et naturellement nous nommerons également cette fonction HelloWorldStoreProce. Peu importe si nous donnons un nom à la fonction. DocumentDB ne fera référence à cette procédure stockée que par l'ID que nous fournissons lorsque nous la créons.
function HelloWorldStoreProce() {
var context = getContext();
var response = context.getResponse();
response.setBody('Hello, and welcome to DocumentDB!');
}La procédure stockée ne fait que récupérer l'objet de réponse du contexte et appeler son setBodypour renvoyer une chaîne à l'appelant. Dans le code C #, nous allons créer la procédure stockée, l'exécuter, puis la supprimer.
Les procédures stockées sont étendues par collection, nous aurons donc besoin du SelfLink de la collection pour créer la procédure stockée.
Step 5 - Première requête pour le myfirstdb base de données, puis pour la MyCollection collection.
La création d'une procédure stockée est comme la création de toute autre ressource dans DocumentDB.
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink, "SELECT * FROM
c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client.
CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client.ExecuteStoredProcedureAsync
(sproc.SelfLink); Console.WriteLine("Executed stored procedure; response = {0}", result.Response); // Delete stored procedure await client.DeleteStoredProcedureAsync(sproc.SelfLink); Console.WriteLine("Deleted stored procedure {0} ({1})", sproc.Id, sproc.ResourceId); } }
Step 6 - Créez d'abord un objet de définition avec l'ID de la nouvelle ressource, puis appelez l'une des méthodes Create sur le DocumentClientobjet. Dans le cas d'une procédure stockée, la définition comprend l'ID et le code JavaScript réel que vous souhaitez envoyer au serveur.
Step 7 - Appeler File.ReadAllText pour extraire le code de procédure stockée du fichier JS.
Step 8 - Affectez le code de procédure stockée à la propriété body de l'objet de définition.
En ce qui concerne DocumentDB, l'ID que nous spécifions ici, dans la définition, est le nom de la procédure stockée, quel que soit le nom que nous appelons réellement la fonction JavaScript.
Néanmoins, lors de la création de procédures stockées et d'autres objets côté serveur, il est recommandé de nommer les fonctions JavaScript et que ces noms de fonction correspondent à l'ID que nous avons défini dans la définition de DocumentDB.
Step 9 - Appeler CreateStoredProcedureAsync, passant dans le SelfLink pour le MyCollectioncollection et la définition de la procédure stockée. Cela crée la procédure stockée etResourceId que DocumentDB lui a attribué.
Step 10 - Appelez la procédure stockée. ExecuteStoredProcedureAsyncprend un paramètre de type que vous définissez sur le type de données attendu de la valeur renvoyée par la procédure stockée, que vous pouvez spécifier simplement en tant qu'objet si vous souhaitez qu'un objet dynamique soit renvoyé. Il s'agit d'un objet dont les propriétés seront liées au moment de l'exécution.
Dans cet exemple, nous savons que notre procédure stockée renvoie simplement une chaîne et nous appelons donc ExecuteStoredProcedureAsync<string>.
Voici l'implémentation complète du fichier Program.cs.
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBStoreProce {
class Program {
private static void Main(string[] args) {
Task.Run(async () => {
await SimpleStoredProcDemo();
}).Wait();
}
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client
.CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})", sproc
.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client
.ExecuteStoredProcedureAsync<string>(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}",
result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
}
}Lorsque le code ci-dessus est exécuté, il produit la sortie suivante.
Created stored procedure HelloWorldStoreProce (Ic8LAMEUVgACAAAAAAAAgA==)
Executed stored procedure; response = Hello, and welcome to DocumentDB!Comme indiqué dans la sortie ci-dessus, la propriété de réponse a le "Bonjour et bienvenue dans DocumentDB!" renvoyé par notre procédure stockée.
DocumentDB SQL prend en charge les fonctions définies par l'utilisateur (UDF). Les UDF ne sont qu'un autre type de fonctions JavaScript que vous pouvez écrire et qui fonctionnent à peu près comme prévu. Vous pouvez créer des UDF pour étendre le langage de requête avec une logique métier personnalisée que vous pouvez référencer dans vos requêtes.
La syntaxe SQL DocumentDB est étendue pour prendre en charge la logique d'application personnalisée à l'aide de ces UDF. Les fonctions UDF peuvent être enregistrées auprès de DocumentDB, puis référencées dans le cadre d'une requête SQL.
Considérons les trois documents suivants pour cet exemple.
AndersenFamily le document est le suivant.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily le document est le suivant.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily le document est le suivant.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple où nous allons créer des UDF simples.
Voici la mise en œuvre de CreateUserDefinedFunctions.
private async static Task CreateUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create User Defined Functions ****");
Console.WriteLine();
await CreateUserDefinedFunction(client, "udfRegEx");
}Nous avons un udfRegEx, et dans CreateUserDefinedFunction, nous obtenons son code JavaScript à partir de notre fichier local. Nous construisons l'objet de définition pour le nouvel UDF et appelons CreateUserDefinedFunctionAsync avec SelfLink de la collection et l'objet udfDefinition comme indiqué dans le code suivant.
private async static Task<UserDefinedFunction>
CreateUserDefinedFunction(DocumentClient client, string udfId) {
var udfBody = File.ReadAllText(@"..\..\Server\" + udfId + ".js");
var udfDefinition = new UserDefinedFunction {
Id = udfId,
Body = udfBody
};
var result = await client
.CreateUserDefinedFunctionAsync(_collection.SelfLink, udfDefinition);
var udf = result.Resource;
Console.WriteLine("Created user defined function {0}; RID: {1}",
udf.Id, udf.ResourceId);
return udf;
}Nous récupérons le nouvel UDF à partir de la propriété resource du résultat et le renvoyons à l'appelant. Pour afficher l'UDF existante, voici l'implémentation deViewUserDefinedFunctions. Nous appelonsCreateUserDefinedFunctionQuery et parcourez-les comme d'habitude.
private static void ViewUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View UDFs ****");
Console.WriteLine();
var udfs = client
.CreateUserDefinedFunctionQuery(_collection.UserDefinedFunctionsLink)
.ToList();
foreach (var udf in udfs) {
Console.WriteLine("User defined function {0}; RID: {1}", udf.Id, udf.ResourceId);
}
}DocumentDB SQL ne fournit pas de fonctions intégrées pour rechercher des sous-chaînes ou des expressions régulières, par conséquent le petit one-liner suivant comble cette lacune qui est une fonction JavaScript.
function udfRegEx(input, regex) {
return input.match(regex);
}Étant donné la chaîne d'entrée dans le premier paramètre, utilisez la prise en charge des expressions régulières intégrées de JavaScript en passant la chaîne de correspondance de modèle dans le deuxième paramètre dans.match. Nous pouvons exécuter une requête de sous-chaîne pour trouver tous les magasins avec le mot Andersen dans leurlastName propriété.
private static void Execute_udfRegEx(DocumentClient client) {
var sql = "SELECT c.name FROM c WHERE udf.udfRegEx(c.lastName, 'Andersen') != null";
Console.WriteLine();
Console.WriteLine("Querying for Andersen");
var documents = client.CreateDocumentQuery(_collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} Andersen:", documents.Count);
foreach (var document in documents) {
Console.WriteLine("Id: {0}, Name: {1}", document.id, document.lastName);
}
}Notez que nous devons qualifier chaque référence UDF avec le préfixe udf. Nous venons de transmettre le SQL àCreateDocumentQuerycomme toute requête ordinaire. Enfin, appelons les requêtes ci-dessus à partir duCreateDocumentClient tâche
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)){
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE
c.id = 'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'Families'").AsEnumerable().First();
await CreateUserDefinedFunctions(client);
ViewUserDefinedFunctions(client);
Execute_udfRegEx(client);
}
}Lorsque le code ci-dessus est exécuté, il produit la sortie suivante.
**** Create User Defined Functions ****
Created user defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
**** View UDFs ****
User defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
Querying for Andersen
Found 1 Andersen:
Id: AndersenFamily, Name: AndersenComposite Queryvous permet de combiner les données des requêtes existantes, puis d'appliquer des filtres, des agrégats, etc. avant de présenter les résultats du rapport, qui montrent l'ensemble de données combiné. La requête composite récupère plusieurs niveaux d'informations associées sur les requêtes existantes et présente les données combinées sous la forme d'un résultat de requête unique et aplati.
À l'aide de la requête composite, vous avez également la possibilité de -
Sélectionnez l'option d'élagage SQL pour supprimer les tables et les champs qui ne sont pas nécessaires en fonction des sélections d'attributs des utilisateurs.
Définissez les clauses ORDER BY et GROUP BY.
Définissez la clause WHERE comme filtre sur l'ensemble de résultats d'une requête composite.
Les opérateurs ci-dessus peuvent être composés pour former des requêtes plus puissantes. Étant donné que DocumentDB prend en charge les collections imbriquées, la composition peut être concaténée ou imbriquée.
Considérons les documents suivants pour cet exemple.
AndersenFamily le document est le suivant.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily le document est le suivant.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily le document est le suivant.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Jetons un coup d'œil à un exemple de requête concaténée.
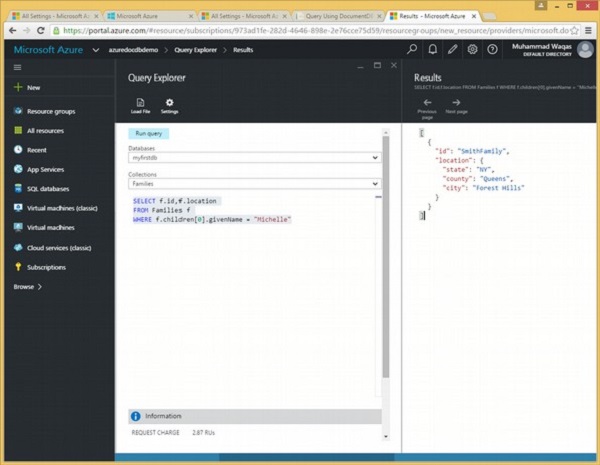
Voici la requête qui récupérera l'id et l'emplacement de la famille où le premier enfant givenName est Michelle.
SELECT f.id,f.location
FROM Families f
WHERE f.children[0].givenName = "Michelle"Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"id": "SmithFamily",
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
}
]Prenons un autre exemple de requête concaténée.
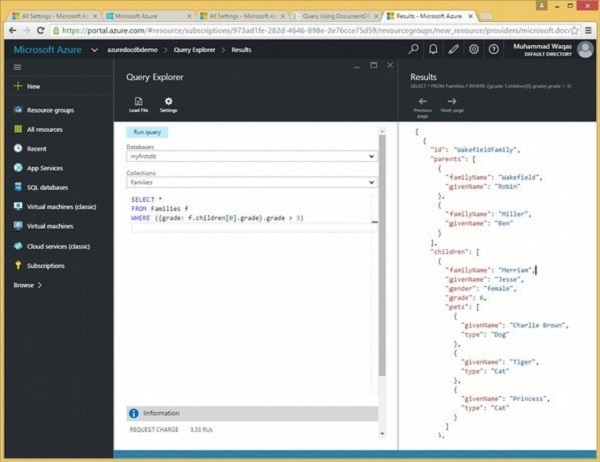
Voici la requête qui renverra tous les documents dont la première note enfant est supérieure à 3.
SELECT *
FROM Families f
WHERE ({grade: f.children[0].grade}.grade > 3)Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Jetons un coup d'œil à un example de requêtes imbriquées.
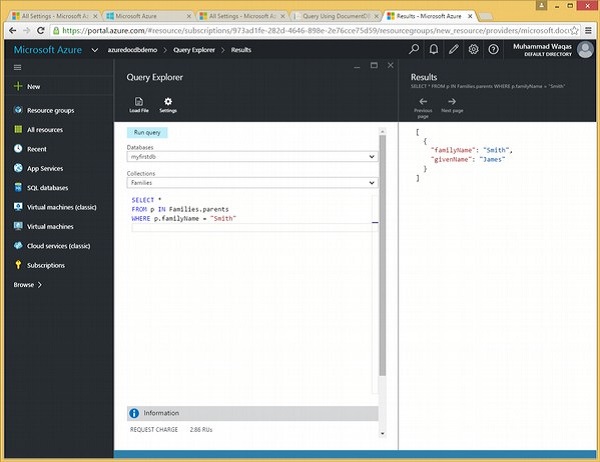
Voici la requête qui itérera tous les parents, puis retournera le document où familyName est Smith.
SELECT *
FROM p IN Families.parents
WHERE p.familyName = "Smith"Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
{
"familyName": "Smith",
"givenName": "James"
}
]Considérons another example de la requête imbriquée.
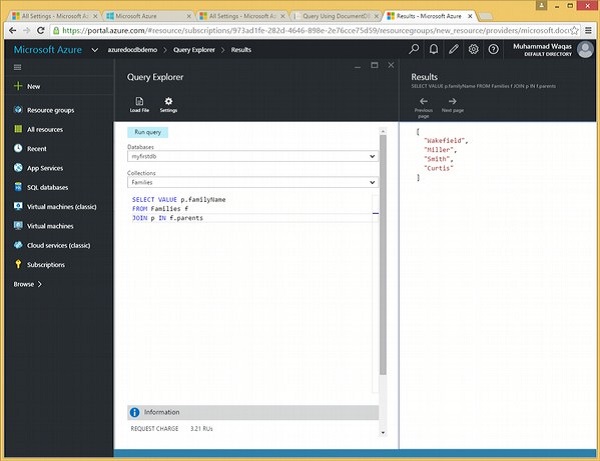
Voici la requête qui retournera tous les familyName.
SELECT VALUE p.familyName
FROM Families f
JOIN p IN f.parentsLorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
[
"Wakefield",
"Miller",
"Smith",
"Curtis"
]