Git - Concepts de base
Système de contrôle de version
Version Control System (VCS) est un logiciel qui aide les développeurs de logiciels à travailler ensemble et à maintenir un historique complet de leur travail.
Vous trouverez ci-dessous les fonctions d'un VCS -
- Permet aux développeurs de travailler simultanément.
- Ne permet pas d'écraser les modifications de l'autre.
- Conserve un historique de chaque version.
Voici les types de VCS -
- Système de contrôle de version centralisé (CVCS).
- Système de contrôle de version distribué / décentralisé (DVCS).
Dans ce chapitre, nous nous concentrerons uniquement sur le système de contrôle de version distribué et en particulier sur Git. Git relève du système de contrôle de version distribué.
Système de contrôle de version distribué
Le système de contrôle de version centralisé (CVCS) utilise un serveur central pour stocker tous les fichiers et permet la collaboration en équipe. Mais l'inconvénient majeur de CVCS est son point de défaillance unique, c'est-à-dire la défaillance du serveur central. Malheureusement, si le serveur central tombe en panne pendant une heure, alors pendant cette heure, personne ne peut collaborer du tout. Et même dans le pire des cas, si le disque du serveur central est corrompu et qu'une sauvegarde appropriée n'a pas été effectuée, vous perdrez alors tout l'historique du projet. Ici, le système de contrôle de version distribué (DVCS) entre en scène.
Les clients DVCS récupèrent non seulement le dernier instantané du répertoire, mais ils reflètent également entièrement le référentiel. Si le serveur tombe en panne, le référentiel de n'importe quel client peut être recopié sur le serveur pour le restaurer. Chaque extraction est une sauvegarde complète du référentiel. Git ne repose pas sur le serveur central et c'est pourquoi vous pouvez effectuer de nombreuses opérations lorsque vous êtes hors ligne. Vous pouvez valider les modifications, créer des branches, afficher les journaux et effectuer d'autres opérations lorsque vous êtes hors ligne. Vous n'avez besoin d'une connexion réseau que pour publier vos modifications et prendre les dernières modifications.
Avantages de Git
Gratuit et open source
Git est publié sous licence open source GPL. Il est disponible gratuitement sur Internet. Vous pouvez utiliser Git pour gérer des projets immobiliers sans payer un seul centime. Comme il s'agit d'une open source, vous pouvez télécharger son code source et également effectuer des modifications en fonction de vos besoins.
Rapide et petit
La plupart des opérations étant effectuées localement, cela présente un énorme avantage en termes de rapidité. Git ne repose pas sur le serveur central; c'est pourquoi, il n'est pas nécessaire d'interagir avec le serveur distant pour chaque opération. La partie principale de Git est écrite en C, ce qui évite les surcharges d'exécution associées à d'autres langages de haut niveau. Bien que Git reflète l'ensemble du référentiel, la taille des données côté client est petite. Cela illustre l'efficacité de Git pour la compression et le stockage des données côté client.
Sauvegarde implicite
Les chances de perdre des données sont très rares lorsqu'il y en a plusieurs copies. Les données présentes sur n'importe quel côté client reflètent le référentiel, elles peuvent donc être utilisées en cas de panne ou de corruption du disque.
Sécurité
Git utilise une fonction de hachage cryptographique commune appelée fonction de hachage sécurisé (SHA1), pour nommer et identifier les objets dans sa base de données. Chaque fichier et commit est additionné de contrôle et récupéré par sa somme de contrôle au moment de l'extraction. Cela implique qu'il est impossible de modifier le fichier, la date et le message de validation et toute autre donnée de la base de données Git sans connaître Git.
Pas besoin de matériel puissant
Dans le cas du CVCS, le serveur central doit être suffisamment puissant pour répondre aux demandes de toute l'équipe. Pour les petites équipes, ce n'est pas un problème, mais à mesure que la taille de l'équipe augmente, les limitations matérielles du serveur peuvent constituer un goulot d'étranglement des performances. Dans le cas de DVCS, les développeurs n'interagissent pas avec le serveur à moins qu'ils n'aient besoin de pousser ou d'extraire des modifications. Tout le gros du travail se passe du côté client, le matériel du serveur peut donc être très simple.
Branchement plus facile
CVCS utilise un mécanisme de copie bon marché.Si nous créons une nouvelle branche, il copiera tous les codes dans la nouvelle branche, ce qui prend du temps et n'est pas efficace. De plus, la suppression et la fusion de branches dans CVCS sont compliquées et prennent du temps. Mais la gestion des succursales avec Git est très simple. La création, la suppression et la fusion des branches ne prennent que quelques secondes.
Terminologies DVCS
Dépôt local
Chaque outil VCS fournit un lieu de travail privé comme copie de travail. Les développeurs apportent des modifications sur leur lieu de travail privé et après validation, ces modifications deviennent une partie du référentiel. Git va encore plus loin en leur fournissant une copie privée de l'ensemble du référentiel. Les utilisateurs peuvent effectuer de nombreuses opérations avec ce référentiel, telles que l'ajout d'un fichier, la suppression d'un fichier, le renommer un fichier, le déplacement d'un fichier, la validation des modifications, etc.
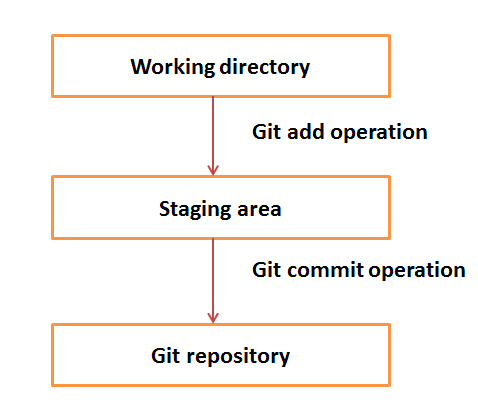
Répertoire de travail et zone de transit ou index
Le répertoire de travail est l'endroit où les fichiers sont extraits. Dans d'autres CVCS, les développeurs apportent généralement des modifications et commettent leurs modifications directement dans le référentiel. Mais Git utilise une stratégie différente. Git ne suit pas chaque fichier modifié. Chaque fois que vous validez une opération, Git recherche les fichiers présents dans la zone de préparation. Seuls les fichiers présents dans la zone intermédiaire sont pris en compte pour la validation et non tous les fichiers modifiés.
Voyons le flux de travail de base de Git.
Step 1 - Vous modifiez un fichier du répertoire de travail.
Step 2 - Vous ajoutez ces fichiers à la zone de préparation.
Step 3- Vous effectuez une opération de validation qui déplace les fichiers de la zone intermédiaire. Après l'opération push, il stocke les modifications de manière permanente dans le référentiel Git.
Supposons que vous ayez modifié deux fichiers, à savoir «sort.c» et «search.c» et que vous vouliez deux commits différents pour chaque opération. Vous pouvez ajouter un fichier dans la zone de préparation et faire une validation. Après le premier commit, répétez la même procédure pour un autre fichier.
# First commit
[bash]$ git add sort.c
# adds file to the staging area
[bash]$ git commit –m “Added sort operation”
# Second commit
[bash]$ git add search.c
# adds file to the staging area
[bash]$ git commit –m “Added search operation”Blobs
Blob signifie Binaire Large Object. Chaque version d'un fichier est représentée par blob. Un objet blob contient les données du fichier mais ne contient aucune métadonnée sur le fichier. C'est un fichier binaire, et dans la base de données Git, il est nommé hachage SHA1 de ce fichier. Dans Git, les fichiers ne sont pas adressés par des noms. Tout est axé sur le contenu.
Des arbres
L'arbre est un objet, qui représente un répertoire. Il contient des objets blob ainsi que d'autres sous-répertoires. Un arbre est un fichier binaire qui stocke les références aux objets blob et aux arbres qui sont également nommés commeSHA1 hachage de l'objet arborescent.
S'engage
Commit contient l'état actuel du référentiel. Un commit est également nommé parSHA1hacher. Vous pouvez considérer un objet de validation comme un nœud de la liste liée. Chaque objet de validation a un pointeur vers l'objet de validation parent. À partir d'un commit donné, vous pouvez revenir en arrière en regardant le pointeur parent pour afficher l'historique du commit. Si un commit a plusieurs commits parents, alors ce commit particulier a été créé en fusionnant deux branches.
Branches
Les branches sont utilisées pour créer une autre ligne de développement. Par défaut, Git a une branche principale, qui est la même que le tronc dans Subversion. Habituellement, une branche est créée pour travailler sur une nouvelle fonctionnalité. Une fois la fonctionnalité terminée, elle est fusionnée avec la branche principale et nous supprimons la branche. Chaque branche est référencée par HEAD, qui pointe vers le dernier commit de la branche. Chaque fois que vous effectuez un commit, HEAD est mis à jour avec le dernier commit.
Mots clés
La balise attribue un nom significatif avec une version spécifique dans le référentiel. Les balises sont très similaires aux branches, mais la différence est que les balises sont immuables. Cela signifie que la balise est une branche, que personne n'a l'intention de modifier. Une fois qu'une balise est créée pour un commit particulier, même si vous créez un nouveau commit, il ne sera pas mis à jour. Habituellement, les développeurs créent des balises pour les versions de produits.
Cloner
L'opération de clonage crée l'instance du référentiel. L'opération de clonage extrait non seulement la copie de travail, mais reflète également le référentiel complet. Les utilisateurs peuvent effectuer de nombreuses opérations avec ce référentiel local. Le seul moment où le réseau est impliqué est lorsque les instances du référentiel sont en cours de synchronisation.
Tirer
L'opération d'extraction copie les modifications d'une instance de référentiel distante vers une instance locale. L'opération d'extraction est utilisée pour la synchronisation entre deux instances de référentiel. Ceci est identique à l'opération de mise à jour dans Subversion.
Pousser
L'opération Push copie les modifications d'une instance de référentiel local vers une instance distante. Ceci est utilisé pour stocker les modifications de manière permanente dans le référentiel Git. C'est la même chose que l'opération de validation dans Subversion.
TÊTE
HEAD est un pointeur, qui pointe toujours vers le dernier commit de la branche. Chaque fois que vous effectuez un commit, HEAD est mis à jour avec le dernier commit. Les têtes des branches sont stockées dans.git/refs/heads/ annuaire.
[CentOS]$ ls -1 .git/refs/heads/
master
[CentOS]$ cat .git/refs/heads/master
570837e7d58fa4bccd86cb575d884502188b0c49Révision
La révision représente la version du code source. Les révisions dans Git sont représentées par des commits. Ces commits sont identifiés parSHA1 hachages sécurisés.
URL
URL représente l'emplacement du référentiel Git. L'URL Git est stockée dans le fichier de configuration.
[tom@CentOS tom_repo]$ pwd
/home/tom/tom_repo
[tom@CentOS tom_repo]$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[remote "origin"]
url = [email protected]:project.git
fetch = +refs/heads/*:refs/remotes/origin/*