KDB + - Guide rapide
Ceci est une quide complète à kdb+des systèmes kx, destinés principalement à ceux qui apprennent de manière indépendante. kdb +, introduit en 2003, est la nouvelle génération de la base de données kdb conçue pour capturer, analyser, comparer et stocker des données.
Un système kdb + contient les deux composants suivants -
KDB+ - la base de données (k base de données plus)
Q - le langage de programmation pour travailler avec kdb +
Tous les deux kdb+ et q sont écrits en k programming language (pareil que q mais moins lisible).
Contexte
Kdb + / q est à l'origine un langage académique obscur, mais au fil des ans, il a progressivement amélioré sa convivialité.
APL (1964, un langage de programmation)
A+ (1988, APL modifié par Arthur Whitney)
K (1993, version nette de A +, développée par A. Whitney)
Kdb (1998, base de données basée sur des colonnes en mémoire)
Kdb+/q (2003, langage q - version plus lisible de k)
Pourquoi et où utiliser KDB +
Pourquoi? - Si vous avez besoin d'une solution unique pour les données en temps réel avec analyse, vous devriez envisager kdb +. Kdb + stocke la base de données sous forme de fichiers natifs ordinaires, de sorte qu'il n'a pas de besoins particuliers en matière d'architecture matérielle et de stockage. Il convient de souligner que la base de données n'est qu'un ensemble de fichiers, votre travail administratif ne sera donc pas difficile.
Où utiliser KDB +?- Il est facile de compter quelles banques d'investissement n'utilisent PAS kdb + car la plupart d'entre elles l'utilisent actuellement ou prévoient de passer des bases de données conventionnelles à kdb +. Comme le volume de données augmente de jour en jour, nous avons besoin d'un système capable de gérer d'énormes volumes de données. KDB + remplit cette exigence. KDB + stocke non seulement une énorme quantité de données, mais les analyse également en temps réel.
Commencer
Avec autant de contexte, laissez-nous maintenant exposer et apprendre comment configurer un environnement pour KDB +. Nous allons commencer par télécharger et installer KDB +.
Téléchargement et installation de KDB +
Vous pouvez obtenir la version 32 bits gratuite de KDB +, avec toutes les fonctionnalités de la version 64 bits à partir de http://kx.com/software-download.php
Acceptez le contrat de licence, sélectionnez le système d'exploitation (disponible pour tous les principaux systèmes d'exploitation). Pour le système d'exploitation Windows, la dernière version est 3.2. Téléchargez la dernière version. Une fois que vous le décompressez, vous obtiendrez le nom du dossier“windows” et dans le dossier Windows, vous obtiendrez un autre dossier “q”. Copiez le toutq dossier sur votre lecteur c: /.
Ouvrez le terminal Run, tapez l'emplacement où vous stockez le qdossier; ce sera comme «c: /q/w32/q.exe». Une fois que vous appuyez sur Entrée, vous obtiendrez une nouvelle console comme suit -
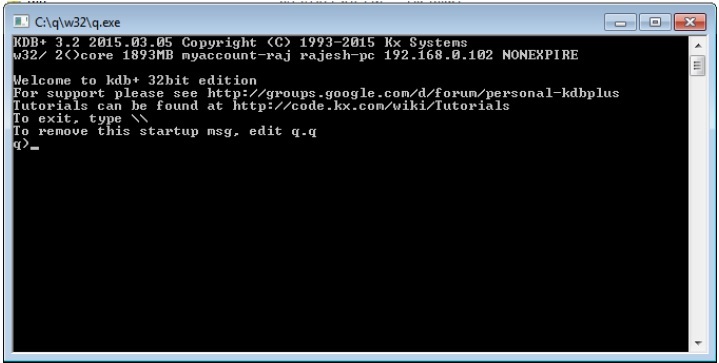
Sur la première ligne, vous pouvez voir le numéro de version qui est 3.2 et la date de sortie comme 2015.03.05
Disposition du répertoire
La version d'essai / gratuite est généralement installée dans les répertoires,
For linux/Mac −
~/q / main q directory (under the user’s home)
~/q/l32 / location of linux 32-bit executable
~/q/m32 / Location of mac 32-bit executableFor Windows −
c:/q / Main q directory
c:/q/w32/ / Location of windows 32-bit executableExample Files −
Une fois que vous avez téléchargé kdb +, la structure de répertoires de la plate-forme Windows apparaîtra comme suit -
Dans la structure de répertoires ci-dessus, trade.q et sp.q sont les fichiers d'exemple que nous pouvons utiliser comme point de référence.
Kdb + est une base de données performante et volumineuse conçue dès le départ pour gérer d'énormes volumes de données. Il est entièrement 64 bits et dispose d'un traitement multicœur et d'un multi-threading intégrés. La même architecture est utilisée pour les données en temps réel et historiques. La base de données intègre son propre langage de requête puissant,q, les analyses peuvent donc être exécutées directement sur les données.
kdb+tick est une architecture qui permet la capture, le traitement et l'interrogation de données historiques et en temps réel.
Architecture Kdb + / tick
L'illustration suivante fournit un aperçu général d'une architecture Kdb + / tick typique, suivi d'une brève explication des différents composants et du flux de données.
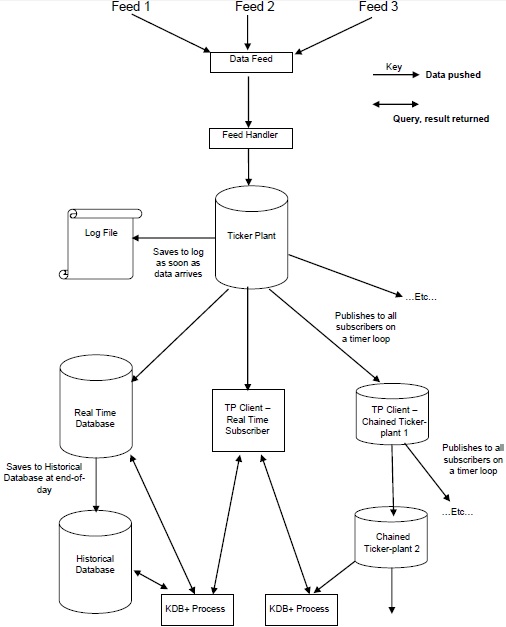
le Data Feeds sont des séries chronologiques de données qui sont principalement fournies par les fournisseurs de flux de données tels que Reuters, Bloomberg ou directement à partir d'échanges.
Pour obtenir les données pertinentes, les données du flux de données sont analysées par le feed handler.
Une fois que les données sont analysées par le gestionnaire de flux, elles sont transmises au ticker-plant.
Pour récupérer les données de tout échec, l'usine de téléscripteur met d'abord à jour / stocke les nouvelles données dans le fichier journal, puis met à jour ses propres tables.
Après la mise à jour des tables internes et des fichiers journaux, les données de boucle à temps sont envoyées / publiées en continu vers la base de données en temps réel et tous les abonnés chaînés qui ont demandé des données.
À la fin d'un jour ouvrable, le fichier journal est supprimé, un nouveau est créé et la base de données en temps réel est enregistrée dans la base de données historique. Une fois que toutes les données sont enregistrées dans la base de données historique, la base de données en temps réel purge ses tables.
Composants de l'architecture Kdb + Tick
Flux de données
Les flux de données peuvent être des données de marché ou d'autres séries chronologiques. Considérez les flux de données comme l'entrée brute du gestionnaire de flux. Les flux peuvent provenir directement de l'échange (données de diffusion en direct), des fournisseurs de nouvelles / données tels que Thomson-Reuters, Bloomberg ou toute autre agence externe.
Gestionnaire d'alimentation
Un gestionnaire de flux convertit le flux de données dans un format adapté à l'écriture dans kdb +. Il est connecté au flux de données et récupère et convertit les données du format spécifique au flux en un message Kdb + qui est publié dans le processus de téléscripteur. Généralement, un gestionnaire de flux est utilisé pour effectuer les opérations suivantes -
- Capturez les données selon un ensemble de règles.
- Traduisez (/ enrichissez) ces données d'un format à un autre.
- Récupérez les valeurs les plus récentes.
Usine de ticker
Ticker Plant est le composant le plus important de l'architecture KDB +. C'est la centrale de téléscripteur avec laquelle la base de données en temps réel ou directement les abonnés (clients) sont connectés pour accéder aux données financières. Il fonctionne enpublish and subscribemécanisme. Une fois que vous avez obtenu un abonnement (licence), une publication de tick (de routine) de l'éditeur (ticker plant) est définie. Il effectue les opérations suivantes -
Reçoit les données du gestionnaire de flux.
Immédiatement après que l'usine de téléscripteur ait reçu les données, elle stocke une copie sous forme de fichier journal et la met à jour une fois que l'usine de téléscripteur reçoit une mise à jour afin qu'en cas de panne, nous ne devrions pas avoir de perte de données.
Les clients (abonné en temps réel) peuvent directement souscrire au ticker-plant.
À la fin de chaque jour ouvrable, c'est-à-dire une fois que la base de données en temps réel reçoit le dernier message, elle stocke toutes les données du jour dans la base de données historique et les transmet à tous les abonnés qui se sont abonnés aux données du jour. Ensuite, il réinitialise toutes ses tables. Le fichier journal est également supprimé une fois que les données sont stockées dans la base de données historique ou dans un autre abonné directement lié à la base de données en temps réel (rtdb).
En conséquence, l'usine de téléscripteur, la base de données en temps réel et la base de données historique sont opérationnelles 24 heures sur 24, 7 jours sur 7.
Puisque le ticker-plant est une application Kdb +, ses tables peuvent être interrogées en utilisant qcomme toute autre base de données Kdb +. Tous les clients de l'usine de téléscripteur ne devraient avoir accès à la base de données qu'en tant qu'abonnés.
Base de données en temps réel
Une base de données en temps réel (rdb) stocke les données du jour. Il est directement connecté à l'usine de ticker. En règle générale, il serait stocké en mémoire pendant les heures de marché (un jour) et écrit dans la base de données historique (hdb) à la fin de la journée. Comme les données (données rdb) sont stockées en mémoire, le traitement est extrêmement rapide.
Comme kdb + recommande d'avoir une taille de RAM qui est quatre fois ou plus la taille attendue des données par jour, la requête qui s'exécute sur rdb est très rapide et offre des performances supérieures. Étant donné qu'une base de données en temps réel ne contient que les données du jour, la colonne de date (paramètre) n'est pas requise.
Par exemple, nous pouvons avoir des requêtes rdb comme,
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100Base de données historique
Si nous devons calculer les estimations d'une entreprise, nous devons disposer de ses données historiques. Une base de données historique (hdb) contient les données des transactions effectuées dans le passé. L'enregistrement de chaque nouvelle journée serait ajouté au hdb à la fin de la journée. Les grandes tables dans le hdb sont soit stockées évasées (chaque colonne est stockée dans son propre fichier), soit elles sont stockées partitionnées par des données temporelles. De plus, certaines bases de données très volumineuses peuvent être davantage partitionnées en utilisantpar.txt (fichier).
Ces stratégies de stockage (évasé, partitionné, etc.) sont efficaces lors de la recherche ou de l'accès aux données à partir d'une grande table.
Une base de données historique peut également être utilisée à des fins de reporting interne et externe, c'est-à-dire à des fins d'analyse. Par exemple, supposons que nous souhaitons obtenir les transactions de l'entreprise d'IBM pour un jour particulier à partir du nom de la table d'échange (ou de tout autre nom), nous devons écrire une requête comme suit -
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - Nous écrirons toutes ces requêtes une fois que nous aurons un aperçu de la q Langue.
Kdb + est livré avec son langage de programmation intégré appelé q. Il intègre un sur-ensemble de SQL standard qui est étendu pour l'analyse de séries chronologiques et offre de nombreux avantages par rapport à la version standard. Toute personne familiarisée avec SQL peut apprendreq en quelques jours et être en mesure de rédiger rapidement ses propres requêtes ad hoc.
Démarrage de l'environnement «q»
Pour commencer à utiliser kdb +, vous devez démarrer le qsession. Il existe trois façons de démarrer unq session -
Tapez simplement «c: /q/w32/q.exe» sur votre terminal d'exécution.
Démarrez le terminal de commande MS-DOS et tapez q.
Copiez le q.exe fichier sur «C: \ Windows \ System32» et sur le terminal d'exécution, tapez simplement «q».
Ici, nous supposons que vous travaillez sur une plate-forme Windows.
Types de données
Le tableau suivant fournit une liste des types de données pris en charge -
| Nom | Exemple | Carboniser | Type | Taille |
|---|---|---|---|---|
| booléen | 1b | b | 1 | 1 |
| octet | 0xff | X | 4 | 1 |
| court | 23h | h | 5 | 2 |
| int | 23i | je | 6 | 4 |
| longue | 23j | j | sept | 8 |
| réel | 2.3e | e | 8 | 4 |
| flotte | 2.3f | F | 9 | 8 |
| carboniser | "une" | c | dix | 1 |
| varchar | `ab | s | 11 | * |
| mois | 2003.03m | m | 13 | 4 |
| Date | 2015.03.17T18: 01: 40.134 | z | 15 | 8 |
| minute | 08:31 | u | 17 | 4 |
| seconde | 08:31:53 | v | 18 | 4 |
| temps | 18: 03: 18.521 | t | 19 | 4 |
| énumération | `u $` b, où u: `a`b | * | 20 | 4 |
Formation d'atomes et de listes
Les atomes sont des entités uniques, par exemple, un seul nombre, un caractère ou un symbole. Dans le tableau ci-dessus (de différents types de données), tous les types de données pris en charge sont des atomes. Une liste est une séquence d'atomes ou d'autres types comprenant des listes.
Passer un atome de n'importe quel type à la fonction de type monadique (c'est-à-dire à un seul argument) retournera une valeur négative, c'est-à-dire –n, alors que passer une simple liste de ces atomes à la fonction type renverra une valeur positive n.
Exemple 1 - Formation d'atomes et de listes
/ Note that the comments begin with a slash “ / ” and cause the parser
/ to ignore everything up to the end of the line.
x: `mohan / `mohan is a symbol, assigned to a variable x
type x / let’s check the type of x
-11h / -ve sign, because it’s single element.
y: (`abc;`bca;`cab) / list of three symbols, y is the variable name.
type y
11h / +ve sign, as it contain list of atoms (symbol).
y1: (`abc`bca`cab) / another way of writing y, please note NO semicolon
y2: (`$”symbols may have interior blanks”) / string to symbol conversion
y[0] / return `abc
y 0 / same as y[0], also returns `abc
y 0 2 / returns `abc`cab, same as does y[0 2]
z: (`abc; 10 20 30; (`a`b); 9.9 8.8 7.7) / List of different types,
z 2 0 / returns (`a`b; `abc),
z[2;0] / return `a. first element of z[2]
x: “Hello World!” / list of character, a string
x 4 0 / returns “oH” i.e. 4th and 0th(first)
elementIl est souvent nécessaire de changer le type de données de certaines données d'un type à un autre. La fonction de diffusion standard est le "$"dyadic operator.
Trois approches sont utilisées pour passer d'un type à un autre (sauf pour la chaîne) -
- Spécifiez le type de données souhaité par son nom de symbole
- Spécifiez le type de données souhaité par son caractère
- Spécifiez le type de données souhaité par sa valeur courte.
Conversion d'entiers en flottants
Dans l'exemple suivant de conversion d'entiers en flottants, les trois différentes méthodes de conversion sont équivalentes -
q)a:9 18 27
q)$[`float;a] / Specify desired data type by its symbol name, 1st way
9 18 27f
q)$["f";a] / Specify desired data type by its character, 2nd way
9 18 27f
q)$[9h;a] / Specify desired data type by its short value, 3rd way
9 18 27fVérifiez si les trois opérations sont équivalentes,
q)($[`float;a]~$["f";a]) and ($[`float;a] ~ $[9h;a])
1bConversion de chaînes en symboles
La conversion d'une chaîne en symboles et vice versa fonctionne un peu différemment. Vérifions-le avec un exemple -
q)b: ("Hello";"World";"HelloWorld") / define a list of strings
q)b
"Hello"
"World"
"HelloWorld"
q)c: `$b / this is how to cast strings to symbols
q)c / Now c is a list of symbols
`Hello`World`HelloWorldTenter de convertir des chaînes en symboles en utilisant les mots clés `symbole ou 11h échouera avec l'erreur de type -
q)b
"Hello"
"World"
"HelloWorld"
q)`symbol$b
'type
q)11h$b
'typeConversion de chaînes en non-symboles
La conversion de chaînes en un type de données autre que symbole est effectuée comme suit:
q)b:900 / b contain single atomic integer
q)c:string b / convert this integer atom to string “900”
q)c
"900"
q)`int $ c / converting string to integer will return the
/ ASCII equivalent of the character “9”, “0” and
/ “0” to produce the list of integer 57, 48 and
/ 48.
57 48 48i
q)6h $ c / Same as above 57 48 48i q)"i" $ c / Same a above
57 48 48i
q)"I" $ c
900iDonc, pour convertir une chaîne entière (la liste des caractères) en un seul atome de type de données x nous oblige à spécifier la lettre majuscule représentant le type de données x comme premier argument de la $opérateur. Si vous spécifiez le type de données dex de toute autre manière, cela entraîne l'application de la distribution à chaque caractère de la chaîne.
le q le langage a de nombreuses façons différentes de représenter et de manipuler des données temporelles telles que les heures et les dates.
Date
Une date en kdb + est stockée en interne sous la forme du nombre entier de jours depuis notre date de référence est 01Jan2000. Une date postérieure à cette date est stockée en interne sous la forme d'un nombre positif et une date antérieure est référencée sous la forme d'un nombre négatif.
Par défaut, une date est écrite au format "AAAA.MM.JJ"
q)x:2015.01.22 / This is how we write 22nd Jan 2015
q)`int$x / Number of days since 2000.01.01 5500i q)`year$x / Extracting year from the date
2015i
q)x.year / Another way of extracting year
2015i
q)`mm$x / Extracting month from the date 1i q)x.mm / Another way of extracting month 1i q)`dd$x / Extracting day from the date
22i
q)x.dd / Another way of extracting day
22iArithmetic and logical operations peut être effectué directement sur les dates.
q)x+1 / Add one day
2015.01.23
q)x-7 / Subtract 7 days
2015.01.15Le 1er janvier 2000 est tombé un samedi. Par conséquent, n'importe quel samedi de l'histoire ou dans le futur, divisé par 7, donnerait un reste de 0, dimanche donne 1, lundi rendement 2.
Day mod 7
Saturday 0
Sunday 1
Monday 2
Tuesday 3
Wednesday 4
Thursday 5
Friday 6Fois
Une heure est stockée en interne sous la forme du nombre entier de millisecondes depuis le coup de minuit. Une heure est écrite au format HH: MM: SS.MSS
q)tt1: 03:30:00.000 / tt1 store the time 03:30 AM
q)tt1
03:30:00.000
q)`int$tt1 / Number of milliseconds in 3.5 hours 12600000i q)`hh$tt1 / Extract the hour component from time
3i
q)tt1.hh
3i
q)`mm$tt1 / Extract the minute component from time 30i q)tt1.mm 30i q)`ss$tt1 / Extract the second component from time
0i
q)tt1.ss
0iComme pour les dates, l'arithmétique peut être effectuée directement sur les heures.
Datetimes
Une date / heure est la combinaison d'une date et d'une heure, séparées par «T» comme dans le format standard ISO. Une valeur datetime stocke le nombre de jours fractionnaires à partir du 1er janvier 2000 à minuit.
q)dt:2012.12.20T04:54:59:000 / 04:54.59 AM on 20thDec2012
q)type dt
-15h
q)dt
2012.12.20T04:54:59.000
9
q)`float$dt
4737.205Le nombre de jours fractionnaires sous-jacent peut être obtenu par coulée pour flotter.
Les listes sont les éléments de base de q language, une compréhension approfondie des listes est donc très importante. Une liste est simplement une collection ordonnée d'atomes (éléments atomiques) et d'autres listes (groupe d'un ou plusieurs atomes).
Types de liste
UNE general listplace ses éléments entre parenthèses correspondantes et les sépare par des points-virgules. Par exemple -
(9;8;7) or ("a"; "b"; "c") or (-10.0; 3.1415e; `abcd; "r")Si une liste comprend des atomes du même type, on parle de uniform list. Else, it is known as a general list (mixed type).
Count
We can obtain the number of items in a list through its count.
q)l1:(-10.0;3.1415e;`abcd;"r") / Assigning variable name to general list
q)count l1 / Calculating number of items in the list l1
4Examples of simple List
q)h:(1h;2h;255h) / Simple Integer List
q)h
1 2 255h
q)f:(123.4567;9876.543;98.7) / Simple Floating Point List
q)f
123.4567 9876.543 98.7
q)b:(0b;1b;0b;1b;1b) / Simple Binary Lists
q)b
01011b
q)symbols:(`Life;`Is;`Beautiful) / Simple Symbols List
q)symbols
`Life`Is`Beautiful
q)chars:("h";"e";"l";"l";"o";" ";"w";"o";"r";"l";"d")
/ Simple char lists and Strings.
q)chars
"hello world"**Note − A simple list of char is called a string.
A list contains atoms or lists. To create a single item list, we use −
q)singleton:enlist 42
q)singleton
,42To distinguish between an atom and the equivalent singleton, examine the sign of their type.
q)signum type 42
-1i
q)signum type enlist 42
1iA list is ordered from left to right by the position of its items. The offset of an item from the beginning of the list is called its index. Thus, the first item has an index 0, the second item (if there is one) has an index 1, etc. A list of count n has index domain from 0 to n–1.
Index Notation
Given a list L, the item at index i is accessed by L[i]. Retrieving an item by its index is called item indexing. For example,
q)L:(99;98.7e;`b;`abc;"z")
q)L[0]
99
q)L[1]
98.7e
q)L[4]
"zIndexed Assignment
Items in a list can also be assigned via item indexing. Thus,
q)L1:9 8 7
q)L1[2]:66 / Indexed assignment into a simple list
/ enforces strict type matching.
q)L1
9 8 66Lists from Variables
q)l1:(9;8;40;200)
q)l2:(1 4 3; `abc`xyz)
q)l:(l1;l2) / combining the two list l1 and l2
q)l
9 8 40 200
(1 4 3;`abc`xyz)Joining Lists
The most common operation on two lists is to join them together to form a larger list. More precisely, the join operator (,) appends its right operand to the end of the left operand and returns the result. It accepts an atom in either argument.
q)1,2 3 4
1 2 3 4
q)1 2 3, 4.4 5.6 / If the arguments are not of uniform type,
/ the result is a general list.
1
2
3
4.4
5.6Nesting
Data complexity is built by using lists as items of lists.
Depth
The number of levels of nesting for a list is called its depth. Atoms have a depth of 0 and simple lists have a depth of 1.
q)l1:(9;8;(99;88))
q)count l1
3Here is a list of depth 3 having two items −
q)l5
9
(90;180;900 1800 2700 3600)
q)count l5
2
q)count l5[1]
3Indexing at Depth
It is possible to index directly into the items of a nested list.
Repeated Item Indexing
Retrieving an item via a single index always retrieves an uppermost item from a nested list.
q)L:(1;(100;200;(300;400;500;600)))
q)L[0]
1
q)L[1]
100
200
300 400 500 600Since the result L[1] is itself a list, we can retrieve its elements using a single index.
q)L[1][2]
300 400 500 600We can repeat single indexing once more to retrieve an item from the innermost nested list.
q)L[1][2][0]
300You can read this as,
Get the item at index 1 from L, and from it retrieve the item at index 2, and from it retrieve the item at index 0.
Notation for Indexing at Depth
There is an alternate notation for repeated indexing into the constituents of a nested list. The last retrieval can also be written as,
q)L[1;2;0]
300Assignment via index also works at depth.
q)L[1;2;1]:900
q)L
1
(100;200;300 900 500 600)Elided Indices
Eliding Indices for a General List
q)L:((1 2 3; 4 5 6 7); (`a`b`c;`d`e`f`g;`0`1`2);("good";"morning"))
q)L
(1 2 3;4 5 6 7)
(`a`b`c;`d`e`f`g;`0`1`2)
("good";"morning")
q)L[;1;]
4 5 6 7
`d`e`f`g
"morning"
q)L[;;2]
3 6
`c`f`2
"or"Interpret L[;1;] as,
Retrieve all items in the second position of each list at the top level.
Interpret L[;;2] as,
Retrieve the items in the third position for each list at the second level.
Dictionaries are an extension of lists which provide the foundation for creating tables. In mathematical terms, dictionary creates the
“domain → Range”
or in general (short) creates
“key → value”
relationship between elements.
A dictionary is an ordered collection of key-value pairs that is roughly equivalent to a hash table. A dictionary is a mapping defined by an explicit I/O association between a domain list and a range list via positional correspondence. The creation of a dictionary uses the "xkey" primitive (!)
ListOfDomain ! ListOfRangeThe most basic dictionary maps a simple list to a simple list.
| Input (I) | Output (O) |
|---|---|
| `Name | `John |
| `Age | 36 |
| `Sex | “M” |
| Weight | 60.3 |
q)d:`Name`Age`Sex`Weight!(`John;36;"M";60.3) / Create a dictionary d
q)d
Name | `John
Age | 36
Sex | "M"
Weight | 60.3
q)count d / To get the number of rows in a dictionary.
4
q)key d / The function key returns the domain
`Name`Age`Sex`Weight
q)value d / The function value returns the range.
`John
36
"M"
60.3
q)cols d / The function cols also returns the domain.
`Name`Age`Sex`WeightLookup
Finding the dictionary output value corresponding to an input value is called looking up the input.
q)d[`Name] / Accessing the value of domain `Name
`John
q)d[`Name`Sex] / extended item-wise to a simple list of keys
`John
"M"Lookup with Verb @
q)d1:`one`two`three!9 18 27
q)d1[`two]
18
q)d1@`two
18Operations on Dictionaries
Amend and Upsert
As with lists, the items of a dictionary can be modified via indexed assignment.
d:`Name`Age`Sex`Weight! (`John;36;"M";60.3)
/ A dictionary d
q)d[`Age]:35 / Assigning new value to key Age
q)d
/ New value assigned to key Age in d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3Dictionaries can be extended via index assignment.
q)d[`Height]:"182 Ft"
q)d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3
Height | "182 Ft"Reverse Lookup with Find (?)
The find (?) operator is used to perform reverse lookup by mapping a range of elements to its domain element.
q)d2:`x`y`z!99 88 77
q)d2?77
`zIn case the elements of a list is not unique, the find returns the first item mapping to it from the domain list.
Removing Entries
To remove an entry from a dictionary, the delete ( _ ) function is used. The left operand of ( _ ) is the dictionary and the right operand is a key value.
q)d2:`x`y`z!99 88 77
q)d2 _`z
x| 99
y| 88Whitespace is required to the left of _ if the first operand is a variable.
q)`x`y _ d2 / Deleting multiple entries
z| 77Column Dictionaries
Column dictionaries are the basics for creation of tables. Consider the following example −
q)scores: `name`id!(`John`Jenny`Jonathan;9 18 27)
/ Dictionary scores
q)scores[`name] / The values for the name column are
`John`Jenny`Jonathan
q)scores.name / Retrieving the values for a column in a
/ column dictionary using dot notation.
`John`Jenny`Jonathan
q)scores[`name][1] / Values in row 1 of the name column
`Jenny
q)scores[`id][2] / Values in row 2 of the id column is
27Flipping a Dictionary
The net effect of flipping a column dictionary is simply reversing the order of the indices. This is logically equivalent to transposing the rows and columns.
Flip on a Column Dictionary
The transpose of a dictionary is obtained by applying the unary flip operator. Take a look at the following example −
q)scores
name | John Jenny Jonathan
id | 9 18 27
q)flip scores
name id
---------------
John 9
Jenny 18
Jonathan 27Flip of a Flipped Column Dictionary
If you transpose a dictionary twice, you obtain the original dictionary,
q)scores ~ flip flip scores
1bTables are at the heart of kdb+. A table is a collection of named columns implemented as a dictionary. q tables are column-oriented.
Creating Tables
Tables are created using the following syntax −
q)trade:([]time:();sym:();price:();size:())
q)trade
time sym price size
-------------------In the above example, we have not specified the type of each column. This will be set by the first insert into the table.
Another way, we can specify column type on initialization −
q)trade:([]time:`time$();sym:`$();price:`float$();size:`int$())Or we can also define non-empty tables −
q)trade:([]sym:(`a`b);price:(1 2))
q)trade
sym price
-------------
a 1
b 2If there are no columns within the square brackets as in the examples above, the table is unkeyed.
To create a keyed table, we insert the column(s) for the key in the square brackets.
q)trade:([sym:`$()]time:`time$();price:`float$();size:`int$())
q)trade
sym | time price size
----- | ---------------One can also define the column types by setting the values to be null lists of various types −
q)trade:([]time:0#0Nt;sym:0#`;price:0#0n;size:0#0N)Getting Table Information
Let’s create a trade table −
trade: ([]sym:`ibm`msft`apple`samsung;mcap:2000 4000 9000 6000;ex:`nasdaq`nasdaq`DAX`Dow)
q)cols trade / column names of a table
`sym`mcap`ex
q)trade.sym / Retrieves the value of column sym
`ibm`msft`apple`samsung
q)show meta trade / Get the meta data of a table trade.
c | t f a
----- | -----
Sym | s
Mcap | j
ex | sPrimary Keys and Keyed Tables
Keyed Table
A keyed table is a dictionary that maps each row in a table of unique keys to a corresponding row in a table of values. Let us take an example −
val:flip `name`id!(`John`Jenny`Jonathan;9 18 27)
/ a flip dictionary create table val
id:flip (enlist `eid)!enlist 99 198 297
/ flip dictionary, having single column eidNow create a simple keyed table containing eid as key,
q)valid: id ! val
q)valid / table name valid, having key as eid
eid | name id
--- | ---------------
99 | John 9
198 | Jenny 18
297 | Jonathan 27ForeignKeys
A foreign key defines a mapping from the rows of the table in which it is defined to the rows of the table with the corresponding primary key.
Foreign keys provide referential integrity. In other words, an attempt to insert a foreign key value that is not in the primary key will fail.
Consider the following examples. In the first example, we will define a foreign key explicitly on initialization. In the second example, we will use foreign key chasing which does not assume any prior relationship between the two tables.
Example 1 − Define foreign key on initialization
q)sector:([sym:`SAMSUNG`HSBC`JPMC`APPLE]ex:`N`CME`DAQ`N;MC:1000 2000 3000 4000)
q)tab:([]sym:`sector$`HSBC`APPLE`APPLE`APPLE`HSBC`JPMC;price:6?9f)
q)show meta tab
c | t f a
------ | ----------
sym | s sector
price | f
q)show select from tab where sym.ex=`N
sym price
----------------
APPLE 4.65382
APPLE 4.643817
APPLE 3.659978Example 2 − no pre-defined relationship between tables
sector: ([symb:`IBM`MSFT`HSBC]ex:`N`CME`N;MC:1000 2000 3000)
tab:([]sym:`IBM`MSFT`MSFT`HSBC`HSBC;price:5?9f)To use foreign key chasing, we must create a table to key into sector.
q)show update mc:(sector([]symb:sym))[`MC] from tab
sym price mc
--------------------------
IBM 7.065297 1000
MSFT 4.812387 2000
MSFT 6.400545 2000
HSBC 3.704373 3000
HSBC 4.438651 3000General notation for a predefined foreign key −
select a.b from c where a is the foreign key (sym), b is a
field in the primary key table (ind), c is the
foreign key table (trade)
Manipulating Tables
Let’s create one trade table and check the result of different table expression −
q)trade:([]sym:5?`ibm`msft`hsbc`samsung;price:5?(303.00*3+1);size:5?(900*5);time:5?(.z.T-365))
q)trade
sym price size time
-----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842Let us now take a look at the statements that are used to manipulate tables using q language.
Select
The syntax to use a Select statement is as follows −
select [columns] [by columns] from table [where clause]Let us now take an example to demonstrate how to use Select statement −
q)/ select expression example
q)select sym,price,size by time from trade where size > 2000
time | sym price size
------------- | -----------------------
01:44:56.936 | msft 641.7307 2917
02:32:17.036 | msft 743.8592 3162
07:24:26.842 | ibm 838.6471 4006Insert
The syntax to use an Insert statement is as follows −
`tablename insert (values)
Insert[`tablename; values]Let us now take an example to demonstrate how to use Insert statement −
q)/ Insert expression example
q)`trade insert (`hsbc`apple;302.0 730.40;3020 3012;09:30:17.00409:15:00.000)
5 6
q)trade
sym price size time
------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
q)/Insert another value
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000]
']
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000)]
,7
q)trade
sym price size time
----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000Delete
The syntax to use a Delete statement is as follows −
delete columns from table
delete from table where clauseLet us now take an example to demonstrate how to use Delete statement −
q)/Delete expression example
q)delete price from trade
sym size time
-------------------------------
msft 3162 02:32:17.036
msft 2917 01:44:56.936
hsbc 1492 00:25:23.210
samsung 1983 00:29:38.945
ibm 4006 07:24:26.842
hsbc 3020 09:30:17.004
apple 3012 09:15:00.000
samsung 3333 10:30:00.000
q)delete from trade where price > 3000
sym price size time
-------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000
q)delete from trade where price > 500
sym price size time
-----------------------------------------
samsung 278.3498 1983 00:29:38.945
hsbc 302 3020 09:30:17.004
samsung 302 3333 10:30:00.000Update
The syntax to use an Update statement is as follows −
update column: newValue from table where ….Use the following syntax to update the format/datatype of a column using the cast function −
update column:newValue from `table where …Let us now take an example to demonstrate how to use Update statement −
q)/Update expression example
q)update size:9000 from trade where price > 600
sym price size time
------------------------------------------
msft 743.8592 9000 02:32:17.036
msft 641.7307 9000 01:44:56.936
hsbc 838.2311 9000 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 9000 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 9000 09:15:00.000
samsung 302 3333 10:30:00.000
q)/Update the datatype of a column using the cast function
q)meta trade
c | t f a
----- | --------
sym | s
price| f
size | j
time | t
q)update size:`float$size from trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)/ Above statement will not update the size column datatype permanently q)meta trade c | t f a ------ | -------- sym | s price | f size | j time | t q)/to make changes in the trade table permanently, we have do q)update size:`float$size from `trade
`trade
q)meta trade
c | t f a
------ | --------
sym | s
price | f
size | f
time | tKdb+ has nouns, verbs, and adverbs. All data objects and functions are nouns. Verbs enhance the readability by reducing the number of square brackets and parentheses in expressions. Adverbs modify dyadic (2 arguments) functions and verbs to produce new, related verbs. The functions produced by adverbs are called derived functions or derived verbs.
Each
The adverb each, denoted by ( ` ), modifies dyadic functions and verbs to apply to the items of lists instead of the lists themselves. Take a look at the following example −
q)1, (2 3 5) / Join
1 2 3 5
q)1, '( 2 3 4) / Join each
1 2
1 3
1 4There is a form of Each for monadic functions that uses the keyword “each”. For example,
q)reverse ( 1 2 3; "abc") /Reverse
a b c
1 2 3
q)each [reverse] (1 2 3; "abc") /Reverse-Each
3 2 1
c b a
q)'[reverse] ( 1 2 3; "abc")
3 2 1
c b aEach-Left and Each-Right
There are two variants of Each for dyadic functions called Each-Left (\:) and Each-Right (/:). The following example explains how to use them.
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each
9 10
18 20
27 30
36 40
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each, will return a list of pairs
9 10
18 20
27 30
36 40
q)x, \:y / each left, returns a list of each element
/ from x with all of y
9 10 20 30 40
18 10 20 30 40
27 10 20 30 40
36 10 20 30 40
q)x,/:y / each right, returns a list of all the x with
/ each element of y
9 18 27 36 10
9 18 27 36 20
9 18 27 36 30
9 18 27 36 40
q)1 _x / drop the first element
18 27 36
q)-2_y / drop the last two element
10 20
q) / Combine each left and each right to be a
/ cross-product (cartesian product)
q)x,/:\:y
9 10 9 20 9 30 9 40
18 10 18 20 18 30 18 40
27 10 27 20 27 30 27 40
36 10 36 20 36 30 36 40In q language, we have different kinds of joins based on the input tables supplied and the kind of joined tables we desire. A join combines data from two tables. Besides foreign key chasing, there are four other ways to join tables −
- Simple join
- Asof join
- Left join
- Union join
Here, in this chapter, we will discuss each of these joins in detail.
Simple Join
Simple join is the most basic type of join, performed with a comma ‘,’. In this case, the two tables have to be type conformant, i.e., both the tables have the same number of columns in the same order, and same key.
table1,:table2 / table1 is assigned the value of table2We can use comma-each join for tables with same length to join sideways. One of the tables can be keyed here,
Table1, `Table2Asof Join (aj)
It is the most powerful join which is used to get the value of a field in one table asof the time in another table. Generally it is used to get the prevailing bid and ask at the time of each trade.
General format
aj[joinColumns;tbl1;tbl2]For example,
aj[`sym`time;trade;quote]Example
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show aj[`a`b;tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Left Join(lj)
It’s a special case of aj where the second argument is a keyed table and the first argument contains the columns of the right argument’s key.
General format
table1 lj Keyed-tableExample
q)/Left join- syntax table1 lj table2 or lj[table1;table2]
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([a:(2 3 4);b:(3 4 5)]; c:( 4 5 6))
q)show lj[tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Union Join (uj)
It allows to create a union of two tables with distinct schemas. It is basically an extension to the simple join ( , )
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show uj[tab1;tab2]
a b d c
------------
1 2 6
2 3 7
3 4 8
4 5 9
2 3 4
3 4 5
4 5 6If you are using uj on keyed tables, then the primary keys must match.
Types of Functions
Functions can be classified in a number of ways. Here we have classified them based on the number and type of argument they take and the result type. Functions can be,
Atomic − Where the arguments are atomic and produce atomic results
Aggregate − atom from list
Uniform (list from list) − Extended the concept of atom as they apply to lists. The count of the argument list equals the count of the result list.
Other − if the function is not from the above category.
Binary operations in mathematics are called dyadic functions in q; for example, “+”. Similarly unary operations are called monadic functions; for example, “abs” or “floor”.
Frequently Used Functions
There are quite a few functions used frequently in q programming. Here, in this section, we will see the usage of some popular functions −
abs
q) abs -9.9 / Absolute value, Negates -ve number & leaves non -ve number
9.9all
q) all 4 5 0 -4 / Logical AND (numeric min), returns the minimum value
0bMax (&), Min (|), and Not (!)
q) /And, Or, and Logical Negation
q) 1b & 1b / And (Max)
1b
q) 1b|0b / Or (Min)
1b
q) not 1b /Logical Negate (Not)
0basc
q)asc 1 3 5 7 -2 0 4 / Order list ascending, sorted list
/ in ascending order i
s returned
`s#-2 0 1 3 4 5 7
q)/attr - gives the attributes of data, which describe how it's sorted.
`s denotes fully sorted, `u denotes unique and `p and `g are used to
refer to lists with repetition, with `p standing for parted and `g for groupedavg
q)avg 3 4 5 6 7 / Return average of a list of numeric values
5f
q)/Create on trade table
q)trade:([]time:3?(.z.Z-200);sym:3?(`ibm`msft`apple);price:3?99.0;size:3?100)by
q)/ by - Groups rows in a table at given sym
q)select sum price by sym from trade / find total price for each sym
sym | price
------ | --------
apple | 140.2165
ibm | 16.11385cols
q)cols trade / Lists columns of a table
`time`sym`price`sizecompter
q)count (til 9) / Count list, count the elements in a list and
/ return a single int value 9Port
q)\p 9999 / assign port number
q)/csv - This command allows queries in a browser to be exported to
excel by prefixing the query, such as http://localhost:9999/.csv?select from trade where sym =`ibmCouper
q)/ cut - Allows a table or list to be cut at a certain point
q)(1 3 5) cut "abcdefghijkl"
/ the argument is split at 1st, 3rd and 5th letter.
"bc"
"de"
"fghijkl"
q)5 cut "abcdefghijkl" / cut the right arg. Into 5 letters part
/ until its end.
"abcde"
"fghij"
"kl"Effacer
q)/delete - Delete rows/columns from a table
q)delete price from trade
time sym size
---------------------------------------
2009.06.18T06:04:42.919 apple 36
2009.11.14T12:42:34.653 ibm 12
2009.12.27T17:02:11.518 apple 97Distinct
q)/distinct - Returns the distinct element of a list
q)distinct 1 2 3 2 3 4 5 2 1 3 / generate unique set of number
1 2 3 4 5enrôler
q)/enlist - Creates one-item list.
q)enlist 37
,37
q)type 37 / -ve type value
-7h
q)type enlist 37 / +ve type value
7hRemplir (^)
q)/fill - used with nulls. There are three functions for processing null values.
The dyadic function named fill replaces null values in the right argument with the atomic left argument.
q)100 ^ 3 4 0N 0N -5
3 4 100 100 -5
q)`Hello^`jack`herry``john`
`jack`herry`Hello`john`HelloRemplit
q)/fills - fills in nulls with the previous not null value.
q)fills 1 0N 2 0N 0N 2 3 0N -5 0N
1 1 2 2 2 2 3 3 -5 -5Première
q)/first - returns the first atom of a list
q)first 1 3 34 5 3
1Retourner
q)/flip - Monadic primitive that applies to lists and associations. It interchange the top two levels of its argument.
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
q)flip trade
time | 2009.06.18T06:04:42.919 2009.11.14T12:42:34.653
2009.12.27T17:02:11.518
sym | apple ibm apple
price | 72.05742 16.11385 68.15909
size | 36 12 97iasc
q)/iasc - Index ascending, return the indices of the ascended sorted list relative to the input list.
q)iasc 5 4 0 3 4 9
2 3 1 4 0 5Idesc
q)/idesc - Index desceding, return the descended sorted list relative to the input list
q)idesc 0 1 3 4
3 2 1 0dans
q)/in - In a list, dyadic function used to query list (on the right-handside) about their contents.
q)(2 4) in 1 2 3
10binsérer
q)/insert - Insert statement, upload new data into a table.
q)insert[`trade;((.z.Z);`samsung;48.35;99)],3
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99clé
q)/key - three different functions i.e. generate +ve integer number, gives content of a directory or key of a table/dictionary.
q)key 9
0 1 2 3 4 5 6 7 8
q)key `:c:
`$RECYCLE.BIN`Config.Msi`Documents and Settings`Drivers`Geojit`hiberfil.sys`I..inférieur
q)/lower - Convert to lower case and floor
q)lower ("JoHn";`HERRY`SYM)
"john"
`herry`symMax et Min (ie | et &)
q)/Max and Min / a|b and a&b
q)9|7
9
q)9&5
5nul
q)/null - return 1b if the atom is a null else 0b from the argument list
q)null 1 3 3 0N
0001bPêche
q)/peach - Parallel each, allows process across slaves
q)foo peach list1 / function foo applied across the slaves named in list1
'list1
q)foo:{x+27}
q)list1:(0 1 2 3 4)
q)foo peach list1 / function foo applied across the slaves named in list1
27 28 29 30 31Précédente
q)/prev - returns the previous element i.e. pushes list forwards
q)prev 0 1 3 4 5 7
0N 0 1 3 4 5Aléatoire( ?)
q)/random - syntax - n?list, gives random sequences of ints and floats
q)9?5
0 0 4 0 3 2 2 0 1
q)3?9.9
0.2426823 1.674133 3.901671Raser
q)/raze - Flattn a list of lists, removes a layer of indexing from a list of lists. for instance:
q)raze (( 12 3 4; 30 0);("hello";7 8); 1 3 4)
12 3 4
30 0
"hello"
7 8
1
3
4lire0
q)/read0 - Read in a text file
q)read0 `:c:/q/README.txt / gives the contents of *.txt filelire1
q)/read1 - Read in a q data file
q)read1 `:c:/q/t1
0xff016200630b000500000073796d0074696d6500707269636…inverser
q)/reverse - Reverse a list
q)reverse 2 30 29 1 3 4
4 3 1 29 30 2
q)reverse "HelloWorld"
"dlroWolleH"ensemble
q)/set - set value of a variable
q)`x set 9
`x
q)x
9
q)`:c:/q/test12 set trade
`:c:/q/test12
q)get `:c:/q/test12
time sym price size
---------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99ssr
q)/ssr - String search and replace, syntax - ssr["string";searchstring;replaced-with]
q)ssr["HelloWorld";"o";"O"]
"HellOWOrld"chaîne
q)/string - converts to string, converts all types to a string format.
q)string (1 2 3; `abc;"XYZ";0b)
(,"1";,"2";,"3")
"abc"
(,"X";,"Y";,"Z")
,"0"SV
q)/sv - Scalar from vector, performs different tasks dependent on its arguments.
It evaluates the base representation of numbers, which allows us to calculate the number of seconds in a month or convert a length from feet and inches to centimeters.
q)24 60 60 sv 11 30 49
41449 / number of seconds elapsed in a day at 11:30:49système
q)/system - allows a system command to be sent,
q)system "dir *.py"
" Volume in drive C is New Volume"
" Volume Serial Number is 8CD2-05B2"
""
" Directory of C:\\Users\\myaccount-raj"
""
"09/14/2014 06:32 PM 22 hello1.py"
" 1 File(s) 22 bytes"les tables
q)/tables - list all tables
q)tables `
`s#`tab1`tab2`tradeTil
q)/til - Enumerate
q)til 5
0 1 2 3 4réduire
q)/trim - Eliminate string spaces
q)trim " John "
"John"contre
q)/vs - Vector from scaler , produces a vector quantity from a scaler quantity
q)"|" vs "20150204|msft|20.45"
"20150204"
"msft"
"20.45"xasc
q)/xasc - Order table ascending, allows a table (right-hand argument) to be sorted such that (left-hand argument) is in ascending order
q)`price xasc trade
time sym price size
----------------------------------------------------------
2009.11.14T12:42:34.653 ibm 16.11385 12
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.12.27T17:02:11.518 apple 68.15909 97
2009.06.18T06:04:42.919 apple 72.05742 36xcol
q)/xcol - Renames columns of a table
q)`timeNew`symNew xcol trade
timeNew symNew price size
-------------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99xcols
q)/xcols - Reorders the columns of a table,
q)`size`price xcols trade
size price time sym
-----------------------------------------------------------
36 72.05742 2009.06.18T06:04:42.919 apple
12 16.11385 2009.11.14T12:42:34.653 ibm
97 68.15909 2009.12.27T17:02:11.518 apple
99 48.35 2015.04.06T10:03:36.738 samsung
99 48.35 2015.04.06T10:03:47.540 samsung
99 48.35 2015.04.06T10:04:44.844 samsungxdesc
q)/xdesc - Order table descending, allows tables to be sorted such that the left-hand argument is in descending order.
q)`price xdesc trade
time sym price size
-----------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.11.14T12:42:34.653 ibm 16.11385 12xgroup
q)/xgroup - Creates nested table
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40)
'length
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40 10)
x | y
---- | -----------
9 | 10 10 40 10
18 | 20 20
27 | ,30xkey
q)/xkey - Set key on table
q)`sym xkey trade
sym | time price size
--------- | -----------------------------------------------
apple | 2009.06.18T06:04:42.919 72.05742 36
ibm | 2009.11.14T12:42:34.653 16.11385 12
apple | 2009.12.27T17:02:11.518 68.15909 97
samsung | 2015.04.06T10:03:36.738 48.35 99
samsung | 2015.04.06T10:03:47.540 48.35 99
samsung | 2015.04.06T10:04:44.844 48.35 99Commandes système
Les commandes système contrôlent qenvironnement. Ils sont de la forme suivante -
\cmd [p] where p may be optionalCertaines des commandes système populaires ont été discutées ci-dessous -
\ a [namespace] - Liste des tables dans l'espace de noms donné
q)/Tables in default namespace
q)\a
,`trade
q)\a .o / table in .o namespace.
,`TI\ b - Afficher les dépendances
q)/ views/dependencies
q)a:: x+y / global assingment
q)b:: x+1
q)\b
`s#`a`b\ B - Vues / dépendances en attente
q)/ Pending views/dependencies
q)a::x+1 / a depends on x
q)\B / the dependency is pending
' / the dependency is pending
q)\B
`s#`a`b
q)\b
`s#`a`b
q)b
29
q)a
29
q)\B
`symbol$()\ cd - Changer de répertoire
q)/change directory, \cd [name]
q)\cd
"C:\\Users\\myaccount-raj"
q)\cd ../new-account
q)\cd
"C:\\Users\\new-account"\ d - définit l'espace de noms actuel
q)/ sets current namespace \d [namespace]
q)\d /default namespace
'
q)\d .o /change to .o
q.o)\d
`.o
q.o)\d . / return to default
q)key ` /lists namespaces other than .z
`q`Q`h`j`o
q)\d .john /change to non-existent namespace
q.john)\d
`.john
q.john)\d .
q)\d
`.\ l - charge le fichier ou le répertoire depuis la base de données
q)/ Load file or directory, \l
q)\l test2.q / loading test2.q which is stored in current path.
ric | date ex openP closeP MCap
----------- | -------------------------------------------------
JPMORGAN | 2008.05.23 SENSEX 18.30185 17.16319 17876
HSBC | 2002.05.21 NIFTY 2.696749 16.58846 26559
JPMORGAN | 2006.09.07 NIFTY 14.15219 20.05624 14557
HSBC | 2010.10.11 SENSEX 7.394497 25.45859 29366
JPMORGAN | 2007.10.02 SENSEX 1.558085 25.61478 20390
ric | date ex openP closeP MCap
---------- | ------------------------------------------------
INFOSYS | 2003.10.30 DOW 21.2342 7.565652 2375
RELIANCE | 2004.08.12 DOW 12.34132 17.68381 4201
SBIN | 2008.02.14 DOW 1.830857 9.006485 15465
INFOSYS | 2009.06.11 HENSENG 19.47664 12.05208 11143
SBIN | 2010.07.05 DOW 18.55637 10.54082 15873\ p - numéro de port
q)/ assign port number, \p
q)\p
5001i
q)\p 8888
q)\p
8888i\\ - Quitter la console q
\\ - exit
Exit form q.le qLe langage de programmation a un ensemble de fonctions intégrées riches et puissantes. Une fonction intégrée peut être des types suivants -
String function - Prend une chaîne comme entrée et renvoie une chaîne.
Aggregate function - Prend une liste comme entrée et renvoie un atome.
Uniform function - Prend une liste et renvoie une liste du même nombre.
Mathematical function - Prend un argument numérique et renvoie un argument numérique.
Miscellaneous function - Toutes les fonctions autres que celles mentionnées ci-dessus.
Fonctions de chaîne
Like - correspondance de motifs
q)/like is a dyadic, performs pattern matching, return 1b on success else 0b
q)"John" like "J??n"
1b
q)"John My Name" like "J*"
1bltrim - supprime les blancs de début
q)/ ltrim - monadic ltrim takes string argument, removes leading blanks
q)ltrim " Rick "
"Rick "rtrim - supprime les blancs de fin
q)/rtrim - takes string argument, returns the result of removing trailing blanks
q)rtrim " Rick "
" Rick"ss - recherche de chaîne
q)/ss - string search, perform pattern matching, same as "like" but return the indices of the matches of the pattern in source.
q)"Life is beautiful" ss "i"
1 5 13trim - supprime les blancs de début et de fin
q)/trim - takes string argument, returns the result of removing leading & trailing blanks
q)trim " John "
"John"Fonctions mathématiques
acos - inverse de cos
q)/acos - inverse of cos, for input between -1 and 1, return float between 0 and pi
q)acos 1
0f
q)acos -1
3.141593
q)acos 0
1.570796cor - donne une corrélation
q)/cor - the dyadic takes two numeric lists of same count, returns a correlation between the items of the two arguments
q)27 18 18 9 0 cor 27 36 45 54 63
-0.9707253cross - produit cartésien
q)/cross - takes atoms or lists as arguments and returns their Cartesian product
q)9 18 cross `x`y`z
9 `x
9 `y
9 `z
18 `x
18 `y
18 `zvar - variance
q)/var - monadic, takes a scaler or numeric list and returns a float equal to the mathematical variance of the items
q)var 45
0f
q)var 9 18 27 36
101.25wavg
q)/wavg - dyadic, takes two numeric lists of the same count and returns the average of the second argument weighted by the first argument.
q)1 2 3 4 wavg 200 300 400 500
400fFonctions d'agrégation
tout - & opération
q)/all - monadic, takes a scaler or list of numeric type and returns the result of & applied across the items.
q)all 0b
0b
q)all 9 18 27 36
1b
q)all 10 20 30
1bTout - | opération
q)/any - monadic, takes scaler or list of numeric type and the return the result of | applied across the items
q)any 20 30 40 50
1b
q)any 20012.02.12 2013.03.11
'20012.02.12prd - produit arithmétique
q)/prd - monadic, takes scaler, list, dictionary or table of numeric type and returns the arithmetic product.
q)prd `x`y`z! 10 20 30
6000
q)prd ((1 2; 3 4);(10 20; 30 40))
10 40
90 160Sum - somme arithmétique
q)/sum - monadic, takes a scaler, list,dictionary or table of numeric type and returns the arithmetic sum.
q)sum 2 3 4 5 6
20
q)sum (1 2; 4 5)
5 7Fonctions uniformes
Deltas - différence par rapport à son élément précédent.
q)/deltas -takes a scalar, list, dictionary or table and returns the difference of each item from its predecessor.
q)deltas 2 3 5 7 9
2 1 2 2 2
q)deltas `x`y`z!9 18 27
x | 9
y | 9
z | 9remplit - remplit la valeur nulle
q)/fills - takes scalar, list, dictionary or table of numeric type and returns a c copy of the source in which non-null items are propagated forward to fill nulls
q)fills 1 0N 2 0N 4
1 1 2 2 4
q)fills `a`b`c`d! 10 0N 30 0N
a | 10
b | 10
c | 30
d | 30maxs - maximum cumulatif
q)/maxs - takes scalar, list, dictionary or table and returns the cumulative maximum of the source items.
q)maxs 1 2 4 3 9 13 2
1 2 4 4 9 13 13
q)maxs `a`b`c`d!9 18 0 36
a | 9
b | 18
c | 18
d | 36Fonctions diverses
Count - renvoie le nombre d'élément
q)/count - returns the number of entities in its argument.
q)count 10 30 30
3
q)count (til 9)
9
q)count ([]a:9 18 27;b:1.1 2.2 3.3)
3Distinct - renvoie des entités distinctes
q)/distinct - monadic, returns the distinct entities in its argument
q)distinct 1 2 3 4 2 3 4 5 6 9
1 2 3 4 5 6 9Sauf - élément non présent dans le second argument.
q)/except - takes a simple list (target) as its first argument and returns a list containing the items of target that are not in its second argument
q)1 2 3 4 3 1 except 1
2 3 4 3fill - remplir null avec le premier argument
q)/fill (^) - takes an atom as its first argument and a list(target) as its second argument and return a list obtained by substituting the first argument for every occurrence of null in target
q)42^ 9 18 0N 27 0N 36
9 18 42 27 42 36
q)";"^"Life is Beautiful"
"Life;is;Beautiful"Requêtes dans qsont plus courts et plus simples et étendent les capacités de sql. L'expression de requête principale est l '«expression de sélection», qui dans sa forme la plus simple extrait des sous-tables mais peut également créer de nouvelles colonnes.
La forme générale d'un Select expression est comme suit -
Select columns by columns from table where conditions**Note − by & where les expressions sont facultatives, seule l'expression «à partir de» est obligatoire.
En général, la syntaxe sera -
select [a] [by b] from t [where c]
update [a] [by b] from t [where c]La syntaxe de q les expressions ressemblent beaucoup à SQL, mais qles expressions sont simples et puissantes. Une expression SQL équivalente pour ce qui précèdeq l'expression serait la suivante -
select [b] [a] from t [where c] [group by b order by b]
update t set [a] [where c]Toutes les clauses s'exécutent sur les colonnes et donc qpeut profiter de la commande. Comme les requêtes SQL ne sont pas basées sur l'ordre, elles ne peuvent pas profiter de cet avantage.
qLes requêtes relationnelles sont généralement beaucoup plus petites par rapport à leur sql correspondant. Les requêtes ordonnées et fonctionnelles font des choses difficiles dans SQL.
Dans une base de données historique, la commande des whereLa clause est très importante car elle affecte les performances de la requête. lepartition La variable (date / mois / jour) vient toujours en premier, suivie de la colonne triée et indexée (généralement la colonne sym).
Par exemple,
select from table where date in d, sym in sest beaucoup plus rapide que,
select from table where sym in s, date in dRequêtes de base
Écrivons un script de requête dans le bloc-notes (comme ci-dessous), enregistrez-le (sous * .q), puis chargez-le.
sym:asc`AIG`CITI`CSCO`IBM`MSFT;
ex:"NASDAQ"
dst:`$":c:/q/test/data/"; /database destination @[dst;`sym;:;sym]; n:1000000; trade:([]sym:n?`sym;time:10:30:00.0+til n;price:n?3.3e;size:n?9;ex:n?ex); quote:([]sym:n?`sym;time:10:30:00.0+til n;bid:n?3.3e;ask:n?3.3e;bsize:n?9;asize:n?9;ex:n?ex); {@[;`sym;`p#]`sym xasc x}each`trade`quote; d:2014.08.07 2014.08.08 2014.08.09 2014.08.10 2014.08.11; /Date vector can also be changed by the user dt:{[d;t].[dst;(`$string d;t;`);:;value t]};
d dt/:\:`trade`quote;
Note: Once you run this query, two folders .i.e. "test" and "data" will be created under "c:/q/", and date partition data can be seen inside data folder.Requêtes avec contraintes
* Denotes HDB query
Select all IBM trades
select from trade where sym in `IBM*Select all IBM trades on a certain day
thisday: 2014.08.11
select from trade where date=thisday,sym=`IBMSelect all IBM trades with a price > 100
select from trade where sym=`IBM, price > 100.0Select all IBM trades with a price less than or equal to 100
select from trade where sym=`IBM,not price > 100.0*Select all IBM trades between 10.30 and 10.40, in the morning, on a certain date
thisday: 2014.08.11
select from trade where
date = thisday, sym = `IBM, time > 10:30:00.000,time < 10:40:00.000Select all IBM trades in ascending order of price
`price xasc select from trade where sym =`IBM*Select all IBM trades in descending order of price in a certain time frame
`price xdesc select from trade where date within 2014.08.07 2014.08.11, sym =`IBMComposite sort − sort ascending order by sym and then sort the result in descending order of price
`sym xasc `price xdesc select from trade where date = 2014.08.07,size = 5Select all IBM or MSFT trades
select from trade where sym in `IBM`MSFT*Calculate count of all symbols in ascending order within a certain time frame
`numsym xasc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11*Calculate count of all symbols in descending order within a certain time frame
`numsym xdesc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11* What is the maximum price of IBM stock within a certain time frame, and when does this first happen?
select time,ask from quote where date within 2014.08.07 2014.08.11,
sym =`IBM, ask = exec first ask from select max ask from quote where
sym =`IBMSelect the last price for each sym in hourly buckets
select last price by hour:time.hh, sym from tradeRequêtes avec agrégations
* Calculate vwap (Volume Weighted Average Price) of all symbols
select vwap:size wavg price by sym from trade* Count the number of records (in millions) for a certain month
(select trade:1e-6*count i by date.dd from trade where date.month=2014.08m) + select quote:1e-6*count i by date.dd from quote where date.month=2014.08m* HLOC – Daily High, Low, Open and Close for CSCO in a certain month
select high:max price,low:min price,open:first price,close:last price by date.dd from trade where date.month=2014.08m,sym =`CSCO* Daily Vwap for CSCO in a certain month
select vwap:size wavg price by date.dd from trade where date.month = 2014.08m ,sym = `CSCO* Calculate the hourly mean, variance and standard deviation of the price for AIG
select mean:avg price, variance:var price, stdDev:dev price by date, hour:time.hh from trade where sym = `AIGSelect the price range in hourly buckets
select range:max[price] – min price by date,sym,hour:time.hh from trade* Daily Spread (average bid-ask) for CSCO in a certain month
select spread:avg bid-ask by date.dd from quote where date.month = 2014.08m, sym = `CSCO* Daily Traded Values for all syms in a certain month
select dtv:sum size by date,sym from trade where date.month = 2014.08mExtract a 5 minute vwap for CSCO
select size wavg price by 5 xbar time.minute from trade where sym = `CSCO* Extract 10 minute bars for CSCO
select high:max price,low:min price,close:last price by date, 10 xbar time.minute from trade where sym = `CSCO* Find the times when the price exceeds 100 basis points (100e-4) over the last price for CSCO for a certain day
select time from trade where date = 2014.08.11,sym = `CSCO,price > 1.01*last price* Full Day Price and Volume for MSFT in 1 Minute Intervals for the last date in the database
select last price,last size by time.minute from trade where date = last date, sym = `MSFTKDB + permet à un processus de communiquer avec un autre processus via une communication interprocessus. Les processus Kdb + peuvent se connecter à n'importe quel autre kdb + sur le même ordinateur, le même réseau ou même à distance. Nous avons juste besoin de spécifier le port et ensuite les clients peuvent parler à ce port. Toutq processus peut communiquer avec tout autre q tant qu'il est accessible sur le réseau et qu'il écoute les connexions.
un processus serveur écoute les connexions et traite toutes les demandes
un processus client initie la connexion et envoie des commandes à exécuter
Le client et le serveur peuvent être sur la même machine ou sur des machines différentes. Un processus peut être à la fois un client et un serveur.
Une communication peut être,
Synchronous (attendez qu'un résultat soit renvoyé)
Asynchronous (pas d'attente et aucun résultat renvoyé)
Initialiser le serveur
UNE q le serveur est initialisé en spécifiant le port d'écoute,
q –p 5001 / command line
\p 5001 / session commandPoignée de communication
Un descripteur de communication est un symbole qui commence par «:» et a la forme -
`:[server]:port-numberExemple
`::5001 / server and client on same machine
`:jack:5001 / server on machine jack
`:192.168.0.156 / server on specific IP address
`:www.myfx.com:5001 / server at www.myfx.comPour démarrer la connexion, nous utilisons la fonction «hopen» qui renvoie un descripteur de connexion entier. Ce handle est utilisé pour toutes les demandes client ultérieures. Par exemple -
q)h:hopen `::5001
q)h"til 5"
0 1 2 3 4
q)hclose hMessages synchrones et asynchrones
Une fois que nous avons une poignée, nous pouvons envoyer un message de manière synchrone ou asynchrone.
Synchronous Message- Une fois qu'un message est envoyé, il attend et renvoie le résultat. Son format est le suivant -
handle “message”Asynchronous Message- Après l'envoi d'un message, commencez immédiatement à traiter l'instruction suivante sans avoir à attendre et renvoyer un résultat. Son format est le suivant -
neg[handle] “message”Les messages qui nécessitent une réponse, par exemple des appels de fonction ou des instructions de sélection, utiliseront normalement la forme synchrone; tandis que les messages qui n'ont pas besoin de renvoyer une sortie, par exemple l'insertion de mises à jour dans une table, seront asynchrones.
Lorsqu'un q processus se connecte à un autre qprocessus via une communication inter-processus, il est traité par des gestionnaires de messages. Ces gestionnaires de messages ont un comportement par défaut. Par exemple, en cas de gestion de message synchrone, le gestionnaire renvoie la valeur de la requête. Le gestionnaire synchrone dans ce cas est.z.pg, que nous pourrions remplacer selon l'exigence.
Les processus Kdb + ont plusieurs gestionnaires de messages prédéfinis. Les gestionnaires de messages sont importants pour la configuration de la base de données. Certains des usages incluent -
Logging - Enregistrer les messages entrants (utile en cas d'erreur fatale),
Security- Autoriser / interdire l'accès à la base de données, à certains appels de fonction, etc., en fonction du nom d'utilisateur / de l'adresse IP. Il aide à fournir un accès uniquement aux abonnés autorisés.
Handle connections/disconnections d'autres processus.
Gestionnaires de messages prédéfinis
Certains des gestionnaires de messages prédéfinis sont décrits ci-dessous.
.z.pg
C'est un gestionnaire de messages synchrone (processus get). Cette fonction est appelée automatiquement chaque fois qu'un message de synchronisation est reçu sur une instance kdb +.
Le paramètre est l'appel de chaîne / fonction à exécuter, c'est-à-dire le message passé. Par défaut, il est défini comme suit -
.z.pg: {value x} / simply execute the message
received but we can overwrite it to
give any customized result.
.z.pg : {handle::.z.w;value x} / this will store the remote handle
.z.pg : {show .z.w;value x} / this will show the remote handle.z.ps
Il s'agit d'un gestionnaire de messages asynchrone (ensemble de processus). C'est le gestionnaire équivalent pour les messages asynchrones. Le paramètre est l'appel de chaîne / fonction à exécuter. Par défaut, il est défini comme,
.z.pg : {value x} / Can be overriden for a customized action.Voici le gestionnaire de messages personnalisé pour les messages asynchrones, où nous avons utilisé l'exécution protégée,
.z.pg: {@[value; x; errhandler x]}Ici errhandler est une fonction utilisée en cas d'erreur inattendue.
.z.po []
C'est un gestionnaire d'ouverture de connexion (processus ouvert). Il est exécuté lorsqu'un processus distant ouvre une connexion. Pour voir le handle lorsqu'une connexion à un processus est ouverte, nous pouvons définir le .z.po comme,
.z.po : {Show “Connection opened by” , string h: .z.h}.z.pc []
Il s'agit d'un gestionnaire de connexion étroite (processus-close). Il est appelé lorsqu'une connexion est fermée. Nous pouvons créer notre propre gestionnaire de fermeture qui peut réinitialiser le handle de connexion global à 0 et émettre une commande pour que le minuteur se déclenche (s'exécute) toutes les 3 secondes (3000 millisecondes).
.z.pc : { h::0; value “\\t 3000”}Le gestionnaire de minuterie (.z.ts) tente de rouvrir la connexion. En cas de succès, il éteint la minuterie.
.z.ts : { h:: hopen `::5001; if [h>0; value “\\t 0”] }.z.pi []
PI signifie entrée de processus. Il est appelé pour toute sorte d'entrée. Il peut être utilisé pour gérer l'entrée de la console ou l'entrée du client distant. En utilisant .z.pi [], on peut valider l'entrée de la console ou remplacer l'affichage par défaut. De plus, il peut être utilisé pour tout type d'opérations de journalisation.
q).z.pi
'.z.pi
q).z.pi:{">", .Q.s value x}
q)5+4
>9
q)30+42
>72
q)30*2
>60
q)\x .z.pi
>q)
q)5+4
9.z.pw
C'est un gestionnaire de connexion de validation (authentification de l'utilisateur). Il ajoute un rappel supplémentaire lorsqu'une connexion est ouverte à une session kdb +. Il est appelé après les vérifications –u / -U et avant le .z.po (port ouvert).
.z.pw : {[user_id;passwd] 1b}Les entrées sont userid (symbole) et password (texte).
Les listes, dictionnaires ou colonnes d'une table peuvent avoir des attributs qui leur sont appliqués. Les attributs imposent certaines propriétés à la liste. Certains attributs peuvent disparaître lors de la modification.
Types d'attributs
Trié (`s #)
`s # signifie que la liste est triée dans un ordre croissant. Si une liste est explicitement triée par asc (ou xasc), la liste aura automatiquement le jeu d'attributs triés.
q)L1: asc 40 30 20 50 9 4
q)L1
`s#4 9 20 30 40 50Une liste dont on sait qu'elle est triée peut également avoir l'attribut défini explicitement. Q vérifiera si la liste est triée, et si ce n'est pas le cas, un s-fail l'erreur sera lancée.
q)L2:30 40 24 30 2
q)`s#L2
's-failL'attribut trié sera perdu lors d'un ajout non trié.
Séparé (`p #)
`p # signifie que la liste est séparée et que les éléments identiques sont stockés de manière contiguë.
La gamme est un int ou temporal type ayant une valeur int sous-jacente, telle que des années, des mois, des jours, etc. Vous pouvez également partitionner un symbole à condition qu'il soit énuméré.
L'application de l'attribut parted crée un dictionnaire d'index qui mappe chaque valeur de sortie unique à la position de sa première occurrence. Lorsqu'une liste est séparée, la recherche est beaucoup plus rapide, car la recherche linéaire est remplacée par une recherche de table de hachage.
q)L:`p# 99 88 77 1 2 3
q)L
`p#99 88 77 1 2 3
q)L,:3
q)L
99 88 77 1 2 3 3Note −
L'attribut parted n'est pas conservé sous une opération sur la liste, même si l'opération préserve le partitionnement.
L'attribut séparé doit être pris en compte lorsque le nombre d'entités atteint un milliard et que la plupart des partitions sont de taille substantielle, c'est-à-dire qu'il y a une répétition significative.
Groupé (`g #)
`g # signifie que la liste est groupée. Un dictionnaire interne est construit et maintenu qui mappe chaque élément unique à chacun de ses index, nécessitant un espace de stockage considérable. Pour une liste de longueurL contenant u articles uniques de taille s, ce sera (L × 4) + (u × s) octets.
Le regroupement peut être appliqué à une liste lorsqu'aucune autre hypothèse sur sa structure ne peut être faite.
L'attribut peut être appliqué à toutes les listes saisies. Il est conservé lors des ajouts, mais perdu lors des suppressions.
q)L: `g# 1 2 3 4 5 4 2 3 1 4 5 6
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6
q)L,:9
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6 9
q)L _:2
q)L
1 2 4 5 4 2 3 1 4 5 6 9Unique (`#u)
L'application de l'attribut unique (`u #) à une liste indique que les éléments de la liste sont distincts. Savoir que les éléments d'une liste sont uniques accélère considérablementdistinct et permet q pour effectuer des comparaisons tôt.
Lorsqu'une liste est marquée comme unique, une mappe de hachage interne est créée pour chaque élément de la liste. Les opérations de la liste doivent préserver l'unicité ou l'attribut est perdu.
q)LU:`u#`MSFT`SAMSUNG`APPLE
q)LU
`u#`MSFT`SAMSUNG`APPLE
q)LU,:`IBM /Uniqueness preserved
q)LU
`u#`MSFT`SAMSUNG`APPLE`IBM
q)LU,:`SAMSUNG / Attribute lost
q)LU
`MSFT`SAMSUNG`APPLE`IBM`SAMSUNGNote −
`u # est préservé sur les concaténations qui préservent l'unicité. Il est perdu lors des suppressions et des concaténations non uniques.
Les recherches sur les listes `u # se font via une fonction de hachage.
Suppression d'attributs
Les attributs peuvent être supprimés en appliquant `#.
Appliquer des attributs
Les trois formats d'application des attributs sont -
L: `s# 14 2 3 3 9/ Précisez lors de la création de la liste
@[ `.; `L ; `s#]/ Application fonctionnelle, c'est-à-dire à la liste de variables L
/ dans l'espace de noms par défaut (c'est-à-dire `.) applique
/ l'attribut `s # trié
Update `s#time from `tab
/ Mettez à jour le tableau (onglet) pour appliquer
/ attribut.
Appliquons les trois formats différents ci-dessus avec des exemples.
q)/ set the attribute during creation
q)L:`s# 3 4 9 10 23 84 90
q)/apply the attribute to existing list data
q)L1: 9 18 27 36 42 54
q)@[`.;`L1;`s#]
`.
q)L1 / check
`s#9 18 27 36 42 54
q)@[`.;`L1;`#] / clear attribute
`.
q)L1
9 18 27 36 42 54
q)/update a table to apply the attribute
q)t: ([] sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t:([]time:09:00 09:30 10:00t;sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t
time sym mcap
---------------------------------
09:00:00.000 ibm 9000
09:30:00.000 msft 18000
10:00:00.000 samsung 27000
q)update `s#time from `t
`t
q)meta t / check it was applied
c | t f a
------ | -----
time | t s
sym | s
mcap | j
Above we can see that the attribute column in meta table results shows the time column is sorted (`s#).Les requêtes fonctionnelles (dynamiques) permettent de spécifier des noms de colonnes sous forme de symboles dans des colonnes q-sql de sélection / exécution / suppression typiques. Cela est très pratique lorsque nous voulons spécifier des noms de colonnes de manière dynamique.
Les formes fonctionnelles sont -
?[t;c;b;a] / for select
![t;c;b;a] / for updateoù
t est une table;
a est un dictionnaire d'agrégats;
bla par-phrase; et
c est une liste de contraintes.
Remarque -
Tout q entités dans a, b, et c doit être référencé par son nom, c'est-à-dire sous forme de symboles contenant les noms d'entités.
Les formes syntaxiques de select et update sont analysées dans leurs formes fonctionnelles équivalentes par le q interprète, il n'y a donc pas de différence de performance entre les deux formulaires.
Sélection fonctionnelle
Le bloc de code suivant montre comment utiliser functional select -
q)t:([]n:`ibm`msft`samsung`apple;p:40 38 45 54)
q)t
n p
-------------------
ibm 40
msft 38
samsung 45
apple 54
q)select m:max p,s:sum p by name:n from t where p>36, n in `ibm`msft`apple
name | m s
------ | ---------
apple | 54 54
ibm | 40 40
msft | 38 38Exemple 1
Commençons par le cas le plus simple, la version fonctionnelle de “select from t” ressemblera à -
q)?[t;();0b;()] / select from t
n p
-----------------
ibm 40
msft 38
samsung 45
apple 54Exemple 2
Dans l'exemple suivant, nous utilisons la fonction enlist pour créer des singletons afin de garantir que les entités appropriées sont des listes.
q)wherecon: enlist (>;`p;40)
q)?[`t;wherecon;0b;()] / select from t where p > 40
n p
----------------
samsung 45
apple 54Exemple 3
q)groupby: enlist[`p] ! enlist `p
q)selcols: enlist [`n]!enlist `n
q)?[ `t;(); groupby;selcols] / select n by p from t
p | n
----- | -------
38 | msft
40 | ibm
45 | samsung
54 | appleExécutif fonctionnel
La forme fonctionnelle d'exec est une forme simplifiée de select.
q)?[t;();();`n] / exec n from t (functional form of exec)
`ibm`msft`samsung`apple
q)?[t;();`n;`p] / exec p by n from t (functional exec)
apple | 54
ibm | 40
msft | 38
samsung | 45Mise à jour fonctionnelle
La forme fonctionnelle de mise à jour est tout à fait analogue à celle de select. Dans l'exemple suivant, l'utilisation d'enlist consiste à créer des singletons, pour garantir que les entités d'entrée sont des listes.
q)c:enlist (>;`p;0)
q)b: (enlist `n)!enlist `n
q)a: (enlist `p) ! enlist (max;`p)
q)![t;c;b;a]
n p
-------------
ibm 40
msft 38
samsung 45
apple 54Suppression fonctionnelle
La suppression fonctionnelle est une forme simplifiée de mise à jour fonctionnelle. Sa syntaxe est la suivante -
![t;c;0b;a] / t is a table, c is a list of where constraints, a is a
/ list of column namesPrenons maintenant un exemple pour montrer comment fonctionne la suppression fonctionnelle -
q)![t; enlist (=;`p; 40); 0b;`symbol$()]
/ delete from t where p = 40
n p
---------------
msft 38
samsung 45
apple 54Dans ce chapitre, nous allons apprendre à utiliser des dictionnaires puis des tableaux. Commençons par les dictionnaires -
q)d:`u`v`x`y`z! 9 18 27 36 45 / Creating a dictionary d
q)/ key of this dictionary (d) is given by
q)key d
`u`v`x`y`z
q)/and the value by
q)value d
9 18 27 36 45
q)/a specific value
q)d`x
27
q)d[`x]
27
q)/values can be manipulated by using the arithmetic operator +-*% as,
q)45 + d[`x`y]
72 81Si l'on a besoin de modifier les valeurs du dictionnaire, alors la formulation de modification peut être -
q)@[`d;`z;*;9]
`d
q)d
u | 9
v | 18
x | 27
y | 36
q)/Example, table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
z | 405
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)] 0 1 2 3 4 5 6 7 8 9 q)`time xasc `tab `tab q)/ to get particular column from table tab q)tab[`size] 12 10 1 90 73 90 43 90 84 63 q)tab[`size]+9 21 19 10 99 82 99 52 99 93 72 q)/Example table tab q)tab:([]sym:`;time:0#0nt;price:0n;size:0N) q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/We can also use the @ amend too
q)@[tab;`price;-;2]
sym time price size
--------------------------------------------
APPLE 11:16:39.779 6.388858 12
MSFT 11:16:39.779 17.59907 10
IBM 11:16:39.779 35.5638 1
SAMSUNG 11:16:39.779 59.37452 90
APPLE 11:16:39.779 50.94808 73
SAMSUNG 11:16:39.779 67.16099 90
APPLE 11:16:39.779 20.96615 43
SAMSUNG 11:16:39.779 67.19531 90
IBM 11:16:39.779 45.07883 84
IBM 11:16:39.779 61.46716 63
q)/if the table is keyed
q)tab1:`sym xkey tab[0 1 2 3 4]
q)tab1
sym | time price size
--------- | ----------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73
q)/To work on specific column, try this
q){tab1[x]`size} each sym
1 90 12 10
q)(0!tab1)`size
12 10 1 90 73
q)/once we got unkeyed table, manipulation is easy
q)2+ (0!tab1)`size
14 12 3 92 75Les données sur votre disque dur (également appelé base de données historique) peuvent être enregistrées dans trois formats différents: fichiers plats, tables évasées et tables partitionnées. Ici, nous allons apprendre à utiliser ces trois formats pour enregistrer des données.
Fichier plat
Les fichiers plats sont entièrement chargés en mémoire, c'est pourquoi leur taille (encombrement mémoire) doit être réduite. Les tables sont enregistrées sur disque entièrement dans un seul fichier (la taille compte donc).
Les fonctions utilisées pour manipuler ces tables sont set/get -
`:path_to_file/filename set tablenamePrenons un exemple pour montrer comment cela fonctionne -
q)tables `.
`s#`t`tab`tab1
q)`:c:/q/w32/tab1_test set tab1
`:c:/q/w32/tab1_testDans l'environnement Windows, les fichiers plats sont enregistrés à l'emplacement - C:\q\w32
Récupérez le fichier plat de votre disque (base de données historique) et utilisez le get commande comme suit -
q)tab2: get `:c:/q/w32/tab1_test
q)tab2
sym | time price size
--------- | -------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73Une nouvelle table est créée tab2 avec son contenu stocké dans tab1_test fichier.
Tables évasées
S'il y a trop de colonnes dans une table, alors nous stockons ces tables dans un format évasé, c'est-à-dire que nous les sauvegardons sur disque dans un répertoire. Dans le répertoire, chaque colonne est enregistrée dans un fichier séparé sous le même nom que le nom de la colonne. Chaque colonne est enregistrée sous forme de liste de type correspondant dans un fichier binaire kdb +.
L'enregistrement d'une table au format évasé est très utile lorsque nous devons accéder fréquemment à seulement quelques colonnes sur ses nombreuses colonnes. Un répertoire de table évasé contient.d fichier binaire contenant l'ordre des colonnes.
Tout comme un fichier plat, un tableau peut être enregistré comme évasé en utilisant le setcommander. Pour enregistrer une table comme évasée, le chemin du fichier doit se terminer par un jeu -
`:path_to_filename/filename/ set tablenamePour lire une table évasée, nous pouvons utiliser le get fonction -
tablename: get `:path_to_file/filenameNote - Pour qu'une table soit enregistrée comme évasée, elle doit être sans clé et énumérée.
Dans l'environnement Windows, votre structure de fichiers apparaîtra comme suit -
Tables partitionnées
Les tables partitionnées offrent un moyen efficace de gérer d'énormes tables contenant des volumes de données importants. Les tables partitionnées sont des tables réparties sur plusieurs partitions (répertoires).
A l'intérieur de chaque partition, une table aura son propre répertoire, avec la structure d'une table évasée. Les tableaux pourraient être répartis sur une base jour / mois / année afin de fournir un accès optimisé à son contenu.
Pour obtenir le contenu d'une table partitionnée, utilisez le bloc de code suivant -
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder
quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0
0 0 0….
trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 ….Essayons d'obtenir le contenu d'une table d'échange -
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 ANote - Le mode partitionné convient aux tables contenant des millions d'enregistrements par jour (c'est-à-dire des données de séries chronologiques)
Fichier Sym
Le fichier sym est un fichier binaire kdb + contenant la liste des symboles de toutes les tables évasées et partitionnées. Il peut être lu avec,
get `:symfichier par.txt (facultatif)
Il s'agit d'un fichier de configuration, utilisé lorsque les partitions sont réparties sur plusieurs répertoires / lecteurs de disque, et contient les chemins vers les partitions de disque.
.Q.en
.Q.enest une fonction dyadique qui aide à élargir une table en énumérant une colonne de symboles. Il est particulièrement utile lorsque nous traitons de la base de données historique (évasée, tables de partition, etc.). -
.Q.en[`:directory;table]où directory est le répertoire personnel de la base de données historique où sym file se trouve et table est la table à énumérer.
L'énumération manuelle des tables n'est pas nécessaire pour les enregistrer en tant que tables évasées, car cela sera fait par -
.Q.en[`:directory_where_symbol_file_stored]table_name.Q.dpft
le .Q.dpftLa fonction aide à créer des tables partitionnées et segmentées. C'est une forme avancée de.Q.en, car il divise non seulement la table mais crée également une table de partition.
Il y a quatre arguments utilisés dans .Q.dpft -
descripteur de fichier symbolique de la base de données où l'on veut créer une partition,
q valeur de données avec laquelle nous allons partitionner la table,
nom du champ avec lequel l'attribut parted (`p #) va être appliqué (généralement` sym), et
le nom de la table.
Prenons un exemple pour voir comment cela fonctionne -
q)tab:([]sym:5?`msft`hsbc`samsung`ibm;time:5?(09:30:30);price:5?30.25)
q).Q.dpft[`:c:/q/;2014.08.24;`sym;`tab]
`tab
q)delete tab from `
'type
q)delete tab from `/
'type
q)delete tab from .
'type
q)delete tab from `.
`.
q)tab
'tabNous avons supprimé le tableau tabde la mémoire. Chargez-le maintenant depuis la base de données
q)\l c:/q/2014.08.24/
q)\a
,`tab
q)tab
sym time price
-------------------------------
hsbc 07:38:13 15.64201
hsbc 07:21:05 5.387037
msft 06:16:58 11.88076
msft 08:09:26 12.30159
samsung 04:57:56 15.60838.Q.chk
.Q.chk est une fonction monadique dont le seul paramètre est le descripteur de fichier symbolique du répertoire racine. Il crée des tables vides dans une partition, si nécessaire, en examinant chaque sous-répertoire de partition à la racine.
.Q.chk `:directoryoù directory est le répertoire personnel de la base de données historique.