CNTK - Réseau neuronal récurrent
Maintenant, comprenons comment construire un réseau neuronal récurrent (RNN) en CNTK.
introduction
Nous avons appris à classer des images avec un réseau de neurones, et c'est l'un des métiers emblématiques de l'apprentissage profond. Mais les réseaux neuronaux récurrents (RNN) sont un autre domaine dans lequel le réseau de neurones excelle et où de nombreuses recherches sont en cours. Ici, nous allons savoir ce qu'est RNN et comment il peut être utilisé dans des scénarios où nous devons traiter des données chronologiques.
Qu'est-ce que le réseau neuronal récurrent?
Les réseaux de neurones récurrents (RNN) peuvent être définis comme la race spéciale de NN capables de raisonner dans le temps. Les RNN sont principalement utilisés dans les scénarios, où nous devons traiter des valeurs qui changent dans le temps, c'est-à-dire des données de séries chronologiques. Afin de mieux le comprendre, faisons une petite comparaison entre les réseaux de neurones réguliers et les réseaux de neurones récurrents -
Comme nous savons que, dans un réseau de neurones régulier, nous ne pouvons fournir qu'une seule entrée. Cela limite les résultats à une seule prédiction. Pour vous donner un exemple, nous pouvons faire un travail de traduction de texte en utilisant des réseaux de neurones réguliers.
D'autre part, dans les réseaux de neurones récurrents, nous pouvons fournir une séquence d'échantillons qui aboutissent à une seule prédiction. En d'autres termes, en utilisant les RNN, nous pouvons prédire une séquence de sortie basée sur une séquence d'entrée. Par exemple, il y a eu pas mal d'expériences réussies avec RNN dans les tâches de traduction.
Utilisations du réseau neuronal récurrent
Les RNN peuvent être utilisés de plusieurs manières. Certains d'entre eux sont les suivants -
Prédire une sortie unique
Avant de plonger dans les étapes, comment RNN peut prédire une sortie unique basée sur une séquence, voyons à quoi ressemble un RNN de base -

Comme nous pouvons dans le diagramme ci-dessus, RNN contient une connexion en boucle vers l'entrée et chaque fois que nous alimentons une séquence de valeurs, il traitera chaque élément de la séquence comme des pas de temps.
De plus, en raison de la connexion en boucle, RNN peut combiner la sortie générée avec l'entrée pour l'élément suivant dans la séquence. De cette manière, RNN construira une mémoire sur toute la séquence qui peut être utilisée pour faire une prédiction.
Afin de faire une prédiction avec RNN, nous pouvons effectuer les étapes suivantes -
Tout d'abord, pour créer un état caché initial, nous devons alimenter le premier élément de la séquence d'entrée.
Après cela, pour produire un état caché mis à jour, nous devons prendre l'état caché initial et le combiner avec le deuxième élément de la séquence d'entrée.
Enfin, pour produire l'état caché final et pour prédire la sortie du RNN, nous devons prendre l'élément final dans la séquence d'entrée.
De cette manière, avec l'aide de cette connexion en boucle, nous pouvons apprendre à un RNN à reconnaître les modèles qui se produisent au fil du temps.
Prédire une séquence
Le modèle de base, discuté ci-dessus, de RNN peut également être étendu à d'autres cas d'utilisation. Par exemple, nous pouvons l'utiliser pour prédire une séquence de valeurs basée sur une seule entrée. Dans ce scénario, afin de faire une prédiction avec RNN, nous pouvons effectuer les étapes suivantes -
Tout d'abord, pour créer un état caché initial et prédire le premier élément de la séquence de sortie, nous devons alimenter un échantillon d'entrée dans le réseau neuronal.
Après cela, pour produire un état masqué mis à jour et le deuxième élément de la séquence de sortie, nous devons combiner l'état masqué initial avec le même échantillon.
Enfin, pour mettre à jour l'état caché une fois de plus et prédire l'élément final dans la séquence de sortie, nous alimentons l'échantillon une autre fois.
Prédire les séquences
Comme nous l'avons vu, comment prédire une valeur unique basée sur une séquence et comment prédire une séquence basée sur une valeur unique. Voyons maintenant comment nous pouvons prédire les séquences des séquences. Dans ce scénario, afin de faire une prédiction avec RNN, nous pouvons effectuer les étapes suivantes -
Tout d'abord, pour créer un état masqué initial et prédire le premier élément de la séquence de sortie, nous devons prendre le premier élément de la séquence d'entrée.
Après cela, pour mettre à jour l'état masqué et prédire le deuxième élément de la séquence de sortie, nous devons prendre l'état masqué initial.
Enfin, pour prédire l'élément final dans la séquence de sortie, nous devons prendre l'état caché mis à jour et l'élément final dans la séquence d'entrée.
Fonctionnement de RNN
Pour comprendre le fonctionnement des réseaux de neurones récurrents (RNN), nous devons d'abord comprendre comment fonctionnent les couches récurrentes du réseau. Voyons d'abord comment e peut prédire la sortie avec une couche récurrente standard.
Prédire la sortie avec la couche RNN standard
Comme nous l'avons vu précédemment, une couche de base dans RNN est assez différente d'une couche régulière dans un réseau neuronal. Dans la section précédente, nous avons également démontré dans le diagramme l'architecture de base de RNN. Afin de mettre à jour l'état masqué pour la séquence de démarrage initiale, nous pouvons utiliser la formule suivante -

Dans l'équation ci-dessus, nous calculons le nouvel état caché en calculant le produit scalaire entre l'état caché initial et un ensemble de poids.
Maintenant, pour l'étape suivante, l'état caché pour le pas de temps actuel est utilisé comme état caché initial pour le pas de temps suivant dans la séquence. C'est pourquoi, pour mettre à jour l'état masqué pour le deuxième pas de temps, nous pouvons répéter les calculs effectués lors de la première étape comme suit -
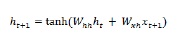
Ensuite, nous pouvons répéter le processus de mise à jour de l'état caché pour la troisième et dernière étape de la séquence comme ci-dessous -

Et lorsque nous avons traité toutes les étapes ci-dessus dans la séquence, nous pouvons calculer la sortie comme suit -

Pour la formule ci-dessus, nous avons utilisé un troisième ensemble de poids et l'état caché du pas de temps final.
Unités récurrentes avancées
Le problème principal avec la couche récurrente de base est le problème du gradient de fuite et, de ce fait, il n'est pas très bon pour apprendre les corrélations à long terme. En termes simples, la couche récurrente de base ne gère pas très bien les longues séquences. C'est la raison pour laquelle certains autres types de calques récurrents qui sont beaucoup plus adaptés pour travailler avec des séquences plus longues sont les suivants:
Mémoire à long terme (LSTM)

Les réseaux de mémoire à long terme (LSTM) ont été introduits par Hochreiter & Schmidhuber. Cela a résolu le problème d'obtenir une couche récurrente de base pour se souvenir des choses pendant longtemps. L'architecture de LSTM est donnée ci-dessus dans le schéma. Comme nous pouvons le voir, il a des neurones d'entrée, des cellules mémoire et des neurones de sortie. Afin de lutter contre le problème du gradient de disparition, les réseaux de mémoire à long terme utilisent une cellule mémoire explicite (stocke les valeurs précédentes) et les portes suivantes -
Forget gate- Comme son nom l'indique, il indique à la cellule mémoire d'oublier les valeurs précédentes. La cellule de mémoire stocke les valeurs jusqu'à ce que la porte, c'est-à-dire «oublier la porte», lui dise de les oublier.
Input gate- Comme son nom l'indique, il ajoute de nouveaux éléments à la cellule.
Output gate- Comme son nom l'indique, la porte de sortie décide quand passer les vecteurs de la cellule à l'état caché suivant.
Unités récurrentes fermées (GRU)

Gradient recurrent units(GRUs) est une légère variation du réseau LSTM. Il a une porte de moins et son câblage est légèrement différent des LSTM. Son architecture est illustrée dans le diagramme ci-dessus. Il a des neurones d'entrée, des cellules de mémoire gated et des neurones de sortie. Le réseau d'unités récurrentes Gated a les deux portes suivantes -
Update gate- Il détermine les deux choses suivantes -
Quelle quantité d'informations doit être conservée depuis le dernier état?
Quelle quantité d'informations doit être introduite à partir de la couche précédente?
Reset gate- La fonctionnalité de la porte de réinitialisation ressemble beaucoup à celle de la porte oublié du réseau LSTM. La seule différence est qu'il est situé légèrement différemment.
Contrairement au réseau de mémoire à long terme, les réseaux d'unités récurrentes fermées sont légèrement plus rapides et plus faciles à exécuter.
Création de la structure RNN
Avant de pouvoir commencer, faire des prédictions sur la sortie de l'une de nos sources de données, nous devons d'abord construire RNN et construire RNN est tout à fait la même chose que nous avions construit un réseau neuronal régulier dans la section précédente. Voici le code pour en construire un -
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10Implantation de plusieurs couches
Nous pouvons également empiler plusieurs couches récurrentes dans CNTK. Par exemple, nous pouvons utiliser la combinaison de couches suivante -
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)Comme nous pouvons le voir dans le code ci-dessus, nous avons les deux façons suivantes de modéliser RNN dans CNTK -
Premièrement, si nous ne voulons que la sortie finale d'une couche récurrente, nous pouvons utiliser le Fold couche en combinaison avec une couche récurrente, telle que GRU, LSTM ou même RNNStep.
Deuxièmement, comme alternative, nous pouvons également utiliser le Recurrence bloquer.
Formation RNN avec des données de séries chronologiques
Une fois que nous avons construit le modèle, voyons comment nous pouvons former RNN en CNTK -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)Maintenant, pour charger les données dans le processus de formation, nous devons désérialiser les séquences d'un ensemble de fichiers CTF. Le code suivant a lecreate_datasource fonction, qui est une fonction utilitaire utile pour créer à la fois la source de données d'entraînement et de test.
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.Maintenant que nous avons configuré les sources de données, le modèle et la fonction de perte, nous pouvons démarrer le processus de formation. C'est assez similaire à ce que nous avons fait dans les sections précédentes avec les réseaux de neurones de base.
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)Nous obtiendrons la sortie similaire comme suit -
Sortie−
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]Valider le modèle
En fait, redire avec un RNN est assez similaire à faire des prédictions avec n'importe quel autre modèle CNK. La seule différence est que nous devons fournir des séquences plutôt que des échantillons uniques.
Maintenant que notre RNN est enfin terminé avec l'entraînement, nous pouvons valider le modèle en le testant à l'aide de quelques séquences d'échantillons comme suit -
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZESortie−
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)