Chunking & Extraction d'informations
Qu'est-ce que Chunking?
La segmentation, l'un des processus importants du traitement du langage naturel, est utilisée pour identifier des parties du discours (POS) et des phrases courtes. En d'autres termes simples, avec le découpage, nous pouvons obtenir la structure de la phrase. Il est également appelépartial parsing.
Modèles de morceaux et fentes
Chunk patternssont les modèles de balises de partie de discours (POS) qui définissent le type de mots qui composent un morceau. Nous pouvons définir des modèles de blocs à l'aide d'expressions régulières modifiées.
De plus, nous pouvons également définir des modèles pour quels types de mots ne doivent pas être dans un morceau et ces mots non groupés sont connus sous le nom de chinks.
Exemple d'implémentation
Dans l'exemple ci-dessous, avec le résultat de l'analyse de la phrase “the book has many chapters”, il existe une grammaire pour les phrases nominales qui combine à la fois un morceau et un motif de fente -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Production
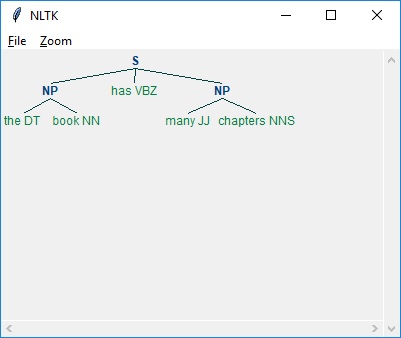
Comme vu ci-dessus, le modèle pour spécifier un morceau consiste à utiliser des accolades comme suit -
{<DT><NN>}Et pour spécifier une faille, nous pouvons inverser les accolades comme suit -
}<VB>{.Maintenant, pour un type de phrase particulier, ces règles peuvent être combinées dans une grammaire.
Extraction d'informations
Nous sommes passés par des taggers ainsi que des analyseurs qui peuvent être utilisés pour construire un moteur d'extraction d'informations. Voyons un pipeline d'extraction d'informations de base -
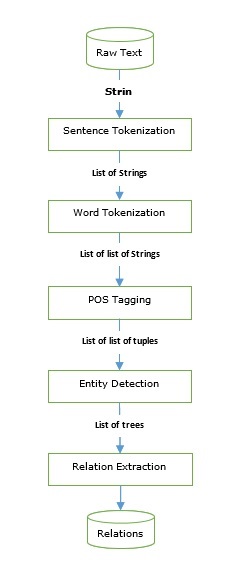
L'extraction d'informations a de nombreuses applications, notamment -
- L'intelligence d'entreprise
- Reprendre la récolte
- Analyse des médias
- Détection des sentiments
- Recherche de brevets
- Analyse des e-mails
Reconnaissance des entités nommées (NER)
La reconnaissance d'entités nommées (NER) est en fait un moyen d'extraire certaines des entités les plus courantes telles que les noms, les organisations, l'emplacement, etc. et suit le pipeline fourni dans la figure ci-dessus.
Exemple
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Une partie de la reconnaissance d'entité nommée modifiée (NER) peut également être utilisée pour extraire des entités telles que les noms de produits, les entités biomédicales, le nom de marque et bien plus encore.
Extraction de relation
L'extraction de relations, une autre opération d'extraction d'informations couramment utilisée, est le processus d'extraction des différentes relations entre diverses entités. Il peut y avoir différentes relations comme l'héritage, les synonymes, analogues, etc., dont la définition dépend du besoin d'information. Par exemple, supposons que si nous voulons rechercher l'écriture d'un livre, alors la paternité serait une relation entre le nom de l'auteur et le nom du livre.
Exemple
Dans l'exemple suivant, nous utilisons le même pipeline IE, comme indiqué dans le diagramme ci-dessus, que nous avons utilisé jusqu'à la relation d'entité nommée (NER) et l'étendons avec un modèle de relation basé sur les balises NER.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Production
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']Dans le code ci-dessus, nous avons utilisé un corpus intégré nommé ieer. Dans ce corpus, les phrases sont étiquetées jusqu'à la relation d'entité nommée (NER). Ici, nous devons seulement spécifier le modèle de relation que nous voulons et le type de NER que nous voulons que la relation définisse. Dans notre exemple, nous avons défini la relation entre une organisation et un emplacement. Nous avons extrait toutes les combinaisons de ces modèles.