Algorithme parallèle - Modèles
Le modèle d'un algorithme parallèle est développé en considérant une stratégie de division des données et une méthode de traitement et en appliquant une stratégie appropriée pour réduire les interactions. Dans ce chapitre, nous aborderons les modèles d'algorithmes parallèles suivants -
- Modèle parallèle de données
- Modèle de graphique de tâches
- Modèle de piscine de travail
- Modèle maître esclave
- Modèle de consommateur ou de pipeline producteur
- Modèle hybride
Parallèle de données
Dans le modèle parallèle de données, les tâches sont affectées à des processus et chaque tâche effectue des types d'opérations similaires sur différentes données. Data parallelism est une conséquence d'opérations uniques appliquées à plusieurs éléments de données.
Le modèle parallèle aux données peut être appliqué aux espaces d'adresses partagées et aux paradigmes de transmission de messages. Dans le modèle parallèle aux données, les frais généraux d'interaction peuvent être réduits en sélectionnant une décomposition préservant la localité, en utilisant des routines d'interaction collective optimisées ou en superposant le calcul et l'interaction.
La principale caractéristique des problèmes de modèle parallèle aux données est que l'intensité du parallélisme des données augmente avec la taille du problème, ce qui permet à son tour d'utiliser plus de processus pour résoudre des problèmes plus importants.
Example - Multiplication matricielle dense.

Modèle de graphique de tâches
Dans le modèle de graphe de tâches, le parallélisme est exprimé par un task graph. Un graphe de tâches peut être trivial ou non. Dans ce modèle, la corrélation entre les tâches est utilisée pour promouvoir la localité ou pour minimiser les coûts d'interaction. Ce modèle est appliqué pour résoudre des problèmes dans lesquels la quantité de données associées aux tâches est énorme par rapport au nombre de calculs qui leur sont associés. Les tâches sont assignées pour aider à améliorer le coût du mouvement des données entre les tâches.
Examples - Tri rapide parallèle, factorisation matricielle clairsemée et algorithmes parallèles dérivés via l'approche diviser-pour-conquérir.
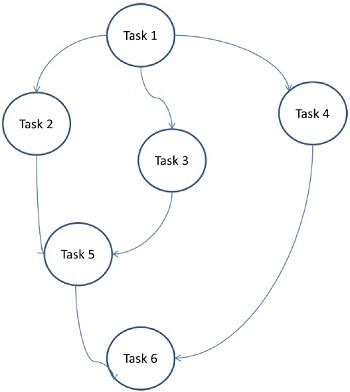
Ici, les problèmes sont divisés en tâches atomiques et implémentés sous forme de graphique. Chaque tâche est une unité de travail indépendante qui a des dépendances sur une ou plusieurs tâches antérieures. Après l'achèvement d'une tâche, la sortie d'une tâche antérieure est transmise à la tâche dépendante. Une tâche avec une tâche antécédente ne démarre l'exécution que lorsque la totalité de sa tâche antécédente est terminée. La sortie finale du graphique est reçue lorsque la dernière tâche dépendante est terminée (tâche 6 dans la figure ci-dessus).
Modèle de pool de travail
Dans le modèle de pool de travail, les tâches sont affectées dynamiquement aux processus pour équilibrer la charge. Par conséquent, n'importe quel processus peut potentiellement exécuter n'importe quelle tâche. Ce modèle est utilisé lorsque la quantité de données associées aux tâches est comparativement inférieure au calcul associé aux tâches.
Il n'y a pas de pré-affectation souhaitée des tâches sur les processus. L'attribution des tâches est centralisée ou décentralisée. Les pointeurs vers les tâches sont enregistrés dans une liste physiquement partagée, dans une file d'attente prioritaire ou dans une table ou une arborescence de hachage, ou ils peuvent être enregistrés dans une structure de données physiquement distribuée.
La tâche peut être disponible au début ou peut être générée dynamiquement. Si la tâche est générée dynamiquement et qu'une attribution de tâche décentralisée est effectuée, un algorithme de détection de fin est nécessaire pour que tous les processus puissent effectivement détecter l'achèvement de l'ensemble du programme et cesser de rechercher plus de tâches.
Example - Recherche d'arbres parallèles

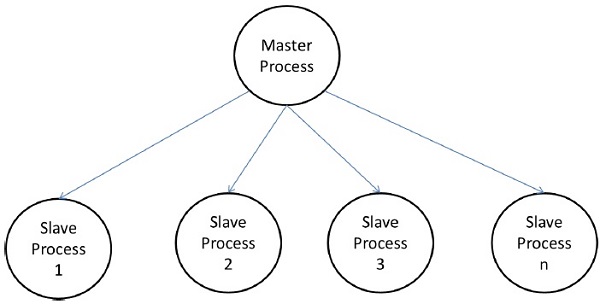
Modèle maître-esclave
Dans le modèle maître-esclave, un ou plusieurs processus maîtres génèrent une tâche et l'affectent aux processus esclaves. Les tâches peuvent être attribuées au préalable si -
- le capitaine peut estimer le volume des tâches, ou
- une attribution aléatoire peut faire un travail satisfaisant d'équilibrage de la charge, ou
- les esclaves se voient attribuer des tâches plus petites à des moments différents.
Ce modèle est généralement également adapté à shared-address-space ou message-passing paradigms, puisque l'interaction se fait naturellement de deux manières.
Dans certains cas, une tâche peut devoir être accomplie en phases, et la tâche de chaque phase doit être terminée avant que la tâche des phases suivantes puisse être générée. Le modèle maître-esclave peut être généralisé àhierarchical ou multi-level master-slave model dans lequel le maître de niveau supérieur fournit la grande partie des tâches au maître de second niveau, qui subdivise en outre les tâches entre ses propres esclaves et peut effectuer une partie de la tâche elle-même.
Précautions d'utilisation du modèle maître-esclave
Il faut veiller à ce que le maître ne devienne pas un point de congestion. Cela peut arriver si les tâches sont trop petites ou si les travailleurs sont relativement rapides.
Les tâches doivent être sélectionnées de manière à ce que le coût de l'exécution d'une tâche domine le coût de la communication et le coût de la synchronisation.
L'interaction asynchrone peut aider à chevaucher l'interaction et le calcul associé à la génération de travail par le maître.
Modèle de pipeline
Il est également connu sous le nom de producer-consumer model. Ici, un ensemble de données est transmis à travers une série de processus, dont chacun exécute une tâche. Ici, l'arrivée de nouvelles données génère l'exécution d'une nouvelle tâche par un processus dans la file d'attente. Les processus peuvent former une file d'attente sous la forme de tableaux linéaires ou multidimensionnels, d'arbres ou de graphes généraux avec ou sans cycles.
Ce modèle est une chaîne de producteurs et de consommateurs. Chaque processus de la file d'attente peut être considéré comme un consommateur d'une séquence d'éléments de données pour le processus qui le précède dans la file d'attente et comme un producteur de données pour le processus qui le suit dans la file d'attente. La file d'attente n'a pas besoin d'être une chaîne linéaire; cela peut être un graphe orienté. La technique de minimisation d'interaction la plus courante applicable à ce modèle est l'interaction chevauchante avec le calcul.
Example - Algorithme de factorisation LU parallèle.

Modèles hybrides
Un modèle d'algorithme hybride est nécessaire lorsque plus d'un modèle peut être nécessaire pour résoudre un problème.
Un modèle hybride peut être composé de plusieurs modèles appliqués hiérarchiquement ou de plusieurs modèles appliqués séquentiellement à différentes phases d'un algorithme parallèle.
Example - Tri rapide parallèle