Méthodologies de programmation - Guide rapide
Lorsque des programmes sont développés pour résoudre des problèmes réels tels que la gestion des stocks, le traitement de la paie, les admissions d'étudiants, le traitement des résultats d'examen, etc., ils ont tendance à être énormes et complexes. L'approche permettant d'analyser ces problèmes complexes, de planifier le développement de logiciels et de contrôler le processus de développement est appeléeprogramming methodology.
Types de méthodologies de programmation
Il existe de nombreux types de méthodologies de programmation répandues parmi les développeurs de logiciels -
Programmation procédurale
Le problème est décomposé en procédures ou en blocs de code exécutant chacun une tâche. L'ensemble des procédures constitue l'ensemble du programme. Il convient uniquement aux petits programmes qui ont un faible niveau de complexité.
Example- Pour un programme de calcul qui effectue l'addition, la soustraction, la multiplication, la division, la racine carrée et la comparaison, chacune de ces opérations peut être développée en tant que procédures distinctes. Dans le programme principal, chaque procédure serait invoquée sur la base du choix de l'utilisateur.
Programmation orientée objet
Ici, la solution tourne autour d'entités ou d'objets qui font partie du problème. La solution traite de la façon de stocker les données liées aux entités, du comportement des entités et de la façon dont elles interagissent les unes avec les autres pour donner une solution cohérente.
Example - Si nous devons développer un système de gestion de la paie, nous aurons des entités comme les employés, la structure salariale, les règles de congés, etc. autour desquelles la solution doit être construite.
Programmation fonctionnelle
Ici, le problème, ou la solution souhaitée, est décomposé en unités fonctionnelles. Chaque unité effectue sa propre tâche et est autonome. Ces unités sont ensuite cousues ensemble pour former la solution complète.
Example - Un traitement de la paie peut avoir des unités fonctionnelles telles que la gestion des données des employés, le calcul du salaire de base, le calcul du salaire brut, le traitement des congés, le traitement du remboursement des prêts, etc.
Programmation logique
Ici, le problème est décomposé en unités logiques plutôt qu'en unités fonctionnelles. Example:Dans un système de gestion scolaire, les utilisateurs ont des rôles très définis comme enseignant de classe, enseignant de matière, assistant de laboratoire, coordinateur, responsable académique, etc. Ainsi, le logiciel peut être divisé en unités en fonction des rôles des utilisateurs. Chaque utilisateur peut avoir différentes interfaces, autorisations, etc.
Les développeurs de logiciels peuvent choisir une ou une combinaison de plusieurs de ces méthodologies pour développer un logiciel. Notez que dans chacune des méthodologies discutées, le problème doit être décomposé en unités plus petites. Pour ce faire, les développeurs utilisent l'une des deux approches suivantes:
- Approche descendante
- Une approche en profondeur
Approche descendante ou modulaire
Le problème est décomposé en unités plus petites, qui peuvent être décomposées en unités encore plus petites. Chaque unité est appelée unmodule. Chaque module est une unité autonome qui possède tout le nécessaire pour accomplir sa tâche.
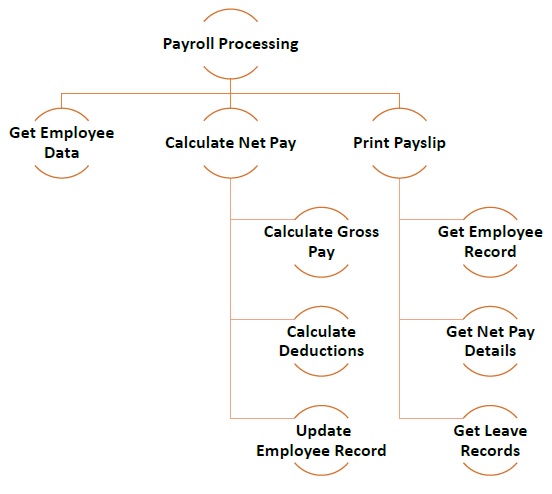
L'illustration suivante montre un exemple de la façon dont vous pouvez suivre une approche modulaire pour créer différents modules lors du développement d'un programme de traitement de la paie.
Une approche en profondeur
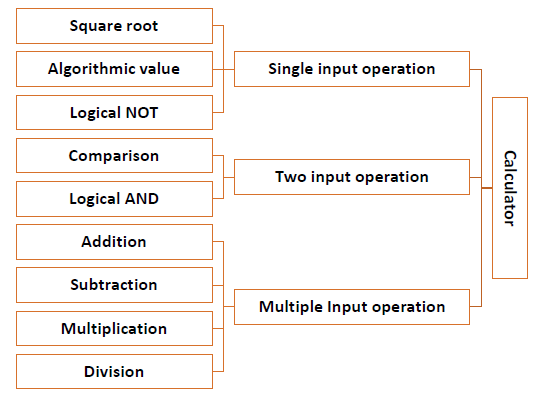
Dans une approche ascendante, la conception du système commence par le niveau le plus bas de composants, qui sont ensuite interconnectés pour obtenir des composants de niveau supérieur. Ce processus se poursuit jusqu'à ce qu'une hiérarchie de tous les composants du système soit générée. Cependant, dans un scénario réel, il est très difficile de connaître au départ tous les composants de niveau inférieur. L'approche ascendante n'est donc utilisée que pour des problèmes très simples.
Regardons les composants d'un programme de calculatrice.
Un processus de développement logiciel typique suit ces étapes -
- Recueil des exigences
- Définition du problème
- Conception du système
- Implementation
- Testing
- Documentation
- Formation et accompagnement
- Maintenance
Les deux premières étapes aident l'équipe à comprendre le problème, la première étape la plus cruciale pour trouver une solution. La personne responsable de la collecte des exigences, de la définition du problème et de la conception du système est appeléesystem analyst.
Rassemblement des exigences
Habituellement, les clients ou les utilisateurs ne sont pas en mesure de définir clairement leurs problèmes ou leurs exigences. Ils ont une vague idée de ce qu'ils veulent. Les développeurs de systèmes doivent donc rassembler les exigences des clients pour comprendre le problème qui doit être résolu ou ce qui doit être livré. Une compréhension détaillée du problème n'est possible qu'en comprenant d'abord le domaine d'activité pour lequel la solution est développée. Certaines questions clés qui aident à comprendre une entreprise comprennent:
- Que fait-on?
- Comment cela se fait-il?
- Quelle est la fréquence d'une tâche?
- Quel est le volume de décisions ou de transactions?
- Quels sont les problèmes rencontrés?
Certaines techniques qui aident à recueillir ces informations sont:
- Interviews
- Questionnaires
- Etudier les documents système existants
- Analyser les données commerciales
Les analystes système doivent créer un document d'exigences clair et concis mais complet afin d'identifier les exigences SMART - spécifiques, mesurables, convenues, réalistes et temporelles. Ne pas le faire entraîne -
- Définition de problème incomplète
- Objectifs de programme incorrects
- Retravailler pour fournir le résultat requis au client
- Augmentation des coûts
- Livraison retardée
En raison de la profondeur des informations requises, la collecte des exigences est également appelée detailed investigation.
Définition du problème
Après avoir rassemblé les exigences et les avoir analysées, l'énoncé du problème doit être clairement énoncé. La définition du problème doit indiquer sans ambiguïté le ou les problèmes à résoudre. Avoir un énoncé clair du problème est nécessaire pour -
- Définir la portée du projet
- Gardez l'équipe concentrée
- Gardez le projet sur la bonne voie
- Valider que le résultat souhaité a été atteint à la fin du projet
Souvent, le codage est censé être la partie la plus essentielle de tout processus de développement logiciel. Cependant, le codage n'est qu'une partie du processus et peut en fait prendre le minimum de temps si le système est conçu correctement. Avant que le système puisse être conçu, une solution doit être identifiée pour le problème en question.
La première chose à noter à propos de la conception d'un système est qu'au départ, l'analyste système peut proposer plus d'une solution. Mais la solution finale ou le produit ne peut être qu'une seule. Une analyse approfondie des données collectées pendant la phase de collecte des exigences peut aider à trouver une solution unique. La définition correcte du problème est également cruciale pour arriver à la solution.
Lorsqu'ils sont confrontés au problème des solutions multiples, les analystes optent pour des aides visuelles telles que des organigrammes, des diagrammes de flux de données, des diagrammes de relations d'entités, etc. pour comprendre chaque solution en profondeur.
Organigramme
L'organigramme est le processus qui consiste à illustrer les flux de travail et les flux de données dans un système à l'aide de symboles et de diagrammes. C'est un outil important pour aider l'analyste système à identifier une solution au problème. Il représente visuellement les composants du système.
Voici les avantages de l'organigramme -
La représentation visuelle aide à comprendre la logique du programme
Ils agissent comme des modèles pour le codage de programme réel
Les organigrammes sont importants pour la documentation du programme
Les organigrammes sont une aide importante lors de la maintenance du programme
Ce sont les inconvénients de l'organigramme -
La logique complexe ne peut pas être représentée à l'aide d'organigrammes
En cas de changement de logique ou de flux de données / de travail, l'organigramme doit être complètement redessiné
Diagramme de flux de données
Le diagramme de flux de données ou DFD est une représentation graphique du flux de données à travers un système ou un sous-système. Chaque processus a son propre flux de données et il existe des niveaux de diagrammes de flux de données. Le niveau 0 affiche les données d'entrée et de sortie pour l'ensemble du système. Ensuite, le système est divisé en modules et le DFD de niveau 1 montre le flux de données pour chaque module séparément. Les modules peuvent en outre être divisés en sous-modules si nécessaire et le DFD de niveau 2 dessiné.
Pseudocode
Une fois le système conçu, il est remis au chef de projet pour mise en œuvre, c'est-à-dire codage. Le codage proprement dit d'un programme se fait dans un langage de programmation, qui ne peut être compris que par des programmeurs formés à ce langage. Cependant, avant le codage proprement dit, les principes de fonctionnement de base, les flux de travail et les flux de données du programme sont écrits en utilisant une notation similaire au langage de programmation à utiliser. Une telle notation s'appellepseudocode.
Voici un exemple de pseudocode en C ++. Le programmeur a juste besoin de traduire chaque instruction en syntaxe C ++ pour obtenir le code du programme.

Identifier les opérations mathématiques
Toutes les instructions à l'ordinateur sont finalement implémentées sous forme d'opérations arithmétiques et logiques au niveau de la machine. Ces opérations sont importantes car elles -
- Occuper l'espace mémoire
- Prenez du temps dans l'exécution
- Déterminer l'efficacité du logiciel
- Affectent les performances globales du logiciel
Les analystes système tentent d'identifier toutes les opérations mathématiques majeures tout en identifiant la solution unique au problème en question.
Un problème réel est complexe et important. Si une solution monolithique est développée, cela pose ces problèmes -
Difficile d'écrire, de tester et de mettre en œuvre un seul gros programme
Les modifications après la livraison du produit final sont presque impossibles
Maintien du programme très difficile
Une erreur peut arrêter l'ensemble du système
Pour surmonter ces problèmes, la solution doit être divisée en parties plus petites appelées modules. La technique consistant à décomposer une grande solution en modules plus petits pour faciliter le développement, la mise en œuvre, la modification et la maintenance est appeléemodular technique de programmation ou de développement de logiciels.
Avantages de la programmation modulaire
La programmation modulaire offre ces avantages -
Permet un développement plus rapide car chaque module peut être développé en parallèle
Les modules peuvent être réutilisés
Comme chaque module doit être testé indépendamment, les tests sont plus rapides et plus robustes
Débogage et maintenance de l'ensemble du programme plus faciles
Les modules sont plus petits et ont un niveau de complexité moindre, ils sont donc faciles à comprendre
Identification des modules
Identifier les modules dans un logiciel est une tâche ahurissante car il ne peut y avoir une seule manière correcte de le faire. Voici quelques conseils pour identifier les modules -
Si les données sont l'élément le plus important du système, créez des modules qui gèrent les données associées.
Si le service fourni par le système est diversifié, divisez le système en modules fonctionnels.
Si tout le reste échoue, décomposez le système en modules logiques selon votre compréhension du système pendant la phase de collecte des exigences.
Pour le codage, chaque module doit à nouveau être décomposé en modules plus petits pour faciliter la programmation. Cela peut à nouveau être fait en utilisant les trois conseils partagés ci-dessus, combinés avec des règles de programmation spécifiques. Par exemple, pour un langage de programmation orienté objet comme C ++ et Java, chaque classe avec ses données et méthodes pourrait former un seul module.
Solution étape par étape
Pour implémenter les modules, le flux de processus de chaque module doit être décrit étape par étape. La solution étape par étape peut être développée en utilisantalgorithms ou pseudocodes. Fournir une solution étape par étape offre ces avantages -
Quiconque lit la solution peut comprendre le problème et la solution.
Il est également compréhensible par les programmeurs et les non-programmeurs.
Lors du codage, chaque instruction doit simplement être convertie en instruction de programme.
Il peut faire partie de la documentation et aider à la maintenance du programme.
Les détails de niveau micro comme les noms d'identifiant, les opérations requises, etc. sont élaborés automatiquement
Regardons un exemple.

Structures de contrôle
Comme vous pouvez le voir dans l'exemple ci-dessus, il n'est pas nécessaire qu'une logique de programme s'exécute sequentially. En langage de programmation,control structuresprendre des décisions sur le déroulement du programme en fonction de paramètres donnés. Ce sont des éléments très importants de tout logiciel et doivent être identifiés avant le début de tout codage.
Algorithmes et pseudocodes aider les analystes et les programmeurs à identifier où des structures de contrôle sont nécessaires.
Les structures de contrôle sont de ces trois types -
Structures de contrôle de décision
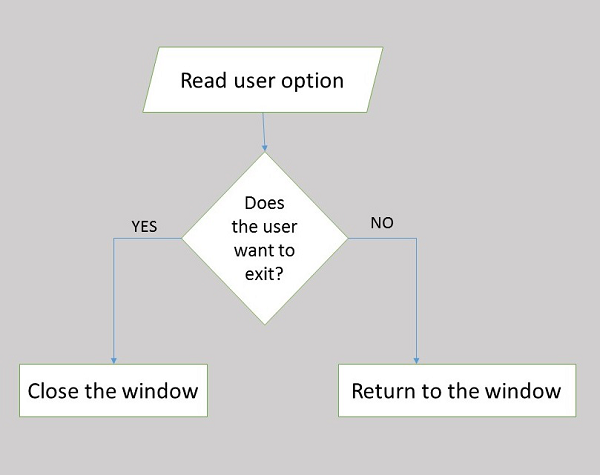
Les structures de contrôle de décision sont utilisées lorsque l'étape suivante à exécuter dépend d'un critère. Ce critère est généralement une ou plusieurs expressions booléennes qui doivent être évaluées. Une expression booléenne est toujours évaluée à «vrai» ou «faux». Un ensemble d'instructions est exécuté si le critère est «vrai» et un autre ensemble est exécuté si le critère est évalué à «faux». Par exemple, si instruction
Structures de contrôle de sélection
Les structures de contrôle de sélection sont utilisées lorsque la séquence du programme dépend de la réponse à une question spécifique. Par exemple, un programme a de nombreuses options pour l'utilisateur. L'instruction à exécuter ensuite dépendra de l'option choisie. Par exemple,switch déclaration, case déclaration.
Structures de contrôle de répétition / boucle
La structure de contrôle de répétition est utilisée lorsqu'un ensemble d'instructions doit être répété plusieurs fois. Le nombre de répétitions peut être connu avant de commencer ou peut dépendre de la valeur d'une expression. Par exemple,for déclaration, while déclaration, do while déclaration, etc.
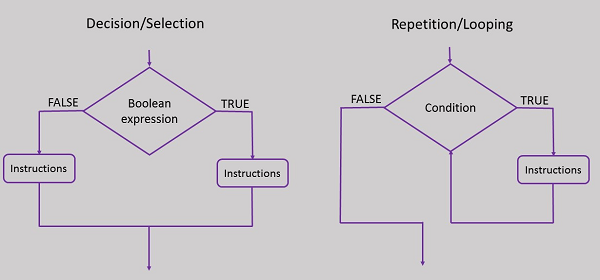
Comme vous pouvez le voir dans l'image ci-dessus, les structures de sélection et de décision sont implémentées de la même manière dans un organigramme. Le contrôle de sélection n'est rien d'autre qu'une série d'énoncés de décision pris séquentiellement.
Voici quelques exemples de programmes pour montrer comment ces instructions fonctionnent -

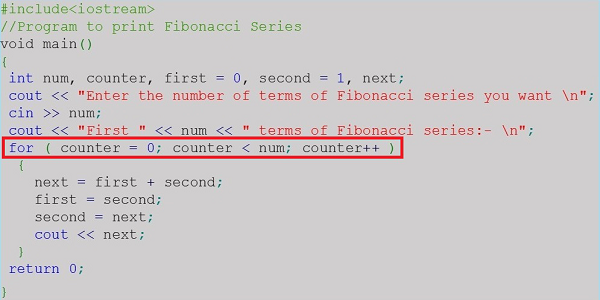
Un ensemble fini d'étapes qui doivent être suivies pour résoudre tout problème est appelé un algorithm. L'algorithme est généralement développé avant le codage proprement dit. Il est écrit en utilisant un langage semblable à l'anglais afin qu'il soit facilement compréhensible même par les non-programmeurs.
Parfois, les algorithmes sont écrits en utilisant pseudocodes, c'est-à-dire un langage similaire au langage de programmation à utiliser. L'écriture d'algorithme pour résoudre un problème offre ces avantages -
Favorise une communication efficace entre les membres de l'équipe
Permet l'analyse du problème à portée de main
Agit comme modèle pour le codage
Aide au débogage
Fait partie de la documentation du logiciel pour référence future pendant la phase de maintenance
Ce sont les caractéristiques d'un bon et correct algorithme -
A un ensemble d'entrées
Les étapes sont définies de manière unique
A un nombre fini d'étapes
Produit la sortie souhaitée
Exemples d'algorithmes
Prenons d'abord un exemple de situation réelle pour créer un algorithme. Voici l'algorithme pour se rendre sur le marché pour acheter un stylo.

L'étape 4 de cet algorithme est en soi une tâche complète et un algorithme séparé peut être écrit pour cela. Créons maintenant un algorithme pour vérifier si un nombre est positif ou négatif.

Flowchartest une représentation schématique de la séquence des étapes logiques d'un programme. Les organigrammes utilisent des formes géométriques simples pour représenter les processus et des flèches pour montrer les relations et le flux de processus / données.
Symboles de l'organigramme
Voici un graphique pour certains des symboles courants utilisés dans le dessin des organigrammes.
| symbole | Nom du symbole | Objectif |
|---|---|---|

|
Commencer arrêter | Utilisé au début et à la fin de l'algorithme pour afficher le début et la fin du programme. |

|
Processus | Indique des processus tels que des opérations mathématiques. |

|
Entrée sortie | Utilisé pour désigner les entrées et sorties du programme. |

|
Décision | Signifie les déclarations de décision dans un programme, où la réponse est généralement Oui ou Non. |
|
|
La Flèche | Montre les relations entre différentes formes. |

|
Connecteur sur la page | Connecte deux ou plusieurs parties d'un organigramme, qui se trouvent sur la même page. |

|
Connecteur hors page | Relie deux parties d'un organigramme qui sont réparties sur différentes pages. |
Directives pour l'élaboration des organigrammes
Voici quelques points à garder à l'esprit lors de l'élaboration d'un organigramme -
L'organigramme ne peut avoir qu'un seul symbole de démarrage et un seul symbole d'arrêt
Les connecteurs sur la page sont référencés à l'aide de nombres
Les connecteurs hors page sont référencés à l'aide d'alphabets
Le flux général des processus est de haut en bas ou de gauche à droite
Les flèches ne doivent pas se croiser
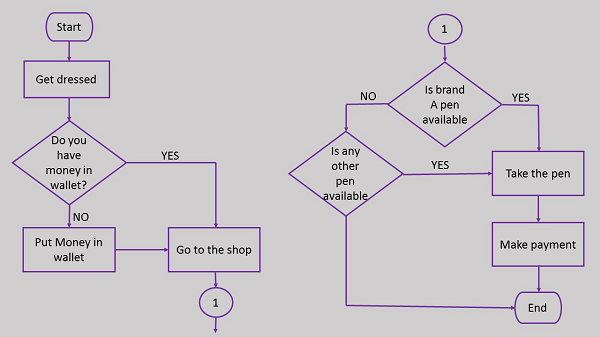
Exemples d'organigrammes
Voici l'organigramme pour se rendre sur le marché pour acheter un stylo.
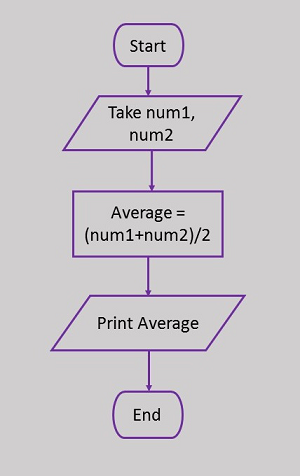
Voici un organigramme pour calculer la moyenne de deux nombres.
Comme vous le savez, l'ordinateur n'a pas sa propre intelligence; il suit simplement leinstructions donné par l'utilisateur. Instructionssont les éléments constitutifs d'un programme informatique, et donc d'un logiciel. Donner des instructions claires est essentiel pour construire un programme réussi. En tant que programmeur ou développeur de logiciels, vous devez prendre l'habitude d'écrire des instructions claires. Voici deux façons de procéder.
Clarté des expressions
L'expression dans un programme est une séquence d'opérateurs et d'opérandes pour effectuer un calcul arithmétique ou logique. Voici quelques exemples d'expressions valides -
- Comparer deux valeurs
- Définition d'une variable, d'un objet ou d'une classe
- Calculs arithmétiques utilisant une ou plusieurs variables
- Récupération des données de la base de données
- Mise à jour des valeurs dans la base de données
Ecrire des expressions sans ambiguïté est une compétence qui doit être développée par chaque programmeur. Voici quelques points à garder à l'esprit lors de l'écriture de telles expressions -
Résultat sans ambiguïté
L'évaluation de l'expression doit donner un résultat net. Par exemple, les opérateurs unaires doivent être utilisés avec prudence.
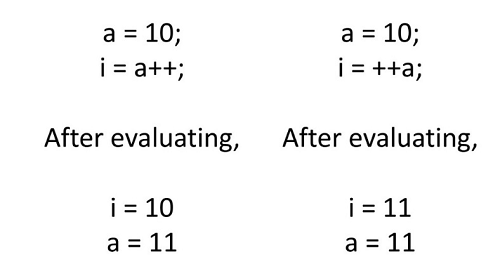
Évitez les expressions complexes
N'essayez pas de réaliser beaucoup de choses en une seule expression. Divisez en deux ou plusieurs expressions au moment où les choses commencent à se compliquer.
Simplicité des instructions
Ce n'est pas seulement pour les ordinateurs que vous devez rédiger des instructions claires. Quiconque lira le programme plus tard (même vous-même !!) devrait être capable de comprendre ce que l'instruction essaie de réaliser. Il est très courant que les programmeurs ne se familiarisent pas avec leurs propres programmes lorsqu'ils les revisitent après un certain temps. Cela indique que la maintenance et la modification de tels programmes seraient assez difficiles.
L'écriture d'instructions simples permet d'éviter ce problème. Voici quelques conseils pour rédiger des instructions simples -
Avoid clever instructions - Les instructions intelligentes peuvent ne pas paraître aussi intelligentes plus tard si personne n'est capable de les comprendre correctement.
One instruction per task - Essayer de faire plus d'une chose à la fois complique les instructions.
Use standards- Chaque langue a ses normes, suivez-les. N'oubliez pas que vous ne travaillez pas seul sur le projet; suivre les normes du projet et les directives de codage.
Dans ce chapitre, nous verrons comment écrire un bon programme. Mais avant de faire cela, voyons quelles sont les caractéristiques d'un bon programme -
Portable- Le programme ou le logiciel doit fonctionner sur tous les ordinateurs du même type. Par même type, nous entendons qu'un logiciel développé pour les ordinateurs personnels doit fonctionner sur tous les PC. Ou un logiciel pour les tablettes doit fonctionner sur toutes les tablettes ayant les bonnes spécifications.
Efficient- Un logiciel qui effectue rapidement les tâches assignées est considéré comme efficace. L'optimisation du code et l'optimisation de la mémoire sont quelques-uns des moyens d'augmenter l'efficacité du programme.

Effective- Le logiciel doit aider à résoudre le problème en question. On dit qu'un logiciel qui fait cela est efficace.
Reliable - Le programme doit donner la même sortie chaque fois que le même ensemble d'entrées est donné.
User friendly - L'interface du programme, les liens cliquables et les icônes, etc. doivent être conviviaux.
Self-documenting - Tout programme ou logiciel dont les noms d'identifiant, les noms de module, etc. peuvent se décrire grâce à l'utilisation de noms explicites.
Voici quelques moyens d'écrire de bons programmes.
Noms d'identifiant corrects
Un nom qui identifie toute variable, objet, fonction, classe ou méthode est appelé identifier. Donner des noms d'identificateurs appropriés rend un programme auto-documenté. Cela signifie que le nom de l'objet dira ce qu'il fait ou quelles informations il stocke. Prenons un exemple de cette instruction SQL:
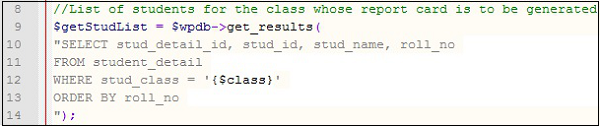
Regardez la ligne 10. Il indique à quiconque lit le programme que l'ID, le nom et le numéro de rôle d'un étudiant doivent être sélectionnés. Les noms des variables rendent cela explicite. Voici quelques conseils pour créer des noms d'identifiant appropriés -
Utilisez les directives linguistiques
N'ayez pas peur de donner des noms longs pour maintenir la clarté
Utilisez des lettres majuscules et minuscules
Ne donnez pas le même nom à deux identifiants même si la langue le permet
Ne donnez pas les mêmes noms à plus d'un identifiant même s'ils ont une portée mutuellement exclusive
commentaires
Dans l'image ci-dessus, regardez la ligne 8. Elle indique au lecteur que les prochaines lignes de code récupéreront la liste des élèves dont le bulletin scolaire doit être généré. Cette ligne ne fait pas partie du code mais est donnée uniquement pour rendre le programme plus convivial.
Une telle expression qui n'est pas compilée mais écrite comme une note ou une explication pour le programmeur est appelée un comment. Regardez les commentaires dans le segment de programme suivant. Les commentaires commencent par //.

Les commentaires peuvent être insérés comme -
Prologue du programme pour expliquer son objectif
Au début et / ou à la fin des blocs logiques ou fonctionnels
Prenez note des scénarios spéciaux ou des exceptions
Vous devez éviter d'ajouter des commentaires superflus car cela peut s'avérer contre-productif en interrompant le flux de code lors de la lecture. Le compilateur peut ignorer les commentaires et les indentations mais le lecteur a tendance à lire chacun d'eux.
Échancrure
La distance du texte par rapport à la marge gauche ou droite est appelée indent. Dans les programmes, l'indentation est utilisée pour séparer les blocs de code logiquement séparés. Voici un exemple de segment de programme en retrait:
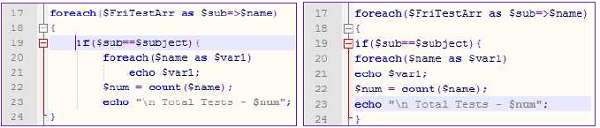
Comme vous pouvez le voir, le programme indenté est plus compréhensible. Flux de contrôle defor loop à if et retour à forest très clair. L'indentation est particulièrement utile dans le cas de structures de contrôle.
L'insertion d'espaces ou de lignes vides fait également partie de l'indentation. Voici quelques situations dans lesquelles vous pouvez et devez utiliser l'indentation -
Lignes vides entre les blocs logiques ou fonctionnels de code dans le programme
Espaces vides autour des opérateurs
Onglets au début des nouvelles structures de contrôle
L'identification et la suppression des erreurs d'un programme ou d'un logiciel s'appelle debugging. Le débogage fait idéalement partie du processus de test, mais en réalité, il est effectué à chaque étape de la programmation. Les codeurs doivent déboguer le plus petit de leurs modules avant de continuer. Cela réduit le nombre d'erreurs générées pendant la phase de test et réduit considérablement le temps et l'effort de test. Examinons les types d'erreurs qui peuvent survenir dans un programme.
Erreurs de syntaxe
Syntax errorssont les erreurs grammaticales dans un programme. Chaque langage a son propre ensemble de règles, comme la création d'identificateurs, l'écriture d'expressions, etc. pour l'écriture de programmes. Lorsque ces règles ne sont pas respectées, les erreurs sont appeléessyntax errors. Beaucoup de modernesintegrated development environmentspeut identifier les erreurs de syntaxe lors de la saisie de votre programme. Sinon, il sera affiché lorsque vous compilerez le programme. Prenons un exemple -
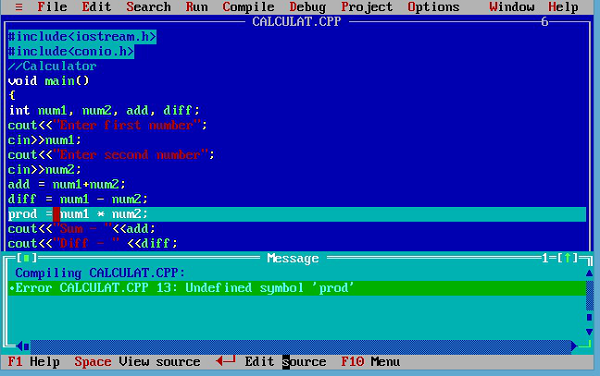
Dans ce programme, la variable prod n'a pas été déclarée, ce qui est lancé par le compilateur.
Erreurs sémantiques
Semantic errors sont aussi appelés logical errors. L'instruction ne contient aucune erreur de syntaxe, elle sera donc compilée et exécutée correctement. Cependant, il ne donnera pas la sortie souhaitée car la logique n'est pas correcte. Prenons un exemple.
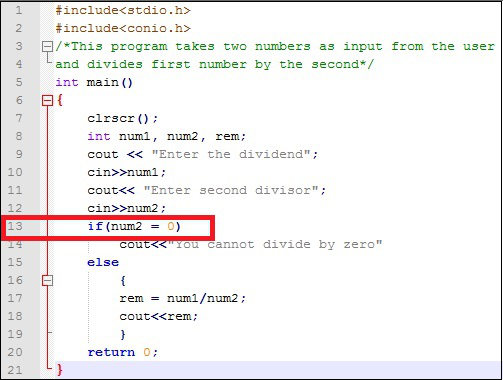
Regardez la ligne 13. Ici, le programmeur veut vérifier si le diviseur est 0, pour éviter la division par 0. Cependant, au lieu d'utiliser l'opérateur de comparaison ==, l'opérateur d'affectation = a été utilisé. Maintenant, à chaque fois, l'expression «si» sera évaluée à vrai et le programme donnera la sortie comme «Vous ne pouvez pas diviser par 0». Certainement pas ce qui était prévu !!
Les erreurs logiques ne peuvent être détectées par aucun programme; ils doivent être identifiés par le programmeur lui-même lorsque la sortie souhaitée n'est pas atteinte.
Erreurs d'exécution
Les erreurs d'exécution sont des erreurs qui se produisent lors de l'exécution du programme. Cela implique que le programme n'a aucune erreur de syntaxe. Certaines des erreurs d'exécution les plus courantes que votre programme peut rencontrer sont:
- Boucle infinie
- Division par '0'
- Mauvaise valeur entrée par l'utilisateur (par exemple, une chaîne au lieu d'un entier)
Optimisation du code
Toute méthode par laquelle le code est modifié pour améliorer sa qualité et son efficacité est appelée code optimization. Code qualitydétermine la durée de vie du code. Si le code peut être utilisé et maintenu pendant une longue période, transféré d'un produit à l'autre, sa qualité est jugée élevée et sa durée de vie est plus longue. Au contraire, si un morceau de code ne peut être utilisé et maintenu que pendant de courtes durées, par exemple jusqu'à ce qu'une version soit valide, il est considéré comme de mauvaise qualité et a une courte durée de vie.
La fiabilité et la rapidité d'un code déterminent code efficiency. L'efficacité du code est un facteur important pour garantir la haute performance d'un logiciel.
Il existe deux approches pour l'optimisation du code -
Intuition based optimization (IBO)- Ici, le programmeur essaie d'optimiser le programme en fonction de ses propres compétences et expérience. Cela peut fonctionner pour les petits programmes mais échoue lamentablement à mesure que la complexité du programme augmente.
Evidence based optimization (EBO)- Ici, des outils automatisés sont utilisés pour découvrir les goulots d'étranglement des performances, puis les parties pertinentes sont optimisées en conséquence. Chaque langage de programmation possède son propre ensemble d'outils d'optimisation de code. Par exemple, PMD, FindBug et Clover sont utilisés pour optimiser le code Java.
Le code est optimisé pour le temps d'exécution et la consommation de mémoire car le temps est rare et la mémoire chère. Il doit y avoir un équilibre entre les deux. Sitime optimization augmente la charge de la mémoire ou memory optimization rend le code plus lent, le but de l'optimisation sera perdu.

Optimisation du temps d'exécution
L'optimisation du code pour le temps d'exécution est nécessaire pour fournir un service rapide aux utilisateurs. Voici quelques conseils pour l'optimisation du temps d'exécution -
Utilisez des commandes qui ont une optimisation du temps d'exécution intégrée
Utilisez le commutateur au lieu de la condition if
Minimiser les appels de fonction dans les structures de boucle
Optimiser les structures de données utilisées dans le programme
Optimisation de la mémoire
Comme vous le savez, les données et les instructions consomment de la mémoire. Lorsque nous parlons de données, cela fait également référence à des données intermédiaires qui sont le résultat d'expressions. Nous devons également garder une trace du nombre d'instructions composant le programme ou le module que nous essayons d'optimiser. Voici quelques conseils pourmemory optimization -
Utilisez des commandes qui ont une optimisation de la mémoire intégrée
Gardez au minimum l'utilisation des variables qui doivent être stockées dans les registres
Évitez de déclarer des variables globales dans des boucles exécutées plusieurs fois
Évitez d'utiliser des fonctions gourmandes en ressources processeur comme sqrt ()
Tout texte écrit, illustration ou vidéo décrivant un logiciel ou un programme à ses utilisateurs est appelé program or software document. L'utilisateur peut être n'importe qui, du programmeur, de l'analyste système et de l'administrateur à l'utilisateur final. À différents stades de développement, plusieurs documents peuvent être créés pour différents utilisateurs. En réalité,software documentation est un processus critique dans le processus global de développement logiciel.
Dans la programmation modulaire, la documentation devient encore plus importante car différents modules du logiciel sont développés par différentes équipes. Si quelqu'un d'autre que l'équipe de développement veut ou a besoin de comprendre un module, une bonne documentation détaillée facilitera la tâche.
Voici quelques conseils pour créer les documents -
La documentation doit être du point de vue du lecteur
Le document doit être sans ambiguïté
Il ne devrait pas y avoir de répétition
Les normes de l'industrie doivent être utilisées
Les documents doivent toujours être mis à jour
Tout document obsolète devrait être éliminé après l'enregistrement en bonne et due forme de l'élimination.
Avantages de la documentation
Voici quelques-uns des avantages de fournir une documentation de programme -
Garde une trace de toutes les parties d'un logiciel ou d'un programme
L'entretien est plus facile
Les programmeurs autres que le développeur peuvent comprendre tous les aspects du logiciel
Améliore la qualité globale du logiciel
Aide à la formation des utilisateurs
Assure la décentralisation des connaissances, réduisant les coûts et les efforts si les gens quittent brusquement le système
Exemples de documents
Un logiciel peut être associé à de nombreux types de documents. Certains des plus importants incluent -
User manual - Il décrit les instructions et les procédures permettant aux utilisateurs finaux d'utiliser les différentes fonctionnalités du logiciel.
Operational manual - Il répertorie et décrit toutes les opérations en cours et leurs interdépendances.
Design Document- Il donne un aperçu du logiciel et décrit les éléments de conception en détail. Il documente des détails commedata flow diagrams, entity relationship diagrams, etc.
Requirements Document- Il contient une liste de toutes les exigences du système ainsi qu'une analyse de la viabilité des exigences. Il peut avoir des cas d'utilisateurs, des scénarios réels, etc.
Technical Documentation - Il s'agit d'une documentation de composants de programmation réels tels que des algorithmes, des organigrammes, des codes de programme, des modules fonctionnels, etc.
Testing Document - Il enregistre le plan de test, les cas de test, le plan de validation, le plan de vérification, les résultats des tests, etc. Les tests sont une phase du développement logiciel qui nécessite une documentation intensive.
List of Known Bugs- Chaque logiciel présente des bogues ou des erreurs qui ne peuvent pas être supprimés car ils ont été découverts très tardivement ou sont inoffensifs ou nécessiteront plus d'efforts et de temps que nécessaire pour les corriger. Ces bogues sont répertoriés avec la documentation du programme afin qu'ils puissent être supprimés ultérieurement. Ils aident également les utilisateurs, les implémenteurs et les responsables de la maintenance si le bogue est activé.
Program maintenance est le processus de modification d'un logiciel ou d'un programme après la livraison pour atteindre l'un de ces résultats -
- Corriger les erreurs
- Améliorer les performances
- Ajouter des fonctionnalités
- Supprimer les portions obsolètes
Malgré la perception courante selon laquelle la maintenance est nécessaire pour corriger les erreurs qui surviennent après la mise en service du logiciel, en réalité, la plupart des travaux de maintenance impliquent l'ajout de capacités mineures ou majeures aux modules existants. Par exemple, de nouvelles données sont ajoutées à un rapport, un nouveau champ ajouté aux formulaires de saisie, un code à modifier pour incorporer des lois gouvernementales modifiées, etc.
Types de maintenance
Les activités de maintenance peuvent être classées sous quatre rubriques -
Corrective maintenance- Ici, les erreurs qui surviennent après la mise en œuvre sur site sont corrigées. Les erreurs peuvent être signalées par les utilisateurs eux-mêmes.
Preventive maintenance - Les modifications effectuées pour éviter des erreurs à l'avenir sont appelées maintenance préventive.
Adaptive maintenance- Les modifications de l'environnement de travail nécessitent parfois des modifications du logiciel. C'est ce qu'on appelle la maintenance adaptative. Par exemple, si la politique gouvernementale en matière d'éducation change, les modifications correspondantes doivent être apportées au module de traitement des résultats des élèves du logiciel de gestion scolaire.
Perfective maintenance- Les modifications apportées au logiciel existant pour intégrer les nouvelles exigences du client sont appelées maintenance perfective. L'objectif ici est d'être toujours à jour avec les dernières technologies.
Outils de maintenance
Les développeurs de logiciels et les programmeurs utilisent de nombreux outils pour les aider dans la maintenance des logiciels. Voici quelques-uns des plus utilisés -
Program slicer - sélectionne une partie du programme qui serait affectée par le changement
Data flow analyzer - suit tous les flux de données possibles dans le logiciel
Dynamic analyzer - trace le chemin d'exécution du programme
Static analyzer - permet une visualisation générale et un résumé du programme
Dependency analyzer - aide à comprendre et à analyser l'interdépendance des différentes parties du programme