Persistance des données Python - Guide rapide
Présentation de Python - Persistance des données
Au cours de l'utilisation de toute application logicielle, l'utilisateur fournit certaines données à traiter. Les données peuvent être saisies à l'aide d'un périphérique d'entrée standard (clavier) ou d'autres périphériques tels qu'un fichier disque, un scanner, une caméra, un câble réseau, une connexion WiFi, etc.
Les données ainsi reçues sont stockées dans la mémoire principale de l'ordinateur (RAM) sous la forme de diverses structures de données telles que des variables et des objets jusqu'à ce que l'application soit en cours d'exécution. Ensuite, le contenu de la mémoire de la RAM est effacé.
Cependant, le plus souvent, il est souhaitable que les valeurs des variables et / ou des objets soient stockées de telle manière qu'elles puissent être récupérées chaque fois que nécessaire, au lieu de saisir à nouveau les mêmes données.
Le mot «persistance» signifie «la continuation d'un effet après que sa cause a été supprimée». Le terme persistance des données signifie qu'il continue d'exister même après la fin de l'application. Ainsi, les données stockées dans un support de stockage non volatile tel qu'un fichier disque est un stockage de données persistant.
Dans ce didacticiel, nous explorerons divers modules Python intégrés et tiers pour stocker et récupérer des données vers / depuis divers formats tels que des fichiers texte, CSV, JSON et XML, ainsi que des bases de données relationnelles et non relationnelles.
En utilisant l'objet File intégré à Python, il est possible d'écrire des données de chaîne dans un fichier disque et de les lire. La bibliothèque standard de Python fournit des modules pour stocker et récupérer des données sérialisées dans diverses structures de données telles que JSON et XML.
DB-API de Python fournit un moyen standard d'interagir avec les bases de données relationnelles. D'autres packages Python tiers présentent des fonctionnalités d'interfaçage avec des bases de données NOSQL telles que MongoDB et Cassandra.
Ce tutoriel présente également la base de données ZODB qui est une API de persistance pour les objets Python. Le format Microsoft Excel est un format de fichier de données très populaire. Dans ce didacticiel, nous allons apprendre à gérer le fichier .xlsx via Python.
Python utilise des input() et print()fonctions pour effectuer des opérations d'entrée / sortie standard. La fonction input () lit les octets d'un périphérique de flux d'entrée standard, c'est-à-dire le clavier.
le print()d'autre part, envoie les données vers le périphérique de flux de sortie standard, c'est-à-dire le moniteur d'affichage. Le programme Python interagit avec ces périphériques IO via des objets de flux standardstdin et stdout défini dans le module sys.
le input()function est en fait un wrapper autour de la méthode readline () de l'objet sys.stdin. Toutes les frappes du flux d'entrée sont reçues jusqu'à ce que la touche «Entrée» soit enfoncée.
>>> import sys
>>> x=sys.stdin.readline()
Welcome to TutorialsPoint
>>> x
'Welcome to TutorialsPoint\n'Notez que, readline()fonction laisse un caractère '\ n' à la fin. Il existe également une méthode read () qui lit les données du flux d'entrée standard jusqu'à ce qu'elles soient terminées parCtrl+D personnage.
>>> x=sys.stdin.read()
Hello
Welcome to TutorialsPoint
>>> x
'Hello\nWelcome to TutorialsPoint\n'De même, print() est une fonction pratique émulant la méthode write () de l'objet stdout.
>>> x='Welcome to TutorialsPoint\n'
>>> sys.stdout.write(x)
Welcome to TutorialsPoint
26Tout comme les objets de flux prédéfinis stdin et stdout, un programme Python peut lire des données et les envoyer vers un fichier disque ou une socket réseau. Ce sont aussi des flux. Tout objet qui a la méthode read () est un flux d'entrée. Tout objet qui a la méthode write () est un flux de sortie. La communication avec le flux est établie en obtenant une référence à l'objet de flux avec la fonction open () intégrée.
fonction open ()
Cette fonction intégrée utilise les arguments suivants -
f=open(name, mode, buffering)Le paramètre name est le nom du fichier disque ou une chaîne d'octets, le mode est une chaîne facultative à un caractère pour spécifier le type d'opération à effectuer (lecture, écriture, ajout, etc.) et le paramètre de mise en mémoire tampon est soit 0, 1 ou -1 indiquant la mise en mémoire tampon est désactivée, activée ou par défaut du système.
Le mode d'ouverture de fichier est énuméré selon le tableau ci-dessous. Le mode par défaut est «r»
| Sr.Non | Paramètres et description |
|---|---|
| 1 | R Ouvrir pour lecture (par défaut) |
| 2 | W Ouvrir pour l'écriture, tronquer d'abord le fichier |
| 3 | X Créez un nouveau fichier et ouvrez-le pour l'écriture |
| 4 | A Ouvert à l'écriture, en ajoutant à la fin du fichier s'il existe |
| 5 | B Mode binaire |
| 6 | T Mode texte (par défaut) |
| sept | + Ouvrez un fichier disque pour la mise à jour (lecture et écriture) |
Afin d'enregistrer les données dans un fichier, il doit être ouvert en mode «w».
f=open('test.txt','w')Cet objet fichier agit comme un flux de sortie et a accès à la méthode write (). La méthode write () envoie une chaîne à cet objet et est stockée dans le fichier sous-jacent.
string="Hello TutorialsPoint\n"
f.write(string)Il est important de fermer le flux pour s'assurer que toutes les données restant dans la mémoire tampon y sont complètement transférées.
file.close()Essayez d'ouvrir «test.txt» à l'aide de n'importe quel éditeur de test (comme le bloc-notes) pour confirmer la création réussie du fichier.
Pour lire le contenu de «test.txt» par programme, il doit être ouvert en mode «r».
f=open('test.txt','r')Cet objet se comporte comme un flux d'entrée. Python peut récupérer les données du flux en utilisantread() méthode.
string=f.read()
print (string)Le contenu du fichier est affiché sur la console Python. L'objet File prend également en chargereadline() méthode qui est capable de lire la chaîne jusqu'à ce qu'elle rencontre le caractère EOF.
Cependant, si le même fichier est ouvert en mode «w» pour y stocker du texte supplémentaire, les contenus antérieurs sont effacés. Chaque fois qu'un fichier est ouvert avec une autorisation d'écriture, il est traité comme s'il s'agissait d'un nouveau fichier. Pour ajouter des données à un fichier existant, utilisez «a» pour le mode d'ajout.
f=open('test.txt','a')
f.write('Python Tutorials\n')Le fichier maintenant, a une chaîne plus ancienne et nouvellement ajoutée. L'objet fichier prend également en chargewritelines() pour écrire chaque chaîne d'un objet de liste dans le fichier.
f=open('test.txt','a')
lines=['Java Tutorials\n', 'DBMS tutorials\n', 'Mobile development tutorials\n']
f.writelines(lines)
f.close()Exemple
le readlines()renvoie une liste de chaînes, chacune représentant une ligne dans le fichier. Il est également possible de lire le fichier ligne par ligne jusqu'à la fin du fichier.
f=open('test.txt','r')
while True:
line=f.readline()
if line=='' : break
print (line, end='')
f.close()Production
Hello TutorialsPoint
Python Tutorials
Java Tutorials
DBMS tutorials
Mobile development tutorialsMode binaire
Par défaut, les opérations de lecture / écriture sur un objet fichier sont effectuées sur des données de chaîne de texte. Si nous voulons gérer des fichiers de différents autres types tels que les médias (mp3), les exécutables (exe), les images (jpg), etc., nous devons ajouter le préfixe «b» au mode lecture / écriture.
L'instruction suivante convertira une chaîne en octets et l'écrira dans un fichier.
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()La conversion d'une chaîne de texte en octets est également possible à l'aide de la fonction encode ().
data="Hello World".encode('utf-8')Nous devons utiliser ‘rb’mode pour lire le fichier binaire. La valeur retournée de la méthode read () est d'abord décodée avant l'impression.
f=open('test.bin', 'rb')
data=f.read()
print (data.decode(encoding='utf-8'))Afin d'écrire des données entières dans un fichier binaire, l'objet entier doit être converti en octets par to_bytes() méthode.
n=25
n.to_bytes(8,'big')
f=open('test.bin', 'wb')
data=n.to_bytes(8,'big')
f.write(data)Pour relire un fichier binaire, convertissez la sortie de la fonction read () en entier par la fonction from_bytes ().
f=open('test.bin', 'rb')
data=f.read()
n=int.from_bytes(data, 'big')
print (n)Pour les données en virgule flottante, nous devons utiliser struct module de la bibliothèque standard de Python.
import struct
x=23.50
data=struct.pack('f',x)
f=open('test.bin', 'wb')
f.write(data)Décompression de la chaîne de la fonction read (), pour récupérer les données flottantes du fichier binaire.
f=open('test.bin', 'rb')
data=f.read()
x=struct.unpack('f', data)
print (x)Lecture / écriture simultanée
Lorsqu'un fichier est ouvert pour l'écriture (avec 'w' ou 'a'), il n'est pas possible d'en lire et vice versa. Cela génère une erreur UnSupportedOperation. Nous devons fermer le fichier avant d'effectuer une autre opération.
Afin d'effectuer les deux opérations simultanément, nous devons ajouter le caractère «+» dans le paramètre mode. Par conséquent, le mode 'w +' ou 'r +' permet d'utiliser les méthodes write () ainsi que read () sans fermer un fichier. L'objet File prend également en charge la fonction seek () pour rembobiner le flux à n'importe quelle position d'octet souhaitée.
f=open('test.txt','w+')
f.write('Hello world')
f.seek(0,0)
data=f.read()
print (data)
f.close()Le tableau suivant résume toutes les méthodes disponibles pour un fichier comme un objet.
| Sr.Non | Méthode et description |
|---|---|
| 1 | close() Ferme le fichier. Un fichier fermé ne peut plus être lu ou écrit. |
| 2 | flush() Videz le tampon interne. |
| 3 | fileno() Renvoie le descripteur de fichier entier. |
| 4 | next() Renvoie la ligne suivante du fichier chaque fois qu'il est appelé. Utilisez l'itérateur next () dans Python 3. |
| 5 | read([size]) Lit au maximum les octets de taille du fichier (moins si la lecture atteint EOF avant d'obtenir des octets de taille). |
| 6 | readline([size]) Lit une ligne entière du fichier. Un caractère de fin de ligne est conservé dans la chaîne. |
| sept | readlines([sizehint]) Lit jusqu'à EOF en utilisant readline () et renvoie une liste contenant les lignes. |
| 8 | seek(offset[, whence]) Définit la position actuelle du fichier. 0-début 1-courant 2-fin. |
| 9 | seek(offset[, whence]) Définit la position actuelle du fichier. 0-début 1-courant 2-fin. |
| dix | tell() Renvoie la position actuelle du fichier |
| 11 | truncate([size]) Tronque la taille du fichier. |
| 12 | write(str) Écrit une chaîne dans le fichier. Il n'y a pas de valeur de retour. |
En plus de l'objet File renvoyé par open()fonction, les opérations d'E / S de fichier peuvent également être effectuées à l'aide de la bibliothèque intégrée de Python, dotée d'un module os qui fournit des fonctions utiles dépendant du système d'exploitation. Ces fonctions effectuent des opérations de lecture / écriture de bas niveau sur le fichier.
le open()La fonction du module os est similaire à l'open () intégré. Cependant, il ne renvoie pas un objet fichier mais un descripteur de fichier, un entier unique correspondant au fichier ouvert. Les valeurs 0, 1 et 2 du descripteur de fichier représentent les flux stdin, stdout et stderr. Les autres fichiers recevront un descripteur de fichier incrémentiel à partir de 2.
Comme dans le cas de open() fonction intégrée, os.open()La fonction doit également spécifier le mode d'accès aux fichiers. Le tableau suivant répertorie les différents modes définis dans le module os.
| Sr.No. | Module OS et description |
|---|---|
| 1 | os.O_RDONLY Ouvert en lecture uniquement |
| 2 | os.O_WRONLY Ouvert à l'écriture uniquement |
| 3 | os.O_RDWR Ouvert à la lecture et à l'écriture |
| 4 | os.O_NONBLOCK Ne bloquez pas à l'ouverture |
| 5 | os.O_APPEND Ajouter à chaque écriture |
| 6 | os.O_CREAT Créer un fichier s'il n'existe pas |
| sept | os.O_TRUNC Tronquer la taille à 0 |
| 8 | os.O_EXCL Erreur si la création et le fichier existent |
Pour ouvrir un nouveau fichier pour y écrire des données, spécifiez O_WRONLY aussi bien que O_CREATmodes en insérant l'opérateur pipe (|). La fonction os.open () renvoie un descripteur de fichier.
f=os.open("test.dat", os.O_WRONLY|os.O_CREAT)Notez que les données sont écrites sur le fichier disque sous la forme d'une chaîne d'octets. Par conséquent, une chaîne normale est convertie en chaîne d'octets en utilisant la fonction encode () comme précédemment.
data="Hello World".encode('utf-8')La fonction write () du module os accepte cette chaîne d'octets et ce descripteur de fichier.
os.write(f,data)N'oubliez pas de fermer le fichier en utilisant la fonction close ().
os.close(f)Pour lire le contenu d'un fichier à l'aide de la fonction os.read (), utilisez les instructions suivantes:
f=os.open("test.dat", os.O_RDONLY)
data=os.read(f,20)
print (data.decode('utf-8'))Notez que la fonction os.read () nécessite un descripteur de fichier et le nombre d'octets à lire (longueur de la chaîne d'octets).
Si vous souhaitez ouvrir un fichier pour des opérations de lecture / écriture simultanées, utilisez le mode O_RDWR. Le tableau suivant montre les fonctions importantes liées à l'opération de fichier dans le module os.
| Sr.Non | Fonctions et description |
|---|---|
| 1 | os.close(fd) Fermez le descripteur de fichier. |
| 2 | os.open(file, flags[, mode]) Ouvrez le fichier et définissez différents drapeaux selon les drapeaux et éventuellement son mode selon le mode. |
| 3 | os.read(fd, n) Lit au plus n octets à partir du descripteur de fichier fd. Renvoie une chaîne contenant les octets lus. Si la fin du fichier référencé par fd est atteinte, une chaîne vide est renvoyée. |
| 4 | os.write(fd, str) Ecrivez la chaîne str dans le descripteur de fichier fd. Renvoie le nombre d'octets réellement écrits. |
L'objet fichier intégré de Python retourné par la fonction open () intégrée de Python présente un inconvénient important. Lorsqu'elle est ouverte avec le mode 'w', la méthode write () n'accepte que l'objet string.
Cela signifie que si vous avez des données représentées sous une forme non-chaîne, l'objet de classes intégrées (nombres, dictionnaire, listes ou tuples) ou d'autres classes définies par l'utilisateur, elles ne peuvent pas être écrites directement dans un fichier. Avant d'écrire, vous devez le convertir dans sa représentation sous forme de chaîne.
numbers=[10,20,30,40]
file=open('numbers.txt','w')
file.write(str(numbers))
file.close()Pour un fichier binaire, argument à write()La méthode doit être un objet octet. Par exemple, la liste d'entiers est convertie en octets parbytearray() fonction puis écrit dans le fichier.
numbers=[10,20,30,40]
data=bytearray(numbers)
file.write(data)
file.close()Pour lire les données du fichier dans le type de données respectif, une conversion inverse doit être effectuée.
file=open('numbers.txt','rb')
data=file.read()
print (list(data))Ce type de conversion manuelle, d'un objet au format chaîne ou octet (et vice versa) est très encombrant et fastidieux. Il est possible de stocker l'état d'un objet Python sous forme de flux d'octets directement dans un fichier ou un flux mémoire et de le récupérer dans son état d'origine. Ce processus est appelé sérialisation et désérialisation.
La bibliothèque intégrée de Python contient divers modules pour le processus de sérialisation et de désérialisation.
| Sr.No. | Nom et description |
|---|---|
| 1 | pickle Bibliothèque de sérialisation spécifique à Python |
| 2 | marshal Bibliothèque utilisée en interne pour la sérialisation |
| 3 | shelve Persistance des objets pythoniques |
| 4 | dbm bibliothèque offrant une interface avec la base de données Unix |
| 5 | csv bibliothèque pour le stockage et la récupération des données Python au format CSV |
| 6 | json Bibliothèque pour la sérialisation au format JSON universel |
La terminologie de Python pour la sérialisation et la désérialisation est respectivement le pickling et le unpickling. Le module pickle de la bibliothèque Python utilise un format de données très spécifique à Python. Par conséquent, les applications non Python peuvent ne pas être en mesure de désérialiser correctement les données décapées. Il est également conseillé de ne pas décoller les données d'une source non authentifiée.
Les données sérialisées (picklées) peuvent être stockées dans une chaîne d'octets ou un fichier binaire. Ce module définitdumps() et loads()fonctions pour sélectionner et décoller les données à l'aide d'une chaîne d'octets. Pour les processus basés sur des fichiers, le module adump() et load() fonction.
Les protocoles pickle de Python sont les conventions utilisées dans la construction et la déconstruction d'objets Python vers / à partir de données binaires. Actuellement, le module pickle définit 5 protocoles différents comme indiqué ci-dessous -
| Sr.No. | Noms et description |
|---|---|
| 1 | Protocol version 0 Protocole original «lisible par l'homme» rétrocompatible avec les versions antérieures. |
| 2 | Protocol version 1 Ancien format binaire également compatible avec les versions antérieures de Python. |
| 3 | Protocol version 2 Introduit dans Python 2.3, il fournit un décapage efficace des classes de nouveau style. |
| 4 | Protocol version 3 Ajouté dans Python 3.0. recommandé lorsque la compatibilité avec d'autres versions de Python 3 est requise. |
| 5 | Protocol version 4 a été ajouté dans Python 3.4. Il ajoute la prise en charge des très gros objets |
Exemple
Le module pickle se compose de la fonction dumps () qui renvoie une représentation sous forme de chaîne de données picklées.
from pickle import dump
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
dctstring=dumps(dct)
print (dctstring)Production
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00Raviq\x02X\x03\x00\x00\x00ageq\x03K\x17X\x06\x00\x00\x00Genderq\x04X\x01\x00\x00\x00Mq\x05X\x05\x00\x00\x00marksq\x06KKu.Exemple
Utilisez la fonction charges () pour décocher la chaîne et obtenir l'objet dictionnaire d'origine.
from pickle import load
dct=loads(dctstring)
print (dct)Production
{'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}Les objets marinés peuvent également être stockés de manière persistante dans un fichier disque, à l'aide de la fonction dump () et récupérés à l'aide de la fonction load ().
import pickle
f=open("data.txt","wb")
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
pickle.dump(dct,f)
f.close()
#to read
import pickle
f=open("data.txt","rb")
d=pickle.load(f)
print (d)
f.close()Le module pickle fournit également une API orientée objet pour un mécanisme de sérialisation sous la forme de Pickler et Unpickler Des classes.
Comme mentionné ci-dessus, tout comme les objets intégrés dans Python, les objets des classes définies par l'utilisateur peuvent également être sérialisés de manière persistante dans un fichier disque. Dans le programme suivant, nous définissons une classe User avec le nom et le numéro de mobile comme attributs d'instance. En plus du constructeur __init __ (), la classe remplace la méthode __str __ () qui renvoie une représentation sous forme de chaîne de son objet.
class User:
def __init__(self,name, mob):
self.name=name
self.mobile=mob
def __str__(self):
return ('Name: {} mobile: {} '. format(self.name, self.mobile))Pour décaper l'objet de la classe ci-dessus dans un fichier, nous utilisons la classe pickler et sa méthode dump ().
from pickle import Pickler
user1=User('Rajani', '[email protected]', '1234567890')
file=open('userdata','wb')
Pickler(file).dump(user1)
Pickler(file).dump(user2)
file.close()Inversement, la classe Unpickler a la méthode load () pour récupérer l'objet sérialisé comme suit -
from pickle import Unpickler
file=open('usersdata','rb')
user1=Unpickler(file).load()
print (user1)Les fonctionnalités de sérialisation d'objets du module marshal dans la bibliothèque standard de Python sont similaires au module pickle. Cependant, ce module n'est pas utilisé pour les données à usage général. D'autre part, il est utilisé par Python lui-même pour la sérialisation d'objets internes de Python afin de prendre en charge les opérations de lecture / écriture sur les versions compilées des modules Python (fichiers .pyc).
Le format de données utilisé par le module marshal n'est pas compatible entre les versions de Python. Par conséquent, un script Python compilé (fichier .pyc) d'une version ne s'exécutera probablement pas sur une autre.
Tout comme le module pickle, le module marshal a également défini les fonctions load () et dump () pour lire et écrire des objets rassemblés depuis / vers un fichier.
déverser()
Cette fonction écrit une représentation octet de l'objet Python pris en charge dans un fichier. Le fichier lui-même est un fichier binaire avec autorisation d'écriture
charge()
Cette fonction lit les données d'octets d'un fichier binaire et les convertit en objet Python.
L'exemple suivant montre l'utilisation des fonctions dump () et load () pour gérer les objets code de Python, qui sont utilisés pour stocker des modules Python précompilés.
Le code utilise des compile() pour construire un objet de code à partir d'une chaîne source qui incorpore des instructions Python.
compile(source, file, mode)Le paramètre de fichier doit être le fichier à partir duquel le code a été lu. S'il n'a pas été lu à partir d'un fichier, passez une chaîne arbitraire.
Le paramètre mode est 'exec' si la source contient une séquence d'instructions, 'eval' s'il existe une seule expression ou 'single' s'il contient une seule instruction interactive.
L'objet de code de compilation est ensuite stocké dans un fichier .pyc à l'aide de la fonction dump ().
import marshal
script = """
a=10
b=20
print ('addition=',a+b)
"""
code = compile(script, "script", "exec")
f=open("a.pyc","wb")
marshal.dump(code, f)
f.close()Pour désérialiser, l'objet du fichier .pyc utilise la fonction load (). Puisqu'il retourne un objet code, il peut être exécuté en utilisant exec (), une autre fonction intégrée.
import marshal
f=open("a.pyc","rb")
data=marshal.load(f)
exec (data)Le module shelve de la bibliothèque standard de Python fournit un mécanisme de persistance d'objet simple mais efficace. L'objet d'étagère défini dans ce module est un objet de type dictionnaire qui est stocké de manière persistante dans un fichier disque. Cela crée un fichier similaire à la base de données dbm sur les systèmes UNIX.
Le dictionnaire d'étagère a certaines restrictions. Seul le type de données chaîne peut être utilisé comme clé dans cet objet dictionnaire spécial, tandis que tout objet Python sélectionnable peut être utilisé comme valeur.
Le module shelve définit trois classes comme suit -
| Sr.Non | Module Shelve et description |
|---|---|
| 1 | Shelf Il s'agit de la classe de base pour les implémentations de plateau. Il est initialisé avec un objet de type dict. |
| 2 | BsdDbShelf Ceci est une sous-classe de la classe Shelf. L'objet dict passé à son constructeur doit prendre en charge les méthodes first (), next (), previous (), last () et set_location (). |
| 3 | DbfilenameShelf C'est aussi une sous-classe de Shelf mais accepte un nom de fichier comme paramètre pour son constructeur plutôt que comme objet dict. |
La fonction open () définie dans le module shelve qui renvoie un DbfilenameShelf objet.
open(filename, flag='c', protocol=None, writeback=False)Le paramètre de nom de fichier est affecté à la base de données créée. La valeur par défaut du paramètre d'indicateur est «c» pour l'accès en lecture / écriture. Les autres indicateurs sont «w» (écriture seule), «r» (lecture seule) et «n» (nouveau avec lecture / écriture).
La sérialisation elle-même est régie par le protocole pickle, la valeur par défaut est aucune. Le dernier paramètre d'écriture différée par défaut est false. Si la valeur est true, les entrées accédées sont mises en cache. Chaque accès appelle les opérations sync () et close (), le processus peut donc être lent.
Le code suivant crée une base de données et y stocke les entrées de dictionnaire.
import shelve
s=shelve.open("test")
s['name']="Ajay"
s['age']=23
s['marks']=75
s.close()Cela créera le fichier test.dir dans le répertoire actuel et stockera les données clé-valeur sous forme hachée. L'objet Shelf dispose des méthodes suivantes:
| Sr.No. | Méthodes et description |
|---|---|
| 1 | close() synchroniser et fermer l'objet dict persistant. |
| 2 | sync() Réécrivez toutes les entrées du cache si l'étagère a été ouverte avec l'écriture différée définie sur True. |
| 3 | get() renvoie la valeur associée à la clé |
| 4 | items() liste de tuples - chaque tuple est une paire clé / valeur |
| 5 | keys() liste des clés d'étagère |
| 6 | pop() supprime la clé spécifiée et renvoie la valeur correspondante. |
| sept | update() Mettre à jour l'étagère à partir d'un autre dict / itérable |
| 8 | values() liste des valeurs de conservation |
Pour accéder à la valeur d'une clé particulière dans l'étagère -
s=shelve.open('test')
print (s['age']) #this will print 23
s['age']=25
print (s.get('age')) #this will print 25
s.pop('marks') #this will remove corresponding k-v pairComme dans un objet dictionnaire intégré, les méthodes items (), keys () et values () renvoient des objets view.
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('marks', 75)]
print (list(s.keys()))
['name', 'age', 'marks']
print (list(s.values()))
['Ajay', 25, 75]Pour fusionner des éléments d'un autre dictionnaire avec une étagère, utilisez la méthode update ().
d={'salary':10000, 'designation':'manager'}
s.update(d)
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('salary', 10000), ('designation', 'manager')]Le package dbm présente un dictionnaire comme les bases de données de style DBM d'interface. DBM stands for DataBase Manager. Ceci est utilisé par le système d'exploitation UNIX (et similaire à UNIX). La bibliothèque dbbm est un moteur de base de données simple écrit par Ken Thompson. Ces bases de données utilisent des objets chaîne codés en binaire comme clé, ainsi que comme valeur.
La base de données stocke les données à l'aide d'une seule clé (une clé primaire) dans des compartiments de taille fixe et utilise des techniques de hachage pour permettre une récupération rapide des données par clé.
Le paquet dbm contient les modules suivants -
dbm.gnu module est une interface vers la version de la bibliothèque DBM implémentée par le projet GNU.
dbm.ndbm module fournit une interface à l'implémentation UNIX nbdm.
dbm.dumbest utilisée comme option de secours dans le cas où d'autres implémentations de dbm ne sont pas trouvées. Cela ne nécessite aucune dépendance externe mais est plus lent que d'autres.
>>> dbm.whichdb('mydbm.db')
'dbm.dumb'
>>> import dbm
>>> db=dbm.open('mydbm.db','n')
>>> db['name']=Raj Deshmane'
>>> db['address']='Kirtinagar Pune'
>>> db['PIN']='431101'
>>> db.close()La fonction open () permet le mode ces drapeaux -
| Sr.No. | Valeur et signification |
|---|---|
| 1 | 'r' Ouvrir la base de données existante pour lecture uniquement (par défaut) |
| 2 | 'w' Ouvrez la base de données existante pour la lecture et l'écriture |
| 3 | 'c' Ouvrez la base de données pour la lecture et l'écriture, en la créant si elle n'existe pas |
| 4 | 'n' Créez toujours une nouvelle base de données vide, ouverte à la lecture et à l'écriture |
L'objet dbm est un objet de type dictionnaire, tout comme un objet d'étagère. Par conséquent, toutes les opérations de dictionnaire peuvent être effectuées. L'objet dbm peut invoquer les méthodes get (), pop (), append () et update (). Le code suivant ouvre «mydbm.db» avec l'indicateur «r» et itère sur la collection de paires clé-valeur.
>>> db=dbm.open('mydbm.db','r')
>>> for k,v in db.items():
print (k,v)
b'name' : b'Raj Deshmane'
b'address' : b'Kirtinagar Pune'
b'PIN' : b'431101'CSV stands for comma separated values. Ce format de fichier est un format de données couramment utilisé lors de l'exportation / importation de données vers / depuis des feuilles de calcul et des tables de données dans des bases de données. Le module csv a été incorporé dans la bibliothèque standard de Python à la suite de PEP 305. Il présente des classes et des méthodes pour effectuer des opérations de lecture / écriture sur un fichier CSV conformément aux recommandations de PEP 305.
CSV est un format de données d'exportation préféré par le logiciel de feuille de calcul Excel de Microsoft. Cependant, le module csv peut également gérer les données représentées par d'autres dialectes.
L'interface API CSV comprend les classes d'écrivain et de lecteur suivantes:
écrivain()
Cette fonction du module csv renvoie un objet écrivain qui convertit les données en une chaîne délimitée et les stocke dans un objet fichier. La fonction a besoin d'un objet fichier avec autorisation d'écriture comme paramètre. Chaque ligne écrite dans le fichier émet un caractère de nouvelle ligne. Pour éviter tout espace supplémentaire entre les lignes, le paramètre de nouvelle ligne est défini sur «».
La classe écrivain a les méthodes suivantes -
écrivainow ()
Cette méthode écrit les éléments dans un itérable (liste, tuple ou chaîne), en les séparant par une virgule.
écrivain ()
Cette méthode prend une liste d'itérables, comme paramètre et écrit chaque élément sous la forme d'une ligne d'éléments séparés par des virgules dans le fichier.
Example
L'exemple suivant montre l'utilisation de la fonction writer (). Tout d'abord, un fichier est ouvert en mode «w». Ce fichier est utilisé pour obtenir un objet écrivain. Chaque tuple de la liste des tuples est ensuite écrit dans le fichier à l'aide de la méthode writerow ().
import csv
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
csvfile=open('persons.csv','w', newline='')
obj=csv.writer(csvfile)
for person in persons:
obj.writerow(person)
csvfile.close()Output
Cela créera le fichier «persons.csv» dans le répertoire courant. Il affichera les données suivantes.
Lata,22,45
Anil,21,56
John,20,60Au lieu d'itérer sur la liste pour écrire chaque ligne individuellement, nous pouvons utiliser la méthode writerows ().
csvfile=open('persons.csv','w', newline='')
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
obj=csv.writer(csvfile)
obj.writerows(persons)
obj.close()lecteur()
Cette fonction renvoie un objet lecteur qui renvoie un itérateur de lignes dans le csv file. En utilisant la boucle for régulière, toutes les lignes du fichier sont affichées dans l'exemple suivant -
Exemple
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
for row in obj:
print (row)Production
['Lata', '22', '45']
['Anil', '21', '56']
['John', '20', '60']L'objet lecteur est un itérateur. Par conséquent, il prend en charge la fonction next () qui peut également être utilisée pour afficher toutes les lignes du fichier csv au lieu d'unfor loop.
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
while True:
try:
row=next(obj)
print (row)
except StopIteration:
breakComme mentionné précédemment, le module csv utilise Excel comme dialecte par défaut. Le module csv définit également une classe de dialectes. Dialect est un ensemble de normes utilisées pour implémenter le protocole CSV. La liste des dialectes disponibles peut être obtenue par la fonction list_dialects ().
>>> csv.list_dialects()
['excel', 'excel-tab', 'unix']En plus des itérables, le module csv peut exporter un objet dictionnaire vers un fichier CSV et le lire pour remplir l'objet dictionnaire Python. A cet effet, ce module définit les classes suivantes -
DictWriter ()
Cette fonction renvoie un objet DictWriter. Il est similaire à l'objet écrivain, mais les lignes sont mappées à l'objet dictionnaire. La fonction a besoin d'un objet fichier avec autorisation d'écriture et d'une liste de clés utilisées dans le dictionnaire comme paramètre fieldnames. Ceci est utilisé pour écrire la première ligne du fichier comme en-tête.
en-tête d'écriture ()
Cette méthode écrit la liste des clés dans le dictionnaire sous la forme d'une ligne séparée par des virgules en tant que première ligne du fichier.
Dans l'exemple suivant, une liste d'éléments de dictionnaire est définie. Chaque élément de la liste est un dictionnaire. En utilisant la méthode writrows (), ils sont écrits dans un fichier séparés par des virgules.
persons=[
{'name':'Lata', 'age':22, 'marks':45},
{'name':'Anil', 'age':21, 'marks':56},
{'name':'John', 'age':20, 'marks':60}
]
csvfile=open('persons.csv','w', newline='')
fields=list(persons[0].keys())
obj=csv.DictWriter(csvfile, fieldnames=fields)
obj.writeheader()
obj.writerows(persons)
csvfile.close()Le fichier persons.csv affiche le contenu suivant -
name,age,marks
Lata,22,45
Anil,21,56
John,20,60DictReader ()
Cette fonction renvoie un objet DictReader à partir du fichier CSV sous-jacent. Comme, dans le cas d'un objet lecteur, celui-ci est également un itérateur, à l'aide duquel le contenu du fichier est récupéré.
csvfile=open('persons.csv','r', newline='')
obj=csv.DictReader(csvfile)La classe fournit l'attribut fieldnames, renvoyant les clés de dictionnaire utilisées comme en-tête du fichier.
print (obj.fieldnames)
['name', 'age', 'marks']Utilisez une boucle sur l'objet DictReader pour récupérer des objets de dictionnaire individuels.
for row in obj:
print (row)Cela entraîne la sortie suivante -
OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
OrderedDict([('name', 'Anil'), ('age', '21'), ('marks', '56')])
OrderedDict([('name', 'John'), ('age', '20'), ('marks', '60')])Pour convertir l'objet OrderedDict en dictionnaire normal, nous devons d'abord importer OrderedDict à partir du module de collections.
from collections import OrderedDict
r=OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
dict(r)
{'name': 'Lata', 'age': '22', 'marks': '45'}JSON signifie JavaScript Object Notation. C'est un format d'échange de données léger. Il s'agit d'un format texte indépendant du langage et multiplateforme, pris en charge par de nombreux langages de programmation. Ce format est utilisé pour l'échange de données entre le serveur Web et les clients.
Le format JSON est similaire à pickle. Cependant, la sérialisation pickle est spécifique à Python alors que le format JSON est implémenté par de nombreux langages et est donc devenu une norme universelle. La fonctionnalité et l'interface du module json dans la bibliothèque standard de Python sont similaires aux modules pickle et marshal.
Tout comme dans le module pickle, le module json fournit également dumps() et loads() fonction pour la sérialisation de l'objet Python en chaîne codée JSON, et dump() et load() Les fonctions écrivent et lisent des objets Python sérialisés vers / depuis un fichier.
dumps() - Cette fonction convertit l'objet au format JSON.
loads() - Cette fonction convertit une chaîne JSON en objet Python.
L'exemple suivant montre l'utilisation de base de ces fonctions -
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data)
json.loads(s)La fonction dumps () peut prendre l'argument sort_keys facultatif. Par défaut, il est faux. Si la valeur est True, les clés du dictionnaire apparaissent dans l'ordre trié dans la chaîne JSON.
La fonction dumps () a un autre paramètre facultatif appelé indent qui prend un nombre comme valeur. Il décide de la longueur de chaque segment de la représentation formatée de la chaîne json, similaire à la sortie d'impression.
Le module json a également une API orientée objet correspondant aux fonctions ci-dessus. Il existe deux classes définies dans le module - JSONEncoder et JSONDecoder.
Classe JSONEncoder
L'objet de cette classe est l'encodeur pour les structures de données Python. Chaque type de données Python est converti en type JSON correspondant, comme indiqué dans le tableau suivant -
| Python | JSON |
|---|---|
| Dict | objet |
| liste, tuple | tableau |
| Str | chaîne |
| Enums dérivés int, float, int et float | nombre |
| Vrai | vrai |
| Faux | faux |
| Aucun | nul |
La classe JSONEncoder est instanciée par le constructeur JSONEncoder (). Les méthodes importantes suivantes sont définies dans la classe d'encodeur -
| Sr.No. | Méthodes et description |
|---|---|
| 1 | encode() sérialise l'objet Python au format JSON |
| 2 | iterencode() Encode l'objet et renvoie un itérateur donnant la forme codée de chaque élément de l'objet. |
| 3 | indent Détermine le niveau de retrait de la chaîne codée |
| 4 | sort_keys est soit vrai soit faux pour que les clés apparaissent dans l'ordre trié ou non. |
| 5 | Check_circular si True, vérifiez la référence circulaire dans l'objet de type conteneur |
L'exemple suivant encode l'objet de liste Python.
e=json.JSONEncoder()
e.encode(data)Classe JSONDecoder
L'objet de cette classe aide à décodé en chaîne json à la structure de données Python. La méthode principale de cette classe est decode (). L'exemple de code suivant récupère l'objet de liste Python à partir de la chaîne codée à l'étape précédente.
d=json.JSONDecoder()
d.decode(s)Le module json définit load() et dump() fonctions pour écrire des données JSON dans un fichier comme un objet - qui peut être un fichier disque ou un flux d'octets et en lire les données.
déverser()
Cette fonction écrit les données d'objet JSONed Python dans un fichier. Le fichier doit être ouvert en mode «w».
import json
data=['Rakesh', {'marks': (50, 60, 70)}]
fp=open('json.txt','w')
json.dump(data,fp)
fp.close()Ce code créera 'json.txt' dans le répertoire courant. Il montre le contenu comme suit -
["Rakesh", {"marks": [50, 60, 70]}]charge()
Cette fonction charge les données JSON du fichier et renvoie un objet Python à partir de celui-ci. Le fichier doit être ouvert avec l'autorisation de lecture (doit avoir le mode «r»).
Example
fp=open('json.txt','r')
ret=json.load(fp)
print (ret)
fp.close()Output
['Rakesh', {'marks': [50, 60, 70]}]le json.tool module a également une interface de ligne de commande qui valide les données dans le fichier et imprime l'objet JSON d'une manière assez formatée.
C:\python37>python -m json.tool json.txt
[
"Rakesh",
{
"marks": [
50,
60,
70
]
}
]XML est l'acronyme de eXtensible Markup Language. C'est un langage portable, open source et multiplateforme très semblable au HTML ou au SGML et recommandé par le World Wide Web Consortium.
Il s'agit d'un format d'échange de données bien connu, utilisé par un grand nombre d'applications telles que les services Web, les outils bureautiques et Service Oriented Architectures(SOA). Le format XML est à la fois lisible par machine et lisible par l'homme.
Le package xml de la bibliothèque Python standard se compose des modules suivants pour le traitement XML -
| Sr.No. | Modules et description |
|---|---|
| 1 | xml.etree.ElementTree l'API ElementTree, un processeur XML simple et léger |
| 2 | xml.dom la définition de l'API DOM |
| 3 | xml.dom.minidom une implémentation DOM minimale |
| 4 | xml.sax Implémentation de l'interface SAX2 |
| 5 | xml.parsers.expat la liaison de l'analyseur Expat |
Les données du document XML sont organisées dans un format hiérarchique arborescent, en commençant par la racine et les éléments. Chaque élément est un nœud unique dans l'arborescence et possède un attribut entre les balises <> et </>. Un ou plusieurs sous-éléments peuvent être affectés à chaque élément.
Voici un exemple typique de document XML -
<?xml version = "1.0" encoding = "iso-8859-1"?>
<studentlist>
<student>
<name>Ratna</name>
<subject>Physics</subject>
<marks>85</marks>
</student>
<student>
<name>Kiran</name>
<subject>Maths</subject>
<marks>100</marks>
</student>
<student>
<name>Mohit</name>
<subject>Biology</subject>
<marks>92</marks>
</student>
</studentlist>Tout en utilisant ElementTreemodule, la première étape consiste à configurer l'élément racine de l'arbre. Chaque élément a une balise et un attrib qui est un objet dict. Pour l'élément racine, un attrib est un dictionnaire vide.
import xml.etree.ElementTree as xmlobj
root=xmlobj.Element('studentList')Maintenant, nous pouvons ajouter un ou plusieurs éléments sous l'élément racine. Chaque objet élément peut avoirSubElements. Chaque sous-élément a un attribut et une propriété de texte.
student=xmlobj.Element('student')
nm=xmlobj.SubElement(student, 'name')
nm.text='name'
subject=xmlobj.SubElement(student, 'subject')
nm.text='Ratna'
subject.text='Physics'
marks=xmlobj.SubElement(student, 'marks')
marks.text='85'Ce nouvel élément est ajouté à la racine en utilisant la méthode append ().
root.append(student)Ajoutez autant d'éléments que vous le souhaitez en utilisant la méthode ci-dessus. Enfin, l'objet élément racine est écrit dans un fichier.
tree = xmlobj.ElementTree(root)
file = open('studentlist.xml','wb')
tree.write(file)
file.close()Maintenant, nous voyons comment analyser le fichier XML. Pour cela, construisez une arborescence de documents en donnant son nom comme paramètre de fichier dans le constructeur ElementTree.
tree = xmlobj.ElementTree(file='studentlist.xml')L'objet arbre a getroot() méthode pour obtenir l'élément racine et getchildren () retourne une liste d'éléments en dessous.
root = tree.getroot()
children = root.getchildren()Un objet dictionnaire correspondant à chaque sous-élément est construit en itérant sur la collection de sous-éléments de chaque nœud enfant.
for child in children:
student={}
pairs = child.getchildren()
for pair in pairs:
product[pair.tag]=pair.textChaque dictionnaire est ensuite ajouté à une liste renvoyant la liste d'origine des objets du dictionnaire.
SAXest une interface standard pour l'analyse XML basée sur les événements. L'analyse XML avec SAX nécessite ContentHandler en sous-classant xml.sax.ContentHandler. Vous enregistrez des rappels pour les événements intéressants, puis laissez l'analyseur parcourir le document.
SAX est utile lorsque vos documents sont volumineux ou que vous avez des limitations de mémoire car il analyse le fichier pendant qu'il le lit à partir du disque. Par conséquent, le fichier entier n'est jamais stocké dans la mémoire.
Modèle d'objet de document
(DOM) API est une recommandation du World Wide Web Consortium. Dans ce cas, le fichier entier est lu dans la mémoire et stocké sous une forme hiérarchique (arborescente) pour représenter toutes les fonctionnalités d'un document XML.
SAX, pas aussi rapide que DOM, avec des fichiers volumineux. D'un autre côté, DOM peut tuer des ressources s'il est utilisé sur de nombreux petits fichiers. SAX est en lecture seule, tandis que DOM autorise les modifications du fichier XML.
Le format plist est principalement utilisé par MAC OS X. Ces fichiers sont essentiellement des documents XML. Ils stockent et récupèrent les propriétés d'un objet. La bibliothèque Python contient le module plist, qui est utilisé pour lire et écrire des fichiers 'liste de propriétés' (ils ont généralement l'extension .plist ').
le plistlib module est plus ou moins similaire aux autres bibliothèques de sérialisation dans le sens, il fournit également des fonctions dumps () et charges () pour la représentation sous forme de chaîne d'objets Python et des fonctions load () et dump () pour le fonctionnement du disque.
L'objet dictionnaire suivant conserve la propriété (clé) et la valeur correspondante -
proplist = {
"name" : "Ganesh",
"designation":"manager",
"dept":"accts",
"salary" : {"basic":12000, "da":4000, "hra":800}
}Afin d'écrire ces propriétés dans un fichier disque, nous appelons la fonction dump () dans le module plist.
import plistlib
fileName=open('salary.plist','wb')
plistlib.dump(proplist, fileName)
fileName.close()Inversement, pour relire les valeurs de propriété, utilisez la fonction load () comme suit -
fp= open('salary.plist', 'rb')
pl = plistlib.load(fp)
print(pl)Un inconvénient majeur des fichiers CSV, JSON, XML, etc. est qu'ils ne sont pas très utiles pour l'accès aléatoire et le traitement des transactions car ils sont en grande partie non structurés. Par conséquent, il devient très difficile de modifier le contenu.
Ces fichiers plats ne conviennent pas à l'environnement client-serveur car ils ne disposent pas de capacité de traitement asynchrone. L'utilisation de fichiers de données non structurés entraîne une redondance et une incohérence des données.
Ces problèmes peuvent être surmontés en utilisant une base de données relationnelle. Une base de données est une collection organisée de données pour supprimer la redondance et les incohérences et maintenir l'intégrité des données. Le modèle de base de données relationnelle est très populaire.
Son concept de base est d'organiser les données dans une table d'entité (appelée relation). La structure de la table d'entités fournit un attribut dont la valeur est unique pour chaque ligne. Un tel attribut est appelé'primary key'.
Lorsque la clé primaire d'une table apparaît dans la structure d'autres tables, elle est appelée 'Foreign key'et cela forme la base de la relation entre les deux. Sur la base de ce modèle, de nombreux produits SGBDR populaires sont actuellement disponibles -
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
- SQLite
SQLite est une base de données relationnelle légère utilisée dans une grande variété d'applications. Il s'agit d'un moteur de base de données SQL transactionnel autonome, sans serveur et sans configuration. La base de données entière est un fichier unique, qui peut être placé n'importe où dans le système de fichiers. C'est un logiciel open source, avec un très faible encombrement et une configuration nulle. Il est couramment utilisé dans les appareils intégrés, l'IOT et les applications mobiles.
Toutes les bases de données relationnelles utilisent SQL pour gérer les données dans les tables. Cependant, auparavant, chacune de ces bases de données était connectée à l'application Python à l'aide du module Python spécifique au type de base de données.
Par conséquent, il y avait un manque de compatibilité entre eux. Si un utilisateur souhaitait changer de produit de base de données, cela s'avérerait difficile. Ce problème d'incompatibilité a été résolu en lançant «Python Enhancement Proposal (PEP 248)» pour recommander une interface cohérente avec les bases de données relationnelles appelées DB-API. Les dernières recommandations sont appeléesDB-APIVersion 2.0. (PEP 249)
La bibliothèque standard de Python se compose du module sqlite3 qui est un module compatible DB-API pour gérer la base de données SQLite via le programme Python. Ce chapitre explique la connectivité de Python avec la base de données SQLite.
Comme mentionné précédemment, Python a un support intégré pour la base de données SQLite sous la forme d'un module sqlite3. Pour les autres bases de données, le module Python compatible DB-API respectif devra être installé à l'aide de l'utilitaire pip. Par exemple, pour utiliser la base de données MySQL, nous devons installer le module PyMySQL.
pip install pymysqlLes étapes suivantes sont recommandées dans DB-API -
Établissez la connexion avec la base de données en utilisant connect() fonction et obtenir l'objet de connexion.
Appel cursor() méthode d'objet de connexion pour obtenir un objet curseur.
Formez une chaîne de requête composée d'une instruction SQL à exécuter.
Exécutez la requête souhaitée en appelant execute() méthode.
Fermez la connexion.
import sqlite3
db=sqlite3.connect('test.db')Ici, db est l'objet de connexion représentant test.db. Notez que cette base de données sera créée si elle n'existe pas déjà. L'objet de connexion db a les méthodes suivantes -
| Sr.No. | Méthodes et description |
|---|---|
| 1 | cursor(): Renvoie un objet Cursor qui utilise cette connexion. |
| 2 | commit(): Valide explicitement toutes les transactions en attente dans la base de données. |
| 3 | rollback(): Cette méthode facultative entraîne la restauration d'une transaction au point de départ. |
| 4 | close(): Ferme définitivement la connexion à la base de données. |
Un curseur agit comme un handle pour une requête SQL donnée permettant la récupération d'une ou plusieurs lignes du résultat. L'objet curseur est obtenu à partir de la connexion pour exécuter des requêtes SQL à l'aide de l'instruction suivante -
cur=db.cursor()L'objet curseur a les méthodes suivantes définies -
| Sr.Non | Méthodes et description |
|---|---|
| 1 | execute() Exécute la requête SQL dans un paramètre de chaîne. |
| 2 | executemany() Exécute la requête SQL à l'aide d'un ensemble de paramètres dans la liste des tuples. |
| 3 | fetchone() Récupère la ligne suivante du jeu de résultats de la requête. |
| 4 | fetchall() Récupère toutes les lignes restantes de l'ensemble de résultats de la requête. |
| 5 | callproc() Appelle une procédure stockée. |
| 6 | close() Ferme l'objet curseur. |
Le code suivant crée une table dans test.db: -
import sqlite3
db=sqlite3.connect('test.db')
cur =db.cursor()
cur.execute('''CREATE TABLE student (
StudentID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT (20) NOT NULL,
age INTEGER,
marks REAL);''')
print ('table created successfully')
db.close()L'intégrité des données souhaitée dans une base de données est obtenue par commit() et rollback()méthodes de l'objet de connexion. La chaîne de requête SQL peut avoir une requête SQL incorrecte qui peut déclencher une exception, qui doit être correctement gérée. Pour cela, l'instruction execute () est placée dans le bloc try. Si elle réussit, le résultat est sauvegardé de manière persistante à l'aide de la méthode commit (). Si la requête échoue, la transaction est annulée à l'aide de la méthode rollback ().
Le code suivant exécute la requête INSERT sur la table Student dans test.db.
import sqlite3
db=sqlite3.connect('test.db')
qry="insert into student (name, age, marks) values('Abbas', 20, 80);"
try:
cur=db.cursor()
cur.execute(qry)
db.commit()
print ("record added successfully")
except:
print ("error in query")
db.rollback()
db.close()Si vous souhaitez que les données de la clause values de la requête INSERT soient fournies dynamiquement par l'entrée utilisateur, utilisez la substitution de paramètres comme recommandé dans Python DB-API. Le ? character est utilisé comme espace réservé dans la chaîne de requête et fournit les valeurs sous la forme d'un tuple dans la méthode execute (). L'exemple suivant insère un enregistrement à l'aide de la méthode de substitution de paramètre. Le nom, l'âge et les notes sont pris en compte.
import sqlite3
db=sqlite3.connect('test.db')
nm=input('enter name')
a=int(input('enter age'))
m=int(input('enter marks'))
qry="insert into student (name, age, marks) values(?,?,?);"
try:
cur=db.cursor()
cur.execute(qry, (nm,a,m))
db.commit()
print ("one record added successfully")
except:
print("error in operation")
db.rollback()
db.close()Le module sqlite3 définit le executemany()méthode qui est capable d'ajouter plusieurs enregistrements à la fois. Les données à ajouter doivent être données dans une liste de tuples, chaque tuple contenant un enregistrement. L'objet list est le paramètre de la méthode executemany (), avec la chaîne de requête. Cependant, la méthode executemany () n'est pas prise en charge par certains des autres modules.
le UPDATELa requête contient généralement une expression logique spécifiée par la clause WHERE. La chaîne de requête de la méthode execute () doit contenir une syntaxe de requête UPDATE. Pour mettre à jour la valeur de 'age' à 23 pour name = 'Anil', définissez la chaîne comme ci-dessous:
qry="update student set age=23 where name='Anil';"Pour rendre le processus de mise à jour plus dynamique, nous utilisons la méthode de substitution de paramètres décrite ci-dessus.
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
a=int(input(‘enter age’))
qry="update student set age=? where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (a, nm))
db.commit()
print("record updated successfully")
except:
print("error in query")
db.rollback()
db.close()De même, l'opération DELETE est effectuée en appelant la méthode execute () avec une chaîne ayant la syntaxe de requête DELETE de SQL. Incidemment,DELETE la requête contient également généralement un WHERE clause.
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
qry="DELETE from student where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (nm,))
db.commit()
print("record deleted successfully")
except:
print("error in operation")
db.rollback()
db.close()L'une des opérations importantes sur une table de base de données est la récupération des enregistrements à partir de celle-ci. SQL fournitSELECTrequête pour le but. Lorsqu'une chaîne contenant la syntaxe de requête SELECT est donnée à la méthode execute (), un objet de jeu de résultats est renvoyé. Il existe deux méthodes importantes avec un objet curseur à l'aide desquelles un ou plusieurs enregistrements du jeu de résultats peuvent être récupérés.
fetchone ()
Récupère le prochain enregistrement disponible de l'ensemble de résultats. Il s'agit d'un tuple composé des valeurs de chaque colonne de l'enregistrement extrait.
fetchall ()
Récupère tous les enregistrements restants sous la forme d'une liste de tuples. Chaque tuple correspond à un enregistrement et contient les valeurs de chaque colonne de la table.
L'exemple suivant répertorie tous les enregistrements de la table Student
import sqlite3
db=sqlite3.connect('test.db')
37
sql="SELECT * from student;"
cur=db.cursor()
cur.execute(sql)
while True:
record=cur.fetchone()
if record==None:
break
print (record)
db.close()Si vous prévoyez d'utiliser une base de données MySQL au lieu d'une base de données SQLite, vous devez installer PyMySQLmodule comme décrit ci-dessus. Toutes les étapes du processus de connectivité de la base de données étant identiques, puisque la base de données MySQL est installée sur un serveur, la fonction connect () a besoin de l'URL et des informations de connexion.
import pymysql
con=pymysql.connect('localhost', 'root', '***')La seule chose qui peut différer avec SQLite est les types de données spécifiques à MySQL. De même, toute base de données compatible ODBC peut être utilisée avec Python en installant le module pyodbc.
Toute base de données relationnelle contient des données dans des tables. La structure de la table définit le type de données des attributs qui sont essentiellement des types de données primaires uniquement qui sont mappés aux types de données intégrés correspondants de Python. Cependant, les objets définis par l'utilisateur de Python ne peuvent pas être stockés et récupérés de manière permanente vers / depuis des tables SQL.
Il s'agit d'une disparité entre les types SQL et les langages de programmation orientés objet tels que Python. SQL n'a pas de type de données équivalent pour d'autres tels que dict, tuple, liste ou toute classe définie par l'utilisateur.
Si vous devez stocker un objet dans une base de données relationnelle, ses attributs d'instance doivent d'abord être déconstruits en types de données SQL, avant d'exécuter la requête INSERT. En revanche, les données extraites d'une table SQL sont de types primaires. Un objet Python du type souhaité devra être construit en utilisant pour une utilisation dans un script Python. C'est là que les mappeurs relationnels d'objets sont utiles.
Mappeur de relation d'objets (ORM)
Un Object Relation Mapper(ORM) est une interface entre une classe et une table SQL. Une classe Python est mappée à une certaine table dans la base de données, de sorte que la conversion entre les types objet et SQL est effectuée automatiquement.
La classe Students écrite en code Python est mappée à la table Students dans la base de données. Par conséquent, toutes les opérations CRUD sont effectuées en appelant les méthodes respectives de la classe. Cela élimine le besoin d'exécuter des requêtes SQL codées en dur dans un script Python.
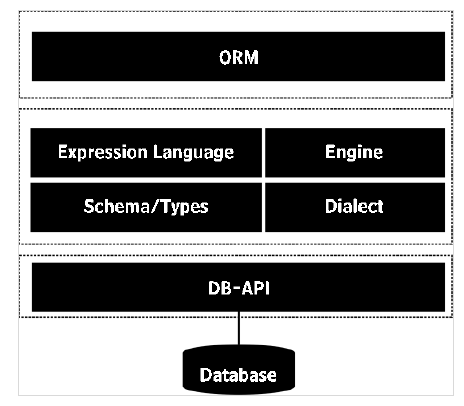
La bibliothèque ORM agit ainsi comme une couche d'abstraction sur les requêtes SQL brutes et peut être utile dans le développement rapide d'applications. SQLAlchemyest un mappeur relationnel d'objet populaire pour Python. Toute manipulation d'état de l'objet modèle est synchronisée avec sa ligne associée dans la table de base de données.
La bibliothèque SQLALchemy comprend ORM API et langage d'expression SQL (SQLAlchemy Core). Le langage d'expression exécute directement les constructions primitives de la base de données relationnelle.
ORM est un modèle d'utilisation abstrait et de haut niveau construit au-dessus du langage d'expression SQL. On peut dire que ORM est une utilisation appliquée du langage d'expression. Nous discuterons de l'API SQLAlchemy ORM et utiliserons la base de données SQLite dans cette rubrique.
SQLAlchemy communique avec différents types de bases de données via leurs implémentations DBAPI respectives en utilisant un système de dialectes. Tous les dialectes nécessitent l'installation d'un pilote DBAPI approprié. Les dialectes pour les types de bases de données suivants sont inclus -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
L'installation de SQLAlchemy est simple et directe, à l'aide de l'utilitaire pip.
pip install sqlalchemyPour vérifier si SQLalchemy est correctement installé et sa version, entrez la suite à l'invite Python -
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.3.11'Les interactions avec la base de données sont effectuées via l'objet Engine obtenu en tant que valeur de retour de create_engine() fonction.
engine =create_engine('sqlite:///mydb.sqlite')SQLite permet la création d'une base de données en mémoire. Le moteur SQLAlchemy pour la base de données en mémoire est créé comme suit -
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')Si vous avez l'intention d'utiliser la base de données MySQL à la place, utilisez son module DB-API - pymysql et le pilote de dialecte correspondant.
engine = create_engine('mysql+pymydsql://root@localhost/mydb')Le create_engine a un argument d'écho facultatif. S'il est défini sur true, les requêtes SQL générées par le moteur seront répercutées sur le terminal.
SQLAlchemy contient declarative baseclasse. Il agit comme un catalogue de classes de modèles et de tables mappées.
from sqlalchemy.ext.declarative import declarative_base
base=declarative_base()L'étape suivante consiste à définir une classe de modèle. Il doit être dérivé de base - object de la classe declarative_base comme ci - dessus.
Ensemble __tablename__ propriété au nom de la table que vous souhaitez créer dans la base de données. D'autres attributs correspondent aux champs. Chacun est un objet Column dans SQLAlchemy et son type de données provient de l'une des listes ci-dessous -
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
Le code suivant est la classe de modèle nommée Student qui est mappée à la table Students.
#myclasses.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Numeric
base=declarative_base()
class Student(base):
__tablename__='Students'
StudentID=Column(Integer, primary_key=True)
name=Column(String)
age=Column(Integer)
marks=Column(Numeric)Pour créer une table Elèves ayant une structure correspondante, exécutez la méthode create_all () définie pour la classe de base.
base.metadata.create_all(engine)Nous devons maintenant déclarer un objet de notre classe Student. Toutes les transactions de base de données telles que l'ajout, la suppression ou la récupération de données de la base de données, etc., sont gérées par un objet Session.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()Les données stockées dans l'objet Student sont physiquement ajoutées dans la table sous-jacente par la méthode add () de la session.
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()Voici le code complet pour ajouter un enregistrement dans la table des étudiants. Lors de son exécution, le journal des instructions SQL correspondant s'affiche sur la console.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()Sortie de la console
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMITle session object fournit également la méthode add_all () pour insérer plus d'un objet dans une seule transaction.
sessionobj.add_all([s2,s3,s4,s5])
sessionobj.commit()Maintenant que les enregistrements sont ajoutés dans la table, nous aimerions en extraire comme le fait la requête SELECT. L'objet session a la méthode query () pour effectuer la tâche. L'objet de requête est retourné par la méthode query () sur notre modèle Student.
qry=seesionobj.query(Student)Utilisez la méthode get () de cet objet Query pour récupérer l'objet correspondant à la clé primaire donnée.
S1=qry.get(1)Pendant que cette instruction est exécutée, son instruction SQL correspondante renvoyée sur la console sera la suivante -
BEGIN (implicit)
SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS
"Students_name", "Students".age AS "Students_age",
"Students".marks AS "Students_marks"
FROM "Students"
WHERE "Products"."Students" = ?
sqlalchemy.engine.base.Engine (1,)La méthode query.all () renvoie une liste de tous les objets qui peuvent être parcourus à l'aide d'une boucle.
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)La mise à jour d'un enregistrement dans la table mappée est très simple. Tout ce que vous avez à faire est de récupérer un enregistrement à l'aide de la méthode get (), d'attribuer une nouvelle valeur à l'attribut souhaité, puis de valider les modifications à l'aide de l'objet session. Ci-dessous, nous changeons les notes de l'étudiant Juhi à 100.
S1=qry.get(1)
S1.marks=100
sessionobj.commit()La suppression d'un enregistrement est tout aussi simple, en supprimant l'objet souhaité de la session.
S1=qry.get(1)
Sessionobj.delete(S1)
sessionobj.commit()MongoDB est un document orienté NoSQLbase de données. Il s'agit d'une base de données multiplateforme distribuée sous licence publique côté serveur. Il utilise des documents de type JSON comme schéma.
Afin de fournir la capacité de stocker d'énormes données, plusieurs serveurs physiques (appelés fragments) sont interconnectés, de sorte qu'une évolutivité horizontale est obtenue. La base de données MongoDB est constituée de documents.
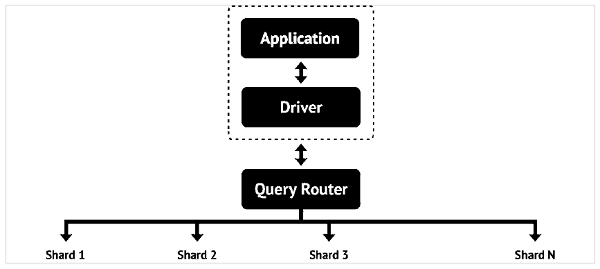
Un document est analogue à une ligne dans une table de base de données relationnelle. Cependant, il n'a pas de schéma particulier. Le document est une collection de paires clé-valeur - similaire au dictionnaire. Cependant, le nombre de paires kv dans chaque document peut varier. Tout comme une table dans une base de données relationnelle a une clé primaire, le document de la base de données MongoDB a une clé spéciale appelée"_id".
Avant de voir comment la base de données MongoDB est utilisée avec Python, comprenons brièvement comment installer et démarrer MongoDB. La version communautaire et commerciale de MongoDB est disponible. La version communautaire peut être téléchargée sur www.mongodb.com/download-center/community .
En supposant que MongoDB est installé dans c: \ mongodb, le serveur peut être appelé à l'aide de la commande suivante.
c:\mongodb\bin>mongodLe serveur MongoDB est actif au numéro de port 22017 par défaut. Les bases de données sont stockées dans le dossier data / bin par défaut, bien que l'emplacement puisse être modifié par l'option –dbpath.
MongoDB a son propre ensemble de commandes à utiliser dans un shell MongoDB. Pour appeler le shell, utilisezMongo commander.
x:\mongodb\bin>mongoUne invite de shell similaire à l'invite de shell MySQL ou SQLite apparaît devant laquelle les commandes NoSQL natives peuvent être exécutées. Cependant, nous sommes intéressés par la connexion de la base de données MongoDB à Python.
PyMongoLe module a été développé par MongoDB Inc lui-même pour fournir une interface de programmation Python. Utilisez l'utilitaire pip bien connu pour installer PyMongo.
pip3 install pymongoEn supposant que le serveur MongoDB est opérationnel (avec mongod commande) et écoute sur le port 22017, nous devons d'abord déclarer un MongoClientobjet. Il contrôle toutes les transactions entre la session Python et la base de données.
from pymongo import MongoClient
client=MongoClient()Utilisez cet objet client pour établir la connexion avec le serveur MongoDB.
client = MongoClient('localhost', 27017)Une nouvelle base de données est créée avec la commande suivante.
db=client.newdbLa base de données MongoDB peut avoir de nombreuses collections, similaires aux tables d'une base de données relationnelle. Un objet Collection est créé parCreate_collection() fonction.
db.create_collection('students')Maintenant, nous pouvons ajouter un ou plusieurs documents dans la collection comme suit -
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
db.create_collection("students")
student=db['students']
studentlist=[{'studentID':1,'Name':'Juhi','age':20, 'marks'=100},
{'studentID':2,'Name':'dilip','age':20, 'marks'=110},
{'studentID':3,'Name':'jeevan','age':24, 'marks'=145}]
student.insert_many(studentlist)
client.close()Pour récupérer les documents (similaire à la requête SELECT), nous devons utiliser find()méthode. Il renvoie un curseur à l'aide duquel tous les documents peuvent être obtenus.
students=db['students']
docs=students.find()
for doc in docs:
print (doc['Name'], doc['age'], doc['marks'] )Pour trouver un document particulier au lieu de tous dans une collection, nous devons appliquer un filtre à la méthode find (). Le filtre utilise des opérateurs logiques. MongoDB a son propre ensemble d'opérateurs logiques comme ci-dessous -
| Sr.Non | Opérateur MongoDB et opérateur logique traditionnel |
|---|---|
| 1 | $eq égal à (==) |
| 2 | $gt supérieur à (>) |
| 3 | $gte supérieur ou égal à (> =) |
| 4 | $in si égal à n'importe quelle valeur du tableau |
| 5 | $lt moins de (<) |
| 6 | $lte inférieur ou égal à (<=) |
| sept | $ne différent de (! =) |
| 8 | $nin sinon égal à n'importe quelle valeur du tableau |
Par exemple, nous souhaitons obtenir la liste des étudiants de plus de 21 ans. Utilisation de l'opérateur $ gt dans le filtre pourfind() méthode comme suit -
students=db['students']
docs=students.find({'age':{'$gt':21}})
for doc in docs:
print (doc.get('Name'), doc.get('age'), doc.get('marks'))Le module PyMongo fournit update_one() et update_many() méthodes pour modifier un ou plusieurs documents satisfaisant une expression de filtre spécifique.
Mettons à jour l'attribut des marques d'un document dont le nom est Juhi.
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
doc=db.students.find_one({'Name': 'Juhi'})
db['students'].update_one({'Name': 'Juhi'},{"$set":{'marks':150}})
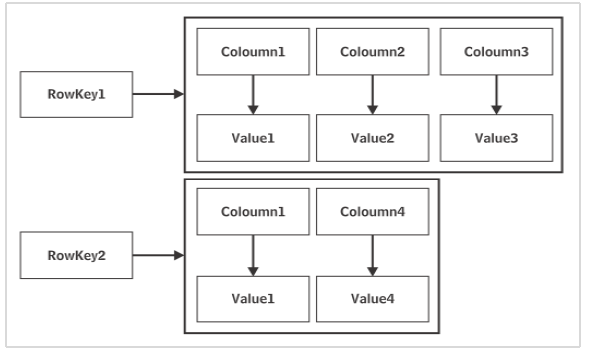
client.close()Cassandra est une autre base de données NoSQL populaire. Évolutivité, cohérence et tolérance aux pannes élevées - ce sont quelques-unes des caractéristiques importantes de Cassandra. C'estColumn storebase de données. Les données sont stockées sur de nombreux serveurs de base. En conséquence, les données sont hautement disponibles.
Cassandra est un produit de la fondation Apache Software. Les données sont stockées de manière distribuée sur plusieurs nœuds. Chaque nœud est un serveur unique composé d'espaces de clés. La pierre angulaire de la base de données Cassandra estkeyspace qui peut être considéré comme analogue à une base de données.
Les données dans un nœud de Cassandra sont répliquées dans d'autres nœuds sur un réseau de nœuds peer-to-peer. Cela fait de Cassandra une base de données infaillible. Le réseau s'appelle un centre de données. Plusieurs centres de données peuvent être interconnectés pour former un cluster. La nature de la réplication est configurée en définissant la stratégie de réplication et le facteur de réplication au moment de la création d'un espace de clés.
Un espace de clés peut avoir plus d'une famille de colonnes - tout comme une base de données peut contenir plusieurs tables. L'espace de clés de Cassandra n'a pas de schéma prédéfini. Il est possible que chaque ligne d'une table Cassandra ait des colonnes avec des noms différents et en nombres variables.
Le logiciel Cassandra est également disponible en deux versions: communauté et entreprise. La dernière version entreprise de Cassandra est disponible en téléchargement surhttps://cassandra.apache.org/download/. L'édition communautaire se trouve surhttps://academy.datastax.com/planet-cassandra/cassandra.
Cassandra a son propre langage de requête appelé Cassandra Query Language (CQL). Les requêtes CQL peuvent être exécutées à partir d'un shell CQLASH - similaire au shell MySQL ou SQLite. La syntaxe CQL ressemble à celle du SQL standard.
L'édition communautaire Datastax est également fournie avec un IDE Develcenter illustré dans la figure suivante -
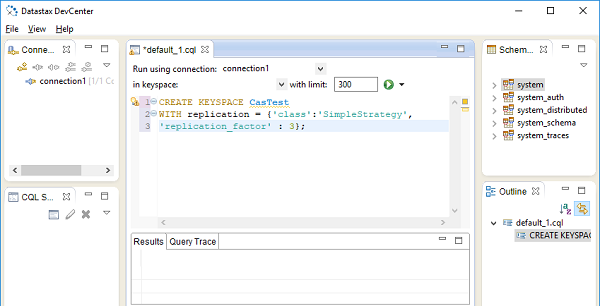
Le module Python pour travailler avec la base de données Cassandra est appelé Cassandra Driver. Il est également développé par la fondation Apache. Ce module contient une API ORM, ainsi qu'une API principale de nature similaire à DB-API pour les bases de données relationnelles.
L'installation du pilote Cassandra se fait facilement en utilisant pip utility.
pip3 install cassandra-driverL'interaction avec la base de données Cassandra se fait via l'objet Cluster. Le module Cassandra.cluster définit la classe de cluster. Nous devons d'abord déclarer l'objet Cluster.
from cassandra.cluster import Cluster
clstr=Cluster()Toutes les transactions telles que l'insertion / la mise à jour, etc., sont effectuées en démarrant une session avec un espace de clés.
session=clstr.connect()Pour créer un nouvel espace de clés, utilisez execute()méthode de l'objet de session. La méthode execute () prend un argument de chaîne qui doit être une chaîne de requête. Le CQL a l'instruction CREATE KEYSPACE comme suit. Le code complet est comme ci-dessous -
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”Ici, SimpleStrategy est une valeur pour replication strategy et replication factorest défini sur 3. Comme mentionné précédemment, un espace de clés contient une ou plusieurs tables. Chaque table est caractérisée par son type de données. Les types de données Python sont automatiquement analysés avec les types de données CQL correspondants conformément au tableau suivant -
| Type de Python | Type CQL |
|---|---|
| Aucun | NUL |
| Booléen | Booléen |
| Flotte | flotteur, double |
| int, long | int, bigint, varint, smallint, tinyint, compteur |
| décimal.Décimal | Décimal |
| str, Unicode | ascii, varchar, texte |
| tampon, bytearray | Goutte |
| Date | Date |
| Datetime | Horodatage |
| Temps | Temps |
| liste, tuple, générateur | liste |
| ensemble, frozenset | Ensemble |
| dict, OrderedDict | Carte |
| uuid.UUID | timeuuid, uuid |
Pour créer une table, utilisez un objet de session pour exécuter une requête CQL pour créer une table.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)L'espace de clés ainsi créé peut être utilisé pour insérer des lignes. La version CQL de la requête INSERT est similaire à l'instruction SQL Insert. Le code suivant insère une ligne dans la table des étudiants.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"Comme vous vous en doutez, l'instruction SELECT est également utilisée avec Cassandra. Dans le cas de la méthode execute () contenant la chaîne de requête SELECT, elle retourne un objet de jeu de résultats qui peut être parcouru à l'aide d'une boucle.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))La requête SELECT de Cassandra prend en charge l'utilisation de la clause WHERE pour appliquer le filtre sur l'ensemble de résultats à extraire. Les opérateurs logiques traditionnels comme <,> == etc. sont reconnus. Pour récupérer, uniquement les lignes de la table des étudiants pour les noms d'âge> 20 ans, la chaîne de requête dans la méthode execute () doit être la suivante -
rows=session.execute("select * from students WHERE age>20 allow filtering;")Notez que l'utilisation de ALLOW FILTERING. La partie ALLOW FILTERING de cette instruction permet d'autoriser explicitement (certaines) requêtes qui nécessitent un filtrage.
L'API du pilote Cassandra définit les classes suivantes de type Statement dans son module cassendra.query.
SimpleStatement
Une requête CQL simple et non préparée contenue dans une chaîne de requête. Tous les exemples ci-dessus sont des exemples de SimpleStatement.
BatchStatement
Plusieurs requêtes (telles que INSERT, UPDATE et DELETE) sont placées dans un lot et exécutées en même temps. Chaque ligne est d'abord convertie en SimpleStatement, puis ajoutée dans un lot.
Mettons les lignes à ajouter dans la table Students sous la forme d'une liste de tuples comme suit -
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]Pour ajouter les lignes ci-dessus à l'aide de BathStatement, exécutez le script suivant -
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)Affirmation préparée
L'instruction préparée est comme une requête paramétrée dans DB-API. Sa chaîne de requête est enregistrée par Cassandra pour une utilisation ultérieure. La méthode Session.prepare () renvoie une instance PreparedStatement.
Pour notre table des étudiants, une requête PreparedStatement for INSERT est la suivante -
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")Par la suite, il suffit d'envoyer les valeurs des paramètres à lier. Par exemple -
qry=stmt.bind([1,'Ram', 23,175])Enfin, exécutez l'instruction liée ci-dessus.
session.execute(qry)Cela réduit le trafic réseau et l'utilisation du processeur car Cassandra n'a pas à réanalyser la requête à chaque fois.
ZODB (Zope object Database) est une base de données pour stocker des objets Python. Il est compatible ACID - fonctionnalité introuvable dans les bases de données NOSQL. Le ZODB est également open source, évolutif horizontalement et sans schéma, comme de nombreuses bases de données NoSQL. Cependant, il n'est pas distribué et n'offre pas une réplication facile. Il fournit un mécanisme de persistance pour les objets Python. Il fait partie du serveur d'applications Zope, mais peut également être utilisé indépendamment.
ZODB a été créé par Jim Fulton de Zope Corporation. Il a commencé comme un simple système d'objets persistants. Sa version actuelle est la 5.5.0 et est entièrement écrite en Python. en utilisant une version étendue de la persistance d'objet intégrée de Python (pickle).
Certaines des principales fonctionnalités de ZODB sont:
- transactions
- history/undo
- stockage enfichable de manière transparente
- mise en cache intégrée
- contrôle de concurrence multiversion (MVCC)
- évolutivité sur un réseau
Le ZODB est un hierarchicalbase de données. Il existe un objet racine, initialisé lors de la création d'une base de données. L'objet racine est utilisé comme un dictionnaire Python et il peut contenir d'autres objets (qui peuvent eux-mêmes ressembler à un dictionnaire). Pour stocker un objet dans la base de données, il suffit de l'attribuer à une nouvelle clé à l'intérieur de son conteneur.
ZODB est utile pour les applications où les données sont hiérarchiques et où il y aura probablement plus de lectures que d'écritures. ZODB est une extension de l'objet pickle. C'est pourquoi il ne peut être traité que via un script Python.
Pour installer la dernière version de ZODB, utilisez l'utilitaire pip -
pip install zodbLes dépendances suivantes sont également installées -
- BTrees==4.6.1
- cffi==1.13.2
- persistent==4.5.1
- pycparser==2.19
- six==1.13.0
- transaction==2.4.0
ZODB fournit les options de stockage suivantes -
FileStorage
C'est la valeur par défaut. Tout est stocké dans un fichier Big Data.fs, qui est essentiellement un journal de transactions.
RépertoireStorage
Cela stocke un fichier par révision d'objet. Dans ce cas, il ne nécessite pas la reconstruction de Data.fs.index lors d'un arrêt impur.
RelStorage
Cela stocke les cornichons dans une base de données relationnelle. PostgreSQL, MySQL et Oracle sont pris en charge.
Pour créer une base de données ZODB, nous avons besoin d'un stockage, d'une base de données et enfin d'une connexion.
La première étape consiste à avoir un objet de stockage.
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('mydata.fs')La classe DB utilise cet objet de stockage pour obtenir un objet de base de données.
db = ZODB.DB(storage)Passez None au constructeur DB pour créer une base de données en mémoire.
Db=ZODB.DB(None)Enfin, nous établissons la connexion avec la base de données.
conn=db.open()L'objet de connexion vous donne alors accès à la 'racine' de la base de données avec la méthode 'root ()'. L'objet «racine» est le dictionnaire qui contient tous vos objets persistants.
root = conn.root()Par exemple, nous ajoutons une liste d'étudiants à l'objet racine comme suit -
root['students'] = ['Mary', 'Maya', 'Meet']Cette modification n'est pas enregistrée de manière permanente dans la base de données tant que nous ne validons pas la transaction.
import transaction
transaction.commit()Pour stocker l'objet d'une classe définie par l'utilisateur, la classe doit être héritée de la classe parente persistent.Persistent.
Avantages du sous-classement
Sous-classer la classe persistante a ses avantages comme suit -
La base de données suivra automatiquement les modifications apportées aux objets en définissant des attributs.
Les données seront enregistrées dans son propre enregistrement de base de données.
Vous pouvez enregistrer des données qui ne sont pas sous-classe Persistent, mais elles seront stockées dans l'enregistrement de base de données de tout objet persistant qui y fait référence. Les objets non persistants appartiennent à leur objet persistant et si plusieurs objets persistants font référence au même sous-objet non persistant, ils obtiendront leurs propres copies.
Laissez utiliser définir une classe d'étudiants sous-classant la classe persistante comme sous -
import persistent
class student(persistent.Persistent):
def __init__(self, name):
self.name = name
def __repr__(self):
return str(self.name)Pour ajouter un objet de cette classe, commençons par configurer la connexion comme décrit ci-dessus.
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('studentdata.fs')
db = ZODB.DB(storage)
conn=db.open()
root = conn.root()Déclarez un objet un ajout à la racine, puis validez la transaction
s1=student("Akash")
root['s1']=s1
import transaction
transaction.commit()
conn.close()La liste de tous les objets ajoutés à la racine peut être récupérée en tant qu'objet de vue à l'aide de la méthode items () car l'objet racine est similaire au dictionnaire intégré.
print (root.items())
ItemsView({'s1': Akash})Pour récupérer l'attribut d'un objet spécifique à partir de la racine,
print (root['s1'].name)
AkashL'objet peut être facilement mis à jour. Étant donné que l'API ZODB est un package Python pur, elle ne nécessite aucun langage de type SQL externe pour être utilisé.
root['s1'].name='Abhishek'
import transaction
transaction.commit()La base de données sera mise à jour instantanément. Notez que la classe de transaction définit également la fonction abort () qui est similaire au contrôle de transaction rollback () dans SQL.
Microsoft Excel est l'application de feuille de calcul la plus populaire. Il est utilisé depuis plus de 25 ans. Les versions ultérieures d'Excel utilisentOffice Open XML (OOXML) format de fichier. Par conséquent, il a été possible d'accéder aux fichiers de feuilles de calcul via d'autres environnements de programmation.
OOXMLest un format de fichier standard ECMA. Pythonopenpyxl package fournit des fonctionnalités pour lire / écrire des fichiers Excel avec l'extension .xlsx.
Le package openpyxl utilise une nomenclature de classe similaire à la terminologie Microsoft Excel. Un document Excel est appelé comme classeur et est enregistré avec l'extension .xlsx dans le système de fichiers. Un classeur peut avoir plusieurs feuilles de calcul. Une feuille de calcul présente une grande grille de cellules, chacune d'entre elles pouvant stocker une valeur ou une formule. Les lignes et les colonnes qui forment la grille sont numérotées. Les colonnes sont identifiées par des alphabets, A, B, C,…., Z, AA, AB, etc. Les lignes sont numérotées à partir de 1.
Une feuille de calcul Excel typique apparaît comme suit -
L'utilitaire pip est assez bon pour installer le package openpyxl.
pip install openpyxlLa classe Workbook représente un classeur vide avec une feuille de calcul vierge. Nous devons l'activer pour que certaines données puissent être ajoutées à la feuille de calcul.
from openpyxl import Workbook
wb=Workbook()
sheet1=wb.active
sheet1.title='StudentList'Comme nous le savons, une cellule dans la feuille de calcul est nommée au format ColumnNameRownumber. En conséquence, la cellule supérieure gauche est A1. Nous attribuons une chaîne à cette cellule comme -
sheet1['A1']= 'Student List'Sinon, utilisez la feuille de calcul cell()méthode qui utilise le numéro de ligne et de colonne pour identifier une cellule. Appelez la propriété value à l'objet cellule pour attribuer une valeur.
cell1=sheet1.cell(row=1, column=1)
cell1.value='Student List'Après avoir rempli la feuille de calcul avec des données, le classeur est enregistré en appelant la méthode save () de l'objet classeur.
wb.save('Student.xlsx')Ce fichier de classeur est créé dans le répertoire de travail actuel.
Le script Python suivant écrit une liste de tuples dans un document de classeur. Chaque tuple stocke le numéro de rouleau, l'âge et les notes de l'élève.
from openpyxl import Workbook
wb = Workbook()
sheet1 = wb.active
sheet1.title='Student List'
sheet1.cell(column=1, row=1).value='Student List'
studentlist=[('RollNo','Name', 'age', 'marks'),(1,'Juhi',20,100),
(2,'dilip',20, 110) , (3,'jeevan',24,145)]
for col in range(1,5):
for row in range(1,5):
sheet1.cell(column=col, row=1+row).value=studentlist[row-1][col-1]
wb.save('students.xlsx')Le classeur student.xlsx est enregistré dans le répertoire de travail actuel. S'il est ouvert à l'aide de l'application Excel, il apparaît comme ci-dessous -
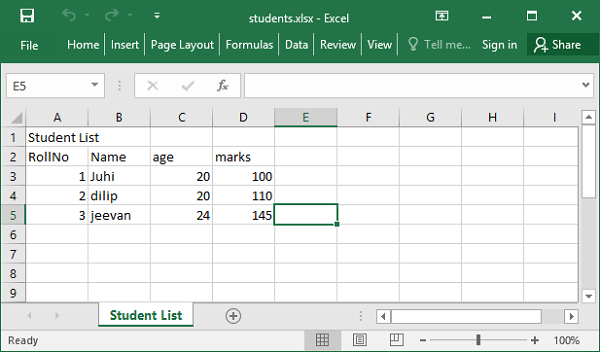
Le module openpyxl propose load_workbook() fonction qui aide à lire les données dans le document de classeur.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')Vous pouvez désormais accéder à la valeur de n'importe quelle cellule spécifiée par le numéro de ligne et de colonne.
cell1=sheet1.cell(row=1, column=1)
print (cell1.value)
Student ListExemple
Le code suivant remplit une liste avec des données de feuille de travail.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
studentlist=[]
for row in range(1,5):
stud=[]
for col in range(1,5):
val=sheet1.cell(column=col, row=1+row).value
stud.append(val)
studentlist.append(tuple(stud))
print (studentlist)Production
[('RollNo', 'Name', 'age', 'marks'), (1, 'Juhi', 20, 100), (2, 'dilip', 20, 110), (3, 'jeevan', 24, 145)]Une caractéristique très importante de l'application Excel est la formule. Pour attribuer une formule à une cellule, affectez-la à une chaîne contenant la syntaxe de formule d'Excel. Attribuez la fonction MOYENNE à la cellule c6 ayant l'âge.
sheet1['C6']= 'AVERAGE(C3:C5)'Le module Openpyxl a Translate_formula()pour copier la formule sur une plage. Le programme suivant définit la fonction MOYENNE dans C6 et la copie dans C7 qui calcule la moyenne des notes.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
from openpyxl.formula.translate import Translator#copy formula
sheet1['B6']='Average'
sheet1['C6']='=AVERAGE(C3:C5)'
sheet1['D6'] = Translator('=AVERAGE(C3:C5)', origin="C6").translate_formula("D6")
wb.save('students.xlsx')La feuille de calcul modifiée apparaît maintenant comme suit -