SAP ABAP - Guide rapide
ABAP signifie Advanced Business Application Programming, un langage 4GL (4e génération). Actuellement, il se positionne, avec Java, comme le principal langage de programmation du serveur d'applications SAP.
Commençons par l'architecture de haut niveau du système SAP. L'architecture client / serveur à 3 niveaux d'un système SAP typique est décrite comme suit.

le Presentation layerse compose de tout périphérique d'entrée pouvant être utilisé pour contrôler le système SAP. Cela peut être un navigateur Web, un appareil mobile, etc. Tout le traitement central a lieu dansApplication server. Le serveur d'applications n'est pas seulement un système en soi, mais il peut s'agir de plusieurs instances du système de traitement. Le serveur communique avec leDatabase layerqui est généralement conservé sur un serveur séparé, principalement pour des raisons de performances et également pour des raisons de sécurité. La communication se produit entre chaque couche du système, de la couche Présentation à la base de données, puis sauvegarde la chaîne.
Note- Les programmes ABAP s'exécutent au niveau du serveur d'applications. La distribution technique du logiciel est indépendante de son emplacement physique. Cela signifie essentiellement que les trois niveaux peuvent être installés les uns sur les autres sur un ordinateur ou que chaque niveau peut être installé sur un ordinateur ou un serveur différent.
Les programmes ABAP résident dans la base de données SAP. Ils s'exécutent sous le contrôle du système d'exécution qui fait partie du noyau SAP. Le système d'exécution traite toutes les instructions ABAP, contrôle la logique de flux et répond aux événements utilisateur.
Ainsi, contrairement à C ++ et Java, les programmes ABAP ne sont pas stockés dans des fichiers externes séparés. À l'intérieur de la base de données, le code ABAP existe sous deux formes -
Source code qui peut être visualisé et édité avec les outils ABAP Workbench.
Generated code, qui est une représentation binaire. Si vous êtes familier avec Java, ce code généré est quelque peu comparable au code d'octet Java.
Le système d'exécution peut être considéré comme une machine virtuelle, tout comme la machine virtuelle Java. Un composant clé du système d'exécution ABAP est l'interface de base de données qui transforme les instructions indépendantes de la base de données (Open SQL) en instructions comprises par la base de données sous-jacente (Native SQL). SAP peut fonctionner avec une grande variété de bases de données et le même programme ABAP peut s'exécuter sur toutes celles-ci.
Les rapports sont un bon point de départ pour vous familiariser avec les principes et outils ABAP généraux. Les rapports ABAP sont utilisés dans de nombreux domaines. Dans ce chapitre, nous verrons à quel point il est facile d'écrire un rapport ABAP simple.
Bonjour ABAP
Commençons par l'exemple courant "Hello World".
Chaque instruction ABAP commence par un mot clé ABAP et se termine par un point. Les mots clés doivent être séparés par au moins un espace. Peu importe que vous utilisiez ou non une ou plusieurs lignes pour une instruction ABAP.
Vous devez entrer votre code à l'aide de l'éditeur ABAP qui fait partie des outils ABAP fournis avec le serveur d'applications SAP NetWeaver ABAP (également appelé «AS ABAP»).
«AS ABAP» est un serveur d'applications avec sa propre base de données, un environnement d'exécution ABAP et des outils de développement ABAP tels que l'éditeur ABAP. L'AS ABAP offre une plate-forme de développement indépendante du matériel, du système d'exploitation et de la base de données.
Utilisation de l'éditeur ABAP
Step 1- Démarrez la transaction SE38 pour accéder à l'éditeur ABAP (décrit dans le chapitre suivant). Commençons par créer un rapport qui est l'un des nombreux objets ABAP.
Step 2- Sur l'écran initial de l'éditeur, indiquez le nom de votre rapport dans le champ de saisie PROGRAM. Vous pouvez spécifier le nom comme ZHELLO1. Le Z précédent est important pour le nom. Z garantit que votre rapport réside dans l'espace de noms client.
L'espace de noms client inclut tous les objets avec le préfixe Y ou Z. Il est toujours utilisé lorsque les clients ou partenaires créent des objets (comme un rapport) pour différencier ces objets des objets de SAP et pour éviter les conflits de nom avec les objets.
Step 3- Vous pouvez taper le nom du rapport en minuscules, mais l'éditeur le changera en majuscules. Ainsi, les noms des objets ABAP ne sont pas sensibles à la casse.
Step 4- Après avoir spécifié le nom du rapport, cliquez sur le bouton CRÉER. Une fenêtre contextuelle ABAP: ATTRIBUTS DU PROGRAMME apparaîtra et vous fournira plus d'informations sur votre rapport.
Step 5- Choisissez «Programme exécutable» comme type de rapport, entrez le titre «Mon premier rapport ABAP», puis sélectionnez ENREGISTRER pour continuer. La fenêtre CRÉER UNE ENTRÉE DANS LE RÉPERTOIRE D'OBJETS apparaîtra ensuite. Sélectionnez le bouton OBJET LOCAL et la fenêtre contextuelle se fermera.
Vous pouvez compléter votre premier rapport en entrant l'instruction WRITE sous l'instruction REPORT, de sorte que le rapport complet ne contienne que deux lignes comme suit -
REPORT ZHELLO1.
WRITE 'Hello World'.Démarrer le rapport
Nous pouvons utiliser le clavier (Ctrl + S) ou l'icône de sauvegarde (à droite à côté du champ de commande) pour enregistrer le rapport. Le développement ABAP a lieu dans AS ABAP.
Démarrer le rapport est aussi simple que de le sauvegarder. Cliquez sur le bouton ACTIVATION (à gauche à côté de l'icône de démarrage) et démarrez le rapport en utilisant l'icône TRAITEMENT DIRECT ou la touche de fonction F8. Le titre «Mon premier rapport ABAP» ainsi que la sortie «Hello World» sont également affichés. Voici la sortie -
My First ABAP Report
Hello WorldTant que vous n'activez pas un nouveau rapport ou n'activez pas une modification d'un rapport existant, cela n'est pas pertinent pour leurs utilisateurs. Ceci est important dans un environnement de développement central où vous pouvez travailler sur des objets que d'autres développeurs utilisent dans leurs projets.
Affichage du code existant
Si vous regardez le champ Programme et double-cliquez sur la valeur ZHELLO1, l'éditeur ABAP affichera le code de votre rapport. C'est ce qu'on appelle la navigation vers l'avant. Un double-clic sur le nom d'un objet ouvre cet objet dans l'outil approprié.
Afin de comprendre SAP ABAP, vous devez avoir des connaissances de base sur les écrans tels que la connexion, l'éditeur ABAP, la déconnexion, etc. Ce chapitre se concentre sur la navigation à l'écran et les fonctionnalités de la barre d'outils standard.
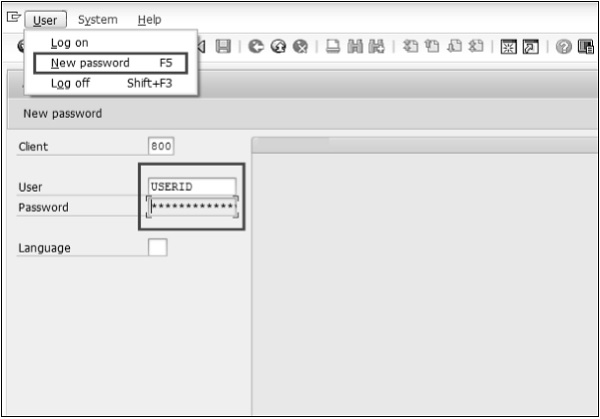
Écran de connexion
Après vous être connecté au serveur SAP, l'écran de connexion SAP vous demandera l'ID utilisateur et le mot de passe. Vous devez fournir un ID utilisateur et un mot de passe valides et appuyer sur Entrée (l'ID utilisateur et le mot de passe sont fournis par l'administrateur système). Voici l'écran de connexion.
Icône de la barre d'outils
Voici la barre d'outils de l'écran SAP.
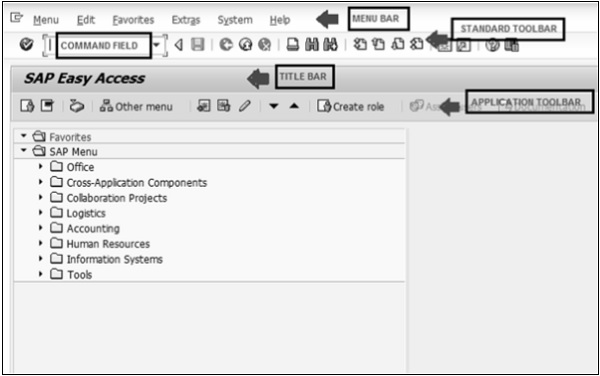
Menu Bar - La barre de menus est la première ligne de la fenêtre de dialogue.
Standard Toolbar - La plupart des fonctions standard telles que Haut de page, Fin de page, Page précédente, Page suivante et Enregistrer sont disponibles dans cette barre d'outils.
Title Bar - La barre de titre affiche le nom de l'application / du processus métier dans lequel vous vous trouvez actuellement.
Application Toolbar - Les options de menu spécifiques à l'application sont disponibles ici.
Command Field- Nous pouvons démarrer une application sans naviguer dans les transactions du menu et certains codes logiques sont affectés aux processus métier. Les codes de transaction sont saisis dans le champ de commande pour démarrer directement l'application.
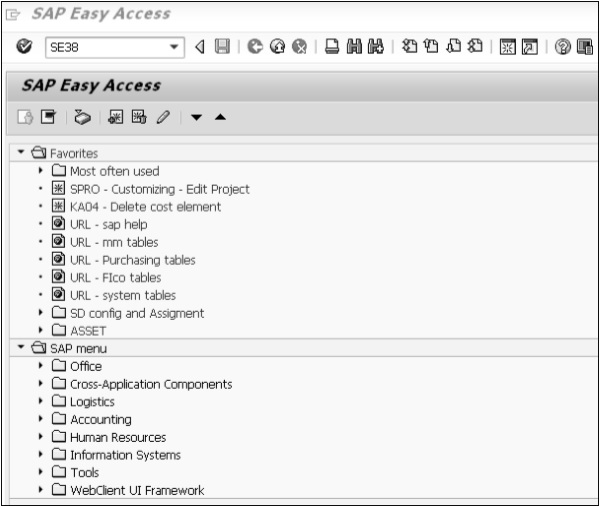
Éditeur ABAP
Vous pouvez simplement démarrer la transaction SE38 (entrez SE38 dans le champ de commande) pour accéder à l'éditeur ABAP.
Touches et icônes standard
Exit keyssont utilisés pour quitter le programme / module ou pour se déconnecter. Ils permettent également de revenir au dernier écran consulté.
Voici les clés de sortie standard utilisées dans SAP, comme indiqué dans l'image.
Voici les options de vérification, d'activation et de traitement des rapports.
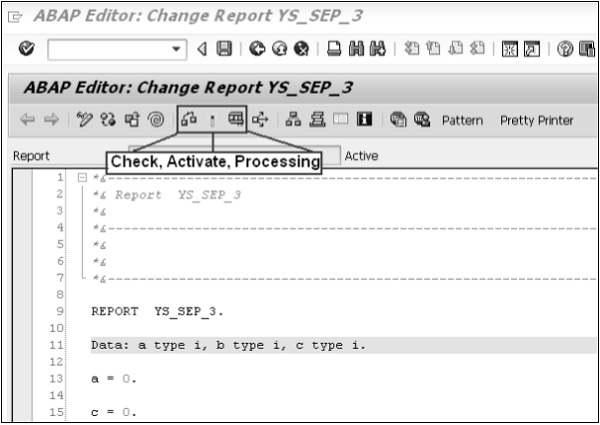
Se déconnecter
Il est toujours recommandé de quitter votre éditeur ABAP ou / et de vous déconnecter du système SAP après avoir terminé votre travail.
Déclarations
Le programme source ABAP se compose de commentaires et d'instructions ABAP. Chaque instruction dans ABAP commence par un mot clé et se termine par un point, et ABAP n'est pas sensible à la casse.
La première ligne sans commentaire dans un programme commence par le mot REPORT. Le rapport sera toujours la première ligne de tout programme exécutable créé. L'instruction est suivie du nom du programme qui a été créé précédemment. La ligne se termine alors par un point.
La syntaxe est -
REPORT [Program_Name].
[Statements…].Cela permet à l'instruction de prendre autant de lignes dans l'éditeur que nécessaire. Par exemple, le RAPPORT peut ressembler à ceci -
REPORT Z_Test123_01.Les instructions se composent d'une commande et de toutes les variables et options, se terminant par un point. Tant que la période apparaîtra à la fin du relevé, aucun problème ne se posera. C'est cette période qui marque la fin de la déclaration.
Écrivons le code.
Sur la ligne en dessous de l'instruction REPORT, tapez simplement cette instruction: Écrivez 'ABAP Tutorial'.
REPORT Z_Test123_01.
Write 'This is ABAP Tutorial'.Four things to consider while writing statements -
L'instruction write écrit tout ce qui est entre guillemets dans la fenêtre de sortie.
L'éditeur ABAP convertit tout le texte en majuscules, à l'exception des chaînes de texte, qui sont entourées de guillemets simples.
Contrairement à certains langages de programmation plus anciens, ABAP ne se soucie pas de l'endroit où une instruction commence sur une ligne. Vous pouvez en profiter et améliorer la lisibilité de votre programme en utilisant l'indentation pour indiquer des blocs de code.
ABAP n'a aucune restriction sur la présentation des instructions. Autrement dit, plusieurs instructions peuvent être placées sur une seule ligne, ou une seule instruction peut s'étendre sur plusieurs lignes.
Notation du côlon
Les instructions consécutives peuvent être enchaînées si le début de chaque instruction est identique. Cela se fait avec l'opérateur deux-points (:) et des virgules, qui sont utilisés pour terminer les instructions individuelles, tout comme les points terminent les instructions normales.
Voici un exemple de programme qui pourrait sauver quelques touches -
WRITE 'Hello'.
WRITE 'ABAP'.
WRITE 'World'.En utilisant la notation deux-points, il pourrait être réécrit de cette façon -
WRITE: 'Hello',
'ABAP',
'World'.Comme toute autre instruction ABAP, la mise en page n'a pas d'importance. C'est une déclaration tout aussi correcte -
WRITE: 'Hello', 'ABAP', 'World'.commentaires
Les commentaires en ligne peuvent être déclarés n'importe où dans un programme par l'une des deux méthodes -
Les commentaires de ligne complète sont indiqués en plaçant un astérisque (*) en première position de la ligne, auquel cas la ligne entière est considérée par le système comme un commentaire. Les commentaires n'ont pas besoin d'être terminés par un point car ils ne peuvent pas s'étendre sur plus d'une ligne -
* This is the comment lineLes commentaires de ligne partielle sont indiqués par la saisie d'un guillemet double (") après une déclaration. Tout le texte qui suit le double guillemet est considéré par le système comme un commentaire. Vous n'avez pas besoin de terminer les commentaires de ligne partielle par un point car ils ne peuvent pas s'étendre sur plus d'une ligne -
WRITE 'Hello'. "Here is the partial commentNote - Le code commenté n'est pas mis en majuscule par l'éditeur ABAP.
Suppression des blancs
La commande NO-ZERO suit l'instruction DATA. Il supprime tous les zéros non significatifs d'un champ numérique contenant des blancs. La sortie est généralement plus facile à lire pour les utilisateurs.
Exemple
REPORT Z_Test123_01.
DATA: W_NUR(10) TYPE N.
MOVE 50 TO W_NUR.
WRITE W_NUR NO-ZERO.Le code ci-dessus produit la sortie suivante -
50Note - Sans commande NO-ZERO, la sortie est: 0000000050
Lignes vierges
La commande SKIP aide à insérer des lignes vierges sur la page.
Exemple
La commande de message est la suivante -
WRITE 'This is the 1st line'.
SKIP.
WRITE 'This is the 2nd line'.La commande de message ci-dessus produit la sortie suivante -
This is the 1st line
This is the 2nd lineNous pouvons utiliser la commande SKIP pour insérer plusieurs lignes vides.
SKIP number_of_lines.La sortie serait plusieurs lignes vides définies par le nombre de lignes. La commande SKIP peut également positionner le curseur sur une ligne souhaitée de la page.
SKIP TO LINE line_number.Cette commande est utilisée pour déplacer dynamiquement le curseur vers le haut et vers le bas de la page. En général, une instruction WRITE se produit après cette commande pour placer la sortie sur la ligne souhaitée.
Insérer des lignes
La commande ULINE insère automatiquement une ligne horizontale sur la sortie. Il est également possible de contrôler la position et la longueur de la ligne. La syntaxe est assez simple -
ULINE.Exemple
La commande de message est la suivante -
WRITE 'This is Underlined'.
ULINE.Le code ci-dessus produit la sortie suivante -
This is Underlined (and a horizontal line below this).messages
La commande MESSAGE affiche les messages définis par un ID de message spécifié dans l'instruction REPORT au début du programme. L'ID de message est un code à 2 caractères qui définit à quel ensemble de 1 000 messages le programme accédera lorsque la commande MESSAGE est utilisée.
Les messages sont numérotés de 000 à 999. Un texte de message de 80 caractères maximum est associé à chaque numéro. Lorsque le numéro de message est appelé, le texte correspondant s'affiche.
Voici les caractères à utiliser avec la commande Message -
| Message | Type | Conséquences |
|---|---|---|
| E | Erreur | Le message apparaît et l'application s'arrête à son point actuel. Si le programme s'exécute en mode d'arrière-plan, le travail est annulé et le message est enregistré dans le journal des travaux. |
| W | Attention | Le message apparaît et l'utilisateur doit appuyer sur Entrée pour que l'application continue. En mode arrière-plan, le message est enregistré dans le journal des travaux. |
| je | Information | Une fenêtre contextuelle s'ouvre avec le texte du message et l'utilisateur doit appuyer sur Entrée pour continuer. En mode arrière-plan, le message est enregistré dans le journal des travaux. |
| UNE | Un virage | Cette classe de message annule la transaction que l'utilisateur utilise actuellement. |
| S | Succès | Cela fournit un message d'information en bas de l'écran. Les informations affichées sont de nature positive et ne sont destinées qu'aux commentaires des utilisateurs. Le message n'entrave en aucune façon le programme. |
| X | Avorter | Ce message abandonne le programme et génère un bref vidage ABAP. |
Les messages d'erreur sont normalement utilisés pour empêcher les utilisateurs de faire des choses qu'ils ne sont pas censés faire. Les messages d'avertissement sont généralement utilisés pour rappeler aux utilisateurs les conséquences de leurs actions. Les messages d'information donnent aux utilisateurs des informations utiles.
Exemple
Lorsque nous créons un message pour le message ID AB, la commande MESSAGE - MESSAGE E011 donne la sortie suivante -
EAB011 This report does not support sub-number summarization.Lors de la programmation en ABAP, nous devons utiliser une variété de variables pour stocker diverses informations. Les variables ne sont rien d'autre que des emplacements de mémoire réservés pour stocker des valeurs. Cela signifie que lorsque vous créez une variable, vous réservez de l'espace en mémoire. Vous pouvez souhaiter stocker des informations de différents types de données comme des caractères, des entiers, des virgules flottantes, etc. En fonction du type de données d'une variable, le système d'exploitation alloue de la mémoire et décide de ce qui peut être stocké dans la mémoire réservée.
Types de données élémentaires
ABAP offre au programmeur un riche assortiment de types de données de longueur fixe et variable. Le tableau suivant répertorie les types de données élémentaires ABAP -
| Type | Mot-clé |
|---|---|
| Champ d'octet | X |
| Champ de texte | C |
| Entier | je |
| Point flottant | F |
| Numéro emballé | P |
| Chaîne de texte | CHAÎNE |
Certains champs et numéros peuvent être modifiés en utilisant un ou plusieurs noms comme suit -
- byte
- numeric
- character-like
Le tableau suivant montre le type de données, la quantité de mémoire nécessaire pour stocker la valeur en mémoire et la valeur minimale et maximale pouvant être stockée dans ce type de variables.
| Type | Longueur typique | Gamme typique |
|---|---|---|
| X | 1 octet | Toutes les valeurs d'octet (00 à FF) |
| C | 1 caractère | 1 à 65535 |
| N (texte numérique déposé) | 1 caractère | 1 à 65535 |
| D (date semblable à un caractère) | 8 caractères | 8 caractères |
| T (temps semblable à un caractère) | 6 caractères | 6 caractères |
| je | 4 octets | -2147483648 à 2147483647 |
| F | 8 octets | 2.2250738585072014E-308 à 1.7976931348623157E + 308 positif ou négatif |
| P | 8 octets | [-10 ^ (2len -1) +1] à [+ 10 ^ (2len -1) 1] (où len = longueur fixe) |
| CHAÎNE | Variable | Tous les caractères alphanumériques |
| XSTRING (chaîne d'octets) | Variable | Toutes les valeurs d'octet (00 à FF) |
Exemple
REPORT YR_SEP_12.
DATA text_line TYPE C LENGTH 40.
text_line = 'A Chapter on Data Types'.
Write text_line.
DATA text_string TYPE STRING.
text_string = 'A Program in ABAP'.
Write / text_string.
DATA d_date TYPE D.
d_date = SY-DATUM.
Write / d_date.Dans cet exemple, nous avons une chaîne de caractères de type C avec une longueur prédéfinie de 40. STRING est un type de données qui peut être utilisé pour toute chaîne de caractères de longueur variable (chaînes de texte). Les objets de données de type STRING doivent généralement être utilisés pour le contenu de type caractère où la longueur fixe n'est pas importante.
Le code ci-dessus produit la sortie suivante -
A Chapter on Data Types
A Program in ABAP
12092015Le type DATE est utilisé pour le stockage des informations de date et peut stocker huit chiffres comme indiqué ci-dessus.
Types complexes et de référence
Les types complexes sont classés en Structure types et Table types. Dans les types de structure, les types élémentaires et les structures (c'est-à-dire la structure intégrée dans une structure) sont regroupés. Vous pouvez envisager uniquement le regroupement des types élémentaires. Mais vous devez être conscient de la disponibilité de l'imbrication des structures.
Lorsque les types élémentaires sont regroupés, la donnée élémentaire est accessible en tant que donnée élémentaire groupée ou les éléments de données individuels de type élémentaire (champs de structure) sont accessibles. Les types de table sont mieux connus sous le nom de tableaux dans d'autres langages de programmation.Arrayspeuvent être des tableaux simples ou structurés. Dans ABAP, les tableaux sont appelés tables internes et peuvent être déclarés et exploités de nombreuses manières par rapport à d'autres langages de programmation. Le tableau suivant montre les paramètres selon lesquels les tableaux internes sont caractérisés.
| S.No. | Paramètre et description |
|---|---|
| 1 | Line or row type La ligne d'un tableau interne peut être de type élémentaire, complexe ou de référence. |
| 2 | Key Spécifie un champ ou un groupe de champs comme clé d'une table interne qui identifie les lignes de la table. Une clé contient les champs de types élémentaires. |
| 3 | Access method Décrit comment les programmes ABAP accèdent aux entrées de table individuelles. |
Les types de référence sont utilisés pour faire référence à des instances de classes, d'interfaces et d'éléments de données d'exécution. Les services de type d'exécution ABAP OOP (RTTS) permettent la déclaration des éléments de données au moment de l'exécution.
Les variables sont des objets de données nommés utilisés pour stocker des valeurs dans la zone de mémoire allouée d'un programme. Comme son nom l'indique, les utilisateurs peuvent modifier le contenu des variables à l'aide d'instructions ABAP. Chaque variable dans ABAP a un type spécifique, qui détermine la taille et la disposition de la mémoire de la variable; la plage de valeurs pouvant être stockées dans cette mémoire; et l'ensemble des opérations qui peuvent être appliquées à la variable.
Vous devez déclarer toutes les variables avant de pouvoir les utiliser. La forme de base d'une déclaration de variable est -
DATA <f> TYPE <type> VALUE <val>.Ici <f> spécifie le nom d'une variable. Le nom de la variable peut comporter jusqu'à 30 caractères. <type> spécifie le type de variable. Tout type de données avec des attributs techniques entièrement spécifiés est appelé <type>. Le <val> spécifie la valeur initiale de la variable of <f>. Si vous définissez une variable élémentaire de longueur fixe, l'instruction DATA remplit automatiquement la valeur de la variable avec la valeur initiale spécifique au type. Les autres valeurs possibles pour <val> peuvent être une clause littérale, constante ou explicite, telle que Is INITIAL.
Voici des exemples valides de déclarations de variables.
DATA d1(2) TYPE C.
DATA d2 LIKE d1.
DATA minimum_value TYPE I VALUE 10.Dans l'extrait de code ci-dessus, d1 est une variable de type C, d2 est une variable de type d1 et minimum_value est une variable de type entier ABAP I.
Ce chapitre explique les différents types de variables disponibles dans ABAP. Il existe trois types de variables dans ABAP -
- Variables statiques
- Variables de référence
- Variables système
Variables statiques
Les variables statiques sont déclarées dans des sous-programmes, des modules de fonction et des méthodes statiques.
La durée de vie est liée au contexte de la déclaration.
Avec l'instruction 'CLASS-DATA', vous pouvez déclarer des variables dans les classes.
L'instruction 'PARAMETERS' peut être utilisée pour déclarer les objets de données élémentaires liés aux champs de saisie sur un écran de sélection.
Vous pouvez également déclarer les tables internes liées aux champs de saisie sur un écran de sélection à l'aide de l'instruction 'SELECT-OPTIONS'.
Voici les conventions utilisées pour nommer une variable -
Vous ne pouvez pas utiliser de caractères spéciaux tels que "t" et "," pour nommer des variables.
Le nom des objets de données prédéfinis ne peut pas être modifié.
Le nom de la variable ne peut pas être le même que n'importe quel mot clé ou clause ABAP.
Le nom des variables doit transmettre la signification de la variable sans nécessiter d'autres commentaires.
Les traits d'union sont réservés pour représenter les composants des structures. Par conséquent, vous êtes censé éviter les tirets dans les noms de variables.
Le caractère de soulignement peut être utilisé pour séparer les mots composés.
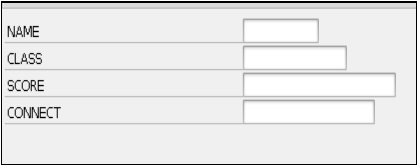
Ce programme montre comment déclarer une variable à l'aide de l'instruction PARAMETERS -
REPORT ZTest123_01.
PARAMETERS: NAME(10) TYPE C,
CLASS TYPE I,
SCORE TYPE P DECIMALS 2,
CONNECT TYPE MARA-MATNR.Ici, NAME représente un paramètre de 10 caractères, CLASS spécifie un paramètre de type entier avec la taille par défaut en octets, SCORE représente un paramètre de type compact avec des valeurs jusqu'à deux décimales et CONNECT fait référence au type MARA-MATNF du dictionnaire ABAP .
Le code ci-dessus produit la sortie suivante -
Variables de référence
La syntaxe pour déclarer les variables de référence est -
DATA <ref> TYPE REF TO <type> VALUE IS INITIAL.L'ajout REF TO déclare une variable de référence réf.
La spécification après REF TO spécifie le type statique de la variable de référence.
Le type statique restreint l'ensemble des objets auxquels <ref> peut faire référence.
Le type dynamique de variable de référence est le type de données ou la classe auquel elle fait actuellement référence.
Le type statique est toujours plus général ou identique au type dynamique.
L'ajout de TYPE est utilisé pour créer un type de référence lié et comme valeur de départ, et seul IS INITIAL peut être spécifié après l'ajout de VALUE.
Exemple
CLASS C1 DEFINITION.
PUBLIC SECTION.
DATA Bl TYPE I VALUE 1.
ENDCLASS. DATA: Oref TYPE REF TO C1 ,
Dref1 LIKE REF TO Oref,
Dref2 TYPE REF TO I .
CREATE OBJECT Oref.
GET REFERENCE OF Oref INTO Dref1.
CREATE DATA Dref2.
Dref2→* = Dref1→*→Bl.Dans l'extrait de code ci-dessus, une référence d'objet Oref et deux variables de référence de données Dref1 et Dref2 sont déclarées.
Les deux variables de référence de données sont entièrement typées et peuvent être déréférencées à l'aide de l'opérateur de déréférencement → * aux positions d'opérande.
Variables système
Les variables système ABAP sont accessibles depuis tous les programmes ABAP.
Ces champs sont en fait remplis par l'environnement d'exécution.
Les valeurs de ces champs indiquent l'état du système à un moment donné.
Vous pouvez trouver la liste complète des variables système dans la table SYST de SAP.
Les champs individuels de la structure SYST sont accessibles en utilisant «SYST-» ou «SY-».
Exemple
REPORT Z_Test123_01.
WRITE:/'SY-ABCDE', SY-ABCDE,
/'SY-DATUM', SY-DATUM,
/'SY-DBSYS', SY-DBSYS,
/'SY-HOST ', SY-HOST,
/'SY-LANGU', SY-LANGU,
/'SY-MANDT', SY-MANDT,
/'SY-OPSYS', SY-OPSYS,
/'SY-SAPRL', SY-SAPRL,
/'SY-SYSID', SY-SYSID,
/'SY-TCODE', SY-TCODE,
/'SY-UNAME', SY-UNAME,
/'SY-UZEIT', SY-UZEIT.Le code ci-dessus produit la sortie suivante -
SY-ABCDE ABCDEFGHIJKLMNOPQRSTUVWXYZ
SY-DATUM 12.09.2015
SY-DBSYS ORACLE
SY-HOST sapserver
SY-LANGU EN
SY-MANDT 800
SY-OPSYS Windows NT
SY-SAPRL 700
SY-SYSID DMO
SY-TCODE SE38
SY-UNAME SAPUSER
SY-UZEIT 14:25:48Les littéraux sont des objets de données sans nom que vous créez dans le code source d'un programme. Ils sont pleinement définis par leur valeur. Vous ne pouvez pas modifier la valeur d'un littéral. Les constantes sont des objets de données nommés créés de manière statique à l'aide d'instructions déclaratives. Une constante est déclarée en lui affectant une valeur qui est stockée dans la zone mémoire du programme. La valeur affectée à une constante ne peut pas être modifiée pendant l'exécution du programme. Ces valeurs fixes peuvent également être considérées comme des littéraux. Il existe deux types de littéraux: numérique et caractère.
Littéraux numériques
Les littéraux numériques sont des séquences de chiffres qui peuvent avoir un signe préfixé. Dans les littéraux numériques, il n'y a pas de séparateurs décimaux et pas de notation avec mantisse et exposant.
Voici quelques exemples de littéraux numériques -
183.
-97.
+326.Littéraux de caractères
Les littéraux de caractères sont des séquences de caractères alphanumériques dans le code source d'un programme ABAP entre guillemets simples. Les littéraux de caractères entre guillemets ont le type ABAP prédéfini C et sont décrits comme des littéraux de champ de texte. Les littéraux entre «guillemets» ont le type ABAP STRING et sont décrits comme des chaînes littérales. La longueur du champ est définie par le nombre de caractères.
Note - Dans les littéraux de champ de texte, les espaces de fin sont ignorés, mais dans les littéraux de chaîne, ils sont pris en compte.
Voici quelques exemples de littéraux de caractères.
Littéraux de champ de texte
REPORT YR_SEP_12.
Write 'Tutorials Point'.
Write / 'ABAP Tutorial'.Littéraux de champ de chaîne
REPORT YR_SEP_12.
Write `Tutorials Point `.
Write / `ABAP Tutorial `.La sortie est la même dans les deux cas ci-dessus -
Tutorials Point
ABAP TutorialNote- Lorsque nous essayons de changer la valeur de la constante, une erreur de syntaxe ou d'exécution peut se produire. Les constantes que vous déclarez dans la partie déclaration d'une classe ou d'une interface appartiennent aux attributs statiques de cette classe ou interface.
Déclaration CONSTANTS
Nous pouvons déclarer les objets de données nommés à l'aide de l'instruction CONSTANTS.
Voici la syntaxe -
CONSTANTS <f> TYPE <type> VALUE <val>.L'instruction CONSTANTS est similaire à l'instruction DATA.
<f> spécifie un nom pour la constante. TYPE <type> représente une constante nommée <f>, qui hérite des mêmes attributs techniques que le type de données existant <type>. VALUE <val> affecte une valeur initiale au nom de constante déclaré <f>.
Note- Nous devrions utiliser la clause VALUE dans l'instruction CONSTANTS. La clause 'VALUE' permet d'affecter une valeur initiale à la constante lors de sa déclaration.
Nous avons 3 types de constantes telles que les constantes élémentaires, complexes et de référence. L'instruction suivante montre comment définir des constantes à l'aide de l'instruction CONSTANTS -
REPORT YR_SEP_12.
CONSTANTS PQR TYPE P DECIMALS 4 VALUE '1.2356'.
Write: / 'The value of PQR is:', PQR.La sortie est -
The value of PQR is: 1.2356Ici, il fait référence au type de données élémentaire et est appelé constante élémentaire.
Voici un exemple de constantes complexes -
BEGIN OF EMPLOYEE,
Name(25) TYPE C VALUE 'Management Team',
Organization(40) TYPE C VALUE 'Tutorials Point Ltd',
Place(10) TYPE C VALUE 'India',
END OF EMPLOYEE.Dans l'extrait de code ci-dessus, EMPLOYEE est une constante complexe composée des champs Nom, Organisation et Lieu.
L'instruction suivante déclare une référence constante -
CONSTANTS null_pointer TYPE REF TO object VALUE IS INITIAL.Nous pouvons utiliser la référence constante dans les comparaisons ou nous pouvons la transmettre aux procédures.
ABAP fournit un riche ensemble d'opérateurs pour manipuler les variables. Tous les opérateurs ABAP sont classés en quatre catégories -
- Opérateurs arithmétiques
- Opérateurs de comparaison
- Opérateurs au niveau du bit
- Opérateurs de chaîne de caractères
Opérateurs arithmétiques
Les opérateurs arithmétiques sont utilisés dans les expressions mathématiques de la même manière qu'ils sont utilisés dans l'algèbre. La liste suivante décrit les opérateurs arithmétiques. Supposons que la variable entière A contienne 20 et la variable B 40.
| S.No. | Opérateur arithmétique et description |
|---|---|
| 1 | + (Addition) Ajoute des valeurs de chaque côté de l'opérateur. Exemple: A + B donnera 60. |
| 2 | − (Subtraction) Soustrait l'opérande de droite de l'opérande de gauche. Exemple: A - B donnera -20. |
| 3 | * (Multiplication) Multiplie les valeurs de chaque côté de l'opérateur. Exemple: A * B donnera 800. |
| 4 | / (Division) Divise l'opérande de gauche par l'opérande de droite. Exemple: B / A donnera 2. |
| 5 | MOD (Modulus) Divise l'opérande de gauche par l'opérande de droite et renvoie le reste. Exemple: B MOD A donnera 0. |
Exemple
REPORT YS_SEP_08.
DATA: A TYPE I VALUE 150,
B TYPE I VALUE 50,
Result TYPE I.
Result = A / B.
WRITE / Result.Le code ci-dessus produit la sortie suivante -
3Opérateurs de comparaison
Discutons des différents types d'opérateurs de comparaison pour différents opérandes.
| S.No. | Opérateur de comparaison et description |
|---|---|
| 1 | = (equality test). Alternate form is EQ. Vérifie si les valeurs de deux opérandes sont égales ou non, si oui, la condition devient vraie. L'exemple (A = B) n'est pas vrai. |
| 2 | <> (Inequality test). Alternate form is NE. Vérifie si les valeurs de deux opérandes sont égales ou non. Si les valeurs ne sont pas égales, la condition devient vraie. Exemple (A <> B) est vrai. |
| 3 | > (Greater than test). Alternate form is GT. Vérifie si la valeur de l'opérande gauche est supérieure à la valeur de l'opérande droit. Si oui, la condition devient vraie. L'exemple (A> B) n'est pas vrai. |
| 4 | < (Less than test). Alternate form is LT. Vérifie si la valeur de l'opérande gauche est inférieure à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. L'exemple (A <B) est vrai. |
| 5 | >= (Greater than or equals) Alternate form is GE. Vérifie si la valeur de l'opérande gauche est supérieure ou égale à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. L'exemple (A> = B) n'est pas vrai. |
| 6 | <= (Less than or equals test). Alternate form is LE. Vérifie si la valeur de l'opérande gauche est inférieure ou égale à la valeur de l'opérande droit. Si oui, alors la condition devient vraie. Exemple (A <= B) est vrai. |
| sept | a1 BETWEEN a2 AND a3 (Interval test) Vérifie si a1 se situe entre a2 et a3 (inclus). Si oui, alors la condition devient vraie. Exemple (A BETWEEN B AND C) est vrai. |
| 8 | IS INITIAL La condition devient vraie si le contenu de la variable n'a pas changé et que sa valeur initiale lui a été attribuée automatiquement. Exemple (A IS INITIAL) n'est pas vrai |
| 9 | IS NOT INITIAL La condition devient vraie si le contenu de la variable a changé. Exemple (A IS NOT INITIAL) est vrai. |
Note- Si le type de données ou la longueur des variables ne correspond pas, une conversion automatique est effectuée. L'ajustement automatique du type est effectué pour l'une ou les deux valeurs tout en comparant deux valeurs de types de données différents. Le type de conversion est décidé par le type de données et l'ordre de préférence du type de données.
Voici l'ordre de préférence -
Si un champ est de type I, l'autre est converti en type I.
Si un champ est de type P, l'autre est converti en type P.
Si un champ est de type D, l'autre est converti en type D. Mais les types C et N ne sont pas convertis et ils sont comparés directement. Le cas est similaire avec le type T.
Si un champ est de type N et l'autre de type C ou X, les deux champs sont convertis en type P.
Si un champ est de type C et l'autre de type X, le type X est converti en type C.
Exemple 1
REPORT YS_SEP_08.
DATA: A TYPE I VALUE 115,
B TYPE I VALUE 119.
IF A LT B.
WRITE: / 'A is less than B'.
ENDIFLe code ci-dessus produit la sortie suivante -
A is less than BExemple 2
REPORT YS_SEP_08.
DATA: A TYPE I.
IF A IS INITIAL.
WRITE: / 'A is assigned'.
ENDIF.Le code ci-dessus produit la sortie suivante -
A is assigned.Opérateurs au niveau du bit
ABAP fournit également une série d'opérateurs logiques au niveau du bit qui peuvent être utilisés pour créer des expressions algébriques booléennes. Les opérateurs au niveau du bit peuvent être combinés dans des expressions complexes à l'aide de parenthèses, etc.
| S.No. | Opérateur et description au niveau du bit |
|---|---|
| 1 | BIT-NOT Opérateur unaire qui retourne tous les bits d'un nombre hexadécimal à la valeur opposée. Par exemple, appliquer cet opérateur à un nombre hexadécimal ayant la valeur de niveau de bit 10101010 (par exemple «AA») donnerait 01010101. |
| 2 | BIT-AND Cet opérateur binaire compare chaque champ bit par bit à l'aide de l'opérateur booléen AND. |
| 3 | BIT-XOR Opérateur binaire qui compare chaque champ bit par bit à l'aide de l'opérateur booléen XOR (OU exclusif). |
| 4 | BIT-OR Opérateur binaire qui compare chaque champ bit par bit à l'aide de l'opérateur booléen OR. |
Par exemple, voici la table de vérité qui montre les valeurs générées lors de l'application des opérateurs booléens AND, OR ou XOR par rapport aux deux valeurs de bits contenues dans le champ A et le champ B.
| Champ A | Champ B | ET | OU | XOR |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
Opérateurs de chaîne de caractères
Voici une liste d'opérateurs de chaîne de caractères -
| S.No. | Opérateur de chaîne de caractères et description |
|---|---|
| 1 | CO (Contains Only) Vérifie si A est uniquement composé des caractères de B. |
| 2 | CN (Not Contains ONLY) Vérifie si A contient des caractères qui ne sont pas dans B. |
| 3 | CA (Contains ANY) Vérifie si A contient au moins un caractère de B. |
| 4 | NA (NOT Contains Any) Vérifie si A ne contient aucun caractère de B. |
| 5 | CS (Contains a String) Vérifie si A contient la chaîne de caractères B. |
| 6 | NS (NOT Contains a String) Vérifie si A ne contient pas la chaîne de caractères B. |
| sept | CP (Contains a Pattern) Il vérifie si A contient le motif de B. |
| 8 | NP (NOT Contains a Pattern) Il vérifie si A ne contient pas le motif de B. |
Exemple
REPORT YS_SEP_08.
DATA: P(10) TYPE C VALUE 'APPLE',
Q(10) TYPE C VALUE 'CHAIR'.
IF P CA Q.
WRITE: / 'P contains at least one character of Q'.
ENDIF.Le code ci-dessus produit la sortie suivante -
P contains at least one character of Q.Il peut arriver que vous deviez exécuter un bloc de code plusieurs fois. En général, les instructions sont exécutées de manière séquentielle: la première instruction d'une fonction est exécutée en premier, suivie de la seconde, et ainsi de suite.
Les langages de programmation fournissent diverses structures de contrôle qui permettent des chemins d'exécution plus compliqués. UNEloop statement nous permet d'exécuter une instruction ou un groupe d'instructions plusieurs fois et voici la forme générale d'une instruction de boucle dans la plupart des langages de programmation.
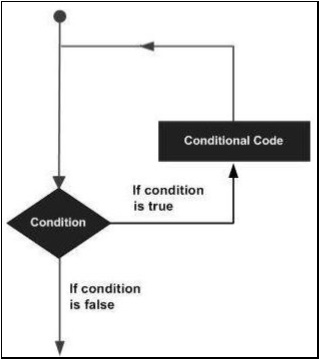
Le langage de programmation ABAP fournit les types de boucle suivants pour gérer les exigences de bouclage.
| S.No. | Type de boucle et description |
|---|---|
| 1 | Boucle WHILE Répète une instruction ou un groupe d'instructions lorsqu'une condition donnée est vraie. Il teste la condition avant d'exécuter le corps de la boucle. |
| 2 | Faire une boucle L'instruction DO est utile pour répéter une tâche particulière un certain nombre de fois. |
| 3 | Boucle imbriquée Vous pouvez utiliser une ou plusieurs boucles dans n'importe quelle autre boucle WHILE ou DO. |
Déclarations de contrôle de boucle
Les instructions de contrôle de boucle modifient l'exécution de sa séquence normale. ABAP inclut des instructions de contrôle qui permettent aux boucles de se terminer prématurément. Il prend en charge les instructions de contrôle suivantes.
| S.No. | Déclaration de contrôle et description |
|---|---|
| 1 | CONTINUER Fait en sorte que la boucle ignore le reste de son corps et commence la prochaine passe de boucle. |
| 2 | VÉRIFIER Si la condition est fausse, les instructions restantes après le CHECK sont simplement ignorées et le système démarre la prochaine passe de boucle. |
| 3 | SORTIE Termine entièrement la boucle et transfère l'exécution à l'instruction immédiatement après la boucle. |
Les structures de prise de décision ont une ou plusieurs conditions à évaluer ou à tester par le programme, ainsi qu'une ou plusieurs instructions à exécuter, si la condition est jugée vraie, et éventuellement d'autres instructions à exécuter, si la condition est déterminé comme étant faux.
Voici la forme générale d'une structure de prise de décision typique trouvée dans la plupart des langages de programmation -

Le langage de programmation ABAP fournit les types suivants d'énoncés décisionnels.
| S.No. | Déclaration et description |
|---|---|
| 1 | Déclaration IF Une instruction IF consiste en une expression logique suivie d'une ou plusieurs instructions. |
| 2 | IF .. Else Statement Une instruction IF peut être suivie d'une instruction ELSE facultative qui s'exécute lorsque l'expression est fausse. |
| 3 | Instruction IF imbriquée Vous pouvez utiliser une instruction IF ou ELSEIF dans une autre instruction IF ou ELSEIF. |
| 4 | Déclaration de contrôle CASE L'instruction CASE est utilisée lorsque nous devons comparer deux ou plusieurs champs ou variables. |
Strings, qui sont largement utilisées dans la programmation ABAP, sont une séquence de caractères.
Nous utilisons des variables de type C pour contenir des caractères alphanumériques, avec un minimum de 1 caractère et un maximum de 65 535 caractères. Par défaut, ceux-ci sont alignés à gauche.
Création de chaînes
La déclaration et l'initialisation suivantes créent une chaîne composée du mot «Hello». La taille de la chaîne correspond exactement au nombre de caractères du mot «Bonjour».
Data my_Char(5) VALUE 'Hello'.Le programme suivant est un exemple de création de chaînes.
REPORT YT_SEP_15.
DATA my_Char(5) VALUE 'Hello'.
Write my_Char.Le code ci-dessus produit la sortie suivante -
HelloLongueur de chaine
Afin de trouver la longueur des chaînes de caractères, nous pouvons utiliser STRLEN statement. La fonction STRLEN () renvoie le nombre de caractères contenus dans la chaîne.
Exemple
REPORT YT_SEP_15.
DATA: title_1(10) VALUE 'Tutorials',
length_1 TYPE I.
length_1 = STRLEN( title_1 ).
Write: / 'The Length of the Title is:', length_1.Le code ci-dessus produit la sortie suivante -
The Length of the Title is: 9ABAP prend en charge un large éventail d'instructions qui manipulent des chaînes.
| S.No. | Déclaration et objectif |
|---|---|
| 1 | CONCATENATE Deux chaînes sont jointes pour former une troisième chaîne. |
| 2 | CONDENSE Cette instruction supprime les caractères d'espacement. |
| 3 | STRLEN Utilisé pour trouver la longueur d'un champ. |
| 4 | REPLACE Utilisé pour faire des remplacements de caractères. |
| 5 | SEARCH Pour exécuter des recherches dans des chaînes de caractères. |
| 6 | SHIFT Utilisé pour déplacer le contenu d'une chaîne vers la gauche ou la droite. |
| sept | SPLIT Utilisé pour diviser le contenu d'un champ en deux champs ou plus. |
L'exemple suivant utilise certaines des instructions mentionnées ci-dessus -
Exemple
REPORT YT_SEP_15.
DATA: title_1(10) VALUE 'Tutorials',
title_2(10) VALUE 'Point',
spaced_title(30) VALUE 'Tutorials Point Limited',
sep,
dest1(30),
dest2(30).
CONCATENATE title_1 title_2 INTO dest1.
Write: / 'Concatenation:', dest1.
CONCATENATE title_1 title_2 INTO dest2 SEPARATED BY sep.
Write: / 'Concatenation with Space:', dest2.
CONDENSE spaced_title.
Write: / 'Condense with Gaps:', spaced_title.
CONDENSE spaced_title NO-GAPS.
Write: / 'Condense with No Gaps:', spaced_title.Le code ci-dessus produit la sortie suivante -
Concatenation: TutorialsPoint
Concatenation with Space: Tutorials Point
Condense with Gaps: Tutorials Point Limited
Condense with No Gaps: TutorialsPointLimitedNote -
En cas de concaténation, le «sep» insère un espace entre les champs.
L'instruction CONDENSE supprime les espaces vides entre les champs, mais ne laisse qu'un espace de 1 caractère.
«NO-GAPS» est un ajout facultatif à l'instruction CONDENSE qui supprime tous les espaces.
ABAP fait implicitement référence au calendrier grégorien, valable dans la plupart des pays du monde. Nous pouvons convertir la sortie en calendriers spécifiques au pays. Une date est une heure spécifiée à un jour, une semaine ou un mois précis par rapport à un calendrier. Une heure est spécifiée à une seconde ou à une minute précise par rapport à un jour. ABAP économise toujours du temps au format 24 heures. La sortie peut avoir un format spécifique au pays. Les dates et l'heure sont généralement interprétées comme des dates locales valides dans le fuseau horaire actuel.
ABAP fournit deux types intégrés pour travailler avec les dates et l'heure -
- Type de données D
- Type de données T
Voici le format de base -
DATA: date TYPE D,
time TYPE T.
DATA: year TYPE I,
month TYPE I,
day TYPE I,
hour TYPE I,
minute TYPE I,
second TYPE I.Ces deux types sont des types de caractères de longueur fixe qui ont respectivement la forme AAAAMMJJ et HHMMSS.
Horodatages
En plus de ces types intégrés, les deux autres types TIMESTAMP et TIMESTAMPLsont utilisés dans de nombreuses tables d'application standard pour stocker un horodatage au format UTC. Le tableau suivant présente les types de date et d'heure de base disponibles dans ABAP.
| S.No. | Type de données et description |
|---|---|
| 1 | D Un type de date de longueur fixe intégré au format AAAAMMJJ. Par exemple, la valeur 20100913 représente la date du 13 septembre 2010. |
| 2 | T Un type de temps de longueur fixe intégré de la forme HHMMSS. Par exemple, la valeur 102305 représente l'heure 10:23:05 AM. |
| 3 | TIMESTAMP (Type P - Longueur 8 sans décimales) Ce type est utilisé pour représenter des horodatages courts au format AAAAMMJJhhmmss. Par exemple, la valeur 20100913102305 représente la date du 13 septembre 2010 à 10 h 23 min 05 s. |
| 4 | TIMESTAMPL (Type P - Longueur 11 décimales 7) TIMESTAMPL représente des horodatages longs au format AAAAMMJJhhmmss, mmmuuun. Ici, les chiffres supplémentaires «mmmuuun» représentent les fractions de seconde. |
Date et heure actuelles
Les extraits de code suivants récupèrent la date et l'heure système actuelles.
REPORT YR_SEP_15.
DATA: date_1 TYPE D.
date_1 = SY-DATUM.
Write: / 'Present Date is:', date_1 DD/MM/YYYY.
date_1 = date_1 + 06.
Write: / 'Date after 6 Days is:', date_1 DD/MM/YYYY.Le code ci-dessus produit la sortie suivante -
Present Date is: 21.09.2015
Date after 6 Days is: 27.09.2015La variable date_1 reçoit la valeur de la date système courante SY-DATUM. Ensuite, nous incrémentons la valeur de date de 6. En termes de calcul de date dans ABAP, cela implique que nous augmentons la composante jour de l'objet date de 6 jours. L'environnement d'exécution ABAP est suffisamment intelligent pour reporter la valeur de la date chaque fois qu'elle atteint la fin d'un mois.
Les calculs de temps fonctionnent de manière similaire aux calculs de date. Le code suivant incrémente l'heure système actuelle de 75 secondes à l'aide de l'arithmétique temporelle de base.
REPORT YR_SEP_15.
DATA: time_1 TYPE T.
time_1 = SY-UZEIT.
Write /(60) time_1 USING EDIT MASK
'Now the Time is: __:__:__'.
time_1 = time_1 + 75.
Write /(60) time_1 USING EDIT MASK
'A Minute and a Quarter from Now, it is: __:__:__'.Le code ci-dessus produit la sortie suivante -
Now the Time is 11:45:05
A Minute and a Quarter from Now, it is: 11:46:20Utilisation des horodatages
Vous pouvez récupérer l'heure système actuelle et la stocker dans une variable d'horodatage en utilisant GET TIME STAMPcomme indiqué dans le code suivant. L'instruction GET TIME STAMP stocke l'horodatage dans un format long ou court selon le type de l'objet de données d'horodatage utilisé. La valeur d'horodatage est codée à l'aide de la norme UTC.
REPORT YR_SEP_12.
DATA: stamp_1 TYPE TIMESTAMP,
stamp_2 TYPE TIMESTAMPL.
GET TIME STAMP FIELD stamp_1.
Write: / 'The short time stamp is:', stamp_1
TIME ZONE SY-ZONLO.
GET TIME STAMP FIELD stamp_2.
Write: / 'The long time stamp is:', stamp_2
TIME ZONE SY-ZONLO.Le code ci-dessus produit la sortie suivante -
The short time stamp is: 18.09.2015 11:19:40
The long time stamp is: 18.09.2015 11:19:40,9370000Dans l'exemple ci-dessus, nous affichons l'horodatage à l'aide de l'ajout TIME ZONE de l'instruction WRITE. Cet ajout met en forme la sortie de l'horodatage selon les règles du fuseau horaire spécifié. Le champ système SY-ZONLO permet d'afficher le fuseau horaire local configuré dans les préférences de l'utilisateur.
ABAP propose différents types d'options de formatage pour formater la sortie des programmes. Par exemple, vous pouvez créer une liste qui comprend divers éléments dans différentes couleurs ou styles de mise en forme.
L'instruction WRITE est une instruction de mise en forme utilisée pour afficher des données sur un écran. Il existe différentes options de mise en forme pour l'instruction WRITE. La syntaxe de l'instruction WRITE est -
WRITE <format> <f> <options>.Dans cette syntaxe, <format> représente la spécification du format de sortie, qui peut être une barre oblique (/) qui indique l'affichage de la sortie à partir d'une nouvelle ligne. En plus de la barre oblique, la spécification de format inclut un numéro de colonne et une longueur de colonne. Par exemple, l'instruction WRITE / 04 (6) montre qu'une nouvelle ligne commence par la colonne 4 et la longueur de la colonne est 6, tandis que l'instruction WRITE 20 montre la ligne actuelle avec la colonne 20. Le paramètre <f> représente une variable de données ou texte numéroté.
Le tableau suivant décrit les différentes clauses utilisées pour le formatage -
| S.No. | Clause et description |
|---|---|
| 1 | LEFT-JUSTIFIED Spécifie que la sortie est justifiée à gauche. |
| 2 | CENTERED Indique que la sortie est centrée. |
| 3 | RIGHT-JUSTIFIED Spécifie que la sortie est justifiée à droite. |
| 4 | UNDER <g> La sortie démarre directement sous le champ <g>. |
| 5 | NO-GAP Spécifie que le blanc après le champ <f> est rejeté. |
| 6 | USING EDIT MASK <m> Désigne la spécification du modèle de format <m>. Utilisation sans masque EDIT: Ceci spécifie que le modèle de format spécifié dans le dictionnaire ABAP est désactivé. |
| sept | NO-ZERO Si un champ ne contient que des zéros, ils sont remplacés par des blancs. |
Voici les options de mise en forme des champs de type numérique -
| S.No. | Clause et description |
|---|---|
| 1 | NO-SIGN Spécifie qu'aucun signe de tête n'est affiché à l'écran. |
| 2 | EXPONENT <e> Spécifie que dans le type F (les champs à virgule flottante), l'exposant est défini dans <e>. |
| 3 | ROUND <r> Les champs de type P (types de données numériques compactés) sont d'abord multipliés par 10 ** (- r), puis arrondis à une valeur entière. |
| 4 | CURRENCY <c> Indique que le formatage est effectué en fonction de la valeur de la devise <c> stockée dans la table de base de données TCURX. |
| 5 | UNIT <u> Spécifie que le nombre de décimales est fixé en fonction de l'unité <u> comme spécifié dans la table de base de données T006 pour le type P. |
| 6 | DECIMALS <d> Spécifie que le nombre de chiffres <d> doit être affiché après la virgule décimale. |
Par exemple, le tableau suivant montre différentes options de mise en forme pour les champs de date -
| Option de formatage | Exemple |
|---|---|
| JJ / MM / AA | 13/01/15 |
| MM / JJ / AA | 13/01/15 |
| JJ / MM / AAAA | 13/01/2015 |
| MM / JJ / AAAA | 13/01/2015 |
| JJMMAA | 130115 |
| MMJJAA | 011315 |
| AAMMJJ | 150113 |
Ici, JJ représente la date en deux chiffres, MM représente le mois en deux chiffres, AA représente l'année en deux chiffres et AAAA représente l'année en quatre chiffres.
Jetons un coup d'œil à un exemple de code ABAP qui implémente certaines des options de formatage ci-dessus -
REPORT ZTest123_01.
DATA: n(9) TYPE C VALUE 'Tutorials',
m(5) TYPE C VALUE 'Point'.
WRITE: n, m.
WRITE: / n,
/ m UNDER n.
WRITE: / n NO-GAP, m.
DATA time TYPE T VALUE '112538'.
WRITE: / time,
/(8) time Using EDIT MASK '__:__:__'.Le code ci-dessus produit la sortie suivante -
Tutorials Point
Tutorials
Point
TutorialsPoint
112538
11:25:38Un exceptionest un problème qui survient lors de l'exécution d'un programme. Lorsqu'une exception se produit, le déroulement normal du programme est interrompu et l'application du programme se termine anormalement, ce qui n'est pas recommandé. Par conséquent, ces exceptions doivent être traitées.
Les exceptions fournissent un moyen de transférer le contrôle d'une partie d'un programme à une autre. La gestion des exceptions ABAP repose sur trois mots-clés: RAISE, TRY, CATCH et CLEANUP. En supposant qu'un bloc lève une exception, une méthode intercepte une exception en utilisant une combinaison des mots-clés TRY et CATCH. Un bloc TRY - CATCH est placé autour du code qui peut générer une exception. Voici la syntaxe pour utiliser TRY - CATCH -
TRY.
Try Block <Code that raises an exception>
CATCH
Catch Block <exception handler M>
. . .
. . .
. . .
CATCH
Catch Block <exception handler R>
CLEANUP.
Cleanup block <to restore consistent state>
ENDTRY.RAISE- Des exceptions sont soulevées pour indiquer qu'une situation exceptionnelle s'est produite. Habituellement, un gestionnaire d'exceptions tente de réparer l'erreur ou de trouver une solution alternative.
TRY- Le bloc TRY contient le codage de l'application dont les exceptions doivent être traitées. Ce bloc d'instructions est traité séquentiellement. Il peut contenir d'autres structures de contrôle et des appels de procédures ou d'autres programmes ABAP. Il est suivi d'un ou plusieurs blocs catch.
CATCH- Un programme intercepte une exception avec un gestionnaire d'exceptions à l'endroit dans un programme où vous voulez gérer le problème. Le mot-clé CATCH indique la capture d'une exception.
CLEANUP- Les instructions du bloc CLEANUP sont exécutées chaque fois qu'une exception se produit dans un bloc TRY qui n'est pas intercepté par le gestionnaire de la même construction TRY - ENDTRY. Dans la clause CLEANUP, le système peut restaurer un objet dans un état cohérent ou libérer des ressources externes. Autrement dit, le travail de nettoyage peut être exécuté pour le contexte du bloc TRY.
Lever des exceptions
Des exceptions peuvent être déclenchées à tout moment dans une méthode, un module fonction, un sous-programme, etc. Une exception peut être déclenchée de deux manières:
Exceptions levées par le système d'exécution ABAP.
Par exemple Y = 1 / 0. Cela entraînera une erreur d'exécution de type CX_SY_ZERODIVIDE.
Exceptions soulevées par le programmeur.
Soulevez et créez un objet d'exception simultanément. Déclenchez une exception avec un objet d'exception qui existe déjà dans le premier scénario. La syntaxe est la suivante: RAISE EXCEPTION exep.
Attraper les exceptions
Les gestionnaires sont utilisés pour intercepter les exceptions.
Jetons un coup d'œil à un extrait de code -
DATA: result TYPE P LENGTH 8 DECIMALS 2,
exref TYPE REF TO CX_ROOT,
msgtxt TYPE STRING.
PARAMETERS: Num1 TYPE I, Num2 TYPE I.
TRY.
result = Num1 / Num2.
CATCH CX_SY_ZERODIVIDE INTO exref.
msgtxt = exref→GET_TEXT( ).
CATCH CX_SY_CONVERSION_NO_NUMBER INTO exref.
msgtxt = exref→GET_TEXT( ).Dans l'extrait de code ci-dessus, nous essayons de diviser Num1 par Num2 pour obtenir le résultat dans une variable de type flottant.
Deux types d'exceptions pourraient être générés.
Erreur de conversion numérique.
Divisez par zéro exception. Les gestionnaires interceptent l'exception CX_SY_CONVERSION_NO_NUMBER ainsi que l'exception CX_SY_ZERODIVIDE. Ici, la méthode GET_TEXT () de la classe d'exception est utilisée pour obtenir la description de l'exception.
Attributs des exceptions
Voici les cinq attributs et méthodes d'exceptions -
| S.No. | Attribut et description |
|---|---|
| 1 | Textid Utilisé pour définir différents textes pour les exceptions et affecte également le résultat de la méthode get_text. |
| 2 | Previous Cet attribut peut stocker l'exception d'origine qui vous permet de créer une chaîne d'exceptions. |
| 3 | get_text Cela renvoie la représentation textuelle sous forme de chaîne selon la langue système de l'exception. |
| 4 | get_longtext Cela renvoie la variante longue de la représentation textuelle de l'exception sous forme de chaîne. |
| 5 | get_source_position Donne le nom du programme et le numéro de ligne atteint où l'exception a été déclenchée. |
Exemple
REPORT ZExceptionsDemo.
PARAMETERS Num_1 TYPE I.
DATA res_1 TYPE P DECIMALS 2.
DATA orf_1 TYPE REF TO CX_ROOT.
DATA txt_1 TYPE STRING.
start-of-selection.
Write: / 'Square Root and Division with:', Num_1.
write: /.
TRY.
IF ABS( Num_1 ) > 150.
RAISE EXCEPTION TYPE CX_DEMO_ABS_TOO_LARGE.
ENDIF.
TRY.
res_1 = SQRT( Num_1 ).
Write: / 'Result of square root:', res_1.
res_1 = 1 / Num_1.
Write: / 'Result of division:', res_1.
CATCH CX_SY_ZERODIVIDE INTO orf_1.
txt_1 = orf_1→GET_TEXT( ).
CLEANUP.
CLEAR res_1.
ENDTRY.
CATCH CX_SY_ARITHMETIC_ERROR INTO orf_1.
txt_1 = orf_1→GET_TEXT( ).
CATCH CX_ROOT INTO orf_1.
txt_1 = orf_1→GET_TEXT( ).
ENDTRY.
IF NOT txt_1 IS INITIAL.
Write / txt_1.
ENDIF.
Write: / 'Final Result is:', res_1.Dans cet exemple, si le nombre est supérieur à 150, l'exception CX_DEMO_ABS_TOO_LARGE est déclenchée. Le code ci-dessus produit la sortie suivante pour le nombre 160.
Square Root and Division with: 160
The absolute value of number is too high
Final Result is: 0.00Comme vous le savez, SQL peut être divisé en deux parties -
- DML (langage de manipulation de données)
- DDL (langage de définition de données)
La partie DML se compose de commandes de requête et de mise à jour telles que SELECT, INSERT, UPDATE, DELETE, etc. et les programmes ABAP gèrent la partie DML de SQL. La partie DDL se compose de commandes telles que CREATE TABLE, CREATE INDEX, DROP TABLE, ALTER TABLE, etc. et ABAP Dictionary gère la partie DDL de SQL.
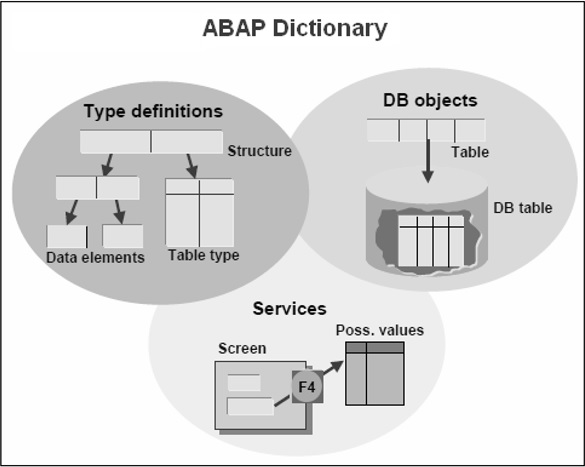
Le dictionnaire ABAP peut être considéré comme des métadonnées (c'est-à-dire des données sur les données) qui résident dans la base de données SAP avec les métadonnées gérées par la base de données. Le dictionnaire est utilisé pour créer et gérer des définitions de données et pour créer des tables, des éléments de données, des domaines, des vues et des types.
Types de base dans le dictionnaire ABAP
Les types de base dans le dictionnaire ABAP sont les suivants -
Data elements décrire un type élémentaire en définissant le type de données, la longueur et éventuellement des décimales.
Structures avec des composants qui peuvent avoir n'importe quel type.
Table types décrire la structure d'une table interne.
Différents objets de l'environnement Dictionary peuvent être référencés dans les programmes ABAP. Le dictionnaire est connu comme la zone globale. Les objets du dictionnaire sont globaux pour tous les programmes ABAP et les données des programmes ABAP peuvent être déclarées par référence à ces objets globaux Dictionary.
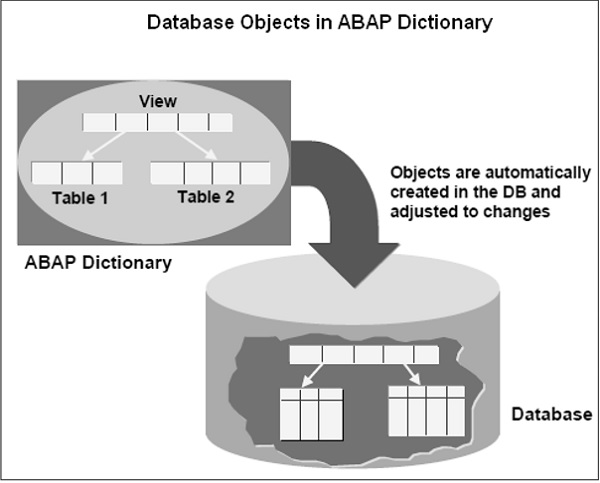
Le dictionnaire prend en charge la définition des types définis par l'utilisateur et ces types sont utilisés dans les programmes ABAP. Ils définissent également la structure des objets de base de données tels que les tables, les vues et les index. Ces objets sont créés automatiquement dans la base de données sous-jacente dans leurs définitions de dictionnaire lorsque les objets sont activés. Le dictionnaire fournit également des outils d'édition comme l'aide à la recherche et un outil de verrouillage comme Verrouiller les objets.
Tâches du dictionnaire
Le dictionnaire ABAP permet d'obtenir les résultats suivants -
- Renforce l'intégrité des données.
- Gère les définitions de données sans redondance.
- S'intègre étroitement avec le reste de l'atelier de développement ABAP.
Exemple
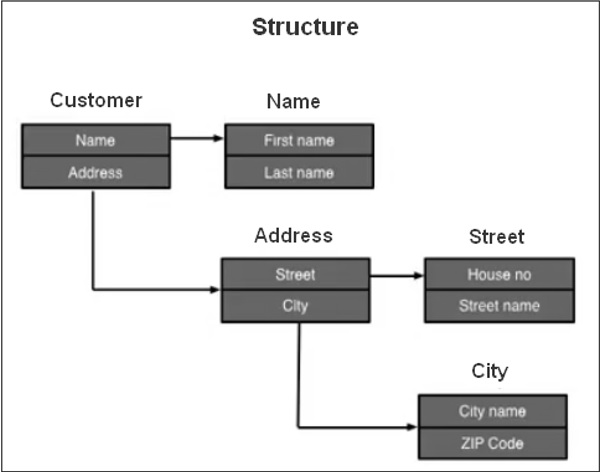
Tout type complexe défini par l'utilisateur peut être construit à partir des 3 types de base du dictionnaire. Les données client sont stockées dans une structure «Client» avec les composants Nom, Adresse et Téléphone comme illustré dans l'image suivante. Le nom est également une structure avec des composants, un prénom et un nom. Ces deux composants sont élémentaires car leur type est défini par un élément de données.
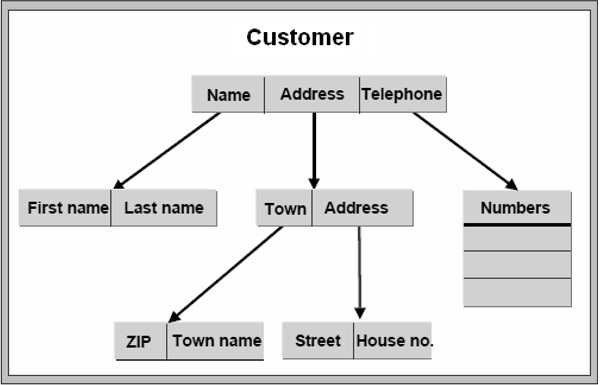
Le type de composant Adresse est défini par une structure dont les composants sont également des structures, et le composant Téléphone est défini par un type de table car un client peut avoir plus d'un numéro de téléphone. Les types sont utilisés dans les programmes ABAP et également pour définir les types de paramètres d'interface des modules fonction.
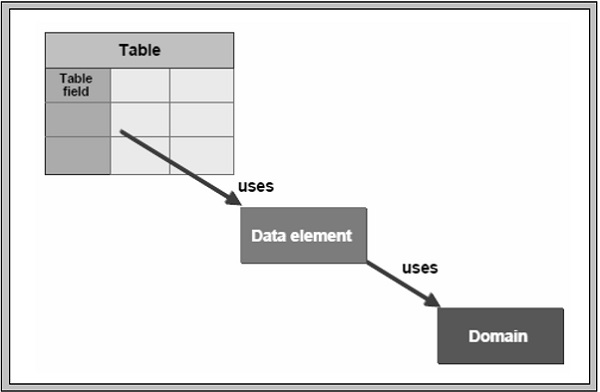
Les trois objets de base pour définir les données dans le dictionnaire ABAP sont les domaines, les éléments de données et les tables. Le domaine est utilisé pour la définition technique d'un champ de table tel que le type et la longueur du champ, et l'élément de données est utilisé pour la définition sémantique (brève description). Un élément de données décrit la signification d'un domaine dans un certain contexte commercial. Il contient principalement l'aide sur le terrain et les étiquettes de champ à l'écran.
Le domaine est attribué à l'élément de données, qui à son tour est affecté aux champs de table ou aux champs de structure. Par exemple, le domaine MATNR (numéro de matériau CHAR) est attribué à des éléments de données tels que MATNR_N, MATNN et MATNR_D, et ceux-ci sont affectés à de nombreux champs de table et champs de structure.
Créer des domaines
Avant de créer un nouveau domaine, vérifiez si des domaines existants ont les mêmes spécifications techniques requises dans votre champ de table. Si tel est le cas, nous sommes censés utiliser ce domaine existant. Discutons de la procédure de création du domaine.
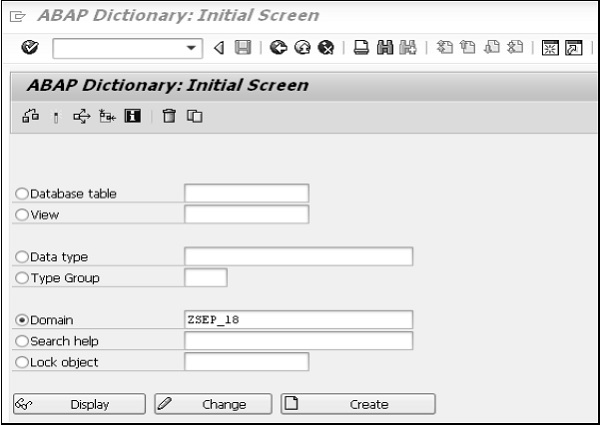
Step 1 - Accédez à la transaction SE11.
Step 2- Sélectionnez le bouton radio pour le domaine dans l'écran initial du dictionnaire ABAP, et entrez le nom du domaine comme indiqué dans la capture d'écran suivante. Cliquez sur le bouton CRÉER. Vous pouvez créer des domaines sous les espaces de noms des clients et le nom de l'objet commence toujours par «Z» ou «Y».
Step 3- Saisissez la description dans le champ de texte court de l'écran de maintenance du domaine. Dans ce cas, il s'agit du «domaine client».Note - Vous ne pouvez entrer aucun autre attribut tant que vous n'avez pas entré cet attribut.
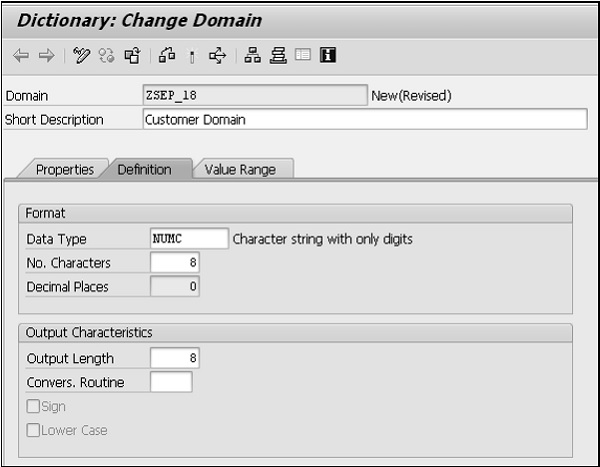
Step 4- Entrez le type de données, le nombre de caractères et les décimales dans le bloc Format de l'onglet Définition. Appuyez sur la touche sur Longueur de sortie et il propose et affiche la longueur de sortie. Si vous écrasez la longueur de sortie proposée, un avertissement peut s'afficher lors de l'activation du domaine. Vous pouvez remplir le Convers. Champs Routine, Sign et Minuscules si nécessaire. Mais ce sont toujours des attributs facultatifs.
Step 5- Sélectionnez l'onglet Plage de valeurs. Si le domaine est limité à n'avoir que des valeurs fixes, entrez les valeurs fixes ou les intervalles. Définissez la table de valeurs si le système doit proposer cette table comme table de contrôle tout en définissant une clé étrangère pour les champs faisant référence à ce domaine. Mais tous ces attributs sont facultatifs.
Step 6- Enregistrez vos modifications. La fenêtre contextuelle Créer une entrée de répertoire d'objets apparaît et demande un package. Vous pouvez saisir le nom du package dans lequel vous travaillez. Si vous ne disposez d'aucun package, vous pouvez le créer dans le Navigateur d'objets ou enregistrer votre domaine à l'aide du bouton Objet local.
Step 7- Activez votre domaine. Cliquez sur l'icône Activer (icône d'allumette) ou appuyez sur CTRL + F3 pour activer le domaine. Une fenêtre pop-up apparaît, listant les 2 objets actuellement inactifs comme indiqué dans l'instantané suivant -
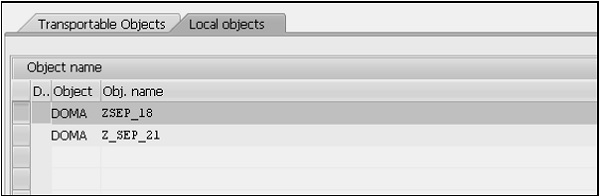
Step 8- À ce stade, l'entrée supérieure étiquetée «DOMA» avec le nom ZSEP_18 doit être activée. Lorsque cela est mis en évidence, cliquez sur le bouton de coche verte. Cette fenêtre disparaît et la barre d'état affiche le message «Objet activé».
Si des messages d'erreur ou des avertissements se sont produits lors de l'activation du domaine, le journal d'activation s'affiche automatiquement. Le journal d'activation affiche des informations sur le flux d'activation. Vous pouvez également appeler le journal d'activation avec Utilitaires (M) → Journal d'activation.
Les éléments de données décrivent les différents champs du dictionnaire de données ABAP. Ce sont les plus petites unités indivisibles des types complexes et elles sont utilisées pour définir le type de champ de table, de composant de structure ou de type de ligne d'une table. Des informations sur la signification d'un champ de table et également des informations sur l'édition du champ d'écran correspondant pourraient être attribuées à un élément de données. Ces informations sont automatiquement disponibles pour tous les champs d'écran qui font référence à l'élément de données. Les éléments de données décrivent des types élémentaires ou des types de référence.
Création d'éléments de données
Avant de créer un nouvel élément de données, vous devez vérifier si des éléments de données existants ont les mêmes spécifications sémantiques requises dans votre champ de table. Si tel est le cas, vous pouvez utiliser cet élément de données existant. Vous pouvez attribuer à l'élément de données un type, un domaine ou un type de référence prédéfini.
Voici la procédure de création de l'élément de données -
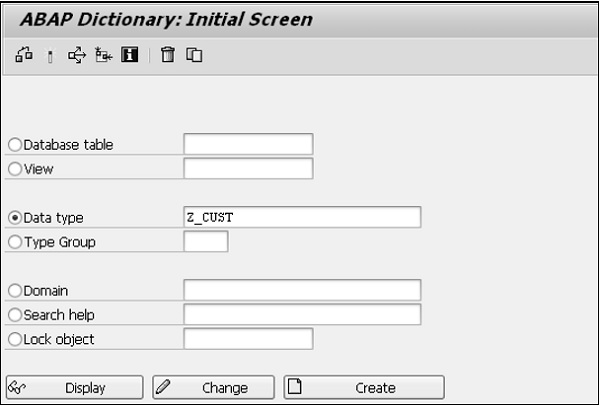
Step 1 - Accédez à la transaction SE11.
Step 2 - Sélectionnez le bouton radio pour le type de données dans l'écran initial du dictionnaire ABAP et entrez le nom de l'élément de données comme indiqué ci-dessous.
Step 3- Cliquez sur le bouton CRÉER. Vous pouvez créer des éléments de données sous les espaces de noms client, et le nom de l'objet commence toujours par «Z» ou «Y».
Step 4 - Cochez le bouton radio Élément de données dans la fenêtre contextuelle CRÉER TYPE qui apparaît avec trois boutons radio.
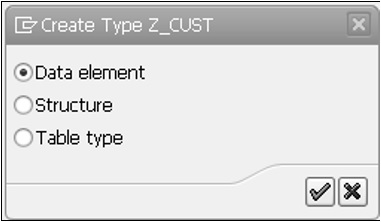
Step 5- Cliquez sur l'icône de coche verte. Vous êtes dirigé vers l'écran de maintenance de l'élément de données.
Step 6- Saisissez la description dans le champ de texte court de l'écran de maintenance de l'élément de données. Dans ce cas, il s'agit de «Élément de données client».Note - Vous ne pouvez entrer aucun autre attribut tant que vous n'avez pas entré cet attribut.
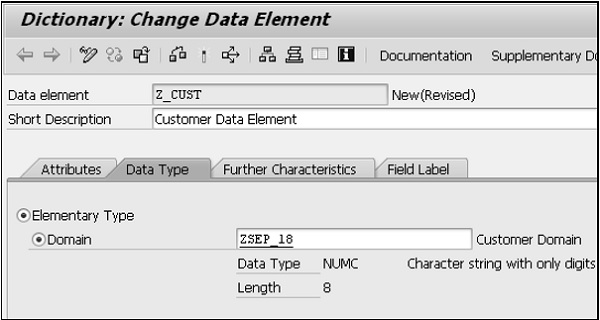
Step 7- Attribuez à l'élément de données le type. Vous pouvez créer un élément de données élémentaire en vérifiant le type élémentaire ou un élément de données de référence en vérifiant le type de référence. Vous pouvez affecter un élément de données à un domaine ou à un type prédéfini dans le type élémentaire et avec le nom du type de référence ou une référence au type prédéfini dans le type de référence.
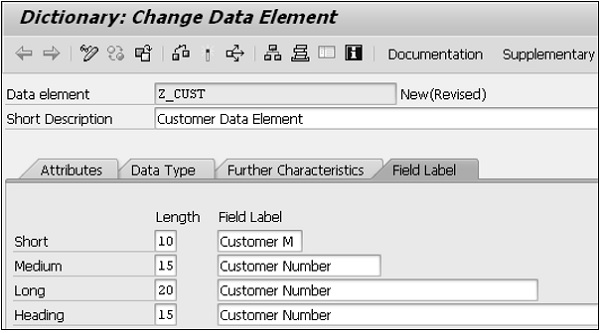
Step 8- Entrez les champs pour le texte court, le texte moyen, le texte long et l'en-tête dans l'onglet Étiquette de champ. Vous pouvez appuyer sur Entrée et la longueur est automatiquement générée pour ces étiquettes.
Step 9- Enregistrez vos modifications. La fenêtre contextuelle Créer une entrée de répertoire d'objets apparaît et demande un package. Vous pouvez saisir le nom du package dans lequel vous travaillez. Si vous ne disposez d'aucun package, vous pouvez le créer dans le navigateur d'objets ou enregistrer votre élément de données à l'aide du bouton Objet local.
Step 10- Activez votre élément de données. Cliquez sur l'icône Activer (icône d'allumette) ou appuyez sur CTRL + F3 pour activer l'élément de données. Une fenêtre contextuelle apparaît, répertoriant les 2 objets actuellement inactifs, comme illustré dans la capture d'écran suivante.
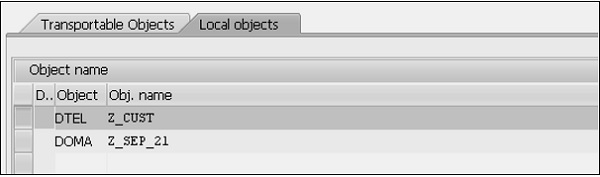
Step 11- À ce stade, l'entrée supérieure intitulée «DTEL» avec le nom Z_CUST doit être activée. Lorsque cela est mis en évidence, cliquez sur le bouton de coche verte. Cette fenêtre disparaît et la barre d'état affiche le message «Objet activé».
Si des messages d'erreur ou des avertissements se sont produits lorsque vous avez activé l'élément de données, le journal d'activation s'affiche automatiquement. Le journal d'activation affiche des informations sur le flux d'activation. Vous pouvez également appeler le journal d'activation avec Utilitaires (M) → Journal d'activation.
Les tables peuvent être définies indépendamment de la base de données dans le dictionnaire ABAP. Lorsqu'une table est activée dans le dictionnaire ABAP, une copie similaire de ses champs est également créée dans la base de données. Les tables définies dans le dictionnaire ABAP sont traduites automatiquement dans le format compatible avec la base de données car la définition de la table dépend de la base de données utilisée par le système SAP.
Une table peut contenir un ou plusieurs champs, chacun défini avec son type de données et sa longueur. La grande quantité de données stockées dans une table est répartie entre les différents champs définis dans la table.
Types de champs de table
Une table se compose de nombreux champs et chaque champ contient de nombreux éléments. Le tableau suivant répertorie les différents éléments des champs de table -
| S.No. | Éléments et description |
|---|---|
| 1 | Field name C'est le nom donné à un champ qui peut contenir un maximum de 16 caractères. Le nom du champ peut être composé de chiffres, de lettres et de traits de soulignement. Il doit commencer par une lettre. |
| 2 | Key flag Détermine si un champ appartient ou non à un champ clé. |
| 3 | Field type Attribue un type de données à un champ. |
| 4 | Field length Le nombre de caractères pouvant être saisis dans un champ. |
| 5 | Decimal places Définit le nombre de chiffres autorisés après la virgule décimale. Cet élément est utilisé uniquement pour les types de données numériques. |
| 6 | Short text Décrit la signification du champ correspondant. |
Création de tables dans le dictionnaire ABAP
Step 1- Accédez à la transaction SE11, sélectionnez le bouton radio 'Table de base de données' et entrez un nom pour la table à créer. Dans notre cas, nous avons entré le nom ZCUSTOMERS1. Cliquez sur le bouton Créer. L'écran Dictionnaire: gérer la table apparaît. Ici, l'onglet «Livraison et maintenance» est sélectionné par défaut.
Step 2 - Saisissez un court texte explicatif dans le champ Description courte.
Step 3- Cliquez sur l'icône Aide à la recherche à côté du champ Classe de livraison. Sélectionnez l'option «A [Table d'application (données de base et de transaction)]».
Step 4- Sélectionnez l'option «Affichage / Maintenance autorisée» dans le menu déroulant «Explorateur de données / Vue de table». L'écran Dictionnaire: Table de maintenance s'affiche.
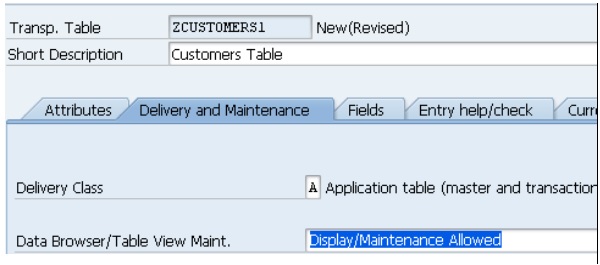
Step 5- Sélectionnez l'onglet Champs. L'écran contenant les options liées à l'onglet Champs apparaît.
Step 6- Entrez les noms des champs de table dans la colonne Champ. Un nom de champ peut contenir des lettres, des chiffres et des traits de soulignement, mais il doit toujours commencer par une lettre et ne doit pas dépasser 16 caractères.
Les champs à créer doivent également contenir des éléments de données, car ils prennent les attributs, tels que le type de données, la longueur, les décimales et le texte court, de l'élément de données défini.
Step 7- Sélectionnez la colonne Clé si vous souhaitez que le champ fasse partie de la clé de table. Créons des champs tels que CLIENT, CLIENT, NOM, TITRE et DOB.
Step 8- Le premier champ est important et identifie le client auquel les enregistrements sont associés. Entrez «Client» comme champ et «MANDT» comme élément de données. Le système remplit automatiquement le type de données, la longueur, les décimales et la description courte. Le champ «Client» devient un champ clé en cochant la case «Clé».
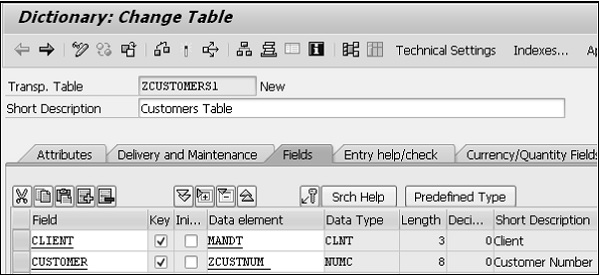
Step 9- Le champ suivant est «Client». Cochez la case pour en faire un champ clé et saisissez le nouvel élément de données «ZCUSTNUM». Cliquez sur le bouton Enregistrer.
Step 10- Comme l'élément de données 'ZCUSTNUM' n'existe pas encore, il doit être créé. Double-cliquez sur le nouvel élément de données et la fenêtre «Créer un élément de données» apparaît. Répondez «Oui» à cela et une fenêtre «Maintenir l'élément de données» apparaît.
Step 11- Saisissez «Numéro de client» dans la zone Description courte. Le type de données élémentaire appelé «domaine» doit être défini pour le nouvel élément de données. Entrez donc 'ZCUSTD1', double-cliquez dessus et acceptez d'enregistrer les modifications apportées. Choisissez «Oui» pour créer le domaine et saisissez dans la case «Description courte» une description du domaine.
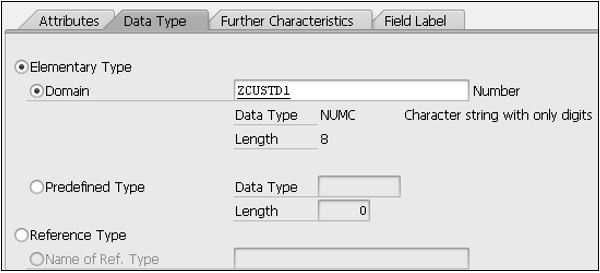
L'onglet «Définition» s'ouvre automatiquement. Le premier champ est «Type de données».
Step 12- Cliquez à l'intérieur de la boîte et sélectionnez le type «NUMC» dans le menu déroulant. Entrez le chiffre 8 dans le 'No. de caractères (maximum 8 caractères) et entrez 0 dans la zone «Décimales». La longueur de sortie de 8 doit être sélectionnée, puis appuyez sur Entrée. La description du champ 'NUMC' doit réapparaître, confirmant qu'il s'agit d'une entrée valide.
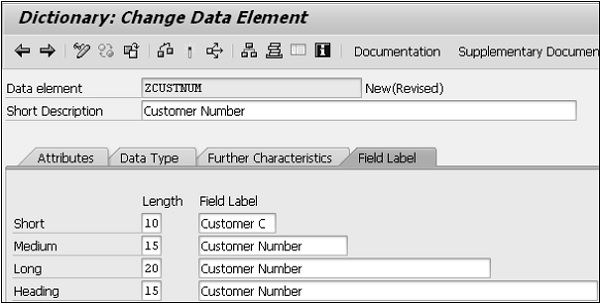
Step 13 - Cliquez sur le bouton Enregistrer et activez l'objet.
Step 14- Appuyez sur F3 pour revenir à l'écran «Maintain / Change Data Element». Créez quatre étiquettes de champ comme indiqué dans l'instantané suivant. Après cela, enregistrez et activez l'élément.
Step 15- Appuyez sur le bouton retour pour revenir à l'écran d'entretien de la table. La colonne Client a le type de données, la longueur, les décimales et la description courte corrects. Cela indique la création réussie d'un élément de données et également le domaine utilisé.
De même, nous devons créer trois champs supplémentaires tels que NOM, TITLE et DOB.
Step 16- Sélectionnez «Paramètres techniques» dans la barre d'outils. Choisissez APPL0 pour la «Classe de données» et la première catégorie de taille 0 pour le champ «Catégorie de taille» ». Dans le cas des options de mise en mémoire tampon, «Mise en mémoire tampon non autorisée» doit être sélectionné.
Step 17- Cliquez sur Enregistrer. Revenez à la table et activez-la. L'écran suivant apparaît.
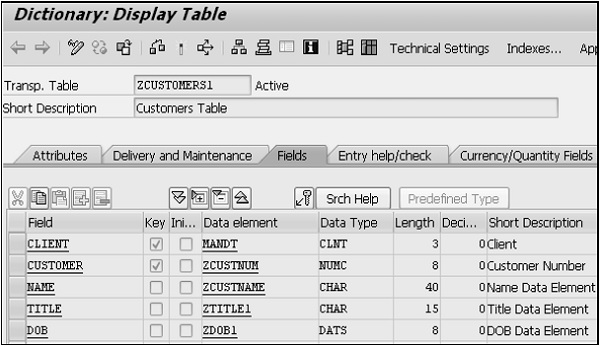
La table 'ZCUSTOMERS1' est activée.
Structure est un objet de données constitué de composants de tout type de données stockés les uns après les autres dans la mémoire.
Les structures sont utiles pour peindre les champs d'écran et pour manipuler des données qui ont un format cohérent défini par un nombre discret de champs.
Une structure peut n'avoir qu'un seul enregistrement au moment de l'exécution, mais une table peut avoir plusieurs enregistrements.
Créer une structure
Step 1 - Accédez à la transaction SE11.
Step 2- Cliquez sur l'option «Type de données» à l'écran. Entrez le nom «ZSTR_CUSTOMER1» et cliquez sur le bouton Créer.
Step 3- Sélectionnez l'option «Structure» dans l'écran suivant et appuyez sur Entrée. Vous pouvez voir l'assistant «Maintenir / Modifier la structure».
Step 4 - Entrez la description courte comme indiqué dans l'instantané suivant.
Step 5 - Entrez le composant (nom du champ) et le type de composant (élément de données).
Note: Ici, les noms des composants commencent par Z selon la recommandation SAP. Utilisons des éléments de données que nous avons déjà créés dans la table de base de données.
Step 6 - Vous devez enregistrer, vérifier et activer après avoir fourni tous les composants et types de composants.
L'écran suivant apparaît -
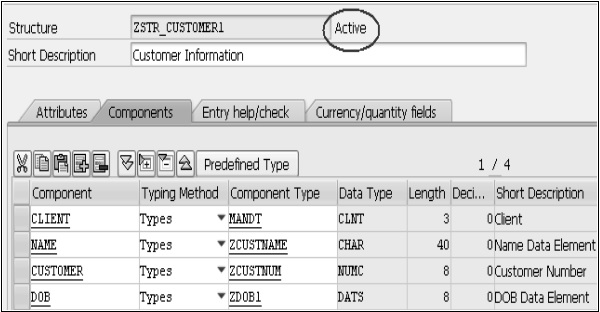
Step 7- Lorsque ce 'ZSTR_CUSTOMER1' est mis en surbrillance, cliquez sur le bouton de coche verte. Cette fenêtre disparaît et la barre d'état affiche le message «Actif».
La structure est maintenant activée comme indiqué dans l'instantané suivant -
Une vue agit uniquement comme une table de base de données. Mais il n'occupera pas d'espace de stockage. Une vue agit de la même manière qu'une table virtuelle - une table qui n'a aucune existence physique. Une vue est créée en combinant les données d'une ou plusieurs tables contenant des informations sur un objet d'application. À l'aide des vues, vous pouvez représenter un sous-ensemble des données contenues dans une table ou vous pouvez joindre plusieurs tables en une seule table virtuelle.
Les données liées à un objet d'application sont réparties entre plusieurs tables à l'aide de vues de base de données. Ils utilisent la condition de jointure interne pour joindre les données de différentes tables. Une vue de maintenance permet d'afficher et de modifier les données stockées dans un objet d'application. Chaque vue de maintenance est associée à un statut de maintenance.
Nous utilisons la vue de projection pour masquer les champs indésirables et n'afficher que les champs pertinents dans une table. Les vues de projection doivent être définies sur une seule table transparente. Une vue de projection contient exactement une table. Nous ne pouvons pas définir de conditions de sélection pour les vues de projection.
Créer une vue
Step 1- Sélectionnez le bouton radio Afficher sur l'écran initial du dictionnaire ABAP. Entrez le nom de la vue à créer, puis cliquez sur le bouton Créer. Nous avons entré le nom de la vue comme ZVIEW_TEST.
Step 2- Sélectionnez le bouton radio de la vue de projection tout en choisissant le type de vue et cliquez sur le bouton Copier. L'écran «Dictionnaire: Changer de vue» apparaît.
Step 3 - Entrez une brève description dans le champ Description courte et le nom de la table à utiliser dans le champ Table de base comme indiqué dans l'instantané suivant.
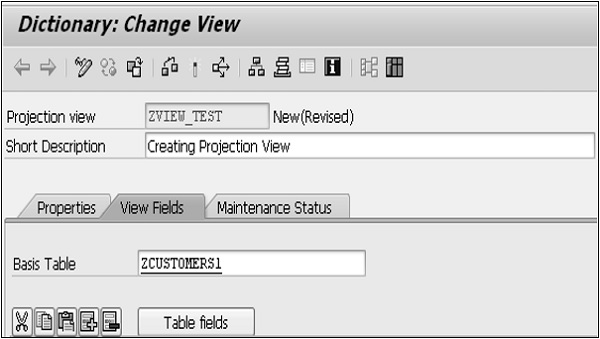
Step 4 - Cliquez sur le bouton «Champs de table» pour inclure les champs de la table ZCUSTOMERS1 dans la vue de projection.
Step 5- L'écran Sélection de champ à partir du tableau ZCUSTOMERS1 apparaît. Sélectionnez les champs que vous souhaitez inclure dans la vue de projection comme indiqué dans l'instantané suivant.
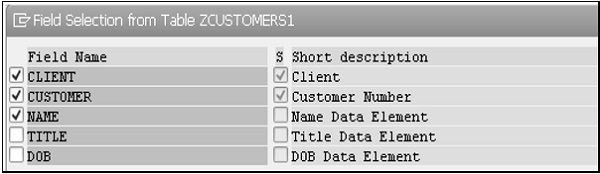
Step 6 - Après avoir cliqué sur le bouton Copier, tous les champs sélectionnés pour la vue de projection sont affichés sur l'écran «Dictionnaire: Changer de vue».
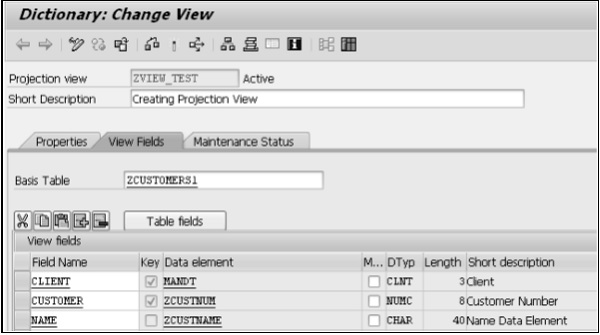
Step 7- Sélectionnez l'onglet État de la maintenance pour définir une méthode d'accès. Choisissez le bouton radio en lecture seule et l'option «Affichage / Maintenance autorisée avec restrictions» dans le menu déroulant de «Maintenance du navigateur de données / vue de table».
Step 8- Enregistrez et activez-le. Dans l'écran «Dictionnaire: Modifier la vue», sélectionnez Utilitaires (M)> Contenu pour afficher l'écran de sélection de ZVIEW_TEST.
Step 9- Cliquez sur l'icône Exécuter. La sortie de la vue de projection apparaît comme indiqué dans la capture d'écran suivante.
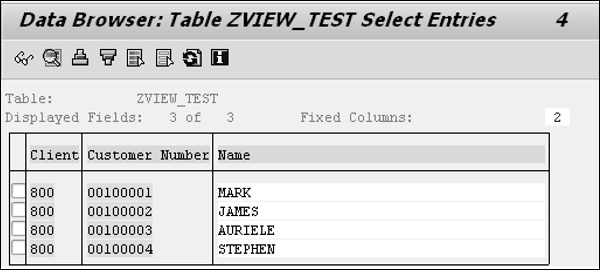
La table ZCUSTOMERS1 se compose de 5 champs. Ici, les champs affichés sont 3 (client, numéro de client et nom) avec 4 entrées. Les numéros de client vont de 100001 à 100004 avec les noms appropriés.
L'aide à la recherche, un autre objet de référentiel du dictionnaire ABAP, permet d'afficher toutes les valeurs possibles d'un champ sous la forme d'une liste. Cette liste est également connue sous le nom dehit list. Vous pouvez sélectionner les valeurs à saisir dans les champs de cette liste de résultats au lieu de saisir manuellement la valeur, ce qui est fastidieux et sujet aux erreurs.
Créer une aide à la recherche
Step 1- Accédez à la transaction SE11. Sélectionnez le bouton radio de l'aide à la recherche. Saisissez le nom de l'aide à la recherche à créer. Entrons le nom ZSRCH1. Cliquez sur le bouton Créer.
Step 2- Le système vous demandera le type d'aide à la recherche à créer. Sélectionnez l'aide à la recherche élémentaire, qui est par défaut. L'écran pour créer une aide à la recherche élémentaire, comme illustré dans la capture d'écran suivante, apparaît.
Step 3- Dans la méthode de sélection, nous devons indiquer si notre source de données est un tableau ou une vue. Dans notre cas, il s'agit d'une table. Le tableau est ZCUSTOMERS1. Il est sélectionné dans une liste de sélection.
Step 4- Une fois la méthode de sélection entrée, le champ suivant est le type de dialogue. Cela contrôle l'apparence de la boîte de dialogue restrictive. Il existe une liste déroulante avec trois options. Sélectionnons l'option «Afficher les valeurs immédiatement».
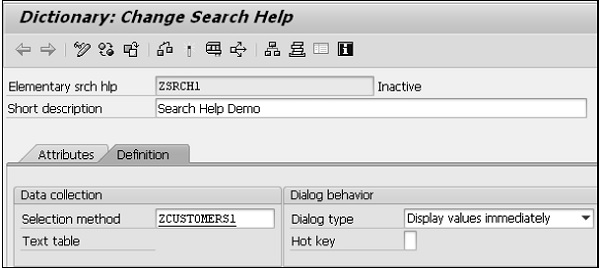
Step 5- Vient ensuite la zone des paramètres. Pour chaque paramètre ou champ d'aide à la recherche, ces champs de colonne doivent être saisis conformément aux exigences.
Search help parameter- Ceci est un champ de la source des données. Les champs du tableau sont répertoriés dans la liste de sélection. Les champs participant à l'aide à la recherche seraient saisis, un champ dans chaque ligne. Incluons les deux champs CLIENT et NOM. La participation de ces deux champs est indiquée dans le reste des colonnes.
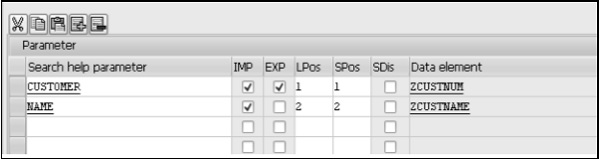
Import- Ce champ est une case à cocher pour indiquer si un paramètre d'aide à la recherche est un paramètre d'importation. L'exportation ou l'importation se fait en référence à l'aide à la recherche.
Export- Ce champ est une case à cocher pour indiquer si un paramètre d'aide à la recherche est un paramètre d'exportation. L'exportation sera le transfert des valeurs de champ de la liste de sélection aux champs d'écran.
LPos- Sa valeur contrôle la position physique du paramètre ou du champ d'aide à la recherche dans la liste de sélection. Si vous entrez une valeur 1, le champ apparaîtra en première position dans la liste de sélection et ainsi de suite.
SPos- Il contrôle la position physique du paramètre ou du champ Aide à la recherche dans la boîte de dialogue restrictive. Si vous entrez une valeur de 1, le champ apparaîtra en première position dans la boîte de dialogue restrictive et ainsi de suite.
Data element- Chaque paramètre ou champ d'aide à la recherche se voit attribuer par défaut un élément de données qui lui a été affecté dans la source de données (table ou vue). Ce nom d'élément de données apparaît en mode d'affichage.
Step 6- Effectuez un contrôle de cohérence et activez l'aide à la recherche. Appuyez sur F8 pour exécuter. L'écran 'Test Search Help ZSRCH1' apparaît comme illustré dans la capture d'écran suivante.

Step 7- Entrons le numéro 100004 dans le champ de l'écran «Prêt pour entrée» du CLIENT. Appuyez sur Entrée.
Le numéro de client, 100004 et le nom «STEPHEN» s'affichent.
Verrouiller un objet est une fonctionnalité offerte par ABAP Dictionary qui est utilisée pour synchroniser l'accès aux mêmes données par plusieurs programmes. Les enregistrements de données sont accessibles à l'aide de programmes spécifiques. Les objets de verrouillage sont utilisés dans SAP pour éviter l'incohérence lorsque des données sont insérées ou modifiées dans la base de données. Les tables dont les enregistrements de données doivent être verrouillés doivent être définies dans un objet de verrouillage, avec leurs champs clés.
Mécanisme de verrouillage
Voici les deux principales fonctions accomplies avec le mécanisme de verrouillage -
Un programme peut communiquer avec d'autres programmes à propos des enregistrements de données qu'il est juste en train de lire ou de modifier.
Un programme peut s'empêcher de lire des données qui viennent d'être modifiées par un autre programme.
UNE lock requestest d'abord généré par le programme. Ensuite, cette demande est envoyée au serveur Enqueue et le verrou est créé dans la table de verrouillage. Le serveur Enqueue définit le verrou et le programme est enfin prêt à accéder aux données.
Création d'objets de verrouillage
Step 1- Accédez à la transaction SE11. L'écran suivant s'ouvre.
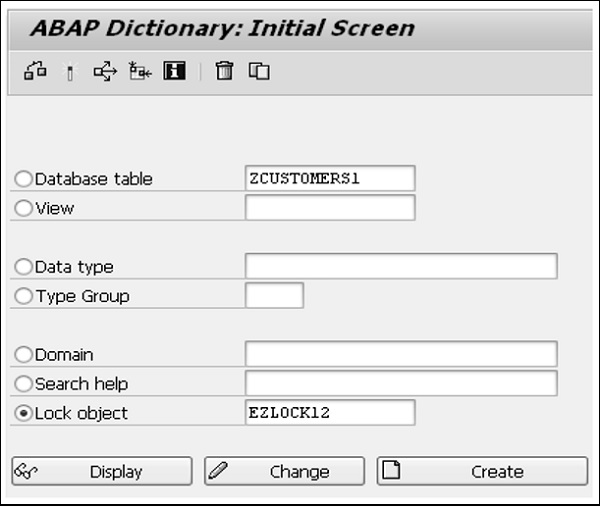
Step 2- Cliquez sur le bouton radio «Verrouiller l'objet». Entrez le nom de l'objet de verrouillage commençant par E et cliquez sur le bouton Créer. Ici, nous utilisons EZLOCK12.
Step 3 - Entrez dans le champ de description courte et cliquez sur l'onglet Tables.
Step 4 - Entrez le nom de la table dans le champ Nom et sélectionnez le mode de verrouillage comme Verrou d'écriture.
Step 5 - Cliquez sur l'onglet Paramètres de verrouillage, l'écran suivant apparaîtra.

Step 6- Enregistrez et activez. Générer automatiquement 2 modules de fonction. Pour vérifier les modules de fonction, nous pouvons utiliser Aller à → Verrouiller les modules.
Step 7 - Cliquez sur Verrouiller les modules et l'écran suivant s'ouvrira.
L'objet de verrouillage est créé avec succès.
Les champs clés d'une table incluse dans un objet de verrouillage sont appelés arguments de verrouillage et ils sont utilisés comme paramètres d'entrée dans les modules fonction. Ces arguments sont utilisés pour définir et supprimer les verrous générés par la définition d'objet de verrouillage.
C'est une bonne pratique de garder vos programmes aussi autonomes et faciles à lire que possible. Essayez simplement de diviser les tâches volumineuses et compliquées en tâches plus petites et plus simples en plaçant chaque tâche dans son module individuel, sur lequel le développeur peut se concentrer sans autre distraction.
Dans l'environnement SAP ABAP, la modularisation implique l'organisation de programmes en unités modulaires, également appelées logical blocks. Il réduit la redondance et augmente la lisibilité du programme même lorsque vous le créez et par la suite pendant le cycle de maintenance. La modularisation permet également de réutiliser le même code. ABAP a obligé les développeurs à modulariser, c'est-à-dire organiser les programmes relativement plus, que dans les langages basés sur OOPS qui ont relativement plus de fonctionnalités modulaires intégrées. Une fois qu'une petite section de code modulaire est terminée, déboguée, etc., il n'est pas nécessaire d'y retourner par la suite, et les développeurs peuvent alors passer à autre chose et se concentrer sur d'autres problèmes.
Les programmes ABAP sont constitués de blocs de traitement appelés blocs de traitement de modularisation. Ils sont -
Les blocs de traitement appelés depuis l'extérieur du programme et depuis l'environnement d'exécution ABAP (c'est-à-dire les blocs d'événements et les modules de dialogue).
Traitement des blocs appelés depuis les programmes ABAP.
Outre la modularisation avec des blocs de traitement, les modules de code source sont utilisés pour modulariser votre code source via des macros et inclure des programmes.
Modularisation au niveau du code source -
- Macros locales
- Programmes d'inclusion mondiaux
Modularisation via des blocs de traitement appelés depuis les programmes ABAP -
- Subroutines
- Modules fonctionnels
Modulariser un code source signifie placer une séquence d'instructions ABAP dans un module. Le code source modulaire peut être appelé dans un programme selon l'exigence de l'utilisateur. Les modules de code source améliorent la lisibilité et la compréhensibilité des programmes ABAP. La création de modules de code source individuels évite également d'avoir à écrire à plusieurs reprises les mêmes instructions encore et encore, ce qui rend le code plus facile à comprendre pour quiconque l'utilise pour la première fois.
Un sous-programme est une section de code réutilisable. C'est une unité de modularisation au sein du programme où une fonction est encapsulée sous forme de code source. Vous pagez une partie d'un programme vers un sous-programme pour obtenir une meilleure vue d'ensemble du programme principal et pour utiliser la séquence d'instructions correspondante plusieurs fois comme illustré dans le diagramme suivant.

Nous avons le programme X avec 3 différents source code blocks. Chaque bloc a les mêmes instructions ABAP. Fondamentalement, ce sont les mêmes blocs de code. Pour rendre ce code plus facile à maintenir, nous pouvons encapsuler le code dans un sous-programme. Nous pouvons appeler ce sous-programme dans nos programmes autant de fois que nous le souhaitons. Un sous-programme peut être défini à l'aide d'instructions Form et EndForm.
Voici la syntaxe générale d'une définition de sous-programme.
FORM <subroutine_name>.
<statements>
ENDFORM.Nous pouvons appeler un sous-programme en utilisant l'instruction PERFORM. Le contrôle saute à la première instruction exécutable dans le sous-programme <subroutine_name>. Lorsque ENDFORM est rencontré, le contrôle revient à l'instruction suivant l'instruction PERFORM.
Exemple
Step 1- Accédez à la transaction SE80. Ouvrez le programme existant, puis cliquez avec le bouton droit sur le programme. Dans ce cas, il s'agit de «ZSUBTEST».
Step 2- Sélectionnez Créer, puis sélectionnez Sous-programme. Écrivez le nom du sous-programme dans le champ, puis cliquez sur le bouton Continuer. Le nom du sous-programme est «Sub_Display», comme illustré dans la capture d'écran suivante.

Step 3- Ecrivez le code dans le bloc d'instructions FORM et ENDFORM. Le sous-programme a été créé avec succès.
Nous devons inclure l'instruction PERFORM pour appeler le sous-programme. Jetons un coup d'œil au code -
REPORT ZSUBTEST.
PERFORM Sub_Display.
* Form Sub_Display
* --> p1 text
* <-- p2 text
FORM Sub_Display.
Write: 'This is Subroutine'.
Write: / 'Subroutine created successfully'.
ENDFORM. " Sub_DisplayStep 4- Enregistrez, activez et exécutez le programme. Le code ci-dessus produit la sortie suivante -
Subroutine Test:
This is Subroutine
Subroutine created successfullyPar conséquent, l'utilisation de sous-programmes rend votre programme plus orienté fonction. Il divise la tâche du programme en sous-fonctions, de sorte que chaque sous-programme est responsable d'une sous-fonction. Votre programme devient plus facile à maintenir car les modifications des fonctions ne doivent souvent être implémentées que dans le sous-programme.
Si nous voulons réutiliser le même ensemble d'instructions plus d'une fois dans un programme, nous devons les inclure dans une macro. Par exemple, une macro peut être utile pour des calculs longs ou pour écrire des instructions WRITE complexes. Nous ne pouvons utiliser une macro que dans un programme dans lequel elle est définie. La définition de macro doit avoir lieu avant que la macro ne soit utilisée dans le programme.
Les macros sont conçues sur la base d'espaces réservés. L'espace réservé fonctionne comme des pointeurs en langage C. Vous pouvez définir une macro dans l'instruction DEFINE ... END-OF-DEFINITION.
Voici la syntaxe de base d'une définition de macro -
DEFINE <macro_name>. <statements>
END-OF-DEFINITION.
......
<macro_name> [<param1> <param2>....].Il est nécessaire de définir une macro avant de l'appeler. Le <param1>…. remplace les espaces réservés & 1 ... dans les instructions ABAP contenues dans la définition de macro.
Le nombre maximum d'espaces réservés dans une définition de macro est de neuf. Autrement dit, quand un programme est exécuté, le système SAP remplace la macro par des instructions appropriées et les espaces réservés & 1, & 2,…. & 9 sont remplacés par les paramètres param1, param2, .... param9. Nous pouvons invoquer une macro dans une autre macro, mais pas la même macro.
Exemple
Accédez à la transaction SE38. Créez un nouveau programme ZMACRO_TEST avec la description dans le champ de texte court, et également avec les attributs appropriés tels que le type et l'état, comme indiqué dans la capture d'écran suivante -
Voici le code -
REPORT ZMACRO_TEST.
DEFINE mac_test.
WRITE: 'This is Macro &1'.
END-OF-DEFINITION.
PARAMETERS: s1 type C as checkbox.
PARAMETERS: s2 type C as checkbox.
PARAMETERS: s3 type C as checkbox default 'X'.
START-OF-SELECTION.
IF s1 = 'X'.
mac_test 1. ENDIF.
IF s2 = 'X'.
mac_test 2.
ENDIF.
IF s3 = 'X'.
mac_test 3.
ENDIF.Nous avons 3 cases à cocher. Lors de l'exécution du programme, sélectionnons la case S2.
Le code ci-dessus produit la sortie suivante -
A Macro Program
This is Macro 2Si toutes les cases à cocher sont cochées, le code produit la sortie suivante -
A Macro Program
This is Macro 1 This is Macro 2 This is Macro 3Les modules de fonction constituent une partie importante d'un système SAP, car pendant des années, SAP a modulaire le code à l'aide de modules de fonction, permettant la réutilisation du code, par eux-mêmes, leurs développeurs et également par leurs clients.
Les modules de fonction sont des sous-programmes contenant un ensemble d'instructions réutilisables avec des paramètres d'importation et d'exportation. Contrairement aux programmes Inclure, les modules fonction peuvent être exécutés indépendamment. Le système SAP contient plusieurs modules fonction prédéfinis qui peuvent être appelés à partir de n'importe quel programme ABAP. Le groupe de fonctions agit comme une sorte de conteneur pour un certain nombre de modules de fonction qui appartiendraient logiquement ensemble. Par exemple, les modules de fonction pour un système de paie RH seraient regroupés dans un groupe de fonctions.
Pour voir comment créer des modules fonctionnels, le générateur de fonctions doit être exploré. Vous pouvez trouver le générateur de fonctions avec le code de transaction SE37. Tapez simplement une partie du nom d'un module de fonction avec un caractère générique pour illustrer la manière dont les modules de fonction peuvent être recherchés. Tapez * montant * puis appuyez sur la touche F4.
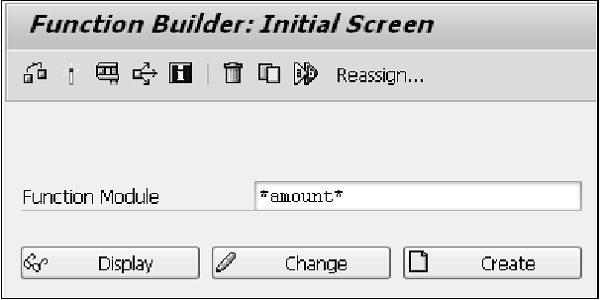
Les résultats de la recherche seront affichés dans une nouvelle fenêtre. Les modules de fonction sont affichés dans les lignes sur fond bleu et leurs groupes de fonctions dans les lignes roses. Vous pouvez regarder plus loin le groupe de fonctions ISOC en utilisant l'écran Object Navigator (Transaction SE80). Vous pouvez voir une liste des modules de fonction et également d'autres objets contenus dans le groupe de fonctions. Considérons le module fonction SPELL_AMOUNT. Ce module fonction convertit les chiffres numériques en mots.
Créer un nouveau programme
Step 1 - Accédez à la transaction SE38 et créez un nouveau programme appelé Z_SPELLAMOUNT.
Step 2- Entrer un code afin qu'un paramètre puisse être défini où une valeur pourrait être saisie et transmise au module fonction. L'élément de texte text-001 lit ici «Entrez une valeur».
Step 3- Pour écrire le code pour cela, utilisez CTRL + F6. Après cela, une fenêtre apparaît où «FONCTION D'APPEL» est la première option dans une liste. Entrez 'spell_amount' dans la zone de texte et cliquez sur le bouton Continuer.
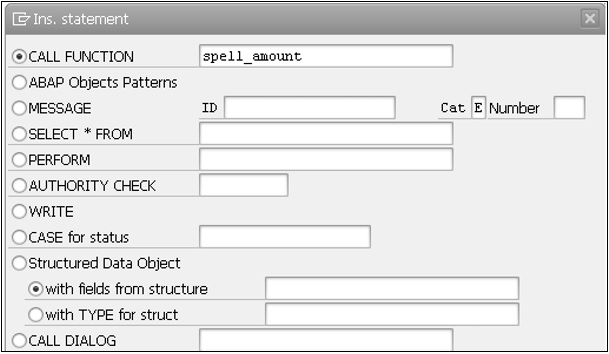
Step 4- Certains codes sont générés automatiquement. Mais nous devons améliorer l'instruction IF pour inclure un code pour ÉCRIRE un message à l'écran pour dire «Le module fonction a renvoyé une valeur de: sy-subrc» et ajouter l'instruction ELSE afin d'écrire le résultat correct lorsque la fonction module réussit. Ici, une nouvelle variable doit être configurée pour contenir la valeur renvoyée par le module fonction. Appelons cela comme «résultat».
Voici le code -
REPORT Z_SPELLAMOUNT.
data result like SPELL.
selection-screen begin of line.
selection-screen comment 1(15) text-001.
parameter num_1 Type I.
selection-screen end of line.
CALL FUNCTION 'SPELL_AMOUNT'
EXPORTING
AMOUNT = num_1
IMPORTING
IN_WORDS = result.
IF SY-SUBRC <> 0.
Write: 'Value returned is:', SY-SUBRC.
else.
Write: 'Amount in words is:', result-word.
ENDIF.Step 5- La variable renvoyée par le module fonction est appelée IN_WORDS. Configurez la variable correspondante dans le programme appelé «résultat». Définissez IN_WORDS à l'aide de l'instruction LIKE pour faire référence à une structure appelée SPELL.
Step 6- Enregistrez, activez et exécutez le programme. Entrez une valeur comme indiqué dans la capture d'écran suivante et appuyez sur F8.
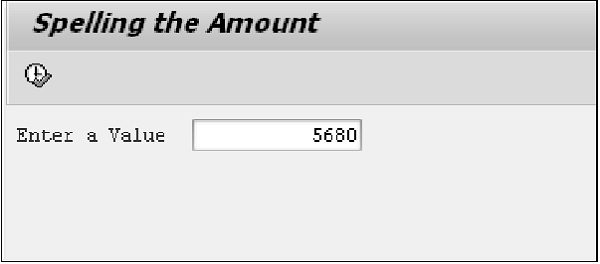
Le code ci-dessus produit la sortie suivante -
Spelling the Amount
Amount in words is:
FIVE THOUSAND SIX HUNDRED EIGHTYLes programmes d'inclusion sont des objets de référentiel global utilisés pour modulariser le code source. Ils vous permettent d'utiliser le même code source dans différents programmes. Les programmes Inclure vous permettent également de gérer des programmes complexes de manière ordonnée. Afin d'utiliser un programme d'inclusion dans un autre programme, nous utilisons la syntaxe suivante -
INCLUDE <program_name>.L'instruction INCLUDE a le même effet que la copie du code source du programme d'inclusion <nom_programme> dans un autre programme. Le programme include ne pouvant pas s'exécuter indépendamment, il doit être intégré à d'autres programmes. Vous pouvez également intégrer des programmes.
Voici quelques restrictions lors de l'écriture du code pour les programmes Inclure -
- Les programmes d'inclusion ne peuvent pas s'appeler.
- Les programmes d'inclusion doivent contenir des instructions complètes.
Voici les étapes pour créer et utiliser un programme d'inclusion -
Step 1- Créez le programme (Z_TOBEINCLUDED) à inclure dans ABAP Editor. Le code à inclure dans l'éditeur ABAP est -
PROGRAM Z_TOBEINCLUDED.
Write: / 'This program is started by:', SY-UNAME,
/ 'The Date is:', SY-DATUM,
/ 'Time is', SY-UZEIT.Step 2 - Définissez le type du programme sur programme INCLUDE, comme indiqué dans la capture d'écran suivante.
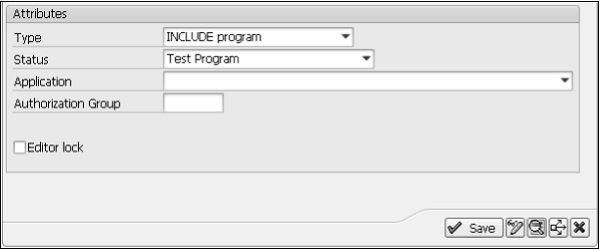
Step 3 - Cliquez sur le bouton «Enregistrer» et enregistrez le programme dans un package nommé ZINCL_PCKG.
Step 4- Créez un autre programme dans lequel le programme Z_TOBEINCLUDED doit être utilisé. Ici, nous avons créé un autre programme nommé Z_INCLUDINGTEST et attribué le type du programme en tant que programme exécutable.
Step 5 - Le codage du programme Z_INCLUDINGTEST inclut le programme Z_TOBEINCLUDED à l'aide de l'instruction INCLUDE comme indiqué dans le code suivant.
REPORT Z_INCLUDINGTEST.
INCLUDE Z_TOBEINCLUDED.Step 6 - Enregistrez, activez et exécutez le programme.
Le code ci-dessus produit la sortie suivante -
This program is started by: SAPUSER
The Date is: 06.10.2015
Time is 13:25:11Open SQL indique le sous-ensemble d'instructions ABAP qui permettent un accès direct aux données de la base de données centrale de l'AS ABAP actuel. Les instructions Open SQL mappent la fonctionnalité Data Manipulation Language de SQL dans ABAP qui est prise en charge par tous les systèmes de base de données.
Les instructions d'Open SQL sont converties en SQL spécifique à la base de données dans l'interface Open SQL de l'interface de base de données. Ils sont ensuite transférés vers le système de base de données et exécutés. Les instructions Open SQL peuvent être utilisées pour accéder aux tables de base de données déclarées dans le dictionnaire ABAP. La base de données centrale d'AS ABAP est accessible par défaut et l'accès à d'autres bases de données est également possible via des connexions de base de données secondaires.
Chaque fois que l'une de ces instructions est utilisée dans un programme ABAP, il est important de vérifier si l'action exécutée a réussi. Si l'on essaie d'insérer un enregistrement dans une table de base de données et qu'il n'est pas inséré correctement, il est très important de le savoir afin que l'action appropriée puisse être prise dans le programme. Cela peut être fait en utilisant un champ système qui a déjà été utilisé, à savoir SY-SUBRC. Lorsqu'une instruction est exécutée avec succès, le champ SY-SUBRC contiendra une valeur de 0, donc cela peut être vérifié et on peut continuer avec le programme s'il apparaît.
L'instruction DATA est utilisée pour déclarer une zone de travail. Donnons à cela le nom «wa_customers1». Plutôt que de déclarer un type de données pour cela, plusieurs champs qui composent la table peuvent être déclarés. Le moyen le plus simple de procéder consiste à utiliser l'instruction LIKE.
Instruction INSERT
L'espace de travail wa_customers1 est déclaré ici COMME la table ZCUSTOMERS1, prenant la même structure sans devenir une table elle-même. Cette zone de travail ne peut stocker qu'un seul enregistrement. Une fois déclarée, l'instruction INSERT peut être utilisée pour insérer la zone de travail et l'enregistrement qu'elle contient dans la table. Le code ici se lira comme «INSÉRER ZCUSTOMERS1 FROM wa_customers1».
La zone de travail doit être remplie de quelques données. Utilisez les noms de champ de la table ZCUSTOMERS1. Cela peut être fait par navigation vers l'avant, double-cliquant sur le nom de la table dans le code ou en ouvrant une nouvelle session et en utilisant la transaction SE11. Les champs de la table peuvent ensuite être copiés et collés dans l'éditeur ABAP.
Voici l'extrait de code -
DATA wa_customers1 LIKE ZCUSTOMERS1.
wa_customers1-customer = '100006'.
wa_customers1-name = 'DAVE'.
wa_customers1-title = 'MR'.
wa_customers1-dob = '19931017'.
INSERT ZCUSTOMERS1 FROM wa_customers1.L'instruction CHECK peut ensuite être utilisée comme suit. Cela signifie que si l'enregistrement est inséré correctement, le système l'indiquera. Sinon, le code SY-SUBRC qui ne sera pas égal à zéro sera affiché. Voici l'extrait de code -
IF SY-SUBRC = 0.
WRITE 'Record Inserted Successfully'.
ELSE.
WRITE: 'The return code is ', SY-SUBRC.
ENDIF.Vérifiez le programme, enregistrez, activez le code, puis testez-le. La fenêtre de sortie devrait s'afficher comme «Enregistrement inséré avec succès».
Déclaration CLEAR
L'instruction CLEAR permet d'effacer un champ ou une variable pour l'insertion de nouvelles données à sa place, ce qui lui permet d'être réutilisé. L'instruction CLEAR est généralement utilisée dans les programmes et permet aux champs existants d'être utilisés plusieurs fois.
Dans l'extrait de code précédent, la structure de la zone de travail a été remplie de données pour créer un nouvel enregistrement à insérer dans la table ZCUSTOMERS1, puis un contrôle de validation est effectué. Si nous voulons insérer un nouvel enregistrement, l'instruction CLEAR doit être utilisée afin qu'elle puisse ensuite être remplie à nouveau avec les nouvelles données.
Déclaration UPDATE
Si vous souhaitez mettre à jour un ou plusieurs enregistrements existants dans une table en même temps, utilisez l'instruction UPDATE. Semblable à l'instruction INSERT, une zone de travail est déclarée, remplie des nouvelles données qui sont ensuite placées dans l'enregistrement pendant l'exécution du programme. L'enregistrement précédemment créé avec l'instruction INSERT sera mis à jour ici. Modifiez simplement le texte stocké dans les champs NAME et TITLE. Ensuite, sur une nouvelle ligne, la même structure que pour l'instruction INSERT est utilisée, et cette fois en utilisant l'instruction UPDATE comme indiqué dans l'extrait de code suivant -
DATA wa_customers1 LIKE ZCUSTOMERS1.
wa_customers1-customer = '100006'.
wa_customers1-name = 'RICHARD'.
wa_customers1-title = 'MR'.
wa_customers1-dob = '19931017'.
UPDATE ZCUSTOMERS1 FROM wa_customers1.Lorsque l'instruction UPDATE est exécutée, vous pouvez afficher le navigateur de données dans le dictionnaire ABAP pour voir que l'enregistrement a été mis à jour avec succès.
Instruction MODIFY
L'instruction MODIFY peut être considérée comme une combinaison des instructions INSERT et UPDATE. Il peut être utilisé pour insérer un nouvel enregistrement ou modifier un enregistrement existant. Il suit une syntaxe similaire aux deux instructions précédentes pour modifier l'enregistrement à partir des données entrées dans une zone de travail.
Lorsque cette instruction est exécutée, les champs clés impliqués seront comparés à ceux de la table. Si un enregistrement avec ces valeurs de champ clé existe déjà, il sera mis à jour. Sinon, un nouvel enregistrement sera créé.
Voici l'extrait de code pour créer un nouvel enregistrement -
CLEAR wa_customers1.
DATA wa_customers1 LIKE ZCUSTOMERS1.
wa_customers1-customer = '100007'.
wa_customers1-name = 'RALPH'.
wa_customers1-title = 'MR'.
wa_customers1-dob = '19910921'.
MODIFY ZCUSTOMERS1 FROM wa_customers1.Dans cet exemple, l'instruction CLEAR est utilisée afin qu'une nouvelle entrée puisse être placée dans la zone de travail, puis le client (numéro) 100007 est ajouté. Puisqu'il s'agit d'une nouvelle valeur de champ clé unique, un nouvel enregistrement sera inséré et un autre contrôle de validation est exécuté.
Lorsque cela est exécuté et que les données sont visualisées dans le navigateur de données, un nouvel enregistrement aura été créé pour le numéro de client 100007 (RALPH).
Le code ci-dessus produit la sortie suivante (contenu de la table) -
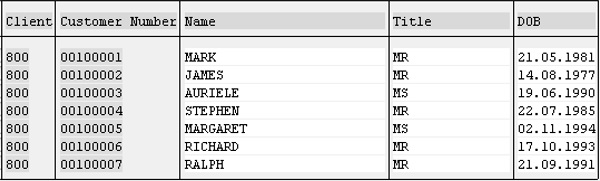
Le terme «SQL natif» fait référence à toutes les instructions qui peuvent être transférées statiquement vers l'interface Native SQL de l'interface de base de données. Les instructions SQL natives n'entrent pas dans la portée du langage d'ABAP et ne suivent pas la syntaxe ABAP. ABAP contient simplement des instructions pour isoler les sections de programme dans lesquelles les instructions Native SQL peuvent être répertoriées.

En SQL natif, des instructions SQL spécifiques à la base de données peuvent être utilisées principalement. Celles-ci sont transférées telles quelles de l'interface SQL native vers un système de base de données et exécutées. La portée complète du langage SQL de la base de données appropriée peut être utilisée et les tables de la base de données adressées n'ont pas à être déclarées dans le dictionnaire ABAP. Il existe également un petit ensemble d'instructions SQL natives spécifiques à SAP qui sont gérées d'une manière spécifique par l'interface SQL native.
Pour utiliser une instruction Native SQL, vous devez la précéder de l'instruction SQL EXEC et la terminer par l'instruction ENDEXEC.
Voici la syntaxe -
EXEC SQL PERFORMING <form>.
<Native SQL statement>
ENDEXEC.Ces instructions définissent une zone dans un programme ABAP dans laquelle une ou plusieurs instructions Native SQL peuvent être répertoriées. Les instructions saisies sont transmises à l'interface Native SQL puis traitées comme suit -
Toutes les instructions SQL valides pour l'interface programme du système de base de données adressé peuvent être répertoriées entre EXEC et ENDEXEC, en particulier les instructions DDL (langage de définition de données).
Ces instructions SQL sont transmises de l'interface Native SQL au système de base de données en grande partie inchangées. Les règles de syntaxe sont spécifiées par le système de base de données, en particulier les règles de respect de la casse pour les objets de base de données.
Si la syntaxe autorise un séparateur entre les instructions individuelles, vous pouvez inclure de nombreuses instructions SQL natives entre EXEC et ENDEXEC.
Des éléments de langage Native SQL spécifiques à SAP peuvent être spécifiés entre EXEC et ENDEXEC. Ces instructions ne sont pas transmises directement de l'interface Native SQL à la base de données, mais elles sont transformées de manière appropriée.
Exemple
SPFLI est une table SAP standard utilisée pour stocker les informations sur les horaires de vol. Ceci est disponible dans les systèmes SAP R / 3 en fonction de la version et du niveau de version. Vous pouvez afficher ces informations lorsque vous saisissez le nom de table SPFLI dans la transaction SAP appropriée telle que SE11 ou SE80. Vous pouvez également afficher les données contenues dans cette table de base de données en utilisant ces deux transactions.
REPORT ZDEMONATIVE_SQL.
DATA: BEGIN OF wa,
connid TYPE SPFLI-connid,
cityfrom TYPE SPFLI-cityfrom,
cityto TYPE SPFLI-cityto,
END OF wa.
DATA c1 TYPE SPFLI-carrid VALUE 'LH'.
EXEC SQL PERFORMING loop_output.
SELECT connid, cityfrom, cityto
INTO :wa
FROM SPFLI
WHERE carrid = :c1
ENDEXEC.
FORM loop_output.
WRITE: / wa-connid, wa-cityfrom, wa-cityto.
ENDFORM.Le code ci-dessus produit la sortie suivante -
0400 FRANKFURT NEW YORK
2402 FRANKFURT BERLIN
0402 FRANKFURT NEW YORKLa table interne est en fait une table temporaire, qui contient les enregistrements d'un programme ABAP en cours d'exécution. Une table interne n'existe que pendant l'exécution d'un programme SAP. Ils sont utilisés pour traiter de gros volumes de données en utilisant le langage ABAP. Nous devons déclarer une table interne dans un programme ABAP lorsque vous devez récupérer des données à partir de tables de base de données.
Les données d'une table interne sont stockées dans des lignes et des colonnes. Chaque ligne est appelée unline et chaque colonne est appelée un field. Dans une table interne, tous les enregistrements ont la même structure et la même clé. Les enregistrements individuels d'une table interne sont accessibles avec un index ou une clé. Comme la table interne existe jusqu'à ce que le programme associé soit exécuté, les enregistrements de la table interne sont supprimés lorsque l'exécution du programme est terminée. Ainsi, les tables internes peuvent être utilisées comme zones de stockage temporaires ou tampons temporaires où les données peuvent être modifiées selon les besoins. Ces tables n'occupent de la mémoire qu'au moment de l'exécution et non au moment de leur déclaration.
Les tables internes n'existent que lorsqu'un programme est en cours d'exécution, donc lorsque le code est écrit, la table interne doit être structurée de manière à ce que le programme puisse l'utiliser. Vous constaterez que les tables internes fonctionnent de la même manière que les structures. La principale différence est que les structures n'ont qu'une seule ligne, tandis qu'une table interne peut avoir autant de lignes que nécessaire.
Une table interne peut être constituée d'un certain nombre de champs, correspondant aux colonnes d'une table, tout comme dans le dictionnaire ABAP une table a été créée à l'aide de plusieurs champs. Les champs clés peuvent également être utilisés avec des tables internes et, lors de la création de ces tables internes, ils offrent un peu plus de flexibilité. Avec les tables internes, on peut spécifier une clé non unique, permettant de stocker n'importe quel nombre d'enregistrements non uniques et permettant le stockage d'enregistrements en double si nécessaire.
La taille d'une table interne ou le nombre de lignes qu'elle contient n'est pas fixe. La taille d'une table interne change en fonction de l'exigence du programme associé à la table interne. Mais il est recommandé de garder les tables internes aussi petites que possible. Cela permet d'éviter que le système ne fonctionne lentement car il a du mal à traiter d'énormes quantités de données.
Les tables internes sont utilisées à de nombreuses fins -
Ils peuvent être utilisés pour conserver les résultats de calculs qui pourraient être utilisés ultérieurement dans le programme.
Une table interne peut également contenir des enregistrements et des données afin d'y accéder rapidement plutôt que d'avoir à accéder à ces données à partir des tables de la base de données.
Ils sont extrêmement polyvalents. Ils peuvent être définis en utilisant n'importe quel nombre d'autres structures définies.
Exemple
Supposons qu'un utilisateur souhaite créer une liste de numéros de contact de différents clients à partir d'une ou plusieurs grandes tables. L'utilisateur crée d'abord une table interne, sélectionne les données pertinentes dans les tables client, puis place les données dans la table interne. Les autres utilisateurs peuvent accéder et utiliser cette table interne directement pour récupérer les informations souhaitées, au lieu d'écrire des requêtes de base de données pour effectuer chaque opération pendant l'exécution du programme.
L'instruction DATA est utilisée pour déclarer une table interne. Le programme doit être informé du début et de la fin de la table. Utilisez donc l'instruction BEGIN OF, puis déclarez le nom de la table. Après cela, l'ajout OCCURS est utilisé, suivi d'un nombre, ici 0. OCCURS indique à SAP qu'une table interne est en cours de création et le 0 indique qu'elle ne contiendra aucun enregistrement au départ. Il s'agrandira ensuite au fur et à mesure qu'il sera rempli de données.
Voici la syntaxe -
DATA: BEGIN OF <internal_tab> Occurs 0,Créons les champs sur une nouvelle ligne. Par exemple, créez 'nom' qui est déclaré comme LIKE ZCUSTOMERS1-name. Créez un autre champ appelé «dob», LIKE ZCUSTOMERS1-dob. Il est utile au départ de donner aux noms de champs dans les tables internes les mêmes noms que les autres champs qui ont été créés ailleurs. Enfin, déclarez la fin de la table interne avec «END OF <tab_internal>». comme indiqué dans le code suivant -
DATA: BEGIN OF itab01 Occurs 0,
name LIKE ZCUSTOMERS1-name,
dob LIKE ZCUSTOMERS1-dob,
END OF itab01.Ici, «itab01» est un raccourci couramment utilisé lors de la création de tables temporaires dans SAP. La clause OCCURS est utilisée pour définir le corps d'une table interne en déclarant les champs de la table. Lorsque la clause OCCURS est utilisée, vous pouvez spécifier une constante numérique «n» pour déterminer la mémoire par défaut supplémentaire si nécessaire. La taille de mémoire par défaut utilisée par la clause OCCUR 0 est de 8 Ko. La structure de la table interne est maintenant créée et le code peut être écrit pour la remplir d'enregistrements.
Une table interne peut être créée avec ou sans utilisation d'une ligne d'en-tête. Pour créer une table interne avec une ligne d'en-tête, utilisez la clause BEGIN OF avant la clause OCCURS ou la clause WITH HEADER LINE après la clause OCCURS dans la définition de la table interne. Pour créer une table interne sans ligne d'en-tête, utilisez la clause OCCURS sans la clause BEGIN OF.
Vous pouvez également créer une table interne en tant que type de données local (un type de données utilisé uniquement dans le contexte du programme en cours) à l'aide de l'instruction TYPES. Cette instruction utilise la clause TYPE ou LIKE pour faire référence à une table existante.
La syntaxe pour créer une table interne en tant que type de données local est -
TYPES <internal_tab> TYPE|LIKE <internal_tab_type> OF
<line_type_itab> WITH <key> INITIAL SIZE <size_number>.Ici, <internal_tab_type> spécifie un type de table pour une table interne <internal_tab> et <line_type_itab> spécifie le type pour une ligne d'une table interne. Dans l'instruction TYPES, vous pouvez utiliser la clause TYPE pour spécifier le type de ligne d'une table interne en tant que type de données et la clause LIKE pour spécifier le type de ligne en tant qu'objet de données. La spécification d'une clé pour une table interne est facultative et si l'utilisateur ne spécifie pas de clé, le système SAP définit un type de table avec une clé arbitraire.
INITIAL SIZE <size_number> crée un objet de table interne en lui allouant une quantité initiale de mémoire. Dans la syntaxe précédente, la clause INITIAL SIZE réserve un espace mémoire pour les lignes de la table size_number. Chaque fois qu'un objet de table interne est déclaré, la taille de la table n'appartient pas au type de données de la table.
Note - Beaucoup moins de mémoire est consommée lorsqu'une table interne est remplie pour la première fois.
Exemple
Step 1- Ouvrez l'éditeur ABAP en exécutant le code de transaction SE38. L'écran initial d'ABAP Editor apparaît.
Step 2 - Dans l'écran initial, entrez un nom pour le programme, sélectionnez le bouton radio Code source et cliquez sur le bouton Créer pour créer un nouveau programme.
Step 3- Dans la boîte de dialogue 'ABAP: Attributs du programme', entrez une brève description du programme dans le champ Titre, sélectionnez l'option 'Programme exécutable' dans le menu déroulant Type de la zone de groupe Attributs. Cliquez sur le bouton Enregistrer.
Step 4 - Écrivez le code suivant dans l'éditeur ABAP.
REPORT ZINTERNAL_DEMO.
TYPES: BEGIN OF CustomerLine,
Cust_ID TYPE C,
Cust_Name(20) TYPE C,
END OF CustomerLine.
TYPES mytable TYPE SORTED TABLE OF CustomerLine
WITH UNIQUE KEY Cust_ID.
WRITE:/'The mytable is an Internal Table'.Step 5 - Enregistrez, activez et exécutez le programme comme d'habitude.
Dans cet exemple, mytable est une table interne et une clé unique est définie dans le champ Cust_ID.
Le code ci-dessus produit la sortie suivante -
The mytable is an Internal Table.Dans les tableaux internes, le remplissage inclut des fonctionnalités telles que la sélection, l'insertion et l'ajout. Ce chapitre se concentre sur les instructions INSERT et APPEND.
Instruction INSERT
L'instruction INSERT est utilisée pour insérer une seule ligne ou un groupe de lignes dans une table interne.
Voici la syntaxe pour ajouter une seule ligne à une table interne -
INSERT <work_area_itab> INTO <internal_tab> INDEX <index_num>.Dans cette syntaxe, l'instruction INSERT insère une nouvelle ligne dans la table interne internal_tab. Une nouvelle ligne peut être insérée à l'aide de l'expression work_area_itab INTO avant le paramètre internal_tab. Lorsque l'expression work_area_itab INTO est utilisée, la nouvelle ligne est extraite de la zone de travail work_area_itab et insérée dans la table internal_tab. Cependant, lorsque l'expression work_area_itab INTO n'est pas utilisée pour insérer une ligne, la ligne est extraite de la ligne d'en-tête de la table internal_tab.
Lorsqu'une nouvelle ligne est insérée dans une table interne à l'aide de la clause INDEX, le numéro d'index des lignes après la ligne insérée est incrémenté de 1. Si une table interne contient <index_num> - 1 lignes, la nouvelle ligne est ajoutée à la fin de la table. Lorsque le système SAP ajoute avec succès une ligne à une table interne, la variable SY-SUBRC est définie sur 0.
Exemple
Voici un exemple de programme qui utilise l'instruction d'insertion.
REPORT ZCUSLIST1.
DATA: BEGIN OF itable1 OCCURS 4,
F1 LIKE SY-INDEX,
END OF itable1.
DO 4 TIMES.
itable1-F1 = sy-index.
APPEND itable1.
ENDDO.
itable1-F1 = -96.
INSERT itable1 INDEX 2.
LOOP AT itable1.
Write / itable1-F1.
ENDLOOP.
LOOP AT itable1 Where F1 ≥ 3.
itable1-F1 = -78.
INSERT itable1.
ENDLOOP.
Skip.
LOOP AT itable1.
Write / itable1-F1.
ENDLOOP.Le code ci-dessus produit l'outp suivant -
1
96-
2
3
4
1
96-
2
78-
3
78-
4Dans l'exemple ci-dessus, la boucle DO y ajoute 4 lignes contenant les nombres 1 à 4. Le composant de ligne d'en-tête itable1-F1 a reçu une valeur de -96. L'instruction Insert insère la ligne d'en-tête en tant que nouvelle ligne dans le corps avant la ligne 3. La ligne 3 existante devient la ligne 4 après l'insertion. L'instruction LOOP AT récupère les lignes de la table interne qui ont une valeur F1 supérieure ou égale à 3. Avant chaque ligne, l'instruction Insert insère une nouvelle ligne à partir de la ligne d'en-tête de celui-ci. Avant l'insertion, le composant F1 a été modifié pour contenir -78.
Après l'exécution de chaque instruction d'insertion, le système réindexe toutes les lignes sous celle insérée. Cela introduit une surcharge lorsque vous insérez des lignes près du haut d'une grande table interne. Si vous devez insérer un bloc de lignes dans un grand tableau interne, préparez un autre tableau avec les lignes à insérer et utilisez plutôt des lignes d'insertion.
Lorsque vous insérez une nouvelle ligne dans itable1 à l'intérieur d'une boucle à itable1, cela n'affecte pas instantanément la table interne. Il devient en fait efficace au prochain passage de boucle. Lors de l'insertion d'une ligne après la ligne actuelle, la table est réindexée à ENDLOOP. Le sy-tabix est incrémenté et la boucle suivante traite la ligne pointée par sy-tabix. Par exemple, si vous êtes dans la deuxième passe de boucle et que vous insérez un enregistrement avant la ligne 3. Lorsque endloop est exécuté, la nouvelle ligne devient la ligne 3 et l'ancienne ligne 3 devient la ligne 4 et ainsi de suite. Sy-tabix est incrémenté de 1 et la passe de boucle suivante traite l'enregistrement nouvellement inséré.
Déclaration APPEND
L'instruction APPEND est utilisée pour ajouter une seule ligne ou ligne à une table interne existante. Cette instruction copie une seule ligne d'une zone de travail et l'insère après la dernière ligne existante dans une table interne. La zone de travail peut être une ligne d'en-tête ou toute autre chaîne de champ avec la même structure qu'une ligne d'une table interne. Voici la syntaxe de l'instruction APPEND qui est utilisée pour ajouter une seule ligne dans une table interne -
APPEND <record_for_itab> TO <internal_tab>.Dans cette syntaxe, l'expression <record_for_itab> peut être représentée par la zone de travail <work_area_itab>, qui est convertible en type de ligne ou par la clause INITIAL LINE. Si l'utilisateur utilise une zone de travail <work_area_itab>, le système SAP ajoute une nouvelle ligne à la table interne <internal_tab> et la remplit avec le contenu de la zone de travail. La clause INITIAL LINE ajoute une ligne vide qui contient la valeur initiale de chaque champ de la structure de table. Après chaque instruction APPEND, la variable SY-TABIX contient le numéro d'index de la ligne ajoutée.
L'ajout de lignes aux tables standard et triées avec une clé non unique fonctionne indépendamment du fait que les lignes avec la même clé existent déjà dans la table. En d'autres termes, des entrées en double peuvent se produire. Cependant, une erreur d'exécution se produit si l'utilisateur tente d'ajouter une entrée en double à une table triée avec une clé unique ou si l'utilisateur enfreint l'ordre de tri d'une table triée en y ajoutant les lignes.
Exemple
REPORT ZCUSLIST1.
DATA: BEGIN OF linv Occurs 0,
Name(20) TYPE C,
ID_Number TYPE I,
END OF linv.
DATA table1 LIKE TABLE OF linv.
linv-Name = 'Melissa'.
linv-ID_Number = 105467.
APPEND linv TO table1.
LOOP AT table1 INTO linv.
Write: / linv-name, linv-ID_Number.
ENDLOOP.Le code ci-dessus produit la sortie suivante -
Melissa 105467Lorsque nous lisons un enregistrement à partir d'une table interne avec une ligne d'en-tête, cet enregistrement est déplacé de la table elle-même vers la ligne d'en-tête. C'est alors la ligne d'en-tête avec laquelle notre programme fonctionne. La même chose s'applique lors de la création d'un nouvel enregistrement. Il s'agit de la ligne d'en-tête avec laquelle vous travaillez et à partir de laquelle le nouvel enregistrement est envoyé au corps de la table lui-même.
Pour copier les enregistrements, nous pouvons utiliser une instruction SELECT pour sélectionner tous les enregistrements de la table, puis utiliser l'instruction MOVE qui déplacera les enregistrements de la table d'origine vers la nouvelle table interne dans les champs où les noms correspondent.
Voici la syntaxe de l'instruction MOVE -
MOVE <table_field> TO <internal_tab_field>.Exemple
REPORT ZCUSLIST1.
TABLES: ZCUSTOMERS1.
DATA: BEGIN OF itab01 Occurs 0,
name LIKE ZCUSTOMERS1-name,
dob LIKE ZCUSTOMERS1-dob,
END OF itab01.
Select * FROM ZCUSTOMERS1.
MOVE ZCUSTOMERS1-name TO itab01-name.
MOVE ZCUSTOMERS1-dob TO itab01-dob.
ENDSELECT.
Write: / itab01-name, itab01-dob.Le code ci-dessus produit la sortie suivante -
MARGARET 02.11.1994La boucle de sélection remplit chaque champ un par un, en utilisant l'instruction MOVE pour déplacer les données d'un champ de table vers l'autre. Dans l'exemple ci-dessus, les instructions MOVE ont été utilisées pour déplacer le contenu de la table ZCUSTOMERS1 vers les champs correspondants de la table interne. Vous pouvez accomplir cette action avec une seule ligne de code. Vous pouvez utiliser l'instruction MOVECORRESPONDING.
Voici la syntaxe de l'instruction MOVE-CORRESPONDING -
MOVE-CORRESPONDING <table_name> TO <internal_tab>.Il indique au système de déplacer les données des champs de ZCUSTOMERS1 vers leurs champs correspondants dans itab01.
Exemple
REPORT ZCUSTOMERLIST.
TABLES: ZCUSTOMERS1.
DATA: Begin of itab01 occurs 0,
customer LIKE ZCUSTOMERS1-customer,
name LIKE ZCUSTOMERS1-name,
title LIKE ZCUSTOMERS1-title,
dob LIKE ZCUSTOMERS1-dob,
END OF itab01.
SELECT * from ZCUSTOMERS1.
MOVE-Corresponding ZCUSTOMERS1 TO itab01.
APPEND itab01.
ENDSELECT.
LOOP AT itab01.
Write: / itab01-name, itab01-dob.
ENDLOOP.Le code ci-dessus produit la sortie suivante -
MARK 21.05.1981
JAMES 14.08.1977
AURIELE 19.06.1990
STEPHEN 22.07.1985
MARGARET 02.11.1994Ceci est rendu possible par le fait que les deux ont des noms de champ correspondants. Lorsque vous utilisez cette instruction, vous devez vous assurer que les deux champs ont des types de données et des longueurs correspondants. Cela a été fait ici avec l'instruction LIKE précédemment.
Nous pouvons lire les lignes d'une table en utilisant la syntaxe suivante de l'instruction READ TABLE -
READ TABLE <internal_table> FROM <work_area_itab>.Dans cette syntaxe, l'expression <work_area_itab> représente une zone de travail compatible avec le type de ligne de la table <internal_table>. Nous pouvons spécifier une clé de recherche, mais pas une clé de table, dans l'instruction READ en utilisant la clause WITH KEY, comme indiqué dans la syntaxe suivante -
READ TABLE <internal_table> WITH KEY = <internal_tab_field>.Ici, toute la ligne de la table interne est utilisée comme search key. Le contenu de la ligne entière de la table est comparé au contenu du champ <internal_tab_field>. Si les valeurs du champ <internal_tab_field> ne sont pas compatibles avec le type de ligne de la table, ces valeurs sont converties en fonction du type de ligne de la table. La clé de recherche vous permet de rechercher des entrées dans des tables internes qui n'ont pas de type de ligne structuré, c'est-à-dire où la ligne est un champ unique ou un type de table interne.
La syntaxe suivante de l'instruction READ est utilisée pour spécifier une zone de travail ou un symbole de champ à l'aide de la clause COMPARING -
READ TABLE <internal_table> <key> INTO <work_area_itab>
[COMPARING <F1> <F2>...<Fn>].Lorsque la clause COMPARING est utilisée, les champs de table spécifiés <F1>, <F2> .... <Fn> de type ligne structurée sont comparés aux champs correspondants de l'espace de travail avant d'être transportés. Si la clause ALL FIELDS est spécifiée, le système SAP compare tous les composants. Lorsque le système SAP trouve une entrée sur la base d'une clé, la valeur de la variable SY-SUBRC est mise à 0. De plus, la valeur de la variable SY-SUBRC est mise à 2 ou 4 si le contenu de la comparaison ne sont pas les mêmes ou si le système SAP ne parvient pas à trouver une entrée. Cependant, le système SAP copie l'entrée dans la zone de travail cible chaque fois qu'il trouve une entrée, quel que soit le résultat de la comparaison.
Exemple
REPORT ZREAD_DEMO.
*/Creating an internal table
DATA: BEGIN OF Record1,
ColP TYPE I,
ColQ TYPE I,
END OF Record1.
DATA mytable LIKE HASHED TABLE OF Record1 WITH UNIQUE KEY ColP.
DO 6 Times.
Record1-ColP = SY-INDEX.
Record1-ColQ = SY-INDEX + 5.
INSERT Record1 INTO TABLE mytable.
ENDDO.
Record1-ColP = 4.
Record1-ColQ = 12.
READ TABLE mytable FROM Record1 INTO Record1 COMPARING ColQ.
WRITE: 'SY-SUBRC =', SY-SUBRC.
SKIP.
WRITE: / Record1-ColP, Record1-ColQ.Le code ci-dessus produit la sortie suivante -
SY-SUBRC = 2
4 9Dans l'exemple ci-dessus, mytable est une table interne du type table hachée, avec Record1 comme zone de travail et ColP comme clé unique. Initialement, mytable contient six lignes, où le champ ColP contient les valeurs de la variable SY-INDEX et le champ ColQ contient les valeurs (SY-INDEX + 5).
La zone de travail Record1 est remplie avec 4 et 12 comme valeurs pour les champs ColP et ColQ respectivement. L'instruction READ lit la ligne de la table après avoir comparé la valeur du champ de clé ColP avec la valeur de la zone de travail Record1 à l'aide de la clause COMPARING, puis copie le contenu de la ligne de lecture dans la zone de travail. La valeur de la variable SY-SUBRC est affichée comme 2 car lorsque la valeur du champ ColP est 4, la valeur de ColQ n'est pas 12, mais 9.
L'instruction DELETE est utilisée pour supprimer un ou plusieurs enregistrements d'une table interne. Les enregistrements d'une table interne sont supprimés soit en spécifiant une clé ou une condition de table, soit en recherchant des entrées en double. Si une table interne a une clé non unique et contient des entrées en double, la première entrée de la table est supprimée.
Voici la syntaxe pour utiliser l'instruction DELETE pour supprimer un enregistrement ou une ligne d'une table interne -
DELETE TABLE <internal_table> FROM <work_area_itab>.Dans la syntaxe ci-dessus, l'expression <work_area_itab> est une zone de travail et elle doit être compatible avec le type de la table interne <internal_table>. L'opération de suppression est effectuée sur la base d'une clé par défaut pouvant être extraite des composants de l'espace de travail.
Vous pouvez également spécifier une clé de table explicitement dans l'instruction DELETE TABLE en utilisant la syntaxe suivante -
DELETE TABLE <internal_table> WITH TABLE KEY <K1> = <F1>………… <Kn> = <Fn>.Dans cette syntaxe, <F1>, <F2> .... <Fn> sont les champs d'une table interne et <K1>, <K2> .... <Kn> sont les champs clés de la table. L'instruction DELETE est utilisée pour supprimer les enregistrements ou les lignes de la table <internal_table> en fonction des expressions <K1> = <F1>, <K2> = <F2> ... <Kn> = <Fn>.
Note - Si les types de données des champs <F1>, <F2> .... <Fn> ne sont pas compatibles avec les champs clés <K1>, <K2> ... <Kn>, le système SAP les convertit automatiquement en le format compatible.
Exemple
REPORT ZDELETE_DEMO.
DATA: BEGIN OF Line1,
ColP TYPE I,
ColQ TYPE I,
END OF Line1.
DATA mytable LIKE HASHED TABLE OF Line1
WITH UNIQUE KEY ColP.
DO 8 TIMES.
Line1-ColP = SY-INDEX.
Line1-ColQ = SY-INDEX + 4.
INSERT Line1 INTO TABLE mytable.
ENDDO.
Line1-ColP = 1.
DELETE TABLE mytable: FROM Line1,
WITH TABLE KEY ColP = 3.
LOOP AT mytable INTO Line1.
WRITE: / Line1-ColP, Line1-ColQ.
ENDLOOP.Le code ci-dessus produit la sortie suivante -
2 6
4 8
5 9
6 10
7 11
8 12Dans cet exemple, mytable a deux champs, ColP et ColQ. Au départ, mytable contient huit lignes, où le ColP contient les valeurs 1, 2, 3, 4, 5, 6, 7 et 8. Le ColQ contient les valeurs 5, 6, 7, 8, 9, 10, 11 et 12 car les valeurs ColP sont incrémentées de 4 à chaque fois.
L'instruction DELETE est utilisée pour supprimer les lignes de mytable où la valeur du champ de clé ColP est 1 ou 3. Après la suppression, le champ ColP de mytable contient les valeurs 2, 4, 5, 6, 7 et 8, comme indiqué dans la sortie. Le champ ColQ contient les valeurs 6, 8, 9, 10, 11 et 12.
L'orientation objet simplifie la conception du logiciel pour en faciliter la compréhension, la maintenance et la réutilisation. Object Oriented Programming(POO) représente une manière différente de penser dans l'écriture de logiciels. La beauté de la POO réside dans sa simplicité. L'expressivité de la POO facilite la livraison de composants logiciels de qualité à temps.
Comme les solutions sont conçues en termes d'objets du monde réel, il devient beaucoup plus facile pour les programmeurs et les analystes commerciaux d'échanger des idées et des informations sur une conception qui utilise un langage de domaine commun. Ces améliorations de la communication aident à révéler les exigences cachées, à identifier les risques et à améliorer la qualité des logiciels en cours de développement. L'approche orientée objet se concentre sur des objets qui représentent des choses abstraites ou concrètes du monde réel. Ces objets sont définis par leur caractère et leurs propriétés qui sont représentés par leur structure interne et leurs attributs (données). Le comportement de ces objets est décrit par des méthodes (ie fonctionnalité).
Comparons la programmation procédurale et orientée objet -
| traits | Approche orientée procédure | Approche orientée objet |
|---|---|---|
| Accentuation | L'accent est mis sur les tâches. | L'accent est mis sur les choses qui accomplissent ces tâches. |
| La modularisation | Les programmes peuvent être divisés en programmes plus petits appelés fonctions. | Les programmes sont organisés en classes et objets et les fonctionnalités sont intégrées dans les méthodes d'une classe. |
| Sécurité des données | La plupart des fonctions partagent des données globales. | Les données peuvent être masquées et ne sont pas accessibles par des sources externes. |
| Extensibilité | Cela prend plus de temps pour modifier et étendre la fonctionnalité existante. | De nouvelles données et fonctions peuvent être ajoutées sans effort en cas de besoin. |
ABAP a été initialement développé en tant que langage procédural (juste similaire au langage de programmation procédural antérieur comme COBOL). Mais ABAP a maintenant adapté les principes des paradigmes orientés objet avec l'introduction des objets ABAP. Les concepts orientés objet dans ABAP tels que la classe, l'objet, l'héritage et le polymorphisme sont essentiellement les mêmes que ceux des autres langages orientés objet modernes tels que Java ou C ++.
Au fur et à mesure que l'orientation des objets prend forme, chaque classe assume des attributions de rôles spécifiques. Cette division du travail permet de simplifier le modèle de programmation global, permettant à chaque classe de se spécialiser dans la résolution d'une partie particulière du problème en question. Ces classes ont une cohésion élevée et les opérations de chaque classe sont étroitement liées d'une manière intuitive.
Les principales caractéristiques de l'orientation des objets sont:
- Structure de programmation efficace.
- Les entités du monde réel peuvent être très bien modélisées.
- Insistez sur la sécurité et l'accès aux données.
- Minimise la redondance du code.
- Abstraction et encapsulation des données.
Un objet est un type spécial de variable qui a des caractéristiques et des comportements distincts. Les caractéristiques ou attributs d'un objet sont utilisés pour décrire l'état d'un objet, et les comportements ou méthodes représentent les actions effectuées par un objet.
Un objet est un modèle ou une instance d'une classe. Il représente une entité du monde réel telle qu'une personne ou une entité de programmation comme des variables et des constantes. Par exemple, les comptes et les étudiants sont des exemples d'entités du monde réel. Mais les composants matériels et logiciels d'un ordinateur sont des exemples d'entités de programmation.
Un objet a les trois caractéristiques principales suivantes -
- A un état.
- A une identité unique.
- Peut ou non afficher le comportement.
L'état d'un objet peut être décrit comme un ensemble d'attributs et leurs valeurs. Par exemple, un compte bancaire possède un ensemble d'attributs tels que le numéro de compte, le nom, le type de compte, le solde et les valeurs de tous ces attributs. Le comportement d'un objet fait référence aux changements qui se produisent dans ses attributs au cours d'une période donnée.
Chaque objet a une identité unique qui peut être utilisée pour le distinguer des autres objets. Deux objets peuvent présenter le même comportement et avoir ou non le même état, mais ils n'ont jamais la même identité. Deux personnes peuvent avoir le même nom, âge et sexe mais elles ne sont pas identiques. De même, l'identité d'un objet ne changera jamais tout au long de sa vie.
Les objets peuvent interagir les uns avec les autres en envoyant des messages. Les objets contiennent des données et du code pour manipuler les données. Un objet peut également être utilisé comme type de données défini par l'utilisateur à l'aide d'une classe. Les objets sont également appelés variables de la classe de type. Après avoir défini une classe, vous pouvez créer n'importe quel nombre d'objets appartenant à cette classe. Chaque objet est associé aux données de la classe de type avec laquelle il a été créé.
Créer un objet
La création d'objet comprend généralement les étapes suivantes -
Création d'une variable de référence en référence à la classe. La syntaxe pour laquelle est -
DATA: <object_name> TYPE REF TO <class_name>.Création d'un objet à partir de la variable de référence. La syntaxe pour laquelle est -
CREATE Object: <object_name>.Exemple
REPORT ZDEMO_OBJECT.
CLASS Class1 Definition.
Public Section.
DATA: text1(45) VALUE 'ABAP Objects.'.
METHODS: Display1.
ENDCLASS.
CLASS Class1 Implementation.
METHOD Display1.
Write:/ 'This is the Display method.'.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
DATA: Class1 TYPE REF TO Class1.
CREATE Object: Class1.
Write:/ Class1->text1.
CALL METHOD: Class1->Display1.Le code ci-dessus produit la sortie suivante -
ABAP Objects.
This is the Display method.Une classe est utilisée pour spécifier la forme d'un objet et combine la représentation des données et les méthodes de manipulation de ces données dans un package soigné. Les données et les fonctions d'une classe sont appeléesmembers of the class.
Définition et implémentation de classe
Lorsque vous définissez une classe, vous définissez un plan pour un type de données. Cela ne définit en fait aucune donnée, mais définit ce que signifie le nom de la classe, en quoi consistera un objet de la classe et quelles opérations peuvent être effectuées sur un tel objet. Autrement dit, il définit les caractéristiques abstraites d'un objet, telles que les attributs, les champs et les propriétés.
La syntaxe suivante montre comment définir une classe -
CLASS <class_name> DEFINITION.
..........
..........
ENDCLASS.Une définition de classe commence par le mot-clé CLASS suivi du nom de la classe, DEFINITION et du corps de la classe. La définition d'une classe peut contenir divers composants de la classe tels que des attributs, des méthodes et des événements. Lorsque nous déclarons une méthode dans la déclaration de classe, l'implémentation de la méthode doit être incluse dans l'implémentation de la classe. La syntaxe suivante montre comment implémenter une classe -
CLASS <class_name> IMPLEMENTATION.
...........
..........
ENDCLASS.Note- L'implémentation d'une classe contient l'implémentation de toutes ses méthodes. Dans les objets ABAP, la structure d'une classe contient des composants tels que des attributs, des méthodes, des événements, des types et des constantes.
Les attributs
Les attributs sont des champs de données d'une classe qui peuvent avoir n'importe quel type de données tel que C, I, F et N. Ils sont déclarés dans la déclaration de classe. Ces attributs peuvent être divisés en 2 catégories: les attributs d'instance et les attributs statiques. Uninstance attributedéfinit l'état spécifique à l'instance d'un objet. Les états sont différents pour différents objets. Un attribut d'instance est déclaré à l'aide de l'instruction DATA.
Static attributesdéfinir un état commun d'une classe qui est partagé par toutes les instances de la classe. Autrement dit, si vous modifiez un attribut statique dans un objet d'une classe, la modification est également visible par tous les autres objets de la classe. Un attribut statique est déclaré à l'aide de l'instruction CLASS-DATA.
Méthodes
Une méthode est une fonction ou une procédure qui représente le comportement d'un objet dans la classe. Les méthodes de la classe peuvent accéder à n'importe quel attribut de la classe. La définition d'une méthode peut également contenir des paramètres, de sorte que vous pouvez fournir les valeurs à ces paramètres lorsque des méthodes sont appelées. La définition d'une méthode est déclarée dans la déclaration de classe et implémentée dans la partie implémentation d'une classe. Les instructions METHOD et ENDMETHOD sont utilisées pour définir la partie implémentation d'une méthode. La syntaxe suivante montre comment implémenter une méthode -
METHOD <m_name>.
..........
..........
ENDMETHOD.Dans cette syntaxe, <m_name> représente le nom d'une méthode. Note - Vous pouvez appeler une méthode à l'aide de l'instruction CALL METHOD.
Accès aux attributs et méthodes
Les composants de classe peuvent être définis dans des sections de visibilité publiques, privées ou protégées qui contrôlent l'accès à ces composants. La section de visibilité privée est utilisée pour refuser l'accès aux composants depuis l'extérieur de la classe. Ces composants ne sont accessibles que depuis l'intérieur de la classe, comme une méthode.
Les composants définis dans la section de visibilité publique sont accessibles à partir de n'importe quel contexte. Par défaut, tous les membres d'une classe seraient privés. En pratique, nous définissons les données dans la section privée et les méthodes associées dans la section publique afin qu'elles puissent être appelées de l'extérieur de la classe comme indiqué dans le programme suivant.
Les attributs et méthodes déclarés dans la section Public d'une classe sont accessibles par cette classe et toute autre classe, sous-classe du programme.
Lorsque les attributs et méthodes sont déclarés dans la section Protected d'une classe, ceux-ci sont accessibles uniquement par cette classe et ses sous-classes (classes dérivées).
Lorsque les attributs et méthodes sont déclarés dans la section Private d'une classe, ceux-ci ne sont accessibles que par cette classe et pas par une autre classe.
Exemple
Report ZAccess1.
CLASS class1 Definition.
PUBLIC Section.
Data: text1 Type char25 Value 'Public Data'.
Methods meth1.
PROTECTED Section.
Data: text2 Type char25 Value 'Protected Data'.
PRIVATE Section.
Data: text3 Type char25 Value 'Private Data'.
ENDCLASS.
CLASS class1 Implementation.
Method meth1.
Write: / 'Public Method:',
/ text1,
/ text2,
/ text3.
Skip.
EndMethod.
ENDCLASS.
Start-Of-Selection.
Data: Objectx Type Ref To class1.
Create Object: Objectx.
CALL Method: Objectx→meth1.
Write: / Objectx→text1.Le code ci-dessus produit la sortie suivante -
Public Method:
Public Data
Protected Data
Private Data
Public DataAttributs statiques
Un attribut statique est déclaré avec l'instruction CLASS-DATA. Tous les objets ou instances peuvent utiliser l'attribut statique de la classe. Les attributs statiques sont accessibles directement à l'aide du nom de classe comme class_name⇒name_1 = 'Some Text'.
Exemple
Voici un programme dans lequel nous voulons imprimer un texte avec le numéro de ligne 4 à 8 fois. Nous définissons une classe class1 et dans la section publique nous déclarons CLASS-DATA (attribut statique) et une méthode. Après avoir implémenté la classe et la méthode, nous accédons directement à l'attribut statique dans l'événement Start-Of-Selection. Ensuite, nous créons simplement l'instance de la classe et appelons la méthode.
Report ZStatic1.
CLASS class1 Definition.
PUBLIC Section.
CLASS-DATA: name1 Type char45,
data1 Type I.
Methods: meth1.
ENDCLASS.
CLASS class1 Implementation.
Method meth1.
Do 4 Times.
data1 = 1 + data1.
Write: / data1, name1.
EndDo.
Skip.
EndMethod.
ENDCLASS.
Start-Of-Selection.
class1⇒name1 = 'ABAP Object Oriented Programming'.
class1⇒data1 = 0.
Data: Object1 Type Ref To class1,
Object2 Type Ref To class1.
Create Object: Object1, Object2.
CALL Method: Object1→meth1,
Object2→meth1.Le code ci-dessus produit la sortie suivante -

Constructeurs
Les constructeurs sont des méthodes spéciales qui sont appelées automatiquement, soit lors de la création d'un objet, soit lors de l'accès aux composants d'une classe. Le constructeur est déclenché chaque fois qu'un objet est créé, mais nous devons appeler une méthode pour déclencher la méthode générale. Dans l'exemple suivant, nous avons déclaré deux méthodes publiques method1 et constructor. Ces deux méthodes ont des opérations différentes. Lors de la création d'un objet de la classe, la méthode constructeur déclenche son opération.
Exemple
Report ZConstructor1.
CLASS class1 Definition.
PUBLIC Section.
Methods: method1, constructor.
ENDCLASS.
CLASS class1 Implementation.
Method method1.
Write: / 'This is Method1'.
EndMethod.
Method constructor.
Write: / 'Constructor Triggered'.
EndMethod.
ENDCLASS.
Start-Of-Selection.
Data Object1 Type Ref To class1.
Create Object Object1.Le code ci-dessus produit la sortie suivante -
Constructor TriggeredOpérateur ME en méthodes
Lorsque vous déclarez une variable de n'importe quel type dans la section publique d'une classe, vous pouvez l'utiliser dans n'importe quelle autre implémentation. Une variable peut être déclarée avec une valeur initiale dans la section publique. Nous pouvons déclarer à nouveau la variable dans une méthode avec une valeur différente. Lorsque nous écrivons la variable à l'intérieur de la méthode, le système affichera la valeur modifiée. Pour refléter la valeur précédente de la variable, nous devons utiliser l'opérateur «ME».
Dans ce programme, nous avons déclaré une variable publique text1 et initialisée avec une valeur. Nous avons de nouveau déclaré la même variable, mais instanciée avec une valeur différente. Dans la méthode, nous écrivons cette variable avec l'opérateur 'ME' pour obtenir la valeur précédemment initiée. Nous obtenons la valeur modifiée en déclarant directement.
Exemple
Report ZMEOperator1.
CLASS class1 Definition.
PUBLIC Section.
Data text1 Type char25 Value 'This is CLASS Attribute'.
Methods method1.
ENDCLASS.
CLASS class1 Implementation.
Method method1.
Data text1 Type char25 Value 'This is METHOD Attribute'.
Write: / ME→text1,
/ text1.
ENDMethod.
ENDCLASS.
Start-Of-Selection.
Data objectx Type Ref To class1.
Create Object objectx.
CALL Method objectx→method1.Le code ci-dessus produit la sortie suivante -
This is CLASS Attribute
This is METHOD AttributeL'un des concepts les plus importants de la programmation orientée objet est celui de l'héritage. L'héritage nous permet de définir une classe en termes d'une autre classe, ce qui facilite la création et la maintenance d'une application. Cela offre également la possibilité de réutiliser la fonctionnalité de code et un temps de mise en œuvre rapide.
Lors de la création d'une classe, au lieu d'écrire des membres de données et des méthodes complètement nouveaux, le programmeur peut désigner que la nouvelle classe doit hériter des membres d'une classe existante. Cette classe existante s'appelle lebase class ou super class, et la nouvelle classe est appelée derived class ou sub class.
Un objet d'une classe peut acquérir les propriétés d'une autre classe.
La classe dérivée hérite des données et des méthodes d'une super classe. Cependant, ils peuvent écraser des méthodes et ajouter de nouvelles méthodes.
Le principal avantage de l'héritage est la réutilisabilité.
La relation d'héritage est spécifiée à l'aide de l'ajout 'INHERITING FROM' à l'instruction de définition de classe.
Voici la syntaxe -
CLASS <subclass> DEFINITION INHERITING FROM <superclass>.Exemple
Report ZINHERITAN_1.
CLASS Parent Definition.
PUBLIC Section.
Data: w_public(25) Value 'This is public data'.
Methods: ParentM.
ENDCLASS.
CLASS Child Definition Inheriting From Parent.
PUBLIC Section.
Methods: ChildM.
ENDCLASS.
CLASS Parent Implementation.
Method ParentM.
Write /: w_public.
EndMethod. ENDCLASS.
CLASS Child Implementation.
Method ChildM.
Skip.
Write /: 'Method in child class', w_public.
EndMethod.
ENDCLASS.
Start-of-selection.
Data: Parent Type Ref To Parent,
Child Type Ref To Child.
Create Object: Parent, Child.
Call Method: Parent→ParentM,
child→ChildM.Le code ci-dessus produit la sortie suivante -
This is public data
Method in child class
This is public dataContrôle d'accès et héritage
Une classe dérivée peut accéder à tous les membres non privés de sa classe de base. Ainsi, les membres de la super classe qui ne devraient pas être accessibles aux fonctions membres des sous-classes devraient être déclarés privés dans la super classe. Nous pouvons résumer les différents types d'accès selon qui peut y accéder de la manière suivante -
| Accès | Publique | Protégé | Privé |
|---|---|---|---|
| Mêmes cals | Oui | Oui | Oui |
| Classe dérivée | Oui | Oui | Non |
| Hors classe | Oui | Non | Non |
Lors de la dérivation d'une classe à partir d'une super-classe, elle peut être héritée via un héritage public, protégé ou privé. Le type d'héritage est spécifié par le spécificateur d'accès comme expliqué ci-dessus. Nous n'utilisons guère l'héritage protégé ou privé, mais l'héritage public est couramment utilisé. Les règles suivantes sont appliquées lors de l'utilisation de différents types d'héritage.
Public Inheritance- Lors de la dérivation d'une classe d'une superclasse publique, les membres publics de la superclasse deviennent des membres publics de la sous-classe et les membres protégés de la superclasse deviennent des membres protégés de la sous-classe. Les membres privés de la super classe ne sont jamais accessibles directement à partir d'une sous-classe, mais sont accessibles via des appels aux membres publics et protégés de la super classe.
Protected Inheritance - Lorsqu'ils dérivent d'une super-classe protégée, les membres publics et protégés de la super-classe deviennent des membres protégés de la sous-classe.
Private Inheritance - Lorsqu'ils dérivent d'une super classe privée, les membres publics et protégés de la super classe deviennent des membres privés de la sous-classe.
Redéfinition des méthodes dans la sous-classe
Les méthodes de la super classe peuvent être réimplémentées dans la sous-classe. Peu de règles de redéfinition des méthodes -
L'instruction de redéfinition de la méthode héritée doit se trouver dans la même section que la définition de la méthode d'origine.
Si vous redéfinissez une méthode, vous n'avez pas besoin de saisir à nouveau son interface dans la sous-classe, mais uniquement le nom de la méthode.
Dans la méthode redéfinie, vous pouvez accéder aux composants de la super classe directe à l'aide de la super référence.
La pseudo référence super ne peut être utilisée que dans des méthodes redéfinies.
Exemple
Report Zinheri_Redefine.
CLASS super_class Definition.
Public Section.
Methods: Addition1 importing g_a TYPE I
g_b TYPE I
exporting g_c TYPE I.
ENDCLASS.
CLASS super_class Implementation.
Method Addition1.
g_c = g_a + g_b.
EndMethod.
ENDCLASS.
CLASS sub_class Definition Inheriting From super_class.
Public Section.
METHODS: Addition1 Redefinition.
ENDCLASS.
CLASS sub_class Implementation.
Method Addition1.
g_c = g_a + g_b + 10.
EndMethod.
ENDCLASS.
Start-Of-Selection.
Parameters: P_a Type I, P_b TYPE I.
Data: H_Addition1 TYPE I.
Data: H_Sub TYPE I.
Data: Ref1 TYPE Ref TO sub_class.
Create Object Ref1.
Call Method Ref1→Addition1 exporting g_a = P_a
g_b = P_b
Importing g_c = H_Addition1.
Write:/ H_Addition1.Après avoir exécuté F8, si nous entrons les valeurs 9 et 10, le code ci-dessus produit la sortie suivante -
Redefinition Demo
29Le terme polymorphisme signifie littéralement «plusieurs formes». D'un point de vue orienté objet, le polymorphisme fonctionne en conjonction avec l'héritage pour permettre à différents types dans une arborescence d'héritage d'être utilisés de manière interchangeable. Autrement dit, le polymorphisme se produit lorsqu'il existe une hiérarchie de classes et qu'elles sont liées par héritage. Le polymorphisme ABAP signifie qu'un appel à une méthode entraînera l'exécution d'une méthode différente en fonction du type d'objet qui invoque la méthode.
Le programme suivant contient une classe abstraite 'class_prgm', 2 sous-classes (class_procedural et class_OO) et une classe de pilote de test 'class_type_approach'. Dans cette implémentation, la méthode de classe 'start' nous permet d'afficher le type de programmation et son approche. Si vous regardez attentivement la signature de la méthode 'start', vous observerez qu'elle reçoit un paramètre d'importation de type class_prgm. Cependant, dans l'événement Start-Of-Selection, cette méthode a été appelée au moment de l'exécution avec des objets de type class_procedural et class_OO.
Exemple
Report ZPolymorphism1.
CLASS class_prgm Definition Abstract.
PUBLIC Section.
Methods: prgm_type Abstract,
approach1 Abstract.
ENDCLASS.
CLASS class_procedural Definition
Inheriting From class_prgm.
PUBLIC Section.
Methods: prgm_type Redefinition,
approach1 Redefinition.
ENDCLASS.
CLASS class_procedural Implementation.
Method prgm_type.
Write: 'Procedural programming'.
EndMethod. Method approach1.
Write: 'top-down approach'.
EndMethod. ENDCLASS.
CLASS class_OO Definition
Inheriting From class_prgm.
PUBLIC Section.
Methods: prgm_type Redefinition,
approach1 Redefinition.
ENDCLASS.
CLASS class_OO Implementation.
Method prgm_type.
Write: 'Object oriented programming'.
EndMethod.
Method approach1.
Write: 'bottom-up approach'.
EndMethod.
ENDCLASS.
CLASS class_type_approach Definition.
PUBLIC Section.
CLASS-METHODS:
start Importing class1_prgm
Type Ref To class_prgm.
ENDCLASS.
CLASS class_type_approach IMPLEMENTATION.
Method start.
CALL Method class1_prgm→prgm_type.
Write: 'follows'.
CALL Method class1_prgm→approach1.
EndMethod.
ENDCLASS.
Start-Of-Selection.
Data: class_1 Type Ref To class_procedural,
class_2 Type Ref To class_OO.
Create Object class_1.
Create Object class_2.
CALL Method class_type_approach⇒start
Exporting
class1_prgm = class_1.
New-Line.
CALL Method class_type_approach⇒start
Exporting
class1_prgm = class_2.Le code ci-dessus produit la sortie suivante -
Procedural programming follows top-down approach
Object oriented programming follows bottom-up approachL'environnement d'exécution ABAP effectue une conversion de restriction implicite lors de l'affectation du paramètre d'importation class1_prgm. Cette fonctionnalité aide la méthode «start» à être implémentée de manière générique. Les informations de type dynamique associées à une variable de référence d'objet permettent à l'environnement d'exécution ABAP de lier dynamiquement un appel de méthode à l'implémentation définie dans l'objet pointé par la variable de référence d'objet. Par exemple, le paramètre d'importation «class1_prgm» pour la méthode «start» dans la classe «class_type_approach» fait référence à un type abstrait qui ne pourrait jamais être instancié seul.
Chaque fois que la méthode est appelée avec une implémentation de sous-classe concrète telle que class_procedural ou class_OO, le type dynamique du paramètre de référence class1_prgm est lié à l'un de ces types concrets. Par conséquent, les appels aux méthodes 'prgm_type' et 'approach1' font référence aux implémentations fournies dans les sous-classes class_procedural ou class_OO plutôt qu'aux implémentations abstraites non définies fournies dans la classe 'class_prgm'.
L'encapsulation est un concept de programmation orientée objet (POO) qui lie les données et les fonctions qui manipulent les données et les protège des interférences extérieures et des abus. L'encapsulation des données a conduit à l'important concept POO de masquage des données. L'encapsulation est un mécanisme de regroupement des données et des fonctions qui les utilisent, et l'abstraction des données est un mécanisme permettant d'exposer uniquement les interfaces et de masquer les détails d'implémentation à l'utilisateur.
ABAP prend en charge les propriétés d'encapsulation et de masquage des données via la création de types définis par l'utilisateur appelés classes. Comme indiqué précédemment, une classe peut contenir des membres privés, protégés et publics. Par défaut, tous les éléments définis dans une classe sont privés.
Encapsulation par interface
L'encapsulation signifie en fait qu'un attribut et une méthode peuvent être modifiés dans différentes classes. Par conséquent, les données et la méthode peuvent avoir une forme et une logique différentes qui peuvent être masquées pour séparer la classe.
Considérons l'encapsulation par interface. L'interface est utilisée lorsque nous devons créer une méthode avec différentes fonctionnalités dans différentes classes. Ici, le nom de la méthode n'a pas besoin d'être changé. La même méthode devra être implémentée dans différentes implémentations de classe.
Exemple
Le programme suivant contient une interface inter_1. Nous avons déclaré un attribut et une méthode method1. Nous avons également défini deux classes comme Class1 et Class2. Nous devons donc implémenter la méthode 'method1' dans les deux implémentations de classe. Nous avons implémenté la méthode 'method1' différemment dans différentes classes. Au début de la sélection, nous créons deux objets Object1 et Object2 pour deux classes. Ensuite, nous appelons la méthode par différents objets pour obtenir la fonction déclarée dans des classes séparées.
Report ZEncap1.
Interface inter_1.
Data text1 Type char35.
Methods method1.
EndInterface.
CLASS Class1 Definition.
PUBLIC Section.
Interfaces inter_1.
ENDCLASS.
CLASS Class2 Definition.
PUBLIC Section.
Interfaces inter_1.
ENDCLASS.
CLASS Class1 Implementation.
Method inter_1~method1.
inter_1~text1 = 'Class 1 Interface method'.
Write / inter_1~text1.
EndMethod.
ENDCLASS.
CLASS Class2 Implementation.
Method inter_1~method1.
inter_1~text1 = 'Class 2 Interface method'.
Write / inter_1~text1.
EndMethod.
ENDCLASS.
Start-Of-Selection.
Data: Object1 Type Ref To Class1,
Object2 Type Ref To Class2.
Create Object: Object1, Object2.
CALL Method: Object1→inter_1~method1,
Object2→inter_1~method1.Le code ci-dessus produit la sortie suivante -
Class 1 Interface method
Class 2 Interface methodLes classes encapsulées n'ont pas beaucoup de dépendances avec le monde extérieur. De plus, les interactions qu'ils ont avec les clients externes sont contrôlées via une interface publique stabilisée. Autrement dit, une classe encapsulée et ses clients sont faiblement couplés. Pour la plupart, les classes avec des interfaces bien définies peuvent être connectées à un autre contexte. Lorsqu'elles sont conçues correctement, les classes encapsulées deviennent des actifs logiciels réutilisables.
Conception de la stratégie
La plupart d'entre nous ont appris par expérience amère à rendre les membres de la classe privés par défaut, à moins que nous n'ayons vraiment besoin de les exposer. C'est juste une bonne encapsulation. Cette sagesse est appliquée le plus fréquemment aux membres de données et s'applique également à tous les membres.
À l'instar des classes d'ABAP, les interfaces agissent comme des types de données pour les objets. Les composants des interfaces sont les mêmes que les composants des classes. Contrairement à la déclaration de classes, la déclaration d'une interface n'inclut pas les sections de visibilité. En effet, les composants définis dans la déclaration d'une interface sont toujours intégrés dans la section de visibilité publique des classes.
Les interfaces sont utilisées lorsque deux classes similaires ont une méthode portant le même nom, mais les fonctionnalités sont différentes l'une de l'autre. Les interfaces peuvent sembler similaires aux classes, mais les fonctions définies dans une interface sont implémentées dans une classe pour étendre la portée de cette classe. Les interfaces ainsi que la fonction d'héritage fournissent une base pour le polymorphisme. En effet, une méthode définie dans une interface peut se comporter différemment dans différentes classes.
Voici le format général pour créer une interface -
INTERFACE <intf_name>.
DATA.....
CLASS-DATA.....
METHODS.....
CLASS-METHODS.....
ENDINTERFACE.Dans cette syntaxe, <nom_intf> représente le nom d'une interface. Les instructions DATA et CLASSDATA peuvent être utilisées pour définir respectivement les attributs d'instance et statiques de l'interface. Les instructions METHODS et CLASS-METHODS peuvent être utilisées pour définir respectivement l'instance et les méthodes statiques de l'interface. Comme la définition d'une interface n'inclut pas la classe d'implémentation, il n'est pas nécessaire d'ajouter la clause DEFINITION dans la déclaration d'une interface.
Note- Toutes les méthodes d'une interface sont abstraites. Ils sont entièrement déclarés avec leur interface de paramètres, mais ne sont pas implémentés dans l'interface. Toutes les classes qui souhaitent utiliser une interface doivent implémenter toutes les méthodes de l'interface. Sinon, la classe devient une classe abstraite.
Nous utilisons la syntaxe suivante dans la partie implémentation de la classe -
INTERFACE <intf_name>.Dans cette syntaxe, <nom_intf> représente le nom d'une interface. Notez que cette syntaxe doit être utilisée dans la section publique de la classe.
La syntaxe suivante est utilisée pour implémenter les méthodes d'une interface dans l'implémentation d'une classe -
METHOD <intf_name~method_m>.
<statements>.
ENDMETHOD.Dans cette syntaxe, <intf_name ~ method_m> représente le nom entièrement déclaré d'une méthode de l'interface <intf_name>.
Exemple
Report ZINTERFACE1.
INTERFACE my_interface1.
Methods msg.
ENDINTERFACE.
CLASS num_counter Definition.
PUBLIC Section.
INTERFACES my_interface1.
Methods add_number.
PRIVATE Section.
Data num Type I.
ENDCLASS.
CLASS num_counter Implementation.
Method my_interface1~msg.
Write: / 'The number is', num.
EndMethod.
Method add_number.
ADD 7 TO num.
EndMethod.
ENDCLASS.
CLASS drive1 Definition.
PUBLIC Section.
INTERFACES my_interface1.
Methods speed1.
PRIVATE Section.
Data wheel1 Type I.
ENDCLASS.
CLASS drive1 Implementation.
Method my_interface1~msg.
Write: / 'Total number of wheels is', wheel1.
EndMethod.
Method speed1.
Add 4 To wheel1.
EndMethod.
ENDCLASS.
Start-Of-Selection.
Data object1 Type Ref To num_counter.
Create Object object1.
CALL Method object1→add_number.
CALL Method object1→my_interface1~msg.
Data object2 Type Ref To drive1.
Create Object object2.
CALL Method object2→speed1.
CALL Method object2→my_interface1~msg.Le code ci-dessus produit la sortie suivante -
The number is 7
Total number of wheels is 4Dans l'exemple ci-dessus, my_interface1 est le nom d'une interface contenant la méthode 'msg'. Ensuite, deux classes, num_counter et drive1 sont définies et implémentées. Ces deux classes implémentent la méthode 'msg' ainsi que des méthodes spécifiques qui définissent le comportement de leurs instances respectives, telles que les méthodes add_number et speed1.
Note - Les méthodes add_number et speed1 sont spécifiques aux classes respectives.
Un eventest un ensemble de résultats définis dans une classe pour déclencher les gestionnaires d'événements dans d'autres classes. Lorsqu'un événement est déclenché, nous pouvons appeler n'importe quel nombre de méthodes de gestion d'événements. Le lien entre un déclencheur et sa méthode de gestion est en fait décidé de manière dynamique au moment de l'exécution.
Dans un appel de méthode normal, un programme appelant détermine quelle méthode d'un objet ou d'une classe doit être appelée. Comme la méthode de gestionnaire fixe n'est pas enregistrée pour chaque événement, en cas de gestion d'événements, la méthode de gestionnaire détermine l'événement qui doit être déclenché.
Un événement d'une classe peut déclencher une méthode de gestionnaire d'événements de la même classe à l'aide de l'instruction RAISE EVENT. Pour un événement, la méthode du gestionnaire d'événements peut être définie dans la même classe ou dans une classe différente à l'aide de la clause FOR EVENT, comme indiqué dans la syntaxe suivante -
FOR EVENT <event_name> OF <class_name>.Semblable aux méthodes d'une classe, un événement peut avoir une interface de paramètres mais il n'a que des paramètres de sortie. Les paramètres de sortie sont transmis à la méthode du gestionnaire d'événements par l'instruction RAISE EVENT qui les reçoit en tant que paramètres d'entrée. Un événement est lié à sa méthode de gestionnaire de manière dynamique dans un programme à l'aide de l'instruction SET HANDLER.
Lorsqu'un événement est déclenché, les méthodes de gestion d'événements appropriées sont supposées être exécutées dans toutes les classes de gestion.
Exemple
REPORT ZEVENT1.
CLASS CL_main DEFINITION.
PUBLIC SECTION.
DATA: num1 TYPE I.
METHODS: PRO IMPORTING num2 TYPE I.
EVENTS: CUTOFF.
ENDCLASS.
CLASS CL_eventhandler DEFINITION.
PUBLIC SECTION.
METHODS: handling_CUTOFF FOR EVENT CUTOFF OF CL_main.
ENDCLASS.
START-OF-SELECTION.
DATA: main1 TYPE REF TO CL_main.
DATA: eventhandler1 TYPE REF TO CL_eventhandler.
CREATE OBJECT main1.
CREATE OBJECT eventhandler1.
SET HANDLER eventhandler1→handling_CUTOFF FOR main1.
main1→PRO( 4 ).
CLASS CL_main IMPLEMENTATION.
METHOD PRO.
num1 = num2.
IF num2 ≥ 2.
RAISE EVENT CUTOFF.
ENDIF.
ENDMETHOD.
ENDCLASS.
CLASS CL_eventhandler IMPLEMENTATION.
METHOD handling_CUTOFF.
WRITE: 'Handling the CutOff'.
WRITE: / 'Event has been processed'.
ENDMETHOD. ENDCLASS.Le code ci-dessus produit la sortie suivante -
Handling the CutOff
Event has been processedUNE reportest une présentation de données dans une structure organisée. De nombreux systèmes de gestion de base de données incluent un rédacteur de rapports qui vous permet de concevoir et de générer des rapports. Les applications SAP prennent en charge la création de rapports.
Un rapport classique est créé en utilisant les données de sortie dans l'instruction WRITE à l'intérieur d'une boucle. Ils ne contiennent aucun sous-rapport. SAP fournit également certains rapports standard tels que RSCLTCOP qui est utilisé pour copier des tables entre les clients et RSPARAM qui est utilisé pour afficher les paramètres d'instance.
Ces rapports se composent d'un seul écran comme sortie. Nous pouvons utiliser divers événements tels que INITIALIZATON & TOP-OF-PAGE pour créer un rapport classique, et chaque événement a sa propre importance lors de la création d'un rapport classique. Chacun de ces événements est associé à une action utilisateur spécifique et est déclenché uniquement lorsque l'utilisateur effectue cette action.
Voici un tableau décrivant les événements et leurs descriptions -
| S.No. | Description de l'évenement |
|---|---|
| 1 | INITIALIZATON Déclenché avant d'afficher l'écran de sélection. |
| 2 | AT SELECTION-SCREEN Déclenché après le traitement de la saisie utilisateur sur l'écran de sélection. Cet événement vérifie l'entrée de l'utilisateur avant l'exécution d'un programme. Après le traitement de la saisie utilisateur, l'écran de sélection reste en mode actif. |
| 3 | START-OF-SELECTION Déclenché seulement après la fin du traitement de l'écran de sélection; autrement dit, lorsque l'utilisateur clique sur l'icône Exécuter sur l'écran de sélection. |
| 4 | END-OF-SELECTION Déclenché après l'exécution de la dernière instruction de l'événement START-OF-SELECTON. |
| 5 | TOP-OF-PAGE Déclenché par la première instruction WRITE pour afficher les données sur une nouvelle page. |
| 6 | END-OF-PAGE Déclenché pour afficher le texte à la fin d'une page dans un rapport. Notez que cet événement est le dernier événement lors de la création d'un rapport et doit être combiné avec la clause LINE-COUNT de l'instruction REPORT. |
Exemple
Créons un rapport classique. Nous afficherons les informations stockées dans la base de données standard MARA (contient des données matérielles générales) en utilisant une séquence d'instructions dans l'éditeur ABAP.
REPORT ZREPORT2
LINE-SIZE 75
LINE-COUNT 30(3)
NO STANDARD PAGE HEADING.
Tables: MARA.
TYPES: Begin of itab,
MATNR TYPE MARA-MATNR,
MBRSH TYPE MARA-MBRSH,
MEINS TYPE MARA-MEINS,
MTART TYPE MARA-MTART,
End of itab.
DATA: wa_ma TYPE itab,
it_ma TYPE STANDARD TABLE OF itab.
SELECT-OPTIONS: MATS FOR MARA-MATNR OBLIGATORY.
INITIALIZATION.
MATS-LOW = '1'.
MATS-HIGH = '500'.
APPEND MATS.
AT SELECTION-SCREEN. .
IF MATS-LOW = ' '.
MESSAGE I000(ZKMESSAGE).
ELSEIF MATS-HIGH = ' '.
MESSAGE I001(ZKMESSAGE).
ENDIF.
TOP-OF-PAGE.
WRITE:/ 'CLASSICAL REPORT CONTAINING GENERAL MATERIAL DATA
FROM THE TABLE MARA' COLOR 7.
ULINE.
WRITE:/ 'MATERIAL' COLOR 1,
24 'INDUSTRY' COLOR 2,
38 'UNITS' COLOR 3,
53 'MATERIAL TYPE' COLOR 4.
ULINE.
END-OF-PAGE.
START-OF-SELECTION.
SELECT MATNR MBRSH MEINS MTART FROM MARA
INTO TABLE it_ma WHERE MATNR IN MATS.
LOOP AT it_ma into wa_ma.
WRITE:/ wa_ma-MATNR,
25 wa_ma-MBRSH,
40 wa_ma-MEINS,
55 wa_ma-MTART.
ENDLOOP.
END-OF-SELECTION.
ULINE.
WRITE:/ 'CLASSICAL REPORT HAS BEEN CREATED' COLOR 7.
ULINE.
SKIP.Le code ci-dessus produit la sortie suivante contenant les données générales sur les matériaux de la table standard MARA -
La programmation de dialogue traite du développement de plusieurs objets. Tous ces objets sont liés hiérarchiquement au programme principal et ils sont exécutés dans une séquence. Le développement de programmes de dialogue utilise les outils de l'atelier ABAP. Ce sont les mêmes outils utilisés dans le développement d'applications SAP standard.
Voici les principaux composants des programmes de dialogue -
- Screens
- Pools de modules
- Subroutines
- Menus
- Transactions
Le jeu d'outils
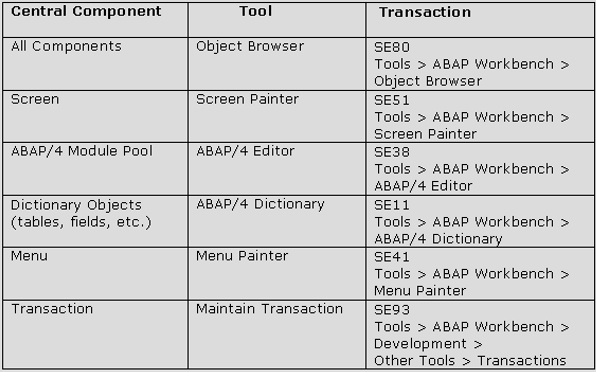
Les programmes de dialogue doivent être développés par le navigateur d'objets (transaction: SE80) afin que tous les objets soient liés au programme principal sans avoir à pointer explicitement chaque objet. Les techniques de navigation avancées améliorent le processus de déplacement d'un objet à l'autre.
Les écrans sont composés d'attributs d'écran, de disposition d'écran, de champs et de logique de flux. Le pool de modules se compose d'une syntaxe modulaire qui est placée à l'intérieur des programmes d'inclusion du programme de dialogue. Ces modules peuvent être appelés par la logique de flux, qui est traitée par le processeur de dialogue.
Création d'un nouveau programme de dialogue
Step 1 - Dans la transaction SE80, sélectionnez «Programme» dans la liste déroulante et entrez un nom Z pour votre programme SAP personnalisé en tant que «ZSCREENEX».
Step 2 - Appuyez sur Entrée, choisissez «Avec TOP INCL» et cliquez sur le bouton «Oui».
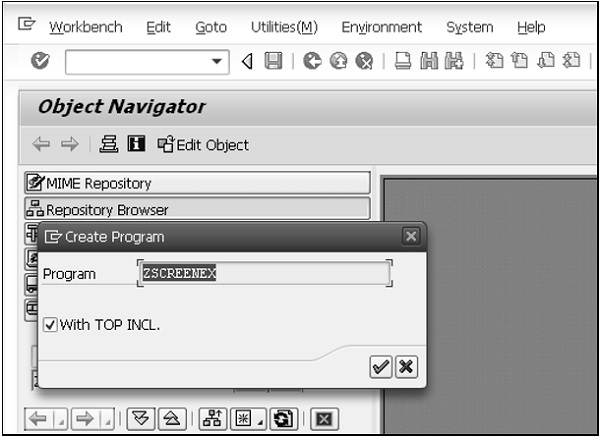
Step 3 - Entrez un nom pour votre top include en tant que «ZSCRTOP» et cliquez sur la coche verte.
Step 4 - Dans l'écran des attributs, entrez simplement un titre et cliquez sur le bouton Enregistrer.
Ajout d'un écran au programme de dialogue
Step 1 - Pour ajouter un écran au programme, faites un clic droit sur le nom du programme et sélectionnez les options Créer → Écran.
Step 2 - Entrez un numéro d'écran comme «0211» et cliquez sur la coche verte.
Step 3 - Dans l'écran suivant, entrez un titre court, définissez le type d'écran normal et cliquez sur le bouton Enregistrer dans la barre d'outils supérieure de l'application.
Disposition de l'écran et ajout du texte «Hello World»
Step 1 - Cliquez sur le bouton de mise en page dans la barre d'outils de l'application et la fenêtre Screen Painter apparaît.
Step 2 - Ajoutez un champ de texte et entrez du texte tel que "Hello World".

Step 3 - Enregistrez et activez l'écran.
Créer une transaction
Step 1 - Pour créer un code de transaction pour votre programme, cliquez simplement avec le bouton droit sur le nom du programme et choisissez l'option Créer → Transaction et entrez un code de transaction comme «ZTRANEX».
Step 2 - Entrez le texte de la transaction, le programme et l'écran que vous venez de créer (ZSCREENEX & 0211) et cochez la case «SAPGUI pour Windows» dans la section «Prise en charge de l'interface graphique».
Exécution du programme
Enregistrez et activez tout. Vous pouvez exécuter le programme. Au fur et à mesure que le programme s'exécute, le texte que vous avez saisi s'affiche à l'écran comme illustré dans la capture d'écran suivante.
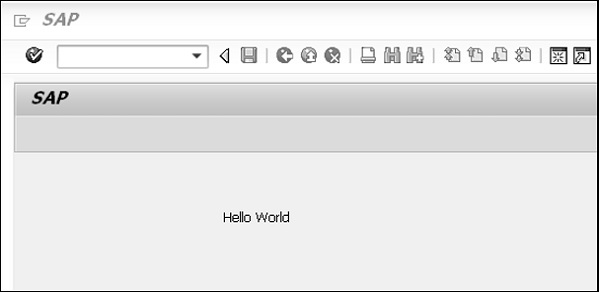
L'outil SAP Smart Forms peut être utilisé pour imprimer et envoyer des documents. Cet outil est utile pour développer des formulaires, des fichiers PDF, des courriers électroniques et des documents pour Internet. L'outil fournit une interface pour créer et maintenir la disposition et la logique d'un formulaire. SAP propose également une sélection de formulaires pour les processus commerciaux tels que ceux utilisés dans la gestion de la relation client (CRM), les ventes et la distribution (SD), la comptabilité financière (FI) et les ressources humaines (RH).
L'outil vous permet de modifier les formulaires en utilisant des outils graphiques simples au lieu d'utiliser n'importe quel outil de programmation. Cela signifie qu'un utilisateur sans connaissances en programmation peut configurer ces formulaires avec des données pour un processus métier sans effort.
Dans un formulaire intelligent, les données sont extraites de tables statiques et dynamiques. L'en-tête et le sous-total du tableau sont spécifiés par les événements déclenchés et les données sont ensuite triées avant la sortie finale. Un formulaire intelligent vous permet d'incorporer des graphiques qui peuvent être affichés dans le cadre du formulaire ou en arrière-plan. Vous pouvez également supprimer un graphique d'arrière-plan si nécessaire lors de l'impression d'un formulaire.
Voici quelques exemples de Smart Forms standard disponibles dans le système SAP:
SF_EXAMPLE_01 représente une facture avec une sortie de table pour la réservation de vol pour un client.
SF_EXAMPLE_02 représente une facture similaire à SF_EXAMPLE_01, mais avec des sous-totaux.
SF_EXAMPLE_03 spécifie une facture similaire à SF_EXAMPLE_02, mais dans laquelle plusieurs clients peuvent être sélectionnés dans un programme d'application.
Créer un formulaire
Créons un formulaire à l'aide de l'outil SAP Smart Forms. Vous apprendrez également comment ajouter un nœud dans le formulaire intelligent et tester le formulaire dans ce didacticiel. Ici, nous commençons par créer une copie du formulaire SF_EXAMPLE_01. Le formulaire SF_EXAMPLE_01 est un formulaire intelligent standard disponible dans le système SAP.
Step 1- Smart Form Builder est l'interface principale utilisée pour créer un Smart Form. Il est disponible sur l'écran initial de SAP Smart Forms. Nous devons taper le code de transaction «SMARTFORMS» dans le champ Commande pour ouvrir l'écran initial de SAP Smart Forms. Dans cet écran, saisissez le nom du formulaire, SF_EXAMPLE_01, dans le champ Formulaire.
Step 2 - Sélectionnez Formulaires intelligents → Copier ou cliquez sur l'icône Copier pour ouvrir la boîte de dialogue Copier le formulaire ou le texte.
Step 3- Dans le champ Objet cible, saisissez un nom pour le nouveau formulaire. Le nom doit commencer par la lettre Y ou Z. Dans ce cas, le nom du formulaire est «ZSMM1».
Step 4 - Cliquez sur l'icône Continuer ou appuyez sur la touche ENTRÉE dans la boîte de dialogue Copier le formulaire ou le texte afin que le formulaire ZSMM1 soit créé en tant que copie du formulaire prédéfini SF_EXAMPLE_01.
Step 5- Cliquez sur l'icône Enregistrer. Le nom du formulaire s'affiche dans le champ Formulaire de l'écran initial de SAP Smart Forms.
Step 6- Cliquez sur le bouton Créer sur l'écran initial de SAP Smart Forms. Le formulaire ZSMM1 apparaît dans Form Builder.
Step 7- La première page de brouillon est créée avec une fenêtre PRINCIPALE. Tous les composants du nouveau formulaire sont basés sur le formulaire prédéfini SF_EXAMPLE_01. Vous pouvez simplement cliquer sur un nœud dans le menu de navigation pour afficher son contenu.

Création d'un nœud de texte dans le formulaire
Step 1 - Ouvrez un formulaire dans le mode de modification de l'écran SAP Form Builder et cliquez avec le bouton droit sur l'option Fenêtre principale dans le nœud Première page et sélectionnez Créer → Texte dans le menu contextuel.
Step 2- Modifiez le texte du champ Texte en «Mon_Texte» et le texte du champ Signification en «Texte_Démo». Entrez le texte 'Hello TutorialsPoint .....' dans la zone d'édition de texte dans le cadre central de Form Builder comme indiqué dans l'instantané suivant -

Step 3 - Cliquez sur le bouton Enregistrer pour enregistrer le nœud.
Step 4- Activez et testez le nœud en cliquant respectivement sur les icônes Activer et Tester. L'écran initial de Function Builder apparaît.
Step 5- Activez et testez le module fonction en cliquant sur les icônes Activer et Exécuter. Les paramètres du module fonction sont affichés dans l'écran initial de Function Builder.
Step 6- Exécutez le module fonction en cliquant sur l'icône Exécuter. La boîte de dialogue Imprimer apparaît.
Step 7 - Spécifiez le périphérique de sortie comme «LP01» et cliquez sur le bouton Aperçu avant impression.
Les étapes ci-dessus produiront la sortie suivante -
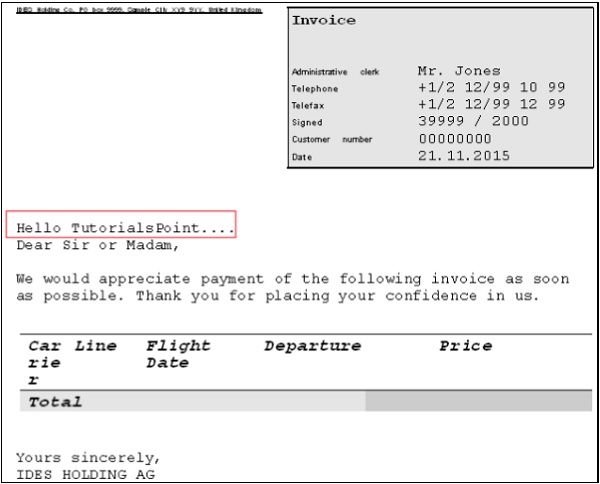
L'outil SAPscript du système SAP peut être utilisé pour créer et gérer des formulaires commerciaux tels que des factures et des bons de commande. L'outil SAPscript fournit de nombreux modèles qui simplifient dans une large mesure la conception d'un formulaire commercial.
Le système SAP est fourni avec des formulaires SAPscript standard livrés avec le client standard SAP (généralement en tant que client 000). Voici quelques exemples de formulaires SAPscript standard livrés avec le client 000 -
| S.No. | Nom et description du formulaire |
|---|---|
| 1 | RVORDER01 Formulaire de confirmation de commande client |
| 2 | RVDELNOTE Liste de colisage |
| 3 | RVINVOICE01 Facture d'achat |
| 4 | MEDRUCK Bon de commande |
| 5 | F110_PRENUM_CHCK Chèque pré-numéroté |
La structure d'un formulaire SAPscript se compose de 2 composants principaux -
Content - Il peut s'agir de texte (données commerciales) ou de graphiques (logo d'entreprise).
Layout - Ceci est défini par un ensemble de fenêtres dans lesquelles le contenu du formulaire apparaît.
SAPscript - Outil Form Painter
L'outil Form Painter fournit la présentation graphique d'un formulaire SAPscript et diverses fonctionnalités pour manipuler le formulaire. Dans l'exemple suivant, nous allons créer un formulaire de facture après avoir copié sa structure de mise en page à partir d'un formulaire SAPscript standard RVINVOICE01, et afficher sa mise en page en accédant à l'outil Form Painter.
Step 1- Ouvrez le Form Painter. Vous pouvez demander l'écran en naviguant dans le menu SAP ou en utilisant le code de transaction SE71.
Step 2- Dans l'écran Form Painter, request, entrez un nom et une langue pour un formulaire SAPscript dans les champs Formulaire et Langue, respectivement. Entrons respectivement «RVINVOICE01» et «EN» dans ces champs.
Step 3 - Sélectionnez le bouton radio Mise en page dans la zone de groupe Sous-objets.
Step 4- Sélectionnez Utilitaires → Copier du client pour créer une copie du formulaire RVINVOICE01. L'écran «Copier les formulaires entre clients» apparaît.
Step 5- Dans l'écran 'Copier les formulaires entre clients', entrez le nom d'origine du formulaire, 'RVINVOICE01', dans le champ Nom du formulaire, le numéro du client source '000' dans le champ Client source et le nom de la cible formulaire comme 'ZINV_01' dans le champ Formulaire cible. Assurez-vous que les autres paramètres restent inchangés.
Step 6- Ensuite, cliquez sur l'icône Exécuter dans l'écran «Copier les formulaires entre clients». La boîte de dialogue "Créer une entrée de répertoire d'objets" apparaît. Cliquez sur l'icône Enregistrer.
Le formulaire ZINV_01 est copié à partir du formulaire RVINVOICE01 et affiché dans l'écran `` Copier les formulaires entre clients '' comme illustré dans l'instantané suivant -
Step 7 - Cliquez deux fois sur l'icône de retour et revenez à l'écran Form Painter: Request, qui contient le nom du formulaire ZINV_01 copié.
Step 8 - Après avoir cliqué sur le bouton Afficher, la fenêtre «Formulaire ZINV_01: Mise en page de la page EN PREMIER» et l'écran «Formulaire: Modifier la mise en page: ZINV_01» apparaissent comme illustré dans la capture d'écran suivante.
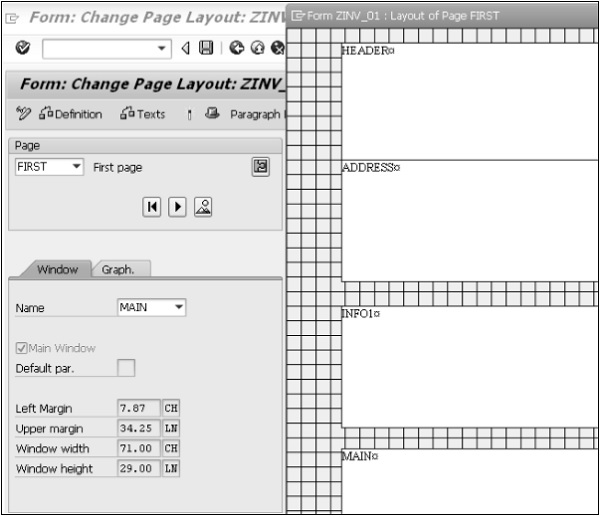
Step 9- La fenêtre «Formulaire ZINV_01: Mise en page de la page EN PREMIER» affiche la mise en page initiale du formulaire. La mise en page du formulaire contient cinq fenêtres: HEADER, ADDRESS, INFO, INFO1 et MAIN. La description de ces fenêtres est accessible dans PC Editor.
Par exemple, en sélectionnant simplement la fenêtre PRINCIPALE et en cliquant sur l'icône Texte dans l'écran `` Formulaire: Modifier la mise en page: ZINV_01 '', vous pouvez afficher toutes les valeurs de marge comme indiqué dans la capture d'écran suivante -
Les sorties client peuvent être considérées comme des crochets aux programmes standard SAP. Nous n'avons pas besoin d'une clé d'accès pour écrire le code et il n'est pas nécessaire de modifier le programme standard SAP. Ces sorties n'ont aucune fonctionnalité et elles sont vides. Une logique métier pourrait être ajoutée afin de répondre aux diverses exigences des clients. Cependant, les sorties client ne sont pas disponibles pour tous les programmes.
Sorties client pour les transactions standard
Voici les étapes à suivre pour trouver les sorties client en ce qui concerne les transactions standard. Identifions les exits client disponibles dans MM01 (création de base de données articles).
Step 1 - Accédez à la transaction MM01 et identifiez le nom du programme de MM01 en allant dans Barre de menus → Système → État comme indiqué dans la capture d'écran ci-dessus.
Step 2- Obtenez le nom du programme à partir de l'écran contextuel. Le nom du programme est «SAPLMGMM».
Step 3 - Accédez à la transaction SE38, entrez le nom du programme et cliquez sur Afficher.
Step 4 - Accédez à Aller à → Propriétés et découvrez le package de ce nom de programme.
Le nom du package est «MGA».
Step 5- Accédez au code de transaction SMOD qui est généralement utilisé pour identifier les sorties client. Accédez à Utilitaires → Rechercher (ou) vous pouvez appuyer directement sur Ctrl + F sur le code de transaction SMOD.
Step 6 - Après être allé à l'écran «Rechercher des sorties», entrez le nom du package que nous avons obtenu précédemment et appuyez sur le bouton F8 (Exécuter).
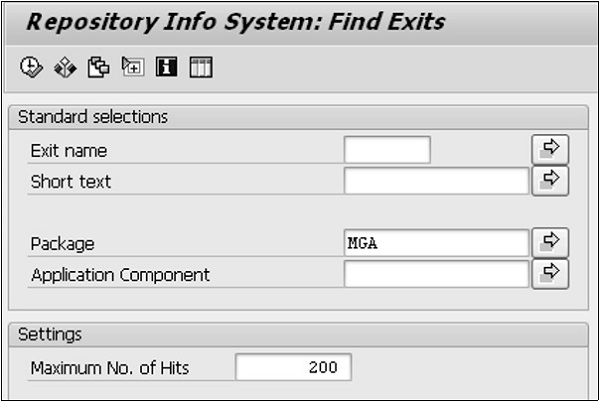
Les étapes ci-dessus produisent la sortie suivante avec la liste des sorties disponibles dans la création de la fiche article.
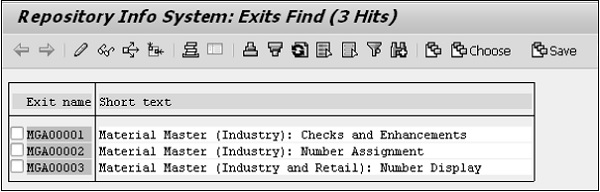
Les exits utilisateur sont utilisés dans une extraction si les extracteurs SAP standard ne fournissent pas les données attendues ou les fonctionnalités requises, par exemple dans les autorisations ou les contrôles horaires. Les exits utilisateur sont couramment utilisés dans les modules Ventes et distribution (SD). Il existe de nombreuses sorties proposées par SAP dans les domaines de la vente, du transport, de l'expédition et de la facturation. Un exit utilisateur est conçu pour apporter des modifications lorsque SAP standard n'est pas capable de répondre à toutes les exigences.
Pour pouvoir accéder aux sorties disponibles dans chaque domaine de vente, accédez à IMG en utilisant ce chemin: IMG → Ventes et distribution → Modifications du système → Exits utilisateur. La documentation pour chaque sortie dans les zones SD est expliquée en détail.
Par exemple, si vous souhaitez trouver des exits utilisateur dans le traitement des documents de vente (contrat, devis ou commande client), suivez le chemin mentionné ci-dessus et continuez à développer le nœud Exits utilisateur dans Ventes → Exits utilisateur. Cliquez sur l'icône de documentation pour voir tous les exits utilisateur disponibles dans le traitement des documents de vente.
| S.No. | Sortie utilisateur et description |
|---|---|
| 1 | USEREXIT_FIELD_MODIFICATION Utilisé pour modifier les attributs de l'écran. |
| 2 | USEREXIT_SAVE_DOCUMENT Aide à effectuer des opérations lorsque l'utilisateur appuie sur Enregistrer. |
| 3 | USEREXIT_SAVE_DOCUMENT_PREPARE Très utile pour vérifier les champs de saisie, mettre n'importe quelle valeur dans le champ ou afficher une fenêtre contextuelle aux utilisateurs et pour confirmer le document. |
| 4 | USEREXIT_MOVE_FIELD_TO_VBAK Utilisé lorsque les modifications d'en-tête utilisateur sont déplacées vers la zone de travail d'en-tête. |
| 5 | USEREXIT_MOVE_FIELD_TO_VBAP Utilisé lorsque les modifications d'élément utilisateur sont déplacées vers la zone de travail d'élément SAP. |
Une sortie utilisateur a le même objectif que les sorties client, mais elles ne sont disponibles que pour le module SD. L'exit est implémenté comme un appel à un module de fonction. Les exits utilisateur sont des modifications des programmes standard SAP.
Exemple
REPORT ZUSEREXIT1.
TABLES:
TSTC, TSTCT,
TADIR, TRDIR, TFDIR, ENLFDIR,
MODSAPT, MODACT.
DATA:
JTAB LIKE TADIR OCCURS 0 WITH HEADER LINE,
field1(30),
v_devclass LIKE TADIR-devclass.
PARAMETERS:
P_TCODE LIKE TSTC-tcode OBLIGATORY.
SELECT SINGLE *
FROM TSTC
WHERE tcode EQ P_TCODE.
IF SY-SUBRC EQ 0.
SELECT SINGLE *
FROM TADIR
WHERE pgmid = 'R3TR' AND
object = 'PROG' AND
obj_name = TSTC-pgmna.
MOVE TADIR-devclass TO v_devclass.
IF SY-SUBRC NE 0.
SELECT SINGLE *
FROM TRDIR
WHERE name = TSTC-pgmna.
IF TRDIR-subc EQ 'F'.
SELECT SINGLE *
FROM TFDIR
WHERE pname = TSTC-pgmna.
SELECT SINGLE *
FROM ENLFDIR
WHERE funcname = TFDIR-funcname.
SELECT SINGLE *
FROM TADIR
WHERE pgmid = 'R3TR' AND
object = 'FUGR' AND
obj_name EQ ENLFDIR-area.
MOVE TADIR-devclass TO v_devclass.
ENDIF.
ENDIF.
SELECT *
FROM TADIR
INTO TABLE JTAB
WHERE pgmid = 'R3TR' AND
object = 'SMOD' AND
devclass = v_devclass.
SELECT SINGLE *
FROM TSTCT
WHERE sprsl EQ SY-LANGU AND
tcode EQ P_TCODE.
FORMAT COLOR COL_POSITIVE INTENSIFIED OFF.
WRITE:/(19) 'Transaction Code - ',
20(20) P_TCODE,
45(50) TSTCT-ttext.
SKIP.
IF NOT JTAB[] IS INITIAL.
WRITE:/(95) SY-ULINE.
FORMAT COLOR COL_HEADING INTENSIFIED ON.
WRITE:/1 SY-VLINE,
2 'Exit Name',
21 SY-VLINE ,
22 'Description',
95 SY-VLINE.
WRITE:/(95) SY-ULINE.
LOOP AT JTAB.
SELECT SINGLE * FROM MODSAPT
WHERE sprsl = SY-LANGU AND
name = JTAB-obj_name.
FORMAT COLOR COL_NORMAL INTENSIFIED OFF.
WRITE:/1 SY-VLINE,
2 JTAB-obj_name HOTSPOT ON,
21 SY-VLINE ,
22 MODSAPT-modtext,
95 SY-VLINE.
ENDLOOP.
WRITE:/(95) SY-ULINE.
DESCRIBE TABLE JTAB.
SKIP.
FORMAT COLOR COL_TOTAL INTENSIFIED ON.
WRITE:/ 'No of Exits:' , SY-TFILL.
ELSE.
FORMAT COLOR COL_NEGATIVE INTENSIFIED ON.
WRITE:/(95) 'User Exit doesn’t exist'.
ENDIF.
ELSE.
FORMAT COLOR COL_NEGATIVE INTENSIFIED ON.
WRITE:/(95) 'Transaction Code Does Not Exist'.
ENDIF.
AT LINE-SELECTION.
GET CURSOR FIELD field1.
CHECK field1(4) EQ 'JTAB'.
SET PARAMETER ID 'MON' FIELD sy-lisel+1(10).
CALL TRANSACTION 'SMOD' AND SKIP FIRST SCREEN.Pendant le traitement, entrez le code de transaction «ME01» et appuyez sur le bouton F8 (Exécuter). Le code ci-dessus produit la sortie suivante -
Dans certains cas, des fonctions spéciales doivent être prédéfinies dans une application logicielle pour améliorer la fonctionnalité de diverses applications. Il existe de nombreux compléments Microsoft Excel pour améliorer les fonctionnalités de MS Excel. De même, SAP facilite certaines fonctions prédéfinies en fournissantBusiness Add-Ins connu sous le nom de BADI.
Un BADI est une technique d'amélioration qui permet à un programmeur SAP, à un utilisateur ou à une industrie spécifique d'ajouter du code supplémentaire au programme existant dans le système SAP. Nous pouvons utiliser une logique standard ou personnalisée pour améliorer le système SAP. Un BADI doit d'abord être défini puis implémenté pour améliorer l'application SAP. Lors de la définition d'un BADI, une interface est créée. BADI est implémenté par cette interface, qui à son tour est implémentée par une ou plusieurs classes d'adaptateur.
La technique BADI est différente des autres techniques d'amélioration de deux manières -
- La technique d'amélioration ne peut être mise en œuvre qu'une seule fois.
- Cette technique d'amélioration peut être utilisée par de nombreux clients simultanément.
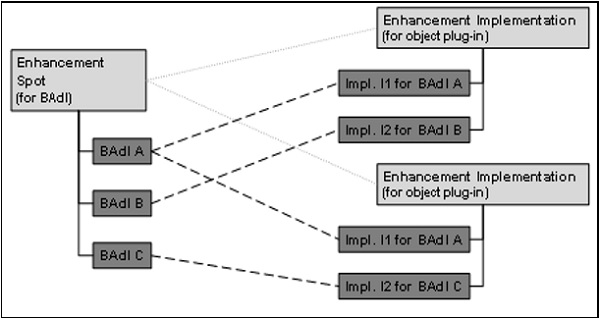
Vous pouvez également créer des BADI de filtre, ce qui signifie que les BADI sont définis sur la base de données filtrées, ce qui n'est pas possible avec les techniques d'amélioration. Le concept des BADI a été redéfini dans SAP Release 7.0 avec les objectifs suivants:
Amélioration des applications standard dans un système SAP en ajoutant deux nouveaux éléments dans le langage ABAP, à savoir «GET BADI» et «CALL BADI».
Offrant plus de fonctionnalités de flexibilité telles que des contextes et des filtres pour l'amélioration des applications standard dans un système SAP.
Lorsqu'un BADI est créé, il contient une interface et d'autres composants supplémentaires, tels que des codes de fonction pour des améliorations de menu et des améliorations d'écran. Une création BADI permet aux clients d'inclure leurs propres améliorations dans l'application SAP standard. L'amélioration, l'interface et les classes générées se trouvent dans un espace de noms de développement d'application approprié.
Par conséquent, un BADI peut être considéré comme une technique d'amélioration qui utilise des objets ABAP pour créer des «points prédéfinis» dans les composants SAP. Ces points prédéfinis sont ensuite mis en œuvre par des solutions industrielles individuelles, des variantes de pays, des partenaires et des clients en fonction de leurs besoins spécifiques. SAP a en fait introduit la technique d'amélioration BADI avec la version 4.6A, et la technique a été de nouveau implémentée dans la version 7.0.
Web Dynpro (WD) pour ABAP est la technologie d'interface utilisateur standard SAP développée par SAP AG. Il peut être utilisé dans le développement d'applications Web dans l'environnement SAP ABAP qui utilise des outils et des concepts de développement SAP. Il fournit une interface utilisateur Web frontale pour se connecter directement aux systèmes backend SAP R / 3 pour accéder aux données et aux fonctions de reporting.
Web Dynpro for ABAP se compose d'un environnement d'exécution et d'un environnement de développement graphique avec des outils de développement spécifiques intégrés dans ABAP Workbench (transaction: SE80).
Architecture de Web Dynpro
L'illustration suivante montre l'architecture globale de Web Dynpro -
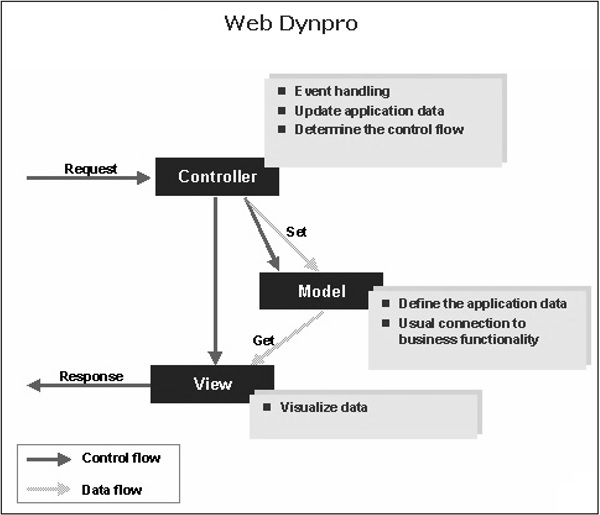
Voici quelques points à garder à l'esprit concernant Web Dynpro -
Web Dynpro est le modèle de programmation SAP NetWeaver pour les interfaces utilisateur.
Toutes les applications Web Dynpro sont structurées selon le modèle de programmation Model View Controller (MVC).
Le modèle définit une interface avec le système principal et l'application Web Dynpro peut avoir accès aux données système.
La vue est responsable de l'affichage des données dans le navigateur Web.
Le contrôleur réside entre la vue et le modèle. Le contrôleur formate les données du modèle à afficher dans la vue. Il traite les entrées utilisateur effectuées par l'utilisateur et les renvoie au modèle.
Avantages
Web Dynpro offre les avantages suivants aux développeurs d'applications -
L'utilisation d'outils graphiques réduit considérablement l'effort de mise en œuvre.
Réutilisation et meilleure maintenabilité en utilisant des composants.
La mise en page et la navigation sont facilement modifiées à l'aide des outils Web Dynpro.
L'accessibilité de l'interface utilisateur est prise en charge.
Intégration complète dans l'environnement de développement ABAP.
Composant et fenêtre Web Dynpro
Le composant est l'unité globale du projet d'application Web Dynpro. La création d'un composant Web Dynpro est la première étape du développement d'une nouvelle application Web Dynpro. Une fois le composant créé, il agit comme un nœud dans la liste d'objets Web Dynpro. Vous pouvez créer n'importe quel nombre de vues de composant dans un composant et les assembler dans n'importe quel nombre de fenêtres Web Dynpro correspondantes.
Au moins une fenêtre Web Dynpro est contenue dans chaque composant Web Dynpro. La fenêtre Web Dynpro intègre toutes les vues affichées dans l'application Web frontale. La fenêtre est traitée dans les éditeurs de fenêtres d'ABAP Workbench.
Note
La vue du composant affiche tous les détails administratifs de l'application, y compris la description, le nom de la personne qui l'a créée, la date de création et le package de développement affecté.
L'application Web Dynpro est l'objet indépendant dans la liste d'objets d'ABAP Workbench. L'interaction entre la fenêtre et l'application est créée par la vue d'interface d'une fenêtre donnée.