SAP BODS - Guide rapide
Un entrepôt de données est connu comme un référentiel central pour stocker les données d'une ou de plusieurs sources de données hétérogènes. L'entrepôt de données est utilisé pour le reporting et l'analyse des informations et stocke les données historiques et actuelles. Les données du système DW sont utilisées pour les rapports analytiques, qui sont ensuite utilisés par les analystes commerciaux, les directeurs des ventes ou les travailleurs du savoir pour la prise de décision.
Les données du système DW sont chargées à partir d'un système de transaction opérationnel comme les ventes, le marketing, les ressources humaines, le SCM, etc. Elles peuvent passer par le magasin de données opérationnelles ou d'autres transformations avant d'être chargées dans le système DW pour le traitement de l'information.
Entrepôt de données - Fonctionnalités clés
Les principales caractéristiques d'un système DW sont:
Il s'agit d'un référentiel de données central où les données sont stockées à partir d'une ou plusieurs sources de données hétérogènes.
Un système DW stocke à la fois les données actuelles et historiques. Normalement, un système DW stocke 5 à 10 ans de données historiques.
Un système DW est toujours séparé d'un système de transaction opérationnel.
Les données du système DW sont utilisées pour différents types de rapports analytiques allant de la comparaison trimestrielle à la comparaison annuelle.
Besoin d'un système DW
Supposons que vous ayez une agence de prêt immobilier où les données proviennent de plusieurs applications telles que le marketing, les ventes, l'ERP, la GRH, la MM, etc. Ces données sont extraites, transformées et chargées dans Data Warehouse.
Par exemple, si vous devez comparer les ventes trimestrielles / annuelles d'un produit, vous ne pouvez pas utiliser une base de données transactionnelle opérationnelle, car cela bloquera le système de transaction. Par conséquent, un entrepôt de données est utilisé à cette fin.
Différence entre DW et ODB
Les différences entre un entrepôt de données et une base de données opérationnelle (base de données transactionnelle) sont les suivantes -
Un système transactionnel est conçu pour des charges de travail et des transactions connues telles que la mise à jour d'un enregistrement d'utilisateur, la recherche d'un enregistrement, etc. Cependant, les transactions de l'entrepôt de données sont plus complexes et présentent une forme générale de données.
Un système transactionnel contient les données actuelles d'une organisation et l'entrepôt de données contient normalement les données historiques.
Le système transactionnel prend en charge le traitement parallèle de plusieurs transactions. Des mécanismes de contrôle d'accès et de récupération sont nécessaires pour maintenir la cohérence de la base de données.
Une requête de base de données opérationnelle permet de lire et de modifier des opérations (suppression et mise à jour) alors qu'une requête OLAP ne nécessite qu'un accès en lecture seule aux données stockées (instruction Select).
Architecture DW
L'entreposage de données implique le nettoyage des données, l'intégration des données et la consolidation des données.

Un entrepôt de données a une architecture à 3 couches - Data Source Layer, Integration Layer, et Presentation Layer. L'illustration ci-dessus montre l'architecture commune d'un système Data Warehouse.
Il existe quatre types de système d'entreposage de données.
- Data Mart
- Traitement analytique en ligne (OLAP)
- Traitement transactionnel en ligne (OLTP)
- Analyse prédictive (PA)
Data Mart
Un magasin de données est connu comme la forme la plus simple d'un système d'entrepôt de données et se compose normalement d'un seul domaine fonctionnel dans une organisation comme les ventes, les finances ou le marketing, etc.
Data Mart dans une organisation et est créé et géré par un seul service. Comme il appartient à un seul département, le département obtient généralement des données à partir de quelques ou d'un seul type de sources / applications. Cette source peut être un système opérationnel interne, un entrepôt de données ou un système externe.
Processus analytique en ligne
Dans un système OLAP, le nombre de transactions est inférieur à celui d'un système transactionnel. Les requêtes exécutées sont de nature complexe et impliquent des agrégations de données.
Qu'est-ce qu'une agrégation?
Nous enregistrons des tableaux avec des données agrégées telles que annuelle (1 ligne), trimestrielle (4 lignes), mensuelle (12 lignes) ou plus, si quelqu'un doit faire une comparaison d'une année à l'autre, une seule ligne sera traitée. Cependant, dans un tableau non agrégé, il comparera toutes les lignes.
SELECT SUM(salary)
FROM employee
WHERE title = 'Programmer';Mesures efficaces dans un système OLAP
Le temps de réponse est reconnu comme l'une des mesures les plus efficaces et les plus importantes OLAPsystème. Les données stockées agrégées sont conservées dans des schémas multidimensionnels tels que des schémas en étoile (lorsque les données sont organisées en groupes hiérarchiques, souvent appelés dimensions et en faits et faits agrégés, on parle de schémas).
La latence d'un système OLAP est de quelques heures par rapport aux data marts où la latence est attendue plus proche d'un jour.
Traitement des transactions en ligne
Dans un système OLTP, il existe un grand nombre de transactions en ligne courtes telles que INSERT, UPDATE et DELETE.
Dans un système OLTP, une mesure efficace est le temps de traitement des transactions courtes et est très inférieur. Il contrôle l'intégrité des données dans les environnements multi-accès. Pour un système OLTP, le nombre de transactions par seconde mesure leeffectiveness. Un système d'entrepôt de données OLTP contient des données actuelles et détaillées et est conservé dans les schémas du modèle d'entité (3NF).
Exemple
Système de transaction au jour le jour dans un magasin de détail, où les enregistrements des clients sont insérés, mis à jour et supprimés quotidiennement. Il fournit un traitement des requêtes très rapide. Les bases de données OLTP contiennent des données détaillées et actuelles. Le schéma utilisé pour stocker la base de données OLTP est le modèle Entity.
Différences entre OLTP et OLAP
Les illustrations suivantes montrent les principales différences entre un OLTP et OLAP système.

Indexes - Le système OLTP n'a que quelques index tandis que dans un système OLAP, il existe de nombreux index pour l'optimisation des performances.
Joins- Dans un système OLTP, un grand nombre de jointures et de données sont normalisées. Cependant, dans un système OLAP, il y a moins de jointures et sont dé-normalisées.
Aggregation - Dans un système OLTP, les données ne sont pas agrégées alors que dans une base de données OLAP, davantage d'agrégations sont utilisées.
Analyse prédictive
L'analyse prédictive est connue comme la recherche des modèles cachés dans les données stockées dans le système DW en utilisant différentes fonctions mathématiques pour prédire les résultats futurs.
Le système d'analyse prédictive est différent d'un système OLAP en termes d'utilisation. Il est utilisé pour se concentrer sur les résultats futurs. Un système OALP se concentre sur le traitement des données actuelles et historiques pour les rapports analytiques.
Il existe divers systèmes d'entrepôt de données / bases de données disponibles sur le marché qui répondent aux capacités d'un système DW. Les fournisseurs les plus courants de systèmes d'entrepôt de données sont:
- Microsoft SQL Server
- Oracle Exadata
- IBM Netezza
- Teradata
- Sybase IQ
- SAP Business Warehouse (SAP BW)
Entrepôt d'entreprise SAP
SAP Business Warehousefait partie de la plate-forme de publication SAP NetWeaver. Avant NetWeaver 7.4, il était appelé SAP NetWeaver Business Warehouse.
L'entreposage de données dans SAP BW signifie l'intégration, la transformation, le nettoyage des données, le stockage et la mise en scène des données. Le processus DW comprend la modélisation des données dans le système BW, la mise en scène et l'administration. L'outil principal, utilisé pour gérer les tâches DW dans le système BW, est l'atelier d'administration.
Principales caractéristiques
SAP BW fournit des fonctionnalités telles que la Business Intelligence, qui comprend des services analytiques et de la planification commerciale, des rapports analytiques, le traitement des requêtes et des informations, ainsi que l'entreposage de données d'entreprise.
Il fournit une combinaison de bases de données et d'outils de gestion de bases de données qui aident à prendre des décisions.
Les autres fonctionnalités clés du système BW incluent l'interface de programmation d'applications métier (BAPI) qui prend en charge la connexion aux applications non SAP R / 3, l'extraction et le chargement automatisés des données, un processeur OLAP intégré, un référentiel de métadonnées, des outils d'administration, une prise en charge multilingue et interface Web activée.
SAP BW a été introduit pour la première fois en 1998 par SAP, une société allemande. Le système SAP BW était basé sur une approche basée sur un modèle pour rendre l'Enterprise Data Warehouse facile, simple et plus efficace pour les données SAP R3.
Au cours des 16 dernières années, SAP BW est devenu l'un des systèmes clés permettant à de nombreuses entreprises de gérer leurs besoins d'entreposage de données d'entreprise.
Le Business Explorer (BEx) offre une option de reporting flexible, d'analyse stratégique et de reporting opérationnel dans l'entreprise.
Il est utilisé pour effectuer des rapports, des fonctions d'exécution de requêtes et d'analyse dans le système BI. Vous pouvez également traiter des données actuelles et historiques jusqu'à divers degrés de détails sur le Web et au format Excel.
En utilisant BEx diffusion d'informations, le contenu BI peut être partagé par e-mail en tant que document ou sous forme de liens sous forme de données en direct ou vous pouvez également publier à l'aide des fonctions SAP EP.
Objets et produits commerciaux
SAP Business Objects est connu comme l'outil de Business Intelligence le plus courant et est utilisé pour manipuler les données, l'accès des utilisateurs, l'analyse, le formatage et la publication d'informations sur différentes plates-formes. Il s'agit d'un ensemble d'outils basés sur le front-end, qui permet aux utilisateurs métier et aux décideurs d'afficher, de trier et d'analyser les données actuelles et historiques de Business Intelligence.
Il comprend les outils suivants -
Intelligence Web
Web Intelligence (WebI) est considéré comme l'outil de reporting détaillé de Business Objects le plus courant qui prend en charge diverses fonctionnalités d'analyse de données telles que l'exploration, les hiérarchies, les graphiques, les mesures calculées, etc. Il permet aux utilisateurs finaux de créer des requêtes ad hoc dans l'Editeur de requête et pour effectuer l'analyse des données en ligne et hors ligne.
SAP Business Objects Xcelsius / Tableaux de bord
Les tableaux de bord fournissent aux utilisateurs finaux des fonctionnalités de visualisation des données et de tableau de bord et vous pouvez créer des tableaux de bord interactifs à l'aide de cet outil.
Vous pouvez également ajouter divers types de graphiques et de graphiques et créer des tableaux de bord dynamiques pour les visualisations de données et ceux-ci sont principalement utilisés dans les réunions financières dans une organisation.
Rapports Crystal
Les rapports Crystal sont utilisés pour des rapports au pixel près. Cela permet aux utilisateurs de créer et de concevoir des rapports et de les utiliser ultérieurement à des fins d'impression.
Explorateur
L'explorateur permet à un utilisateur de rechercher le contenu dans le référentiel BI et les meilleures correspondances sont affichées sous forme de graphiques. Il n'est pas nécessaire de noter les requêtes pour effectuer la recherche.
Divers autres composants et outils introduits à des fins de reporting détaillé, de visualisation des données et de tableau de bord sont Design Studio, Analysis Edition pour Microsoft Office, BI Repository et la plateforme Business Objects Mobile.
ETL signifie Extraire, Transformer et Charger. Un outil ETL extrait les données de différents systèmes sources SGBDR, transforme les données comme l'application de calculs, concaténation, etc., puis charge les données dans le système Data Warehouse. Les données sont chargées dans le système DW sous la forme de tables de dimensions et de faits.
Extraction
Une zone de transit est requise pendant le chargement ETL. Il y a plusieurs raisons pour lesquelles une zone de rassemblement est nécessaire.
Les systèmes sources ne sont disponibles que pendant une période spécifique pour extraire les données. Cette période est inférieure au temps total de chargement des données. Par conséquent, la zone de transit vous permet d'extraire les données du système source et de les conserver dans la zone de transit avant la fin de la plage horaire.
La zone de transit est requise lorsque vous souhaitez rassembler les données de plusieurs sources de données ou si vous souhaitez joindre deux ou plusieurs systèmes ensemble. Par exemple, vous ne pourrez pas exécuter une requête SQL joignant deux tables de deux bases de données physiquement différentes.
Le créneau horaire des extractions de données pour différents systèmes varie en fonction du fuseau horaire et des heures de fonctionnement.
Les données extraites des systèmes sources peuvent être utilisées dans plusieurs systèmes d'entrepôt de données, magasins de données d'exploitation, etc.
ETL vous permet d'effectuer des transformations complexes et nécessite une zone supplémentaire pour stocker les données.

Transformer
Dans la transformation de données, vous appliquez un ensemble de fonctions sur les données extraites pour les charger dans le système cible. Les données, qui ne nécessitent aucune transformation, sont appelées déplacement direct ou transfert de données.
Vous pouvez appliquer différentes transformations aux données extraites du système source. Par exemple, vous pouvez effectuer des calculs personnalisés. Si vous voulez un revenu de somme des ventes et que celui-ci ne figure pas dans la base de données, vous pouvez appliquer leSUM formule pendant la transformation et chargez les données.
Par exemple, si vous avez le prénom et le nom dans une table dans différentes colonnes, vous pouvez utiliser concaténer avant le chargement.
Charge
Pendant la phase de chargement, les données sont chargées dans le système cible final et il peut s'agir d'un fichier plat ou d'un système Data Warehouse.
SAP BO Data Services est un outil ETL utilisé pour l'intégration des données, la qualité des données, le profilage des données et le traitement des données. Il vous permet d'intégrer et de transformer un système d'entrepôt de données fiable pour des rapports analytiques.
BO Data Services se compose d'une interface de développement d'interface utilisateur, d'un référentiel de métadonnées, d'une connectivité de données au système source et cible et d'une console de gestion pour la planification des travaux.
Intégration et gestion des données
SAP BO Data Services est un outil d'intégration et de gestion des données et se compose de Data Integrator Job Server et Data Integrator Designer.
Principales caractéristiques
Vous pouvez appliquer diverses transformations de données à l'aide du langage Data Integrator pour appliquer des transformations de données complexes et créer des fonctions personnalisées.
Data Integrator Designer est utilisé pour stocker les jobs en temps réel et par lots et les nouveaux projets dans le référentiel.
DI Designer fournit également une option pour le développement ETL en équipe en fournissant un référentiel central avec toutes les fonctionnalités de base.
Le serveur de travaux Data Integrator est chargé de traiter les travaux créés à l'aide de DI Designer.
Administrateur Web
L'administrateur Web de Data Integrator est utilisé par les administrateurs système et l'administrateur de base de données pour gérer les référentiels dans les services de données. Les services de données comprennent le référentiel de métadonnées, le référentiel central pour le développement en équipe, Job Server et les services Web.
Fonctions clés de DI Web Administrator
- Il est utilisé pour planifier, surveiller et exécuter des travaux par lots.
- Il est utilisé pour la configuration et le démarrage et l'arrêt des serveurs en temps réel.
- Il est utilisé pour configurer Job Server, Access Server et l'utilisation du référentiel.
- Il est utilisé pour configurer les adaptateurs.
- Il est utilisé pour configurer et contrôler tous les outils de BO Data Services.
La fonction de gestion des données met l'accent sur la qualité des données. Cela implique le nettoyage des données, l'amélioration et la consolidation des données pour obtenir des données correctes dans le système DW.
Dans ce chapitre, nous découvrirons l'architecture SAP BODS. L'illustration montre l'architecture du système BODS avec zone de transit.
Couche source
La couche source comprend différentes sources de données telles que les applications SAP et le système SGBDR non SAP et l'intégration des données a lieu dans la zone de transit.
SAP Business Objects Data Services comprend différents composants tels que Data Service Designer, Data Services Management Console, Repository Manager, Data Services Server Manager, Work bench, etc. Le système cible peut être un système DW comme SAP HANA, SAP BW ou un non-SAP Système d'entrepôt de données.

La capture d'écran suivante montre les différents composants de SAP BODS.

Vous pouvez également diviser l'architecture BODS dans les couches suivantes -
- Couche d'application Web
- Couche du serveur de base de données
- Couche de service des services de données
L'illustration suivante montre l'architecture BODS.

Évolution du produit - ATL, DI et DQ
Acta Technology Inc. a développé SAP Business Objects Data Services et plus tard Business Objects Company l'a acquis. Acta Technology Inc. est une société basée aux États-Unis et était responsable du développement de la première plate-forme d'intégration de données. Les deux logiciels ETL développés par Acta Inc. étaient lesData Integration (DI) outil et le Data Management ou Data Quality (DQ) outil.
Business Objects, une société française a acquis Acta Technology Inc. en 2002 et plus tard, les deux produits ont été renommés Business Objects Data Integration (BODI) outil et Business Objects Data Quality (BODQ) outil.
SAP a acquis Business Objects en 2007 et les deux produits ont été renommés SAP BODI et SAP BODQ. En 2008, SAP a intégré les deux produits dans un seul produit logiciel appelé SAP Business Objects Data Services (BODS).
SAP BODS fournit une solution d'intégration de données et de gestion de données et dans la version antérieure de BODS, la solution de traitement de données textuelles était incluse.
BODS - Objets
Toutes les entités utilisées dans BO Data Services Designer sont appelées Objects. Tous les objets tels que les projets, les travaux, les métadonnées et les fonctions système sont stockés dans la bibliothèque d'objets locale. Tous les objets sont de nature hiérarchique.
Les objets contiennent principalement les éléments suivants -
Properties- Ils sont utilisés pour décrire un objet et n'affectent pas son fonctionnement. Exemple - Nom d'un objet, date de sa création, etc.
Options - Qui contrôlent le fonctionnement des objets.
Types d'objets
Il existe deux types d'objets dans le système: les objets réutilisables et les objets à usage unique. Le type d'objet détermine comment cet objet est utilisé et récupéré.
Objets réutilisables
La plupart des objets stockés dans le référentiel peuvent être réutilisés. Lorsqu'un objet réutilisable est défini et enregistré dans le référentiel local, vous pouvez réutiliser l'objet en créant des appels à la définition. Chaque objet réutilisable n'a qu'une seule définition et tous les appels à cet objet font référence à cette définition. Maintenant, si la définition d'un objet est modifiée à un endroit, vous modifiez la définition de l'objet à tous les endroits où cet objet apparaît.
Une bibliothèque d'objets est utilisée pour contenir une définition d'objet et lorsqu'un objet est glissé et déposé de la bibliothèque, une nouvelle référence à un objet existant est créée.
Objets à usage unique
Tous les objets définis spécifiquement pour un travail ou un flux de données sont appelés objets à usage unique. Par exemple, une transformation spécifique utilisée dans n'importe quel chargement de données.
BODS - Hiérarchie des objets
Tous les objets sont de nature hiérarchique. Le diagramme suivant montre la hiérarchie des objets dans le système SAP BODS -

BODS - Outils et fonctions
Sur la base de l'architecture illustrée ci-dessous, nous avons de nombreux outils définis dans SAP Business Objects Data Services. Chaque outil a sa propre fonction selon le paysage du système.

En haut, les services de plateforme d'informations sont installés pour les utilisateurs et la gestion de la sécurité des droits. BODS dépend de la console de gestion centrale (CMC) pour l'accès utilisateur et la fonction de sécurité. Cela s'applique à la version 4.x. Dans la version précédente, cela se faisait dans la console de gestion.
Data Services Designer est un outil de développement utilisé pour créer des objets comprenant le mappage de données, la transformation et la logique. Il est basé sur une interface graphique et fonctionne en tant que concepteur pour les services de données.
Dépôt
Le référentiel est utilisé pour stocker les métadonnées des objets utilisés dans BO Data Services. Chaque référentiel doit être enregistré dans Central Management Console et est lié à un ou plusieurs serveurs de travaux, qui sont responsables de l'exécution des travaux que vous créez.
Types de référentiels
Il existe trois types de référentiels.
Local Repository - Il est utilisé pour stocker les métadonnées de tous les objets créés dans Data Services Designer comme les projets, les travaux, le flux de données, le flux de travail, etc.
Central Repository- Il permet de contrôler la gestion des versions des objets et est utilisé pour le développement multi-usage. Le référentiel central stocke toutes les versions d'un objet d'application. Par conséquent, il vous permet de passer aux versions précédentes.
Profiler Repository- Ceci est utilisé pour gérer toutes les métadonnées liées aux tâches du profileur effectuées dans SAP BODS Designer. Le référentiel CMS stocke les métadonnées de toutes les tâches effectuées dans CMC sur la plateforme de BI. Information Steward Repository stocke toutes les métadonnées des tâches de profilage et des objets créés dans Information Steward.
Job Server
Le serveur de travaux est utilisé pour exécuter les travaux en temps réel et par lots que vous avez créés. Il obtient les informations de travail des référentiels respectifs et lance le moteur de données pour exécuter le travail. Le serveur de travaux peut exécuter les travaux en temps réel ou planifiés et utilise le multithreading dans la mise en cache mémoire et le traitement parallèle pour optimiser les performances.
Serveur d'accès
Le serveur d'accès dans les services de données est connu sous le nom de système de courtier de messages en temps réel, qui prend les demandes de message, passe au service en temps réel et affiche un message dans un laps de temps spécifique.
Console de gestion des services de données
La console de gestion du service de données est utilisée pour effectuer des activités d'administration telles que la planification des travaux, la génération des rapports de qualité dans le système DS, la validation des données, la documentation, etc.
BODS - Normes de dénomination
Il est conseillé d'utiliser des conventions de dénomination standard pour tous les objets de tous les systèmes car cela vous permet d'identifier facilement les objets dans les référentiels.
Le tableau présente la liste des conventions de dénomination recommandées qui doivent être utilisées pour tous les travaux et autres objets.
| Préfixe | Suffixe | Objet |
|---|---|---|
| DF_ | n / a | Flux de données |
| EDF_ | _Contribution | Flux de données intégré |
| EDF_ | _Production | Flux de données intégré |
| RTJob_ | n / a | Travail en temps réel |
| WF_ | n / a | Flux de travail |
| EMPLOI_ | n / a | Emploi |
| n / a | _DS | Magasin de données |
| DC_ | n / a | Configuration des données |
| SC_ | n / a | Configuration du système |
| n / a | _Memory_DS | Banque de données mémoire |
| PROC_ | n / a | Procédure stockée |
Les bases de BO Data Service incluent des objets clés dans la conception de flux de travail tels que projet, travail, flux de travail, flux de données, référentiels.
BODS - Référentiel et types
Le référentiel est utilisé pour stocker les métadonnées des objets utilisés dans BO Data Services. Chaque référentiel doit être enregistré dans Central Management Console, CMC et est lié à un ou plusieurs serveurs de travaux, qui sont chargés d'exécuter les travaux que vous avez créés.
Types de référentiels
Il existe trois types de référentiels.
Local Repository - Il est utilisé pour stocker les métadonnées de tous les objets créés dans Data Services Designer comme les projets, les travaux, le flux de données, le flux de travail, etc.
Central Repository- Il permet de contrôler la gestion des versions des objets et est utilisé pour le développement multi-usage. Le référentiel central stocke toutes les versions d'un objet d'application. Par conséquent, il vous permet de passer aux versions précédentes.
Profiler Repository- Ceci est utilisé pour gérer toutes les métadonnées liées aux tâches du profileur effectuées dans SAP BODS Designer. Le référentiel CMS stocke les métadonnées de toutes les tâches effectuées dans CMC sur la plateforme de BI. Information Steward Repository stocke toutes les métadonnées des tâches de profilage et des objets créés dans Information Steward.
Pour créer le référentiel BODS, vous devez avoir une base de données installée. Vous pouvez utiliser SQL Server, base de données Oracle, My SQL, SAP HANA, Sybase, etc.
Création du référentiel
Vous devez créer les utilisateurs suivants dans la base de données lors de l'installation de BODS et créer des référentiels. Ces utilisateurs doivent se connecter à différents serveurs tels que le serveur CMS, le serveur d'audit, etc.
Créer un BOD utilisateur identifié par Bodsserver1
- Grant Connect to BODS;
- Accorder la création d'une session à BODS;
- Accorder DBA au BODS;
- Accordez Create Any Table à BODS;
- Accordez Create Any View à BODS;
- Accordez Drop Any Table à BODS;
- Accordez Drop Any View à BODS;
- Accordez Insérer n'importe quelle table à BODS;
- Accorder la mise à jour de toute table à BODS;
- Accorder Supprimer toute table à BODS;
- Modifier le QUOTA DES CORPS D'UTILISATEURS ILLIMITÉ SUR LES UTILISATEURS;
Créer un CMS utilisateur identifié par CMSserver1
- Grant Connect to CMS;
- Accorder la création de session au CMS;
- Accorder DBA au CMS;
- Accordez Create Any Table au CMS;
- Accordez Create Any View au CMS;
- Accordez Drop Any Table au CMS;
- Accordez la suppression de n'importe quelle vue au CMS;
- Accordez Insérer n'importe quelle table au CMS;
- Accorder la mise à jour de toute table au CMS;
- Accorder Supprimer toute table au CMS;
- Modifier USER CMS QUOTA ILLIMITÉ SUR LES UTILISATEURS;
Créer un utilisateur CMSAUDIT identifié par CMSAUDITserver1
- Grant Connect à CMSAUDIT;
- Accorder la création de session à CMSAUDIT;
- Accorder DBA à CMSAUDIT;
- Accordez Create Any Table à CMSAUDIT;
- Accordez Create Any View à CMSAUDIT;
- Accordez Drop Any Table à CMSAUDIT;
- Accordez Drop Any View à CMSAUDIT;
- Accordez Insert Any table à CMSAUDIT;
- Accorder la mise à jour de toute table à CMSAUDIT;
- Accordez Delete Any table à CMSAUDIT;
- Modifier USER CMSAUDIT QUOTA ILLIMITÉ SUR LES UTILISATEURS;
Pour créer un nouveau référentiel après l'installation
Step 1 - Créer une base de données Local_Repoet accédez à Data Services Repository Manager. Configurez la base de données en tant que référentiel local.

Une nouvelle fenêtre s'ouvrira.
Step 2 - Entrez les détails dans les champs suivants -
Type de référentiel, type de base de données, nom du serveur de base de données, port, nom d'utilisateur et mot de passe.

Step 3 - Cliquez sur le Createbouton. Vous obtiendrez le message suivant -

Step 4 - Connectez-vous maintenant à la CMC de la Central Management Console dans SAP BI Platform avec nom d'utilisateur et mot de passe.
Step 5 - Sur la page d'accueil de CMC, cliquez sur Data Services.

Step 6 - De la Data Services menu, cliquez sur Configure a new Data Services Dépôt.

Step 7 - Entrez les détails comme indiqué dans la nouvelle fenêtre.
- Nom du référentiel: Local_Repo
- Type de base de données: SAP HANA
- Nom du serveur de base de données: meilleur
- Nom de la base de données: LOCAL_REPO
- Nom d'utilisateur:
- Password:*****

Step 8 - Cliquez sur le bouton Test Connection et s'il réussit, cliquez sur Save. Une fois que vous l'avez enregistré, il apparaîtra sous l'onglet Référentiel dans la CMC.
Step 9 - Appliquer les droits d'accès et la sécurité sur le référentiel local dans CMC → User and Groups.
Step 10 - Une fois l'accès donné, accédez à Data Services Designer → Sélectionnez Repository → Entrez le nom d'utilisateur et le mot de passe pour vous connecter.

Mise à jour du référentiel
Pour mettre à jour un référentiel, suivez les étapes indiquées.
Step 1 - Pour mettre à jour un référentiel après l'installation, créez une base de données Local_Repo et accédez à Data Services Repository Manager.
Step 2 - Configurer la base de données en tant que référentiel local.

Une nouvelle fenêtre s'ouvrira.
Step 3 - Saisissez les détails des champs suivants.
Type de référentiel, type de base de données, nom du serveur de base de données, port, nom d'utilisateur et mot de passe.

Vous verrez la sortie comme indiqué dans la capture d'écran ci-dessous.

Data Service Management Console (DSMC) est utilisé pour effectuer des activités d'administration telles que la planification des travaux, la génération de rapports de qualité dans le système DS, la validation des données, la documentation, etc.
Vous pouvez accéder à Data Services Management Console des manières suivantes:
Vous pouvez accéder à la console de gestion des services de données en accédant à Start → All Programs → Data Services → Data Service Management Console.
Vous pouvez également accéder à la console de gestion des services de données via Designer si vous êtes déjà connecté.
Pour accéder à la console de gestion des services de données via Designer Home Page suivez les étapes ci-dessous.

Pour accéder à la console de gestion des services de données via les outils, suivez les étapes indiquées -
Step 1 - Aller à Tools → Data Services Management Console comme indiqué dans l'image suivante.

Step 2 - Une fois connecté à Data Services Management Console, l'écran d'accueil s'ouvrira comme indiqué dans la capture d'écran ci-dessous. En haut, vous pouvez voir le nom d'utilisateur par lequel vous êtes connecté.
Sur la page d'accueil, vous verrez les options suivantes -
- Administrator
- Documentation automatique
- La validation des données
- Analyse d'impact et de lignage
- Tableau de bord opérationnel
- Rapports sur la qualité des données

Les principales fonctions de chaque module de Data Services Management Console sont expliquées dans ce chapitre.
Module administrateur
Une option Administrateur est utilisée pour gérer -
- Utilisateurs et rôles
- Pour ajouter des connexions pour accéder aux serveurs et aux référentiels
- Pour accéder aux données d'emploi publiées pour les services Web
- Pour la planification et la surveillance des travaux par lots
- Pour vérifier l'état du serveur d'accès et les services en temps réel.
Une fois que vous cliquez sur le Administratoronglet, vous pouvez voir de nombreux liens dans le volet gauche. Ce sont: l'état, le lot, les services Web, les connexions SAP, les groupes de serveurs, la gestion des référentiels de profils et l'historique d'exécution des travaux.

Nœuds
Les différents nœuds se trouvent sous le module Administrateur et sont décrits ci-dessous.
Statut
Le nœud État est utilisé pour vérifier l'état des travaux par lots et en temps réel, accéder à l'état du serveur, aux référentiels d'adaptateur et de profileur et à d'autres états du système.
Cliquez sur Statut → Sélectionnez un référentiel
Dans le volet droit, vous verrez les onglets des options suivantes -
Batch Job Status- Il est utilisé pour vérifier l'état du travail par lots. Vous pouvez vérifier les informations de travail telles que Trace, Monitor, Error et Performance Monitor, Heure de début, Heure de fin, Durée, etc.

Batch Job Configuration - La configuration des travaux par lots est utilisée pour vérifier la planification des travaux individuels ou vous pouvez ajouter une action telle que Exécuter, Ajouter une planification, Exporter la commande d'exécution.
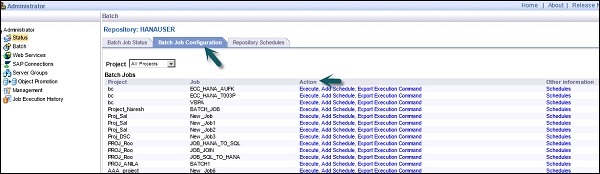
Repositories Schedules - Il est utilisé pour afficher et configurer les plannings de tous les travaux du référentiel.
Nœud de lot
Sous le nœud Batch Job, vous verrez les mêmes options que ci-dessus.
| Sr. No. | Option et description |
|---|---|
| 1 | Batch Job Status Affichez l'état de la dernière exécution et des informations détaillées sur chaque travail. |
| 2 | Batch Job Configuration Configurez les options d'exécution et de planification pour les travaux individuels. |
| 3 | Repository Schedules Affichez et configurez les planifications de tous les travaux du référentiel. |
Nœud de services Web
Les services Web sont utilisés pour publier des travaux en temps réel et des travaux par lots en tant qu'opération de service Web et pour vérifier l'état de ces opérations. Ceci est également utilisé pour maintenir la sécurité des travaux publiés en tant que service Web et pour afficherWSDL fichier.

Connexions SAP
SAP Connections permet de vérifier l'état ou de configurer RFC server interface dans Data Services Management Console.
Pour vérifier l'état de l'interface du serveur RFC, accédez à l'onglet État de l'interface du serveur RFC. Pour ajouter une nouvelle interface serveur RFC, dans l'onglet de configuration, cliquez surAdd.
Lorsqu'une nouvelle fenêtre s'ouvre, entrez les détails de configuration du serveur RFC cliquez sur Apply.

Groupes de serveurs
Ceci est utilisé pour regrouper tous les serveurs de travaux associés au même référentiel dans un groupe de serveurs. Cet onglet est utilisé pour l'équilibrage de charge lors de l'exécution des travaux dans les services de données.
Lorsqu'un travail est exécuté, il recherche le serveur de travaux correspondant et s'il est arrêté, il déplace le travail vers un autre serveur de travaux du même groupe. Il est principalement utilisé en production pour l'équilibrage de charge.

Référentiels de profils
Lorsque vous connectez le référentiel de profils à l'administrateur, cela vous permet de développer le nœud du référentiel de profils. Vous pouvez accéder à la page d'état des tâches de profil.
Nœud de gestion
Pour utiliser la fonction de l'onglet Administrateur, vous devez ajouter des connexions aux services de données à l'aide du nœud de gestion. Le nœud de gestion se compose de différentes options de configuration pour l'application d'administration.

Historique d'exécution des travaux
Ceci est utilisé pour vérifier l'historique d'exécution d'un travail ou d'un flux de données. À l'aide de cette option, vous pouvez vérifier l'historique d'exécution d'un travail par lots ou de tous les travaux par lots que vous avez créés.
Lorsque vous sélectionnez un travail, les informations sont affichées sous forme de tableau, qui comprend le nom du référentiel, le nom du travail, l'heure de début, l'heure de fin, l'heure d'exécution, l'état, etc.

Data Service Designer est un outil de développement utilisé pour créer des objets comprenant le mappage de données, la transformation et la logique. Il est basé sur une interface graphique et fonctionne en tant que concepteur pour les services de données.
Vous pouvez créer divers objets à l'aide de Data Services Designer tels que des projets, des travaux, des flux de travail, des flux de données, des mappages, des transformations, etc.
Pour démarrer le concepteur de services de données, suivez les étapes ci-dessous.
Step 1 - Pointez sur Démarrer → Tous les programmes → SAP Data Services 4.2 → Data Services Designer.

Step 2 - Sélectionnez le référentiel et entrez le mot de passe pour vous connecter.

Une fois que vous avez sélectionné le référentiel et que vous vous êtes connecté au concepteur de services de données, un écran d'accueil apparaîtra comme indiqué dans l'image ci-dessous.

Dans le volet gauche, vous avez la zone de projet, où vous pouvez créer un nouveau projet, Job, flux de données, flux de travail, etc. Dans la zone de projet, vous avez la bibliothèque d'objets locaux, qui comprend tous les objets créés dans Data Services.
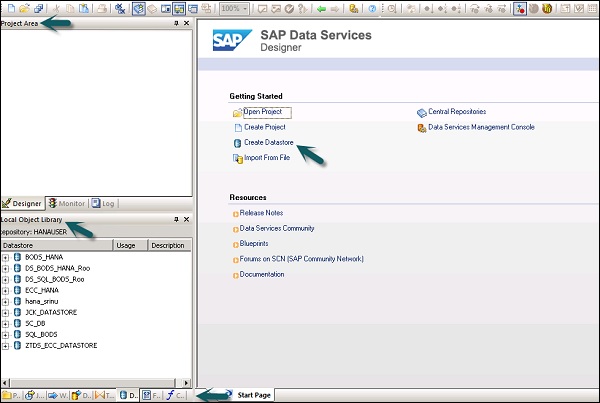
Dans le volet inférieur, vous pouvez ouvrir les objets existants en accédant à des options spécifiques telles que Projet, Travaux, Flux de données, Flux de travail, etc. Une fois que vous sélectionnez l'un des objets dans le volet inférieur, il vous montrera déjà tous les objets similaires créé dans le référentiel sous la bibliothèque d'objets locale.
Sur le côté droit, vous avez un écran d'accueil, qui peut être utilisé pour -
- Créer un projet
- Projet ouvert
- Créer des magasins de données
- Créer des référentiels
- Importer à partir d'un fichier plat
- Console de gestion des services de données
Pour développer un flux ETL, vous devez d'abord créer des magasins de données pour le système source et cible. Suivez les étapes données pour développer un flux ETL -
Step 1 - Cliquez Create Data Stores.

Une nouvelle fenêtre s'ouvrira.
Step 2 - Entrez le Datastore Nom, Datastoretype et type de base de données comme indiqué ci-dessous. Vous pouvez sélectionner une base de données différente comme système source comme indiqué dans la capture d'écran ci-dessous.

Step 3- Pour utiliser le système ECC comme source de données, sélectionnez Applications SAP comme type de banque de données. Entrez le nom d'utilisateur et le mot de passe et sur leAdvance onglet, entrez le numéro de système et le numéro de client.

Step 4- Cliquez sur OK et la banque de données sera ajoutée à la liste des bibliothèques d'objets locales. Si vous développez Datastore, il n'affiche aucune table.

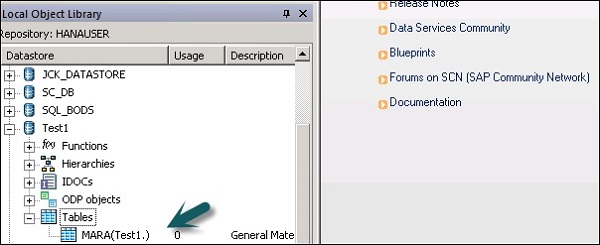
Step 5 - Pour extraire une table du système ECC à charger sur le système cible, cliquez avec le bouton droit sur Tables → Importer par noms.

Step 6 - Entrez le nom de la table et cliquez sur Import. Ici, Table – Mara est utilisé, qui est une table par défaut dans le système ECC.
Step 7 - De la même manière, créez un Datastorepour le système cible. Dans cet exemple, HANA est utilisé comme système cible.

Une fois que vous cliquez sur OK, ceci Datastore sera ajouté à la bibliothèque d'objets locale et il n'y aura pas de table à l'intérieur.
Créer un flux ETL
Pour créer un flux ETL, créez un nouveau projet.
Step 1 - Cliquez sur l'option, Create Project. Entrez le nom du projet et cliquez surCreate. Il sera ajouté à la zone du projet.

Step 2 - Faites un clic droit sur le nom du projet et créez un nouveau travail par lots / travail en temps réel.

Step 3- Saisissez le nom du travail et appuyez sur Entrée. Vous devez ajouter un flux de travail et un flux de données à cela. Sélectionnez un flux de travail et cliquez sur la zone de travail pour l'ajouter au travail. Entrez le nom du workflow et double-cliquez dessus pour l'ajouter à la zone Projet.
Step 4- De la même manière, sélectionnez le flux de données et amenez-le dans la zone Projet. Entrez le nom du flux de données et double-cliquez pour l'ajouter sous le nouveau projet.

Step 5- Faites maintenant glisser la table source sous la banque de données vers la zone de travail. Vous pouvez maintenant faire glisser la table cible avec un type de données similaire vers la zone de travail ou vous pouvez créer une nouvelle table modèle.
Pour créer une nouvelle table modèle, cliquez avec le bouton droit sur la table source, Ajouter nouveau → Table modèle.

Step 6- Entrez le nom de la table et sélectionnez la banque de données dans la liste comme banque de données cible. Le nom du propriétaire représente le nom du schéma dans lequel la table doit être créée.

La table sera ajoutée à la zone de travail avec ce nom de table.
Step 7- Faites glisser la ligne de la table source vers la table cible. Clique leSave All option en haut.

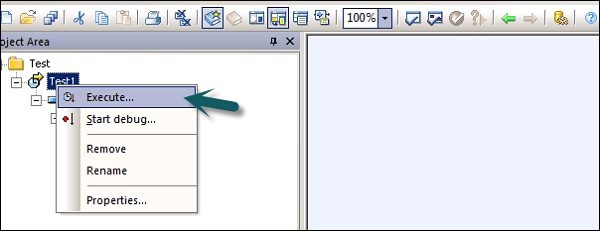
Vous pouvez maintenant planifier le travail à l'aide de Data Service Management Console ou vous pouvez l'exécuter manuellement en cliquant avec le bouton droit sur le nom du travail et exécuter.
Les banques de données sont utilisées pour configurer la connexion entre une application et la base de données. Vous pouvez créer directement un magasin de données ou être créé à l'aide d'adaptateurs. Datastore permet à une application / logiciel de lire ou d'écrire des métadonnées à partir d'une application ou d'une base de données et d'écrire dans cette base de données ou cette application.
Dans Business Objects Data Services, vous pouvez vous connecter aux systèmes suivants à l'aide de Datastore:
- Systèmes mainframe et base de données
- Applications et logiciels avec adaptateurs écrits par l'utilisateur
- Applications SAP, SAP BW, Oracle Apps, Siebel, etc.
SAP Business Objects Data Services fournit une option pour se connecter aux interfaces mainframe à l'aide AttunityConnecteur. En utilisantAttunity, connectez le magasin de données à la liste des sources ci-dessous -
- DB2 UDB pour OS / 390
- DB2 UDB pour OS / 400
- IMS/DB
- VSAM
- Adabas
- Fichiers plats sur OS / 390 et OS / 400

En utilisant le connecteur Attunity, vous pouvez vous connecter aux données mainframe à l'aide d'un logiciel. Ce logiciel doit être installé manuellement sur le serveur mainframe et le serveur de travaux client local à l'aide d'une interface ODBC.
Entrez les détails tels que l'emplacement de l'hôte, le port, l'espace de travail Attunity, etc.
Créer une banque de données pour une base de données
Pour créer une banque de données pour une base de données, suivez les étapes ci-dessous.
Step 1- Entrez le nom de la banque de données, le type de banque de données et le type de base de données comme indiqué dans l'image ci-dessous. Vous pouvez sélectionner une base de données différente comme système source indiqué dans la liste.

Step 2- Pour utiliser le système ECC comme source de données, sélectionnez Applications SAP comme type de banque de données. Saisissez le nom d'utilisateur et le mot de passe. Clique leAdvance onglet et entrez le numéro de système et le numéro de client.

Step 3- Cliquez sur OK et la banque de données sera ajoutée à la liste des bibliothèques d'objets locales. Si vous développez la banque de données, il n'y a aucune table à afficher.
Dans ce chapitre, nous allons apprendre comment éditer ou changer le magasin de données. Pour changer ou modifier la banque de données, suivez les étapes ci-dessous.
Step 1- Pour modifier une banque de données, cliquez avec le bouton droit sur le nom de la banque de données et cliquez sur Modifier. Cela ouvrira l'éditeur Datastore.

Vous pouvez modifier les informations de connexion pour la configuration actuelle de la banque de données.
Step 2 - Cliquez sur le Advance et vous pouvez modifier le numéro de client, l'identifiant du système et d'autres propriétés.
Step 3 - Cliquez sur le Edit option pour ajouter, modifier et supprimer les configurations.

Step 4 - Cliquez sur OK et les modifications seront appliquées.
Vous pouvez créer une banque de données en utilisant la mémoire comme type de base de données. Les banques de données de mémoire sont utilisées pour améliorer les performances des flux de données dans les travaux en temps réel, car elles stockent les données dans la mémoire pour faciliter un accès rapide et ne nécessitent pas d'accéder à la source de données d'origine.
Une banque de données mémoire est utilisée pour stocker les schémas de table mémoire dans le référentiel. Ces tables de mémoire obtiennent des données à partir de tables dans la base de données relationnelle ou à l'aide de fichiers de données hiérarchiques tels que les messages XML et les IDocs. Les tables mémoire restent actives jusqu'à ce que le travail soit exécuté et les données des tables mémoire ne peuvent pas être partagées entre différents travaux en temps réel.
Création d'une banque de données mémoire
Pour créer une banque de données de mémoire, suivez les étapes ci-dessous.
Step 1 - Cliquez sur Créer une banque de données et entrez le nom de la banque de données “Memory_DS_TEST”. Les tables de mémoire sont présentées avec des tables SGBDR normales et peuvent être identifiées avec des conventions de dénomination.
Step 2 - Dans Type de banque de données, sélectionnez Base de données et dans le type de base de données, sélectionnez Memory. Cliquez sur OK.

Step 3 - Maintenant, allez dans Projet → Nouveau → Projet comme indiqué dans la capture d'écran ci-dessous.

Step 4- Créez un nouveau travail en cliquant avec le bouton droit de la souris. Ajoutez un flux de travail et un flux de données comme indiqué ci-dessous.
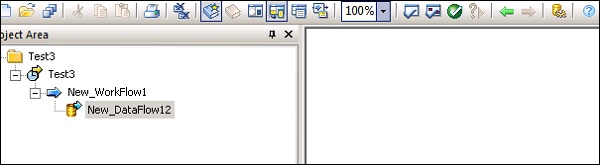
Step 5- Sélectionnez un tableau de modèles et faites-le glisser dans la zone de travail. Une fenêtre Créer une table s'ouvre.

Step 6- Entrez le nom de la table et dans Datastore, sélectionnez Memory Datastore. Si vous voulez un identifiant de ligne généré par le système, sélectionnez lecreate row idcase à cocher. Cliquez sur OK.
Step 7 - Connectez cette table mémoire au flux de données et cliquez sur Save All au sommet.

Table mémoire comme source et cible
Pour utiliser une table mémoire comme cible -
Step 1- Accédez à la bibliothèque d'objets locale, cliquez sur l'onglet Datastore. Développez la banque de données de mémoire → Développez les tables.
Step 2- Sélectionnez la table mémoire que vous souhaitez utiliser comme table source ou cible et faites-la glisser vers le flux de travail. Connectez cette table mémoire en tant que source ou cible dans le flux de données.
Step 3 - Cliquez sur le save bouton pour enregistrer le travail.
Il existe différents fournisseurs de bases de données, qui ne fournissent qu'un chemin de communication à sens unique d'une base de données à une autre base de données. Ces chemins sont appelés liens de base de données. Dans SQL Server, le serveur lié autorise un chemin de communication unidirectionnel d'une base de données à une autre.
Exemple
Considérez un serveur de base de données local nommé “Product” stocke le lien de base de données pour accéder aux informations sur le serveur de base de données distant appelé Customer. Désormais, les utilisateurs connectés au serveur de base de données distant Client ne peuvent pas utiliser le même lien pour accéder aux données du serveur de base de données Produit. Utilisateurs connectés à“Customer” doit avoir un lien distinct dans le dictionnaire de données du serveur pour accéder aux données dans le serveur de base de données Produit.
Ce chemin de communication entre les deux bases de données est appelé lien de base de données. Les banques de données créées entre ces relations de base de données liées sont appelées banques de données liées.
Il est possible de connecter une banque de données à une autre banque de données et d'importer un lien de base de données externe en option dans la banque de données.

Adapter Datastore vous permet d'importer des métadonnées d'application dans le référentiel. Vous pouvez accéder aux métadonnées de l'application et déplacer le lot et les données en temps réel entre différentes applications et logiciels.
Il existe un kit de développement logiciel adaptateur - SDK fourni par SAP qui peut être utilisé pour développer des adaptateurs personnalisés. Ces adaptateurs sont affichés dans le concepteur de services de données par les banques de données d'adaptateurs.
Pour extraire ou charger les données à l'aide d'un adaptateur, vous devez définir au moins une banque de données à cet effet.
Banque de données d'adaptateurs - Définition
Pour définir Adaptive Datastore, suivez les étapes indiquées -
Step 1 - Cliquez Create Datastore→ Saisissez le nom du magasin de données. Sélectionnez le type de banque de données comme adaptateur. Sélectionnez leJob Server dans la liste et le nom de l'instance d'adaptateur et cliquez sur OK.

Pour parcourir les métadonnées d'application
Cliquez avec le bouton droit sur le nom de la banque de données et cliquez sur Open. Cela ouvrira une nouvelle fenêtre affichant les métadonnées source. Cliquez sur + signe pour vérifier les objets et faites un clic droit sur l'objet à importer.
Le format de fichier est défini comme un ensemble de propriétés pour présenter la structure des fichiers plats. Il définit la structure des métadonnées. Le format de fichier est utilisé pour se connecter à la base de données source et cible lorsque les données sont stockées dans les fichiers et non dans la base de données.
Le format de fichier est utilisé pour les fonctions suivantes -
- Créez un modèle de format de fichier pour définir la structure d'un fichier.
- Créez un format de fichier source et cible spécifique dans le flux de données.
Les types de fichiers suivants peuvent être utilisés comme fichier source ou cible en utilisant le format de fichier -
- Delimited
- Transport SAP
- Texte non structuré
- Binaire non structuré
- Largeur fixe
Éditeur de format de fichier
L'éditeur de format de fichier est utilisé pour définir les propriétés des modèles de format de fichier et des formats de fichier source et cible.
Les modes suivants sont disponibles dans l'éditeur de format de fichier -
New mode - Il vous permet de créer un nouveau modèle de format de fichier.
Edit mode - Il vous permet de modifier un modèle de format de fichier existant.
Source mode - Il vous permet de modifier le format de fichier d'un fichier source particulier.
Target mode - Il vous permet de modifier le format de fichier d'un fichier cible particulier.
Il existe trois zones de travail pour l'éditeur de format de fichier -
Properties Values - Il est utilisé pour modifier les valeurs des propriétés de format de fichier.
Column Attributes - Il permet d'éditer et de définir les colonnes ou les champs du fichier.
Data Preview - Il est utilisé pour voir comment les paramètres affectent les données d'échantillon.
Création d'un format de fichier
Pour créer un format de fichier, suivez les étapes ci-dessous.
Step 1 - Allez dans Bibliothèque d'objets locaux → Fichiers plats.

Step 2 - Faites un clic droit sur l'option Fichiers plats → Nouveau.

Une nouvelle fenêtre de l'éditeur de format de fichier s'ouvre.
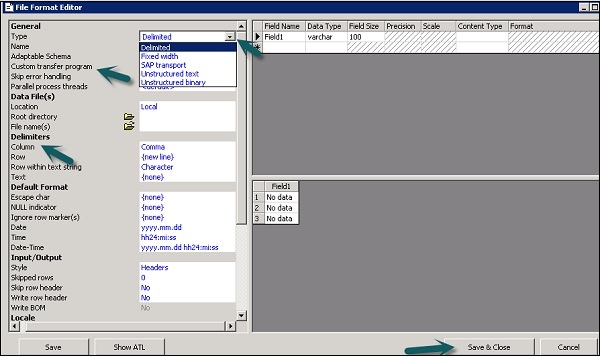
Step 3- Sélectionnez le type de format de fichier. Entrez le nom qui décrit le modèle de format de fichier. Pour les fichiers de largeur délimitée et fixe, vous pouvez lire et charger à l'aide du programme de transfert personnalisé. Entrez les autres propriétés pour décrire les fichiers que ce modèle représente.
Vous pouvez également spécifier la structure des colonnes dans la zone de travail des attributs de colonne pour quelques formats de fichiers spécifiques. Une fois toutes les propriétés définies, cliquez sur le boutonSave bouton.
Modification d'un format de fichier
Pour modifier les formats de fichier, suivez les étapes ci-dessous.
Step 1 - Dans la bibliothèque d'objets locale, accédez à la Format languette.
Step 2- Sélectionnez le format de fichier que vous souhaitez modifier. Faites un clic droit surEdit option.

Apportez des modifications dans l'éditeur de format de fichier et cliquez sur le bouton Save bouton.
Vous pouvez créer un format de fichier de cahier COBOL qui vous ralentit pour créer uniquement le format. Vous pouvez configurer la source ultérieurement une fois que vous avez ajouté le format au flux de données.
Vous pouvez créer le format de fichier et le connecter au fichier de données en même temps. Suivez les étapes ci-dessous.
Step 1 - Allez dans Bibliothèque d'objets locale → Format de fichier → Cahiers COBOL.

Step 2 - Faites un clic droit sur New option.

Step 3- Entrez le nom du format. Allez dans l'onglet Format → Sélectionnez le cahier COBOL à importer. L'extension du fichier est.cpy.
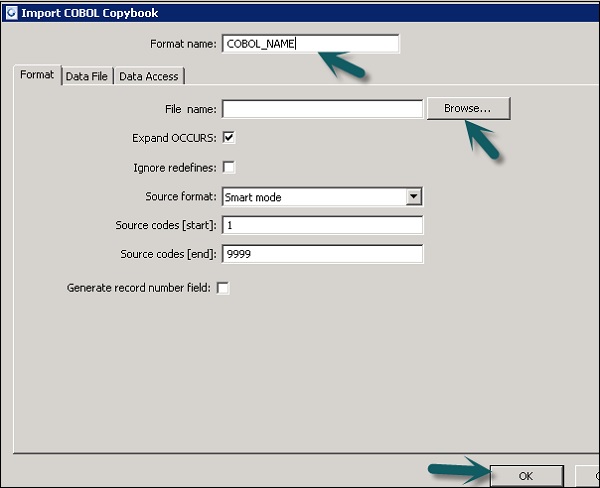
Step 4 - Cliquez OK. Ce format de fichier est ajouté à la bibliothèque d'objets locaux. La boîte de dialogue Nom du schéma COBOL Copybook s'ouvre. Si nécessaire, renommez le schéma et cliquez surOK.
En utilisant des banques de données de base de données, vous pouvez extraire les données des tables et des fonctions de la base de données. Lorsque vous effectuez une importation de données pour les métadonnées,Tool vous permet de modifier les noms de colonnes, les types de données, la description, etc.
Vous pouvez modifier les objets suivants -
- Nom de la table
- Nom de colonne
- Description de la table
- Description de la colonne
- Type de données de colonne
- Type de contenu de colonne
- Attributs de table
- Clé primaire
- Le nom du propriétaire
Importer des métadonnées
Pour importer des métadonnées, suivez les étapes ci-dessous -
Step 1 - Accédez à la bibliothèque d'objets locale → accédez à la banque de données que vous souhaitez utiliser.

Step 2 - Cliquez avec le bouton droit sur Datastore → Ouvrir.
Dans l'espace de travail, tous les éléments disponibles pour l'importation seront affichés. Sélectionnez les éléments pour lesquels vous souhaitez importer les métadonnées.

Dans la bibliothèque d'objets, accédez à la banque de données pour voir la liste des objets importés.
Vous pouvez utiliser le classeur Microsoft Excel comme source de données à l'aide des formats de fichier dans Data Services. Le classeur Excel doit être disponible sur le système de fichiers Windows ou le système de fichiers Unix.
| N ° Sr. | Accès et description |
|---|---|
| 1 | In the object library, click the Formats tab. Un classeur Excel formel décrit la structure définie dans un classeur Excel (indiquée par une extension .xls). Vous stockez des modèles de format pour les plages de données Excel dans la bibliothèque d'objets. Vous utilisez le modèle pour définir le format d'une source particulière dans un flux de données. SAP Data Services accède aux classeurs Excel en tant que source uniquement (et non en tant que cibles). |
Faites un clic droit sur New option et sélectionnez Excel Workbook comme indiqué dans la capture d'écran ci-dessous.

Extraction de données à partir de fichiers XML DTD, XSD
Vous pouvez également importer le format de fichier de schéma XML ou DTD.
Step 1 - Allez dans Bibliothèque d'objets locaux → onglet Format → Schéma imbriqué.
Step 2 - Pointez sur New(Vous pouvez sélectionner un fichier DTD ou un schéma XML ou un format de fichier JSON). Entrez le nom du format de fichier et sélectionnez le fichier que vous souhaitez importer. Cliquez sur OK.
Extraction de données à partir de cahiers COBOL
Vous pouvez également importer le format de fichier dans les cahiers COBOL. Accédez à Bibliothèque d'objets locaux → Format → Cahiers COBOL.

Le flux de données est utilisé pour extraire, transformer et charger des données de la source vers le système cible. Toutes les transformations, le chargement et le formatage se produisent dans le flux de données.
Une fois que vous avez défini un flux de données dans un projet, celui-ci peut être ajouté à un flux de travail ou à un travail ETL. Le flux de données peut envoyer ou recevoir des objets / informations à l'aide de paramètres. Le flux de données est nommé dans le formatDF_Name.

Exemple de flux de données
Supposons que vous souhaitiez charger une table de faits dans le système DW avec les données de deux tables du système source.
Le flux de données contient les objets suivants -
- Table à deux sources
- Joindre entre deux tables et défini dans la transformation de requête
- Table cible

Il existe trois types d'objets qui peuvent être ajoutés à un flux de données. Ils sont -
- Source
- Target
- Transforms
Step 1 - Accédez à la bibliothèque d'objets locale et faites glisser les deux tables vers l'espace de travail.

Step 2 - Pour ajouter une transformation de requête, faites glisser depuis la barre d'outils de droite.
Step 3 - Joignez les deux tables et créez un modèle de table cible en cliquant avec le bouton droit sur la case Requête → Ajouter un nouveau → Nouveau modèle de table.

Step 4 - Entrez le nom de la table cible, le nom du magasin de données et le propriétaire (nom du schéma) sous lesquels la table doit être créée.
Step 5 - Faites glisser la table cible devant et joignez-la à la transformation Requête.
Passer des paramètres
Vous pouvez également transmettre différents paramètres dans et hors du flux de données. Lors du passage d'un paramètre à un flux de données, les objets du flux de données référencent ces paramètres. À l'aide de paramètres, vous pouvez transmettre différentes opérations à un flux de données.
Exemple - Supposons que vous ayez entré un paramètre dans une table concernant la dernière mise à jour. Il vous permet d'extraire uniquement les lignes modifiées depuis la dernière mise à jour.
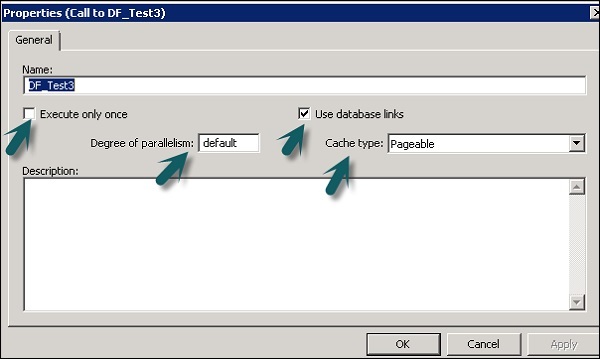
Vous pouvez modifier les propriétés d'un flux de données comme Exécuter une fois, le type de cache, le lien de base de données, le parallélisme, etc.
Step 1 - Pour modifier les propriétés du flux de données, faites un clic droit sur Flux de données → Propriétés
Vous pouvez définir diverses propriétés pour un flux de données. Les propriétés sont données ci-dessous.
| Sr. No. | Propriétés et description |
|---|---|
| 1 | Execute only once Lorsque vous spécifiez qu'un flux de données ne doit s'exécuter qu'une seule fois, un travail par lots ne réexécutera jamais ce flux de données une fois le flux de données terminé, sauf si le flux de données est contenu dans un flux de travail qui est une unité de récupération qui se réexécute et n'a pas réussi ailleurs en dehors de l'unité de récupération. Il est recommandé de ne pas marquer un flux de données comme Exécuter une seule fois si un flux de travail parent est une unité de récupération. |
| 2 | Use database links Les liens de base de données sont des chemins de communication entre un serveur de base de données et un autre. Les liens de base de données permettent aux utilisateurs locaux d'accéder aux données sur une base de données distante, qui peut se trouver sur l'ordinateur local ou distant du même type de base de données ou d'un autre. |
| 3 | Degree of parallelism Degré de parallélisme (DOP) est une propriété d'un flux de données qui définit combien de fois chaque transformation dans un flux de données se réplique pour traiter un sous-ensemble parallèle de données. |
| 4 | Cache type Vous pouvez mettre en cache les données pour améliorer les performances des opérations telles que les jointures, les groupes, les tris, le filtrage, les recherches et les comparaisons de tables. Vous pouvez sélectionner l'une des valeurs suivantes pour l'option Type de cache dans la fenêtre Propriétés de votre flux de données -
|
Step 2 - Modifiez les propriétés telles que Exécuter une seule fois, Degré de parallélisme et types de cache.
Objets source et cible
Un flux de données peut extraire ou charger des données directement à l'aide des objets suivants -
Source objects - Les objets source définissent la source à partir de laquelle les données sont extraites ou vous lisez les données.
Target objects - Target Objects définit la cible sur laquelle vous chargez ou écrivez les données.
Le type d'objet source suivant peut être utilisé et différentes méthodes d'accès sont utilisées pour les objets source.
| Table | Un fichier formaté avec des colonnes et des lignes comme utilisé dans les bases de données relationnelles | Adaptateur direct ou via |
| Tableau des modèles | Un modèle de table qui a été créé et enregistré dans un autre flux de données (utilisé dans le développement) | Direct |
| Fichier | Un fichier plat délimité ou de largeur fixe | Direct |
| Document | Un fichier avec un format spécifique à l'application (non lisible par l'analyseur SQL ou XML) | Grâce à l'adaptateur |
| Fichier XML | Un fichier formaté avec des balises XML | Direct |
| Message XML | Utilisé comme source dans les travaux en temps réel | Direct |
Les objets Target suivants peuvent être utilisés et différentes méthodes d'accès peuvent être appliquées.
| Table | Un fichier formaté avec des colonnes et des lignes comme utilisé dans les bases de données relationnelles | Adaptateur direct ou via |
| Tableau des modèles | Une table dont le format est basé sur la sortie de la transformation précédente (utilisée en développement) | Direct |
| Fichier | Un fichier plat délimité ou de largeur fixe | Direct |
| Document | Un fichier avec un format spécifique à l'application (non lisible par l'analyseur SQL ou XML) | Grâce à l'adaptateur |
| Fichier XML | Un fichier formaté avec des balises XML | Direct |
| Fichier de modèle XML | Un fichier XML dont le format est basé sur la sortie de transformation précédente (utilisé en développement, principalement pour le débogage des flux de données) | Direct |
Les workflows sont utilisés pour déterminer le processus d'exécution. L'objectif principal du workflow est de se préparer à exécuter les flux de données et de définir l'état du système, une fois l'exécution du flux de données terminée.
Les travaux par lots dans les projets ETL sont similaires aux flux de travail à la seule différence que le travail n'a pas de paramètres.
Différents objets peuvent être ajoutés à un flux de travail. Ils sont -
- Flux de travail
- Flux de données
- Scripts
- Loops
- Conditions
- Essayez ou attrapez des blocs
Vous pouvez également faire un flux de travail appeler un autre flux de travail ou un flux de travail peut s'appeler lui-même.
Note - Dans le workflow, les étapes sont exécutées dans une séquence de gauche à droite.
Exemple de flux de travail
Supposons qu'il existe une table de faits que vous souhaitez mettre à jour et que vous avez créé un flux de données avec la transformation. Maintenant, si vous souhaitez déplacer les données du système source, vous devez vérifier la dernière modification de la table de faits afin d'extraire uniquement les lignes qui sont ajoutées après la dernière mise à jour.
Pour ce faire, vous devez créer un script, qui détermine la date de la dernière mise à jour, puis le transmet en tant que paramètre d'entrée au flux de données.
Vous devez également vérifier si la connexion de données à une table de faits particulière est active ou non. S'il n'est pas actif, vous devez configurer un bloc catch, qui envoie automatiquement un e-mail à l'administrateur pour l'informer de ce problème.
Les flux de travail peuvent être créés à l'aide des méthodes suivantes -
- Bibliothèque d'objets
- Palette d'outils
Création d'un flux de travail à l'aide de la bibliothèque d'objets
Pour créer un flux de travail à l'aide de la bibliothèque d'objets, suivez les étapes ci-dessous.
Step 1 - Allez dans la bibliothèque d'objets → onglet Workflow.

Step 2 - Faites un clic droit sur New option.

Step 3 - Saisissez le nom du workflow.
Création d'un workflow à l'aide de la palette d'outils
Pour créer un flux de travail à l'aide de la palette d'outils, cliquez sur l'icône sur le côté droit et faites glisser le flux de travail dans l'espace de travail.
Vous pouvez également définir pour exécuter le flux de travail une seule fois en accédant aux propriétés du flux de travail.
Conditionnels
Vous pouvez également ajouter des conditions au flux de travail. Cela vous permet d'implémenter la logique If / Else / Then sur les workflows.
| N ° Sr. | Conditionnel et description |
|---|---|
| 1 | If Expression booléenne évaluée à TRUE ou FALSE. Vous pouvez utiliser des fonctions, des variables et des opérateurs standard pour construire l'expression. |
| 2 | Then Eléments de flux de travail à exécuter si le If expression prend la valeur TRUE. |
| 3 | Else (Facultatif) Éléments de flux de travail à exécuter si le If expression prend la valeur FALSE. |
Pour définir un conditionnel
Step 1 - Allez dans Workflow → Cliquez sur l'icône Conditionnel dans la palette d'outils sur le côté droit.
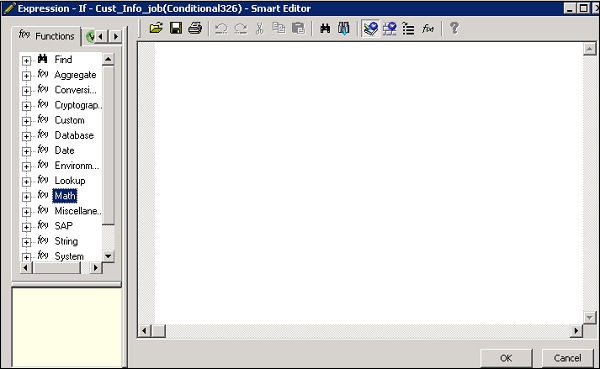
Step 2 - Double-cliquez sur le nom de Conditionnel pour ouvrir le If-Then–Else éditeur conditionnel.
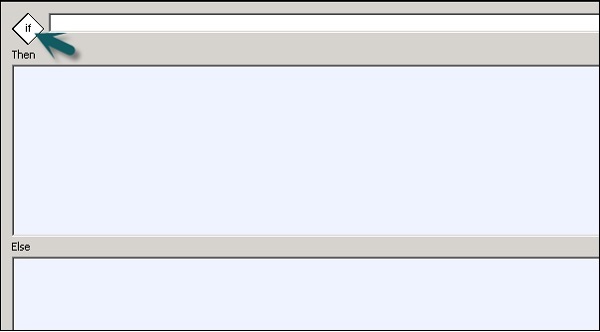
Step 3- Entrez l'expression booléenne qui contrôle le conditionnel. Cliquez sur OK.
Step 4 - Faites glisser le flux de données que vous souhaitez exécuter Then and Else fenêtre selon l'expression en condition IF.

Une fois la condition remplie, vous pouvez déboguer et valider la condition.
Les transformations sont utilisées pour manipuler les ensembles de données en tant qu'entrées et créer une ou plusieurs sorties. Il existe différentes transformations, qui peuvent être utilisées dans les services de données. Le type de transformations dépend de la version et du produit acheté.
Les types de transformations suivants sont disponibles -
Intégration de données
Les transformations d'intégration de données sont utilisées pour l'extraction, la transformation et le chargement des données dans le système DW. Il garantit l'intégrité des données et améliore la productivité des développeurs.
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Table_Comparision, etc.
Qualité des données
Les transformations de la qualité des données sont utilisées pour améliorer la qualité des données. Vous pouvez appliquer l'analyse, corriger, normaliser, enrichir l'ensemble de données à partir du système source.
- Associate
- Nettoyage des données
- Séquenceur de marche DSF2, etc.
Plate-forme
La plate-forme est utilisée pour le mouvement de l'ensemble de données. Grâce à cela, vous pouvez générer, mapper et fusionner des lignes à partir de deux ou plusieurs sources de données.
- Case
- Merge
- Requête, etc.
Traitement des données textuelles
Le traitement des données texte vous permet de traiter un grand volume de données texte.
Dans ce chapitre, vous verrez comment ajouter Transform à un flux de données.
Step 1 - Allez dans la bibliothèque d'objets → onglet Transformer.
Step 2- Sélectionnez la transformation que vous souhaitez ajouter au flux de données. Si vous ajoutez une transformation qui a l'option de sélectionner la configuration, une invite s'ouvrira.
Step 3 - Dessinez la connexion de flux de données pour connecter la source à une transformation.
Step 4 - Double-cliquez sur le nom de la transformation pour ouvrir l'éditeur de transformation.
Une fois la définition terminée, cliquez sur OK pour fermer l'éditeur.
Il s'agit de la transformation la plus courante utilisée dans les services de données et vous pouvez exécuter les fonctions suivantes:
- Filtrage des données à partir des sources
- Joindre des données provenant de plusieurs sources
- Effectuer des fonctions et des transformations sur les données
- Mappage de colonne des schémas d'entrée aux schémas de sortie
- Attribution de clés primaires
- L'ajout de nouvelles colonnes, schémas et fonctions a abouti aux schémas de sortie
La transformation de requête étant la transformation la plus couramment utilisée, un raccourci est fourni pour cette requête dans la palette d'outils.
Pour ajouter une transformation de requête, suivez les étapes ci-dessous -
Step 1- Cliquez sur la palette d'outils de transformation de requête. Cliquez n'importe où dans l'espace de travail Flux de données. Connectez-le aux entrées et sorties.

Lorsque vous double-cliquez sur l'icône de transformation de requête, il ouvre un éditeur de requête utilisé pour effectuer des opérations de requête.
Les zones suivantes sont présentes dans la transformation de requête -
- Schéma d'entrée
- Schéma de sortie
- Parameters
Les schémas d'entrée et de sortie contiennent des colonnes, des schémas imbriqués et des fonctions. Schema In et Schema Out affiche le schéma actuellement sélectionné en transformation.
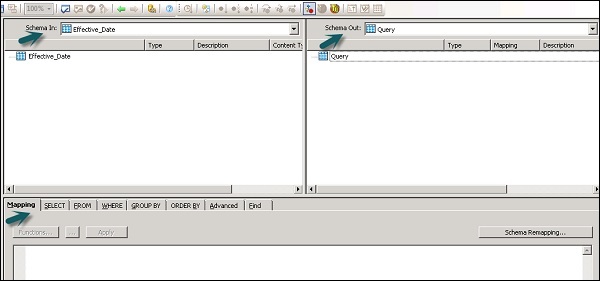
Pour modifier le schéma de sortie, sélectionnez le schéma dans la liste, cliquez avec le bouton droit et sélectionnez Rendre courant.

Transformation de la qualité des données
Les transformations de qualité des données ne peuvent pas être directement connectées à la transformation en amont, qui contient des tables imbriquées. Pour connecter ces transformations, vous devez ajouter une transformation de requête ou une transformation de pipeline XML entre la transformation de la table imbriquée et la transformation de la qualité des données.
Comment utiliser la transformation de la qualité des données?
Step 1 - Allez dans la bibliothèque d'objets → onglet Transformer
Step 2 - Développez la transformation Data Quality et ajoutez la transformation ou la configuration de transformation que vous souhaitez ajouter au flux de données.
Step 3- Dessinez les connexions de flux de données. Double-cliquez sur le nom de la transformation, cela ouvre l'éditeur de transformation. Dans le schéma d'entrée, sélectionnez les champs d'entrée que vous souhaitez mapper.
Note - Pour utiliser Associer la transformation, vous pouvez ajouter des champs définis par l'utilisateur à l'onglet d'entrée.
Transformation du traitement des données textuelles
La transformation de traitement des données de texte vous permet d'extraire les informations spécifiques d'un grand volume de texte. Vous pouvez rechercher des faits et des entités tels que des données client, produit et financier, spécifiques à une organisation.
Cette transformation vérifie également la relation entre les entités et permet l'extraction. Les données extraites, à l'aide du traitement de données textuelles, peuvent être utilisées dans la Business Intelligence, les rapports, les requêtes et les analyses.
Transformation d'extraction d'entité
Dans Data Services, le traitement des données textuelles est effectué à l'aide de Entity Extraction, qui extrait des entités et des faits à partir de données non structurées.
Cela implique l'analyse et le traitement d'un grand volume de données textuelles, la recherche d'entités, leur attribution au type approprié et la présentation des métadonnées au format standard.
La transformation Extraction d'entités peut extraire des informations de tout contenu texte, HTML, XML ou de certains formats binaires (comme PDF) et générer une sortie structurée. Vous pouvez utiliser la sortie de plusieurs manières en fonction de votre flux de travail. Vous pouvez l'utiliser comme entrée dans une autre transformation ou écrire dans plusieurs sources de sortie telles qu'une table de base de données ou un fichier plat. La sortie est générée en codage UTF-16.
Entity Extract Transform can be used in the following scenarios −
Recherche d'informations spécifiques à partir d'une grande quantité de texte.
Recherche d'informations structurées à partir d'un texte non structuré avec des informations existantes pour établir de nouvelles connexions.
Reporting et analyse de la qualité des produits.
Différences entre le TDP et le nettoyage des données
Le traitement des données textuelles est utilisé pour trouver des informations pertinentes à partir de données textuelles non structurées. Cependant, le nettoyage des données est utilisé pour la standardisation et le nettoyage des données structurées.
| Paramètres | Traitement des données textuelles | Nettoyage des données |
|---|---|---|
| Type d'entrée | Données non structurées | Données structurées |
| Taille d'entrée | Plus de 5 Ko | Moins de 5 Ko |
| Portée d'entrée | Large domaine avec de nombreuses variantes | Variations limitées |
| Utilisation potentielle | Informations potentiellement significatives issues de données non structurées | Qualité des données à stocker dans le référentiel |
| Production | Créez des annotations sous forme d'entités, de type, etc. L'entrée n'est pas modifiée | Créer des champs standardisés, l'entrée est modifiée |
L'administration des services de données comprend la création de travaux en temps réel et par lots, la planification des travaux, le flux de données intégré, les variables et paramètres, le mécanisme de récupération, le profilage des données, le réglage des performances, etc.
Emplois en temps réel
Vous pouvez créer des tâches en temps réel pour traiter les messages en temps réel dans le concepteur de services de données. Comme un travail par lots, le travail en temps réel extrait les données, les transforme et les charge.
Chaque travail en temps réel peut extraire des données d'un seul message. Vous pouvez également extraire des données à partir d'autres sources telles que des tables ou des fichiers.
Les jobs en temps réel ne sont pas exécutés à l'aide de déclencheurs contrairement aux jobs batch. Ils sont exécutés en tant que services en temps réel par les administrateurs. Les services en temps réel attendent les messages du serveur d'accès. Le serveur d'accès reçoit ce message et le transmet aux services en temps réel, qui sont configurés pour traiter le type de message. Les services en temps réel exécutent le message et retournent le résultat et continuent à traiter les messages jusqu'à ce qu'ils reçoivent une instruction pour arrêter l'exécution.
Emplois en temps réel vs lots
Les transformations telles que les branches et la logique de contrôle sont utilisées plus souvent dans les jobs en temps réel, ce qui n'est pas le cas des jobs batch dans Designer.
Les jobs en temps réel ne sont pas exécutés en réponse à une planification ou à un déclencheur interne contrairement aux jobs batch.
Création d'emplois en temps réel
Les tâches en temps réel peuvent être créées en utilisant les mêmes objets que les flux de données, les flux de travail, les boucles, les conditions, les scripts, etc.
Vous pouvez utiliser les modèles de données suivants pour créer des tâches en temps réel -
- Modèle de flux de données unique
- Modèle de flux de données multiples
Modèle de flux de données unique
Vous pouvez créer un travail en temps réel avec un flux de données unique dans sa boucle de traitement en temps réel et il comprend une seule source de message et une seule cible de message.
Creating Real Time job using single data model −
Pour créer une tâche en temps réel à l'aide d'un modèle de données unique, suivez les étapes indiquées.
Step 1 - Accédez à Data Services Designer → Projet Nouveau → Projet → Entrez le nom du projet

Step 2 - Faites un clic droit sur l'espace blanc dans la zone Projet → Nouveau travail en temps réel.

Workspace montre deux composants du travail en temps réel -
- RT_Process_begins
- Step_ends
Il montre le début et la fin du travail en temps réel.

Step 3 - Pour créer un travail en temps réel avec un flux de données unique, sélectionnez le flux de données dans la palette d'outils du volet droit et faites-le glisser vers l'espace de travail.
Cliquez à l'intérieur de la boucle, vous pouvez utiliser une source de message et une cible de message dans la boucle de traitement en temps réel. Connectez les marques de début et de fin au flux de données.

Step 4 - Ajoutez des objets de configuration dans le flux de données selon vos besoins et enregistrez le travail.
Modèle de flux de données multiples
Cela vous permet de créer un travail en temps réel avec plusieurs flux de données dans sa boucle de traitement en temps réel. Vous devez également vous assurer que les données de chaque modèle de données sont entièrement traitées avant de passer au message suivant.
Tester des emplois en temps réel
Vous pouvez tester le travail en temps réel en transmettant l'exemple de message comme message source à partir du fichier. Vous pouvez vérifier si les services de données génèrent le message cible attendu.
Pour vous assurer que votre travail vous donne le résultat attendu, vous pouvez exécuter le travail en mode Afficher les données. En utilisant ce mode, vous pouvez capturer les données de sortie pour vous assurer que votre travail en temps réel fonctionne correctement.
Flux de données intégrés
Le flux de données intégré est connu sous le nom de flux de données, qui sont appelés à partir d'un autre flux de données dans la conception. Le flux de données intégré peut contenir plusieurs nombres de sources et de cibles, mais une seule entrée ou sortie transmet les données au flux de données principal.
Les types suivants de flux de données intégrés peuvent être utilisés:
One Input - Le flux de données intégré est ajouté à la fin du flux de données.
One Output - Le flux de données intégré est ajouté au début d'un flux de données.
No input or output - Répliquez un flux de données existant.
Le flux de données intégré peut être utilisé aux fins suivantes -
Pour simplifier l'affichage du flux de données.
Si vous souhaitez enregistrer la logique de flux et la réutiliser dans d'autres flux de données.
Pour le débogage, dans lequel vous créez des sections de flux de données en tant que flux de données intégré et les exécutez séparément.
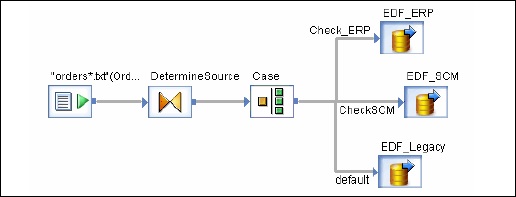
Vous pouvez sélectionner un objet dans le flux de données existant. Il existe deux manières de créer un flux de données intégré.
Option 1
Cliquez avec le bouton droit sur l'objet et sélectionnez-le pour le rendre flux de données incorporé.

Option 2
Faites glisser le flux de données complet et validez de la bibliothèque d'objets vers un flux de données ouvert dans l'espace de travail. Ensuite, ouvrez le flux de données qui a été créé. Sélectionnez l'objet que vous souhaitez utiliser comme port d'entrée et de sortie et cliquez surmake port pour cet objet.

Les services de données ajoutent cet objet comme point de connexion pour le flux de données intégré.
Variables et paramètres
Vous pouvez utiliser des variables locales et globales avec le flux de données et le flux de travail, qui offrent plus de flexibilité dans la conception des travaux.
Les principales caractéristiques sont -
Le type de données d'une variable peut être un nombre, un entier, un décimal, une date ou une chaîne de texte comme un caractère.
Les variables peuvent être utilisées dans les flux de données et les flux de travail comme fonction dans le Where clause.
Les variables locales dans les services de données sont limitées à l'objet dans lequel elles sont créées.
Les variables globales sont limitées aux emplois dans lesquels elles sont créées. À l'aide de variables globales, vous pouvez modifier les valeurs des variables globales par défaut au moment de l'exécution.
Les expressions utilisées dans le flux de travail et le flux de données sont appelées parameters.
Toutes les variables et paramètres du flux de travail et des flux de données sont affichés dans la fenêtre des variables et des paramètres.
Pour afficher les variables et les paramètres, suivez les étapes ci-dessous -
Allez dans Outils → Variables.

Une nouvelle fenêtre Variables and parametersest affiché. Il comporte deux onglets - Définitions et Appels.
le DefinitionsL'onglet vous permet de créer et d'afficher des variables et des paramètres. Vous pouvez utiliser des variables et des paramètres locaux au niveau du flux de travail et du flux de données. Les variables globales peuvent être utilisées au niveau du poste.
Emploi |
Variables locales Variables globales |
Un script ou conditionnel dans le travail Tout objet du travail |
Flux de travail |
Variables locales Paramètres |
Ce flux de travail ou transmis à d'autres flux de travail ou flux de données à l'aide d'un paramètre. Objets parents pour transmettre des variables locales. Les flux de travail peuvent également renvoyer des variables ou des paramètres aux objets parents. |
Flux de données |
Paramètres |
Une clause WHERE, un mappage de colonne ou une fonction dans le flux de données. Flux de données. Les flux de données ne peuvent pas renvoyer de valeurs de sortie. |
Dans l'onglet d'appel, vous pouvez voir le nom du paramètre défini pour tous les objets dans la définition d'un objet parent.
Définition d'une variable locale
Pour définir la variable locale, ouvrez le travail en temps réel.
Step 1- Allez dans Outils → Variables. Un nouveauVariables and Parameters la fenêtre s'ouvrira.
Step 2 - Aller à Variable → Clic droit → Insérer

Cela créera un nouveau paramètre $NewVariable0.
Step 3- Entrez le nom de la nouvelle variable. Sélectionnez le type de données dans la liste.

Une fois défini, fermez la fenêtre. De la même manière, vous pouvez définir les paramètres du flux de données et du flux de travail.

Si votre travail ne s'exécute pas correctement, vous devez corriger l'erreur et réexécuter le travail. En cas d'échec des travaux, il est possible que certaines tables aient été chargées, modifiées ou partiellement chargées. Vous devez réexécuter le travail pour obtenir toutes les données et supprimer les données en double ou manquantes.
Deux techniques pouvant être utilisées pour la récupération sont les suivantes:
Automatic Recovery - Cela vous permet d'exécuter des travaux infructueux en mode de récupération.
Manually Recovery - Cela vous permet de réexécuter les travaux sans tenir compte de la réexécution partielle la fois précédente.
To run a job with Recovery option enabled in Designer
Step 1 - Cliquez avec le bouton droit sur le nom du travail → Exécuter.

Step 2 - Enregistrez toutes les modifications et exécutez → Oui.
Step 3- Allez dans l'onglet Exécution → case à cocher Activer la récupération. Si cette case n'est pas cochée, les services de données ne récupéreront pas le travail en cas d'échec.

To run a job in Recovery mode from Designer
Step 1- Faites un clic droit et exécutez le travail comme ci-dessus. Sauvegarder les modifications.
Step 2- Accédez aux options d'exécution. Vous devez vous assurer que l'optionRecover from last failed execution la case est cochée.
Note- Cette option n'est pas activée si un travail n'est pas encore exécuté. C'est ce qu'on appelle la récupération automatique d'un travail ayant échoué.

Data Services Designer fournit une fonctionnalité de profilage des données pour garantir et améliorer la qualité et la structure des données source.
Data Profiler vous permet de -
Trouvez les anomalies dans les données sources, la validation et les actions correctives et la qualité des données sources.
Définissez la structure et la relation des données sources pour une meilleure exécution des travaux, des flux de travail et des flux de données.
Recherchez le contenu du système source et cible pour déterminer que votre travail renvoie un résultat attendu.
Data Profiler fournit les informations suivantes sur l'exécution du serveur Profiler -
Analyse des colonnes
Basic Profiling - Comprend des informations telles que min, max, avg, etc.
Detailed Profiling - Comprend des informations telles que le nombre distinct, le pourcentage distinct, la médiane, etc.
Analyse des relations
Anomalies de données entre deux colonnes pour lesquelles vous définissez une relation.
La fonction de profilage des données peut être utilisée sur les données des sources de données suivantes -
- serveur SQL
- Oracle
- DB2
- Connecteur Attunity
- Sybase IQ
- Teradata
Connexion au serveur Profiler
Pour vous connecter à un serveur de profils -
Step 1 - Allez dans Outils → Connexion au serveur Profiler

Step 2 - Entrez les détails tels que le système, le nom d'utilisateur, le mot de passe et l'authentification.
Step 3 - Cliquez sur le Log on bouton.
Lorsque vous êtes connecté, une liste des référentiels du profileur s'affiche. SélectionnerRepository et cliquez Connect.
Les performances d'un travail ETL dépendent du système sur lequel vous utilisez le logiciel Data Services, du nombre de déplacements, etc.
Il existe divers autres facteurs qui contribuent aux performances dans une tâche ETL. Ils sont -
Source Data Base - La base de données source doit être configurée pour effectuer Selectdéclarations rapidement. Cela peut être fait en augmentant la taille des E / S de la base de données, en augmentant la taille du tampon partagé pour mettre en cache plus de données et en ne permettant pas le parallèle pour les petites tables, etc.
Source Operating System- Le système d'exploitation source doit être configuré pour lire rapidement les données à partir des disques. Définissez le protocole de lecture anticipée sur 64 Ko.
Target Database - La base de données cible doit être configurée pour fonctionner INSERT et UPDATErapidement. Cela peut être fait par -
- Désactivation de la journalisation des archives.
- Désactivation de la journalisation de rétablissement pour toutes les tables.
- Maximisation de la taille du tampon partagé.
Target Operating System- Le système d'exploitation cible doit être configuré afin d'écrire rapidement les données sur les disques. Vous pouvez activer les E / S asynchrones pour rendre les opérations d'entrée / sortie aussi rapides que possible.
Network - La bande passante du réseau doit être suffisante pour transférer les données du système source au système cible.
BODS Repository Database - Pour améliorer les performances des travaux BODS, les opérations suivantes peuvent être effectuées -
Monitor Sample Rate - Si vous traitez une grande quantité de données dans un travail ETL, surveillez la fréquence d'échantillonnage à une valeur plus élevée pour réduire le nombre d'appels d'E / S vers le fichier journal, améliorant ainsi les performances.
Vous pouvez également exclure les journaux Data Services de l'analyse antivirus si l'analyse antivirus est configurée sur le serveur de travaux, car elle peut entraîner une dégradation des performances.
Job Server OS - Dans les services de données, un flux de données dans une tâche en lance un ‘al_engine’processus, qui lance quatre threads. Pour des performances maximales, envisagez une conception qui en exécute une‘al_engine’processus par CPU à la fois. Le système d'exploitation du Job Server doit être réglé de manière à ce que tous les threads soient répartis sur toutes les CPU disponibles.
SAP BO Data Services prend en charge le développement multi-utilisateur où chaque utilisateur peut travailler sur une application dans son propre référentiel local. Chaque équipe utilise un référentiel central pour enregistrer la copie principale d'une application et toutes les versions des objets de l'application.
Les principales caractéristiques sont -
Dans SAP Data Services, vous pouvez créer un référentiel central pour stocker la copie d'équipe d'une application. Il contient toutes les informations également disponibles dans le référentiel local. Cependant, il fournit simplement un emplacement de stockage pour les informations sur l'objet. Pour apporter des modifications, vous devez travailler dans le référentiel local.
Vous pouvez copier des objets du référentiel central vers le référentiel local. Cependant, si vous devez apporter des modifications, vous devez extraire cet objet dans le référentiel central. Pour cette raison, les autres utilisateurs ne peuvent pas extraire cet objet dans le référentiel central et, par conséquent, ne peuvent pas apporter de modifications au même objet.
Une fois que vous avez apporté les modifications à l'objet, vous devez archiver l'objet. Il permet aux services de données d'enregistrer un nouvel objet modifié dans le référentiel central.
Les services de données permettent à plusieurs utilisateurs disposant de référentiels locaux de se connecter au référentiel central en même temps, mais un seul utilisateur peut extraire et apporter des modifications à un objet spécifique.
Le référentiel central conserve également l'historique de chaque objet. Il vous permet de revenir à la version précédente d'un objet, si les modifications ne sont pas nécessaires.
Utilisateurs multiples
SAP BO Data Services permet à plusieurs utilisateurs de travailler sur la même application en même temps. Les termes suivants doivent être pris en compte dans un environnement multi-utilisateurs -
| N ° Sr. | Multi-utilisateur et description |
|---|---|
| 1 | Highest level object L'objet de niveau le plus élevé est l'objet qui n'est dépendant d'aucun objet de la hiérarchie d'objets. Par exemple, si la tâche 1 comprend le flux de travail 1 et le flux de données 1, la tâche 1 est l'objet de niveau le plus élevé. |
| 2 | Object dependents Les objets dépendants sont des objets associés sous l'objet de niveau le plus élevé de la hiérarchie. Par exemple, si le travail 1 est composé du flux de travail 1 qui contient le flux de données 1, alors le flux de travail 1 et le flux de données 1 sont dépendants du travail 1. De plus, le flux de données 1 dépend du flux de travail 1. |
| 3 | Object version Une version d'objet est une instance d'un objet. Chaque fois que vous ajoutez ou archivez un objet dans le référentiel central, le logiciel crée une nouvelle version de l'objet. La dernière version d'un objet est la dernière ou la plus récente version créée. |
Pour mettre à jour le référentiel local dans un environnement multi-utilisateur, vous pouvez obtenir la dernière copie de chaque objet à partir du référentiel central. Pour modifier un objet, vous pouvez utiliser l'option d'extraction et d'archivage.
Il existe différents paramètres de sécurité qui peuvent être appliqués sur un référentiel central pour le sécuriser.
Différents paramètres de sécurité sont -
Authentication - Cela permet uniquement aux utilisateurs authentiques de se connecter au référentiel central.
Authorization - Cela permet à l'utilisateur d'attribuer différents niveaux d'autorisations pour chaque objet.
Auditing- Ceci est utilisé pour maintenir l'historique de toutes les modifications apportées à un objet. Vous pouvez vérifier toutes les versions précédentes et revenir aux anciennes versions.
Création d'un référentiel central non sécurisé
Dans un environnement de développement multi-utilisateur, il est toujours conseillé de travailler en méthode de référentiel central.
Pour créer un référentiel central non sécurisé, suivez les étapes indiquées -
Step 1 - Créer une base de données, en utilisant le système de gestion de base de données, qui agira comme un référentiel central.
Step 2 - Accédez à un gestionnaire de référentiel.

Step 3- Sélectionnez le type de référentiel comme Central. Entrez les détails de la base de données tels que le nom d'utilisateur et le mot de passe et cliquezCreate.

Step 4 - Pour définir une connexion au référentiel central, Tools → Central Repository.

Step 5 - Sélectionnez le référentiel dans la connexion au référentiel central et cliquez sur le Add icône.

Step 6 - Saisissez le mot de passe du référentiel central et cliquez sur le bouton Activate bouton.
Création d'un référentiel central sécurisé
Pour créer un référentiel central sécurisé, accédez au gestionnaire de référentiel. Sélectionnez le type de référentiel comme central. Clique leEnable Security Case à cocher.

Pour un développement réussi dans l'environnement multi-utilisateur, il est conseillé d'implémenter certains processus tels que l'archivage et l'extraction.
Vous pouvez utiliser les processus suivants dans un environnement multi-utilisateur -
- Filtering
- Extraire des objets
- Annulation de l'extraction
- Archiver des objets
- Étiqueter des objets
Le filtrage est applicable lorsque vous ajoutez des objets, archivez, récupérez et étiquetez des objets dans le référentiel central.
Migration de travaux multi-utilisateurs
Dans SAP Data Services, la migration des tâches peut être appliquée à différents niveaux, c'est-à-dire au niveau de l'application, au niveau du référentiel, au niveau de la mise à niveau.
Vous ne pouvez pas copier directement le contenu d'un référentiel central vers un autre référentiel central; vous devez utiliser le référentiel local.
La première étape consiste à obtenir la dernière version de tous les objets du référentiel central vers le référentiel local. Activez le référentiel central dans lequel vous souhaitez copier le contenu. Ajoutez tous les objets que vous souhaitez copier du référentiel local au référentiel central.
Migration du référentiel central
Si vous mettez à jour la version de SAP Data Services, vous devez également mettre à jour la version de Repository.
Les points suivants doivent être pris en compte lors de la migration d'un référentiel central pour mettre à niveau la version -
Effectuez une sauvegarde du référentiel central de toutes les tables et objets.
Pour conserver la version des objets dans les services de données, maintenez un référentiel central pour chaque version. Créez un nouvel historique central avec la nouvelle version du logiciel Data Services et copiez tous les objets dans ce référentiel.
Si vous installez une nouvelle version de Data Services, il est toujours recommandé de mettre à niveau votre référentiel central vers une nouvelle version d'objets.
Mettez à niveau votre référentiel local vers la même version, car différentes versions du référentiel central et local peuvent ne pas fonctionner en même temps.
Avant de migrer le référentiel central, archivez tous les objets. Comme vous ne mettez pas à niveau le référentiel central et local simultanément, il est donc nécessaire d'archiver tous les objets. Une fois que votre référentiel central a été mis à niveau vers une version plus récente, vous ne pourrez plus archiver les objets du référentiel local, qui a une version plus ancienne des services de données.