Spark - Présentation
Les industries utilisent largement Hadoop pour analyser leurs ensembles de données. La raison en est que le framework Hadoop est basé sur un modèle de programmation simple (MapReduce) et qu'il permet une solution informatique évolutive, flexible, tolérante aux pannes et rentable. Ici, la principale préoccupation est de maintenir la vitesse de traitement des grands ensembles de données en termes de temps d'attente entre les requêtes et de temps d'attente pour exécuter le programme.
Spark a été introduit par Apache Software Foundation pour accélérer le processus du logiciel informatique Hadoop.
Contrairement à une croyance commune, Spark is not a modified version of Hadoopet ne dépend pas vraiment de Hadoop car il dispose de sa propre gestion de cluster. Hadoop n'est que l'un des moyens d'implémenter Spark.
Spark utilise Hadoop de deux manières - l'une est storage et le second est processing. Comme Spark dispose de son propre calcul de gestion de cluster, il utilise Hadoop uniquement à des fins de stockage.
Apache Spark
Apache Spark est une technologie de calcul en cluster ultra-rapide, conçue pour des calculs rapides. Il est basé sur Hadoop MapReduce et étend le modèle MapReduce pour l'utiliser efficacement pour plus de types de calculs, ce qui inclut les requêtes interactives et le traitement de flux. La principale caractéristique de Spark est sain-memory cluster computing qui augmente la vitesse de traitement d'une application.
Spark est conçu pour couvrir un large éventail de charges de travail telles que les applications par lots, les algorithmes itératifs, les requêtes interactives et le streaming. Outre la prise en charge de toutes ces charges de travail dans un système respectif, cela réduit la charge de gestion liée à la maintenance d'outils séparés.
Évolution d'Apache Spark
Spark est l'un des sous-projets d'Hadoop développé en 2009 dans AMPLab d'UC Berkeley par Matei Zaharia. Il a été Open Sourced en 2010 sous une licence BSD. Il a été donné à la fondation logicielle Apache en 2013, et maintenant Apache Spark est devenu un projet Apache de haut niveau à partir de février 2014.
Caractéristiques d'Apache Spark
Apache Spark possède les fonctionnalités suivantes.
Speed- Spark permet d'exécuter une application dans un cluster Hadoop, jusqu'à 100 fois plus rapide en mémoire et 10 fois plus rapide lors de l'exécution sur disque. Ceci est possible en réduisant le nombre d'opérations de lecture / écriture sur le disque. Il stocke les données de traitement intermédiaires en mémoire.
Supports multiple languages- Spark fournit des API intégrées en Java, Scala ou Python. Par conséquent, vous pouvez écrire des applications dans différentes langues. Spark propose 80 opérateurs de haut niveau pour les requêtes interactives.
Advanced Analytics- Spark ne prend pas seulement en charge «Map» et «réduire». Il prend également en charge les requêtes SQL, les données de streaming, l'apprentissage automatique (ML) et les algorithmes de graph.
Spark construit sur Hadoop
Le diagramme suivant montre trois façons de créer Spark avec des composants Hadoop.
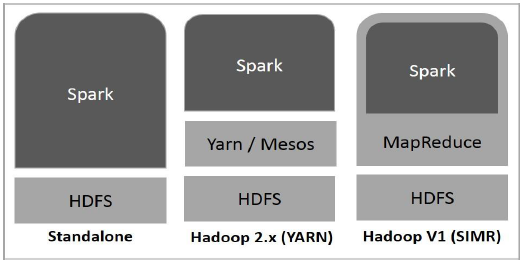
Il existe trois façons de déployer Spark, comme expliqué ci-dessous.
Standalone- Le déploiement de Spark Standalone signifie que Spark occupe la place au-dessus de HDFS (Hadoop Distributed File System) et de l'espace est alloué pour HDFS, explicitement. Ici, Spark et MapReduce s'exécuteront côte à côte pour couvrir toutes les tâches Spark sur le cluster.
Hadoop Yarn- Le déploiement de Hadoop Yarn signifie, simplement, que Spark fonctionne sur Yarn sans aucune pré-installation ou accès root requis. Il aide à intégrer Spark dans l'écosystème Hadoop ou la pile Hadoop. Il permet à d'autres composants de fonctionner au-dessus de la pile.
Spark in MapReduce (SIMR)- Spark dans MapReduce est utilisé pour lancer le travail Spark en plus du déploiement autonome. Avec SIMR, l'utilisateur peut démarrer Spark et utiliser son shell sans aucun accès administratif.
Composants de Spark
L'illustration suivante décrit les différents composants de Spark.
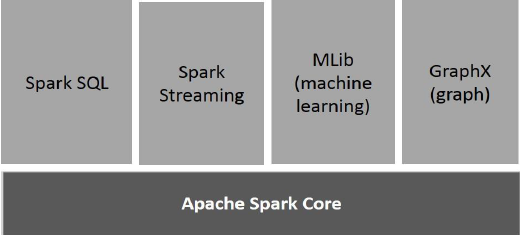
Apache Spark Core
Spark Core est le moteur d'exécution générale sous-jacent de la plate-forme Spark sur lequel toutes les autres fonctionnalités sont basées. Il fournit un calcul en mémoire et des ensembles de données de référence dans des systèmes de stockage externes.
Spark SQL
Spark SQL est un composant au-dessus de Spark Core qui introduit une nouvelle abstraction de données appelée SchemaRDD, qui prend en charge les données structurées et semi-structurées.
Spark Streaming
Spark Streaming exploite la capacité de planification rapide de Spark Core pour effectuer des analyses de streaming. Il ingère les données en mini-lots et effectue des transformations RDD (Resilient Distributed Datasets) sur ces mini-lots de données.
MLlib (bibliothèque d'apprentissage automatique)
MLlib est un framework d'apprentissage automatique distribué au-dessus de Spark en raison de l'architecture Spark basée sur la mémoire distribuée. C'est, selon les benchmarks, fait par les développeurs MLlib contre les implémentations ALS (Alternating Meast Squares). Spark MLlib est neuf fois plus rapide que la version sur disque Hadoop deApache Mahout (avant que Mahout n'obtienne une interface Spark).
GraphX
GraphX est un framework de traitement de graphes distribué au-dessus de Spark. Il fournit une API pour exprimer le calcul de graphes qui peut modéliser les graphes définis par l'utilisateur à l'aide de l'API d'abstraction Pregel. Il fournit également un runtime optimisé pour cette abstraction.