Teradata - Guide rapide
Qu'est-ce que Teradata?
Teradata est l'un des systèmes de gestion de bases de données relationnelles les plus populaires. Il convient principalement à la création d'applications d'entreposage de données à grande échelle. Teradata y parvient grâce au concept de parallélisme. Il est développé par la société Teradata.
Histoire de Teradata
Voici un bref résumé de l'histoire de Teradata, énumérant les principales étapes.
1979 - Teradata a été incorporée.
1984 - Sortie du premier ordinateur de base de données DBC / 1012.
1986- Le magazine Fortune nomme Teradata «Produit de l'année».
1999 - La plus grande base de données au monde utilisant Teradata avec 130 téraoctets.
2002 - Teradata V2R5 publié avec l'index primaire de partition et la compression.
2006 - Lancement de la solution Teradata Master Data Management.
2008 - Teradata 13.0 est disponible avec Active Data Warehousing.
2011 - Acquiert Teradata Aster et entre dans Advanced Analytics Space.
2012 - Introduction de Teradata 14.0.
2014 - Introduction de Teradata 15.0.
Caractéristiques de Teradata
Voici quelques-unes des fonctionnalités de Teradata -
Unlimited Parallelism- Le système de base de données Teradata est basé sur l'architecture de traitement massivement parallèle (MPP). L'architecture MPP répartit la charge de travail uniformément sur l'ensemble du système. Le système Teradata répartit la tâche entre ses processus et les exécute en parallèle pour s'assurer que la tâche est terminée rapidement.
Shared Nothing Architecture- L'architecture de Teradata est appelée architecture de rien partagé. Les nœuds Teradata, ses processeurs de module d'accès (AMP) et les disques associés aux AMP fonctionnent indépendamment. Ils ne sont pas partagés avec les autres.
Linear Scalability- Les systèmes Teradata sont hautement évolutifs. Ils peuvent évoluer jusqu'à 2048 nœuds. Par exemple, vous pouvez doubler la capacité du système en doublant le nombre d'AMP.
Connectivity - Teradata peut se connecter à des systèmes connectés au canal tels que les systèmes mainframe ou connectés au réseau.
Mature Optimizer- L'optimiseur Teradata est l'un des optimiseurs mûrs du marché. Il a été conçu pour être parallèle depuis ses débuts. Il a été affiné pour chaque version.
SQL- Teradata prend en charge SQL standard pour interagir avec les données stockées dans les tables. En plus de cela, il fournit sa propre extension.
Robust Utilities - Teradata fournit des utilitaires robustes pour importer / exporter des données depuis / vers le système Teradata tels que FastLoad, MultiLoad, FastExport et TPT.
Automatic Distribution - Teradata distribue automatiquement les données uniformément sur les disques sans aucune intervention manuelle.
Teradata fournit Teradata express pour VMWARE qui est une machine virtuelle Teradata pleinement opérationnelle. Il fournit jusqu'à 1 téraoctet de stockage. Teradata fournit une version de 40 Go et 1 To de VMware.
Conditions préalables
Étant donné que la machine virtuelle est 64 bits, votre processeur doit prendre en charge 64 bits.
Étapes d'installation pour Windows
Step 1 - Téléchargez la version de VM requise à partir du lien, https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 - Extrayez le fichier et spécifiez le dossier cible.
Step 3 - Téléchargez le lecteur VMWare Workstation à partir du lien, https://my.vmware.com/web/vmware/downloads. Il est disponible pour Windows et Linux. Téléchargez le lecteur de station de travail VMWARE pour Windows.
Step 4 - Une fois le téléchargement terminé, installez le logiciel.
Step 5 - Une fois l'installation terminée, exécutez le client VMWARE.
Step 6- Sélectionnez «Ouvrir une machine virtuelle». Naviguez dans le dossier Teradata VMWare extrait et sélectionnez le fichier avec l'extension .vmdk.
Step 7- Teradata VMWare est ajouté au client VMWare. Sélectionnez le Teradata VMware ajouté et cliquez sur «Play Virtual Machine».

Step 8 - Si vous obtenez une fenêtre contextuelle sur les mises à jour logicielles, vous pouvez sélectionner «Me le rappeler plus tard».
Step 9 - Entrez le nom d'utilisateur en tant que root, appuyez sur tab et entrez le mot de passe en tant que root et appuyez à nouveau sur Entrée.
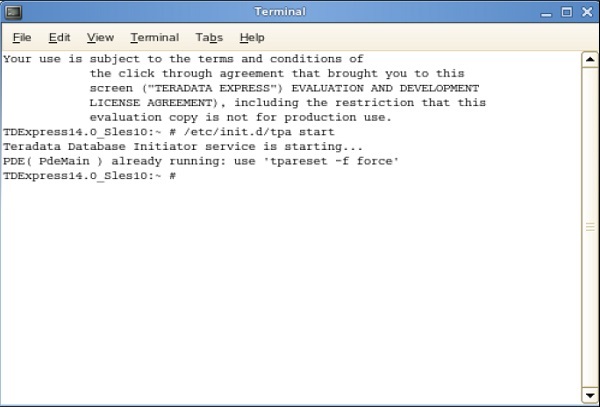
Step 10- Une fois que l'écran suivant apparaît sur le bureau, double-cliquez sur «root's home». Ensuite, double-cliquez sur 'Genome's Terminal'. Cela ouvrira le Shell.

Step 11- Depuis le shell suivant, entrez la commande /etc/init.d/tpa start. Cela démarrera le serveur Teradata.
Démarrage de BTEQ
L'utilitaire BTEQ est utilisé pour soumettre des requêtes SQL de manière interactive. Voici les étapes pour démarrer l'utilitaire BTEQ.
Step 1 - Entrez la commande / sbin / ifconfig et notez l'adresse IP du VMWare.
Step 2- Exécutez la commande bteq. À l'invite de connexion, entrez la commande.
Connectez-vous <adresseip> / dbc, dbc; et entrez À l'invite du mot de passe, entrez le mot de passe comme dbc;
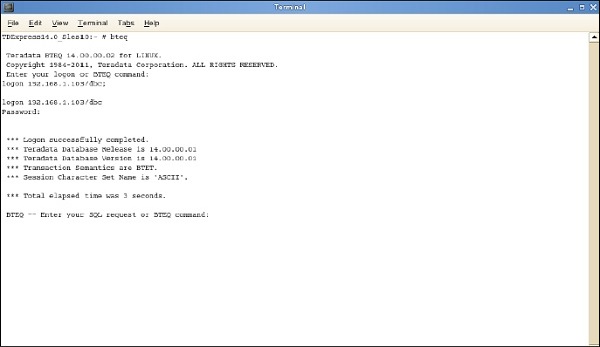
Vous pouvez vous connecter au système Teradata à l'aide de BTEQ et exécuter toutes les requêtes SQL.
L'architecture Teradata est basée sur une architecture de traitement massivement parallèle (MPP). Les principaux composants de Teradata sont le moteur d'analyse, le BYNET et les processeurs de module d'accès (AMP). Le diagramme suivant montre l'architecture de haut niveau d'un nœud Teradata.
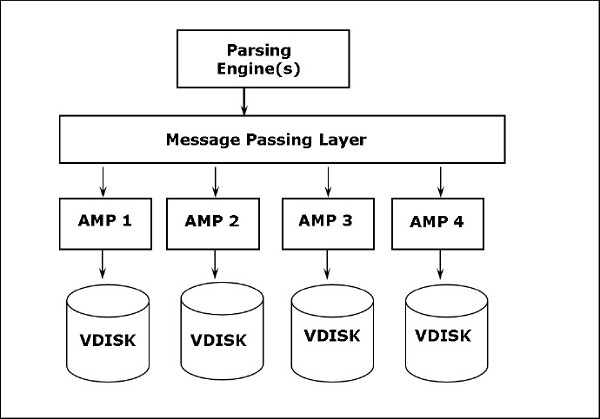
Composants de Teradata
Les composants clés de Teradata sont les suivants -
Node- C'est l'unité de base de Teradata System. Chaque serveur individuel d'un système Teradata est appelé un nœud. Un nœud se compose de son propre système d'exploitation, de son processeur, de sa mémoire, de sa propre copie du logiciel Teradata RDBMS et de son espace disque. Une armoire se compose d'un ou de plusieurs nœuds.
Parsing Engine- Parsing Engine est responsable de la réception des requêtes du client et de la préparation d'un plan d'exécution efficace. Les responsabilités du moteur d'analyse sont -
Recevoir la requête SQL du client
Analyser la recherche de requête SQL pour les erreurs de syntaxe
Vérifiez si l'utilisateur dispose des privilèges requis sur les objets utilisés dans la requête SQL
Vérifier si les objets utilisés dans le SQL existent réellement
Préparer le plan d'exécution pour exécuter la requête SQL et le transmettre à BYNET
Reçoit les résultats des AMP et les envoie au client
Message Passing Layer- La couche de transmission de messages appelée BYNET, est la couche réseau du système Teradata. Il permet la communication entre PE et AMP ainsi qu'entre les nœuds. Il reçoit le plan d'exécution du Parsing Engine et l'envoie à AMP. De même, il reçoit les résultats des AMP et les envoie au Parsing Engine.
Access Module Processor (AMP)- Les AMP, appelés processeurs virtuels (vprocs), sont ceux qui stockent et récupèrent réellement les données. Les AMP reçoivent les données et le plan d'exécution du Parsing Engine, effectuent toute conversion de type de données, agrégation, filtrage, tri et stocke les données sur les disques qui leur sont associés. Les enregistrements des tables sont répartis uniformément entre les SAP du système. Chaque AMP est associé à un ensemble de disques sur lesquels les données sont stockées. Seul cet AMP peut lire / écrire des données à partir des disques.
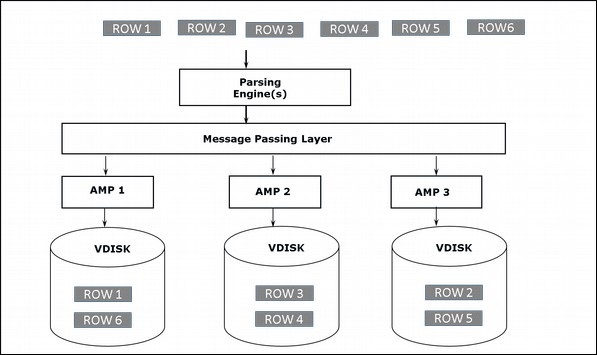
Architecture de stockage
Lorsque le client exécute des requêtes pour insérer des enregistrements, le moteur d'analyse envoie les enregistrements à BYNET. BYNET récupère les enregistrements et envoie la ligne à l'AMP cible. AMP stocke ces enregistrements sur ses disques. Le diagramme suivant montre l'architecture de stockage de Teradata.
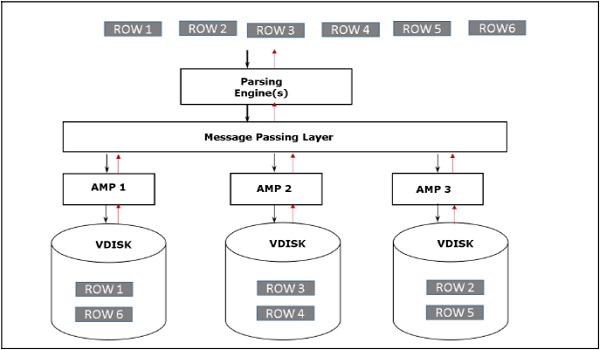
Architecture de récupération
Lorsque le client exécute des requêtes pour récupérer des enregistrements, le moteur d'analyse envoie une requête à BYNET. BYNET envoie la demande de récupération aux AMP appropriés. Les AMP recherchent ensuite leurs disques en parallèle et identifient les enregistrements requis et les envoient à BYNET. BYNET envoie ensuite les enregistrements à Parsing Engine qui à son tour les enverra au client. Voici l'architecture de récupération de Teradata.
Le système de gestion de base de données relationnelle (SGBDR) est un logiciel de SGBD qui permet d'interagir avec les bases de données. Ils utilisent le langage SQL (Structured Query Language) pour interagir avec les données stockées dans les tables.
Base de données
La base de données est une collection de données liées logiquement. Ils sont accessibles par de nombreux utilisateurs à des fins différentes. Par exemple, une base de données des ventes contient des informations complètes sur les ventes qui sont stockées dans de nombreuses tables.
les tables
Les tables sont l'unité de base du SGBDR où les données sont stockées. Une table est une collection de lignes et de colonnes. Voici un exemple de table des employés.
| Numéro d'employé | Prénom | Nom de famille | Date de naissance |
|---|---|---|---|
| 101 | Mike | James | 05/01/1980 |
| 104 | Alex | Stuart | 06/11/1984 |
| 102 | Robert | Williams | 05/03/1983 |
| 105 | Robert | James | 01/12/1984 |
| 103 | Peter | Paul | 01/04/1983 |
Colonnes
Une colonne contient des données similaires. Par exemple, la colonne Date de naissance dans la table Employé contient des informations de date de naissance pour tous les employés.
| Date de naissance |
|---|
| 05/01/1980 |
| 06/11/1984 |
| 05/03/1983 |
| 01/12/1984 |
| 01/04/1983 |
Rangée
Row est une instance de toutes les colonnes. Par exemple, dans la table des employés, une ligne contient des informations sur un seul employé.
| Numéro d'employé | Prénom | Nom de famille | Date de naissance |
|---|---|---|---|
| 101 | Mike | James | 05/01/1980 |
Clé primaire
La clé primaire est utilisée pour identifier de manière unique une ligne dans une table. Aucune valeur en double n'est autorisée dans une colonne de clé primaire et ils ne peuvent pas accepter les valeurs NULL. C'est un champ obligatoire dans une table.
Clé étrangère
Les clés étrangères sont utilisées pour construire une relation entre les tables. Une clé étrangère dans une table enfant est définie comme clé primaire dans la table parent. Une table peut avoir plus d'une clé étrangère. Il peut accepter des valeurs en double et également des valeurs nulles. Les clés étrangères sont facultatives dans une table.
Chaque colonne d'une table est associée à un type de données. Les types de données spécifient le type de valeurs qui seront stockées dans la colonne. Teradata prend en charge plusieurs types de données. Voici quelques-uns des types de données fréquemment utilisés.
| Types de données | Longueur (octets) | Gamme de valeurs |
|---|---|---|
| BYTEINT | 1 | -128 à +127 |
| PETITE MENTHE | 2 | -32768 à +32767 |
| ENTIER | 4 | -2 147 483 648 à +2 147 483 647 |
| GRAND | 8 | -9,233,372,036,854,775,80 8 à +9,233,372,036,854,775,8 07 |
| DÉCIMAL | 1-16 | |
| NUMÉRIQUE | 1-16 | |
| FLOTTE | 8 | Format IEEE |
| CARBONISER | Format fixe | 1 à 64 000 |
| VARCHAR | Variable | 1 à 64 000 |
| DATE | 4 | AAAAMMJJ |
| TEMPS | 6 ou 8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| HORAIRE | 10 ou 12 | AAMMJJHHMMSS.nnnnnn or AAMMJJHHMMSS.nnnnnn + HHMM |
Les tableaux du modèle relationnel sont définis comme une collection de données. Ils sont représentés sous forme de lignes et de colonnes.
Types de table
Types Teradata prend en charge différents types de tables.
Permanent Table - Il s'agit du tableau par défaut et il contient des données insérées par l'utilisateur et stocke les données en permanence.
Volatile Table- Les données insérées dans une table volatile ne sont conservées que pendant la session utilisateur. La table et les données sont supprimées à la fin de la session. Ces tables sont principalement utilisées pour contenir les données intermédiaires lors de la transformation des données.
Global Temporary Table - La définition des tables temporaires globales est persistante mais les données de la table sont supprimées à la fin de la session utilisateur.
Derived Table- La table dérivée contient les résultats intermédiaires dans une requête. Leur durée de vie est comprise dans la requête dans laquelle ils sont créés, utilisés et supprimés.
Définir contre multiset
Teradata classe les tables en tant que tables SET ou MULTISET en fonction de la façon dont les enregistrements en double sont traités. Une table définie comme table SET ne stocke pas les enregistrements en double, tandis que la table MULTISET peut stocker des enregistrements en double.
| Sr.Non | Commandes et description de la table |
|---|---|
| 1 | Créer une table La commande CREATE TABLE est utilisée pour créer des tables dans Teradata. |
| 2 | Modifier table La commande ALTER TABLE est utilisée pour ajouter ou supprimer des colonnes d'une table existante. |
| 3 | Table de dépôt La commande DROP TABLE est utilisée pour supprimer une table. |
Ce chapitre présente les commandes SQL utilisées pour manipuler les données stockées dans les tables Teradata.
Insérer des enregistrements
L'instruction INSERT INTO est utilisée pour insérer des enregistrements dans la table.
Syntaxe
Voici la syntaxe générique pour INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);Exemple
L'exemple suivant insère des enregistrements dans la table des employés.
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);Une fois la requête ci-dessus insérée, vous pouvez utiliser l'instruction SELECT pour afficher les enregistrements de la table.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementNon | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
Insérer à partir d'une autre table
L'instruction INSERT SELECT est utilisée pour insérer des enregistrements d'une autre table.
Syntaxe
Voici la syntaxe générique pour INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;Exemple
L'exemple suivant insère des enregistrements dans la table des employés. Créez une table appelée Employee_Bkup avec la même définition de colonne que la table employee avant d'exécuter la requête d'insertion suivante.
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;Lorsque la requête ci-dessus est exécutée, elle insère tous les enregistrements de la table employee dans la table employee_bkup.
Règles
Le nombre de colonnes spécifié dans la liste VALUES doit correspondre aux colonnes spécifiées dans la clause INSERT INTO.
Les valeurs sont obligatoires pour les colonnes NOT NULL.
Si aucune valeur n'est spécifiée, NULL est inséré pour les champs NULL.
Les types de données des colonnes spécifiés dans la clause VALUES doivent être compatibles avec les types de données des colonnes de la clause INSERT.
Mettre à jour les enregistrements
L'instruction UPDATE est utilisée pour mettre à jour les enregistrements de la table.
Syntaxe
Voici la syntaxe générique pour UPDATE.
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];Exemple
L'exemple suivant met à jour le service des employés à 03 pour l'employé 101.
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;Dans la sortie suivante, vous pouvez voir que le DepartmentNo est mis à jour de 1 à 3 pour EmployeeNo 101.
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3Règles
Vous pouvez mettre à jour une ou plusieurs valeurs de la table.
Si la condition WHERE n'est pas spécifiée, toutes les lignes de la table sont affectées.
Vous pouvez mettre à jour une table avec les valeurs d'une autre table.
Supprimer des enregistrements
L'instruction DELETE FROM est utilisée pour mettre à jour les enregistrements de la table.
Syntaxe
Voici la syntaxe générique de DELETE FROM.
DELETE FROM <tablename>
[WHERE condition];Exemple
L'exemple suivant supprime l'employé 101 de la table employé.
DELETE FROM Employee
WHERE EmployeeNo = 101;Dans la sortie suivante, vous pouvez voir que l'employé 101 est supprimé de la table.
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.Règles
Vous pouvez mettre à jour un ou plusieurs enregistrements de la table.
Si la condition WHERE n'est pas spécifiée, toutes les lignes de la table sont supprimées.
Vous pouvez mettre à jour une table avec les valeurs d'une autre table.
L'instruction SELECT est utilisée pour récupérer des enregistrements d'une table.
Syntaxe
Voici la syntaxe de base de l'instruction SELECT.
SELECT
column 1, column 2, .....
FROM
tablename;Exemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementNon | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
| 102 | Robert | Williams | 25/04/2007 | 2 | 05/03/1983 |
| 103 | Peter | Paul | 21/03/2007 | 2 | 01/04/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 06/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 01/12/1984 |
Voici un exemple d'instruction SELECT.
SELECT EmployeeNo,FirstName,LastName
FROM Employee;Lorsque cette requête est exécutée, elle extrait les colonnes EmployeeNo, FirstName et LastName de la table Employee.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulSi vous souhaitez récupérer toutes les colonnes d'une table, vous pouvez utiliser la commande suivante au lieu de lister toutes les colonnes.
SELECT * FROM Employee;La requête ci-dessus récupérera tous les enregistrements de la table des employés.
Clause WHERE
La clause WHERE est utilisée pour filtrer les enregistrements renvoyés par l'instruction SELECT. Une condition est associée à la clause WHERE. Seuls, les enregistrements qui satisfont à la condition de la clause WHERE sont renvoyés.
Syntaxe
Voici la syntaxe de l'instruction SELECT avec la clause WHERE.
SELECT * FROM tablename
WHERE[condition];Exemple
La requête suivante récupère les enregistrements où EmployeeNo est 101.
SELECT * FROM Employee
WHERE EmployeeNo = 101;Lorsque cette requête est exécutée, elle renvoie les enregistrements suivants.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike JamesCOMMANDÉ PAR
Lorsque l'instruction SELECT est exécutée, les lignes renvoyées ne sont pas dans un ordre spécifique. La clause ORDER BY est utilisée pour organiser les enregistrements dans l'ordre croissant / décroissant sur toutes les colonnes.
Syntaxe
Voici la syntaxe de l'instruction SELECT avec la clause ORDER BY.
SELECT * FROM tablename
ORDER BY column 1, column 2..;Exemple
La requête suivante récupère les enregistrements de la table des employés et classe les résultats par FirstName.
SELECT * FROM Employee
ORDER BY FirstName;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesPAR GROUPE
La clause GROUP BY est utilisée avec l'instruction SELECT et organise les enregistrements similaires en groupes.
Syntaxe
Voici la syntaxe de l'instruction SELECT avec la clause GROUP BY.
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;Exemple
L'exemple suivant regroupe les enregistrements par colonne DepartmentNo et identifie le nombre total de chaque service.
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradata prend en charge les opérateurs logiques et conditionnels suivants. Ces opérateurs sont utilisés pour effectuer des comparaisons et combiner plusieurs conditions.
| Syntaxe | Sens |
|---|---|
| > | Plus grand que |
| < | Moins que |
| >= | Plus grand ou égal à |
| <= | Inférieur ou égal à |
| = | Égal à |
| BETWEEN | Si les valeurs dans la plage |
| IN | Si les valeurs dans <expression> |
| NOT IN | Si les valeurs ne sont pas dans <expression> |
| IS NULL | Si la valeur est NULL |
| IS NOT NULL | Si la valeur n'est PAS NULL |
| AND | Combinez plusieurs conditions. Évalue à vrai uniquement si toutes les conditions sont remplies |
| OR | Combinez plusieurs conditions. Évalue à vrai uniquement si l'une des conditions est remplie. |
| NOT | Inverse le sens de la condition |
ENTRE
La commande BETWEEN est utilisée pour vérifier si une valeur se trouve dans une plage de valeurs.
Exemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementNon | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
| 102 | Robert | Williams | 25/04/2007 | 2 | 05/03/1983 |
| 103 | Peter | Paul | 21/03/2007 | 2 | 01/04/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 06/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 01/12/1984 |
L'exemple suivant récupère les enregistrements avec des numéros d'employés compris entre 101,102 et 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;Lorsque la requête ci-dessus est exécutée, elle renvoie les enregistrements d'employés dont le numéro d'employé est compris entre 101 et 103.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterDANS
La commande IN est utilisée pour vérifier la valeur par rapport à une liste de valeurs donnée.
Exemple
L'exemple suivant récupère les enregistrements avec les numéros d'employés 101, 102 et 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);La requête ci-dessus renvoie les enregistrements suivants.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterPAS DEDANS
La commande NOT IN inverse le résultat de la commande IN. Il récupère les enregistrements dont les valeurs ne correspondent pas à la liste donnée.
Exemple
L'exemple suivant récupère les enregistrements dont les numéros d'employés ne figurent pas dans 101, 102 et 103.
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);La requête ci-dessus renvoie les enregistrements suivants.
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert JamesLes opérateurs SET combinent les résultats de plusieurs instructions SELECT. Cela peut ressembler à Joins, mais les jointures combinent des colonnes de plusieurs tables, tandis que les opérateurs SET combinent des lignes de plusieurs lignes.
Règles
Le nombre de colonnes de chaque instruction SELECT doit être le même.
Les types de données de chaque SELECT doivent être compatibles.
ORDER BY doit être inclus uniquement dans l'instruction SELECT finale.
SYNDICAT
L'instruction UNION est utilisée pour combiner les résultats de plusieurs instructions SELECT. Il ignore les doublons.
Syntaxe
Voici la syntaxe de base de l'instruction UNION.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Exemple
Considérez le tableau des employés et le tableau des salaires suivants.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementNon | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
| 102 | Robert | Williams | 25/04/2007 | 2 | 05/03/1983 |
| 103 | Peter | Paul | 21/03/2007 | 2 | 01/04/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 06/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 01/12/1984 |
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 103 | 90 000 | 7 000 | 83 000 |
| 104 | 75 000 | 5 000 | 70 000 |
La requête UNION suivante combine la valeur EmployeeNo de la table Employee et Salary.
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;Lorsque la requête est exécutée, elle produit la sortie suivante.
EmployeeNo
-----------
101
102
103
104
105UNION TOUT
L'instruction UNION ALL est similaire à UNION, elle combine les résultats de plusieurs tables, y compris les lignes en double.
Syntaxe
Voici la syntaxe de base de l'instruction UNION ALL.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Exemple
Voici un exemple pour l'instruction UNION ALL.
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. Vous pouvez voir qu'il renvoie également les doublons.
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103COUPER
La commande INTERSECT est également utilisée pour combiner les résultats de plusieurs instructions SELECT. Il renvoie les lignes de la première instruction SELECT qui a une correspondance correspondante dans les secondes instructions SELECT. En d'autres termes, il renvoie les lignes qui existent dans les deux instructions SELECT.
Syntaxe
Voici la syntaxe de base de l'instruction INTERSECT.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Exemple
Voici un exemple de déclaration INTERSECT. Il renvoie les valeurs EmployeeNo qui existent dans les deux tables.
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;Lorsque la requête ci-dessus est exécutée, elle renvoie les enregistrements suivants. EmployeeNo 105 est exclu car il n'existe pas dans la table SALARY.
EmployeeNo
-----------
101
104
102
103MOINS / SAUF
Les commandes MINUS / EXCEPT combinent les lignes de plusieurs tables et retournent les lignes qui se trouvent dans le premier SELECT mais pas dans le second SELECT. Ils renvoient tous les deux les mêmes résultats.
Syntaxe
Voici la syntaxe de base de l'instruction MINUS.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Exemple
Voici un exemple de déclaration MINUS.
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;Lorsque cette requête est exécutée, elle renvoie l'enregistrement suivant.
EmployeeNo
-----------
105Teradata fournit plusieurs fonctions pour manipuler les chaînes. Ces fonctions sont compatibles avec la norme ANSI.
| Sr.Non | Fonction de chaîne et description |
|---|---|
| 1 | || Concatène les chaînes ensemble |
| 2 | SUBSTR Extrait une partie d'une chaîne (extension Teradata) |
| 3 | SUBSTRING Extrait une partie d'une chaîne (norme ANSI) |
| 4 | INDEX Localise la position d'un caractère dans une chaîne (extension Teradata) |
| 5 | POSITION Localise la position d'un caractère dans une chaîne (norme ANSI) |
| 6 | TRIM Coupe les blancs d'une chaîne |
| sept | UPPER Convertit une chaîne en majuscules |
| 8 | LOWER Convertit une chaîne en minuscules |
Exemple
Le tableau suivant répertorie certaines des fonctions de chaîne avec les résultats.
| Fonction de chaîne | Résultat |
|---|---|
| SELECT SUBSTRING ('entrepôt' DE 1 POUR 4) | articles |
| SELECT SUBSTR ('entrepôt', 1,4) | articles |
| SELECT "données" || '' || 'entrepôt' | entrepôt de données |
| SELECT UPPER ('données') | LES DONNÉES |
| SÉLECTIONNER INFÉRIEUR ('DONNÉES') | Les données |
Ce chapitre traite des fonctions de date / heure disponibles dans Teradata.
Stockage de la date
Les dates sont stockées sous forme d'entiers en interne à l'aide de la formule suivante.
((YEAR - 1900) * 10000) + (MONTH * 100) + DAYVous pouvez utiliser la requête suivante pour vérifier comment les dates sont stockées.
SELECT CAST(CURRENT_DATE AS INTEGER);Les dates étant stockées sous forme d'entiers, vous pouvez effectuer certaines opérations arithmétiques sur elles. Teradata fournit des fonctions pour effectuer ces opérations.
EXTRAIT
La fonction EXTRACT extrait des parties du jour, du mois et de l'année à partir d'une valeur DATE. Cette fonction est également utilisée pour extraire les heures, les minutes et les secondes de la valeur TIME / TIMESTAMP.
Exemple
Les exemples suivants montrent comment extraire les valeurs Année, Mois, Date, Heure, Minute et Seconde des valeurs Date et Horodatage.
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000INTERVALLE
Teradata fournit la fonction INTERVAL pour effectuer des opérations arithmétiques sur les valeurs DATE et TIME. Il existe deux types de fonctions INTERVAL.
Intervalle année-mois
- YEAR
- ANNÉE AU MOIS
- MONTH
Intervalle jour-heure
- DAY
- JOUR À HEURE
- JOUR À MINUTE
- JOUR À DEUXIÈME
- HOUR
- HEURE EN MINUTE
- HEURE À SECONDE
- MINUTE
- MINUTE À SECONDE
- SECOND
Exemple
L'exemple suivant ajoute 3 ans à la date actuelle.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01L'exemple suivant ajoute 3 ans et 01 mois à la date actuelle.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01L'exemple suivant ajoute 01 jour, 05 heures et 10 minutes à l'horodatage actuel.
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradata fournit des fonctions intégrées qui sont des extensions de SQL. Voici les fonctions intégrées courantes.
| Fonction | Résultat |
|---|---|
| SÉLECTIONNER UNE DATE; | Date -------- 16/01/01 |
| SELECT CURRENT_DATE; | Date -------- 16/01/01 |
| CHOISISSEZ L'HEURE; | Heure -------- 04:50:29 |
| SELECT CURRENT_TIME; | Heure -------- 04:50:29 |
| SELECT CURRENT_TIMESTAMP; | Horodatage actuel (6) -------------------------------- 01/01/2016 04: 51: 06.990000 + 00: 00 |
| SELECT DATABASE; | Base de données ------------------------------ TDUSER |
Teradata prend en charge les fonctions d'agrégation courantes. Ils peuvent être utilisés avec l'instruction SELECT.
COUNT - Compte les lignes
SUM - Résume les valeurs de la ou des colonnes spécifiées
MAX - Renvoie la grande valeur de la colonne spécifiée
MIN - Renvoie la valeur minimale de la colonne spécifiée
AVG - Renvoie la valeur moyenne de la colonne spécifiée
Exemple
Considérez le tableau des salaires suivant.
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 104 | 75 000 | 5 000 | 70 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 105 | 70 000 | 4 000 | 66 000 |
| 103 | 90 000 | 7 000 | 83 000 |
COMPTER
L'exemple suivant compte le nombre d'enregistrements dans la table Salary.
SELECT count(*) from Salary;
Count(*)
-----------
5MAX
L'exemple suivant renvoie la valeur salariale nette maximale de l'employé.
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000MIN
L'exemple suivant renvoie la valeur du salaire net minimum de l'employé à partir de la table Salary.
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000AVG
L'exemple suivant renvoie la valeur moyenne du salaire net des employés à partir de la table.
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800SOMME
L'exemple suivant calcule la somme du salaire net des employés à partir de tous les enregistrements de la table Salary.
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000Ce chapitre explique les fonctions CASE et COALESCE de Teradata.
Expression CASE
L'expression CASE évalue chaque ligne par rapport à une condition ou à une clause WHEN et renvoie le résultat de la première correspondance. S'il n'y a pas de correspondance, le résultat de la partie ELSE est renvoyé.
Syntaxe
Voici la syntaxe de l'expression CASE.
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
ENDExemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementNon | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
| 102 | Robert | Williams | 25/04/2007 | 2 | 05/03/1983 |
| 103 | Peter | Paul | 21/03/2007 | 2 | 01/04/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 06/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 01/12/1984 |
L'exemple suivant évalue la colonne DepartmentNo et renvoie la valeur 1 si le numéro de service est 1; renvoie 2 si le numéro de département est 3; sinon, il renvoie la valeur en tant que département non valide.
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 ITL'expression CASE ci-dessus peut également être écrite sous la forme suivante qui produira le même résultat que ci-dessus.
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;SE FONDRE
COALESCE est une instruction qui renvoie la première valeur non nulle de l'expression. Il renvoie NULL si tous les arguments de l'expression sont évalués à NULL. Voici la syntaxe.
Syntaxe
COALESCE(expression 1, expression 2, ....)Exemple
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
L'instruction NULLIF renvoie NULL si les arguments sont égaux.
Syntaxe
Voici la syntaxe de l'instruction NULLIF.
NULLIF(expression 1, expression 2)Exemple
L'exemple suivant renvoie NULL si DepartmentNo est égal à 3. Sinon, il renvoie la valeur DepartmentNo.
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;La requête ci-dessus renvoie les enregistrements suivants. Vous pouvez voir que l'employé 105 a le département no. comme NULL.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2L'index principal est utilisé pour spécifier l'emplacement des données dans Teradata. Il est utilisé pour spécifier quel AMP obtient la ligne de données. Chaque table de Teradata doit avoir un index principal défini. Si l'index principal n'est pas défini, Teradata attribue automatiquement l'index principal. L'index primaire fournit le moyen le plus rapide d'accéder aux données. Un primaire peut avoir un maximum de 64 colonnes.
L'index primaire est défini lors de la création d'une table. Il existe 2 types d'index primaires.
- Index primaire unique (UPI)
- Index primaire non unique (NUPI)
Index primaire unique (UPI)
Si la table est définie comme ayant UPI, la colonne considérée comme UPI ne doit pas avoir de valeurs en double. Si des valeurs en double sont insérées, elles seront rejetées.
Créer un index primaire unique
L'exemple suivant crée la table Salary avec la colonne EmployeeNo en tant qu'index principal unique.
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Index primaire non unique (NUPI)
Si la table est définie comme ayant NUPI, la colonne considérée comme UPI peut accepter des valeurs en double.
Créer un index primaire non unique
L'exemple suivant crée la table des comptes d'employés avec la colonne EmployeeNo comme index primaire non unique. EmployeeNo est défini comme un index primaire non unique car un employé peut avoir plusieurs comptes dans la table; un pour le compte de salaire et un autre pour le compte de remboursement.
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);Join est utilisé pour combiner des enregistrements de plusieurs tables. Les tables sont jointes en fonction des colonnes / valeurs communes de ces tables.
Il existe différents types de jointures disponibles.
- Jointure interne
- Jointure externe gauche
- Jointure externe droite
- Jointure externe complète
- Auto-rejoindre
- Jointure croisée
- Jointure de production cartésienne
JOINTURE INTERNE
Inner Join combine les enregistrements de plusieurs tables et renvoie les valeurs qui existent dans les deux tables.
Syntaxe
Voici la syntaxe de l'instruction INNER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Exemple
Considérez le tableau des employés et le tableau des salaires suivants.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementNon | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
| 102 | Robert | Williams | 25/04/2007 | 2 | 05/03/1983 |
| 103 | Peter | Paul | 21/03/2007 | 2 | 01/04/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 06/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 01/12/1984 |
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 103 | 90 000 | 7 000 | 83 000 |
| 104 | 75 000 | 5 000 | 70 000 |
La requête suivante joint la table Employee et la table Salary sur la colonne commune EmployeeNo. Chaque table se voit attribuer un alias A & B et les colonnes sont référencées avec l'alias correct.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);Lorsque la requête ci-dessus est exécutée, elle renvoie les enregistrements suivants. L'employé 105 n'est pas inclus dans le résultat car il n'a pas d'enregistrements correspondants dans la table Salaire.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000JOINTURE EXTÉRIEURE
LEFT OUTER JOIN et RIGHT OUTER JOIN combinent également les résultats de plusieurs tables.
LEFT OUTER JOIN renvoie tous les enregistrements de la table de gauche et renvoie uniquement les enregistrements correspondants de la table de droite.
RIGHT OUTER JOIN renvoie tous les enregistrements de la table de droite et ne renvoie que les lignes correspondantes de la table de gauche.
FULL OUTER JOINcombine les résultats des JOINTES EXTÉRIEURES GAUCHE et DROITE. Il renvoie à la fois les lignes correspondantes et non correspondantes des tables jointes.
Syntaxe
Voici la syntaxe de l'instruction OUTER JOIN. Vous devez utiliser l'une des options de jointure externe gauche, jointure externe droite ou jointure externe complète.
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Exemple
Prenons l'exemple suivant de la requête LEFT OUTER JOIN. Il renvoie tous les enregistrements de la table Employee et les enregistrements correspondants de la table Salary.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. Pour l'employé 105, la valeur NetPay est NULL, car il n'a pas d'enregistrements correspondants dans la table Salary.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?JOINDRE CROISÉ
La jointure croisée joint chaque ligne de la table de gauche à chaque ligne de la table de droite.
Syntaxe
Voici la syntaxe de l'instruction CROSS JOIN.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. L'employé n ° 101 de la table des employés est joint à chaque enregistrement de la table des salaires.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000Une sous-requête renvoie les enregistrements d'une table en fonction des valeurs d'une autre table. Il s'agit d'une requête SELECT dans une autre requête. La requête SELECT appelée comme requête interne est exécutée en premier et le résultat est utilisé par la requête externe. Certaines de ses principales caractéristiques sont -
Une requête peut avoir plusieurs sous-requêtes et les sous-requêtes peuvent contenir une autre sous-requête.
Les sous-requêtes ne renvoient pas les enregistrements en double.
Si la sous-requête ne renvoie qu'une seule valeur, vous pouvez utiliser l'opérateur = pour l'utiliser avec la requête externe. S'il renvoie plusieurs valeurs, vous pouvez utiliser IN ou NOT IN.
Syntaxe
Voici la syntaxe générique des sous-requêtes.
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);Exemple
Considérez le tableau des salaires suivant.
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 103 | 90 000 | 7 000 | 83 000 |
| 104 | 75 000 | 5 000 | 70 000 |
La requête suivante identifie le numéro d'employé avec le salaire le plus élevé. Le SELECT interne exécute la fonction d'agrégation pour renvoyer la valeur NetPay maximale et la requête SELECT externe utilise cette valeur pour renvoyer l'enregistrement d'employé avec cette valeur.
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);Lorsque cette requête est exécutée, elle produit la sortie suivante.
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradata prend en charge les types de table suivants pour contenir des données temporaires.
- Table dérivée
- Table volatile
- Table temporaire globale
Table dérivée
Les tables dérivées sont créées, utilisées et supprimées dans une requête. Ceux-ci sont utilisés pour stocker les résultats intermédiaires dans une requête.
Exemple
L'exemple suivant crée une table dérivée EmpSal avec des enregistrements d'employés dont le salaire est supérieur à 75 000.
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;Lorsque la requête ci-dessus est exécutée, elle renvoie les employés dont le salaire est supérieur à 75 000.
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000Table volatile
Les tables volatiles sont créées, utilisées et supprimées dans une session utilisateur. Leur définition n'est pas stockée dans le dictionnaire de données. Ils contiennent des données intermédiaires de la requête fréquemment utilisées. Voici la syntaxe.
Syntaxe
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWSExemple
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
*** Table has been created.
*** Total elapsed time was 1 second.Table temporaire globale
La définition de la table temporaire globale est stockée dans le dictionnaire de données et peut être utilisée par de nombreux utilisateurs / sessions. Mais les données chargées dans la table temporaire globale ne sont conservées que pendant la session. Vous pouvez matérialiser jusqu'à 2000 tables temporaires globales par session. Voici la syntaxe.
Syntaxe
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>Exemple
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
*** Table has been created.
*** Total elapsed time was 1 second.Il existe trois types d'espaces disponibles à Teradata.
Espace permanent
L'espace permanent est la quantité maximale d'espace disponible pour que l'utilisateur / la base de données contienne des lignes de données. Les tables permanentes, les journaux, les tables de secours et les sous-tables d'index secondaires utilisent un espace permanent.
L'espace permanent n'est pas pré-alloué pour la base de données / l'utilisateur. Ils sont simplement définis comme la quantité maximale d'espace que la base de données / l'utilisateur peut utiliser. La quantité d'espace permanent est divisée par le nombre de SAP. Chaque fois que la limite AMP dépasse, un message d'erreur est généré.
Espace de bobine
L'espace de spoule est l'espace permanent inutilisé utilisé par le système pour conserver les résultats intermédiaires de la requête SQL. Les utilisateurs sans espace de spoule ne peuvent exécuter aucune requête.
Semblable à l'espace permanent, l'espace spool définit la quantité maximale d'espace que l'utilisateur peut utiliser. L'espace de spool est divisé par le nombre d'AMP. Chaque fois que la limite AMP dépasse, l'utilisateur obtiendra une erreur d'espace de spoule.
Espace temporaire
L'espace temporaire est l'espace permanent inutilisé utilisé par les tables temporaires globales. L'espace temporaire est également divisé par le nombre d'AMP.
Une table ne peut contenir qu'un seul index primaire. Le plus souvent, vous rencontrerez des scénarios dans lesquels la table contient d'autres colonnes, à l'aide desquelles les données sont fréquemment consultées. Teradata effectuera une analyse complète de la table pour ces requêtes. Les index secondaires résolvent ce problème.
Les index secondaires sont un autre chemin d'accès aux données. Il existe quelques différences entre l'index primaire et l'index secondaire.
L'index secondaire n'est pas impliqué dans la distribution des données.
Les valeurs d'index secondaires sont stockées dans des sous-tables. Ces tableaux sont intégrés à tous les AMP.
Les index secondaires sont facultatifs.
Ils peuvent être créés lors de la création d'une table ou après la création d'une table.
Ils occupent un espace supplémentaire car ils construisent des sous-tableaux et ils nécessitent également une maintenance puisque les sous-tableaux doivent être mis à jour pour chaque nouvelle ligne.
Il existe deux types d'index secondaires -
- Indice secondaire unique (USI)
- Index secondaire non unique (NUSI)
Indice secondaire unique (USI)
Un index secondaire unique autorise uniquement des valeurs uniques pour les colonnes définies comme USI. L'accès à la ligne par USI est une opération à deux ampères.
Créer un index secondaire unique
L'exemple suivant crée USI sur la colonne EmployeeNo de la table employee.
CREATE UNIQUE INDEX(EmployeeNo) on employee;Index secondaire non unique (NUSI)
Un index secondaire non unique permet des valeurs en double pour les colonnes définies comme NUSI. L'accès à la ligne par NUSI est une opération tout ampli.
Créer un index secondaire non unique
L'exemple suivant crée NUSI sur la colonne FirstName de la table des employés.
CREATE INDEX(FirstName) on Employee;L'optimiseur Teradata propose une stratégie d'exécution pour chaque requête SQL. Cette stratégie d'exécution est basée sur les statistiques collectées sur les tables utilisées dans la requête SQL. Les statistiques sur la table sont collectées à l'aide de la commande COLLECT STATISTICS. L'optimiseur a besoin d'informations sur l'environnement et de données démographiques pour proposer une stratégie d'exécution optimale.
Informations sur l'environnement
- Nombre de nœuds, d'AMP et de processeurs
- Quantité de mémoire
Données démographiques
- Nombre de rangées
- Taille de ligne
- Plage de valeurs dans le tableau
- Nombre de lignes par valeur
- Nombre de valeurs nulles
Il existe trois approches pour recueillir des statistiques sur la table.
- Échantillonnage AMP aléatoire
- Collection complète de statistiques
- Utilisation de l'option SAMPLE
Collecte de statistiques
La commande COLLECT STATISTICS est utilisée pour collecter des statistiques sur une table.
Syntaxe
Voici la syntaxe de base pour collecter des statistiques sur une table.
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;Exemple
L'exemple suivant collecte des statistiques sur la colonne EmployeeNo de la table Employee.
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.Affichage des statistiques
Vous pouvez afficher les statistiques collectées à l'aide de la commande HELP STATISTICS.
Syntaxe
Voici la syntaxe pour afficher les statistiques collectées.
HELP STATISTICS <tablename>;Exemple
Voici un exemple pour afficher les statistiques collectées sur la table Employee.
HELP STATISTICS employee;Lorsque la requête ci-dessus est exécutée, elle produit le résultat suivant.
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNoLa compression est utilisée pour réduire le stockage utilisé par les tables. Dans Teradata, la compression peut compresser jusqu'à 255 valeurs distinctes, y compris NULL. Le stockage étant réduit, Teradata peut stocker plus d'enregistrements dans un bloc. Cela améliore le temps de réponse aux requêtes, car toute opération d'E / S peut traiter plus de lignes par bloc. La compression peut être ajoutée à la création de la table à l'aide de CREATE TABLE ou après la création de la table à l'aide de la commande ALTER TABLE.
Limites
- Seules 255 valeurs peuvent être compressées par colonne.
- La colonne d'index primaire ne peut pas être compressée.
- Les tables volatiles ne peuvent pas être compressées.
Compression à valeurs multiples (MVC)
Le tableau suivant compresse le champ DepatmentNo pour les valeurs 1, 2 et 3. Lorsque la compression est appliquée à une colonne, les valeurs de cette colonne ne sont pas stockées avec la ligne. Au lieu de cela, les valeurs sont stockées dans l'en-tête Table de chaque AMP et seuls les bits de présence sont ajoutés à la ligne pour indiquer la valeur.
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);La compression à valeurs multiples peut être utilisée lorsque vous avez une colonne dans une grande table avec des valeurs finies.
La commande EXPLAIN renvoie le plan d'exécution du moteur d'analyse en anglais. Il peut être utilisé avec n'importe quelle instruction SQL sauf sur une autre commande EXPLAIN. Lorsqu'une requête est précédée de la commande EXPLAIN, le plan d'exécution du moteur d'analyse est renvoyé à l'utilisateur au lieu des AMP.
Exemples d'EXPLAIN
Considérez la table Employee avec la définition suivante.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );Quelques exemples de plan EXPLAIN sont donnés ci-dessous.
Balayage complet de la table (FTS)
Lorsqu'aucune condition n'est spécifiée dans l'instruction SELECT, l'optimiseur peut choisir d'utiliser l'analyse complète de la table où chaque ligne de la table est accessible.
Exemple
Voici un exemple de requête dans lequel l'optimiseur peut choisir FTS.
EXPLAIN SELECT * FROM employee;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. Comme on peut le voir, l'optimiseur choisit d'accéder à tous les AMP et à toutes les lignes de l'AMP.
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.Index primaire unique
Lorsque les lignes sont accessibles à l'aide d'un index primaire unique, il s'agit d'une opération AMP.
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. Comme on peut le voir, il s'agit d'une extraction à un seul AMP et l'optimiseur utilise l'index principal unique pour accéder à la ligne.
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Index secondaire unique
Lorsque les lignes sont accessibles à l'aide de l'index secondaire unique, il s'agit d'une opération à deux ampères.
Exemple
Considérez le tableau Salaire avec la définition suivante.
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Considérez l'instruction SELECT suivante.
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. Comme on peut le voir, l'optimiseur récupère la ligne dans une opération à deux ampères à l'aide d'un index secondaire unique.
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Conditions supplémentaires
Voici la liste des termes couramment utilisés dans le plan EXPLAIN.
... (Last Use) …
Un fichier spoule n'est plus nécessaire et sera libéré lorsque cette étape sera terminée.
... with no residual conditions …
Toutes les conditions applicables ont été appliquées aux lignes.
... END TRANSACTION …
Les verrous de transaction sont libérés et les modifications sont validées.
... eliminating duplicate rows ...
Les lignes en double existent uniquement dans les fichiers spool, pas dans les tables définies. Effectuer une opération DISTINCT.
... by way of a traversal of index #n extracting row ids only …
Un fichier spoule est généré contenant les ID de ligne trouvés dans un index secondaire (index #n)
... we do a SMS (set manipulation step) …
Combinaison de lignes à l'aide d'un opérateur UNION, MINUS ou INTERSECT.
... which is redistributed by hash code to all AMPs.
Redistribution des données en préparation d'une jointure.
... which is duplicated on all AMPs.
Duplication des données de la table plus petite (en termes de SPOOL) en vue d'une jointure.
... (one_AMP) or (group_AMPs)
Indique qu'un AMP ou un sous-ensemble d'AMP sera utilisé à la place de tous les AMP.
Une ligne est attribuée à un AMP particulier en fonction de la valeur d'index primaire. Teradata utilise un algorithme de hachage pour déterminer quel AMP obtient la ligne.
Voici un diagramme de haut niveau sur l'algorithme de hachage.

Voici les étapes pour insérer les données.
Le client soumet une requête.
L'analyseur reçoit la requête et transmet la valeur PI de l'enregistrement à l'algorithme de hachage.
L'algorithme de hachage hache la valeur d'index primaire et renvoie un nombre de 32 bits, appelé Row Hash.
Les bits d'ordre supérieur du hachage de ligne (16 premiers bits) sont utilisés pour identifier l'entrée de mappe de hachage. La carte de hachage contient un AMP #. La carte de hachage est un tableau de buckets contenant un numéro AMP spécifique.
BYNET envoie les données à l'AMP identifié.
AMP utilise le hachage de ligne 32 bits pour localiser la ligne sur son disque.
S'il existe un enregistrement avec le même hachage de ligne, il incrémente l'ID d'unicité qui est un nombre de 32 bits. Pour le nouveau hachage de ligne, l'ID d'unicité est attribué à 1 et incrémenté chaque fois qu'un enregistrement avec le même hachage de ligne est inséré.
La combinaison du hachage de ligne et de l'ID d'unicité est appelée ID de ligne.
L'ID de ligne préfixe chaque enregistrement du disque.
Chaque ligne de table dans l'AMP est triée logiquement en fonction de leurs ID de ligne.
Comment les tables sont stockées
Les tables sont triées par leur ID de ligne (hachage de ligne + ID d'unicité), puis stockées dans les AMP. L'ID de ligne est stocké avec chaque ligne de données.
| Hash de ligne | ID d'unicité | Numéro d'employé | Prénom | Nom de famille |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paul |
JOIN INDEX est une vue matérialisée. Sa définition est stockée en permanence et les données sont mises à jour chaque fois que les tables de base référencées dans l'index de jointure sont mises à jour. JOIN INDEX peut contenir une ou plusieurs tables et également des données pré-agrégées. Les index de jointure sont principalement utilisés pour améliorer les performances.
Il existe différents types d'index de jointure disponibles.
- Index de jointure de table unique (STJI)
- Index de jointure multi-table (MTJI)
- Index de jointure agrégé (AJI)
Index de jointure de table unique
L'index de jointure de table unique permet de partitionner une grande table en fonction des différentes colonnes d'index primaire que celle de la table de base.
Syntaxe
Voici la syntaxe d'un JOIN INDEX.
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;Exemple
Considérez les tableaux des employés et des salaires suivants.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Voici un exemple qui crée un index de jointure nommé Employee_JI sur la table Employee.
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);Si l'utilisateur soumet une requête avec une clause WHERE sur EmployeeNo, le système interrogera la table Employee à l'aide de l'index primaire unique. Si l'utilisateur interroge la table des employés en utilisant nom_employé, le système peut accéder à l'index de jointure Employee_JI en utilisant nom_employé. Les lignes de l'index de jointure sont hachées sur la colonne nom_employé. Si l'index de jointure n'est pas défini et que le nom_employé n'est pas défini comme index secondaire, le système effectuera une analyse complète de la table pour accéder aux lignes, ce qui prend du temps.
Vous pouvez exécuter le plan EXPLAIN suivant et vérifier le plan d'optimisation. Dans l'exemple suivant, vous pouvez voir que l'optimiseur utilise l'index de jointure au lieu de la table Employee de base lorsque la table interroge à l'aide de la colonne Employee_Name.
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.Index de jointure multi-table
Un index de jointure multi-table est créé en joignant plusieurs tables. L'index de jointure multi-table peut être utilisé pour stocker le jeu de résultats des tables fréquemment jointes afin d'améliorer les performances.
Exemple
L'exemple suivant crée un JOIN INDEX nommé Employee_Salary_JI en joignant les tables Employee et Salary.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);Chaque fois que les tables de base Employee ou Salary sont mises à jour, l'index de jointure Employee_Salary_JI est également mis à jour automatiquement. Si vous exécutez une requête joignant les tables Employee et Salary, l'optimiseur peut choisir d'accéder directement aux données de Employee_Salary_JI au lieu de joindre les tables. Le plan EXPLAIN sur la requête peut être utilisé pour vérifier si l'optimiseur choisira la table de base ou l'index de jointure.
Index de jointure agrégé
Si une table est agrégée de manière cohérente sur certaines colonnes, un index de jointure agrégé peut être défini sur la table pour améliorer les performances. Une limitation de l'index de jointure agrégé est qu'il prend en charge uniquement les fonctions SUM et COUNT.
Exemple
Dans l'exemple suivant, l'employé et le salaire sont joints pour identifier le salaire total par service.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);Les vues sont des objets de base de données créés par la requête. Les vues peuvent être créées à l'aide d'une seule table ou de plusieurs tables par voie de jointure. Leur définition est stockée en permanence dans le dictionnaire de données mais ils ne stockent pas de copie des données. Les données de la vue sont créées dynamiquement.
Une vue peut contenir un sous-ensemble de lignes de la table ou un sous-ensemble de colonnes de la table.
Créer une vue
Les vues sont créées à l'aide de l'instruction CREATE VIEW.
Syntaxe
Voici la syntaxe pour créer une vue.
CREATE/REPLACE VIEW <viewname>
AS
<select query>;Exemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | Date de naissance |
|---|---|---|---|
| 101 | Mike | James | 05/01/1980 |
| 104 | Alex | Stuart | 06/11/1984 |
| 102 | Robert | Williams | 05/03/1983 |
| 105 | Robert | James | 01/12/1984 |
| 103 | Peter | Paul | 01/04/1983 |
L'exemple suivant crée une vue sur la table Employee.
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;Utilisation des vues
Vous pouvez utiliser une instruction SELECT standard pour récupérer des données à partir de Views.
Exemple
L'exemple suivant récupère les enregistrements de Employee_View;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulModifier les vues
Une vue existante peut être modifiée à l'aide de l'instruction REPLACE VIEW.
Voici la syntaxe pour modifier une vue.
REPLACE VIEW <viewname>
AS
<select query>;Exemple
L'exemple suivant modifie la vue Employee_View pour ajouter des colonnes supplémentaires.
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;Drop View
Une vue existante peut être supprimée à l'aide de l'instruction DROP VIEW.
Syntaxe
Voici la syntaxe de DROP VIEW.
DROP VIEW <viewname>;Exemple
Voici un exemple de suppression de la vue Employee_View.
DROP VIEW Employee_View;Avantages des vues
Les vues offrent un niveau de sécurité supplémentaire en limitant les lignes ou les colonnes d'une table.
Les utilisateurs peuvent avoir accès uniquement aux vues au lieu des tables de base.
Simplifie l'utilisation de plusieurs tables en les joignant préalablement à l'aide de Views.
Macro est un ensemble d'instructions SQL qui sont stockées et exécutées en appelant le nom de la macro. La définition des macros est stockée dans le dictionnaire de données. Les utilisateurs n'ont besoin que du privilège EXEC pour exécuter la macro. Les utilisateurs n'ont pas besoin de privilèges distincts sur les objets de base de données utilisés dans la macro. Les instructions de macro sont exécutées en une seule transaction. Si l'une des instructions SQL de Macro échoue, toutes les instructions sont annulées. Les macros peuvent accepter des paramètres. Les macros peuvent contenir des instructions DDL, mais cela devrait être la dernière instruction de Macro.
Créer des macros
Les macros sont créées à l'aide de l'instruction CREATE MACRO.
Syntaxe
Voici la syntaxe générique de la commande CREATE MACRO.
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);Exemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | Date de naissance |
|---|---|---|---|
| 101 | Mike | James | 05/01/1980 |
| 104 | Alex | Stuart | 06/11/1984 |
| 102 | Robert | Williams | 05/03/1983 |
| 105 | Robert | James | 01/12/1984 |
| 103 | Peter | Paul | 01/04/1983 |
L'exemple suivant crée une macro appelée Get_Emp. Il contient une instruction de sélection pour récupérer les enregistrements de la table des employés.
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);Exécution de macros
Les macros sont exécutées à l'aide de la commande EXEC.
Syntaxe
Voici la syntaxe de la commande EXECUTE MACRO.
EXEC <macroname>;Exemple
L'exemple suivant exécute les noms de macro Get_Emp; Lorsque la commande suivante est exécutée, elle récupère tous les enregistrements de la table des employés.
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert JamesMacros paramétrées
Les macros Teradata peuvent accepter des paramètres. Dans une macro, ces paramètres sont référencés avec; (point-virgule).
Voici un exemple de macro qui accepte des paramètres.
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);Exécution de macros paramétrées
Les macros sont exécutées à l'aide de la commande EXEC. Vous avez besoin du privilège EXEC pour exécuter les macros.
Syntaxe
Voici la syntaxe de l'instruction EXECUTE MACRO.
EXEC <macroname>(value);Exemple
L'exemple suivant exécute les noms de macro Get_Emp; Il accepte l'employé no comme paramètre et extrait les enregistrements de la table des employés pour cet employé.
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000Une procédure stockée contient un ensemble d'instructions SQL et d'instructions de procédure. Ils ne peuvent contenir que des déclarations de procédure. La définition de la procédure stockée est stockée dans la base de données et les paramètres sont stockés dans les tables de dictionnaire de données.
Avantages
Les procédures stockées réduisent la charge réseau entre le client et le serveur.
Fournit une meilleure sécurité puisque les données sont accessibles via des procédures stockées au lieu d'y accéder directement.
Donne une meilleure maintenance puisque la logique métier est testée et stockée dans le serveur.
Procédure de création
Les procédures stockées sont créées à l'aide de l'instruction CREATE PROCEDURE.
Syntaxe
Voici la syntaxe générique de l'instruction CREATE PROCEDURE.
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;Exemple
Considérez le tableau des salaires suivant.
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 103 | 90 000 | 7 000 | 83 000 |
| 104 | 75 000 | 5 000 | 70 000 |
L'exemple suivant crée une procédure stockée nommée InsertSalary pour accepter les valeurs et les insérer dans la table des salaires.
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;Exécution des procédures
Les procédures stockées sont exécutées à l'aide de l'instruction CALL.
Syntaxe
Voici la syntaxe générique de l'instruction CALL.
CALL <procedure name> [(parameter values)];Exemple
L'exemple suivant appelle la procédure stockée InsertSalary et insère des enregistrements dans la table des salaires.
CALL InsertSalary(105,20000,2000,18000);Une fois la requête ci-dessus exécutée, elle produit la sortie suivante et vous pouvez voir la ligne insérée dans la table Salary.
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 103 | 90 000 | 7 000 | 83 000 |
| 104 | 75 000 | 5 000 | 70 000 |
| 105 | 20 000 | 2 000 | 18 000 |
Ce chapitre présente les différentes stratégies JOIN disponibles dans Teradata.
Méthodes de jointure
Teradata utilise différentes méthodes de jointure pour effectuer des opérations de jointure. Certaines des méthodes de jointure couramment utilisées sont -
- Fusionner la jointure
- Jointure imbriquée
- Rejoindre le produit
Fusionner la jointure
La méthode Merge Join a lieu lorsque la jointure est basée sur la condition d'égalité. La jointure par fusion nécessite que les lignes de jointure soient sur le même AMP. Les lignes sont jointes en fonction de leur hachage de ligne. La jointure de fusion utilise différentes stratégies de jointure pour amener les lignes vers le même AMP.
Stratégie n ° 1
Si les colonnes de jointure sont les index principaux des tables correspondantes, les lignes de jointure se trouvent déjà sur le même AMP. Dans ce cas, aucune distribution n'est requise.
Considérez les tableaux des employés et des salaires suivants.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Lorsque ces deux tables sont jointes sur la colonne EmployeeNo, aucune redistribution n'a lieu puisque EmployeeNo est l'index principal des deux tables qui sont jointes.
Stratégie n ° 2
Considérez les tableaux d'employés et de services suivants.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );Si ces deux tables sont jointes sur la colonne DeparmentNo, les lignes doivent être redistribuées car DepartmentNo est un index primaire dans une table et un index non primaire dans une autre table. Dans ce scénario, joindre des lignes peut ne pas être sur le même AMP. Dans ce cas, Teradata peut redistribuer la table des employés sur la colonne DepartmentNo.
Stratégie n ° 3
Pour les tables Employé et Département ci-dessus, Teradata peut dupliquer la table Département sur toutes les SAP, si la taille de la table Département est petite.
Jointure imbriquée
La jointure imbriquée n'utilise pas tous les AMP. Pour que la jointure imbriquée ait lieu, l'une des conditions doit être l'égalité sur l'index primaire unique d'une table, puis la jonction de cette colonne à n'importe quel index de l'autre table.
Dans ce scénario, le système récupérera la ligne à l'aide de l'index principal unique d'une table et utilisera ce hachage de ligne pour récupérer les enregistrements correspondants à partir d'une autre table. La jointure imbriquée est la plus efficace de toutes les méthodes de jointure.
Rejoindre le produit
Product Join compare chaque ligne éligible d'une table avec chaque ligne éligible d'une autre table. La jonction de produit peut avoir lieu en raison de certains des facteurs suivants -
- Où la condition est manquante.
- La condition de jointure n'est pas basée sur une condition d'égalité.
- Les alias de table ne sont pas corrects.
- Conditions de jointure multiples.
L'index primaire partitionné (PPI) est un mécanisme d'indexation utile pour améliorer les performances de certaines requêtes. Lorsque des lignes sont insérées dans une table, elles sont stockées dans un AMP et classées par ordre de hachage des lignes. Lorsqu'une table est définie avec PPI, les lignes sont triées par leur numéro de partition. Dans chaque partition, ils sont classés par hachage de ligne. Les lignes sont affectées à une partition en fonction de l'expression de partition définie.
Avantages
Évitez l'analyse complète de la table pour certaines requêtes.
Évitez d'utiliser un index secondaire qui nécessite une structure physique supplémentaire et une maintenance d'E / S supplémentaire.
Accédez rapidement à un sous-ensemble d'une grande table.
Supprimez rapidement les anciennes données et ajoutez de nouvelles données.
Exemple
Considérez la table Orders suivante avec l'index principal sur OrderNo.
| MagasinNon | N ° de commande | Date de commande | Total de la commande |
|---|---|---|---|
| 101 | 7501 | 01/10/2015 | 900 |
| 101 | 7502 | 02/10/2015 | 1 200 |
| 102 | 7503 | 02/10/2015 | 3 000 |
| 102 | 7504 | 03/10/2015 | 2 454 |
| 101 | 7505 | 03/10/2015 | 1201 |
| 103 | 7506 | 04/10/2015 | 2 454 |
| 101 | 7507 | 05/10/2015 | 1201 |
| 101 | 7508 | 05/10/2015 | 1201 |
Supposons que les enregistrements sont répartis entre les AMP comme indiqué dans les tableaux suivants. Les enregistrements sont stockés dans des AMP, triés en fonction de leur hachage de ligne.
| RowHash | N ° de commande | Date de commande |
|---|---|---|
| 1 | 7505 | 03/10/2015 |
| 2 | 7504 | 03/10/2015 |
| 3 | 7501 | 01/10/2015 |
| 4 | 7508 | 05/10/2015 |
| RowHash | N ° de commande | Date de commande |
|---|---|---|
| 1 | 7507 | 05/10/2015 |
| 2 | 7502 | 02/10/2015 |
| 3 | 7506 | 04/10/2015 |
| 4 | 7503 | 02/10/2015 |
Si vous exécutez une requête pour extraire les commandes pour une date particulière, l'optimiseur peut choisir d'utiliser l'analyse complète de la table, puis tous les enregistrements de l'AMP sont accessibles. Pour éviter cela, vous pouvez définir la date de la commande en tant qu'index primaire partitionné. Lorsque des lignes sont insérées dans la table des commandes, elles sont partitionnées par date de commande. Dans chaque partition, ils seront classés par hachage de ligne.
Les données suivantes montrent comment les enregistrements seront stockés dans les AMP, s'ils sont partitionnés par date de commande. Si une requête est exécutée pour accéder aux enregistrements par date de commande, seule la partition qui contient les enregistrements pour cette commande particulière sera accessible.
| Cloison | RowHash | N ° de commande | Date de commande |
|---|---|---|---|
| 0 | 3 | 7501 | 01/10/2015 |
| 1 | 1 | 7505 | 03/10/2015 |
| 1 | 2 | 7504 | 03/10/2015 |
| 2 | 4 | 7508 | 05/10/2015 |
| Cloison | RowHash | N ° de commande | Date de commande |
|---|---|---|---|
| 0 | 2 | 7502 | 02/10/2015 |
| 0 | 4 | 7503 | 02/10/2015 |
| 1 | 3 | 7506 | 04/10/2015 |
| 2 | 1 | 7507 | 05/10/2015 |
Voici un exemple pour créer une table avec l'index principal de la partition. La clause PARTITION BY est utilisée pour définir la partition.
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);Dans l'exemple ci-dessus, la table est partitionnée par colonne OrderDate. Il y aura une partition distincte pour chaque jour.
Les fonctions OLAP sont similaires aux fonctions d'agrégation, sauf que les fonctions d'agrégation ne renverront qu'une seule valeur tandis que la fonction OLAP fournira les lignes individuelles en plus des agrégats.
Syntaxe
Voici la syntaxe générale de la fonction OLAP.
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)Les fonctions d'agrégation peuvent être SUM, COUNT, MAX, MIN, AVG.
Exemple
Considérez le tableau des salaires suivant.
| Numéro d'employé | Brut | Déduction | Salaire net |
|---|---|---|---|
| 101 | 40 000 | 4 000 | 36 000 |
| 102 | 80 000 | 6 000 | 74 000 |
| 103 | 90 000 | 7 000 | 83 000 |
| 104 | 75 000 | 5 000 | 70 000 |
Voici un exemple pour trouver la somme cumulée ou le total cumulé de NetPay sur la table des salaires. Les enregistrements sont triés par EmployeeNo et la somme cumulée est calculée sur la colonne NetPay.
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000RANG
La fonction RANK classe les enregistrements en fonction de la colonne fournie. La fonction RANK peut également filtrer le nombre d'enregistrements renvoyés en fonction du rang.
Syntaxe
Voici la syntaxe générique pour utiliser la fonction RANK.
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])Exemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | JoinedDate | DépartementID | Date de naissance |
|---|---|---|---|---|---|
| 101 | Mike | James | 27/03/2005 | 1 | 05/01/1980 |
| 102 | Robert | Williams | 25/04/2007 | 2 | 05/03/1983 |
| 103 | Peter | Paul | 21/03/2007 | 2 | 01/04/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 06/11/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 01/12/1984 |
La requête suivante classe les enregistrements de la table des employés par date de connexion et attribue le classement à la date de connexion.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante.
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5La clause PARTITION BY regroupe les données par les colonnes définies dans la clause PARTITION BY et exécute la fonction OLAP dans chaque groupe. Voici un exemple de la requête qui utilise la clause PARTITION BY.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;Lorsque la requête ci-dessus est exécutée, elle produit la sortie suivante. Vous pouvez voir que le rang est réinitialisé pour chaque département.
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1Ce chapitre décrit les fonctionnalités disponibles pour la protection des données dans Teradata.
Journal transitoire
Teradata utilise Transient Journal pour protéger les données contre les échecs de transaction. Chaque fois que des transactions sont exécutées, le journal des transitoires conserve une copie des images avant des lignes affectées jusqu'à ce que la transaction réussisse ou soit annulée avec succès. Ensuite, les images avant sont supprimées. Le journal des transitoires est conservé dans chaque AMP. Il s'agit d'un processus automatique et ne peut pas être désactivé.
Se retirer
Fallback protège les données de la table en stockant la deuxième copie des lignes d'une table sur un autre AMP appelé Fallback AMP. Si un AMP échoue, les lignes de secours sont accédées. Avec cela, même si un AMP échoue, les données sont toujours disponibles via AMP de secours. L'option de secours peut être utilisée lors de la création de la table ou après la création de la table. Le repli garantit que la deuxième copie des lignes de la table est toujours stockée dans un autre AMP pour protéger les données de l'échec AMP. Cependant, le secours occupe deux fois le stockage et les E / S pour l'insertion / la suppression / la mise à jour.
Le diagramme suivant montre comment la copie de secours des lignes est stockée dans un autre AMP.
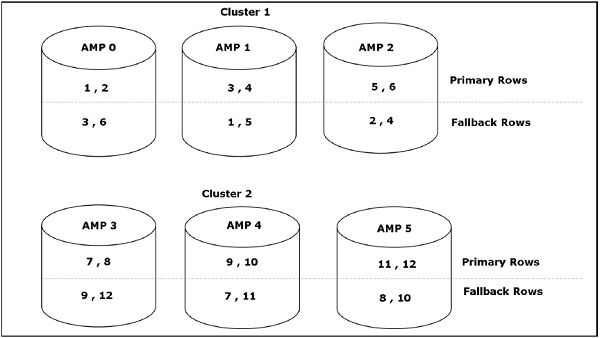
Down AMP Recovery Journal
Le journal de récupération Down AMP est activé lorsque l'AMP échoue et que la table est protégée contre le repli. Ce journal garde une trace de toutes les modifications apportées aux données de l'AMP défaillant. Le journal est activé sur les AMP restants du cluster. Il s'agit d'un processus automatique et ne peut pas être désactivé. Une fois que l'AMP défaillant est actif, les données du journal de récupération Down AMP sont synchronisées avec l'AMP. Une fois que cela est fait, le journal est supprimé.
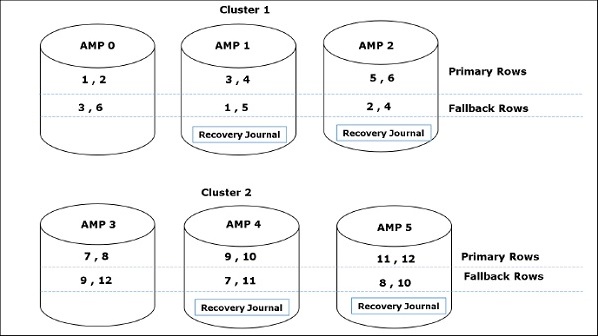
Cliques
Clique est un mécanisme utilisé par Teradata pour protéger les données des pannes de nœud. Une clique n'est rien d'autre qu'un ensemble de nœuds Teradata qui partagent un ensemble commun de baies de disques. Lorsqu'un nœud tombe en panne, les vprocs du nœud défaillant migrent vers d'autres nœuds de la clique et continuent d'accéder à leurs baies de disques.
Nœud de redondance d'UC
Le nœud de redondance d'UC est un nœud qui ne participe pas à l'environnement de production. Si un nœud échoue, les vprocs des nœuds défaillants migreront vers le nœud de secours. Une fois le nœud défaillant récupéré, il devient le nœud de secours. Les nœuds de redondance d'UC sont utilisés pour maintenir les performances en cas de défaillance des nœuds.
RAID
La matrice redondante de disques indépendants (RAID) est un mécanisme utilisé pour protéger les données contre les pannes de disque. La matrice de disques se compose d'un ensemble de disques regroupés sous la forme d'une unité logique. Cette unité peut ressembler à une seule unité pour l'utilisateur, mais elles peuvent être réparties sur plusieurs disques.
RAID 1 est couramment utilisé dans Teradata. En RAID 1, chaque disque est associé à un disque miroir. Toute modification des données du disque principal est également reflétée dans la copie miroir. Si le disque principal tombe en panne, les données du disque miroir sont alors accessibles.

Ce chapitre a abordé les différentes stratégies de gestion des utilisateurs dans Teradata.
Utilisateurs
Un utilisateur est créé à l'aide de la commande CREATE USER. Dans Teradata, un utilisateur est également similaire à une base de données. Ils peuvent tous deux se voir attribuer un espace et contenir des objets de base de données, sauf qu'un mot de passe est attribué à l'utilisateur.
Syntaxe
Voici la syntaxe de CREATE USER.
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;Lors de la création d'un utilisateur, les valeurs du nom d'utilisateur, de l'espace permanent et du mot de passe sont obligatoires. Les autres champs sont facultatifs.
Exemple
Voici un exemple pour créer l'utilisateur TD01.
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;Comptes
Lors de la création d'un nouvel utilisateur, l'utilisateur peut être affecté à un compte. L'option COMPTE dans CREATE USER est utilisée pour attribuer le compte. Un utilisateur peut être affecté à plusieurs comptes.
Syntaxe
Voici la syntaxe de CREATE USER avec l'option de compte.
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountidExemple
L'exemple suivant crée l'utilisateur TD02 et affecte le compte en tant qu'informatique et administrateur.
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);L'utilisateur peut spécifier l'ID de compte lors de la connexion au système Teradata ou après avoir été connecté au système à l'aide de la commande SET SESSION.
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountidAccorder des privilèges
La commande GRANT est utilisée pour attribuer un ou plusieurs privilèges sur les objets de base de données à l'utilisateur ou à la base de données.
Syntaxe
Voici la syntaxe de la commande GRANT.
GRANT privileges ON objectname TO username;Les privilèges peuvent être INSERT, SELECT, UPDATE, REFERENCES.
Exemple
Voici un exemple d'instruction GRANT.
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;Révoquer les privilèges
La commande REVOKE supprime les privilèges des utilisateurs ou des bases de données. La commande REVOKE ne peut supprimer que les privilèges explicites.
Syntaxe
Voici la syntaxe de base de la commande REVOKE.
REVOKE [ALL|privileges] ON objectname FROM username;Exemple
Voici un exemple de commande REVOKE.
REVOKE INSERT,SELECT ON Employee FROM TD01;Ce chapitre décrit la procédure de réglage des performances dans Teradata.
Explique
La première étape du réglage des performances consiste à utiliser EXPLAIN sur votre requête. Le plan EXPLAIN donne les détails sur la manière dont l'optimiseur exécutera votre requête. Dans le plan Explain, vérifiez les mots-clés tels que le niveau de confiance, la stratégie de jointure utilisée, la taille du fichier de spoule, la redistribution, etc.
Collecter des statistiques
Optimizer utilise les données démographiques pour élaborer une stratégie d'exécution efficace. La commande COLLECT STATISTICS est utilisée pour collecter les données démographiques de la table. Assurez-vous que les statistiques collectées sur les colonnes sont à jour.
Collectez des statistiques sur les colonnes utilisées dans la clause WHERE et sur les colonnes utilisées dans la condition de jointure.
Collectez des statistiques sur les colonnes d'index primaire unique.
Collectez des statistiques sur les colonnes d'index secondaire non unique. L'optimiseur décidera s'il peut utiliser NUSI ou l'analyse complète de la table.
Collectez des statistiques sur l'index de jointure en collectant les statistiques sur la table de base.
Collectez des statistiques sur les colonnes de partitionnement.
Types de données
Assurez-vous que les types de données appropriés sont utilisés. Cela évitera l'utilisation d'un stockage excessif que nécessaire.
Conversion
Assurez-vous que les types de données des colonnes utilisées dans la condition de jointure sont compatibles pour éviter les conversions de données explicites.
Trier
Supprimez les clauses ORDER BY inutiles, sauf si nécessaire.
Problème d'espace de spool
Une erreur d'espace de spoule est générée si la requête dépasse la limite d'espace de spoule AMP pour cet utilisateur. Vérifiez le plan d’explication et identifiez l’étape qui consomme plus d’espace de spoule. Ces requêtes intermédiaires peuvent être divisées et placées séparément pour créer des tables temporaires.
Index primaire
Assurez-vous que l'index primaire est correctement défini pour la table. La colonne d'index primaire doit répartir uniformément les données et doit être fréquemment utilisée pour accéder aux données.
Table SET
Si vous définissez une table SET, l'optimiseur vérifiera si l'enregistrement est dupliqué pour chaque enregistrement inséré. Pour supprimer la condition de vérification en double, vous pouvez définir un index secondaire unique pour la table.
MISE À JOUR sur la grande table
La mise à jour de la grande table prendra du temps. Au lieu de mettre à jour la table, vous pouvez supprimer les enregistrements et insérer les enregistrements avec des lignes modifiées.
Suppression de tables temporaires
Supprimez les tables temporaires (tables intermédiaires) et volatiles si elles ne sont plus nécessaires. Cela libérera de l'espace permanent et de l'espace de bobine.
Table MULTISET
Si vous êtes sûr que les enregistrements d'entrée n'auront pas d'enregistrements en double, vous pouvez définir la table cible comme table MULTISET pour éviter la vérification de ligne en double utilisée par la table SET.
L'utilitaire FastLoad est utilisé pour charger des données dans des tables vides. Puisqu'il n'utilise pas de journaux temporaires, les données peuvent être chargées rapidement. Il ne charge pas les lignes dupliquées même si la table cible est une table MULTISET.
Limitation
La table cible ne doit pas avoir d'index secondaire, d'index de jointure et de référence de clé étrangère.
Fonctionnement de FastLoad
FastLoad est exécuté en deux phases.
La phase 1
Les moteurs d'analyse lisent les enregistrements du fichier d'entrée et envoient un bloc à chaque AMP.
Chaque AMP stocke les blocs d'enregistrements.
Ensuite, les AMP hachent chaque enregistrement et les redistribuent vers l'AMP approprié.
À la fin de la phase 1, chaque AMP a ses lignes mais elles ne sont pas dans la séquence de hachage des lignes.
Phase 2
La phase 2 démarre lorsque FastLoad reçoit l'instruction END LOADING.
Chaque AMP trie les enregistrements sur le hachage de ligne et les écrit sur le disque.
Les verrous sur la table cible sont libérés et les tables d'erreur sont supprimées.
Exemple
Créez un fichier texte avec les enregistrements suivants et nommez le fichier comme employee.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Voici un exemple de script FastLoad pour charger le fichier ci-dessus dans la table Employee_Stg.
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;Exécution d'un script FastLoad
Une fois le fichier d'entrée employee.txt créé et le script FastLoad nommé EmployeeLoad.fl, vous pouvez exécuter le script FastLoad à l'aide de la commande suivante sous UNIX et Windows.
FastLoad < EmployeeLoad.fl;Une fois la commande ci-dessus exécutée, le script FastLoad s'exécutera et produira le journal. Dans le journal, vous pouvez voir le nombre d'enregistrements traités par FastLoad et le code d'état.
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsConditions de FastLoad
Voici la liste des termes courants utilisés dans le script FastLoad.
LOGON - Se connecte à Teradata et lance une ou plusieurs sessions.
DATABASE - Définit la base de données par défaut.
BEGIN LOADING - Identifie la table à charger.
ERRORFILES - Identifie les 2 tables d'erreurs qui doivent être créées / mises à jour.
CHECKPOINT - Définit quand prendre le point de contrôle.
SET RECORD - Spécifie si le format du fichier d'entrée est formaté, binaire, texte ou non formaté.
DEFINE - Définit la disposition du fichier d'entrée.
FILE - Spécifie le nom et le chemin du fichier d'entrée.
INSERT - Insère les enregistrements du fichier d'entrée dans la table cible.
END LOADING- Lance la phase 2 du FastLoad. Distribue les enregistrements dans la table cible.
LOGOFF - Met fin à toutes les sessions et met fin à FastLoad.
MultiLoad peut charger plusieurs tables à la fois et il peut également effectuer différents types de tâches telles que INSERT, DELETE, UPDATE et UPSERT. Il peut charger jusqu'à 5 tables à la fois et effectuer jusqu'à 20 opérations DML dans un script. La table cible n'est pas requise pour MultiLoad.
MultiLoad prend en charge deux modes -
- IMPORT
- DELETE
MultiLoad nécessite une table de travail, une table de journal et deux tables d'erreurs en plus de la table cible.
Log Table - Utilisé pour maintenir les points de contrôle pris pendant le chargement qui seront utilisés pour le redémarrage.
Error Tables- Ces tables sont insérées lors du chargement lorsqu'une erreur survient. La première table d'erreurs stocke les erreurs de conversion tandis que la seconde table d'erreurs stocke les enregistrements en double.
Log Table - Conserve les résultats de chaque phase de MultiLoad à des fins de redémarrage.
Work table- Le script MultiLoad crée une table de travail par table cible. La table de travail est utilisée pour conserver les tâches DML et les données d'entrée.
Limitation
MultiLoad a quelques limitations.
- Index secondaire unique non pris en charge sur la table cible.
- L'intégrité référentielle n'est pas prise en charge.
- Déclencheurs non pris en charge.
Comment fonctionne MultiLoad
L'importation MultiLoad comporte cinq phases -
Phase 1 - Phase préliminaire - Exécute les activités de configuration de base.
Phase 2 - Phase de transaction DML - Vérifie la syntaxe des instructions DML et les apporte au système Teradata.
Phase 3 - Phase d'acquisition - Apporte les données d'entrée dans les tables de travail et verrouille la table.
Phase 4 - Phase d'application - Applique toutes les opérations DML.
Phase 5 - Phase de nettoyage - Libère le verrouillage de la table.
Les étapes impliquées dans un script MultiLoad sont:
Step 1 - Configurez la table des journaux.
Step 2 - Connectez-vous à Teradata.
Step 3 - Spécifiez les tables Target, Work et Error.
Step 4 - Définissez la disposition du fichier INPUT.
Step 5 - Définissez les requêtes DML.
Step 6 - Nommez le fichier IMPORT.
Step 7 - Spécifiez la DISPOSITION à utiliser.
Step 8 - Lancez le chargement.
Step 9 - Terminez le chargement et terminez les sessions.
Exemple
Créez un fichier texte avec les enregistrements suivants et nommez le fichier comme employee.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3L'exemple suivant est un script MultiLoad qui lit les enregistrements de la table Employee et se charge dans la table Employee_Stg.
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;Exécution d'un script MultiLoad
Une fois que le fichier d'entrée employee.txt est créé et que le script de chargement multiple est nommé EmployeeLoad.ml, vous pouvez exécuter le script de chargement multiple à l'aide de la commande suivante sous UNIX et Windows.
Multiload < EmployeeLoad.ml;L'utilitaire FastExport est utilisé pour exporter les données des tables Teradata dans des fichiers plats. Il peut également générer les données au format rapport. Les données peuvent être extraites d'une ou plusieurs tables à l'aide de Join. Étant donné que FastExport exporte les données dans des blocs de 64 Ko, il est utile pour extraire un grand volume de données.
Exemple
Considérez le tableau des employés suivant.
| Numéro d'employé | Prénom | Nom de famille | Date de naissance |
|---|---|---|---|
| 101 | Mike | James | 05/01/1980 |
| 104 | Alex | Stuart | 06/11/1984 |
| 102 | Robert | Williams | 05/03/1983 |
| 105 | Robert | James | 01/12/1984 |
| 103 | Peter | Paul | 01/04/1983 |
Voici un exemple de script FastExport. Il exporte les données de la table des employés et écrit dans un fichier employeedata.txt.
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;Exécution d'un script FastExport
Une fois le script écrit et nommé employé.fx, vous pouvez utiliser la commande suivante pour exécuter le script.
fexp < employee.fxAprès avoir exécuté la commande ci-dessus, vous recevrez la sortie suivante dans le fichier employeedata.txt.
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06Conditions de FastExport
Voici la liste des termes couramment utilisés dans le script FastExport.
LOGTABLE - Spécifie la table du journal à des fins de redémarrage.
LOGON - Se connecte à Teradata et lance une ou plusieurs sessions.
DATABASE - Définit la base de données par défaut.
BEGIN EXPORT - Indique le début de l'exportation.
EXPORT - Spécifie le fichier cible et le format d'exportation.
SELECT - Spécifie la requête de sélection pour exporter les données.
END EXPORT - Spécifie la fin de FastExport.
LOGOFF - Met fin à toutes les sessions et met fin à FastExport.
L'utilitaire BTEQ est un utilitaire puissant de Teradata qui peut être utilisé à la fois en mode batch et interactif. Il peut être utilisé pour exécuter n'importe quelle instruction DDL, instruction DML, créer des macros et des procédures stockées. BTEQ peut être utilisé pour importer des données dans des tables Teradata à partir d'un fichier plat et il peut également être utilisé pour extraire des données de tables dans des fichiers ou des rapports.
Termes BTEQ
Voici la liste des termes couramment utilisés dans les scripts BTEQ.
LOGON - Utilisé pour se connecter au système Teradata.
ACTIVITYCOUNT - Renvoie le nombre de lignes affectées par la requête précédente.
ERRORCODE - Renvoie le code d'état de la requête précédente.
DATABASE - Définit la base de données par défaut.
LABEL - Attribue une étiquette à un ensemble de commandes SQL.
RUN FILE - Exécute la requête contenue dans un fichier.
GOTO - Transfère le contrôle vers une étiquette.
LOGOFF - Se déconnecte de la base de données et met fin à toutes les sessions.
IMPORT - Spécifie le chemin du fichier d'entrée.
EXPORT - Spécifie le chemin du fichier de sortie et lance l'exportation.
Exemple
Voici un exemple de script BTEQ.
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;Le script ci-dessus effectue les tâches suivantes.
Se connecte au système Teradata.
Définit la base de données par défaut.
Crée une table appelée employee_bkup.
Sélectionne un enregistrement de la table Employee pour vérifier si la table contient des enregistrements.
Supprime la table employee_bkup, si la table est vide.
Transfère le contrôle vers un Label InsertEmployee qui insère des enregistrements dans la table employee_bkup
Vérifie ERRORCODE pour s'assurer que l'instruction est réussie, après chaque instruction SQL.
ACTIVITYCOUNT renvoie le nombre d'enregistrements sélectionnés / impactés par la requête SQL précédente.