TIKA - Extraction du fichier .class
Vous trouverez ci-dessous le programme pour extraire le contenu et les métadonnées d'un fichier .class.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Enregistrez le code ci-dessus sous JavaClassParse.javaet compilez-le à partir de l'invite de commande en utilisant les commandes suivantes -
javac JavaClassParse.java
java JavaClassParseCi-dessous, un aperçu de Example.java qui générera Example.class après la compilation.

Example.class le fichier a les propriétés suivantes -
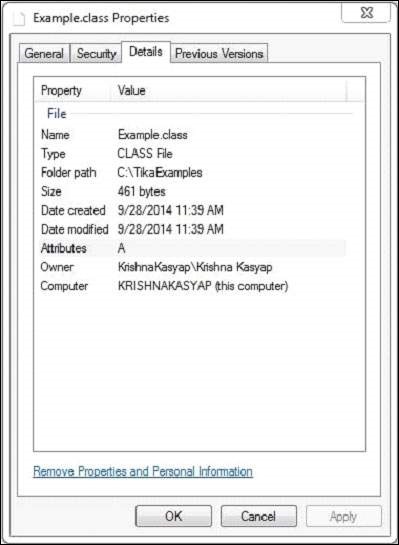
Après avoir exécuté le programme ci-dessus, vous obtiendrez la sortie suivante.
Output -
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: Example