अपाचे तूफान - त्वरित गाइड
अपाचे तूफान क्या है?
अपाचे स्टॉर्म एक वितरित वास्तविक समय की बड़ी डेटा-प्रोसेसिंग प्रणाली है। तूफान को बड़ी मात्रा में डेटा को एक दोष-सहिष्णु और क्षैतिज स्केलेबल विधि में संसाधित करने के लिए डिज़ाइन किया गया है। यह एक स्ट्रीमिंग डेटा फ्रेमवर्क है जिसमें उच्चतम अंतर्ग्रहण दर की क्षमता है। हालांकि स्टॉर्म स्टेटलेस है, यह अपाचे ज़ूकिपर के माध्यम से वितरित पर्यावरण और क्लस्टर राज्य का प्रबंधन करता है। यह सरल है और आप समानांतर में वास्तविक समय के डेटा पर सभी प्रकार के जोड़तोड़ कर सकते हैं।
अपाचे स्टॉर्म रियल-टाइम डेटा एनालिटिक्स में अग्रणी बना हुआ है। तूफान को सेटअप करना, संचालित करना आसान है और यह गारंटी देता है कि प्रत्येक संदेश को कम से कम एक बार टोपोलॉजी के माध्यम से संसाधित किया जाएगा।
अपाचे स्टॉर्म बनाम हैडोप
मूल रूप से Hadoop और Storm चौखटों का उपयोग बड़े डेटा के विश्लेषण के लिए किया जाता है। दोनों एक दूसरे के पूरक हैं और कुछ पहलुओं में भिन्न हैं। अपाचे स्टॉर्म दृढ़ता के अलावा सभी ऑपरेशन करता है, जबकि हडोप सब कुछ अच्छा है लेकिन वास्तविक समय की गणना में पिछड़ जाता है। निम्न तालिका स्टॉर्म और हडोप की विशेषताओं की तुलना करती है।
| आंधी | Hadoop |
|---|---|
| वास्तविक समय धारा प्रसंस्करण | बैच प्रसंस्करण |
| राज्यविहीन | स्टेटफुल |
| ज़ूकेपर आधारित समन्वय के साथ मास्टर / दास वास्तुकला। मास्टर नोड के रूप में कहा जाता हैnimbus और गुलाम हैं supervisors। | ज़ूकेपर आधारित समन्वय के साथ मास्टर-दास वास्तुकला। मास्टर नोड हैjob tracker और दास नोड है task tracker। |
| एक स्टॉर्म स्ट्रीमिंग प्रक्रिया, क्लस्टर पर प्रति सेकंड हजारों संदेशों तक पहुंच सकती है। | Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम (HDFS) बड़ी मात्रा में डेटा को संसाधित करने के लिए MapReduce फ्रेमवर्क का उपयोग करता है जिसमें मिनट या घंटे लगते हैं। |
| तूफान टोपोलॉजी उपयोगकर्ता द्वारा बंद होने या एक अप्रत्याशित अप्राप्य विफलता तक चलता है। | MapReduce नौकरियों को एक अनुक्रमिक क्रम में निष्पादित किया जाता है और अंततः पूरा किया जाता है। |
| Both are distributed and fault-tolerant | |
| यदि निंबस / सुपरवाइजर की मृत्यु हो जाती है, तो पुनरारंभ करने से यह जारी रहता है कि यह कहाँ से रुका है, इसलिए कुछ भी प्रभावित नहीं होता है। | यदि JobTracker की मृत्यु हो जाती है, तो सभी चलने वाली नौकरियां खो जाती हैं। |
अपाचे तूफान के उपयोग-मामले
अपाचे स्टॉर्म रियल-टाइम बड़े डेटा स्ट्रीम प्रोसेसिंग के लिए बहुत प्रसिद्ध है। इस कारण से, अधिकांश कंपनियां स्टॉर्म को अपने सिस्टम के अभिन्न अंग के रूप में उपयोग कर रही हैं। कुछ उल्लेखनीय उदाहरण इस प्रकार हैं -
Twitter- ट्विटर "प्रकाशक विश्लेषिकी उत्पादों" की अपनी सीमा के लिए अपाचे स्टॉर्म का उपयोग कर रहा है। "प्रकाशक Analytics उत्पाद" ट्विटर प्लेटफ़ॉर्म में प्रत्येक ट्वीट और क्लिक को संसाधित करता है। अपाचे स्टॉर्म का ट्विटर इंफ्रास्ट्रक्चर से गहरा नाता है।
NaviSite- NaviSite इवेंट लॉग मॉनिटरिंग / ऑडिटिंग सिस्टम के लिए स्टॉर्म का उपयोग कर रहा है। सिस्टम में उत्पन्न हर लॉग स्टॉर्म से गुजरेगा। तूफान नियमित अभिव्यक्ति के कॉन्फ़िगर किए गए सेट के खिलाफ संदेश की जांच करेगा और यदि कोई मेल है, तो उस विशेष संदेश को डेटाबेस में सहेजा जाएगा।
Wego- वेगो सिंगापुर में स्थित एक यात्रा मेटासर्च इंजन है। यात्रा संबंधी डेटा दुनिया भर में कई स्रोतों से अलग-अलग समय के साथ आता है। तूफान वास्तविक समय के डेटा को खोजने के लिए वीगो की मदद करता है, समसामयिक मुद्दों को हल करता है और अंत-उपयोगकर्ता के लिए सबसे अच्छा मैच ढूंढता है।
अपाचे तूफान के फायदे
यहां उन लाभों की सूची दी गई है जो अपाचे स्टॉर्म प्रदान करते हैं -
तूफान खुला स्रोत, मजबूत और उपयोगकर्ता के अनुकूल है। इसका उपयोग छोटी कंपनियों के साथ-साथ बड़े निगमों में भी किया जा सकता है।
तूफान गलती सहिष्णु, लचीला, विश्वसनीय है, और किसी भी प्रोग्रामिंग भाषा का समर्थन करता है।
वास्तविक समय स्ट्रीम प्रसंस्करण की अनुमति देता है।
तूफान अविश्वसनीय रूप से तेज़ है क्योंकि इसमें डेटा को संसाधित करने की भारी शक्ति है।
रेखीय रूप से संसाधनों को जोड़कर बढ़ते लोड के तहत भी तूफान प्रदर्शन को बनाए रख सकता है। यह अत्यधिक स्केलेबल है।
तूफान सेकंड या मिनटों में डेटा रिफ्रेश और एंड-टू-एंड डिलीवरी प्रतिक्रिया करता है जो समस्या पर निर्भर करता है। इसकी बहुत कम विलंबता है।
तूफान में परिचालन बुद्धि होती है।
यदि क्लस्टर में कोई भी कनेक्टेड नोड्स मर जाते हैं या संदेश खो जाते हैं, तो भी स्टॉर्म गारंटी डेटा प्रोसेसिंग प्रदान करता है।
अपाचे स्टॉर्म एक छोर से वास्तविक समय के डेटा की कच्ची धारा को पढ़ता है और इसे छोटी प्रसंस्करण इकाइयों के अनुक्रम से गुजरता है और दूसरे छोर पर संसाधित / उपयोगी जानकारी को आउटपुट करता है।
निम्नलिखित चित्र में अपाचे तूफान की मुख्य अवधारणा को दर्शाया गया है।

आइए अब हम अपाचे स्टॉर्म के घटकों पर करीब से नज़र डालें -
| अवयव | विवरण |
|---|---|
| टपल | तूफ़ान तूफान में मुख्य डेटा संरचना है। यह आदेशित तत्वों की एक सूची है। डिफ़ॉल्ट रूप से, एक टपल सभी डेटा प्रकारों का समर्थन करता है। आम तौर पर, यह अल्पविराम द्वारा अलग किए गए मानों के एक सेट के रूप में तैयार किया जाता है और एक स्टॉर्म क्लस्टर में पारित किया जाता है। |
| धारा | स्ट्रीम ट्यूपल्स का एक अनियोजित अनुक्रम है। |
| spouts | धारा का स्रोत। आमतौर पर, स्टॉर्म कच्चे डेटा स्रोतों जैसे ट्विटर स्ट्रीमिंग एपीआई, अपाचे काफ्का कतार, केस्ट्रेल कतार आदि से इनपुट डेटा को स्वीकार करता है, अन्यथा आप डेटा स्रोत से डेटा पढ़ने के लिए स्प्राउट्स लिख सकते हैं। "ISpout" टोंटी को लागू करने के लिए मुख्य इंटरफ़ेस है। कुछ विशिष्ट इंटरफेस IRichSpout, BaseRichSpout, KafkaSpout, आदि हैं। |
| बोल्ट | बोल्ट तार्किक प्रसंस्करण इकाइयाँ हैं। स्प्राउट्स बोल्ट और बोल्ट प्रक्रिया के लिए डेटा पास करते हैं और एक नया आउटपुट स्ट्रीम तैयार करते हैं। बोल्ट डेटा स्रोतों और डेटाबेस के साथ फ़िल्टरिंग, एकत्रीकरण, जुड़ने, बातचीत करने के संचालन को निष्पादित कर सकते हैं। बोल्ट डेटा प्राप्त करता है और एक या अधिक बोल्टों का उत्सर्जन करता है। बोल्ट को लागू करने के लिए "आईबोल्ट" मुख्य इंटरफ़ेस है। कुछ सामान्य इंटरफेस IRichBolt, IBasicBolt, आदि हैं। |
आइए "ट्विटर विश्लेषण" का एक वास्तविक समय उदाहरण लें और देखें कि इसे अपाचे स्टॉर्म में कैसे बनाया जा सकता है। निम्नलिखित चित्र संरचना को दर्शाता है।

"ट्विटर विश्लेषण" का इनपुट ट्विटर स्ट्रीमिंग एपीआई से आता है। स्पाउट ट्विटर स्ट्रीमिंग एपीआई और आउटपुट की ट्यूपल्स की धारा के रूप में उपयोग करने वाले उपयोगकर्ताओं के ट्वीट्स को पढ़ेगा। टोंटी के एक एकल टपल में एक ट्विटर उपयोगकर्ता नाम और एक एकल ट्वीट अल्पविराम द्वारा अलग किए गए मान होंगे। फिर, टुपल्स की इस भाप को बोल्ट के आगे भेजा जाएगा और बोल्ट व्यक्तिगत शब्द में ट्वीट को विभाजित करेगा, शब्द गणना की गणना करेगा, और एक कॉन्फ़िगर किए गए डेटा स्रोत पर जानकारी को बनाए रखेगा। अब, हम डेटासोर्स को क्वेरी करके आसानी से परिणाम प्राप्त कर सकते हैं।
टोपोलॉजी
टोंटी और बोल्ट एक साथ जुड़े हुए हैं और वे एक टोपोलॉजी बनाते हैं। स्टॉर्म टोपोलॉजी के अंदर रियल-टाइम एप्लिकेशन लॉजिक निर्दिष्ट है। सरल शब्दों में, एक टोपोलॉजी एक निर्देशित ग्राफ है जहां कोने की गणना होती है और किनारों को डेटा की धारा होती है।
एक साधारण टोपोलॉजी टोंटी से शुरू होती है। टोंटी डेटा को एक या एक से अधिक बोल्ट तक उत्सर्जित करती है। बोल्ट टोपोलॉजी में सबसे छोटे प्रोसेसिंग लॉजिक वाले नोड का प्रतिनिधित्व करता है और बोल्ट के आउटपुट को इनपुट के रूप में दूसरे बोल्ट में उत्सर्जित किया जा सकता है।
स्टॉर्म टोपोलॉजी को हमेशा चालू रखता है, जब तक कि आप टोपोलॉजी को मार नहीं देते। अपाचे स्टॉर्म का मुख्य काम टोपोलॉजी चलाना है और किसी भी समय किसी भी टोपोलॉजी को चलाना होगा।
कार्य
अब आपके पास टोंटी और बोल्ट पर एक मूल विचार है। वे टोपोलॉजी की सबसे छोटी तार्किक इकाई हैं और एक टोपोलॉजी एकल टोंटी और बोल्ट की एक सरणी का उपयोग करके बनाया गया है। टोपोलॉजी को सफलतापूर्वक चलाने के लिए उन्हें एक विशेष क्रम में ठीक से निष्पादित किया जाना चाहिए। स्टॉर्म द्वारा प्रत्येक स्पाउट और बोल्ट के निष्पादन को "कार्य" कहा जाता है। सरल शब्दों में, एक कार्य या तो एक टोंटी या एक बोल्ट का निष्पादन है। एक निश्चित समय पर, प्रत्येक टोंटी और बोल्ट में कई अलग-अलग थ्रेड्स में चलने वाले कई उदाहरण हो सकते हैं।
कर्मी
एक टोपोलॉजी कई कार्यकर्ता नोड्स पर, वितरित तरीके से चलती है। तूफान सभी कार्यकर्ता नोड्स पर समान रूप से कार्यों को फैलाता है। जब भी कोई नया काम आता है, तो श्रमिक नोड की भूमिका नौकरियों को सुनने और प्रक्रियाओं को शुरू करने या रोकने की होती है।
स्ट्रीम ग्रुपिंग
डेटा की स्ट्रीम स्प्राउट्स से बोल्ट तक या एक बोल्ट से दूसरे बोल्ट तक प्रवाहित होती है। स्ट्रीम ग्रुपिंग नियंत्रण करता है कि टोपोलॉजी को टोपोलॉजी में कैसे रूट किया जाता है और हमें टोपोलॉजी के प्रवाह को समझने में मदद मिलती है। नीचे बताए गए अनुसार चार-निर्मित समूह हैं।
फेरबदल समूहन
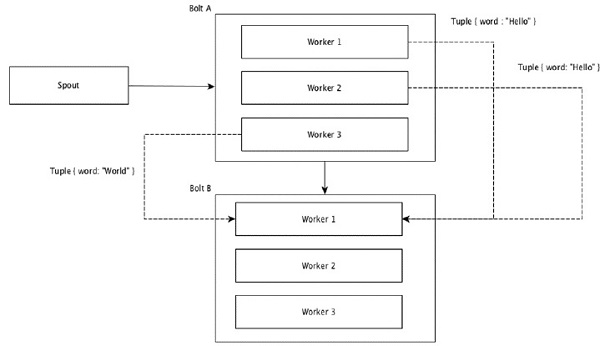
फेरबदल समूहन में, बोल्ट को निष्पादित करने वाले सभी श्रमिकों में समान रूप से टुपल्स को बेतरतीब ढंग से वितरित किया जाता है। निम्नलिखित चित्र संरचना को दर्शाता है।

फील्ड ग्रुपिंग
टुपल्स में समान मान वाले फ़ील्ड को एक साथ समूहीकृत किया जाता है और शेष ट्यूपल्स को बाहर रखा जाता है। फिर, उसी फ़ील्ड मान वाले टुपल्स को बोल्ट को निष्पादित करने वाले एक ही कार्यकर्ता के लिए आगे भेजा जाता है। उदाहरण के लिए, यदि स्ट्रीम को "शब्द" द्वारा समूहित किया जाता है, तो उसी स्ट्रिंग के साथ ट्यूपल्स, "हेलो" उसी कार्यकर्ता के पास जाएंगे। निम्न आरेख से पता चलता है कि फील्ड ग्रुपिंग कैसे काम करती है।

ग्लोबल ग्रुपिंग
सभी धाराओं को एक बोल्ट के लिए समूहीकृत और आगे किया जा सकता है। यह समूहीकरण स्रोत के सभी उदाहरणों द्वारा उत्पन्न ट्यूपल्स को एकल लक्ष्य उदाहरण (विशेष रूप से, सबसे कम आईडी वाले कार्यकर्ता को चुनें) को भेजता है।
सभी समूहन
सभी समूहीकरण प्रत्येक टपल की एक एकल प्रति प्राप्त बोल्ट के सभी उदाहरणों को भेजता है। बोल्ट को सिग्नल भेजने के लिए इस तरह के समूह का उपयोग किया जाता है। सभी समूहीकरण कार्य में शामिल होने के लिए उपयोगी है।

अपाचे स्टॉर्म का एक मुख्य आकर्षण यह है कि यह एक दोष-सहिष्णु है, जिसमें कोई "एकल बिंदु विफलता" (एसपीओएफ) वितरित आवेदन नहीं है। एप्लिकेशन की क्षमता बढ़ाने के लिए हम अपाचे स्टॉर्म को अधिक से अधिक सिस्टम में स्थापित कर सकते हैं।
आइए नजर डालते हैं कि अपाचे स्टॉर्म क्लस्टर को किस तरह से डिजाइन किया गया है और इसकी आंतरिक वास्तुकला। निम्नलिखित चित्र में क्लस्टर डिज़ाइन को दर्शाया गया है।

अपाचे स्टॉर्म में दो प्रकार के नोड होते हैं, Nimbus (मास्टर नोड) और Supervisor(कार्यकर्ता नोड)। निम्बस अपाचे स्टॉर्म का केंद्रीय घटक है। निम्बस का मुख्य काम स्टॉर्म टोपोलॉजी को चलाना है। निम्बस टोपोलॉजी का विश्लेषण करता है और निष्पादित होने वाले कार्य को इकट्ठा करता है। फिर, यह उपलब्ध सुपरवाइज़र को कार्य वितरित करेगा।
एक पर्यवेक्षक के पास एक या अधिक कार्यकर्ता प्रक्रिया होगी। पर्यवेक्षक कार्यों को कार्यकर्ता प्रक्रियाओं को सौंप देगा। कार्यकर्ता प्रक्रिया आवश्यकतानुसार कई निष्पादकों को प्रायोजित करेगी और कार्य को चलाएगी। अपाचे स्टॉर्म निंबस और पर्यवेक्षकों के बीच संचार के लिए एक आंतरिक वितरित संदेश प्रणाली का उपयोग करता है।
| अवयव | विवरण |
|---|---|
| चमक | निम्बस स्टॉर्म क्लस्टर का एक मास्टर नोड है। क्लस्टर के अन्य सभी नोड्स को कहा जाता हैworker nodes। मास्टर नोड सभी कार्यकर्ता नोड्स के बीच डेटा वितरित करने, कार्यकर्ता नोड्स को कार्य सौंपने और विफलताओं की निगरानी करने के लिए जिम्मेदार है। |
| पर्यवेक्षक | निम्बस द्वारा दिए गए निर्देशों का पालन करने वाले नोड्स को पर्यवेक्षक कहा जाता है। एsupervisor कई कार्यकर्ता प्रक्रियाएं हैं और यह निंबस द्वारा सौंपे गए कार्यों को पूरा करने के लिए कार्यकर्ता प्रक्रियाओं को नियंत्रित करती है। |
| कार्यकर्ता प्रक्रिया | एक कार्यकर्ता प्रक्रिया एक विशिष्ट टोपोलॉजी से संबंधित कार्यों को निष्पादित करेगी। एक कार्यकर्ता प्रक्रिया स्वयं के द्वारा एक कार्य नहीं चलाएगी, इसके बजाय यह बनाता हैexecutorsऔर उन्हें एक विशेष कार्य करने के लिए कहता है। एक कार्यकर्ता प्रक्रिया में कई निष्पादक होंगे। |
| निर्वाहक | एक निष्पादक कुछ भी नहीं है, लेकिन एक कार्यकर्ता प्रक्रिया द्वारा एक एकल धागा स्पॉन है। एक निष्पादक एक या अधिक कार्य चलाता है लेकिन केवल एक विशिष्ट टोंटी या बोल्ट के लिए। |
| टास्क | एक कार्य वास्तविक डाटा प्रोसेसिंग करता है। तो, यह एक टोंटी या एक बोल्ट है। |
| चिड़ियाघर की चौकी | Apache ZooKeeper एक क्लस्टर (नोड्स का समूह) द्वारा उपयोग की जाने वाली सेवा है जो आपस में समन्वय करने और मजबूत तुल्यकालन तकनीकों के साथ साझा डेटा को बनाए रखने के लिए है। निंबस स्टेटलेस है, इसलिए यह कार्य नोड की स्थिति की निगरानी करने के लिए ज़ूकेपर पर निर्भर करता है। ज़ुकीपर पर्यवेक्षक को निंबस के साथ बातचीत करने में मदद करता है। यह निंबस और पर्यवेक्षक की स्थिति को बनाए रखने के लिए जिम्मेदार है। |
तूफान प्रकृति में स्टेटलेस है। भले ही स्टेटलेस प्रकृति के अपने नुकसान हैं, यह वास्तव में तूफान को वास्तविक समय के डेटा को सर्वोत्तम संभव और त्वरित तरीके से संसाधित करने में मदद करता है।
हालांकि तूफान पूरी तरह से स्टेटलेस नहीं है। यह अपाचे चिड़ियाघर कीपर में अपने राज्य को संग्रहीत करता है। चूंकि राज्य Apache ZooKeeper में उपलब्ध है, इसलिए एक असफल निंबस को फिर से शुरू किया जा सकता है और जहां इसे छोड़ा गया है, वहां से काम करने के लिए बनाया जा सकता है। आमतौर पर, सेवा निगरानी उपकरण जैसेmonit निंबस की निगरानी करेगा और यदि कोई विफलता है तो उसे पुनः आरंभ करें।
अपाचे स्टॉर्म में एडवांस टोपोलॉजी भी कहते हैं Trident Topologyराज्य के रखरखाव के साथ और यह सुअर की तरह एक उच्च-स्तरीय एपीआई भी प्रदान करता है। हम आने वाले अध्यायों में इन सभी विशेषताओं पर चर्चा करेंगे।
एक कार्यशील स्टॉर्म क्लस्टर में एक निंबस और एक या अधिक पर्यवेक्षक होने चाहिए। एक और महत्वपूर्ण नोड Apache ZooKeeper है, जिसका उपयोग निम्बस और पर्यवेक्षकों के बीच समन्वय के लिए किया जाएगा।
आइए अब हम अपाचे स्टॉर्म के वर्कफ़्लो पर एक नज़र डालें -
प्रारंभ में, निंबस "स्टॉर्म टोपोलॉजी" के लिए इंतजार करेगा ताकि इसे प्रस्तुत किया जा सके।
एक बार एक टोपोलॉजी सबमिट करने के बाद, यह टोपोलॉजी को प्रोसेस करेगा और उन सभी कार्यों को इकट्ठा करेगा जो किए जाने हैं और जिस क्रम में कार्य निष्पादित किया जाना है।
फिर, निंबस सभी उपलब्ध पर्यवेक्षकों को कार्य समान रूप से वितरित करेगा।
एक विशेष समय अंतराल पर, सभी पर्यवेक्षक निंबस को यह बताने के लिए दिल की धड़कन भेज देंगे कि वे अभी भी जीवित हैं।
जब एक पर्यवेक्षक मर जाता है और निंबस को दिल की धड़कन नहीं भेजता है, तो निंबस दूसरे पर्यवेक्षक को कार्य सौंपता है।
जब निंबस खुद ही मर जाता है, पर्यवेक्षक बिना किसी मुद्दे के पहले से ही असाइन किए गए कार्य पर काम करेंगे।
सभी कार्य पूर्ण हो जाने के बाद, पर्यवेक्षक एक नए कार्य के आने की प्रतीक्षा करेगा।
इस बीच, सेवा मॉनिटरिंग टूल द्वारा मृत निंब को स्वचालित रूप से फिर से चालू किया जाएगा।
फिर से शुरू किया गया निंबस वहीं से जारी रहेगा जहां यह रुका था। इसी तरह, मृत पर्यवेक्षक को भी स्वचालित रूप से फिर से शुरू किया जा सकता है। चूंकि निंबस और पर्यवेक्षक दोनों को स्वचालित रूप से फिर से शुरू किया जा सकता है और दोनों पहले की तरह जारी रहेंगे, स्टॉर्म को गारंटी दी जाती है कि वह कम से कम एक बार सभी कार्यों को संसाधित करे।
एक बार सभी टोपोलॉजी के संसाधित होने के बाद, निंबस आने के लिए एक नई टोपोलॉजी की प्रतीक्षा करता है और इसी तरह पर्यवेक्षक नए कार्यों की प्रतीक्षा करता है।
डिफ़ॉल्ट रूप से, एक स्टॉर्म क्लस्टर में दो मोड हैं -
Local mode- इस मोड का उपयोग विकास, परीक्षण और डिबगिंग के लिए किया जाता है क्योंकि यह सभी टोपोलॉजी घटकों को एक साथ काम करने का सबसे आसान तरीका है। इस मोड में, हम उन मापदंडों को समायोजित कर सकते हैं जो हमें यह देखने के लिए सक्षम करते हैं कि हमारी टोपोलॉजी विभिन्न तूफान विन्यास वातावरण में कैसे चलती है। स्थानीय मोड में, एकल जेवीएम में स्थानीय मशीन पर तूफान टोपोलॉजी चलती है।
Production mode- इस मोड में, हम अपने टोपोलॉजी को काम करने वाले तूफान क्लस्टर में जमा करते हैं, जो कई प्रक्रियाओं से बना होता है, जो आमतौर पर विभिन्न मशीनों पर चलता है। जैसा कि तूफान के वर्कफ़्लो में चर्चा की गई है, एक कामकाजी क्लस्टर अनिश्चित काल तक बंद रहेगा।
अपाचे स्टॉर्म वास्तविक समय के डेटा को संसाधित करता है और इनपुट आम तौर पर एक संदेश कतार प्रणाली से आता है। एक बाहरी वितरित मैसेजिंग सिस्टम रीयल टाइम गणना के लिए आवश्यक इनपुट प्रदान करेगा। स्पाउट मैसेजिंग सिस्टम से डेटा को पढ़ेगा और इसे ट्यूपल्स और इनपुट में अपाचे स्टॉर्म में परिवर्तित करेगा। दिलचस्प तथ्य यह है कि अपाचे स्टॉर्म अपने स्वयं के वितरित संदेश प्रणाली का उपयोग अपने निंबस और पर्यवेक्षक के बीच संचार के लिए आंतरिक रूप से करता है।
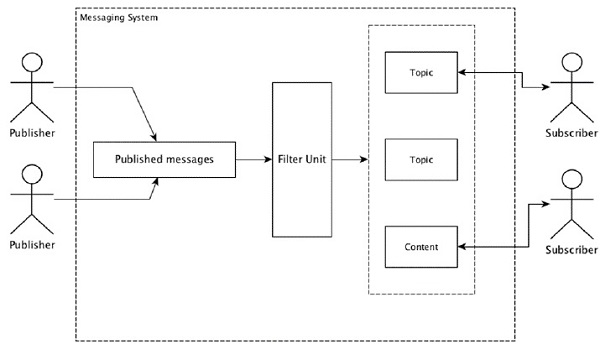
डिस्ट्रीब्यूटेड मैसेजिंग सिस्टम क्या है?
वितरित संदेश विश्वसनीय संदेश कतार की अवधारणा पर आधारित है। संदेशों को क्लाइंट एप्लिकेशन और मैसेजिंग सिस्टम के बीच अतुल्यकालिक रूप से कतारबद्ध किया जाता है। एक वितरित संदेश प्रणाली विश्वसनीयता, स्केलेबिलिटी और दृढ़ता का लाभ प्रदान करती है।
मैसेजिंग के ज्यादातर पैटर्न फॉलो करते हैं publish-subscribe मॉडल (बस Pub-Sub) जहां संदेश भेजने वालों को बुलाया जाता है publishers और जो संदेश प्राप्त करना चाहते हैं उन्हें कहा जाता है subscribers।
एक बार जब संदेश प्रेषक द्वारा प्रकाशित किया जाता है, तो ग्राहक फ़िल्टर किए गए विकल्प की सहायता से चयनित संदेश प्राप्त कर सकते हैं। आमतौर पर हमारे पास दो प्रकार के फ़िल्टरिंग होते हैं, एक हैtopic-based filtering और एक अन्य है content-based filtering।
ध्यान दें कि पब-उप मॉडल केवल संदेशों के माध्यम से संवाद कर सकता है। यह बहुत शिथिल युग्मित वास्तुकला है; यहां तक कि प्रेषकों को पता नहीं है कि उनके ग्राहक कौन हैं। कई ग्राहकों द्वारा समय पर पहुंच के लिए प्रकाशित संदेशों का आदान-प्रदान करने के लिए कई संदेश पैटर्न, संदेश ब्रोकर के साथ सक्षम होते हैं। एक वास्तविक जीवन का उदाहरण डिश टीवी है, जो विभिन्न चैनलों जैसे खेल, फिल्म, संगीत आदि को प्रकाशित करता है, और कोई भी अपने स्वयं के चैनलों की सदस्यता ले सकता है और जब भी उनके सदस्यता प्राप्त चैनल उपलब्ध हैं, उन्हें प्राप्त कर सकता है।
निम्न तालिका कुछ लोकप्रिय उच्च थ्रूपुट संदेश प्रणालियों का वर्णन करती है -
| वितरित संदेश प्रणाली | विवरण |
|---|---|
| अपाचे काफ्का | काफ्का को लिंक्डइन कॉर्पोरेशन में विकसित किया गया था और बाद में यह अपाचे की एक उप-परियोजना बन गई। अपाचे काफ्का दलाली, निरंतर, वितरित प्रकाशन-सदस्यता मॉडल पर आधारित है। काफ्का तेज़, स्केलेबल और अत्यधिक कुशल है। |
| RabbitMQ | RabbitMQ एक खुला स्रोत वितरित मजबूत संदेश अनुप्रयोग है। सभी प्लेटफार्मों पर इसका उपयोग करना आसान है और चलता है। |
| JMS (जावा संदेश सेवा) | जेएमएस एक खुला स्रोत एपीआई है जो एक एप्लिकेशन से दूसरे में संदेश बनाने, पढ़ने और भेजने का समर्थन करता है। यह गारंटीकृत संदेश वितरण प्रदान करता है और प्रकाशन-सदस्यता मॉडल का अनुसरण करता है। |
| ActiveMQ | ActiveMQ मैसेजिंग सिस्टम JMS का एक ओपन सोर्स API है। |
| ZeroMQ | ZeroMQ ब्रोकर-कम सहकर्मी संदेश प्रसंस्करण है। यह पुश-पुल, राउटर-डीलर संदेश पैटर्न प्रदान करता है। |
| एक प्रकार का छोटा बाज | Kestrel एक तेज, विश्वसनीय और सरल वितरित संदेश कतार है। |
थ्रिफ्ट प्रोटोकॉल
फेसबुक पर क्रॉस-लैंग्वेज सर्विसेज डेवलपमेंट और रिमोट प्रोसेस कॉल (RPC) के लिए थ्रिफ्ट बनाया गया था। बाद में, यह एक खुला स्रोत अपाचे परियोजना बन गया। अपाचे थ्रिफ्ट एक हैInterface Definition Language और एक आसान तरीके से परिभाषित डेटा प्रकारों के शीर्ष पर नए डेटा प्रकारों और सेवाओं के कार्यान्वयन को परिभाषित करने की अनुमति देता है।
अपाचे थ्रिफ्ट भी एक संचार ढांचा है जो एम्बेडेड सिस्टम, मोबाइल एप्लिकेशन, वेब एप्लिकेशन और कई अन्य प्रोग्रामिंग भाषाओं का समर्थन करता है। अपाचे थ्रिफ्ट से जुड़ी कुछ प्रमुख विशेषताएं इसकी प्रतिरूपकता, लचीलापन और उच्च प्रदर्शन हैं। इसके अलावा, यह वितरित अनुप्रयोगों में स्ट्रीमिंग, मैसेजिंग और आरपीसी प्रदर्शन कर सकता है।
तूफान अपने आंतरिक संचार और डेटा परिभाषा के लिए थ्रिफ्ट प्रोटोकॉल का बड़े पैमाने पर उपयोग करता है। तूफान टोपोलॉजी बस हैThrift Structs। स्टॉर्म निंबस जो अपाचे स्टॉर्म में टोपोलॉजी चलाता है aThrift service।
आइए अब देखते हैं कि अपाचे स्टॉर्म फ्रेमवर्क को अपनी मशीन पर कैसे स्थापित किया जाए। यहां तीन मेजो चरण हैं -
- यदि आपके पास यह पहले से नहीं है, तो अपने सिस्टम पर जावा स्थापित करें।
- ZooKeeper फ्रेमवर्क स्थापित करें।
- अपाचे स्टॉर्म फ्रेमवर्क स्थापित करें।
चरण 1 - जावा इंस्टॉलेशन को सत्यापित करना
यह जाँचने के लिए कि क्या आपके पास जावा पहले से ही आपके सिस्टम पर स्थापित है, निम्न कमांड का उपयोग करें।
$ java -versionयदि जावा पहले से मौजूद है, तो आपको इसका संस्करण नंबर दिखाई देगा। इसके अलावा, JDK का नवीनतम संस्करण डाउनलोड करें।
चरण 1.1 - JDK डाउनलोड करें
निम्नलिखित लिंक का उपयोग करके JDK का नवीनतम संस्करण डाउनलोड करें - www.oracle.com
नवीनतम संस्करण JDK 8u 60 है और फ़ाइल है “jdk-8u60-linux-x64.tar.gz”। अपनी मशीन पर फ़ाइल डाउनलोड करें।
चरण 1.2 - फ़ाइलों को निकालें
आम तौर पर फ़ाइलों को डाउनलोड किया जा रहा है downloadsफ़ोल्डर। निम्न आदेशों का उपयोग करके टार सेटअप निकालें।
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzचरण 1.3 - ऑप्ट निर्देशिका में ले जाएँ
जावा को सभी उपयोगकर्ताओं के लिए उपलब्ध कराने के लिए, निकाले गए जावा कंटेंट को "/ usr / लोकल / जावा" फोल्डर में ले जाएँ।
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/चरण १.४ - पथ निर्धारित करें
पथ और JAVA_HOME चर सेट करने के लिए, निम्न आदेशों को ~ / .bashrc फ़ाइल में जोड़ें।
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binअब वर्तमान में चल रहे सिस्टम में सभी परिवर्तनों को लागू करें।
$ source ~/.bashrcचरण 1.5 - जावा अल्टरनेटिव
जावा विकल्प को बदलने के लिए निम्न कमांड का उपयोग करें।
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100चरण १.६
अब सत्यापन आदेश का उपयोग करके जावा इंस्टॉलेशन को सत्यापित करें (java -version) चरण 1 में समझाया गया।
चरण 2 - चिड़ियाघर कीपर फ्रेमवर्क स्थापना
चरण 2.1 - चिड़ियाघरकीपर डाउनलोड करें
अपनी मशीन पर चिड़ियाघरकीपर फ्रेमवर्क स्थापित करने के लिए, निम्न लिंक पर जाएं और चिड़ियाघरकीपर का नवीनतम संस्करण डाउनलोड करें http://zookeeper.apache.org/releases.html
अब तक, ज़ूकीपर का नवीनतम संस्करण 3.4.6 (ज़ूकिपर-3.4.6.tar.gz) है।
चरण 2.2 - टार फ़ाइल निकालें
निम्नलिखित आदेशों का उपयोग करके टार फ़ाइल निकालें -
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataचरण 2.3 - कॉन्फ़िगरेशन फ़ाइल बनाएँ
"Vi conf / zoo.cfg" कमांड का उपयोग करके "conf / zoo.cfg" नाम की ओपन कॉन्फ़िगरेशन फ़ाइल और आरंभिक बिंदु के रूप में सभी निम्नलिखित पैरामीटर सेट करें।
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2एक बार कॉन्फ़िगरेशन फ़ाइल को सफलतापूर्वक सहेजने के बाद, आप चिड़ियाघरकीपर सर्वर शुरू कर सकते हैं।
चरण 2.4 - ज़ूकीपर सर्वर प्रारंभ करें
ZooKeeper सर्वर शुरू करने के लिए निम्न कमांड का उपयोग करें।
$ bin/zkServer.sh startइस कमांड को निष्पादित करने के बाद, आपको निम्नानुसार प्रतिक्रिया मिलेगी -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDचरण 2.5 - सीएलआई शुरू करें
CLI शुरू करने के लिए निम्न कमांड का उपयोग करें।
$ bin/zkCli.shउपरोक्त कमांड को निष्पादित करने के बाद, आप ज़ूकीपर सर्वर से जुड़ जाएंगे और निम्नलिखित प्रतिक्रिया प्राप्त करेंगे।
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]चरण २.६ - रोक ज़ुकीपर सर्वर
सर्वर से कनेक्ट करने और सभी ऑपरेशन करने के बाद, आप निम्न कमांड का उपयोग करके चिड़ियाघरकीपर सर्वर को रोक सकते हैं।
bin/zkServer.sh stopआपने अपनी मशीन पर जावा और चिड़ियाघरकीपर को सफलतापूर्वक स्थापित किया है। आइये अब अपाचे स्टॉर्म फ्रेमवर्क को स्थापित करने के चरण देखते हैं।
चरण 3 - अपाचे तूफान फ्रेमवर्क स्थापना
चरण 3.1 स्टॉर्म डाउनलोड करें
अपनी मशीन पर स्टॉर्म फ्रेमवर्क स्थापित करने के लिए, निम्न लिंक पर जाएं और स्टॉर्म का नवीनतम संस्करण डाउनलोड करें http://storm.apache.org/downloads.html
अब तक, स्टॉर्म का नवीनतम संस्करण "अपाचे-स्टॉर्म-0.9.5.tar.gz" है।
चरण 3.2 - टार फ़ाइल निकालें
निम्नलिखित आदेशों का उपयोग करके टार फ़ाइल निकालें -
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataचरण 3.3 - कॉन्फ़िगरेशन फ़ाइल खोलें
स्टॉर्म की वर्तमान रिलीज़ में "conf / storm.yaml" फ़ाइल होती है जो स्टॉर्म डेमन्स को कॉन्फ़िगर करती है। उस फ़ाइल में निम्न जानकारी जोड़ें।
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703सभी परिवर्तनों को लागू करने के बाद, सहेजें और टर्मिनल पर लौटें।
चरण 3.4 - निम्बस शुरू करें
$ bin/storm nimbusचरण 3.5 - पर्यवेक्षक शुरू करें
$ bin/storm supervisorचरण 3.6 UI प्रारंभ करें
$ bin/storm uiस्टॉर्म यूजर इंटरफेस एप्लिकेशन शुरू करने के बाद, URL टाइप करें http://localhost:8080अपने पसंदीदा ब्राउज़र में और आप स्टॉर्म क्लस्टर जानकारी और उसके चल रहे टोपोलॉजी को देख सकते हैं। पृष्ठ को निम्न स्क्रीनशॉट के समान दिखना चाहिए।

हम अपाचे स्टॉर्म के मुख्य तकनीकी विवरण से गुजरे हैं और अब कुछ सरल परिदृश्यों को कोड करने का समय आ गया है।
परिदृश्य - मोबाइल कॉल लॉग विश्लेषक
मोबाइल कॉल और इसकी अवधि अपाचे स्टॉर्म के इनपुट के रूप में दी जाएगी और स्टॉर्म एक ही कॉलर और रिसीवर और उनके कुल कॉल के बीच कॉल को संसाधित और समूह करेगा।
सृजन करो
टोंटी एक घटक है जो डेटा पीढ़ी के लिए उपयोग किया जाता है। मूल रूप से, एक टोंटी एक IRichSpout इंटरफ़ेस को लागू करेगा। "IRichSpout" इंटरफ़ेस में निम्नलिखित महत्वपूर्ण विधियाँ हैं -
open- निष्पादित करने के लिए वातावरण के साथ टोंटी प्रदान करता है। जल्लाद को इनिशियलाइज़ करने के लिए एग्जिक्यूटर्स इस विधि को चलाएंगे।
nextTuple - कलेक्टर के माध्यम से उत्पन्न डेटा का उत्सर्जन करता है।
close - इस पद्धति को कहा जाता है जब एक टोंटी बंद करने जा रही है।
declareOutputFields - टपल के आउटपुट स्कीमा की घोषणा करता है।
ack - यह स्वीकार करता है कि एक विशिष्ट टपल संसाधित है
fail - निर्दिष्ट करता है कि एक विशिष्ट टपल को संसाधित नहीं किया जाता है और न ही पुन: संसाधित किया जाता है।
खुला हुआ
के हस्ताक्षर open विधि इस प्रकार है -
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - इस टोंटी के लिए तूफान विन्यास प्रदान करता है।
context - टोपोलॉजी के बारे में पूरी जानकारी, उसकी टास्क आईडी, इनपुट और आउटपुट की जानकारी।
collector - बोल्ट द्वारा संसाधित किए जाने वाले टपल का उत्सर्जन करने में हमें सक्षम बनाता है।
nextTuple
के हस्ताक्षर nextTuple विधि इस प्रकार है -
nextTuple()अगली ट्यूपल () को समय-समय पर एक ही लूप से ack () और फेल () विधियों के रूप में कहा जाता है। यह थ्रेड का नियंत्रण जारी करना चाहिए जब कोई काम नहीं करना है, ताकि अन्य तरीकों को कॉल करने का मौका मिले। तो अगली लाइन की अगली पंक्ति यह देखने के लिए जांचती है कि प्रसंस्करण समाप्त हो गया है या नहीं। यदि हां, तो लौटने से पहले प्रोसेसर पर लोड को कम करने के लिए कम से कम एक मिलीसेकंड के लिए सोना चाहिए।
बंद करे
के हस्ताक्षर close विधि इस प्रकार है -
close()declareOutputFields
के हस्ताक्षर declareOutputFields विधि इस प्रकार है -
declareOutputFields(OutputFieldsDeclarer declarer)declarer - इसका उपयोग आउटपुट स्ट्रीम आईडी, आउटपुट फ़ील्ड आदि घोषित करने के लिए किया जाता है।
इस पद्धति का उपयोग टुपल के आउटपुट स्कीमा को निर्दिष्ट करने के लिए किया जाता है।
एसीके
के हस्ताक्षर ack विधि इस प्रकार है -
ack(Object msgId)यह विधि स्वीकार करती है कि एक विशिष्ट टपल संसाधित किया गया है।
विफल
के हस्ताक्षर nextTuple विधि इस प्रकार है -
ack(Object msgId)यह विधि बताती है कि एक विशिष्ट टपल को पूरी तरह से संसाधित नहीं किया गया है। तूफान विशिष्ट टपल को पुन: उत्पन्न करेगा।
FakeCallLogReaderSpout
हमारे परिदृश्य में, हमें कॉल लॉग विवरण एकत्र करने की आवश्यकता है। कॉल लॉग की जानकारी शामिल है।
- कॉलर नंबर
- रिसीवर संख्या
- duration
चूंकि, हमारे पास कॉल लॉग की वास्तविक समय की जानकारी नहीं है, हम नकली कॉल लॉग उत्पन्न करेंगे। फर्जी सूचना का उपयोग रैंडम क्लास का उपयोग करके बनाया जाएगा। पूरा प्रोग्राम कोड नीचे दिया गया है।
कोडिंग - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}बोल्ट निर्माण
बोल्ट एक घटक है जो ट्यूपल्स को इनपुट के रूप में लेता है, टपल को संसाधित करता है, और आउटपुट के रूप में नए ट्यूपल्स का उत्पादन करता है। बोल्ट लागू करेंगेIRichBoltइंटरफेस। इस कार्यक्रम में, दो बोल्ट कक्षाएंCallLogCreatorBolt तथा CallLogCounterBolt संचालन करने के लिए उपयोग किया जाता है।
IRichBolt इंटरफ़ेस के निम्नलिखित तरीके हैं -
prepare- निष्पादित करने के लिए पर्यावरण के साथ बोल्ट प्रदान करता है। जल्लाद को इनिशियलाइज़ करने के लिए एग्जिक्यूटर्स इस विधि को चलाएंगे।
execute - इनपुट के एकल टपल की प्रक्रिया करें।
cleanup - जब बोल्ट बंद करने जा रहा हो तो कॉल किया जाता है।
declareOutputFields - टपल के आउटपुट स्कीमा की घोषणा करता है।
तैयार
के हस्ताक्षर prepare विधि इस प्रकार है -
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - इस बोल्ट के लिए तूफान विन्यास प्रदान करता है।
context - टोपोलॉजी के भीतर बोल्ट की जगह, उसकी टास्क आईडी, इनपुट और आउटपुट की जानकारी आदि के बारे में पूरी जानकारी देता है।
collector - हमें प्रोसेस्ड ट्यूपल का उत्सर्जन करने में सक्षम बनाता है।
निष्पादित
के हस्ताक्षर execute विधि इस प्रकार है -
execute(Tuple tuple)यहाँ tuple संसाधित करने के लिए इनपुट टपल है।
executeविधि एक बार में एक ही नलिका बनाती है। टपल डेटा को टपल क्लास के गेटवैल्यू विधि द्वारा एक्सेस किया जा सकता है। इनपुट टपल को तुरंत संसाधित करना आवश्यक नहीं है। एकाधिक ट्यूपल को एकल आउटपुट टपल के रूप में संसाधित और आउटपुट किया जा सकता है। आउटपुट ट्यूपल को आउटपुटकॉल्टर क्लास का उपयोग करके उत्सर्जित किया जा सकता है।
साफ - सफाई
के हस्ताक्षर cleanup विधि इस प्रकार है -
cleanup()declareOutputFields
के हस्ताक्षर declareOutputFields विधि इस प्रकार है -
declareOutputFields(OutputFieldsDeclarer declarer)यहाँ पैरामीटर declarer का उपयोग आउटपुट स्ट्रीम आईडी, आउटपुट फ़ील्ड आदि घोषित करने के लिए किया जाता है।
इस पद्धति का उपयोग टुपल के आउटपुट स्कीमा को निर्दिष्ट करने के लिए किया जाता है
कॉल लॉग निर्माता बोल्ट
कॉल लॉग निर्माता बोल्ट कॉल लॉग ट्यूपल प्राप्त करता है। कॉल लॉग ट्यूपल में कॉलर नंबर, रिसीवर नंबर और कॉल की अवधि होती है। यह बोल्ट बस कॉलर नंबर और रिसीवर नंबर को मिलाकर एक नया मूल्य बनाता है। नए मूल्य का प्रारूप "कॉलर नंबर - रिसीवर नंबर" है और इसे नए फ़ील्ड के रूप में नामित किया गया है, "कॉल"। पूरा कोड नीचे दिया गया है।
कोडिंग - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}कॉल लॉग काउंटर बोल्ट
कॉल लॉग काउंटर बोल्ट कॉल और इसकी अवधि टुपल के रूप में प्राप्त करता है। यह बोल्ट तैयार विधि में एक शब्दकोश (मानचित्र) ऑब्जेक्ट को इनिशियलाइज़ करता है। मेंexecuteविधि, यह टपल की जाँच करता है और टपल में हर नए "कॉल" मूल्य के लिए डिक्शनरी ऑब्जेक्ट में एक नई प्रविष्टि बनाता है और डिक्शनरी ऑब्जेक्ट में 1 मान सेट करता है। शब्दकोश में पहले से ही उपलब्ध प्रविष्टि के लिए, यह सिर्फ इसके मूल्य में वृद्धि करता है। सरल शब्दों में, यह बोल्ट डिक्शनरी ऑब्जेक्ट में कॉल और उसकी गिनती बचाता है। शब्दकोश में कॉल और इसकी गिनती को बचाने के बजाय, हम इसे एक डेटा स्रोत पर भी सहेज सकते हैं। पूरा कार्यक्रम कोड इस प्रकार है -
कोडिंग - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}टोपोलॉजी बनाना
स्टॉर्म टोपोलॉजी मूल रूप से एक थ्रिफ्ट संरचना है। TopologyBuilder वर्ग जटिल टोपोलॉजी बनाने के लिए सरल और आसान तरीके प्रदान करता है। TopologyBuilder वर्ग में टोंटी लगाने के तरीके हैं(setSpout) और बोल्ट सेट करने के लिए (setBolt)। अंत में, TopologyBuilder टोपोलॉजी बनाने के लिए टोपोलॉजी है। टोपोलॉजी बनाने के लिए निम्न कोड स्निपेट का उपयोग करें -
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping तथा fieldsGrouping विधियाँ टोंटी और बोल्ट के लिए धारा समूह निर्धारण में मदद करती हैं।
स्थानीय क्लस्टर
विकास के उद्देश्य के लिए, हम "लोकल क्लस्टर" ऑब्जेक्ट का उपयोग करके एक स्थानीय क्लस्टर बना सकते हैं और फिर "लोकल क्लस्टर" क्लास के "सबमिटटॉपोलॉजी" पद्धति का उपयोग करके टोपोलॉजी जमा कर सकते हैं। "SubmitTopology" के तर्कों में से एक "कॉन्फ़िगर" वर्ग का एक उदाहरण है। "कॉन्फिगरेशन" क्लास का उपयोग टोपोलॉजी को सबमिट करने से पहले कॉन्फ़िगरेशन विकल्पों को सेट करने के लिए किया जाता है। यह कॉन्फ़िगरेशन विकल्प रन समय पर क्लस्टर कॉन्फ़िगरेशन के साथ विलय कर दिया जाएगा और तैयार विधि के साथ सभी कार्य (टोंटी और बोल्ट) को भेजा जाएगा। एक बार जब टोपोलॉजी क्लस्टर में जमा हो जाती है, तो हम सबमिट किए गए टोपोलॉजी की गणना करने के लिए क्लस्टर के लिए 10 सेकंड इंतजार करेंगे और फिर "लोकल क्लस्टर" के "शटडाउन" विधि का उपयोग करके क्लस्टर को बंद कर देंगे। पूरा कार्यक्रम कोड इस प्रकार है -
कोडिंग - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}बिल्डिंग और अनुप्रयोग चल रहा है
पूर्ण आवेदन में चार जावा कोड हैं। वे हैं -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
आवेदन निम्नलिखित आदेश का उपयोग कर बनाया जा सकता है -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaएप्लिकेशन को निम्न आदेश का उपयोग करके चलाया जा सकता है -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormउत्पादन
एक बार आवेदन शुरू होने के बाद, यह क्लस्टर स्टार्टअप प्रक्रिया, टोंटी और बोल्ट प्रसंस्करण, और अंत में, क्लस्टर बंद करने की प्रक्रिया के बारे में पूरा विवरण आउटपुट करेगा। "CallLogCounterBolt" में, हमने कॉल और उसके गणना विवरण को प्रिंट किया है। यह जानकारी कंसोल पर इस प्रकार प्रदर्शित की जाएगी -
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93गैर-जेवीएम भाषाएँ
तूफान टोपोलॉजी को थ्रिफ्ट इंटरफेस द्वारा कार्यान्वित किया जाता है जो किसी भी भाषा में टोपोलॉजी प्रस्तुत करना आसान बनाता है। तूफान रूबी, पायथन और कई अन्य भाषाओं का समर्थन करता है। आइए अजगर बंधन पर एक नज़र डालें।
अजगर बाँधना
पायथन एक सामान्य रूप से व्याख्या की गई, इंटरैक्टिव, ऑब्जेक्ट-ओरिएंटेड, और उच्च-स्तरीय प्रोग्रामिंग भाषा है। तूफान अपनी टोपोलॉजी को लागू करने के लिए पायथन का समर्थन करता है। पायथन उत्सर्जन, एंकरिंग, एंकिंग और लॉगिंग ऑपरेशन का समर्थन करता है।
जैसा कि आप जानते हैं, बोल्ट को किसी भी भाषा में परिभाषित किया जा सकता है। किसी अन्य भाषा में लिखी गई बोलियों को उप-प्रक्रियाओं के रूप में निष्पादित किया जाता है, और स्टॉर्म उन उप-प्रक्रियाओं के साथ संवाद करता है जो स्टड / स्टडआउट पर JSON संदेशों के साथ होती हैं। सबसे पहले एक नमूना बोल्ट वर्डकाउंट लें जो अजगर बंधन का समर्थन करता है।
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}इधर की क्लास WordCount लागू करता है IRichBoltइंटरफ़ेस और पायथन कार्यान्वयन के साथ चल रहा है निर्दिष्ट सुपर विधि तर्क "स्प्लिटोर्डहोम"। अब एक "pythword.py" नाम का अजगर कार्यान्वयन बनाएं।
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()यह पायथन के लिए नमूना कार्यान्वयन है जो किसी दिए गए वाक्य में शब्दों को गिनता है। इसी तरह आप अन्य सहायक भाषाओं के साथ भी बाँध सकते हैं।
ट्राइडेंट स्टॉर्म का विस्तार है। स्टॉर्म की तरह, ट्रिडेंट भी ट्विटर द्वारा विकसित किया गया था। ट्राइडेंट को विकसित करने के पीछे मुख्य कारण स्टॉर्म के शीर्ष पर स्टेटफुल स्ट्रीम प्रोसेसिंग और कम विलंबता वितरित क्वेरी के साथ एक उच्च-स्तरीय अमूर्तता प्रदान करना है।
ट्रिडेंट टोंटी और बोल्ट का उपयोग करता है, लेकिन निष्पादन से पहले ये निम्न-स्तरीय घटक ट्रिडेंट द्वारा ऑटो-जेनरेट किए जाते हैं। ट्राइडेंट में फंक्शन, फिल्टर, जॉइन, ग्रुपिंग और एग्रीगेशन होता है।
ट्राइडेंट प्रक्रिया बैचों की एक श्रृंखला के रूप में प्रवाहित होती है जिसे लेनदेन के रूप में संदर्भित किया जाता है। आम तौर पर उन छोटे बैचों का आकार इनपुट स्ट्रीम के आधार पर हजारों या लाखों टुपल्स के क्रम पर होगा। इस तरह, ट्राइडेंट स्टॉर्म से अलग है, जो ट्यूपल-बाय-ट्यूपल प्रोसेसिंग करता है।
बैच प्रसंस्करण अवधारणा डेटाबेस लेनदेन के समान है। हर लेन-देन को एक लेनदेन आईडी सौंपा गया है। लेन-देन सफल माना जाता है, एक बार इसकी सारी प्रक्रिया पूरी हो जाती है। हालाँकि, लेन-देन में से किसी एक को संसाधित करने में विफलता के कारण संपूर्ण लेन-देन पीछे हट जाएगा। प्रत्येक बैच के लिए, ट्राइडेंट लेन-देन की शुरुआत में शुरुआत को कॉल करेगा, और इसके अंत में प्रतिबद्ध होगा।
त्रिशूल टोपोलॉजी
ट्रिडेंट एपीआई "ट्राइडेंट टापोलॉजी" वर्ग का उपयोग करके ट्राइडेंट टोपोलॉजी बनाने का एक आसान विकल्प उजागर करता है। मूल रूप से, ट्राइडेंट टोपोलॉजी को टोंटी से इनपुट स्ट्रीम प्राप्त होती है और स्ट्रीम पर ऑपरेशन (फ़िल्टर, एग्रीगेशन, ग्रुपिंग, आदि) के अनुक्रम का आदेश दिया है। तूफान टपल की जगह त्रिशूल टपल और बोल्ट को ऑपरेशन द्वारा प्रतिस्थापित किया गया है। एक सरल त्रिशूल टोपोलॉजी के रूप में बनाया जा सकता है -
TridentTopology topology = new TridentTopology();त्रिशूल टुपल्स
ट्राइडेंट टपल मूल्यों की एक नामित सूची है। TridentTuple इंटरफ़ेस एक Trident टोपोलॉजी का डेटा मॉडल है। TridentTuple इंटरफ़ेस डेटा की मूल इकाई है जिसे Trident टोपोलॉजी द्वारा संसाधित किया जा सकता है।
ट्रिडेंट स्पाउट
ट्राइडेंट की विशेषताओं का उपयोग करने के लिए अतिरिक्त विकल्पों के साथ ट्राइडेंट टोंटी स्टॉर्म टोंटी के समान है। वास्तव में, हम अभी भी IRichSpout का उपयोग कर सकते हैं, जिसका उपयोग हमने स्टॉर्म टोपोलॉजी में किया है, लेकिन यह प्रकृति में गैर-लेन-देन होगा और हम ट्रिडेंट द्वारा प्रदान किए गए लाभों का उपयोग नहीं कर पाएंगे।
ट्रिडेंट की सुविधाओं का उपयोग करने के लिए सभी कार्यक्षमता वाले मूल टोंटी "ITridentSpout" है। यह ट्रांजेक्शनल और अपारदर्शी दोनों ट्रांजेक्शनल शब्दार्थ का समर्थन करता है। अन्य स्पाउट्स IBatchSpout, IPartitionedTridentSpout और IOpaquePartitionedTridentSpout हैं।
इन जेनेरिक स्पाउट्स के अलावा, ट्रिडेंट में ट्राइडेंट स्पाउट के कई नमूना कार्यान्वयन हैं। उनमें से एक फीडरबैचस्पाउट टोंटी है, जिसका उपयोग हम बैच प्रसंस्करण, समानता आदि के बारे में चिंता किए बिना ट्रिडेंट ट्यूपल्स की नाम सूची आसानी से भेजने के लिए उपयोग कर सकते हैं।
फीडरबैचस्पाउट निर्माण और डेटा फीडिंग नीचे दिखाए अनुसार किया जा सकता है -
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));ट्राइडेंट ऑपरेशन
ट्रिडेंट ट्रिडेंट ट्यूपल्स के इनपुट स्ट्रीम को प्रोसेस करने के लिए "ट्राइडेंट ऑपरेशन" पर निर्भर करता है। ट्रिडेंट एपीआई के पास सरल-से-जटिल स्ट्रीम प्रोसेसिंग को संभालने के लिए कई इन-बिल्ट ऑपरेशन हैं। ये ऑपरेशन सरल सत्यापन से लेकर जटिल समूहन और त्रिशूल ट्यूल के एकत्रीकरण तक होते हैं। आइए हम सबसे महत्वपूर्ण और अक्सर उपयोग किए जाने वाले संचालन से गुजरते हैं।
फ़िल्टर
फ़िल्टर एक ऐसी वस्तु है जिसका उपयोग इनपुट सत्यापन के कार्य को करने के लिए किया जाता है। एक ट्राइडेंट फिल्टर को ट्राइडेंट टपल फ़ील्ड्स के एक सबसेट के रूप में इनपुट मिलता है और कुछ शर्तों के संतुष्ट होने या न होने के आधार पर सही या गलत होता है। अगर सच लौटा है, तो आउटपुट स्ट्रीम में टपल को रखा गया है; अन्यथा, टपल को धारा से हटा दिया जाता है। फ़िल्टर मूल रूप से इनहेरिट करेगाBaseFilter कक्षा और कार्यान्वित करें isKeepतरीका। यहाँ फिल्टर ऑपरेशन का एक नमूना कार्यान्वयन है -
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]फ़िल्टर फ़ंक्शन को "प्रत्येक" विधि का उपयोग करके टोपोलॉजी में बुलाया जा सकता है। "फ़ील्ड" वर्ग का उपयोग इनपुट निर्दिष्ट करने के लिए किया जा सकता है (ट्रिडेंट टपल का सबसेट)। नमूना कोड इस प्रकार है -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())समारोह
Functionएक एकल त्रिशूल पर एक साधारण ऑपरेशन करने के लिए उपयोग की जाने वाली वस्तु है। यह ट्राइडेंट टपल फ़ील्ड्स का सबसेट लेता है और शून्य या अधिक नए ट्राइडेंट टपल फ़ील्ड्स का उत्सर्जन करता है।
Function मूल रूप से विरासत में मिला है BaseFunction वर्ग और लागू करता है executeतरीका। एक नमूना कार्यान्वयन नीचे दिया गया है -
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]फ़िल्टर ऑपरेशन की तरह, फंक्शन ऑपरेशन का उपयोग करके टोपोलॉजी में बुलाया जा सकता है eachतरीका। नमूना कोड इस प्रकार है -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));एकत्रीकरण
एकत्रीकरण एक वस्तु है जिसका उपयोग इनपुट बैच या विभाजन या स्ट्रीम पर एकत्रीकरण संचालन करने के लिए किया जाता है। त्रिशूल के तीन प्रकार के एकत्रीकरण हैं। वे इस प्रकार हैं -
aggregate- अलगाव में त्रिशूल के प्रत्येक बैच को एकत्र करता है। कुल प्रक्रिया के दौरान, ट्यूपल्स को शुरू में एक ही बैच के सभी विभाजन को एक ही विभाजन में संयोजित करने के लिए ग्लोबल ग्रुपिंग का उपयोग करके पुनः आरंभ किया जाता है।
partitionAggregate- ट्राइडेंट टपल के पूरे बैच के बजाय प्रत्येक विभाजन को एकत्र करता है। विभाजन समुच्चय का आउटपुट पूरी तरह से इनपुट टपल को बदल देता है। विभाजन समुच्चय के उत्पादन में एकल फ़ील्ड टपल शामिल है।
persistentaggregate - सभी बैचों में सभी त्रिशूल पर एकत्र होते हैं और परिणाम को मेमोरी या डेटाबेस में संग्रहीत करते हैं।
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));एकत्रीकरण ऑपरेशन या तो CombinerAggregator, ReducerAggregator, या सामान्य Aggregator इंटरफ़ेस का उपयोग करके बनाया जा सकता है। उपरोक्त उदाहरण में उपयोग किया गया "गणना" एग्रीगेटर बिल्ड-इन एग्रीगेटर्स में से एक है। इसे "कंबाइनएगएग्रेगेटर" का उपयोग करके लागू किया गया है। कार्यान्वयन इस प्रकार है -
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}समूहन
ग्रुपिंग ऑपरेशन एक इनबिल्ट ऑपरेशन है और इसके द्वारा कॉल किया जा सकता है groupByतरीका। GroupBy मेथड एक पार्टीशन के द्वारा पुन: विभाजन करता है निर्दिष्ट क्षेत्रों पर, और फिर प्रत्येक पार्टीशन के अंदर, यह ग्रुप्स को एक साथ ट्यूप करता है जिनके ग्रुप फील्ड्स बराबर होते हैं। आम तौर पर, हम समूहीकृत एकत्रीकरण प्राप्त करने के लिए "persistentAggregate" के साथ "groupBy" का उपयोग करते हैं। नमूना कोड इस प्रकार है -
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));विलय और जुड़ना
विलय और जुड़ाव क्रमशः "मर्ज" और "जॉइन" विधि का उपयोग करके किया जा सकता है। विलय एक या एक से अधिक धाराओं को जोड़ता है। जुड़ना विलय के समान है, इस तथ्य को छोड़कर कि जुड़ने से दो धाराओं की जांच और शामिल होने के लिए दोनों ओर से त्रिशूल टपल क्षेत्र का उपयोग होता है। इसके अलावा, जॉइनिंग केवल बैच स्तर के तहत काम करेगा। नमूना कोड इस प्रकार है -
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));राज्य का रखरखाव
त्रिशूल राज्य रखरखाव के लिए एक तंत्र प्रदान करता है। राज्य की जानकारी टोपोलॉजी में ही संग्रहीत की जा सकती है, अन्यथा आप इसे एक अलग डेटाबेस में भी संग्रहीत कर सकते हैं। कारण एक राज्य बनाए रखने के लिए है कि यदि प्रसंस्करण के दौरान कोई भी ट्यूपल विफल हो जाता है, तो असफल ट्यूपल पीछे हट जाता है। यह राज्य को अपडेट करते समय एक समस्या पैदा करता है क्योंकि आप सुनिश्चित नहीं हैं कि इस ट्यूपल की स्थिति पहले से अपडेट की गई है या नहीं। यदि राज्य को अपडेट करने से पहले ट्यूपल विफल हो गया है, तो टपल को पुनः प्राप्त करने से राज्य स्थिर हो जाएगा। हालांकि, अगर राज्य को अपडेट करने के बाद ट्यूपल विफल हो गया है, तो उसी ट्यूपल को फिर से प्रयास करने से डेटाबेस में गिनती बढ़ जाएगी और राज्य अस्थिर हो जाएगा। किसी संदेश को केवल एक बार संसाधित करने के लिए निम्नलिखित चरणों को करने की आवश्यकता है -
छोटे बैचों में ट्यूपल्स को संसाधित करें।
प्रत्येक बैच को एक अद्वितीय आईडी असाइन करें। यदि बैच को वापस लिया जाता है, तो उसे एक ही विशिष्ट आईडी दी जाती है।
बैच के बीच राज्य अद्यतन का आदेश दिया जाता है। उदाहरण के लिए, दूसरे बैच का राज्य अद्यतन तब तक संभव नहीं होगा जब तक कि पहले बैच के लिए राज्य का अपडेट पूरा नहीं हो जाता।
आरपीसी का वितरण किया
वितरित RPC का उपयोग ट्राइडेंट टोपोलॉजी से परिणाम को क्वेरी और पुनः प्राप्त करने के लिए किया जाता है। तूफान में एक इनबिल्ट वितरित आरपीसी सर्वर है। वितरित RPC सर्वर क्लाइंट से RPC अनुरोध प्राप्त करता है और इसे टोपोलॉजी में भेजता है। टोपोलॉजी अनुरोध को संसाधित करता है और वितरित आरपीसी सर्वर को परिणाम भेजता है, जिसे क्लाइंट को वितरित आरपीसी सर्वर द्वारा पुनर्निर्देशित किया जाता है। ट्रिडेंट की वितरित RPC क्वेरी सामान्य RPC क्वेरी की तरह निष्पादित होती है, इस तथ्य को छोड़कर कि ये क्वेरी समानांतर में चलती हैं।
त्रिशूल का उपयोग कब करें?
जैसा कि कई उपयोग-मामलों में, यदि आवश्यकता केवल एक बार क्वेरी करने की है, तो हम इसे ट्राइडेंट में एक टोपोलॉजी लिखकर प्राप्त कर सकते हैं। दूसरी ओर, स्टॉर्म के मामले में एक बार प्रसंस्करण प्राप्त करना मुश्किल होगा। इसलिए त्रिशूल उन उपयोग-मामलों के लिए उपयोगी होगा जहां आपको एक बार प्रसंस्करण की आवश्यकता होती है। ट्रिडेंट सभी उपयोग के मामलों के लिए नहीं है, विशेष रूप से उच्च-प्रदर्शन उपयोग के मामले क्योंकि यह स्टॉर्म में जटिलता जोड़ता है और राज्य का प्रबंधन करता है।
ट्राइडेंट का कार्य उदाहरण
हम अपने कॉल लॉग एनालाइज़र एप्लिकेशन को पिछले भाग में किए गए ट्राइडेंट फ्रेमवर्क में परिवर्तित करने जा रहे हैं। सादे तूफान की तुलना में ट्रिडेंट एप्लिकेशन अपेक्षाकृत आसान होगा, इसकी उच्च-स्तरीय एपीआई के लिए धन्यवाद। ट्राइडेंट में फंक्शन, फिल्टर, एग्रीगेट, ग्रुपबाय, जॉइन और मर्ज ऑपरेशंस में से किसी एक को करने के लिए स्टॉर्म की आवश्यकता होगी। अंत में हम DRPC सर्वर का उपयोग शुरू करेंगेLocalDRPC कक्षा और कुछ कीवर्ड का उपयोग करके खोजें execute LocalDRPC वर्ग की विधि।
कॉल जानकारी को स्वरूपित करना
FormatCall वर्ग का उद्देश्य "कॉलर नंबर" और "रिसीवर नंबर" सहित कॉल जानकारी को प्रारूपित करना है। पूरा कार्यक्रम कोड इस प्रकार है -
कोडिंग: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
CSVSplit वर्ग का उद्देश्य इनपुट स्ट्रिंग को "अल्पविराम ()" के आधार पर विभाजित करना है और स्ट्रिंग में प्रत्येक शब्द का उत्सर्जन करना है। यह फ़ंक्शन वितरित क्वेरी के इनपुट तर्क को पार्स करने के लिए उपयोग किया जाता है। पूरा कोड इस प्रकार है -
कोडिंग: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}लॉग एनालाइजर
यह मुख्य अनुप्रयोग है। प्रारंभ में, एप्लिकेशन TridentTopology को आरंभ करेगा और उपयोग करने वाले कॉलर जानकारी को फीड करेगाFeederBatchSpout। का उपयोग करके त्रिशूल टोपोलॉजी स्ट्रीम बनाई जा सकती हैnewStreamTridentTopology वर्ग की विधि। इसी तरह, त्रिशूल टोपोलॉजी DRPC स्ट्रीम का उपयोग करके बनाया जा सकता हैnewDRCPStreamTridentTopology वर्ग की विधि। एक साधारण DRCP सर्वर LocalDRPC वर्ग का उपयोग करके बनाया जा सकता है।LocalDRPCकुछ कीवर्ड खोज करने के लिए निष्पादन विधि है। पूरा कोड नीचे दिया गया है।
कोडिंग: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}बिल्डिंग और अनुप्रयोग चल रहा है
पूर्ण आवेदन में तीन जावा कोड हैं। वे इस प्रकार हैं -
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
आवेदन निम्नलिखित कमांड का उपयोग करके बनाया जा सकता है -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaआवेदन निम्नलिखित आदेश का उपयोग करके चलाया जा सकता है -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentउत्पादन
एक बार आवेदन शुरू होने के बाद, एप्लिकेशन क्लस्टर स्टार्टअप प्रक्रिया, संचालन प्रसंस्करण, DRPC सर्वर और क्लाइंट जानकारी और अंत में क्लस्टर बंद करने की प्रक्रिया के बारे में पूरा विवरण आउटपुट करेगा। यह आउटपुट कंसोल पर प्रदर्शित होगा जैसा कि नीचे दिखाया गया है।
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsयहाँ इस अध्याय में, हम अपाचे स्टॉर्म के एक वास्तविक समय के अनुप्रयोग पर चर्चा करेंगे। हम देखेंगे कि ट्विटर में तूफान का उपयोग कैसे किया जाता है।
ट्विटर
Twitter एक ऑनलाइन सोशल नेटवर्किंग सेवा है जो उपयोगकर्ता के ट्वीट भेजने और प्राप्त करने के लिए एक मंच प्रदान करती है। पंजीकृत उपयोगकर्ता ट्वीट पढ़ और पोस्ट कर सकते हैं, लेकिन अपंजीकृत उपयोगकर्ता केवल ट्वीट पढ़ सकते हैं। हैशटैग का उपयोग प्रासंगिक कीवर्ड से पहले # जोड़कर कीवर्ड द्वारा ट्वीट को वर्गीकृत करने के लिए किया जाता है। अब हम प्रति विषय सबसे अधिक उपयोग किए जाने वाले हैशटैग को खोजने का एक वास्तविक समय परिदृश्य लेते हैं।
सृजन करो
टोंटी का उद्देश्य लोगों द्वारा जल्द से जल्द ट्वीट प्रस्तुत करना है। ट्विटर "ट्विटर स्ट्रीमिंग एपीआई" प्रदान करता है, जो वास्तविक समय में लोगों द्वारा प्रस्तुत किए गए ट्वीट को पुनः प्राप्त करने के लिए एक वेब सेवा आधारित उपकरण है। ट्विटर स्ट्रीमिंग एपीआई को किसी भी प्रोग्रामिंग भाषा में एक्सेस किया जा सकता है।
twitter4j एक खुला स्रोत है, अनौपचारिक जावा पुस्तकालय, जो ट्विटर स्ट्रीमिंग एपीआई तक आसानी से पहुंचने के लिए जावा आधारित मॉड्यूल प्रदान करता है। twitter4jट्वीट्स तक पहुंचने के लिए एक श्रोता-आधारित ढांचा प्रदान करता है। Twitter स्ट्रीमिंग API तक पहुंचने के लिए, हमें Twitter डेवलपर खाते के लिए साइन इन करना होगा और निम्नलिखित OAuth प्रमाणीकरण विवरण प्राप्त करना चाहिए।
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
तूफान एक चहचहाना टोंटी प्रदान करता है, TwitterSampleSpout,इसकी स्टार्टर किट में। हम इसका उपयोग ट्वीट्स को पुनः प्राप्त करने के लिए करेंगे। टोंटी को OAuth प्रमाणीकरण विवरण और कम से कम एक कीवर्ड की आवश्यकता है। टोंटी कीवर्ड के आधार पर वास्तविक समय के ट्वीट्स का उत्सर्जन करेगी। पूरा प्रोग्राम कोड नीचे दिया गया है।
कोडिंग: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}हैशटैग रीडर बोल्ट
टोंटी द्वारा उत्सर्जित ट्वीट को अग्रेषित किया जाएगा HashtagReaderBolt, जो ट्वीट को संसाधित करेगा और सभी उपलब्ध हैशटैग का उत्सर्जन करेगा। HashtagReaderBolt का उपयोग करता हैgetHashTagEntitiestwitter4j द्वारा प्रदान की गई विधि। getHashTagEntities ने ट्वीट को पढ़ा और हैशटैग की सूची लौटा दी। पूरा कार्यक्रम कोड इस प्रकार है -
कोडिंग: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}हैशटैग काउंटर बोल्ट
उत्सर्जित हैशटैग को अग्रेषित किया जाएगा HashtagCounterBolt। यह बोल्ट सभी हैशटैग को संसाधित करेगा और जावा मैप ऑब्जेक्ट का उपयोग करके प्रत्येक और प्रत्येक हैशटैग और इसकी गिनती को बचाएगा। पूरा प्रोग्राम कोड नीचे दिया गया है।
कोडिंग: हैशटैग एनकाउंटरबोल्ट.जवा
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}टोपोलॉजी सबमिट करना
एक टोपोलॉजी जमा करना मुख्य अनुप्रयोग है। ट्विटर टोपोलॉजी के होते हैंTwitterSampleSpout, HashtagReaderBolt, तथा HashtagCounterBolt। निम्न प्रोग्राम कोड दिखाता है कि टोपोलॉजी कैसे जमा करें।
कोडिंग: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}बिल्डिंग और अनुप्रयोग चल रहा है
पूर्ण आवेदन में चार जावा कोड हैं। वे इस प्रकार हैं -
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
आप निम्नलिखित कमांड का उपयोग करके एप्लिकेशन को संकलित कर सकते हैं -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaनिम्नलिखित आदेशों का उपयोग करके आवेदन निष्पादित करें -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>उत्पादन
आवेदन वर्तमान उपलब्ध हैशटैग और उसकी गिनती को प्रिंट करेगा। आउटपुट निम्नलिखित के समान होना चाहिए -
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1याहू! वित्त इंटरनेट की प्रमुख व्यावसायिक समाचार और वित्तीय डेटा वेबसाइट है। यह याहू का एक हिस्सा है! और वित्तीय समाचार, बाजार के आंकड़े, अंतर्राष्ट्रीय बाजार के आंकड़ों और वित्तीय संसाधनों के बारे में अन्य जानकारी के बारे में जानकारी देता है जिसे कोई भी उपयोग कर सकता है।
यदि आप एक पंजीकृत याहू हैं! उपयोगकर्ता, तो आप याहू अनुकूलित कर सकते हैं! इसके निश्चित प्रसाद का लाभ उठाने के लिए वित्त। याहू! वित्त एपीआई याहू से वित्तीय डेटा क्वेरी करने के लिए प्रयोग किया जाता है!
यह एपीआई वास्तविक समय से 15 मिनट की देरी से डेटा प्रदर्शित करता है, और अपने डेटाबेस को हर 1 मिनट में अपडेट करता है, ताकि स्टॉक से संबंधित जानकारी का उपयोग किया जा सके। अब हम किसी कंपनी के वास्तविक समय का परिदृश्य लेते हैं और देखते हैं कि जब स्टॉक का मूल्य 100 से नीचे चला जाता है तो अलर्ट कैसे बढ़ाएं।
सृजन करो
टोंटी का उद्देश्य कंपनी का विवरण प्राप्त करना और कीमतों को बोल्ट तक पहुंचाना है। टोंटी बनाने के लिए आप निम्न प्रोग्राम कोड का उपयोग कर सकते हैं।
कोडिंग: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}बोल्ट निर्माण
यहां बोल्ट का उद्देश्य दिए गए कंपनी के मूल्यों को संसाधित करना है जब कीमतें 100 से नीचे आती हैं। यह कटऑफ मूल्य सीमा चेतावनी को निर्धारित करने के लिए जावा मैप ऑब्जेक्ट का उपयोग करता है। trueजब शेयर की कीमतें 100 से नीचे आती हैं; अन्यथा झूठ है। पूरा कार्यक्रम कोड इस प्रकार है -
कोडिंग: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}टोपोलॉजी सबमिट करना
यह मुख्य एप्लिकेशन है जहां YahooFinanceSpout.java और PriceCutOffBolt.java एक साथ जुड़े हुए हैं और एक टोपोलॉजी का उत्पादन करते हैं। निम्न प्रोग्राम कोड दिखाता है कि आप टोपोलॉजी कैसे प्रस्तुत कर सकते हैं।
कोडिंग: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}बिल्डिंग और अनुप्रयोग चल रहा है
पूर्ण आवेदन में तीन जावा कोड हैं। वे इस प्रकार हैं -
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
आवेदन निम्नलिखित आदेश का उपयोग कर बनाया जा सकता है -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaएप्लिकेशन को निम्न आदेश का उपयोग करके चलाया जा सकता है -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormउत्पादन
आउटपुट निम्न के समान होगा -
GOOGL : false
AAPL : false
INTC : trueअपाचे स्टॉर्म फ्रेमवर्क आज के सर्वश्रेष्ठ औद्योगिक अनुप्रयोगों में से कई का समर्थन करता है। हम इस अध्याय में तूफान के सबसे उल्लेखनीय अनुप्रयोगों में से कुछ का एक संक्षिप्त विवरण प्रदान करेंगे।
Klout
क्लाउट एक ऐसा एप्लिकेशन है जो ऑनलाइन सोशल प्रभाव के आधार पर अपने उपयोगकर्ताओं को रैंक करने के लिए सोशल मीडिया एनालिटिक्स का उपयोग करता है Klout Score, जो 1 और 100 के बीच का संख्यात्मक मान है। क्लॉट अपाचे स्टॉर्म के इनबिल्ट ट्राइडेंट एब्स्ट्रैक्शन का उपयोग जटिल टोपोलॉजी बनाने के लिए करता है जो डेटा स्ट्रीम करते हैं।
मौसम चैनल
वेदर चैनल मौसम के आंकड़ों को निगाने के लिए स्टॉर्म टोपोलॉजी का उपयोग करता है। इसने ट्विटर और मोबाइल एप्लिकेशन पर मौसम की सूचना देने वाले विज्ञापन को सक्षम करने के लिए ट्विटर के साथ करार किया है।OpenSignal एक कंपनी है जो वायरलेस कवरेज मैपिंग में माहिर है। StormTag तथा WeatherSignalमौसम आधारित परियोजनाएं हैं जो ओपनसिग्नल द्वारा बनाई गई हैं। स्टॉर्मटैग एक ब्लूटूथ वेदर स्टेशन है जो कीचेन से जुड़ता है। डिवाइस द्वारा एकत्रित मौसम डेटा को वेदरसिग्नल ऐप और ओपनसिग्नल सर्वर पर भेजा जाता है।
दूरसंचार उद्योग
दूरसंचार प्रदाता प्रति सेकंड लाखों फोन कॉल की प्रक्रिया करते हैं। वे गिराई गई कॉल और खराब साउंड क्वालिटी पर फोरेंसिक करते हैं। कॉल डिटेल रिकॉर्ड लाखों प्रति सेकंड की दर से प्रवाहित होते हैं और अपाचे स्टॉर्म वास्तविक समय में प्रक्रिया करते हैं और किसी भी परेशान पैटर्न की पहचान करते हैं। कॉल की गुणवत्ता में लगातार सुधार के लिए तूफान विश्लेषण का उपयोग किया जा सकता है।