DocumentDB SQL - त्वरित गाइड
DocumentDB Microsoft का नवीनतम NoSQL दस्तावेज़ डेटाबेस प्लेटफ़ॉर्म है जो Azure पर चलता है। इस ट्यूटोरियल में, हम DocumentDB द्वारा समर्थित SQL के विशेष संस्करण का उपयोग करके दस्तावेज़ों को क्वेरी करने के बारे में सीखेंगे।
NoSQL दस्तावेज़ डेटाबेस
DocumentDB Microsoft का सबसे नया NoSQL डॉक्यूमेंट डेटाबेस है, हालाँकि, जब हम कहते हैं कि NoSQL डॉक्यूमेंट डेटाबेस, तो NoSQL से हमारा क्या तात्पर्य है, और डॉक्यूमेंट डेटाबेस?
SQL का मतलब स्ट्रक्चर्ड क्वेरी लैंग्वेज है जो रिलेशनल डेटाबेस की एक पारंपरिक क्वेरी लैंग्वेज है। SQL को अक्सर रिलेशनल डेटाबेस के साथ बराबर किया जाता है।
NoSQL डेटाबेस को एक गैर-रिलेशनल डेटाबेस के रूप में सोचना वास्तव में अधिक उपयोगी है, इसलिए NoSQL वास्तव में गैर-रिलेशनल है।
NoSQL डेटाबेस के विभिन्न प्रकार हैं जिनमें प्रमुख मूल्य भंडार शामिल हैं जैसे -
- एज़्योर टेबल स्टोरेज
- स्तंभ-आधारित स्टोर, जैसे कैसंड्रा
- ग्राफ़ डेटाबेस, NEO4 की तरह
- दस्तावेज़ डेटाबेस, जैसे MongoDB और Azure DocumentDB
SQL सिंटेक्स क्यों?
यह पहली बार में अजीब लग सकता है, लेकिन DocumentDB में जो एक NoSQL डेटाबेस है, हम SQL का उपयोग करके क्वेरी करते हैं। जैसा कि ऊपर उल्लेख किया गया है, यह JSON और जावास्क्रिप्ट शब्दार्थ में निहित SQL का एक विशेष संस्करण है।
SQL सिर्फ एक भाषा है, लेकिन यह एक बहुत लोकप्रिय भाषा है जो समृद्ध और अभिव्यंजक है। इस प्रकार, यह निश्चित रूप से एसक्यूएल की कुछ बोली का उपयोग करने के लिए एक अच्छा विचार की तरह लगता है, बल्कि प्रश्नों को व्यक्त करने का एक नया तरीका है, जिसे आपको सीखना होगा यदि आप अपने डेटाबेस से दस्तावेज़ प्राप्त करना चाहते हैं।
SQL रिलेशनल डेटाबेस के लिए डिज़ाइन किया गया है, और DocumentDB एक गैर-रिलेशनल दस्तावेज़ डेटाबेस है। DocumentDB टीम ने वास्तव में दस्तावेज़ डेटाबेस की गैर-संबंधपरक दुनिया के लिए SQL सिंटैक्स को अनुकूलित किया है, और इसका मतलब JSON और जावास्क्रिप्ट में SQL को रूट करके है।
भाषा अभी भी परिचित SQL के रूप में पढ़ती है, लेकिन शब्दार्थ सभी संबंधपरक तालिकाओं के बजाय स्कीमाफ्री JSON दस्तावेजों पर आधारित हैं। DocumentDB में, हम SQL डेटा प्रकारों के बजाय जावास्क्रिप्ट डेटा प्रकारों के साथ काम करेंगे। हम SELECT, FROM, WHERE, इत्यादि से परिचित होंगे, लेकिन जावास्क्रिप्ट प्रकारों के साथ, जो संख्या और तार तक सीमित हैं, ऑब्जेक्ट, सरणियाँ, बूलियन, और नल SQL डेटा प्रकारों की विस्तृत श्रृंखला से बहुत कम हैं।
इसी तरह, अभिव्यक्तियों को टी-एसक्यूएल के कुछ रूप के बजाय जावास्क्रिप्ट अभिव्यक्तियों के रूप में मूल्यांकन किया जाता है। उदाहरण के लिए, एक डेटा की दुनिया में, हम पंक्तियों और स्तंभों के साथ काम नहीं कर रहे हैं, लेकिन स्कीयर रहित दस्तावेज़ों में पदानुक्रमित संरचनाएं होती हैं जिनमें नेस्टेड एरे और ऑब्जेक्ट होते हैं।
SQL कैसे काम करता है?
DocumentDB टीम ने कई अभिनव तरीकों से इस सवाल का जवाब दिया है। उनमें से कुछ इस प्रकार सूचीबद्ध हैं -
पहले, यह मानकर कि आपने किसी प्रॉपर्टी में किसी प्रॉपर्टी को अपने आप इंडेक्स करने के लिए डिफॉल्ट बिहेवियर को नहीं बदला है, आप डॉक्युमेंटेशन नोटेशन का उपयोग किसी भी प्रॉपर्टी पर जाने के लिए कर सकते हैं, चाहे वह डॉक्यूमेंट में कितनी भी नेस्टेड क्यों न हो।
आप एक इंट्रा-डॉक्यूमेंट जॉइन भी कर सकते हैं जिसमें नेस्टेड ऐरे एलिमेंट्स अपने पेरेंट एलिमेंट के साथ डॉक्यूमेंट के भीतर जुड़ते हैं जिस तरह से रिलेटेड वर्ल्ड में दो टेबलों के बीच जॉइन होता है।
आपके क्वेरीज़ डेटाबेस से दस्तावेज़ों को वापस कर सकते हैं, जैसा कि आप कर सकते हैं, या आप जितने चाहें उतने कस्टम दस्तावेज़ JSON आकार पर आधारित कर सकते हैं या जितने दस्तावेज़ डेटा चाहते हैं।
DocumentDB में SQL सहित कई आम ऑपरेटरों का समर्थन करता है -
अंकगणित और बिटवाइज संचालन
और या तर्क
समानता और सीमा की तुलना
स्ट्रिंग संगति
क्वेरी भाषा बिल्ट-इन फ़ंक्शन के होस्ट का भी समर्थन करती है।
Azure पोर्टल में एक क्वेरी एक्सप्लोरर है जिससे हम अपने DocumentDB डेटाबेस के खिलाफ कोई SQL क्वेरी चला सकते हैं। हम क्वेरी एक्सप्लोरर का उपयोग सबसे सरल संभव क्वेरी से शुरू होने वाली क्वेरी भाषा की कई विभिन्न क्षमताओं और विशेषताओं को प्रदर्शित करने के लिए करेंगे।
Step 1 - एज़्योर पोर्टल खोलें, और डेटाबेस ब्लेड में, क्वेरी एक्सप्लोरर ब्लेड पर क्लिक करें।
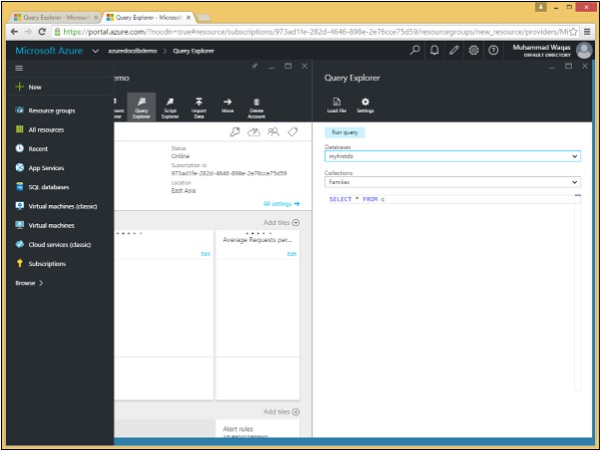
याद रखें कि क्वेरी एक संग्रह के दायरे में चलती हैं, और इसलिए क्वेरी एक्सप्लोरर हमें इस ड्रॉपडाउन में संग्रह चुनने देता है। हम इसे अपने परिवार संग्रह में सेट कर देंगे, जिसमें तीन दस्तावेज़ शामिल हैं। आइए इस उदाहरण में इन तीन दस्तावेजों पर विचार करें।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
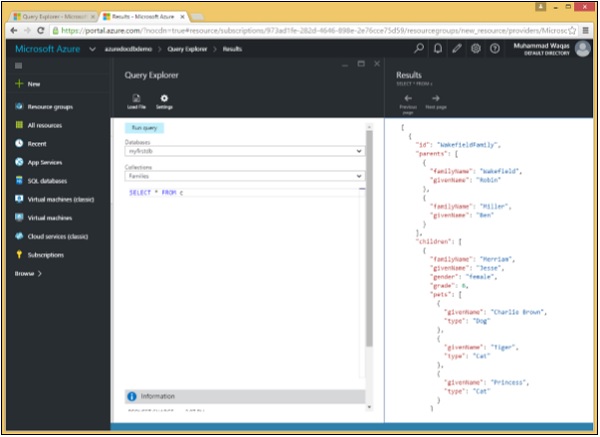
}क्वेरी एक्सप्लोरर इस सरल क्वेरी के साथ खुलता है * FROM c, जो संग्रह से सभी दस्तावेजों को पुनः प्राप्त करता है। हालांकि यह सरल है, यह अभी भी एक रिलेशनल डेटाबेस में समकक्ष क्वेरी से काफी अलग है।
Step 2- संबंधपरक डेटाबेस में, सेलेक्ट * का मतलब है कि डॉक्यूमेंटीडीबी में सभी कॉलम वापस कर दें। इसका मतलब है कि आप चाहते हैं कि आपके परिणाम में प्रत्येक दस्तावेज़ डेटाबेस में संग्रहीत होने के समान ही लौटाया जाए।
लेकिन जब आप केवल एक सेलेक्ट * जारी करने के बजाय विशिष्ट गुणों और अभिव्यक्तियों का चयन करते हैं, तो आप एक नया आकार पेश कर रहे हैं जिसे आप परिणाम में प्रत्येक दस्तावेज़ के लिए चाहते हैं।
Step 3 - क्वेरी निष्पादित करने और परिणाम ब्लेड खोलने के लिए 'रन' पर क्लिक करें।

जैसा कि वेकफील्डफैमिली, स्मिथफैमिली और एंडरसनफैमिली को देखा जा सकता है।
निम्नलिखित तीन दस्तावेज हैं जिन्हें इसके परिणामस्वरूप प्राप्त किया गया है SELECT * FROM c क्वेरी।
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
"givenName": "Fluffy",
"type": "Rabbit"
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]हालाँकि, इन परिणामों में सिस्टम-जनरेट किए गए गुण भी शामिल हैं जो सभी अंडरस्कोर वर्ण के साथ उपसर्ग किए गए हैं।
इस अध्याय में, हम FROM क्लॉज को कवर करेंगे, जो नियमित SQL में एक मानक FROM क्लॉज की तरह कुछ भी काम नहीं करता है।
प्रश्न हमेशा एक विशिष्ट संग्रह के संदर्भ में चलते हैं और संग्रह के भीतर दस्तावेजों में शामिल नहीं हो सकते हैं, जो हमें आश्चर्यचकित करता है कि हमें FROM क्लॉज की आवश्यकता क्यों है। वास्तव में, हम नहीं करते हैं, लेकिन अगर हम इसे शामिल नहीं करते हैं, तो हम संग्रह में दस्तावेजों को क्वेरी नहीं करेंगे।
इस खंड का उद्देश्य उस डेटा स्रोत को निर्दिष्ट करना है जिस पर क्वेरी को काम करना चाहिए। आम तौर पर संपूर्ण संग्रह स्रोत होता है, लेकिन कोई इसके बजाय संग्रह का सबसेट निर्दिष्ट कर सकता है। FROM <from_specification> क्लॉज वैकल्पिक है जब तक कि स्रोत को फ़िल्टर या क्वेरी में बाद में अनुमानित नहीं किया जाता है।
चलिए फिर से उसी उदाहरण पर एक नज़र डालते हैं। निम्नलिखित हैAndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
उपरोक्त प्रश्न में, “SELECT * FROM c"इंगित करता है कि संपूर्ण परिवार संग्रह वह स्रोत है जिस पर गणना करना है।
उप दस्तावेजों
स्रोत को एक छोटे उपसमूह में भी घटाया जा सकता है। जब हम प्रत्येक दस्तावेज़ में केवल एक सबट्री प्राप्त करना चाहते हैं, तो उप-रूट तब स्रोत बन सकता है, जैसा कि निम्नलिखित उदाहरण में दिखाया गया है।
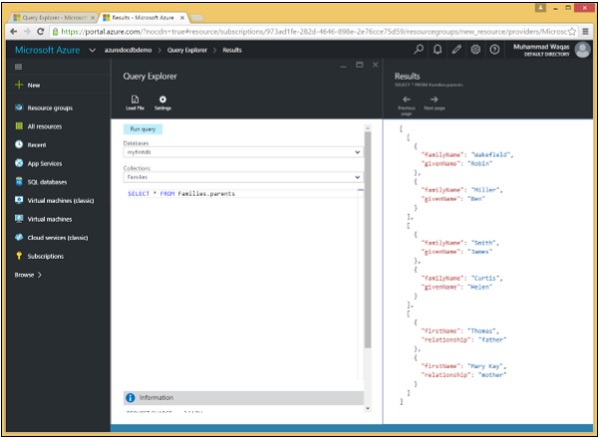
जब हम निम्नलिखित क्वेरी चलाते हैं -
SELECT * FROM Families.parentsनिम्नलिखित उप-दस्तावेजों को पुनः प्राप्त किया जाएगा।
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]इस क्वेरी के परिणामस्वरूप, हम देख सकते हैं कि केवल माता-पिता उप-दस्तावेज़ों को पुनः प्राप्त कर रहे हैं।
इस अध्याय में, हम WHERE क्लॉज को कवर करेंगे, जो FROM क्लॉज की तरह वैकल्पिक भी है। इसका उपयोग स्रोत द्वारा प्रदान किए गए JSON दस्तावेज़ों के रूप में डेटा प्राप्त करते समय एक शर्त निर्दिष्ट करने के लिए किया जाता है। किसी भी JSON दस्तावेज़ को "सत्य" होने के लिए निर्दिष्ट शर्तों का मूल्यांकन करना चाहिए ताकि परिणाम के लिए विचार किया जा सके। यदि दी गई स्थिति संतुष्ट है, तो केवल JSON दस्तावेज़ (ओं) के रूप में विशिष्ट डेटा देता है। हम रिकॉर्ड्स को फ़िल्टर करने और केवल आवश्यक रिकॉर्ड लाने के लिए WHERE क्लॉज़ का उपयोग कर सकते हैं।
हम इस उदाहरण में उन्हीं तीन दस्तावेजों पर विचार करेंगे। निम्नलिखित हैAndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक साधारण उदाहरण देखें जिसमें WHERE क्लॉज का उपयोग किया गया है।
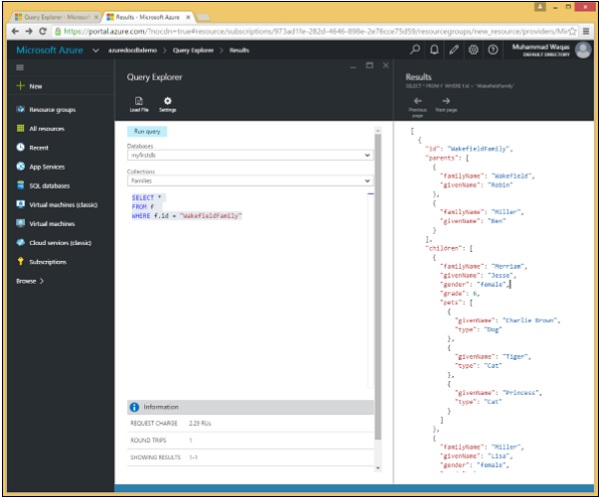
इस क्वेरी में, WHERE क्लॉज में, (WHERE f.id = "WakefieldFamily") स्थिति निर्दिष्ट है।
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"जब उपरोक्त क्वेरी निष्पादित होती है, तो यह WakefieldFamily के लिए पूरा JSON दस्तावेज़ लौटाएगा जैसा कि निम्नलिखित आउटपुट में दिखाया गया है।
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]एक ऑपरेटर एक आरक्षित शब्द या एक चरित्र है जिसका उपयोग मुख्यतः SQL WHERE क्लॉज में ऑपरेशन (ओं) के लिए किया जाता है, जैसे कि तुलना और अंकगणितीय ऑपरेशन। DocumentDB SQL भी विभिन्न प्रकार के अदिश भाव का समर्थन करता है। सबसे अधिक उपयोग किया जाता हैbinary and unary expressions।
निम्न SQL ऑपरेटर वर्तमान में समर्थित हैं और क्वेरीज़ में उपयोग किए जा सकते हैं।
एसक्यूएल तुलना ऑपरेटर
डॉक्यूमेंटडीबी एसक्यूएल व्याकरण में उपलब्ध सभी तुलना ऑपरेटरों की सूची निम्नलिखित है।
| क्र.सं. | ऑपरेटर और विवरण |
|---|---|
| 1 | = जाँच करता है कि दो ऑपरेंड का मान बराबर है या नहीं। यदि हाँ, तो स्थिति सच हो जाती है। |
| 2 | != जाँच करता है कि दो ऑपरेंड का मान बराबर है या नहीं। यदि मूल्य समान नहीं हैं तो स्थिति सत्य हो जाती है। |
| 3 | <> जाँच करता है कि दो ऑपरेंड का मान बराबर है या नहीं। यदि मूल्य समान नहीं हैं तो स्थिति सत्य हो जाती है। |
| 4 | > जाँचता है कि क्या बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से अधिक है। यदि हाँ, तो स्थिति सच हो जाती है। |
| 5 | < जाँचता है कि क्या बाएं संकार्य का मान दाहिने संचालक के मान से कम है। यदि हाँ, तो स्थिति सच हो जाती है। |
| 6 | >= यह जाँचता है कि बाएँ ऑपरेंड का मान सही ऑपरेंड के मान से अधिक या उसके बराबर है या नहीं। यदि हाँ, तो स्थिति सच हो जाती है। |
| 7 | <= जाँच करता है कि क्या बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से कम या बराबर है। यदि हाँ, तो स्थिति सच हो जाती है। |
SQL लॉजिकल ऑपरेटर्स
निम्नलिखित सभी तार्किक ऑपरेटरों की एक सूची है डॉक्यूमेंटडीबी एसक्यूएल व्याकरण में उपलब्ध है।
| क्र.सं. | ऑपरेटर और विवरण |
|---|---|
| 1 | AND AND ऑपरेटर SQL स्टेटमेंट के WHERE क्लॉज में कई स्थितियों के अस्तित्व की अनुमति देता है। |
| 2 | BETWEEN BETWEEN ऑपरेटर का उपयोग उन मानों की खोज के लिए किया जाता है जो मानों के एक सेट के भीतर होते हैं, न्यूनतम मूल्य और अधिकतम मूल्य दिया जाता है। |
| 3 | IN IN ऑपरेटर का उपयोग उन मानों की सूची की मान की तुलना करने के लिए किया जाता है जिन्हें निर्दिष्ट किया गया है। |
| 4 | OR OR ऑपरेटर का उपयोग SQL स्टेटमेंट के WHERE क्लॉज में कई स्थितियों को संयोजित करने के लिए किया जाता है। |
| 5 | NOT NOT ऑपरेटर उस तार्किक ऑपरेटर के अर्थ को उलट देता है जिसके साथ इसका उपयोग किया जाता है। उदाहरण के लिए, EXISTS, NOT BETWEEN, NOT IN, आदि। यह एक नकारात्मक संचालक है। |
SQL अंकगणितीय ऑपरेटर
डॉक्यूमेंटडीबी एसक्यूएल व्याकरण में उपलब्ध सभी अंकगणितीय ऑपरेटरों की एक सूची निम्नलिखित है।
| क्र.सं. | ऑपरेटर और विवरण |
|---|---|
| 1 | + Addition - ऑपरेटर के दोनों ओर मान जोड़ता है। |
| 2 | - Subtraction - बाएँ हाथ से दाहिने हाथ के ऑपरेंड को घटाता है। |
| 3 | * Multiplication - ऑपरेटर के दोनों ओर मूल्यों को गुणा करता है। |
| 4 | / Division - दाहिने हाथ के ऑपरेंड से बाएं हाथ के ऑपरेंड को विभाजित करता है। |
| 5 | % Modulus - बाएं हाथ के ऑपरेंड को दाहिने हाथ के ऑपरेंड से विभाजित करता है और शेष को वापस करता है। |
हम इस उदाहरण में भी उसी दस्तावेजों पर विचार करेंगे। निम्नलिखित हैAndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक साधारण उदाहरण देखें जिसमें एक तुलना ऑपरेटर का उपयोग WHERE क्लॉज में किया गया है।
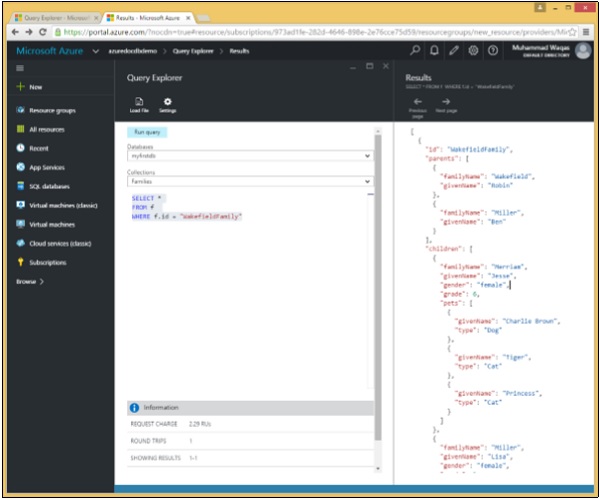
इस क्वेरी में, WHERE क्लॉज में, (WHERE f.id = "WakefieldFamily") स्थिति निर्दिष्ट है, और यह उस दस्तावेज़ को पुनः प्राप्त करेगा, जिसकी आईडी WakefieldFamily के बराबर है।
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"जब उपरोक्त क्वेरी निष्पादित होती है, तो यह WakefieldFamily के लिए पूरा JSON दस्तावेज़ लौटाएगा जैसा कि निम्नलिखित आउटपुट में दिखाया गया है।
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]आइए एक और उदाहरण देखें जिसमें क्वेरी उन बच्चों के डेटा को पुनः प्राप्त करेगी जिनकी ग्रेड 5 से अधिक है।
SELECT *
FROM Families.children[0] c
WHERE (c.grade > 5)जब उपरोक्त क्वेरी निष्पादित की जाती है, तो यह आउटपुट में दिखाए अनुसार निम्न उप दस्तावेज़ को पुनः प्राप्त करेगा।
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]BETWEEN कीवर्ड का उपयोग SQL में मानों की श्रेणी के विरुद्ध क्वेरीज़ को व्यक्त करने के लिए किया जाता है। BETWEEN का उपयोग स्ट्रिंग्स या संख्याओं के खिलाफ किया जा सकता है। DocumentDB और ANSI SQL में BETWEEN का उपयोग करने के बीच मुख्य अंतर यह है कि आप मिश्रित प्रकारों के गुणों के खिलाफ रेंज क्वेरी व्यक्त कर सकते हैं।
उदाहरण के लिए, कुछ दस्तावेज़ों में यह संभव है कि आपके पास एक संख्या के रूप में "ग्रेड" हो सकता है और अन्य दस्तावेजों में यह तार हो सकता है। इन मामलों में, दो अलग-अलग प्रकार के परिणामों के बीच तुलना "अपरिभाषित" होती है, और दस्तावेज़ को छोड़ दिया जाएगा।
आइए पिछले उदाहरण से तीन दस्तावेजों पर विचार करें। निम्नलिखित हैAndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक उदाहरण देखें, जहां क्वेरी सभी परिवार के दस्तावेजों को लौटाती है जिसमें पहले बच्चे का ग्रेड 1-5 (दोनों समावेशी) के बीच होता है।
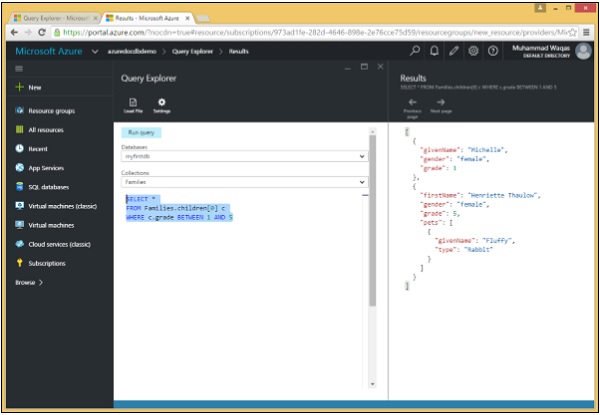
निम्नलिखित वह क्वेरी है जिसमें BETWEEN कीवर्ड का उपयोग किया जाता है और फिर AND तार्किक ऑपरेटर।
SELECT *
FROM Families.children[0] c
WHERE c.grade BETWEEN 1 AND 5जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
]पिछले उदाहरण की श्रेणी के बाहर ग्रेड प्रदर्शित करने के लिए, निम्न क्वेरी में दिखाए गए अनुसार NOT BETWEEN का उपयोग करें।
SELECT *
FROM Families.children[0] c
WHERE c.grade NOT BETWEEN 1 AND 5जब इस क्वेरी को निष्पादित किया जाता है। यह निम्न आउटपुट का उत्पादन करता है।
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]IN कीवर्ड का उपयोग यह जांचने के लिए किया जा सकता है कि किसी सूची में कोई निर्दिष्ट मान किसी मूल्य से मेल खाता है या नहीं। IN ऑपरेटर आपको WHERE क्लॉज में कई मान निर्दिष्ट करने की अनुमति देता है। IN कई या खंडों को जोड़ने के बराबर है।
इसी तरह के तीन दस्तावेजों को पहले के उदाहरणों में माना जाता है। निम्नलिखित हैAndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक साधारण उदाहरण देखें।
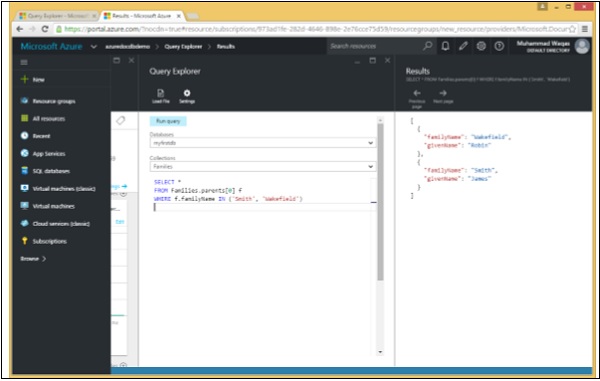
निम्नलिखित क्वेरी है जो डेटा को पुनः प्राप्त करेगी जिसका परिवारनाम या तो "स्मिथ" या वेकफ़ील्ड है।
SELECT *
FROM Families.parents[0] f
WHERE f.familyName IN ('Smith', 'Wakefield')जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Smith",
"givenName": "James"
}
]आइए एक और सरल उदाहरण पर विचार करें जिसमें सभी परिवार के दस्तावेजों को पुनः प्राप्त किया जाएगा जहां आईडी "स्मिथफैमिली" या "एंडर्सनफैमिली" में से एक है। निम्नलिखित प्रश्न है।
SELECT *
FROM Families
WHERE Families.id IN ('SmithFamily', 'AndersenFamily')जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]जब आप जानते हैं कि आप केवल एक ही मान लौटा रहे हैं, तो VALUE कीवर्ड पूर्ण-विकसित ऑब्जेक्ट बनाने के ओवरहेड से बचने के द्वारा निर्धारित एक लीनियर परिणाम बनाने में मदद कर सकता है। VALUE कीवर्ड JSON मान को वापस करने का एक तरीका प्रदान करता है।
आइए एक साधारण उदाहरण देखें।
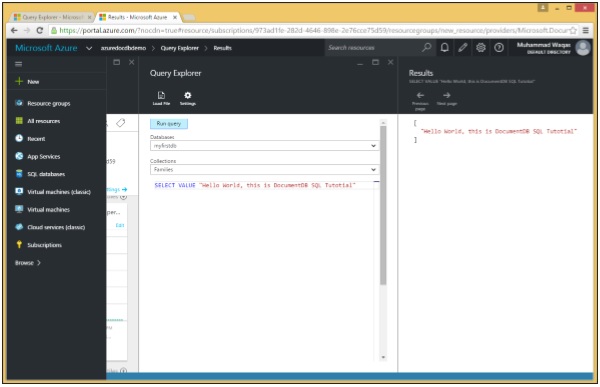
निम्नलिखित VALUE कीवर्ड के साथ क्वेरी है।
SELECT VALUE "Hello World, this is DocumentDB SQL Tutorial"जब इस क्वेरी को निष्पादित किया जाता है, तो यह "हैलो वर्ल्ड, यह डॉक्यूमेंटीडीबी एसक्यूएल ट्यूटोरियल" है।
[
"Hello World, this is DocumentDB SQL Tutorial"
]दूसरे उदाहरण में, आइए पिछले उदाहरणों से तीन दस्तावेजों पर विचार करें।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}निम्नलिखित प्रश्न है।
SELECT VALUE f.location
FROM Families fजब इस क्वेरी को निष्पादित किया जाता है, तो यह स्थान लेबल के बिना पता लौटाता है।
[
{
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
{
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
{
"state": "WA",
"county": "King",
"city": "Seattle"
}
]अगर अब हम उसी क्वेरी को VALUE कीवर्ड के बिना निर्दिष्ट करते हैं, तो वह स्थान लेबल के साथ पता वापस कर देगा। निम्नलिखित प्रश्न है।
SELECT f.location
FROM Families fजब इस क्वेरी को निष्पादित किया जाता है, तो यह निम्न आउटपुट का उत्पादन करता है।
[
{
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
}
},
{
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
},
{
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
}
}
]Microsoft Azure DocumentDB JSON दस्तावेज़ों पर SQL का उपयोग करते हुए क्वेरीज़ दस्तावेजों का समर्थन करता है। आप अपनी क्वेरी में ORDER BY क्लॉज़ का उपयोग करके संख्या और स्ट्रिंग्स पर संग्रह में दस्तावेज़ों को सॉर्ट कर सकते हैं। क्लॉज में ऑर्डर को निर्दिष्ट करने के लिए वैकल्पिक ASC / DESC तर्क को शामिल किया जा सकता है जिसमें परिणाम पुनः प्राप्त करना होगा।
हम पिछले उदाहरणों के समान ही दस्तावेजों पर विचार करेंगे।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक साधारण उदाहरण देखें।
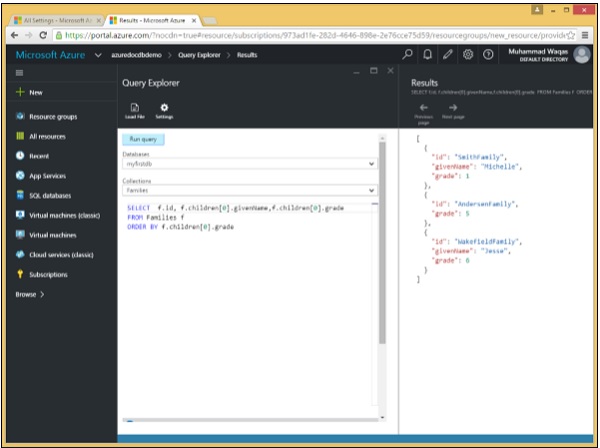
निम्नलिखित क्वेरी है जिसमें ORDER BY कीवर्ड शामिल है।
SELECT f.id, f.children[0].givenName,f.children[0].grade
FROM Families f
ORDER BY f.children[0].gradeजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"id": "SmithFamily",
"givenName": "Michelle",
"grade": 1
},
{
"id": "AndersenFamily",
"grade": 5
},
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]आइए एक और सरल उदाहरण पर विचार करें।
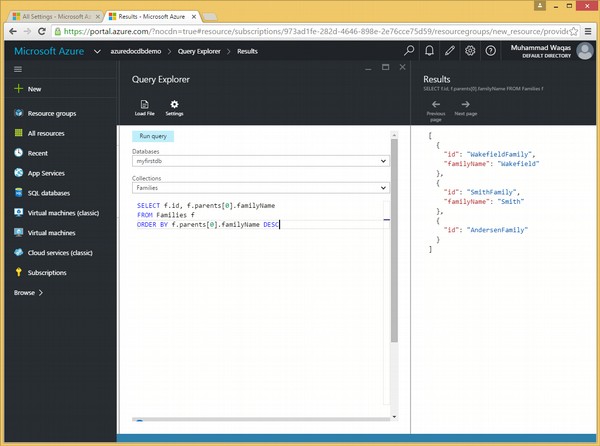
निम्नलिखित क्वेरी है जिसमें ORDER BY कीवर्ड और DESC वैकल्पिक कीवर्ड शामिल हैं।
SELECT f.id, f.parents[0].familyName
FROM Families f
ORDER BY f.parents[0].familyName DESCजब उपरोक्त क्वेरी निष्पादित की जाती है, तो यह निम्न आउटपुट का उत्पादन करेगी।
[
{
"id": "WakefieldFamily",
"familyName": "Wakefield"
},
{
"id": "SmithFamily",
"familyName": "Smith"
},
{
"id": "AndersenFamily"
}
]DocumentDB SQL में, Microsoft ने एक नया निर्माण जोड़ा है जिसका उपयोग JSON सरणियों पर पुनरावृत्ति के लिए समर्थन प्रदान करने के लिए IN कीवर्ड के साथ किया जा सकता है। FROM क्लॉज में पुनरावृत्ति के लिए सहायता प्रदान की जाती है।
हम पिछले उदाहरणों के समान तीन दस्तावेजों पर फिर से विचार करेंगे।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए FROM क्लॉज में IN कीवर्ड के बिना एक सरल उदाहरण देखें।
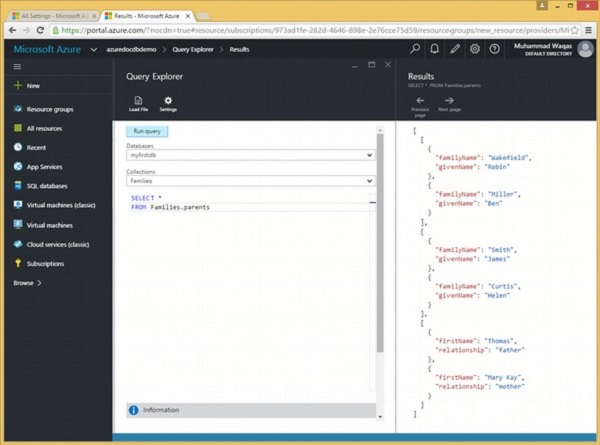
निम्नलिखित क्वेरी है जो सभी माता-पिता को परिवार संग्रह से वापस कर देगी।
SELECT *
FROM Families.parentsजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]जैसा कि उपरोक्त आउटपुट में देखा जा सकता है, प्रत्येक परिवार के माता-पिता एक अलग JSON सरणी में प्रदर्शित होते हैं।
आइए एक ही उदाहरण पर एक नज़र डालें, हालांकि इस बार हम IN कीवर्ड का उपयोग FROM क्लॉज़ में करेंगे।
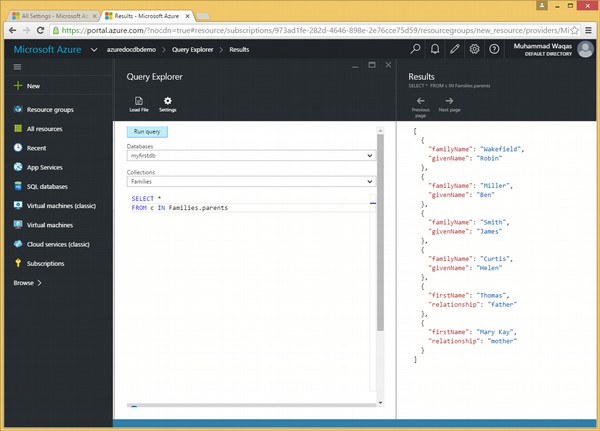
निम्नलिखित वह क्वेरी है जिसमें IN कीवर्ड होता है।
SELECT *
FROM c IN Families.parentsजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
},
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
},
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]उपरोक्त उदाहरण में, यह देखा जा सकता है कि पुनरावृत्ति के साथ, संग्रह में माता-पिता पर पुनरावृत्ति करने वाली क्वेरी में अलग-अलग आउटपुट सरणी होती है। इसलिए, प्रत्येक परिवार के सभी माता-पिता एक ही सरणी में जुड़ जाते हैं।
संबंधपरक डेटाबेस में, एक डेटाबेस में दो या अधिक तालिकाओं से रिकॉर्ड को संयोजित करने के लिए जॉइन क्लॉज का उपयोग किया जाता है, और सामान्यीकृत स्कीमा डिजाइन करते समय तालिकाओं में शामिल होने की आवश्यकता बहुत महत्वपूर्ण है। चूंकि डॉक्युमेंटडीबी स्कीमा-रहित दस्तावेजों के डिनरलाइज्ड डेटा मॉडल से संबंधित है, इसलिए डॉक्यूमेंटीडीबी एसक्यूएल में जॉइन एक "सेल्फजेन" के तार्किक समकक्ष है।
आइए तीन दस्तावेजों पर पिछले उदाहरणों के रूप में विचार करें।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक उदाहरण पर गौर करें कि यह समझने के लिए कि जोइन क्लॉज कैसे काम करता है।
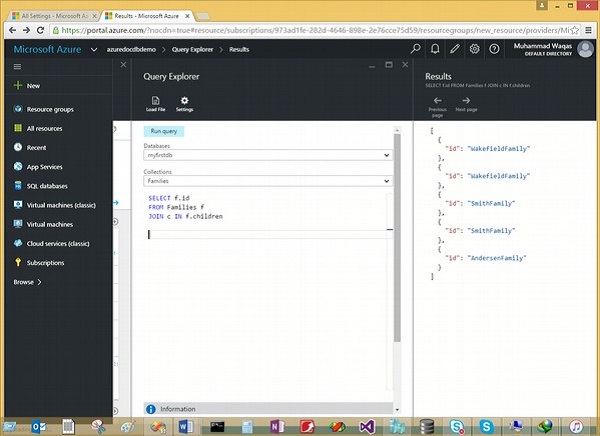
निम्नलिखित क्वेरी है जो रूट को बच्चों के सबडिमेन्मेंट में शामिल करेगी।
SELECT f.id
FROM Families f
JOIN c IN f.childrenजब उपरोक्त क्वेरी निष्पादित की जाती है, तो यह निम्न आउटपुट का उत्पादन करेगी।
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]उपरोक्त उदाहरण में, दस्तावेज़ डॉक्यूमेंट रूट और बच्चों के बीच सब-रूट है जो दो JSON ऑब्जेक्ट्स के बीच क्रॉस-प्रोडक्ट बनाता है। नोट करने के लिए कुछ बिंदु निम्नलिखित हैं -
FROM क्लॉज में, JOIN क्लॉज एक इटरेटर है।
पहले दो दस्तावेज वेकफील्डफैमिली और स्मिथफैमिली में दो बच्चे शामिल हैं, इसलिए परिणाम सेट में क्रॉस-उत्पाद भी शामिल है जो प्रत्येक बच्चे के लिए एक अलग वस्तु का उत्पादन करता है।
तीसरे दस्तावेज एंडरसनफैमिली में केवल एक बच्चे शामिल हैं, इसलिए इस दस्तावेज के लिए केवल एक ही वस्तु है।
आइए एक ही उदाहरण पर एक नज़र डालते हैं, हालांकि इस बार हम जोइन क्लॉज की बेहतर समझ के लिए बच्चे के नाम को पुनः प्राप्त करते हैं।
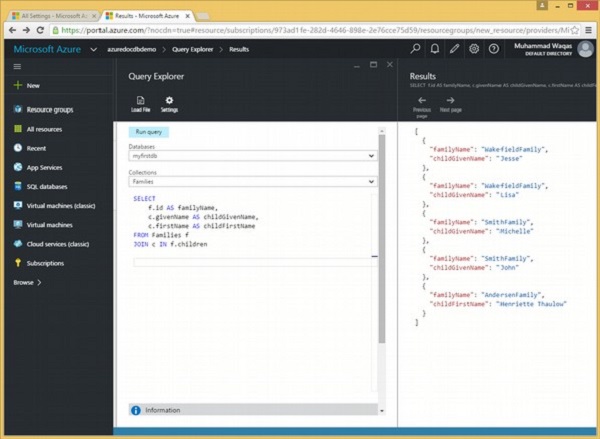
निम्नलिखित क्वेरी है जो रूट को बच्चों के सबडिमेन्मेंट में शामिल करेगी।
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]संबंधपरक डेटाबेस में, SQL उपनामों का उपयोग अस्थायी रूप से किसी तालिका या स्तंभ शीर्षक को बदलने के लिए किया जाता है। इसी प्रकार, डॉक्यूमेंटडीबी में, उपनामों को अस्थायी रूप से JSON दस्तावेज़, उप-दस्तावेज़, ऑब्जेक्ट या किसी भी फ़ील्ड का नाम बदलने के लिए उपयोग किया जाता है।
नाम बदलना एक अस्थायी परिवर्तन है और वास्तविक दस्तावेज़ नहीं बदलता है। असल में, क्षेत्र / दस्तावेज़ नामों को अधिक पठनीय बनाने के लिए उपनाम बनाए जाते हैं। उपनाम के लिए, एएस कीवर्ड का उपयोग किया जाता है जो वैकल्पिक है।
आइए पिछले उदाहरणों में उपयोग किए गए तीन समान दस्तावेजों पर विचार करें।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए उपनामों पर चर्चा करने के लिए एक उदाहरण देखें।
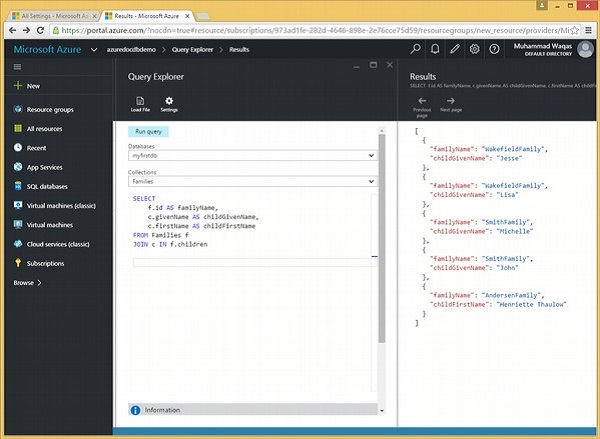
निम्नलिखित क्वेरी है जो रूट को बच्चों के सबडिमेन्मेंट में शामिल करेगी। हमारे पास उपनाम जैसे f.id as familyName, c.givenName AS childGivenName, और c.firstName AS चाइल्डफ़र्स्टनाम है।
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]उपरोक्त आउटपुट से पता चलता है कि दर्ज किए गए नाम बदल दिए गए हैं, लेकिन यह एक अस्थायी बदलाव है और मूल दस्तावेजों को संशोधित नहीं किया गया है।
DocumentDB SQL में Microsoft ने एक प्रमुख विशेषता जोड़ी है जिसकी सहायता से हम आसानी से एक अरै बना सकते हैं। इसका मतलब है कि जब हम एक क्वेरी चलाते हैं, तो परिणामस्वरूप यह क्वेरी के परिणामस्वरूप JSON ऑब्जेक्ट के समान संग्रह की एक सरणी बनाएगा।
चलो पिछले उदाहरणों के समान दस्तावेजों पर विचार करें।
निम्नलिखित है AndersenFamily दस्तावेज़।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}निम्नलिखित है SmithFamily दस्तावेज़।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}निम्नलिखित है WakefieldFamily दस्तावेज़।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक उदाहरण देखें।
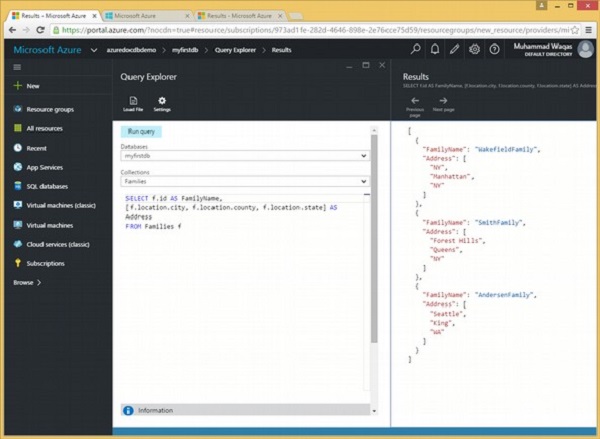
निम्नलिखित क्वेरी है जो परिवार के नाम और प्रत्येक परिवार के पते को वापस कर देगी।
SELECT f.id AS FamilyName,
[f.location.city, f.location.county, f.location.state] AS Address
FROM Families fजैसा कि देखा जा सकता है कि शहर, काउंटी और राज्य क्षेत्र वर्ग कोष्ठक में संलग्न हैं, जो एक सरणी बनाएगा और इस सरणी का नाम पता है। जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"FamilyName": "WakefieldFamily",
"Address": [
"NY",
"Manhattan",
"NY"
]
},
{
"FamilyName": "SmithFamily",
"Address": [
"Forest Hills",
"Queens",
"NY"
]
},
{
"FamilyName": "AndersenFamily",
"Address": [
"Seattle",
"King",
"WA"
]
}
]उपरोक्त आउटपुट में पता सरणी में शहर, काउंटी और राज्य की जानकारी जोड़ी जाती है।
DocumentDB SQL में, SELECT क्लॉज भी स्केलर एक्सप्रेशन जैसे कॉन्स्टेंट, अरिथमेटिक एक्सप्रेशन, लॉजिकल एक्सप्रेशंस आदि को सपोर्ट करता है। आमतौर पर, स्केलर क्वेश्चन का इस्तेमाल बहुत कम किया जाता है, क्योंकि वे कलेक्शन में डॉक्युमेंट्स को क्वेरी नहीं करते हैं, वे सिर्फ एक्सप्रेशन का मूल्यांकन करते हैं। लेकिन यह अभी भी मूल बातें जानने के लिए स्केलर अभिव्यक्ति प्रश्नों का उपयोग करने में मददगार है, एक क्वेरी में अभिव्यक्ति और JSON का उपयोग कैसे करें, और ये अवधारणा उन वास्तविक प्रश्नों पर सीधे लागू होती हैं जिन्हें आप एक संग्रह में दस्तावेजों के खिलाफ चला रहे हैं।
आइए एक उदाहरण देखें जिसमें कई स्केलर प्रश्न होते हैं।
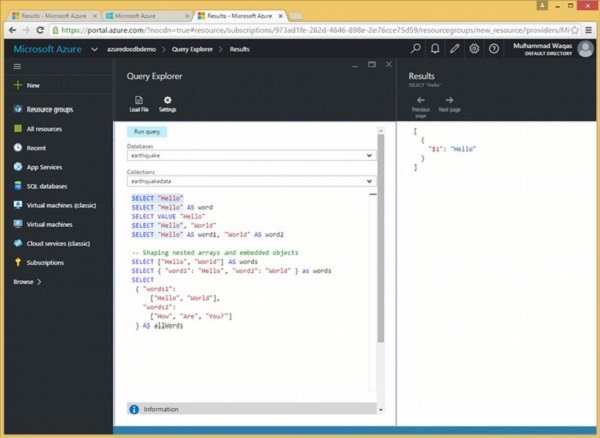
क्वेरी एक्सप्लोरर में, निष्पादित किए जाने वाले पाठ का चयन करें और 'रन' पर क्लिक करें। चलो इसे पहले चलाएं।
SELECT "Hello"जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"$1": "Hello"
}
]यह आउटपुट थोड़ा भ्रामक लग सकता है, इसलिए इसे तोड़ दें।
सबसे पहले, जैसा कि हमने पिछले डेमो में देखा, क्वेरी परिणाम हमेशा स्क्वायर ब्रैकेट में निहित होते हैं क्योंकि उन्हें JSON सरणी के रूप में लौटाया जाता है, यहां तक कि स्केलर एक्सप्रेशन प्रश्नों से भी ऐसा होता है कि केवल एक ही दस्तावेज़ लौटाता है।
हमारे पास इसमें एक दस्तावेज़ के साथ एक सरणी है, और उस दस्तावेज़ में एकल अभिव्यक्ति के लिए एक एकल संपत्ति है।
SELECT स्टेटमेंट इस प्रॉपर्टी के लिए कोई नाम प्रदान नहीं करता है, इस प्रकार डॉक्यूमेंटडीबी ऑटो $ 1 का उपयोग करके उत्पन्न करता है।
यह आमतौर पर वह नहीं है जो हम चाहते हैं, यही कारण है कि हम क्वेरी में अभिव्यक्ति को उपनाम करने के लिए एएस का उपयोग कर सकते हैं, जो उत्पन्न दस्तावेज में संपत्ति का नाम सेट करता है जिस तरह से आप चाहें, इस उदाहरण में, शब्द।
SELECT "Hello" AS wordजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"word": "Hello"
}
]इसी तरह, निम्नलिखित एक और सरल प्रश्न है।
SELECT ((2 + 11 % 7)-2)/3क्वेरी निम्न आउटपुट को पुनः प्राप्त करती है।
[
{
"$1": 1.3333333333333333
}
]आइए नेस्टेड सरणियों और एम्बेडेड ऑब्जेक्ट्स को आकार देने के एक और उदाहरण पर एक नज़र डालें।
SELECT
{
"words1":
["Hello", "World"],
"words2":
["How", "Are", "You?"]
} AS allWordsजब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"allWords": {
"words1": [
"Hello",
"World"
],
"words2": [
"How",
"Are",
"You?"
]
}
}
]संबंधपरक डेटाबेस में, एक पैरामीटर क्वेरी एक क्वेरी है जिसमें प्लेसहोल्डर का उपयोग मापदंडों के लिए किया जाता है और निष्पादन समय पर पैरामीटर मान की आपूर्ति की जाती है। डॉक्यूमेंटीडीबी भी पैरामीटरयुक्त प्रश्नों का समर्थन करता है, और पैरामीटर किए गए क्वेरी में पैरामीटर परिचित @ संकेतन के साथ व्यक्त किए जा सकते हैं। पैरामीटर किए गए प्रश्नों का उपयोग करने का सबसे महत्वपूर्ण कारण SQL इंजेक्शन के हमलों से बचना है। यह उपयोगकर्ता इनपुट से मजबूत हैंडलिंग और भागने की सुविधा भी प्रदान कर सकता है।
आइए एक उदाहरण देखें, जहां हम .Net SDK का उपयोग कर रहे हैं। निम्नलिखित कोड है जो संग्रह को हटा देगा।
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine(">>> Delete Collection {0} in {1} <<<",
collectionId, _database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}",
collectionId, _database.Id);
}एक पैरामीटर क्वेरी का निर्माण निम्नानुसार है।
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};हम संग्रह को हार्डकोड नहीं कर रहे हैं, इसलिए इस विधि का उपयोग किसी भी संग्रह को हटाने के लिए किया जा सकता है। हम SQL सर्वर के समान पैरामीटर नाम उपसर्ग के लिए '@' प्रतीक का उपयोग कर सकते हैं।
उपरोक्त उदाहरण में, हम Id द्वारा एक विशिष्ट संग्रह के लिए क्वेरी कर रहे हैं जहां इस पैरामीटर को SqlParameterCollection में परिभाषित किया गया है जो इस SqlQuerySpec के पैरामीटर की संपत्ति को सौंपा गया है। एसडीके तब डॉक्यूमेंटडीबी के लिए अंतिम क्वेरी स्ट्रिंग के निर्माण का काम करता है, इसके अंदर संग्रहित आईडीआई के साथ। हम क्वेरी चलाते हैं और फिर संग्रह को हटाने के लिए इसके सेल्फलिंक का उपयोग करते हैं।
निम्नलिखित CreateDocumentClient कार्य कार्यान्वयन है।
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM
c WHERE c.id = 'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "MyCollection1");
await DeleteCollection(client, "MyCollection2");
}
}जब कोड निष्पादित होता है, तो यह निम्न आउटपुट का उत्पादन करता है।
**** Delete Collection MyCollection1 in mydb ****
Deleted collection MyCollection1 from database myfirstdb
**** Delete Collection MyCollection2 in mydb ****
Deleted collection MyCollection2 from database myfirstdbआइए एक और उदाहरण देखें। हम एक क्वेरी लिख सकते हैं जो अंतिम नाम और पते की स्थिति को पैरामीटर के रूप में लेती है, और फिर इसे अंतिम नाम और स्थान के विभिन्न मानों के लिए निष्पादित करती है। उपयोगकर्ता इनपुट के आधार पर।
SELECT *
FROM Families f
WHERE f.lastName = @lastName AND f.location.state = @addressStateयह अनुरोध तब एक डॉक्यूमेंटेड JSON क्वेरी के रूप में DocumentDB पर भेजा जा सकता है जैसा कि निम्नलिखित कोड में दिखाया गया है।
{
"query": "SELECT * FROM Families f WHERE f.lastName = @lastName AND
f.location.state = @addressState",
"parameters": [
{"name": "@lastName", "value": "Wakefield"},
{"name": "@addressState", "value": "NY"},
]
}DocumentDB सामान्य कार्यों के लिए अंतर्निहित कार्यों के एक मेजबान का समर्थन करता है जो प्रश्नों के अंदर उपयोग किया जा सकता है। गणितीय गणना करने के लिए कार्यों का एक समूह है, और अलग-अलग स्कीमाओं के साथ काम करते समय चेकिंग फ़ंक्शन भी बेहद उपयोगी हैं। ये फ़ंक्शन परीक्षण कर सकते हैं कि क्या एक निश्चित संपत्ति मौजूद है और यदि यह है कि यह संख्या या स्ट्रिंग, बूलियन या ऑब्जेक्ट है या नहीं।
हमें तार लगाने और हेरफेर करने के लिए ये आसान कार्य भी मिलते हैं, साथ ही साथ सरणियों के साथ काम करने के लिए कई फ़ंक्शन आपको समवर्ती सरणियों जैसे काम करने की अनुमति देते हैं और यह देखने के लिए परीक्षण करते हैं कि किसी सरणी में कोई विशेष तत्व है या नहीं।
निम्नलिखित विभिन्न प्रकार के अंतर्निहित कार्य हैं -
| क्र.सं. | अंतर्निहित कार्य और विवरण |
|---|---|
| 1 | गणितीय कार्य गणितीय फ़ंक्शन एक गणना करते हैं, आमतौर पर इनपुट मानों पर आधारित होते हैं जो तर्क के रूप में प्रदान किए जाते हैं, और एक संख्यात्मक मान लौटाते हैं। |
| 2 | प्रकार जाँच कार्य प्रकार जाँच फ़ंक्शन आपको SQL क्वेरी के भीतर एक अभिव्यक्ति के प्रकार की जांच करने की अनुमति देते हैं। |
| 3 | स्ट्रिंग फ़ंक्शंस स्ट्रिंग फ़ंक्शन एक स्ट्रिंग इनपुट मान पर एक ऑपरेशन करते हैं और एक स्ट्रिंग, संख्यात्मक या बूलियन मान लौटाते हैं। |
| 4 | ऐरे कार्य सरणी फ़ंक्शन सरणी इनपुट मान पर एक ऑपरेशन करते हैं और संख्यात्मक, बूलियन या सरणी मूल्य के रूप में वापस करते हैं। |
| 5 | स्थानिक कार्य डॉक्यूमेंटडीबी भू-स्थानिक क्वेरी के लिए निर्मित कार्यों में ओपन जियोस्पेशियल कंसोर्टियम (ओजीसी) का भी समर्थन करता है। |
DocumentDB में, हम वास्तव में दस्तावेज़ों को क्वेरी करने के लिए SQL का उपयोग करते हैं। यदि हम .NET विकास कर रहे हैं, तो एक LINQ प्रदाता भी है जिसका उपयोग किया जा सकता है और जो LINQ क्वेरी से उपयुक्त SQL उत्पन्न कर सकता है।
समर्थित डेटा प्रकार
DocumentDB में, सभी JSON प्राइमिटिव प्रकारों को LINQ प्रदाता में DocumentDB .NET SDK के साथ शामिल किया गया है जो इस प्रकार समर्थित हैं -
- Numeric
- Boolean
- String
- Null
समर्थित अभिव्यक्ति
निम्नलिखित स्केलर अभिव्यक्तियाँ LINDB प्रदाता में DocumentDB .NET SDK के साथ समर्थित हैं।
Constant Values - आदिम डेटा प्रकारों के निरंतर मान शामिल हैं।
Property/Array Index Expressions - भाव एक वस्तु या एक सरणी तत्व की संपत्ति को संदर्भित करता है।
Arithmetic Expressions - संख्यात्मक और बूलियन मूल्यों पर सामान्य अंकगणितीय अभिव्यक्ति शामिल हैं।
String Comparison Expression - एक स्ट्रिंग मान को कुछ निरंतर स्ट्रिंग मान से तुलना करना शामिल है।
Object/Array Creation Expression- यौगिक मूल्य प्रकार या अनाम प्रकार की वस्तु या ऐसी वस्तुओं की एक सरणी लौटाता है। इन मूल्यों को नेस्टेड किया जा सकता है।
LINQ ऑपरेटर्स को सपोर्ट किया
यहाँ दस्तावेज़ LINDB प्रदाता में LINQ प्रदाता में समर्थित LINQ ऑपरेटरों की एक सूची दी गई है।
Select - अनुमानों का निर्माण सहित एसक्यूएल चयन में अनुवाद होता है।
Where- फिल्टर SQL WHERE में अनुवाद करते हैं, और &&, के बीच अनुवाद का समर्थन करते हैं, || तथा ! SQL ऑपरेटरों के लिए।
SelectMany- SQL जोन क्लॉज के लिए सरणियों को अनइंस्टॉल करने की अनुमति देता है। सरणी तत्वों को फ़िल्टर करने के लिए चेन / नेस्ट एक्सप्रेशनों के लिए उपयोग किया जा सकता है।
OrderBy and OrderByDescending - आरोही / उतरते हुए ORDER के लिए अनुवाद।
CompareTo- तुलना करने के लिए अनुवाद। सामान्य रूप से स्ट्रिंग्स के लिए उपयोग किया जाता है क्योंकि वे .NET में तुलनीय नहीं हैं।
Take - क्वेरी से परिणाम सीमित करने के लिए SQL TOP में अनुवाद।
Math Functions - .NET के Abs, Acos, Asin, Atan, Ceiling, Cos, Exp, Floor, Log, Log10, Pow, Round, Sign, Sin, Sqrt, Tan, Truncate से ट्रांसलेट किए गए एसक्यूएल बिल्ट-इन फंक्शन्स का अनुवाद करता है।
String Functions - .NET के कॉनैट, कॉन्टेक्ट्स, एंडसविथ, इंडेक्सऑफ, काउंट, टावलर, ट्रिमस्टार्ट, रिप्लेस, रिवर्स, ट्रिमएंड, स्टार्टस्विथ, सबस्ट्रिंग, टुपर से ट्रांसलेशन का समर्थन करता है।
Array Functions - .NET के कॉनैट, कॉन्टेन्स से अनुवाद का समर्थन करता है, और समतुल्य SQL अंतर्निहित कार्यों के लिए गणना।
Geospatial Extension Functions - स्टब तरीकों से अनुवाद का समर्थन करता है दूरी, भीतर, IsValid, और IsValidDetailed समतुल्य SQL अंतर्निहित कार्यों के लिए।
User-Defined Extension Function - स्टब विधि UserDefinedFunctionProvider.Invoke से संबंधित उपयोगकर्ता-परिभाषित फ़ंक्शन में अनुवाद का समर्थन करता है।
Miscellaneous- मोटे और सशर्त ऑपरेटरों के अनुवाद का समर्थन करता है। स्ट्रिंग संदर्भों, ARRAY_CONTAINS या SQL IN में संदर्भ के आधार पर अनुवाद कर सकते हैं।
आइए एक उदाहरण देखें, जहां हम .Net SDK का उपयोग कर रहे हैं। निम्नलिखित तीन दस्तावेज हैं जिन पर हम इस उदाहरण पर विचार करेंगे।
नया ग्राहक 1
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}नया ग्राहक २
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "678 Main Street",
"location": {
"city": "London",
"stateProvinceName": " London "
},
"postalCode": "11229",
"countryRegionName": "United Kingdom"
},
}नया ग्राहक ३
{
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "12 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}निम्नलिखित वह कोड है जिसमें हम LINQ का उपयोग करके क्वेरी करते हैं। हमने एक LINQ क्वेरी परिभाषित की हैq, लेकिन यह तब तक क्रियान्वित नहीं होगा जब तक हम इसे नहीं चलाते।
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == "United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} US customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}SDK हमारे LINQ क्वेरी को SQLDB सिंटैक्स में DocumentDB के लिए कन्वर्ट करेगा, हमारे लिनेन सिंटैक्स पर आधारित SELECT और WHERE क्लॉज का निर्माण करेगा।
चलो CreateDocumentClient कार्य से उपरोक्त प्रश्नों को कॉल करें।
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
QueryDocumentsWithLinq(client);
}
}जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्न आउटपुट का उत्पादन करता है।
**** Query Documents (LINQ) ****
Quering for US customers (LINQ)
Found 2 US customers
Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn
Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: Brooklynइन दिनों जावास्क्रिप्ट हर जगह है, और न केवल ब्राउज़रों में। DocumentDB आधुनिक दिन T-SQL के रूप में जावास्क्रिप्ट को गले लगाता है और डेटाबेस इंजन के अंदर, मूल रूप से जावास्क्रिप्ट तर्क के ट्रांजेक्शनल निष्पादन का समर्थन करता है। डॉक्यूमेंट डी बी ने संग्रहित प्रक्रियाओं और ट्रिगर्स के संग्रह पर सीधे जावास्क्रिप्ट-आधारित एप्लिकेशन लॉजिक को निष्पादित करने के लिए एक प्रोग्रामिंग मॉडल प्रदान करता है।
आइए एक उदाहरण देखें जहां हम एक सरल स्टोर प्रक्रिया बनाते हैं। निम्नलिखित चरण हैं -
Step 1 - एक नया कंसोल एप्लिकेशन बनाएं।
Step 2- NuGet से .NET SDK में जोड़ें। हम यहां .NET SDK का उपयोग कर रहे हैं, जिसका अर्थ है कि हम अपनी संग्रहीत प्रक्रिया को बनाने, निष्पादित करने और फिर हटाने के लिए कुछ C # कोड लिखेंगे, लेकिन संग्रहीत प्रक्रिया स्वयं जावास्क्रिप्ट में लिखी जाती है।
Step 3 - समाधान एक्सप्लोरर में परियोजना पर राइट-क्लिक करें।
Step 4 - संग्रहीत कार्यविधि के लिए एक नई जावास्क्रिप्ट फ़ाइल जोड़ें और इसे HelloWorldStoreProce.js कहें
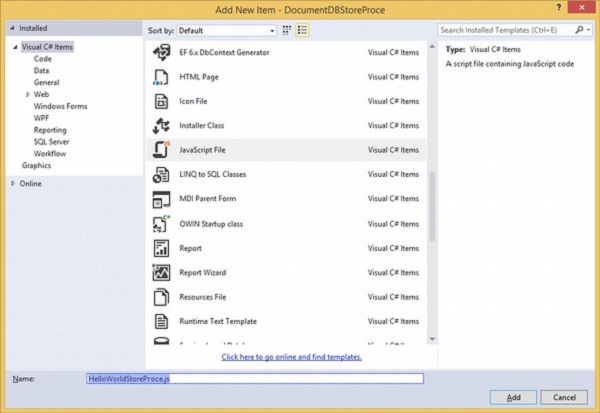
प्रत्येक संग्रहीत कार्यविधि केवल एक जावास्क्रिप्ट फ़ंक्शन है इसलिए हम एक नया फ़ंक्शन बनाएंगे और स्वाभाविक रूप से हम इस फ़ंक्शन को भी नाम देंगे HelloWorldStoreProce। इससे कोई फर्क नहीं पड़ता कि हम फ़ंक्शन को एक नाम देते हैं। DocumentDB केवल इस संग्रहीत कार्यविधि को ईद द्वारा संदर्भित करेगा जो हम इसे बनाते समय प्रदान करते हैं।
function HelloWorldStoreProce() {
var context = getContext();
var response = context.getResponse();
response.setBody('Hello, and welcome to DocumentDB!');
}सभी संग्रहीत कार्यविधि संदर्भ से प्रतिक्रिया ऑब्जेक्ट प्राप्त करती है और इसे कॉल करती है setBodyकॉलर को स्ट्रिंग वापस करने की विधि। C # कोड में, हम संग्रहीत कार्यविधि बनाएंगे, इसे निष्पादित करेंगे, और फिर इसे हटा देंगे।
संग्रहित प्रक्रियाओं को संग्रहित रूप से स्कैन किया जाता है, इसलिए हमें संग्रहित प्रक्रिया बनाने के लिए संग्रह के सेल्फलिंक की आवश्यकता होगी।
Step 5 - के लिए पहली क्वेरी myfirstdb डेटाबेस और फिर के लिए MyCollection संग्रह।
किसी संग्रहीत कार्यविधि को बनाना किसी अन्य संसाधन DocumentDB में बनाने की तरह है।
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink, "SELECT * FROM
c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client.
CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client.ExecuteStoredProcedureAsync
(sproc.SelfLink); Console.WriteLine("Executed stored procedure; response = {0}", result.Response); // Delete stored procedure await client.DeleteStoredProcedureAsync(sproc.SelfLink); Console.WriteLine("Deleted stored procedure {0} ({1})", sproc.Id, sproc.ResourceId); } }
Step 6 - पहले नए संसाधन के लिए आईडी के साथ एक डेफिनिशन ऑब्जेक्ट बनाएं और फिर एक बनाएँ तरीकों पर कॉल करें DocumentClientवस्तु। संग्रहीत कार्यविधि के मामले में, परिभाषा में आईडी और वास्तविक जावास्क्रिप्ट कोड शामिल होता है जिसे आप सर्वर पर भेजना चाहते हैं।
Step 7 - बुलाओ File.ReadAllText जेएस फ़ाइल से बाहर संग्रहीत प्रक्रिया कोड निकालने के लिए।
Step 8 - डेफिनिशन ऑब्जेक्ट की बॉडी प्रॉपर्टी में स्टोर किए गए प्रक्रिया कोड को असाइन करें।
जहां तक डॉक्यूमेंटडीबी का संबंध है, हम जिस आईडी को यहां निर्दिष्ट करते हैं, परिभाषा में, संग्रहीत कार्यविधि का नाम है, चाहे हम वास्तव में जावास्क्रिप्ट फ़ंक्शन का नाम दें।
फिर भी संग्रहीत प्रक्रियाओं और अन्य सर्वर-साइड ऑब्जेक्ट बनाते समय, यह अनुशंसा की जाती है कि हम जावास्क्रिप्ट फ़ंक्शन का नाम दें और उन फ़ंक्शन नाम उस आईडी से मेल खाते हैं जो हमने दस्तावेज़डीबी के लिए परिभाषा में निर्धारित किया है।
Step 9 - बुलाओ CreateStoredProcedureAsyncमें गुजर रहा है SelfLink के लिए MyCollectionसंग्रह और संग्रहीत कार्यविधि परिभाषा। यह संग्रहीत कार्यविधि बनाता है औरResourceId यह DocumentDB उसे सौंपा गया है।
Step 10 - संग्रहित प्रक्रिया को कॉल करें। ExecuteStoredProcedureAsyncएक प्रकार का पैरामीटर लेता है जो आप संग्रहीत प्रक्रिया द्वारा लौटाए गए मान के अपेक्षित डेटा प्रकार पर सेट करते हैं, जिसे आप केवल एक ऑब्जेक्ट के रूप में निर्दिष्ट कर सकते हैं यदि आप एक गतिशील ऑब्जेक्ट वापस चाहते हैं। यह एक ऐसी वस्तु है जिसके गुण रन-टाइम पर बाध्य होंगे।
इस उदाहरण में हम जानते हैं कि हमारी संग्रहीत प्रक्रिया केवल एक स्ट्रिंग लौटा रही है और इसलिए हम कॉल करते हैं ExecuteStoredProcedureAsync<string>।
निम्नलिखित Program.cs फ़ाइल का पूर्ण कार्यान्वयन है।
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBStoreProce {
class Program {
private static void Main(string[] args) {
Task.Run(async () => {
await SimpleStoredProcDemo();
}).Wait();
}
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client
.CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})", sproc
.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client
.ExecuteStoredProcedureAsync<string>(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}",
result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
}
}जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्न आउटपुट का उत्पादन करता है।
Created stored procedure HelloWorldStoreProce (Ic8LAMEUVgACAAAAAAAAgA==)
Executed stored procedure; response = Hello, and welcome to DocumentDB!जैसा कि उपरोक्त आउटपुट में देखा गया है, प्रतिक्रिया संपत्ति में "हैलो, और डॉक्यूमेंटडीबी में आपका स्वागत है!" हमारी संग्रहीत प्रक्रिया द्वारा लौटाया गया।
डॉक्यूमेंटडीबी एसक्यूएल यूजर-डिफाइंड फंक्शंस (यूडीएफ) के लिए सहायता प्रदान करता है। UDFs केवल दूसरे प्रकार के जावास्क्रिप्ट फ़ंक्शंस हैं, जिन्हें आप लिख सकते हैं और ये काम बहुत उम्मीद के मुताबिक होंगे। आप कस्टम व्यवसाय तर्क के साथ क्वेरी भाषा का विस्तार करने के लिए यूडीएफ बना सकते हैं जिसे आप अपने प्रश्नों में संदर्भित कर सकते हैं।
इन UDF का उपयोग करके कस्टम एप्लिकेशन लॉजिक का समर्थन करने के लिए DocumentDB SQL सिंटैक्स का विस्तार किया जाता है। UDF को DocumentDB के साथ पंजीकृत किया जा सकता है और फिर SQL क्वेरी के भाग के रूप में संदर्भित किया जा सकता है।
आइए इस उदाहरण के लिए निम्नलिखित तीन दस्तावेजों पर विचार करें।
AndersenFamily दस्तावेज़ इस प्रकार है।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily दस्तावेज़ इस प्रकार है।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily दस्तावेज़ इस प्रकार है।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए एक उदाहरण देखें, जहां हम कुछ सरल यूडीएफ बनाएंगे।
निम्नलिखित का कार्यान्वयन है CreateUserDefinedFunctions।
private async static Task CreateUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create User Defined Functions ****");
Console.WriteLine();
await CreateUserDefinedFunction(client, "udfRegEx");
}हमारे पास एक udfRegEx है, और CreateUserDefinedFunction में हमें अपनी स्थानीय फ़ाइल से इसका जावास्क्रिप्ट कोड मिलता है। हम नए UDF के लिए परिभाषा ऑब्जेक्ट का निर्माण करते हैं, और CreateUserDefinedFunctionAsync को संग्रह के SelfLink और udfDefinition ऑब्जेक्ट के साथ निम्न कोड में दिखाया गया है।
private async static Task<UserDefinedFunction>
CreateUserDefinedFunction(DocumentClient client, string udfId) {
var udfBody = File.ReadAllText(@"..\..\Server\" + udfId + ".js");
var udfDefinition = new UserDefinedFunction {
Id = udfId,
Body = udfBody
};
var result = await client
.CreateUserDefinedFunctionAsync(_collection.SelfLink, udfDefinition);
var udf = result.Resource;
Console.WriteLine("Created user defined function {0}; RID: {1}",
udf.Id, udf.ResourceId);
return udf;
}हम परिणाम के संसाधन संपत्ति से नया यूडीएफ प्राप्त करते हैं और इसे वापस कॉलर को वापस कर देते हैं। मौजूदा यूडीएफ प्रदर्शित करने के लिए, निम्नलिखित का कार्यान्वयन हैViewUserDefinedFunctions। हम फोन करते हैंCreateUserDefinedFunctionQuery और हमेशा की तरह उनके माध्यम से पाश।
private static void ViewUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View UDFs ****");
Console.WriteLine();
var udfs = client
.CreateUserDefinedFunctionQuery(_collection.UserDefinedFunctionsLink)
.ToList();
foreach (var udf in udfs) {
Console.WriteLine("User defined function {0}; RID: {1}", udf.Id, udf.ResourceId);
}
}डॉक्यूमेंटडीबी एसक्यूएल सब्सट्रक्शन या नियमित अभिव्यक्ति के लिए खोज करने के लिए बिल्ट-इन फ़ंक्शन प्रदान नहीं करता है, इसलिए निम्न एक-लाइनर उस अंतराल को भरता है जो एक जावास्क्रिप्ट फ़ंक्शन है।
function udfRegEx(input, regex) {
return input.match(regex);
}पहले पैरामीटर में इनपुट स्ट्रिंग को देखते हुए, दूसरे पैरामीटर में पैटर्न मिलान स्ट्रिंग में पासिंग जावास्क्रिप्ट की अंतर्निहित नियमित अभिव्यक्ति समर्थन का उपयोग करें।match। हम उनके नाम में एंडरसन शब्द के साथ सभी दुकानों को खोजने के लिए एक विकल्प क्वेरी चला सकते हैंlastName संपत्ति।
private static void Execute_udfRegEx(DocumentClient client) {
var sql = "SELECT c.name FROM c WHERE udf.udfRegEx(c.lastName, 'Andersen') != null";
Console.WriteLine();
Console.WriteLine("Querying for Andersen");
var documents = client.CreateDocumentQuery(_collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} Andersen:", documents.Count);
foreach (var document in documents) {
Console.WriteLine("Id: {0}, Name: {1}", document.id, document.lastName);
}
}ध्यान दें कि हमें उपसर्ग के साथ हर यूडीएफ संदर्भ को अर्हता प्राप्त करनी चाहिए udf। हम बस के साथ एसक्यूएल पारित कर दियाCreateDocumentQueryकिसी भी सामान्य प्रश्न की तरह। अंत में, उपरोक्त प्रश्नों को कॉल करते हैंCreateDocumentClient टास्क
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)){
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE
c.id = 'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'Families'").AsEnumerable().First();
await CreateUserDefinedFunctions(client);
ViewUserDefinedFunctions(client);
Execute_udfRegEx(client);
}
}जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्न आउटपुट का उत्पादन करता है।
**** Create User Defined Functions ****
Created user defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
**** View UDFs ****
User defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
Querying for Andersen
Found 1 Andersen:
Id: AndersenFamily, Name: AndersenComposite Queryआपको मौजूदा प्रश्नों से डेटा गठबंधन करने में सक्षम बनाता है और फिर रिपोर्ट परिणाम पेश करने से पहले फ़िल्टर, एग्रीगेट और इतने पर आवेदन करता है, जो संयुक्त डेटा सेट को दिखाता है। समग्र क्वेरी मौजूदा प्रश्नों पर संबंधित जानकारी के कई स्तरों को प्राप्त करती है और संयुक्त डेटा को एकल और चपटा क्वेरी परिणाम के रूप में प्रस्तुत करती है।
समग्र क्वेरी का उपयोग करते हुए, आपके पास यह विकल्प भी है -
उपयोगकर्ता की विशेषता चयनों के आधार पर आवश्यक तालिकाओं और फ़ील्ड को निकालने के लिए SQL प्रूनिंग विकल्प का चयन करें।
ORDER BY और GROUP BY क्लॉस सेट करें।
एक समग्र क्वेरी के परिणाम सेट पर फ़िल्टर के रूप में WHERE क्लॉज़ सेट करें।
उपरोक्त ऑपरेटरों को अधिक शक्तिशाली प्रश्न बनाने के लिए तैयार किया जा सकता है। चूंकि दस्तावेज़डीबी नेस्टेड संग्रह का समर्थन करता है, इसलिए रचना को संक्षिप्त या नेस्टेड किया जा सकता है।
आइए इस उदाहरण के लिए निम्नलिखित दस्तावेजों पर विचार करें।
AndersenFamily दस्तावेज़ इस प्रकार है।
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily दस्तावेज़ इस प्रकार है।
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily दस्तावेज़ इस प्रकार है।
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}आइए, संक्षिप्त क्वेरी के उदाहरण पर एक नज़र डालें।
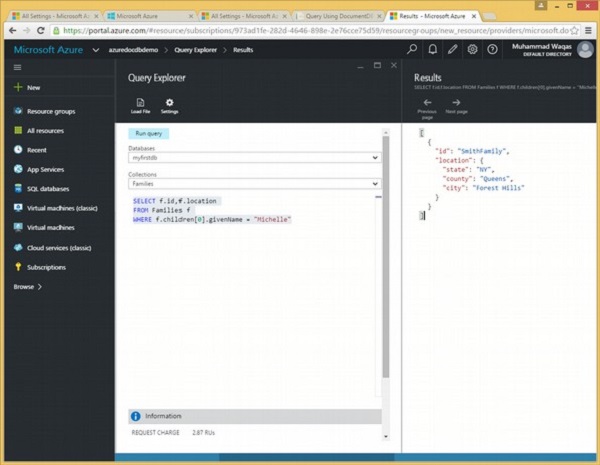
निम्नलिखित क्वेरी है जो उस परिवार की आईडी और स्थान को पुनः प्राप्त करेगी जहां पहला बच्चा है givenName मिशेल है।
SELECT f.id,f.location
FROM Families f
WHERE f.children[0].givenName = "Michelle"जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"id": "SmithFamily",
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
}
]आइए संक्षिप्त क्वेरी का एक और उदाहरण देखें।
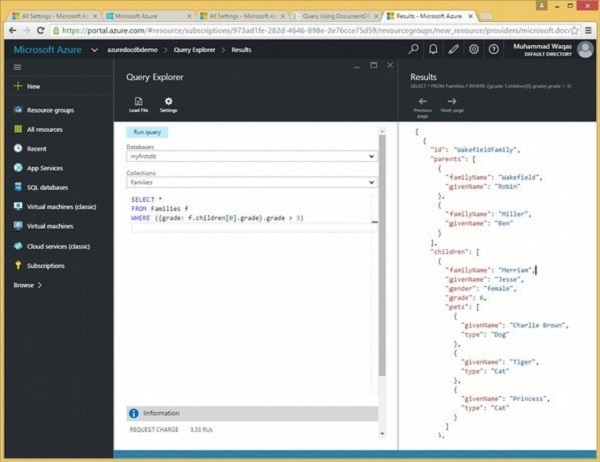
निम्नलिखित क्वेरी है जो सभी दस्तावेजों को लौटाएगी जहां पहले बच्चे का ग्रेड 3 से अधिक है।
SELECT *
FROM Families f
WHERE ({grade: f.children[0].grade}.grade > 3)जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]आइए एक नजर डालते हैं ए पर example नेस्टेड प्रश्नों का।
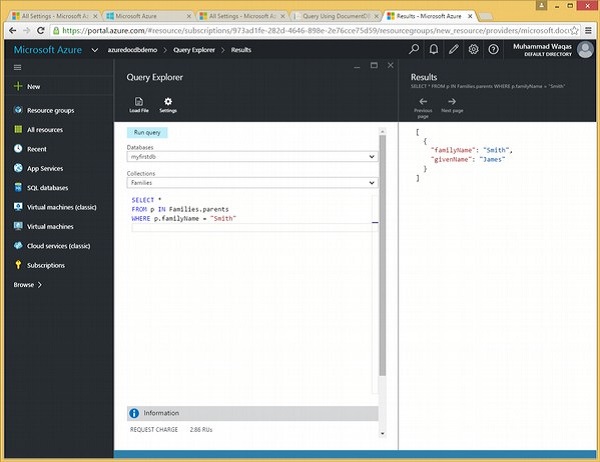
निम्नलिखित क्वेरी है जो सभी माता-पिता को पुन: व्यवस्थित करेगी और फिर दस्तावेज़ को वापस कर देगी familyName स्मिथ है।
SELECT *
FROM p IN Families.parents
WHERE p.familyName = "Smith"जब उपरोक्त क्वेरी निष्पादित होती है, तो यह निम्न आउटपुट का उत्पादन करती है।
[
{
"familyName": "Smith",
"givenName": "James"
}
]चलो गौर करते हैं another example नेस्टेड क्वेरी की।
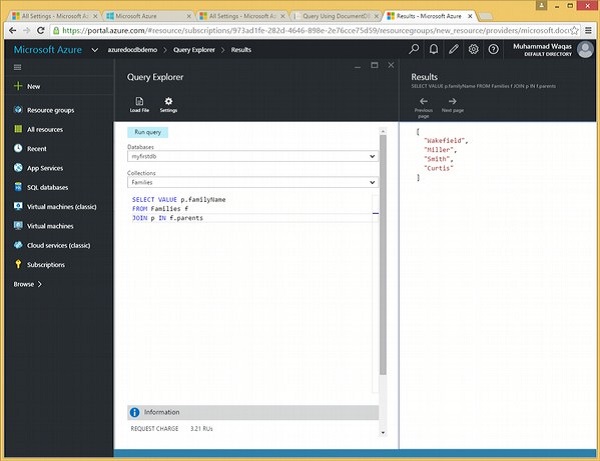
निम्नलिखित क्वेरी है जो सभी वापस आ जाएगी familyName।
SELECT VALUE p.familyName
FROM Families f
JOIN p IN f.parentsजब उपरोक्त क्वेरी निष्पादित होती है, तो वह निम्नलिखित आउटपुट का उत्पादन करती है।
[
"Wakefield",
"Miller",
"Smith",
"Curtis"
]