Gensim - वर्ड एंबेडिंग का विकास करना
अध्याय हमें Gensim में शब्द एम्बेडिंग को समझने में मदद करेगा।
वर्ड एम्बेडिंग, शब्दों और दस्तावेज़ का प्रतिनिधित्व करने के लिए दृष्टिकोण, पाठ के लिए एक सघन वेक्टर प्रतिनिधित्व है जहाँ समान अर्थ वाले शब्दों का समान प्रतिनिधित्व होता है। शब्द एम्बेड करने की कुछ विशेषताएँ निम्नलिखित हैं -
यह तकनीक का एक वर्ग है जो पूर्व-परिभाषित वेक्टर अंतरिक्ष में वास्तविक-मूल्यवान वैक्टर के रूप में व्यक्तिगत शब्दों का प्रतिनिधित्व करता है।
इस तकनीक को अक्सर DL (डीप लर्निंग) के क्षेत्र में ढकेल दिया जाता है क्योंकि हर शब्द को एक वेक्टर में मैप किया जाता है और वेक्टर मानों को उसी तरह से सीखा जाता है जैसे NN (न्यूरल नेटवर्क्स) करता है।
शब्द एम्बेडिंग तकनीक का मुख्य दृष्टिकोण हर शब्द के लिए एक सघन वितरित प्रतिनिधित्व है।
विभिन्न वर्ड एंबेडिंग मेथड्स / एल्गोरिदम
जैसा कि ऊपर चर्चा की गई है, शब्द एम्बेड करने के तरीके / एल्गोरिदम पाठ के एक कोष से वास्तविक-मूल्यवान वेक्टर प्रतिनिधित्व सीखते हैं। यह सीखने की प्रक्रिया या तो NN मॉडल के साथ डॉक्यूमेंट के वर्गीकरण जैसे कार्य का उपयोग कर सकती है या एक असुरक्षित प्रक्रिया है जैसे डॉक्यूमेंट के आँकड़े। यहां हम दो तरीकों / एल्गोरिथ्म पर चर्चा करने जा रहे हैं जिनका उपयोग पाठ से शब्द को सीखने के लिए किया जा सकता है -
Google द्वारा Word2Vec
टॉमस मिकोलोव, एट द्वारा विकसित वर्ड 2 वीईसी। अल। 2013 में Google पर, पाठ कोष से एम्बेड किए गए किसी शब्द को कुशलतापूर्वक सीखने के लिए एक सांख्यिकीय पद्धति है। यह वास्तव में एनएन आधारित शब्द प्रशिक्षण को और अधिक कुशल बनाने के लिए एक प्रतिक्रिया के रूप में विकसित किया गया है। यह शब्द एम्बेडिंग के लिए वास्तविक मानक बन गया है।
Word2Vec द्वारा शब्द एम्बेडिंग में सीखे हुए वैक्टरों के विश्लेषण के साथ-साथ शब्दों के प्रतिनिधित्व पर वेक्टर गणित की खोज शामिल है। निम्नलिखित दो अलग-अलग शिक्षण विधियाँ हैं जिनका उपयोग Word2Vec विधि के भाग के रूप में किया जा सकता है -
- CBoW (शब्दों का निरंतर थैला) मॉडल
- सतत स्किप-ग्राम मॉडल
स्टैंडफोर्ड द्वारा ग्लोव
GloVe (वर्ड प्रतिनिधि के लिए ग्लोबल वैक्टर), Word2Vec विधि का विस्तार है। यह पेनिंगटन एट अल द्वारा विकसित किया गया था। स्टैनफोर्ड में। GloVe एल्गोरिथ्म दोनों का मिश्रण है -
- एलएसए (अव्यक्त अर्थ विश्लेषण) जैसे मैट्रिक्स फैक्टराइजेशन तकनीकों के वैश्विक आंकड़े
- Word2Vec में स्थानीय संदर्भ-आधारित शिक्षा।
अगर हम इसके काम के बारे में बात करते हैं तो स्थानीय संदर्भ को परिभाषित करने के लिए एक विंडो का उपयोग करने के बजाय, GloVe पूरे पाठ कॉर्पस के आंकड़ों का उपयोग करके एक स्पष्ट शब्द सह-घटना मैट्रिक्स का निर्माण करता है।
Word2Vec एंबेडिंग का विकास करना
यहां, हम Gensim का उपयोग करके Word2Vec एम्बेडिंग विकसित करेंगे। Word2Vec मॉडल के साथ काम करने के लिए, Gensim हमें प्रदान करता हैWord2Vec वर्ग जो आयात किया जा सकता है models.word2vec। इसके कार्यान्वयन के लिए, word2vec को बहुत सारे पाठ की आवश्यकता होती है जैसे संपूर्ण अमेज़ॅन समीक्षा कॉर्पस। लेकिन यहां, हम इस सिद्धांत को स्मॉल-इन मेमोरी टेक्स्ट पर लागू करेंगे।
कार्यान्वयन उदाहरण
सबसे पहले हमें gensim.models से Word2Vec वर्ग को निम्नानुसार आयात करना होगा -
from gensim.models import Word2Vecअगला, हमें प्रशिक्षण डेटा को परिभाषित करने की आवश्यकता है। बड़ी टेक्स्ट फ़ाइल लेने के बजाय, हम इस प्रिंसिपल को लागू करने के लिए कुछ वाक्यों का उपयोग कर रहे हैं।
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]एक बार प्रशिक्षण डेटा प्रदान करने के बाद, हमें मॉडल को प्रशिक्षित करने की आवश्यकता है। इसे निम्नानुसार किया जा सकता है -
model = Word2Vec(sentences, min_count=1)हम मॉडल को संक्षेप में निम्नानुसार कर सकते हैं -;
print(model)हम निम्नानुसार शब्दावली को संक्षेप में प्रस्तुत कर सकते हैं -
words = list(model.wv.vocab)
print(words)अगला, आइए एक शब्द के लिए वेक्टर तक पहुंचें। हम इसे 'ट्यूटोरियल' शब्द के लिए कर रहे हैं।
print(model['tutorial'])अगला, हमें मॉडल को बचाने की आवश्यकता है -
model.save('model.bin')अगला, हमें मॉडल लोड करने की आवश्यकता है -
new_model = Word2Vec.load('model.bin')अंत में, सहेजे गए मॉडल को निम्नानुसार प्रिंट करें -
print(new_model)पूर्ण कार्यान्वयन उदाहरण
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)उत्पादन
Word2Vec(vocab=20, size=100, alpha=0.025)
[
'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint',
'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are',
'implementing', 'word2vec', 'learn', 'full'
]
[
-2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03
-1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03
-1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03
3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03
-2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03
-4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03
9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03
4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03
1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04
4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03
4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03
6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03
-2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03
7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03
4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03
-3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03
3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04
-3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03
-3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03
2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03
-3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03
1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03
3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04
3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03
-1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03
]
Word2Vec(vocab=20, size=100, alpha=0.025)विज़ुअलाइज़िंग वर्ड एंबेडिंग
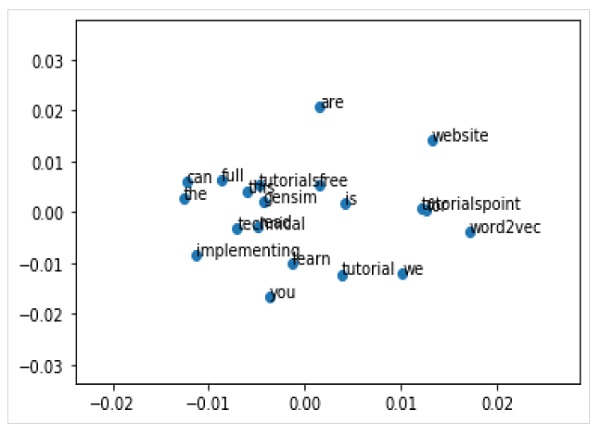
हम विज़ुअलाइज़ेशन के साथ एम्बेडिंग शब्द का भी पता लगा सकते हैं। यह उच्च-आयामी शब्द वैक्टर को 2-डी भूखंडों को कम करने के लिए एक शास्त्रीय प्रक्षेपण विधि (पीसीए की तरह) का उपयोग करके किया जा सकता है। एक बार कम हो जाने पर, हम उन्हें ग्राफ पर प्लॉट कर सकते हैं।
पीसीए का उपयोग करके वर्ड वेक्टर्स को प्लॉट करना
सबसे पहले, हमें एक प्रशिक्षित मॉडल से सभी वैक्टरों को पुनः प्राप्त करने की आवश्यकता है -
Z = model[model.wv.vocab]अगला, हमें पीसीए वर्ग का उपयोग करके शब्द वैक्टरों का 2-डी पीसीए मॉडल बनाना होगा -
pca = PCA(n_components=2)
result = pca.fit_transform(Z)अब, हम matplotlib का उपयोग करके परिणामी प्रक्षेपण की साजिश कर सकते हैं -
Pyplot.scatter(result[:,0],result[:,1])हम शब्दों के साथ ग्राफ पर बिंदुओं को भी एनोटेट कर सकते हैं। निम्न के रूप में matplotlib का उपयोग करके परिणामी प्रक्षेपण प्लॉट करें -
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))पूर्ण कार्यान्वयन उदाहरण
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()उत्पादन