IMS DB - सेकेंडरी इंडेक्सिंग
सेकेंडरी इंडेक्सिंग का उपयोग तब किया जाता है जब हम किसी डेटाबेस को पूरी तरह से कुंजी का उपयोग किए बिना या जब हम अनुक्रम प्राथमिक क्षेत्रों का उपयोग नहीं करना चाहते हैं।
सूचकांक सूचक खंड
DL / I सूचक को अलग डेटाबेस में अनुक्रमित डेटाबेस के खंडों में संग्रहीत करता है। इंडेक्स पॉइंटर सेगमेंट एकमात्र प्रकार का सेकेंडरी इंडेक्स है। इसमें दो भाग होते हैं -
- उपसर्ग तत्व
- डेटा तत्व
उपसर्ग तत्व
इंडेक्स पॉइंटर सेगमेंट के उपसर्ग वाले हिस्से में इंडेक्स टार्गेट सेगमेंट का एक पॉइंटर होता है। सूचकांक लक्ष्य खंड वह खंड है जो द्वितीयक सूचकांक का उपयोग करके सुलभ है।
डेटा तत्व
डेटा तत्व में अनुक्रमित डेटाबेस में सेगमेंट से कुंजी मूल्य है, जिस पर इंडेक्स बनाया गया है। इसे इंडेक्स सोर्स सेगमेंट के रूप में भी जाना जाता है।
माध्यमिक अनुक्रमण के बारे में ध्यान देने योग्य मुख्य बातें इस प्रकार हैं -
सूचकांक स्रोत खंड और लक्ष्य स्रोत खंड समान होने की आवश्यकता नहीं है।
जब हम एक द्वितीयक सूचकांक स्थापित करते हैं, तो यह स्वचालित रूप से DL / I द्वारा बनाए रखा जाता है।
DBA कई पहुँच पथ के अनुसार कई माध्यमिक अनुक्रमितों को परिभाषित करता है। ये द्वितीयक सूचकांक एक अलग सूचकांक डेटाबेस में संग्रहीत होते हैं।
हमें अधिक माध्यमिक अनुक्रम नहीं बनाने चाहिए, क्योंकि वे DL / I पर अतिरिक्त प्रसंस्करण ओवरहेड लगाते हैं।
माध्यमिक कुंजी
नोट करने के लिए अंक -
इंडेक्स सोर्स सेगमेंट में जिस फील्ड पर सेकेंडरी इंडेक्स बनाया जाता है उसे सेकेंडरी की कहा जाता है।
किसी भी क्षेत्र को द्वितीयक कुंजी के रूप में उपयोग किया जा सकता है। यह खंड अनुक्रम फ़ील्ड नहीं होना चाहिए।
इंडेक्स सोर्स सेगमेंट के भीतर सिंगल कीज़ का कोई भी संयोजन हो सकता है।
द्वितीयक प्रमुख मानों को विशिष्ट नहीं होना चाहिए।
माध्यमिक डेटा संरचनाएँ
नोट करने के लिए अंक -
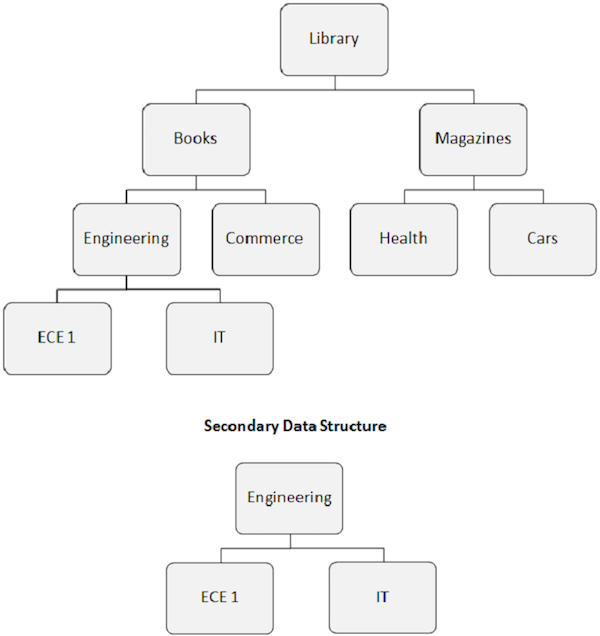
जब हम एक द्वितीयक सूचकांक बनाते हैं, तो डेटाबेस की स्पष्ट पदानुक्रमित संरचना भी बदल जाती है।
सूचकांक लक्ष्य खंड स्पष्ट मूल खंड बन जाता है। जैसा कि निम्नलिखित छवि में दिखाया गया है, इंजीनियरिंग खंड रूट सेगमेंट बन जाता है, भले ही वह रूट सेगमेंट न हो।
सेकेंडरी इंडेक्स के कारण होने वाले डेटाबेस स्ट्रक्चर की पुनर्व्यवस्था को सेकेंडरी डेटा स्ट्रक्चर के रूप में जाना जाता है।
माध्यमिक डेटा संरचनाएं डिस्क पर मौजूद मुख्य भौतिक डेटाबेस संरचना में कोई बदलाव नहीं करती हैं। यह एप्लिकेशन प्रोग्राम के सामने डेटाबेस संरचना को बदलने का एक तरीका है।
स्वतंत्र और संचालक
नोट करने के लिए अंक -
जब कोई AND (* या &) ऑपरेटर सेकंडरी इंडेक्स के साथ उपयोग किया जाता है, तो उसे एक निर्भर और ऑपरेटर के रूप में जाना जाता है।
एक स्वतंत्र और (#) हमें योग्यता निर्दिष्ट करने की अनुमति देता है जो एक आश्रित और के साथ असंभव होगा।
इस ऑपरेटर का उपयोग केवल द्वितीयक सूचकांक के लिए किया जा सकता है, जहां सूचकांक स्रोत खंड सूचकांक लक्ष्य खंड पर निर्भर है।
हम एक एसएसए को एक स्वतंत्र के साथ कोड कर सकते हैं और यह निर्दिष्ट करने के लिए कि लक्ष्य खंड की एक घटना को दो या अधिक निर्भर क्षेत्रों में फ़ील्ड के आधार पर संसाधित किया जा सकता है।
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.विरल सीक्वेंसिंग
नोट करने के लिए अंक -
स्पार्स अनुक्रमण को स्पार्स अनुक्रमण के रूप में भी जाना जाता है। हम कुछ इंडेक्स सोर्स सेगमेंट को सेकेंडरी इंडेक्स डेटाबेस के साथ स्पार्स सीक्वेंसिंग का उपयोग करके इंडेक्स से हटा सकते हैं।
प्रदर्शन में सुधार के लिए स्पार्स अनुक्रमण का उपयोग किया जाता है। जब सूचकांक स्रोत खंड की कुछ घटनाओं का उपयोग नहीं किया जाता है, तो हम इसे हटा सकते हैं।
डीएल / मैं एक दमन मूल्य या एक दमन दिनचर्या या दोनों का उपयोग करता है यह निर्धारित करने के लिए कि क्या एक खंड को अनुक्रमित किया जाना चाहिए।
यदि इंडेक्स सोर्स सेगमेंट में अनुक्रम फ़ील्ड का मान दमन मूल्य से मेल खाता है, तो कोई इंडेक्स संबंध स्थापित नहीं होता है।
दमन दिनचर्या एक उपयोगकर्ता-लिखित कार्यक्रम है जो खंड का मूल्यांकन करता है और निर्धारित करता है कि इसे अनुक्रमित किया जाना चाहिए या नहीं।
जब स्पार्स इंडेक्सिंग का उपयोग किया जाता है, तो इसके कार्यों को DL / I द्वारा नियंत्रित किया जाता है। हमें आवेदन कार्यक्रम में इसके लिए विशेष प्रावधान करने की आवश्यकता नहीं है।
DBDGEN आवश्यकताएँ
जैसा कि पहले के मॉड्यूल में चर्चा की गई है, DBDGEN का उपयोग DBD बनाने के लिए किया जाता है। जब हम सेकंडरी इंडेक्स बनाते हैं, तो दो डेटाबेस शामिल होते हैं। एक डीबीए को अनुक्रमित डेटाबेस और द्वितीयक अनुक्रमित डेटाबेस के बीच संबंध बनाने के लिए दो DBDGEN का उपयोग करके दो DBDs बनाने की आवश्यकता होती है।
PSBGEN आवश्यकताएँ
एक डेटाबेस के लिए द्वितीयक सूचकांक बनाने के बाद, डीबीए को पीएसबी बनाने की आवश्यकता है। कार्यक्रम के लिए PSBGEN PSB मैक्रो के PROCSEQ पैरामीटर पर डेटाबेस के लिए उचित प्रसंस्करण अनुक्रम को निर्दिष्ट करता है। PROCSEQ पैरामीटर के लिए, DBA माध्यमिक इंडेक्स डेटाबेस के लिए DBD नाम को कोड करता है।