समय - अन्वेषण वर्कफ़्लो
यदि आप वर्कफ़्लो में नोड्स की जाँच करते हैं, तो आप देख सकते हैं कि इसमें निम्नलिखित शामिल हैं -
फ़ाइल रीडर,
रंग प्रबंधक
Partitioning
निर्णय ट्री लर्नर
निर्णय ट्री प्रिडिक्टर
Score
इंटरएक्टिव टेबल
स्कैटर प्लॉट
Statistics
इनमें आसानी से देखा जा सकता है Outline जैसा कि यहाँ दिखाया गया है -

प्रत्येक नोड वर्कफ़्लो में एक विशिष्ट कार्यक्षमता प्रदान करता है। हम अब वांछित कार्यक्षमता को पूरा करने के लिए इन नोड्स को कॉन्फ़िगर करने का तरीका देखेंगे। कृपया ध्यान दें कि हम केवल उन नोड्स पर चर्चा करेंगे जो वर्कफ़्लो की खोज के वर्तमान संदर्भ में हमारे लिए प्रासंगिक हैं।
फाइल रीडर
फाइल रीडर नोड को नीचे स्क्रीनशॉट में दर्शाया गया है -

विंडो के शीर्ष पर कुछ विवरण है जो वर्कफ़्लो के निर्माता द्वारा प्रदान किया गया है। यह बताता है कि यह नोड वयस्क डेटा सेट पढ़ता है। फ़ाइल का नाम हैadult.csvजैसा कि नोड प्रतीक के नीचे विवरण से देखा गया है। File Reader दो आउटपुट हैं - एक को जाता है Color Manager नोड और अन्य एक को जाता है Statistics नोड।
अगर आप राइट क्लिक करते हैं File Manager, एक पॉपअप मेनू निम्नानुसार दिखाई देगा -

Configureमेनू विकल्प नोड कॉन्फ़िगरेशन के लिए अनुमति देता है। Executeमेनू नोड चलाता है। ध्यान दें कि यदि नोड पहले ही चल चुका है और यदि यह हरे रंग की स्थिति में है, तो यह मेनू अक्षम है। इसके अलावा, की उपस्थिति पर ध्यान देंEdit Note Descriptionमेनू विकल्प। यह आपको अपने नोड के लिए विवरण लिखने की अनुमति देता है।
अब, चयन करें Configure मेनू विकल्प, यह स्क्रीन को स्क्रीन से दिखाता है।

जब आप इस नोड को निष्पादित करते हैं, तो डेटा को मेमोरी में लोड किया जाएगा। संपूर्ण डेटा लोडिंग प्रोग्राम कोड उपयोगकर्ता से छिपा हुआ है। अब आप ऐसे नोड्स की उपयोगिता की सराहना कर सकते हैं - कोई कोडिंग की आवश्यकता नहीं है।
हमारा अगला नोड है Color Manager।
रंग प्रबंधक
को चुनिए Color Managerनोड पर क्लिक करके इसके कॉन्फ़िगरेशन में जाएं। एक रंग सेटिंग्स संवाद दिखाई देगा। को चुनिएincome ड्रॉपडाउन सूची से कॉलम।
आपकी स्क्रीन निम्नलिखित की तरह दिखाई देगी -

दो बाधाओं की उपस्थिति पर ध्यान दें। यदि आमदनी 50K से कम है, तो डेटापॉइंट हरे रंग का अधिग्रहण करेगा और यदि यह अधिक है तो यह लाल रंग का हो जाता है। जब हम बाद में इस अध्याय में तितर बितर भूखंड को देखते हैं तो आप डेटा बिंदु मैपिंग देखेंगे।
विभाजन
मशीन लर्निंग में, हम आम तौर पर पूरे उपलब्ध डेटा को दो भागों में विभाजित करते हैं। बड़े हिस्से का उपयोग मॉडल के प्रशिक्षण में किया जाता है, जबकि छोटे हिस्से का उपयोग परीक्षण के लिए किया जाता है। डेटा को विभाजित करने के लिए विभिन्न रणनीतियों का उपयोग किया जाता है।
वांछित विभाजन को परिभाषित करने के लिए, दाईं ओर क्लिक करें Partitioning नोड और चयन करें Configureविकल्प। आपको निम्न स्क्रीन दिखाई देगी -

मामले में, सिस्टम मॉडेलर ने उपयोग किया है Relative(%) मोड और डेटा 80:20 अनुपात में विभाजित है। विभाजन करते समय, डेटा बिंदुओं को यादृच्छिक रूप से उठाया जाता है। यह सुनिश्चित करता है कि आपका परीक्षण डेटा पक्षपाती न हो। रैखिक नमूनाकरण के मामले में, परीक्षण के लिए उपयोग किए गए शेष 20% डेटा प्रशिक्षण डेटा का सही प्रतिनिधित्व नहीं कर सकते हैं क्योंकि यह आपके संग्रह के दौरान पूरी तरह से पक्षपाती हो सकता है।
यदि आप सुनिश्चित हैं कि डेटा संग्रह के दौरान, यादृच्छिकता की गारंटी है, तो आप रैखिक नमूने का चयन कर सकते हैं। एक बार जब आपका डेटा मॉडल के प्रशिक्षण के लिए तैयार हो जाता है, तो उसे अगले नोड पर खिलाएं, जो कि हैDecision Tree Learner।
निर्णय ट्री लर्नर
Decision Tree Learnerनाम के अनुसार नोड प्रशिक्षण डेटा का उपयोग करता है और एक मॉडल बनाता है। इस नोड की कॉन्फ़िगरेशन सेटिंग देखें, जो नीचे स्क्रीनशॉट में दर्शाया गया है -

जैसा कि आप देखते हैं Class है income। इस प्रकार वृक्ष आय स्तंभ के आधार पर बनाया जाएगा और यही हम इस मॉडल में हासिल करने की कोशिश कर रहे हैं। हम 50K से अधिक या कम आय वाले लोगों का अलगाव चाहते हैं।
यह नोड सफलतापूर्वक चलने के बाद, आपका मॉडल परीक्षण के लिए तैयार होगा।
निर्णय ट्री प्रिडिक्टर
डिसीजन ट्री प्रिडिक्टर नोड विकसित मॉडल को परीक्षण डेटा सेट पर लागू करता है और मॉडल की भविष्यवाणियों को जोड़ता है।

भविष्यवक्ता का आउटपुट दो अलग-अलग नोड्स को खिलाया जाता है - Scorer तथा Scatter Plot। अगला, हम भविष्यवाणी के आउटपुट की जांच करेंगे।
गणक
यह नोड उत्पन्न करता है confusion matrix। इसे देखने के लिए, नोड पर राइट क्लिक करें। आपको निम्न पॉपअप मेनू दिखाई देगा -

दबाएं View: Confusion Matrix मेनू विकल्प और मैट्रिक्स एक अलग विंडो में पॉप अप होगा जैसा कि यहां स्क्रीनशॉट में दिखाया गया है -
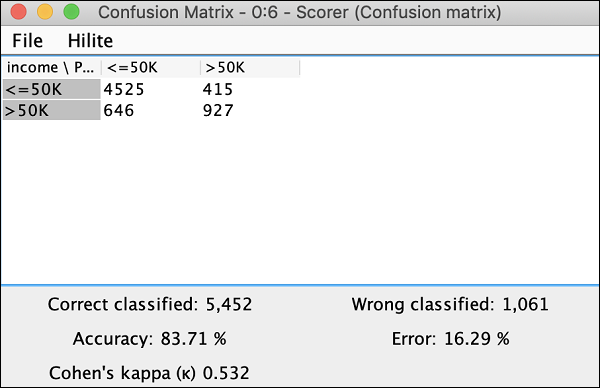
यह इंगित करता है कि हमारे विकसित मॉडल की सटीकता 83.71% है। यदि आप इससे संतुष्ट नहीं हैं, तो आप मॉडल निर्माण में अन्य मापदंडों के साथ खेल सकते हैं, विशेष रूप से, आप अपने डेटा को फिर से देखना और शुद्ध करना पसंद कर सकते हैं।
स्कैटर प्लॉट
डेटा वितरण के स्कैटर प्लॉट को देखने के लिए, राइट क्लिक करें Scatter Plot नोड और मेनू विकल्प का चयन करें Interactive View: Scatter Plot। आप निम्नलिखित कथानक देखेंगे -

भूखंड 50K की सीमा के आधार पर अलग-अलग आय वर्ग के लोगों को दो अलग-अलग रंग के डॉट्स - लाल और नीले रंग में देता है। ये हमारे रंग में सेट थेColor Managerनोड। वितरण एक्स-अक्ष पर प्लॉट किए गए आयु के सापेक्ष है। आप नोड के कॉन्फ़िगरेशन को बदलकर x- अक्ष के लिए एक अलग सुविधा का चयन कर सकते हैं।
कॉन्फ़िगरेशन डायलॉग यहाँ दिखाया गया है जहाँ हमने चुना है marital-status एक्स-अक्ष के लिए एक सुविधा के रूप में।
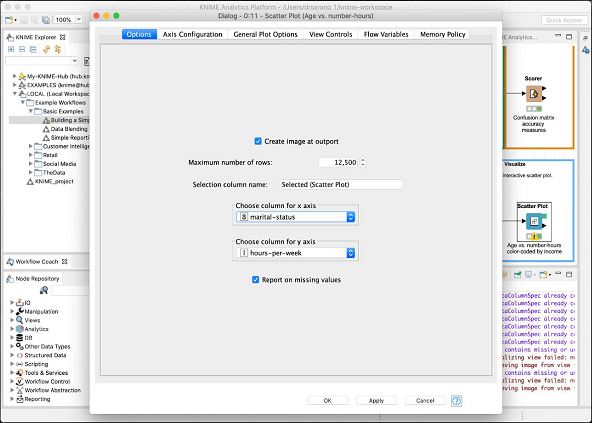
यह KNIME द्वारा प्रदान किए गए पूर्वनिर्धारित मॉडल पर हमारी चर्चा को पूरा करता है। हम आपको अपने स्व-अध्ययन के लिए मॉडल में अन्य दो नोड्स (सांख्यिकी और इंटरएक्टिव टेबल) लेने का सुझाव देते हैं।
आइए अब हम ट्यूटोरियल के सबसे महत्वपूर्ण भाग पर चलते हैं - अपना स्वयं का मॉडल बनाते हैं।