महावत - मशीन लर्निंग
Apache Mahout एक उच्च स्केलेबल मशीन लर्निंग लाइब्रेरी है जो डेवलपर्स को अनुकूलित एल्गोरिदम का उपयोग करने में सक्षम बनाती है। महतो लोकप्रिय मशीन सीखने की तकनीक जैसे सिफारिश, वर्गीकरण और क्लस्टरिंग लागू करते हैं। इसलिए, इससे पहले कि हम आगे बढ़ें, मशीन लर्निंग पर एक संक्षिप्त खंड रखना समझदारी है।
मशीन लर्निंग क्या है?
मशीन लर्निंग विज्ञान की एक शाखा है जो सिस्टम को इस तरह से प्रोग्रामिंग करती है कि वे अनुभव के साथ स्वचालित रूप से सीखते हैं और सुधारते हैं। यहां, सीखने का मतलब इनपुट डेटा को पहचानना और समझना और आपूर्ति किए गए डेटा के आधार पर बुद्धिमानी से निर्णय लेना है।
सभी संभावित आदानों के आधार पर सभी निर्णयों को पूरा करना बहुत मुश्किल है। इस समस्या से निपटने के लिए, एल्गोरिदम विकसित किए जाते हैं। ये एल्गोरिदम विशिष्ट आंकड़ों और अतीत के अनुभव से सांख्यिकी, संभाव्यता सिद्धांत, तर्क, दहनशील अनुकूलन, खोज, सुदृढीकरण सीखने और नियंत्रण सिद्धांत के ज्ञान का निर्माण करते हैं।
विकसित एल्गोरिदम विभिन्न अनुप्रयोगों का आधार बनाते हैं जैसे:
- दृष्टि प्रसंस्करण
- भाषा प्रसंस्करण
- पूर्वानुमान (जैसे, शेयर बाजार के रुझान)
- पैटर्न मान्यता
- Games
- डेटा माइनिंग
- विशेषज्ञ प्रणालियां
- Robotics
मशीन लर्निंग एक विशाल क्षेत्र है और यह इस ट्यूटोरियल के दायरे से काफी परे है ताकि इसकी सभी विशेषताओं को कवर किया जा सके। मशीन लर्निंग तकनीक को लागू करने के कई तरीके हैं, हालांकि सबसे अधिक उपयोग किए जाने वाले हैंsupervised तथा unsupervised learning।
पर्यवेक्षित अध्ययन
उपलब्ध प्रशिक्षण डेटा से एक फ़ंक्शन सीखने के साथ पर्यवेक्षित शिक्षण सौदे। एक पर्यवेक्षित शिक्षण एल्गोरिथ्म प्रशिक्षण डेटा का विश्लेषण करता है और एक अनुमानित फ़ंक्शन का उत्पादन करता है, जिसका उपयोग नए उदाहरणों को मैप करने के लिए किया जा सकता है। पर्यवेक्षित शिक्षण के सामान्य उदाहरणों में शामिल हैं:
- ई-मेल को स्पैम के रूप में वर्गीकृत करना,
- उनकी सामग्री के आधार पर वेबपृष्ठों को लेबल करना, और
- आवाज की पहचान।
तंत्रिका नेटवर्क, सपोर्ट वेक्टर मशीनें (एसवीएम) और नैवे बेस क्लासिफायर जैसे कई पर्यवेक्षित शिक्षण एल्गोरिदम हैं। महतो नेव बेयस क्लासिफायर लागू करता है।
अनसुचित शिक्षा
बिना प्रशिक्षण के बिना किसी प्रशिक्षण के बिना किसी पूर्वनिर्धारित डेटासेट के अनलिस्टेड डेटा की समझ बनती है। उपलब्ध डेटा का विश्लेषण करने और पैटर्न और रुझानों की तलाश के लिए अनसुर्विलाइज्ड लर्निंग एक बेहद शक्तिशाली उपकरण है। यह आमतौर पर तार्किक समूहों में समान इनपुट को क्लस्टर करने के लिए उपयोग किया जाता है। अनुपयोगी शिक्षा के लिए सामान्य दृष्टिकोणों में शामिल हैं:
- k-means
- आत्म-व्यवस्थित मानचित्र, और
- पदानुक्रमित क्लस्टरिंग
सिफ़ारिश करना
सिफारिश एक लोकप्रिय तकनीक है जो पिछली खरीद, क्लिक और रेटिंग जैसी उपयोगकर्ता जानकारी के आधार पर करीबी सिफारिशें प्रदान करती है।
अमेज़ॅन इस तकनीक का उपयोग उन अनुशंसित वस्तुओं की एक सूची प्रदर्शित करने के लिए करता है जिन्हें आप रुचि रखते हैं, अपने पिछले कार्यों से जानकारी खींच सकते हैं। सिफारिशकर्ता इंजन हैं जो उपयोगकर्ता के व्यवहार को पकड़ने के लिए अमेज़ॅन के पीछे काम करते हैं और आपके पहले के कार्यों के आधार पर चयनित वस्तुओं की सिफारिश करते हैं।
फेसबुक "आप जिन लोगों की सूची जान सकते हैं" की पहचान करने और उनकी सिफारिश करने के लिए सिफारिशकर्ता तकनीक का उपयोग करता है।

वर्गीकरण
वर्गीकरण, के रूप में भी जाना जाता है categorization, एक मशीन लर्निंग तकनीक है जो ज्ञात डेटा का उपयोग करती है यह निर्धारित करने के लिए कि नए डेटा को मौजूदा श्रेणियों के सेट में कैसे वर्गीकृत किया जाना चाहिए। वर्गीकरण पर्यवेक्षित शिक्षण का एक रूप है।
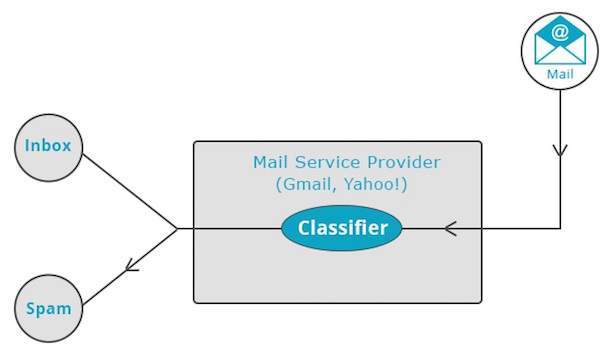
याहू जैसे मेल सेवा प्रदाता! और जीमेल इस तकनीक का उपयोग यह तय करने के लिए करता है कि क्या एक नए मेल को स्पैम के रूप में वर्गीकृत किया जाना चाहिए। वर्गीकरण एल्गोरिदम खुद को कुछ मेल को स्पैम के रूप में चिह्नित करने की उपयोगकर्ता की आदतों का विश्लेषण करके प्रशिक्षित करता है। उसके आधार पर, क्लासिफायरियर तय करता है कि भविष्य का मेल आपके इनबॉक्स में या स्पैम फ़ोल्डर में जमा होना चाहिए या नहीं।
आईट्यून्स एप्लिकेशन प्लेलिस्ट को तैयार करने के लिए वर्गीकरण का उपयोग करता है।
क्लस्टरिंग
क्लस्टरिंग का उपयोग सामान्य विशेषताओं के आधार पर समान डेटा के समूह या क्लस्टर बनाने के लिए किया जाता है। क्लस्टरिंग एक प्रकार का अप्रशिक्षित अधिगम है।
Google और Yahoo जैसे सर्च इंजन! समान विशेषताओं वाले समूह डेटा के लिए क्लस्टरिंग तकनीकों का उपयोग करें।
समाचार समूह संबंधित विषयों पर आधारित विभिन्न लेखों को समूहीकृत करने के लिए क्लस्टरिंग तकनीकों का उपयोग करते हैं।
क्लस्टरिंग इंजन पूरी तरह से इनपुट डेटा के माध्यम से जाता है और डेटा की विशेषताओं के आधार पर, यह तय करेगा कि इसे किस समूह में रखा जाना चाहिए। निम्नलिखित उदाहरण पर एक नज़र डालें।
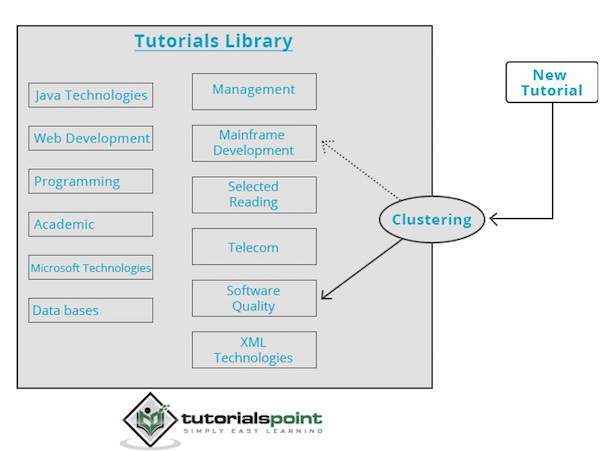
ट्यूटोरियल के हमारे पुस्तकालय में विभिन्न विषयों पर विषय हैं। जब हम TutorialsPoint में एक नया ट्यूटोरियल प्राप्त करते हैं, तो यह एक क्लस्टरिंग इंजन द्वारा संसाधित होता है जो निर्णय लेता है, इसकी सामग्री के आधार पर, जहां इसे समूहीकृत किया जाना चाहिए।