वेब स्क्रैपिंग की वैधता
पायथन के साथ, हम किसी भी वेबसाइट या वेब पेज के विशेष तत्वों को परिमार्जन कर सकते हैं लेकिन क्या आपको इस बात का कोई अंदाजा है कि यह कानूनी है या नहीं? किसी भी वेबसाइट को स्क्रैप करने से पहले हमें वेब स्क्रैपिंग की वैधता के बारे में जानना होगा। यह अध्याय वेब स्क्रैपिंग की वैधता से संबंधित अवधारणाओं की व्याख्या करेगा।
परिचय
आमतौर पर, यदि आप व्यक्तिगत उपयोग के लिए स्क्रैप किए गए डेटा का उपयोग करने जा रहे हैं, तो कोई समस्या नहीं हो सकती है। लेकिन अगर आप उस डेटा को पुनर्प्रकाशित करने जा रहे हैं, तो वही करने से पहले आपको स्वामी से डाउनलोड का अनुरोध करना चाहिए या नीतियों के बारे में कुछ पृष्ठभूमि अनुसंधान करना चाहिए और साथ ही उस डेटा के बारे में भी जो आप परिमार्जन करने जा रहे हैं।
स्क्रैपिंग से पहले आवश्यक अनुसंधान
यदि आप इससे डेटा खुरचने के लिए किसी वेबसाइट को लक्षित कर रहे हैं, तो हमें इसके पैमाने और संरचना को समझने की आवश्यकता है। निम्नलिखित कुछ फाइलें हैं, जिन्हें वेब स्क्रैपिंग शुरू करने से पहले हमें विश्लेषण करने की आवश्यकता है।
Robots.txt का विश्लेषण करना
वास्तव में अधिकांश प्रकाशक प्रोग्रामर को कुछ हद तक अपनी वेबसाइटों को क्रॉल करने की अनुमति देते हैं। दूसरे अर्थ में, प्रकाशक चाहते हैं कि वेबसाइटों के विशिष्ट भाग क्रॉल किए जाएं। इसे परिभाषित करने के लिए, वेबसाइटों को यह बताने के लिए कुछ नियम रखने चाहिए कि कौन से हिस्से क्रॉल किए जा सकते हैं और कौन से नहीं। ऐसे नियमों को एक फ़ाइल में परिभाषित किया गया हैrobots.txt।
robots.txtमानव पठनीय फ़ाइल का उपयोग वेबसाइट के उन हिस्सों की पहचान करने के लिए किया जाता है जिन्हें क्रॉलर को अनुमति दी जाती है और साथ ही उसे परिमार्जन करने की अनुमति नहीं होती है। Robots.txt फ़ाइल का कोई मानक प्रारूप नहीं है और वेबसाइट के प्रकाशक अपनी आवश्यकताओं के अनुसार संशोधन कर सकते हैं। हम उस वेबसाइट के url के बाद स्लैश और robots.txt प्रदान करके किसी विशेष वेबसाइट के लिए robots.txt फ़ाइल की जांच कर सकते हैं। उदाहरण के लिए, यदि हम इसे Google.com के लिए जांचना चाहते हैं, तो हमें टाइप करना होगाhttps://www.google.com/robots.txt और हमें कुछ इस प्रकार मिलेगा -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..कुछ सामान्य नियम जो किसी वेबसाइट के robots.txt फ़ाइल में परिभाषित किए गए हैं वे इस प्रकार हैं -
User-agent: BadCrawler
Disallow: /उपरोक्त नियम का अर्थ है कि robots.txt फ़ाइल क्रॉलर से पूछती है BadCrawler उपयोगकर्ता एजेंट अपनी वेबसाइट को क्रॉल करने के लिए नहीं।
User-agent: *
Crawl-delay: 5
Disallow: /trapउपरोक्त नियम का अर्थ है कि रोबो.टैक्स फ़ाइल ओवरलोडिंग सर्वर से बचने के लिए सभी उपयोगकर्ता-एजेंटों के डाउनलोड अनुरोधों के बीच 5 सेकंड के लिए क्रॉलर को विलंबित करती है। /trapलिंक दुर्भावनापूर्ण क्रॉलर को ब्लॉक करने का प्रयास करेगा जो अस्वीकृत लिंक का पालन करते हैं। कई और नियम हैं जिन्हें वेबसाइट के प्रकाशक द्वारा उनकी आवश्यकताओं के अनुसार परिभाषित किया जा सकता है। उनमें से कुछ यहाँ चर्चा की गई हैं -
साइटमैप फ़ाइलों का विश्लेषण
यदि आप अद्यतन जानकारी के लिए किसी वेबसाइट को क्रॉल करना चाहते हैं तो आपको क्या करना चाहिए? आप उस अद्यतन जानकारी को प्राप्त करने के लिए हर वेब पेज को क्रॉल करेंगे, लेकिन इससे उस विशेष वेबसाइट के सर्वर ट्रैफ़िक में वृद्धि होगी। यही कारण है कि वेबसाइटें क्रॉलरों को हर वेब पेज को क्रॉल करने की आवश्यकता के बिना अपडेट करने वाली सामग्री का पता लगाने के लिए साइटमैप फाइलें प्रदान करती हैं। साइटमैप मानक पर परिभाषित किया गया हैhttp://www.sitemaps.org/protocol.html।
साइटमैप फ़ाइल की सामग्री
निम्नलिखित साइटमैप फ़ाइल की सामग्री है https://www.microsoft.com/robots.txt जो कि robots.txt फ़ाइल में खोजा गया है -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlउपरोक्त सामग्री से पता चलता है कि साइटमैप वेबसाइट पर URL को सूचीबद्ध करता है और आगे एक वेबमास्टर को अंतिम अद्यतन तिथि, सामग्री के परिवर्तन, URL के संबंध में URL के महत्व और प्रत्येक URL के बारे में आदि जैसी कुछ अतिरिक्त जानकारी निर्दिष्ट करने की अनुमति देता है।
वेबसाइट का आकार क्या है?
क्या एक वेबसाइट का आकार, यानी एक वेबसाइट के वेब पेजों की संख्या हमारे क्रॉल करने के तरीके को प्रभावित करती है? निश्चित रूप से हां। क्योंकि यदि हमारे पास क्रॉल करने के लिए वेब पेजों की संख्या कम है, तो दक्षता एक गंभीर मुद्दा नहीं होगा, लेकिन मान लीजिए कि अगर हमारी वेबसाइट में लाखों वेब पेज हैं, उदाहरण के लिए Microsoft.com, तो प्रत्येक वेब पेज को क्रमिक रूप से डाउनलोड करने में कई महीने लगेंगे और तब दक्षता एक गंभीर चिंता का विषय होगा।
वेबसाइट के आकार की जाँच करना
Google के क्रॉलर के परिणाम के आकार की जाँच करके, हम एक वेबसाइट के आकार का अनुमान लगा सकते हैं। कीवर्ड का उपयोग करके हमारे परिणाम को फ़िल्टर किया जा सकता हैsiteGoogle खोज करते समय। उदाहरण के लिए, के आकार का अनुमान लगानाhttps://authoraditiagarwal.com/ नीचे दिया गया है -
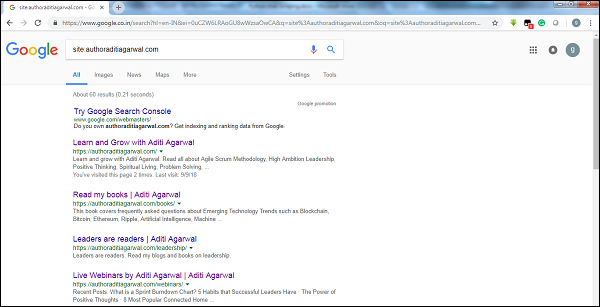
आप देख सकते हैं कि लगभग 60 परिणाम हैं, जिसका अर्थ है कि यह एक बड़ी वेबसाइट नहीं है और क्रॉलिंग दक्षता मुद्दे का नेतृत्व नहीं करेगा।
वेबसाइट किस तकनीक का उपयोग करती है?
एक और महत्वपूर्ण सवाल यह है कि क्या वेबसाइट द्वारा उपयोग की जाने वाली तकनीक हमारे क्रॉल करने के तरीके को प्रभावित करती है? हाँ, यह प्रभावित करता है। लेकिन हम एक वेबसाइट द्वारा उपयोग की जाने वाली तकनीक के बारे में कैसे जांच कर सकते हैं? एक पायथन लाइब्रेरी है जिसका नाम हैbuiltwith जिसकी मदद से हम किसी वेबसाइट द्वारा इस्तेमाल की जाने वाली तकनीक के बारे में पता लगा सकते हैं।
उदाहरण
इस उदाहरण में हम वेबसाइट द्वारा उपयोग की जाने वाली तकनीक की जांच करने जा रहे हैं https://authoraditiagarwal.com अजगर पुस्तकालय की मदद से builtwith। लेकिन इस पुस्तकालय का उपयोग करने से पहले, हमें इसे निम्नानुसार स्थापित करना होगा -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3अब, कोड की सरल रेखा का पालन करने की मदद से हम किसी विशेष वेबसाइट द्वारा उपयोग की जाने वाली तकनीक की जांच कर सकते हैं -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}वेबसाइट का मालिक कौन है?
वेबसाइट का मालिक इसलिए भी मायने रखता है क्योंकि अगर मालिक को क्रॉलर को ब्लॉक करने के लिए जाना जाता है, तो वेबसाइट पर डेटा को स्क्रैप करते समय क्रॉलर्स को सावधान रहना चाहिए। नाम का एक प्रोटोकॉल हैWhois जिसकी मदद से हम वेबसाइट के मालिक के बारे में पता लगा सकते हैं।
उदाहरण
इस उदाहरण में हम वेबसाइट के मालिक की जाँच करने जा रहे हैं, जो microsoft.com को Whois की सहायता से कहते हैं । लेकिन इस पुस्तकालय का उपयोग करने से पहले, हमें इसे निम्नानुसार स्थापित करना होगा -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0अब, कोड की सरल रेखा का पालन करने की मदद से हम किसी विशेष वेबसाइट द्वारा उपयोग की जाने वाली तकनीक की जांच कर सकते हैं -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}