पायथन क्विक गाइड
पायथन एक उच्च-स्तरीय, व्याख्यात्मक, संवादात्मक और वस्तु-उन्मुख स्क्रिप्टिंग भाषा है। पायथन को अत्यधिक पठनीय बनाया गया है। यह अक्सर अंग्रेजी कीवर्ड का उपयोग करता है जहां अन्य भाषाएं विराम चिह्न का उपयोग करती हैं, और इसमें अन्य भाषाओं की तुलना में कम वाक्यात्मक निर्माण होते हैं।
Python is Interpreted- इंटरप्रेटर द्वारा पायथन को रनटाइम पर प्रोसेस किया जाता है। इसे निष्पादित करने से पहले आपको अपने कार्यक्रम को संकलित करने की आवश्यकता नहीं है। यह PERL और PHP के समान है।
Python is Interactive - आप वास्तव में पायथन प्रॉम्प्ट पर बैठ सकते हैं और अपने प्रोग्राम को लिखने के लिए दुभाषिया के साथ सीधे बातचीत कर सकते हैं।
Python is Object-Oriented - पायथन ऑब्जेक्ट-ओरिएंटेड शैली या प्रोग्रामिंग की तकनीक का समर्थन करता है जो वस्तुओं के भीतर कोड को एन्क्रिप्ट करता है।
Python is a Beginner's Language - पायथन शुरुआती स्तर के प्रोग्रामर के लिए एक बेहतरीन भाषा है और सरल टेक्स्ट प्रोसेसिंग से लेकर डब्ल्यूडब्ल्यूडब्ल्यू ब्राउजर्स तक के कई तरह के अनुप्रयोगों के विकास में सहायता करता है।
अजगर का इतिहास
पायथन को अस्सी के दशक के अंत में और नीदरलैंड में नेशनल रिसर्च इंस्टीट्यूट फॉर मैथेमेटिक्स एंड कंप्यूटर साइंस में नब्बे के दशक के शुरुआती दिनों में गुइडो वैन रोसुम द्वारा विकसित किया गया था।
अजगर कई अन्य भाषाओं से लिया गया है, जिनमें एबीसी, मोडुला -3, सी, सी ++, अल्गोल -68, स्मॉलटॉक और यूनिक्स शेल और अन्य स्क्रिप्टिंग भाषाएं शामिल हैं।
अजगर को कॉपीराइट किया गया है। पर्ल की तरह, पायथन सोर्स कोड अब जीएनयू जनरल पब्लिक लाइसेंस (जीपीएल) के तहत उपलब्ध है।
पायथन को अब संस्थान में एक कोर डेवलपमेंट टीम द्वारा बनाए रखा गया है, हालांकि गुइडो वैन रोसुम अभी भी अपनी प्रगति को निर्देशित करने में एक महत्वपूर्ण भूमिका निभाता है।
पायथन फीचर्स
पायथन की विशेषताओं में शामिल हैं -
Easy-to-learn- पायथन में कुछ कीवर्ड, सरल संरचना और एक स्पष्ट रूप से परिभाषित वाक्यविन्यास है। इससे छात्र जल्दी से भाषा चुन सकता है।
Easy-to-read - पायथन कोड अधिक स्पष्ट रूप से परिभाषित और आंखों के लिए दृश्यमान है।
Easy-to-maintain - पायथन का सोर्स कोड काफी आसान है।
A broad standard library - लाइब्रेरी का पाइथन बल्क यूनिक्स, विंडोज और मैकिंटोश पर बहुत पोर्टेबल और क्रॉस-प्लेटफॉर्म संगत है।
Interactive Mode - पायथन में एक इंटरैक्टिव मोड के लिए समर्थन है जो कोड के स्निपेट्स के इंटरैक्टिव परीक्षण और डीबगिंग की अनुमति देता है।
Portable - अजगर विभिन्न प्रकार के हार्डवेयर प्लेटफार्मों पर चल सकता है और सभी प्लेटफार्मों पर एक ही इंटरफ़ेस है।
Extendable- आप पायथॉन दुभाषिया में निम्न-स्तरीय मॉड्यूल जोड़ सकते हैं। ये मॉड्यूल प्रोग्रामर को अधिक कुशल होने के लिए अपने टूल को जोड़ने या कस्टमाइज़ करने में सक्षम बनाते हैं।
Databases - पायथन सभी प्रमुख वाणिज्यिक डेटाबेस को इंटरफेस प्रदान करता है।
GUI Programming - पायथन जीयूआई अनुप्रयोगों का समर्थन करता है जो विंडोज एमएफसी, मैकिंटोश और यूनिक्स के एक्स विंडो सिस्टम जैसे कई सिस्टम कॉल, लाइब्रेरी और विंडोज सिस्टम को बनाया और पोर्ट किया जा सकता है।
Scalable - पायथन शेल स्क्रिप्टिंग की तुलना में बड़े कार्यक्रमों के लिए एक बेहतर संरचना और समर्थन प्रदान करता है।
उपर्युक्त सुविधाओं के अलावा, पायथन में अच्छी विशेषताओं की एक बड़ी सूची है, कुछ नीचे सूचीबद्ध हैं -
यह कार्यात्मक और संरचित प्रोग्रामिंग विधियों के साथ-साथ OOP का समर्थन करता है।
इसका उपयोग स्क्रिप्टिंग भाषा के रूप में किया जा सकता है या बड़े अनुप्रयोगों के निर्माण के लिए बाइट-कोड के लिए संकलित किया जा सकता है।
यह बहुत ही उच्च-स्तरीय गतिशील डेटा प्रकार प्रदान करता है और गतिशील प्रकार की जाँच का समर्थन करता है।
यह स्वचालित कचरा संग्रहण का समर्थन करता है।
इसे C, C ++, COM, ActiveX, CORBA, और Java के साथ आसानी से एकीकृत किया जा सकता है।
पायथन लिनक्स और मैक ओएस एक्स सहित विभिन्न प्रकार के प्लेटफार्मों पर उपलब्ध है। आइए समझते हैं कि हमारे पायथन पर्यावरण को कैसे स्थापित किया जाए।
स्थानीय पर्यावरण सेटअप
एक टर्मिनल विंडो खोलें और यह पता लगाने के लिए "पायथन" टाइप करें कि क्या यह पहले से स्थापित है और कौन सा संस्करण स्थापित है।
- यूनिक्स (Solaris, Linux, FreeBSD, AIX, HP / UX, SunOS, IRIX, आदि)
- विन 9x / NT / 2000
- मैकिंटोश (इंटेल, पीपीसी, 68K)
- OS/2
- DOS (कई संस्करण)
- PalmOS
- नोकिया मोबाइल फोन
- विंडोज सीई
- एकोर्न / आरआईएससी ओएस
- BeOS
- Amiga
- VMS/OpenVMS
- QNX
- VxWorks
- Psion
- पायथन को जावा और .NET वर्चुअल मशीनों में भी पोर्ट किया गया है
पायथन हो रही है
पायथन की आधिकारिक वेबसाइट पर सबसे अद्यतित और वर्तमान स्रोत कोड, बायनेरिज़, प्रलेखन, समाचार, आदि उपलब्ध है। https://www.python.org/
आप Python प्रलेखन को डाउनलोड कर सकते हैं https://www.python.org/doc/। प्रलेखन HTML, पीडीएफ और पोस्टस्क्रिप्ट स्वरूपों में उपलब्ध है।
पायथन स्थापित करना
अजगर वितरण विभिन्न प्रकार के प्लेटफार्मों के लिए उपलब्ध है। आपको अपने प्लेटफ़ॉर्म के लिए लागू केवल बाइनरी कोड को डाउनलोड करने और पायथन को स्थापित करने की आवश्यकता है।
यदि आपके प्लेटफ़ॉर्म के लिए बाइनरी कोड उपलब्ध नहीं है, तो आपको मैन्युअल रूप से सोर्स कोड को संकलित करने के लिए C कंपाइलर की आवश्यकता होगी। स्रोत कोड को संकलित करना उन विशेषताओं के विकल्प के संदर्भ में अधिक लचीलापन प्रदान करता है जिनकी आपको अपनी स्थापना में आवश्यकता होती है।
यहाँ विभिन्न प्लेटफार्मों पर अजगर स्थापित करने का एक त्वरित अवलोकन है -
यूनिक्स और लिनक्स इंस्टॉलेशन
यहां यूनिक्स / लिनक्स मशीन पर पायथन को स्थापित करने के सरल उपाय दिए गए हैं।
एक वेब ब्राउज़र खोलें और पर जाएं https://www.python.org/downloads/।
यूनिक्स / लिनक्स के लिए उपलब्ध ज़िप्ड सोर्स कोड डाउनलोड करने के लिए लिंक का पालन करें।
फ़ाइलों को डाउनलोड करें और निकालें।
यदि आप कुछ विकल्पों को अनुकूलित करना चाहते हैं, तो मॉड्यूल / सेटअप फ़ाइल का संपादन ।
रन ./configure स्क्रिप्ट
make
स्थापित करें
यह पायथन को मानक स्थान / usr / स्थानीय / बिन पर और इसके पुस्तकालयों को / usr / स्थानीय / lib / pythonXX पर स्थापित करता है जहां XX Python का संस्करण है।
विंडोज इंस्टॉलेशन
यहां विंडोज मशीन पर पायथन को स्थापित करने के चरण दिए गए हैं।
एक वेब ब्राउज़र खोलें और पर जाएं https://www.python.org/downloads/।
Windows इंस्टॉलर के लिए लिंक का पालन करें python-XYZ.msi फ़ाइल जहां XYZ संस्करण है जिसे आपको इंस्टॉल करने की आवश्यकता है।
इस इंस्टॉलर python-XYZ.msi का उपयोग करने के लिए , विंडोज सिस्टम को Microsoft इंस्टालर 2.0 का समर्थन करना चाहिए। अपने स्थानीय मशीन में इंस्टॉलर फ़ाइल को सहेजें और फिर यह पता लगाने के लिए इसे चलाएं कि क्या आपकी मशीन एमएसआई का समर्थन करती है।
डाउनलोड की गई फ़ाइल चलाएँ। यह पायथन स्थापित विज़ार्ड लाता है, जो वास्तव में उपयोग करना आसान है। बस डिफ़ॉल्ट सेटिंग्स स्वीकार करें, इंस्टॉल पूरा होने तक प्रतीक्षा करें, और आप कर रहे हैं।
लबादा स्थापना
हाल ही में मैक पायथन स्थापित किए गए के साथ आते हैं, लेकिन यह कई वर्षों से पुराना हो सकता है। देखhttp://www.python.org/download/mac/मैक पर विकास का समर्थन करने के लिए अतिरिक्त उपकरणों के साथ वर्तमान संस्करण प्राप्त करने के निर्देश के लिए। मैक ओएस एक्स 10.3 (2003 में जारी) से पहले पुराने मैक ओएस के लिए, मैक पाइथन उपलब्ध है।
जैक जाॅनसन इसे बनाए रखते हैं और आप उनकी वेबसाइट पर पूरे दस्तावेज तक पहुंच सकते हैं - http://www.cwi.nl/~jack/macpython.html। आप मैक ओएस इंस्टॉलेशन के लिए पूर्ण स्थापना विवरण पा सकते हैं।
पथ की स्थापना
प्रोग्राम और अन्य निष्पादन योग्य फाइलें कई निर्देशिकाओं में हो सकती हैं, इसलिए ऑपरेटिंग सिस्टम एक खोज पथ प्रदान करता है जो उन निर्देशिकाओं को सूचीबद्ध करता है जो ओएस निष्पादनयोग्य के लिए खोजता है।
पथ को एक पर्यावरण चर में संग्रहीत किया जाता है, जो ऑपरेटिंग सिस्टम द्वारा बनाए गए एक नामित स्ट्रिंग है। इस चर में कमांड शेल और अन्य कार्यक्रमों के लिए उपलब्ध जानकारी है।
path वेरिएबल को विंडोज में PATH या पथ में नाम दिया गया है (Unix केस सेंसिटिव है; विंडोज नहीं है)।
मैक ओएस में, इंस्टॉलर पथ विवरण को संभालता है। किसी विशेष निर्देशिका से अजगर दुभाषिया को आमंत्रित करने के लिए, आपको अपने पथ पर पायथन निर्देशिका को जोड़ना होगा।
यूनिक्स / लिनक्स पर सेटिंग पथ
यूनिक्स में एक विशेष सत्र के लिए पथ निर्देशिका को जोड़ने के लिए -
In the csh shell - setenv PATH "$ PATH: / usr / local / bin / python" टाइप करें और एंटर दबाएं।
In the bash shell (Linux) - टाइप करें PATH = "$ PATH: / usr / local / bin / python" और एंटर दबाएं।
In the sh or ksh shell - PATH = "$ PATH: / usr / local / bin / python" टाइप करें और एंटर दबाएं।
Note - / usr / स्थानीय / बिन / अजगर अजगर की निर्देशिका का मार्ग है
विंडोज पर सेटिंग पथ
विंडोज में एक विशेष सत्र के लिए पथ निर्देशिका को जोड़ने के लिए -
At the command prompt - टाइप पथ% पथ%; C: \ Python और Enter दबाएँ।
Note - C: \ Python पायथन डायरेक्टरी का मार्ग है
अजगर पर्यावरण चर
यहां महत्वपूर्ण पर्यावरण चर हैं, जिन्हें पायथन द्वारा पहचाना जा सकता है -
| अनु क्रमांक। | चर और विवरण |
|---|---|
| 1 | PYTHONPATH इसमें PATH के समान भूमिका है। यह चर पायथन इंटरप्रेटर को बताता है जहां एक प्रोग्राम में आयातित मॉड्यूल फ़ाइलों का पता लगाने के लिए। इसमें पायथन स्रोत पुस्तकालय निर्देशिका और पायथन स्रोत कोड वाली निर्देशिकाएं शामिल होनी चाहिए। PYTHONPATH को कभी-कभी पायथन इंस्टॉलर द्वारा पूर्व निर्धारित किया जाता है। |
| 2 | PYTHONSTARTUP इसमें पायथन सोर्स कोड वाले इनिशियलाइज़ेशन फ़ाइल का पथ शामिल है। यह हर बार जब आप दुभाषिया शुरू करते हैं तब निष्पादित किया जाता है। इसे यूनिक्स में .pythonrc.py नाम दिया गया है और इसमें कमांड्स हैं जो उपयोगिताओं को लोड करते हैं या PYTHONPATH को संशोधित करते हैं। |
| 3 | PYTHONCASEOK इसका उपयोग विंडोज में आयात के बयान में पहला केस-असंवेदनशील मैच खोजने के लिए पायथन को निर्देश देने के लिए किया जाता है। इसे सक्रिय करने के लिए किसी भी मान पर इस चर को सेट करें। |
| 4 | PYTHONHOME यह एक वैकल्पिक मॉड्यूल खोज पथ है। स्विचिंग मॉड्यूल पुस्तकालयों को आसान बनाने के लिए इसे आमतौर पर PYTHONSTARTUP या PYTHONPATH निर्देशिका में एम्बेड किया जाता है। |
पायथन चला रहा है
पायथन शुरू करने के तीन अलग-अलग तरीके हैं -
इंटरएक्टिव दुभाषिया
आप यूनिक्स, डॉस, या किसी अन्य प्रणाली से पायथन शुरू कर सकते हैं जो आपको कमांड-लाइन दुभाषिया या शेल विंडो प्रदान करता है।
दर्ज python कमांड लाइन।
इंटरैक्टिव दुभाषिया में तुरंत कोडिंग शुरू करें।
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSयहाँ सभी उपलब्ध कमांड लाइन विकल्पों की सूची दी गई है -
| अनु क्रमांक। | विकल्प और विवरण |
|---|---|
| 1 | -d यह डिबग आउटपुट प्रदान करता है। |
| 2 | -O यह अनुकूलित बायटेकोड उत्पन्न करता है (जिसके परिणामस्वरूप .pyo फ़ाइलें)। |
| 3 | -S स्टार्टअप पर पायथन रास्तों की तलाश के लिए आयात साइट न चलाएं। |
| 4 | -v वर्बोज़ आउटपुट (आयात विवरणों पर विस्तृत ट्रेस)। |
| 5 | -X क्लास-आधारित अंतर्निहित अपवादों को अक्षम करें (बस स्ट्रिंग्स का उपयोग करें); संस्करण 1.6 के साथ अप्रचलित। |
| 6 | -c cmd cmd स्ट्रिंग के रूप में भेजा गया पायथन स्क्रिप्ट चलाएं |
| 7 | file पायथन स्क्रिप्ट दी गई फ़ाइल से चलाएँ |
कमांड-लाइन से स्क्रिप्ट
आपके आवेदन पर दुभाषिया को आमंत्रित करके एक पायथन स्क्रिप्ट को कमांड लाइन पर निष्पादित किया जा सकता है, निम्नानुसार -
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSNote - सुनिश्चित करें कि फ़ाइल अनुमति मोड निष्पादन की अनुमति देता है।
समन्वित विकास पर्यावरण
यदि आप अपने सिस्टम पर एक GUI अनुप्रयोग है जो Python का समर्थन करता है, तो आप एक ग्राफिकल यूजर इंटरफेस (GUI) वातावरण से Python चला सकते हैं।
Unix - पायलटन के लिए IDLE बहुत पहला यूनिक्स IDE है।
Windows - PythonWin Python के लिए पहला विंडोज इंटरफ़ेस है और एक GUI के साथ एक IDE है।
Macintosh - IDLE IDE के साथ अजगर का मैकिंटोश संस्करण मुख्य वेबसाइट से उपलब्ध है, जो मैकबिनल या बिनहैकेड फाइलों के रूप में डाउनलोड करने योग्य है।
यदि आप पर्यावरण को ठीक से स्थापित करने में सक्षम नहीं हैं, तो आप अपने सिस्टम व्यवस्थापक की मदद ले सकते हैं। सुनिश्चित करें कि पायथन वातावरण ठीक से स्थापित हो और पूरी तरह से ठीक काम कर रहा हो।
Note - बाद के अध्यायों में दिए गए सभी उदाहरणों को लिनक्स के CentOS स्वाद पर उपलब्ध पायथन 2.4.3 संस्करण के साथ निष्पादित किया गया है।
हमने पहले ही पायथन प्रोग्रामिंग वातावरण ऑनलाइन स्थापित कर दिया है, ताकि आप एक ही समय में सभी उपलब्ध उदाहरणों को निष्पादित कर सकें जब आप सिद्धांत सीख रहे हैं। किसी भी उदाहरण को संशोधित करने और इसे ऑनलाइन निष्पादित करने के लिए स्वतंत्र महसूस करें।
पायथन भाषा में पर्ल, सी और जावा में कई समानताएं हैं। हालाँकि, भाषाओं के बीच कुछ निश्चित अंतर हैं।
पहला पायथन प्रोग्राम
आइए हम प्रोग्रामिंग के विभिन्न तरीकों में कार्यक्रमों को निष्पादित करें।
इंटरएक्टिव मोड प्रोग्रामिंग
एक स्क्रिप्ट फ़ाइल को एक पैरामीटर के रूप में पारित किए बिना दुभाषिया को आमंत्रित करना निम्नलिखित संकेत लाता है -
$ python
Python 2.4.3 (#1, Nov 11 2010, 13:34:43)
[GCC 4.1.2 20080704 (Red Hat 4.1.2-48)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>निम्नलिखित पाठ को पायथन प्रॉम्प्ट पर टाइप करें और Enter दबाएं -
>>> print "Hello, Python!"यदि आप पायथन का नया संस्करण चला रहे हैं, तो आपको कोष्ठक के साथ प्रिंट स्टेटमेंट का उपयोग करना होगा print ("Hello, Python!");। हालांकि अजगर संस्करण 2.4.3 में, यह निम्नलिखित परिणाम पैदा करता है -
Hello, Python!स्क्रिप्ट मोड प्रोग्रामिंग
स्क्रिप्ट पैरामीटर के साथ दुभाषिया को आमंत्रित करना स्क्रिप्ट का निष्पादन शुरू करता है और स्क्रिप्ट समाप्त होने तक जारी रहता है। जब स्क्रिप्ट समाप्त हो जाती है, तो दुभाषिया सक्रिय नहीं होता है।
आइए हम एक स्क्रिप्ट में एक साधारण पायथन प्रोग्राम लिखते हैं। पायथन फाइलों में विस्तार है.py। निम्नलिखित स्रोत कोड को एक टेस्ट-सी फ़ाइल में टाइप करें -
print "Hello, Python!"हम मानते हैं कि आपके पास पैथ वेरिएबल में पाइथन इंटरप्रेटर सेट है। अब, इस कार्यक्रम को इस प्रकार चलाने की कोशिश करें -
$ python test.pyयह निम्न परिणाम उत्पन्न करता है -
Hello, Python!आइए हम पायथन स्क्रिप्ट को निष्पादित करने का एक और तरीका आज़माते हैं। यहाँ संशोधित test.py फ़ाइल है -
#!/usr/bin/python
print "Hello, Python!"हम मानते हैं कि आपके पास / usr / बिन निर्देशिका में पायथन इंटरप्रेटर उपलब्ध है। अब, इस कार्यक्रम को इस प्रकार चलाने की कोशिश करें -
$ chmod +x test.py # This is to make file executable
$./test.pyयह निम्न परिणाम उत्पन्न करता है -
Hello, Python!पायथन पहचानकर्ता
एक पायथन पहचानकर्ता एक चर, फ़ंक्शन, वर्ग, मॉड्यूल या अन्य ऑब्जेक्ट की पहचान करने के लिए उपयोग किया जाने वाला नाम है। एक पहचानकर्ता एक अक्षर से शुरू होता है Z या z या एक अंडरस्कोर (_) जिसके बाद शून्य या अधिक अक्षर, अंडरस्कोर और अंक (0 से 9) आते हैं।
पायथन पहचान के भीतर @, $, और% जैसे विराम चिह्न वर्णों की अनुमति नहीं देता है। पायथन एक केस संवेदी प्रोग्रामिंग लैंग्वेज है। इस प्रकार,Manpower तथा manpower पायथन में दो अलग-अलग पहचानकर्ता हैं।
यहाँ पायथन पहचानकर्ताओं के लिए नामकरण परंपराएँ हैं -
कक्षा के नाम एक बड़े अक्षर से शुरू होते हैं। अन्य सभी पहचानकर्ता लोअरकेस अक्षर से शुरू होते हैं।
एक एकल प्रमुख अंडरस्कोर के साथ एक पहचानकर्ता शुरू करना दर्शाता है कि पहचानकर्ता निजी है।
दो प्रमुख अंडरस्कोर के साथ एक पहचानकर्ता शुरू करना एक दृढ़ता से निजी पहचानकर्ता को इंगित करता है।
यदि पहचानकर्ता दो अनुगामी अंडरस्कोर के साथ भी समाप्त होता है, तो पहचानकर्ता एक भाषा-परिभाषित विशेष नाम है।
सुरक्षित शब्द
निम्न सूची पायथन कीवर्ड दिखाती है। ये आरक्षित शब्द हैं और आप इन्हें निरंतर या परिवर्तनशील या किसी अन्य पहचानकर्ता के नाम के रूप में उपयोग नहीं कर सकते हैं। सभी पायथन कीवर्ड में केवल निचले अक्षर होते हैं।
| तथा | कार्यकारी | नहीं |
| ज़ोर | आखिरकार | या |
| टूटना | के लिये | उत्तीर्ण करना |
| कक्षा | से | प्रिंट |
| जारी रखें | वैश्विक | बढ़ाने |
| डीईएफ़ | अगर | वापसी |
| डेल | आयात | प्रयत्न |
| elif | में | जबकि |
| अन्य | है | साथ में |
| के सिवाय | लैम्ब्डा | प्राप्ति |
लाइन्स और इंडेंटेशन
पायथन वर्ग और फ़ंक्शन परिभाषाओं या प्रवाह नियंत्रण के लिए कोड के ब्लॉक को इंगित करने के लिए कोई ब्रेसिज़ प्रदान नहीं करता है। कोड के खंडों को लाइन इंडेंटेशन द्वारा दर्शाया जाता है, जिसे सख्ती से लागू किया जाता है।
इंडेंटेशन में रिक्त स्थान की संख्या परिवर्तनशील है, लेकिन ब्लॉक के भीतर सभी कथनों को समान मात्रा में इंडेंट किया जाना चाहिए। उदाहरण के लिए -
if True:
print "True"
else:
print "False"हालाँकि, निम्न ब्लॉक एक त्रुटि उत्पन्न करता है -
if True:
print "Answer"
print "True"
else:
print "Answer"
print "False"इस प्रकार, पायथन में समान संख्या में रिक्त स्थानों के साथ सभी निरंतर रेखाएं एक ब्लॉक का निर्माण करेंगी। निम्नलिखित उदाहरण के विभिन्न कथन ब्लॉक हैं -
Note- इस समय तर्क को समझने की कोशिश न करें। बस सुनिश्चित करें कि आपने विभिन्न ब्लॉकों को समझ लिया है, भले ही वे ब्रेसिज़ के बिना हों।
#!/usr/bin/python
import sys
try:
# open file stream
file = open(file_name, "w")
except IOError:
print "There was an error writing to", file_name
sys.exit()
print "Enter '", file_finish,
print "' When finished"
while file_text != file_finish:
file_text = raw_input("Enter text: ")
if file_text == file_finish:
# close the file
file.close
break
file.write(file_text)
file.write("\n")
file.close()
file_name = raw_input("Enter filename: ")
if len(file_name) == 0:
print "Next time please enter something"
sys.exit()
try:
file = open(file_name, "r")
except IOError:
print "There was an error reading file"
sys.exit()
file_text = file.read()
file.close()
print file_textमल्टी-लाइन स्टेटमेंट
पायथन में बयान आम तौर पर एक नई लाइन के साथ समाप्त होते हैं। पाइथन, हालांकि, रेखा निरंतरता चरित्र (\) के उपयोग की अनुमति देता है ताकि यह दर्शाया जा सके कि रेखा जारी रहनी चाहिए। उदाहरण के लिए -
total = item_one + \
item_two + \
item_three[], {}, या () कोष्ठक के भीतर निहित विवरणों को पंक्ति निरंतरता वर्ण का उपयोग करने की आवश्यकता नहीं है। उदाहरण के लिए -
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']पायथन में उद्धरण
पायथन स्ट्रिंग स्ट्रिंग को दर्शाने के लिए सिंगल ('), डबल (") और ट्रिपल (' '' या" "") को स्वीकार करता है, जब तक कि एक ही प्रकार का उद्धरण शुरू होता है और स्ट्रिंग को समाप्त करता है।
कई पंक्तियों में स्ट्रिंग को स्पैन करने के लिए ट्रिपल कोट्स का उपयोग किया जाता है। उदाहरण के लिए, सभी निम्नलिखित कानूनी हैं -
word = 'word'
sentence = "This is a sentence."
paragraph = """This is a paragraph. It is
made up of multiple lines and sentences."""पायथन में टिप्पणियाँ
एक हैश संकेत (#) जो एक स्ट्रिंग शाब्दिक के अंदर नहीं है, एक टिप्पणी शुरू करता है। शारीरिक रेखा के # और अंत तक सभी वर्ण टिप्पणी का हिस्सा हैं और पायथन दुभाषिया उन्हें अनदेखा करते हैं।
#!/usr/bin/python
# First comment
print "Hello, Python!" # second commentयह निम्न परिणाम उत्पन्न करता है -
Hello, Python!आप एक बयान या अभिव्यक्ति के बाद उसी लाइन पर एक टिप्पणी टाइप कर सकते हैं -
name = "Madisetti" # This is again commentआप कई पंक्तियों को निम्नानुसार टिप्पणी कर सकते हैं -
# This is a comment.
# This is a comment, too.
# This is a comment, too.
# I said that already.खाली लाइनों का उपयोग करना
केवल व्हॉट्सएप युक्त एक लाइन, संभवतः एक टिप्पणी के साथ, एक रिक्त रेखा के रूप में जानी जाती है और पायथन पूरी तरह से इसे अनदेखा करता है।
एक इंटरएक्टिव इंटरप्रेटर सेशन में, आपको मल्टीलाइन स्टेटमेंट को समाप्त करने के लिए एक खाली भौतिक रेखा दर्ज करनी चाहिए।
उपयोगकर्ता की प्रतीक्षा कर रहा है
कार्यक्रम की निम्न पंक्ति शीघ्र प्रदर्शित करती है, कथन "बाहर निकलने के लिए Enter कुंजी दबाएं", और उपयोगकर्ता द्वारा ले जाने के लिए इंतजार कर रहा है -
#!/usr/bin/python
raw_input("\n\nPress the enter key to exit.")यहां, वास्तविक लाइन प्रदर्शित करने से पहले दो नई लाइनें बनाने के लिए "\ n \ n" का उपयोग किया जाता है। एक बार जब उपयोगकर्ता कुंजी दबाता है, तो कार्यक्रम समाप्त होता है। उपयोगकर्ता द्वारा किसी एप्लिकेशन के साथ किए जाने तक कंसोल विंडो को खुला रखने के लिए यह एक अच्छी ट्रिक है।
एक लाइन पर कई कथन
अर्धविराम (;) दिए गए सिंगल लाइन पर कई स्टेटमेंट देता है कि न तो स्टेटमेंट एक नया कोड ब्लॉक शुरू करता है। यहाँ अर्धविराम का उपयोग कर एक नमूना लिया गया है -
import sys; x = 'foo'; sys.stdout.write(x + '\n')सूट के रूप में कई बयान समूह
व्यक्तिगत बयानों का एक समूह, जो एक एकल कोड ब्लॉक बनाते हैं, कहलाते हैं suitesअजगर में। कम्पाउंड या जटिल कथन, जैसे कि, जबकि, डीआईएफ, और क्लास को हेडर लाइन और एक सूट की आवश्यकता होती है।
हेडर लाइन्स स्टेटमेंट (कीवर्ड के साथ) शुरू करते हैं और कॉलन (:) के साथ समाप्त होते हैं और इसके बाद एक या एक से अधिक लाइनें होती हैं जो सूट बनाती हैं। उदाहरण के लिए -
if expression :
suite
elif expression :
suite
else :
suiteकमांड लाइन तर्क
उन्हें कैसे चलाया जाना चाहिए, इसके बारे में कुछ बुनियादी जानकारी प्रदान करने के लिए कई कार्यक्रम चलाए जा सकते हैं। पायथन आपको -h के साथ ऐसा करने में सक्षम बनाता है -
$ python -h
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser (also PYTHONDEBUG=x)
-E : ignore environment variables (such as PYTHONPATH)
-h : print this help message and exit
[ etc. ]आप अपनी स्क्रिप्ट को इस तरह से भी प्रोग्राम कर सकते हैं कि उसे विभिन्न विकल्पों को स्वीकार करना चाहिए। कमांड लाइन तर्क एक उन्नत विषय है और आपको पायथन अवधारणाओं के बाकी हिस्सों से गुजरने के बाद थोड़ा अध्ययन करना चाहिए।
वेरिएबल्स मूल्यों को संग्रहीत करने के लिए आरक्षित मेमोरी स्थानों के अलावा कुछ भी नहीं हैं। इसका मतलब यह है कि जब आप एक चर बनाते हैं तो आप स्मृति में कुछ स्थान आरक्षित करते हैं।
एक चर के डेटा प्रकार के आधार पर, दुभाषिया मेमोरी आवंटित करता है और यह तय करता है कि आरक्षित मेमोरी में क्या संग्रहीत किया जा सकता है। इसलिए, विभिन्न डेटा प्रकारों को चर में निर्दिष्ट करके, आप इन चर में पूर्णांक, दशमलव या वर्ण संग्रहीत कर सकते हैं।
चर को मान देना
पायथन चरों को मेमोरी स्पेस आरक्षित करने के लिए स्पष्ट घोषणा की आवश्यकता नहीं है। जब आप किसी वैरिएबल को मान देते हैं तो घोषणा स्वतः ही हो जाती है। समान चिह्न (=) का उपयोग चर को मान निर्दिष्ट करने के लिए किया जाता है।
= ऑपरेटर के बाईं ओर वाला ऑपरेटर चर का नाम है और ऑपरेटर के दाईं ओर का ऑपरेटर चर में संग्रहीत मान है। उदाहरण के लिए -
#!/usr/bin/python
counter = 100 # An integer assignment
miles = 1000.0 # A floating point
name = "John" # A string
print counter
print miles
print nameयहां, 100, 1000.0 और "जॉन" क्रमशः काउंटर , मील और नाम चर के लिए निर्दिष्ट मान हैं। यह निम्न परिणाम उत्पन्न करता है -
100
1000.0
Johnएकाधिक असाइनमेंट
पायथन आपको एक साथ कई चर के लिए एक मूल्य प्रदान करने की अनुमति देता है। उदाहरण के लिए -
a = b = c = 1यहां, मान 1 के साथ एक पूर्णांक ऑब्जेक्ट बनाया जाता है, और सभी तीन चर एक ही मेमोरी स्थान पर असाइन किए जाते हैं। आप कई ऑब्जेक्ट को कई वेरिएबल्स में भी असाइन कर सकते हैं। उदाहरण के लिए -
a,b,c = 1,2,"john"यहां, मान 1 और 2 के साथ दो पूर्णांक ऑब्जेक्ट क्रमशः चर और बी के लिए असाइन किए जाते हैं, और मूल्य "जॉन" के साथ एक स्ट्रिंग ऑब्जेक्ट चर सी को सौंपा जाता है।
मानक डेटा प्रकार
मेमोरी में संग्रहीत डेटा कई प्रकार के हो सकते हैं। उदाहरण के लिए, किसी व्यक्ति की आयु को संख्यात्मक मान के रूप में संग्रहीत किया जाता है और उसके पते को अल्फ़ान्यूमेरिक वर्णों के रूप में संग्रहीत किया जाता है। पायथन में विभिन्न मानक डेटा प्रकार होते हैं जो उन पर संभव संचालन और उनमें से प्रत्येक के लिए भंडारण विधि को परिभाषित करने के लिए उपयोग किया जाता है।
अजगर के पाँच मानक डेटा प्रकार हैं -
- Numbers
- String
- List
- Tuple
- Dictionary
पायथन संख्या
संख्या डेटा प्रकार संख्यात्मक मानों को संग्रहीत करते हैं। जब आप उनके लिए कोई मान निर्दिष्ट करते हैं तो नंबर ऑब्जेक्ट बनाए जाते हैं। उदाहरण के लिए -
var1 = 1
var2 = 10आप डेल स्टेटमेंट का उपयोग करके किसी नंबर ऑब्जेक्ट के संदर्भ को हटा भी सकते हैं। डेल स्टेटमेंट का सिंटैक्स है -
del var1[,var2[,var3[....,varN]]]]आप डेल स्टेटमेंट का उपयोग करके किसी एकल ऑब्जेक्ट या कई ऑब्जेक्ट को हटा सकते हैं। उदाहरण के लिए -
del var
del var_a, var_bअजगर चार विभिन्न संख्यात्मक प्रकारों का समर्थन करता है -
- int (हस्ताक्षरित पूर्णांक)
- लंबे (लंबे पूर्णांक, इन्हें अष्टक और षोडश आधारी में भी दर्शाया जा सकता है)
- फ्लोट (अस्थायी बिंदु वास्तविक मूल्य)
- जटिल (जटिल संख्या)
उदाहरण
यहां संख्याओं के कुछ उदाहरण दिए गए हैं -
| पूर्णांक | लंबा | नाव | जटिल |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3 + E18 | .876j |
| -0490 | 535633629843L | -90। | -.6545 + 0J |
| -0x260 | -052318172735L | -32.54e100 | 3E + 26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7J |
पायथन आपको लंबे समय तक एक लोअरकेस एल का उपयोग करने की अनुमति देता है, लेकिन यह अनुशंसा की जाती है कि आप केवल 1 के साथ भ्रम से बचने के लिए एक अपरकेस एल का उपयोग करें। पायथन एक अपरकेस एल के साथ लंबे पूर्णांक प्रदर्शित करता है।
एक जटिल संख्या में x + yj द्वारा निरूपित वास्तविक फ्लोटिंग-पॉइंट संख्याओं का एक आदेशित युग्म होता है, जहाँ x और y वास्तविक संख्याएँ होती हैं और j काल्पनिक इकाई है।
पायथन स्ट्रिंग्स
पायथन में स्ट्रिंग्स की पहचान उद्धरण चिह्नों में दर्शाए गए पात्रों के एक आकस्मिक सेट के रूप में की जाती है। अजगर एकल या दोहरे उद्धरण के जोड़े के लिए अनुमति देता है। स्ट्रिंग की शुरुआत में 0 से शुरू होने वाले और अंत में -1 से अपने तरीके से काम करने वाले इंडेक्स वाले स्लाइस ऑपरेटर ([] और [:]) का उपयोग करके स्ट्रिंग्स के सबस्क्रिप्शन लिए जा सकते हैं।
प्लस (+) चिह्न स्ट्रिंग कॉन्फैक्शन ऑपरेटर है और तारांकन चिह्न (*) दोहराव ऑपरेटर है। उदाहरण के लिए -
#!/usr/bin/python
str = 'Hello World!'
print str # Prints complete string
print str[0] # Prints first character of the string
print str[2:5] # Prints characters starting from 3rd to 5th
print str[2:] # Prints string starting from 3rd character
print str * 2 # Prints string two times
print str + "TEST" # Prints concatenated stringयह निम्नलिखित परिणाम का उत्पादन करेगा -
Hello World!
H
llo
llo World!
Hello World!Hello World!
Hello World!TESTपायथन लिस्ट्स
सूचियाँ पायथन के यौगिक डेटा प्रकारों में सबसे बहुमुखी हैं। एक सूची में अल्पविराम द्वारा अलग किए गए और वर्ग कोष्ठक ([]) के भीतर संलग्न आइटम होते हैं। कुछ हद तक, सूची सी में सरणियों के समान हैं। उनके बीच एक अंतर यह है कि सूची से संबंधित सभी आइटम अलग-अलग डेटा प्रकार के हो सकते हैं।
सूची में संग्रहीत मानों को स्लाइस ऑपरेटर ([] और [:]) के साथ सूची की शुरुआत में 0 पर शुरू होने वाले इंडेक्स के साथ एक्सेस किया जा सकता है और -1 को समाप्त करने के लिए अपने तरीके से काम कर सकता है। प्लस (+) चिह्न सूची संघनक ऑपरेटर है, और तारांकन चिह्न (*) दोहराव ऑपरेटर है। उदाहरण के लिए -
#!/usr/bin/python
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tinylist = [123, 'john']
print list # Prints complete list
print list[0] # Prints first element of the list
print list[1:3] # Prints elements starting from 2nd till 3rd
print list[2:] # Prints elements starting from 3rd element
print tinylist * 2 # Prints list two times
print list + tinylist # Prints concatenated listsयह निम्न परिणाम उत्पन्न करता है -
['abcd', 786, 2.23, 'john', 70.2]
abcd
[786, 2.23]
[2.23, 'john', 70.2]
[123, 'john', 123, 'john']
['abcd', 786, 2.23, 'john', 70.2, 123, 'john']पायथन टुपल्स
एक ट्यूपल एक अन्य अनुक्रम डेटा प्रकार है जो सूची के समान है। टुपल में अल्पविराम द्वारा अलग-अलग कई मान होते हैं। सूचियों के विपरीत, हालांकि, टुपल्स कोष्ठक के भीतर संलग्न हैं।
सूचियों और टुपल्स के बीच मुख्य अंतर हैं: सूची कोष्ठक ([]) में संलग्न हैं और उनके तत्वों और आकार को बदला जा सकता है, जबकि ट्यूपल्स कोष्ठक ()) में संलग्न हैं और उन्हें अपडेट नहीं किया जा सकता है। टुपल्स के बारे में सोचा जा सकता हैread-onlyसूचियों। उदाहरण के लिए -
#!/usr/bin/python
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
tinytuple = (123, 'john')
print tuple # Prints the complete tuple
print tuple[0] # Prints first element of the tuple
print tuple[1:3] # Prints elements of the tuple starting from 2nd till 3rd
print tuple[2:] # Prints elements of the tuple starting from 3rd element
print tinytuple * 2 # Prints the contents of the tuple twice
print tuple + tinytuple # Prints concatenated tuplesयह निम्न परिणाम उत्पन्न करता है -
('abcd', 786, 2.23, 'john', 70.2)
abcd
(786, 2.23)
(2.23, 'john', 70.2)
(123, 'john', 123, 'john')
('abcd', 786, 2.23, 'john', 70.2, 123, 'john')निम्न कोड tuple के साथ अमान्य है, क्योंकि हमने एक tuple को अपडेट करने का प्रयास किया, जिसकी अनुमति नहीं है। सूचियों के साथ भी ऐसा ही मामला संभव है -
#!/usr/bin/python
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tuple[2] = 1000 # Invalid syntax with tuple
list[2] = 1000 # Valid syntax with listपायथन शब्दकोश
पायथन के शब्दकोश हश तालिका प्रकार के प्रकार हैं। वे पर्ल में पाए जाने वाले साहचर्य सरणियों या हैश की तरह काम करते हैं और इसमें कुंजी-मूल्य जोड़े शामिल होते हैं। एक शब्दकोश कुंजी लगभग किसी भी पायथन प्रकार की हो सकती है, लेकिन आमतौर पर संख्या या तार होते हैं। दूसरी ओर मान, कोई भी मनमाना पायथन ऑब्जेक्ट हो सकता है।
शब्दकोश घुंघराले ब्रेसिज़ ({}) से घिरे होते हैं और वर्गाकार ब्रेसिज़ ([]) का उपयोग करके मूल्यों को असाइन और एक्सेस किया जा सकता है। उदाहरण के लिए -
#!/usr/bin/python
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'john','code':6734, 'dept': 'sales'}
print dict['one'] # Prints value for 'one' key
print dict[2] # Prints value for 2 key
print tinydict # Prints complete dictionary
print tinydict.keys() # Prints all the keys
print tinydict.values() # Prints all the valuesयह निम्न परिणाम उत्पन्न करता है -
This is one
This is two
{'dept': 'sales', 'code': 6734, 'name': 'john'}
['dept', 'code', 'name']
['sales', 6734, 'john']शब्दकोशों में तत्वों के बीच क्रम की कोई अवधारणा नहीं है। यह कहना गलत है कि तत्व "ऑर्डर से बाहर" हैं; वे बस अनियंत्रित हैं।
डेटा प्रकार रूपांतरण
कभी-कभी, आपको अंतर्निहित प्रकारों के बीच रूपांतरण करने की आवश्यकता हो सकती है। प्रकारों के बीच कनवर्ट करने के लिए, आप केवल फ़ंक्शन के रूप में नाम टाइप करें।
एक डेटा प्रकार से दूसरे में रूपांतरण करने के लिए कई अंतर्निहित कार्य हैं। ये फ़ंक्शन परिवर्तित मान का प्रतिनिधित्व करते हुए एक नई वस्तु लौटाते हैं।
| अनु क्रमांक। | समारोह विवरण |
|---|---|
| 1 | int(x [,base]) X को पूर्णांक में परिवर्तित करता है। आधार निर्दिष्ट करता है अगर x एक स्ट्रिंग है। |
| 2 | long(x [,base] ) एक्स को एक लंबे पूर्णांक में परिवर्तित करता है। आधार निर्दिष्ट करता है अगर x एक स्ट्रिंग है। |
| 3 | float(x) X को एक फ्लोटिंग-पॉइंट संख्या में परिवर्तित करता है। |
| 4 | complex(real [,imag]) एक जटिल संख्या बनाता है। |
| 5 | str(x) ऑब्जेक्ट एक्स को एक स्ट्रिंग प्रतिनिधित्व में परिवर्तित करता है। |
| 6 | repr(x) ऑब्जेक्ट एक्स को एक अभिव्यक्ति स्ट्रिंग में परिवर्तित करता है। |
| 7 | eval(str) एक स्ट्रिंग का मूल्यांकन करता है और एक वस्तु देता है। |
| 8 | tuple(s) धर्मान्तरित एक tuple के लिए। |
| 9 | list(s) किसी सूची में धर्मान्तरित। |
| 10 | set(s) एक सेट पर धर्मान्तरित। |
| 1 1 | dict(d) एक शब्दकोश बनाता है। d (कुंजी, मान) टुपल्स का एक क्रम होना चाहिए। |
| 12 | frozenset(s) धर्मान्तरित सेट पर धर्मान्तरित। |
| 13 | chr(x) किसी वर्ण को पूर्णांक देता है। |
| 14 | unichr(x) एक पूर्णांक को एक यूनिकोड वर्ण में परिवर्तित करता है। |
| 15 | ord(x) किसी एकल वर्ण को उसके पूर्णांक मान में परिवर्तित करता है। |
| 16 | hex(x) एक पूर्णांक को हेक्साडेसिमल स्ट्रिंग में परिवर्तित करता है। |
| 17 | oct(x) एक पूर्णांक को एक अष्टक स्ट्रिंग में परिवर्तित करता है। |
ऑपरेटर्स वे निर्माण हैं जो ऑपरेंड के मूल्य में हेरफेर कर सकते हैं।
अभिव्यक्ति पर विचार करें 4 + 5 = 9. यहां, 4 और 5 को ऑपरेंड कहा जाता है और + को ऑपरेटर कहा जाता है।
संचालक के प्रकार
पायथन भाषा निम्नलिखित प्रकार के ऑपरेटरों का समर्थन करती है।
- अंकगणितीय आपरेटर
- तुलना (संबंधपरक) संचालक
- असाइनमेंट ऑपरेटर्स
- लॉजिकल ऑपरेटर्स
- बिटवाइज ऑपरेटर्स
- सदस्यता संचालक
- आइडेंटिटी ऑपरेटर्स
एक-एक करके सभी ऑपरेटरों पर नजर डालते हैं।
पायथन अरिथमेटिक ऑपरेटर्स
चर को 10 मानिए और चर b को 20 मानिए, तब -
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| + जोड़ | ऑपरेटर के दोनों ओर मान जोड़ता है। | a + b = 30 है |
| - घटाव | बाएं हाथ के ऑपरेंड से दाएं हाथ के ऑपरेंड को घटाएं। | a - b = -10 |
| * गुणा | ऑपरेटर के दोनों ओर मान बढ़ता है | ए * बी = २०० |
| / विभाजन | दाएं हाथ के ऑपरेंड से बाएं हाथ का ऑपरेशन | b / a = २ |
| % मापुल | दाएं हाथ के ऑपरेंड से बाएं हाथ का ऑपरेंड और शेष रिटर्न | b% ए = ० |
| ** घातांक | ऑपरेटरों पर घातीय (शक्ति) गणना करता है | एक ** बी = 10 शक्ति 20 तक |
| // | फ्लोर डिवीजन - ऑपरेंड्स का विभाजन जहां परिणाम भागफल होता है जिसमें दशमलव बिंदु हटाए जाने के बाद के अंक। लेकिन यदि किसी एक ऑपरेंड नकारात्मक है, तो परिणाम शून्य हो जाता है, अर्थात शून्य से दूर (नकारात्मक अनंत की ओर) - | 9 // 2 = 4 और 9.0 // 2.0 = 4.0, -11 // 3 = -4, -11.0 // 3 = -4.0 |
पायथन तुलनात्मक संचालक
ये ऑपरेटर उनके दोनों ओर के मूल्यों की तुलना करते हैं और उनके बीच संबंध तय करते हैं। उन्हें रिलेशनल ऑपरेटर भी कहा जाता है।
चर को 10 मानिए और चर b को 20 मानिए, तब -
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| == | यदि दो ऑपरेंड का मान बराबर है, तो स्थिति सच हो जाती है। | (a == b) सत्य नहीं है। |
| ! = | यदि दो ऑपरेंड के मान समान नहीं हैं, तो स्थिति सच हो जाती है। | (a! = b) सत्य है। |
| <> | यदि दो ऑपरेंड के मान समान नहीं हैं, तो स्थिति सच हो जाती है। | (अ <> ख) सत्य है। यह = = ऑपरेटर के समान है। |
| > | यदि बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से अधिक है, तो स्थिति सच हो जाती है। | (a> b) सत्य नहीं है। |
| < | यदि बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से कम है, तो स्थिति सच हो जाती है। | (a <b) सत्य है। |
| > = | यदि बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से अधिक या बराबर है, तो स्थिति सच हो जाती है। | (a> = b) सत्य नहीं है। |
| <= | यदि बाएं ऑपरेंड का मूल्य सही ऑपरेंड के मूल्य से कम या उसके बराबर है, तो स्थिति सच हो जाती है। | (ए <= बी) सच है। |
पायथन असाइनमेंट ऑपरेटर्स
चर को 10 मानिए और चर b को 20 मानिए, तब -
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| = | राइट साइड ऑपरेंड से लेफ्ट साइड ऑपरेंड तक वैल्यू असाइन करता है | c = a + b c में a + b का मान प्रदान करता है |
| + = जोड़ें और | यह बाएं ऑपरेंड में दाईं ओर ऑपरेंड जोड़ता है और परिणाम को बाएं ऑपरेंड में असाइन करता है | c + = a, c = c + a के बराबर है |
| - = घटाना और | यह बाएं ऑपरेंड से दाएं ऑपरेंड को घटाता है और लेफ्ट ऑपरेंड को रिजल्ट सौंपता है | c - = a, c = c - a के बराबर है |
| * - गुणा और | यह बाएं ऑपरेंड के साथ दाएं ऑपरेंड को गुणा करता है और परिणाम को बाएं ऑपरेंड में असाइन करता है | c * = a, c = c * a के बराबर है |
| / = विभाजित करें और | यह बाएं ऑपरेंड को दाएं ऑपरेंड के साथ विभाजित करता है और परिणाम को बाएं ऑपरेंड को सौंपता है | c / = a, c = c / a के बराबर है |
| % = मापांक और | यह दो ऑपरेंड का उपयोग करके मापांक लेता है और परिणाम को बाएं ऑपरेंड में असाइन करता है | c% = a, c = c% a के बराबर है |
| ** = प्रतिपादक और | ऑपरेटरों पर घातांक (शक्ति) गणना करता है और बाएं ऑपरेंड को मान प्रदान करता है | c ** = a, c = c ** a के बराबर है |
| // = फ्लोर डिवीजन | यह ऑपरेटरों पर फर्श विभाजन करता है और बाएं ऑपरेंड को मूल्य प्रदान करता है | c // = a, c = c // a के बराबर है |
पायथन बिटवाइज ऑपरेटर्स
बिटवाइज़ ऑपरेटर बिट पर काम करता है और बिट ऑपरेशन द्वारा बिट करता है। मान लें तो = a 60; और बी = 13; अब द्विआधारी प्रारूप में उनके मूल्य क्रमशः 0011 1100 और 0000 1101 होंगे। निम्नलिखित तालिका में उन उदाहरणों के साथ पायथन भाषा द्वारा समर्थित बिटवाइज़ ऑपरेटरों को सूचीबद्ध किया गया है, हम उपरोक्त दो चर (a और b) को ऑपरेंड के रूप में उपयोग करते हैं -
a = 0011 1100
b = ०००० ११०१
-----------------
a & b = 0000 1100
a | b = 0011 1101
ए ^ बी = 0011 0001
~ a = 1100 0011
पायथन भाषा द्वारा समर्थित बिटवाइज़ ऑपरेटरों का अनुसरण कर रहे हैं
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| और बाइनरी और | यदि ऑपरेटर दोनों ऑपरेंड में मौजूद है, तो ऑपरेटर परिणाम को थोड़ा कॉपी करता है | (ए और बी) (0000 1100 का मतलब है) |
| | बाइनरी या | यदि यह किसी भी ऑपरेंड में मौजूद है, तो यह थोड़ा सा कॉपी करता है। | (a। b) = 61 (मतलब 0011 1101) |
| ^ बाइनरी एक्सओआर | यह बिट को कॉपी करता है अगर यह एक ऑपरेंड में सेट होता है लेकिन दोनों नहीं। | (ए ^ बी) = 49 (0011 0001 का मतलब है) |
| ~ बाइनरी ओन्स पूरक | यह एकात्मक है और इसमें 'फ्लिपिंग' बिट्स का प्रभाव है। | (~ ए) = -61 (मतलब हस्ताक्षरित बाइनरी नंबर के कारण २ के पूरक रूप में ११०० ००११। |
| << बाइनरी वाम शिफ्ट | बाएं ऑपरेंड वैल्यू को दाएं ऑपरेंड द्वारा निर्दिष्ट बिट्स की संख्या से छोड़ दिया जाता है। | एक << 2 = 240 (मतलब 1111 0000) |
| >> बाइनरी राइट शिफ्ट | बाएं ऑपरेंड वैल्यू को दाएं ऑपरेंड द्वारा निर्दिष्ट बिट्स की संख्या से दाएं स्थानांतरित किया जाता है। | >> >> 2 = 15 (0000 1111 का मतलब है) |
पायथन लॉजिकल ऑपरेटर्स
पायथन भाषा द्वारा समर्थित तार्किक ऑपरेटर निम्नलिखित हैं। चर को 10 मान लीजिए और चर b का मान 20 है
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| और तार्किक और | यदि दोनों संकार्य सत्य हैं तो स्थिति सत्य हो जाती है। | (a और b) सत्य है। |
| या तार्किक या | यदि दोनों संचालकों में से कोई भी गैर-शून्य है तो स्थिति सत्य हो जाती है। | (a या b) सत्य है। |
| लॉजिकल नहीं | अपने ऑपरेंड की तार्किक स्थिति को उलट देता था। | नहीं (ए और बी) गलत है। |
पायथन सदस्यता संचालक
पायथन के सदस्यता संचालक एक क्रम में सदस्यता के लिए परीक्षण करते हैं, जैसे कि तार, सूचियाँ, या टुपल्स। नीचे बताए अनुसार दो सदस्यता संचालक हैं -
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| में | सत्य का मूल्यांकन करता है यदि यह निर्दिष्ट अनुक्रम में एक चर पाता है और अन्यथा गलत है। | x में y, यहाँ परिणाम में 1 यदि x अनुक्रम y का सदस्य है। |
| अंदर नही | सत्य का मूल्यांकन करता है यदि यह निर्दिष्ट अनुक्रम में एक चर नहीं पाता है और अन्यथा गलत है। | x y में नहीं है, यहाँ 1 में परिणाम नहीं है यदि x अनुक्रम y का सदस्य नहीं है। |
पायथन आइडेंटिटी ऑपरेटर्स
पहचान ऑपरेटर दो वस्तुओं के मेमोरी लोकेशन की तुलना करते हैं। नीचे बताए गए दो पहचानकर्ता हैं -
[ उदाहरण दिखाएँ ]
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| है | सही करने के लिए मूल्यांकन अगर ऑपरेटर के दोनों ओर चर एक ही वस्तु की ओर इशारा करते हैं और अन्यथा झूठे। | x y है, यहाँ is 1 में परिणाम अगर आईडी (x) आईडी (y) के बराबर है। |
| नहीं है | यदि ऑपरेटर के दोनों ओर चर एक ही वस्तु और सत्य की ओर इंगित करते हैं तो असत्य का मूल्यांकन करता है। | x यहां y नहीं है is not 1 में परिणाम अगर आईडी (x) आईडी (y) के बराबर नहीं है। |
पायथन ऑपरेटर्स प्रिसेंसेंस
निम्न तालिका सभी ऑपरेटरों को उच्चतम वरीयता से निम्नतम तक सूचीबद्ध करती है।
[ उदाहरण दिखाएँ ]
| अनु क्रमांक। | ऑपरेटर और विवरण |
|---|---|
| 1 | ** घातांक (शक्ति तक बढ़ाएं) |
| 2 | ~ + - पूरक, यूनीरी प्लस और माइनस (अंतिम दो के लिए विधि नाम + @ और - @ @ हैं) |
| 3 | * / % // गुणा, विभाजित, मोडुलो और फर्श विभाजन |
| 4 | + - जोड़ और घटाव |
| 5 | >> << दाएं और बाएं बिटवाइड शिफ्ट |
| 6 | & बिटवाइज़ 'और' |
| 7 | ^ | बिटवाइज़ एक्सक्लूसिव `OR’ और रेगुलर `OR’ |
| 8 | <= < > >= तुलना संचालक |
| 9 | <> == != समानता ऑपरेटरों |
| 10 | = %= /= //= -= += *= **= असाइनमेंट ऑपरेटर |
| 1 1 | is is not पहचान के संचालक |
| 12 | in not in सदस्यता संचालक |
| 13 | not or and लॉजिकल ऑपरेटर्स |
निर्णय लेने से परिस्थितियों का पूर्वानुमान होता है जबकि कार्यक्रम का निष्पादन और शर्तों के अनुसार कार्रवाई को निर्दिष्ट करना।
निर्णय संरचना कई अभिव्यक्तियों का मूल्यांकन करती है जो परिणाम के रूप में TRUE या FALSE का उत्पादन करती हैं। आपको यह निर्धारित करने की आवश्यकता है कि कौन सी कार्रवाई करनी है और कौन से कथन निष्पादित करने के लिए यदि परिणाम TRUE या FALSE है अन्यथा।
अधिकांश प्रोग्रामिंग भाषाओं में पाया जाने वाला एक विशिष्ट निर्णय लेने की संरचना का सामान्य रूप निम्नलिखित है -
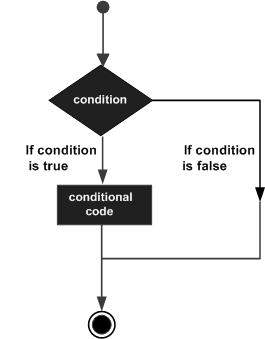
पायथन प्रोग्रामिंग भाषा किसी भी मानता है non-zero तथा non-null मान TRUE के रूप में, और यदि यह या तो है zero या null, तब इसे FALSE मान माना जाता है।
पायथन प्रोग्रामिंग भाषा निम्नलिखित निर्णय लेने के प्रकार प्रदान करती है। उनके विवरण की जाँच करने के लिए निम्न लिंक पर क्लिक करें।
| अनु क्रमांक। | विवरण और विवरण |
|---|---|
| 1 | अगर बयान एक if statement एक या अधिक बयानों के बाद एक बूलियन अभिव्यक्ति के होते हैं। |
| 2 | अगर ... और बयान एक if statement एक वैकल्पिक द्वारा पीछा किया जा सकता है else statement, जो निष्पादित करता है जब बूलियन अभिव्यक्ति FALSE है। |
| 3 | बयान दिया तो नेस्टेड आप एक का उपयोग कर सकते हैं if या else if दूसरे के अंदर बयान if या else if कथन (नों)। |
आइए हम संक्षेप में निर्णय लेने के प्रत्येक निर्णय से गुजरते हैं -
सिंगल स्टेटमेंट सूट
यदि एक का सूट if क्लॉज में केवल एक ही लाइन होती है, यह हेडर स्टेटमेंट के समान लाइन पर जा सकती है।
यहाँ एक उदाहरण है one-line if खंड -
#!/usr/bin/python
var = 100
if ( var == 100 ) : print "Value of expression is 100"
print "Good bye!"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Value of expression is 100
Good bye!सामान्य तौर पर, बयानों को क्रमिक रूप से निष्पादित किया जाता है: किसी फ़ंक्शन में पहला कथन पहले निष्पादित किया जाता है, उसके बाद दूसरा, और इसी तरह। ऐसी स्थिति हो सकती है जब आपको कई बार कोड के ब्लॉक को निष्पादित करने की आवश्यकता होती है।
प्रोग्रामिंग भाषाएँ विभिन्न नियंत्रण संरचनाएं प्रदान करती हैं जो अधिक जटिल निष्पादन पथों के लिए अनुमति देती हैं।
एक लूप स्टेटमेंट हमें कई बार स्टेटमेंट या स्टेटमेंट ऑफ स्टेट को निष्पादित करने की अनुमति देता है। निम्नलिखित आरेख एक लूप स्टेटमेंट दिखाता है -
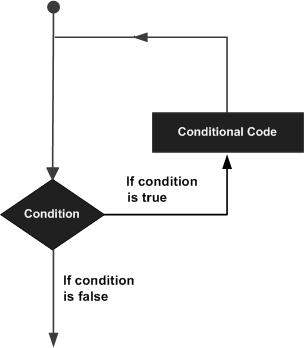
पायथन प्रोग्रामिंग भाषा लूपिंग आवश्यकताओं को संभालने के लिए निम्न प्रकार के लूप प्रदान करती है।
| अनु क्रमांक। | लूप प्रकार और विवरण |
|---|---|
| 1 | घुमाव के दौरान किसी कथन या कथन का समूह दोहराता है जबकि दी गई स्थिति TRUE है। यह लूप बॉडी को निष्पादित करने से पहले स्थिति का परीक्षण करता है। |
| 2 | पाश के लिए कई बार बयानों का क्रम निष्पादित करता है और उस कोड को संक्षिप्त करता है जो लूप चर का प्रबंधन करता है। |
| 3 | स्थिर फंदा आप किसी अन्य के अंदर एक या अधिक लूप का उपयोग कर सकते हैं, जबकि या इसके लिए लूप का उपयोग कर सकते हैं। |
लूप नियंत्रण विवरण
लूप नियंत्रण स्टेटमेंट अपने सामान्य अनुक्रम से निष्पादन को बदल देता है। जब निष्पादन एक गुंजाइश छोड़ देता है, तो उस दायरे में बनाए गए सभी स्वचालित ऑब्जेक्ट नष्ट हो जाते हैं।
पायथन निम्नलिखित नियंत्रण कथनों का समर्थन करता है। उनके विवरण की जाँच करने के लिए निम्न लिंक पर क्लिक करें।
आइए हम संक्षिप्त रूप से लूप नियंत्रण कथनों के माध्यम से चलते हैं
| अनु क्रमांक। | नियंत्रण विवरण और विवरण |
|---|---|
| 1 | तोड़ बयान लूप स्टेटमेंट को समाप्त करता है और लूप के तुरंत बाद स्टेटमेंट को ट्रांसफर करता है। |
| 2 | जारी रखें बयान लूप को उसके शरीर के शेष हिस्से को छोड़ने के लिए कहता है और पुनरावृत्ति करने से पहले तुरंत उसकी स्थिति को फिर से बना देता है। |
| 3 | बयान दर्ज करें पायथन में पास स्टेटमेंट का उपयोग तब किया जाता है जब किसी स्टेटमेंट को वाक्यविन्यास की आवश्यकता होती है लेकिन आप नहीं चाहते हैं कि कोई कमांड या कोड निष्पादित हो। |
संख्या डेटा प्रकार संख्यात्मक मानों को संग्रहीत करते हैं। वे अपरिवर्तनीय डेटा प्रकार हैं, इसका मतलब है कि एक नई आवंटित वस्तु में संख्या डेटा प्रकार के मूल्य को बदलना।
जब आप उनके लिए कोई मान निर्दिष्ट करते हैं तो नंबर ऑब्जेक्ट बनाए जाते हैं। उदाहरण के लिए -
var1 = 1
var2 = 10आप किसी ऑब्जेक्ट का संदर्भ हटाकर भी उपयोग कर सकते हैं delबयान। डेल स्टेटमेंट का सिंटैक्स है -
del var1[,var2[,var3[....,varN]]]]आप किसी एकल ऑब्जेक्ट या कई ऑब्जेक्ट का उपयोग करके हटा सकते हैं delबयान। उदाहरण के लिए -
del var
del var_a, var_bअजगर चार विभिन्न संख्यात्मक प्रकारों का समर्थन करता है -
int (signed integers) - उन्हें अक्सर केवल पूर्णांक या ints कहा जाता है, बिना दशमलव बिंदु के सकारात्मक या नकारात्मक पूर्ण संख्याएं होती हैं।
long (long integers ) - इसे लोंग भी कहा जाता है, वे असीमित आकार के पूर्णांक होते हैं, पूर्णांक की तरह लिखे जाते हैं और उसके बाद एक अपरकेस या लोअरकेस एल।
float (floating point real values)- इसके अलावा फ़्लोट्स, वे वास्तविक संख्याओं का प्रतिनिधित्व करते हैं और पूर्णांक और भिन्नात्मक भागों को विभाजित करते हुए दशमलव बिंदु के साथ लिखे जाते हैं। फ्लोट्स वैज्ञानिक संकेतन में भी हो सकते हैं, ई या ई के साथ 10 (2.5e2 = 2.5 x 10 2 = 250) की शक्ति का संकेत देते हैं ।
complex (complex numbers)- फॉर्म a + bJ के हैं, जहां a और b फ्लोट हैं और J (या j) -1 का वर्गमूल (जो कि एक काल्पनिक संख्या है) का प्रतिनिधित्व करता है। संख्या का वास्तविक भाग a है और काल्पनिक भाग b है। पायथन प्रोग्रामिंग में जटिल संख्याओं का अधिक उपयोग नहीं किया जाता है।
उदाहरण
यहां संख्याओं के कुछ उदाहरण दिए गए हैं
| पूर्णांक | लंबा | नाव | जटिल |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEL | 32.3 + E18 | .876j |
| -0490 | 535633629843L | -90। | -.6545 + 0J |
| -0x260 | -052318172735L | -32.54e100 | 3E + 26J |
| 0x69 | -4721885298529L | 70.2-E12 | 4.53e-7J |
पायथन आपको लंबे समय तक एक लोअरकेस एल का उपयोग करने की अनुमति देता है, लेकिन यह अनुशंसा की जाती है कि आप संख्या के साथ भ्रम से बचने के लिए केवल एक अपरकेस एल का उपयोग करें। पायथन एक अपरकेस एल के साथ लंबे पूर्णांक प्रदर्शित करता है।
एक जटिल संख्या में वास्तविक फ़्लोटिंग पॉइंट संख्याओं का एक जोड़ा जोड़ा होता है जिसे a + bj द्वारा निरूपित किया जाता है, जहाँ a वास्तविक भाग होता है और b जटिल संख्या का काल्पनिक भाग होता है।
संख्या प्रकार रूपांतरण
मूल्यांकन के लिए मिश्रित प्रकार से युक्त अभिव्यक्ति में पायथन आंतरिक रूप से संख्याओं को परिवर्तित करता है। लेकिन कभी-कभी, आपको ऑपरेटर या फ़ंक्शन पैरामीटर की आवश्यकताओं को पूरा करने के लिए स्पष्ट रूप से एक प्रकार से दूसरे प्रकार के लिए एक संख्या का तालमेल करने की आवश्यकता होती है।
प्रकार int(x) एक सादे पूर्णांक में x परिवर्तित करने के लिए।
प्रकार long(x) x को एक लंबे पूर्णांक में बदलने के लिए।
प्रकार float(x) x को फ्लोटिंग-पॉइंट नंबर में बदलने के लिए।
प्रकार complex(x) वास्तविक भाग x और काल्पनिक भाग शून्य के साथ x को एक जटिल संख्या में बदलने के लिए।
प्रकार complex(x, y)वास्तविक भाग x और काल्पनिक भाग y के साथ x और y को एक जटिल संख्या में परिवर्तित करना। x और y संख्यात्मक भाव हैं
गणितीय कार्य
पायथन में निम्नलिखित कार्य शामिल हैं जो गणितीय गणना करते हैं।
| अनु क्रमांक। | समारोह और विवरण (विवरण) |
|---|---|
| 1 | पेट (एक्स) X का पूर्ण मान: x और शून्य के बीच की सकारात्मक (धनात्मक) दूरी। |
| 2 | प्लस्तर लगाना (एक्स) X की छत: सबसे छोटा पूर्णांक x से कम नहीं है |
| 3 | सीएमपी (एक्स, वाई) -1 अगर x <y, 0 अगर x == y, या 1 अगर x> y |
| 4 | exp (x) एक्स का घातांक: ई एक्स |
| 5 | fabs (एक्स) एक्स का पूर्ण मूल्य। |
| 6 | मंजिल (एक्स) X का तल: सबसे बड़ा पूर्णांक x से अधिक नहीं है |
| 7 | लॉग (एक्स) X> 0 के लिए x का प्राकृतिक लघुगणक |
| 8 | log10 (एक्स) X> 0 के लिए x का आधार -10 लघुगणक। |
| 9 | अधिकतम (X1, x2, ...) इसके तर्कों का सबसे बड़ा: सकारात्मक अनंत के लिए निकटतम मूल्य |
| 10 | मिनट (X1, x2, ...) इसके तर्कों का सबसे छोटा: नकारात्मक अनंत के सबसे करीब मूल्य |
| 1 1 | modf (एक्स) दो-आइटम टपल में x का भिन्नात्मक और पूर्णांक भाग। दोनों भागों में x के समान चिन्ह हैं। पूर्णांक भाग को फ्लोट के रूप में लौटाया जाता है। |
| 12 | पाव (x, y) X ** y का मान। |
| 13 | गोल (x [, n]) xदशमलव बिंदु से n अंकों तक गोल। पायथन एक टाई-ब्रेकर के रूप में शून्य से दूर है: राउंड (0.5) 1.0 है और राउंड (-0.5) -1.0 है। |
| 14 | sqrt (एक्स) X> 0 के लिए x का वर्गमूल |
रैंडम संख्या कार्य
गेम, सिमुलेशन, परीक्षण, सुरक्षा और गोपनीयता अनुप्रयोगों के लिए यादृच्छिक संख्याओं का उपयोग किया जाता है। पायथन में निम्नलिखित कार्य शामिल हैं जो आमतौर पर उपयोग किए जाते हैं।
| अनु क्रमांक। | समारोह विवरण |
|---|---|
| 1 | विकल्प (सेक) सूची, टपल या स्ट्रिंग से एक यादृच्छिक आइटम। |
| 2 | रैंड्रेंज ([शुरू,] स्टॉप [, स्टेप]) श्रेणी से एक यादृच्छिक रूप से चयनित तत्व (प्रारंभ, रोक, चरण) |
| 3 | यादृच्छिक () एक यादृच्छिक फ्लोट आर, जैसे कि 0 आर से कम या बराबर है और आर 1 से कम है |
| 4 | बीज ([x]) यादृच्छिक संख्या उत्पन्न करने में उपयोग किए जाने वाले पूर्णांक के मूल्य को सेट करता है। किसी अन्य यादृच्छिक मॉड्यूल फ़ंक्शन को कॉल करने से पहले इस फ़ंक्शन को कॉल करें। कोई नहीं लौटाता। |
| 5 | फेरबदल (lst) एक सूची के आइटम को जगह में यादृच्छिक करता है। कोई नहीं लौटाता। |
| 6 | वर्दी (x, y) एक यादृच्छिक फ्लोट आर, जैसे कि x, r से कम या बराबर है और r, y से कम है |
त्रिकोणमितीय फलन
पायथन में निम्नलिखित कार्य शामिल हैं जो त्रिकोणमितीय गणना करते हैं।
| अनु क्रमांक। | समारोह विवरण |
|---|---|
| 1 | acos (एक्स) रेडियन में x का चाप कोसाइन लौटाएं। |
| 2 | असिन (एक्स) रेडियन में x की चाप साइन लौटें। |
| 3 | atan (एक्स) रेडियन में x का चाप स्पर्शक लौटाएं। |
| 4 | atan2 (y, x) रेडियन में वापसी एटैन (y / x)। |
| 5 | क्योंकि (एक्स) एक्स रेडियंस के कोसाइन को लौटाएं। |
| 6 | हाइप (x, y) यूक्लिडियन मानदंड, sqrt (x * x + y * y) वापस करें। |
| 7 | sin (x) एक्स रेडियंस की साइन लौटें। |
| 8 | तन (एक्स) एक्स रेडियंस के स्पर्शरेखा लौटें। |
| 9 | डिग्री (एक्स) रेडियन से डिग्री तक कोण x को परिवर्तित करता है। |
| 10 | रेडियंस (एक्स) कोण x को डिग्री से रेडियन में परिवर्तित करता है। |
गणितीय निरंतर
मॉड्यूल दो गणितीय स्थिरांक को भी परिभाषित करता है -
| अनु क्रमांक। | लगातार और विवरण |
|---|---|
| 1 | pi गणितीय निरंतर पी। |
| 2 | e गणितीय स्थिर ई। |
पायथन में स्ट्रिंग्स सबसे लोकप्रिय प्रकारों में से हैं। हम उन्हें केवल उद्धरणों में वर्ण संलग्न करके बना सकते हैं। पायथन सिंगल कोट्स को डबल कोट्स के समान मानता है। स्ट्रिंग्स बनाना उतना ही सरल है जितना कि एक वैरिएबल के लिए एक मान निर्दिष्ट करना। उदाहरण के लिए -
var1 = 'Hello World!'
var2 = "Python Programming"स्ट्रिंग्स में वेल्यूज एक्सेस करना
अजगर एक चरित्र प्रकार का समर्थन नहीं करता है; इन्हें लंबाई के तार के रूप में माना जाता है, इस प्रकार इसे एक विकल्प माना जाता है।
सब्सट्रिंग तक पहुंचने के लिए, अपने सबरिंग को प्राप्त करने के लिए इंडेक्स या सूचकांकों के साथ स्लाइसिंग के लिए चौकोर कोष्ठक का उपयोग करें। उदाहरण के लिए -
#!/usr/bin/python
var1 = 'Hello World!'
var2 = "Python Programming"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
var1[0]: H
var2[1:5]: ythoअद्यतन स्ट्रिंग्स
आप किसी अन्य स्ट्रिंग को एक वैरिएबल असाइन करके (री) मौजूदा स्ट्रिंग को "अपडेट" कर सकते हैं। नया मान उसके पिछले मूल्य या पूरी तरह से अलग स्ट्रिंग से संबंधित हो सकता है। उदाहरण के लिए -
#!/usr/bin/python
var1 = 'Hello World!'
print "Updated String :- ", var1[:6] + 'Python'जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Updated String :- Hello Pythonवर्ण से बचो
निम्नलिखित तालिका भागने या गैर-मुद्रण योग्य पात्रों की एक सूची है जिसे बैकलैश नोटेशन के साथ दर्शाया जा सकता है।
एक बच चरित्र की व्याख्या हो जाती है; एक उद्धृत में और साथ ही दोहरे उद्धृत तार।
| बैकस्लैश नोटेशन | षोडश चरित्र | विवरण |
|---|---|---|
| \ए | 0x07 | बेल या अलर्ट |
| \ b | 0x08 | बैकस्पेस |
| \ cx | नियंत्रण एक्स | |
| \ Cx | नियंत्रण एक्स | |
| \इ | 0x1b | पलायन |
| \ च | 0x0c | फ़ीड बनाएं |
| \ एम \ Cx | मेटा-नियंत्रण-x | |
| \ n | 0x0A | नई पंक्ति |
| \ NNN | ऑक्टल नोटेशन, जहां n, 0.7 की सीमा में है | |
| \ r | 0x0d | कैरिज रिटर्न |
| \ रों | 0x20 | अंतरिक्ष |
| \ t | 0x09 | टैब |
| \ v | 0x0b | लंबवत टैब |
| \एक्स | चरित्र x | |
| \ xnn | हेक्साडेसिमल नोटेशन, जहां n 0.9, एफआर, या एएफ रेंज में है |
स्ट्रिंगर स्पेशल ऑपरेटर्स
स्ट्रिंग चर मान लें a 'Hello' और वैरिएबल रखता है b 'पायथन' धारण करता है, तब -
| ऑपरेटर | विवरण | उदाहरण |
|---|---|---|
| + | कॉनटेनटेशन - ऑपरेटर के दोनों ओर मान जोड़ता है | a + b HelloPython देगा |
| * | पुनरावृत्ति - एक ही तार की कई प्रतियों को समेटते हुए नए तार बनाता है | एक * 2 देंगे -हेल्लो |
| [] | स्लाइस - दिए गए सूचकांक से चरित्र देता है | एक [1] ई देगा |
| [:] | रेंज स्लाइस - दिए गए रेंज के अक्षर देता है | एक [1: 4] ईल देगा |
| में | सदस्यता - यदि दिए गए स्ट्रिंग में कोई वर्ण मौजूद है, तो सत्य है | H एक वसीयत में 1 देगा |
| अंदर नही | सदस्यता - यदि दिए गए स्ट्रिंग में कोई चरित्र मौजूद नहीं है, तो यह सच है | M एक नहीं 1 देगा |
| आर / आर | रॉ स्ट्रिंग - बच पात्रों के वास्तविक अर्थ को दबाता है। कच्चे तार के लिए सिंटैक्स बिल्कुल उसी तरह होता है जैसे कच्चे स्ट्रिंग ऑपरेटर के अपवाद के साथ सामान्य अक्षर "r" होता है, जो उद्धरण चिह्नों से पहले होता है। "आर" लोअरकेस (आर) या अपरकेस (आर) हो सकता है और पहले उद्धरण चिह्न से पहले तुरंत रखा जाना चाहिए। | प्रिंट r '\ n' प्रिंट \ n और R '\ n'prints \ n प्रिंट करें |
| % | प्रारूप - स्ट्रिंग प्रारूपण करता है | अगले भाग में देखें |
स्ट्रिंग स्वरूपण ऑपरेटर
पायथन की सबसे अच्छी विशेषताओं में से एक स्ट्रिंग प्रारूप ऑपरेटर% है। यह ऑपरेटर स्ट्रिंग्स के लिए अद्वितीय है और सी के प्रिंटफ () परिवार से कार्यों के पैक के लिए बनाता है। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
print "My name is %s and weight is %d kg!" % ('Zara', 21)जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
My name is Zara and weight is 21 kg!यहाँ प्रतीकों के पूर्ण सेट की सूची दी गई है जिसका उपयोग% के साथ किया जा सकता है -
| प्रारूप प्रतीक | परिवर्तन |
|---|---|
| %सी | चरित्र |
| % s | स्ट्रिंग के माध्यम से स्ट्रिंग रूपांतरण () स्वरूपण से पहले |
| %मैं | दशमलव पूर्णांक पर हस्ताक्षर किए |
| % d | दशमलव पूर्णांक पर हस्ताक्षर किए |
| % u | अहस्ताक्षरित दशमलव पूर्णांक |
| % ओ | अष्टक पूर्णांक |
| %एक्स | हेक्साडेसिमल पूर्णांक (छोटे अक्षर) |
| %एक्स | हेक्साडेसिमल पूर्णांक (UPPERcase पत्र) |
| %इ | घातीय संकेतन (लोअरकेस 'ई' के साथ) |
| %इ | घातीय संकेतन (UPPERcase 'E' के साथ) |
| % च | फ्लोटिंग पॉइंट रियल नंबर |
| % छ | द% च और% ई |
| % जी | % f और% E से छोटा है |
अन्य समर्थित प्रतीक और कार्यक्षमता निम्न तालिका में सूचीबद्ध हैं -
| प्रतीक | कार्यक्षमता |
|---|---|
| * | तर्क चौड़ाई या परिशुद्धता निर्दिष्ट करता है |
| - | औचित्य छोड़ दिया |
| + | संकेत प्रदर्शित करें |
| <एसपी> | एक सकारात्मक संख्या से पहले एक रिक्त स्थान छोड़ दें |
| # | ओक्टेल अग्रणी शून्य ('0') या हेक्साडेसिमल अग्रणी '0x' या '0X' को जोड़ें, यह निर्भर करता है कि 'x' या 'X' का उपयोग किया गया था। |
| 0 | शून्य से बाएँ पैड (रिक्त स्थान के बजाय) |
| % | '%%' आपको एकल शाब्दिक '%' के साथ छोड़ता है |
| (वर) | मानचित्रण चर (शब्दकोश तर्क) |
| एम.एन. | मीटर न्यूनतम कुल चौड़ाई है और n दशमलव बिंदु के बाद प्रदर्शित करने के लिए अंकों की संख्या है (यदि appl।) |
ट्रिपल कोट्स
पायथन के ट्रिपल उद्धरणों में स्ट्रिंग को वर्बाइटिम NEWLINEs, TABs, और किसी भी अन्य विशेष वर्णों सहित कई लाइनों की अनुमति देता है।
ट्रिपल उद्धरण के लिए वाक्यविन्यास में लगातार तीन होते हैं single or double उद्धरण।
#!/usr/bin/python
para_str = """this is a long string that is made up of
several lines and non-printable characters such as
TAB ( \t ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [ \n ], or just a NEWLINE within
the variable assignment will also show up.
"""
print para_strजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है। ध्यान दें कि हर एक विशेष वर्ण को उसके मुद्रित रूप में परिवर्तित कर दिया गया है, "स्ट्रिंग" के बीच स्ट्रिंग के अंत में अंतिम NEWLINE के ठीक नीचे। और ट्रिपल उद्धरण समापन। यह भी ध्यान दें कि NEWLINE एक पंक्ति के अंत में एक स्पष्ट कैरिज रिटर्न के साथ होता है या इसके एस्केप कोड (\ n) -
this is a long string that is made up of
several lines and non-printable characters such as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [
], or just a NEWLINE within
the variable assignment will also show up.कच्चे तार बैकस्लैश को एक विशेष चरित्र नहीं मानते हैं। हर पात्र जिसे आप एक कच्चे तार में रखते हैं, वह आपके लिखे हुए तरीके से रहता है -
#!/usr/bin/python
print 'C:\\nowhere'जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
C:\nowhereअब कच्चे कड़े का उपयोग करते हैं। हम इसमें अभिव्यक्ति देंगेr'expression' निम्नानुसार है -
#!/usr/bin/python
print r'C:\\nowhere'जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
C:\\nowhereयूनिकोड स्ट्रिंग
पायथन में सामान्य तारों को आंतरिक रूप से 8-बिट एएससीआईआई के रूप में संग्रहीत किया जाता है, जबकि यूनिकोड के तारों को 16-बिट यूनिकोड के रूप में संग्रहीत किया जाता है। यह वर्णों के अधिक विविध सेट की अनुमति देता है, जिसमें दुनिया की अधिकांश भाषाओं के विशेष वर्ण शामिल हैं। मैं यूनिकोड के अपने उपचार को निम्नलिखित तक सीमित करूंगा -
#!/usr/bin/python
print u'Hello, world!'जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Hello, world!जैसा कि आप देख सकते हैं, यूनिकोड के तार उपसर्ग यू का उपयोग करते हैं, जैसे कच्चे तार उपसर्ग आर का उपयोग करते हैं।
बिल्ट-इन स्ट्रींग मेथड्स
पायथन में स्ट्रिंग्स में हेरफेर करने के लिए निम्नलिखित अंतर्निहित तरीके शामिल हैं -
| अनु क्रमांक। | विवरण के साथ तरीके |
|---|---|
| 1 | कैपिटल () स्ट्रिंग के पहले अक्षर को कैपिटल करता है |
| 2 | केंद्र (चौड़ाई, भराव) कुल चौड़ाई वाले स्तंभों पर केंद्रित मूल स्ट्रिंग के साथ एक स्पेस-पेड स्ट्रिंग लौटाता है। |
| 3 | गिनती (str, beg = 0, end = len (string)) गणना करता है कि स्ट्रिंग में या स्ट्रिंग के विकल्प में कितनी बार स्ट्रिंग होती है यदि इंडेक्स बीग शुरू करके और इंडेक्स एंड को समाप्त किया जाता है। |
| 4 | डिकोड (एन्कोडिंग = 'UTF-8', त्रुटियों = 'सख्त') एन्कोडिंग के लिए पंजीकृत कोडेक का उपयोग करके स्ट्रिंग को डिकोड करता है। डिफ़ॉल्ट स्ट्रिंग एन्कोडिंग में एन्कोडिंग को डिफ़ॉल्ट बनाता है। |
| 5 | एनकोड (एन्कोडिंग = 'UTF-8', त्रुटियों = 'सख्त') स्ट्रिंग का एन्कोडेड स्ट्रिंग संस्करण लौटाता है; जब तक त्रुटियों को 'अनदेखा' या 'प्रतिस्थापित' के साथ नहीं दिया जाता है, तब तक डिफ़ॉल्ट, एक ValueError को उठाना है। |
| 6 | एंडविथ (प्रत्यय, भीख = 0, अंत = लेन (स्ट्रिंग)) यह निर्धारित करता है कि क्या स्ट्रिंग या स्ट्रिंग का एक विकल्प (यदि अनुक्रमणिका भीख शुरू करना और सूचकांक अंत देना) प्रत्यय के साथ समाप्त होते हैं; यदि ऐसा है तो झूठे और अन्यथा सही है। |
| 7 | expandtabs (tabsize = 8) स्ट्रिंग को कई स्थानों में विस्तारित करता है; टैब प्रति 8 रिक्त स्थान को डिफॉल्ट करता है यदि टैब प्रदान नहीं किया जाता है। |
| 8 | खोजें (str, beg = 0 end = len (string)) निर्धारित करें कि क्या स्ट्रिंग स्ट्रिंग में होती है या स्ट्रिंग के विकल्प में यदि इंडेक्स बीग शुरू करने और इंडेक्स एंड को समाप्त करने पर रिटर्न इंडेक्स दिया जाता है यदि मिला और -1। |
| 9 | सूचकांक (str, beg = 0, end = len (string)) खोज के रूप में भी (), लेकिन एक अपवाद उठाता है अगर नहीं मिला। |
| 10 | isalnum () यदि स्ट्रिंग में कम से कम 1 वर्ण है और सभी वर्ण अल्फ़ान्यूमेरिक हैं और अन्यथा झूठे हैं तो सही है। |
| 1 1 | isalpha () यदि स्ट्रिंग में कम से कम 1 वर्ण है और सभी वर्ण अल्फ़ाबेटिक हैं और अन्यथा झूठे हैं तो सही है। |
| 12 | isdigit () यदि स्ट्रिंग में केवल अंक और असत्य हैं तो यह सही है। |
| 13 | कम है() यह सच है कि अगर स्ट्रिंग में कम से कम 1 कैसिड कैरेक्टर है और सभी कैस्ड कैरेक्टर लोअरकेस में हैं और अन्यथा झूठे हैं। |
| 14 | isnumeric () यदि एक यूनिकोड स्ट्रिंग में केवल संख्यात्मक वर्ण हैं और अन्यथा झूठे हैं तो यह सही है। |
| 15 | isspace () सही है अगर स्ट्रिंग में केवल व्हाट्सएप अक्षर हैं और अन्यथा गलत हैं। |
| 16 | istitle () सच है अगर स्ट्रिंग ठीक से "शीर्षकबद्ध" है और अन्यथा गलत है। |
| 17 | isupper () यह सच है कि अगर स्ट्रिंग में कम से कम एक कैस्ड कैरेक्टर है और सभी कैस्ड कैरेक्टर्स अपरकेस और झूठे हैं तो। |
| 18 | में शामिल होने के (सेक) अनुक्रमों में तत्वों के स्ट्रिंग निरूपण (संघात) को स्ट्रिंग में विभाजक स्ट्रिंग के साथ जोड़ दिया जाता है। |
| 19 | लेन (स्ट्रिंग) स्ट्रिंग की लंबाई देता है |
| 20 | अन्याय (चौड़ाई [, भराव]) कुल चौड़ाई वाले स्तंभों के मूल-बाएँ मूल स्ट्रिंग के साथ एक स्पेस-पेड स्ट्रिंग लौटाता है। |
| 21 | कम () स्ट्रिंग में सभी बड़े अक्षरों को लोअरकेस में कनवर्ट करता है। |
| 22 | lstrip () स्ट्रिंग में सभी प्रमुख व्हाट्सएप को हटाता है। |
| 23 | maketrans () अनुवाद फ़ंक्शन में उपयोग की जाने वाली अनुवाद तालिका लौटाता है। |
| 24 | अधिकतम (एसटीआर) स्ट्रिंग स्ट्रिंग से अधिकतम वर्णमाला वर्ण लौटाता है। |
| 25 | मिनट (एसटीआर) स्ट्रिंग स्ट्रिंग से मिनी वर्णमाला वर्ण लौटाता है। |
| 26 | बदलें (पुराना, नया [, अधिकतम]) स्ट्रिंग में पुराने की सभी घटनाओं को नए के साथ या अधिकतम दिए जाने पर अधिकतम घटनाओं में बदल देता है। |
| 27 | Rfind (str, beg = 0, end = len (string)) खोज के समान (), लेकिन स्ट्रिंग में पीछे की ओर खोजें। |
| 28 | Rindex (str, beg = 0, end = len (string)) सूचकांक के रूप में भी (), लेकिन स्ट्रिंग में पीछे की ओर खोजें। |
| 29 | अन्यायपूर्ण (चौड़ाई, [, भराव]) कुल चौड़ाई वाले स्तंभों के सही मूल स्ट्रिंग के साथ एक स्पेस-पेड स्ट्रिंग लौटाता है। |
| 30 | rstrip () स्ट्रिंग के सभी अनुगामी व्हाट्सएप को हटाता है। |
| 31 | विभाजन (str = "", num = string.count (str)) स्ट्रिमिटर स्ट्रै के अनुसार स्प्लिट्स स्ट्रिंग (यदि प्रदान नहीं की गई है) और सब्सट्रिंग की सूची लौटाता है; सबसे अधिक संख्या में विभाजन पर अगर दिया। |
| 32 | विभाजन (संख्या = string.count ('\ n')) सभी स्ट्रिंग (या संख्या) NEWLINE को विभाजित करता है और हटाए गए NEWLINE के साथ प्रत्येक पंक्ति की एक सूची देता है। |
| 33 | स्टार्टस्विथ (str, beg = 0, end = len (string)) यह निर्धारित करता है कि क्या स्ट्रिंग या स्ट्रिंग का एक स्ट्रिंग (यदि इंडेक्स बीग शुरू करने और इंडेक्स एंड को समाप्त करने के लिए दिए गए हैं) स्ट्रिंग स्ट्रिंग के साथ शुरू होता है; यदि ऐसा है तो झूठे और अन्यथा सही है। |
| 34 | पट्टी ([वर्ण]) स्ट्रिंग पर lstrip () और rstrip () दोनों करता है। |
| 35 | swapcase () स्ट्रिंग में सभी अक्षरों के लिए इन्वर्ट केस। |
| 36 | शीर्षक () स्ट्रिंग का "शीर्षकबद्ध" संस्करण लौटाता है, अर्थात, सभी शब्द अपरकेस से शुरू होते हैं और बाकी निचले हिस्से में होते हैं। |
| 37 | अनुवाद (सारणी, विलोपन = "") ट्रांस स्ट्रिंग टेबल (256 वर्ण) के अनुसार स्ट्रिंग का अनुवाद करता है, डेल स्ट्रिंग में उन लोगों को हटा रहा है। |
| 38 | ऊपरी () स्ट्रिंग में अक्षरों को अपरकेस में परिवर्तित करता है। |
| 39 | zfill (चौड़ाई) कुल चौड़ाई वाले वर्णों के साथ मूल स्ट्रिंग को छोड़ दिया गया; संख्याओं के लिए, zfill () दिए गए किसी भी संकेत (कम एक शून्य) को बरकरार रखता है। |
| 40 | isdecimal () यदि एक यूनिकोड स्ट्रिंग में केवल दशमलव वर्ण और झूठे हैं तो सही है। |
पायथन में सबसे बुनियादी डेटा संरचना है sequence। अनुक्रम के प्रत्येक तत्व को एक संख्या सौंपी जाती है - इसकी स्थिति या सूचकांक। पहला इंडेक्स शून्य है, दूसरा इंडेक्स एक है, और आगे है।
पायथन में छह अंतर्निहित प्रकार के अनुक्रम हैं, लेकिन सबसे सामान्य सूची और ट्यूपल हैं, जिन्हें हम इस ट्यूटोरियल में देखेंगे।
कुछ चीजें हैं जो आप सभी अनुक्रम प्रकारों के साथ कर सकते हैं। इन कार्यों में अनुक्रमण, स्लाइसिंग, जोड़ना, गुणा करना और सदस्यता की जाँच शामिल है। इसके अलावा, पायथन ने एक अनुक्रम की लंबाई खोजने के लिए और इसके सबसे बड़े और सबसे छोटे तत्वों को खोजने के लिए अंतर्निहित कार्य किए हैं।
पायथन लिस्ट्स
सूची पायथन में उपलब्ध एक सबसे बहुमुखी डेटाटाइप है जिसे वर्ग कोष्ठक के बीच अल्पविराम से अलग किए गए मान (आइटम) की सूची के रूप में लिखा जा सकता है। किसी सूची के बारे में महत्वपूर्ण बात यह है कि किसी सूची में वस्तुओं को एक ही प्रकार का नहीं होना चाहिए।
एक सूची बनाना वर्ग कोष्ठकों के बीच विभिन्न अल्पविराम द्वारा अलग किए गए मानों को डालने जैसा सरल है उदाहरण के लिए -
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"]स्ट्रिंग सूचकांकों के समान, सूची सूचकांक 0 से शुरू होते हैं, और सूचियों को कटा हुआ, संक्षिप्त किया जा सकता है और इसी तरह।
सूचियों में पहुँच मान
सूचियों में मानों तक पहुंचने के लिए, उस सूचकांक पर उपलब्ध मूल्य प्राप्त करने के लिए इंडेक्स या सूचकांकों के साथ स्लाइसिंग के लिए चौकोर कोष्ठक का उपयोग करें। उदाहरण के लिए -
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5, 6, 7 ];
print "list1[0]: ", list1[0]
print "list2[1:5]: ", list2[1:5]जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
list1[0]: physics
list2[1:5]: [2, 3, 4, 5]अद्यतन सूची
आप असाइनमेंट ऑपरेटर के बायीं ओर स्लाइस देकर सूचियों के एकल या एकाधिक तत्वों को अपडेट कर सकते हैं, और आप ऐपेंड () विधि के साथ सूची में तत्वों को जोड़ सकते हैं। उदाहरण के लिए -
#!/usr/bin/python
list = ['physics', 'chemistry', 1997, 2000];
print "Value available at index 2 : "
print list[2]
list[2] = 2001;
print "New value available at index 2 : "
print list[2]Note - परिशिष्ट () विधि की चर्चा बाद के खंड में की गई है।
जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Value available at index 2 :
1997
New value available at index 2 :
2001सूची तत्वों को हटाएं
किसी सूची तत्व को निकालने के लिए, आप या तो डेल स्टेटमेंट का उपयोग कर सकते हैं यदि आप जानते हैं कि वास्तव में कौन सा तत्व (ओं) को आप नहीं हटा रहे हैं या हटा दें () विधि यदि आप नहीं जानते हैं। उदाहरण के लिए -
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000];
print list1
del list1[2];
print "After deleting value at index 2 : "
print list1जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
['physics', 'chemistry', 1997, 2000]
After deleting value at index 2 :
['physics', 'chemistry', 2000]Note - निकालें () विधि के बाद के अनुभाग में चर्चा की गई है।
मूल सूची संचालन
सूचियाँ + और * संचालकों को स्ट्रिंग की तरह ज्यादा जवाब देती हैं; उनका मतलब यहाँ पर अनुगमन और पुनरावृत्ति भी है, सिवाय इसके कि परिणाम एक नई सूची है, न कि एक स्ट्रिंग।
वास्तव में, सूचियाँ उन सभी सामान्य अनुक्रम ऑपरेशनों का जवाब देती हैं, जिनका उपयोग हमने पहले अध्याय में तार पर किया था।
| पायथन अभिव्यक्ति | परिणाम | विवरण |
|---|---|---|
| लेन ([१, २, ३]) | 3 | लंबाई |
| [१, २, ३] + [४, ५, ६] | [१, २, ३, ४, ५, ६] | कड़ी |
| ['हाय!'] * ४ | [[हाय! ’,! हाय!’, 'हाय! ’,' हाय!’] | दुहराव |
| 3 में [1, 2, 3] | सच | सदस्यता |
| x में [1, 2, 3] के लिए: प्रिंट x, | १ २ ३ | यात्रा |
अनुक्रमण, स्लाइसिंग, और मैट्रिक्स
क्योंकि सूचियाँ अनुक्रम हैं, अनुक्रमण और स्लाइसिंग सूचियों के लिए उसी तरह काम करते हैं जैसे वे तार के लिए करते हैं।
निम्नलिखित इनपुट को मानते हुए -
L = ['spam', 'Spam', 'SPAM!']| पायथन अभिव्यक्ति | परिणाम | विवरण |
|---|---|---|
| एल [2] | स्पैम! | ऑफ़सेट शून्य पर शुरू होते हैं |
| एल [-2] | स्पैम | ऋणात्मक: दाईं ओर से गिनें |
| एल [1:] | ['स्पैम', 'स्पैम'!] | कटा हुआ भ्रूण वर्गों |
अंतर्निहित सूची कार्य और विधियाँ
पायथन में निम्नलिखित सूची कार्य शामिल हैं -
| अनु क्रमांक। | विवरण के साथ कार्य |
|---|---|
| 1 | सीएमपी (सूची 1, सूची 2) दोनों सूचियों के तत्वों की तुलना करता है। |
| 2 | लेन (सूची) सूची की कुल लंबाई देता है। |
| 3 | अधिकतम (सूची) अधिकतम मूल्य के साथ सूची से आइटम लौटाता है। |
| 4 | मिनट (सूची) न्यूनतम मूल्य के साथ सूची से आइटम लौटाता है। |
| 5 | सूची (सेक) सूची में एक tuple परिवर्तित करता है। |
पायथन में निम्नलिखित सूची विधियां शामिल हैं
| अनु क्रमांक। | विवरण के साथ तरीके |
|---|---|
| 1 | list.append (obj) सूची के लिए ऑब्जेक्ट obj जोड़ता है |
| 2 | list.count (obj) सूची में कितनी बार obj होता है, इसकी गणना करता है |
| 3 | list.extend (सेक) सूची में seq की सामग्री को लागू करता है |
| 4 | list.index (obj) सूची में सबसे कम इंडेक्स देता है जो obj प्रकट होता है |
| 5 | सूची। सूची (सूचकांक, obj) ऑफसेट इंडेक्स में सूची में ऑब्जेक्ट को सम्मिलित करता है |
| 6 | list.pop (obj = सूची [-1]) सूची से अंतिम ऑब्जेक्ट या obj को निकालता है और वापस करता है |
| 7 | list.remove (obj) सूची से ऑब्जेक्ट obj हटाता है |
| 8 | list.reverse () जगह की सूची की वस्तुओं को उलट देता है |
| 9 | list.sort ([समारोह]) सूची की वस्तुओं को सॉर्ट करता है, अगर दी गई फंक की तुलना करें |
एक टुपल पायथन वस्तुओं का एक अपरिवर्तनीय अनुक्रम है। ट्यूपल अनुक्रम हैं, सूचियों की तरह। ट्यूपल्स और सूचियों के बीच अंतर है, सूचियों के विपरीत ट्यूपल्स को नहीं बदला जा सकता है और ट्यूपल्स कोष्ठक का उपयोग करते हैं, जबकि सूचियां वर्ग कोष्ठक का उपयोग करती हैं।
अलग-अलग अल्पविराम द्वारा अलग किए गए मानों को बनाने के लिए एक टपल बनाना उतना ही सरल है। वैकल्पिक रूप से आप इन अल्पविराम द्वारा अलग किए गए मानों को कोष्ठक के बीच भी रख सकते हैं। उदाहरण के लिए -
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";खाली टपल को दो कोष्ठक के रूप में लिखा गया है जिसमें कुछ भी नहीं है -
tup1 = ();एक एकल मान लिखने के लिए आपको एक अल्पविराम शामिल करना होगा, भले ही केवल एक ही मूल्य हो -
tup1 = (50,);स्ट्रिंग सूचकांकों की तरह, ट्यूल इंडेक्स 0 से शुरू होते हैं, और उन्हें कटा हुआ, संक्षिप्त किया जा सकता है, और इसी तरह।
टुपल्स में पहुँच मान
टपल में मानों तक पहुँचने के लिए, इंडेक्स या सूचकांकों के साथ स्लाइसिंग के लिए वर्गाकार कोष्ठक का उपयोग करें जो उस इंडेक्स पर उपलब्ध मूल्य प्राप्त करने के लिए। उदाहरण के लिए -
#!/usr/bin/python
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5, 6, 7 );
print "tup1[0]: ", tup1[0];
print "tup2[1:5]: ", tup2[1:5];जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
tup1[0]: physics
tup2[1:5]: [2, 3, 4, 5]अद्यतन Tuples
टुपल्स अपरिवर्तनीय हैं जिसका मतलब है कि आप टपल तत्वों के मूल्यों को अपडेट या बदल नहीं सकते हैं। आप निम्न उदाहरणों के प्रदर्शन के रूप में नए tuples बनाने के लिए मौजूदा tuples के भाग लेने में सक्षम हैं -
#!/usr/bin/python
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# Following action is not valid for tuples
# tup1[0] = 100;
# So let's create a new tuple as follows
tup3 = tup1 + tup2;
print tup3;जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
(12, 34.56, 'abc', 'xyz')टपल तत्वों को हटाएं
व्यक्तिगत टपल तत्वों को हटाना संभव नहीं है। निस्संदेह, हटाए गए अवांछित तत्वों के साथ एक और टपल लगाने के साथ कुछ भी गलत नहीं है।
स्पष्ट रूप से संपूर्ण टपल को निकालने के लिए, बस का उपयोग करें delबयान। उदाहरण के लिए -
#!/usr/bin/python
tup = ('physics', 'chemistry', 1997, 2000);
print tup;
del tup;
print "After deleting tup : ";
print tup;यह निम्न परिणाम उत्पन्न करता है। एक अपवाद पर ध्यान दें, यह बाद में हैdel tup टपल का कोई अस्तित्व नहीं है -
('physics', 'chemistry', 1997, 2000)
After deleting tup :
Traceback (most recent call last):
File "test.py", line 9, in <module>
print tup;
NameError: name 'tup' is not definedबुनियादी नलिका संचालन
टुपल्स + और * ऑपरेटरों को स्ट्रिंग्स की तरह जवाब देते हैं; उनका मतलब यहाँ पर अनुगमन और पुनरावृत्ति भी है, सिवाय इसके कि परिणाम एक नया टपल है, न कि एक स्ट्रिंग।
वास्तव में, टुपल्स उन सभी सामान्य अनुक्रम ऑपरेशनों का जवाब देते हैं, जिनका उपयोग हमने पहले अध्याय में स्ट्रिंग्स पर किया था -
| पायथन अभिव्यक्ति | परिणाम | विवरण |
|---|---|---|
| लेन ((1, 2, 3)) | 3 | लंबाई |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | कड़ी |
| ((हाय! ’,) * ४ | ((हाय! ’,! हाय!’, 'हाय! ’,' हाय!’) | दुहराव |
| 3 में (1, 2, 3) | सच | सदस्यता |
| x के लिए (1, 2, 3): प्रिंट x, | १ २ ३ | यात्रा |
अनुक्रमण, स्लाइसिंग, और मैट्रिक्स
क्योंकि ट्यूपल्स अनुक्रम हैं, अनुक्रमण और स्लाइसिंग ट्यूपल्स के लिए उसी तरह काम करते हैं जैसे वे स्ट्रिंग्स के लिए करते हैं। निम्नलिखित इनपुट को मानते हुए -
L = ('spam', 'Spam', 'SPAM!')
| पायथन अभिव्यक्ति | परिणाम | विवरण |
|---|---|---|
| एल [2] | 'स्पैम!' | ऑफ़सेट शून्य पर शुरू होते हैं |
| एल [-2] | 'स्पैम' | ऋणात्मक: दाईं ओर से गिनें |
| एल [1:] | ['स्पैम', 'स्पैम'!] | कटा हुआ भ्रूण वर्गों |
कोई संलग्नक परिमाण नहीं
कई वस्तुओं का कोई सेट, अल्पविराम से अलग, प्रतीकों की पहचान के बिना लिखा गया, यानी, सूचियों के लिए कोष्ठक, टुपल्स के लिए कोष्ठक, आदि, टुपल्स के लिए डिफ़ॉल्ट, जैसा कि इन छोटे उदाहरणों में संकेत दिया गया है -
#!/usr/bin/python
print 'abc', -4.24e93, 18+6.6j, 'xyz';
x, y = 1, 2;
print "Value of x , y : ", x,y;जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2बिल्ट-इन ट्यूपल फ़ंक्शंस
अजगर में निम्नलिखित कार्य शामिल हैं -
| अनु क्रमांक। | विवरण के साथ कार्य |
|---|---|
| 1 | cmp (tuple1, tuple2) दोनों टुपल्स के तत्वों की तुलना करता है। |
| 2 | लेन (टपल) टपल की कुल लंबाई देता है। |
| 3 | अधिकतम (टपल) अधिकतम मूल्य के साथ टपल से आइटम लौटाता है। |
| 4 | मिनट (टपल) न्यूनतम मूल्य के साथ टपल से आइटम लौटाता है। |
| 5 | टपल (सेक) एक सूची को टुप में परिवर्तित करता है। |
प्रत्येक कुंजी को उसके मूल्य से एक बृहदान्त्र (:) से अलग किया जाता है, वस्तुओं को अल्पविराम से अलग किया जाता है, और पूरी चीज़ को कर्व ब्रेस में संलग्न किया जाता है। बिना किसी आइटम के एक खाली शब्दकोष केवल दो घुंघराले ब्रेसिज़ के साथ लिखा जाता है, जैसे: {}।
कुंजी एक शब्दकोश के भीतर अद्वितीय हैं जबकि मूल्य नहीं हो सकते हैं। एक शब्दकोश के मूल्य किसी भी प्रकार के हो सकते हैं, लेकिन कुंजी एक अपरिवर्तनीय डेटा प्रकार की होनी चाहिए जैसे कि तार, संख्या, या टुपल्स।
शब्दकोश में पहुँच मान
शब्दकोश तत्वों तक पहुंचने के लिए, आप इसके मूल्य को प्राप्त करने के लिए कुंजी के साथ परिचित वर्ग कोष्ठक का उपयोग कर सकते हैं। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Name']: ", dict['Name']
print "dict['Age']: ", dict['Age']जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
dict['Name']: Zara
dict['Age']: 7यदि हम एक कुंजी के साथ एक डेटा आइटम तक पहुंचने का प्रयास करते हैं, जो शब्दकोश का हिस्सा नहीं है, तो हमें निम्नानुसार एक त्रुटि मिलती है -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Alice']: ", dict['Alice']जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
dict['Alice']:
Traceback (most recent call last):
File "test.py", line 4, in <module>
print "dict['Alice']: ", dict['Alice'];
KeyError: 'Alice'शब्दकोश अद्यतन
आप एक नई प्रविष्टि या एक कुंजी-मूल्य जोड़ी जोड़कर एक शब्दकोश अपडेट कर सकते हैं, एक मौजूदा प्रविष्टि को संशोधित कर सकते हैं, या एक मौजूदा प्रविष्टि को हटा सकते हैं जैसा कि सरल उदाहरण में नीचे दिखाया गया है -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
dict['Age']: 8
dict['School']: DPS Schoolशब्दकोश तत्वों को हटाएँ
आप या तो व्यक्तिगत शब्दकोश तत्वों को हटा सकते हैं या किसी शब्दकोश की संपूर्ण सामग्री को साफ़ कर सकते हैं। आप एकल ऑपरेशन में पूरे शब्दकोश को हटा भी सकते हैं।
स्पष्ट रूप से एक संपूर्ण शब्दकोश निकालने के लिए, बस का उपयोग करें delबयान। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict['Name']; # remove entry with key 'Name'
dict.clear(); # remove all entries in dict
del dict ; # delete entire dictionary
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']यह निम्न परिणाम उत्पन्न करता है। ध्यान दें कि एक अपवाद उठाया जाता है क्योंकि बाद मेंdel dict शब्दकोश में कोई और मौजूद नहीं है -
dict['Age']:
Traceback (most recent call last):
File "test.py", line 8, in <module>
print "dict['Age']: ", dict['Age'];
TypeError: 'type' object is unsubscriptableNote - बाद के अनुभाग में डेल () विधि पर चर्चा की गई है।
शब्दकोश कुंजी के गुण
शब्दकोश मूल्यों पर कोई प्रतिबंध नहीं है। वे किसी भी मनमानी पायथन ऑब्जेक्ट हो सकते हैं, या तो मानक ऑब्जेक्ट या उपयोगकर्ता-परिभाषित ऑब्जेक्ट। हालाँकि, यह कुंजियों के लिए सही नहीं है।
शब्दकोश कुंजियों के बारे में याद रखने के लिए दो महत्वपूर्ण बिंदु हैं -
(a)प्रति कुंजी एक से अधिक प्रविष्टि की अनुमति नहीं है। जिसका अर्थ है कि डुप्लिकेट कुंजी की अनुमति नहीं है। जब असाइनमेंट के दौरान डुप्लिकेट कुंजियों का सामना करना पड़ता है, तो अंतिम असाइनमेंट जीत जाता है। उदाहरण के लिए -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'}
print "dict['Name']: ", dict['Name']जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
dict['Name']: Manni(b)चाबियाँ अपरिवर्तनीय होनी चाहिए। जिसका अर्थ है कि आप शब्द कुंजियों के रूप में तार, संख्याओं या टुपल्स का उपयोग कर सकते हैं, लेकिन ['कुंजी' जैसी किसी चीज़ की अनुमति नहीं है। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
dict = {['Name']: 'Zara', 'Age': 7}
print "dict['Name']: ", dict['Name']जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'Zara', 'Age': 7};
TypeError: unhashable type: 'list'बिल्ट-इन डिक्शनरी फ़ंक्शंस और मेथड्स
पायथन में निम्नलिखित शब्दकोश कार्य शामिल हैं -
| अनु क्रमांक। | विवरण के साथ कार्य |
|---|---|
| 1 | सीएमपी (तानाशाही 1, तानाशाही 2) दोनों तानाशाहों के तत्वों की तुलना करता है। |
| 2 | लेन (dict) शब्दकोश की कुल लंबाई देता है। यह शब्दकोश में मदों की संख्या के बराबर होगा। |
| 3 | str (dict) एक शब्दकोश के एक मुद्रण योग्य स्ट्रिंग प्रतिनिधित्व का उत्पादन करता है |
| 4 | प्रकार (चर) पारित चर का प्रकार लौटाता है। यदि पारित चर शब्दकोश है, तो यह एक शब्दकोश प्रकार लौटाएगा। |
पायथन में निम्नलिखित शब्दकोश विधियाँ शामिल हैं -
| अनु क्रमांक। | विवरण के साथ तरीके |
|---|---|
| 1 | dict.clear () शब्दकोश के सभी तत्वों को निकालता है dict |
| 2 | dict.copy () रिटर्न शब्दकोश के एक उथले प्रतिलिपि dict |
| 3 | dict.fromkeys () Seq से कुंजी और मूल्यों के साथ एक नया शब्दकोश बनाएं सेट करने के लिए मूल्य । |
| 4 | dict.get (कुंजी, डिफ़ॉल्ट = कोई नहीं) के लिए कुंजी कुंजी, रिटर्न कुंजी नहीं शब्दकोश में यदि मान या डिफ़ॉल्ट |
| 5 | dict.has_key (key) रिटर्न सच अगर शब्दकोश में कुंजी dict , झूठी अन्यथा |
| 6 | dict.items () की एक सूची देता है dict रों (कुंजी, मूल्य) टपल जोड़े ' |
| 7 | dict.keys () डिक्शनरी की कुंजियों की सूची लौटाता है |
| 8 | dict.setdefault (कुंजी, डिफ़ॉल्ट = कोई नहीं) पाने के लिए समान (), लेकिन निर्धारित करेगा कुंजी [कुंजी] = डिफ़ॉल्ट यदि कुंजी पहले से ही तानाशाह में नहीं है |
| 9 | dict.update (dict2) शब्दकोश जोड़ता dict2 करने की मुख्य-मान जोड़े dict |
| 10 | dict.values () शब्दकोश की रिटर्न सूची dict के मूल्यों |
एक पायथन कार्यक्रम कई तरीकों से तारीख और समय को संभाल सकता है। दिनांक प्रारूपों के बीच परिवर्तित करना कंप्यूटर के लिए एक सामान्य काम है। पायथन का समय और कैलेंडर मॉड्यूल तारीख और समय को ट्रैक करने में मदद करते हैं।
टिक क्या है
समय अंतराल सेकंड की इकाइयों में फ्लोटिंग-पॉइंट नंबर हैं। 1 जनवरी, 1970 (युग) 00:00:00 बजे के बाद से समय में विशेष रूप से उदाहरणों को सेकंड में व्यक्त किया जाता है।
एक लोकप्रिय है timeपायथन में उपलब्ध मॉड्यूल जो समय के साथ काम करने और अभ्यावेदन के बीच परिवर्तित करने के लिए कार्य प्रदान करता है। फ़ंक्शन टाइम.टाइम () 00:00:00 बजे से 1 जनवरी, 1970 (युग) के बाद से टिक्स में वर्तमान सिस्टम समय देता है।
उदाहरण
#!/usr/bin/python
import time; # This is required to include time module.
ticks = time.time()
print "Number of ticks since 12:00am, January 1, 1970:", ticksयह इस प्रकार कुछ परिणाम देगा -
Number of ticks since 12:00am, January 1, 1970: 7186862.73399तिथि अंकगणित टिक के साथ करना आसान है। हालाँकि, इस रूप में युग से पहले की तारीखों का प्रतिनिधित्व नहीं किया जा सकता है। सुदूर भविष्य की तारीखों का भी इस तरह प्रतिनिधित्व नहीं किया जा सकता है - कटऑफ पॉइंट 2038 में UNIX और Windows के लिए कुछ समय है।
TimeTuple क्या है?
पायथन के कई कार्य समय को 9 संख्याओं के टपल के रूप में संभालते हैं, जैसा कि नीचे दिखाया गया है -
| सूची | मैदान | मूल्यों |
|---|---|---|
| 0 | 4-अंक वर्ष | 2008 |
| 1 | महीना | 1 से 12 |
| 2 | दिन | 1 से 31 |
| 3 | इस घंटे | 0 से 23 |
| 4 | मिनट | 0 से 59 |
| 5 | दूसरा | 0 से 61 (60 या 61 लीप-सेकंड हैं) |
| 6 | सप्ताह के दिन | 0 से 6 (0 सोमवार है) |
| 7 | साल का दिन | 1 से 366 (जूलियन दिन) |
| 8 | दिन के उजाले की बचत | -1, 0, 1, -1 का मतलब है लाइब्रेरी डीएसटी निर्धारित करती है |
उपरोक्त टुपल के बराबर है struct_timeसंरचना। इस संरचना में निम्नलिखित विशेषताएं हैं -
| सूची | गुण | मूल्यों |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | 1 से 12 |
| 2 | tm_mday | 1 से 31 |
| 3 | tm_hour | 0 से 23 |
| 4 | tm_min | 0 to 59 |
| 5 | tm_sec | 0 to 61 (60 or 61 are leap-seconds) |
| 6 | tm_wday | 0 to 6 (0 is Monday) |
| 7 | tm_yday | 1 to 366 (Julian day) |
| 8 | tm_isdst | -1, 0, 1, -1 means library determines DST |
Getting current time
To translate a time instant from a seconds since the epoch floating-point value into a time-tuple, pass the floating-point value to a function (e.g., localtime) that returns a time-tuple with all nine items valid.
#!/usr/bin/python
import time;
localtime = time.localtime(time.time())
print "Local current time :", localtimeThis would produce the following result, which could be formatted in any other presentable form −
Local current time : time.struct_time(tm_year=2013, tm_mon=7,
tm_mday=17, tm_hour=21, tm_min=26, tm_sec=3, tm_wday=2, tm_yday=198, tm_isdst=0)Getting formatted time
You can format any time as per your requirement, but simple method to get time in readable format is asctime() −
#!/usr/bin/python
import time;
localtime = time.asctime( time.localtime(time.time()) )
print "Local current time :", localtimeThis would produce the following result −
Local current time : Tue Jan 13 10:17:09 2009Getting calendar for a month
The calendar module gives a wide range of methods to play with yearly and monthly calendars. Here, we print a calendar for a given month ( Jan 2008 ) −
#!/usr/bin/python
import calendar
cal = calendar.month(2008, 1)
print "Here is the calendar:"
print calThis would produce the following result −
Here is the calendar:
January 2008
Mo Tu We Th Fr Sa Su
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30 31The time Module
There is a popular time module available in Python which provides functions for working with times and for converting between representations. Here is the list of all available methods −
| Sr.No. | Function with Description |
|---|---|
| 1 | time.altzone The offset of the local DST timezone, in seconds west of UTC, if one is defined. This is negative if the local DST timezone is east of UTC (as in Western Europe, including the UK). Only use this if daylight is nonzero. |
| 2 | time.asctime([tupletime]) Accepts a time-tuple and returns a readable 24-character string such as 'Tue Dec 11 18:07:14 2008'. |
| 3 | time.clock( ) Returns the current CPU time as a floating-point number of seconds. To measure computational costs of different approaches, the value of time.clock is more useful than that of time.time(). |
| 4 | time.ctime([secs]) Like asctime(localtime(secs)) and without arguments is like asctime( ) |
| 5 | time.gmtime([secs]) Accepts an instant expressed in seconds since the epoch and returns a time-tuple t with the UTC time. Note : t.tm_isdst is always 0 |
| 6 | time.localtime([secs]) Accepts an instant expressed in seconds since the epoch and returns a time-tuple t with the local time (t.tm_isdst is 0 or 1, depending on whether DST applies to instant secs by local rules). |
| 7 | time.mktime(tupletime) Accepts an instant expressed as a time-tuple in local time and returns a floating-point value with the instant expressed in seconds since the epoch. |
| 8 | time.sleep(secs) Suspends the calling thread for secs seconds. |
| 9 | time.strftime(fmt[,tupletime]) Accepts an instant expressed as a time-tuple in local time and returns a string representing the instant as specified by string fmt. |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') Parses str according to format string fmt and returns the instant in time-tuple format. |
| 11 | time.time( ) Returns the current time instant, a floating-point number of seconds since the epoch. |
| 12 | time.tzset() Resets the time conversion rules used by the library routines. The environment variable TZ specifies how this is done. |
Let us go through the functions briefly −
There are following two important attributes available with time module −
| Sr.No. | Attribute with Description |
|---|---|
| 1 | time.timezone Attribute time.timezone is the offset in seconds of the local time zone (without DST) from UTC (>0 in the Americas; <=0 in most of Europe, Asia, Africa). |
| 2 | time.tzname Attribute time.tzname is a pair of locale-dependent strings, which are the names of the local time zone without and with DST, respectively. |
The calendar Module
The calendar module supplies calendar-related functions, including functions to print a text calendar for a given month or year.
By default, calendar takes Monday as the first day of the week and Sunday as the last one. To change this, call calendar.setfirstweekday() function.
Here is a list of functions available with the calendar module −
| Sr.No. | Function with Description |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) Returns a multiline string with a calendar for year year formatted into three columns separated by c spaces. w is the width in characters of each date; each line has length 21*w+18+2*c. l is the number of lines for each week. |
| 2 | calendar.firstweekday( ) Returns the current setting for the weekday that starts each week. By default, when calendar is first imported, this is 0, meaning Monday. |
| 3 | calendar.isleap(year) Returns True if year is a leap year; otherwise, False. |
| 4 | calendar.leapdays(y1,y2) Returns the total number of leap days in the years within range(y1,y2). |
| 5 | calendar.month(year,month,w=2,l=1) Returns a multiline string with a calendar for month month of year year, one line per week plus two header lines. w is the width in characters of each date; each line has length 7*w+6. l is the number of lines for each week. |
| 6 | calendar.monthcalendar(year,month) Returns a list of lists of ints. Each sublist denotes a week. Days outside month month of year year are set to 0; days within the month are set to their day-of-month, 1 and up. |
| 7 | calendar.monthrange(year,month) Returns two integers. The first one is the code of the weekday for the first day of the month month in year year; the second one is the number of days in the month. Weekday codes are 0 (Monday) to 6 (Sunday); month numbers are 1 to 12. |
| 8 | calendar.prcal(year,w=2,l=1,c=6) Like print calendar.calendar(year,w,l,c). |
| 9 | calendar.prmonth(year,month,w=2,l=1) Like print calendar.month(year,month,w,l). |
| 10 | calendar.setfirstweekday(weekday) Sets the first day of each week to weekday code weekday. Weekday codes are 0 (Monday) to 6 (Sunday). |
| 11 | calendar.timegm(tupletime) The inverse of time.gmtime: accepts a time instant in time-tuple form and returns the same instant as a floating-point number of seconds since the epoch. |
| 12 | calendar.weekday(year,month,day) Returns the weekday code for the given date. Weekday codes are 0 (Monday) to 6 (Sunday); month numbers are 1 (January) to 12 (December). |
Other Modules & Functions
If you are interested, then here you would find a list of other important modules and functions to play with date & time in Python −
The datetime Module
The pytz Module
The dateutil Module
एक फ़ंक्शन संगठित, पुन: प्रयोज्य कोड का एक ब्लॉक है जो एकल, संबंधित कार्रवाई करने के लिए उपयोग किया जाता है। फ़ंक्शंस आपके आवेदन के लिए बेहतर मॉड्युलैरिटी और उच्च श्रेणी का कोड पुन: उपयोग कर रहे हैं।
जैसा कि आप पहले से ही जानते हैं, पायथन आपको कई अंतर्निहित कार्यों जैसे प्रिंट (), आदि देता है, लेकिन आप अपने स्वयं के कार्य भी बना सकते हैं। इन कार्यों को उपयोगकर्ता-परिभाषित फ़ंक्शन कहा जाता है।
एक कार्य को परिभाषित करना
आप आवश्यक कार्यक्षमता प्रदान करने के लिए कार्यों को परिभाषित कर सकते हैं। पायथन में एक फ़ंक्शन को परिभाषित करने के लिए यहां सरल नियम हैं।
फंक्शन ब्लॉक कीवर्ड से शुरू होता है def इसके बाद फ़ंक्शन नाम और कोष्ठक ())।
किसी भी इनपुट पैरामीटर या तर्क को इन कोष्ठकों के भीतर रखा जाना चाहिए। आप इन कोष्ठकों के अंदर मापदंडों को भी परिभाषित कर सकते हैं।
फ़ंक्शन का पहला स्टेटमेंट एक वैकल्पिक स्टेटमेंट हो सकता है - फ़ंक्शन या डॉकस्ट्रिंग के प्रलेखन स्ट्रिंग ।
प्रत्येक फ़ंक्शन के भीतर कोड ब्लॉक एक कोलन (:) के साथ शुरू होता है और इंडेंट होता है।
स्टेटमेंट रिटर्न [अभिव्यक्ति] एक फ़ंक्शन से बाहर निकलता है, वैकल्पिक रूप से कॉलर को एक अभिव्यक्ति वापस दे रहा है। बिना किसी दलील के एक रिटर्न स्टेटमेंट रिटर्न नो के समान है।
वाक्य - विन्यास
def functionname( parameters ):
"function_docstring"
function_suite
return [expression]डिफ़ॉल्ट रूप से, मापदंडों का एक व्यवहारिक व्यवहार होता है और आपको उन्हें उसी क्रम में सूचित करने की आवश्यकता होती है जिसे वे परिभाषित किए गए थे।
उदाहरण
निम्न फ़ंक्शन इनपुट पैरामीटर के रूप में एक स्ट्रिंग लेता है और इसे मानक स्क्रीन पर प्रिंट करता है।
def printme( str ):
"This prints a passed string into this function"
print str
returnएक समारोह बुला रहा है
किसी फ़ंक्शन को परिभाषित करना केवल इसे एक नाम देता है, फ़ंक्शन में शामिल होने वाले पैरामीटर को निर्दिष्ट करता है और कोड के ब्लॉक को संरचना देता है।
किसी फ़ंक्शन की मूल संरचना को अंतिम रूप देने के बाद, आप इसे किसी अन्य फ़ंक्शन से कॉल करके या सीधे पायथन प्रॉम्प्ट से निष्पादित कर सकते हैं। निम्नलिखित प्रिंटमे () फ़ंक्शन को कॉल करने के लिए उदाहरण है -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme("I'm first call to user defined function!")
printme("Again second call to the same function")जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
I'm first call to user defined function!
Again second call to the same functionसंदर्भ बनाम मान से पास करें
पायथन भाषा में सभी पैरामीटर (तर्क) संदर्भ द्वारा पारित किए जाते हैं। इसका मतलब है कि अगर आप किसी फ़ंक्शन के भीतर एक पैरामीटर को संदर्भित करते हैं, तो परिवर्तन कॉलिंग फ़ंक्शन में वापस भी दिखाई देता है। उदाहरण के लिए -
#!/usr/bin/python
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist.append([1,2,3,4]);
print "Values inside the function: ", mylist
return
# Now you can call changeme function
mylist = [10,20,30];
changeme( mylist );
print "Values outside the function: ", mylistयहां, हम एक ही वस्तु में उत्तीर्ण वस्तु और संलग्न मान का संदर्भ बनाए हुए हैं। तो, यह निम्नलिखित परिणाम का उत्पादन करेगा -
Values inside the function: [10, 20, 30, [1, 2, 3, 4]]
Values outside the function: [10, 20, 30, [1, 2, 3, 4]]एक और उदाहरण है जहां संदर्भ द्वारा तर्क पारित किया जा रहा है और संदर्भ को फ़ंक्शन के अंदर लिखा जा रहा है।
#!/usr/bin/python
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist = [1,2,3,4]; # This would assig new reference in mylist
print "Values inside the function: ", mylist
return
# Now you can call changeme function
mylist = [10,20,30];
changeme( mylist );
print "Values outside the function: ", mylistपैरामीटर mylist फंक्शन चेंजमे के लिए स्थानीय है। समारोह के भीतर MyList बदलने को प्रभावित नहीं करता MyList । फ़ंक्शन कुछ भी पूरा नहीं करता है और अंत में यह निम्न परिणाम उत्पन्न करेगा -
Values inside the function: [1, 2, 3, 4]
Values outside the function: [10, 20, 30]कार्य तर्क
आप निम्न प्रकार के औपचारिक तर्कों का उपयोग करके किसी फ़ंक्शन को कॉल कर सकते हैं -
- आवश्यक तर्क
- कीवर्ड तर्क
- डिफ़ॉल्ट तर्क
- चर-लंबाई तर्क
आवश्यक तर्क
आवश्यक तर्क सही स्थितिगत क्रम में एक फ़ंक्शन को दिए गए तर्क हैं। यहां, फ़ंक्शन कॉल में तर्कों की संख्या फ़ंक्शन की परिभाषा के साथ बिल्कुल मेल खाना चाहिए।
फ़ंक्शन प्रिंटमे () को कॉल करने के लिए , आपको निश्चित रूप से एक तर्क पारित करने की आवश्यकता है, अन्यथा यह निम्नानुसार एक सिंटैक्स त्रुटि देता है -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme()जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Traceback (most recent call last):
File "test.py", line 11, in <module>
printme();
TypeError: printme() takes exactly 1 argument (0 given)कीवर्ड तर्क
कीवर्ड तर्क फ़ंक्शन कॉल से संबंधित हैं। जब आप किसी फ़ंक्शन कॉल में कीवर्ड तर्क का उपयोग करते हैं, तो कॉल करने वाला पैरामीटर नाम से तर्कों की पहचान करता है।
इससे आप तर्कों को छोड़ सकते हैं या उन्हें क्रम से बाहर कर सकते हैं क्योंकि पायथन दुभाषिया मापदंडों के साथ मूल्यों से मेल खाने के लिए प्रदान किए गए कीवर्ड का उपयोग करने में सक्षम है। आप निम्न तरीकों से प्रिंटमे () फ़ंक्शन पर कीवर्ड कॉल भी कर सकते हैं -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme( str = "My string")जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
My stringनिम्नलिखित उदाहरण अधिक स्पष्ट तस्वीर देता है। ध्यान दें कि मापदंडों का क्रम मायने नहीं रखता है।
#!/usr/bin/python
# Function definition is here
def printinfo( name, age ):
"This prints a passed info into this function"
print "Name: ", name
print "Age ", age
return;
# Now you can call printinfo function
printinfo( age=50, name="miki" )जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Name: miki
Age 50डिफ़ॉल्ट तर्क
एक डिफ़ॉल्ट तर्क एक तर्क है जो उस तर्क के लिए फ़ंक्शन कॉल में एक मूल्य प्रदान नहीं किए जाने पर डिफ़ॉल्ट मान को मानता है। निम्नलिखित उदाहरण डिफ़ॉल्ट तर्कों पर एक विचार देता है, यह डिफ़ॉल्ट उम्र को प्रिंट करता है यदि यह पारित नहीं हुआ है -
#!/usr/bin/python
# Function definition is here
def printinfo( name, age = 35 ):
"This prints a passed info into this function"
print "Name: ", name
print "Age ", age
return;
# Now you can call printinfo function
printinfo( age=50, name="miki" )
printinfo( name="miki" )जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Name: miki
Age 50
Name: miki
Age 35चर-लंबाई तर्क
फ़ंक्शन को परिभाषित करते समय आपको निर्दिष्ट से अधिक तर्कों के लिए एक फ़ंक्शन को संसाधित करने की आवश्यकता हो सकती है। इन तर्कों को चर-लंबाई तर्क कहा जाता है और आवश्यक और डिफ़ॉल्ट तर्कों के विपरीत, फ़ंक्शन परिभाषा में नाम नहीं हैं।
गैर-कीवर्ड चर तर्कों के साथ फ़ंक्शन के लिए सिंटैक्स यह है -
def functionname([formal_args,] *var_args_tuple ):
"function_docstring"
function_suite
return [expression]एक तारांकन चिह्न (*) को चर नाम से पहले रखा जाता है जो सभी नॉनकॉर्डर चर तर्कों के मूल्यों को रखता है। फ़ंक्शन कॉल के दौरान कोई अतिरिक्त तर्क निर्दिष्ट नहीं किए जाने पर यह टपल खाली रहता है। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
# Function definition is here
def printinfo( arg1, *vartuple ):
"This prints a variable passed arguments"
print "Output is: "
print arg1
for var in vartuple:
print var
return;
# Now you can call printinfo function
printinfo( 10 )
printinfo( 70, 60, 50 )जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Output is:
10
Output is:
70
60
50बेनामी कार्य
इन कार्यों को अनाम कहा जाता है क्योंकि वे मानक तरीके से डिफॉल्ट कीवर्ड का उपयोग करके घोषित नहीं किए जाते हैं । छोटे अनाम फ़ंक्शंस बनाने के लिए आप लैम्ब्डा कीवर्ड का उपयोग कर सकते हैं ।
लैंबडा फॉर्म किसी भी तर्क को ले सकते हैं लेकिन एक अभिव्यक्ति के रूप में सिर्फ एक मूल्य लौटाते हैं। उनमें कमांड या कई एक्सप्रेशन नहीं हो सकते।
एक अनाम फ़ंक्शन प्रिंट करने के लिए प्रत्यक्ष कॉल नहीं हो सकता है क्योंकि लैम्ब्डा को एक अभिव्यक्ति की आवश्यकता होती है
लैम्ब्डा फंक्शंस के अपने स्थानीय नाम स्थान होते हैं और वे अपने पैरामीटर सूची में और वैश्विक नामस्थान में उन लोगों के अलावा चर का उपयोग नहीं कर सकते हैं।
यद्यपि ऐसा प्रतीत होता है कि लैम्ब्डा एक फ़ंक्शन का एक-पंक्ति संस्करण है, वे C या C ++ में इनलाइन स्टेटमेंट के समकक्ष नहीं हैं, जिसका उद्देश्य प्रदर्शन कारणों के लिए मंगलाचरण के दौरान फ़ंक्शन स्टैक आवंटन पास करना है।
वाक्य - विन्यास
लंबोदर फ़ंक्शन के सिंटैक्स में केवल एक ही कथन होता है, जो इस प्रकार है -
lambda [arg1 [,arg2,.....argn]]:expressionनिम्नलिखित उदाहरण यह दिखाने के लिए है कि मेमने का कार्य कैसे कार्य करता है -
#!/usr/bin/python
# Function definition is here
sum = lambda arg1, arg2: arg1 + arg2;
# Now you can call sum as a function
print "Value of total : ", sum( 10, 20 )
print "Value of total : ", sum( 20, 20 )जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Value of total : 30
Value of total : 40वापसी वक्तव्य
स्टेटमेंट रिटर्न [अभिव्यक्ति] एक फ़ंक्शन से बाहर निकलता है, वैकल्पिक रूप से कॉलर को एक अभिव्यक्ति वापस दे रहा है। बिना किसी दलील के एक रिटर्न स्टेटमेंट रिटर्न नो के समान है।
उपरोक्त सभी उदाहरण कोई मूल्य नहीं लौटा रहे हैं। आप एक फ़ंक्शन से एक मान वापस कर सकते हैं -
#!/usr/bin/python
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2
print "Inside the function : ", total
return total;
# Now you can call sum function
total = sum( 10, 20 );
print "Outside the function : ", totalजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Inside the function : 30
Outside the function : 30चर का दायरा
एक कार्यक्रम में सभी चर उस कार्यक्रम के सभी स्थानों पर सुलभ नहीं हो सकते हैं। यह इस बात पर निर्भर करता है कि आपने चर कहां घोषित किया है।
एक चर का दायरा कार्यक्रम के उस हिस्से को निर्धारित करता है जहां आप किसी विशेष पहचानकर्ता तक पहुंच सकते हैं। पायथन में चर के दो बुनियादी दायरे हैं -
- सार्वत्रिक चर
- स्थानीय चर
वैश्विक बनाम स्थानीय चर
चर जो एक फ़ंक्शन बॉडी के अंदर परिभाषित किए गए हैं उनके पास एक स्थानीय गुंजाइश है, और बाहर परिभाषित लोगों के पास एक वैश्विक गुंजाइश है।
इसका मतलब यह है कि स्थानीय चर को केवल उस फ़ंक्शन के अंदर एक्सेस किया जा सकता है जिसमें उन्हें घोषित किया गया है, जबकि वैश्विक चर को सभी फ़ंक्शन के दौरान पूरे फ़ंक्शन तक पहुँचा जा सकता है। जब आप किसी फ़ंक्शन को कॉल करते हैं, तो उसके अंदर घोषित चर दायरे में लाए जाते हैं। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
total = 0; # This is global variable.
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2; # Here total is local variable.
print "Inside the function local total : ", total
return total;
# Now you can call sum function
sum( 10, 20 );
print "Outside the function global total : ", totalजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Inside the function local total : 30
Outside the function global total : 0एक मॉड्यूल आपको तार्किक रूप से अपने पायथन कोड को व्यवस्थित करने की अनुमति देता है। एक मॉड्यूल में संबंधित कोड को समूह को समझना और उपयोग करना आसान बनाता है। एक मॉड्यूल एक पायथन ऑब्जेक्ट है जिसका मनमाने ढंग से नामित विशेषताओं के साथ आप बाँध सकते हैं और संदर्भ दे सकते हैं।
बस, एक मॉड्यूल पायथन कोड से युक्त एक फ़ाइल है। एक मॉड्यूल कार्यों, वर्गों और चर को परिभाषित कर सकता है। एक मॉड्यूल रन करने योग्य कोड भी शामिल कर सकता है।
उदाहरण
Aname नामक एक मॉड्यूल के लिए पायथन कोड आम तौर पर aname.py नाम की फ़ाइल में रहता है । यहाँ एक सरल मॉड्यूल का एक उदाहरण है, support.py
def print_func( par ):
print "Hello : ", par
returnआयात वक्तव्य
आप किसी अन्य पायथन स्रोत फ़ाइल में आयात कथन को निष्पादित करके किसी भी पायथन स्रोत फ़ाइल को मॉड्यूल के रूप में उपयोग कर सकते हैं। आयात निम्न सिंटैक्स है -
import module1[, module2[,... moduleN]जब दुभाषिया एक आयात विवरण का सामना करता है, तो यह मॉड्यूल को आयात करता है यदि मॉड्यूल खोज पथ में मौजूद है। एक खोज पथ उन निर्देशिकाओं की एक सूची है जो एक मॉड्यूल आयात करने से पहले दुभाषिया खोजता है। उदाहरण के लिए, मॉड्यूल support.py आयात करने के लिए, आपको निम्न कमांड को स्क्रिप्ट के शीर्ष पर रखना होगा -
#!/usr/bin/python
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Zara")जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Hello : Zaraएक मॉड्यूल केवल एक बार लोड किया जाता है, चाहे वह कितनी बार आयात किया गया हो। यह कई बार आयात होने पर मॉड्यूल के निष्पादन को बार-बार होने से रोकता है।
से ... आयात वक्तव्य
अजगर है से बयान आप वर्तमान नाम स्थान में एक मॉड्यूल से विशिष्ट विशेषताओं के आयात करने देता है। से ... आयात निम्नलिखित वाक्य रचना है -
from modname import name1[, name2[, ... nameN]]उदाहरण के लिए, मॉड्यूल फ़ाइबर से फ़ंक्शन रिट्रेसमेंट आयात करने के लिए, निम्नलिखित कथन का उपयोग करें -
from fib import fibonacciयह कथन संपूर्ण मॉड्यूल फ़ाइब को वर्तमान नामस्थान में आयात नहीं करता है; यह इंपोर्ट मॉड्यूल के ग्लोबल सिंबल टेबल में मॉड्यूल फाइब से सिर्फ आइटम का परिचय देता है।
से ... आयात * वक्तव्य
निम्नलिखित आयात विवरण का उपयोग करके एक मॉड्यूल से सभी नामों को वर्तमान नामस्थान में आयात करना संभव है -
from modname import *यह मॉड्यूल से सभी वस्तुओं को वर्तमान नामस्थान में आयात करने का एक आसान तरीका प्रदान करता है; हालाँकि, इस कथन को संयम से इस्तेमाल किया जाना चाहिए।
मॉड्यूल का पता लगाना
जब आप एक मॉड्यूल आयात करते हैं, तो पायथन दुभाषिया निम्न अनुक्रमों में मॉड्यूल की खोज करता है -
वर्तमान निर्देशिका।
यदि मॉड्यूल नहीं मिला है, तो पायथन शेल शेल PYTHONPATH में प्रत्येक निर्देशिका को खोजता है।
यदि अन्य सभी विफल रहता है, तो पायथन डिफ़ॉल्ट पथ की जांच करता है। UNIX पर, यह डिफ़ॉल्ट पथ सामान्य रूप से / usr / स्थानीय / lib / python / है।
मॉड्यूल खोज पथ सिस्टम मॉड्यूल sys में संग्रहीत है sys.pathचर। Sys.path चर में वर्तमान निर्देशिका, PYTHONPATH और स्थापना-निर्भर डिफ़ॉल्ट शामिल हैं।
PYTHONPATH चर
PYTHONPATH एक पर्यावरण चर है, जिसमें निर्देशिकाओं की सूची है। PYTHONPATH का सिंटैक्स शेल चर पथ के समान है।
यहाँ एक विंडोज सिस्टम से एक ठेठ PYTHONPATH है -
set PYTHONPATH = c:\python20\lib;और यहाँ एक UNIX प्रणाली से एक विशिष्ट PYTHONPATH है -
set PYTHONPATH = /usr/local/lib/pythonनामस्थान और स्कोपिंग
चर ऐसे नाम (पहचानकर्ता) हैं जो वस्तुओं का नक्शा बनाते हैं। एक नाम स्थान चर नामों (कुंजियों) और उनकी संबंधित वस्तुओं (मूल्यों) का एक शब्दकोश है।
एक पायथन स्टेटमेंट एक स्थानीय नाम स्थान और वैश्विक नाम स्थान में चर का उपयोग कर सकता है । यदि किसी स्थानीय और वैश्विक चर का एक ही नाम है, तो स्थानीय चर वैश्विक चर का छाया करता है।
प्रत्येक फ़ंक्शन का अपना स्थानीय नामस्थान होता है। कक्षा के तरीके सामान्य कार्यों के समान ही नियम का पालन करते हैं।
पायथन शिक्षित अनुमान लगाता है कि क्या चर स्थानीय या वैश्विक हैं। यह मानता है कि किसी फ़ंक्शन में दिए गए किसी भी चर को स्थानीय माना जाता है।
इसलिए, किसी फ़ंक्शन के भीतर एक वैश्विक चर के लिए एक मूल्य निर्दिष्ट करने के लिए, आपको पहले वैश्विक कथन का उपयोग करना होगा।
बयान वैश्विक VarName पायथन बताता है कि VarName एक वैश्विक चर है। पायथन ने चर के लिए स्थानीय नाम स्थान खोजना बंद कर दिया है।
उदाहरण के लिए, हम वैश्विक नाम स्थान में एक चर मुद्रा को परिभाषित करते हैं । फ़ंक्शन मनी के भीतर , हम मनी को एक मूल्य प्रदान करते हैं , इसलिए पायथन मनी को एक स्थानीय चर के रूप में मानता है । हालाँकि, हमने इसे सेट करने से पहले लोकल वैरिएबल मनी के मान को एक्सेस किया है, इसलिए एक अनबाउंडलोक्योरर परिणाम है। वैश्विक कथन को रद्द करने से समस्या ठीक हो जाती है।
#!/usr/bin/python
Money = 2000
def AddMoney():
# Uncomment the following line to fix the code:
# global Money
Money = Money + 1
print Money
AddMoney()
print Moneyदिर () फंक्शन
Dir () अंतर्निहित फ़ंक्शन एक मॉड्यूल द्वारा परिभाषित नामों वाले तारों की एक क्रमबद्ध सूची देता है।
सूची में सभी मॉड्यूल, चर और फ़ंक्शन के नाम हैं जो एक मॉड्यूल में परिभाषित हैं। निम्नलिखित एक सरल उदाहरण है -
#!/usr/bin/python
# Import built-in module math
import math
content = dir(math)
print contentजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']यहां, विशेष स्ट्रिंग चर __name__ मॉड्यूल का नाम है, और __file__ वह फ़ाइल नाम है जिसमें से मॉड्यूल लोड किया गया था।
वैश्विक () और स्थानीय लोगों () कार्य
वैश्विक () और स्थानीय लोगों () कार्यों वैश्विक और स्थानीय जहां वे कहा जाता है से स्थान के आधार पर नामस्थान में नाम वापस जाने के लिए इस्तेमाल किया जा सकता।
यदि किसी फ़ंक्शन के भीतर से लोकल () को कॉल किया जाता है, तो यह उन सभी नामों को लौटा देगा, जिन्हें उस फ़ंक्शन से स्थानीय रूप से एक्सेस किया जा सकता है।
यदि ग्लोबल्स () को किसी फ़ंक्शन के भीतर से कॉल किया जाता है, तो यह उन सभी नामों को लौटा देगा जिन्हें उस फ़ंक्शन से वैश्विक रूप से एक्सेस किया जा सकता है।
इन दोनों कार्यों का रिटर्न प्रकार शब्दकोश है। इसलिए, कुंजियों () फ़ंक्शन का उपयोग करके नाम निकाले जा सकते हैं।
पुनः लोड () समारोह
जब मॉड्यूल को स्क्रिप्ट में आयात किया जाता है, तो मॉड्यूल के शीर्ष-स्तरीय भाग में कोड को केवल एक बार निष्पादित किया जाता है।
इसलिए, यदि आप किसी मॉड्यूल में शीर्ष-स्तरीय कोड को पुनः प्राप्त करना चाहते हैं, तो आप पुनः लोड () फ़ंक्शन का उपयोग कर सकते हैं । पुनः लोड () फ़ंक्शन पहले से आयातित मॉड्यूल को फिर से आयात करता है। पुनः लोड () फ़ंक्शन का सिंटैक्स यह है -
reload(module_name)यहां, मॉड्यूल_नाम उस मॉड्यूल का नाम है जिसे आप फिर से लोड करना चाहते हैं न कि स्ट्रिंग जिसमें मॉड्यूल नाम है। उदाहरण के लिए, हेलो मॉड्यूल को पुनः लोड करने के लिए, निम्नलिखित करें -
reload(hello)पायथन में पैकेज
एक पैकेज एक पदानुक्रमित फ़ाइल निर्देशिका संरचना है जो एकल पायथन अनुप्रयोग वातावरण को परिभाषित करता है जिसमें मॉड्यूल और उप-पैकेज और उप-उप-पैकेज शामिल होते हैं, और इसी तरह।
फ़ोन निर्देशिका में उपलब्ध एक फ़ाइल पॉटशो पर विचार करें । इस फ़ाइल में स्रोत कोड की लाइन है -
#!/usr/bin/python
def Pots():
print "I'm Pots Phone"इसी तरह, हमारे पास एक और दो फाइलें हैं जिनके ऊपर एक ही नाम के साथ अलग-अलग फ़ंक्शन हैं -
फ़ंक्शन Isdn () वाले फ़ोन / Isdn.py फ़ाइल
फ़ंक्शन G3 () वाले फ़ोन / G3.py फ़ाइल
अब, फ़ोन निर्देशिका में एक और फ़ाइल __init__.py बनाएँ -
- Phone/__init__.py
फ़ोन आयात करते समय अपने सभी फ़ंक्शन उपलब्ध कराने के लिए, आपको __init__.py में स्पष्ट आयात स्टेटमेंट डालने की आवश्यकता है -
from Pots import Pots
from Isdn import Isdn
from G3 import G3जब आप इन लाइनों को __init__.py में जोड़ लेते हैं, तो आपके पास ये सभी वर्ग उपलब्ध होते हैं जब आप फ़ोन पैकेज आयात करते हैं।
#!/usr/bin/python
# Now import your Phone Package.
import Phone
Phone.Pots()
Phone.Isdn()
Phone.G3()जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
I'm Pots Phone
I'm 3G Phone
I'm ISDN Phoneउपरोक्त उदाहरण में, हमने प्रत्येक फ़ाइल में एकल फ़ंक्शन का उदाहरण लिया है, लेकिन आप अपनी फ़ाइलों में कई फ़ंक्शन रख सकते हैं। आप उन फ़ाइलों में विभिन्न पायथन कक्षाओं को भी परिभाषित कर सकते हैं और फिर आप उन कक्षाओं से अपने पैकेज बना सकते हैं।
इस अध्याय में पायथन में उपलब्ध सभी बुनियादी I / O फ़ंक्शन शामिल हैं। अधिक कार्यों के लिए, कृपया मानक पायथन प्रलेखन देखें।
स्क्रीन पर मुद्रण
आउटपुट का उत्पादन करने का सबसे सरल तरीका प्रिंट स्टेटमेंट का उपयोग करना है जहां आप शून्य या अधिक अभिव्यक्तियों को कॉमा से अलग कर सकते हैं। यह फ़ंक्शन आपके द्वारा दिए गए भावों को एक स्ट्रिंग में परिवर्तित करता है और मानक आउटपुट को निम्नानुसार लिखता है -
#!/usr/bin/python
print "Python is really a great language,", "isn't it?"यह आपके मानक स्क्रीन पर निम्न परिणाम उत्पन्न करता है -
Python is really a great language, isn't it?कीबोर्ड इनपुट पढ़ना
पायथन मानक इनपुट से पाठ की एक पंक्ति को पढ़ने के लिए दो अंतर्निहित कार्य प्रदान करता है, जो डिफ़ॉल्ट रूप से कीबोर्ड से आता है। ये कार्य हैं -
- raw_input
- input
raw_input समारोह
Raw_input ([शीघ्र]) समारोह में यह एक स्ट्रिंग (अनुगामी न्यू लाइन को हटाने के) के रूप में मानक इनपुट और रिटर्न से एक पंक्ति पढ़ता है।
#!/usr/bin/python
str = raw_input("Enter your input: ")
print "Received input is : ", strयह आपको किसी भी स्ट्रिंग में प्रवेश करने का संकेत देता है और यह स्क्रीन पर समान स्ट्रिंग प्रदर्शित करेगा। जब मैंने "हेलो पायथन!" टाइप किया, तो इसका आउटपुट इस तरह है -
Enter your input: Hello Python
Received input is : Hello Pythonइनपुट समारोह
इनपुट ([शीघ्र]) समारोह raw_input करने के लिए, को छोड़कर यह मानता है कि एक मान्य अजगर अभिव्यक्ति है और आप के लिए मूल्यांकन परिणाम देता बराबर है।
#!/usr/bin/python
str = input("Enter your input: ")
print "Received input is : ", strयह दर्ज किए गए इनपुट के खिलाफ निम्न परिणाम उत्पन्न करेगा -
Enter your input: [x*5 for x in range(2,10,2)]
Recieved input is : [10, 20, 30, 40]फ़ाइलें खोलना और बंद करना
अब तक, आप मानक इनपुट और आउटपुट को पढ़ते और लिखते रहे हैं। अब, हम देखेंगे कि वास्तविक डेटा फ़ाइलों का उपयोग कैसे करें।
पायथन डिफ़ॉल्ट रूप से फ़ाइलों में हेरफेर करने के लिए आवश्यक बुनियादी कार्य और तरीके प्रदान करता है। आप का उपयोग कर फ़ाइल हेरफेर के अधिकांश कर सकते हैंfile वस्तु।
खुला समारोह
किसी फ़ाइल को पढ़ने या लिखने से पहले, आपको इसे पायथन के बिल्ट-इन ओपन () फ़ंक्शन का उपयोग करके खोलना होगा । यह फंक्शन क्रिएट करता हैfile ऑब्जेक्ट, जिसका उपयोग इसके साथ जुड़े अन्य समर्थन विधियों को कॉल करने के लिए किया जाएगा।
वाक्य - विन्यास
file object = open(file_name [, access_mode][, buffering])यहाँ पैरामीटर विवरण हैं -
file_name - file_name तर्क एक स्ट्रिंग मान है जिसमें उस फ़ाइल का नाम है जिसे आप एक्सेस करना चाहते हैं।
access_mode- access_mode उस मोड को निर्धारित करता है जिसमें फ़ाइल को खोलना होता है, अर्थात, पढ़ना, लिखना, अपेंड करना, आदि संभावित मानों की पूरी सूची नीचे दी गई है। यह वैकल्पिक पैरामीटर है और डिफ़ॉल्ट फ़ाइल एक्सेस मोड पढ़ा जाता है (आर)।
buffering- यदि बफ़रिंग मान 0 पर सेट है, तो कोई बफ़रिंग नहीं होती है। यदि बफ़रिंग मान 1 है, तो फ़ाइल को एक्सेस करते समय लाइन बफ़रिंग किया जाता है। यदि आप बफ़रिंग मान को 1 से अधिक पूर्णांक के रूप में निर्दिष्ट करते हैं, तो बफ़रिंग क्रिया को संकेत बफ़र आकार के साथ किया जाता है। यदि नकारात्मक है, तो बफ़र आकार सिस्टम डिफ़ॉल्ट (डिफ़ॉल्ट व्यवहार) है।
यहाँ एक फ़ाइल खोलने के विभिन्न तरीकों की एक सूची है -
| अनु क्रमांक। | मोड और विवरण |
|---|---|
| 1 | r केवल पढ़ने के लिए एक फ़ाइल खोलता है। फ़ाइल पॉइंटर को फ़ाइल की शुरुआत में रखा जाता है। यह डिफ़ॉल्ट मोड है। |
| 2 | rb केवल बाइनरी प्रारूप में पढ़ने के लिए एक फ़ाइल खोलता है। फ़ाइल पॉइंटर को फ़ाइल की शुरुआत में रखा जाता है। यह डिफ़ॉल्ट मोड है। |
| 3 | r+ पढ़ने और लिखने दोनों के लिए एक फाइल खोलता है। फ़ाइल पॉइंटर फ़ाइल की शुरुआत में रखा गया है। |
| 4 | rb+ द्विआधारी प्रारूप में पढ़ने और लिखने दोनों के लिए एक फ़ाइल खोलता है। फ़ाइल पॉइंटर फ़ाइल की शुरुआत में रखा गया है। |
| 5 | w केवल लिखने के लिए एक फ़ाइल खोलता है। यदि फ़ाइल मौजूद है, तो फ़ाइल को ओवरराइट करता है। यदि फ़ाइल मौजूद नहीं है, तो लिखने के लिए एक नई फ़ाइल बनाता है। |
| 6 | wb केवल बाइनरी प्रारूप में लिखने के लिए एक फ़ाइल खोलता है। यदि फ़ाइल मौजूद है, तो फ़ाइल को ओवरराइट करता है। यदि फ़ाइल मौजूद नहीं है, तो लिखने के लिए एक नई फ़ाइल बनाता है। |
| 7 | w+ लिखने और पढ़ने दोनों के लिए एक फाइल खोलता है। मौजूदा फ़ाइल को अधिलेखित करता है यदि फ़ाइल मौजूद है। यदि फ़ाइल मौजूद नहीं है, तो पढ़ने और लिखने के लिए एक नई फ़ाइल बनाता है। |
| 8 | wb+ द्विआधारी प्रारूप में लिखने और पढ़ने दोनों के लिए एक फ़ाइल खोलता है। मौजूदा फ़ाइल को अधिलेखित करता है यदि फ़ाइल मौजूद है। यदि फ़ाइल मौजूद नहीं है, तो पढ़ने और लिखने के लिए एक नई फ़ाइल बनाता है। |
| 9 | a अपील करने के लिए एक फ़ाइल खोलता है। यदि फ़ाइल मौजूद है तो फ़ाइल पॉइंटर फ़ाइल के अंत में है। यही है, फ़ाइल एपेंड मोड में है। यदि फ़ाइल मौजूद नहीं है, तो यह लिखने के लिए एक नई फ़ाइल बनाता है। |
| 10 | ab द्विआधारी प्रारूप में लागू करने के लिए एक फ़ाइल खोलता है। यदि फ़ाइल मौजूद है तो फ़ाइल पॉइंटर फ़ाइल के अंत में है। यही है, फ़ाइल एपेंड मोड में है। यदि फ़ाइल मौजूद नहीं है, तो यह लिखने के लिए एक नई फ़ाइल बनाता है। |
| 1 1 | a+ दोनों को जोड़ने और पढ़ने के लिए एक फ़ाइल खोलता है। यदि फ़ाइल मौजूद है तो फ़ाइल पॉइंटर फ़ाइल के अंत में है। फ़ाइल परिशिष्ट मोड में खुलती है। यदि फ़ाइल मौजूद नहीं है, तो यह पढ़ने और लिखने के लिए एक नई फ़ाइल बनाता है। |
| 12 | ab+ द्विआधारी प्रारूप में दोनों को जोड़ने और पढ़ने के लिए एक फ़ाइल खोलता है। यदि फ़ाइल मौजूद है तो फ़ाइल पॉइंटर फ़ाइल के अंत में है। फ़ाइल परिशिष्ट मोड में खुलती है। यदि फ़ाइल मौजूद नहीं है, तो यह पढ़ने और लिखने के लिए एक नई फ़ाइल बनाता है। |
फ़ाइल वस्तु गुण
एक बार जब कोई फ़ाइल खोली जाती है और आपके पास एक फ़ाइल ऑब्जेक्ट होता है, तो आप उस फ़ाइल से संबंधित विभिन्न जानकारी प्राप्त कर सकते हैं।
यहाँ फ़ाइल ऑब्जेक्ट से संबंधित सभी विशेषताओं की एक सूची दी गई है -
| अनु क्रमांक। | विशेषता और विवरण |
|---|---|
| 1 | file.closed यदि फ़ाइल बंद है, तो सत्य है अन्यथा गलत। |
| 2 | file.mode रिटर्न एक्सेस मोड जिसके साथ फाइल खोली गई थी। |
| 3 | file.name फ़ाइल का नाम लौटाता है। |
| 4 | file.softspace यदि गलत रूप से प्रिंट के साथ स्पष्ट रूप से आवश्यक है, तो झूठे रिटर्न। |
उदाहरण
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspaceयह निम्न परिणाम उत्पन्न करता है -
Name of the file: foo.txt
Closed or not : False
Opening mode : wb
Softspace flag : 0करीब () विधि
किसी फ़ाइल ऑब्जेक्ट का क्लोज़ () तरीका किसी भी अलिखित जानकारी को फ्लश करता है और फ़ाइल ऑब्जेक्ट को बंद कर देता है, जिसके बाद कोई और लेखन नहीं किया जा सकता है।
पायथन स्वचालित रूप से एक फ़ाइल को बंद कर देता है जब किसी फ़ाइल का संदर्भ ऑब्जेक्ट किसी अन्य फ़ाइल को पुन: असाइन किया जाता है। फ़ाइल बंद करने के लिए क्लोज़ () विधि का उपयोग करना एक अच्छा अभ्यास है।
वाक्य - विन्यास
fileObject.close()उदाहरण
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
# Close opend file
fo.close()यह निम्न परिणाम उत्पन्न करता है -
Name of the file: foo.txtफाइल पढ़ना और लिखना
फ़ाइल वस्तु का उपयोग तरीकों का एक सेट हमारे जीवन को आसान बनाने के लिए प्रदान करता है। हम देखेंगे कि फ़ाइलों को पढ़ने और लिखने के तरीकों को कैसे पढ़ें () और लिखें () ।
लिखने () विधि
लिखने () विधि एक खुली फाइल करने के लिए किसी भी स्ट्रिंग लिखता है। यह ध्यान रखना महत्वपूर्ण है कि पायथन तार में बाइनरी डेटा हो सकता है और न केवल पाठ।
लेखन () विधि स्ट्रिंग के अंत में एक नई पंक्ति वर्ण ('\ n') नहीं जोड़ता है -
वाक्य - विन्यास
fileObject.write(string)यहां, दिया गया पैरामीटर खुली हुई फ़ाइल में लिखा जाने वाला कंटेंट है।
उदाहरण
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
fo.write( "Python is a great language.\nYeah its great!!\n")
# Close opend file
fo.close()उपरोक्त विधि foo.txt फ़ाइल बनाएगी और उस फ़ाइल में दी गई सामग्री को लिखेगी और अंत में वह उस फ़ाइल को बंद कर देगी। यदि आप इस फ़ाइल को खोलते हैं, तो इसमें निम्न सामग्री होगी।
Python is a great language.
Yeah its great!!पढ़ने () विधि
पढ़ने () विधि एक खुली फ़ाइल से एक स्ट्रिंग पढ़ता है। यह ध्यान रखना महत्वपूर्ण है कि पायथन तार में बाइनरी डेटा हो सकता है। पाठ डेटा के अलावा।
वाक्य - विन्यास
fileObject.read([count])यहां, पारित पैरामीटर खुली हुई फ़ाइल से पढ़ने के लिए बाइट्स की संख्या है। यह विधि फ़ाइल की शुरुआत से पढ़ना शुरू कर देती है और यदि गिनती गायब है, तो यह यथासंभव पढ़ने की कोशिश करता है, शायद फ़ाइल के अंत तक।
उदाहरण
चलिए एक फाइल लेते हैं foo.txt , जिसे हमने ऊपर बनाया है।
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10);
print "Read String is : ", str
# Close opend file
fo.close()यह निम्न परिणाम उत्पन्न करता है -
Read String is : Python isफ़ाइल स्थिति
बताएं () विधि आप फ़ाइल के भीतर वर्तमान स्थिति बताता है; दूसरे शब्दों में, अगली रीड या राइट फ़ाइल की शुरुआत से कई बाइट्स में होगी।
(ऑफसेट [, से]) की तलाश विधि वर्तमान फ़ाइल स्थिति में परिवर्तन। ऑफसेट तर्क बाइट की संख्या स्थानांतरित करने इंगित करता है। से तर्क से जहां बाइट्स ले जाया जा रहे हैं संदर्भ की स्थिति निर्दिष्ट करता है।
यदि से 0 पर सेट किया गया है, तो इसका मतलब है कि फ़ाइल का उपयोग संदर्भ स्थिति के रूप में करें और 1 का अर्थ वर्तमान स्थिति को संदर्भ स्थिति के रूप में उपयोग करें और यदि यह 2 पर सेट है, तो फ़ाइल का अंत संदर्भ स्थिति के रूप में लिया जाएगा। ।
उदाहरण
आइए हम एक फ़ाइल foo.txt लेते हैं , जिसे हमने ऊपर बनाया है।
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10)
print "Read String is : ", str
# Check current position
position = fo.tell()
print "Current file position : ", position
# Reposition pointer at the beginning once again
position = fo.seek(0, 0);
str = fo.read(10)
print "Again read String is : ", str
# Close opend file
fo.close()यह निम्न परिणाम उत्पन्न करता है -
Read String is : Python is
Current file position : 10
Again read String is : Python isफ़ाइलों का नाम बदलना और हटाना
अजगर os मॉड्यूल ऐसे तरीके प्रदान करता है जो आपको फ़ाइल-प्रोसेसिंग ऑपरेशन करने में मदद करते हैं, जैसे फ़ाइलों का नाम बदलना और हटाना।
इस मॉड्यूल का उपयोग करने के लिए आपको पहले इसे आयात करना होगा और फिर आप किसी भी संबंधित कार्य को कॉल कर सकते हैं।
नाम () विधि
नाम बदलने () विधि दो तर्क, वर्तमान फ़ाइल नाम और नया फ़ाइल नाम लेता है।
वाक्य - विन्यास
os.rename(current_file_name, new_file_name)उदाहरण
एक मौजूदा फ़ाइल test1.txt का नाम बदलने के लिए निम्नलिखित उदाहरण है -
#!/usr/bin/python
import os
# Rename a file from test1.txt to test2.txt
os.rename( "test1.txt", "test2.txt" )निकालें () विधि
आप फ़ाइल का नाम हटाकर तर्क को हटाने के लिए फ़ाइलों को हटाने के लिए हटाने () विधि का उपयोग कर सकते हैं ।
वाक्य - विन्यास
os.remove(file_name)उदाहरण
मौजूदा फ़ाइल test2.txt को हटाने के लिए उदाहरण निम्नलिखित है -
#!/usr/bin/python
import os
# Delete file test2.txt
os.remove("text2.txt")पायथन में निर्देशिकाएँ
सभी फाइलें विभिन्न निर्देशिकाओं में निहित हैं, और पायथन को भी इनसे निपटने में कोई समस्या नहीं है। os मॉड्यूल में कई तरीके हैं जो निर्देशिका बनाने, हटाने और बदलने में आपकी सहायता करते हैं।
Mkdir () विधि
आप mkdir () की विधि का उपयोग कर सकते हैंosवर्तमान निर्देशिका में निर्देशिका बनाने के लिए मॉड्यूल। आपको इस पद्धति पर एक तर्क की आपूर्ति करने की आवश्यकता है जिसमें निर्देशिका का नाम बनाया जाना है।
वाक्य - विन्यास
os.mkdir("newdir")उदाहरण
वर्तमान निर्देशिका में निर्देशिका परीक्षण बनाने के लिए उदाहरण निम्नलिखित है -
#!/usr/bin/python
import os
# Create a directory "test"
os.mkdir("test")Chdir () विधि
आप वर्तमान निर्देशिका को बदलने के लिए chdir () विधि का उपयोग कर सकते हैं । Chdir () पद्धति एक तर्क लेती है, जो उस निर्देशिका का नाम है जिसे आप वर्तमान निर्देशिका बनाना चाहते हैं।
वाक्य - विन्यास
os.chdir("newdir")उदाहरण
निम्नलिखित उदाहरण के लिए "/ घर / newdir" निर्देशिका में जाना है -
#!/usr/bin/python
import os
# Changing a directory to "/home/newdir"
os.chdir("/home/newdir")Getcwd () विधि
Getcwd () विधि प्रदर्शित करता है वर्तमान कार्यशील निर्देशिका।
वाक्य - विन्यास
os.getcwd()उदाहरण
वर्तमान निर्देशिका देने के लिए उदाहरण निम्नलिखित है -
#!/usr/bin/python
import os
# This would give location of the current directory
os.getcwd()Rmdir () विधि
Rmdir () विधि निर्देशिका है, जो विधि में एक तर्क के रूप पारित हो जाता है हटा देता है।
एक निर्देशिका को हटाने से पहले, इसमें सभी सामग्री को हटा दिया जाना चाहिए।
वाक्य - विन्यास
os.rmdir('dirname')उदाहरण
निम्नलिखित "/ tmp / test" निर्देशिका को हटाने के लिए उदाहरण है। निर्देशिका का पूरी तरह से योग्य नाम देना आवश्यक है, अन्यथा यह वर्तमान निर्देशिका में उस निर्देशिका की खोज करेगा।
#!/usr/bin/python
import os
# This would remove "/tmp/test" directory.
os.rmdir( "/tmp/test" )फ़ाइल और निर्देशिका संबंधित तरीके
तीन महत्वपूर्ण स्रोत हैं, जो विंडोज और यूनिक्स ऑपरेटिंग सिस्टम पर फ़ाइलों और निर्देशिकाओं को संभालने और हेरफेर करने के लिए उपयोगिता विधियों की एक विस्तृत श्रृंखला प्रदान करते हैं। वे इस प्रकार हैं -
फ़ाइल ऑब्जेक्ट तरीके : फ़ाइल ऑब्जेक्ट फ़ाइलों में हेरफेर करने के लिए फ़ंक्शन प्रदान करता है।
OS Object Methods : यह फाइलों के साथ-साथ डायरेक्टरीज़ को प्रोसेस करने के तरीके प्रदान करता है।
पायथन अपने पायथन कार्यक्रमों में किसी भी अप्रत्याशित त्रुटि को संभालने के लिए और उनमें डिबगिंग क्षमताओं को जोड़ने के लिए दो बहुत महत्वपूर्ण सुविधाएँ प्रदान करता है -
Exception Handling- यह इस ट्यूटोरियल में शामिल किया जाएगा। यहाँ एक सूची मानक अपवाद पायथन में उपलब्ध है: मानक अपवाद ।
Assertions- यह अजगर ट्यूटोरियल में जोर में कवर किया जाएगा ।
मानक अपवादों की सूची -
| अनु क्रमांक। | अपवाद का नाम और विवरण |
|---|---|
| 1 | Exception सभी अपवादों के लिए बेस क्लास |
| 2 | StopIteration उठाया जब एक पुनरावृत्ति की अगली () विधि किसी भी वस्तु को इंगित नहीं करता है। |
| 3 | SystemExit Sys.exit () फ़ंक्शन द्वारा उठाया गया। |
| 4 | StandardError StopIteration और SystemExit को छोड़कर सभी अंतर्निहित अपवादों के लिए बेस क्लास। |
| 5 | ArithmeticError संख्यात्मक गणना के लिए होने वाली सभी त्रुटियों के लिए बेस क्लास। |
| 6 | OverflowError उठाया जब एक संख्यात्मक प्रकार के लिए एक गणना अधिकतम सीमा से अधिक है। |
| 7 | FloatingPointError एक अस्थायी बिंदु गणना विफल होने पर उठाया गया। |
| 8 | ZeroDivisionError उठाया जब शून्य या modulo शून्य से सभी संख्यात्मक प्रकार के लिए जगह लेता है। |
| 9 | AssertionError एसेर कथन की विफलता के मामले में उठाया गया। |
| 10 | AttributeError विशेषता संदर्भ या असाइनमेंट की विफलता के मामले में उठाया गया। |
| 1 1 | EOFError उठाया जब कच्चे_इनपुट () या इनपुट () फ़ंक्शन से कोई इनपुट नहीं है और फ़ाइल का अंत तक पहुंच गया है। |
| 12 | ImportError आयात कथन विफल होने पर उठाया गया। |
| 13 | KeyboardInterrupt जब उपयोगकर्ता प्रोग्राम निष्पादन को बाधित करता है, तो आमतौर पर Ctrl + c दबाकर उठाया जाता है। |
| 14 | LookupError सभी लुकअप त्रुटियों के लिए बेस क्लास। |
| 15 | IndexError जब एक अनुक्रम में एक अनुक्रम नहीं मिला तो उठाया। |
| 16 | KeyError शब्दकोश में निर्दिष्ट कुंजी नहीं मिलने पर उठाया। |
| 17 | NameError उठाया जब एक पहचानकर्ता स्थानीय या वैश्विक नाम स्थान में नहीं पाया जाता है। |
| 18 | UnboundLocalError किसी फ़ंक्शन या विधि में एक स्थानीय चर का उपयोग करने का प्रयास करते समय उठाया गया, लेकिन इसके लिए कोई मूल्य नहीं सौंपा गया है। |
| 19 | EnvironmentError पायथन पर्यावरण के बाहर होने वाले सभी अपवादों के लिए बेस क्लास। |
| 20 | IOError जब इनपुट / आउटपुट ऑपरेशन विफल हो जाता है, जैसे कि प्रिंट स्टेटमेंट या ओपन () फ़ंक्शन तब होता है जब किसी फाइल को खोलने की कोशिश की जाती है जो मौजूद नहीं होती है। |
| 21 | IOError ऑपरेटिंग सिस्टम से संबंधित त्रुटियों के लिए उठाया गया। |
| 22 | SyntaxError पायथन सिंटैक्स में कोई त्रुटि होने पर उठाया गया। |
| 23 | IndentationError उठाया जब इंडेंटेशन ठीक से निर्दिष्ट नहीं है। |
| 24 | SystemError उठाया जब दुभाषिया एक आंतरिक समस्या पाता है, लेकिन जब इस त्रुटि का सामना किया जाता है तो पायथन दुभाषिया बाहर नहीं निकलता है। |
| 25 | SystemExit उठा जब पायथन दुभाषिया sys.exit () फ़ंक्शन का उपयोग करके छोड़ दिया जाता है। यदि कोड में संभाला नहीं जाता है, तो दुभाषिया से बाहर निकलने का कारण बनता है। |
| 26 | TypeError उठाया जब एक ऑपरेशन या फ़ंक्शन का प्रयास किया जाता है जो निर्दिष्ट डेटा प्रकार के लिए अमान्य है। |
| 27 | ValueError उठाया जब डेटा प्रकार के लिए अंतर्निहित फ़ंक्शन में मान्य प्रकार के तर्क होते हैं, लेकिन तर्कों में अमान्य मान निर्दिष्ट होते हैं। |
| 28 | RuntimeError जब उत्पन्न त्रुटि किसी भी श्रेणी में नहीं आती है तो उठाया गया। |
| 29 | NotImplementedError उठाया जब एक अमूर्त विधि है कि एक विरासत वर्ग में कार्यान्वित करने की आवश्यकता है वास्तव में लागू नहीं है। |
अजगर में जोर
एक संन्यास एक पवित्रता-जांच है जिसे आप कार्यक्रम के अपने परीक्षण के साथ पूरा करने पर चालू या बंद कर सकते हैं।
एक विचार करने के लिए सबसे आसान तरीका यह एक के लिए तुलना करने के लिए है raise-ifकथन (या अधिक सटीक होने के लिए, एक उठा-अगर-नहीं बयान)। एक अभिव्यक्ति का परीक्षण किया जाता है, और यदि परिणाम गलत आता है, तो एक अपवाद उठाया जाता है।
अभिकथन कथन के अनुसार, संस्करण 1.5 में पेश किए गए पायथन के लिए सबसे नया कीवर्ड है।
प्रोग्रामर अक्सर मान्य इनपुट के लिए जाँच करने के लिए किसी फ़ंक्शन की शुरुआत में और एक फ़ंक्शन कॉल के बाद मान्य आउटपुट के लिए जाँच करते हैं।
ज़ोर वक्तव्य
जब यह एक मुखर कथन का सामना करता है, तो पायथन साथ की अभिव्यक्ति का मूल्यांकन करता है, जो उम्मीद है कि सच है। यदि अभिव्यक्ति झूठी है, तो पायथन एक जोर-शोर से अपवाद उठाता है।
मुखर के लिए वाक्य रचना है -
assert Expression[, Arguments]यदि दावा विफल हो जाता है, तो पायथन तर्क के रूप में तर्क का उपयोग करता है। जोर-जबरदस्ती के अपवादों को किसी अन्य अपवाद की तरह पकड़ा जा सकता है और कोशिश-को छोड़कर बयान का उपयोग किया जा सकता है, लेकिन यदि संभाला नहीं जाता है, तो वे कार्यक्रम को समाप्त कर देंगे और ट्रेसबैक का उत्पादन करेंगे।
उदाहरण
यहाँ एक फ़ंक्शन है जो तापमान को केल्विन से डिग्री फ़ारेनहाइट तक बदलता है। चूंकि शून्य डिग्री केल्विन जितना ठंडा होता है, यह एक नकारात्मक तापमान देखने पर फंक्शन की घंटी बजाता है -
#!/usr/bin/python
def KelvinToFahrenheit(Temperature):
assert (Temperature >= 0),"Colder than absolute zero!"
return ((Temperature-273)*1.8)+32
print KelvinToFahrenheit(273)
print int(KelvinToFahrenheit(505.78))
print KelvinToFahrenheit(-5)जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
32.0
451
Traceback (most recent call last):
File "test.py", line 9, in <module>
print KelvinToFahrenheit(-5)
File "test.py", line 4, in KelvinToFahrenheit
assert (Temperature >= 0),"Colder than absolute zero!"
AssertionError: Colder than absolute zero!अपवाद क्या है?
एक अपवाद एक घटना है, जो एक कार्यक्रम के निष्पादन के दौरान होती है जो कार्यक्रम के निर्देशों के सामान्य प्रवाह को बाधित करती है। सामान्य तौर पर, जब पाइथन स्क्रिप्ट एक ऐसी स्थिति का सामना करती है, जिसका वह सामना नहीं कर सकती, तो वह एक अपवाद को जन्म देती है। एक अपवाद एक पायथन ऑब्जेक्ट है जो एक त्रुटि का प्रतिनिधित्व करता है।
जब एक पायथन स्क्रिप्ट एक अपवाद उठाती है, तो उसे या तो अपवाद को तुरंत संभालना चाहिए अन्यथा वह समाप्त हो जाती है और समाप्त हो जाती है।
एक अपवाद को संभालना
यदि आपके पास कुछ संदिग्ध कोड हैं जो अपवाद उठा सकते हैं, तो आप संदिग्ध कोड को एक में रखकर अपने कार्यक्रम का बचाव कर सकते हैंtry:खंड मैथा। कोशिश के बाद: ब्लॉक, शामिल हैंexcept: कथन, कोड के एक ब्लॉक के बाद जो समस्या को यथासंभव प्रभावी ढंग से संभालता है।
वाक्य - विन्यास
यहाँ कोशिश की सरल वाक्य रचना है .... सिवाय ... और ब्लॉक -
try:
You do your operations here;
......................
except ExceptionI:
If there is ExceptionI, then execute this block.
except ExceptionII:
If there is ExceptionII, then execute this block.
......................
else:
If there is no exception then execute this block.यहाँ उपर्युक्त वाक्यविन्यास के बारे में कुछ महत्वपूर्ण बिंदु हैं -
एक सिंगल स्टेटमेंट स्टेटमेंट को छोड़कर कई स्टेटमेंट हो सकते हैं। यह तब उपयोगी होता है जब ट्राई ब्लॉक में ऐसे कथन होते हैं जो विभिन्न प्रकार के अपवादों को फेंक सकते हैं।
आप क्लॉज़ को छोड़कर एक सामान्य भी प्रदान कर सकते हैं, जो किसी भी अपवाद को संभालता है।
क्लॉज (एस) को छोड़कर, आप एक और-क्लॉज शामिल कर सकते हैं। अन्य ब्लॉक में कोड अगर कोशिश में कोड निष्पादित करता है: ब्लॉक अपवाद नहीं उठाता है।
अन्य-ब्लॉक कोड के लिए एक अच्छी जगह है जिसे कोशिश की आवश्यकता नहीं है: ब्लॉक की सुरक्षा।
उदाहरण
यह उदाहरण एक फ़ाइल खोलता है, सामग्री को लिखता है, फ़ाइल करता है और इनायत से बाहर आता है क्योंकि इसमें कोई समस्या नहीं है -
#!/usr/bin/python
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
except IOError:
print "Error: can\'t find file or read data"
else:
print "Written content in the file successfully"
fh.close()यह निम्न परिणाम उत्पन्न करता है -
Written content in the file successfullyउदाहरण
यह उदाहरण एक फ़ाइल को खोलने की कोशिश करता है जहां आपके पास लिखने की अनुमति नहीं है, इसलिए यह एक अपवाद उठाता है -
#!/usr/bin/python
try:
fh = open("testfile", "r")
fh.write("This is my test file for exception handling!!")
except IOError:
print "Error: can\'t find file or read data"
else:
print "Written content in the file successfully"यह निम्न परिणाम उत्पन्न करता है -
Error: can't find file or read dataको छोड़कर बिना किसी अपवाद के खण्ड
आप अपवाद को छोड़कर इस कथन का उपयोग भी कर सकते हैं, जो इस प्रकार है -
try:
You do your operations here;
......................
except:
If there is any exception, then execute this block.
......................
else:
If there is no exception then execute this block.इस तरह का ए try-exceptबयान सभी अपवादों को पकड़ता है जो घटित होते हैं। इस तरह की कोशिश को छोड़कर बयान का उपयोग करना एक अच्छा प्रोग्रामिंग अभ्यास नहीं माना जाता है, क्योंकि यह सभी अपवादों को पकड़ता है, लेकिन प्रोग्रामर को समस्या के मूल कारण की पहचान नहीं करता है जो हो सकता है।
सिवाय एकाधिक अपवाद के साथ खण्ड
आप कई अपवादों को संभालने के लिए कथन को छोड़कर उसी का उपयोग कर सकते हैं -
try:
You do your operations here;
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
If there is any exception from the given exception list,
then execute this block.
......................
else:
If there is no exception then execute this block.कोशिश-अंत में खंड
आप एक का उपयोग कर सकते हैं finally: साथ में ब्लॉक करें try:खंड मैथा। अंत में ब्लॉक किसी भी कोड को डालने के लिए एक जगह है जिसे निष्पादित करना होगा, चाहे कोशिश-ब्लॉक ने एक अपवाद उठाया या नहीं। कोशिश-आखिर बयान का वाक्य विन्यास यह है -
try:
You do your operations here;
......................
Due to any exception, this may be skipped.
finally:
This would always be executed.
......................आप किसी अन्य क्लॉज के साथ-साथ अंतिम क्लॉज का उपयोग नहीं कर सकते ।
उदाहरण
#!/usr/bin/python
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
finally:
print "Error: can\'t find file or read data"यदि आपके पास लिखित मोड में फ़ाइल खोलने की अनुमति नहीं है, तो यह निम्नलिखित परिणाम देगा -
Error: can't find file or read dataएक ही उदाहरण को और अधिक सफाई से इस प्रकार लिखा जा सकता है -
#!/usr/bin/python
try:
fh = open("testfile", "w")
try:
fh.write("This is my test file for exception handling!!")
finally:
print "Going to close the file"
fh.close()
except IOError:
print "Error: can\'t find file or read data"जब एक अपवाद को कोशिश ब्लॉक में फेंक दिया जाता है , तो निष्पादन तुरंत अंत में ब्लॉक में जाता है। बाद में सभी बयानों अंत में ब्लॉक क्रियान्वित कर रहे हैं, अपवाद फिर से उठाया जाता है और में नियंत्रित किया जाता है को छोड़कर बयान करता है, तो के अगले उच्च परत में मौजूद कोशिश को छोड़कर बयान।
एक अपवाद का तर्क
एक अपवाद में एक तर्क हो सकता है , जो एक मूल्य है जो समस्या के बारे में अतिरिक्त जानकारी देता है। तर्क की सामग्री अपवाद से भिन्न होती है। आप निम्न खंड में एक चर की आपूर्ति करके अपवाद के तर्क को पकड़ते हैं -
try:
You do your operations here;
......................
except ExceptionType, Argument:
You can print value of Argument here...यदि आप किसी एकल अपवाद को संभालने के लिए कोड लिखते हैं, तो आपके पास अपवाद के अपवाद को छोड़कर अपवाद कथन का अनुसरण कर सकते हैं। यदि आप कई अपवादों को फँसा रहे हैं, तो आप अपवाद के tuple का अनुसरण कर सकते हैं।
यह चर अपवाद का मूल्य प्राप्त करता है जिसमें अधिकतर अपवाद का कारण होता है। चर एक ट्यूपल के रूप में एकल मान या कई मान प्राप्त कर सकता है। इस ट्यूपल में आमतौर पर त्रुटि स्ट्रिंग, त्रुटि संख्या और एक त्रुटि स्थान होता है।
उदाहरण
निम्नलिखित एकल अपवाद के लिए एक उदाहरण है -
#!/usr/bin/python
# Define a function here.
def temp_convert(var):
try:
return int(var)
except ValueError, Argument:
print "The argument does not contain numbers\n", Argument
# Call above function here.
temp_convert("xyz");यह निम्न परिणाम उत्पन्न करता है -
The argument does not contain numbers
invalid literal for int() with base 10: 'xyz'एक अपवाद उठाना
आप कई तरह से अपवाद को बढ़ा-चढ़ाकर बयान कर सकते हैं। के लिए सामान्य वाक्यविन्यासraise कथन इस प्रकार है।
वाक्य - विन्यास
raise [Exception [, args [, traceback]]]यहां, अपवाद अपवाद का प्रकार है (उदाहरण के लिए, NameError) और तर्क अपवाद तर्क के लिए एक मान है। तर्क वैकल्पिक है; यदि आपूर्ति नहीं की गई है, तो अपवाद तर्क कोई भी नहीं है।
अंतिम तर्क, ट्रेसबैक भी वैकल्पिक है (और शायद ही कभी व्यवहार में उपयोग किया जाता है), और यदि मौजूद है, तो अपवाद के लिए उपयोग किया जाने वाला ट्रेसबैक ऑब्जेक्ट है।
उदाहरण
एक अपवाद एक स्ट्रिंग, एक कक्षा या एक वस्तु हो सकता है। पायथन कोर द्वारा उठाए गए अधिकांश अपवाद एक तर्क के साथ वर्ग हैं, जो वर्ग का एक उदाहरण है। नए अपवादों को परिभाषित करना काफी आसान है और निम्नानुसार किया जा सकता है -
def functionName( level ):
if level < 1:
raise "Invalid level!", level
# The code below to this would not be executed
# if we raise the exceptionNote:एक अपवाद को पकड़ने के लिए, एक "को छोड़कर" खंड को उसी अपवाद को संदर्भित करना चाहिए जिसे या तो क्लास ऑब्जेक्ट या सरल स्ट्रिंग में फेंक दिया गया है। उदाहरण के लिए, अपवाद के ऊपर कब्जा करने के लिए, हमें निम्न खंड को छोड़कर लिखना होगा -
try:
Business Logic here...
except "Invalid level!":
Exception handling here...
else:
Rest of the code here...उपयोगकर्ता-परिभाषित अपवाद
पायथन आपको मानक निर्मित अपवादों से कक्षाओं को प्राप्त करके अपने स्वयं के अपवाद बनाने की अनुमति देता है।
यहाँ RuntimeError से संबंधित एक उदाहरण है । यहाँ, एक वर्ग बनाया गया है जो RuntimeError से उप- वर्गित है । यह तब उपयोगी है जब आपको अपवाद के पकड़े जाने पर अधिक विशिष्ट जानकारी प्रदर्शित करने की आवश्यकता होती है।
कोशिश ब्लॉक में, उपयोगकर्ता-परिभाषित अपवाद को उठाया जाता है और अपवाद ब्लॉक में पकड़ा जाता है। चर का उपयोग वर्ग Networkerror का एक उदाहरण बनाने के लिए किया जाता है ।
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = argतो एक बार जब आप कक्षा के ऊपर परिभाषित कर लेते हैं, तो आप अपवाद को निम्न प्रकार से उठा सकते हैं -
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.argsपाइथन अस्तित्व में आने के बाद से एक वस्तु-उन्मुख भाषा रही है। इस वजह से, कक्षाएं और ऑब्जेक्ट बनाना और उपयोग करना बिल्कुल आसान है। यह अध्याय आपको पायथन के ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग समर्थन का उपयोग करने में एक विशेषज्ञ बनने में मदद करता है।
यदि आपके पास ऑब्जेक्ट-ओरिएंटेड (OO) प्रोग्रामिंग के साथ कोई पिछला अनुभव नहीं है, तो आप उस पर एक परिचयात्मक पाठ्यक्रम या कम से कम किसी प्रकार के एक ट्यूटोरियल से परामर्श करना चाह सकते हैं ताकि आपके पास मूल अवधारणाओं की समझ हो।
हालांकि, यहां आपको गति लाने के लिए ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग (OOP) का छोटा परिचय दिया गया है -
ओओपी शब्दावली का अवलोकन
Class- किसी ऑब्जेक्ट के लिए एक उपयोगकर्ता-निर्धारित प्रोटोटाइप जो विशेषताओं के एक सेट को परिभाषित करता है जो वर्ग के किसी भी ऑब्जेक्ट को चिह्नित करता है। विशेषताएँ डेटा सदस्य (वर्ग चर और उदाहरण चर) और विधियां हैं, जिन्हें डॉट नोटेशन के माध्यम से एक्सेस किया जाता है।
Class variable- एक चर जो किसी वर्ग के सभी उदाहरणों द्वारा साझा किया जाता है। वर्ग चर को कक्षा के भीतर परिभाषित किया जाता है लेकिन कक्षा के किसी भी तरीके के बाहर। क्लास वेरिएबल्स का उपयोग तब नहीं किया जाता है जब तक कि उदाहरण वेरिएबल होते हैं।
Data member - एक वर्ग चर या उदाहरण चर जो एक वर्ग और उसकी वस्तुओं से जुड़ा डेटा रखता है।
Function overloading- एक विशेष कार्य के लिए एक से अधिक व्यवहार का कार्य। प्रदर्शन की गई प्रक्रिया वस्तुओं या तर्कों के प्रकार से भिन्न होती है।
Instance variable - एक चर जो एक विधि के अंदर परिभाषित किया गया है और केवल एक वर्ग की वर्तमान आवृत्ति से संबंधित है।
Inheritance - एक वर्ग की विशेषताओं को अन्य वर्गों से स्थानांतरित करना जो उससे प्राप्त होते हैं।
Instance- एक निश्चित वर्ग की एक व्यक्तिगत वस्तु। एक ऑब्जेक्ट ओब्ज, जो एक वर्ग सर्कल से संबंधित है, उदाहरण के लिए, वर्ग सर्कल का एक उदाहरण है।
Instantiation - एक वर्ग के उदाहरण का निर्माण।
Method - एक विशेष प्रकार का फ़ंक्शन जिसे एक वर्ग परिभाषा में परिभाषित किया गया है।
Object- एक डेटा संरचना का एक अनूठा उदाहरण जो इसकी कक्षा द्वारा परिभाषित किया गया है। ऑब्जेक्ट में डेटा सदस्य (वर्ग चर और उदाहरण चर) और विधियाँ दोनों शामिल हैं।
Operator overloading - एक विशेष ऑपरेटर को एक से अधिक फ़ंक्शन का असाइनमेंट।
कक्षाएं बनाना
वर्ग बयान एक नया वर्ग परिभाषा पैदा करता है। क्लास का नाम तुरंत कीवर्ड क्लास का अनुसरण करता है और उसके बाद कोलन निम्नानुसार है -
class ClassName:
'Optional class documentation string'
class_suiteकक्षा में एक प्रलेखन स्ट्रिंग है, जिसे ClassName .__ doc__ के माध्यम से एक्सेस किया जा सकता है ।
Class_suite वर्ग के सदस्यों, डेटा विशेषताओं और कार्यों को परिभाषित सभी घटक बयान के होते हैं।
उदाहरण
निम्नलिखित एक साधारण अजगर वर्ग का उदाहरण है -
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salaryवैरिएबल एंपकाउंट एक क्लास वैरिएबल है, जिसका वैल्यू इस क्लास के सभी इंस्टेंस में शेयर किया जाता है। इसे क्लास के अंदर या कक्षा के बाहर से Employee.empCount के रूप में एक्सेस किया जा सकता है ।
पहली विधि __init __ () एक विशेष विधि है, जिसे क्लास कंस्ट्रक्टर या इनिशियलाइज़ेशन विधि कहा जाता है जिसे पायथन कॉल करते हैं जब आप इस क्लास का एक नया उदाहरण बनाते हैं।
आप अन्य कक्षा विधियों को सामान्य कार्यों की तरह इस अपवाद के साथ घोषित करते हैं कि प्रत्येक विधि का पहला तर्क स्वयं है । पायथन आपके लिए सूची में स्व तर्क जोड़ता है ; विधियों को कॉल करने पर आपको इसे शामिल करने की आवश्यकता नहीं है।
इंस्टेंस ऑब्जेक्ट बनाना
एक कक्षा के उदाहरण बनाने के लिए, आप कक्षा को कक्षा के नाम का उपयोग करते हुए बुलाते हैं और इसके __init__ विधि को स्वीकार करने वाले तर्कों में पास करते हैं ।
"This would create first object of Employee class"
emp1 = Employee("Zara", 2000)
"This would create second object of Employee class"
emp2 = Employee("Manni", 5000)पहुँच गुण
आप ऑब्जेक्ट ऑपरेटर के ऑब्जेक्ट के साथ डॉट ऑपरेटर का उपयोग करके एक्सेस करते हैं। कक्षा का नाम निम्नानुसार वर्ग नाम का उपयोग करके प्राप्त किया जाएगा -
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCountअब, सभी अवधारणाओं को एक साथ रखना -
#!/usr/bin/python
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
"This would create first object of Employee class"
emp1 = Employee("Zara", 2000)
"This would create second object of Employee class"
emp2 = Employee("Manni", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCountजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Name : Zara ,Salary: 2000
Name : Manni ,Salary: 5000
Total Employee 2आप किसी भी समय कक्षाओं और वस्तुओं की विशेषताओं को जोड़, हटा या संशोधित कर सकते हैं -
emp1.age = 7 # Add an 'age' attribute.
emp1.age = 8 # Modify 'age' attribute.
del emp1.age # Delete 'age' attribute.विशेषताओं तक पहुंचने के लिए सामान्य विवरणों का उपयोग करने के बजाय, आप निम्नलिखित कार्यों का उपयोग कर सकते हैं -
getattr(obj, name[, default]) - वस्तु की विशेषता तक पहुँचने के लिए।
hasattr(obj,name) - यह देखने के लिए कि कोई विशेषता मौजूद है या नहीं।
setattr(obj,name,value)- एक विशेषता सेट करने के लिए। यदि विशेषता मौजूद नहीं है, तो इसे बनाया जाएगा।
delattr(obj, name) - एक विशेषता को हटाने के लिए।
hasattr(emp1, 'age') # Returns true if 'age' attribute exists
getattr(emp1, 'age') # Returns value of 'age' attribute
setattr(emp1, 'age', 8) # Set attribute 'age' at 8
delattr(empl, 'age') # Delete attribute 'age'बिल्ट-इन क्लास विशेषताएँ
प्रत्येक पायथन वर्ग अंतर्निहित विशेषताओं का पालन करता है और उन्हें किसी अन्य विशेषता की तरह डॉट ऑपरेटर का उपयोग करके एक्सेस किया जा सकता है -
__dict__ - शब्दकोश वर्ग के नाम स्थान युक्त।
__doc__ - वर्ग प्रलेखन स्ट्रिंग या कोई नहीं, यदि अपरिभाषित है।
__name__ - कक्षा का नाम।
__module__- मॉड्यूल नाम जिसमें कक्षा को परिभाषित किया गया है। यह विशेषता इंटरैक्टिव मोड में "__main__" है।
__bases__ - बेस क्लास सूची में उनकी घटना के क्रम में, बेस कक्षाओं से युक्त संभवतः एक खाली ट्यूपल।
उपरोक्त वर्ग के लिए आइए हम इन सभी विशेषताओं तक पहुँचने का प्रयास करें -
#!/usr/bin/python
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
print "Employee.__doc__:", Employee.__doc__
print "Employee.__name__:", Employee.__name__
print "Employee.__module__:", Employee.__module__
print "Employee.__bases__:", Employee.__bases__
print "Employee.__dict__:", Employee.__dict__जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Employee.__doc__: Common base class for all employees
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: ()
Employee.__dict__: {'__module__': '__main__', 'displayCount':
<function displayCount at 0xb7c84994>, 'empCount': 2,
'displayEmployee': <function displayEmployee at 0xb7c8441c>,
'__doc__': 'Common base class for all employees',
'__init__': <function __init__ at 0xb7c846bc>}वस्तुओं को नष्ट करना (कचरा संग्रहण)
पाइथन मेमोरी स्पेस को खाली करने के लिए स्वचालित रूप से अनावश्यक वस्तुओं (अंतर्निहित प्रकार या वर्ग उदाहरण) को हटा देता है। जिस प्रक्रिया से पायथन समय-समय पर स्मृति के ब्लॉक को याद करता है कि अब उपयोग में नहीं हैं, कचरा संग्रह कहा जाता है।
पायथन का कचरा कलेक्टर कार्यक्रम निष्पादन के दौरान चलता है और किसी वस्तु की संदर्भ गणना शून्य तक पहुंचने पर चालू हो जाता है। एक ऑब्जेक्ट का संदर्भ गिनती में परिवर्तन करने वाले उपनामों की संख्या के रूप में बदलता है।
किसी ऑब्जेक्ट का संदर्भ काउंट तब बढ़ जाता है जब उसे एक नया नाम सौंपा जाता है या कंटेनर (सूची, टपल, या शब्दकोश) में रखा जाता है। ऑब्जेक्ट की रेफरेंस काउंट तब कम हो जाती है जब उसे डेल के साथ डिलीट कर दिया जाता है , उसका रेफरेंस रिजेक्ट हो जाता है या उसका रेफरेंस स्कोप से बाहर चला जाता है। जब किसी ऑब्जेक्ट की संदर्भ संख्या शून्य तक पहुँच जाती है, तो पायथन इसे स्वचालित रूप से एकत्र करता है।
a = 40 # Create object <40>
b = a # Increase ref. count of <40>
c = [b] # Increase ref. count of <40>
del a # Decrease ref. count of <40>
b = 100 # Decrease ref. count of <40>
c[0] = -1 # Decrease ref. count of <40>जब कचरा कलेक्टर अनाथ उदाहरण को नष्ट कर देता है और अपने स्थान को पुनः प्राप्त करता है, तो आप सामान्य रूप से नोटिस नहीं करेंगे। लेकिन एक वर्ग विशेष विधि को लागू कर सकता है __del __ () , जिसे एक विध्वंसक कहा जाता है, जिसे तब लागू किया जाता है जब उदाहरण नष्ट होने वाला हो। इस पद्धति का उपयोग किसी भी गैर-स्मृति संसाधन को उदाहरण के लिए साफ़ करने के लिए किया जा सकता है।
उदाहरण
यह __del __ () विध्वंसक एक उदाहरण के वर्ग नाम को प्रिंट करता है जो नष्ट होने वाला है -
#!/usr/bin/python
class Point:
def __init__( self, x=0, y=0):
self.x = x
self.y = y
def __del__(self):
class_name = self.__class__.__name__
print class_name, "destroyed"
pt1 = Point()
pt2 = pt1
pt3 = pt1
print id(pt1), id(pt2), id(pt3) # prints the ids of the obejcts
del pt1
del pt2
del pt3जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
3083401324 3083401324 3083401324
Point destroyedNote- आदर्श रूप से, आपको अपनी कक्षाओं को अलग फ़ाइल में परिभाषित करना चाहिए, फिर आपको उन्हें आयात विवरण का उपयोग करके अपनी मुख्य प्रोग्राम फ़ाइल में आयात करना चाहिए ।
कक्षा में प्रवेश
स्क्रैच से शुरू करने के बजाय, आप नए वर्ग के नाम के बाद मूल वर्ग में कोष्ठक में सूचीबद्ध करके एक पूर्ववर्ती कक्षा से प्राप्त करके एक वर्ग बना सकते हैं।
बाल वर्ग अपने मूल वर्ग की विशेषताओं को विरासत में देता है, और आप उन विशेषताओं का उपयोग कर सकते हैं जैसे कि उन्हें बाल वर्ग में परिभाषित किया गया था। एक बच्चा वर्ग माता-पिता से डेटा सदस्यों और विधियों को भी ओवरराइड कर सकता है।
वाक्य - विन्यास
व्युत्पन्न वर्गों को उनके मूल वर्ग की तरह घोषित किया जाता है; हालाँकि, वर्ग के नाम के बाद से आधार वर्ग की एक सूची दी गई है -
class SubClassName (ParentClass1[, ParentClass2, ...]):
'Optional class documentation string'
class_suiteउदाहरण
#!/usr/bin/python
class Parent: # define parent class
parentAttr = 100
def __init__(self):
print "Calling parent constructor"
def parentMethod(self):
print 'Calling parent method'
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print "Parent attribute :", Parent.parentAttr
class Child(Parent): # define child class
def __init__(self):
print "Calling child constructor"
def childMethod(self):
print 'Calling child method'
c = Child() # instance of child
c.childMethod() # child calls its method
c.parentMethod() # calls parent's method
c.setAttr(200) # again call parent's method
c.getAttr() # again call parent's methodजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Calling child constructor
Calling child method
Calling parent method
Parent attribute : 200इसी तरह, आप कई मूल वर्गों से निम्नानुसार एक कक्षा चला सकते हैं -
class A: # define your class A
.....
class B: # define your class B
.....
class C(A, B): # subclass of A and B
.....आप दो वर्गों और उदाहरणों के रिश्तों की जांच करने के लिए issubclass () या आइंस्टीन () फ़ंक्शंस का उपयोग कर सकते हैं।
issubclass(sub, sup) अगर बचे हुए उपवर्ग में बूलियन फ़ंक्शन सही है sub वास्तव में सुपरक्लास का एक उपवर्ग है sup।
isinstance(obj, Class)बूलियन फंक्शन सही साबित होता है यदि ओब्ज क्लास क्लास का एक उदाहरण है या क्लास के एक उपवर्ग का एक उदाहरण है
ओवरराइडिंग के तरीके
आप हमेशा अपने पैरेंट क्लास के तरीकों को ओवरराइड कर सकते हैं। माता-पिता के तरीकों को ओवरराइड करने का एक कारण यह है कि आप अपने उपवर्ग में विशेष या अलग कार्यक्षमता चाहते हैं।
उदाहरण
#!/usr/bin/python
class Parent: # define parent class
def myMethod(self):
print 'Calling parent method'
class Child(Parent): # define child class
def myMethod(self):
print 'Calling child method'
c = Child() # instance of child
c.myMethod() # child calls overridden methodजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Calling child methodबेस ओवरलोडिंग के तरीके
निम्न तालिका कुछ सामान्य कार्यक्षमता को सूचीबद्ध करती है जिसे आप अपनी कक्षाओं में ओवरराइड कर सकते हैं -
| अनु क्रमांक। | विधि, विवरण और नमूना कॉल |
|---|---|
| 1 | __init__ ( self [,args...] ) कंस्ट्रक्टर (किसी भी वैकल्पिक तर्क के साथ) नमूना कॉल: obj = className (args) |
| 2 | __del__( self ) विध्वंसक, किसी वस्तु को हटा देता है नमूना कॉल: डेल obj |
| 3 | __repr__( self ) अमूल्य स्ट्रिंग प्रतिनिधित्व नमूना कॉल: repr (obj) |
| 4 | __str__( self ) मुद्रण योग्य स्ट्रिंग प्रतिनिधित्व नमूना कॉल: str (obj) |
| 5 | __cmp__ ( self, x ) वस्तु तुलना नमूना कॉल: cmp (obj, x) |
ओवरलोडिंग संचालक
मान लीजिए कि आपने द्वि-आयामी वैक्टर का प्रतिनिधित्व करने के लिए एक वेक्टर वर्ग बनाया है, जब आप उन्हें जोड़ने के लिए प्लस ऑपरेटर का उपयोग करते हैं तो क्या होता है? सबसे अधिक संभावना है कि पायथन आप पर चिल्लाएगा।
हालाँकि, आप वेक्टर को पूरा करने के लिए अपनी कक्षा में __add__ विधि को परिभाषित कर सकते हैं और फिर प्लस ऑपरेटर अपेक्षा के अनुसार व्यवहार करेगा -
उदाहरण
#!/usr/bin/python
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print v1 + v2जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Vector(7,8)डेटा छिपाना
किसी ऑब्जेक्ट की विशेषताएँ वर्ग परिभाषा के बाहर दिखाई दे सकती हैं या नहीं भी। आपको डबल अंडरस्कोर उपसर्ग वाली विशेषताओं को नाम देने की आवश्यकता है, और फिर वे विशेषताएँ बाहरी लोगों के लिए प्रत्यक्ष रूप से दिखाई नहीं देती हैं।
उदाहरण
#!/usr/bin/python
class JustCounter:
__secretCount = 0
def count(self):
self.__secretCount += 1
print self.__secretCount
counter = JustCounter()
counter.count()
counter.count()
print counter.__secretCountजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
1
2
Traceback (most recent call last):
File "test.py", line 12, in <module>
print counter.__secretCount
AttributeError: JustCounter instance has no attribute '__secretCount'पायथन आंतरिक रूप से वर्ग नाम को शामिल करने के लिए नाम बदलकर उन सदस्यों की रक्षा करता है। आप ऐसी विशेषताओं को ऑब्जेक्ट के रूप में एक्सेस कर सकते हैं । _className__attrName यदि आप निम्नलिखित के रूप में अपनी अंतिम पंक्ति को बदल देंगे, तो यह आपके लिए काम करता है -
.........................
print counter._JustCounter__secretCountजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
1
2
2एक नियमित अभिव्यक्ति वर्णों का एक विशेष अनुक्रम है जो आपको एक पैटर्न में आयोजित एक विशेष वाक्यविन्यास का उपयोग करके, अन्य तारों या तारों के सेट को खोजने या खोजने में मदद करता है। UNIX दुनिया में नियमित अभिव्यक्ति का व्यापक रूप से उपयोग किया जाता है।
मॉड्यूल reपायथन में पर्ल जैसी नियमित अभिव्यक्तियों के लिए पूर्ण समर्थन प्रदान करता है। यदि नियमित रूप से अभिव्यक्ति का संकलन या उपयोग करते समय कोई त्रुटि होती है, तो re मॉड्यूल अपवाद re.error को बढ़ाता है।
हम दो महत्वपूर्ण कार्यों को कवर करेंगे, जिनका उपयोग नियमित अभिव्यक्ति को संभालने के लिए किया जाएगा। लेकिन पहले एक छोटी सी बात: विभिन्न वर्ण हैं, जिनका विशेष अर्थ होगा जब उन्हें नियमित अभिव्यक्ति में उपयोग किया जाता है। नियमित अभिव्यक्ति के साथ काम करते समय किसी भी भ्रम से बचने के लिए, हम रॉ स्ट्रिंग्स का उपयोग करेंगेr'expression'।
मैच समारोह
इस समारोह का प्रयास आरई मैच के लिए पैटर्न को स्ट्रिंग वैकल्पिक साथ झंडे ।
यहाँ इस समारोह के लिए वाक्य रचना है -
re.match(pattern, string, flags=0)यहाँ मापदंडों का वर्णन है -
| अनु क्रमांक। | पैरामीटर और विवरण |
|---|---|
| 1 | pattern यह मिलान की जाने वाली नियमित अभिव्यक्ति है। |
| 2 | string यह स्ट्रिंग है, जिसे स्ट्रिंग की शुरुआत में पैटर्न से मिलान करने के लिए खोजा जाएगा। |
| 3 | flags आप बिटवाइस या (|) का उपयोग करके विभिन्न झंडे निर्दिष्ट कर सकते हैं। ये संशोधक हैं, जो नीचे दी गई तालिका में सूचीबद्ध हैं। |
Re.match समारोह रिटर्न एकmatch सफलता पर वस्तु, Noneअसफलता पर। हम समूह (संख्या) या समूहों () के फ़ंक्शन का उपयोग करते हैंmatch मैच्योर एक्सप्रेशन पाने के लिए ऑब्जेक्ट।
| अनु क्रमांक। | मैच ऑब्जेक्ट विधि और विवरण |
|---|---|
| 1 | group(num=0) यह विधि संपूर्ण मिलान (या विशिष्ट उपसमूह संख्या) लौटाती है |
| 2 | groups() यह विधि सभी मिलान उपसमूह को एक टपल में खाली कर देती है (यदि कोई नहीं था तो खाली है) |
उदाहरण
#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarterखोज समारोह
यह फ़ंक्शन वैकल्पिक झंडे के साथ स्ट्रिंग के भीतर आरई पैटर्न की पहली घटना की खोज करता है ।
यहाँ इस समारोह के लिए वाक्य रचना है -
re.search(pattern, string, flags=0)यहाँ मापदंडों का वर्णन है -
| अनु क्रमांक। | पैरामीटर और विवरण |
|---|---|
| 1 | pattern यह मिलान की जाने वाली नियमित अभिव्यक्ति है। |
| 2 | string यह स्ट्रिंग है, जिसे स्ट्रिंग में कहीं भी पैटर्न से मिलान करने के लिए खोजा जाएगा। |
| 3 | flags आप बिटवाइस या (|) का उपयोग करके विभिन्न झंडे निर्दिष्ट कर सकते हैं। ये संशोधक हैं, जो नीचे दी गई तालिका में सूचीबद्ध हैं। |
Re.search समारोह रिटर्न एकmatch सफलता पर वस्तु, noneअसफलता पर। हम समूह (संख्या) या समूहों () के फ़ंक्शन का उपयोग करते हैंmatch मैच्योर एक्सप्रेशन पाने के लिए ऑब्जेक्ट।
| अनु क्रमांक। | मैच ऑब्जेक्ट के तरीके और विवरण |
|---|---|
| 1 | group(num=0) यह विधि संपूर्ण मिलान (या विशिष्ट उपसमूह संख्या) लौटाती है |
| 2 | groups() यह विधि सभी मिलान उपसमूह को एक टपल में खाली कर देती है (यदि कोई नहीं था तो खाली है) |
उदाहरण
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarterमिलान बनाम खोज
पायथन नियमित अभिव्यक्ति के आधार पर दो अलग-अलग आदिम संचालन प्रदान करता है: match केवल स्ट्रिंग की शुरुआत में एक मैच के लिए जाँच करता है, जबकि search स्ट्रिंग में कहीं भी मैच के लिए जाँच (यह डिफ़ॉल्ट रूप से पर्ल क्या करता है)।
उदाहरण
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print "search --> searchObj.group() : ", searchObj.group()
else:
print "Nothing found!!"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
No match!!
search --> searchObj.group() : dogsखोजें और बदलें
सबसे महत्वपूर्ण में से एक re ऐसे तरीके जो नियमित अभिव्यक्ति का उपयोग करते हैं sub।
वाक्य - विन्यास
re.sub(pattern, repl, string, max=0)इस विधि आरई की सभी घटनाओं की जगह पैटर्न में स्ट्रिंग के साथ repl , सभी घटनाओं प्रतिस्थापन जब तक अधिकतम प्रदान की है। यह विधि संशोधित स्ट्रिंग लौटाती है।
उदाहरण
#!/usr/bin/python
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print "Phone Num : ", num
# Remove anything other than digits
num = re.sub(r'\D', "", phone)
print "Phone Num : ", numजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Phone Num : 2004-959-559
Phone Num : 2004959559नियमित अभिव्यक्ति संशोधक: विकल्प झंडे
मिलान के विभिन्न पहलुओं को नियंत्रित करने के लिए नियमित अभिव्यक्ति शाब्दिक में एक वैकल्पिक संशोधक शामिल हो सकता है। संशोधक को एक वैकल्पिक ध्वज के रूप में निर्दिष्ट किया गया है। आप अनन्य या () का उपयोग करके कई संशोधक प्रदान कर सकते हैं, जैसा कि पहले दिखाया गया है और इनमें से किसी एक का प्रतिनिधित्व किया जा सकता है -
| अनु क्रमांक। | संशोधक और विवरण |
|---|---|
| 1 | re.I केस-असंवेदनशील मिलान करता है। |
| 2 | re.L वर्तमान स्थान के अनुसार शब्दों की व्याख्या करता है। यह व्याख्या अक्षर समूह (\ w और \ W) को प्रभावित करती है, साथ ही शब्द सीमा व्यवहार (\ b और \ B) को भी प्रभावित करती है। |
| 3 | re.M $ एक पंक्ति के अंत से मेल खाता है (न केवल स्ट्रिंग के अंत में) और किसी भी पंक्ति की शुरुआत से मेल खाता है (न केवल स्ट्रिंग की शुरुआत)। |
| 4 | re.S एक अवधि (डॉट) किसी भी वर्ण से मेल खाती है, जिसमें एक नई रेखा भी शामिल है। |
| 5 | re.U यूनिकोड वर्ण सेट के अनुसार अक्षरों की व्याख्या करता है। यह ध्वज \ w, \ W, \ b, \ B के व्यवहार को प्रभावित करता है। |
| 6 | re.X "अभिव्यक्ति" नियमित अभिव्यक्ति वाक्यविन्यास की अनुमति देता है। यह व्हाट्सएप को अनदेखा करता है (सिवाय एक सेट के अंदर [या जब एक बैकस्लैश से बच जाता है) और एक टिप्पणी मार्कर के रूप में # बिना लिखा हुआ व्यवहार करता है। |
नियमित अभिव्यक्ति पैटर्न
नियंत्रण वर्णों को छोड़कर, (+ ? . * ^ $ ( ) [ ] { } | \), सभी वर्ण खुद से मेल खाते हैं। आप एक बैकस्लैश के साथ पूर्ववर्ती द्वारा एक नियंत्रण चरित्र से बच सकते हैं।
निम्न तालिका पायथन में उपलब्ध नियमित अभिव्यक्ति सिंटैक्स को सूचीबद्ध करती है -
| अनु क्रमांक। | पैटर्न और विवरण |
|---|---|
| 1 | ^ लाइन की शुरुआत से मेल खाता है। |
| 2 | $ लाइन के अंत मेल खाता है। |
| 3 | . न्यूलाइन को छोड़कर किसी भी एकल वर्ण से मेल खाता है। M विकल्प का उपयोग करने से यह न्यूलाइन को भी मैच कर सकता है। |
| 4 | [...] कोष्ठक में किसी एक वर्ण से मेल खाता है। |
| 5 | [^...] किसी भी एकल वर्ण को कोष्ठक में नहीं मिलाता है |
| 6 | re* पूर्ववर्ती अभिव्यक्ति के 0 या अधिक घटनाओं से मेल खाता है। |
| 7 | re+ पूर्ववर्ती अभिव्यक्ति की 1 या अधिक घटना से मेल खाती है। |
| 8 | re? पूर्ववर्ती अभिव्यक्ति की 0 या 1 घटना से मेल खाता है। |
| 9 | re{ n} पूर्ववर्ती अभिव्यक्ति की घटनाओं की बिल्कुल n संख्या से मेल खाता है। |
| 10 | re{ n,} पूर्ववर्ती अभिव्यक्ति की n या अधिक घटनाओं से मेल खाता है। |
| 1 1 | re{ n, m} कम से कम n और पूर्ववर्ती अभिव्यक्ति के अधिकांश m घटनाओं पर मेल खाता है। |
| 12 | a| b माचिस या तो एक या बी। |
| 13 | (re) समूह नियमित अभिव्यक्ति और याद किए गए पाठ से मेल खाते हैं। |
| 14 | (?imx) नियमित अभिव्यक्ति के भीतर i, m या x विकल्पों पर अस्थायी रूप से टॉगल किया जाता है। यदि कोष्ठक में, केवल वह क्षेत्र प्रभावित होता है। |
| 15 | (?-imx) एक नियमित अभिव्यक्ति के भीतर मैं, मी, या x विकल्प बंद करता है। यदि कोष्ठक में, केवल वह क्षेत्र प्रभावित होता है। |
| 16 | (?: re) मिलान किए गए पाठ को याद किए बिना समूह नियमित अभिव्यक्ति। |
| 17 | (?imx: re) कोष्ठकों के भीतर i, m या x विकल्पों पर अस्थायी रूप से टॉगल किया जाता है। |
| 18 | (?-imx: re) कोष्ठक के भीतर मैं, मी, या x विकल्प बंद करता है। |
| 19 | (?#...) टिप्पणी। |
| 20 | (?= re) एक पैटर्न का उपयोग करके स्थिति निर्दिष्ट करता है। एक सीमा नहीं है। |
| 21 | (?! re) पैटर्न नकार का उपयोग करके स्थिति निर्दिष्ट करता है। एक सीमा नहीं है। |
| 22 | (?> re) बैकट्रैकिंग के बिना स्वतंत्र पैटर्न से मेल खाता है। |
| 23 | \w शब्द वर्णों से मेल खाता है। |
| 24 | \W नॉनवर्ड कैरेक्टर से मेल खाता है। |
| 25 | \s व्हॉट्सएप से मेल खाता है। [\ T \ n \ r \ f] के बराबर है। |
| 26 | \S मैच नॉनवॉइटस्पेस। |
| 27 | \d अंकों का मिलान करता है। [0-9] के बराबर है। |
| 28 | \D Nondigits से मेल खाता है। |
| 29 | \A स्ट्रिंग की शुरुआत से मेल खाता है। |
| 30 | \Z स्ट्रिंग का अंत मेल खाता है। यदि कोई नई रेखा मौजूद है, तो यह नई रेखा से ठीक पहले मेल खाती है। |
| 31 | \z स्ट्रिंग का अंत मेल खाता है। |
| 32 | \G मैच प्वाइंट जहां अंतिम मैच समाप्त हुआ। |
| 33 | \b शब्द सीमाएँ मेल खाती हैं जब बाहर कोष्ठक। कोष्ठक के अंदर होने पर बैकस्पेस (0x08) से मेल खाता है। |
| 34 | \B गैर-सीमा सीमाओं से मेल खाता है। |
| 35 | \n, \t, etc. मेल खाता है नई गाड़ी, गाड़ी का रिटर्न, टैब आदि। |
| 36 | \1...\9 मेल nth समूहीकृत उपपरेशन। |
| 37 | \10 यदि यह पहले से ही मेल खाता है तो nth समूहीकृत उपपरेशन से मेल खाता है। अन्यथा एक चरित्र कोड के अष्टक प्रतिनिधित्व को संदर्भित करता है। |
नियमित अभिव्यक्ति के उदाहरण
शाब्दिक अक्षर
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | python मैच "अजगर"। |
चरित्र वर्ग
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | [Pp]ython मैच "पायथन" या "अजगर" |
| 2 | rub[ye] मैच "माणिक" या "रुबे" |
| 3 | [aeiou] किसी भी लोअरकेस स्वर का मिलान करें |
| 4 | [0-9] किसी अंक का मिलान करें; समान [0123456789] |
| 5 | [a-z] किसी भी लोअरकेस ASCII पत्र का मिलान करें |
| 6 | [A-Z] किसी भी अपरकेस ASCII पत्र से मिलान करें |
| 7 | [a-zA-Z0-9] उपरोक्त में से कोई भी मिलान करें |
| 8 | [^aeiou] लोअरकेस स्वर के अलावा किसी भी चीज़ का मिलान करें |
| 9 | [^0-9] एक अंक के अलावा कुछ भी मिलान करें |
विशेष वर्ण वर्ग
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | . न्यूलाइन को छोड़कर किसी भी वर्ण से मेल करें |
| 2 | \d एक अंक का मिलान करें: [0-9] |
| 3 | \D एक nondigit मैच: [^ 0-9] |
| 4 | \s एक व्हाट्सएप पात्र से मिलान करें: [\ t \ r \ n \ f] |
| 5 | \S मैच नॉनवॉइटस्पेस: [^ \ t \ r \ n \ f] |
| 6 | \w एक एकल शब्द चरित्र से मेल खाएँ: [A-Za-z0-9_] |
| 7 | \W एक चरित्र का मिलान करें: [^ A-Za-z0-9_] |
दोहराव के मामले
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | ruby? मैच "रगड़" या "रूबी": y वैकल्पिक है |
| 2 | ruby* मैच "रगड़" प्लस 0 या अधिक ys |
| 3 | ruby+ मैच "रगड़" प्लस 1 या अधिक वाईएस |
| 4 | \d{3} बिल्कुल 3 अंको का मिलान करें |
| 5 | \d{3,} 3 या अधिक अंकों का मिलान करें |
| 6 | \d{3,5} मैच 3, 4, या 5 अंक |
निन्दात्मक पुनरावृत्ति
यह सबसे छोटी संख्या में दोहराव से मेल खाता है -
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | <.*> लालची पुनरावृत्ति: "<python> perl>" से मेल खाता है |
| 2 | <.*?> Nongreedy: "<python> perl>" में "<python>" से मेल खाता है |
कोष्ठकों के साथ समूहन
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | \D\d+ कोई समूह नहीं: + दोहराता है |
| 2 | (\D\d)+ समूहीकृत: + दोहराता \ D \ d जोड़ी |
| 3 | ([Pp]ython(, )?)+ मैच "पायथन", "पायथन, अजगर, अजगर", आदि। |
Backreferences
यह पहले से मिलान किए गए समूह से फिर से मेल खाता है -
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | ([Pp])ython&\1ails अजगर और पाल या अजगर और पूंछ का मिलान करें |
| 2 | (['"])[^\1]*\1 सिंगल या डबल-उद्धृत स्ट्रिंग। 1 समूह से जो भी मेल खाता है, \ 1 मैच। \ 2 मैच 2 समूह से जो भी मेल खाता है, आदि। |
वैकल्पिक
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | python|perl मैच "अजगर" या "पर्ल" |
| 2 | rub(y|le)) मैच "माणिक" या "रूबल" |
| 3 | Python(!+|\?) "पायथन" एक या एक से अधिक के बाद! या एक? |
एंकर
यह मैच की स्थिति निर्दिष्ट करने की आवश्यकता है।
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | ^Python एक स्ट्रिंग या आंतरिक रेखा की शुरुआत में "पायथन" का मिलान करें |
| 2 | Python$ एक स्ट्रिंग या लाइन के अंत में "पायथन" का मिलान करें |
| 3 | \APython एक स्ट्रिंग की शुरुआत में "पायथन" मैच |
| 4 | Python\Z एक स्ट्रिंग के अंत में "पायथन" मैच |
| 5 | \bPython\b एक शब्द सीमा पर "पायथन" मैच |
| 6 | \brub\B \ B नॉनवर्ड सीमा है: "रब" और "रूबी" में "रगड़" मिलाएं लेकिन अकेले नहीं |
| 7 | Python(?=!) मैच "पायथन", यदि एक विस्मयादिबोधक बिंदु के बाद। |
| 8 | Python(?!!) मैच "पायथन", यदि एक विस्मयादिबोधक बिंदु के बाद नहीं। |
कोष्ठक के साथ विशेष सिंटैक्स
| अनु क्रमांक। | उदाहरण और विवरण |
|---|---|
| 1 | R(?#comment) "आर" से मेल खाता है। बाकी सभी एक टिप्पणी है |
| 2 | R(?i)uby केस-असंवेदनशील "uby" से मेल खाते हुए |
| 3 | R(?i:uby) ऊपर की तरह |
| 4 | rub(?:y|le)) केवल \ 1 backreference बनाए बिना समूह |
कॉमन गेटवे इंटरफेस या सीजीआई, मानकों का एक सेट है जो यह परिभाषित करता है कि वेब सर्वर और कस्टम स्क्रिप्ट के बीच सूचनाओं का आदान-प्रदान कैसे किया जाता है। वर्तमान में सीजीआई चश्मा एनसीएसए द्वारा बनाए रखा जाता है।
CGI क्या है?
सामान्य गेटवे इंटरफ़ेस, या CGI, बाहरी सर्वर के लिए एक मानक है जो HTTP सर्वर जैसे सूचना सर्वरों के साथ इंटरफेस करता है।
वर्तमान संस्करण CGI / 1.1 है और CGI / 1.2 प्रगति पर है।
वेब ब्राउज़िंग
CGI की अवधारणा को समझने के लिए, आइए देखें कि जब हम किसी विशेष वेब पेज या URL को ब्राउज़ करने के लिए हाइपर लिंक पर क्लिक करते हैं तो क्या होता है।
आपका ब्राउज़र HTTP वेब सर्वर से संपर्क करता है और URL के लिए मांग करता है, अर्थात फ़ाइल नाम।
वेब सर्वर URL को पार्स करता है और फ़ाइल नाम के लिए देखता है। यदि यह उस फ़ाइल को ढूंढता है तो उसे ब्राउज़र में वापस भेज देता है, अन्यथा एक त्रुटि संदेश भेजता है जो बताता है कि आपने गलत फ़ाइल का अनुरोध किया है।
वेब ब्राउज़र वेब सर्वर से प्रतिक्रिया लेता है और प्राप्त फ़ाइल या त्रुटि संदेश को प्रदर्शित करता है।
हालाँकि, HTTP सर्वर को सेट करना संभव है ताकि जब भी किसी निश्चित निर्देशिका में किसी फ़ाइल का अनुरोध किया जाए तो वह फ़ाइल वापस नहीं भेजी जाए; इसके बजाय इसे एक प्रोग्राम के रूप में निष्पादित किया जाता है, और जो भी प्रोग्राम आउटपुट को प्रदर्शित करने के लिए आपके ब्राउज़र में वापस भेजा जाता है। इस फ़ंक्शन को कॉमन गेटवे इंटरफ़ेस या CGI कहा जाता है और कार्यक्रमों को CGI स्क्रिप्ट कहा जाता है। ये CGI प्रोग्राम एक पायथन स्क्रिप्ट, पेरेल स्क्रिप्ट, शेल स्क्रिप्ट, C या C ++ प्रोग्राम आदि हो सकते हैं।
CGI आर्किटेक्चर आरेख
वेब सर्वर समर्थन और विन्यास
इससे पहले कि आप CGI प्रोग्रामिंग के साथ आगे बढ़ें, सुनिश्चित करें कि आपका वेब सर्वर CGI का समर्थन करता है और CGI प्रोग्राम को संभालने के लिए इसे कॉन्फ़िगर किया गया है। HTTP सर्वर द्वारा निष्पादित किए जाने वाले सभी CGI प्रोग्राम को प्री-कॉन्फ़िगर डायरेक्टरी में रखा जाता है। इस निर्देशिका को CGI निर्देशिका कहा जाता है और सम्मेलन द्वारा इसे / var / www / cgi-bin नाम दिया गया है। कन्वेंशन द्वारा, सीजीआई फाइलों का विस्तार है।cgi, लेकिन आप अपनी फाइलों को अजगर विस्तार के साथ रख सकते हैं .py भी।
डिफ़ॉल्ट रूप से, लिनक्स सर्वर को केवल cgi-bin निर्देशिका में / var / www में स्क्रिप्ट को चलाने के लिए कॉन्फ़िगर किया गया है। यदि आप अपनी CGI स्क्रिप्ट को चलाने के लिए कोई अन्य निर्देशिका निर्दिष्ट करना चाहते हैं, तो httpd.conf फ़ाइल में निम्न पंक्तियों पर टिप्पणी करें -
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>यहां, हम यह मानते हैं कि आपके पास वेब सर्वर है और सफलतापूर्वक चल रहा है और आप किसी अन्य CGI प्रोग्राम जैसे पर्ल या शेल आदि को चलाने में सक्षम हैं।
पहला सीजीआई कार्यक्रम
यहाँ एक सरल लिंक दिया गया है, जो एक CGI स्क्रिप्ट से जुड़ा है जिसे hello.py कहा जाता है । इस फ़ाइल को / var / www / cgi-bin डायरेक्टरी में रखा गया है और इसमें निम्नलिखित सामग्री है। अपने CGI प्रोग्राम को चलाने से पहले, सुनिश्चित करें कि आपके पास उपयोग करने वाली फ़ाइल का परिवर्तन मोड हैchmod 755 hello.py फ़ाइल को निष्पादन योग्य बनाने के लिए UNIX कमांड।
#!/usr/bin/python
print "Content-type:text/html\r\n\r\n"
print '<html>'
print '<head>'
print '<title>Hello World - First CGI Program</title>'
print '</head>'
print '<body>'
print '<h2>Hello World! This is my first CGI program</h2>'
print '</body>'
print '</html>'यदि आप hello.py पर क्लिक करते हैं, तो यह निम्न आउटपुट उत्पन्न करता है -
नमस्ते दुनिया! यह मेरा पहला सीजीआई कार्यक्रम है |
यह hello.py स्क्रिप्ट एक साधारण पायथन स्क्रिप्ट है, जो STDOUT फाइल, यानी स्क्रीन पर अपना आउटपुट लिखती है। एक महत्वपूर्ण और अतिरिक्त सुविधा उपलब्ध है जिसे मुद्रित करना पहली पंक्ति हैContent-type:text/html\r\n\r\n। यह लाइन ब्राउज़र को वापस भेज दी जाती है और यह ब्राउज़र स्क्रीन पर प्रदर्शित होने वाली सामग्री प्रकार को निर्दिष्ट करती है।
अब तक आप CGI की मूल अवधारणा को समझ गए होंगे और आप Python का उपयोग करके कई जटिल CGI प्रोग्राम लिख सकते हैं। यह स्क्रिप्ट किसी अन्य बाहरी सिस्टम के साथ भी बातचीत कर सकती है, जैसे कि आरडीबीएमएस जैसी सूचनाओं का आदान-प्रदान करने के लिए।
HTTP हैडर
रेखा Content-type:text/html\r\n\r\nHTTP हेडर का एक हिस्सा है जो सामग्री को समझने के लिए ब्राउज़र को भेजा जाता है। सभी HTTP शीर्ष लेख निम्नलिखित रूप में होंगे -
HTTP Field Name: Field Content
For Example
Content-type: text/html\r\n\r\nकुछ अन्य महत्वपूर्ण HTTP हेडर हैं, जिन्हें आप अपने CGI प्रोग्रामिंग में अक्सर उपयोग करेंगे।
| अनु क्रमांक। | हेडर और विवरण |
|---|---|
| 1 | Content-type: फ़ाइल के प्रारूप को परिभाषित करने वाला MIME स्ट्रिंग वापस किया जा रहा है। उदाहरण सामग्री-प्रकार: पाठ / html है |
| 2 | Expires: Date जानकारी अमान्य होने की तिथि। इसका उपयोग ब्राउज़र द्वारा यह तय करने के लिए किया जाता है कि किसी पृष्ठ को ताज़ा करने की आवश्यकता कब है। एक मान्य दिनांक स्ट्रिंग प्रारूप 01 जनवरी 1998 12:00:00 GMT में है। |
| 3 | Location: URL URL जो अनुरोध किए गए URL के बजाय लौटाया गया है। आप किसी भी फ़ाइल के अनुरोध को पुनर्निर्देशित करने के लिए इस फ़ील्ड का उपयोग कर सकते हैं। |
| 4 | Last-modified: Date संसाधन के अंतिम संशोधन की तारीख। |
| 5 | Content-length: N डेटा को लौटाए जाने की लंबाई, बाइट्स में। फ़ाइल के लिए अनुमानित डाउनलोड समय की रिपोर्ट करने के लिए ब्राउज़र इस मान का उपयोग करता है। |
| 6 | Set-Cookie: String कुकी स्ट्रिंग के माध्यम से पारित सेट करें |
CGI पर्यावरण चर
सभी सीजीआई कार्यक्रमों में निम्नलिखित पर्यावरण चर तक पहुंच है। ये चर किसी भी CGI प्रोग्राम को लिखते समय एक महत्वपूर्ण भूमिका निभाते हैं।
| अनु क्रमांक। | परिवर्तनीय नाम और विवरण |
|---|---|
| 1 | CONTENT_TYPE सामग्री का डेटा प्रकार। उपयोग किया जाता है जब क्लाइंट सर्वर से जुड़ी सामग्री भेज रहा है। उदाहरण के लिए, फ़ाइल अपलोड करें। |
| 2 | CONTENT_LENGTH क्वेरी जानकारी की लंबाई। यह केवल POST अनुरोधों के लिए उपलब्ध है। |
| 3 | HTTP_COOKIE कुंजी और मूल्य जोड़ी के रूप में सेट कुकीज़ लौटाता है। |
| 4 | HTTP_USER_AGENT उपयोगकर्ता-एजेंट अनुरोध-हेडर फ़ील्ड में अनुरोध को उत्पन्न करने वाले उपयोगकर्ता एजेंट के बारे में जानकारी होती है। यह वेब ब्राउज़र का नाम है। |
| 5 | PATH_INFO CGI स्क्रिप्ट के लिए पथ। |
| 6 | QUERY_STRING GET विधि अनुरोध के साथ भेजी गई URL-एन्कोडेड जानकारी। |
| 7 | REMOTE_ADDR अनुरोध करने वाले दूरस्थ होस्ट का IP पता। यह उपयोगी लॉगिंग या प्रमाणीकरण के लिए है। |
| 8 | REMOTE_HOST अनुरोध करने वाले मेजबान का पूरी तरह से योग्य नाम। यदि यह जानकारी उपलब्ध नहीं है, तो IR पता प्राप्त करने के लिए REMOTE_ADDR का उपयोग किया जा सकता है। |
| 9 | REQUEST_METHOD अनुरोध करने के लिए उपयोग की जाने वाली विधि। सबसे आम तरीके GET और POST हैं। |
| 10 | SCRIPT_FILENAME CGI स्क्रिप्ट का पूरा रास्ता। |
| 1 1 | SCRIPT_NAME CGI लिपि का नाम। |
| 12 | SERVER_NAME सर्वर का होस्टनाम या आईपी एड्रेस |
| 13 | SERVER_SOFTWARE सर्वर पर चल रहे सॉफ़्टवेयर का नाम और संस्करण। |
यहाँ सभी CGI चर को सूचीबद्ध करने के लिए छोटा CGI कार्यक्रम है। परिणाम प्राप्त करें पर्यावरण देखने के लिए इस लिंक पर क्लिक करें
#!/usr/bin/python
import os
print "Content-type: text/html\r\n\r\n";
print "<font size=+1>Environment</font><\br>";
for param in os.environ.keys():
print "<b>%20s</b>: %s<\br>" % (param, os.environ[param])GET और POST के तरीके
जब आप अपने ब्राउज़र से वेब सर्वर और अंततः अपने CGI प्रोग्राम के लिए कुछ जानकारी पास करने की आवश्यकता होती है, तो आप कई स्थितियों में आ गए होंगे। सबसे अधिक बार, ब्राउज़र दो तरीकों का उपयोग करता है दो इस जानकारी को वेब सर्वर को पास करते हैं। ये तरीके हैं GET मेथड और POST मेथड।
जीईटी पद्धति का उपयोग करके सूचना पास करना
GET विधि पेज अनुरोध के लिए संलग्न एन्कोडेड उपयोगकर्ता जानकारी भेजता है। पृष्ठ और एन्कोडेड जानकारी को किसके द्वारा अलग किया जाता है? चरित्र इस प्रकार है -
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2जीईटी विधि ब्राउज़र से वेब सर्वर तक जानकारी पारित करने के लिए डिफ़ॉल्ट विधि है और यह आपके ब्राउज़र के स्थान: बॉक्स में दिखाई देने वाली लंबी स्ट्रिंग का उत्पादन करती है। यदि आपके पास सर्वर के पास जाने के लिए पासवर्ड या अन्य संवेदनशील जानकारी है तो कभी भी GET विधि का उपयोग न करें। GET विधि का आकार सीमा है: केवल 1024 वर्णों को अनुरोध स्ट्रिंग में भेजा जा सकता है। GET विधि QUERY_STRING हेडर का उपयोग करके जानकारी भेजती है और आपके CGI प्रोग्राम में QUERY_STRING वातावरण चर के माध्यम से सुलभ होगी।
आप किसी भी URL के साथ केवल कुंजी और मूल्य जोड़े को संक्षिप्त करके जानकारी पास कर सकते हैं या GET विधि का उपयोग करके जानकारी पास करने के लिए HTML <FORM> टैग का उपयोग कर सकते हैं।
सरल URL उदाहरण: विधि प्राप्त करें
यहां एक सरल URL है, जो GET विधि का उपयोग करके hello_get.py प्रोग्राम में दो मान पास करता है।
/cgi-bin/hello_get.py?first_name=ZARA&last_name=ALIनीचे है hello_get.pyवेब ब्राउज़र द्वारा दिए गए इनपुट को संभालने के लिए स्क्रिप्ट। हम उपयोग करने जा रहे हैंcgi मॉड्यूल, जो उत्तीर्ण जानकारी तक पहुंचना बहुत आसान बनाता है -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"यह निम्नलिखित परिणाम उत्पन्न करेगा -
हैलो जरा ALI |
सरल फार्म उदाहरण: विधि प्राप्त करें
यह उदाहरण HTML FORM और सबमिट बटन का उपयोग करके दो मान पास करता है। हम इस इनपुट को संभालने के लिए उसी CGI स्क्रिप्ट hello_get.py का उपयोग करते हैं।
<form action = "/cgi-bin/hello_get.py" method = "get">
First Name: <input type = "text" name = "first_name"> <br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>यहां उपरोक्त फॉर्म का वास्तविक आउटपुट है, आप पहले और अंतिम नाम दर्ज करें और फिर परिणाम देखने के लिए सबमिट बटन पर क्लिक करें।
POST विधि का उपयोग कर जानकारी पास करना
एक CGI प्रोग्राम को सूचना देने का एक आम तौर पर अधिक विश्वसनीय तरीका POST विधि है। यह सूचनाओं को GET विधियों की तरह ही पैकेज करता है, लेकिन इसके बाद इसे टेक्स्ट स्ट्रिंग के रूप में भेजने के बजाय? URL में यह इसे एक अलग संदेश के रूप में भेजता है। यह संदेश मानक इनपुट के रूप में CGI स्क्रिप्ट में आता है।
नीचे एक ही hello_get.py स्क्रिप्ट है जो GET और साथ ही POST विधि को संभालती है।
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"चलिए फिर से एक ही उदाहरण लेते हैं, जो HTML FORM और सबमिट बटन का उपयोग करके दो मानों को पार करता है। हम इस इनपुट को संभालने के लिए उसी CGI स्क्रिप्ट hello_get.py का उपयोग करते हैं।
<form action = "/cgi-bin/hello_get.py" method = "post">
First Name: <input type = "text" name = "first_name"><br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>यहाँ उपरोक्त फॉर्म का वास्तविक आउटपुट है। आप पहले और अंतिम नाम दर्ज करें और फिर परिणाम देखने के लिए सबमिट बटन पर क्लिक करें।
सीजीआई प्रोग्राम को चेकबॉक्स डेटा पास करना
चेकबॉक्स का उपयोग तब किया जाता है जब एक से अधिक विकल्प चुनने की आवश्यकता होती है।
यहाँ दो चेकबॉक्स के साथ एक फॉर्म के लिए उदाहरण के लिए HTML कोड है -
<form action = "/cgi-bin/checkbox.cgi" method = "POST" target = "_blank">
<input type = "checkbox" name = "maths" value = "on" /> Maths
<input type = "checkbox" name = "physics" value = "on" /> Physics
<input type = "submit" value = "Select Subject" />
</form>इस कोड का परिणाम निम्न रूप है -
चेकबॉक्स बटन के लिए वेब ब्राउज़र द्वारा दिए गए इनपुट को संभालने के लिए नीचे checkbox.cgi स्क्रिप्ट है।
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('maths'):
math_flag = "ON"
else:
math_flag = "OFF"
if form.getvalue('physics'):
physics_flag = "ON"
else:
physics_flag = "OFF"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Checkbox - Third CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> CheckBox Maths is : %s</h2>" % math_flag
print "<h2> CheckBox Physics is : %s</h2>" % physics_flag
print "</body>"
print "</html>"CGI प्रोग्राम को रेडियो बटन डेटा पास करना
रेडियो बटन का उपयोग तब किया जाता है जब केवल एक विकल्प का चयन करना आवश्यक होता है।
यहाँ दो रेडियो बटन के साथ एक फॉर्म के लिए उदाहरण के लिए HTML कोड है -
<form action = "/cgi-bin/radiobutton.py" method = "post" target = "_blank">
<input type = "radio" name = "subject" value = "maths" /> Maths
<input type = "radio" name = "subject" value = "physics" /> Physics
<input type = "submit" value = "Select Subject" />
</form>इस कोड का परिणाम निम्न रूप है -
रेडियो बटन के लिए वेब ब्राउज़र द्वारा दिए गए इनपुट को संभालने के लिए नीचे radiobutton.py स्क्रिप्ट है -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('subject'):
subject = form.getvalue('subject')
else:
subject = "Not set"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Radio - Fourth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"CGI प्रोग्राम के लिए पाठ क्षेत्र डेटा पास करना
TEXTAREA तत्व का उपयोग तब किया जाता है जब बहुस्तरीय पाठ को CGI प्रोग्राम को पास करना होता है।
TEXTAREA बॉक्स के साथ फ़ॉर्म के लिए उदाहरण HTML कोड है -
<form action = "/cgi-bin/textarea.py" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>इस कोड का परिणाम निम्न रूप है -
नीचे वेब ब्राउज़र द्वारा दिए गए इनपुट को संभालने के लिए textarea.cgi स्क्रिप्ट है -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>";
print "<title>Text Area - Fifth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Entered Text Content is %s</h2>" % text_content
print "</body>"CGI प्रोग्राम में ड्रॉप डाउन बॉक्स डेटा पास करना
ड्रॉप डाउन बॉक्स का उपयोग तब किया जाता है जब हमारे पास कई विकल्प उपलब्ध होते हैं लेकिन केवल एक या दो का चयन किया जाएगा।
यहाँ एक ड्रॉप डाउन बॉक्स के साथ एक फॉर्म के लिए उदाहरण के लिए HTML कोड है -
<form action = "/cgi-bin/dropdown.py" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>इस कोड का परिणाम निम्न रूप है -
नीचे वेब ब्राउज़र द्वारा दिए गए इनपुट को संभालने के लिए ड्रॉपडाउन एरो स्क्रिप्ट है।
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('dropdown'):
subject = form.getvalue('dropdown')
else:
subject = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Dropdown Box - Sixth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"CGI में कुकीज़ का उपयोग करना
HTTP प्रोटोकॉल एक स्टेटलेस प्रोटोकॉल है। एक वाणिज्यिक वेबसाइट के लिए, विभिन्न पृष्ठों के बीच सत्र की जानकारी को बनाए रखना आवश्यक है। उदाहरण के लिए, एक उपयोगकर्ता पंजीकरण कई पृष्ठों को पूरा करने के बाद समाप्त होता है। सभी वेब पृष्ठों पर उपयोगकर्ता की सत्र जानकारी कैसे बनाए रखें?
कई स्थितियों में, कुकीज़ का उपयोग करना याद रखने और वरीयताओं के अनुभव, या साइट के आँकड़ों के लिए आवश्यक वरीयताओं, खरीद, कमीशन और अन्य जानकारी को ट्रैक करने का सबसे प्रभावी तरीका है।
यह काम किस प्रकार करता है?
आपका सर्वर कुकी के रूप में विज़िटर के ब्राउज़र में कुछ डेटा भेजता है। ब्राउज़र कुकी को स्वीकार कर सकता है। यदि ऐसा होता है, तो इसे विज़िटर की हार्ड ड्राइव पर एक सादे टेक्स्ट रिकॉर्ड के रूप में संग्रहीत किया जाता है। अब, जब आगंतुक आपकी साइट पर किसी अन्य पेज पर आता है, तो कुकी पुनः प्राप्ति के लिए उपलब्ध होती है। एक बार पुनर्प्राप्त करने के बाद, आपका सर्वर जानता है / याद रखता है कि क्या संग्रहीत किया गया था।
कुकीज़ 5 चर-लंबाई वाले क्षेत्रों का एक सादा पाठ डेटा रिकॉर्ड हैं -
Expires- कुकी की तारीख समाप्त हो जाएगी। यदि यह रिक्त है, तो आगंतुक के ब्राउज़र को छोड़ने पर कुकी समाप्त हो जाएगी।
Domain - आपकी साइट का डोमेन नाम।
Path- निर्देशिका या वेब पेज के लिए पथ जो कुकी सेट करता है। यदि आप किसी भी निर्देशिका या पृष्ठ से कुकी को पुनः प्राप्त करना चाहते हैं तो यह रिक्त हो सकता है।
Secure- यदि इस फ़ील्ड में "सुरक्षित" शब्द है, तो कुकी को केवल एक सुरक्षित सर्वर के साथ पुनर्प्राप्त किया जा सकता है। यदि यह फ़ील्ड रिक्त है, तो ऐसा कोई प्रतिबंध मौजूद नहीं है।
Name=Value - कुंजी और मूल्य जोड़े के रूप में कुकीज़ सेट और पुनर्प्राप्त किए जाते हैं।
कुकीज़ की स्थापना
ब्राउजर में कुकीज भेजना बहुत आसान है। ये कुकीज़ सामग्री-प्रकार फ़ील्ड से पहले HTTP हैडर के साथ भेजी जाती हैं। मान लें कि आप UserID और Password को कूकीज के रूप में सेट करना चाहते हैं। कुकीज़ को सेट करना इस प्रकार है -
#!/usr/bin/python
print "Set-Cookie:UserID = XYZ;\r\n"
print "Set-Cookie:Password = XYZ123;\r\n"
print "Set-Cookie:Expires = Tuesday, 31-Dec-2007 23:12:40 GMT";\r\n"
print "Set-Cookie:Domain = www.tutorialspoint.com;\r\n"
print "Set-Cookie:Path = /perl;\n"
print "Content-type:text/html\r\n\r\n"
...........Rest of the HTML Content....इस उदाहरण से, आप समझ गए होंगे कि कुकीज़ कैसे सेट करें। हम प्रयोग करते हैंSet-Cookie कुकीज़ को सेट करने के लिए HTTP हेडर।
यह एक्सपायर, डोमेन और पाथ जैसी कुकीज़ विशेषताओं को सेट करने के लिए वैकल्पिक है। यह उल्लेखनीय है कि मैजिक लाइन भेजने से पहले कुकीज सेट की जाती हैं"Content-type:text/html\r\n\r\n।
कुकीज़ वापस ले रहा है
सभी सेट कुकीज़ को पुनः प्राप्त करना बहुत आसान है। कुकीज़ CGI पर्यावरण चर HTTP_COOKIE में संगृहीत हैं और उनके निम्नलिखित रूप होंगे -
key1 = value1;key2 = value2;key3 = value3....कुकीज़ कैसे प्राप्त करें, इसका एक उदाहरण यहां दिया गया है।
#!/usr/bin/python
# Import modules for CGI handling
from os import environ
import cgi, cgitb
if environ.has_key('HTTP_COOKIE'):
for cookie in map(strip, split(environ['HTTP_COOKIE'], ';')):
(key, value ) = split(cookie, '=');
if key == "UserID":
user_id = value
if key == "Password":
password = value
print "User ID = %s" % user_id
print "Password = %s" % passwordयह स्क्रिप्ट द्वारा उपरोक्त कुकीज़ के लिए निम्न परिणाम तैयार करता है -
User ID = XYZ
Password = XYZ123फ़ाइल अपलोड उदाहरण
किसी फ़ाइल को अपलोड करने के लिए, HTML फॉर्म में enctype विशेषता सेट होनी चाहिए multipart/form-data। फ़ाइल प्रकार के साथ इनपुट टैग एक "ब्राउज़ करें" बटन बनाता है।
<html>
<body>
<form enctype = "multipart/form-data"
action = "save_file.py" method = "post">
<p>File: <input type = "file" name = "filename" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>इस कोड का परिणाम निम्न रूप है -
उपरोक्त उदाहरण को जानबूझकर हमारे सर्वर पर फ़ाइल अपलोड करने वाले लोगों को बचाने के लिए अक्षम किया गया है, लेकिन आप अपने सर्वर के साथ उपरोक्त कोड की कोशिश कर सकते हैं।
यहाँ स्क्रिप्ट है save_file.py फ़ाइल अपलोड को संभालने के लिए -
#!/usr/bin/python
import cgi, os
import cgitb; cgitb.enable()
form = cgi.FieldStorage()
# Get filename here.
fileitem = form['filename']
# Test if the file was uploaded
if fileitem.filename:
# strip leading path from file name to avoid
# directory traversal attacks
fn = os.path.basename(fileitem.filename)
open('/tmp/' + fn, 'wb').write(fileitem.file.read())
message = 'The file "' + fn + '" was uploaded successfully'
else:
message = 'No file was uploaded'
print """\
Content-Type: text/html\n
<html>
<body>
<p>%s</p>
</body>
</html>
""" % (message,)यदि आप उपरोक्त स्क्रिप्ट को यूनिक्स / लिनक्स पर चलाते हैं, तो आपको फ़ाइल सेपरेटर को निम्नानुसार बदलने की देखभाल करने की आवश्यकता है, अन्यथा खुले () कथन के ऊपर आपके विंडोज़ मशीन पर ठीक काम करना चाहिए।
fn = os.path.basename(fileitem.filename.replace("\\", "/" ))एक "फ़ाइल डाउनलोड" डायलॉग बॉक्स कैसे उठाएं?
कभी-कभी, यह वांछित होता है कि आप विकल्प देना चाहते हैं जहां उपयोगकर्ता लिंक पर क्लिक कर सकता है और यह वास्तविक सामग्री प्रदर्शित करने के बजाय उपयोगकर्ता को "फ़ाइल डाउनलोड" संवाद बॉक्स पॉप अप करेगा। यह बहुत आसान है और इसे HTTP हेडर के माध्यम से प्राप्त किया जा सकता है। यह HTTP हेडर पिछले अनुभाग में उल्लिखित हेडर से अलग है।
उदाहरण के लिए, यदि आप एक बनाना चाहते हैं FileName किसी दिए गए लिंक से डाउनलोड करने योग्य फ़ाइल, फिर उसका सिंटैक्स निम्नानुसार है -
#!/usr/bin/python
# HTTP Header
print "Content-Type:application/octet-stream; name = \"FileName\"\r\n";
print "Content-Disposition: attachment; filename = \"FileName\"\r\n\n";
# Actual File Content will go here.
fo = open("foo.txt", "rb")
str = fo.read();
print str
# Close opend file
fo.close()आशा है कि आप इस ट्यूटोरियल का आनंद लेंगे। यदि हाँ, तो कृपया मुझे अपनी प्रतिक्रिया भेजें: हमसे संपर्क करें
डेटाबेस इंटरफेस के लिए पायथन मानक पायथन डीबी-एपीआई है। अधिकांश पायथन डेटाबेस इंटरफेस इस मानक का पालन करते हैं।
आप अपने आवेदन के लिए सही डेटाबेस चुन सकते हैं। अजगर डेटाबेस एपीआई डेटाबेस सर्वर की एक विस्तृत श्रृंखला का समर्थन करता है जैसे -
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
यहां उपलब्ध पायथन डेटाबेस इंटरफेस की सूची दी गई है: पायथन डेटाबेस इंटरफेस और एपीआई । आपके द्वारा उपयोग किए जाने वाले प्रत्येक डेटाबेस के लिए आपको एक अलग DB एपीआई मॉड्यूल डाउनलोड करना होगा। उदाहरण के लिए, यदि आपको ओरेकल डेटाबेस के साथ-साथ MySQL डेटाबेस तक पहुँचने की आवश्यकता है, तो आपको Oracle और MySQL डेटाबेस मॉड्यूल दोनों को डाउनलोड करना होगा।
डीबी एपीआई जहां संभव हो पायथन संरचनाओं और सिंटैक्स का उपयोग कर डेटाबेस के साथ काम करने के लिए एक न्यूनतम मानक प्रदान करता है। इस एपीआई में निम्नलिखित शामिल हैं -
- एपीआई मॉड्यूल आयात करना।
- डेटाबेस के साथ एक कनेक्शन प्राप्त करना।
- SQL कथन और संग्रहीत कार्यविधियाँ जारी करना।
- कनेक्शन बंद करना
हम MySQL का उपयोग करके सभी अवधारणाओं को सीखेंगे, इसलिए हमें MySQLdb मॉड्यूल के बारे में बात करें।
MySQLdb क्या है?
MySQLdb पायथन से MySQL डेटाबेस सर्वर से कनेक्ट करने के लिए एक इंटरफ़ेस है। यह Python Database API v2.0 को लागू करता है और इसे MySQL C API के ऊपर बनाया गया है।
मैं MySQLdb कैसे स्थापित करूँ?
आगे बढ़ने से पहले, आप सुनिश्चित करें कि आपके पास MySQLdb आपके मशीन पर स्थापित है। बस अपनी पायथन लिपि में निम्नलिखित टाइप करें और इसे निष्पादित करें -
#!/usr/bin/python
import MySQLdbयदि यह निम्नलिखित परिणाम उत्पन्न करता है, तो इसका मतलब है कि MySQLdb मॉड्यूल स्थापित नहीं है -
Traceback (most recent call last):
File "test.py", line 3, in <module>
import MySQLdb
ImportError: No module named MySQLdbMySQLdb मॉड्यूल को स्थापित करने के लिए, निम्न कमांड का उपयोग करें -
For Ubuntu, use the following command -
$ sudo apt-get install python-pip python-dev libmysqlclient-dev For Fedora, use the following command - $ sudo dnf install python python-devel mysql-devel redhat-rpm-config gcc
For Python command prompt, use the following command -
pip install MySQL-pythonNote - सुनिश्चित करें कि आप मॉड्यूल से ऊपर स्थापित करने के लिए रूट विशेषाधिकार है।
डेटाबेस कनेक्शन
MySQL डेटाबेस से कनेक्ट करने से पहले, फॉलोइंग सुनिश्चित करें -
आपने एक डेटाबेस बनाया है TESTDB।
आपने TESTDB में एक टेबल EMPLOYEE बनाया है।
इस तालिका में FIRST_NAME, LAST_NAME, AGE, SEX और INCOME हैं।
उपयोगकर्ता ID "testuser" और पासवर्ड "test123" TESTDB तक पहुँचने के लिए निर्धारित हैं।
पायथन मॉड्यूल MySQLdb आपकी मशीन पर ठीक से स्थापित है।
आप MySQL बेसिक्स को समझने के लिए MySQL ट्यूटोरियल से गुजरे हैं।
उदाहरण
निम्नलिखित MySQL डेटाबेस "TESTDB" से जुड़ने का उदाहरण है
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# execute SQL query using execute() method.
cursor.execute("SELECT VERSION()")
# Fetch a single row using fetchone() method.
data = cursor.fetchone()
print "Database version : %s " % data
# disconnect from server
db.close()इस स्क्रिप्ट को चलाते समय, यह मेरी लिनक्स मशीन में निम्नलिखित परिणाम उत्पन्न कर रहा है।
Database version : 5.0.45यदि कोई कनेक्शन डेटा स्रोत के साथ स्थापित किया गया है, तो एक कनेक्शन ऑब्जेक्ट लौटाया जाता है और इसमें सहेजा जाता है db आगे के उपयोग के लिए, अन्यथा dbकोई भी सेट नहीं है। आगे,db ऑब्जेक्ट का उपयोग a बनाने के लिए किया जाता है cursorऑब्जेक्ट, जो बदले में SQL प्रश्नों को निष्पादित करने के लिए उपयोग किया जाता है। अंत में, बाहर आने से पहले, यह सुनिश्चित करता है कि डेटाबेस कनेक्शन बंद है और संसाधन जारी किए गए हैं।
डेटाबेस तालिका बनाना
डेटाबेस कनेक्शन स्थापित होने के बाद, हम डेटाबेस तालिकाओं में तालिकाओं या रिकॉर्ड बनाने के लिए तैयार हैं execute निर्मित कर्सर की विधि।
उदाहरण
आइए हम डेटाबेस तालिका EMPLOYEE बनाएं -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Drop table if it already exist using execute() method.
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
# Create table as per requirement
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql)
# disconnect from server
db.close()INSERT ऑपरेशन
जब आप अपने रिकॉर्ड को डेटाबेस तालिका में बनाना चाहते हैं तो इसकी आवश्यकता होती है।
उदाहरण
निम्न उदाहरण, EMPLOYEE तालिका में रिकॉर्ड बनाने के लिए SQL INSERT विवरण निष्पादित करता है -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()उपरोक्त प्रश्नों को गतिशील रूप से SQL क्वेरी बनाने के लिए निम्नानुसार लिखा जा सकता है -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = "INSERT INTO EMPLOYEE(FIRST_NAME, \
LAST_NAME, AGE, SEX, INCOME) \
VALUES ('%s', '%s', '%d', '%c', '%d' )" % \
('Mac', 'Mohan', 20, 'M', 2000)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()उदाहरण
निम्नलिखित कोड सेगमेंट निष्पादन का एक और रूप है जहाँ आप सीधे मापदंडों को पारित कर सकते हैं -
..................................
user_id = "test123"
password = "password"
con.execute('insert into Login values("%s", "%s")' % \
(user_id, password))
..................................पढ़ें ऑपरेशन
किसी भी डेटाबेस पर पढ़ें ऑपरेशन का मतलब डेटाबेस से कुछ उपयोगी जानकारी प्राप्त करना है।
एक बार हमारा डेटाबेस कनेक्शन स्थापित हो जाने के बाद, आप इस डेटाबेस में एक प्रश्न बनाने के लिए तैयार हैं। आप या तो उपयोग कर सकते हैंfetchone() एकल रिकॉर्ड या लाने के लिए विधि fetchall() एक डेटाबेस तालिका से कई मूल्यों को लाने की विधि।
fetchone()- यह एक क्वेरी परिणाम सेट की अगली पंक्ति लाती है। एक परिणाम सेट एक ऑब्जेक्ट है जो एक टेबल को क्वेरी करने के लिए कर्सर ऑब्जेक्ट का उपयोग करने पर वापस किया जाता है।
fetchall()- यह एक परिणाम सेट में सभी पंक्तियों को लाता है। यदि परिणाम सेट से कुछ पंक्तियों को पहले ही निकाला जा चुका है, तो यह परिणाम पंक्ति से शेष पंक्तियों को पुनः प्राप्त करता है।
rowcount - यह केवल पढ़ने के लिए विशेषता है और उन पंक्तियों की संख्या को लौटाता है जो एक निष्पादन () विधि से प्रभावित थे।
उदाहरण
निम्नलिखित प्रक्रिया EMPLOYEE तालिका से 1000 से अधिक वेतन वाले सभी अभिलेखों पर प्रश्न करती है -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
sql = "SELECT * FROM EMPLOYEE \
WHERE INCOME > '%d'" % (1000)
try:
# Execute the SQL command
cursor.execute(sql)
# Fetch all the rows in a list of lists.
results = cursor.fetchall()
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# Now print fetched result
print "fname=%s,lname=%s,age=%d,sex=%s,income=%d" % \
(fname, lname, age, sex, income )
except:
print "Error: unable to fecth data"
# disconnect from server
db.close()यह निम्नलिखित परिणाम का उत्पादन करेगा -
fname=Mac, lname=Mohan, age=20, sex=M, income=2000अद्यतन अद्यतन करें
किसी भी डेटाबेस पर अद्यतन ऑपरेशन का मतलब एक या एक से अधिक रिकॉर्ड को अद्यतन करना है, जो पहले से ही डेटाबेस में उपलब्ध हैं।
निम्न प्रक्रिया SEX वाले सभी रिकॉर्ड को अपडेट करती है 'M'। यहां, हम सभी पुरुषों के एजीई को एक वर्ष तक बढ़ाते हैं।
उदाहरण
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to UPDATE required records
sql = "UPDATE EMPLOYEE SET AGE = AGE + 1
WHERE SEX = '%c'" % ('M')
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()DELETE ऑपरेशन
DELETE ऑपरेशन की आवश्यकता तब होती है जब आप अपने डेटाबेस से कुछ रिकॉर्ड हटाना चाहते हैं। EMPLOYEE से सभी रिकॉर्ड को हटाने की प्रक्रिया निम्नलिखित है जहाँ AGE 20 से अधिक है -
उदाहरण
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()लेन-देन करना
लेन-देन एक ऐसा तंत्र है जो डेटा स्थिरता सुनिश्चित करता है। लेनदेन के निम्नलिखित चार गुण हैं -
Atomicity - या तो लेन-देन पूरा हो जाता है या कुछ भी नहीं होता है।
Consistency - लेन-देन सुसंगत अवस्था में शुरू होना चाहिए और सिस्टम को सुसंगत अवस्था में छोड़ना चाहिए।
Isolation - लेन-देन के मध्यवर्ती परिणाम वर्तमान लेनदेन के बाहर दिखाई नहीं देते हैं।
Durability - एक बार लेनदेन किए जाने के बाद, सिस्टम की विफलता के बाद भी प्रभाव लगातार बना रहता है।
पायथन डीबी एपीआई 2.0 लेनदेन करने के लिए कमिट या रोलबैक करने के लिए दो तरीके प्रदान करता है ।
उदाहरण
आप लेन-देन को लागू करने का तरीका पहले से ही जानते हैं। यहाँ फिर से इसी तरह का उदाहरण है -
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()COMMIT ऑपरेशन
कमिट वह ऑपरेशन है, जो बदलावों को अंतिम रूप देने के लिए डेटाबेस को हरी झंडी देता है और इस ऑपरेशन के बाद कोई भी बदलाव वापस नहीं किया जा सकता है।
यहां कॉल करने के लिए एक सरल उदाहरण है commit तरीका।
db.commit()रोलबैक ऑपरेशन
यदि आप एक या अधिक परिवर्तनों से संतुष्ट नहीं हैं और आप उन परिवर्तनों को पूरी तरह से वापस लेना चाहते हैं, तो उपयोग करें rollback() तरीका।
यहां कॉल करने के लिए एक सरल उदाहरण है rollback() तरीका।
db.rollback()डेटाबेस को डिस्कनेक्ट कर रहा है
डेटाबेस कनेक्शन को डिस्कनेक्ट करने के लिए, करीब () विधि का उपयोग करें।
db.close()यदि किसी डेटाबेस का कनेक्शन उपयोगकर्ता द्वारा बंद () विधि के साथ बंद किया जाता है, तो किसी भी बकाया लेनदेन को डीबी द्वारा वापस रोल किया जाता है। हालांकि, डीबी निचले स्तर के कार्यान्वयन के किसी भी विवरण पर निर्भर करने के बजाय, स्पष्ट रूप से कॉलिंग कमिट या रोलबैक से आपका आवेदन बेहतर होगा।
त्रुटियों को संभालना
त्रुटियों के कई स्रोत हैं। कुछ उदाहरण निष्पादित SQL कथन, कनेक्शन विफलता या पहले से रद्द किए गए स्टेटमेंट हैंडल के लिए भ्रूण विधि को कॉल करने में एक सिंटैक्स त्रुटि है।
डीबी एपीआई कई त्रुटियों को परिभाषित करता है जो प्रत्येक डेटाबेस मॉड्यूल में मौजूद होना चाहिए। निम्न तालिका इन अपवादों को सूचीबद्ध करती है।
| अनु क्रमांक। | अपवाद और विवरण |
|---|---|
| 1 | Warning गैर-घातक मुद्दों के लिए उपयोग किया जाता है। सबक्लेयर को पूरा करें। |
| 2 | Error त्रुटियों के लिए आधार वर्ग। सबक्लेयर को पूरा करें। |
| 3 | InterfaceError डेटाबेस मॉड्यूल में त्रुटियों के लिए उपयोग किया जाता है, डेटाबेस ही नहीं। उपवर्ग त्रुटि। |
| 4 | DatabaseError डेटाबेस में त्रुटियों के लिए उपयोग किया जाता है। उपवर्ग त्रुटि। |
| 5 | DataError DatabaseError का उपवर्ग जो डेटा में त्रुटियों को संदर्भित करता है। |
| 6 | OperationalError DatabaseError का उपवर्ग जो त्रुटियों को संदर्भित करता है जैसे डेटाबेस से कनेक्शन का नुकसान। ये त्रुटियां आमतौर पर पायथन ट्रॉटर के नियंत्रण से बाहर होती हैं। |
| 7 | IntegrityError डेटाबेसइरॉर्स की उप-स्थितियों में उन परिस्थितियों के लिए जो विशिष्ट अखंडता को नुकसान पहुंचाएंगे, जैसे कि विशिष्टता की कमी या विदेशी कुंजी। |
| 8 | InternalError DatabaseError का उपवर्ग जो डेटाबेस मॉड्यूल में आंतरिक त्रुटियों को संदर्भित करता है, जैसे कि कर्सर अब सक्रिय नहीं है। |
| 9 | ProgrammingError DatabaseError का उपवर्ग जो एक खराब तालिका नाम और अन्य चीजों के रूप में त्रुटियों को संदर्भित करता है जिन्हें सुरक्षित रूप से आप पर दोष दिया जा सकता है। |
| 10 | NotSupportedError DatabaseError का उपवर्ग जो असमर्थित कार्यक्षमता को कॉल करने का प्रयास करता है। |
आपकी पायथन लिपियों को इन त्रुटियों को संभालना चाहिए, लेकिन उपरोक्त अपवादों में से किसी का भी उपयोग करने से पहले, सुनिश्चित करें कि आपके MySQLdb के पास उस अपवाद के लिए समर्थन है। आप DB API 2.0 विनिर्देश पढ़कर उनके बारे में अधिक जानकारी प्राप्त कर सकते हैं।
पायथन नेटवर्क सेवाओं तक पहुँच के दो स्तर प्रदान करता है। निम्न स्तर पर, आप अंतर्निहित ऑपरेटिंग सिस्टम में मूल सॉकेट समर्थन तक पहुंच सकते हैं, जो आपको कनेक्शन-उन्मुख और कनेक्शन रहित प्रोटोकॉल दोनों के लिए क्लाइंट और सर्वर को लागू करने की अनुमति देता है।
पायथन में ऐसी लाइब्रेरी भी हैं जो विशिष्ट एप्लिकेशन-स्तर नेटवर्क प्रोटोकॉल जैसे कि एफ़टीपी, एचटीटीपी और इतने पर उच्च-स्तरीय पहुंच प्रदान करती हैं।
यह अध्याय आपको नेटवर्किंग - सॉकेट प्रोग्रामिंग में सबसे प्रसिद्ध अवधारणा पर समझ देता है।
सॉकेट्स क्या है?
सॉकेट्स एक द्विदिश संचार चैनल के समापन बिंदु हैं। सॉकेट्स एक प्रक्रिया के भीतर, एक ही मशीन पर प्रक्रियाओं के बीच, या विभिन्न महाद्वीपों पर प्रक्रियाओं के बीच संवाद कर सकते हैं।
सॉकेट्स को विभिन्न चैनल प्रकारों पर लागू किया जा सकता है: यूनिक्स डोमेन सॉकेट्स, टीसीपी, यूडीपी, और इसी तरह। सॉकेट पुस्तकालय आम परिवहन के साथ-साथ बाकी से निपटने के लिए एक सामान्य इंटरफ़ेस से निपटने के लिए विशिष्ट वर्गों प्रदान करता है।
सॉकेट्स की अपनी शब्दावली है -
| अनु क्रमांक। | शब्द और विवरण |
|---|---|
| 1 | Domain प्रोटोकॉल का परिवार जो परिवहन तंत्र के रूप में उपयोग किया जाता है। ये मान AF_INET, PF_INET, PF_UNIX, PF_X25, और इतने पर जैसे स्थिरांक हैं। |
| 2 | type दो एंडपॉइंट के बीच संचार का प्रकार, आमतौर पर कनेक्शन-उन्मुख प्रोटोकॉल के लिए SOCK_STREAM और कनेक्शन रहित प्रोटोकॉल के लिए SOCK_DGRAM। |
| 3 | protocol आमतौर पर शून्य, इसका उपयोग किसी डोमेन और प्रकार के प्रोटोकॉल के एक प्रकार की पहचान करने के लिए किया जा सकता है। |
| 4 | hostname नेटवर्क इंटरफ़ेस की पहचानकर्ता -
|
| 5 | port प्रत्येक सर्वर एक या अधिक पोर्ट पर कॉल करने वाले क्लाइंट के लिए सुनता है। एक पोर्ट एक Fixnum पोर्ट संख्या, एक पोर्ट नंबर वाली स्ट्रिंग या सेवा का नाम हो सकता है। |
सॉकेट मॉड्यूल
सॉकेट बनाने के लिए, आपको सॉकेट मॉड्यूल में उपलब्ध सॉकेट.सोकेट () फ़ंक्शन का उपयोग करना होगा , जिसमें सामान्य सिंटेलर है -
s = socket.socket (socket_family, socket_type, protocol=0)यहाँ मापदंडों का वर्णन है -
socket_family - यह या तो AF_UNIX या AF_INET है, जैसा कि पहले बताया गया है।
socket_type - यह या तो SOCK_STREAM है या SOCK_DGRAM।
protocol - यह आमतौर पर 0 से डिफॉल्ट होता है।
एक बार जब आपके पास सॉकेट ऑब्जेक्ट होता है, तो आप अपने क्लाइंट या सर्वर प्रोग्राम बनाने के लिए आवश्यक कार्यों का उपयोग कर सकते हैं। निम्नलिखित कार्यों की सूची आवश्यक है -
सर्वर सॉकेट विधियाँ
| अनु क्रमांक। | विधि और विवरण |
|---|---|
| 1 | s.bind() यह विधि सॉकेट के पते (होस्टनाम, पोर्ट नंबर जोड़ी) को बांधती है। |
| 2 | s.listen() यह विधि टीसीपी श्रोता को सेट और शुरू करती है। |
| 3 | s.accept() यह टीसीपी क्लाइंट कनेक्शन को निष्क्रिय रूप से स्वीकार करता है, कनेक्शन आने तक (अवरुद्ध) होने तक प्रतीक्षा करता है। |
ग्राहक सॉकेट तरीके
| अनु क्रमांक। | विधि और विवरण |
|---|---|
| 1 | s.connect() यह विधि सक्रिय रूप से टीसीपी सर्वर कनेक्शन शुरू करती है। |
सामान्य सॉकेट विधि
| अनु क्रमांक। | विधि और विवरण |
|---|---|
| 1 | s.recv() यह विधि टीसीपी संदेश प्राप्त करती है |
| 2 | s.send() यह विधि टीसीपी संदेश प्रसारित करती है |
| 3 | s.recvfrom() यह विधि यूडीपी संदेश प्राप्त करती है |
| 4 | s.sendto() यह विधि यूडीपी संदेश प्रसारित करती है |
| 5 | s.close() यह विधि सॉकेट को बंद कर देती है |
| 6 | socket.gethostname() होस्टनाम लौटाता है। |
एक साधारण सर्वर
इंटरनेट सर्वर लिखने के लिए, हम उपयोग करते हैं socketसॉकेट ऑब्जेक्ट बनाने के लिए सॉकेट मॉड्यूल में उपलब्ध फ़ंक्शन। सॉकेट ऑब्जेक्ट का उपयोग सॉकेट सर्वर को सेटअप करने के लिए अन्य फ़ंक्शन को कॉल करने के लिए किया जाता है।
अब बुलाओ bind(hostname, port)दिए गए होस्ट पर आपकी सेवा के लिए एक पोर्ट निर्दिष्ट करने के लिए फ़ंक्शन ।
इसके बाद, लौटे हुए ऑब्जेक्ट की स्वीकार पद्धति को कॉल करें । यह विधि तब तक प्रतीक्षा करती है जब तक कोई क्लाइंट आपके द्वारा निर्दिष्ट पोर्ट से कनेक्ट नहीं होता है, और फिर एक कनेक्शन ऑब्जेक्ट देता है जो उस क्लाइंट के कनेक्शन का प्रतिनिधित्व करता है।
#!/usr/bin/python # This is server.py file
import socket # Import socket module
s = socket.socket() # Create a socket object
host = socket.gethostname() # Get local machine name
port = 12345 # Reserve a port for your service.
s.bind((host, port)) # Bind to the port
s.listen(5) # Now wait for client connection.
while True:
c, addr = s.accept() # Establish connection with client.
print 'Got connection from', addr
c.send('Thank you for connecting')
c.close() # Close the connectionएक साधारण ग्राहक
आइए हम एक बहुत ही सरल क्लाइंट प्रोग्राम लिखते हैं जो किसी दिए गए पोर्ट 12345 और दिए गए होस्ट के लिए एक कनेक्शन खोलता है। पायथन के सॉकेट मॉड्यूल फ़ंक्शन का उपयोग करके सॉकेट क्लाइंट बनाना बहुत सरल है ।
socket.connect(hosname, port )पोर्ट पर होस्टनाम के लिए एक टीसीपी कनेक्शन खोलता है । एक बार जब आपके पास एक सॉकेट खुला होता है, तो आप इसे किसी भी IO ऑब्जेक्ट की तरह पढ़ सकते हैं। जब किया जाता है, तो इसे बंद करना याद रखें, क्योंकि आप एक फ़ाइल बंद कर देंगे।
निम्न कोड एक बहुत ही सरल क्लाइंट है जो किसी दिए गए होस्ट और पोर्ट से जुड़ता है, सॉकेट से किसी भी उपलब्ध डेटा को पढ़ता है, और फिर इसे हटा देता है -
#!/usr/bin/python # This is client.py file
import socket # Import socket module
s = socket.socket() # Create a socket object
host = socket.gethostname() # Get local machine name
port = 12345 # Reserve a port for your service.
s.connect((host, port))
print s.recv(1024)
s.close() # Close the socket when doneअब इस सर्वरहोम को बैकग्राउंड में रन करें और फिर रिजल्ट देखने के लिए ऊपर क्लाइंटहोम के लिए रन करें।
# Following would start a server in background.
$ python server.py & # Once server is started run client as follows: $ python client.pyइसका परिणाम निम्न होगा -
Got connection from ('127.0.0.1', 48437)
Thank you for connectingपायथन इंटरनेट मॉड्यूल
पायथन नेटवर्क / इंटरनेट प्रोग्रामिंग में कुछ महत्वपूर्ण मॉड्यूल की एक सूची।
| मसविदा बनाना | सामान्य समारोह | पोर्ट नं | पायथन मॉड्यूल |
|---|---|---|---|
| एचटीटीपी | वेब पृष्ठ | 80 | कैनपिलिब, यूरलिब, एक्सएमएलआरपीक्लिब |
| एनएनटीपी | यूज़नेट समाचार | 119 | nntplib |
| एफ़टीपी | फ़ाइल स्थानांतरण | 20 | ftplib, urllib |
| एसएमटीपी | ईमेल भेज रहा हूं | 25 | smtplib |
| पॉप 3 | ईमेल ला रहा है | 110 | poplib |
| IMAP4 | ईमेल ला रहा है | 143 | imaplib |
| टेलनेट | कमांड लाइन | 23 | telnetlib |
| धानीमूष | दस्तावेज़ स्थानांतरित | 70 | गोर्फ़्लिब, यूरलिब |
कृपया ऊपर उल्लिखित सभी पुस्तकालयों को एफ़टीपी, एसएमटीपी, पीओपी और आईएमएपी प्रोटोकॉल के साथ काम करने के लिए जांचें।
आगे की रीडिंग
यह सॉकेट प्रोग्रामिंग के साथ एक त्वरित शुरुआत थी। यह एक विशाल विषय है। अधिक विस्तार खोजने के लिए निम्न लिंक से गुजरने की सलाह दी जाती है -
यूनिक्स सॉकेट प्रोग्रामिंग ।
पायथन सॉकेट लाइब्रेरी और मॉड्यूल ।
सिंपल मेल ट्रांसफर प्रोटोकॉल (SMTP) एक प्रोटोकॉल है, जो मेल सर्वर के बीच ई-मेल और राउटिंग ई-मेल भेजने का काम करता है।
अजगर प्रदान करता है smtplib मॉड्यूल, जो एक SMTP क्लाइंट सत्र ऑब्जेक्ट को परिभाषित करता है जिसका उपयोग किसी भी इंटरनेट मशीन को SMTP या ESMTP श्रोता डेमॉन के साथ मेल भेजने के लिए किया जा सकता है।
यहाँ एक SMTP ऑब्जेक्ट बनाने के लिए एक सरल वाक्यविन्यास है, जिसे बाद में ई-मेल भेजने के लिए इस्तेमाल किया जा सकता है -
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )यहाँ मापदंडों का विस्तार है -
host- यह होस्ट आपके SMTP सर्वर को चलाने वाला है। आप होस्ट का आईपी पता या एक ट्यूटोरियल जैसे डोमेन नाम निर्दिष्ट कर सकते हैं। यह वैकल्पिक तर्क है।
port- यदि आप होस्ट तर्क प्रदान कर रहे हैं , तो आपको एक पोर्ट निर्दिष्ट करने की आवश्यकता है, जहां एसएमटीपी सर्वर सुन रहा है। आमतौर पर यह पोर्ट 25 का होगा।
local_hostname- यदि आपका एसएमटीपी सर्वर आपके स्थानीय मशीन पर चल रहा है, तो आप इस विकल्प के रूप में सिर्फ स्थानीयहोस्ट निर्दिष्ट कर सकते हैं ।
एसएमटीपी ऑब्जेक्ट में एक इंस्टेंस विधि होती है जिसे कहा जाता है sendmail, जो आम तौर पर एक संदेश भेजने का काम करने के लिए उपयोग किया जाता है। इसके तीन मापदंड हैं -
इस - प्रेषक का पता के साथ एक स्ट्रिंग।
रिसीवर - स्ट्रिंग की एक सूची, प्रत्येक प्राप्तकर्ता के लिए एक।
संदेश - एक स्ट्रिंग विभिन्न RFC के में निर्दिष्ट के रूप में स्वरूपित के रूप में एक संदेश।
उदाहरण
यहां पाइथन स्क्रिप्ट का उपयोग करके एक ई-मेल भेजने का एक सरल तरीका है। एक बार आजमा कर देखें -
#!/usr/bin/python
import smtplib
sender = '[email protected]'
receivers = ['[email protected]']
message = """From: From Person <[email protected]>
To: To Person <[email protected]>
Subject: SMTP e-mail test
This is a test e-mail message.
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"यहां, आपने संदेश में एक बुनियादी ई-मेल रखा है, एक ट्रिपल उद्धरण का उपयोग करते हुए, हेडर को सही ढंग से प्रारूपित करने के लिए। एक ई-मेल की आवश्यकता हैFrom, To, तथा Subject हेडर, एक खाली लाइन के साथ ई-मेल के शरीर से अलग हो गया।
मेल भेजने के लिए आप smtpObj का उपयोग स्थानीय मशीन पर SMTP सर्वर से कनेक्ट करने के लिए करते हैं और फिर संदेश, पते, और गंतव्य पते को मापदंडों के रूप में (भले ही से और पते ई के भीतर हैं) सेंडमेल विधि का उपयोग करें। अपने आप को, ये हमेशा मेल रूट करने के लिए उपयोग नहीं किए जाते हैं)।
यदि आप अपने स्थानीय मशीन पर SMTP सर्वर नहीं चला रहे हैं, तो आप दूरस्थ SMTP सर्वर के साथ संचार करने के लिए smtplib क्लाइंट का उपयोग कर सकते हैं । जब तक आप एक वेबमेल सेवा (जैसे हॉटमेल या याहू-मेल) का उपयोग नहीं कर रहे हैं, तब तक आपके ई-मेल प्रदाता ने आपको आउटगोइंग मेल सर्वर विवरण प्रदान किया होगा जो आप उन्हें आपूर्ति कर सकते हैं, निम्नानुसार -
smtplib.SMTP('mail.your-domain.com', 25)Python का उपयोग करके एक HTML ई-मेल भेजना
जब आप पायथन का उपयोग करके एक पाठ संदेश भेजते हैं, तो सभी सामग्री को सरल पाठ माना जाता है। यहां तक कि अगर आप एक टेक्स्ट संदेश में HTML टैग शामिल करते हैं, तो इसे सरल पाठ के रूप में प्रदर्शित किया जाता है और HTML टैग्स को HTML सिंटैक्स के अनुसार स्वरूपित नहीं किया जाएगा। लेकिन पायथन एक HTML संदेश को वास्तविक HTML संदेश के रूप में भेजने का विकल्प प्रदान करता है।
ई-मेल संदेश भेजते समय, आप HTML ई-मेल भेजने के लिए एक माइम संस्करण, सामग्री प्रकार और वर्ण सेट निर्दिष्ट कर सकते हैं।
उदाहरण
HTML सामग्री को ई-मेल के रूप में भेजने के लिए निम्नलिखित उदाहरण है। एक बार आजमा कर देखें -
#!/usr/bin/python
import smtplib
message = """From: From Person <[email protected]>
To: To Person <[email protected]>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP HTML e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"ई-मेल के रूप में अटैचमेंट भेजना
मिश्रित सामग्री के साथ एक ई-मेल भेजने के लिए सेट करने की आवश्यकता होती है Content-type हेडर करने के लिए multipart/mixed। फिर, पाठ और अनुलग्नक अनुभागों को निर्दिष्ट किया जा सकता हैboundaries।
एक सीमा को दो हाइफ़न के साथ शुरू किया जाता है, जिसके बाद एक अद्वितीय संख्या होती है, जो ई-मेल के संदेश भाग में दिखाई नहीं देती है। ई-मेल के अंतिम खंड को दर्शाने वाली एक अंतिम सीमा भी दो हाइफ़न के साथ समाप्त होनी चाहिए।
संलग्न फ़ाइलों को इनकोड किया जाना चाहिए pack("m") ट्रांसमिशन से पहले बेस 64 एनकोडिंग का कार्य करता है।
उदाहरण
निम्नलिखित उदाहरण है, जो एक फ़ाइल भेजता है /tmp/test.txtएक अनुलग्नक के रूप में। एक बार आजमा कर देखें -
#!/usr/bin/python
import smtplib
import base64
filename = "/tmp/test.txt"
# Read a file and encode it into base64 format
fo = open(filename, "rb")
filecontent = fo.read()
encodedcontent = base64.b64encode(filecontent) # base64
sender = '[email protected]'
reciever = '[email protected]'
marker = "AUNIQUEMARKER"
body ="""
This is a test email to send an attachement.
"""
# Define the main headers.
part1 = """From: From Person <[email protected]>
To: To Person <[email protected]>
Subject: Sending Attachement
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary=%s
--%s
""" % (marker, marker)
# Define the message action
part2 = """Content-Type: text/plain
Content-Transfer-Encoding:8bit
%s
--%s
""" % (body,marker)
# Define the attachment section
part3 = """Content-Type: multipart/mixed; name=\"%s\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename=%s
%s
--%s--
""" %(filename, filename, encodedcontent, marker)
message = part1 + part2 + part3
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, reciever, message)
print "Successfully sent email"
except Exception:
print "Error: unable to send email"कई धागे चलाना समवर्ती रूप से कई अलग-अलग कार्यक्रमों को चलाने के समान है, लेकिन निम्नलिखित लाभ के साथ -
एक प्रक्रिया के भीतर कई थ्रेड्स मुख्य थ्रेड के साथ एक ही डेटा स्पेस साझा करते हैं और इसलिए वे जानकारी साझा कर सकते हैं या एक दूसरे के साथ आसानी से संवाद कर सकते हैं यदि वे अलग-अलग प्रक्रियाएं थीं।
थ्रेड्स को कभी-कभी हल्के वजन की प्रक्रिया कहा जाता है और उन्हें अधिक मेमोरी ओवरहेड की आवश्यकता नहीं होती है; वे प्रक्रियाओं की तुलना में सस्ते हैं।
एक सूत्र में एक शुरुआत, एक निष्पादन अनुक्रम और एक निष्कर्ष है। इसमें एक निर्देश सूचक है जो इस संदर्भ में वर्तमान में चल रहा है, जहां पर नज़र रखता है।
यह पहले से खाली (बाधित) हो सकता है
इसे अस्थायी रूप से होल्ड पर रखा जा सकता है (सोते हुए भी कहा जाता है) जबकि अन्य धागे चल रहे हैं - इसे उपज कहा जाता है।
एक नया सूत्र शुरू करना
एक और धागा स्पॉन करने के लिए, आपको थ्रेड मॉड्यूल में उपलब्ध निम्नलिखित विधि को कॉल करना होगा -
thread.start_new_thread ( function, args[, kwargs] )यह विधि कॉल लिनक्स और विंडोज दोनों में नए धागे बनाने के लिए एक तेज और कुशल तरीका सक्षम करता है।
विधि कॉल तुरंत वापस आती है और बच्चा थ्रेड शुरू होता है और आर्ग की पारित सूची के साथ कार्य करता है । जब फ़ंक्शन लौटता है, तो थ्रेड समाप्त हो जाता है।
इधर, आर्ग तर्कों की किसी टपल है; किसी भी तर्क को पारित किए बिना फ़ंक्शन को कॉल करने के लिए एक खाली टपल का उपयोग करें। kwargs कीवर्ड तर्कों का एक वैकल्पिक शब्दकोश है।
उदाहरण
#!/usr/bin/python
import thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print "%s: %s" % ( threadName, time.ctime(time.time()) )
# Create two threads as follows
try:
thread.start_new_thread( print_time, ("Thread-1", 2, ) )
thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print "Error: unable to start thread"
while 1:
passजब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Thread-1: Thu Jan 22 15:42:17 2009
Thread-1: Thu Jan 22 15:42:19 2009
Thread-2: Thu Jan 22 15:42:19 2009
Thread-1: Thu Jan 22 15:42:21 2009
Thread-2: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:25 2009
Thread-2: Thu Jan 22 15:42:27 2009
Thread-2: Thu Jan 22 15:42:31 2009
Thread-2: Thu Jan 22 15:42:35 2009यद्यपि यह निम्न-स्तरीय थ्रेडिंग के लिए बहुत प्रभावी है, लेकिन नए थ्रेडिंग मॉड्यूल की तुलना में थ्रेड मॉड्यूल बहुत सीमित है।
थ्रेडिंग मॉड्यूल
पायथन 2.4 के साथ शामिल नया थ्रेडिंग मॉड्यूल पिछले अनुभाग में चर्चा किए गए थ्रेड मॉड्यूल की तुलना में थ्रेड्स के लिए अधिक शक्तिशाली, उच्च-स्तरीय समर्थन प्रदान करता है।
सूत्रण मॉड्यूल के सभी तरीकों को उजागर करता है धागा मॉड्यूल और कुछ अतिरिक्त तरीकों प्रदान करता है -
threading.activeCount() - थ्रेड ऑब्जेक्ट्स की संख्या लौटाता है जो सक्रिय हैं।
threading.currentThread() - कॉलर के थ्रेड कंट्रोल में थ्रेड ऑब्जेक्ट्स की संख्या लौटाता है।
threading.enumerate() - वर्तमान में सक्रिय सभी थ्रेड ऑब्जेक्ट्स की सूची लौटाता है।
विधियों के अलावा, थ्रेडिंग मॉड्यूल में थ्रेड क्लास है जो थ्रेडिंग को लागू करता है। थ्रेड वर्ग द्वारा दिए गए तरीके निम्नानुसार हैं -
run() - रन () विधि एक थ्रेड के लिए प्रवेश बिंदु है।
start() - रन विधि को कॉल करके स्टार्ट () विधि एक धागा शुरू करती है।
join([time]) - द ज्वाइन () थ्रेड्स के समाप्त होने का इंतजार करता है।
isAlive() - isAlive () विधि जांचती है कि क्या कोई थ्रेड अभी भी निष्पादित हो रहा है।
getName() - getName () विधि एक थ्रेड का नाम देता है।
setName() - सेटनाम () विधि एक थ्रेड का नाम सेट करती है।
थ्रेडिंग मॉड्यूल का उपयोग करके थ्रेड बनाना
सूत्रण मॉड्यूल का उपयोग करके एक नया धागा लागू करने के लिए, आपको निम्नलिखित कार्य करने होंगे -
थ्रेड वर्ग के एक नए उपवर्ग को परिभाषित करें ।
अतिरिक्त तर्क जोड़ने के लिए __init __ (स्व [, args]) विधि को ओवरराइड करें ।
फिर, थ्रेड को शुरू करने पर क्या करना चाहिए इसे लागू करने के लिए रन (स्वयं [, args]) विधि को ओवरराइड करें।
एक बार जब आपने नया थ्रेड उपवर्ग बना लिया है, तो आप इसका एक उदाहरण बना सकते हैं और फिर प्रारंभ () , जो कॉल कॉल रन () विधि को लागू करके एक नया सूत्र शुरू करते हैं ।
उदाहरण
#!/usr/bin/python
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
print_time(self.name, self.counter, 5)
print "Exiting " + self.name
def print_time(threadName, counter, delay):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
print "Exiting Main Thread"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Starting Thread-1
Starting Thread-2
Exiting Main Thread
Thread-1: Thu Mar 21 09:10:03 2013
Thread-1: Thu Mar 21 09:10:04 2013
Thread-2: Thu Mar 21 09:10:04 2013
Thread-1: Thu Mar 21 09:10:05 2013
Thread-1: Thu Mar 21 09:10:06 2013
Thread-2: Thu Mar 21 09:10:06 2013
Thread-1: Thu Mar 21 09:10:07 2013
Exiting Thread-1
Thread-2: Thu Mar 21 09:10:08 2013
Thread-2: Thu Mar 21 09:10:10 2013
Thread-2: Thu Mar 21 09:10:12 2013
Exiting Thread-2सूत्र सिंक्रनाइज़ करना
पायथन के साथ प्रदान किए गए थ्रेडिंग मॉड्यूल में एक सरल-से-लागू लॉकिंग तंत्र शामिल है जो आपको थ्रेड्स को सिंक्रनाइज़ करने की अनुमति देता है। लॉक () विधि को कॉल करके एक नया लॉक बनाया जाता है , जो नया लॉक लौटाता है।
नए लॉक ऑब्जेक्ट की अधिग्रहित (अवरुद्ध) विधि का उपयोग थ्रेड को सिंक्रोनाइज़ करने के लिए बाध्य करने के लिए किया जाता है। वैकल्पिक अवरोधक पैरामीटर आपको यह नियंत्रित करने में सक्षम बनाता है कि थ्रेड लॉक प्राप्त करने के लिए प्रतीक्षा करता है या नहीं।
यदि अवरुद्ध करना 0 पर सेट है, तो थ्रेड 0 प्राप्त होने पर तुरंत वापस आ जाता है यदि लॉक को अधिग्रहित नहीं किया जा सकता है और 1 के साथ यदि लॉक प्राप्त किया गया है। यदि अवरोधन 1 पर सेट है, तो थ्रेड ब्लॉक हो जाता है और लॉक के रिलीज़ होने की प्रतीक्षा करता है।
नए लॉक ऑब्जेक्ट की रिलीज़ () विधि का उपयोग लॉक को रिलीज़ करने के लिए किया जाता है जब इसकी आवश्यकता नहीं होती है।
उदाहरण
#!/usr/bin/python
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Starting Thread-1
Starting Thread-2
Thread-1: Thu Mar 21 09:11:28 2013
Thread-1: Thu Mar 21 09:11:29 2013
Thread-1: Thu Mar 21 09:11:30 2013
Thread-2: Thu Mar 21 09:11:32 2013
Thread-2: Thu Mar 21 09:11:34 2013
Thread-2: Thu Mar 21 09:11:36 2013
Exiting Main Threadबहुविध प्राथमिकता कतार
कतार मॉड्यूल आप एक नया कतार उद्देश्य यह है कि आइटम की एक विशिष्ट संख्या धारण कर सकते हैं बनाने के लिए अनुमति देता है। कतार को नियंत्रित करने के लिए निम्नलिखित तरीके हैं -
get() - प्राप्त () कतार से एक आइटम को निकालता है और वापस करता है।
put() - पुट एक कतार में आइटम जोड़ता है।
qsize() - qsize () उन आइटमों की संख्या लौटाता है जो वर्तमान में कतार में हैं।
empty()- खाली () सही है अगर कतार खाली है; अन्यथा, गलत।
full()- पूर्ण () सही है अगर कतार भरी हुई है; अन्यथा, गलत।
उदाहरण
#!/usr/bin/python
import Queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print "Starting " + self.name
process_data(self.name, self.q)
print "Exiting " + self.name
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print "%s processing %s" % (threadName, data)
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = Queue.Queue(10)
threads = []
threadID = 1
# Create new threads
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# Fill the queue
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# Wait for queue to empty
while not workQueue.empty():
pass
# Notify threads it's time to exit
exitFlag = 1
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"जब उपरोक्त कोड निष्पादित किया जाता है, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
Starting Thread-1
Starting Thread-2
Starting Thread-3
Thread-1 processing One
Thread-2 processing Two
Thread-3 processing Three
Thread-1 processing Four
Thread-2 processing Five
Exiting Thread-3
Exiting Thread-1
Exiting Thread-2
Exiting Main ThreadXML एक पोर्टेबल, ओपन सोर्स भाषा है, जो प्रोग्रामर को उन एप्लिकेशन को विकसित करने की अनुमति देता है, जो ऑपरेटिंग सिस्टम और / या डेवलपमेंट लैंग्वेज की परवाह किए बिना अन्य एप्लिकेशन द्वारा पढ़े जा सकते हैं।
XML क्या है?
एक्स्टेंसिबल मार्कअप लैंग्वेज (एक्सएमएल) एचटीएमएल या एसजीएमएल जैसी मार्कअप भाषा है। यह वर्ल्ड वाइड वेब कंसोर्टियम द्वारा अनुशंसित है और एक खुले मानक के रूप में उपलब्ध है।
SQL- आधारित बैकबोन की आवश्यकता के बिना डेटा की छोटी से मध्यम मात्रा का ट्रैक रखने के लिए XML बेहद उपयोगी है।
XML पार्सर आर्किटेक्चर और एपीआई
पायथन मानक पुस्तकालय XML के साथ काम करने के लिए इंटरफेस का एक न्यूनतम लेकिन उपयोगी सेट प्रदान करता है।
XML डेटा में दो सबसे बुनियादी और व्यापक रूप से उपयोग किए जाने वाले एपीआई SAX और DOM इंटरफेस हैं।
Simple API for XML (SAX)- यहां, आप ब्याज की घटनाओं के लिए कॉलबैक रजिस्टर करते हैं और फिर दस्तावेज़ के माध्यम से पार्सर को आगे बढ़ने देते हैं। यह तब उपयोगी होता है जब आपके दस्तावेज़ बड़े होते हैं या आपकी मेमोरी सीमाएँ होती हैं, यह फ़ाइल को पार्स करता है क्योंकि यह इसे डिस्क से पढ़ता है और पूरी फ़ाइल कभी मेमोरी में संग्रहीत नहीं होती है।
Document Object Model (DOM) API - यह एक वर्ल्ड वाइड वेब कंसोर्टियम सिफारिश है जिसमें पूरी फ़ाइल को मेमोरी में पढ़ा जाता है और एक XML दस्तावेज़ की सभी विशेषताओं का प्रतिनिधित्व करने के लिए एक पदानुक्रमित (ट्री-आधारित) रूप में संग्रहीत किया जाता है।
SAX स्पष्ट रूप से बड़ी फ़ाइलों के साथ काम करते समय डोम के रूप में उपवास की जानकारी को संसाधित नहीं कर सकता है। दूसरी ओर, विशेष रूप से DOM का उपयोग वास्तव में आपके संसाधनों को मार सकता है, खासकर यदि बहुत सारी छोटी फ़ाइलों पर उपयोग किया जाता है।
SAX केवल-पढ़ने के लिए है, जबकि DOM XML फ़ाइल में परिवर्तन की अनुमति देता है। चूंकि ये दो अलग-अलग एपीआई सचमुच एक-दूसरे के पूरक हैं, इसलिए कोई कारण नहीं है कि आप बड़ी परियोजनाओं के लिए इन दोनों का उपयोग नहीं कर सकते।
हमारे सभी XML कोड उदाहरणों के लिए, आइए इनपुट के रूप में एक सरल XML फ़ाइल मूवी. xml का उपयोग करें -
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>एसएएक्स एपीआई के साथ पार्सिंग एक्सएमएल
SAX ईवेंट-चालित XML पार्सिंग के लिए एक मानक इंटरफ़ेस है। SAX के साथ XML को पार्स करने के लिए आम तौर पर आपको xml.sax.ContentHandler को उप-लिंक करके अपना खुद का ContentHandler बनाना पड़ता है।
आपका ContentHandler XML के विशेष स्वादों और विशेषताओं को संभालता है। एक ContentHandler ऑब्जेक्ट विभिन्न पार्सिंग घटनाओं को संभालने के लिए तरीके प्रदान करता है। इसका अपना पार्सर कंटेंटहैंडलर विधियों को कॉल करता है क्योंकि यह XML फ़ाइल को पार्स करता है।
XML फ़ाइल के प्रारंभ और अंत में तरीके startDocument और endDocument को कहा जाता है। विधि वर्ण (पाठ) पैरामीटर पाठ के माध्यम से XML फ़ाइल का वर्ण डेटा पारित किया जाता है।
ContentHandler को प्रत्येक तत्व के आरंभ और अंत में कहा जाता है। यदि पार्सर नेमस्पेस मोड में नहीं है, तो तरीके startElement (टैग, गुण) और endElement (टैग) कहा जाता है; अन्यथा, इसी तरीके startElementNS और endElementNS को कहा जाता है। यहाँ, टैग तत्व टैग है, और गुण एक वस्तु वस्तु है।
आगे बढ़ने से पहले समझने के लिए अन्य महत्वपूर्ण तरीके हैं -
make_parser विधि
निम्नलिखित विधि एक नया पार्सर ऑब्जेक्ट बनाता है और इसे वापस करता है। बनाया गया पार्सर ऑब्जेक्ट पहले पार्सर प्रकार का होगा जो सिस्टम पाता है।
xml.sax.make_parser( [parser_list] )यहाँ मापदंडों का विस्तार है -
parser_list - वैकल्पिक तर्क जिसमें पार्सर्स की एक सूची शामिल है जिसका उपयोग करने के लिए सभी को मेक_पर्सर विधि लागू करनी चाहिए।
पार्स विधि
निम्नलिखित विधि एसएएक्स पार्सर बनाती है और इसका उपयोग किसी दस्तावेज़ को पार्स करने के लिए करती है।
xml.sax.parse( xmlfile, contenthandler[, errorhandler])यहाँ मापदंडों का विस्तार है -
xmlfile - यह पढ़ने के लिए XML फ़ाइल का नाम है।
contenthandler - यह एक ContentHandler ऑब्जेक्ट होना चाहिए।
errorhandler - यदि निर्दिष्ट किया गया है, तो एरैंडहैंडलर SAX ErrorHandler ऑब्जेक्ट होना चाहिए।
parseString विधि
SAX पार्सर बनाने और निर्दिष्ट पार्स करने के लिए एक और तरीका है XML string।
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])यहाँ मापदंडों का विस्तार है -
xmlstring - यह पढ़ने के लिए XML स्ट्रिंग का नाम है।
contenthandler - यह एक ContentHandler ऑब्जेक्ट होना चाहिए।
errorhandler - यदि निर्दिष्ट किया गया है, तो एरैंडहैंडलर SAX ErrorHandler ऑब्जेक्ट होना चाहिए।
उदाहरण
#!/usr/bin/python
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# Call when an element starts
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print "*****Movie*****"
title = attributes["title"]
print "Title:", title
# Call when an elements ends
def endElement(self, tag):
if self.CurrentData == "type":
print "Type:", self.type
elif self.CurrentData == "format":
print "Format:", self.format
elif self.CurrentData == "year":
print "Year:", self.year
elif self.CurrentData == "rating":
print "Rating:", self.rating
elif self.CurrentData == "stars":
print "Stars:", self.stars
elif self.CurrentData == "description":
print "Description:", self.description
self.CurrentData = ""
# Call when a character is read
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# override the default ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")इसका परिणाम निम्न होगा -
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Stars: 10
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Stars: 2
Description: Viewable boredomएसएएक्स एपीआई प्रलेखन पर एक पूर्ण विवरण के लिए, कृपया मानक पायथन एसएएक्स एपीआई का संदर्भ लें ।
डोम एपीआई के साथ पार्सिंग एक्सएमएल
दस्तावेज़ ऑब्जेक्ट मॉडल ("DOM") XML दस्तावेज़ों को एक्सेस और संशोधित करने के लिए वर्ल्ड वाइड वेब कंसोर्टियम (W3C) से एक क्रॉस-भाषा एपीआई है।
DOM रैंडम-एक्सेस एप्लिकेशन के लिए बेहद उपयोगी है। SAX आपको केवल एक समय में दस्तावेज़ के एक बिट के दृश्य की अनुमति देता है। यदि आप एक एसएएक्स तत्व को देख रहे हैं, तो आपके पास दूसरे तक पहुंच नहीं है।
यहां XML दस्तावेज़ को जल्दी से लोड करने और xml.dom मॉड्यूल का उपयोग करके एक मिनीडोम ऑब्जेक्ट बनाने का सबसे आसान तरीका है। मिनीडोम ऑब्जेक्ट एक साधारण पार्सर विधि प्रदान करता है जो एक्सएमएल फ़ाइल से जल्दी से डोम ट्री बनाता है।
नमूना वाक्यांश पार्स (फ़ाइल [, पार्सर]) मिनिडम ऑब्जेक्ट के कार्य को डोम ट्री ऑब्जेक्ट में फ़ाइल द्वारा निर्दिष्ट XML फ़ाइल को पार्स करने के लिए कहता है।
#!/usr/bin/python
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document using minidom parser
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print "Root element : %s" % collection.getAttribute("shelf")
# Get all the movies in the collection
movies = collection.getElementsByTagName("movie")
# Print detail of each movie.
for movie in movies:
print "*****Movie*****"
if movie.hasAttribute("title"):
print "Title: %s" % movie.getAttribute("title")
type = movie.getElementsByTagName('type')[0]
print "Type: %s" % type.childNodes[0].data
format = movie.getElementsByTagName('format')[0]
print "Format: %s" % format.childNodes[0].data
rating = movie.getElementsByTagName('rating')[0]
print "Rating: %s" % rating.childNodes[0].data
description = movie.getElementsByTagName('description')[0]
print "Description: %s" % description.childNodes[0].dataयह निम्नलिखित परिणाम का उत्पादन करेगा -
Root element : New Arrivals
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Rating: PG
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Rating: R
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Description: Viewable boredomDOM API प्रलेखन पर पूर्ण विवरण के लिए, कृपया मानक Python DOM APIs देखें ।
पायथन ग्राफिकल यूजर इंटरफेस (जीयूआई) विकसित करने के लिए विभिन्न विकल्प प्रदान करता है। सबसे महत्वपूर्ण नीचे सूचीबद्ध हैं।
Tkinter- Tkinter Python के साथ शिप किया गया TK GUI टूलकिट का पायथन इंटरफ़ेस है। हम इस अध्याय में इस विकल्प को देखेंगे।
wxPython - यह wxWindows के लिए एक ओपन-सोर्स पायथन इंटरफ़ेस है http://wxpython.org।
JPython - जेपीथॉन जावा के लिए एक पायथन पोर्ट है जो स्थानीय मशीन पर जावा वर्ग के पुस्तकालयों के लिए पायथन स्क्रिप्ट को सहज पहुंच देता है। http://www.jython.org।
कई अन्य इंटरफेस उपलब्ध हैं, जिन्हें आप नेट पर पा सकते हैं।
टिंकर प्रोग्रामिंग
टिंकर पायथन के लिए मानक GUI पुस्तकालय है। जब टिक्टर के साथ संयुक्त पायथन GUI अनुप्रयोगों को बनाने के लिए एक तेज और आसान तरीका प्रदान करता है। टिक्कर टीके जीयूआई टूलकिट के लिए एक शक्तिशाली वस्तु-उन्मुख इंटरफ़ेस प्रदान करता है।
Tkinter का उपयोग करके GUI एप्लिकेशन बनाना एक आसान काम है। आपको बस निम्न चरणों का पालन करना है -
Tkinter मॉड्यूल आयात करें ।
GUI एप्लिकेशन मुख्य विंडो बनाएं।
उपरोक्त एक या एक से अधिक विजेट्स को GUI एप्लिकेशन में जोड़ें।
उपयोगकर्ता द्वारा ट्रिगर प्रत्येक घटना के खिलाफ कार्रवाई करने के लिए मुख्य ईवेंट लूप दर्ज करें।
उदाहरण
#!/usr/bin/python
import Tkinter
top = Tkinter.Tk()
# Code to add widgets will go here...
top.mainloop()यह एक निम्न विंडो बनाएगा -
टिक्कटर विजेट
Tkinter एक GUI एप्लिकेशन में उपयोग किए गए बटन, लेबल और टेक्स्ट बॉक्स जैसे विभिन्न नियंत्रण प्रदान करता है। इन नियंत्रणों को सामान्यतः विगेट्स कहा जाता है।
Tkinter में वर्तमान में 15 प्रकार के विजेट हैं। हम निम्न तालिका में इन विगेट्स के साथ-साथ एक संक्षिप्त विवरण प्रस्तुत करते हैं -
| अनु क्रमांक। | ऑपरेटर और विवरण |
|---|---|
| 1 | बटन बटन विजेट का उपयोग आपके एप्लिकेशन में बटन प्रदर्शित करने के लिए किया जाता है। |
| 2 | कैनवास कैनवस विजेट का उपयोग आपके आवेदन में, रेखाओं, अंडाकार, बहुभुज और आयतों जैसे आकृतियों को खींचने के लिए किया जाता है। |
| 3 | Checkbutton चेकबटन विजेट का उपयोग चेकबॉक्स के रूप में कई विकल्पों को प्रदर्शित करने के लिए किया जाता है। उपयोगकर्ता एक बार में कई विकल्पों का चयन कर सकता है। |
| 4 | प्रवेश एंट्री विजेट का उपयोग उपयोगकर्ता से मूल्यों को स्वीकार करने के लिए एकल-पंक्ति पाठ क्षेत्र को प्रदर्शित करने के लिए किया जाता है। |
| 5 | ढांचा फ़्रेम विजेट का उपयोग अन्य विजेट्स को व्यवस्थित करने के लिए कंटेनर विजेट के रूप में किया जाता है। |
| 6 | लेबल अन्य विजेट्स के लिए सिंगल-लाइन कैप्शन प्रदान करने के लिए लेबल विजेट का उपयोग किया जाता है। इसमें चित्र भी हो सकते हैं। |
| 7 | सूची बाक्स किसी उपयोगकर्ता को विकल्पों की सूची प्रदान करने के लिए Listbox विजेट का उपयोग किया जाता है। |
| 8 | मेनू बटन आपके एप्लिकेशन में मेनू प्रदर्शित करने के लिए Menubutton विजेट का उपयोग किया जाता है। |
| 9 | मेन्यू मेनू विजेट का उपयोग उपयोगकर्ता को विभिन्न कमांड प्रदान करने के लिए किया जाता है। ये आदेश मेनूबुट्टन के अंदर निहित हैं। |
| 10 | संदेश संदेश विजेट का उपयोग उपयोगकर्ता से मूल्यों को स्वीकार करने के लिए बहु-पाठ फ़ील्ड प्रदर्शित करने के लिए किया जाता है। |
| 1 1 | रेडियो बटन रेडियोबटन विजेट का उपयोग रेडियो बटन के रूप में कई विकल्प प्रदर्शित करने के लिए किया जाता है। उपयोगकर्ता एक बार में केवल एक विकल्प का चयन कर सकता है। |
| 12 | स्केल स्केल विजेट का उपयोग स्लाइडर विजेट प्रदान करने के लिए किया जाता है। |
| 13 | स्क्रॉल पट्टी स्क्रॉलबार विजेट का उपयोग विभिन्न विजेट जैसे सूची बॉक्स में स्क्रॉलिंग क्षमता जोड़ने के लिए किया जाता है। |
| 14 | टेक्स्ट टेक्स्ट विजेट को कई लाइनों में टेक्स्ट प्रदर्शित करने के लिए उपयोग किया जाता है। |
| 15 | सर्वोच्च स्तर Toplevel विजेट का उपयोग एक अलग विंडो कंटेनर प्रदान करने के लिए किया जाता है। |
| 16 | Spinbox स्पिनबॉक्स विजेट मानक टिंकर एंट्री विजेट का एक प्रकार है, जिसका उपयोग निश्चित संख्या में मानों को चुनने के लिए किया जा सकता है। |
| 17 | PanedWindow PanedWindow एक कंटेनर विजेट है जिसमें क्षैतिज या लंबवत रूप से व्यवस्थित पैन की संख्या हो सकती है। |
| 18 | लेबल फ्रेम एक Labelframe एक साधारण कंटेनर विजेट है। इसका प्राथमिक उद्देश्य जटिल विंडो लेआउट के लिए स्पेसर या कंटेनर के रूप में कार्य करना है। |
| 19 | tkMessageBox इस मॉड्यूल का उपयोग आपके एप्लिकेशन में संदेश बॉक्स प्रदर्शित करने के लिए किया जाता है। |
आइये इन विजेट्स पर विस्तार से अध्ययन करते हैं -
मानक गुण
आइए एक नजर डालते हैं कि कैसे उनके कुछ सामान्य फीचर्स हैं। जैसे कि आकार, रंग और फोंट निर्दिष्ट हैं।
Dimensions
Colors
Fonts
Anchors
राहत शैलियों
Bitmaps
Cursors
आइए हम उनका संक्षिप्त अध्ययन करें -
ज्यामिति प्रबंधन
सभी टिंकर विजेट में विशिष्ट ज्यामिति प्रबंधन विधियों का उपयोग होता है, जिसका उद्देश्य माता-पिता विजेट क्षेत्र में विजेट्स को व्यवस्थित करना है। Tkinter निम्नलिखित ज्यामिति प्रबंधक वर्गों को उजागर करता है: पैक, ग्रिड और स्थान।
पैक () विधि - यह ज्यामिति प्रबंधक उन्हें माता-पिता विजेट में रखने से पहले ब्लॉक में विजेट्स आयोजन करता है।
ग्रिड () विधि - यह ज्यामिति प्रबंधक माता पिता विजेट में एक संरचना तालिका जैसी में विजेट्स आयोजन करता है।
जगह () विधि - यह ज्यामिति प्रबंधक उन्हें माता-पिता विजेट में एक विशिष्ट स्थान में रखकर विगेट्स आयोजन करता है।
आइए हम संक्षेप में ज्यामिति प्रबंधन विधियों का अध्ययन करते हैं -
कोई भी कोड जिसे आप किसी भी संकलित भाषा का उपयोग करके लिखते हैं जैसे C, C ++, या Java को अन्य पायथन लिपि में एकीकृत या आयात किया जा सकता है। इस कोड को "एक्सटेंशन" माना जाता है।
एक पायथन एक्सटेंशन मॉड्यूल एक सामान्य सी लाइब्रेरी से अधिक कुछ नहीं है। यूनिक्स मशीनों पर, ये पुस्तकालय आमतौर पर समाप्त हो जाते हैं.so(साझा वस्तु के लिए)। विंडोज मशीनों पर, आप आमतौर पर देखते हैं.dll (गतिशील रूप से जुड़े पुस्तकालय के लिए)।
लेखन एक्सटेंशन के लिए पूर्व आवश्यक
अपना विस्तार लिखना शुरू करने के लिए, आपको पायथन हेडर फ़ाइलों की आवश्यकता होगी।
यूनिक्स मशीनों पर, इसे आमतौर पर डेवलपर-विशिष्ट पैकेज जैसे कि python2.5-dev स्थापित करने की आवश्यकता होती है ।
जब वे बाइनरी पायथन इंस्टॉलर का उपयोग करते हैं, तो विंडोज उपयोगकर्ताओं को ये हेडर पैकेज के हिस्से के रूप में मिलते हैं।
इसके अतिरिक्त, यह माना जाता है कि आपके पास C प्रोग्रामिंग का उपयोग करके किसी भी पायथन एक्सटेंशन को लिखने के लिए C या C ++ का अच्छा ज्ञान है।
सबसे पहले एक पायथन एक्सटेंशन को देखें
पायथन एक्सटेंशन मॉड्यूल को देखने के लिए, आपको अपने कोड को चार भाग में समूहित करने की आवश्यकता है -
हेडर फ़ाइल Python.h ।
सी फ़ंक्शन जिसे आप अपने मॉड्यूल से इंटरफ़ेस के रूप में उजागर करना चाहते हैं।
पायथन डेवलपर्स के रूप में आपके कार्यों के नाम मैप करने वाली एक तालिका उन्हें एक्सटेंशन मॉड्यूल के अंदर सी फ़ंक्शन को देखती है।
एक प्रारंभिक कार्य।
हेडर फ़ाइल Python.h
आपको अपनी C स्रोत फ़ाइल में Python.h हेडर फ़ाइल शामिल करने की आवश्यकता है , जो आपको इंटरप्रिटर में अपने मॉड्यूल को हुक करने के लिए उपयोग किए जाने वाले आंतरिक पायथन एपीआई तक पहुंच प्रदान करता है।
पाइथन को शामिल करना सुनिश्चित करें। इससे पहले कि आप किसी अन्य हेडर की आवश्यकता हो। आपको उन कार्यों के साथ शामिल करने की आवश्यकता है जिन्हें आप पायथन से कॉल करना चाहते हैं।
सी कार्य
आपके कार्यों के C कार्यान्वयन के हस्ताक्षर हमेशा निम्नलिखित तीन रूपों में से एक लेते हैं -
static PyObject *MyFunction( PyObject *self, PyObject *args );
static PyObject *MyFunctionWithKeywords(PyObject *self,
PyObject *args,
PyObject *kw);
static PyObject *MyFunctionWithNoArgs( PyObject *self );पूर्ववर्ती घोषणाओं में से प्रत्येक एक पायथन ऑब्जेक्ट देता है। पायथन में शून्य फ़ंक्शन के रूप में ऐसी कोई चीज नहीं है जैसा कि सी में है। यदि आप नहीं चाहते हैं कि आपके कार्य एक मान लौटाएं, तो पायथन के सी के बराबर लौटेंNoneमूल्य। पायथन हेडर एक मैक्रो, Py_RETURN_NONE को परिभाषित करते हैं, जो हमारे लिए ऐसा करता है।
आपके सी फ़ंक्शंस के नाम वे हो सकते हैं जो आपको पसंद हैं क्योंकि वे कभी भी विस्तार मॉड्यूल के बाहर नहीं देखे जाते हैं। उन्हें स्थिर कार्य के रूप में परिभाषित किया गया है।
आपके सी फ़ंक्शन आमतौर पर पायथन मॉड्यूल और फ़ंक्शन नामों को एक साथ जोड़कर नामित किए जाते हैं, जैसा कि यहां दिखाया गया है -
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}यह एक पायथन फ़ंक्शन है जिसे मॉड्यूल मॉड्यूल के अंदर फंक कहा जाता है । आप मॉड्यूल के लिए विधि तालिका में अपने सी फ़ंक्शंस में पॉइंटर्स डाल रहे होंगे जो आमतौर पर आपके स्रोत कोड में आता है।
विधि मानचित्रण तालिका
यह विधि तालिका PyMethodDef संरचनाओं का एक सरल सरणी है। वह संरचना कुछ इस तरह दिखती है -
struct PyMethodDef {
char *ml_name;
PyCFunction ml_meth;
int ml_flags;
char *ml_doc;
};यहाँ इस संरचना के सदस्यों का वर्णन है -
ml_name - यह फ़ंक्शन का नाम है जब पायथन इंटरप्रेटर प्रस्तुत करता है जब इसका उपयोग पायथन कार्यक्रमों में किया जाता है।
ml_meth - यह उस फ़ंक्शन का पता होना चाहिए जिसमें पिछले सीज़न में वर्णित हस्ताक्षर में से कोई एक है।
ml_flags - यह दुभाषिया बताता है कि कौन सा तीन हस्ताक्षर ml_meth का उपयोग कर रहा है।
इस ध्वज में आमतौर पर METH_VARARGS का मान होता है।
यदि आप अपने फ़ंक्शन में कीवर्ड तर्क देना चाहते हैं तो यह ध्वज METH_KEYWORDS के साथ बिट या ऑर्ड किया जा सकता है।
इसमें METH_NOARGS का मान भी हो सकता है जो यह दर्शाता है कि आप किसी भी तर्क को स्वीकार नहीं करना चाहते हैं।
ml_doc - यह फंक्शन के लिए डॉकस्ट्रिंग है, जिसे NULL हो सकता है अगर आपको एक लिखने का मन नहीं है।
इस तालिका को एक प्रहरी के साथ समाप्त करने की आवश्यकता है जिसमें पूर्ण सदस्य के लिए NULL और 0 मान शामिल हैं।
उदाहरण
उपरोक्त परिभाषित फ़ंक्शन के लिए, हमारे पास निम्न विधि मानचित्रण तालिका है -
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};प्रारंभिक समारोह
आपके एक्सटेंशन मॉड्यूल का अंतिम भाग इनिशियलाइज़ेशन फंक्शन है। मॉड्यूल लोड होने पर इस फ़ंक्शन को पायथन इंटरप्रेटर द्वारा बुलाया जाता है। यह आवश्यक है कि फ़ंक्शन का नाम दिया जाएinitModule, जहां मॉड्यूल मॉड्यूल का नाम है।
आरंभीकरण फ़ंक्शन को आपके द्वारा बनाए जा रहे पुस्तकालय से निर्यात करने की आवश्यकता है। पायथन हेडर PyMODINIT_FUNC को परिभाषित करते हैं ताकि उस विशेष वातावरण के लिए जो हम संकलित कर रहे हैं, उसके लिए उचित अवतरण शामिल करें। आपको फ़ंक्शन को परिभाषित करते समय इसका उपयोग करना होगा।
आपके सी आरंभीकरण समारोह में आम तौर पर निम्नलिखित समग्र संरचना होती है -
PyMODINIT_FUNC initModule() {
Py_InitModule3(func, module_methods, "docstring...");
}यहाँ Py_InitModule3 फ़ंक्शन का वर्णन है -
func - यह निर्यात किया जाने वाला कार्य है।
module_methods - यह ऊपर परिभाषित मानचित्रण तालिका नाम है।
docstring - यह वह टिप्पणी है जिसे आप अपने विस्तार में देना चाहते हैं।
यह सब एक साथ रखना निम्नलिखित की तरह दिखता है -
#include <Python.h>
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};
PyMODINIT_FUNC initModule() {
Py_InitModule3(func, module_methods, "docstring...");
}उदाहरण
एक सरल उदाहरण जो उपरोक्त सभी अवधारणाओं का उपयोग करता है -
#include <Python.h>
static PyObject* helloworld(PyObject* self) {
return Py_BuildValue("s", "Hello, Python extensions!!");
}
static char helloworld_docs[] =
"helloworld( ): Any message you want to put here!!\n";
static PyMethodDef helloworld_funcs[] = {
{"helloworld", (PyCFunction)helloworld,
METH_NOARGS, helloworld_docs},
{NULL}
};
void inithelloworld(void) {
Py_InitModule3("helloworld", helloworld_funcs,
"Extension module example!");
}यहाँ Py_BuildValue फ़ंक्शन का उपयोग Python मान बनाने के लिए किया जाता है। Hello.c फ़ाइल में उपरोक्त कोड सहेजें। हम देखेंगे कि पायथन स्क्रिप्ट से इस मॉड्यूल को कैसे संकलित और स्थापित किया जाए।
एक्सटेंशन का निर्माण और स्थापना
Distutils पैकेज यह बहुत आसान अजगर मॉड्यूल, दोनों शुद्ध पायथन और विस्तार माड्यूल वितरित करने, एक मानक तरीके से करता है। मॉड्यूल को स्रोत रूप में वितरित किया जाता है और सेटअप स्क्रिप्ट के माध्यम से बनाया और स्थापित किया जाता है, जिसे आमतौर पर setup.py कहा जाता है।
उपरोक्त मॉड्यूल के लिए, आपको निम्नलिखित सेटअप स्क्रिप्ट को तैयार करने की आवश्यकता है -
from distutils.core import setup, Extension
setup(name='helloworld', version='1.0', \
ext_modules=[Extension('helloworld', ['hello.c'])])अब, निम्न कमांड का उपयोग करें, जो सभी आवश्यक संकलन और लिंकिंग चरणों का प्रदर्शन करेगा, सही कंपाइलर और लिंकर कमांड और झंडे के साथ, और परिणामस्वरूप डायनेमिक लाइब्रेरी को एक उपयुक्त निर्देशिका में कॉपी करता है -
$ python setup.py installयूनिक्स-आधारित सिस्टम पर, आपको साइट-पैकेज निर्देशिका में लिखने के लिए अनुमतियाँ रखने के लिए मूल रूप से इस कमांड को चलाने की आवश्यकता होगी। यह आमतौर पर विंडोज पर कोई समस्या नहीं है।
आयात का विस्तार
एक बार जब आप अपना एक्सटेंशन स्थापित कर लेते हैं, तो आप उस एक्सटेंशन को अपनी पाइथन स्क्रिप्ट में निम्नानुसार आयात और कॉल कर सकेंगे -
#!/usr/bin/python
import helloworld
print helloworld.helloworld()यह निम्नलिखित परिणाम का उत्पादन करेगा -
Hello, Python extensions!!पासिंग फंक्शन पैरामीटर्स
जैसा कि आप तर्क को स्वीकार करने वाले कार्यों को परिभाषित करना चाहते हैं, आप अपने सी कार्यों के लिए अन्य हस्ताक्षरों में से एक का उपयोग कर सकते हैं। उदाहरण के लिए, निम्नलिखित फ़ंक्शन, जो कुछ मापदंडों को स्वीकार करता है, इस तरह परिभाषित किया जाएगा -
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Parse args and do something interesting here. */
Py_RETURN_NONE;
}नए फ़ंक्शन के लिए प्रविष्टि वाली विधि तालिका इस तरह दिखाई देगी -
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ "func", module_func, METH_VARARGS, NULL },
{ NULL, NULL, 0, NULL }
};आप अपने Py फ़ंक्शन में दिए गए एक PyObject पॉइंटर से आर्गुमेंट निकालने के लिए API PyArg_ParseTuple फ़ंक्शन का उपयोग कर सकते हैं ।
PyArg_ParseTuple का पहला तर्क आर्ग्स तर्क है। यह वह वस्तु है जिसे आप पार्स कर रहे होंगे । दूसरा तर्क एक प्रारूप स्ट्रिंग है जो तर्कों का वर्णन करता है जैसा कि आप उनसे प्रकट होने की उम्मीद करते हैं। प्रत्येक तर्क प्रारूप स्ट्रिंग में एक या एक से अधिक वर्णों द्वारा दर्शाया गया है।
static PyObject *module_func(PyObject *self, PyObject *args) {
int i;
double d;
char *s;
if (!PyArg_ParseTuple(args, "ids", &i, &d, &s)) {
return NULL;
}
/* Do something interesting here. */
Py_RETURN_NONE;
}अपने मॉड्यूल के नए संस्करण को संकलित करना और इसे आयात करना आपको किसी भी प्रकार के तर्क के साथ नए फ़ंक्शन को लागू करने में सक्षम बनाता है -
module.func(1, s="three", d=2.0)
module.func(i=1, d=2.0, s="three")
module.func(s="three", d=2.0, i=1)आप शायद और भी विविधताओं के साथ आ सकते हैं।
PyArg_ParseTuple समारोह
यहाँ के लिए मानक हस्ताक्षर है PyArg_ParseTuple कार्य -
int PyArg_ParseTuple(PyObject* tuple,char* format,...)यह फ़ंक्शन त्रुटियों के लिए 0, और सफलता के लिए 0 के बराबर मान नहीं देता है। tuple PyObject * है जो C फ़ंक्शन का दूसरा तर्क था। यहां प्रारूप एक सी स्ट्रिंग है जो अनिवार्य और वैकल्पिक तर्कों का वर्णन करता है।
यहाँ प्रारूप कोड की एक सूची है PyArg_ParseTuple कार्य -
| कोड | C प्रकार | जिसका अर्थ है |
|---|---|---|
| सी | चार | 1 की लंबाई वाला पायथन स्ट्रिंग सी चार हो जाता है। |
| घ | दोहरा | एक पायथन फ्लोट सी डबल हो जाता है। |
| च | नाव | एक पायथन फ्लोट एक सी फ्लोट बन जाता है। |
| मैं | पूर्णांक | एक पायथन इंट एक C int बन जाता है। |
| एल | लंबा | एक पायथन इंट एक C लंबा हो जाता है। |
| एल | लम्बा लम्बा | एक पायथन इंट एक लंबे लंबे सी बन जाता है |
| हे | PyObject * | पायथन तर्क के लिए गैर-पूर्ण उधार लिया संदर्भ प्राप्त होता है। |
| रों | चार * | सी चार * के लिए एम्बेडेड नल के बिना पायथन स्ट्रिंग। |
| रों # | चार * + पूर्णांक | किसी भी पायथन स्ट्रिंग को C पता और लंबाई। |
| टी # | चार * + पूर्णांक | सी-एड्रेस और लंबाई तक केवल-एकल-खंड बफर पढ़ें। |
| यू | Py_UNICODE * | सी के लिए एम्बेडेड नल के बिना पायथन यूनिकोड। |
| यू # | Py_UNICODE * + पूर्णांक | कोई पायथन यूनिकोड सी पता और लंबाई। |
| डब्ल्यू # | चार * + पूर्णांक | सी पते और लंबाई के लिए एकल-खंड बफर पढ़ें / लिखें। |
| जेड | चार * | एस की तरह, भी कोई नहीं स्वीकार करता है (सी चार * को NULL सेट करता है)। |
| z # | चार * + पूर्णांक | # की तरह, भी कोई नहीं स्वीकार करता है (सेट सी चार * NULL के लिए)। |
| (...) | के अनुसार ... | एक पायथन अनुक्रम को प्रति आइटम एक तर्क के रूप में माना जाता है। |
| | | निम्नलिखित तर्क वैकल्पिक हैं। | |
| : | प्रारूप अंत, त्रुटि संदेशों के लिए फ़ंक्शन नाम के बाद। | |
| ; | संपूर्ण त्रुटि संदेश पाठ के बाद प्रारूप अंत,। |
लौटाने का मूल्य
Py_BuildValue एक स्वरूप स्ट्रिंग में लेता है जैसे PyArg_ParseTuple करता है। आपके द्वारा बनाए जा रहे मूल्यों के पते में पारित होने के बजाय, आप वास्तविक मूल्यों में पास होते हैं। यहाँ एक उदाहरण दिखाया गया है कि ऐड फंक्शन कैसे लागू किया जाता है -
static PyObject *foo_add(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("i", a + b);
}यदि पायथन में इसे लागू किया जाता है तो यह कैसा होगा -
def add(a, b):
return (a + b)आप अपने फ़ंक्शन से दो मान निम्नानुसार लौटा सकते हैं, यह पायथन में एक सूची का उपयोग करके तोड़ दिया जाएगा।
static PyObject *foo_add_subtract(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("ii", a + b, a - b);
}यदि पायथन में इसे लागू किया जाता है तो यह कैसा होगा -
def add_subtract(a, b):
return (a + b, a - b)Py_BuildValue समारोह
यहाँ के लिए मानक हस्ताक्षर है Py_BuildValue कार्य -
PyObject* Py_BuildValue(char* format,...)यहां प्रारूप एक सी स्ट्रिंग है जो निर्माण के लिए पायथन ऑब्जेक्ट का वर्णन करता है। Py_BuildValue के निम्नलिखित तर्क C मान हैं जिनसे परिणाम बनाया गया है। PyObject * परिणाम एक नया संदर्भ है।
निम्नलिखित तालिका सूची में आमतौर पर उपयोग किए जाने वाले कोड स्ट्रिंग्स हैं, जिनमें से शून्य या अधिक को स्ट्रिंग प्रारूप में शामिल किया गया है।
| कोड | C प्रकार | जिसका अर्थ है |
|---|---|---|
| सी | चार | एसी चार लंबाई का पायथन स्ट्रिंग बन जाता है। |
| घ | दोहरा | एसी डबल पायथन फ्लोट बन जाता है। |
| च | नाव | एसी फ्लोट एक पायथन फ्लोट बन जाता है। |
| मैं | पूर्णांक | एसी इंट पायथन इंट बन जाता है। |
| एल | लंबा | एसी लॉन्ग पायथन इंट बन जाता है। |
| एन | PyObject * | एक पायथन ऑब्जेक्ट पास करता है और एक संदर्भ चोरी करता है। |
| हे | PyObject * | एक पायथन ऑब्जेक्ट को पास करता है और इसे सामान्य रूप से बढ़ाता है। |
| ओ एंड | धर्मांतरित + शून्य * | मनमाना रूपांतरण |
| रों | चार * | सी 0-टर्मिनेटेड चार * से पायथन स्ट्रिंग, या कोई भी नहीं। |
| रों # | चार * + पूर्णांक | C चार * और पायथन स्ट्रिंग की लंबाई, या NULL से कोई भी नहीं। |
| यू | Py_UNICODE * | सी-वाइड, शून्य-टर्मिनेटेड स्ट्रिंग टू पायथन यूनिकोड, या कोई नहीं। |
| यू # | Py_UNICODE * + पूर्णांक | सी-वाइड स्ट्रिंग और लंबाई पायथन यूनिकोड, या NULL से कोई नहीं। |
| डब्ल्यू # | चार * + पूर्णांक | सी पते और लंबाई के लिए एकल-खंड बफर पढ़ें / लिखें। |
| जेड | चार * | एस की तरह, भी कोई नहीं स्वीकार करता है (सी चार * को NULL सेट करता है)। |
| z # | चार * + पूर्णांक | # की तरह, भी कोई नहीं स्वीकार करता है (सेट सी चार * NULL के लिए)। |
| (...) | के अनुसार ... | C मान से पायथन टपल बनाता है। |
| [...] | के अनुसार ... | C मान से पायथन सूची बनाता है। |
| {...} | के अनुसार ... | सी मूल्यों, वैकल्पिक कुंजी और मूल्यों से पायथन शब्दकोश बनाता है। |
कोड {...} सी मानों की एक समान संख्या से शब्दकोष बनाता है, वैकल्पिक रूप से कुंजी और मान। उदाहरण के लिए, Py_BuildValue ("{issi}", 23, "zig", "zag", 42) Python के {23: 'zig', 'zag': 42} जैसे शब्दकोश देता है।