SAP BODS - त्वरित गाइड
डेटा वेयरहाउस को एक या एकाधिक विषम डेटा स्रोतों से डेटा स्टोर करने के लिए एक केंद्रीय भंडार के रूप में जाना जाता है। डेटा वेयरहाउस का उपयोग सूचना की रिपोर्टिंग और विश्लेषण के लिए किया जाता है और ऐतिहासिक और वर्तमान डेटा दोनों को संग्रहीत करता है। DW प्रणाली में डेटा का उपयोग विश्लेषणात्मक रिपोर्टिंग के लिए किया जाता है, जो बाद में निर्णय लेने के लिए व्यावसायिक विश्लेषकों, बिक्री प्रबंधकों या ज्ञान श्रमिकों द्वारा उपयोग किया जाता है।
DW सिस्टम में डेटा को परिचालन लेनदेन प्रणाली जैसे कि Sales, Marketing, HR, SCM, आदि से लोड किया जाता है। यह सूचना प्रसंस्करण के लिए DW सिस्टम में लोड होने से पहले परिचालन डेटा स्टोर या अन्य परिवर्तनों से गुजर सकता है।
डेटा वेयरहाउस - मुख्य विशेषताएं
एक DW सिस्टम की प्रमुख विशेषताएं हैं -
यह केंद्रीय डेटा भंडार है जहां डेटा एक या अधिक विषम डेटा स्रोतों से संग्रहीत किया जाता है।
एक DW सिस्टम वर्तमान और ऐतिहासिक डेटा दोनों को संग्रहीत करता है। आम तौर पर एक DW सिस्टम 5-10 साल के ऐतिहासिक डेटा को संग्रहीत करता है।
एक DW प्रणाली हमेशा एक परिचालन लेनदेन प्रणाली से अलग रखी जाती है।
DW प्रणाली में डेटा का उपयोग क्वार्टरली से वार्षिक तुलनात्मक तुलना में विभिन्न प्रकार की विश्लेषणात्मक रिपोर्टिंग रेंज के लिए किया जाता है।
एक डीडब्ल्यू प्रणाली की आवश्यकता है
मान लीजिए कि आपके पास एक होम लोन एजेंसी है, जहां डेटा कई अनुप्रयोगों जैसे- मार्केटिंग, बिक्री, ईआरपी, एचआरएम, एमएम आदि से आ रहा है। यह डेटा डेटा वेयरहाउस में निकाला, परिवर्तित और लोड किया गया है।
उदाहरण के लिए, यदि आपको किसी उत्पाद की त्रैमासिक / वार्षिक बिक्री की तुलना करनी है, तो आप एक ऑपरेशनल ट्रांसेक्शनल डेटाबेस का उपयोग नहीं कर सकते, क्योंकि यह लेनदेन प्रणाली को लटका देगा। इसलिए, इस उद्देश्य के लिए एक डेटा वेयरहाउस का उपयोग किया जाता है।
DW और ODB के बीच अंतर
डेटा वेयरहाउस और ऑपरेशनल डेटाबेस (ट्रांसेक्शनल डेटाबेस) के बीच अंतर इस प्रकार हैं -
एक लेनदेन प्रणाली ज्ञात कार्यभार और लेनदेन के लिए डिज़ाइन की गई है जैसे कि उपयोगकर्ता रिकॉर्ड को अपडेट करना, रिकॉर्ड खोजना, आदि। हालांकि, डेटा वेयरहाउस लेनदेन अधिक जटिल हैं और डेटा का एक सामान्य रूप प्रस्तुत करते हैं।
एक लेनदेन प्रणाली में एक संगठन का वर्तमान डेटा होता है और डेटा वेयरहाउस में आम तौर पर ऐतिहासिक डेटा होता है।
लेन-देन प्रणाली कई लेनदेन के समानांतर प्रसंस्करण का समर्थन करती है। डेटाबेस की निरंतरता बनाए रखने के लिए कंसीडर कंट्रोल और रिकवरी मैकेनिज्म की आवश्यकता होती है।
किसी ऑपरेशनल डेटाबेस क्वेरी को ऑपरेशंस (डिलीट और अपडेट) को पढ़ने और संशोधित करने की अनुमति मिलती है जबकि OLAP क्वेरी को केवल संग्रहीत डेटा की केवल रीड एक्सेस (स्टेटमेंट का चयन करें) की आवश्यकता होती है।
DW आर्किटेक्चर
डेटा वेयरहाउसिंग में डेटा सफाई, डेटा एकीकरण और डेटा समेकन शामिल हैं।

डेटा वेयरहाउस में 3-लेयर आर्किटेक्चर है - Data Source Layer, Integration Layer, तथा Presentation Layer। ऊपर दिया गया चित्र डेटा वेयरहाउस सिस्टम की सामान्य वास्तुकला को दर्शाता है।
चार प्रकार के डेटा वेयरहाउसिंग सिस्टम हैं।
- आंकड़ों का बाजार
- ऑनलाइन विश्लेषणात्मक प्रसंस्करण (OLAP)
- ऑनलाइन लेनदेन प्रसंस्करण (OLTP)
- भविष्य कहनेवाला विश्लेषण (PA)
आंकड़ों का बाजार
एक डेटा मार्ट को डेटा वेयरहाउस सिस्टम के सबसे सरल रूप के रूप में जाना जाता है और सामान्य रूप से बिक्री, वित्त या विपणन, आदि जैसे संगठन में एक ही कार्यात्मक क्षेत्र होता है।
एक संगठन में डेटा मार्ट और एक एकल विभाग द्वारा बनाया और प्रबंधित किया जाता है। जैसा कि यह एक एकल विभाग का है, विभाग आमतौर पर केवल कुछ या एक प्रकार के स्रोतों / अनुप्रयोगों से डेटा प्राप्त करता है। यह स्रोत आंतरिक परिचालन प्रणाली, डेटा वेयरहाउस या बाहरी सिस्टम हो सकता है।
ऑनलाइन विश्लेषणात्मक प्रक्रिया
एक OLAP प्रणाली में, लेनदेन प्रणाली की तुलना में लेनदेन की संख्या कम होती है। निष्पादित क्वेरीज़ प्रकृति में जटिल हैं और इसमें डेटा एकत्रीकरण शामिल है।
एक एकत्रीकरण क्या है?
हम वार्षिक (1 पंक्ति), त्रैमासिक (4 पंक्तियों), मासिक (12 पंक्तियों) या जैसे कुल डेटा के साथ तालिकाओं को बचाते हैं, यदि किसी को वर्ष-दर-वर्ष तुलना करना है, तो केवल एक पंक्ति संसाधित की जाएगी। हालांकि, एक संयुक्त तालिका में यह सभी पंक्तियों की तुलना करेगा।
SELECT SUM(salary)
FROM employee
WHERE title = 'Programmer';एक OLAP प्रणाली में प्रभावी उपाय
प्रतिक्रिया समय को एक में सबसे प्रभावी और महत्वपूर्ण उपाय के रूप में जाना जाता है OLAPप्रणाली। एग्रिगेटेड स्टोरेज डेटा को मल्टी-स्कीमा स्कीमा में बनाए रखा जाता है जैसे स्टार स्कीमा (जब डेटा को श्रेणीबद्ध समूहों में व्यवस्थित किया जाता है, जिसे अक्सर आयाम कहा जाता है और तथ्यों और समग्र तथ्यों में इसे स्कीमा कहा जाता है)।
OLAP सिस्टम की विलंबता कुछ घंटों की होती है, जहां डेटा मौसा की तुलना में जहां विलंबता एक दिन के करीब होने की उम्मीद है।
ऑनलाइन लेनदेन प्रसंस्करण
एक ओएलटीपी प्रणाली में, बड़ी संख्या में लघु लेनदेन जैसे INSERT, UPDATE और DELETE हैं।
एक ओएलटीपी प्रणाली में, एक प्रभावी उपाय छोटे लेनदेन का प्रसंस्करण समय है और बहुत कम है। यह मल्टी-एक्सेस वातावरण में डेटा अखंडता को नियंत्रित करता है। एक ओएलटीपी प्रणाली के लिए, प्रति सेकंड लेनदेन की संख्या के उपायeffectiveness। एक ओएलटीपी डेटा वेयरहाउस सिस्टम में वर्तमान और विस्तृत डेटा होता है और यह इकाई मॉडल (3NF) में स्कीमा में बनाए रखा जाता है।
उदाहरण
रिटेल स्टोर में दिन-प्रति-दिन लेनदेन प्रणाली, जहां ग्राहक रिकॉर्ड डाले जाते हैं, अद्यतन किए जाते हैं और दैनिक आधार पर हटाए जाते हैं। यह बहुत तेजी से क्वेरी प्रसंस्करण प्रदान करता है। ओएलटीपी डेटाबेस में विस्तृत और वर्तमान डेटा होते हैं। ओएलटीपी डेटाबेस को स्टोर करने के लिए उपयोग की जाने वाली स्कीमा इकाई मॉडल है।
OLTP और OLAP के बीच अंतर
निम्न चित्रणों में महत्वपूर्ण अंतर दिखाया गया है OLTP तथा OLAP प्रणाली।

Indexes - OLTP सिस्टम में केवल कुछ इंडेक्स होते हैं जबकि OLAP सिस्टम में परफॉर्मेंस ऑप्टिमाइजेशन के लिए कई इंडेक्स होते हैं।
Joins- एक ओएलटीपी प्रणाली में, बड़ी संख्या में जुड़ने और डेटा सामान्यीकृत होते हैं। हालांकि, एक ओएलएपी प्रणाली में कम जोड़ होते हैं और डी-सामान्यीकृत होते हैं।
Aggregation - एक OLTP सिस्टम में, डेटा को एकत्र नहीं किया जाता है जबकि OLAP डेटाबेस में अधिक एकत्रीकरण का उपयोग किया जाता है।
भविष्य कहनेवाला विश्लेषण
भविष्य के परिणामों की भविष्यवाणी करने के लिए विभिन्न गणितीय कार्यों का उपयोग करके DWI प्रणाली में संग्रहीत डेटा में छिपे हुए पैटर्न को खोजने के रूप में भविष्य कहनेवाला विश्लेषण को जाना जाता है।
पूर्वानुमानात्मक विश्लेषण प्रणाली अपने उपयोग के संदर्भ में एक OLAP प्रणाली से अलग है। इसका उपयोग भविष्य के परिणामों पर ध्यान केंद्रित करने के लिए किया जाता है। OALP प्रणाली विश्लेषणात्मक रिपोर्टिंग के लिए वर्तमान और ऐतिहासिक डेटा प्रसंस्करण पर केंद्रित है।
बाजार में विभिन्न डेटा वेयरहाउस / डेटाबेस सिस्टम उपलब्ध हैं जो एक DW सिस्टम की क्षमताओं को पूरा करते हैं। डेटा वेयरहाउस सिस्टम के लिए सबसे आम विक्रेता हैं -
- Microsoft SQL सर्वर
- ओरेकल एक्सडाटा
- IBM Netezza
- Teradata
- साइबेस आईक्यू
- एसएपी बिजनेस वेयरहाउस (एसएपी BW)
एसएपी बिजनेस वेयरहाउस
SAP Business WarehouseSAP NetWeaver रिलीज़ प्लेटफ़ॉर्म का एक हिस्सा है। NetWeaver 7.4 से पहले, इसे SAP NetWeaver Business Warehouse के रूप में संदर्भित किया गया था।
SAP BW में डेटा वेयरहाउसिंग का मतलब है डेटा इंटीग्रेशन, ट्रांसफॉर्मेशन, डेटा क्लींजिंग, स्टोरिंग और डेटा स्टेजिंग। DW प्रक्रिया में BW सिस्टम, स्टेजिंग और प्रशासन में डेटा मॉडलिंग शामिल है। मुख्य उपकरण, जिसका उपयोग BW सिस्टम में DW कार्यों के प्रबंधन के लिए किया जाता है, प्रशासन कार्यक्षेत्र है।
प्रमुख विशेषताऐं
एसएपी बीडब्ल्यू बिजनेस इंटेलिजेंस जैसी क्षमताएं प्रदान करता है, जिसमें एनालिटिकल सर्विसेज और बिजनेस प्लानिंग, एनालिटिकल रिपोर्टिंग, क्वेरी प्रोसेसिंग और सूचना और एंटरप्राइज डेटा वेयरहाउसिंग शामिल हैं।
यह डेटाबेस और डेटाबेस प्रबंधन उपकरणों का एक संयोजन प्रदान करता है जो निर्णय लेने में मदद करता है।
BW सिस्टम की अन्य प्रमुख विशेषताओं में व्यावसायिक अनुप्रयोग प्रोग्रामिंग इंटरफ़ेस (BAPI) शामिल है जो गैर-SAP R / 3 अनुप्रयोगों, स्वचालित डेटा निष्कर्षण और लोडिंग, एक एकीकृत OLAP प्रोसेसर, मेटाडाटा रिपॉजिटरी, प्रशासन उपकरण, बहु-भाषा समर्थन और वेब सक्षम इंटरफ़ेस।
SAP BW को पहली बार 1998 में SAP, एक जर्मन कंपनी द्वारा पेश किया गया था। SAP R3 डेटा के लिए एंटरप्राइज़ डेटा वेयरहाउस को आसान, सरल और अधिक कुशल बनाने के लिए SAP BW सिस्टम एक मॉडल-चालित दृष्टिकोण पर आधारित था।
पिछले 16 वर्षों से, SAP BW कई कंपनियों के लिए अपने उद्यम डेटा भंडारण आवश्यकताओं का प्रबंधन करने के लिए एक महत्वपूर्ण प्रणाली के रूप में विकसित हुई है।
व्यापार एक्सप्लोरर (BEx) कंपनी में लचीली रिपोर्टिंग, रणनीतिक विश्लेषण और ऑपरेटिव रिपोर्टिंग के लिए एक विकल्प प्रदान करता है।
इसका उपयोग BI सिस्टम में रिपोर्टिंग, क्वेरी निष्पादन और विश्लेषण कार्य करने के लिए किया जाता है। आप वेब पर और एक्सेल प्रारूप में विभिन्न डिग्री तक वर्तमान और ऐतिहासिक डेटा को संसाधित कर सकते हैं।
का उपयोग करते हुए BEx सूचना प्रसारण, बीआई सामग्री को दस्तावेज़ के रूप में या लाइव डेटा के रूप में लिंक के माध्यम से साझा किया जा सकता है या आप एसएपी ईपी कार्यों का उपयोग करके भी प्रकाशित कर सकते हैं।
व्यापार वस्तुओं और उत्पादों
SAP बिजनेस ऑब्जेक्ट्स को सबसे आम बिजनेस इंटेलिजेंस टूल के रूप में जाना जाता है और इसका उपयोग विभिन्न प्लेटफार्मों पर डेटा, उपयोगकर्ता पहुंच, विश्लेषण, प्रारूपण और प्रकाशन में हेरफेर करने के लिए किया जाता है। यह उपकरणों का एक फ्रंट-एंड आधारित सेट है, जो व्यापार उपयोगकर्ताओं और निर्णय निर्माताओं को व्यापार खुफिया वर्तमान और ऐतिहासिक डेटा को प्रदर्शित करने, सॉर्ट करने और विश्लेषण करने में सक्षम बनाता है।
इसमें निम्नलिखित उपकरण शामिल हैं -
वेब इंटेलिजेंस
वेब इंटेलिजेंस (WebI) को सबसे आम बिजनेस ऑब्जेक्ट विस्तृत रिपोर्टिंग टूल कहा जाता है जो डेटा विश्लेषण की विभिन्न विशेषताओं जैसे ड्रिल, पदानुक्रम, चार्ट, परिकलित उपायों आदि का समर्थन करता है। यह एंड-यूजर्स को क्वेरी पैनल में एड-हॉक क्वेरी बनाने की अनुमति देता है और ऑनलाइन और ऑफलाइन दोनों में डेटा विश्लेषण करने के लिए।
SAP व्यापार वस्तुओं Xc सेल्सियस / डैशबोर्ड
डैशबोर्ड अंतिम उपयोगकर्ताओं को डेटा विज़ुअलाइज़ेशन और डैश-बोर्डिंग क्षमताएं प्रदान करता है और आप इस टूल का उपयोग करके इंटरैक्टिव डैशबोर्ड बना सकते हैं।
आप विभिन्न प्रकार के चार्ट और ग्राफ़ भी जोड़ सकते हैं और डेटा विज़ुअलाइज़ेशन के लिए डायनामिक डैशबोर्ड बना सकते हैं और ये ज्यादातर किसी संगठन में वित्तीय बैठकों में उपयोग किए जाते हैं।
क्रिस्टल रिपोर्ट
क्रिस्टल रिपोर्ट का उपयोग पिक्सेल-परफेक्ट रिपोर्टिंग के लिए किया जाता है। यह उपयोगकर्ताओं को रिपोर्ट बनाने और डिजाइन करने में सक्षम बनाता है और बाद में इसका उपयोग मुद्रण उद्देश्य के लिए करता है।
एक्सप्लोरर
एक्सप्लोरर बीआई रिपॉजिटरी में सामग्री को खोजने के लिए एक उपयोगकर्ता को अनुमति देता है और चार्ट के रूप में सबसे अच्छे मिलान दिखाए जाते हैं। खोज करने के लिए प्रश्नों को लिखने की आवश्यकता नहीं है।
विस्तृत रिपोर्टिंग, डेटा विज़ुअलाइज़ेशन और डैश-बोर्डिंग उद्देश्य के लिए पेश किए गए विभिन्न अन्य घटक और उपकरण डिज़ाइन स्टूडियो, माइक्रोसॉफ्ट ऑफिस, बीआई रिपोजिटरी और बिजनेस ऑब्जेक्ट्स मोबाइल प्लेटफॉर्म के लिए विश्लेषण संस्करण हैं।
ETL का मतलब एक्सट्रैक्ट, ट्रांसफॉर्म और लोड है। एक ईटीएल उपकरण विभिन्न आरडीबीएमएस स्रोत प्रणालियों से डेटा को निकालता है, डेटा को गणना, समवर्ती, आदि को लागू करने और फिर डेटा को डेटा वेयरहाउस सिस्टम में लोड करता है। डेटा को डीडब्ल्यू प्रणाली में आयाम और तथ्य तालिकाओं के रूप में लोड किया जाता है।
निष्कर्षण
ETL लोड के दौरान एक स्टेजिंग क्षेत्र की आवश्यकता होती है। स्टेजिंग क्षेत्र की आवश्यकता के विभिन्न कारण हैं।
स्रोत प्रणालियां केवल डेटा निकालने के लिए विशिष्ट अवधि के लिए उपलब्ध हैं। समय की यह अवधि कुल डेटा-लोड समय से कम है। इसलिए, स्टेजिंग क्षेत्र आपको स्रोत सिस्टम से डेटा निकालने की अनुमति देता है और समय स्लॉट समाप्त होने से पहले इसे स्टेजिंग क्षेत्र में रखता है।
स्टेजिंग क्षेत्र की आवश्यकता तब होती है जब आप एक साथ कई डेटा स्रोतों से डेटा प्राप्त करना चाहते हैं या यदि आप एक साथ दो या अधिक सिस्टम से जुड़ना चाहते हैं। उदाहरण के लिए, आप दो अलग-अलग डेटाबेस से दो तालिकाओं में शामिल होने वाली SQL क्वेरी करने में सक्षम नहीं होंगे।
अलग-अलग सिस्टम के लिए डेटा एक्सट्रैक्ट्स का टाइम स्लॉट टाइम ज़ोन और ऑपरेशनल घंटों के अनुसार अलग-अलग होता है।
स्रोत सिस्टम से निकाले गए डेटा का उपयोग कई डेटा वेयरहाउस सिस्टम, ऑपरेशन डेटा स्टोर आदि में किया जा सकता है।
ईटीएल आपको जटिल परिवर्तन करने की अनुमति देता है और डेटा को स्टोर करने के लिए अतिरिक्त क्षेत्र की आवश्यकता होती है।

परिवर्तन
डेटा परिवर्तन में, आप निकाले गए डेटा पर लक्ष्य प्रणाली में इसे लोड करने के लिए फ़ंक्शन का एक सेट लागू करते हैं। डेटा, जिसे किसी भी परिवर्तन की आवश्यकता नहीं होती है उसे प्रत्यक्ष चाल या डेटा के माध्यम से जाना जाता है।
आप स्रोत प्रणाली से निकाले गए डेटा पर विभिन्न परिवर्तनों को लागू कर सकते हैं। उदाहरण के लिए, आप अनुकूलित गणना कर सकते हैं। यदि आप सम-बिक्री राजस्व चाहते हैं और यह डेटाबेस में नहीं है, तो आप आवेदन कर सकते हैंSUM परिवर्तन के दौरान सूत्र और डेटा लोड।
उदाहरण के लिए, यदि आपके पास अलग-अलग स्तंभों में तालिका में पहला नाम और अंतिम नाम है, तो आप लोड करने से पहले कॉनेटेट का उपयोग कर सकते हैं।
भार
लोड चरण के दौरान, डेटा को अंतिम-लक्ष्य प्रणाली में लोड किया जाता है और यह एक फ्लैट फ़ाइल या डेटा वेयरहाउस सिस्टम हो सकता है।
एसएपी बीओ डेटा सेवाएँ एक ईटीएल उपकरण है जिसका उपयोग डेटा एकीकरण, डेटा गुणवत्ता, डेटा रूपरेखा और डेटा प्रसंस्करण के लिए किया जाता है। यह आपको विश्लेषणात्मक रिपोर्टिंग के लिए विश्वसनीय डेटा-टू-डेटा वेयरहाउस सिस्टम को एकीकृत करने, बदलने की अनुमति देता है।
बीओ डेटा सेवाओं में यूआई विकास इंटरफ़ेस, मेटाडेटा रिपॉजिटरी, स्रोत के लिए डेटा कनेक्टिविटी और नौकरियों के निर्धारण के लिए लक्ष्य प्रणाली और प्रबंधन कंसोल शामिल हैं।
डेटा एकीकरण और डेटा प्रबंधन
SAP BO डेटा सेवाएँ एक डेटा एकीकरण और प्रबंधन उपकरण है और इसमें डेटा इंटीग्रेटर जॉब सर्वर और डेटा इंटीग्रेटर डिज़ाइनर शामिल हैं।
प्रमुख विशेषताऐं
आप जटिल डेटा परिवर्तन और अनुकूलित कार्यों के निर्माण के लिए डेटा इंटीग्रेटर भाषा का उपयोग करके विभिन्न डेटा परिवर्तनों को लागू कर सकते हैं।
डेटा इंटीग्रेटर डिज़ाइनर का उपयोग वास्तविक समय और बैच की नौकरियों और भंडार में नई परियोजनाओं को संग्रहीत करने के लिए किया जाता है।
डीआई डिज़ाइनर सभी बेसिक्स कार्यक्षमता के साथ केंद्रीय भंडार प्रदान करके टीम आधारित ईटीएल विकास के लिए एक विकल्प प्रदान करता है।
डेटा इंटीग्रेटर जॉब सर्वर DI डिज़ाइनर का उपयोग करके बनाई गई नौकरियों को संसाधित करने के लिए जिम्मेदार है।
वेब प्रशासक
डेटा इंटीग्रेटर वेब एडमिनिस्ट्रेटर का उपयोग सिस्टम एडमिनिस्ट्रेटर और डेटाबेस एडमिनिस्ट्रेटर द्वारा डेटा सेवाओं में रिपॉजिटरी बनाए रखने के लिए किया जाता है। डेटा सेवाओं में मेटाडाटा रिपॉजिटरी, टीम-आधारित विकास के लिए केंद्रीय भंडार, जॉब सर्वर और वेब सेवाएँ शामिल हैं।
DI वेब प्रशासक के प्रमुख कार्य
- इसका उपयोग बैच जॉब को शेड्यूल करने, मॉनिटर करने और निष्पादित करने के लिए किया जाता है।
- इसका उपयोग कॉन्फ़िगरेशन के लिए किया जाता है और रीयल-टाइम सर्वर को शुरू और बंद करता है।
- इसका उपयोग जॉब सर्वर, एक्सेस सर्वर और रिपॉजिटरी उपयोग को कॉन्फ़िगर करने के लिए किया जाता है।
- इसका उपयोग एडेप्टर को कॉन्फ़िगर करने के लिए किया जाता है।
- इसका उपयोग BO डेटा सेवाओं में सभी उपकरणों को कॉन्फ़िगर करने और नियंत्रित करने के लिए किया जाता है।
डेटा प्रबंधन फ़ंक्शन डेटा गुणवत्ता पर जोर देता है। इसमें डीडब्ल्यू सिस्टम में सही डेटा प्राप्त करने के लिए डेटा की सफाई, वृद्धि और समेकन शामिल है।
इस अध्याय में, हम SAP BODS वास्तुकला के बारे में जानेंगे। चित्रण स्टेजिंग क्षेत्र के साथ बीओडीएस प्रणाली की वास्तुकला को दर्शाता है।
स्रोत परत
स्रोत परत में एसएपी अनुप्रयोगों और गैर-एसएपी आरडीबीएमएस प्रणाली जैसे विभिन्न डेटा स्रोत शामिल हैं और मंचन क्षेत्र में डेटा एकीकरण होता है।
SAP Business Objects डेटा सेवाओं में डेटा सर्विस डिज़ाइनर, डेटा सर्विसेज मैनेजमेंट कंसोल, रिपॉजिटरी मैनेजर, डेटा सर्विसेज सर्वर मैनेजर, वर्क बेंच इत्यादि जैसे विभिन्न घटक शामिल हैं। लक्ष्य प्रणाली DWP जैसे SAP HANA, SAP BW या एक गैर-SAP प्रणाली हो सकती है। डेटा वेयरहाउस सिस्टम।

निम्न स्क्रीनशॉट SAP BODS के विभिन्न घटकों को दर्शाता है।

आप निम्न परतों में BODS वास्तुकला को भी विभाजित कर सकते हैं -
- वेब अनुप्रयोग परत
- डेटाबेस सर्वर परत
- डेटा सेवा सेवा परत
निम्नलिखित दृष्टांत BODS वास्तुकला को दर्शाता है।

उत्पाद विकास - ATL, DI और DQ
एक्टा टेक्नोलॉजी इंक ने एसएपी बिजनेस ऑब्जेक्ट्स डेटा सर्विसेज विकसित की और बाद में बिजनेस ऑब्जेक्ट्स कंपनी ने इसे हासिल कर लिया। एक्टा टेक्नोलॉजी इंक एक यूएस बेस्ड कंपनी है और पहले डेटा इंटीग्रेशन प्लेटफॉर्म के विकास के लिए जिम्मेदार थी। एक्टा इंक द्वारा विकसित दो ईटीएल सॉफ्टवेयर उत्पाद थेData Integration (DI) उपकरण और Data Management या Data Quality (DQ) उपकरण।
व्यापार वस्तुओं, एक फ्रांसीसी कंपनी ने 2002 में Acta Technology Inc. का अधिग्रहण किया और बाद में, दोनों उत्पादों का नाम बदल दिया गया Business Objects Data Integration (BODI) उपकरण और Business Objects Data Quality (BODQ) उपकरण।
SAP ने 2007 में व्यावसायिक वस्तुओं का अधिग्रहण किया और दोनों उत्पादों का नाम SAP BODI और SAP BODQ रखा गया। 2008 में, SAP ने दोनों उत्पादों को SAP बिज़नेस ऑब्जेक्ट डेटा सर्विसेज (BODS) के रूप में नामित एकल सॉफ़्टवेयर उत्पाद में एकीकृत किया।
SAP BODS डेटा एकीकरण और डेटा प्रबंधन समाधान प्रदान करता है और BODS के पुराने संस्करण में, पाठ डेटा-प्रोसेसिंग समाधान शामिल किया गया था।
BODS - ऑब्जेक्ट
बो डेटा सर्विसेज डिज़ाइनर में उपयोग होने वाली सभी संस्थाओं को कहा जाता है Objects। सभी ऑब्जेक्ट जैसे प्रोजेक्ट, जॉब, मेटाडेटा और सिस्टम फ़ंक्शन स्थानीय ऑब्जेक्ट लाइब्रेरी में संग्रहीत किए जाते हैं। सभी वस्तुएँ प्रकृति में पदानुक्रमित हैं।
वस्तुओं में मुख्य रूप से निम्नलिखित हैं -
Properties- उनका उपयोग किसी वस्तु का वर्णन करने के लिए किया जाता है और इसके संचालन को प्रभावित नहीं करता है। उदाहरण - किसी वस्तु का नाम, इसे बनाते समय दिनांक आदि।
Options - जो वस्तुओं के संचालन को नियंत्रित करते हैं।
वस्तुओं के प्रकार
सिस्टम में दो तरह की वस्तुएं हैं- पुन: उपयोग योग्य वस्तुएं और एकल उपयोग की वस्तुएं। ऑब्जेक्ट का प्रकार यह निर्धारित करता है कि उस ऑब्जेक्ट का उपयोग और पुनर्प्राप्ति कैसे की जाती है।
पुन: प्रयोज्य वस्तुएँ
भंडार में संग्रहीत अधिकांश वस्तुओं का पुन: उपयोग किया जा सकता है। जब एक पुन: प्रयोज्य वस्तु को स्थानीय रिपॉजिटरी में परिभाषित और सहेजा जाता है, तो आप कॉल्स को परिभाषा में बनाकर ऑब्जेक्ट का पुन: उपयोग कर सकते हैं। प्रत्येक पुन: प्रयोज्य ऑब्जेक्ट की केवल एक परिभाषा होती है और उस ऑब्जेक्ट के सभी कॉल उस परिभाषा को संदर्भित करते हैं। अब, यदि किसी ऑब्जेक्ट की परिभाषा एक जगह पर बदल दी जाती है, तो आप ऑब्जेक्ट की परिभाषा को उन सभी स्थानों पर बदल रहे हैं, जहां वह ऑब्जेक्ट दिखाई देता है।
ऑब्जेक्ट लायब्रेरी का उपयोग ऑब्जेक्ट डेफिनेशन को सम्मिलित करने के लिए किया जाता है और जब किसी ऑब्जेक्ट को लाइब्रेरी से ड्रैग और ड्रॉप किया जाता है, तो मौजूदा ऑब्जेक्ट का एक नया संदर्भ बनाया जाता है।
एकल उपयोग की वस्तुएं
वे सभी वस्तुएँ जिन्हें विशेष रूप से किसी कार्य या डेटा प्रवाह में परिभाषित किया जाता है, उन्हें एकल उपयोग ऑब्जेक्ट के रूप में जाना जाता है। उदाहरण के लिए, किसी भी डेटा लोड में उपयोग किए जाने वाले विशिष्ट परिवर्तन।
बीओडीएस - वस्तु पदानुक्रम
सभी वस्तुएँ प्रकृति में पदानुक्रमित हैं। निम्न आरेख SAP BODS सिस्टम में ऑब्जेक्ट पदानुक्रम दिखाता है -

BODS - उपकरण और कार्य
नीचे दिए गए आर्किटेक्चर के आधार पर, हमारे पास एसएपी बिजनेस ऑब्जेक्ट्स डेटा सर्विसेज में परिभाषित कई उपकरण हैं। सिस्टम के परिदृश्य के अनुसार प्रत्येक उपकरण का अपना कार्य होता है।

शीर्ष पर, आपके पास उपयोगकर्ताओं और अधिकारों के सुरक्षा प्रबंधन के लिए सूचना प्लेटफ़ॉर्म सेवाएँ स्थापित हैं। बीओडीएस केंद्रीय प्रबंधन कंसोल पर निर्भर करता है (CMC) उपयोगकर्ता पहुँच और सुरक्षा सुविधा के लिए। यह 4.x संस्करण पर लागू होता है। पिछले संस्करण में, यह प्रबंधन कंसोल में किया गया था।
डेटा सर्विसेज डिज़ाइनर एक डेवलपर टूल है, जिसका उपयोग डेटा मैपिंग, ट्रांसफ़ॉर्मेशन और लॉजिक से संबंधित ऑब्जेक्ट बनाने के लिए किया जाता है। यह GUI आधारित है और डेटा सेवाओं के लिए एक डिजाइनर के रूप में काम करता है।
कोष
बीओ डेटा सेवाओं में उपयोग की जाने वाली वस्तुओं के मेटाडेटा को संग्रहीत करने के लिए रिपॉजिटरी का उपयोग किया जाता है। प्रत्येक रिपॉजिटरी को सेंट्रल मैनेजमेंट कंसोल में पंजीकृत किया जाना चाहिए और इसे एकल या कई जॉब सर्वर के साथ जोड़ा जाना चाहिए, जो आपके द्वारा बनाई गई नौकरियों को निष्पादित करने के लिए जिम्मेदार हैं।
रिपोजिटरी के प्रकार
तीन प्रकार के रिपॉजिटरी हैं।
Local Repository - इसका इस्तेमाल Data Services Designer में बनाई गई सभी वस्तुओं के मेटाडेटा को स्टोर करने के लिए किया जाता है, जैसे प्रोजेक्ट, जॉब, डेटा फ्लो, वर्क फ्लो आदि।
Central Repository- इसका उपयोग वस्तुओं के संस्करण प्रबंधन को नियंत्रित करने के लिए किया जाता है और इसका उपयोग बहुपयोगी विकास के लिए किया जाता है। सेंट्रल रिपॉजिटरी एक एप्लिकेशन ऑब्जेक्ट के सभी संस्करणों को संग्रहीत करता है। इसलिए, यह आपको पिछले संस्करणों में जाने की अनुमति देता है।
Profiler Repository- इसका उपयोग SAP BODS डिज़ाइनर में किए गए प्रोफाइलर कार्यों से संबंधित सभी मेटाडेटा को प्रबंधित करने के लिए किया जाता है। CMS रिपोजिटरी BI मंच पर CMC में किए गए सभी कार्यों के मेटाडेटा को संग्रहीत करता है। सूचना स्टीवर्ड रिपॉजिटरी प्रोफाइलिंग के सभी मेटाडेटा और सूचना संग्रह में बनाई गई वस्तुओं को संग्रहीत करती है।
नौकरी का सर्वर
नौकरी सर्वर का उपयोग आपके द्वारा बनाए गए वास्तविक समय और बैच की नौकरियों को निष्पादित करने के लिए किया जाता है। यह संबंधित रिपॉजिटरी से नौकरी की जानकारी प्राप्त करता है और नौकरी को निष्पादित करने के लिए डेटा इंजन शुरू करता है। नौकरी सर्वर वास्तविक समय या अनुसूचित नौकरियों को निष्पादित कर सकता है और मेमोरी कैशिंग में मल्टीथ्रेडिंग, और प्रदर्शन अनुकूलन प्रदान करने के लिए समानांतर प्रसंस्करण का उपयोग करता है।
सर्वर का उपयोग
डेटा सेवाओं में एक्सेस सर्वर को वास्तविक समय संदेश दलाल प्रणाली के रूप में जाना जाता है, जो संदेश अनुरोधों को लेता है, वास्तविक समय सेवा में जाता है और विशिष्ट सेवा फ्रेम में एक संदेश प्रदर्शित करता है।
डेटा सेवा प्रबंधन कंसोल
डेटा सेवा प्रबंधन कंसोल का उपयोग प्रशासन गतिविधियों को करने के लिए किया जाता है जैसे नौकरियों का समय निर्धारण, डीएस प्रणाली में गुणवत्ता रिपोर्ट तैयार करना, डेटा सत्यापन, प्रलेखन आदि।
बीओडीएस - नामकरण मानक
सभी प्रणालियों में सभी वस्तुओं के लिए मानक नामकरण सम्मेलनों का उपयोग करना उचित है क्योंकि इससे आप आसानी से रिपॉजिटरी में वस्तुओं की पहचान कर सकते हैं।
तालिका अनुशंसित नामकरण सम्मेलनों की सूची दिखाती है, जिनका उपयोग सभी नौकरियों और अन्य वस्तुओं के लिए किया जाना चाहिए।
| उपसर्ग | प्रत्यय | वस्तु |
|---|---|---|
| DF_ | n / a | डाटा प्रवाह |
| EDF_ | _Input | एंबेडेड डेटा प्रवाह |
| EDF_ | _Output | एंबेडेड डेटा प्रवाह |
| RTJob_ | n / a | वास्तविक समय की नौकरी |
| WF_ | n / a | काम का प्रवाह |
| काम_ | n / a | काम |
| n / a | _DS | डेटा भंडार |
| DC_ | n / a | डेटा कॉन्फ़िगरेशन |
| SC_ | n / a | प्रणाली विन्यास |
| n / a | _Memory_DS | मेमोरी डेटस्टोर |
| PROC_ | n / a | संग्रहीत प्रक्रिया |
बीओ डेटा सेवा की मूल बातें परियोजना, नौकरी, कार्य प्रवाह, डेटा प्रवाह, रिपोजिटरी जैसे कार्य प्रवाह को डिजाइन करने में महत्वपूर्ण वस्तुएं शामिल हैं।
BODS - रिपॉजिटरी और प्रकार
बीओ डेटा सेवाओं में प्रयुक्त वस्तुओं के मेटाडेटा को संग्रहीत करने के लिए रिपॉजिटरी का उपयोग किया जाता है। प्रत्येक रिपॉजिटरी को केंद्रीय प्रबंधन कंसोल, सीएमसी में पंजीकृत किया जाना चाहिए, और एकल या कई नौकरी सर्वरों के साथ जुड़ा हुआ है, जो आपके द्वारा बनाई गई नौकरियों को निष्पादित करने के लिए जिम्मेदार हैं।
रिपोजिटरी के प्रकार
तीन प्रकार के रिपॉजिटरी हैं।
Local Repository - इसका इस्तेमाल Data Services Designer में बनाई गई सभी वस्तुओं के मेटाडेटा को स्टोर करने के लिए किया जाता है, जैसे प्रोजेक्ट, जॉब, डेटा फ्लो, वर्क फ्लो आदि।
Central Repository- इसका उपयोग वस्तुओं के संस्करण प्रबंधन को नियंत्रित करने के लिए किया जाता है और इसका उपयोग बहुपयोगी विकास के लिए किया जाता है। सेंट्रल रिपॉजिटरी एक एप्लिकेशन ऑब्जेक्ट के सभी संस्करणों को संग्रहीत करता है। इसलिए, यह आपको पिछले संस्करणों में जाने की अनुमति देता है।
Profiler Repository- इसका उपयोग SAP BODS डिज़ाइनर में किए गए प्रोफाइलर कार्यों से संबंधित सभी मेटाडेटा को प्रबंधित करने के लिए किया जाता है। CMS रिपोजिटरी BI मंच पर CMC में किए गए सभी कार्यों के मेटाडेटा को संग्रहीत करता है। सूचना स्टीवर्ड रिपॉजिटरी प्रोफाइलिंग के सभी मेटाडेटा और सूचना संग्रह में बनाई गई वस्तुओं को संग्रहीत करती है।
BODS रिपोजिटरी बनाने के लिए, आपको एक डेटाबेस स्थापित करना होगा। आप SQL सर्वर, Oracle डेटाबेस, My SQL, SAP HANA, Sybase आदि का उपयोग कर सकते हैं।
रिपोजिटरी बनाना
आपको बीओडीएस स्थापित करते समय और रिपॉजिटरी बनाने के लिए डेटाबेस में निम्नलिखित उपयोगकर्ता बनाने होंगे। इन उपयोगकर्ताओं को विभिन्न सर्वरों जैसे सीएमएस सर्वर, ऑडिट सर्वर आदि में लॉगिन करना आवश्यक है।
Bodsserver1 द्वारा पहचाने गए उपयोगकर्ता BODS बनाएँ
- BODS से कनेक्ट करें;
- BODS को सत्र बनाएँ;
- BODS को DBA प्रदान करें;
- BODS के लिए कोई तालिका बनाएं;
- BODS को कोई भी दृश्य प्रदान करें;
- बीओडीएस को किसी भी तालिका को छोड़ दें;
- बीओडीएस को कोई भी दृश्य प्रदान करना;
- BODS में कोई तालिका डालें;
- BODS को किसी भी तालिका को अपडेट करें;
- BODS को कोई तालिका हटाएं;
- Alter USER BODS QUOTA UNLIMITED ऑन USERS;
CMSserver1 द्वारा पहचाने गए उपयोगकर्ता CMS बनाएँ
- CMS से कनेक्ट करें;
- CMS को सत्र बनाएँ;
- सीएमएस को अनुदान डीबीए;
- CMS के लिए कोई तालिका बनाएँ;
- CMS को कोई भी दृश्य प्रदान करें;
- सीएमएस को कोई भी तालिका दें;
- CMS को कोई भी दृश्य दें;
- CMS के लिए कोई भी तालिका सम्मिलित करें;
- सीएमएस को किसी भी तालिका को अपडेट करें;
- सीएमएस को किसी भी तालिका को हटाएं;
- ऑल्टर USER CMS QUOTA UNLIMITED ऑन USERS;
CMSAUDITserver1 द्वारा पहचाने गए उपयोगकर्ता CMSAUDIT बनाएँ
- CMSAUDIT से कनेक्ट करें;
- CMSAUDIT को सत्र बनाएँ;
- CMSAUDIT को डीबीए प्रदान करें;
- CMSAUDIT को कोई तालिका बनाएँ;
- CMSAUDIT को कोई भी दृश्य प्रदान करें;
- CMSAUDIT को कोई तालिका दें;
- CMSAUDIT को कोई भी दृश्य प्रदान करें;
- CMSAUDIT में कोई भी तालिका सम्मिलित करें;
- CMSAUDIT को किसी भी तालिका को अपडेट करें;
- CMSAUDIT को कोई तालिका हटाएं;
- ऑल्टर USER CMSAUDIT QUOTA UNLIMITED ऑन USERS;
स्थापना के बाद एक नया रिपोजिटरी बनाने के लिए
Step 1 - एक डेटाबेस बनाएँ Local_Repoऔर डाटा सर्विसेज रिपोजिटरी मैनेजर के पास जाएं। डेटाबेस को स्थानीय रिपॉजिटरी के रूप में कॉन्फ़िगर करें।

एक नयी विंडो खुलेगी।
Step 2 - निम्नलिखित क्षेत्रों में विवरण दर्ज करें -
रिपॉजिटरी प्रकार, डेटाबेस प्रकार, डेटाबेस सर्वर नाम, पोर्ट, उपयोगकर्ता नाम और पासवर्ड।

Step 3 - क्लिक करें Createबटन। आपको निम्न संदेश मिलेगा -

Step 4 - अब सेंट्रल मैनेजमेंट कंसोल सीएमसी में लॉगइन करें SAP BI Platform उपयोगकर्ता नाम और पासवर्ड के साथ।
Step 5 - CMC होम पेज पर, क्लिक करें Data Services।

Step 6 - से Data Services मेनू, क्लिक करें Configure a new Data Services भंडार।

Step 7 - नई विंडो में दिए गए विवरण दर्ज करें।
- रिपॉजिटरी का नाम: Local_Repo
- डेटा बेस प्रकार: एसएपी हाना
- डेटा बेस सर्वर का नाम: सबसे अच्छा
- डेटाबेस का नाम: LOCAL_REPO
- उपयोगकर्ता नाम:
- Password:*****

Step 8 - बटन पर क्लिक करें Test Connection और अगर यह सफल है, तो क्लिक करें Save। एक बार सेव करने के बाद, यह CMC में रिपोजिटरी टैब के अंतर्गत आएगा।
Step 9 - में स्थानीय भंडार पर पहुँच अधिकार और सुरक्षा लागू करें CMC → User and Groups।
Step 10 - एक बार एक्सेस दिए जाने के बाद, डेटा सर्विसेज डिज़ाइनर → रिपॉजिटरी का चयन करें → लॉगिन करने के लिए उपयोगकर्ता नाम और पासवर्ड दर्ज करें।

रिपॉजिटरी को अपडेट करना
एक रिपॉजिटरी को अपडेट करने के लिए, दिए गए चरणों का पालन करें।
Step 1 - स्थापना के बाद एक रिपॉजिटरी को अपडेट करने के लिए, एक डेटाबेस बनाएं Local_Repo और डाटा सर्विसेज रिपोजिटरी मैनेजर के पास जाएं।
Step 2 - स्थानीय भंडार के रूप में डेटाबेस को कॉन्फ़िगर करें।

एक नयी विंडो खुलेगी।
Step 3 - निम्नलिखित क्षेत्रों के लिए विवरण दर्ज करें।
रिपॉजिटरी प्रकार, डेटाबेस प्रकार, डेटाबेस सर्वर नाम, पोर्ट, उपयोगकर्ता नाम और पासवर्ड।

आपको आउटपुट दिखाई देगा जैसा कि नीचे दिखाए गए स्क्रीनशॉट में दिखाया गया है।

डेटा सर्विस मैनेजमेंट कंसोल (डीएसएमसी) का उपयोग प्रशासन गतिविधियों को करने के लिए किया जाता है जैसे नौकरियों का समय निर्धारण, डीएस प्रणाली में गुणवत्ता रिपोर्ट तैयार करना, डेटा सत्यापन, प्रलेखन आदि।
आप निम्नलिखित तरीकों से डेटा सेवा प्रबंधन कंसोल तक पहुँच सकते हैं -
आप डेटा सेवा प्रबंधन कंसोल पर जा सकते हैं Start → All Programs → Data Services → Data Service Management Console।
आप डेटा सेवा प्रबंधन कंसोल को भी एक्सेस कर सकते हैं Designer यदि आप पहले से लॉग इन हैं।
के माध्यम से डेटा सेवा प्रबंधन कंसोल तक पहुँचने के लिए Designer Home Page नीचे दिए गए चरणों का पालन करें।

उपकरण के माध्यम से डेटा सेवा प्रबंधन कंसोल तक पहुँचने के लिए दिए गए चरणों का पालन करें -
Step 1 - पर जाएं Tools → Data Services Management Console जैसा कि निम्नलिखित छवि में दिखाया गया है।

Step 2 - एक बार जब आप लॉगइन करें Data Services Management Console, होम स्क्रीन खुल जाएगी जैसा कि नीचे दिए गए स्क्रीनशॉट में दिखाया गया है। शीर्ष पर, आप उपयोगकर्ता नाम देख सकते हैं जिसके माध्यम से आप लॉग इन हैं।
मुख पृष्ठ पर, आपको निम्नलिखित विकल्प दिखाई देंगे -
- Administrator
- ऑटो प्रलेखन
- डेटा मान्य
- प्रभाव और वंश विश्लेषण
- ऑपरेशनल डैशबोर्ड
- डेटा गुणवत्ता रिपोर्ट

डेटा सेवा प्रबंधन कंसोल के प्रत्येक मॉड्यूल के प्रमुख कार्यों को इस अध्याय में समझाया गया है।
प्रशासक मॉड्यूल
प्रबंधन करने के लिए एक प्रशासक विकल्प का उपयोग किया जाता है -
- उपयोगकर्ता और भूमिकाएँ
- सर्वर और रिपॉजिटरी तक पहुंचने के लिए कनेक्शन जोड़ना
- वेब सेवाओं के लिए प्रकाशित नौकरी डेटा तक पहुँचने के लिए
- शेड्यूल और बैच नौकरियों की निगरानी के लिए
- एक्सेस सर्वर की स्थिति और वास्तविक समय सेवाओं की जांच करने के लिए।
एक बार जब आप क्लिक करें Administratorटैब, आप बाएँ फलक में कई लिंक देख सकते हैं। वे हैं - स्टेटस, बैच, वेब सर्विसेज, एसएपी कनेक्शंस, सर्वर ग्रुप्स, प्रॉसेसर रिपॉजिटरी मैनेजमेंट एंड जॉब एक्जक्यूटिव हिस्ट्री।

नोड्स
विभिन्न मॉड्यूल प्रशासक मॉड्यूल के अधीन हैं नीचे चर्चा की गई है।
स्थिति
स्टेटस नोड का उपयोग बैच और रियल टाइम जॉब्स, एक्सेस सर्वर स्टेटस, एडॉप्टर और प्रोफाइलर रिपॉजिटरी और अन्य सिस्टम स्टेटस की स्थिति की जांच के लिए किया जाता है।
स्थिति पर क्लिक करें → एक रिपॉजिटरी का चयन करें
दाएँ फलक पर, आपको निम्न विकल्पों के टैब दिखाई देंगे -
Batch Job Status- इसका उपयोग बैच की नौकरी की स्थिति की जांच करने के लिए किया जाता है। आप नौकरी की जानकारी जैसे ट्रेस, मॉनिटर, एरर और परफॉर्मेंस मॉनिटर, स्टार्ट टाइम, एंड टाइम, ड्यूरेशन आदि की जांच कर सकते हैं।

Batch Job Configuration - बैच जॉब कॉन्फिगरेशन का इस्तेमाल अलग-अलग जॉब्स के शेड्यूल को चेक करने के लिए किया जाता है या आप एक्शन, ऐड शेड्यूल, एक्सपोर्ट एक्सक्यूट कमांड जैसी एक्शन जोड़ सकते हैं।
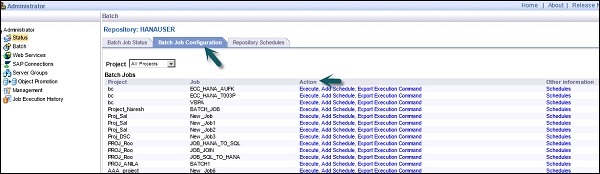
Repositories Schedules - इसका उपयोग रिपॉजिटरी में सभी नौकरियों के लिए शेड्यूल देखने और कॉन्फ़िगर करने के लिए किया जाता है।
बैच नोड
बैच जॉब नोड के तहत, आपको ऊपर के समान विकल्प दिखाई देंगे।
| अनु क्रमांक। | विकल्प और विवरण |
|---|---|
| 1 | Batch Job Status प्रत्येक कार्य के बारे में अंतिम निष्पादन और गहन जानकारी की स्थिति देखें। |
| 2 | Batch Job Configuration व्यक्तिगत नौकरियों के लिए निष्पादन और शेड्यूलिंग विकल्प कॉन्फ़िगर करें। |
| 3 | Repository Schedules रिपॉजिटरी में सभी नौकरियों के लिए शेड्यूल देखें और कॉन्फ़िगर करें। |
वेब सेवा नोड
वेब सेवा का उपयोग वास्तविक समय नौकरियों और बैच नौकरियों को वेब सेवा संचालन के रूप में प्रकाशित करने और इन कार्यों की स्थिति की जांच करने के लिए किया जाता है। इसका उपयोग वेब सेवा के रूप में प्रकाशित नौकरियों और देखने के लिए सुरक्षा बनाए रखने के लिए भी किया जाता हैWSDL फ़ाइल।

एसएपी कनेक्शन
SAP Connections का उपयोग स्टेटस की जांच करने या कॉन्फ़िगर करने के लिए किया जाता है RFC server interface डेटा सेवा प्रबंधन कंसोल में।
RFC सर्वर इंटरफ़ेस की स्थिति की जाँच करने के लिए, RFC सर्वर इंटरफ़ेस स्थिति टैब पर जाएँ। कॉन्फ़िगरेशन टैब पर एक नया RFC सर्वर इंटरफ़ेस जोड़ने के लिए, क्लिक करेंAdd।
जब एक नई विंडो खुलती है, तो RFC सर्वर कॉन्फ़िगरेशन विवरण दर्ज करें Apply।

सर्वर समूह
इसका उपयोग उन सभी जॉब सर्वरों को समूहीकृत करने के लिए किया जाता है जो एक रिपॉजिटरी के साथ एक सर्वर समूह में जुड़े होते हैं। इस टैब का उपयोग डेटा सेवाओं में नौकरियों को निष्पादित करते समय लोड संतुलन के लिए किया जाता है।
जब कोई कार्य निष्पादित होता है, तो वह संबंधित जॉब सर्वर के लिए जाँच करता है और यदि यह नीचे है तो यह जॉब को उसी समूह के अन्य जॉब सर्वर पर ले जाता है। यह ज्यादातर लोड संतुलन के लिए उत्पादन में उपयोग किया जाता है।

प्रोफाइल रिपोजिटरी
जब आप प्रोफ़ाइल रिपॉजिटरी को व्यवस्थापक से कनेक्ट करते हैं, तो यह आपको प्रोफ़ाइल रिपॉजिटरी नोड का विस्तार करने की अनुमति देता है। आप प्रोफाइल कार्य स्थिति पृष्ठ पर जा सकते हैं।
प्रबंधन नोड
व्यवस्थापक टैब की सुविधा का उपयोग करने के लिए, आपको प्रबंधन नोड का उपयोग करके डेटा सेवाओं से कनेक्शन जोड़ना होगा। प्रबंधन नोड में प्रशासन अनुप्रयोग के लिए विभिन्न विन्यास विकल्प होते हैं।

जॉब एक्जामिनेशन हिस्ट्री
इसका उपयोग नौकरी या डेटा प्रवाह के निष्पादन इतिहास की जांच करने के लिए किया जाता है। इस विकल्प का उपयोग करके, आप एक बैच नौकरी या आपके द्वारा बनाई गई सभी बैच नौकरियों के निष्पादन इतिहास की जांच कर सकते हैं।
जब आप एक नौकरी का चयन करते हैं, तो जानकारी तालिका के रूप में प्रदर्शित होती है, जिसमें रिपॉजिटरी नाम, नौकरी का नाम, प्रारंभ समय, अंत समय, निष्पादन समय, स्थिति आदि शामिल होते हैं।

डेटा सर्विस डिज़ाइनर एक डेवलपर टूल है, जिसका उपयोग डेटा मैपिंग, ट्रांसफ़ॉर्मेशन और लॉजिक से संबंधित ऑब्जेक्ट बनाने के लिए किया जाता है। यह GUI आधारित है और डेटा सेवाओं के लिए एक डिजाइनर के रूप में काम करता है।
आप Data Services Designer का उपयोग करके विभिन्न ऑब्जेक्ट्स बना सकते हैं जैसे प्रोजेक्ट्स, जॉब्स, वर्क फ्लो, डेटा फ़्लो, मैपिंग, ट्रांसफ़ॉर्मेशन आदि।
डेटा सेवा डिजाइनर को शुरू करने के लिए नीचे दिए गए चरणों का पालन करें।
Step 1 - पॉइंट टू स्टार्ट → सभी प्रोग्राम्स → SAP डेटा सर्विसेज 4.2 → डेटा सर्विसेज डिज़ाइनर।

Step 2 - रिपॉजिटरी का चयन करें और लॉगिन करने के लिए पासवर्ड दर्ज करें।

एक बार जब आप रिपॉजिटरी का चयन करते हैं और डेटा सेवा डिजाइनर के लिए लॉगिन करते हैं, तो एक होम स्क्रीन दिखाई देगी जैसा कि नीचे की छवि में दिखाया गया है।

बाएँ फलक में, आपके पास प्रोजेक्ट क्षेत्र है, जहाँ आप एक नया प्रोजेक्ट, नौकरी, डेटा प्रवाह, कार्य प्रवाह आदि बना सकते हैं। प्रोजेक्ट क्षेत्र में, आपके पास स्थानीय ऑब्जेक्ट लाइब्रेरी है, जिसमें डेटा सेवाओं में बनाई गई सभी ऑब्जेक्ट शामिल हैं।
नीचे के फलक में, आप प्रोजेक्ट, जॉब्स, डेटा फ़्लो, वर्क फ़्लो आदि जैसे विशिष्ट विकल्पों पर जाकर मौजूदा ऑब्जेक्ट्स को खोल सकते हैं। एक बार जब आप निचले फलक से किसी भी ऑब्जेक्ट का चयन करते हैं, तो यह आपको पहले से ही सभी समान ऑब्जेक्ट दिखाएगा। स्थानीय वस्तु पुस्तकालय के तहत रिपोजिटरी में बनाया गया।
दाईं ओर, आपके पास एक होम स्क्रीन है, जिसका उपयोग किया जा सकता है -
- प्रोजेक्ट बनाएं
- ओपन प्रोजेक्ट
- डेटा स्टोर बनाएँ
- रिपोजिटरी बनाएं
- फ्लैट फ़ाइल से आयात करें
- डेटा सेवा प्रबंधन कंसोल
ईटीएल प्रवाह विकसित करने के लिए, आपको पहले स्रोत और लक्ष्य प्रणाली के लिए डेटा स्टोर बनाने की आवश्यकता है। ETL प्रवाह विकसित करने के लिए दिए गए चरणों का पालन करें -
Step 1 - क्लिक करें Create Data Stores।

एक नयी विंडो खुलेगी।
Step 2 - दर्ज करें Datastore नाम, Datastoreप्रकार और डेटाबेस प्रकार नीचे दिखाया गया है। आप नीचे दिए गए स्क्रीनशॉट में दिखाए गए अनुसार अलग-अलग डेटाबेस को सोर्स सिस्टम के रूप में चुन सकते हैं।

Step 3- डेटा स्रोत के रूप में ईसीसी प्रणाली का उपयोग करने के लिए, डेटापोरे प्रकार के रूप में एसएपी एप्लिकेशन का चयन करें। उपयोगकर्ता नाम और पासवर्ड दर्ज करें और परAdvance टैब, सिस्टम नंबर और क्लाइंट नंबर दर्ज करें।

Step 4- ओके पर क्लिक करें और डाटास्टोर को स्थानीय ऑब्जेक्ट लाइब्रेरी सूची में जोड़ा जाएगा। यदि आप डेटास्टोर का विस्तार करते हैं, तो यह कोई तालिका नहीं दिखाता है।

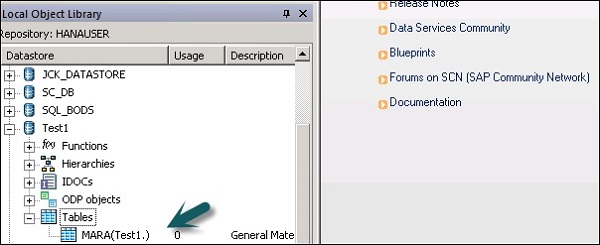
Step 5 - लक्ष्य प्रणाली पर लोड करने के लिए ईसीसी प्रणाली से किसी भी तालिका को निकालने के लिए, टेबल्स पर राइट-क्लिक करें → आयात द्वारा नाम।

Step 6 - तालिका नाम दर्ज करें और क्लिक करें Import। यहां, टेबल-मारा का उपयोग किया जाता है, जो ईसीसी प्रणाली में एक डिफ़ॉल्ट तालिका है।
Step 7 - इसी तरह से, एक बनाएँ Datastoreलक्ष्य प्रणाली के लिए। इस उदाहरण में, HANA का उपयोग लक्ष्य प्रणाली के रूप में किया जाता है।

एक बार जब आप ठीक क्लिक करते हैं, तो यह Datastore स्थानीय ऑब्जेक्ट लाइब्रेरी में जोड़ा जाएगा और इसके अंदर कोई तालिका नहीं होगी।
एक ETL फ्लो बनाएँ
ईटीएल प्रवाह बनाने के लिए, एक नई परियोजना बनाएं।
Step 1 - विकल्प पर क्लिक करें, Create Project। प्रोजेक्ट का नाम दर्ज करें और क्लिक करेंCreate। इसे प्रोजेक्ट एरिया में जोड़ा जाएगा।

Step 2 - प्रोजेक्ट के नाम पर राइट क्लिक करें और एक नया बैच जॉब / रियल टाइम जॉब बनाएं।

Step 3- नौकरी का नाम दर्ज करें और Enter दबाएं। आपको इसमें कार्य प्रवाह और डेटा प्रवाह जोड़ना होगा। वर्कफ़्लो का चयन करें और नौकरी में जोड़ने के लिए कार्य क्षेत्र पर क्लिक करें। वर्कफ़्लो का नाम दर्ज करें और प्रोजेक्ट क्षेत्र में जोड़ने के लिए इसे डबल क्लिक करें।
Step 4- इसी तरह, डेटा प्रवाह का चयन करें और इसे प्रोजेक्ट क्षेत्र में लाएं। डेटा प्रवाह का नाम दर्ज करें और इसे नए प्रोजेक्ट के तहत जोड़ने के लिए डबल-क्लिक करें।

Step 5- अब डेटासोर के तहत स्रोत तालिका को कार्य क्षेत्र में खींचें। अब आप लक्ष्य तालिका को समान डेटा-प्रकार के साथ कार्य क्षेत्र तक खींच सकते हैं या आप एक नई टेम्प्लेट तालिका बना सकते हैं।
नया टेम्प्लेट टेबल बनाने के लिए, स्रोत तालिका पर राइट क्लिक करें, नया → टेम्प्लेट तालिका जोड़ें।

Step 6- तालिका का नाम दर्ज करें और सूची से लक्ष्य दातास्तूर के रूप में दातास्तूर चुनें। मालिक नाम स्कीमा नाम का प्रतिनिधित्व करता है जहाँ तालिका बनाई जानी है।

तालिका को इस तालिका नाम के साथ कार्य क्षेत्र में जोड़ा जाएगा।
Step 7- स्रोत तालिका से लक्ष्य तालिका तक रेखा खींचें। दबाएंSave All शीर्ष पर विकल्प।

अब आप डेटा सेवा प्रबंधन कंसोल का उपयोग करके नौकरी को शेड्यूल कर सकते हैं या आप नौकरी के नाम और निष्पादन पर राइट क्लिक करके इसे मैन्युअल रूप से निष्पादित कर सकते हैं।
डेटास्टोर्स का उपयोग किसी एप्लिकेशन और डेटाबेस के बीच संबंध स्थापित करने के लिए किया जाता है। आप सीधे डेटास्टोर बना सकते हैं या एडेप्टर की मदद से बनाया जा सकता है। डेटास्टोर किसी एप्लिकेशन / सॉफ़्टवेयर को किसी एप्लिकेशन या डेटाबेस से मेटाडेटा पढ़ने या लिखने और उस डेटाबेस या एप्लिकेशन को लिखने की अनुमति देता है।
व्यावसायिक ऑब्जेक्ट डेटा सेवाओं में, आप डेटास्टोर का उपयोग करके निम्नलिखित सिस्टम से कनेक्ट कर सकते हैं -
- मेनफ्रेम सिस्टम और डेटाबेस
- उपयोगकर्ता लिखित एडेप्टर के साथ अनुप्रयोग और सॉफ्टवेयर
- एसएपी एप्लिकेशन, एसएपी बीडब्ल्यू, ओरेकल एप्स, सीबेल आदि।
एसएपी बिजनेस ऑब्जेक्ट डेटा सर्विसेज मेनफ्रेम इंटरफेस का उपयोग करके कनेक्ट करने का विकल्प प्रदान करता है Attunityकनेक्टर। का उपयोग करते हुएAttunity, नीचे दिए गए स्रोतों की सूची के लिए दातास्टोर से जुड़ें -
- OS / 390 के लिए DB2 UDB
- OS / 400 के लिए DB2 UDB
- IMS/DB
- VSAM
- Adabas
- ओएस / 390 और ओएस / 400 पर फ्लैट फाइलें

Attunity कनेक्टर का उपयोग करके, आप सॉफ्टवेयर की मदद से मेनफ्रेम डेटा से जुड़ सकते हैं। इस सॉफ़्टवेयर को मेनफ़्रेम सर्वर और स्थानीय क्लाइंट जॉब सर्वर पर ODBC इंटरफ़ेस का उपयोग करके मैन्युअल रूप से इंस्टॉल करने की आवश्यकता है।
होस्ट स्थान, पोर्ट, एट्यूनिटी कार्यक्षेत्र, आदि जैसे विवरण दर्ज करें।
डेटाबेस के लिए डेटास्टोर बनाएँ
डेटाबेस के लिए डेटास्टोर बनाने के लिए नीचे दिए गए चरणों का पालन करें।
Step 1- नीचे दी गई छवि में दिखाए अनुसार डेटास्टोर नाम, डेटास्टोर प्रकार और डेटाबेस प्रकार दर्ज करें। आप सूची में दिए गए स्रोत सिस्टम के रूप में विभिन्न डेटाबेस का चयन कर सकते हैं।

Step 2- डेटा स्रोत के रूप में ईसीसी प्रणाली का उपयोग करने के लिए, डाटस्टोर प्रकार के रूप में एसएपी एप्लिकेशन का चयन करें। उपयोगकर्ता नाम और पासवर्ड दर्ज करें। दबाएंAdvance टैब और सिस्टम नंबर और क्लाइंट नंबर दर्ज करें।

Step 3- ओके पर क्लिक करें और डाटास्टोर को स्थानीय ऑब्जेक्ट लाइब्रेरी सूची में जोड़ा जाएगा। यदि आप डेटास्टोर का विस्तार करते हैं, तो प्रदर्शित करने के लिए कोई तालिका नहीं है।
इस अध्याय में, हम सीखेंगे कि डेटास्टोर को कैसे संपादित या परिवर्तित किया जाए। डेटास्टोर को बदलने या संपादित करने के लिए, नीचे दिए गए चरणों का पालन करें।
Step 1- डेटास्टोर संपादित करने के लिए, डेटास्टोर नाम पर राइट क्लिक करें और संपादित करें पर क्लिक करें। यह Datastore संपादक खोल देगा।

आप वर्तमान डेटास्टोर कॉन्फ़िगरेशन के लिए कनेक्शन जानकारी संपादित कर सकते हैं।
Step 2 - क्लिक करें Advance बटन और आप ग्राहक संख्या, सिस्टम आईडी और अन्य गुण संपादित कर सकते हैं।
Step 3 - क्लिक करें Edit कॉन्फ़िगरेशन जोड़ने, संपादित करने और हटाने का विकल्प।

Step 4 - ओके पर क्लिक करें और परिवर्तन लागू हो जाएंगे।
आप डेटाबेस प्रकार के रूप में मेमोरी का उपयोग करके एक डेटस्टोर बना सकते हैं। मेमोरी डेटास्टोर्स का उपयोग वास्तविक समय की नौकरियों में डेटा प्रवाह के प्रदर्शन को बेहतर बनाने के लिए किया जाता है क्योंकि यह मेमोरी में डेटा को त्वरित पहुंच की सुविधा के लिए संग्रहीत करता है और मूल डेटा स्रोत पर जाने की आवश्यकता नहीं होती है।
एक मेमोरी डेटास्टोर का उपयोग रिपॉजिटरी में मेमोरी टेबल स्कीमा को स्टोर करने के लिए किया जाता है। ये मेमोरी टेबल रिलेशनल डेटाबेस में टेबलों से डेटा प्राप्त करते हैं या XML संदेश और IDocs जैसे पदानुक्रमित डेटा फ़ाइलों का उपयोग करते हैं। मेमोरी टेबल तब तक जीवित रहती है जब तक कि नौकरी निष्पादित नहीं हो जाती है और मेमोरी टेबल में डेटा को विभिन्न वास्तविक समय नौकरियों के बीच साझा नहीं किया जा सकता है।
मेमोरी डाटस्टोर बनाना
मेमोरी डाटस्टोर बनाने के लिए, नीचे दिए गए चरणों का पालन करें।
Step 1 - Create Datastore पर क्लिक करें और Datastore का नाम दर्ज करें “Memory_DS_TEST”। मेमोरी टेबल को सामान्य आरडीबीएमएस टेबल के साथ प्रस्तुत किया जाता है और नामकरण सम्मेलनों के साथ पहचाना जा सकता है।
Step 2 - डेटास्टोर प्रकार में, डेटाबेस का चयन करें और डेटाबेस प्रकार में चयन करें Memory। ओके पर क्लिक करें।

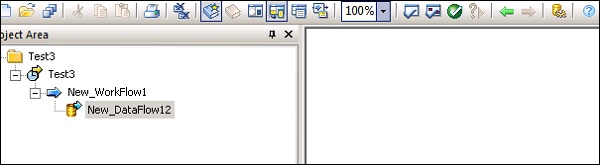
Step 3 - अब प्रोजेक्ट → न्यू → प्रोजेक्ट पर जाएं जैसा कि नीचे दिए गए स्क्रीनशॉट में दिखाया गया है।

Step 4- राइट क्लिक करके नया जॉब बनाएं। नीचे दिखाए अनुसार कार्य प्रवाह और डेटा प्रवाह जोड़ें।
Step 5- टेम्प्लेट टेबल का चयन करें और कार्य क्षेत्र में खींचें और छोड़ें। एक Create Table विंडो खुलेगी।

Step 6- तालिका का नाम दर्ज करें और डेटास्टोर में, मेमोरी डेटास्टोर का चयन करें। यदि आप एक सिस्टम जनरेट पंक्ति आईडी चाहते हैं, तो चुनेंcreate row idचेक बॉक्स। ओके पर क्लिक करें।
Step 7 - इस मेमोरी टेबल को डेटाफ्लो से कनेक्ट करें और क्लिक करें Save All शीर्ष पर।

स्रोत और लक्ष्य के रूप में मेमोरी टेबल
लक्ष्य के रूप में मेमोरी टेबल का उपयोग करने के लिए -
Step 1- स्थानीय ऑब्जेक्ट लाइब्रेरी पर जाएं, डाटस्टोर टैब पर क्लिक करें। मेमोरी डाटस्टोर का विस्तार करें → तालिकाओं का विस्तार करें।
Step 2- मेमोरी टेबल का चयन करें जिसे आप स्रोत या लक्ष्य तालिका के रूप में उपयोग करना चाहते हैं और इसे कार्य प्रवाह में खींचें। इस मेमोरी टेबल को स्रोत के रूप में या डेटा प्रवाह में लक्ष्य से कनेक्ट करें।
Step 3 - क्लिक करें save बटन नौकरी बचाने के लिए।
विभिन्न डेटाबेस विक्रेता हैं, जो केवल एक डेटाबेस से दूसरे डेटाबेस में एक-तरफ़ा संचार पथ प्रदान करते हैं। इन रास्तों को डेटाबेस लिंक के रूप में जाना जाता है। SQL सर्वर में, लिंक्ड सर्वर एक डेटाबेस से दूसरे में एक-तरफ़ा संचार पथ की अनुमति देता है।
उदाहरण
नामित एक स्थानीय डेटाबेस सर्वर पर विचार करें “Product” डेटाबेस डेटाबेस को दूरस्थ डेटाबेस सर्वर पर सूचना तक पहुंचने के लिए लिंक कहा जाता है Customer। अब, जो उपयोगकर्ता दूरस्थ डेटाबेस सर्वर से जुड़े हैं, डेटाबेस सर्वर उत्पाद में डेटा तक पहुँचने के लिए उसी लिंक का उपयोग नहीं कर सकते हैं। जो उपयोगकर्ता से जुड़े हैं“Customer” उत्पाद डेटाबेस सर्वर में डेटा तक पहुँचने के लिए सर्वर के डेटा डिक्शनरी में एक अलग लिंक होना चाहिए।
दो डेटाबेस के बीच के इस संचार पथ को डेटाबेस लिंक कहा जाता है। डेटास्टोर्स, जो इन लिंक किए गए डेटाबेस रिश्तों के बीच बनाए जाते हैं, लिंकड डेटोर्स के रूप में जाने जाते हैं।
एक डेटास्टोर को दूसरे डेटास्टोर से जोड़ने और डेटास्टोर के विकल्प के रूप में एक बाहरी डेटाबेस लिंक आयात करने की संभावना है।

एडेप्टर डेटास्टोर आपको एप्लिकेशन मेटाडेटा को रिपॉजिटरी में आयात करने की अनुमति देता है। आप एप्लिकेशन मेटाडेटा तक पहुंच सकते हैं और विभिन्न अनुप्रयोगों और सॉफ़्टवेयर के बीच बैच और वास्तविक समय डेटा स्थानांतरित कर सकते हैं।
एक एडेप्टर सॉफ्टवेयर डेवलपमेंट किट है - एसडीपी एसएपी द्वारा प्रदान किया जाता है जिसे अनुकूलित एडेप्टर विकसित करने के लिए इस्तेमाल किया जा सकता है। ये एडाप्टर एडेप्टर डेटास्टोर्स द्वारा डेटा सेवा डिजाइनर में प्रदर्शित किए जाते हैं।
एडेप्टर का उपयोग करके डेटा को निकालने या लोड करने के लिए, आपको इस उद्देश्य के लिए कम से कम एक डेटास्टोर को परिभाषित करना चाहिए।
एडेप्टर डेटास्टोर - परिभाषा
अनुकूली डेटास्टोर को परिभाषित करने के लिए दिए गए चरणों का पालन करें -
Step 1 - क्लिक करें Create Datastore→ डेटास्टोर के लिए नाम दर्ज करें। एडॉप्टर के रूप में डेटास्टोर प्रकार चुनें। को चुनिएJob Server सूची और एडाप्टर इंस्टेंस नाम से और क्लिक करें OK।

एप्लिकेशन मेटाडेटा ब्राउज़ करने के लिए
डाटस्टोर नाम पर राइट क्लिक करें और क्लिक करें Open। यह स्रोत मेटाडेटा दिखाते हुए एक नई विंडो खोलेगा। ऑब्जेक्ट चेक करने के लिए + साइन ऑन करें और आयात करने के लिए ऑब्जेक्ट पर राइट क्लिक करें।
फ़ाइल प्रारूप को फ्लैट फ़ाइलों की संरचना पेश करने के लिए गुणों के एक सेट के रूप में परिभाषित किया गया है। यह मेटाडेटा संरचना को परिभाषित करता है। फाइल फॉर्मेट का उपयोग सोर्स और टारगेट डेटाबेस से कनेक्ट करने के लिए किया जाता है जब डेटा को फाइलों में स्टोर किया जाता है और डेटाबेस में नहीं।
फ़ाइल प्रारूप का उपयोग निम्नलिखित कार्यों के लिए किया जाता है -
- एक फ़ाइल की संरचना को परिभाषित करने के लिए एक फ़ाइल प्रारूप टेम्पलेट बनाएँ।
- डेटाफ़्लो में एक विशिष्ट स्रोत और लक्ष्य फ़ाइल प्रारूप बनाएँ।
निम्न प्रकार की फ़ाइलों को फ़ाइल प्रारूप का उपयोग करके स्रोत या लक्ष्य फ़ाइल के रूप में उपयोग किया जा सकता है -
- Delimited
- एसएपी परिवहन
- अशिक्षित पाठ
- असंरचित बाइनरी
- निश्चित चौड़ाई
फ़ाइल प्रारूप संपादक
फ़ाइल स्वरूप संपादक का उपयोग फ़ाइल प्रारूप टेम्पलेट और स्रोत और लक्ष्य फ़ाइल स्वरूपों के लिए गुण सेट करने के लिए किया जाता है।
निम्नलिखित प्रारूप फ़ाइल प्रारूप संपादक में उपलब्ध हैं -
New mode - यह आपको एक नया फ़ाइल प्रारूप टेम्पलेट बनाने की अनुमति देता है।
Edit mode - यह आपको एक मौजूदा फ़ाइल प्रारूप टेम्पलेट को संपादित करने की अनुमति देता है।
Source mode - यह आपको किसी विशेष स्रोत फ़ाइल के फ़ाइल प्रारूप को संपादित करने की अनुमति देता है।
Target mode - यह आपको एक विशेष लक्ष्य फ़ाइल के फ़ाइल प्रारूप को संपादित करने की अनुमति देता है।
फ़ाइल स्वरूप संपादक के लिए तीन कार्य क्षेत्र हैं -
Properties Values - इसका उपयोग फ़ाइल प्रारूप गुणों के लिए मानों को संपादित करने के लिए किया जाता है।
Column Attributes - इसका उपयोग फाइल में कॉलम या फील्ड को एडिट और डिफाइन करने के लिए किया जाता है।
Data Preview - यह देखने के लिए उपयोग किया जाता है कि सेटिंग्स नमूना डेटा को कैसे प्रभावित करती हैं।
फ़ाइल स्वरूप बनाना
फ़ाइल प्रारूप बनाने के लिए नीचे दिए गए चरणों का पालन करें।
Step 1 - लोकल ऑब्जेक्ट लाइब्रेरी → फ्लैट फाइलों पर जाएं।

Step 2 - फ्लैट फाइलों के विकल्प पर राइट क्लिक करें → नया।

फ़ाइल स्वरूप संपादक की एक नई विंडो खुल जाएगी।
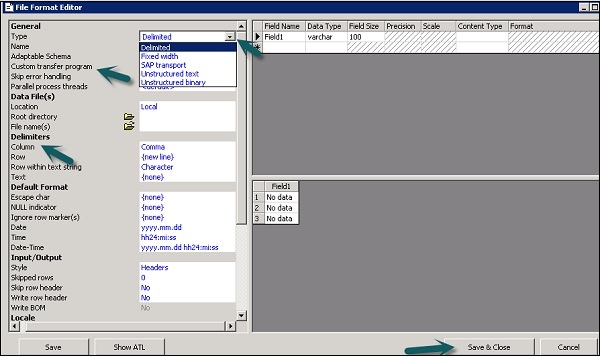
Step 3- फाइल फॉर्मेट के प्रकार का चयन करें। वह नाम दर्ज करें जो फ़ाइल प्रारूप टेम्पलेट का वर्णन करता है। डिलीट और फिक्स्ड चौड़ाई फ़ाइलों के लिए, आप कस्टम ट्रांसफर प्रोग्राम का उपयोग करके पढ़ और लोड कर सकते हैं। इस टेम्पलेट का प्रतिनिधित्व करने वाली फ़ाइलों का वर्णन करने के लिए अन्य गुण दर्ज करें।
आप कुछ विशिष्ट फ़ाइल स्वरूपों के लिए स्तंभ विशेषताओं के कार्य-क्षेत्र में स्तंभों को निर्दिष्ट भी कर सकते हैं। सभी गुण परिभाषित हो जाने के बाद, क्लिक करेंSave बटन।
एक फ़ाइल प्रारूप का संपादन
फ़ाइल स्वरूपों को संपादित करने के लिए, नीचे दिए गए चरणों का पालन करें।
Step 1 - लोकल ऑब्जेक्ट लाइब्रेरी में, पर जाएं Format टैब।
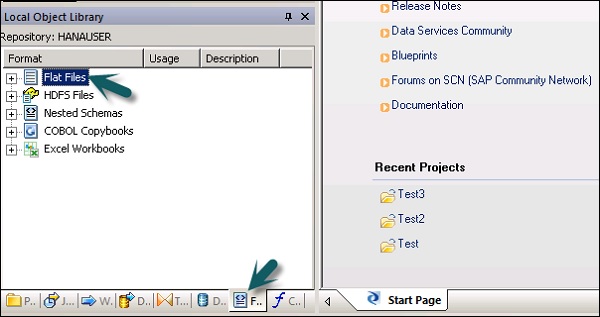
Step 2- वह फ़ाइल प्रारूप चुनें जिसे आप संपादित करना चाहते हैं। राइट क्लिक करेंEdit विकल्प।

फ़ाइल स्वरूप संपादक में परिवर्तन करें और क्लिक करें Save बटन।
आप एक COBOL कॉपीबुक फ़ाइल प्रारूप बना सकते हैं जो आपको सिर्फ प्रारूप बनाने के लिए धीमा कर देता है। डेटाफ़्लो में प्रारूप जोड़ने के बाद आप स्रोत को बाद में कॉन्फ़िगर कर सकते हैं।
आप फ़ाइल प्रारूप बना सकते हैं और इसे उसी समय डेटा फ़ाइल से जोड़ सकते हैं। नीचे दिए गए चरणों का पालन करें।
Step 1 - लोकल ऑब्जेक्ट लाइब्रेरी → फाइल फॉर्मेट → COBOL कॉपीबुक्स पर जाएं।

Step 2 - राइट क्लिक करें New विकल्प।

Step 3- प्रारूप नाम दर्ज करें। प्रारूप टैब पर जाएँ → आयात करने के लिए COBOL कॉपीबुक चुनें। फ़ाइल का विस्तार है.cpy।
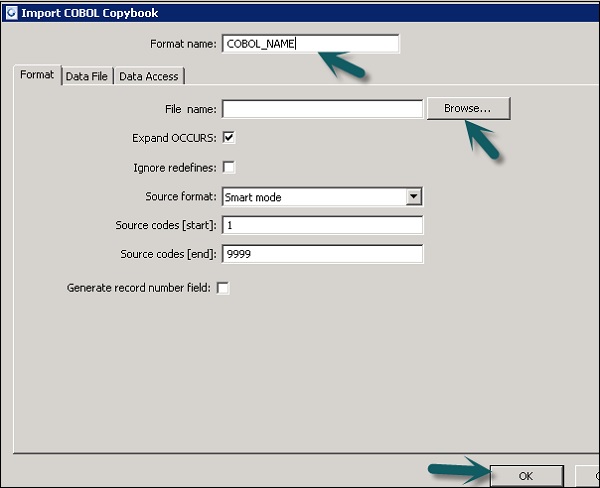
Step 4 - क्लिक करें OK। यह फ़ाइल स्वरूप स्थानीय ऑब्जेक्ट लायब्रेरी में जोड़ा गया है। COBOL कॉपीबुक स्कीमा नाम संवाद बॉक्स खुलता है। यदि आवश्यक हो, तो स्कीमा का नाम बदलें और क्लिक करेंOK।
डेटाबेस डेटास्टोर्स का उपयोग करके, आप डेटाबेस में तालिकाओं और कार्यों से डेटा निकाल सकते हैं। जब आप मेटाडेटा के लिए डेटा आयात करते हैं,Tool आपको कॉलम के नाम, डेटा प्रकार, विवरण आदि को संपादित करने की अनुमति देता है।
आप निम्नलिखित वस्तुओं को संपादित कर सकते हैं -
- तालिका नाम
- आम नाम
- तालिका विवरण
- कॉलम विवरण
- कॉलम डेटा प्रकार
- कॉलम सामग्री प्रकार
- तालिका विशेषताएँ
- प्राथमिक कुंजी
- मालिक का नाम
मेटाडेटा आयात करना
मेटाडेटा आयात करने के लिए, नीचे दिए गए चरणों का पालन करें -
Step 1 - लोकल ऑब्जेक्ट लाइब्रेरी में जाएं → डाटस्टोर पर जाएं जिसे आप उपयोग करना चाहते हैं।

Step 2 - दातास्टोर पर राइट क्लिक करें → ओपन।
कार्यक्षेत्र में, आयात के लिए उपलब्ध सभी वस्तुओं को प्रदर्शित किया जाएगा। उन वस्तुओं का चयन करें जिनके लिए आप मेटाडेटा आयात करना चाहते हैं।

ऑब्जेक्ट लायब्रेरी में, आयातित ऑब्जेक्ट्स की सूची देखने के लिए डेटास्टोर पर जाएँ।
आप Microsoft Excel कार्यपुस्तिका को डेटा सेवाओं में फ़ाइल स्वरूपों का उपयोग करके डेटा स्रोत के रूप में उपयोग कर सकते हैं। एक्सेल वर्कबुक विंडोज फाइल सिस्टम या यूनिक्स फाइल सिस्टम पर उपलब्ध होनी चाहिए।
| अनु क्रमांक। | पहुंच और विवरण |
|---|---|
| 1 | In the object library, click the Formats tab. एक एक्सेल कार्यपुस्तिका औपचारिक एक्सेल वर्कबुक में परिभाषित संरचना का वर्णन करती है (एक .xls एक्सटेंशन के साथ चिह्नित)। आप ऑब्जेक्ट लायब्रेरी में Excel डेटा श्रेणियों के लिए प्रारूप टेम्पलेट संग्रहीत करते हैं। आप डेटा प्रवाह में किसी विशेष स्रोत के प्रारूप को परिभाषित करने के लिए टेम्पलेट का उपयोग करते हैं। SAP Data Services एक्सेल वर्कबुक को केवल स्रोत के रूप में (लक्ष्य के रूप में नहीं) स्वीकार करती है। |
राइट क्लिक करें New विकल्प और चयन करें Excel Workbook जैसा कि नीचे स्क्रीनशॉट में दिखाया गया है।

XML FILE DTD, XSD से डेटा एक्सट्रैक्शन
आप XML या DTD स्कीमा फ़ाइल स्वरूप भी आयात कर सकते हैं।
Step 1 - लोकल ऑब्जेक्ट लाइब्रेरी → फॉर्मेट टैब → नेस्टेड स्कीमा पर जाएं।
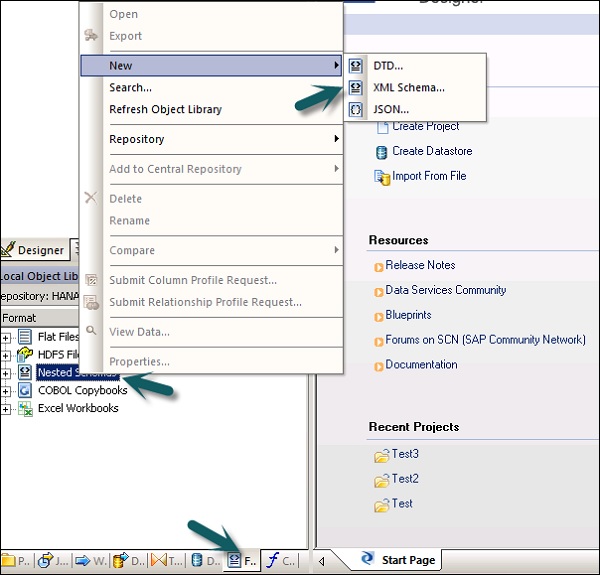
Step 2 - को इंगित करें New(आप DTD फ़ाइल या XML स्कीमा या JSON फ़ाइल प्रारूप का चयन कर सकते हैं)। फ़ाइल प्रारूप का नाम दर्ज करें और उस फ़ाइल का चयन करें जिसे आप आयात करना चाहते हैं। ओके पर क्लिक करें।
COBOL Copybooks से डेटा निष्कर्षण
आप COBOL copybooks में फ़ाइल प्रारूप भी आयात कर सकते हैं। स्थानीय ऑब्जेक्ट लाइब्रेरी → फॉर्मेट → COBOL कॉपीबुक पर जाएं।

डेटा प्रवाह का उपयोग स्रोत से लक्ष्य प्रणाली में डेटा को निकालने, बदलने और लोड करने के लिए किया जाता है। सभी परिवर्तन, लोडिंग और स्वरूपण डेटाफ़्लो में होता है।
एक बार जब आप किसी प्रोजेक्ट में डेटा प्रवाह को परिभाषित करते हैं, तो इसे वर्कफ़्लो या ईटीएल जॉब में जोड़ा जा सकता है। डेटा प्रवाह मापदंडों का उपयोग करके वस्तुओं / सूचना को भेज या प्राप्त कर सकता है। डेटा प्रवाह को प्रारूप में नाम दिया गया हैDF_Name।

डेटा फ्लो का उदाहरण
आइए हम मान लें कि आप स्रोत प्रणाली में दो तालिकाओं के डेटा के साथ डीडब्ल्यू प्रणाली में एक तथ्य तालिका लोड करना चाहते हैं।
डेटा फ़्लो में निम्नलिखित वस्तुएँ शामिल हैं -
- दो स्रोत तालिका
- दो तालिकाओं के बीच जुड़ें और क्वेरी रूपांतरित में परिभाषित करें
- लक्ष्य तालिका

डेटा प्रवाह में तीन प्रकार की ऑब्जेक्ट्स को जोड़ा जा सकता है। वे हैं -
- Source
- Target
- Transforms
Step 1 - लोकल ऑब्जेक्ट लाइब्रेरी में जाएं और दोनों टेबल को काम की जगह पर खींचें।

Step 2 - क्वेरी परिवर्तन जोड़ने के लिए, सही टूल बार से खींचें।
Step 3 - दोनों तालिकाओं में शामिल हों और क्वेरी बॉक्स पर दाईं ओर क्लिक करके टेम्पलेट लक्ष्य तालिका बनाएं → नया → नया टेम्पलेट तालिका जोड़ें।

Step 4 - लक्ष्य तालिका, डेटा स्टोर का नाम और मालिक (स्कीमा नाम) दर्ज करें जिसके तहत तालिका बनाई जानी है।
Step 5 - सामने लक्ष्य तालिका खींचें और क्वेरी परिवर्तन में शामिल हों।
पासिंग पैरामीटर्स
आप डेटा प्रवाह में और बाहर विभिन्न मापदंडों को भी पास कर सकते हैं। डेटा प्रवाह के लिए एक पैरामीटर पास करते समय, डेटा प्रवाह में ऑब्जेक्ट उन मापदंडों को संदर्भित करते हैं। मापदंडों का उपयोग करते हुए, आप एक डेटा प्रवाह के लिए विभिन्न ऑपरेशन पास कर सकते हैं।
उदाहरण - मान लीजिए कि आपने पिछले अद्यतन के बारे में एक तालिका में एक पैरामीटर दर्ज किया है। यह आपको अंतिम अद्यतन के बाद से संशोधित पंक्तियों को निकालने की अनुमति देता है।
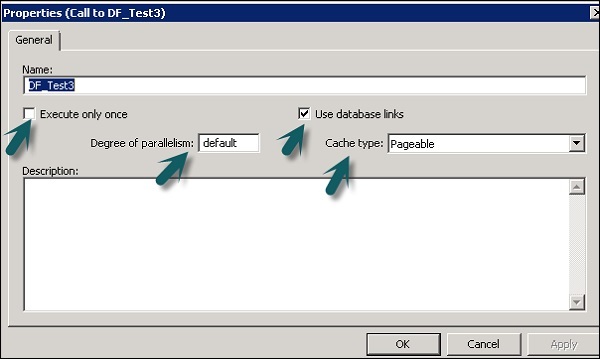
आप डेटाफ्लो के गुणों को बदल सकते हैं जैसे एक बार एक्स्यूट्यूट, कैश प्रकार, डेटाबेस लिंक, समानता, आदि।
Step 1 - डेटा प्रवाह के गुणों को बदलने के लिए, डेटा प्रवाह → गुण पर राइट क्लिक करें
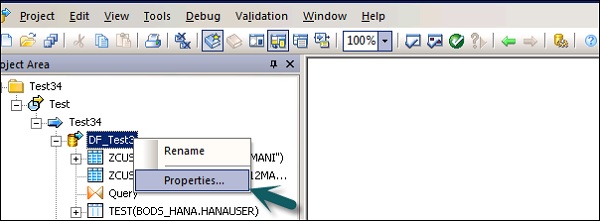
आप डेटाफ़्लो के लिए विभिन्न गुण सेट कर सकते हैं। गुण नीचे दिए गए हैं।
| अनु क्रमांक। | गुण और विवरण |
|---|---|
| 1 | Execute only once जब आप यह निर्दिष्ट करते हैं कि एक डेटाफ़्लो केवल एक बार निष्पादित होना चाहिए, तो एक बैच जॉब डेटा प्रवाह के सफलतापूर्वक पूरा होने के बाद उस डेटा प्रवाह को फिर से निष्पादित नहीं करेगा, सिवाय इसके कि डेटा प्रवाह एक कार्य प्रवाह में निहित है जो एक पुनर्प्राप्ति इकाई है जो फिर से निष्पादित होती है और रिकवरी यूनिट के बाहर कहीं और सफलतापूर्वक पूरा नहीं हुआ है। यह अनुशंसा की जाती है कि आप केवल एक बार एक्सक्यूट के रूप में एक डेटाफ़्लो को चिह्नित न करें यदि कोई मूल कार्य प्रवाह पुनर्प्राप्ति इकाई है। |
| 2 | Use database links डेटाबेस लिंक एक डेटाबेस सर्वर और दूसरे के बीच संचार पथ हैं। डेटाबेस लिंक स्थानीय उपयोगकर्ताओं को एक दूरस्थ डेटाबेस पर डेटा का उपयोग करने की अनुमति देते हैं, जो स्थानीय या एक ही या अलग डेटाबेस प्रकार के दूरस्थ कंप्यूटर पर हो सकता है। |
| 3 | Degree of parallelism समानांतरवाद (डीओपी) की डिग्री एक डेटा प्रवाह की एक संपत्ति है जो परिभाषित करती है कि डेटा प्रवाह के भीतर प्रत्येक बार कितनी बार डेटा के समानांतर सबसेट को संसाधित करने के लिए प्रतिकृति होती है। |
| 4 | Cache type आप जुड़ने, समूहों, प्रकार, फ़िल्टरिंग, लुकअप और टेबल तुलना जैसे ऑपरेशन के प्रदर्शन को बेहतर बनाने के लिए डेटा को कैश कर सकते हैं। आप अपने डेटा प्रवाह गुण विंडो पर कैश प्रकार विकल्प के लिए निम्न में से एक मान का चयन कर सकते हैं -
|
Step 2 - केवल एक बार Execute, समानता और कैश प्रकार की डिग्री जैसे गुणों को बदलें।
स्रोत और लक्ष्य ऑब्जेक्ट
एक डेटा प्रवाह सीधे निम्नलिखित वस्तुओं का उपयोग करके डेटा को निकाल या लोड कर सकता है -
Source objects - स्रोत ऑब्जेक्ट उस स्रोत को परिभाषित करते हैं जिससे डेटा निकाला जाता है या आप डेटा पढ़ते हैं।
Target objects - लक्ष्य ऑब्जेक्ट उस लक्ष्य को परिभाषित करता है, जिस पर आप डेटा लोड या लिखते हैं।
निम्न प्रकार के स्रोत ऑब्जेक्ट का उपयोग किया जा सकता है और स्रोत वस्तुओं के लिए विभिन्न एक्सेस विधियों का उपयोग किया जाता है।
| टेबल | संबंधपरक डेटाबेस में उपयोग किए गए स्तंभों और पंक्तियों के साथ एक फ़ाइल | एडाप्टर के माध्यम से प्रत्यक्ष या |
| टेम्प्लेट टेबल | एक टेम्प्लेट टेबल जिसे दूसरे डेटा फ्लो में (विकास में प्रयुक्त) बनाया और सहेजा गया है | प्रत्यक्ष |
| फ़ाइल | एक सीमांकित या निश्चित-चौड़ाई वाली फ्लैट फ़ाइल | प्रत्यक्ष |
| डाक्यूमेंट | एप्लिकेशन-विशिष्ट प्रारूप वाली फ़ाइल (SQL या XML पार्सर द्वारा पठनीय नहीं) | एडॉप्टर के माध्यम से |
| XML फ़ाइल | XML टैग के साथ एक फ़ाइल स्वरूपित | प्रत्यक्ष |
| XML संदेश | वास्तविक समय की नौकरियों में एक स्रोत के रूप में उपयोग किया जाता है | प्रत्यक्ष |
निम्नलिखित लक्ष्य वस्तुओं का उपयोग किया जा सकता है और विभिन्न पहुंच विधि को लागू किया जा सकता है।
| टेबल | संबंधपरक डेटाबेस में उपयोग किए गए स्तंभों और पंक्तियों के साथ एक फ़ाइल | एडाप्टर के माध्यम से प्रत्यक्ष या |
| टेम्प्लेट टेबल | एक तालिका जिसका प्रारूप पूर्ववर्ती परिवर्तन के उत्पादन (विकास में प्रयुक्त) पर आधारित है | प्रत्यक्ष |
| फ़ाइल | एक सीमांकित या निश्चित-चौड़ाई वाली फ्लैट फ़ाइल | प्रत्यक्ष |
| डाक्यूमेंट | एप्लिकेशन-विशिष्ट प्रारूप वाली फ़ाइल (SQL या XML पार्सर द्वारा पठनीय नहीं) | एडॉप्टर के माध्यम से |
| XML फ़ाइल | XML टैग के साथ एक फ़ाइल स्वरूपित | प्रत्यक्ष |
| XML टेम्पलेट फ़ाइल | एक XML फ़ाइल जिसका प्रारूप पूर्ववर्ती ट्रांसफ़ॉर्मिंग आउटपुट (विकास में प्रयुक्त, मुख्य रूप से डेटा फ़्लो डीबग करने के लिए) पर आधारित है | प्रत्यक्ष |
निष्पादन के लिए प्रक्रिया निर्धारित करने के लिए वर्कफ़्लो का उपयोग किया जाता है। वर्कफ़्लो का मुख्य उद्देश्य डेटा प्रवाह को पूरा करने के लिए डेटा प्रवाह को निष्पादित करने और सिस्टम की स्थिति निर्धारित करने के लिए तैयार करना है।
ETL प्रोजेक्ट्स में बैच जॉब्स एकमात्र अंतर के साथ वर्कफ़्लोज़ के समान हैं जिनमें जॉब के पैरामीटर नहीं हैं।
विभिन्न वस्तुओं को एक कार्य प्रवाह में जोड़ा जा सकता है। वे हैं -
- काम का प्रवाह
- डाटा प्रवाह
- Scripts
- Loops
- Conditions
- कोशिश करो या ब्लॉक पकड़ो
आप कार्य प्रवाह को अन्य कार्य प्रवाह भी कह सकते हैं या कार्य प्रवाह स्वयं कॉल कर सकते हैं।
Note - वर्कफ़्लो में, चरणों को बाएं से दाएं अनुक्रम में निष्पादित किया जाता है।
कार्य प्रवाह का उदाहरण
मान लीजिए कि एक तथ्य तालिका है जिसे आप अपडेट करना चाहते हैं और आपने परिवर्तन के साथ एक डेटा प्रवाह बनाया है। अब, यदि आप स्रोत प्रणाली से डेटा को स्थानांतरित करना चाहते हैं, तो आपको तथ्य तालिका के लिए अंतिम संशोधन की जांच करनी होगी ताकि आप केवल उन पंक्तियों को निकालें जो अंतिम अद्यतन के बाद जोड़े जाते हैं।
इसे प्राप्त करने के लिए, आपको एक स्क्रिप्ट बनानी होगी, जो अंतिम अद्यतन तिथि निर्धारित करती है और फिर इसे डेटा प्रवाह में इनपुट पैरामीटर के रूप में पास किया जाता है।
आपको यह भी जांचना होगा कि किसी विशेष तथ्य तालिका का डेटा कनेक्शन सक्रिय है या नहीं। यदि यह सक्रिय नहीं है, तो आपको कैच ब्लॉक को सेटअप करने की आवश्यकता है, जो इस समस्या के बारे में सूचित करने के लिए व्यवस्थापक को स्वचालित रूप से एक ईमेल भेजता है।
निम्न विधियों का उपयोग करके वर्कफ़्लो बनाया जा सकता है -
- ऑब्जेक्ट लाइब्रेरी
- टूल पैलेट
ऑब्जेक्ट लाइब्रेरी का उपयोग करके वर्कफ़्लो बनाना
ऑब्जेक्ट लाइब्रेरी का उपयोग करके कार्य प्रवाह बनाने के लिए, नीचे दिए गए चरणों का पालन करें।
Step 1 - ऑब्जेक्ट लाइब्रेरी → वर्कफ़्लो टैब पर जाएं।

Step 2 - राइट क्लिक करें New विकल्प।

Step 3 - वर्कफ़्लो का नाम दर्ज करें।
टूल पैलेट का उपयोग करके वर्कफ़्लो बनाना
टूल पैलेट का उपयोग करके वर्कफ़्लो बनाने के लिए, दाईं ओर आइकन पर क्लिक करें और कार्य स्थान में कार्य प्रवाह खींचें।
आप वर्कफ़्लो के गुणों पर जाकर केवल एक बार वर्कफ़्लो निष्पादित करने के लिए भी सेट कर सकते हैं।
सशर्त,
आप वर्कफ़्लो में सशर्तियाँ भी जोड़ सकते हैं। यह आपको वर्कफ़्लोज़ पर इफ़ / एल्स / फिर लॉजिक को लागू करने की अनुमति देता है।
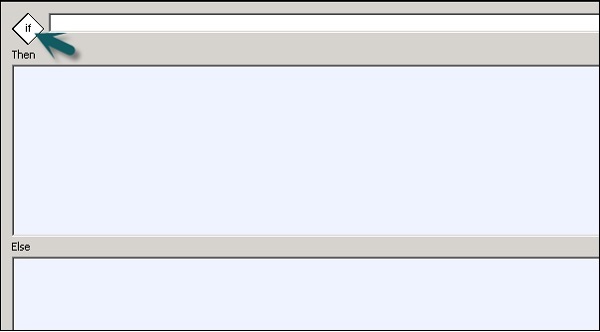
| अनु क्रमांक। | सशर्त और विवरण |
|---|---|
| 1 | If एक बूलियन अभिव्यक्ति जो TRUE या FALSE का मूल्यांकन करती है। आप अभिव्यक्ति के निर्माण के लिए फ़ंक्शंस, चर और मानक ऑपरेटरों का उपयोग कर सकते हैं। |
| 2 | Then कार्य प्रवाह तत्वों को निष्पादित करने के लिए यदि If अभिव्यक्ति TRUE का मूल्यांकन करती है। |
| 3 | Else (वैकल्पिक) कार्य प्रवाह तत्वों को निष्पादित करने के लिए यदि If अभिव्यक्ति FALSE का मूल्यांकन करती है। |
एक सशर्त को परिभाषित करने के लिए
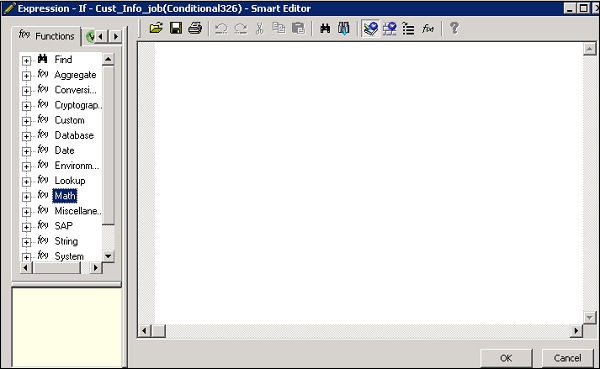
Step 1 - वर्कफ़्लो पर जाएं → राइट साइड में टूल पैलेट पर कंडिशनल आइकन पर क्लिक करें।
Step 2 - खोलने के लिए सशर्त के नाम पर डबल क्लिक करें If-Then–Else सशर्त संपादक।
Step 3- बूलियन अभिव्यक्ति दर्ज करें जो सशर्त को नियंत्रित करता है। ओके पर क्लिक करें।
Step 4 - उस डेटा प्रवाह को खींचें जिसे आप निष्पादित करना चाहते हैं Then and Else IF कंडीशन में अभिव्यक्ति के अनुसार विंडो।

एक बार जब आप शर्त पूरी कर लेते हैं, तो आप सशर्त को डिबग और मान्य कर सकते हैं।
ट्रांसफ़ॉर्म का उपयोग डेटा सेट को इनपुट के रूप में हेरफेर करने और एक या कई आउटपुट बनाने के लिए किया जाता है। विभिन्न परिवर्तन हैं, जिनका उपयोग डेटा सेवाओं में किया जा सकता है। परिवर्तनों का प्रकार खरीदे गए संस्करण और उत्पाद पर निर्भर करता है।
निम्नलिखित प्रकार के ट्रांसफ़ॉर्मेशन उपलब्ध हैं -
डेटा एकीकरण
डेटा इंटीग्रेशन ट्रांसफ़ॉर्म का उपयोग डेटा निष्कर्षण, ट्रांसफ़ॉर्मेशन और लोड के लिए DW सिस्टम के लिए किया जाता है। यह डेटा अखंडता सुनिश्चित करता है और डेवलपर उत्पादकता में सुधार करता है।
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Table_Comparision, आदि।
आँकड़े की गुणवत्ता
डेटा की गुणवत्ता में सुधार के लिए डेटा क्वालिटी ट्रांसफ़ॉर्म का उपयोग किया जाता है। आप स्रोत प्रणाली से सेट डेटा को पार्स, सही, मानकीकृत, समृद्ध कर सकते हैं।
- Associate
- डेटा शुद्ध
- DSF2 वॉक सीक्वेंसर, आदि।
मंच
प्लेटफ़ॉर्म का उपयोग डेटासेट की आवाजाही के लिए किया जाता है। इसका उपयोग करके आप दो या अधिक डेटा स्रोतों से पंक्तियों को उत्पन्न, मैप और मर्ज कर सकते हैं।
- Case
- Merge
- क्वेरी, आदि।
टेक्स्ट डेटा प्रोसेसिंग
टेक्स्ट डेटा प्रोसेसिंग से आप बड़ी मात्रा में टेक्स्ट डेटा प्रोसेस कर सकते हैं।
इस अध्याय में, आप देखेंगे कि कैसे जोड़ना है Transform डेटा प्रवाह के लिए।
Step 1 - ऑब्जेक्ट लाइब्रेरी → ट्रांसफ़ॉर्म टैब पर जाएं।
Step 2- उस ट्रांसफॉर्म को चुनें जिसे आप डेटा फ्लो में जोड़ना चाहते हैं। यदि आप एक परिवर्तन जोड़ते हैं जिसमें कॉन्फ़िगरेशन का चयन करने का विकल्प है, तो एक प्रॉम्प्ट खुलेगा।
Step 3 - स्रोत से कनेक्ट करने के लिए डेटा फ़्लो कनेक्शन ड्रा करें।
Step 4 - ट्रांसफॉर्मेशन एडिटर को खोलने के लिए ट्रांसफॉर्मेशन नेम पर डबल क्लिक करें।
एक बार परिभाषा पूरी हो जाने पर, क्लिक करें OK संपादक को बंद करने के लिए।
यह डेटा सेवाओं में उपयोग किया जाने वाला सबसे आम परिवर्तन है और आप निम्नलिखित कार्य कर सकते हैं -
- स्रोतों से डेटा फ़िल्टरिंग
- कई स्रोतों से डेटा को जोड़ना
- डेटा पर फ़ंक्शंस और ट्रांसफ़ॉर्मेशन करें
- इनपुट से आउटपुट स्कीमा तक कॉलम की मैपिंग
- प्राथमिक कुंजियाँ सौंपना
- नए कॉलम जोड़ें, स्कीमा और फ़ंक्शन के परिणामस्वरूप आउटपुट स्कीमा
जैसा कि क्वेरी परिवर्तन सबसे अधिक उपयोग किया जाने वाला परिवर्तन है, टूल पैलेट में इस क्वेरी के लिए एक शॉर्टकट प्रदान किया गया है।
क्वेरी परिवर्तन जोड़ने के लिए, नीचे दिए गए चरणों का पालन करें -
Step 1- क्वेरी-ट्रांसफॉर्मेशन टूल पैलेट पर क्लिक करें। डेटा प्रवाह कार्यक्षेत्र पर कहीं भी क्लिक करें। इसे इनपुट्स और आउटपुट से कनेक्ट करें।

जब आप क्वेरी ट्रांसफ़ॉर्म आइकन पर डबल क्लिक करते हैं, तो यह एक क्वेरी संपादक खोलता है जो क्वेरी ऑपरेशन करने के लिए उपयोग किया जाता है।
निम्नलिखित क्षेत्र क्वेरी परिवर्तन में मौजूद हैं -
- इनपुट स्कीम
- आउटपुट स्कीमा
- Parameters
इनपुट और आउटपुट स्कीमा में कॉलम, नेस्टेड स्कीम्स और फ़ंक्शंस होते हैं। स्कीमा इन और स्कीमा आउट परिवर्तन में वर्तमान में चयनित स्कीमा दिखाता है।
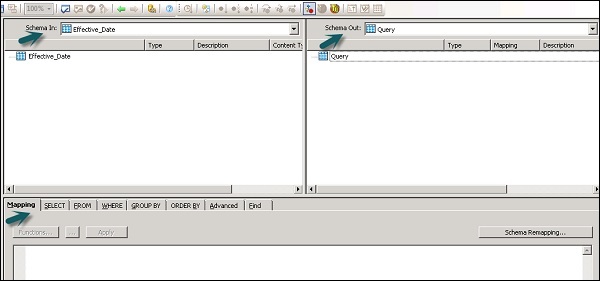
आउटपुट स्कीमा बदलने के लिए, सूची में स्कीमा का चयन करें, राइट क्लिक करें और मेक करेंट चुनें।

डेटा गुणवत्ता रूपांतरण
डेटा गुणवत्ता रूपांतरण सीधे अपस्ट्रीम ट्रांसफ़ॉर्म से कनेक्ट नहीं किया जा सकता, जिसमें नेस्टेड टेबल होते हैं। इन ट्रांसफ़ॉर्मेशन को कनेक्ट करने के लिए आपको नेस्ट टेबल से ट्रांसफ़ॉर्मेशन और डेटा क्वालिटी ट्रांसफ़ॉर्मेशन के बीच क्वेरी ट्रांसफ़ॉर्मेशन या XML पाइपलाइन ट्रांसफ़ॉर्म जोड़ना चाहिए।
डेटा गुणवत्ता परिवर्तन का उपयोग कैसे करें?
Step 1 - ऑब्जेक्ट लाइब्रेरी → ट्रांसफ़ॉर्म टैब पर जाएं
Step 2 - डेटा क्वालिटी ट्रांसफ़ॉर्मेशन का विस्तार करें और उस ट्रांसफ़ॉर्मेशन या ट्रांसफ़ॉर्मेशन कॉन्फ़िगरेशन को जोड़ें जो आप डेटा फ़्लो में जोड़ना चाहते हैं।
Step 3- डेटा प्रवाह कनेक्शन ड्रा करें। ट्रांसफॉर्मेशन के नाम पर डबल क्लिक करें, यह ट्रांसफॉर्म एडिटर को खोलता है। इनपुट स्कीमा में, उस इनपुट फ़ील्ड का चयन करें जिसे आप मैप करना चाहते हैं।
Note - एसोसिएट ट्रांसफॉर्म का उपयोग करने के लिए, आप उपयोगकर्ता परिभाषित क्षेत्रों को इनपुट टैब में जोड़ सकते हैं।
टेक्स्ट डेटा प्रोसेसिंग ट्रांसफ़ॉर्म
टेक्स्ट डेटा प्रोसेसिंग ट्रांसफॉर्म आपको बड़ी मात्रा में टेक्स्ट से विशिष्ट जानकारी निकालने की अनुमति देता है। आप किसी संगठन के लिए ग्राहक, उत्पाद और वित्तीय तथ्यों जैसे तथ्यों और संस्थाओं की खोज कर सकते हैं।
यह परिवर्तन संस्थाओं के बीच संबंधों की भी जाँच करता है और निकासी की अनुमति देता है। टेक्स्ट डेटा प्रोसेसिंग का उपयोग करके निकाले गए डेटा का उपयोग बिजनेस इंटेलिजेंस, रिपोर्टिंग, क्वेरी और एनालिटिक्स में किया जा सकता है।
इकाई निष्कर्षण रूपांतरण
डेटा सेवाओं में, एंटिटी एक्सट्रैक्शन की मदद से टेक्स्ट डेटा प्रोसेसिंग किया जाता है, जो असंरचित डेटा से संस्थाओं और तथ्यों को निकालता है।
इसमें बड़ी मात्रा में पाठ डेटा का विश्लेषण और प्रसंस्करण करना, संस्थाओं की खोज करना, उन्हें उपयुक्त प्रकार प्रदान करना और मानक प्रारूप में मेटाडेटा प्रस्तुत करना शामिल है।
एंटिटी एक्सट्रैक्शन ट्रांसफ़ॉर्मेशन किसी भी टेक्स्ट, HTML, XML या कुछ बाइनरी-फॉर्मेट (जैसे पीडीएफ) सामग्री से जानकारी निकाल सकता है और स्ट्रक्चरल आउटपुट उत्पन्न कर सकता है। आप अपने काम के प्रवाह के आधार पर आउटपुट को कई तरीकों से उपयोग कर सकते हैं। आप इसे किसी अन्य ट्रांसफ़ॉर्म के इनपुट के रूप में उपयोग कर सकते हैं या कई आउटपुट स्रोतों जैसे डेटाबेस टेबल या फ्लैट फ़ाइल में लिख सकते हैं। आउटपुट UTF-16 एन्कोडिंग में उत्पन्न होता है।
Entity Extract Transform can be used in the following scenarios −
बड़ी मात्रा में पाठ मात्रा से एक विशिष्ट जानकारी प्राप्त करना।
नए कनेक्शन बनाने के लिए मौजूदा जानकारी के साथ असंरचित पाठ से संरचित जानकारी प्राप्त करना।
उत्पाद की गुणवत्ता के लिए रिपोर्टिंग और विश्लेषण।
टीडीपी और डेटा सफाई के बीच अंतर
टेक्स्ट डेटा प्रोसेसिंग का उपयोग अनस्ट्रक्चर्ड टेक्स्ट डेटा से प्रासंगिक जानकारी खोजने के लिए किया जाता है। हालांकि, मानकीकृत डेटा को साफ करने और संरचित डेटा के लिए डेटा क्लींजिंग का उपयोग किया जाता है।
| मापदंडों | टेक्स्ट डेटा प्रोसेसिंग | डेटा सफाई |
|---|---|---|
| निवेष का प्रकार | असंरचित डेटा | संरचित डेटा |
| इनपुट का आकार | 5KB से अधिक | 5KB से कम है |
| इनपुट स्कोप | कई विविधताओं वाला व्यापक डोमेन | सीमित रूपांतर |
| संभावित उपयोग | असंरचित डेटा से संभावित सार्थक जानकारी | रिपोजिटरी में भंडारण के लिए डेटा की गुणवत्ता |
| उत्पादन | संस्थाओं, प्रकार, आदि के रूप में एनोटेशन बनाएं इनपुट को परिवर्तित नहीं किया गया है | मानकीकृत फ़ील्ड बनाएँ, इनपुट बदला गया है |
डेटा सेवा प्रशासन में वास्तविक समय और बैच की नौकरियों, शेड्यूलिंग नौकरियों, एम्बेडेड डेटा प्रवाह, चर और पैरामीटर, पुनर्प्राप्ति तंत्र, डेटा प्रोफाइलिंग, प्रदर्शन ट्यूनिंग, आदि शामिल हैं।
रियल टाइम जॉब्स
आप डेटा सेवा डिजाइनर में वास्तविक समय संदेशों को संसाधित करने के लिए वास्तविक समय की नौकरियां बना सकते हैं। एक बैच जॉब की तरह, रियल टाइम जॉब डेटा को निकालता है, ट्रांसफॉर्म करता है और उसे लोड करता है।
प्रत्येक वास्तविक समय की नौकरी एक संदेश से डेटा निकाल सकती है। आप अन्य स्रोतों जैसे तालिका या फ़ाइलों से डेटा भी निकाल सकते हैं।
वास्तविक समय की नौकरियों को बैच की नौकरियों के विपरीत ट्रिगर्स की मदद से निष्पादित नहीं किया जाता है। उन्हें प्रशासकों द्वारा वास्तविक समय सेवाओं के रूप में निष्पादित किया जाता है। रीयल टाइम सेवाएं एक्सेस सर्वर के संदेशों की प्रतीक्षा करती हैं। एक्सेस सर्वर यह संदेश प्राप्त करता है और इसे वास्तविक समय सेवाओं में भेजता है, जो संदेश प्रकार को संसाधित करने के लिए कॉन्फ़िगर किया गया है। वास्तविक समय सेवाएं संदेश को निष्पादित करती हैं और परिणाम लौटाती हैं और संदेशों को संसाधित करना जारी रखती हैं जब तक कि उन्हें निष्पादन को रोकने का निर्देश नहीं मिलता है।
वास्तविक समय बनाम बैच नौकरियां
शाखाओं और नियंत्रण तर्क की तरह ट्रांसफ़ॉर्म का उपयोग वास्तविक समय की नौकरी में अधिक बार किया जाता है, जो डिजाइनर में बैच की नौकरियों के साथ ऐसा नहीं है।
वास्तविक समय की नौकरियों को बैच की नौकरियों के विपरीत किसी अनुसूची या आंतरिक ट्रिगर के जवाब में निष्पादित नहीं किया जाता है।
रियल टाइम जॉब्स बनाना
डेटा फ्लो, वर्क फ्लो, लूप, कंडीशन, स्क्रिप्ट आदि जैसी समान वस्तुओं का उपयोग करके रियल टाइम जॉब्स बनाई जा सकती हैं।
रियल टाइम जॉब बनाने के लिए आप निम्न डेटा मॉडल का उपयोग कर सकते हैं -
- एकल डेटा प्रवाह मॉडल
- एकाधिक डेटा प्रवाह मॉडल
एकल डेटा प्रवाह मॉडल
आप अपने वास्तविक समय प्रसंस्करण लूप में एकल डेटा प्रवाह के साथ एक वास्तविक समय नौकरी बना सकते हैं और इसमें एक एकल संदेश स्रोत और एकल संदेश लक्ष्य शामिल है।
Creating Real Time job using single data model −
एकल डेटा मॉडल का उपयोग करके रीयल टाइम नौकरी बनाने के लिए, दिए गए चरणों का पालन करें।
Step 1 - डेटा सर्विसेज डिज़ाइनर → प्रोजेक्ट न्यू → प्रोजेक्ट → प्रोजेक्ट नाम दर्ज करें

Step 2 - प्रोजेक्ट एरिया में व्हाइट स्पेस पर राइट क्लिक करें → न्यू रियल टाइम जॉब।

कार्यक्षेत्र रियल टाइम जॉब के दो घटक दिखाता है -
- RT_Process_begins
- Step_ends
यह रियल टाइम जॉब की शुरुआत और अंत को दर्शाता है।

Step 3 - एकल डेटा प्रवाह के साथ एक वास्तविक समय की नौकरी बनाने के लिए, दाएं फलक पर उपकरण पैलेट से डेटा प्रवाह का चयन करें और इसे कार्य स्थान पर खींचें।
लूप के अंदर क्लिक करें, आप वास्तविक समय प्रसंस्करण लूप में एक संदेश स्रोत और एक संदेश लक्ष्य का उपयोग कर सकते हैं। डेटा प्रवाह के लिए प्रारंभिक और अंतिम निशान कनेक्ट करें।

Step 4 - आवश्यकतानुसार डेटा प्रवाह में कॉन्फ़िगर वस्तुओं को जोड़ें और नौकरी को बचाएं।
एकाधिक डेटा प्रवाह मॉडल
यह आपको अपने वास्तविक समय प्रसंस्करण लूप में कई डेटा प्रवाह के साथ एक वास्तविक समय की नौकरी बनाने की अनुमति देता है। आपको यह भी सुनिश्चित करना होगा कि प्रत्येक डेटा मॉडल में डेटा अगले संदेश पर जाने से पहले पूरी तरह से संसाधित हो।
रियल टाइम जॉब्स का परीक्षण
आप फ़ाइल से स्रोत संदेश के रूप में नमूना संदेश पास करके वास्तविक समय की नौकरी का परीक्षण कर सकते हैं। यदि आप डेटा सेवा अपेक्षित लक्ष्य संदेश उत्पन्न करते हैं, तो आप देख सकते हैं।
यह सुनिश्चित करने के लिए कि आपकी नौकरी आपको अपेक्षित परिणाम देती है, आप डेटा मोड को देखते हुए कार्य निष्पादित कर सकते हैं। इस मोड का उपयोग करके, आप यह सुनिश्चित करने के लिए आउटपुट डेटा कैप्चर कर सकते हैं कि आपका रियल टाइम जॉब ठीक काम कर रहा है।
एंबेडेड डेटा फ़्लो
एंबेडेड डेटा प्रवाह को डेटा फ्लो के रूप में जाना जाता है, जिसे डिज़ाइन में किसी अन्य डेटा प्रवाह से कहा जाता है। एम्बेडेड डेटा प्रवाह में कई स्रोत और लक्ष्य हो सकते हैं लेकिन मुख्य डेटा प्रवाह में केवल एक इनपुट या आउटपुट पास डेटा होता है।
निम्न प्रकार के एम्बेडेड डेटा प्रवाह का उपयोग किया जा सकता है -
One Input - एंबेडेड डेटा का प्रवाह डेटाफ्लो के अंत में जोड़ा जाता है।
One Output - एंबेडेड डेटा प्रवाह डेटा प्रवाह की शुरुआत में जोड़ा जाता है।
No input or output - एक मौजूदा डेटा प्रवाह को फिर से दोहराएं।
निम्न उद्देश्य के लिए एंबेडेड डेटा प्रवाह का उपयोग किया जा सकता है -
डेटा प्रवाह प्रदर्शन को सरल बनाने के लिए।
यदि आप फ़्लो लॉजिक को सहेजना चाहते हैं और इसे अन्य डेटा फ़्लो में पुनः उपयोग करना चाहते हैं।
डिबगिंग के लिए, जिसमें आप डेटा प्रवाह के अनुभागों को एम्बेडेड डेटा प्रवाह के रूप में बनाते हैं और उन्हें अलग से निष्पादित करते हैं।
आप मौजूदा डेटा प्रवाह में किसी ऑब्जेक्ट का चयन कर सकते हैं। दो तरीके हैं जिनमें एम्बेडेड डेटा फ्लो बनाया जा सकता है।
विकल्प 1
ऑब्जेक्ट पर राइट क्लिक करें और इसे एंबेडेड डेटा प्रवाह बनाने के लिए चुनें।

विकल्प 2
ऑब्जेक्ट लाइब्रेरी से पूर्ण और मान्य डेटा प्रवाह को कार्य स्थान में एक खुले डेटा प्रवाह में खींचें। इसके बाद, बनाया गया डेटा प्रवाह खोलें। उस ऑब्जेक्ट का चयन करें जिसे आप इनपुट और आउटपुट पोर्ट के रूप में उपयोग करना चाहते हैं और क्लिक करेंmake port उस वस्तु के लिए।

डेटा सेवाएँ उस ऑब्जेक्ट को एम्बेडेड डेटा प्रवाह के लिए कनेक्शन बिंदु के रूप में जोड़ते हैं।
चर और पैरामीटर
आप डेटा प्रवाह और कार्य प्रवाह के साथ स्थानीय और वैश्विक चर का उपयोग कर सकते हैं, जो डिजाइनिंग नौकरियों में अधिक लचीलापन प्रदान करते हैं।
प्रमुख विशेषताएं हैं -
एक चर का डेटा प्रकार एक संख्या, पूर्णांक, दशमलव, दिनांक या चरित्र की तरह एक पाठ स्ट्रिंग हो सकता है।
चर का उपयोग डेटा प्रवाह में और कार्य प्रवाह में कार्य के रूप में किया जा सकता है Where खंड।
डेटा सेवाओं में स्थानीय चर उस वस्तु तक सीमित हैं, जिसमें वे बनाई गई हैं।
ग्लोबल वेरिएबल्स उन नौकरियों तक ही सीमित हैं जिनमें वे बनाए गए हैं। वैश्विक चर का उपयोग करते हुए, आप रन समय में डिफ़ॉल्ट वैश्विक चर के लिए मान बदल सकते हैं।
कार्य प्रवाह और डेटा प्रवाह में उपयोग की जाने वाली अभिव्यक्तियों को कहा जाता है parameters।
कार्य प्रवाह और डेटा प्रवाह में सभी चर और पैरामीटर को चर और पैरामीटर विंडो में दिखाया गया है।
चर और मापदंडों को देखने के लिए, नीचे दिए गए चरणों का पालन करें -
टूल्स → वेरिएबल्स पर जाएं।

एक नई खिड़की Variables and parametersप्रदर्शित किया गया है। इसकी दो टैब हैं - परिभाषाएँ और कॉल।
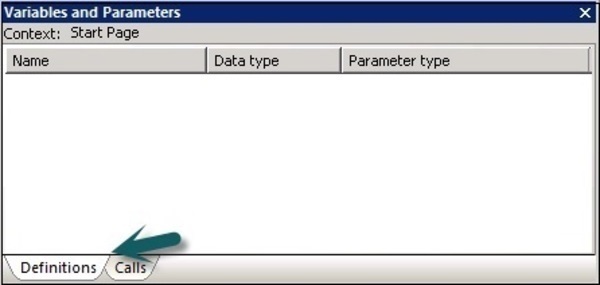
Definitionsटैब आपको चर और पैरामीटर बनाने और देखने की अनुमति देता है। आप कार्य प्रवाह और डेटा प्रवाह स्तर पर स्थानीय चर और मापदंडों का उपयोग कर सकते हैं। वैश्विक चर का उपयोग नौकरी के स्तर पर किया जा सकता है।
काम |
स्थानीय चर सार्वत्रिक चर |
नौकरी में एक पटकथा या शर्त नौकरी में कोई वस्तु |
काम का प्रवाह |
स्थानीय चर मापदंडों |
यह कार्य प्रवाह या एक पैरामीटर का उपयोग करके अन्य कार्य प्रवाह या डेटा प्रवाह के लिए नीचे चला गया। स्थानीय चर को पास करने के लिए मूल वस्तुएँ। कार्य प्रवाह भी पैरेंट ऑब्जेक्ट्स के चर या पैरामीटर वापस कर सकते हैं। |
डाटा प्रवाह |
मापदंडों |
WHERE क्लॉज, कॉलम मैपिंग या डेटाफ्लो में एक फंक्शन। डाटा प्रवाह। डेटा प्रवाह आउटपुट मान नहीं लौटा सकता। |
कॉल टैब में, आप मूल ऑब्जेक्ट की परिभाषा में सभी ऑब्जेक्ट्स के लिए परिभाषित पैरामीटर का नाम देख सकते हैं।
स्थानीय चर को परिभाषित करना
स्थानीय चर को परिभाषित करने के लिए, वास्तविक समय नौकरी खोलें।
Step 1- टूल्स → वेरिएबल्स पर जाएं। एक नयाVariables and Parameters विंडो खुल जाएगी।
Step 2 - चर पर जाएं → राइट क्लिक करें → डालें

यह एक नया पैरामीटर बनाएगा $NewVariable0।
Step 3- नए चर का नाम दर्ज करें। सूची से डेटा प्रकार का चयन करें।

एक बार यह परिभाषित हो जाने के बाद, विंडो बंद करें। इसी तरह से, आप डेटा प्रवाह और कार्य प्रवाह के मापदंडों को परिभाषित कर सकते हैं।

यदि आपकी नौकरी सफलतापूर्वक नहीं चलती है, तो आपको त्रुटि को ठीक करना चाहिए और नौकरी को फिर से भरना चाहिए। असफल नौकरियों के मामले में, ऐसी संभावना है कि कुछ तालिकाओं को लोड, परिवर्तित या आंशिक रूप से लोड किया गया है। आपको सभी डेटा प्राप्त करने और किसी भी डुप्लिकेट या लापता डेटा को हटाने के लिए नौकरी को फिर से चलाने की आवश्यकता है।
वसूली के लिए इस्तेमाल की जा सकने वाली दो तकनीकें इस प्रकार हैं -
Automatic Recovery - यह आपको रिकवरी मोड में असफल नौकरियों को चलाने की अनुमति देता है।
Manually Recovery - यह आपको पिछली बार आंशिक रेरन पर विचार किए बिना नौकरियों को फिर से चलाने की अनुमति देता है।
To run a job with Recovery option enabled in Designer
Step 1 - जॉब के नाम पर राइट क्लिक करें → Execute

Step 2 - सभी परिवर्तनों को सहेजें और निष्पादित करें → हाँ।
Step 3- निष्पादन टैब पर जाएं → रिकवरी चेक बॉक्स सक्षम करें। यदि इस बॉक्स की जाँच नहीं की जाती है, तो डेटा सेवाएँ विफल होने पर, कार्य को पुनर्प्राप्त नहीं करेगी।

To run a job in Recovery mode from Designer
Step 1- राइट क्लिक करें और ऊपर दिए गए कार्य को निष्पादित करें। परिवर्तनों को सुरक्षित करें।
Step 2- एक्सेप्शन के ऑप्शन पर जाएं। आपको यह सुनिश्चित करना होगा कि विकल्पRecover from last failed execution बॉक्स चेक किया है।
Note- यह विकल्प सक्षम नहीं है, अगर नौकरी अभी तक निष्पादित नहीं हुई है। यह एक असफल नौकरी की स्वचालित वसूली के रूप में जाना जाता है।

डेटा सेवा डिजाइनर स्रोत डेटा की गुणवत्ता और संरचना को सुनिश्चित करने और बेहतर बनाने के लिए डेटा प्रोफाइलिंग की एक सुविधा प्रदान करता है।
डेटा प्रोफाइलर आपको इसकी अनुमति देता है -
स्रोत डेटा, सत्यापन और सुधारात्मक कार्रवाई और स्रोत डेटा की गुणवत्ता में विसंगतियों का पता लगाएं।
नौकरियों, काम के प्रवाह और डेटा प्रवाह के बेहतर निष्पादन के लिए स्रोत डेटा की संरचना और संबंध को परिभाषित करें।
यह निर्धारित करने के लिए कि आपका काम अपेक्षित परिणाम देता है, स्रोत और लक्ष्य प्रणाली की सामग्री खोजें।
डेटा Profiler प्रोवाइलर सर्वर निष्पादन की निम्नलिखित जानकारी प्रदान करता है -
कॉलम विश्लेषण
Basic Profiling - न्यूनतम, अधिकतम, औसत, आदि जैसी जानकारी शामिल है।
Detailed Profiling - अलग गिनती, अलग प्रतिशत, मंझला आदि जैसी जानकारी शामिल है।
संबंध विश्लेषण
दो स्तंभों के बीच डेटा विसंगतियों जिसके लिए आप एक रिश्ते को परिभाषित करते हैं।
डेटा प्रोफाइलिंग सुविधा का उपयोग निम्न डेटा स्रोतों के डेटा पर किया जा सकता है -
- एस क्यू एल सर्वर
- Oracle
- DB2
- Attunity कनेक्टर
- साइबेस आईक्यू
- Teradata
Profiler सर्वर से कनेक्ट हो रहा है
प्रोफ़ाइल सर्वर से कनेक्ट करने के लिए -
Step 1 - टूल पर जाएं → प्रोफाइलर सर्वर लॉगिन

Step 2 - सिस्टम, उपयोगकर्ता नाम, पासवर्ड और प्रमाणीकरण जैसे विवरण दर्ज करें।
Step 3 - क्लिक करें Log on बटन।
जब आप कनेक्ट होते हैं, तो प्रोफाइलर रिपॉजिटरी की एक सूची प्रदर्शित की जाएगी। चुनते हैंRepository और क्लिक करें Connect।
ETL जॉब का प्रदर्शन उस सिस्टम पर निर्भर करता है, जिस पर आप Data Services सॉफ्टवेयर, मूव्स की संख्या, आदि का उपयोग कर रहे हैं।
ईटीएल कार्य में प्रदर्शन में योगदान देने वाले विभिन्न अन्य कारक हैं। वे हैं -
Source Data Base - स्रोत डेटाबेस को प्रदर्शन करने के लिए सेट किया जाना चाहिए Selectजल्दी से बयान। यह डेटाबेस I / O के आकार को बढ़ाकर, अधिक डेटा को कैश करने के लिए साझा बफ़र के आकार को बढ़ाकर और अन्य तालिकाओं के लिए समानांतर की अनुमति नहीं देकर किया जा सकता है, आदि।
Source Operating System- स्रोत ऑपरेटिंग सिस्टम को डिस्क से डेटा को जल्दी से पढ़ने के लिए कॉन्फ़िगर किया जाना चाहिए। 64KB करने के लिए आगे पढ़ें प्रोटोकॉल सेट करें।
Target Database - लक्ष्य डेटाबेस को प्रदर्शन करने के लिए कॉन्फ़िगर किया जाना चाहिए INSERT तथा UPDATEजल्दी से। इसके द्वारा किया जा सकता है -
- संग्रह लॉगिंग को अक्षम करना।
- सभी तालिकाओं के लिए Redo लॉगिंग को अक्षम करना।
- साझा बफर के आकार को अधिकतम करना।
Target Operating System- डिस्क को डेटा जल्दी से लिखने के लिए लक्ष्य ऑपरेटिंग सिस्टम को कॉन्फ़िगर करना होगा। आप इनपुट / आउटपुट ऑपरेशन्स को जितना संभव हो सके बनाने के लिए एसिंक्रोनस I / O चालू कर सकते हैं।
Network - नेटवर्क बैंडविड्थ को स्रोत से लक्ष्य प्रणाली में डेटा स्थानांतरित करने के लिए पर्याप्त होना चाहिए।
BODS Repository Database - बीओडीएस नौकरियों के प्रदर्शन में सुधार करने के लिए, निम्नलिखित कार्य किए जा सकते हैं -
Monitor Sample Rate - यदि आप ईटीएल नौकरी में बड़ी मात्रा में डेटा सेट कर रहे हैं, तो लॉग फ़ाइल में आई / ओ कॉल की संख्या को कम करने के लिए नमूना दर की निगरानी करें जिससे प्रदर्शन में सुधार हो।
यदि वायरस स्कैन को कार्य सर्वर पर कॉन्फ़िगर किया जाता है तो आप डेटा सेवा लॉग को वायरस स्कैन से भी बाहर कर सकते हैं क्योंकि यह एक प्रदर्शन गिरावट का कारण बन सकता है
Job Server OS - डेटा सेवाओं में, एक नौकरी में एक डेटा प्रवाह एक आरंभ करता है ‘al_engine’प्रक्रिया, जो चार सूत्र आरंभ करती है। अधिकतम प्रदर्शन के लिए, एक डिज़ाइन पर विचार करें जो एक चलता है‘al_engine’एक समय में सीपीयू की प्रक्रिया। जॉब सर्वर ओएस को इस तरह से ट्यून किया जाना चाहिए कि सभी थ्रेड्स सभी उपलब्ध सीपीयू में फैल जाएं।
SAP BO डेटा सेवाएँ मल्टीएयर डेवलपमेंट का समर्थन करती हैं जहाँ प्रत्येक उपयोगकर्ता अपने स्थानीय रिपॉजिटरी में एक एप्लिकेशन पर काम कर सकता है। प्रत्येक टीम एक आवेदन की मुख्य प्रति और आवेदन में वस्तुओं के सभी संस्करणों को बचाने के लिए केंद्रीय भंडार का उपयोग करती है।
प्रमुख विशेषताएं हैं -
एसएपी डेटा सेवाओं में, आप किसी एप्लिकेशन की टीम कॉपी संग्रहीत करने के लिए एक केंद्रीय भंडार बना सकते हैं। इसमें सभी जानकारी शामिल है जो स्थानीय रिपॉजिटरी में भी उपलब्ध है। हालाँकि, यह ऑब्जेक्ट जानकारी के लिए सिर्फ एक संग्रहण स्थान प्रदान करता है। कोई भी परिवर्तन करने के लिए, आपको स्थानीय भंडार में काम करने की आवश्यकता है।
आप केंद्रीय भंडार से वस्तुओं को स्थानीय भंडार में कॉपी कर सकते हैं। हालाँकि, यदि आपको कोई परिवर्तन करना है, तो आपको केंद्रीय भंडार में उस वस्तु को देखना होगा। इसके कारण, अन्य उपयोगकर्ता केंद्रीय भंडार में उस वस्तु की जांच नहीं कर सकते हैं और इसलिए, वे उसी वस्तु में परिवर्तन नहीं कर सकते हैं।
एक बार जब आप ऑब्जेक्ट में बदलाव करते हैं, तो आपको ऑब्जेक्ट के लिए जांच करने की आवश्यकता होती है। यह डेटा सेवाओं को केंद्रीय भंडार में नई संशोधित वस्तु को बचाने की अनुमति देता है।
डेटा सेवाएँ एक से अधिक उपयोगकर्ता को स्थानीय रिपॉजिटरी के साथ एक ही समय में केंद्रीय रिपॉजिटरी से कनेक्ट करने की अनुमति देती हैं, लेकिन केवल एक उपयोगकर्ता ही किसी विशिष्ट ऑब्जेक्ट में बदलाव कर सकता है।
केंद्रीय भंडार भी प्रत्येक वस्तु के इतिहास को बनाए रखता है। यह आपको किसी ऑब्जेक्ट के पिछले संस्करण में वापस जाने की अनुमति देता है, यदि परिवर्तन आवश्यक रूप से परिणाम नहीं करता है।
एकाधिक उपयोगकर्ता
SAP BO डेटा सेवाएँ एक ही समय में कई उपयोगकर्ताओं को एक ही एप्लिकेशन पर काम करने की अनुमति देती हैं। बहु-उपयोगकर्ता वातावरण में निम्नलिखित शर्तों पर विचार किया जाना चाहिए -
| अनु क्रमांक। | बहु-उपयोगकर्ता और विवरण |
|---|---|
| 1 | Highest level object उच्चतम स्तर की वस्तु वह वस्तु है जो वस्तु पदानुक्रम में किसी भी वस्तु पर निर्भर नहीं है। उदाहरण के लिए, यदि जॉब 1 वर्क फ्लो 1 और डेटा फ्लो 1 शामिल है, तो जॉब 1 उच्चतम स्तर की वस्तु है। |
| 2 | Object dependents ऑब्जेक्ट आश्रित, पदानुक्रम में उच्चतम स्तर की वस्तु के नीचे जुड़ी हुई वस्तुएं हैं। उदाहरण के लिए, यदि जॉब 1 में वर्क फ्लो 1 शामिल है, जिसमें डेटा फ़्लो 1 शामिल है, तो वर्क फ़्लो 1 और डेटा फ़्लो 1 दोनों जॉब 1 के आश्रित हैं। इसके अलावा, डेटा फ़्लो 1 वर्क फ़्लो 1 पर निर्भर है। |
| 3 | Object version ऑब्जेक्ट संस्करण ऑब्जेक्ट का एक उदाहरण है। हर बार जब आप केंद्रीय भंडार में किसी वस्तु को जोड़ते या जांचते हैं, तो सॉफ्टवेयर वस्तु का एक नया संस्करण बनाता है। किसी ऑब्जेक्ट का नवीनतम संस्करण अंतिम या हाल ही में बनाया गया संस्करण है। |
मल्टीसियर वातावरण में स्थानीय रिपॉजिटरी को अपडेट करने के लिए, आप केंद्रीय रिपॉजिटरी से प्रत्येक ऑब्जेक्ट की नवीनतम कॉपी प्राप्त कर सकते हैं। किसी ऑब्जेक्ट को संपादित करने के लिए, आप चेक आउट और विकल्प में जांच कर सकते हैं।
विभिन्न सुरक्षा पैरामीटर हैं जो इसे सुरक्षित बनाने के लिए एक केंद्रीय भंडार पर लागू किए जा सकते हैं।
विभिन्न सुरक्षा पैरामीटर हैं -
Authentication - यह केवल प्रामाणिक उपयोगकर्ताओं को केंद्रीय भंडार में प्रवेश करने की अनुमति देता है।
Authorization - यह उपयोगकर्ता को प्रत्येक ऑब्जेक्ट के लिए अलग-अलग स्तर की अनुमतियों को असाइन करने की अनुमति देता है।
Auditing- किसी वस्तु में किए गए सभी परिवर्तनों के इतिहास को बनाए रखने के लिए इसका उपयोग किया जाता है। आप सभी पिछले संस्करणों की जांच कर सकते हैं और पुराने संस्करणों को वापस ला सकते हैं।
नॉन सिक्योर सेंट्रल रिपोजिटरी बनाना
एक बहुपक्षीय विकास के माहौल में, केंद्रीय रिपॉजिटरी विधि में काम करना हमेशा उचित होता है।
एक गैर-सुरक्षित केंद्रीय भंडार बनाने के लिए दिए गए चरणों का पालन करें -
Step 1 - डेटाबेस प्रबंधन प्रणाली का उपयोग करके एक डेटाबेस बनाएं, जो केंद्रीय भंडार के रूप में कार्य करेगा।
Step 2 - एक रिपोजिटरी मैनेजर के पास जाएं।

Step 3- केंद्रीय के रूप में रिपोजिटरी प्रकार का चयन करें। उपयोगकर्ता नाम और पासवर्ड जैसे डेटाबेस विवरण दर्ज करें और क्लिक करेंCreate।

Step 4 - सेंट्रल रिपोजिटरी से कनेक्शन को परिभाषित करने के लिए, Tools → Central Repository।

Step 5 - सेंट्रल रिपोजिटरी कनेक्शन में रिपॉजिटरी का चयन करें और क्लिक करें Add आइकन।

Step 6 - केंद्रीय भंडार के लिए पासवर्ड दर्ज करें और क्लिक करें Activate बटन।
एक सुरक्षित केंद्रीय भंडार बनाना
एक सुरक्षित सेंट्रल रिपोजिटरी बनाने के लिए, रिपॉजिटरी मैनेजर में जाएं। केंद्रीय के रूप में रिपॉजिटरी प्रकार का चयन करें। दबाएंEnable Security चेक बॉक्स।

मल्टीसियर वातावरण में एक सफल विकास के लिए, कुछ प्रक्रियाओं को लागू करना उचित है जैसे चेक इन और चेक आउट।
आप निम्न प्रक्रियाओं का उपयोग एक बहुउपयोगी वातावरण में कर सकते हैं -
- Filtering
- वस्तुओं की जाँच करना
- पूर्ववत जांच करें
- वस्तुओं में जाँच करना
- वस्तुओं को लेबल करना
फ़िल्टरिंग तब लागू होती है जब आप किसी भी ऑब्जेक्ट को जोड़ते हैं, चेक करते हैं, चेक आउट करते हैं और सेंट्रल रिपॉजिटरी में ऑब्जेक्ट्स को लेबल करते हैं।
पलायन करने वाले बहुउद्देशीय नौकरियां
SAP Data Services में नौकरी के माइग्रेशन को विभिन्न स्तरों पर लागू किया जा सकता है अर्थात Application Level, Repository Level, Upgrad Level।
आप एक केंद्रीय रिपॉजिटरी की सामग्री को अन्य केंद्रीय रिपॉजिटरी से सीधे कॉपी नहीं कर सकते हैं; आपको स्थानीय भंडार का उपयोग करने की आवश्यकता है।
पहला कदम केंद्रीय भंडार से स्थानीय भंडार के लिए सभी वस्तुओं का नवीनतम संस्करण प्राप्त करना है। उस केंद्रीय भंडार को सक्रिय करें जिसमें आप सामग्री को कॉपी करना चाहते हैं। उन सभी ऑब्जेक्ट्स को जोड़ें जिन्हें आप स्थानीय रिपॉजिटरी से सेंट्रल रिपॉजिटरी में कॉपी करना चाहते हैं।
सेंट्रल रिपोजिटरी माइग्रेशन
यदि आप SAP डेटा सेवाओं के संस्करण को अपडेट करते हैं, तो आपको रिपॉजिटरी के संस्करण को भी अपडेट करना होगा।
संस्करण को अपग्रेड करने के लिए केंद्रीय भंडार को स्थानांतरित करते समय निम्नलिखित बिंदुओं पर विचार किया जाना चाहिए -
सभी तालिकाओं और वस्तुओं के केंद्रीय भंडार का बैकअप लें।
डेटा सेवाओं में वस्तुओं के संस्करण को बनाए रखने के लिए, प्रत्येक संस्करण के लिए एक केंद्रीय भंडार बनाए रखें। डेटा सेवा सॉफ़्टवेयर के नए संस्करण के साथ एक नया केंद्रीय इतिहास बनाएं और सभी वस्तुओं को इस भंडार में कॉपी करें।
यदि आप डेटा सेवाओं का एक नया संस्करण स्थापित करते हैं, तो यह हमेशा अनुशंसित होता है, आपको अपने केंद्रीय भंडार को वस्तुओं के नए संस्करण में अपग्रेड करना चाहिए।
अपने स्थानीय रिपॉजिटरी को एक ही संस्करण में अपग्रेड करें, क्योंकि केंद्रीय और स्थानीय रिपॉजिटरी के विभिन्न संस्करण एक ही समय में काम नहीं कर सकते हैं।
केंद्रीय भंडार को स्थानांतरित करने से पहले, सभी वस्तुओं में जांच करें। जैसा कि आप केंद्रीय और स्थानीय रिपॉजिटरी को एक साथ अपग्रेड नहीं करते हैं, इसलिए सभी ऑब्जेक्ट्स में जांच करने की आवश्यकता है। एक बार जब आप अपने केंद्रीय भंडार को नए संस्करण में अपग्रेड कर लेते हैं, तो आप स्थानीय रिपॉजिटरी से ऑब्जेक्ट्स में जांच नहीं कर पाएंगे, जिसमें डेटा सेवाओं का एक पुराना संस्करण है।